ڈیجیٹل FTE بنانا: ایک 4 گھنٹے کا فوری کورس
پندرہ تصورات اور ایک عملی build: Skills، سسٹم آف ریکارڈ، اور ان کے بیچ کی MCP تار۔
پچھلے کورس میں آپ نے ایک ایجنٹ بنایا تھا۔ اس کورس میں آپ ایجنٹ سے AI ورکر کی طرف پہلا حقیقی قدم اٹھاتے ہیں۔ (یہ Mode 2، یعنی Manufacturing ٹریک کا دوسرا کورس ہے، سات میں سے دوسری چال۔) وہ ایجنٹ، جو Build AI Agents میں بنا تھا، sessions، guardrails، اور tracing کے ساتھ ایک streaming چیٹ ایجنٹ تھا، جو compute کے لیے ایک سینڈ باکس پر چلتا تھا۔ وہ کام کرتا تھا۔ مگر جیسے ہی آپ ٹرمینل بند کرتے، وہ سب کچھ بھول جاتا، اور اس کے پاس جو بھی ٹول تھا وہ اس کی Python میں لکھا ہوتا۔
پہلے بس اسے چلتا دیکھنا چاہتے ہیں؟ نیچے 15 منٹ کی فوری کامیابی پر چلے جائیں۔ آپ ایک حقیقی ڈیٹابیس اور ایک چھوٹا ورکر بنائیں گے جو اس میں لکھتا اور یاد رکھتا ہے، پھر واپس آ کر وہ تصورات پڑھیں گے جو بتاتے ہیں کہ اس کی شکل ایسی کیوں ہے۔
ایک AI ورکر وہی چیٹ ایجنٹ ہے، بڑا ہو کر۔ لوگ اسے AI ایمپلائی یا ڈیجیٹل FTE بھی کہتے ہیں: ایک ہی چیز، جس کا نام اس بات پر ہے کہ آپ اسے کیسے بناتے ہیں، یہ کس کے ساتھ شامل ہوتا ہے، اور اس کی لاگت کیا ہے۔ یہ کورس اس کی بنیاد بناتا ہے: ایک ایجنٹ جسے آپ بڑھا سکتے ہیں، جو یاد رکھتا ہے، اور جس کے آپ مالک ہیں۔ ایک مکمل ورکر چوبیس گھنٹے بھی چلتا ہے، اپنی مرضی سے عمل کرتا ہے، اور آپ تک کسی بھی ایپ پر پہنچتا ہے، مگر وہ بعد میں آتا ہے۔ پچھلے کورس کا SDK اور SandboxAgent runtime وہی رہتا ہے؛ ان کے ارد گرد جو کچھ ہے وہی بدلتا ہے۔
یہ تبدیلی دو چالوں سے ہوتی ہے، اور ان کے بیچ کی تار:
- اس کی صلاحیتیں Skills بن جاتی ہیں: چھوٹے فولڈرز جنہیں ایجنٹ خود ڈھونڈ اور لوڈ کر لیتا ہے، اس کے بجائے کہ ٹولز اس کی Python میں سختی سے جڑے ہوں۔
- جو چیزیں یہ ہر restart پر بھول جاتا تھا، وہ Postgres میں منتقل ہو جاتی ہیں، یعنی اس کا سسٹم آف ریکارڈ: وہ واحد بااختیار اسٹور جس کے مقابل ورکر چلتا ہے، وہ سچ کا منبع جس پر کوئی کاروبار چلتا ہے، بالکل جیسے کوئی CRM یا کھاتہ۔ اس میں چند قسم کا ڈیٹا رہتا ہے:
- کاروباری ریکارڈز: عملی سچ۔ گاہک، tickets، آرڈرز۔ آپ یہ دیکھتے اور اپ ڈیٹ کرتے ہیں۔
- ریفرنس لائبریری: وہ علم جسے یہ معنی سے تلاش کرتا ہے۔ پالیسی لائبریری، حوالہ جاتی دستاویزات، گزشتہ کیسز۔
- State: ابھی کام کیسا دکھتا ہے۔ کون سی chats کھلی ہیں، کیا منظوری کا منتظر ہے۔
- Trace: اس نے جو کیا اس کا ریکارڈ، تاکہ کمپنی اس کے اعمال دوبارہ چلا کر دیکھ سکے اور ان پر بھروسہ کر سکے۔
- MCP (یعنی Model Context Protocol) ایجنٹس کو باہر کے ٹولز اور ڈیٹا سے جوڑنے کا کھلا معیار ہے۔ یہاں یہ وہ تار ہے جسے ایجنٹ اس اسٹور تک پہنچنے کے لیے استعمال کرتا ہے۔

Semantic recall وہ واحد ٹکڑا ہے جس پر لوگ غلط لیبل لگاتے ہیں۔ اس کا مطلب ہے چیزیں معنی سے ڈھونڈنا، نہ کہ بالکل ٹھیک الفاظ سے۔ یہ خود کوئی اسٹور نہیں، بلکہ ایک تلاش کا طریقہ ہے: آپ اسے ریفرنس لائبریری پر چلا سکتے ہیں، گزشتہ گفتگوؤں پر، یا خود کاروباری ریکارڈز پر۔ یہ ایک چلتے ورکر کے دو حصے ہوتے ہیں جنہیں production الگ الگ deploy کرتا ہے۔ harness ایجنٹ کا runtime ہے: خود SDK لوپ۔ compute وہ سینڈ باکس ہے جہاں ایجنٹ کا کوڈ اصل میں چلتا ہے؛ جب ایجنٹ کوئی ٹول کال کرتا ہے، تو وہ کوڈ اس سینڈ باکس کے حوالے کر دیتا ہے۔ اس کورس میں دونوں مقامی رہتے ہیں۔ مکمل پریزنٹیشن دیکھیں: ڈیجیٹل FTE کی بنیاد بنائیں مقالہ سات ایسے Invariants کا نام لیتا ہے جنہیں ہر production ایجنٹ سسٹم کو پورا کرنا ہوتا ہے۔ پچھلے کورس نے engine بنایا تھا (Invariant 4): سینڈ باکس پر OpenAI Agents SDK۔ یہ کورس Invariant 5 شامل کرتا ہے: ہر ورکر کسی سسٹم آف ریکارڈ کے مقابل چلتا ہے۔ engine وہ ہے جس پر ورکر چلتا ہے؛ سسٹم آف ریکارڈ وہ ہے جس کے مقابل یہ چلتا ہے۔ دو کھلے معیار اسے قابلِ انتقال رکھتے ہیں۔ Skills (اصل میں Anthropic کی، اب پورے ماحول میں agentskills.io پر) صلاحیتوں کو ٹولز کے بیچ سفر کرنے دیتی ہیں۔ MCP وہ معیاری تار ہے جسے ایجنٹ ریکارڈ تک پہنچنے کے لیے استعمال کرتا ہے؛ پچھلے کورس میں کوئی نہ تھی، اور یہی یہاں کا کلیدی نیا پیٹرن ہے۔ خود ریکارڈ Neon Postgres + pgvector ہے، جو اس لیے چنا گیا کہ یہ شروع کرنے میں مفت ہے، فارغ ہونے پر صفر تک گھٹ جاتا ہے، اور ایک سرکاری MCP سرور کے ساتھ آتا ہے۔ پروڈکٹ بدلی جا سکتی ہے؛ Swap گائیڈ متبادل گنواتی ہے۔pgvector سے آتا ہے، جو Postgres میں معنی سے تلاش کا اضافہ کرتا ہے۔ایک ورکر کیسے چلتا ہے: harness بمقابلہ compute (یہاں آپ کوئی بھی deploy نہیں کرتے)
UnixLocalSandboxClient سینڈ باکس کو آپ کی مشین پر چلاتا ہے (صفر انفراسٹرکچر، ایک API کلید)، اور آپ اسے ایک لائن کی تبدیلی سے Docker، Cloudflare، E2B، یا Modal کی طرف موڑ سکتے ہیں (Part 5 کی Swap گائیڈ)۔ خود harness کو ہمیشہ آن رہنے والی کلاؤڈ سروس کے طور پر deploy کرنا اپنا الگ کورس ہے، Deploy Your Agent Harness to the Cloud۔یہ کورس Agent Factory کے مقالے میں کہاں بیٹھتا ہے
📚 تدریسی معاون
یہ پندرہ تصورات تین تہوں میں بٹے ہیں: Skills، سسٹم آف ریکارڈ، اور MCP۔ نیچے کی میز پورا نقشہ ہے۔پندرہ تصورات ایک نظر میں (پورے نقشے کے لیے کھولیں)
# تصور تہہ یہ کس سوال کا جواب دیتا ہے 1 Agent Skill کیا ہے Skills قابلِ استعمال صلاحیت کہاں رہتی ہے؟ ایک فولڈر میں، SKILL.md کے ساتھ اور اختیاری scripts/references کے ساتھ۔2 Progressive disclosure Skills skills کو پاس رکھنا سستا کیوں ہے؟ Discovery → activation → execution صرف وہی لوڈ کرتا ہے جو وقت پر درکار ہو۔ 3 SKILL.md لکھنا Skills ایک skill فائل میں اصل میں کیا ہوتا ہے؟ Metadata، trigger description، عملی ہدایات۔ 4 Skill packaging کے اصول Skills skills ٹولز کے بیچ کیسے سفر کرتی ہیں؟ وہی فولڈر Claude Code، OpenCode، اور ہر تابع کلائنٹ میں چلتا ہے۔ 5 Skills کو ملانا Skills چھوٹی skills کو filesystem handoff سے جوڑنا بمقابلہ ایک بڑی skill لکھنا، کب؟ 6 managed Postgres کیوں سسٹم آف ریکارڈ کون سا اسٹور "سسٹم آف ریکارڈ" کہلانے کا حقدار ہے؟ وہ جس میں persistence، branching، governance، اور وہ vector primitives ہوں جو ایجنٹ کو چاہئیں۔ 7 ورکر کا schema سسٹم آف ریکارڈ ایک ایجنٹ کو اصل میں کون سی tables چاہئیں؟ Conversations، documents، embeddings، audit log، capability invocations، اور turns کے لیے SDK Session۔ 8 pgvector کی بنیادیں سسٹم آف ریکارڈ Postgres میں semantic search کیسے کام کرتی ہے؟ Embedding column، distance operators، index types۔ 9 embedding pipeline سسٹم آف ریکارڈ متن ایک قابلِ تلاش vector کیسے بنتا ہے؟ Chunking، embedding ماڈل، دوبارہ embed کب کریں۔ 10 بطورِ نظم audit trail سسٹم آف ریکارڈ ایک ورکر کے لیے "reads اور writes" کا کیا مطلب ہے؟ ورکر کا ہر عمل ایک trace چھوڑتا ہے جسے کمپنی دوبارہ چلا سکے۔ 11 MCP کیا ہے اور کیا نہیں MCP tools، resources، اور prompts کا ایک protocol: کوئی framework نہیں، کوئی service نہیں۔ 12 Neon MCP سرور MCP ایجنٹ کا اس کے ڈیٹابیس سے interface: یہ کیا پیش کرتا ہے، کیسے authenticate ہوتا ہے۔ 13 MCP کو Agents SDK سے جوڑنا MCP SDK کا MCP integration: ایک سرور کیسے register کریں، ماڈل کو کیا دکھتا ہے، trust boundary کہاں رہتی ہے۔ 14 custom MCP سرورز MCP اپنا سرور کب لکھیں بمقابلہ صرف @function_tool استعمال کریں۔ فیصلے کا درخت۔15 بوجھ تلے MCP MCP Transport کے انتخاب، connection pooling، queue کب کریں۔
ایک بار یہ نقشہ آپ کے پاس آ جائے، تو باقی زیادہ تر مشینری ہے۔ production میں کوئی ناکامی ان میں سے ایک کی طرف جاتی ہے: ایسی Skill جو کبھی دریافت نہ ہوئی (description بہت مبہم)، ایسا سسٹم آف ریکارڈ جس پر دو ورکرز اختلاف کرتے ہیں (schema race)، یا ایسی MCP تار جو events گرا دیتی ہے (workload کے لیے غلط transport)۔ تشخیص آپ کو بتاتی ہے کہ کون سی ہے۔
یہ کورس کس کے لیے ہے
درمیانی سطح۔ آپ کے پاس یہ ہونا چاہیے:
- بہتر ہو کہ Build AI Agents کر چکے ہوں، اگرچہ اگر آپ نے چھوڑ دیا ہو تو آپ کا ایجنٹ base پر اس کی آخری حالت scaffold کر سکتا ہے۔
- Agentic Coding Crash Course کی Plan-mode اور rules-file عادتیں۔
- ایک PRIMM-AI+ سائیکل آپ کے تجربے میں۔
یہ ایک Python-first تسلسل ہے: آپ Python یا SQL ہاتھ سے نہیں لکھیں گے، آپ کا ایجنٹ کوڈ لکھتا ہے جبکہ آپ رہنمائی کرتے ہیں، اور Parts 2 اور 3 زیادہ گھنے ہو جاتے ہیں (Pydantic ماڈلز، asyncpg pools، ایک چھوٹا custom MCP سرور)، تو وہاں زیادہ آگے پیچھے کی توقع رکھیں۔ ایک ڈیٹابیس معلومات کو tables میں رکھتا ہے۔ ایک spreadsheet تصور کریں: ہر row ایک چیز ہے (ایک گاہک، ایک support ticket) اور ہر column اس کی ایک تفصیل ہے (ایک نام، ایک تاریخ، ایک status)۔ یہاں آپ کو یہی پورا ذہنی نقشہ چاہیے۔ آپ کبھی ڈیٹابیس کوڈ خود نہیں لکھتے؛ آپ کا ایجنٹ لکھتا ہے، اور یہ دو لفظ بس آپ کو وہ پڑھنے میں مدد دیتے ہیں جو یہ بناتا ہے۔ پانچ الفاظ جنہیں یہ کورس ایسے استعمال کرتا ہے جیسے آپ جانتے ہوں:databases میں نئے ہیں؟ 60 سیکنڈ والا version
مئی 2026 تک حالیہ، openai-agents 0.17.x، mcp SDK، Neon کی MCP docs، اور pgvector 0.8+ کے مقابل تصدیق شدہ۔ جب آپ build کر لیں تو اپنی versions pin کر لیں؛ اگر docs اور یہ صفحہ کبھی اختلاف کریں، تو Cloudflare Sandbox tutorial اور Neon docs جیتتی ہیں۔
آپ ہدایت دیتے ہیں، ایجنٹ بناتا ہے، اور چونکہ base ایک AGENTS.md کے ساتھ آتا ہے جسے یہ کھلتے ہی پڑھ لیتا ہے، آپ کے prompts مختصر رہ سکتے ہیں: بس بتائیں کہ آگے کیا بنانا ہے۔
پندرہ منٹ کی فوری کامیابی: ایک بار کامیاب ہوں، پھر مطالعہ کریں کہ یہ کیوں چلا
ان 15 تصورات کو پڑھنے سے پہلے جو بتاتے ہیں کہ یہ آرکیٹیکچر کیوں کام کرتا ہے، اس کا سب سے چھوٹا version بنا لیں جو واقعی چلتا ہے۔ آخر تک آپ کے پاس ہوگا:
- ایک تازہ Neon project جس میں دو tables،
notesاورaudit_logہیں، جو آپ نے MCP پر بنائیں اور console میں دیکھیں، - ایک کم سے کم AI ورکر جس نے اپنے
save_noteٹول کے ذریعے ایک ہی transaction میں دونوں میں لکھا، - اور اس سوال کا ایک عملی جواب کہ "کیا کسی سسٹم آف ریکارڈ نے واقعی میرے لیے کچھ کیا؟": آپ کا note اور اس کی audit row، ایک ہی id بانٹتے ہوئے۔
یہ prompts کی ایک ہی اسکرین ہے: آپ کا coding ایجنٹ Neon MCP پر اسٹور بناتا ہے، پھر ایک چھوٹا ورکر scaffold کرتا ہے جو اس میں لکھتا ہے، اور آپ ورکر کو یاد رکھتے دیکھتے ہیں۔ مکمل ورکر (آٹھ فیصلے، پانچ tables والا schema) Part 4 میں آتا ہے۔ اگر آپ کے پاس صرف ایک نشست ہے، تو یہ کریں، پھر تصورات کے لیے واپس آئیں۔
اس میں سے دو planes گزرتے ہیں، اور انہیں الگ رکھنا ہی پورا ذہنی نقشہ ہے۔ آپ کا coding ایجنٹ (Claude Code یا OpenCode) ڈیٹابیس کو بنانے اور دیکھنے کے لیے Neon MCP استعمال کرتا ہے۔ آپ کا بنایا ورکر runtime پر اس میں لکھنے کے لیے اپنا ہی ٹول استعمال کرتا ہے۔ ورکر کبھی Neon MCP کو ہاتھ نہیں لگاتا، اور Neon کی اپنی docs اس کی وجہ صاف بتاتی ہیں: MCP سرور صرف "development اور testing کے لیے" ہے، کبھی کسی چلتی ایپ میں نہیں جوڑا جاتا۔

base حاصل کریں اور اسے کھولیں
base ڈاؤن لوڈ کریں اور فولڈر کو اپنے عام ایجنٹ میں کھولیں۔ ایجنٹ setup خود کرتا ہے، بالکل نیچے دیے prompts سے۔ آپ یہ ایک بار سیٹ کرتے ہیں: digital-fte/ پورے کورس کے لیے آپ کا فولڈر ہے، Quick Win اور Part 4 دونوں کے لیے۔ ہر build اپنا تازہ Neon project (ایک ڈیٹابیس) فراہم کرتا ہے، مگر آپ کبھی دوبارہ ڈاؤن لوڈ یا دوبارہ unzip نہیں کرتے۔
digital-fte-base.zip ڈاؤن لوڈ کریں
cd digital-fte
claude
cd digital-fte
opencode
یہ base ایک سکّہ بند عام ایجنٹ فرض کرتا ہے (Claude Code، یا OpenCode جو Claude Sonnet یا Opus، GPT-5، یا اسی جیسا چلا رہا ہو)۔ ایک چھوٹا ماڈل build prompt پر بھٹک جائے گا؛ اگر اس کا پہلا plan مخصوص ہونے کے بجائے مبہم لگے، تو آگے بڑھنے سے پہلے کسی مضبوط تر ماڈل پر سوئچ کر لیں۔
base تیار کریں (تقریباً 3 منٹ)
base قواعد اور wiring کے ساتھ آتا ہے؛ skills اور آپ کی کلید آگے آتی ہیں۔ اپنے ایجنٹ سے کہیں کہ خود کو سیٹ کرے۔ یہ paste کریں:
Read AGENTS.md, then get this base ready: install the skills it lists for whichever agent you are, copy
.env.exampleto.envfor me, and tell me exactly what you need from me to bring the Neon and Context7 MCP servers online.
اس پر نظر رکھیں: ایجنٹ skill-creator، mcp-builder، اور neon-postgres انسٹال کرتا ہے (آپ install چلتا دیکھتے ہیں)، .env بناتا ہے، پھر آپ سے دو چیزیں مانگتا ہے: آپ کی OPENAI_API_KEY جو .env میں paste ہو، اور ایک browser کلک تاکہ Neon کو OAuth پر authorize کیا جا سکے۔ Neon مفت ہے؛ اگر آپ کا ابھی اکاؤنٹ نہیں، تو neon.com پر تقریباً ایک منٹ میں sign up کریں، یا authorization اسکرین پر ہی بنا لیں۔ جب install اور wiring مکمل ہو جائے، تو ایجنٹ آپ سے اسے restart کرنے کو کہتا ہے (نکلیں اور دوبارہ کھولیں) تاکہ نئی skills اور MCP سرورز لوڈ ہوں؛ دونوں میں سے کوئی session کے بیچ لوڈ نہیں ہوتا۔
تب مکمل جب: skills انسٹال ہوں، .env میں آپ کی کلید ہو، Neon authorized ہو، اور آپ نے ایجنٹ restart کر دیا ہو تاکہ نئی skills اور MCP سرورز زندہ ہوں۔
gate: تصدیق کریں کہ ایجنٹ ڈیٹابیس تک پہنچ سکتا ہے (تقریباً 1 منٹ)
اس کورس کا واحد واقعی نیا اضافہ یہ ہے کہ ایجنٹ MCP پر ایک حقیقی سسٹم آف ریکارڈ تک پہنچتا ہے۔ تو کچھ بنانے سے پہلے، تصدیق کر لیں کہ وہ سرحد زندہ ہے۔ یہ paste کریں:
List the Neon tools you can see.
اس پر نظر رکھیں: Neon tool ناموں کی ایک حقیقی فہرست (ایک project بنانا، SQL چلانا، tables بیان کرنا، اور اسی طرح)۔ وہ فہرست ڈیٹابیس پر ایجنٹ کا ہاتھ ہے، اور نیچے سب کچھ اسی پر سوار ہے۔
gate کھلا: جواب میں حقیقی Neon tool نام درج ہوں۔ اگر ایسا نہ ہو: آپ نے تقریباً یقینی طور پر restart چھوڑ دیا، تو tools ابھی لوڈ نہیں ہوئے۔ نکلیں، دوبارہ کھولیں، اور پھر پوچھیں۔ پھر بھی کچھ نہیں؟ Neon OAuth مکمل نہیں ہوا: اسے دوبارہ کریں اور پھر آزمائیں۔
اسٹور بنائیں، اور اس کی connection string لیں (تقریباً 3 منٹ)
اپنے coding ایجنٹ سے Neon MCP پر ڈیٹابیس بنوائیں، پھر اپنے ورکر کو وہ ایک چیز دیں جو اسے بعد میں اس تک پہنچنے کے لیے درکار ہوگی: ایک connection string۔
یہ اپنے عام ایجنٹ کو paste کریں۔ پہلے plan کرے؛ منظوری پر عمل کرے۔
On a fresh Neon project, create two tables:
notes(the note text) andaudit_log(a record of what happened). Then callget_connection_stringand write that URL into my.envasDATABASE_URL. Use the Neon tools for all of it; don't write SQL for me to run.
اس پر نظر رکھیں: ایجنٹ project اور دونوں tables بنانے کے لیے Neon MCP tools کال کرتا ہے (آپ وہ tool calls دیکھتے ہیں، نہ کہ آپ کی ٹائپ کی ہوئی SQL)، پھر DATABASE_URL کو .env میں لکھتا ہے۔ وہ string ہی handoff ہے: Neon MCP نے اسٹور فراہم کیا، اور آپ کا ورکر string استعمال کرے گا، نہ کہ MCP سرور۔
تب مکمل جب: ایک تازہ Neon project موجود ہو جس میں ایک notes table اور ایک audit_log table ہو، اور .env میں ایک DATABASE_URL ہو۔
اسے اپنی آنکھوں سے دیکھیں (تقریباً 1 منٹ)
کوئی کوڈ چلنے سے پہلے، Neon console میں خالی tables دیکھیں۔ یہ "یہ واقعی وہاں ہے" والا لمحہ ہے، اور آپ کو ایک browser tab کا خرچہ پڑتا ہے۔
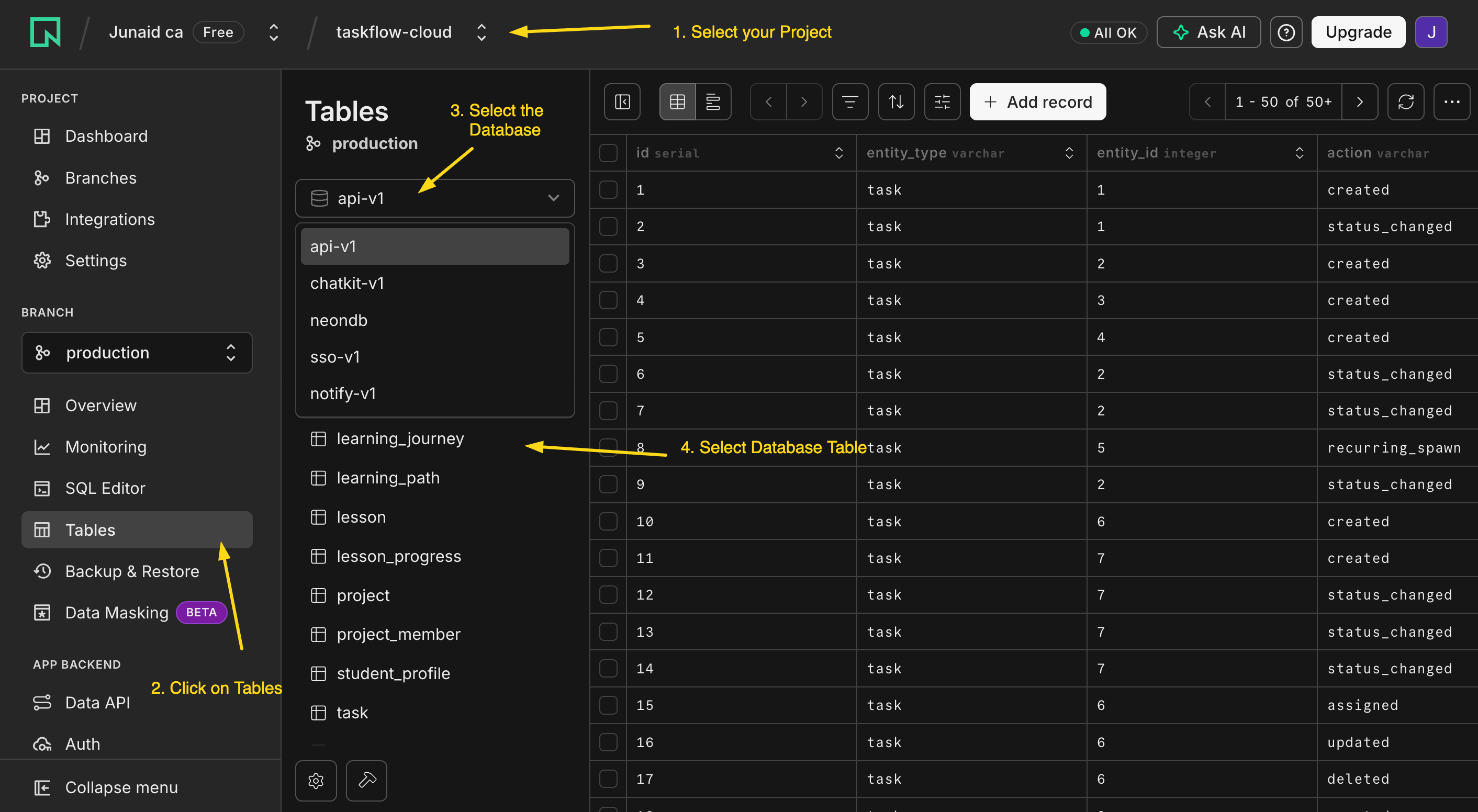
console.neon.tech کھولیں، وہ project چنیں جو ایجنٹ نے ابھی بنایا، اور Tables کھولیں۔ وہاں notes اور audit_log بیٹھے ہیں، فی الحال خالی۔ ایک table بس ایک spreadsheet ہے: ہر row ایک چیز، ہر column ایک تفصیل۔ آپ آخر میں اس view کو refresh کریں گے اور ایک row کو ظاہر ہوتے دیکھیں گے۔
ورکر scaffold کریں اور اسے ایک بار چلائیں (تقریباً 2 منٹ)
اب خود ورکر بنائیں: ایک کم سے کم SandboxAgent، وہی runtime جو باقی کورس استعمال کرتا ہے، ابھی کسی ٹول کے بغیر۔ اسے پہلے خالی چلانا یہ ثابت کرتا ہے کہ runtime کام کرتا ہے اور آپ کی کلید درست ہے، اس سے پہلے کہ آپ کوئی اور چیز شامل کریں جو ناکام ہو سکتی ہے۔
Using
uv, scaffold a minimal OpenAI Agents SDK project in this folder: aSandboxAgenton a gpt-5-class model (e.g.gpt-5-mini) with no tools yet, run from the terminal on a local sandbox, readingOPENAI_API_KEYfrom.env. Run it once with "hello" so I can see it answer.
اس پر نظر رکھیں: ایجنٹ uv سے project سیٹ کرتا ہے، ایک چھوٹا SandboxAgent اور Runner script لکھتا ہے (UnixLocalSandboxClient پر، صفر انفراسٹرکچر)، اور اسے چلاتا ہے۔ ایک جواب واپس آتا ہے۔
یہ پہلی بار ہے کہ آپ کی کلید استعمال ہوتی ہے، تو یہی پہلی جگہ ہے جہاں خراب کلید سامنے آتی ہے۔ اگر run 401 دے، تو کلید غلط ہے یا آپ کا provider OpenAI نہیں: یہ paste کریں "the run failed with a 401; read the error and propose one fix I can approve."
تب مکمل جب: خالی ورکر چلے اور جواب دے۔
ورکر کو اس کا ٹول دیں، اور اسے یاد رکھتے دیکھیں (تقریباً 3 منٹ)
اب ایک ہی صلاحیت شامل کریں: ایک ٹول جو ایک note اور اس کی audit row، ایک ہی transaction میں، اس ڈیٹابیس میں لکھتا ہے جو آپ نے بنایا۔
Add a
save_notetool to the Worker, written as a@function_tool, that inserts a row intonotesand a matching row intoaudit_login a single transaction, using theDATABASE_URLin.env. Then run the Worker and send it: "Remember this: the production deploy needs a new env var before Friday." Show me what happened.
اس پر نظر رکھیں: ماڈل خود آپ کے جملے کو save_note سے ملاتا ہے (ٹول کی description ہی اس کا واحد routing signal ہے)، اور ٹول DATABASE_URL سے ایک connection کھولتا ہے اور دونوں rows ایک ہی transaction میں لکھتا ہے۔ ورکر بتاتا ہے کہ note محفوظ ہو گیا۔ غور کریں اس نے کیا نہیں کیا: اس نے کبھی Neon MCP کی طرف ہاتھ نہیں بڑھایا۔ admin تار نے اسٹور بنایا؛ ورکر اپنا ہی تنگ ٹول استعمال کرتا ہے۔
تب مکمل جب: ورکر تصدیق کرے کہ note محفوظ ہوا اور آپ کو وہ save_note کال دکھائے جس نے یہ کیا۔ ایک جملہ اندر، ایک tool call، دو rows لکھی گئیں۔
جیت: اسے واپس پڑھیں (تقریباً 2 منٹ)
ابھی کا Neon console Tables view refresh کریں۔ آپ کا note اب notes میں ایک row ہے، اور audit_log میں ایک ملتی row note_saved ریکارڈ کرتی ہے، جو اسی id سے اس سے بندھی ہے۔ (ٹرمینل میں رہنا چاہتے ہیں؟ اپنے coding ایجنٹ سے پوچھیں: "using the Neon tools, show me the new notes row and its matching audit_log row side by side.")
