Part 0: Thinking is the Curriculum
11 Chapters. 10 Skills. Every Exercise Requires You to Think Before AI Thinks for You.
AI did not create a thinking crisis. It exposed one.
Everyone is telling you to reskill. Learn AI tools or get left behind. They are right, but they are solving the wrong problem. The tools are easy. Thinking is hard. A twelve-year-old can prompt ChatGPT. The hard part is knowing whether what it gave you is true. The hard part is asking the question it would never ask itself. The hard part is thinking. AI does not reward people who can use it. AI rewards people who can think clearly enough to direct it, question it, and know when it is wrong. Our education systems spent twenty years giving us knowledge and never once taught us how to think with it. Part 0 fixes that.
Millions of students can now generate essays, analyses, code, and business plans in seconds. Almost none of them can tell whether what AI produced is correct. They cannot ask the question that AI never thought to ask. They cannot spot the reasoning flaw buried in a fluent paragraph. They cannot look at a system and see the second-order consequence that breaks everything. They have the most powerful cognitive tool in human history, and no idea how to think with it.
This is not their fault. They were never taught to think in a world where thinking can be outsourced. Every AI curriculum on earth starts in the wrong place. They start with tools. Prompts. APIs. Frameworks. They teach people to operate AI. Not one of them puts thinking first.
Part 0 puts thinking first.
This is not a warm-up. This is not "soft skills before the real stuff." This is the load-bearing foundation of everything that follows. Remove it, and every technical skill in this book becomes dangerous. A developer who cannot detect broken reasoning will ship broken agents. A business leader who cannot reason from first principles will automate the wrong processes. An architect who cannot think in systems will build AI that optimizes one metric and destroys three others.
The rest of this book will make you powerful. This part determines whether you use that power well.
These are not academic exercises. Every chapter builds a thinking skill that commands a premium in technology, healthcare, operations, finance, education, and leadership because when AI can generate anything, the person who can actually think becomes the scarce one.
In the AI era, education must develop more than intelligence. It must also develop judgment, originality, adaptability, and agency. Students must learn not only how to think, but how to use AI wisely, build what does not yet exist, solve ambiguous real-world problems, defend their reasoning, and keep learning as the world changes.
The Unsolved Problem
Every university, every bootcamp, every corporate training program is asking the same question: If students have access to AI, how do we know they actually learned to think?
The honest answer, until now, has been: we don't.
Some institutions ban AI. That is denial. Some allow AI and grade the output. That is grading AI, not the student. Some add oral exams on top. That helps, but does not scale.
Part 0 is a different answer. It introduces six assessment layers (prediction locks, reasoning receipts, live defence, contradiction challenges, divergence tests, and iterative drafts) engineered so that passing all six requires genuine human thinking. No single layer is cheat-proof. All six together are. This is not a policy. It is an architecture.
And it scales. AI gives every student instant, personalized feedback on every exercise. Peer review circles add human judgment. Instructors intervene only on flagged cases. The result: rigorous thinking assessment for tens of thousands of students; with no multiple-choice exams, no essay mills, and no guesswork about who actually learned.
Eleven chapters. Ten thinking skills. Forty exercises. One rule:
The deliverable is never the answer. The deliverable is the documented evidence of thinking.
You will not be graded on what you produced. You will be graded on whether you can prove you thought.
Exercise: Should a startup build a custom AI agent or use an off-the-shelf tool?
Step 1. Prediction Lock (before you touch AI): Write your position and seal it. You cannot change it later.
"I predict custom-built wins for companies with unique workflows. Confidence: 55%. I'd change my mind if off-the-shelf tools handle customization better than I expect."
Step 2. AI Research (now you open AI): Give the same question to Claude and ChatGPT. Read their arguments. Do not copy them. Decide what you agree with, what you reject, and why.
Step 3. Reasoning Receipt (document your decisions):
"AI argued that off-the-shelf saves 6 months. I agreed on speed but rejected its assumption that the startup's workflow is standard. My confidence shifted from 55% to 70%."
Step 4. AI Grades Your Thinking (not your answer): Submit your prediction lock and reasoning receipt to AI using the prompt provided in the exercise. AI scores you on five dimensions: independent thinking, critical evaluation, reasoning depth, originality, and self-awareness. The grade is on how you thought; not what you concluded.
