Axiom VII: Tests Are the Specification
The first six axioms built the structure and locked down the data. James's code had orchestration, markdown knowledge, program discipline, composition, typed interfaces, and relational constraints. Every guardrail was in place — except one. None of them checked whether the code did the right thing.
Then he shipped apply_discount() — a function that accepted a PricedOrder and returned a DiscountedOrder. The types were perfect. The function compiled without errors. Pyright showed zero warnings. The code looked correct.
It was not. The function returned 0.15 instead of 0.85 — it subtracted the discount from 1.0 in the wrong order, giving customers an 85% discount instead of a 15% discount. The company lost $12,000 in a single weekend before anyone noticed.
"Types catch structural errors," Emma reminded him on Monday morning. "But types cannot tell you that 0.15 is wrong and 0.85 is right. Only one thing can: a test that says assert apply_discount(order, 0.15) == expected_price. If that test existed before the AI generated the function, the error would have been caught before it left your machine."
Emma showed James a different workflow. Instead of asking the AI to "write a discount function" and reviewing the output by reading it, she wrote five tests first. One asserted a 10% discount on a $100 order produced $90. Another asserted a 0% discount returned the original price. A third tested the boundary where the discount equals the order total. A fourth tested invalid discount values. A fifth tested that the return type was DiscountedOrder, not a raw float. Then she handed the tests to the AI: "Write the implementation that passes all five."
The AI generated code. She ran the tests. Four passed. One failed — the boundary case. She told the AI: "Test 4 is failing. Fix the implementation." It regenerated. All five passed. She accepted the code without reading it line by line, because the tests defined what correct meant.
"The tests are not verification," Emma told James. "They are the specification. You write them first. The AI writes the code second. If the code passes, it is correct by definition. If it fails, you do not debug — you regenerate."
This is Axiom VII.
The Problem Without This Axiom
James's $12,000 discount bug followed a pattern that every developer who works with AI will recognize:
He described what he wanted in natural language. "Write a function that applies a percentage discount to a priced order." This felt precise, but it was ambiguous. Does "apply a 15% discount" mean multiply by 0.15 or multiply by 0.85? Does the function return a new order or modify the existing one? What happens when the discount is 0%? What about 100%?
The AI filled in the gaps with assumptions. It interpreted "apply 15% discount" as "multiply by the discount rate" — returning price * 0.15 instead of price * (1 - 0.15). The assumption was linguistically plausible. It was mathematically wrong.
James verified by reading the code. He scanned the implementation, saw the multiplication, and convinced himself it looked right. But reading code is not the same as running it against known correct values. His eyes saw "multiply by discount" and his brain filled in "of course that gives the discounted price."
The bug appeared in production. $12,000 lost in a weekend. Every guardrail — types, composition, database constraints — had passed. The code was structurally perfect. It was logically wrong.
This pattern is not unique to AI. It is the oldest problem in software development: ambiguous specifications produce correct-looking code that does the wrong thing. But AI amplifies the problem because it generates plausible code faster than you can verify it by reading. The solution is not to read more carefully. The solution is to stop reading and start specifying.
The Axiom Defined
Test-Driven Generation (TDG): Write tests FIRST that define correct behavior, then prompt AI: "Write the implementation that passes these tests." Tests are the specification. The implementation is disposable.
This axiom transforms tests from a verification tool into a specification language — the shift Emma demonstrated to James after the discount disaster. Tests are not something you write after the code to check it works. Tests are the precise, executable definition of what "works" means.
Three consequences follow:
-
Tests are permanent. Implementations are disposable. If the AI generates bad code, you do not debug it. You throw it away and regenerate. The tests remain unchanged because they define the requirement, not the solution.
-
Tests are precise where natural language is ambiguous. "Calculate shipping costs" is vague.
assert calculate_shipping(weight=5.0, destination="UK", total=45.99) == 12.50is unambiguous. The test says exactly what the function must return for exactly those inputs. -
Tests enable parallel generation. You can ask the AI to generate ten different implementations. Run all ten against your tests. Keep the one that passes. This is selection, not debugging.