یہ پورا آرکیٹیکچر چھوٹے پیمانے پر ہے: ایک سسٹم آف ریکارڈ جو سچ رکھتا ہے، ایک ورکر جس نے اپنے ہی ٹول کے ذریعے اس میں لکھا، اور ایک audit trail جسے آپ دوبارہ چلا سکتے ہیں۔
آپ نے کیا بنایا، اور یہ کہاں بڑھتا ہے
آپ نے ایک سادہ @function_tool استعمال کیا کیونکہ ایک ورکر ایک اسٹور میں لکھتا ہے، جو درست default ہے، شارٹ کٹ نہیں۔ آپ کسی چھوٹے MCP سرور کی طرف تب ہاتھ بڑھاتے ہیں جب ان میں سے کوئی ایک ظاہر ہو: ایک دوسرا consumer جسے وہی save_note چاہیے (ایک اور ورکر، آپ کا coding ایجنٹ، خود Claude)، ایک زیادہ تنگ scope جسے آپ نافذ کرنا چاہتے ہیں، یا process isolation۔ وہ فیصلہ، یعنی function tool بمقابلہ اپنا سرور، Concept 14 ہے، اور Part 4 وہ سرور بناتا ہے۔
Part 4 اسی شکل کو کئی Skills، پانچ tables والے schema، چند ٹولز، اور ایک embedding pipeline تک بڑھاتا ہے۔ شکل نہیں بدلتی: ایک سسٹم آف ریکارڈ، اسی transaction میں audit، اور admin تار اور ورکر کی اپنی رسائی کے بیچ ایک صاف لکیر۔ اگر یہ Quick Win چل گیا، تو باقی کورس بس یہ سمجھانا ہے کہ ہر ٹکڑا اس شکل میں کیوں ہے۔
اگر کوئی چیز نہ چلی، تو وہ ایک recovery چال paste کریں جو سب کچھ سنبھال لیتی ہے: "Something didn't work. Read the error, tell me in plain language what you see, and propose one fix I can approve." پھر یہاں واپس آئیں۔
Part 1: Skills، صلاحیت بطورِ قابلِ انتقال فولڈرز
آپ پہلے ہی Claude Code کے اندر Skills استعمال کر چکے ہیں۔ Part 1 وہی on-demand، پیشہ ورانہ workflows اس ایجنٹ کو دیتا ہے جو آپ بناتے ہیں۔ ایک Skill ایک قابلِ استعمال صلاحیت ہے جو آپ کسی ایجنٹ کو سونپتے ہیں: ایک فولڈر جو ایک workflow پیک کرتا ہے (ہدایات، اور کوئی scripts یا references)، جسے ایجنٹ صرف تب لوڈ کرتا ہے جب کوئی کام اس کا تقاضا کرے، اور جو ایک ایجنٹ کے کوڈ میں پکا کیے جانے کے بجائے ایجنٹس کے بیچ قابلِ انتقال ہے۔ یہ پانچ تصورات آپ کو ایسی Skills لکھنا سکھاتے ہیں جو تب فائر ہوں جب انہیں ہونا چاہیے، اور Part 1 آپ کے ورکر کے اپنے SDK میں، اسی digital-fte فولڈر میں، ایک Skill چلا کر ختم ہوتا ہے۔
Concept 1: Agent Skill کیا ہے
ایک Agent Skill ایک فولڈر ہے جس میں ایک SKILL.md فائل ہے (اور اختیاری scripts/، references/، assets/)۔ SKILL.md داخلے کا نقطہ ہے۔ یہ Anthropic کا ایک کھلا معیار ہے جسے کوئی بھی ایجنٹ پڑھ سکتا ہے: آج Claude Code اور OpenCode، اور وہ OpenAI Agents SDK ورکر جو آپ بنا رہے ہیں۔ سب سے چھوٹی skill ایک ہی فائل ہے:
---
name: hello-skill
description: Greets the user by name and time of day. Use when the user says hello or asks to be greeted.
---
# Hello skill
1. Check the local time of day.
2. Greet the user warmly, by name if known, in under 25 words.
کوئی کوڈ نہیں، کوئی deploy نہیں، کوئی SDK call نہیں۔ چونکہ یہ ڈسک پر ایک فائل ہے، اس لیے ایک skill کسی Python object یا API endpoint کی طرح نہیں بلکہ کسی بھی متن کی طرح version ہوتی، سفر کرتی، اور review ہوتی ہے۔
PRIMM, Predict. کوئی پیغام آنے سے پہلے، startup پر ایجنٹ کیا لوڈ کرتا ہے؟ (a) پورا
SKILL.md؛ (b) صرفnameاورdescription؛ (c) جب تک invoke نہ ہو، کچھ نہیں۔ اعتماد 1 سے 5۔
جواب (b) ہے: startup پر ایجنٹ صرف ہر skill کا metadata پڑھتا ہے؛ body طلب پر لوڈ ہوتا ہے۔ یہی progressive disclosure ہے، اگلا تصور۔
Concept 2: Progressive disclosure، تین مرحلوں والا loading ماڈل
ایک ساتھ پچاس skills لوڈ کرنا ماڈل کو ان ہدایات میں دبا دے گا جن کی اسے ضرورت نہیں۔ تو ایک skill تین مرحلوں میں لوڈ ہوتی ہے، ہر ایک تب فائر ہوتا ہے جب پچھلا کہے کہ یہ متعلقہ ہے۔
مرحلہ 1، Discovery۔ startup پر ایجنٹ ہر skill کا name اور description لوڈ کرتا ہے، تقریباً 100 ٹوکن فی skill۔ پچاس skills کی لاگت تقریباً 5,000 ٹوکن فی turn ہے: یہ جاننے کی قیمت کہ لائبریری میں کیا ہے۔
مرحلہ 2، Activation۔ جب ماڈل کسی کام کو ایک description سے ملاتا ہے، تو وہ پورا SKILL.md body لوڈ کرتا ہے (اسے تقریباً 5,000 ٹوکن سے کم رکھیں؛ زیادہ تر 500 سے 2,000 پر بیٹھتے ہیں)۔ صرف ان turns پر ادا ہوتا ہے جو skill استعمال کرتے ہیں۔
مرحلہ 3، Execution۔ وہ فائلیں جنہیں body حوالہ دیتا ہے (ایک scripts/ script، ایک references/ دستاویز) صرف تب لوڈ ہوتی ہیں جب ایجنٹ ان کی طرف ہاتھ بڑھاتا ہے۔
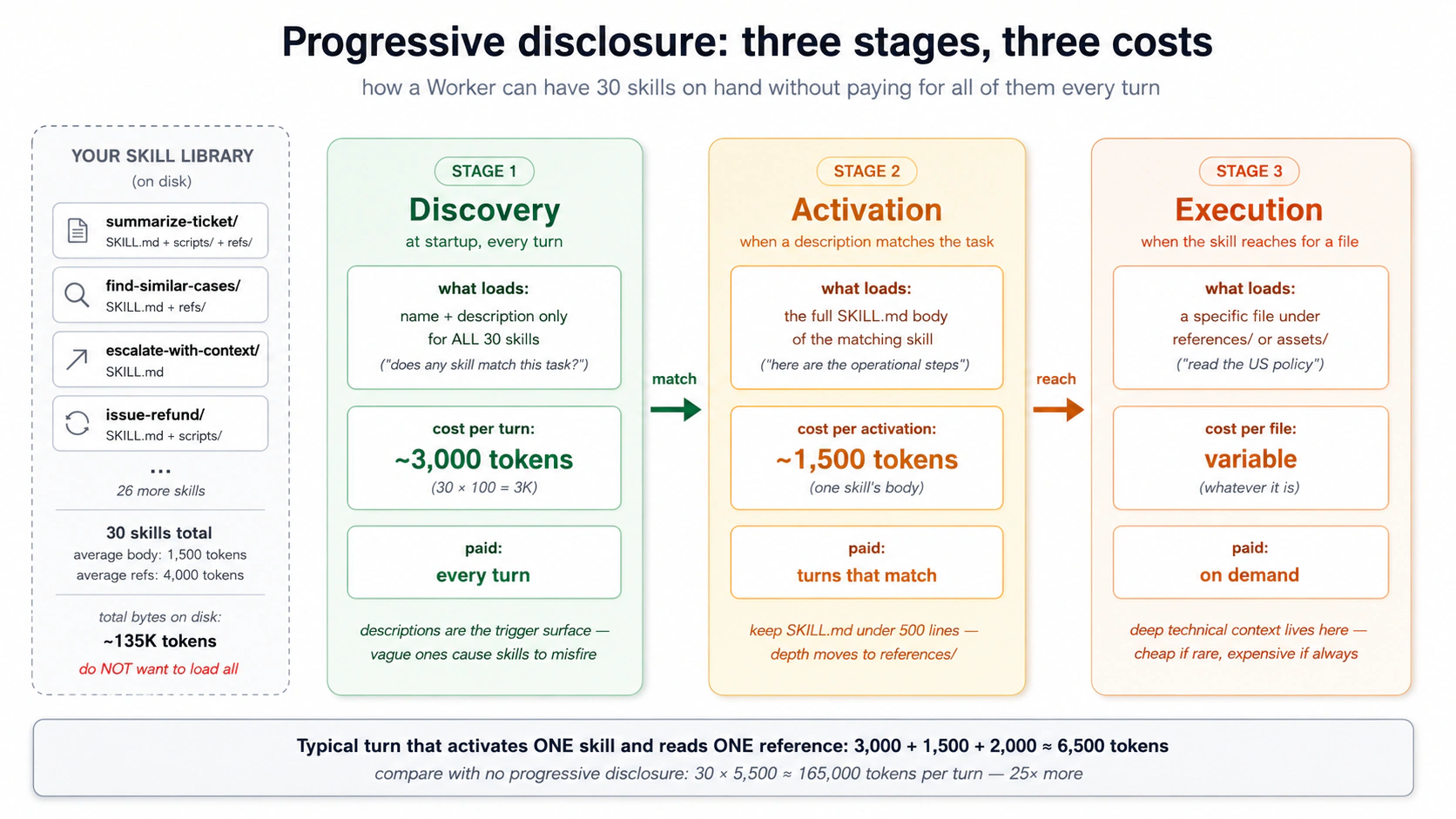
PRIMM, Predict. ایک ورکر کے پاس 30 skills ہیں: ہر ایک کی تقریباً 100 ٹوکن description، تقریباً 1,500 ٹوکن body، ہر ایک کی دو reference فائلیں (کل تقریباً 4,000 ٹوکن)۔ ایسے turn پر جو ایک skill کو activate کرتا ہے اور اس کے کسی ایک reference کو پڑھتا ہے، تخمینی context لاگت ہے: (a) تقریباً 3,000 ٹوکن؛ (b) تقریباً 6,500 ٹوکن؛ (c) تقریباً 135,000 ٹوکن۔ اعتماد 1 سے 5۔
جواب (b)، تقریباً 6,500 ٹوکن ہے: discovery کے لیے 30 × 100 (3,000)، جمع ایک 1,500 ٹوکن body، جمع ایک تقریباً 2,000 ٹوکن reference۔ Discovery لائبریری کے حجم کے ساتھ بڑھتی ہے؛ activation اور execution فی turn ثابت رہتے ہیں۔ progressive disclosure کے بغیر آپ ہر turn پر تمام 30 bodies اور ان کے references ادا کرتے، صرف یہ جاننے کے لیے کہ ایجنٹ کیا کر سکتا ہے، تقریباً 165,000 ٹوکن۔ کوئی یہ نہیں چلاتا۔
دو باتیں نکلتی ہیں، اور یہی اگلے تین تصورات چلاتی ہیں: description ہی وہ ہے جو مرحلہ 1 میں فائر ہوتا ہے، تو یہی سب کچھ طے کرتا ہے؛ اور لمبے bodies ہر ملنے والے turn پر آپ کو مہنگے پڑتے ہیں، تو SKILL.md کو تنگ رکھیں اور گہرائی کو references/ میں دھکیلیں۔
Concept 3: description ہی trigger ہے، اور وہ واحد حصہ جس کے آپ مالک ہیں
ایک SKILL.md کے دو حصے ہیں: YAML frontmatter (وہ معاہدہ جو ماڈل پڑھتا ہے) اور markdown body (وہ ہدایات جن پر یہ عمل کرتا ہے)۔ frontmatter کے صرف دو fields لازمی ہیں:
| Field | لازمی | یہ کیا ہے |
|---|---|---|
name | ہاں | skill کا شناخت کنندہ (لوئر کیس، hyphens، فولڈر کے نام سے ملتا ہے)۔ |
description | ہاں | trigger surface: وہ جو ایجنٹ discovery پر پڑھتا ہے تاکہ فیصلہ کرے کہ یہ skill فائر کرے یا نہیں۔ |
(license، compatibility، metadata، allowed-tools اختیاری ہیں اور شاذ ہی درکار ہوتے ہیں؛ skill-creator انہیں بھر دیتا ہے۔)
description ہی پورا کھیل ہے، اور یہی وہ حصہ ہے جسے scaffold غلط کر دیتا ہے۔ یہ ایک دائروی description لکھتا ہے: "Summarizes a ticket into five sections. Use when the user wants to summarize a ticket." یہ "summarize this ticket" پر فائر ہوتا ہے مگر اس بات کو نہیں پکڑتا کہ support اصل میں کیسے بات کرتا ہے: "write a handoff note for #4471," "TL;DR this thread," "give my lead the rundown before I escalate." عام version آٹھ میں سے تقریباً 6 حقیقی phrasings پکڑتا ہے؛ ہاتھ سے لکھا ہوا آٹھوں پکڑتا ہے۔
ایک ایسی description جو قابلِ اعتماد طور پر فائر ہو تین کام کرتی ہے، اور ایک guardrail بھی:
- کیا یہ پیدا کرتا ہے (اصل output کا نام لیں: پانچ sections، ایک ticket پر)۔
- کب اس کی طرف ہاتھ بڑھائیں (حقیقی صورتیں: handoff، escalation، manager کو briefing، کسی اور کا thread اٹھانا)۔
- وہ Keywords جو صارفین واقعی ٹائپ کرتے ہیں، بشمول وہ جو کبھی واضح لفظ نہیں کہتے ("handoff note," "TL;DR this thread," "where does this stand")۔
- ملتی جلتی چیزوں کے لیے ایک do-NOT لائن جنہیں خاموش رہنا چاہیے (گاہک کا جواب draft کرنا، ایک batch triage کرنا، ticket volume پر رپورٹنگ)۔
ایک self-check جو دائروی descriptions کو مار دیتا ہے: اپنی description سے واضح keyword ("summarize") حذف کریں۔ کیا یہ پھر بھی بتاتا ہے کہ کب فائر کرنا ہے؟ اگر نہیں، تو یہ بہت تنگ ہے۔
body، بطورِ رواج۔ کوئی لازمی فارمیٹ نہیں، مگر اچھی skills امری ہوتی ہیں ("Read the full thread. List what was tried.")، ایک یا دو حقیقی مثالیں رکھتی ہیں (steering کے لیے تقریباً ایک description کی 5 گنا قیمت)، اور دو یا تین edge cases کا نام لیتی ہیں جو واقعی ٹوٹ چکے ہیں۔
PRIMM, Predict. دو skills کا
namesummarize-documentایک ہی ہے: ایک~/.claude/skills/میں (user-level)، ایک.claude/skills/میں (project-level)۔ ایک کام دونوں سے ملتا ہے۔ کیا ہوتا ہے؟ (a) random چناؤ؛ (b) project-level جیتتا ہے؛ (c) ماڈل چنتا ہے۔ اعتماد 1 سے 5۔
(b)، project-level جیتتا ہے Claude Code اور OpenCode دونوں میں: زیادہ مخصوص context زیادہ عام پر غالب آتا ہے، بالکل اسی طرح جیسے ایک project rules فائل ایک global پر غالب آتی ہے۔
Concept 4: Packaging، skills کہاں رہتی ہیں اور کیسے سفر کرتی ہیں
ایک skill بس ڈسک پر ایک فولڈر ہے، تو آپ اسے کہاں رکھتے ہیں یہ طے کرتا ہے کہ کون سے ایجنٹس اسے ڈھونڈتے ہیں۔ ایک اصول پورا کورس سنبھالتا ہے: اپنی skills کو OpenCode پہلے اپنا فولڈر دیکھتا ہے، پھر .claude/skills/ میں رکھیں۔ Claude Code وہ فولڈر پڑھتا ہے، OpenCode اس پر fall back کرتا ہے، اور آپ کے ورکر کا SDK سیدھا اسی کی طرف اشارہ کرتا ہے (LocalDir(src=".claude/skills")، اوپر والے عملی حصے سے)۔ skill ایک بار لکھیں اور تینوں وہی فولڈر، byte-for-byte لوڈ کرتے ہیں۔مکمل path نقشہ (فی tool، project بمقابلہ user-level)
Tool Project-level User-level (global) Claude Code .claude/skills/<name>/SKILL.md~/.claude/skills/<name>/SKILL.mdOpenCode .opencode/skills/<name>/SKILL.md~/.config/opencode/skills/<name>/SKILL.mdOpenCode (fallback) .claude/skills/<name>/SKILL.md~/.claude/skills/<name>/SKILL.md.claude/skills/ پر fall back کرتا ہے؛ Claude Code صرف .claude/ پڑھتا ہے۔ اسی لیے .claude/skills/ وہ واحد جگہ ہے جو ہر جگہ کام کرتی ہے۔
ایک skill کے فولڈر میں ایک لازمی فائل اور تین اختیاری فولڈرز ہوتے ہیں، ہر ایک کا ایک کام:
my-skill/
├── SKILL.md # required: frontmatter + body, the entry point
├── scripts/ # optional: code the agent runs (by relative path)
├── references/ # optional: deep docs, loaded on demand, one topic per file
└── assets/ # optional: templates, schemas, lookup tables
SKILL.md کے اندر، ان فائلوں کی طرف relative path سے اشارہ کریں (references/policies/us.md، scripts/extract.py)؛ یہ skill کے اپنے فولڈر سے resolve ہوتی ہیں، نہ کہ جہاں ایجنٹ چل رہا ہو۔ references/ کو اتھلا رکھیں، فی فائل ایک موضوع۔
Concept 5: Skills کو ملانا، ایک بڑی بمقابلہ کئی چھوٹی
ایک "weekly customer-health report" ایک ہی skill ہو سکتی ہے جو research، draft، format، اور review کرتی ہے، یا چار skills جو filesystem کے ذریعے handoff کرتی ہیں۔ دونوں کام کرتی ہیں، الٹ trade-offs کے ساتھ۔
- ایک بڑی skill: ڈھونڈنا آسان، ایک activation۔ مگر ہر قدم ایک ہی context میں چلتا ہے، کوئی چیز اکیلے قابلِ استعمال نہیں، اور بیچ میں ناکامی ماڈل کو context میں باسی کام کے ساتھ سنبھلتا چھوڑ دیتی ہے۔
- کئی چھوٹی skills: ہر ایک اکیلے test، تبدیل، اور دوبارہ استعمال ہو سکتی ہے؛ ناکامی مقامی رہتی ہے؛ ہر قدم تازہ activate ہوتا ہے، تو کوئی بچا کھچا context نہیں جمع ہوتا۔ قیمت یہ ہے کہ زیادہ discovery entries اور انہیں جوڑنے والی کوئی چیز۔
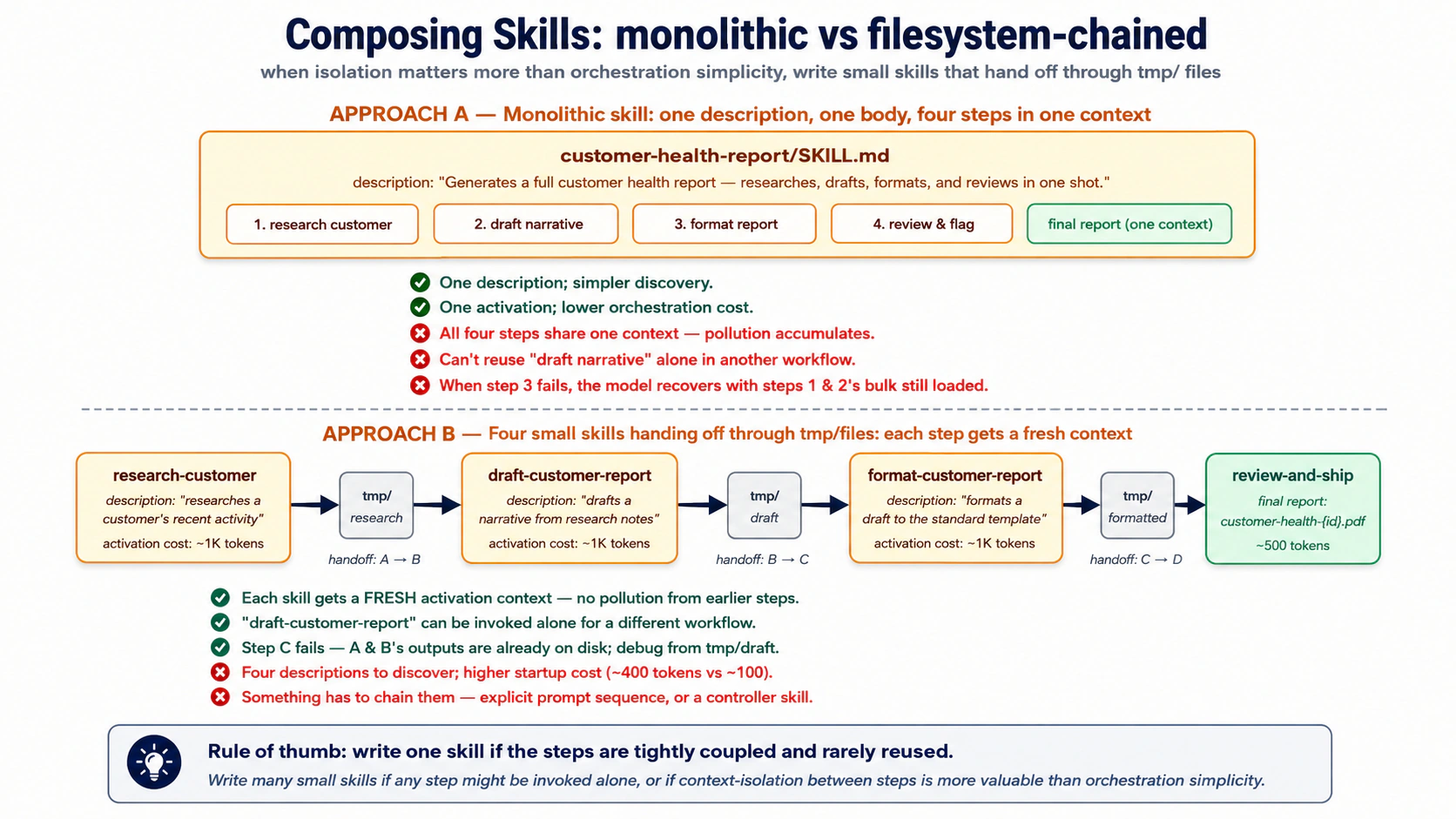
ایک skill لکھیں جب قدم سختی سے جڑے ہوں اور کبھی اکیلے دوبارہ استعمال نہ ہوں۔ کئی لکھیں جب کوئی قدم اکیلے بھی کال ہو سکتا ہو، یا جب ہر قدم کا context صاف رکھنا wiring کو سادہ رکھنے سے زیادہ اہم ہو۔ دو یا تین قدموں کے بعد علیحدگی عموماً جیتتی ہے۔
انہیں filesystem کے ذریعے جوڑیں، گفتگو کے ذریعے نہیں۔ Skill A tmp/research-{id}.md لکھتی ہے، Skill B اسے پڑھتی اور tmp/draft-{id}.md لکھتی ہے، اور اسی طرح آگے۔ گفتگو صرف آخری نتیجہ دیکھتی ہے؛ بیچ کے قدم ایجنٹ، آپ، اور audit trail کے لیے ڈسک پر رہتے ہیں۔ وہی isolation جو پچھلے کورس نے subagents کے لیے استعمال کیا، اب skill کے سائز پر۔
اور یہ Part 2 کا پل ہے: کچھ handoffs کسی temp فائل میں نہیں، سسٹم آف ریکارڈ میں جاتی ہیں۔ ایک skill جو tmp/ میں لکھتی ہے ایک مسودہ ہے؛ ایک skill جو سسٹم آف ریکارڈ میں لکھتی ہے ایک عمل ہے۔ یہی فرق Part 2 بناتا ہے۔
Try with AI
Compare two designs for a customer-refund workflow:
A: one "issue-refund" skill (eligibility, policy, amount, gateway, ticket, notify).
B: five small skills chained via tmp/ handoffs.
For each, name one situation where it's the right call and one failure mode
it's vulnerable to. Then say which you'd ship, and why.
دونوں runtimes میں ایک skill فائر کریں (تقریباً 10 منٹ، عملی)
آپ نے کافی پڑھ لیا؛ اب اس ایجنٹ کے اندر ایک skill کو فائر ہوتے دیکھیں جو آپ بناتے ہیں۔ Quick Win والا وہی digital-fte فولڈر کھولیں، جہاں آپ کا SandboxAgent پہلے ہی چلتا ہے۔ اسے ایک ضائع کرنے والی skill پر ایک بار چلائیں تاکہ مشینری مانوس ہو (یہی چال Decision 4 اصل میں کرتا ہے)، اور دیکھیں کہ .claude/skills/ کی وہی فائلیں جو آپ پہلے سے Claude Code میں استعمال کرتے ہیں، آپ کے ورکر کے اپنے SDK میں بھی اسی طرح کام کرتی ہیں۔
1. اسے scaffold کریں۔ آپ کو ایک عام ایجنٹ اور Node انسٹال چاہیے (npx کے لیے)۔ یہ paste کریں:
Use skill-creator to scaffold a summarize-ticket skill. It turns one support ticket into a
short five-section handoff. Make it fire on how support actually asks (handoff note, TL;DR
this thread, "what's the status and next step"), including phrasings that never say
"summarize", and not on look-alikes (drafting a reply, triaging a batch). Then check it:
delete "summarize" from the description; if it no longer says when to fire, sharpen it.
body اچھا واپس آتا ہے؛ description پڑھیں اور اسے تیز کریں جب تک یہ delete-the-keyword check پاس نہ کر لے۔ وہی review ہی skill ہے، اور وہ حصہ جو کوئی scaffold آپ کے لیے نہیں کرتا۔
2. اسے کسی client میں فائر کریں (اختیاری، صفر wiring)۔ اگر آپ کے پاس Claude Code یا OpenCode انسٹال اور signed in ہے، تو فولڈر وہاں کھولیں اور اس سے ایک ticket سنبھالنے کو کہیں بغیر "summarize" کہے (مثلاً "write a handoff note for case #4471 before I escalate")۔ client .claude/skills/ ڈھونڈتا ہے، آپ کی description سے ملاتا ہے، اور summarize-ticket activate کرتا ہے۔ ایک تنبیہ: اگر کوئی درخواست اتنی سادہ ہو کہ ماڈل اسے سیدھا جواب دے دے، تو کوئی skill فائر نہیں ہوتی، اور یہ ماڈل کا فیصلہ ہے، کوئی description bug نہیں؛ ایک حقیقی handoff سے test کریں، ایک سطری سوال سے نہیں۔ صرف SDK والے قارئین قدم 3 پر جا سکتے ہیں۔
3. اسے OpenAI Agents SDK میں فائر کریں۔ اب skill کو اپنے ورکر کے اپنے runtime میں wire کریں، اور وہ اسی طرح کریں جیسے آپ Part 4 میں ہر چیز کریں گے: آپ prompt کرتے ہیں، ایجنٹ plan کرتا ہے، آپ منظوری دیتے ہیں، یہ بناتا اور چلاتا ہے۔ آپ ابھی بھی digital-fte فولڈر میں ہیں، تو uv project اور OPENAI_API_KEY ساتھ چلتے ہیں۔ یہ paste کریں:
Wire the
summarize-ticketskill into a minimalSandboxAgentI can run from this folder: aSkillscapability pointed at.claude/skills, the default capabilities kept, a gpt-5-class model, on a local sandbox. Make sureopenai-agentsis installed. Plan first.
یہ Quick Win جیسی ہی SandboxAgent شکل ہے، جس میں save_note ٹول کی جگہ ایک Skills capability ہے (ایک gpt-5-class ماڈل اہم ہے: default capabilities میں ایک filesystem ٹول شامل ہے جسے چھوٹے ماڈل 400 سے رد کرتے ہیں)۔ جب plan درست لگے، تو منظوری دیں اور ایک ہی بار میں اسے live-test کریں:
Implement it, then run it with "write a handoff note for case #4471: no refund, two weeks" and show me the trace so I can see the skill fire.
