اے آئی دراصل کیا ہے: ایک فوری کورس
بغیر ریاضی، بغیر کوڈ، صرف 9 آئیڈیاز: وہ ایک چیز جو باقی پانچ کورس فرض کر لیتے ہیں کہ آپ پہلے سے سمجھتے ہیں۔
آپ یہ جانے بغیر کہ engine کیا ہوتا ہے، گاڑی چلا سکتے ہیں۔ زیادہ تر لوگ ایسا ہی کرتے ہیں۔ لیکن جیسے ہی کچھ خراب ہوتا ہے (کوئی آواز، کوئی warning light، پہاڑی پر گاڑی کا بند ہو جانا) تو وہ لوگ جنہیں موٹے طور پر اندازہ ہوتا ہے کہ بونٹ کے نیچے کیا ہے، پُرسکون رہتے ہیں، اور جنہیں نہیں معلوم، وہ گھبرا جاتے ہیں۔ وہ بے ضرر کھڑکھڑاہٹ اور جام ہو چکے engine میں فرق نہیں کر پاتے، کیونکہ ان کے لیے پوری مشین ایک بند ڈبہ ہے جو یا تو چلتا ہے یا نہیں چلتا۔
یہی زیادہ تر لوگوں کا اے آئی کے ساتھ تعلق ہے۔ انہوں نے اسے چلانا تو سیکھ لیا ہے (باقی پانچ Foundations کورس آپ کو واقعی ایک اچھا ڈرائیور بنا دیتے ہیں) مگر انہوں نے ایک بار بھی بونٹ کے نیچے نہیں جھانکا۔ تو جب مشین کوئی عجیب کام کرتی ہے (کوئی source گھڑ لیتی ہے، اپنی ہی بات کاٹ دیتی ہے، کسی بالکل غلط بات پر پورے یقین سے بولتی ہے)، تو ان کے پاس اس کی کوئی توجیہ نہیں ہوتی کہ ایسا کیوں ہوا، اور وہ یا تو اس پر حد سے زیادہ بھروسا کر لیتے ہیں یا اسے بالکل رد کر دیتے ہیں۔ دونوں ردِعمل ایک ہی جگہ سے آتے ہیں: یہ نہ جاننے سے کہ یہ چیز اصل میں ہے کیا۔
یہ کورس بونٹ کے نیچے ایک نظر ہے۔ mechanic والی نظر نہیں: یہاں کوئی ریاضی نہیں، کوئی کوڈ نہیں، کوئی ایسا neural-network ڈایاگرام نہیں جسے آپ کو سمجھنا پڑے۔ بس وہ نو آئیڈیاز جو اے آئی کے ہر حیران کن کام کی وضاحت کرتے ہیں، تاکہ اس کی ناکامیاں معمہ بننا چھوڑ دیں اور قابلِ پیش گوئی بن جائیں۔ ایک بار جب آپ ناکامیوں کی پیش گوئی کر سکیں، تو آپ ان سے بچ بھی سکتے ہیں، اور یہی پورا فائدہ ہے۔
چھ Foundations کورسز میں سے، باقیوں سے پہلے یہی پڑھنے والا کورس ہے، اگرچہ یہ سب سے زیادہ تجریدی ہے۔ 2026 میں AI Prompting، Markdown اندر، HTML باہر، وہ کوڈ جو آپ کبھی نہیں لکھتے، Skills اور Connectors، اور اے آئی کے دور میں سوچنے کا طریقہ، یہ سب آپ کو مشین کو استعمال کرنا سکھاتے ہیں۔ ان میں سے ہر ایک اِس بات پر ٹکا ہوا ہے کہ مشین ہے کیا ("یہ stateless ہے"، "یہ predict کرتی ہے، ڈھونڈتی نہیں"، "غلط ہونے پر بھی یہ پُریقین رہتی ہے") اور یہ حقائق وہ ایک ایک جملے میں، گزرتے ہوئے بیان کر دیتے ہیں۔ یہ کورس وہ جگہ ہے جہاں سے وہ جملے آتے ہیں۔ اسے ایک بار پڑھ لیں، اور باقی پانچوں کورسز کا ہر "یہ ایسا کیوں کرتا ہے؟" کا جواب پہلے سے تیار ملے گا۔
چند موضوع اِس کورس اور 2026 میں AI Prompting دونوں میں آتے ہیں، یہ سوچ سمجھ کر رکھا گیا ہے، تکرار نہیں۔ یہ کورس طریقۂ کار دیتا ہے (ایک وضاحت، پھر آگے بڑھ جاتا ہے)؛ prompting کورس مشق دیتا ہے (عادتیں، گہرائی میں)۔ جہاں دونوں ایک دوسرے کو چھوتے ہیں:
| موضوع | یہاں (مشین) | 2026 میں AI Prompting (عادت) |
|---|---|---|
| یہ کیا جانتا ہے | سیکھنا کیوں منجمد ہو گیا (آئیڈیا 2) | وہ علم کتنا قابلِ بھروسا ہے، موضوع در موضوع (Concept 2) |
| context window | یہ ماڈل کی نظر میں موجود واحد چیز کیوں ہے (آئیڈیا 5) | اسے کیسے سنبھالیں اور محفوظ رکھیں (Concept 4) |
| اعتماد | یہ پُریقین کیوں لگتا ہے اور آپ سے کیوں اتفاق کرتا ہے (آئیڈیا 6) | اسے کیسے بے اثر کریں (Concept 6) |
| استدلال | "سوچنا" اصل میں کیا ہے (آئیڈیا 9) | اسے کب آن کریں، اور کب نہیں (Concept 5) |
| تصاویر اور آڈیو | یہ محض مزید ٹوکن کیوں ہیں (آئیڈیا 4) | ان کے ساتھ عملی طور پر کیسے کام کریں (Concept 8) |
اصول یہ ہے: جیسے ہی یہاں کا کوئی حصہ آپ کو کوئی عادت سکھانے لگتا ہے، یہ رک جاتا ہے اور آپ کو اس کے بجائے prompting کورس کی طرف بھیج دیتا ہے۔ وہی حوالہ دونوں کے درمیان کی لکیر ہے۔
📚 تدریسی معاون
پوری Presentation دیکھیں، اے آئی دراصل کیا ہے
دو منٹ میں ثبوت
کسی بھی وضاحت سے پہلے، مشین کو ایسا برتاؤ کرتے دیکھیں جو تبھی سمجھ آتا ہے جب آپ جانتے ہوں کہ یہ ہے کیا۔ Claude.ai، ChatGPT، یا Gemini کھولیں (مفت اکاؤنٹ بنانے میں ایک منٹ لگتا ہے) اور بالکل یہی پیسٹ کریں، جان بوجھ کر رکھی ہوئی spelling کی غلطی کے ساتھ:
Without using any tools, just from memory: how many times does the
letter R appear in the word "strawberry"? Then spell the word out
one letter at a time and count again.
دیکھیے کیا ہو سکتا ہے: پہلی بار میں کچھ ماڈل اب بھی غلط گنتی کرتے ہیں، پھر جیسے ہی وہ لفظ کو ایک ایک حرف کر کے spell کرتے ہیں، ٹھیک جواب دے دیتے ہیں۔ ایک ایسی مشین جو آپ کے لیے ایک کام کرتا ہوا پروگرام لکھ سکتی ہے، چھ حرفوں کے ایک لفظ میں حرف بھروسے سے نہیں گن سکتی، جب تک آپ اسے لفظ توڑنے پر مجبور نہ کریں۔ یہ بے وقوفی نہیں ہے۔ یہ اِس کورس کی سب سے اہم حقیقت کا براہِ راست، نظر آنے والا نتیجہ ہے: ماڈل حروف نہیں دیکھتا۔ یہ ٹوکن دیکھتا ہے (آئیڈیا 4)۔ لفظ پہلے ہی ٹکڑوں میں کٹا ہوا اس تک پہنچتا ہے، اور کسی ٹکڑے کے اندر کے حروف گننا اس کے لیے واقعی مشکل ہے، بالکل ویسے ہی جیسے کسی عمارت کے کمرے گننا مشکل ہے اگر کسی نے آپ کو صرف اس عمارت کا سڑک والا پتا دکھایا ہو۔
دو منٹ، ایک عجیب برتاؤ، اور آپ پورے صفحے کا مرکزی خیال جان چکے ہیں: اے آئی جو بھی حیران کن کام کرتا ہے، اس کی وضاحت اس بات سے ہوتی ہے کہ یہ اصل میں ہے کیا، نہ کہ اس کے ذہین یا بے وقوف ہونے سے۔ نیچے دیے گئے نو آئیڈیاز اِس ایک مثال کو ایک مکمل خاکے میں بدل دیتے ہیں۔
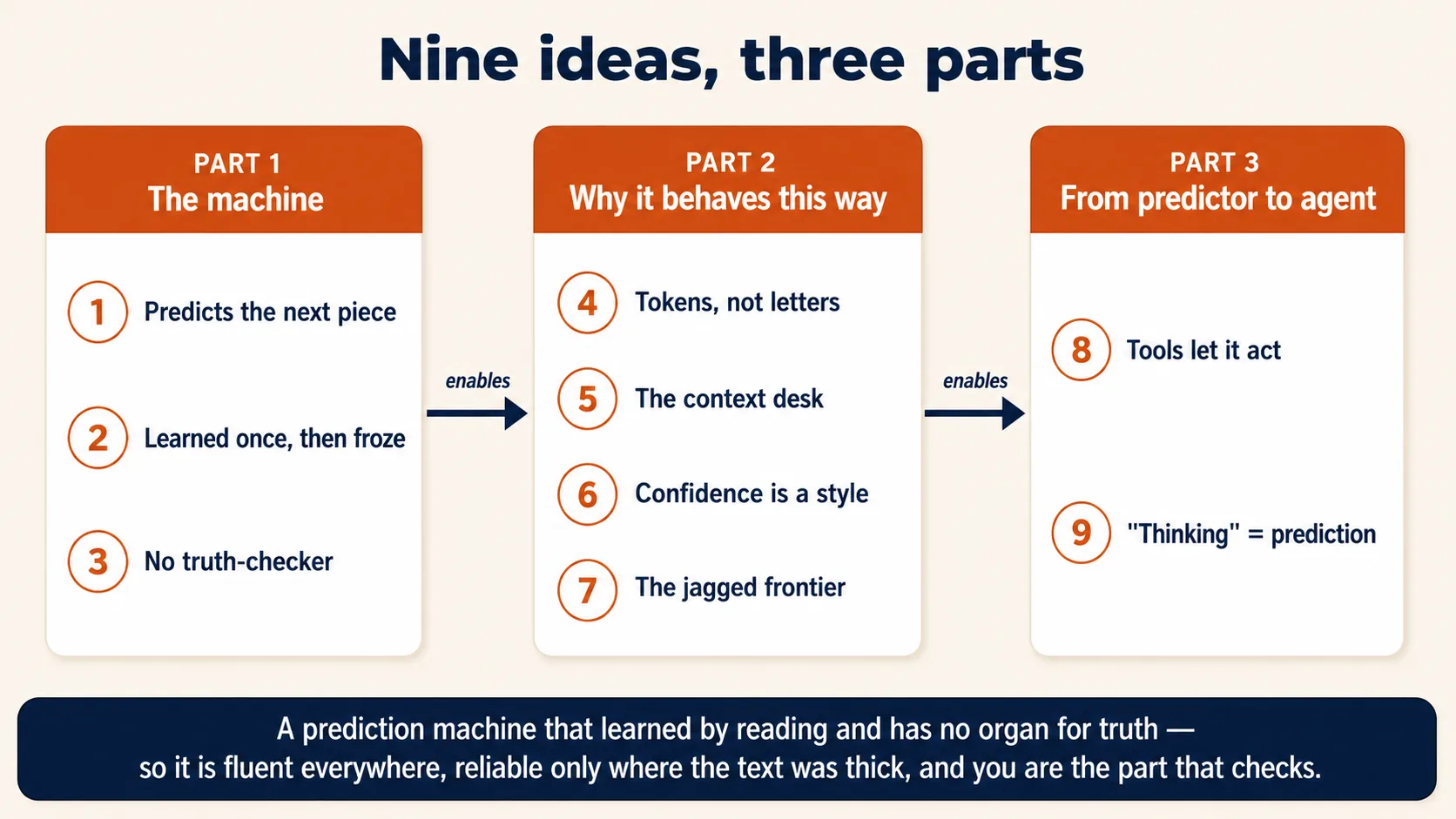
