ڈیجیٹل FTE بنانا: 4 گھنٹے کا مختصر عملی کورس
15 تصورات، 80% کا حقیقی استعمال کریں - skills، نظام کا Record، اور MCP
ایک continuation مختصر عملی کورس. یہ ہے کورس #4 میں agentic-coding track. previous کورس، تعمیر AI Agents کے ساتھ OpenAI Agents SDK اور Cloudflare سینڈ باکس، taught آپ کو تعمیر کریں ایک سٹریمنگ chat agent کے ساتھ سیشنز، حفاظتی حدود، اور ایک سینڈ باکسڈ ڈیپلائمنٹ. کے ذریعے end کا that کورس آپ had ایک agent کہ worked. کے ذریعے end کا this کورس آپ'll رکھتے ہیں ایک ورکر: وہی OpenAI Agents SDK foundation، وہی Cloudflare سینڈ باکس runtime، مگر کے ساتھ three additions کہ تبدیلی کیا agent is: portable skills یہ loads on demand، ایک Neon Postgres ریکارڈ کا مستند نظام یہ reads سے اور writes کو، اور ماڈل سیاق و سباق پروٹوکول connections کہ رابطہ دو together.
single insight کہ بناتا ہے everything else click: بدلنا ایک agent میں ایک ورکر ہے دو ڈھانچے سے متعلق فیصلے، کہاں اس کا صلاحیتیں live، اور کہاں اس کا truth lives. skills جواب پہلا. MCP-connected ریکارڈ کے مستند نظام جواب second. Everything میں یہ مختصر عملی کورس ہے ایک کا those دو جوابات یا wiring درمیان انہیں.
میں plain English: ایک chat agent کہ lives میں ایک single Python عمل has اس کا صلاحیتیں baked میں کوڈ اور اس کا memory baked میں RAM. Restart عمل اور دونوں disappear. ایک ورکر ( ڈھانچے سے متعلق اصطلاح our thesis استعمال کرتا ہے کے لیے ایک agent کہ operates اندر ایک کمپنی) has اس کا صلاحیتیں packaged بطور skills (portable فولڈرز agent discovers on demand) اور اس کا memory packaged میں ایک ریکارڈ کا مستند نظام (ایک پائیدار ڈیٹا بیس agent reads سے اور writes کو کے ذریعے ماڈل سیاق و سباق پروٹوکول). previous کورس built engine. یہ کورس builds کیا engine چلتا ہے کے خلاف.
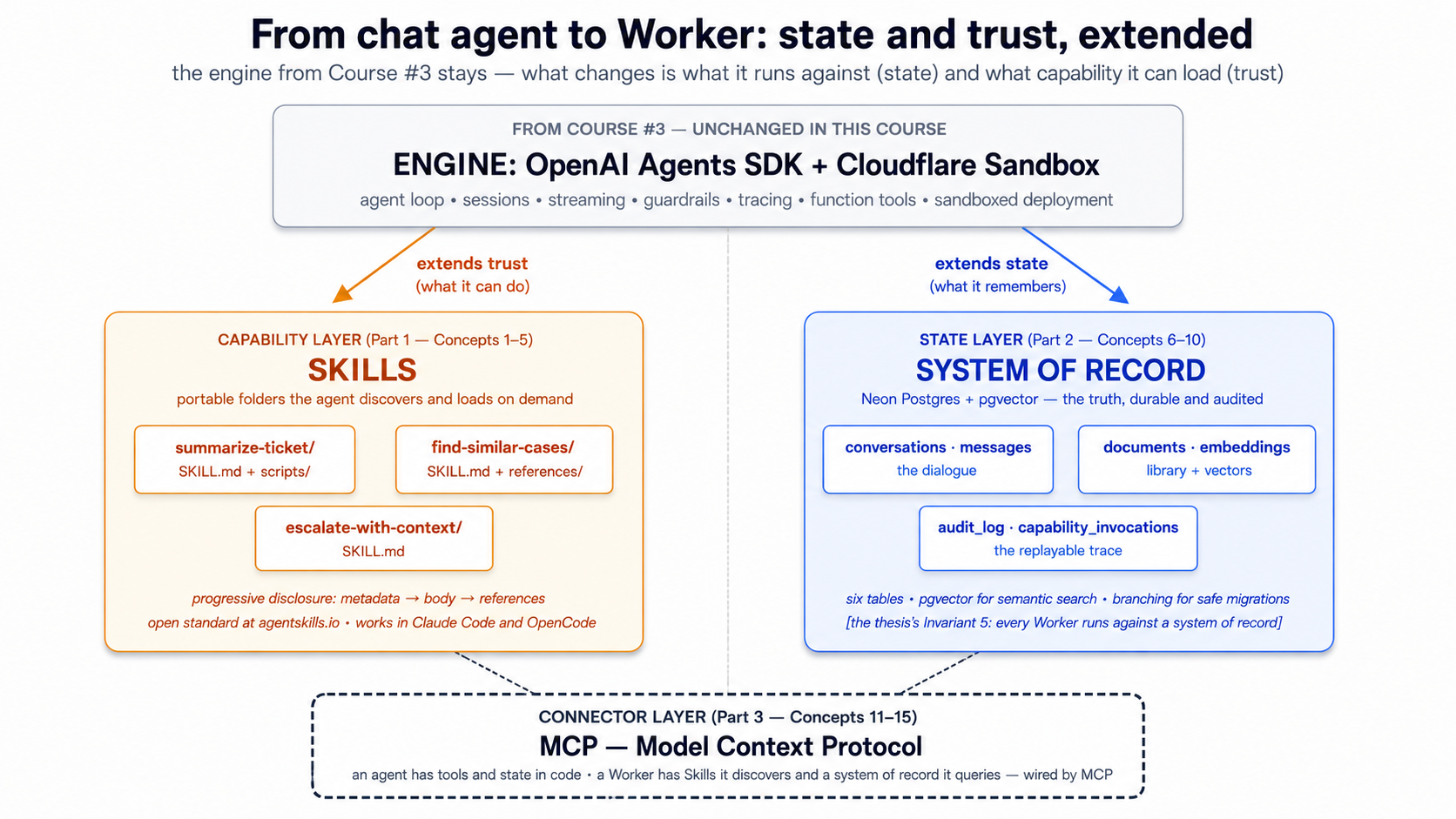
شروع کریں یہاں: ڈھانچے سے متعلق placement اور 15-concept cheat sheet
کہاں یہ کورس sits میں ڈھانچہ. ایجنٹ فیکٹری thesis describes Seven Invariants کہ any پروڈکشن agent نظام لازمی satisfy. Course #3 covered engine layer (Invariant 4): OpenAI Agents SDK بطور harness، Cloudflare سینڈ باکس بطور compute. یہ کورس covers دو زیادہ invariants اور ایک کا پروڈکشن engine کا three pillars:
- Invariant 5: ہر ورکر چلتا ہے کے خلاف ایک ریکارڈ کا مستند نظام. "Engine ہے کیا ہر ورکر چلتا ہے on; ریکارڈ کا مستند نظام ہے کیا ہر ورکر چلتا ہے against. ہر AI ورکر reads سے اور writes کو ایک authoritative store کا state." Neon Postgres + pgvector ہے ایک concrete realization کا یہ invariant. thesis ہے واضح: any پائیدار، addressable، governed store افرادی قوت سکتا ہے پڑھیں اور لکھیں satisfies requirement. We استعمال کریں Neon کیونکہ یہ کا free کو شروع کریں، scales کو zero، اور ships ایک official MCP server. ڈھانچہ ہے invariant; پروڈکٹ ہے replaceable.
- ** skills صلاحیت layer.** آپ کا thesis names "صلاحیت packaged بطور portable skills" بطور ایک کا ڈھانچہ کا stable invariants. skills ہیں کھولیں standard (originally Anthropic، اب نظام-wide پر agentskills.io) کہ lets ایک ورکر کا صلاحیتیں live outside اس کا کوڈ، میں فولڈرز ایک agent discovers، loads، اور executes on demand.
- MCP بطور connector. آپ کا thesis frames MCP بطور "کیسے افرادی قوت reaches" اس کا ریکارڈ کے مستند نظام. Course #3 استعمال ہوا MCP lightly; یہ کورس بناتا ہے MCP load-bearing نمونہ درمیان agent اور Neon.
** thesis sentence، expanded.** دو ڈھانچے سے متعلق فیصلے turn ایک agent میں ایک ورکر:
- کہاں کریں اس کا صلاحیتیں live? In کوڈ، بطور
@function_tooldecorators → fine کے لیے ایک demo. In skill فولڈرز agent discovers پر startup اور loads on demand → fine کے لیے ایک ورکر کہ ships، evolves، gets added کو بغیر redeploying، اور ہے sharable across ورکرز میں وہی کمپنی. - کہاں کرتا ہے اس کا truth live? In RAM اور ایک local SQLite فائل → fine کے لیے ایک chat demo. In ایک پائیدار Postgres ڈیٹا بیس agent reads سے اور writes کو کے تحت audit، کے ساتھ vector search پر کیا یہ has learned → fine کے لیے ایک ورکر کہ has کو جواب "کیا did آپ tell customer six weeks ago?" اور "رکھتے ہیں we seen یہ سوال پہلے?"
connector کہ joins دو ہے ماڈل سیاق و سباق پروٹوکول: ایک کھولیں standard کے لیے کیسے ایک agent reaches external state اور external صلاحیت. کے ذریعے end کا یہ کورس، آپ گا رکھتے ہیں replaced یہ کورس's predecessor کا stub ٹولز اور SQLite سیشن کے ساتھ: three skills agent loads on demand، ایک Neon Postgres + pgvector ڈیٹا بیس holding agent کا authoritative state، اور ایک MCP layer کہ wires انہیں کو agent بغیر coupling agent کو either.
** 15-concept cheat sheet.** ایک ناکامی میں پروڈکشن almost ہمیشہ traces کو ایک کا three root causes: ایک missing یا wrong skill، ایک ریکارڈ کا مستند نظام کہ isn't اصل میں حقیقت کا مستند ماخذ، یا ایک MCP wiring کہ loses ڈیٹا. یہ table ہے diagnostic.
| # | تصور | Layer | کیا سوال یہ جوابات |
|---|---|---|---|
| 1 | کیا ایک Agent skill ہے | skills | کہاں کرتا ہے reusable صلاحیت live? میں ایک فولڈر، کے ساتھ SKILL.md plus optional scripts/references. |
| 2 | Progressive disclosure | skills | کیوں ہیں skills سستا کو رکھیں on hand? Discovery → activation → عمل درآمد loads صرف کیا کا needed جب یہ کا needed. |
| 3 | Writing ایک SKILL.md | skills | کیا کرتا ہے ایک skill فائل اصل میں contain? metadata، trigger description، operational instructions. |
| 4 | skill packaging conventions | skills | کیسے کریں skills travel درمیان ٹولز? وہی فولڈر کام کرتا ہے میں Claude Code، OpenCode، اور any compliant client. |
| 5 | Composing skills | skills | جب کو chain چھوٹا skills via filesystem ہینڈ آف vs. لکھیں ایک big skill. |
| 6 | کیوں managed Postgres | نظام کا record | کیا store earns "ریکارڈ کا مستند نظام"? ایک کے ساتھ persistence، branching، نظم و نگرانی، اور vector بنیادی اکائیاں ایک agent ضرورت ہے. |
| 7 | ورکر کا schema | نظام کا record | کیا tables کرتا ہے ایک agent اصل میں ضرورت? Conversations، messages، دستاویزات، embeddings، audit log، صلاحیت invocations. |
| 8 | pgvector basics | نظام کا record | کیسے کرتا ہے semantic search کام میں Postgres? Embedding column، distance operators، index types. |
| 9 | embedding pipeline | نظام کا record | کیسے کرتا ہے text بن جاتے ہیں ایک queryable vector? Chunking، embedding ماڈل، جب کو re-embed. |
| 10 | audit trail بطور طریقہ کار | نظام کا record | کیا کرتا ہے "reads اور writes" mean کے لیے ایک ورکر? ہر action ایک ورکر لیتا ہے leaves ایک trace کمپنی سکتا ہے replay. |
| 11 | کیا MCP ہے اور isn't | MCP | ایک پروٹوکول کے لیے ٹولز، resources، اور پرامپٹس: نہیں ایک فریم ورک، نہیں ایک service. |
| 12 | Neon MCP server | MCP | agent کا interface کو اس کا ڈیٹا بیس: کیا یہ exposes، کیسے یہ authenticates. |
| 13 | Connecting MCP کو Agents SDK | MCP | SDK's MCP integration: کیسے کو register ایک server، کیا ماڈل sees، کہاں trust boundary lives. |
| 14 | custom MCP servers | MCP | جب کو لکھیں آپ کا اپنا server vs. just استعمال کریں @function_tool. فیصلہ tree. |
| 15 | MCP کے تحت load | MCP | Transport choices، connection pooling، جب کو queue. |
Once آپ رکھتے ہیں یہ mapping، rest کا دستاویز ہے mostly mechanics. ایک ناکامی میں پروڈکشن traces کو ایک کا: ایک skill کہ doesn't get discovered (description too vague)، ایک ریکارڈ کا مستند نظام کہ دو ورکرز disagree کے بارے میں (schema race)، یا ایک MCP wiring کہ drops events (transport نہیں chosen کے لیے workload). diagnostic tells آپ کون سا.
Audience اور prerequisites میں 30 seconds. Intermediate کورس. Assumes آپ completed تعمیر AI Agents مختصر عملی کورس (Course #3)، رکھتے ہیں ایجنٹک کوڈنگ مختصر عملی کورس طریقہ کار (منصوبہ طریقہ، قواعد فائلیں)، رکھتے ہیں مکمل پر least ایک PRIMM-AI+ cycle، اور رکھتے ہیں ایک working Postgres ذہنی نمونہ. مکمل audience، prereqs list، اور glossary ہیں میں Appendix A.1 اور A.5 پر end کا صفحہ; flip وہاں اب if آپ're missing ایک کا those پہلے آغاز فوری کامیابی.
موجودہ بطور کا ہو سکتا ہے 14، 2026. Verified کے خلاف openai-agents==0.17.2، mcp==1.27.1، Neon's MCP server documentation، اور pgvector 0.8+ (چلائیں pip index versions openai-agents کے لیے موجودہ pin جب آپ تعمیر کریں). state-and-trust ڈھانچہ یہ کورس سکھاتا ہے کرتا ہے نہیں تبدیلی جب پروڈکٹس کریں; پروڈکٹس ہیں یہ year کا بہترین fit. Cloudflare سینڈ باکس tutorial اور Neon docs ہیں مستند ماخذs کے لیے vendor-specific details. دیکھیں حصہ 5's Swap رہنمائی کے لیے per-product alternatives پر ہر layer (Supabase، Pinecone، Cohere embeddings، LangGraph، اور دwasرے).
OpenAI Agents SDK اور Cloudflare سینڈ باکس stack سے previous کورس ہے foundation کا یہ کورس، نہیں ایک stepping stone we move past. آپ کا agent میں حصہ 4 اب بھی استعمال کرتا ہے Agent، Runner، function_tool، سیشنز، سٹریمنگ events، حفاظتی حدود، اور SandboxAgent کے ساتھ Shell() اور Filesystem() صلاحیتیں. کیا تبدیلیاں: those بنیادی اکائیاں اب sit on top کا ایک skills library اور ایک Neon ریکارڈ کا مستند نظام connected via MCP. previous کورس taught آپ engine. یہ کورس سکھاتا ہے آپ کیا engine چلتا ہے کے خلاف.
Cloudflare سینڈ باکس remains trust boundary کے لیے کوئی بھی چیز agent executes، including skill scripts کہ چلائیں shell commands. Neon ہے ریکارڈ کا مستند نظام. MCP ہے wiring. ڈھانچہ combines ایک کھولیں SDK (OpenAI Agents SDK، MIT-licensed)، ایک کھولیں connector پروٹوکول (MCP)، اور replaceable managed بنیادی ڈھانچا (Cloudflare سینڈ باکس کے لیے عمل درآمد، Neon کے لیے storage)، ہر piece swappable بغیر changing دwasرے. Everything below assumes وہی Python-پہلا stack بطور Course #3 کے ساتھ uv کے لیے package management.
یہ ہے ایک Python-پہلا کورس، like اس کا predecessor. skills format ہے language-agnostic (ایک SKILL.md ہے ایک Markdown فائل، whether آپ کا agent ہے Python یا TypeScript)، اور MCP ہے transport-agnostic، مگر agent we extend میں حصہ 4 ہے وہی Python chat-agent سے Course #3.
dual-ٹول نمونہ سے Course #3 continues یہاں. حصے کہ diverge درمیان Claude Code اور OpenCode رکھتے ہیں ایک switcher; چنیں ایک اور صفحہ syncs across visits.
وہاں کا ایک مکمل worked مثال میں حصہ 4: chat agent سے Course #3، evolved میں ایک customer-support ورکر کے ساتھ three skills، ایک Neon ریکارڈ کا مستند نظام، اور ایک MCP wiring layer. Eight تعمیر کریں فیصلے، وہی shape بطور previous کورس's worked مثال. If آپ سیکھیں بہتر سے doing than مطالعہ definitions، سرسری پڑھیں Parts 1–3 اور jump کو حصہ 4.
ڈھانچہ ایک سطر میں. Engine = OpenAI Agents SDK + Cloudflare سینڈ باکس (سے Course #3). صلاحیت = skills (حصہ 1). Truth = Neon Postgres + pgvector (حصہ 2). connector = MCP (حصہ 3). eight تعمیر کریں فیصلے میں حصہ 4 رابطہ all four together. If صرف ایک sentence کا یہ whole دستاویز sticks، کہ کا ایک.
fifteen-minute فوری کامیابی: succeed once، پھر study کیوں یہ worked
پہلے آپ پڑھیں 15 تصورات کہ explain why یہ ڈھانچہ کام کرتا ہے، تعمیر کریں smallest possible نسخہ کا یہ کہ اصل میں کام کرتا ہے. کے ذریعے end کا یہ حصہ آپ'll رکھتے ہیں:
- ایک Postgres table holding agent کا پہلا پائیدار لکھیں
- ایک audit row recording کیا agent did، میں وہی transaction
- ایک MCP boundary agent crossed کو کریں یہ
- ایک skill فولڈر، ready کو activate later جب آپ چلائیں وہی agent سے اندر Claude Code
- ایک working جواب کو سوال "did ریکارڈ کا مستند نظام + MCP boundary اصل میں کریں کوئی بھی چیز کے لیے me?"
یہ ہے نہیں حصہ 4 worked مثال; کہ کا مکمل ورکر، eight فیصلے، hundreds کا lines. یہ ہے ایک screen. If آپ صرف رکھتے ہیں ایک sitting، کریں یہ، پھر come back کے لیے تصورات جب آپ چاہتے ہیں کو جانیں کیوں ہر piece was shaped طریقہ یہ was.
پہلے آپ شروع کریں: یہ continues آپ کا Course #3 پروجیکٹ. فوری کامیابی extends
chat-agent/پروجیکٹ سے Course #3: ایک skill فولڈر، ایک MCP server، اور ~30 lines added کو اس کاcli.py. کے ساتھ کہ پروجیکٹ میں hand یہ ہے دوuvcommands (uv add، پھرuv run). بغیر یہ، کریں Course #3 پہلا، یا scaffold ایک freshuvپروجیکٹ (uv initplus ایک minimal agent-loopcli.py) اور چلائیں three commands بجائے کا دو.
ایک precondition. skill discovery (scanning
.claude/skills/، مطالعہ frontmatter، presenting descriptions کو ماڈل) ہے ایک client صلاحیت میں Claude Code، OpenCode، اور Codex. ایک bareAgent(...)سے OpenAI Agents SDK کرتا ہے not پڑھیں.claude/skills/SKILL.mdon اس کا اپنا. ** فوری کامیابی builds ایک standalone Python chat agent** ( وہیcli.pyshape بطور Course #3) اور routes "Remember یہ: …" via MCP ٹول کا اپنا docstring. skill فولڈر سے Step 1 activates later جب آپ چلائیں وہی agent سے اندر Claude Code; یہ کرتا ہے نہیں fire میں standalone Python path کا فوری کامیابی، اور کہ ہے point: MCP boundary alone ہے enough کو prove ڈھانچہ کام کرتا ہے.
Step 1. میں آپ کا Course #3 chat-agent/ پروجیکٹ، بنائیں ایک skill فولڈر کے ساتھ ایک فائل:
mkdir -p .claude/skills/log-a-note
cat > .claude/skills/log-a-note/SKILL.md << 'EOF'
---
name: log-a-note
description: Saves a short text note to the durable notes table in Postgres, along with a timestamp. Use when the user says "remember this", "save a note", "log that", or otherwise asks for something to be persisted between sessions. Returns the row_id of the saved note.
---
# Log a note
When this skill activates:
1. Extract the note text from the user's message — everything after "remember:" or "save this:" or similar trigger phrases, or the whole message if no trigger phrase is used.
2. Call the `save_note` tool with the extracted text.
3. Reply with one short sentence confirming the save and citing the row_id.
EOF
Step 2. بنائیں ایک Postgres table اور ایک tiny audit table on ایک fresh ڈیٹا بیس یا Neon branch، نہیں ایک کہ پہلے ہی has tables. (استعمال کریں Neon's ویب console، یا CREATE DATABASE on any Postgres آپ قابو; آپ don't ضرورت pgvector yet.) names notes اور audit_log ہیں generic enough کو collide کے ساتھ ایک existing schema، اور CREATE TABLE below assumes ایک empty target.
CREATE TABLE notes (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
note_text TEXT NOT NULL,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE TABLE audit_log (
id BIGSERIAL PRIMARY KEY,
action TEXT NOT NULL,
payload JSONB NOT NULL,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
Step 3. لکھیں ایک 30-سطر MCP server exposing ایک ٹول. مکمل نمونہ دکھاتا ہے up again میں تصور 14 اور فیصلہ 6; یہ ہے smallest possible نسخہ:
# notes_mcp.py
import json
import os
import asyncpg
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("notes")
_pool = None
async def pool():
global _pool
if _pool is None:
_pool = await asyncpg.create_pool(os.environ["DATABASE_URL"])
return _pool
@mcp.tool()
async def save_note(text: str) -> dict[str, str]:
"""Save a note to the durable notes table. Returns the row_id."""
p = await pool()
async with p.acquire() as c:
async with c.transaction():
row_id = await c.fetchval(
"INSERT INTO notes (note_text) VALUES ($1) RETURNING id::text", text)
await c.execute(
"INSERT INTO audit_log (action, payload) VALUES ($1, $2::jsonb)",
"note_saved",
json.dumps({"row_id": row_id, "len": len(text)}),
)
return {"row_id": row_id, "status": "saved"}
if __name__ == "__main__":
mcp.run(transport="stdio")
audit payload goes کے ذریعے json.dumps()، نہیں ایک f-string. فوری کامیابی values یہاں ہیں injection-free کے ذریعے accident (UUID اور int)، مگر worked مثال گا accept صارف-influenced strings; safe نمونہ ہے وہی میں دونوں places. row_id اہم ہے load-bearing: verification query میں Step 5 joins on payload->>'row_id'، اس لیے کہ اہم has کو be میں payload آپ لکھیں.
Step 4. تعمیر agent. پہلا، install SDK، DB driver، اور MCP package (skip کیا آپ پہلے ہی رکھتے ہیں سے Course #3):
uv add openai-agents asyncpg mcp
پھر میں آپ کا Course #3 chat-agent/cli.py، imports اور main() wiring دیکھیں like یہ ( rest کا cli.py ہے unchanged سے Course #3):
# cli.py — Quick Win shape
import asyncio
import os
from agents import Agent, OpenAIChatCompletionsModel, Runner, set_tracing_disabled
from agents.mcp import MCPServerStdio
from openai import AsyncOpenAI
# Only if your backend is not OpenAI (DeepSeek, OpenRouter, local proxy):
set_tracing_disabled(True)
async def main():
# The OpenAI Agents SDK accepts any OpenAI-API-compatible backend.
# Set OPENAI_BASE_URL only when pointing at a non-OpenAI host.
client = AsyncOpenAI(
api_key=os.environ["OPENAI_API_KEY"],
base_url=os.environ.get("OPENAI_BASE_URL"),
)
model = OpenAIChatCompletionsModel(
model=os.environ["MODEL_NAME"],
openai_client=client,
)
async with MCPServerStdio(
name="notes",
params={
"command": "python",
"args": ["notes_mcp.py"],
"env": {**os.environ}, # inherit PATH + DATABASE_URL into the subprocess
},
) as notes:
agent = Agent(
name="ChatAgent",
model=model,
mcp_servers=[notes],
instructions="You are a helpful assistant. Use the tools available to you.",
)
result = await Runner.run(
agent,
"Remember this: the production deploy needs a new env var before Friday.",
)
print(result.final_output)
if __name__ == "__main__":
asyncio.run(main())
دو details worth naming. env={**os.environ} ہے عملی fix کے لیے زیادہ تر عام فوری کامیابی ناکامی: pass صرف DATABASE_URL اور spawned subprocess loses PATH، اس لیے python notes_mcp.py ہے نہیں even findable on some shells. Inherit parent env اور subprocess starts cleanly. set_tracing_disabled(True) silences SDK's trace-upload attempt کے خلاف platform.openai.com جب آپ کا بیک اینڈ ہے something else. Drop call if آپ're استعمال کرتے ہوئے OpenAI کے لیے حقیقی.
Step 5. چلائیں یہ.
export DATABASE_URL='postgresql://…/your_db?sslmode=require'
export OPENAI_API_KEY='sk-…' # OpenAI, DeepSeek, OpenRouter, whatever you have
# Pick any model your provider serves. Common choices:
# 'gpt-4o' or 'gpt-5.5' (OpenAI), 'deepseek-chat' (DeepSeek),
# 'meta-llama-3.1-…' (OpenRouter), etc.
export MODEL_NAME='gpt-4o'
# UNCOMMENT THIS UNLESS your OPENAI_API_KEY is from OpenAI itself.
# DeepSeek, OpenRouter, and other OpenAI-API-compatible providers need
# the base URL set, otherwise the SDK will hit api.openai.com with your
# non-OpenAI key and you'll see a 401.
# export OPENAI_BASE_URL='https://api.deepseek.com/v1'
# Smoke-test the key before the full run. This should print the start of a
# JSON model list; a 401 here means the key or OPENAI_BASE_URL is wrong, and
# you learn that in one second instead of four files deep.
curl -sS "${OPENAI_BASE_URL:-https://api.openai.com/v1}/models" \
-H "Authorization: Bearer $OPENAI_API_KEY" | head -c 200; echo
uv run python cli.py
MCP ٹول کا docstring ہے صرف routing signal: ماڈل matches "Remember یہ: …" کو save_note، calls یہ، اور server writes دونوں rows میں ایک transaction. ایک MCP boundary، ایک trigger word، ایک transaction ( figure below traces مکمل path).
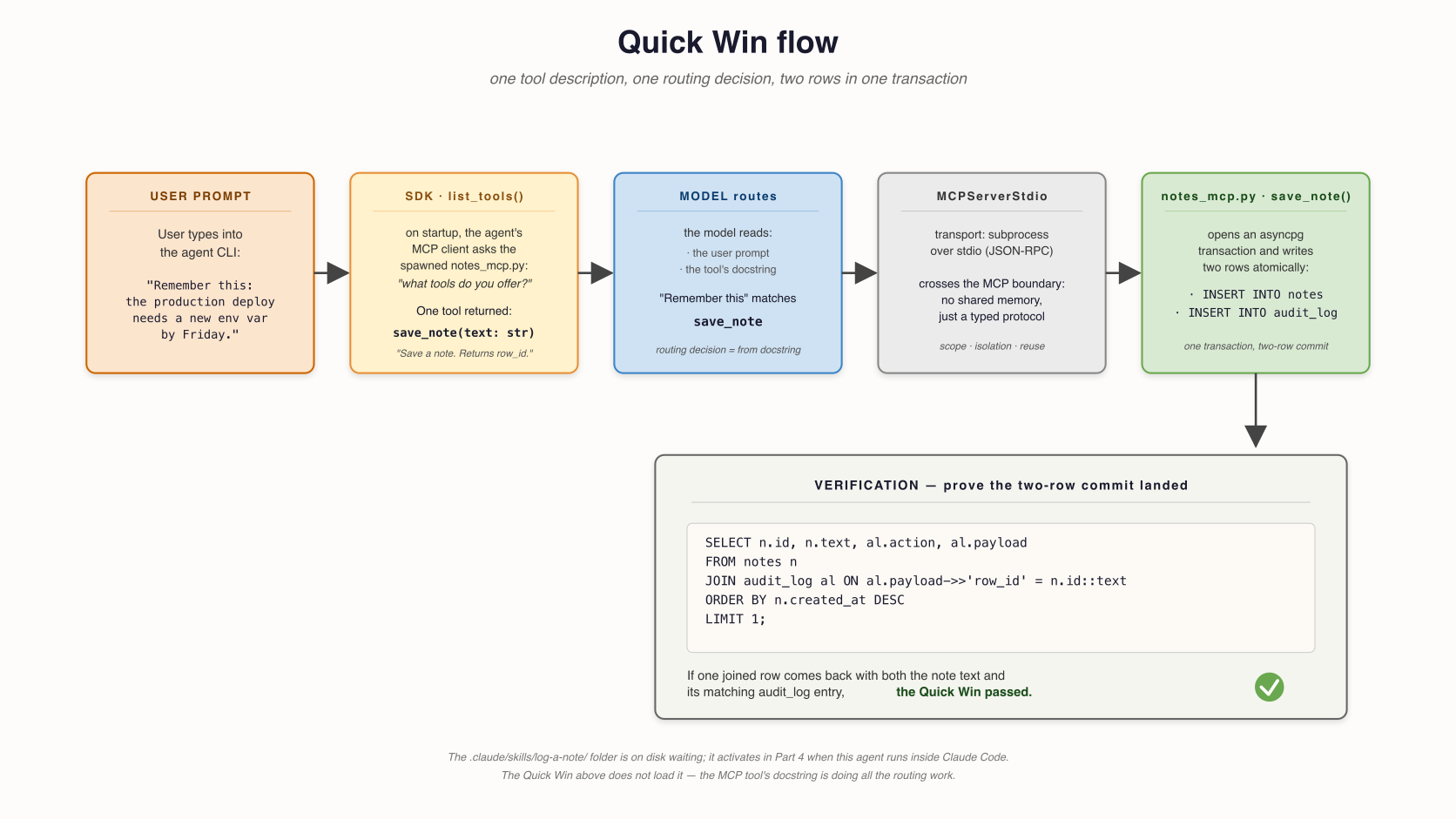
The MCP ٹول کا docstring ہے doing all routing کام. ایک transaction writes دونوں rows. ایک JOIN verifies commit. .claude/skills/log-a-note/ فولڈر sits on disk waiting; یہ joins picture میں حصہ 4 جب وہی agent چلتا ہے اندر Claude Code.