The student who copied AI's answer scores low. The student who disagreed with AI and explained why scores high; even if their final answer is the same.

Part 0 teaches humans how to thrive in the AI era. The rest of the book builds the era itself.
What You Need
- A web browser
- Access to claude.ai, chatgpt.com, or gemini.google.com (free tiers work; any modern chat AI is fine)
- No code. No setup. No IDE. Just your brain and a browser.
- If you have never used these tools beyond a casual search-engine style prompt, read AI Prompting in 2026 first. It is the 12-concept primer this part assumes you already know.
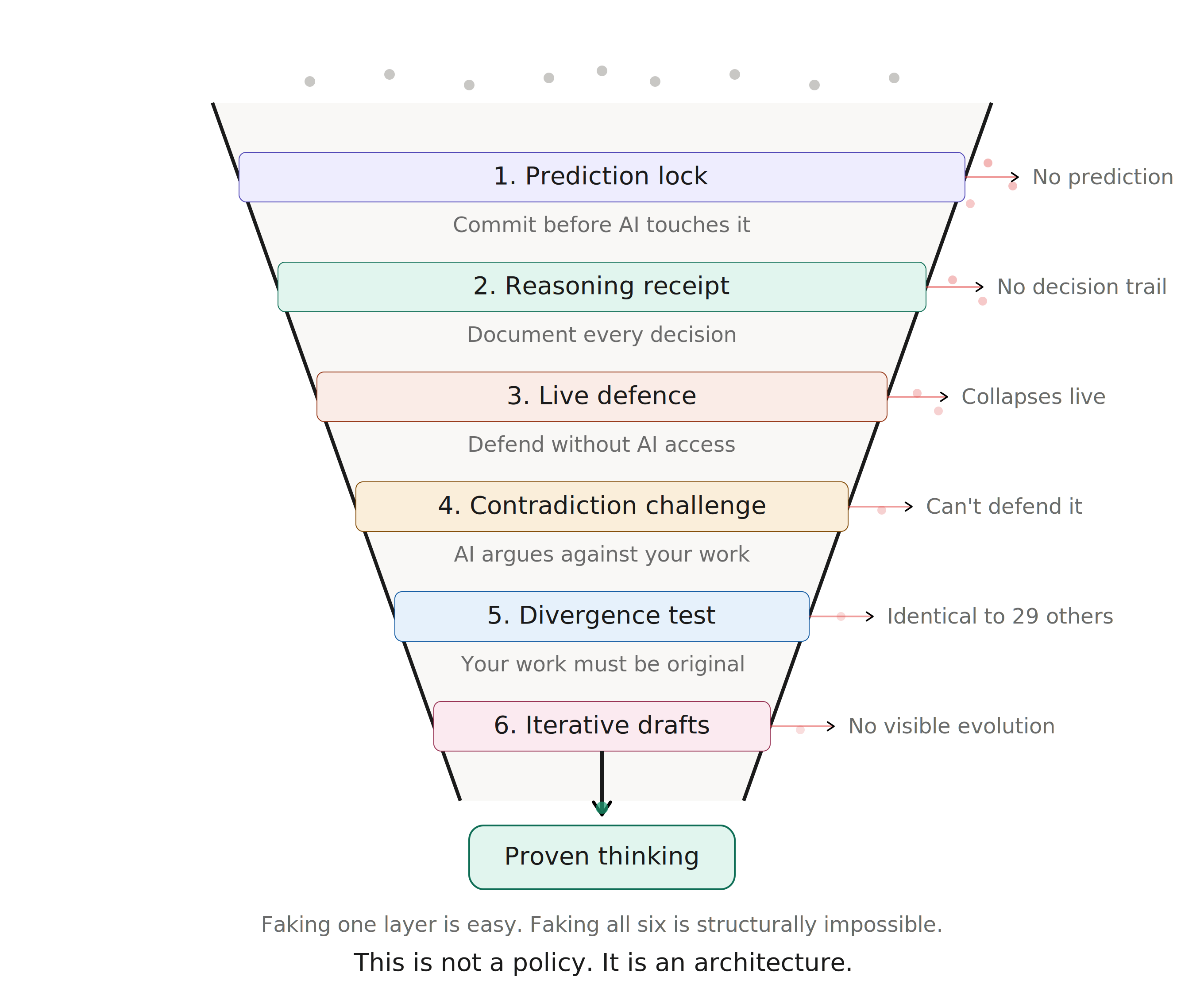
The Six Layers of Thinking-Proof Assessment
To make the foundational principle operational, every chapter in Part 0 is built on six layers. These layers are embedded into the exercises so that it becomes structurally impossible to succeed by outsourcing thinking to AI.