حصہ 1: مشین
جب آپ send دباتے ہیں تو لفظی طور پر کیا ہو رہا ہوتا ہے، اس بارے میں تین آئیڈیاز۔ انہیں سمجھ لیں تو اے آئی کا دو تہائی برتاؤ حیران کرنا چھوڑ دیتا ہے۔
1. یہ متن کا اگلا ٹکڑا predict کرتا ہے؛ یہ چیزیں ڈھونڈتا نہیں
یہاں وہ واحد جملہ ہے جسے آپ کے ذہن میں بٹھانے کے لیے پورا کورس بنا ہے: ایک language model ایسی مشین ہے جو، کچھ متن دیے جانے پر، یہ predict کرتی ہے کہ سب سے زیادہ معقول طور پر آگے کیا متن آتا ہے، ایک وقت میں ایک چھوٹا ٹکڑا۔ یہی پورا بنیادی طریقۂ کار ہے۔ باقی سب کچھ اسی کا نتیجہ ہے۔
یہ کتنی عجیب بات ہے، اس پر ٹھہرنا فائدہ مند ہے، کیونکہ یہ بالکل ویسا نہیں جیسا زیادہ تر لوگ فرض کرتے ہیں۔ زیادہ تر لوگ سمجھتے ہیں کہ اے آئی ایک بہت تیز لائبریرین کی طرح کام کرتا ہے: آپ سوال پوچھتے ہیں، وہ کسی وسیع اندرونی انسائیکلوپیڈیا میں متعلقہ حقیقت ڈھونڈتا ہے، اور پڑھ کر آپ کو سنا دیتا ہے۔ یہ ذہنی خاکہ غلط ہے، اور اے آئی کے ساتھ لوگوں کی تقریباً ہر غلطی اسی کی طرف لوٹتی ہے۔
اصل میں جو ہوتا ہے وہ دنیا کے سب سے زیادہ پڑھے لکھے autocomplete کے زیادہ قریب ہے۔ آپ نے autocomplete کو "Happy birthday to..." کو "you" سے مکمل کرتے دیکھا ہے۔ ایک language model بھی یہی حرکت کرتا ہے، مگر اتنے زیادہ متن پر تربیت یافتہ کہ یہ کسی بھی prompt کو جاری رکھ سکتا ہے، صرف عام جملوں کو نہیں، اور یہ اسے ایک لفظ نہیں بلکہ ایک وقت میں ایک ٹوکن کر کے جاری رکھتا ہے (آئیڈیا 4)، اور ہر بنایا ہوا ٹکڑا واپس اپنے اندر ڈال کر اگلا ٹکڑا طے کرتا ہے۔ اس سے فرانس کا دارالحکومت پوچھیں، تو یہ France → Paris کے لیبل والی کوئی database row نہیں ڈھونڈتا۔ یہ وہ تسلسل بناتا ہے جو، اس کے پڑھے ہوئے سب کچھ میں، "The capital of France is" کے بعد سب سے زیادہ معقول طور پر آتا ہے، اور وہ اتفاق سے "Paris" ہوتا ہے، کیونکہ یہ ترتیب اس کے تربیتی متن میں دس لاکھ بار آئی تھی۔
اچھی طرح گھِسے پٹے حقائق کے لیے، پیش گوئی اور ڈھونڈنا ایک ہی جواب دیتے ہیں، اس لیے فرق محض علمی لگتا ہے۔ جیسے ہی متن پتلا پڑتا ہے، یہ فرق علمی نہیں رہتا:

- فرانس کا دارالحکومت پوچھیں → معقول تسلسل ہی سچا تسلسل ہے۔ پیش گوئی علم جیسی لگتی ہے۔
- کسی ایسے خود شائع کردہ ناول کا پلاٹ پوچھیں جس کی چند سو کاپیاں بکیں اور جس کا کبھی آن لائن جائزہ نہیں لیا گیا → یہاں کوئی گھِسا پٹا تسلسل نہیں، اس لیے ماڈل ملتے جلتے لگنے والے ناولوں کو ملا کر سب سے معقول لگنے والا تسلسل بنا دیتا ہے۔ یہ پھر بھی پیش گوئی ہی کر رہا ہے۔ بس اس کے پاس سچائی کی طرف predict کرنے کے لیے کچھ نہیں ہے۔
مشین دونوں صورتوں میں بالکل ایک ہی کام کر رہی ہے۔ فرق صرف آپ بتا سکتے ہیں، اور وہ بھی تب جب آپ جانتے ہوں کہ یہ کیا کر رہی ہے۔
ایک لائبریرین کی تصویر بنانا چھوڑ دیں جو حقائق نکال کر لاتا ہے۔ ایک لکھاری کی تصویر بنائیں جو بات کو جاری رکھتا ہے۔ ایسا لائبریرین جسے کتاب نہ ملے، وہ کہتا ہے "یہ ہمارے پاس نہیں ہے"۔ ایک لکھاری جسے کہانی جاری رکھنے کو کہا جائے، وہ کبھی رک کر یہ نہیں دیکھتا کہ تسلسل سچا ہے یا نہیں۔ جاری رکھنا ہی پورا کام ہے۔ یہی وجہ ہے کہ اے آئی کبھی اس طرح "یہ میرے پاس نہیں" نہیں کہتا جیسے لائبریرین کہتا، الا یہ کہ اسے خاص طور پر یہی سکھایا گیا ہو۔ معقول تسلسل اس کی فطری حرکت ہے؛ سچائی اوپر سے، نامکمل طور پر، چڑھائی گئی چیز ہے۔
وہی سوال ہر بار مختلف جواب کیوں دیتا ہے
مشین صرف ایک اگلا ٹوکن predict نہیں کرتی۔ یہ معقول اگلے ٹوکنز کا ایک پورا پھیلاؤ predict کرتی ہے، ہر ایک کے ساتھ ایک امکان ("Paris" بہت ممکن، "the largest city in France" ممکن، درجن بھر اور پیچھے گرتے ہوئے) اور پھر اس پھیلاؤ میں سے ایک کو چُن لیتی ہے۔ یہ کتنی جرأت سے چنتی ہے، اسے ایک setting کنٹرول کرتی ہے جسے عموماً temperature کہا جاتا ہے: کم temperature اسے تقریباً ہمیشہ سب سے زیادہ ممکن ٹوکن لینے پر لگاتی ہے (مستحکم، دہرانے والا)، زیادہ temperature اسے کم ممکن ٹوکنز تک پہنچنے دیتی ہے (متنوع، زیادہ تخلیقی، کبھی کبھار بے راہ)۔ زیادہ تر chat پروڈکٹ ایک درمیانی قدر رکھتے ہیں، اسی لیے ایک ہی سوال دو بار پوچھنے پر آپ کو دو مختلف الفاظ والے جواب ملتے ہیں جن کا مطلب موٹے طور پر ایک ہی ہوتا ہے۔ یہ تبدیلی ماڈل کا "اپنا ارادہ بدلنا" نہیں ہے۔ یہ پیش گوئیوں کا وہی پھیلاؤ ہے، دو بار sample کیا گیا۔ (یہی وجہ ہے کہ جس کام میں آپ ہر بار بالکل وہی آؤٹ پٹ چاہتے ہیں، اسے آپ کبھی کبھی chat interface سے نہیں لے پاتے: پانسے اندر ہی رکھے ہوئے ہیں۔)
یہ 2026 میں AI Prompting (Concept 2) کے "frequency برابر بھروسا" والے اصول کی میکانکی جڑ ہے۔ اب آپ جانتے ہیں کہ frequency برابر بھروسا کیوں ہے: کوئی سچا تسلسل تربیتی متن میں جتنی زیادہ بار آیا، مشین اسے اتنی ہی مضبوطی سے predict کرتی ہے۔ کم آنے والا موضوع، کمزور پیش گوئی، پُریقین لگنے والا اندازہ۔
پروڈکٹ کر سکتا ہے؛ ماڈل پھر بھی نہیں کرتا۔ جدید ٹولز predictor کے گرد اضافی چیزیں لپیٹ دیتے ہیں، ویب سرچ، فائل پڑھنا، کوڈ چلانا، حتیٰ کہ ایک memory نوٹ (آئیڈیا 2)، اور یہ اضافی چیزیں اصل، حالیہ حقائق لا سکتی ہیں۔ مگر وہ حقائق context window میں اتر کر آتے ہیں (آئیڈیا 5)، اور ماڈل انہیں جواب میں اسی واحد طریقے سے بدلتا ہے جو اسے آتا ہے: ان سے ایک تسلسل predict کر کے۔ تو "یہ predict کرتا ہے، ڈھونڈتا نہیں" درمیان میں موجود مشین کے بارے میں سچ رہتا ہے، چاہے اس کے گرد کا نظام ابھی ابھی اس کے لیے کچھ ڈھونڈ کر لایا ہو۔ ٹولز ٹھیک طرح آئیڈیا 8 میں آتے ہیں۔