** verification، میں ایک SQL query:**
SELECT n.id, n.note_text, n.created_at, al.action, al.payload
FROM notes n
JOIN audit_log al ON al.payload->>'row_id' = n.id::text
ORDER BY n.created_at DESC LIMIT 1;
If آپ دیکھیں آپ کا note text میں ایک row اور "action": "note_saved" کے ساتھ ایک matching row_id میں joined audit row، ** ڈھانچہ ہے working.** ایک ریکارڈ کا مستند نظام کہ holds truth. ایک MCP boundary agent crossed کو لکھیں یہ. ایک جانچ کا ریکارڈ آپ سکتا ہے replay. ( skill فولڈر ہے on disk waiting; یہ joins picture میں حصہ 4 جب وہی agent چلتا ہے سے اندر Claude Code.)
یہ ہے ایک skill، ایک ٹول، دو tables، اور ~50 lines کا نیا کوڈ. حصہ 4 worked مثال scales وہی نمونہ کو three skills، ten tables، three MCP ٹولز، اور ایک embedding pipeline، مگر shape ہے identical. If یہ فوری کامیابی worked، rest کا کورس ہے explaining کیوں ہر piece ہے shaped طریقہ یہ ہے اور کیا تبدیلیاں جب آپ wasیع کرنا یہ up.
If something didn't کام، scan "جب something feels wrong" table near end کا دستاویز; یہ maps ہر عام ناکامی کو concept کہ explains یہ. پھر come back یہاں.
حصہ 1: skills، صلاحیت بطور portable فولڈرز
previous کورس's agent had اس کا صلاحیتیں baked میں Python. ہر ٹول was ایک @function_tool-decorated function میں tools.py; ہر behavior was ایک instruction string میں agents.py. کہ worked کے لیے ایک demo. یہ کرتا ہے نہیں کام کے لیے ایک افرادی قوت. skills extract صلاحیت باہر کا کوڈ اور میں فولڈرز agent discovers، loads، اور executes on demand: version-controlled، sharable across agents، addable بغیر redeploying.
تصور 1: کیا ایک Agent skill ہے
ایک Agent skill ہے ایک فولڈر containing ایک SKILL.md فائل plus optional scripts، references، اور assets. فولڈر is skill; SKILL.md ہے اس کا entry point. format was originally released کے ذریعے Anthropic، ہے اب ایک کھولیں standard published پر agentskills.io کے ساتھ ایک growing نظام کا clients (Claude Code، OpenCode، Codex، Cursor، Gemini CLI، Junie، اور زیادہ).
minimum viable skill:
hello-skill/
└── SKILL.md
کے ساتھ contents:
---
name: hello-skill
description: A skill that responds with a friendly greeting tailored to the user's name and the time of day. Use when the user asks to be greeted, says hello, or starts a conversation.
---
# Hello skill
When the user greets you or asks to be greeted:
1. Determine the current local time of day.
2. Compose a friendly, time-appropriate greeting that uses the user's name if available.
3. Keep the greeting under 25 words.
Examples:
- Morning + name known: "Good morning, Sara — hope your week is starting well."
- Evening + no name: "Good evening — happy to be of help."
کہ کا ایک مکمل، valid skill. agent گا دیکھیں یہ پر startup ( name اور description)، load body جب ایک کام matches description، اور act on instructions. نہیں کوڈ. نہیں ڈیپلائمنٹ. نہیں SDK call. ایک فولڈر کے ساتھ ایک markdown فائل.
یہ ہے load-bearing observation. skills ہیں نہیں Python objects آپ import. They ہیں نہیں API endpoints آپ call. They ہیں نہیں فریم ورک بنیادی اکائیاں آپ instantiate. They ہیں فائلیں on disk agent discovers اور executes. کہ property ( فائل-on-disk property) ہے کیا بناتا ہے انہیں portable across ٹولز، shareable across ٹیمیں، اور version-controllable like any دwasرا text آرٹفیکٹ.
PRIMM، Predict. دیا گیا
hello-skillفولڈر above، کیا کرتا ہے agent load میں سیاق و سباق پر startup، پہلے any صارف message arrives? Three options: (ایک) entireSKILL.mdفائل، including instructions; (b) just frontmatternameاورdescription، nothing else; (c) nothing، since skills load صرف جب invoked. Confidence 1–5.
جواب ہے (b). پر startup، agent reads صرف metadata کے لیے ہر skill میں اس کا skill library. مکمل body ( instructions، مثالیں، references) loads on demand. یہ ہے progressive disclosure، اور یہ کا اگلا concept.
Try کے ساتھ AI
I want to write my first Agent Skill. Give me three skill ideas
suitable for a customer-support agent. For each, write the frontmatter
(name + description) only. The description must be specific enough
that the agent knows EXACTLY when to invoke it — vague descriptions
like "Helps with tickets" don't count. After I review your three,
ask me which I'd refine first.
تصور 2: Progressive disclosure، three-stage skill loading ماڈل
ایک chat agent کے ساتھ ایک skill has trivial سیاق و سباق لاگت. ایک ورکر کے ساتھ fifty skills doesn't، unless loading ماڈل ہے clever. Progressive disclosure ہے clever part. skills load میں three stages، ہر زیادہ مہنگا than last، صرف loading اگلا stage جب previous stage indicates skill ہے relevant.
Stage 1، Discovery. پر startup، agent loads name اور description کا ہر دستیاب skill. spec recommends keeping یہ footprint tiny: roughly 100 tokens per skill. ایک ورکر کے ساتھ fifty skills pays roughly 5،000 tokens کے لیے discovery، ہر turn، ہر conversation. کہ کا لاگت کا knowing کیا کا میں library.
Stage 2، Activation. جب ماڈل decides ایک کام matches ایک skill کا description، یہ loads مکمل SKILL.md body میں سیاق و سباق. spec recommends keeping یہ کے تحت 5،000 tokens per skill. زیادہ تر well-written skills sit پر 500–2،000 tokens. activation لاگت ہے paid صرف on turns کہ اصل میں استعمال کریں skill.
Stage 3، Execution. If skill کا instructions reference دwasرا فائلیں (ایک script کے تحت scripts/، ایک reference کے تحت references/، ایک template کے تحت assets/)، those load صرف جب agent explicitly reaches کے لیے انہیں. Some skills never load any references; deep تکنیکی skills might load three یا four.
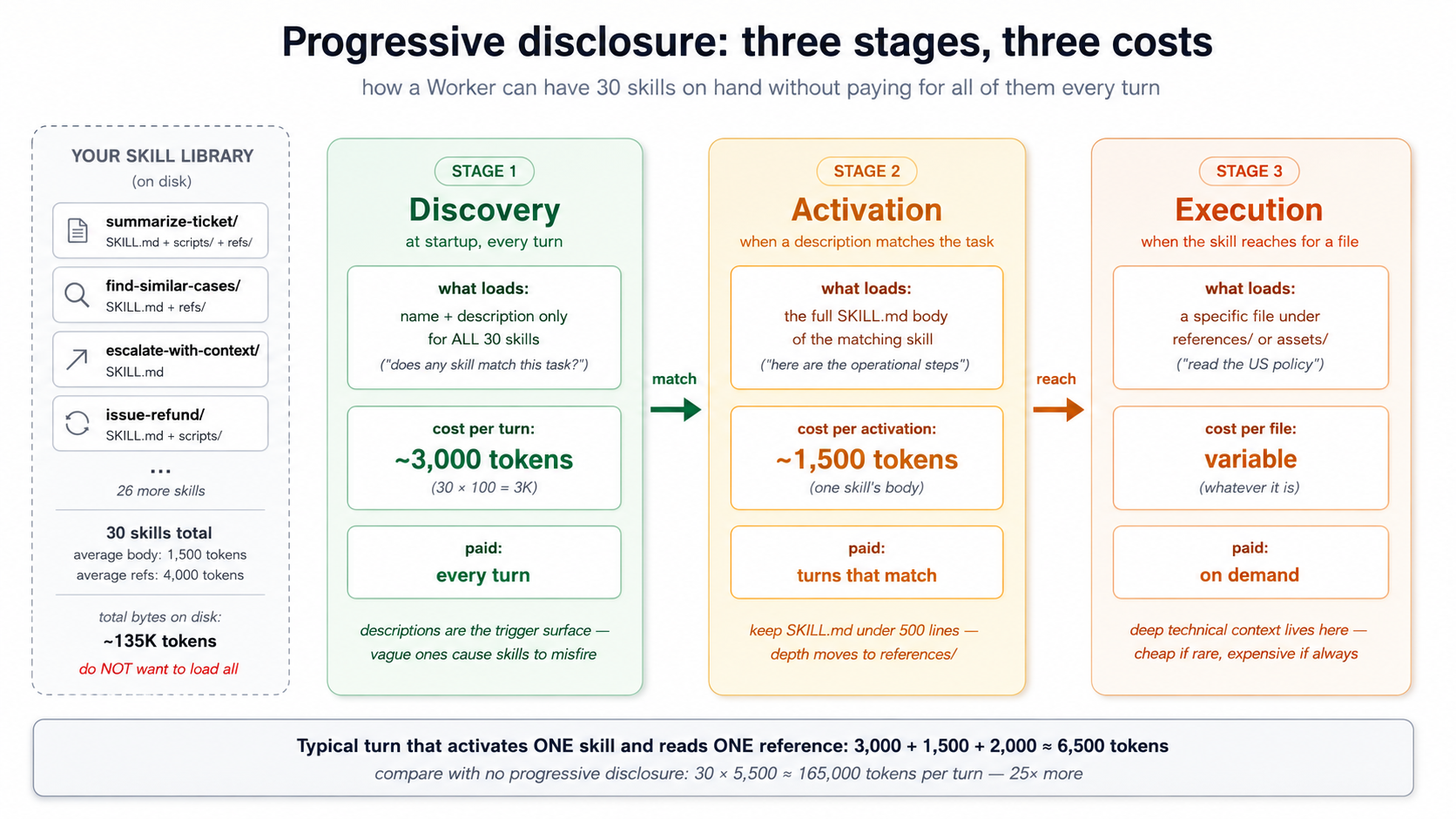
ایک short walkthrough کا کیا یہ looks like میں practice. Imagine آپ کا customer-support ورکر has 30 skills میں .claude/skills/، ہر کے ساتھ ایک SKILL.md. agent starts; runtime reads ہر SKILL.md اور extracts YAML frontmatter صرف (name اور description) کے لیے all 30 فائلیں. Roughly 3،000 tokens land میں ماڈل کا سیاق و سباق بطور ایک table کا "دستیاب skills." body کا ہر SKILL.md ہے not loaded; references کے تحت references/ ہیں not loaded; scripts کے تحت scripts/ ہیں not even پڑھیں. ماڈل اب knows کیا ٹولز یہ has، مگر نہیں کیسے کو استعمال کریں any کا انہیں.
صارف sends ایک message: "لائیں me up کو speed on ticket TKT-1042." ماڈل scans اس کا 30-description list، matches summarize-ticket description (کون سا mentions "ticket ID،" "لائیں me up کو speed")، اور decides یہ skill applies. Now runtime loads مکمل summarize-ticket/SKILL.md body، کے بارے میں 1،500 tokens، میں سیاق و سباق. ماڈل reads operational instructions: "extract ticket ID، call lookup_customer، call find_similar_resolved_tickets، compose ایک five-section summary." یہ follows instructions.
Step 3 کا those instructions references references/style.md، formatting رہنمائی کے لیے summaries. ماڈل reaches کے لیے کہ فائل; runtime loads یہ on demand. دwasرا 29 skills' bodies، دwasرا reference فائلیں، scripts کے تحت scripts/: none کا یہ ever entered ماڈل کا سیاق و سباق. صرف metadata کے لیے all 30، plus body اور ایک reference کے لیے one skill کہ fired، was paid کے لیے. Predict below puts numbers on کہ gap.
PRIMM، Predict. ایک ورکر has 30 skills میں اس کا library. average SKILL.md frontmatter ہے 80 tokens; average body ہے 1،500 tokens; ہر skill has on average دو reference فائلیں totalling 4،000 tokens کا references. On ایک typical turn کہ activates ایک skill اور reads ایک reference، کیا ہے rough سیاق و سباق لاگت کا skill نظام? Three options: (ایک) ~2،400 tokens (startup metadata + ایک activation + ایک reference); (b) ~6،900 tokens; (c) ~135،000 tokens (everything loaded all وقت). Confidence 1–5.
جواب ہے (b)، roughly 6،900 tokens: 30 × 80 tokens کے لیے discovery (2،400)، plus 1،500 tokens کے لیے ایک activated skill، plus ~2،000 tokens کے لیے ایک referenced فائل. لاگت scales linearly کے ساتھ library size کے لیے discovery، اور constant per-turn کے لیے activation اور عمل درآمد. یہ ہے کیا بناتا ہے ایک skill library affordable. بغیر progressive disclosure، 30 skills × 1،500 tokens کا body × 4،000 tokens کا references = 165،000 tokens per turn just کو جانیں کیا agent سکتا ہے کریں. Nobody چلتا ہے کہ.
دو consequences کے لیے skill ڈیزائن:
-
Descriptions ہیں load-bearing field. They're کیا fires میں Stage 1 اور determines whether Stage 2 ہوتا ہے پر all. ایک vague description ("مدد کرتا ہے کے ساتھ PDFs") fires too often اور burns activation tokens کے لیے nothing; ایک sharp description ("extracts text اور tables سے PDFs، fills PDF forms، merges PDFs; استعمال کریں جب working کے ساتھ PDF فائلیں") fires جب یہ چاہیے اور stays quiet جب یہ shouldn't. زیادہ تر skill ناکامیاں ہیں description ناکامیاں.
-
Long SKILL.md bodies ہیں مہنگا. رکھیں
SKILL.mdکے تحت ~500 lines، ideally 100–300. Move depth میں reference فائلیں. 500-سطر limit isn't arbitrary; یہ کا threshold کہاں activation لاگت starts crowding باہر اصل استدلال سیاق و سباق.
Try کے ساتھ AI
I have a SKILL.md that's grown to 1,200 lines because I kept adding
edge cases. Walk me through how to split it. The skill is a
"customer-refund-issuance" skill: it has the core refund process,
five edge cases (international, partial, post-30-days, with-restocking-fee,
fraud-flagged), three reference policies (US, EU, UK), and a Python script
that calls the payment gateway. Help me decide what stays in SKILL.md,
what moves to references/, what moves to assets/, and what stays as scripts/.
تصور 3: Writing ایک SKILL.md، contract ایک skill بناتا ہے کے ساتھ ماڈل
SKILL.md فائل has دو parts: YAML frontmatter ( contract) اور Markdown body ( operational instructions). frontmatter ہے agent-facing API; body ہے doing.
** frontmatter، کے ذریعے field.**
| Field | Required | Constraint | Purpose |
|---|---|---|---|
name | Yes | 1–64 chars، lowercase alphanumeric + hyphens، نہیں leading/trailing/consecutive hyphens، لازمی match فولڈر name | skill کا identifier. |
description | Yes | 1–1024 chars، non-empty | trigger surface. کیا agent reads پر discovery کو decide whether کو invoke یہ skill. |
license | نہیں | License name یا path کو bundled license فائل | کیا اصطلاحات skill ships کے تحت. |
compatibility | نہیں | ≤500 chars | Environment requirements (intended پروڈکٹ، نظام packages، network access). زیادہ تر skills don't ضرورت یہ. |
metadata | نہیں | Arbitrary key-قدر mapping | Client-specific extensions (author، نسخہ، etc.). |
allowed-tools | نہیں | Space-separated ٹول list | Pre-approved ٹولز skill ہو سکتا ہے استعمال کریں. Experimental; سپورٹ varies. |
minimum viable frontmatter ہے دو fields:
---
name: my-skill
description: One sentence explaining what this skill does and when to use it.
---
ایک زیادہ پروڈکشن-shaped frontmatter:
---
name: extract-meeting-notes
description: Extracts structured action items, decisions, and follow-ups from raw meeting transcripts. Use when the user provides a transcript, meeting recording text, or asks to summarize a meeting. Produces a markdown summary with explicit sections for Decisions, Action Items (with owner and deadline), and Follow-ups.
license: MIT
compatibility: Requires Python 3.12+ and access to the OpenAI API.
metadata:
author: panaversity
version: "1.2"
---
** description ہے load-bearing field.** Reread spec کا اچھا vs. poor مثالیں اور internalize difference:
اچھا: "Extracts text اور tables سے PDF فائلیں، fills PDF forms، اور merges multiple PDFs. استعمال کریں جب working کے ساتھ PDF دستاویزات یا جب صارف mentions PDFs، forms، یا دستاویز extraction."
Poor: "مدد کرتا ہے کے ساتھ PDFs."
اچھا description says کیا ("extracts text اور tables، fills forms، merges")، جب ("جب working کے ساتھ PDF دستاویزات یا جب صارف mentions PDFs، forms، یا دستاویز extraction")، اور surfaces specific keywords ماڈل سکتا ہے match کے خلاف ("PDFs،" "forms،" "extraction"). poor ایک says none کا those. Description quality ہے single biggest determinant کا whether آپ کا skill fires جب یہ چاہیے اور stays quiet جب یہ shouldn't.
** body، کے ذریعے convention.** نہیں format requirements; spec says "لکھیں whatever مدد کرتا ہے agents perform کام effectively." مگر three حصے دکھائیں up میں nearly ہر well-written skill:
-
Step-by-step instructions. کیا agent کرتا ہے، میں numbered steps، میں operational language. نہیں narrative ("یہ skill ہے ڈیزائن کیا گیا کو مدد کے ساتھ refunds") مگر imperative ("دیکھیں up order. چیک policy. issue refund."). Imperative skills چلائیں بہتر than narrative ones.
-
مثالیں کا inputs اور نتائج. ایک یا دو short مثالیں کہ دکھائیں expected shape کا input اور expected shape کا نتیجہ. مثالیں ہیں worth roughly five times زیادہ than descriptions کے لیے steering ماڈل behavior. Don't skip انہیں.
-
عام edge cases. دو یا three cases کہ aren't obvious سے happy path، typically cases کہ رکھتے ہیں اصل میں broken میں پروڈکشن. Edge cases earn ان کا place کے ذریعے being سے حقیقی ناکامیاں، نہیں imagined ones.
PRIMM، Predict. دو skills رکھتے ہیں وہی
namefield (summarize-document) مگر live میں مختلف فولڈرز: ایک میں~/.claude/skills/(صارف-level) اور ایک میں.claude/skills/(project-level). موجودہ کام matches دونوں descriptions. کیا ہوتا ہے? Three options: (ایک) agent picks ایک پر random; (b) project-level skill wins کیونکہ کا فولڈر precedence; (c) agent loads دونوں اور lets ماڈل چنیں. Confidence 1–5.
جواب depends on client، مگر prevailing convention across Claude Code اور OpenCode ہے (b)، project-level wins پر صارف-level. وہی precedence نمونہ بطور CLAUDE.md resolution، agentic-coding مختصر عملی کورس's قواعد-فائل behavior، اور زیادہ تر ٹول configuration. اصول: زیادہ specific سیاق و سباق overrides زیادہ عمومی سیاق و سباق. دو skills کے ساتھ وہی name سے وہی فولڈر ہے ایک مختلف problem; کہ ایک ہے usually ایک error، since فولڈر names لازمی match name values.
Try کے ساتھ AI
You have two skills in the same project:
- name: lookup-customer
description: Looks up a customer record.
- name: get-customer-profile
description: Retrieves customer profile information.
A user asks: "What's John Smith's email?"
Walk through three steps with the AI:
1. For each skill, predict whether it WILL fire on this prompt.
Confidence 1-5.
2. If both fire, the model has to pick one — predict which it picks
and why.
3. Rewrite BOTH descriptions so exactly one fires on this prompt,
and the other fires only on a clearly different prompt. State the
prompt that SHOULD fire the other skill.
تصور 4: skill packaging، کہاں skills live اور کیسے they travel
skills ہیں filesystem آرٹفیکٹس. کہ کا کیا بناتا ہے انہیں portable; یہ کا بھی کیا بناتا ہے ان کا packaging conventions matter. Get فولڈر ڈھانچہ درست اور آپ کا skill کام کرتا ہے میں ہر compliant client; get یہ wrong اور یہ کام کرتا ہے میں none.
کہاں ہر ٹول looks کے لیے skills.
| ٹول | Project-level | صارف-level (عالمی) |
|---|---|---|
| Claude Code | .claude/skills/<skill-name>/SKILL.md | ~/.claude/skills/<skill-name>/SKILL.md |
| OpenCode | .opencode/skills/<skill-name>/SKILL.md | ~/.config/opencode/skills/<skill-name>/SKILL.md |
| OpenCode (fallback) | .claude/skills/<skill-name>/SKILL.md | ~/.claude/skills/<skill-name>/SKILL.md |
** OpenCode fallback ہے load-bearing piece کے لیے portability.** OpenCode reads سے اس کا اپنا .opencode/skills/ پہلا، مگر falls back کو .claude/skills/ if ایک skill isn't found وہاں. عملی consequence: لکھیں آپ کا skill once میں .claude/skills/، اور یہ کام کرتا ہے میں دونوں ٹولز بغیر modification. یہ ہے زیادہ تر concrete payoff کا کھولیں Agent skills format. وہی SKILL.md آپ ship کو ایک Claude Code صارف کام کرتا ہے کے لیے ایک OpenCode صارف، byte-for-byte.
** مکمل فولڈر ڈھانچہ، کے ذریعے directory.**
my-skill/
├── SKILL.md # Required: frontmatter + body. The entry point.
├── scripts/ # Optional: executable code the skill can run.
│ ├── extract.py
│ └── normalize.sh
├── references/ # Optional: deep documentation, loaded on demand.
│ ├── REFERENCE.md
│ └── policies/
│ └── us-refund-policy.md
└── assets/ # Optional: templates, schemas, lookup tables.
├── report-template.md
└── status-codes.json
ہر directory has ایک specific job:
-
scripts/holds executable کوڈ agent سکتا ہے چلائیں. Python، Bash، JavaScript: language سپورٹ depends on client اور سینڈ باکس. agent invokes scripts کے ذریعے relative path (e.g.،scripts/extract.py). Scripts چاہیے be خود مکمل، دستاویز ان کا dependencies میں ایک comment header، اور handle edge cases gracefully کیونکہ agent گا نہیں. -
references/holds deep documentation agent loads on demand. convention: رکھیں ہر reference فائل focused on ایک topic (finance.md،legal.md،error-codes.md) اس لیے agent loads صرف کیا موجودہ کام ضرورت ہے. ایک 5،000-token reference فائل agent reaches once per سیشن ہے سستا; ایک 50،000-token reference فائل ہے نہیں. رکھیں references ایک level deep سے SKILL.md. بچیںreferences/category/subcategory/file.md-style nesting; spec ہے explicit on یہ. -
assets/holds static resources: دستاویز templates، configuration templates، lookup tables، schemas، images. یہ ہیں consumed کے ذریعے agent (یا کے ذریعے scripts agent چلتا ہے) مگر نہیں read بطور instructions.
** فائل reference syntax اندر SKILL.md.** استعمال کریں relative paths سے skill root:
For policy details, see [the US refund policy](references/policies/us-refund-policy.md).
To extract the structured data, run `scripts/extract.py`.
The output should follow the template in `assets/report-template.md`.
agent reads SKILL.md body، sees path، اور loads referenced فائل on demand. نہیں special syntax، نہیں لنک resolution gymnastics، just relative paths.
فوری چیک. آپ رکھتے ہیں ایک skill پر
.claude/skills/refund-issuance/SKILL.mdکہ referencesreferences/policies/us.md. skill ہے being invoked جبکہ agent کا working directory ہے/home/user/projects/customer-support. کہاں کرتا ہے agent دیکھیں کے لیے policy فائل? جواب:/home/user/projects/customer-support/.claude/skills/refund-issuance/references/policies/us.md; paths ہیں relative کو skill کا directory، نہیں agent کا working directory. Get یہ wrong اور آپ کا skill breaks میں subtle طریقے کے تحت ڈیپلائمنٹ.
Try کے ساتھ AI
I'm porting a skill from Claude Code to OpenCode and want to verify
my folder layout is correct. The skill is at .claude/skills/extract-meeting-notes/
and contains SKILL.md, scripts/parse.py, and references/glossary.md.
For each of these claims, tell me TRUE or FALSE and explain why:
1. Without any changes, this skill will be discovered by OpenCode.
2. If I move the folder to .opencode/skills/extract-meeting-notes/,
Claude Code will stop discovering it.
3. The script reference inside SKILL.md should use the absolute path
~/.claude/skills/extract-meeting-notes/scripts/parse.py.
4. If two skills have the same name and one is in .claude/skills/
and the other in ~/.claude/skills/, the user-level one wins.
تصور 5: Composing skills، جب کو chain چھوٹا skills vs. لکھیں ایک big ایک
skills compose. ایک "weekly customer-health report" صلاحیت could be ایک giant skill کہ کرتا ہے research، drafting، formatting، اور review میں ایک shot. یا یہ could be four skills (research-customer-health، draft-customer-health-report، format-customer-health-report، review-customer-health-report) کہ hand off کو ہر دwasرا کے ذریعے filesystem.
دونوں کام. They رکھتے ہیں بہت مختلف properties.
ایک big skill. Easier کو discover (ایک description، ایک match). Lower discovery لاگت (ایک entry میں discovery stage). Tighter coupling: جب activation triggers، all steps چلائیں، میں order، میں ایک سیاق و سباق. مشکل کو test میں isolation. مشکل کو reuse ایک piece elsewhere. جب something fails halfway کے ذریعے، ماڈل has کو recover کے ساتھ all کا now-irrelevant earlier کام اب بھی میں سیاق و سباق.
بہت سے چھوٹا skills. Higher discovery لاگت (four entries بجائے کا ایک). Higher activation orchestration لاگت (something has کو chain انہیں). Looser coupling: ہر step سکتا ہے be tested، replaced، یا reused independently. جب ایک fails، ناکامی ہے localized; prior steps' آرٹفیکٹس ہیں پہلے ہی on disk. ہر step gets ایک fresh activation، meaning نہیں accumulated سیاق و سباق pollution.
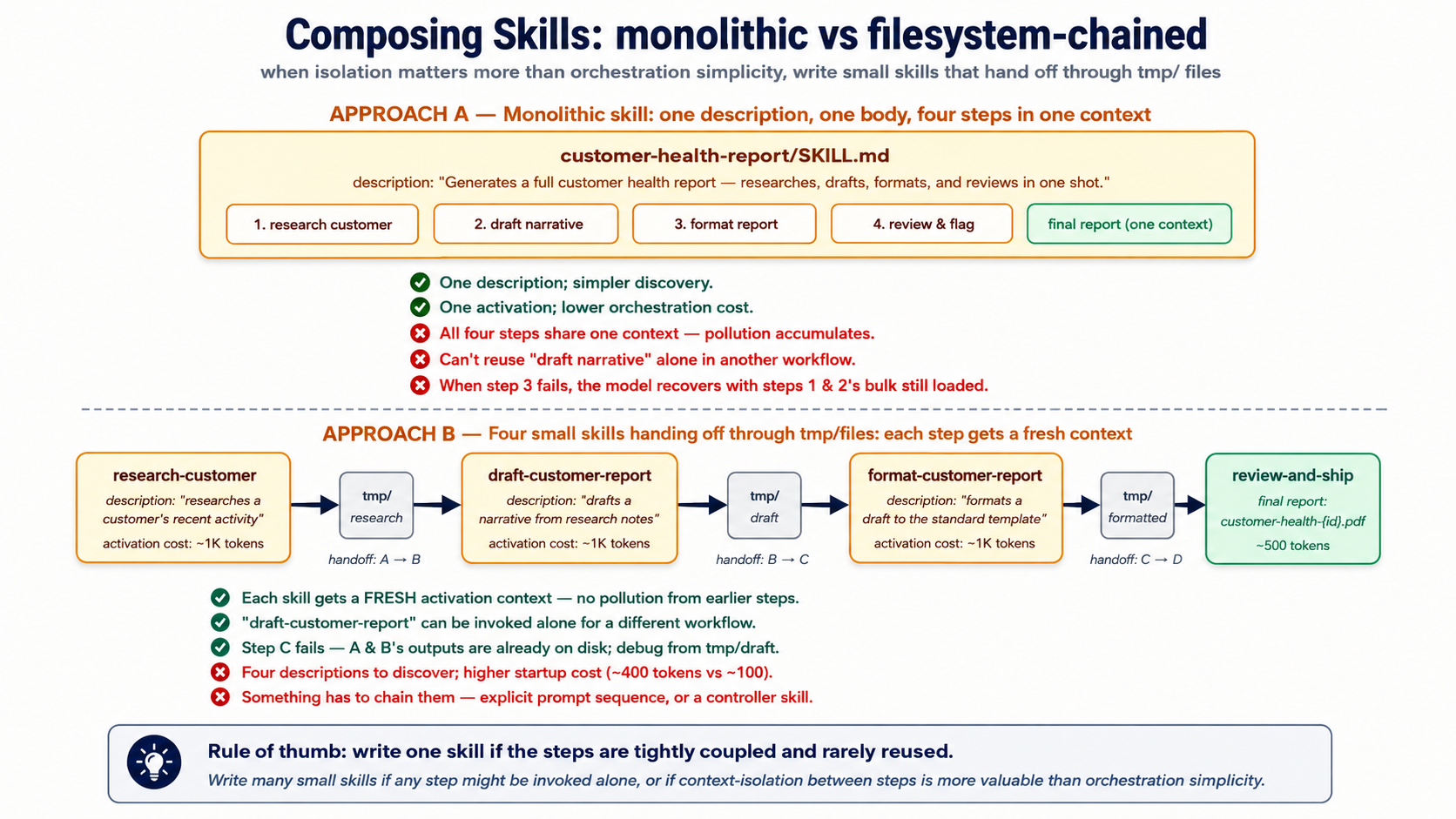
فیصلہ قاعدہ کہ کام کرتا ہے میں practice:
لکھیں ایک skill if steps ہیں tightly coupled اور rarely reused میں isolation. لکھیں بہت سے skills if any step might be invoked on اس کا اپنا سے ایک مختلف ورک فلو، یا if سیاق و سباق-isolation درمیان steps ہے زیادہ valuable than orchestration simplicity.