Before the student touches any AI tool, they must commit to a position in writing. This is timestamped and cannot be changed. Only after this prediction is sealed do they open claude.ai or chatgpt.com. AI cannot do this part because it requires the student to have had an independent thought first that they are now comparing against.
Applied in: Every chapter. The prediction lock is the universal starting point.
Students do not submit answers. They submit a reasoning trail; every prompt they wrote, every AI response they received, every decision they made to accept, reject, or modify. The grade is on the decisions. AI can generate answers but it cannot generate a genuine record of someone else's decision-making process.
Applied in: Chapters 1, 2, 5, 6, 8, 9. The reasoning receipt is the primary grading artifact.
The student submits their work, then defends it without AI access. If the student outsourced all thinking to AI, they collapse under the first question. This is the oldest assessment method in academia (the oral examination) and it is suddenly the most AI-proof one.
Applied in: Chapters 1, 3, 5, 7, 10. Every chapter with live performance uses this layer.
After a student submits their work, it is fed into AI with the prompt "argue against this." The student must respond in real-time. The student who copied from AI does not understand what they submitted well enough to defend it against AI's own counter-attack.
Applied in: Chapters 1, 2, 4, 7, 9. Submitting work is never the end; defending it is the real assessment.
When 30 students receive the same problem and AI tools, those who outsourced thinking produce nearly identical outputs. Those who actually thought will diverge. Originality becomes a measurable signal of cognitive engagement.
Applied in: Chapters 1, 4, 6, 8. Divergence is measured whenever the class receives the same prompt.
Students submit three drafts: before AI, after AI collaboration, and after reflection. The grade lives in the gaps between drafts. AI can produce a polished final draft but it cannot produce a genuine record of thinking evolving across three stages.
Applied in: Chapters 2, 3, 4, 6, 7, 8, 9, 10. The three-draft structure makes cognitive growth visible.
How the Layers Work Together
No single layer is sufficient on its own. But surviving all six simultaneously requires genuine thinking. The prediction lock creates a baseline the reasoning receipt must be consistent with. The reasoning receipt documents decisions the live defence will interrogate. The contradiction challenge attacks the position committed to in the prediction lock. The divergence test catches students who bypassed earlier layers. And iterative drafts make the entire trajectory visible.
How AI Checks Your Thinking in Every Exercise
Every exercise in this part follows a four-step cycle:
- You think first and produce a deliverable without AI or with documented AI collaboration.
- You submit your deliverable to AI using an exact prompt provided in the exercise.
- AI grades your work, identifies your blind spots, and gives you specific feedback.
- You reflect on the gap between your self-assessment and AI's assessment; that gap is where the deepest learning happens.
This is not AI doing your thinking for you. This is AI acting as a rigorous, tireless, infinitely patient evaluator of your thinking. A human instructor cannot read 30 students' reasoning receipts in real-time and give each one detailed feedback. AI can. The instructor's role shifts from grading to designing exercises and conducting live defences; the parts that require human judgment.
When AI Feedback Seems Wrong
Part 0 uses AI to evaluate your thinking, while Chapter 2 teaches you that AI is frequently wrong. Both are true. AI is a powerful evaluator but not a perfect one. Sometimes its feedback will be inaccurate, unfair, or shallow. When that happens, do not ignore it and do not blindly accept it. Use the following protocol:
- Identify the specific feedback point you disagree with.
- Write your counter-argument explaining why the AI's evaluation is incorrect (100-150 words).
- Submit your counter-argument back to AI with this prompt: "I disagree with your evaluation on [specific point]. Here is my counter-argument: [paste]. Either defend your original evaluation with specific reasoning or acknowledge the error."
- Include the full exchange (AI feedback, your challenge, AI response) in your portfolio.
- This is graded as bonus evidence of critical thinking.
Challenging AI feedback is not a sign of failure. It is the highest application of the skills this part teaches. A student who accepts bad feedback uncritically has missed the entire point.