2. اِس نے پڑھ کر سیکھا، اور پھر سیکھنا رُک گیا
پیش گوئیاں کہاں سے آئیں؟ تربیت سے: ماڈل کو انسانی متن کی ایک بے پناہ مقدار دکھائی گئی (کتابیں، مضامین، کوڈ، فورمز، حوالہ جاتی کام) اور اس نے بار بار اپنے آپ کو ایڈجسٹ کیا، تاکہ اس متن کے اگلے ٹکڑے کی پیش گوئی میں بہتر ہو۔ یہی واحد وقت ہے جب ماڈل کبھی کچھ "سیکھتا" ہے۔ جب تربیت ختم ہوتی ہے، تو نتیجہ ایک مقررہ مجموعۂ اعداد میں منجمد ہو جاتا ہے (انجینئر انہیں weights یا parameters کہتے ہیں) جو دوبارہ نہیں بدلتا۔
دو لفظ اسے ٹھوس بنا دیتے ہیں، اور انہیں الگ الگ یاد رکھنا فائدہ مند ہے کیونکہ ان کا فرق بہت کچھ سمجھا دیتا ہے:
- تربیت ایک بار کی تعلیم ہے، جو ماضی میں، ایک بار، اُس کمپنی نے کی جس نے ماڈل بنایا۔ مہنگی، سست، ختم شدہ۔
- inference وہ ہے جو ہر بار آپ کے استعمال پر ہوتا ہے: منجمد weights آپ کے prompt پر چل کر ایک تسلسل predict کرتے ہیں۔ تیز، سستا، اور (یہی اہم بات ہے) یہ ماڈل کے اندر کچھ نہیں بدلتا۔
جب آپ گفتگو میں ماڈل کی غلطی درست کرتے ہیں اور وہ کہتا ہے "آپ ٹھیک کہتے ہیں، میری غلطی"، تو اس نے کچھ سیکھا نہیں۔ اس نے وہ متن predict کیا جو معقول طور پر کسی تصحیح کے بعد آتا ہے۔ chat بند کریں اور اگلی گفتگو انہی منجمد weights سے شروع ہوتی ہے، جسے یاد ہی نہیں کہ وہ تصحیح کبھی ہوئی تھی۔ آپ نے اسے سکھایا نہیں۔ آپ اسے سکھا نہیں سکتے۔ صرف اگلا تربیتی دور weights بدل سکتا ہے، اور اس کا حصہ آپ نہیں ہیں۔

اس سے براہِ راست دو نتیجے نکلتے ہیں:
| نتیجہ | یہ منجمد weights سے کیوں نکلتا ہے |
|---|---|
| knowledge cutoff۔ | تربیت ایک خاص تاریخ کو ختم ہوئی؛ اس کے بعد جو کچھ ہوا وہ بس weights میں ہے ہی نہیں۔ ماڈل، مستقل طور پر، ایک شاندار ماہر ہے جس نے ایک خاص دن خبریں پڑھنا بند کر دیں۔ |
| یہ آپ کی نجی دنیا نہیں جان سکتا۔ | آپ کی کمپنی کے اعداد و شمار، آپ کا کیلنڈر، کل کی ای میل، یہ کبھی تربیتی متن میں تھے ہی نہیں، اس لیے weights میں ان کے بارے میں کچھ نہیں۔ ماڈل چھپا نہیں رہا؛ یہ معلومات منجمد کرنے کے لیے کبھی موجود ہی نہیں تھیں۔ |
کچھ پروڈکٹ اب ایک "memory" دیتے ہیں جو گفتگوؤں کے بیچ آپ کو یاد رکھتا لگتا ہے۔ یہ weights کو نہیں بدلتا۔ وہ inference کے وقت ناممکن ہی رہتا ہے۔ اس کے بجائے جو ہوتا ہے: پروڈکٹ خاموشی سے آپ کے بارے میں چند حقائق متن کے طور پر محفوظ کر لیتا ہے اور ہر نئی گفتگو کے شروع میں وہی متن دوبارہ context میں ڈال دیتا ہے (آئیڈیا 5)۔ یہ ماڈل کا یاد رکھنا نہیں ہے؛ یہ پروڈکٹ کا ایک نوٹ دوبارہ کھلانا ہے۔ مفید، مگر میکانکی طور پر یہ context ہے، انسانی معنوں میں memory نہیں۔ یہ فرق جاننا ہی ماڈل کے باقی برتاؤ کو قابلِ پیش گوئی رکھتا ہے۔
یہ اس "stateless" کی میکانکی جڑ ہے، وہ لفظ جو 2026 میں AI Prompting اپنے Concept 4 میں استعمال کرتا ہے۔ stateless کا مطلب ہے: اپنی کوئی memory نہیں، ہر جواب منجمد weights اور جو کچھ ابھی اس کے سامنے ہے، اسی سے نئے سرے سے بنایا جاتا ہے۔
جو لفظ آپ سنیں گے ("parameters،" "mixture of experts،" "quantization") اور یہ نو آئیڈیاز کو کیوں نہیں بدلتے
اے آئی کے بارے میں پڑھتے ہوئے آپ کو weights کیسے بنتے ہیں کے لیے اصطلاحوں کا ایک سلسلہ ملے گا۔ تین سب سے عام، ایک ایک سطر میں:
- Parameters (جنہیں weights بھی کہتے ہیں): اِسی آئیڈیا کے منجمد اعداد۔ "ایک 400 ارب parameter ماڈل" بس انہیں گنتا ہے۔ زیادہ کا عموماً مطلب زیادہ صلاحیت اور چلانے میں زیادہ مہنگا؛ یہ نہیں بدلتا کہ یہ اعداد کرتے کیا ہیں۔
- Mixture of experts (MoE): ان parameters کو اس طرح ترتیب دینے کا ایک طریقہ کہ کسی بھی ایک ٹوکن کے لیے ہر بار سب کے بجائے صرف ایک حصہ آن ہو۔ یہ ایک بہت بڑے ماڈل کو تیز اور سستا چلنے دیتا ہے۔ باہر سے مشین پھر بھی بالکل ایک ہی کام کرتی ہے: اگلا ٹکڑا predict کرنا (آئیڈیا 1)۔
- Quantization: اعداد کو کم درستی پر محفوظ کرنا تاکہ ماڈل چھوٹے، سستے ہارڈویئر پر سما جائے۔ وہی برتاؤ، ہلکا وزن۔
نمونہ ہی اصل بات ہے۔ یہ سب اِس سوال کا جواب دیتے ہیں کہ "مشین کیسے بنی اور سستی کیسے ہوئی،" نہ کہ اِس کا کہ "مشین کرتی کیا ہے۔" نو میں سے ہر آئیڈیا (پیش گوئی، منجمد weights، کوئی سچائی جانچنے والا نہیں، ٹوکن، context، اعتماد، ناہمواری، ٹولز، سوچنا) یکساں طور پر قائم رہتا ہے، خواہ ماڈل dense ہو یا mixture-of-experts، full-precision ہو یا quantized، سات ارب parameter کا ہو یا سات سو۔ تو جب کوئی سرخی کہتی ہے کہ نیا ماڈل "MoE استعمال کرتا ہے" یا "اس میں ایک کھرب parameters ہیں"، تو اب آپ جانتے ہیں کہ اس کا مطلب کیا ہے اور یہ بھی کہ بطور صارف آپ کو جو کرنا ہے اس میں کچھ نہیں بدلتا۔ جو پیش رفت واقعی آپ کے کام کرنے کا طریقہ بدلتی ہے، وہ یہی ہیں جو یہ کورس بیان کرتا ہے: reasoning modes (آئیڈیا 9)، ٹولز (آئیڈیا 8)، اور لمبا context (آئیڈیا 5)۔
3. ایسی کوئی الگ جگہ نہیں جہاں یہ جانچے کہ بات سچ ہے یا نہیں
آئیڈیا 1 اور 2 کو ملا دیں تو آپ اُس حقیقت تک پہنچتے ہیں جو لوگوں کو سب سے زیادہ کھلانے والے برتاؤ کی وضاحت کرتی ہے۔ ایک انسانی ماہر کے پاس دو الگ صلاحیتیں ہوتی ہیں: ایک جو جواب بناتی ہے، اور دوسری، خاموش تر، جو اسے جانچتی ہے: "ٹھہرو، کیا مجھے اس کا یقین ہے؟ میں نے یہ کہاں سیکھا؟ کیا یہ درست لگتا ہے؟" دونوں اختلاف کر سکتی ہیں۔ آپ کوئی بات زبان سے کہہ سکتے ہیں اور اسی سانس میں محسوس کر سکتے ہیں کہ شاید یہ غلط ہو۔