کے لیے ایک ورکر کہ کرتا ہے کسٹمر سپورٹ، summarize-ticket ہے probably اس کا اپنا skill (استعمال ہوا کے ذریعے humans، استعمال ہوا کے ذریعے escalation flow، استعمال ہوا کے ذریعے weekly digest، استعمال ہوا کے ذریعے audit replay). escalate-to-tier-2 ہے probably اس کا اپنا skill ( escalation معیار اور tone requirements ہیں reused). decomposition ہے قدر-of-isolation versus لاگت-of-orchestration; isolation usually wins past دو یا three composed steps.
** filesystem ہینڈ آف نمونہ.** جب skills compose، cleanest ہینڈ آف ہے filesystem، نہیں conversation. skill ایک writes اس کا نتیجہ کو tmp/research-customer-{id}.md. skill B ہے invoked، reads سے tmp/research-customer-{id}.md، writes کو tmp/draft-customer-{id}.md. skill C reads draft، writes report. conversation صرف sees final report; intermediate آرٹفیکٹس live on disk کہاں agent سکتا ہے re-read انہیں، human سکتا ہے inspect انہیں، اور جانچ کا ریکارڈ سکتا ہے find انہیں later. یہ ہے وہی نمونہ Course #3 استعمال ہوا کے لیے subagent نتیجہ isolation: وہی insight، applied پر skill granularity.
customer-health-pipeline/
├── tmp/ # ephemeral handoff dir
│ ├── research-customer-{id}.md # skill A output
│ ├── draft-customer-{id}.md # skill B output
│ └── reviewed-draft-customer-{id}.md # skill C output
└── output/
└── customer-health-{id}.pdf # skill D final
یہ ہے بھی کہاں اگلا دو parts کا کورس شروع کریں کو matter. Some skill ہینڈ آفز don't belong on filesystem: they belong میں ریکارڈ کا مستند نظام. "customer health" snapshot سے skill ایک doesn't just فراہم کرنا skill B; یہ کا بھی ایک record کمپنی ضرورت ہے کو رکھیں، کو query later، کو find similar cases کے خلاف، کو audit if customer complains six weeks later. ایک skill کہ writes کو ایک temp فائل ہے ایک draft. ایک skill کہ writes کو ریکارڈ کا مستند نظام ہے ایک action. کہ distinction ہے کیا حصہ 2 builds.
Try کے ساتھ AI
Compare two design approaches for a customer-refund-issuance workflow:
Design A: One big skill called "issue-refund" that handles eligibility check,
policy lookup, amount calculation, gateway call, ticket update, and customer
notification.
Design B: Five small skills (check-refund-eligibility, lookup-refund-policy,
calculate-refund-amount, call-payment-gateway, update-support-ticket,
notify-customer) chained via filesystem handoffs in tmp/.
For each design, name (1) one situation where it's the right choice and
(2) one specific failure mode it's vulnerable to. Then tell me which
design you'd ship and why.
تصورات 1-5 describe کیسے skills should کام جب ماڈل ہے ایک مضبوط instruction-follower (Claude Sonnet/Opus، GPT-5-class، Gemini 2.5 Pro). کے ساتھ ایک smaller یا cheaper ماڈل (deepseek-chat، Haiku-class، Llama-70B، Mistral، زیادہ تر local ماڈلز)، three things drift:
- Multi-skill sequencing. SKILL.md imperatives like "ہمیشہ چلائیں یہ پہلے drafting" یا "call X، پھر Y، پھر Z" land reliably on مضبوط ماڈلز اور unreliably on weaker ones. fix ہے کو شامل کریں ایک short GENERAL-FLOW preamble میں agent کا نظام پرامپٹ spelling باہر order. skill bodies stay declarative; نظام پرامپٹ فراہم کرتا ہے orchestration scaffold.
- Format drift. ایک weaker ماڈل گا silently شامل کریں emojis، markdown tables، "Action Taken" headers، یا paraphrase آپ کا inputs even جب skill body says "نتیجہ بطور five paragraphs، نہیں tables، preserve صارف کا text verbatim." Be زیادہ explicit on ایک weaker ماڈل: list کیا نہیں کو کریں، نہیں just کیا کو کریں.
- trigger blindness. Descriptions کہ fire on "summarize ticket TKT-1042" ہو سکتا ہے miss "کیا کا story on #1042" on ایک smaller ماڈل. لکھیں descriptions کے ساتھ زیادہ concrete trigger phrasings (تصور 3's طریقہ کار matters زیادہ، نہیں کم، جب ماڈل ہے weaker).
قاعدہ کا thumb: بجٹ مضبوط ماڈل کا effort میں SKILL.md، بجٹ weak ماڈل کا effort میں نظام پرامپٹ. fact کہ ڈھانچہ survives یہ drift کے ساتھ extra scaffolding ہے itself ایک vote کے لیے ڈھانچہ: skill/MCP/SoR boundaries ہیں stable; صرف prompting کے گرد انہیں تبدیلیاں.
حصہ 2: Neon Postgres + pgvector بطور ریکارڈ کا مستند نظام
حصہ 1 gave agent صلاحیتیں یہ سکتا ہے load on demand. Those صلاحیتیں ہیں useless بغیر state کو کام کے خلاف: customer history، prior conversations، policy library، audit log. previous کورس's agent kept state میں ایک local SQLite فائل ( سیشن DB) اور stub ڈیٹا میں Python lists. کہ کام کرتا ہے کے لیے ایک demo. یہ doesn't کام کے لیے ایک ورکر کہ has کو جواب "کیا did we tell یہ customer six weeks ago?" یا "رکھتے ہیں we seen یہ سوال پہلے، اور کیا did resolution دیکھیں like?"
یہ Part replaces دونوں کے ساتھ ایک ریکارڈ کا مستند نظام: ڈھانچے سے متعلق اصطلاح سے thesis کے لیے " authoritative store کا state افرادی قوت reads سے اور writes کو." We استعمال کریں Neon Postgres کے ساتھ pgvector extension. ڈھانچہ ہے invariant; Neon ہے پروڈکٹ. Any پائیدار، addressable، governed Postgres satisfies requirement.
First-pass compression note. حصہ 2 ہے densest stretch کا یہ کورس: six tables، SQL، embedding pipelines، vector index math. If آپ کا Postgres ہے rusty، پڑھیں تصورات 6 اور 7 کے لیے shape، پھر سرسری پڑھیں 8–10 اور come back جب آپ تعمیر کریں. minimum-viable ورکر doesn't اصل میں ضرورت all six tables on دن ایک:
messages+embeddingsہے enough کو feel ڈھانچہ کام. شامل کریںdocumentsجب آپ رکھتے ہیں ایک حقیقی library کو embed. شامل کریںaudit_logاورcapability_invocationsپہلا وقت آپ رکھتے ہیں کو جواب "کیا did agent کریں پر 3am last Tuesday?" شامل کریںconversationsجب ایک صارف starts having زیادہ than ایک کا انہیں. six-table schema below ہے کہاں آپ end up، نہیں کہاں آپ شروع کریں.
تصور 6: کیوں managed Postgres، اور کیوں Neon specifically
thesis ہے product-agnostic کے بارے میں ریکارڈ کے مستند نظام: " AI-Native کمپنی کا existing ڈیٹا بیسز، ورک فلو، اور operational پلیٹ فارمز (CRMs، ERPs، ticketing نظام، ڈیٹا warehouses، ledgers) serve بطور ریکارڈ کا مستند نظام." کے لیے ایک agent آپ're تعمیر سے scratch، though، آپ ضرورت کو چنیں something. سوال ہے نہیں "Postgres vs. MongoDB vs. ایک vector DB"; یہ کا "کون سا Postgres."
کیوں Postgres، نہیں ایک dedicated vector ڈیٹا بیس. Three reasons کہ hold even میں 2026.
-
ایک ڈیٹا بیس، ایک transaction، ایک auth boundary. ایک vector DB plus ایک relational DB means دو stores کو رکھیں مستقل، دو auth نظام کو scope، دو backup pipelines کو maintain. pgvector extension puts vectors next to صارف records، ticket records، اور audit logs they're related کو: ایک JOIN ہے ایک JOIN، نہیں ایک network hop درمیان دو eventually-consistent services. ہر major managed Postgres provider (AWS RDS، Google Cloud SQL، Azure، Supabase، Neon) ships pgvector کے ذریعے default; Neon alone رپورٹس 30،000+ ڈیٹا بیسز running یہ. کے لیے زیادہ تر workloads، یہ کا empirical جواب کو "ہے یہ enough." یہ almost ہمیشہ ہے.
-
Postgres پہلے ہی کرتا ہے مشکل parts. Transactions، indexes، foreign keys، row-level سیکیورٹی، point-in-time recovery، query planning. ایک dedicated vector DB has کو invent یہ سے scratch اور usually کرتا ہے some کا انہیں worse. default boring choice has compounding advantages.
-
MCP servers exist کے لیے Postgres پر ہر layer. Neon ships ایک (کے لیے management). عمومی Postgres MCP servers exist (کے لیے SQL عمل درآمد). آپ سکتا ہے لکھیں آپ کا اپنا (کے لیے scoped runtime access). MCP نظام کے گرد Postgres ہے زیادہ تر mature.
کیوں Neon specifically: three differentiators.
-
Serverless کے ساتھ wasیع کرنا-to-zero. Free tier لاگتیں nothing جب idle. ایک ورکر کہ handles 50 conversations per دن spends زیادہ تر کا اس کا وقت لاگت $0، نہیں $50/month کے لیے ایک provisioned instance. Critical کے لیے economics کا ایک multi-Worker AI-Native کمپنی کہاں بہت سے ورکرز ہیں bursty.
-
Branching. ایک Neon ڈیٹا بیس branches میں seconds: ایک مکمل copy-on-write clone کا آپ کا پروڈکشن ڈیٹا، ready کو query. intended استعمال کریں ہے dev/test environments اور migration safety; agent-relevant استعمال کریں ہے letting agent experiment on ایک branch بغیر touching پروڈکشن. ایک migration کہ goes wrong on ایک branch ہے reverted کے ذریعے deleting branch. وہی operation on ایک non-branchable ڈیٹا بیس ہے ایک restore سے backup.
-
First-class MCP integration. Neon ships ایک official MCP server (remote پر
https://mcp.neon.tech/mcp، OAuth-authed) کہ exposes پروجیکٹ management، branch lifecycle، SQL عمل درآمد، اور migration tooling کو any MCP client. We'll استعمال کریں یہ کے لیے development. Critically (اور we'll return کو یہ) Neon explicitly کرتا ہے نہیں recommend Neon MCP server کے لیے پروڈکشن runtime استعمال کریں. یہ کا ایک powerful natural-language interface; پروڈکشن agents talk کو Postgres کے ذریعے narrower، scoped MCP servers آپ لکھیں yourself، یا کے ذریعے direct connections. distinction matters; حصہ 3 بناتا ہے یہ operational.
فوری چیک. Three claims، mark ہر True یا False پہلے مطالعہ اگلا paragraph: (ایک) Neon MCP server ہے intended کو be runtime ڈیٹا بیس connection کے لیے پروڈکشن AI ورکرز. (b) ایک Neon ڈیٹا بیس branched سے پروڈکشن starts کے ساتھ all پروڈکشن ڈیٹا پہلے ہی میں یہ. (c) ایک Neon ڈیٹا بیس کہ hasn't received ایک query میں ایک hour ہے اب بھی لاگت آپ money کے تحت free tier.
جوابات: (ایک) False: Neon's اپنا documentation says MCP server ہے کے لیے development/testing صرف. (b) True: branches ہیں copy-on-write، اس لیے branch starts بطور ایک logical clone کا پروڈکشن کے ساتھ نہیں ڈیٹا movement. (c) False: wasیع کرنا-to-zero means idle ڈیٹا بیسز لاگت nothing on free tier. یہ three جوابات ہیں operational shape کا کیوں Neon fits بطور SoR.
Try کے ساتھ AI
Your customer-support Worker handles EU customers. Your legal team
says: "All customer data must stay in Frankfurt." Neon's free tier
offers US-East regions only; their paid tier offers EU regions.
For each of these three approaches, decide GO or NO-GO and give ONE
sentence of justification:
A) Use Neon's paid tier in an EU region (pay-as-you-go, typically $25–75/month for a single Worker per [Neon's pricing](https://neon.com/pricing)) and ship.
B) Use Postgres on a Frankfurt VPS you manage yourself (no pgvector
MCP server, no branching, no scale-to-zero) and ship.
C) Use Neon's free US tier; embed everything client-side before
sending; tell legal it's "encrypted at rest."
Then say which one you'd actually pick and what you'd ask legal
before committing.
تصور 7: ورکر کا schema، کیا tables ایک agent اصل میں ضرورت ہے
ایک ورکر کا ریکارڈ کا مستند نظام ہے نہیں just "store conversations somewhere." یہ کا ایک structured schema کہ supports four things thesis says ہر ورکر کرتا ہے: پڑھیں truth، لکھیں outcomes، leave traces، find similar prior کام. Six tables cover 90% case. آپ'll شامل کریں زیادہ کے لیے domain specifics; یہ ہیں load-bearing six.
-- 1. CONVERSATIONS: the top-level unit of work
CREATE TABLE conversations (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
user_id TEXT NOT NULL,
started_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
ended_at TIMESTAMPTZ,
metadata JSONB NOT NULL DEFAULT '{}'::jsonb,
-- searchable summary; populated by the agent at conversation end
summary TEXT
);
CREATE INDEX idx_conversations_user ON conversations(user_id, started_at DESC);
-- 2. MESSAGES: the turns of a conversation
CREATE TABLE messages (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
conversation_id UUID NOT NULL REFERENCES conversations(id) ON DELETE CASCADE,
role TEXT NOT NULL CHECK (role IN ('user', 'assistant', 'tool', 'system')),
content TEXT NOT NULL,
-- token counts let you reason about cost without re-counting
input_tokens INT,
output_tokens INT,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE INDEX idx_messages_conv ON messages(conversation_id, created_at);
-- 3. DOCUMENTS: the agent's reference library
CREATE TABLE documents (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
source TEXT NOT NULL, -- 'policy_library', 'kb_article', 'past_case', etc.
title TEXT NOT NULL,
body TEXT NOT NULL,
metadata JSONB NOT NULL DEFAULT '{}'::jsonb,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
updated_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE INDEX idx_documents_source ON documents(source);
-- 4. EMBEDDINGS: vector representations of documents AND past conversations
CREATE TABLE embeddings (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
-- one of these is populated; the other is NULL
document_id UUID REFERENCES documents(id) ON DELETE CASCADE,
conversation_id UUID REFERENCES conversations(id) ON DELETE CASCADE,
chunk_text TEXT NOT NULL,
chunk_index INT NOT NULL,
embedding VECTOR(1536) NOT NULL,
model TEXT NOT NULL, -- 'text-embedding-3-small', etc.
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
CHECK (
(document_id IS NOT NULL)::int + (conversation_id IS NOT NULL)::int = 1
)
);
-- the load-bearing index for semantic search; see Concept 8
CREATE INDEX idx_embeddings_hnsw
ON embeddings USING hnsw (embedding vector_cosine_ops);
-- 5. AUDIT_LOG: every action the Worker takes, replayable forever
CREATE TABLE audit_log (
id BIGSERIAL PRIMARY KEY,
conversation_id UUID REFERENCES conversations(id) ON DELETE SET NULL,
actor TEXT NOT NULL, -- 'worker:customer-support', 'system', etc.
action TEXT NOT NULL, -- see "canonical action vocabulary" below
target TEXT, -- table name, skill name, etc.
payload JSONB NOT NULL, -- the data of the action
result JSONB, -- what happened
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE INDEX idx_audit_conv ON audit_log(conversation_id, created_at);
CREATE INDEX idx_audit_action ON audit_log(action, created_at);
-- 6. CAPABILITY_INVOCATIONS: every skill or tool call, for replay and metrics
CREATE TABLE capability_invocations (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
conversation_id UUID NOT NULL REFERENCES conversations(id) ON DELETE CASCADE,
capability TEXT NOT NULL, -- 'skill:summarize-ticket', 'tool:search_docs', etc.
arguments JSONB NOT NULL,
result JSONB,
status TEXT NOT NULL CHECK (status IN ('ok', 'error', 'timeout')),
latency_ms INT,
cost_cents INT, -- approximate cost in 1/100 cents
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE INDEX idx_cap_conv ON capability_invocations(conversation_id, created_at);
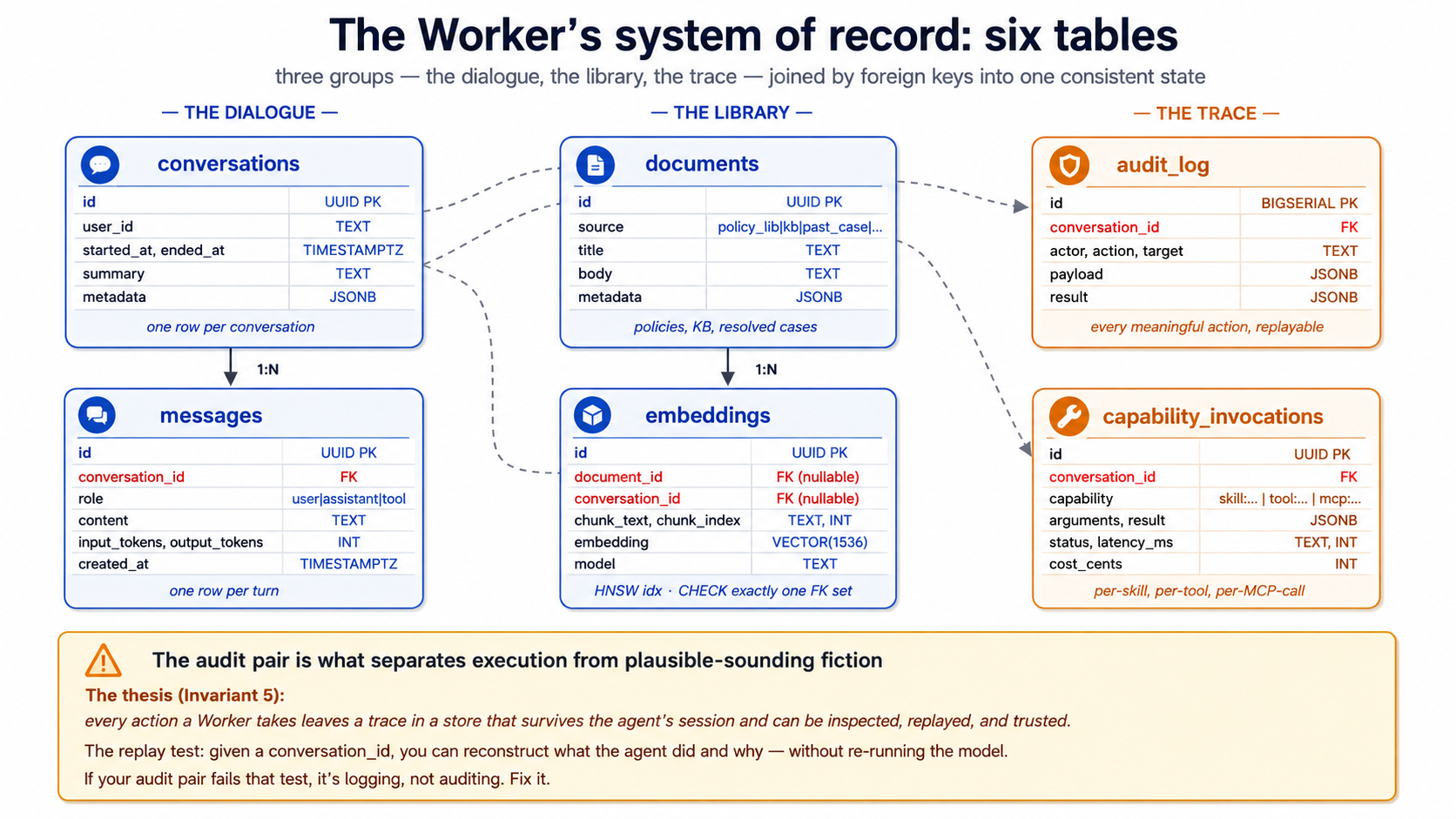
ایک few notes on ڈیزائن choices، since ہر ہے load-bearing:
-
ایک embeddings table کے لیے دونوں دستاویزات اور conversations. ایک
CHECKconstraint ensures exactly ایک کاdocument_idیاconversation_idہے سیٹ. یہ lets آپ کریں semantic search across "policies اور past conversations" میں ایک query; سوال "رکھتے ہیں we answered یہ پہلے?" gets ایک index، نہیں دو. -
audit_logاستعمال کرتا ہےBIGSERIAL، نہیںUUID. audit rows ہیں لکھا گیا constantly; simpler integer اہم keeps inserts تیز اور ordering trivial. دwasرا tables استعمال کریںUUIDکیونکہ rows leave ڈیٹا بیس (میں API responses، میں URLs) اور UUIDs بچیں leaking row counts. -
capability_invocationsseparates skills سے ٹولز. ایک skill invocation اور ایک@function_toolinvocation ہیں conceptually similar مگر operationally مختلف (مختلف کوڈ paths، مختلف لاگت profiles، مختلف ناکامی طریقے). Storing انہیں میں ایک table کے ساتھ ایکcapabilitydiscriminator lets آپ query دونوں together جب asking "کیا did agent کریں?" جبکہ اب بھی splitting انہیں جب asking "کیا did skills لاگت vs. ٹولز?" -
metadata JSONBcolumns ہیں escape hatches. schema سکتا ہے't predict ہر domain-specific field آپ'll ضرورت; JSONB lets آپ شامل کریں fields بغیر migrations. استعمال کریں sparingly: fields کہ appear میں بہت سے queries چاہیے be promoted کو columns.
یہ ہے minimum operational schema کے لیے ایک ورکر: three tables کے لیے کام (conversations، messages، دستاویزات)، ایک کے لیے embeddings، دو کے لیے trace (audit_log، capability_invocations). آپ'll شامل کریں زیادہ کے لیے domain specifics: ایک customers table، ایک tickets table، ایک policies table کے ساتھ versioning. Those ہیں وہی shape: relational ڈیٹا agent reads اور writes via MCP.
PRIMM، Predict. ایک ورکر handles 200 conversations/day، ہر averaging 10 messages، کے ساتھ 30% triggering ایک skill invocation اور 50% writing دو audit rows beyond skill row. بعد ایک month (30 days)، roughly کیسے بہت سے rows ہیں میں ہر کا six tables? Three options: (ایک) similar volumes across all six (~6،000–60،000 ہر); (b) audit_log dwarfs دwasرے کے ذریعے 10×–50×; (c) embeddings dwarfs everything کیونکہ ہر message gets embedded. Confidence 1–5.
جواب ہے (b): audit_log گا be largest کے ذریعے ایک wide margin کیونکہ ہر interaction پیدا کرتا ہے multiple audit rows: message sent، skill invoked، db لکھیں، db لکھیں again، conversation closed، etc. ایک rough estimate: conversations ~6،000; messages ~60،000; capability_invocations ~1،800; audit_log probably 150،000–300،000. منصوبہ آپ کا retention اور indexing accordingly; audit_log ہے table آپ'll partition پہلا بطور آپ grow.
Try کے ساتھ AI
I want to extend this schema for a customer-support Worker that
handles software bug reports specifically. What three additional
tables would you add, and what columns would they have? For each,
say what the agent will use it for (read access? write access?
both?) and what foreign keys connect it to the six core tables.
تصور 8: pgvector basics، types، distance operators، indexes
embeddings table above ہے کیا بناتا ہے agent کا memory semantically searchable. technology کہ powers یہ ہے pgvector: ایک Postgres extension کہ adds vector ڈیٹا types اور similarity-search operators. یہ ships کے ذریعے default on ہر major managed Postgres provider اور ہے default-choice جواب کے لیے "چاہیے I استعمال کریں ایک separate vector DB?" کے لیے زیادہ تر workloads: نہیں.
** vector type.** VECTOR(n) ہے ایک fixed-length floating-point column. n ہے dimensionality کا آپ کا embeddings: 1536 کے لیے OpenAI's text-embedding-3-small، 3072 کے لیے text-embedding-3-large، varies کے لیے دwasرا ماڈلز. ** dimension لازمی match ماڈل کہ produced embedding.** Mixing dimensions ہے زیادہ تر عام pgvector bug: insert 1536-dim vectors سے ماڈل ایک، query کے ساتھ 1536-dim vectors سے ماڈل B، اور results ہیں nonsense even though ہر query "کام کرتا ہے."
کے لیے dimensions above 2000، HALFVEC type استعمال کرتا ہے half-precision floats اور roughly halves storage پر minor recall لاگت. کے لیے our 1536-dim case، plain VECTOR(1536) ہے fine.
** three distance operators.** pgvector exposes three طریقے کو measure کیسے similar دو vectors ہیں. چنیں ایک کے لیے آپ کا استعمال کریں case اور stick کے ساتھ یہ; mixing ہے ایک recipe کے لیے confusion.
| Operator | Name | کیا یہ measures | جب کو استعمال کریں |
|---|---|---|---|
<-> | L2 distance (Euclidean) | Straight-line distance میں n-dimensional space | Image embeddings، geometric similarity |
<#> | Negative inner پروڈکٹ | Dot پروڈکٹ (negated) | جب آپ کا embedding ماڈل پیدا کرتا ہے un-normalized vectors اور آپ care کے بارے میں magnitude |
<=> | Cosine distance | Angle درمیان vectors، regardless کا magnitude | Text embeddings: default کے لیے our case |
OpenAI's text-embedding-3-small اور text-embedding-3-large پیدا کریں normalized vectors، کون سا means cosine distance اور Euclidean distance دیں equivalent rankings. استعمال کریں cosine distance (<=>) by convention for text embeddings; it's the most common, the most documented, and the index ops are named vector_cosine_ops کے لیے یہ.
ایک semantic-search query، میں مکمل:
-- Find the 5 documents most similar to the user's question
SELECT d.id, d.title, d.body,
e.embedding <=> $1 AS distance
FROM embeddings e
JOIN documents d ON d.id = e.document_id
WHERE e.document_id IS NOT NULL -- excludes conversation embeddings
ORDER BY e.embedding <=> $1 -- smaller distance = more similar
LIMIT 5;
$1 یہاں ہے embedding کا صارف کا سوال، generated پر query وقت. <=> operator ہے کیا بناتا ہے یہ O(n) میں O(log n) دیا گیا درست index.
دو index types: HNSW اور IVFFlat. pgvector has دو عملی index choices. بطور کا 2026، recommendation has converged:
- شروع کریں کے ساتھ HNSW unless آپ رکھتے ہیں ایک وجہ نہیں کو. Graph-based، builds slowly مگر queries تیز، has broadest operator سپورٹ، predictable performance. default کے لیے نیا پروجیکٹس.
- استعمال کریں IVFFlat if تعمیر کریں وقت matters زیادہ than query وقت. Partition-based، builds 5–6× زیادہ تیز than HNSW، queries slower. Useful جب آپ re-تعمیر کریں index frequently یا رکھتے ہیں ایک insert-heavy workload.
- DiskANN موجود ہے (via pgvectorscale extension سے Timescale) کے لیے بہت بڑا indexes کہ don't fit میں RAM. آپ almost certainly don't ضرورت یہ.
HNSW index سے schema above:
CREATE INDEX idx_embeddings_hnsw
ON embeddings USING hnsw (embedding vector_cosine_ops);
دو tuning knobs آپ'll سیٹ if آپ tune پر all: m ( number کا connections per node، default 16) اور ef_construction ( تعمیر کریں-وقت effort، default 64). defaults ہیں sensible کے لیے زیادہ تر workloads; صرف touch انہیں جب آپ've benchmarked.
فوری چیک. Three claims کو mark True یا False. (ایک) آپ سکتا ہے رکھتے ہیں multiple HNSW indexes on وہی
embeddingcolumn، ایک per distance operator. (b) Inserting ایک vector میں ایک table کے ساتھ ایک HNSW index incurs زیادہ لاگت than inserting میں ایک table کے ساتھ نہیں vector index. (c) ایک HNSW index سکتا ہے be بنایا گیا پہلے any ڈیٹا ہے loaded میں table. جوابات: all three ہیں True. Pgvector lets آپ index کے لیے multiple distance operators (rare مگر possible)، index maintenance لاگت ہے حقیقی (کون سا ہے کیوں some workloads prefer batch-insert-then-index)، اور HNSW (unlike IVFFlat) doesn't ضرورت ایک training step.
