Axiom V: Types Are Guardrails
Axioms I through IV gave you the structure — shell orchestration, markdown knowledge, disciplined programs, composed systems. James's refactored order system had all four. But structure tells you how code is organized. It does not tell you what shape the data should be. That gap is where the next mistake was waiting.
The team needed a new endpoint — fetch a customer's order history and return a summary. James's composed architecture was clean, Emma had signed off, so he asked his AI assistant to generate it. The code came back clean: readable variable names, sensible logic, a helper function called customer.get_orders() that returned a list of order summaries.
James reviewed it, liked what he saw, and merged it. The endpoint crashed in staging twenty minutes later. AttributeError: 'dict' object has no attribute 'total_amount'. The AI had generated code that treated the API response as objects with attributes, but the actual response was a list of plain dictionaries. The code looked correct. The variable names suggested correctness. But nothing in the codebase had told the AI — or James — what shape the data actually was.
Emma pulled up the diff. "Your composed functions from last week had typed interfaces — ValidatedOrder, PricedOrder, PaidOrder. The type checker would have caught any mismatch. This new code has no types at all. You gave the AI a blank canvas and hoped it would guess your data model."
She added a CustomerOrder dataclass with typed fields, annotated the function's return type, and ran Pyright. Three errors appeared instantly — the same errors that had crashed staging. Fixed in five minutes. The types had turned a runtime mystery into a development-time checklist.
"Composition gives AI the right scope," Emma said. "Types give AI the right shape. Without both, you are reviewing code by reading it — and you will miss what the machine would catch."
The Problem Without This Axiom
James's staging crash was not a one-time mistake. It was the predictable result of untyped AI collaboration. Without type annotations, every AI-generated function operates in a world of implicit assumptions — a function returns "something," but what shape is that something? A parameter accepts "data," but what structure does that data have? A method exists on an object — but does it really, or did the AI invent it?
When humans write untyped code, they carry mental models of what each variable contains. When AI writes untyped code, it has token probabilities — patterns that look plausible but may not correspond to your codebase. The AI does not know which methods exist on your objects. It generates what looks right based on training data. James's customer.get_orders() looked right. It was not.
The trajectory is the same every time:
| Stage | What Happens | Cost |
|---|---|---|
| Generation | AI produces clean, readable code | Free |
| Review | Developer reads code, sees no obvious issues | Minutes |
| Merge | Code enters the codebase | Seconds |
| Runtime crash | AttributeError, KeyError, TypeError | Hours of debugging |
| Root cause | AI assumed an interface that does not exist | Could have been caught in seconds with types |
Types shift error detection from runtime to development time. They turn implicit assumptions into explicit contracts. And critically, they give AI a specification to generate against — not a vague intent, but a precise description of what goes in, what comes out, and what is guaranteed.
The Axiom Defined
Axiom V: Types Are Guardrails. Type systems prevent errors before they happen. In the AI era, types are essential because they give AI a specification to generate against and catch hallucinations at compile time.
Types are not bureaucracy. They are not "extra work for no benefit." They are the code-level equivalent of a specification — a machine-verifiable contract that constrains what valid code looks like.
When Emma rewrote James's endpoint as def get_order_history(customer_id: int) -> list[CustomerOrder], she stated three things in a single line:
- What goes in: an integer (not a string, not a UUID object, not None)
- What comes out: a list of
CustomerOrderobjects (not dictionaries, not None, not a tuple) - What is guaranteed: if this function returns without raising, you have valid, typed data
This contract is enforced by the type checker before your code ever runs. No test needed. No manual review needed. The machine verifies it automatically, every time. James's AI-generated code would have failed Pyright the moment it tried to access .total_amount on a dict.
From Principle to Axiom
In Chapter 4, you learned Principle 6: Constraints and Safety — the insight that boundaries enable capability. You saw how permission models, sandboxing, and approval workflows create the safety that lets you give AI more autonomy. The paradox: more constraints lead to more freedom, because you trust the system enough to let it operate.
