2026 میں AI پرامپٹنگ
Claude، ChatGPT، اور Gemini کو اچھی طرح استعمال کرنے کے 13 تصورات: سیاق و سباق، استدلالی طریقے، گہری تحقیق، کثیر الwasائط، AI ڈیسک ٹاپ ایپس، اور وہ ماڈلز کے باہمی جائزے جو "اچھا enough" کو "ship یہ" میں بدل دیتی ہے۔
زیادہ تر لوگ AI کو Google تلاش کی طرح استعمال کرتے ہیں۔ وہ ایک مختصر سوال ٹائپ کرتے ہیں، جواب پر سرسری نظر ڈالتے ہیں، اور آگے بڑھ جاتے ہیں۔ یہ معمولی معلومات کے لیے چل جاتا ہے۔ مگر آپ کی زندگی اور کام کی وہ چیزیں جو واقعی اہم ہیں، ان کے لیے یہ ناکام رہتا ہے۔
ماہر صارفین کچھ اور کرتے ہیں۔ وہ AI کو اسی طرح brief کرتے ہیں جیسے کسی ذہین مگر نئے colleague کو brief کیا جاتا ہے: فائلز، سیاق و سباق، constraints، اور ایک واضح پوچھیں کے ساتھ۔ وہ ایک جواب نہیں بلکہ تین options مانگتے ہیں۔ وہ بحث کرتے ہیں۔ تکرار کرتے ہیں۔ کام کو چیک کرتے ہیں۔ ابتدائی پرامپٹ اور ماہر صارف brief کے درمیان فرق ذہانت کا نہیں، بلکہ چند ایسی عادتوں کا ہے جو کوئی بھی ایک دوپہر میں سیکھ سکتا ہے۔
یہ صفحہ اسی دوپہر کے لیے ہے۔ تیرہ تصورات، چار مختصر حصوں میں تقسیم کیے گئے ہیں۔ نہ کوڈ، نہ سیٹ اپ، نہ ایسا jargon جسے آپ سیاق و سباق سے نہ سمجھ سکیں۔ وہ ایک insight جو باقی سب چیزوں کو سمجھنے میں مدد دیتی ہے یہ ہے: اس صفحے کی تقریبا ہر "advanced technique" آخرکار دو ہی حرکتوں میں سمٹتی ہے: درست سیاق و سباق اندر لاؤ، یا غلط سیاق و سباق باہر رکھو۔ ہر حصہ کو اسی نظر سے پڑھیں۔
ٹولز کے بارے میں ایک نوٹ: مثالوں میں ChatGPT، Claude، اور Gemini کا ذکر اس لیے ہے کہ زیادہ تر قارئین کے پاس ان میں سے کوئی ایک موجود ہوتا ہے۔ یہ مہارتیں کسی بھی جدید chat AI پر منتقل ہو جاتی ہیں۔ جہاں کوئی feature صرف ایک پروڈکٹ میں ہو، وہاں اس کا نام صاف طور پر دیا گیا ہے۔
پہلی بار اسے تسلسل سے پورا پڑھیں تاکہ مجموعی shape سمجھ میں آ جائے۔ پھر واپس آئیں اور آخر میں دیے گئے پرامپٹس آزما کر دیکھیں۔ صرف پڑھنے سے آپ کو الفاظ ملتے ہیں؛ آزمانے سے مہارت ملتی ہے۔
پچھلی بار کے بعد کیا بدلا
اگر آپ نے 2022 یا 2023 میں ChatGPT استعمال کیا تھا اور یہ طے کر لیا تھا کہ یہ صرف ایک clever toy ہے، تو اب آپ کے پاس وہی ٹول نہیں ہے۔ چند تبدیلیاں خاموشی سے آ چکی ہیں:
- سیاق و سباق کی گنجائشیں تقریبا 1000x بڑھ گئیں۔ 2022 کا ماڈل چند ہزار الفاظ رکھ سکتا تھا۔ 2026 کا ماڈل لاکھوں الفاظ، اور کبھی کبھی ایک million تک سنبھال سکتا ہے۔ اس سے یہ بدل جاتا ہے کہ آپ پرامپٹ میں کیا بھر سکتے ہیں: پوری کتاب، کئی دن کی speech، یا contracts کا ایک فولڈر۔
- استدلال حقیقی ہو گئی۔ "Think step کے ذریعے step" کبھی ایک جادوئی فقرہ تھا۔ اب ماڈلز کے پاس explicit thinking طریقے ہیں جو چند seconds، کبھی منٹ تک چلتے ہیں، اور جواب دینے سے پہلے کئی approaches آزما سکتے ہیں۔ تقریبا اٹھارہ مہینوں میں وہ مسائل جنہیں یہ سنبھال سکتے ہیں "انسان کے چند منٹ" سے "انسان کے کئی گھنٹے" تک پہنچ گئے۔
- ویب تلاش اور کوڈ عمل درآمد built-in ٹولز بن گئے۔ ماڈل خود طے کرتا ہے کہ کب ویب تلاش کرنی ہے یا کوڈ چلانا ہے، پھر اس کے نتائج اپنے جواب میں استعمال کرتا ہے۔ زیادہ تر صارفین کے لیے یہ پس منظر میں ہوتا ہے؛ جب آپ کو معلوم ہو جاتا ہے کہ یہ ہو رہا ہے، تو آپ کے پرامپٹس زیادہ واضح ہو جاتے ہیں۔
- کثیر الwasائط اب حاشیے کی چیز نہیں رہی۔ آپ ایک تصویر، PDF، اسپریڈ شیٹ، آواز کا نوٹ، یا فائلز کا پورا فولڈر پرامپٹ میں ڈال کر ان کے بارے میں سوال پوچھ سکتے ہیں۔ ماڈل ان سب کو ایک ہی stream میں سنبھالتا ہے۔
- ڈیسک ٹاپ ایپس آ گئیں۔ پروڈکٹس کی ایک نئی خانہ (Cowork، Microsoft Copilot، Google Antigravity) آپ کی اجازت سے آپ کی فائلز تلاش کر سکتی ہے اور ان پر عمل کر سکتی ہے۔ یہ اب محض chat نہیں رہی؛ یہ کسی coworker کو ایک چھوٹا کام نمائندہ کرنے کے زیادہ قریب ہے۔
اگر ان ٹولز کے بارے میں آپ کا ذہنی تصور صرف اٹھارہ مہینے پرانا بھی ہے، تو ممکن ہے آپ انہیں آج کی صلاحیت کے صرف 20% پر استعمال کر رہے ہوں۔ یہ صفحہ وہ خلا کم کرتا ہے۔
حصہ 1: AI چیزیں کیسے جانتی ہے
پہلے تین تصورات اس بات کے بارے میں ہیں کہ جب آپ AI سے کوئی سوال پوچھتے ہیں تو اصل میں کیا ہو رہا ہوتا ہے۔ اگر آپ یہ سمجھ لیں تو ناکامیاں آپ کو حیران کرنا چھوڑ دیتے ہیں۔
1. ابتدائی صارف بمقابلہ ماہر صارف
نیچے دیے گئے دو columns میں دیکھیے کہ کیا بدلتا ہے۔ سوال ایک ہی ہے؛ پرامپٹ ایک جیسا نہیں۔
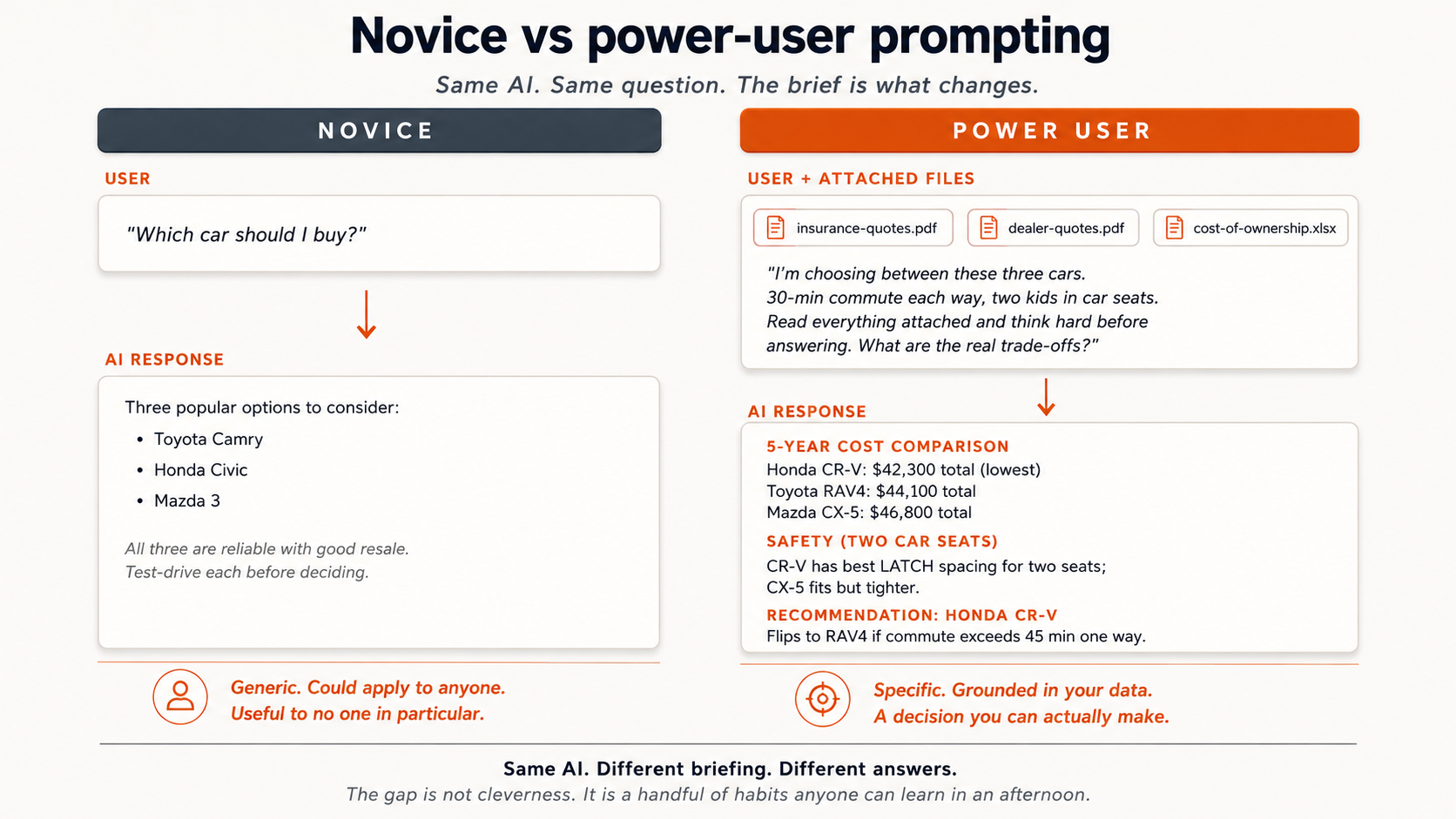
| ابتدائی پرامپٹ | ماہر صارف brief | |
|---|---|---|
| Length | ایک سطر | ایک مختصر brief، ساتھ میں attached فائلز |
| سیاق و سباق دیا گیا | کچھ نہیں | Insurance quotes، dealer قیمتوں کا تعین، لاگت-of-ownership اسپریڈ شیٹ |
| Constraints stated | کچھ نہیں | "30-منٹ commute ہر طریقہ، دو kids میں car seats" |
| Instruction کو think | کچھ نہیں | "پڑھیں everything attached اور think مشکل پہلے answering" |
| AI response | تین مشہور ماڈلز، عمومی | Five-year لاگت comparison، car-seat constraint سے جڑی safety تجزیہ، اور ان conditions کے ساتھ recommendation |
عملی دنیا سے چند واضح فرق:
- car خریدنا۔ ابتدائی صارف: "کون سا car ہے بہترین?" ماہر صارف: spec sheets، dealer quotes، اور insurance منصوبے upload کرتا ہے، پھر پوچھتا ہے "کیا ہیں اہم trade-offs? پڑھیں everything اور think مشکل."
- کام پر self-جائزہ۔ ابتدائی صارف: "لکھیں ایک self-جائزہ کے لیے my boss." ماہر صارف: اپنے پروجیکٹ tracker کا screenshot، حالیہ پروجیکٹ docs، اور notes کا آواز کا نوٹ upload کرتا ہے، پھر مسودہ مانگتا ہے۔
- کاروباری خیال کا تنقیدی جائزہ۔ ابتدائی صارف: "I رکھتے ہیں ایک بہترین کاروبار خیال، mobile tie-dyeing، تنقیدی جائزہ یہ." یہ خوشامدانہ رجحان bait ہے؛ AI زیادہ تر تعریف کرے گا۔ ماہر صارف: "Analyze objectively. استعمال کریں یہ معیار نامہ: ہے وہاں ایک problem worth solving، ہے وہاں ایک market، ہے وہاں ایک competitive advantage?" AI نے اس خیال کو 100 میں سے 8 نمبر دیے اور بتایا کیوں۔
- blog post لکھنا۔ ابتدائی صارف: "لکھیں ایک blog post کے بارے میں BlackBerry." نتیجہ: AI slop۔ ماہر صارف: پہلے outline، پھر outline پر تنقیدی جائزہ، پھر ہر heading کو bullets میں expand، پھر bullets پر تنقیدی جائزہ، اور صرف اس کے بعد prose۔
ان سب کو جوڑنے والا mental ماڈل یہ ہے: AI ایک بہت ذہین مگر نیا college graduate ہے۔ انتہائی motivated، مگر ابھی آپ کے بارے میں زیادہ نہیں جانتا۔ اسے اسی طرح brief کریں۔ کیا ایک نئے colleague کے پاس یہ کام اچھی طرح کرنے کے لیے کافی معلومات ہوں گی؟ اگر نہیں، تو اسے مزید دیں۔
2. پہلے سے سیکھی ہوئی علم
AI نے دنیا کو پڑھ کر نہیں سیکھا۔ اس نے دنیا کے بارے میں لکھی گئی چیزیں پڑھ کر سیکھا۔ خاص طور پر: انٹرنیٹ پر موجود بہت بڑی مقدار میں text۔ Reddit اور Quora threads، Wikipedia، کتابیں، news articles، تحقیق papers، blogs، forums۔
training ڈیٹا میں کثرت تقریبا جواب کی reliability کے برابر ہوتی ہے۔ اس لیے:
- مضبوط: cooking، celebrity gossip، عام medical advice، top-1000 movies، مشہور programming languages، Voyager 1 record پر کیا ہے (NASA کا spacecraft جو 1970s میں launch ہوا، زمین سے تقریبا 25 billion miles دور ہے، اور 55 languages میں greetings لے جا رہا ہے)، اور cats دیواروں کو کیوں گھورتی ہیں (وہ ایسی ہلکی آوازیں اور حرکات پکڑ لیتی ہیں جو انسان نہیں پکڑ پاتے)۔
- Sparse: quasars (آسمان میں انتہائی روشن objects جو black holes سے powered ہوتے ہیں)، Cantonese (انٹرنیٹ text کا 0.1% سے بھی کم)، regional history، niche professional علم۔
- Absent: آپ کی کمپنی کا خفیہ ڈیٹا، آپ کا private calendar، ماڈل کی علم cutoff date کے بعد شائع ہونے والی کوئی بھی چیز، اور وہ ہر چیز جو کبھی public انٹرنیٹ پر آئی ہی نہیں۔
اس کے دو عملی نتائج ہیں:
typos درست کرنے میں وقت ضائع نہ کریں۔ AI انٹرنیٹ text پر train ہوا ہے، اور انٹرنیٹ text typos سے بھرا پڑا ہے۔ یہ misspelled پرامپٹس کو اچھی طرح سنبھال لیتا ہے۔ "definately" غلط لکھنے سے جواب نہیں بدلتا۔
absorbed errors سے ہوشیار رہیں۔ AI نے انہی ذرائع سے غلط فہمیاں اور outdated معلومات بھی جذب کی ہیں۔ forum کی ایک confidently wrong post ماڈل کے اندر confidently wrong جواب بن سکتی ہے۔ اہم بات کو primary ماخذ کے مقابلے میں چیک کریں۔
Part 0 آپ کو broken استدلال پکڑنا سکھائے گا۔ اسے تلاش کرنے کی پہلی جگہ وہ confidently sounding pretrained جوابات ہیں جو ایسے موضوعات پر ہوں جہاں training ڈیٹا کمزور یا disputed تھا۔ confidence درست ہونے کی علامت نہیں ہے۔
کسی pretrained جواب پر اعتماد کرنے سے پہلے ایک مختصر ذہنی آزمائش:
| سوال type | training ڈیٹا میں کتنی نمائندگی؟ | Trust level |
|---|---|---|
| "کیسے کریں I بنائیں ایک roux?" | cooking انٹرنیٹ کے سب سے زیادہ زیربحث موضوعات میں سے ہے۔ | High. |
| "Plot کا ایک top-1000 movie." | ہزاروں بار جائزہ اور re-جائزہ ہو چکا۔ | High. |
| "History کا ایک obscure village." | شاید صرف ایک Wikipedia paragraph، یا وہ بھی نہیں۔ | Low; primary ماخذ سے verify کریں۔ |
| "Recent regulatory تبدیلی میں my industry." | غالبا علم cutoff کے بعد کی چیز ہے۔ | Web تلاش کے بغیر کچھ trust نہ کریں۔ |
| "کیا did our کمپنی decide last quarter?" | training ڈیٹا میں سرے سے موجود نہیں۔ | کچھ بھی trust نہ کریں؛ ماڈل guess کر رہا ہے۔ |
یہ کوئی ایسا قاعدہ نہیں جسے یاد کرنا ضروری ہو۔ یہ وہی instinct ہے جو آپ کسی بھی ماخذ پر لگاتے ہیں: "اس شخص کو یہ کیسے معلوم ہوگا؟" یہی سوال AI پر بھی لگائیں۔
ایک non-سافٹ ویئر مثال۔ ایک قاری نے AI سے اپنی دادی کے گاؤں میں کھیلے جانے والے ایک regional folk game کے قواعد کا خلاصہ مانگا۔ AI نے پورے اعتماد سے تین paragraphs میں قواعد لکھ دیے۔ دادی سے پوچھا گیا تو انہوں نے کہا کہ قواعد تقریبا پوری طرح غلط ہیں: AI نے دwasرے علاقوں کے ملتے جلتے کھیلوں کی معلومات ملا دی تھیں کیونکہ مخصوص کھیل انٹرنیٹ پر تقریبا موجود ہی نہ تھا۔ AI نے جھوٹ نہیں بولا؛ اس نے sparse ڈیٹا سے generalize کیا۔ غلطی سوال پوچھنے میں نہیں، بلکہ confidence کو accuracy سمجھ لینے میں تھی۔
3. تین Retrieval طریقے: pretrained، ویب تلاش، اور گہری تحقیق
جب آپ سوال پوچھتے ہیں تو جدید AI ٹولز خاموشی سے طے کرتے ہیں کہ جواب کیسے دینا ہے۔ یا تو وہ صرف pretrained علم سے جواب دیتے ہیں، یا ویب تلاش چلا کر چند صفحات پڑھتے ہیں، یا گہری تحقیق چلاتے ہیں، جس میں وہ کئی منٹ لگا کر dozens کا ذرائع دیکھتے ہیں اور ایک منظم رپورٹ لکھتے ہیں۔