From Principle to Axiom
In Chapter 4, you learned Principle 3: Verification as Core Step. That principle taught you to verify every action an agent takes, to never trust output without checking it, and to build verification into your workflow rather than treating it as optional cleanup.
Axiom VII takes that principle and sharpens it into a specific practice:
| Principle 3 | Axiom VII |
|---|---|
| Verify that actions succeeded | Define what "success" means before the action |
| Check work after it is done | Specify correct behavior before generation |
| Verification is reactive | Specification is proactive |
| "Did this work?" | "What does working look like?" |
| Catches errors | Prevents errors from being accepted |
The principle says: always verify. The axiom says: design through verification. Write the verification first, and it becomes the specification that guides generation.
This distinction matters in practice. James before the discount disaster followed Principle 3 — he verified by reading code. James after the disaster follows Axiom VII — he specifies by writing tests. The first approach is reactive: "Did this work?" The second is proactive: "What does working look like?"
The Discipline That Preceded TDG
The idea that tests could drive development — not just verify it — has a history that predates AI by decades. In 2002, Kent Beck published Test-Driven Development: By Example, codifying a practice he had been refining since the 1990s as part of the Extreme Programming movement. Beck himself credited the core idea to older practices — as early as 1957, D.D. McCracken's Digital Computer Programming recommended preparing test cases before coding, and NASA's Project Mercury team in the early 1960s used similar test-first practices during development.
Beck's insight was deceptively simple: write a failing test, write the minimum code to make it pass, then refactor. The test comes first. The implementation serves the test. This reversed the dominant workflow where code came first and tests — if they existed at all — came after.
Test-Driven Development — TDD — was controversial. Many developers argued it was slower, that writing tests before code was unnatural, that it produced brittle test suites. But the developers who adopted it discovered something unexpected: the tests were not just catching bugs. They were designing the interface. By writing the test first, you were forced to think about what the function should accept, what it should return, and what "correct" meant — before you got lost in implementation details.
James's $12,000 bug was exactly what Beck's discipline was designed to prevent. If James had written assert apply_discount(order, 0.15).total == 85.0 before asking the AI for an implementation, the wrong interpretation would have been caught in the first test run. The test did not need to know how the discount was calculated. It only needed to state what the result should be.
Beck later described the deeper value: TDD gave you "code you have the confidence to change." Without tests, every modification was a risk. With tests, you could refactor freely because the tests would catch regressions instantly. That confidence — the ability to change code without fear — is exactly what TDG amplifies. When the AI generates an implementation you do not like, you throw it away and regenerate. The tests give you the confidence to discard code, because you can always get it back.
TDG is Beck's TDD adapted for the AI era. The rhythm is the same: test first, implementation second. But the implementation is no longer written by the developer. It is generated by AI, constrained by the tests, and disposable if it fails.
TDG: The AI-Era Testing Workflow
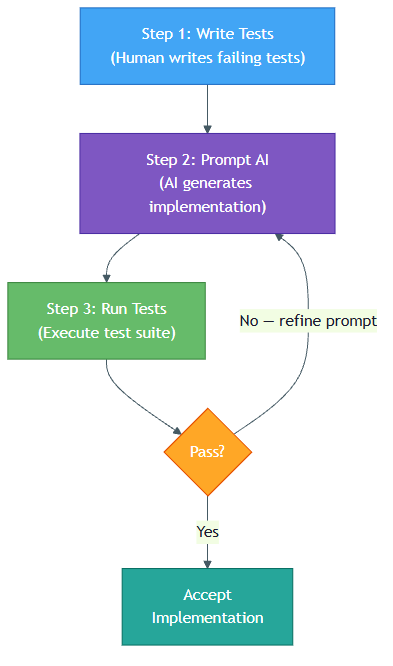
TDG adapts Beck's TDD cycle for AI-powered development. Here is how the two compare:
TDD (Traditional)
Write failing test → Write implementation → Refactor → Repeat
In TDD, you write both the test and the implementation yourself. The test guides your implementation decisions. Refactoring improves code quality while keeping tests green.