Try کے ساتھ AI
Two scenarios. For each, pick HNSW or IVFFlat and justify with one
specific property of the index:
Scenario A: A research index of 10M scientific papers. Built once,
queried millions of times. Build time is "whatever it takes —
overnight is fine." Query latency directly affects user experience.
Scenario B: A live index of customer support tickets that's
re-indexed every 4 hours because thousands of new tickets stream in.
Query patterns are simple (top-5 nearest neighbors). The current
HNSW build takes 20 minutes — a third of the re-index cycle.
After you answer: name ONE thing that would change your answer for
each scenario. Be specific about what you'd need to see in
production metrics before switching.
تصور 9: embedding pipeline، text میں، queryable vector باہر
Embeddings don't appear کے ذریعے magic; آپ generate انہیں کے ذریعے calling ایک embedding ماڈل. pipeline ہے straightforward، مگر ہر step has ایک فیصلہ point کہ bites if آپ get یہ wrong.
** four-step pipeline.**
- Chunk دستاویز میں pieces چھوٹا enough کو embed coherently.
- Embed ہر chunk کے ذریعے calling embedding ماڈل.
- Store chunk text، embedding، اور metadata میں
embeddingstable. - Query کے ذریعے embedding صارف کا سوال اور finding nearest neighbors.
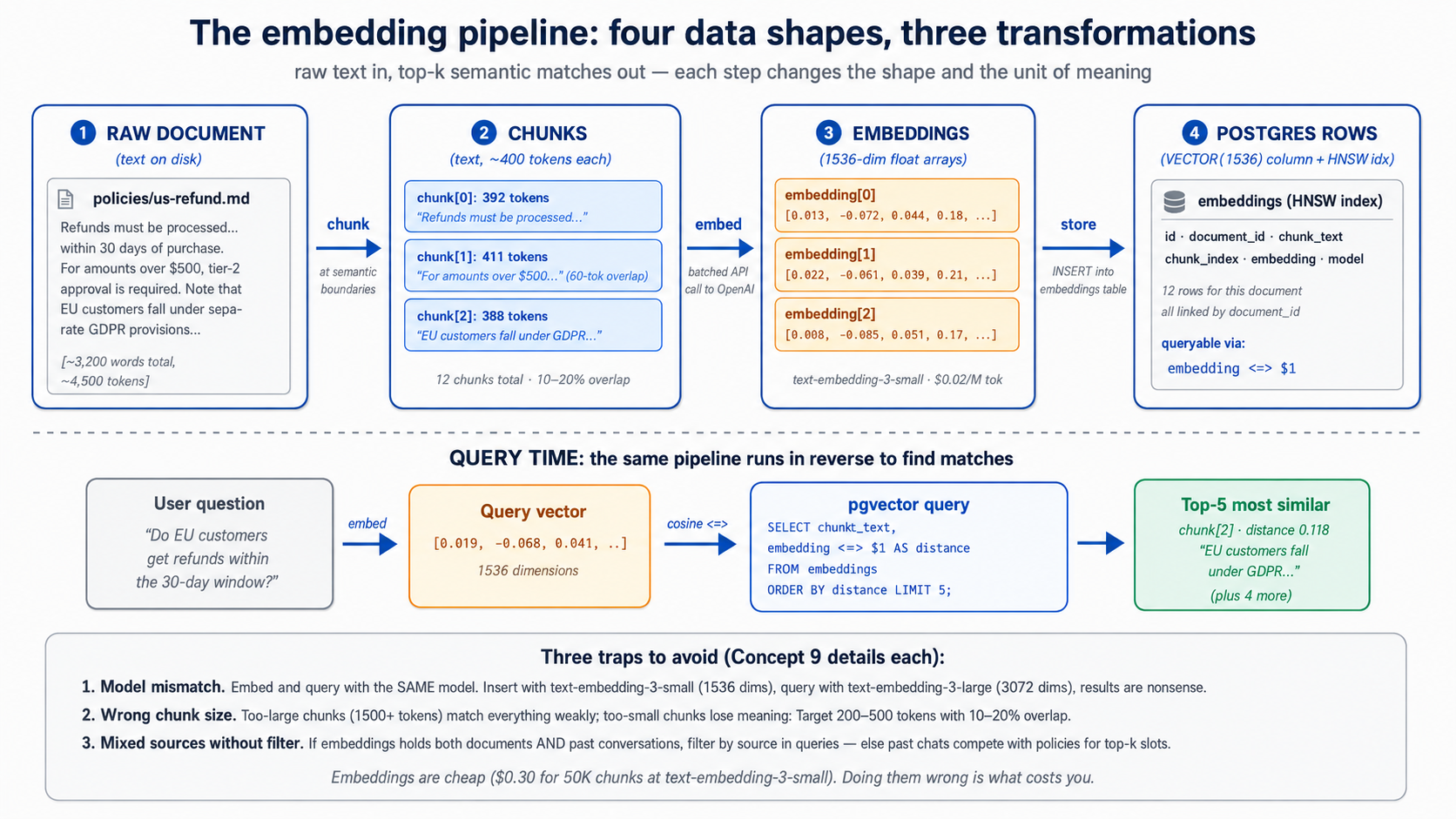
Chunking. Embedding ماڈلز رکھتے ہیں token limits: OpenAI's text-embedding-3-small accepts up کو 8،191 tokens per chunk، far زیادہ than آپ typically چاہتے ہیں. سوال isn't "کیا کا maximum" مگر "کیا کا chunk size کہ preserves unit کا meaning صارف گا search کے لیے." Three قواعد کہ کام میں practice:
- Chunk پر semantic boundaries جب آپ سکتا ہے. حصہ headings، paragraph breaks، structural markers میں آپ کا ماخذ. ایک chunk کہ ends mid-sentence retrieves badly.
- Target 200–500 tokens per chunk کے لیے زیادہ تر text. Long enough کو carry meaning، short enough کو be specific. Documents کے ساتھ longer chunks tend کو "match everything weakly" rather than "match درست thing strongly."
- Include 10–20% overlap درمیان chunks کے لیے chunks کہ fall across natural boundaries. overlap لاگتیں storage مگر improves recall جب صارف کا سوال lies near ایک chunk boundary.
- Don't chunk کیا کا پہلے ہی short. Documents پہلے ہی کے تحت ~300 tokens (single resolved tickets، short policy paragraphs، FAQ entries) don't ضرورت chunking; embed انہیں بطور ایک piece. chunker below ہے shaped کے لیے longer ماخذ دستاویزات (policy PDFs، knowledge-base articles، conversation transcripts). کے لیے worked مثال کا seed corpus کا short resolved tickets، آپ سکتا ہے skip chunker اور embed ہر ticket بطور ایک single chunk (فیصلہ 5 stores ہر ticket بطور ایک
documentsrow whosebodyہےsummary || '\n' || resolution، اور embeds کہ).
ایک typed chunking function کے لیے worked مثال:
# src/chat_agent/embedding/chunker.py
from dataclasses import dataclass
@dataclass(frozen=True)
class Chunk:
text: str
index: int
source_offset: int # character offset in the original document
def chunk_text(
text: str,
target_tokens: int = 400,
overlap_tokens: int = 60,
) -> list[Chunk]:
"""Split text into overlapping chunks at paragraph boundaries.
Approximates tokens as words * 0.75 — fine for chunking; not for
actual token counting. Use tiktoken for precise counts.
"""
paragraphs: list[str] = [p.strip() for p in text.split("\n\n") if p.strip()]
target_words: int = int(target_tokens / 0.75)
overlap_words: int = int(overlap_tokens / 0.75)
chunks: list[Chunk] = []
current: list[str] = []
current_word_count: int = 0
source_offset: int = 0
for para in paragraphs:
para_words: int = len(para.split())
if current_word_count + para_words > target_words and current:
chunks.append(Chunk(
text="\n\n".join(current),
index=len(chunks),
source_offset=source_offset,
))
# carry overlap forward
overlap_chunk: list[str] = []
overlap_count: int = 0
for prev in reversed(current):
if overlap_count + len(prev.split()) > overlap_words:
break
overlap_chunk.insert(0, prev)
overlap_count += len(prev.split())
current = overlap_chunk
current_word_count = overlap_count
source_offset += sum(len(p) for p in current) + 2 * len(current)
current.append(para)
current_word_count += para_words
if current:
chunks.append(Chunk(
text="\n\n".join(current),
index=len(chunks),
source_offset=source_offset,
))
return chunks
Embedding. Call ماڈل کے ساتھ batched chunks ( OpenAI API accepts arrays کا inputs میں ایک request، much زیادہ efficient than ایک call per chunk):
# src/chat_agent/embedding/embedder.py
from openai import AsyncOpenAI
EMBEDDING_MODEL: str = "text-embedding-3-small"
EMBEDDING_DIM: int = 1536 # the table column must match
async def embed_chunks(
client: AsyncOpenAI, chunks: list[str],
) -> list[list[float]]:
"""Embed a batch of chunks. Returns one vector per chunk, in order."""
response = await client.embeddings.create(
model=EMBEDDING_MODEL, input=chunks,
)
return [item.embedding for item in response.data]
کہاں کریں embeddings come سے جب آپ کا inference provider isn't OpenAI? یہ ہے ایک حقیقی ڈھانچے سے متعلق fork باب has اس لیے far papered پر. OpenAI ہے صرف major inference provider کہ also ships ایک first-class embeddings API; if آپ're routing inference کے ذریعے DeepSeek، Anthropic، Gemini، یا ایک local ماڈل، آپ رکھتے ہیں four options. چنیں ایک پہلے آپ touch VECTOR(n) column، کیونکہ column dimension لازمی match ماڈل.
| ماڈل | Dimensions | Cost (input، per 1M tokens) | کہاں یہ lives | جب کو استعمال کریں |
|---|---|---|---|---|
text-embedding-3-small | 1536 | $0.02 | OpenAI (اور OpenAI-compatible aggregators like OpenRouter) | ** default if آپ رکھتے ہیں ایک OpenAI اہم.** سستا، تیز، اچھا کے لیے زیادہ تر retrieval. |
text-embedding-3-large | 3072 | $0.13 (ماڈل card) / $0.065 (قیمتوں کا تعین صفحہ) | OpenAI | جب آپ've measured -small underperforming. |
embed-english-v3 / embed-multilingual-v3 | 1024 | $0.10 | Cohere | جب آپ're پہلے ہی on Cohere کے لیے inference، یا جب multilingual recall matters. |
voyage-3 / voyage-3-lite | 1024 | $0.06 / $0.02 | Voyage | Embeddings-as-a-service; integrates cleanly کے ساتھ Anthropic-shaped stacks. |
all-MiniLM-L6-v2 / bge-small-en-v1.5 (local) | 384 / 384 | "free" (آپ کا compute) | sentence-transformers package; چلتا ہے CPU-only کے ساتھ نہیں API call | جب آپ کا inference provider has نہیں embeddings API (DeepSeek، زیادہ تر local LLMs)، یا جب ڈیٹا residency forbids sending text کو ایک third party. |
headline لاگت number: embedding 50،000 chunks پر ~300 tokens ہر = 15M tokens × $0.02/M = $0.30 on OpenAI. وہی کے ساتھ -large ہے $1.95. کے ساتھ ایک local 384-dim ماڈل، $0 plus 30 seconds کا CPU. Embeddings ہیں cheapest سطر on bill; choice rarely moves dollar dial، مگر یہ کرتا ہے move ڈھانچہ.
** dimension ہے contract.** VECTOR(1536) صرف accepts 1536-dim vectors. If آپ switch سے text-embedding-3-small (1536) کو all-MiniLM-L6-v2 (384)، آپ re-create column بطور VECTOR(384) اور re-embed ہر row. وہاں ہے نہیں "fits if close enough" کے ساتھ pgvector; dimensions ہیں absolute.
Re-embedding. جب کریں آپ re-embed? Three triggers:
- ** ماخذ دستاویز changed.** Delete اور re-insert all embeddings whose
document_idmatches. - ** embedding ماڈل changed.** migration کا ایک lifetime; if آپ switch سے
-smallکو-large، ہر existing embedding ہے incompatible کے ساتھ نیا ones. Re-embed everything، یا چلائیں دو embedding columns during ایک transition. - ** chunking حکمت عملی changed.** If آپ decide 400 tokens was wrong اور 250 ہے درست، re-chunk اور re-embed. Versioning آپ کا chunks (storing
chunk_strategy_versionمیںmetadataJSONB) lets آپ کریں یہ safely.
PRIMM، Predict. آپ've embedded 100،000 chunks کے ساتھ
text-embedding-3-small. آپ پھر decide کو بھی embed all messages (نہیں just دستاویزات) اس لیے agent سکتا ہے کریں "رکھتے ہیں we discussed یہ پہلے?" lookups. آپ لکھیں message embeddings میں وہیembeddingstable کے ساتھ وہی column. ایک semantic search query (find 5 nearest neighbors کو ایک صارف سوال، نہیں filter) آتا ہے back کے ساتھ mixed دستاویز اور message results. ہے یہ کیا آپ wanted? کیا کا درست query shape? Confidence 1–5.
جواب: almost certainly نہیں کیا آپ wanted. Mixing دستاویزات اور messages میں retrieval results بغیر distinguishing انہیں پیدا کرتا ہے incoherent جوابات: ماڈل sees ایک top result کہ کا ایک customer کا prior message اور treats یہ بطور authoritative documentation. درست نمونہ ہے کو filter کے ذریعے ماخذ type میں query: either کے ذریعے joining اور filtering on WHERE document_id IS NOT NULL کے لیے دستاویز search، یا کے ذریعے running دو separate searches اور ranking انہیں differently. schema کا CHECK constraint کہ exactly ایک کا document_id/conversation_id ہے سیٹ بناتا ہے یہ filter سستا اور intent explicit.
Debugging poor retrieval. جب top-k results don't match expectations، four checks میں order، ہر ruling باہر ایک عام cause:
| Symptom | Likely cause | Fix |
|---|---|---|
| All top-5 distances ہیں > 0.7 (cosine distance، اس لیے کوئی بھی چیز > 0.5 ہے "far") | Query embedding ماڈل differs سے corpus embedding ماڈل | Confirm دونوں went کے ذریعے وہی EMBEDDING_MODEL. Mixing text-embedding-3-small کے ساتھ -large، یا local کے ساتھ OpenAI، پیدا کرتا ہے nonsense ranks across دونوں pools. |
| Top-5 results ہیں all سے ایک ماخذ type جب آپ expected variety | ماخذ-type filter missing | شامل کریں WHERE document_id IS NOT NULL (یا درست side کا CHECK constraint) کو query، یا split میں دو ranked queries اور merge انہیں کے ساتھ explicit weights. |
| Top-k تبدیلیاں wildly درمیان near-identical queries | Chunk size too چھوٹا (ہر chunk lacks enough سیاق و سباق) | Re-chunk کے ساتھ بڑا chunks (200، پھر 400، پھر 600 tokens) اور re-embed. Re-running وہی query چاہیے اب پیدا کریں stable top-k. |
| Query returns nothing | HNSW index missing، یا vector dimension mismatch | \d+ embeddings میں psql کو confirm column ہے VECTOR(1536) اور HNSW index موجود ہے کے ساتھ vector_cosine_ops. If column ہے wrong dimensionality، re-create یہ. |
Three diagnostic queries worth keeping میں ایک scratch.sql:
-- 1. Distance band on the top-5 for a known-good query
SELECT chunk_text, embedding <=> :query_vec AS distance
FROM embeddings ORDER BY distance LIMIT 5;
-- 2. Source-type breakdown of top-20 (catch the "wrong source dominates" bug)
SELECT
CASE WHEN document_id IS NOT NULL THEN 'document' ELSE 'message' END AS src,
COUNT(*)
FROM (SELECT * FROM embeddings ORDER BY embedding <=> :query_vec LIMIT 20) t
GROUP BY src;
-- 3. Confirm the index is actually being used
EXPLAIN (FORMAT TEXT) SELECT id FROM embeddings ORDER BY embedding <=> :query_vec LIMIT 10;
Retrieval quality ہے silent killer کا ورکر accuracy. final جواب سکتا ہے sound perfectly reasonable جبکہ citing wrong evidence; صرف طریقہ کو catch یہ ہے کو جانچیں retrieval پہلے final جواب.
Try کے ساتھ AI
I'm chunking a corpus of legal contracts (each averaging 8,000 words)
for semantic search. The user will query things like "what's the
termination clause in this contract" — phrases that map cleanly to
specific sections. Walk me through three chunking strategies:
A) Fixed 400-token chunks with 60-token overlap (the default)
B) Chunk at section headings only, with no overlap
C) A two-level approach: store both 400-token chunks AND
whole-section chunks, search both, combine results
For each, name (1) when it wins and (2) when it loses.
تصور 10: audit trail بطور طریقہ کار، کیا "reads اور writes" means کے لیے ایک ورکر
thesis ہے unusually direct کے بارے میں یہ: "ہر action ایک ورکر لیتا ہے leaves ایک trace میں ایک store کہ survives agent کا سیشن اور سکتا ہے be inspected، replayed، اور trusted. ریکارڈ کا مستند نظام ہے کیا separates عمل درآمد سے plausible-sounding fiction. یہ ہے بھی کیا بناتا ہے افرادی قوت legible بعد fact."
Translated کو operational اصطلاحات: ہر meaningful action agent لیتا ہے writes ایک row کو audit_log، plus ایک زیادہ structured row کو capability_invocations if یہ کا ایک skill یا ٹول call. ڈیٹا being acted on lives میں اس کا appropriate table (ایک message goes میں messages، ایک دستاویز update goes میں documents); fact کہ action happened lives میں audit_log. دو ہیں joined کے ذریعے foreign اہم.
کیا کو log.
- ہر ماڈل call: input tokens، نتیجہ tokens، ماڈل name، لاگت estimate
- ہر skill invocation: skill name، arguments، result summary، latency، success/error/timeout
- ہر ڈیٹا بیس لکھیں: کون سا table، کیا changed ( JSONB payload)، کے تحت کون سا conversation سیاق و سباق
- ہر external ٹول call: ٹول name، input، نتیجہ summary، latency
- ہر حفاظتی حد event: کون سا حفاظتی حد tripped، کیا input was، کیا action was (blocked/allowed/modified)
کیا نہیں کو log.
- مکمل conversation history on ہر turn; کہ کا پہلے ہی میں
messages، آپ'd be storing یہ twice - sensitive payload ڈیٹا verbatim if row ہے queryable کو humans; store ایک hash یا summary، رکھیں مکمل ڈیٹا میں ایک restricted table
- Internal ماڈل استدلال کہ صارف shouldn't دیکھیں; کہ کا ایک سیاق و سباق-management فیصلہ، نہیں ایک audit فیصلہ
** replay test.** ایک اچھا جانچ کا ریکارڈ passes ایک specific test: دیا گیا ایک conversation_id اور ایک timestamp، آپ سکتا ہے reconstruct کیا agent did اور کیوں، بغیر re-running ماڈل. If آپ کا audit log doesn't pass یہ test، یہ کا logging، نہیں auditing.
ایک concrete write-on-action helper، استعمال ہوا everywhere ایک صلاحیت چلتا ہے:
# src/chat_agent/audit.py
import time
import json
from typing import Any
from uuid import UUID
import asyncpg
async def log_capability(
pool: asyncpg.Pool,
conversation_id: UUID,
capability: str,
arguments: dict[str, Any],
result: Any,
status: str,
started_at: float,
cost_cents: int | None = None,
) -> None:
"""Write a capability_invocations row plus a denormalized audit_log row.
Both writes happen in one transaction so they're either both present
or both absent — the audit trail never gets partial.
"""
latency_ms: int = int((time.monotonic() - started_at) * 1000)
async with pool.acquire() as conn:
async with conn.transaction():
await conn.execute(
"""INSERT INTO capability_invocations
(conversation_id, capability, arguments, result, status,
latency_ms, cost_cents)
VALUES ($1, $2, $3::jsonb, $4::jsonb, $5, $6, $7)""",
conversation_id, capability,
json.dumps(arguments), json.dumps(result),
status, latency_ms, cost_cents,
)
await conn.execute(
"""INSERT INTO audit_log
(conversation_id, actor, action, target, payload, result)
VALUES ($1, $2, $3, $4, $5::jsonb, $6::jsonb)""",
conversation_id, "worker:customer-support",
"capability_invoked", capability,
json.dumps({"arguments": arguments, "latency_ms": latency_ms}),
json.dumps({"status": status, "result": result}),
)
دو writes میں ایک transaction ہے load-bearing detail. Half-written جانچ کا ریکارڈs ہیں worse than missing جانچ کا ریکارڈs: they suggest completeness بغیر delivering یہ. Either دونوں rows جائیں میں یا neither کرتا ہے.
مستند action vocabulary. ہر site کہ writes کو audit_log picks ایک action قدر سے ایک چھوٹا، agreed list. Drift یہاں ( وہی event gets called three مختلف names across codebase) ہے کیا بناتا ہے replay queries fragile six months later. six values worked مثال استعمال کرتا ہے، اور کون سا کوڈ path writes ہر:
action | target | کہاں لکھا گیا |
|---|---|---|
message_received | (null) | cli.py، جب صارف sends ایک message اور ایک row lands میں messages |
message_sent | (null) | cli.py، جب agent کا reply lands میں messages |
skill_activated | skill name | cli.py، on RunItemStreamEvent کے لیے ایک skill load |
capability_invoked | صلاحیت id | log_capability helper above، on ہر skill یا MCP-ٹول call |
mcp_called | ٹول name | cli.py، بعد ہر MCP ٹول returns (lower-level than capability_invoked; استعمال کریں ایک یا دwasرا consistently) |
refund_issued / refund_blocked | order id | customer-data MCP server کا issue_refund ٹول، on success اور policy denial |
چنیں ایک کا capability_invoked اور mcp_called اور stick کے ساتھ یہ; writing دونوں per call double-counts. worked مثال استعمال کرتا ہے capability_invoked کے لیے agent-side helper (فیصلہ 7) اور named domain actions like refund_issued کے لیے state-changing writes اندر MCP ٹولز (فیصلہ 6). Domain-state writes ہمیشہ get ان کا اپنا action name اس لیے audit row ہے receipt کے لیے کاروباری event، نہیں just کے لیے ٹول call کہ triggered یہ.
کیوں یہ isn't just logging. Three properties separate audit ڈیٹا سے log ڈیٹا:
- Replayable. schema lets آپ reconstruct agent کا استدلال trace سے
audit_logjoined کے ساتھmessagesjoined کے ساتھcapability_invocations. ایک log سطر میں ایک JSONL فائل doesn't. - Queryable. "کیا did agent tell customer X last month، اور کون سا policy did یہ cite?" ہے ایک SQL query. "کون سا skill triggered زیادہ تر timeouts میں last 7 days?" ہے ایک SQL query. Logs require grep اور luck.
- Trustworthy. audit rows ہیں میں وہی ڈیٹا بیس بطور کاروباری ڈیٹا. They're backed up together، point-in-time-recoverable together، access-controlled together. They survive agent عمل، ڈیپلائمنٹ region، اور ماڈل نسخہ.
یہ ہے کیا thesis means جب یہ says "ورکرز صرف بن جاتے ہیں governable بطور ایک افرادی قوت جب ایک ledger بناتا ہے انہیں legible، بطور units کا صلاحیت، لاگت، latency، اور نتیجہ." آپ کا audit_log اور capability_invocations tables are کہ ledger. Treat انہیں like ایک.
Try کے ساتھ AI
Here's a customer support scenario: a customer claims the Worker told
them they would receive a $50 refund, but the actual refund issued was
$30. The Worker handled the conversation 19 days ago.
Walk me through the audit-trail query path to resolve this:
1. Find the conversation. (Which columns of which tables?)
2. Find the message where the refund amount was promised. (How do you
distinguish "discussed" from "promised"?)
3. Find the capability invocation that issued the refund.
4. Find the database write that recorded the $30 amount.
For each step, name the table you'd query and the WHERE clauses.
Then say what's MISSING from the six-table schema that would make
this query easier.
حصہ 3: MCP، wiring agent کو ریکارڈ کا مستند نظام
حصہ 1 gave agent ایک library کا skills. حصہ 2 gave یہ ایک Postgres ریکارڈ کا مستند نظام. حصہ 3 wires دو together کے ساتھ ماڈل سیاق و سباق پروٹوکول: کھولیں standard کے لیے کیسے agents reach external state اور external صلاحیت. thesis ہے direct کے بارے میں MCP's place: "MCP ہے کیسے افرادی قوت reaches [اس کا ریکارڈ کے مستند نظام]: ہر authoritative store بن جاتا ہے addressable کو any ورکر کے ذریعے ایک MCP server، کے تحت policy." یہ Part بناتا ہے کہ operational.
تصور 11: کیا MCP ہے اور isn't
ماڈل سیاق و سباق پروٹوکول (modelcontextprotocol.io) ہے ایک کھولیں client/server پروٹوکول (originally سے Anthropic، اب governed بطور ایک کھولیں standard) کے لیے کیسے ایک AI agent جوڑتا ہے کو external ٹولز، ڈیٹا، اور پرامپٹس. framing کہ gets repeated ہے "USB-C کے لیے AI ٹولز": ایک پروٹوکول، بہت سے implementations، swap any side بغیر breaking دwasرا. framing ہے accurate; like all metaphors، یہ has limits worth naming.
کیا MCP ہے. ایک پروٹوکول. ایک specification. Three بنیادی اکائیاں server سکتا ہے expose کو client.
- ٹولز: functions ماڈل سکتا ہے invoke. client lists انہیں، ماڈل picks ایک، server executes یہ. Conceptually similar کو ایک
@function_tooldecorator سے Course #3، مگر implementation lives میں MCP server عمل، نہیں agent کا عمل. یہ ہے most-used بنیادی اکائی کے ذریعے far. - Resources: read-only ڈیٹا agent سکتا ہے fetch. Files، ڈیٹا بیس query results، API responses. Think کا انہیں بطور GET-only side کا MCP. کم عام than ٹولز میں practice، مگر useful کے لیے "let agent پڑھیں یہ دستاویز on demand."
- پرامپٹس: reusable پرامپٹ templates server فراہم کرتا ہے. ایک ٹیم سکتا ہے publish standardised پرامپٹس ("summarize-incident-report") کہ any agent connecting کو server سکتا ہے invoke. Rarely استعمال ہوا compared کو ٹولز اور resources.
Three transports، کے ساتھ موجودہ recommendations بطور کا 2026:
| Transport | جب کو استعمال کریں | Status |
|---|---|---|
stdio | local subprocess; agent اور server on وہی machine | Mature. default کے لیے local ٹولز. |
streamable HTTP | Remote server; پروڈکشن deployments | Recommended کے لیے نیا remote کام. Bidirectional، resumable، single endpoint. |
SSE | Remote server; older deployments | Legacy. بہت سے servers اب بھی expose یہ; نیا ones increasingly default کو streamable HTTP. |
کیا MCP ہے نہیں.
- نہیں ایک فریم ورک. یہ کا ایک پروٹوکول. آپ کا agent doesn't "استعمال کریں MCP" طریقہ یہ استعمال کرتا ہے Agents SDK; آپ کا agent کا MCP client speaks MCP کو ایک MCP server. Agents SDK includes ایک MCP client; کہ کا integration point.
- نہیں ایک service. وہاں ہے نہیں "MCP cloud." MCP servers ہیں programs آپ چلائیں (یا کہ vendors چلائیں کے لیے آپ). Neon MCP server ہے hosted پر
mcp.neon.tech; filesystem MCP server چلتا ہے بطور ایک local subprocess; ایک custom MCP server آپ لکھیں چلتا ہے wherever آپ ڈیپلائے یہ. - نہیں ایک سیکیورٹی boundary. MCP تعریف کرتا ہے transport اور پروٹوکول; what ٹولز ایک MCP server exposes اور کیا they سکتا ہے کریں ہے server کا responsibility. ایک malicious MCP server سکتا ہے کریں کوئی بھی چیز اس کا server-side کوڈ کرتا ہے. trust boundary ہے اب بھی agent loop deciding کون سا ٹولز کو call، اور سینڈ باکس ٹولز execute میں.
- نہیں ایک replacement کے لیے
@function_tool. دونوں اب بھی رکھتے ہیں ایک place. فیصلہ tree ہے تصور 14.
فوری چیک. True یا false: (ایک) ایک MCP client talks کو exactly ایک MCP server پر ایک وقت. (b) وہی
@function_tool-style function، if آپ wanted، could be exposed بطور ایک MCP ٹول یا kept بطور ایک function ٹول، اور ماڈل wouldn't جانیں difference. (c) MCP servers اور OpenAI Agents SDK ہیں tightly coupled، اس لیے کو استعمال کریں MCP آپ لازمی استعمال کریں SDK. جوابات: (ایک) False: ایک agent سکتا ہے جوڑیں کو multiple MCP servers اور دیکھیں union کا ان کا ٹولز. (b) True: کو ماڈل، دونوں دیکھیں like callable ٹولز کے ساتھ schemas. difference ہے کہاں implementation lives. (c) False: MCP ہے ماڈل سے آزاد. Claude، Gemini، اور دwasرے رکھتے ہیں ان کا اپنا MCP clients. OpenAI Agents SDK ہے ایک client among بہت سے.
Try کے ساتھ AI
You're building three capabilities for an internal "weekly report"
Worker. For each, decide: @function_tool, custom MCP server, or
vendor MCP server (use the existing one). Justify with ONE specific
property from Concept 11:
A) generate_summary(text: str) -> str — wraps OpenAI's completion
API to summarize the input. Used only by this Worker.
B) read_jira_issues(project: str, since: date) -> list[Issue] — your
company already runs Atlassian's official Jira MCP server in
production.
C) post_to_slack(channel: str, message: str) -> None — used by this
Worker today. The Engineering team's incident-response Worker
needs the same capability next quarter.
Then answer: which of the three is the EASIEST design decision, and
why? Which is the HARDEST, and why?