آپ کو معلوم ہونا چاہیے کہ کون سا طریقہ چل رہا ہے، کیونکہ ہر طریقہ کی طاقتیں اور ناکامی طریقے الگ ہیں۔
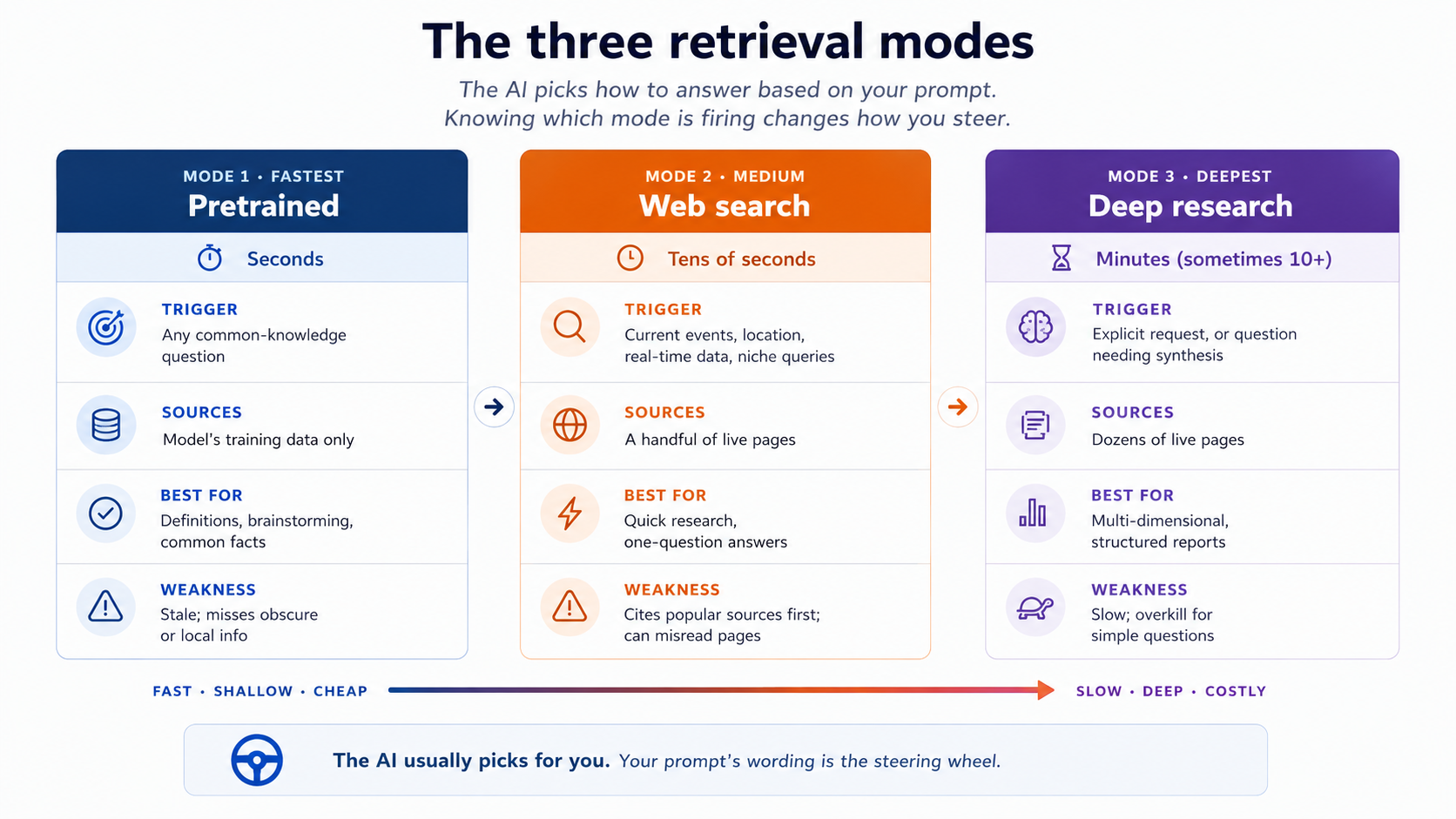
یہ تینوں طریقے ایک ساتھ:
| طریقہ | trigger | وقت | Sources | بہترین استعمال | Weakness |
|---|---|---|---|---|---|
| Pretrained | کوئی بھی common-knowledge سوال | Seconds | ماڈل کا training ڈیٹا | Definitions، brainstorming، عام facts | پرانی معلومات؛ obscure یا مقامی info miss ہو سکتی ہے |
| Web تلاش | تازہ events، location، niche queries، real-time ڈیٹا | Tens کا seconds | چند live صفحات | فوری تحقیق، ایک سوال کے جواب | پہلے popular ذرائع cite کرتا ہے؛ صفحات misread ہو سکتے ہیں |
| Deep تحقیق | explicit request، یا ایسا سوال جس میں synthesis درکار ہو | منٹ (sometimes 10+) | dozens کا live صفحات | multi-dimensional، structured رپورٹس | سست؛ سادہ سوالات کے لیے overkill |
چند مثالیں اس کو واضح کرتی ہیں:
- pretrained جوابات کافی ہیں: "کیوں کریں cats stare پر walls،" "کیا کا on Voyager 1 record،" "summarize plot کا Hamlet." یہ ہفتہ بہ ہفتہ نہیں بدلتے۔
- ویب تلاش پرانا ماڈل بچا لیتی ہے: GPT-5.4 کی علم cutoff August 2025 تھی۔ "6 7" meme اس کے بعد viral ہوا۔ ویب تلاش کے بغیر AI کو معلوم نہیں ہوگا کہ آپ کیا کہہ رہے ہیں۔ ویب تلاش کے ساتھ یہ ایک تازہ article نکالتا ہے اور درست جواب دیتا ہے۔
- ویب تلاش غلط بھی جا سکتی ہے: ایک دwasت نے پوچھا "کہاں کو چلائیں میں Henderson، Nevada." AI نے 20 سال پرانا ویب صفحہ cite کیا اور ایسا school تجویز کیا جو اب عوام کے لیے کھلا نہیں تھا۔ ویب تلاش خود یہ نہیں چیک کرتی کہ ماخذ تازہ ہے یا نہیں۔
- گہری تحقیق انتظار کے قابل ہے: "منصوبہ ایک Halloween haunted house میں our neighborhood، including permits، fire safety، اور noise ordinances." AI تحقیق منصوبہ بناتی ہے، کئی متوازی searches چلاتی ہے، خلاصہ کرتی ہے، طے کرتی ہے کہ اگلا کون سا پہلو کھودنا ہے، اور آخر میں checklists کے ساتھ multi-section رپورٹ دیتی ہے۔ یہ chatbot والا جواب نہیں؛ یہ زیادہ اس طرح ہے جیسے آپ نے ایک junior researcher کو ایک گھنٹے کے لیے کام دے دیا ہو۔
پس منظر میں اکثر دو ماڈلز ایک ساتھ کام کر رہے ہوتے ہیں۔ ایک صارف-facing ماڈل آپ سے بات کرتی ہے۔ ایک الگ معاون ماڈل searches issue کرتی ہے، result list scan کرتی ہے، زیادہ relevant صفحات download کرتی ہے، اور ان میں سے ہر ایک کا مختصر summary لکھتی ہے۔ پھر یہی summaries صارف-facing ماڈل تک واپس جاتی ہیں۔
صارف-facing ماڈل اصل صفحہ نہیں پڑھتی۔ یہ اس صفحہ کا summary پڑھتی ہے جو کسی اور AI نے لکھا ہوتا ہے۔ اسی لیے یہ کبھی اس چیز کو غلط بیان کر دیتی ہے جو صفحہ نے حقیقت میں کہی تھی: معلومات آپ تک پہنچنے سے پہلے ایک translation layer سے گزرتی ہے، اور translation layers nuance کھو دیتی ہیں۔
عملی حل: AI کو بتائیں کہ کس قسم کے ذرائع استعمال کرنے ہیں۔ "ہیں vaccines safe" کے بجائے یوں کہیں: "استعمال کریں دنیا Health Organization، FDA، European Medicines Agency، اور peer-reviewed studies. کریں نہیں استعمال کریں forums یا ذاتی blogs." ماخذ معیار ایک knob ہے جسے آپ گھما سکتے ہیں۔ default settings پہلے popular ذرائع cite کرتی ہیں (Reddit، Wikipedia، YouTube، Google itself، Yelp)، جو اکثر قابل استعمال تو ہوتے ہیں مگر high-stakes سوالات کے لیے ہمیشہ قابل اعتماد نہیں۔
دwasرا حل: AI سے ماخذ quote کروائیں۔ "کے لیے ہر claim، quote exact sentence سے ماخذ صفحہ کہ supports یہ." اس سے معاون ماڈل کو اصل wording سامنے لانی پڑتی ہے، اور summary-layer drift کا بڑا حصہ پکڑا جاتا ہے۔
ایک non-سافٹ ویئر مثال۔ ایک استاد نے اپنی 7th-درجہ class کے لیے مقامی water معیار پر unit منصوبہ بنانے میں گہری تحقیق استعمال کی۔ اس کا پرامپٹ تھا: "Research تازہ water معیار issues میں [her city] پر last 24 months. استعمال کریں EPA، city کا public utility رپورٹس، اور peer-reviewed studies. بچیں news editorials اور forums. پیدا کریں ایک منظم رپورٹ کے ساتھ: (1) three most-cited issues، (2) ڈیٹا جداول showing trends، (3) three age-appropriate classroom activities students could کریں کو investigate ایک کا یہ issues پر home." آٹھ منٹ بعد اس کے پاس تازہ مقامی ڈیٹا پر مبنی ایک unit منصوبہ تھا۔ pretrained طریقہ یہ نہیں کر سکتی تھی؛ صرف ویب تلاش زیادہ سطحی جواب دیتی؛ گہری تحقیق ہی درست ٹول تھی کیونکہ سوال multi-dimensional بھی تھا اور تازہ بھی۔
اپنے ذہن میں طریقہ چننا۔ عام طور پر آپ button دبا کر طریقہ نہیں چنتے؛ AI آپ کے پرامپٹ کی بنیاد پر چنتی ہے۔ مگر آپ اسے steer کر سکتے ہیں:
| Phrasing طریقہ | یہ عموما کیا trigger کرتی ہے |
|---|---|
| "کیا ہے X" / "Summarize Y" | صرف pretrained. |
| "کیا کا تازہ ترین on X" / "Today" / "یہ week" / کوئی specific city | Web تلاش. |
| "Research X thoroughly،" "پیدا کریں ایک رپورٹ کے ساتھ حوالہ جات،" "استعمال کریں یہ ماخذ types" | Deep تحقیق (ان ٹولز میں جہاں یہ ہو؛ ورنہ extended ویب تلاش). |
| فائلز attach کرنا | فائلز کے لیے pretrained رہتی ہے؛ اگر تازہ info درکار ہو تو سیاق و سباق کے لیے ویب تلاش کر سکتی ہے۔ |
AI بمقابلہ Google۔ یہ ایک ہی ٹول نہیں ہیں۔ Google اس وقت استعمال کریں جب آپ کو فوری scanning کرنی ہو، کسی معلوم site پر جانا ہو، یا کوئی چیز خریدنی ہو (مثلا 2013 Honda Civic کے لیے air filter)۔ AI اس وقت استعمال کریں جب آپ کو synthesis چاہیے ہو: pros اور cons، multi-ماخذ comparison، یا لکھی ہوئی تجزیہ۔ انتخاب اس بات پر ہے کہ آپ کو لنک چاہیے یا جواب۔
ایک سادہ قاعدہ کا thumb:
| کام | Google کے ساتھ بہتر | AI کے ساتھ بہتر |
|---|---|---|
| "Find official IRS صفحہ کے لیے form 1040." | Yes. آپ ایک specific known site پر جانا چاہتے ہیں۔ | نہیں. |
| "Compare three diabetes medications اور کیا recent evidence says." | سست؛ آپ کو 8 tabs پڑھنی پڑیں گی۔ | تیز؛ AI ایک جگہ evidence synthesize کر دیتی ہے۔ |
| "Buy ایک replacement charger کے لیے ایک 2018 ThinkPad." | Yes. آپ کو پروڈکٹ لنک چاہیے۔ | نہیں. |
| "منصوبہ ایک 4-دن Lisbon trip کے ساتھ ایک 6-year-old، نہیں museums." | سست؛ آپ blogs اور جائزے سنبھالتے رہیں گے۔ | تیز؛ AI constraints کو یکجا کر دیتی ہے۔ |
| "کیا کا weather tomorrow?" | Either. | Either. |
| "کیوں ہیں my tomato plant leaves yellowing?" | ٹھیک؛ کئی gardening sites مل جائیں گی۔ | تصویر attach ہو تو AI بہتر۔ |
اگر آپ کا سوال "X کہاں ہے؟" ہو تو Google کی طرف جائیں۔ اگر سوال "یہ سب دیکھ کر مجھے کیا سوچنا چاہیے؟" ہو تو AI کی طرف جائیں۔
ویب-تلاش results کو زیادہ قابل اعتماد کیسے بنائیں
جب آپ واقعی ویب تلاش چاہتے ہیں تو تین چھوٹی عادتیں معیار بڑھا دیتی ہیں:
- وہ ذرائع نام سے بتائیں جن پر آپ اعتماد کرتے ہیں۔ "استعمال کریں WHO، FDA، اور peer-reviewed studies، نہیں forums."
- inline حوالہ جات مانگیں۔ "Cite ماخذ بعد ہر claim."
- AI سے کہیے کہ جو verify نہ ہو سکے اسے نشان زد کرے۔ "If ایک claim نہیں کر سکتا be supported کے ذریعے cited ذرائع، mark یہ 'unverified'."
یہ تین سطریں، اگر آپ کسی بھی ویب-تلاش پرامپٹ میں شامل کر دیں، تو عام ناکامی طریقہ کافی کم ہو جاتا ہے: یعنی AI کئی ذرائع کو ملا کر خاموشی سے ایک ایسا confident sentence بنا دے جسے کوئی ایک ماخذ سپورٹ ہی نہ کرتا ہو۔
حصہ 2: AI سے بہتر بات کرنا
اگلے چار تصورات اس صفحے کا دل ہیں۔ یہی وہ عادتیں ہیں جو AI کو صرف مفیڈ سمجھنے والے شخص اور اسے transformative پانے والے شخص کے درمیان فرق پیدا کرتی ہیں۔
4. سیاق و سباق ہی اصل کھیل ہے
انسان active working memory میں تقریبا 7 چیزیں رکھتے ہیں۔ جدید AI ماڈلز ایک وقت میں لاکھوں الفاظ تک سنبھال سکتی ہیں، اور کبھی ایک million تک۔ تناسب سمجھنے کے لیے یوں سوچیے: تقریبا 750،000 الفاظ Harry Potter کی پہلی 4 سے 5 کتابوں کے برابر ہیں، یا کئی دن کی مسلسل speech کے برابر۔ ماڈل جواب دینے سے پہلے یہ سب پڑھ سکتی ہے۔
مگر وہ صرف وہی پڑھ سکتی ہے جو آپ اسے دیتے ہیں۔ سیاق و سباق وہ سب کچھ ہے جو کسی ایک response کے لیے ماڈل کی window میں جا پہنچتا ہے: نظام پرامپٹ جو پروڈکٹ نے سیٹ کیا ہو، ان ٹولز کی descriptions جنہیں یہ call کر سکتی ہو (ویب تلاش، کوڈ، فائل access)، آپ کا پرامپٹ، اس گفتگو کی chat history، اور وہ فائلز جو آپ نے upload کی ہوں۔
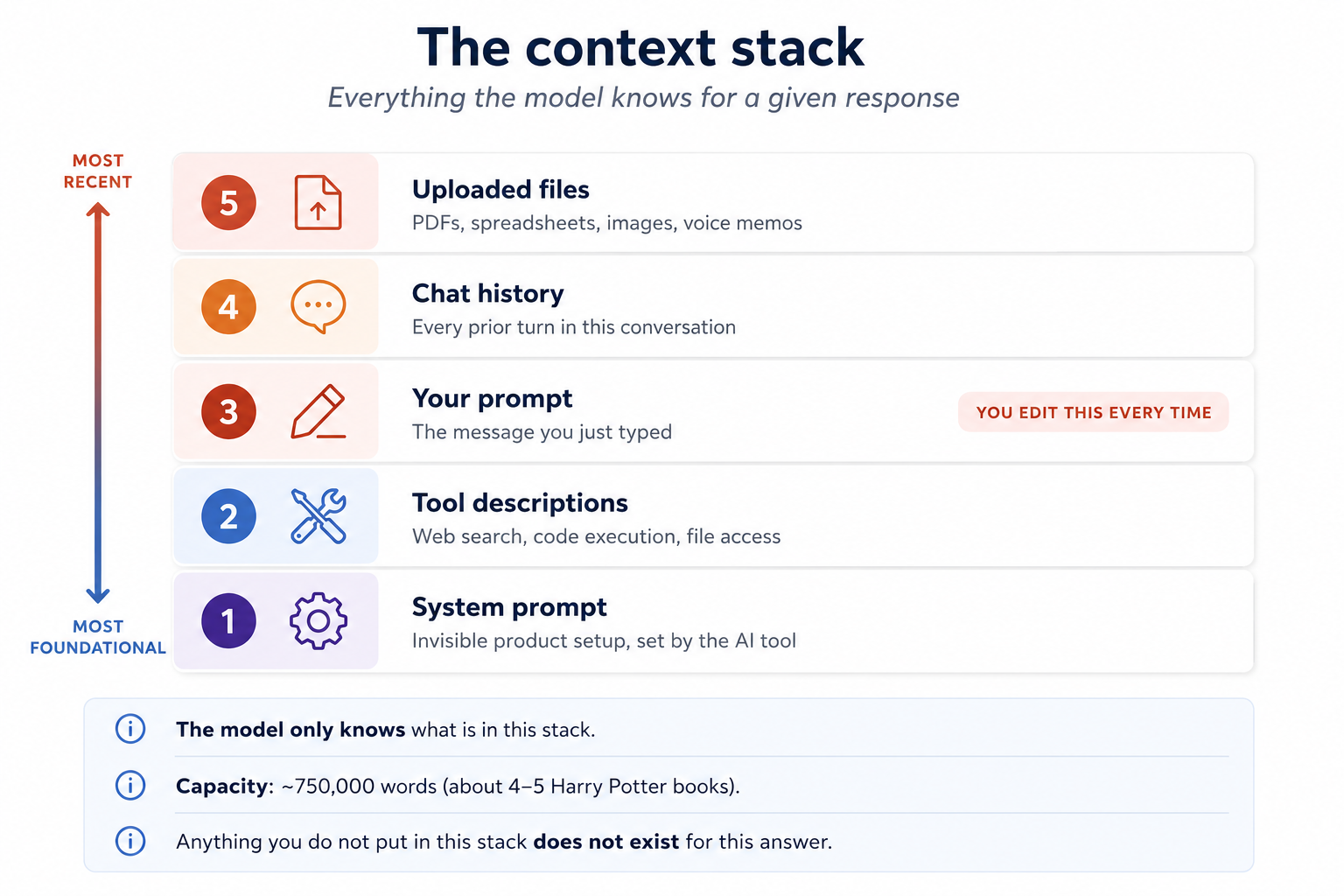
ایک واضح contrast:
- Bare پرامپٹ: "pros اور cons کا studying physics versus zoology." آپ کو ایک عمومی high-school-counselor طرز کا جواب ملے گا۔
- سیاق و سباق-rich پرامپٹ: یہی سوال، مگر ساتھ میں آپ کے career assessment results بطور PDF اور آپ کے high-school schedule کا screenshot attach ہو۔ اب AI آپ کی مخصوص aptitude profile، آپ کی کورس history، اور دونوں choices کے آپ کے لیے موزوں ہونے پر بات کر سکتی ہے۔
وہی ماڈل۔ وہی سوال۔ مختلف جواب۔ فرق پرامپٹ کی cleverness میں نہیں، سیاق و سباق میں ہے۔
ایک non-سافٹ ویئر مثال۔ ایک چھوٹے کاروبار کی مالک بار بار AI سے پوچھتی رہی "کیسے کریں I price my consulting کام" اور اسے عمومی مشورے ملتے رہے (hourly بمقابلہ project-based، قدر-based قیمتوں کا تعین وغیرہ)۔ پھر اس نے تین چیزیں attach کیں: اپنی پچھلی چھ invoices، competitors کے rate sheets کا screenshot، اور اپنے client mix پر ایک مختصر note۔ وہی AI، اب ground ہونے کے بعد، ایک واضح recommendation دیتی ہے: named anchor price کے ساتھ tiered ڈھانچہ، competitors کی positioning پر مبنی justification، اور ایک صاف ستھرا ای میل مسودہ جو اگلے prospect کو بھیجا جا سکے۔ ماڈل دونوں بار equally smart تھی؛ دwasری بار اسے کام کے لیے کافی مواد دیا گیا تھا۔
آپ جو طریقہ کار سیکھ رہے ہیں وہ یہ ہے: send دبانے سے پہلے خود سے پوچھیں کہ ایک ذہین نئے colleague کو یہ کام اچھی طرح کرنے کے لیے سامنے کیا چاہیے ہوگا۔ پھر وہ چیزیں attach کر دیں۔
یہاں ایک متحد mental ماڈل بھی ہے: AI ایک بہت ذہین مگر نیا college graduate ہے جو انتہائی motivated ہے، مگر ابھی آپ کے بارے میں زیادہ نہیں جانتا۔ آپ اس کے سامنے جو رکھیں گے، یہ اسے غور سے پڑھے گی۔ جو آپ نہیں بتائیں گے، اسے یہ guess نہیں کرے گی۔ یہ خود سے آپ کی filing cabinet نہیں کھولے گی۔ آپ کی industry، آپ کی ٹیم کی history، پچھلی سہ ماہی کے نتائج، یا کل والی ای میل thread اس وقت تک infer نہیں کرے گی جب تک آپ وہ سب brief میں شامل نہ کریں۔ تھوڑا empathy سے سوچیے: کیا اس پرامپٹ میں اس کے پاس واقعی اتنی معلومات ہیں کہ یہ کام کر سکے؟ اگر نہیں، تو مزید دیں۔