TDG (AI-Era)
Write failing test → Prompt AI with test + types → Run tests → Accept or Regenerate
In TDG, you write the test yourself but the AI generates the implementation. If tests fail, you do not debug. You regenerate. The implementation is disposable because you can always get another one. The test is permanent because it encodes your requirements. This is the workflow Emma demonstrated to James after the discount disaster — and the one he never deviated from again.
The TDG Workflow in Detail
Step 1: Write Failing Tests
Define what correct behavior looks like. Be specific about inputs, outputs, edge cases, and error conditions:
# test_shipping.py — James's first TDG specification
import pytest
from shipping import calculate_shipping
class TestDomesticShipping:
"""Domestic orders: flat rate by weight bracket."""
def test_lightweight(self):
assert calculate_shipping(weight_kg=0.5, destination="US", order_total=25.00) == 5.99
def test_medium_weight(self):
assert calculate_shipping(weight_kg=3.0, destination="US", order_total=25.00) == 9.99
def test_heavy(self):
assert calculate_shipping(weight_kg=12.0, destination="US", order_total=25.00) == 14.99
class TestInternationalShipping:
"""International orders: domestic rate + surcharge."""
def test_international_surcharge(self):
# Domestic medium (9.99) + international surcharge (8.00)
assert calculate_shipping(weight_kg=2.0, destination="UK", order_total=30.00) == 17.99
class TestFreeShipping:
"""Orders above threshold get free domestic shipping."""
def test_above_threshold(self):
assert calculate_shipping(weight_kg=5.0, destination="US", order_total=75.00) == 0.00
def test_below_threshold(self):
assert calculate_shipping(weight_kg=5.0, destination="US", order_total=74.99) == 9.99
def test_international_no_free_shipping(self):
assert calculate_shipping(weight_kg=1.0, destination="UK", order_total=100.00) == 13.99
class TestEdgeCases:
"""Invalid inputs and boundary conditions."""
def test_zero_weight_raises(self):
with pytest.raises(ValueError, match="Weight must be positive"):
calculate_shipping(weight_kg=0, destination="US", order_total=25.00)
def test_empty_destination_raises(self):
with pytest.raises(ValueError, match="Destination required"):
calculate_shipping(weight_kg=2.0, destination="", order_total=25.00)
Notice what these tests accomplish: they define the weight brackets, the international surcharge amount, the free shipping threshold, and the error conditions. Someone reading these tests knows exactly what the function must do — without seeing any implementation. This is what James wished he had written for apply_discount() before asking the AI to generate it.
Step 2: Prompt AI with Tests + Types
Give the AI your tests and any type annotations that constrain the solution:
Here are my pytest tests for a shipping calculator (see test_shipping.py above).
Write the implementation in shipping.py that passes all these tests.
Constraints:
- Function signature: calculate_shipping(weight_kg: float, destination: str, order_total: float) -> float
- Use only standard library
- Raise ValueError for invalid inputs with the exact messages tested
Step 3: Run Tests on AI Output
pytest test_shipping.py -v
If all tests pass, the implementation matches your specification. If some fail, you have two options: regenerate the entire implementation, or show the AI the failing tests and ask it to fix only those cases.
Step 4: Accept or Regenerate
If tests pass: accept the implementation. It conforms to your specification. You do not need to read it line by line (though you may want to check for obvious inefficiencies).
If tests fail: do not debug the generated code. Tell the AI which tests fail and ask for a new implementation. The tests are right. The implementation is wrong. Regenerate.
