Building a Digital FTE: A 4-Hour Crash Course
Fifteen concepts and a worked build: Skills, the system of record, and the MCP wire between them.
Last course, you built an agent. This course, you take the first real step from agent to AI Worker. (This is the second course in Mode 2, the Manufacturing track, move two of seven.) That agent, from Build AI Agents, was a streaming chat agent with sessions, guardrails, and tracing, running on a sandbox for compute. It worked. It also forgot everything the moment you closed the terminal, and every tool it had was written into its Python.
Just want to see it work first? Jump to the 15-minute Quick Win below. You'll create a real database and a small Worker that writes to it and remembers, then come back for the concepts that explain why it's shaped that way.
An AI Worker is that same chat agent, grown up. People also call it an AI Employee or a Digital FTE: one thing, named for how you build it, who it joins, and what it costs. This course builds its foundation: an agent you can grow, that remembers, and that you own. A full Worker also runs around the clock, acts on its own, and reaches you on any app, but that comes later. The SDK and SandboxAgent runtime from the last course stay the same; everything around them is what changes.
Making that change takes two moves, plus the wire between them:
- Its abilities become Skills: small folders the agent finds and loads on its own, instead of tools hard-wired into its Python.
- The things it used to forget on restart move into Postgres, its system of record: the one authoritative store the Worker runs against, the source of truth a business runs on, the way a CRM or a ledger is. A few kinds of data live in it:
- Business records: the operational truth. Customers, tickets, orders. You look these up and update them.
- Reference library: knowledge it searches by meaning. The policy library, reference documents, past cases.
- State: what the work looks like right now. Which chats are open, what is waiting for approval.
- Trace: a record of what it did, so the company can replay and trust its actions.
- MCP (the Model Context Protocol) is the open standard for connecting agents to outside tools and data. Here, it is the wire the agent uses to reach that store.

Semantic recall is the one piece people mislabel. It means finding things by meaning, not by exact words. It is a way of searching, not a store of its own: you can run it over the reference library, over past conversations, or over the business records themselves. It comes from A running Worker has two parts that production deploys separately. The harness is the agent's runtime: the SDK loop itself. The compute is the sandbox where the agent's code actually runs; when the agent calls a tool, it hands the code to that sandbox. In this course both stay local. View Full Presentation — Build Digital FTE Foundation The thesis names Seven Invariants every production agent system must satisfy. The previous course built the engine (Invariant 4): the OpenAI Agents SDK on a sandbox. This course adds Invariant 5: every Worker runs against a system of record. The engine is what a Worker runs on; the system of record is what it runs against. Two open standards keep that portable. Skills (originally Anthropic, now ecosystem-wide at agentskills.io) let capabilities travel between tools. MCP is the standard wire the agent uses to reach the record; the previous course had none, and it is the key new pattern here. The record itself is Neon Postgres + pgvector, chosen because it is free to start, scales to zero when idle, and ships an official MCP server. The product is replaceable; the Swap guide lists alternatives.pgvector, which adds search-by-meaning to Postgres.How a Worker runs: harness vs. compute (you deploy neither here)
UnixLocalSandboxClient runs the sandbox on your machine (zero infrastructure, one API key), and you can point it at Docker, Cloudflare, E2B, or Modal with a one-line change (Part 5's Swap guide). Deploying the harness itself as an always-on cloud service is its own course, Deploy Your Agent Harness to the Cloud.Where this course sits in the Agent Factory thesis
📚 Teaching Aid
These fifteen concepts split across three layers: Skills, system of record, and MCP. The table below is the whole map.The 15 concepts at a glance (expand for the full map)
# Concept Layer What question it answers 1 What an Agent Skill is Skills Where does reusable capability live? In a folder, with SKILL.md plus optional scripts/references.2 Progressive disclosure Skills Why are skills cheap to keep on hand? Discovery → activation → execution loads only what's needed when it's needed. 3 Writing a SKILL.md Skills What does a skill file actually contain? Metadata, trigger description, operational instructions. 4 Skill packaging conventions Skills How do skills travel between tools? Same folder works in Claude Code, OpenCode, and any compliant client. 5 Composing skills Skills When to chain small skills via filesystem handoff vs. write one big skill. 6 Why managed Postgres System of record What store earns "system of record"? One with persistence, branching, governance, and the vector primitives an agent needs. 7 The Worker's schema System of record What tables does an agent actually need? Conversations, documents, embeddings, audit log, capability invocations, plus the SDK Session for the turns. 8 pgvector basics System of record How does semantic search work in Postgres? Embedding column, distance operators, index types. 9 The embedding pipeline System of record How does text become a queryable vector? Chunking, the embedding model, when to re-embed. 10 Audit trail as discipline System of record What does "reads and writes" mean for a Worker? Every action a Worker takes leaves a trace the company can replay. 11 What MCP is and isn't MCP A protocol for tools, resources, and prompts: not a framework, not a service. 12 The Neon MCP server MCP The agent's interface to its database: what it exposes, how it authenticates. 13 Connecting MCP to the Agents SDK MCP The SDK's MCP integration: how to register a server, what the model sees, where the trust boundary lives. 14 Custom MCP servers MCP When to write your own server vs. just use @function_tool. The decision tree.15 MCP under load MCP Transport choices, connection pooling, when to queue.
Once you have this mapping, the rest is mostly mechanics. A failure in production traces to one of: a Skill that never got discovered (description too vague), a system of record two Workers disagree about (schema race), or an MCP wire that drops events (wrong transport for the workload). The diagnostic tells you which.
Who this course is for
Intermediate. You should have:
- Ideally done Build AI Agents, though your agent can scaffold its end state on the base if you skipped it.
- The Plan-mode and rules-file habits from the Agentic Coding Crash Course.
- One PRIMM-AI+ cycle under your belt.
This is a Python-first sequel: you won't hand-type Python or SQL, your agent writes the code while you steer, and Parts 2 and 3 get denser (Pydantic models, asyncpg pools, a small custom MCP server), so expect more back-and-forth there. A database keeps information in tables. Picture a spreadsheet: each row is one thing (a customer, a support ticket) and each column is one detail about it (a name, a date, a status). That is the whole mental model you need here. You never write database code yourself; your agent does, and these two words just help you read what it builds. Five words this course uses as if you know them:New to databases? The 60-second version
Current as of May 2026, verified against openai-agents 0.17.x, the mcp SDK, Neon's MCP docs, and pgvector 0.8+. Pin your versions once you build; if the docs and this page ever disagree, the Cloudflare Sandbox tutorial and Neon docs win.
You direct, the agent builds, and because the base ships an AGENTS.md it reads on open, your prompts can stay short: just say what to build next.
The fifteen-minute quick win: succeed once, then study why it worked
Before you read the 15 concepts that explain why this architecture works, build the smallest version of it that actually works. By the end you will have:
- a fresh Neon project with two tables,
notesandaudit_log, that you created over MCP and saw in the console, - a minimal AI Worker that wrote to both in one transaction through its own
save_notetool, - and a worked answer to "did a system of record actually do anything for me?": your note and its audit row, sharing one id.
This is one screen of prompts: your coding agent builds the store over Neon MCP, then scaffolds a small Worker that writes to it, and you watch the Worker remember. The full Worker (eight decisions, a five-table schema) comes in Part 4. If you only have one sitting, do this, then come back for the concepts.
Two planes run through this, and keeping them straight is the whole mental model. Your coding agent (Claude Code or OpenCode) uses Neon MCP to build and inspect the database. The Worker you build uses its own tool to write to it at runtime. The Worker never touches Neon MCP, and Neon's own docs are blunt about why: the MCP server is for "development and testing only," never wired into a running app.

Get the base and open it
Download the base and open the folder in your general agent. The agent does the setup itself, from the prompts just below. You set this up once: digital-fte/ is your folder for the whole course, the Quick Win and Part 4 alike. Each build provisions its own fresh Neon project (a database), but you never re-download or re-unzip.
cd digital-fte
claude
cd digital-fte
opencode
This base assumes a capable general agent (Claude Code, or OpenCode running Claude Sonnet or Opus, GPT-5, or similar). A smaller model will drift on the build prompt; if its first plan looks vague instead of specific, switch to a stronger one before you go further.
Prep the base (~3 min)
The base ships rules and wiring; the skills and your key come next. Have your agent set itself up. Paste this:
Read AGENTS.md, then get this base ready: install the skills it lists for whichever agent you are, copy
.env.exampleto.envfor me, and tell me exactly what you need from me to bring the Neon and Context7 MCP servers online.
Watch for: the agent installing skill-creator, mcp-builder, and neon-postgres (you see the install run), creating .env, then asking you for two things: your OPENAI_API_KEY to paste into .env, and one browser click to authorize Neon over OAuth. Neon is free; if you don't have an account yet, sign up at neon.com in about a minute, or create one right at the authorization screen. When the install and wiring are done, the agent asks you to restart it (exit and relaunch) so the new skills and MCP servers load; neither loads mid-session.
Done when: the skills are installed, .env holds your key, Neon is authorized, and you have restarted the agent so the new skills and MCP servers are live.
The gate: confirm the agent can reach the database (~1 min)
The one genuinely new thing this course adds is the agent reaching a real system of record over MCP. So before you build anything, confirm that boundary is live. Paste this:
List the Neon tools you can see.
Watch for: a real list of Neon tool names (creating a project, running SQL, describing tables, and the like). That list is the agent's hand on the database, and everything below rides on it.
Gate open: the reply lists real Neon tool names. If it doesn't: you almost certainly skipped the restart, so the tools aren't loaded yet. Exit, relaunch, and ask again. Still nothing? The Neon OAuth didn't finish: redo it and retry.
Build the store, and grab its connection string (~3 min)
Have your coding agent create the database over Neon MCP, then hand your Worker the one thing it will need to reach it later: a connection string.
Paste this to your general agent. Plan first; execute on approval.
On a fresh Neon project, create two tables:
notes(the note text) andaudit_log(a record of what happened). Then callget_connection_stringand write that URL into my.envasDATABASE_URL. Use the Neon tools for all of it; don't write SQL for me to run.
Watch for: the agent calling the Neon MCP tools to create the project and the two tables (you see those tool calls, not SQL you typed), then writing DATABASE_URL into .env. That string is the handoff: Neon MCP provisioned the store, and your Worker will use the string, not the MCP server.
Done when: a fresh Neon project exists with a notes table and an audit_log table, and .env holds a DATABASE_URL.
See it with your own eyes (~1 min)
Before any code runs, look at the empty tables in the Neon console. This is the "it is really there" beat, and it costs you one browser tab.
Open console.neon.tech, pick the project the agent just made, and open Tables. There sit notes and audit_log, empty for now. A table is just a spreadsheet: each row one thing, each column one detail. You will refresh this view at the end and watch a row appear.
Scaffold the Worker and run it once (~2 min)
Now build the Worker itself: a minimal SandboxAgent, the same runtime the rest of the course uses, with no tools yet. Running it empty first proves the runtime works and your key is good, before you add anything else that can fail.
Using
uv, scaffold a minimal OpenAI Agents SDK project in this folder: aSandboxAgenton a gpt-5-class model (e.g.gpt-5-mini) with no tools yet, run from the terminal on a local sandbox, readingOPENAI_API_KEYfrom.env. Run it once with "hello" so I can see it answer.
Watch for: the agent setting up the project with uv, writing a small SandboxAgent plus Runner script (on UnixLocalSandboxClient, zero infrastructure), and running it. A reply comes back.
This is the first time your key is used, so it is the first place a bad key shows up. If the run 401s, the key is wrong or your provider isn't OpenAI: paste "the run failed with a 401; read the error and propose one fix I can approve."
Done when: the empty Worker runs and answers.
Give the Worker its tool, and watch it remember (~3 min)
Now add the one capability: a tool that writes a note and its audit row, in one transaction, to the database you built.
Add a
save_notetool to the Worker, written as a@function_tool, that inserts a row intonotesand a matching row intoaudit_login a single transaction, using theDATABASE_URLin.env. Then run the Worker and send it: "Remember this: the production deploy needs a new env var before Friday." Show me what happened.
Watch for: the model matching your sentence to save_note on its own (the tool's description is its only routing signal), and the tool opening a connection with DATABASE_URL and writing both rows in one transaction. The Worker reports the note saved. Notice what it did not do: it never reached for Neon MCP. The admin wire built the store; the Worker uses its own narrow tool.
Done when: the Worker confirms the note was saved and shows you the save_note call that did it. One sentence in, one tool call, two rows written.
The win: read it back (~2 min)
Refresh the Neon console Tables view from a moment ago. Your note is now a row in notes, and a matching row in audit_log records note_saved, tied to it by the same id. (Prefer to stay in the terminal? Ask your coding agent: "using the Neon tools, show me the new notes row and its matching audit_log row side by side.")
That is the whole architecture in miniature: a system of record holding the truth, a Worker that wrote to it through its own tool, and an audit trail you can replay.
What you built, and where it grows
You used a plain @function_tool because one Worker writes to one store, which is the right default, not a shortcut. You reach for a small MCP server when one of three things shows up: a second consumer that needs the same save_note (another Worker, your coding agent, Claude itself), a tighter scope you want to enforce, or process isolation. That decision, a function tool versus your own server, is Concept 14, and Part 4 builds the server.
Part 4 scales this same shape to several Skills, the five-table schema, a few tools, and an embedding pipeline. The shape does not change: a system of record, audit in the same transaction, and a clean line between the admin wire and the Worker's own access. If this Quick Win worked, the rest of the course is just explaining why each piece is shaped the way it is.
If something did not work, paste the one recovery move that covers everything: "Something didn't work. Read the error, tell me in plain language what you see, and propose one fix I can approve." Then come back here.
Part 1: Skills, capability as portable folders
You have already used Skills inside Claude Code. Part 1 gives the same on-demand, professional workflows to the agent you build. A Skill is a reusable capability you hand to an agent: a folder packaging a workflow (instructions, plus any scripts or references) that the agent loads only when a task calls for it, portable across agents instead of baked into one agent's code. These five concepts teach you to write Skills that fire when they should, and Part 1 ends by running one in your Worker's own SDK, in the same digital-fte folder.
Concept 1: What an Agent Skill is
An Agent Skill is a folder with a SKILL.md file (plus optional scripts/, references/, assets/). SKILL.md is the entry point. It's an open standard from Anthropic that any agent can read: Claude Code and OpenCode today, and the OpenAI Agents SDK Worker you are building. The smallest skill is one file:
---
name: hello-skill
description: Greets the user by name and time of day. Use when the user says hello or asks to be greeted.
---
# Hello skill
1. Check the local time of day.
2. Greet the user warmly, by name if known, in under 25 words.
No code, no deploy, no SDK call. Because it's a file on disk, a skill versions, travels, and gets reviewed like any text, not like a Python object or an API endpoint.
PRIMM, Predict. What does the agent load at startup, before any message arrives? (a) the whole
SKILL.md; (b) just thenameanddescription; (c) nothing until invoked. Confidence 1–5.
The answer is (b): at startup the agent reads only each skill's metadata; the body loads on demand. That is progressive disclosure, the next concept.
Concept 2: Progressive disclosure, the three-stage loading model
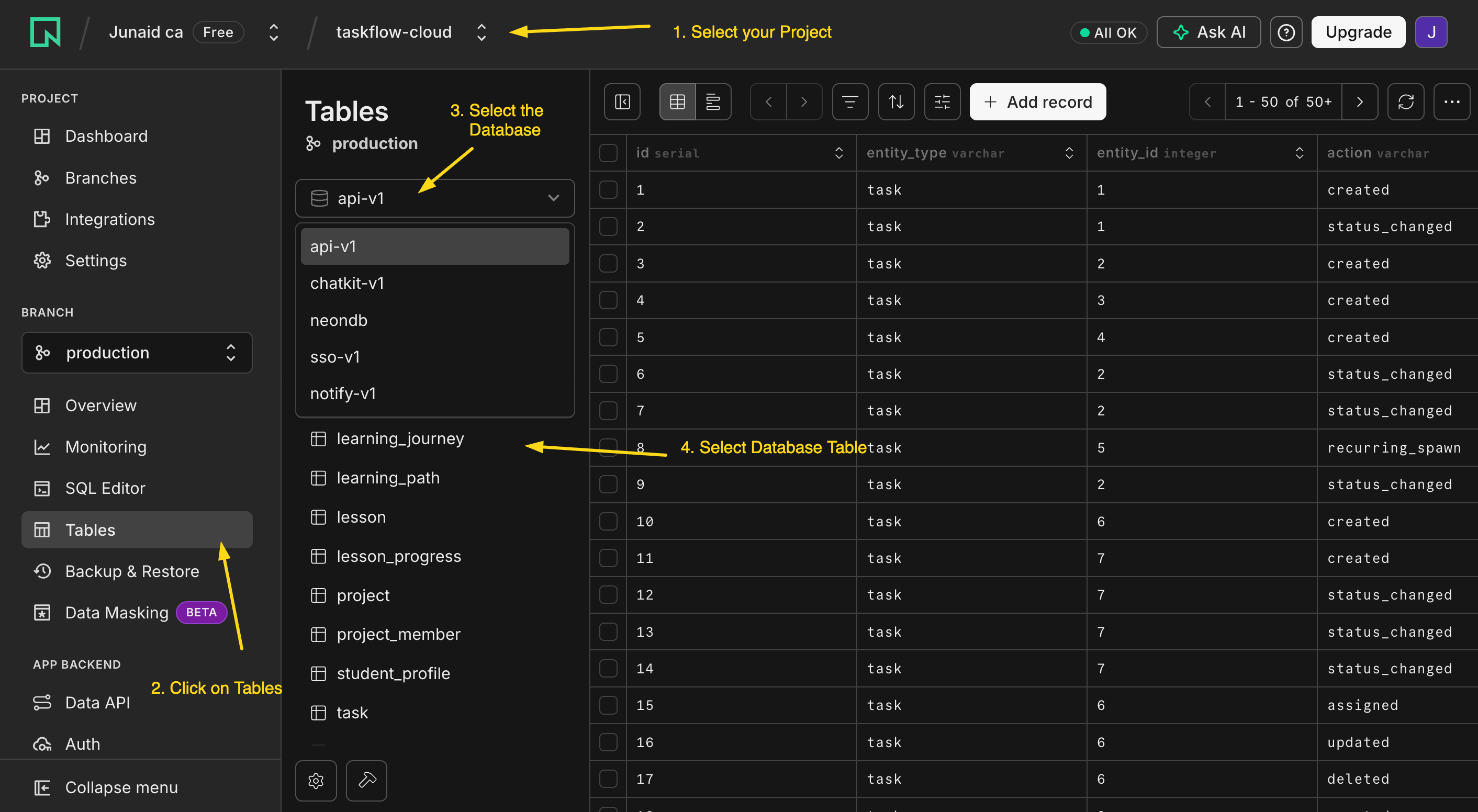
Loading fifty skills at once would bury the model in instructions it doesn't need. So a skill loads in three stages, each firing only when the last says it's relevant.
