AI Prompting in 2026: A Crash Course
13 Concepts, 80% of Real Use
Most people use AI like a Google search. They type a short question, skim the answer, and move on. That works for trivia. It fails for everything that actually matters in your life and your work.
Power users do something different. They brief AI the way they would brief a smart-but-new colleague: with files, context, constraints, and a clear ask. They expect three options instead of one. They argue. They iterate. They check the work. The gap between a novice prompt and a power-user prompt is not cleverness; it is a handful of habits anyone can learn in an afternoon.
This page is that afternoon. Thirteen concepts, grouped into four short parts. No code, no setup, no jargon you cannot guess from context.
Before this page: read What AI Actually Is. That course explains what the machine is; this one teaches how to talk to it.
📚 Teaching Aid
View Full Presentation — AI Prompting 2026
One fact underlies everything else on this page, and you met it in What AI Actually Is (Idea 2): the model is stateless — it has no memory of its own between turns, and answers each time using only what is in its context window right now. Everything below is downstream of that one fact.
That is why one insight runs through every section below: almost every "advanced technique" on this page is one of two moves — getting the right context in, or keeping the wrong context out. The model sees only what is in its context window for this response. Your job is to control what goes in. Read each section through that lens.
A note on tools: examples reference ChatGPT, Claude, and Gemini because most readers have one of those. The skills transfer to any modern chat AI. Where a feature is exclusive to one product, it is named explicitly.
Open a free account with one of Claude, ChatGPT, or Gemini in another browser tab right now, before you keep reading. Each has a free tier that takes about a minute to sign up for. You don't need to do anything in it yet; just have it open. Then read straight through once for the shape, and come back to try the prompts in the closing block. Reading without trying gives you the words; trying gives you the skill. (One of the closing exercises asks you to compare two tools side by side, so you may want a second free account open by the time you get there.)
A short note on what changed since you last looked
If you used ChatGPT in 2022 or 2023 and decided it was a clever toy, the tool you remember is not the tool you have now. A few changes that happened quietly:
-
Context windows grew by roughly 1000x. A 2022 model held a few thousand words. A 2026 model holds hundreds of thousands, sometimes a million. That changes what you can stuff into a prompt: a whole book, several days of speech, a folder of contracts.
-
Reasoning became real. "Think step by step" used to be a magic phrase. Now models have explicit thinking modes that run for seconds, sometimes minutes, exploring multiple approaches before answering. One way to size this: a year ago, the hardest task AI could reliably finish was something that would have taken a person a few minutes. Today it is something that would have taken a person an hour or more. Concept 5 has the measured numbers.
-
Web search became a built-in tool. The model decides when a question needs fresh information, fires off a search, reads a few pages, and uses what it finds in the answer. A 2022 model could only answer from what it had memorized at training time; a 2026 model can go look something up mid-response. This matters most for anything that changes — news, prices, recent regulations, this week's sports scores.
-
Code execution became a built-in tool too. The model can write a small program, run it, see the result, and use that result in its answer. This matters most for anything it would otherwise estimate in its head — arithmetic on real numbers, parsing a spreadsheet, running a quick simulation. Both search and code execution tools are mostly invisible: most users do not notice when one fires, so they cannot tell whether an answer came from memory, a fresh web page, or a calculation. Once you start noticing, your prompts get sharper — you can ask "did you actually search for this?" or tell the model "run the numbers, don't estimate."
-
Multimodal stopped being a sidebar. You can drop a photo, a PDF, a spreadsheet, a voice memo, or a folder of files into a prompt and ask questions about them. The model handles all of those in one stream.
-
Desktop apps appeared. A new category of products (Cowork, OpenWork) can find your files, draft emails, and update spreadsheets with permission. This is not chat anymore; it is closer to delegating a small task to a coworker.
-
Command-line agents appeared for developers. Tools like Claude Code and OpenCode live in the terminal, read across a whole codebase, edit many files at once, run tests, and report back. Same shift as the desktop apps — AI acting on real artifacts instead of describing them — but aimed at people who write code.
If your mental model of these tools is out of date by even eighteen months, you are using them at maybe 20% of what they can do today. This page closes that gap.
Part 1: How AI knows things
Once you understand what is actually happening when you ask AI a question, you stop being surprised by the failures.
1. Novice vs power user
These slides are designed specifically for school students learning AI prompting for the first time. Teachers can use them in the classroom to introduce Concept 1 through age-appropriate examples (school trips, homework help, birthday parties) and interactive exercises. Download PPTX for offline classroom use.
Watch what changes between the two prompts. The question is the same; the briefing is not.
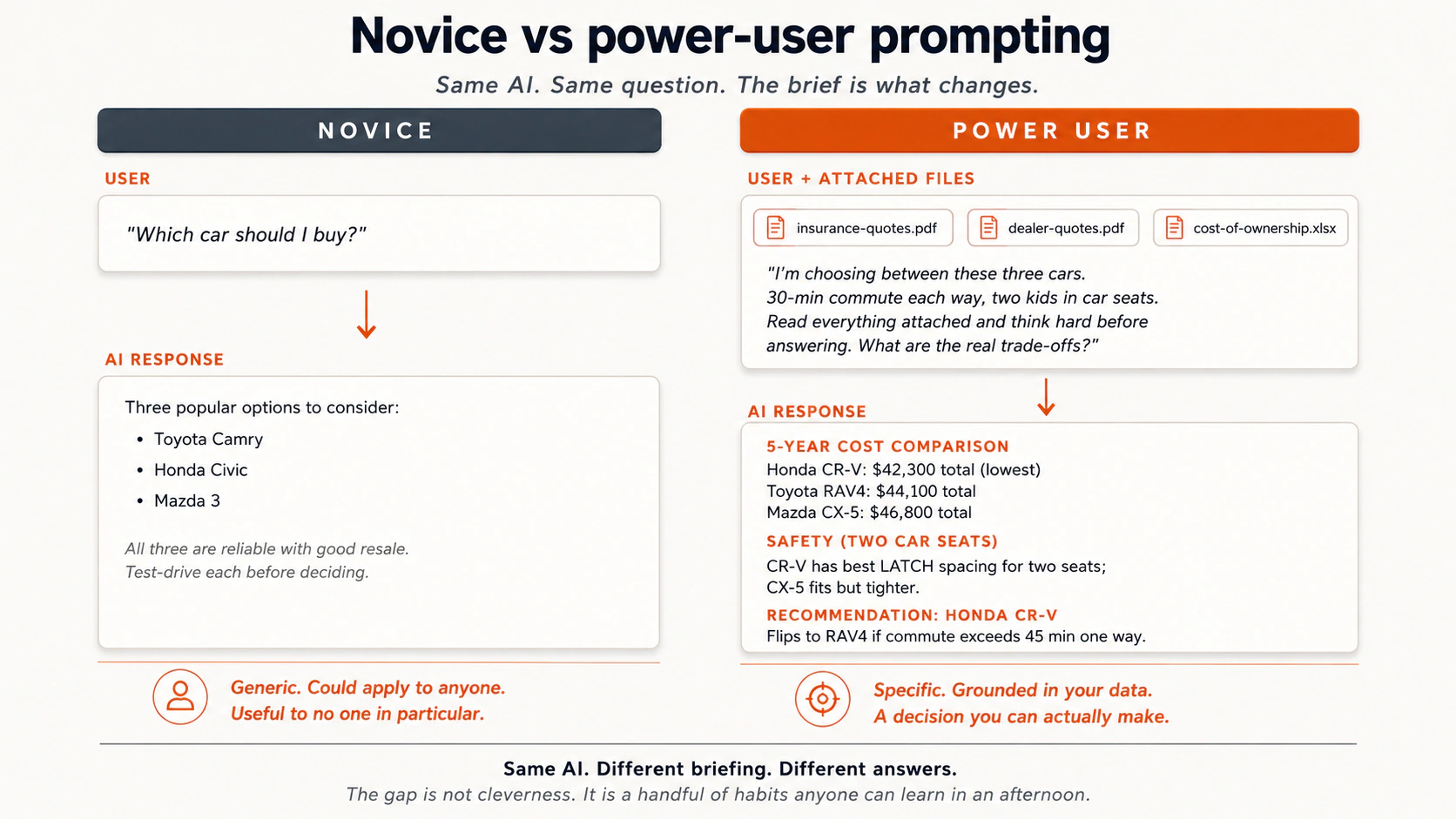
A few more real contrasts from the field:
- Buying a car. Novice: "which car is best?" Power user: uploads spec sheets, dealer quotes, and insurance plans, then asks "what are the trade-offs? Read everything and think hard."
- Self-review at work. Novice: "write a self-review for my boss." Power user: uploads a screenshot of their project tracker, recent project docs, and a voice memo of notes, then asks for a draft.
- Critiquing a business idea. Novice: "I have a great business idea, mobile tie-dyeing, critique it." That is sycophancy bait, the AI will mostly applaud. Power user: "Analyze objectively. Use this rubric: is there a problem worth solving, is there a market, is there a competitive advantage?" The AI scored that idea 8 out of 100 and explained why.
- Writing a blog post. Novice: "write a blog post about the BlackBerry." Result: AI slop. Slop is the term of art for AI output that is fluent on the surface and empty underneath — grammatically clean, faintly Wikipedian, full of phrases like "in today's fast-paced world," and saying nothing a reader would remember an hour later. It is what AI produces by default when you give it no context and no constraints. Power user: outline first, critique outline, expand each heading into bullets, critique bullets, only then ask for prose.
The mental model that ties these together: AI is like a really smart fresh college grad. Highly motivated. Doesn't know much about you yet. Brief them like one. Would a new colleague have enough information to do this job well? If not, give them more.
2. Pretrained knowledge
These slides are designed specifically for school students. They explain pretrained knowledge through a child-friendly lens: AI learned by reading, not by living. Covers the "Loud, Quiet, Secret" framework (topics talked about a lot, a little, or never), interactive classroom games (Trust-o-Meter, Stump the Robot, Be a Fact-Checker), and the key lesson: "Sounding sure is NOT the same as being right." Download PPTX for offline classroom use.
AI did not learn by experiencing the world. It has no body, no senses, no time spent moving around in it. It learned by reading text about the world — massive amounts of internet text. Reddit and Quora threads, Wikipedia, books, news articles, research papers, blogs, forums.
Frequency in training data is roughly equal to reliability of the answer. So:
- Strong: cooking, celebrity gossip, common medical advice, top-1000 movies, popular programming languages, what is on the Voyager 1 record (NASA spacecraft launched in the 1970s, around 25 billion miles from Earth, carrying greetings in 55 languages), why cats stare at walls (they detect subtle sounds and movements humans miss).
- Sparse: quasars (extremely bright objects in the sky powered by black holes), Cantonese (under 0.1% of internet text), regional history, niche professional knowledge.
- Absent: your company's secret data, your private calendar, anything published after the model's knowledge cutoff date, anything someone never put on the public internet.
Two practical consequences:
Don't waste time fixing typos. AI was trained on internet text, which is full of typos. It handles misspelled prompts gracefully. Misspelling "definately" will not change the answer.
Watch for absorbed errors. AI also absorbed misconceptions and outdated information from those same sources. A confidently wrong forum post becomes confidently wrong in the model. Check anything important against a primary source.
Spotting broken reasoning is its own discipline, and the Thinking in AI Era Crash Course teaches it directly. The first place to look for it is in confident-sounding pretrained answers about topics where the training data was thin or contested. Confidence is not a signal of correctness.
A quick mental test before you trust a pretrained answer:
| Question type | How well-represented in training data? | Trust level |
|---|---|---|
| "How do I make a roux?" | Cooking is one of the most discussed topics on the internet. | High. |
| "Plot of a top-1000 movie." | Reviewed and re-reviewed thousands of times. | High. |
| "History of an obscure village." | Possibly only one Wikipedia paragraph, or none. | Low; verify against a primary source. |
| "Recent regulatory change in my industry." | Almost certainly after the knowledge cutoff. | Trust nothing without web search. |
| "What did our company decide last quarter?" | Not in the training data at all. | Trust nothing; the model is guessing. |
This is not a rule you have to memorize. It is the same instinct you would apply to any other source: "how would this person know that?" Apply it to AI too.
A non-software example. A reader once asked an AI for a summary of the rules of a regional folk game played in their grandmother's village. The AI confidently produced three paragraphs of rules. The grandmother, asked, said the rules were almost entirely wrong: the AI had blended descriptions of similar games from other regions because the specific game was barely on the internet. The AI did not lie; it generalized from sparse data. The reader's mistake was not asking, but assuming confidence equaled accuracy.
Curious why AI can sound completely confident and still be wrong? There's a deeper reason behind it. Elan Barenholtz's article "LLMs show language does not describe reality" (IAI, 2026) walks through how these models actually work, in plain English. The article also makes some bigger philosophical claims about human language; feel free to take the part you find useful and ignore the rest.
A fun interactive exercise designed specifically for school students. Students categorize topics (pizza, dogs, a rare deep-sea fish, your WiFi password, what you ate today, your family's special Ludo rules) into three zones: Loud (everyone talks about it, AI knows it well), Quiet (only a few do, AI might get it wrong), or Secret (nobody wrote it down, AI cannot know it). Play the Exercise Online | Download PPTX for offline classroom use.
3. The 3 retrieval modes: pretrained, web search, deep research
When you ask a question, modern AI tools quietly choose how to answer. Either they answer from pretrained knowledge alone, they fire off a web search and read a few pages, or they run deep research, where they spend several minutes scanning dozens of sources and write a structured report.
You should know which mode is firing, because each has different strengths and different failure modes.
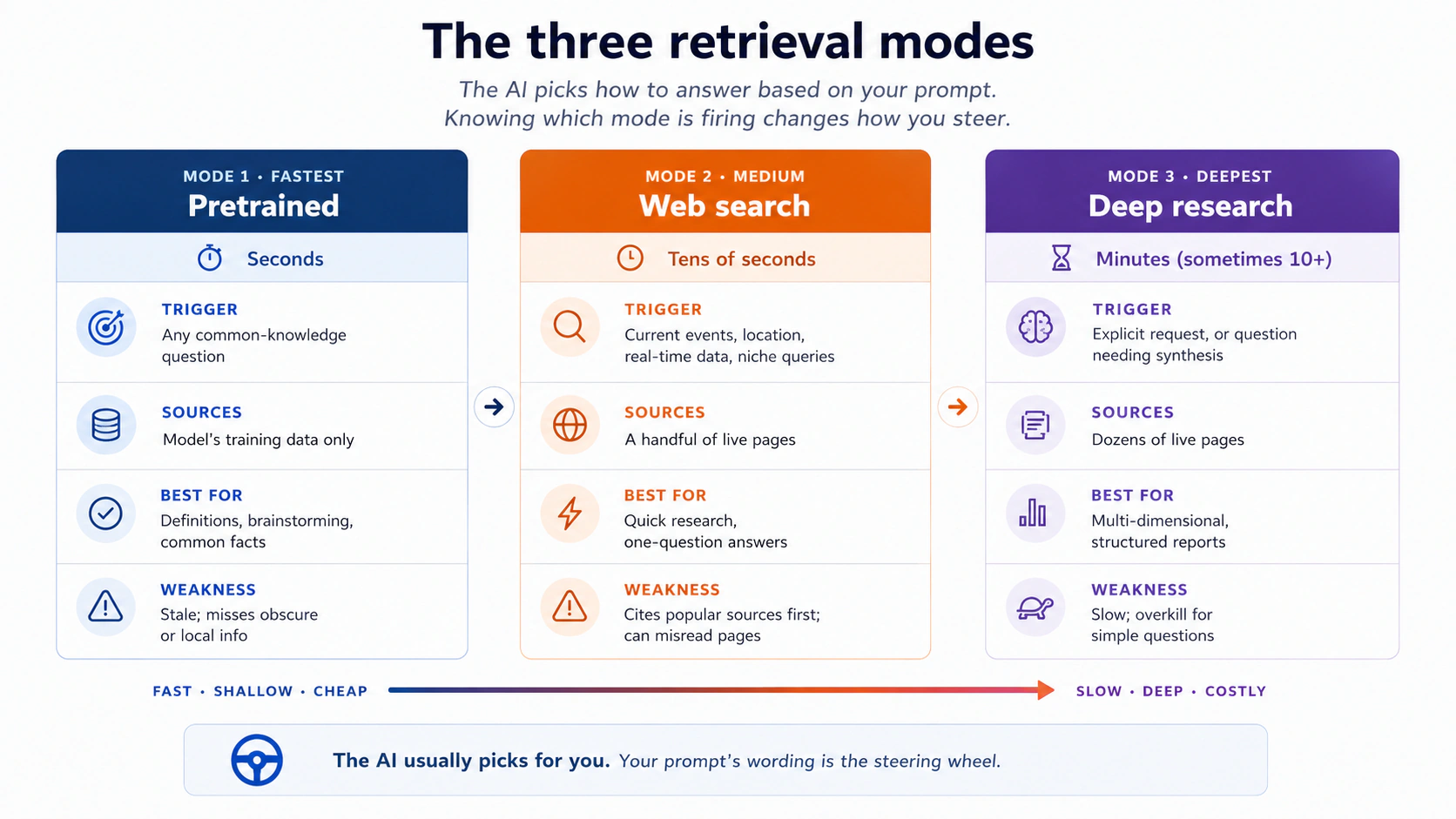
A few examples to make this concrete:
- Pretrained answers fine: "why do cats stare at walls," "what's on the Voyager 1 record," "summarize the plot of Hamlet." These do not change week to week.
- Web search rescues a stale model: every model has a knowledge cutoff date, and anything that went viral after that date is invisible to it. A meme, a regulation, a product launch: without web search, the AI has no idea what you are talking about. With web search, it pulls a recent article and answers correctly.
- Web search going wrong: a friend asked "where to run in Henderson, Nevada." The AI cited a 20-year-old web page and recommended a school no longer open to the public. Web search does not check whether sources are current.
- Deep research worth the wait: "plan a Halloween haunted house in our neighborhood, including permits, fire safety, and noise ordinances." The AI proposes a research plan, runs many parallel searches, summarizes, decides what to dig into next, and produces a multi-section report with checklists. This is not a chatbot answer; it is closer to handing the work to a junior researcher for an hour.
Under the hood, the exact mechanics vary by tool, but the shape is consistent. A search-and-retrieval layer issues the searches, scans the result list, pulls the most relevant pages, and reduces each one to a short passage or summary. Often that layer is a separate, smaller model. Only the reduced version flows to the user-facing model that talks to you.