Tests 8 and 9 are failing. The international orders should NOT get free shipping
even when order_total exceeds 75.00. Fix the implementation.
This is the power of TDG: you never argue with the AI about correctness. The tests define correctness. Either the code passes or it does not.
Writing Effective Specifications (Tests)
After adopting TDG, James learned that not all tests are good specifications. Some tests specify what the function must do. Others specify how it must work internally. Emma taught him the distinction — and it is critical for TDG.
Specify Behavior, Not Implementation
A behavior specification says what the function must do:
def test_sorted_output():
result = find_top_customers(orders, limit=3)
assert result == ["Alice", "Bob", "Carol"]
An implementation check says how the function must work:
def test_uses_heapq():
"""BAD: Tests implementation detail, not behavior."""
with patch("heapq.nlargest") as mock_heap:
find_top_customers(orders, limit=3)
mock_heap.assert_called_once()
The first test remains valid whether the function uses sorting, a heap, or a linear scan. The second test breaks if you refactor the internals, even if behavior is preserved. In TDG, implementation-coupled tests are especially harmful because they prevent the AI from choosing the best approach.
Use pytest Fixtures for Shared State
As James wrote more TDG specifications, his tests grew beyond simple input-output assertions. The shipping tests needed sample weight data. The order tests needed sample customers and products. He found himself copying the same setup into every test function — violating the same DRY principle he had learned in Axiom IV. Emma showed him pytest fixtures, which define the world your tests operate in without repeating setup code:
import pytest
from datetime import date
from task_manager import TaskManager, Task
@pytest.fixture
def manager():
"""Fresh TaskManager with sample tasks."""
mgr = TaskManager()
mgr.add(Task(title="Write spec", due=date(2025, 6, 1), priority="high"))
mgr.add(Task(title="Run tests", due=date(2025, 6, 2), priority="medium"))
mgr.add(Task(title="Deploy", due=date(2025, 6, 3), priority="low"))
return mgr
class TestFiltering:
def test_filter_by_priority(self, manager):
high = manager.filter(priority="high")
assert len(high) == 1
assert high[0].title == "Write spec"
def test_filter_by_date_range(self, manager):
tasks = manager.filter(due_before=date(2025, 6, 2))
assert len(tasks) == 1
assert tasks[0].title == "Write spec"
def test_filter_no_match_returns_empty(self, manager):
result = manager.filter(priority="critical")
assert result == []
Fixtures define the world your tests operate in. When you send these to the AI, the fixture tells it exactly what data structures and setup the implementation must support.
Use Parametrize for Specification Tables
James's discount function needed to handle dozens of cases: 10% off, 25% off, 0% off, 100% off, amounts with cents, amounts with rounding. Writing a separate test function for each case would have produced a file longer than the implementation itself. Emma showed him pytest.mark.parametrize, which expresses the specification as a table — every row is a test case, and the table is the complete specification:
import pytest
@pytest.mark.parametrize("input_text,expected", [
("hello world", "Hello World"), # Basic case
("HELLO WORLD", "Hello World"), # All caps
("hello", "Hello"), # Single word
("", ""), # Empty string
("hello world", "Hello World"), # Multiple spaces preserved
("hello-world", "Hello-World"), # Hyphenated
("hello\nworld", "Hello\nWorld"), # Newline preserved
("123abc", "123Abc"), # Leading digits
])
def test_title_case(input_text, expected):
from text_utils import to_title_case
assert to_title_case(input_text) == expected
This is a specification table. It says: "For these exact inputs, produce these exact outputs." The AI can implement any algorithm it wants as long as it matches the table. James realized that if he had written a parametrize table for apply_discount() — with rows like (100.0, 0.15, 85.0) and (100.0, 0.0, 100.0) — the $12,000 bug would have been impossible. The table is the business rule, written in a form that runs automatically.