Stage 1, Discovery. At startup the agent loads the name and description of every skill, roughly 100 tokens each. Fifty skills cost about 5,000 tokens per turn: the price of knowing what's in the library.
Stage 2, Activation. When the model matches a task to a description, it loads that full SKILL.md body (keep it under ~5,000 tokens; most sit at 500–2,000). Paid only on turns that use the skill.
Stage 3, Execution. Files the body references (a scripts/ script, a references/ doc) load only when the agent reaches for them.
PRIMM, Predict. A Worker has 30 skills: ~100-token descriptions each, ~1,500-token bodies, two reference files (~4,000 tokens total) each. On a turn that activates one skill and reads one of its references, the rough context cost is: (a) ~3,000 tokens; (b) ~6,500 tokens; (c) ~135,000 tokens. Confidence 1–5.
The answer is (b), ~6,500 tokens: 30 × 100 for discovery (3,000), plus one 1,500-token body, plus one ~2,000-token reference. Discovery scales with library size; activation and execution stay constant per turn. Without progressive disclosure you would pay all 30 bodies and their references every turn, ~165,000 tokens just to know what the agent can do. Nobody runs that.
Two things follow, and they drive the next three concepts: the description is what fires in Stage 1, so it decides everything; and long bodies cost you on every matching turn, so keep SKILL.md tight and push depth into references/.
Concept 3: The description is the trigger, and the one part you own
A SKILL.md has two parts: YAML frontmatter (the contract the model reads) and the markdown body (the instructions it follows). Only two frontmatter fields are required:
| Field | Required | What it is |
|---|---|---|
name | Yes | The skill's identifier (lowercase, hyphens, matches the folder name). |
description | Yes | The trigger surface: what the agent reads at discovery to decide whether to fire this skill. |
(license, compatibility, metadata, allowed-tools are optional and rarely needed; skill-creator fills them.)
The description is the whole game, and it's the part the scaffold gets wrong. It writes a circular one: "Summarizes a ticket into five sections. Use when the user wants to summarize a ticket." That fires on "summarize this ticket" but misses how support actually talks: "write a handoff note for #4471," "TL;DR this thread," "give my lead the rundown before I escalate." The generic version catches about 6 of 8 real phrasings; a hand-written one catches all 8.
A description that fires reliably does three things, plus a guardrail:
- What it produces (name the actual output: the five sections, on one ticket).
- When to reach for it (the real situations: handoff, escalation, briefing a manager, picking up someone else's thread).
- Keywords users actually type, including the ones that never say the obvious word ("handoff note," "TL;DR this thread," "where does this stand").
- A do-NOT line for look-alikes that must stay quiet (drafting a customer reply, triaging a batch, reporting on ticket volume).
A self-check that kills circular descriptions: delete the obvious keyword ("summarize") from your description. Does it still say when to fire? If not, it is too narrow.
The body, by convention. No required format, but good skills are imperative ("Read the full thread. List what was tried."), carry one or two real examples (worth roughly 5× a description for steering), and name two or three edge cases that have actually broken.
PRIMM, Predict. Two skills share the
namesummarize-document: one in~/.claude/skills/(user-level), one in.claude/skills/(project-level). A task matches both. What happens? (a) random pick; (b) project-level wins; (c) the model chooses. Confidence 1–5.
(b), project-level wins across Claude Code and OpenCode: more specific context overrides more general, the same way a project rules file overrides a global one.
Concept 4: Packaging, where skills live and how they travel
A skill is just a folder on disk, so where you put it decides which agents find it. One rule covers this whole course: put your skills in OpenCode checks its own folder first, then falls back to .claude/skills/. Claude Code reads that folder, OpenCode falls back to it, and your Worker's SDK points straight at it (LocalDir(src=".claude/skills"), from the hands-on above). Write the skill once and all three load the same folder, byte-for-byte.The full path map (per tool, project vs. user-level)
Tool Project-level User-level (global) Claude Code .claude/skills/<name>/SKILL.md~/.claude/skills/<name>/SKILL.mdOpenCode .opencode/skills/<name>/SKILL.md~/.config/opencode/skills/<name>/SKILL.mdOpenCode (fallback) .claude/skills/<name>/SKILL.md~/.claude/skills/<name>/SKILL.md.claude/skills/; Claude Code only reads .claude/. That's why .claude/skills/ is the one location that works everywhere.
A skill's folder has one required file and three optional folders, each with one job:
my-skill/
├── SKILL.md # required: frontmatter + body, the entry point
├── scripts/ # optional: code the agent runs (by relative path)
├── references/ # optional: deep docs, loaded on demand, one topic per file
└── assets/ # optional: templates, schemas, lookup tables
Inside SKILL.md, point to those files by relative path (references/policies/us.md, scripts/extract.py); they resolve from the skill's own folder, not wherever the agent happens to be running. Keep references/ shallow, one topic per file.
Concept 5: Composing skills, one big one vs. several small
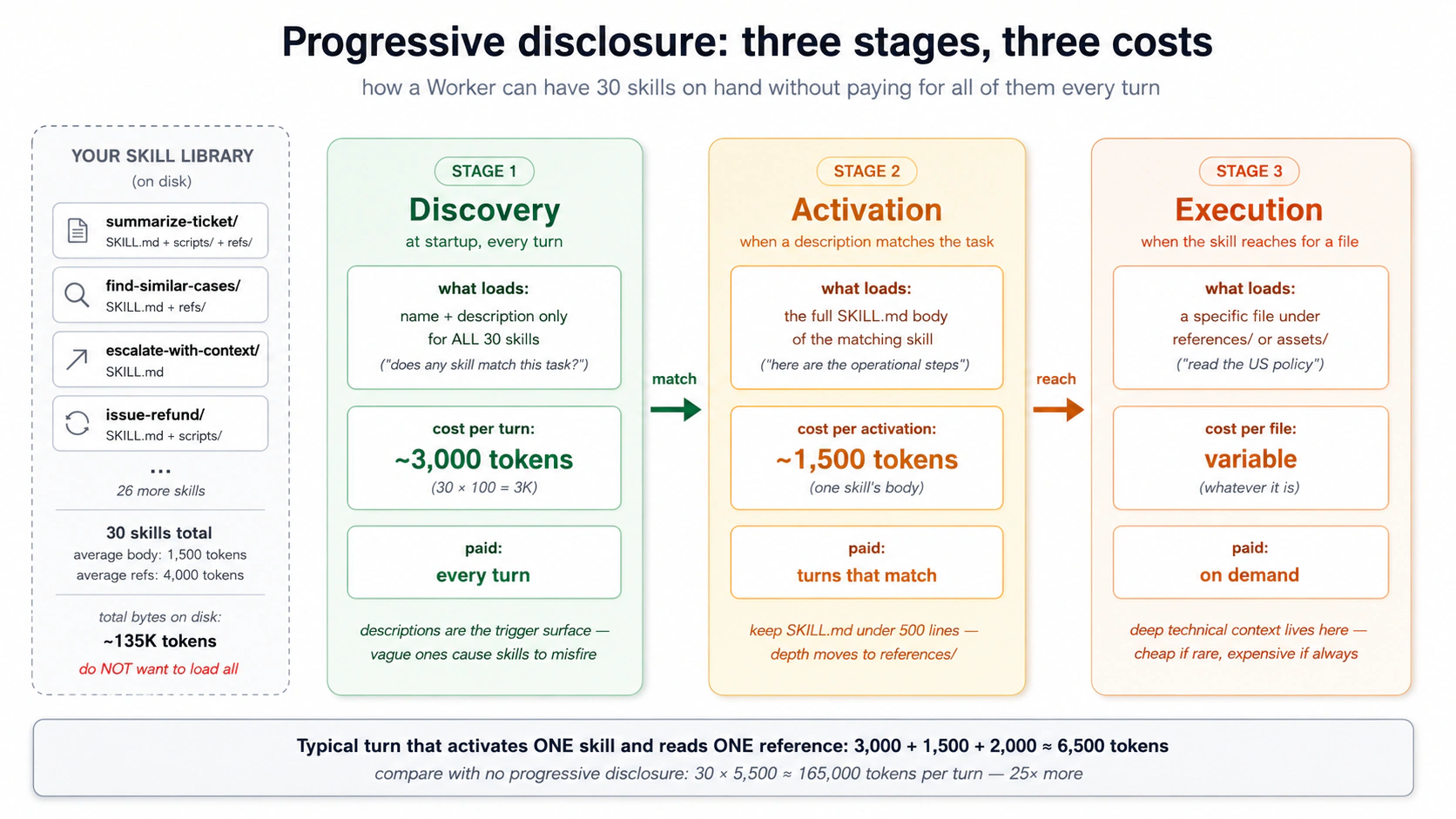
A "weekly customer-health report" could be one skill that researches, drafts, formats, and reviews, or four skills that hand off through the filesystem. Both work, with opposite trade-offs.
- One big skill: easy to discover, one activation. But every step runs in one context, nothing is reusable alone, and a mid-way failure leaves the model recovering with stale work in context.
- Many small skills: each can be tested, replaced, and reused on its own; a failure is localized; each step activates fresh, so no leftover context piles up. The cost is more discovery entries and something to chain them.
Write one skill when the steps are tightly coupled and never reused alone. Write several when a step might be called on its own, or when keeping each step's context clean matters more than keeping the wiring simple. Separation usually wins past two or three steps.
Chain them through the filesystem, not the conversation. Skill A writes tmp/research-{id}.md, Skill B reads it and writes tmp/draft-{id}.md, and so on. The conversation sees only the final result; the steps in between stay on disk for the agent, you, and the audit trail. Same isolation the last course used for subagents, now at skill size.
And it is the bridge to Part 2: some handoffs don't belong in a temp file, they belong in the system of record. A skill that writes to tmp/ is a draft; a skill that writes to the system of record is an action. That distinction is what Part 2 builds.
Try with AI
Compare two designs for a customer-refund workflow:
A: one "issue-refund" skill (eligibility, policy, amount, gateway, ticket, notify).
B: five small skills chained via tmp/ handoffs.
For each, name one situation where it's the right call and one failure mode
it's vulnerable to. Then say which you'd ship, and why.
Fire a skill in both runtimes (~10 min, hands-on)
You have read enough; now watch a skill fire inside the agent you build. Open the same digital-fte folder from the Quick Win, where your SandboxAgent already runs. Run this once on a throwaway skill so the mechanics are familiar (it is the move Decision 4 does for real), and see the .claude/skills/ files you already use in Claude Code work the same way in your Worker's own SDK.
1. Scaffold it. You need a general agent and Node installed (for npx). Paste this:
Use skill-creator to scaffold a summarize-ticket skill. It turns one support ticket into a
short five-section handoff. Make it fire on how support actually asks (handoff note, TL;DR
this thread, "what's the status and next step"), including phrasings that never say
"summarize", and not on look-alikes (drafting a reply, triaging a batch). Then check it:
delete "summarize" from the description; if it no longer says when to fire, sharpen it.
The body comes back good; read the description and sharpen it until it passes the delete-the-keyword check. That review is the skill, and the part no scaffold does for you.
2. Fire it in a client (optional, zero wiring). If you have Claude Code or OpenCode installed and signed in, open the folder there and ask it to handle a ticket without saying "summarize" (e.g. "write a handoff note for case #4471 before I escalate"). The client discovers .claude/skills/, matches your description, and activates summarize-ticket. One caveat: if a request is simple enough that the model just answers it directly, no skill fires, and that is the model's call, not a description bug; test with a real handoff, not a one-line question. SDK-only readers can skip to step 3.
3. Fire it in the OpenAI Agents SDK. Now wire the skill into your Worker's own runtime, and do it the way you'll do everything in Part 4: you prompt, the agent plans, you approve, it builds and runs. You are still in the digital-fte folder, so the uv project and OPENAI_API_KEY carry over. Paste this:
Wire the
summarize-ticketskill into a minimalSandboxAgentI can run from this folder: aSkillscapability pointed at.claude/skills, the default capabilities kept, a gpt-5-class model, on a local sandbox. Make sureopenai-agentsis installed. Plan first.
It is the same SandboxAgent shape as the Quick Win, with the save_note tool swapped for a Skills capability (a gpt-5-class model matters: the default capabilities include a filesystem tool that smaller models reject with a 400). When the plan looks right, approve and live-test it in one go:
Implement it, then run it with "write a handoff note for case #4471: no refund, two weeks" and show me the trace so I can see the skill fire.
Verify it fired, in the trace. The SDK traces every run to the same OpenAI dashboard you used last course: open platform.openai.com/traces and you will see the load_skill call for summarize-ticket in the run, then the five-section reply. (No dashboard? The print loop shows the same load in your terminal.) .claude/skills is the source; .agents/ is where a loaded skill is staged at run time. Same file, two runtimes: that is portable capability, and Decision 8 wires it into the full Worker.
These concepts assume a strong instruction-follower (Claude Sonnet/Opus, GPT-5-class). On a smaller model (deepseek-chat, Haiku-class, most local models), three things drift:
- Multi-skill sequencing. "ALWAYS run X before Y" lands on strong models, slips on weak ones. Fix: put the order in a short GENERAL-FLOW preamble in the system prompt; keep SKILL bodies declarative.
- Format drift. A weaker model adds emojis, tables, or paraphrases your inputs. Be explicit about what NOT to do, not just what to do.
- Trigger blindness. A description that fires on "summarize ticket TKT-1042" may miss "what's the story on #1042." Concept 3's discipline matters more, not less, on a weak model.
Rule of thumb: budget the strong model's effort into the SKILL.md, the weak model's effort into the system prompt. The architecture holds; you just write more scaffolding around it.
Part 2: Neon Postgres + pgvector as system of record
Part 1 gave the agent capabilities. Now it needs somewhere durable to keep what it can't afford to forget: the customer record, the policy library, past resolved cases, and a trace of everything it did.
That store is your Worker's system of record, the authoritative store it runs against (the opening map's CRM-or-ledger idea, now made concrete). It's Postgres with the pgvector extension; Concept 6 explains why over a dedicated vector database. We use Neon: free to start, costs nothing while idle, and your coding agent can drive it directly, but any managed Postgres with pgvector works.
Of the four kinds of data from that map, the business records (customers, orders, tickets) are specific to your business, so you build those in Part 4. What this Part builds is the other three, the parts every Worker shares, now mapped to the real tables that hold them:
- Reference library: knowledge the Worker searches by meaning, the policy library, knowledge-base articles, summaries of past resolved cases. It lives in
documentsandembeddings(Concepts 8 and 9). - State: the live conversation. Its turns live in the agent SDK's Session, which the SDK creates and writes for you, so you never design those tables (Concept 7); a
conversationsrow sits beside them, linked by the session id, as the envelope: who, when, a closing summary. - Trace: the record of what the Worker did, the
audit_logledger (Concept 10). (An optional companion table,capability_invocations, adds per-skill and per-tool metrics.)
Concept 6: Why managed Postgres, and why Neon specifically
The thesis stays product-agnostic about systems of record: "the AI-Native Company's existing databases, workflows, and operational platforms (CRMs, ERPs, ticketing systems, data warehouses, ledgers) serve as the system of record." For an agent you build from scratch, though, you have to pick something. The question is not "Postgres vs. MongoDB vs. a vector DB." It's "which Postgres."
Why Postgres, not a dedicated vector database. Three reasons that hold even in 2026.
-
One database, one transaction, one auth boundary. A separate vector DB means two stores to keep in sync, two auth systems, two backup pipelines.
pgvectorkeeps the vectors next to the records they relate to, so a JOIN stays a JOIN, not a network hop between two services. Every major managed Postgres (AWS RDS, Cloud SQL, Azure, Supabase, Neon) ships it, and it's among the most-installed Postgres extensions. For most workloads it's enough. -
Postgres already does the hard parts. Transactions, indexes, foreign keys, row-level security, point-in-time recovery, query planning. A dedicated vector DB has to invent these from scratch and usually does some of them worse. The default boring choice has compounding advantages.
-
MCP servers exist for Postgres at every layer. Neon ships one (for management). General Postgres MCP servers exist (for SQL execution). You can write your own (for scoped runtime access). The MCP ecosystem around Postgres is the most mature.
When a dedicated vector DB does win. Tools like Pinecone, Weaviate, Qdrant, and Milvus are worth it when search-by-meaning is the product, not a feature sitting next to your business data. The signs are extreme: so many vectors they no longer fit in one Postgres server's memory, search traffic heavy enough to need an engine built only for vectors, or vectors used on their own by many separate services. There's no fixed number where pgvector gives out, so test your own data rather than trust a figure. A Worker with a tickets table and its embeddings beside it is nowhere near that point, so pgvector is the right default.
Why Neon specifically: three differentiators.
-
It scales to zero. When the database is idle, it costs nothing. A Worker handling 50 conversations a day sits idle most of the time, so it stays near $0 instead of paying monthly for a server that's always on. That matters when you run many Workers that are each busy only in bursts.
-
It branches. In seconds, Neon makes a full copy of your live database to work on, without touching the original. The agent-relevant use: let the agent try a change on a branch, and if it goes wrong, just delete the branch. On a database that can't branch, undoing a bad change means restoring from a backup.
-
It has an official MCP server. Neon ships an MCP server your coding agent can talk to, so it can create projects, manage branches, and run migrations in plain language. Use it while building; Concept 12 explains why it's not for the running Worker.
Try with AI
A teammate proposes splitting the stores: Postgres for the relational
data (customers, tickets, orders) AND a separate Pinecone index for the
embeddings, "because Pinecone is purpose-built for vectors."