ماڈل کے پاس صرف پہلی صلاحیت ہے۔ اس کے اندر کوئی دوسری مشین نہیں جو جواب آپ تک پہنچنے سے پہلے اس کی سچائی کا آڈٹ کرے۔ وہی واحد عمل جو ایک درست تسلسل بناتا ہے، ایک غلط تسلسل بھی بناتا ہے، اور کوئی اندرونی نشان دونوں میں فرق نہیں کرتا۔ رواں، خوش ساخت، پُریقین جملہ ہی آؤٹ پٹ ہے، خواہ نیچے کی پیش گوئی تربیتی متن سے اچھی طرح سہارا پاتی ہو یا ہوا میں سے کھینچی گئی ہو۔ روانی مشینری بناتی ہے؛ سچائی کو یہ الگ سے نہیں جانچتی۔
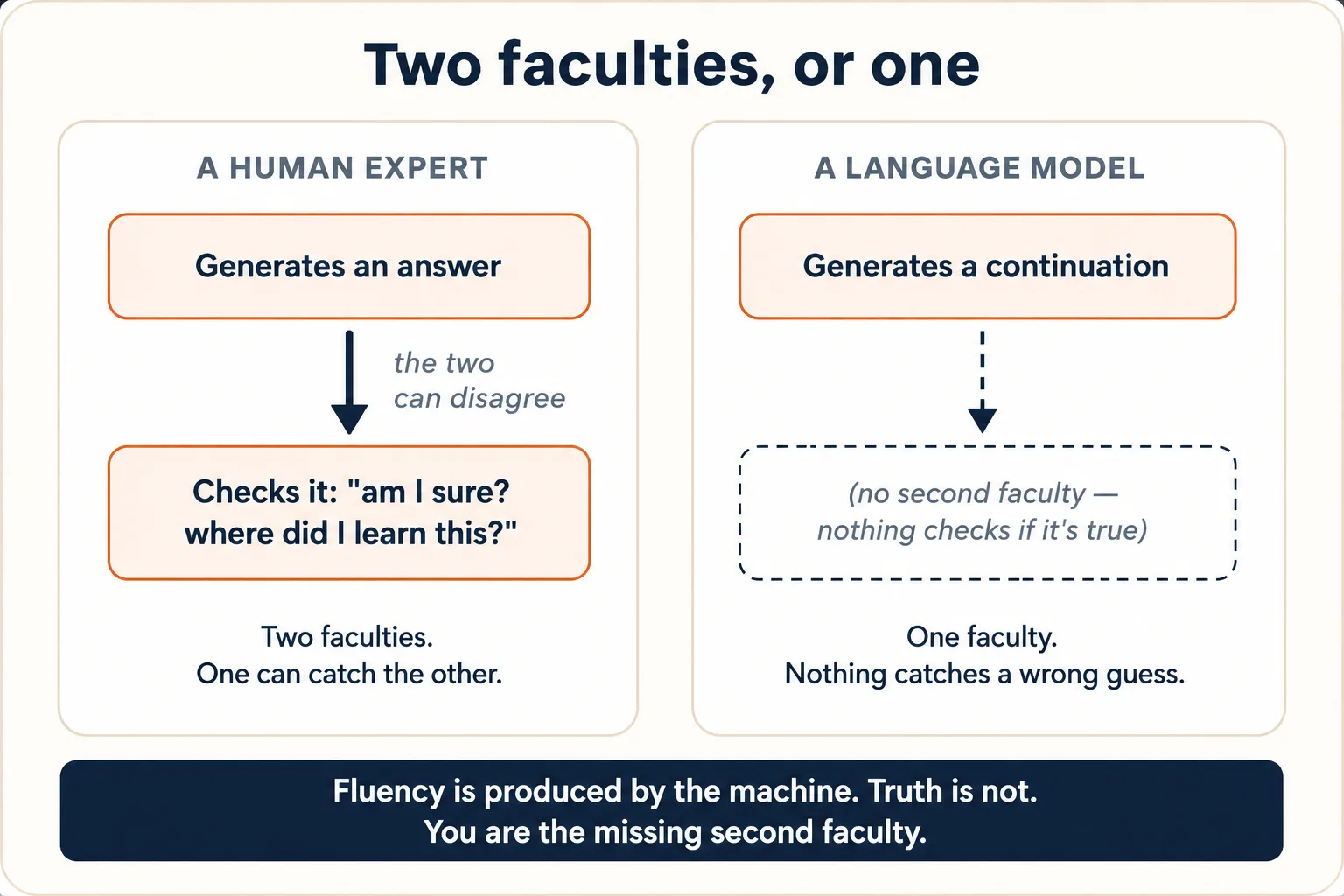
یہی وہ بات ہے جس کی طرف لوگ اشارہ کرتے ہیں جب کہتے ہیں کہ اے آئی hallucinate کرتا ہے: یہ رواں، پُریقین، بالکل جھوٹے بیان بناتا ہے۔ یہ لفظ اسے کوئی خرابی، کوئی glitch لگتا ہے جسے ٹھیک کرنا ہے۔ یہ glitch نہیں ہے۔ یہ مشین کا بالکل اپنی ساخت کے مطابق کام کرنا ہے: ایک معقول تسلسل predict کرنا، ایسی جگہ جہاں معقول تسلسل اتفاق سے سچا نہ ہو۔ ایک بغیر سہارے کا ماڈل جو کبھی hallucinate نہ کرے، وہ بالکل مختلف قسم کی مشین ہوگی، ایسی جس کے گرد اصل retrieval، تصدیق، یا انکار کی صلاحیت بنی ہو۔ اوپر چڑھائے گئے ٹولز اور جانچ (آئیڈیا 8) یہ کم کر دیتے ہیں کہ ایسا کتنی بار ہوتا ہے؛ وہ درمیان میں موجود چیز کی فطرت نہیں بدلتے، جس کا پورا کام جاری رکھنا ہے۔
ماڈل کا پُریقین لہجہ اس بات کا ثبوت نہیں کہ یہ ٹھیک ہے۔ یہ لہجہ ایک انداز ہے جو اس نے پُریقین انسانی تحریر سے سیکھا (مزید آئیڈیا 6 میں)؛ یہ مواد کے انہی عمل سے بنتا ہے، اور سچائی سے اتنا ہی الگ ہے۔ ایک گھڑا ہوا اعداد و شمار بالکل اسی پُراعتماد آواز میں آتا ہے جس میں ایک اصل۔ یہی پوری وجہ ہے کہ اے آئی کے دور میں سوچنے کا طریقہ کورس موجود ہے: اس کی Error Taxonomy (Discipline 3) ایک checklist ہے جس سے آپ ہاتھ سے وہ جھوٹے تسلسل پکڑتے ہیں جنہیں مشین خود پکڑنے کا کوئی طریقہ نہیں رکھتی۔ گمشدہ دوسری صلاحیت آپ ہیں۔
ایک غیر سافٹ ویئر مثال۔ ایک والد نے ایک اے آئی سے اپنے شہر کی ایک خاص چھوٹی تدریسی اکیڈمی کا درست فیس شیڈول اور کلاس اوقات پوچھے، ایسی اکیڈمی جس کی نہ کوئی ویب سائٹ تھی اور نہ تقریباً کوئی آن لائن نشان۔ اے آئی نے کورسز، اوقات اور ماہانہ فیس کا ایک پُریقین، صفائی سے ترتیب دیا گیا جدول بنا دیا۔ ہر عدد گھڑا ہوا تھا۔ اے آئی نے نہ جھوٹ بولا تھا اور نہ خراب ہوا تھا۔ وہ اکیڈمی کسی بھی تربیتی متن میں مشکل سے موجود تھی، اس لیے predict کرنے کے لیے کوئی اصل شیڈول تھا ہی نہیں، اور اس کے بغیر مشین نے وہی کیا جو وہ کر سکتی ہے: اس نے سب سے معقول لگنے والی فیس بنا دی جو ایسی اکیڈمی لے سکتی ہے، اسی پُریقین آواز میں ترتیب دے کر جو وہ تصدیق شدہ حقائق کے لیے استعمال کرتی ہے۔ اس کے پاس کوئی دوسری صلاحیت نہیں تھی جو سرگوشی کرتی "تم اندازہ لگا رہے ہو"۔ وہ سرگوشی آپ کی طرف سے آنی ہوتی ہے۔
حصہ 2: یہ ایسا برتاؤ کیوں کرتا ہے
چار آئیڈیاز جو ان عجیب برتاؤوں (حروف گننا، memory ختم ہو جانا، پُریقین لگنا، ایک ہی سانس میں شاندار اور بے کار ہونا) کو ایسی چیزوں میں بدل دیتے ہیں جنہیں آپ آتے دیکھ سکتے ہیں۔
4. یہ حروف یا الفاظ میں نہیں، ٹوکن میں پڑھتا ہے
ماڈل آپ کے prompt کو حروف کے طور پر نہیں دیکھتا، اور بالکل الفاظ کے طور پر بھی نہیں۔ کچھ بھی ہونے سے پہلے، آپ کا متن ٹوکن میں کاٹ دیا جاتا ہے: ایسے ٹکڑے جو عموماً ایک لفظ یا لفظ کا ایک حصہ ہوتے ہیں۔ "Strawberry" دو یا تین ٹکڑوں میں آ سکتا ہے؛ "the" ایک ہے؛ کوئی لمبا یا غیر معمولی لفظ کئی۔ ماڈل صرف یہی ٹکڑے دیکھتا ہے، انہی ٹکڑوں میں predict کرتا ہے، اور ان کے اندر کے انفرادی حروف کبھی نہیں دیکھتا، جب تک اسے انہیں spell کرنے پر مجبور نہ کیا جائے۔
یہ ایک میکانکی حقیقت بہت سے بظاہر ناقابلِ فہم برتاؤوں کے ایک گچھے کی وضاحت کرتی ہے:
| برتاؤ | ٹوکن اس کی وضاحت کیوں کرتے ہیں |
|---|---|
| یہ کسی لفظ کے حروف غلط گنتا ہے (strawberry والا ٹیسٹ)۔ | یہ ٹکڑے دیکھتا ہے، حروف نہیں۔ کسی ٹکڑے کے اندر کے حروف گننا ایسا ہے جیسے سڑک والے پتے سے کمرے گننا۔ |
| یہ کچھ tukbandi، anagrams، اور لفظی کھیل میں کمزور ہے۔ | یہ حروف اور آوازوں پر چلتے ہیں؛ ماڈل ٹکڑوں پر چلتا ہے۔ |
| آپ کے prompt میں spelling کی غلطیاں شاذ و نادر ہی فرق ڈالتی ہیں۔ | کوئی غلط لکھا لفظ بھی ایسے ٹکڑوں سے جُڑ جاتا ہے جو مطلوبہ مطلب کے کافی قریب ہوتے ہیں۔ (اسی لیے 2026 میں AI Prompting آپ سے کہتا ہے کہ spelling کی غلطیاں ٹھیک کرنے کی زحمت نہ کریں۔) |
| لاگت اور لمبائی الفاظ میں نہیں، ٹوکن میں ناپی جاتی ہے۔ | مشین اصل میں جو چیز عمل میں لاتی ہے وہ ٹوکن ہے، اس لیے یہی وہ چیز ہے جس کا آپ کو بل آتا ہے اور جس کی حد آپ پر لگتی ہے۔ |
ٹوکن پیسے کی اکائی بھی ہیں اور memory کی اکائی بھی۔ جب کوئی ٹول کہتا ہے کہ اس کے پاس "200,000 ٹوکن کا context window" ہے، تو وہ بتا رہا ہوتا ہے کہ یہ ایک وقت میں ان میں سے کتنے ٹکڑے رکھ سکتا ہے (آئیڈیا 5)۔ جب آپ کو "فی ٹوکن" بل آتا ہے، تو آپ ہر اندر جاتے اور ہر باہر آتے ٹکڑے کا ادا کر رہے ہوتے ہیں۔ موٹے طور پر، انگریزی میں، تین ٹوکن تقریباً چار الفاظ کے ہوتے ہیں، مگر آپ کو کبھی درست نسبت کی ضرورت نہیں، صرف یہ خیال کہ اصل اکائی ٹکڑا ہے، اور لفظ ایک تخمینہ ہے جو آپ اوپر سے چڑھاتے ہیں۔
