Agentic Architectures کا انتخاب: فیصلے پر مبنی فوری کورس
پیٹرن selection پر ایک تصوری فوری کورس: سلسلہ وار ورک فلو، ایک ایجنٹ + ReAct + ٹولز، منصوبہ بندی + ReAct execution، یا multi-agent ماہر نظام کب استعمال کرنا ہے؛ ان چار بنیادی پیٹرنز میں سے کسی پر reflection کب چڑھانی ہے؛ اور یہ سب ان انجینئرز کے لیے جو agents ship کر چکے ہیں اور اگلی architecture اصولی طریقے سے چننا چاہتے ہیں، صرف اس بنا پر نہیں کہ کیا impressive لگتا ہے۔
اس کورس میں 22 Concepts • 5 Decisions • سیکھنے کے چار راستے ہیں۔ Reader track: 2-3 گھنٹے خالص تصوری مطالعہ (decision tree، پانچ پیٹرنز، failure signals، کوئی setup نہیں)۔ Beginner / Intermediate / Advanced tracks: ہر ایک تقریباً 1 دن، 2-3 دن، 4-5 دن (تصوری مطالعہ کے ساتھ real tasks classify کرنے، deployment topologies sketch کرنے، اور ہر pattern کے مخصوص eval signals wire کرنے میں بڑھتی ہوئی گہرائی)۔ دیانت دار کل اندازہ: Reader track کے لیے 2-3 گھنٹے؛ pattern selection کو ایک working discipline کے طور پر اندر بٹھانے کے لیے team کو 4-5 دن۔ Part 5 کی decision lab سے پہلے اپنا track منتخب کریں۔
مرکزی مضمون: Bala Priya C، "Choosing the Right Agentic Design Pattern: A Decision-Tree Approach," Machine Learning Mastery، May 15, 2026: machinelearningmastery.com/choosing-the-right-agentic-design-pattern-a-decision-tree-approach۔ اس course کی ریڑھ کی ہڈی والا decision tree انہی کا ہے۔ اس کے اوپر یہ course composition layer شامل کرتا ہے: ہر pattern آپ کی deployment topology اور eval suite کے لیے کیا معنی رکھتا ہے۔
سادہ زبان میں خلاصہ (پہلے یہ پڑھیں)
آپ agents بنا چکے ہیں۔ شاید Digital FTE course میں Maya کا بنایا ہوا customer-support Worker، eval-driven course میں evaluation agent، یا cloud deployment course میں وہ Tier-1 Support agent جسے آپ production تک لے گئے۔ اب آپ ایک agent بنا سکتے ہیں۔ جو کام ابھی اصولی طریقے سے نہیں آتا وہ یہ ہے کہ اگلی بار کس قسم کا agent بنانا چاہیے۔
پروڈکشن AI میں ایک حقیقی failure mode یہ ہے: engineers اس pattern کی طرف جاتے ہیں جو impressive دکھتا ہے، عموماً multi-agent، حالانکہ task کو ایک سلسلہ وار ورک فلو چاہیے ہوتا ہے جس کے پانچ میں سے تین steps میں LLM کی ضرورت بھی نہیں۔ جس مسئلے کو دو tools والے اچھے prompt کیے ہوئے ایک agent سے ایک دن میں حل کیا جا سکتا تھا، اس کے لیے orchestration پر ہفتے لگ جاتے ہیں۔ الٹا failure mode بھی اتنا ہی حقیقی ہے: task کو واقعی specialists میں decomposition چاہیے ہوتی ہے، مگر engineers لمبے system prompt والے ایک agent پر زور دیتے ہیں، اور agent ایسے context کے بوجھ تلے ٹوٹ جاتا ہے جو ایک mental model میں fit ہی نہیں آتا۔
پیٹرن selection build سے پہلے آنے والا design work ہے۔ اصل سوال یہ ہے کہ "اس agent system کی شکل واقعی کیا ہونی چاہیے؟" اس کا اصولی جواب ہے: اپنے task کے بارے میں پانچ سوال پوچھیں، اور جواب پانچ starting patterns میں سے ایک تک لے جاتے ہیں۔ یہ course وہ پانچ سوال، پانچ patterns، وہ failure signals جو بتاتے ہیں کہ pattern غلط تھا، اور (جب آپ واقعی ship کر رہے ہوں تو سب سے اہم حصہ) ہر pattern کا deployment topology اور eval suite پر اثر سکھاتا ہے۔
اصل discipline یہ نہیں کہ "ہمیشہ سب سے simple pattern چنو"۔ اصل discipline یہ ہے کہ "سب سے simple pattern چنو جو task کی حقیقی ضرورت سے match کرے، اور complexity صرف تب add کرو جب آپ اس specific task property کا نام لے سکیں جو اس complexity کا تقاضا کرتی ہے"۔ Multi-agent system تب درست جواب ہے جب specialization یا scale واقعی bottleneck بنائے، نہ کہ اس لیے کہ slide پر زیادہ advanced دکھتا ہے۔
یہ course جان بوجھ کر eval-driven course اور cloud deployment course سے چھوٹا ہے۔ Decision-logic framework tight ہے؛ ہر pattern کی history پر survey content ڈالنے سے discipline dilute ہو جائے گی۔ Tight framework یہاں feature ہے، bug نہیں۔
اگر آپ نے Agent Factory track کے پہلے courses نہیں کیے
یہ course operational envelope (Inngest)، eval discipline، اور cloud deployment کو cross-reference کرتا ہے، اور ان courses سے "Maya's Tier-1 Support agent" کو running example کے طور پر استعمال کرتا ہے۔ آپ یہ course ان courses کو پڑھے بغیر بھی بالکل استعمال کر سکتے ہیں۔ پانچ سوالوں والا decision tree، پانچ patterns، اور failure-signal discipline اپنی جگہ ایک transferable framework ہیں۔
پہلے courses کے context کے بغیر focused first pass کے لیے اس ترتیب میں پڑھیں:
- پہلے Part 1 (pattern-selection problem): discipline قائم کرتا ہے
- پھر Part 2 (پانچ سوالوں والا decision tree): conceptual spine
- پھر Part 3 کے patterns، مگر first pass میں operational-envelope sidebars skim کریں
- یہ Part 4 (failure signals اور revision)
- یہ Part 5 (decision lab): Maya context کے بغیر بھی پانچ worked examples سمجھ آ جاتے ہیں
- یہ Part 7 closing
یہ first pass میں preview یا optional سمجھنے والی چیزیں:
- یہ Concept 8.5 (SDK primitives): اگر آپ OpenAI Agents SDK استعمال کر رہے ہیں تو useful؛ اگر کوئی دوسرا framework استعمال کر رہے ہیں تو skim کریں، کیونکہ underlying pattern shapes transfer ہو جاتی ہیں
- یہ Concept 8.6 (Inngest کے ساتھ operational envelope): اگر production agentic systems ship کر رہے ہیں تو useful؛ اگر ابھی design-only stage پر ہیں تو skim کریں۔ "زیادہ elaborate patterns کو زیادہ operational machinery چاہیے" والی دلیل Inngest سے آگے بھی generalize ہوتی ہے
- یہ Part 3 کی deployment-composition sidebars: اگر آپ اسی cloud stack پر ہیں تو useful؛ general principle (کون سے patterns sandbox چاہتے ہیں اور کون سے نہیں) کسی بھی cloud setup پر transfer ہو جاتا ہے
یہ Cross-references کو general principles کی concrete examples سمجھیں، gatekeeping prerequisites نہیں۔ Framework ان کے بغیر بھی کام کرتا ہے۔
پلیٹ فارم translation table: Agent Factory کا ہر انتخاب کس چیز سے map ہوتا ہے
اگر آپ مختلف stack پر ہیں تو یہ table ہر Agent Factory reference کو common alternatives سے map کرتا ہے۔ Decision tree، پانچ patterns، failure signals، اور anti-pattern gallery ان platforms پر بھی اسی طرح کام کرتے ہیں؛ صرف primitive names بدلتے ہیں۔
| Agent Factory reference (یہاں استعمال ہونے والا stack) | 2026 میں common alternatives | layer کا کام |
|---|---|---|
| Inngest (operational envelope) | Temporal، Restate، Dapr Workflows، AWS Step Functions، Azure Durable Functions، LangGraph (partial؛ durable execution بذریعہ checkpointers) | Triggers، durable execution، flow control، HITL gates |
| OpenAI Agents SDK (agent engine) | LangGraph، AutoGen، CrewAI، AWS Strands، Pydantic AI، LlamaIndex Workflows | Agent loop، tool routing، multi-agent composition، structured output |
| Phoenix / Arize (trace observability) | Langfuse، Helicone، LangSmith، Logfire، Honeycomb، Datadog APM | ہر trace پر agent-behavior observability اور trace-to-eval pipeline |
| Azure Container Apps (harness runtime) | AWS Fargate، Google Cloud Run، Fly.io، Railway، Render، Kubernetes (کوئی بھی cloud) | long-running HTTP service host، autoscale، secrets، ingress |
| Neon Postgres (durable state) | Supabase، AWS RDS Postgres، PlanetScale، CockroachDB، Google Cloud SQL | Sessions، runs، traces، audit log: durable agent state |
| Cloudflare R2 (file storage) | AWS S3، Google Cloud Storage، Azure Blob، Backblaze B2 | Inputs، outputs، knowledge artifacts؛ sandbox کے لیے presigned-URL access |
| Cloudflare Sandbox (code execution) | E2B، Modal، Daytona، Vercel Sandbox، Fly.io Machines، Cloudflare Containers | agent-generated code کے لیے isolated workspace |
@inngest_client.create_function (envelope primitive) | @workflow.defn (Temporal)، state machine definition (Step Functions)، StateGraph(...) (LangGraph) | durable function unit register کرتا ہے |
ctx.step.run(name, fn) (envelope primitive) | workflow.execute_activity() (Temporal)، Task state (Step Functions)، StateGraph میں node (LangGraph) | durable checkpoint جو retry پر memoize کرتا ہے |
ctx.step.wait_for_event(...) (envelope primitive) | workflow.wait_condition() (Temporal)، waitForTaskToken (Step Functions)، interrupt() (LangGraph) | event یا timeout تک durable suspend، HITL primitive |
