اپنے AI کو قابلِ تلاش سیاق دیں: pgvector کے ساتھ Postgres پر RAG کا ایک فوری کورس
15 تصورات · حقیقی استعمال کا 80٪ · آپ کے ایجنٹ کا بنایا ہوا، ہاتھ سے نہیں
تصور کریں کہ آپ اپنے کمپیوٹر کو یہ کہہ سکیں: "دستاویزات کا یہ فولڈر لو، ایک ایسا ڈیٹابیس کھڑا کرو جو اِن کے معنی سمجھتا ہو، اور مجھے ایسی تلاش بنا دو جہاں 'وہ شہر جو کبھی نہیں سوتا' مانگنے پر نیویارک کے بارے میں اقتباسات واپس آئیں، حتیٰ کہ وہ بھی جو کبھی اس کا نام تک نہیں لیتے۔" اور وہ واقعی یہ کر دکھائے۔
تین الفاظ، اگر یہ آپ کے لیے نئے ہوں۔ ایک ڈیٹابیس ڈیٹا کے لیے ایک گودام ہے: وہ عمارت جہاں کوئی کاروبار اپنا سامان رکھتا ہے، سوائے اس کے کہ یہاں سامان معلومات ہے۔ SQL وہ زبان ہے جو آپ اس گودام سے بولتے ہیں؛ ڈیٹا کو محفوظ کرنے، ڈھونڈنے، یا بدلنے کی ہر درخواست اسی میں ایک جملہ ہوتی ہے۔ Postgres (اس کورس کے عنوان میں موجود ڈیٹابیس) دنیا میں سب سے زیادہ استعمال ہونے والوں میں سے ایک ہے۔ اور ایک عام گودام صرف اپنے بالکل ٹھیک لیبل سے ہی کوئی ڈبہ ڈھونڈ سکتا ہے؛ جو آپ بنانے جا رہے ہیں وہ چیزوں کو اس بنیاد پر ڈھونڈتا ہے کہ اُن کا مطلب کیا ہے۔
معنی کی بنیاد پر تلاش کا یہی نظام اس کورس کا موضوع ہے، اور یہاں اصل پیچ ہے: آپ SQL ہاتھ سے نہیں لکھیں گے؛ Claude Code یا OpenCode اس کا سارا حصہ بناتا ہے۔ آپ کا کام Postgres اور pgvector (وہ ایڈ آن جو اسے یہ طاقت دیتا ہے) کے بارے میں اتنا جاننا ہے کہ آپ واضح ہدایات دے سکیں اور فیصلہ کر سکیں کہ ایجنٹ نے ٹھیک کیا یا نہیں۔ یہ دوسرا حصہ ہی پوری مہارت ہے، اور آخر تک آپ جان جائیں گے کہ کون سے نوب اہم ہیں اور کن کو چھوڑ دینا بہتر ہے۔
ایک خیال اس پورے کورس کو واضح کر دیتا ہے۔ ایک AI ماڈل ایک وقت میں صرف اتنی ہی چیز پر دھیان دے سکتا ہے: جو کچھ بھی وہ آپ کو جواب دینے کے لیے پڑھتا ہے اسے اس کے context window (سیاق کی کھڑکی) میں سمانا پڑتا ہے، اور اس میں جتنا زیادہ غیر متعلقہ مواد ہوگا، جواب اتنا ہی بدتر ہوگا۔ تو کسی بھی AI نظام میں بنیادی کام یہی ہے کہ صحیح معلومات کو صحیح لمحے پر ماڈل کے سامنے رکھا جائے، اور باقی سب کچھ باہر رکھا جائے۔ آپ یہ کام اپنے کوڈنگ ایجنٹ کے لیے پہلے ہی کرتے ہیں: ایک rules فائل، صرف وہی فائلیں جو کام کے لیے درکار ہوں۔ ایک ویکٹر ڈیٹابیس یہی کام آپ کی ایپ کے صارفین کے لیے کرتا ہے: دس لاکھ محفوظ شدہ قطاروں میں سے یہ وہ چند نکالتا ہے جو سوال کے معنی سے ملتی ہیں اور صرف وہی ماڈل کے حوالے کرتا ہے۔ اس چال کا ایک نام ہے، RAG، یعنی Retrieval-Augmented Generation، اور یہ ایک تہہ نیچے سیاق کا انتظام ہی ہے: جو آپ اپنے کوڈنگ ایجنٹ کے لیے ہاتھ سے کرتے ہیں، وہی آپ کی ایپ اپنے صارفین کے لیے خودکار طور پر کرتی ہے۔ یہاں ہر تصور اسی بات سے جا کر جڑتا ہے۔

یہ کورس فرض کرتا ہے کہ آپ نے Agentic Coding فوری کورس کر لیا ہے؛ آپ کو Claude Code یا OpenCode چلانے، plan mode استعمال کرنے، اور سیاق سنبھالنے میں آرام ہونا چاہیے۔ یہ 2026 میں AI پرامپٹنگ پر بھی تعمیر کرتا ہے، یعنی AI سے بالکل وہی مانگنے کا ہنر جو آپ چاہتے ہیں۔ اگر "embedding" اور "vector" آپ کے لیے بالکل نئے ہیں تو فکر نہ کریں؛ تصور 2 انہیں صفر سے سمجھاتا ہے۔
📚 تدریسی مدد
پوری presentation دیکھیں — AI Searchable Context
دو ٹولز، ایک ہی نظم
ایجنٹ گاڑی چلاتا ہے؛ آپ کا Postgres ڈیٹابیس وہ گاڑی ہے جسے یہ چلاتا ہے۔ ڈیٹابیس Neon پر رہتا ہے، ایک کلاؤڈ سروس جو آپ کے لیے Postgres چلاتی ہے، کچھ انسٹال کرنے کی ضرورت نہیں، کوئی مشین سنبھالنے کی ضرورت نہیں (serverless کا بس یہی مطلب ہے: جب آپ استعمال کریں تو جاگ جاتا ہے، جب نہ کریں تو سو جاتا ہے)۔ ایجنٹ Neon کو Neon MCP سرور کے ذریعے چلاتا ہے: یہ پروجیکٹ بناتا ہے، ایک برانچ کھولتا ہے، SQL چلاتا ہے، اور commit کرنے سے پہلے اس برانچ پر ہر تبدیلی کا پیش منظر دکھاتا ہے۔ آپ خود کبھی Neon کنسول میں ادھر ادھر کلک نہیں کرتے اور نہ خود psql کھولتے ہیں۔ اور دونوں ٹولز میں نظم بالکل ایک جیسا ہے: Claude Code اور OpenCode یہاں برابر کے ہیں، اور جہاں کوئی کمانڈ واقعی مختلف ہوتی ہے، وہ فرق میں اسی جگہ بتا دیتا ہوں۔
یہ کورس کیا کچھ احاطہ کرتا ہے
| حصہ | موضوع | آپ کیا سیکھتے ہیں |
|---|---|---|
| 1 | بنیادیں | بطورِ AI انجینئر آپ کا کام، ویکٹرز بالکل صفر سے، معنی کی بنیاد پر تلاش کے لیے Postgres کو کیا چاہیے، اور آپ کا ایجنٹ Neon سے جڑا ہوا |
| 2 | آپ کا پہلا RAG | اپنا ڈیٹا لوڈ کریں، اسے ٹکڑوں میں بانٹیں، ہر ٹکڑے کو ایک معنی-ویکٹر میں بدلیں، معنی کی بنیاد پر تلاش کریں، اور ایک LLM سے اس میں سے جواب دلوائیں |
| 3 | تلاش کو تیز بنانا | کب کسی سُست ہوتی تلاش کو انڈیکس کی ضرورت ہوتی ہے، کون سا چنیں، اور رفتار بمقابلہ درستگی کا وہ واحد نوب جو اہم ہے |
| 4 | تلاش کو عمدہ بنانا | ناپیں کہ جواب واقعی درست ہیں یا نہیں، فلٹرز شامل کریں، معنی کو عین کی ورڈز کے ساتھ ملائیں، ہر گاہک کا ڈیٹا الگ دیوار میں بند کریں، اور اپنے ڈیٹابیس سے سادہ انگریزی میں سوال کریں |
| 5 | مکمل عملی مثال | ایک مکمل کام، خالی ڈیٹابیس سے چلتے ہوئے RAG تک، دونوں ٹولز میں چلایا گیا |
| 6 | اسے ایک ٹول کے طور پر شِپ کریں | اپنے RAG کو ایک MCP سرور میں لپیٹیں تاکہ کوئی بھی ایجنٹ، Claude Code، OpenCode، یا کوئی Digital FTE جو آپ بعد میں بنائیں گے، اسے کال کر سکے |
| 7 | یہ کہاں چلتا ہے | اپنے ڈیٹابیس کی فوری کاپیوں پر تبدیلیاں آزمائیں، ڈیٹا بدلنے کے ساتھ ساتھ ویکٹرز کو تازہ رکھیں، اور production میں کیا مختلف ہوتا ہے |
| 8 | اسے ایک ایجنٹ کے حوالے کریں | اپنے RAG کو ایک ایجنٹ (OpenAI Agents SDK) میں جوڑیں، یعنی Build AI Agents کورس کی طرف پل |
یہ پورا system ایک صفحے پر ہے: وہ map جس میں ہر concept بیٹھنے کے ساتھ آپ grow کریں گے:
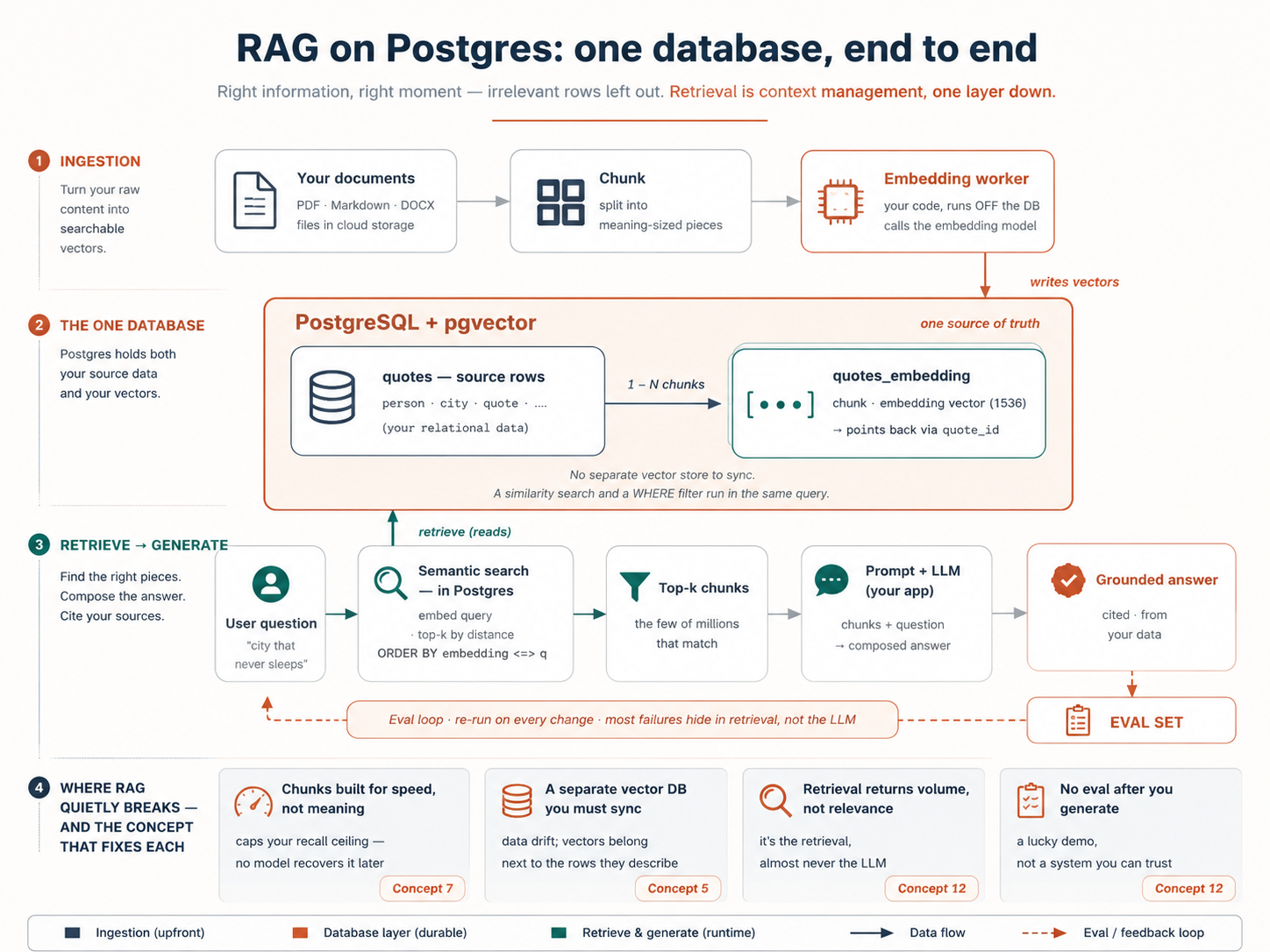 |
|
آخر تک آپ کے پاس ایک چلتا ہوا RAG پروجیکٹ ہوگا: آپ کا دستاویزات والا docs/ فولڈر ایک Neon ڈیٹابیس میں لوڈ ہوا، pgvector آن کیا ہوا، ایک چھوٹا ورکر جو دستاویزات بدلنے کے ساتھ معنی-ویکٹرز کو تازہ رکھتا ہے، ایک ایسی تلاش جو معنی سے ڈھونڈتی ہے، ایک answer_question() فنکشن جو آپ کے اپنے ڈیٹا سے جواب دیتا ہے، اور ایک رپورٹ جو دکھاتی ہے کہ پانچ آزمائشی سوالوں کے جواب درست آتے ہیں یا نہیں۔ اور آپ آسان 80٪ پر نہیں رکیں گے: آپ نے ایک HNSW انڈیکس کو سُست سے فوری تک بینچ مارک کیا ہوگا، تلاش کو زمرے کے حساب سے فلٹر کیا ہوگا، ہائبرڈ سرچ سے کی ورڈ اور معنی کو ملایا ہوگا، اور Row-Level Security سے ایک ٹیننٹ کو دوسرے سے الگ دیوار میں بند کیا ہوگا، ہر ایک حقیقت میں چلایا گیا، آپ کے eval سیٹ کے مقابل ناپا گیا۔ اختیاری طور پر، ایک MCP سرور پوری چیز کسی بھی ایجنٹ کے حوالے کر دیتا ہے۔
اسے کیسے پڑھیں۔ حصہ 1 تا 2 (تصورات 1 تا 9) اور حصہ 5 کی عملی مثال مل کر مکمل نظام ہیں، شروع سے آخر تک، تقریباً 90 منٹ کا مطالعہ، اور build کے لیے چند گھنٹے کی بورڈ پر۔ حصہ 3 تا 4 (تصورات 10 تا 15) ٹیوننگ کی تہہ ہیں، یعنی وہ چیز جو تلاش کو تیز (حصہ 3) اور عمدہ (حصہ 4) بناتی ہے۔ انہیں "کیوں" کے لیے پڑھیں، پھر ان میں سے ہر ایک کو چلائیں: حصہ 5 ایک عملی لُوپ پر ختم ہوتا ہے (مرحلے 5 تا 8) جہاں آپ ایک انڈیکس بینچ مارک، ایک فلٹر، ہائبرڈ سرچ، اور ٹیننٹ علیحدگی حقیقت میں بناتے ہیں، اسی ڈیٹا پر جو آپ نے ابھی لوڈ کیا۔ یہ گہرائی کوئی اختیاری پڑھائی نہیں جس پر آپ شاید بعد میں لوٹیں، یہ build کا دوسرا حصہ ہے، اور ہر کوئی اسے کرتا ہے۔ پہلے بنانا اور "کیوں" بعد میں پڑھنا چاہتے ہیں؟ سیدھے حصہ 5 پر چلے جائیں۔
اپنا ماحول سیٹ اپ کریں (ایک بار)
اس کورس میں آپ جو کچھ بناتے ہیں وہ سب ایک چھوٹے فولڈر کے اندر ہوتا ہے: کورس بیس۔ یہ پہلے سے جُڑا ہوا آتا ہے، آپ کا ایجنٹ پہلے سے جانتا ہے کہ Neon (وہ کلاؤڈ ڈیٹابیس جو یہ کورس استعمال کرتا ہے) اور Context7 (تازہ دستاویزات کی تلاش، تاکہ ایجنٹ اندازے لگانے کے بجائے موجودہ دستاویزات دیکھے) تک کیسے پہنچنا ہے، اور یہ ایک مختصر rules فائل، AGENTS.md، کے ساتھ آتا ہے جس میں پروجیکٹ کی مستقل ہدایات ہوتی ہیں۔ آپ کا ایجنٹ ہر بار شروع ہوتے وقت یہ فائل خودکار طور پر پڑھتا ہے، اسی لیے اس کورس میں آپ کے پرامپٹ مختصر رہ سکتے ہیں۔
اسے ایک بار ڈاؤن لوڈ کریں؛ وہی فولڈر پورے کورس کے لیے کام آتا ہے، حصہ 5 کی عملی مثال اور حصہ 6 کا MCP سرور دونوں کے لیے۔ اسے ابھی سیٹ اپ کریں یا بعد میں، پڑھائی کے لیے خود کچھ بھی انسٹال کرنے کی ضرورت نہیں۔
postgres-ai-base.zip ڈاؤن لوڈ کریں
اسے unzip کریں، پھر فولڈر کے اندر اپنا ایجنٹ کھولیں:
cd postgres-ai
claude
cd postgres-ai
opencode
ایک شرط: ایک قابل ماڈل۔ اگر ایجنٹ کا پہلا منصوبہ کبھی مخصوص ہونے کے بجائے مبہم لگے، تو آگے بڑھنے سے پہلے کسی مضبوط ماڈل (Claude Sonnet یا Opus، GPT-5، یا اسی جیسا) پر سوئچ کریں۔
بیس کو تیار کریں (تقریباً 3 منٹ)۔ ایجنٹ اپنا سیٹ اپ خود کرتا ہے، آپ ایک پرامپٹ پیسٹ کرتے ہیں اور جو یہ پوچھے اس کا جواب دیتے ہیں۔ یہ پیسٹ کریں:
اس بیس کو تیار کریں: یہ جو skills درج کرتا ہے انہیں install کریں، میرا
.envسیٹ اپ کریں، اور مجھے بالکل ٹھیک ٹھیک بتائیں کہ Neon اور Context7 کے MCP سرورز کو آن لائن لانے کے لیے آپ کو مجھ سے کیا چاہیے۔
اس کا خیال رکھیں: ایجنٹ دو skills (neon-postgres اور mcp-builder) install کرتا ہے، .env بناتا ہے، پھر آپ سے دو چیزیں مانگتا ہے: ایک API key (وہی key embeddings اور جوابات دونوں کے لیے کافی ہے)، اور Neon کو اجازت دینے کے لیے براؤزر میں ایک کلک۔ Key مفت ہے۔ یہ کورس Google Gemini کے free tier پر چلتا ہے (credit card نہیں چاہیے)، اس لیے ایجنٹ آپ کو aistudio.google.com/apikey پر بھیجتا ہے؛ Google سے sign in کریں، تقریباً ایک منٹ میں key بنائیں، اسے واپس paste کریں، اور ایجنٹ اسی وقت test call سے ثابت کر دیتا ہے کہ یہ کام کر رہی ہے۔ (اگر آپ کے پاس پہلے سے OpenAI key ہے اور آپ اسے ترجیح دیتے ہیں، تو بس کہہ دیں؛ ایجنٹ وہی استعمال کر لے گا، کورس میں کچھ اور نہیں بدلتا۔) Neon بھی مفت ہے؛ ابھی اکاؤنٹ نہیں؟ اجازت والی اسکرین پر ہی ایک بنا لیں۔ اگر براؤزر کی کوئی ونڈو خود نہ کھلے، تو ایجنٹ میں /mcp ٹائپ کریں، Neon چنیں، اور یہ آپ کے لیے سائن اِن شروع کر دے گا۔
تب مکمل جب: skills install ہو جائیں، .env میں آپ کی key موجود ہو اور ایجنٹ quick test call سے اس کی تصدیق کر چکا ہو، Neon کی اجازت مل جائے، اور آپ ایجنٹ کو دوبارہ شروع کر چکے ہوں (باہر نکلیں، دوبارہ کھولیں) تاکہ نئی skills اور MCP سرورز لوڈ ہو جائیں (ان میں سے کوئی بھی سیشن کے درمیان لوڈ نہیں ہوتا)۔
حصہ 1: بنیادیں
1. آپ اصل میں کیا بنا رہے ہیں (اور اس میں آپ کا کام)
سب سے عام غلط فہمی: AI ایپلیکیشنز بنانے کے لیے ایک machine-learning ٹیم درکار ہوتی ہے۔ ایسا نہیں ہے۔ ماڈلز پہلے سے بنے بنائے دستیاب ہیں۔ بنیادی ڈھانچہ ایک ڈیٹابیس ہے جو شاید آپ پہلے ہی چلاتے ہوں۔ جو بچتا ہے وہ ایک AI انجینئر کا کام ہے، یعنی وہ شخص جو پروڈکٹس بنانے کے لیے AI کو استعمال کرتا ہے، نہ کہ وہ محقق جو ماڈلز کو train کرتا ہے۔ یہ پوری کتاب آپ کو اسی کردار کے لیے تیار کر رہی ہے، اور یہ خاصا قابلِ حصول ہے۔
دوسری غلط فہمی وہ ہے جسے دور کرنے کے لیے یہ کورس موجود ہے: کہ آپ کو سارا SQL ہاتھ سے لکھنا پڑے گا۔ آپ کو نہیں لکھنا پڑتا۔ آپ ایک ایسے ایجنٹ کو ہدایت دیتے ہیں جو pgvector کے operators اور embedding ورک فلو کو پہلے ہی اچھی طرح جانتا ہے۔ آپ کی قدر اوپر کی طرف منتقل ہو جاتی ہے، یعنی CREATE INDEX ٹائپ کرنے سے بڑھ کر یہ فیصلہ کرنے کی طرف کہ کون سا انڈیکس، اور کوئری لکھنے سے بڑھ کر یہ پرکھنے کی طرف کہ نتائج کسی کام کے ہیں یا نہیں۔
اس سے "اس مواد کو جاننے" کا مطلب بدل جاتا ہے۔ آپ syntax یاد نہیں کر رہے؛ آپ اتنا ذہنی خاکہ بنا رہے ہیں کہ:
- ایجنٹ کو ایک عین مطابق ہدایت دے سکیں ("embedding کو اسی ٹیبل میں رکھو، cosine distance استعمال کرو، اسے HNSW سے index کرو")،
- جو اس نے بنایا اسے واپس پڑھ سکیں اور پکڑ سکیں کہ کب وہ غلط ہے،
