اپنا ایجنٹ ہارنس کلاؤڈ پر ڈیپلائے کریں: ایک ملٹی ٹریک فوری کورس
*17 تصورات • چار تعلیمی ٹریک۔ Reader ٹریک: 3-4 گھنٹے خالص تصوراتی مطالعہ (کوئی سیٹ اپ نہیں، کوئی ڈیپلائے نہیں، ان انجینئرنگ لیڈرز اور آرکیٹیکٹس کے لیے جو یہ فیصلہ کر رہے ہیں کہ ٹیم کا وقت لگانا چاہیے یا نہیں)۔ Beginner / Intermediate / Advanced ٹریکس: ہر ایک 1-2 دن، 3-5 دن، 7-10 دن (تصوراتی مطالعہ، پھر پانچ کمپوننٹ اسٹیک پر بتدریج گہری تعیناتی، آبزرویبلٹی اور eval suite کے ساتھ)۔ لیب سے پہلے اپنا ٹریک چنیں، نیچے "چار تعلیمی ٹریک" والا حصہ دیکھیں۔*
پچھلے کورسز میں آپ نے ایجنٹس بنائے ہیں، مگر ان میں سے ہر ایک صرف آپ کے لیپ ٹاپ پر چلا ہے۔ یہ کورس آپ کے ڈیزائن کیے ہوئے ایجنٹ کو ایک حقیقی کلاؤڈ سروس کے طور پر شپ کرتا ہے جس تک صارفین انٹرنیٹ سے پہنچ سکتے ہیں۔ آپ ایجنٹ کا دماغ ایک managed cloud runtime پر ہوسٹ کریں گے، اس کی یادداشت ڈیٹابیس میں رکھیں گے، اس کی فائلیں object storage میں محفوظ کریں گے، اور اس کا خطرناک کوڈ الگ، بند سینڈ باکس میں چلائیں گے۔ پوری چیز آپ کا کوڈنگ ایجنٹ بناتا اور بوٹ کرتا ہے، اس ساتھی brief سے کام لیتے ہوئے جسے آپ ڈاؤن لوڈ کرتے ہیں۔ آخر تک ہارنس live ہو گا، اور آپ ہر ٹکڑے کو سمجھتے ہوں گے۔
🔤 آگے پڑھنے سے پہلے تین اصطلاحات جان لیں (اگر آپ پچھلے کورسز کر چکے ہیں تو شاید یہ پہلے سے معلوم ہوں؛ نیچے سادہ انسانی وضاحت تک جا سکتے ہیں)۔
یہ کورس پچھلے کورسز کے مقابلے میں انفراسٹرکچر پر زیادہ بھاری ہے۔ یہ تین اصطلاحات بار بار آئیں گی، اس لیے پہلے انہیں صاف لفظوں میں دیکھ لینا بہتر ہے:
- ہارنس۔ ایجنٹ کا "دماغ" اور کنٹرولز: وہ کوڈ جو ایجنٹ لوپ چلاتا ہے، اگلا ٹول چننے کا فیصلہ کرتا ہے، secrets رکھتا ہے، اور runs کے درمیان state محفوظ رکھتا ہے۔ یہ ایجنٹ کا generated code خود نہیں چلاتا۔ اس کورس میں ہارنس کلاؤڈ میں چلنے والی FastAPI ویب app ہے۔
- سینڈ باکس۔ الگ، بند workspace جہاں ایجنٹ کا generated code اصل میں چلتا ہے۔ یہ فائلیں پڑھ سکتا ہے اور shell commands چلا سکتا ہے، مگر اسے ہارنس کے secrets یا ڈیٹابیس تک access نہیں ہوتا۔ سینڈ باکس سستے بنتے ہیں، ایک بار استعمال ہوتے ہیں، پھر پھینک دیے جاتے ہیں۔
- مینفیسٹ۔ سینڈ باکس کو کیا چاہیے، اس کی مختصر وضاحت: کون سی فائلیں mount کرنی ہیں، کون سی storage attach کرنی ہے، کون سی صلاحیتیں (shell، filesystem) آن کرنی ہیں۔ آپ workspace ایک بار بیان کرتے ہیں، پھر OpenAI Agents SDK اسے کسی بھی supported sandbox provider پر چلا سکتا ہے۔
دو اور اصطلاحات بہت استعمال ہوں گی جنہیں مکمل glossary بیان کرتی ہے: Azure Container Apps (managed cloud service جو آپ کا container autoscale اور public web address کے ساتھ چلاتی ہے) اور Neon Postgres (serverless Postgres database جس میں سستی branching ہے)۔ مکمل glossary نیچے ایک section میں ہے۔
سادہ انسانی وضاحت: اگر پہلے انسانی version چاہیے تو یہاں سے شروع کریں۔ (Technical readers نیچے "یہ کورس production deployment..." تک جا سکتے ہیں۔)
پچھلے کورسز نے تصور کی سطح پر ایک AI-native کمپنی بنائی تھی۔ آپ نے ایجنٹ ڈیزائن کرنا، اسے knowledge دینا، اسے durable طریقے سے چلانا، بہت سے ایجنٹس manage کرنا، انہیں hire اور fire کرنا، owner کو delegate دینا، اور یہ ناپنا سیکھا کہ کیا کوئی چیز واقعی کام کر رہی ہے۔ ان سب کورسز میں ایک کام آپ نے نہیں کیا: اسے واقعی ایسے کلاؤڈ پر ڈیپلائے کرنا جہاں اصل صارفین پہنچ سکیں۔ یہ کورس اسی کے لیے ہے۔ آپ اپنا بنایا ہوا ایجنٹ، پچھلے کورسز کا آرکیٹیکچر، اور eval suite لیتے ہیں، اور انہیں live cloud service کے طور پر شپ کرتے ہیں۔ آپ سیکھیں گے کہ ایجنٹ کا دماغ کہاں چلتا ہے، یادداشت کہاں رہتی ہے، فائلیں کہاں محفوظ ہوتی ہیں، اور اس کا خطرناک کوڈ محفوظ طریقے سے کہاں چلتا ہے۔ یہ شروع سے آخر تک ایک مکمل راستہ ہے جو کام کرتا ہے۔ دوسرے راستے بھی موجود ہیں؛ مگر سب کا سروے کرنے سے بہتر ہے کہ ایک راستہ مکمل چل کر سیکھا جائے۔
یہ کورس کلاؤڈ میں OpenAI Agents SDK ہارنس کی production deployment سکھاتا ہے۔ پچھلے کورسز نے AI-native کمپنی کا آرکیٹیکچر بنایا، پھر اسے اس discipline میں لپیٹا جس سے وہ measurable طور پر قابل اعتماد بنتی ہے۔ یہ کورس پوری چیز شپ کرتا ہے۔
پورا کورس ایک ہی خیال تک سمٹتا ہے۔ ہارنس وہ کنٹرول پلین ہے جو آپ own کرتے اور چلاتے رکھتے ہیں۔ سینڈ باکس وہ ایگزیکیوشن پلین ہے جسے آپ بناتے، ایک بار استعمال کرتے، پھر ختم کر دیتے ہیں۔ ہارنس keys، state، اور audit log رکھتا ہے؛ سینڈ باکس ان میں سے کچھ نہیں رکھتا اور خطرناک کام کرتا ہے۔ اس کورس کا ہر تصور اور ہر فیصلہ اسی ایک split کی تفصیل ہے۔ اگر ایک جملہ ذہن میں بٹھانا ہو تو یہی جملہ بٹھائیں۔
🆕 اپریل 2026 میں کیا بدلا، اور یہ کورس اب کیوں موجود ہے۔ OpenAI نے 15 اپریل 2026 کو Agents SDK کی بڑی update جاری کی جس نے agent harness کو sandbox compute سے SDK کے first-class حصے کے طور پر الگ کر دیا۔ اس release سے پہلے production agents deploy کرنے والی teams کو model clients، container runtimes، credential isolation، state، اور tool routing ہاتھ سے جوڑنی پڑتی تھی۔ اپریل release نے harness/sandbox split کو built-in primitive بنا دیا، ایسا pattern نہیں جسے ہر team دوبارہ ایجاد کرے۔ اسی سے یہ کورس قابل تدریس بنا: ایک سال پہلے یہ زیادہ تر speculative ہوتا؛ اب یہ recipe ہے۔
ماخذ: OpenAI، "The next evolution of the Agents SDK،" 15 اپریل 2026۔
فوری کامیابی: تقریباً 15 منٹ میں اپنے لیپ ٹاپ پر ہارنس بوٹ کریں
کلاؤڈ کو ہاتھ لگانے سے پہلے ثابت کریں کہ ہارنس آپ کی اپنی مشین پر چلتا ہے۔ کلاؤڈ کو ہاتھ لگانے سے پہلے ہارنس آپ کے لیپ ٹاپ پر چلتا ہے۔ آپ companion code ڈاؤن لوڈ کریں گے، اسے اپنے کوڈنگ ایجنٹ میں کھولیں گے، اور اسے boot ہوتے اور health check کا جواب دیتے دیکھیں گے۔ یہی پوری جیت ہے: کنٹرول پلین زندہ ہے اور بتا رہا ہے کہ کون سے pieces wired ہیں۔
پہلے companion zip ڈاؤن لوڈ کریں اور unzip کریں۔ فولڈر اپنے کوڈنگ ایجنٹ (Claude Code، OpenCode، یا اسی طرح کے tool) میں کھولیں۔ ایجنٹ root پر موجود AGENTS.md فائل پڑھتا ہے، جو اسے بتاتی ہے کہ project کیسے بنا ہے اور اسے boot کیسے کرنا ہے۔ پھر نیچے دیا گیا prompt paste کریں۔
یہ اپنے کوڈنگ ایجنٹ میں paste کریں۔ پہلے plan بنائے؛ approval پر execute کرے۔
فائل AGENTS.md پڑھیں، پھر Maya کا ہارنس locally boot کریں تاکہ میں اسے چلتا ہوا دیکھ سکوں۔
- آخر میں موجود AGENTS.md کا SDK probe چلائیں تاکہ installed
openai-agentsversion اور core imports کی تصدیق ہو جائے۔- ضروری dependencies انسٹال کریں (
make install) اور.env.exampleکو.envمیں copy کریں۔ ابھی کوئی keys نہ ڈالیں؛ ہارنس کو ان کے بغیر boot ہونا چاہیے۔- ہارنس start کریں (
make run، جوhttp://localhost:8000پر serve کرتا ہے)۔- دوسرے shell میں
GET /healthrequest کریں اور مجھے exact response دکھائیں۔
جب یہ ہو جائے:
- آپ کا کوڈنگ ایجنٹ installed
openai-agentsversion (0.17.x) report کرے۔ - ہارنس start ہو اور keys set کیے بغیر running رہے۔
GET /healthبالکل یہ return کرے:
{
"status": "ok",
"model": "gpt-5.4-mini",
"backends": { "postgres": false, "sandbox": false, "r2": false }
}
یہ response ہارنس کا سچ بتاتا ہے: یہ alive ہے ("status": "ok")، اسے اپنا model معلوم ہے، اور optional backends میں سے ابھی کوئی wired نہیں (سب false)۔ بعد کا ہر decision ان flags میں سے ایک کو true کرتا ہے۔ ہارنس صرف اپنے code کے ساتھ boot ہوتا ہے، پھر آپ ایک ایک piece add کرتے ہیں۔
خلاصہ: آپ نے ابھی اپنے لیپ ٹاپ پر control plane چلا لیا۔ باقی کورس state، storage، sandbox، اور cloud address کو ایک ایک verified قدم کے ساتھ add کرتا ہے۔
چار تعلیمی ٹریک، اپنا ٹریک چنیں
یہ کورس چار مختلف depths کے لیے کام کرتا ہے۔ لیب سے پہلے اپنا ٹریک صاف طور پر چنیں؛ conceptual content چاروں کے لیے بنایا گیا ہے، اور lab ٹریکس 2-4 کے لیے بنائی گئی ہے۔
| Track | وقت کی commitment | آپ کیا complete کرتے ہیں | یہ کس کے لیے ہے |
|---|---|---|---|
| Reader (pure conceptual) | تقریباً 3-4 گھنٹے، کوئی lab نہیں | Quick Win، تمام 17 تصورات، اور closing۔ نہ cloud accounts، نہ Docker، نہ Python setup۔ آرکیٹیکچر سمجھ آ جاتا ہے؛ deployment ملتوی رہتی ہے۔ | Engineering leaders، platform architects، اور ML platform owners جو فیصلہ کر رہے ہیں کہ team کا وقت اس deployment pattern پر لگانا چاہیے یا نہیں۔ |
| Beginner | تقریباً 1-2 دن (conceptual + local lab) | Reader track کے ساتھ SDK probe، scaffold، اور containerizing۔ ہارنس Docker میں locally چلتا ہے، OpenAI اور local database سے بات کرتا ہے۔ ابھی cloud deployment نہیں۔ | AI services کی cloud deployment میں نئے engineers۔ مقصد harness/sandbox split کو internalize کرنا اور ایک containerized agent شپ کرنا ہے جو laptop پر end to end چلے۔ |
| Intermediate | تقریباً 3-5 دن | Beginner track کے ساتھ cloud deploy، durable state wire کرنا، file storage wire کرنا، اور observability wire کرنا۔ ہارنس real users کو serve کرتا ہے؛ sandbox ابھی stubbed ہے؛ eval suite Advanced تک deferred ہے۔ | وہ teams جو deployed اور observable harness چاہتی ہیں، مگر ابھی code execution یا مکمل eval discipline wire نہیں کر رہیں۔ |
| Advanced | تقریباً 7-10 دن | Intermediate track کے ساتھ sandbox wire کرنا، eval suite wire کرنا، اور production checklist۔ مکمل discipline: harness deployed، sandbox wired، observability live، eval suite CI کو gate کرتی اور nightly چلتی ہے۔ | Production teams جو full discipline، complete end-to-end deployment، observability، اور quality-assurance path شپ کر رہی ہیں۔ |
ٹریک چننے کی رہنمائی۔ جو engineering leaders اور architects اس pattern میں invest کرنے کا فیصلہ کر رہے ہیں انہیں Reader track سے شروع کرنا چاہیے: 3-4 گھنٹے، کوئی accounts نہیں، کوئی خرچ نہیں، اور آخر تک آپ جان جائیں گے کہ team کو higher track پر commit کرنا چاہیے یا نہیں۔ Beginners کو پہلی pass میں Advanced تک پہنچنے کا دباؤ محسوس نہیں کرنا چاہیے۔ یہ discipline iterative ہے؛ teams عموماً ایک weekend میں Reader سے Beginner، ایک sprint میں Beginner سے Intermediate، اور deployment mature ہوتے ہوتے weeks میں Intermediate سے Advanced تک جاتی ہیں۔ Standalone readers (جو earlier courses سے نہیں آئے) پہلے Reader track کو default بنائیں، پھر فیصلہ کریں کہ lab کا Simulated mode next step ہے یا نہیں۔
ایک نظر میں sprint
اگر آپ Advanced track کو focused دو ہفتوں کی sprint کے طور پر کرتے ہیں تو cadence یہ ہے۔ اس میں ایک engineer کے لیے روزانہ 4-6 productive گھنٹے فرض کیے گئے ہیں؛ teams اسے compress کر سکتی ہیں۔ Day 5 قدرتی "shippable" checkpoint ہے: ہارنس deployed ہے اور users کو serve کر رہا ہے۔ Days 6-10 وہ hardening add کرتے ہیں جو deployment کو long-term operable بناتی ہے۔
| Day | Focus | Cumulative artifact |
|---|---|---|
| 1 | Concepts 1-4 + scaffold | stubbed /runs endpoint کے ساتھ local FastAPI app۔ |
| 2 | Containerize + deploy | ہارنس آپ کے phone سے public internet پر reachable۔ |
| 3 | Wire Neon Postgres | durable state جو container restart کے بعد بھی رہتی ہے۔ |
| 4 | Wire Cloudflare R2 | file storage؛ agent inputs پڑھ سکتا ہے اور outputs لکھ سکتا ہے۔ |
| 5 | ⭐ Shippable checkpoint | deployed harness جسے real users استعمال کر سکتے ہیں۔ اگر MVP ہی goal ہے تو یہاں رک جائیں۔ |
| 6 | Wire the sandbox | code execution working؛ agent محفوظ طریقے سے code چلاتا ہے۔ |
| 7 | Wire observability | infrastructure alert سے agent behavior تک تیزی سے navigate کریں۔ |
| 8-9 | Wire the eval suite | کوئی agent regression CI notice کیے بغیر ship نہیں ہوتی؛ nightly behavior reports چلتی ہیں۔ |
| 10 | Production checklist + handoff | production-ready harness اور ایسی team جو اسے operate کر سکتی ہے۔ |
دو حصے۔ Decisions 1-6 core deployment course ہیں: یہ code execution کے ساتھ working، deployed harness بناتے ہیں۔ Decisions 7-9 production hardening ہیں: observability، eval suite، security، اور runbook discipline۔ دباؤ میں teams پہلے 1-6 ship کر سکتی ہیں، پھر اگلے weeks میں hardening add کر سکتی ہیں؛ hardening production کے لیے واقعی ضروری ہے، مگر harness live ہونے کے بعد add بھی ہو سکتی ہے۔
آخر میں آپ کے پاس کیا ہو گا
اس Reader track میں artifacts نہیں، سمجھ پیدا ہوتی ہے۔ آخر تک آپ control plane اور execution plane split کو اپنے الفاظ میں سمجھا سکتے ہیں، بتا سکتے ہیں کہ پانچ components میں سے ہر ایک کیا contribute کرتا ہے، کہاں یہ pattern مضبوط ہے اور کہاں اس کی honest limits ہیں، اور small، medium، یا large deployment کی monthly cloud cost estimate کر سکتے ہیں۔
ان Beginner، Intermediate، اور Advanced tracks میں concrete artifacts بنتے ہیں۔ اپنے track کے حساب سے آپ بنا چکے ہوں گے:
- ایسا FastAPI ہارنس جو OpenAI Agents SDK کو wrap کرتا ہے (Beginner اور اوپر): locally running، ایسی API serve کرتا ہوا جو agent tasks قبول کرتی اور results return کرتی ہے۔
- کنٹینر image (Beginner اور اوپر): cloud deployment کے لیے مناسب production-sized image۔
- وہ ہارنس جو Azure Container Apps پر deployed ہے (Intermediate اور اوپر): public address، secrets، autoscale، اور revision history کے ساتھ۔
- پائیدار state store کے طور پر Neon Postgres (Intermediate اور اوپر): sessions، runs، traces، artifacts، اور audit log کا schema؛ version control میں migrations؛ connection pooling۔
- فائلوں اور artifacts کے لیے Cloudflare R2 (Intermediate اور اوپر): sandbox سے presigned-URL access والا bucket، lifecycle cleanup کے ساتھ۔
- سینڈ باکس code execution (Advanced): ہارنس Manifest compose کرتا ہے، sandbox workspace provision کرتا ہے، artifacts R2 کے ذریعے واپس آتے ہیں۔
- چار surfaces پر observability (Intermediate اور اوپر): infrastructure traces اور agent traces، ایک shared
run_idکے ساتھ تاکہ ان کے درمیان navigate کیا جا سکے۔ - شروع سے آخر تک integrated eval suite (Advanced): CI regression gate، nightly behavior reports، اور trace-to-eval pipeline۔
- مکمل production checklist (Advanced): secrets rotation، blue/green deploys، on-call runbook، backup and recovery، rate limits، اور cost alerts۔
ہر track internally complete ہے: Beginner-track deliverable کسی higher track deliverable پر depend نہیں کرتا۔
اس کورس میں آنے والی vocabulary
لغت، expand کرنے کے لیے click کریں
- ہارنس۔ ایجنٹ کا control plane: وہ code جو agent loop چلاتا ہے، secrets رکھتا ہے، اور state محفوظ رکھتا ہے۔ اس کورس میں یہ cloud میں FastAPI app ہے۔ یہ ایجنٹ کا generated code نہیں چلاتا۔
- سینڈ باکس۔ ایجنٹ کا execution plane: isolated workspace جہاں ایجنٹ کا generated code چلتا ہے، ہارنس کے secrets یا database تک access کے بغیر۔
- کنٹرول پلین / ایگزیکیوشن پلین۔ یہ اصول کہ ایجنٹ کی orchestration (secrets، database access، model keys) اس جگہ سے الگ security boundary میں رہتی ہے جہاں ایجنٹ کا generated code چلتا ہے۔ یہ اس کورس کی بنیاد ہے۔
- مینفیسٹ۔ sandbox workspace کی مختصر description: file mounts، attach ہونے والی storage، enable ہونے والی abilities۔ supported sandbox providers میں portable۔
- کنٹینر۔ آپ کی app اور اسے چلانے کے لیے درکار ہر چیز کا sealed bundle، تاکہ وہ لیپ ٹاپ اور cloud دونوں پر ایک جیسا چلے۔
- فریم ورک FastAPI۔ web APIs بنانے کے لیے Python library۔ اس کورس میں harness کے HTTP layer کے لیے choice، کیونکہ یہ SDK کے async Python client کے ساتھ natural fit ہے۔
- سروس Azure Container Apps (ACA)۔ managed cloud service جو آپ کا container autoscale، public address، secrets، اور revisions کے ساتھ چلاتی ہے۔ اس کورس کا harness runtime۔
- ڈیٹابیس Neon Postgres۔ serverless Postgres database جس میں سستی branching ہے۔ اس کورس کا durable state store۔
- اسٹوریج Cloudflare R2۔ S3-compatible object storage جہاں اپنی files read کرنے پر egress free ہے۔ اس کورس کا file اور artifact store۔
- پری سائنڈ URL۔ مختصر مدت کا web link جو sandbox کو storage password رکھے بغیر storage میں ایک specific file read یا write کرنے دیتا ہے۔
- پائیدار state۔ restart کے بعد باقی رہنے والی memory: sessions، run history، اور audit log، جو container کے بجائے database میں رہتی ہے کیونکہ container stop ہوتے ہی سب بھول جاتا ہے۔