Context for you, the assistant: keeping vectors in Postgres (via the
pgvector extension) next to the relational data means one query can
filter by business state, rank by similarity, and return the full
record in a single transaction. Splitting the stores forces the agent
to round-trip between two services, denormalize and sync metadata
across them, and give up cross-store transactional consistency.
1. Make the case against the split as concretely as you can on ONE
request: a support Worker gets a message and must answer "have we
seen this before, and what did we tell them?" Show exactly what that
request costs when the vectors live in Pinecone and the tickets live
in Postgres. Name the join, what happens to ranking at the LIMIT
boundary when you filter in application code, and how an embedding
goes stale after a resolution is updated.
2. Name the ONE condition under which the teammate is actually right and
a dedicated vector DB is the better call. Be specific about the scale
at which the crossover happens.
3. Neon adds two properties a plain Postgres box doesn't: scale-to-zero
(an idle Worker's database costs nothing) and branching (the agent
forks a production-fidelity copy of the data, experiments or migrates
on it in isolation, then verifies before merging). Which matters more
for an AI Worker specifically, and why? Defend your pick in two
sentences.
Concept 7: The Worker's schema, what tables an agent actually needs
A database schema is just the tables you keep and the columns in each, the shape of your data. The five tables the worked example builds are the shared parts of the system of record that every Worker needs; the business records themselves come in Part 4. They fall into two groups, so you can see what is essential and what is optional.
Four tables every Worker keeps, the shared spine. They hold the state, the reference library, and the trace from the Part opener, now as tables:
conversations(state): one row per conversation, who it was with, when, and a short summary at the end. (The turn-by-turn messages are stored separately, by the SDK; see below.)documentsandembeddings(the reference library):documentsholds the text (policies, past cases);embeddingsis what makes it searchable by meaning. An embedding turns a piece of text into a list of numbers that captures its topic, so related text ends up close together, like pinning notes on a board where similar ones cluster, and "find relevant" becomes "find the nearest." (Concept 9 builds this; here, just knowembeddingsis the search-by-meaning layer.)audit_log(the trace): a running record of what the Worker did, every action in order, including business events like a refund being issued.
One more you add when you need it, usage analytics.
capability_invocations: one row each time the Worker runs a skill or calls a tool (both share this one table; a column marks which, so you never grow a table per tool), with how long it took, whether it succeeded or failed, and a rough cost. Add it when you want capability-usage analytics in SQL: how often a skill fires, its error rate, what tends to precede an escalation.
Two more tables live outside this set, both in Part 4: your business-specific tables (customers, tickets, orders), and run_states, which stores a paused approval when a human signs off later or in another process rather than right away. Neither is part of the shared spine.
Where do the messages themselves go? Picture a transcript and a cover sheet. The transcript is every message, your question, the model's reply, each tool call, each kept as its own row; the SDK writes and keeps it for you (wired in Decision 3), so you never build it. The cover sheet is the single conversations row you write: who, when, a summary, plus business details like user_id that the SDK's own tables don't carry. You keep it because the transcript can't answer "show this customer's last five conversations"; that's a quick lookup on conversations, joined to the transcript by the session id they share. It's optional: if you never need per-user lists or summaries, the transcript alone is enough.
The full SQL for all five tables is in the box below. Your coding agent writes it from the plan in Decision 3, so you can skim past it; what matters is knowing what each table is for.The schema, in full (four shared tables plus the optional capability_invocations)
-- 1. CONVERSATIONS: business metadata per conversation (your app writes this row)
CREATE TABLE conversations (
session_id TEXT PRIMARY KEY, -- the SAME id you pass to SQLAlchemySession
user_id TEXT NOT NULL,
started_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
ended_at TIMESTAMPTZ,
metadata JSONB NOT NULL DEFAULT '{}'::jsonb,
-- searchable summary; your app writes it at conversation end
summary TEXT
);
CREATE INDEX idx_conversations_user ON conversations(user_id, started_at DESC);
-- The turns themselves live in the SDK Session's tables (agent_sessions /
-- agent_messages, via SQLAlchemySession), created automatically on this same
-- database and keyed by this session_id; you do not hand-build them.
-- 2. DOCUMENTS: the agent's reference library
CREATE TABLE documents (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
source TEXT NOT NULL, -- 'policy_library', 'kb_article', 'past_case', etc.
title TEXT NOT NULL,
body TEXT NOT NULL,
metadata JSONB NOT NULL DEFAULT '{}'::jsonb,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
updated_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE INDEX idx_documents_source ON documents(source);
-- 3. EMBEDDINGS: vector representations of documents AND past conversations
CREATE TABLE embeddings (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
-- one of these is populated; the other is NULL
document_id UUID REFERENCES documents(id) ON DELETE CASCADE,
conversation_id TEXT REFERENCES conversations(session_id) ON DELETE CASCADE,
chunk_text TEXT NOT NULL,
chunk_index INT NOT NULL,
embedding VECTOR(1536) NOT NULL,
model TEXT NOT NULL, -- 'text-embedding-3-small', etc.
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
CHECK (
(document_id IS NOT NULL)::int + (conversation_id IS NOT NULL)::int = 1
)
);
-- the key index for semantic search; see Concept 8
CREATE INDEX idx_embeddings_hnsw
ON embeddings USING hnsw (embedding vector_cosine_ops);
-- 4. AUDIT_LOG: replayable trace of how the Worker changed or used the record
CREATE TABLE audit_log (
id BIGSERIAL PRIMARY KEY,
conversation_id TEXT REFERENCES conversations(session_id) ON DELETE SET NULL,
actor TEXT NOT NULL, -- 'worker:customer-support', 'system', etc.
action TEXT NOT NULL CHECK (action IN (
'message_received', 'message_sent', 'skill_activated',
'capability_invoked', 'refund_issued', 'refund_blocked',
'guardrail_tripped', 'corpus_seeded'
)), -- closed vocabulary; widening it is a migration (Concept 10)
target TEXT, -- table name, skill name, etc.
payload JSONB NOT NULL, -- the data of the action
result JSONB, -- what happened
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE INDEX idx_audit_conv ON audit_log(conversation_id, created_at);
CREATE INDEX idx_audit_action ON audit_log(action, created_at);
-- 5. CAPABILITY_INVOCATIONS: every skill or tool call, for replay and metrics
CREATE TABLE capability_invocations (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
conversation_id TEXT NOT NULL REFERENCES conversations(session_id) ON DELETE CASCADE,
capability TEXT NOT NULL, -- 'skill:summarize-ticket', 'tool:search_docs', etc.
arguments JSONB NOT NULL,
result JSONB,
status TEXT NOT NULL CHECK (status IN ('ok', 'error', 'blocked', 'timeout')), -- 'blocked' = approval rejected
latency_ms INT,
cost_cents INT, -- approximate cost in 1/100 cents
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE INDEX idx_cap_conv ON capability_invocations(conversation_id, created_at);

A few design choices worth understanding:
-
One
embeddingstable for both documents and conversations. ACHECKconstraint makes each row point at exactly one, a document or a conversation. So a single search can cover policies and past conversations at once, and "have we answered this before?" uses one index, not two. -
audit_logusesBIGSERIAL(an auto-incrementing number), not aUUID. Audit rows pile up fast, and a plain integer key keeps writes quick and the order obvious. The other tables useUUIDs (random, globally unique ids) because their rows show up in API responses and URLs, where aUUIDhides how many rows you have. -
Skills and tools share
capability_invocations. A skill call and a tool call are similar but not identical (different code, different costs, different ways they fail). Keeping both in one table, with a column that says which, lets you ask "what did the agent do?" across both, or split them to ask "which skills are slow or failing?" -
metadataJSONB columns are escape hatches. No schema can guess every field a given business will need, so a JSONB column lets you add fields without changing the table. Use it sparingly: anything you query often should become its own column.
You'll add more tables for your business: a customers table, a tickets table, an orders table, ordinary relational tables the agent reads and writes through MCP.
PRIMM, Predict. A Worker handles 200 conversations/day, each averaging 10 turns, with 30% triggering one skill invocation and 50% writing two audit rows beyond the skill row. After one month (30 days), which store grows fastest? Three options: (a) all of them at similar volume; (b)
audit_loggrows fastest by a wide margin; (c) the embeddings table, because every turn gets embedded. Confidence 1–5.
The answer is (b): among the tables you build, audit_log grows fastest, because one interaction can write several action rows (a skill or tool call, a write to the record, sometimes a refund) while it adds just one conversations row and no new documents. So it's the table whose retention and indexing you plan for first as you grow. (The SDK's own turn store grows faster still, but you don't manage it.)
Try with AI
I'm building a customer-support Worker. Its database already
has the four shared tables from Concept 7: `conversations` (one row per
conversation, plus a summary), `documents` and `embeddings` (a
searchable reference library), and `audit_log` (the record of what it
did). The turn-by-turn messages are held by the agent SDK's Session,
not a table I built.
I want to extend this for a Worker that handles software bug reports
specifically. What three additional tables would you add, and what
columns would they have? For each, say what the agent will use it for
(read access? write access? both?) and what foreign keys connect it to
the tables above.
Concept 8: pgvector basics, types, distance operators, indexes
The embeddings table is what lets the Worker find text by meaning, not just by matching words. Think back to the board: every piece of text (a policy, a past case, a record) gets a pin, and related things sit near each other. A pin's position is the embedding, a list of numbers. pgvector (a Postgres extension) is what lets Postgres store those pins and find the nearest ones, so you don't need a separate vector database (Concept 6 is why).
The vector type. VECTOR(n) is a column that holds one pin: a fixed list of n numbers. The model that makes the embeddings decides n, 1536 for OpenAI's text-embedding-3-small, 3072 for text-embedding-3-large, other models differ. The rule that bites people: your stored text and your search query must come from the same model. Two models are like two maps drawn to different scales, a spot that means "downtown" on one lands in the ocean on the other. Embed your documents with one model and your queries with another, and the "nearest" results come back as nonsense even though the query runs without error. It's the most common pgvector mistake.
For very large embeddings (more than 2,000 numbers), a halfvec column stores each number at half the precision: that roughly halves the storage and can still be indexed (up to 4,000 numbers), for a small accuracy cost. Our 1536-number case doesn't need it; plain vector(1536) is fine.
Three ways to measure "how close." Once text is pinned, "similar" just means "near." pgvector gives three ways to measure the distance between two pins. Pick one and stick with it; switching between them mid-project only confuses the results.
| Operator | Name | What it measures | When to use |
|---|---|---|---|
<=> | Cosine | how aligned two pins are, ignoring length | text, our default |
<-> | Straight-line | the plain distance between two points | image search and other geometric data |
<#> | Dot product | direction and length together | rare: only when your vectors aren't all one length |
For text, use cosine (<=>). It compares meaning no matter how long the vectors are, which is what you want, and it's the standard choice (its index is named vector_cosine_ops).
To search, you turn the user's question into an embedding and ask Postgres for the rows whose <=> distance to it is smallest, nearest first, top few. Your agent writes that SQL; you'll watch a real query run in "Feel it work" below.
Indexes: what makes search fast. Checking every pin one by one gets slow once you have thousands of them. An index fixes that, the way the index at the back of a book lets you jump to a topic instead of reading every page. pgvector can build this index two ways, named HNSW and IVFFlat; you don't need to know what the letters stand for, only what each does. As of 2026 the advice is settled:
- Start with HNSW. It links each pin to its neighbors so a search can hop straight toward the closest ones: fast searches, slower to build, more memory. The right default.
- Use IVFFlat only if build speed matters more than search speed. It sorts pins into buckets and searches the nearest buckets: quicker to build and lighter on memory, but slower searches, and you can only build it after the table has data (it learns the buckets from the rows already there). Worth it if you rebuild the index often.
- DiskANN (a separate add-on) is for indexes too big to fit in memory. You almost certainly don't need it.
The HNSW index from the schema above:
CREATE INDEX idx_embeddings_hnsw
ON embeddings USING hnsw (embedding vector_cosine_ops);
HNSW has two dials, m and ef_construction. The defaults are fine for most workloads; leave them alone unless you've measured a reason to change them.
Quick check. True or false? (a) You can put more than one HNSW index on the same column, one per distance operator. (b) Adding a row to a table with an HNSW index costs more than adding one with no vector index. (c) You can create an HNSW index before any data is loaded. All three are true: you can index for several operators (rarely needed), keeping the index current as rows arrive has a real cost (so some teams bulk-load first, then build the index), and HNSW needs no training data, unlike IVFFlat.
Try with AI
Two scenarios. For each, pick HNSW or IVFFlat and justify with one
specific property of the index:
Scenario A: A research index of 10M scientific papers. Built once,
queried millions of times. Build time is "whatever it takes,
overnight is fine." Query latency directly affects user experience.
Scenario B: A live index of customer support tickets that's
re-indexed every 4 hours because thousands of new tickets stream in.
Query patterns are simple (top-5 nearest neighbors). The current
HNSW build takes 20 minutes, a third of the re-index cycle.
After you answer: name ONE thing that would change your answer for
each scenario. Be specific about what you'd need to see in
production metrics before switching.
Concept 9: The embedding pipeline, text in, queryable vector out
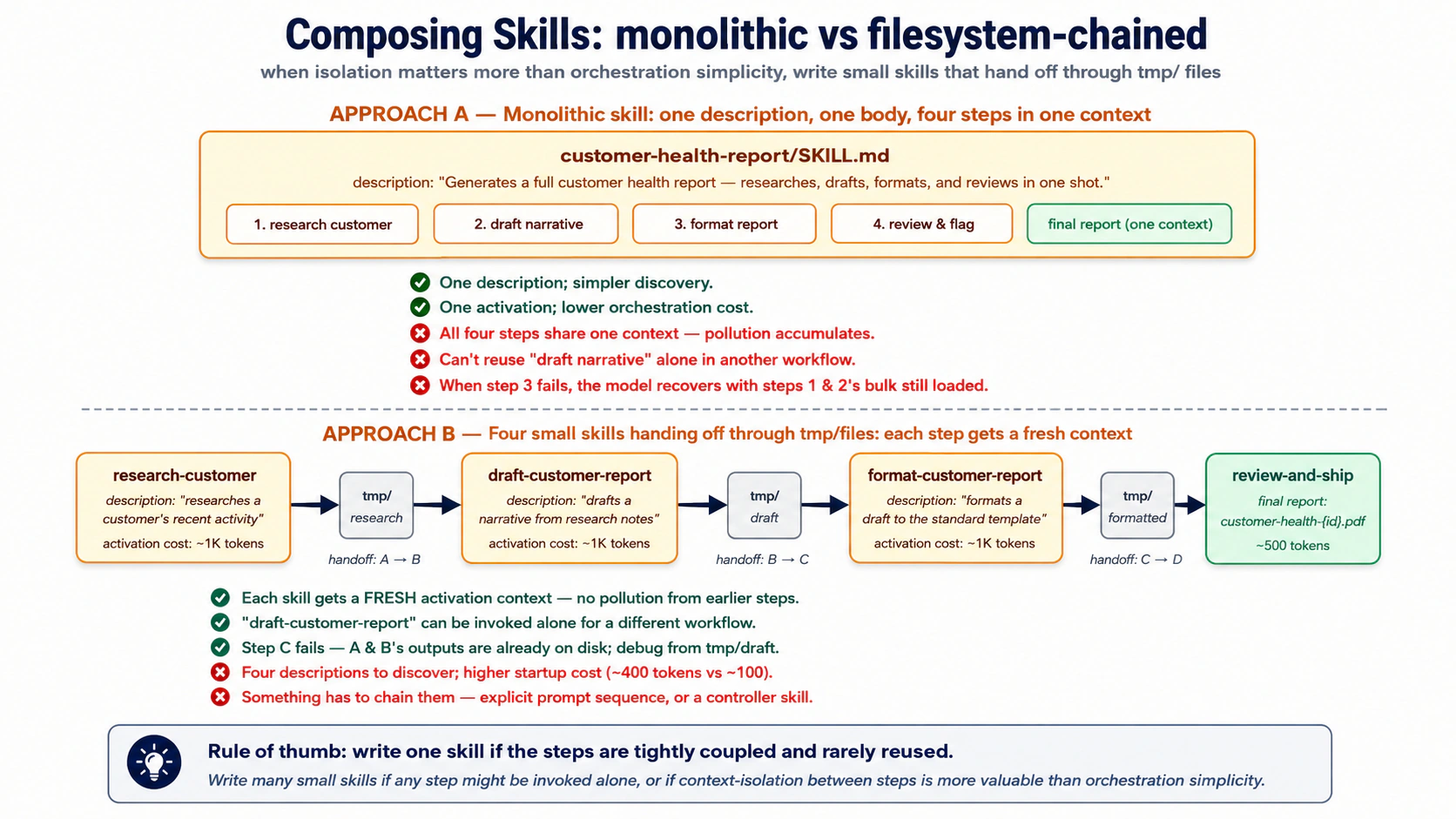
An embedding turns a piece of text into a point in space. Text about refunds lands near other text about refunds; text about login bugs lands somewhere else. So "find similar tickets" becomes "find the nearest points." That is the whole idea. The rest is plumbing.
The plumbing is four steps, and each has one decision that matters:
- Chunk the document into pieces small enough to carry one idea each.
- Embed each piece by calling the model; you get its point back.
- Store the text, its point, and a little metadata in the
embeddingstable. - Query by turning the user's question into a point too, then finding the nearest stored points.
Chunking: split long text first. A long document shouldn't become one giant embedding. You split it into chunks, and the chunk size is the one decision that matters:
- Split at natural breaks (headings, paragraphs). A chunk that stops mid-sentence searches badly.
- Aim for a few hundred words per chunk. Too big and it "matches everything weakly"; too small and it loses the context that made it meaningful.
- Overlap chunks a little, so an idea that straddles a boundary still gets found.
- Don't chunk what's already short. A single resolved ticket or a short FAQ entry is already one chunk; embed it as is.
Your agent writes the splitting code; what you decide is the chunk size and the overlap.
Embedding: turn each chunk into a point. You hand each chunk to the embedding model and store the point it gives back (in batches, which is far cheaper than one call per chunk). Keep Concept 8's rule in force: embed your stored text and your search queries with the same model, or the matches come back as noise. One setup trap worth knowing (your agent handles it): the database driver has to be told about the vector type, or your inserts can fail silently.