- اور وہ آرکیٹیکچرل انتخاب خود کریں جو ایجنٹ کو آپ کے لیے نہیں کرنے چاہئیں۔
یہ وہی plan-then-execute عادت ہے جو کوڈنگ کورس سے آئی ہے، اور یہاں اس کی اہمیت اور بھی زیادہ ہے، کیونکہ ایجنٹ ابھی ایسے فیصلے کرنے والا ہے (کون سا extension، کون سا انڈیکس، کون سا distance function) جنہیں ڈیٹا آ جانے کے بعد واپس پلٹنا مہنگا پڑتا ہے۔
سوچ کی تبدیلی: یہ پوچھنا چھوڑ دیں کہ "semantic search کے لیے SQL کیا ہے؟" یہ کہنا شروع کریں کہ "اس ٹیبل پر میرے لیے semantic search بناؤ؛ یہ رہی میری شرائط؛ پہلے مجھے منصوبہ دکھاؤ۔"
اس کا ایک بڑا نام ہے۔ کتاب کی اصطلاح میں، جو ڈیٹابیس آپ بنانے جا رہے ہیں وہ ایجنٹ کے دور کا سسٹم آف ریکارڈ ہے، یعنی وہ بااختیار بنیادی سچائی جس سے آپ کے ایجنٹس پڑھتے ہیں، جس میں لکھتے ہیں، اور جس کے مقابل تصدیق کرتے ہیں۔ Jensen Huang کی دلیل یہ ہے کہ ایجنٹس سسٹم آف ریکارڈ کی ضرورت ختم نہیں کرتے؛ بلکہ یہ اس پر منحصر ہوتے ہیں۔ بااختیار بنیادی سچائی کے بغیر ایجنٹ hallucinate کرتا ہے؛ اس کے ساتھ، یہ عمل کر گزرتا ہے۔ Postgres پر RAG وہ طریقہ ہے جس سے آپ ایجنٹ کو وہ بنیادی سچائی تھماتے ہیں، اور یہی وجہ ہے کہ اس کورس کا باقی حصہ retrieval کی کیفیت کو وہ چیز سمجھتا ہے جو طے کرتی ہے کہ ایجنٹ پر بھروسہ کیا جا سکتا ہے یا نہیں۔
اسے باقی کورس کے لیے لفظی طور پر لیں: نیچے ہر SQL بلاک اس لیے دکھایا گیا ہے کہ آپ ایجنٹ کے بنائے کو پڑھ اور پرکھ سکیں، اس لیے نہیں کہ آپ اسے ٹائپ کریں۔ اسے پڑھنا جاننا ہی وہ چیز ہے جو آپ کو شِپ ہونے سے پہلے کسی غلط distance function یا غائب فلٹر کو پکڑنے دیتی ہے۔
2. ویکٹرز اور embeddings، ایک منٹ میں
اگر "vector" اور "embedding" نئے ہیں، تو شروع کرنے کے لیے آپ کو جو کچھ چاہیے وہ یہ ہے۔
ایک vector بس اعداد کی ایک فہرست ہے، [0.021, -0.88, 0.14, …]۔ ایک embedding ماڈل مواد کا کوئی ٹکڑا (ایک جملہ، ایک پیراگراف، ایک تصویر) لیتا ہے اور اسے ان میں سے ایک فہرست میں بدل دیتا ہے۔ کمال یہ ہے کہ یہ فہرست مواد کے معنی کو پکڑ لیتی ہے: متن کے دو ٹکڑے جن کے معنی ملتے جلتے ہوں، اعداد کی ایسی فہرستیں پاتے ہیں جو ایک دوسرے کے قریب بیٹھتی ہیں۔ دو جملے جن کا مطلب ایک ہی ہو، "وہ شہر جو کبھی نہیں سوتا" اور "نیویارک کی بے چین گلیاں"، ایک دوسرے کے قریب جا بیٹھتے ہیں حالانکہ ان میں کوئی لفظ سانجھا نہیں۔
ایک vector ڈیٹابیس بس ایک ایسا نظام ہے جو ان فہرستوں کو محفوظ کرتا ہے اور دی گئی فہرست کے قریب ترین فہرستیں تیزی سے ڈھونڈ نکالتا ہے۔ بس اتنا ہی۔ جب کوئی صارف سوال کرتا ہے، آپ کی ایپ اس کے سوال کو ایک vector میں بدلتی ہے، پھر ڈیٹابیس سے پوچھتی ہے: "کون سے محفوظ vectors اس کے سب سے قریب ہیں؟" جو سب سے قریب ہوں وہ معنوی لحاظ سے سب سے زیادہ متعلقہ ہوتے ہیں، اور یہی وہ طریقہ ہے جس سے آپ کی ایپ LLM کو تھمانے کے لیے صحیح سیاق نکالتی ہے۔ (شروع کا خاکہ دیکھیں: یہ آپ کے صارفین کے لیے سیاق کا انتظام ہے۔)
آپ کو یہ سمجھنے کی ضرورت نہیں کہ embedding ماڈل اندر سے کیسے کام کرتا ہے، بالکل اسی طرح جیسے آپ کو یہ سمجھنے کی ضرورت نہیں کہ ایک JPEG تصویر کو کیسے compress کرتا ہے۔ آپ کو بس یہ جاننا ہے کہ یہ موجود ہے، کہ یہ مواد کو معنی-ویکٹرز میں بدلتا ہے، اور یہ کہ قربت کا مطلب مشابہت ہے۔
ایک سیشن کھولیں اور اپنے ایجنٹ سے پوچھیں: "سادہ زبان میں سمجھاؤ کہ embedding کیا ہے، پھر مجھے دو ایسے مختصر جملے دکھاؤ جن کے vectors قریب ہوں گے اور دو جو دور ہوں گے، اور کیوں۔ پھر مزے والا سوال: کیا میرے شہر کا کوئی مشہور گانا یا عرفی نام شہر کے نام کے قریب جا بیٹھے گا، چاہے الفاظ میں وہ کبھی کہا ہی نہ جائے؟" اس کا جواب پڑھنا آپ کی اپنی سمجھ کا اس حصے کو دوبارہ پڑھنے سے کہیں تیز اندازہ دے دیتا ہے۔
3. extensions، اور Neon پر آپ کو کیا ملتا ہے
Postgres ایک vector ڈیٹابیس extensions کے ذریعے بنتا ہے، یعنی وہ ایڈ آنز جو اسے نئی طاقتیں دیتے ہیں بغیر اس کے کہ Postgres جو پہلے ہی اچھا کرتا ہے (transactions، joins، بھروسہ مندی، SQL) اسے قربان کرنا پڑے۔ اس پورے کورس کے لیے سیکھنے کو بس ایک ہی ہے: pgvector۔ یہ تین چیزیں شامل کرتا ہے، embeddings رکھنے کے لیے ایک vector type، انہیں موازنہ کرنے کے لیے distance operators، اور انہیں تیزی سے تلاش کرنے کے لیے indexes، اور Neon پر یہ پہلے سے انسٹال شدہ آتا ہے، اس لیے ایک بیان اسے آن کر دیتا ہے۔ یہی آپ کا مکمل RAG انجن ہے۔ بس اتنا تھامے رکھیں۔ (دو حاشیے جنہیں آپ ایک طرف رکھ سکتے ہیں: ایک دوسرا extension، pgvectorscale، بہت بڑے پیمانے کے لیے موجود ہے، یہ وہ درجہ ہے جس پر آپ ترقی کرتے ہیں، نہ کہ وہاں سے شروع کرتے ہیں۔ اور خود embeddings کوئی extension ہیں ہی نہیں؛ یہ ایک چھوٹے ورکر سے آتے ہیں جسے آپ کا ایجنٹ لکھتا ہے، جو تصور 6 میں بنتا ہے۔)
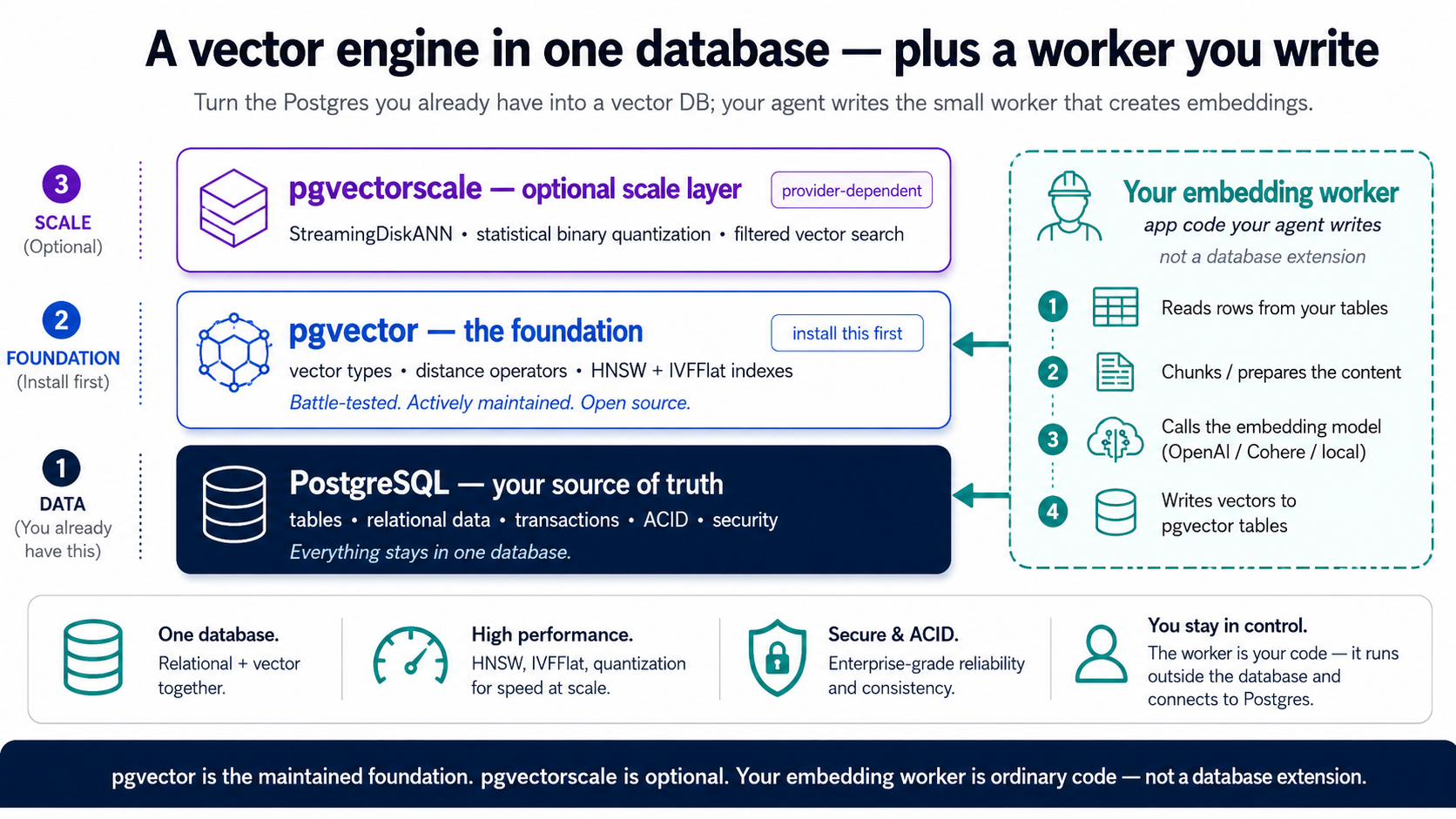
| Extension | یہ کیا شامل کرتا ہے | آپ کو اس کی ضرورت کب ہے |
|---|---|---|
| pgvector | vector ڈیٹا type، distance operators، اور HNSW + IVFFlat انڈیکسز | ہمیشہ، اور Neon پر یہ پہلے سے انسٹال شدہ ہے |
| pgvectorscale | StreamingDiskANN انڈیکس، vector compression، بڑے پیمانے پر اعلیٰ درستگی والی فلٹرڈ سرچ | TigerData پر native؛ Neon پر نہیں، جہاں یہ وہ درجہ ہے جس پر آپ ترقی کرتے ہیں |
اس ٹیبل میں انڈیکس کے نام، HNSW، IVFFlat، StreamingDiskANN، ابھی کے لیے بس لیبل ہیں؛ حصہ 3 سکھاتا ہے کہ یہ کیا کرتے ہیں اور ہر ایک کب استعمال کرنا ہے۔
Neon پر، pgvector ہی آپ کا پورا اسٹیک ہے۔ یہ بِلٹ اِن آتا ہے، اور embedding کے بعد یہ کورس جو کچھ بھی کرتا ہے، یعنی semantic search، indexing، evals، فلٹرز، ہائبرڈ سرچ، RLS، حصہ 6 کا MCP سرور، وہ خالص pgvector ہے۔ embeddings ورکر (تصور 6) سے آتے ہیں، کسی managed extension سے نہیں۔ رہی pgvectorscale کی بات: یہ Neon کے جانچے ہوئے سیٹ میں نہیں، اس لیے اسے وہ host سمجھیں جس پر آپ صرف تب جائیں گے جب آپ HNSW سے آگے بڑھ جائیں، اور pgvector اور ایک ورکر آپ کو پہلے ہی کافی دور تک لے جاتے ہیں۔ پہلے ہی دن سے native اسکیل درجہ چاہتے ہیں؟ وہ TigerData Cloud ہے، پورے دوران وہی ورک فلو، تصور 4 کے آخر میں موجود ایک نوٹ اسے سمیٹتا ہے، اور آپ باقی پورے کورس کو صرف Neon کے طور پر پڑھ سکتے ہیں۔
ایک-ڈیٹابیس والا فائدہ پھر بھی قائم رہتا ہے: آپ کے vectors اُن قطاروں کے ساتھ ہی رہتے ہیں جنہیں وہ بیان کرتے ہیں، اس لیے ایک similarity search اور ایک WHERE price < 2000 AND in_stock فلٹر ایک ہی کوئری میں، ایک ہی سچ کے منبع پر ہوتے ہیں۔ کوئی دوسرا ڈیٹابیس نہیں، کوئی sync pipeline نہیں، کوئی ڈیٹا drift نہیں۔ (اسے تھامے رکھیں، یہی پوری وجہ ہے کہ تصور 13 میں فلٹرڈ سرچ اتنی آسان ہے۔)
pgvector ایک پختہ، وسیع پیمانے پر استعمال ہونے والا Postgres extension ہے، یعنی وہ مستحکم چٹان جس پر یہ پورا کورس کھڑا ہے۔ embedding کے بعد ہر چیز (semantic search، indexing، evals، فلٹرز، ہائبرڈ سرچ، RLS، MCP سرور) خالص pgvector ہے۔
ایک چیز جو pgvector آپ کے لیے نہیں کرتا وہ embeddings کو بنانا ہے، یعنی embedding ماڈل کو کال کرنا اور vectors کو واپس لکھنا۔ یہ کرنے کا صاف، قابلِ انتقال طریقہ ایک چھوٹا ورکر ہے جسے آپ کا ایجنٹ لکھتا ہے: source ٹیبل ← chunk ← API کال کے ذریعے embed ← vectors کو ایک embeddings ٹیبل میں لکھیں ← pgvector سے تلاش کریں۔ اس کام کو ڈیٹابیس کے باہر رکھنا ہی اصل نکتہ ہے، کوئی جگاڑ نہیں، ایک stateful سسٹم آف ریکارڈ کو کسی غیر مستحکم بیرونی API پر منحصر نہیں ہونا چاہیے، اس لیے embedding (اور تصور 9 میں LLM کالز) ورکر اور ایپ کی تہوں میں رہتے ہیں، جہاں وہ ناکام ہو سکتے ہیں، دوبارہ کوشش کر سکتے ہیں، اور آپ کے ڈیٹا کو چھوئے بغیر اسکیل ہو سکتے ہیں، اور پوری چیز صاف ستھرے انداز میں کسی بھی host یا container پر port ہو جاتی ہے۔ (ایک managed سہولت تہہ نے کبھی embedding کو ڈیٹابیس کے اندر پکا دیا تھا، یعنی pgai کا Vectorizer، مگر وہ جوڑ کمزور ثابت ہوا، اور اس کا repository فروری 2026 میں maintainer نے archive کر دیا؛ یہ کورس اس پر منحصر نہیں۔) ورکر چند لائنوں کا ہے جو آپ کا ایجنٹ بناتا ہے اور آپ جائزہ لیتے ہیں۔ پیٹرن سیکھیں؛ یہ کسی بھی ایک package سے زیادہ دیر چلتا ہے۔
4. اپنے ایجنٹ کو Neon سے جوڑیں
ہم اپنا ڈیٹابیس خود انسٹال یا چلاتے نہیں۔ ہم Neon استعمال کرتے ہیں، یعنی serverless Postgres جس میں pgvector پہلے سے بِلٹ اِن ہے، اور ہم ایجنٹ کو اسے Neon MCP سرور کے ذریعے چلانے دیتے ہیں۔ MCP وہی connector طریقہ ہے جو کوڈنگ کورس سے آیا ہے؛ یہاں یہ Claude Code اور OpenCode کو ٹولز کا ایک سیٹ (create_project، create_branch، run_sql، get_database_tables، prepare_database_migration، complete_database_migration) تھما دیتا ہے تاکہ وہ Neon کو مکمل طور پر سادہ زبان میں سنبھال سکیں۔ آپ خود کبھی Neon کنسول یا کوئی psql shell نہیں کھولتے۔ (یہ کورس Neon کو اپنے ڈیفالٹ host کے طور پر استعمال کرتا ہے؛ سب کچھ TigerData Cloud پر بالکل ویسے ہی کام کرتا ہے، اس تصور کے آخر میں "TigerData کو ترجیح دیتے ہیں؟" دیکھیں۔)
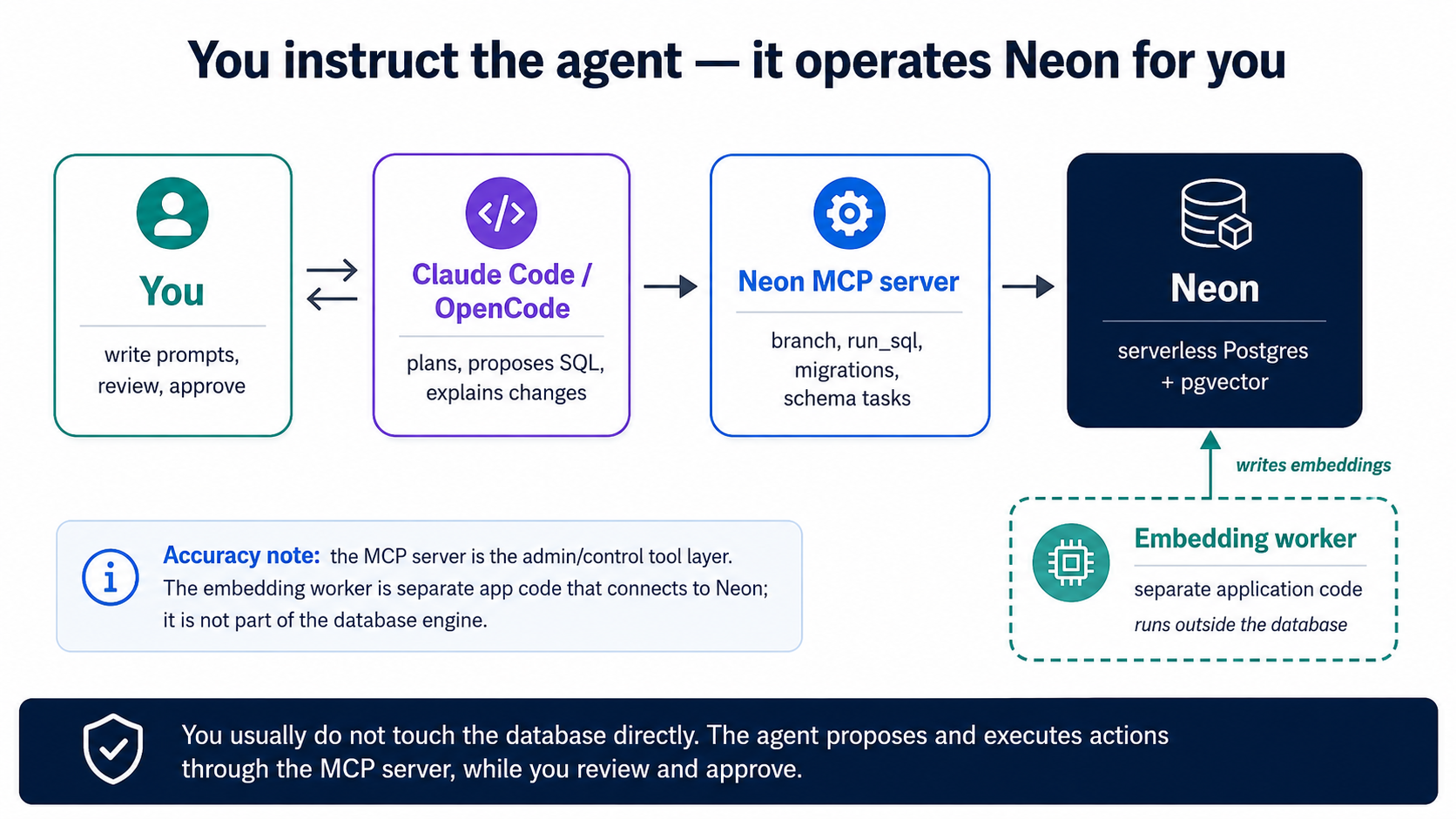
ایک بار کی وائرنگ۔ اگر آپ نے کورس بیس سے شروع کیا، تو Neon MCP سرور پہلے ہی .mcp.json (Claude Code) اور opencode.json (OpenCode) میں ظاہر شدہ ہے، آپ اسے براؤزر میں OAuth کے ذریعے ایک بار اجازت دیتے ہیں، سنبھالنے کے لیے کوئی API key نہیں۔ (اس کے بجائے اسے ہاتھ سے وائر کرنا بھی وہی ایک قدم ہے: اپنے ٹول میں Neon MCP سرور شامل کریں اور اسے اجازت دیں۔) یہ واحد دستی سیٹ اپ ہے؛ یہاں سے آگے، سب کچھ ایجنٹ کو ہدایت دے کر ہوتا ہے۔ اسے plan mode میں چلائیں:
Neon MCP سرور استعمال کرتے ہوئے،
agent-factory-ragنام کا ایک پروجیکٹ بناؤ اور اس پر pgvector extension فعال کرو۔ پھر ہمارے build کرنے کے لیےdevنام کی ایک branch بناؤ، اور اس branch کی connection string کو.envمیںDATABASE_URLکے طور پر محفوظ کرو تاکہ ورکر اور ایپ بعد میں اسے پڑھ سکیں (میری API key کبھی print نہ کرنا)۔ کچھ بھی چلانے سے پہلے مجھے منصوبہ دکھاؤ۔
پھر منصوبہ پڑھیں۔ آپ جس چیز کی جانچ کر رہے ہیں:
- یہ ایک branch پر کام کرتا ہے، براہِ راست production پر نہیں۔ Branching Neon کی خاص طاقت ہے: ایک branch آپ کے پورے ڈیٹابیس کا فوری clone ہے (copy-on-write: یہ صرف وہی محفوظ کرتا ہے جو آپ بدلتے ہیں، اس لیے cloning مفت اور فوری ہے)۔ ایجنٹ schema کی تبدیلیاں ایک branch پر کرتا ہے، آپ ان کا پیش منظر دیکھتے ہیں، اور صرف تب ڈیفالٹ branch پر commit کرتے ہیں، یعنی وہی plan-then-execute نظم، جسے پلیٹ فارم خود نافذ کرتا ہے۔ (یہی وہ طریقہ بھی ہے جس سے آپ بعد میں انڈیکسز کو بینچ مارک کریں گے اور evals چلائیں گے: branch بناؤ، آزماؤ، branch پھینک دو۔)
- یہ pgvector کو فعال کرتا ہے، یعنی وہ واحد extension جس کی اس کورس کو ضرورت ہے، ایک ہی بیان سے:
CREATE EXTENSION IF NOT EXISTS vector; -- pgvector is pre-installed on Neon; this just switches it on
- embeddings (تصور 6) کے لیے، ایجنٹ ایک چھوٹا ورکر بناتا ہے، یعنی ایک مختصر Python اسکرپٹ یا سروس، جو نئی یا بدلی ہوئی قطاریں پڑھتا ہے، embedding ماڈل کو کال کرتا ہے، اور vectors کو ایک embeddings ٹیبل میں لکھتا ہے۔ یہ Neon سے باہر چلتا ہے، اپنی connection string کے ذریعے آپ کی branch تک پہنچتا ہے۔ embedding provider کی API key ورکر کے ماحول میں رہتی ہے، کبھی ڈیٹابیس میں نہیں۔
آپ کو MCP ٹول کے نام یا Neon کی API یاد کرنے کی ضرورت نہیں۔ plan mode کا نکتہ یہی ہے کہ آپ منصوبہ پڑھیں، تصدیق کریں کہ یہ کسی branch پر کام کر رہا ہے اور pgvector کو فعال کر رہا ہے، اور پھر منظوری دیں۔ اگر منصوبہ کوئی ایسی چیز کرے جسے آپ نہیں پہچانتے، تو ہاں کہنے سے پہلے ایجنٹ سے وجہ پوچھیں، یہی سوال آپ کا اصل کام ہے۔