- آبزرویبلٹی۔ وہ tools جو بتاتے ہیں کہ running harness کیا کر رہا ہے، کب کچھ ٹوٹتا ہے، اور cause کیسے تلاش کرنی ہے۔
- اوپن ٹیلی میٹری (OTel)۔ services کے across request trace کرنے کا open standard۔
- ٹول Phoenix۔ ایسا tool جو agent traces کو watch کرتا ہے اور خراب traces کو future tests میں بدلتا ہے۔
- ایول۔ test جو agent behavior ناپتا ہے (کیا answer درست تھا، tool correct تھا، reasoning sound تھی)، صرف یہ نہیں کہ code چلا یا نہیں۔
- طریقہ Blue/green۔ downtime کے بغیر نیا version ship کرنے کا طریقہ: new version کو old version کے ساتھ چلائیں، پھر traffic shift کریں۔
- صفر تک scale۔ جب traffic نہ ہو تو cloud آپ کی app کی zero copies چلاتا ہے اور آپ کچھ pay نہیں کرتے؛ quiet spell کے بعد پہلی request کو copy wake ہونے میں چند seconds لگتے ہیں۔
- کنکشن pooling۔ open database connections کا shared set جو requests میں reuse ہوتا ہے، تاکہ database ایک ساتھ ہزاروں connections سے نہ گر جائے۔
کیا آپ تیار ہیں؟
📦 سب سے پہلے: companion download۔ Companion zip سب کے لیے on-ramp ہے، خاص طور پر standalone readers کے لیے جنہوں نے earlier courses نہیں کیے۔
deploying-agents-crash-course.zipڈاؤن لوڈ کریں اور unzip کریں۔ اس میں ہارنس کا booted scaffold (FastAPI plus SDK plus stubbed clients)، وہAGENTS.mdbrief جو آپ کا coding agent پڑھتا ہے، پانچ database tables کے لیےschema.sql، ایکDockerfile، Azure deploy script، اور common commands کے لیےMakefileشامل ہیں۔ اندر موجود stub agent (Maya کا Tier-1 Support agent) lab کو اس وقت بھی کام کرنے دیتا ہے جب آپ نے Maya خود نہ بنائی ہو، اس لیے Simulated track کے پاس point کرنے کے لیے کچھ real ہے۔اگر آپ Reader سے آگے کسی بھی track کو follow کرنے کا ارادہ رکھتے ہیں تو آگے پڑھنے سے پہلے folder کو اپنے coding agent میں کھولیں۔ Reader track کے لیے read-only browsing کافی ہے۔
- آپ companion zip ڈاؤن لوڈ کر چکے ہیں (اوپر callout دیکھیں)۔ اگر آپ Reader track پر ہیں اور کچھ چلانے کا plan نہیں رکھتے تو اسے skip کریں۔
- آپ command line پر comfortable ہیں۔ آپ packages install کر سکتے ہیں، چند commands چلا سکتے ہیں، اور filesystem میں move کر سکتے ہیں۔ اگر آپ نے کبھی terminal استعمال نہیں کیا تو Reader track صحیح entry point ہے۔
- آپ Python code پڑھ سکتے ہیں۔ ہارنس Python میں ہے؛ آپ
async def،await، decorators، اور type hints دیکھیں گے۔ expert ہونا ضروری نہیں؛ پڑھ لینا کافی ہے۔- آپ کے پاس Agents SDK access والی OpenAI API key ہے (Beginner track اور اوپر)۔ یہ model account ہے، صرف chat account نہیں۔ platform.openai.com دیکھیں۔
- آپ کے پاس Azure account ہے (Intermediate track اور اوپر)۔ Lab Azure Container Apps پر deploy کرتی ہے؛ free credits lab کو cover کر لیتے ہیں۔ portal.azure.com دیکھیں۔
- آپ کے پاس Neon account ہے (Intermediate track اور اوپر)۔ Free tier کافی ہے۔ console.neon.com دیکھیں۔
- آپ کے پاس R2 enabled Cloudflare account ہے (Intermediate track اور اوپر)۔ R2 free tier lab کے لیے کافی ہے۔ Cloudflare sandbox کو paid Workers plan چاہیے، اس لیے lab code execution کے realistic free path کے طور پر E2B کا free tier استعمال کرتی ہے۔
اگر cloud accounts missing ہیں تو Reader track واقعی صحیح starting point ہے: پہلے پڑھیں، بعد میں sign up کریں۔ اگر earlier courses missing ہیں تو companion zip کا stub agent آپ کا bridge ہے، اس لیے آپ Maya خود بنائے بغیر lab follow کر سکتے ہیں۔
شروع میں جاننے والی rough edges
- یہاں کا code booted companion تک traceable ہے۔ اس course کا SDK code download میں موجود harness سے match کرتا ہے، جسے course ship ہونے سے پہلے real
openai-agentspackage کے against install اور boot کیا گیا تھا۔ یہ "illustrative، untested" code نہیں۔- یہ SDK تیزی سے move کرتا ہے۔ اپریل 2026 release پہلا version ہے جو یہ pattern teachable بناتا ہے، اور harness/sandbox APIs evolve ہوتی رہیں گی۔ اس لیے lab کا پہلا قدم probe Decision ہے: آپ کا coding agent SDK install کرتا ہے، installed version print کرتا ہے، live docs fetch کرتا ہے، اور companion brief کو ان کے against reconcile کرتا ہے۔ جب brief اور live docs disagree کریں تو live docs win کرتے ہیں۔
- صرف Python۔ اپریل 2026 release harness اور sandbox features صرف Python میں ship کرتی ہے۔ TypeScript support planned ہے مگر dated نہیں۔ اگر آپ کی app TypeScript میں ہے تو Python harness کو الگ service کے طور پر چلائیں جسے آپ کی TypeScript app HTTP کے ذریعے call کرے۔
- ایک cloud، ایک sandbox، ایک database، ایک storage provider۔ یہ course ایک specific stack commit کرتا ہے تاکہ مکمل path سکھا سکے۔ principles دوسرے clouds میں obvious طریقوں سے transfer ہوتے ہیں؛ course substitutions کا survey نہیں کرتا، اگرچہ Concept 9 اور Concept 15 main substitutions کا نام لیتے ہیں۔
- لاگت real ہے۔ Fully deployed harness low-traffic personal use کے لیے ماہانہ roughly چند tens of dollars، اور moderate production traffic کے لیے hundreds تک جا سکتا ہے۔ Reader اور Beginner tracks free ہیں؛ cloud tracks کے real bills ہوتے ہیں۔ Concept 13 میں breakdown ہے۔
- یہ multi-region نہیں۔ یہ course ایک region میں deploy کرتا ہے۔ Multi-region active-active operational complexity add کرتا ہے جسے اپنا treatment چاہیے؛ Concept 14 اسے honestly name کرتا ہے۔
مختصر خلاصہ: چار claims جن کا یہ کورس دفاع کرتا ہے
- ہارنس اور سینڈ باکس الگ planes کے طور پر deploy ہونے چاہئیں۔ Prototype کے لیے harness کو sandbox کے اندر رکھنا convenient ہے؛ production کے لیے غلط architecture ہے۔ ہارنس secrets، state، اور orchestration own کرتا ہے؛ sandbox execution own کرتا ہے۔ یہ الگ security boundaries میں رہتے ہیں۔ اپریل 2026 SDK release اس split کو SDK کا built-in حصہ بناتی ہے۔
- ایک مکمل path پانچ surveys سے بہتر ہے۔ پانچ کمپوننٹ اسٹیک (FastAPI، Azure Container Apps، Neon، R2، اور sandbox provider) coherent recipe ہے؛ ہر component نے وہ role play کر کے اپنی جگہ کمائی ہے جو دوسرے نہیں کر سکتے۔ دوسری recipes بھی کام کرتی ہیں؛ ایک کو completion تک چل کر آپ تیز سیکھتے ہیں۔
- کلاؤڈ cost architecture کا حصہ ہے۔ ایسا harness جو خوب scale کرے مگر چلانے میں بہت مہنگا ہو، real problem ہے۔ یہ course cost کو first-class concern کے طور پر name کرتا ہے (Concept 13)۔ ہر scale پر model API bill dominate کرتی ہے؛ cloud infrastructure چھوٹا slice ہے۔
- یہ eval discipline اس deployment کے ساتھ compose ہوتی ہے۔ Decisions 7-8 observability اور eval suite کو live harness کے ساتھ wire کرتے ہیں۔ Eval-suite wiring Eval-Driven Development course پر depend کرتی ہے، اور operational envelope (durable execution، retries، human-approval gates) Production Worker course کا territory ہے۔
آپ جو بنا رہے ہیں اس کی شکل
یہ course 17 تصورات introduce کرتا ہے اور 9 deployment decisions سے گزارتا ہے۔ اس سب سے پہلے، پوری architecture ایک تصویر میں دیکھیں۔ جب بھی کوئی concept یا decision abstract لگے، اس کی طرف واپس آئیں۔
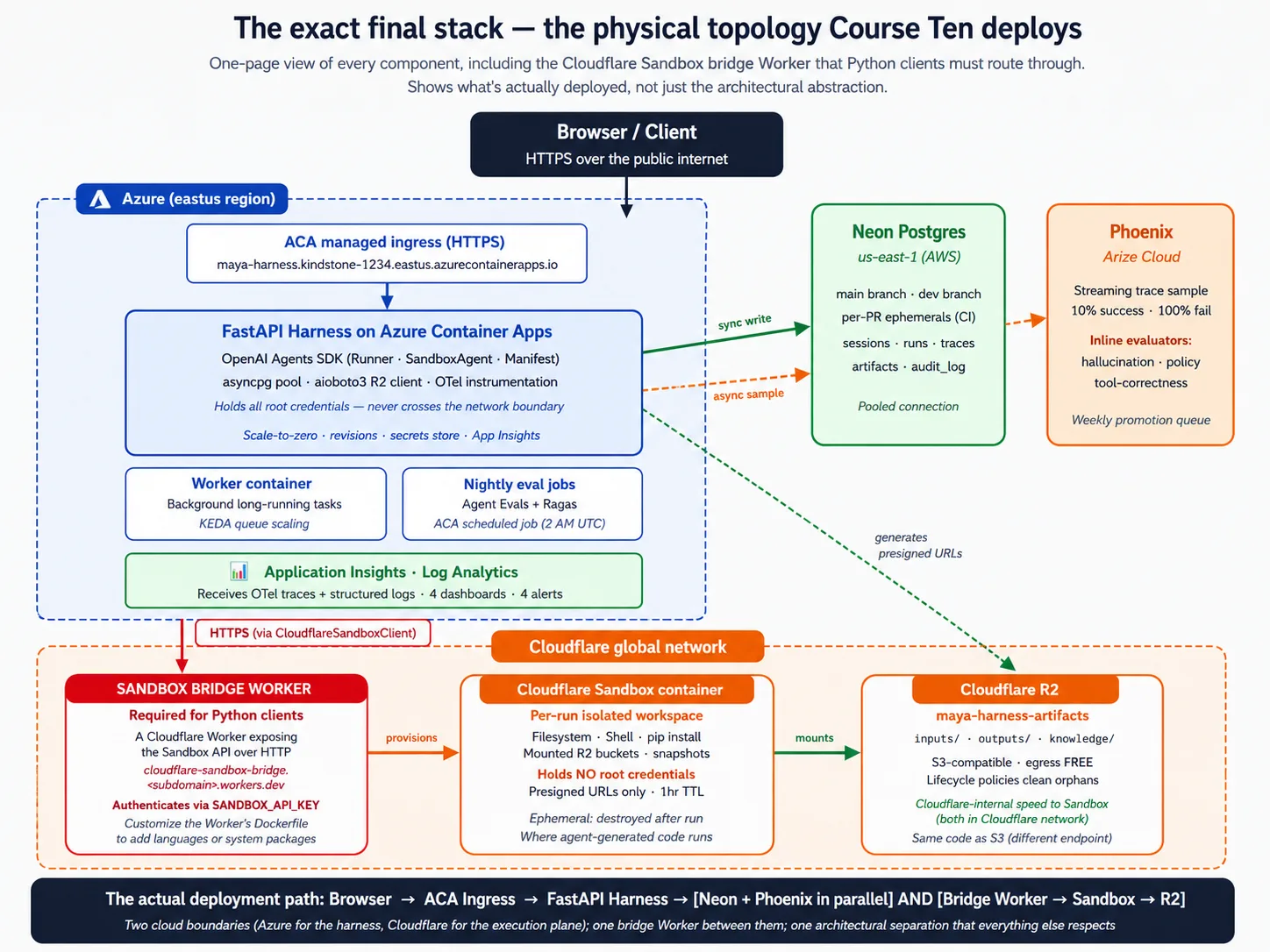
اسٹیک primer: ہر component اصل میں کیا ہے
اگر آپ پہلے production web services ship کر چکے ہیں تو یہ section skip کریں۔ اگر earlier courses آپ کی اب تک کی سب سے زیادہ infrastructure exposure ہیں تو اسے پڑھیں۔ یہ course ایسے background پر depend کرتا ہے جو زیادہ تر beginners نے ابھی نہیں بنایا، اور اس کے بغیر lab incantations جیسی لگے گی۔ چار مختصر pieces: Docker، FastAPI، Neon، اور Cloudflare R2۔ مقصد lab follow کرنے کے لیے minimum mental model ہے، deep mastery نہیں۔
پہلا stack primer: Docker اور containers
یہ Container آپ کی app اور اسے چلانے کے لیے درکار ہر چیز کا sealed bundle ہے: آپ کا code، اس کے Python packages، system libraries، حتیٰ کہ operating-system pieces جن پر یہ depend کرتا ہے۔ آپ bundle ایک بار build کرتے ہیں، پھر اسے کہیں بھی run کرتے ہیں۔ جو bundle آپ کے laptop پر چلتا ہے، وہ cloud میں بھی unchanged چلتا ہے۔
یہ software کی سب سے پرانی complaint حل کرتا ہے: "it works on my machine." Python script جو آپ کے laptop پر آپ کے exact packages کے ساتھ چلتا ہے، غالباً colleague کے laptop یا cloud server پر بہت fiddling کے بغیر نہیں چلے گا۔ Container اس fiddling کو collapse کرتا ہے: image ایک بار build کریں، پھر جہاں container engine چلے وہاں run کریں۔
لیب میں آنے والی vocabulary:
- یہ Dockerfile bundle build کرنے کی recipe ہے: plain text file جو کہتی ہے "اس base سے start کرو، یہ files copy کرو، یہ commands run کرو"۔
- یہ Base image starting point ہے، عموماً چھوٹا Linux system جس میں language پہلے سے installed ہوتی ہے۔ ہارنس
python:3.12-slimسے شروع ہوتا ہے۔ - یہ Multi-stage build app build کرنے کے لیے ایک image استعمال کرتا ہے (compilers اور tools کے ساتھ) اور چلانے کے لیے دوسری، چھوٹی image (صرف result کے ساتھ)۔ Runtime image چھوٹی رہتی ہے کیونکہ build tools اس میں ship نہیں ہوتے۔
- یہ Registry وہ جگہ ہے جہاں built images store اور share ہوتی ہیں۔ Deploy flow یہ ہے: image build کریں، registry میں push کریں، cloud اسے pull کر کے run کرے۔
کم سے کم mental model: container کو working machine کے snapshot کی طرح سمجھیں جس میں آپ کی app installed اور ready ہے۔ Image build کرنا snapshot لیتا ہے؛ اسے run کرنا isolated copy boot کرتا ہے۔ جب copy shut down ہوتی ہے تو اس کے اندر سب غائب ہو جاتا ہے۔ یہی وجہ ہے کہ durable state کو outside database اور durable files کو outside storage چاہیے۔ Container throwaway ہے؛ data نہیں۔
دوسرا stack primer: FastAPI
یہ FastAPI web APIs بنانے کی Python library ہے: ایسے programs جو network پر requests سنتے ہیں اور data سے respond کرتے ہیں، عموماً JSON۔ یہ "Fast" اس لیے ہے کہ concurrency کے لیے Python کے async features استعمال کرتا ہے، اور "API" اس لیے کہ web pages render کرنے کے بجائے request-and-response pattern کے لیے بنا ہے۔
یہ problem حل کرتا ہے: آپ کا agent server پر چلتا ہے، مگر real users (یا other services) کو کہیں اور سے، network کے ذریعے، اس تک پہنچنا ہوتا ہے۔ FastAPI آپ کے Python code کو ایسی چیز بناتا ہے جس سے network بات کر سکے۔
لیب میں آنے والی vocabulary:
- یہ Endpoint وہ specific path ہے جسے آپ کی API handle کرتی ہے، جیسے task start کرنے کے لیے
POST /runsیا ہارنس alive ہے یا نہیں دیکھنے کے لیےGET /health۔ - یہ Route handler وہ Python function ہے جو endpoint call ہونے پر چلتا ہے۔ آپ اسے decorator سے mark کرتے ہیں، جیسے
@app.post("/runs")۔ async defاورawaitPython کے keywords ہیں ایسے code کے لیے جو wait کرتا ہے۔ ہارنس انہیں استعمال کرتا ہے کیونکہ اس کا زیادہ تر کام waiting ہے: model، database، sandbox کا انتظار۔ Async code ایک process کو ایک وقت میں hundreds of waiting requests handle کرنے دیتا ہے۔- یہ Pydantic models Python classes ہیں جو request اور response data کی shape بیان کرتی ہیں۔ FastAPI انہیں incoming requests خودکار طور پر check کرنے اور malformed requests کو آپ کے code چلنے سے پہلے reject کرنے کے لیے استعمال کرتا ہے۔
- یہ Uvicorn وہ program ہے جو FastAPI app کو actual run کرتا ہے اور network کو handlers سے connect کرتا ہے۔ آپ اسے
uvicorn maya_harness.main:appجیسی command سے start کرتے ہیں۔
کم سے کم mental model: FastAPI app ایک Python file ہے جو app object بناتی ہے اور functions کو endpoints کے طور پر decorate کرتی ہے۔ ہر function checked data receive کرتا ہے، اپنا کام کرتا ہے (اکثر other async operations کا wait کرتے ہوئے)، اور data return کرتا ہے جسے FastAPI JSON بنا دیتا ہے۔ Uvicorn اس کے سامنے server ہے۔
تیسرا stack primer: Neon Postgres
یہ Database data کو disk پر store کرتا ہے تاکہ restarts کے بعد بچا رہے، ایک ساتھ many readers and writers support کرے، اور SQL نامی language سے query ہو سکے۔ Postgres ایک specific open-source database ہے، دنیا کے سب سے زیادہ استعمال ہونے والے databases میں سے ایک۔ Neon آپ کے لیے Postgres کو service کے طور پر چلاتا ہے، دو twists کے ساتھ: یہ serverless ہے (اپنے طور پر scale up/down ہوتا ہے) اور branching support کرتا ہے (آپ اپنے database کی ایسی copy بنا سکتے ہیں جو parent کے ساتھ storage share کرتی ہے جب تک آپ اسے change نہ کریں)۔
یہ problem حل کرتا ہے: آپ کے harness کو requests اور container restarts کے across چیزیں یاد رکھنی ہیں۔ Conversation state، run history، traces، audit log۔ Container کا local disk ہر restart پر غائب ہو جاتا ہے، اس لیے harness کو یہ data ایسی جگہ رکھنا ہے جہاں یہ survive کرے۔ خاص طور پر Neon اس لیے کہ اس کا scale-up اور scale-down behavior harness سے match کرتا ہے: جب harness idle ہو تو Neon بھی scale down ہو سکتا ہے، اور آپ pay کرنا stop کر دیتے ہیں۔
لیب میں آنے والی vocabulary:
- یہ Table structured records کی named collection ہے، جیسے spreadsheet مگر ہر column کے strict types کے ساتھ۔ ہارنس کے پانچ tables ہیں: sessions، runs، traces، artifacts، اور audit log۔
- یہ Schema آپ کے تمام tables اور columns کی definition ہے۔
- یہ Primary key وہ column ہے جو ہر row کو uniquely identify کرتا ہے؛ foreign key وہ column ہے جو کسی دوسرے table کی primary key کی طرف point کرتا ہے، اور یہی data کو relational بناتا ہے۔
- یہ Migration versioned SQL script ہے جو schema change کرتی ہے، repo میں committed ہوتی ہے تاکہ ہر change tracked رہے۔
- یہ Connection pooling open connections کا shared set ہے جو requests میں reuse ہوتا ہے۔ اس کے بغیر ہر request نیا connection کھولتی ہے، اور Postgres کی limit ہوتی ہے۔ Neon pooled endpoint دیتا ہے جو یہ multiplexing آپ کے لیے کرتا ہے۔
کم سے کم mental model: Postgres data کو strict shapes والے tables میں store کرتا ہے، اور آپ SQL سے query کرتے ہیں۔ ہارنس اس سے asyncpg Python library کے ذریعے بات کرتا ہے۔ Neon database host کرتا ہے اور اوپر serverless scaling اور branching add کرتا ہے۔
چوتھا stack primer: Cloudflare R2
یہ Object storage internet پر files store کرنے کی service ہے۔ آپ اسے name (ایک "key") اور کچھ bytes دیتے ہیں، وہ store کر لیتا ہے؛ بعد میں آپ name سے bytes مانگتے ہیں اور واپس لے لیتے ہیں۔ ایسی پہلی service AWS S3 تھی، اور اس کی API de facto standard بن گئی جسے بہت سے providers implement کرتے ہیں۔ Cloudflare R2 Cloudflare کی object storage ہے۔ یہ S3 API implement کرتا ہے، ایک twist کے ساتھ: اپنی files read کرنا free ہے۔ S3 سے data read out کرنے پر تقریباً nine cents per gigabyte لگتے ہیں؛ R2 سے کچھ نہیں۔
یہ problem حل کرتا ہے: آپ کا agent files پڑھتا ہے (uploaded documents، knowledge content) اور files لکھتا ہے (generated reports، artifacts)۔ ان files کو ایسی جگہ رہنا ہے جہاں harness اور sandbox دونوں reach کر سکیں، اور یہ database کے لیے بہت بڑی یا بہت زیادہ ہو سکتی ہیں۔ Database large files کے لیے نہیں بنا؛ container کا disk restarts کے بعد نہیں بچتا؛ files کے لیے object storage صحیح shape ہے۔
لیب میں آنے والی vocabulary:
- یہ Bucket files کے لیے named container ہے، top-level folder جیسا۔ ہارنس کا bucket agent artifacts رکھتا ہے۔
- یہ Object ایک stored file ہے، جس کی key (bucket میں path) اور value (bytes) ہوتی ہے۔
- یہ Prefix key کا وہ حصہ ہے جو related files group کرتا ہے، جیسے
inputs/یاoutputs/۔ - یہ S3-compatible کا مطلب ہے R2 وہی API بولتا ہے جو S3 نے invent کی، اس لیے جو Python library S3 سے بات کرتی ہے وہ ایک setting، endpoint URL، بدل کر R2 سے بات کر لیتی ہے۔
- یہ Presigned URL short-lived link ہے جو ایک specific object تک access دیتا ہے۔ ہارنس root credentials رکھتا ہے؛ جب sandbox کو ایک file چاہیے، ہارنس اسے short expiry والا presigned URL دیتا ہے، اور sandbox صرف اسی file تک پہنچ سکتا ہے۔
- یہ Lifecycle policy rule ہے جو ایک عمر سے پرانے objects delete کر دیتا ہے، تاکہ storage write-only graveyard نہ بن جائے۔