What if you're not on OpenAI? OpenAI is the only major provider that also ships a first-class embeddings API, so if you run inference through DeepSeek, Anthropic, Gemini, or a local model, you pick an embedding model separately, and the dimension is what has to match. The usual escape hatch is a local sentence-transformers model like all-MiniLM-L6-v2 (384 dims): no API call, and no text leaves your machine. Either way embeddings are the cheapest line on the bill, so this choice moves your architecture, not your budget.
When to re-embed. Three triggers:
- The source text changed, re-embed those rows.
- You switched embedding models, every old point now lives on a different map and likely a different size, so you rebuild the column and re-embed every row (or keep both during the switchover). There's no "close enough."
- You changed the chunk size, re-chunk and re-embed.
PRIMM, Predict. You've embedded 100,000 chunks with
text-embedding-3-small. You then decide to also embed your past conversations (not just documents) so the agent can do "have we discussed this before?" lookups. You write the conversation embeddings into the sameembeddingstable with the same column. A semantic search query (find the 5 nearest neighbors to a user question, no filter) comes back with mixed document and conversation results. Is this what you wanted? What's the right query shape? Confidence 1–5.
The answer: almost certainly not what you wanted. With documents and past conversations mixed in the results, the agent can treat a snippet of an old chat as if it were authoritative policy. The fix is to filter by source when you search: ask for documents only, or run two searches and weigh them, so the two kinds never blur together.
When results look wrong, the cause is almost always one of three: the query and the stored text went through different models (matches are noise), you forgot to filter by source type, or your chunks are too small to carry meaning. Check those first.
Retrieval quality is the silent killer of Worker accuracy. The final answer can sound perfectly reasonable while citing the wrong evidence. The only way to catch it is to check retrieval before the answer.
Try with AI
I'm chunking a corpus of legal contracts (each averaging 8,000 words)
for semantic search. The user will query things like "what's the
termination clause in this contract", phrases that map cleanly to
specific sections. Walk me through three chunking strategies:
A) Fixed 400-token chunks with 60-token overlap (the default)
B) Chunk at section headings only, with no overlap
C) A two-level approach: store both 400-token chunks AND
whole-section chunks, search both, combine results
For each, name (1) when it wins and (2) when it loses.
Feel it work: semantic search in ten minutes
You have read about pgvector and the embedding pipeline without seeing either return a single result. Before the last piece of the schema, the audit trail, take ten minutes to watch semantic search actually rank by meaning. This is a throwaway, not the Worker: a scratch table, five sentences, one query. Part 4 builds the real thing.
Your Neon is already wired from the Quick Win, so this is one prompt:
On a fresh scratch branch of my Neon project, create a tiny
notes(id, text, embedding vector(1536))table with an HNSW index. Embed these five sentences withtext-embedding-3-smalland insert them: "the refund hasn't arrived", "my package is late", "how do I reset my password", "the charge appears twice", "I was billed for something I didn't buy". Then embed the query "I never got my money back", run a cosine-distance search, and show me the rows ranked by distance.
Watch for: the billing and refund sentences rank above "my package is late" and far above "reset my password", even though the query shares almost no words with any of them. Ranking by meaning, not by keyword overlap, is the entire reason the embeddings table exists.
Done when: you have seen the ranked list with the refund and billing sentences on top. Tell your agent to delete the scratch branch; the real schema is Part 4.
If the refund sentences did not win, the usual cause is the Concept 9 model mismatch: insert and query went through different embedding models. Same model both ends, or the distances are noise.
Concept 10: Audit trail as discipline, what "reads and writes" means for a Worker
Every meaningful action the agent takes should leave a row in the database. Without that row, you can't later answer "what did the agent do, and when?" That trail is what separates a real action from a plausible-sounding reply.
Two things sit close together here and get confused, so keep them apart:
- The truth itself: what is currently the case, a customer's tier, a ticket's status, a policy's text. It lives in the business records and the reference library, and the Worker reads and updates it.
- The audit trail: the replayable record of what the Worker did to that truth, which tool it called, what it changed, what it returned, who approved it. It lives in
audit_log, in the same database, and it answers a different question, not "what is true?" but "what did the Worker do, and can you prove it?" It is not a second copy of the conversation (the Session already holds every message); it records the typed actions and their results, including ones that never appear as a message, a database write, a refund, a guardrail block. (A separate, optionalcapability_invocationstable sits beside it for per-skill and per-tool metrics; see Concept 7.)
So every meaningful action writes its own audit row even though the data it touched is stored elsewhere. The fact that the action happened lives in audit_log; the two are joined by foreign key.
What goes in it. The meaningful actions, with enough detail to replay them: every tool or skill call (name, inputs, result, how long it took, whether it succeeded), every change to the record (which table, what changed, under which conversation), every guardrail decision, and each model call with its token cost.
What stays out. The full conversation text, the Session already holds it, so storing it again just doubles your storage. Raw sensitive data in a row humans can read, keep a hash or a summary and lock the full thing away. And the model's private reasoning.
The test that makes it an audit trail, not just logs: given a conversation and a time, you can reconstruct what the Worker did and why, without re-running the model. If you can't, you have logs.
Write the action and its record together. Whatever code issues a refund writes the refund and its audit row in one transaction: both land or neither does. A half-written audit trail is worse than none, it looks complete and isn't. (Your agent writes this in Part 4.)
Give every action a name from a small, agreed set (refund_issued, message_sent, and so on) and don't let those names drift. Three different names for the same event, six months from now, is what makes the trail impossible to query. Domain events like refund_issued get their own name so the row reads as a receipt for the business event, not just for the tool call that triggered it.
Because that set is small and fixed, enforce it with a CHECK constraint on audit_log.action (the Concept 7 schema does). The catch a build hits weeks later: the vocabulary is now closed, so introducing a new verb (a guardrail_tripped row in Decision 9, the corpus_seeded row Decision 5 writes for its own seed run) is a one-line ALTER TABLE ... DROP/ADD CONSTRAINT migration, not just new code, and the error surfaces as a DB constraint violation that points nowhere near "you forgot to plan your vocabulary." So decide the full set up front; Concept 7's CHECK already lists the eight this course uses.
What the audit trail is not. Not just logs: it's queryable SQL in your own database ("what did the agent tell customer X last month, and which policy did it cite?" is one query), not grep over text files, and it's backed up and access-controlled alongside your business data. Not event sourcing: it's an append-only trace beside your state, not the thing you rebuild state from (your tickets, documents, and the Session are the state). Not your traces: tracing (OpenTelemetry, the OpenAI dashboard) is the flight recorder for debugging, it lives in a separate system, can be switched off, and is unavailable under Zero-Data-Retention; the audit log is the receipt, committed in the same transaction as the action and kept as long as you need. Run both: the trace to debug, the ledger to prove.
This is what the thesis means: "Workers only become governable as a workforce when a ledger makes them legible." Your audit_log is that ledger. And legible is what makes a Worker sellable: you can't charge for an outcome you can't prove happened. Per-seat pricing counts logins; outcome pricing counts what the Worker did, per resolved ticket, per processed invoice, per drafted reply. The refund_issued and ticket_resolved rows are those outcomes, sitting in the same log as the low-level events, something you can point a customer at and invoice against. So a Worker needs a system of record not only so it stops forgetting between runs, but so its work becomes a provable, billable artifact. That is the line between wiring an agent to a database and building a Worker you can actually sell.
Try with AI
Here's a customer support scenario: a customer claims the Worker told
them they would receive a $50 refund, but the actual refund issued was
$30. The Worker handled the conversation 19 days ago.
Walk me through the audit-trail query path to resolve this:
1. Find the conversation. (Which columns of which tables?)
2. Find the message where the refund amount was promised. (How do you
distinguish "discussed" from "promised"?)
3. Find the capability invocation that issued the refund.
4. Find the database write that recorded the $30 amount.
For each step, name the table you'd query and the WHERE clauses.
Then say what's MISSING from the five-table schema that would make
this query easier.
Part 3: MCP, wiring the agent to the system of record
Part 1 gave the agent a library of Skills. Part 2 gave it a Postgres system of record. Part 3 wires the two together with the Model Context Protocol: the open standard for how agents reach external state and external capability. The thesis is direct about MCP's place: "MCP is how the workforce reaches [its systems of record]: every authoritative store becomes addressable to any Worker through an MCP server, under policy." This Part makes that operational.
Concept 11: What MCP is and isn't
The Model Context Protocol (modelcontextprotocol.io) is an open client/server protocol (originally from Anthropic, now governed as an open standard) for how an AI agent connects to external tools, data, and prompts. The framing that gets repeated is "USB-C for AI tools": one protocol, many implementations, swap any side without breaking the other. The framing is accurate; like all metaphors, it has limits worth naming.
What MCP is. A protocol. A specification. Three primitives the server can expose to the client.
- Tools: functions the model can invoke. The client lists them, the model picks one, the server executes it. Conceptually similar to a
@function_tooldecorator from the previous course, but the implementation lives in the MCP server process, not the agent's process. This is the most-used primitive by far. - Resources: read-only data the agent can fetch. Files, database query results, API responses. Think of them as the GET-only side of MCP. Less common than tools in practice, but useful for "let the agent read this document on demand."
- Prompts: reusable prompt templates the server provides. A team can publish standardised prompts ("summarize-incident-report") that any agent connecting to the server can invoke. Rarely used compared to tools and resources.
Three transports, with current recommendations as of 2026:
| Transport | When to use | Status |
|---|---|---|
stdio | Local subprocess; agent and server on the same machine | Mature. Default for local tools. |
streamable HTTP | Remote server; production deployments | Recommended for new remote work. Single endpoint over plain HTTPS. |
SSE | Remote server; older deployments | Legacy. Many servers still expose it; new ones increasingly default to streamable HTTP. |
Streamable HTTP comes in two flavors, and the difference matters when you deploy. Stateless is the default to reach for: each call is an independent request and response, exactly like an ordinary API call, so you can run many copies of the server behind a load balancer and any one of them can answer. Stateful keeps a live session open so the server can stream partial results back or push notifications mid-task, which is what you need for long-running work, but it pins each client to one server instance and is more to operate. Use stateless unless you have a specific reason (live streaming, server-initiated messages) to need the open session.
What MCP is not.
- Not a framework. It's a protocol. Your agent doesn't "use MCP" the way it uses the Agents SDK; your agent's MCP client speaks MCP to an MCP server. The Agents SDK includes an MCP client; that's the integration point.
- Not a service. There is no "MCP cloud." MCP servers are programs you run (or that vendors run for you). The Neon MCP server is hosted at
mcp.neon.tech; the filesystem MCP server runs as a local subprocess; a custom MCP server you write runs wherever you deploy it. - Not a security boundary. MCP defines transport and protocol; what tools an MCP server exposes and what they can do is the server's responsibility. A malicious MCP server can do anything its server-side code does. The trust boundary is still the agent loop deciding which tools to call, and the sandbox the tools execute in.
- Not a replacement for
@function_tool. Both still have a place. The decision tree is Concept 14.
Quick check. True or false: (a) An MCP client talks to exactly one MCP server at a time. (b) The same
@function_tool-style function, if you wanted, could be exposed as an MCP tool or kept as a function tool, and the model wouldn't know the difference. (c) MCP servers and OpenAI Agents SDK are tightly coupled, so to use MCP you must use the SDK. Answers: (a) False: an agent can connect to multiple MCP servers and see the union of their tools. (b) True: to the model, both look like callable tools with schemas. The difference is where the implementation lives. (c) False: MCP is model-agnostic. Claude, Gemini, and others have their own MCP clients. The OpenAI Agents SDK is one client among many.
Try with AI
For each item, say which MCP primitive fits best (tool, resource, or
prompt), and why in one line:
A) The agent reads the current text of a policy document on demand,
but never writes it.
B) The agent issues a refund through the payment gateway.
C) Every Worker on the team should summarize incidents the same way,
from one shared, versioned template.
Then a judgment question. A teammate says: "We put the refund logic
behind an MCP server, so the agent can't do anything dangerous." Using
this concept's "what MCP is NOT," explain why that sentence is false,
and name where the real trust boundary actually lives.
Concept 12: The Neon MCP server, development plane, not runtime
The specifics in this concept will age. The pattern won't. Neon's MCP server tooling, auth flow, and exact tool surface change every few months. What stays true: a managed-database vendor exposes its management API through MCP for natural-language operations, while runtime production traffic uses direct connections or scoped custom servers. Verify against Neon's docs before pinning specifics.
You already connected the Neon MCP server to your coding agent during setup, and you've been leaning on it since: asking for the schema in plain English, checking what's in the tables, pulling a connection string. That fifteen-minute connection is worth pausing on, because it teaches the single most important line in this whole Part: what the Neon MCP server is for, and what it must never be wired to.
It exposes Neon's management API (projects, branches, schema, migrations, ad-hoc SQL) as tools your agent can call in plain language. That makes it a development tool, not a production one. Neon's own docs are blunt: "Never connect MCP agents to production databases."
Here is why that line is so hard. The server's run_sql tool runs any SQL the model writes. While you're building, that's the whole point: you say "show me users who signed up last week and never logged in," the model writes the query, the server runs it, you get your answer. Point that same tool at your live database and it becomes a door. Anyone who can slip instructions into your Worker (a customer typing a cleverly worded message) can ask it to read your entire database, because the tool's job is to run whatever SQL it's handed.
So keep using it where it shines, all of it during development:
- Schema and migrations. "Add a
prioritycolumn to the tickets table." The server tests the change on a throwaway branch first, then merges it. That branch-first habit is the safe way to evolve a schema. - Exploring your own data. "How many embeddings are in there, grouped by source?" Faster than hand-writing SQL for a one-off question.
- Looking things up. Connection strings, project settings, table shapes, without opening the Neon console.
You saw this in setup: you asked your agent to create the project, turn on pgvector, run the schema, and report the connection string, and it did all of it through these tools, testing the migration on a branch before touching main. No SQL typed by hand.
PRIMM, Predict. Your finished customer-support Worker needs to: (a) look up a customer's orders; (b) check the refund policy for their tier; (c) issue a refund; (d) write an audit row of what it did and why. Should it reach Neon through this same MCP server, or some other way? Confidence 1–5.
The answer: some other way, for all four. A live Worker should never hold a run_sql-style tool, that's a door you can't fully lock. It needs a few narrow abilities, not the power to run arbitrary SQL. The two production patterns are a custom MCP server that exposes only the specific operations it needs (Concept 14), or a direct Postgres connection wrapping them. Part 4 uses both: a custom customer-data server for the business operations, and a direct connection only for the audit subsystem (Decision 7 explains why audit stays off the MCP boundary it's auditing).
This is exactly Invariant 5: the workforce reads and writes through governed stores. A broad run_sql tool isn't governance, it's a friendly face on no governance at all. The Neon MCP server is how you build the store. It is not how your Worker touches it.
Try with AI
Read Neon's MCP server documentation page and answer three questions:
1. List THREE management operations the Neon MCP server exposes that
would be useful while you're building a customer-support Worker.
2. List THREE things a running Worker NEEDS to do that you should NOT
use the Neon MCP server for, and why.
3. For each of the three in (2), say what the Worker should use instead
(direct Postgres connection? custom MCP server? function_tool?).
Concept 13: Connecting MCP to the OpenAI Agents SDK
You've been driving the Neon MCP server from your coding agent. Your Worker, the one you build in Part 4, is a different program: an OpenAI Agents SDK agent. So the question this concept answers is simply: how does that agent talk to an MCP server? You won't write the connection plumbing by hand, the SDK ships it. What's worth understanding is the shape, so you can steer the build and debug it when it misbehaves.
Here's the whole picture. The SDK has a built-in MCP client with one connector per transport: a local one for stdio, a modern one for remote streamable HTTP, and a legacy one for SSE (avoid SSE for anything new). You open a connection to a server, hand it to your agent, and from there the SDK does everything: it asks the server what tools it has, lays those tools in front of the model right next to the @function_tools you wrote yourself, and when the model picks one, routes the call to the right server and brings the answer back. The model can't tell an MCP tool from a local function tool, and it doesn't need to. That sameness is the point: MCP is just another way to hand the model a capability.
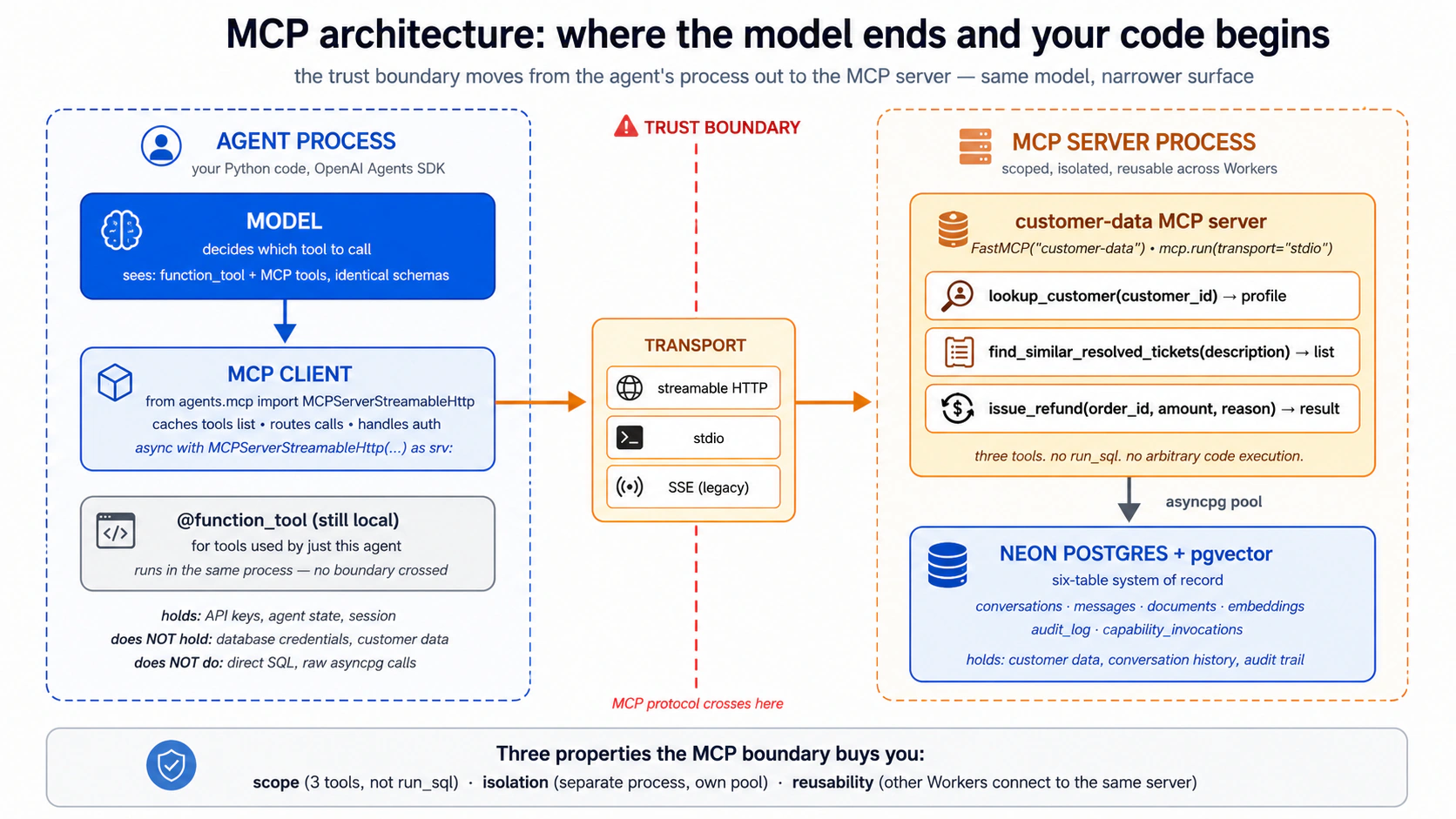
Four things to keep in mind, all of which your agent handles for you once you ask for them:
- Open the connection cleanly, and close it cleanly. An MCP connection holds something open: a subprocess for stdio, an HTTPS session for remote. If it isn't closed properly the connection leaks. The SDK's connection objects are built to be opened and closed as a managed block, so this is handled as long as you don't fight it.