Neon کی اپنی رہنمائی یہ ہے کہ MCP سرور مقامی ڈیولپمنٹ اور IDE انضمام کے لیے بنا ہے، یہ طاقتور operations چلا سکتا ہے، اس لیے اسے اپنے dev ورک فلو تک محدود رکھیں اور منظوری سے پہلے ایجنٹ کے تجویز کردہ ہر عمل کا جائزہ لیں۔ production کی تبدیلیاں اب بھی آپ کے معمول کے جائزہ شدہ migration عمل سے ہی گزرتی ہیں۔
کورس بیس میں پہلے ہی ایک مختصر AGENTS.md / CLAUDE.md شامل ہے جس میں وہ rules ہیں جن کی اس کورس کو ضرورت ہے: آپ کس Neon branch پر ہیں، یہ کہ keys ماحول میں رہتی ہیں (کبھی commit نہیں ہوتیں)، آپ کا چنا ہوا distance function، اور دو سخت rules، "schema کی تبدیلیاں ہمیشہ کسی Neon branch پر کرو اور commit سے پہلے مجھے پیش منظر دیکھنے دو،" اور "کبھی تباہ کن SQL (DROP، TRUNCATE، WHERE کے بغیر DELETE) پہلے مجھے دکھائے بغیر مت چلاؤ۔" بیس کے بغیر build کر رہے ہیں؟ /init چلائیں اور بالکل اسی پر تراش لیں۔
اس کورس میں ہر چیز TigerData Cloud پر بغیر کسی تبدیلی کے چلتی ہے، یعنی وہ ٹیم جو pgvector کے ساتھی extensions کے پیچھے ہے، جو اسے "Agentic Postgres" کے طور پر پیش کرتی ہے۔ ایجنٹ-چلِت لُوپ بالکل ایک جیسا ہے؛ صرف نام بدلتے ہیں:
- Neon MCP سرور کی جگہ Tiger MCP۔ یہ Tiger CLI میں بِلٹ اِن ہے، اسے
tiger mcp installسے انسٹال کریں، پھر Tiger Cloud کو سادہ زبان میں بالکل اوپر جیسا چلائیں ("ایک service بناؤ، اسے fork کرو، extensions فعال کرو، پہلے مجھے منصوبہ دکھاؤ")۔ یہ Postgres Skills بھی فراہم کرتا ہے جو ایجنٹ کو بہترین طریقے سکھاتی ہیں۔ - branches کی جگہ Forks:
tiger service fork …ایک فوری، zero-copy clone بناتا ہے، یعنی وہی fork ← آزماؤ ← پھینک دو نظم جو آپ evals اور index بینچ مارکس کے لیے استعمال کریں گے۔ - pgvectorscale native ہے (pgvector کے ساتھ ساتھ)، اس لیے StreamingDiskANN کا "graduate درجہ" (تصور 11) پہلے ہی دن سے ڈبے میں موجود ہے، اور اس کا انڈیکس 16,000 dimensions تک کے vectors کو سہارا دیتا ہے (
text-embedding-3-largeجیسے بڑے ماڈلز کو پھر کسیhalfvecکی ضرورت نہیں)۔ آپ کا embedding ورکر بالکل اسی طرح چلتا ہے جیسے Neon پر۔
آپ کا embedding ورکر اور generation کا قدم دونوں ایپ کوڈ میں رہتے ہیں، Neon جیسے ہی۔ اصول: سب سے سادہ serverless آغاز کے لیے Neon؛ اور جب آپ بغیر کبھی migrate کیے pgvectorscale کا اسکیل اور فلٹرڈ-سرچ کی کارکردگی چاہیں تو TigerData۔
یہ کورس Neon کو دو وجہوں سے استعمال کرتا ہے: credit card کے بغیر free tier، اور instant branching جسے ایجنٹ Neon MCP server کے ذریعے drive کرتا ہے۔ Postgres کو locally (Homebrew، Docker) یا کسی اور host پر چلانا پسند ہے؟ Data side بالکل ایک جیسی ہے، وہی CREATE EXTENSION vector، وہی schema، وہی worker، وہی queries؛ بس DATABASE_URL کو اپنے instance کی طرف point کر دیں۔ جو چیز آپ چھوڑتے ہیں وہ MCP-driven branching ہے (وہ "branch, test, throw away" move جو آپ indexes اور evals کے لیے استعمال کریں گے)، اس لیے وہ steps آپ براہِ راست چلائیں گے۔ یہاں جو کچھ آپ سیکھتے ہیں وہ بغیر بدلے منتقل ہو جاتا ہے۔
حصہ 2: آپ کا پہلا RAG، آپ کے ایجنٹ کا بنایا ہوا
ہم ایک چھوٹی، کلاسک مثال بنائیں گے: امریکی شہروں کے بارے میں تاریخی شخصیات کے اقتباسات کا ایک ٹیبل، پھر اسے معنی سے تلاش کریں گے، پھر ایک LLM سے اس پر سوالوں کے جواب دلوائیں گے۔
5. اسکیما: ویکٹرز آپ کے ڈیٹا کے ساتھ ہی رہتے ہیں
پہلے ایجنٹ سے source ٹیبل مانگیں۔ ایک بات تھامے رکھیں: معنی-ویکٹرز کسی الگ store میں نہیں رہیں گے، یہ اسی ڈیٹابیس میں، اگلے تصور میں آپ کے بنائے جانے والے ساتھی ٹیبل میں جائیں گے، بالکل اس ڈیٹا کے ساتھ جسے وہ بیان کرتے ہیں۔
ایک
quotesٹیبل بناؤ جس میں یہ کالم ہوں:person،city، اورquote۔ ہم اگلی بار embeddings کو ایک ساتھی ٹیبل میں شامل کریں گے، جسے ایک چھوٹا ورکر بھرے گا، تو ابھی صرف source ڈیٹا۔ پھر نیویارک، سان فرانسسکو، اور شکاگو کے بارے میں چند حقیقی اقتباسات insert کرو تاکہ ہمارے پاس تلاش کرنے کو کچھ ہو۔
جو ٹیبل ایجنٹ لکھے گا وہ کچھ ایسا دکھے گا:
CREATE TABLE quotes (
id bigint GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
person text NOT NULL,
city text NOT NULL,
quote text NOT NULL
);
تھامنے کے لیے ذہنی خاکہ: سچ کا ایک ہی منبع۔ اقتباس، کس نے کہا، شہر، اور (جلد ہی) اس کا معنی-ویکٹر، سب ایک ہی ڈیٹابیس میں رہتے ہیں۔ یہی وہ چیز ہے جو حصہ 4 میں فلٹرنگ کو معمولی بنا دیتی ہے۔
6. embeddings بنائیں: وہ ورکر جو آپ کا ایجنٹ بناتا ہے
آپ کا quotes ٹیبل متن رکھتا ہے۔ ڈیٹابیس کے لیے اس متن کو معنی سے تلاش کرنے کی خاطر، اس کے ہر ٹکڑے کو ایک vector چاہیے، اور وہ vectors بنانا وہ واحد کام ہے جو pgvector آپ کے لیے نہیں کرتا۔ تو ایجنٹ ایک چھوٹا پروگرام لکھتا ہے: embedding ورکر۔ اس کا پورا کام ایک لُوپ ہے، ایسے quotes ڈھونڈو جن کے ابھی کوئی vectors نہیں ← کسی بھی لمبے متن کو ٹکڑوں (chunks) میں بانٹو ← ہر ٹکڑے کا vector embedding ماڈل سے مانگو ← vectors محفوظ کرو۔ اسے ایک بار چلائیں اور ہر موجودہ quote کا احاطہ ہو جاتا ہے؛ اسے کسی شیڈول پر دوبارہ چلائیں اور نئے یا بدلے ہوئے quotes کا بھی احاطہ ہو جاتا ہے۔ بس یہی پوری مشین ہے۔
vectors کہاں محفوظ ہوتے ہیں؟ ایک دوسرے ٹیبل میں، یعنی ساتھی ٹیبل میں، ہر chunk کے لیے ایک قطار، ہر ایک اُس quote کی طرف واپس اشارہ کرتی ہوئی جہاں سے وہ آئی۔ اس سے وہ سوال حل ہو جاتا ہے جو یہاں ہر کوئی پوچھتا ہے (ایک قطار، ایک embedding؟): ایک مختصر quote ایک chunk ہے، اس لیے ایک vector قطار؛ ایک لمبی تقریر کئی ٹکڑے بنتی ہے، اس لیے کئی قطاریں۔ (کیوں بانٹیں آخر؟ یہ تصور 7 ہے، بالکل اس کے بعد۔) دو ٹیبل، اور وہ ایسے دکھتے ہیں:
quotes (your source table) quotes_embedding (companion table)
┌────┬─────────────────────┐ ┌─────┬──────────┬──────────────┬───────────┐
│ id │ quote │ │ id │ quote_id │ chunk │ embedding │
├────┼─────────────────────┤ ├─────┼──────────┼──────────────┼───────────┤
│ 7 │ a short quote │ ────→ │ 1 │ 7 │ whole quote │ [0.02, …] │
│ 8 │ a long speech… │ ──┬─→ │ 2 │ 8 │ first piece │ [0.11, …] │
└────┴─────────────────────┘ └─→ │ 3 │ 8 │ second piece │ [0.54, …] │
└─────┴──────────┴──────────────┴───────────┘
one row per quote one row per CHUNK (its own id),
pointing back via quote_id
ایجنٹ کے اسے بنانے سے پہلے ایک فیصلہ: کون سا embedding ماڈل متن کو vectors میں بدلتا ہے۔ یہاں یہی واحد انتخاب ہے جسے پلٹنا تنگ کرتا ہے، کیونکہ ماڈل بدلنے کا مطلب ہر چیز کو دوبارہ embed کرنا ہے، اس لیے اسے سمجھنا فائدہ مند ہے، اگرچہ base نے آپ کے لیے ایک مناسب default پہلے ہی چن لیا ہے۔ وہ default وہی provider ہے جو آپ نے setup کیا: free Gemini path پر Google کا gemini-embedding-001، یا اگر آپ نے OpenAI چنا تو OpenAI کا text-embedding-3-small۔ یہاں دونوں 1536 dimensions پر چلتے ہیں، دونوں زیادہ تر RAG کے لیے کافی ہیں، اور Gemini مفت ہے، اس لیے آپ model name خود نہیں چنتے؛ base نے اسے آپ کی دی ہوئی key سے match کر دیا۔ default سے ہٹنے کی دو وجوہات ہوتی ہیں: آپ کا مواد انگریزی میں نہیں (یا گہرا تخصصی ہے، جیسے قانونی، طبی، کوڈ)، جہاں کوئی multilingual یا domain-tuned ماڈل جیت سکتا ہے؛ یا آپ کے evals بعد میں دکھائیں کہ کوئی بڑا ماڈل واقعی بہتر retrieve کرتا ہے۔ ورکر میں ماڈل ایک ہی setting ہے، اس لیے آپ اندازے لگانے کے بجائے متبادل کو اپنے eval سیٹ (تصور 12) پر آزماتے ہیں: MTEB leaderboard (embedding ماڈلز کا معیاری عوامی benchmark) سے امیدواروں کی فہرست بنائیں اور اپنے ڈیٹا کو فاتح چننے دیں۔
dimension کی باریک تفصیل (جب آپ ڈیفالٹ سے ہٹیں تو پڑھیں)
زیادہ dimensions کا مطلب زیادہ storage اور memory اور قدرے سُست تلاش ہے۔ دو عملی باتیں: بہت سے جدید ماڈلز آپ کو دوبارہ-train کیے بغیر کم dimensions مانگنے دیتے ہیں (یہ کورس دونوں providers کو 1536 پر pin کرنے کے لیے یہی استعمال کرتا ہے)، اور، ایک حقیقی پھندا، pgvector کے HNSW/IVFFlat انڈیکسز vector type کو 2,000 dimensions پر محدود کر دیتے ہیں (halfvec type اسے 4,000 تک بڑھا دیتا ہے)، اس لیے کوئی full-size 3072-dim ماڈل (OpenAI کا text-embedding-3-large، یا Gemini full size پر) indexable ہونے کے لیے halfvec یا reduced dimensions چاہتا ہے۔ 1536 پر رہنا آپ کو اس سب سے بچا دیتا ہے؛ اگر آپ کبھی dimensions بڑھائیں تو آپ کے ایجنٹ کو یہ cap flag کرنا چاہیے، اور جب وہ کرے تو آپ کو اسے پہچاننا چاہیے۔ (TigerData پر، pgvectorscale کا StreamingDiskANN انڈیکس 16,000 dimensions تک vectors کو سہارا دیتا ہے، اس لیے یہ حد شاذ و نادر ہی آڑے آتی ہے۔)
پہلے، کوڈ کو ایک گھر دیں، ایک Python پروجیکٹ، جسے uv سنبھالے (Python پروجیکٹ منیجر؛ ایجنٹ اسے جانتا ہے، اور ہر dependency کو اسی کے ذریعے گزارنا پروجیکٹ کو دوبارہ-قابلِ تشکیل رکھتا ہے):
اس فولڈر میں uv کے ساتھ ایک Python پروجیکٹ سیٹ اپ کرو۔ یہاں سے آگے، ہر dependency شامل کرو اور ہر اسکرپٹ uv کے ذریعے چلاؤ۔
پھر ایجنٹ سے ورکر اور اس کا ٹیبل بنوائیں:
ایک ساتھی ٹیبل
quotes_embeddingبناؤ جس میںquotesکی طرف ایک foreign key ہو، chunk کا متن ہو، اور ایکembedding vector(1536)کالم ہو۔ پھر ایک چھوٹا embedding ورکر لکھو جو ایسے quotes ڈھونڈے جن کا کوئی موجودہ embedding نہیں،quoteمتن کو chunk کرے، ہر chunk کو course کے embedding model سے embed کرے، اور vectors کوquotes_embeddingمیں insert کرے۔ اسے ایک بار backfill کے لیے چلاؤ، مجھے دکھاؤ کہ قطاریں آ گئیں اس کی تصدیق کیسے کروں، اور سمجھاؤ کہ میں اسے شیڈول کیسے کروں گا۔ API key ماحول سے پڑھو۔
اس کا خیال رکھیں: ایجنٹ ساتھی ٹیبل بناتا ہے (بالکل وہی شکل جو اوپر خاکے میں ہے)، ورکر کو ایک بار چلاتا ہے، اور آپ کو وہ vector قطاریں دکھاتا ہے جو آ گئیں۔ اگر ورکر اپنی پہلی embedding کال پر 401 یا 429 کے ساتھ مر جائے، تو آپ کے کوڈ میں کچھ ٹوٹا نہیں ہے؛ مسئلہ key کا ہے، اور غالباً آپ نے اسے setup میں پہلے ہی پکڑ لیا ہوگا، جہاں ایجنٹ نے test call کی تھی۔ Gemini پر free key کو aistudio.google.com/apikey سے دوبارہ copy کریں؛ OpenAI پر بالکل نئے account کو اکثر embed کرنے سے پہلے payment method چاہیے۔ 429 rate limit ہے، اس لیے ذرا انتظار کریں اور دوبارہ چلائیں۔ key درست کریں، پھر دوبارہ چلائیں۔ اگر اس کے بجائے expected 1536 dimensions, got 3072 دکھے، تو embedding call نے 1536 dims request نہیں کیے؛ دونوں providers default طور پر بڑا vector دیتے ہیں، اس لیے call کو vector(1536) column سے match کرنے کے لیے 1536 مانگنا لازمی ہے۔ base worker یہ پہلے ہی کرتا ہے، اس لیے یہ error بتاتا ہے کہ ہاتھ سے edit کی گئی call سے وہ setting نکل گئی۔ تب مکمل جب: ہر quote کی quotes_embedding میں کم از کم ایک قطار ہو، اور آپ وہ واحد کمانڈ جانتے ہوں جو ورکر کو دوبارہ چلاتی ہے۔
سب سے سادہ شکل poll کرتی ہے: ورکر کسی شیڈول پر دوبارہ چلتا ہے اور ایسی قطاروں کو دوبارہ embed کرتا ہے جن کا متن بدلا۔ اس کے بجائے تبدیلی-چلِت اپ ڈیٹس چاہتے ہیں؟ ایک INSERT/UPDATE trigger کسی قطار کو dirty نشان زد کر سکتا ہے، یعنی "اِسے ایک تازہ embedding چاہیے" کا جھنڈا لگا دے، اور ورکر اپنے اگلے چکر میں اُن نشان زد قطاروں کو اٹھا لیتا ہے۔ اگر آپ کبھی ورکر کی ایک سے زیادہ کاپیاں چلائیں تاکہ رفتار برقرار رہے، تو انہیں ایک ہی قطار دو بار نہیں پکڑنی چاہیے؛ Postgres یہ آپ کے لیے سنبھال لیتا ہے، ہر ورکر کو غیر دعویٰ شدہ قطاروں کا الگ batch دیتے ہوئے (یہی SKIP LOCKED والی چال ہے)۔ تو embedding-کی-منتظر قطاروں کی to-do فہرست بس ایک عام Postgres ٹیبل ہے، چلانے کے لیے کوئی الگ queue سروس نہیں، وہی ایک-ڈیٹابیس والا فائدہ جو آپ کے vectors کا ہے۔ کسی بھی طرح trigger صرف نشان لگاتا ہے؛ embedding کال پھر بھی باہر ورکر میں ہوتی ہے، اور خود ڈیٹابیس کبھی embedding API کو کال نہیں کرتا۔