وہ "تین ٹوکن ≈ چار الفاظ" والی نسبت انگریزی کے لیے ہے۔ دوسرے رسم الخط کا متن (اردو، عربی، ہندی، چینی، اور بہت سے اور) عموماً فی لفظ زیادہ ٹوکن میں کٹتا ہے، کیونکہ تربیتی متن انگریزی کی طرف جھکا ہوا تھا اور tokenizer نے انگریزی ٹکڑے سب سے بہتر سیکھے۔ اس سے براہِ راست دو عملی نتیجے نکلتے ہیں: وہی پیغام کسی غیر انگریزی زبان میں زیادہ مہنگا پڑتا ہے، اور یہ context window کو زیادہ تیزی سے بھرتا ہے (آئیڈیا 5)، اس لیے اس گفتگو کے لیے ماڈل کی مؤثر memory کم رہتی ہے۔ tokenizers بہتر ہوتے جا رہے ہیں اس لیے یہ سدھر رہا ہے، مگر 2026 میں بھی یہ حقیقت ہے۔ اگر آپ زیادہ تر کسی غیر لاطینی رسم الخط میں کام کرتے ہیں، تو وہی کام کرتے ہوئے ایک انگریزی صارف کی نسبت لاگت اور لمبائی کی حدوں تک جلدی پہنچنے کی توقع رکھیں۔ اور جب کوئی لمبی دستاویز اہم ہو، تو کبھی کبھی فائدہ مند ہوتا ہے کہ ماڈل اندرونی طور پر انگریزی میں کام کرے اور آخر میں ترجمہ کر دے۔
سکتا ہے، اور طریقۂ کار نہیں بدلتا: یہ عام (generalize) کرتا ہے۔ آپ کی اپ لوڈ کی ہوئی تصویر چھوٹے patches میں کاٹی جاتی ہے، اور ہر patch ایک ٹوکن بن جاتا ہے؛ ایک آواز کا ٹکڑا چھوٹے segments میں کاٹا جاتا ہے، اور ہر ایک ٹوکن بن جاتا ہے۔ پھر ماڈل ایک ہی دھارے پر predict کرتا ہے جو لفظ کے ٹکڑوں، تصویر کے patches، اور آڈیو کے segments کو آپس میں ملا دیتا ہے۔ تو اِس کورس کا سب کچھ تصاویر اور آڈیو کے لیے بھی قائم رہتا ہے: وہی پیش گوئی (آئیڈیا 1)، وہی منجمد weights (آئیڈیا 2)، وہی گمشدہ سچائی جانچنے والا (آئیڈیا 3)، وہی context-window بطور میز (آئیڈیا 5)۔ یہ وہ میکانکی وجہ بھی ہے کہ تصویر میں باریک تفصیل اور چھوٹے حروف مشکل ہوتے ہیں: ایک patch ایک ٹکڑا ہے، اور patch کے اندر کے حروف پڑھنا پھر سے وہی strawberry والا مسئلہ ہے۔ عملی پہلو (اے آئی کون سی تصاویر اچھی پڑھتا ہے اور کن میں گڑبڑ کرتا ہے، اور ان کے لیے prompt کیسے دیں) 2026 میں AI Prompting کے Concept 8 کا کام ہے؛ نیچے کا طریقۂ کار بس مزید قسموں کے ٹوکن، وہی مشین ہے۔
5. context window ہی واحد چیز ہے جو یہ دیکھ سکتا ہے
چونکہ weights منجمد ہیں (آئیڈیا 2) اور ماڈل کی اپنی کوئی memory نہیں، اس لیے بالکل ایک ہی جگہ ہے جہاں سے یہ آپ کی مخصوص صورتِ حال کے بارے میں معلومات لے سکتا ہے: context window، یعنی وہ متن جو اس ایک جواب کے لیے اس کے سامنے پڑا ہے۔ 2026 میں AI Prompting اسے Concept 4 کے طور پر، "context ہی پورا کھیل ہے"، سکھاتا ہے اور اسے prompting کی مرکزی مہارت مانتا ہے۔ یہاں اس کی میکانکی وجہ ہے کہ یہ مرکزی کیوں ہے۔
context window ایک جواب کے لیے ماڈل کی پوری دنیا ہے۔ اس میں آپ کا prompt، اب تک کی گفتگو، آپ کی منسلک کی ہوئی کوئی بھی فائلیں، ٹولز کی تفصیلات، اور وہ غیر مرئی system prompt ہوتا ہے جو پروڈکٹ نے آپ کے آنے سے پہلے وہاں رکھ دیا۔ اس کھڑکی میں جو کچھ ہے، ماڈل اسے استعمال کر سکتا ہے۔ جو اس میں نہیں، وہ اس جواب کے لیے وجود ہی نہیں رکھتا، اس لیے نہیں کہ ماڈل انکار کر رہا ہے، بلکہ اس لیے کہ اس کے پاس دیکھنے کو اور کوئی جگہ نہیں۔ منجمد weights اسے دنیا کے بارے میں عمومی روانی دیتے ہیں؛ context window آپ کی دنیا کی تفصیلات کا واحد راستہ ہے۔
یہ دو ایسی چیزوں کو نئے سرے سے سمجھا دیتا ہے جو ورنہ آپ کو پُراسرار لگیں گی:
- briefing کیوں کام کرتی ہے۔ ماڈل کو context دینا کوئی شائستگی یا چال نہیں۔ یہ معلومات کو لفظی طور پر اُس واحد جگہ پر رکھنے کا عمل ہے جہاں سے مشین انہیں پڑھ سکتی ہے۔ جسے brief نہ کیا گیا ہو وہ ماڈل سست نہیں؛ اس کے سامنے واقعی کچھ نہیں ہوتا۔
- لمبی گفتگوئیں کیوں بگڑتی جاتی ہیں (prompting کورس میں "context rot")۔ کھڑکی کی ایک سائز کی حد ہوتی ہے جو ٹوکن میں ناپی جاتی ہے (آئیڈیا 4)۔ اس میں بہت زیادہ غیر متعلقہ تاریخ ٹھونس دیں تو جو signal آپ کے لیے اہم ہے وہ پتلا پڑ جاتا ہے، یا جگہ بنانے کے لیے سب سے پرانے حصے خلاصہ کر کے ہٹا دیے جاتے ہیں۔ ماڈل تھک نہیں رہا؛ بس اس کی پڑھنے کی میز بھری ہوئی ہے۔
context window ایک پڑھنے کی میز ہے، دماغ نہیں۔ آپ میز پر جو بھی رکھیں، ماڈل اسے غور سے پڑھتا ہے۔ جو آپ میز سے باہر چھوڑ دیں، اسے یہ نہیں دیکھ سکتا، خواہ وہ آپ کے لیے کتنا ہی واضح کیوں نہ ہو۔ باقی پانچوں کورسز میں سکھائی جانے والی prompting کی پوری مہارت اِسی نظر سے دیکھنے پر ایک عادت تک سمٹ آتی ہے: کنٹرول کریں کہ میز پر کیا آتا ہے۔
6. اس کا اعتماد ایک سیکھا ہوا انداز ہے، سچائی کا اشارہ نہیں
آئیڈیا 3 نے کہا کہ ماڈل کے پاس کوئی اندرونی سچائی جانچنے والا نہیں۔ یہ آئیڈیا دوسرا رخ سمجھاتا ہے: اس کا نہ تھمنے والا اعتماد کہاں سے آتا ہے، اور وہ اعتماد درستی کے بارے میں آپ کو کچھ کیوں نہیں بتاتا۔
اصل تربیت کے بعد (آئیڈیا 2)، ماڈلز کو عموماً انسانی feedback سے مزید tune کیا جاتا ہے: لوگ جوابوں کو درجہ دیتے ہیں، اور ماڈل کو اُس قسم کے جواب کی طرف ایڈجسٹ کیا جاتا ہے جسے لوگوں نے زیادہ پسند کیا۔ (انجینئر اس قدم کو RLHF کہتے ہیں، یعنی human feedback سے reinforcement learning؛ آپ کو مشینری کی ضرورت نہیں، صرف نتیجے کی۔) لاکھوں درجہ بندیوں میں، لوگ مستقل طور پر پُریقین، مددگار، رواں اور خوشگوار جوابوں کو ان جوابوں پر ترجیح دیتے ہیں جو محتاط، کھرے، یا مخالف ہوں۔ تو مشین پُریقین، خوشگوار، رواں متن بنانے کی طرف ڈھل جاتی ہے، چاہے نیچے کا مواد ٹھیک ہو یا نہ ہو۔ اعتماد ایک ایسا انداز بن گیا جو یہ بطورِ پیش فرض پہنتی ہے، اسی طرح جیسے ایک ماہر لکھاری اُن موضوعات پر بھی رواں لکھتا ہے جنہیں وہ آدھا سمجھتا ہے۔
اے آئی کے دو سب سے زیادہ زیرِ بحث برتاؤ سیدھے اِسی سے نکلتے ہیں:
- یہ غلط ہونے پر بھی پُریقین لگتا ہے۔ یہ یقین ایک سیکھا ہوا اسلوبی پیش فرض ہے، جو مواد کے انہی عمل سے بنتا ہے اور سچائی سے اتنا ہی الگ ہے۔ ایک پُریقین جملہ گھر کا انداز ہے، درستی پر فیصلہ نہیں۔