The model talking to you frequently does not read the original page directly. It reads a condensed version of it. That is why it sometimes misrepresents what a page actually said: the information went through a translation layer before it reached the model, and translation layers lose nuance.
Practical fix: tell the AI which kinds of sources to use. Instead of "are vaccines safe," try "use the World Health Organization, the FDA, the European Medicines Agency, and peer-reviewed studies. Do not use forums or personal blogs." Source quality is a knob you can turn. Default settings cite popular sources first (Reddit, Wikipedia, YouTube, Google itself, Yelp), which are often reliable but not always trustworthy for high-stakes questions.
A second fix: ask the AI to quote the source. "For each claim, quote the exact sentence from the source page that supports it." This forces the retrieval layer to surface original wording, which catches a lot of summary-layer drift.
A non-software example. A neighborhood-association volunteer used deep research to prepare for a town meeting on local water quality. Her prompt: "Research current water quality issues in [her city] over the last 24 months. Use the EPA, the city's public utility reports, and peer-reviewed studies. Avoid news editorials and forums. Produce a structured report with: (1) the three most-cited issues, (2) data tables showing trends, (3) three concrete questions residents should put to the utility." Eight minutes later she had a briefing grounded in current local data. Pretrained mode could not have done this; web search alone would have produced a shallower answer; deep research was the right tool because the question was multi-dimensional and current.
Choosing a mode in your head. You usually do not pick a mode by clicking a button; the AI picks based on your prompt. But you can steer:
| Phrasing pattern | What it usually triggers |
|---|---|
| "What is X" / "Summarize Y" | Pretrained only. |
| "What's the latest on X" / "Today" / "This week" / a specific city | Web search. |
| "Research X thoroughly," "produce a report with citations," "use these source types" | Deep research (in tools that have it; otherwise extended web search). |
| Attaching files | Stays pretrained for the files; may search the web for context if the prompt asks for current info. |
AI vs Google. They are not the same tool. Use Google for quick scans, navigating to a specific known site, or buying a thing (the air filter for a 2013 Honda Civic). Use AI when you need synthesis: pros and cons, multi-source comparison, a written-out analysis. The choice depends on whether you want a link or an answer.
A side-by-side rule of thumb:
| Task | Better with Google | Better with AI |
|---|---|---|
| "Find the official IRS page for form 1040." | Yes. You want to land on a specific known site. | No. |
| "Compare three diabetes medications and what the recent evidence says." | Slower. You'll read 8 tabs. | Faster. AI synthesizes the evidence in one place. |
| "Buy a replacement charger for a 2018 ThinkPad." | Yes. You want a product link. | No. |
| "Plan a 4-day Lisbon trip with a 6-year-old, no museums." | Slow. You'll juggle blogs and reviews. | Fast. AI integrates constraints. |
| "What's the weather tomorrow?" | Either. | Either. |
| "Why are my tomato plant leaves yellowing?" | OK. Multiple gardening sites. | Better with a photo attached. |
If your question is "where is X," reach for Google. If your question is "given all this, what should I think," reach for AI.
How to get more reliable web-search results with AI
When you do want web search, three small habits raise the quality:
- Name the sources you trust. "Use the WHO, the FDA, and peer-reviewed studies, not forums."
- Ask for citations inline. "Cite the source after each claim."
- Ask the AI to flag what it could not verify. "If a claim cannot be supported by the cited sources, mark it 'unverified'."
These three lines, pasted into any web-search prompt, cut down on the most common failure mode: the AI quietly synthesizing across sources and producing a confident sentence that no single source supports.
Part 2: Talking to AI well
4. Context is the whole game
Humans hold only a handful of things in active working memory: classic estimates say about seven, newer ones closer to four. Modern AI models can hold hundreds of thousands of words at once, sometimes a million. To put that in proportion: about 750,000 words is the first 4 to 5 Harry Potter books, or several days of continuous speech. The model can read all of it before answering.
But it can only read what you give it. Context is everything that ends up in the model's window for a given response: the system prompt the product set, the descriptions of any tools it can call (web search, code, file access), your prompt, the chat history of this conversation, and any files you uploaded.
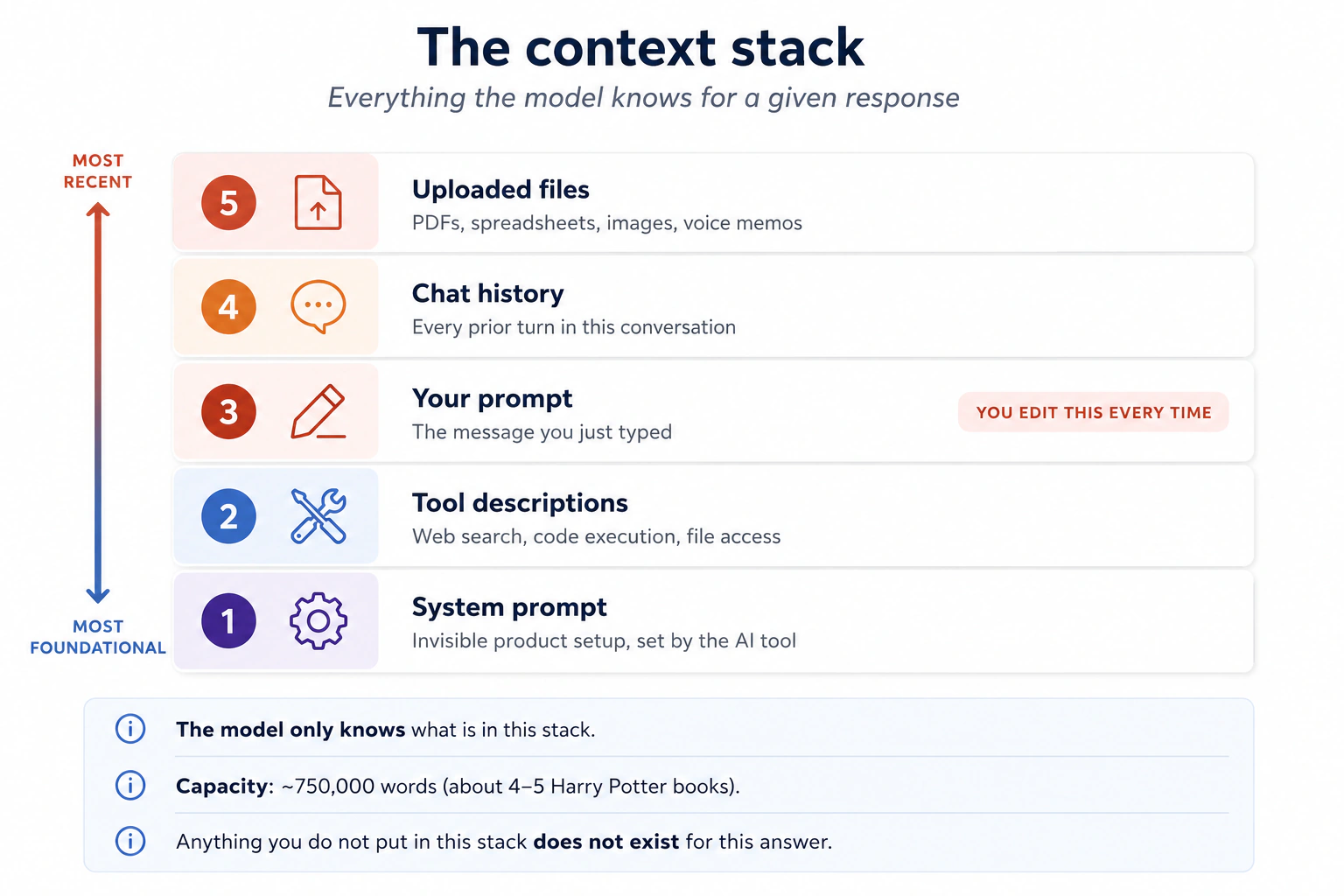
A question before we continue. When you open ChatGPT, Claude, or Gemini and type your very first message, does the AI start completely from zero, working only from what you just typed? Or has someone already given it instructions before you arrived?
Most people assume it starts blank. It does not.
The window is not empty when you arrive. The "window" here is the context window: the reading desk from What AI Actually Is (Idea 5). Whatever is on that desk right now (your prompt, the conversation so far, any files you attached, and a few things the tool placed there before you arrived) is all the model knows, and anything not on the desk does not exist for this answer. The diagram above shows the five things that can land on it.
Now look at the bottom layer of that desk: the system prompt. When you open a fresh chat, you might think you are starting with a blank surface. You are not. Before you type a single character, the company that built the tool has already placed a set of instructions on the desk. You will never see them in the chat, but the model reads them before it reads anything you write.
Think of it the way a restaurant owner briefs a new waiter before the first customer sits down. "Be friendly. Recommend the daily special. If someone asks about allergens, always check with the kitchen, never guess." The waiter follows those instructions with every table, and you never hear the briefing. The AI works the same way. Engineers call those invisible instructions the system prompt.
What is typically in that briefing:
- How to behave (helpful, honest, careful).
- What to refuse (harmful content, dangerous instructions).
- What tone to use (formal, chatty, concise).
- When to add disclaimers ("I'm an AI and can't provide medical advice").
- What tools it can call (web search, code execution, file access).
This is why Claude, ChatGPT, and Gemini feel different even when you ask them the exact same thing. The "personality" you sense is not baked into the model itself. It is baked into the instructions the company loaded before you arrived. Claude's instructions emphasize careful reasoning and honesty. ChatGPT's emphasize conversational warmth and broad helpfulness. Gemini's emphasize conciseness and source grounding. Same question, three different briefings, three different tones.
Try it yourself: ask all three "explain why the sky is blue, in one paragraph." The facts will be similar. The tone, length, and style will be noticeably different. That difference is mostly the system prompt.
Now you know why:
- The AI is polite even when you are rude (it was told to be).
- It refuses certain requests (it was told to).
- It adds safety disclaimers you never asked for (it was told to).
- It sometimes apologizes more than seems necessary (it was told to err on the side of caution).
- Different tools give the same facts in a different voice (different briefings).
These are not personality traits. They are instructions.
You can add your own layer. The company's system prompt is fixed, but most tools now let you write your own instructions that load alongside it into every chat. When you write "I am a nurse, assume clinical vocabulary" or "always respond in formal English" in your tool's instruction settings, you are writing your own line in the system prompt. The model reads it before every response, just like the company's briefing, which is why it sticks without you repeating it.
Where to find this in each tool:
| Tool | Setting name | Direct link |
|---|---|---|
| Claude | Personal preferences (Settings > General) | claude.ai/new#settings/general |
| ChatGPT | Personalization (under Settings) | chatgpt.com/#settings/Personalization |
| Gemini | Personalization settings | gemini.google.com/personalization-settings |
Here is what these settings pages actually look like in all three tools. Each has a text area where you type your instructions, and every future chat starts with those instructions already on the model's desk.
Claude: Open Settings > General and scroll down to "Instructions for Claude." Type your instructions in the text area. Claude will keep these in mind across all your chats.
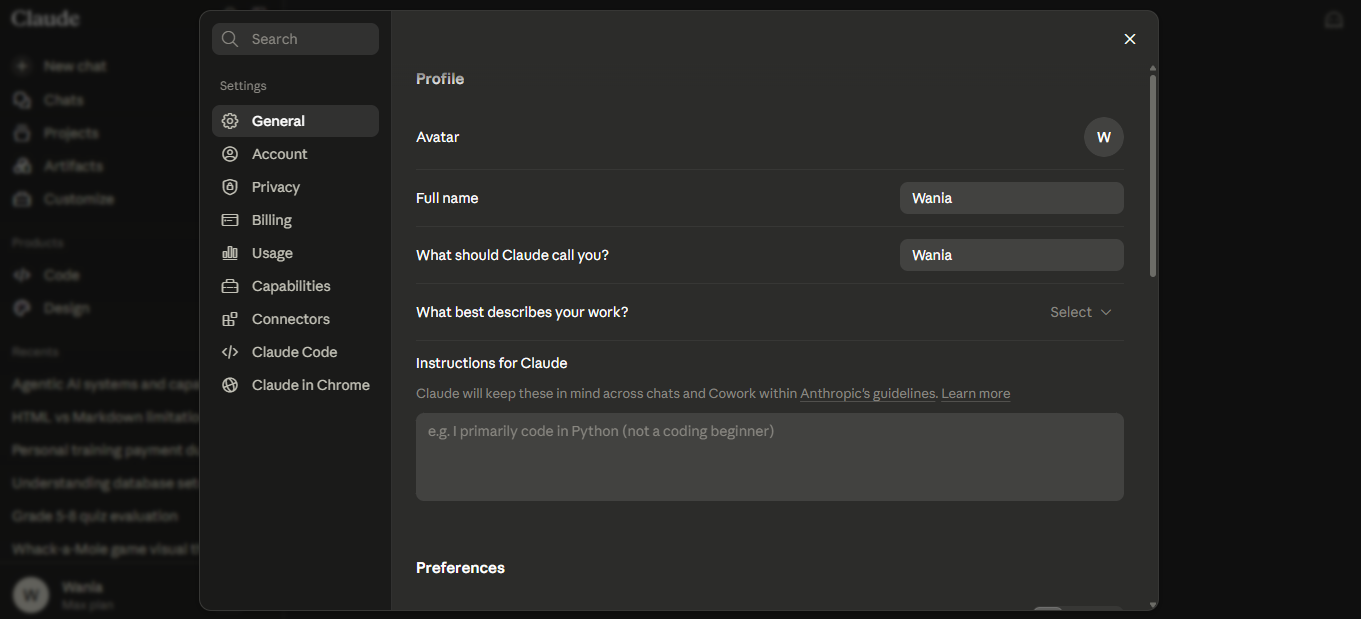
ChatGPT: Open Settings > Personalization. You will see style controls (Warm, Enthusiastic, Headers and Lists, Emoji) and a "Custom instructions" section at the bottom. Scroll down to Custom instructions and type your instructions there.
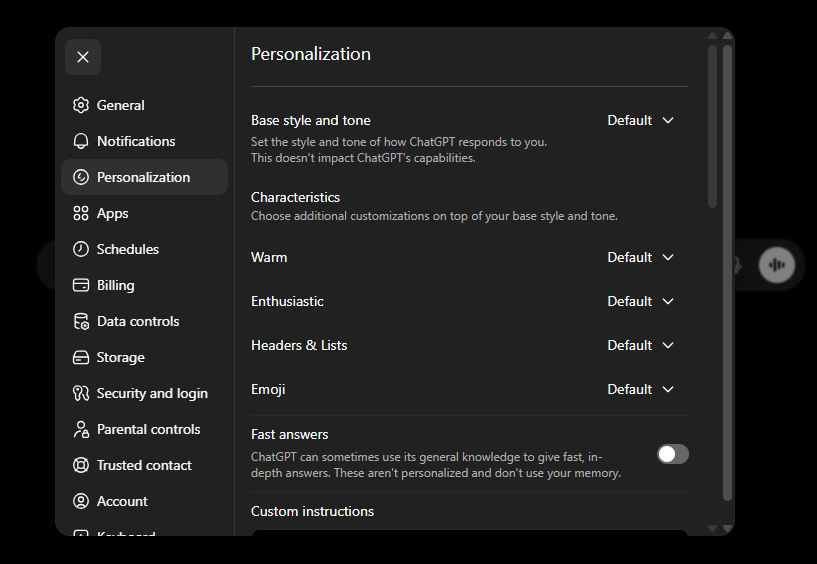
Gemini: Open Personalization settings. Toggle the switch on, then click the Add button to write your instructions.
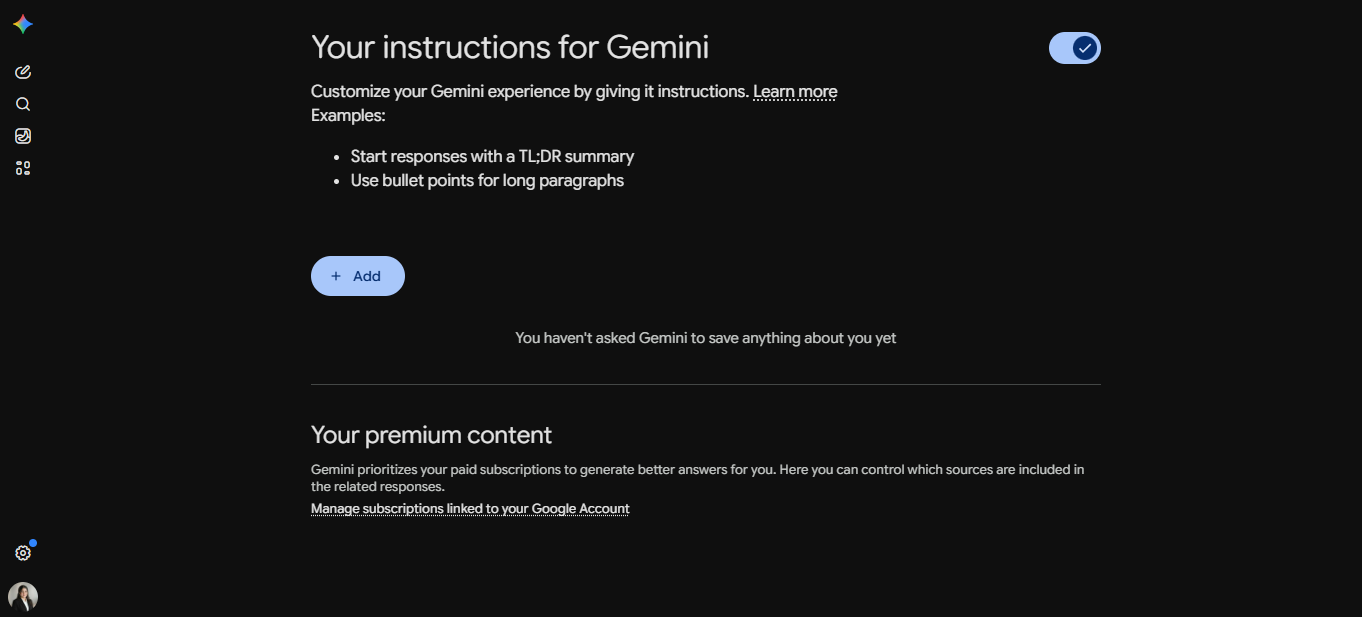
In all three, the steps are the same: open the link, write a few sentences about who you are and how you want the AI to respond, and save. From that moment on, every new chat starts with your briefing already loaded. You do not have to repeat yourself.