تصور 12: Neon MCP server، development plane، نہیں runtime
** specifics میں یہ concept گا age. نمونہ won't.** Neon's MCP server tooling، auth flow، اور exact ٹول surface تبدیلی ہر few months. کیا stays true: ایک managed-database vendor exposes اس کا management API کے ذریعے MCP کے لیے natural-language عملی کام، جبکہ runtime پروڈکشن traffic استعمال کرتا ہے direct connections یا scoped custom servers. Verify کے خلاف Neon's docs پہلے pinning specifics.
Neon MCP server ہے زیادہ تر polished مثال کا ایک vendor-shipped MCP server. یہ exposes Neon's management API (پروجیکٹس، branches، ڈیٹا بیسز، migrations، ad-hoc SQL) بطور MCP ٹولز آپ کا agent سکتا ہے call میں natural language. یہ ہے profoundly useful during development. یہ ہے explicitly نہیں کے لیے پروڈکشن runtime. Neon's اپنا warning ہے unambiguous: "We recommend MCP کے لیے development اور testing صرف، نہیں پروڈکشن environments." اور stronger نسخہ، بھی سے Neon's docs: "Never جوڑیں MCP agents کو پروڈکشن ڈیٹا بیسز."
کیوں distinction matters. Neon MCP server کا run_sql ٹول سکتا ہے execute any SQL ماڈل پیدا کرتا ہے. ایک development ورک فلو کہاں آپ کہتے ہیں "دکھائیں me صارفین who signed up last week اور haven't logged میں" → ماڈل generates SELECT * FROM users WHERE ... → server چلتا ہے یہ → results come back ہے delightful. وہی path میں پروڈکشن would be ایک سیکیورٹی nightmare: ایک attacker who could پرامپٹ-inject آپ کا customer-support ورکر could exfiltrate آپ کا entire ڈیٹا بیس کے ذریعے asking درست سوال.
کیا Neon MCP server ہے کے لیے. Three roles کہاں یہ کا درست ٹول:
- Schema ڈیزائن اور migrations during development. "شامل کریں ایک
prioritycolumn کو tickets table." Branch-based migrations let ماڈل test migration on ایک branch پہلے committing; Neon's اپنا MCP ڈیزائن نمونہ. یہ ہے درست طریقہ کو استعمال کریں یہ. - Exploratory ڈیٹا کام میں آپ کا agent-تعمیر loop. "کیسے بہت سے embeddings ہیں میں ڈیٹا بیس، broken down کے ذریعے ماخذ?" Working کے ذریعے ماڈل ہے often زیادہ تیز than typing SQL کے ذریعے hand، especially کے لیے one-off سوالات.
- Connection-string retrieval اور پروجیکٹ introspection. MCP server سکتا ہے hand آپ ایک connection string کے لیے درست branch بغیر آپ کا having کو log میں Neon console.
فوری setup کے لیے development استعمال کریں. Neon MCP server ہے دستیاب three طریقے. استعمال کریں OAuth-based remote server کے لیے simplest path:
# In your project, run:
npx -y mcp-remote@latest https://mcp.neon.tech/mcp
یا شامل کریں کو .claude/settings.json:
{
"mcpServers": {
"neon": {
"command": "npx",
"args": ["-y", "mcp-remote@latest", "https://mcp.neon.tech/mcp"]
}
}
}
Claude Code پرامپٹس کے لیے OAuth on پہلا استعمال کریں.
ایک development سیشن کے ساتھ Neon MCP server، نہیں SQL typed. (Approximate transcript; ٹول names ہیں accurate بطور کا Neon's موجودہ MCP documentation; exact phrasing اور نتیجہ format گا vary. shape کا interaction ہے کیا matters.)
You: Set up the chat-agent SoR. Create a project called "chat-agent",
enable pgvector, run the schema from migrations/001_initial.sql,
and tell me the connection string for the main branch.
Agent: [calls create_project] Created project chat-agent (ID: abc123).
[calls run_sql] Ran CREATE EXTENSION vector; — succeeded.
[calls prepare_database_migration with migrations/001_initial.sql]
Created temporary branch migration-test/abc123.
Migration ran on the branch; 6 tables created, 7 indexes built.
Want me to commit to main?
You: Yes, commit.
Agent: [calls complete_database_migration] Committed. Main branch
updated. Connection string:
postgresql://...@ep-cool-name.neon.tech/chat-agent?sslmode=require
کہ entire interaction ہے ایک Claude Code یا OpenCode سیشن، نہیں SQL typed کے ذریعے hand، migration tested on ایک branch پہلے going کو مرکزی. یہ ہے کیا MCP ہے کے لیے during development. یہ ہے نہیں کیا agent گا استعمال کریں کو لکھیں ایک single audit row پر runtime.
PRIMM، Predict. آپ're writing ایک customer-support ورکر. ورکر ضرورت ہے کو: (ایک) دیکھیں up customer کا order history; (b) چیک refund policy کے لیے customer کا tier; (c) issue ایک refund; (d) لکھیں ایک audit row recording کیا was issued اور کیوں. چاہیے یہ talk کو Neon کے ذریعے official Neon MCP server، یا some دwasرا طریقہ? Confidence 1–5.
جواب: some دwasرا طریقہ. کے لیے all four عملی کام. Neon MCP server کا run_sql ہے too broad ایک interface کے لیے ایک پروڈکشن agent: یہ grants agent اجازت کو چلائیں arbitrary SQL، کون سا ہے far زیادہ اختیار than four narrow عملی کام above require. پروڈکشن نمونے ہیں direct Postgres connections (ایک connection_pool سے asyncpg) wrapping scoped کاروباری عملی کام، یا ایک custom MCP server کہ exposes صرف those four عملی کام. تصور 14 covers latter; حصہ 4's worked مثال استعمال کرتا ہے دونوں: ایک custom customer-data MCP server کے لیے کاروباری عملی کام (lookups، vector search، refunds)، اور direct asyncpg only کے لیے audit subsystem (فیصلہ 7 explains وجہ: audit ہے meta-layer اور لازمی نہیں share MCP boundary یہ کا auditing).
distinction thesis ہے making کے ساتھ Invariant 5 (کہ افرادی قوت reads سے اور writes کو governed stores) depends on یہ distinction. ایک broad run_sql MCP ٹول ہے نہیں نظم و نگرانی; یہ ہے absence کا نظم و نگرانی کے ساتھ ایک friendly interface.
** Neon MCP ٹولز آپ کا ورکر گا touch.** Neon MCP server exposes roughly twenty ٹولز across پروجیکٹ management، branching، schema، SQL عمل درآمد، اور query tuning. فیصلہ 3 کا worked مثال استعمال کرتا ہے ایک چھوٹا subset; rest ہیں useful کے لیے follow-on کام (extending schema later، sandboxing ایک what-if migration on ایک branch). کے لیے reference:
| ٹول | کیا یہ کرتا ہے | کہاں استعمال ہوا میں حصہ 4 |
|---|---|---|
list_projects | List Neon پروجیکٹس on آپ کا account | فیصلہ 3، کو confirm پروجیکٹ کرتا ہے نہیں پہلے ہی exist |
create_project | Provision ایک نیا Neon پروجیکٹ (Postgres ڈیٹا بیس + default main branch) | فیصلہ 3، کو بنائیں chat-agent پروجیکٹ |
describe_project | Get پروجیکٹ metadata (default branch، region، compute settings) | فیصلہ 3، sanity-check بعد provisioning |
get_connection_string | Return Postgres connection string کے لیے ایک named branch | فیصلہ 3، کو populate NEON_DATABASE_URL کے لیے asyncpg |
prepare_database_migration | شروع کریں ایک migration: opens ایک temporary branch اور lets agent چلائیں DDL وہاں | فیصلہ 3، کو test six-table schema پہلے merging کو main |
run_sql | Execute SQL on ایک named branch (اندر ایک MCP-mediated سیشن) | فیصلہ 3، کو چلائیں schema creation on temporary branch |
complete_database_migration | Commit ایک migration: merges temporary branch back کو main | فیصلہ 3، بعد schema verifies clean on temporary branch |
describe_table_schema | Dump مکمل DDL کا ایک named table (useful کے لیے agent کو ground future plan-mode کام) | Optional، جب آپ پوچھیں منصوبہ طریقہ کو extend schema later |
create_branch / delete_branch | Manage isolated copy-on-write branches | Optional، جب آپ چاہتے ہیں ایک سینڈ باکس branch کے لیے ایک what-if migration |
پروڈکشن runtime ورکرز کریں نہیں touch یہ server. They reach Postgres کے ذریعے custom MCP server آپ لکھیں میں فیصلہ 6، یا کے ذریعے direct asyncpg کے لیے audit subsystem (فیصلہ 7).
Try کے ساتھ AI
Read Neon's MCP server documentation page and answer three questions:
1. List THREE management operations the Neon MCP server exposes that
would be useful during development of a customer-support Worker.
2. List THREE operations a runtime Worker would NEED that the Neon MCP
server should NOT be used for, and why.
3. For each of the three in (2), propose what the Worker should use
instead (direct Postgres connection? custom MCP server? function_tool?).
تصور 13: Connecting MCP کو OpenAI Agents SDK
Agents SDK ships کے ساتھ ایک first-class MCP client. Three classes کریں کام، ایک per transport:
from agents.mcp import (
MCPServerStdio, # local subprocess
MCPServerStreamableHttp, # remote, modern transport
MCPServerSse, # remote, legacy transport (avoid for new work)
)
All three ہیں async سیاق و سباق مینیجرز (async with server as ...:). Once connected، آپ pass انہیں کو Agent via mcp_servers argument. agent automatically discovers ہر server کا ٹولز پر startup، presents انہیں کو ماڈل alongside any @function_tools آپ've defined، اور routes calls back کو درست server مبنی on کون سا ٹول ماڈل picks.
MCPServerStdio's default client_session_timeout_seconds=5 ہے enough کے لیے ایک pure-Python server کہ صرف imports mcp اور asyncpg. یہ ہے نہیں enough جب server imports torch، sentence-transformers، یا کوئی بھی چیز کہ loads ایک ماڈل میں memory پر import وقت، کون سا سکتا ہے لیں 10–60 seconds on پہلا launch. symptom ہے ایک confusing init ناکامی ("MCP server did نہیں respond میں وقت"); fix ہے ایک parameter:
MCPServerStdio(
name="customer-data",
params={...},
client_session_timeout_seconds=60,
)
سیٹ یہ once کے لیے any server whose عمل کرتا ہے حقیقی کام پر startup، اور forget یہ.
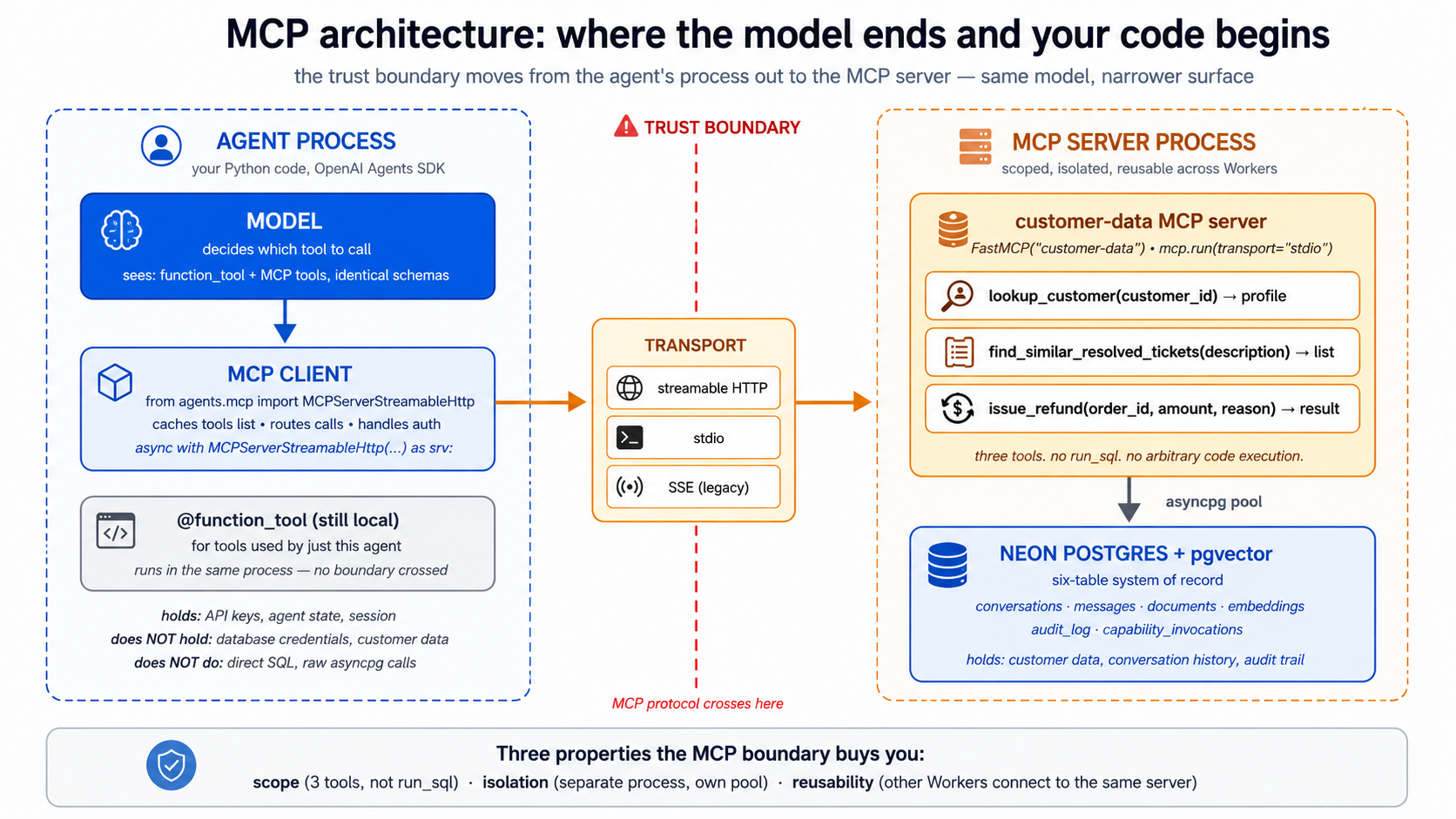 ایک minimal مثال، استعمال کرتے ہوئے Neon MCP server during development:
ایک minimal مثال، استعمال کرتے ہوئے Neon MCP server during development:
# tools/scratch_with_neon.py — development utility, not production
import asyncio
from agents import Agent, Runner
from agents.mcp import MCPServerStreamableHttp
async def main() -> None:
async with MCPServerStreamableHttp(
name="Neon (development)",
params={"url": "https://mcp.neon.tech/mcp"},
cache_tools_list=True,
) as neon:
agent: Agent = Agent(
name="DBAssistant",
instructions=(
"You help with Neon database operations during development. "
"Always use prepare_database_migration / complete_database_migration "
"for schema changes — never run DDL directly on main."
),
mcp_servers=[neon],
model="gpt-5.5",
)
result = await Runner.run(
agent,
"List all projects, then show me the schema of the largest one.",
)
print(result.final_output)
if __name__ == "__main__":
asyncio.run(main())
Three details worth naming:
-
async withہے نہیں optional. MCP connection holds ایک کھولیں transport (ایک subprocess کے لیے stdio، ایک HTTPS سیشن کے لیے streamable HTTP). بغیر سیاق و سباق مینیجر، connection leaks اور server-side state goes stale. ہمیشہ استعمال کریںasync with. -
cache_tools_list=Trueہے ایک substantial speedup کے لیے پروڈکشن. کے ذریعے default SDK callslist_tools()on ہرRunner.run، کون سا ہے ایک network round-trip. Caching بناتا ہے یہ once-per-process. Cache invalidation ہے manual: callserver.invalidate_tools_cache()جب آپ've added یا removed ٹولز. کے لیے development کے ساتھ ایک server whose ٹولز تبدیلی، leave یہFalse. -
Multiple MCP servers stack naturally. Pass
mcp_servers=[neon, custom_server, hosted_server]; ماڈل sees union کا all ٹولز. استعمال کریںMCPServerManagerif آپ ضرورت lifecycle management across بہت سے; یہ کا ایک thin helper کے گرد وہی نمونہ.
** require_approval parameter** ہے پروڈکشن switch worth knowing کے بارے میں. کے ذریعے default، MCP ٹول calls چلائیں بغیر confirmation. کے لیے sensitive servers، آپ سکتا ہے require انسانی منظوری per-ٹول:
async with MCPServerStreamableHttp(
name="Neon (development, guarded)",
params={"url": "https://mcp.neon.tech/mcp"},
require_approval={
"always": {"tool_names": ["delete_project", "delete_branch", "run_sql"]},
"never": {"tool_names": ["list_projects", "describe_project"]},
},
) as neon:
...
destructive عملی کام get ایک انسانی نگرانی کے ساتھ چیک; read-only ones چلائیں silently. یہ ہے عملی knob کے لیے development-vs-پروڈکشن gap سے تصور 12: even جب آپ're استعمال کرتے ہوئے Neon MCP server کے لیے عملی کام، gating اس کا destructive ٹولز کے ذریعے منظوری ہے ایک حقیقی safety improvement.
ایک دیکھیں پر کیسے ماڈل sees MCP ٹولز. جب Agent چلتا ہے، ماڈل gets ایک ٹول list کہ looks structurally similar کو ایک @function_tool list:
[
{"type": "function", "function": {"name": "search_docs", "description": "...", "parameters": {...}}},
{"type": "function", "function": {"name": "get_billing_invoice", "description": "...", "parameters": {...}}},
// These three came from the Neon MCP server:
{"type": "function", "function": {"name": "list_projects", "description": "Lists the first 10 Neon projects ...", "parameters": {...}}},
{"type": "function", "function": {"name": "run_sql", "description": "Executes a single SQL query ...", "parameters": {...}}},
{"type": "function", "function": {"name": "prepare_database_migration", "description": "Initiates a database migration by creating a temporary branch ...", "parameters": {...}}}
]
ماڈل سکتا ہے't tell difference درمیان ایک MCP ٹول اور ایک @function_tool، اور shouldn't ضرورت کو. SDK's routing layer dispatches ہر call کو درست بیک اینڈ.
Try کے ساتھ AI
I want to connect my OpenAI Agents SDK agent to TWO MCP servers
simultaneously: (a) the Neon MCP server for database operations, and
(b) a local filesystem MCP server (npx @modelcontextprotocol/server-filesystem)
for reading project files.
Write the async setup code that connects to both servers and uses
them in a single Agent. Include:
1. The right imports.
2. Both connections as async context managers (one streamable HTTP,
one stdio).
3. An Agent that uses both, with require_approval set to require
approval for any tool that writes to the filesystem.
4. A sample Runner.run that exercises tools from both servers in
one turn.
تصور 14: custom MCP servers، جب کو لکھیں آپ کا اپنا vs. جب نہیں کو
Neon MCP server ہے generic: یہ سکتا ہے کریں کوئی بھی چیز Neon's API سکتا ہے کریں. کہ کا اس کا strength کے لیے development اور اس کا weakness کے لیے runtime. ایک custom MCP server inverts trade-off: narrow surface، نہیں general-purpose run_sql، صرف specific عملی کام آپ کا ورکر اصل میں ضرورت ہے.
** فیصلہ tree، میں order کا priority.**
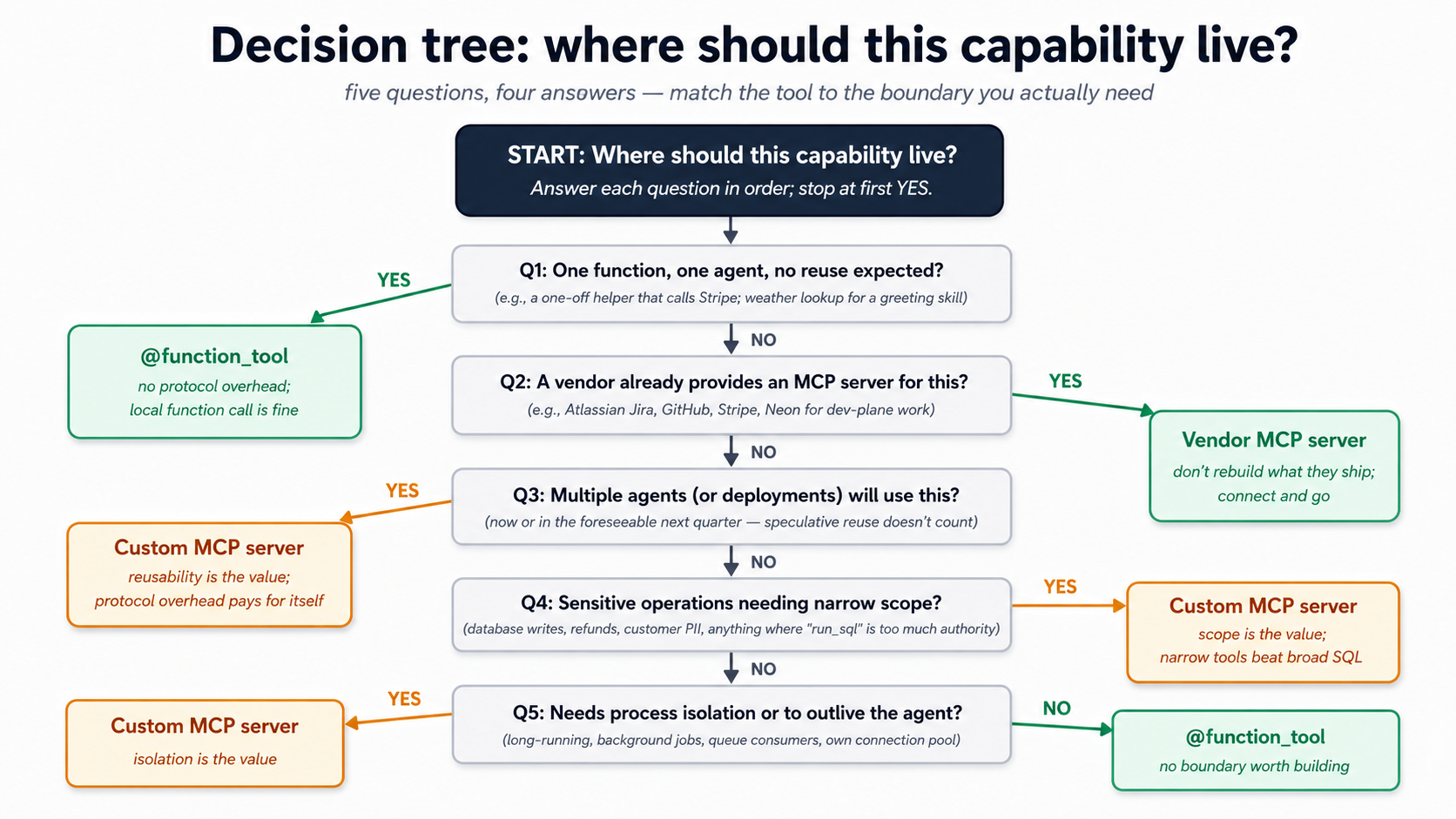
وہی logic میں ایک quick-scan table:
| آپ چاہتے ہیں کو expose... | استعمال کریں یہ | کیوں |
|---|---|---|
| ایک function کے ساتھ ایک input، استعمال ہوا کے ذریعے ایک agent | @function_tool | نہیں ضرورت کے لیے پروٹوکول overhead. local function call ہے fine. |
| Several functions tightly coupled کو آپ کا agent کا کوڈ | @function_tool | If they share state کے ساتھ agent اور live میں وہی repo، they're part کا agent. |
| ایک صلاحیت کہ multiple agents (یا multiple deployments) گا استعمال کریں | custom MCP server | پروٹوکول ہے کیا بناتا ہے یہ reusable. |
| ایک صلاحیت کہ ضرورت ہے کو outlive agent کا عمل | custom MCP server | Long-running connections، background jobs، queue consumers. |
| Vendor-provided functionality (Neon، GitHub، Linear) | Vendor کا MCP server | Don't rebuild کیا they ship. |
| sensitive عملی کام کہ ضرورت narrow scope | custom MCP server | تعریف کریں exactly ٹولز آپ ضرورت; nothing else. |
** minimum-viable custom MCP server** میں Python، استعمال کرتے ہوئے official MCP SDK:
# servers/customer_data_mcp/server.py
# Run with: python -m customer_data_mcp.server
import os
from typing import Annotated
import asyncpg
from mcp.server.fastmcp import FastMCP
from pydantic import Field
mcp: FastMCP = FastMCP("customer-data")
# Connection pool: created once, reused across tool calls.
_pool: asyncpg.Pool | None = None
async def get_pool() -> asyncpg.Pool:
global _pool
if _pool is None:
_pool = await asyncpg.create_pool(
os.environ["DATABASE_URL"],
min_size=1, max_size=10,
)
return _pool
@mcp.tool()
async def lookup_customer(
customer_id: Annotated[
str, Field(description="The customer's UUID, as provided by the user."),
],
) -> dict[str, str | int]:
"""Look up a customer by ID. Returns id, email, tier, and active_tickets count.
Use when the user provides a customer ID and you need their basic profile.
Does NOT return billing details — use lookup_billing for that.
"""
pool = await get_pool()
async with pool.acquire() as conn:
row = await conn.fetchrow(
"""SELECT id::text, email, tier,
(SELECT COUNT(*) FROM tickets t
WHERE t.customer_id = c.id AND t.status='open') AS active_tickets
FROM customers c WHERE id = $1::uuid""",
customer_id,
)
if row is None:
return {"error": f"customer {customer_id} not found"}
return dict(row)
@mcp.tool()
async def find_similar_resolved_tickets(
description: Annotated[
str, Field(description="The user's question or description of the issue."),
],
limit: Annotated[int, Field(description="Max results.", ge=1, le=10)] = 5,
) -> list[dict[str, str | float]]:
"""Find resolved tickets similar to a description, via pgvector.
Use when the user describes an issue and you want to check if a similar
issue has been resolved before. Returns ticket_id, summary, resolution,
and similarity score (lower is more similar).
"""
pool = await get_pool()
# In production, embed the description here; for brevity, assume it's
# already an embedding column being matched. See Part 4 for the full pipeline.
#
# Note the JOIN path: embeddings.document_id references documents(id), not
# tickets(id). See Concept 7's schema. A resolved ticket is embedded by
# storing it as a `documents` row (source='past_case') whose metadata holds
# the ticket id, so the join goes embeddings -> documents -> tickets.
async with pool.acquire() as conn:
rows = await conn.fetch(
"""SELECT t.id::text AS ticket_id, t.summary, t.resolution,
(e.embedding <=> $1::vector) AS distance
FROM embeddings e
JOIN documents d ON d.id = e.document_id
JOIN tickets t ON t.id = (d.metadata->>'ticket_id')::uuid
WHERE d.source = 'past_case' AND t.status = 'resolved'
ORDER BY e.embedding <=> $1::vector
LIMIT $2""",
description, limit, # description here is illustrative; real version embeds first
)
return [dict(r) for r in rows]
if __name__ == "__main__":
mcp.run(transport="stdio")
پھر میں آپ کا agent:
async with MCPServerStdio(
name="customer-data",
params={
"command": "python",
"args": ["-m", "customer_data_mcp.server"],
"env": {"DATABASE_URL": os.environ["DATABASE_URL"]},
},
cache_tools_list=True,
) as customer_data:
agent: Agent = Agent(
name="CustomerSupport",
mcp_servers=[customer_data],
...,
)
Three things یہ server دیتا ہے آپ کہ @function_tool doesn't.
-
عمل isolation. MCP server چلتا ہے میں اس کا اپنا عمل (subprocess کے لیے stdio، separate service کے لیے streamable HTTP). ایک crash میں server doesn't crash agent; ایک memory leak میں server doesn't leak میں agent.
-
Scope. server has exactly دو ٹولز. نہیں
run_sql. نہیں "execute arbitrary کوڈ." ماڈل سکتا ہے't escape یہ scope کیونکہ protocol doesn't expose کوئی بھی چیز else. یہ ہے ایک حقیقی defense میں depth: even if ماڈل decided کو کریں something stupid، surface area کو کریں یہ کے ذریعے ہے دو functions. -
Reusability across agents. ایک second agent (ایک sales ورکر، ایک Reporting ورکر) سکتا ہے talk کو وہی
customer-dataMCP server. وہی scope، وہی پروٹوکول، وہی trust boundary. صلاحیت بن جاتا ہے ایک shared piece کا بنیادی ڈھانچا rather than ایک copy-paste درمیان agents.
** trade-off ہے حقیقی.** custom MCP servers شامل کریں operational complexity: دwasرا عمل کو ڈیپلائے، دwasرا سیٹ کا logs، دwasرا network hop (if remote)، دwasرا نسخہ کو manage. Don't لکھیں ایک کے لیے ایک single function استعمال ہوا کے ذریعے ایک single agent. لکھیں ایک جب صلاحیت ہے going کو be reused، جب scoping matters، یا جب isolation buys آپ safety.
PRIMM، Predict. آپ're designing customer-support ورکر. آپ ضرورت: (1) semantic search پر past resolved tickets; (2) writing ایک refund audit row; (3) مطالعہ موجودہ weather (استعمال ہوا میں ایک greeting skill کہ says "اچھا morning سے sunny Karachi"); (4) calling payment gateway کو issue ایک refund. کے لیے ہر، predict:
@function_tool، custom MCP server، یا vendor MCP server (e.g.، Stripe کا، if such موجود ہے)?
جوابات tease باہر فریم ورک:
- custom MCP server (
customer-data). Reused across agents; sensitive ڈیٹا; scoped ٹولز beat ایک broadrun_sql. - custom MCP server (
customer-data) یا@function_tool. Either کام کرتا ہے; if ورکر ہے صرف writer، function ٹول ہے fine. If multiple ورکرز گا لکھیں audit rows، MCP server. @function_tool. ایک agent، ایک tiny function، نہیں سیکیورٹی surface کو defend. Don't تعمیر کریں ایک server کے لیے یہ.- Vendor MCP server (Stripe MCP) if یہ موجود ہے، else
@function_toolcalling Stripe کا API. Don't wrap third-party APIs میں آپ کا اپنا MCP server unless آپ ضرورت کو شامل کریں policy on top.