Use Markers for Test Categories
Organize tests by scope using @pytest.mark decorators — @pytest.mark.unit for fast pure-logic tests, @pytest.mark.integration for tests that touch databases or APIs, @pytest.mark.slow for expensive operations. Run subsets with pytest -m unit for fast feedback during TDG cycles, pytest -m integration for thorough verification before committing.
The Test Pyramid
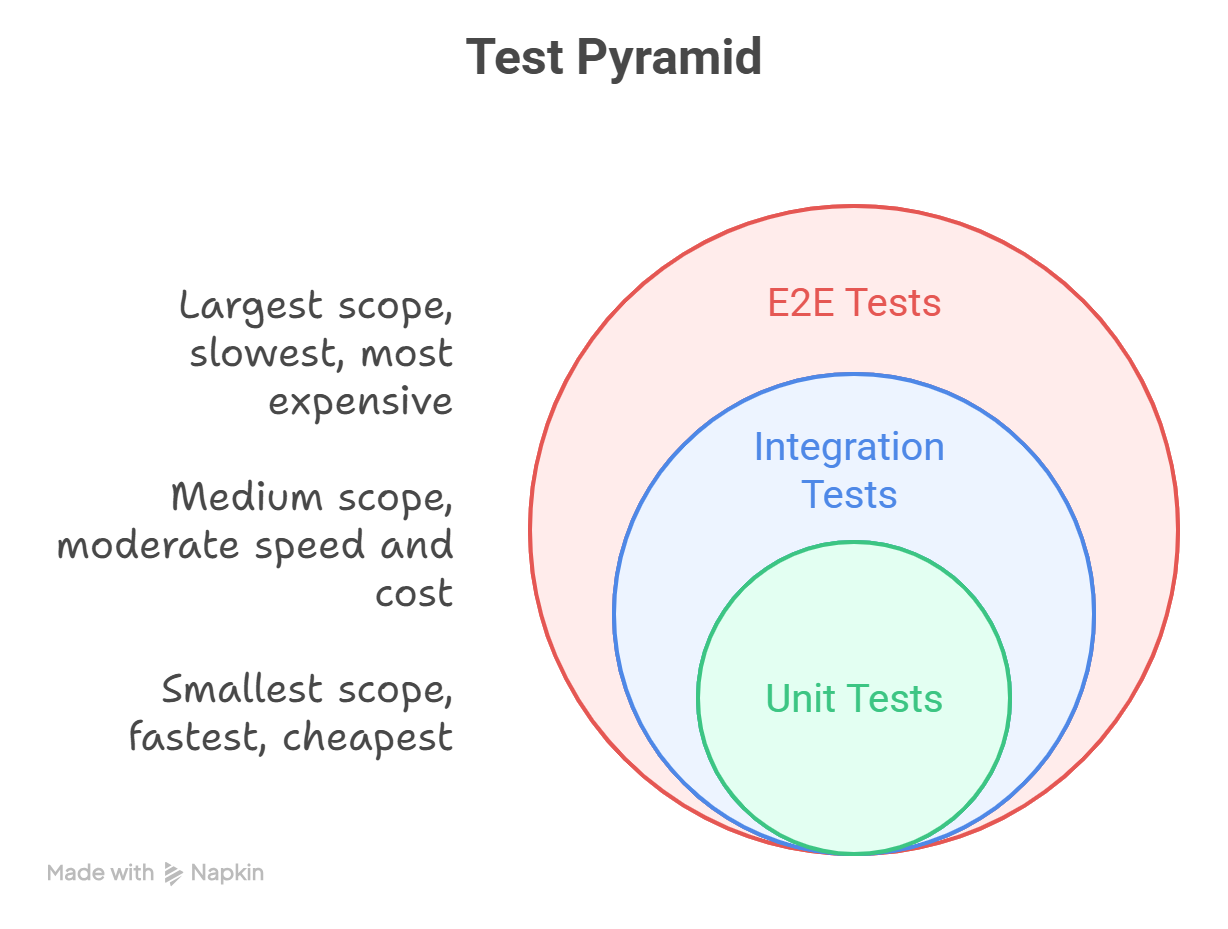
Emma showed James that not all tests serve the same purpose. The test pyramid — a concept popularized by Mike Cohn — organizes tests by scope and cost:
| Level | What It Tests | Speed | Cost | When to Use |
|---|---|---|---|---|
| Unit | Single function, pure logic | Milliseconds | Free | Every function with business logic |
| Integration | Components working together | Seconds | Low | API endpoints, database queries |
| E2E | Full system behavior | Minutes | High | Critical user workflows |
TDG at Each Level
Unit tests are your primary TDG specification. They define individual function behavior precisely:
def test_discount_calculation():
assert apply_discount(price=100.0, discount_pct=10) == 90.0
Integration tests define how components interact:
def test_order_creates_invoice(db_session):
order = create_order(db_session, items=[{"sku": "A1", "qty": 2}])
invoice = get_invoice(db_session, order_id=order.id)
assert invoice.total == order.total
assert invoice.status == "pending"
E2E tests define user-visible behavior:
def test_checkout_flow(client):
client.post("/cart/add", json={"sku": "A1", "qty": 1})
response = client.post("/checkout", json={"payment": "card"})
assert response.status_code == 200
assert response.json()["order_status"] == "confirmed"
For TDG, aim for this distribution: 70% unit, 20% integration, 10% E2E. Unit tests are the most effective specifications because they are precise, fast, and independent.
Coverage as a Metric
Code coverage measures how much of your implementation is exercised by tests. Teams commonly target 80% coverage as a practical baseline for TDG work:
pytest --cov=shipping --cov-report=term-missing
Coverage tells you where your specification has gaps. When James ran coverage on his shipping module for the first time, he discovered that the free-shipping threshold had an untested branch: what happens when the order total is exactly $75.00? He had tested above and below, but not the boundary itself. The AI had guessed "above" — which happened to be correct — but it could just as easily have guessed wrong. One more test line closed the gap permanently.
But coverage is a floor, not a ceiling. 100% line coverage does not mean your specification is complete. A function can have every line executed but still be wrong for inputs you did not test. Coverage catches omissions. Good test design catches incorrect behavior.