- Cache the tool list in production. By default the agent re-asks the server "what tools do you have?" on every single run, a wasted network round-trip. Turning on caching makes it ask once. The one catch: if you change the server's tools, you tell the agent to refresh the cache (or restart it). While building, leave caching off so changes show up immediately.
- Servers stack. You can hand your agent several MCP servers at once, and the model simply sees the combined set of tools. Part 4's Worker connects to its custom
customer-dataserver this way. - Gate the dangerous tools behind approval. By default tool calls run with no confirmation. For sensitive ones you can require a human to approve each call. This is the practical knob for the development-vs-runtime gap from Concept 12: even while you use the Neon MCP server by hand, putting its destructive tools (anything that drops or rewrites) behind an approval prompt is a real safety win.
One gotcha worth filing away: if an MCP server loads something heavy at startup (a machine-learning model, for instance), the agent's default "did the server answer in time?" window can be too short and you'll see a confusing connection-failure error. The fix is a single setting that lengthens that window. You'll only meet this if a server does real work the moment it boots.
Hands-on, for understanding only. This is the fastest way to make the shape concrete. Paste the prompt below into your coding agent. It builds a tiny throwaway script that points an OpenAI Agents SDK agent at the Neon MCP server you already have connected, and lets you watch the agent list your projects in plain language. This is a learning exercise, not the production path: a real Worker never connects to the Neon MCP server (Concept 12). You're doing it once, here, to see an Agents SDK agent drive an MCP server end to end.
Write me a small throwaway Python script (call it scratch_neon_agent.py)
that uses the OpenAI Agents SDK to connect to the Neon MCP server over
its remote streamable-HTTP transport, then runs one agent turn asking it
to "list my Neon projects and show the schema of the largest one."
Use the current OpenAI Agents SDK MCP classes (check the docs for the
exact import and class name). Open the connection as a managed block so
it closes cleanly, turn on tool-list caching, and print the final output.
Then run it and show me what the agent did, step by step. Remind me in a
comment that this is for understanding only and a real Worker should
never connect to the Neon MCP server.
Watch what happens: the agent connects, the SDK pulls in Neon's tools, the model picks list_projects on its own, and you get an answer in English. You just saw the same wiring your Part 4 Worker will use, only pointed at a server it shouldn't use in production, which is exactly why you're throwing this script away.
Try with AI
Explain, in plain language and without writing code, how you would
connect one OpenAI Agents SDK agent to TWO MCP servers at once: the
Neon MCP server (remote) and a local filesystem MCP server for reading
project files. Cover:
1. Which transport each server would use, and why.
2. How the model decides which server's tool to call.
3. Which tools you'd put behind human approval, and why.
4. One thing that could go wrong with two servers connected, and how
you'd notice it.
Concept 14: Custom MCP servers, when to write your own vs. when not to
The Neon MCP server is generic: it can do anything Neon's API can do. That's its strength for development and its weakness for runtime. A custom MCP server inverts the trade-off: narrow surface, no general-purpose run_sql, only the specific operations your Worker actually needs.
The decision tree, in order of priority.
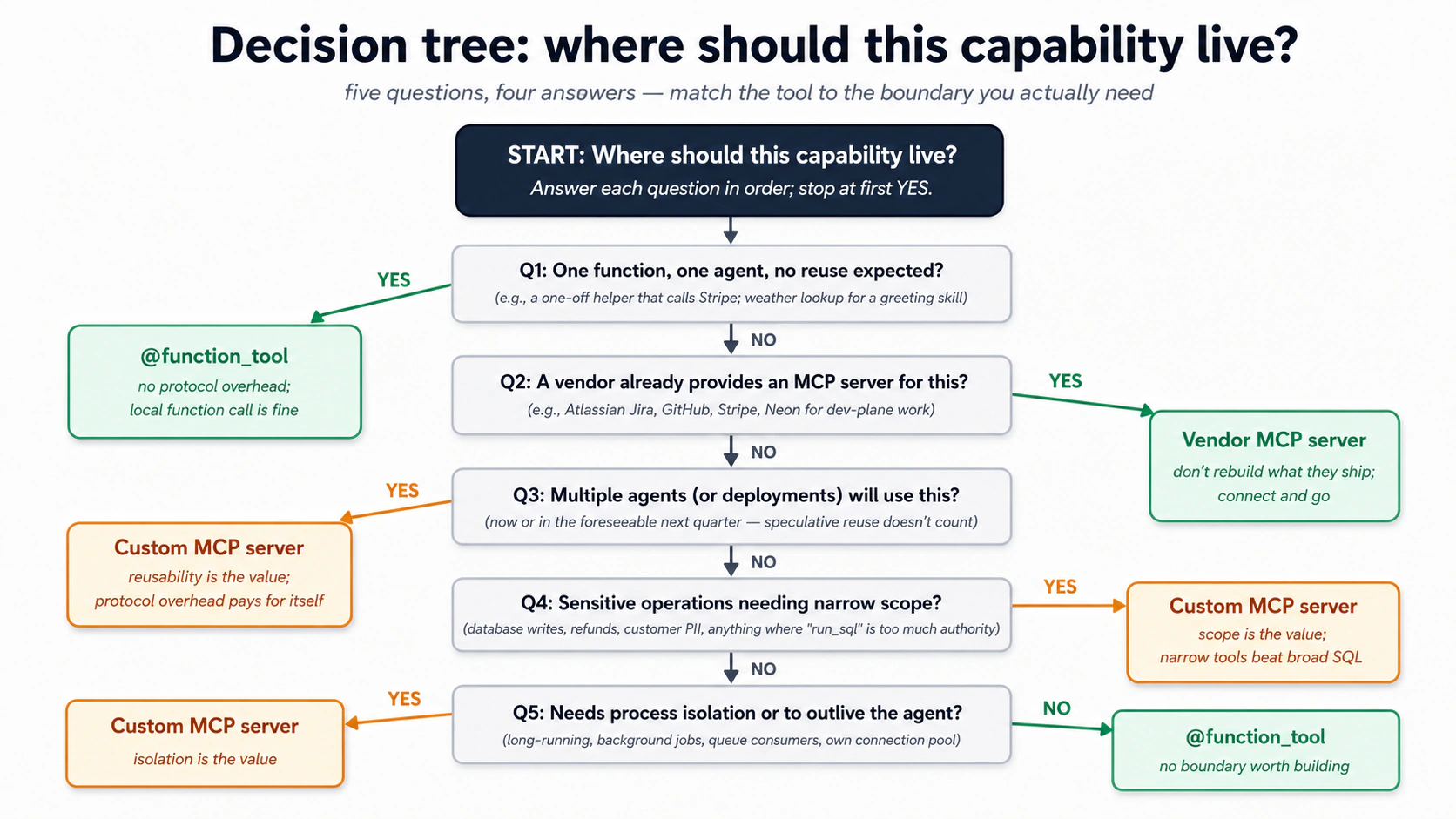
The same logic in a quick-scan table:
| You want to expose... | Use this | Why |
|---|---|---|
| One function with one input, used by one agent | @function_tool | No need for protocol overhead. Local function call is fine. |
| Several functions tightly coupled to your agent's code | @function_tool | If they share state with the agent and live in the same repo, they're part of the agent. |
| A capability that multiple agents (or multiple deployments) will use | Custom MCP server | The protocol is what makes it reusable. |
| A capability that needs to outlive the agent's process | Custom MCP server | Long-running connections, background jobs, queue consumers. |
| Vendor-provided functionality (Neon, GitHub, Linear) | Vendor's MCP server | Don't rebuild what they ship. |
| Sensitive operations that need narrow scope | Custom MCP server | Define exactly the tools you need; nothing else. |
The shape of a custom MCP server is simpler than it sounds. It's a small program that declares a handful of named tools. Each tool has a plain-English description (the same kind of trigger text a SKILL.md carries) that tells the model when to reach for it, and a short list of typed inputs so the model knows what to pass. That's it: a few well-described, narrow tools and nothing else. No general run_sql, no escape hatch.
And you don't hand-write that program. The same way you've installed skills and let your agent do the work, there's an mcp-builder skill that turns a scope description into a working, tested server. Your judgment goes into the scope, which tools exist, what each one is allowed to do, and which ones deliberately don't, not into the plumbing. The prompt flow looks like this:
/mcp-builder Let's design a custom MCP server called "customer-data"
on the streamable-HTTP transport, stateless flavor (each call an
independent request, no open session, so it scales). Plan the
implementation first, then build it.
Scope: exactly three tools, nothing else.
- lookup_customer(customer_id): return id, email, tier, open-ticket count
- find_similar_resolved_tickets(description, limit): semantic search over
past resolved tickets
- issue_refund(order_id, amount_cents, reason): issue a refund (amount in
integer cents, never a float) AND write an audit row in the same transaction
No general SQL tool. Each tool gets a clear description so the model
knows when to call it. Start a fresh project with uv, walk me through
the plan before writing code, then build and verify it.
The agent scaffolds a new uv project, plans the tools, builds the server, and verifies it runs. Once it exists, you connect it the same two ways you've already seen MCP servers connected: to your general coding agent (Claude Code or OpenCode, so you can test it by hand) and to your OpenAI Agents SDK Worker (so the Worker can actually use it). Decision 6 of Part 4 walks this build end to end.
Three things this server gives you that @function_tool doesn't.
-
Process isolation. The MCP server runs in its own process (subprocess for stdio, separate service for streamable HTTP). A crash in the server doesn't crash the agent; a memory leak in the server doesn't leak in the agent.
-
Scope. The server exposes only the handful of tools you define (the worked example's
customer-dataserver has three). Norun_sql. No "execute arbitrary code." The model can't escape this scope because the protocol doesn't expose anything else. This is a real defense in depth: even if the model decided to do something stupid, the surface area to do it through is those few functions. -
Reusability across agents. A second agent (a Sales Worker, a Reporting Worker) can talk to the same
customer-dataMCP server. Same scope, same protocol, same trust boundary. The capability becomes a shared piece of infrastructure rather than a copy-paste between agents.
The trade-off is real. Custom MCP servers add operational complexity: another process to deploy, another set of logs, another network hop (if remote), another version to manage. Don't write one for a single function used by a single agent. Write one when the capability is going to be reused, when scoping matters, or when isolation buys you safety.
PRIMM, Predict. You're designing the customer-support Worker. You need: (1) semantic search over past resolved tickets; (2) writing a refund audit row; (3) reading the current weather (used in one greeting skill that says "good morning from sunny Karachi"); (4) calling the payment gateway to issue a refund. For each, predict:
@function_tool, custom MCP server, or vendor MCP server (e.g., Stripe's, if such exists)?
The answers tease out the framework:
- Custom MCP server (
customer-data). Reused across agents; sensitive data; scoped tools beat a broadrun_sql. - Custom MCP server (
customer-data) or@function_tool. Either works; if the Worker is the only writer, function tool is fine. If multiple Workers will write audit rows, MCP server. @function_tool. One agent, one tiny function, no security surface to defend. Don't build a server for it.- Vendor MCP server (Stripe MCP) if it exists, else
@function_toolcalling Stripe's API. Don't wrap third-party APIs in your own MCP server unless you need to add policy on top.
The framework is clear once you trace it: the value of MCP rises with the value of the boundary it creates. A boundary you don't need is overhead.
Try with AI
Paste this into your coding agent. It applies the decision tree to the customer-support Worker you're actually building, so every choice is one you could ship, not a guess about infrastructure you don't have.
Here are five capabilities I'm thinking of adding to my customer-support
Worker. For each, walk the Concept 14 decision tree with me and recommend
one: a @function_tool, my custom customer-data MCP server, or a vendor
MCP server (if a credible one exists). Justify each choice with ONE of
the three properties (isolation, scope, reusability), or say plainly why
no boundary is worth building.
1. Look up a customer by email (the gap Decision 8 leaves open).
2. Issue the real refund through Stripe (actual money, third-party API).
3. Send the drafted reply as an email through our mail provider.
4. Convert a UTC timestamp to the customer's local time for a greeting.
5. Let a second Worker (a sales assistant) reuse the customer lookups.
Then push back on me: which TWO of these would you deliberately NOT put
behind a custom MCP server, and what does that say about when the
boundary earns its cost?
Concept 15: MCP under load: transports, pooling, and what happens at scale
A demo with one agent and one server just works. Real traffic, many conversations a minute, adds three pressures. You don't need to act on these for a first Worker, but knowing they exist saves you a confused afternoon later. Each has a plain fix.
- The wire between agent and server. A local subprocess (stdio) is fine while everything runs on one machine. The moment more than one agent shares the server, or the server moves to its own hardware, switch to the remote transport (streamable HTTP). That's a deployment change, not a rewrite.
- Don't pay the same setup cost over and over. Three small habits turn repeated costs into one-time ones: connect to each server once when the Worker boots and keep that connection open, rather than reconnecting on every request; let the agent remember the server's tool list instead of re-asking "what can you do?" every run (refresh it when you change the tools); and keep a ready pool of database connections inside the server, so a query doesn't wait to open a fresh one each time. One quirk a long-lived Worker hits on a scale-to-zero or pooled Postgres (Neon): the pooler closes idle connections, so if the process blocks (a terminal
input()prompt freezes the asyncio event loop), the next write fails with "connection was closed in the middle of operation." Run blocking prompts off the loop (asyncio.to_thread) and have the pool re-acquire once on that error. - Put a ceiling on everything, and keep the trace whole. Cap how many steps one request may take, retry a failed tool call a couple of times before giving up, and rate-limit the server so one burst can't swamp it. And make sure your trace follows the call across the MCP boundary: when the Worker calls a tool, you want the server's own database work to show up in the same picture. Otherwise a slow query inside the server is invisible from the outside, and you'll chase the latency in the wrong place.
The deeper knobs (per-tenant concurrency caps, fine transport tuning) are past what a first Worker needs. These three are the ones that bite first.
Quick check. True or false: (a) Moving a server from the legacy SSE transport to streamable HTTP forces you to rewrite the server's tools. (b) Letting the agent cache a server's tool list is safe in production, as long as you refresh the cache after you change the tools. (c) Exposing five abilities as MCP tools always costs the model more context budget than exposing the same five as local function tools. Answers: (a) Mostly false: the tools are unchanged; the server just needs to speak the newer transport, which most modern ones already do. (b) True: that's the intended pattern. (c) False: to the model a tool is a tool. Five tool descriptions cost about the same whichever side they live on.
Try with AI
My customer-support Worker is in production. It runs 80 conversations/minute
at peak. Each conversation makes 2-4 MCP tool calls on average. I'm seeing
intermittent latency spikes: most calls return in 200ms, but a small
percentage take 5-15 seconds.
Walk me through five places I'd investigate, in order of priority:
1. The agent-side MCP client connection management.
2. The transport choice between agent and MCP server.
3. The MCP server's internal connection pool to Postgres.
4. Postgres-side query performance (slow queries blocking the pool).
5. Network or DNS issues between agent and MCP server.
For each, name the specific signal I'd look for and the rough fix.
Part 4: The worked example, customer-support Worker
One realistic build that uses every concept above. You start with a minimal chat agent (one prompt, about a minute), then grow that same worker into a customer-support Worker, one piece at a time. Each Decision adds a piece, the system of record, then Skills, then the MCP layer, then the audit trail, and you re-run the worker each time so you see the new piece work before moving on. Eight Decisions build the worker; a ninth puts a human in front of the one action that moves money.

Step 0: stand up the chat agent (one prompt, ~1 minute). So everyone starts Decision 1 from the same place. (Did Build AI Agents? Open that project instead, it's the same agent, and skip to Decision 1.)
In this digital-fte folder, build me a small terminal chat agent with the
OpenAI Agents SDK: a uv project, a gpt-5-class model, on a local sandbox.
Check the current SDK docs for the API. Get it answering "hi", then stop,
we grow it in the steps below.
Creates: the worker file (e.g. worker.py) plus its uv project.
Check. You send "hi" and it answers. That's the starting line; Decision 1 teaches it the new architecture through
AGENTS.md.
The brief
Evolve the minimal chat agent from Step 0 into a customer-support Worker that:
- Loads three Skills on demand:
summarize-ticket,find-similar-cases, andescalate-with-context. - Reads from and writes to a Neon Postgres system of record with the five tables from Concept 7 (conversation turns live in the SDK Session on the same database).
- Uses pgvector for semantic search over a small library of past resolved cases.