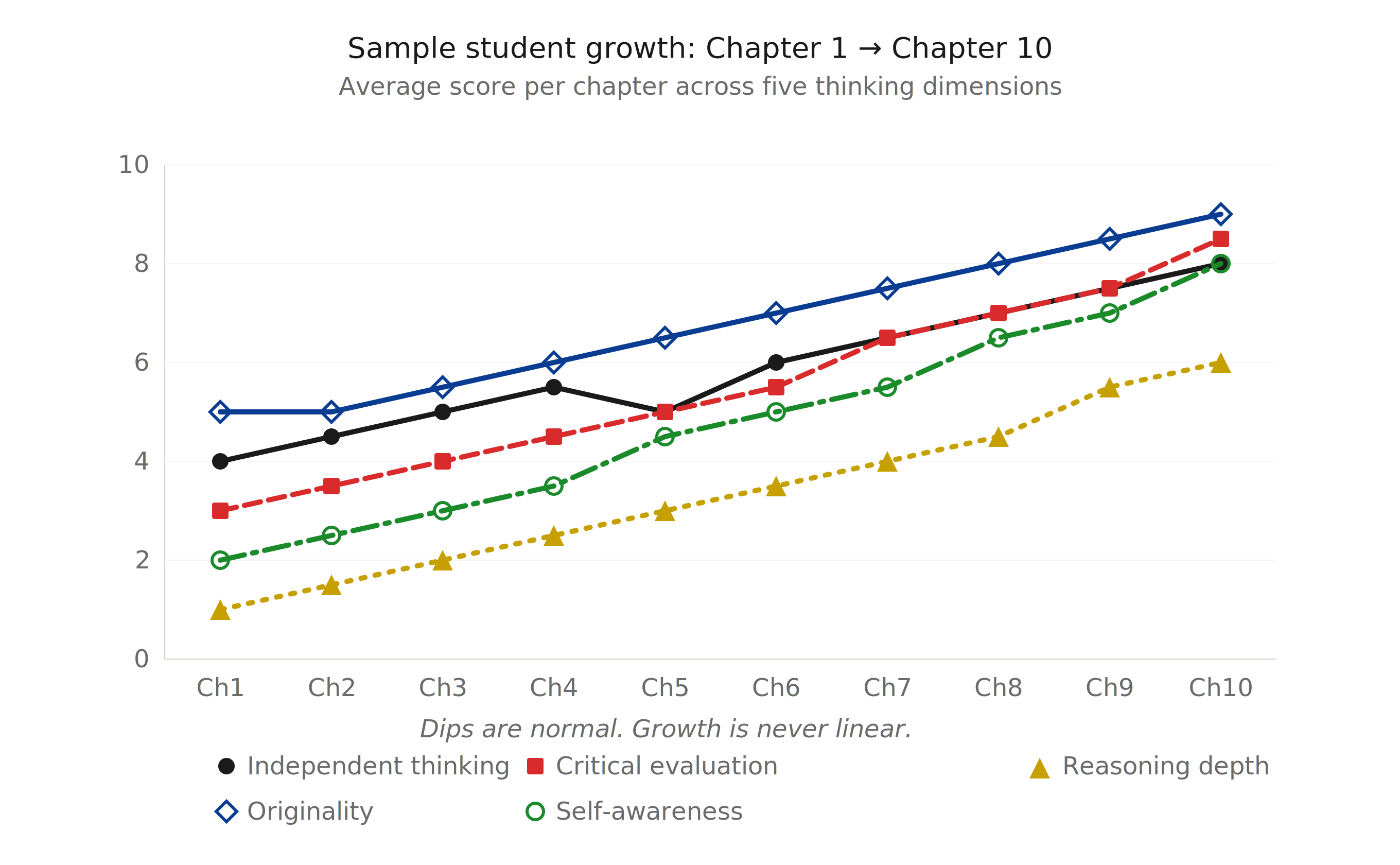
The Thinking Score Card
Every AI check prompt in this part ends with the same standardized scoring request: the Thinking Score Card. This gives you five consistent scores (each 1-10) across all 40 exercises in Chapters 1–10, allowing you to track your growth on a single chart from Chapter 1, Exercise 1 to Chapter 10, Exercise 4. Chapter 11 provides the final post-assessment comparison.