| Fan-out trigger (envelope primitive) | workflow.execute_child_workflow() parallel (Temporal)، Map state (Step Functions)، parallel edges (LangGraph) | ایک coordinator → N specialist runs |
Agent(...) + Runner.run() (SDK primitive) | Agent.execute() (LangGraph)، Agent + initiate_chat() (AutoGen)، Crew + kickoff() (CrewAI) | agent loop چلاتا ہے |
@function_tool (SDK primitive) | @tool (LangGraph/LangChain)، Tool(...) (AutoGen)، CrewAI میں Pydantic models | Python function کو agent tool کے طور پر expose کرتا ہے |
handoff(target_agent) (SDK primitive) | Command(goto=...) (LangGraph)، nested chats (AutoGen)، task delegation (CrewAI) | specialist conversation take over کرتا ہے |
Agent.as_tool() (SDK primitive) | Subgraph-as-node (LangGraph)، nested agent calls (AutoGen)، CrewAI میں as_tool patterns | coordinator specialist کو tool کے طور پر استعمال کرتا ہے |
output_guardrail (SDK primitive) | custom node + conditional edge (LangGraph)، validator pattern (Pydantic AI)، AWS Strands guardrails | agent output پر critique/validation pass |
اس table کو یوں استعمال کریں۔ جب یہ course کہتا ہے کہ "Runner.run() کو step.run میں wrap کریں" اور آپ Temporal plus LangGraph پر ہیں، اسے یوں پڑھیں کہ "Agent.execute() کو workflow.execute_activity() میں wrap کریں"۔ Architectural argument ایک ہی ہے؛ syntax مختلف ہے۔ ایک anti-pattern سے بچیں: صرف یہ course پڑھنے کے لیے Agent Factory stack سیکھنے کی کوشش نہ کریں۔ Primitives map کریں، framework پڑھیں، اور اسے اپنے stack پر apply کریں۔
ایک row صاف map نہیں ہوتی: Agent.as_tool() بمقابلہ handoff()۔ OpenAI Agents SDK "coordinator stays in charge" (as_tool) اور "specialist takes over" (handoff) کو first-class primitives کے طور پر الگ کرتا ہے۔ زیادہ تر دوسرے frameworks یا تو distinction collapse کر دیتے ہیں یا صرف ایک half implement کرتے ہیں۔ Architecture کے لیے اہم چیز primitive name نہیں، distinction خود ہے۔ جب آپ اپنے framework میں as_tool-style اور handoff-style composition کے درمیان choose کرتے ہیں، تو آپ وہی architectural choice کر رہے ہوتے ہیں جسے یہ course نام دیتا ہے؛ بس آپ کا framework اسے مختلف سطح پر دکھا سکتا ہے۔
لغت (ایک بار پڑھیں، ضرورت پر واپس آئیں)
پوری لغت کھولنے کے لیے click کریں۔
- یہ Agentic design pattern۔ AI agent systems کی بار بار آنے والی architectural شکل: سلسلہ وار ورک فلو، ReAct + tools، planning + execution، reflection، multi-agent specialist۔ ہر pattern task کے بارے میں خاص مفروضے رکھتا ہے؛ جب وہ مفروضے درست ہوں تو pattern value add کرتا ہے؛ جب درست نہ ہوں تو overhead بن جاتا ہے۔
- یہ Sequential workflow۔ steps کی fixed pipeline جہاں ہر step کا output اگلے step کو feed کرتا ہے۔ Solution path پہلے سے معلوم ہوتا ہے؛ LLM calls صرف interpretation یا generation کے لیے رکھی جاتی ہیں، اگلا کام decide کرنے کے لیے نہیں۔ مثال: invoice intake → extract → validate → store → notify۔
- یہ ReAct (Reason + Act)۔ agentic loop جس میں agent اپنی موجودہ state پر reason کرتا ہے، action لیتا ہے (عام طور پر tool call)، result observe کرتا ہے، اور repeat کرتا ہے۔ defining property: اگلا action runtime پر decide ہوتا ہے، پہلے سے specify نہیں ہوتا۔
- یہ Planning agent۔ وہ agent جو execution شروع ہونے سے پہلے explicit plan بناتا ہے (dependencies کے ساتھ stages کی sequence)۔ Plan کام کو structure دیتا ہے؛ individual steps پھر بھی اندرونی طور پر ReAct استعمال کر سکتے ہیں۔ مثال: "market research" → 5-step plan generate کریں → ہر step tools کے ساتھ execute کریں۔
- یہ Reflection (self-critique)۔ وہ pattern جہاں agent output generate کرتا ہے، اسے explicit criteria کے خلاف critique کرتا ہے، اور critique کی بنیاد پر refine کرتا ہے۔ Latency اور cost بڑھتی ہے؛ صرف تب valuable ہے جب criteria checkable ہوں اور errors مہنگے پڑتے ہوں۔ مثال: correctness checks کے ساتھ SQL generation۔
- یہ Multi-agent specialist system۔ ایسا system جس میں مختلف roles (researcher، writer، reviewer) والے کئی agents ایک task پر collaborate کرتے ہیں، routing یا supervisor agent انہیں coordinate کرتا ہے۔ Justification specialization، context-overload، یا parallel-execution needs سے آتی ہے؛ aesthetic سے نہیں۔
- یہ Solution path۔ وہ steps sequence جو task solve کرتی ہے۔ Known path کا مطلب ہے steps runtime سے پہلے specify کیے جا سکتے ہیں؛ unknown path کا مطلب ہے steps agent کی investigation سے emerge ہوتے ہیں۔
- یہ Task structure۔ بڑے stages اور ان کی dependencies۔ Articulable structure کا مطلب ہے کہ execution سے پہلے stages describe کیے جا سکتے ہیں؛ emergent structure کا مطلب ہے stages feedback کے ذریعے ظاہر ہوتے ہیں۔
- یہ Architectural fit۔ pattern کے assumptions اور task کی actual properties کے درمیان match۔ Pattern selection fit-matching ہے، capability-matching نہیں: سب سے capable pattern چننا غلط heuristic ہے۔
- یہ Coordination overhead۔ کئی agents کے درمیان routing یا handoffs coordinate کرنے کی cost: tokens، latency، debugging complexity، اور failure modes۔ Multi-agent systems یہ cost pay کرتے ہیں؛ اسے اس value سے justify ہونا چاہیے جو coordination دیتی ہے۔
- یہ Failure signal۔ runtime symptom جو بتاتا ہے کہ chosen pattern task سے mismatch ہے۔ مثالیں: ReAct loops solved work کو revisit کرتے ہیں (structure missing)، planner ایسے plans بناتا ہے جن سے execution diverge کرتی ہے (overstructured)، reflection output improve نہیں کرتی (criteria vague)۔
- یہ Pattern composition۔ بڑے system کی مختلف layers پر مختلف patterns استعمال کرنا۔ مثال: top layer پر planning agent، ہر plan step کے اندر ReAct + tools، final synthesis پر reflection۔
Agent(OpenAI Agents SDK)۔ core SDK class: LLM-driven entity جوinstructions=، optionaltools=، structured output کے لیے optionaloutput_type=، اور optionalhandoffs=سے define ہوتی ہے۔ اس course میں ہر pattern کی atomic unit۔Runner.run(agent, input)(OpenAI Agents SDK)۔ SDK call جوAgentکو final output تک run کرتی ہے۔ SDK reason-act-observe loop اندرونی طور پر چلاتا ہے: hand-rolled loop کی ضرورت نہیں۔max_turns=parameter step budget ہے۔@function_tool(OpenAI Agents SDK)۔ decorator جو Python function کو tool میں بدل دیتا ہے جسے agent call کر سکتا ہے۔ Type hints اور docstrings خود بخود tool کا JSON schema بن جاتے ہیں۔handoff()(OpenAI Agents SDK)۔ multi-agent transitions کے لیے first-class SDK primitive: ایک agent conversation کو explicit طور پر دوسرے agent کو hand off کرتا ہے، اور SDK context preserve کرتا ہے۔ جب specialist کو user-facing interaction take over کرنی ہو تو use کریں۔Agent.as_tool()(OpenAI Agents SDK)۔ SDK method جو ایکAgentکو callable tool بنا دیتا ہے جسے دوسراAgentinvoke کر سکتا ہے۔ جب coordinator کو in charge رہنا ہو اور specialist outputs compose کرنے ہوں تو use کریں۔output_guardrail(OpenAI Agents SDK)۔ SDK decorator جو validation/critique agent کو دوسرے agent کے output path میں wire کرتا ہے۔ block-bad-outputs-style reflection کے لیے SDK-native primitive؛ fire ہونے پرOutputGuardrailTripwireTriggeredraise کرتا ہے۔- یہ Operational envelope (Inngest)۔ runtime layer جو agent function کو جگاتی ہے (triggers)، mid-flight crashes survive کرتی ہے (durable execution via
step.run)، load limit کرتی ہے (concurrency، throttle، priority)، اور HITL coordinate کرتی ہے (step.wait_for_event)۔ یہ cloud deployment اور SDK engine کے ساتھ compose ہوتی ہے۔ operational-envelope course میں سکھائی گئی ہے۔ @inngest_client.create_function(Inngest)۔ decorator جو Python async function کو Inngest کے ساتھ durably-executed unit کے طور پر register کرتا ہے۔ Trigger surface اور flow-control policy declare کرتا ہے۔ctx.step.run(name, fn, args)(Inngest)۔ durability checkpoint۔ Completed steps retry پر memoized output return کرتے ہیں؛ failed steps exponential backoff کے ساتھ independently retry ہوتے ہیں۔ctx.step.wait_for_event(...)(Inngest)۔ matching event یا timeout تک durable suspend۔ Suspension کے دوران zero compute consume ہوتا ہے۔ HITL gates کے پیچھے runtime primitive یہی ہے۔- یہ Fan-out trigger pattern (Inngest)۔ ایک coordinator function N events emit کرتا ہے؛ ہر event اپنی subscriber function کو wake کرتا ہے۔ Multi-agent systems میں parallel specialist execution کے پیچھے runtime primitive۔