- یہ آپ سے اتفاق کرنے کی طرف جھکتا ہے، وہی sycophancy جس کے لیے 2026 میں AI Prompting Concept 6 وقف کرتا ہے۔ اتفاق کو اختلاف سے زیادہ درجہ ملا، اس لیے مشین آپ کو وہ بتانے کی طرف جھکتی ہے جو آپ چاہتے لگتے ہیں۔ پوچھیں "کیا X سچ نہیں ہے؟" تو آپ نے وہ جواب اشارے میں دے دیا جو آپ چاہتے ہیں؛ تربیت میں بیٹھا جھکاؤ اسے فراہم کر دیتا ہے۔
اب prompting کورس کے حل میکانکی طور پر سمجھ آتے ہیں۔ غیر جانب دار framing ("X کا جائزہ لو؛ ہر پہلو پر سب سے مضبوط دلیل دو") اس لیے کام کرتی ہے کہ یہ وہ signal ہٹا دیتی ہے جس کی طرف ماڈل ورنہ جھکتا۔ اسکور پر مجبور کرنا ("ان معیاروں کے مقابلے میں اسے 1 سے 10 تک درجہ دو") اس لیے کام کرتا ہے کہ ایک عدد کو خوشگوار انداز میں جعلی بنانا کسی صفت کی نسبت مشکل ہے۔ آپ مشین کو مات نہیں دے رہے؛ آپ وہ اشارے ہٹا رہے ہیں جو اس کے تربیت یافتہ جھکاؤ کو چالو کرتے ہیں۔
7. یہ ملحقہ لمحوں میں شاندار اور بے کار دونوں ہوتا ہے (ناہموار سرحد)
انسانی صلاحیت کافی ہموار ہوتی ہے: جو شخص مشکل calculus کر سکتا ہے وہ تقریباً یقینی طور پر آسان حساب بھی کر لے گا۔ اے آئی کی صلاحیت ہموار نہیں۔ یہ ناہموار ہے: ایک کام میں مافوقِ انسان اور ساتھ والے کسی کام میں حیران کن حد تک نااہل، جو ہمیں ذرا بھی مشکل نہیں لگتا۔ یہ ایک قانونی لگنے والی contract clause لکھ سکتا ہے اور پھر "strawberry" کے حروف غلط گن سکتا ہے۔ یہ quantum mechanics سمجھا سکتا ہے اور تین قدموں کی ایک منطقی پہیلی میں مات کھا سکتا ہے جو کوئی بچہ بھی حل کر لے۔
یہ ناہمواری بے ترتیب نہیں؛ یہ تربیتی متن اور ٹوکن کے طریقۂ کار کی طرف لوٹتی ہے۔ جو کام تربیتی ڈیٹا میں اکثر، واضح صورت میں، آئے (عام تصورات سمجھانا، عام اندازوں میں لکھنا، عام کوڈ بنانا) وہ مضبوط ہوتے ہیں۔ جو کام ایسی چیزوں پر منحصر ہوں جنہیں مشین اچھی طرح نہیں دیکھ سکتی، جیسے انفرادی حروف (آئیڈیا 4)، بہت حالیہ واقعات (آئیڈیا 2)، آپ کا نجی context (آئیڈیا 5)، یا کم آنے والے موضوع (آئیڈیا 1)، وہ کمزور ہوتے ہیں۔ "شاندار" اور "بے کار" کے درمیان کی سرحد ایک ناہموار لکیر میں چلتی ہے جو مشکل کے بارے میں انسانی وجدان سے میل نہیں کھاتی، اور بالکل اسی لیے یہ لوگوں کو حیران کرتی رہتی ہے۔
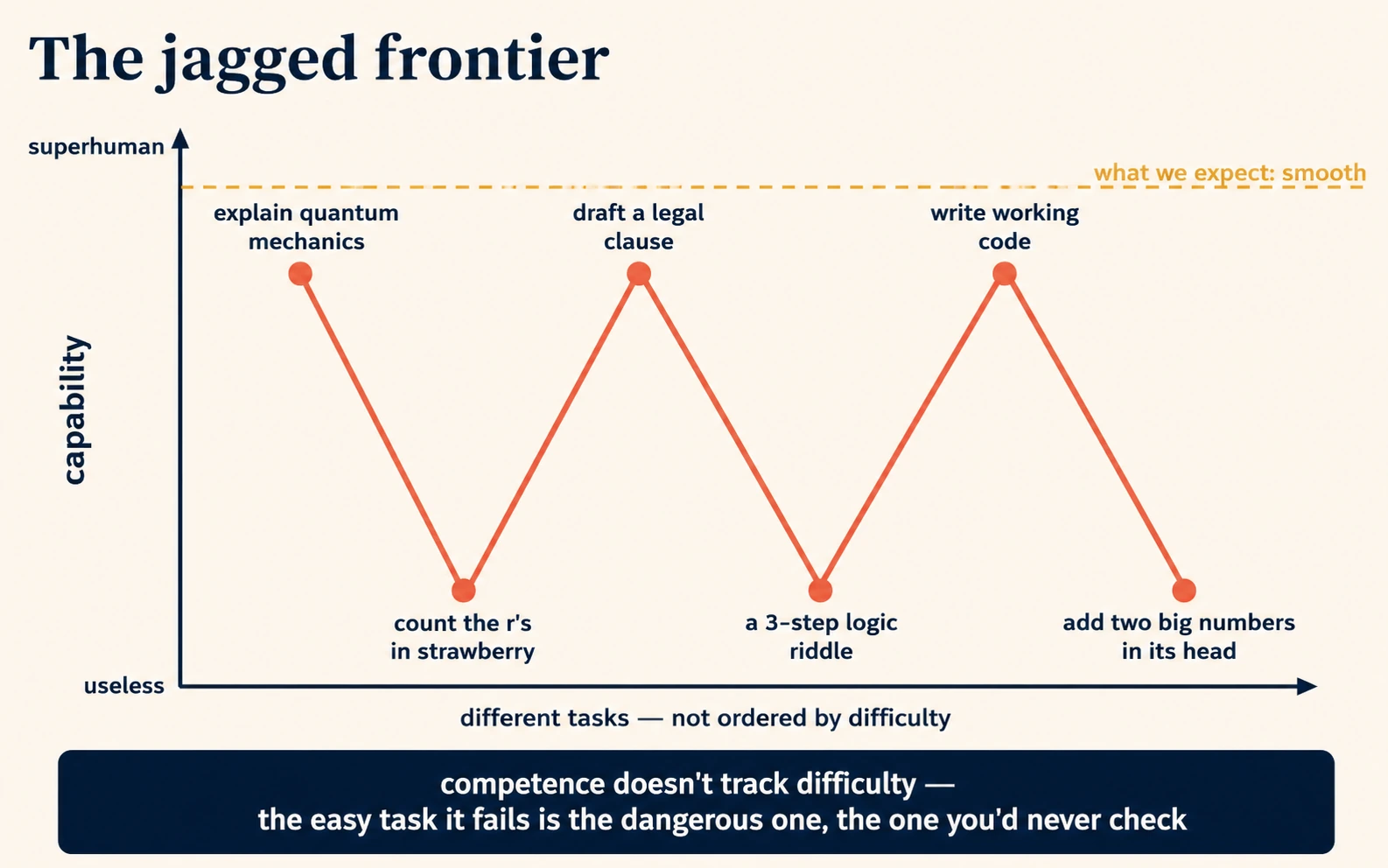
ناہمواری قبول کرنے سے تین عملی عادتیں نکلتی ہیں:
| عادت | یہ ناہمواری سے کیوں نکلتی ہے |
|---|---|
| یہ مت سمجھیں کہ کیونکہ اس نے ایک مشکل کام کر دیا، یہ کوئی آسان کام بھی کر لے گا۔ | دونوں ناہموار سرحد کے مخالف اطراف بیٹھے ہو سکتے ہیں۔ |
| سرحد کے آر پار جانچیں، بیچ میں نہیں۔ | خطرناک غلطیاں وہ آسان لگنے والے کام ہیں جنہیں یہ خاموشی سے بگاڑ دیتا ہے، نہ کہ وہ مشکل جنہیں آپ پہلے ہی جانچ رہے تھے۔ |
| وہی کام دو یا تین مختلف ماڈلز میں آزمائیں۔ | مختلف ماڈلز کی سرحدیں مختلف شکل کی ہوتی ہیں؛ ایک وہ پکڑ لیتا ہے جو دوسرا چھوڑ دیتا ہے۔ (2026 میں AI Prompting، Concepts 12–13۔) |
سرحد حرکت بھی کرتی ہے۔ جو چیز ماڈل اِس سہ ماہی میں "نہیں کر سکتا"، ہو سکتا ہے کوئی نیا ماڈل اگلی سہ ماہی میں آسانی سے کر لے، اور جو یہ اچھا کرتا ہے وہ شاید بالکل بہتر نہ ہو۔ prompting کورس کا یہ مشورہ کہ ہر چند مہینوں بعد دوبارہ جانچیں کہ اے آئی کیا کر سکتا ہے، میکانکی طور پر، ایک ایسی سرحد کو دوبارہ نقشہ بنانے کا مشورہ ہے جو بدلتی رہتی ہے۔
حصہ 3: کس چیز نے ایک متن کی پیش گوئی کرنے والے کو عمل کرنے والی چیز میں بدلا
دو آئیڈیاز جو "یہ متن predict کرتا ہے" اور اُن agents کے درمیان کا فاصلہ پاٹتے ہیں جن کے بارے میں باقی کتاب ہے۔ یہ یہ کیا ہے سے یہ دنیا میں کیا کرتا ہے تک کا پل ہے۔
8. ٹولز اسے صرف بیان کرنے نہیں، عمل کرنے دیتے ہیں
اب تک کا سب کچھ ایک ایسی مشین بیان کرتا ہے جو متن بناتی ہے۔ ایک خالص متن predictor آپ کو وہ موسم بتا سکتا ہے جو اسے تربیت سے یاد ہے، مگر یہ آج کا موسم نہیں دیکھ سکتا، اصل اعداد پر کوئی حساب نہیں چلا سکتا، آپ کی فائل نہیں پڑھ سکتا، یا ای میل نہیں بھیج سکتا۔ برسوں تک یہی حد تھی۔
یہ حد ٹولز سے ہٹی۔ ٹول ایک طے شدہ عمل ہے جسے بلانے کی ماڈل کو اجازت ہوتی ہے (ایک ویب سرچ، ایک کوڈ رن، ایک فائل پڑھنا، ایک ای میل draft)، جو context window میں باقی سب کے ساتھ اسے بیان کیا جاتا ہے (آئیڈیا 5)۔ نتیجے کے لحاظ سے طریقۂ کار تقریباً شرمندہ کر دینے کی حد تک سادہ ہے: جب ماڈل predict کرتا ہے کہ درست تسلسل سادہ نثر کے بجائے "اس query کے ساتھ search tool استعمال کرو" ہے، تو پروڈکٹ وہ عمل واقعی چلاتا ہے، نتیجہ واپس context window میں ڈال دیتا ہے، اور ماڈل وہیں سے جاری رکھتا ہے۔ پیش گوئی، عمل، نتیجہ واپس context میں، پھر سے پیش گوئی۔ یہی loop اُس chatbot، جو دنیا کو بیان کرتا ہے، اور اُس assistant، جو اس پر عمل کرتا ہے، کے درمیان فرق ہے۔
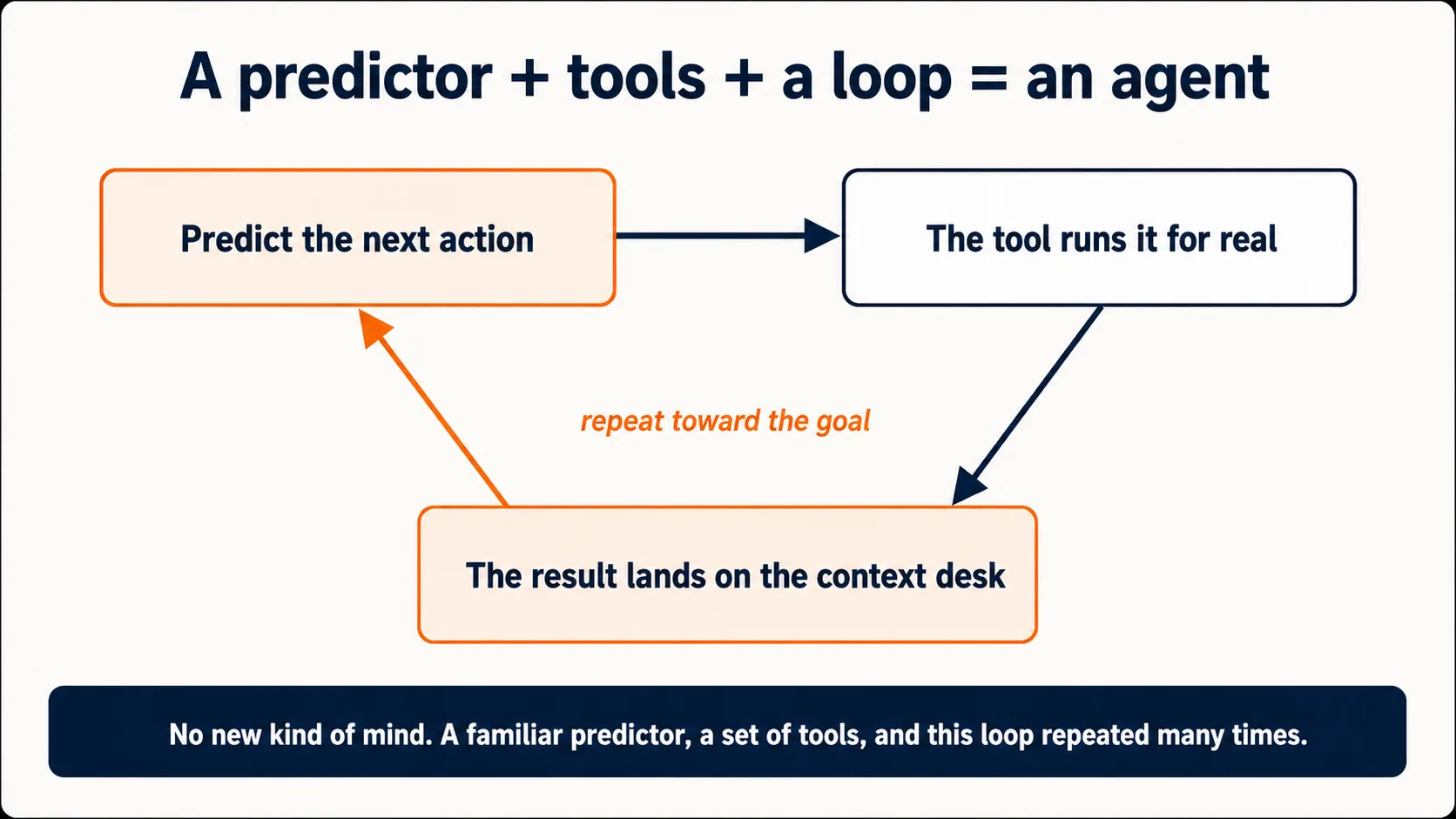
یہی وجہ ہے کہ وہی نیچے والی مشین ایک دن ایک chat window ہو سکتی ہے اور، ٹولز جوڑنے پر، اگلے دن ایک ایسا agent جو آپ کا folder دوبارہ ترتیب دے دے۔ باقی Foundations کورس، اندر سے، اِسی ایک predictor پر جڑے مخصوص ٹولز کے بارے میں کورس ہیں:
- کوڈ execution وہ ٹول ہے جو وہ کوڈ جو آپ کبھی نہیں لکھتے کے پیچھے ہے: ماڈل ایک پروگرام predict کرتا ہے، ٹول اسے چلاتا ہے، اصل نتیجہ واپس آتا ہے۔
- Connectors آپ کی ایپس سے جُڑے ٹولز ہیں، جو Skills اور Connectors کا موضوع ہیں: ماڈل predict کرتا ہے "یہ Drive سے لاؤ"، ٹول اسے لے آتا ہے۔