A small but real example. A teacher sets her instruction to: "I teach Grade 5 science. Explain everything at a 10-year-old's reading level. Never use jargon without defining it first." What happens behind the scenes: those sentences get added to the system prompt, right next to the company's own instructions. So every time she opens a new chat, the model already has both briefings on its desk before she types a word: the company's ("be helpful, be honest, refuse harmful requests") and hers ("I teach Grade 5 science, keep it simple"). She never has to say "I'm a teacher" again. She never has to repeat "explain it simply" in every prompt. The AI already knows, the same way the waiter already knows to check with the kitchen, because the owner's briefing said so before the first customer sat down.
Now look at the full stack one more time. The system prompt is the foundation, the bottom layer. Your prompt, your chat history, and your uploaded files all sit on top of it. When you write your own instructions in those settings, you are adding your own layer right next to the company's, so every chat starts with your context already loaded. That is the complete picture of what the model sees, and this is the only thing the model sees. Because it has no memory of its own, nothing outside this stack exists for this answer. The stack is the world for this response.
Concrete contrast:
- Bare prompt: "pros and cons of studying physics versus zoology." You will get generic high-school-counselor advice.
- Context-rich prompt: the same question, plus your career assessment results uploaded as a PDF and a screenshot of your high-school schedule. Now the AI can talk about your specific aptitude profile, your specific course history, and which choice fits which.
Same model. Same question. Different answer. The difference is the context, not the cleverness of the prompt.
The discipline you are learning: before you press send, ask yourself what a smart new colleague would need in front of them to answer this well. Then attach those things. The colleague will read everything you put in front of them carefully; they will not guess what you did not tell them, will not search your filing cabinet, will not infer your industry, your team's history, or yesterday's email thread. If they would have needed a document or a constraint to do the job, you need to include it.
A non-software example. A 7th-grade teacher asked AI to "draft a lesson plan on the water cycle." The output was a generic plan she could have found in any textbook: definitions, a diagram, three discussion questions. The next day she tried again, with three things attached: her course syllabus (so the AI knew what came before and what came after this lesson), last week's student worksheets with grades visible (so the AI knew which concepts had landed and which had not), and her school's standardized test format. The new lesson plan opened with a five-minute review of the two concepts last week's worksheets had shown were weak, threaded the new material through the test format the students would see in May, and closed with a check-for-understanding question matched to her syllabus's next topic. Same model, same teacher, same subject. The only difference was that the second prompt told the AI what a smart new colleague would have needed to know.
The habit, restated as a checklist before any non-trivial prompt:
| Question | If yes, attach or describe it |
|---|---|
| Is there a document the answer should be consistent with? | Yes: attach it. |
| Is there a constraint the AI cannot infer (budget, time, who's on the team)? | Yes: state it. |
| Is there prior context (a previous decision, an existing process)? | Yes: summarize in one paragraph. |
| Is there an output format you want (table, email, bullet list)? | Yes: name it. |
| Is there an audience (a boss, a child, a stranger)? | Yes: name them. |
Five lines of context, properly chosen, beats five paragraphs of cleverness.
Modern context windows are large, but not infinite, and recall degrades inside them. The biggest practical mistake people make: they keep one very long conversation going across many unrelated topics. AI just helped you plan a workout, now you ask it to debug a spreadsheet, now you ask it to write a thank-you note to your aunt. The workout context is still in there, distracting the model.
Rule of thumb: when the topic changes, start a new conversation. Cheap to do, free to do, and the answers get visibly better.
Symptoms that tell you a conversation has gone stale:
- The AI starts referencing earlier parts of the chat that have nothing to do with what you just asked.
- Its answers get longer and vaguer over time, with more hedging.
- It contradicts a constraint you stated five turns ago.
- It starts apologizing repeatedly without making progress.
A name for what is happening: most modern chat tools, once a conversation gets long enough, quietly compact the older parts of the chat — they take the early turns, summarize them into a short paragraph, and replace the originals with the summary to make room. Claude shows a small "compacting" message when this happens; ChatGPT and Gemini do it silently. The narrative survives, but the specifics do not. The library you told it to use three hours ago, the naming convention you agreed on, the constraint you stated in turn four — any of these can quietly disappear into the summary and stop showing up in the model's answers. The fix is the same as the rule above, just better motivated: a chat window is working memory, not storage. Anything that needs to survive past one long session belongs in a project, an attached file, or a note you can re-paste — not in the chat history itself.
When you see these, the instinct is to fix it with one more clarifying prompt. Resist it: that just adds more tangled context to a context that is already tangled. Apply the rule above instead. Start the new chat, paste in the one or two facts that actually matter, and continue from there. The reset is almost always faster than the rescue.
If the dead chat produced something worth keeping (a plan, a draft, a decision), save it to a file before resetting. That way you don't lose the work, but you also don't drag the noise into the next task.
The Concept 4 checklist above raises an obvious question: if AI needs to be briefed like a colleague every time, that is a lot of repeated typing. The answer most modern tools now ship is a feature called projects — a workspace you set up once, with the files, instructions, and audience that always apply to a kind of work, so every chat you start inside it inherits that setup automatically.
When to make a project. The moment you notice you have pasted the same files, the same audience description, or the same constraints into two or more chats on the same topic. That is the signal: the context belongs in a project, not in a prompt.
A few examples of what a project earns you:
- A "tax filing" project with last year's return, your W-2s and 1099s, and an instruction like "Assume I am a US filer with one dependent. Always show your math." Every question you ask in there starts from that base.
- A "kids' school" project with the syllabus and the school calendar, and an instruction like "Always check the date against the calendar before answering." Useful when "is there school on Monday?" comes up four times a year.
- A "writing voice" project with three samples of your writing and an instruction like "Match the cadence and word choice of the samples. Do not add hedging or qualifiers I did not use." Now every draft starts in your voice instead of generic-AI-voice.
Connection to the context rot rule above. Inside a project, "start a new chat" no longer means losing what the AI knows about your situation — it means losing only the noise of the previous conversation. The standing files and instructions ride along. So the reset rule gets cheaper to follow: you reset the chat, not the context.
Three tools, three names, one idea. Claude calls it Projects, ChatGPT calls it Projects, and Gemini calls it Notebooks (which sync with NotebookLM, Google's standalone research tool — anything you add in one shows up in the other). All three let you upload files, save instructions, and run many chats grounded in the same persistent context. They differ in emphasis:
- Claude and ChatGPT Projects tilt toward instructions and behavior. You set the voice, the role, the rules, the audience, and the model holds that persona reliably across every chat in the project. Best when how the AI responds matters as much as what it knows — writing in a specific voice, working on a codebase, maintaining a brand tone, anything where consistency of style is the point.
- Gemini Notebooks (and NotebookLM) go further on the source side. Drop in PDFs, Google Docs, web URLs, YouTube videos, even audio files, and every answer comes back grounded in those sources with inline citations you can click. The unusual part: the workspace flows both ways. Anything you put into NotebookLM appears in the same notebook inside the Gemini app, and any chat you have inside a Gemini notebook automatically becomes a source back in NotebookLM. So the workspace accumulates your own reasoning over time — last week's chat is one more source this week's chat can cite, which "connects the learning to the practicing" in a way the other tools do not. NotebookLM also generates Audio Overviews (podcast-style summaries you can listen to), Mind Maps, Flashcards, and Slide Decks built automatically from your sources. Best when you are studying, researching, or working through material over many sessions where each session should make the next one smarter.
Quick rule of thumb. Reach for Gemini Notebooks / NotebookLM if the workspace will grow over time — study notes, ongoing research, anything where you want each session to feed the next. Reach for Claude or ChatGPT Projects if the workspace is built around a persona or set of instructions you want the AI to hold consistently across chats.
What is available where, as of mid-2026:
| Tool | What it is called | Free tier? |
|---|---|---|
| Claude | Projects | Yes — up to 5 projects on the free plan; files within each project are unlimited |
| ChatGPT | Projects | Yes — free plan supports up to 5 files per project; paid plans raise this to 25 or 40 |
| Notebooks (in Gemini) and NotebookLM | Yes — both are free; paid tiers (NotebookLM Plus, Gemini AI Pro/Ultra) raise the source limits |
Note the different shape of the free-tier caps: Claude limits how many projects you can have; ChatGPT limits how many files each project can hold. Plan your project structure around whichever cap will bite first.
5. Reasoning, or "think hard"
These slides are designed specifically for school students. They introduce the concept of reasoning modes through a simple two-speed model: quick answers vs slow, careful thinking. Teachers can use them in the classroom to explain when and why to ask AI to "think hard" before answering, with age-appropriate examples and interactive exercises. View Full Presentation
Until about 2023, the standard advice for hard prompts was "think step by step." That advice is now mostly obsolete. Modern models have built-in reasoning modes that you can invoke directly.
How to invoke it:
- Ask for it in plain language. "Think hard" or "think carefully before answering" in your prompt. This is the portable move: it works across every modern chat tool, with no special syntax to remember.
- Use the thinking-mode toggle in the interface, where one is offered.
- On some products you do not have to ask at all: the tool decides on its own when a question is hard enough to warrant extended thinking, and turns it on for you.
When extended thinking is on, the model can think for many seconds. On hard problems, sometimes more than ten minutes. It is not just typing slower; it is internally exploring multiple approaches, checking its own work, and only then writing the answer you see.
A 2025 METR study tracked the longest task a frontier model could reliably complete. In mid-2024 a leading model handled tasks that take humans around seven minutes. By early 2025 that was up to roughly an hour, and the study found the length it measures has been doubling roughly every seven months. The implication for you: hand AI real, hard tasks, not just easy ones. It can handle more than your 2023 instincts suggest.
A power-user pattern that uses this well:
I'm choosing between two cars. Attached: spec sheets for both,
my insurance quote for each, and a spreadsheet of my driving
patterns over the last six months.
Read everything. Think hard. Then tell me:
1. The three trade-offs that actually matter for my driving pattern.
2. Which car you'd choose and why.
3. Under what conditions your recommendation flips.
Three things this prompt does: it loads the relevant context, it explicitly invokes thinking, and it asks for structured output instead of a wall of prose. All three are habits.
Quick lookups, summaries of a paragraph, casual brainstorming. Thinking mode is slower and uses more of your usage budget. Save it for the questions where you would have wanted a human to take their time.
That is what thinking mode is for: not faster, but able to handle the kind of multi-input, multi-trade-off question you would otherwise hand to a thoughtful colleague and wait two days for. The trade is real. You spend a few minutes of compute and a small amount of usage budget. You get back something you would have spent half a day producing yourself.
The implication of that METR trajectory mentioned above: the tasks you mentally categorized as "too complex for AI" two years ago are mostly now tasks AI can handle, if you brief it well and turn on thinking mode. Re-test your assumptions about what AI can do every six months. They will be wrong.
6. Sycophancy and how to neutralize it
AI models are trained on human feedback. Specifically, on which responses got a thumbs up. Across millions of users, agreeing with people gets more thumbs up than disagreeing. The result: models are biased toward telling you what you want to hear.
A November 2025 Washington Post analysis of 47,000 ChatGPT conversations found the model opened with an affirmation ("yes," "correct," and similar) about 10 times more often than it opened with "no" or "wrong." The reported openings clustered around phrases like "that's correct" and "you're on the right track."
You can verify this yourself. Same model, opposite framings:
- "Don't you think remote work is better than office work?" → AI agrees, lists reasons.
- "Is it true that office work is more productive?" → AI agrees, lists reasons.
The fix is not magic. It is just neutral framing. The pattern shows up at two levels: surface ("don't you think X?") and subtle ("find evidence that X works"). Watch for both in your own prompts:
| Subtle bait you might write | What it signals to the AI | Neutral rewrite |
|---|---|---|
| "Find evidence that this strategy will work." | The conclusion is fixed; AI fills in support. | "Evaluate this strategy. List the strongest arguments for and against." |
| "Why is approach A better than approach B?" | A wins; AI lists reasons. | "Compare approach A and approach B. Score each on cost, risk, and time." |
| "Help me defend my decision to hire X." | Decision is locked; AI provides ammunition. | "Here is my decision and the context. What's the strongest counter-argument I should be ready for?" |
| "Tell me my draft is ready to send." | AI tells you it is ready. | "Score this draft 1-10 on these 4 criteria. For each one, tell me the change that would raise the score the most. There is always a next level." |
| "Confirm that this code is correct." | AI confirms. | "Find any bug, edge case, or unstated assumption in this code. If there are none, say so." |
The pattern: any phrasing that contains a verb like find, defend, confirm, prove, support hands the AI a conclusion before the question. Replace with verbs like evaluate, compare, critique, find any, list both sides. The model will still bias slightly toward agreement, but you have removed the loudest signal.
The general rule: lay out two options without hinting at preference, then ask for pros and cons of each. If you find yourself writing "isn't X true," stop and rewrite as "to what extent, if at all, is X true?"
This concept is the cheap version of a much deeper skill. The Thinking in AI Era Crash Course trains the deep version: how to formulate questions that surface what you do not already know. The neutral-framing trick gets you 80% of the way there for everyday use. The crash course gets you the rest.
A non-software example. A founder asked AI: "I have a great business idea, mobile tie-dyeing for kids' birthday parties, critique it." The AI praised the idea warmly and listed reasons it might succeed. The founder then tried again with a rubric: "Analyze this idea objectively. For each of the following, score 1 to 10 and justify: (1) is there a real problem here, (2) is there a market willing to pay, (3) is there a competitive advantage, (4) what's the unit economics, (5) what are the top three reasons this fails." The same AI gave the idea 8 out of 100 and explained, in concrete terms, why the founder should rethink it. The first prompt was sycophancy bait. The second was an objective rubric. Same model, same idea, opposite verdicts. The difference was how the question was asked.
The objective-rubric pattern. A rubric is just a list of specific things to check, each scored or answered separately. When you ask AI to evaluate something (a draft, a plan, an idea) without one, ambiguous criteria collapse into "great work." With one, specific criteria force the AI to actually look. Compare:

The image above shows the contrast: vague prompts collapse into praise; structured prompts with scores and yes/no checks produce real feedback.
Force a number. A small but powerful add-on to the rubric pattern: for each criterion, require the AI to give a score on a fixed scale — 1 to 5, or 1 to 10 — with a one-sentence justification. This works for two reasons.
The first is what the number does to the AI: vague feedback is cheap, but a specific number is not. A model that wants to please you can call your draft "strong" without committing to anything. The same model, asked to pick between 6 and 7 out of 10, has to commit, and the act of committing forces it to look more carefully. You will notice the difference immediately: scores tend to come in lower than the prose summary suggests they should, because the prose was sycophantic and the number is not.
The second is what the number does for you. Adjectives like "strong," "solid," or "could be tighter" give you nothing to act on — you cannot compare them, prioritize them, or track them over time. Scores do all three. A 4 and a 7 tell you which criterion to fix first. Today's 6 versus last week's 5 tells you whether your second draft actually improved. The number is not just a more honest verdict; it is a unit of measurement you can use to make decisions.
Grade each criterion out of 10, with a one-sentence justification. Then tell me how to take each one to the next level — including the ones that already scored high. If something is at 9, tell me how to get to 9.5. If it is at 9.5, tell me how to get to 9.8. There is always a next level.
That last instruction is what turns the rubric from a verdict into a tool. You do not just learn the score; you learn the smallest move that would lift it — and crucially, that move exists at every level. The AI does not get to declare you finished. You decide when to stop.
7. The brainstorm-iterate loop
These slides are designed specifically for school students. They teach the brainstorm-iterate loop as "The Magic Loop" in four kid-friendly steps: Load (tell AI everything), Options (ask for many ideas), Feedback (be the boss and say what you like and don't), and Repeat (keep going until it's perfect). Includes a secret Step 0 (research first!), two worked examples students can relate to (planning a birthday party and writing a school essay), and a try-it-yourself challenge. Download PPTX for offline classroom use.
This is the single highest-leverage habit on this page. If you skip every other section, do not skip this one.
When AI was trained on the internet, most of the internet was common ideas, not creative ones. So the average AI response on a creative question is also common. "Ways to exercise at home": squats, push-ups, planks. Not wrong. Just average.
The way around this is not a magic prompt. It is a loop.
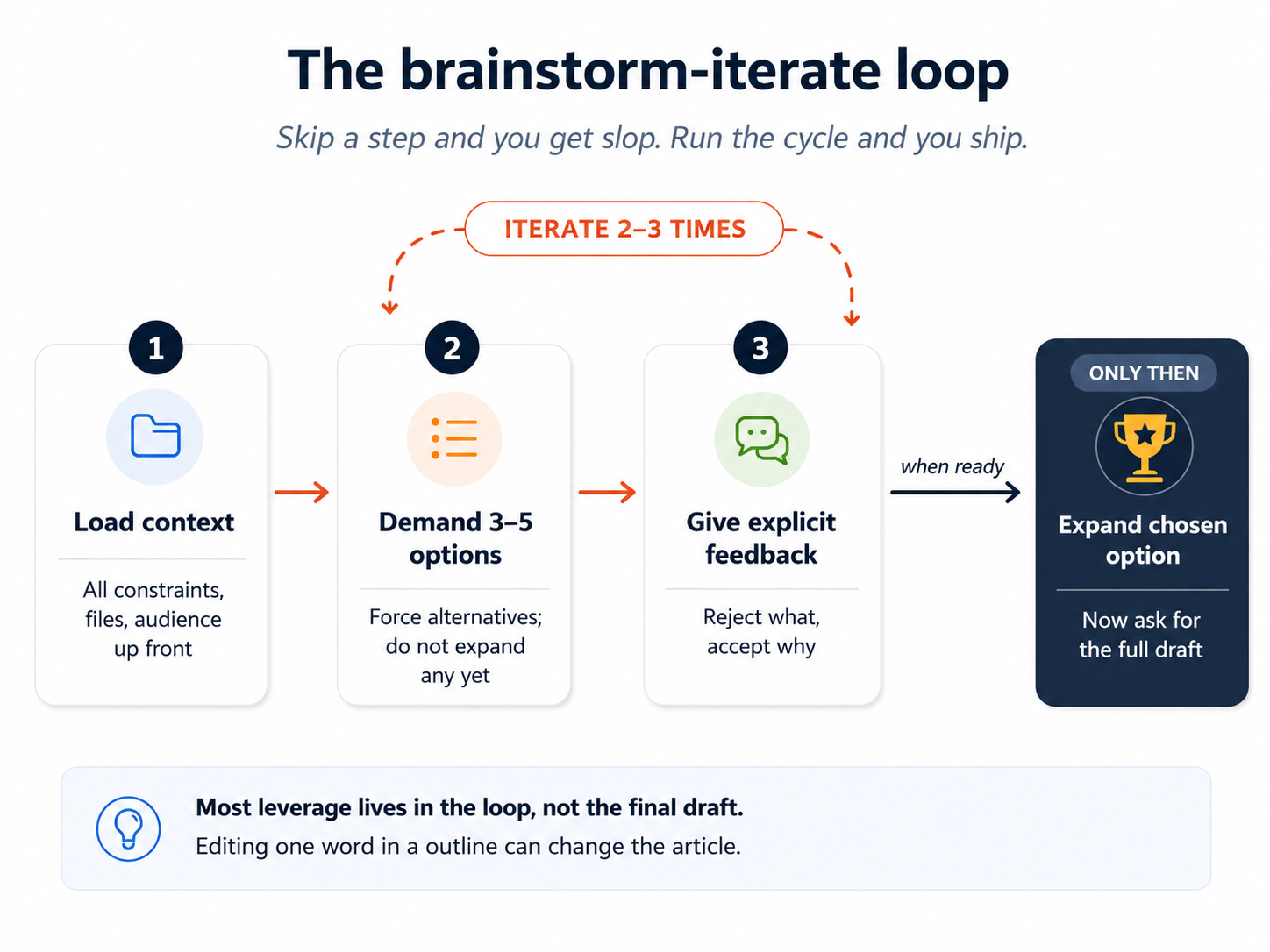
The recipe:
- Give all relevant context up front. Not just "ways to exercise"; "ways to exercise given that I have stairs in my home, a bad knee, and I cannot stick to plans for more than three days."