- یہ Replay (Inngest)۔ Failed runs full trace کے ساتھ persist رہتے ہیں۔ Fix ship کریں، replay click کریں؛ function failed step سے نئے code کے ساتھ resume کرتی ہے۔ Successful steps memoized رہتے ہیں۔
کیا آپ تیار ہیں؟ (prerequisites)
- آپ اپنا پہلا agent بنا چکے ہیں، یا equivalent experience رکھتے ہیں۔ اس course کے patterns فرض کرتے ہیں کہ آپ agent loop، tool call، اور model کے structured output return کرنے کا basic مطلب سمجھتے ہیں۔ اگر آپ نے ابھی agent نہیں بنایا تو پہلے agent-building course کریں۔
- آپ کم از کم ایک working agent بنا چکے ہیں۔ چاہے وہ Maya کا customer-support Worker ہو، research agent، chatbot، یا coding agent، آپ کو architectural choice کرنے (چاہے اس وقت احساس نہ ہوا ہو) اور اس کے نتائج کے ساتھ رہنے کا experience چاہیے۔
- آپ pseudocode پڑھ سکتے ہیں۔ یہ conceptual course ہے، اس لیے executable code بہت کم ہے۔ جو code دکھے گا وہ patterns illustrate کرنے کے لیے pseudocode ہوگا؛ اگر آپ Python یا TypeScript پڑھ سکتے ہیں تو اسے پڑھ سکتے ہیں۔
- (Optional مگر strongly recommended) آپ eval اور cloud deployment courses کر چکے ہیں۔ اس course کی main contribution pattern selection کو deployment topology اور eval suite کے ساتھ compose کرنا ہے۔ جن readers نے وہ courses نہیں کیے وہ بھی framework سے فائدہ اٹھا سکتے ہیں، مگر integration arguments کا کچھ حصہ miss ہوگا۔
اگر item 4 missing ہے تو بھی یہ course پڑھیں، اور deployment-composition اور eval-composition sidebars کو previews سمجھیں۔ Framework ان کے بغیر بھی land کرتا ہے۔
شروع میں جاننے والی خامیاں (دیانت دار scope)
- یہ conceptual course ہے، code course نہیں۔ یہ architecture چننا سکھاتا ہے، implement کرنا نہیں۔ Implementation discipline پہلے Agent Factory courses میں ہے۔ تقریباً 30 pages architectural reasoning اور کل ملا کر تقریباً 5 pages pseudocode expect کریں۔
- پانچ patterns exhaustive نہیں۔ Reality میں graph-based agent systems، debate patterns، blackboard patterns، hierarchical task networks، اور دوسرے patterns بھی ہیں جو یہاں cover نہیں۔ یہ course article میں dominant architectural starting points کے طور پر identified پانچ patterns cover کرتا ہے؛ mid-2026 تک production agent systems کی بڑی اکثریت انہی پانچ میں آ جاتی ہے، مگر سب نہیں۔
- یہ Decision tree starting point ہے، final answer نہیں۔ Real agent architectures evolve کرتی ہیں۔ Tools والا single agent workload diversify ہونے پر multi-agent system بن سکتا ہے؛ planning-then-execution system paths واضح ہونے پر sequential workflow میں simplify ہو سکتا ہے۔ یہ course starting decision سکھاتا ہے، evolution نہیں۔
- یہ Cost اور latency choice کا حصہ ہیں۔ Reflection latency add کرتی ہے۔ Multi-agent tokens add کرتا ہے۔ Planning ایک extra LLM call add کرتی ہے۔ یہ course ان costs کو real constraints سمجھتا ہے؛ Concept 18 بتاتا ہے کہ ہر pattern کا overhead کب justified ہے۔
- یہ Article spine ہے؛ composition layer extension ہے۔ Bala Priya C کا decision tree اس course کی structural backbone ہے۔ یہ course دو layers add کرتا ہے جو article میں نہیں: (a) ہر pattern آپ کی deployment topology کے لیے کیا معنی رکھتا ہے، اور (b) ہر pattern کے failure modes آپ کی eval suite میں کیسے دکھتے ہیں۔ اگر آپ نے صرف article پڑھا ہے تو یہ course production-discipline layer add کرتا ہے۔
سیکھنے کے چار راستے
| Track | Time commitment | آپ کیا complete کرتے ہیں | کس کے لیے ہے |
|---|---|---|---|
| Reader (خالص conceptual) | ~2-3 گھنٹے، no lab | مکمل conceptual arc: Part 1 (problem)، Part 2 (decision tree)، Part 3 (پانچ patterns)، Part 4 (failure signals)، اور Part 7 closing۔ classification exercises یا decision lab نہیں۔ | Engineering leaders، platform architects، یا curious مگر non-engineer readers جو decide کر رہے ہیں کہ team time systematic pattern selection میں لگانا ہے یا نہیں۔ |
| Beginner | ~1 دن | Reader track + decision lab میں Decisions 1-2۔ Decision tree استعمال کر کے دو tasks classify کریں (Maya کا Tier-1 Support اور incident-response agent)؛ chosen pattern کا high-level sketch بنائیں۔ | Agentic architecture میں نئے engineers جو guided pattern-selection practice کا ایک round چاہتے ہیں۔ |
| Intermediate | ~2-3 دن | Beginner track + Decisions 3-4۔ Research agent اور enterprise onboarding agent add کریں؛ اپنے cloud stack پر ان کی deployment topologies sketch کریں؛ eval signals identify کریں جو ہر pattern کے failure mode کو catch کریں۔ | Agentic systems ship کرنے والے engineers جو pattern selection کو deployment اور evaluation کے ساتھ compose کرنا چاہتے ہیں۔ |
| Advanced | ~4-5 دن | Intermediate track + Decision 5 + Parts 6 & 7۔ Coding agent (سب سے مشکل case) add کریں؛ pattern composition explore کریں؛ full discipline کے ساتھ hypothetical agent system end-to-end architect کریں۔ | Senior engineers اور tech leads جو pattern selection کو team-wide discipline بنانا چاہتے ہیں۔ |
یہ Track-fork guidance۔ Engineering leaders کو Reader track سے start کرنا چاہیے۔ Engineers کے لیے default Intermediate track ہے؛ decision lab ہی وہ جگہ ہے جہاں framework واقعی internalize ہوتا ہے۔ صرف اس لیے Part 5 مکمل skip نہ کریں کہ Part 2 جلدی پڑھ لیا۔ Framework تب stick کرتا ہے جب اسے real tasks پر apply کیا جائے۔
یہ Minimum viable path: working pattern selection تک سب سے مختصر راستہ۔ Part 1 (problem)، Part 2 (decision tree)، اور lab سے Decision 1 (Maya کا Tier-1 Support) پڑھیں۔ یہ تقریباً 90 منٹ ہیں؛ آخر میں آپ پانچ questions استعمال کر کے new task classify کر سکتے ہیں اور starting pattern چن سکتے ہیں۔ باقی سب discipline کو deepen کرتا ہے؛ seed یہی ہے۔
آخر میں آپ کے پاس کیا ہوگا (concrete outcomes)
یہ Reader track artifacts نہیں، understanding پیدا کرتا ہے۔ آپ explain کر سکیں گے کہ code لکھنے سے پہلے pattern selection کیوں اہم ہے؛ پانچ patterns اور ان کے characteristic task assumptions describe کر سکیں گے؛ پانچ common failure signals پہچان سکیں گے جو pattern mismatch بتاتے ہیں۔
یہ Beginner / Intermediate / Advanced tracks ایک working classification discipline پیدا کرتے ہیں:
- یہ New task پر پانچ سوالوں والا decision tree walk کرنے اور principled starting pattern چننے کی صلاحیت۔
- اپنے cloud stack پر ہر pattern کی deployment topology کا sketch: sequential workflow کو کون سے components چاہیے، اور multi-agent یا planning system کو کون سے۔
- ہر pattern کے likely failure modes سے ان specific eval signals تک mapping جو انہیں catch کریں گے۔
- یہ Team-shareable artifact: design reviews میں استعمال کے لیے ایک-page "classify-this-task" template۔
مختصر خلاصہ: اس course کے چار بنیادی دعوے
یہ Pattern selection architectural fit ہے، capability matching نہیں۔ ہر pattern task کے بارے میں ایک assumption رکھتا ہے۔ درست pattern وہ ہے جس کے assumptions task کی actual properties سے match کریں، نہ کہ وہ جس میں سب سے زیادہ capability یا سب سے impressive structure ہو۔ Multi-agent sequential workflow سے "better" نہیں؛ یہ صرف اس specific case میں better ہے جہاں specialization یا scale bottleneck بنائے۔
چار core patterns + ایک additive layer۔ Decision tree کے Q1-Q3 core pattern چنتے ہیں: sequential workflow، single agent + ReAct + tools، planning + ReAct execution، یا multi-agent specialist system۔ Q4 decide کرتا ہے کہ chosen core پر reflection کو additive layer کے طور پر add کرنا ہے یا نہیں۔ Reflection پانچواں peer pattern نہیں؛ یہ quality-control layer ہے جو چاروں cores میں سے کسی کو wrap کرتی ہے۔ یہ distinction اہم ہے: جو students reflection کو standalone pattern سمجھتے ہیں وہ architectural truth miss کرتے ہیں کہ reflection پہلے سے chosen core pattern کے ساتھ compose ہوتی ہے۔