Axiom V applies the same insight at the code level:
| Principle 6 (Workflow Level) | Axiom V (Code Level) |
|---|---|
| Permission models constrain AI actions | Type annotations constrain AI-generated code |
| Sandbox environments isolate risk | Type checkers isolate errors before execution |
| Destructive operations require approval | Type mismatches require correction before running |
| Trust builds through verified safety | Trust builds through verified type correctness |
Principle 6 says "don't let AI delete files without permission." Axiom V says "don't let AI return a dict where a UserProfile is expected." Both are guardrails. Both prevent damage. Both enable confident collaboration by making boundaries explicit and machine-enforced.
The constraint is the same: explicit boundaries, automatically enforced, enabling greater autonomy. At the workflow level, this is permissions and sandboxing. At the code level, this is types and type checking.
The Long Argument for Types
The idea that types could catch errors before runtime is older than most programmers realize. In 1978, Robin Milner at the University of Edinburgh published "A Theory of Type Polymorphism in Programming," introducing the type inference system for the ML programming language. Milner proved a property that became the foundation of typed programming: well-typed programs cannot go wrong. If the type checker accepted your program, an entire class of runtime errors — accessing fields that do not exist, passing arguments of the wrong shape, returning values the caller cannot use — was mathematically impossible.
For decades, this guarantee lived only in academic languages like ML, Haskell, and OCaml. Mainstream languages like Python, JavaScript, and Ruby chose dynamism over discipline — faster to write, easier to prototype, no compiler standing between you and your running code. The trade-off was acceptable when humans wrote all the code, because humans carried mental models that compensated for the missing types.
The trade-off stopped being acceptable when AI entered the picture. AI carries no mental model. It generates code from statistical patterns, and those patterns can produce functions that look typed but are not — variables named user_profile that are actually dictionaries, methods called get_orders() that do not exist on the actual class. James's staging crash was a textbook example of what Milner's type system was designed to prevent.
Python's answer came in 2014, when Guido van Rossum, Jukka Lehtosalo, and Łukasz Langa authored PEP 484 — "Type Hints." The proposal gave Python an opt-in type annotation syntax that preserved the language's dynamic nature while enabling static analysis. You could still write untyped Python. But if you chose to annotate, tools like Mypy and later Pyright could verify Milner's guarantee: well-typed programs cannot go wrong. The discipline was available. The question was whether you would opt in.
Milner's insight — that a machine could verify program correctness before execution — earned him the Turing Award in 1991. Decades later, his guarantee protects developers from a collaborator he never imagined: AI that generates code with absolute confidence and zero understanding.
In the AI era, the answer is not optional. Types are the specification that constrains what AI generates. Without them, you are James — reviewing code by reading it, hoping you catch what the machine would have caught automatically.
Types in Python: The Discipline Stack
Python is dynamically typed — it does not require type annotations. But "does not require" does not mean "should not have." Python's type system is opt-in, and the return on that opt-in is enormous.
Emma walked James through the three layers she used on every project — the same layers that would have caught his staging crash before the code ever left his machine.