trace میں تصدیق کریں کہ یہ فائر ہوا۔ SDK ہر run کو اسی OpenAI dashboard پر trace کرتا ہے جو آپ نے پچھلے کورس میں استعمال کیا: platform.openai.com/traces کھولیں اور آپ run میں summarize-ticket کے لیے load_skill call دیکھیں گے، پھر پانچ sections والا جواب۔ (کوئی dashboard نہیں؟ print لوپ وہی load آپ کے ٹرمینل میں دکھاتا ہے۔) .claude/skills منبع ہے؛ .agents/ وہ جگہ ہے جہاں ایک لوڈ شدہ skill run time پر staged ہوتی ہے۔ وہی فائل، دو runtimes: یہی قابلِ انتقال صلاحیت ہے، اور Decision 8 اسے مکمل ورکر میں wire کرتا ہے۔
یہ تصورات ایک مضبوط ہدایت پر چلنے والا ماڈل فرض کرتے ہیں (Claude Sonnet/Opus، GPT-5-class)۔ کسی چھوٹے ماڈل پر (deepseek-chat، Haiku-class، زیادہ تر local ماڈلز)، تین چیزیں بھٹکتی ہیں:
- Multi-skill sequencing۔ "ALWAYS run X before Y" مضبوط ماڈلز پر لگتا ہے، کمزور پر پھسلتا ہے۔ حل: ترتیب کو system prompt میں ایک مختصر GENERAL-FLOW تمہید میں رکھیں؛ SKILL bodies کو declarative رکھیں۔
- Format drift۔ ایک کمزور ماڈل emojis، tables، یا آپ کے inputs کی paraphrase شامل کر دیتا ہے۔ صاف بتائیں کہ کیا نہیں کرنا، صرف یہ نہیں کہ کیا کرنا۔
- Trigger blindness۔ ایک description جو "summarize ticket TKT-1042" پر فائر ہوتی ہے "what's the story on #1042" کو چھوڑ سکتی ہے۔ Concept 3 کا نظم کمزور ماڈل پر زیادہ اہم ہے، کم نہیں۔
اصولِ عام: مضبوط ماڈل کی محنت SKILL.md میں لگائیں، کمزور ماڈل کی محنت system prompt میں۔ آرکیٹیکچر قائم رہتا ہے؛ آپ بس اس کے ارد گرد زیادہ scaffolding لکھتے ہیں۔
Part 2: Neon Postgres + pgvector بطورِ سسٹم آف ریکارڈ
Part 1 نے ایجنٹ کو صلاحیتیں دیں۔ اب اسے کہیں پائیدار جگہ چاہیے جہاں وہ رکھے جو یہ بھولنے کا متحمل نہیں ہو سکتا: گاہک کا ریکارڈ، پالیسی لائبریری، گزشتہ حل شدہ کیسز، اور اس نے جو کچھ کیا اس کا trace۔
وہ اسٹور آپ کے ورکر کا سسٹم آف ریکارڈ ہے، وہ بااختیار اسٹور جس کے مقابل یہ چلتا ہے (شروع کے نقشے کا CRM-یا-کھاتہ والا خیال، اب ٹھوس ہو کر)۔ یہ pgvector extension کے ساتھ Postgres ہے؛ Concept 6 بتاتا ہے کہ کسی مخصوص vector database کے بجائے یہ کیوں۔ ہم Neon استعمال کرتے ہیں: شروع کرنے میں مفت، فارغ رہتے ہوئے کچھ خرچ نہیں، اور آپ کا coding ایجنٹ اسے سیدھا چلا سکتا ہے، مگر pgvector والا کوئی بھی managed Postgres چلتا ہے۔
اس نقشے کی چار قسموں کے ڈیٹا میں سے، کاروباری ریکارڈز (گاہک، آرڈرز، tickets) آپ کے کاروبار کے لیے مخصوص ہیں، تو وہ آپ Part 4 میں بناتے ہیں۔ یہ Part جو بناتا ہے وہ باقی تین ہیں، وہ حصے جو ہر ورکر بانٹتا ہے، اب ان حقیقی tables سے نقشہ بند جو انہیں رکھتی ہیں:
- ریفرنس لائبریری: وہ علم جسے ورکر معنی سے تلاش کرتا ہے، پالیسی لائبریری، knowledge-base مضامین، گزشتہ حل شدہ کیسز کے خلاصے۔ یہ
documentsاورembeddingsمیں رہتا ہے (Concepts 8 اور 9)۔ - State: زندہ گفتگو۔ اس کے turns ایجنٹ SDK کی Session میں رہتے ہیں، جسے SDK آپ کے لیے بناتا اور لکھتا ہے، تو آپ وہ tables کبھی design نہیں کرتے (Concept 7)؛ ایک
conversationsrow ان کے ساتھ بیٹھتی ہے، session id سے بندھی، بطورِ لفافہ: کون، کب، ایک اختتامی خلاصہ۔ - Trace: ورکر نے جو کیا اس کا ریکارڈ، یعنی
audit_logکھاتہ (Concept 10)۔ (ایک اختیاری ساتھی table،capability_invocations، فی skill اور فی tool metrics شامل کرتی ہے۔)
Concept 6: managed Postgres کیوں، اور خاص طور پر Neon کیوں
مقالہ سسٹمز آف ریکارڈ کے بارے میں product-agnostic رہتا ہے: "AI-Native کمپنی کے موجودہ databases، workflows، اور operational platforms (CRMs، ERPs، ticketing systems، data warehouses، ledgers) سسٹم آف ریکارڈ کا کام کرتے ہیں۔" مگر جو ایجنٹ آپ شروع سے بناتے ہیں، اس کے لیے آپ کو کچھ نہ کچھ چننا ہوتا ہے۔ سوال "Postgres بمقابلہ MongoDB بمقابلہ ایک vector DB" نہیں۔ سوال "کون سا Postgres" ہے۔
Postgres کیوں، نہ کہ کوئی مخصوص vector database۔ تین وجوہ جو 2026 میں بھی قائم ہیں۔
-
ایک ڈیٹابیس، ایک transaction، ایک auth سرحد۔ الگ vector DB کا مطلب ہے دو اسٹور جنہیں sync میں رکھنا ہے، دو auth سسٹم، دو backup pipelines۔
pgvectorvectors کو ان ریکارڈز کے ساتھ رکھتا ہے جن سے وہ متعلق ہیں، تو ایک JOIN، JOIN ہی رہتا ہے، دو services کے بیچ network hop نہیں۔ ہر بڑا managed Postgres (AWS RDS، Cloud SQL، Azure، Supabase، Neon) اسے بھیجتا ہے، اور یہ سب سے زیادہ انسٹال ہونے والی Postgres extensions میں سے ہے۔ زیادہ تر workloads کے لیے یہی کافی ہے۔ -
Postgres پہلے ہی مشکل حصے کرتا ہے۔ Transactions، indexes، foreign keys، row-level security، point-in-time recovery، query planning۔ ایک مخصوص vector DB کو یہ شروع سے ایجاد کرنا ہوتا ہے اور عموماً کچھ کو بدتر کرتا ہے۔ default بورنگ انتخاب کے فائدے بڑھتے رہتے ہیں۔
-
Postgres کے لیے ہر تہہ پر MCP سرورز موجود ہیں۔ Neon ایک بھیجتا ہے (management کے لیے)۔ عام Postgres MCP سرورز موجود ہیں (SQL execution کے لیے)۔ آپ اپنا لکھ سکتے ہیں (scoped runtime access کے لیے)۔ Postgres کے گرد MCP کا ماحول سب سے پختہ ہے۔
ایک مخصوص vector DB کب جیتتی ہے۔ Pinecone، Weaviate، Qdrant، اور Milvus جیسے tools تب قابلِ قدر ہیں جب معنی سے تلاش ہی پروڈکٹ ہو، آپ کے کاروباری ڈیٹا کے ساتھ بیٹھنے والی کوئی feature نہیں۔ علامتیں شدید ہوتی ہیں: اتنے زیادہ vectors کہ وہ ایک Postgres سرور کی memory میں نہ سمائیں، اتنی بھاری search traffic کہ صرف vectors کے لیے بنا ایک engine چاہیے، یا vectors کا بہت سی الگ services کے ذریعے خود سے استعمال۔ کوئی مقررہ عدد نہیں جہاں pgvector جواب دے، تو کسی شکل پر بھروسہ کرنے کے بجائے اپنے ڈیٹا پر test کریں۔ ایک tickets table اور اس کے ساتھ embeddings والا ورکر اس نقطے سے کہیں دور ہے، تو pgvector درست default ہے۔
خاص طور پر Neon کیوں: تین امتیازات۔
-
یہ صفر تک گھٹتا ہے۔ جب ڈیٹابیس فارغ ہو، تو کچھ خرچ نہیں ہوتا۔ ایک ورکر جو دن میں 50 گفتگوئیں سنبھالتا ہے زیادہ تر فارغ بیٹھتا ہے، تو یہ ہمیشہ آن رہنے والے سرور کا ماہانہ ادا کرنے کے بجائے تقریباً $0 کے قریب رہتا ہے۔ یہ تب اہم ہے جب آپ بہت سے ورکرز چلائیں جو ہر ایک صرف جھونکوں میں مصروف ہو۔
-
یہ branch ہوتا ہے۔ سیکنڈوں میں، Neon آپ کے زندہ ڈیٹابیس کی مکمل کاپی بنا دیتا ہے کام کرنے کے لیے، اصل کو ہاتھ لگائے بغیر۔ ایجنٹ سے متعلق استعمال: ایجنٹ کو کسی branch پر تبدیلی آزمانے دیں، اور اگر غلط ہو جائے تو بس branch حذف کر دیں۔ ایسے ڈیٹابیس پر جو branch نہیں ہو سکتا، خراب تبدیلی کو واپس کرنے کا مطلب ہے backup سے بحالی۔
-
اس کے پاس ایک سرکاری MCP سرور ہے۔ Neon ایک MCP سرور بھیجتا ہے جس سے آپ کا coding ایجنٹ بات کر سکتا ہے، تو یہ سادہ زبان میں projects بنا سکتا، branches manage کر سکتا، اور migrations چلا سکتا ہے۔ build کرتے ہوئے اسے استعمال کریں؛ Concept 12 بتاتا ہے کہ یہ چلتے ورکر کے لیے کیوں نہیں۔
Try with AI
A teammate proposes splitting the stores: Postgres for the relational
data (customers, tickets, orders) AND a separate Pinecone index for the
embeddings, "because Pinecone is purpose-built for vectors."
Context for you, the assistant: keeping vectors in Postgres (via the
pgvector extension) next to the relational data means one query can
filter by business state, rank by similarity, and return the full
record in a single transaction. Splitting the stores forces the agent
to round-trip between two services, denormalize and sync metadata
across them, and give up cross-store transactional consistency.
1. Make the case against the split as concretely as you can on ONE
request: a support Worker gets a message and must answer "have we
seen this before, and what did we tell them?" Show exactly what that
request costs when the vectors live in Pinecone and the tickets live
in Postgres. Name the join, what happens to ranking at the LIMIT
boundary when you filter in application code, and how an embedding
goes stale after a resolution is updated.
2. Name the ONE condition under which the teammate is actually right and
a dedicated vector DB is the better call. Be specific about the scale
at which the crossover happens.
3. Neon adds two properties a plain Postgres box doesn't: scale-to-zero
(an idle Worker's database costs nothing) and branching (the agent
forks a production-fidelity copy of the data, experiments or migrates
on it in isolation, then verifies before merging). Which matters more
for an AI Worker specifically, and why? Defend your pick in two
sentences.
Concept 7: ورکر کا schema، ایک ایجنٹ کو اصل میں کون سی tables چاہئیں
ایک ڈیٹابیس schema بس وہ tables ہیں جو آپ رکھتے ہیں اور ہر ایک میں columns، یعنی آپ کے ڈیٹا کی شکل۔ وہ پانچ tables جو عملی مثال بناتی ہے سسٹم آف ریکارڈ کے وہ مشترکہ حصے ہیں جو ہر ورکر کو چاہئیں؛ خود کاروباری ریکارڈز Part 4 میں آتے ہیں۔ یہ دو گروہوں میں آتے ہیں، تو آپ دیکھ سکتے ہیں کہ کیا لازمی ہے اور کیا اختیاری۔
چار tables جو ہر ورکر رکھتا ہے، مشترکہ ریڑھ۔ یہ Part کے آغاز سے state، ریفرنس لائبریری، اور trace رکھتی ہیں، اب بطورِ tables:
conversations(state): فی گفتگو ایک row، کس کے ساتھ تھی، کب، اور آخر میں ایک مختصر خلاصہ۔ (turn-by-turn پیغامات الگ سے، SDK کے ذریعے رکھے جاتے ہیں؛ نیچے دیکھیں۔)documentsاورembeddings(ریفرنس لائبریری):documentsمتن رکھتی ہے (پالیسیاں، گزشتہ کیسز)؛embeddingsوہ ہے جو اسے معنی سے قابلِ تلاش بناتی ہے۔ ایک embedding ایک متن کو اعداد کی فہرست میں بدلتی ہے جو اس کا موضوع پکڑتی ہے، تو متعلق متن قریب آ جاتا ہے، جیسے ایک board پر notes پن کرنا جہاں ملتے جلتے اکٹھے ہو جاتے ہیں، اور "متعلق ڈھونڈو" "قریب ترین ڈھونڈو" بن جاتا ہے۔ (Concept 9 یہ بناتا ہے؛ یہاں بس جان لیں کہembeddingsمعنی سے تلاش والی تہہ ہے۔)audit_log(trace): ورکر نے جو کیا اس کا ایک چلتا ریکارڈ، ہر عمل ترتیب میں، بشمول کاروباری events جیسے ایک refund جاری ہونا۔
ایک اور جو آپ ضرورت پر شامل کرتے ہیں، usage analytics۔
capability_invocations: ہر بار جب ورکر کوئی skill چلاتا یا ٹول کال کرتا ہے ایک row (دونوں یہی ایک table بانٹتے ہیں؛ ایک column نشان لگاتا ہے کہ کون سا، تو آپ فی tool ایک table نہیں بڑھاتے)، اس کے ساتھ کہ کتنا وقت لگا، کامیاب ہوا یا ناکام، اور ایک تخمینی لاگت۔ اسے تب شامل کریں جب آپ SQL میں capability-usage analytics چاہیں: کوئی skill کتنی بار فائر ہوتی ہے، اس کی error rate، کسی escalation سے پہلے عموماً کیا آتا ہے۔
دو اور tables اس سیٹ سے باہر رہتی ہیں، دونوں Part 4 میں: آپ کی business-specific tables (customers، tickets، orders)، اور run_states، جو ایک رکی ہوئی منظوری رکھتی ہے جب کوئی انسان بعد میں یا کسی اور process میں sign off کرے، نہ کہ فوراً۔ ان میں سے کوئی مشترکہ ریڑھ کا حصہ نہیں۔
خود پیغامات کہاں جاتے ہیں؟ ایک transcript اور ایک cover sheet تصور کریں۔ transcript ہر پیغام ہے، آپ کا سوال، ماڈل کا جواب، ہر tool call، ہر ایک اپنی row کے طور پر؛ SDK اسے آپ کے لیے لکھتا اور رکھتا ہے (Decision 3 میں wire ہوتا ہے)، تو آپ اسے کبھی نہیں بناتے۔ cover sheet وہ واحد conversations row ہے جو آپ لکھتے ہیں: کون، کب، ایک خلاصہ، اور کاروباری تفصیلات جیسے user_id جو SDK کی اپنی tables نہیں رکھتیں۔ آپ اسے رکھتے ہیں کیونکہ transcript "اس گاہک کی آخری پانچ گفتگوئیں دکھاؤ" کا جواب نہیں دے سکتا؛ یہ conversations پر ایک تیز lookup ہے، transcript سے اسی session id پر joined جو وہ بانٹتے ہیں۔ یہ اختیاری ہے: اگر آپ کو کبھی فی صارف فہرستیں یا خلاصے نہ چاہئیں، تو transcript اکیلا کافی ہے۔
پانچوں tables کی مکمل SQL نیچے کے باکس میں ہے۔ آپ کا coding ایجنٹ اسے Decision 3 کے plan سے لکھتا ہے، تو آپ اسے سرسری دیکھ کر آگے بڑھ سکتے ہیں؛ جو اہم ہے وہ یہ جاننا ہے کہ ہر table کس کے لیے ہے۔schema، مکمل (چار مشترکہ tables اور اختیاری capability_invocations)
-- 1. CONVERSATIONS: business metadata per conversation (your app writes this row)
CREATE TABLE conversations (
session_id TEXT PRIMARY KEY, -- the SAME id you pass to SQLAlchemySession
user_id TEXT NOT NULL,
started_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
ended_at TIMESTAMPTZ,
metadata JSONB NOT NULL DEFAULT '{}'::jsonb,
-- searchable summary; your app writes it at conversation end
summary TEXT
);
CREATE INDEX idx_conversations_user ON conversations(user_id, started_at DESC);
-- The turns themselves live in the SDK Session's tables (agent_sessions /
-- agent_messages, via SQLAlchemySession), created automatically on this same
-- database and keyed by this session_id; you do not hand-build them.
-- 2. DOCUMENTS: the agent's reference library
CREATE TABLE documents (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
source TEXT NOT NULL, -- 'policy_library', 'kb_article', 'past_case', etc.
title TEXT NOT NULL,
body TEXT NOT NULL,
metadata JSONB NOT NULL DEFAULT '{}'::jsonb,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
updated_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE INDEX idx_documents_source ON documents(source);
-- 3. EMBEDDINGS: vector representations of documents AND past conversations
CREATE TABLE embeddings (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
-- one of these is populated; the other is NULL
document_id UUID REFERENCES documents(id) ON DELETE CASCADE,
conversation_id TEXT REFERENCES conversations(session_id) ON DELETE CASCADE,
chunk_text TEXT NOT NULL,
chunk_index INT NOT NULL,
embedding VECTOR(1536) NOT NULL,
model TEXT NOT NULL, -- 'text-embedding-3-small', etc.
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
CHECK (
(document_id IS NOT NULL)::int + (conversation_id IS NOT NULL)::int = 1
)
);
-- the key index for semantic search; see Concept 8
CREATE INDEX idx_embeddings_hnsw
ON embeddings USING hnsw (embedding vector_cosine_ops);
-- 4. AUDIT_LOG: replayable trace of how the Worker changed or used the record
CREATE TABLE audit_log (
id BIGSERIAL PRIMARY KEY,
conversation_id TEXT REFERENCES conversations(session_id) ON DELETE SET NULL,
actor TEXT NOT NULL, -- 'worker:customer-support', 'system', etc.
action TEXT NOT NULL CHECK (action IN (
'message_received', 'message_sent', 'skill_activated',
'capability_invoked', 'refund_issued', 'refund_blocked',
'guardrail_tripped', 'corpus_seeded'
)), -- closed vocabulary; widening it is a migration (Concept 10)
target TEXT, -- table name, skill name, etc.
payload JSONB NOT NULL, -- the data of the action
result JSONB, -- what happened
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE INDEX idx_audit_conv ON audit_log(conversation_id, created_at);
CREATE INDEX idx_audit_action ON audit_log(action, created_at);
-- 5. CAPABILITY_INVOCATIONS: every skill or tool call, for replay and metrics
CREATE TABLE capability_invocations (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
conversation_id TEXT NOT NULL REFERENCES conversations(session_id) ON DELETE CASCADE,
capability TEXT NOT NULL, -- 'skill:summarize-ticket', 'tool:search_docs', etc.
arguments JSONB NOT NULL,
result JSONB,
status TEXT NOT NULL CHECK (status IN ('ok', 'error', 'blocked', 'timeout')), -- 'blocked' = approval rejected
latency_ms INT,
cost_cents INT, -- approximate cost in 1/100 cents
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE INDEX idx_cap_conv ON capability_invocations(conversation_id, created_at);

چند design انتخاب سمجھنے کے قابل ہیں:
-
documents اور conversations دونوں کے لیے ایک
embeddingstable۔ ایکCHECKconstraint ہر row کو بالکل ایک کی طرف اشارہ کراتی ہے، ایک document یا ایک conversation۔ تو ایک ہی search پالیسیوں اور گزشتہ گفتگوؤں کو ایک ساتھ سمیٹ سکتی ہے، اور "کیا ہم اس کا جواب پہلے دے چکے ہیں؟" ایک index استعمال کرتی ہے، دو نہیں۔ -
audit_logایکUUIDنہیں بلکہBIGSERIAL(خود بڑھتا عدد) استعمال کرتی ہے۔ Audit rows تیزی سے جمع ہوتی ہیں، اور ایک سادہ integer key writes کو تیز اور ترتیب کو واضح رکھتا ہے۔ باقی tablesUUID(random، عالمی طور پر منفرد ids) استعمال کرتی ہیں کیونکہ ان کی rows API responses اور URLs میں دکھتی ہیں، جہاں ایکUUIDچھپا دیتا ہے کہ آپ کی کتنی rows ہیں۔ -
Skills اور tools
capability_invocationsبانٹتے ہیں۔ ایک skill call اور ایک tool call ملتے جلتے ہیں مگر یکساں نہیں (مختلف کوڈ، مختلف لاگتیں، ناکامی کے مختلف طریقے)۔ دونوں کو ایک table میں رکھنا، ایک column کے ساتھ جو بتاتا ہے کون سا، آپ کو "ایجنٹ نے کیا کیا؟" دونوں پر پوچھنے دیتا ہے، یا انہیں الگ کر کے "کون سی skills سست یا ناکام ہیں؟" پوچھنے دیتا ہے۔ -
metadataJSONB columns بچاؤ کے راستے ہیں۔ کوئی schema ہر field کا اندازہ نہیں لگا سکتا جو کسی کاروبار کو چاہیے، تو ایک JSONB column آپ کو table بدلے بغیر fields شامل کرنے دیتا ہے۔ اسے کم استعمال کریں: جو بھی آپ اکثر query کرتے ہیں اسے اپنا column بننا چاہیے۔
آپ اپنے کاروبار کے لیے مزید tables شامل کریں گے: ایک customers table، ایک tickets table، ایک orders table، عام relational tables جنہیں ایجنٹ MCP کے ذریعے پڑھتا اور لکھتا ہے۔
PRIMM, Predict. ایک ورکر دن میں 200 گفتگوئیں سنبھالتا ہے، ہر ایک اوسطاً 10 turns، جن میں سے 30% ایک skill invocation چلاتی ہیں اور 50% skill row کے علاوہ دو audit rows لکھتی ہیں۔ ایک مہینے (30 دن) کے بعد، کون سا اسٹور سب سے تیز بڑھتا ہے؟ تین اختیارات: (a) سب ملتے جلتے حجم پر؛ (b)
audit_logبہت زیادہ فرق سے تیز ترین بڑھتی ہے؛ (c) embeddings table، کیونکہ ہر turn embed ہوتا ہے۔ اعتماد 1 سے 5۔
جواب (b) ہے: جو tables آپ بناتے ہیں ان میں سے audit_log تیز ترین بڑھتی ہے، کیونکہ ایک interaction کئی action rows لکھ سکتا ہے (ایک skill یا tool call، ریکارڈ میں ایک write، کبھی ایک refund) جبکہ یہ صرف ایک conversations row شامل کرتا ہے اور کوئی نیا documents نہیں۔ تو یہی وہ table ہے جس کی retention اور indexing آپ بڑھتے ہوئے پہلے planning کرتے ہیں۔ (SDK کا اپنا turn store اس سے بھی تیز بڑھتا ہے، مگر آپ اسے manage نہیں کرتے۔)
Try with AI
I'm building a customer-support Worker. Its database already
has the four shared tables from Concept 7: `conversations` (one row per
conversation, plus a summary), `documents` and `embeddings` (a
searchable reference library), and `audit_log` (the record of what it
did). The turn-by-turn messages are held by the agent SDK's Session,
not a table I built.
I want to extend this for a Worker that handles software bug reports
specifically. What three additional tables would you add, and what
columns would they have? For each, say what the agent will use it for
(read access? write access? both?) and what foreign keys connect it to
the tables above.
Concept 8: pgvector کی بنیادیں، types، distance operators، indexes
embeddings table وہی ہے جو ورکر کو متن معنی سے ڈھونڈنے دیتی ہے، نہ کہ صرف الفاظ ملا کر۔ board کو یاد کریں: متن کا ہر ٹکڑا (ایک پالیسی، ایک گزشتہ کیس، ایک ریکارڈ) ایک پن پاتا ہے، اور متعلق چیزیں ایک دوسرے کے قریب بیٹھتی ہیں۔ ایک پن کی پوزیشن ہی embedding ہے، اعداد کی ایک فہرست۔ pgvector (ایک Postgres extension) وہی ہے جو Postgres کو ان پنوں کو رکھنے اور قریب ترین کو ڈھونڈنے دیتی ہے، تو آپ کو الگ vector database کی ضرورت نہیں (Concept 6 وجہ ہے)۔
vector type۔ VECTOR(n) ایک column ہے جو ایک پن رکھتا ہے: n اعداد کی ایک مقررہ فہرست۔ جو ماڈل embeddings بناتا ہے وہی n طے کرتا ہے، OpenAI کے text-embedding-3-small کے لیے 1536، text-embedding-3-large کے لیے 3072، دوسرے ماڈل مختلف۔ وہ اصول جو لوگوں کو ڈستا ہے: آپ کا رکھا ہوا متن اور آپ کی search query ایک ہی ماڈل سے آنے چاہئیں۔ دو ماڈل دو نقشوں جیسے ہیں جو مختلف پیمانوں پر بنے ہیں، ایک پر جو جگہ "downtown" کا مطلب دیتی ہے دوسرے پر سمندر میں اترتی ہے۔ اپنے documents کو ایک ماڈل سے اور اپنی queries کو دوسرے سے embed کریں، تو "قریب ترین" نتائج بکواس کے طور پر واپس آتے ہیں چاہے query بغیر error کے چلے۔ یہ سب سے عام pgvector غلطی ہے۔
بہت بڑے embeddings کے لیے (2,000 سے زیادہ اعداد)، ایک halfvec column ہر عدد کو آدھی precision پر رکھتا ہے: یہ storage تقریباً آدھی کر دیتا ہے اور پھر بھی index ہو سکتا ہے (4,000 اعداد تک)، ایک چھوٹی accuracy لاگت پر۔ ہمارے 1536-اعداد والے معاملے کو اس کی ضرورت نہیں؛ سادہ vector(1536) ٹھیک ہے۔
"کتنا قریب" ناپنے کے تین طریقے۔ ایک بار متن پن ہو جائے، تو "ملتا جلتا" بس "قریب" کا مطلب ہے۔ pgvector دو پنوں کے بیچ فاصلہ ناپنے کے تین طریقے دیتا ہے۔ ایک چنیں اور اسی پر رہیں؛ project کے بیچ ان کے بیچ بدلنا صرف نتائج کو الجھاتا ہے۔
| Operator | نام | یہ کیا ناپتا ہے | کب استعمال کریں |
|---|---|---|---|
<=> | Cosine | دو پن کتنے ہم رخ ہیں، لمبائی نظرانداز کر کے | متن، ہمارا default |
<-> | سیدھی لکیر | دو نقطوں کے بیچ سادہ فاصلہ | image search اور دوسرے geometric data |
<#> | Dot product | سمت اور لمبائی ایک ساتھ | شاذ: صرف جب آپ کے vectors سب ایک لمبائی کے نہ ہوں |
متن کے لیے، cosine (<=>) استعمال کریں۔ یہ معنی کا موازنہ کرتا ہے چاہے vectors کتنے ہی لمبے ہوں، جو آپ کو چاہیے، اور یہ معیاری انتخاب ہے (اس کا index vector_cosine_ops کہلاتا ہے)۔
تلاش کے لیے، آپ صارف کے سوال کو ایک embedding میں بدلتے ہیں اور Postgres سے ان rows کا پوچھتے ہیں جن کا <=> فاصلہ اس سے سب سے کم ہو، قریب ترین پہلے، اوپر کے چند۔ آپ کا ایجنٹ وہ SQL لکھتا ہے؛ آپ نیچے "Feel it work" میں ایک حقیقی query چلتی دیکھیں گے۔
Indexes: جو search کو تیز بناتا ہے۔ ہر پن کو ایک ایک کر کے دیکھنا تب سست ہو جاتا ہے جب آپ کے پاس ہزاروں ہوں۔ ایک index اسے ٹھیک کرتا ہے، جیسے کتاب کے پیچھے index آپ کو ہر صفحہ پڑھنے کے بجائے کسی موضوع پر کودنے دیتا ہے۔ pgvector یہ index دو طرح بنا سکتا ہے، نام HNSW اور IVFFlat؛ آپ کو یہ جاننے کی ضرورت نہیں کہ حروف کس کے لیے ہیں، صرف یہ کہ ہر ایک کیا کرتا ہے۔ 2026 تک مشورہ طے ہے:
- HNSW سے شروع کریں۔ یہ ہر پن کو اس کے پڑوسیوں سے جوڑتا ہے تاکہ ایک search سیدھا قریب ترین کی طرف چھلانگ لگا سکے: تیز searches، بنانے میں سست، زیادہ memory۔ درست default۔
- IVFFlat صرف تب استعمال کریں جب build speed، search speed سے زیادہ اہم ہو۔ یہ پنوں کو buckets میں چھانٹتا ہے اور قریب ترین buckets میں search کرتا ہے: بنانے میں تیز اور memory پر ہلکا، مگر سست searches، اور آپ اسے صرف table میں ڈیٹا آنے کے بعد بنا سکتے ہیں (یہ buckets پہلے سے موجود rows سے سیکھتا ہے)۔ قابلِ قدر اگر آپ index اکثر دوبارہ بناتے ہیں۔
- DiskANN (ایک الگ add-on) ان indexes کے لیے ہے جو memory میں سمانے سے بہت بڑے ہوں۔ آپ کو تقریباً یقیناً اس کی ضرورت نہیں۔
اوپر کے schema سے HNSW index:
CREATE INDEX idx_embeddings_hnsw
ON embeddings USING hnsw (embedding vector_cosine_ops);
HNSW کے دو dials ہیں، m اور ef_construction۔ defaults زیادہ تر workloads کے لیے ٹھیک ہیں؛ جب تک آپ نے بدلنے کی کوئی وجہ ناپ نہ لی ہو، انہیں چھوڑ دیں۔
Quick check. سچ یا جھوٹ؟ (a) آپ ایک ہی column پر ایک سے زیادہ HNSW index رکھ سکتے ہیں، فی distance operator ایک۔ (b) HNSW index والی table میں row شامل کرنا کسی vector index کے بغیر والی میں ایک شامل کرنے سے زیادہ مہنگا ہے۔ (c) آپ کوئی ڈیٹا لوڈ ہونے سے پہلے HNSW index بنا سکتے ہیں۔ تینوں سچ ہیں: آپ کئی operators کے لیے index کر سکتے ہیں (شاذ ہی درکار)، rows آتے ہی index کو حالیہ رکھنا ایک حقیقی لاگت رکھتا ہے (تو کچھ teams پہلے bulk-load کرتی ہیں، پھر index بناتی ہیں)، اور HNSW کو IVFFlat کے برعکس کوئی training data نہیں چاہیے۔
Try with AI
Two scenarios. For each, pick HNSW or IVFFlat and justify with one
specific property of the index:
Scenario A: A research index of 10M scientific papers. Built once,
queried millions of times. Build time is "whatever it takes,
overnight is fine." Query latency directly affects user experience.
Scenario B: A live index of customer support tickets that's
re-indexed every 4 hours because thousands of new tickets stream in.
Query patterns are simple (top-5 nearest neighbors). The current
HNSW build takes 20 minutes, a third of the re-index cycle.
After you answer: name ONE thing that would change your answer for
each scenario. Be specific about what you'd need to see in
production metrics before switching.
Concept 9: embedding pipeline، متن اندر، قابلِ تلاش vector باہر
ایک embedding متن کے ایک ٹکڑے کو خلا میں ایک نقطہ بنا دیتی ہے۔ refunds کے بارے میں متن دوسرے refund متن کے قریب اترتا ہے؛ login bugs کے بارے میں متن کہیں اور۔ تو "ملتے جلتے tickets ڈھونڈو" "قریب ترین نقطے ڈھونڈو" بن جاتا ہے۔ یہی پورا خیال ہے۔ باقی plumbing ہے۔
plumbing چار قدم ہیں، اور ہر ایک کا ایک فیصلہ اہم ہے:
- document کو ٹکڑوں میں Chunk کریں جو اتنے چھوٹے ہوں کہ ہر ایک ایک خیال اٹھائے۔
- ماڈل کال کر کے ہر ٹکڑے کو Embed کریں؛ آپ کو اس کا نقطہ واپس ملتا ہے۔
- متن، اس کا نقطہ، اور تھوڑا metadata
embeddingstable میں Store کریں۔ - صارف کے سوال کو بھی ایک نقطہ بنا کر، پھر قریب ترین رکھے نقطے ڈھونڈ کر Query کریں۔
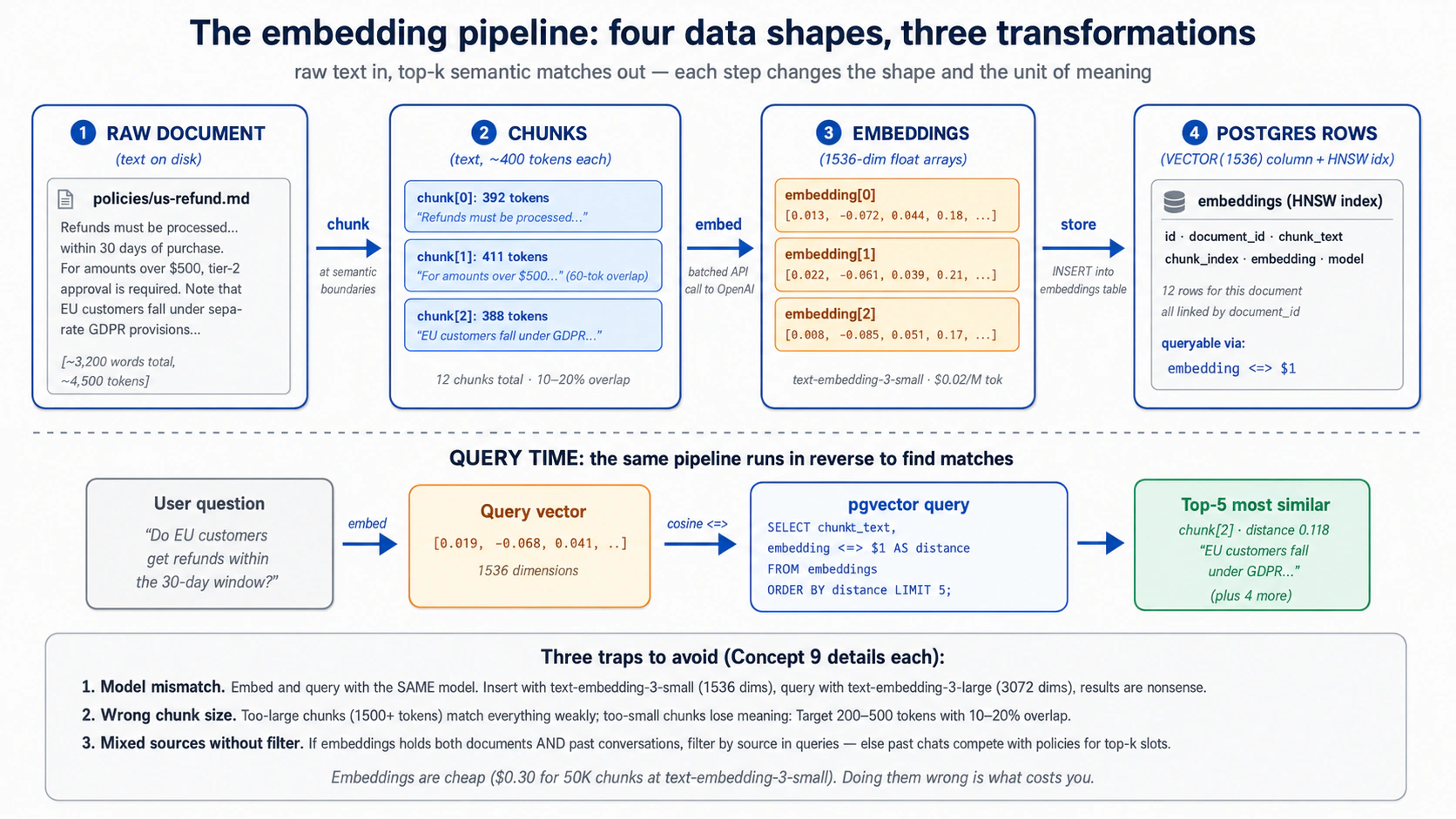
Chunking: لمبا متن پہلے تقسیم کریں۔ ایک لمبا document ایک دیو ہیکل embedding نہیں بننا چاہیے۔ آپ اسے chunks میں تقسیم کرتے ہیں، اور chunk size وہ واحد فیصلہ ہے جو اہم ہے:
- قدرتی breaks پر تقسیم کریں (headings، paragraphs)۔ ایسا chunk جو جملے کے بیچ رکتا ہے بری طرح search کرتا ہے۔
- فی chunk چند سو الفاظ کا ہدف رکھیں۔ بہت بڑا تو یہ "ہر چیز کو کمزور طور پر match کرتا ہے"؛ بہت چھوٹا تو وہ context کھو دیتا ہے جس نے اسے معنی خیز بنایا تھا۔
- chunks کو تھوڑا overlap کریں، تو ایک خیال جو حد کے آرپار ہو پھر بھی مل جائے۔
- جو پہلے ہی چھوٹا ہو اسے chunk نہ کریں۔ ایک ہی حل شدہ ticket یا ایک مختصر FAQ entry پہلے ہی ایک chunk ہے؛ اسے ویسے ہی embed کریں۔
آپ کا ایجنٹ تقسیم والا کوڈ لکھتا ہے؛ جو آپ طے کرتے ہیں وہ chunk size اور overlap ہے۔
Embedding: ہر chunk کو ایک نقطہ بنائیں۔ آپ ہر chunk embedding ماڈل کو سونپتے ہیں اور جو نقطہ یہ واپس دیتا ہے اسے store کرتے ہیں (batches میں، جو فی chunk ایک call سے کہیں سستا ہے)۔ Concept 8 کا اصول قائم رکھیں: اپنے رکھے متن اور اپنی search queries کو ایک ہی ماڈل سے embed کریں، ورنہ matches شور کے طور پر واپس آتے ہیں۔ ایک setup trap جاننے کے قابل (آپ کا ایجنٹ اسے سنبھالتا ہے): database driver کو vector type کے بارے میں بتانا پڑتا ہے، ورنہ آپ کی inserts خاموشی سے ناکام ہو سکتی ہیں۔
اگر آپ OpenAI پر نہیں؟ OpenAI واحد بڑا provider ہے جو ایک first-class embeddings API بھی بھیجتا ہے، تو اگر آپ DeepSeek، Anthropic، Gemini، یا کسی local ماڈل سے inference چلاتے ہیں، تو آپ embedding ماڈل الگ سے چنتے ہیں، اور dimension وہ ہے جسے match ہونا ہے۔ معمول کا بچاؤ راستہ ایک local sentence-transformers ماڈل جیسے all-MiniLM-L6-v2 (384 dims) ہے: کوئی API call نہیں، اور کوئی متن آپ کی مشین نہیں چھوڑتا۔ کسی بھی طرح embeddings بل پر سب سے سستی لائن ہیں، تو یہ انتخاب آپ کا آرکیٹیکچر بدلتا ہے، آپ کا بجٹ نہیں۔
دوبارہ embed کب کریں۔ تین triggers:
- source متن بدل گیا، ان rows کو دوبارہ embed کریں۔
- آپ نے embedding ماڈل بدل دیا، ہر پرانا نقطہ اب ایک مختلف نقشے اور غالباً مختلف size پر رہتا ہے، تو آپ column دوبارہ بناتے اور ہر row دوبارہ embed کرتے ہیں (یا تبدیلی کے دوران دونوں رکھتے ہیں)۔ کوئی "کافی قریب" نہیں۔
- آپ نے chunk size بدلا، دوبارہ chunk اور دوبارہ embed کریں۔
PRIMM, Predict. آپ نے
text-embedding-3-smallسے 100,000 chunks embed کیے ہیں۔ پھر آپ فیصلہ کرتے ہیں کہ اپنی گزشتہ گفتگوئیں بھی embed کریں (صرف documents نہیں) تاکہ ایجنٹ "کیا ہم نے اس پر پہلے بات کی ہے؟" lookups کر سکے۔ آپ conversation embeddings کو اسیembeddingstable میں اسی column سے لکھتے ہیں۔ ایک semantic search query (صارف کے سوال کے 5 قریب ترین neighbors ڈھونڈو، کوئی filter نہیں) ملے جلے document اور conversation نتائج کے ساتھ واپس آتی ہے۔ کیا یہی آپ چاہتے تھے؟ درست query شکل کیا ہے؟ اعتماد 1 سے 5۔
جواب: تقریباً یقیناً وہ نہیں جو آپ چاہتے تھے۔ نتائج میں documents اور گزشتہ گفتگوؤں کے ملنے سے، ایجنٹ کسی پرانی chat کے ٹکڑے کو ایسے سمجھ سکتا ہے جیسے وہ بااختیار پالیسی ہو۔ حل یہ ہے کہ search کرتے وقت source سے filter کریں: صرف documents مانگیں، یا دو searches چلائیں اور انہیں تولیں، تاکہ دونوں قسمیں کبھی نہ مل جائیں۔
جب نتائج غلط لگیں، تو وجہ تقریباً ہمیشہ ان تین میں سے ایک ہوتی ہے: query اور رکھا متن مختلف ماڈلز سے گزرے (matches شور ہیں)، آپ source type سے filter کرنا بھول گئے، یا آپ کے chunks معنی اٹھانے کے لیے بہت چھوٹے ہیں۔ پہلے انہیں دیکھیں۔
Retrieval کا معیار ورکر کی درستی کا خاموش قاتل ہے۔ آخری جواب بالکل معقول لگ سکتا ہے جبکہ غلط ثبوت کا حوالہ دے رہا ہو۔ اسے پکڑنے کا واحد طریقہ یہ ہے کہ جواب سے پہلے retrieval کو check کریں۔
Try with AI
I'm chunking a corpus of legal contracts (each averaging 8,000 words)
for semantic search. The user will query things like "what's the
termination clause in this contract", phrases that map cleanly to
specific sections. Walk me through three chunking strategies:
A) Fixed 400-token chunks with 60-token overlap (the default)
B) Chunk at section headings only, with no overlap
C) A two-level approach: store both 400-token chunks AND
whole-section chunks, search both, combine results
For each, name (1) when it wins and (2) when it loses.