- Ask for 3 to 5 options, not one. Forcing alternatives pushes the model past its first instinct.
- Give explicit feedback. "I don't like option 1, it's too passive. I do like the stair-climbing idea but want it shorter. I forgot to mention my knee gets worse on impact."
- Ask for 3 to 5 new options informed by the feedback.
- Iterate until you have one or two you genuinely like.
- Then, and only then, ask AI to flesh out the chosen option in detail.
Worked example, debt payoff:
I have $8,000 in credit card debt at 19% APR, $4,000 in student
loans at 5%, and $1,200 in a retail card at 24%. I have $700/month
free after expenses. I just learned I'll get $450 in cash from a
tax refund. Risk tolerance: low. I sleep badly when I see big
balances.
Give me 5 different repayment strategies, each with a one-line
rationale. Don't expand any of them yet.
Then, after reading the five options:
Reject option 2 (avalanche by interest rate alone): I want
psychological wins early. Reject option 4: I won't open new
accounts. I like option 1 (snowball with the retail card first)
but I'd want to fold the $450 in. Give me 5 new options that
combine snowball-style wins with smart use of that lump sum.
You are not waiting for the AI to read your mind. You are showing your taste; the AI reshapes the option space around it. After two or three rounds, you have one option that feels exactly right. Then ask for the full plan.
The same loop works for writing, where it has its own name: outline before drafting.
- Iteration 1: ask for 3 outline options for a post on X.
- Iteration 2: pick one outline, ask AI to critique it and grade it out of 10. Note what scored below 9.
- Iteration 3: revise the outline based on the critique, then ask AI to expand each heading into 3 to 5 bullets.
- Iteration 4: critique the bullets, grade them out of 10, fix the ones below 9.
- Iteration 5: only now ask for the full draft.
- Iteration 6: critique the draft, grade it out of 10, ask for the changes that would raise the score the most — ranked by impact, with the highest-impact change at the top. Repeat until the score plateaus around 9.5 or higher — that is your stopping signal, not "the AI says it is done."
Why this works: editing one word in an outline can change the direction of the whole article. Editing one word in a final draft changes one word. Almost all of the leverage in writing happens at the outline level. AI generates word-by-word from the start, so unless you force structure first, it cannot see the whole shape.
The temptation is to ask for the full draft on the first try. Resist it. AI's first draft of anything is slop: looks polished, says little. The loop — ten or twelve minutes of structural work before any drafting, then several rounds of grade-and-fix on top — turns a forgettable post into one that lands. The total time is rarely more than forty-five minutes for a 600-word piece. The first ten of those minutes save the other thirty-five from being wasted.
A worked writing example. A team lead wants to write a 600-word post titled "Why our small AI team is shipping faster than the big team across the hall." Here is what each round of the loop looks like in practice:
Round 1, research first:
I'm writing a 600-word post arguing that small AI-augmented teams
ship faster than larger non-AI teams. Don't write yet. First, give
me the 5 strongest research-backed arguments and the 3 strongest
counter-arguments. One sentence each.
Round 2, three outlines:
Now produce 3 different outline options for the post. Each outline
should have 4-6 headings. They should differ in structure: one
narrative, one analytical, one contrarian. One line per heading.
Round 3, pick one and add an analogy:
I'll go with outline 2 (analytical). I want to weave in a Pixar
analogy: how the original Toy Story team was small and faster than
the giant Disney studio because of new tools. Add this as a recurring
example, not its own section. Revise outline 2.
Round 4, expand to bullets:
Now expand each heading into 3-5 bullets. Telegraphic style, not prose.
Round 5, grade and fix the bullets:
Critique each bullet and grade it out of 10 with a one-sentence
justification. List the bullets scoring below 9. For each one,
suggest the change that would raise the score the most.
Only now does the lead ask for the full draft — and then keeps grading and re-iterating on the draft itself until the score plateaus around 9.5 or higher. The whole process takes about forty-five minutes. The output reads like the lead wrote it, because every load-bearing decision was the lead's. The extra thirty-five minutes over "write me a post" is what makes the difference between a draft no one finishes reading and a draft that lands.
Scope the territory before drafting. The first round in that example ("don't write yet, give me the strongest research-backed arguments and counter-arguments") looks small but does heavy work. Most people skip it and ask for the draft directly. Skipping it is why their drafts feel thin: they're built on whatever ideas the model surfaces first, not on the actual landscape of the topic. One round of "scope the territory" before drafting is the difference between a post that quotes three studies and a post that lists three opinions. This pattern generalizes far past writing. Before any substantial decision, plan, or analysis, ask the AI to map what's known before asking it to produce what's needed. Competitive landscape before product naming. Prior research before a strategy memo. Existing approaches before designing a new one. The research pass takes five minutes and changes what every subsequent round of the loop is iterating against.
The loop is domain-agnostic. It works the same way for: planning a trip, structuring a sales pitch, picking a college major, naming a product, writing a wedding toast, deciding on a renovation, choosing a charity to support. The shape stays constant: load context, demand options, give explicit feedback, demand new options, iterate, expand — and then grade and re-iterate until the score plateaus. If you find yourself accepting the AI's first answer, or stopping the moment something looks "good enough," you have skipped the loop. Whatever you are working on, it deserves the loop.
A short table of where the loop fits across daily life:
| Decision or task | What "context" looks like | What "options with feedback" looks like |
|---|---|---|
| Planning a 4-day trip | Constraints (budget, dates, who's going, what they hate) | 5 itinerary skeletons; reject two; iterate the rest |
| Naming a product | What it does, who buys it, what it must NOT sound like | 10 names; pick 3 you like, ask for variants on those |
| Writing a difficult email | The recipient, the relationship, the desired outcome | 3 different tones; pick one, refine its specifics |
| Choosing a contractor | Three quotes, three reference notes, your priorities | Side-by-side scoring; ask for the strongest counter to your favorite |
| Picking a learning path | Current skills, time available, end goal | 3 different curriculum shapes; pick one, expand to weekly milestones |
| Designing a logo brief (for a designer) | Brand values, audience, examples you like | 5 mood-board directions; pick one, ask for 5 variants in that lane |
In every row, once you have a concrete candidate (a chosen itinerary, a shortlisted name, a draft email), the grading move from the loop applies the same way: score it out of 10 against the criteria that matter for that task, then iterate. Grade an itinerary on cost, pacing, and group-fit. Grade a product name on memorability, fit, and risk. Grade an email on clarity, tone, and likely effect. The criteria change; the move does not.
Part 3: Beyond text
AI is not just a text box. It can see images, work with audio in both directions, build small working apps, and run code on your data. Most people never try any of it.
8. Multimodal: images, audio, and what's next
Modern AI handles images and audio in both directions: it can read images you upload, listen to recordings, generate new images from text prompts, and produce spoken audio. The skills are different across modalities, and worth learning separately.
Image input. AI sees images coarsely. It is strong on:
- Overall scene and composition.
- Distinct, large object shapes (a giant human-sized hamster wheel treadmill).
- Whiteboard contents, including diagrams.
- Handwritten and cursive text (decent, double-check for high stakes).
It is weak on:
- Fine details. "What gym machines are these?" tends to fail because gym machines look similar through a slightly blurry lens. The AI may answer confidently and wrongly.
- Counting many small things in a cluttered scene.
- Reading small print at the edge of an image.
A useful real-world test: a teacher photographed a whiteboard where his head blocked the word "convolutional" in a neural network diagram. The AI inferred the missing word correctly from the rest of the diagram. That is what AI is good at: inferring from the gist. It is not good at zooming in.
For receipts, splitting a bill, or transcribing handwritten notes, AI works well, but always double-check the totals. For multi-image inputs (post-its plus a whiteboard photo plus handwritten notes from a brainstorm), AI can summarize the combined ideas; this is genuinely useful and saves real time.
Image output. Modern AI can generate images from text prompts. Two practical tips:
- Use a text AI to write your image prompt. "Generate me a prompt for a fantasy forest illustration in a Studio Ghibli style for a children's book cover." Take that output, paste it into the image tool. The text AI is much better at writing rich image prompts than you are on a first try.
- Build visual vocabulary. Words like cinematic, watercolor, cyberpunk, anime, isometric, low-poly, art-deco, claymation are levers. Image models were trained on captioned images and learned these styles by name. Upload images you like and ask AI how it would describe them. That trains your vocabulary.
How image generation works: it is a diffusion model, trained to remove noise from random pixel grids step by step until an image emerges. Not pixel-by-pixel like text. The whole image is generated at once. That is why you cannot stop image generation early to save time, the way you can interrupt a text response.
Older diffusion models had famous weaknesses: weird hands (six fingers), garbled text on signs, characters that change appearance from frame to frame in a comic. Modern models (such as Google's Nano Banana or ChatGPT Images) handle text reasonably, generate consistent characters, and can convert research papers into infographics.
A short table of failure modes still worth watching for, even on modern image models:
| Failure mode | What it looks like | How to mitigate |
|---|---|---|
| Garbled text on signs | The signage in the image reads "HAPRY BIRTDAY" instead of "HAPPY BIRTHDAY". | Specify the text in quotes in the prompt. Generate three variants. Pick the one where the text is right. |
| Inconsistent characters across frames | The same character has different hair color in panels 1 and 2 of a comic. | Use models with explicit character-consistency support; pass the first image back as a reference for the next. |
| Hand and finger errors | Six fingers, fused hands, twisted wrists. | Ask for compositions where hands are partially out of frame, or in pockets, or clearly described. |
| Cluttered backgrounds with implausible objects | A coffee shop where a bicycle merges into a chair. | Specify a simple background, or describe the background explicitly. |
| Wrong aspect ratio | The model defaults to square; you wanted landscape. | Always specify aspect ratio explicitly: "1024x768 landscape" or "16:9". |
A non-software example for image input. A reader photographed a stack of three handwritten recipe cards from a deceased grandmother and uploaded them to AI. The prompt: "Transcribe these three cards. Preserve the original wording and any abbreviations. If a word is unclear, mark it [unclear] and offer your two best guesses." Five minutes later, all three recipes were typed cleanly, with [unclear] marks on the four words the AI could not confidently read. The reader checked those four against the originals (two were obvious, two needed a phone call to an aunt), and the family had a clean digital archive of recipes that had been at risk of being lost. AI did the boring 90% so the reader could focus on the careful 10%.
A power-user recipe: designer-quality diagrams without a designer. If you ever need to make a diagram for a document, a slide, or a chapter of your own, there is a workflow that produces designer-quality output in about fifteen minutes, without using Figma and without any visual design skill. Most non-designers do not realize this is now possible. It is the simplest way to produce designer-quality diagrams without learning a design tool. This section is more involved than anything else on the page; read it now if you make diagrams regularly, or skip it for the first time you need one.
The recipe, in four steps:
- Ask Claude to visualize the concept as SVG. Paste the underlying paragraph or text. Ask: "Visualize this as a diagram. Output it as SVG. Make sure every label, arrow, and relationship from the text is present." Claude is a strong choice for this step because its reasoning ability is among the strongest of the major models: given a paragraph, it figures out the right boxes, the right arrows, the right hierarchy, and the right labels with very little guidance. The SVG it returns will be structurally correct but visually plain (bare rectangles, default fonts, no design polish). That is fine; the next step adds the polish.
- Convert the SVG to PNG. Ask Claude to render the SVG as a PNG (Claude can do this directly), or use any online SVG-to-PNG converter (cloudconvert.com, svgtopng.com), or just take a screenshot of the SVG rendered in a browser at high zoom. Render at 2× resolution (1600 to 2400 pixels wide) so the next step has enough detail to work with.
- Paste the PNG into ChatGPT (or Gemini) and ask it to redraw. ChatGPT's in-product image generation tends to be strong for this step because it is unusually good at text-heavy images: it preserves labels, gets typography right, and respects the structural relationships in the source. The prompt: "Redraw this diagram with professional design quality. Preserve every label, every box, every arrow, and the exact structural relationships. Improve typography, spacing, color palette, and visual hierarchy. The information must remain identical; only the visual finish changes."
- Iterate on the result. ChatGPT/Gemini sometimes drops a label or rearranges a box. Compare its output against the original SVG side by side. If something is wrong, just type the correction: "The third box should be labeled 'Iterate', not 'Repeat'. The arrow from box 2 should point to box 3, not box 4." Three or four rounds typically produces something that looks like it came from a professional design studio. Save the final PNG.
Why each tool for each step. Claude tends to win step 1 because deciding what belongs in a diagram (which boxes, which arrows, which hierarchy) is a reasoning task, and Claude's reasoning is among the strongest of the major models for this kind of structured-thinking work. ChatGPT (or Gemini) tends to win step 3 because rendering text-heavy images well (labels that stay readable, arrows that connect to the right boxes, layouts that look designed) is the category where its image generation currently leads. Asking either tool to do the other's job produces noticeably worse results than chaining them. Each does what it is best at, in sequence.
Total time: roughly ten to fifteen minutes per diagram, compared to an hour or more in Figma assuming you knew how to use it.
The pattern that survives the tools. The leader in each category will rotate. Claude may not be the strongest reasoning model next year. Today's leading image model will be replaced by whatever ships next. The recipe above will go stale at the tool layer. What survives: structure first in the strongest reasoning model, polish second in the strongest text-heavy image model. Pick whichever tools lead each category at the moment you read this. The two-step chain is the move.
A small story about image generation. A father whose 7-year-old daughter loved cats wanted a custom birthday cake for her. He used Nano Banana to brainstorm cake designs (generating dozens of variations: cat-shaped, multi-tiered, frosting-styles, color palettes), picked the one she loved, then handed the chosen image to a baker who rendered it as a real 3D cake. Total iteration time on the design: an afternoon. Total cost: a few cents in image generation.
The point is not the cake. The point is that for ~$0.30 and an hour of taste-driven iteration, a person who is not a designer produced a one-of-a-kind brief that a professional could execute against. That is a new kind of creative leverage, and it is widely available.
Audio in, audio out. The same shift that happened with images is now happening with audio. You can dictate a long prompt instead of typing it; you can drop in a meeting recording and ask for a summary; you can ask the model to read its answer aloud. Most modern AI tools support all three, often without an extra fee on free tiers.
The non-obvious uses are where the real leverage lives:
- Long-form dictation. Talking through a problem out loud captures nuance that typed prompts skip. People who hate typing produce dramatically better prompts when they speak them: the prompt grows from one line to several paragraphs without effort, and the AI's answer is correspondingly better. Speak as if briefing a colleague over coffee, then let the AI clean up the resulting transcript before answering.
- Meeting transcripts as context. Drop in a one-hour meeting recording (or a transcript from one of the dominant 2026 vendors like Otter, Granola, or Fireflies, or your phone's voice memos) and ask: "Summarize the decisions made, the open questions, and the action items by owner." This is one of the highest-leverage workflows on the page for anyone in a job with meetings, and almost nobody outside of tech is using it yet.
- Audio for accessibility and movement. Long commute, walking the dog, driving: voice in/voice out turns dead time into thinking time. The conversation quality drops slightly versus typing because you cannot edit your input as cleanly, but the time you would otherwise have lost is recovered entirely.
What audio is good and bad at, in 2026:
| Audio task | How well it works | Watch out for |
|---|---|---|
| Transcription of clear speech | Excellent | Heavy accents, technical jargon, multiple overlapping speakers |
| Speaker identification (who said what) | Decent on 2 speakers, weak on 4+ | Always check before quoting someone |
| Tone, sarcasm, emotion | Improving but unreliable | Ask the AI to flag its uncertainty rather than assume |
| Music or non-speech audio analysis | Limited | Use a specialized tool, not a general-purpose AI |
| Real-time voice conversation | Good for casual, weak for technical depth | Switch to text when precision matters |
A non-software example. A doctor recorded a 45-minute patient consultation (with consent), uploaded the audio, and asked the AI: "Produce a structured clinical note in SOAP format. Flag anything you could not understand confidently. Highlight the three most important things the patient said about their symptom history." Eight minutes later the doctor had a draft note that took her 5 minutes to verify and finalize, instead of the 25 minutes the typed version would have taken. The AI did not replace clinical judgment; it removed the typing.
Cost note: audio in/out is the second-cheapest tier after text, pennies per minute (concept 12). For meeting summaries, daily voice journaling, or dictating prompts on a walk, the cost is essentially invisible. Iterate freely.
A pattern worth keeping in mind: the future of multimodal is not "AI can do voice now, isn't that cool." It is that the boundary between modalities disappears. You will increasingly drop in a mixed bundle (an image, a voice memo, a PDF, a screenshot) and treat it as one prompt. The skill is not "how do I use voice" but "what is the right combination of inputs for this job?"