یہ Task کے بارے میں پانچ سوال architecture determine کرتے ہیں۔ Q1-Q3 core pattern چنتے ہیں: کیا solution path known ہے؟ کیا workflow fixed ہے؟ کیا task structure articulable ہے؟ Q4 decide کرتا ہے کہ reflection layer add ہو یا نہیں: کیا quality speed سے زیادہ اہم ہے اور criteria checkable ہیں؟ Q5 decide کرتا ہے کہ multi-agent میں upgrade کرنا ہے یا نہیں: کیا specialization، context، یا scale bottleneck ہے؟ جواب deterministically starting architecture تک map ہوتے ہیں۔ Article درست کہتا ہے کہ literature میں missing چیز patterns خود نہیں، decision logic ہے۔
یہ Pattern selection deployment topology اور eval signals کے ساتھ compose ہوتی ہے۔ ہر pattern cloud stack کا different subset use کرتا ہے: sequential workflows کو sandbox execution نہیں چاہیے؛ multi-agent systems کو careful audit logging چاہیے کیونکہ coordination failures production میں سب سے مشکل bug ہوتے ہیں۔ ہر pattern کے characteristic failure modes ہیں جنہیں آپ کی eval suite مختلف طریقے سے catch کرتی ہے۔ اس topic پر کم courses یہ composition سکھاتے ہیں، کیونکہ اس کے لیے deployment اور eval courses foundation کے طور پر چاہیے ہوتے ہیں۔
یہ Decision tree starting point دیتا ہے، final answer نہیں۔ Real systems evolve کرتے ہیں۔ Discipline یہ نہیں کہ "architecture ہمیشہ کے لیے lock کر دو"؛ discipline یہ ہے کہ starting decision principled بناؤ، failure signals دیکھتے رہو، اور runtime evidence کو evolution guide کرنے دو۔ Pattern selection first move ہے؛ pattern revision ongoing move ہے۔
آپ جو سیکھ رہے ہیں اس کی شکل (ایک diagram، پورے course میں واپس دیکھیں)
یہ course 22 Concepts (19 main plus 8.5، 8.6، اور 16.5 پر 3 bridge concepts) introduce کرتا ہے اور 5 Decisions walk کرتا ہے۔ اس سب سے پہلے، یہ وہ decision tree ہے جس کے گرد باقی سب compose ہوتا ہے۔
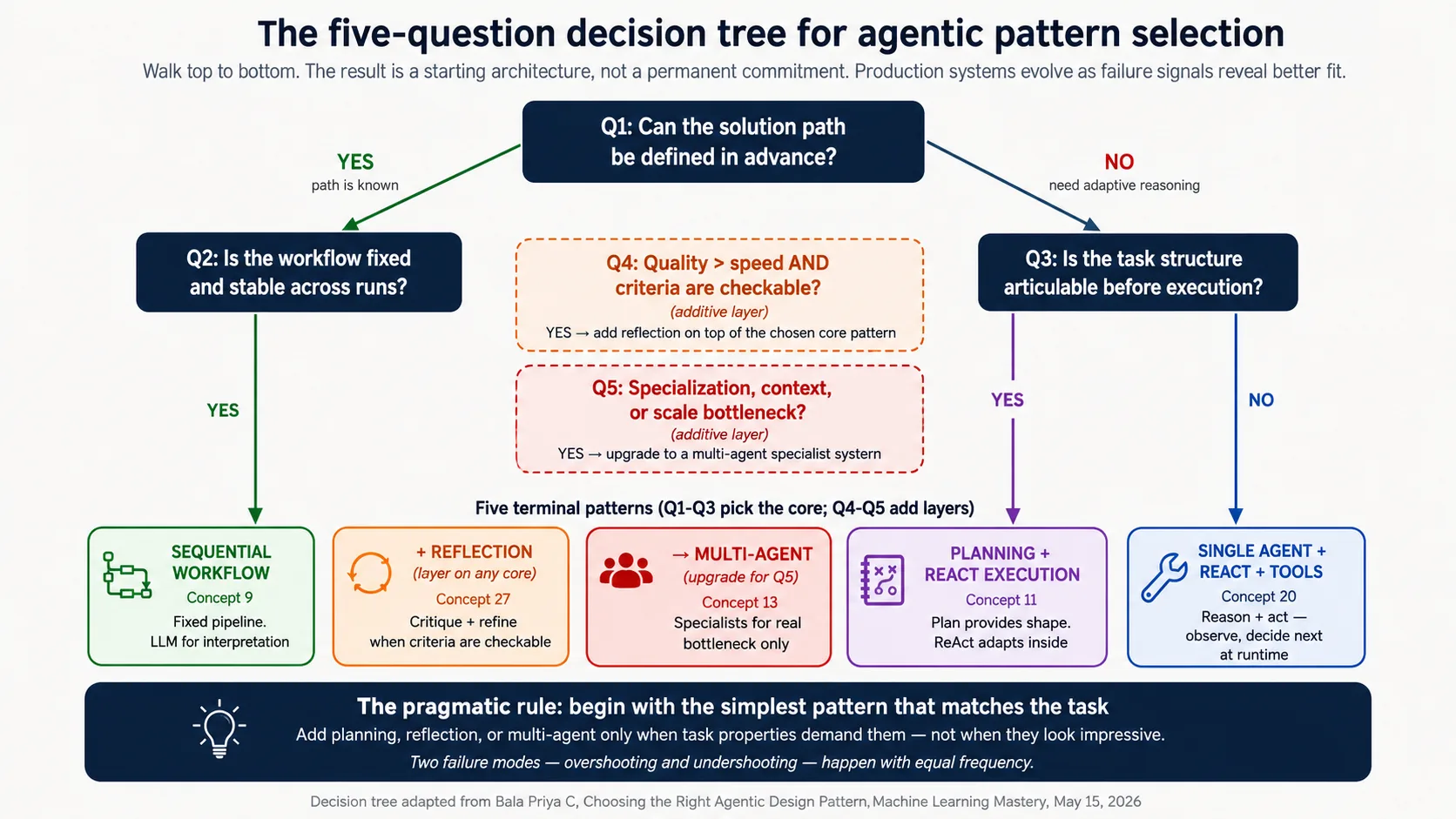
یہ Tree کی shape: پہلے پوچھیں کہ کیا آپ کو LLM-driven agent کی ضرورت بھی ہے (Q1-Q2)؛ اگر ہے تو task کتنا structured ہے (Q3)؛ پھر quality (Q4) اور scale (Q5) صرف تب layer کریں جب وہ real value create کریں۔ جب بھی کوئی Concept یا Decision abstract لگے، اس diagram پر واپس آئیں۔
یہ Part 1: pattern-selection problem
یہ Concept 1: pattern selection build سے پہلے آنے والا design work ہے
یہ Agentic systems کے زیادہ تر courses ہر pattern build کرنا سکھاتے ہیں۔ یہ course ایک مختلف سوال کے بارے میں ہے: task given ہو تو کون سا pattern build کرنا چاہیے؟ یہ سوال build سے پہلے آتا ہے، اور آنا چاہیے، مگر عموماً اسے ایک awkward وجہ سے نہیں سکھایا جاتا: ہر pattern کی implementation اچھی طرح documented ہے؛ ان کے درمیان choose کرنے کی decision logic documented نہیں۔
یہ Pattern catalog mature ہے۔ ReAct ایک 2022 paper سے آتا ہے۔ Planning-then-execution patterns classical AI میں STRIPS تک جاتے ہیں اور 2023 میں LLMs کے لیے rediscover ہوئے۔ Reflection 2023 سے formalized ہے۔ Multi-agent architectures ہر بڑے framework میں سکھائی جاتی ہیں۔ آپ کسی بھی pattern کا tutorial پانچ منٹ سے کم میں ڈھونڈ سکتے ہیں۔ جو آسانی سے نہیں ملتا وہ یہ ہے: اس specific task اور ان specific constraints کے لیے کون سا pattern fit ہے؟
یہ failure mode پیدا ہوتا ہے۔ Engineers default کرتے ہیں اس pattern پر جو انہوں نے حال ہی میں دیکھا ہو یا talks میں زیادہ impressive لگتا ہو۔ Multi-agent demos خاص طور پر tempting ہیں کیونکہ وہ "real AI" جیسے لگتے ہیں: agents آپس میں بات کر رہے ہیں، work divide کر رہے ہیں، coordinate کر رہے ہیں۔ Teams ایسے problems کے لیے orchestration پر ہفتے لگا دیتی ہیں جنہیں well-defined دو tools والا single agent ایک دن میں solve کر سکتا تھا۔ نتیجہ: وہ slower ship کرتے ہیں، debugging harder ہوتی ہے، اور task کی ضرورت سے زیادہ tokens pay کرتے ہیں۔
الٹا failure mode بھی حقیقی ہے اور کم discuss ہوتا ہے۔ Engineers "بس ایک really long system prompt والا single agent use کرو" کی طرف جاتے ہیں جب task کو واقعی structural decomposition چاہیے ہوتی ہے۔ Agent ایسے context کے نیچے collapse کرتا ہے جو ایک mental model میں fit نہیں آتا۔ Tool-calling errors cascade کرتے ہیں۔ Reflection team کو واحد fix معلوم ہوتا ہے، تو وہ اسے ہر جگہ add کر دیتے ہیں، اور اب ہر response 30 seconds لیتا ہے۔ وہ ایک brittle system ship کرتے ہیں جسے درست architectural choice prevent کر سکتی تھی۔
یہ course جو discipline سکھاتا ہے: pattern selection architectural fit-matching ہے، capability matching نہیں۔ "Best pattern کون سا ہے؟" مت پوچھیں (ایسا کوئی نہیں)۔ پوچھیں: "یہ task واقعی کیا demand کرتا ہے، اور وہ demand پوری کرنے والا smallest pattern کیا ہے؟" Part 2 کا پانچ سوالوں والا decision tree اس کا systematic جواب ہے۔
یہ پہلے سے زیادہ کیوں matter کرتا ہے۔ 2023 میں agentic systems experimental تھے۔ غلط pattern choose کرنے سے ایک weekend waste ہوتا تھا۔ 2026 میں agentic systems real users کو serve کرتے ہوئے production میں ہیں؛ chosen pattern آپ کی deployment topology، eval discipline، اور scale پر operational cost decide کرتا ہے۔ غلط pattern اب compounding ways میں expensive ہے: wrong assumption کے لیے infrastructure، wrong failure modes کے لیے evals، wrong incidents کے لیے runbooks۔ Pattern selection "preference" سے high-stakes design decision بن چکا ہے۔
خلاصہ: patterns خود well-documented ہیں؛ ان کے درمیان choose کرنے کی decision logic وہ gap ہے جو یہ course fill کرتا ہے۔ Pattern selection architectural fit-matching ہے، capability matching نہیں۔ Production میں wrong pattern expensive compounding پیدا کرتا ہے: wrong infrastructure، wrong evals، wrong runbooks۔ یہ course پانچ سوالوں والی discipline سکھاتا ہے جو سب سے common pattern-selection failures prevent کرتی ہے۔
یہ Concept 2: ہر pattern task کے بارے میں مختلف مفروضہ رکھتا ہے
یہ Pattern selection کو tractable بنانے والا deep idea یہ ہے: ہر agentic pattern task کی شکل کے بارے میں ایک شرط یا bet ہے۔ جب bet reality سے match کرے تو pattern value add کرتا ہے۔ جب bet غلط ہو تو pattern overhead بن جاتا ہے، کبھی invisible overhead جو صرف tokens cost کرتا ہے، کبھی catastrophic overhead جو پورا system توڑ دیتا ہے۔
پانچوں patterns کی bets یہ ہیں:
یہ Sequential workflow کی bet: مجھے steps پہلے سے معلوم ہیں، اور ہر بار وہی ہیں۔ Bet یہ ہے کہ solution path runtime سے پہلے fixed اور articulable ہے۔ اگر یہ درست ہو، تو اگلا کام decide کرنے کے لیے LLM کی ضرورت نہیں: workflow کو معلوم ہے۔ LLM calls صرف ان steps کے لیے رکھیں جو واقعی interpretation چاہتے ہیں (اس text سے یہ extract کریں، وہ summary generate کریں)۔ Cost predictable؛ latency bounded؛ failure modes واضح۔ اگر یہ غلط ہو: steps input کے content کے مطابق بدلتے ہوں تو workflow غلط path force کرے گا یا noisily fail ہوگا۔
یہ Single agent + ReAct + tools کی bet: مجھے path پہلے سے معلوم نہیں؛ agent خود figure out کرے گا۔ Bet یہ ہے کہ task اتنا open-ended ہے کہ next step ابھی تک observe ہونے والی چیزوں پر depend کرتا ہے۔ اگر یہ درست ہو تو ReAct loop (reason → act → observe → repeat) ہی اسے handle کر سکتا ہے؛ predetermined plan step 3 تک غلط ہو جائے گا۔ اگر یہ غلط ہو: path اصل میں stable تھا اور لکھا جا سکتا تھا، تو ReAct latency، cost، اور loop/revisit risk add کرتا ہے، وہ بھی ایسی value کے بغیر جو sequential workflow سے نہ مل سکتی ہو۔
یہ Planning + ReAct execution کی bet: major stages اور dependencies پہلے سے articulate ہو سکتی ہیں، مگر ہر stage میں adaptive reasoning چاہیے۔ Bet یہ ہے کہ work کی shape معلوم ہے (research → analyze → synthesize → report) مگر ہر stage کا content investigation چاہتا ہے۔ اگر درست ہو، plan scaffolding دیتا ہے اور agent کو بھٹکنے سے روکتا ہے، جبکہ ہر stage کے اندر ReAct uncertainty handle کرتا ہے۔ اگر غلط ہو: plan واقعی articulate نہیں کیا جا سکتا (pure ReAct use کریں) یا ہر stage کو adaptive reasoning کی ضرورت نہیں (sequential workflow use کریں)، تو plan ایسا overhead بن جاتا ہے جس سے execution ویسے بھی diverge کرتی ہے۔