کم سے کم mental model: R2 وہ جگہ ہے جہاں harness files رکھتا اور پڑھتا ہے، S3 API کے ذریعے۔ ہارنس root credentials رکھتا ہے (سب کچھ read/write کر سکتا ہے)؛ sandbox کو صرف presigned URLs ملتے ہیں (ایک file، مختصر وقت)۔
آپ کو کیا نہیں چاہیے۔ یہ course complete کرنے کے لیے Kubernetes، infrastructure-as-code، service mesh، یا message broker نہیں چاہیے۔ اوپر managed services operational machinery handle کرتی ہیں۔ Deep SQL fluency بھی نہیں چاہیے؛ lab کے code کو recognize کرنا کافی ہے۔
حصہ 1: Deployment problem
تین concepts establish کرتے ہیں کہ یہ course کیوں موجود ہے اور "deployment problem" اصل میں کیا ہے۔ Beginners کو یہاں grounding ملتی ہے؛ advanced readers Part 2 تک skim کر سکتے ہیں۔
تصور 1: "Works on my machine" deployment نہیں
آپ کے پاس Python میں defined agent ہے، مثلاً Maya کا Tier-1 Support agent: یہ tools call کرتا ہے، specialists کو handoff کرتا ہے، اپنی limits respect کرتا ہے، اور eval suite pass کرتا ہے۔ آپ اسے اپنے laptop سے run کرتے ہیں اور یہ کام کرتا ہے۔
"آپ کے laptop پر کام کرتا ہے" کا اصل مطلب یہ ہے۔ Agent ایک Python process کے طور پر چلتا ہے جسے آپ نے ہاتھ سے start کیا۔ یہ اپنی API keys project folder کی file سے پڑھتا ہے۔ اپنی state اسی folder کی local file میں لکھتا ہے۔ Code کو اسی process میں libraries import کر کے چلاتا ہے۔ Model internet کے ذریعے call ہوتا ہے، مگر باقی سب آپ کی machine پر رہتا ہے۔
یہاں production کا مطلب یہ ہے، اور ہر piece کیسے مختلف ہے:
- یہ Real users public internet پر agent تک پہنچتے ہیں۔ صرف آپ، اپنے laptop سے، نہیں۔
- بہت سے users ایک ساتھ agent کو hit کرتے ہیں۔ ایک single Python script ایک وقت میں ایک handle کرتا ہے۔
- یہ Agent کی state host restart ہونے کے بعد بھی survive کرتی ہے۔ Temp folder کی local file نہیں۔
- یہ Agent کا generated code ایسی جگہ چلتا ہے جہاں یہ آپ کے data کو نقصان نہ پہنچا سکے۔ اسے اپنے ہی process میں، database credentials کے پاس، چلانا serious security mistake ہے۔
- یہ Agent کے secrets اس code کی reach سے باہر رہتے ہیں جو agent generate کرتا ہے۔ Working directory میں key file ایسا نہیں کرتی۔
- ہر run observable، auditable، اور recoverable ہوتی ہے۔ Crash ہونے والا process ان میں سے کچھ نہیں۔
ان چھ properties میں سے کتنی آپ laptop script میں minor changes اور ایک دو دن کے کام سے add کر سکتے ہیں؟ Honest answer ایک یا zero ہے۔ ان میں سے کسی ایک کو بھی production-surviving طریقے سے add کرنا کم از کم ایک week کی focused infrastructure work ہے؛ تمام چھ add کرنا وہ پوری body of work ہے جو یہ course سکھاتا ہے۔ Production deployment "works on my laptop" کے گرد thin wrapper نہیں۔ یہ مختلف architecture ہے۔
خاص طور پر AI services deploy کرنے میں نئی teams کی temptation ہوتی ہے کہ اس realization کو skip کر دیں۔ "ہم بس script کو server پر چلا دیں گے۔" دو months بعد team کے پاس ایک server ہوتا ہے جو کبھی کبھی crash کرتا ہے، agent کبھی کبھی user-influenced code کو production database تک full access کے ساتھ چلاتا ہے، state ہر reboot پر غائب ہوتی ہے، اور agent نے کیا کیا اس کا record نہیں ہوتا۔ Production کو script رکھنے کی جگہ سمجھنے کا یہی predictable result ہے، اسے مختلف architecture سمجھنے کے بجائے۔
یہ Deployment problem "script کہاں run کریں؟" نہیں۔ یہ ہے: "agent کو کیسے re-architect کریں تاکہ اس کے harness میں یہ چھ production properties ہوں، اور اس کی execution safe رہے؟" یہ course ایک مکمل answer سکھاتا ہے۔
خلاصہ: agent deploy کرنا laptop code کے گرد wrapper نہیں۔ اس کا مطلب agent کو control plane (ہارنس) اور execution plane (سینڈ باکس) میں re-architect کرنا ہے، جہاں ہر plane production properties دیتا ہے جو laptop script نہیں دے سکتا۔ یہ course اس re-architecture کو realize کرنے کا ایک مکمل path سکھاتا ہے۔
تصور 2: Harness/sandbox split، control plane vs execution plane
اس course کا single most important idea ہارنس (control plane) اور سینڈ باکس (execution plane) کا split ہے۔ ہر later concept اور decision اسی پر rest کرتا ہے۔
ہارنس agent کا دماغ ہے۔ یہ network پر users کی requests receive کرتا ہے۔ یہ agent loop چلاتا ہے: model call کرنا، اگلا tool چننا، specialist agents کو handoffs handle کرنا، guardrails apply کرنا۔ یہ many runs کے across durable state رکھتا ہے: conversation history، run history، audit log۔ یہ secrets رکھتا ہے: model key، database credentials، storage credentials۔ اور یہ users کو results return کرتا ہے۔
سینڈ باکس agent کے ہاتھ ہیں۔ یہ harness سے workspace description (Manifest) receive کرتا ہے۔ اس description کے مطابق isolated workspace provision کرتا ہے۔ Agent کی request پر shell commands، file reads and writes، اور code چلاتا ہے۔ Results harness کو return کرتا ہے۔ اور اسے harness کے secrets، database، یا production systems تک access نہیں ہوتا، سوائے اس کے جو Manifest explicit طور پر mount کرے۔
ان دونوں کے درمیان boundary network اور security boundary ہے۔ Harness sandbox credentials استعمال کر کے network پر sandbox سے بات کرتا ہے؛ یہ اپنے secrets sandbox کے ساتھ share نہیں کرتا۔ Sandbox harness کا environment، database، یا filesystem read نہیں کر سکتا۔ یہی production discipline اپریل 2026 SDK release نے SDK itself میں ڈال دی ہے۔
یہ split کیوں matter کرتا ہے؟ چار وجوہات ہیں۔
سیکیورٹی کی وجہ: agent code generate کرتا ہے۔ Code غلط ہو سکتا ہے، subtle انداز میں side effects کے ساتھ incorrect ہو سکتا ہے، یا adversarial setting میں malicious ہو سکتا ہے۔ آپ نہیں چاہتے کہ یہ code اسی process میں چلے جس کے پاس database credentials ہیں۔ Split generated code اور harness secrets کے درمیان network اور OS boundary رکھتا ہے۔ اگر agent ایسی request generate کرے جو files delete کر دے تو نقصان صرف sandbox کو ہو گا، اور sandbox throwaway ہے۔
پائیداری کی وجہ: sandboxes بار بار create اور destroy ہونے کے لیے ہوتے ہیں۔ Harness کو sandbox کے مرنے کے بعد بھی survive کرنا ہے۔ ایک task sandbox provision کر سکتا ہے، دس minutes run کر سکتا ہے، hiccup کی وجہ سے sandbox lose کر سکتا ہے، نئے sandbox میں checkpoint سے restore کر سکتا ہے، اور finish کر سکتا ہے۔ Harness یہ orchestrate کرتا ہے۔ اگر harness sandbox کے اندر رہتا تو sandbox مرنے پر سب کچھ lose ہو جاتا۔
اسکیل ایبلٹی کی وجہ: ایک harness جو many sandboxes coordinate کرتا ہے، ایک harness-plus-sandbox lump سے کہیں بہتر scale کرتا ہے۔ Harness کی needs modest ہیں (requests handle کرنا، model call کرنا، database سے بات کرنا)؛ sandbox کی needs spiky ہیں (code compile کرنا، tests run کرنا، files process کرنا)۔ Split کرنے سے ہر ایک خود scale ہو سکتا ہے۔
آبزرویبلٹی کی وجہ: record harness own کرتا ہے۔ Agent نے کیا decide کیا، کون سے tools call کیے، کون سی trace produce کی، سب harness کے ساتھ رہتا ہے۔ Sandbox execution ہے؛ harness audit log ہے۔ جب کچھ wrong ہو تو آپ harness کا record پڑھتے ہیں۔
یہ course دو anti-patterns avoid کرتا ہے:
- یہ Harness کو sandbox کے اندر چلانا۔ Prototype کے لیے convenient، production کے لیے wrong۔ Sandboxes throwaway ہیں؛ harness کو persist کرنا ہے۔ Sandboxes کو secrets کے ساتھ trust نہیں کیا جا سکتا؛ harness کو انہیں hold کرنا ہے۔
- یہ Agent-generated code کو harness کے اندر چلانا۔ AI deployment کا original sin۔ Harness database credentials، model key، اور users کے data تک access رکھتا ہے۔ آپ اس access surface کے ساتھ agent-generated code نہیں چلا سکتے۔ آخرکار یہ wrong ہو گا، اور جب ہو گا تو damage unbounded ہو گا۔
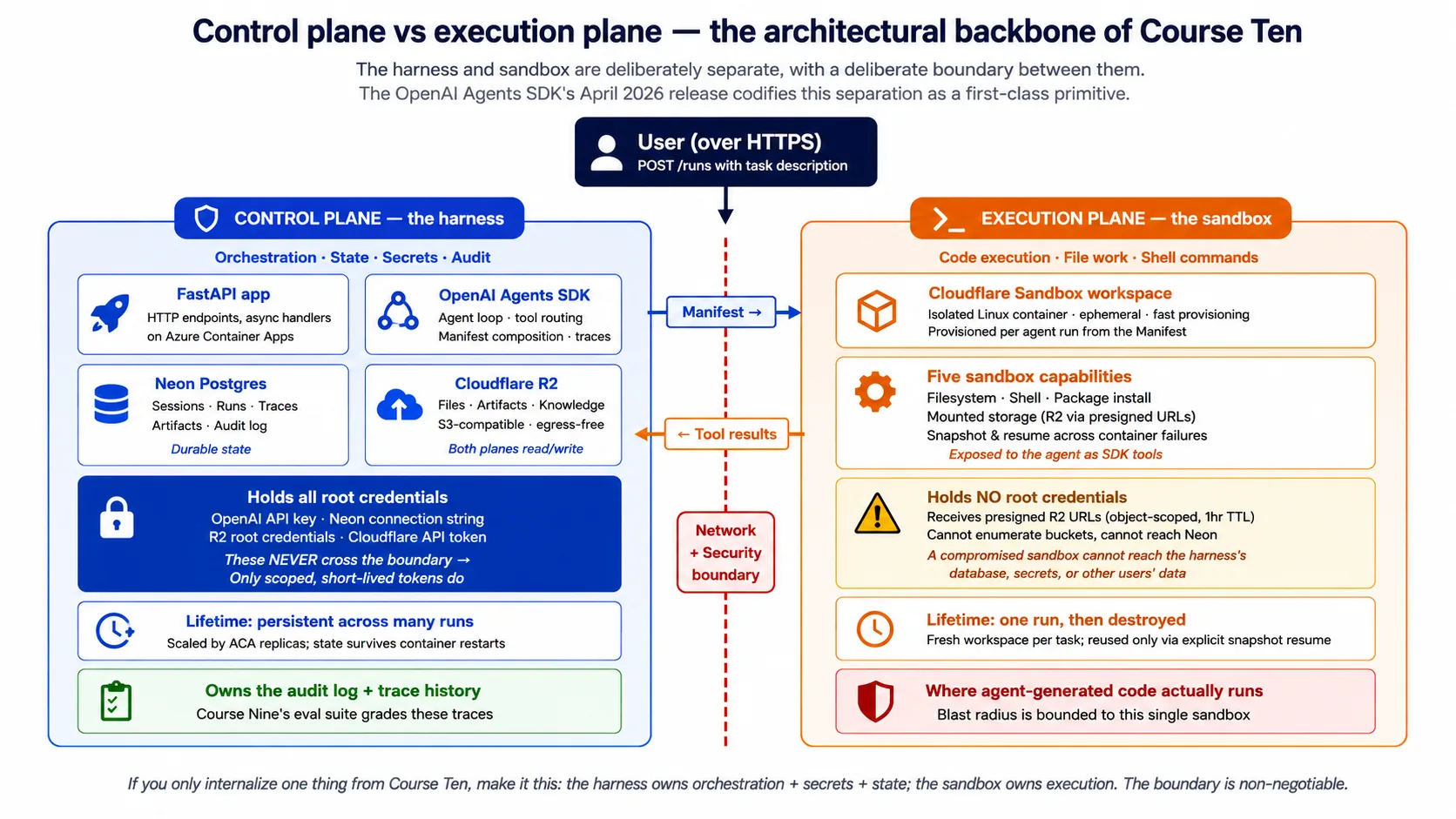
خلاصہ: production agent deployment کے لیے harness (control plane: orchestration، state، secrets، audit) کو sandbox (execution plane: code execution، file work، shell) سے split کرنا لازم ہے۔ Boundary network اور security boundary ہے۔ اپریل 2026 SDK release اس split کو SDK کا built-in حصہ بناتی ہے۔ دو anti-patterns avoid کریں: harness inside sandbox، اور agent code inside harness۔
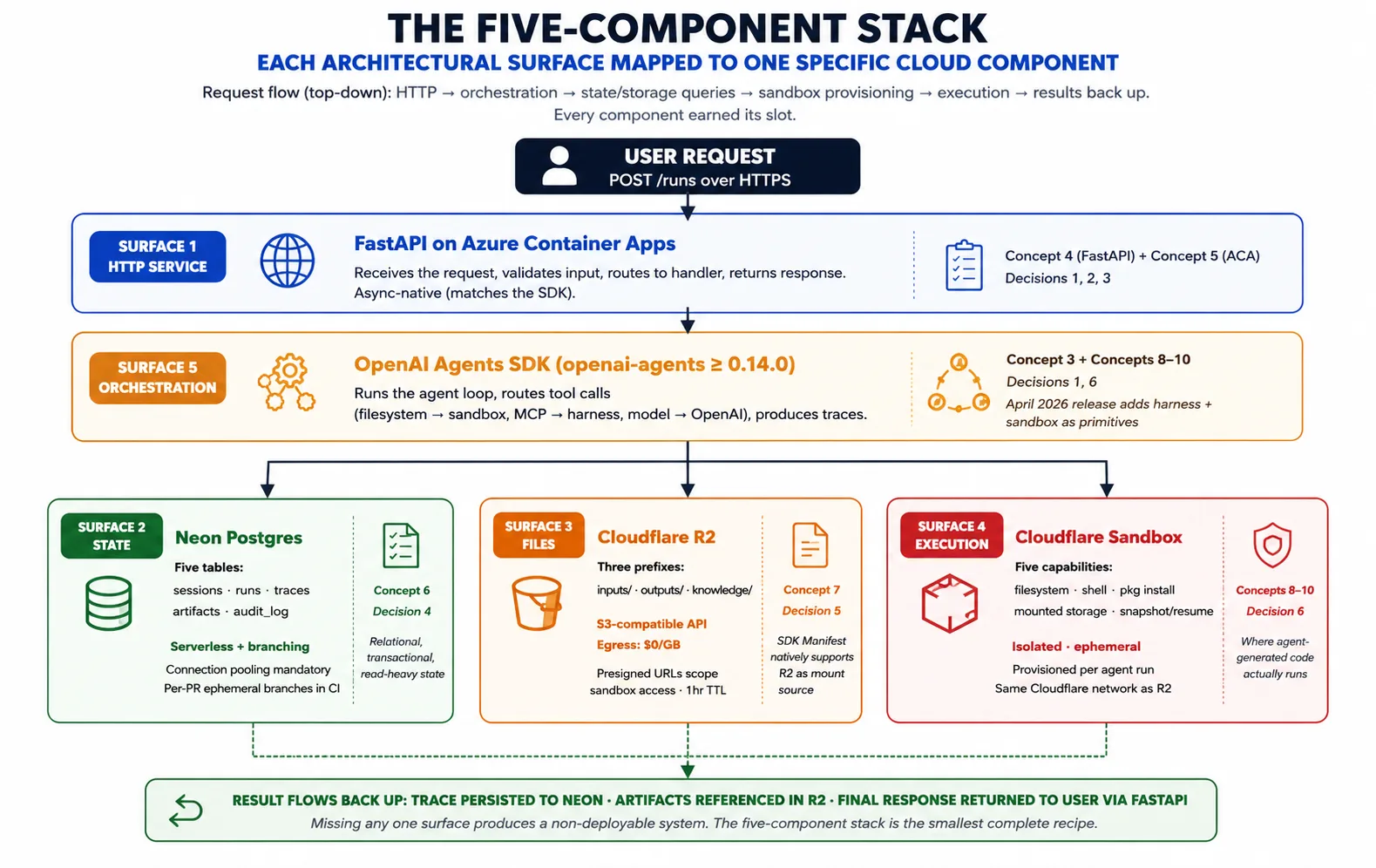
تصور 3: SDK کو cloud infrastructure سے کیا چاہیے، پانچ surfaces
یہ Concept 2 نے pattern name کیا۔ Concept 3 پوچھتا ہے: اس pattern کو realize کرنے کے لیے OpenAI Agents SDK کو cloud infrastructure سے اصل میں کیا چاہیے؟ جواب پانچ surfaces ہے، اور پانچ کمپوننٹ stack ہر surface کو ایک component سے map کرتا ہے۔
یہ Surface 1: harness host کرنے کے لیے long-running HTTP service۔ Harness ایک Python process ہے جسے users سے requests accept کرنی ہیں، indefinite طور پر running رہنا ہے (task seconds سے hours تک ہو سکتا ہے)، traffic بڑھنے پر scale out اور کم ہونے پر scale back ہونا ہے، اور host failure survive کرنا ہے۔ Azure Container Apps پر FastAPI یہ دیتا ہے۔ Concept 4 FastAPI cover کرتا ہے؛ Concept 5 Azure Container Apps۔
یہ Surface 2: runs کے across durable state۔ Harness sessions، runs، traces، approvals، اور audit log رکھتا ہے۔ Neon Postgres یہ دیتا ہے: Postgres اس لیے کہ یہ best-understood transactional database ہے، Neon اس لیے کہ اس کی serverless scaling اور branching harness کے deployment patterns سے match کرتی ہیں۔ Concept 6 Neon cover کرتا ہے۔
یہ Surface 3: file اور artifact storage جس تک دونوں planes پہنچ سکیں۔ Agents files produce کرتے ہیں (reports، code، exports) اور files consume کرتے ہیں (uploads، datasets، knowledge content)۔ انہیں ایسی جگہ رہنا ہے جہاں harness اور sandbox دونوں reach کر سکیں۔ Cloudflare R2 یہ دیتا ہے: S3-compatible API، اپنی files read out کرنے پر free، اور اپریل 2026 SDK میں Manifest mount source کے طور پر native support۔ Concept 7 R2 cover کرتا ہے۔
یہ Surface 4: agent-generated code کے لیے isolated execution۔ جب agent shell command چلاتا ہے، package install کرتا ہے، یا code execute کرتا ہے، اس کام کو ایسی home چاہیے جو harness secrets سے isolated ہو، demand پر create ہو، storage سے inputs read کر سکے، اور outputs واپس write کر سکے۔ Code-execution sandbox یہ دیتا ہے۔ Concepts 8-10 sandbox layer کو depth میں cover کرتے ہیں۔
یہ Surface 5: وہ orchestration جو surfaces 1-4 کو جوڑتی ہے۔ یہ خود SDK ہے۔ یہ agent loop چلاتا ہے، tool calls route کرتا ہے (filesystem اور shell sandbox کو، model calls OpenAI کو)، Manifest manage کرتا ہے، اور traces produce کرتا ہے۔ Harness SDK import کرتا ہے اور اس کے primitives استعمال کرتا ہے؛ انہیں دوبارہ invent نہیں کرتا۔
ترکیب کا خلاصہ: request Azure Container Apps پر FastAPI تک آتی ہے۔ Harness agent اور prior state کو Neon سے load کرتا ہے۔ یہ task کے لیے workspace describe کرنے والا Manifest compose کرتا ہے۔ یہ sandbox provider سے workspace provision کرواتا ہے۔ SDK agent loop چلاتا ہے، tool calls sandbox کو بھیجتا ہے اور trace record کرتا ہے۔ Artifacts R2 میں جاتے ہیں؛ trace Neon میں جاتی ہے۔ Result user کو return ہوتا ہے۔ یہی composition پورا course ہے؛ ہر concept اور decision اس کے ایک piece کی detail ہے۔
🚫 Python پر نہیں؟ اپریل 2026 release کے وقت harness اور sandbox features Python-only ہیں؛ TypeScript support planned ہے مگر dated نہیں۔ اگر آپ کی app TypeScript میں ہے تو Python harness کو separate service کے طور پر چلائیں اور اپنی TypeScript app سے اس کے endpoints HTTP پر call کروائیں۔ یہ course جو harness بناتا ہے، بالکل وہی service ہے۔
خلاصہ: اپریل 2026 SDK release پانچ architectural surfaces define کرتی ہے: long-running HTTP service، durable state، file storage، isolated execution، اور orchestration۔ پانچ کمپوننٹ stack (Azure Container Apps پر FastAPI، Neon، R2، sandbox، اور خود SDK) ہر surface کو ایک component سے map کرتا ہے۔ کسی بھی surface کی کمی non-deployable system بناتی ہے۔ اس کے گرد operational envelope (durable execution، retries، human-approval gates) Production Worker course ہے۔
حصہ 2: پانچ کمپوننٹ stack
یہ Part 1 نے pattern establish کیا؛ Part 2 harness side of the stack (FastAPI، Azure Container Apps، Neon، R2) اور یہ کہ ہر component نے اپنی جگہ کیوں کمائی، walkthrough کرتا ہے۔ پانچواں component، sandbox، اپنے Part 3 میں آتا ہے۔
تصور 4: Harness web layer کے طور پر FastAPI
یہ Harness کو long-running HTTP service ہونا ہے، اور کئی Python frameworks اسے host کر سکتے ہیں: Flask، Django، FastAPI، Starlette۔ اس course کی choice FastAPI ہے، ایسی specific reasons کے لیے جنہیں name کرنا چاہیے۔
اس async story کا خلاصہ: OpenAI Agents SDK Python کے asyncio کے گرد بنا ہے۔ Model، tools، اور sandbox کو calls سب await calls ہیں۔ FastAPI async-native ہے، اس لیے آپ async def handlers لکھتے ہیں جو thread-pool workarounds کے بغیر SDK کو directly await کرتے ہیں۔ Sync-native framework کا مطلب ہوتا event loop per request spin up کرنا یا SDK کو thread pool میں run کرنا: دونوں work کرتے ہیں، دونوں friction add کرتے ہیں اور concurrency lose کرتے ہیں۔ وہ framework استعمال کریں جس کا concurrency model آپ کی dependencies سے match کرتا ہو۔
اس schema story کا خلاصہ: FastAPI آپ کے handlers کی type hints سے OpenAPI schema generate کرتا ہے۔ یہاں اس کے تین فائدے ہیں۔ Eval suite harness endpoints کو checked requests کے ساتھ hit کر سکتی ہے کیونکہ schema machine-readable ہے۔ کسی بھی language، including last sidebar والی TypeScript app، کے لیے typed client libraries generate ہو سکتی ہیں۔ اور schema آپ کی team اور future self کے لیے API document کرتا ہے، الگ doc-writing effort کے بغیر۔
اس Pydantic story کا خلاصہ: FastAPI request اور response data check کرنے کے لیے Pydantic استعمال کرتا ہے، اور SDK بھی internally Pydantic استعمال کرتا ہے۔ Validation boundary پر ایک بار، اسی library اور patterns کے ساتھ ہوتی ہے جو SDK پہلے ہی استعمال کرتا ہے۔ دوسرے frameworks separate validation layer چاہتے ہیں؛ FastAPI یہ mismatch remove کرتا ہے۔
اس community story کا خلاصہ: May 2026 تک FastAPI AI services کے لیے dominant Python framework ہے۔ اس workload کے tutorials، examples، اور answers عموماً اسے assume کرتے ہیں۔ Well-supported tool چننا friction کم کرتا ہے۔
یہ FastAPI کیا نہیں ہے۔ یہ ہر چیز کے لیے general framework نہیں؛ اگر آپ کو template-rendered HTML pages یا Django-style admin چاہیے تو FastAPI wrong choice ہے۔ Harness API server ہے، web app نہیں۔ یہ queue کا replacement بھی نہیں: اگر task request کے reasonably open رہنے سے زیادہ long run کرتا ہے تو آپ connection open نہیں رکھتے۔ Harness work queue کرتا ہے اور client کو check back کرنے دیتا ہے؛ lab یہی pattern setup کرتی ہے۔
لیب میں آپ harness کا POST /runs endpoint دیکھیں گے: ایک async def handler جو session load کرتا ہے، agent run کرتا ہے، run persist کرتا ہے، اور reply return کرتا ہے۔ Function short ہے، کیونکہ FastAPI اور Pydantic آپ کو HTTP handling، validation، اور serialization free دیتے ہیں، اور async def آپ کو SDK directly await کرنے دیتا ہے۔ اس code کا real، booted version companion download میں اور lab Decision میں ہے، جہاں یہ actual running harness تک traceable ہے۔
خلاصہ: FastAPI harness کا web framework ہے کیونکہ یہ async-native ہے (SDK کی
asynciofoundation سے match کرتا ہے)، OpenAPI schemas generate کرتا ہے (eval اور client needs سے match کرتا ہے)، اور Pydantic استعمال کرتا ہے (SDK کے internal models سے match کرتا ہے)۔ یہ choice تین places پر friction remove کرتی ہے۔ یہ job queue نہیں؛ harness queue pattern استعمال کرتا ہے جو lab setup کرتی ہے۔
تصور 5: Harness runtime کے طور پر Azure Container Apps
یہ Harness containerized FastAPI service ہے جسے continuously run ہونا، traffic کے ساتھ scale ہونا، secrets safely hold کرنا، اور host failure survive کرنا ہے۔ اس course کی choice Azure Container Apps (ACA) ہے، جسے Microsoft exactly اس workload کے لیے position کرتا ہے۔