Feel it work: دس منٹ میں semantic search
آپ نے pgvector اور embedding pipeline کے بارے میں پڑھ لیا بغیر کسی کو ایک بھی نتیجہ دیتے دیکھے۔ schema کے آخری ٹکڑے، audit trail، سے پہلے، دس منٹ لیں اور semantic search کو واقعی معنی سے رینک کرتے دیکھیں۔ یہ ایک ضائع کرنے والی چیز ہے، ورکر نہیں: ایک scratch table، پانچ جملے، ایک query۔ Part 4 اصل چیز بناتا ہے۔
آپ کا Neon Quick Win سے پہلے ہی wired ہے، تو یہ ایک prompt ہے:
On a fresh scratch branch of my Neon project, create a tiny
notes(id, text, embedding vector(1536))table with an HNSW index. Embed these five sentences withtext-embedding-3-smalland insert them: "the refund hasn't arrived", "my package is late", "how do I reset my password", "the charge appears twice", "I was billed for something I didn't buy". Then embed the query "I never got my money back", run a cosine-distance search, and show me the rows ranked by distance.
اس پر نظر رکھیں: billing اور refund والے جملے "my package is late" سے اوپر اور "reset my password" سے بہت اوپر رینک کرتے ہیں، حالانکہ query کے ان میں سے کسی سے تقریباً کوئی الفاظ مشترک نہیں۔ معنی سے رینک کرنا، نہ کہ keyword overlap سے، وہ پوری وجہ ہے جس کے لیے embeddings table موجود ہے۔
تب مکمل جب: آپ نے رینک شدہ فہرست refund اور billing جملوں کے ساتھ اوپر دیکھ لی ہو۔ اپنے ایجنٹ سے کہیں کہ scratch branch حذف کر دے؛ اصل schema Part 4 ہے۔
اگر refund جملے نہ جیتے، تو معمول کی وجہ Concept 9 کا model mismatch ہے: insert اور query مختلف embedding ماڈلز سے گزرے۔ دونوں سروں پر وہی ماڈل، ورنہ فاصلے شور ہیں۔
Concept 10: بطورِ نظم audit trail، ایک ورکر کے لیے "reads اور writes" کا کیا مطلب ہے
ایجنٹ کا ہر بامعنی عمل ڈیٹابیس میں ایک row چھوڑے۔ اس row کے بغیر، آپ بعد میں "ایجنٹ نے کیا کیا، اور کب؟" کا جواب نہیں دے سکتے۔ وہ trail ہی ایک حقیقی عمل کو ایک معقول لگتے جواب سے الگ کرتا ہے۔
دو چیزیں یہاں قریب بیٹھتی اور الجھ جاتی ہیں، تو انہیں الگ رکھیں:
- خود سچ: ابھی کیا حال ہے، کسی گاہک کا tier، کسی ticket کا status، کسی پالیسی کا متن۔ یہ کاروباری ریکارڈز اور ریفرنس لائبریری میں رہتا ہے، اور ورکر اسے پڑھتا اور اپ ڈیٹ کرتا ہے۔
- audit trail: اس بات کا دوبارہ چلنے کے قابل ریکارڈ کہ ورکر نے اس سچ کے ساتھ کیا کیا، کون سا ٹول کال کیا، کیا بدلا، کیا واپس کیا، کس نے منظوری دی۔ یہ
audit_logمیں، اسی ڈیٹابیس میں رہتا ہے، اور یہ ایک مختلف سوال کا جواب دیتا ہے، "کیا سچ ہے؟" نہیں بلکہ "ورکر نے کیا کیا، اور کیا آپ اسے ثابت کر سکتے ہیں؟" یہ گفتگو کی دوسری کاپی نہیں (Session پہلے ہی ہر پیغام رکھتی ہے)؛ یہ ٹائپ شدہ اعمال اور ان کے نتائج ریکارڈ کرتی ہے، بشمول وہ جو کبھی پیغام کے طور پر ظاہر نہیں ہوتے، ایک database write، ایک refund، ایک guardrail block۔ (ایک الگ، اختیاریcapability_invocationstable اس کے ساتھ فی skill اور فی tool metrics کے لیے بیٹھتی ہے؛ Concept 7 دیکھیں۔)
تو ہر بامعنی عمل اپنی audit row لکھتا ہے چاہے جس ڈیٹا کو اس نے چھوا وہ کہیں اور رکھا ہو۔ یہ حقیقت کہ عمل ہوا audit_log میں رہتی ہے؛ دونوں foreign key سے جڑے ہیں۔
اس میں کیا جاتا ہے۔ بامعنی اعمال، انہیں دوبارہ چلانے کے لیے کافی تفصیل کے ساتھ: ہر tool یا skill call (نام، inputs، نتیجہ، کتنا وقت لگا، کامیاب ہوا یا نہیں)، ریکارڈ میں ہر تبدیلی (کون سی table، کیا بدلا، کس گفتگو کے تحت)، ہر guardrail فیصلہ، اور ہر model call اس کی token لاگت کے ساتھ۔
کیا باہر رہتا ہے۔ پوری گفتگو کا متن، Session پہلے ہی اسے رکھتی ہے، تو اسے دوبارہ store کرنا بس آپ کی storage دگنی کرتا ہے۔ کسی انسان کے پڑھنے کے قابل row میں خام حساس ڈیٹا، ایک hash یا خلاصہ رکھیں اور پوری چیز محفوظ تالے میں رکھیں۔ اور ماڈل کا نجی استدلال۔
وہ test جو اسے audit trail بناتا ہے، صرف logs نہیں: ایک گفتگو اور ایک وقت دیے جائیں، تو آپ بغیر ماڈل دوبارہ چلائے، یہ دوبارہ بنا سکتے ہیں کہ ورکر نے کیا کیا اور کیوں۔ اگر نہیں کر سکتے، تو آپ کے پاس logs ہیں۔
عمل اور اس کا ریکارڈ ایک ساتھ لکھیں۔ جو بھی کوڈ refund جاری کرتا ہے وہ refund اور اس کی audit row ایک ہی transaction میں لکھتا ہے: دونوں لگتے ہیں یا کوئی نہیں۔ آدھی لکھی audit trail نہ ہونے سے بدتر ہے، یہ مکمل دکھتی ہے اور نہیں ہے۔ (آپ کا ایجنٹ یہ Part 4 میں لکھتا ہے۔)
ہر عمل کو ایک چھوٹے، طے شدہ سیٹ سے ایک نام دیں (refund_issued، message_sent، وغیرہ) اور ان ناموں کو بھٹکنے نہ دیں۔ ایک ہی event کے لیے تین مختلف نام، آج سے چھ ماہ بعد، وہی ہے جو trail کو query کرنا ناممکن بناتا ہے۔ refund_issued جیسے domain events کو ان کا اپنا نام ملتا ہے تاکہ row کاروباری event کی رسید کے طور پر پڑھی جائے، نہ کہ صرف اس tool call کی جس نے اسے چلایا۔
چونکہ وہ سیٹ چھوٹا اور مقررہ ہے، اسے audit_log.action پر ایک CHECK constraint سے نافذ کریں (Concept 7 کا schema کرتا ہے)۔ وہ پکڑ جو ایک build ہفتوں بعد لگاتی ہے: vocabulary اب بند ہے، تو ایک نیا verb متعارف کرانا (Decision 9 میں ایک guardrail_tripped row، وہ corpus_seeded row جو Decision 5 اپنے seed run کے لیے لکھتا ہے) ایک ایک-سطری ALTER TABLE ... DROP/ADD CONSTRAINT migration ہے، صرف نیا کوڈ نہیں، اور error ایک DB constraint violation کے طور پر اٹھتی ہے جو "آپ اپنی vocabulary planning کرنا بھول گئے" کے قریب کہیں اشارہ نہیں کرتی۔ تو پورا سیٹ پہلے سے طے کریں؛ Concept 7 کا CHECK پہلے ہی ان آٹھ کو درج کرتا ہے جو یہ کورس استعمال کرتا ہے۔
audit trail کیا نہیں ہے۔ صرف logs نہیں: یہ آپ کے اپنے ڈیٹابیس میں queryable SQL ہے ("ایجنٹ نے گزشتہ مہینے گاہک X کو کیا بتایا، اور کون سی پالیسی کا حوالہ دیا؟" ایک query ہے)، نہ کہ text فائلوں پر grep، اور یہ آپ کے کاروباری ڈیٹا کے ساتھ backed up اور access-controlled ہے۔ Event sourcing نہیں: یہ آپ کے state کے ساتھ ایک append-only trace ہے، وہ چیز نہیں جس سے آپ state دوبارہ بناتے ہیں (آپ کے tickets، documents، اور Session ہی state ہیں)۔ آپ کے traces نہیں: tracing (OpenTelemetry، OpenAI dashboard) debugging کے لیے flight recorder ہے، یہ ایک الگ سسٹم میں رہتا ہے، بند کیا جا سکتا ہے، اور Zero-Data-Retention کے تحت دستیاب نہیں؛ audit log رسید ہے، عمل کی اسی transaction میں committed اور جتنا چاہیں رکھی جاتی ہے۔ دونوں چلائیں: debug کے لیے trace، ثابت کرنے کے لیے کھاتہ۔
یہی مقالے کا مطلب ہے: "ورکرز بطورِ افرادی قوت تب ہی قابلِ حکمرانی بنتے ہیں جب ایک کھاتہ انہیں قابلِ مطالعہ بناتا ہے۔" آپ کا audit_log ہی وہ کھاتہ ہے۔ اور قابلِ مطالعہ ہونا ہی ورکر کو قابلِ فروخت بناتا ہے: آپ ایسے نتیجے کا معاوضہ نہیں لے سکتے جس کا ہونا آپ ثابت نہ کر سکیں۔ Per-seat pricing logins گنتی ہے؛ outcome pricing گنتی ہے کہ ورکر نے کیا کیا، فی حل شدہ ticket، فی پراسیس شدہ invoice، فی draft شدہ جواب۔ refund_issued اور ticket_resolved rows ہی وہ نتائج ہیں، اسی log میں نچلی سطح کے events کے ساتھ بیٹھے، ایسی چیز جسے آپ کسی گاہک کو دکھا اور اس پر invoice کر سکتے ہیں۔ تو ایک ورکر کو سسٹم آف ریکارڈ صرف اس لیے نہیں چاہیے کہ یہ runs کے بیچ بھولنا بند کر دے، بلکہ اس لیے کہ اس کا کام ایک قابلِ ثبوت، قابلِ بل artifact بن جائے۔ یہی وہ لکیر ہے جو ایک ایجنٹ کو ڈیٹابیس سے جوڑنے اور ایک ایسا ورکر بنانے کے بیچ ہے جسے آپ واقعی بیچ سکتے ہیں۔
Try with AI
Here's a customer support scenario: a customer claims the Worker told
them they would receive a $50 refund, but the actual refund issued was
$30. The Worker handled the conversation 19 days ago.
Walk me through the audit-trail query path to resolve this:
1. Find the conversation. (Which columns of which tables?)
2. Find the message where the refund amount was promised. (How do you
distinguish "discussed" from "promised"?)
3. Find the capability invocation that issued the refund.
4. Find the database write that recorded the $30 amount.
For each step, name the table you'd query and the WHERE clauses.
Then say what's MISSING from the five-table schema that would make
this query easier.
Part 3: MCP، ایجنٹ کو سسٹم آف ریکارڈ سے جوڑنا
Part 1 نے ایجنٹ کو Skills کی ایک لائبریری دی۔ Part 2 نے اسے ایک Postgres سسٹم آف ریکارڈ دیا۔ Part 3 دونوں کو Model Context Protocol سے جوڑتا ہے: وہ کھلا معیار کہ ایجنٹس باہر کے state اور باہر کی صلاحیت تک کیسے پہنچتے ہیں۔ مقالہ MCP کی جگہ کے بارے میں صاف ہے: "MCP وہ طریقہ ہے جس سے افرادی قوت اپنے سسٹمز آف ریکارڈ تک پہنچتی ہے: ہر بااختیار اسٹور کسی بھی ورکر کے لیے ایک MCP سرور کے ذریعے، policy کے تحت، قابلِ رسائی بن جاتا ہے۔" یہ Part اسے عملی بناتا ہے۔
Concept 11: MCP کیا ہے اور کیا نہیں
Model Context Protocol (modelcontextprotocol.io) ایک کھلا client/server protocol ہے (اصل میں Anthropic سے، اب ایک کھلے معیار کے طور پر چلایا جاتا ہے) کہ ایک AI ایجنٹ باہر کے tools، data، اور prompts سے کیسے جڑتا ہے۔ جو framing بار بار دہرائی جاتی ہے وہ "AI tools کے لیے USB-C" ہے: ایک protocol، بہت سی implementations، کسی بھی طرف کو بغیر دوسری کو توڑے بدلیں۔ یہ framing درست ہے؛ ہر استعارے کی طرح، اس کی حدود بھی ہیں جنہیں بتانا چاہیے۔
MCP کیا ہے۔ ایک protocol۔ ایک specification۔ تین primitives جو سرور client کو پیش کر سکتا ہے۔
- Tools: functions جنہیں ماڈل invoke کر سکتا ہے۔ client انہیں درج کرتا ہے، ماڈل ایک چنتا ہے، سرور اسے چلاتا ہے۔ تصوراتی طور پر پچھلے کورس کے ایک
@function_tooldecorator جیسا، مگر implementation MCP سرور process میں رہتا ہے، ایجنٹ کے process میں نہیں۔ یہ کہیں زیادہ استعمال ہونے والا primitive ہے۔ - Resources: صرف پڑھنے والا ڈیٹا جو ایجنٹ لا سکتا ہے۔ Files، database query results، API responses۔ انہیں MCP کا GET-only پہلو سمجھیں۔ عملی طور پر tools سے کم عام، مگر "ایجنٹ کو یہ document طلب پر پڑھنے دو" کے لیے مفید۔
- Prompts: قابلِ استعمال prompt templates جو سرور فراہم کرتا ہے۔ ایک team معیاری prompts شائع کر سکتی ہے ("summarize-incident-report") جنہیں سرور سے جڑنے والا کوئی بھی ایجنٹ invoke کر سکے۔ tools اور resources کے مقابلے میں شاذ ہی استعمال ہوتے ہیں۔
تین transports، 2026 تک حالیہ سفارشات کے ساتھ:
| Transport | کب استعمال کریں | حالت |
|---|---|---|
stdio | مقامی subprocess؛ ایجنٹ اور سرور ایک ہی مشین پر | پختہ۔ مقامی tools کے لیے default۔ |
streamable HTTP | دور دراز سرور؛ production deployments | نئے دور دراز کام کے لیے سفارش شدہ۔ سادہ HTTPS پر ایک endpoint۔ |
SSE | دور دراز سرور؛ پرانے deployments | پرانا۔ بہت سے سرور اب بھی اسے پیش کرتے ہیں؛ نئے بڑھتے ہوئے streamable HTTP کو default کرتے ہیں۔ |
Streamable HTTP دو ذائقوں میں آتا ہے، اور جب آپ deploy کرتے ہیں تو فرق اہم ہوتا ہے۔ Stateless وہ default ہے جس کی طرف ہاتھ بڑھائیں: ہر call ایک خود مختار request اور response ہے، بالکل کسی عام API call کی طرح، تو آپ سرور کی بہت سی کاپیاں ایک load balancer کے پیچھے چلا سکتے ہیں اور ان میں سے کوئی بھی جواب دے سکتا ہے۔ Stateful ایک زندہ session کھلا رکھتا ہے تاکہ سرور جزوی نتائج واپس stream کر سکے یا task کے بیچ notifications بھیج سکے، جو آپ کو لمبے کام کے لیے چاہیے، مگر یہ ہر client کو ایک سرور instance سے باندھ دیتا ہے اور چلانے میں زیادہ ہے۔ stateless استعمال کریں جب تک آپ کے پاس کوئی مخصوص وجہ (live streaming، server-initiated messages) نہ ہو جس کے لیے کھلا session چاہیے۔
MCP کیا نہیں ہے۔
- کوئی framework نہیں۔ یہ ایک protocol ہے۔ آپ کا ایجنٹ "MCP استعمال" اس طرح نہیں کرتا جیسے یہ Agents SDK استعمال کرتا ہے؛ آپ کے ایجنٹ کا MCP client ایک MCP سرور سے MCP بولتا ہے۔ Agents SDK میں ایک MCP client شامل ہے؛ یہی integration نقطہ ہے۔
- کوئی service نہیں۔ کوئی "MCP cloud" نہیں۔ MCP سرور ایسے programs ہیں جنہیں آپ چلاتے ہیں (یا vendors آپ کے لیے چلاتے ہیں)۔ Neon MCP سرور
mcp.neon.techپر hosted ہے؛ filesystem MCP سرور ایک مقامی subprocess کے طور پر چلتا ہے؛ آپ کا لکھا ہوا custom MCP سرور وہیں چلتا ہے جہاں آپ اسے deploy کرتے ہیں۔ - کوئی security سرحد نہیں۔ MCP transport اور protocol بیان کرتا ہے؛ ایک MCP سرور کون سے tools پیش کرتا ہے اور وہ کیا کر سکتے ہیں یہ سرور کی ذمہ داری ہے۔ ایک بدنیت MCP سرور وہ سب کچھ کر سکتا ہے جو اس کا server-side کوڈ کرتا ہے۔ Trust سرحد اب بھی وہ ایجنٹ لوپ ہے جو فیصلہ کرتا ہے کہ کون سے tools کال کرنے ہیں، اور وہ سینڈ باکس جہاں tools چلتے ہیں۔
@function_toolکا متبادل نہیں۔ دونوں کی جگہ اب بھی ہے۔ فیصلے کا درخت Concept 14 ہے۔
Quick check. سچ یا جھوٹ: (a) ایک MCP client ایک وقت میں بالکل ایک MCP سرور سے بات کرتا ہے۔ (b) وہی
@function_tool-طرز کا function، اگر آپ چاہیں، ایک MCP tool کے طور پر پیش کیا جا سکتا یا function tool کے طور پر رکھا جا سکتا ہے، اور ماڈل کو فرق نہیں پتا چلے گا۔ (c) MCP سرورز اور OpenAI Agents SDK سختی سے جڑے ہیں، تو MCP استعمال کرنے کے لیے آپ کو SDK استعمال کرنا ہی ہوگا۔ جوابات: (a) جھوٹ: ایک ایجنٹ کئی MCP سرورز سے جڑ سکتا اور ان کے tools کا اتحاد دیکھ سکتا ہے۔ (b) سچ: ماڈل کے لیے، دونوں schemas والے قابلِ کال tools دکھتے ہیں۔ فرق یہ ہے کہ implementation کہاں رہتا ہے۔ (c) جھوٹ: MCP model-agnostic ہے۔ Claude، Gemini، اور دوسروں کے اپنے MCP clients ہیں۔ OpenAI Agents SDK کئی میں سے ایک client ہے۔
Try with AI
For each item, say which MCP primitive fits best (tool, resource, or
prompt), and why in one line:
A) The agent reads the current text of a policy document on demand,
but never writes it.
B) The agent issues a refund through the payment gateway.
C) Every Worker on the team should summarize incidents the same way,
from one shared, versioned template.
Then a judgment question. A teammate says: "We put the refund logic
behind an MCP server, so the agent can't do anything dangerous." Using
this concept's "what MCP is NOT," explain why that sentence is false,
and name where the real trust boundary actually lives.
Concept 12: Neon MCP سرور، development plane، نہ کہ runtime
اس تصور کی تفصیلات پرانی ہو جائیں گی۔ pattern نہیں۔ Neon کے MCP سرور کے tooling، auth flow، اور ٹھیک ٹھیک tool surface ہر چند ماہ بعد بدلتے ہیں۔ جو سچ رہتا ہے: ایک managed-database vendor اپنی management API کو MCP کے ذریعے سادہ زبان کے operations کے لیے پیش کرتا ہے، جبکہ runtime production traffic براہِ راست connections یا scoped custom سرورز استعمال کرتا ہے۔ تفصیلات pin کرنے سے پہلے Neon کی docs کے مقابل تصدیق کریں۔
آپ نے setup کے دوران Neon MCP سرور کو پہلے ہی اپنے coding ایجنٹ سے جوڑ دیا تھا، اور تب سے آپ اس پر ٹیک لگا رہے ہیں: سادہ انگریزی میں schema مانگنا، tables میں کیا ہے دیکھنا، ایک connection string کھینچنا۔ وہ پندرہ منٹ کا connection رک کر سوچنے کے قابل ہے، کیونکہ یہ اس پورے Part کی واحد سب سے اہم لائن سکھاتا ہے: Neon MCP سرور کس کے لیے ہے، اور اسے کبھی کس سے نہیں جوڑنا۔
یہ Neon کی management API (projects، branches، schema، migrations، ad-hoc SQL) کو ایسے tools کے طور پر پیش کرتا ہے جنہیں آپ کا ایجنٹ سادہ زبان میں کال کر سکتا ہے۔ یہی اسے ایک development tool بناتا ہے، production والا نہیں۔ Neon کی اپنی docs صاف ہیں: "MCP agents کو کبھی production databases سے نہ جوڑیں۔"
یہاں وجہ کہ یہ لائن اتنی مشکل کیوں ہے۔ سرور کا run_sql tool کوئی بھی SQL چلاتا ہے جو ماڈل لکھتا ہے۔ جب آپ build کر رہے ہوں، تو یہی پورا مقصد ہے: آپ کہتے ہیں "وہ users دکھاؤ جنہوں نے گزشتہ ہفتے sign up کیا اور کبھی log in نہیں کیا،" ماڈل query لکھتا ہے، سرور اسے چلاتا ہے، آپ کو جواب ملتا ہے۔ اسی tool کو اپنے زندہ ڈیٹابیس کی طرف موڑیں اور یہ ایک دروازہ بن جاتا ہے۔ کوئی بھی جو آپ کے ورکر میں ہدایات سرکا سکے (ایک گاہک جو ہوشیاری سے لکھا پیغام ٹائپ کرے) اس سے کہہ سکتا ہے کہ آپ کا پورا ڈیٹابیس پڑھ لے، کیونکہ tool کا کام ہی یہ ہے کہ جو SQL اسے سونپی جائے وہ چلائے۔
تو اسے وہیں استعمال کرتے رہیں جہاں یہ چمکتا ہے، یہ سب development کے دوران:
- Schema اور migrations۔ "tickets table میں ایک
prioritycolumn شامل کرو۔" سرور تبدیلی کو پہلے ایک ضائع کرنے والی branch پر test کرتا ہے، پھر اسے merge کرتا ہے۔ وہ branch-first عادت schema کو ارتقا دینے کا محفوظ طریقہ ہے۔ - اپنا ڈیٹا کھنگالنا۔ "وہاں کتنے embeddings ہیں، source کے حساب سے گروپ بند؟" کسی ایک بار کے سوال کے لیے ہاتھ سے SQL لکھنے سے تیز۔
- چیزیں دیکھنا۔ Connection strings، project settings، table shapes، Neon console کھولے بغیر۔
آپ نے یہ setup میں دیکھا: آپ نے اپنے ایجنٹ سے کہا کہ project بنائے، pgvector آن کرے، schema چلائے، اور connection string بتائے، اور اس نے یہ سب ان tools کے ذریعے کیا، main کو ہاتھ لگانے سے پہلے migration کو ایک branch پر test کرتے ہوئے۔ کوئی SQL ہاتھ سے ٹائپ نہیں۔
PRIMM, Predict. آپ کے مکمل customer-support ورکر کو یہ کرنا ہے: (a) کسی گاہک کے آرڈرز دیکھنا؛ (b) ان کے tier کے لیے refund policy check کرنا؛ (c) ایک refund جاری کرنا؛ (d) اس نے کیا اور کیوں کیا اس کی ایک audit row لکھنا۔ کیا اسے اسی MCP سرور کے ذریعے Neon تک پہنچنا چاہیے، یا کسی اور طریقے سے؟ اعتماد 1 سے 5۔
جواب: کسی اور طریقے سے، چاروں کے لیے۔ ایک زندہ ورکر کو کبھی run_sql-طرز کا tool نہیں رکھنا چاہیے، یہ ایک ایسا دروازہ ہے جسے آپ پوری طرح بند نہیں کر سکتے۔ اسے چند تنگ صلاحیتیں چاہئیں، نہ کہ arbitrary SQL چلانے کی طاقت۔ دو production patterns ہیں: ایک custom MCP سرور جو صرف وہ مخصوص operations پیش کرتا ہے جن کی اسے ضرورت ہے (Concept 14)، یا انہیں لپیٹتا ایک براہِ راست Postgres connection۔ Part 4 دونوں استعمال کرتا ہے: کاروباری operations کے لیے ایک custom customer-data سرور، اور صرف audit subsystem کے لیے ایک براہِ راست connection (Decision 7 بتاتا ہے کہ audit اس MCP سرحد سے باہر کیوں رہتا ہے جس کا یہ audit کرتا ہے)۔
یہی بالکل Invariant 5 ہے: افرادی قوت قابلِ حکمرانی اسٹورز کے ذریعے پڑھتی اور لکھتی ہے۔ ایک وسیع run_sql tool حکمرانی نہیں، حکمرانی نہ ہونے پر ایک دوستانہ چہرہ ہے۔ Neon MCP سرور وہ ہے جس سے آپ اسٹور بناتے ہیں۔ یہ وہ نہیں جس سے آپ کا ورکر اسے چھوتا ہے۔
Try with AI
Read Neon's MCP server documentation page and answer three questions:
1. List THREE management operations the Neon MCP server exposes that
would be useful while you're building a customer-support Worker.
2. List THREE things a running Worker NEEDS to do that you should NOT
use the Neon MCP server for, and why.
3. For each of the three in (2), say what the Worker should use instead
(direct Postgres connection? custom MCP server? function_tool?).