یہ Reflection کی bet: output quality speed سے زیادہ اہم ہے، اور quality checkable ہے۔ Bet یہ ہے کہ critique pass وہ defects catch کر سکتا ہے جو generator سے miss ہوئے، اور "good output" کے criteria اتنے explicit ہیں کہ critique meaningful ہو۔ اگر درست ہو، reflection first pass کی errors (غلط SQL، کمزور legal arguments، reports میں factual mistakes) catch کر کے reliability improve کرتی ہے۔ اگر غلط ہو: criteria vague ہوں یا critic اور generator کے blind spots same ہوں، تو reflection output improve کیے بغیر latency اور cost add کرتی ہے۔ اس سے بھی worse: یہ false confidence دے سکتی ہے کہ critique نے quality "verify" کر دی، حالانکہ نہیں کی۔
یہ Multi-agent specialist system کی bet: کوئی single agent اس کام کو اچھی طرح کرنے کے لیے کافی expertise، context، یا capacity نہیں رکھتا۔ Bet یہ ہے کہ task واقعی specialist roles میں partition ہوتا ہے (researcher + writer + reviewer؛ coder + security + docs)، اور specialists کی coordination ایک agent کے overload سے cheaper ہے۔ اگر درست ہو، specialists اپنے domains میں generalist سے better outputs دیتے ہیں، اور parallel execution throughput improve کرتی ہے۔ اگر غلط ہو: "specialists" زیادہ تر same کام کر رہے ہوں، یا coordination overhead work پر dominate کرے، تو آپ نے ایسی complexity add کی جو کچھ نہیں خریدتی اور نئے failure modes introduce کر دیے (routing errors، integration errors، ownership ambiguity)۔
یہ Pattern ہی bet ہے؛ task کی actual properties decide کرتی ہیں کہ bet درست ہے یا نہیں۔ اسی لیے pattern selection fit-matching ہے۔ آپ یہ نہیں پوچھ رہے کہ "کون سا pattern سب سے powerful ہے؟" آپ پوچھ رہے ہیں: "اس task کے بارے میں جو مجھے واقعی معلوم ہے، اس سے کون سے pattern کی bet best match کرتی ہے؟"
خلاصہ: ہر agentic pattern task کے بارے میں ایک bet ہے: sequential workflow known fixed paths پر bet کرتا ہے، ReAct unknown adaptive paths پر، planning articulable structure پر، reflection checkable quality criteria پر، multi-agent real specialization needs پر۔ درست pattern وہ ہے جس کی bet reality سے match کرے؛ pattern selection fit-matching ہے، capability matching نہیں۔
یہ Concept 3: دو failure modes، overshooting اور undershooting
یہ Concept 2 نے بتایا کہ ہر pattern ایک bet ہے۔ Concept 3 بتاتا ہے کہ وہ bet دو طریقوں سے غلط ہوتی ہے، اور real production systems میں دونوں تقریباً equally frequent ہیں۔
یہ Overshooting: task کی ضرورت سے زیادہ elaborate pattern چننا۔ یہ زیادہ famous failure mode ہے، وہ جس میں talks اور demos آپ کو آسانی سے پھنسا دیتے ہیں۔ مثالیں:
- ایک single LinkedIn-post generation جیسے task کے لیے تین-agent system بنانا (researcher، writer، reviewer)۔ "researcher" agent کا output دو paragraphs ہے جنہیں "writer" پھر summarize کرتا ہے۔ Reviewer 5% outputs ایسے issues پر reject کرتا ہے جو self-checking prompt catch کر لیتا۔ تین agents، تین گنا cost، measurable quality improvement صفر۔
- ایسے task میں planning add کرنا جو اصل میں fixed workflow ہے۔ Planner ہر بار same plan produce کرتا ہے (کیونکہ task same ہے)۔ ہر run ایک extra LLM call free میں pay کرتا ہے۔ Worse: input تھوڑا unusual ہو تو planner slightly different plan produce کرتا ہے، اور اب team کو debug کرنا پڑتا ہے کہ "اس input پر planner نے different path کیوں لیا؟"
- یہ checkable criteria کے بغیر task میں reflection add کرنا۔ Critic اور generator same model، same training data، اور اکثر same blind spots share کرتے ہیں۔ Reflection pass output کو rubber-stamp کرتا ہے یا verbose مگر non-actionable critique generate کرتا ہے۔ Latency double؛ quality flat۔
یہ Overshooting failure pattern: آپ نے ایسی capability کے لیے pay کیا جس کی task کو ضرورت نہیں تھی، اور اسے undo کرنا آسان نہیں کیونکہ orchestration اب load-bearing بن چکی ہے۔ چھ ماہ production میں رہنے والے multi-agent system کو remove کرنا refactor نہیں، rewrite ہے۔
یہ Undershooting: task کو واقعی جس pattern کی ضرورت ہے اس سے simpler pattern چننا۔ یہ failure mode talks میں کم دکھائی دیتی ہے کیونکہ اسے dramatize کرنا کم impressive ہے، مگر یہ کم از کم اتنی ہی common ہے۔ مثالیں:
- یہ billing، technical، account، اور refund issues پر customer support handle کرنے کے لیے 4,000-token system prompt والا single agent استعمال کرنا۔ Agent billing rules کو technical rules سے confuse کرتا ہے۔ Reflection marginally help کرتی ہے مگر root cause fix نہیں کرتی۔ Task کو واقعی specialist routing چاہیے تھی؛ ایک agent context hold نہیں کر سکتا تھا۔
- ایسے workflow کے لیے ReAct + tools استعمال کرنا جو fixed pipeline ہونا چاہیے تھا۔ Agent کبھی steps skip کرتا ہے، کبھی completed work revisit کرتا ہے، کبھی nonexistent tool calls invent کرتا ہے۔ Team prompt میں "stop conditions" اور "progress criteria" add کرتی ہے، symptoms treat کرتی ہے، underlying mismatch نہیں۔ Cost variance runbook problem بن جاتا ہے۔
- ایسے outputs پر reflection skip کرنا جنہیں واقعی verification چاہیے۔ Subtle errors والی SQL queries production تک چلی جاتی ہیں۔ Legal drafts citation mistakes کے ساتھ clients کو بھیج دیے جاتے ہیں۔ Team بعد میں tests add کرتی ہے، مگر natural catch point generation time پر reflection pass تھا۔
یہ Undershooting failure pattern: آپ نے ایک brittle چیز ship کی جو manual oversight یا luck کے سہارے survive کرتی ہے۔ Production gaps reveal کرتا ہے؛ remediation میں یا تو وہ pattern add کرنا پڑتا ہے جس سے start کرنا چاہیے تھا، یا failure rate کو business cost سمجھ کر accept کرنا پڑتا ہے۔
دونوں failure modes equally important کیوں ہیں۔ Pattern selection کی discussions overshooting پر focus کرتی ہیں (کیونکہ زیادہ visible failure ہے، multi-agent system جسے کوئی debug نہیں کر سکتا)۔ مگر undershooting بھی اتنی ہی common اور arguably زیادہ dangerous ہے: یہ ایسے systems produce کرتی ہے جو کام کرتے دکھتے ہیں جب تک نہیں کرتے، اور failure modes subtle ہوتے ہیں۔ جو team overshooting avoid کرنا سیکھ لے مگر undershooting recognize نہ کرے، اس نے discipline کا آدھا حصہ ہی سیکھا ہے۔
یہ Part 2 کا decision tree دونوں failure modes surface کرنے کے لیے design کیا گیا ہے۔ ہر سوال ایک task property کے بارے میں پوچھتا ہے (path known ہے؟ structure articulable ہے؟ quality checkable ہے؟)؛ اگر جواب elaborate pattern justify نہیں کرتا، tree simpler pattern کی طرف route کرتا ہے (overshoot prevent کرتا ہے)۔ اگر جواب elaborate pattern justify کرتا ہے، tree explicit طور پر وہاں route کرتا ہے (upgrade کو conscious بنا کر undershoot prevent کرتا ہے)۔
خلاصہ: pattern selection دو طریقوں سے fail ہوتی ہے: overshooting (task سے زیادہ elaborate pattern چننا، ایسی capability کے لیے pay کرنا جو help نہیں کرتی) اور undershooting (task سے simpler pattern چننا، brittle system ship کرنا)۔ دونوں تقریباً equally frequent ہیں؛ talks overshooting emphasize کرتی ہیں مگر undershooting کم از کم اتنی ہی dangerous ہے کیونکہ زیادہ subtle ہے۔ Part 2 کا decision tree pattern preferences کے بجائے task properties پوچھ کر دونوں failures surface کرتا ہے۔
یہ Part 2: پانچ سوالوں والا decision tree
یہ part decision tree کو question by question walk کرتا ہے۔ ہر Concept پانچ questions میں سے ایک cover کرتا ہے: وہ کیا test کرتا ہے، real task کے لیے اسے کیسے answer کرنا ہے، اور answer کس pattern کی طرف route کرتا ہے۔ Part 2 کے آخر تک آپ پورا tree ایک بار walk کر چکے ہوں گے۔
یہ Tree کی structure:
| # | سوال | یہ کیا test کرتا ہے | کس طرف route کرتا ہے |
|---|---|---|---|
| Q1 | کیا solution path پہلے سے define ہو سکتا ہے؟ | کیا process runtime سے پہلے specify ہو سکتا ہے | yes ہو تو Q2 (fixed workflow check)؛ no ہو تو adaptive reasoning needed، Q3 پر جائیں |
| Q2 | کیا workflow ہر run میں fixed اور stable ہے؟ | کیا same steps ہر بار apply ہوتے ہیں | yes ہو تو Sequential Workflow؛ no ہو تو adaptive patterns revisit کریں |
| Q3 | کیا task structure execution سے پہلے articulable ہے؟ | کیا major stages اور dependencies clear ہیں | yes ہو تو Planning + ReAct execution؛ no ہو تو Single agent + ReAct + tools |