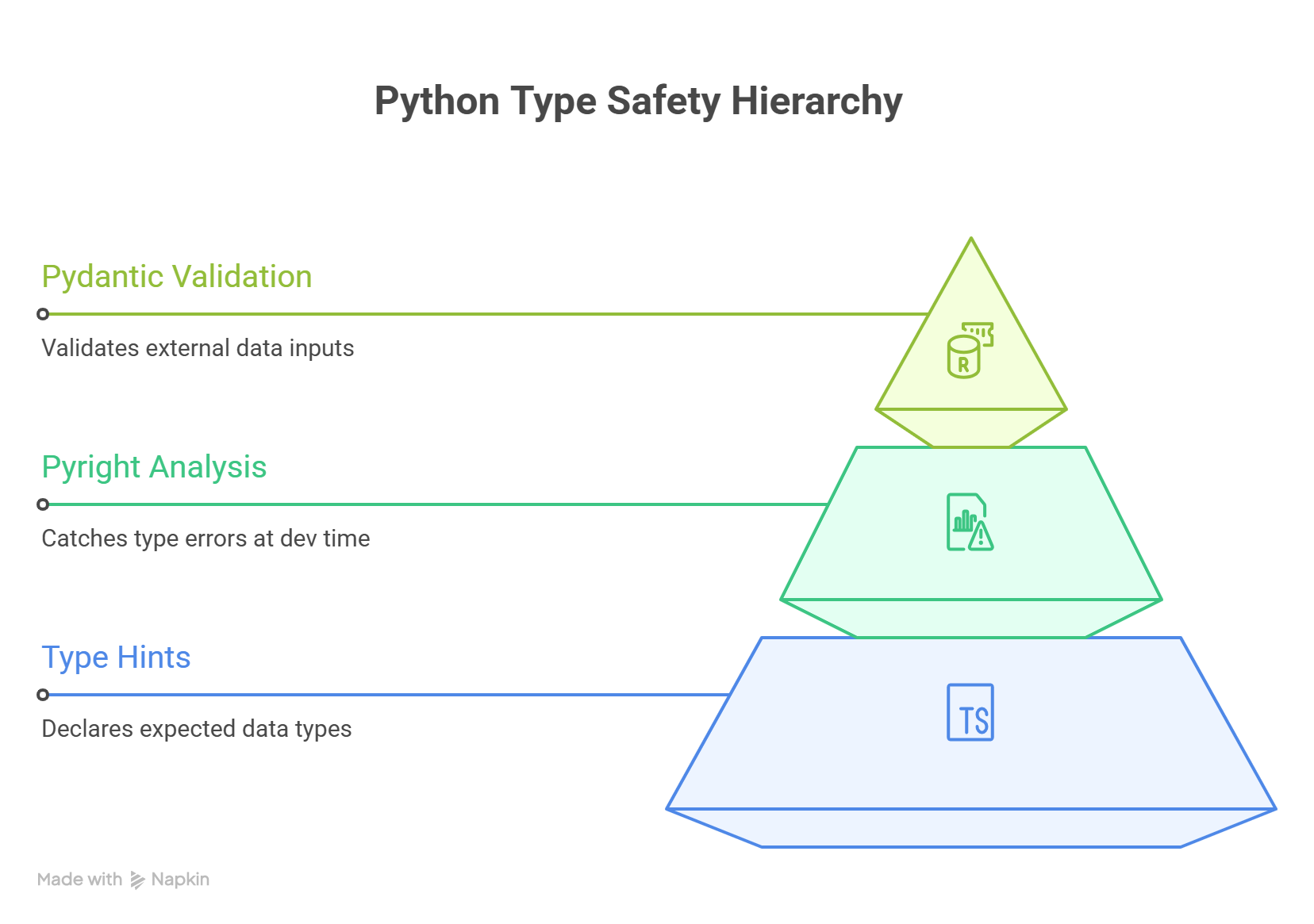
Layer 1: Type Hints (The Annotations)
Type hints are Python's built-in syntax for declaring types. This is the CustomerOrder dataclass Emma added after James's crash — the one that made the AI's mistakes visible:
from dataclasses import dataclass
from datetime import datetime
@dataclass
class CustomerOrder:
order_id: int
customer_name: str
total_amount: float
created_at: datetime
items: list[str]
def get_order_history(customer_id: int) -> list[CustomerOrder]:
"""Fetch all orders for a customer."""
...
Type hints alone do not enforce anything at runtime — Python ignores them during execution. But they serve two critical purposes:
- Documentation that never goes stale: Unlike comments, type hints are part of the code structure. They cannot drift from reality without the type checker flagging it.
- Machine-readable specification: Type checkers and AI systems can read these annotations to understand what code expects and provides.