ایک اور non-سافٹ ویئر مثال۔ ایک 7th-درجہ استاد نے AI سے کہا: "مسودہ ایک سبق منصوبہ on water cycle." جواب ایک عمومی سبق منصوبہ تھا جو کسی بھی textbook میں مل جاتا: definitions، ایک خاکہ، اور تین discussion سوالات۔ اگلے دن اس نے دوبارہ کوشش کی، مگر اس بار تین چیزوں کے ساتھ: کورس syllabus (تاکہ AI کو پتا ہو کہ اس سبق سے پہلے اور بعد میں کیا ہے)، پچھلے ہفتے کے students worksheets جن پر grades نظر آ رہے تھے (تاکہ AI کو معلوم ہو کہ کون سے تصورات بیٹھ گئے اور کون سے نہیں)، اور school کے standardized test format۔ نیا سبق منصوبہ ان دو تصورات کے پانچ منٹ کے جائزہ سے شروع ہوا جو worksheets کے مطابق کمزور تھے، پھر نئے material کو اسی test format میں باندھا جس کا students مئی میں سامنا کریں گے، اور آخر میں ایک check-for-understanding سوال دیا جو syllabus کے اگلے topic سے مطابق کرتا تھا۔ وہی ماڈل، وہی استاد، وہی subject۔ فرق صرف اتنا تھا کہ دwasرے پرامپٹ میں AI کو وہ بتایا گیا تھا جو ایک smart نیا colleague کو جاننا ضروری ہوتا۔
اس عادت کو ایک checklist کی شکل میں دوبارہ دیکھیے:
| سوال | اگر جواب yes ہو تو کیا کریں |
|---|---|
| کیا کوئی دستاویز ہے جس کے مطابق جواب مستقل ہونا چاہیے؟ | Yes: اسے attach کریں۔ |
| کیا کوئی ایسا constraint ہے جسے AI خود infer نہیں کر سکتی (بجٹ، وقت، ٹیم)؟ | Yes: اسے واضح لکھیں۔ |
| کیا کوئی prior سیاق و سباق ہے (پہلا فیصلہ، موجودہ عمل)؟ | Yes: ایک paragraph میں summarize کریں۔ |
| کیا آپ کو خاص نتیجہ format چاہیے (جدول، ای میل، bullet list)؟ | Yes: اسے نام لے کر بتائیں۔ |
| کیا کوئی audience متعین ہے (boss، child، stranger)؟ | Yes: انہیں نام سے بتائیں۔ |
صحیح طور پر چنی گئی سیاق و سباق کی پانچ سطریں، cleverness کے پانچ paragraphs سے بہتر ہوتی ہیں۔
جدید سیاق و سباق کی گنجائشیں بڑی ضرور ہیں، مگر infinite نہیں، اور ان کے اندر recall کی معیار کم بھی ہو سکتی ہے۔ لوگوں کی سب سے عام عملی غلطی یہ ہے کہ وہ ایک ہی بہت لمبی گفتگو کو مختلف موضوعات میں کھینچتے چلے جاتے ہیں۔ AI نے ابھی آپ کا workout منصوبہ بنایا، اب آپ اسپریڈ شیٹ خرابی دور کرنا کروا رہے ہیں، اب آپ اپنی aunt کے لیے thank-you note لکھوا رہے ہیں۔ workout والا سیاق و سباق ابھی تک اندر پڑا ہے، اور ماڈل کو distract کر رہا ہے۔
سادہ اصول: جب موضوع بدل جائے، نئی گفتگو شروع کریں۔ یہ آسان ہے، مفت ہے، اور اس سے جوابات نمایاں طور پر بہتر ہو جاتے ہیں۔
کچھ علامات جو بتاتی ہیں کہ گفتگو باسی ہو چکی ہے:
- AI پہلے کی باتوں کا حوالہ دینے لگتی ہے جن کا آپ کے نئے سوال سے تعلق ہی نہیں۔
- وقت کے ساتھ جواب لمبے اور مبہم ہونے لگتے ہیں، اور hedging بڑھ جاتی ہے۔
- یہ کسی ایسے constraint کی خلاف ورزی کرتی ہے جو آپ نے پانچ turns پہلے بتایا تھا۔
- یہ بار بار معذرت کرتی ہے مگر پیش رفت نہیں ہوتی۔
جب یہ علامات نظر آئیں تو اسے "ایک اور clarifying پرامپٹ" سے ٹھیک کرنے کی کوشش نہ کریں۔ اس سے پہلے سے الجھے ہوئے سیاق و سباق میں اور الجھن بڑھتی ہے۔ نئی chat کھولیں، صرف وہ ایک یا دو facts paste کریں جو واقعی اہم ہیں، اور وہاں سے آگے بڑھیں۔ reset تقریبا ہمیشہ rescue سے تیز ہوتا ہے۔
دو عادتوں کی ایک مفیڈ pairing:
| Habit | یہ کیا کرتی ہے | کب استعمال کریں |
|---|---|---|
| ہر topic کے لیے نئی chat | جمع شدہ شور ہٹا دیتی ہے۔ | جب بھی آپ کام بدلیں۔ |
| مفیڈ state کو فائل میں save کریں | اگلی chat میں صرف ضروری چیزیں دوبارہ load ہوتی ہیں۔ | جب لمبی گفتگو سے کوئی قابل حفاظت چیز نکلی ہو (منصوبہ، مسودہ، فیصلہ)۔ |
دونوں مل کر فائدہ یہ دیتی ہیں: آپ کام بھی نہیں کھوتے، اور noise بھی اگلے کام میں ساتھ نہیں لے جاتے۔
5. استدلال، یا "think مشکل"
تقریبا 2023 تک مشکل پرامپٹس کے لیے عام مشورہ "think step کے ذریعے step" تھا۔ اب یہ مشورہ بڑی حد تک پرانا ہو چکا ہے۔ جدید ماڈلز کے پاس built-in استدلالی طریقے ہیں جنہیں آپ براہ راست invoke کر سکتے ہیں۔
نئے keywords:
- اپنے پرامپٹ میں "Think مشکل" یا "think carefully پہلے answering"
- ان ٹولز میں "Ultrathink" جو اسے پہچانتے ہیں (مثلا Claude کی بعض پروڈکٹس)
- interface میں موجود thinking-طریقہ toggle، اگر وہاں ہو
جب آپ اسے آن کرتے ہیں تو ماڈل کئی seconds تک سوچ سکتی ہے۔ مشکل مسائل میں، کبھی دس منٹ سے بھی زیادہ۔ یہ صرف آہستہ typing نہیں؛ یہ اندرونی طور پر کئی approaches explore کرتی ہے، اپنا کام چیک کرتی ہے، اور پھر وہ جواب لکھتی ہے جو آپ دیکھتے ہیں۔
2025 کی ایک METR مطالعہ نے یہ track کیا کہ frontier ماڈل کس لمبے کام کو قابل اعتماد طریقے سے مکمل کر سکتی ہے۔ 2024 میں جواب تھا: وہ کام جو انسان کو چند منٹ لیتے ہیں۔ 2025 میں جواب ہو گیا: وہ کام جو انسان کے کئی گھنٹے لیتے ہیں۔ یہ trajectory اب بھی اوپر جا رہی ہے۔ آپ کے لیے اس کا مطلب یہ ہے: AI کو حقیقی، مشکل کام دیجیے، صرف آسان نہیں۔ یہ آپ کی 2023 والی intuition سے کہیں زیادہ سنبھال سکتی ہے۔
ایک ماہر صارف طریقہ:
I'm choosing between two cars. Attached: spec sheets for both,
my insurance quote for each, and a spreadsheet of my driving
patterns over the last six months.
Read everything. Think hard. Then tell me:
1. The three trade-offs that actually matter for my driving pattern.
2. Which car you'd choose and why.
3. Under what conditions your recommendation flips.
اس پرامپٹ میں تین اہم چیزیں ہیں: relevant سیاق و سباق load کی گئی ہے، thinking explicitly invoke کی گئی ہے، اور ایک دیوار جیسے prose کے بجائے منظم جواب مانگی گئی ہے۔ یہ تینوں عادتیں اہم ہیں۔
فوری lookups، ایک paragraph کا summary، casual brainstorming۔ سوچنے کا طریقہ سست ہوتی ہے اور آپ کے usage بجٹ کا زیادہ حصہ لیتی ہے۔ اسے انہی سوالات کے لیے بچا کر رکھیں جن میں آپ چاہتے کہ کوئی انسان واقعی وقت لے۔
ایک non-سافٹ ویئر مثال۔ ایک small-کاروبار مالک کو اپنے office کے لیے تین commercial cleaning vendors میں سے ایک چننا تھا۔ اس کے پاس تینوں کے quotes، references، اور ہر کمپنی کی history کا ایک صفحہ تھا۔ اس کا پہلا پرامپٹ تھا: "کون سا کا یہ vendors چاہیے I چنیں?" AI نے ایک عمومی checklist دے دی (price دیکھیے، جائزے دیکھیے، references لیجیے)۔ مفیڈ تھی، مگر فیصلہ نہیں۔
پھر اس نے سوچنے کا طریقہ آن کی اور یہ مختلف پرامپٹ استعمال کیا:
Attached: three commercial cleaning vendor quotes, three reference
sheets I called myself, and a one-paragraph note on what matters
most to me (consistency over price, since I've been burned twice).
Think hard before answering. Then:
1. Identify the three trade-offs I should actually be weighing.
2. Score each vendor on each trade-off, with one-sentence
justifications grounded in the attached files.
3. Recommend one, and tell me what would make you switch.
AI نے تقریبا چار منٹ سوچا۔ جواب ایک one-page میمو کی صورت میں آیا، بالکل اسی ڈھانچہ میں جو مانگا گیا تھا، اور اسی دوپہر عمل کے قابل تھا۔ شروع سے آخر تک فیصلہ وقت: ایک پرامپٹ، چار منٹ کی سوچ، دس منٹ کی مطالعہ۔ یہی فیصلہ اس کی desk پر دو ہفتے سے پڑا تھا۔
سوچنے کا طریقہ اسی کے لیے ہے: صرف تیز ہونے کے لیے نہیں، بلکہ ایسے multi-داخلہ، multi-trade-off سوالات سنبھالنے کے لیے جنہیں آپ ورنہ کسی thoughtful colleague کو دیتے اور دو دن انتظار کرتے۔ trade حقیقی ہے۔ آپ چند منٹ کا compute اور usage بجٹ کا ایک چھوٹا حصہ خرچ کرتے ہیں۔ جواب میں آپ کو وہ چیز ملتی ہے جس پر ورنہ آپ آدھا دن لگا دیتے۔
METR finding پر ایک نوٹ۔ METR ایک تحقیق group ہے جو یہ ناپتی ہے کہ frontier AI ماڈل کس لمبے کام کو قابل اعتماد طور پر مکمل کر سکتی ہے۔ 2024 میں یہ حد ایسے کام تھی جو انسان کے چند منٹ لیتے ہیں۔ 2025 تک یہ ایسے کام ہو گئے جو انسان کے کئی گھنٹے لیتے ہیں۔ رفتار تیز ہے اور اوپر جا رہی ہے۔ آپ کے لیے مطلب واضح ہے: وہ کام جنہیں آپ نے دو سال پہلے ذہنی طور پر "AI کے لیے بہت پیچیدہ" قرار دیا تھا، اب ان میں سے اکثر AI کر سکتی ہے، اگر آپ اسے اچھی طرح brief کریں اور سوچنے کا طریقہ on کریں۔ ہر چھ ماہ بعد اپنے assumptions دوبارہ آزمائیں۔ وہ پرانے ہو جائیں گے۔
6. Sycophancy اور اسے غیر جانبدار کیسے کیا جائے
AI ماڈلز کو human رائے پر train کیا جاتا ہے۔ خاص طور پر اس پر کہ کن responses کو thumbs up ملا۔ لاکھوں صارفین کے aggregate میں لوگوں سے اتفاق کرنے والے جواب زیادہ thumbs up لیتے ہیں، اختلاف کرنے والے کم۔ نتیجہ یہ ہے کہ ماڈلز آپ کو وہی سنانے کی طرف biased ہوتی ہیں جو آپ سننا چاہتے ہیں۔
2024 کی Washington Post تجزیہ نے ChatGPT conversations میں پایا کہ ماڈل صارفین سے اختلاف کے مقابلے میں تقریبا 10 گنا زیادہ اتفاق کر رہی تھی۔ عام جملے تھے: "کہ کا درست،" "اچھا point،" "آپ're on درست track،" اور ایک خاصا تکلیف دہ جملہ: "dude، آپ just said something deep بغیر even flinching، آپ're ایک thousand percent درست."
آپ خود بھی یہ آزما سکتے ہیں۔ وہی ماڈل، مگر opposite framings:
- "Don't آپ think remote کام ہے بہتر than office کام?" → AI اتفاق کرتی ہے اور وجوہات گنوا دیتی ہے۔
- "ہے یہ true کہ office کام ہے زیادہ productive?" → AI پھر بھی اتفاق کرتی ہے اور دwasری وجوہات گنا دیتی ہے۔
حل کوئی جادو نہیں۔ بس غیر جانبدار framing ہے۔ دیکھیے:
| Bait phrasing (آپ کا پسندیدہ جواب signal کرتی ہے) | Neutral phrasing (اصل جواب مانگتی ہے) |
|---|---|
| "Don't آپ think remote کام ہے بہتر?" | "کیسے کرتا ہے productivity compare درمیان remote اور in-office کام?" |
| "Aren't carbon taxes bad کے لیے چھوٹا businesses?" | "کیسے کریں carbon taxes affect چھوٹا businesses? Cite دونوں directions." |
| "کریں آپ agree AI گا بنائیں ایک lot کا jobs?" | "کیا کرتا ہے تازہ تحقیق کہتے ہیں کے بارے میں AI's net effect on jobs?" |
| "کرتا ہے remote کام reduce productivity?" | "کیا کرتا ہے evidence کہتے ہیں کے بارے میں remote کام اور productivity?" |
| "Find all positive measures کا performance یہ quarter." | "Summarize یہ quarter کا performance ڈیٹا. Flag دونوں positive اور negative trends." |
bait کی ایک زیادہ subtle شکل یہ ہے کہ آپ AI سے کہیں: "find all positive measures کا performance"۔ آپ پہلے ہی ماڈل کو بتا چکے ہوتے ہیں کہ آپ کون سا جواب چاہتے ہیں۔ یہ وہی ڈھونڈ لے گی، چاہے ڈیٹا زیادہ تر negative ہو۔ اس کے بجائے غیر جانبدار instruction دیں: "summarize ڈیٹا، flag کیا ہے improving اور کیا ہے degrading."