یہ کیا ہے: managed cloud service۔ آپ اسے container image اور configuration دیتے ہیں؛ یہ container چلاتی ہے، public address دیتی ہے، autoscale handle کرتی ہے، secrets store کرتی ہے، اور revisions track کرتی ہے۔ آپ servers manage نہیں کرتے، Kubernetes ہاتھ سے نہیں چلاتے، یا underlying compute کے لیے infrastructure code نہیں لکھتے۔ آپ declare کرتے ہیں کہ کیا چاہیے؛ ACA اسے بنا دیتی ہے۔
یہ Harness کو اس سے پانچ capabilities چاہئیں:
- یہ Public address۔ ACA ہر app کو managed certificates کے ساتھ stable HTTPS address دیتی ہے۔ نہ web-server config، نہ certificate setup، نہ DNS gymnastics۔
- یہ Autoscale۔ ACA running copies کی تعداد آپ کے set کیے ہوئے rules پر scale کرتی ہے، عموماً in-flight requests کی تعداد پر۔ Scale-to-zero cost lever ہے: traffic نہ ہو تو ACA zero copies چلاتی ہے اور آپ pay نہیں کرتے؛ quiet spell کے بعد پہلی request کو copy wake ہونے کے لیے چند seconds انتظار کرنا پڑتا ہے۔
- یہ Secrets۔ ACA secrets store کرتی ہے اور environment variables میں انہیں name سے reference کرنے دیتی ہے؛ actual values آپ کی configuration یا image میں کبھی appear نہیں ہوتیں۔ یہ disk پر key file سے کہیں بہتر ہے۔
- یہ Revisions۔ ہر deploy immutable revision بناتا ہے، اور ACA traffic کو revisions میں کسی بھی percentage سے split کر سکتی ہے۔ اس سے blue/green deploys اور rollback built-in ہو جاتے ہیں: rollback traffic change ہے، redeploy نہیں۔
- یہ Observability۔ ACA logs، metrics، اور traces کو Azure کے monitoring tools میں feed کرتی ہے، اس لیے request rate، error rate، اور latency free ملتے ہیں؛ harness اوپر agent کی اپنی traces add کرتا ہے۔
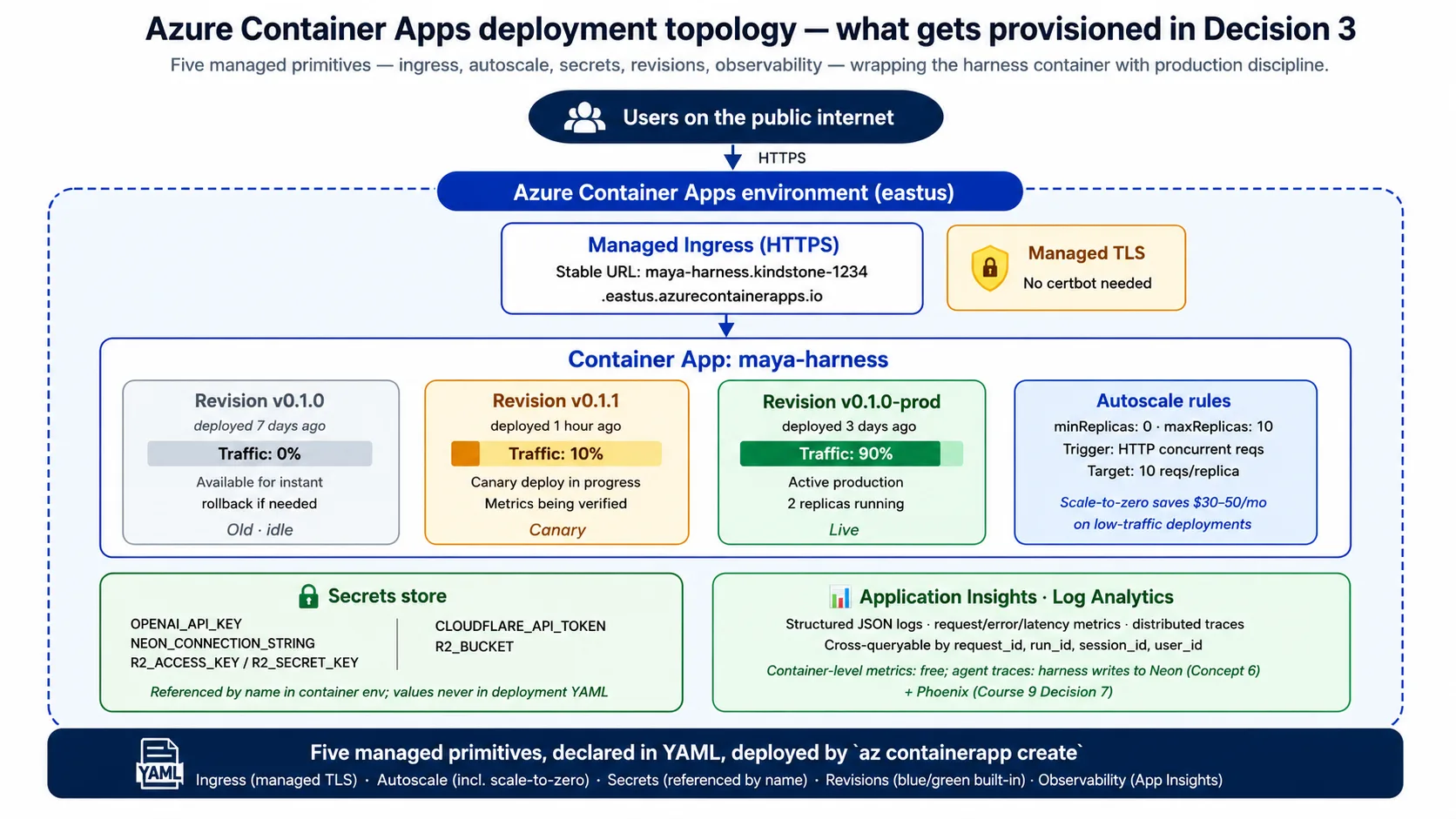
خاص طور پر ACA کیوں، Cloud Run یا Fly.io یا raw Kubernetes کیوں نہیں؟ تین honest reasons۔ Microsoft ACA کو exactly اس profile کے لیے position کرتا ہے: containerized APIs، background jobs، اور microservices۔ اس کی revisions اور traffic splitting first-class ہیں، جہاں کئی services blue/green کو bolt-on treat کرتی ہیں۔ اور اس کا scale-to-zero honest ہے: یہ واقعی zero copies چلاتا ہے اور آپ کو bill نہیں کرتا، جبکہ کچھ "managed" services ایک copy warm رکھ کر bill کرتی ہیں۔ دوسرے clouds میں clean equivalents ہیں (Google Cloud Run، AWS App Runner)؛ architectural shape identical ہے، اور Concept 9 اور Concept 15 substitutions cover کرتے ہیں۔
یہ ACA کب wrong choice ہے: اگر peak پر roughly 25 copies سے زیادہ چاہیے تو per-app limits awkward ہو جاتی ہیں اور full Kubernetes بہتر fit ہے؛ اگر active-active multi-region چاہیے تو اس کی multi-region story less mature ہے (Concept 14 اسے name کرتا ہے)۔ Harness جو container deploy کرتا ہے وہ small ہے، python:3.12-slim سے multi-stage build کے ساتھ built ہے، uvicorn سے start ہوتا ہے، اور اسی GET /health endpoint سے checked ہے جسے آپ نے Quick Win میں hit کیا تھا۔
لیب کا Decision 3 مختصر ACA configuration produce کرتا ہے جو public address، name سے referenced secrets، resource size، اور scale rule (request volume پر zero سے چند copies تک) declare کرتا ہے۔ آپ اسے پڑھیں گے اور اس concept سے ہر line recognize کریں گے۔
خلاصہ: Azure Container Apps harness runtime ہے کیونکہ یہ public address، autoscale (scale-to-zero سمیت)، secrets، revisions، اور observability managed primitives کے طور پر دیتی ہے، server یا Kubernetes management کے بغیر۔ Microsoft اسے containerized APIs اور microservices کے لیے position کرتا ہے، exactly harness کا profile۔ اس کی recipe boundary roughly 25 copies اور single-region ہے؛ اس سے آگے Concept 15 migration cover کرتا ہے۔
تصور 6: Durable state کے لیے Neon Postgres
یہ Harness کو runs کے across چیزیں یاد رکھنی ہیں: conversation history، run records، traces، audit log۔ یہ سب container restart، scale، یا replace ہونے کے بعد survive کرنا چاہیے۔ اس course کی choice Neon Postgres ہے۔
یہ Postgres ہی کیوں، Redis یا document store کیوں نہیں؟ Harness state کی تین properties relational، transactional database کی طرف point کرتی ہیں۔ Shape relational ہے: sessions کی many runs ہوتی ہیں، runs کی traces اور artifacts ہوتے ہیں، اس لیے foreign keys اور joins cleanly map ہوتے ہیں۔ Transactional integrity چاہیے: "اس run کو complete mark کرو، trace insert کرو، اور session timestamp update کرو" سب ہو یا کچھ بھی نہ ہو، جو Postgres transactions free دیتے ہیں۔ Reads بھی relational ہیں: "اس session کی last ten runs traces کے ساتھ دو" textbook SQL query ہے۔ Redis جیسا cache key lookups کے لیے faster ہے مگر system of record کے لیے wrong shape ہے۔
خاص طور پر Neon کیوں، RDS یا VM پر database کیوں نہیں؟ Serverless story: Neon compute کو خود up/down scale کرتا ہے، اور harness idle ہونے پر near-zero تک scale ہو سکتا ہے، باقی stack کے cost model سے match کرتے ہوئے۔ Traditional managed instance آپ کو bill کرتا ہے چاہے آپ query کریں یا نہ کریں۔ Branching story: Neon آپ کو database branch بنانے دیتا ہے، ایسی copy جو parent کے ساتھ storage share کرتی ہے جب تک آپ اسے change نہ کریں، جس سے per-developer copies اور per-PR throwaway test databases seconds میں ملتے ہیں۔ اور یہ Postgres ہے، approximation نہیں: وہی SQL، وہی client libraries، اس لیے Neon پر یا off move کرنا connection-string change ہے۔
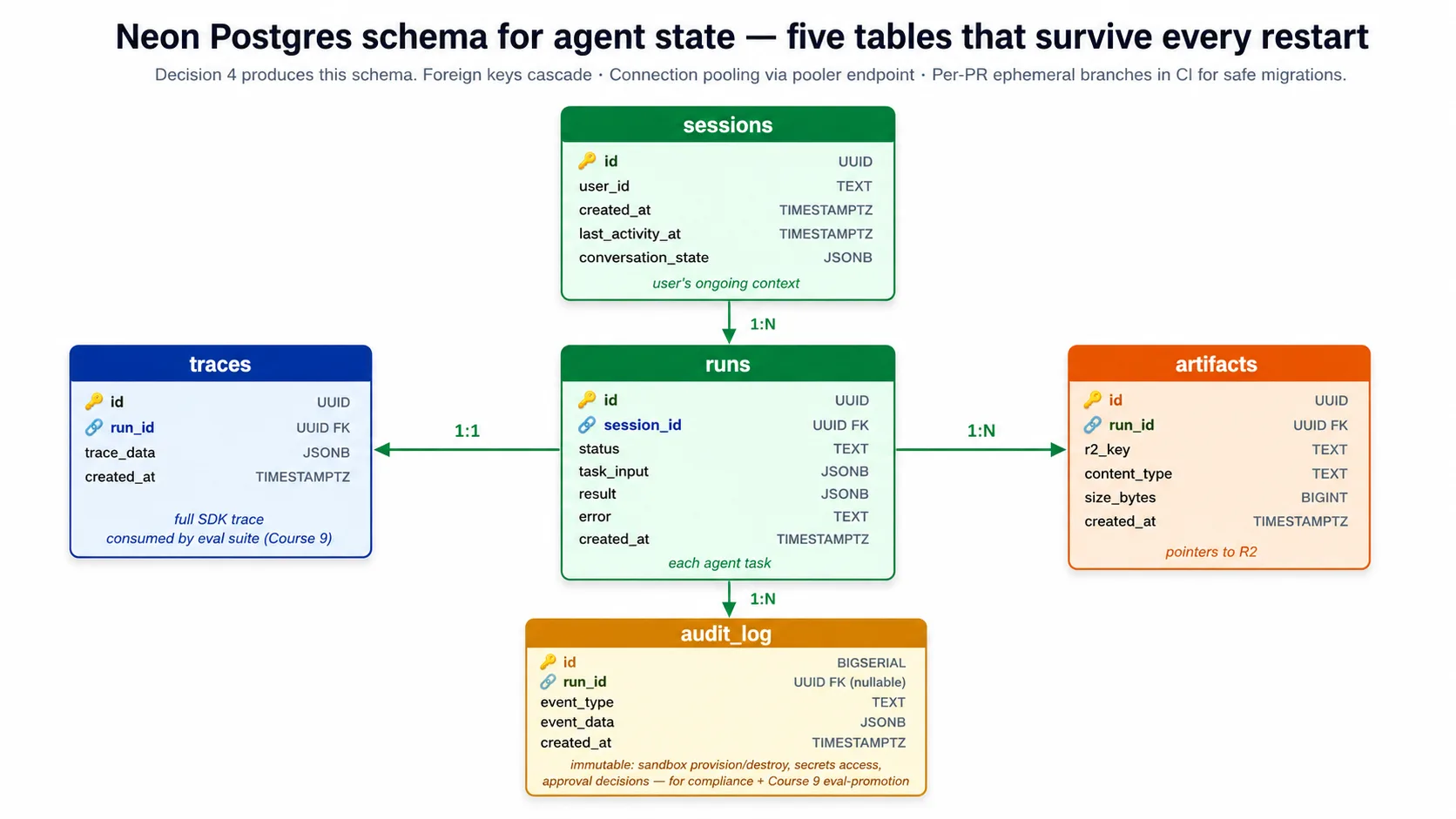
یہ Harness کا schema پانچ tables ہے: sessions (user کا ongoing context)، runs (ہر agent task)، traces (run کی full SDK trace)، artifacts (R2 میں files کی pointers)، اور audit log (جو ہوا اس کا immutable record، eval suite اور compliance کے لیے)۔ Lab کا Decision 4 companion download کی schema.sql file سے یہ schema create کرتا ہے۔
⚠️ Neon کی دو footguns جنہیں lab آپ کے لیے fix کرتی ہے۔ Neon کی copy-paste connection string میں
channel_binding=requireشامل ہوتا ہے۔asyncpgdriver اسے recognize نہیں کرتا اور pooled endpoint کے against fail ہو جاتا ہے، اس لیے harness connect کرنے سے پہلےchannel_bindingstrip کرتا ہے (یہsslmode=requireرکھتا ہے)۔ الگ سے، pooled endpoint silentlysearch_pathserver settings drop کر دیتا ہے، اس لیے harness ہر statement schema-qualify کرتا ہے (public.runs،public.sessions) اور آپ schema کو direct، non-pooled endpoint کے against run کرتے ہیں۔ دونوں real footguns ہیں، companion code انہیں handle کرتا ہے؛ lab انہیں explicit acceptance criteria کے طور پر call out کرتی ہے۔
یہ Connection pooling optional نہیں۔ Harness many copies تک scale ہوتا ہے، ہر copy connections کھولتی ہے، اور Postgres چند hundred connections سے اوپر fall over کر جاتا ہے۔ Neon pooled endpoint دیتا ہے جو ہزاروں harness connections کو تھوڑے real Postgres connections میں multiplex کرتا ہے۔ Harness normal work کے لیے pooled endpoint سے connect کرتا ہے، اور schema changes کے لیے صرف direct endpoint سے۔
خلاصہ: Neon Postgres harness کا durable state store ہے کیونکہ Postgres relational، transactional، read-heavy state کے لیے صحیح shape ہے، اور Neon خاص طور پر اس لیے کہ اس کی serverless scaling ACA سے match کرتی ہے اور branching per-developer اور per-PR databases cheaply دیتی ہے۔ Connection pooling لازمی ہے؛ harness app کے لیے pooled endpoint اور migrations کے لیے direct endpoint استعمال کرتا ہے۔ Schema پانچ tables ہے، Decision 4 میں built۔
تصور 7: Files اور artifacts کے لیے Cloudflare R2
یہ Harness اور sandbox دونوں کو files چاہیے: input documents جو agent پڑھتا ہے، output artifacts جو یہ بناتا ہے، knowledge content جو یہ retrieve کرتا ہے۔ اس course کی choice Cloudflare R2 ہے، تین specific reasons کے لیے۔
یہ Object storage ہی کیوں، database یا container disk کیوں نہیں؟ Files relational database کے لیے wrong shape ہیں: Postgres large file کو column میں hold کر سکتا ہے، مگر backups balloon ہوں گے اور connection bottleneck بن جائے گا۔ Database کو relational state کے لیے استعمال کریں اور files کی pointers store کریں؛ file bytes object storage میں رہیں۔ Files container local disk کے لیے بھی wrong ہیں، کیونکہ وہ restart پر disappear ہو جاتا ہے اور copies کے across easily share نہیں ہوتا۔ Object storage صحیح shape ہے جب files کو کسی ایک container سے زیادہ survive کرنا اور many copies سے reachable ہونا ہو۔
خاص طور پر R2 کیوں، S3 یا GCS کیوں نہیں؟ Egress story main reason ہے۔ R2 سے اپنی files read out کرنا free ہے۔ S3، Google Cloud Storage، اور Azure Blob transferred-out data پر charge کرتے ہیں، عموماً five to twelve cents per gigabyte۔ ایسے agent کے لیے جو harness اور sandbox کے درمیان files بار بار move کرتا ہے، یہ جلدی add up ہوتا ہے۔ اگر harness ماہانہ چند terabytes move کرے تو S3 پر egress کے hundreds of dollars دے گا اور R2 پر zero؛ storage اور request costs roughly comparable ہیں، اس لیے egress line simply disappear ہو جاتی ہے۔ Low-traffic harness کے لیے فرق چھوٹا ہے، مگر real volume پر free egress viable اور unviable cloud costs کا فرق ہے۔
یہ R2 S3 API بھی بولتا ہے، اس لیے کوئی بھی Python S3 library endpoint URL کی ایک setting بدل کر اس سے بات کرتی ہے، client rewrite کے بغیر اگر آپ کبھی migrate کریں۔ اور اپریل 2026 SDK release R2 کو S3، GCS، اور Azure Blob کے ساتھ supported Manifest mount source کے طور پر list کرتی ہے، اس لیے harness Manifest میں R2 buckets declare کرتا ہے اور sandbox انہیں custom bridging code کے بغیر mount کرتا ہے۔
یہ Harness اپنے bucket میں تین prefixes استعمال کرتا ہے: users کی uploaded files کے لیے inputs/، agent کی produced files کے لیے outputs/، اور long-lived knowledge content کے لیے knowledge/۔ Lab کا Decision 5 اسے setup کرتا ہے۔
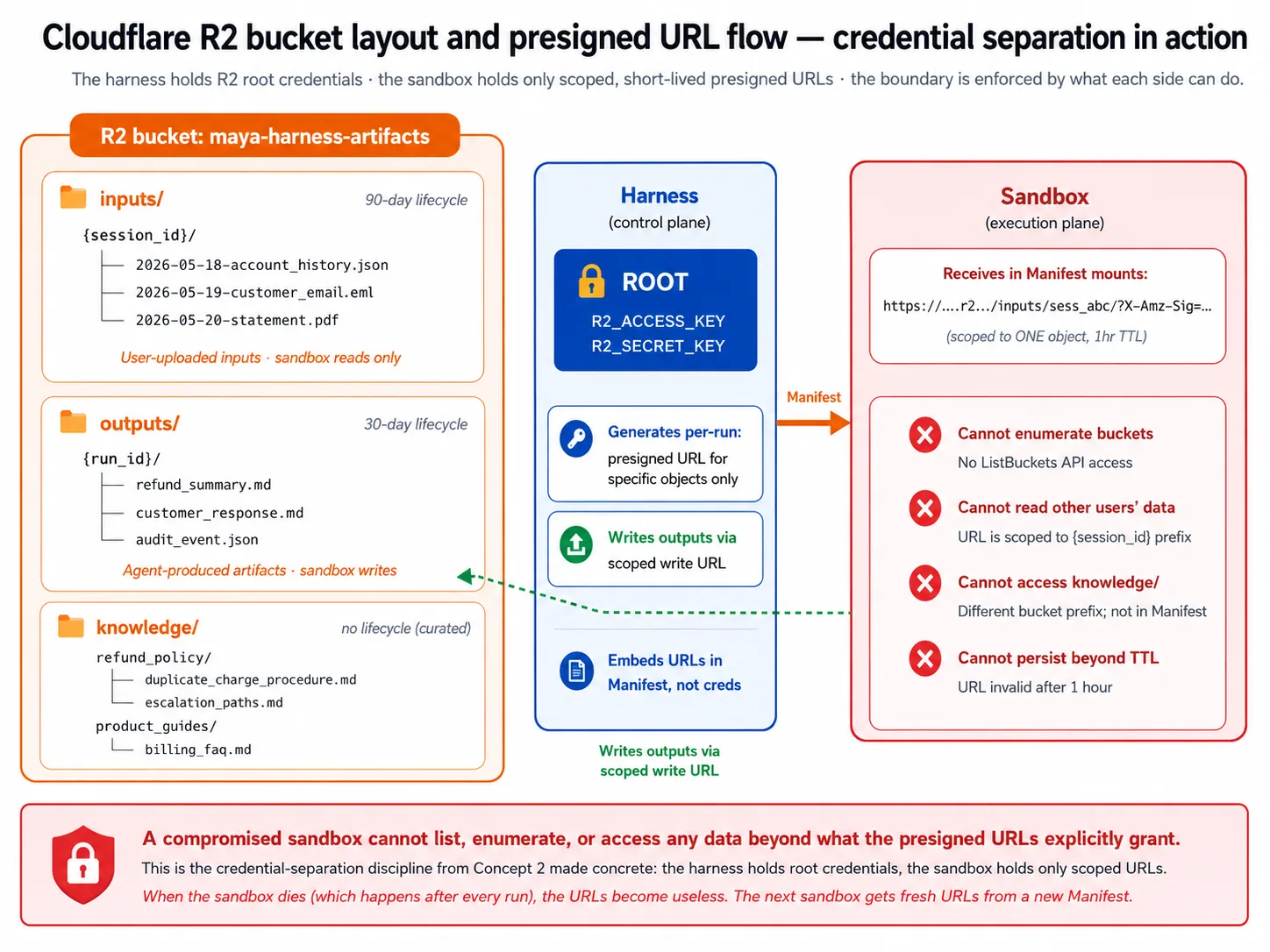
یہ Presigned URLs وہ طریقہ ہیں جس سے sandbox کو root credentials کے بغیر access ملتا ہے۔ Harness root credentials hold کرتا ہے جو anything read یا write کر سکتے ہیں۔ یہ انہیں sandbox کے ساتھ share نہیں کرتا۔ اس کے بجائے یہ one specific object کے لیے short expiry والا presigned URL mint کرتا ہے اور sandbox کو دیتا ہے۔ Sandbox صرف وہی reach کر سکتا ہے جس کی URL اجازت دیتی ہے؛ جب sandbox die ہوتا ہے تو URL useless ہو جاتا ہے، اور اگلے sandbox کو fresh URLs ملتی ہیں۔ یہ Concept 2 کی credential separation کو concrete بناتا ہے: compromised sandbox buckets list نہیں کر سکتا اور دوسرے user کے data تک نہیں پہنچ سکتا۔
یہ Lifecycle policies storage کو write-only graveyard بننے سے بچاتی ہیں: lab outputs/ پر 30-day cleanup set کرتی ہے، اور curated knowledge/ پر none۔
خلاصہ: Cloudflare R2 harness کا file store ہے کیونکہ object storage صحیح shape ہے (نہ database، نہ container disk)، اور R2 خاص طور پر اس لیے کہ اپنی files read out کرنا free ہے (volume پر ماہانہ hundreds to thousands of dollars بچاتا ہے)، اس کی S3 API کو SDK migration نہیں چاہیے، اور SDK اسے Manifest mount source کے طور پر support کرتا ہے۔ Harness presigned URLs سے sandbox کو root credentials کے بغیر scoped access دیتا ہے؛ lifecycle policies old artifacts clean کرتی ہیں۔
حصہ 3: Execution plane
یہ Part 2 نے harness side cover کی: orchestration، state، اور storage۔ Part 3 execution side cover کرتا ہے، وہ sandbox جہاں agent کا generated code actual run ہوتا ہے۔ تین concepts: sandbox کیا provide کرتا ہے، کون سا provider choose کریں، اور harness اور sandbox کے درمیان handoff کیسے کام کرتا ہے۔
تصور 8: Sandbox execution capabilities
یہ Concept 2 نے sandbox کو execution plane کے طور پر name کیا: وہ جگہ جہاں code harness secrets تک access کے بغیر چلتا ہے۔ Concept 8 اسے concrete بناتا ہے۔ Agent کو sandbox سے اصل میں کیا چاہیے؟
پانچ capabilities:
- یہ Filesystem۔ Agent files read اور write کرتا ہے: inputs، intermediate artifacts، outputs۔ Sandbox Unix-like filesystem دیتا ہے جس میں read، write، edit، اور list operations tools کے طور پر exposed ہوتے ہیں۔ اس کے بغیر agent file work نہیں کر سکتا۔
- یہ Shell۔ Agent commands چلاتا ہے: test runner، package install، clone، custom tool۔ Sandbox shell دیتا ہے جہاں یہ run ہوتے ہیں۔ اس کے بغیر agent صرف اس تک limited ہے جسے harness explicitly wrap کرتا ہے۔
- یہ Package install۔ Agent demand پر packages install کرتا ہے: "یہ library install کرو، پھر user کی uploaded file پڑھو، پھر summarize کرو۔" اس کے بغیر agent capability اس تک locked رہتی ہے جو base image کے ساتھ ship ہوا۔
- یہ Mounted storage۔ Agent کو local disk سے بڑی files چاہیے: uploads، knowledge content، datasets۔ Sandbox external storage (R2، S3، GCS) کو normal paths کے طور پر mount کرتا ہے، اور Manifest declare کرتا ہے کہ کون سا where mount ہو۔ اس کے بغیر agent صرف اتنی چھوٹی files touch کر سکتا ہے جو image میں ship ہو سکیں۔
- یہ Snapshot and resume۔ Sandboxes throwaway ہیں اور mid-run fail ہو سکتے ہیں۔ Sandbox اپنی state checkpoint کر سکتا ہے اور fresh workspace میں اس checkpoint سے resume کر سکتا ہے، یہی طریقہ SDK کو long tasks کو workspace dying کے باوجود survive کراتا ہے۔ اس کے بغیر sandbox lifetime سے longer task waiting failure ہے۔
یہ Production-grade sandbox کو prototype سے تین properties الگ کرتی ہیں۔ Isolation: sandbox harness network، filesystem، یا other sandboxes تک reach نہیں کر سکتا، provider infrastructure enforce کرتا ہے trust نہیں، اس لیے compromised sandbox صرف خود کو harm کرتا ہے۔ Ephemerality: ہر task کو fresh sandbox ملتا ہے، task end ہوتے ہی destroy ہو جاتا ہے، اس لیے compromised sandbox next task میں carry نہیں ہوتا۔ Fast provisioning: sandbox چند seconds میں start ہوتا ہے، کیونکہ thirty-second start ہر task کو thirty-second-plus operation بناتا ہے اور chat-style agents slow محسوس ہوتے ہیں۔
یہ Sandbox کیا نہیں ہے۔ یہ long-lived VM نہیں جسے آپ tasks کے across running رکھیں؛ ایسا کرنا problem دوبارہ invent کرتا ہے، state accumulate کرتا ہے اور harness secrets کے ساتھ entanglement بناتا ہے۔ یہ serverless function نہیں، جو ایک function run کر کے return کرتا ہے؛ sandbox workspace ہے جو one run کے اندر many tool calls کے across persist کرتا ہے، run کے دوران filesystem میں state رکھتا ہے، اور shell access دیتا ہے۔ اور یہ Kubernetes نہیں؛ sandbox provider container orchestration کو entirely abstract کرتا ہے، اس لیے آپ cluster چلائے بغیر isolation اور ephemerality لیتے ہیں۔
خلاصہ: production-grade sandbox filesystem، shell، package install، mounted storage، اور snapshot-and-resume دیتا ہے، isolation، ephemerality، اور fast provisioning کو foundational properties کے طور پر رکھتے ہوئے۔ یہ long-lived VM نہیں، serverless function نہیں، اور Kubernetes نہیں۔ اپریل 2026 SDK release کسی بھی compatible provider سے یہی expect کرتی ہے۔
تصور 9: Sandbox provider چننا
یہ Concept 8 نے capabilities name کیں؛ Concept 9 provider pick کرتا ہے۔ یہ course choice اور realistic free path کے بارے میں honest ہے۔
اس tradeoff سے شروع کریں جو most readers کے لیے فیصلہ کر دیتا ہے۔ Cloudflare sandbox کو paid Workers plan چاہیے، اور آپ کے Python harness اور sandbox کے درمیان ایک چھوٹا bridge Worker بھی چاہیے۔ E2B کے پاس free Hobby tier، SDK میں native client، اور deploy کرنے کے لیے کوئی bridge نہیں۔ اس لیے اگر آپ lab بغیر خرچ complete کرنا چاہتے ہیں تو E2B realistic free path ہے؛ اگر آپ پہلے ہی paid Cloudflare plan پر ہیں اور R2 استعمال کر رہے ہیں تو Cloudflare sandbox proximity benefit کی وجہ سے worth it ہے۔ Lab اس طرح لکھی گئی ہے کہ دونوں work کریں، اور companion code E2B default کرتا ہے کیونکہ اسی کو آپ actual میں free test کر سکتے ہیں۔