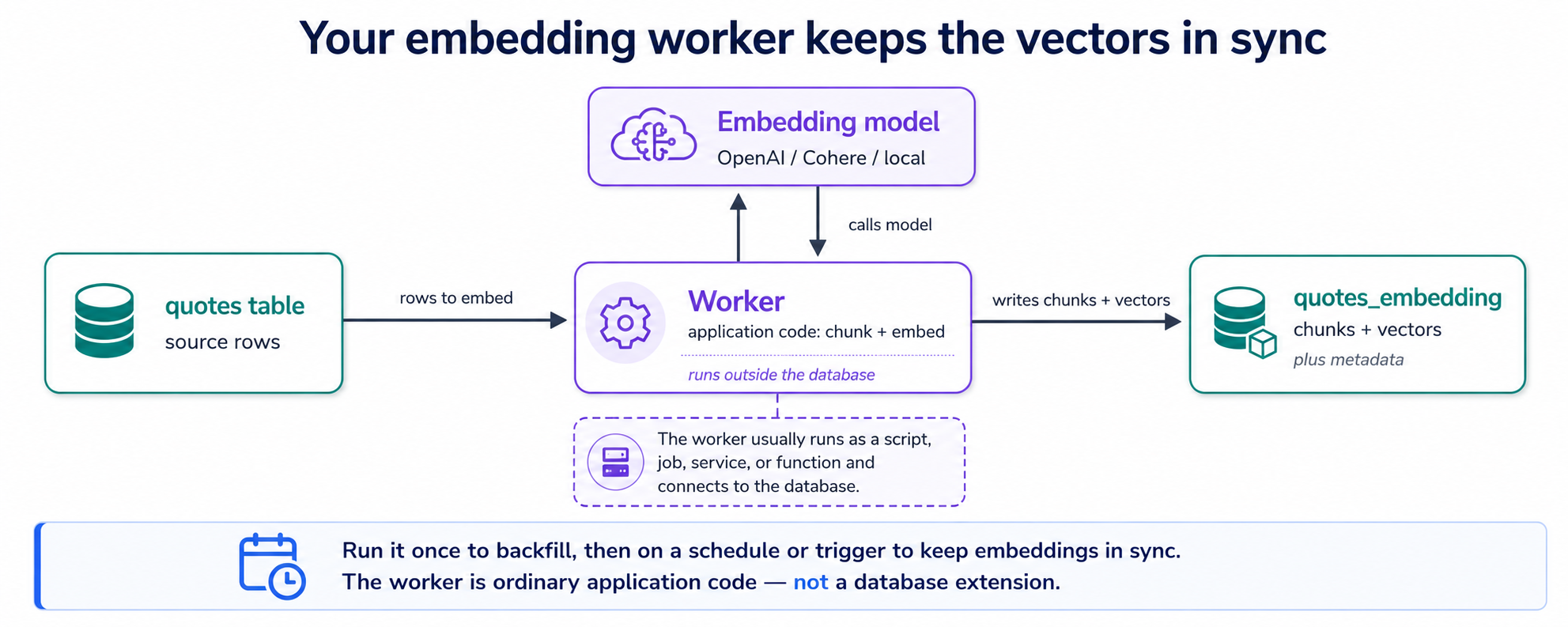
وہی ورکر پیٹرن دستاویزات کو embed کرتا ہے، صرف مختصر فیلڈز کو نہیں، اسے PDFs، DOCX، یا cloud storage کی فائلوں (مثلاً ایک Amazon S3 bucket) کی طرف موڑیں اور اس سے انہیں parse، chunk، اور اسی ساتھی ٹیبل میں embed کروائیں۔ اور چونکہ ماڈل ورکر میں ایک ہی setting ہے، آپ providers بدل سکتے ہیں (Gemini، OpenAI، Cohere، Voyage، کوئی local ماڈل) تاکہ آزمائیں کہ آپ کے ڈیٹا پر کون بہتر retrieve کرتا ہے، یعنی اوپر والا ماڈل تجربہ۔
ورکر ایک بیرونی embedding provider کو کال کرتا ہے، اس لیے اسے اس provider کی API key چاہیے۔ key کا تعلق ورکر کے ماحول سے ہے (یا آپ کے cloud provider کے secret store سے)، کبھی SQL میں hard-code نہیں، نہ آپ کے repo میں commit۔ اپنے ایجنٹ کو صراحت سے بتائیں: "API key کسی environment variable سے پڑھو، اسے کبھی کسی ایسی فائل میں مت لکھو جسے ہم commit کرتے ہیں۔" پھر منظوری سے پہلے diff کی تصدیق کریں۔ بعد میں embedding providers بدلنا (Gemini اور OpenAI کے بیچ، یا Cohere، Voyage، کوئی local ماڈل) ورکر میں ایک لائن کی تبدیلی ہے؛ آپ کی باقی ایپ ہلتی نہیں۔
7. چنکنگ: وہ لیور جو آپ کی حد مقرر کرتا ہے
چنکنگ آپ کے ورکر کے اندر ایک قدم ہے، اور خاموشی سے، سب سے اہم۔ ایک لمبی دستاویز جسے ایک ہی vector کے طور پر embed کیا جائے وہ لُگدی بن جاتی ہے، یعنی ہر اُس بات کی ایک دھندلی اوسط جو وہ کہتی ہے، اس لیے آپ اسے چھوٹے chunks میں بانٹتے ہیں، اور ہر chunk کو اپنا الگ vector ملتا ہے۔ جو چیز ایک chunk شمار ہوتی ہے وہ طے کرتی ہے کہ آپ کی تلاش کبھی کیا کچھ نکال سکتی ہے۔
دو ڈائل:
- سائز۔ بہت بڑا اور ایک chunk کئی موضوعات پر پھیل جاتا ہے، اس لیے اس کا vector غیر مرتکز ہوتا ہے اور آپ قریب-قریب-مگر-غلط نتائج نکالتے ہیں۔ بہت چھوٹا اور ایک chunk وہ سیاق کھو دیتا ہے جس نے اسے بامعنی بنایا تھا۔ چند سو tokens ایک عام نقطۂ آغاز ہے؛ صحیح جواب آپ کے مواد پر منحصر ہے۔
- اوورلیپ۔ chunks کو تھوڑا سا ایک دوسرے پر چڑھنے دینا (مثلاً 10 تا 20٪) ایک ایسے جملے کو، جو کسی حد پر دو ٹکڑوں میں بٹا ہو، یتیم ہونے سے بچاتا ہے۔ کچھ اوورلیپ تقریباً ہمیشہ مدد دیتا ہے؛ بہت زیادہ storage ضائع کرتا ہے اور قریب-قریب-نقول نکالتا ہے۔
ایک حکمتِ عملی بھی ہے: character count سے بانٹیں (سادہ ڈیفالٹ)، ساخت سے (markdown headings، پیراگراف)، یا معنی سے (ایسے جملے گروپ کریں جو ساتھ بنتے ہوں)۔ ساخت والی دستاویزات کے لیے، headings پر بانٹنا عام طور پر اندھے character counts کو ہرا دیتا ہے۔
یہ اپنا الگ تصور کیوں کماتا ہے: چنکنگ آپ کی recall کی حد مقرر کرتی ہے، یہاں recall کا مطلب بس یہ ہے کہ آپ کی تلاش نے پہلی جگہ صحیح chunks واپس کیے یا نہیں۔ اگر صحیح جواب کبھی صاف ستھرے انداز میں کسی ایک chunk میں نہ آئے، تو نہ کوئی embedding ماڈل اور نہ کوئی چالاک پرامپٹ اسے بحال کر سکتا ہے، اور یہی وجہ ہے کہ خراب چنکنگ ان سب سے عام وجوہات میں سے ایک ہے جن کی بنا پر کوئی RAG نظام خاموشی سے کم کارکردگی دیتا ہے۔ تو آپ اندازہ نہیں لگاتے: جب آپ حقیقی دستاویزات کے ساتھ کام کر رہے ہوں اور آپ کا eval سیٹ موجود ہو (تصور 12)، آپ ایجنٹ سے Neon branches پر چند چنکنگ سیٹ اپ آزماتے ہیں، ہر ایک کو اپنے eval سوالوں کے مقابل ناپتے ہیں، اور فاتح رکھ لیتے ہیں، یعنی وہی آزماؤ-اور-پھینکو والی چال جو آپ حصہ 3 میں انڈیکسز کے لیے استعمال کریں گے۔ یہی چال آپ عملی مثال (حصہ 5) میں بعینہٖ کریں گے۔
8. سیمانٹک سرچ: فاصلے کے حساب سے ترتیب
اب وہ جادو جو تعارف میں تھا۔ کسی فقرے سے معنی میں ملتے جلتے quotes ڈھونڈنے کے لیے، آپ کی ایپ اس فقرے کو اپنا ایک vector بنا لیتی ہے، یعنی query vector، اور ڈیٹابیس محفوظ شدہ chunks کو اس بنیاد پر ترتیب دیتا ہے کہ ان کے vectors اس کے کتنے قریب بیٹھتے ہیں۔
SQL کا واحد نیا ٹکڑا ایک distance operator ہے، یعنی وہ علامت جو پوچھتی ہے "کتنا قریب؟"۔ آپ کو صرف ایک کی ضرورت ہے، <=>، یعنی cosine distance: متن embeddings کے لیے ڈیفالٹ، اور یہی پورا کورس استعمال کرتا ہے۔ (pgvector کے پاس دو اور ہیں، <-> سیدھی لکیر کے فاصلے کے لیے، <#> inner product کے لیے، جن سے آپ کا واسطہ صرف تب پڑے گا جب کسی ماڈل کی دستاویزات خاص طور پر کسی ایک کا تقاضا کریں؛ آپ کا ایجنٹ جانتا ہوگا۔)
مجھے ایک ایسی کوئری لکھ دو جو کسی تلاش کے فقرے سے معنی میں سب سے زیادہ ملتے جلتے ٹاپ 5 quotes واپس کرے۔ فقرے کا embedding application code سے ایک parameter کے طور پر pass کیا جائے گا، اسے SQL کے اندر embed مت کرنا۔
جو کوئری یہ واپس تھماتا ہے (آپ کے پڑھنے کے لیے، ٹائپ کرنے کے لیے نہیں):
SELECT q.person, q.city, q.quote
FROM quotes_embedding e -- the table your worker populates: chunks + vectors
JOIN quotes q ON q.id = e.quote_id -- each chunk points back to its source quote
ORDER BY e.embedding <=> $1 -- $1 = the query phrase, embedded in app code
LIMIT 5;
"وہ شہر جو کبھی نہیں سوتا" تلاش کریں اور سب سے اوپر کے نتائج نیویارک کے بارے میں quotes ہوتے ہیں، بشمول وہ جن میں کبھی "New York" کے الفاظ آتے ہی نہیں، کیونکہ معنی قریب ہیں۔ یہی، بالآخر ٹھوس شکل میں، سیمانٹک سرچ ہے۔
$1 کے طور پر کیوں آتا ہےصارف کے فقرے کو vector میں بدلنا آپ کے application code میں ہوتا ہے، یعنی چند لائنیں جو ایجنٹ لکھتا ہے، اور نتیجہ کوئری میں $1 parameter کے طور پر pass ہوتا ہے۔ ماڈل کال آپ کی ایپ میں رہتی ہے، جہاں آپ ماڈل، retries، اور caching کو قابو کرتے ہیں؛ Postgres وہی کرتا ہے جس میں وہ بہترین ہے، یعنی vectors رکھنا، قریب ترین ڈھونڈنا۔
9. RAG: پہلے بازیافت، پھر جواب سازی
سیمانٹک سرچ متعلقہ متن ڈھونڈ لیتی ہے۔ RAG (Retrieval-Augmented Generation) ایک قدم اور آگے جاتا ہے: یہ ان نکالے گئے chunks کو لیتا ہے، انہیں سیاق کے طور پر ایک پرامپٹ میں بھرتا ہے، اور ایک LLM سے کہتا ہے کہ آپ کے ڈیٹا میں جڑا ہوا جواب تشکیل دے۔ یہی customer-support bot ہے، یہی docs assistant، یہی "اپنی فائلوں سے چیٹ" والا فیچر، یہ سب اسی لُوپ ہیں۔
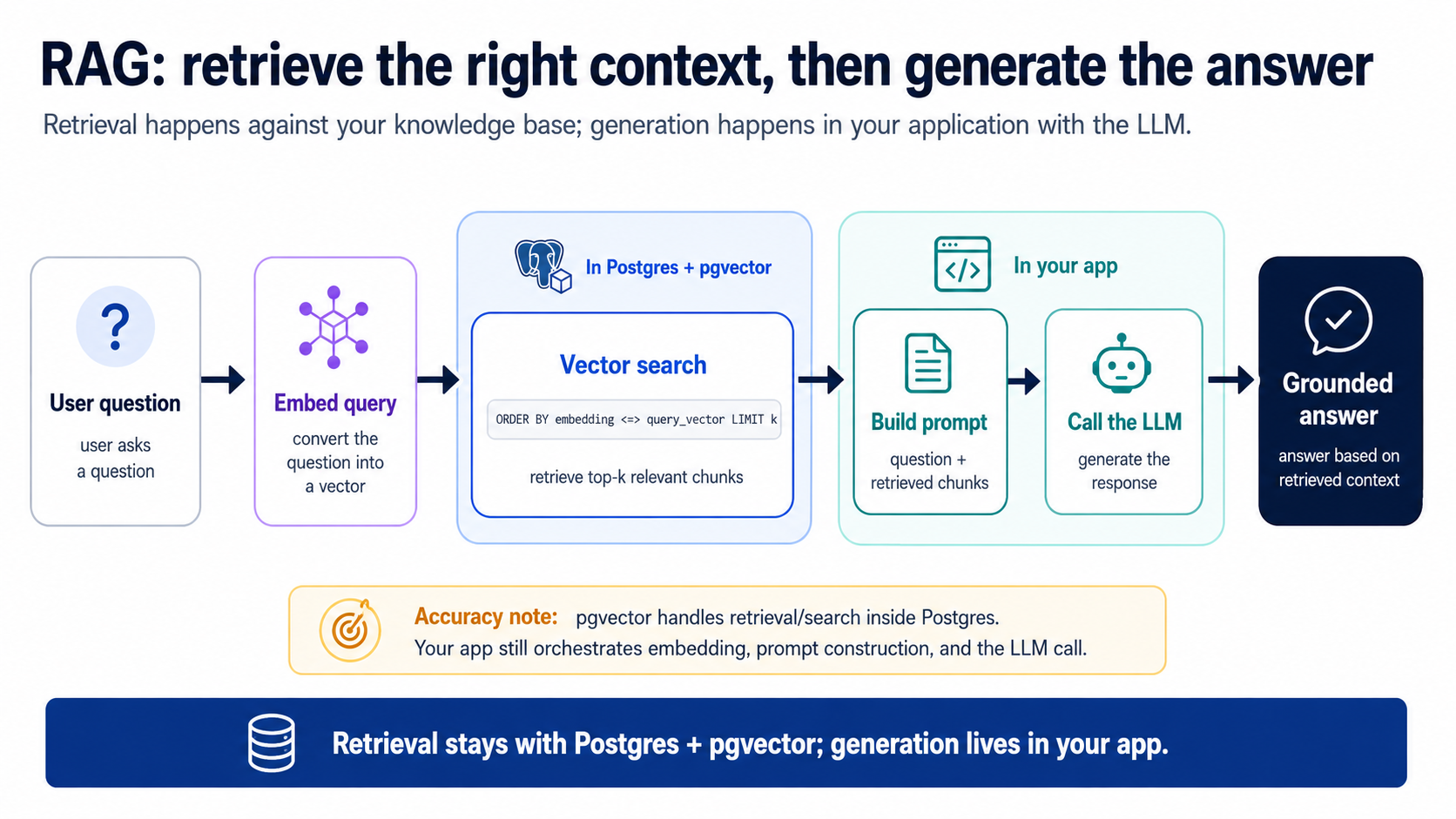
لُوپ کے دو مرحلے ہیں، اور یہی تقسیم پورا نکتہ ہے:
- بازیافت (Postgres میں): سب سے زیادہ متعلقہ ٹاپ k chunks نکالنے کے لیے تصور 8 والی کوئری چلائیں (k بس اتنا ہے کہ آپ کتنے مانگتے ہیں؛ 5 ایک اچھا آغاز ہے)۔ یہی سیاق-کے-انتظام والا قدم ہے، یعنی signal نکالیں، دس لاکھ غیر متعلقہ قطاریں باہر چھوڑ دیں۔
- جواب سازی (آپ کی ایپ میں): ایک پرامپٹ بنائیں = system instructions + نکالے گئے chunks + صارف کا سوال، اسے ایک LLM کو بھیجیں، جواب واپس کریں۔ ایجنٹ یہ ایپ-سائیڈ glue آپ کے لیے لکھتا ہے؛ یہ چھوٹا ہے۔
اسے دو قدموں میں بنائیں، تاکہ generation کے اسے لپیٹنے سے پہلے آپ retrieval کو خود اپنے طور پر کام کرتے دیکھ سکیں۔ پہلے، ایک گھر کا انتظام کرنے والا پرامپٹ تاکہ کوڈ کو ایک گھر ملے، اگر آپ نے تصور 6 میں ورکر بنایا تو یہ پہلے ہی سچ ہے، جس صورت میں ایجنٹ بس اس کی تصدیق کرے گا:
یقینی بناؤ کہ یہ فولڈر ایک uv-managed Python پروجیکٹ ہے، اگر نہیں تو سیٹ اپ کرو، اور ہر dependency اور اسکرپٹ کو uv کے ذریعے چلتا رکھو۔
اب تلاش والا حصہ:
application code میں ایک
search_quotes(question)فنکشن بناؤ: سوال کو embed کرو، ہماری ٹاپ-k سیمانٹک سرچquotes_embeddingکے مقابل چلاؤ، اور ملنے والے chunks کو ان کے source quotes کے ساتھ واپس کرو۔ پھر اسے "وہ شہر جو کبھی نہیں سوتا" پر چلاؤ اور مجھے دکھاؤ کہ کیا واپس آتا ہے۔
جو واپس آتا ہے وہ صرف مرحلہ 1 ہے، یعنی صحیح chunks، معنی سے ڈھونڈے گئے، کسی بھی جواب کے لکھے جانے سے پہلے۔ اب اس کے گرد مرحلہ 2 لپیٹیں:
اب اس کے اوپر
answer_question(question)بناؤ:search_quotesکو کال کرو، ان chunks کو سیاق کے طور پر ایک پرامپٹ میں ترتیب دو، LLM کو کال کرو، اور جڑا ہوا جواب واپس کرو، retrieval SQL میں رہے، generation ایپ کوڈ میں۔ پھر اس سے ایک سوال پوچھو اور مجھے نکالے گئے chunks آخری جواب کے ساتھ ساتھ دکھاؤ۔
غور کریں کہ مرحلہ 1 کیا کر رہا ہے: LLM کو بالکل وہی سیاق تھمانا جو اسے چاہیے اور اس کے علاوہ کچھ نہیں، یعنی سیاق کا انتظام، بالکل جیسا شروع کے خاکے نے وعدہ کیا تھا۔ اگر retrieval لاپروا ہے، یعنی غلط chunks، بہت زیادہ، غیر متعلقہ، تو LLM ایک خراب جواب دیتا ہے اور لوگ "AI" کو الزام دیتے ہیں۔ یہ تقریباً ہمیشہ retrieval ہی ہوتی ہے۔ اسی لیے حصہ 4 موجود ہے۔
پھر اگلی ہی سانس میں انہوں نے ایک ایسا system describe کیا جو documents index کرتا ہے، queries embed کرتا ہے، اور answer generate کرنے سے پہلے relevant chunks retrieve کرتا ہے۔ احترام کے ساتھ: یہ اب بھی RAG ہے۔
اب آپ نے اس کا ہر step build کر لیا ہے۔ پوری machine ایک card پر:
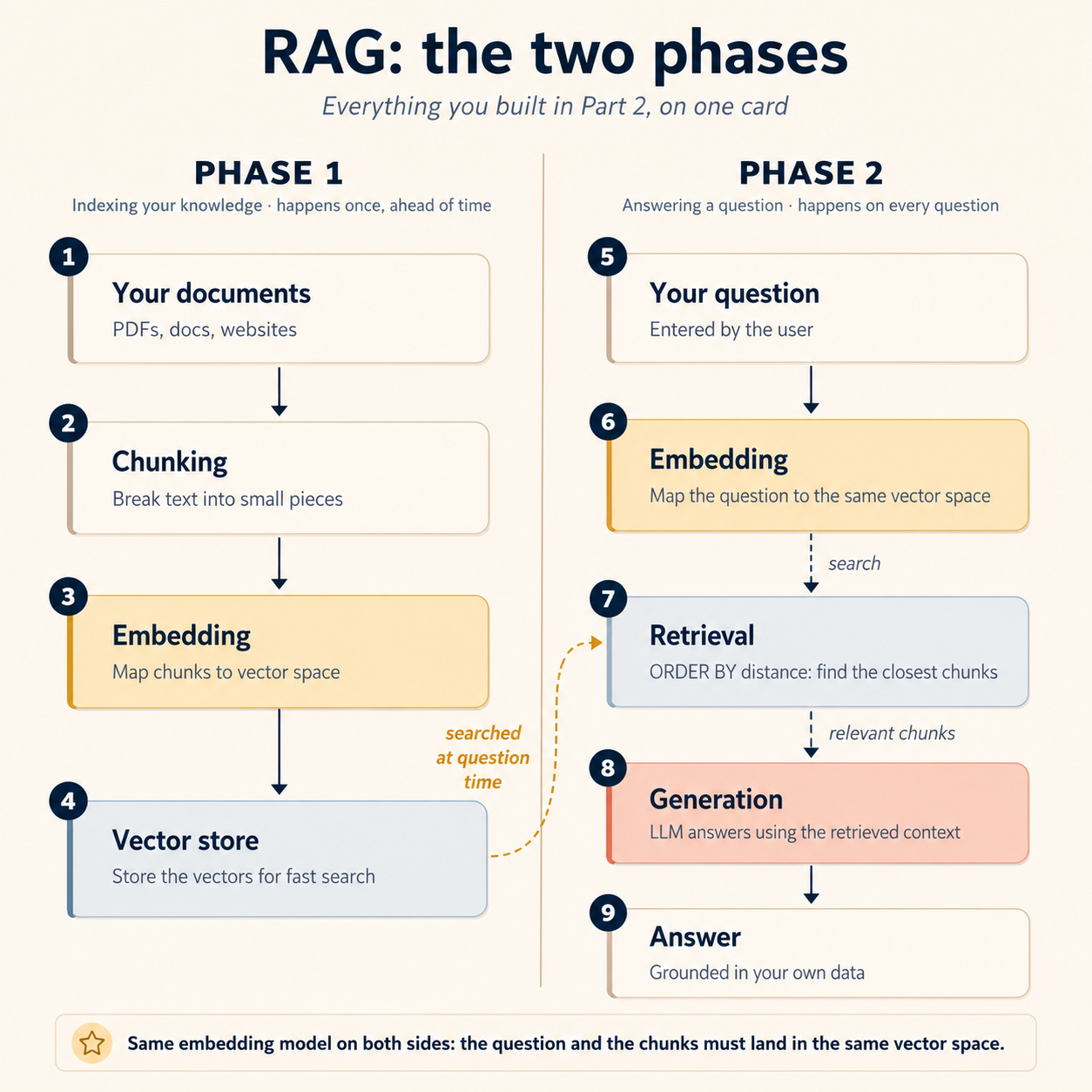
Phase 1: indexing (ایک بار، پہلے سے ہوتی ہے):
- آپ کے documents chunks میں ٹوٹتے ہیں (Concept 7)
- ہر chunk آپ کا worker vector space میں embed کرتا ہے (Concept 6)
- Vectors Postgres میں land کرتے ہیں، اس data کے ساتھ جسے وہ describe کرتے ہیں (Concept 5)
Phase 2: answering (ہر question پر ہوتی ہے):
- User کا question اسی same vector space میں embed ہوتا ہے
- Retrieval question کے closest chunks کھینچتا ہے (Concept 8)
- وہ chunks model کو pass ہوتے ہیں، جو ان پر grounded answer generate کرتا ہے (یہ concept)
پہلی pipeline میں لوگوں کو جو حصہ الجھاتا ہے وہ اوپر ایک word میں چھپا ہے: same۔ Question اور documents کو same vector space میں land کرنا ہوتا ہے: same embedding model، same dimensions، same settings، دونوں sides پر۔ Documents ایک model سے embed کریں اور queries دوسرے سے، تو retrieval چپ چاپ ٹوٹ جاتا ہے، کہیں کوئی error نہیں: دو models کے vector spaces بس الگ coordinate systems ہیں، اس لیے "closest" کا مطلب "most similar" رہنا بند ہو جاتا ہے۔ کوئی leaderboard ranking اس mismatch سے نہیں بچاتی۔ (یہ Concept 6 والے expected 1536 dimensions, got 3072 error کا model-level cousin ہے، بس یہ version loud fail بھی نہیں کرتا۔)
تو "RAG is dead" headlines کے بعد اصل میں کیا بدلا؟ Mechanism نہیں، packaging۔ Agents، tool calls، اور multi-step reasoning اب اسی retrieve-then-generate loop کے اوپر بیٹھتے ہیں۔ آپ Part 6 میں اسی exact loop کو agent tool کے طور پر wrap کریں گے اور Part 8 میں agent کو دیں گے: loop مرتا نہیں، promote ہوتا ہے۔
answer_question() صرف کوئی chatbot backend نہیں، یہ ایک ٹول ہے جسے ایجنٹ کال کرتا ہے۔ ایجنٹ والے ابواب میں، retrieval ان ٹولز میں سے ایک بن جاتی ہے جن کی طرف کوئی بڑا ایجنٹ تب ہاتھ بڑھاتا ہے جب اسے جڑے ہوئے حقائق چاہئیں، بالکل اسی طرح جیسے وہ کسی calculator یا web search کی طرف ہاتھ بڑھاتا ہے۔ RAG وہ قابلِ تلاش سیاق ہے جس پر ایک ایجنٹ تکیہ کرتا ہے۔
حصہ 3: تلاش کو تیز بنانا، انڈیکسز
یہاں سے درمیانی سطح۔ حصہ 3 اور 4 ٹیوننگ کی تہہ ہیں: آپ صرف حصہ 1 تا 2 پر شِپ کر سکتے ہیں، مگر آپ وہاں نہیں رکیں گے، انہیں "کیوں" کے لیے پڑھیں، پھر ان سب کو حصہ 5، مرحلے 5 تا 8 میں حقیقت میں چلائیں۔ تیز تر (حصہ 3) اور تیز دھار (حصہ 4) وہ مہارتیں ہیں جنہیں آپ نے کر چکا ہوگا، صرف پڑھا نہیں ہوگا۔
10. آپ کو ویکٹر انڈیکس کی ضرورت کیوں ہے (اور کب نہیں)
انڈیکس کے بغیر، ایک similarity search query vector کا موازنہ ہر قطار سے کرتی ہے، یعنی ایک عین nearest-neighbor اسکین۔ یہ بالکل درست ہے، اور جب تک آپ چھوٹے ہیں بالکل ٹھیک ہے۔ جیسے جیسے ٹیبل بڑھتا ہے، یہ سُست ہو جاتا ہے۔
حل ایک تخمینی تلاش ہے: ہر vector کو نہ جانچ کر، درستگی کا ایک ذرہ رفتار میں بڑی بہتری کے بدلے دے دیں۔ ایک ویکٹر انڈیکس وہ ڈیٹا ڈھانچہ ہے جو اس تخمینے کو عمدہ بناتا ہے۔