اپنے پرامپٹس میں پہچاننے کے لیے چند اور bait phrasings:
| Subtle bait آپ might لکھیں | AI کے لیے اس کا اشارہ | Neutral rewrite |
|---|---|---|
| "Find evidence کہ یہ حکمت عملی گا کام." | نتیجہ پہلے سے طے ہے؛ AI صرف سپورٹ بھر دے۔ | "جانچیں یہ حکمت عملی. List strongest arguments کے لیے اور کے خلاف." |
| "کیوں ہے طریقہ ایک بہتر than طریقہ B?" | ایک جیت چکا؛ AI اس کے حق میں reasons دے۔ | "Compare طریقہ ایک اور طریقہ B. Score ہر on لاگت، خطرہ، اور وقت." |
| "مدد me defend my فیصلہ کو hire X." | فیصلہ بند ہو چکا؛ AI ammunition دے۔ | "یہاں ہے my فیصلہ اور سیاق و سباق. کیا کا strongest counter-argument I چاہیے be ready کے لیے?" |
| "Tell me my مسودہ ہے ready کو send." | AI کہے گی کہ تیار ہے۔ | "Critique یہ مسودہ کے خلاف یہ 4 yes/no معیارات. Recommend smallest تبدیلی کہ would lift lowest درجہ." |
| "Confirm کہ یہ کوڈ ہے درست." | AI تصدیق کرے گی۔ | "Find any bug، edge case، یا unstated assumption میں یہ کوڈ. If وہاں ہیں none، کہتے ہیں اس لیے." |
طریقہ یہ ہے: ایسا کوئی بھی verb جیسے find، defend، confirm، prove، support سوال سے پہلے ہی نتیجہ ماڈل کے ہاتھ میں دے دیتا ہے۔ انہیں evaluate، compare، تنقیدی جائزہ، find any، list دونوں sides جیسے verbs سے بدلیں۔ bias پوری طرح ختم نہیں ہوگی، مگر سب سے بڑا signal غائب ہو جائے گا۔
عام اصول: دو options اس طرح رکھیں کہ آپ کی preference ظاہر نہ ہو، پھر دونوں کے pros اور cons پوچھیں۔ اگر آپ خود کو "isn't X true" لکھتے پکڑیں، تو رکیں اور اسے "کو کیا extent، if پر all، ہے X true?" میں بدل دیں۔
یہ تصور ایک زیادہ گہری مہارت کا سستا ورژن ہے۔ Part 0 باب 1 (Asking بہتر سوالات) اس گہری مہارت کو train کرتا ہے: ایسے سوال کیسے بنائے جائیں جو وہ سامنے لائیں جو آپ پہلے سے نہیں جانتے۔ غیر جانبدار-framing والا trick روزمرہ استعمال میں آپ کو 80% فائدہ دے دیتا ہے۔ باب باقی حصہ سکھاتا ہے۔
ایک non-سافٹ ویئر مثال۔ ایک بانی نے AI سے پوچھا: "I رکھتے ہیں ایک بہترین کاروبار خیال، mobile tie-dyeing کے لیے kids' birthday parties، تنقیدی جائزہ یہ." AI نے گرمجوشی سے تعریف کی اور کامیابی کی ممکنہ وجوہات گنوا دیں۔ پھر بانی نے دوبارہ یوں پوچھا: "Analyze یہ خیال objectively. کے لیے ہر کا following، درجہ 1 کو 10 اور justify: (1) ہے وہاں ایک حقیقی problem یہاں، (2) ہے وہاں ایک market willing کو pay، (3) ہے وہاں ایک competitive advantage، (4) کیا کا unit economics، (5) کیا ہیں top three reasons یہ fails." وہی AI اس خیال کو 100 میں سے 8 دینے لگی اور بہت ٹھwas انداز میں بتایا کہ بانی کو کیوں دوبارہ سوچنا چاہیے۔ پہلا پرامپٹ خوشامدانہ رجحان bait تھا۔ دwasرا ایک objective معیار نامہ تھا۔ وہی ماڈل، وہی خیال، مگر الٹا verdict۔ فرق صرف سوال کے انداز میں تھا۔
objective-معیار نامہ طریقہ۔ جب آپ AI سے کسی چیز کا جائزہ مانگتے ہیں (مسودہ، منصوبہ، خیال)، تو مبہم معیارات اکثر "بہترین کام" میں collapse ہو جاتے ہیں۔ مخصوص yes/no معیارات AI کو واقعی دیکھنے پر مجبور کرتے ہیں۔ دیکھیے:
| Vague تنقیدی جائزہ پرامپٹ (خوشامدانہ رجحان پیدا کرتی ہے) | Rubric-based تنقیدی جائزہ پرامپٹ (ایماندار جواب دیتی ہے) |
|---|---|
| "Score my sci-fi short story باہر کا 100." | "Critique استعمال کرتے ہوئے یہ 4 معیارات، ہر 1-5، ہر justified میں ایک sentence." |
| "ہے یہ ای میل professional?" | "چیک یہ ای میل کے خلاف یہ 5 yes/no tests: greeting present، پوچھیں ہے میں پہلا paragraph، نہیں jargon، single واضح request، polite close." |
| "کیسے ہے my workout منصوبہ?" | "کے لیے ہر دن، جواب: کرتا ہے یہ include ایک warm-up، کرتا ہے total volume fit my وقت بجٹ، ہیں وہاں 48 گھنٹے درمیان same-muscle سیشنز?" |
اصل trick یہ ہے کہ معیار نامہ کا ہر criterion واضح yes یا نہیں کے ساتھ answerable ہو، یا 1-to-5 درجہ اور مختصر justification کے ساتھ۔ نرم معیارات ("ہے یہ engaging?") خوشامدانہ رجحان کے لیے جگہ چھوڑ دیتے ہیں۔ سخت معیارات نہیں چھوڑتے۔
7. Brainstorm-Iterate Loop
یہ اس صفحے کی سب سے زیادہ leverage دینے والی عادت ہے۔ اگر آپ باقی سب کچھ چھوڑ بھی دیں تو یہ حصہ مت چھوڑیے۔
AI جب انٹرنیٹ پر train ہوئی، تو انٹرنیٹ پر زیادہ تر خیالات عام نوعیت کے تھے، غیر معمولی نہیں۔ اس لیے creative سوال پر average AI response بھی عام ہوتی ہے۔ "طریقے کو مشق پر home": squats، push-ups، planks۔ غلط نہیں، بس عام۔
اس سے بچنے کا راستہ کوئی جادوئی پرامپٹ نہیں۔ یہ ایک چکر ہے۔
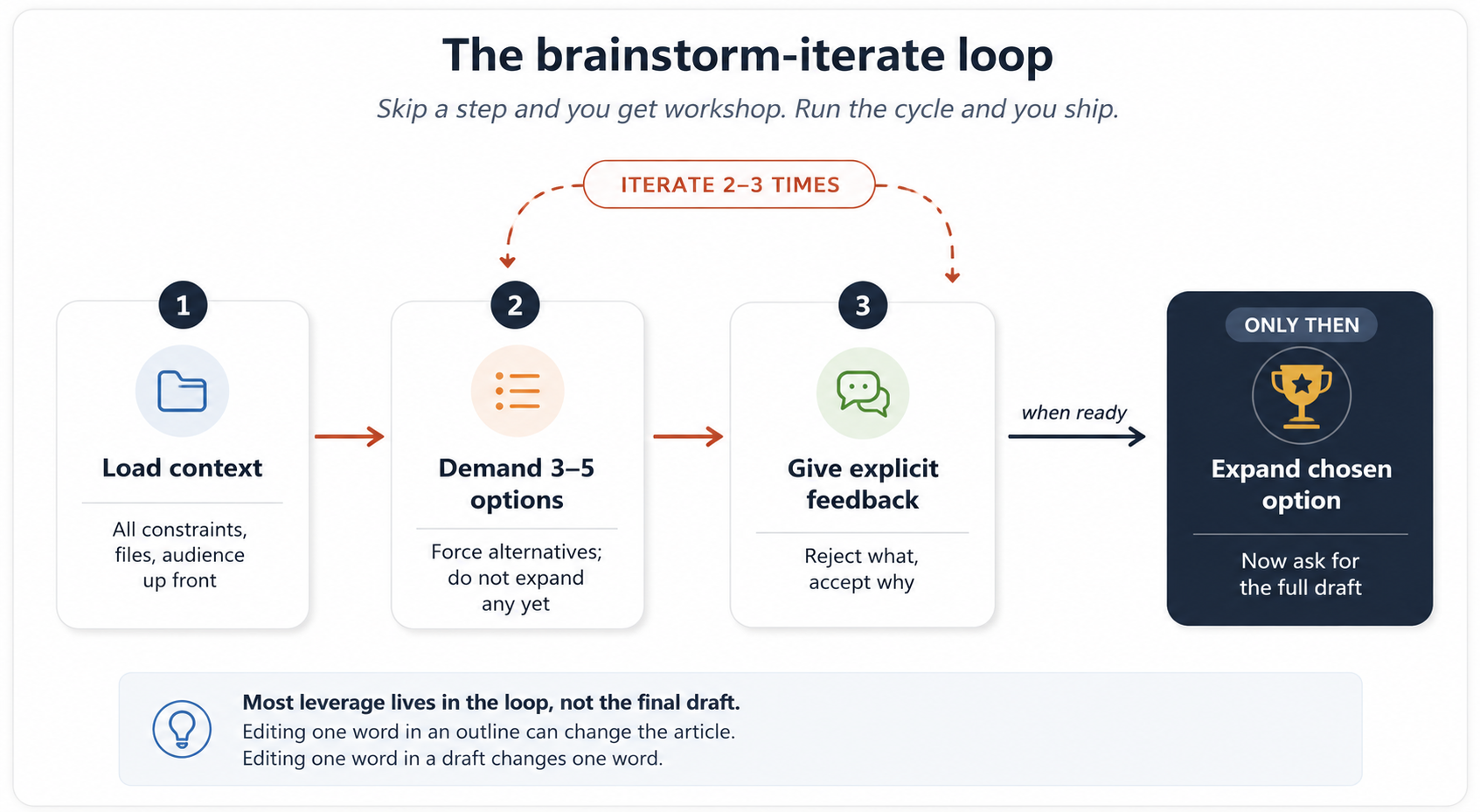
طریقہ یہ ہے:
- تمام relevant سیاق و سباق شروع ہی میں دے دیں۔ صرف "طریقے کو مشق" نہیں؛ بلکہ "طریقے کو مشق دیا گیا کہ I رکھتے ہیں ایک trampoline، ایک cat، اور I نہیں کر سکتا stick کو منصوبے کے لیے زیادہ than three days."
- ایک نہیں، 3 سے 5 options مانگیں۔ alternatives مانگنے سے ماڈل اپنے پہلے instinct سے آگے نکلتا ہے۔
- explicit رائے دیں۔ "I don't like option 1، یہ کا too passive. I کریں like trampoline خیال مگر چاہتے ہیں یہ shorter. I forgot کو mention I رکھتے ہیں ایک bad knee."
- رائے کے مطابق 3 سے 5 نئی options مانگیں۔
- دہرائیں کرتے رہیں جب تک ایک یا دو options واقعی پسند نہ آ جائیں۔
- پھر، اور صرف پھر، AI سے منتخب option کو detail میں flesh باہر کرنے کو کہیں۔
ایک عملی مثال، debt payoff:
I have $8,000 in credit card debt at 19% APR, $4,000 in student
loans at 5%, and $1,200 in a retail card at 24%. I have $700/month
free after expenses. I just learned I'll get $450 in cash from a
tax refund. Risk tolerance: low. I sleep badly when I see big
balances.
Give me 5 different repayment strategies, each with a one-line
rationale. Don't expand any of them yet.
پھر پانچوں options پڑھنے کے بعد:
Reject option 2 (avalanche by interest rate alone): I want
psychological wins early. Reject option 4: I won't open new
accounts. I like option 1 (snowball with the retail card first)
but I'd want to fold the $450 in. Give me 5 new options that
combine snowball-style wins with smart use of that lump sum.
دیکھیے کیا ہو رہا ہے۔ آپ AI سے mind مطالعہ کی توقع نہیں کر رہے۔ آپ اپنی taste دکھا رہے ہیں، اور AI options کی دنیا کو اسی کے مطابق reshape کر رہی ہے۔ دو یا تین rounds کے بعد آپ کے پاس ایک ایسا option ملتا ہے جو واقعی ٹھیک لگتی ہے۔ اب مکمل منصوبہ مانگا جا سکتا ہے۔
لکھنے میں یہی چکر ایک اور نام سے سامنے آتی ہے: drafting سے پہلے outline۔
Iteration 1: ask for 3 outline options for a post on X.
Iteration 2: pick one outline, ask AI to critique it.
Iteration 3: revise the outline, ask AI to expand each heading
into 3-5 bullets.
Iteration 4: critique the bullets, fix the weak ones.
Iteration 5: only now ask for the full draft.
یہ کام کیوں کرتی ہے؟ outline میں ایک لفظ بدلنے سے پورے article کی direction بدل سکتی ہے۔ final مسودہ میں ایک لفظ بدلنے سے صرف ایک لفظ بدلتا ہے۔ لکھنے میں اصل leverage outline level پر ہوتی ہے۔ AI شروع سے آخر تک لفظ بہ لفظ generate کرتی ہے، اس لیے جب تک آپ ڈھانچہ پہلے force نہیں کرتے، یہ پورا shape نہیں دیکھتی۔
لالچ یہ ہوتا ہے کہ پہلی ہی بار مکمل مسودہ مانگ لی جائے۔ اس سے بچیں۔ AI کا پہلا مسودہ اکثر workslop ہوتا ہے: polished دکھتی ہے، مگر کہتی کم ہے۔ یہ چکر polished nothing کو اصل میں useful something میں بدلتا ہے۔
ایک لکھنے کی عملی مثال۔ ایک ٹیم lead 600-word post لکھنا چاہتی ہے جس کا عنوان ہے: "کیوں our چھوٹا AI ٹیم ہے shipping زیادہ تیز than big ٹیم across hall." عملی طور پر ہر round کچھ یوں لگے گا:
Round 1، پہلے تحقیق:
I'm writing a 600-word post arguing that small AI-augmented teams
ship faster than larger non-AI teams. Don't write yet. First, give
me the 5 strongest research-backed arguments and the 3 strongest
counter-arguments. One sentence each.
Round 2، تین outlines:
Now produce 3 different outline options for the post. Each outline
should have 4-6 headings. They should differ in structure: one
narrative, one analytical, one contrarian. One line per heading.
Round 3، ایک outline چن کر analogy شامل کرنا:
I'll go with outline 2 (analytical). I want to weave in a Pixar
analogy: how the original Toy Story team was small and faster than
the giant Disney studio because of new tools. Add this as a recurring
example, not its own section. Revise outline 2.
Round 4، bullets تک expand کرنا:
Now expand each heading into 3-5 bullets. Telegraphic style, not prose.
Round 5، bullets کا تنقیدی جائزہ:
Critique the bullets. Which ones are weakest? Which would a skeptical
reader push back on hardest?
صرف اب lead مکمل مسودہ مانگتی ہے۔ پورا عمل تقریبا تیس منٹ لیتا ہے۔ نتیجہ lead کے لکھے ہوئے متن جیسی محسwas ہوتی ہے، کیونکہ ساری load-bearing فیصلے lead کی اپنی تھیں۔ یہی چکر ہے۔
جس instinct سے بچنا ہے وہ یہ ہے: یہ سب "لکھیں me ایک post" کہنے سے زیادہ کام لگتا ہے۔ ہاں، تقریبا بیس منٹ زیادہ۔ مگر جو چیز اس سے بنتی ہے وہ بیس گھنٹے کی قدر کے زیادہ قریب ہوتی ہے، کیونکہ وہی نسخہ ہوتی ہے جسے آخر تک پڑھا جاتا ہے۔
drafting سے پہلے territory scope کریں۔ اوپر والی مثال میں پہلی round، یعنی "don't لکھیں yet، دیں me strongest تحقیق-backed arguments اور counter-arguments"، بظاہر چھوٹی لگتی ہے مگر بھاری کام کرتی ہے۔ زیادہ تر لوگ اسے چھوڑ کر سیدھا مسودہ مانگتے ہیں۔ یہی وجہ ہے کہ ان کی مسودے پتلی محسwas ہوتی ہیں: وہ topic کے اصل landscape کے بجائے ان خیالات پر بنی ہوتی ہیں جو ماڈل پہلے surface کر دیتی ہے۔ drafting سے پہلے صرف ایک round "scope territory" کرنے سے تین studies quote کرنے والی post اور صرف تین opinions گنوانے والی post کے درمیان فرق آ جاتا ہے۔ یہ طریقہ writing سے بہت آگے تک عام ہے: کسی بھی بڑے فیصلہ، منصوبہ، یا تجزیہ سے پہلے AI سے map کیا کا known کرائیں، پھر پیدا کریں کیا کا needed مانگیں۔ پروڈکٹ naming سے پہلے competitive landscape۔ حکمت عملی میمو سے پہلے prior تحقیق۔ نئی ڈیزائن سے پہلے موجود approaches۔ یہ تحقیق pass صرف پانچ منٹ لیتی ہے، مگر چکر کی ہر اگلی round کس چیز کے خلاف دہرائیں کرے گی، اسے بدل دیتی ہے۔
یہ چکر domain-agnostic ہے۔ یہی طریقہ trip planning، sales pitch، college major چننے، پروڈکٹ naming، wedding toast، renovation فیصلہ، یا charity select کرنے میں بھی چلتا ہے۔ shape وہی رہتی ہے: سیاق و سباق load کریں، options مانگیں، explicit رائے دیں، نئی options مانگیں، دہرائیں کریں، پھر expand کریں۔ اگر آپ خود کو AI کا پہلا جواب قبول کرتے دیکھیں، تو سمجھیں چکر چھوڑ دی گئی ہے۔ جو بھی کام ہو، اسے یہ چکر ملنی چاہیے۔
روزمرہ زندگی میں اس چکر کی جگہ:
| فیصلہ یا کام | "سیاق و سباق" کی شکل کیا ہوگی | "options کے ساتھ رائے" کی شکل کیا ہوگی |
|---|---|---|
| 4-دن trip منصوبہ کرنا | constraints (بجٹ، dates، کون جا رہا ہے، کس چیز سے نفرت ہے) | 5 itinerary skeletons؛ دو reject کریں؛ باقی refine کریں |
| پروڈکٹ کا نام رکھنا | یہ کیا کرتا ہے، کون خریدتا ہے، کس جیسا نہیں لگنا چاہیے | 10 names؛ 3 پسند کریں؛ انہی پر variants مانگیں |
| مشکل ای میل لکھنا | recipient، relationship، desired نتیجہ | 3 مختلف tones؛ ایک چنیں؛ اس کی specifics refine کریں |
| contractor چننا | تین quotes، تین reference notes، آپ کی priorities | side-by-side scoring؛ اپنے favorite کے خلاف strongest counter مانگیں |
| سیکھنا path چننا | تازہ مہارتیں، دستیاب وقت، end مقصد | 3 curriculum shapes؛ ایک چنیں؛ weekly milestones میں expand کریں |
| designer کے لیے logo brief بنانا | brand values، audience، پسندیدہ مثالیں | 5 mood-board directions؛ ایک چنیں؛ اسی راستہ میں 5 variants مانگیں |
حصہ 3: text سے آگے
تین ایسے تصورات جو ان چیزوں کے دروازے کھولتے ہیں جن کے بارے میں لوگ اکثر اندازہ ہی نہیں کرتے کہ AI یہ سب کر بھی سکتی ہے۔
8. کثیر الwasائط: تصاویر، آواز، اور آگے کیا آنے والا ہے
جدید AI تصاویر اور آواز دونوں کو دو سمتوں میں سنبھالتی ہے: یہ آپ کی upload کی ہوئی تصاویر پڑھ سکتی ہے، recordings سن سکتی ہے، text پرامپٹس سے نئی تصاویر generate کر سکتی ہے، اور بولی ہوئی آواز بھی بنا سکتی ہے۔ ہر modality کی مہارتیں الگ ہیں، اور انہیں الگ الگ سیکھنا فائدہ مند ہے۔
Image داخلہ۔ AI تصاویر کو قدرے coarse انداز میں دیکھتی ہے۔ یہ ان چیزوں میں مضبوط ہے:
- مجموعی scene اور composition۔
- بڑی اور نمایاں object shapes (مثلا giant human-sized hamster wheel treadmill)۔
- whiteboard کے contents، diagrams سمیت۔
- handwritten اور cursive text (معقول حد تک؛ high-stakes کام میں دوبارہ چیک کریں)۔
اور یہ ان چیزوں میں کمزور ہے:
- باریک details۔ "کیا gym machines ہیں یہ?" اکثر غلط جاتا ہے کیونکہ gym machines ایک دھندلے lens سے ایک جیسی لگتی ہیں۔ AI اعتماد سے مگر غلط جواب دے سکتی ہے۔
- گنجان scene میں بہت سی چھوٹی چیزوں کی counting۔
- تصویر کے کناروں پر موجود چھوٹا print پڑھنا۔
ایک مفیڈ عملی test: ایک استاد نے whiteboard کی تصویر کھینچی جس میں اس کا سر neural network خاکہ میں "convolutional" والے لفظ کو ڈھانپ رہا تھا۔ AI نے خاکہ کے باقی حصے سے missing word درست infer کر لیا۔ یہی وہ کام ہے جس میں AI اچھی ہے: gist سے inference۔ zoom کر کے باریک detail پڑھنے میں نہیں۔
receipts، bill split کرنے، یا handwritten notes transcribe کرنے میں AI اچھی مدد دیتی ہے، مگر totals ہمیشہ دوبارہ چیک کریں۔ multi-تصویر داخلے (post-its، whiteboard تصویر، خیالات بنانا کے handwritten notes) کی صورت میں AI مجموعی خیالات کا summary بنا سکتی ہے؛ یہ واقعی مفیڈ ہے اور حقیقی وقت بچاتی ہے۔
Image نتیجہ۔ جدید AI text پرامپٹس سے تصاویر generate کر سکتی ہے۔ دو عملی tips:
- اپنا تصویر پرامپٹ لکھوانے کے لیے text AI استعمال کریں۔ "Generate me ایک پرامپٹ کے لیے ایک fantasy forest illustration میں ایک Studio Ghibli style کے لیے ایک children کا کتاب cover." پھر اس نتیجہ کو تصویر ٹول میں paste کر دیں۔ پہلی کوشش میں rich تصویر پرامپٹس لکھنے میں text AI آپ سے بہتر ہوتی ہے۔
- اپنی visual اصطلاحی زبان بنائیں۔ cinematic، watercolor، cyberpunk، anime، isometric، low-poly، art-deco، claymation جیسے الفاظ levers ہیں۔ تصویر ماڈلز captioned تصاویر پر train ہوئی ہیں اور ان styles کو نام سے سیکھا ہے۔ اپنی پسند کی تصاویر upload کریں اور AI سے پوچھیں کہ یہ انہیں کیسے describe کرے گی۔ اس سے آپ کی اصطلاحی زبان بنتی ہے۔
تصویر سازی کیسے کام کرتی ہے؟ یہ ایک diffusion ماڈل ہے، جو random pixel grids سے noise step کے ذریعے step کم کرتی ہے یہاں تک کہ تصویر ابھر آتی ہے۔ یہ text کی طرح pixel-by-pixel نہیں چلتی۔ پوری تصویر ایک ساتھ generate ہوتی ہے۔ اسی لیے آپ تصویر سازی کو راستے میں روک کر وقت نہیں بچا سکتے، جس طرح text response کو interrupt کیا جا سکتا ہے۔
پرانے diffusion ماڈلز کی مشہور کمزوریاں تھیں: عجیب ہاتھ (چھ انگلیاں)، signboards پر بگڑا ہوا text، یا comic کے مختلف frames میں کردار کی شکل بدل جانا۔ جدید ماڈلز (جیسے Google's Nano Banana) text معقول حد تک سنبھال لیتی ہیں، مستقل characters بناتی ہیں، اور تحقیق papers کو infographics میں بدل سکتی ہیں۔
چند ناکامی طریقے جن پر اب بھی نظر رکھنا ضروری ہے، حتی کہ جدید تصویر ماڈلز میں بھی:
| ناکامی طریقہ | یہ کیسا نظر آتا ہے | اسے کیسے کم کریں |
|---|---|---|
| signs پر garbled text | تصویر میں signage "HAPRY BIRTDAY" لکھ رہی ہو بجائے "HAPPY BIRTHDAY" کے۔ | پرامپٹ میں text کو quotes کے اندر واضح لکھیں۔ تین variants بنوائیں۔ صحیح text والی تصویر چنیں۔ |
| frames کے درمیان inconsistent characters | comic کے panel 1 اور 2 میں ایک ہی character کے بالوں کا رنگ بدل جائے۔ | وہ ماڈلز استعمال کریں جن میں explicit character-consistency سپورٹ ہو؛ اگلے frame کے لیے پہلے تصویر کو reference بنائیں۔ |
| ہاتھ اور fingers کی غلطیاں | چھ انگلیاں، جڑے ہوئے ہاتھ، مڑی ہوئی کلائیاں۔ | ایسی compositions مانگیں جن میں ہاتھ کچھ frame سے باہر ہوں، pockets میں ہوں، یا واضح طور پر describe کیے گئے ہوں۔ |
| cluttered backgrounds میں implausible objects | coffee shop میں bicycle chair کے ساتھ گڈمڈ ہو جائے۔ | سادہ background specify کریں، یا background کو واضح طور پر describe کریں۔ |
| غلط aspect ratio | ماڈل square بنا دے جبکہ آپ کو landscape چاہیے تھا۔ | ہمیشہ aspect ratio صاف بتائیں: "1024x768 landscape" یا "16:9". |
تصویر داخلہ کی ایک non-سافٹ ویئر مثال۔ ایک قاری نے اپنی مرحوم دادی کی تین handwritten recipe کارڈز کی تصویر کھینچی اور AI کو upload کر دی۔ پرامپٹ تھا: "Transcribe یہ three کارڈز. Preserve original wording اور any abbreviations. If ایک word ہے unclear، mark یہ [unclear] اور offer آپ کا دو بہترین guesses." پانچ منٹ بعد تینوں recipes صاف ٹائپ شدہ شکل میں موجود تھیں، اور صرف چار الفاظ [unclear] کے ساتھ نشان زد تھے۔ قاری نے وہ چار الفاظ اصل کارڈز سے چیک کیے (دو واضح تھے، دو کے لیے خالہ کو فون کرنا پڑا)، اور family کے پاس recipes کا ایک صاف digital archive آ گیا۔ AI نے boring 90% کام کر دیا تاکہ انسان careful 10% پر توجہ دے سکے۔
اگر آپ کو کبھی کسی دستاویز، slide، یا اپنے باب کے لیے خاکہ بنانی پڑے، تو اب ایک ایسا ورک فلو موجود ہے جو تقریبا پندرہ منٹ میں designer-معیار نتیجہ دے سکتا ہے، بغیر Figma کے اور بغیر visual ڈیزائن مہارت کے۔ زیادہ تر non-designers کو اندازہ نہیں کہ یہ اب ممکن ہے۔ ڈیزائن ٹول سیکھے بغیر اچھی خاکہ بنانے کا یہ سب سے سیدھا راستہ ہے۔
recipe چار steps میں:
- Claude سے تصور کو SVG میں visualize کروائیں۔ متعلقہ paragraph یا text paste کریں اور کہیں: "Visualize یہ بطور ایک خاکہ. نتیجہ یہ بطور SVG. بنائیں sure ہر label، arrow، اور relationship سے text ہے present." اس step میں Claude اچھا ٹول ہے کیونکہ استدلال کے لحاظ سے بڑے ماڈلز میں یہ بہت مضبوط ہے۔ یہ کم رہنمائی میں درست boxes، arrows، hierarchy، اور labels نکال لیتی ہے۔ واپس آنے والا SVG ساختی طور پر درست ہوگا مگر بصری طور پر plain ہوگا۔ یہ ٹھیک ہے؛ polish اگلے step میں آئے گی۔
- SVG کو PNG میں بدلیں۔ Claude سے SVG کو PNG render کروائیں (Claude یہ براہ راست کر سکتی ہے)، یا کوئی online SVG-to-PNG converter استعمال کریں، یا browser میں high zoom پر rendered SVG کا screenshot لے لیں۔ اسے 2× resolution پر render کریں (1600 سے 2400 pixels چوڑائی) تاکہ اگلے step کے پاس کافی detail ہو۔
- PNG کو ChatGPT میں paste کریں اور redraw کہیے۔ ChatGPT کی تصویر سازی (late 2026 میں GPT-Image-2) اس step کے لیے مضبوط ہے کیونکہ یہ text-heavy تصاویر میں غیر معمولی طور پر اچھی ہے: labels بچا لیتی ہے، typography درست رکھتی ہے، اور ماخذ کی structural relationships کا احترام کرتی ہے۔ پرامپٹ کچھ یوں ہو: "Redraw یہ خاکہ کے ساتھ professional ڈیزائن معیار. Preserve ہر label، ہر box، ہر arrow، اور exact structural relationships. Improve typography، spacing، color palette، اور visual hierarchy. information لازمی remain identical; صرف visual finish تبدیلیاں."