Concept 13: MCP کو OpenAI Agents SDK سے جوڑنا
آپ اپنے coding ایجنٹ سے Neon MCP سرور چلا رہے ہیں۔ آپ کا ورکر، وہ جو آپ Part 4 میں بناتے ہیں، ایک مختلف program ہے: ایک OpenAI Agents SDK ایجنٹ۔ تو یہ تصور جس سوال کا جواب دیتا ہے وہ سادہ ہے: وہ ایجنٹ کسی MCP سرور سے کیسے بات کرتا ہے؟ آپ connection plumbing ہاتھ سے نہیں لکھیں گے، SDK اسے بھیجتا ہے۔ جو سمجھنے کے قابل ہے وہ شکل ہے، تاکہ آپ build کو رہنمائی دے سکیں اور جب یہ بدکے تو debug کر سکیں۔
یہ پوری تصویر ہے۔ SDK میں ایک built-in MCP client ہے جس میں فی transport ایک connector ہے: stdio کے لیے ایک مقامی، دور دراز streamable HTTP کے لیے ایک جدید، اور SSE کے لیے ایک پرانا (کسی بھی نئی چیز کے لیے SSE سے بچیں)۔ آپ ایک سرور سے connection کھولتے ہیں، اسے اپنے ایجنٹ کو سونپتے ہیں، اور وہاں سے SDK سب کچھ کرتا ہے: یہ سرور سے پوچھتا ہے کہ اس کے پاس کون سے tools ہیں، انہیں ماڈل کے سامنے ٹھیک ان @function_tools کے ساتھ رکھتا ہے جو آپ نے خود لکھے، اور جب ماڈل ایک چنتا ہے، تو call کو درست سرور کی طرف route کرتا اور جواب واپس لاتا ہے۔ ماڈل ایک MCP tool کو ایک مقامی function tool سے الگ نہیں کر سکتا، اور اسے ضرورت نہیں۔ وہی یکسانیت ہی نکتہ ہے: MCP بس ماڈل کو ایک صلاحیت سونپنے کا ایک اور طریقہ ہے۔
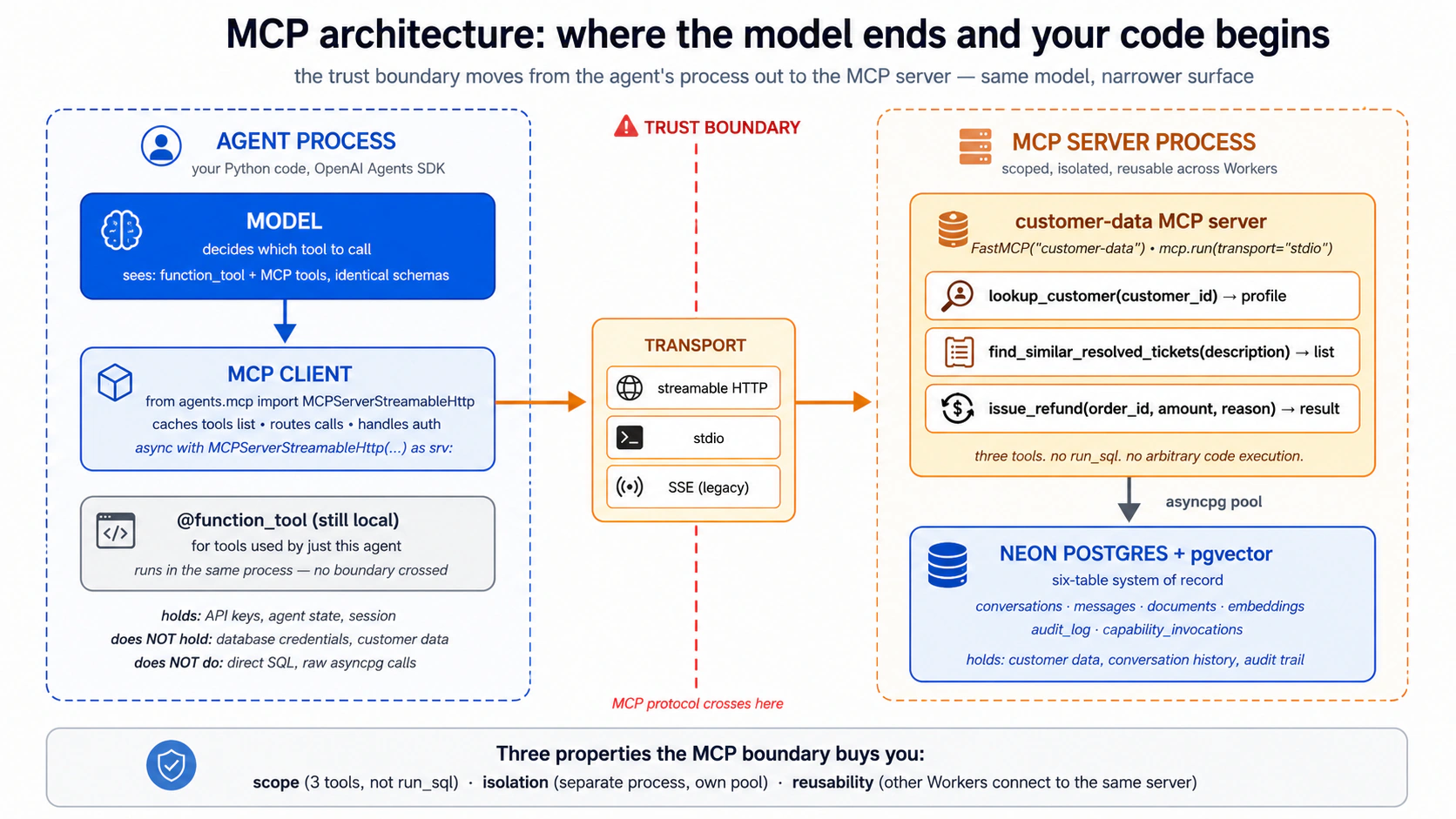
چار باتیں ذہن میں رکھیں، جنہیں آپ کا ایجنٹ آپ کے کہنے پر آپ کے لیے سنبھالتا ہے:
- connection صاف کھولیں، اور صاف بند کریں۔ ایک MCP connection کوئی چیز کھلی رکھتا ہے: stdio کے لیے ایک subprocess، دور دراز کے لیے ایک HTTPS session۔ اگر یہ ٹھیک سے بند نہ ہو تو connection leak کرتا ہے۔ SDK کے connection objects ایک managed block کے طور پر کھولنے اور بند کرنے کے لیے بنے ہیں، تو یہ سنبھل جاتا ہے جب تک آپ اس سے نہ لڑیں۔
- production میں tool list cache کریں۔ default سے ایجنٹ ہر ہر run پر سرور سے دوبارہ پوچھتا ہے "تمہارے پاس کون سے tools ہیں؟"، ایک ضائع network round-trip۔ caching آن کرنا اسے ایک بار پوچھواتا ہے۔ ایک پکڑ: اگر آپ سرور کے tools بدلیں، تو ایجنٹ کو cache refresh کرنے کو کہیں (یا اسے restart کریں)۔ build کرتے ہوئے، caching بند رکھیں تاکہ تبدیلیاں فوراً دکھیں۔
- سرور جمع ہوتے ہیں۔ آپ اپنے ایجنٹ کو ایک ساتھ کئی MCP سرور سونپ سکتے ہیں، اور ماڈل بس tools کا مشترکہ سیٹ دیکھتا ہے۔ Part 4 کا ورکر اپنے custom
customer-dataسرور سے یوں ہی جڑتا ہے۔ - خطرناک tools کو منظوری کے پیچھے gate کریں۔ default سے tool calls بغیر تصدیق چلتے ہیں۔ حساس کے لیے آپ ہر call کی انسانی منظوری کی شرط رکھ سکتے ہیں۔ یہ Concept 12 کے development-بمقابلہ-runtime فرق کا عملی knob ہے: حتیٰ کہ جب آپ Neon MCP سرور ہاتھ سے استعمال کریں، اس کے تباہ کن tools (جو بھی drop یا rewrite کرتا ہے) کو ایک منظوری prompt کے پیچھے رکھنا ایک حقیقی safety فائدہ ہے۔
ایک gotcha فائل کرنے کے قابل: اگر کوئی MCP سرور startup پر کوئی بھاری چیز لوڈ کرتا ہے (مثلاً ایک machine-learning ماڈل)، تو ایجنٹ کی default "کیا سرور نے وقت پر جواب دیا؟" کھڑکی بہت چھوٹی ہو سکتی ہے اور آپ کو ایک الجھن بھرا connection-failure error دکھے گا۔ حل ایک ہی setting ہے جو وہ کھڑکی لمبی کرتی ہے۔ آپ سے یہ صرف تب ملے گا جب کوئی سرور boot ہوتے ہی حقیقی کام کرے۔
عملی، صرف سمجھنے کے لیے۔ شکل کو ٹھوس بنانے کا یہ سب سے تیز طریقہ ہے۔ نیچے کا prompt اپنے coding ایجنٹ میں paste کریں۔ یہ ایک چھوٹا ضائع کرنے والا script بناتا ہے جو ایک OpenAI Agents SDK ایجنٹ کو اس Neon MCP سرور کی طرف اشارہ کرتا ہے جو آپ کا پہلے سے جڑا ہے، اور آپ کو ایجنٹ کو سادہ زبان میں آپ کے projects درج کرتے دیکھنے دیتا ہے۔ یہ ایک سیکھنے کی مشق ہے، production راستہ نہیں: ایک حقیقی ورکر کبھی Neon MCP سرور سے نہیں جڑتا (Concept 12)۔ آپ اسے ایک بار، یہاں، کر رہے ہیں تاکہ ایک Agents SDK ایجنٹ کو ایک MCP سرور سرے سے سرے تک چلاتے دیکھیں۔
Write me a small throwaway Python script (call it scratch_neon_agent.py)
that uses the OpenAI Agents SDK to connect to the Neon MCP server over
its remote streamable-HTTP transport, then runs one agent turn asking it
to "list my Neon projects and show the schema of the largest one."
Use the current OpenAI Agents SDK MCP classes (check the docs for the
exact import and class name). Open the connection as a managed block so
it closes cleanly, turn on tool-list caching, and print the final output.
Then run it and show me what the agent did, step by step. Remind me in a
comment that this is for understanding only and a real Worker should
never connect to the Neon MCP server.
دیکھیں کیا ہوتا ہے: ایجنٹ جڑتا ہے، SDK Neon کے tools کھینچتا ہے، ماڈل خود list_projects چنتا ہے، اور آپ کو انگریزی میں جواب ملتا ہے۔ آپ نے ابھی وہی wiring دیکھی جو آپ کا Part 4 ورکر استعمال کرے گا، صرف ایک ایسے سرور کی طرف اشارہ کرتے ہوئے جسے اسے production میں استعمال نہیں کرنا چاہیے، جو بالکل وہ وجہ ہے کہ آپ یہ script پھینک رہے ہیں۔
Try with AI
Explain, in plain language and without writing code, how you would
connect one OpenAI Agents SDK agent to TWO MCP servers at once: the
Neon MCP server (remote) and a local filesystem MCP server for reading
project files. Cover:
1. Which transport each server would use, and why.
2. How the model decides which server's tool to call.
3. Which tools you'd put behind human approval, and why.
4. One thing that could go wrong with two servers connected, and how
you'd notice it.
Concept 14: custom MCP سرورز، اپنا کب لکھیں بمقابلہ کب نہ لکھیں
Neon MCP سرور عام ہے: یہ وہ سب کچھ کر سکتا ہے جو Neon کی API کر سکتی ہے۔ یہی development کے لیے اس کی طاقت ہے اور runtime کے لیے اس کی کمزوری۔ ایک custom MCP سرور trade-off الٹ دیتا ہے: تنگ surface، کوئی عام مقصد والا run_sql نہیں، صرف وہ مخصوص operations جن کی آپ کے ورکر کو واقعی ضرورت ہے۔
فیصلے کا درخت، ترجیح کی ترتیب میں۔
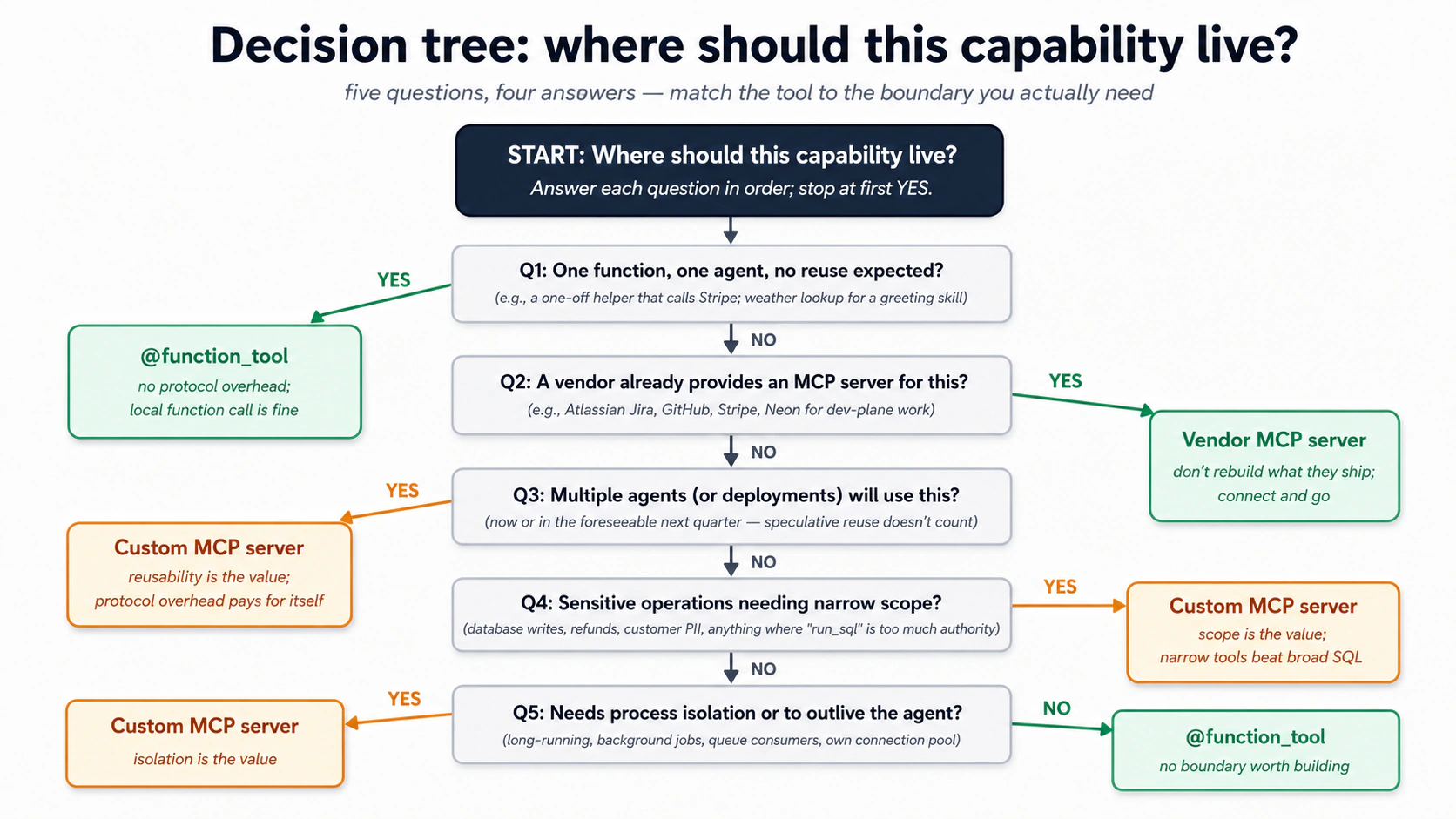
وہی منطق ایک تیز نظر والی table میں:
| آپ یہ پیش کرنا چاہتے ہیں... | یہ استعمال کریں | کیوں |
|---|---|---|
| ایک input والا ایک function، ایک ایجنٹ استعمال کرتا ہے | @function_tool | protocol overhead کی ضرورت نہیں۔ مقامی function call ٹھیک ہے۔ |
| کئی functions جو آپ کے ایجنٹ کے کوڈ سے سختی سے جڑے ہیں | @function_tool | اگر وہ ایجنٹ کے ساتھ state بانٹتے اور اسی repo میں رہتے ہیں، تو وہ ایجنٹ کا حصہ ہیں۔ |
| ایک صلاحیت جسے کئی ایجنٹس (یا کئی deployments) استعمال کریں گے | custom MCP server | protocol ہی اسے قابلِ استعمال بناتا ہے۔ |
| ایک صلاحیت جسے ایجنٹ کے process سے زیادہ زندہ رہنا ہے | custom MCP server | لمبے connections، background jobs، queue consumers۔ |
| Vendor فراہم کردہ functionality (Neon، GitHub، Linear) | vendor's MCP server | جو وہ بھیجتے ہیں اسے دوبارہ نہ بنائیں۔ |
| حساس operations جنہیں تنگ scope چاہیے | custom MCP server | بالکل وہ tools بیان کریں جو آپ کو چاہئیں؛ اور کچھ نہیں۔ |
ایک custom MCP سرور کی شکل اتنی پیچیدہ نہیں جتنی لگتی ہے۔ یہ ایک چھوٹا program ہے جو چند نام والے tools کا اعلان کرتا ہے۔ ہر tool کی ایک سادہ انگریزی description ہوتی ہے (وہی قسم کا trigger متن جو ایک SKILL.md رکھتا ہے) جو ماڈل کو بتاتی ہے کہ اس کی طرف کب ہاتھ بڑھائے، اور typed inputs کی ایک مختصر فہرست تاکہ ماڈل جانے کیا pass کرنا ہے۔ بس یہی: چند اچھی طرح بیان کیے گئے، تنگ tools اور کچھ نہیں۔ کوئی عام run_sql نہیں، کوئی بچاؤ کا راستہ نہیں۔
اور آپ وہ program ہاتھ سے نہیں لکھتے۔ اسی طرح جیسے آپ نے skills انسٹال کیں اور اپنے ایجنٹ کو کام کرنے دیا، ایک mcp-builder skill ہے جو ایک scope description کو ایک چلتے، test شدہ سرور میں بدل دیتی ہے۔ آپ کی رائے scope میں جاتی ہے، کون سے tools موجود ہیں، ہر ایک کو کیا کرنے کی اجازت ہے، اور کون سے جان بوجھ کر نہیں، نہ کہ plumbing میں۔ prompt flow ایسا دکھتا ہے:
/mcp-builder Let's design a custom MCP server called "customer-data"
on the streamable-HTTP transport, stateless flavor (each call an
independent request, no open session, so it scales). Plan the
implementation first, then build it.
Scope: exactly three tools, nothing else.
- lookup_customer(customer_id): return id, email, tier, open-ticket count
- find_similar_resolved_tickets(description, limit): semantic search over
past resolved tickets
- issue_refund(order_id, amount_cents, reason): issue a refund (amount in
integer cents, never a float) AND write an audit row in the same transaction
No general SQL tool. Each tool gets a clear description so the model
knows when to call it. Start a fresh project with uv, walk me through
the plan before writing code, then build and verify it.
ایجنٹ ایک نیا uv project scaffold کرتا ہے، tools plan کرتا ہے، سرور بناتا ہے، اور تصدیق کرتا ہے کہ یہ چلتا ہے۔ ایک بار یہ موجود ہو، تو آپ اسے انہی دو طریقوں سے جوڑتے ہیں جنہیں آپ MCP سرورز جڑتے دیکھ چکے ہیں: اپنے عام coding ایجنٹ سے (Claude Code یا OpenCode، تاکہ آپ اسے ہاتھ سے test کر سکیں) اور اپنے OpenAI Agents SDK ورکر سے (تاکہ ورکر واقعی اسے استعمال کر سکے)۔ Part 4 کا Decision 6 یہ build سرے سے سرے تک لے کر چلتا ہے۔
تین چیزیں جو یہ سرور آپ کو دیتا ہے جو @function_tool نہیں دیتا۔
-
Process isolation۔ MCP سرور اپنے ہی process میں چلتا ہے (stdio کے لیے subprocess، streamable HTTP کے لیے ایک الگ service)۔ سرور میں ایک crash ایجنٹ کو crash نہیں کرتا؛ سرور میں ایک memory leak ایجنٹ میں leak نہیں کرتا۔
-
Scope۔ سرور صرف وہ چند tools پیش کرتا ہے جو آپ بیان کرتے ہیں (عملی مثال کے
customer-dataسرور کے پاس تین ہیں)۔ کوئیrun_sqlنہیں۔ کوئی "arbitrary code چلاؤ" نہیں۔ ماڈل اس scope سے بچ نہیں سکتا کیونکہ protocol اور کچھ پیش نہیں کرتا۔ یہ ایک حقیقی defense in depth ہے: حتیٰ کہ اگر ماڈل کوئی بے وقوفی کرنے کا فیصلہ کرے، تو اسے کرنے کا surface وہی چند functions ہیں۔ -
ایجنٹس کے آرپار reusability۔ ایک دوسرا ایجنٹ (ایک Sales ورکر، ایک Reporting ورکر) اسی
customer-dataMCP سرور سے بات کر سکتا ہے۔ وہی scope، وہی protocol، وہی trust سرحد۔ صلاحیت ایجنٹس کے بیچ copy-paste کے بجائے ایک مشترکہ infrastructure کا ٹکڑا بن جاتی ہے۔
trade-off حقیقی ہے۔ Custom MCP سرورز operational پیچیدگی شامل کرتے ہیں: deploy کرنے کے لیے ایک اور process، logs کا ایک اور سیٹ، ایک اور network hop (اگر دور دراز ہو)، manage کرنے کے لیے ایک اور version۔ ایک ایجنٹ کے استعمال میں آنے والے ایک function کے لیے ایک نہ لکھیں۔ تب لکھیں جب صلاحیت دوبارہ استعمال ہونے والی ہو، جب scoping اہم ہو، یا جب isolation آپ کو safety خرید کر دے۔
PRIMM, Predict. آپ customer-support ورکر design کر رہے ہیں۔ آپ کو چاہیے: (1) گزشتہ حل شدہ tickets پر semantic search؛ (2) ایک refund audit row لکھنا؛ (3) موجودہ موسم پڑھنا (ایک greeting skill میں استعمال جو کہتی ہے "good morning from sunny Karachi")؛ (4) ایک refund جاری کرنے کے لیے payment gateway کال کرنا۔ ہر ایک کے لیے، پیش گوئی کریں:
@function_tool، custom MCP سرور، یا vendor MCP سرور (مثلاً Stripe کا، اگر ایسا موجود ہو)؟
جوابات framework کو نمایاں کرتے ہیں:
- Custom MCP سرور (
customer-data)۔ ایجنٹس کے آرپار دوبارہ استعمال؛ حساس ڈیٹا؛ scoped tools ایک وسیعrun_sqlسے بہتر۔ - Custom MCP سرور (
customer-data) یا@function_tool۔ دونوں چلتے ہیں؛ اگر ورکر واحد writer ہو، تو function tool ٹھیک ہے۔ اگر کئی ورکرز audit rows لکھیں گے، تو MCP سرور۔ @function_tool۔ ایک ایجنٹ، ایک ننھا function، بچانے کے لیے کوئی security surface نہیں۔ اس کے لیے سرور نہ بنائیں۔- Vendor MCP سرور (Stripe MCP) اگر موجود ہو، ورنہ
@function_toolجو Stripe کی API کال کرے۔ third-party APIs کو اپنے MCP سرور میں نہ لپیٹیں جب تک آپ کو ان کے اوپر policy شامل نہ کرنی ہو۔
framework واضح ہے جب آپ اسے ٹریس کریں: MCP کی قدر اس سرحد کی قدر کے ساتھ بڑھتی ہے جو یہ بناتا ہے۔ ایسی سرحد جس کی آپ کو ضرورت نہیں، overhead ہے۔
Try with AI
اسے اپنے coding ایجنٹ میں paste کریں۔ یہ فیصلے کے درخت کو اس customer-support ورکر پر لاگو کرتا ہے جو آپ واقعی بنا رہے ہیں، تو ہر انتخاب وہ ہے جسے آپ ship کر سکتے ہیں، نہ کہ ایسی infrastructure کے بارے میں اندازہ جو آپ کے پاس نہیں۔
Here are five capabilities I'm thinking of adding to my customer-support
Worker. For each, walk the Concept 14 decision tree with me and recommend
one: a @function_tool, my custom customer-data MCP server, or a vendor
MCP server (if a credible one exists). Justify each choice with ONE of
the three properties (isolation, scope, reusability), or say plainly why
no boundary is worth building.
1. Look up a customer by email (the gap Decision 8 leaves open).
2. Issue the real refund through Stripe (actual money, third-party API).
3. Send the drafted reply as an email through our mail provider.
4. Convert a UTC timestamp to the customer's local time for a greeting.
5. Let a second Worker (a sales assistant) reuse the customer lookups.
Then push back on me: which TWO of these would you deliberately NOT put
behind a custom MCP server, and what does that say about when the
boundary earns its cost?
Concept 15: بوجھ تلے MCP: transports، pooling، اور پیمانے پر کیا ہوتا ہے
ایک ایجنٹ اور ایک سرور والا demo بس چل جاتا ہے۔ حقیقی traffic، فی منٹ کئی گفتگوئیں، تین دباؤ شامل کرتا ہے۔ آپ کو پہلے ورکر کے لیے ان پر عمل کرنے کی ضرورت نہیں، مگر ان کا موجود ہونا جاننا آپ کو بعد میں ایک الجھی دوپہر سے بچاتا ہے۔ ہر ایک کا ایک سادہ حل ہے۔
- ایجنٹ اور سرور کے بیچ کی تار۔ ایک مقامی subprocess (stdio) ٹھیک ہے جب تک سب کچھ ایک مشین پر چلے۔ جس لمحے ایک سے زیادہ ایجنٹ سرور بانٹیں، یا سرور اپنے ہی hardware پر منتقل ہو، دور دراز transport (streamable HTTP) پر سوئچ کریں۔ یہ ایک deployment تبدیلی ہے، rewrite نہیں۔
- وہی setup لاگت بار بار نہ دیں۔ تین چھوٹی عادتیں بار بار کی لاگتوں کو ایک بار کی لاگت میں بدلتی ہیں: جب ورکر boot ہو تو ہر سرور سے ایک بار جڑیں اور وہ connection کھلا رکھیں، نہ کہ ہر request پر دوبارہ جڑیں؛ ایجنٹ کو سرور کی tool list یاد رکھنے دیں نہ کہ ہر run پر "تم کیا کر سکتے ہو؟" دوبارہ پوچھیں (tools بدلیں تو اسے refresh کریں)؛ اور سرور کے اندر database connections کا ایک تیار pool رکھیں، تاکہ ایک query ہر بار ایک تازہ کھلنے کا انتظار نہ کرے۔ ایک quirk جو ایک لمبے عرصے چلتا ورکر scale-to-zero یا pooled Postgres (Neon) پر لگاتا ہے: pooler فارغ connections بند کر دیتا ہے، تو اگر process block ہو جائے (ایک terminal
input()prompt asyncio event loop کو جما دیتا ہے)، تو اگلی write "connection was closed in the middle of operation" سے ناکام ہوتی ہے۔ block کرنے والے prompts loop سے باہر چلائیں (asyncio.to_thread) اور pool کو اس error پر ایک بار دوبارہ acquire کروائیں۔ - ہر چیز پر ایک حد لگائیں، اور trace مکمل رکھیں۔ ایک request کتنے steps لے سکتی ہے اس پر cap لگائیں، ایک ناکام tool call کو ہار ماننے سے پہلے دو بار retry کریں، اور سرور کو rate-limit کریں تاکہ ایک جھونکا اسے ڈبو نہ دے۔ اور یقینی بنائیں کہ آپ کا trace MCP سرحد کے آرپار call کا پیچھا کرے: جب ورکر کوئی tool کال کرے، تو آپ سرور کا اپنا database کام اسی تصویر میں دکھنا چاہتے ہیں۔ ورنہ سرور کے اندر ایک سست query باہر سے غیر مرئی ہے، اور آپ latency کا پیچھا غلط جگہ کریں گے۔
گہرے knobs (per-tenant concurrency caps، باریک transport tuning) اس سے آگے ہیں جو ایک پہلے ورکر کو چاہیے۔ یہ تین وہ ہیں جو پہلے ڈستے ہیں۔
Quick check. سچ یا جھوٹ: (a) کسی سرور کو پرانے SSE transport سے streamable HTTP پر منتقل کرنا آپ کو سرور کے tools دوبارہ لکھنے پر مجبور کرتا ہے۔ (b) ایجنٹ کو سرور کی tool list cache کرنے دینا production میں محفوظ ہے، بشرطیکہ آپ tools بدلنے کے بعد cache refresh کریں۔ (c) پانچ صلاحیتیں MCP tools کے طور پر پیش کرنا ہمیشہ ماڈل کا زیادہ context بجٹ خرچ کرتا ہے انہی پانچ کو مقامی function tools کے طور پر پیش کرنے سے۔ جوابات: (a) زیادہ تر جھوٹ: tools بدلے ہوئے نہیں؛ سرور کو بس نیا transport بولنا ہے، جو زیادہ تر جدید پہلے ہی بولتے ہیں۔ (b) سچ: یہی مطلوبہ pattern ہے۔ (c) جھوٹ: ماڈل کے لیے ایک tool ایک tool ہے۔ پانچ tool descriptions تقریباً وہی خرچ ہیں چاہے وہ کسی بھی طرف رہیں۔
Try with AI
My customer-support Worker is in production. It runs 80 conversations/minute
at peak. Each conversation makes 2-4 MCP tool calls on average. I'm seeing
intermittent latency spikes: most calls return in 200ms, but a small
percentage take 5-15 seconds.
Walk me through five places I'd investigate, in order of priority:
1. The agent-side MCP client connection management.
2. The transport choice between agent and MCP server.
3. The MCP server's internal connection pool to Postgres.
4. Postgres-side query performance (slow queries blocking the pool).
5. Network or DNS issues between agent and MCP server.
For each, name the specific signal I'd look for and the rough fix.
Part 4: عملی مثال، customer-support ورکر
ایک حقیقت پسند build جو اوپر کا ہر تصور استعمال کرتا ہے۔ آپ ایک کم سے کم چیٹ ایجنٹ سے شروع کرتے ہیں (ایک prompt، تقریباً ایک منٹ)، پھر اسی worker کو ایک ایک ٹکڑا کر کے ایک customer-support ورکر میں بڑھاتے ہیں۔ ہر Decision ایک ٹکڑا شامل کرتا ہے، سسٹم آف ریکارڈ، پھر Skills، پھر MCP تہہ، پھر audit trail، اور آپ ہر بار worker دوبارہ چلاتے ہیں تاکہ آگے بڑھنے سے پہلے نیا ٹکڑا چلتا دیکھیں۔ آٹھ Decisions worker بناتے ہیں؛ نواں اس واحد عمل کے سامنے ایک انسان رکھتا ہے جو پیسہ ہلاتا ہے۔

قدم 0: چیٹ ایجنٹ کھڑا کریں (ایک prompt، تقریباً 1 منٹ)۔ تاکہ ہر کوئی Decision 1 کو ایک ہی جگہ سے شروع کرے۔ (Build AI Agents کیا؟ اس کے بجائے وہ project کھولیں، یہ وہی ایجنٹ ہے، اور Decision 1 پر چلے جائیں۔)
In this digital-fte folder, build me a small terminal chat agent with the
OpenAI Agents SDK: a uv project, a gpt-5-class model, on a local sandbox.
Check the current SDK docs for the API. Get it answering "hi", then stop,
we grow it in the steps below.