وہ حد جو آپ کو حد سے زیادہ انجینئرنگ سے بچاتی ہے: تقریباً 100,000 vectors سے نیچے، عین تلاش اکثر کافی تیز ہوتی ہے، اور ہمیشہ درست۔ مگر اصل حد dimensions، compute کے سائز، رفتار کے ہدف، فلٹرز، concurrency، اور vectors کتنی بار دوبارہ لکھے جاتے ہیں، اِن سب کے ساتھ کھسکتی ہے، اس لیے انڈیکس کو ڈیفالٹ کے طور پر اٹھانے کے بجائے ایجنٹ سے شامل کرنے سے پہلے benchmark کرائیں؛ اسے تب شامل کریں جب تلاش واقعی سُست ہو جائے، پہلے نہیں۔ (یہ کوڈنگ کورس کے "جب کچھ غلط ہو تب rule شامل کرو، پہلے نہیں" سے مماثل ہے۔)
11. انڈیکسز، کون سا استعمال کریں، اور انہیں ٹیون کیسے کریں

Neon پر، زندہ انتخاب درمیانی کارڈ ہے: HNSW آپ کا کام کرنے والا گھوڑا ہے (IVFFlat ایک legacy آپشن کے طور پر)۔ StreamingDiskANN کارڈ TigerData پر native ہے؛ Neon سے، اس تک پہنچنے کا مطلب کسی ایسے host پر جانا ہے جو pgvectorscale فراہم کرے۔
ایجنٹ آپ کے لیے انڈیکس بناتا ہے، آپ کا کام یہ پہچاننا ہے کہ اس نے کیا بنایا اور تصدیق کرنا کہ یہ آپ کی کوئریوں سے میل کھاتا ہے۔ ایک پابندی جو کارڈ نہیں دکھاتے: ایک کالم صرف ایک ویکٹر انڈیکس type رکھ سکتا ہے، اس لیے یہ ایک حقیقی یا-یہ-یا-وہ والا معاملہ ہے۔ ہر ایک کچھ ایسا دکھتا ہے:
-- HNSW — your default on Neon
CREATE INDEX ON quotes_embedding USING hnsw (embedding vector_cosine_ops);
-- IVFFlat — also on Neon; legacy, needs a lists parameter; recall drifts as data grows, so periodic rebuilds
CREATE INDEX ON quotes_embedding USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);
-- StreamingDiskANN — native on TigerData; on Neon only via a pgvectorscale host
CREATE INDEX ON quotes_embedding USING diskann (embedding vector_cosine_ops);
vector_cosine_ops پر غور کریں، انڈیکس کو اُس distance function سے میل کھانا چاہیے جو آپ کی کوئریاں استعمال کرتی ہیں (<=> ← cosine)۔ اسے غلط ملائیں اور انڈیکس خاموشی سے کوئی مدد نہیں کرے گا۔
اصل میں فیصلہ کیسے کریں: اسے benchmark کریں۔ HNSW کی دو build-time settings ہیں، m اور ef_construction، جو انڈیکس بنتے وقت graph کی شکل طے کرتی ہیں۔ یہ بالکل اسی قسم کی چیز ہیں جنہیں آپ کبھی یاد نہیں کرتے: اپنے حقیقی workload کو بیان کریں، اور ایک پھینکنے والی branch کو تجربے کی قیمت چکانے دیں۔ دو پرامپٹ (یہاں قطاروں کی تعداد ایک حقیقی-پیمانے کا متبادل ہے، آپ یہی benchmark حصہ 5، مرحلہ 5 میں حقیقت میں چلائیں گے، ایک پھینکنے والی branch پر جو پیمانے تک بھری ہو، تاکہ یہ ایک مہارت بن کر بیٹھے نہ کہ ایک کہانی):
ہمارے پاس تقریباً 2 ملین quote-vectors ہیں اور ہم زیادہ تر تلاشیں شہر کے حساب سے فلٹر کرتے ہیں۔ ایک تازہ Neon branch پر، اپنی ڈیفالٹ settings کے ساتھ ایک HNSW انڈیکس بناؤ، دس نمائندہ تلاشیں چلاؤ، اور p95 latency رپورٹ کرو۔
اب
mاورef_constructionکو ٹیون کرو: چند settings آزماؤ، ہر ایک پر وہی دس تلاشیں دوبارہ چلاؤ، اور ایک کی سفارش کرو، tradeoff کو ایک پیراگراف میں سمجھاؤ۔ پھر branch پھینک دو۔
یہی AI-انجینئر والی چال ہے: آپ یاد نہیں کرتے کہ کون سی settings تیز ہیں، آپ ایجنٹ سے کسی Neon branch پر نپوائی کراتے ہیں اور ایک ایسی سفارش لاتے ہیں جسے آپ اوپر دیے کارڈز کے مقابل عقل کی کسوٹی پر پرکھ سکیں، پھر branch کو بغیر کسی قیمت کے پھینک دیں۔ یہ benchmark رفتار ناپتا ہے، recall نہیں: یہاں آنکھوں سے یہ مت دیکھیں کہ نتائج "صحیح لگتے ہیں" یا نہیں، recall کو ایمانداری سے، حقیقی embeddings پر اپنے eval سیٹ (تصور 12) کے مقابل پرکھیں، کبھی کسی مصنوعی run پر سرسری نظر سے نہیں۔ (p95 latency کا بس مطلب وہ رفتار ہے جس کے اندر 95٪ کوئریاں آ جاتی ہیں، یعنی ایک معقول بدترین-صورت جس پر آپ لکیر کھینچتے ہیں، مگر صرف تب جب کوئریاں کافی ہوں: سینکڑوں سوچیں، دس نہیں، اور صرف چند warm-up تلاشوں کے بعد جو branch کا cache گرما دیں، کیونکہ ایک تازہ Neon branch اپنی پہلی reads storage سے ٹھنڈی سرو کرتا ہے۔ دس ٹھنڈے نمونوں پر، p95 بنیادی طور پر آپ کی واحد بدترین کوئری ہے۔)
قطاروں کی تعداد ہی واحد محور نہیں، churn دوسرا ہے۔ آپ کے vectors کتنی بار دوبارہ لکھے جاتے ہیں (دوبارہ-چنکنگ، embedding ماڈلز بدلنا، time-decay دوبارہ-indexing) یہ اپنی الگ لاگت ہے۔ HNSW بغیر مکمل دوبارہ-بنے incremental inserts اور updates لیتا ہے، مگر بھاری دوبارہ-لکھائی کی مقدار وقت کے ساتھ graph کو پھلا دیتی ہے، recall کھسکتی ہے اور بالآخر آپ کو ایک REINDEX چاہیے، اور خود دوبارہ-embedding وہ compute ہے جس کی آپ قیمت چکاتے ہیں۔ تو وہ ڈیٹا جو مسلسل دوبارہ لکھا جاتا ہے، بڑا ہونے سے بہت پہلے مہنگا ہو سکتا ہے۔ ایجنٹ کو صرف اپنی قطاروں کی تعداد نہیں، اپنا حقیقی اپ ڈیٹ پیٹرن بتائیں، اور اسے اسی کے مقابل benchmark کرائیں۔
روزمرہ جاننے کے لائق واحد نوب: ef_search۔ اوپر کی build-time settings انڈیکس بن جانے کے بعد پکی ہو جاتی ہیں؛ جو ڈائل آپ اصل میں چھوئیں گے وہ query-time پر ہے، ef_search قابو کرتا ہے کہ ایک تلاش کتنی محنت سے دیکھتی ہے: زیادہ کا مطلب بہتر recall اور سُست کوئریاں، کم کا مطلب تیز اور کم درست۔ ایجنٹ اسے فی کوئری سیٹ کرتا ہے؛ یہ وہ لائن ہے جو آپ اسے چلتے دیکھیں گے:
SET LOCAL hnsw.ef_search = 100; -- raise for more recall, lower for more speed
تو چال یہ ہے: ایجنٹ کو وہ recall بتائیں جو آپ کو واقعی چاہیے اور اس سے ef_search کو اسے پانے کے لیے ٹیون کرائیں، اسے اندھا دھند زیادہ سے زیادہ مت کرائیں۔ پھر اس سے ثابت کرائیں کہ انڈیکس اپنا کام کر رہا ہے: EXPLAIN ANALYZE چلائیں، sequential scan کے بجائے ایک index scan کی جانچ کریں، اور رپورٹ دیں۔ یہ رہا فرق، output کے اُس حصے میں جو آپ اصل میں پڑھتے ہیں (وہی 2M-vector ٹیبل، ایک قابلِ استعمال انڈیکس کے ساتھ اور بغیر):
✅ GOOD — the index is doing the work
-> Index Scan using quotes_embedding_hnsw_idx on quotes_embedding
Order By: (embedding <=> $1)
Execution Time: 0.8 ms
❌ BAD — no index used; every row got scanned and sorted
-> Seq Scan on quotes_embedding (rows=2000000)
Sort Key: (embedding <=> $1)
Execution Time: 52.4 ms
دو لائنیں آپ کو بتا دیتی ہیں کہ کون سا ملا: operator لائن (Index Scan using …hnsw… بمقابلہ Seq Scan on …) اور execution time (ذیلی-ملی سیکنڈ بمقابلہ اسی ڈیٹا پر دسیوں ملی سیکنڈ)۔ Seq Scan کا مطلب ہے انڈیکس استعمال نہیں ہو رہا، عام طور پر اس لیے کہ کوئری کا distance operator انڈیکس سے میل نہیں کھاتا، یا اس لیے کہ ابھی کوئی انڈیکس موجود ہی نہیں۔ یہی وہ ایک چیز ہے جس کی ایجنٹ سے تصدیق کرائیں اس سے پہلے کہ آپ indexing کو "مکمل" کہیں۔
یہ وہ بار بار آنے والے طریقے ہیں جن سے ویکٹر سرچ خاموشی سے ٹوٹتی ہے، اور چونکہ آپ کا کام ایجنٹ کے کام کو پرکھنا ہے، یہی وہ چیزیں ہیں جن کا خیال رکھنا ہے:
- Dimension mismatch، کالم کے dimensions embedding ماڈل کے output سے میل نہیں کھاتے۔
- client میں vector type رجسٹر نہیں، ورکر (اور تلاش کا کوڈ) کو ہر اُس ڈیٹابیس connection پر pgvector رجسٹر کرنا چاہیے جو
embeddingکالم کو چھوتی ہے (register_vector)، ورنہ vectors خاموشی سے سادہ متن کے طور پر آتے جاتے ہیں: پھر inserts اور searches بغیر کسی error کے غلط برتاؤ کرتے ہیں۔ یہ وہ واحد خاموش-بگاڑ والا موڈ ہے جو SQL میں نظر نہیں آتا، اس لیے ایجنٹ سے تصدیق کرائیں کہ اس نے type رجسٹر کیا۔ - کوئی انڈیکس نہیں اُس نقطے سے آگے جہاں آپ کو اس کی ضرورت تھی، ایک خاموش سُستی، کوئی error نہیں۔
- operator / index mismatch، کوئری
<->استعمال کرتی ہے مگر انڈیکس cosine ہے، اس لیے انڈیکس نظر انداز ہو جاتا ہے۔ - chunks کے بجائے پوری دستاویزات، تصور 7 والی غلطی؛ retrieval کبھی کوئی عین چیز نہیں ڈھونڈ سکتی۔
EXPLAIN ANALYZEچھوڑ دینا، تاکہ اوپر میں سے کوئی بھی چیز کوئی نہ پکڑے یہاں تک کہ صارفین پکڑ لیں۔
فلٹرنگ میں ایک جاننے کے لائق پھندا ہے، اور یہ بالکل اوپر والے benchmark کا "زیادہ تر تلاشیں شہر کے حساب سے فلٹر" والا معاملہ ہے۔ ایک HNSW انڈیکس آپ کا WHERE clause اپنے مقررہ امیدوار بجٹ (ef_search، ڈیفالٹ 40) کو اسکین کرنے کے بعد لگاتا ہے، اس لیے کوئی انتخابی فلٹر آپ کو آپ کے LIMIT سے کم قطاروں پر چھوڑ سکتا ہے اور خاموشی سے حقیقی matches گرا سکتا ہے، جب آپ ان تلاشوں کی توثیق کریں تو LIMIT سے کم نتیجہ-تعداد پر نظر رکھیں۔ recall اونچی رکھنے والے لیور query-time پر ہیں، کوئی گھنا graph نہیں: ef_search بڑھائیں، یا iterative scans آن کریں (SET hnsw.iterative_scan = strict_order، ڈیفالٹ بند)، یا فی فلٹر-قیمت ایک جزوی HNSW انڈیکس بنائیں۔ فلٹر کالم پر ایک عام B-tree انڈیکس بھی مدد دیتا ہے، مگر HNSW اسکین کو پہلے سے تنگ کر کے نہیں، Postgres فی اسکین ایک انڈیکس استعمال کرتا ہے، اس لیے B-tree بس planner کو ایک عین-فاصلے والا متبادل دیتا ہے جسے وہ تب چن سکتا ہے جب فلٹر کافی انتخابی ہو (پوری recall، کوئی post-filter نقصان نہیں)۔ (StreamingDiskANN، یعنی اوپر کا تیسرا کارڈ، بہت بڑے پیمانے پر بھاری فلٹرڈ سرچ کے لیے بنا ہے۔) Neon پر، یہ لیور اور اچھے فلٹر انڈیکسز آپ کو پہلے کافی دور تک لے جاتے ہیں۔
حصہ 4: تلاش کو عمدہ بنانا، اعلیٰ سطح کی تہہ
ایک چلتا ہوا RAG کوئی عمدہ RAG نہیں ہوتا۔ یہیں زیادہ تر پروجیکٹ اٹک جاتے ہیں، اور یہیں چالیں جاننا آپ کو اُس شخص سے الگ کر دیتا ہے جو صرف ایک demo بنا سکتا ہے۔
12. تشخیص پر مبنی ڈیولپمنٹ (eval-driven development)
یہی عادت ایک قابلِ شِپ نظام کو ایک خوش قسمت demo سے الگ کرتی ہے۔ زیادہ تر لوگ بنانے سے شروع کرتے ہیں، پھر آنکھوں سے دیکھتے ہیں کہ output "صحیح لگتا ہے" یا نہیں۔ اس کے بجائے، سوالوں سے شروع کریں۔ کچھ بھی لکھنے سے پہلے، ایک درجن ایسے سوال لکھ لیں جو آپ کے صارفین واقعی پوچھیں گے اور انہیں ایک فائل میں رکھیں۔ وہ فائل آپ کا evaluation سیٹ ہے، یعنی آپ کا پیمانہ کہ کسی تبدیلی نے چیزوں کو بہتر کیا یا بدتر۔
پھر، جب بھی آپ نظام بدلیں، یعنی نیا embedding ماڈل، مختلف چنکنگ حکمتِ عملی، ایک شامل کردہ فلٹر، آپ eval سیٹ دوبارہ چلاتے ہیں اور اثر دیکھتے ہیں، اندازہ نہیں لگاتے۔ جیسے جیسے ایپ بڑھتی ہے، سیٹ اس کے ساتھ بڑھتا ہے (20، 50 سوال)، اور آپ regressions اپنے صارفین سے پہلے پکڑ لیتے ہیں۔
دوسرا حصہ ہے مسئلے کو ٹکڑوں میں بانٹیں۔ جب کوئی جواب خراب ہو، یہ نتیجہ مت نکالیں کہ "AI بے وقوف ہے۔" مرحلوں کا سراغ لگائیں:
- بازیافت: کیا سیمانٹک سرچ نے صحیح chunks واپس بھی کیے؟ (اکثر اصل مسئلہ ایک inventory خلا ہوتا ہے، یعنی صارفین کسی ایسی چیز کے بارے میں پوچھتے ہیں جو آپ نے ڈیٹابیس میں رکھی ہی نہیں۔)
- سیاق: کیا صحیح chunks LLM کو دیے گئے، یا بہت زیادہ/بہت کم؟
- جواب سازی: اچھا سیاق دیے جانے کے باوجود، کیا ماڈل نے پھر بھی خراب جواب دیا؟
دس میں سے نو بار ناکامی retrieval ہوتی ہے، LLM نہیں۔ اُس مرحلے کو درست کریں جو اصل میں ٹوٹا ہے۔
اپنا ابھی بنائیں، جو کچھ بھی آپ نے لوڈ کیا اس کے مقابل، یعنی حصہ 2 کے quotes، یا آپ کا اپنا ڈیٹا۔ پہلے سوال، ایجنٹ مسودہ بناتا ہے، آپ تراشتے ہیں:
ہمارا source ٹیبل پڑھو اور 12 eval سوالوں کا مسودہ بناؤ جو کوئی صارف حقیقتاً پوچھ سکتا ہے، کچھ ایک واضح source قطار والے، کچھ جن کا جواب کئی پر پھیلا ہو، اور دو چار ایسے جن کا جواب ہمارا ڈیٹا دے ہی نہیں سکتا۔ ہر ایک کے لیے متوقع جواب نوٹ کرو (یا "جواب نہیں دیا جا سکتا")، اور انہیں میرے ایڈٹ کرنے کے لیے
evals/questions.mdمیں محفوظ کرو۔
اس فائل کو برکت دینے سے پہلے ایڈٹ کریں، آپ اپنے صارفین کو جانتے ہیں، ایجنٹ نہیں۔ پھر harness جوڑیں:
ایک چھوٹا harness بناؤ جو
evals/questions.mdکے ہر سوال کو ہمارے retrieve-then-generate pipeline سے گزارے، اور ہر ایک کے لیے دکھائے: نکالے گئے chunks، آخری جواب، اور یہ کہ وہ میری توقع سے میل کھاتا ہے یا نہیں۔ خلاصہ کرو کہ کہاں ناکامی ہو رہی ہے، retrieval یا generation۔
اب سے، ہر تبدیلی اسی کے مقابل ناپی جائے گی:
evals چلاؤ اور نتائج کو آج کی baseline کے طور پر محفوظ کرو۔ ہماری اگلی تبدیلی کے بعد، دوبارہ چلاؤ اور مجھے diff دکھاؤ، کون سے سوال بہتر ہوئے، کون سے بدتر۔
429 free-tier cap ہے، bug نہیںہر eval run ہر سوال کے لیے ایک model call کرتا ہے، اور آپ set کو کئی بار دوبارہ چلائیں گے۔ Free tier پر آپ آخرکار provider کے daily request cap سے ٹکرائیں گے اور درمیان میں 429 دیکھیں گے۔ یہ cap ہے، آپ نے کچھ نہیں توڑا: انتظار کر کے retry کریں، harness کو back off اور automatic retry کروائیں، routine runs کے لیے چھوٹا free model استعمال کریں، یا billing enable کریں۔ exact limits بدلتی رہتی ہیں، اس لیے کسی number پر بھروسہ کرنے کے بجائے provider کا dashboard دیکھیں۔
تشخیص پر مبنی ڈیولپمنٹ قابلِ بھروسہ ایجنٹس کی ریڑھ کی ہڈی ہے، صرف RAG کی نہیں۔ اس کا مخصوص بیان Eval-Driven Development فوری کورس ہے، اسے اِس کے بعد کریں۔
13. فلٹرڈ سرچ: WHERE clause آپ کا دوست ہے
خالص سیمانٹک سرچ عالمی سطح پر سب سے زیادہ ملتی جلتی قطاریں واپس کرتی ہے۔ اکثر آپ وہ سب سے ملتی جلتی قطاریں چاہتے ہیں جو کسی شرط کو بھی پورا کریں۔ چونکہ آپ کے vectors آپ کے ڈیٹا کے ساتھ ہی رہتے ہیں (تصور 5)، یہ بس اسی کوئری پر ایک WHERE clause ہے، کوئی دوسرا نظام نہیں، کوئی جگل بندی نہیں۔ پانچ پیٹرن تقریباً ہر چیز کا احاطہ کرتے ہیں:
| پیٹرن | مثالی استعمال | شامل کیا گیا clause (خاکہ) |
|---|---|---|
| Metadata فلٹر | کئی پروڈکٹس میں docs کی تلاش | WHERE product = 'CRM' AND doc_type = 'api-reference' |
| Composite فلٹر | ای کامرس کی سفارشات | WHERE category = 'electronics' AND price BETWEEN 500 AND 2000 AND in_stock |
| Time فلٹر | نیوز recommender: صرف حالیہ مضامین | WHERE published_at > now() - interval '7 days' |
| Permissions فلٹر | اندرونی RAG جہاں صارفین صرف وہی دیکھیں جس کے وہ مجاز ہوں | WHERE clearance_level <= $user_level |
| Geospatial فلٹر | "5 km کے اندر چیزوں کی سفارش کرو" (PostGIS شامل کریں) | WHERE ST_DWithin(location, $point, 5000) |
ہر ایک کی شکل ایک جیسی ہے: ORDER BY embedding <=> $1 کے آگے ایک WHERE۔ permissions والا غور کرنے کے لائق ہے، یہی وہ طریقہ ہے جس سے آپ tenant A کو tenant B کی دستاویزات کبھی نکالنے سے روکتے ہیں، جو application code میں امید کرنے کے بجائے ڈیٹابیس میں نافذ کیا جاتا ہے۔
ہماری سیمانٹک سرچ میں ایک اختیاری city فلٹر شامل کرو۔ ایک Neon branch پر،
cityکالم پر ایک B-tree انڈیکس شامل کرو، یقینی بناؤ کہ فلٹرڈ کوئریاں تیز رہیں، اور مجھے ہمارے eval سیٹ پر پہلے/بعد کی latency دکھاؤ۔
14. ہائبرڈ سرچ: معنی اور کی ورڈز دونوں
2026 تک hybrid search سنجیدہ retrieval کے لیے سب سے مضبوط candidate upgrade ہے، ایسا candidate جسے آپ اپنے eval set پر confirm کرتے ہیں، آنکھ بند کر کے default کے طور پر ship نہیں کرتے۔ idea یہ ہے: keyword search اور vector search دونوں چلائیں، پھر ضم کریں۔ ہر ایک دوسرے کے اندھے دھبے کا احاطہ کرتا ہے، vector search جملے کو دوسرے انداز میں سمجھتی ہے مگر عین نایاب اصطلاحات (کوئی product code، کسی شخص کا نام) کو کم وزن دیتی ہے؛ keyword search عین اصطلاح کو ٹھیک پکڑتی ہے مگر معنی سے چوک جاتی ہے۔ Postgres دونوں کام نیٹِو طور پر کرتا ہے، keyword search full-text search (tsvector) کے ذریعے، vectors pgvector کے ذریعے، اس لیے یہ ایک ہی ڈیٹابیس رہتا ہے اور، اکثر، ایک ہی کوئری۔
وہ شکل جو معیاری بن گئی:
- دونوں سے نکالیں، حد سے زیادہ کھینچتے ہوئے، کہیں keyword سے ٹاپ 20 اور vector سے ٹاپ 20، تاکہ ضم کرنے کے لیے کافی signal ہو۔
- Reciprocal Rank Fusion (RRF) سے ضم کریں۔ RRF دونوں درجہ بند فہرستوں کو مقام سے ضم کرتا ہے، score سے نہیں، جو اس اصل سر درد کو سائیڈ سٹیپ کر دیتا ہے کہ keyword scores اور cosine distances بالکل مختلف پیمانوں پر رہتے ہیں اور انہیں معقول طریقے سے اوسط نہیں کیا جا سکتا۔ یہ SQL کی چند لائنیں ہیں اور اسے کسی ماڈل کی ضرورت نہیں۔
- (اختیاری) سب سے اوپر کے امیدواروں کو ایک cross-encoder سے دوبارہ درجہ بند کریں، یعنی ایک چھوٹا ماڈل جو ہر query–chunk جوڑے کو براہِ راست score دیتا ہے۔ یہ درستگی کا قدم ہے: RRF تقریباً 100 کا ایک اچھا pool چنتا ہے، cross-encoder وہ آخری چند ترتیب دیتا ہے جو آپ LLM کو دیتے ہیں۔ اسے صرف تب شامل کریں جب آپ کے evals کہیں کہ بہتری اضافی latency کے قابل ہے۔
وہ شکل جو ایجنٹ بناتا ہے (آپ کے پڑھنے کے لیے، ٹائپ کرنے کے لیے نہیں)، اس نے پہلے vectors کے ساتھ ایک ts full-text کالم شامل کیا ہوگا، دو درجہ بند فہرستیں RRF سے ضم، سب ایک ہی کوئری میں:
WITH kw AS ( -- keyword side: full-text search, ranked
SELECT id, row_number() OVER (ORDER BY ts_rank_cd(ts, plainto_tsquery($1)) DESC) AS rank
FROM quotes_embedding WHERE ts @@ plainto_tsquery($1) LIMIT 20
),
vec AS ( -- vector side: semantic search, ranked
SELECT id, row_number() OVER (ORDER BY embedding <=> $2) AS rank
FROM quotes_embedding ORDER BY embedding <=> $2 LIMIT 20
)
SELECT id, SUM(1.0 / (60 + rank)) AS score -- RRF: k = 60, summed across both lists
FROM (SELECT * FROM kw UNION ALL SELECT * FROM vec) r
GROUP BY id ORDER BY score DESC LIMIT 10; -- $1 = query text, $2 = query vector
اسے پڑھنا: kw keyword میل سے ٹاپ 20 واپس کرتا ہے اور vec معنی سے ٹاپ 20، ہر قطار اُس فہرست میں اپنے rank سے نشان زد (1 = بہترین)۔ آخری کوئری دونوں فہرستوں میں ہر قطار کے لیے 1 / (60 + rank) جمع کرتی ہے، اس لیے وہ قطار جو کسی بھی فہرست کے اوپر کے قریب ہو اچھا score کرتی ہے، اور وہ قطار جو دونوں میں آئے جیت جاتی ہے۔ 60 (معیاری RRF مستقل) کسی ایک اونچے rank کو حاوی ہونے سے روکتا ہے، اور چونکہ یہ مقامات پر کام کرتا ہے، آپ کو کبھی keyword scores اور cosine distances کو مختلف پیمانوں پر آپس میں ملانا نہیں پڑتا۔
ہماری vector search کے ساتھ ساتھ
quoteکالم پر full-text search شامل کرو، دونوں کو RRF سے ضم کرو، اور ہمارا eval سیٹ vector-only بمقابلہ hybrid چلاؤ۔ مجھے بتاؤ کون سے سوال بہتر ہوئے اور کتنا۔
ہائبرڈ سرچ سب سے زیادہ اُن کوئریوں پر جیتتی ہے جو کسی تصور کو کسی مخصوص اصطلاح کے ساتھ ملاتی ہیں، "Truman Capote نے شہر کے بارے میں کیا کہا" کے لیے نام کو عین ملنا چاہیے اور معنی کو سمجھنا چاہیے۔ آیا یہ واقعی آپ کے ڈیٹا پر مدد دیتی ہے، اور کتنی، یہ ایک ایسا سوال ہے جس کا جواب صرف آپ کا eval سیٹ دے سکتا ہے، اس لیے اضافی پرزے سنبھالنے سے پہلے vector-only بمقابلہ hybrid ناپیں۔
15. ملٹی ٹیننسی اور text-to-SQL
دو اور جنہیں آپ کو پہچاننا چاہیے چاہے آپ آج انہیں نہ بنائیں۔
ملٹی ٹیننسی۔ اگر آپ SaaS بنا رہے ہیں، تو ہر گاہک کا ڈیٹا ہر دوسرے سے الگ دیوار میں بند رہنا چاہیے۔ علیحدگی کی ایک سیڑھی ہے، سب سے ڈھیلی سے سب سے سخت تک:
| طریقہ | علیحدگی | لاگت / پیچیدگی | عام موزونیت |
|---|---|---|---|
مشترکہ ٹیبل + tenant_id فلٹر | سب سے کمزور | سب سے سستا | اندرونی ٹولز، کم-خطرہ ڈیٹا |
| فی tenant schema | اچھی | معتدل | زیادہ تر SaaS کے لیے بہترین مقام |
| فی tenant ڈیٹابیس | سب سے مضبوط | سب سے زیادہ (backups، ops) | اعلیٰ-سیکیورٹی / ضابطہ بند گاہک |
فی-tenant-schema عام توازن ہے: حقیقی علیحدگی، چلانے کے لیے ایک ڈیٹابیس۔ کسی بھی طرح، تصور 13 والا اصول قائم رہتا ہے، حد کو ڈیٹابیس میں نافذ کریں، صرف اپنے ایپ کوڈ میں نہیں۔ سب سے صاف Postgres طریقہ Row-Level Security (RLS) ہے: آپ ایجنٹ سے ایک بار ایک policy لکھواتے ہیں (قطاریں صرف وہیں نظر آئیں جہاں، مثلاً، tenant_id = current_setting('app.tenant')) اور پھر Postgres اسے ہر کوئری پر خودکار طور پر لاگو کرتا ہے، اس لیے ایک بھولا ہوا WHERE clause ایک tenant کے vectors کسی دوسرے کو لیک نہیں کر سکتا۔ ایک پھندا جاننے کے لائق، کیونکہ یہ پہلی بار ہر کسی کو کاٹتا ہے: RLS کو superusers اور ٹیبل کا owner بائی پاس کر دیتے ہیں، اس لیے آپ کی ایپ کو ایک عام، non-owner role کے طور پر connect کرنا چاہیے (حصہ 6 والا read-only role بالکل ٹھیک ہے)، policy کو اسی role کے طور پر آزمائیں، ورنہ آپ کو کوئی علیحدگی نظر نہیں آئے گی اور آپ غلطی سے یہ نتیجہ نکالیں گے کہ یہ کام نہیں کرتی۔
Text-to-SQL۔ Postgres ساخت والا ڈیٹا بھی رکھتا ہے، یعنی اعداد، تاریخیں، relations۔ Text-to-SQL کسی صارف کو سادہ انگریزی میں پوچھنے دیتا ہے ("Q3 میں region کے حساب سے sales کیا تھیں؟") اور ایک ایجنٹ سے اسے آپ کے حقیقی ٹیبلز کے مقابل ایک درست SQL کوئری میں ترجمہ کرواتا ہے۔ جو چیز اسے درست بناتی ہے وہ ایک اچھی طرح بیان کردہ schema ہے: واضح ٹیبل اور کالم کے نام، COMMENTs جو سمجھائیں کہ ہر ایک کا مطلب کیا ہے، اور چند مثالی سوال→کوئری جوڑے جن سے ایجنٹ سیکھ سکے۔ ایجنٹ کو وہ سیاق دیں، SQL چلنے سے پہلے اس کا جائزہ لینے کے لیے ایک انسان کو لُوپ میں رکھیں، اور اسے سیمانٹک سرچ (اپنی دستاویزات کے لیے) کے ساتھ ملائیں، یعنی ایک ایجنٹ جو فی سوال صحیح ٹول چنتا ہے، ایک حقیقی data assistant کی بنیاد ہے۔
اسے ہماری schema پر دو پرامپٹس میں حقیقی بنائیں۔ پہلے، ایجنٹ سے زمین تیار کروائیں:
ہمارے ٹیبلز کو یوں دستاویز کرو کہ انگریزی سوال اچھی طرح ترجمہ ہوں: ٹیبلز اور کالمز پر comments شامل کرو جو بتائیں کہ ہر ایک میں کیا ہے، اور چند مثالی سوال اُس SQL کے ساتھ محفوظ کرو جو انہیں پیدا کرنا چاہیے۔
پھر بس پوچھیں، سادہ انگریزی میں:
کس شخص کے سب سے زیادہ quotes ہیں، اور اُن کے quotes شہروں میں کیسے پھیلے ہیں؟ پہلے مجھے وہ SQL دکھاؤ جو تم چلاؤ گے، صرف میری منظوری کے بعد عمل کرو۔
Text-to-SQL ایک اور نام سے plan mode ہی ہے: ایجنٹ سے پہلے SQL دکھواؤ، خاص طور پر ہر وہ چیز جو لکھتی ہے۔ ایک غلط SELECT ایک سیکنڈ ضائع کرتا ہے؛ ایک غلط UPDATE آپ کی دوپہر برباد کر دیتا ہے۔
حصہ 5: ایک مکمل عملی مثال
ایک کام، شروع سے آخر تک: ایک خالی Neon پروجیکٹ سے ایک چلتے ہوئے Q&A تک جو آپ کی دستاویزات سے جواب دیتا ہے۔ نیچے دیے پرامپٹ ہی پورا کام ہیں، انہیں کسی بھی ٹول میں ٹائپ کریں۔ طریقہ وہی کوڈنگ کورس والی ایک چال ہے، پورے سائز پر: ایک مضبوط ماڈل سے منصوبہ بنائیں، منصوبہ جانچیں، پھر ایک سستے ماڈل کو روزمرہ کا build کرنے دیں۔
یہ ہر صورت میں کام کرتا ہے، آپ جیسے بھی پہنچیں۔ آپ اسی postgres-ai/ فولڈر میں رہتے ہیں، مگر build ایک بالکل نیا Neon پروجیکٹ بناتا ہے، اس لیے quotes والے build کی کوئی چیز نہیں چھیڑی جاتی، چاہے آپ نے تصورات 5 تا 9 پر کام کیا ہو یا سیدھے یہاں آ گئے ہوں۔ اگر منصوبہ ایسے functions دوبارہ استعمال کرنے کی تجویز دے جو آپ پہلے ہی بنا چکے، تو ٹھیک ہے؛ جائزے میں اسے پرکھیں۔
0. build کو دستاویزات اور ایک گھر دیں، بیس کوئی نہیں دیتا، تو کچھ بنائیں (اور اگر یہ فولڈر ابھی تک uv پروجیکٹ نہیں ہے، تو یہ وہ بھی ٹھیک کر دیتا ہے)۔ پیسٹ کریں:
اس فولڈر کو ایک uv-managed Python پروجیکٹ کے طور پر سیٹ اپ کرو اگر یہ پہلے سے نہیں ہے۔ پھر ایک
docs/فولڈر بناؤ جس میں دس مختصر markdown فائلیں ہوں: ایک خیالی کمپنی کے لیے ایک چھوٹی ملازم ہینڈ بک، یعنی چھٹی، اخراجات، سیکیورٹی، onboarding، آلات۔
1. پہلے منصوبہ، ایک مضبوط ماڈل کے ساتھ plan mode میں داخل ہوں (Claude Code میں Shift+Tab، OpenCode میں Tab)، پھر پیسٹ کریں:
میرے پاس markdown فائلوں کا ایک فولڈر
./docsہے۔ Neon پر ایک RAG نظام بناؤ: Neon MCP سرور استعمال کرتے ہوئے، ایک پروجیکٹ اور ایکdevbranch بناؤ، pgvector فعال کرو، docs کو ایک ٹیبل میں لوڈ کرو، ایک چھوٹا embedding ورکر بناؤ جو انہیں chunk اور embed کر کے ایک ساتھیchunksٹیبل میں ڈالے، اور مجھے ایکanswer_question()فنکشن دو جو پہلے retrieve پھر generate کرے۔ کچھ بھی چلانے سے پہلے مجھے پورا منصوبہ اور schema دکھاؤ۔
2. منظوری سے پہلے منصوبہ پڑھیں۔ جانچیں: کیا یہ کسی Neon branch پر کام کر رہا ہے؟ کیا pgvector فعال ہے؟ کیا embedding ورکر API key ماحول سے پڑھتا ہے (اور کیا key repo سے باہر رکھی گئی ہے)؟ کیا generation ایپ کوڈ میں ہے؟ اگر سب ہاں، تو منظوری دیں۔