- Talks to Postgres for business data at runtime through a scoped, custom MCP server (
customer-data), never the Neon MCP server and never directasyncpgin agent code. - Writes an audit row for every meaningful action (every skill invoked, every database write, every refund considered) through its own direct connection, the one path that deliberately bypasses the MCP boundary, so the audit trail can't be starved by the system it audits.
The "verification at the end" test: a customer messages "I haven't received my refund from order #4429, it's been two weeks." The Worker finds three similar past cases via vector search, drafts a response that cites the most similar case's resolution, and writes an audit row of what it did (and, in a real deploy, escalates if the customer is Pro-tier). Resolving the exact customer or order record from the message needs a lookup tool you add later; Decision 8 shows where that gap is.
How to read the prompts that follow. You grow this Worker by prompting your coding agent one small task at a time, and every Decision ends the same way: the new piece is wired into the one worker and you run it, so you see it work before the next Decision builds on it. You won't type SQL, Python, or config: the agent writes it, you steer and check. Your agent already read
AGENTS.mdwhen it opened the folder, so it knows the project; your prompts stay short. Two habits:
- One step, one task. Paste that step's prompt and nothing else. For anything that writes real code, the prompt says "plan first": read the plan, push back, approve, then let it build.
- Check before the next step. Each step ends with a Check: one plain-English question you ask ("show me X"). Don't move on until it passes, or you'll be four steps deep before you find step one was wrong.
Decision 1: Update the rules file with the new architecture
Where you are: a minimal chat agent that answers "hi"; this Decision adds the three architecture rules to AGENTS.md; by the end you will see those rules in the file's diff.
Your agent already knows this project from AGENTS.md. What it doesn't yet know are the few rules this course's architecture adds, so you write those into AGENTS.md now, and every later prompt can stay short. One task.
Step 1: Add the new rules to AGENTS.md.
Add a short "Rules" section to AGENTS.md so a fresh session follows these:
- business data is read and written only through the customer-data MCP
server, never raw SQL from the running worker
- the audit log uses its own direct database connection, and each action
and its audit row are committed together
- embeddings use the same model to store and to search
Show me the diff before you write it.
Edits: AGENTS.md.
Check. Read the diff. Those three rules are there, in plain language, the first one especially: it's what stops the model from quietly going around the MCP boundary later. If the agent softened or dropped one, re-prompt.
Why. A weak rules file fails silently weeks later, when the model takes the shortcut the rule was meant to forbid. Writing it now is what keeps every prompt after this one short.
Decision 2: Plan the schema and the Skill set
Where you are: an AGENTS.md that states the architecture but no design for it yet; this Decision adds a reviewed written plan; by the end you will see a markdown plan you've pushed back on and approved.
You end this Decision with a written plan you've reviewed, before a line of code exists. One task. Press Shift+Tab twice to enter Plan Mode (in OpenCode, press Tab to switch to the Plan agent): the model can read your project but can't edit anything.
Step 1: Get the plan.
Plan the customer-support Worker evolution of this project. The
foundation (OpenAI Agents SDK, your sandbox runtime, sessions, streaming,
guardrails) stays. We're adding:
1. Three Skills: summarize-ticket, find-similar-cases, escalate-with-context.
For each, propose: the description, the operational shape (script-driven
or instruction-driven), and what reference files it needs.
2. The five-table schema from Part 2 Concept 7, plus any tables specific
to a customer-support domain (probably: customers, orders, tickets, refunds).
3. The custom MCP server (customer-data), with exactly the runtime tools
our agent will need. Propose the tool list and signatures. No run_sql.
4. The audit-logging plan: what writes an audit row, what doesn't.
Output the plan as a markdown file at plans/customer-support-worker-plan.md.
Do not write code yet.
For reference the part 2 here: https://agentfactory.panaversity.org/docs/digital-fte-crash-course
Creates: plans/customer-support-worker-plan.md.
Check. Read the plan and push back on the two things the first draft usually gets wrong: vague Skill descriptions ("Summarizes tickets", a description that never fires correctly, Concept 3) and over-broad MCP tool inputs ("query: string", which is just
run_sqlin disguise;lookup_customershould take acustomer_id, not free text you build SQL from). Don't approve the plan until both are tight.
Why a plan first. Both failure modes cost hours once they're built and minutes to fix in a markdown plan. This is the cheapest place in the whole Part to be wrong.
You are about to touch the database for the first time, and you will see a lot of SQL across Decisions 3 through 8. You never type it or run it by hand. Three components own it, and there are two different MCP servers doing two different jobs.
| SQL / data path | Who writes it | Who runs it | When |
|---|---|---|---|
| Schema + migrations (this Decision) | You describe it; the agent drafts it | Neon MCP server (a dev tool you connect to your agent) | Once, at setup |
| Verification queries (the "Done when" checks) | Shown in the lesson | Neon MCP server run_sql, driven by you in plain English | To confirm a step worked |
| Runtime business SQL: lookups, vector search, refunds (D6) | mcp-builder generates it | The customer-data MCP server you build | Every customer interaction |
| Audit writes (D7) | The audit subsystem code | A separate asyncpg pool (no MCP) | Every action |
Two MCP servers, never confused. The Neon MCP server (which you authenticated in the setup step above) is a development tool: you use it to provision and verify the database in plain English, and you never use it at runtime. The customer-data MCP server is the scoped server you build in Decision 6; the running Worker talks to that one, and only that one, for business data. Concept 12 explains why a general-purpose run_sql in production is a prompt-injection hole.
Read, write, and drop are not equal authority. The running Worker's tools split by risk:
- Read (
lookup_customer,find_similar_resolved_tickets, built in D6): runs freely, no gate. Reads are cheap to allow. - Write (
issue_refund, built in D6): the one tool that moves money. You gate it behind human approval in Decision 9, after the Worker works end to end, so a human signs off before any refund goes through. Audit writes are append-only: inserted, never updated or deleted. - Drop / schema change (
CREATE/DROP TABLE, DDL): not callable at runtime at all. The custom server never exposes a DDL tool, so there is nothing to approve. Schema changes happen only at dev time (this Decision), through the Neon MCP server, on a temporary branch before they ever touchmain.
The rule of thumb: reads run free, writes are gated, and structural changes never reach production through the agent.
Decision 3: Provision Neon and run the schema migration
Neon's free tier covers a single Worker at the volume Part 5 assumes (~200 conversations/day). Plan on $0/month here. The free plan limits are 0.5 GB storage and 100 compute-hours per project (Neon pricing); above that, the Launch tier is pay-as-you-go (roughly $0.11/CU-hour + $0.35/GB-month), and a worked-example Worker typically stays under $25/month. See Part 5's cost shape table for the full breakdown.
Where you are: an approved plan but no database; this Decision adds a live Neon database with your schema and a persistent Session; by the end you will see nine tables in Postgres and a worker that recalls earlier turns.
You end this Decision with a live Neon database holding your schema, plus a Session that persists conversation turns into it. Four small steps, and you check each before the next, because a broken database step is invisible until something downstream reads nothing. Press Shift+Tab to exit Plan Mode and make sure the Neon MCP server is connected (Concept 12). The agent runs all of this through the Neon MCP tools; you never open a database console.
Step 1: Create the project.
Create a fresh Neon project called "chat-agent" and give me the
connection string for its main branch.
Check. Ask the agent to confirm the project exists and paste the
mainconnection string back. (You can also see it in the Neon console.) Don't continue without a connection string in hand.
Step 2: Turn on pgvector.
Enable the pgvector extension on the chat-agent database.
Check. "Confirm the
vectorextension is now listed on the database." If it isn't, nothing downstream that stores embeddings will work, so stop here until it is.
Step 3: Apply the schema, branch-first.
Apply our schema to chat-agent: the five-table core from Concept 7
(conversations, documents, embeddings, audit_log, capability_invocations)
plus four domain tables, customers, orders, tickets, refunds. Build the
audit_log and capability_invocations columns EXACTLY as Concept 7 prints
them: audit_log keeps its `target` column and the closed `action` CHECK
set, capability_invocations keeps its `status` CHECK set, so Decision 8's
replay query matches the schema you built. Test it on a temporary branch
first, then merge to main. Plan the DDL first; I'll approve before you merge.
Check. "Count the tables in the public schema, I expect nine, and confirm the embeddings index exists." Nine tables means the migration landed. If it's short, the merge didn't apply cleanly: have the agent re-run on a fresh branch. (This is exactly Concept 12's development use case: schema work in plain English, tested on a branch, merged to
mainonly after your "go ahead.")
Roughly what you should see:
table_count = 9
embeddings index: present
Step 4: Give the worker its Session, and prove it remembers.
Write the connection string to .env as NEON_DATABASE_URL, then give the
worker a SQLAlchemySession on that database so it remembers across turns.
Install what the session needs (the sqlalchemy extra, asyncpg, pgvector,
and greenlet), and use the postgresql+asyncpg:// form of the URL for it.
Edits: the worker file (adds the Session); writes NEON_DATABASE_URL to .env.
Check. Run a two-turn conversation: tell the worker your name and an order number, then in a second turn ask it to repeat them back. It recalls both, that is the Session doing its job, not just a row sitting in a table. Then ask: "show me those turns in the
agent_messagestable." Seeing them in Postgres proves state now lives in the system of record, not just in memory. (Two things the agent often misses: the[sqlalchemy]extra does not pull ingreenlet, so it needsuv add greenlet; and the async engine needs thepostgresql+asyncpg://form of the URL, not the barepostgresql://.SQLAlchemySessioncreatesagent_sessionsandagent_messagesfor you.)
Decision 4: Define and prove the first Skill, summarize-ticket, then wire it in
Where you are: a worker that remembers but has no portable capability; this Decision adds three Skills on disk and wires them into the worker; by the end you will see one fire on a real run.
You end this Decision with three Skills on disk, the first one proved against criteria you set, and the Skills capability wired into the worker so you watch it fire. Here is the shift from how people usually write skills: you don't hand-author the skill and eyeball it. You tell skill-creator when the skill should fire and what a good result looks like, and it builds, tests, and tightens the skill against those criteria. Defining success and judging the results is the job a domain expert does in the real world; the authoring underneath is the tool's.
Step 1: Confirm skill-creator is available. You already installed it (with mcp-builder and neon-postgres) back in the base prep, so it is sitting in .claude/skills/ and you do not reinstall it here. Re-add it only if it has somehow gone missing:
npx skills add https://github.com/anthropics/skills --skill skill-creator --agent claude-code -y
Check.
skill-creatoris present in.claude/skills/. (One install served both tools: OpenCode reads.claude/skills/as a fallback, so there was never a separate--agent opencodeinstall to run.)
Step 2: Define what the skill does and when it fires. skill-creator asks you for the two things only you can decide, the trigger and the output. Give it both up front, in plain language, and let it draft.
Use skill-creator to build a summarize-ticket skill. Here is the spec.
Output: turn one support ticket into a five-section handoff (Customer
Context, Issue, Resolution Steps Taken, Current Status, Recommended Next
Action). It SHOULD fire on phrasings like "write a handoff note for #4471",
"TL;DR this thread", and "where does this stand before I escalate",
including ones that never say "summarize". It should NOT fire on drafting a
customer reply, triaging a batch, or reporting on ticket volume. Draft the
skill from that, then we'll test it.
Creates: .claude/skills/summarize-ticket/.
Check. A draft exists under
.claude/skills/summarize-ticket/, and itsdescriptionreflects YOUR fire / don't-fire list, not a generic "summarizes tickets." That description is the one input that decides whether the skill ever runs (Concept 3); you handed it over as testable criteria instead of guessing at the wording.
Step 3: Let skill-creator test it and tighten it. This is the part that replaces eyeballing the description. skill-creator turns your fire / don't-fire list into trigger evals, runs them, and improves the description until the skill fires when it should and stays quiet when it shouldn't.
Test summarize-ticket against the fire and don't-fire cases I gave you:
turn them into trigger evals, run them, and tighten the description until
it passes. Show me which cases pass and which fail, before and after.
Check. You read the eval results, not the raw description: the skill fires on the handoff, TL;DR, and status phrasings and stays quiet on the near-misses (drafting a reply, batch triage). That pass / fail table is the rigorous version of Concept 3's "delete the keyword and see if it still says when to fire" instinct. The model decides whether to run this skill from its description alone, so getting that table green is the whole game.
Both tools, one discipline. In Claude Code, skill-creator runs this as an automated loop: it splits your cases into a training set and a held-out set, runs each a few times for a reliable trigger rate, and optimizes over several rounds, keeping the description that scores best on the cases it did not train on. In OpenCode you run the same loop by hand: define cases, test, tighten, repeat. The automation differs; the discipline of proving the trigger against real phrasings is identical.
Step 4: Define the other two Skills the same way. Same move: define when each fires and what it produces, and let skill-creator build them. You don't need the full test loop on all three; running it once on summarize-ticket taught you the cycle. Give it the trigger and the output shape for each; the descriptions it lands on should read like the ones below. The Worker needs all three.
# .claude/skills/find-similar-cases/SKILL.md (frontmatter only)
---
name: find-similar-cases
description: Searches the resolved-tickets library for tickets semantically similar to a customer's described issue, returning the top 3-5 with their resolutions, ranked by how closely each matches. Use when the user describes a problem, complaint, or symptom and you need to check whether the team has handled something similar before. Calls the find_similar_resolved_tickets MCP tool. Always run this BEFORE drafting a response, so the response can reference proven prior resolutions rather than inventing a new approach.
---
The body walks through these steps:
- Extract the issue description from context.
- Call
find_similar_resolved_ticketswithlimit=5. - Present the top three with their distance values in a markdown table.
- Explicitly flag low-confidence matches (distance above ~0.3, where lower means more similar) as "no strong prior precedent found."
The instruction "always run this BEFORE drafting" is doing real work; without it, the model sometimes drafts a reply from priors and never looks at the library.
# .claude/skills/escalate-with-context/SKILL.md (frontmatter only)
---
name: escalate-with-context
description: Packages a customer conversation for handoff to a tier-2 support agent. Produces a structured escalation note with customer profile, issue summary, what was already tried, why escalation is recommended, and the suggested specialist team. Use when (a) the customer is on the Pro or Enterprise tier AND the issue is unresolved after one round of investigation, (b) the customer's sentiment is clearly negative, (c) the issue involves billing >$500 or a refund decision, or (d) the user explicitly asks for a human.
---
The body invokes summarize-ticket first to get the structured context, then writes a six-section escalation note (customer context, issue, attempted resolutions, sentiment signals, recommended team, suggested SLA). The four explicit trigger conditions in the description are what stop this skill from over-firing; a Worker with vague escalation logic escalates everything, which defeats the purpose.
Check. Both descriptions name explicit, specific triggers, not "use when relevant."
escalate-with-contextespecially: its four conditions are what keep it from firing on every message. All three Skills now live in.claude/skills/.
Creates: .claude/skills/find-similar-cases/ and .claude/skills/escalate-with-context/.
Step 5: Wire the Skills capability into the worker, and watch one fire. The three Skills are on disk; now the worker itself has to load them. Give it the Skills capability on top of its default capabilities, then run it.
Give the worker the Skills capability pointed at .claude/skills, on top of
its default capabilities, and run it from the project root with: "write a
handoff note for ticket #4471, refund delayed two weeks, customer Sam."
Show me the run so I can see the skill load.
Edits: the worker file (adds the Skills capability).
Check. The run shows a
load_skillcall forsummarize-ticketand the reply comes back in the five sections: that is the skill firing inside your own worker, not just sitting on disk. If instead the worker free-writes a summary and noload_skillappears, the path resolved wrong: Skills load from a path relative to where the worker runs, so run from the project root with a relative.claude/skills, not an absolute one. (On macOS an absolute path under/tmpsilently loads zero skills, with no error at all, which is the most confusing way this can fail.) One more: you add Skills to the default capabilities, you don't replace them, or the worker loses the filesystem and shell it relies on.
Roughly what you should see in the run:
tool call: load_skill(name="summarize-ticket")
reply: Customer Context / Issue / Resolution Steps Taken / Current Status / Recommended Next Action
Why wire it now. This is the moment Skills stop being files and become capability: the next message that mentions a ticket fires this skill from its description alone. The other two Skills lean on the MCP tools you build next, so summarize-ticket, which stands on its own, is the honest one to verify here.
Decision 5: Build the embedding pipeline and seed the document library
A seed corpus of a few dozen resolved tickets at ~300 tokens each embeds for a fraction of a cent at text-embedding-3-small's $0.02 per 1M input tokens. Ongoing embedding of new tickets and conversations typically stays under $3/month at the worked-example volume. The cost lever is the inference budget, not the embedding budget.
Where you are: a schema with empty tables and skills that have nothing to search; this Decision adds a seeded, embedded library of past resolved tickets; by the end you will see a similarity search return ranked matches.
You end this Decision with a small library of past resolved tickets, embedded and searchable. Two steps.
Step 1: Generate the seed library in code. The Worker's "library" is a set of past resolved tickets: small enough to run fast, varied enough that search has something to tell apart. You don't hand-write it, and you don't fill in a CSV; the agent generates it.
Have the worker's own SDK generate a dozen-plus varied resolved tickets as
structured data (a Pydantic model is the clean way): each with a customer
email, a one-line summary, and the resolution. Vary the issues across
refunds, logins, duplicate charges, and shipping, so semantic search has
something to tell apart. Write the generator and run it; don't hand me a CSV.
Creates: the ticket generator script.
Check. A dozen-plus generated tickets across genuinely different issues (refunds, logins, charges, shipping), not rewordings of three. You never hand-typed a row, and that is the point: a Worker's own seed data is something the Worker can produce.
Step 2: Seed and embed. Each generated ticket carries a customer_email, which lets the seeder find-or-create a customers row before inserting the ticket (the tickets.customer_id foreign key is NOT NULL). Then:
Seed the generated resolved tickets so the Worker can search them later.
For each one: find-or-create the customer by email, insert a resolved
ticket, store the case text as a documents row tagged source='past_case'
with the ticket id at metadata->>'ticket_id' (there is no ticket_id column
on documents), then embed that text with
text-embedding-3-small and link the embedding to the document. Write one
audit_log row for the whole seed run. Plan first.
Creates: the seed-and-embed script.