بناتا ہے: worker فائل (مثلاً worker.py) اور اس کا uv project۔
Check. آپ "hi" بھیجتے ہیں اور یہ جواب دیتا ہے۔ یہی شروعاتی لکیر ہے؛ Decision 1 اسے
AGENTS.mdکے ذریعے نیا آرکیٹیکچر سکھاتا ہے۔
brief
قدم 0 سے کم سے کم چیٹ ایجنٹ کو ایک customer-support ورکر میں ارتقا دیں جو:
- تین Skills طلب پر لوڈ کرے:
summarize-ticket،find-similar-cases، اورescalate-with-context۔ - Concept 7 کی پانچ tables والے ایک Neon Postgres سسٹم آف ریکارڈ سے پڑھے اور لکھے (conversation turns اسی database پر SDK Session میں رہتے ہیں)۔
- گزشتہ حل شدہ کیسز کی ایک چھوٹی لائبریری پر semantic search کے لیے pgvector استعمال کرے۔
- runtime پر business data کے لیے Postgres سے ایک scoped، custom MCP سرور (
customer-data) کے ذریعے بات کرے، کبھی Neon MCP سرور سے نہیں اور کبھی ایجنٹ کوڈ میں براہِ راستasyncpgسے نہیں۔ - ہر بامعنی عمل (ہر invoke ہونے والی skill، ہر database write، ہر زیرِ غور refund) کے لیے اپنے اپنے براہِ راست connection کے ذریعے ایک audit row لکھے، وہ واحد راستہ جو جان بوجھ کر MCP سرحد کو bypass کرتا ہے، تاکہ audit trail کو وہ سسٹم بھوکا نہ مار سکے جس کا یہ audit کرتا ہے۔
"آخر میں تصدیق" والا test: ایک گاہک پیغام بھیجتا ہے "I haven't received my refund from order #4429, it's been two weeks۔" ورکر vector search کے ذریعے تین ملتے جلتے گزشتہ کیسز ڈھونڈتا ہے، ایک جواب draft کرتا ہے جو سب سے ملتے جلتے کیس کے حل کا حوالہ دیتا ہے، اور اس نے جو کیا اس کی ایک audit row لکھتا ہے (اور، ایک حقیقی deploy میں، اگر گاہک Pro-tier ہو تو escalate کرتا ہے)۔ پیغام سے ٹھیک گاہک یا آرڈر ریکارڈ کو resolve کرنے کے لیے ایک lookup tool چاہیے جو آپ بعد میں شامل کرتے ہیں؛ Decision 8 دکھاتا ہے کہ وہ خلا کہاں ہے۔
آگے آنے والے prompts کیسے پڑھیں۔ آپ یہ ورکر اپنے coding ایجنٹ کو ایک وقت میں ایک چھوٹا کام prompt کر کے بڑھاتے ہیں، اور ہر Decision اسی طرح ختم ہوتا ہے: نیا ٹکڑا ایک worker میں wire ہوتا ہے اور آپ اسے چلاتے ہیں، تاکہ اگلا Decision اس پر بننے سے پہلے آپ اسے چلتا دیکھیں۔ آپ SQL، Python، یا config ٹائپ نہیں کریں گے: ایجنٹ لکھتا ہے، آپ رہنمائی اور check کرتے ہیں۔ آپ کا ایجنٹ فولڈر کھولتے ہی
AGENTS.mdپہلے ہی پڑھ چکا ہے، تو یہ project جانتا ہے؛ آپ کے prompts مختصر رہتے ہیں۔ دو عادتیں:
- ایک قدم، ایک کام۔ اسی قدم کا prompt paste کریں اور کچھ نہیں۔ جو بھی حقیقی کوڈ لکھے، اس کا prompt کہتا ہے "plan first": plan پڑھیں، پیچھے دھکیلیں، منظوری دیں، پھر اسے بننے دیں۔
- اگلے قدم سے پہلے check کریں۔ ہر قدم ایک Check پر ختم ہوتا ہے: ایک سادہ انگریزی سوال جو آپ پوچھتے ہیں ("show me X")۔ پاس ہونے تک آگے نہ بڑھیں، ورنہ آپ چار قدم اندر ہوں گے جب پتا چلے گا کہ قدم ایک غلط تھا۔
Decision 1: rules فائل کو نئے آرکیٹیکچر سے اپ ڈیٹ کریں
آپ کہاں ہیں: ایک کم سے کم چیٹ ایجنٹ جو "hi" کا جواب دیتا ہے؛ یہ Decision تین آرکیٹیکچر قواعد AGENTS.md میں شامل کرتا ہے؛ آخر تک آپ وہ قواعد فائل کے diff میں دیکھیں گے۔
آپ کا ایجنٹ AGENTS.md سے یہ project پہلے ہی جانتا ہے۔ جو یہ ابھی نہیں جانتا وہ چند قواعد ہیں جو اس کورس کا آرکیٹیکچر شامل کرتا ہے، تو آپ وہ ابھی AGENTS.md میں لکھتے ہیں، اور ہر بعد کا prompt مختصر رہ سکتا ہے۔ ایک کام۔
قدم 1: AGENTS.md میں نئے قواعد شامل کریں۔
Add a short "Rules" section to AGENTS.md so a fresh session follows these:
- business data is read and written only through the customer-data MCP
server, never raw SQL from the running worker
- the audit log uses its own direct database connection, and each action
and its audit row are committed together
- embeddings use the same model to store and to search
Show me the diff before you write it.
بدلتا ہے: AGENTS.md۔
Check. diff پڑھیں۔ وہ تینوں قواعد وہاں ہیں، سادہ زبان میں، خاص طور پر پہلا: یہی ماڈل کو بعد میں خاموشی سے MCP سرحد کے گرد جانے سے روکتا ہے۔ اگر ایجنٹ نے کسی کو نرم یا گرا دیا ہو، تو دوبارہ prompt کریں۔
کیوں۔ ایک کمزور rules فائل ہفتوں بعد خاموشی سے ناکام ہوتی ہے، جب ماڈل وہ شارٹ کٹ لیتا ہے جسے روکنے کے لیے قاعدہ بنا تھا۔ اسے ابھی لکھنا ہی ہر بعد کے prompt کو مختصر رکھتا ہے۔
Decision 2: schema اور Skill set کا plan کریں
آپ کہاں ہیں: ایک AGENTS.md جو آرکیٹیکچر بیان کرتا ہے مگر اس کا کوئی design ابھی نہیں؛ یہ Decision ایک review شدہ تحریری plan شامل کرتا ہے؛ آخر تک آپ ایک markdown plan دیکھیں گے جس پر آپ نے پیچھے دھکیلا اور منظوری دی۔
آپ یہ Decision ایک تحریری plan کے ساتھ ختم کرتے ہیں جسے آپ نے review کیا، کوڈ کی ایک لائن موجود ہونے سے پہلے۔ ایک کام۔ Plan Mode میں داخل ہونے کے لیے Shift+Tab دو بار دبائیں (OpenCode میں، Plan ایجنٹ پر سوئچ کرنے کے لیے Tab دبائیں): ماڈل آپ کا project پڑھ سکتا ہے مگر کچھ edit نہیں کر سکتا۔
قدم 1: plan لیں۔
Plan the customer-support Worker evolution of this project. The
foundation (OpenAI Agents SDK, your sandbox runtime, sessions, streaming,
guardrails) stays. We're adding:
1. Three Skills: summarize-ticket, find-similar-cases, escalate-with-context.
For each, propose: the description, the operational shape (script-driven
or instruction-driven), and what reference files it needs.
2. The five-table schema from Part 2 Concept 7, plus any tables specific
to a customer-support domain (probably: customers, orders, tickets, refunds).
3. The custom MCP server (customer-data), with exactly the runtime tools
our agent will need. Propose the tool list and signatures. No run_sql.
4. The audit-logging plan: what writes an audit row, what doesn't.
Output the plan as a markdown file at plans/customer-support-worker-plan.md.
Do not write code yet.
For reference the part 2 here: https://agentfactory.panaversity.org/docs/digital-fte-crash-course
بناتا ہے: plans/customer-support-worker-plan.md۔
Check. plan پڑھیں اور ان دو چیزوں پر پیچھے دھکیلیں جو پہلا مسودہ عموماً غلط کرتا ہے: مبہم Skill descriptions ("Summarizes tickets"، ایک ایسی description جو کبھی درست فائر نہیں ہوتی، Concept 3) اور بہت وسیع MCP tool inputs ("query: string"، جو بھیس بدلا
run_sqlہے؛lookup_customerکو ایکcustomer_idلینا چاہیے، نہ کہ آزاد متن جس سے آپ SQL بناتے ہیں)۔ plan کو منظور نہ کریں جب تک دونوں تنگ نہ ہوں۔
plan پہلے کیوں۔ دونوں failure modes بننے کے بعد گھنٹے لیتے ہیں اور ایک markdown plan میں ٹھیک کرنے میں منٹ۔ یہ پورے Part میں غلط ہونے کی سب سے سستی جگہ ہے۔
آپ پہلی بار database کو ہاتھ لگانے والے ہیں، اور آپ Decisions 3 سے 8 میں بہت سی SQL دیکھیں گے۔ آپ اسے ہاتھ سے نہ ٹائپ کرتے ہیں نہ چلاتے ہیں۔ تین components اس کے مالک ہیں، اور دو مختلف کام کرتے دو مختلف MCP سرور ہیں۔
| SQL / data path | کون لکھتا ہے | کون چلاتا ہے | کب |
|---|---|---|---|
| Schema + migrations (یہ Decision) | آپ بیان کرتے ہیں؛ ایجنٹ مسودہ بناتا ہے | Neon MCP سرور (ایک dev tool جو آپ اپنے ایجنٹ سے جوڑتے ہیں) | ایک بار، setup پر |
| Verification queries ("Done when" checks) | سبق میں دکھائی گئیں | Neon MCP سرور run_sql، آپ سادہ انگریزی میں چلاتے ہیں | تصدیق کرنے کے لیے کہ قدم چلا |
| Runtime business SQL: lookups، vector search، refunds (D6) | mcp-builder بناتا ہے | آپ کا بنایا customer-data MCP سرور | ہر گاہک interaction |
| Audit writes (D7) | audit subsystem کوڈ | ایک الگ asyncpg pool (کوئی MCP نہیں) | ہر عمل |
دو MCP سرور، کبھی نہ الجھیں۔ Neon MCP سرور (جسے آپ نے اوپر setup قدم میں authenticate کیا) ایک development tool ہے: آپ اسے database کو سادہ انگریزی میں فراہم اور تصدیق کرنے کے لیے استعمال کرتے ہیں، اور runtime پر کبھی استعمال نہیں کرتے۔ customer-data MCP سرور وہ scoped سرور ہے جو آپ Decision 6 میں بناتے ہیں؛ چلتا ورکر اسی ایک سے، اور صرف اسی سے، business data کے لیے بات کرتا ہے۔ Concept 12 بتاتا ہے کہ production میں ایک عام مقصد والا run_sql ایک prompt-injection سوراخ کیوں ہے۔
Read، write، اور drop برابر اختیار نہیں۔ چلتے ورکر کے tools خطرے سے بٹتے ہیں:
- Read (
lookup_customer،find_similar_resolved_tickets، D6 میں بنے): آزادانہ چلتے ہیں، کوئی gate نہیں۔ Reads کی اجازت دینا سستا ہے۔ - Write (
issue_refund، D6 میں بنا): وہ واحد tool جو پیسہ ہلاتا ہے۔ آپ اسے Decision 9 میں انسانی منظوری کے پیچھے gate کرتے ہیں، ورکر کے سرے سے سرے تک چلنے کے بعد، تاکہ کوئی انسان کسی refund کے گزرنے سے پہلے sign off کرے۔ Audit writes append-only ہیں: داخل ہوتی ہیں، کبھی update یا delete نہیں ہوتیں۔ - Drop / schema change (
CREATE/DROP TABLE، DDL): runtime پر بالکل قابلِ کال نہیں۔ custom سرور کبھی DDL tool پیش نہیں کرتا، تو منظور کرنے کو کچھ نہیں۔ Schema changes صرف dev وقت پر (یہ Decision)، Neon MCP سرور کے ذریعے، ایک عارضی branch پرmainکو چھونے سے پہلے ہوتی ہیں۔
اصولِ عام: reads آزاد چلتے ہیں، writes gate ہوتے ہیں، اور structural changes ایجنٹ کے ذریعے کبھی production تک نہیں پہنچتیں۔
Decision 3: Neon فراہم کریں اور schema migration چلائیں
Neon کا free tier Part 5 کے فرض کردہ حجم (تقریباً 200 گفتگو/دن) پر ایک ورکر کو سمیٹتا ہے۔ یہاں $0/ماہ کی منصوبہ بندی کریں۔ Free plan کی حدود فی project 0.5 GB storage اور 100 compute-hours ہیں (Neon pricing)؛ اس سے اوپر، Launch tier pay-as-you-go ہے (تقریباً $0.11/CU-hour + $0.35/GB-month)، اور ایک عملی مثال والا ورکر عموماً $25/ماہ سے نیچے رہتا ہے۔ مکمل تفصیل کے لیے Part 5 کی cost shape table دیکھیں۔
آپ کہاں ہیں: ایک منظور شدہ plan مگر کوئی database نہیں؛ یہ Decision آپ کے schema اور ایک مستقل Session والا ایک زندہ Neon database شامل کرتا ہے؛ آخر تک آپ Postgres میں نو tables اور ایک ایسا worker دیکھیں گے جو پچھلے turns یاد رکھتا ہے۔
آپ یہ Decision ایک زندہ Neon database کے ساتھ ختم کرتے ہیں جو آپ کا schema رکھتا ہے، اور ایک Session جو conversation turns اس میں محفوظ کرتی ہے۔ چار چھوٹے قدم، اور آپ ہر ایک اگلے سے پہلے check کرتے ہیں، کیونکہ ایک ٹوٹا database قدم تب تک غیر مرئی رہتا ہے جب تک downstream میں کوئی چیز کچھ نہ پڑھے۔ Plan Mode سے نکلنے کے لیے Shift+Tab دبائیں اور یقینی بنائیں کہ Neon MCP سرور جڑا ہے (Concept 12)۔ ایجنٹ یہ سب Neon MCP tools کے ذریعے چلاتا ہے؛ آپ کبھی database console نہیں کھولتے۔
قدم 1: project بنائیں۔
Create a fresh Neon project called "chat-agent" and give me the
connection string for its main branch.
Check. ایجنٹ سے کہیں کہ تصدیق کرے کہ project موجود ہے اور
mainconnection string واپس paste کرے۔ (آپ اسے Neon console میں بھی دیکھ سکتے ہیں۔) ہاتھ میں connection string کے بغیر آگے نہ بڑھیں۔
قدم 2: pgvector آن کریں۔
Enable the pgvector extension on the chat-agent database.
Check. "Confirm the
vectorextension is now listed on the database۔" اگر نہ ہو، تو downstream میں کوئی چیز جو embeddings رکھتی ہے کام نہیں کرے گی، تو یہاں رکیں جب تک یہ نہ ہو۔
قدم 3: schema لگائیں، branch-first۔
Apply our schema to chat-agent: the five-table core from Concept 7
(conversations, documents, embeddings, audit_log, capability_invocations)
plus four domain tables, customers, orders, tickets, refunds. Build the
audit_log and capability_invocations columns EXACTLY as Concept 7 prints
them: audit_log keeps its `target` column and the closed `action` CHECK
set, capability_invocations keeps its `status` CHECK set, so Decision 8's
replay query matches the schema you built. Test it on a temporary branch
first, then merge to main. Plan the DDL first; I'll approve before you merge.
Check. "Count the tables in the public schema, I expect nine, and confirm the embeddings index exists۔" نو tables کا مطلب migration لگ گئی۔ اگر کم ہوں، تو merge صاف نہیں لگا: ایجنٹ سے ایک تازہ branch پر دوبارہ چلوائیں۔ (یہ بالکل Concept 12 کا development use case ہے: سادہ انگریزی میں schema کام، ایک branch پر test شدہ، آپ کے "آگے بڑھو" کے بعد ہی
mainمیں merged۔)
تقریباً جو آپ کو دکھنا چاہیے:
table_count = 9
embeddings index: present
قدم 4: worker کو اس کی Session دیں، اور ثابت کریں کہ یہ یاد رکھتا ہے۔
Write the connection string to .env as NEON_DATABASE_URL, then give the
worker a SQLAlchemySession on that database so it remembers across turns.
Install what the session needs (the sqlalchemy extra, asyncpg, pgvector,
and greenlet), and use the postgresql+asyncpg:// form of the URL for it.
بدلتا ہے: worker فائل (Session شامل کرتا ہے)؛ NEON_DATABASE_URL کو .env میں لکھتا ہے۔
Check. دو-turn گفتگو چلائیں: worker کو اپنا نام اور ایک آرڈر نمبر بتائیں، پھر دوسرے turn میں اس سے انہیں واپس دہرانے کو کہیں۔ یہ دونوں یاد رکھتا ہے، یہی Session کا اپنا کام کرنا ہے، نہ کہ صرف ایک table میں بیٹھی row۔ پھر پوچھیں: "show me those turns in the
agent_messagestable." انہیں Postgres میں دیکھنا ثابت کرتا ہے کہ state اب صرف memory میں نہیں، سسٹم آف ریکارڈ میں رہتا ہے۔ (دو چیزیں جو ایجنٹ اکثر چوک جاتا ہے:[sqlalchemy]extragreenletنہیں لاتا، تو اسےuv add greenletچاہیے؛ اور async engine کو URL کیpostgresql+asyncpg://شکل چاہیے، نہ کہ سادہpostgresql://۔SQLAlchemySessionآپ کے لیےagent_sessionsاورagent_messagesبناتی ہے۔)
Decision 4: پہلی Skill، summarize-ticket، بیان اور ثابت کریں، پھر اسے wire کریں
آپ کہاں ہیں: ایک worker جو یاد رکھتا ہے مگر کوئی قابلِ انتقال صلاحیت نہیں؛ یہ Decision ڈسک پر تین Skills شامل کرتا ہے اور انہیں worker میں wire کرتا ہے؛ آخر تک آپ ایک کو حقیقی run پر فائر ہوتے دیکھیں گے۔
آپ یہ Decision ڈسک پر تین Skills کے ساتھ ختم کرتے ہیں، پہلی ان معیارات کے مقابل ثابت جو آپ طے کرتے ہیں، اور Skills capability worker میں wired تاکہ آپ اسے فائر ہوتے دیکھیں۔ یہاں اس سے فرق ہے کہ لوگ عموماً skills کیسے لکھتے ہیں: آپ skill ہاتھ سے نہیں لکھتے اور آنکھ سے نہیں دیکھتے۔ آپ skill-creator کو بتاتے ہیں skill کب فائر ہونی چاہیے اور اچھا نتیجہ کیسا دکھتا ہے، اور یہ ان معیارات کے مقابل skill بناتا، test کرتا، اور تنگ کرتا ہے۔ کامیابی بیان کرنا اور نتائج پرکھنا وہ کام ہے جو حقیقی دنیا میں ایک شعبہ جاتی ماہر کرتا ہے؛ نیچے کی authoring tool کی ہے۔
قدم 1: تصدیق کریں کہ skill-creator دستیاب ہے۔ آپ نے اسے پہلے ہی (base prep میں mcp-builder اور neon-postgres کے ساتھ) انسٹال کیا تھا، تو یہ .claude/skills/ میں بیٹھی ہے اور آپ اسے یہاں دوبارہ انسٹال نہیں کرتے۔ صرف تب دوبارہ شامل کریں اگر یہ کسی طرح غائب ہو گئی ہو:
npx skills add https://github.com/anthropics/skills --skill skill-creator --agent claude-code -y
Check.
skill-creator.claude/skills/میں موجود ہے۔ (ایک install دونوں tools کے کام آیا: OpenCode.claude/skills/کو fallback کے طور پر پڑھتا ہے، تو کبھی الگ--agent opencodeinstall چلانا نہیں تھا۔)
قدم 2: بیان کریں کہ skill کیا کرتی ہے اور کب فائر ہوتی ہے۔ skill-creator آپ سے وہ دو چیزیں مانگتا ہے جو صرف آپ طے کر سکتے ہیں، trigger اور output۔ دونوں اسے پہلے سے، سادہ زبان میں دیں، اور اسے مسودہ بنانے دیں۔
Use skill-creator to build a summarize-ticket skill. Here is the spec.
Output: turn one support ticket into a five-section handoff (Customer
Context, Issue, Resolution Steps Taken, Current Status, Recommended Next
Action). It SHOULD fire on phrasings like "write a handoff note for #4471",
"TL;DR this thread", and "where does this stand before I escalate",
including ones that never say "summarize". It should NOT fire on drafting a
customer reply, triaging a batch, or reporting on ticket volume. Draft the
skill from that, then we'll test it.
بناتا ہے: .claude/skills/summarize-ticket/۔
Check.
.claude/skills/summarize-ticket/کے تحت ایک مسودہ موجود ہے، اور اس کیdescriptionآپ کی fire / don't-fire فہرست کی عکاسی کرتی ہے، نہ کہ کوئی عام "summarizes tickets۔" وہ description واحد input ہے جو طے کرتی ہے کہ skill کبھی چلے گی یا نہیں (Concept 3)؛ آپ نے اسے لفظوں کا اندازہ لگانے کے بجائے قابلِ test معیار کے طور پر سونپا۔
قدم 3: skill-creator کو اسے test اور تنگ کرنے دیں۔ یہی وہ حصہ ہے جو description کو آنکھ سے دیکھنے کی جگہ لیتا ہے۔ skill-creator آپ کی fire / don't-fire فہرست کو trigger evals میں بدلتا ہے، انہیں چلاتا ہے، اور description کو بہتر کرتا ہے جب تک skill تب فائر نہ ہو جب چاہیے اور تب خاموش رہے جب نہ چاہیے۔
Test summarize-ticket against the fire and don't-fire cases I gave you:
turn them into trigger evals, run them, and tighten the description until
it passes. Show me which cases pass and which fail, before and after.
Check. آپ خام description نہیں، eval results پڑھتے ہیں: skill handoff، TL;DR، اور status phrasings پر فائر ہوتی اور قریب کے غلط (ایک جواب draft کرنا، batch triage) پر خاموش رہتی ہے۔ وہ pass / fail table Concept 3 کے "keyword حذف کرو اور دیکھو یہ پھر بھی بتاتا ہے کہ کب فائر کرنا ہے" والے احساس کا سخت version ہے۔ ماڈل اس skill کو چلانے کا فیصلہ صرف اس کی description سے کرتا ہے، تو اس table کو سبز کرنا ہی پورا کھیل ہے۔
دونوں tools، ایک نظم۔ Claude Code میں، skill-creator اسے ایک خودکار loop کے طور پر چلاتا ہے: یہ آپ کے cases کو ایک training set اور ایک held-out set میں بانٹتا ہے، ہر ایک کو ایک قابلِ اعتماد trigger rate کے لیے چند بار چلاتا ہے، اور کئی rounds میں optimize کرتا ہے، اس description کو رکھتے ہوئے جو ان cases پر سب سے بہتر score کرتی ہے جن پر اس نے train نہیں کیا۔ OpenCode میں آپ وہی loop ہاتھ سے چلاتے ہیں: cases بیان کریں، test کریں، تنگ کریں، دہرائیں۔ automation مختلف ہے؛ trigger کو حقیقی phrasings کے مقابل ثابت کرنے کا نظم یکساں ہے۔
قدم 4: باقی دو Skills اسی طرح بیان کریں۔ وہی چال: بیان کریں کہ ہر ایک کب فائر ہوتی ہے اور کیا پیدا کرتی ہے، اور skill-creator کو انہیں بنانے دیں۔ آپ کو تینوں پر مکمل test loop کی ضرورت نہیں؛ summarize-ticket پر اسے ایک بار چلانے نے آپ کو سائیکل سکھا دیا۔ ہر ایک کے لیے trigger اور output shape دیں؛ یہ جن descriptions پر اترے انہیں نیچے والوں جیسا پڑھنا چاہیے۔ ورکر کو تینوں چاہئیں۔
# .claude/skills/find-similar-cases/SKILL.md (frontmatter only)
---
name: find-similar-cases
description: Searches the resolved-tickets library for tickets semantically similar to a customer's described issue, returning the top 3-5 with their resolutions, ranked by how closely each matches. Use when the user describes a problem, complaint, or symptom and you need to check whether the team has handled something similar before. Calls the find_similar_resolved_tickets MCP tool. Always run this BEFORE drafting a response, so the response can reference proven prior resolutions rather than inventing a new approach.
---
body ان قدموں سے گزرتا ہے:
- context سے issue description نکالیں۔
find_similar_resolved_ticketsکوlimit=5کے ساتھ کال کریں۔- اوپر کے تین کو ان کی distance values کے ساتھ ایک markdown table میں پیش کریں۔
- کم اعتماد والے matches (distance تقریباً 0.3 سے اوپر، جہاں کم کا مطلب زیادہ ملتا جلتا) کو "no strong prior precedent found" کے طور پر صراحتاً نشان لگائیں۔
ہدایت "always run this BEFORE drafting" حقیقی کام کر رہی ہے؛ اس کے بغیر، ماڈل کبھی کبھار priors سے جواب draft کر دیتا ہے اور لائبریری کو کبھی نہیں دیکھتا۔
# .claude/skills/escalate-with-context/SKILL.md (frontmatter only)
---
name: escalate-with-context
description: Packages a customer conversation for handoff to a tier-2 support agent. Produces a structured escalation note with customer profile, issue summary, what was already tried, why escalation is recommended, and the suggested specialist team. Use when (a) the customer is on the Pro or Enterprise tier AND the issue is unresolved after one round of investigation, (b) the customer's sentiment is clearly negative, (c) the issue involves billing >$500 or a refund decision, or (d) the user explicitly asks for a human.
---
body پہلے summarize-ticket invoke کرتا ہے تاکہ structured context ملے، پھر ایک چھ-section escalation note لکھتا ہے (customer context، issue، آزمائے گئے حل، sentiment signals، تجویز کردہ team، تجویز کردہ SLA)۔ description میں چار صریح trigger conditions وہی ہیں جو اس skill کو زیادہ فائر ہونے سے روکتی ہیں؛ مبہم escalation منطق والا ورکر ہر چیز escalate کرتا ہے، جو مقصد ہی شکست دے دیتا ہے۔
Check. دونوں descriptions صریح، مخصوص triggers کا نام لیتی ہیں، نہ کہ "use when relevant۔" خاص طور پر
escalate-with-context: اس کی چار conditions ہی اسے ہر پیغام پر فائر ہونے سے روکتی ہیں۔ تینوں Skills اب.claude/skills/میں رہتی ہیں۔
بناتا ہے: .claude/skills/find-similar-cases/ اور .claude/skills/escalate-with-context/۔
قدم 5: Skills capability کو worker میں wire کریں، اور ایک کو فائر ہوتے دیکھیں۔ تینوں Skills ڈسک پر ہیں؛ اب خود worker کو انہیں لوڈ کرنا ہے۔ اسے اس کی default capabilities کے اوپر Skills capability دیں، پھر اسے چلائیں۔
Give the worker the Skills capability pointed at .claude/skills, on top of
its default capabilities, and run it from the project root with: "write a
handoff note for ticket #4471, refund delayed two weeks, customer Sam."
Show me the run so I can see the skill load.
بدلتا ہے: worker فائل (Skills capability شامل کرتا ہے)۔
Check. run
summarize-ticketکے لیے ایکload_skillcall دکھاتا ہے اور جواب پانچ sections میں واپس آتا ہے: یہی skill کا آپ کے اپنے worker کے اندر فائر ہونا ہے، نہ کہ بس ڈسک پر بیٹھنا۔ اگر اس کے بجائے worker آزادانہ خلاصہ لکھ دے اور کوئیload_skillظاہر نہ ہو، تو path غلط resolve ہوا: Skills ایک ایسے path سے لوڈ ہوتی ہیں جو worker کے چلنے کی جگہ سے relative ہے، تو project root سے ایک relative.claude/skillsکے ساتھ چلائیں، absolute کے ساتھ نہیں۔ (macOS پر/tmpکے تحت ایک absolute path خاموشی سے صفر skills لوڈ کرتا ہے، بالکل کوئی error نہیں، جو یہ ناکام ہونے کا سب سے الجھن بھرا طریقہ ہے۔) ایک اور: آپ Skills کو default capabilities میں شامل کرتے ہیں، انہیں بدلتے نہیں، ورنہ worker وہ filesystem اور shell کھو دیتا ہے جن پر یہ بھروسہ کرتا ہے۔
تقریباً جو آپ کو run میں دکھنا چاہیے:
tool call: load_skill(name="summarize-ticket")
reply: Customer Context / Issue / Resolution Steps Taken / Current Status / Recommended Next Action
اسے ابھی کیوں wire کریں۔ یہ وہ لمحہ ہے جب Skills فائلیں رہنا چھوڑتی اور صلاحیت بنتی ہیں: اگلا پیغام جو کسی ticket کا ذکر کرے، اس skill کو اس کی description سے فائر کرتا ہے۔ باقی دو Skills ان MCP tools پر ٹیک لگاتی ہیں جو آپ آگے بناتے ہیں، تو summarize-ticket، جو اپنے پاؤں پر کھڑی ہے، یہاں تصدیق کے لیے ایماندار ہے۔
Decision 5: embedding pipeline بنائیں اور document لائبریری seed کریں
چند درجن حل شدہ tickets کا ایک seed corpus، فی ایک تقریباً 300 ٹوکن، text-embedding-3-small کے $0.02 فی 1M input tokens پر ایک پیسے کے کسرے میں embed ہوتا ہے۔ نئے tickets اور گفتگوؤں کا جاری embedding عملی مثال والے حجم پر عموماً $3/ماہ سے نیچے رہتا ہے۔ cost lever inference بجٹ ہے، embedding بجٹ نہیں۔
آپ کہاں ہیں: خالی tables والا ایک schema اور ایسی skills جن کے پاس تلاش کرنے کو کچھ نہیں؛ یہ Decision گزشتہ حل شدہ tickets کی ایک seeded، embedded لائبریری شامل کرتا ہے؛ آخر تک آپ ایک similarity search کو رینک شدہ matches لوٹاتے دیکھیں گے۔
آپ یہ Decision گزشتہ حل شدہ tickets کی ایک چھوٹی لائبریری کے ساتھ ختم کرتے ہیں، embedded اور قابلِ تلاش۔ دو قدم۔
قدم 1: seed لائبریری کوڈ میں پیدا کریں۔ ورکر کی "لائبریری" گزشتہ حل شدہ tickets کا ایک سیٹ ہے: اتنا چھوٹا کہ تیز چلے، اتنا متنوع کہ search کے پاس فرق کرنے کو کچھ ہو۔ آپ اسے ہاتھ سے نہیں لکھتے، اور کوئی CSV نہیں بھرتے؛ ایجنٹ اسے پیدا کرتا ہے۔
Have the worker's own SDK generate a dozen-plus varied resolved tickets as
structured data (a Pydantic model is the clean way): each with a customer
email, a one-line summary, and the resolution. Vary the issues across
refunds, logins, duplicate charges, and shipping, so semantic search has
something to tell apart. Write the generator and run it; don't hand me a CSV.
بناتا ہے: ticket generator script۔
Check. ایک درجن سے زیادہ پیدا شدہ tickets واقعی مختلف issues پر (refunds، logins، charges، shipping)، نہ کہ تین کی دوبارہ لفظ بندی۔ آپ نے کبھی ایک row ہاتھ سے نہیں ٹائپ کی، اور یہی نکتہ ہے: ایک ورکر کا اپنا seed data وہ چیز ہے جو ورکر خود پیدا کر سکتا ہے۔
قدم 2: seed اور embed کریں۔ ہر پیدا شدہ ticket ایک customer_email رکھتا ہے، جو seeder کو ticket داخل کرنے سے پہلے ایک customers row find-or-create کرنے دیتا ہے (tickets.customer_id foreign key NOT NULL ہے)۔ پھر:
Seed the generated resolved tickets so the Worker can search them later.
For each one: find-or-create the customer by email, insert a resolved
ticket, store the case text as a documents row tagged source='past_case'
with the ticket id at metadata->>'ticket_id' (there is no ticket_id column
on documents), then embed that text with
text-embedding-3-small and link the embedding to the document. Write one
audit_log row for the whole seed run. Plan first.