Layer 2: Pyright in Strict Mode (The Enforcer)
Pyright is a static type checker that reads your annotations and finds errors before you run anything. This is exactly what would have caught James's crash — Pyright sees the mismatch between dict and CustomerOrder and refuses to proceed:
# pyright: strict
# James's AI-generated code (BROKEN):
def get_order_history(customer_id: int) -> list[CustomerOrder]:
response = fetch_api(f"/customers/{customer_id}/orders")
return response # Error: list[dict] is not list[CustomerOrder]
# Pyright also catches attribute hallucinations:
def summarize_orders(orders: list[CustomerOrder]) -> float:
return sum(o.total_price for o in orders)
# Error: "CustomerOrder" has no attribute "total_price"
# Did you mean "total_amount"?
To enable Pyright strict mode, add a pyrightconfig.json to your project:
{
"typeCheckingMode": "strict",
"pythonVersion": "3.12"
}
Strict mode means Pyright will reject:
- Functions without return type annotations
- Variables with ambiguous types
- Operations that might fail on certain types
- Missing None checks for optional values
Layer 3: Pydantic (The Validator)
Pydantic adds runtime validation on top of static types. Where Pyright catches errors at development time, Pydantic catches errors when external data enters your system — like the API response that James's endpoint consumed:
from pydantic import BaseModel, Field
class OrderCreateRequest(BaseModel):
"""Validates incoming order data from the API."""
customer_id: int
item_ids: list[int] = Field(min_length=1)
discount_code: str | None = None
total_amount: float = Field(gt=0)
# Pydantic validates at runtime:
try:
order = OrderCreateRequest(customer_id=42, item_ids=[], total_amount=-5)
except Exception as e:
# ValidationError:
# item_ids: List should have at least 1 item
# total_amount: Input should be greater than 0
print(e)
The three layers work together:
| Layer | What It Does | When It Catches Errors |
|---|---|---|
| Type Hints | Declare contracts | Never (documentation only) |
| Pyright | Verify contracts statically | Development time (before running) |
| Pydantic | Validate data at boundaries | Runtime (when data arrives) |
Types and AI: Why They Are Non-Negotiable
Here is the core insight of this axiom, and the lesson James learned in staging: types matter more with AI-generated code than with human-written code. Here is why.
AI Hallucination: Methods That Do Not Exist
AI confidently generates calls to methods that do not exist on your objects — exactly what happened with James's customer.get_orders():
# AI generates this (looks reasonable):
def get_active_tasks(manager: TaskManager) -> list[Task]:
return manager.get_active() # Does this method exist?
# With types, Pyright catches it immediately:
# Error: "TaskManager" has no attribute "get_active"
# Did you mean "get_tasks"?
Without types, this error only surfaces at runtime. With types, it surfaces the instant the AI generates the code.
AI Confusion: Wrong Return Types
AI can misunderstand what a function should return:
# You asked for "a function that finds a user by email"
# AI generates:
def find_user(email: str) -> dict[str, str]:
# Returns a dictionary...
return {"name": "Alice", "email": email}
# But your codebase expects:
def find_user(email: str) -> User | None:
# Returns a User object or None if not found
...
If you typed the function signature first, the AI generates against your type. If you did not, the AI guesses — and may guess wrong.
AI Interface Drift: Wrong Assumptions About Your Code
AI doesn't have access to your full codebase context when generating code. It makes assumptions about interfaces:
# AI assumes your database module works like this:
from db import get_connection
def save_task(task: Task) -> bool:
conn = get_connection()
conn.execute("INSERT INTO tasks ...", task.to_dict())
conn.commit()
return True
# But your actual db module exposes:
from db import get_session
def save_task(task: Task) -> Task:
session = get_session()
session.add(task)
session.flush()
return task # Returns the task with generated ID
With typed imports and function signatures, the type checker catches every mismatch: wrong function name, wrong parameter types, wrong return type.