3. عمل، تین checkpoints میں، روزمرہ کے build کے لیے ایک سستے ماڈل پر سوئچ کریں (کسی بھی ٹول میں /model)، اور پورا منصوبہ آنکھ بند کر کے مت چلائیں: اسے مرحلوں میں چلائیں، ہر ایک کے بعد دیکھنے کو کچھ ہو۔ پہلے ڈیٹابیس:
ٹھیک لگتا ہے۔ ڈیٹابیس اور ورکر کے ساتھ آگے بڑھو: پروجیکٹ اور
devbranch بناؤ، pgvector فعال کرو، docs لوڈ کرو، اور ورکر کو ایک بار چلاؤ۔ پھر مجھے دکھاؤ کہ ہر دستاویز نے کتنے chunks بنائے، تاکہ میں دیکھ سکوں کہ دستاویزات آ گئیں۔
retrieval اگلا، جواب سے پہلے chunks، بالکل تصور 9 جیسا:
اب تلاش والا حصہ۔ retrieval فنکشن بناؤ اور اسے تین سوالوں پر چلاؤ جو کوئی نیا ملازم پوچھ سکتا ہے، مجھے صرف وہ chunks دکھاؤ جو واپس آتے ہیں، ابھی کوئی جواب نہیں۔
اگر صحیح chunks واپس آ رہے ہیں، تو generation آسان حصہ ہے:
اس کے گرد
answer_question()لپیٹو۔ پھر پانچ سوال پوچھو جو کوئی نیا ملازم واقعی پوچھے گا اور مجھے نکالے گئے chunks ہر جواب کے ساتھ ساتھ دکھاؤ۔
4. تشخیص کریں، پھر دہرائیں، کچھ جواب دوسروں سے کمزور ہوں گے؛ یہ لُوپ کا آغاز ہے، ناکامی نہیں۔ پیسٹ کریں:
سب سے کمزور جوابات نے غیر متعلقہ chunks استعمال کیے۔ تشخیص کرو: یہ retrieval ہے یا generation؟ اگر retrieval، تو ایک تازہ branch پر مختلف چنکنگ حکمتِ عملی آزماؤ اور وہی پانچ سوال دوبارہ چلاؤ۔
اب آپ کے پاس ایک چلتا ہوا RAG ہے۔ اگلے چار مرحلے ٹیوننگ کی تہہ ہیں (حصہ 3 تا 4)، اور آپ ہر ایک کو چلائیں گے، صرف اس کے بارے میں پڑھیں گے نہیں۔ ہر سیکھنے والا یہ کرتا ہے، اُسی ڈیٹا پر جو آپ کے پاس پہلے سے ہے، تاکہ گہرائی ایک مہارت بن کر بیٹھے۔ یہ آزاد ہیں: انہیں کسی بھی ترتیب میں کریں، کوئی نہ چھوڑیں۔
5. اسے تیز بنائیں، اور انڈیکس کو اپنی کمائی کرتے دیکھیں (تصور 11)۔ دس دستاویزات اتنی چھوٹی ہیں کہ انہیں انڈیکس کی ضرورت نہیں، تو آپ پیمانہ خود بنائیں گے، ایک ایسی branch پر جسے آپ پھینک دیں گے، اور تلاش کو اسی ڈیٹا پر سُست سے فوری ہوتے دیکھیں گے۔ پیسٹ کریں:
ایک پھینکنے والی Neon branch پر، ایک benchmark ٹیبل بناؤ اور اسے اتنے random vectors سے بھرو کہ تقریباً 100k کی حد عبور ہو جائے جہاں انڈیکس جیتنا شروع کرتا ہے، کوئی embeddings یا حقیقی متن نہیں چاہیے، یہ خالصتاً پیمانہ بنانے کے لیے ہے۔ یقینی بناؤ کہ ہر row کو اپنا الگ random vector ملے (عام غلطی ہر row میں وہی vector بھر دیتی ہے، agent سے
count(distinct embedding)کے ساتھ verify کرواؤ)۔ اسے اتنا رکھو کہ یہ Neon کے مفت storage کے اندر رہے؛ اگر اس سے یہ سما جاتا ہے تو اس مصنوعی ٹیبل کے لیے ایک چھوٹی vector dimension استعمال کرو۔ ایک nearest-neighbour تلاشEXPLAIN ANALYZEکے ساتھ چلاؤ اور مجھے منصوبہ اور وقت دکھاؤ۔ پھر HNSW انڈیکس بناؤ، build کے لیےmaintenance_work_memبڑھاؤ تاکہ یہ رینگتا نہ رہے، اور وہی تلاش دوبارہ چلاؤ۔ دونوں کو ساتھ ساتھ رکھو: operator لائن اور execution time، پہلے اور بعد۔ پھرef_searchکو بڑھاؤ اور گھٹاؤ اور مجھے دکھاؤ کہ latency کیسے حرکت کرتی ہے۔ ہمارے فارغ ہونے پر branch حذف کر دو، اس سے storage واپس مل جاتا ہے۔
تب مکمل جب: آپ نے اپنی آنکھوں سے Seq Scan کو Index Scan using …hnsw… بنتے اور اُسی ڈیٹا پر execution time گرتے دیکھ لیا، اور آپ نے ef_search کو latency ہلاتے دیکھ لیا۔ یہی تصور 11 کا speed والا نصف، ہو گیا۔ (تین چیزیں جو مسئلے لگتی ہیں مگر ہیں نہیں: 100k+ vectors پر HNSW انڈیکس بننے میں چند منٹ لگتے ہیں، سیکنڈ نہیں، یہ متوقع ہے، کوئی hang نہیں، اور build کے لیے maintenance_work_mem بڑھانے سے یہ کافی کم ہوتا ہے؛ اس پھینکنے والے ٹیبل کے لیے ایک چھوٹی dimension استعمال کرنا سبق کے بارے میں کچھ نہیں بدلتا، کیونکہ index-scan-بمقابلہ-seq-scan اور ef_search latency ڈائل کسی بھی dimension پر ایک جیسا برتاؤ کرتے ہیں؛ اور یہ random vectors ایمانداری سے speed دکھاتے ہیں، مگر real recall نہیں دکھا سکتے، کیونکہ random points میں neighbourhood structure نہیں ہوتا، اس لیے یہاں poor recall number کا کوئی مطلب نہیں۔ recall کو real embeddings پر اپنے eval set کے خلاف judge کریں، synthetic data پر کبھی نہیں۔ آپ انڈیکس benchmark کر رہے ہیں، retrieval نہیں۔)
6. معنی اور ایک شرط دونوں سے فلٹر کریں (تصور 13)۔ آپ کی ہینڈ بک دستاویزات قدرتی زمروں میں آتی ہیں (چھٹی، اخراجات، سیکیورٹی، onboarding، آلات)، تو آپ حقیقت میں فلٹر کر سکتے ہیں:
ہر chunk کو اُس دستاویز کے زمرے سے ٹیگ کرو جہاں سے وہ آیا۔ ہماری تلاش میں ایک اختیاری
categoryفلٹر شامل کرو۔ "مجھے چھٹی کے کتنے دن ملتے ہیں؟" دو بار پوچھو، ایک بار ہر چیز پر، ایک بار چھٹی کے زمرے تک فلٹر کر کے، اور مجھے دکھاؤ کہ نکالے گئے chunks کیسے بدلتے ہیں۔categoryپر ایک B-tree انڈیکس شامل کرو اورEXPLAIN ANALYZEسے تصدیق کرو کہ فلٹر اسے استعمال کرتا ہے۔
تب مکمل جب: فلٹرڈ کوئری زیادہ گٹھے ہوئے، موضوع پر chunks واپس کرے، اور آپ نے منصوبے میں B-tree انڈیکس دیکھ لیا، یعنی تصور 5 والا WHERE-clause-اسی-کوئری-پر والا فائدہ، حقیقی بن گیا۔
7. وہ عین اصطلاح پکڑیں جو اکیلا معنی چوک جاتا ہے (تصور 14)۔ یہیں آپ محسوس کرتے ہیں کہ ہائبرڈ سرچ ڈیفالٹ کیوں بنی:
ایک نایاب عین code کسی ایک دستاویز میں رکھو، کہیں اخراجات والی فائل میں
EXP-2031۔ "EXP-2031 کیا ہے؟" vector-only تلاش سے پوچھو اور مجھے دکھاؤ یہ کہاں درجہ پاتا ہے۔ اب chunk متن پر full-text search شامل کرو، دونوں فہرستوں کو RRF سے ضم کرو، اور دوبارہ پوچھو، عین match کا rank کیسے بدلتا ہے یہ دکھاؤ۔ پھر ہمارے پانچ eval سوال vector-only بمقابلہ hybrid دوبارہ چلاؤ اور بتاؤ کون سے بہتر ہوئے۔
تب مکمل جب: آپ compare کر چکے ہوں کہ code vector-only بمقابلہ hybrid میں کہاں rank کرتا ہے اور اپنے eval set کو net effect دکھانے دیا ہو، اس لیے آپ نے hybrid کا فیصلہ ثبوت پر کیا، کسی سرخی کی وجہ سے نہیں۔ (اتنے چھوٹے corpus میں vector search rare code کو پہلے ہی top کے قریب rank کر سکتی ہے؛ hybrid جس gap کو بند کرتا ہے وہ corpus بڑھنے اور rare token کے بہت سے chunks میں dilute ہونے پر چوڑا ہوتا ہے۔ اگر hybrid یہاں صاف move نہ کرے تو یہ scale effect ہے، failure نہیں، RRF query چلتی ہے یہ confirm کریں اور eval comparison کو verdict بننے دیں۔)
8. ایک tenant کو دوسرے سے الگ دیوار میں بند کریں (تصور 15)۔ وہ علیحدگی جو اسے ایسی چیز بنا دیتی ہے جسے آپ بیک وقت دو گاہکوں کو بیچ سکیں:
ہمارے chunks کو دو فرضی tenants سے ٹیگ کرو، docs کو آدھا آدھا بانٹو۔ ایک Row-Level Security policy لکھو تاکہ tenant A پر سیٹ کیا گیا سیشن صرف tenant A کے chunks ہی کبھی نکال سکے۔ پھر اسے ایک عام، non-owner ڈیٹابیس role سے ثابت کرو (RLS کو superusers اور ٹیبل owner بائی پاس کر دیتے ہیں، اس لیے اُسی admin role کے طور پر آزمانا جس نے ٹیبل بنایا کوئی علیحدگی نہیں دکھاتا، اس کے بجائے ایک سادہ read-only role استعمال کرو): agent سے وہ role آپ کے لیے بنواؤ (ایک
CREATE ROLE+GRANT SELECT،SET ROLEیا الگ Neon role اور connection string سے connected، ہاتھ سے setup نہیں)، سیشن tenant A پر سیٹ کرو اور ایسی تلاش چلاؤ جو ورنہ کسی tenant-B chunk سے ملتی، دکھاؤ کہ یہ کبھی واپس نہیں آتا، پھر tenant B پر سوئچ کرو اور آئینے والی تصویر دکھاؤ۔
تب مکمل جب: وہی ایک جیسی کوئری صرف اِس بنیاد پر مختلف قطاریں واپس کرے کہ سیشن کس tenant پر سیٹ ہے، اور آپ نے اسے ایک non-owner role کے طور پر چلایا (تاکہ دیوار حقیقی ہو)۔ یہی تصور 15 کا "اسے ڈیٹابیس میں نافذ کرو" ٹھوس شکل میں ہے، یعنی RLS، نہ کہ کوئی WHERE clause جو آپ بھول سکتے ہیں۔
تال پر غور کریں، اور غور کریں کہ مشکل حصوں کے لیے یہ بدلی نہیں: منصوبہ ← جائزہ ← عمل ← تشخیص ← دہراؤ۔ انڈیکسز، فلٹرز، hybrid، اور tenant علیحدگی وہی لُوپ ہیں جو پہلا RAG build تھا، ہر بار صرف نئی چیز یہ ہے کہ آپ کس چیز کا جائزہ لے رہے ہیں (schema، ورکر، انڈیکس کا منصوبہ، RLS policy)۔ اُس لُوپ میں مہارت پا لیں اور مخصوص SQL کی اہمیت ختم ہو جاتی ہے، کیونکہ آپ ہمیشہ ایجنٹ سے اسے بنوا سکتے ہیں اور آپ ہمیشہ بتا سکتے ہیں کہ یہ صحیح ہے یا نہیں، کسی بھی گہرائی پر، صرف آسان والی پر نہیں۔
حصہ 6: اپنے RAG کو MCP ٹول کے طور پر شِپ کریں
آپ نے search_quotes() اور answer_question() (تصور 9) بنائے ہیں، اور حصہ 5 میں، ان کے دستاویزی جڑواں؛ یہ حصہ ان میں سے جسے بھی آپ سرو کرنا چاہیں اسے لپیٹتا ہے۔ ابھی صرف آپ کا کوڈ انہیں کال کر سکتا ہے۔ انہیں ایک Model Context Protocol (MCP) سرور میں لپیٹیں اور وہی retrieval ایک ایسا ٹول بن جاتی ہے جسے کوئی بھی ایجنٹ دریافت اور کال کر سکتا ہے، یعنی Claude Code، OpenCode، Claude Desktop، Cursor، یا کوئی Digital FTE جو آپ بعد میں بنائیں۔ MCP وہ کھلا معیار ہے جس کی طرف یہ کتاب بار بار لوٹتی ہے: صلاحیت ایک بار لکھیں، اور ہر ایجنٹ اس سے ایک ہی طرح بات کرتا ہے۔
یہ تصور 9 کا وعدہ ہے، کہ retrieval وہ قابلِ تلاش سیاق ہے جس پر ایک ایجنٹ تکیہ کرتا ہے، حقیقی شکل میں۔ آپ کی ویکٹر سرچ ایک ایپ میں دبا ہوا فیچر ہونا چھوڑ دیتی ہے اور ایک دوبارہ-قابلِ استعمال صلاحیت بن جاتی ہے: ایسی چیز جس کی طرف ایک ایجنٹ یوں ہاتھ بڑھاتا ہے جیسے کسی calculator کی طرف۔
آپ اب دونوں سے مل چکے ہیں، اور وہ ایک دوسرے کے الٹ کام کرتے ہیں:
- Neon MCP سرور (تصور 4) ایک dev-time admin ٹول ہے۔ client اسے build کے دوران مقامی طور پر stdio پر چلاتا ہے، یعنی branches بنانا، SQL چلانا، migrations کا پیش منظر دیکھنا۔ یہ production یا آخری صارفین کے لیے نہیں ہے۔
- RAG MCP سرور (یہ حصہ) runtime پر آپ کی پروڈکٹ کی سطح ہے، یعنی ایک Streamable HTTP سروس جو آپ خود چلاتے اور cloud میں host کرتے ہیں، جہاں کوئی بھی ایجنٹ اسے URL سے پہنچتا ہے۔ یہ read-only retrieval کھولتا ہے، یعنی "میرے علم کو تلاش کرو،" "میرے ڈیٹا سے جواب دو"، جس بھی ایجنٹ کی طرف آپ اسے موڑیں۔
پہلا والا نظام کو بناتا ہے۔ دوسرا والا خود نظام ہے، جو ایجنٹس کو پیش کیا جاتا ہے۔ transport کردار کے پیچھے چلتا ہے: ایک مقامی dev ٹول جسے client چلاتا ہے stdio بولتا ہے؛ ایک host شدہ پروڈکٹ جسے آپ deploy کرتے ہیں HTTP بولتا ہے۔ Neon admin سرور کبھی آخری صارفین کے حوالے نہ کریں۔
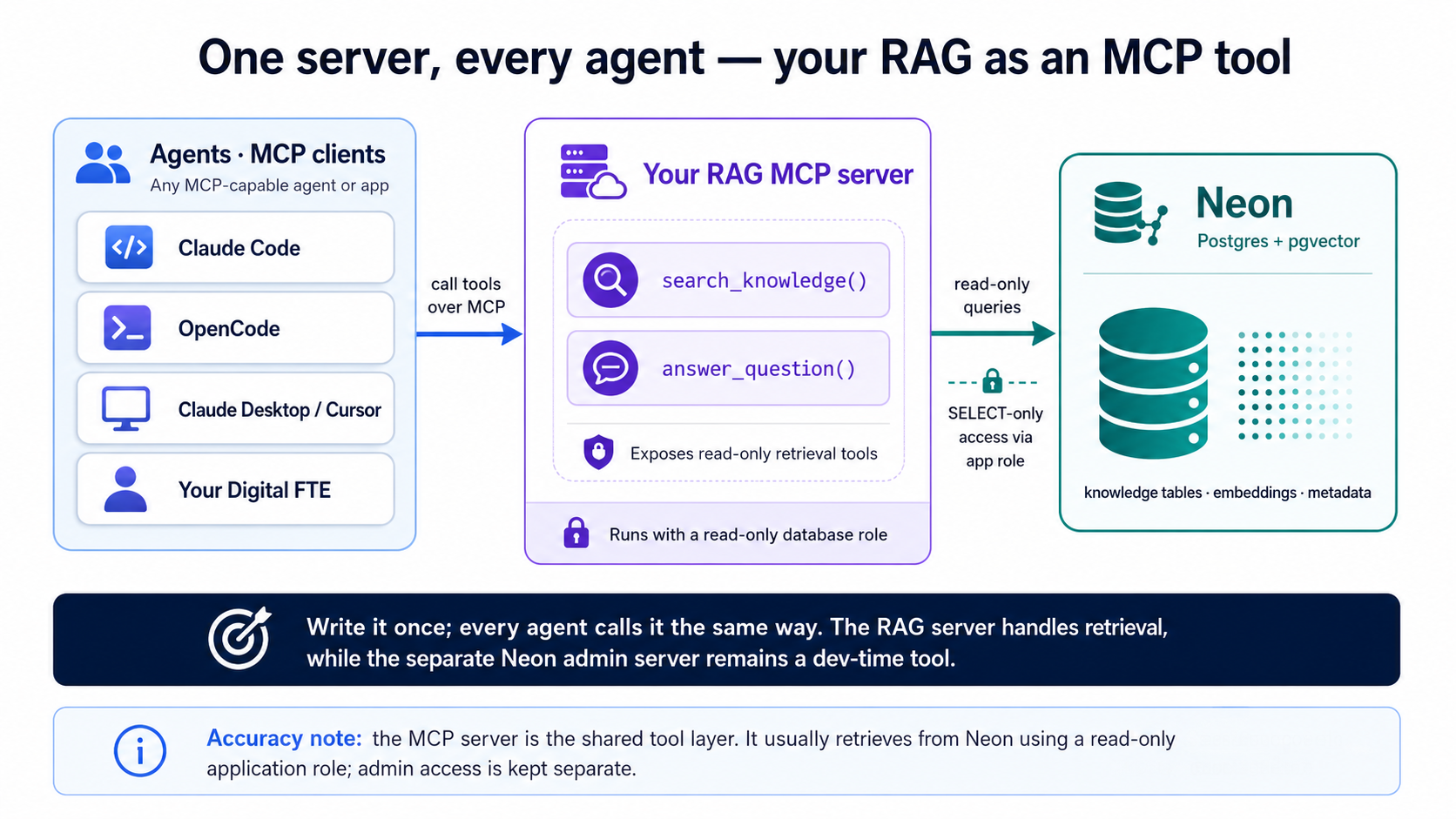
سرور کیسا دکھتا ہے
ایک MCP سرور ایک چھوٹا پروگرام ہے جو ٹولز کی ایک فہرست کا اعلان کرتا ہے جنہیں ایک ایجنٹ کال کر سکتا ہے۔ FastMCP کے ساتھ، یعنی معیاری Python لائبریری، جو سرکاری MCP SDK پر ایک پتلی decorator تہہ ہے، ہر ٹول بس ایک typed فنکشن ہوتا ہے جس کا ایک docstring ہوتا ہے؛ آپ کوئی JSON-RPC والی پلمبنگ نہیں لکھتے۔ ہمیشہ کی طرح، یہ ایجنٹ لکھتا ہے، یہ اس لیے دکھایا گیا ہے کہ آپ اسے پرکھ سکیں:
# server.py — your RAG, exposed as MCP tools (review material, not to type)
import os
from fastmcp import FastMCP
from rag import search_quotes, answer_question as rag_answer # your Concept 9 functions —
# renamed on import so the MCP tool below can keep the public name "answer_question"
mcp = FastMCP("agent-factory-rag")
@mcp.tool()
def search_knowledge(query: str, limit: int = 5) -> list[dict]:
"""Search the knowledge base by meaning and return the closest chunks.
Use this when you need grounded facts from the user's own data."""
# embeds `query` in app code, runs the Concept 8 search on Neon,
# returns [{text, source, score}, ...] — retrieval only, read-only role
return search_quotes(query, limit)
@mcp.tool()
def answer_question(question: str) -> str:
"""Answer a question grounded in the knowledge base (retrieve, then generate)."""
return rag_answer(question) # the Concept 9 pipeline
if __name__ == "__main__":