جب آپ Cloudflare sandbox choose کریں تو course کا named primary وہ کیوں ہے: یہ Cloudflare network میں چلتا ہے، اور R2 بھی وہیں ہے، اس لیے R2 buckets mount کرنا public internet کے بجائے Cloudflare-internal speeds پر ہوتا ہے۔ کسی اور provider کی R2 سے یہ proximity نہیں۔ اسے first-class SDK support بھی ہے اور cost structure idle time bill نہیں کرتا (اور agent model پر wait execution سے کہیں زیادہ کرتا ہے)۔ Catch paid plan اور bridge Worker ہے: Python harness جیسے non-Worker clients Cloudflare sandboxes directly create نہیں کر سکتے، اس لیے الگ deployed چھوٹا Worker harness calls کو sandbox operations میں translate کرتا ہے۔ E2B سمیت دوسرے providers Python API directly expose کرتے ہیں اور bridge نہیں چاہتے۔
یہ Honest alternatives، ہر ایک کے winning use case کے ساتھ:
- یہ E2B۔ Realistic free-tier path اور polished general-purpose provider۔ یہ S3، GCS، یا Azure Blob کے ساتھ equally well work کرتا ہے، اور SDK میں اس کا native client ہے۔ E2B تب استعمال کریں جب آپ storage-agnostic ہوں، R2 پر نہ ہوں، یا lab free complete کرنا چاہتے ہوں۔
- یہ Modal۔ Python ML workloads کے لیے strong؛ agent tasks کو GPU-backed inference کے ساتھ چلانا trivial۔ Modal تب استعمال کریں اگر آپ کا agent custom model serving شامل کرتا ہے۔
- یہ Daytona۔ آپ کے own cloud account میں چلتا ہے۔ Regulated industries کے لیے استعمال کریں جہاں data residency sandbox کو آپ کے specific cloud میں رہنے کا تقاضا کرے، higher operational complexity کی قیمت پر۔
- یہ Vercel۔ اگر آپ کی team پہلے ہی Vercel ecosystem میں deep ہے تو استعمال کریں؛ non-JavaScript workloads کے لیے less mature۔
- یہ Bring-your-own۔ SDK آپ کے own container infrastructure کے against sandbox client implement کرنے کو support کرتا ہے۔ Worth it صرف تب جب security team period کے ساتھ sandboxes آپ کے cloud میں require کرے؛ operational complexity بہت بڑھتی ہے۔
یہ Providers کے درمیان substitution زیادہ تر mechanical ہے۔ Manifest provider-agnostic ہے، اس لیے آپ workspace shape same declare کرتے ہیں۔ Provider client class بدلتی ہے (ایک کے لیے Cloudflare client، دوسرے کے لیے E2B client)۔ Storage mounting network proximity سے differ کرتی ہے (Cloudflare sandbox کے ساتھ R2 fast ہے؛ E2B کے ساتھ R2 public internet سے جاتا ہے، پھر بھی work کرتا ہے)۔ Credential pattern identical ہے: harness provider credentials hold کرتا ہے اور sandbox کو صرف short-lived access دیتا ہے۔
یہ Recommendation، ایک line میں: اگر آپ paid Workers plan پر ہیں اور R2 استعمال کر رہے ہیں تو Cloudflare sandbox استعمال کریں؛ otherwise E2B استعمال کریں، خاص طور پر اگر free path چاہیے؛ ایک pick کریں اور ship کریں، سب کا survey نہ کریں۔
خلاصہ: Cloudflare sandbox R2 proximity اور first-class SDK support کی وجہ سے اس course کا named primary ہے، مگر اسے paid Workers plan اور bridge Worker چاہیے۔ E2B realistic free path ہے: free Hobby tier، native SDK client، اور no bridge۔ Companion code E2B default کرتا ہے؛ lab دونوں کے ساتھ work کرتی ہے۔ Providers switch کرنا mechanical ہے کیونکہ Manifest provider-agnostic ہے۔
تصور 10: Harness-to-sandbox handoff
یہ Harness orchestrate کرتا ہے؛ sandbox execute کرتا ہے۔ Concept 10 handoff walkthrough کرتا ہے: harness sandbox کو provision کرنے کے لیے کیا بتاتا ہے، credentials boundary safely کیسے cross کرتے ہیں، اور run کے across sandbox lifecycle کیسے manage ہوتا ہے۔
یہ Manifest handoff contract ہے۔ Harness Manifest compose کرتا ہے جو describe کرتا ہے workspace کو کیا چاہیے؛ provider اسے receive کرتا ہے اور matching workspace provision کرتا ہے۔ اپریل 2026 SDK میں Manifest entries کے set سے built ہے: ہر entry workspace کا path ہے جو وہاں جانے والی چیز سے map ہوتا ہے، file، directory، git repo، یا storage mount۔ Mounts (R2Mount، S3Mount، اور باقی) agents.sandbox.entries میں live کرتے ہیں اور انہی entries کے اندر جاتے ہیں۔ Manifest پر mounts کی separate list اور base-image یا resource-limit fields نہیں ہوتیں؛ entries workspace describe کرتی ہیں۔
from agents.sandbox import Manifest
from agents.sandbox.entries import R2Mount
# Mounts go inside entries, keyed by their path in the workspace.
manifest = Manifest(
entries={
"/workspace/inputs": R2Mount(
bucket="maya-harness-artifacts",
prefix=f"inputs/{session_id}/",
),
"/workspace/outputs": R2Mount(
bucket="maya-harness-artifacts",
prefix=f"outputs/{run_id}/",
),
}
)
یہ Capabilities SDK defaults سے chosen ہوتی ہیں، اور passed list انہیں replace کرتی ہے۔ Capabilities.default() standard set return کرتا ہے (filesystem، shell، اور compaction)۔ اگر آپ اپنی list pass کریں تو یہ default میں add نہیں ہوتی بلکہ اسے replace کرتی ہے، اس لیے defaults keep کرنے اور ایک ability add کرنے کے لیے concatenate کریں:
from agents.sandbox.capabilities import Capabilities, Skills
# Keep the defaults and add one: a passed list REPLACES the default,
# so concatenate rather than passing [Skills(...)] alone.
capabilities = Capabilities.default() + [Skills(name="data-tools")]
یہ real footgun ہے: capabilities=[Shell()] لکھنا silently filesystem اور compaction abilities drop کر دیتا ہے جو default میں included تھیں۔ Default keep کریں اور اس میں add کریں۔
یہ Sandbox RunConfig کے ذریعے attach ہوتا ہے، Runner.run argument کے طور پر نہیں۔ کوئی Runner.run(..., sandbox=...) parameter نہیں۔ آپ provider client اور اس کے options object سے SandboxRunConfig بناتے ہیں، اسے RunConfig پر رکھتے ہیں، اور RunConfig run کو pass کرتے ہیں۔ ہر provider client اپنے options object کے ساتھ pair ہوتا ہے، اور options SandboxRunConfig میں ride کرتے ہیں، client constructor میں نہیں:
from agents import Runner
from agents.run import RunConfig
from agents.sandbox import SandboxRunConfig
from agents.extensions.sandbox.e2b import E2BSandboxClient, E2BSandboxClientOptions
# The client reads E2B_API_KEY from the environment; the options carry the
# required sandbox_type. The sandbox rides on RunConfig, not a Runner kwarg.
sandbox = SandboxRunConfig(
client=E2BSandboxClient(),
options=E2BSandboxClientOptions(sandbox_type="e2b"),
)
result = await Runner.run(agent, message, run_config=RunConfig(sandbox=sandbox))
یہ Cloudflare sandbox کے لیے shape same ہے؛ صرف client اور options بدلتے ہیں (ایک CloudflareSandboxClient with CloudflareSandboxClientOptions(worker_url=...))۔ Companion download کے sandbox.py اور runner.py میں یہی exact code ہے، installed SDK کے against booted۔
یہ Credential discipline سب سے اہم security point ہے۔ Harness storage root credentials اور provider credentials hold کرتا ہے۔ یہ specific objects کے لیے short expiry والے presigned URLs mint کرتا ہے، اور وہ workspace میں جاتے ہیں، root credentials نہیں۔ Sandbox صرف وہ scoped URLs receive کرتا ہے: buckets enumerate نہیں کر سکتا، harness database تک reach نہیں کر سکتا (connection string boundary cross نہیں کرتی)، اور harness کی other services تک reach نہیں کر سکتا (network policy اسے صرف needed چیزوں تک restrict کرتی ہے، جیسے model API اور package registries)۔ اس کے علاوہ کچھ بھی، root credentials یا database string کو workspace میں embed کرنا، وہ security mistake ہے جسے روکنے کے لیے اپریل 2026 release design ہوئی۔
یہ Single run کا lifecycle: harness request receive کرتا ہے اور session state load کرتا ہے؛ task کے لیے Manifest compose کرتا ہے؛ provider سے workspace provision کرواتا ہے؛ SDK agent loop چلاتا ہے، filesystem اور shell calls sandbox کو route کرتا ہے اور trace record کرتا ہے؛ اگر workspace fail ہو اور snapshots enabled ہوں تو SDK latest snapshot سے نیا workspace provision کر کے continue کرتا ہے؛ completion پر harness R2 سے outputs read کرتا ہے، trace اور artifact pointers Neon میں persist کرتا ہے، sandbox destroy کرتا ہے تاکہ کچھ idle نہ رہے، اور user کو result return کرتا ہے۔
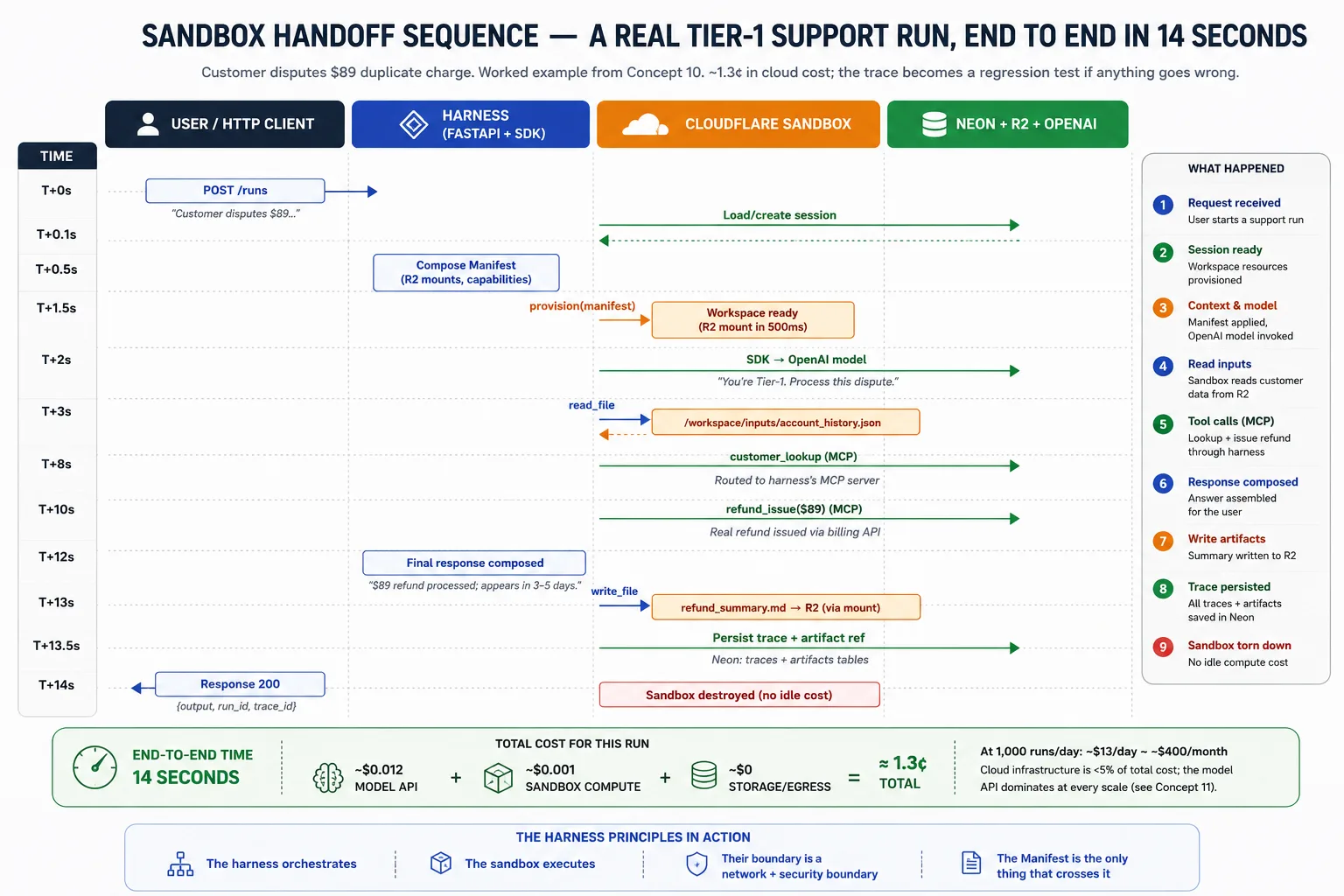
خلاصہ: harness-to-sandbox handoff Manifest سے mediated ہے، جو workspace describe کرنے والی entries سے built ہے (mounts
agents.sandbox.entriesمیں live کرتے ہیں)۔ CapabilitiesCapabilities.default()سے آتی ہیں، اور passed list اسے replace کرتی ہے۔ SandboxRunConfig(sandbox=SandboxRunConfig(client=..., options=...))کے ذریعے attach ہوتا ہے،Runner.runargument نہیں۔ Credentials root level پر کبھی cross نہیں کرتے؛ sandbox کو صرف scoped presigned URLs ملتے ہیں۔ Lifecycle ہے provision، run، snapshot-and-resume if needed، destroy۔ یہ Concept 2 کی credential separation کو concrete بناتا ہے۔
حصہ 4: Observability اور Evals بطور Architectural Surfaces
یہ Parts 1-3 نے harness deploy کیا۔ Part 5 کی lab اسے build کرے گی۔ Part 4 ان کے بیچ آ کر دو surfaces name کرتا ہے جن کی Part 1 کے harness/sandbox split کو ابھی بھی ضرورت ہے: وہ systems جو بتاتے ہیں running harness کیا کر رہا ہے، اور وہ systems جو measure کرتے ہیں کہ کیا یہ ابھی بھی right thing کر رہا ہے۔ جو teams انہیں skip کرتی ہیں وہ ایسا harness ship کرتی ہیں جو day one پر work کرتا ہے اور پھر quietly degrade ہوتا ہے۔ دو concepts، پھر lab۔
تصور 11: Observability as an architectural surface
یہ Observability: وہ tools جو بتاتے ہیں کہ running harness کیا کر رہا ہے، کب کچھ break ہوتا ہے، اور cause کیسے find کرنی ہے۔ زیادہ تر production AI failures observability failures ہوتے ہیں۔ Agent کچھ wrong کرتا ہے، کئی days تک کسی کو notice نہیں ہوتا، اور delay کی cost grow کرتی رہتی ہے۔ اس لیے observability end پر bolt-on feature نہیں۔ یہ ایک اور architectural surface ہے، start سے planned۔ Decision 7 اسے wire کرتا ہے۔
جب harness run ہوتا ہے تو چار surfaces ایک ساتھ اسے watch کرتے ہیں۔ یہ ملتے جلتے ہیں۔ ہر ایک different question own کرتا ہے۔
| Surface | Owns the question |
|---|---|
| Application Insights | کیا harness infrastructure healthy ہے؟ |
| OpenTelemetry traces | ایک request services میں کیسے flow ہوئی؟ |
| OpenAI Agents SDK traces | اس run کے دوران agent نے کیا کیا؟ |
| Phoenix | وقت کے ساتھ agent کا behavior کیسے بدل رہا ہے؟ |
یہ Application Insights Azure کا built-in monitor ہے۔ یہ container view own کرتا ہے: request rate، error rate، latency، CPU اور memory، restart counts، log streams۔ جب replica crash ہوتی ہے تو پہلے یہی notice کرتا ہے۔ یہ agent behavior نہیں دیکھ سکتا۔ اس کے لیے ہر request "POST /runs returned 200 in 12 seconds" ہے؛ answer correct تھا یا نہیں invisible ہے۔
یہ OpenTelemetry (OTel) ایک request کو services کے across trace کرنے کا open standard ہے۔ Trace ایک run کا complete record ہے۔ جب single request model call، three tool calls، اور four database queries میں fan out ہوتی ہے تو OTel ان سب کی parent-child timing دکھاتا ہے۔ یہ tool calls کے درمیان agent کی reasoning نہیں دیکھتا؛ یہ record کرتا ہے کہ model called ہوا، کیوں نہیں۔
یہ OpenAI Agents SDK اپنی trace emit کرتا ہے: کون سے model decisions ہوئے، کون سے tools کس arguments کے ساتھ call ہوئے، handoffs کہاں گئے۔ یہ agent-behavior view own کرتا ہے۔ Agent execution سے باہر کچھ نہیں دیکھتا۔
یہ Phoenix وقت کے ساتھ agent traces watch کرتا ہے اور bad ones کو future tests میں بدلتا ہے۔ یہ SDK traces sample کرتا ہے، score کرتا ہے، اور worst traces کو eval suite میں promotion کے لیے flag کرتا ہے۔ یہ trend view own کرتا ہے: agent نے کیا کیا ہی نہیں، کون سے runs tomorrow's regression tests بننے چاہئیں۔ یہ transient infrastructure outages نہیں دیکھتا۔
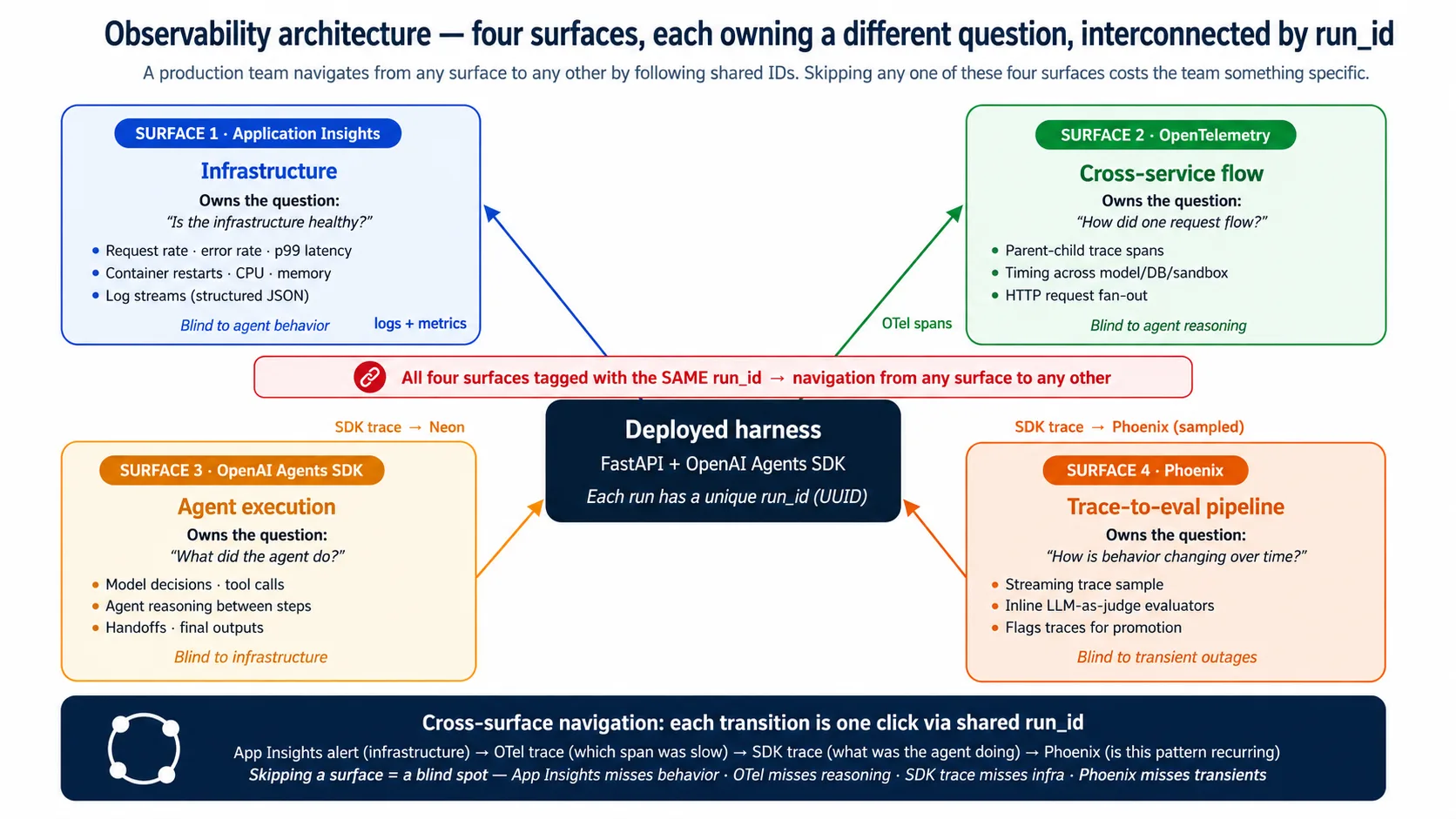
یہ Surfaces overlap کرتی ہیں؛ replace نہیں کرتیں۔ یہ shared run_id سے interconnect ہوتی ہیں، تاکہ team کسی بھی surface سے start کر کے ایک click میں کسی اور پر jump کر سکے۔ Application Insights alert infrastructure spike flag کرتا ہے؛ OTel trace دکھاتی ہے کون سا span slow تھا؛ SDK trace دکھاتی ہے agent کیا کر رہا تھا؛ Phoenix دکھاتا ہے کیا وہی pattern recur ہو رہا ہے۔ ایک surface skip کریں اور ان steps میں سے ایک lose کرتے ہیں: Application Insights skip کریں تو outages miss ہوتے ہیں، OTel skip کریں تو slow span miss ہوتا ہے، SDK trace skip کریں تو agent decision miss ہوتا ہے، Phoenix skip کریں تو eval suite stale ہو جاتی ہے۔
خلاصہ: observability checklist item نہیں، architectural surface ہے، اور یہ چار ہیں۔ Application Insights infrastructure own کرتا ہے، OpenTelemetry request flow own کرتی ہے، SDK trace agent execution own کرتی ہے، اور Phoenix time trend own کرتا ہے۔ Shared run_id انہیں جوڑتا ہے تاکہ team کسی بھی symptom سے cause تک navigate کر سکے۔ Day one پر چاروں wire کریں؛ missing surface اتنا بڑا blind spot ہے جتنا وہ own کرتی تھی۔
پانچویں surface صرف اس وقت آتی ہے جب آپ runs کو durable-execution layer میں wrap کریں۔ اس layer کا dashboard run-level operational lineage add کرتا ہے (کون سا step fail ہوا، retry ہوا، پھر succeed ہوا)۔ یہ Production Worker course کا territory ہے، یہ course نہیں۔ اگر آپ اسے build کریں تو Production Worker with a Nervous System دیکھیں۔
تصور 12: Evals as an architectural surface
یہ Eval: test جو agent behavior measure کرتا ہے (answer right تھا، tool correct تھا، reasoning sound تھی)، صرف یہ نہیں کہ code ran ہوا۔ Eval-Driven Development course نے چار eval frameworks build کیے۔ یہ concept name کرتا ہے کہ وہ deployed harness سے کہاں attach ہوتے ہیں۔ Attachment ہی point ہے: اس کے بغیر eval suite theory ہے۔
یہ Boundary ایک جگہ ہے: traces۔ Eval suite جو کچھ grade کرتی ہے وہ trace سے read کرتی ہے، اور traces دو stores میں live کرتی ہیں۔ Neon durable record رکھتا ہے، scheduled jobs اور audit سے queried۔ Phoenix real-time sample رکھتا ہے، live dashboard پر displayed۔ اگر اس concept سے ایک بات یاد رکھنی ہو تو یہ رکھیں کہ integration traces سے mediated ہے، اور traces Neon اور Phoenix میں live کرتی ہیں۔
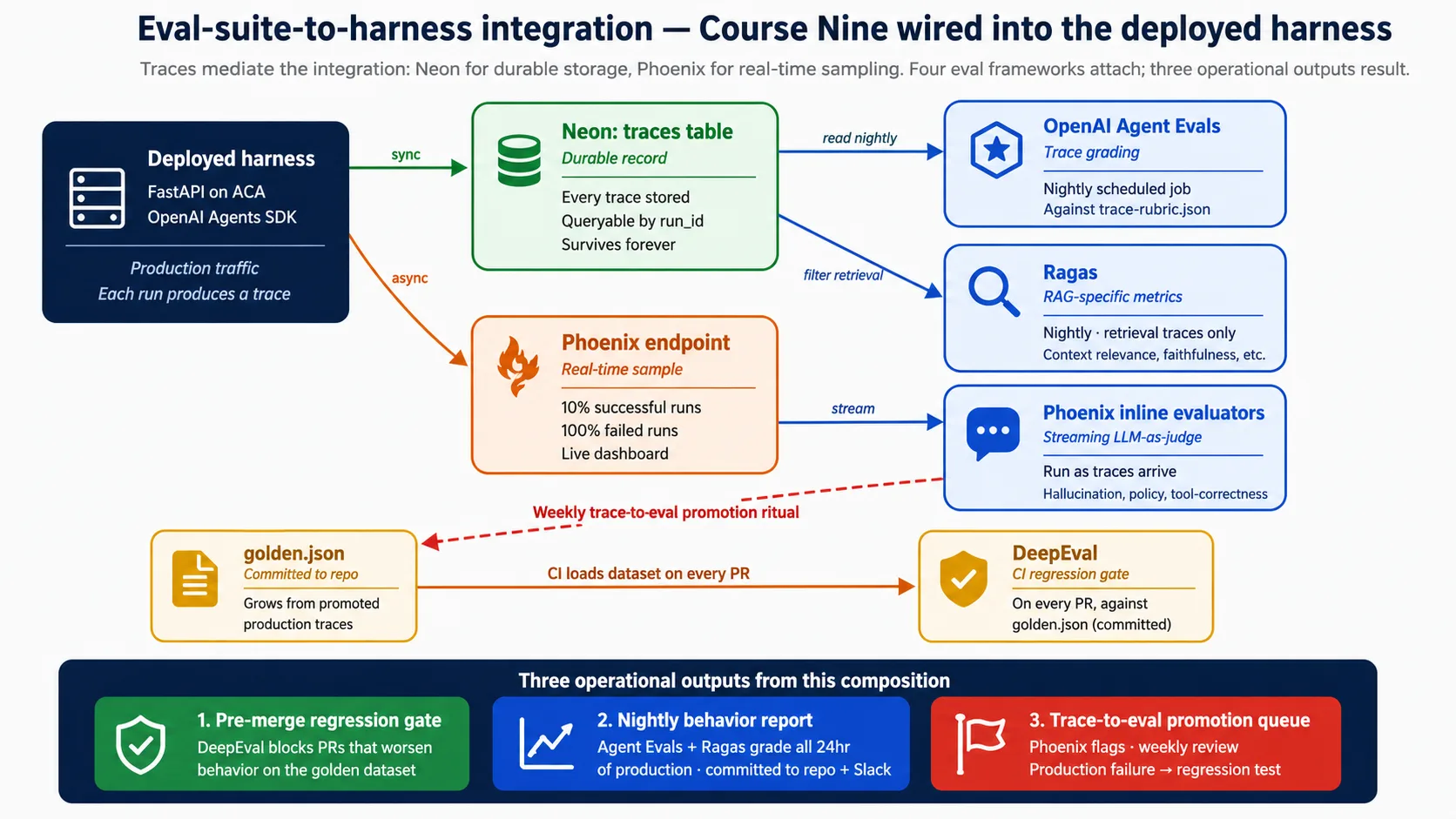
یہ Run finish ہونے پر harness trace کو Neon میں synchronously لکھتا ہے (durable record) اور sample کو Phoenix میں asynchronously stream کرتا ہے (live view)۔ وہاں سے eval frameworks specific points پر attach ہوتے ہیں: CI gate ہر pull request پر چلتا ہے، scheduled jobs پچھلے دن کی traces nightly grade کرتے ہیں، اور Phoenix inline checks traces آتے ہی run کرتے ہیں۔ Decision 8 یہ سب full wire کرتا ہے۔ اسے now plan کرنے کی وجہ simple ہے: observability wire ہونے سے پہلے produced traces gone ہیں، اور eval suite صرف ان traces سے grow ہوتی ہے جو اس نے actually دیکھی ہوں۔
خلاصہ: evals deployed harness سے traces کے ذریعے attach ہوتے ہیں، جو دو stores میں لکھے جاتے ہیں۔ Neon durable، queryable record رکھتا ہے؛ Phoenix real-time sample رکھتا ہے۔ Eval frameworks ان دو surfaces سے read کرتے ہیں۔ Trace-writing day one پر wire کریں، کیونکہ wiring exist کرنے سے پہلے produced traces کبھی regression tests نہیں بن سکتیں۔ Decision 8 wiring build کرتا ہے؛ یہ concept صرف boundary fix کرتا ہے۔
حصہ 5: Deployment Lab
یہ Parts 1-4 نے architecture اور surfaces cover کیں۔ Part 5 پوری چیز build کرتا ہے: دس Decisions جو آپ کو empty folder سے deployed، observable، eval-gated harness تک لے جاتے ہیں۔ Shape وہی ہے جو earlier courses استعمال کرتے ہیں۔ آپ coding agent کو direct کرتے ہیں؛ agent code لکھتا اور run کرتا ہے۔ ہر Decision ایک short brief ہے جو آپ paste کرتے ہیں، ایک "Done when:" line جسے آپ observe کر سکتے ہیں، اور readers کے لیے one-line note جو deploy کیے بغیر follow کرتے ہیں۔