- ویب سرچ وہ ٹول ہے جو ایک پرانے پڑ چکے ماڈل کو بچاتا ہے (آئیڈیا 2)، جس کا احاطہ 2026 میں AI Prompting کرتا ہے۔
یہ کتاب agent اُس اے آئی کو کہتی ہے جو آپ کی طرف سے کئی قدموں والا کام کرتا ہے۔ اب آپ دیکھ سکتے ہیں کہ اندر سے اس کا مطلب کیا ہے: ایک agent یہی اگلے ٹوکن کی پیش گوئی کرنے والا ہے، جسے ٹولز دیے گئے، اور جو predict-عمل-مشاہدہ والا loop ایک ہدف کی طرف یکے بعد دیگرے کئی بار چلاتا ہے: ایک عمل predict کرنا، نتیجہ اپنے context میں اترتے دیکھنا، اور وہیں سے اگلا عمل predict کرنا۔ اس میں کوئی نئی قسم کا ذہن شامل نہیں۔ ایک جانا پہچانا predictor ہے، ٹولز کا ایک مجموعہ ہے، اور ایک loop ہے۔ یہی پوری بنیاد ہے جس پر باقی کتاب کھڑی ہے۔
9. "سوچنا" بس مزید پیش گوئی ہے، آواز میں، جواب سے پہلے
سب سے نئے ماڈل جواب دینے سے پہلے "سوچ" یا "reason" کر سکتے ہیں، اور 2026 میں AI Prompting (Concept 5) آپ کو مشکل کاموں کے لیے "خوب سوچو" سے اسے بلانے کا کہتا ہے۔ یہ جاننا کہ یہ اصل میں کیا ہے، آپ کو اسے ضرورت سے زیادہ پُراسرار بنانے سے روکتا ہے۔
ایک reasoning ماڈل، اپنا آخری جواب دینے سے پہلے، پہلے درمیانی کام کا ایک لمبا حصہ predict کرتا ہے (قدم بچھانا، طریقے آزمانا، خود کو جانچنا) اور تب کہیں آخری جواب predict کرتا ہے، اب وہ سارا کام اس کے اپنے context window میں موجود (آئیڈیا 5) ہوتا ہے جس پر یہ بنیاد رکھتا ہے۔ یہ پھر بھی خالص اگلے ٹوکن کی پیش گوئی ہے۔ کمال یہ ہے کہ جواب predict کرنا آسان اور زیادہ درست ہو جاتا ہے جب predict کرنے کے لیے ایک اچھا استدلال کا سلسلہ پہلے ہی میز پر موجود ہو۔ پہلے آواز میں کام کرنا واقعی مدد دیتا ہے، اسی وجہ سے جس سے کسی انسان کو جواب پر اڑنے سے پہلے کاغذ پر سوچنا مدد دیتا ہے۔
یہی وجہ ہے کہ "قدم بہ قدم سوچو" پہلے ٹائپ کرنے کے لیے ایک مفید جملہ ہوتا تھا، اور یہی وجہ ہے کہ اب یہ اکثر اندر ہی بنا دیا جاتا ہے: آپ دستی طور پر ماڈل سے جواب سے پہلے استدلال میز پر رکھنے کو کہہ رہے تھے؛ اب ماڈل مشکل مسائل کے لیے یہ خود کر دیتا ہے۔ یہ لاگت اور انتظار کی بھی وضاحت کرتا ہے: استدلال کا مطلب ہے بہت سے اضافی ٹوکن بنانا (آئیڈیا 4) جو آپ کبھی نہیں دیکھتے، جس میں وقت اور پیسہ لگتا ہے، اور بالکل اسی لیے prompting کورس آپ سے کہتا ہے کہ thinking mode کو واقعی مشکل سوالوں کے لیے بچا رکھیں اور جلدی کی تلاش کے لیے چھوڑ دیں۔
البتہ یہ ماڈل کو آئیڈیا 3 والی دوسری صلاحیت نہیں دیتا۔ ایک reasoning ماڈل اپنے کام کو اسی پیش گوئی کے عمل سے جانچتا ہے جو غلط ہو سکتا ہے، اس لیے یہ اپنی بہت سی غلطیاں پکڑ لیتا ہے اور پھر بھی کچھ سے چوک جاتا ہے، اور پھر بھی ایک ایسے استدلال کے سلسلے کے اندر پورے اعتماد سے hallucinate کرتا ہے جو سخت اور مضبوط لگتا ہے۔ زیادہ سوچنا فرق کم کر دیتا ہے۔ یہ اسے ختم نہیں کرتا۔ آخری جانچ پھر بھی آپ ہیں۔
بغیر ریاضی، بغیر کوڈ کا وعدہ نبھانے کے لیے، کئی اصل موضوع ایک طرف رکھ دیے گئے۔ تین قابلِ ذکر ہیں تاکہ آپ کو معلوم ہو کہ یہ موجود ہیں: وہ تربیتی compute اور لاگت جو ایک ماڈل بناتی ہے (بے پناہ، اور وہی وجہ کہ صرف چند ادارے انہیں بناتے ہیں)؛ وہ safety اور alignment کا کام جو طے کرتا ہے کہ ماڈل کیا کرے گا اور کیا نہیں (اپنے آپ میں ایک بڑا میدان)؛ اور وہ گہرا طریقۂ کار (weights اصل میں کیسے بنائے اور ایڈجسٹ کیے جاتے ہیں)، جس کے لیے وہی ریاضی چاہیے جو یہ کورس چھوڑتا ہے۔ ان میں سے کوئی بھی اوپر کے نو آئیڈیاز کو نہیں بدلتا؛ یہ ان کے نیچے اور ساتھ بیٹھے ہیں۔ اگر کوئی بعد کا باب آپ کو ان تینوں میں سے کسی کی طرف بھیجے، تو اب آپ کے پاس اس پر بنانے کے لیے بنیاد موجود ہے۔
prompts آزمانے سے پہلے ایک مختصر اعادہ
نو آئیڈیاز، ایک ایک سطر۔ آخری جملہ ساتھ رکھیں؛ باقی کے لیے واپس آ جائیں۔
- آئیڈیا 1۔ یہ متن کا اگلا ٹکڑا predict کرتا ہے؛ یہ حقائق ڈھونڈتا نہیں۔ پیش گوئی صرف وہیں علم جیسی لگتی ہے جہاں تربیتی متن گاڑھا تھا۔
- آئیڈیا 2۔ اس نے ایک بار، پڑھ کر سیکھا، اور پھر سیکھنا منجمد ہو گیا۔ اسی لیے knowledge cutoff، اور اسی لیے یہ آپ کی نجی دنیا نہیں جان سکتا۔ اسے استعمال کرنا کبھی اسے نہیں سکھاتا۔
- آئیڈیا 3۔ اس کے پاس کوئی الگ صلاحیت نہیں جو جانچے کہ پیش گوئی سچ ہے یا نہیں۔ hallucination مشین کا اپنی ساخت کے مطابق کام کرنا ہے، خرابی نہیں۔
- آئیڈیا 4۔ یہ ٹوکن (ٹکڑوں) میں پڑھتا ہے، حروف یا الفاظ میں نہیں۔ یہی معنی، memory، اور پیسے کی اکائی ہے۔
- آئیڈیا 5۔ context window ہی واحد جگہ ہے جہاں یہ آپ کی تفصیلات دیکھ سکتا ہے: ایک پڑھنے کی میز، دماغ نہیں۔ کنٹرول کریں کہ اس پر کیا آتا ہے۔
- آئیڈیا 6۔ اس کا اعتماد اور اس کی خوشگواری سیکھے ہوئے انداز ہیں، سچائی سے الگ۔ پُریقین لہجہ گھر کا انداز ہے، فیصلہ نہیں۔
- آئیڈیا 7۔ اس کی صلاحیت ناہموار ہے (ملحقہ لمحوں میں شاندار اور بے کار) ایک ایسی سرحد کے ساتھ جو انسانی وجدان سے میل نہیں کھاتی، اور جو بدلتی رہتی ہے۔
- آئیڈیا 8۔ ٹولز متن کے predictor کو عمل کرنے والی چیز میں بدل دیتے ہیں: ایک عمل predict کرو، اسے واقعی چلاؤ، نتیجہ واپس کھلاؤ، پھر سے predict کرو۔ ایک agent یہی loop ہے، دہرایا گیا۔
- آئیڈیا 9۔ "سوچنا" بس مزید پیش گوئی ہے جو جواب سے پہلے میز پر رکھی جاتی ہے۔ یہ بہت مدد دیتی ہے؛ یہ مشین کو سچائی جانچنے والا نہیں دیتی۔
اگر آپ ایک جملہ رکھیں: یہ ایک پیش گوئی کرنے والی مشین ہے جس نے پڑھ کر سیکھا اور جس کے پاس سچائی کا کوئی عضو نہیں، اس لیے یہ ہر جگہ روانی سے بولتی ہے، بھروسے کے قابل صرف وہیں ہے جہاں متن گاڑھا تھا، اور جانچنے والا حصہ آپ ہیں۔