Anti-Patterns
There is a phrase that has killed more software projects than any technical debt: "We'll add tests later." Later never comes. The codebase grows, every AI-generated function gets merged after a visual review and a prayer, and "it worked when I ran it" substitutes for a specification.
Then someone asks the AI to generate both the code and the tests, and the tests pass because they test the AI's assumptions instead of the business requirements — and nobody notices until the invoicing system charges every customer twice. Refactoring becomes impossible because there are no tests to confirm that behavior is preserved. Every change is a gamble.
The untested codebase is not missing tests by accident. It is missing tests because each developer chose the thirty-second shortcut of "just ship it," and a hundred thirty-second shortcuts became a system that nobody trusts.
These specific patterns undermine TDG. Recognize and avoid them:
| Anti-Pattern | Why It Fails | TDG Alternative |
|---|---|---|
| Testing after implementation | Tests confirm what code does, not what it should do. You test the AI's assumptions instead of your requirements. | Write tests first. The tests define requirements. |
| Tests coupled to implementation | Mocking internals, checking call order, asserting private state. Tests break on any refactor, preventing regeneration. | Test inputs and outputs only. Any correct implementation should pass. |
| No tests ("it's just a script") | Without specification, you cannot regenerate. Every bug requires manual debugging of code you did not write. | Even scripts need specs. Three tests beat zero tests. |
| AI-generated tests for AI-generated code | Circular logic: the same assumptions that produce wrong code produce wrong tests. Neither catches the other's errors. | You write tests (the specification). AI writes implementation (the solution). |
| Happy-path-only testing | Only testing the expected case. Edge cases, error conditions, and boundary values are unspecified. AI handles them however it wants. | Test the sad path. Test boundaries. Test invalid inputs. |
| Overly rigid assertions | Asserting exact floating-point values, exact string formatting, exact timestamps. Tests fail on valid implementations. | Use pytest.approx(), pattern matching, and relative assertions where appropriate. |
The Circular Testing Trap
The most dangerous anti-pattern — and the one James almost fell into after adopting TDG — deserves special attention. When you ask AI to generate both the implementation and the tests, you get circular validation:
You: "Write a function to calculate tax and tests for it."