فریم ورک ہے واضح once آپ trace یہ: ** قدر کا MCP rises کے ساتھ قدر کا boundary یہ بناتا ہے.** ایک boundary آپ don't ضرورت ہے overhead.
Try کے ساتھ AI
You're designing the architecture for a research-Worker that does these
five things:
A. Reads PDFs from a Google Drive folder (uses Google Drive's API)
B. Queries a private Snowflake warehouse the company owns
C. Calls a third-party data-enrichment API (Clearbit-like)
D. Logs every action to the company's central audit log database
E. Generates a Markdown report by string-formatting the results
For each, decide: @function_tool, custom MCP server, or vendor MCP
server (if a credible vendor MCP server exists). For each choice,
justify with ONE of the three properties of MCP from Concept 14
(isolation, scope, reusability) OR justify why the boundary isn't
worth building.
تصور 15: MCP کے تحت load: transports، pooling، اور کیا ہوتا ہے بڑے پیمانے پر
ایک demo کے ساتھ ایک MCP server اور ایک agent on ایک laptop کام کرتا ہے fine. سوالات get harder جب ورکر ہے میں پروڈکشن handling 10 conversations ایک منٹ. یہ تصور ہے operational checklist.
Transport choice، بڑے پیمانے پر.
-
stdioہے کے لیے local development اور single-process deployments. MCP server چلتا ہے بطور ایک subprocess کا agent. Restart agent → server restarts → fresh state. سستا. کام کرتا ہے. Doesn't wasیع کرنا across machines. -
streamable HTTPہے کے لیے پروڈکشن remote servers. Multiple agents سکتا ہے جوڑیں کو ایک MCP server. server سکتا ہے چلائیں on مختلف hardware than agent. Auto-reconnect، resumable streams، single endpoint: ڈیزائن کیا گیا کے لیے پروڈکشن سے ground up. -
SSEموجود ہے، mostly کے لیے legacy reasons. نیا کام چاہیے default کو streamable HTTP. Existing SSE-only servers ہیں اب بھی عام ( SDK supports انہیں); don't rewrite ایک server just کو switch transport.
Connection management. MCP connections ہیں نہیں free. ہر ایک ہے ایک سیشن: ایک authentication handshake، ایک list_tools round-trip، ایک persistent connection. Three نمونے کہ matter:
-
Cache ٹولز list.
cache_tools_list=Truesaves ایک round-trip perRunner.run. یہ ہے single biggest latency کامیابی کے لیے typical agent loop. Invalidate cache جب آپ ڈیپلائے ایک نیا نسخہ کا server. -
Reuse server instances across چلتا ہے. Don't بنائیں ایک نیا
MCPServerStreamableHttp(...)per request. کھولیں once پر agent startup، holdasync withکھولیں کے لیے lifetime کا agent عمل، close پر shutdown. connection لاگت ہے amortized across thousands کا agent چلتا ہے. -
Connection pooling lives اندر MCP server، نہیں client. If آپ کا MCP server talks کو Postgres (بطور
customer-dataمثال کرتا ہے)، server چاہیے رکھتے ہیں ایکasyncpg.create_pool(min_size=1, max_size=10)اور share pool across ٹول calls. client side talks کو ایک MCP server connection; server side fans باہر کو ایک pool کا ڈیٹا بیس connections.
Concurrency limits. Three places کو سیٹ انہیں، میں order سے cheapest کو زیادہ تر مہنگا کو get wrong:
max_turnson agent. پہلے ہی familiar سے Course #3. Caps loop length regardless کا ٹولز.max_retry_attemptson MCP server connection. Caps retry storms جب ایک MCP server ہے flaky. default 0 (نہیں retries); سیٹ کو 2–3 کے لیے پروڈکشن resilience.- Server-side rate limits. اندر آپ کا custom MCP server، count concurrent calls per agent اور reject above some threshold. پروٹوکول allows ٹول calls کو return errors; clients دیکھیں انہیں بطور ٹول ناکامیاں اور ماڈل سکتا ہے decide کو retry، دیں up، یا چنیں ایک مختلف ٹول.
ٹریسنگ across MCP boundary. Course #3's ٹریسنگ setup carries کے ذریعے، مگر کے ساتھ ایک اہم detail: MCP ٹول calls appear میں agent کا trace بطور ordinary ٹول calls: وہی span shape، وہی span name ( MCP ٹول کا name)، وہی timing. کیا کا not visible سے agent side ہے کیا happened اندر MCP server کا عمل. If آپ کا custom MCP server بناتا ہے اس کا اپنا ڈیٹا بیس calls یا downstream API calls، those ضرورت ان کا اپنا ٹریسنگ اندر server.
ایک عملی نمونہ: propagate trace سیاق و سباق across MCP boundary استعمال کرتے ہوئے _meta. SDK supports ایک tool_meta_resolver کہ adds metadata کو ہر ٹول call (tenant IDs، trace IDs، request IDs); آپ کا server سکتا ہے extract اور استعمال کریں انہیں. یہ ہے کیسے ایک single agent چلائیں کا ٹریسنگ chain stays unbroken سے agent → MCP client → MCP server → Postgres.
فوری چیک. True یا false: (ایک) Switching سے
MCPServerSseکوMCPServerStreamableHttpدرکار ہے تبدیلیاں کو MCP server itself. (b)cache_tools_list=Trueہے safe میں پروڈکشن بطور long بطور آپ callinvalidate_tools_cache()بعد ڈیپلائے کرنا ایک نیا server نسخہ. (c) ایک MCP server کے ساتھ five ٹولز ہمیشہ استعمال کرتا ہے زیادہ agent سیاق و سباق بجٹ than ایک@function_toolکے ساتھ five functions. جوابات: (ایک) Depends: server لازمی سپورٹ streamable HTTP transport; زیادہ تر modern servers کریں، older ones ہو سکتا ہے صرف speak SSE. (b) True: کہ کا intended نمونہ. (c) False: پر schema level they're equivalent. Five ٹول definitions لاگت کے بارے میں وہی میں either form.
Try کے ساتھ AI
My customer-support Worker is in production. It runs 80 conversations/minute
at peak. Each conversation makes 2-4 MCP tool calls on average. I'm seeing
intermittent latency spikes — most calls return in 200ms, but a small
percentage take 5-15 seconds.
Walk me through five places I'd investigate, in order of priority:
1. The agent-side MCP client connection management.
2. The transport choice between agent and MCP server.
3. The MCP server's internal connection pool to Postgres.
4. Postgres-side query performance (slow queries blocking the pool).
5. Network or DNS issues between agent and MCP server.
For each, name the specific signal I'd look for and the rough fix.
حصہ 4: worked مثال، customer-support ورکر
ایک realistic evolution، ہر concept above، دونوں ٹولز. We لیں chat-agent پروجیکٹ سے Course #3 اور turn یہ میں ایک customer-support ورکر کے ذریعے adding three skills، ایک Neon ریکارڈ کا مستند نظام، اور ایک MCP wiring layer. Eight تعمیر کریں فیصلے، وہی shape بطور Course #3's حصہ 5.
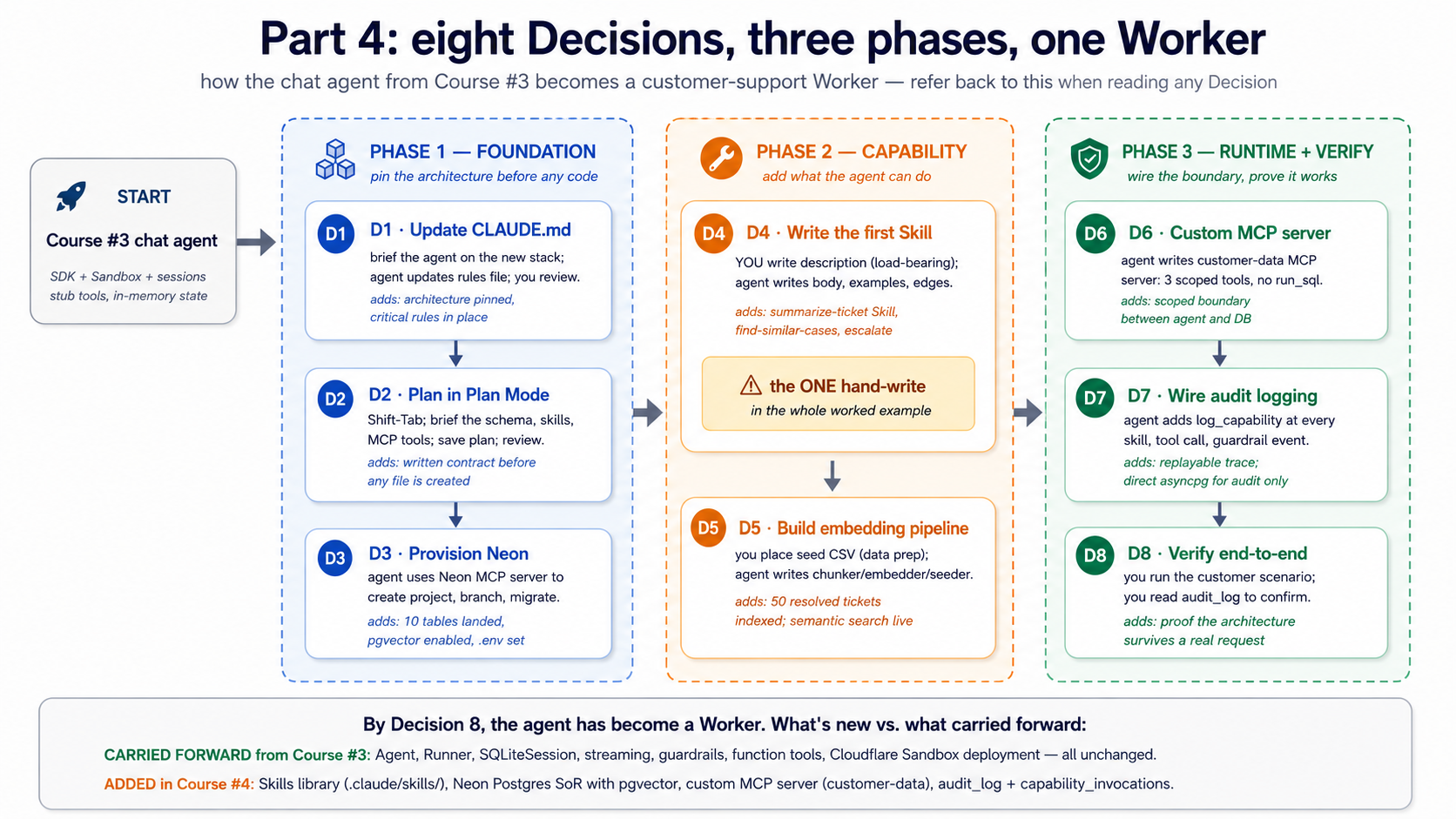
پہلے آپ شروع کریں: setup آپ ضرورت کہ isn't میں prereqs. Three things یہ Part assumes ہیں پہلے ہی مکمل. (1) آپ رکھتے ہیں completed Course #3's worked مثال اور رکھتے ہیں ایک working
chat-agent/پروجیکٹ کے ساتھcli.py،agents.py،tools.py،models.py،guardrails.py. We modify یہ فائلیں; we کریں نہیں replace انہیں. (2) آپ رکھتے ہیں ایک free Neon account اور رکھتے ہیں چلائیںnpx neonctl@latest initonce کو authenticate. (3) آپ رکھتے ہیں either Claude Code یا OpenCode installed and authenticated. If any کا یہ ہے missing، fix یہ پہلے فیصلہ 1.
brief
Evolve chat-agent سے Course #3 میں ایک customer-support ورکر کہ:
- Loads three skills on demand:
summarize-ticket،find-similar-cases، اورescalate-with-context. - Reads سے اور writes کو ایک Neon Postgres ریکارڈ کا مستند نظام کے ساتھ six tables سے تصور 7.
- استعمال کرتا ہے pgvector کے لیے semantic search پر ایک چھوٹا library کا past resolved cases.
- Talks کو Postgres پر runtime کے ذریعے ایک scoped، custom MCP server (
customer-data)، نہیں کے ذریعے Neon MCP server، اور نہیں کے ذریعے directasyncpgcalls میں agent کوڈ. - Writes ایک audit row کے لیے ہر meaningful action: ہر skill invoked، ہر ڈیٹا بیس لکھیں، ہر refund considered.
"verification پر end" test: ایک customer messages "I haven't received my refund سے order #4429، یہ کا been دو weeks." ورکر looks up order via MCP، finds three similar past cases via vector search، drafts ایک response کہ cites resolution سے زیادہ تر similar case، writes ایک audit row recording کیا یہ did، اور (میں ایک حقیقی ڈیپلائے) escalates if customer ہے ایک Pro tier صارف.
ایک note on پرامپٹس کہ follow. ہر فیصلہ دکھاتا ہے ایک structured پوچھیں بطور ایک block-quoted پرامپٹ. نمونہ کہ کام کرتا ہے بہترین میں practice ہے کو precede ہر پوچھیں کے ساتھ ایک orient move ("پڑھیں
CLAUDE.mdاور relevant فائلیں، tell me کیا آپ دیکھیں، اور پوچھیں 1-2 سوالات پہلے we شروع کریں") اور پھر send structured پوچھیں once agent has loaded سیاق و سباق اور clarified ambiguities. structured پوچھتا ہے below ہیں destination، نہیں پہلا move. Pasting انہیں cold کام کرتا ہے; pasting انہیں بعد orientation کام کرتا ہے بہتر، especially بطور پروجیکٹ grows.
فیصلہ 1: Update قواعد فائل کے ساتھ نیا ڈھانچہ
کیا آپ کریں (Claude Code). کھولیں Claude Code میں آپ کا existing chat-agent/ پروجیکٹ. brief agent on ڈھانچے سے متعلق تبدیلیاں Course #4 ہے adding، اور پوچھیں یہ کو update CLAUDE.md accordingly:
We're extending this project with three additions on top of the Course
#3 stack: Skills loaded from .claude/skills/, a Neon Postgres system of
record (six-table schema in migrations/001_initial.sql), and MCP wiring
(Neon MCP server for development; a custom customer-data MCP server at
servers/customer_data_mcp/ for runtime).
Update CLAUDE.md to add:
1. New stack lines (Neon Postgres + pgvector, MCP).
2. A new "Architecture (NEW)" section describing where each piece lives.
3. Critical rules preventing three failure modes: business data access
must go through the customer-data MCP server (agent decision logic
never bypasses MCP for business reads or writes); the only permitted
direct asyncpg usage is in the audit subsystem via a separate audit
pool; never use the Neon MCP server's run_sql in production paths
(it's a dev tool); every skill invocation, refund, or database write
produces an audit_log row; skills live in .claude/skills/ (OpenCode
reads as fallback) — do not duplicate in .opencode/skills/.
4. New uv-run commands for the MCP server and migrations.
Keep the file under 2,500 tokens. Show me the diff before writing.
Claude Code drafts update. پڑھیں diff carefully. "Critical قواعد" حصہ ہے load-bearing part; کوئی بھی چیز weak وہاں fails کو prevent ناکامی طریقے یہ کا supposed کو prevent. result چاہیے دیکھیں roughly like یہ:
# chat-agent
## Stack
Python 3.12+, uv, openai-agents >=0.14.0 (latest at time of writing: 0.17.2),
Cloudflare Sandbox, Neon Postgres + pgvector, MCP (custom server for runtime).
## Architecture (NEW)
- Capabilities: three Skills in .claude/skills/
(summarize-ticket, find-similar-cases, escalate-with-context).
See [agentskills.io](https://agentskills.io/specification) for the format.
- System of record: Neon Postgres, schema in migrations/001_initial.sql.
Six tables: conversations, messages, documents, embeddings, audit_log,
capability_invocations.
- MCP: Neon MCP server for development ONLY (schema, migrations).
Runtime traffic uses a custom MCP server at servers/customer_data_mcp/,
exposing scoped tools (lookup_customer, find_similar_resolved_tickets,
issue_refund). No run_sql in production paths.
- Embeddings: text-embedding-3-small (1536 dims), cosine distance,
HNSW index.
## Critical rules (NEW)
- Business data access must go through the `customer-data` MCP server.
Agent decision logic must never bypass MCP to query or mutate business
data. The only permitted direct asyncpg usage is inside the audit
subsystem, through a separate audit connection pool (Decision 7
explains why audit can't share the MCP boundary it's auditing).
- Never use the Neon MCP server's run_sql tool in production paths.
It's a development tool.
- Every skill invocation, every refund consideration, every database
write produces an audit_log row. No silent actions.
- Skills are in .claude/skills/ (OpenCode reads this as a fallback);
do not duplicate in .opencode/skills/.
## Commands
- `uv run python -m chat_agent.cli`: local dev (uses customer-data MCP via stdio)
- `uv run python -m chat_agent.sandboxed`: sandbox deployment
- `uv run python -m customer_data_mcp.server`: run MCP server standalone
- `uv run alembic upgrade head`: apply pending migrations
فائل grows سے ~30 lines کو ~50 lines، اب بھی اچھی طرح کے تحت 2،500-token بجٹ سے Course #3. If diff Claude Code دکھاتا ہے آپ misses any کا critical قواعد یا hallucinates ایک constraint کہ isn't میں brief، push back اور re-پرامپٹ. قواعد فائل ہے ایک place کہاں چھوٹا inaccuracies رکھتے ہیں outsized downstream effects.
کیوں. Course #3's قواعد فائل pinned engine اور سینڈ باکس. یہ update pins ڈھانچہ layered on top: skills، ریکارڈ کا مستند نظام، MCP boundaries. "کاروباری ڈیٹا کے ذریعے MCP، audit کے ذریعے scoped direct asyncpg" قاعدہ ہے load-bearing ایک: یہ prevents agent سے short-circuiting MCP boundary later جب somebody ہے میں ایک hurry، جبکہ keeping audit subsystem independent کا boundary یہ audits. فیصلہ 7 explains کیوں کہ independence matters.
کیا تبدیلیاں میں OpenCode. وہی flow: brief agent، review diff. Rename فائل کو AGENTS.md (if آپ haven't پہلے ہی سے Course #3) یا leave بطور CLAUDE.md (OpenCode reads یہ بطور ایک fallback). وہی content.
فیصلہ 2: منصوبہ schema اور skill سیٹ
کیا آپ کریں (Claude Code). Press Shift+Tab twice کو enter منصوبہ طریقہ. ماڈل سکتا ہے پڑھیں آپ کا existing پروجیکٹ مگر نہیں کر سکتا edit کوئی بھی چیز. brief یہ:
Plan the customer-support Worker evolution of this project. The
foundation (OpenAI Agents SDK, Cloudflare Sandbox, sessions, streaming,
guardrails) stays. We're adding:
1. Three Skills: summarize-ticket, find-similar-cases, escalate-with-context.
For each, propose: the description, the operational shape (script-driven
or instruction-driven), and what reference files it needs.
2. The six-table schema from Part 2 Concept 7, plus any tables specific
to a customer-support domain (probably: customers, orders, tickets, refunds).
3. The custom MCP server (customer-data), with exactly the runtime tools
our agent will need. Propose the tool list and signatures. No run_sql.
4. The audit-logging plan — what writes an audit row, what doesn't.
Output the plan as a markdown file at plans/customer-support-worker-plan.md.
Do not write code yet.
ماڈل پیدا کرتا ہے ایک منصوبہ. پڑھیں یہ carefully. دو places کہاں پہلا draft ہے usually wrong:
- skills' descriptions گا be vague ("Summarizes tickets"). Push back: descriptions لازمی be specific enough کو fire correctly (تصور 3 کا یہ کورس was کے بارے میں exactly یہ).
- MCP ٹولز' input schemas گا be broader than needed ("query: string"). Push back: ہر ٹول چاہیے رکھتے ہیں minimum input یہ ضرورت ہے. ایک
lookup_customerٹول ضرورت ہے ایکcustomer_id، نہیں ایکqueryآپ تعمیر کریں SQL باہر کا.
کیوں. دو ناکامی طریقے منصوبہ طریقہ catches کہ لاگت گھنٹے later: ایک skill کے ساتھ ایک vague description never fires، اور ایک MCP ٹول کے ساتھ ایک broad input schema ہے just run_sql کے ساتھ extra steps. دونوں ہیں easier کو fix میں ایک markdown منصوبہ than بعد they're built.
کیا تبدیلیاں میں OpenCode. Press Tab کو switch کو منصوبہ agent. وہی پرامپٹ، وہی منصوبہ نتیجہ. Save منصوبہ فائل کے ساتھ وہی name.
فیصلہ 3: Provision Neon اور چلائیں schema migration
Neon's free tier covers ایک single ورکر پر volume حصہ 5 assumes (~200 conversations/day). منصوبہ on $0/month یہاں. free منصوبہ limits ہیں 0.5 GB storage اور 100 compute-hours per پروجیکٹ (Neon قیمتوں کا تعین); above کہ، Launch tier ہے pay-as-you-go (roughly $0.11/CU-hour + $0.35/GB-month)، اور ایک worked-example ورکر typically stays کے تحت $25/month. دیکھیں حصہ 5's لاگت shape table کے لیے مکمل breakdown.
کیا آپ کریں (Claude Code). Press Shift+Tab کو exit منصوبہ طریقہ. بنائیں sure Neon MCP server ہے connected (سے تصور 12). پھر:
Using the Neon MCP server, provision a project called "chat-agent",
enable the vector extension, and run the schema from
migrations/001_initial.sql (which you'll generate from the plan).
Use prepare_database_migration to test on a branch before committing
to main. Then add NEON_DATABASE_URL to my .env (use the main-branch
connection string).
agent استعمال کرتا ہے Neon MCP server کا ٹولز: create_project، run_sql (کے لیے CREATE EXTENSION vector)، prepare_database_migration (کو test on ایک branch)، اور complete_database_migration (کو apply کو مرکزی). Worker-side schema lands. پر end کا یہ فیصلہ، آپ رکھتے ہیں ایک working Neon ڈیٹا بیس کے ساتھ six tables، pgvector enabled، indexes built، اور connection string میں .env.
یہ ہے exactly development-use case سے تصور 12. Schema management via natural language on ایک branch، کے ساتھ explicit انسانی منظوری (آپ said "جائیں ahead") پہلے مرکزی ہے touched. Neon MCP server has earned اس کا place یہاں.
کیا تبدیلیاں میں OpenCode. وہی flow. OpenCode's MCP integration استعمال کرتا ہے Neon server identically; visible UI differs ( منظوری پرامپٹ format) مگر عملی کام ہیں وہی.
کیا migrations/001_initial.sql looks like
مکمل migration ہے six-table schema سے تصور 7، plus four domain-specific tables کے لیے customer-support مثال. دو pieces worth showing یہاں:
-- migrations/001_initial.sql — abbreviated; full file in the repo
CREATE EXTENSION IF NOT EXISTS vector;
-- [Six tables from Concept 7 omitted: conversations, messages, documents,
-- embeddings, audit_log, capability_invocations. See Concept 7.]
-- Domain-specific tables for customer-support
CREATE TABLE customers (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
email TEXT NOT NULL UNIQUE,
tier TEXT NOT NULL CHECK (tier IN ('free', 'pro', 'enterprise')),
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE TABLE orders (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
customer_id UUID NOT NULL REFERENCES customers(id) ON DELETE CASCADE,
public_id TEXT NOT NULL UNIQUE, -- the #4429-style display ID
placed_at TIMESTAMPTZ NOT NULL,
amount_cents INT NOT NULL,
status TEXT NOT NULL CHECK (status IN ('placed','shipped','delivered','refunded','cancelled'))
);
CREATE TABLE tickets (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
customer_id UUID NOT NULL REFERENCES customers(id) ON DELETE CASCADE,
order_id UUID REFERENCES orders(id) ON DELETE SET NULL,
summary TEXT NOT NULL,
resolution TEXT,
status TEXT NOT NULL CHECK (status IN ('open','in_progress','resolved','escalated')),
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
resolved_at TIMESTAMPTZ
);
CREATE TABLE refunds (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
order_id UUID NOT NULL REFERENCES orders(id) ON DELETE CASCADE,
ticket_id UUID REFERENCES tickets(id) ON DELETE SET NULL,
amount_cents INT NOT NULL,
reason TEXT NOT NULL,
issued_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
Verify فیصلہ 3 worked. کھولیں psql کے ساتھ آپ کا NEON_DATABASE_URL اور چلائیں:
SELECT extname FROM pg_extension WHERE extname = 'vector'; -- one row: 'vector'
SELECT COUNT(*) AS table_count FROM information_schema.tables
WHERE table_schema='public'; -- expect 10
SELECT indexname FROM pg_indexes
WHERE indexname = 'idx_embeddings_hnsw'; -- one row
Three rows back، نہیں errors: فیصلہ 3 ہے مکمل. If vector ہے missing، CREATE EXTENSION step on temporary branch didn't merge کو مرکزی; re-run complete_database_migration. If table count ہے off، migration didn't apply cleanly.
فیصلہ 4: لکھیں پہلا skill، summarize-ticket
کیا آپ کریں (Claude Code)، اور ایک deliberate exception.
** زیادہ تر اہم sentence on یہ صفحہ.** فیصلہ 4 ہے ** صرف place میں whole worked مثال کہاں آپ لکھیں something کے ذریعے hand بجائے کا briefing agent.** Everywhere else (CLAUDE.md، migration، MCP server، audit wiring) human briefs اور agent drafts. فیصلہ 4 ہے مختلف میں exactly ایک piece:
descriptionfield کاSKILL.md. یہ split (human owns description، agent owns everything else) ہے load-bearing pedagogy کا entire باب.
وجہ ہے تصور 3. description ہے کیا determines whether skill ever fires; getting یہ wrong means skill either silently never activates یا fires on ہر پرامپٹ (worse). Description quality ہے ایک judgment call کے بارے میں which صارف phrasings چاہیے trigger یہ skill، اور کہ judgment compounds پر life کا skill. پوچھیں agent کو لکھیں یہ اور آپ'll get ایک description کہ satisfies spec مگر ہے generic; لکھیں یہ yourself اور آپ'll get ایک کہ captures specific triggers آپ care کے بارے میں. body، مثالیں، edge cases: all agent-written کے تحت human review، وہی بطور ہر دwasرا فیصلہ. frontmatter description alone ہے part human owns.
پہلا، بنائیں skill فولڈر ڈھانچہ:
mkdir -p .claude/skills/summarize-ticket
frontmatter، hand-written:
---
name: summarize-ticket
description: Summarizes a customer support ticket into a structured format with sections for Customer Context, Issue Description, Resolution Steps Taken, Current Status, and Recommended Next Action. Use when the user provides a ticket ID, asks for a ticket summary, asks "what's the status of ticket X", or asks to be brought up to speed on a ticket. Produces a concise summary suitable for handoff to another agent.
---
کہ description took five drafts کو لکھیں. طریقہ کار سے تصور 3: name کیا ("summarizes ایک کسٹمر سپورٹ ticket میں ایک structured format")، name جب ("جب صارف فراہم کرتا ہے ایک ticket ID، پوچھتا ہے کے لیے ایک ticket summary، پوچھتا ہے 'کیا کا status کا ticket X'، یا پوچھتا ہے کو be brought up کو speed on ایک ticket")، surface specific keywords ("ticket ID،" "ticket summary،" "status کا ticket،" "brought up کو speed").
پھر پوچھیں Claude Code:
Open .claude/skills/summarize-ticket/SKILL.md. The frontmatter is
done. Write the body — step-by-step operational instructions, two
examples (one short ticket, one complex), and three edge cases
(escalated ticket, ticket with no resolution yet, ticket where the
customer is irate). Keep the body under 200 lines.
ماڈل پیدا کرتا ہے body. پڑھیں یہ. Push back on کوئی بھی چیز narrative. skills چلائیں بہتر کے ساتھ imperative instructions ("دیکھیں up ticket. Extract X. Format بطور Y.") than narrative descriptions ("یہ skill ہے ڈیزائن کیا گیا کو مدد کے ساتھ..."). تصور 3 طریقہ کار applies میں مکمل.
کیوں. یہ ہے پہلا وقت agent gets صلاحیت کہ wasn't میں tools.py. اگلا conversation کہ mentions ایک ticket ID won't جائیں کے ذریعے search_docs stub; یہ'll activate یہ skill اور follow اس کا instructions. ماڈل decides skill applies مبنی on description; body controls کیا ہوتا ہے اگلا.
کیا تبدیلیاں میں OpenCode. skill میں .claude/skills/summarize-ticket/SKILL.md ہے auto-discovered کے ذریعے OpenCode via اس کا fallback path (تصور 4). نہیں duplication needed.
کیا .claude/skills/summarize-ticket/SKILL.md looks like
---
name: summarize-ticket
description: Summarizes a customer support ticket into a structured format with sections for Customer Context, Issue Description, Resolution Steps Taken, Current Status, and Recommended Next Action. Use when the user provides a ticket ID, asks for a ticket summary, asks "what's the status of ticket X", or asks to be brought up to speed on a ticket. Produces a concise summary suitable for handoff to another agent.
---
# Summarize ticket
When this skill activates:
1. Extract the ticket ID from the user's message. Format: a UUID, or a
public ID like "TKT-1234". If both forms are present, prefer the UUID.
2. Call the `lookup_customer` tool with the ticket's customer_id (which
you'll get in step 4).
3. Call `find_similar_resolved_tickets` with the ticket's summary, to
surface 2-3 prior similar resolutions.
4. Fetch the ticket itself by querying for ticket_id = <id>. If the ticket
has order_id set, fetch the order too.