That shape is not arbitrary, and it's the part the agent can't guess: Decision 6's find_similar_resolved_tickets searches by joining embeddings to documents (where source='past_case') to tickets. If the seed doesn't lay the rows down that way, the search in Decision 8 silently returns nothing and you'll have no idea why. The agent writes the actual seeder; you're specifying the shape it has to produce. Two rules to confirm in the result, both from Concept 9 and both already in your AGENTS.md: embed with the same model you'll query with later, and register pgvector on the connection (or the vectors write back as garbage).
Check. Ask the agent to read the result back: "Count the documents tagged as past cases (should match the number of tickets you generated), count the embeddings (should match too), confirm only one embedding model is present, and run one similarity search to show the closest match to 'refund delayed two weeks' comes back ranked." Two failure shapes: if it reports two embedding models, the seed mixed models partway, reset and re-run; if the counts come back zero, the seeder swallowed an error, have it read back the
audit_logrow it wrote for the seed run (which is exactly why the seeder writes one). Don't move to Decision 6 until a similarity search returns ranked results.
Roughly what the similarity search should return:
query: "refund delayed two weeks"
1. "refund not received after 14 days" distance 0.08
2. "duplicate charge, awaiting reversal" distance 0.24
Why this is a direct connection, not MCP. A seed script is infrastructure: it runs once, by hand, by you, not something the Worker does on its own. The MCP boundary is for what the agent does autonomously; the seed script is something you do. Don't put a boundary between yourself and your own database when you're the one at the keyboard.
Decision 6: Define, build, and connect the customer-data MCP server
The custom MCP server runs as a small service alongside your Worker; co-located on the same host it adds no meaningful hosting cost (only if you push it onto separate hardware does a compute line appear). Where the bill actually shows up is in inference: every lookup_customer or find_similar_resolved_tickets call adds a round-trip's worth of tokens to the next model turn. Concept 15 covers the latency and pool-size side of MCP-under-load.
Where you are: a seeded library the worker can't yet reach at runtime; this Decision adds the scoped customer-data MCP server and wires it in; by the end you will see the worker call one of its tools on a real message.
You end this Decision with the scoped customer-data server running and wired into your worker, its three tools callable from a real run. It is the same shape as the Skills in Decision 4: you define what the connector must do and how narrow it stays, mcp-builder builds it, and you prove it by using it. You steer the scope; you don't hand-write any FastMCP boilerplate. (Gating the one dangerous tool, issue_refund, comes in Decision 9, after the whole thing works.)
Step 1: Confirm mcp-builder is available. Like skill-creator, you installed it in the base prep, so it is already here. Re-add it only if it has gone missing:
npx skills add https://github.com/anthropics/skills --skill mcp-builder --agent claude-code -y
Check.
mcp-builderis present in.claude/skills/.
Step 2: Define the tool contract and the scope. This is the connector's version of defining a Skill's criteria: you say exactly which tools exist, what each takes, and how narrow the server stays (no general SQL), and mcp-builder plans it. Build it on streamable HTTP, stateless flavor (Concept 11's default): each call is an independent request, so the server is a real addressable service the Worker reaches by URL, and you can run more than one copy if traffic grows. (A purely local single-Worker build could use stdio; the stateless service matches what you'd actually ship.)
/mcp-builder Plan a custom MCP server called "customer-data" on the
streamable-HTTP transport, stateless flavor, with exactly three scoped
tools and no general SQL tool:
- lookup_customer(customer_id): return id, email, tier, open-ticket count.
Tier lives in customers.metadata->>'tier' (COALESCE to 'standard'); there
is no tier column.
- find_similar_resolved_tickets(description, limit): semantic search over
past resolved cases. Embed the description with text-embedding-3-small
(the SAME model the seed used) and register pgvector on the connection.
The search joins embeddings -> documents -> tickets, where the
documents->tickets link is documents.metadata->>'ticket_id' (there is no
ticket_id column on documents).
- issue_refund(order_id, amount_cents, reason): insert the refund (amount in
integer cents), set the order to refunded, AND write the audit_log row,
all in ONE transaction.
Give each tool a clear description so the model knows when to call it.
Show me the plan before any code.
Check. Read the plan before any code: exactly three tools, no general SQL tool, and
issue_refundwriting the refund, the order-status change, and the audit row in one transaction. Push back if any is missing. (One Neon gotcha to hand the agent only if you moved the schema off the defaultpublic: schema-qualify the table names, because Neon's pooled endpoint resetssearch_pathon connection release, soSET search_pathwon't survive. On the course's default migration it just works.) One Neon gotcha that always applies, here and in Decision 7: the pooled endpoint (PgBouncer, transaction mode) breaks asyncpg's prepared statements, so both this server's pool and the audit pool must passstatement_cache_size=0toasyncpg.create_pool(...), or the very first query errors.
Step 3: Build it, and let mcp-builder test the tools. Once the plan is right: "Build the server exactly as we planned, three tools and no more, then start it and confirm it boots cleanly. Don't add tools I didn't ask for." mcp-builder can go one step further and generate evaluations, realistic tasks the tools have to satisfy end to end, which is the connector's version of the trigger eval you ran on the Skill. For the course the decisive test is the next step, calling a tool from the worker, so a clean boot here is enough to move on.
Creates: the customer-data-mcp/ server.
Check. Read every tool's description in the built server: it's what the model reads to decide when to call the tool (the same role a
SKILL.mddescription plays), and a vague one fires at the wrong time. Then confirm the one thing the agent most often gets subtly wrong: theissue_refundbody does all three writes in a single transaction. Most of these disciplines also live in yourAGENTS.md, so a careful agent applies them; you're confirming they survived.
The customer-data server is a streamable-HTTP service, so it has to be running before the worker can reach it. From here on, the live runs (this Decision, and Decisions 8 and 9) need two terminals: start the server in one, run the worker in the other, server first. Stop the server and the worker's tool calls fail with a connection error, not a wrong answer.
Step 4: Connect it to the worker and call a tool. Wire the server into the worker that already has its Session and Skills, and prove a tool actually runs. This is the connector's version of watching the Skill fire in Decision 4:
Register the customer-data server with the worker as a remote
streamable-HTTP server at its URL, alongside the Session and Skills it
already has. Check the current SDK docs for the exact registration API.
Edits: the worker file (registers the customer-data server).
Check. It's a streamable-HTTP service, so start the server first, then run the worker on a real message: "Start the customer-data server, then run the worker on 'I'm Sam, and I haven't had my refund for order #4429 in two weeks.'" The worker should call
find_similar_resolved_ticketsand come back with ranked past cases, not an empty result and not a made-up answer. That is the MCP wire working: the worker reached business data through the scoped server, and only that server. Two red flags: a generalrun_sql-style tool in the list means the worker is still wired to the Neon MCP server at runtime, take it out (Concept 12); an empty result from the search means Decision 5's seed didn't land in the shape the join reads (embeddingstodocumentswheresource='past_case'totickets). If the server itself won't start, have the agent read its logs (the Concept 13 startup-import note is the usual cause).
Why a custom server, not just asyncpg in agent code. Concept 14's three reasons, in the order they matter here: scope (the agent can do exactly three things to the database, not anything SQL allows), isolation (the server runs in its own process with its own pool the agent can't exhaust), and reusability (a second Worker that needs lookup_customer talks to this same server). That narrow surface is the whole security argument, which is why Step 3's check is about the boundary, not the plumbing.
Decision 7: Wire audit logging everywhere
Where you are: a worker that acts but only records the one refund write; this Decision adds the agent's own actions to the audit trail; by the end you will see a message_received / skill_activated / capability_invoked / message_sent trace for one conversation.
This is one of the two Decisions where a first build usually hits an error; the callouts below name each one before you meet it, so read them first.
You end this Decision with the agent's own actions recorded in audit_log. The MCP server already logs one thing, issue_refund writes its audit row inside the refund transaction (Decision 6); what's left is the agent-side writes: skill invocations, model calls, tool calls, guardrail trips. One task, using the log_capability helper from Concept 10.
Step 1: Wire the audit helper at every boundary.
Wire the audit helper around the agent's own actions, at three points:
the start and end of each skill invocation, after each MCP tool call,
and around any guardrail trip. Use the separate audit connection (its
own pool), not the customer-data MCP boundary. Plan first.
Edits: the worker file (adds the audit wiring at each boundary).
The three "boundaries" above do not map to three matching hooks, and the naive wiring crashes the run. The reality:
- There is no skill hook. In the lazy Skills mode this course uses, a skill activates by the model calling the
load_skilltool, so observe skill start/end inon_tool_start/on_tool_endwheretool.name == "load_skill". MCP tool calls arrive through that sameon_tool_end. - Guardrail trips are raised exceptions, not a hook. Catch
InputGuardrailTripwireTriggered(and the output/tool variants) withtry/exceptaroundRunner.run, and write theguardrail_trippedrow there. on_tool_end'sresultis typedstrbut hands you the tool's raw object (a Pydantic model or dict). Slicing or string-ops on it throws, and an unhandled exception inside a hook kills the whole turn (it surfaces as a confusingUserError: Error running tool ...). Coerce withstr(...)AND wrap the hook body intry/exceptso an audit bug can never abort the user's turn.on_tool_endalso fires when a tool fails, handing you an"Error executing tool ..."result. Detect that (a substring check, notstartswith) and recordstatus="error", or a failed refund gets logged as a success.
Write the conversations row first. audit_log.conversation_id is a foreign key to conversations(session_id). If an audit row references a session that has no conversations row yet, the FK violates and rolls back the whole transaction, including the refund it was recording. Upsert the conversations row at message_received, before any audit row points at it (Decision 3 creates the table but never says when the row is written: it is here).
An input guardrail with a Session sees the whole transcript. Not just the new message: the full prepared history plus the new turn. So a flagged word from any earlier turn trips every later turn (a benign "say hello" gets blocked because a test token is still in history). Screen only the latest role: user item, not the whole input.
Check. Run one throwaway conversation, then: "Using the Neon tools, find the most recent conversation and show me every
audit_logrow for it, in order." You should see at least amessage_received, askill_activated(the worker has had its Skills since Decision 4), onecapability_invokedfor the MCP call, and amessage_sent. Two failure shapes: if you see only the MCP server's own rows (capability_invoked,refund_issued) and none of the agent-side ones, the helper is wired but never fires, have the agent confirm it runs from inside the streaming loop, not just once at startup; if you see zero rows, the audit connection isn't reaching the database, have it check the audit pool against your database URL.
Roughly what you should see (one conversation, in order):
message_received
skill_activated
capability_invoked
message_sent
Why the audit pool is separate. It uses its own connection, not the customer-data MCP pool, for two reasons: audit must succeed even when the data pool is saturated, and audit writes shouldn't compete with business writes for connections. An audit subsystem that can be starved by the system it's auditing is not an audit subsystem. The mechanics are small (Concept 7 ships the tables, Concept 10 ships the helper); the discipline is calling it at every boundary, consistently. (Identical in OpenCode: it's plain Python.)
Decision 8: Verify the whole worker on one scenario
Where you are: every layer wired and checked in isolation; this Decision adds nothing new, it proves them working together on one scenario and replays it from the log; by the end you will see one ordered trace that crosses all the layers.
By now the worker has all three layers wired and each checked on its own: the Session (Decision 3), Skills (Decision 4), and the MCP server (Decision 6), with audit underneath (Decision 7). This Decision proves they work together on one real scenario, then replays it from the audit log alone.
Step 1: Run the scenario and read its trace. Have your agent run the Worker against the one message that exercises the whole stack (server in one terminal, worker in another, server first; see Decision 6):
Run the Worker and send it this customer message, then show me the
audit_log rows that conversation produced, in order:
"I haven't received my refund from order #4429, it's been two weeks."
You should see these rows within a few seconds:
action=message_received: the message arrives, the conversation row is created.action=skill_activated(only if a skill loads): the worker may load a Skill (find-similar-casesorsummarize-ticket) to handle the request. The model can also reachfind_similar_resolved_ticketsdirectly without loading a skill first, in which case this row is simply absent and the trace goes straight tocapability_invoked. Both are correct builds, so don't treat a missingskill_activatedas a bug.action=capability_invoked, target=mcp:find_similar_resolved_tickets: the skill drives a vector search through the MCP server, and the worker reads the closest past resolution to draft from.action=message_sent: the drafted reply, recorded.
A conditional fifth, action=capability_invoked, target=mcp:lookup_customer, shows up only if the worker already has a customer id. The first turn usually doesn't (the customer gave an order number and an email, not a UUID), so it is skipped until something upstream resolves the customer: auth, the orchestrator, or a lookup_customer_by_email tool you add later. That is fine; the reply can still cite the past case.
Check. The core rows are present and in order (with
skill_activatedonly if a skill loaded), and they cross the layers in one trace: an MCP tool ran against the system of record, the conversation was recorded, and a Skill may have activated. That is the whole worker working together. Ifcapability_invokedormessage_sentis missing, go back to the Decision that wired it and re-run that Decision's own check.
message_received, skill_activated, and message_sent are written by Decision 7's agent-side audit wiring; the capability_invoked rows come from that same wiring around each MCP call. The MCP server writes its own row only when a tool changes data (the refund_issued row inside issue_refund). So a read-only scenario like this one leaves agent-side rows plus the capability_invoked reads, and no business-write rows until a refund actually happens, in Decision 9.
Now that Skills run inside the worker, a skill's scripts/ is executable code in the sandbox. UnixLocalSandboxClient gives no isolation; Docker, E2B, Cloudflare, or Modal contain it. Treat write access to your skill library like deploy access, and isolate the sandbox before you load skills you did not write.
Memory capability, and what it isn'tThe same capabilities list takes a Memory() alongside Skills() (both from agents.sandbox.capabilities). It is worth knowing precisely, because it sounds like the thing you just built and is not. Memory() lets a Worker learn from its own past runs: it distills each run's conversation into workspace files (a MEMORY.md and a summary) when the sandbox session closes, and later runs read those back, so the agent explores less and repeats fewer corrections. That is Concept 3's "have we seen a question like this before?" recall, handled by the runtime, so you don't hand-build it.
What it is not is the durable business record. Sandbox memory is file-based, prunes its oldest entries by recency, and is in beta; a fresh sandbox starts empty, and the agent is told to treat it as guidance, not authoritative storage. Your Neon tables are the opposite on every count: durable, complete, stable, queryable in SQL. So you want both, for different jobs. Memory() makes the agent smarter across runs; the system of record makes its work durable, provable, and sellable: the asset you own. The four pages under Sandbox agents in the SDK docs are the source for this whole layer; the companion AGENTS.md links all four.
Step 2: Run the replay query. This is the proof the whole audit layer was for. Ask the agent to pull the trace for the conversation you just ran:
Using the Neon tools, take the most recent conversation and show me its full
audit_logtrace, in order: created_at, action, target, payload, result.
Check. Reading that output, you can reconstruct line by line what the agent did and why, without re-running the model. If you can't, if a step happened that isn't in the log, or a row claims an action the business tables don't reflect, there's a wiring bug. Fix it before you call the Worker done.
Roughly what the replay should read like:
created_at action target result
10:02:11 message_received conversation:abc ok
10:02:12 capability_invoked mcp:find_similar_resolved_tickets ok
10:02:14 message_sent conversation:abc ok
Why this scenario. It exercises every architectural piece this course adds, in one pass: a Skill activates, an MCP-backed tool runs a semantic search against the system of record, and the audit trail records the whole path, replayable in SQL. None of that existed in the minimal chat agent you started with. What it does not do yet is move money; that is the one action you put a human in front of next.
Decision 9: Harden the one action that moves money
Where you are: a worker that runs end to end but issues refunds with no check; this Decision adds a human-approval gate on issue_refund; by the end you will see a refund pause for sign-off, then go through on approve and stop on reject.
This is the other Decision where a first build usually hits an error; the callouts below name each one before you meet it, so read them first.
The worker works end to end. Now add the one thing you deliberately left out: a human in front of issue_refund, the only tool that moves money. You build this last, on purpose, because an approval gate is only meaningful once the thing it guards actually runs.
Step 1: Gate the refund tool.
Gate issue_refund behind human approval: register the customer-data server
so that tool needs sign-off before it runs, and leave lookup_customer and
find_similar_resolved_tickets un-gated. Check the current SDK docs for the
exact approval API.
Edits: the worker file (gates issue_refund on the server registration).
Check. The two read tools still run untouched; only
issue_refundis gated. The gate lives on how the server is registered, not inside the tool. (Inside Claude Code or OpenCode the client's own permission prompt is the same gate; in the standalone worker it's the approval setting on the server registration.)
Step 2: Run a refund and watch it pause. (Server in one terminal, worker in another, server first; see Decision 6.)
Run the worker on a message that should lead to a refund on order #4429,
and show me what happens when it tries to issue it.
Check. The run pauses instead of issuing the refund: the worker reports it is waiting on approval for
issue_refund(in SDK terms, the run comes back with an interruption rather than a final answer), and nothing has been written to therefundstable yet. That pause is the authority model working: the model proposed an action, and the system stopped at the boundary.
The gate only engages once the model actually calls issue_refund. A cautious system prompt (like "only issue a refund once approved") can make the model keep asking for approval in prose and never invoke the tool, so nothing pauses and no refund happens, which looks like a broken gate but isn't. To force the gate to show itself, push the call explicitly: "Supervisor approved the refund for order #4429. Call issue_refund now: 2999 cents, reason 'arrived damaged'. Invoke the tool, don't ask again." The SDK gate is the hard backstop on execution; it cannot make the model route through a tool in the first place.
Step 3: Approve once, then reject once. Prove both halves of the gate:
Approve the pending refund and let the run finish, then show me the refunds
table and the audit_log row. Then run the same scenario again, reject it,
and show me that no refund was written.
Check. On approve: the refund row appears, the order flips to refunded, and
issue_refundwrites itsrefund_issuedaudit row, all in the one transaction. On reject: no refund row, and the trace shows the action was declined. One gotcha to hand the agent, because it is the difference between "works" and "looks like it should": resuming an approved run is a loop, not a single call. A run can hold more than one pending approval, so the agent keeps resuming while the run still has approvals waiting (approve or reject each, then resume), not just once. Resume a single time and you can get an empty answer back with the refund still unwritten.