AI: [Writes function that uses 7% rate]
AI: [Writes tests that assert 7% rate]
The tests pass. Everything looks correct. But you never specified what the tax rate should be. The AI assumed 7%. If your business requires 8.5%, both the code and the tests are wrong, and neither catches the other.
In TDG, you are the specification authority. You decide what correct means. The AI is the implementation engine. It figures out how to achieve what you specified. Never delegate both roles to the AI.
Never let AI generate both the tests and the implementation. If the same model writes both, it will encode the same assumptions in both — and neither will catch the other's errors. You write the specification (tests). AI writes the solution (code). This separation is what makes TDG work.
The Green Bar Illusion
After a month of TDG, James experienced a subtler version of the Annotation Illusion from Axiom V. All tests passed — the green bar appeared in his terminal. He assumed the code was production-ready. Then the shipping function, which passed all eleven specification tests, turned out to be O(n^2) — it recalculated rates by looping through every historical order for each new calculation. Functionally correct. Performance catastrophe.
"The green bar means your specification is satisfied," Emma told him. "It does not mean the code is secure, performant, or free of resource leaks. Tests specify functional correctness: given these inputs, produce these outputs. They do not automatically catch security vulnerabilities, performance problems, concurrency bugs, or memory leaks."
The Green Bar Illusion is the belief that passing tests means production-ready code. TDG gives you functional correctness — the confidence that the code does what you specified. But specifications are not exhaustive. A function can pass every test and still be vulnerable to SQL injection (Axiom VI), still leak database connections, still take ten seconds for an operation that should take ten milliseconds. Functional tests are one layer. Security testing, performance assertions, and runtime observability (Axiom X) are the others. James learned to treat the green bar not as "ship it" but as "the specification is satisfied — now check everything else."
Try With AI
Prompt 1: Your First TDG Cycle (Experiencing the Workflow)
I want to practice TDG. Here is my specification as pytest tests:
```python static
import pytest
from converter import temperature_convert
def test_celsius_to_fahrenheit():
assert temperature_convert(0, "C", "F") == 32.0
def test_fahrenheit_to_celsius():
assert temperature_convert(212, "F", "C") == 100.0
def test_celsius_to_kelvin():
assert temperature_convert(0, "C", "K") == 273.15
def test_invalid_unit_raises():
with pytest.raises(ValueError, match="Unknown unit"):
temperature_convert(100, "C", "X")
def test_below_absolute_zero_raises():
with pytest.raises(ValueError, match="below absolute zero"):
temperature_convert(-300, "C", "K")
Write the implementation in converter.py that passes all 5 tests. Do NOT modify the tests. The tests are the specification.
**What you're learning:** The core TDG rhythm. You wrote the specification (tests). The AI generates the implementation. You run the tests to verify. If they pass, you accept. If they fail, you regenerate. Notice how the tests precisely define behavior (including error messages) without dictating how the conversion is calculated internally.
### Prompt 2: Specification Design (Writing Tests That Specify, Not Constrain)
I need to build a function called summarize_scores(scores: list[int]) -> dict that takes a
list of student test scores (0-100) and returns a summary dictionary.
Help me write pytest tests that SPECIFY the behavior without constraining the implementation. I want to test:
- Normal case (mix of scores)
- Empty list (edge case)
- All same scores
- Invalid scores (negative, above 100)
- Single score
For each test, explain:
- What behavior am I specifying?