5. Compose a five-section summary:
**Customer Context** — name, tier, account age, any recent prior tickets
**Issue Description** — the ticket summary, the affected order if any
**Resolution Steps Taken** — actions logged in audit_log scoped to this ticket
**Current Status** — status field, who is assigned, time since last update
**Recommended Next Action** — based on similar resolved tickets, propose ONE
specific action: respond with template, escalate, request more info, close
6. Keep the summary under 200 words total.
## Example: short ticket
Ticket TKT-1042 from a free-tier customer who reported a missing order. Status:
open, 18 minutes old, no actions yet. Three similar resolved tickets show
this is usually a delivery-tracking issue resolved in 2 hours.
Output:
**Customer Context**: Sara K. (free tier, 7-month account, 0 prior tickets)
**Issue Description**: Order #4912 not received, 5 days post-shipping date
**Resolution Steps Taken**: None — ticket 18 minutes old
**Current Status**: Open, unassigned
**Recommended Next Action**: Reply with delivery-tracking template; auto-close
in 24h if no follow-up.
## Example: complex ticket
[A second worked example with an escalated ticket — omitted for brevity.]
## Edge cases
**Escalated ticket** — include the escalation reason and the assignee. Mark the
"Recommended Next Action" as "Continue with assignee; do not duplicate."
**No resolution yet** — explicit "no actions logged" in Resolution Steps Taken.
Don't infer.
**Irate customer (from message sentiment)** — flag in Customer Context.
Recommend tier-2 review even if the issue is small.
** دwasرا دو skills، میں brief.** وہی shape applies. دو زیادہ frontmatter blocks، ہر forty منٹ کا careful description-writing، اور ورکر has three skills یہ ضرورت ہے.
# .claude/skills/find-similar-cases/SKILL.md (frontmatter only)
---
name: find-similar-cases
description: Searches the resolved-tickets library for tickets semantically similar to a customer's described issue, returning the top 3-5 with their resolutions and a similarity score. Use when the user describes a problem, complaint, or symptom and you need to check whether the team has handled something similar before. Calls the find_similar_resolved_tickets MCP tool. Always run this BEFORE drafting a response, so the response can reference proven prior resolutions rather than inventing a new approach.
---
body walks کے ذریعے three steps: extract issue description سے سیاق و سباق، call find_similar_resolved_tickets کے ساتھ limit=5، present top three کے ساتھ similarity scores میں ایک markdown table، اور explicitly flag low-confidence matches (similarity > 0.3) بطور "نہیں مضبوط prior precedent found." instruction "ہمیشہ چلائیں یہ پہلے drafting" ہے doing حقیقی کام; بغیر یہ، ماڈل sometimes drafts ایک reply سے priors اور never looks پر library.
# .claude/skills/escalate-with-context/SKILL.md (frontmatter only)
---
name: escalate-with-context
description: Packages a customer conversation for handoff to a tier-2 support agent. Produces a structured escalation note with customer profile, issue summary, what was already tried, why escalation is recommended, and the suggested specialist team. Use when (a) the customer is on the Pro or Enterprise tier AND the issue is unresolved after one round of investigation, (b) the customer's sentiment is clearly negative, (c) the issue involves billing >$500 or a refund decision, or (d) the user explicitly asks for a human.
---
body invokes summarize-ticket پہلا کو get structured سیاق و سباق، پھر writes ایک six-section escalation note (customer سیاق و سباق، issue، attempted resolutions، sentiment signals، recommended ٹیم، suggested SLA). four explicit trigger conditions میں description ہیں کیا stop یہ skill سے over-firing; ایک ورکر کے ساتھ vague escalation logic escalates everything، کون سا defeats purpose.
کے ذریعے فیصلہ 7 all three skills گا be live میں .claude/skills/. ڈھانچہ transfers; صرف descriptions اور operational specifics تبدیلی.
فیصلہ 5: تعمیر embedding pipeline اور seed دستاویز library
ایک seed corpus کا ایک few dozen resolved tickets پر ~300 tokens ہر embeds کے لیے ایک fraction کا ایک cent پر text-embedding-3-small's $0.02 per 1M input tokens. Ongoing embedding کا نیا tickets اور messages typically stays کے تحت $3/month پر worked-example volume. Embeddings ہیں cheapest سطر on bill; لاگت lever ہے inference بجٹ، نہیں embedding بجٹ.
کیا آپ کریں. دو pieces یہاں: embedding pipeline کوڈ (سے تصور 9) اور ایک چھوٹا corpus کو embed. ورکر کا "library" کے لیے یہ مثال ہے ایک curated سیٹ کا past resolved tickets: چھوٹا enough کو چلائیں تیز، big enough کہ semantic search دکھاتا ہے اس کا قدر. ایک dozen rows ہے enough کو feel ڈھانچہ کام; ایک few dozen بناتا ہے retrieval results زیادہ interesting. کورس doesn't ship corpus، کیونکہ writing یہ ہے part کا مشق: دیں آپ کا agent column shape اور ایک few مثال rows، اور رکھتے ہیں یہ generate rest.
mkdir -p data/seed
# data/seed/resolved-tickets.csv (columns: id, customer_email, summary, resolution)
# A few starter rows; ask your agent to expand this to a dozen or more,
# varied enough that semantic search has something to discriminate between.
id,customer_email,summary,resolution
1,sara@example.com,Refund not showing up two weeks after return approved,Refund was stuck in pending due to a payment-gateway batch delay; manually re-triggered and funds posted within 24h.
2,raj@example.com,Cannot log in after email change,Account email was updated but the session cache held the old address; cleared the session and the customer logged in normally.
3,mei@example.com,Duplicate charge on a single order,Gateway retry created a second authorization; voided the duplicate and confirmed only one capture settled.
customer_email column lets seeder find-or-create ایک customers row پہلے inserting ticket ( tickets.customer_id foreign اہم ہے NOT NULL، اس لیے seed نہیں کر سکتا skip یہ step). پھر پوچھیں agent:
Implement src/chat_agent/embedding/{chunker,embedder,seeder}.py based on
the patterns from Concepts 9 and 10 of the course. Add a CLI command
`python -m chat_agent.embedding.seeder data/seed/resolved-tickets.csv`
that:
1. Reads the CSV.
2. For each row:
a. Find or create a customers row by email (default tier='free').
b. Insert a tickets row with status='resolved' and customer_id set.
c. Insert a documents row with source='past_case', title=the ticket
summary, body=summary+resolution combined, and metadata containing
the ticket id ({"ticket_id": "<uuid>"}). This is the row the
embedding will link to: embeddings.document_id references
documents(id), not tickets(id). See Concept 7's schema and the
Concept 14 query.
d. Chunk the documents row's body.
e. Embed each chunk with text-embedding-3-small.
f. Insert each chunk into embeddings with document_id set to the
documents row from step (c) (not conversation_id).
3. Write a single audit_log row recording "seed_run" with the row count.
Use asyncpg via a connection pool. Do NOT use the Neon MCP server for
this; direct connection only. We're populating data, not managing
the database.
ماڈل پیدا کرتا ہے seeder. چلائیں یہ. Watch embedding count grow. Confirm index کام کرتا ہے:
-- A sanity-check query you should run after seeding
SELECT COUNT(*) FROM embeddings WHERE document_id IS NOT NULL;
SELECT model, COUNT(*) FROM embeddings GROUP BY model;
EXPLAIN ANALYZE
SELECT chunk_text, embedding <=> (SELECT embedding FROM embeddings LIMIT 1) AS d
FROM embeddings ORDER BY d LIMIT 5;
EXPLAIN ANALYZE چاہیے دکھائیں "Index Scan استعمال کرتے ہوئے idx_embeddings_hnsw"; کہ کا HNSW index doing اس کا job. If یہ دکھاتا ہے "Seq Scan،" index isn't being استعمال ہوا (usually ایک result کا table being too چھوٹا; pgvector کا planner falls back کو sequential scans below ایک certain row count، کون سا ہے fine کے لیے ایک چھوٹا seed corpus مگر worth knowing).
کیوں یہ ہے direct asyncpg، نہیں MCP. Seed scripts ہیں بنیادی ڈھانچا. They چلائیں once، کے ذریعے hand، کے ذریعے ایک authorized operator. They ہیں نہیں ایک ورکر کا runtime path. ** MCP boundary ہے کے لیے things agent کرتا ہے autonomously; seed script ہے کے لیے things آپ کریں.** Don't put unnecessary boundaries درمیان yourself اور آپ کا اپنا ڈیٹا بیس.
کیا تبدیلیاں میں OpenCode. وہی طریقہ. استعمال کریں OpenCode's /build slash command equivalent (یا just direct prompting) کو generate وہی فائلیں.
Verify فیصلہ 5 worked. sanity-check block above ہے آپ کا verification surface. Specifically:
SELECT COUNT(*) FROM documents WHERE source = 'past_case'چاہیے equal row count میں آپ کا CSV. ہر resolved ticket بن جاتا ہے ایکdocumentsrow; یہ ہے row embedding لنکس کو.SELECT COUNT(*) FROM embeddings WHERE document_id IS NOT NULLچاہیے بھی equal CSV row count (ایک embedding per short ticket، since seed corpus ہے below chunking threshold).SELECT model, COUNT(*) FROM embeddings GROUP BY modelچاہیے دکھائیں ایک row، naming embedding ماڈل آپ اصل میں استعمال ہوا. دو rows means آپ mixed ماڈلز mid-seed; re-run سے ایک clean state.EXPLAIN ANALYZEسطر چاہیے دکھائیںIndex Scan using idx_embeddings_hnswکے لیے corpora پر ایک few hundred rows. کے ساتھ ایک چھوٹا seed corpus pgvector کا planner falls back کوSeq Scanاور کہ کا fine.
If counts ہیں zero، آپ کا seeder swallowed ایک exception silently; چیک audit_log row آپ کا seeder wrote کے لیے seed چلائیں.
فیصلہ 6: لکھیں custom MCP server کے لیے runtime access
custom MCP server چلتا ہے میں آپ کا سینڈ باکس عمل، اس لیے وہاں ہے نہیں separate hosting لاگت. کہاں bill دکھاتا ہے up ہے میں inference: ہر lookup_customer یا find_similar_resolved_tickets call adds ایک round-trip کا worth کا tokens کو اگلا ماڈل turn. تصور 15 covers latency اور pool-size side کا MCP-under-load.
کیا آپ کریں. بنائیں custom MCP server کہ agent گا استعمال کریں پر runtime. Three ٹولز کو شروع کریں: lookup_customer، find_similar_resolved_tickets، issue_refund. نہیں run_sql. ہر ٹول ہے narrowly scoped.
mkdir -p src/customer_data_mcp
touch src/customer_data_mcp/__init__.py
touch src/customer_data_mcp/server.py
uv add mcp asyncpg
server ہے built on mcp.server.fastmcp.FastMCP فریم ورک سے Python MCP SDK. زیادہ تر کا ڈھانچہ ہے shown میں تصور 14's مثال; worked مثال یہاں extends یہ.
Implement src/customer_data_mcp/server.py with three @mcp.tool() functions:
1. lookup_customer(customer_id) → returns id, email, tier, active_tickets.
2. find_similar_resolved_tickets(description, limit=5) → embeds description
via text-embedding-3-small, runs the vector query joining embeddings to
documents (embeddings.document_id → documents.id) and on to tickets via
documents.metadata->>'ticket_id', filtered to source='past_case' and
status='resolved'. Returns ticket_id, summary, resolution, similarity_score.
3. issue_refund(order_id, amount_cents, reason) → inserts a row into
refunds, marks the order status='refunded', writes an audit_log row
marking the action.
Use asyncpg with a connection pool. Type every function. Set up the server
to run via stdio when invoked as __main__.
ماڈل پیدا کرتا ہے server. پڑھیں ہر ٹول کا docstring. ہر docstring ہے model-facing description کا جب کو استعمال کریں کہ ٹول: وہی load-bearing role بطور ایک SKILL.md description. Vague docstrings cause ٹولز کو fire پر wrong times.
کیوں یہ ہے ایک custom MCP server، نہیں just asyncpg calls میں agent کوڈ. تصور 14's three reasons، میں order they matter کے لیے یہ ورکر: scope ( agent سکتا ہے کریں exactly three things کو ڈیٹا بیس، نہیں کوئی بھی چیز SQL allows)، isolation ( MCP server چلتا ہے میں اس کا اپنا عمل، کے ساتھ اس کا اپنا connection pool کہ agent سکتا ہے't accidentally exhaust)، اور reusability (جب we تعمیر کریں second ورکر کہ بھی ضرورت ہے lookup_customer، یہ talks کو وہی server).
کیا تبدیلیاں میں OpenCode. MCP server itself ہے ٹول-agnostic. agent کا MCP server registration moves کو opencode.json:
{
"mcp": {
"customer-data": {
"type": "local",
"command": ["python", "-m", "customer_data_mcp.server"],
"env": { "DATABASE_URL": "${env:DATABASE_URL}" }
}
}
}
Skeleton کا customer_data_mcp/server.py
# src/customer_data_mcp/server.py
import json
import os
from typing import Annotated
import asyncpg
from mcp.server.fastmcp import FastMCP
from openai import AsyncOpenAI
from pydantic import Field
mcp: FastMCP = FastMCP("customer-data")
_pool: asyncpg.Pool | None = None
_oai: AsyncOpenAI | None = None
async def get_pool() -> asyncpg.Pool:
global _pool
if _pool is None:
_pool = await asyncpg.create_pool(
os.environ["DATABASE_URL"], min_size=1, max_size=10,
)
return _pool
# The SQL in this server uses unqualified table names (embeddings, tickets, ...),
# which assumes the tables live in the `public` schema. That holds if you
# followed the course's migration as-is. If you put the schema somewhere else
# (a Neon branch with a non-default schema), schema-qualify the table names:
# Neon's pooled endpoint silently drops `server_settings` startup params and
# resets `SET search_path` on connection release, so search_path isolation does
# not survive a pooled connection.
def get_oai() -> AsyncOpenAI:
global _oai
if _oai is None:
_oai = AsyncOpenAI()
return _oai
@mcp.tool()
async def lookup_customer(
customer_id: Annotated[str, Field(description="Customer UUID.")],
) -> dict[str, str | int]:
"""Look up customer by UUID. Returns id, email, tier, active_tickets count.
Use when the user provides a customer ID and you need their profile.
"""
pool = await get_pool()
async with pool.acquire() as conn:
row = await conn.fetchrow(
"""SELECT id::text, email, tier,
(SELECT COUNT(*) FROM tickets t
WHERE t.customer_id = c.id AND t.status='open') AS active_tickets
FROM customers c WHERE id = $1::uuid""",
customer_id,
)
return dict(row) if row else {"error": "customer not found"}
@mcp.tool()
async def find_similar_resolved_tickets(
description: Annotated[str, Field(description="Customer's issue description.")],
limit: Annotated[int, Field(ge=1, le=10)] = 5,
) -> list[dict[str, str | float]]:
"""Find resolved tickets similar to a description, via pgvector.
Use when the user describes an issue and you want to check prior resolutions.
"""
oai = get_oai()
emb = await oai.embeddings.create(
model="text-embedding-3-small", input=[description],
)
query_vec = emb.data[0].embedding
pool = await get_pool()
async with pool.acquire() as conn:
# embeddings.document_id references documents(id), not tickets(id).
# Decision 5's seeder stores each resolved ticket as a documents row
# (source='past_case') with the ticket id in metadata, so the join
# path is embeddings -> documents -> tickets.
rows = await conn.fetch(
"""SELECT t.id::text AS ticket_id, t.summary, t.resolution,
(e.embedding <=> $1::vector) AS distance
FROM embeddings e
JOIN documents d ON d.id = e.document_id
JOIN tickets t ON t.id = (d.metadata->>'ticket_id')::uuid
WHERE d.source = 'past_case' AND t.status = 'resolved'
ORDER BY e.embedding <=> $1::vector
LIMIT $2""",
query_vec, limit,
)
return [dict(r) for r in rows]
@mcp.tool()
async def issue_refund(
order_id: Annotated[str, Field(description="Order UUID.")],
amount_cents: Annotated[int, Field(ge=1, description="Refund amount in cents.")],
reason: Annotated[str, Field(description="Reason recorded with the refund.")],
) -> dict[str, str]:
"""Issue a refund for an order. Writes refunds row, updates order.status,
and writes an audit_log row. Use only when refund is authorized.
"""
pool = await get_pool()
async with pool.acquire() as conn:
async with conn.transaction():
refund_id: str = await conn.fetchval(
"""INSERT INTO refunds (order_id, amount_cents, reason)
VALUES ($1::uuid, $2, $3) RETURNING id::text""",
order_id, amount_cents, reason,
)
await conn.execute(
"UPDATE orders SET status='refunded' WHERE id = $1::uuid",
order_id,
)
await conn.execute(
"""INSERT INTO audit_log
(actor, action, target, payload, result)
VALUES ($1, $2, $3, $4::jsonb, $5::jsonb)""",
"worker:customer-support", "refund_issued", order_id,
json.dumps({"amount_cents": amount_cents, "reason": reason}),
json.dumps({"refund_id": refund_id}),
)
return {"refund_id": refund_id, "order_id": order_id, "status": "ok"}
if __name__ == "__main__":
mcp.run(transport="stdio")
Verify فیصلہ 6 worked. شروع کریں server standalone اور confirm یہ lists اس کا three custom ٹولز:
# In one terminal: start the MCP server as if it were being launched by the agent
uv run python -m customer_data_mcp.server &
# In another terminal, or after the server prints "Server listening on stdio":
# Try the agent
uv run python -m chat_agent.cli "test: list your available tools"
agent کا پہلا response چاہیے name three custom ٹولز: lookup_customer، find_similar_resolved_tickets، issue_refund. (Some ماڈلز بھی surface ان کا اپنا meta-ٹولز، like OpenAI's multi_tool_use.parallel، ایک parallel-call wrapper; کہ ہے normal اور نہیں سے آپ کا MCP server.) If آپ دیکھیں ایک generic ڈیٹا بیس ٹول (run_sql یا similar)، agent ہے بھی connected کو Neon MCP server پر runtime; remove کہ سے آپ کا runtime mcp_servers= list (یہ کا development-only per تصور 12). If three custom ٹولز ہیں missing یا آپ get ایک init-timeout error، MCP server crashed پر startup; چیک subprocess stderr کے لیے اصل exception. تصور 13 timeout admonition covers ML-import case.
Event loop is closed traceback on shutdown is harmlessیہ server holds ایک AsyncOpenAI client (کے لیے embedding اندر find_similar_resolved_tickets). جب MCP subprocess shuts down، HTTP library کا connection cleanup سکتا ہے race stdio transport کا event-loop teardown اور print ایک multi-line Fatal error on SSL transport / RuntimeError: Event loop is closed traceback کو stderr. یہ ہے teardown noise: چلائیں پہلے ہی completed. Judge success کے ذریعے exit کوڈ اور جانچ کا ریکارڈ، نہیں کے ذریعے ایک clean-looking shutdown. (If noise bothers آپ، deeper fix ہے کو move embedding call میں agent عمل اور pass vector کو ٹول بطور ایک argument; کہ بھی narrows server کا scope، کون سا ہے whole point کا تصور 14.)
فیصلہ 7: رابطہ audit logging everywhere
کیا آپ کریں. دو pieces کا wiring: agent کا اپنا audit writes (skill invocations، ماڈل calls)، اور audit writes اندر MCP server (پہلے ہی shown میں issue_refund above). دونوں happen alongside actions، never بطور ایک afterthought.
agent-side helper سے تصور 10 (log_capability) gets استعمال ہوا پر three sites میں cli.py اور sandboxed.py: پر شروع کریں اور end کا ہر skill invocation، بعد ہر MCP ٹول call، اور کے گرد حفاظتی حد trips. اہم طریقہ کار: ** audit لکھیں اور action یہ logs happen میں وہی کوڈ path، ideally میں وہی transaction.**
پوچھیں agent:
Modify src/chat_agent/cli.py to log_capability around each
Runner.run_streamed call. Capture: which skills activated (visible
from RunItemStreamEvent.tool_called for skill events), which MCP
tools were called, total tokens, latency, status. Write to audit_log
via a direct asyncpg connection (NOT through the customer-data MCP
server — audit is the meta-layer; it shouldn't share the same MCP
boundary as the data it audits).
audit connection pool ہے separate سے customer-data MCP server کا pool. دو reasons: audit لازمی succeed even if ڈیٹا pool ہے saturated، اور audit writes shouldn't compete کے ساتھ کاروباری writes کے لیے وہی connections. ایک audit subsystem کہ سکتا ہے be starved کے ذریعے نظام یہ کا auditing ہے نہیں ایک audit subsystem.
کیوں audit بنیادی ڈھانچا looks complicated اور isn't. schema سے تصور 7 پہلے ہی has audit_log اور capability_invocations. helper سے تصور 10 پہلے ہی writes دونوں میں ایک transaction. کیا یہ فیصلہ adds ہے calling کہ helper پر ہر meaningful boundary. mechanics ہیں سادہ; طریقہ کار ہے میں remembering کو کریں یہ consistently.
کیا تبدیلیاں میں OpenCode. Identical. audit کوڈ ہے plain Python; نہیں ٹول-specific differences.
Verify فیصلہ 7 worked. چلائیں ایک throwaway conversation کے خلاف agent، پھر پوچھیں ڈیٹا بیس whether audit fired:
-- Pick the most recent conversation
SELECT id FROM conversations ORDER BY started_at DESC LIMIT 1;
-- ... then for that conversation_id, every meaningful event should have a row
SELECT action, target, created_at FROM audit_log
WHERE conversation_id = '<id-from-above>'
ORDER BY created_at;
Running سے standalone Python cli.py، آپ چاہیے دیکھیں پر minimum: message_received، پر least ایک capability_invoked، اور message_sent. (نہیں skill_activated row سے standalone path; فیصلہ 8 explains کیوں اور دکھاتا ہے کیسے کو دیکھیں ایک اندر Claude Code.) If آپ دیکھیں صرف MCP-side rows (capability_invoked + domain actions like refund_issued)، agent-side log_capability helper ہے wired مگر نہیں firing; چیک کہ آپ invoked یہ سے Runner.run_streamed event loop، نہیں just پر چلائیں شروع کریں. If آپ دیکھیں zero rows: audit connection pool isn't connecting; چیک audit.py's asyncpg.create_pool(...) کے خلاف آپ کا NEON_DATABASE_URL.
فیصلہ 8: Verify شروع سے آخر تک کے ساتھ test scenario
کیا آپ کریں. چلائیں customer scenario سے brief:
You: I haven't received my refund from order #4429 — it's been two weeks.
Trace کیا ہوتا ہے. Running سے standalone Python cli.py، four things آپ چاہیے دیکھیں میں audit log اندر ایک few seconds:
action=message_received: صارف کا message arrives، conversation row بنایا گیا.action=capability_invoked, target=mcp:lookup_customer: agent finds customer behind order #4429.action=capability_invoked, target=mcp:find_similar_resolved_tickets: vector search finds similar past cases.action=message_sent: agent کا draft reply، recorded.
If ایک refund were authorized: ایک action=capability_invoked, target=mcp:issue_refund row، plus ایک action=refund_issued row لکھا گیا کے ذریعے MCP ٹول itself (فیصلہ 6) carrying amount اور وجہ میں payload. If ایک refund ہے not authorized ( policy چیک fails)، ایک action=refund_blocked row کے ساتھ وجہ: no-action case ہے just بطور اہم بطور action case کے لیے replay. All کا یہ action names match مستند vocabulary table میں تصور 10.
کیا آپ گا نہیں دیکھیں سے standalone Python path ہے ایک skill_activated row. skill discovery ہے ایک Claude Code / OpenCode client صلاحیت ( "ایک precondition" callout near فوری کامیابی); ایک bare Agent(...) کرتا ہے نہیں scan .claude/skills/. three skills سے فیصلہ 4 ہیں on disk، valid، اور ready، مگر standalone agent reaches lookup_customer اور find_similar_resolved_tickets کے ذریعے MCP boundary directly، نہیں کے ذریعے summarize-ticket skill. کو دیکھیں skills layer fire، چلائیں وہی agent اندر Claude Code (اگلا callout).
Rows 1 اور 4 (message_received، message_sent) come سے فیصلہ 7's agent-side audit wiring. Rows 2، 3، اور refund rows come سے ** MCP server itself** (فیصلہ 6). If آپ implemented فیصلے 1-6 + 8 مگر skipped فیصلہ 7 (ایک defensible slice کے لیے ایک سیکھنا pass; MCP-side audit ہے پہلے ہی enough کو prove ڈھانچہ)، آپ گا دیکھیں صرف MCP-side rows. کہ ہے بھی ایک success state: کاروباری writes رکھتے ہیں ایک receipt; agent-side trace ہے کیا آپ شامل کریں جب آپ ضرورت کو replay استدلال، نہیں just outcomes.
Everything above چلتا ہے کے ذریعے standalone Python cli.py، کون سا نہیں کر سکتا load .claude/skills/. کو مشق skills layer brief promised، کھولیں یہ وہی پروجیکٹ میں Claude Code (یا OpenCode) اور دیں یہ scenario پرامپٹ directly. اب skill discovery ہے active: client scans .claude/skills/، ماڈل matches summarize-ticket description، اور آپ کا agent-side log_capability wiring records ایک skill_activated row alongside capability_invoked rows. وہی audit schema، وہی مستند vocabulary، ایک زیادہ action قدر: row standalone path structurally نہیں کر سکتا پیدا کریں. یہ ہے moment three layers، skills + ریکارڈ کا مستند نظام + MCP، ہیں all visible میں ایک trace.
پھر چلائیں replay query، ایک کہ proves آپ کا audit log ہے replayable:
SELECT al.created_at, al.action, al.target, al.payload, al.result
FROM audit_log al
WHERE conversation_id = $1
ORDER BY al.created_at;
پڑھیں result. آپ چاہیے be able کو reconstruct، سطر کے ذریعے سطر، کیا agent did اور کیوں، بغیر re-running ماڈل. If آپ سکتا ہے't (if ایک step happened کہ isn't میں log، یا if ایک row ہے میں log مگر action یہ claims happened isn't reflected میں کاروباری tables) وہاں کا ایک wiring bug. Fix یہ اب.
کیوں یہ scenario. یہ مشقیں ڈھانچے سے متعلق pieces یہ کورس adds: MCP-backed ٹولز (lookup_customer، find_similar_resolved_tickets) چلائیں کے خلاف Neon ریکارڈ کا مستند نظام، اور ایک جانچ کا ریکارڈ records path، all replayable میں SQL. None کا کہ existed میں Course #3's chat agent. skills layer ہے third piece: built اور ready میں .claude/skills/، اور یہ joins trace moment آپ چلائیں وہی agent اندر Claude Code ( callout above)، کہاں skill discovery ہے active اور ایک skill_activated row appears alongside rest.
کیا تبدیلیاں میں OpenCode. verification ہے client-agnostic: چلائیں اندر Claude Code یا OpenCode اور آپ get وہی trace، skill_activated row included، بطور long بطور agent کوڈ، skills، اور MCP server ہیں وہی. standalone Python cli.py پیدا کرتا ہے وہی trace minus کہ ایک row، کے لیے وجہ فیصلہ 8 explains.
کیا just happened
Eight فیصلے، اور chat agent سے Course #3 ہے اب ایک ورکر. دیکھیں back پر کیا changed:
- صلاحیت moved باہر کا کوڈ. Three skills sit میں
.claude/skills/، version-controlled، sharable across agents. - state moved میں ایک ریکارڈ کا مستند نظام. Six tables میں Neon، کے ساتھ semantic search via pgvector، اور ایک حقیقی domain schema کے لیے customers/orders/tickets/refunds.
- runtime ڈیٹا بیس access ہے mediated. agent doesn't رکھتے ہیں
asyncpgمیں اس کا imports; یہ talks کو Postgres کے ذریعے ایک scoped MCP server کہ exposes exactly three ٹولز. - ہر action leaves ایک trace. audit log سکتا ہے replay مکمل استدلال trace کا any conversation، weeks یا months بعد fact، میں SQL.
OpenAI Agents SDK ہے اب بھی وہاں. Cloudflare سینڈ باکس ہے اب بھی وہاں. سٹریمنگ، حفاظتی حدود، ٹریسنگ سے Course #3 ہیں all اب بھی وہاں. کیا کا مختلف ہے ڈھانچہ layered on top: skills بطور صلاحیت، Neon بطور truth، MCP بطور wiring درمیان انہیں.
کہ ہے کیا thesis calls difference درمیان ایک agent اور ایک ورکر.
حصہ 5: کہاں یہ کورس leaves off
Cost shape کا ایک ورکر: کیا کرتا ہے یہ اصل میں لاگت کو operate?
Course #3 had "ہر turn re-bills دنیا" thread; یہ کورس has اس لیے far been quiet کے بارے میں dollars. Closing gap، کے لیے حصہ 4 worked مثال specifically: ایک customer-support ورکر doing 200 conversations per دن، ~10 messages per conversation، average سیاق و سباق 8K tokens per turn، three skills، three MCP ٹولز.
Four لاگت lines، میں order کا size.
| سطر | Driver | Rough monthly لاگت | جب یہ bites |
|---|---|---|---|
| ماڈل inference | input tokens × turns × $/M | $60–$200 | Volume × پرامپٹ size. Cache hits on stable prefixes (CLAUDE.md، skills metadata، نظام پرامپٹ) typically recover 60–80% کا input لاگت. |
| Neon Postgres | storage + active compute | $0–$25 | Free tier covers ایک single ورکر doing یہ volume. Scale-to-zero means idle گھنٹے لاگت nothing. Paid tier kicks میں once ایک پروجیکٹ crosses 0.5 GB / 100 CU-hours free-plan limits (دیکھیں Neon قیمتوں کا تعین کے لیے موجودہ numbers). |
| Embeddings | chunks × $0.02/M tokens | $0.30–$3 | One-time لاگت کے لیے seed ڈیٹا plus incremental embedding کا نیا tickets/messages. Negligible unless آپ're embedding entire conversation histories continuously. |
| Cloudflare سینڈ باکس | container منٹ | $0–$15 | Depends on سیشن length اور concurrency. Idle reaping مدد کرتا ہے; long-running سیشنز don't. |
Total monthly کے لیے حصہ 4 ورکر: roughly $60–$240. ماڈل ہے largest سطر، کے ذریعے ایک order کا magnitude پر everything else. ریکارڈ کا مستند نظام ہے essentially free پر یہ volume. skills طریقہ کار (progressive disclosure، تصور 2) ہے بھی لاگت طریقہ کار: ایک ورکر کے ساتھ bloated SKILL.md bodies pays کے لیے ہر turn کہ activates انہیں; ایک ورکر کے ساتھ descriptions-only-at-discovery اور tight bodies-on-activation pays کے لیے کیا یہ استعمال کرتا ہے.