| Q4 | کیا checkable criteria کے ساتھ quality speed سے زیادہ اہم ہے؟ | کیا extra critique/refinement passes latency/cost کے قابل ہیں | yes ہو تو chosen pattern پر Reflection layer add کریں؛ no ہو تو reflection skip کریں |
| Q5 | کیا specialization، context، یا scale bottleneck ہے؟ | کیا ایک agent expertise، context، یا parallel capacity میں کم پڑتا ہے | yes ہو تو Multi-Agent Specialist System؛ no ہو تو single agent رکھیں |
یہ Questions 1-3 core pattern determine کرتے ہیں۔ Questions 4-5 additive layers ہیں؛ وہ کسی بھی core pattern کے اوپر apply ہو سکتے ہیں، مگر صرف تب جب ان کے assumptions درست ہوں۔
یہ Concept 4: Q1: کیا solution path پہلے سے define ہو سکتا ہے؟
یہ سب سے اہم سوال ہے، کیونکہ یہ decide کرتا ہے کہ آپ کو agentic system کی ضرورت ہے بھی یا نہیں۔
"Solution path" کا مطلب۔ Concretely: اگر میں input بتاؤں تو کیا آپ output produce کرنے والی exact steps sequence بتا سکتے ہیں؟ Answer خود نہیں، صرف path۔ Invoice intake کے لیے: email receive کریں → structured fields extract کریں → database کے خلاف validate کریں → store کریں → requester کو notify کریں۔ پانچ steps، same پانچ steps، ہر بار۔ یہ known solution path ہے۔
یہ Contrast کریں: customer پوچھتا ہے "November 12 کو مجھ سے دو بار charge کیوں ہوا؟" Path اس پر depend کرتا ہے جو آپ find کرتے ہیں۔ Transaction history دیکھیں۔ مل گئی۔ دو charges different merchants سے ہیں، تو "کیا یہ fraud ہے؟" پر pivot کریں۔ یا same merchant کے different timestamps ہیں، تو "کیا second retry تھا؟" پر pivot کریں۔ یا customer account میں multiple users ہیں، تو "کیا کسی اور نے purchase کی؟" پر pivot کریں۔ ہر branch different next step تک لے جاتی ہے۔ Path پہلے سے specify نہیں ہو سکتا؛ investigation جو reveal کرتی ہے اس سے emerge ہوتا ہے۔ یہ unknown solution path ہے۔
اسے honestly test کرنے کا طریقہ۔ تین tests، اسی order میں:
- کیا input دیکھنے سے پہلے steps کا flowchart لکھ سکتے ہیں؟ اگر yes، path known ہے۔ اگر flowchart کو "اب agent decide کرے کہ کیا کرنا ہے" boxes چاہیے ہوں، path unknown ہے۔
- کیا steps بہت سے runs میں unchanged repeat ہوتے ہیں؟ Invoice intake repeat ہوتا ہے۔ Customer support investigations نہیں۔ Research report کا outline ہر بار same shape ہو سکتا ہے (intro، تین sections، conclusion) مگر content discovery step sequence نہیں؛ adaptive search ہے۔
- یہ Input بدلنے پر steps بدلتے ہیں؟ Known path different inputs کے لیے same step sequence produce کرتا ہے۔ Unknown path ہر step کے reveal کرنے والی چیز کے مطابق different step sequences produce کرتا ہے۔
یہ Teams یہاں کہاں غلط ہوتی ہیں۔ سب سے common error یہ ہے کہ task description structured لگتا ہے، اس لیے path کو known سمجھ لیا جاتا ہے۔ "Refund requests process کریں" known لگتا ہے: request receive کریں، order lookup کریں، refund issue کریں، customer notify کریں۔ Real refund requests ایسی نہیں ہوتیں۔ کچھ dispute investigation چاہتی ہیں (کیا یہ chargeback تھا؟)، کچھ policy lookup چاہتی ہیں (کیا اس customer's plan میں refunds allowed ہیں؟)، کچھ escalation چاہتی ہیں (amount agent authority سے زیادہ ہے)، کچھ میں multiple charges ہوتے ہیں جنہیں disambiguate کرنا پڑتا ہے۔ چار-step flowchart غلط ہے؛ actual path adaptive ہے۔
یہ Mirror error: task description open-ended لگتا ہے، اس لیے path unknown سمجھ لیا جاتا ہے۔ "آج رات شہر میں اچھی restaurant ڈھونڈنے میں help کریں" adaptive لگتا ہے، مگر اگر actual implementation یہ ہے: request parse کریں → restaurant database کو filters کے ساتھ query کریں → rating کے حساب سے top 5 return کریں، تو path known ہے اور sequential workflow درست pattern ہے۔ "agentic" framing misleading تھی۔
یہ Route۔ اگر path known ہے (اور stable ہے، next Q2 دیکھیں)، تو آپ sequential workflow کی طرف جا رہے ہیں۔ ہو سکتا ہے آپ کو LLM-driven agent کی ضرورت ہی نہ ہو؛ interpretation یا generation کے specific steps میں embedded LLM calls والا workflow چاہیے ہو۔ اگر path unknown ہے تو agentic reasoning چاہیے؛ question یہ ہے کہ structure articulable ہے (Q3، planning) یا نہیں (Q3، pure ReAct)۔
یہ Useful heuristic۔ خود سے پوچھیں: "اگر مجھے یہ no LLM calls والی Python function کے طور پر لکھنا پڑے تو کیا میں اسے structure کرنا جانتا ہوں؟" اگر yes، path غالباً known ہے؛ LLM صرف specific reasoning یا generation moments کے لیے چاہیے۔ اگر no، path غالباً unknown ہے؛ LLM structural decisions کر رہا ہے، صرف generative decisions نہیں۔
خلاصہ: Q1 پوچھتا ہے کہ solution path runtime سے پہلے specify ہو سکتا ہے یا نہیں۔ Known paths sequential workflows (Q2) کی طرف route کرتے ہیں؛ unknown paths adaptive agentic reasoning (Q3) کی طرف۔ سب سے common error یہ ہے کہ task description structured لگنے پر path کو known سمجھ لیا جاتا ہے، حالانکہ actual implementation adaptive ہوتی ہے، جیسے refund processing، customer support، debugging۔ الٹا error یہ ہے کہ path کو unknown سمجھ لیا جاتا ہے حالانکہ وہ LLM-flavored input والا workflow ہے۔ "Python function without LLM calls" heuristic سے test کریں۔
یہ Concept 5: Q2: کیا workflow ہر run میں fixed اور stable ہے؟
آپ نے Q1 کا جواب "yes، path known ہے" دیا۔ Q2 دوسرا check ہے: کیا یہ path ان inputs کے across fixed اور stable ہے جن کی آپ واقعی توقع رکھتے ہیں؟ کیونکہ "known" اور "stable" ایک چیز نہیں۔
یہ Distinction۔ Path principle میں known ہو سکتا ہے مگر practice میں vary کر سکتا ہے۔ ایک "research assistant" agent سوچیں جو user queries handle کرتا ہے۔ کبھی user quick answer چاہتا ہے (ایک fact lookup کریں، return کریں)۔ کبھی multi-source synthesis چاہتا ہے (search، compare، summarize)۔ کبھی uploaded document کا analysis چاہتا ہے (read، claims extract، evaluate)۔ آپ ہر case کا path لکھ سکتے ہیں، مگر path input type کے ساتھ vary کرتا ہے۔ یہ known-but-variable ہے، known-and-stable نہیں۔
مقابلے میں invoice intake۔ ہر invoice same پانچ steps سے گزرتی ہے۔ Path stable ہے۔ ہر step کا content vary کرتا ہے (different vendors، different amounts)، مگر step structure نہیں بدلتا۔
یہ کیوں matter کرتا ہے۔ Sequential workflow stability assume کرتا ہے۔ اگر آپ fixed pipeline بنائیں اور path vary کرے، تو pipeline کچھ inputs پر wrong path force کرے گی: یا ایسے steps apply کرے گی جو apply نہیں ہوتے (quick-answer query کو full synthesis treatment ملے گا)، یا noisily fail ہوگی (document-analysis path quick-answer step structure میں fit نہیں ہوگا)۔
یہ Test۔ Real inputs کا representative sample دیکھیں (یا carefully imagine کریں)۔ کیا step sequence ان سب میں same رہتا ہے؟
- اگر ہاں، ہر input same steps سے گزرتا ہے → workflow stable ہے؛ sequential workflow بنائیں۔
- اگر نہیں، different inputs کو different step sequences چاہیے → workflow variable ہے؛ یا (a) explicit branching والا workflow چاہیے جو ہر variant handle کرے، یا (b) agentic pattern چاہیے جو input کے مطابق path adapt کرے۔
یہ Teams یہاں کہاں غلط ہوتی ہیں۔ "Known on average" کو "known and stable" سمجھ لینا۔ 80% case fixed workflow ہے؛ 20% case deviation چاہتا ہے۔ Engineers 80% کے لیے workflow بناتے ہیں اور 20% کے لیے ad-hoc patches add کرتے ہیں۔ آخرکار patches original workflow پر dominate کرتے ہیں، اور ایک undocumented hybrid بن جاتا ہے جسے کوئی نہیں سمجھتا۔ یہ pattern اکثر تب آتا ہے جب team یہ ماننے سے ہچکچا رہی ہوتی ہے کہ task امید سے زیادہ adaptive ہے: sequential workflows safer محسوس ہوتے ہیں، اس لیے over-fit کیے جاتے ہیں۔
یہ Route۔ اگر workflow fixed اور stable ہے → Sequential Workflow۔ Tree کی اس branch کے لیے یہاں رک جائیں۔ Questions 3 اور اکثر 4 skip کریں۔ Q5 صرف تب consider کریں جب scale workflow instances کے across parallelization force کرے۔
اگر workflow known-but-variable ہے → آپ کے پاس دو choices ہیں:
- یہ Explicit branching والا sequential workflow: ہر variant کو branch کے طور پر لکھیں؛ deterministic طور پر route کریں (اکثر ایک چھوٹی LLM call input type classify کر کے route کر دیتی ہے)۔ Best when variants few and stable ہوں۔