بناتا ہے: seed-and-embed script۔
وہ شکل arbitrary نہیں، اور یہی وہ حصہ ہے جس کا ایجنٹ اندازہ نہیں لگا سکتا: Decision 6 کا find_similar_resolved_tickets embeddings کو documents (جہاں source='past_case') سے tickets تک join کر کے search کرتا ہے۔ اگر seed rows کو اس طرح نہ بچھائے، تو Decision 8 کی search خاموشی سے کچھ نہیں لوٹاتی اور آپ کو پتا نہیں چلے گا کیوں۔ ایجنٹ اصل seeder لکھتا ہے؛ آپ اس شکل کی وضاحت کر رہے ہیں جو اسے پیدا کرنی ہے۔ نتیجے میں تصدیق کے لیے دو قواعد، دونوں Concept 9 سے اور دونوں پہلے ہی آپ کے AGENTS.md میں: اسی ہی ماڈل سے embed کریں جس سے آپ بعد میں query کریں گے، اور connection پر pgvector register کریں (ورنہ vectors کوڑے کے طور پر واپس لکھتے ہیں)۔
Check. ایجنٹ سے نتیجہ واپس پڑھنے کو کہیں: "Count the documents tagged as past cases (should match the number of tickets you generated), count the embeddings (should match too), confirm only one embedding model is present, and run one similarity search to show the closest match to 'refund delayed two weeks' comes back ranked." دو failure shapes: اگر یہ دو embedding models بتائے، تو seed نے بیچ میں models ملا دیے، reset کر کے دوبارہ چلائیں؛ اگر counts صفر واپس آئیں، تو seeder نے ایک error نگل لیا، اس سے وہ
audit_logrow واپس پڑھوائیں جو اس نے seed run کے لیے لکھی (جو بالکل وہ وجہ ہے کہ seeder ایک لکھتا ہے)۔ Decision 6 پر تب تک نہ بڑھیں جب تک ایک similarity search رینک شدہ نتائج نہ لوٹائے۔
تقریباً جو similarity search کو لوٹانا چاہیے:
query: "refund delayed two weeks"
1. "refund not received after 14 days" distance 0.08
2. "duplicate charge, awaiting reversal" distance 0.24
یہ ایک براہِ راست connection کیوں ہے، MCP نہیں۔ ایک seed script infrastructure ہے: یہ ایک بار، ہاتھ سے، آپ کے ذریعے چلتا ہے، نہ کہ کوئی چیز جو ورکر خود کرتا ہے۔ MCP سرحد اس کے لیے ہے جو ایجنٹ خود مختاری سے کرتا ہے؛ seed script ایک ایسی چیز ہے جو آپ کرتے ہیں۔ جب آپ ہی keyboard پر ہوں تو اپنے اور اپنے database کے بیچ سرحد نہ رکھیں۔
Decision 6: customer-data MCP سرور بیان، build، اور connect کریں
custom MCP سرور آپ کے ورکر کے ساتھ ایک چھوٹی service کے طور پر چلتا ہے؛ اسی host پر co-located ہونے سے یہ کوئی بامعنی hosting لاگت شامل نہیں کرتا (صرف اگر آپ اسے الگ hardware پر دھکیلیں تب ایک compute لائن نمودار ہوتی ہے)۔ بل اصل میں inference میں دکھتا ہے: ہر lookup_customer یا find_similar_resolved_tickets call اگلے model turn میں ایک round-trip بھر کے tokens شامل کرتا ہے۔ Concept 15 MCP-under-load کا latency اور pool-size پہلو سمیٹتا ہے۔
آپ کہاں ہیں: ایک seeded لائبریری جس تک worker ابھی runtime پر نہیں پہنچ سکتا؛ یہ Decision scoped customer-data MCP سرور شامل کرتا اور اسے wire کرتا ہے؛ آخر تک آپ worker کو ایک حقیقی پیغام پر اس کا ایک tool کال کرتے دیکھیں گے۔
آپ یہ Decision scoped customer-data سرور کے ساتھ ختم کرتے ہیں جو چل رہا ہے اور آپ کے worker میں wired ہے، اس کے تین tools ایک حقیقی run سے قابلِ کال۔ یہ Decision 4 کی Skills جیسی ہی شکل ہے: آپ بیان کرتے ہیں کہ connector کو کیا کرنا ہے اور یہ کتنا تنگ رہتا ہے، mcp-builder اسے بناتا ہے، اور آپ اسے استعمال کر کے ثابت کرتے ہیں۔ آپ scope کی رہنمائی کرتے ہیں؛ آپ کوئی FastMCP boilerplate ہاتھ سے نہیں لکھتے۔ (ایک خطرناک tool، issue_refund، کو gate کرنا Decision 9 میں آتا ہے، پوری چیز چلنے کے بعد۔)
قدم 1: تصدیق کریں کہ mcp-builder دستیاب ہے۔ skill-creator کی طرح، آپ نے اسے base prep میں انسٹال کیا، تو یہ پہلے ہی یہاں ہے۔ صرف تب دوبارہ شامل کریں اگر یہ غائب ہو گیا ہو:
npx skills add https://github.com/anthropics/skills --skill mcp-builder --agent claude-code -y
Check.
mcp-builder.claude/skills/میں موجود ہے۔
قدم 2: tool contract اور scope بیان کریں۔ یہ Skill کے معیار بیان کرنے کا connector والا version ہے: آپ بالکل کہتے ہیں کہ کون سے tools موجود ہیں، ہر ایک کیا لیتا ہے، اور سرور کتنا تنگ رہتا ہے (کوئی عام SQL نہیں)، اور mcp-builder اسے plan کرتا ہے۔ اسے streamable HTTP، stateless flavor پر بنائیں (Concept 11 کا default): ہر call ایک خود مختار request ہے، تو سرور ایک حقیقی addressable service ہے جس تک ورکر URL سے پہنچتا ہے، اور traffic بڑھے تو آپ ایک سے زیادہ کاپیاں چلا سکتے ہیں۔ (ایک خالص مقامی single-Worker build stdio استعمال کر سکتا تھا؛ stateless service وہی match کرتا ہے جو آپ واقعی ship کریں گے۔)
/mcp-builder Plan a custom MCP server called "customer-data" on the
streamable-HTTP transport, stateless flavor, with exactly three scoped
tools and no general SQL tool:
- lookup_customer(customer_id): return id, email, tier, open-ticket count.
Tier lives in customers.metadata->>'tier' (COALESCE to 'standard'); there
is no tier column.
- find_similar_resolved_tickets(description, limit): semantic search over
past resolved cases. Embed the description with text-embedding-3-small
(the SAME model the seed used) and register pgvector on the connection.
The search joins embeddings -> documents -> tickets, where the
documents->tickets link is documents.metadata->>'ticket_id' (there is no
ticket_id column on documents).
- issue_refund(order_id, amount_cents, reason): insert the refund (amount in
integer cents), set the order to refunded, AND write the audit_log row,
all in ONE transaction.
Give each tool a clear description so the model knows when to call it.
Show me the plan before any code.
Check. کسی بھی کوڈ سے پہلے plan پڑھیں: بالکل تین tools، کوئی عام SQL tool نہیں، اور
issue_refundrefund، order-status تبدیلی، اور audit row کو ایک transaction میں لکھ رہا ہے۔ اگر کوئی غائب ہو تو پیچھے دھکیلیں۔ (ایک Neon gotcha ایجنٹ کو صرف تب سونپیں اگر آپ نے schema کو defaultpublicسے ہٹایا ہو: table ناموں کو schema-qualify کریں، کیونکہ Neon کا pooled endpoint connection release پرsearch_pathreset کر دیتا ہے، توSET search_pathزندہ نہیں رہے گا۔ کورس کی default migration پر یہ بس کام کرتا ہے۔) ایک Neon gotcha جو ہمیشہ لاگو ہوتا ہے، یہاں اور Decision 7 میں: pooled endpoint (PgBouncer، transaction mode) asyncpg کے prepared statements توڑ دیتا ہے، تو اس سرور کے pool اور audit pool دونوں کوasyncpg.create_pool(...)میںstatement_cache_size=0pass کرنا ہوگا، ورنہ بالکل پہلی query error دیتی ہے۔
قدم 3: اسے build کریں، اور mcp-builder کو tools test کرنے دیں۔ ایک بار plan درست ہو: "Build the server exactly as we planned, three tools and no more, then start it and confirm it boots cleanly. Don't add tools I didn't ask for." mcp-builder ایک قدم اور آگے جا سکتا اور evaluations پیدا کر سکتا ہے، حقیقت پسند tasks جنہیں tools کو سرے سے سرے تک پورا کرنا ہوتا ہے، جو اس trigger eval کا connector والا version ہے جو آپ نے Skill پر چلایا۔ کورس کے لیے فیصلہ کن test اگلا قدم ہے، worker سے ایک tool کال کرنا، تو یہاں ایک صاف boot آگے بڑھنے کے لیے کافی ہے۔
بناتا ہے: customer-data-mcp/ سرور۔
Check. built سرور میں ہر tool کی description پڑھیں: یہی ماڈل پڑھتا ہے تاکہ فیصلہ کرے کہ tool کب کال کرے (وہی کردار جو
SKILL.mddescription نبھاتی ہے)، اور ایک مبہم غلط وقت پر فائر کرتی ہے۔ پھر وہ ایک چیز تصدیق کریں جسے ایجنٹ سب سے اکثر باریک طور پر غلط کرتا ہے:issue_refundbody تینوں writes ایک ہی transaction میں کرتا ہے۔ ان میں سے زیادہ تر نظم آپ کےAGENTS.mdمیں بھی رہتے ہیں، تو ایک محتاط ایجنٹ انہیں لاگو کرتا ہے؛ آپ تصدیق کر رہے ہیں کہ وہ بچ گئے۔
customer-data سرور ایک streamable-HTTP service ہے، تو worker کے اس تک پہنچنے سے پہلے اسے چلنا ہوتا ہے۔ یہاں سے، live runs (یہ Decision، اور Decisions 8 اور 9) کو دو terminals چاہئیں: ایک میں سرور شروع کریں، دوسرے میں worker چلائیں، پہلے سرور۔ سرور بند کریں تو worker کے tool calls ایک غلط جواب سے نہیں، ایک connection error سے ناکام ہوتے ہیں۔
قدم 4: اسے worker سے connect کریں اور ایک tool کال کریں۔ سرور کو اس worker میں wire کریں جس کے پاس پہلے ہی اس کی Session اور Skills ہیں، اور ثابت کریں کہ ایک tool واقعی چلتا ہے۔ یہ Decision 4 میں Skill کو فائر ہوتے دیکھنے کا connector والا version ہے:
Register the customer-data server with the worker as a remote
streamable-HTTP server at its URL, alongside the Session and Skills it
already has. Check the current SDK docs for the exact registration API.
بدلتا ہے: worker فائل (customer-data سرور register کرتا ہے)۔
Check. یہ ایک streamable-HTTP service ہے، تو پہلے سرور شروع کریں، پھر worker کو ایک حقیقی پیغام پر چلائیں: "Start the customer-data server, then run the worker on 'I'm Sam, and I haven't had my refund for order #4429 in two weeks.'" worker کو
find_similar_resolved_ticketsکال کرنا چاہیے اور رینک شدہ گزشتہ کیسز کے ساتھ واپس آنا چاہیے، نہ کہ ایک خالی نتیجہ اور نہ کوئی گھڑا ہوا جواب۔ یہی MCP تار کا چلنا ہے: worker نے business data کو scoped سرور کے ذریعے، اور صرف اسی سرور کے ذریعے، پہنچا۔ دو red flags: فہرست میں ایک عامrun_sql-طرز کا tool کا مطلب ہے worker runtime پر اب بھی Neon MCP سرور سے wired ہے، اسے نکال دیں (Concept 12)؛ search سے ایک خالی نتیجہ کا مطلب ہے Decision 5 کا seed اس شکل میں نہیں لگا جو join پڑھتی ہے (embeddingsسےdocumentsجہاںsource='past_case'سےtickets)۔ اگر خود سرور شروع نہ ہو، تو ایجنٹ سے اس کے logs پڑھوائیں (Concept 13 کا startup-import نوٹ معمول کی وجہ ہے)۔
ایک custom سرور کیوں، نہ کہ ایجنٹ کوڈ میں صرف asyncpg۔ Concept 14 کی تین وجوہ، اس ترتیب میں جس میں وہ یہاں اہم ہیں: scope (ایجنٹ database کے ساتھ بالکل تین کام کر سکتا ہے، نہ کہ جو بھی SQL اجازت دیتی ہے)، isolation (سرور اپنے ہی process میں اپنے ہی pool کے ساتھ چلتا ہے جسے ایجنٹ ختم نہیں کر سکتا)، اور reusability (ایک دوسرا ورکر جسے lookup_customer چاہیے اسی سرور سے بات کرتا ہے)۔ وہ تنگ surface ہی پورا security دلیل ہے، اسی لیے قدم 3 کا check سرحد کے بارے میں ہے، plumbing کے بارے میں نہیں۔
Decision 7: audit logging ہر جگہ wire کریں
آپ کہاں ہیں: ایک worker جو عمل کرتا ہے مگر صرف وہ ایک refund write ریکارڈ کرتا ہے؛ یہ Decision ایجنٹ کے اپنے اعمال کو audit trail میں شامل کرتا ہے؛ آخر تک آپ ایک گفتگو کے لیے ایک message_received / skill_activated / capability_invoked / message_sent trace دیکھیں گے۔
یہ ان دو Decisions میں سے ایک ہے جہاں ایک پہلا build عموماً ایک error لگاتا ہے؛ نیچے کے callouts اس سے ملنے سے پہلے ہر ایک کا نام لیتے ہیں، تو انہیں پہلے پڑھیں۔
آپ یہ Decision ایجنٹ کے اپنے اعمال کے audit_log میں ریکارڈ ہونے کے ساتھ ختم کرتے ہیں۔ MCP سرور پہلے ہی ایک چیز log کرتا ہے، issue_refund اپنی audit row refund transaction کے اندر لکھتا ہے (Decision 6)؛ جو باقی ہے وہ ایجنٹ-side writes ہیں: skill invocations، model calls، tool calls، guardrail trips۔ ایک کام، Concept 10 کے log_capability helper کے ساتھ۔
قدم 1: audit helper کو ہر boundary پر wire کریں۔
Wire the audit helper around the agent's own actions, at three points:
the start and end of each skill invocation, after each MCP tool call,
and around any guardrail trip. Use the separate audit connection (its
own pool), not the customer-data MCP boundary. Plan first.
بدلتا ہے: worker فائل (ہر boundary پر audit wiring شامل کرتا ہے)۔
اوپر کی تین "boundaries" تین ملتے ہوئے hooks پر نقشہ بند نہیں ہوتیں، اور naive wiring run کو crash کر دیتی ہے۔ حقیقت:
- کوئی skill hook نہیں۔ اس کورس کے lazy Skills mode میں، ایک skill ماڈل کے
load_skilltool کال کرنے سے activate ہوتی ہے، تو skill start/end کوon_tool_start/on_tool_endمیں دیکھیں جہاںtool.name == "load_skill"۔ MCP tool calls اسیon_tool_endکے ذریعے آتے ہیں۔ - Guardrail trips اٹھائے گئے exceptions ہیں، hook نہیں۔
InputGuardrailTripwireTriggered(اور output/tool variants) کوRunner.runکے گردtry/exceptسے پکڑیں، اورguardrail_trippedrow وہاں لکھیں۔ on_tool_endکاresulttypedstrہے مگر آپ کو tool کا خام object دیتا ہے (ایک Pydantic model یا dict)۔ اس پر slicing یا string-ops پھینکتا ہے، اور ایک hook کے اندر بغیر سنبھالا exception پورا turn مار دیتا ہے (یہ ایک الجھن بھرےUserError: Error running tool ...کے طور پر سامنے آتا ہے)۔str(...)سے coerce کریں اور hook body کوtry/exceptمیں لپیٹیں تاکہ ایک audit bug کبھی صارف کا turn ختم نہ کر سکے۔on_tool_endتب بھی فائر ہوتا ہے جب ایک tool ناکام ہو، آپ کو ایک"Error executing tool ..."result دیتے ہوئے۔ اسے detect کریں (ایک substring check،startswithنہیں) اورstatus="error"ریکارڈ کریں، ورنہ ایک ناکام refund کامیابی کے طور پر log ہو جاتا ہے۔
پہلے conversations row لکھیں۔ audit_log.conversation_id conversations(session_id) کا ایک foreign key ہے۔ اگر کوئی audit row ایسے session کا حوالہ دے جس کی ابھی کوئی conversations row نہیں، تو FK خلاف ورزی کرتا ہے اور پوری transaction roll back کر دیتا ہے، بشمول وہ refund جسے یہ ریکارڈ کر رہا تھا۔ conversations row کو message_received پر upsert کریں، اس سے پہلے کہ کوئی audit row اس کی طرف اشارہ کرے (Decision 3 table بناتا ہے مگر کبھی نہیں کہتا کہ row کب لکھی جائے: یہ یہاں ہے)۔
Session والا ایک input guardrail پورا transcript دیکھتا ہے۔ صرف نیا پیغام نہیں: پوری تیار شدہ history جمع نیا turn۔ تو کسی پہلے turn کا ایک flagged لفظ ہر بعد کے turn کو trip کر دیتا ہے (ایک بے ضرر "say hello" block ہو جاتا ہے کیونکہ ایک test token اب بھی history میں ہے)۔ صرف تازہ ترین role: user item کو screen کریں، پورے input کو نہیں۔
Check. ایک ضائع کرنے والی گفتگو چلائیں، پھر: "Using the Neon tools, find the most recent conversation and show me every
audit_logrow for it, in order." آپ کو کم از کم ایکmessage_received، ایکskill_activated(worker کے پاس Decision 4 سے Skills ہیں)، MCP call کے لیے ایکcapability_invoked، اور ایکmessage_sentدکھنا چاہیے۔ دو failure shapes: اگر آپ کو صرف MCP سرور کی اپنی rows (capability_invoked،refund_issued) دکھیں اور کوئی ایجنٹ-side نہ دکھے، تو helper wired ہے مگر کبھی فائر نہیں ہوتا، ایجنٹ سے تصدیق کروائیں کہ یہ streaming loop کے اندر سے چلتا ہے، نہ کہ صرف startup پر ایک بار؛ اگر آپ کو صفر rows دکھیں، تو audit connection database تک نہیں پہنچ رہا، اس سے audit pool کو اپنے database URL کے مقابل check کروائیں۔
تقریباً جو آپ کو دکھنا چاہیے (ایک گفتگو، ترتیب میں):
message_received
skill_activated
capability_invoked
message_sent
audit pool الگ کیوں ہے۔ یہ اپنا connection استعمال کرتا ہے، customer-data MCP pool نہیں، دو وجوہ سے: audit کو تب بھی کامیاب ہونا چاہیے جب data pool بھرا ہو، اور audit writes کو connections کے لیے business writes سے مقابلہ نہیں کرنا چاہیے۔ ایک audit subsystem جسے وہ سسٹم بھوکا مار سکے جس کا یہ audit کرتا ہے، audit subsystem نہیں۔ مشینری چھوٹی ہے (Concept 7 tables بھیجتا ہے، Concept 10 helper بھیجتا ہے)؛ نظم اسے ہر boundary پر، مستقل طور پر کال کرنا ہے۔ (OpenCode میں یکساں: یہ سادہ Python ہے۔)
Decision 8: پورے worker کی ایک scenario پر تصدیق کریں
آپ کہاں ہیں: ہر تہہ wired اور تنہائی میں checked؛ یہ Decision کچھ نیا شامل نہیں کرتا، یہ انہیں ایک scenario پر ایک ساتھ چلتا ثابت کرتا اور اسے log سے دوبارہ چلاتا ہے؛ آخر تک آپ ایک ترتیب شدہ trace دیکھیں گے جو تمام تہوں کو پار کرتا ہے۔
اب تک worker کے پاس تینوں تہیں wired ہیں اور ہر ایک اپنے طور پر checked: Session (Decision 3)، Skills (Decision 4)، اور MCP سرور (Decision 6)، نیچے audit کے ساتھ (Decision 7)۔ یہ Decision ثابت کرتا ہے کہ وہ ایک حقیقی scenario پر ایک ساتھ کام کرتی ہیں، پھر اسے صرف audit log سے دوبارہ چلاتا ہے۔
قدم 1: scenario چلائیں اور اس کا trace پڑھیں۔ اپنے ایجنٹ سے ورکر کو وہ ایک پیغام چلوائیں جو پورا stack آزماتا ہے (ایک terminal میں سرور، دوسرے میں worker، پہلے سرور؛ Decision 6 دیکھیں):
Run the Worker and send it this customer message, then show me the
audit_log rows that conversation produced, in order:
"I haven't received my refund from order #4429, it's been two weeks."
آپ کو یہ rows چند سیکنڈوں میں دکھنی چاہئیں:
action=message_received: پیغام آتا ہے، conversation row بنتی ہے۔action=skill_activated(صرف اگر کوئی skill لوڈ ہو): worker درخواست سنبھالنے کے لیے ایک Skill (find-similar-casesیاsummarize-ticket) لوڈ کر سکتا ہے۔ ماڈل بغیر پہلے کوئی skill لوڈ کیے سیدھاfind_similar_resolved_ticketsتک بھی پہنچ سکتا ہے، اس صورت میں یہ row محض غیر موجود ہوتی ہے اور trace سیدھاcapability_invokedپر جاتا ہے۔ دونوں درست builds ہیں، تو ایک غائبskill_activatedکو bug نہ سمجھیں۔action=capability_invoked, target=mcp:find_similar_resolved_tickets: skill MCP سرور کے ذریعے ایک vector search چلاتی ہے، اور worker draft کرنے کے لیے قریب ترین گزشتہ حل پڑھتا ہے۔action=message_sent: draft شدہ جواب، ریکارڈ شدہ۔
ایک مشروط پانچویں، action=capability_invoked, target=mcp:lookup_customer، صرف تب دکھتی ہے جب worker کے پاس پہلے ہی ایک customer id ہو۔ پہلا turn عموماً نہیں رکھتا (گاہک نے ایک آرڈر نمبر اور ایک email دیا، ایک UUID نہیں)، تو یہ تب تک چھوڑ دیا جاتا ہے جب تک upstream میں کوئی چیز customer کو resolve نہ کرے: auth، orchestrator، یا ایک lookup_customer_by_email tool جو آپ بعد میں شامل کرتے ہیں۔ یہ ٹھیک ہے؛ جواب پھر بھی گزشتہ کیس کا حوالہ دے سکتا ہے۔
Check. بنیادی rows موجود اور ترتیب میں ہیں (
skill_activatedصرف اگر کوئی skill لوڈ ہوئی)، اور وہ ایک trace میں تہوں کو پار کرتی ہیں: ایک MCP tool سسٹم آف ریکارڈ کے مقابل چلا، گفتگو ریکارڈ ہوئی، اور ایک Skill activate ہو سکتی تھی۔ یہی پورے worker کا ایک ساتھ کام کرنا ہے۔ اگرcapability_invokedیاmessage_sentغائب ہو، تو اس Decision پر واپس جائیں جس نے اسے wire کیا اور اس Decision کا اپنا check دوبارہ چلائیں۔
message_received، skill_activated، اور message_sent Decision 7 کی ایجنٹ-side audit wiring لکھتی ہے؛ capability_invoked rows اسی wiring سے ہر MCP call کے گرد آتی ہیں۔ MCP سرور اپنی row صرف تب لکھتا ہے جب کوئی tool data بدلے (issue_refund کے اندر refund_issued row)۔ تو اس جیسا read-only scenario ایجنٹ-side rows جمع capability_invoked reads چھوڑتا ہے، اور کوئی business-write rows نہیں جب تک کوئی refund واقعی نہ ہو، Decision 9 میں۔
اب جب Skills worker کے اندر چلتی ہیں، تو ایک skill کا scripts/ سینڈ باکس میں قابلِ عمل کوڈ ہے۔ UnixLocalSandboxClient کوئی isolation نہیں دیتا؛ Docker، E2B، Cloudflare، یا Modal اسے قید کرتے ہیں۔ اپنی skill لائبریری تک write access کو deploy access کی طرح سمجھیں، اور وہ skills لوڈ کرنے سے پہلے سینڈ باکس کو isolate کریں جو آپ نے نہیں لکھیں۔
Memory capability جانیں، اور یہ کیا نہیںوہی capabilities فہرست Skills() کے ساتھ ایک Memory() بھی لیتی ہے (دونوں agents.sandbox.capabilities سے)۔ اسے ٹھیک سے جاننا قابلِ قدر ہے، کیونکہ یہ اس چیز جیسی لگتی ہے جو آپ نے ابھی بنائی اور وہ نہیں۔ Memory() ایک ورکر کو اپنے اپنے گزشتہ runs سے سیکھنے دیتی ہے: یہ ہر run کی گفتگو کو workspace فائلوں (ایک MEMORY.md اور ایک خلاصہ) میں نچوڑتی ہے جب سینڈ باکس session بند ہوتا ہے، اور بعد کے runs انہیں واپس پڑھتے ہیں، تو ایجنٹ کم explore کرتا اور کم corrections دہراتا ہے۔ یہ Concept 3 کا "کیا ہم نے اس جیسا سوال پہلے دیکھا ہے؟" والا recall ہے، جسے runtime سنبھالتا ہے، تو آپ اسے ہاتھ سے نہیں بناتے۔
یہ جو نہیں ہے وہ پائیدار business record ہے۔ Sandbox memory file-based ہے، اپنی پرانی ترین entries کو recency سے کاٹتی ہے، اور beta میں ہے؛ ایک تازہ سینڈ باکس خالی شروع ہوتا ہے، اور ایجنٹ کو کہا جاتا ہے کہ اسے رہنمائی سمجھے، بااختیار storage نہیں۔ آپ کی Neon tables ہر معاملے میں الٹ ہیں: پائیدار، مکمل، مستحکم، SQL میں queryable۔ تو آپ دونوں چاہتے ہیں، مختلف کاموں کے لیے۔ Memory() ایجنٹ کو runs کے آرپار زیادہ ذہین بناتی ہے؛ سسٹم آف ریکارڈ اس کے کام کو پائیدار، قابلِ ثبوت، اور قابلِ فروخت بناتا ہے: وہ asset جس کے آپ مالک ہیں۔ SDK docs میں Sandbox agents کے تحت چار صفحے اس پوری تہہ کا منبع ہیں؛ ساتھی AGENTS.md چاروں کو link کرتا ہے۔
قدم 2: replay query چلائیں۔ یہ وہ ثبوت ہے جس کے لیے پوری audit تہہ تھی۔ ایجنٹ سے کہیں کہ ابھی چلائی گفتگو کے لیے trace کھینچے:
Using the Neon tools, take the most recent conversation and show me its full
audit_logtrace, in order: created_at, action, target, payload, result.
Check. وہ output پڑھ کر، آپ لائن بہ لائن دوبارہ بنا سکتے ہیں کہ ایجنٹ نے کیا کیا اور کیوں، بغیر ماڈل دوبارہ چلائے۔ اگر نہیں کر سکتے، اگر کوئی قدم ہوا جو log میں نہیں، یا کوئی row ایسے عمل کا دعویٰ کرے جو business tables عکس نہیں کرتیں، تو ایک wiring bug ہے۔ worker کو مکمل کہنے سے پہلے اسے ٹھیک کریں۔
تقریباً جو replay پڑھا جانا چاہیے:
created_at action target result
10:02:11 message_received conversation:abc ok
10:02:12 capability_invoked mcp:find_similar_resolved_tickets ok
10:02:14 message_sent conversation:abc ok
یہ scenario کیوں۔ یہ اس کورس کے شامل کردہ ہر architectural ٹکڑے کو ایک ہی pass میں آزماتا ہے: ایک Skill activate ہوتی ہے، ایک MCP-backed tool سسٹم آف ریکارڈ کے مقابل ایک semantic search چلاتا ہے، اور audit trail پورا راستہ ریکارڈ کرتا ہے، SQL میں replayable۔ ان میں سے کچھ بھی اس کم سے کم چیٹ ایجنٹ میں نہیں تھا جس سے آپ نے شروع کیا۔ جو یہ ابھی نہیں کرتا وہ پیسہ ہلانا ہے؛ یہی وہ ایک عمل ہے جس کے سامنے آپ آگے ایک انسان رکھتے ہیں۔
Decision 9: اس واحد عمل کو سخت کریں جو پیسہ ہلاتا ہے
آپ کہاں ہیں: ایک worker جو سرے سے سرے تک چلتا ہے مگر بغیر کسی check کے refunds جاری کرتا ہے؛ یہ Decision issue_refund پر ایک انسانی منظوری gate شامل کرتا ہے؛ آخر تک آپ ایک refund کو sign-off کے لیے رکتے دیکھیں گے، پھر approve پر گزرتے اور reject پر رکتے۔
یہ دوسرا Decision ہے جہاں ایک پہلا build عموماً ایک error لگاتا ہے؛ نیچے کے callouts اس سے ملنے سے پہلے ہر ایک کا نام لیتے ہیں، تو انہیں پہلے پڑھیں۔
worker سرے سے سرے تک چلتا ہے۔ اب وہ ایک چیز شامل کریں جو آپ نے جان بوجھ کر چھوڑی: issue_refund کے سامنے ایک انسان، وہ واحد tool جو پیسہ ہلاتا ہے۔ آپ اسے آخر میں بناتے ہیں، جان بوجھ کر، کیونکہ ایک منظوری gate تب ہی بامعنی ہوتی ہے جب وہ چیز جس کی یہ حفاظت کرتی ہے واقعی چلتی ہو۔
قدم 1: refund tool کو gate کریں۔
Gate issue_refund behind human approval: register the customer-data server
so that tool needs sign-off before it runs, and leave lookup_customer and
find_similar_resolved_tickets un-gated. Check the current SDK docs for the
exact approval API.
بدلتا ہے: worker فائل (سرور registration پر issue_refund کو gate کرتا ہے)۔
Check. دونوں read tools اب بھی بے روک ٹوک چلتے ہیں؛ صرف
issue_refundgated ہے۔ gate اس بات پر رہتی ہے کہ سرور کیسے register ہوتا ہے، tool کے اندر نہیں۔ (Claude Code یا OpenCode کے اندر client کا اپنا permission prompt وہی gate ہے؛ standalone worker میں یہ سرور registration پر approval setting ہے۔)
قدم 2: ایک refund چلائیں اور اسے رکتے دیکھیں۔ (ایک terminal میں سرور، دوسرے میں worker، پہلے سرور؛ Decision 6 دیکھیں۔)
Run the worker on a message that should lead to a refund on order #4429,
and show me what happens when it tries to issue it.
Check. run refund جاری کرنے کے بجائے رک جاتا ہے: worker بتاتا ہے کہ یہ
issue_refundکے لیے منظوری کا منتظر ہے (SDK کی اصطلاح میں، run ایک حتمی جواب کے بجائے ایک interruption کے ساتھ واپس آتا ہے)، اورrefundstable میں ابھی کچھ نہیں لکھا گیا۔ وہ رکنا ہی authority ماڈل کا چلنا ہے: ماڈل نے ایک عمل تجویز کیا، اور سسٹم سرحد پر رک گیا۔
gate صرف تب لگتی ہے جب ماڈل issue_refund کو واقعی کال کرے۔ ایک محتاط system prompt (جیسے "only issue a refund once approved") ماڈل کو prose میں منظوری مانگتے رہنے دے سکتا ہے اور کبھی tool invoke نہ کرے، تو کچھ نہیں رکتا اور کوئی refund نہیں ہوتا، جو ایک ٹوٹی gate جیسا لگتا ہے مگر نہیں۔ gate کو خود دکھانے پر مجبور کرنے کے لیے، call کو صراحتاً دھکیلیں: "Supervisor approved the refund for order #4429. Call issue_refund now: 2999 cents, reason 'arrived damaged'. Invoke the tool, don't ask again." SDK gate execution پر سخت backstop ہے؛ یہ ماڈل کو پہلے کسی tool کے ذریعے route کرنے پر مجبور نہیں کر سکتی۔
قدم 3: ایک بار approve کریں، پھر ایک بار reject۔ gate کے دونوں نصف ثابت کریں:
Approve the pending refund and let the run finish, then show me the refunds
table and the audit_log row. Then run the same scenario again, reject it,
and show me that no refund was written.