Three knobs کہ move dial زیادہ تر. (1) Cache hit rate: رکھیں آپ کا CLAUDE.md، نظام پرامپٹ، اور skills metadata stable; cache misses لاگت 5–10× زیادہ than hits. (2) ماڈل tier: وہی ورکر on ایک cheaper ماڈل (DeepSeek V4 Flash، Claude Haiku) often کرتا ہے 80% کا job پر 10% کا لاگت; route مشکل فیصلے کو فرنٹیئر ماڈل صرف جب needed. (3) audit table growth: audit_log ہے largest table کے ذریعے row count (تصور 7's PRIMM Predict); partition یا archive past 90 days if آپ don't اصل میں query historical audit ڈیٹا.
** honest scaling number.** ایک افرادی قوت کا 50 ورکرز پر یہ shape (کیا آپ کا اگلا کورس covers) ہے roughly $3،000–$12،000/month کے لیے inference، $50–$200 کے لیے Neon، single-digit dollars کے لیے embeddings، $100–$500 کے لیے سینڈ باکس compute. بنیادی ڈھانچا layer stays سستا; ماڈل bill ہے whبڑے پیمانے پرs. یہ ہے کیوں ہر Course #3 لاگت-طریقہ کار habit (cache hits، ماڈل tiering، سیاق و سباق hygiene) compounds جب آپ جائیں سے ایک ورکر کو بہت سے.
Swap رہنمائی: ڈھانچہ ہے invariant، پروڈکٹس ہیں نہیں
یہ کورس names specific vendors پر ہر layer (OpenAI Agents SDK، Cloudflare سینڈ باکس، Neon، OpenAI embeddings، MCP Python SDK). کہ کا کیونکہ ایک تدریس مثال ضرورت ہے concrete جوابات، نہیں "استعمال کریں any LLM runtime آپ like." مگر ڈھانچہ کام کرتا ہے کے ساتھ any compliant alternative. Five swaps کورس's ڈیزائن explicitly anticipates:
- Postgres host: Neon → Supabase، AWS RDS، self-hosted. کوئی بھی چیز کے ساتھ
pgvectorکام کرتا ہے. آپ lose branching اور wasیع کرنا-to-zero (those ہیں Neon-specific)، مگر six-table schema، embedding pipeline، audit-trail طریقہ کار، اور custom MCP server نمونہ ہیں all transferable byte-for-byte. صرف تبدیلی ہے connection string اور possibly SSL config. - Vector storage: pgvector → Pinecone، Weaviate، Qdrant. If آپ reject "ایک ڈیٹا بیس کے لیے دونوں relational اور vector ڈیٹا" argument سے تصور 6، swap
embeddingstable کے لیے ایک vector-DB client. لاگت: دو stores کو رکھیں مستقل (تصور 6 argues یہ ہے rarely worth یہ). benefit: بہتر recall پر بہت بڑا scales (10M+ vectors)، اور managed-service operational simplicity. - Embedding ماڈل: OpenAI → Cohere، Voyage، BGE-small (local). تبدیلی ایک constant (
EMBEDDING_MODEL) اور ایک column dimension (VECTOR(n)). چلائیں ایک one-shot re-embed کا existing ڈیٹا. تصور 9's pipeline doesn't تبدیلی. - سینڈ باکس: Cloudflare سینڈ باکس → E2B، Modal، Daytona، آپ کا اپنا Docker. کوئی بھی چیز کے ساتھ isolated عمل boundaries اور ایک clean restart کام کرتا ہے. skills'
scripts/execute وہی طریقہ. trust-boundary diagram سے Course #3 اب بھی applies. - Agent runtime: OpenAI Agents SDK → LangGraph، CrewAI، Pydantic AI، آپ کا اپنا loop. MCP boundary ہے کیا survives; ہر modern agent فریم ورک has ایک MCP client. skills کام میں any agent کہ سکتا ہے load
SKILL.mdفائلیں (Claude Code، OpenCode، Goose، اور increasingly Cursor/Windsurf). audit-trail طریقہ کار ہے فریم ورک-agnostic Python.
کیا doesn't swap easily. MCP پروٹوکول itself، skills format spec، اور audit-trail طریقہ کار. یہ ہیں invariants: things آپ'd port درمیان پروڈکٹس، نہیں things آپ'd port درمیان. وہی ڈھانچے سے متعلق shape، replaceable implementations underneath.
کیا یہ کورس doesn't cover (yet)
آپ اب رکھتے ہیں ایک ورکر کہ satisfies دو کا Seven Invariants thesis sets باہر. Specifically: یہ چلتا ہے on ایک engine (Invariant 4، سے Course #3)، اور یہ چلتا ہے کے خلاف ایک ریکارڈ کا مستند نظام (Invariant 5، سے یہ کورس). دwasرا five Invariants ہیں کیا پروڈکشن AI-Native کمپنیاں require، اور کیا subsequent کورسز cover. ہر ہے ایک bullet یہاں، نہیں ایک حصہ.
- Invariant 1: human ہے principal. Authored specs، منظوری gates، بجٹ declarations. ڈھانچہ کے لیے setting intent اور owning outcomes، covered میں حصہ 6 کا کتاب.
- Invariant 2: ہر human ضرورت ہے ایک نمائندہ. ایک personal agent پر edge کہ holds آپ کا سیاق و سباق، represents آپ کا judgment، اور brokers کام کو افرادی قوت. thesis names OpenClaw بطور موجودہ realization.
- Invariant 3: افرادی قوت ضرورت ہے ایک مینیجر. ایک orchestrator کہ assigns کام، enforces budgets، audits عمل درآمد، exposes hiring بطور ایک callable صلاحیت. thesis names Paperclip.
- Invariant 6: افرادی قوت ہے expandable کے تحت policy. ایک meta-layer کہاں ایک authorized agent generates ایک پرامپٹ، provisions ایک runtime، اور registers ایک نیا ورکر، بغیر waking ایک human. Claude Managed Agents ہے ایک realization.
- Invariant 7: افرادی قوت چلتا ہے on ایک nervous نظام. triggers (schedules، webhooks، inbound API calls) wake agent کے تحت اختیار envelope. Inngest (پائیدار functions اور background jobs) ہے ایک realization کے لیے عمومی افرادی قوت events; Claude Code Routines ہے coding-agent-specific path.
ایک single ورکر مطالعہ سے ایک Neon ریکارڈ کا مستند نظام ہے smallest unit کا ڈھانچہ یہ کورس سکھاتا ہے. ** اگلا کورس extends کہ ورکر میں ایک افرادی قوت**: multiple ورکرز coordinated کے ذریعے ایک مینیجر، expandable on demand، woken کے ذریعے triggers. وہی OpenAI Agents SDK foundation، وہی Cloudflare سینڈ باکس runtime، وہی skills format، وہی Neon ریکارڈ کا مستند نظام. ڈھانچہ ہے invariant.
کیسے کو اصل میں get اچھا پر یہ
مطالعہ یہ مختصر عملی کورس کرتا ہے نہیں بنائیں آپ اچھا پر تعمیر ورکرز. استعمال کرتے ہوئے یہ کرتا ہے. path looks وہی بطور کے لیے previous کورس: آپ شروع کریں manual، feel friction، اور let ہر piece کا friction سکھائیں آپ کون سا تصور یہ belongs کو.
mapping کے لیے یہ کورس:
- "کیوں isn't my skill firing جب یہ چاہیے?" → description quality (تصور 3). Rewrite. Test کے ذریعے inventing five مختلف طریقے ایک صارف might phrase trigger.
- "کیوں ہے agent inventing ڈیٹا ڈیٹا بیس doesn't رکھتے ہیں?" → agent isn't اصل میں calling MCP server. چیک trace; چیک
mcp_servers=[...]registration. - "کیوں ہے my audit log incomplete?" → audit لکھیں isn't میں وہی کوڈ path بطور action (تصور 10). Move یہ اگلا کو action، میں وہی transaction.
- "کیوں ہیں my pgvector results irrelevant?" → either chunking ہے wrong (تصور 9)، یا embedding ماڈل پر insert-time doesn't match embedding ماڈل پر query-time. Re-embed.
- "کیوں ہے my MCP server slow کے تحت load?" → connection pool اندر server ہے too چھوٹا، یا ٹولز list isn't cached on client. تصور 15.
- "کیوں کرتا ہے Neon MCP server feel scary میں پروڈکشن?" → کیونکہ Neon's اپنا docs کہتے ہیں یہ کا نہیں کے لیے پروڈکشن. لکھیں ایک custom MCP server (تصور 14). پہلا ایک لیتا ہے 30 منٹ; second لیتا ہے 10.
تعمیر ڈھانچہ ایک piece پر ایک وقت. Don't try کو شامل کریں skills، ریکارڈ کا مستند نظام، اور MCP all میں ایک weekend. لیں chat agent سے Course #3. شامل کریں ایک ریکارڈ کا مستند نظام پہلا (فیصلے 3–5). Watch کیا تبدیلیاں کے بارے میں آپ کا debugging experience. شامل کریں ایک skill (فیصلہ 4). Watch کیسے ماڈل decides کو استعمال کریں یہ. شامل کریں MCP boundary last (فیصلہ 6). ہر step ہے اس کا اپنا سیکھنا. Combined میں ایک big rewrite، they're ایک wall.
** portability dividend extends.** skills آپ لکھیں یہاں کام میں any Agent Skills-compatible client. Schemas آپ لکھیں یہاں کام میں any Postgres. MCP servers آپ لکھیں یہاں کام کے ساتھ any MCP client: Claude، GPT، Gemini، local ماڈلز. ڈھانچہ ہے invariant; پروڈکٹس ہیں 2026. جب پروڈکٹس تبدیلی، آپ کا کوڈ mostly doesn't.
کیا " human owns description، agent owns everything else" اصل میں feels like
بعد فیصلہ 4 sinks میں، آپ کا کام shifts shape. thing آپ استعمال ہوا کو کریں (لکھیں کوڈ) بن جاتا ہے thing آپ brief; thing آپ استعمال ہوا کو سرسری پڑھیں ( description field کا ایک config فائل) بن جاتا ہے thing آپ draft، redraft، اور live کے ساتھ. ایک description کہ took five منٹ کو لکھیں اور دwasرا twenty کو refine ہے doing زیادہ ڈھانچے سے متعلق کام than 200 lines کا MCP server کوڈ کہ agent generated underneath یہ، کیونکہ description ہے routing surface ماڈل reads ہر turn.
internal experience ہے ایک چھوٹا inversion. آپ stop thinking "کیسے کریں I implement یہ?" اور شروع کریں thinking "کیا ہیں five مختلف طریقے ایک حقیقی استعمالr might phrase trigger کے لیے یہ?" آپ stop asking "کیا چاہیے یہ function return?" اور شروع کریں asking "کیا description tells ماڈل نہیں کو fire یہ جب صارف means X بجائے?" کوڈ ہے downstream; description ہے upstream. If description ہے wrong، agent never reaches کوڈ، اور کوڈ کا quality ہے irrelevant.
دwasرا shift: review replaces authorship بطور load-bearing skill. agent drafts; آپ decide whether draft کرتا ہے درست thing میں trigger cases آپ wrote description کے لیے. hardest part ہے resisting urge کو rewrite agent کا draft جب آپ could solve یہ yourself میں three منٹ. کہ urge ہے structurally similar کو urge کو bypass MCP boundary کہ یہ باب warns کے بارے میں. وہی طریقہ کار، مختلف layer.
آپ'll جانیں آپ've internalized یہ جب آپ instinctively spend forty منٹ on ایک description اور three منٹ briefing agent on body، بجائے کا دwasرا طریقہ کے گرد.
فوری reference
15 تصورات ایک سطر میں ہر
- ایک Agent skill ہے ایک فولڈر. SKILL.md plus optional scripts/references/assets.
- Progressive disclosure. metadata پر startup → مکمل body on activation → references on demand.
- ایک SKILL.md ہے frontmatter + body. Name، description، optional metadata، پھر operational instructions.
- skills travel بطور فائلیں. وہی SKILL.md کام کرتا ہے میں Claude Code اور OpenCode بغیر modification.
- Compose چھوٹا skills via filesystem ہینڈ آف جب isolation matters زیادہ than orchestration simplicity.
- Postgres + pgvector beats ایک separate vector DB کے لیے almost all agent workloads. Neon adds branching، wasیع کرنا-to-zero، اور ایک MCP server.
- Six tables ہیں minimum operational schema: conversations، messages، دستاویزات، embeddings، audit_log، capability_invocations.
- pgvector basics:
VECTOR(1536)+<=>cosine distance + HNSW index. استعمال کریں وہی embedding ماڈل on دونوں ends. - ** embedding pipeline:** chunk پر semantic boundaries (~400 tokens کے ساتھ overlap)، batch-embed، store کے ساتھ ماڈل metadata.
- audit ہے نہیں logging. ہر meaningful action writes ایک row میں وہی transaction بطور action یہ records.
- MCP ہے ایک پروٹوکول، نہیں ایک service. Three بنیادی اکائیاں (ٹولز، resources، پرامپٹس)، three transports (stdio، streamable HTTP، legacy SSE).
- ** Neon MCP server ہے کے لیے development.** Schema ڈیزائن، branch-based migrations. نہیں کے لیے پروڈکشن runtime.
- ** OpenAI Agents SDK has ایک built-in MCP client.**
from agents.mcp import MCPServerStdio, MCPServerStreamableHttp. استعمال کریںasync with. Cachelist_toolsمیں پروڈکشن. - custom MCP servers earn ان کا رکھیں via scope، isolation، اور reusability. Don't لکھیں ایک کے لیے ایک single function استعمال ہوا کے ذریعے ایک agent.
- MCP کے تحت load: streamable HTTP کے لیے remote، cache ٹولز، reuse connections، pool اندر server، propagate trace سیاق و سباق via
_meta.
فیصلہ tree: @function_tool vs. custom MCP server vs. vendor MCP server
Capability used by one agent, one process, one function?
→ @function_tool
Capability that multiple agents (or multiple deployments) will reuse?
→ Custom MCP server
Vendor provides one and it does what you need?
→ Vendor MCP server (don't rebuild)
Sensitive operations, needing narrow scope?
→ Custom MCP server (NOT a broad `run_sql` interface)
Long-running, background, or process-isolated work?
→ Custom MCP server (process isolation buys safety)
File location quick-ref
| کیا | Path |
|---|---|
| پروجیکٹ skills | .claude/skills/<name>/SKILL.md (OpenCode reads بطور fallback) |
| Personal skills | ~/.claude/skills/<name>/SKILL.md (OpenCode reads بطور fallback) |
| Schema migrations | migrations/NNN_*.sql |
| Embedding کوڈ | src/chat_agent/embedding/{chunker,embedder,seeder}.py |
| custom MCP server | src/customer_data_mcp/server.py |
| MCP server registration (Claude Code) | .claude/settings.json mcpServers |
| MCP server registration (OpenCode) | opencode.json mcp block |
| audit helper | src/chat_agent/audit.py |
جب something feels wrong
Skill not firing when it should
→ Description too vague. Rewrite with "Use when..." and specific keywords (Concept 3).
Skill firing when it shouldn't
→ Description too broad. Add explicit constraints in the description.
pgvector returning irrelevant results
→ Embedding model mismatch (insert vs. query). Verify the model column in
the embeddings table. Re-embed if needed.
MCP tool not appearing in agent
→ Server not registered, or list_tools cache stale. Check mcp_servers=[...]
and try cache_tools_list=False temporarily.
Audit log has gaps
→ Action and audit write are in different code paths. Move them next to
each other, ideally same transaction.
Agent timing out on Postgres operations under load
→ MCP server's connection pool too small. Check asyncpg.create_pool(max_size=...).
MCP server hangs on startup with torch / sentence-transformers / large imports
→ Default client_session_timeout_seconds=5 is too short for servers that
load ML models at import. Bump to 60. See Concept 13's callout.
CREATE TABLE fails: relation "notes" already exists
→ You're pointing at a database that already has tables. Use a fresh
database or Neon branch for the Quick Win (Step 2).
An OLD asyncpg refuses the Neon DSN with "unsupported startup parameter"
→ Only older asyncpg versions choke on channel_binding=require. The
version this course pins accepts it; if you are pinned to an old
asyncpg, either upgrade or strip that one parameter from the DSN.
TLS posture is unchanged either way.
Neon -pooler endpoint: schema-qualified SQL needed, search_path ignored
→ The pooled endpoint silently drops server_settings startup params
and resets SET search_path on connection release. If your tables
are not in the public schema, schema-qualify them (see the
Decision 6 MCP-server skeleton's get_pool comment). A reader who
built in public is unaffected.
Non-OpenAI key getting 401 against api.openai.com
→ Set OPENAI_BASE_URL to your provider's OpenAI-compatible endpoint
(e.g., https://api.deepseek.com/v1) before running the agent.
Agent fails partway with a 401 / auth / BadRequestError
→ Wrong key, wrong provider, or expired key. Run the curl key smoke-test
from Step 5 before the full run; it fails in one second instead of
four files deep.
Neon MCP server returning errors in production agent code
→ You're using it wrong. Neon's docs are explicit: development only.
Write a custom MCP server instead (Concept 14, ~30 minutes).
Appendix: Audience، prerequisites، glossary
Audience، prerequisites، ایک Course #3 recap، ایک Postgres مختصر رہنما، ایک first-pass مطالعہ رہنمائی، اور ایک glossary. استعمال کریں یہ بطور ایک reference: flip back جب ایک اصطلاح میں مرکزی flow ہے unfamiliar، یا پڑھیں A.1 پہلے آپ شروع کریں if آپ ہیں نہیں sure آپ رکھتے ہیں prerequisites.
A.1: Audience & prerequisites
Audience. یہ ہے ایک intermediate-to-advanced کورس، denser than اس کا predecessors. آپ ضرورت کو رکھتے ہیں completed Course #3 (یا be comfortable کے ساتھ everything یہ taught)، کیونکہ we extend اس کا chat agent rather than re-تعمیر کریں یہ سے scratch. OpenAI Agents SDK، agent loop، سیشنز، سٹریمنگ، function ٹولز، sandboxing: all assumed.
Prerequisites. یہ صفحہ assumes four things.
- آپ رکھتے ہیں completed تعمیر AI Agents کے ساتھ OpenAI Agents SDK اور Cloudflare سینڈ باکس. یہ ہے non-negotiable. We چنیں up کہاں اس کا worked مثال left off: وہی پروجیکٹ layout، وہی
agents.py، وہیcli.py، وہیtools.py. If آپ رکھتے ہیں نہیں، کریں کہ کورس پہلا; یہ ایک گا پڑھیں بطور friction بغیر یہ.- آپ رکھتے ہیں ایجنٹک کوڈنگ مختصر عملی کورس طریقہ کار. منصوبہ طریقہ، قواعد فائلیں (
CLAUDE.md/AGENTS.md)، slash commands، سیاق و سباق طریقہ کار. یہ کورس's worked مثال استعمال کرتا ہے skills as slash commands پر ایک point، اس لیے قواعد-فائل طریقہ کار ہے load-bearing.- آپ رکھتے ہیں مکمل پر least ایک PRIMM-AI+ cycle سے Chapter 42. Predict پرامپٹس میں یہ کورس assume آپ جانیں کو predict، چلائیں، investigate، modify، بنائیں.
- آپ رکھتے ہیں ایک working Postgres ذہنی نمونہ. Tables، indexes، transactions، foreign keys. آپ don't ضرورت کو be ایک DBA. آپ چاہیے جانیں کیا
SELECT ... WHEREکرتا ہے، کیا ایک index ہے کے لیے، اور roughly کیاJOINکرتا ہے. If آپ رکھتے ہیں لکھا گیا ایک CRUD app میں any language، آپ're calibrated.
A.2: کیا Course #3 taught آپ کہ یہ کورس assumes
مکمل کورس: تعمیر AI Agents کے ساتھ OpenAI Agents SDK اور Cloudflare سینڈ باکس. eight things سے کہ کورس یہ ایک builds directly on:
- ** state-and-trust frame.** ہر agent بنیادی اکائی ہے SDK's جواب کو ایک state سوال یا ایک trust سوال. یہ کورس extends دونوں محور: state میں ایک ریکارڈ کا مستند نظام، trust میں ایک skills library.
- ** agent loop.** ماڈل decides → is_final? → run_ٹول (trust boundary) → history grows → اگلا turn. یہ کورس adds MCP ٹول calls اور skills invocations کو کہ loop، مگر loop shape doesn't تبدیلی.
@function_tool. ایک typed Python function exposed کو ماڈل. یہ کورس's تصور 14 contrasts یہ کے ساتھ MCP-exposed ٹولز; آپ ضرورت کو جانیں کیا@function_toolہے کو understand جب نہیں کو reach کے لیے MCP.- سیشنز.
SQLiteSessionسے Course #3 اب بھی کام کرتا ہے. یہ کورس supplements یہ کے ساتھ ایک Postgres-backed جانچ کا ریکارڈ، نہیں ایک replacement. - سٹریمنگ events.
Runner.run_streamedاورRunItemStreamEvent. We log skill activations اور MCP ٹول calls سے یہ events (فیصلہ 7). - Guardrails. Input اور نتیجہ حفاظتی حدود. یہ کورس doesn't شامل کریں نیا حفاظتی حد تصورات; آپ carry پر کیا آپ رکھتے ہیں.
- Cloudflare سینڈ باکس.
SandboxAgentکے ساتھShell()اورFilesystem(). یہ کورس's ورکر اب بھی deploys کو ایک سینڈ باکس; ریکارڈ کا مستند نظام lives outside یہ (میں Neon). - ** dual-ٹول نمونہ (Claude Code + OpenCode).** skills آپ لکھیں میں
.claude/skills/کام میں دونوں. MCP server registration differs کے ذریعے ٹول config; server itself ہے identical.
Stop signal. If " agent loop ہے ماڈل → ٹول → history → loop، کے ساتھ max_turns capping یہ" reads بطور review، continue. If یہ feels like نیا material، stop اور کریں Course #3 پہلا. یہ کورس's worked مثال evolves Course #3's chat agent; مطالعہ بغیر کہ foundation ہے friction.
A.3: Postgres essentials یہ کورس استعمال کرتا ہے
If آپ رکھتے ہیں لکھا گیا ایک CRUD application میں any language، آپ're calibrated. things آپ'll دیکھیں:
- Tables، primary keys، foreign keys. Six tables میں our schema، ہر کے ساتھ ایک UUID primary اہم اور explicit foreign keys کو اس کا parent.
- Indexes. Regular B-tree indexes on lookup columns; HNSW indexes on vector columns. Indexes accelerate queries; they لاگت on inserts.
- Transactions.
BEGIN ... COMMIT(یاasync with conn.transaction():میںasyncpg) گروہ multiple writes اس لیے they all happen یا none کریں. audit لکھیں اور action یہ logs جائیں میں ایک transaction، per تصور 10. - JSONB columns. Postgres's native JSON type. Stores arbitrary key-قدر ڈیٹا، queryable کے ساتھ JSON operators. استعمال ہوا میں
audit_log.payloadاورaudit_log.result. - Extensions.
CREATE EXTENSION vectorenables pgvector. دwasرا extensions exist (pg_trgm کے لیے text search، postgis کے لیے spatial); we صرف ضرورت pgvector.
Stop signal. If "JOIN tickets ON tickets.customer_id = customers.id" reads بطور obvious، continue. If JOIN syntax ہے unfamiliar، worked مثال گا پڑھیں بطور friction. چنیں up ایک 90-منٹ Postgres tutorial پہلا.
A.4: اسے کیسے پڑھیں صفحہ on پہلا pass
وہی قاعدہ بطور previous کورس میں series:
- Expand on پہلا پڑھیں: کوئی بھی چیز labeled "کیا آپ'll دیکھیں،" "Sample transcript،" "Expected نتیجہ،" "Verify." یہ contain runnable behavior کو چیک predictions کے خلاف.
- Skip on پہلا پڑھیں: کوئی بھی چیز labeled "کیا
skill.mdlooks like میں مکمل،" " مکمل migration SQL،" اور دwasرا full-فائل listings میں حصہ 4's worked مثال. narrative above ہر block tells آپ کیا changed; آپ صرف ضرورت فائل contents جب آپ اصل میں تعمیر کریں. - Optional throughout: "Try کے ساتھ AI" blocks پر end کا ہر concept. Extension پرامپٹس کے لیے Claude Code یا OpenCode; skip بغیر guilt if آپ کا ٹول isn't سیٹ up.
مقصد کا پہلا pass ہے کو internalize three-layer ماڈل (skills ہیں صلاحیت layer، Neon ریکارڈ کا مستند نظام ہے state layer، MCP ہے connector) اور طریقہ they sit on top کا OpenAI Agents SDK + Cloudflare سینڈ باکس stack آپ پہلے ہی جانیں. Second pass کے ساتھ آپ کا hands on keyboard ہے کہاں آپ تعمیر کریں.
A.5: Glossary
یہ ہیں اصطلاحات زیادہ تر likely کو trip ایک قاری on پہلا encounter. ہر ہے explained again میں سیاق و سباق بطور یہ appears.
-
skill: ایک فولڈر کے ساتھ ایک
SKILL.mdفائل اور optional scripts، references، اور assets. فولڈر is skill; فائل اندر یہ ہے entry point. ایک agent loads skills via progressive disclosure: name+description پر startup، مکمل instructions جب triggered، referenced فائلیں on demand. -
SKILL.md: skill کا entry فائل. YAML frontmatter کے ساتھnameاورdescription(اور optional metadata)، پھر markdown body کے ساتھ instructions agent follows جب skill activates. -
Progressive disclosure: three-stage skill-loading ماڈل. Discovery: agent reads names اور descriptions کا all دستیاب skills پر startup. Activation: agent reads مکمل
SKILL.mdکا matching skill جب ایک کام triggers یہ. Execution: agent loads referenced فائلیں (یا چلتا ہے bundled scripts) on demand during عمل درآمد. -
نظام کا record (SoR): Authoritative store کا state ورکر reads سے اور writes کو. thesis اصطلاح کے لیے " ڈیٹا بیس کہ holds truth." کے لیے یہ کورس: ایک Neon Postgres ڈیٹا بیس.
-
Neon: ایک managed Postgres service کے ساتھ serverless branching، wasیع کرنا-to-zero، اور ایک free tier. اس کا differentiator versus دwasرا managed Postgres ہے branching (copy-on-write ڈیٹا بیس copies میں seconds) اور اس کا first-class MCP server.
-
pgvector: ایک Postgres extension کہ adds ایک
vectorcolumn type plus distance operators کے لیے similarity search. Lets ایک ڈیٹا بیس hold دونوں relational ڈیٹا اور embedding-based semantic search. -
Embedding: ایک fixed-length numerical vector representing ایک piece کا text (یا دwasرا ڈیٹا) such کہ semantic similarity maps کو vector distance. Generated کے ذریعے ایک embedding ماڈل (
text-embedding-3-smallہے OpenAI default). -
MCP (ماڈل سیاق و سباق پروٹوکول): ایک کھولیں standard کے لیے کیسے AI agents جوڑیں کو external ٹولز، resources، اور پرامپٹس. تعریف کرتا ہے ایک client/server ڈھانچہ، three بنیادی اکائیاں (ٹولز، resources، پرامپٹس)، اور three transports (stdio، SSE، streamable HTTP).
-
MCP server: ایک program کہ exposes صلاحیتیں (ٹولز/resources/پرامپٹس) کو MCP clients. Neon MCP server ہے ایک مثال; آپ سکتا ہے لکھیں آپ کا اپنا میں Python یا TypeScript.
-
MCP client: agent-side counterpart کہ جوڑتا ہے کو MCP servers، lists ان کا صلاحیتیں، اور surfaces انہیں کو ماڈل. OpenAI Agents SDK has ایک MCP client built میں.
-
ٹول (MCP): ایک کا three MCP بنیادی اکائیاں. ایک function ماڈل سکتا ہے invoke. سے ماڈل کا perspective، ایک MCP ٹول looks similar کو ایک
@function_tool، مگر implementation lives میں MCP server، نہیں agent کا عمل. -
Resource (MCP): ایک کا three MCP بنیادی اکائیاں. ایک read-only ڈیٹا ماخذ agent سکتا ہے fetch. Files، ڈیٹا بیس query results، API responses. پڑھیں مگر نہیں لکھیں.
-
پرامپٹ (MCP): ایک کا three MCP بنیادی اکائیاں. ایک reusable پرامپٹ template server فراہم کرتا ہے کے لیے ماڈل کو invoke. کم عام than ٹولز اور resources; useful کے لیے standardized templates across ٹیمیں.
-
audit log: ایک ڈیٹا بیس table کہ records ہر meaningful action ایک ورکر لیتا ہے (ہر ٹول call، ہر ڈیٹا بیس لکھیں، ہر صلاحیت invocation) میں ایک form کمپنی سکتا ہے replay، query، اور وجہ کے بارے میں بعد fact.
A.6: کیا یہ appendix کرتا ہے نہیں replace
مکمل curriculum includes کورسز on مینیجر layer (Paperclip)، meta-layer (hiring AI ورکرز پر runtime)، اور trigger gateway (Inngest). None کا those ہیں summarized یہاں، کیونکہ they extend rather than precede یہ کورس. پڑھیں انہیں جب آپ reach انہیں; یہ کورس's ورکر doesn't ضرورت انہیں yet.