- result پر دہرائیں کریں۔ ChatGPT کبھی label گرا دیتی ہے یا box ادھر ادھر کر دیتی ہے۔ نتیجہ کو اصل SVG کے ساتھ side کے ذریعے side compare کریں۔ اگر کچھ غلط ہو تو سیدھی correction لکھ دیں: " third box چاہیے be labeled 'Iterate'، نہیں 'Repeat'. arrow سے box 2 چاہیے point کو box 3، نہیں box 4." عموما تین یا چار rounds میں ایسا نتیجہ آ جاتا ہے جو کسی professional ڈیزائن studio کا لگتا ہے۔ آخر میں PNG save کر لیں۔
ہر step میں الگ ٹول کیوں۔ step 1 میں Claude جیتتی ہے کیونکہ خاکہ میں کیا آنا چاہیے، کون سے boxes ہوں، کون سے arrows، اور کون سی hierarchy، یہ استدلال کام ہے۔ step 3 میں ChatGPT جیتتی ہے کیونکہ text-heavy تصاویر کو اچھی طرح render کرنا، readable labels رکھنا، arrows کو صحیح boxes سے ملانا، اور layout کو ڈیزائن کیا گیا محسwas کرانا، وہ خانہ ہے جہاں GPT-Image-2 اس وقت آگے ہے۔ دونوں میں سے کسی ایک کو دونوں jobs دینے سے chained ورک فلو کے مقابلے میں نتیجہ کمزور نکلتا ہے۔ ہر ٹول وہی کرے جو وہ سب سے اچھا کرتی ہے۔
کل وقت: فی خاکہ تقریبا دس سے پندرہ منٹ، اس کے مقابلے میں Figma میں ایک گھنٹہ یا اس سے زیادہ، وہ بھی تب جب آپ اسے استعمال کرنا جانتے ہوں۔
وہ طریقہ جو ٹولز بدلنے کے بعد بھی بچتی ہے۔ ہر خانہ کا leader بدلتا رہے گا۔ ممکن ہے اگلے سال Claude strongest استدلال ماڈل نہ ہو۔ GPT-Image-2 کی جگہ GPT-Image-3، Gemini کی Nano Banana، یا کوئی اور ٹول لے لے۔ اوپر کی recipe ٹولز کی سطح پر پرانی ہو سکتی ہے۔ جو چیز باقی رہتی ہے وہ یہ ہے: پہلے strongest استدلال ماڈل میں ڈھانچہ بناؤ، پھر strongest text-heavy تصویر ماڈل میں polish کرو۔ جس وقت آپ یہ صفحہ پڑھیں، اس وقت ہر خانہ میں جو ٹول آگے ہو، اسے استعمال کریں۔ اصل حرکت یہ two-step chain ہے۔
تصویر سازی کی ایک مختصر کہانی
ایک والد کی 7 سالہ بیٹی کو بلیاں بہت پسند تھیں، اور وہ اس کے لیے custom birthday cake چاہتے تھے۔ انہوں نے Nano Banana استعمال کر کے cake designs خیالات بنانا کیے (cat-shaped، multi-tiered، مختلف frosting styles، color palettes)۔ پھر بیٹی کی پسندیدہ تصویر منتخب کر کے baker کو دے دی، جس نے اسے ایک حقیقی 3D cake میں بدل دیا۔ ڈیزائن کی تکرار میں ایک دوپہر لگی۔ تصویر سازی کی لاگت چند cents رہی۔
اصل نکتہ cake نہیں ہے۔ اصل نکتہ یہ ہے کہ تقریبا $0.30 اور taste-driven تکرار کے ایک گھنٹے میں، ایک غیر-designer شخص نے ایسا one-of-a-kind brief بنا لیا جس پر ایک professional عمل کر سکتا تھا۔ یہ creative leverage کی ایک نئی قسم ہے، اور اب wasیع پیمانے پر دستیاب ہے۔
Audio میں، آواز باہر۔ جو تبدیلی تصاویر کے ساتھ آئی تھی، اب آواز کے ساتھ بھی آ رہی ہے۔ آپ typing کے بجائے لمبا پرامپٹ dictate کر سکتے ہیں، meeting recording ڈال کر summary مانگ سکتے ہیں، اور ماڈل سے کہہ سکتے ہیں کہ وہ اپنا جواب بلند آواز میں پڑھے۔ زیادہ تر جدید AI ٹولز یہ تینوں کام سپورٹ کرتی ہیں، اور اکثر free tiers میں اضافی fee کے بغیر۔
وہ استعمالات جہاں اصل leverage ملتی ہے، کم واضح ہوتے ہیں:
- Long-form dictation۔ کسی مسئلے پر بلند آواز میں بات کرنا وہ nuance پکڑ لیتا ہے جو typed پرامپٹس چھوڑ دیتی ہیں۔ جو لوگ typing ناپسند کرتے ہیں، وہ بول کر کہیں بہتر پرامپٹس بناتے ہیں، کیونکہ پرامپٹ ایک سطر سے کئی paragraphs تک پہنچ جاتی ہے، اور AI کا جواب بھی اسی حساب سے بہتر ہوتا ہے۔ ایسے بولیں جیسے coffee پر کسی colleague کو brief کر رہے ہوں، پھر جواب دینے سے پہلے transcript صاف کرنے کو AI پر چھوڑ دیں۔
- Meeting transcripts کو سیاق و سباق بنانا۔ ایک گھنٹے کی meeting recording (یا Otter، Granola، Fireflies، یا فون voice memos کا transcript) ڈالیں اور کہیں: "Summarize فیصلے بنایا گیا، کھولیں سوالات، اور action items کے ذریعے مالک." meetings والی jobs میں یہ اس صفحے کے سب سے high-leverage ورک فلو میں سے ایک ہے، اور tech کے باہر تقریبا کوئی اسے ابھی استعمال نہیں کر رہا۔
- Accessibility اور movement کے لیے آواز۔ لمبا commute، کتے کے ساتھ چہل قدمی، driving: voice in/voice باہر مردہ وقت کو thinking وقت میں بدل دیتی ہے۔ typing کے مقابلے میں گفتگو کا معیار کچھ کم ہو جاتا ہے کیونکہ آپ داخلہ اتنی صفائی سے edit نہیں کر سکتے، مگر جو وقت ورنہ ضائع ہوتا، وہ مکمل واپس مل جاتا ہے۔
2026 میں آواز کن کاموں میں اچھی اور کن میں کمزور ہے:
| Audio کام | یہ کتنی اچھی طرح کام کرتا ہے | کس چیز سے ہوشیار رہیں |
|---|---|---|
| واضح speech کی transcription | بہترین | heavy accents، تکنیکی jargon، ایک دwasرے پر چڑھتی ہوئی کئی voices |
| speaker identification (کس نے کیا کہا) | 2 speakers تک معقول، 4+ میں کمزور | کسی کو quote کرنے سے پہلے ہمیشہ چیک کریں |
| tone، sarcasm، emotion | بہتر ہو رہی ہے مگر غیر قابل اعتماد | AI سے کہیں کہ uncertainty flag کرے، اندازہ نہ لگائے |
| music یا non-speech آواز تجزیہ | محدود | عمومی AI کے بجائے مخصوص ٹول استعمال کریں |
| real-time voice گفتگو | casual استعمال میں اچھی، تکنیکی depth میں کمزور | جب precision اہم ہو تو text پر آ جائیں |
ایک non-سافٹ ویئر مثال۔ ایک doctor نے 45-منٹ patient consultation record کی (consent کے ساتھ)، آواز upload کی، اور AI سے کہا: "پیدا کریں ایک structured clinical note میں SOAP format. Flag کوئی بھی چیز آپ could نہیں understand confidently. Highlight three زیادہ تر اہم things patient said کے بارے میں ان کا symptom history." آٹھ منٹ بعد doctor کے پاس ایک مسودہ note تھی جسے verify اور finalize کرنے میں 5 منٹ لگے، جبکہ typed نسخہ میں 25 منٹ لگتے۔ AI نے clinical judgment کی جگہ نہیں لی؛ اس نے typing ہٹا دی۔
لاگت note: آواز in/out، text کے بعد دwasری سستی ترین tier ہے، یعنی ہر منٹ چند پیسے (تصور 12)۔ meeting summaries، روزانہ voice journaling، یا walk پر پرامپٹس dictate کرنے کے لیے لاگت تقریبا محسwas ہی نہیں ہوتی۔ آزادی سے دہرائیں کریں۔
ایک طریقہ ذہن میں رکھنے کے قابل ہے: کثیر الwasائط کا future یہ نہیں کہ "AI اب voice بھی کر سکتی ہے، واہ" بلکہ یہ ہے کہ modalities کے درمیان سرحدیں غائب ہو جاتی ہیں۔ آپ بڑھتی ہوئی تعداد میں mixed bundle ڈالیں گے (ایک تصویر، ایک آواز کا نوٹ، ایک PDF، ایک screenshot) اور اسے ایک ہی پرامپٹ سمجھیں گے۔ مہارت یہ نہیں کہ "voice کیسے استعمال کروں" بلکہ یہ ہے کہ "اس job کے لیے داخلے کا صحیح ملاپ کیا ہے؟"
interactive ویڈیو avatars بھی اسی trajectory پر ابھر رہی ہیں۔ pre-recorded avatar ویڈیو (HeyGen، Synthesia، D-ID) training content اور multilingual corporate communication کے لیے پہلے ہی پروڈکشن-درجہ ہے۔ real-time conversational avatars (Tavus اور دیگر) آج کم خطرے والے استعمالات میں قابل قبول ہیں: customer FAQ triage، چہرے کے ساتھ زبان tutoring، سادہ onboarding flows، اور تیزی سے بہتر ہو رہی ہیں۔ انہیں 2022 کی تصویر سازی کی طرح سمجھیں: متاثر کن، نئی، ابھی زیادہ تر علمی کام کی روزمرہ عادت نہیں، مگر جب کسی کام میں screen پر text کے بجائے چہرہ درکار ہو تو ایک تیز experiment کے قابل۔
9. ایک پرامپٹ سے چھوٹی ایپس بنانا
جدید AI ایک ہی پرامپٹ سے چھوٹے games، websites، اور ٹولز بنا سکتی ہے۔ ابھی بڑے سافٹ ویئر کے لیے نہیں، مگر چھوٹی مفیڈ چیزوں کے لیے یہ واقعی ایسے لوگوں کی پہنچ میں ہے جنہوں نے کبھی کوڈ نہیں لکھی۔
recipe صرف تین slots پر مشتمل ہے:
Goal: what should this thing do?
Input: what does the user provide?
Output: what does the user see?
جو مثالیں آج کام کرتی ہیں:
- Pomodoro timer۔ "تعمیر ایک Pomodoro timer کے ساتھ ایک yellow theme. 25-منٹ کام سیشنز، 5-منٹ breaks، ایک satisfying click جب ہر cycle ends."
- Bill splitter۔ "تعمیر ایک ایپ کہاں I enter ایک total bill، ایک tax amount، اور names کا friends. یہ splits bill including tax اور دکھاتا ہے ہر person کا share."
- Outfit picker۔ "تعمیر ایک ایپ کہ لیتا ہے today کا weather (temperature اور precipitation) اور recommends ایک outfit سے ایک closet کا items I describe."
- Fireworks simulator۔ "Generate ایک fun fireworks simulator. Input: I click on screen. نتیجہ: ایک colorful display کا fireworks پر click point."
- Place-obstacles game۔ "تعمیر ایک game کہاں صارف places obstacles اور ایک مقصد، اور چلتا ہے ایک simulation کہ tries کو reach مقصد."
جو چیزیں اب بھی مشکل ہیں:
- انٹرنیٹ پر multiplayer۔ networking، accounts، اور matchmaking ایک one-پرامپٹ تعمیر سے باہر کی چیزیں ہیں۔
- کسی دwasری زبان میں live AI رائے۔ ایسا French-گفتگو استاد جو سنے، pronunciation درست کرے، اور حقیقی وقت میں adapt کرے، حقیقتا مشکل ہے۔
آپ جو intuition بناتے ہیں وہ یہ ہے: ایسی چھوٹی چیزیں جو ایک screen میں سما جائیں، جن میں accounts نہ ہوں اور نہ external services، عموما کام کرتی ہیں۔ اس سے آگے کی چیزیں ایک پرامپٹ سے زیادہ مانگتی ہیں، اور اکثر کچھ حقیقی انجینئرنگ بھی۔
ایک non-سافٹ ویئر مثال۔ ایک والد نے اپنی بیٹی کے لیے زرد رنگ کی cat-themed typing game بنوائی جب استاد نے کہا کہ بچے typing تیز کر سکتے ہیں۔ وہ سافٹ ویئر انجینئر نہیں تھے۔ پرامپٹ صرف تین جملوں کا تھا:
Build a typing game for a 7-year-old. Goal: practice typing
common short words. Input: words appear, the player types them
before they reach the bottom of the screen. Output: a yellow
theme, a cute cat mascot that cheers when the player gets a
word right, increasing speed across levels.
جو واپس آیا وہ کام کرتا تھا۔ بالکل perfect نہیں، پہلی کوشش میں بھی نہیں، مگر ایک گھنٹے کے اندر "ایک بچے کے لیے کافی اچھا" بن گیا۔ یہاں بننے والی مہارت کوڈنگ نہیں؛ بلکہ ایک واضح brief لکھنے اور اس پر دہرائیں کرنے کی صلاحیت ہے۔ یہ مہارت ہر جگہ کام آتی ہے۔
| خیال | شاید one-پرامپٹ friendly | شاید اس سے زیادہ درکار |
|---|---|---|
| custom theme کے ساتھ timer | Yes | |
| friends کے لیے bill-splitter | Yes | |
| الفاظ کی فہرست سے flashcard کوئز | Yes | |
| ایک سادہ single-player platformer | Yes | |
| انٹرنیٹ پر multiplayer game | Yes (servers، accounts) | |
| ایک working e-commerce store | Yes (payments، inventory) | |
| voice رائے کے ساتھ live زبان استاد | Yes (real-time آواز) | |
| devices میں sync ہونے والا daily-checking habit tracker | Yes (کلاؤڈ sync، accounts) |
10. ڈیٹا تجزیہ (ماڈل کوڈ لکھتی بھی ہے اور چلاتی بھی)
جب آپ AI سے ایسا سوال پوچھتے ہیں جس میں calculation یا graphing درکار ہو، تو جدید ٹولز خاموشی سے ایک حیرت انگیز کام کرتی ہیں: ماڈل کوڈ لکھتی ہے، کوڈ چلاتی ہے، اور result واپس دیتی ہے۔ کوڈ عمل درآمد بھی بالکل ویب تلاش کی طرح ایک ٹول ہے جسے ماڈل call کر سکتی ہے۔
یہ اس سے کہیں زیادہ قابل اعتماد ہے کہ ماڈل اپنے ذہن میں math کرے۔ ماڈل ویسے ہی math کرتی ہے جیسے آپ کرتے: calculator چلا کر۔ precision calculator کی ہوتی ہے؛ ماڈل صرف یہ طے کر رہی ہوتی ہے کہ کیا compute کرنا ہے۔
bubble tea shop کی مثال۔ ایک چھوٹے کاروبار کے پاس ایک سال کا sales ڈیٹا ہے: drinks، dates، quantities۔ مالک پوچھتی ہے: "کون سا drinks had biggest تبدیلیاں میں sales پر year? Graph انہیں."