Check. approve پر: refund row نمودار ہوتی ہے، order refunded پر پلٹتا ہے، اور
issue_refundاپنیrefund_issuedaudit row لکھتا ہے، سب اسی ایک transaction میں۔ reject پر: کوئی refund row نہیں، اور trace دکھاتا ہے کہ عمل رد کیا گیا۔ ایجنٹ کو سونپنے کے لیے ایک gotcha، کیونکہ یہی "چلتا ہے" اور "چلتا دکھتا ہے" کے بیچ فرق ہے: ایک منظور شدہ run کو resume کرنا ایک loop ہے، ایک ہی call نہیں۔ ایک run ایک سے زیادہ زیرِ التوا منظوریاں رکھ سکتا ہے، تو ایجنٹ resume کرتا رہتا ہے جب تک run کے پاس منتظر منظوریاں ہیں (ہر ایک کو approve یا reject کریں، پھر resume)، صرف ایک بار نہیں۔ ایک ہی بار resume کریں اور آپ کو refund اب بھی غیر لکھا چھوڑتا ایک خالی جواب واپس مل سکتا ہے۔
تقریباً جو ہر نصف کو پیدا کرنا چاہیے:
approve -> refunds: 1 new row | orders.status = refunded | audit: refund_issued
reject -> refunds: no new row | audit: action declined
یہ آخر میں کیوں۔ worker کے چلنے سے پہلے شامل کی گئی ایک منظوری gate ناقابلِ test تماشا ہے: جب کچھ بھی اس میں سے نہ بہے تو آپ ایک چلتی gate کو ایک ٹوٹی سے نہیں بتا سکتے۔ یہاں، ایک ایسے worker پر شامل جسے آپ نے search، draft، اور audit کرتے دیکھا، آپ دونوں نصف ثابت کر سکتے ہیں: approve refund کو گزرنے دیتا ہے، reject اسے روکتا ہے، اور audit log ریکارڈ کرتا ہے کہ کون سا۔ یہی پورا authority ماڈل ہے، ایجنٹ تجویز کرتا ہے اور ایک انسان فیصلہ کرتا ہے۔
اوپر کا check فرض کرتا ہے کہ ایک انسان عین وہیں ہے۔ اگر sign-off ایک گھنٹے بعد، کسی اور process میں آئے، تو رکے run کو serialize کرنا ہوگا (SDK کا RunState)، store کرنا ہوگا، اور فیصلہ آنے پر resume کرنا ہوگا۔ اس کا پائیدار گھر ایک چھوٹی run_states table ہے (فی pause ایک row: serialized state جمع awaiting/approved/rejected)، نہ کہ audit_log (append-only) اور نہ conversations پر ایک column (ایک گفتگو ایک سے زیادہ بار رک سکتی ہے)۔ serialize-اور-resume calls چلتی SDK surface کا حصہ ہیں، تو انہیں Context7 سے تصدیق کریں۔
ابھی کیا ہوا
نو Decisions، اور قدم 0 کا کم سے کم چیٹ ایجنٹ اب ایک ورکر کی بنیاد رکھتا ہے۔ پیچھے دیکھیں کیا بدلا:
- صلاحیت کوڈ سے باہر نکل گئی۔ تین Skills
.claude/skills/میں بیٹھی ہیں، version-controlled، ایجنٹس کے بیچ sharable۔ - پائیدار اسٹورز process سے باہر نکل گئے۔ ایک حقیقی Postgres schema (پانچ tables والا core جمع customers، orders، tickets، اور refunds کے لیے ایک domain تہہ) اب ورکر کا سسٹم آف ریکارڈ اور وہ ریفرنس لائبریری رکھتا ہے جسے یہ pgvector سے تلاش کرتا ہے، جبکہ SDK Session ورکر کی conversation state اسی database پر رکھتی ہے۔
- Runtime business access ثالثی شدہ ہے۔ ایجنٹ Postgres میں business data کو صرف ایک scoped MCP سرور کے ذریعے پہنچتا ہے جو بالکل تین tools پیش کرتا ہے؛ ہر business read اور write اسی ایک سرحد کو پار کرتا ہے۔ audit subsystem واحد جان بوجھ کر استثنا ہے، اپنے ہی براہِ راست connection پر، تاکہ اسے وہ سرحد بھوکا نہ مار سکے جس کا یہ audit کرتا ہے۔
- ہر عمل ایک trace چھوڑتا ہے۔ audit log کسی بھی گفتگو کا پورا reasoning trace دوبارہ چلا سکتا ہے، حقیقت کے ہفتوں یا مہینوں بعد، SQL میں۔
- خطرناک عمل کا ایک مالک ہے۔ وہ واحد tool جو پیسہ ہلاتا ہے چلنے سے پہلے ایک انسان کے لیے رکتا ہے؛ approve اسے گزرنے دیتا ہے، reject اسے روکتا ہے، اور کسی بھی طرح audit log فیصلہ ریکارڈ کرتا ہے۔ یہی وہ authority ماڈل ہے جو ایک ورکر کو چاہیے اس سے پہلے کہ کوئی اس پر حقیقی اعمال کا بھروسہ کرے۔
OpenAI Agents SDK اب بھی موجود ہے۔ سینڈ باکس اب بھی آپ کا compute ہے، اور streaming، guardrails، اور tracing جن سے ایجنٹ نے شروع کیا سب اب بھی موجود ہیں۔ جو بدلا وہ اوپر کا آرکیٹیکچر ہے: Skills صلاحیتیں رکھتی ہیں، سسٹم آف ریکارڈ سچ رکھتا ہے، MCP انہیں جوڑتا ہے، اور ایک انسان ان اعمال پر loop میں رہتا ہے جو اہم ہیں۔
یہی ایک ورکر کی بنیاد ہے۔ جو یہ ابھی نہیں وہ ہمیشہ آن، خود کار، یا کسی managed افرادی قوت کا حصہ ہونا ہے۔ وہ چالیں اگلے کورسز شامل کرتے ہیں۔
Decision 10 (اختیاری چیلنج): رکی منظوری کو restart سے بچائیں
Decision 9 میں approver عین terminal پر بیٹھا تھا، تو ایک [y/N] کافی تھا۔ حقیقی منظوریاں شاذ ہی ایسے چلتی ہیں: وہ manager جو refund پر sign off کرے ایک گھنٹے بعد، کسی اور app سے، کسی اور مشین پر جواب دے سکتا ہے۔ آپ کا worker یہ ابھی سنبھال نہیں سکتا۔ جب کوئی refund رکتا ہے، تو رکا run صرف worker کی memory میں رہتا ہے، تو اگر process انسان کے جواب دینے سے پہلے بند ہو جائے، تو زیرِ التوا refund ختم۔
آپ پہلے ہی تین قسم کا state Postgres میں منتقل کر چکے ہیں: conversation turns، business records اور reference library، اور audit trail۔ رکا run وہ واحد قسم ہے جو ابھی memory میں پھنسی ہے۔ یہ اختیاری capstone اسے بھی database میں منتقل کرتا ہے، تاکہ ایک pause بعد میں، کہیں سے بھی approve ہو سکے۔ یہ ایک graded چیلنج ہے، رہنمائی شدہ build نہیں: ہر قدم آپ کو خیال اور prompt دیتا ہے، اور wiring آپ کے ایجنٹ پر چھوڑتا ہے۔
Goal: ایک رکے refund کو اس process سے مختلف ایک process سے approve یا reject کریں جس نے اسے شروع کیا۔
قدم 1: ہر رکے run کو database میں ایک گھر دیں۔ ایک pause کو اپنی row چاہیے: یہ کس گفتگو اور tool سے تعلق رکھتا ہے، خود محفوظ run، اور ایک status جو awaiting سے approved، rejected، یا resumed تک حرکت کرے۔ یہ اپنی table ہے، نہ کہ audit log (وہ مکمل شدہ history ہے) اور نہ conversations پر ایک column (ایک گفتگو ایک سے زیادہ بار رک سکتی ہے)۔
Add a run_states table that stores one paused run per row: the conversation
and tool it belongs to, the saved run, and a status that defaults to
"awaiting" and can become approved, rejected, or resumed. Plan the DDL first;
I'll approve before you apply it on a branch.
Check. ایک
run_statestable موجود ہے اور ایک تازہ pauseawaitingپر default ہوتا ہے۔ آپ نے کبھی SQL ٹائپ نہیں کی: آپ نے بتایا کہ table کس کے لیے ہے، آپ کے ایجنٹ نے اسے لکھا، اسی طرح جیسے schema Decision 3 میں لگا۔
قدم 2: جب کوئی refund رکے، اسے save کریں اور آگے بڑھیں۔ ابھی worker terminal پر انتظار کرتا ہے؛ اس کے بجائے اسے pause ریکارڈ کرنا اور اگلے turn کے لیے خود کو آزاد کرنا چاہیے۔
When a run comes back waiting for approval instead of with a final answer, do
not block on input. Save the paused run as a run_states row marked "awaiting"
and return, so the worker is free for the next turn. One turn is one request
that either finishes or parks. Check the current Agents SDK docs for the exact
"save the paused run" call before you write it.
Check. ایک refund turn اب فوراً واپس آتا ہے، ایک
awaitingrow پیچھے چھوڑتے ہوئے، اور کچھ بھی کسی انسان کا انتظار کرتے ہوئے block نہیں کرتا۔
قدم 3: ایک الگ command سے approve یا reject کریں۔ فیصلہ chat loop سے باہر اپنے چھوٹے entry point میں جاتا ہے، تاکہ یہ پوری طرح کسی اور process میں چل سکے۔
Build a small "decide" command, separate from the chat loop: it lists the
awaiting rows, takes my approve or reject on one, then reloads that saved run
and finishes it. Keep resuming in a loop while the run still has approvals
pending, since resuming once can come back empty with the refund unwritten
(the loop gotcha from Decision 9). Confirm the reload call through Context7.
Check. decide command سے ایک row کو approve کرنا اس refund کو مکمل تک پہنچاتا ہے؛ اسے reject کرنا کوئی refund نہیں لکھتا اور رد ریکارڈ کرتا ہے۔
قدم 4: refund کو retry کے لیے محفوظ بنائیں۔ ایک distributed setup میں ایک network retry اسی منظور شدہ refund کو دو بار فائر کر سکتا ہے۔
Make issue_refund idempotent: dedupe on the order plus a request id, so the
same approved refund cannot run twice.
Check. اسی منظوری کو جان بوجھ کر دو بار resume کریں: آپ کو بالکل ایک
refundsrow ملتی ہے، دو نہیں۔
قدم 5: فی گفتگو ایک فعال turn۔ ایک ہی گفتگو پر ایک ساتھ دو turns اس کا session خراب کر دیں گے۔
Add a per-conversation lock (a Postgres advisory lock on the session id, or a
status guard) so only one turn is active per conversation at a time.
Check. ایک ہی گفتگو پر ایک دوسرا turn انتظار کرتا یا رد ہوتا ہے، پہلے سے race کرنے کے بجائے۔
وہ calls جو ایک رکے run کو save اور بعد میں reload کرتی ہیں beta SDK surface کا حصہ ہیں جو releases کے بیچ بدلتی ہیں۔ کورس کا نظم اپنے ہی چیلنج پر لاگو ہوتا ہے: انہیں یاد کرنے کے بجائے موجودہ Agents SDK docs یا Context7 سے ٹھیک save اور reload calls paste کریں۔ خیال، کہ ایک رکا run ایک row بن جاتا ہے جسے آپ بعد میں اٹھاتے ہیں، مستحکم ہے؛ method نام نہیں۔
Done when:
- آپ ایک process میں ایک refund شروع کرتے ہیں؛ یہ run کو
run_statesمیں parked (statusawaiting) کے ساتھ نکلتا ہے، اور ابھی کوئیrefundsrow نہیں۔- ایک دوسرے process میں، آپ اسے approve کرتے ہیں؛ refund commit ہوتا ہے (refund row، order پلٹتا ہے،
refund_issuedaudit row)، اور parked rowresumedبن جاتی ہے۔- reject راستہ صفر business writes اور ایک
refund_blockedaudit row چھوڑتا ہے۔- اسی parked run کو دو بار approve کرنا کوئی دوسرا refund جاری نہیں کرتا۔
- پورا واقعہ
audit_logجمعrun_statesسے بغیر ماڈل دوبارہ چلائے replayable ہے۔
Stretch (مکمل distributed)۔ customer-data سرور کو authentication کے ساتھ ایک حقیقی URL کے پیچھے رکھیں اور worker کو اس کی طرف اشارہ کریں؛ خود ایجنٹ بدلے بغیر local سینڈ باکس کو ایک hosted سے بدلیں (client بدلیں، ایجنٹ رکھیں)؛ اور اپنے secrets کو .env فائل سے ایک secret manager میں منتقل کریں۔ وہی worker، اب مشینوں کے آرپار چلنے کے قابل۔
Database میں state ضروری ہے مگر کافی نہیں: حرکت پانے والی آخری stateful چیز خود رکا run ہے، اور ایک بار یہ run_states میں رہنے لگے تو آپ کا worker ایک واحد process سے بندھا رہنا چھوڑ دیتا ہے۔
Part 5: یہ کورس کہاں رکتا ہے
ایک ورکر کا cost shape: اس کا اندازہ کیسے لگائیں
یہاں جان بوجھ کر کوئی dollar totals نہیں: per-token قیمتیں اور free-tier حدود ماہانہ بدلتی ہیں، تو جو بھی عدد چھپایا جائے وہ آپ کے پڑھنے تک پرانا ہو جائے گا، اور ایک پرانا عدد نہ ہونے سے بدتر ہے۔ جو قائم رہتا ہے وہ طریقہ ہے۔ یہ رہا، عملی مثال کے اپنے traffic کے ساتھ بطورِ inputs جنہیں آپ plug کرتے ہیں: 200 گفتگو/دن، ہر ایک تقریباً 10 turns، فی turn تقریباً 8K input tokens۔
ایک لائن تقریباً پورا بل ہے؛ باقی تین rounding errors ہیں۔ انہیں ترتیب میں کریں۔
1. Model inference۔ آپ کا ماہانہ token حجم ضرب آپ کے ماڈل کی per-token قیمت۔ حجم آپ کے اپنے traffic سے آتا ہے:
input tokens/month ≈ conversations/day × turns/conversation × tokens/turn × 30
مثال کے لیے: 200 × 10 × 8,000 × 30 ≈ 480M input tokens/month۔ اسے اپنے ماڈل کی input قیمت سے ضرب دیں (اس کے pricing page سے)، پھر output tokens کو اسی طرح شامل کریں (ان میں سے کہیں کم، مگر ایک زیادہ per-token قیمت)۔ وہ ایک ضرب آپ کا بل ہے۔
اس پر سب سے بڑا lever prompt caching ہے۔ آپ کا AGENTS.md، system prompt، اور Skills metadata ہر turn یکساں ہیں، تو جب provider اس مستحکم prefix کو cache کرتا ہے، تو وہ tokens عام rate کے کسرے پر bill ہوتے ہیں۔ prefix کو مستحکم رکھنا (AGENTS.md کو دن کے بیچ نہ بدلیں) آپ کے پاس سب سے زیادہ قیمتی cost چال ہے۔ آسان turns کو ایک چھوٹے ماڈل اور صرف مشکل کو ایک frontier ماڈل پر route کرنا دوسری ہے۔
2. Embeddings۔ embed کیے گئے tokens × embedding ماڈل کی قیمت۔ آپ seed corpus ایک بار اور نئے tickets جیسے وہ آئیں embed کرتے ہیں؛ ایک چھوٹے embedding ماڈل کی rate پر یہ پیسے ہیں، dollars نہیں، جب تک آپ مسلسل پوری conversation histories دوبارہ embed نہ کریں۔ وہی pricing page۔
3. Postgres (Neon)۔ اکثر $0: free tier ایک کم حجم والے ورکر کو سمیٹتا ہے، اور scale-to-zero کا مطلب فارغ گھنٹے کچھ خرچ نہیں کرتے۔ آپ صرف free storage / compute-hour حدود عبور کرنے کے بعد ادا کرتے ہیں، اور پھر یہ storage جمع active compute ہے، دونوں Neon کے pricing page پر۔
4. Sandbox compute۔ یہاں $0، کیونکہ عملی مثال UnixLocalSandboxClient، آپ کی اپنی مشین پر چلتی ہے۔ Production میں یہ container-minutes ہیں جہاں بھی آپ deploy کریں (Docker، Cloudflare، E2B، Modal): session length × concurrency × اس provider کی rate۔
پورا طریقہ ایک لائن میں: اپنی conversation اعداد سے اپنا ماہانہ token حجم نکالیں، آج کی per-token قیمت سے ضرب دیں، اور باقی تین لائنیں pricing pages سے پڑھ لیں۔ بہت سے ورکرز تک scale کرنا formula نہیں بدلتا، یہ inference لائن کو ضرب دیتا ہے کہ کتنے ورکرز اور کتنے مصروف؛ infrastructure لائنیں تقریباً سپاٹ رہتی ہیں، تو model بل وہی ہے جو بڑھتا ہے، اور اوپر کی دو عادتیں (مستحکم cached prefix، آسان turns کے لیے سستا ماڈل) ہی اسے قابو میں رکھتی ہیں۔
Swap گائیڈ: آرکیٹیکچر invariant ہے، products نہیں
یہ کورس ہر تہہ پر مخصوص vendors کا نام لیتا ہے (OpenAI Agents SDK، SDK کا local سینڈ باکس، Neon، OpenAI embeddings، MCP Python SDK)۔ یہ اس لیے کہ ایک تدریسی مثال کو ٹھوس جوابات چاہئیں، نہ کہ "جو بھی LLM runtime پسند ہو استعمال کرو۔" مگر آرکیٹیکچر کسی بھی تابع متبادل کے ساتھ کام کرتا ہے۔ پانچ swaps جن کی کورس کا design صراحتاً توقع کرتا ہے:
- Postgres host: Neon → Supabase، AWS RDS، self-hosted۔
pgvectorوالی کوئی بھی چیز چلتی ہے۔ آپ branching اور scale-to-zero کھوتے ہیں (وہ Neon-specific ہیں)، مگر پانچ tables والا schema، embedding pipeline، audit-trail نظم، اور custom MCP سرور pattern سب byte-for-byte منتقل ہوتے ہیں۔ واحد تبدیلی connection string اور ممکنہ طور پر SSL config ہے۔ - Vector storage: pgvector → Pinecone، Weaviate، Qdrant۔ اگر آپ Concept 6 کی "relational اور vector data دونوں کے لیے ایک database" دلیل رد کرتے ہیں، تو
embeddingstable کو ایک vector-DB client سے بدلیں۔ قیمت: دو اسٹور جنہیں مستقل رکھنا (Concept 6 دلیل دیتا ہے کہ یہ شاذ ہی قابلِ قدر ہے)۔ فائدہ: بہت بڑے پیمانوں (10M+ vectors) پر بہتر recall، اور managed-service operational سادگی۔ - Embedding model: OpenAI → Cohere، Voyage، BGE-small (local)۔ ایک constant (
EMBEDDING_MODEL) اور ایک column dimension (VECTOR(n)) بدلیں۔ موجودہ data کا ایک-shot re-embed چلائیں۔ Concept 9 کی pipeline نہیں بدلتی۔ - Sandbox: local سینڈ باکس → Cloudflare، E2B، Modal، Daytona، آپ کا اپنا Docker۔ isolated process boundaries اور ایک صاف restart والی کوئی بھی چیز چلتی ہے۔
SandboxAgentruntime backend-agnostic ہے؛ عملی مثالUnixLocalSandboxClientپر چلتی ہے، اور production ان میں سے کسی پر swap کرتا ہے۔ Skills کےscripts/اسی طرح چلتے ہیں۔ پچھلے کورس کا trust-boundary diagram اب بھی لاگو ہوتا ہے۔ - Agent runtime: OpenAI Agents SDK → LangGraph، CrewAI، Pydantic AI، آپ کا اپنا loop۔ جو بچتا ہے وہ MCP سرحد ہے؛ ہر جدید agent framework کا ایک MCP client ہے۔ Skills کسی بھی ایجنٹ میں چلتی ہیں جو
SKILL.mdفائلیں لوڈ کر سکے (Claude Code، OpenCode، Goose، اور بڑھتے ہوئے Cursor/Windsurf)۔ audit-trail نظم framework-agnostic Python ہے۔
جو آسانی سے swap نہیں ہوتا۔ خود MCP protocol، Skills format spec، اور audit-trail عادت۔ یہ وہ حصے ہیں جو آپ products کے آرپار لے جاتے ہیں؛ products وہ حصے ہیں جو آپ swap کرتے ہیں۔ نیچے وہی architectural شکل، اوپر قابلِ تبدیل implementations۔
"invariant" اور "owned" پر ایک بات۔ دونوں شرط لگانے کے قابل heuristics ہیں، طے شدہ حقائق نہیں۔ "Invariant" 2026 کے بہترین دستیاب کھلے معیاروں کا نام لیتا ہے: MCP تقریباً اٹھارہ مہینے پرانا ہے اور Skills spec اس سے کم عمر، اور کسی دن خود تار یا capability format ہی وہ چیز ہو سکتی ہے جو بدلے، نہ کہ صرف اس میں plug ہونے والے products۔ proprietary پر کھلے protocols پر شرط لگانا ہی اچھے انداز میں عمر بڑھانے کا طریقہ ہے، مگر آرکیٹیکچر کو durable-by-design سمجھیں، ابدی نہیں۔ اور "owned" کا اصل مطلب owned-by-composition ہے: یہ ورکر Neon کے cloud، ایک vendor کے ماڈلز، ایک coding-agent client، اور third-party repos سے کھینچی skills پر چلتا ہے۔ آپ جس کے مالک ہیں وہ ان میں سے کسی ایک کو باقی کو دوبارہ لکھے بغیر swap کرنے کی آزادی ہے۔ یہ حقیقی اور بہت قیمتی ہے، اور یہ پورے لفظ کی تجویز سے کم ہے۔ seams کے مالک بنیں، substrate کے نہیں۔
یہ کورس کیا نہیں سمیٹتا (ابھی)
آپ کے پاس اب ایک ورکر ہے جو مقالے کے بیان کردہ سات Invariants میں سے دو پورے کرتا ہے۔ بالخصوص: یہ ایک engine پر چلتا ہے (Invariant 4، پچھلے کورس سے)، اور یہ ایک سسٹم آف ریکارڈ کے مقابل چلتا ہے (Invariant 5، اس کورس سے)۔ باقی پانچ Invariants وہ ہیں جو production AI-Native کمپنیوں کو چاہئیں، اور جو بعد کے کورسز سمیٹتے ہیں۔ ہر ایک یہاں ایک bullet ہے، ایک section نہیں۔
- Invariant 1: انسان principal ہے۔ Authored specs، approval gates، budget declarations۔ ارادہ طے کرنے اور نتائج کا مالک ہونے کا آرکیٹیکچر، کتاب کے Part 6 میں۔
- Invariant 2: ہر انسان کو ایک نمائندہ چاہیے۔ سرحد پر ایک ذاتی ایجنٹ جو آپ کا context رکھتا، آپ کے فیصلے کی نمائندگی کرتا، اور افرادی قوت کو کام بانٹتا ہے۔ مقالہ موجودہ تعبیر کے طور پر OpenClaw کا نام لیتا ہے۔
- Invariant 3: افرادی قوت کو ایک manager چاہیے۔ ایک orchestrator جو کام تفویض کرتا، budgets نافذ کرتا، execution audit کرتا، hiring کو ایک قابلِ کال صلاحیت کے طور پر پیش کرتا ہے۔ مقالہ Paperclip کا نام لیتا ہے۔
- Invariant 6: افرادی قوت policy کے تحت قابلِ توسیع ہے۔ ایک meta-layer جہاں ایک مجاز ایجنٹ ایک prompt پیدا کرتا، ایک runtime فراہم کرتا، اور ایک نیا ورکر register کرتا ہے، بغیر کسی انسان کو جگائے۔ Claude Managed Agents ایک تعبیر ہے۔
- Invariant 7: افرادی قوت ایک nervous system پر چلتی ہے۔ Triggers (schedules، webhooks، inbound API calls) ایجنٹ کو authority envelope کے تحت جگاتے ہیں۔ Inngest (durable functions اور background jobs) عام افرادی قوت events کے لیے ایک تعبیر ہے؛ Claude Code Routines coding-agent-specific راستہ ہے۔
اس میں واقعی اچھا کیسے بنیں
اس فوری کورس کو پڑھنا آپ کو ورکرز بنانے میں اچھا نہیں بناتا۔ اسے استعمال کرنا بناتا ہے۔ راستہ پچھلے کورس جیسا ہی دکھتا ہے: آپ manual شروع کرتے ہیں، رگڑ محسوس کرتے ہیں، اور رگڑ کے ہر ٹکڑے کو سکھانے دیتے ہیں کہ یہ کس Concept سے تعلق رکھتا ہے۔
اس کورس کا نقشہ:
- "میری skill تب فائر کیوں نہیں ہو رہی جب ہونی چاہیے؟" → description کا معیار (Concept 3)۔ دوبارہ لکھیں۔ پانچ مختلف طریقوں سے ایجاد کر کے test کریں کہ ایک صارف trigger کیسے کہہ سکتا ہے۔
- "ایجنٹ ایسا data کیوں ایجاد کر رہا ہے جو database میں نہیں؟" → ایجنٹ اصل میں MCP سرور کال نہیں کر رہا۔ trace check کریں؛
mcp_servers=[...]registration check کریں۔ - "میرا audit log نامکمل کیوں ہے؟" → audit write عمل کے اسی code path میں نہیں (Concept 10)۔ اسے عمل کے ساتھ، اسی transaction میں منتقل کریں۔
- "میرے pgvector نتائج غیر متعلق کیوں ہیں؟" → یا تو chunking غلط ہے (Concept 9)، یا insert-time کا embedding ماڈل query-time کے embedding ماڈل سے match نہیں کرتا۔ دوبارہ embed کریں۔
- "میرا MCP سرور بوجھ تلے سست کیوں ہے؟" → سرور کے اندر connection pool بہت چھوٹا ہے، یا client پر tools list cached نہیں۔ Concept 15۔
- "Neon MCP سرور production میں خوفناک کیوں لگتا ہے؟" → کیونکہ Neon کی اپنی docs کہتی ہیں یہ production کے لیے نہیں۔ ایک custom MCP سرور لکھیں (Concept 14)۔ پہلا 30 منٹ لیتا ہے؛ دوسرا 10۔
آرکیٹیکچر کو ایک وقت میں ایک ٹکڑا بنائیں۔ Skills، سسٹم آف ریکارڈ، اور MCP کو ایک ہی weekend میں شامل کرنے کی کوشش نہ کریں۔ قدم 0 چیٹ ایجنٹ سے شروع کریں۔ پہلے ایک سسٹم آف ریکارڈ شامل کریں (Decisions 3 سے 5) اور اپنا debugging تجربہ بدلتا دیکھیں۔ ایک Skill شامل کریں (Decision 4) اور دیکھیں کہ ماڈل اسے استعمال کرنے کا فیصلہ کیسے کرتا ہے۔ MCP سرحد آخر میں شامل کریں (Decision 6)۔ ہر قدم اپنا سیکھنا ہے؛ تینوں ایک ساتھ کرنا ایک دیوار ہے۔
portability منافع حقیقی ہے: Skills، schemas، اور MCP سرور جو آپ یہاں لکھتے ہیں سب دوسرے products پر منتقل ہوتے ہیں۔ Swap گائیڈ فی تہہ متبادل گنواتی ہے۔
آپ کیا چیز پر وقت لگاتے ہیں اس میں تبدیلی
Decision 4 کے بعد، آپ کا کام شکل بدلتا ہے۔ کوڈ لکھنا ایجنٹ کو brief کرنا بن جاتا ہے؛ description review کرنا (ایک config-file field جسے آپ عموماً سرسری دیکھتے) کلیدی ہنر بن جاتا ہے۔ ایک description جسے draft اور refine کرنے میں آپ نے 30 منٹ لگائے اس 200 لائن MCP سرور کوڈ سے زیادہ architectural کام کرتی ہے جو ایجنٹ نے نیچے پیدا کیا، کیونکہ description وہ routing surface ہے جسے ماڈل ہر turn پڑھتا ہے۔
دو عملی تبدیلیاں۔ پہلی، آپ "میں اسے کیسے implement کروں؟" پوچھنا بند کرتے اور "ایک حقیقی صارف trigger کو پانچ مختلف طریقوں سے کیسے کہہ سکتا ہے؟" پوچھنا شروع کرتے ہیں۔ کوڈ downstream ہے؛ اگر description غلط ہے، تو ایجنٹ کبھی کوڈ تک نہیں پہنچتا اور کوڈ کا معیار غیر متعلق ہے۔ دوسری، review، authorship کی جگہ کلیدی ہنر بن جاتا ہے۔ ایجنٹ draft کرتا ہے؛ آپ فیصلہ کرتے ہیں کہ draft ان trigger cases میں چلتا ہے یا نہیں جن کے لیے آپ نے description لکھی۔ مشکل ترین حصہ اس خواہش کا مزاحمت کرنا ہے کہ خود دوبارہ لکھ دیں جب آپ اسے تین منٹ میں خود حل کر سکتے ہوں: وہی نظم جو آپ کو MCP سرحد کو bypass کرنے سے روکتا ہے۔
فوری حوالہ
15 تصورات، ہر ایک ایک لائن میں
- ایک Agent Skill ایک فولڈر ہے۔ SKILL.md جمع اختیاری scripts/references/assets۔
- Progressive disclosure۔ startup پر metadata → activation پر پورا body → طلب پر references۔
- ایک SKILL.md frontmatter + body ہے۔ Name، description، اختیاری metadata، پھر عملی ہدایات۔
- Skills بطورِ فائلیں سفر کرتی ہیں۔ وہی SKILL.md Claude Code اور OpenCode میں بغیر تبدیلی چلتی ہے۔
- چھوٹی skills کو filesystem handoff سے ملائیں جب isolation، orchestration کی سادگی سے زیادہ اہم ہو۔
- Postgres + pgvector تقریباً ہر agent workload کے لیے ایک الگ vector DB سے بہتر ہے۔ Neon branching، scale-to-zero، اور ایک MCP سرور شامل کرتا ہے۔
- پانچ tables کم سے کم operational schema ہیں: conversations، documents، embeddings، audit_log، capability_invocations؛ conversation turns SDK Session میں رہتے ہیں (اسی database پر
SQLAlchemySession)۔ - pgvector کی بنیادیں:
VECTOR(1536)+<=>cosine distance + HNSW index۔ دونوں سروں پر وہی embedding ماڈل استعمال کریں۔ - embedding pipeline: semantic حدود پر chunk کریں (overlap کے ساتھ تقریباً 400 tokens)، batch-embed کریں، model metadata کے ساتھ store کریں۔
- Audit، logging نہیں۔ ہر بامعنی عمل اسی transaction میں ایک row لکھتا ہے جس میں وہ عمل ریکارڈ ہوتا ہے۔
- MCP ایک protocol ہے، service نہیں۔ تین primitives (tools، resources، prompts)، تین transports (stdio، streamable HTTP، پرانا SSE)۔
- Neon MCP سرور development کے لیے ہے۔ Schema design، branch-based migrations۔ production runtime کے لیے نہیں۔
- OpenAI Agents SDK میں ایک built-in MCP client ہے۔
from agents.mcp import MCPServerStdio, MCPServerStreamableHttp۔async withاستعمال کریں۔ production میںlist_toolscache کریں۔ - Custom MCP سرور scope، isolation، اور reusability سے اپنی قیمت کماتے ہیں۔ ایک ایجنٹ کے استعمال کردہ ایک function کے لیے ایک نہ لکھیں۔
- بوجھ تلے MCP: دور دراز کے لیے streamable HTTP، tools cache کریں، connections دوبارہ استعمال کریں، سرور کے اندر pool کریں،
_metaکے ذریعے trace context propagate کریں۔
جب کوئی چیز غلط محسوس ہو
Skill not firing when it should
→ Description too vague. Rewrite with "Use when..." and specific keywords (Concept 3).
Skill firing when it shouldn't
→ Description too broad. Add explicit constraints in the description.
pgvector returning irrelevant results
→ Embedding model mismatch (insert vs. query). Verify the model column in
the embeddings table. Re-embed if needed.
MCP tool not appearing in agent
→ Server not registered, or list_tools cache stale. Check mcp_servers=[...]
and try cache_tools_list=False temporarily.
Audit log has gaps
→ Action and audit write are in different code paths. Move them next to
each other, ideally same transaction.
Agent timing out on Postgres operations under load
→ MCP server's connection pool too small. Check asyncpg.create_pool(max_size=...).
MCP server hangs on startup with torch / sentence-transformers / large imports
→ Default client_session_timeout_seconds=5 is too short for servers that
load ML models at import. Bump to 60. See Concept 13's callout.
CREATE TABLE fails: relation "notes" already exists
→ You're pointing at a database that already has tables. Use a fresh
database or Neon project; the Quick Win's build prompt makes a fresh one.
Non-OpenAI key getting 401 against api.openai.com
→ Set OPENAI_BASE_URL to your provider's OpenAI-compatible endpoint
(e.g., https://api.deepseek.com/v1) before running the agent.
Agent fails partway with a 401 / auth / BadRequestError
→ Wrong key, wrong provider, or expired key. Have your agent confirm
OPENAI_API_KEY is set and test a model call before the full run; it
fails in one second instead of four files deep.
Neon MCP server returning errors in production agent code
→ You're using it wrong. Neon's docs are explicit: development only.
Write a custom MCP server instead (Concept 14, ~30 minutes).
Flashcards سے مطالعہ میں مدد
علم کی جانچ
ان خیالات پر ایک تیز، مرحلہ وار خود-جانچ جن سے آپ ابھی گزرے۔