- Why is this a behavior test, not an implementation test?
- What implementation freedom does the AI retain?
Do NOT write the implementation yet. I want to understand specification design first.
**What you're learning:** The difference between specifying behavior and constraining implementation. Good TDG tests say "given this input, produce this output" without saying "use this algorithm" or "call this internal method." You are learning to leave implementation freedom for the AI while being precise about what correctness means.
### Prompt 3: TDG for Your Domain (Applying to Real Work)
I'm building a pricing function for an order system — similar to this lesson's apply_discount() scenario. The function calculate_order_total() takes a list of items (each with price, quantity, and optional discount_pct) and returns the final total with tax applied.
Help me apply TDG:
-
First, ask me 5 clarifying questions about the expected behavior:
- What are the inputs and their types?
- What are the outputs?
- What are the edge cases (empty cart, zero quantity, 100% discount)?
- What errors should be raised and when?
- What are the business rules (tax rate, rounding, discount stacking)?
-
Based on my answers, write a complete pytest test file that serves as the specification. Include: fixtures for sample items, parametrize for pricing rule tables, edge case tests, error tests.
-
Then generate the implementation that passes all tests.
-
Finally, suggest 3 additional tests I might have missed that would make my specification more complete.
Walk me through each step so I understand the TDG process applied to real business logic where getting the math wrong has financial consequences.
**What you're learning:** Applying TDG to real business logic where correctness has financial stakes — exactly the scenario James faced. The clarifying questions teach you what information a pricing specification needs (rounding rules, tax behavior, discount boundaries). The test file shows you how to structure a complete financial specification. The additional tests reveal the gaps that cause $12,000 weekends. This is the skill that transfers: learning to think in specifications rather than implementations, regardless of what you are building.
---
## Key Takeaways
James lost $12,000 because no test defined what "correct" meant for `apply_discount()`. Emma's fix was not to review code more carefully — it was to write the expected result before the code existed. Kent Beck formalized this discipline in 2002. TDG adapts it for the AI era: the human writes the specification (tests), the AI writes the implementation, and the tests decide whether to accept or regenerate.
- **Tests are the specification, not the verification.** Write them first. They define what "correct" means before any implementation exists. If `assert apply_discount(order, 0.15).total == 85.0` existed before the AI generated the function, the $12,000 bug would have been caught in seconds.
- **Implementations are disposable. Tests are permanent.** If the AI generates bad code, do not debug it — regenerate. The tests remain unchanged because they encode your requirements, not the AI's assumptions. This is TDG's core insight: you never argue with the AI about correctness. The tests decide.
- **Specify behavior, not implementation.** Good TDG tests say "given this input, produce this output" without saying "use this algorithm." Implementation-coupled tests prevent the AI from choosing the best approach and break on every refactor.
- **The Circular Testing Trap is the most dangerous anti-pattern.** Never let AI generate both the implementation and the tests. The same assumptions that produce wrong code produce wrong tests. You are the specification authority. The AI is the implementation engine.
- **The Green Bar Illusion is real.** Passing tests mean the specification is satisfied — not that the code is secure, performant, or production-ready. TDG gives you functional correctness. Security, performance, and observability are separate layers.
---
## Looking Ahead
Your shell orchestrates programs. Your knowledge lives in markdown. Your programs have types and tests. Your systems are composed from focused units. Your types catch structural errors. Your data lives in relational tables. Your tests define what "correct" means. But where do all of these artifacts live? When James fixed the discount bug, he wrote five new tests and regenerated the implementation. A week later, a colleague asked: "What was the original implementation that caused the $12,000 loss? And which version of the tests caught it?" James could not answer. He had overwritten the file and lost the history.
In Axiom VIII, you will discover that version control is not just a backup system — it is the persistent memory that stores your specifications, your implementations, and the entire history of decisions that produced them.