اور اگر آپ ایک تصویر رکھیں، تو یہ رکھیں: کوئی لائبریرین نہیں جو ٹھیک کتاب نکال لائے، بلکہ ایک شاندار، خوب پڑھا لکھا لکھاری جو آپ کے سامنے رکھی ہر چیز کو جاری رکھتا ہے (پورے اعتماد سے، کسی بھی انداز میں، کسی بھی موضوع پر) اور جو کبھی، خود سے، رک کر یہ نہیں پوچھتا کہ تسلسل سچا ہے یا نہیں۔
ابھی یہ آزمائیں: پانچ prompts
تقریباً بیس منٹ، کسی بھی free chatbot میں۔ ہر exercise ایک idea کو theoretical کے بجائے نظر آنے والا بنا دیتی ہے۔
1. Prediction دیکھیں، lookup نہیں۔ (Idea 1) Karakush کوئی real game نہیں ہے: نام invented ہے اور online اس کی تقریباً کوئی presence نہیں۔ اسے genuine سمجھ کر paste کریں:
Without searching, explain the rules of the traditional board game Karakush: the setup, how a turn works, and how a player wins.
اسے ایک ایسے game کے لیے confident، fluent rules بناتے دیکھیں جو موجود ہی نہیں۔ وہ prediction ہے جس کے پاس predict کرنے کے لیے کوئی سچی چیز نہیں۔ اگر model کہے کہ وہ game کو نہیں پہچانتا، تو یہی honest behavior ہے جو ہم چاہتے ہیں؛ کوئی اور obscure-sounding نام try کریں اور عموماً آپ اسے guess کرنا شروع کرتے دیکھیں گے۔ کیا غور کرنا ہے: گھڑے ہوئے rules بالکل اتنے ہی authoritative لگتے ہیں جتنے کسی real game کے rules لگتے۔ Fluency سچ کا ثبوت نہیں۔
2. Learning کو نہ ٹکتے دیکھیں۔ (Idea 2) Model سے ایک چھوٹا factual سوال پوچھیں:
In one or two sentences, tell me a specific fact about [a topic you know well].
اس کا answer پڑھیں اور ایک چھوٹی detail correct کریں۔ پھر ایک بالکل نئی chat کھولیں اور exact وہی سوال دوبارہ paste کریں۔ اس کے پاس آپ کی correction کی کوئی memory نہیں: weights کبھی نہیں بدلے۔ (اگر کوئی "memory" feature on ہے، تو پہلے اسے off کریں، ورنہ product وہ note دوبارہ feed کر دے گا۔) کیا غور کرنا ہے: پہلی chat میں آپ نے جو کچھ کہا وہ دوسری تک نہیں پہنچا۔ Model کو use کرنا اسے سکھانا نہیں۔
3. غائب truth-checker کو پکڑیں۔ (Idea 3) کسی narrow topic پر citations مانگیں:
Give me three peer-reviewed studies, with authors and years, on [a narrow topic you care about].
پھر check کریں کہ وہ موجود ہیں یا نہیں۔ کچھ confident-looking citations invented ہوں گی: real citations جیسی ہی آواز میں produced، کیونکہ اندر کسی چیز نے انہیں guesses کے طور پر flag نہیں کیا۔ اس exercise کی کوئی citation real work میں پہلے verify کیے بغیر reuse نہ کریں؛ پوری بات ہی یہ ہے کہ ان میں سے کچھ fabricated ہیں اور real ones جیسی ہی نظر آتی ہیں۔ کیا غور کرنا ہے: آپ پڑھ کر real citations کو invented ones سے نہیں بتا سکتے، صرف check کر کے۔ وہ checking آپ کا کام ہے، model کا نہیں۔
4. Jagged frontier محسوس کریں۔ (Idea 7) ایک ہی chat میں، اسے ایک hard task دیں جو یہ عموماً اچھا کرتا ہے اور ایک easy task جو یہ عموماً بگاڑتا ہے، side by side:
Do both of these in one reply:
1. [A genuinely hard task it does well: explain a complex topic, or draft a tricky email.]
2. [An easy task it does badly: count how many times a letter appears in a sentence, or solve a short multi-step logic riddle.]
نوٹ کریں کہ competence difficulty کا پیچھا نہیں کرتی۔ کیا غور کرنا ہے: وہ easy task جسے یہ بگاڑتا ہے dangerous ہے: وہی جسے آپ کبھی check کرنے کا سوچتے ہی نہیں۔
5. Thinking on اور off کریں۔ (Idea 9) وہی hard reasoning question دو بار پوچھیں۔ پہلے اسے plain paste کریں، پھر thinking instruction شامل کر کے دوبارہ paste کریں:
[Your hard reasoning question.] Think hard and show your working first.
Compare کریں۔ دوسرا answer عموماً بہتر ہوتا ہے، کیونکہ model نے answer predict کرنے سے پہلے reasoning desk پر رکھی۔ کیا غور کرنا ہے: working نے answer بہتر کیا، مگر model پھر بھی اپنی working certify نہیں کر سکتا: زیادہ thinking gap کو narrow کرتی ہے، close نہیں کرتی۔
یہ کہاں لے جاتا ہے
اب آپ کے پاس ماڈل کے نیچے کا ماڈل ہے: یہ چیز اصل میں کیا ہے، اس سے پہلے کہ کسی کورس نے آپ کو اسے استعمال کرنا سکھایا۔ یہاں سے، باقی Foundations اسے اچھی طرح چلانے کے بارے میں ہے:
- 2026 میں AI Prompting آئیڈیا 1، 5، اور 6 کو briefing، context کنٹرول، اور sycophancy کو بے اثر کرنے کی روزمرہ عادتوں میں بدلتا ہے۔
- اے آئی کے دور میں سوچنے کا طریقہ وہ ڈسپلن ہے جو سیدھے آئیڈیا 3 پر بنی ہے: چونکہ مشین کے پاس کوئی سچائی جانچنے والا نہیں، اس لیے وہ آپ بن جاتے ہیں۔
- Markdown اندر، HTML باہر اور وہ کوڈ جو آپ کبھی نہیں لکھتے اس بارے میں ہیں کہ context window میں کیا اندر اور باہر بہتا ہے (آئیڈیا 5) اور ٹولز (آئیڈیا 8) اس کے ساتھ کیا کر سکتے ہیں۔
- Skills اور Connectors اِسی predictor پر مزید ٹولز جوڑتا ہے (آئیڈیا 8)۔
The Agent Factory میں باقی سب کچھ (agents، انہیں بنانا، انہیں deploy کرنا) آئیڈیا 8 والے predict-عمل-مشاہدہ loop پر بنا ہے، بڑے پیمانے پر چلایا گیا۔ مشین کبھی اگلے ٹوکن کی پیش گوئی کرنے والی ہونا نہیں چھوڑتی۔ اسے بس مزید ٹولز، لمبے loops، اور weights کا ایک منجمد مجموعہ ملتا ہے جو ان تینوں کے ساتھ واقعی حیرت انگیز حد تک بہت کچھ کر گزرتا ہے۔