- یہ Path کو effectively unknown treat کریں: Q3 پر جائیں اور agentic reasoning کو variation handle کرنے دیں۔ Best when variants many یا evolving ہوں۔
یہ Pragmatic heuristic۔ اگر variants ایک ہاتھ پر list ہو سکتے ہیں اور often change نہیں ہوتے، branched workflow۔ اگر نہیں، agentic pattern۔
خلاصہ: Q2 پوچھتا ہے کہ known path expected inputs کے across stable بھی ہے یا نہیں۔ Stable paths sequential workflows کی طرف route کرتے ہیں۔ Known-but-variable paths یا explicit branching والے workflows (few stable variants) یا agentic patterns (many/evolving variants) کی طرف route کرتے ہیں۔ Trap یہ ہے کہ "80% case fixed ہے" کو "fixed" سمجھ لیا جائے؛ 20% case patches میں بدل کر original design پر dominate کرتا ہے۔
یہ Concept 6: Q3: کیا task structure execution سے پہلے articulable ہے؟
آپ نے Q1 کا جواب دیا کہ "path unknown ہے"، agentic reasoning چاہیے۔ Q3 next question پوچھتا ہے: کیا work کی high-level structure پہلے سے articulable ہے، چاہے specific steps نہ ہوں؟
یہاں "structure" کا مطلب۔ Steps themselves نہیں، وہ Q1 کے مطابق unknown ہیں۔ یہاں stages اور ان کی dependencies مراد ہیں۔ مثال: market research agent۔ آپ پہلے سے steps specify نہیں کر سکتے (کون سے sources consult ہوں گے، کون سے competitors investigate ہوں گے، کون سے analyses چلیں گے، یہ findings پر depend کرتا ہے)۔ مگر structure articulate ہو سکتی ہے: gather data → analyze → synthesize → report۔ چار stages، اسی order میں، clear dependencies کے ساتھ۔ یہ articulable structure ہے۔
یہ Contrast: customer-support agent "مجھے issue ہے" handle کر رہا ہے۔ Agent investigate کرتا ہے۔ Findings کے مطابق work account lookup، پھر knowledge-base search، پھر policy check، پھر escalation بھی ہو سکتا ہے؛ یا ان میں سے کچھ بھی نہیں، صرف quick redirection۔ آپ stages articulate نہیں کر سکتے کیونکہ work stage structure میں fit نہیں ہوتا؛ investigation ہے جو complete ہونے پر complete ہوتی ہے۔ یہ articulable نہیں۔
یہ Test۔ Specific input دیکھنے سے پہلے work کو phase diagram کے طور پر draw کرنے کی کوشش کریں۔ کیا major phases اور dependencies label کر سکتے ہیں؟
- اگر phases clear ہیں (gather → analyze → synthesize؛ یا design → implement → test؛ یا research → draft → review) → structure articulable ہے؛ planning use کریں۔
- اگر work phases میں fit نہیں ہوتا، investigation، iteration، یا open-ended exploration ہے → structure articulable نہیں؛ ReAct use کریں۔
یہ Teams یہاں کہاں غلط ہوتی ہیں۔ جہاں structure نہیں وہاں invent کرنا۔ Engineers کو لگتا ہے کہ plan ہمیشہ possible ہونا چاہیے، تو وہ force کرتے ہیں۔ Planner plan generate کرتا ہے؛ execution فوراً diverge کرتی ہے کیونکہ task میں وہ phases تھے ہی نہیں۔ پھر team یا (a) divergence کو planner bug treat کرتی ہے ("planner نے bad plan دیا"؛ planner rewrite کریں؛ repeat)، یا (b) plan کو آہستہ آہستہ اتنا short کر دیتی ہے کہ وہ trivial ہو کر کچھ contribute نہیں کرتا۔ Honest answer یہ تھا: "اس task کو plan کی ضرورت نہیں؛ ReAct use کریں۔"
یہ Opposite error: جو structure واقعی موجود ہے اسے miss کرنا۔ Engineers ایسے tasks کے لیے pure ReAct use کرتے ہیں جن کے واقعی phases ہیں۔ Agent بھٹکتا ہے، solved work revisit کرتا ہے، یا overall progress کا track کھو دیتا ہے۔ Prompt میں "یہ phases یاد رکھنا" add کرنا workaround ہے؛ architectural fix یہ ہے کہ ReAct loop کے اوپر planning add کی جائے۔
یہ Route۔ اگر structure articulable ہے → Planning + ReAct execution۔ Planning agent phase structure produce کرتا ہے؛ ہر phase کے اندر ReAct وہ unknown-step adaptation handle کرتا ہے جسے Q1 نے identify کیا۔
اگر structure articulable نہیں → Single agent + ReAct + tools۔ Agent current state پر reason کرتا ہے، next action لیتا ہے، result observe کرتا ہے، اور repeat کرتا ہے: agent کے اپنے maintained state کے علاوہ کوئی overlay structure نہیں۔
یہ Internalize کرنے کے قابل heuristic۔ Planning تب help کرتی ہے جب work کی shape predictable ہو مگر content نہ ہو۔ ReAct alone تب درست ہے جب shape بھی discovery پر depend کرتی ہو۔ Shape-vs-content distinction ان دونوں کو الگ کرنے کا سب سے clean طریقہ ہے۔
یہ Q2 vs. Q3 confusion: examples کے ساتھ disambiguation
یہ Q2 ("کیا workflow fixed اور stable ہے؟") اور Q3 ("کیا task structure articulable ہے؟") experienced teams کو بھی trip کرتے ہیں۔ دونوں predictability کے بارے میں ہیں؛ فرق یہ ہے کہ predictability کس چیز کی ہے:
Question یہ کیا پوچھتا ہے "yes" کا مطلب "yes" کس طرف route کرتا ہے Q2 کیا steps themselves runs کے across fixed ہیں؟ same Python function-call sequence ہر بار right answer produce کرتی ہے۔ اگلا کیا کرنا ہے اس پر کوئی LLM-driven decisions نہیں۔ Sequential workflow Q3 کیا major stages پہلے سے articulable ہیں، چاہے step-level work vary کرے؟ specific input دیکھنے سے پہلے whiteboard پر phase structure describe کر سکتے ہیں۔ LLM ہر stage کے اندر ابھی بھی decide کرتا ہے کہ کیا کرنا ہے۔ Planning + ReAct execution جو conflation نقصان دیتی ہے: engineers task میں structure دیکھتے ہیں ("یہاں clearly stages ہیں: research، analyze، write") اور Q2 کو YES answer کرتے ہیں۔ مگر "structure exists" Q3 کا سوال ہے، Q2 کا نہیں۔ Q2 پوچھتا ہے کہ کیا runtime پر exact step sequence predict ہو سکتی ہے؛ اگر agent کو ہر stage کے اندر decisions کرنے ہیں (کون سے sources، کون سے analyses، کون سی framings)، تو Q2 کا answer NO ہے اور آپ Q3 پر ہیں۔
یہ Q2 vs. Q3 کو الگ کرنے والی تین boundary examples:
یہ Example A، Invoice intake (Q2 = YES → Sequential workflow): extract → validate → store → notify۔ Same five steps every time۔ LLM fields extract کرتا ہے اور notification لکھتا ہے، مگر اگلا step decide نہیں کرتا۔ Step sequence fixed ہے۔
یہ Example B، Market research report (Q2 = NO، Q3 = YES → Planning + ReAct): gather data → analyze → synthesize → draft → review۔ Stages articulable ہیں، مگر ہر stage کے اندر agent decide کرتا ہے کہ کیا کرنا ہے (کون سے sources consult کرنے ہیں، کن competitors پر focus کرنا ہے، کون سے analyses چلانے ہیں)۔ Stages fixed؛ stages کے اندر steps adaptive۔
یہ Example C، Customer-support investigation (Q2 = NO، Q3 = NO → Single agent + ReAct): agent customer issue investigate کرتا ہے۔ کوئی predetermined phase structure نہیں: findings کے مطابق work ایک lookup ہو سکتا ہے یا پانچ lookups plus policy check plus escalation۔ نہ stages fixed ہیں نہ steps۔
غور کریں کہ example B وہ case ہے جسے Part 5 کے Decisions صرف partially exercise کرتے ہیں۔ اگر آپ خود کو یہ کہتے پائیں کہ "اس میں clear phases ہیں" AND "planner نے plan دیا مگر execution diverge کرتی رہی"، تو آپ Q2/Q3 boundary پر ہیں اور answer تقریباً ہمیشہ Planning + ReAct ہے، Sequential workflow نہیں۔
یہ Q2 کا known-but-variable subcase (جسے name کرنا worth ہے)۔ کبھی Q1 = YES (path known) مگر Q2 = NO (inputs کے across variable)، مثلاً workflow میں input type کے مطابق 3-4 stable variants ہیں (quick lookup vs. multi-source synthesis vs. document analysis)۔ یہ Sequential workflow بھی نہیں اور Planning + ReAct بھی نہیں؛ یہ explicit input-type routing والا branched workflow ہے۔ Concept 5 اسے cover کرتا ہے؛ Decision 4 کا variant anti-pattern gallery میں (Concept 16.5 کی row "stable workflow میں planning add کرنا") inverse failure cover کرتا ہے۔
خلاصہ: Q3 پوچھتا ہے کہ task کی high-level structure (stages and dependencies) execution سے پہلے articulable ہے یا نہیں۔ Articulable structure planning + ReAct execution کی طرف route کرتی ہے (plan shape دیتا ہے؛ ReAct ہر stage کے unknown content کو handle کرتا ہے)۔ Non-articulable structure pure ReAct + tools کی طرف route کرتی ہے (agent shape اور content دونوں adaptively discover کرتا ہے)۔ Traps یہ ہیں: جہاں structure نہیں وہاں invent کرنا (forced plans جن سے execution diverge کرتی ہے) اور جو structure واقعی موجود ہے اسے miss کرنا (phased work پر pure ReAct، جس سے wandering ہوتی ہے)۔
یہ Concept 7: Q4: کیا checkable criteria کے ساتھ quality speed سے زیادہ اہم ہے؟