Interactive video avatars are emerging on the same trajectory. Pre-recorded avatar video (HeyGen, Synthesia, D-ID) is already production-grade for training content and multilingual corporate communication. Real-time conversational avatars (Tavus and others) are passable for low-stakes uses today (customer FAQ triage, language tutoring with a face, simple onboarding flows) and improving fast. Treat them like image generation in 2022: impressive, novel, not yet a daily habit for most knowledge work, but worth a quick experiment when a job calls for a face on the screen rather than text.
9. Building small apps with one prompt
Modern AI can build small games, websites, and tools from a single prompt. Not yet for large software, but for small useful things, this is genuinely accessible to people who have never written code.
Where the app actually runs, and what you can do with it afterward. A reasonable first question: "if the AI builds me an app, where does it actually live?" As of mid-2026, all three major tools render small one-prompt apps right in the chat, in a side panel you can click and interact with — and the thing in that panel is not just a preview, it is an artifact: a persistent object the conversation produced, which you can edit, iterate on, publish to a shareable link, embed elsewhere, or download as code. The feature is called Artifacts in Claude (which is where the name came from), Canvas in ChatGPT, and Canvas in Gemini. A year ago there were meaningful differences between them; today the gap is small for most one-prompt builds. Each still has small strengths — Claude's Artifacts tend to lead on interactive click-and-play things, ChatGPT's Canvas on writing-and-code editing, Gemini's Canvas on tightly-integrated Google-ecosystem outputs — but for "build me a thing," any of the three will work. Two practical consequences worth knowing. First, you can hand the artifact to someone else without sending them the chat: most tools let you publish to a public link, and the recipient does not need an account to use it. Second, the artifact is iterable — when you say "make the button bigger" or "add a dark mode toggle," the tool edits the artifact in place rather than regenerating the whole thing from scratch, which is dramatically faster. For anything beyond a one-prompt build, three adjacent categories are worth knowing exist: dedicated AI app-builders like v0, Bolt, and Lovable (you describe an app in plain language, they produce a full Next.js or React project — Concept 9's natural next step for non-developers); command-line AI coding agents like Claude Code and OpenCode (you give them a real codebase, they edit many files at once and run tests — covered in the changes-since-2022 list at the top of this page, aimed at developers who already write code); and file-aware desktop apps like Cowork and OpenWork (they find your files and act on them with permission — covered in Concept 11, aimed at knowledge workers, not software building). The right tool depends on which ladder you are climbing.
The recipe is just three slots:
Goal: what should this thing do?
Input: what does the user provide?
Output: what does the user see?
Examples that work today:
- Pomodoro timer. "Build a Pomodoro timer with a yellow theme. 25-minute work sessions, 5-minute breaks, a satisfying click when each cycle ends."
- Bill splitter. "Build an app where I enter a total bill, a tax amount, and the names of friends. It splits the bill including tax and shows each person's share."
- Outfit picker. "Build an app that takes today's weather (temperature and precipitation) and recommends an outfit from a closet of items I describe."
- Fireworks simulator. "Generate a fun fireworks simulator. Input: I click on the screen. Output: a colorful display of fireworks at the click point."
- Place-obstacles game. "Build a game where the user places obstacles and a goal, and runs a simulation that tries to reach the goal."
What is still hard:
- Multiplayer over the internet. Networking, accounts, and matchmaking are still beyond a one-prompt build.
- Live AI feedback in a different language. A French-conversation tutor that listens, corrects pronunciation, and adapts in real time is genuinely hard.
The intuition you build: small things that fit on one screen, with no accounts and no external services, work. Anything beyond that needs more than one prompt, and usually some real engineering.
A non-software example. A parent built a yellow cat-themed typing game for his daughter when her teacher mentioned the kids could type faster. He is not a software engineer. The prompt was three sentences:
Build a typing game for a 7-year-old. Goal: practice typing
common short words. Input: words appear, the player types them
before they reach the bottom of the screen. Output: a yellow
theme, a cute cat mascot that cheers when the player gets a
word right, increasing speed across levels.
What came back worked. Not perfectly, not on the first try, but iterated to "good enough for a kid" inside an hour. The skill being built here is not coding. It is the ability to write a clear brief and iterate it. That skill is universal.
10. Data analysis (the model writes and runs code)
When you ask AI a question that needs calculation or graphing — anywhere from "how did my electricity bill change this year" to "which products sold best last quarter" — modern tools quietly do something remarkable: the model writes code, runs it, and returns the result. Code execution is just another tool the model can call, like web search. You do not need to know any code yourself; you just upload your spreadsheet and ask in plain language.
This is much more reliable than asking the model to do math in its head. The model is doing math the way you would: by running a calculator. It is the calculator that is precise; the model is just choosing what to compute.
Before anything else: make sure the AI actually runs code, instead of guessing. This is the silent failure mode of this whole section, and the reason it goes at the top: the AI does not automatically run code on every question — it chooses to, based on how the question is phrased. On smaller questions it sometimes skips the code and answers from a glance, which produces a confident-sounding paragraph with no real computation behind it. From the outside it looks identical to a real analysis. Three small habits prevent this. First, ask explicitly. "Write and run code to answer this. Show me the code you ran." Most models comply when you ask. That one line, pasted into any data prompt, makes the difference between a real analysis and a plausible guess. Second, check that the code is visibly there. If the response does not include a code block that ran, the model probably did not run code. Third, demand a verifiable specific before the analysis. "Tell me the exact row count, the column names, and the date range of this file before you analyze anything." If the model is actually reading the file, those answers will be right. If it is making things up, the row count will be a suspiciously round number and the column names will be plausible-but-wrong. The strongest version of this move is to ask the model to declare its method up front: "Are you running code on the file, or estimating? If estimating, stop and run code instead." Most models will either invoke the tool or admit they were about to skip it.
Once you have that habit, the rest of this section is what data analysis actually looks like in practice.
Bubble tea shop example. A small business has a year of sales data: drinks, dates, quantities. The owner asks: "Which drinks had the biggest changes in sales over the year? Graph them. Write and run code to answer this and show me the code you ran."
Behind the scenes, the AI writes a short program, runs it on the spreadsheet, sees the results, and turns them into an answer. In practice that looks like: the AI computes month-over-month changes per drink, observes that most drinks are flat and four stand out, generates a colored line graph of those four, and notes the patterns. "Strawberry matcha rose sharply in spring; consider re-running that promotion next year." That is not a generic answer. That is an answer grounded in the actual data.
Then a bigger prompt: "Create a one-slide year-in-review graphic for the shop. Analyze the data carefully for insights worth featuring." This is a heavier task, so the AI takes longer — sometimes a few minutes — to work through it. It writes code, runs analyses, picks insights, designs annotations, and produces a finished dashboard.
What this is good for, with examples beginners actually have:
- Household spending. Upload a year of bank or credit card transactions; ask which categories grew, which months were unusual, which subscriptions you forgot about.
- Personal tracking. Running, walking, sleep, weight, screen time — any app that exports a CSV will give you a year of yourself to look at.
- Small business records. Sales spreadsheets, inventory lists, customer lists, expense files.
- Anything someone gave you as a spreadsheet and you don't want to open: school grade reports, utility usage statements, scientific data, survey results.
What to double-check, even when code did run:
- Final totals. Code is precise, but the AI may have summed the wrong column.
- Labels on graphs. The numbers are usually right; the captions are sometimes confidently wrong.
- Anything where the analysis depends on a column the AI may have misinterpreted. If the AI thinks "TXN_AMT" means transaction amount when it actually means transaction account number, the whole analysis is built on sand.
Reliability is much higher than memory-based math, but it is not infallible. Treat AI data analysis the way you would treat work from a sharp junior analyst: useful, fast, almost always right, occasionally wrong in instructive ways.
A non-software example. A runner uploaded six months of running-tracker data (a CSV from a fitness app) and asked: "How are my pace and distance progressing? Are there any patterns I should know about? Write and run code, and show me what you ran." The AI wrote code, plotted weekly averages, and noticed two things the runner had not: pace consistently dropped after every long-run weekend (likely fatigue), and distance plateaued in the third month before climbing again. The recommendation: a deload week every fourth week, and a slower long-run pace. The runner had stared at this same data in the app's dashboard for months without seeing those patterns. AI did not invent insight from nothing; it computed what the runner did not have time to compute.
When you upload data, your first prompt does not have to be the question. It can be: "Describe this dataset. What columns are here, what do they represent, and what 3 charts would best show what is going on?" Read the answer, pick the chart you want, then ask for it. This catches misinterpreted columns before they become wrong analyses.
Part 4: Working safely and choosing tools
Three final concepts: how to safely give AI access to your files and permissions, how to pick the right tool for the job, and how to get an objective signal on quality when no human expert is in the room.
11. AI desktop apps and permissions
There is now a whole category of products called AI desktop apps: apps that run on your computer and, with permission, can find your files, read them, and act on them. Cowork from Claude and OpenWork are two examples, and the category is growing.
What these can do that chat cannot:
- Look through a messy folder of PDFs, propose a new organization (rename files, move them, create subfolders), and execute the plan once you approve.
- Pull together related files for a project (you say "I'm filming on these dates and these people are involved"), and notice things on its own (a crew member's birthday falls during the shoot, do you want to fold in a celebration).
- Read across a folder and summarize: "what did I work on last quarter, based on the contents of this projects/ folder?"
The workflow that makes this safe:
- Tell it the task. ("Reorganize this folder by client.")
- Ask for a plan, not action. The app proposes a list of file operations.
- Review and edit the plan. Catch the rename you do not want before it happens.
- Only then approve execution.
Two facts most people learn the hard way:
- Deleted files often do NOT go to your recycle bin when an AI app deletes them. They are gone.
- Edited files do NOT keep an edit history unless you have version control. The AI's change overwrites the previous version.
Until you have done this safely a few times, scope every permission request to the smallest folder needed for the task. Do not approve "full disk access" for an app you have used twice.
This is a genuinely new shape of tool. Treat it that way: like the first time you handed a junior employee the keys to a real account. Useful, fast, and worth being careful with.
A non-software example. A consultant had a folder called clients/ that had grown to 240 PDFs over four years: contracts, invoices, scoping documents, hand-scanned receipts, meeting notes. She told an AI desktop app: "Look through clients/. Propose an organization scheme. Do not move any files yet. Show me the proposed scheme as a tree." The app produced a clean tree: one folder per client, sub-folders for contracts, invoices, and notes, with a flagged list of 18 files it could not confidently classify. She edited the proposal (renamed two clients, merged two folders), then approved execution. Total time: about fifteen minutes. The same job had been on her "someday" list for three years. The unlock was not the AI doing the thinking; it was the AI doing the tedium so the thinking became cheap.
The permission ladder. A useful sequence for getting comfortable:
| Comfort level | What to allow | What to keep saying no to |
|---|---|---|
| First sessions | Read-only access to a single small folder. | Anything that writes, deletes, or renames. |
| After 2-3 successful runs | Read and write inside one specific folder. | Access to broader directories like the desktop or documents root. |
| After a clean week | Read across a project tree, write inside a scoped subfolder. | Anything outside that project. |
| Trusted | Tool-specific permissions ("rename PDFs in this folder," "edit Word docs in this folder"). | Open-ended "do whatever you need." |
The principle: scope grows with track record, not with how much you trust the company that built the tool. Trust is earned by behavior in your specific workflow.
12. Cost, speed, and which model to use when
A simple stack to keep in your head:
In words:
- Text: seconds, fractions of a cent per response.
- Speech: seconds, a few cents per minute of audio.
- Images: tens of seconds, several cents per generation. No early-stop, the whole image generates at once.
- Video: minutes per generation, many cents to a few dollars. Iteration is painful because each round is slow and expensive.
- Deep research: minutes, several cents to a quarter, but synthesizes dozens of sources for you.
Cost is barely a constraint at the entry level. The major chatbots — ChatGPT, Claude, Gemini, Meta AI, and DeepSeek — all offer free access that handles the kinds of prompts on this page comfortably. You only hit paid plans when you push for heavy deep-research runs, very large file uploads, video generation, or unlimited daily usage. For the exercises in the closing section, the free tier of any of them is enough.
Two implications:
- Iteration cost shapes what you do. You can iterate on text 50 times in an afternoon. You cannot iterate on video 50 times in an afternoon. So when you generate images or video, invest more in the prompt up front (and use a text AI to write it).
- Costs are trending down. The image that costs you 10 cents today will cost a fraction of that next year. Generating art for your home, a birthday card, or a wedding invitation is rapidly becoming free.
Which model for which task? AI is jagged: different models are good at different things, and the leader changes every few months. There is no single best model. Two habits help:
- Try the same prompt in 2 to 3 models routinely. Same question, multiple tools. Read the answers. The differences will surprise you, and they update your intuition about which tool is best for which kind of question.
- Don't marry one tool. A worker who only uses one AI is a worker who is wrong about which tool is best for two-thirds of their tasks. Switching is free; you just paste the prompt in a different tab.
The best AI for your task today is not the best AI for your task in three months. Stay loose.
A rough snapshot of what each major model tends to be good at right now (this will change; treat it as a starting point, not a verdict):
| Tool | Tends to be strong at | Tends to be weaker at |
|---|---|---|
| Claude | Reasoning on hard prompts, long-document understanding, SVG and diagram generation, code and WebDev, careful writing voice, structured analysis. Currently leads most Arena categories. | In-product photo-realistic image generation is less central than ChatGPT and Gemini. |
| ChatGPT | Top-ranked in-product image generation (GPT Image-2 leads Arena's text-to-image and image-edit categories), voice mode, conversational range, broad task coverage. | Sometimes verbose; can over-format with lists and headings. |
| Gemini | Fast web search and source synthesis, deep research with rich output (charts, tables), strong image generation (Nano Banana variants in Arena's top 5), tight Google Workspace integration. | Tone can feel more clipped; some responses lean shorter than ideal. |
| Meta AI | Embedded in WhatsApp, Instagram, Messenger, and Facebook (already on the device of more than a billion people); free with no subscription fee; Muse Spark (April 2026) brings competitive multimodal reasoning and a "Contemplating mode" that runs multiple agents in parallel. Currently sits in the top 5 of Arena's text leaderboard. Best for interactive visual artifacts (web dashboards, mini-games, quizzes) and health or scientific data. | Coding workflows and long-horizon agents lag the big three; smaller ecosystem of integrations like Projects, Canvas, or Artifacts; no public API yet (only a private preview); usage is rate-limited if you push hard. |
| DeepSeek | Open-source weights you can self-host or run via API at low cost; 1M-token context as the default; V4-Pro rivals top closed-source models on STEM and coding benchmarks; V4-Flash is the fast, cheap everyday choice. | Chat-interface polish trails the big three; consumer ecosystem (mobile apps, deep integrations) is smaller; Arena rankings sit below Claude, ChatGPT, Gemini, and Meta on most categories. |
A note on the two newer rows. Meta AI's value used to be "ubiquity + free, not depth" — but Muse Spark closes much of the depth gap for reasoning tasks while keeping the ubiquity-and-free advantage. If you have WhatsApp or Instagram, you can now do serious thinking inside the app you were going to open anyway. Two boundaries worth knowing before you use it for real work, though. First, free does not mean unlimited: Meta applies rate limits behind the scenes, so heavy use of Contemplating mode or rapid automated workflows will eventually throttle. Second, your inputs may be used to train future Meta models. Meta's terms allow this and the consumer product is not configured to opt out by default. That makes Muse Spark a poor fit for sensitive material — internal company documents, private code, medical information, anything you would not want to feed into a training pipeline. For non-sensitive everyday work it is excellent. DeepSeek's value is open-source-and-cheap — it is the right choice when you are price-sensitive, want the option of self-hosting, or need that 1M-token context window for free-tier work. The big three still lead on the deeper workflows this page teaches (Projects, Canvas, Artifacts, deep research), so they remain the worked-example tools.
The leaderboard to bookmark. When you want a current view of which model leads what task, the most useful resource is Arena. Users vote in blind head-to-head comparisons of two anonymous models, so rankings reflect real preferences rather than vendor marketing claims. The site keeps separate leaderboards for text, code, vision, document, image generation, image edit, search, and video. Check it once a month. Leaders rotate quickly — the model topping a category in May may not be there in August, and a new entrant can leap into the top five in weeks (Muse Spark did this in April 2026). Two caveats worth knowing: leaderboards reward conversational charm more than careful work on long documents, and they sample tasks that vote-able users find interesting, which is not always your task. Use it as one signal among several; Concept 13 has more on combining leaderboard signals with your own A/B testing on the kinds of prompts you actually run.
Three habits that compound:
- Have at least two tabs open. A primary tool and a backup. When the primary gives you something that does not feel right, paste the same prompt in the backup. The second answer is often the tiebreaker.
- Keep a prompt scratchpad. A note file (any text file works) where you collect prompts that produced unusually good results. Reuse and adapt them. This is your personal library.
- Notice when the model is wrong. Not as scolding, as data. Wrongness is a free signal about where this tool's edges are. Logging "tool X confidently wrong about Y" once a week is more useful than reading any 2,000-word AI newsletter.
Once a month, do two things together: (1) glance at Arena's leaderboards for any category you care about, and (2) pick one task you do regularly (writing weekly status updates, planning meals, summarizing a recurring document) and run it through three different AI tools. Note which one did it best on your real work. Use that one for that task until next month, when you re-test. Your tooling stays current without effort — and the leaderboard tells you whether you should be testing a newcomer that wasn't on your radar.
13. Models checking models
When there is no ground truth (no answer key, no expert sitting next to you, no test that fails red), you can still get an objective signal on quality. You get it by making models grade each other.
Start with the light version. If you only have one AI tool open today, the single-model self-critique loop (covered just below) gives you most of the benefit, and it is the version most everyday tasks need. The full multi-model recipe that follows it is the high-stakes version: it assumes a second free account open in another browser tab, about a minute of setup, and it is worth that setup only when being wrong is expensive. Read the full recipe now for the shape, but reach for the lighter version first; graduate to the heavier one when something on your desk actually earns it.
Different models have different blind spots. They were trained on overlapping but not identical data, with different reward signals, by teams that emphasized different things. A point one model misses, a second model often catches. The disagreement between them is the signal you cannot get from any single model alone. This only works if the models come from genuinely different families — Anthropic (Claude), OpenAI (ChatGPT), Google (Gemini), Meta (Meta AI / Muse Spark), and DeepSeek are the five distinct families to draw from. Two Claude models cross-checking each other is not cross-model checking; their priors are too similar.