- Independent Thinking (1-10): Did the student produce genuine thought before or beyond AI? Evidence of predictions, original analysis, or ideas that AI would not generate independently.
- Critical Evaluation (1-10): Did the student evaluate AI output critically? Evidence of accepting, rejecting, or modifying AI responses with justified reasoning rather than passive acceptance.
- Reasoning Depth (1-10): How deep is the student's reasoning? Evidence of second-order thinking, tracing causes to consequences, identifying hidden assumptions, and building logical chains rather than surface-level responses.
- Originality (1-10): How much of the student's work diverges from what AI would produce if given the same prompt? Evidence of unique perspectives, novel connections, or creative approaches that go beyond standard AI output.
- Self-Awareness (1-10): Does the student accurately understand their own strengths, weaknesses, and confidence levels? Evidence of calibrated confidence, honest gap identification, and reflections that match the quality of the work.
Score Tracking Table
Maintain this table throughout Part 0. After each exercise, record your five scores:
| Exercise | Independent Thinking | Critical Evaluation | Reasoning Depth | Originality | Self-Awareness | Average |
|---|---|---|---|---|---|---|
| Ch1.Ex1 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch1.Ex2 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch1.Ex3 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch1.Ex4 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch2.Ex1 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch2.Ex2 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch2.Ex3 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch2.Ex4 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch3.Ex1 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch3.Ex2 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch3.Ex3 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch3.Ex4 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch4.Ex1 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch4.Ex2 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch4.Ex3 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch4.Ex4 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch5.Ex1 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch5.Ex2 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch5.Ex3 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch5.Ex4 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch6.Ex1 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch6.Ex2 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch6.Ex3 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch6.Ex4 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch7.Ex1 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch7.Ex2 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch7.Ex3 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch7.Ex4 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch8.Ex1 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch8.Ex2 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch8.Ex3 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch8.Ex4 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch9.Ex1 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch9.Ex2 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch9.Ex3 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch9.Ex4 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch10.Ex1 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch10.Ex2 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch10.Ex3 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Ch10.Ex4 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
| Average | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 | ___/10 |
At the end, calculate your average per dimension across all 40 exercises and compare with your Thinking Baseline scores.
Chapters
| Chapter | Core Skill | What You Build |
|---|---|---|
| 1. Asking Better Questions | Question Formulation | A Question Quality Portfolio with prediction locks, reasoning receipts, and AI-graded evaluations |
| 2. Detecting Broken Reasoning | Verification and Discernment | An Error Detection Portfolio with annotated AI outputs, confidence calibration, and error taxonomy |
| 3. Thinking in Systems | Systems Thinking | A Systems Thinking Portfolio with cascade maps, human-AI comparisons, and variable shift analyses |
| 4. Reasoning From First Principles | First Principles Reasoning | A First Principles Portfolio with derivations, assumption autopsies, and constraint rebuilds |
| 5. Communicating What Matters | Communication Under Pressure | A Communication Portfolio with audience predictions, live adaptations, and hard conversations |
| 6. Working With AI, Not For AI | AI Collaboration | An AI Collaboration Portfolio with three-path comparisons, collaboration logs, and override tests |
| 7. Reasoning Through Dilemmas | Ethical Reasoning | An Ethical Reasoning Portfolio with position locks, adversarial defences, and stakeholder swaps |
| 8. Building Something From Nothing | Creation and Originality | A Creation Portfolio with blank page sprints, creation logs, and three-draft evolutions |
| 9. Deciding Under Uncertainty | Decision-Making | A Decision-Making Portfolio with sealed decisions, reversal triggers, and decision audits |
| 10. Learning How to Learn | Meta-Learning | A Meta-Learning Portfolio with learning plans, 72-hour sprints, and a Personal Learning Framework |
| 11. Thinking Portfolio | Portfolio Synthesis | A Thinking Portfolio assembling all chapter deliverables, a post-assessment comparison, and a Growth Map |
AI can generate reports, draft strategies, write code, and produce analyses that look flawless. What it cannot do is know when its own output is wrong. That single failure is now the most expensive problem in every industry.