The Pattern: Types as AI Specification
The pattern — the one Emma drilled into James after the staging incident — is clear. When you work with AI:
- Define types first (the specification)
- Let AI generate implementations (constrained by types)
- Type checker verifies (catches hallucinations automatically)
This is the same pattern as Principle 6's permission model, applied to code:
Principle 6: Define permissions → AI operates → Safety system verifies
Axiom V: Define types → AI generates → Type checker verifies
Dataclasses vs Pydantic: Internal Types vs Boundary Types
After adopting types across the order system, James asked Emma a question that every developer encounters: "When do I use @dataclass and when do I use Pydantic's BaseModel?" Emma's answer was a single principle: it depends on where the data lives in your system.
| Characteristic | Dataclass | Pydantic BaseModel |
|---|---|---|
| Purpose | Internal data structures | External data validation |
| Validation | None (trusts the caller) | Full (validates all input) |
| Performance | Faster (no validation overhead) | Slower (validates on creation) |
| Where used | Inside your system boundaries | At system boundaries (APIs, files, user input) |
| Mutability | Mutable by default | Immutable by default |
| Serialization | Manual (or asdict()) | Built-in .model_dump(), .model_dump_json() |
| Error handling | None (garbage in, garbage out) | Rich validation errors |
When to Use Each
Use dataclasses for internal domain objects:
from dataclasses import dataclass, field
from datetime import datetime
@dataclass
class Task:
"""Internal representation - trusted data only."""
id: int
title: str
created_at: datetime
tags: list[str] = field(default_factory=list)
completed: bool = False
Use Pydantic for boundaries where external data enters:
from pydantic import BaseModel, Field
from datetime import datetime
class TaskCreateRequest(BaseModel):
"""API request validation - untrusted data."""
title: str = Field(min_length=1, max_length=200)
tags: list[str] = Field(default_factory=list, max_length=10)
priority: int = Field(ge=1, le=5, default=3)
class TaskResponse(BaseModel):
"""API response serialization."""
id: int
title: str
created_at: datetime
completed: bool
The conversion pattern — boundary to internal:
def create_task(request: TaskCreateRequest) -> Task:
"""Convert validated boundary type to internal type."""
return Task(
id=generate_id(),
title=request.title,
created_at=datetime.now(),
tags=request.tags,
completed=False,
)
The rule is simple: Pydantic at the edges, dataclasses at the core. Data entering your system gets validated. Data inside your system is already trusted.
Anti-Patterns: How Types Get Undermined
You have seen the untyped codebase. Every team has one. It is the project where every function accepts data and returns result, where dict[str, Any] is the universal type, where the AI generates beautiful code that crashes at runtime because nothing in the codebase told it what shape anything is.
It is the project where debugging means adding print(type(x)) on every other line, where new developers spend their first week asking "what does this function actually return?" and getting the answer "it depends." It is the project where the type checker was turned off because "it was too strict" — meaning it found real errors that nobody wanted to fix.
The untyped codebase is not missing types by accident. It is missing types because each developer chose the two-second shortcut of skipping the annotation, and a thousand two-second shortcuts became a codebase that no human or AI can safely modify without running it first and praying.
These are the specific patterns that destroy type safety:
| Anti-Pattern | Why It's Harmful | What to Do Instead |
|---|---|---|
dict[str, Any] everywhere | Loses all type information; any key/value accepted | Define a dataclass or TypedDict for the structure |
| Functions without return types | Caller doesn't know what to expect; AI can't constrain output | Always annotate return type, even if -> None |
| Disabling type checker ("too strict") | Removes the entire safety net | Fix the types; strictness IS the value |
| Untyped AI output shipped directly | Hallucinations reach production unchecked | Type-annotate AI code, run Pyright before committing |
The Any Anti-Pattern in Detail
Any is Python's escape hatch from the type system. It means "I do not know the type, and I do not want the checker to care." Every Any in your code is a hole in your guardrails — and James discovered that AI loves to fill those holes with hallucinations:
# BAD: Any disables all checking — AI can return anything
def process_data(data: Any) -> Any:
return data["result"]["items"][0]["name"] # Five unchecked assumptions
# GOOD: Explicit types make every access checkable
@dataclass
class ResultItem:
name: str
@dataclass
class ApiResponse:
result: ResultData
@dataclass
class ResultData:
items: list[ResultItem]
def process_data(data: ApiResponse) -> str:
return data.result.items[0].name # Every access verified by Pyright
The typed version requires more structure. That structure is the specification. When you give this to an AI, it knows exactly what data contains, what operations are valid, and what the function must return. When James added Any to "get things working quickly," he was removing the guardrail that would have saved him hours.