Here is the full multi-model recipe, refined over many documents and written from real practice. This is the high-stakes version; the lighter single-model loop is in the next subsection:
- Start with the best model you have access to. "Best" means the one with the strongest reasoning and long-output coherence on your kind of task. Use multiple signals: Arena's leaderboards as a starting point (concept 12 introduces these), plus your own quick A/B test on a representative sample of the kind of work you actually do. An A/B test here just means: send the same prompt to two or three models, read the answers side by side, and let your eyes tell you which one is better at your kind of task. Do not anchor to one leaderboard alone; they measure different things, and preference-based rankings reward conversational charm more than careful work on long documents.
- Generate the first draft with full context. Brief it like a colleague (concept 1), turn on thinking mode for hard problems (concept 5), use the brainstorm-iterate loop for structure (concept 7).
- Ask it to grade its own output, 1 to 10, against named criteria. Not "is this good?" but "score this on clarity, accuracy, structure, and what is missing, 1-10 each, with a one-sentence justification per score." The first grade is usually 7 or 8.
- Ask it to implement its own suggestions. Repeat until the grade stops climbing, which usually plateaus around 9.
- Take the draft to a second model from a different family. Ask for the same rubric. Different model, different priors, different blind spots. The second model will catch things the first model graded itself on, which is exactly the closed loop you need to escape.
- Bring the second model's critique back to the first model. Frame it honestly: "another model produced this critique. Evaluate which points are worth adopting, and why. Reject anything you disagree with, and explain." The first model adjudicates. You watch the adjudication.
- For high-stakes work, repeat with a third model from a third family. By the time three different-family models have argued over your draft, you have the closest thing to triangulated truth that this technology offers.
- Stop when the score crosses your target across two independent models. A 9.5 from your primary model alone is not the same as a 9 from your primary plus a 9 from a different-family model. The second number is the one that means something.
The single-model self-critique loop, by itself
Steps 3 and 4 above are usable on their own, without ever bringing in a second model. Many tasks do not justify the multi-model overhead but still benefit from one round of "score this 1-10 against this rubric, then implement your own suggestions." A weekly status update, a slightly tricky email, a one-page memo: all of these get visibly better from one self-critique pass.
A higher-leverage variant: set a numerical target and let the model iterate autonomously toward it. Instead of "score this and tell me what's missing," try "iterate against your own rubric until you reach 9.5 across all criteria, then show me the final version." The model will grade, revise, regrade, revise, and keep going (five or six rounds in a single response) and only return to you when it hits the target or plateaus. This is dramatically faster than driving each round manually, and it works especially well for long-form artifacts (a 5,000-word memo, a chapter, a comprehensive plan) where round-tripping by hand would be tedious. The target itself is a steering mechanism: 9 forces a different ceiling than 9.5, and 10 forces the model to keep finding things to improve until it genuinely cannot find any.
This may sound like it contradicts concept 6, which warned that a model grading its own work tends toward sycophancy. The difference is the rubric. Without one, "is this good?" returns "great work!", which is the closed loop concept 6 was about. With named criteria scored 1-10, the model has to point at what is missing from the other points, and that pointer is what you implement against. The rubric is what turns the self-grade from sycophancy into a forcing function.
The page now offers three nested versions of the same DNA. Pick the lightest one that fits the job:
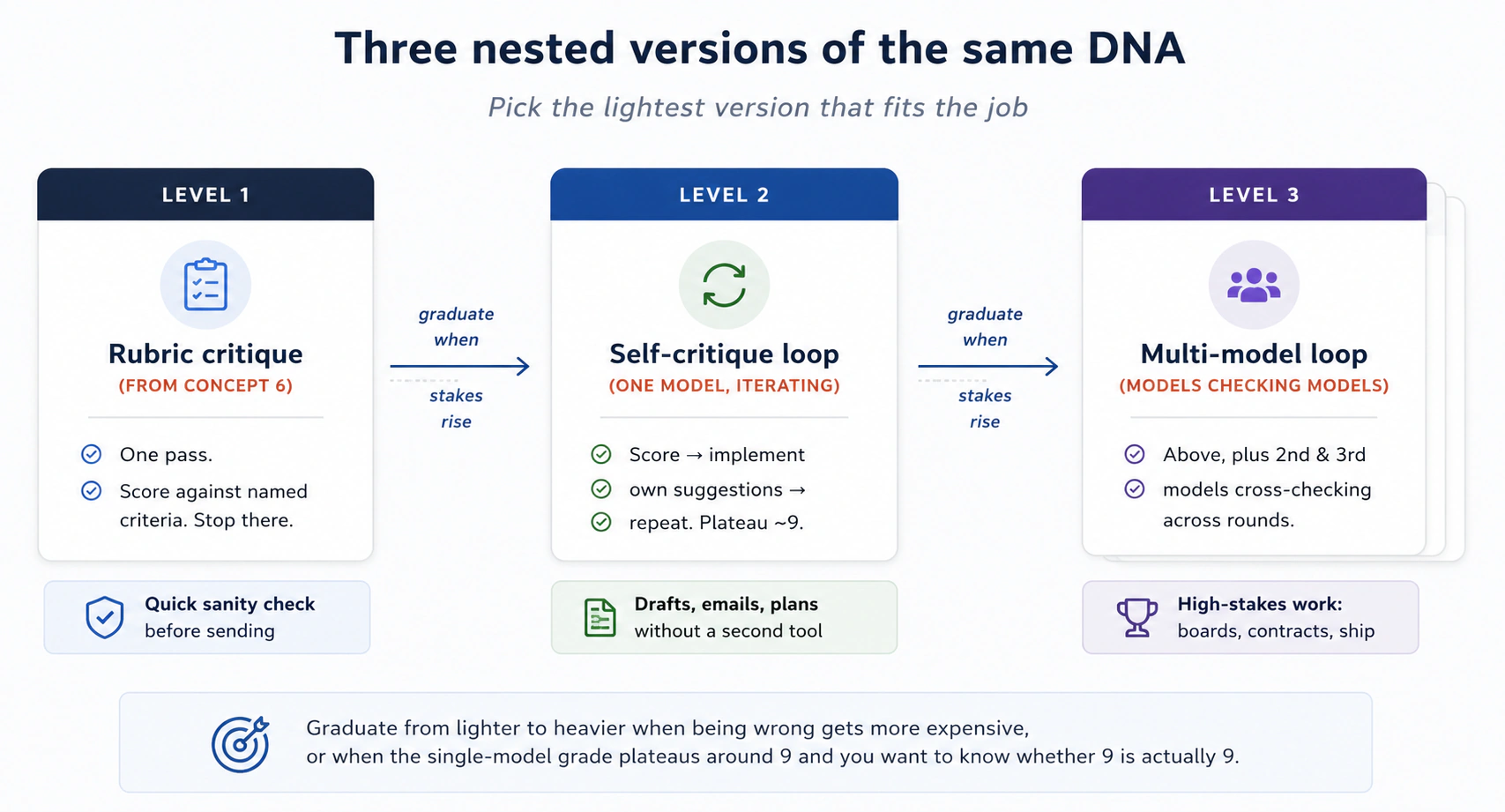
Graduate from the lighter version to the heavier one when being wrong gets more expensive, or when the single-model grade plateaus around 9 and you want to know whether 9 is actually 9.
Why the grade matters. Forcing a number out of the model is not about the number. It is about what producing the number requires. A model that has to score your draft 7/10 has to name what is missing from the other 3 points. Without the score, "this is pretty good" passes for review. With the score, "pretty good" has to become "loses 1 point on structure because the third section repeats the second; loses 2 points on evidence because three claims have no source." The grade is a forcing function for specificity, and specificity is what you can act on. It is also the only readable signal you get to compare iteration N against iteration N+1.
A privacy note for high-stakes work. Cross-model checking by definition means pasting your draft into multiple tools. Pay attention to each tool's data policy before you do this with sensitive material. Some tools (Claude on its consumer product, ChatGPT with training opt-out enabled, paid Gemini tiers) do not train on your inputs. Others (Meta AI's consumer product by default) may. A 40-page strategy memo, an internal financial analysis, or anything covered by an NDA should only pass through tools whose data policies you have actually checked. The point of the multi-model loop is to catch your blind spots; the opposite point of the loop is to feed your confidential work into a training set.
An honest caveat. Three models can still all be wrong about the same thing. They share more training data than you would guess, and on contested or sparse-data topics (concept 2) they often share the same misconceptions. The score is a progress signal, not a truth signal. For high-stakes content (anything legal, medical, financial, or about a real person) no number of cross-model passes replaces a human expert reviewing the load-bearing claims. Models check each other for craft. Humans check the facts that matter.
When to skip the loop.
Not every task earns this. A short email, a quick lookup, a casual brainstorm: single-model is fine. Save the multi-model cross-check for work where being wrong is expensive: a memo your boss will read, a chapter that will be published, a decision that affects other people, a contract you will sign. The rule of thumb: if a thoughtful colleague would have spent two hours reviewing this, it earns the loop.
A non-software example. A consultant preparing a 40-page strategy memo for a client board drafted in her strongest model and iterated against its own grades until they plateaued at 9. She then pasted the full memo into a second model from a different family and asked for the same rubric. The second model gave it 7.5 and listed eleven specific issues, three of which her primary model had not raised in any of its own self-grading rounds. She fed those back to the first model to adjudicate; it adopted seven and rejected four with reasons. A third model from yet another family surfaced two more. The point is not the final scores. It is that the counter-arguments she would never have seen on her own, because her primary model shared her blind spots, were in the memo before the board meeting.
A short recap before you try the prompts
Thirteen concepts is a lot. The shape of the page, one line per concept:
- Concept 1. The gap between a novice prompt and a power-user prompt is a handful of habits: brief AI like a smart new colleague, with context, constraints, and a clear ask.
- Concept 2. AI knows things from a snapshot of the internet — it learned by reading text about the world, not by experiencing the world — so it's strong on common topics and weak on obscure or recent ones.
- Concept 3. Three retrieval modes: pretrained, web search, deep research. Your wording steers which one fires.
- Concept 4. The model has no memory of its own; the context window is its working memory for this response. The single biggest determinant of answer quality is what you put in that window — and projects let you front-load it once instead of every time.
- Concept 5. Modern models can think hard for seconds or minutes if you ask them to.
- Concept 6. Models are biased toward agreement. Neutral framing and rubrics neutralize most of that bias; forcing a 1-10 score per criterion, with the change that would raise each score, neutralizes the rest.
- Concept 7. The iterate-with-explicit-feedback loop is the highest-leverage habit on the page. Grade each stage out of 10 and re-iterate until the score plateaus — the AI does not get to declare you finished.
- Concepts 8–9. AI can see images, work with audio in both directions, and build small apps — the running app is an artifact you can iterate on, share, and embed.
- Concept 10. AI can also write code and run it on your data, but it does not always do this automatically. Ask explicitly, and verify that the code actually ran.
- Concept 11. There's a new category of file-aware desktop apps (Cowork, OpenWork). Scope permissions tightly until you've used them safely.
- Concept 12. The right tool for a job changes every few months. Five families to know (Claude, ChatGPT, Gemini, Meta AI, DeepSeek), free tiers for all, and Arena as the leaderboard to check monthly.
- Concept 13. When no human expert is in the room, making models grade each other — across different families — is the closest thing to an objective quality signal.
Underneath all of that is one move, repeated in a dozen disguises: get the right context in, keep the wrong context out. If you never remember a single thing from this page except that sentence, you will still be in the top quartile of users.
Try this now: twelve prompts before deepening into thinking discipline
Reading is a placeholder for trying. Open Claude, ChatGPT, or Gemini in another tab. Run these twelve prompts in order. They take about twenty-eight minutes total and exercise every concept in this page that you can exercise from a chat tab.
1. Web-search trigger. Forces the AI to leave its training data and look up current info.
What major news happened today in [your country]? Cite each claim
with a source link. Flag any claim you can't support with a citation
as "unverified".
2. Pretrained-only question. Common-knowledge, no lookup needed. Should be fast and confident.
Why do cats stare at walls? Two-paragraph answer.
3. Context-rich personal prompt. Practice loading constraints up front.
Plan a 15-minute home workout for me. Constraints: I have stairs
in my home, a bad knee (no squats), I cannot stick to plans for
more than three days, and I want to feel slightly silly while
doing it. Give me 3 options, no commentary.
4. Neutral-framing rewrite. Practice spotting your own bias in the prompt.
The question I want to ask is: "Don't you think four-day work
weeks are obviously better for everyone?" Rewrite this as a
neutral question that doesn't signal what answer I want.
Then answer the rewritten version.
5. Three-options brainstorm with iteration. The core power-user loop.
Round 1: I want to start a small side project that takes about
3 hours per week and might make money in a year. I'm a [your
profession] who likes [your hobby]. Give me 5 different ideas,
one line each. Don't expand any of them.
(Read the 5. Pick what you like and don't like. Then, in the
SAME conversation:)
Round 2: I reject options [N] and [N] because [reason]. I like
the [keyword] idea but I want it to use less [thing]. Give me
5 new options that incorporate this feedback.
6. Outline-first writing. Force structure before prose.
I want to write a 600-word post about [a topic you care about].
Don't write it yet. Give me 3 different outline options, each
with 4-6 headings. One line per heading.
7. Think-hard reasoning prompt. Use a real personal decision.
I'm choosing between [Option A] and [Option B] for [real personal
decision in your life]. Here's the relevant context: [a paragraph
of context]. Think hard before answering. Tell me:
1. The 3 trade-offs that actually matter.
2. Which you'd choose and why.
3. Under what conditions your recommendation would flip.
8. Grade-and-improve critique. Avoid sycophancy on your own work.
I'm pasting in something I wrote: [paste anything 100-300 words].
Critique it using these 4 criteria, each scored 1-10 with a
one-sentence justification:
- Does it have a clear central claim?
- Is each paragraph in the right order?
- Are there any sentences that could be cut without loss?
- Does the ending earn the time the reader spent getting there?
Then, for each criterion, tell me the change that would raise
its score the most. There is always a next level — even a 9
has a path to 9.5.
9. Image-input task. Practice giving AI a photo to read.
[Upload any handwritten note, receipt, or whiteboard photo]
Transcribe what's written. Then summarize what it's about in
3 bullets. Flag anything you couldn't read with confidence.
10. Small-app prompt. Practice the Goal/Input/Output shape. What comes back will be an artifact you can click on and iterate on, right in the chat.
Build me a Pomodoro timer.
Goal: 25-minute work sessions, 5-minute breaks.
Input: I press start.
Output: Visible timer counting down, a satisfying click when
each cycle ends, a yellow theme. Show me the working version.
11. Data analysis: expose the silent failure mode. Practice the "ask explicitly for code, then verify it ran" discipline. This exercise is in two rounds.
Round 1, the trap: In a fresh conversation, paste this prompt
exactly as written. Do NOT mention code.
"Here are 18 numbers: 47, 52, 89, 91, 23, 67, 78, 12, 95,
44, 88, 71, 33, 56, 99, 18, 64, 82. What is the median,
the average, and which numbers are outliers? Be specific."
Look at the response carefully. Did the AI show you a code
block that it ran? Or did it write a paragraph with numbers
in it and no visible computation? Note your answer.
Round 2, the fix: In the same conversation, paste this:
"Now run that calculation again — but this time write and
run code to do it, and show me the code you ran."
Compare the two answers. If the first answer had the median
wrong, rounded suspicious numbers, or just felt vague — you
just saw the silent failure mode of concept 10 in action.
The correct answers are: median 65.5, average ~61.6,
no clear outliers (the numbers are roughly evenly spread).
12. Cross-model review. Practice the multi-model habit on a real draft. Requires two AI tools open at once — from different families (see Concept 13).
Take any 200-300 word draft you wrote recently (an email, a memo,
or a paragraph from one of these exercises).
Step 1: In your primary AI tool, paste the draft and ask: "Score
this 1-10 on clarity, structure, evidence, and what's missing.
One-sentence justification per score."
Step 2: Open a second AI tool from a different family (if your
primary is Claude, use ChatGPT or Gemini or Meta AI — not another
Anthropic model). Paste the same draft, ask the same question.
Step 3: Compare the two scores and the two critiques side by
side. Note any point only one of them caught. Those are the
points the cross-model loop pays for.
🚀 Projects
The twelve prompts each exercised one concept. The first three projects below chain them together, and they end somewhere a chat window cannot take you: with something you made live on the public internet, at an address you can text to a friend.
Each project takes thirty to sixty minutes on a free account and folds open when you are ready for it. Do Project 1 today; save the rest for the week. They are sequenced: each one teaches a move the next one uses. If something breaks mid-project, the last dropdown in this section has the fix. The shape is the same for the first three:
the chat builds it you download it the internet serves it
┌──────────────────┐ ┌──────────────┐ drag ┌───────────────────────┐
│ a working app in │ ────→ │ index.html │ ──────→ │ your-app.netlify.app │
│ the side panel │ │ (one file) │ │ (a real, public URL) │
└──────────────────┘ └──────────────┘ └───────────────────────┘
Concept 9 said the thing in the side panel is an artifact: a real object you can download, not a preview. The first three projects cash that promise in. Project 4 is the capstone, and it ships a different kind of thing: not a URL but a knowledge artifact you built with AI, plus the documented proof that you can direct it, question it, and correct it.
Project 130-60 minSnake BattleBuild a game by playing it, then ship it to a real URL.
Open ChatGPT, Claude, or Gemini and say:
Let's build and play a game where a snake eats fruit balls to grow.
A playable snake game appears in the side panel. Done when: you can steer the snake with your arrow keys and eat something. If you are on a phone, that is your first wish: "add touch controls." Play it for a minute, and pay attention to the first thing you wish were different. Then do not write a careful brief. Just say the wish:
Can I pick my snake's color before the game starts?
The artifact updates in place: now there is a start screen with a color picker. Keep playing, keep wishing. Then change the rules of the game itself:
Now make it a battle: add computer-controlled snakes, and when a
snake dies its body turns into fruit the others can eat.
This is one reader's Snake Battle, shipped to a real Yours will not look like this one, and that is the point. It will look like whatever you noticed while playing.
▶ Play a finished version (the kind of thing you are building toward)
.netlify.app URL exactly the way you will ship yours. Pick a color, press Start Battle, steer with the arrow keys. It loads live below; you can also open it in its own tab.