The developer who asks better questions (Chapter 1) frames the problem correctly before AI generates a single line of code; because the most expensive bug is the one that solves the wrong problem. The compliance officer who detects broken reasoning (Chapter 2) catches the hallucination before it reaches production; and before it costs the company a lawsuit, a product recall, or a lost customer. The healthcare professional who thinks in systems (Chapter 3) catches the second-order drug interaction that no pattern-matching model will ever flag. The engineer who reasons from first principles (Chapter 4) redesigns the process everyone else assumed was fixed; because AI can optimize a broken system faster than anyone, and only a human will ask whether the system should exist at all. The communicator who knows what matters (Chapter 5) walks into a room full of AI-generated slides and is the only person who can explain what they actually mean. The professional who works with AI without surrendering judgment (Chapter 6) gets ten times the leverage without ten times the risk. The one who surrenders judgment becomes a middleman between a prompt and a product; and middlemen get automated. The leader who reasons through dilemmas (Chapter 7) makes the ethical call that AI will never make; because AI calculates trade-offs and humans own them. The founder who builds from nothing (Chapter 8) creates what no prompt could generate; because prompts remix the past and founders invent the future. The executive who decides under uncertainty (Chapter 9) makes the call when the data is incomplete, the stakeholders disagree, the deadline is tomorrow, and AI has produced three confident, contradictory recommendations. And the person who has learned how to learn (Chapter 10) will still be relevant in ten years. Most of their peers will not. They will be fluent in tools that no longer exist for jobs that no longer need them.
These are not ten skills for school. These are ten skills for a labor market that has already made its verdict:
AI made polished output free. Clear thinking is what's expensive now.
For Solo and Online Learners
Several exercises involve peer interaction; question tournaments, cross-examination, live defence, hard conversations, and teach-back sessions. If you are learning alone or asynchronously online, every peer exercise includes a Solo Learner Alternative. These alternatives use AI to simulate the peer role:
Instead of a peer panel questioning your work, you submit your deliverable to AI with a specific adversarial prompt that generates tough, unpredictable questions; then you respond in writing. Instead of a live role-play partner, AI plays the stakeholder and you practice adapting in real-time through a multi-turn conversation. Instead of peer feedback forms, you use a structured AI evaluation prompt designed to replicate what an engaged peer would notice.
The solo path is not inferior to the peer path; it is different. Peers provide unpredictability, social pressure, and perspectives you cannot anticipate. AI provides consistency, tirelessness, and the ability to generate adversarial challenges on demand. If possible, combine both.
How This Scales: Assessment for Tens of Thousands of Students (Instructor Reference)
Tier 1 . AI First-Pass (every student, every exercise): Every exercise includes an exact AI check prompt. The student submits their work, receives AI-generated scores and feedback, and includes this in their portfolio. This provides immediate, personalized feedback at unlimited scale. AI scores serve as the baseline assessment.
Tier 2 . Peer Review Circles (every student, per chapter): Students are organized into review circles of 4-5 people. At the end of each chapter, circles exchange portfolios and evaluate one peer's work using a provided rubric. Peer reviewers submit their evaluation along with their own portfolio. Reviewing others' thinking is itself a thinking exercise; it reinforces the skills being taught.
Tier 3 . Instructor Spot-Check (flagged portfolios): Instructors do not review every portfolio. They review flagged cases: portfolios where AI scores and peer scores diverge significantly, portfolios with suspiciously high divergence-test similarity, students who challenged AI feedback (to verify the challenge was legitimate), and a random 10% sample for calibration. This keeps instructor load manageable at any scale while ensuring quality control.
This three-tier system means every student gets personalized AI feedback within minutes, peer feedback within days, and instructor attention where it matters most.
Before You Begin
Complete the Thinking Baseline; a 30-minute ungraded assessment that snapshots your current thinking skills. You will repeat it in Chapter 11 to measure your growth.
Learning Path
Thinking Baseline → Chapters 1-10 → Chapter 11: Portfolio, Post-Assessment & Growth Map
Each chapter builds on the previous. Skills introduced early (Prediction Lock, Reasoning Receipt, Error Taxonomy) recur throughout. By Chapter 11, you are applying every skill from every preceding chapter simultaneously.
The litmus test for every skill in this part: Does this make AI a more powerful tool in your hands, or does it make you a slower version of the tool?