یہ Companion download shared context رکھتا ہے۔ اس کے اندر AGENTS.md project rules، architecture، اور verified API shapes رکھتا ہے، اس لیے ہر brief short رہتا ہے: agent details کے لیے AGENTS.md پڑھتا ہے اور آپ صرف goal paste کرتے ہیں۔ Download ابھی لیں: deploying-agents-crash-course.zip۔
کام کرتے ہوئے اس diagram کی طرف واپس آئیں۔ ہر Decision ایک labeled piece add کرتا ہے۔
یہ Lab complete کرنے کے دو طریقے۔
یہ Full build (Intermediate اور Advanced tracks): آپ cloud پر deploy کرتے ہیں۔ ہر session کے بعد resources tear down کریں تو end-to-end bill چھوٹا رہتا ہے؛ انہیں running چھوڑیں تو grow کرتا ہے۔ Concept 13 میں cost breakdown ہے۔
یہ Simulated (Reader اور Beginner tracks): آپ کچھ provision کرنے کے بجائے companion code پڑھتے ہیں۔ Harness پھر بھی locally صرف
OPENAI_API_KEYset ہونے پر boot ہوتا ہے، اس لیے آپ ہر ایسا step run کر سکتے ہیں جسے cloud account نہیں چاہیے۔ ہر Decision میں Simulated note بتاتا ہے کہ instead کیا پڑھنا ہے۔
فیصلہ 0: SDK probe کریں اور brief reconcile کریں
ایک line میں: SDK install کریں، installed version print کریں، live sandbox docs fetch کریں، اور companion AGENTS.md کو ان کے against reconcile کریں۔ Live docs win کرتے ہیں۔
یہ OpenAI Agents SDK تیزی سے ship ہوتا ہے۔ Names، signatures، اور defaults releases کے درمیان move کرتے ہیں۔ Companion AGENTS.md آج کا known-good ہے، ہمیشہ کا نہیں۔ اس لیے پہلا Decision probe ہے: ہر symbol جس پر lab depend کرتی ہے اسے actual installed SDK کے against confirm کریں، اور drift لکھیں۔ یہاں پانچ minutes بعد میں "یہ attribute exist کیوں نہیں کرتا" والے ایک hour کو بچاتے ہیں۔
یہ اپنے coding agent میں paste کریں۔ پہلے plan بنائے؛ approval پر execute کرے۔
یہ Companion download کھولیں۔
AGENTS.mdکے bottom سے SDK probe run کریں:uv sync، پھرagents،agents.sandbox،agents.sandbox.entries، اور E2B client کے import checks۔ Installedopenai-agentsversion print کریں۔ Official docs سے live sandbox API reference fetch کریں۔AGENTS.mdمیں named ہر SDK symbol کو actual imported symbols کے against compare کریں۔ اگر کوئی فرق ہو تو live docs win کرتے ہیں:AGENTS.mdکے top پر مختصر "What changed since the brief" note لکھیں جس میں ہر difference listed ہو، اور اس کے بعد live name استعمال کریں۔ ابھی کوئی code change نہ کریں۔
یہ Done when:
- یہ Agent installed
openai-agentsversion report کرے (expect 0.17.x)۔ - یہ Agent SDK names report کرے جو
AGENTS.mdسے differ کرتے ہیں، اور ہر difference پر live docs win کریں۔ AGENTS.mdکے top پر short "What changed since the brief" note موجود ہو، یا agent state کرے کہ brief installed SDK سے match تھا۔
یہ Simulated track۔
AGENTS.mdکے آخر میں SDK probe section پڑھیں۔ اسے run کرنے کی ضرورت نہیں؛ point drift-resistance habit دیکھنا ہے: کسی symbol پر trust کرنے سے پہلے brief کو live SDK کے against confirm کریں، اور live docs کو win کرنے دیں۔
خلاصہ: Lab اب اس SDK پر rest کرتی ہے جو آپ کے پاس actual ہے، نہ کہ اس SDK پر جس کے against brief لکھا گیا تھا۔ ہر later Decision "What changed" note respect کرتا ہے۔ یہی mechanism lab کو SDK کے move کرنے کے باوجود correct رکھتا ہے۔
فیصلہ 1: ہارنس scaffold کریں
ایک line میں: FastAPI app جس میں agent، state layer، اور storage layer ہوں، سب key missing ہونے پر gracefully degrade کریں، اور locally صرف OPENAI_API_KEY پر boot ہو۔
یہ Decision وہ project setup کرتا ہے جس پر اگلے nine build کرتے ہیں۔ Agent (Maya کا Tier-1 Support) اور اس کے دو tools earlier courses سے آتے ہیں؛ یہ Decision انہیں wrap کرنے والا harness ہے، agent itself نہیں۔
یہ اپنے coding agent میں paste کریں۔ پہلے plan بنائے؛ approval پر execute کرے۔
یہ Companion
AGENTS.mdسے harness scaffold کریں۔ اس کے project rules اور architecture exact follow کریں۔openai-agents>=0.17,<0.18pin کریں۔ FastAPI app بنائیں جس میںGET /health(active backends report کرتا ہے) اورPOST /runs(session load کرتا ہے، Maya کا agent run کرتا ہے، run اور trace persist کرتا ہے، optionally artifact write کرتا ہے) ہوں۔ Graceful degradation wire کریں: app کو صرفOPENAI_API_KEYset ہونے پر import اور boot ہونا چاہیے،DATABASE_URLunset ہو تو SQLite fallback اور R2 keys unset ہوں تو local directory fallback۔ دو tools (lookup_account،draft_reply) کو@function_toolfunctions کے طور پر add کریں جن کی bodies sandbox نہیں، harness میں run ہوں۔ Lockfile commit کریں۔
یہ Done when:
- یہ
uv run uvicorn maya_harness.main:appharness کو errors کے بغیر start کرے۔ - درخواست
GET /health{"status": "ok", ...}return کرے جس میںpostgres،sandbox، اورr2سبfalsereported ہوں، bareOPENAI_API_KEY-only boot پر۔ GET /docsدو endpoints کی auto-generated API دکھائے۔
یہ Simulated track۔ Companion میں یہ scaffold already موجود ہے۔
src/maya_harness/main.py،agent.py، اورsettings.pyپڑھیں، اور notice کریں کہ ہر backend optional ہے: missing key ہر component کو off کرتی ہے اور harness پھر بھی boot ہوتا ہے۔
یہ boot وہ early win ہے جس کا یہ پورا course وعدہ کرتا ہے۔ کسی cloud account، Docker، یا database سے پہلے آپ کے پاس real agent harness اپنی laptop سے /health پر answer دے رہا ہے۔ Harness/sandbox split اب diagram نہیں؛ آپ کی machine پر running ہے۔ اس کے بعد سب کچھ ایک ایک durable backend add کرتا ہے۔
خلاصہ: booting FastAPI harness جس میں agent، optional state، اور optional storage ہے، سب gracefully degrade کرتے ہیں۔ Project کی shape یہاں fixed ہوتی ہے؛ اگلے Decisions real backends ایک ایک کر کے fill کرتے ہیں۔
فیصلہ 2: ہارنس containerize کریں
ایک line میں: harness کی small، reproducible container image جو آپ کے laptop اور cloud میں same run کرتی ہے۔
یہ Container: آپ کی app اور اسے چلانے کے لیے درکار ہر چیز کا sealed bundle، تاکہ یہ ہر جگہ same behave کرے۔ Decision 3 یہ image deploy کرتا ہے؛ Decision 2 اسے build کرتا ہے۔
یہ اپنے coding agent میں paste کریں۔ پہلے plan بنائے؛ approval پر execute کرے۔
یہ Companion کے
Dockerfileshape سے harness container build کریں۔ Committed lockfile سے reproducible install کے لیےpython:3.12-slimwithuvاستعمال کریں۔ Source copy کرنے سے پہلے dependencies cached layer میں install کریں۔ Port 8000 expose کریں اورuvicorn maya_harness.main:app --host 0.0.0.0 --port 8000 --proxy-headersrun کریں (--proxy-headersflag اہم ہے کیونکہ cloud اپنے ingress پر TLS terminate کرتا ہے)۔.dockerignoreadd کریں جو virtualenv، caches، اور.envfiles exclude کرے۔ Image build کریں اور اپنی.envmounted رکھ کر locally run کریں۔
یہ Done when:
- یہ Image errors کے بغیر build ہو۔
- یہ Container locally run ہو اور اس کے اندر سے
GET /healthokreturn کرے۔ - یہ Source file change کر کے rebuild fast ہو (dependency layer cached رہے)۔
یہ Simulated track۔ Companion
Dockerfileپڑھیں۔ Exercise multi-stage idea ہے: dependencies cached layer میں install ہوتی ہیں، source بعد میں copy ہوتا ہے، اور image small رہتی ہے۔ Docker installed ہونا ضروری نہیں۔
خلاصہ: small، reproducible harness image جو locally اور cloud میں same run کرتی ہے۔ Decision 3 یہی image Azure کو push کرتا ہے۔
فیصلہ 3: Azure Container Apps پر deploy کریں
ایک line میں: managed cloud runtime provision کریں، image cloud میں build کریں، اور harness کو deploy کریں تاکہ یہ public internet سے HTTPS پر answer کرے۔
یہ Azure Container Apps (ACA): managed service جو آپ کا container autoscale اور ingress کے ساتھ cloud میں چلاتی ہے، تاکہ آپ servers خود نہ چلائیں۔ یہی Decision ہے جہاں harness آپ کے laptop سے نکلتا ہے۔
یہ اپنے coding agent میں paste کریں۔ پہلے plan بنائے؛ approval پر execute کرے۔
یہ Companion کے
infra/deploy.shshape سے harness کو Azure Container Apps پر deploy کریں۔ Resource group اور container registry create کریں۔az acr buildسے image cloud میں build کریں (local Docker کی ضرورت نہیں)۔ Container Apps environment create کریں، پھر--ingress external،--target-port 8000، اور scale-to-zero کے لیے--min-replicas 0کے ساتھ app create کریں۔OPENAI_API_KEYکو named secret کے طور پر store کریں اورsecretref:سے reference کریں، image میں bake نہ کریں۔ App کا public URL confirm کریں اور/healthHTTPS پر answer کرتا ہو۔ Current environment کسی بھی subprocess کو pass کریں تاکہ keys survive کریں۔
یہ Done when:
- یہ Deploy script finish ہو اور public
*.azurecontainerapps.ioURL print کرے۔ - اپنے phone سے
https://<that-url>/healthکھولنے پر{"status": "ok", ...}return ہو۔ - یہ Quiet spell کے بعد app zero تک scale ہو، اور next request چند seconds میں copy wake کرے (scale-to-zero cold start)۔
یہ Simulated track۔
infra/deploy.shاورinfra/containerapp.yamlپڑھیں۔ سمجھنے والی shape یہ ہے: cloud میں build، external ingress اور scale-to-zero کے ساتھ deploy، اور secrets کو name سے store کرنا۔ Azure account ضروری نہیں۔
یہ Decision 3 سے اب آپ کے پاس deployed Container Apps app اور اس کا public URL ہے۔ Decisions 4 through 9 اسی app پر redeploy کر کے ہر backend add کرتے ہیں۔ اسے رکھیں؛ lab finish کرنے یا session purposefully end کرنے تک az group delete نہ چلائیں۔
خلاصہ: Harness managed cloud infrastructure پر live ہے، HTTPS سے reachable ہے، idle پر zero تک scale ہوتا ہے۔ Done ہونے پر tear-down ایک single
az group deleteہے۔ اگلے Decisions اسے durable state اور storage دیتے ہیں۔
فیصلہ 4: Durable state کے لیے Neon Postgres wire کریں
ایک line میں: serverless Postgres database provision کریں اور harness کو اس کی طرف point کریں، تاکہ sessions، runs، اور traces restart کے بعد survive کریں۔
یہ Durable state: restart کے بعد survive کرنے والی memory، container کے بجائے database میں رکھی ہوئی، کیونکہ container stop ہوتے ہی سب بھول جاتا ہے۔ Neon Postgres: cheap branching والا serverless Postgres database۔ اس Decision کے بعد container restart کریں تو run history پھر بھی موجود ہو گی۔
یہ اپنے coding agent میں paste کریں۔ پہلے plan بنائے؛ approval پر execute کرے۔
یہ Companion
state.pyاورschema.sqlfollow کرتے ہوئے Neon Postgres کو harness کی durable state کے طور پر wire کریں۔ console.neon.com پر Neon project create کریں۔ Five-table schema apply کریں (sessions، runs، traces، artifacts، audit_log)،public.*تک schema-qualified۔asyncpgکے ذریعے harness connect کریں۔ Companion کےnormalize_neon_dsnسے دو acceptance rules optional نہیں اور pooler کے against silent failures روکتے ہیں:
- یہ Neon connection string کو asyncpg کے حوالے کرنے سے پہلے
channel_bindingstrip کریں؛sslmode=requireرکھیں۔ asyncpgchannel_bindingrecognize نہیں کرتا اور pooler کے against یہ left in ہو تو fail ہوتا ہے۔- یہ Running app کے لیے pooled endpoint، اور migrations کے لیے direct (non-pooled) endpoint استعمال کریں۔ Pooled endpoint silently
search_pathdrop کرتا ہے، اسی لیے ہر statement schema-qualified ہے۔
DATABASE_URLکو local.envvalue اور ACA secret کے طور پر add کریں، پھر redeploy کریں۔ Confirm کریں کہ run restart کے across persist ہوتا ہے۔
یہ Done when:
- یہ Redeploy کے بعد
/health"postgres": truereport کرے۔ POST /runsایسی row write کرے جسے آپ Neon کےrunstable سے read back کر سکیں۔- یہ Container restart کرنے پر run history باقی رہے (state durable ہے، container میں نہیں)۔
- یہ Connection string میں
channel_bindingنہ ہو، اور migrations direct endpoint کے against run ہوئی ہوں۔
یہ Simulated track۔
state.pyاورschema.sqlپڑھیں۔ دو چیزیں notice کریں:normalize_neon_dsnfunction جوchannel_bindingstrip کرتا ہے، اور یہ کہ ہر tablepublic.runs،public.sessionsوغیرہ کے طور پر written ہے، کیونکہ pooled endpointsearch_pathignore کرتا ہے۔
یہ Decision 4 سے اب آپ کے پاس Neon project اور دو connection strings ہیں: app کے لیے pooled، migrations کے لیے direct۔ Decision 6 کا sandbox اور Decision 7 کی observability دونوں اس database میں write کرتے ہیں۔ اسے رکھیں۔
خلاصہ: Harness کے پاس memory ہے۔ Sessions، runs، traces، artifacts، اور audit log سب Neon میں live کرتے ہیں اور restarts survive کرتے ہیں، asyncpg کی دو footguns handled ہیں۔ Harness deploys کے درمیان amnesiac نہیں رہا۔
فیصلہ 5: Files اور artifacts کے لیے Cloudflare R2 wire کریں
ایک line میں: object storage provision کریں اور harness کو specific files کے لیے short-lived links دینے دیں، تاکہ agent outputs storage password share کیے بغیر downloadable ہوں۔
یہ Cloudflare R2: S3-compatible object storage جہاں اپنی files read out کرنا free ہے۔ Presigned URL: short-lived link جو کسی کو storage password رکھے بغیر ایک specific file read یا write کرنے دیتا ہے۔ اس Decision کے بعد agent reply file کے طور پر save ہو کر download link کے طور پر واپس آ سکتی ہے۔
یہ اپنے coding agent میں paste کریں۔ پہلے plan بنائے؛ approval پر execute کرے۔
یہ Companion
storage.pyfollow کرتے ہوئے Cloudflare R2 کو harness artifact store کے طور پر wire کریں۔ R2 bucket اور scoped API credentials create کریں۔ Boto3 S3 client کو R2 endpointhttps://<account_id>.r2.cloudflarestorage.comپرregion_name="auto"کے ساتھ point کریں۔ جس run میںsave_artifacttrue ہو، reply کو bucket میں write کریں اور short expiry (one hour) کے ساتھ presigned download URL return کریں۔ چارR2_*values کو.envاور ACA secrets میں add کریں، پھر redeploy کریں۔
یہ Done when:
- یہ Redeploy کے بعد
/health"r2": truereport کرے۔ - جب
POST /runsکوsave_artifacttrue کے ساتھ call کیا جائے تو ایساartifact_urlreturn ہو جو reply download کرے۔ - یہ Presigned URL اپنی expiry کے بعد کام کرنا stop کرے (یہ scoped اور short-lived ہے، permanent password نہیں)۔
یہ Simulated track۔
storage.pyپڑھیں۔ وہ ایک detail notice کریں جو R2 کو boto3 کے ساتھ work کراتی ہے: S3 client کو R2 endpoint پرregion_name="auto"کے ساتھ point کریں، اور باقی S3 API unchanged ہے۔ Local-directory fallback تب run ہوتا ہے جب R2 keys set نہ ہوں۔
یہ Decision 5 سے اب آپ کے پاس R2 bucket اور scoped credentials ہیں۔ Decision 6 کا sandbox اس bucket میں presigned URLs کے ذریعے files read اور write کرتا ہے۔ اسے رکھیں۔
خلاصہ: Harness R2 کے ذریعے files store اور hand back کر سکتا ہے، storage password share کرنے کے بجائے short-lived presigned URLs سے access scope کرتا ہے۔ Harness sandbox کو keys دیے بغیر file access دینے کے لیے ready ہے۔
فیصلہ 6: Sandbox execution wire کریں
ایک line میں: isolated workspace attach کریں جہاں agent کا code چل سکے، harness secrets یا database تک access کے بغیر۔
یہ Sandbox: الگ، بند workspace جہاں agent کا generated code چلتا ہے، harness keys میں سے کچھ نہیں رکھتا۔ Manifest: sandbox کو کیا چاہیے اس کی short description (کون سی files mount کرنی ہیں، کون سی abilities turn on کرنی ہیں)۔ یہ Decision execution plane add کرتا ہے؛ agent اس کے بغیر بھی answer کرتا رہتا ہے، اس لیے harness ہر step پر useful رہتا ہے۔
یہ Build کرنے سے پہلے cost note۔ Course کا primary sandbox provider، Cloudflare، paid Workers plan اور Python harness اور sandbox کے درمیان چھوٹا bridge Worker چاہتا ہے۔ E2B realistic free path ہے: اس کا free Hobby tier ہے، SDK میں first-class client ہے، اور bridge Worker نہیں چاہیے۔ Companion اسی وجہ سے E2B default کرتا ہے۔ E2B استعمال کریں جب تک خاص طور پر Cloudflare نہ چاہیے۔
یہ اپنے coding agent میں paste کریں۔ پہلے plan بنائے؛ approval پر execute کرے۔
یہ Companion
sandbox.pyاورAGENTS.mdمیں verified shapes follow کرتے ہوئے sandbox execution wire کریں۔ Default E2B (free tier) رکھیں۔ Sandbox key set ہو تو ہیSandboxRunConfigbuild کریں، اور اسےRunConfigکے ذریعے attach کریں، کبھیRunner.runkwarg کے طور پر نہیں۔ Companion سے دو verified shapes جو older draft نے غلط کیے تھے:
- یہ E2B path ہے
SandboxRunConfig(client=E2BSandboxClient(), options=E2BSandboxClientOptions(sandbox_type="e2b"))۔ Options object required ہے اور requiredsandbox_typefield carry کرتا ہے؛ client constructoroptions=نہیں لیتا۔- اگر کبھی Manifest build کریں تو یہ
Manifest(entries={...})ہے، mounts (R2Mount،S3Mount)agents.sandbox.entriesسے imported ہیں۔ کوئیbase_image=،mounts=[]، یاMountSpecنہیں۔ Passed capabilities list default replace کرتی ہے، اس لیےCapabilities.default()رکھیں یا اس میں concatenate کریں۔
E2B_API_KEYکو.envاور ACA secrets میں add کریں، پھر redeploy کریں۔ Free-tier path: Cloudflare کو چھوڑ دیں، صرفE2B_API_KEYset کریں، اور آپ کو نہ bridge Worker چاہیے نہ paid plan۔
یہ Done when:
- یہ E2B key set کر کے redeploy کرنے کے بعد
/health"sandbox": truereport کرے۔ - یہ
POST /runs"used_sandbox": truereturn کرے۔ - یہ Sandbox imports
agents.extensions.sandbox.e2bسے ہوں، اور sandbox key set نہ ہونے پر بھی agent answer کرے (harness sandbox disabled ہونے پر useful رہتا ہے)۔
یہ Simulated track۔
sandbox.pyپڑھیں۔ Deferred imports notice کریں (module sandbox extras installed نہ ہونے پر بھی load ہوتا ہے)، E2B-first default with Cloudflare as paid alternative، اور یہ کہ function key نہ ہونے پرNonereturn کرتا ہے، یہی harness کو sandbox disabled ہونے پر running رکھتا ہے۔
یہ Execution plane (Decision 6) اب harness (Decision 1)، اس کے cloud runtime (Decision 3)، اس کی state (Decision 4)، اور اس کی storage (Decision 5) کے اوپر wired ہے۔ Maya کا agent اب پانچ کمپوننٹ stack پر end-to-end deployed ہے۔ Decisions 7 through 9 اسے harden کرتے ہیں۔
خلاصہ: code execution اب isolated sandbox میں چلتی ہے جس کے پاس harness secrets میں سے کچھ نہیں، verified SDK shapes کے ساتھ
RunConfigکے ذریعے attached۔ E2B free path ہے؛ Cloudflare paid primary ہے۔ پانچ کمپوننٹ stack complete ہے؛ باقی اسے observable، measured، اور operable بنانا ہے۔
فیصلہ 7: Observability wire کریں
ایک line میں: چار observability surfaces wire کریں اور انہیں shared run_id سے tie کریں، تاکہ team کسی بھی symptom سے cause تک navigate کر سکے۔
یہ Concept 11 نے چار surfaces name کیں۔ یہ Decision انہیں wire اور reconcile کرتا ہے۔ اس کے بعد team Application Insights، OpenTelemetry، SDK trace، یا Phoenix میں سے کہیں بھی start کر کے ایک ID follow کر کے باقی تین تک پہنچ سکتی ہے۔
یہ اپنے coding agent میں paste کریں۔ پہلے plan بنائے؛ approval پر execute کرے۔
یہ Concept 11 کی چار observability surfaces wire کریں۔ Harness کو OpenTelemetry (FastAPI، asyncpg، اور HTTP spans) سے instrument کریں اور Application Insights کو export کریں۔ ہر surface کو same
run_idسے tag کریں: اسے OTel parent span پر attach کریں، ہر structured log line میں include کریں، SDK trace پر carry کریں، اور Phoenix sample کے ساتھ send کریں۔ Completed SDK traces کو Phoenix میں fire-and-forget stream کریں (اگر Phoenix down ہو تو log کریں اور continue کریں؛ Neon durable record ہے)۔ Successful runs کا تقریباً 10% اور failed runs کا 100% sample کریں،run_idپر deterministic تاکہ sampling stable رہے۔ Observability keys کو ACA secrets کے طور پر redeploy کریں۔
یہ Done when:
- یہ Request کی OTel trace تقریباً ایک minute میں Application Insights میں appear ہو۔
- کسی بھی surface میں ایک
run_idsearch کرنے سے others میں matching record return ہو۔ - یہ Phoenix recent traces دکھائے، all failures اور successes کا fraction sample کرتے ہوئے۔
یہ Simulated track۔ Companion میں observability wiring پڑھیں۔ Learn کرنے والا pattern shared
run_idہے: یہی thread ایک click میں infrastructure alert سے agent reasoning اور time trend تک لے جاتا ہے۔ اس کے بغیر چار surfaces چار disconnected dashboards ہیں۔
خلاصہ: چار surfaces wired ہیں اور shared run_id سے reconciled ہیں، اس لیے team minutes میں کسی بھی symptom سے cause تک navigate کرتی ہے۔ یہ agent harness کی production observability ہے: checklist نہیں، architecture۔
فیصلہ 8: Eval suite wire کریں
ایک line میں: Eval-Driven Development course کے چار frameworks کو harness traces سے connect کریں، تاکہ CI regression gate، nightly behavior report، اور weekly trace-to-eval promotion ritual بنے۔
یہ Concept 12 نے boundary fix کی: Neon اور Phoenix میں traces۔ یہ Decision چار eval frameworks کو ان دو surfaces سے wire کرتا ہے۔ Full eval wiring یہاں teach ہوتی ہے؛ اگر آپ نے eval suite itself نہیں بنائی تو پہلے Eval-Driven Development course کریں، کیونکہ یہ Decision اس suite کو deployment سے attach کرتا ہے۔
یہ اپنے coding agent میں paste کریں۔ پہلے plan بنائے؛ approval پر execute کرے۔
یہ Eval-Driven Development course کے چار eval frameworks کو deployed harness کی traces سے wire کریں۔ ہر ایک کو اس کے point پر attach کریں:
- یہ DeepEval کو CI regression gate کے طور پر۔ ہر pull request پر جو agent یا prompts touch کرے، committed golden dataset کے against DeepEval run کریں by hitting staging
POST /runs، اور اگر previously passing case now fails ہو تو merge block کریں۔- یہ Nightly scheduled job (Container Apps Jobs) جو Neon سے previous 24 hours کی traces read کرے، انہیں team's rubric کے against OpenAI Agent Evals سے grade کرے، retrieval use کرنے والی traces پر Ragas چلائے، repo میں report لکھے، اور summary Slack پر post کرے۔
- یہ Phoenix inline evaluators جو traces arrive ہوتے ہی run ہوں (hallucination، policy، tool-correctness)، scores tag کریں مگر runs block نہ کریں۔
- یہ Weekly ritual، runbook میں documented: Phoenix کی flagged traces review کریں اور eval-worthy traces کو golden dataset میں promote کریں، تاکہ ہر ایک future regression test بن جائے۔
یہ Done when:
- یہ Behavior کو intentionally worsen کرنے والی pull request DeepEval gate سے blocked ہو۔
- یہ Nightly job repo میں behavior report produce کرے اور Slack پر post کرے۔
- یہ Phoenix recent traces پر inline evaluator scores دکھائے، اور promotion ritual documented ہو کر ایک بار end-to-end run ہو۔
یہ Simulated track۔ Companion میں eval pipeline configs اور CI workflows پڑھیں۔ Internalize کرنے والی shape تین operational outputs ہیں: pre-merge gate جو regressions catch کرتا ہے، nightly report جو drift catch کرتی ہے، اور promotion queue جو production failures کو new tests میں بدلتی ہے۔
خلاصہ: Eval suite traces کے ذریعے deployed harness سے connected ہے۔ Integration تین operational outputs produce کرتی ہے: CI regression gate، nightly behavior report، اور weekly promotion queue۔ Eval discipline اب team کی imagination کے بجائے real production traffic سے grow کرتی ہے۔
فیصلہ 9: Production checklist
ایک line میں: operational discipline finish کریں: secrets rotation، blue/green deploys، on-call runbook، backup and recovery، اور rate limits۔
یہ Harness observable (Decision 7) اور measured (Decision 8) ہو جانے کے بعد، یہ Decision وہ چیزیں add کرتا ہے جو اسے worry کے بغیر running چھوڑنے کے لیے چاہیے۔ Blue/green: downtime کے بغیر new version ship کرنا، اسے old version کے ساتھ run کر کے پھر traffic shift کرنا۔
یہ اپنے coding agent میں paste کریں۔ پہلے plan بنائے؛ approval پر execute کرے۔
یہ Harness کے لیے production discipline complete کریں، runbook میں documented۔ Cover کریں:
- یہ Secrets rotation: old credential کے ساتھ new credential add کرنے، redeploy کرنے، verify کرنے، پھر old revoke کرنے کا procedure۔
- یہ Blue/green deploys: script جو 0% traffic پر new revision create کرے، اس پر
/healthcheck کرے، 10% shift کر کے Application Insights watch کرے، پھر 100% shift کرے اور old revision کو rollback کے لیے ایک دن رکھے۔- یہ Five scenarios والا on-call runbook (high error rate، high latency، sandbox provider down، Neon unreachable، R2 unreachable)، ہر ایک کے investigation اور remediation steps کے ساتھ۔
- یہ Backup and recovery: Neon point-in-time recovery، R2 versioning، اور ACA revision rollback۔
- یہ Middleware layer پر per-user rate limits، exceeded ہونے پر
Retry-Afterکے ساتھ 429 return کرتے ہوئے۔- یہ Cost alerts جو daily spend recent average سے well above jump کرنے پر fire ہوں۔
یہ Done when:
- تمام secrets کا documented، tested rotation procedure ہو۔
- ایک blue/green deploy end-to-end run ہو: new revision verified، traffic shifted، old revision rollback کے لیے kept۔
- یہ Rate limiting work کرے (limit کے بعد والی request 429 return کرے)، اور cost alerts configured ہوں۔
یہ Simulated track۔ Companion میں runbook، deploy scripts، اور rotation scripts پڑھیں۔ Absorb کرنے والی discipline یہ ہے کہ ہر failure mode کا named، rehearsed response ہو، اور rate limiting اور cost alerts optional نہیں: traffic spike کے بعد runaway bill سے آپ کے درمیان یہی کھڑے ہیں۔
خلاصہ: Harness full sense میں production-ready ہے: observable، measured، اور operable۔ Secrets rotate ہوتے ہیں، deploys blue/green ہیں، runbook failure modes cover کرتا ہے، backups tested ہیں، اور rate limits spike کے blast radius کو cap کرتے ہیں۔ آپ اسے running چھوڑ سکتے ہیں اور کچھ ٹوٹنے پر confidence کے ساتھ respond کر سکتے ہیں۔
حصہ 6: Honest Frontiers
لیب working deployment produce کرتی ہے۔ Part 6 name کرتا ہے کہ یہ کیا solve نہیں کرتی، کہاں expected سے زیادہ cost آتی ہے، اور اس کی boundary کہاں ہے۔ چار concepts اور پانچ anti-patterns۔
تصور 13: Cloud agent harness کی cost economics
کلاؤڈ cost وہ dimension ہے جسے زیادہ تر courses skip کرتے ہیں۔ اس recipe کی specific economics ہیں، اور commit کرنے والی team کو small، medium، اور large scale پر انہیں جاننا چاہیے۔
یہ Bill کی پانچ layers ہیں، ہر component کے لیے ایک، اور ایک layer باقی سب کو dominate کرتی ہے۔
| Layer | Share of the bill |
|---|---|
| Model API (OpenAI) | ہر scale پر 90-98% |
| Sandbox execution | high volume پر باقی layers میں سب سے بڑی |
| Harness compute (ACA) | چھوٹی؛ scale-to-zero idle پر اسے near zero رکھتا ہے |
| Durable state (Neon) | چھوٹی؛ free tier light use cover کرتا ہے |
| File storage (R2) | چھوٹی؛ egress free ہے |
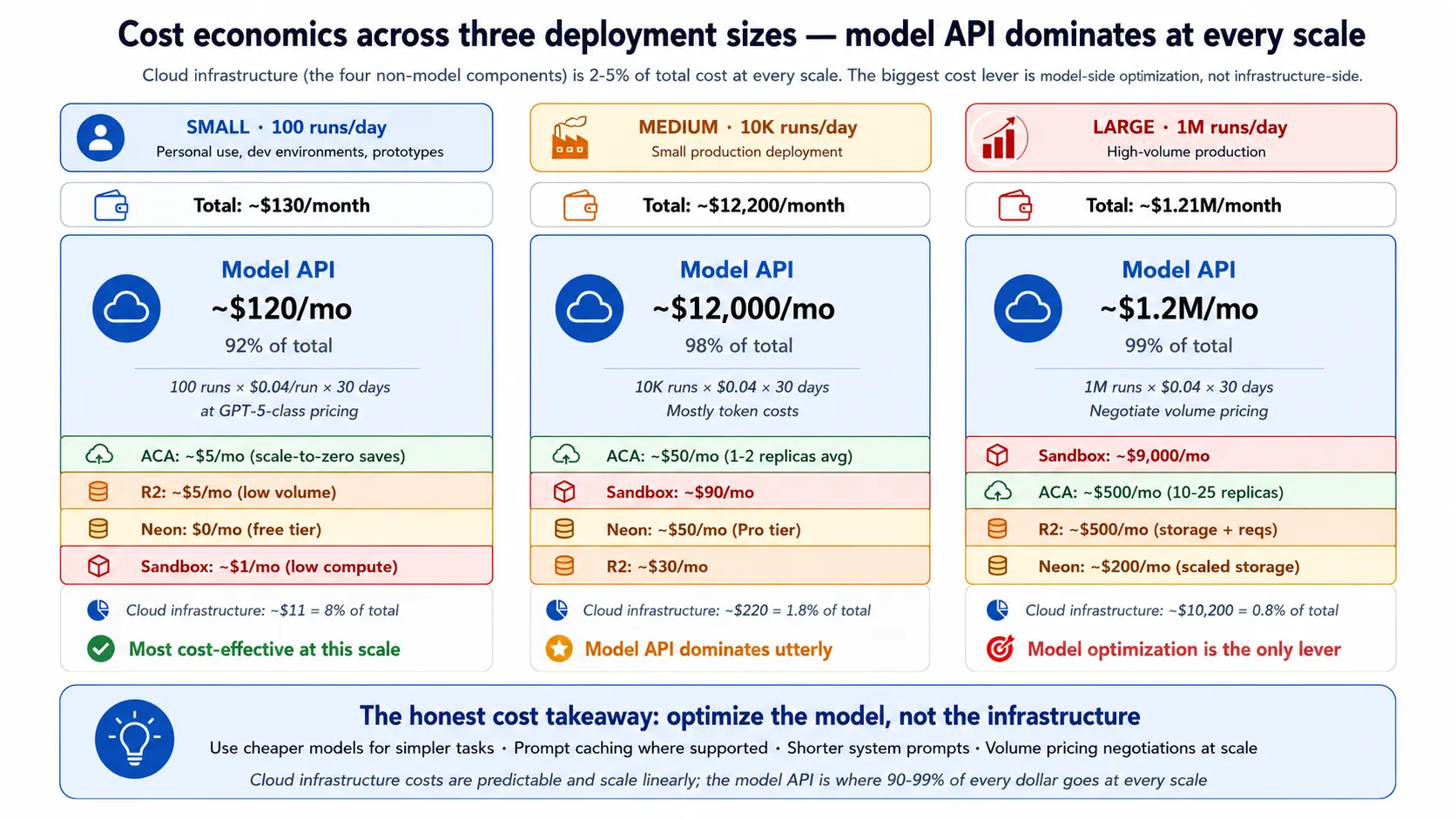
اعداد و شمار کو precise numbers نہیں، rough ranges سمجھیں۔ Small scale پر (روزانہ تقریباً 100 runs)، پوری bill ماہانہ hundred-some dollars کے order میں ہوتی ہے، اور model API roughly nine-tenths ہے۔ Medium scale پر (روزانہ تقریباً 10,000 runs)، bill low tens of thousands a month میں ہوتی ہے، اور model API تقریباً 98% ہوتا ہے۔ Large scale پر (روزانہ تقریباً million runs)، bill ماہانہ seven figures میں جاتی ہے، تقریباً سب model API۔ Infrastructure layers بھی grow کرتی ہیں، مگر throughout total کے 5% سے کم رہتی ہیں۔
دیانت دار takeaways directly follow کرتے ہیں۔ Cloud infrastructure almost always bill کے 5% سے کم ہے، اس لیے highest-leverage cost lever model ہے، infrastructure نہیں: simple decisions کے لیے cheaper model use کریں، جہاں SDK support کرے وہاں prompts cache کریں، اور system prompts short رکھیں۔ Infrastructure cost predictable ہے اور traffic کے ساتھ roughly linear ہے؛ یہاں سے surprise bills نہیں آتے۔ R2 کا free egress file-heavy workloads کے لیے سب سے زیادہ matter کرتا ہے اور Maya جیسے text-heavy workloads کے لیے barely register کرتا ہے۔ Sandbox cost active execution time کے ساتھ scale کرتی ہے، اس لیے compute-heavy agents وہاں زیادہ cost کرتے ہیں جبکہ mostly model پر wait کرنے والے agents cheap رہتے ہیں۔
خلاصہ: اس recipe کی economics predictable ہیں۔ Traffic کے حساب سے cloud infrastructure ماہانہ tens سے few thousand dollars تک جاتی ہے؛ model API ہر scale پر total spend کا 90-98% ہے۔ Recipe infrastructure level پر cheap ہے، اس لیے model optimize کریں، infrastructure نہیں۔ یہاں ہر figure کو order-of-magnitude range سمجھیں، quote نہیں۔
تصور 14: Multi-region considerations
یہ recipe purposefully single region میں deploy کرتی ہے۔ Multi-region active-active بہت harder problem ہے، اور زیادہ تر deployments کو اس کی ضرورت نہیں۔ آپ کو تین میں سے ایک reason کے لیے چاہیے: latency، جب users globe پر spread ہوں اور single region noticeable round-trip delay add کرے؛ availability، جب uptime commitment 99.99% یا higher ہو اور single region outage unacceptable ہو؛ یا compliance، جب data-residency rules user data کو specific region میں رہنے کا تقاضا کریں۔
اجزا multi-region میں difficulty کے لحاظ سے differ کرتے ہیں۔ R2 اور sandbox Cloudflare network پر already global ہیں، اس لیے extra work نہیں چاہیے۔ ACA per environment single-region ہے، اس لیے multi-region کا مطلب global load balancer کے پیچھے several environments ہے۔ Neon other regions میں read replicas support کرتا ہے، مگر writes primary کو ہی جاتے ہیں، اس لیے write-heavy agent state کو زیادہ complex database design چاہیے۔ Honest recipe ہے more environments، read replicas، اور global front door، operational cost ہر region کے ساتھ بڑھتی ہوئی۔ اگر users mostly one region میں ہیں، uptime target 99.9% ہے، اور one region data rules satisfy کرتا ہے تو single-region صحیح answer ہے؛ ایسی complexity کی قیمت نہ دیں جس کی ضرورت نہیں۔
خلاصہ: Single-region default ہے اور most deployments کے لیے right call ہے۔ Multi-region global-latency، high-availability، یا data-residency needs کے لیے real ہے، اور path global front door plus multi-region ACA plus Neon read replicas ہے۔ R2 اور sandbox already global ہیں۔ Deeper active-active اپنا future topic ہے؛ اگر avoid کر سکتے ہیں تو avoid کریں۔
تصور 15: Recipe سے کب migrate کرنا ہے
یہ recipe opinionated ہے اور specific size and shape کے لیے fit ہے۔ پانچ triggers بتاتے ہیں کہ کب اس سے move off کرنا ہے۔ Architectural pattern (control plane execution plane سے separate) ان migrations میں carry ہوتا ہے؛ صرف specific components بدلتے ہیں۔
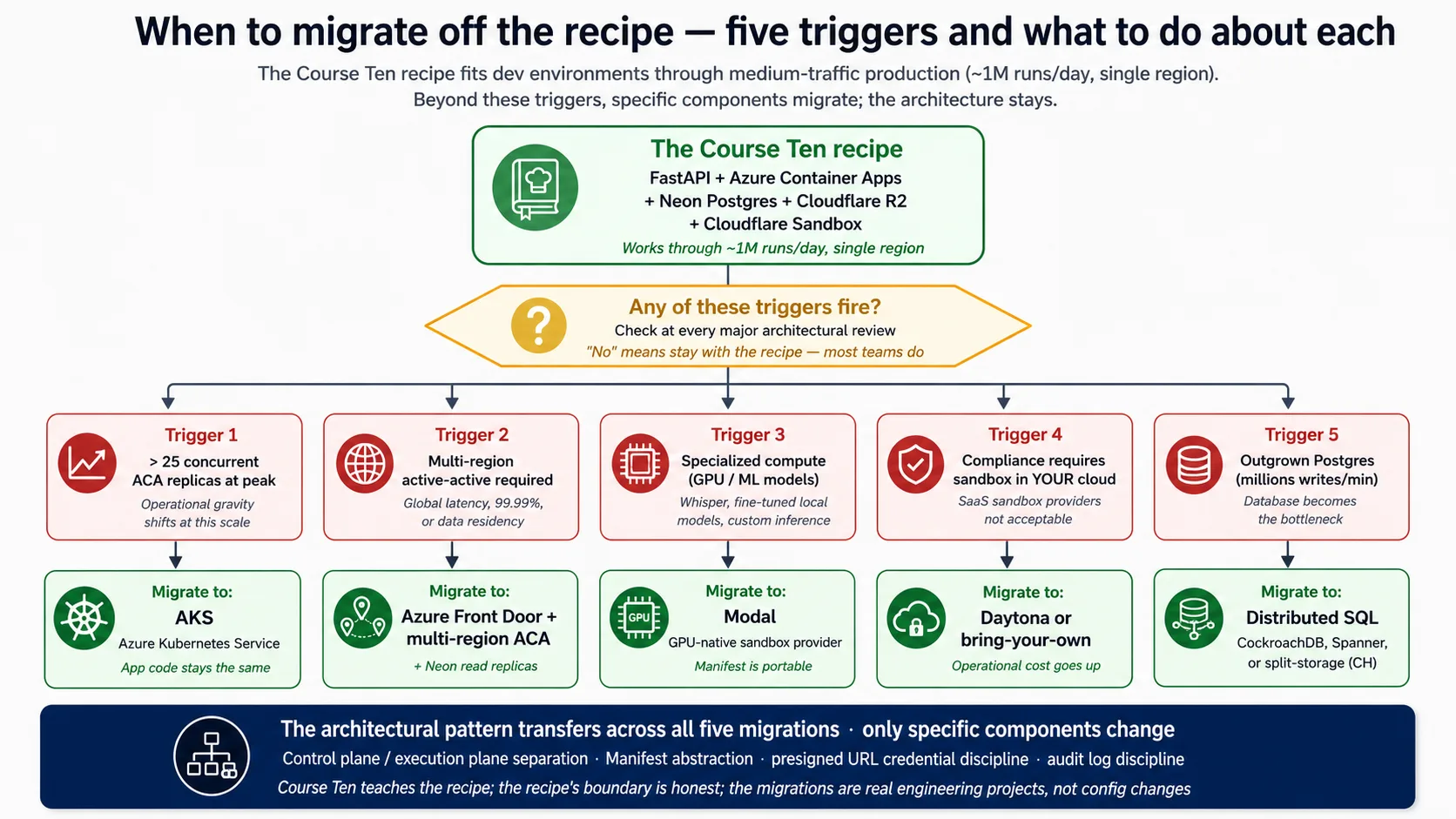
یہ triggers ہیں: roughly 25 ACA replicas سے past sustained heavy concurrency، جہاں economics اور connection math harness کو Kubernetes پر move کرنے کے حق میں ہو (app code same رہتا ہے)۔ Concept 14 کے مطابق multi-region active-active۔ Specialized compute جیسے GPU work، جہاں GPU-native sandbox provider better fit ہے اور portable Manifest ساتھ move کرتا ہے۔ Compliance rule کہ sandbox آپ کے own cloud کے اندر run ہونا چاہیے، جو SaaS sandbox کو rule out کرتا ہے اور bring-your-own provider کی طرف push کرتا ہے۔ اور very high write volumes پر Postgres کو primary store کے طور پر outgrow کرنا، جو distributed SQL یا split storage کی طرف point کرتا ہے اور پانچوں میں سب سے invasive change ہے۔
خلاصہ: Recipe dev environments سے medium-traffic production تک single region پر fit ہے۔ پانچ triggers (heavy concurrency، multi-region، GPU workloads، in-cloud-only sandbox compliance، یا extreme write volume) بتاتے ہیں کب ایک component migrate کرنا ہے۔ Architectural pattern transfer ہوتا ہے؛ migration real engineering project ہے، config change نہیں۔
تصور 16: Deployment کیا solve نہیں کرتی
لیب real production discipline produce کرتی ہے، مگر ہر چیز solve نہیں کرتی۔ Gaps کو name کرنا false confidence سے بچاتا ہے اور بتاتا ہے کہ انہیں close کرنے کے لیے کیا work چاہیے۔