Generics and Protocols: Flexible but Safe
James initially worried that types meant rigid code — that every function would need a specific class for every parameter. Emma showed him that Python's type system offers flexibility without sacrificing safety, through two mechanisms: generics and protocols.
Generics: One Implementation, Many Types
from typing import TypeVar
T = TypeVar("T")
def first_or_none(items: list[T]) -> T | None:
"""Return first item or None if empty. Works with any type."""
return items[0] if items else None
# Works with any list - fully typed:
task: Task | None = first_or_none([task1, task2])
name: str | None = first_or_none(["alice", "bob"])
count: int | None = first_or_none([1, 2, 3])
Protocols: Duck Typing with Safety
When James needed the order pipeline to handle both domestic and international orders — each with different tax rules and shipping logic — Emma showed him Protocols: a way to define what an object must do without forcing it into an inheritance tree. Protocols define the shape an object must have, and the type checker verifies conformance automatically:
from typing import Protocol
class Completable(Protocol):
"""Anything that can be marked complete."""
completed: bool
def mark_complete(self) -> None: ...
def complete_all(items: list[Completable]) -> int:
"""Mark all items complete. Returns count."""
count = 0
for item in items:
if not item.completed:
item.mark_complete()
count += 1
return count
# Any class with 'completed' and 'mark_complete()' works:
@dataclass
class Task:
title: str
completed: bool = False
def mark_complete(self) -> None:
self.completed = True
@dataclass
class Milestone:
name: str
completed: bool = False
def mark_complete(self) -> None:
self.completed = True
# Both work with complete_all() - no inheritance needed:
complete_all([Task("Write tests"), Milestone("v1.0")])
Protocols are particularly powerful with AI: you define the interface (Protocol), and AI generates implementations that must satisfy it. The type checker verifies conformance automatically.
Try With AI
Use these prompts to explore type systems hands-on with your AI assistant. Each targets a different skill in the type discipline stack.
Prompt 1: Type the Untyped
Here's a Python function without type annotations. Help me add complete type hints,
then explain what errors Pyright strict mode would catch if the types were wrong:
def process_users(users, filter_fn, limit):
results = []
for user in users:
if filter_fn(user):
results.append({"name": user.name, "score": user.calculate_score()})
if len(results) >= limit:
break
return results
Walk me through your reasoning:
1. What type should each parameter be?
2. What does the return type look like?
3. Should we use TypedDict for the dict, or a dataclass?
4. What would Pyright catch if someone called this with wrong argument types?
What you're learning: How to read untyped code and infer the correct types from usage patterns. You're practicing the skill of converting implicit assumptions into explicit, machine-checkable contracts — the core discipline that makes AI collaboration safe.
Prompt 2: Pydantic Boundary Design
I'm building an API endpoint that accepts task creation requests.
The request has: title (required, 1-200 chars), description (optional),
priority (1-5, default 3), tags (list of strings, max 5 tags, each max 50 chars),
and due_date (optional ISO format date string).
Help me design:
1. A Pydantic model for the request validation
2. A dataclass for the internal Task representation
3. A conversion function from request to internal type
4. A Pydantic model for the API response
For each model, explain WHY certain fields have validators vs plain types.
What would happen if I used a plain dataclass for the API request instead of Pydantic?
Show me what invalid data would look like and how Pydantic catches it.
What you're learning: The boundary-vs-internal type distinction in practice. You're developing the judgment to know where validation belongs (edges of your system) versus where trust is appropriate (inside your system)---and understanding the consequences of getting this wrong.