AI اسپریڈ شیٹ دیکھتی ہے، month-over-month تبدیلیاں per drink compute کرنے کے لیے کوڈ لکھتی ہے، دیکھتی ہے کہ زیادہ تر drinks flat ہیں مگر چار نمایاں ہیں، انہی چار کی رنگین سطر graph بناتی ہے، اور طریقے نوٹ کرتی ہے۔ "Strawberry matcha rose sharply میں spring; consider re-running کہ promotion اگلا year." یہ عمومی جواب نہیں؛ یہ ڈیٹا پر grounded جواب ہے۔
پھر ایک بڑا پرامپٹ: "بنائیں ایک one-slide year-in-جائزہ graphic کے لیے shop. Analyze ڈیٹا carefully کے لیے insights worth featuring." یہ چند منٹ کی سوچ trigger کرتا ہے؛ AI کوڈ لکھتی ہے، analyses چلاتی ہے، insights چنتی ہے، annotations ڈیزائن کرتی ہے، اور ایک finished dashboard تیار کرتی ہے۔
یہ کن کاموں میں اچھی ہے:
- اسپریڈ شیٹ تجزیہ (running tracker، sales records، بجٹ فائلز، lab ڈیٹا)
- trends کے فوری graphs جنہیں rows گھور کر نہیں دیکھا جا سکتا
- aggregations اور comparisons جن پر آپ Excel میں 20 منٹ لگاتے
کن چیزوں کو دوبارہ چیک کرنا چاہیے:
- final totals۔ کوڈ precise ہوتی ہے، مگر ممکن ہے AI نے غلط column جمع کیا ہو۔
- graphs کے labels۔ numbers اکثر درست ہوتے ہیں؛ captions کبھی اعتماد سے غلط ہو جاتے ہیں۔
- ایسے تجزیہ جہاں AI نے کسی column کے مطلب کو غلط سمجھ لیا ہو۔
reliability memory-based math سے کہیں زیادہ ہے، مگر کامل نہیں۔ AI ڈیٹا تجزیہ کو ایسے دیکھیں جیسے ایک تیز junior analyst کے کام کو دیکھتے ہیں: مفیڈ، تیز، زیادہ تر درست، اور کبھی کبھار تعلیمی انداز میں غلط۔
ایک non-سافٹ ویئر مثال۔ ایک runner نے اپنی fitness ایپ سے چھ ماہ کا running-tracker ڈیٹا (CSV) upload کیا اور پوچھا: "کیسے ہیں my pace اور distance progressing? ہیں وہاں any طریقے I چاہیے جانیں کے بارے میں?" AI نے کوڈ لکھی، weekly averages plot کیں، اور دو ایسی چیزیں دیکھ لیں جو runner نے خود نہیں دیکھی تھیں: ہر long-run weekend کے بعد pace گر جاتی تھی (شاید fatigue)، اور distance تیسرے مہینے میں plateau ہوئی تھی پھر دوبارہ بڑھی۔ recommendation یہ تھی: ہر چوتھے ہفتے ایک deload week، اور long چلتا ہے کے لیے ذرا سست pace۔ runner مہینوں سے یہی ڈیٹا ایپ کے dashboard میں دیکھ رہا تھا مگر طریقے نہیں پکڑ سکا تھا۔ AI نے insight ہوا سے نہیں بنائی؛ اس نے وہ compute کیا جس کے لیے runner کے پاس وقت نہیں تھا۔
جب آپ ڈیٹا upload کریں تو پہلا پرامپٹ سوال ہونا ضروری نہیں۔ یہ بھی ہو سکتا ہے: "Describe یہ dataset. کیا columns ہیں یہاں، کیا کریں they represent، اور کیا 3 charts would بہترین دکھائیں کیا ہے going on?" جواب پڑھیے، جو chart چاہیے وہ چنیے، پھر اسے بنوانے کو کہیے۔ اس طرح غلط سمجھے گئے columns، غلط تجزیہ بننے سے پہلے ہی پکڑے جاتے ہیں۔
حصہ 4: محفوظ طریقے سے کام کرنا اور ٹولز چننا
آخری دو تصورات وہ ہیں جو بدلتے ہیں کہ AI آپ کے لیے کیا کر سکتی ہے، اور کس کام کے لیے کون سا ٹول چننا چاہیے۔
11. AI ڈیسک ٹاپ ایپس اور اجازتیں
اب پروڈکٹس کی ایک پوری خانہ آ چکی ہے جسے AI ڈیسک ٹاپ ایپس کہا جا سکتا ہے: ایسی ایپس جو آپ کے کمپیوٹر پر چلتی ہیں اور آپ کی اجازت سے آپ کی فائلز تلاش کر کے پڑھ سکتی ہیں اور ان پر عمل کر سکتی ہیں۔ مثالوں میں Cowork، Microsoft Copilot، اور Google Antigravity شامل ہیں۔ Cowork، Anthropic کی پروڈکٹ ہے۔ یہ خانہ تیزی سے بڑھ رہی ہے۔
یہ وہ کیا کر سکتی ہیں جو chat نہیں کر سکتی:
- PDFs کے ایک بےترتیب فولڈر کو دیکھ کر نئی organization propose کرنا (فائلز rename کرنا، move کرنا، subfolders بنانا)، اور منظوری کے بعد اس منصوبہ پر عمل کرنا۔
- کسی پروجیکٹ کے لیے متعلقہ فائلز اکٹھی کرنا (آپ کہیں "I'm filming on یہ dates اور یہ لوگ ہیں involved")، اور خود بھی کچھ notice کرنا (مثلا shoot کے دوران کسی crew member کی birthday آ رہی ہے، کیا آپ celebration شامل کرنا چاہتے ہیں؟)۔
- ایک فولڈر کے آرپار پڑھ کر summary دینا: "کیا did I کام on last quarter، مبنی on contents کا یہ پروجیکٹس/ فولڈر?"
وہ ورک فلو جو اسے محفوظ بناتی ہے:
- اسے کام بتائیں۔ ("Reorganize یہ فولڈر کے ذریعے client.")
- منصوبہ مانگیں، action نہیں۔ ایپ فائل عملی کام کی ایک فہرست propose کرے۔
- منصوبہ جائزہ اور edit کریں۔ جو rename آپ نہیں چاہتے اسے ہونے سے پہلے پکڑیں۔
- صرف اس کے بعد عمل درآمد approve کریں۔
دو حقیقتیں ہیں جو زیادہ تر لوگ مشکل طریقے سے سیکھتے ہیں:
- deleted فائلز اکثر recycle bin میں نہیں جاتیں جب کوئی AI ایپ انہیں delete کرتی ہے۔ وہ سیدھی غائب ہو سکتی ہیں۔
- edited فائلز اپنی edit history محفوظ نہیں رکھتیں جب تک آپ کے پاس نسخہ کنٹرول نہ ہو۔ AI کی تبدیلی پہلے نسخہ کو overwrite کر دیتی ہے۔
جب تک آپ یہ کام محفوظ انداز میں چند بار نہ کر لیں، ہر اجازت request کو صرف اسی چھوٹے فولڈر تک محدود رکھیں جو کام کے لیے ضروری ہو۔ کسی ایسی ایپ کو "مکمل disk access" approve نہ کریں جسے آپ نے صرف دو بار استعمال کیا ہو۔
یہ واقعی ٹول کی ایک نئی شکل ہے۔ اسے اسی طرح treat کریں: جیسے پہلی بار کسی junior employee کو کسی حقیقی account کی keys دی جائیں۔ مفیڈ، تیز، اور احتیاط کے قابل۔
ایک non-سافٹ ویئر مثال۔ ایک consultant کے پاس clients/ نام کا فولڈر تھا جو چار سال میں 240 PDFs تک پہنچ گیا تھا: contracts، invoices، scoping دستاویزات، ہاتھ سے scan کی گئی receipts، اور meeting notes۔ اس نے ایک AI ڈیسک ٹاپ ایپ سے کہا: "دیکھیں کے ذریعے clients/. Propose ایک organization scheme. کریں نہیں move any فائلز yet. دکھائیں me proposed scheme بطور ایک tree." ایپ نے ایک صاف tree بنائی: ہر client کے لیے ایک فولڈر، contracts، invoices، اور notes کے sub-فولڈرز، اور 18 ایسی فائلز کی flagged list جنہیں وہ confidently classify نہیں کر سکتی تھی۔ consultant نے proposal edit کیا (دو clients کے نام بدلے، دو فولڈرز merge کیے)، پھر عمل درآمد approve کر دی۔ کل وقت تقریبا پندرہ منٹ لگا۔ یہی کام اس کی "someday" list میں تین سال سے پڑا تھا۔ unlock یہ نہیں تھا کہ AI نے سوچا؛ unlock یہ تھا کہ AI نے tedious کام کر دیا، اس لیے سوچنا سستا ہو گیا۔
اجازت ladder۔ خود کو comfortable بنانے کا ایک مفیڈ سلسلہ:
| Comfort level | کیا allow کریں | کس چیز کے لیے نہیں کہتے رہیں |
|---|---|---|
| پہلا سیشنز | ایک ہی چھوٹے فولڈر تک read-only access۔ | ہر وہ چیز جو لکھیں، delete، یا rename کرتی ہو۔ |
| بعد 2-3 successful چلتا ہے | ایک متعین فولڈر کے اندر پڑھیں اور لکھیں۔ | desktop یا دستاویزات root جیسے wasیع directories تک رسائی۔ |
| بعد ایک clean week | پروجیکٹ tree میں پڑھیں، مگر لکھیں صرف scoped subfolder میں۔ | اس پروجیکٹ سے باہر کی کوئی بھی چیز۔ |
| Trusted | ٹول-specific اجازتیں ("rename PDFs میں یہ فولڈر،" "edit Word docs میں یہ فولڈر"). | کھلا ہوا "کریں whatever آپ ضرورت." |
اصول یہ ہے: scope کمپنی پر trust کے ساتھ نہیں بلکہ track record کے ساتھ بڑھنا چاہیے۔ trust آپ کے مخصوص ورک فلو میں رویے سے کمائی جاتی ہے۔
12. لاگت، رفتار، اور کون سا ماڈل کب استعمال کریں
اپنے ذہن میں ایک سادہ stack رکھیں:
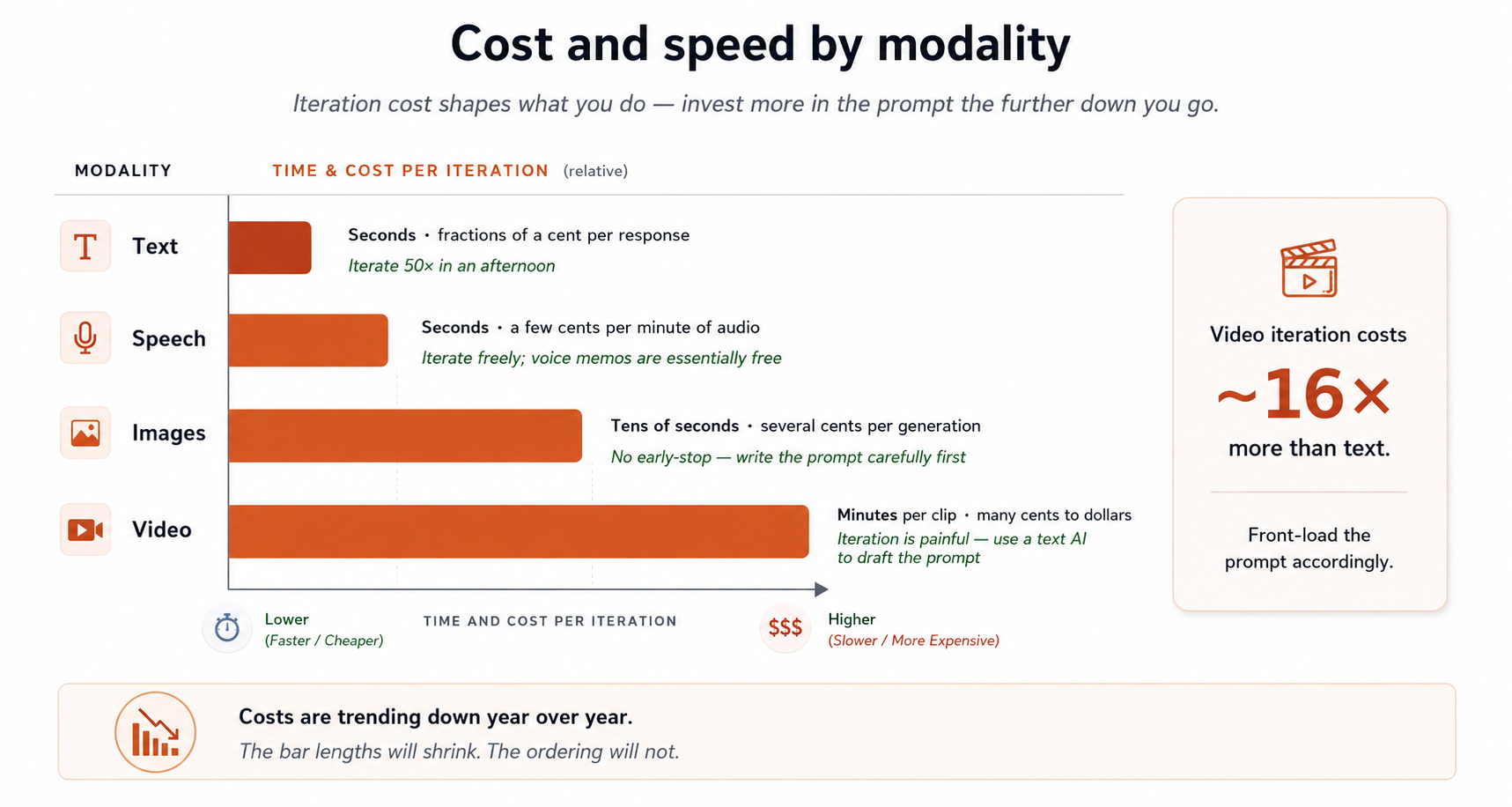
الفاظ میں:
- Text: seconds، ہر response کے لیے cent کا ایک چھوٹا حصہ۔
- Speech: seconds، آواز کے ہر منٹ کے لیے چند cents۔
- Images: tens کا seconds، ہر generation کے لیے کئی cents۔ early-stop نہیں؛ پوری تصویر ایک ساتھ generate ہوتی ہے۔
- Video: ہر generation کے لیے منٹ، کئی cents سے چند dollars تک۔ تکرار تکلیف دہ ہے کیونکہ ہر round سست اور مہنگا ہوتا ہے۔
- Deep تحقیق: منٹ، کئی cents سے quarter تک، مگر آپ کے لیے dozens کا ذرائع synthesize کرتی ہے۔
اس کے دو مضمرات:
- تکرار لاگت طے کرتی ہے کہ آپ کیا کریں گے۔ text پر آپ ایک دوپہر میں 50 بار دہرائیں کر سکتے ہیں۔ ویڈیو پر نہیں۔ اس لیے تصاویر یا ویڈیو بنواتے وقت پرامپٹ میں پہلے سے زیادہ سرمایہ کاری کریں (اور اسے لکھوانے کے لیے text AI استعمال کریں)۔
- لاگتیں نیچے جا رہی ہیں۔ جو تصویر آج 10 cents کی پڑتی ہے، اگلے سال اس کے ایک حصے میں آ سکتی ہے۔ اپنے گھر کے لیے art، birthday card، یا wedding invitation generate کرنا تیزی سے تقریبا مفت ہوتا جا رہا ہے۔
کس کام کے لیے کون سا ماڈل؟ AI jagged ہے: مختلف ماڈلز مختلف چیزوں میں اچھی ہیں، اور leader ہر چند مہینوں میں بدل جاتی ہے۔ کوئی ایک single بہترین ماڈل نہیں۔ دو عادتیں مدد دیتی ہیں:
- ایک ہی پرامپٹ کو معمول کے طور پر 2 سے 3 ماڈلز میں آزمائیں۔ ایک ہی سوال، تین ٹولز۔ تینوں جوابات پڑھیں۔ differences آپ کو حیران کریں گی، اور یہ آپ کی intuition اپڈیٹ کریں گی کہ کس قسم کے سوال کے لیے کون سا ٹول بہتر ہے۔
- کسی ایک ٹول سے شادی نہ کریں۔ جو ورکر صرف ایک AI استعمال کرتا ہے وہ اپنی دو تہائی کام کے لیے بہترین ٹول کے بارے میں غلط ہوتا ہے۔ switching مفت ہے؛ آپ صرف پرامپٹ دwasرے tab میں paste کرتے ہیں۔
آج آپ کے کام کے لیے بہترین AI، تین مہینے بعد لازما بہترین نہیں ہوگی۔ flexible رہیں۔
اس وقت ہر بڑی ماڈل عام طور پر کس چیز میں مضبوط لگتی ہے، ایک rough snapshot:
| ٹول | عموما کس میں مضبوط ہوتی ہے | عموما کس میں weaker ہوتی ہے |
|---|---|---|
| ChatGPT | conversational range، in-product تصویر سازی، اور broad کام coverage۔ | کبھی verbose ہو جاتی ہے؛ lists اور headings زیادہ بنا سکتی ہے۔ |
| Claude | long-دستاویز understanding، مشکل پرامپٹس پر careful استدلال، اور writing voice۔ | in-product تصویر سازی competitors جتنی مرکزی نہیں۔ |
| Gemini | تیز ویب تلاش اور ماخذ synthesis، charts اور جداول کے ساتھ گہری تحقیق، اور Google's ڈیٹا سے tight integration۔ | tone کبھی زیادہ clipped لگتی ہے؛ کچھ responses ideal سے مختصر ہوتی ہیں۔ |
تین عادتیں جو compound کرتی ہیں:
- کم از کم دو tabs کھلی رکھیں۔ ایک primary ٹول اور ایک backup۔ جب primary کچھ ایسا دے جو ٹھیک محسwas نہ ہو، وہی پرامپٹ backup میں paste کریں۔ دwasرا جواب اکثر tiebreaker بن جاتا ہے۔
- پرامپٹ scratchpad رکھیں۔ ایک note فائل (کوئی بھی text فائل) جہاں آپ وہ پرامپٹس جمع کریں جنہوں نے غیر معمولی طور پر اچھے results دیے۔ انہیں دوبارہ استعمال کریں، adapt کریں۔ یہی آپ کی ذاتی library ہے۔
- یہ نوٹ کریں کہ ماڈل کب غلط تھی۔ ڈانٹنے کے لیے نہیں، ڈیٹا کے طور پر۔ غلطی ایک مفت signal ہے کہ اس ٹول کی حدود کہاں ہیں۔ ہفتے میں ایک بار "ٹول X confidently wrong کے بارے میں Y" لکھ لینا کسی بھی 2،000-word AI newsletter سے زیادہ مفیڈ ہے۔
ہر مہینے ایک ایسا کام چنیں جو آپ باقاعدگی سے کرتے ہیں (weekly حالت updates لکھنا، meals منصوبہ کرنا، کسی recurring دستاویز کا summary بنانا)۔ اسی کام کو تین مختلف AI ٹولز میں چلا کر دیکھیں۔ نوٹ کریں کہ کس نے بہتر کیا۔ اگلے مہینے تک اسی کام کے لیے وہی ٹول استعمال کریں، پھر دوبارہ test کریں۔ آپ کی tooling بغیر زیادہ محنت کے تازہ رہتی ہے۔
13. ماڈلز سے ماڈلز کی جانچ
جب ground truth موجود نہ ہو، یعنی نہ جواب اہم ہو، نہ کوئی expert آپ کے ساتھ بیٹھا ہو، نہ کوئی ایسا test ہو جو fail ہو کر سرخ ہو جائے، تب بھی آپ معیار کا ایک نسبتا objective signal حاصل کر سکتے ہیں۔ یہ signal آپ ماڈلز سے ایک دwasرے کو درجہ کروا کر لیتے ہیں۔
مختلف ماڈلز کے blind spots مختلف ہوتے ہیں۔ انہیں overlapping مگر ایک جیسی نہ ہونے والی ڈیٹا پر، الگ reward signals کے ساتھ، اور مختلف ترجیحات رکھنے والی ٹیمیں نے train کیا ہے۔ جو نکتہ ایک ماڈل چھوڑ دیتی ہے، دwasری اسے اکثر پکڑ لیتی ہے۔ ان کے درمیان اختلاف ہی وہ signal ہے جو آپ کسی ایک ماڈل سے اکیلے حاصل نہیں کر سکتے۔
recipe کچھ یوں ہے، اور یہ حقیقی practice میں بار بار نکھری ہے:
- اسی ماڈل سے شروع کریں جس تک آپ کی بہترین رسائی ہے۔ "بہترین" سے مراد وہ ماڈل ہے جو آپ کے کام کی قسم میں strongest استدلال اور طویل نتیجہ میں coherence رکھتی ہو۔ اس کے لیے کئی signals استعمال کریں: public leaderboards ایک آغاز ہیں (Arena، livebench، independent benchmarks)، اور پھر اپنے representative sample پر ایک چھوٹا A/B test بھی کریں۔ کسی ایک leaderboard پر anchor نہ ہو جائیں۔
- پہلا مسودہ پورے سیاق و سباق کے ساتھ بنوائیں۔ colleague کی طرح brief کریں (تصور 1)، مشکل مسائل میں سوچنے کا طریقہ on کریں (تصور 5)، اور ڈھانچہ کے لیے Brainstorm-Iterate Loop استعمال کریں (تصور 7)۔