# Streamable HTTP, stateless — the production shape. The same file runs on
# your laptop and in the cloud; stateless means no session is held between
# requests, so it scales behind a load balancer. (host="0.0.0.0" binds all
# interfaces so a container can route to it; locally you reach it on localhost.)
mcp.run(transport="http", host="0.0.0.0", port=8000, stateless_http=True)
دو چیزیں باقی سب سے زیادہ اہم ہیں۔ docstring ہی interface ہے، یہ وہ متن ہے جسے کال کرنے والا ایجنٹ پڑھتا ہے تاکہ فیصلہ کرے کہ ٹول کب استعمال کرنا ہے، اس لیے اسے صاف صاف بتانا چاہیے کہ ٹول کیا کرتا ہے اور اس کی طرف کب ہاتھ بڑھانا ہے۔ اور retrieval read-only رہتی ہے: ٹول تصور 8 والی parameterized تلاش ایک read-only ڈیٹابیس role کے تحت چلاتا ہے، اس لیے کوئی ٹول argument آپ کے ڈیٹا کو کبھی نہ بدل سکتا ہے نہ لیک کر سکتا ہے۔ تیسری لائن بھی دیکھنے کے لائق ہے، یعنی آخری، mcp.run(transport="http", …, stateless_http=True)، جو اِسے ایک ایسی سروس بنا دیتی ہے جسے آپ host کر سکتے ہیں نہ کہ کوئی local subprocess؛ آپ اسے آگے چلائیں گے، پھر بعینہٖ وہی فائل deploy کریں گے۔
اسے اپنے ایجنٹ کے ساتھ بنائیں
ہر جگہ جیسا ہی نظم، یعنی منصوبہ، جائزہ، عمل۔ یہی وہ لمحہ بھی ہے جب آپ کے setup والی mcp-builder skill اپنی کمائی کرتی ہے، اسے نام لے کر بلائیں، اور ایجنٹ سرور کو ویسے بناتا ہے جیسے skill سکھاتی ہے۔ plan mode میں:
mcp-builder skill استعمال کرتے ہوئے، ہماری retrieval کو
agent-factory-ragنام کے ایک FastMCP سرور میں لپیٹو۔ دو ٹولز کھولو:search_knowledge(query, limit)جو سب سے زیادہ ملتے chunks کو ان کے source اور similarity score کے ساتھ واپس کرے، اورanswer_question(question)جو ایک جڑا ہوا جواب واپس کرے۔ ہمارے موجودہsearch_quotesاورanswer_questionfunctions دوبارہ استعمال کرو۔ Neon کی pooled connection string اور ماڈل API keys ماحول سے پڑھو، اور ایک read-only ڈیٹابیس role سے connect کرو۔ واضح، عمل پر مبنی ٹول docstrings لکھو، یہی وہ ہے جو کال کرنے والا ایجنٹ پڑھتا ہے تاکہ فیصلہ کرے کہ ہر ٹول کب استعمال کرنا ہے۔ کوئی بھی کوڈ لکھنے سے پہلے مجھے منصوبہ اور ٹول کی فہرست دکھاؤ۔
منصوبہ پڑھیں، ٹول کی فہرست اور read-only role کی تصدیق کریں، پھر منظوری دیں اور اسے بنانے دیں۔
اسے چلائیں، پھر جوڑیں
یہاں Neon admin سرور سے فرق آتا ہے: وہ والا client آپ کے لیے چلاتا ہے؛ یہ والا آپ شروع کرتے ہیں، اور ایجنٹس اس کے URL سے جڑتے ہیں۔ یہی production والی شکل ہے، چاہے یہ آپ کے laptop پر چلے یا cloud میں، ایک جیسی۔ اسے شروع کریں:
uv run server.py
یہ چلتا رہتا ہے اور بتاتا ہے کہ کہاں سرو ہو رہا ہے، آپ banner میں http://0.0.0.0:8000/mcp دیکھیں گے (0.0.0.0 کا بس مطلب ہے "ہر interface پر سن رہا ہے"؛ آپ اس سے localhost کے طور پر جڑتے ہیں)۔ اسے اِس terminal میں چلتا چھوڑیں، اپنے ایجنٹ کے لیے ایک اور کھولیں، اور اسے localhost پر رجسٹر کریں:
claude mcp add --transport http rag http://localhost:8000/mcp
اسے claude mcp list سے جانچیں؛ سیشن کے درمیان /mcp سے دوبارہ connect کریں۔
opencode.json میں ایک remote block شامل کریں:
{
"$schema": "https://opencode.ai/config.json",
"mcp": {
"rag": {
"type": "remote",
"url": "http://localhost:8000/mcp",
"enabled": true
}
}
}
پھر بس کسی پرامپٹ میں کہیں "rag ٹول استعمال کرو"، یہی وہ add ← check ← use بہاؤ ہے جو آپ تصور 4 کے Neon سرور سے جانتے ہیں، صرف یہاں آپ کسی کمانڈ کے بجائے ایک URL کی طرف اشارہ کرتے ہیں۔ اسے آزمائیں:
rag ٹول استعمال کر کے جواب دو: نیویارک کے بارے میں لوگوں نے کیا کہا؟ مجھے دکھاؤ اس نے پہلے کون سے chunks نکالے۔
ایجنٹ کو search_knowledge کال کرتے، آپ کے chunks واپس لیتے، اور اپنا جواب ان میں جڑا کرتے دیکھیں۔ وہ راؤنڈ ٹرپ ہی پورا نکتہ ہے: آپ کا ڈیٹا اب ایسی چیز ہے جس پر کوئی بھی ایجنٹ غور کر سکتا ہے۔
اسے cloud پر شِپ کریں
ایک مقامی سرور جس تک صرف آپ پہنچ سکیں ابھی پروڈکٹ نہیں، اور ایک MCP ٹول کا مقصد وہاں چلنا ہے جہاں کوئی بھی ایجنٹ اسے کال کر سکے۔ یہیں اسے شروع سے stateless بنانے کا فائدہ ملتا ہے: اسے deploy کرنے کے لیے سرور میں کچھ نہیں بدلتا۔ آپ وہی server.py کسی بھی ایسے host پر push کرتے ہیں جو Python سروس چلائے (Cloud Run، Render، Railway، Fly پر ایک container، یا آپ کی اپنی VM)، وہاں وہی environment variables سیٹ کرتے ہیں، اور localhost کے بجائے عوامی URL رجسٹر کرتے ہیں:
claude mcp add --transport http rag https://your-host/mcp
اُس .mcp.json کو commit کریں اور ہر وہ شخص جو repo clone کرتا ہے اُسی ایک host شدہ سرور تک پہنچتا ہے (Claude Code انہیں ایک بار اسے منظور کرنے کا کہتا ہے)؛ OpenCode میں، وہی "type": "remote" block عوامی URL کی طرف موڑیں۔ جس لمحے ایک سے زیادہ شخص connect کریں OAuth شامل کریں۔
stateless ہی اسے محفوظ کیوں بناتا ہے: ہر request اپنا سیاق خود ساتھ لاتی ہے، کالوں کے درمیان کوئی سیشن نہیں رکھا جاتا، اس لیے سرور serverless cold-starts کو نظر انداز کر دیتا ہے اور بغیر sticky sessions کے ایک load balancer کے پیچھے کئی replicas کے طور پر چلتا ہے، اور ایک retrieval ٹول، جو فی-صارف کوئی گفتگو نہیں رکھتا، اس سے کچھ نہیں کھوتا۔ جس transport پر آپ بنا رہے ہیں، یعنی Streamable HTTP، وہ مستحکم production ہدف ہے؛ ایک تیز بدلتی تفصیل بس عین FastMCP keyword ہے، اس لیے جب ایجنٹ اسے لکھے تو mcp-builder skill یا live docs سے transport="http" اور stateless_http کی تصدیق کرائیں۔ Neon admin سرور کسی بھی طرح ایک مقامی dev ٹول ہی رہتا ہے۔
کچھ rules جو ایجنٹ سے منوائیں، اور جائزے میں تصدیق کریں:
- Read-only role۔ retrieval ٹولز صرف اور صرف
SELECTکرتے ہیں۔ ایک ایسے ڈیٹابیس role سے connect کریں جو لکھ نہ سکے، تاکہ کوئی ٹول argument ڈیٹا کو حذف یا تبدیل نہ کر سکے۔ - Parameterized queries۔ query متن ایک bound parameter کے طور پر آتا ہے، کبھی SQL میں string-concatenate ہو کر نہیں، یعنی وہی اصول جو تصور 8 کا تھا۔
- ملٹی ٹیننسی: کسی سادہ ٹول argument کے طور پر pass کیے گئے
tenant_idپر کبھی بھروسہ نہ کریں۔ اسے authenticated سیشن سے اخذ کریں اور اسے RLS (تصور 15) سے نافذ کریں، تاکہ ایک tenant کا ایجنٹ کسی دوسرے کے vectors نہ پڑھ سکے۔ اگر آپ نے RLS exercise (حصہ 5، Step 8) اسی table پر چلائی ہے جسے یہ server پڑھتا ہے، تو ایک gotcha یاد رکھیں: read-only role کو ہر request پر tenant set کرنا ہوگا، ورنہ RLS صحیح طور پر zero rows واپس کرے گا، جو کسی error کے بغیر empty results جیسا دکھتا ہے۔ ہر request پر tenant set کریں، یا ابھی سیکھتے ہوئے server کو non-RLS table پر point کریں۔ - config پر بھروسہ۔ ایک local MCP سرور ایک کمانڈ ہے جسے کوئی دوسری مشین چلاتی ہے۔ صرف وہی سرورز رجسٹر کریں، اور صرف وہی
.mcp.json/opencode.jsonفائلیں کھولیں، جن پر آپ بھروسہ کرتے ہیں؛ ایک پروجیکٹ config آپ کی مشین پر ایک process چلا سکتا ہے۔
اور retrieval کبھی اپنے پیچھے موجود ڈیٹا سے بہتر نہیں ہوتی، اس لیے آپ کا eval سیٹ آج بھی راج کرتا ہے: اسے MCP ٹول کی طرف موڑیں اور آپ بالکل وہی چیز ناپ رہے ہیں جو آپ کے ایجنٹس کا تجربہ ہوگا۔
حصہ 7: یہ کہاں چلتا ہے
| کہاں | کس کے لیے بہترین | نوٹس |
|---|---|---|
| Neon (یہ کورس) | پہلے build سے production تک | Serverless Postgres، pgvector بِلٹ اِن، فوری branching، autoscaling۔ آپ کچھ نہیں چلاتے۔ |
| Neon branches | Dev، preview، evals، benchmarks | ہر branch ایک فوری clone ہے، dev پر بنائیں، پیش منظر دیکھیں، ڈیفالٹ branch پر commit کریں۔ |
| TigerData Cloud | Neon کا ایک full-stack متبادل | "Agentic Postgres": pgvector + pgvectorscale native، Tiger MCP، فوری zero-copy forks۔ بغیر کبھی migrate کیے StreamingDiskANN اسکیل اور فلٹرڈ سرچ کے لیے اسے چنیں۔ |
آپ ان میں سے کسی میں قید نہیں ہیں۔ جو آپ نے سیکھا وہ سادہ Postgres اور pgvector ہے، embedding کا کام ایک ایسے ورکر میں جو ڈیٹابیس کے باہر چلتا ہے، اس لیے مہارت Neon سے بندھی نہیں۔ وہی schema، وہی ورکر، اور وہی queries کسی بھی Postgres host پر چلتے ہیں: Supabase، Xata (یہ بھی pgvector والا Postgres)، Amazon RDS، Azure Database for PostgreSQL (pgvector اور پیمانے کے لیے ایک managed DiskANN vector انڈیکس)، یا آپ کے اپنے control والے hardware پر آپ کا اپنا CloudNativePG cluster۔
host اصل میں کیسے چنیں (جب آپ free tier سے آگے بڑھ جائیں)
کسی tutorial کے فی-gigabyte نرخ پر مت چنیں؛ workload کی شکل پر چنیں، پھر بل کو اپنے traffic کے مقابل جانچیں۔
- جھٹکے دار یا زیادہ تر بے کار (ایک side project، کم-traffic assistant، dev اور eval branches): ایک metered serverless host جو صفر تک گھٹتا ہے، جیسے Neon، صرف اُسی وقت چارج کرتا ہے جب آپ واقعی چلا رہے ہوں۔ لمبے بے کار وقفے تقریباً کچھ خرچ نہیں کرتے۔
- ہمیشہ-آن، مستحکم traffic (ایک سروس جو کبھی نہیں سوتی): ایک flat instance قیمت عموماً ایک ایسے میٹر سے سادہ اور سستی ہوتی ہے جو کبھی رکتا نہیں۔ Scale-to-zero اُسی لمحے مدد دینا بند کر دیتا ہے جب کوئی چیز ڈیٹابیس کو جگائے رکھے، بشمول ایک embedding ورکر جو مسلسل poll کرتا ہے (اوپر ورکر والا نوٹ دیکھیں)۔
- ڈیٹابیسز کا بیڑا، یا data-sovereignty کی ضرورتیں: self-hosting (آپ کے اپنے cluster پر CloudNativePG) اگلے ڈیٹابیس کی حاشیائی لاگت کو تقریباً صفر بنا دیتی ہے، اِس قیمت پر کہ آپ اسے خود چلائیں۔
دو چیزیں جو sticker rate سے زیادہ فیصلہ کرتی ہیں: کیا free tier کو credit card چاہیے (اکثر نہیں، جو طلبہ کے لیے اہم ہے)، اور کیا upgrade کا راستہ ایک ہموار ڈھلوان ہے یا ایک کھائی (اگلے درجے پر چند ڈالر سے کئی سو تک کی چھلانگ ایک حقیقی لاگت ہے، تفصیل نہیں)۔ دونوں کو provider کے موجودہ pricing صفحے پر تصدیق کریں، یہ اعداد بدلتے ہیں، اس لیے یہ کورس جان بوجھ کر کوئی عدد نہیں بتاتا۔
چند production حقیقتیں جو پہلے ہی اپنے ایجنٹ کے سامنے رکھنے کے لائق ہیں:
- embedding ورکر ایک حقیقی process ہے، embeddings کو sync میں رہنے کے لیے اس کا چلتے رہنا ضروری ہے۔ production میں یہ ایک سروس ہے جسے آپ deploy اور monitor کرتے ہیں، کوئی ایسی چیز نہیں جسے آپ ہاتھ سے شروع کریں۔
- Migrations: schema اور ورکر کی تبدیلیاں ایک Neon branch پر کریں، ان کا پیش منظر دیکھیں، پھر ڈیفالٹ branch پر commit کریں، ایجنٹ یہ Neon MCP کے migration ٹولز کے ذریعے چلاتا ہے۔ Versioned، جائزہ شدہ، الٹنے کے قابل، اور کبھی production کے مقابل کوئی ad-hoc ایڈٹ نہیں۔
- لاگت embedding کالز اور generation کالز میں رہتی ہے، دونوں بیرونی ماڈل APIs کو لگتی ہیں۔ جہاں ممکن ہو batch کریں، جہاں ممکن ہو cache کریں، اور model-matching کی عادت استعمال کریں، یعنی روزمرہ generation کے لیے ایک سستا ماڈل، اور جہاں کیفیت اہم ہو وہاں ایک مضبوط۔
- Scale-to-zero بمقابلہ ورکر۔ Neon فارغ ہونے پر ڈیٹابیس کو صفر تک گھٹا دیتا ہے تاکہ پیسے بچیں، مگر ایک ایسا embedding ورکر جو مسلسل poll کرتا ہے اسے جگائے رکھتا ہے، خاموشی سے اس بچت کو ختم کر دیتا ہے۔ کم-ٹریفک ایپس کے لیے، ایجنٹ سے ورکر کو tight-polling کے بجائے کسی شیڈول پر چلوائیں (یا embeddings کو batch کرائیں)، تاکہ آپ کو واقعی بچت ملے۔
- ایپ ٹریفک کے لیے pooled connection string استعمال کریں۔ Neon کا pooled endpoint (وہ
-poolerhost، transaction mode میں PgBouncer) اُن بہت سی مختصر-عمر connections کے لیے بنا ہے جو serverless اور high-concurrency ایپس کھولتی ہیں۔ ایجنٹ سے اپنی RAG-سرو کرنے والی ایپ کو اسی کی طرف موڑوائیں؛ migrations اور ورکر براہِ راست string استعمال کر سکتے ہیں۔ - ورکر Neon سے باہر چلتا ہے۔ آپ Neon کے managed compute پر sidecar processes نہیں چلا سکتے، اس لیے embedding ورکر آپ کے ایپ host، ایک چھوٹی VM، یا ایک شیڈول شدہ job پر رہتا ہے، اور اپنی connection string کے ذریعے Neon تک پہنچتا ہے۔ اپنے ایجنٹ کو بتائیں کہ اسے کہاں چلنا چاہیے۔
یہی شور و غل کے پیچھے اصل سوال ہے، اور ایماندارانہ جواب ہے عموماً نہیں۔ اگر آپ پہلے ہی Postgres چلاتے ہیں، تو pgvector آپ کے vectors کو اُس ڈیٹا کے ساتھ ہی رکھتا ہے جسے وہ بیان کرتے ہیں، یعنی سچ کا ایک منبع، فلٹرز اور joins ایک ہی کوئری میں، sync، secure، اور پیسے دینے کے لیے کوئی دوسرا نظام نہیں۔ HNSW آرام سے تقریباً 100k تا 10M کی حد کا احاطہ کرتا ہے، اور pgvectorscale کا StreamingDiskANN ایک ارب سے زیادہ vectors تک پھیلتا ہے، اس لیے خام پیمانہ شاذ و نادر ہی وہ فیصلہ کن عنصر ہوتا ہے جو کبھی تھا۔ زیادہ تر ایپلیکیشنز کے لیے، Postgres ہی vector ڈیٹابیس ہے۔
ایک وقف شدہ store (Pinecone، Weaviate، Qdrant، Milvus، اور دیگر) اپنی جگہ تب کماتا ہے جب آپ نے کوئی ایسی ضرورت ناپ لی ہو جو وہ پوری کرتا ہے اور Postgres نہیں کر سکتا، کہیں بہت اونچا query throughput ایک ارب سے زیادہ کے پیمانے پر، کوئی مخصوص recall/latency ہدف جو آپ کے benchmarks دکھائیں کہ pgvector چوک رہا ہے، یا کوئی مکمل managed vector سروس جسے آپ چلانے کے بجائے کرائے پر لینا چاہیں۔ یہ حقیقی صورتیں ہیں؛ بس یہ اقلیت ہیں۔ پھندا یہ ہے کہ کسی ایک کی طرف ڈیفالٹ کے طور پر ہاتھ بڑھایا جائے کیونکہ کسی tutorial یا سرخی نے ایسا کیا۔ اس کا فیصلہ اسی طرح کریں جیسے آپ انڈیکسز کا کرتے ہیں (تصور 11): اپنے eval سیٹ اور اپنے حقیقی workload پر ایک benchmark کو، بشمول اس کے churn، فیصلہ کرنے دیں، اور ایک دوسرے نظام کی مستقل لاگت کو اس فائدے کے مقابل تولیں جو وہ واقعی دیتا ہے۔
حصہ 8: اسے ایک ایجنٹ کے حوالے کریں
آپ نے retrieval بنائی اور اسے ایک ٹول کے طور پر لپیٹا (حصہ 6)۔ قدرتی اگلا قدم ایک ایجنٹ ہے جو اُس ٹول کو استعمال کر کے حقیقی کام کرتا ہے، اور یہی بالکل وہ جگہ ہے جہاں سے Build AI Agents فوری کورس آغاز کرتا ہے۔ آپ وہاں اس میں سے کچھ بھی دوبارہ نہیں بناتے؛ آپ ایجنٹ کو وہی ٹول تھما دیتے ہیں جو آپ کے پاس پہلے سے ہے۔
یہاں پورا پل ایک خیال میں ہے۔ وہ کورس OpenAI Agents SDK کے ساتھ ایجنٹ لُوپ سکھاتا ہے: ایک Agent ایک ماڈل ہے جو instructions اور tools سے لیس ہے، اور ایک Runner ماڈل سے ٹول سے ماڈل والے لُوپ کو اُس وقت تک چلاتا ہے جب تک کام مکمل نہ ہو جائے۔ آپ کا RAG انہی ٹولز میں سے ایک ہے۔ جہاں یہ کورس ختم ہوتا ہے، یعنی ایک قابلِ کال search_knowledge / answer_question، وہیں سے وہ شروع ہوتا ہے۔
جو آپ نے بنایا اسے جوڑنے کے دو طریقے (ایجنٹس کورس لُوپ کا احاطہ کرتا ہے؛ آپ بس ٹول فراہم کرتے ہیں):
- حصہ 6 والے MCP سرور کے طور پر۔ Agents SDK MCP سرورز کو براہِ راست استعمال کر سکتا ہے، اس لیے آپ ایجنٹ کو اپنے
agent-factory-ragسرور کی طرف موڑتے ہیں اور اس کے ٹولز ایجنٹ کے toolbox میں خودکار طور پر ظاہر ہو جاتے ہیں، یعنی وہی سرور جو آپ نے پہلے ہی Claude Code اور OpenCode میں رجسٹر کیا تھا۔ - ایک function tool کے طور پر۔ اگر آپ اسے in-process رکھنا چاہیں، تو وہی read-only کوئری SDK کے
@function_toolمیں لپیٹیں، یعنی اُس کورس کا اپنا native tool انداز۔ وہی retrieval، ایک Python فنکشن کے طور پر بیان کی گئی جسے ایجنٹ کال کر سکتا ہے۔
گہرا پل: memory بمقابلہ knowledge۔ ایجنٹس کورس ہر ایجنٹ کو دو سوالوں کے گرد ترتیب دیتا ہے: یہ کس چیز پر تکیہ کر سکتا ہے (state) اور اسے کیا کرنے کی اجازت ہے (trust)۔ state کی ایک قسم memory ہے، یعنی جو یہ چلتی ہوئی گفتگو سے یاد رکھتا ہے، جسے وہ کورس sessions سے سنبھالتا ہے۔ آپ کا RAG دوسری قسم فراہم کرتا ہے: knowledge، یعنی پائیدار، قابلِ تلاش سیاق جسے یہ ڈھونڈ سکتا ہے، اتنے زیادہ ڈیٹا میں جتنا کسی window میں نہیں سما سکتا۔ Sessions چیٹ رکھتی ہیں؛ آپ کا Postgres + pgvector وہ سب کچھ رکھتا ہے جو ایجنٹ کو نکالنے کی ضرورت پڑ سکتی ہے۔ ایک ایجنٹ جو دونوں سے جڑا ہو وہ یاد رکھ سکتا ہے کہ ابھی کیا کہا گیا اور وہ ڈھونڈ سکتا ہے جو اسے کبھی معلوم نہ تھا، اور اِس کورس کی "صرف متعلقہ chunks نکالو، دس لاکھ غیر متعلقہ قطاریں باہر چھوڑ دو" والی عادت بالکل وہی چیز ہے جو اُس نکالے گئے سیاق کو window میں سیلاب لانے سے روکتی ہے۔ وہی دھاگہ، اب ایک ایپ کے بجائے ایک ایجنٹ کی خدمت میں۔
کتاب کی زبان میں، وہ knowledge والا حصہ ایجنٹ کا سسٹم آف ریکارڈ ہے، یعنی وہ بنیادی سچائی جس سے یہ پڑھتا ہے (retrieval)، جس میں لکھتا ہے (ورکر اسے تازہ رکھتا ہے)، اور جس کے مقابل تصدیق کرتا ہے (آپ کا eval سیٹ)۔ یہی وہ چیز ہے جو ایک روانی سے اندازے لگانے والے کو ایک ایسے ایجنٹ میں بدل دیتی ہے جو عمل کر گزرتا ہے۔
اسے ویسے ہی جوڑیں جیسے آپ نے باقی سب کچھ بنایا، یعنی ایجنٹ کے ذریعے۔ plan mode میں:
Build AI Agents فوری کورس سے کم سے کم ایجنٹ کا ڈھانچہ بناؤ (OpenAI Agents SDK، یعنی ایک
Agentاور ایکRunnerلُوپ)۔ اسے بالکل ایک ٹول دو: ہماری retrieval۔ یا تو اسے حصہ 6 والےagent-factory-ragMCP سرور سے connect کرو تاکہsearch_knowledgeاورanswer_questionٹولز کے طور پر ظاہر ہوں، یا وہی read-only کوئری ایک@function_toolکے طور پر لپیٹو، سفارش کرو کون سا موزوں ہے اور کیوں۔ ایجنٹ کی اپنی مشینری (sessions، guardrails، model routing) اُس کورس پر چھوڑ دو؛ یہاں، بس ثابت کرو کہ ایجنٹ ہماری retrieval کو کال کر سکتا ہے اور اس میں جواب جوڑ سکتا ہے۔ پہلے مجھے منصوبہ دکھاؤ۔
اسے منظوری دیں، ایک ایسا سوال چلائیں جو ٹول کال پر مجبور کرے، اور ایجنٹ کو اپنے Neon (یا TigerData) ڈیٹابیس سے نکالتے اور اس سے جواب دیتے دیکھیں۔ یہی وہ حوالگی ہے: Build AI Agents لُوپ، guardrails، sessions، اور deployment سکھاتا ہے؛ اِس کورس نے ایجنٹ کو کہنے کے لیے کوئی سچی بات دی۔ آپ کا eval سیٹ سلامت پار چلا جاتا ہے، یہ آج بھی اُسی retrieval کو ناپتا ہے جس پر ایجنٹ اب تکیہ کرتا ہے۔
آگے کہاں جائیں
اب آپ کے پاس 80٪ ہے: آپ Neon کو ایک vector ڈیٹابیس میں بدل سکتے ہیں، ایک جڑا ہوا RAG نظام بنا سکتے ہیں، ثبوت پر ایک انڈیکس چن سکتے ہیں، اور فلٹرز، ہائبرڈ سرچ، اور evals سے retrieval بہتر بنا سکتے ہیں، یہ سب ایک ایجنٹ کو ہدایت دے کر اور اس کے کام کو پرکھ کر۔
- اسے قابلِ بھروسہ بنائیں: Eval-Driven Development فوری کورس
- اسے ایک ایجنٹ بنائیں: حصہ 8 آپ کے RAG ٹول کو ایک ایجنٹ میں جوڑتا ہے؛ پورا لُوپ، guardrails، sessions، اور deployment Build AI Agents میں ہیں
- اسے ایک پروڈکٹ بنائیں: assistant کو ایک قابلِ deploy Digital FTE میں بدلیں
دھاگہ کبھی نہیں بدلتا: صحیح معلومات، صحیح لمحہ، غیر متعلقہ معلومات باہر۔ آپ نے یہ اپنے ایجنٹ کے لیے سیکھا۔ اب آپ اسے باقی سب کے لیے بنا سکتے ہیں۔