Prompt 3: Type-Proof Your Own Code
Take an untyped function from my codebase (or use this example):
def process_data(data, config, output_path):
results = []
for item in data:
if config.get("filter") and not item.get("active"):
continue
transformed = {
"name": item["name"].upper(),
"score": item["value"] * config["multiplier"],
}
results.append(transformed)
with open(output_path, "w") as f:
json.dump(results, f)
return len(results)
Help me:
1. Add complete type annotations (parameters, return type, intermediate variables)
2. Replace the dict types with dataclasses or TypedDicts
3. Run through the logic as if you were Pyright — what errors would strict mode catch?
4. Now regenerate the function body from ONLY the type signatures.
How much closer is the AI-generated version when it has types to work from?
Compare: How much would an AI know about this function with vs without types?
What you're learning: The direct experience of what James discovered — that untyped code forces AI (and humans) to guess, while typed code gives them a specification. By regenerating a function from only its type signatures, you see firsthand how types constrain AI output toward correctness.
The Annotation Illusion
After adopting types, James went through a phase Emma recognized. He typed everything meticulously, ran Pyright, saw zero errors, and assumed his code was correct. Then a test failed: calculate_discount() returned 0.15 when it should have returned 0.85. The types were perfect — float in, float out. The logic was wrong. He had subtracted the discount from 1.0 in the wrong order.
"Types catch structural errors," Emma told him. "Wrong shapes, missing fields, interface mismatches — the machine finds those. But types cannot catch logical errors. A function that returns int when it should return float will be caught. A function that returns 42 when it should return 7 will not. Types and tests are different layers in the same defense."
The Annotation Illusion is the belief that typed code is correct code. It is not. Types guarantee that the pieces fit together — that you are not connecting a square peg to a round hole. Tests guarantee that the assembled machine produces the right output. Code review guarantees that the design makes sense. No single layer is sufficient. Together, they form the defense-in-depth that makes AI collaboration safe. James learned to treat Pyright's green checkmark not as "this code is correct" but as "this code is structurally sound — now test the logic."
Key Takeaways
James merged untyped AI-generated code and learned in staging what Robin Milner formalized in 1978: well-typed programs cannot go wrong. Emma's fix — adding a dataclass with typed fields and running Pyright — caught in five minutes what would have taken hours of runtime debugging. The types did not add new logic. They made existing assumptions explicit and machine-verifiable.
- Types are the specification AI generates against. Without types, AI guesses your data model from statistical patterns. With types, AI has an explicit contract — what goes in, what comes out, what is guaranteed. James's staging crash happened because nothing told the AI what shape the data was.
- Python's type discipline stack has three layers. Type hints declare contracts (documentation). Pyright enforces contracts statically (development time). Pydantic validates data at boundaries (runtime). Together, they catch errors at every stage — the fulfillment of Milner's well-typed guarantee in a dynamically typed language.
- Pydantic at the edges, dataclasses at the core. External data entering your system gets validated by Pydantic. Internal data already trusted by your system uses lightweight dataclasses. The boundary is where errors enter; that is where validation belongs.
- Types matter more with AI than without. Humans carry mental models that compensate for missing types. AI carries token probabilities. Every
Anyin your code is a hole where AI hallucinations pass through unchecked. - The Annotation Illusion is the trap. Typed code is not correct code — it is structurally sound code. Types catch shape errors; tests catch logic errors; review catches design errors. No single layer is sufficient.
Looking Ahead
Your shell orchestrates programs. Your knowledge lives in markdown. Your programs have types and tests. Your systems are composed from focused units. Your types catch structural errors before runtime. But your typed dataclasses and Pydantic models describe individual objects — a CustomerOrder, a Task, a User. Real systems are not collections of isolated objects. They are webs of relationships: a customer has orders, an order contains items, an item belongs to a catalog. How do you model, store, and query those relationships without losing the type safety you just built?
In Axiom VI, you will discover that data is relational — and that understanding how entities connect is what separates a collection of typed objects from a working system.