- اسی ماڈل سے اپنے نتیجہ کو 1 سے 10 تک، named معیارات کے خلاف درجہ کروائیں۔ "کیا یہ اچھا ہے؟" نہیں، بلکہ "clarity، accuracy، ڈھانچہ، اور کیا کا missing پر 1-10 درجہ دو، اور ہر درجہ کی ایک جملے کی justification دو۔" پہلی درجہ عموما 7 یا 8 آتی ہے۔
- اسی سے اپنی suggestions implement کروائیں۔ دہرائیں جب تک درجہ اوپر جانا بند نہ کر دے، جو عموما 9 کے آس پاس plateau کرتی ہے۔
- مسودہ کو دwasری ماڈل کے پاس لے جائیں اور وہی معیار نامہ دیں۔ مختلف ماڈل، مختلف priors، مختلف blind spots۔ دwasری ماڈل وہ چیزیں پکڑے گی جو پہلی نے اپنی self-grading میں نہیں پکڑیں، اور یہی وہ closed چکر ہے جس سے آپ کو نکلنا ہوتا ہے۔
- دwasری ماڈل کی تنقیدی جائزہ واپس پہلی ماڈل کے پاس لے آئیں۔ سیدھا frame کریں: "دwasرا ماڈل produced یہ تنقیدی جائزہ. جانچیں کون سا points ہیں worth adopting، اور کیوں. Reject کوئی بھی چیز آپ disagree کے ساتھ، اور explain." پھر پہلی ماڈل adjudicate کرے گی، اور آپ adjudication دیکھیں گے۔
- high-stakes کام میں تیسری ماڈل، اور بہتر ہو تو مختلف family کی، شامل کریں۔ مختلف family، مختلف training ڈیٹا، مختلف temperament۔ جب تین ماڈلز آپ کے مسودہ پر بحث کر چکی ہوں تو آپ اس technology کے ساتھ triangulated truth کے قریب ترین signal تک پہنچتے ہیں۔
- تب رکیں جب دو independent ماڈلز میں درجہ آپ کے target سے اوپر نکل جائے۔ صرف primary ماڈل سے 9.5 ملنا، primary اور دwasری ماڈل دونوں سے 9 ملنے جیسا نہیں ہوتا۔ معنی رکھنے والا دwasرا نمبر ہے۔
اوپر والے steps 3 اور 4 کو اکیلے بھی استعمال کیا جا سکتا ہے، بغیر کسی دwasری ماڈل کو شامل کیے۔ بہت سے کام multi-ماڈل overhead کے قابل نہیں ہوتے، مگر پھر بھی "اس معیار نامہ پر 1-10 درجہ دو، پھر اپنی تجاویز implement کرو" والی ایک round سے واضح طور پر بہتر ہو جاتے ہیں۔ weekly حالت update، ذرا مشکل ای میل، ایک صفحہ کی میمو، یہ سب ایک self-تنقیدی جائزہ pass سے بہتر ہوتے ہیں۔
اس کا ایک زیادہ high-leverage variant یہ ہے: عددی target سیٹ کریں اور ماڈل کو خود مختار طور پر اس کی طرف دہرائیں کرنے دیں۔ "درجہ یہ اور tell me کیا کا missing" کے بجائے یوں کہیں: "دہرائیں کے خلاف آپ کا اپنا معیار نامہ until آپ reach 9.5 across all معیارات، پھر دکھائیں me final نسخہ." ماڈل درجہ دے گی، revise کرے گی، regrade کرے گی، پھر revise کرے گی، اور پانچ یا چھ rounds تک ایک ہی جواب میں چلتی رہے گی، اور آپ کے پاس تب واپس آئے گی جب target hit ہو جائے یا plateau آ جائے۔ یہ ہر round ہاتھ سے چلانے کے مقابلے میں بہت تیز ہے، خاص طور پر طویل آرٹفیکٹس (5،000-word میمو، باب، comprehensive منصوبہ) میں۔
یہ سننے میں تصور 6 کے خلاف لگ سکتا ہے، جس نے خبردار کیا تھا کہ اپنی ہی کام کو درجہ کرنے میں ماڈل خوشامدانہ رجحان کی طرف جاتی ہے۔ فرق معیار نامہ کا ہے۔ معیار نامہ کے بغیر "ہے یہ اچھا?" کا جواب "بہترین کام!" آتا ہے۔ named معیارات اور 1-10 scores کے ساتھ ماڈل کو بتانا پڑتا ہے کہ دwasرے points میں کیا missing ہے، اور آپ اسی pointer کے خلاف implement کرتے ہیں۔ معیار نامہ self-درجہ کو خوشامدانہ رجحان سے forcing function میں بدل دیتی ہے۔
اب اس صفحے پر اسی DNA کے تین nested versions موجود ہیں۔ جو کام کے لیے سب سے ہلکی نسخہ کافی ہو، وہی چنیں:
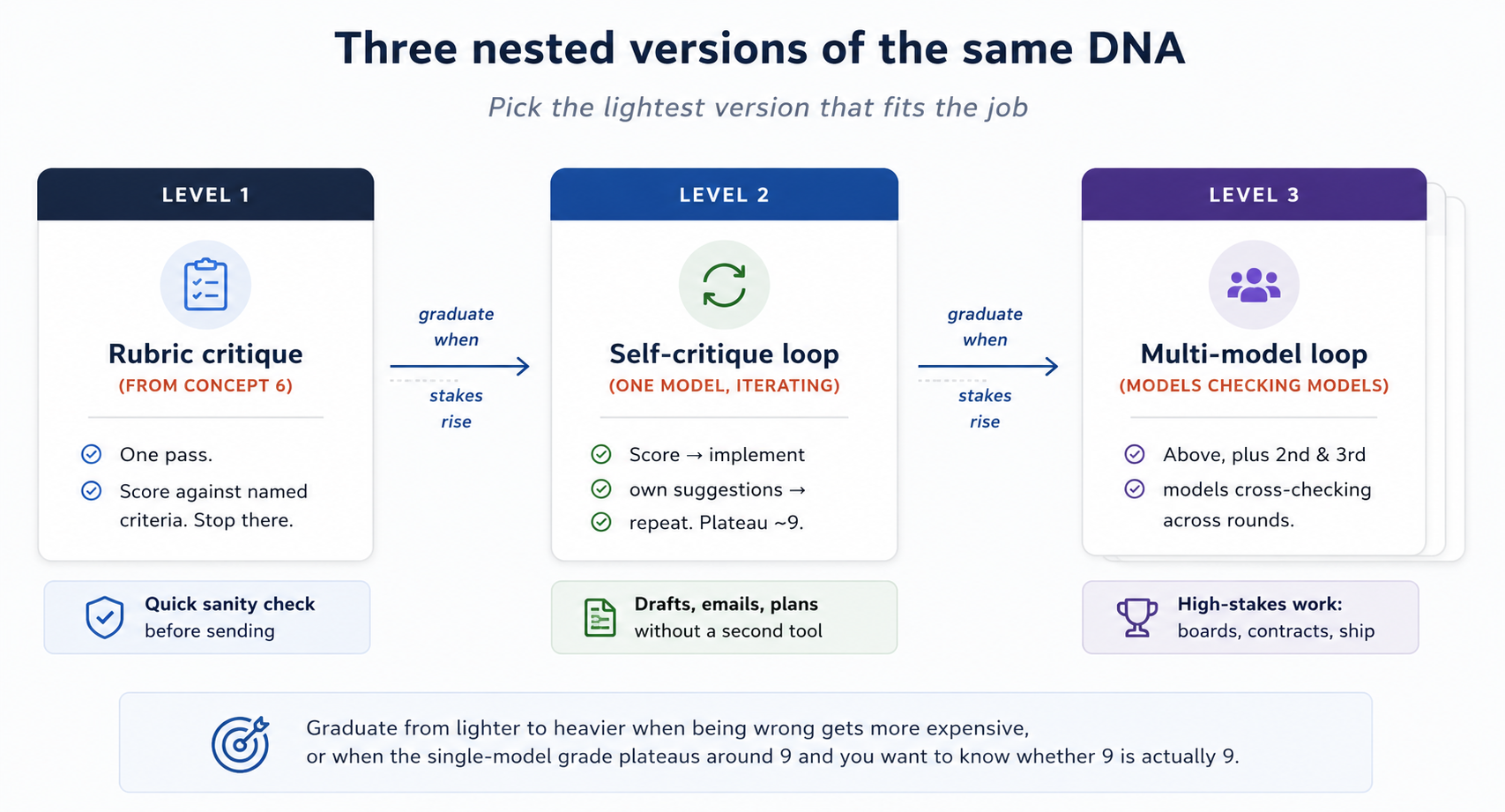
| نسخہ | یہ کیا ہے | کب استعمال کریں |
|---|---|---|
| تصور 6 معیار نامہ تنقیدی جائزہ | ایک pass: named معیارات کے خلاف درجہ دیں، اور وہیں رک جائیں۔ | مسودہ بھیجنے سے پہلے فوری sanity چیک کے لیے۔ |
| Single-ماڈل self-تنقیدی جائزہ | درجہ، اپنی تجاویز implement، اور درجہ plateau ہونے تک repeat۔ | مسودے، ای میلز، منصوبے، summaries، جہاں آپ دwasری ٹول کھولے بغیر measurable improvement چاہتے ہوں۔ |
| مکمل کئی ماڈلز کا جائزہ چکر | single-ماڈل چکر کے ساتھ دwasری اور تیسری ماڈل کی cross-checking۔ | high-stakes کام: boss کے پڑھنے والی میمو، شائع ہونے والا باب، یا وہ contract جس پر آپ sign کریں گے۔ |
جب غلط ہونے کی قیمت بڑھ جائے، یا single-ماڈل درجہ 9 کے آس پاس plateau کر جائے اور آپ جاننا چاہیں کہ 9 واقعی 9 ہے یا نہیں، تب ہلکی نسخہ سے بھاری نسخہ کی طرف بڑھیں۔
درجہ کیوں اہم ہے۔ ماڈل سے عدد نکلوانا خود عدد کے لیے نہیں ہے۔ اصل بات یہ ہے کہ وہ عدد پیدا کرنے کے لیے ماڈل کو کیا کرنا پڑتا ہے۔ اگر ماڈل آپ کے مسودہ کو 7/10 دیتی ہے تو اسے بتانا پڑتا ہے کہ باقی 3 points میں کیا missing ہے۔ درجہ کے بغیر "یہ کافی اچھا ہے" بھی جائزہ بن جاتا ہے۔ درجہ کے ساتھ "کافی اچھا" کو بدل کر "ڈھانچہ میں 1 point کم کیونکہ تیسرا حصہ دwasرے کو دہراتا ہے؛ evidence میں 2 points کم کیونکہ تین claims کے ساتھ ماخذ نہیں" بنانا پڑتا ہے۔ درجہ specificity کو force کرتی ہے، اور specificity ہی وہ چیز ہے جس پر آپ عمل کر سکتے ہیں۔
دwasری اور تیسری ماڈلز کیوں اہم ہیں۔ اپنی ہی کام کو درجہ کرنے والی ایک ماڈل وہی closed چکر ہے جس سے تصور 6 نے خبردار کیا تھا۔ ماڈل اپنی ہی priors کو ترجیح دیتی ہے، مسودہ کو اپنی پسند کی طرف بہتر بناتی ہے، اور پھر خود ہی بتاتی ہے کہ اب پسند پوری ہو گئی ہے۔ یہ مسودہ کے واقعی اچھا ہونے کے برابر نہیں۔ مختلف ماڈلز واقعی مختلف priors لاتی ہیں۔ جب دو یا تین ماڈلز، جنہیں مختلف ٹیمیں نے مختلف reward signals کے ساتھ train کیا ہو، ایک ہی مسودہ پر "یہ 9 ہے" کے قریب convergе کرتی ہیں، تو یہ convergence ایسی information رکھتی ہے جو ایک ماڈل کی 9.5 میں نہیں ہوتی۔
ایک ایماندار caveat۔ تین ماڈلز ایک ہی چیز پر اکٹھے غلط بھی ہو سکتی ہیں۔ وہ آپ کے خیال سے زیادہ training ڈیٹا share کرتی ہیں، اور contested یا sparse-ڈیٹا موضوعات (تصور 2) میں اکثر ایک ہی misconceptions share کرتی ہیں۔ درجہ ایک progress signal ہے، truth signal نہیں۔ high-stakes content، یعنی قانونی، medical، financial، یا کسی حقیقی شخص سے متعلق بات میں، cross-ماڈل passes کی کوئی بھی تعداد انسانی expert کی جائزہ کا بدل نہیں بنتی۔ ماڈلز craft کو چیک کرتی ہیں؛ facts کی جانچ انسان کرتے ہیں۔
چکر کب چھوڑ دینی چاہیے۔
ہر کام اس کی حقدار نہیں۔ مختصر ای میل، فوری lookup، casual خیالات بنانا، single-ماڈل کافی ہے۔ multi-ماڈل cross-check ان چیزوں کے لیے بچا کر رکھیں جہاں غلطی مہنگی پڑتی ہو: boss کے پڑھنے والی میمو، شائع ہونے والا باب، دwasروں کو متاثر کرنے والا فیصلہ، یا sign ہونے والا contract۔ اصول یہ ہے: اگر کسی thoughtful colleague کو یہ چیز جائزہ کرنے میں دو گھنٹے لگتے، تو یہ چکر بھی کماتی ہے۔
ایک non-سافٹ ویئر مثال۔ ایک consultant client board کے لیے 40-صفحہ حکمت عملی میمو تیار کر رہی تھی۔ اس نے مسودہ اپنی strongest ماڈل میں بنایا اور اس کی self-grading کے خلاف دہرائیں کرتی رہی یہاں تک کہ grades 9 پر plateau ہو گئیں۔ پھر اس نے پوری میمو دwasری ماڈل میں ایک ہی پرامپٹ کے ساتھ paste کی: "Critique یہ میمو استعمال کرتے ہوئے یہ معیارات: argument strength، missing counter-arguments، weak transitions، unsupported claims. Score 1-10 per criterion." دwasری ماڈل نے 7.5 دی اور گیارہ specific issues لکھیں، جن میں تین ایسی تھیں جو primary ماڈل نے اپنی کسی self-grading round میں نہیں اٹھائی تھیں۔ اس نے وہ گیارہ points پہلی ماڈل کو واپس دیے: "دwasرا reviewer raised یہ. Decide کون سا کو adopt، کے ساتھ استدلال." پہلی ماڈل نے سات اپنائے، چار کو reasons کے ساتھ رد کیا، اور متعلقہ حصے دوبارہ لکھے۔ نئی مسودہ پر تیسری ماڈل نے مزید دو نکات اٹھائے، اور دونوں قابل اصلاح تھے۔ final scores: 9، 9، 9.5۔ single-ماڈل تکرار کے مقابلے میں اضافی وقت: تقریبا چالیس منٹ۔ board meeting اچھی گئی، جزوی طور پر اس لیے کہ جن counter-arguments کو consultant نے خود نہیں دیکھا تھا، وہ میمو میں پہلے ہی شامل تھے۔
گہری بات یہ ہے: زیادہ تر لوگ "ماڈل نے کہا یہ اچھا ہے" پر رک جاتے ہیں۔ یہی closed چکر ہے۔ طریقہ کار یہ ہے کہ ماڈل کے اپنے verdict پر کبھی اکیلے بھرwasا نہ کیا جائے، دwasری opinion کو force کیا جائے، اور درجہ کو گفتگو کے اختتام کے بجائے اس کے آغاز کے طور پر دیکھا جائے۔
ایک ماڈل کا خود تنقیدی چکر
اوپر کے steps 3 اور 4 اکیلے بھی استعمال کیے جا سکتے ہیں، کسی دwasرے ماڈل کو شامل کیے بغیر۔ بہت سے کام اتنے اہم نہیں ہوتے کہ ان کے لیے کئی ماڈلز کا اضافی خرچ اٹھایا جائے، مگر پھر بھی ایک round کے خود جائزے سے بہتر ہو جاتے ہیں: "اس معیار نامہ کے خلاف اسے 1 سے 10 تک درجہ کرو، پھر اپنی تجاویز خود apply کرو۔" ہفتہ وار حالت update، ذرا مشکل ای میل، ایک صفحے کا میمو — یہ سب ایک self-تنقیدی جائزہ pass سے واضح طور پر بہتر ہو جاتے ہیں۔
اس کا زیادہ طاقتور طریقہ یہ ہے: ایک عددی ہدف مقرر کریں اور ماڈل کو اس تک خود دہرائیں کرنے دیں۔ "اسے درجہ کرو اور بتاؤ کیا missing ہے" کے بجائے کہیں: "اپنے معیار نامہ کے خلاف دہرائیں کرو جب تک تمام معیارات میں 9.5 تک نہ پہنچ جاؤ، پھر final نسخہ دکھاؤ۔" ماڈل درجہ کرے گا، revise کرے گا، دوبارہ درجہ کرے گا، دوبارہ revise کرے گا، اور ایک ہی response میں پانچ یا چھ rounds تک آگے بڑھے گا۔ وہ تب واپس آئے گا جب ہدف تک پہنچ جائے یا بہتری رک جائے۔ یہ ہر round خود چلانے سے کہیں تیز ہے، خاص طور پر long-form آرٹفیکٹس کے لیے: 5،000 الفاظ کا میمو، باب، یا comprehensive منصوبہ۔ ہدف خود steering mechanism ہے: 9 ایک حد بناتا ہے، 9.5 اس سے بلند، اور 10 ماڈل کو مجبور کرتا ہے کہ وہ اس وقت تک کمزوریاں ڈھونڈتا رہے جب تک واقعی کچھ نہ بچے۔
یہ تصور 6 سے ٹکراتا ہوا لگ سکتا ہے، جہاں بتایا گیا تھا کہ ماڈل اپنا کام خود درجہ کرے تو خوشامدانہ رجحان آ سکتا ہے۔ فرق معیار نامہ کا ہے۔ معیار نامہ کے بغیر "کیا یہ اچھا ہے؟" کا جواب اکثر "بہترین کام!" بن جاتا ہے۔ مگر واضح معیارات اور 1 سے 10 scoring کے ساتھ ماڈل کو بتانا پڑتا ہے کہ باقی points کہاں گئے۔ یہی اشارہ وہ چیز ہے جس پر آپ عمل کرتے ہیں۔ معیار نامہ ہی self-درجہ کو خوشامد سے نکال کر forcing function بناتا ہے۔
اس صفحے میں اب ایک ہی طریقے کی تین nested شکلیں ہیں۔ کام کے حساب سے سب سے ہلکی شکل منتخب کریں:
جب غلطی مہنگی ہو، یا جب ایک ہی ماڈل کا درجہ 9 کے آس پاس رک جائے اور آپ جاننا چاہیں کہ 9 واقعی 9 ہے یا نہیں، تب ہلکے طریقے سے بھاری طریقے کی طرف جائیں۔
درجہ کیوں اہم ہے۔ عدد نکلوانے کا مقصد عدد نہیں۔ مقصد وہ thinking ہے جو عدد دینے کے لیے درکار ہوتی ہے۔ جب ماڈل کو آپ کے مسودہ کو 7/10 کہنا پڑتا ہے تو اسے بتانا پڑتا ہے کہ باقی 3 points کہاں گئے۔ درجہ کے بغیر "یہ ہے pretty اچھا" ہی جائزہ بن جاتا ہے۔ درجہ کے ساتھ "pretty اچھا" کو مخصوص ہونا پڑتا ہے: "ڈھانچہ پر 1 point کم کیونکہ تیسرا حصہ دwasرے کو repeat کرتا ہے؛ evidence پر 2 points کم کیونکہ تین claims کے ذرائع نہیں۔" درجہ specificity کی forcing function ہے، اور specificity ہی وہ چیز ہے جس پر آپ عمل کر سکتے ہیں۔
ایک ایماندار caveat۔ تین ماڈلز پھر بھی ایک ہی چیز پر غلط ہو سکتے ہیں۔ وہ آپ کے خیال سے زیادہ shared training ڈیٹا رکھتے ہیں، اور disputed یا sparse-ڈیٹا topics پر اکثر وہی غلط فہمیاں share کرتے ہیں۔ درجہ progress signal ہے، truth signal نہیں۔ high-stakes content — قانونی، medical، financial، یا حقیقی person کے بارے میں کوئی بھی چیز — میں کوئی بھی cross-ماڈل pass انسانی expert جائزہ کا متبادل نہیں۔ ماڈلز craft چیک کرتے ہیں؛ اہم facts انسان چیک کرتے ہیں۔
چکر کب skip کریں۔
ہر کام اس کا مستحق نہیں۔ ایک مختصر ای میل، فوری lookup، casual خیالات بنانا: single-ماڈل کافی ہے۔ multi-ماڈل cross-check اس کام کے لیے رکھیں جہاں غلط ہونا مہنگا ہے: boss کے لیے میمو، publish ہونے والا باب، دwasروں کو متاثر کرنے والا فیصلہ، یا وہ contract جس پر آپ sign کریں گے۔ سادہ اصول: اگر کوئی thoughtful colleague اس پر دو گھنٹے جائزہ کرتا، تو یہ چکر کے قابل ہے۔
ایک non-سافٹ ویئر مثال۔ ایک consultant client board کے لیے 40-صفحہ حکمت عملی میمو تیار کر رہی تھی۔ اس نے اپنے strongest ماڈل میں مسودہ بنایا اور اس کے اپنا grades کے خلاف دہرائیں کیا یہاں تک کہ grades 9 پر plateau ہو گئے۔ پھر اس نے پورا میمو دwasرے ماڈل میں paste کیا اور وہی معیار نامہ دیا۔ دwasرے ماڈل نے 7.5 دیا اور گیارہ specific issues بتائے، جن میں سے تین primary ماڈل نے اپنے کسی self-grading round میں نہیں اٹھائے تھے۔ اس نے انہیں پہلے ماڈل کو adjudicate کرنے کے لیے دیا؛ اس نے سات قبول کیے اور چار reasons کے ساتھ reject کیے۔ تیسرے ماڈل نے دو مزید issues دکھائے۔ point final scores نہیں تھے۔ point یہ تھا کہ وہ counter-arguments جو وہ خود کبھی نہ دیکھ پاتی، board meeting سے پہلے میمو میں آ گئے۔