یہ compliance certification produce نہیں کرتی۔ آپ کو وہ technical controls ملتے ہیں جن کی SOC2 جیسا framework expect کرتا ہے، مگر certification third-party audit اور months of evidence چاہتی ہے؛ اسے separate workstream plan کریں۔ یہ incident-response program نہیں دیتی۔ Runbook technical remediation cover کرتا ہے، یہ نہیں کہ page کس کو ہو گا، incidents کیسے declare ہوں گے، یا post-mortems کیسے run ہوں گے؛ people-and-process layer آپ کو build کرنی ہے۔ یہ agent actions کی legal liability settle نہیں کرتی۔ Audit log record کرتا ہے کہ کیا ہوا، مگر agent decisions کے گرد legal framework ابھی forming ہے۔ یہ behavior level پر prompt injection نہیں روکتی۔ Harness/sandbox split injected code کو آپ کے secrets سے دور رکھتا ہے، مگر crafted message کو agent reply steer کرنے سے نہیں روکتا؛ اس کے لیے guardrails، input checks، اور red-teaming چاہیے، جس کا بڑا حصہ eval suite کا job ہے۔ یہ model upgrades آپ کے لیے handle نہیں کرتی؛ eval suite نیا model switch کرنے سے پہلے test کرنے کی discipline ہے۔ اور یہ cost runaway prevent نہیں کرتی؛ monitoring hours میں spike catch کرتی ہے، مگر daily caps اور kill switches extra defenses ہیں جو آپ اوپر add کرتے ہیں۔
خلاصہ: Deployment وہ substrate سکھاتی ہے جو ان concerns کو addressable بناتا ہے، concerns خود نہیں۔ Compliance certification، incident-response process، legal liability، behavior-level prompt injection، model upgrades، اور cost runaway ہر ایک lab سے beyond real work رہتے ہیں۔ انہیں add کرتے وقت architectural backbone نہیں بدلتی؛ اس کے گرد operational discipline بدلتی ہے۔
پانچ چیزیں جو نہیں کرنی
یہ recipe پانچ anti-patterns avoid کرتی ہے۔ انہیں name کرنا deployment ship ہونے کے بعد team کو backsliding سے بچاتا ہے۔
- یہ Agent-generated code کو harness کے اندر نہ چلائیں۔ Harness process میں
exec(model_output)جیسی call SQL injection سے بھی worse ہے، کیونکہ attack surface پورے model reasoning کا ہے۔ Sandbox boundary non-negotiable ہے؛ harness keys رکھتا ہے، agent code انہیں touch نہیں کر سکتا۔ - یہ Root credentials کو Manifest میں نہ ڈالیں۔ Manifest میں جو کچھ ہے وہ sandbox میں cross کرتا ہے۔ صرف presigned URLs اور short-lived tokens boundary cross کرتے ہیں؛ database strings اور API keys harness میں رہتے ہیں۔
- یہ Development میں scale-to-zero skip نہ کریں۔ Clock کے across warm رکھا گیا dev app، people اور services میں multiply ہو کر، idle compute کے لیے quietly hundreds a month cost کرتا ہے۔ Dev میں cold start accept کریں۔
- یہ Eval suite wired کیے بغیر deploy نہ کریں۔ اسے skip کرنا agent deployment کا سب سے expensive shortcut ہے: آپ changes ship کرتے ہیں جو code review pass کرتے ہیں، behavior regress کرتے ہیں، اور weeks later complaints کے طور پر surface ہوتے ہیں۔ Eval gate deploying agents اور ایسے agents deploy کرنے میں فرق ہے جو اچھے رہتے ہیں۔
- یہ Rate limiting کے بغیر harness نہ چلائیں۔ Day-one deployments بغیر rate limiting کے وہ طریقہ ہیں جس سے teams ایک viral mention کے بعد discover کرتی ہیں کہ انہوں نے single day میں model provider کو fortune pay کر دی۔ Generous limits fine ہیں؛ no limit dangerous setting ہے۔
حصہ 7: Closing
تصور 17: Deployed harness as realization
اس Manufacturing track نے AI-native کمپنی build اور measure کی: agent loop، system of record، workforce layer، delegate، اور وہ discipline جو behavior کو measurable بناتی ہے۔ یہ course اسے ship کرتا ہے۔ Deployed harness وہ جگہ ہے جہاں یہ سب ایسی service بنتا ہے جس تک real users پہنچ سکتے ہیں، چار surfaces پر observed، اور production traffic سے learning eval suite کے against continuously graded۔
پورا course ایک idea پر rest کرتا ہے: harness control plane ہے اور sandbox execution plane، اور یہی single separation deployment کو safe، durable، اور scalable بناتی ہے۔ Lab میں آپ نے جو کچھ wire کیا وہ اسی کی خدمت کرتا ہے۔ Harness keys، state، اور orchestration رکھتا ہے؛ sandbox risky code کو keys کے بغیر چلاتا ہے؛ presigned URLs boundary کے across file access scope کرتے ہیں؛ observability دکھاتی ہے کیا ہو رہا ہے؛ eval suite بتاتی ہے کہ آیا یہ ابھی بھی right ہے۔ Recipe سے deviate کرنا fine ہے۔ Architecture سے deviate کرنا نہیں۔ Harness اور sandbox کو separate planes میں run کریں، چار surfaces کے across observe کریں، اور production سے grow ہونے والی eval suite کے against behavior grade کریں، پھر architecture کام کرتی ہے چاہے آپ cloud components کون سے pick کریں۔
اس کے بعد وہ design discipline آتی ہے جو build سے پہلے چلتی ہے: پہلے task کے لیے کون سی agent shape fit ہے یہ چننا۔ اگر آپ یہ چاہتے ہیں تو Choosing Agentic Architectures پڑھیں، جو agent design اور production deployment کے درمیان connective tissue ہے۔ تین مزید frontiers honest طور پر name کرنے کے قابل ہیں، none shipped yet: agent-to-agent commerce، جہاں agents payment protocols کے ذریعے economic actors کے طور پر act کرتے ہیں؛ owner-delegate agent کے deployment specifics، جس کی signed delegation اور governance ledger worker سے heavier ہے؛ اور deeper multi-cloud، active-active multi-region، جو اپنا substantial topic ہے۔
خلاصہ: یہ course architecture کو observability اور operationally wired eval suite کے ساتھ production-deployed cloud service کے طور پر realize کرتا ہے۔ Recipe (Azure Container Apps پر FastAPI، Neon، R2، code-execution sandbox، OpenTelemetry plus Application Insights plus Phoenix، اور CI میں eval suite) ایسا harness produce کرتی ہے جس میں control-plane اور execution-plane separation، durable state، scoped file access، four-surface observability، اور continuous behavior grading ہے۔ Manufacturing track نے company build کی؛ یہ course اسے deploy کرتا ہے۔
یہ AI کے ساتھ try کریں۔ اپنا coding agent کھولیں۔ Paste کریں:
"میں نے manufacturing track اس deployment course تک complete کر لیا ہے۔ Agents build کرنے کے اگلے سال میں جو تین چیزیں سب سے زیادہ استعمال کروں گا، اور جو تین کم استعمال ہوں گی مگر جب ہوں گی تو critical ہوں گی، انہیں list کریں۔ ہر ایک مختصر explain کریں۔ پھر اس composition کے لیے جو اس course نے wire کی (Eval-Driven Development course کی eval suite attached to a deployed harness)، بتائیں کہ practice میں اسے operate کرنے کا hardest part کیا expect کرتے ہیں: deployment pressure میں team کون سی discipline skip کرنے کی temptation محسوس کرے گی؟"
یہ What you're learning۔ Track wide ہے، اور آپ اس کے حصے unevenly use کریں گے: کچھ daily، کچھ rarely but critically۔ یہ reflection honest read force کرتی ہے کہ کون سے parts آپ کے actual work سے match کرتے ہیں، اور سب سے common production failure mode surface کرتی ہے، یعنی pressure میں eval discipline deprioritized ہو جانا یہاں تک کہ harness drift کرنے لگے۔
ایک دن کی workshop variant
اسے one-day workshop کے طور پر چلانے میں full set of concepts اور Decisions ایک دن کے لیے بہت زیادہ ہیں۔ اپنے available time کے مطابق course fit کرنے کے لیے یہ table استعمال کریں۔
| Time available | Keep | Cut |
|---|---|---|
| 8 hours (1-day intensive) | Stack primer (صرف Docker اور FastAPI) · Concepts 1-3 (architectural backbone) · Decisions 0-5 (probe through R2) · Concept 13 (cost) · Part 7 closing | Stack primer Neon اور R2 (خود پڑھیں) · Concepts 4-12 (reference کے طور پر استعمال کریں) · Decision 6 (sandbox: demo، build نہیں) · Decisions 7-9 (defer) · Concepts 14-16 (defer) |
| 2 days | Decisions 6-7 add کریں (sandbox and observability) · Concepts 8-11 | Decisions 8-9 deferred · Concepts 12، 14-16 deferred |
| 3-4 days | Decision 8 add کریں (eval suite) · Concept 12 | Decision 9 deferred · Concepts 14-16 deferred |
| Full week (5-7 days) | Everything: Advanced track full میں | Nothing |
یہ Short workshops کے لیے architectural backbone (harness/sandbox split اور five-component stack) اور minimum deployment path (Decisions 0-5) رکھیں۔ Hardening اور honest-frontiers material بعد میں self-study ہو سکتا ہے۔ Architectural understanding وہ چیز ہے جس کے ساتھ students کو leave کرنا چاہیے؛ implementation depth وہ چیز ہے جس میں وہ grow کرتے ہیں۔
چٹ شیٹ
| # | Concept | Key takeaway |
|---|---|---|
| 1 | "Works on my machine" deployment نہیں | Production کا مطلب agent کو harness (control plane) plus sandbox (execution plane) میں re-architect کرنا ہے، laptop script wrap کرنا نہیں |
| 2 | Harness/sandbox separation | Backbone: harness secrets اور state کے ساتھ orchestrate کرتا ہے؛ sandbox code execute کرتا ہے؛ boundary network اور security ہے |
| 3 | SDK کو infra سے کیا چاہیے | پانچ surfaces (HTTP service، durable state، file storage، isolated execution، orchestration)، ہر ایک ایک stack component سے mapped |
| 4 | FastAPI as the harness web layer | SDK match کرنے کے لیے async-native، auto-generated API schemas، Pydantic models |
| 5 | Azure Container Apps as the runtime | Ingress، scale-to-zero سمیت autoscale، secrets، اور revisions managed primitives کے طور پر |
| 6 | Neon Postgres for durable state | Relational state کے لیے Postgres؛ serverless scaling اور cheap branching کے لیے Neon |
| 7 | Cloudflare R2 for files | Egress-free، S3-compatible، presigned URLs ایک وقت میں ایک file تک access scope کرتے ہیں |
| 8 | Sandbox execution capabilities | Filesystem، shell، package install، mounted storage، سب isolated اور ephemeral |
| 9 | Sandbox provider چننا | E2B free path ہے؛ Cloudflare paid primary ہے؛ باقی specific needs کے لیے fit ہیں |
| 10 | Harness-to-sandbox handoff | Manifest workspace declare کرتا ہے؛ presigned URLs files scope کرتے ہیں؛ root credentials کبھی cross نہیں کرتے |
| 11 | Observability as a surface | چار surfaces (Application Insights، OpenTelemetry، SDK trace، Phoenix)، shared run_id سے tied |
| 12 | Evals as a surface | Neon (durable) اور Phoenix (real-time) میں traces سے mediated؛ eval frameworks specific points پر attach ہوتے ہیں |
| 13 | Cost economics | Infrastructure bill کے 5% سے کم ہے؛ model API 90-98% ہے؛ model optimize کریں، infrastructure نہیں |
| 14 | Multi-region | Default single-region؛ multi-region صرف global latency، 99.99%+ uptime، یا data residency کے لیے |
| 15 | Recipe سے کب migrate کرنا | Heavy concurrency، multi-region، GPU work، in-cloud-only sandbox، یا extreme write volume |
| 16 | Deployment کیا solve نہیں کرتی | Compliance certification، incident process، legal liability، behavior-level prompt injection، model upgrades، cost runaway |
| 17 | Deployed harness as realization | یہ course وہ چیز ship کرتا ہے جو manufacturing track نے build کی، observability اور eval suite operationally wired کے ساتھ |
| # | Decision | Deliverable |
|---|---|---|
| 0 | SDK probe | Installed version printed، brief live docs کے against reconciled، "What changed" note |
| 1 | Scaffold the harness | FastAPI app، agent، optional state and storage، صرف OPENAI_API_KEY پر boots |
| 2 | Containerize | Small، reproducible image جو locally اور cloud میں same run کرتی ہے |
| 3 | Azure Container Apps پر deploy | Public HTTPS URL، scale-to-zero، secrets stored by name |
| 4 | Wire Neon Postgres | Five-table schema، app کے لیے pooled اور migrations کے لیے direct، channel_binding stripped |
| 5 | Wire Cloudflare R2 | Bucket، scoped credentials، short-lived presigned download URLs |
| 6 | Wire sandbox execution | E2B free-tier client RunConfig کے ذریعے attached؛ Cloudflare paid alternative |
| 7 | Wire observability | Shared run_id سے tied four surfaces؛ fire-and-forget Phoenix sample |
| 8 | Wire the eval suite | CI regression gate، nightly behavior report، weekly trace-to-eval promotion |
| 9 | Production checklist | Secrets rotation، blue/green deploys، on-call runbook، backup and recovery، rate limits |
فوری reference: deployment commands
# Local dev (Beginner track)
uv sync # install from the lockfile
uv run uvicorn maya_harness.main:app --reload # boot the harness locally
# Pin: openai-agents>=0.17,<0.18
# Cloud deployment (Intermediate / Advanced): Azure Container Apps
az group create --name maya-rg --location eastus
az acr create --resource-group maya-rg --name <acr-name> --sku Basic --admin-enabled true
az acr build --registry <acr-name> --image maya-harness:latest . # build in the cloud
az containerapp env create --name maya-env --resource-group maya-rg --location eastus
az containerapp create --name maya-harness --resource-group maya-rg \
--environment maya-env --image <acr-name>.azurecr.io/maya-harness:latest \
--target-port 8000 --ingress external --min-replicas 0 --max-replicas 3 \
--secrets "openai-api-key=$OPENAI_API_KEY" \
--env-vars "OPENAI_API_KEY=secretref:openai-api-key"
# Tear-down (cost discipline)
az group delete --name maya-rg --yes
# Neon Postgres (console.neon.com)
# Strip channel_binding from the connection string before asyncpg; keep sslmode=require.
# Use the pooled endpoint for the app; the direct (non-pooled) endpoint for migrations.
psql "$DIRECT_BRANCH_URL" -f schema.sql # migrations on the direct endpoint
ساتھی download
اس Companion zip میں booted harness، AGENTS.md (brief، project rules، architecture، اور SDK probe)، ہر backend کے verified code، Dockerfile، Azure deploy shapes، اور schema.sql آتے ہیں: deploying-agents-crash-course.zip۔
حوالہ جات
یہ URLs May 2026 تک current ہیں؛ اپنے کام میں cite کرنے سے پہلے verify کریں۔
یہ Agent-factory track:
- یہ Agent loop اور SDK: Build AI Agents۔
- یہ Eval suite جسے یہ course harness سے wire کرتا ہے: Eval-Driven Development۔
- یہ Operational envelope (durable execution، fifth observability surface): Production Worker with a Nervous System۔
- یہ Design discipline جو build سے پہلے آتی ہے: Choosing Agentic Architectures۔
- یہ Track کے پیچھے thesis: /docs/thesis۔
یہ Five-component stack:
- یہ Package OpenAI Agents SDK (Python): package
openai-agents>=0.17,<0.18؛ docs https://openai.github.io/openai-agents-python پر؛ Manifest اور sandbox-provider reference اسی source میں live کرتے ہیں۔ Harness/sandbox separation SDK کے built-in part کے طور پر 15 اپریل 2026 release میں ship ہوئی: https://openai.com/index/the-next-evolution-of-the-agents-sdk/۔ - یہ Service FastAPI: async request handling اور auto-generated API schemas۔ https://fastapi.tiangolo.com
- یہ Service Azure Container Apps: ingress، autoscale، secrets، revisions۔ https://learn.microsoft.com/en-us/azure/container-apps/
- یہ Database Neon Postgres: branching والا serverless Postgres؛ pooled endpoint اور
channel_bindingfootgun Decision 4 کی key details ہیں۔ https://neon.com - یہ Storage Cloudflare R2: free egress کے ساتھ S3-compatible storage؛ SDK R2 کو Manifest mount کے طور پر support کرتا ہے۔ https://developers.cloudflare.com/r2/
- یہ Code-execution sandbox: E2B (https://e2b.dev، free Hobby tier، native SDK client) free path ہے؛ Cloudflare Sandbox (Workers platform کا part) paid primary ہے۔ Modal اور Daytona GPU اور in-your-cloud needs fit کرتے ہیں۔
یہ Operational and security references:
- یہ OpenTelemetry: tracing standard جسے harness export کرتا ہے۔ https://opentelemetry.io
- یہ OWASP API Security Top 10: security checklist جس کا بڑا حصہ Decision 9 cover کرتا ہے۔ https://owasp.org/API-Security/editions/2023/en/0x11-t10/
یہ Course 14 getting-started track کا end-to-end deployment crash course ہے agent-factory track کے لیے۔ Harness، sandbox، observability، اور eval suite composed ہیں، Docker، FastAPI، Neon، اور R2 میں نئے readers کے لیے stack primer کے ساتھ۔