Three sentences in, you have a start screen, color pickers, bot opponents, and a rule you invented. Now notice two things. First, what you never mentioned: HTML, JavaScript, collision detection, game loops. You described an experience and the model did the engineering, exactly as Concept 9 promised. Second, where each sentence came from. Not from planning. From playing. This is Concept 7's loop with the feedback step replaced by the most honest critic available: you, mid-game, noticing what you wish were different. Keep going until the game is yours. Faster snakes, a score, sound effects, one wish per message.
One last pass before it goes live. You have been grading by feel this whole time; every wish was a tiny verdict. Make that explicit once: ask the game to score itself and fix its own weakest spot.
Score this game 1-10 on three things: is it fun, is it clear
what to do, and does it feel finished or rough? One sentence
each. Then make the single change that would raise the lowest
score, and do it.
That is the whole move in miniature. A number forces an honest answer where "is it good?" only ever gets a yes (Concept 6). Do one round here. The next project turns this single ask into a loop that does not stop until the scores do.
Now ship it. This is the move every project reuses, so do it carefully once:
-
Download the game. ChatGPT's canvas has a download icon at the top of the panel; Claude and Gemini have an equivalent download or export control on theirs. You get a single
.htmlfile. That file is the entire game. -
Rename the file to
index.html. That name is the web's convention for "the front page of a site," and the hosting service in the next step looks for it. -
Create a free account at netlify.com. An email address is enough. Netlify is a hosting service: it takes files and serves them to the internet, with a free tier that is more than this project needs.
-
Drag your file into the drop zone. After signup, Netlify shows a "Let's create your new project" page whose drop zone accepts, in its own words, "a single HTML file." (On a phone, tap "browse files to upload" instead of dragging.)
-
Open the address it gives you. A few seconds after the drop, your game is live at an address ending in
.netlify.app. Done when: the game loads in your phone's browser, not just on your computer. Send the link to one person.
A fair question: Concept 9 said the chat tools can publish an artifact to a shareable link, so why bother with the download? Because the published link lives inside the AI product, attached to your chat. The downloaded file is yours: it works on any hosting service, on a USB stick, in ten years. Netlify happens to be the fastest free way to put a file you own onto the open web, and the drag-and-drop you just did is genuinely the same move professionals use to throw up a quick site.
To update a shipped game: keep iterating in the chat, download again, rename again, and drag the new file onto your project's deploys screen in Netlify. Same address, new version.
Project 245-60 minWhack-a-MoleBuild a game, then grade it past 'good enough' until it is genuinely fun.
The snake game got good because you played it, then you graded it once before shipping. Here, that single grade becomes the whole engine: you run every move on the page at once, brainstorm options, brief with structure, test, score against a rubric, and refuse to stop until the scores are high. It is the disciplined version of "build me a thing," and it is the one that produces something you are proud to share. This is one reader's Whack-a-Mole, shipped to a real Yours will not look like this one, and that is the point. It will look like whatever theme you picked and whatever feedback you gave.▶ Play a finished version (the kind of thing you are building toward)
.netlify.app URL exactly the way you will ship yours. Click the moles as they pop up and try to beat your high score. It loads live below; you can also open it in its own tab.
Start by asking for options, not a build (Concept 7):
I want to build a Whack-a-Mole game. Before building anything,
give me 3 different visual theme options. One line each.
Vary the color scheme, what the moles look like (animals,
monsters, aliens), and the overall mood (playful, spooky,
elegant). Don't build any of them yet.
Pick the one you like and hand the model everything it needs to build it. This is Concept 9's Goal / Input / Output, the structure that leaves nothing to guess:
I pick the twilight garden theme: deep blue night sky with
twinkling stars, glowing gold accents, rich dark emerald grass,
and cute animal emojis as moles.
Now build the game with these specs:
Goal: Moles pop up randomly from holes in a 3x3 grid. The
player clicks them to score points. They disappear after a
short time.
Input: Player clicks on moles that appear.
Output:
- 3x3 grid of clearly visible holes with dark centers and
brown dirt rims that stand out from the grass
- Moles using these emojis: hamster, bear, frog, monkey,
rabbit, fox - large and crystal clear when they pop up
- Score counter at the top
- 30-second countdown timer with a color-coded progress bar
- Moles rise up FROM INSIDE the hole, not floating above it
A playable game appears in the side panel. Done when: moles pop up and clicking one adds a point. It will feel flat, and that is expected: you have the skeleton, not the feel. Add the feel in one pass (Concept 4, every detail you leave out the model has to guess):
Add these features to the game:
1. SPEED: Moles start slow, visible for about 2.5 seconds.
Speed ONLY increases when the player's SCORE goes up, not
when time passes. Show a speed label: Easy, Fast, Frenzy.
2. INSTANT START: The first mole appears immediately when the
player clicks Start. No waiting.
3. HIT EFFECTS: When a mole is whacked, show all of these:
- Colorful particle burst at the hit point
- A plus one text floating upward and fading out
- Quick screen shake for impact
- A short sound effect using Web Audio API
4. GAME OVER SCREEN: Show final score large and animated,
total hits, hits-per-minute stat, confetti animation,
New High Score badge if earned, and a Play Again button.
Now play it, and do what Concept 7 taught: say exactly what is wrong AND what you want instead. Vague complaints get vague fixes:
I played the game and found these issues:
1. Moles are mostly hidden inside the hole. They should pop up
clearly above the dirt so I can see the full emoji face.
Fix the layering so moles render in front of the dirt.
2. The holes blend into the dark background. Add a visible
lighter brown rim around each hole opening so they stand
out clearly from the grass.
3. The game takes 2 seconds before the first mole appears
after clicking Start. Make it appear instantly with zero
delay.
Fix all three issues.
Here is the move that separates a toy from a finished game. Do not ask "is it good?", the model will always say yes (Concept 6). Hand it a rubric and make it score itself honestly:
Score this game 1-10 on each criterion. Give a one-sentence
justification per score. Then for EACH criterion, tell me the
single change that would raise the score the most.
1. VISUAL CLARITY - Can I instantly see every hole and mole?
2. FUN FACTOR - Does whacking a mole feel satisfying?
3. DIFFICULTY CURVE - Does it start easy and get harder fairly?
4. POLISH - Does it look like a finished game or a rough draft?
5. GAME FEEL - Do animations and sounds make me want to keep
playing?
There is always a next level. Even a 9 has a path to 9.5.
Then loop until it earns the score, and you decide when it has, not the model (Concept 13):
Implement the top 3 highest-impact changes you suggested. Then
score the game again on the same 5 criteria. Keep going until
all scores are 9 or above. I decide when to stop, not you.
That loop is the whole project. Run it twice and your game crosses the line from "a thing the AI made" to "a thing I would put my name on." When you want a feature that needs real design, not just more detail, ask the model to think before it builds (Concept 5). The phrase "think hard" turns on extended reasoning: And once you have a version you like, find out whether a different tool would have done it better (Concept 12). Combine the theme-and-build prompt and the game-feel prompt from earlier, then paste them into a tool you did not use: A person who only ever uses one AI is guessing about which one is best. Now you will know, for this kind of build, from your own eyes.Two power moves, once the basics work
Think hard about this: I want a smarter difficulty system.
Right now speed just increases with score. But a player who
scores 10 points in 10 seconds is very skilled, while a player
who scores 10 points in 25 seconds is slower. They should face
different difficulty levels.
Design an adaptive difficulty system that considers both the
player's score AND how fast they are scoring. Explain your
approach first, then implement it.Copy your Prompt 2 and Prompt 3 combined and paste them into
a different AI tool. If you used Claude, try ChatGPT or Gemini.
Play both versions side by side and compare:
- Which version has better visuals and colors?
- Which version has clearer moles and holes?
- Which version is more fun to play?
- Which version has better animations and sound?
Take the best ideas from both and ask your main AI tool to
add the features the other version did better.
Ship it exactly like the snake game: download, rename to index.html, drag into Netlify (a new project). Done when: a friend can play your game from the link on their own phone.
Project 330-60 minA page that is youA one-page personal site a stranger understands in five seconds.
A first try at this project usually looks like this. Call it the novice approach (Concept 1 in the wild):
I was in Summer Camp learning AI this June. Now I am thinking
to create a personal website that shows everything about me
and what I have learned in this Summer Camp. Share what goes
into the personal website
Now build a personal website with the above idea and show it
A perfectly fine page comes back, which is exactly the trap. Asking what goes into a personal website was a good instinct, but the question has no one in it, so the answer is generic, and the second prompt accepts all of it. "Everything about me" arrived carrying nothing about the actual me, so the model fills the gap the only way it can (Concept 2): with the average student page from its training data. Stock sections, "passionate about learning," achievements that could be anyone's. Polite, clean, nobody's. The page gets good the way every answer on this page gets good: when the context gets real.
Here is the same project run by one reader, a summer-camp student, the way this page teaches it. Three prompts, start to shipped. First the brief: a goal with an audience in it, and a list of decisions he wants a say in before any design exists:
Now you will build a professional personal website
My Goal: To present myself professionally to everyone
(friends, relatives, businesses)
Here are some points that we have to work on before
designing it:
1. Website Colors
2. Background and Design
3. Text Size, Writing Style
4. What information will be there
5. How we present it professionally
Build and show it
None of that is designer vocabulary. "Text Size, Writing Style" is nobody's official jargon, and it works anyway, because it tells the model which decisions are his to approve. A decent page came back: clean sections, his name at the top. It looked done. He read it the way a visitor would and caught what was missing. Then he attached his summer-camp certificate file to the chat (files are context too, Concept 4) and sent the evidence only he could supply:
It looks good but it is missing the most important information
1. I can design games on the web. Here is an example to
showcase: https://snake-game-by-junaid.netlify.app/
2. I know how to use ChatGPT and similar AI assistants
professionally, like Claude and Gemini
3. I know everything present here
https://agentfactory.panaversity.org/docs/ai-prompting-2026
4. I can professionally guide anyone about the things in the
above link
5. At the end of summer camp there was an exam and I got
certified. I have attached the certificate
Now plan and update it
Every line is a real thing a stranger can check: a game he shipped exactly the way Project 1 ships one, the course he studied (item 3 is the page you are reading right now), a file the model can read for itself. A forgotten thing cost one message, not a restart. And "Now plan and update it" is Concept 7's options-before-commitment instinct in five words: plan first, then touch the page. The version that came back had proof where the adjectives used to be. One look later, the last move: a design wish, snake-game style, specific enough to carry its own fix:
On top I have my full name Muhammad Junaid Shaukat and the
same in the next section. This looks bad. For now the top
should have MJS and my game link
https://snake-game-by-junaid.netlify.app/
▶ See the page those three prompts produced (live)
This is the real shipped result, at an address he renamed to his own name in Netlify's settings, exactly the way the ship step below describes. It loads live here; you can also open it in its own tab.
Yours should not look like this one. It should look like you.
Now run yours. Steal his moves, not his facts: open with your goal and who the page must work for, list the decisions you want a say in, then "Build and show it." If you get a description of the page instead of the page, say: "do it." You will use those two words more than any other prompt in this section. When the first version looks done, read it as a visitor and answer the question he answered: what is the most important information this page is missing? Send it as real, checkable things: links to what you shipped (the game from Project 1 belongs here), a file the model can read, the names of what you studied. Then design wishes, one per message. "The heading is shouting." "Less purple." "More space between sections."
When it looks finished, it is not finished. And here the grader cannot be you: you already know who you are, so you cannot feel whether the page actually says it. This is the one project where you have to borrow someone else's eyes. Run the same grade-and-fix loop you ran on the mole game (Concept 6's honest-rubric move), with one change: hand the AI a specific stranger to become.
Become a specific stranger landing on this page for the first
time. Pick one and stay in their head: a recruiter scanning for
eight seconds, a classmate who has never met me, or someone my
work would actually matter to. Score the page 1-10 on three
things: do you know who I am within five seconds, is it obvious
what I want you to do, and does anything read like filler you
would skip? One sentence each, in their voice. Then make the
single change that raises the lowest score and apply it to the
page, don't just describe it.
Run it twice, a different stranger each time. When two people who would never meet both understand you in five seconds, the page is done. That agreement is the signal you cannot get from your own eyes.
Ship it exactly like the game: download, rename to index.html, drag into Netlify (a new project this time). In your project's settings you can change the random site name to something closer to your own, if it is not taken. Done when: your name resolves to a page you made, and the address sits in your bio.
Project 42-4 hrsAI Mini TextbookUse AI to build a short learning chapter on one topic, then prove you can direct and check it.
The first three projects each ended at a public URL. This one deliberately does not. Here you use AI to build a short mini textbook chapter on one topic you are studying, and the real deliverable is two things: the chapter (the product) and a process notebook that proves you can direct, question, and correct AI (the proof). The framing below is written for a school student picking a topic from class, but it works for anyone: pick any topic you are actually trying to learn, let "teacher" mean anyone who will check your work, and treat submission as optional.
This is the capstone because it exercises everything on this page at once: giving AI strong context (Concept 4), choosing the right retrieval mode (Concept 3), the options-then-feedback loop and rubric scoring (Concept 7), and verifying claims instead of trusting them (Concepts 2 and 13). The mini textbook is the product. Your prompt log, your fact-checks, and your reflection are the proof that you can use AI responsibly.
How this works, read first. You do the real work in ChatGPT, Claude, or Gemini in another browser tab. This card gives you the prompts to run, in order, and a live workbook lower down (at Step 6) where you record what you did by hand, your proof of how you reasoned with the AI. Open that workbook now and fill it in as you move through the steps, rather than leaving it all for the end. Everything you need is on this page plus one free AI account.
Step 1: Pick a small topic and open your AI
Choose one small topic, not a whole subject, because you can actually teach a small topic well in a few pages. Do not pick photosynthesis; the worked example uses it. Then just open ChatGPT, Claude, or Gemini and start a fresh chat for this project. If you happen to have notes or a textbook on the topic, keep them handy to paste in later; if not, the AI's own knowledge is plenty.
| Whole subject | One small topic you can actually teach |
|---|---|
| Biology | Food chains and how energy flows |
| Mathematics | Fractions and percentages |
| Physics | Electric circuits |
| English | Writing a strong essay introduction |
| History | Causes of the 1857 War of Independence |
Local ideas if you want one: electric circuits during load-shedding, percentages using shopping discounts, English grammar using a school announcement, or budgeting a class event using ratios.
Done when: you have picked one small topic and have a fresh AI chat open, ready to go.
Step 2: Brief AI well (Concept 4)
Run two prompts. First a deliberately weak one, and save the answer, so later you can see side by side how much a good brief improves things. Then a real one that hands the AI your context: who you are and what you are learning. That second prompt is the whole lesson of Concept 4 in one move.
Explain ___.
Why: run this first only to see the baseline, the difference between a lazy prompt and a good one.
I am a Grade ___ student. I am learning about ___. Explain it to me
clearly, then tell me what is still unclear and what I might
misunderstand.
Why: this hands the model your real situation, so the answer fits you instead of a generic reader.
Optional, only if you actually have notes, a textbook photo, or a worksheet: paste them in and tell the AI to lean on them. Most readers can skip this and use the AI's own knowledge.
Here are my notes / a textbook photo: ___. Use these first. If you add
anything that is not in them, label it clearly as extra.
Done when: the AI has answered using your real context (your level and what you are learning). Paste each prompt, and a line on what it gave back, into the workbook below as you go.
Step 3: Get options, then push back (Concept 7)
Ask for three different ways to explain your topic, but do not let AI expand any of them into the full chapter yet. Then choose one, reject the others with reasons, and ask for revised outlines. Rejecting with a reason is the move that proves you are directing AI, not just accepting its first idea.
Give me 3 different ways to explain ___ to a Grade ___ student. Do not
expand into the full chapter yet. For each option, give a title,
structure, strengths, and weaknesses.
Why: this forces brainstorming before drafting.
I choose option ___ because ___. I reject option ___ because ___.
Revise the outline into 3 improved versions and make them more
suitable for my class context.
Why: this shows you are directing AI, not just accepting the first answer.
Done when: you have rejected at least one option with a reason and have a revised outline you actually like.
Step 4: Build the chapter (Part A)
Now that the planning loop is done, ask AI to think hard and draft the full chapter from your notes and chosen outline. The chapter must contain all ten Part A sections, listed in the collapsible below.
Read my notes and chosen outline carefully. Think hard about clarity,
accuracy, and age-fit. Now build the full mini textbook chapter for
Grade ___ students. Use simple language, short paragraphs, examples,
common mistakes, flashcards, quiz, and a 7-day revision plan.
Why: this asks for careful work only after the planning loop is done.
Done when: you have a draft that covers all ten Part A sections.
Step 5: Score it, then verify it (Concepts 2, 7, 13)
First ask AI to grade its own draft against a rubric and make the smallest edits it suggests. Then ask it to list its important claims, and check a few of the big ones yourself, against your notes, a textbook, or a quick web search, marking each Accept, Reject, Modify, or Needs checking. A score tells you where to improve; verification tells you what is actually true.
Grade the chapter from 1 to 10 on four criteria: clarity, accuracy,
age-fit, and usefulness for revision. Justify each score in one
sentence. Then tell me the smallest edit that would raise each score
the most.
Why: this turns critique into measurable improvement.
List 6 to 10 important factual claims in the chapter. Mark each claim
as supported by my notes, supported by a named source, needs checking,
or unsupported. Do not pretend you verified something if you did not.
Why: this supports honest checking instead of blind trust.
Done when: you have applied the rubric's edits and checked at least a few important claims. Log the rubric prompt and the claims you checked in the workbook below as you go.
Step 6: Assemble your process notebook and finish
Pull together the proof: your topic brief, sources, prompt log, fact-checks, and reflection. Fill the live workbook below as you work; it saves to your browser automatically and exports to one Markdown file you can keep as your proof, copy, or print. The full Part B specification, with one example row per table, is in the collapsible underneath it.