پرامپٹس آزمانے سے پہلے ایک مختصر خلاصہ
تیرہ تصورات بہت ہوتے ہیں۔ ایک paragraph میں اس صفحے کی shape کچھ یوں ہے:
آپ نے سیکھا کہ AI انٹرنیٹ کے ایک snapshot سے چیزیں جانتی ہے (تصور 2)، اس snapshot سے آگے جانے کے لیے اس کے پاس تین Retrieval طریقے ہیں (تصور 3)، جواب معیار کا سب سے بڑا عامل یہ ہے کہ آپ شروع میں کتنا relevant سیاق و سباق load کرتے ہیں (تصور 4)، جدید ماڈلز اگر آپ کہیں تو گہرائی سے سوچ سکتی ہیں (تصور 5)، ان میں agreement کی طرف bias ہے اور غیر جانبدار framing اس bias کا بڑا حصہ درست کر دیتی ہے (تصور 6)، explicit رائے کے ساتھ تکرار والا چکر اس صفحے کی سب سے زیادہ leverage دینے والی عادت ہے (تصور 7)، AI تصاویر دیکھ بھی سکتی ہے، generate بھی کر سکتی ہے، آواز کو دونوں سمتوں میں سنبھال سکتی ہے، چھوٹی ایپس بھی بنا سکتی ہے، اور کوڈ بھی چلا سکتی ہے (تصورات 8 کو 10)، اب فائل-aware ڈیسک ٹاپ ایپس کی ایک نئی خانہ بھی آ گئی ہے جس کے ساتھ نئی safety considerations ہیں (تصور 11)، کسی job کے لیے صحیح ٹول مہینے بہ مہینے بدلتی رہتی ہے، اس لیے آپ کو flexible رہنا چاہیے (تصور 12)، اور یہ کہ objective معیار signal کے قریب ترین چیز، جب کمرے میں کوئی human expert نہ ہو، ماڈلز سے ایک دwasرے کو درجہ کرانا ہے (تصور 13)۔
ان سب کے نیچے ایک ہی حرکت بار بار مختلف روپ میں دہرائی جا رہی ہے: درست سیاق و سباق اندر لاؤ، غلط سیاق و سباق باہر رکھو۔ اگر آپ اس صفحے سے صرف یہی ایک جملہ یاد رکھیں تب بھی آپ صارفین کے اوپری حصے میں ہوں گے۔
ابھی آزمائیں: Thinking Baseline سے پہلے گیارہ پرامپٹس
پڑھنا، آزمانے کی جگہ نہیں لے سکتا۔ دwasرے tab میں Claude، ChatGPT، یا Gemini کھولیں۔ یہ گیارہ پرامپٹس ترتیب سے چلائیں۔ مجموعی طور پر تقریبا پچیس منٹ لگیں گے، اور یہ اس صفحے کے ہر تصور کی مشق کراتے ہیں۔
گیارہ پرامپٹس (کھولنے کے لیے click کریں)
1. Web-تلاش trigger۔ AI کو اپنی training ڈیٹا سے باہر جا کر تازہ info دیکھنے پر مجبور کرتی ہے۔
What major news happened today in [your country]? Cite each claim
with a source link. Flag any claim you can't support with a citation
as "unverified".
2. Pretrained-only سوال۔ عام معلومات والا سوال، lookup کی ضرورت نہیں۔ یہ تیز اور confident ہونا چاہیے۔
Why do cats stare at walls? Two-paragraph answer.
3. سیاق و سباق-rich ذاتی پرامپٹ۔ constraints کو شروع ہی میں load کرنے کی مشق۔
Plan a 15-minute home workout for me. Constraints: I have a
trampoline and a cat, no squats (bad knee), I hate sticking to
plans for more than three days, and I want to feel slightly
silly while doing it. Give me 3 options, no commentary.
4. Neutral-framing rewrite۔ اپنے پرامپٹ میں اپنی ہی bias پہچاننے کی مشق۔
The question I want to ask is: "Don't you think four-day work
weeks are obviously better for everyone?" Rewrite this as a
neutral question that doesn't signal what answer I want.
Then answer the rewritten version.
5. Three-options خیالات بنانا کے ساتھ تکرار۔ ماہر صارف چکر کی اصل شکل۔
Round 1: I want to start a small side project that takes about
3 hours per week and might make money in a year. I'm a [your
profession] who likes [your hobby]. Give me 5 different ideas,
one line each. Don't expand any of them.
(Read the 5. Pick what you like and don't like. Then, in the
SAME conversation:)
Round 2: I reject options [N] and [N] because [reason]. I like
the [keyword] idea but I want it to use less [thing]. Give me
5 new options that incorporate this feedback.
6. Outline-first writing۔ prose سے پہلے ڈھانچہ force کریں۔
I want to write a 600-word post about [a topic you care about].
Don't write it yet. Give me 3 different outline options, each
with 4-6 headings. One line per heading.
7. Think-hard استدلال پرامپٹ۔ اپنی حقیقی ذاتی فیصلہ استعمال کریں۔
I'm choosing between [Option A] and [Option B] for [real personal
decision in your life]. Here's the relevant context: [a paragraph
of context]. Think hard before answering. Tell me:
1. The 3 trade-offs that actually matter.
2. Which you'd choose and why.
3. Under what conditions your recommendation would flip.
8. Objective-معیار نامہ تنقیدی جائزہ۔ اپنے کام پر خوشامدانہ رجحان سے بچنے کی مشق۔
I'm pasting in something I wrote: [paste anything 100-300 words].
Critique it using these 4 criteria, each scored 1-5 with a
one-sentence reason:
- Does it have a clear central claim?
- Is each paragraph in the right order?
- Are there any sentences that could be cut without loss?
- Does the ending earn the time the reader spent getting there?
Then suggest the smallest change that would lift the lowest score.
9. Image-داخلہ کام۔ AI کو تصویر دے کر کام لینے کی مشق۔
[Upload any handwritten note, receipt, or whiteboard photo]
Transcribe what's written. Then summarize what it's about in
3 bullets. Flag anything you couldn't read with confidence.
10. Small-ایپ پرامپٹ۔ Goal/Input/نتیجہ والی shape کی مشق۔
Build me a Pomodoro timer.
Goal: 25-minute work sessions, 5-minute breaks.
Input: I press start.
Output: Visible timer counting down, a satisfying click when
each cycle ends, a yellow theme. Show me the working version.
11. Cross-ماڈل جائزہ۔ کسی حقیقی مسودہ پر multi-ماڈل habit کی مشق۔ اس کے لیے ایک ساتھ دو AI ٹولز کھلی ہونی چاہییں۔
Take any 200-300 word draft you wrote recently (an email, a memo, or a paragraph from one of these exercises).
Step 1: In your primary AI tool, paste the draft and ask: "Score this 1-10 on clarity, structure, evidence, and what's missing. One-sentence justification per score."
Step 2: Open a second AI tool. Paste the same draft, ask the same question.
Step 3: Compare the two scores and the two critiques side by side. Note any point only one of them caught. Those are the points the cross-model loop pays for.
اب آپ جانتے ہیں کہ یہ ٹولز کیا کر سکتی ہیں۔ کیا آپ ان کی رہنمائی کے لیے کافی صاف سوچ سکتے ہیں، یہ ایک الگ سوال ہے، اور Part 0 اسی سوال کے گرد تعمیر کیا گیا ہے۔
شروع کرنے سے پہلے اکثر پوچھے جانے والے سوالات
کیا Part 0 کی مشقیں کے لیے paid منصوبہ ضروری ہے؟ ChatGPT، Claude، اور Gemini کے free tiers Thinking Baseline اور زیادہ تر باب مشقیں کے لیے کافی ہیں۔ paid منصوبہ اس وقت مددگار ہوتی ہے جب آپ بہت گہری تحقیق کرتے ہوں یا ایک ہی سیشن میں بہت سی فائلز attach کرتے ہوں۔ free سے شروع کریں؛ upgrade صرف تب کریں جب usage limits آپ کے راستے میں آنے لگیں۔
کیا مجھے ایک ٹول استعمال کرنا چاہیے یا تین؟ روزمرہ استعمال کے لیے ایک default ٹول چنیں، مگر comparison کے لیے کم از کم ایک اور بھی رکھیں۔ دwasرے ٹول کا مقصد دوگنا کام کرنا نہیں؛ مقصد یہ ہے کہ جب پہلے ٹول کچھ ایسا دے جو درست محسwas نہ ہو تو آپ کے پاس tiebreaker موجود ہو۔
میری کمپنی ChatGPT block کرتی ہے۔ مشقیں کے لیے میں کیا کروں؟ جو بھی modern AI ٹول آپ کی کمپنی اجازت دیتی ہے، اسے استعمال کریں۔ Part 0 کی مہارتیں کسی بھی text-in، text-out AI میں منتقل ہو جاتی ہیں۔ اگر کچھ بھی allowed نہ ہو، تو باب مشقیں کے لیے اپنے ذاتی account کو ذاتی device پر استعمال کریں (Part 0 کے deliverables کا تعلق کمپنی ڈیٹا سے نہیں، thinking سے ہے)۔
کیا Thinking Baseline کے لیے AI استعمال کرنا cheating ہے؟ ہاں، اور اس سے صرف آپ اپنا ہی نقصان کریں گے۔ baseline ungraded ہے۔ اس کا صرف ایک مقصد ہے: ایک honest snapshot لینا جس کا آپ بعد میں موازنہ کر سکیں۔ AI سے بہتر بنائی گئی baseline آپ کو جھوٹی طور پر زیادہ اونچی نقطہ آغاز دیتی ہے اور آپ کی growth کے شواہد مٹا دیتی ہے۔
اگر میں اس صفحے کی recipes بھول جاؤں تو؟ اس صفحے کو bookmark کر لیں۔ recipes (دہرائیں چکر، معیار نامہ طریقہ، غیر جانبدار-rephrase trick) یاد کرنے کے لیے نہیں بلکہ دوبارہ دیکھنے کے لیے بنائی گئی ہیں۔ صرف ایک چیز ہے جسے یاد رکھنا واقعی کافی ہے: درست سیاق و سباق اندر لاؤ، غلط سیاق و سباق باہر رکھو۔
Part 0 thinking پر اتنا وقت کیوں لگاتا ہے جبکہ AI اتنی capable ہے؟ کیونکہ direction کے بغیر صلاحیت صرف waste کو multiply کرتی ہے۔ AI کی confidently wrong تجزیہ، تجزیہ نہ ہونے سے زیادہ خطرناک ہے، کیونکہ یہ مکمل دکھتی ہے۔ Part 0 وہ judgment بناتا ہے جو طے کرتی ہے کہ AI کے پیدا کردہ مواد کے ساتھ کیا کرنا ہے۔ AI سے بھری workplace میں یہی judgment سب سے قیمتی مہارت ہے، اور زیادہ تر curricula اسے تقریبا مکمل طور پر چھوڑ دیتی ہیں۔
پہلے ہفتے میں نظر رکھنے والی عام غلطیاں
| غلطی | علامت | حل |
|---|---|---|
| AI کو تلاش engine کی طرح treat کرنا | Short پرامپٹس، سطحی جوابات، بار بار frustration | AI کو colleague کی طرح brief کریں: سیاق و سباق، فائلز، constraints، پوچھیں۔ |
| ایک ہی گفتگو کو ہمیشہ کھینچتے رہنا | وقت کے ساتھ جوابات زیادہ vague ہونے لگتی ہیں | topic بدلتے ہی نئی گفتگو شروع کریں۔ |
| پہلی کوشش میں final مسودہ مانگ لینا | polished نتیجہ، مگر hollow content | پہلے outline، پھر outline تنقیدی جائزہ، پھر bullets، پھر مسودہ۔ |
| انجانے میں bait phrasing استعمال کرنا | AI اسی بات سے agree کرتی ہے جس کا اشارہ آپ نے دیا | بھیجنے سے پہلے سوال کو غیر جانبدار انداز میں rewrite کریں۔ |
| تنقیدی جائزہ میں معیار نامہ چھوڑ دینا | "بہترین کام!" مگر بغیر specifics | objective yes/no معیارات دیں؛ ہر criterion پر درجہ مانگیں۔ |
| confidence کو accuracy سمجھ لینا | obscure topics پر حیران کن غلطیاں | پوچھیں "کیسے would آپ جانیں یہ?" high-stakes claims primary ذرائع سے verify کریں۔ |
| پہلے دن broad اجازتیں approve کرنا | فائلز گم ہو جانا، edits overwrite ہو جانا | فولڈرز کی scope تنگ رکھیں۔ scope صرف track record کے ساتھ بڑھائیں۔ |
یہ character flaws نہیں ہیں۔ یہ وہ عادتیں ہیں جو صارفین کی پہلی نسل، یعنی آپ سمیت، ابتدا سے بنا رہی ہے۔ انہیں ایک بار پہچان لینا عموما کافی ہوتا ہے۔
اب اور Part 0 کے ابواب کے درمیان کیا بدلتا ہے، اس پر ایک مختصر بات۔ اس صفحے نے آپ کو ان ٹولز کی بنیادی طریقہ سکھائی۔ ابواب وہ طریقہ کار سکھاتے ہیں جو بنیادی طریقہ کو واقعی فائدہ مند بناتی ہے:
- باب 1 (Asking بہتر سوالات) تصور 6 کے سستے نسخہ سے آگے لے جاتا ہے: ایسے سوال کیسے بنائے جائیں جو وہ سامنے لائیں جو آپ پہلے سے نہیں جانتے۔
- باب 2 (Detecting Broken استدلال) تصور 2 میں ملنے والے اشاروں کو گہرا کرتا ہے: confidently دیے گئے AI جوابات، درست جوابات کے برابر نہیں ہوتے، اور ناکامیاں پکڑنے کی دہرائے جانے کے قابل techniques موجود ہیں۔
- باب 6 (Working کے ساتھ AI، نہیں کے لیے AI) تصور 7 کی سطحی جھلک سے آگے جاتا ہے: Brainstorm-Iterate Loop ایک بہت بڑے collaboration playbook کی صرف ایک حرکت ہے۔
- باقی ابواب ایسی مہارتیں سکھاتے ہیں جنہیں بنیادی طریقہ صفحہ چھوتی بھی نہیں: نظام thinking، پہلا اصول استدلال، ethical استدلال، uncertainty میں فیصلہ سازی، اور سیکھنا کیسے کو سیکھیں۔
آپ کے پاس ٹولز موجود ہیں۔ ابواب آپ کو وہ judgment دیتی ہیں جو ان ٹولز کو واقعی فائدہ مند بناتی ہے۔
جب آپ تیار ہوں تو Part 0: Thinking ہے curriculum کی طرف جائیں اور Thinking Baseline سے آغاز کریں: آپ کی موجودہ thinking مہارتیں کا 30-منٹ ungraded snapshot، کسی بھی training سے پہلے لیا گیا۔ باب 10 کے بعد آپ یہی assessment دوبارہ کریں گے اور دونوں کا موازنہ کریں گے۔ اسے مت چھوڑیں۔ Part 0 کا اصل مقصد آپ کو ایسا شخص بنانا ہے جسے AI amplify کر سکے، ایسا نہیں جسے replace کر دے، اور یہ جاننے کا واحد طریقہ یہی ہے کہ آپ نے کہاں سے آغاز کیا تھا۔
judgment کے بغیر power ٹولز confident mistakes کو صرف زیادہ تیز کر دیتی ہیں۔ اس صفحے نے آپ کو ٹولز سکھائی ہیں۔ اس حصے کا باقی حصہ آپ کو judgment سکھاتا ہے۔