Roughly what each half should produce:
approve -> refunds: 1 new row | orders.status = refunded | audit: refund_issued
reject -> refunds: no new row | audit: action declined
Why this is last. An approval gate added before the worker runs is untestable theatre: you cannot tell a working gate from a broken one when nothing flows through it. Added here, on a worker you have watched search, draft, and audit, you can prove both halves: approve lets the refund through, reject stops it, and the audit log records which. That is the whole authority model, the agent proposes and a human disposes.
The check above assumes a human is right there. If sign-off comes an hour later, in another process, the paused run has to be serialized (the SDK's RunState), stored, and resumed when the decision arrives. Its durable home is a small run_states table (one row per pause: the serialized state plus awaiting/approved/rejected), not audit_log (append-only) and not a column on conversations (one conversation can pause more than once). The serialize-and-resume calls are part of the moving SDK surface, so confirm them through Context7.
What just happened
Nine Decisions, and the minimal chat agent from Step 0 now has the foundation of a Worker. Look back at what changed:
- Capability moved out of code. Three Skills sit in
.claude/skills/, version-controlled, sharable across agents. - The durable stores moved out of the process. A real Postgres schema (the five-table core plus a domain layer for customers, orders, tickets, and refunds) now holds the Worker's system of record and the reference library it searches with pgvector, while the SDK Session keeps the Worker's conversation state on the same database.
- Runtime business access is mediated. The agent reaches business data in Postgres only through a scoped MCP server that exposes exactly three tools; every business read and write crosses that one boundary. The audit subsystem is the one deliberate exception, on its own direct connection, so it can't be starved by the boundary it audits.
- Every action leaves a trace. The audit log can replay the full reasoning trace of any conversation, weeks or months after the fact, in SQL.
- The dangerous action has an owner. The one tool that moves money pauses for a human before it runs; approve lets it through, reject stops it, and either way the audit log records the decision. That is the authority model a Worker needs before anyone trusts it with real actions.
The OpenAI Agents SDK is still there. The sandbox is still your compute, and the streaming, guardrails, and tracing the agent started with are all still there. What changed is the architecture on top: Skills hold the capabilities, the system of record holds the truth, MCP wires them together, and a human stays in the loop on the actions that matter.
That is the foundation of a Worker. What it is not yet is always-on, proactive, or part of a managed workforce. Those are the moves the next courses add.
Decision 10 (optional challenge): make the paused approval survive a restart
In Decision 9 the approver was sitting right at the terminal, so a [y/N] was enough. Real approvals rarely work that way: the manager who signs off on a refund might answer an hour later, from another app, on another machine. Your worker cannot handle that yet. When a refund pauses, the paused run lives only in the worker's memory, so if the process closes before the human answers, the pending refund is gone.
You have already moved three kinds of state into Postgres: the conversation turns, the business records and reference library, and the audit trail. The paused run is the one kind still trapped in memory. This optional capstone moves it into the database too, so a pause can be approved later, from anywhere. It is a graded challenge, not a guided build: each step gives you the idea and the prompt, and leaves the wiring to your agent.
Goal: approve or reject a paused refund from a different process than the one that started it.
Step 1: Give each paused run a home in the database. A pause needs its own row: which conversation and tool it belongs to, the saved run itself, and a status that moves from awaiting to approved, rejected, or resumed. It is its own table, not the audit log (that is finished history) and not a column on conversations (one conversation can pause more than once).
Add a run_states table that stores one paused run per row: the conversation
and tool it belongs to, the saved run, and a status that defaults to
"awaiting" and can become approved, rejected, or resumed. Plan the DDL first;
I'll approve before you apply it on a branch.
Check. A
run_statestable exists and a fresh pause defaults toawaiting. You never typed the SQL: you said what the table is for, your agent wrote it, the same way the schema landed in Decision 3.
Step 2: When a refund pauses, save it and move on. Right now the worker waits at the terminal; instead it should record the pause and free itself for the next turn.
When a run comes back waiting for approval instead of with a final answer, do
not block on input. Save the paused run as a run_states row marked "awaiting"
and return, so the worker is free for the next turn. One turn is one request
that either finishes or parks. Check the current Agents SDK docs for the exact
"save the paused run" call before you write it.
Check. A refund turn now returns promptly, leaving an
awaitingrow behind, and nothing blocks waiting on a human.
Step 3: Approve or reject from a separate command. The decision moves out of the chat loop into its own small entry point, so it can run in another process entirely.
Build a small "decide" command, separate from the chat loop: it lists the
awaiting rows, takes my approve or reject on one, then reloads that saved run
and finishes it. Keep resuming in a loop while the run still has approvals
pending, since resuming once can come back empty with the refund unwritten
(the loop gotcha from Decision 9). Confirm the reload call through Context7.
Check. Approving a row from the decide command drives that refund to completion; rejecting it writes no refund and records the rejection.
Step 4: Make the refund safe to retry. In a distributed setup a network retry can fire the same approved refund twice.
Make issue_refund idempotent: dedupe on the order plus a request id, so the
same approved refund cannot run twice.
Check. Resume the same approval twice on purpose: you get exactly one
refundsrow, not two.
Step 5: One active turn per conversation. Two turns on the same conversation at once will corrupt its session.
Add a per-conversation lock (a Postgres advisory lock on the session id, or a
status guard) so only one turn is active per conversation at a time.
Check. A second turn on the same conversation waits or is refused, instead of racing the first.
The calls that save a paused run and reload it later are part of the beta SDK surface that shifts between releases. The course's discipline applies to its own challenge: paste the exact save and reload calls from the current Agents SDK docs or Context7 rather than recalling them. The idea, that a paused run becomes a row you pick up later, is stable; the method names are not.
Done when:
- You start a refund in one process; it exits with the run parked in
run_states(statusawaiting), and norefundsrow yet.- In a second process, you approve it; the refund commits (refund row, order flips,
refund_issuedaudit row), and the parked row becomesresumed.- The reject path leaves zero business writes and a
refund_blockedaudit row.- Approving the same parked run twice issues no second refund.
- The whole episode is replayable from
audit_logplusrun_stateswithout re-running the model.
Stretch (full distributed). Put the customer-data server behind a real URL with authentication and point the worker at it; swap the local sandbox for a hosted one without changing the agent itself (swap the client, keep the agent); and move your secrets out of the .env file into a secret manager. Same worker, now able to run across machines.
State in the database is necessary but not sufficient: the last stateful thing to move is the paused run itself, and once it lives in run_states your worker stops being tied to a single process.
Part 5: Where this course leaves off
Cost shape of a Worker: how to estimate it
No dollar totals here on purpose: per-token prices and free-tier limits change monthly, so any number printed would be stale by the time you read it, and a stale number is worse than none. What lasts is the method. Here it is, with the worked example's own traffic as the inputs you plug in: 200 conversations/day, about 10 turns each, about 8K input tokens per turn.
One line is almost the whole bill; the other three are rounding errors. Work them in order.
1. Model inference. Your monthly token volume times your model's price per token. The volume comes from your own traffic:
input tokens/month ≈ conversations/day × turns/conversation × tokens/turn × 30
For the example: 200 × 10 × 8,000 × 30 ≈ 480M input tokens/month. Multiply that by your model's input price (from its pricing page), then add output tokens the same way (far fewer of them, but a higher per-token price). That single multiplication is your bill.
The biggest lever on it is prompt caching. Your AGENTS.md, system prompt, and Skills metadata are identical on every turn, so when the provider caches that stable prefix, those tokens bill at a fraction of the normal rate. Keeping the prefix stable (don't churn AGENTS.md mid-day) is the highest-value cost move you have. Routing the easy turns to a smaller model and only the hard ones to a frontier model is the second.
2. Embeddings. tokens embedded × the embedding model's price. You embed the seed corpus once and new tickets as they arrive; at a small embedding model's rate that's cents, not dollars, unless you continuously re-embed whole conversation histories. Same pricing page.
3. Postgres (Neon). Often $0: the free tier covers a single low-volume Worker, and scale-to-zero means idle hours cost nothing. You pay only after crossing the free storage / compute-hour limits, and then it's storage plus active compute, both on Neon's pricing page.
4. Sandbox compute. $0 here, because the worked example runs on UnixLocalSandboxClient, your own machine. In production it's container-minutes wherever you deploy (Docker, Cloudflare, E2B, Modal): session length × concurrency × that provider's rate.
The whole method in one line: compute your monthly token volume from your own conversation numbers, multiply by today's per-token price, and read the other three lines off pricing pages. Scaling to many Workers doesn't change the formula, it multiplies the inference line by how many Workers and how busy they are; the infrastructure lines stay roughly flat, so the model bill is the one that grows, and the two habits above (stable cached prefix, cheaper model for easy turns) are what keep it in check.
Swap guide: the architecture is invariant, the products are not
This course names specific vendors at every layer (OpenAI Agents SDK, the SDK's local sandbox, Neon, OpenAI embeddings, MCP Python SDK). That's because a teaching example needs concrete answers, not "use any LLM runtime you like." But the architecture works with any compliant alternative. Five swaps the course's design explicitly anticipates:
- Postgres host: Neon → Supabase, AWS RDS, self-hosted. Anything with
pgvectorworks. You lose branching and scale-to-zero (those are Neon-specific), but the five-table schema, the embedding pipeline, the audit-trail discipline, and the custom MCP server pattern are all transferable byte-for-byte. The only change is the connection string and possibly the SSL config. - Vector storage: pgvector → Pinecone, Weaviate, Qdrant. If you reject the "one database for both relational and vector data" argument from Concept 6, swap the
embeddingstable for a vector-DB client. The cost: two stores to keep consistent (Concept 6 argues this is rarely worth it). The benefit: better recall at very large scales (10M+ vectors), and managed-service operational simplicity. - Embedding model: OpenAI → Cohere, Voyage, BGE-small (local). Change one constant (
EMBEDDING_MODEL) and one column dimension (VECTOR(n)). Run a one-shot re-embed of existing data. Concept 9's pipeline doesn't change. - Sandbox: the local sandbox → Cloudflare, E2B, Modal, Daytona, your own Docker. Anything with isolated process boundaries and a clean restart works. The
SandboxAgentruntime is backend-agnostic; the worked example runs onUnixLocalSandboxClient, and production swaps to any of these. Skills'scripts/execute the same way. The trust-boundary diagram from the previous course still applies. - Agent runtime: OpenAI Agents SDK → LangGraph, CrewAI, Pydantic AI, your own loop. The MCP boundary is what survives; every modern agent framework has an MCP client. Skills work in any agent that can load
SKILL.mdfiles (Claude Code, OpenCode, Goose, and increasingly Cursor/Windsurf). The audit-trail discipline is framework-agnostic Python.
What doesn't swap easily. The MCP protocol itself, the Skills format spec, and the audit-trail habit. These are the parts you carry across products; the products are the parts you swap. Same architectural shape underneath, replaceable implementations on top.
A word on "invariant" and "owned." Both are heuristics worth betting on, not settled facts. "Invariant" names 2026's best-available open standards: MCP is about eighteen months old and the Skills spec is younger, and one day the wire or the capability format itself could be the thing that gets replaced, not just the products plugged into it. Betting on open protocols over proprietary ones is how you age well, but treat the architecture as durable-by-design, not eternal. And "owned" really means owned-by-composition: this Worker runs on Neon's cloud, a vendor's models, a coding-agent client, and skills pulled from third-party repos. What you own is the freedom to swap any one of them without rewriting the rest. That is real and worth a great deal, and it is less than the full word suggests. Own the seams, not the substrate.
What this course doesn't cover (yet)
You now have a Worker that satisfies two of the Seven Invariants the thesis sets out. Specifically: it runs on an engine (Invariant 4, from the previous course), and it runs against a system of record (Invariant 5, from this course). The other five Invariants are what production AI-Native Companies require, and what subsequent courses cover. Each is one bullet here, not a section.
- Invariant 1: The human is the principal. Authored specs, approval gates, budget declarations. The architecture for setting intent and owning outcomes, covered in Part 6 of the book.
- Invariant 2: Every human needs a delegate. A personal agent at the edge that holds your context, represents your judgment, and brokers work to the workforce. The thesis names OpenClaw as the current realization.
- Invariant 3: The workforce needs a manager. An orchestrator that assigns work, enforces budgets, audits execution, exposes hiring as a callable capability. The thesis names Paperclip.
- Invariant 6: The workforce is expandable under policy. A meta-layer where an authorized agent generates a prompt, provisions a runtime, and registers a new Worker, without waking a human. Claude Managed Agents is one realization.
- Invariant 7: The workforce runs on a nervous system. Triggers (schedules, webhooks, inbound API calls) wake the agent under the authority envelope. Inngest (durable functions and background jobs) is one realization for general workforce events; Claude Code Routines is the coding-agent-specific path.
How to actually get good at this
Reading this crash course does not make you good at building Workers. Using it does. The path looks the same as for the previous course: you start manual, feel the friction, and let each piece of friction teach you which Concept it belongs to.
The mapping for this course:
- "Why isn't my skill firing when it should?" → description quality (Concept 3). Rewrite. Test by inventing five different ways a user might phrase the trigger.
- "Why is the agent inventing data the database doesn't have?" → the agent isn't actually calling the MCP server. Check the trace; check the
mcp_servers=[...]registration. - "Why is my audit log incomplete?" → the audit write isn't in the same code path as the action (Concept 10). Move it next to the action, in the same transaction.
- "Why are my pgvector results irrelevant?" → either chunking is wrong (Concept 9), or the embedding model at insert-time doesn't match the embedding model at query-time. Re-embed.
- "Why is my MCP server slow under load?" → connection pool inside the server is too small, or the tools list isn't cached on the client. Concept 15.
- "Why does the Neon MCP server feel scary in production?" → because Neon's own docs say it's not for production. Write a custom MCP server (Concept 14). The first one takes 30 minutes; the second takes 10.
Build the architecture one piece at a time. Don't try to add Skills, system of record, and MCP all in one weekend. Start from the Step 0 chat agent. Add a system of record first (Decisions 3–5) and watch your debugging experience change. Add a Skill (Decision 4) and watch how the model decides to use it. Add the MCP boundary last (Decision 6). Each step is its own learning; doing all three at once is a wall.
The portability dividend is real: Skills, schemas, and MCP servers you write here all move to other products. The Swap guide lists the per-layer alternatives.
The shift in what you spend time on
After Decision 4, your work changes shape. Writing code becomes briefing the agent; reviewing the description (a config-file field you'd normally skim) becomes the key craft. A description you spent 30 minutes drafting and refining does more architectural work than the 200 lines of MCP server code the agent generated underneath it, because the description is the routing surface the model reads every turn.
Two practical shifts. First, you stop asking "how do I implement this?" and start asking "what are the five different ways a real user might phrase the trigger?" Code is downstream; if the description is wrong, the agent never reaches the code and the code's quality is irrelevant. Second, review replaces authorship as the key skill. The agent drafts; you decide whether the draft works in the trigger cases you wrote the description for. The hardest part is resisting the urge to rewrite when you could solve it yourself in three minutes: the same discipline that keeps you from bypassing the MCP boundary.
Quick reference
The 15 concepts in one line each
- An Agent Skill is a folder. SKILL.md plus optional scripts/references/assets.
- Progressive disclosure. Metadata at startup → full body on activation → references on demand.
- A SKILL.md is frontmatter + body. Name, description, optional metadata, then operational instructions.
- Skills travel as files. Same SKILL.md works in Claude Code and OpenCode without modification.
- Compose small skills via filesystem handoff when isolation matters more than orchestration simplicity.
- Postgres + pgvector beats a separate vector DB for almost all agent workloads. Neon adds branching, scale-to-zero, and an MCP server.
- Five tables are the minimum operational schema: conversations, documents, embeddings, audit_log, capability_invocations; the conversation turns live in the SDK Session (
SQLAlchemySessionon the same database). - pgvector basics:
VECTOR(1536)+<=>cosine distance + HNSW index. Use the same embedding model on both ends. - The embedding pipeline: chunk at semantic boundaries (~400 tokens with overlap), batch-embed, store with model metadata.
- Audit is not logging. Every meaningful action writes a row in the same transaction as the action it records.
- MCP is a protocol, not a service. Three primitives (tools, resources, prompts), three transports (stdio, streamable HTTP, legacy SSE).
- The Neon MCP server is for development. Schema design, branch-based migrations. Not for production runtime.
- The OpenAI Agents SDK has a built-in MCP client.
from agents.mcp import MCPServerStdio, MCPServerStreamableHttp. Useasync with. Cachelist_toolsin production. - Custom MCP servers earn their keep via scope, isolation, and reusability. Don't write one for a single function used by one agent.
- MCP under load: streamable HTTP for remote, cache tools, reuse connections, pool inside the server, propagate trace context via
_meta.
When something feels wrong
Skill not firing when it should
→ Description too vague. Rewrite with "Use when..." and specific keywords (Concept 3).
Skill firing when it shouldn't
→ Description too broad. Add explicit constraints in the description.
pgvector returning irrelevant results
→ Embedding model mismatch (insert vs. query). Verify the model column in
the embeddings table. Re-embed if needed.
MCP tool not appearing in agent
→ Server not registered, or list_tools cache stale. Check mcp_servers=[...]
and try cache_tools_list=False temporarily.
Audit log has gaps
→ Action and audit write are in different code paths. Move them next to
each other, ideally same transaction.
Agent timing out on Postgres operations under load
→ MCP server's connection pool too small. Check asyncpg.create_pool(max_size=...).
MCP server hangs on startup with torch / sentence-transformers / large imports
→ Default client_session_timeout_seconds=5 is too short for servers that
load ML models at import. Bump to 60. See Concept 13's callout.
CREATE TABLE fails: relation "notes" already exists
→ You're pointing at a database that already has tables. Use a fresh
database or Neon project; the Quick Win's build prompt makes a fresh one.
Non-OpenAI key getting 401 against api.openai.com
→ Set OPENAI_BASE_URL to your provider's OpenAI-compatible endpoint
(e.g., https://api.deepseek.com/v1) before running the agent.
Agent fails partway with a 401 / auth / BadRequestError
→ Wrong key, wrong provider, or expired key. Have your agent confirm
OPENAI_API_KEY is set and test a model call before the full run; it
fails in one second instead of four files deep.
Neon MCP server returning errors in production agent code
→ You're using it wrong. Neon's docs are explicit: development only.
Write a custom MCP server instead (Concept 14, ~30 minutes).
Flashcards Study Aid
Knowledge Check
A quick gated self-check on the ideas you just ran through.