Done when: your chapter is done, and your workbook holds the proof: the main prompts you ran, a couple of facts you checked, and a short reflection in your own words. Doing this for a class? The fuller version, more prompts, named sources, the rubric, and the full checklist, is in the collapsibles below. Write the chapter for someone meeting the topic for the first time. Include all ten sections: This is the proof. It has six pieces. Two are short pieces of writing; four are tables you fill in your own notebook or doc, one row at a time. B1, Topic Brief. A short paragraph: what topic, why you chose it, what is hard about it, who it is for, and what the reader should understand by the end. B2, Source List. One row per source, at least two: Retrieval modes (Concept 3). Name at least two sources, at least one from your class material if possible, and say which mode you used: Source types count as either a class source (textbook page, teacher notes, worksheet, a photo of a paragraph) or a trusted learning source (Khan Academy, Britannica, a teacher-approved site). If your tool has no web search, use your textbook and teacher notes and write that down. Do not invent sources. If AI gives you a source, open and check it when you can; if you cannot verify it, mark it "Needs checking." Build your context package. The model only knows what is in the current chat or Project, so feed it: a typed textbook paragraph, a clear photo of a page or worksheet, a photo of a diagram or class note, your teacher's instructions, the vocabulary your teacher wants, and your own words on what already confuses you. Privacy rule: never upload passwords, your home address, phone number, private family details, or private photos. B3, Prompt Log. At least 8 prompts, showing the whole process and not just the final answer. One row per prompt, covering the eight types in the starter prompts above: B4, Rubric Scoring Table. Score the draft, then improve it. Do not accept a score blindly. One row per criterion (clarity, accuracy, age-fit, usefulness): B5, Checking Table. Choose 6 to 10 important AI statements and check them. One row each: B6, Reflection. 150 to 250 words: what AI helped you understand, what it got wrong or left unclear, which prompt worked best and why, what you changed in the final chapter, and what you will do differently next time. Here is the shape of a finished path, so you can see where you are headed: This sample shows the expected structure and quality. You must not copy it: choose your own topic, sources, prompts, checks, and reflection. Title: AI Mini Textbook: Photosynthesis for Grade 8. How green plants make their own food using sunlight, water, carbon dioxide, and chlorophyll. Part A: the chapter 1. Title and audience. Photosynthesis for Grade 8. Written for Grade 8 students. Explains how green plants make their own food using sunlight, water, carbon dioxide, and chlorophyll. 2. Learning goals. Explain what photosynthesis means; identify the main things plants need; explain the role of sunlight, chlorophyll, water, and carbon dioxide; describe what plants produce; avoid common mistakes about how plants make food. 3. Simple explanation. Photosynthesis is the process by which green plants make their own food. Plants do not eat the way humans and animals do; green plants use sunlight to make food inside their leaves. This food is a sugar called glucose. To make glucose, plants need sunlight, water, carbon dioxide, and chlorophyll. Chlorophyll is the green substance in leaves; it helps plants absorb energy from sunlight. Plants take in carbon dioxide from the air through tiny openings in their leaves and absorb water from the soil through their roots. Using sunlight and chlorophyll, the plant changes water and carbon dioxide into glucose and oxygen. The glucose is used by the plant for energy and growth; the oxygen is released into the air. A simple way to remember it: Sunlight + Water + Carbon Dioxide -> Glucose + Oxygen. Photosynthesis matters because it gives plants food and produces oxygen, which humans and animals need for breathing. 4. Key terms. 5. Examples. Example 1, a plant near a sunny window: placed near a sunny window and watered properly, it can make food through photosynthesis; the leaves absorb sunlight, the roots absorb water, the leaves take in carbon dioxide, and the plant uses these to make glucose, which helps it grow. Example 2, a plant kept in darkness: kept in the dark for a long time, it cannot photosynthesize properly because it lacks light; without enough light it cannot make enough glucose and over time may become weak. This shows sunlight is important. 6. Common mistakes. 7. Diagram or visual idea. Draw a green plant with arrows: sunlight into the leaves, water from the soil into the roots, carbon dioxide from the air into the leaves, oxygen out from the leaves, and glucose labeled inside the plant as the food it made. At the bottom write: Sunlight + Water + Carbon Dioxide -> Glucose + Oxygen. 8. Flashcards. 9. Quiz. Q1 What is photosynthesis? Q2 Name three things plants need for photosynthesis. Q3 What is the role of chlorophyll? Q4 What food is made during photosynthesis? Q5 Why is photosynthesis important for humans and animals? Answer key: 1) the process by which green plants make their own food using sunlight; 2) sunlight, water, and carbon dioxide, plus chlorophyll to absorb sunlight; 3) chlorophyll absorbs sunlight; 4) glucose; 5) it produces oxygen and helps plants make food, which supports life on Earth. 10. 7-day revision plan. Part B: the process notebook B1, Topic Brief. I chose photosynthesis because it is an important Grade 8 Biology topic. Many students find it difficult because they confuse the roles of sunlight, water, carbon dioxide, oxygen, glucose, and chlorophyll. Some think plants get all their food from the soil. My chapter is written for Grade 8 students. By the end, they should understand how green plants make their own food and why it matters for life. B2, Source List. B3, Prompt Log. B4, Rubric Scoring Table. B5, Checking Table. B6, Reflection. AI helped me understand photosynthesis by explaining it in simple language and organizing the topic into key terms, examples, common mistakes, flashcards, and a quiz. My first prompt was too weak because it only asked "Explain photosynthesis," so the answer was general and not made for my class level. The best prompt was the one where I gave AI my grade level, textbook context, and teacher vocabulary, and asked for a full chapter. AI gave me a clear structure, but I still had to check the facts. One important correction was that plants do not get all their food from soil: they get water and minerals from soil, but they make glucose in their leaves. Next time I will give AI my class notes first, ask for different outline options, and check important claims before using the final answer. This is only a sample. Choose your own topic, use your own sources, show your own prompts, check the facts, and write your own reflection.What your chapter must contain (the ten Part A sections)
# Section What goes in it Length 1 Title and audience topic, subject, grade level, who it is for half page 2 Learning goals 3 to 5 things the reader should understand short list 3 Simple explanation easy language, headings, short paragraphs 1 to 2 pages 4 Key terms at least 5 words with simple definitions table 5 Examples at least 2 worked or real-life examples half to 1 page 6 Common mistakes at least 5 mistakes and how to avoid them list or table 7 Diagram or visual idea a simple diagram, flowchart, or labeled visual 1 visual 8 Flashcards 10 cards, question on one side, answer the other table 9 Quiz 5 questions with an answer key short quiz 10 7-day revision plan a simple one-week study plan table What your process notebook must contain (Part B)
Source name Type How I used it Grade 8 textbook page on my topic Textbook / class source took the main definition and key terms
# My prompt What AI gave me What I changed next 1 "Explain ___." a general answer with advanced words saw it was too weak, added my grade + notes Criterion AI score (1 to 10) AI reason Smallest edit to improve it My decision Clarity 8 clear, but hard to remember add a simple diagram accepted, I added one AI statement My decision (Accept / Reject / Modify / Needs checking) Evidence or reason Correction if needed "My topic mostly happens in X." Reject my textbook says it happens in Y corrected to Y What a finished path looks like (one example)
Stage In this example Chosen topic Electric circuits during load-shedding, Grade 8 Physics Class context teacher notes on battery, switch, bulb, current, complete circuit, short circuit Named sources a textbook page photo plus a Khan Academy article or video on circuits Options prompt asked for 3 ways to explain circuits (water-flow, home-lighting, drawing-based) Selected option the home-lighting analogy, because students in Kharian know load-shedding Final product a chapter with explanation, key terms, a circuit diagram idea, common mistakes, flashcards, quiz, and a 7-day plan See a full worked example (photosynthesis, Grade 8): do not copy it
Term Meaning Photosynthesis the process by which green plants make food using sunlight Chlorophyll the green substance in leaves that absorbs sunlight Glucose a type of sugar made by plants as food Carbon dioxide a gas from the air that plants use during photosynthesis Oxygen a gas released by plants during photosynthesis Roots the part of the plant that absorbs water from the soil Leaves the main part of the plant where photosynthesis takes place Mistake Correction "Plants get all their food from the soil." plants get water and minerals from soil, but make glucose in leaves "Photosynthesis happens in the roots." it mostly happens in the leaves "Chlorophyll is food for the plant." chlorophyll is not food; it helps absorb sunlight "Oxygen is used to make food." oxygen is produced during photosynthesis, not used to make food "Plants do not need air." plants need carbon dioxide from the air Question Answer What is photosynthesis? the process by which green plants make food using sunlight What food do plants make? glucose What gas do plants take in? carbon dioxide What gas is released? oxygen What part absorbs water? roots Where does it mostly happen? in the leaves What is chlorophyll? the green substance that absorbs sunlight Why is sunlight needed? it provides energy for photosynthesis Do plants get all their food from soil? no, they make glucose through photosynthesis Why is it important for humans? it produces oxygen and supports food chains Day Task Day 1 read the simple explanation and underline key words Day 2 learn photosynthesis, chlorophyll, glucose, carbon dioxide, oxygen Day 3 draw and label the photosynthesis diagram Day 4 review the common mistakes table Day 5 test yourself using the flashcards Day 6 answer the quiz without looking at the answers Day 7 explain photosynthesis to a friend or family member in your own words Source name Type How I used it Grade 8 Science textbook section Textbook / class source the main definition and key terms Teacher notes on photosynthesis Teacher guidance to identify the important vocabulary Khan Academy or Britannica explanation Trusted learning source to check the basic explanation and avoid wrong claims # My prompt What AI gave me What I changed next 1 "Explain photosynthesis." a general answer with some advanced words saw it was too weak and not written for Grade 8 2 "I am a Grade 8 student. Explain photosynthesis in simple words using the key terms." a clearer explanation using the correct key words decided to add my textbook and teacher notes 3 "Use my Grade 8 textbook and teacher notes first. Label any extra information as extra." focused on the textbook vocabulary, avoided extras asked for outline options before writing 4 "Give me 3 ways to explain photosynthesis to a Grade 8 student. Do not write the chapter yet." three options: recipe analogy, factory analogy, diagram-first chose the recipe analogy 5 "I choose the recipe analogy. I reject the factory analogy as too complex. Revise into 3 outlines." three better outlines with terms, mistakes, flashcards, quiz picked the outline with a diagram and mistakes 6 "Read my notes and outline. Think hard about clarity and age-fit. Build the full chapter." a full first draft of the chapter asked AI to score the draft with a rubric 7 "Grade the chapter 1 to 10 on clarity, accuracy, age-fit, usefulness. Justify and suggest edits." scores: clarity 8, accuracy 8, age-fit 9, usefulness 8 improved the diagram and the mistakes section 8 "List 6 to 10 factual claims and mark each supported, needs checking, or unsupported." a list of claims about sunlight, chlorophyll, glucose, oxygen checked them against my textbook and fixed wording Criterion AI score AI reason Smallest edit My decision Clarity 8 clear, but the process is hard to remember add a simple equation and diagram idea accepted, I added both Accuracy 8 facts are correct, but the role of soil is unclear explain soil gives water, leaves make glucose accepted, added to common mistakes Age-fit 9 the language suits Grade 8 keep paragraphs short, avoid advanced chemistry accepted Usefulness for revision 8 useful, but revision tools would help add flashcards and a 7-day plan accepted, I added both AI statement My decision Evidence or reason Correction if needed "Photosynthesis is how green plants make food." Accept matches textbook and teacher notes none "Plants need sunlight for photosynthesis." Accept matches textbook none "Chlorophyll helps absorb sunlight." Accept matches teacher notes none "Plants take in carbon dioxide." Accept matches textbook and trusted source none "Plants release oxygen during photosynthesis." Accept matches textbook none "Glucose is the food made by plants." Accept matches class notes none "Plants get all their food from the soil." Reject teacher notes say plants make glucose in leaves plants get water and minerals from soil, but make glucose in photosynthesis "Photosynthesis mostly happens in the roots." Reject textbook says it mainly happens in leaves photosynthesis mostly happens in leaves How it is graded
Category What strong work shows Points Topic and learning goal clear topic, audience, difficulty, and learning goal 8 Context package useful class notes, textbook text or photo, vocabulary, or teacher instructions given to AI 12 AI workspace discipline used a Project or clearly organized separate chats to avoid context confusion 5 Named sources and retrieval mode at least two named sources, and which mode was used (pretrained, source-based, or web/search) 10 Prompt log and iteration at least 8 prompts: weak, context, source naming, 3-option loop, feedback, draft, rubric, verify 20 Mini textbook quality clear, organized, age-appropriate, complete, and easy to revise from 20 Checking table important AI claims checked, corrected, or honestly marked "Needs checking" 15 Reflection honest account of what AI helped with, what needed correction, and what was learned 10 Safety and honesty rules
Before you submit, the checklist
Your goal is not to show that AI is smart. It is to show that you can guide AI, question AI, correct AI, and use AI to learn better.
Done when: your chapter is complete (all ten Part A sections) and your process notebook proves the work: a prompt log of at least 8 prompts, at least two named sources, your rubric scores, a checking table of 6 to 10 statements you verified, and a reflection in your own words.
Every address you ship from the first three projects exists because you described what you wanted, in plain sentences, to a model that builds. They run on one engine: the snake gets good because of what you notice while playing, the mole game because of the rubric you hold it to, the page because of who you are. Different sources of context, same move. Get the right context in. The capstone is the exception that proves the rule. It ships no address at all, because its product is a thing you understand and the proof that you, not the model, were in charge.
The first three projects are each a single HTML file, because that is the size of idea one prompt can carry. Concept 9 named the boundary honestly: accounts, live multiplayer over the internet, data that has to survive, those need real engineering. The capstone names a different boundary: a model can draft a whole chapter in seconds, but only you can decide whether it is true. When your ideas outgrow one file, or your trust in a draft outgrows one glance, that is where the rest of this book picks up.
When a project goes wrong (one of these will happen; all are normal)
| Symptom | Fix |
|---|---|
| The app in the side panel is blank or frozen | Say so in plain words: "it's a black screen" or "the start button does nothing." The model can see its own code and will usually fix it. Worst case: "rebuild it from scratch, simpler." |
| The downloaded file opens as a wall of text | It opened in a text editor. Right-click the file, choose Open With, and pick your browser. The file is fine. |
| Netlify shows "Page not found" | The file is probably not named index.html. Rename it and drag it in again. |
| The address is ugly | It is a random name by default. Your project's settings let you rename the site, so the address becomes yourname.netlify.app if that name is free. |
| A friend sees the old version after an update | Drag the newest file onto the project's deploys screen, then have them refresh the page. |
You now know what these tools can do. Whether you can think clearly enough to direct them is a separate question, and it is the question the Thinking in AI Era Crash Course is built around.
Frequently asked questions before you start
Do I need a paid plan to do the exercises here or in the Thinking Crash Course? The free tiers of ChatGPT, Claude, and Gemini are enough for the exercises on this page and most of what the Thinking Crash Course asks of you. A paid plan helps if you do a lot of deep research or attach many files in a session. Start free; upgrade only if usage limits start blocking you.
Should I use one tool or three? Pick one as your default for daily use, but install at least one other from a different family for comparison (see Concept 13). The point of having a second tool is not to do twice the work; it is to have a tiebreaker when the first tool gives you something that does not feel right.
My company blocks ChatGPT. What do I do for the exercises? Use whatever modern AI tool your company permits. The skills here transfer to any text-in, text-out AI. If nothing is permitted, use your personal account on a personal device for the exercises — they are about thinking, not company data.
What if I forget the recipes from this page? Bookmark the page. The recipes (the iterate-and-grade loop, the rubric pattern, the neutral-rephrase trick, the project setup, the "smallest change that lifts the score" move) are designed to be looked up, not memorized. The only thing worth memorizing is the single sentence: get the right context in, keep the wrong context out.
Why deepen into thinking discipline when AI is so capable? Because capability without direction multiplies waste. The bottleneck in 2026 work has moved from producing (which AI made cheap) to evaluating (which it did not). A confidently wrong analysis from AI is more dangerous than no analysis at all, because it looks finished. The Thinking Crash Course trains the judgment that decides what to do with what AI produces. That judgment is the most valuable skill in an AI-saturated workplace, and most curricula skip it entirely.
Common mistakes to watch for in your first week
| Mistake | Symptom | Fix |
|---|---|---|
| Treating AI like a search engine | Short prompts, shallow answers, repeated frustration | Brief AI like a colleague: context, files, constraints, ask. |
| Letting one conversation accumulate forever | Answers get vaguer over time as old context gets compacted away | Start a new conversation when the topic changes. Move standing context (files, instructions) into a project. |
| Asking for the final draft on the first try | Polished output, hollow content | Outline first, grade-and-fix at each stage, expand to bullets, then draft. |
| Bait phrasings without realizing | AI agrees with whatever you implied | Rewrite as neutral questions before sending. |
| Settling for vague critique | "Great work!" with no specifics | Demand a 1-10 score per criterion with one-sentence justifications. Ask for the change that would raise each score the most. |
| Stopping when the AI says you're done | "Looks good!" with no path forward | The AI does not get to declare you finished. Iterate until the score plateaus, not until it sounds polished. |
| Trusting confidence as accuracy | Surprising errors on obscure topics | Ask "how would you know this?" Verify high-stakes claims against primary sources. |
| Approving broad permissions on day one | Files lost, edits overwritten | Scope tight folders. Grow scope only with track record. |
These are not character flaws. They are habits the first generation of users (yourself included) is building from scratch. Catching them once tends to stick.
This page taught the mechanics of using these tools. The Thinking in AI Era Crash Course teaches the discipline that makes the mechanics pay off. Its one-sentence rule: the deliverable is never the answer; the deliverable is the documented evidence of thinking. The course is structured as six thinking habits across three parts:
-
Part 1: Foundations — the posture you take before opening AI. The Prediction Lock (write down what you think the answer is before AI tells you, so AI's confident answer does not silently become yours) and the Reasoning Receipt (label every important AI claim as Accept / Reject / Modify / Surfaced / Missed, with a one-sentence why). Together these keep the thinking with you and the typing with AI — the place where Concept 6 was pointing but did not finish the job.
-
Part 2: Detection — catching what AI gets wrong. The Error Taxonomy (six specific failure modes — factual error, logical gap, false confidence, missing context, fabricated source, stale fact — that you scan for by name rather than by feel) is the deep version of Concept 2's "confident answers are not correct answers." Thinking in Systems (tracing the side effects of any AI-suggested decision across the people and groups it touches, including the places where side effects circle back and undo the original decision) is new ground this page does not cover at all.
-
Part 3: Origination — doing what AI cannot do for you. First Principles (questioning the common advice everyone repeats; breaking a problem down to base facts and asking whether the standard answer is even true in your situation) is the deep version of the neutral-framing move from Concept 6. Working WITH AI (the collaboration model where you do the thinking and deciding, AI does the research and drafting; flip that ratio and you become unnecessary) is the deep version of Concept 7's iterate-with-feedback loop.
When you are ready, head to the Thinking in AI Era Crash Course. Power tools without judgment make confident mistakes faster, and deliberate practice is the only honest way to find out whether your judgment is improving.