یہ Q4 دو additive layer questions میں پہلا ہے۔ Core pattern (sequential workflow، ReAct، یا planning + ReAct) Q1-Q3 سے پہلے ہی chosen ہے۔ Q4 پوچھتا ہے کہ اس کے اوپر reflection layer کرنی ہے یا نہیں۔
یہ Reflection کیا کرتی ہے۔ Agent output produce کرنے کے بعد critique pass اسے explicit criteria کے خلاف evaluate کرتا ہے۔ اگر critique defects identify کرے، تو agent refine (یا regenerate) کرتا ہے۔ Pattern کی bet (Concept 2 سے): critique pass generator کی missed errors catch کر سکتا ہے، اور "good output" کے criteria اتنے explicit ہیں کہ critique meaningful ہے۔
یہ Reflection valuable ہونے کے لیے دو conditions دونوں hold ہونی چاہئیں۔
- یہ Quality speed سے زیادہ اہم ہے۔ Reflection کم از کم ایک extra LLM call add کرتی ہے (critique) اور اکثر دو (critique + refinement)۔ Interactive use cases میں جہاں latency matter کرتی ہے (real-time customer support، conversational agents)، یہ cost اکثر prohibitive ہے۔ Batch use cases میں جہاں output humans review کرتے ہیں یا downstream systems کو ship ہوتا ہے (report generation، code generation، document drafting)، latency عموماً acceptable ہوتی ہے۔ Test: کیا meaningfully higher-quality output کے لیے 2-5× slower response acceptable ہوگا؟
- یہ Evaluation criteria explicit اور checkable ہیں۔ Vague criteria vague critiques produce کرتے ہیں۔ "یہ good ہو" criterion نہیں۔ "Verify کریں کہ SQL parse ہو، صرف listed tables hit کرے، اور SELECT * use نہ کرے" criterion ہے۔ Explicit criteria کے بغیر critique pass verbose chatter بن جاتا ہے جو output improve نہیں کرتا، اور اکثر false confidence دیتا ہے کہ "AI نے check کر لیا" جب حقیقت میں کچھ check نہیں ہوا۔
دونوں conditions برابر اہم ہیں۔ Latency-sensitive task میں reflection add کرنا time waste کرتا ہے۔ Vague criteria والے task میں reflection add کرنا theater ہے۔ دونوں failures common ہیں؛ دونوں Q4 skip کر کے reflection صرف rigorous sound ہونے پر add کرنے سے آتے ہیں۔
یہ Test۔ دو سوال پوچھیں:
- اگر یہ response produce ہونے میں 3-5× زیادہ وقت لے، تو کیا میرے users (یا downstream consumers) meaningful quality improvement کے بدلے اس سے okay ہوں گے؟ اگر no، reflection latency budget سے justified نہیں۔
- کیا میں 5-10 specific bullet points میں exactly لکھ سکتا ہوں کہ اس task کے لیے "good output" کیا ہے، اس طرح کہ کوئی different LLM وہ bullets پڑھ کر output کو ان کے خلاف check کر سکے؟ اگر no، reflection criteria clarity سے justified نہیں۔
اگر دونوں answers yes ہیں تو reflection value add کرتی ہے۔ اگر ایک بھی no ہے تو reflection skip کریں۔
یہ Teams یہاں کہاں غلط ہوتی ہیں۔
یہ Critics rigorous لگتے ہیں اس لیے reflection add کرنا۔ "Generate، پھر critique" اچھی engineering لگتی ہے۔ اکثر ہوتی ہے؛ کبھی صرف show ہوتا ہے۔ Test یہ ہے کہ critique output کو measurable ways میں change کرتی ہے یا نہیں۔ اگر reflection add کرنے کے بعد post-reflection output 90% وقت pre-reflection جیسا ہی ہے، تو reflection work نہیں کر رہی؛ cost add کر رہی ہے۔
یہ Generator اور critic دونوں کے لیے same model اور prompt style استعمال کرنا۔ Critic کے پاس generator جیسا training data، biases، اور blind spots ہوتے ہیں۔ وہ rubber-stamp کرتا ہے۔ Effective reflection patterns یا (a) critic کے لیے different model use کرتے ہیں، (b) critic کو fundamentally different perspective سے frame کرتے ہیں ("you are a strict reviewer looking for problems" vs. generator's helpful framing)، یا (c) critic کو explicit checking tools دیتے ہیں (SQL run کریں، JSON parse کریں، schema validate کریں)۔
یہ Uncheckable output والے tasks پر reflection کرنا۔ Reflection ان tasks پر کام کرتی ہے جہاں wrongness define ہو: SQL with errors، code that doesn't compile، summaries that miss key facts in source۔ یہ ان tasks پر poorly work کرتی ہے جہاں "good" subjective ہو: marketing copy، creative writing، conversational responses۔ Subjective domains کو LLM reflection سے زیادہ human-in-the-loop review فائدہ دیتا ہے۔
یہ Route۔ اگر دونوں conditions hold کرتی ہیں تو Q1-Q3 کے core pattern کے اوپر reflection layer add کریں۔ یہ core pattern replace نہیں کرتی؛ اسے wrap کرتی ہے۔ Reflection والا sequential workflow workflow run کرتا ہے، پھر final output critique کرتا ہے۔ Reflection والا ReAct agent loop complete کرتا ہے، پھر final output critique کرتا ہے۔ Reflection post-hoc quality control ہے، core pattern کا replacement نہیں۔
اگر ایک condition بھی fail ہو تو reflection skip کریں۔ اگر آپ کو واقعی quality assurance چاہیے مگر criteria checkable نہیں، تو right fix human review ہے، LLM reflection نہیں۔
خلاصہ: Q4 پوچھتا ہے کہ quality speed سے زیادہ اہم ہے AND evaluation criteria explicit اور checkable ہیں یا نہیں۔ Reflection value add کرنے کے لیے دونوں conditions hold ہونی چاہئیں۔ Latency-sensitive tasks پر reflection time waste کرتی ہے؛ vague-criteria tasks پر reflection theater بناتی ہے۔ دو common failure modes: reflection add کرنا کیونکہ rigorous sound کرتی ہے (یہ check کیے بغیر کہ output change کرتی ہے یا نہیں)، اور generator/critic کے لیے same model/prompt style use کرنا (rubber-stamping پیدا کرتا ہے)۔ جب reflection justified ہو تو یہ core pattern کے اوپر layer ہوتی ہے، اسے replace نہیں کرتی۔
یہ Concept 8: Q5: کیا specialization، context، یا scale bottleneck ہے؟
یہ Q5 دوسرا additive layer question ہے، اور سب سے consequential بھی، کیونکہ multi-agent systems build کرنے میں سب سے expensive pattern ہیں اور غلط نکلیں تو remove کرنے میں بھی سب سے expensive۔
یہ Multi-agent systems کس پر bet کرتے ہیں۔ تین distinct claims، جو اکثر mix ہو جاتے ہیں:
- یہ Specialization claim: task کو distinct expertise چاہیے جو ایک prompt میں single agent اچھی طرح hold نہیں کر سکتا۔ Coder، security reviewer، اور documentation writer کے optimal prompts، optimal tools، اور optimal evaluation criteria مختلف ہیں۔ تینوں کو ایک agent میں fit کرنے سے تینوں میں mediocrity آتی ہے۔
- یہ Context claim: task کو single agent کے effectively use کرنے سے زیادہ context چاہیے۔ Context window technically large ہو تو بھی context بڑھنے کے ساتھ retrieval اور reasoning degrade کرتے ہیں۔ Work کو agents میں split کرنا، ہر ایک کے focused context کے ساتھ، reasoning quality preserve کرتا ہے۔
- یہ Scale claim: task میں ایسا work شامل ہے جو parallel run ہو سکتا ہے، اور multi-agent system اسے single sequential agent سے faster execute کر سکتا ہے۔ 10 competitors کو simultaneously research کرنا ایک ایک کر کے research کرنے سے بہتر ہے۔
ہر claim actual task کے خلاف separately test ہونی چاہیے۔
یہ Specialization claim اکثر evidence کے بغیر believe کی جاتی ہے۔ Engineers "feature build کریں" جیسے task کو roles (architect، coder، tester، reviewer) میں decompose کرتے ہیں کیونکہ intuitive لگتا ہے۔ Intuition جتنی بار right ہوتی ہے اتنی بار wrong بھی۔ Real feature-building اکثر good tool access والے ایک agent میں بہتر ہوتا ہے؛ architect-coder-tester separation handoff costs introduce کرتی ہے جو specialization gain سے زیادہ ہوتے ہیں۔ Claim test کریں: کیا یہ work domain specialist کے صرف اس slice پر focus کرنے سے meaningfully improve ہوگا؟
یہ Context claim scale پر زیادہ often true ہوتی ہے۔ دس knowledge bases پر دس retrievals کرنے والا single agent ایسا context accumulate کرتا ہے جو reasoning degrade کرتا ہے۔ دس retrieval-and-summary agents میں split کرنا، جہاں ہر agent focused brief produce کرے اور پھر briefs compose ہوں، اکثر outperform کرتا ہے، کیونکہ ہر retrieval agent کا context small اور focused رہتا ہے۔ مگر یہ real architectural decision ہے، default نہیں۔
یہ Scale claim test کرنے میں سب سے آسان ہے: کیا parallel execution measurable throughput improvement دیتی ہے، اور کیا task واقعی cleanly parallelize ہوتا ہے؟ اگر work کی strict sequential dependencies ہیں (ہر step کو previous step کا output چاہیے)، تو parallel multi-agent execution coordination cost add کرتی ہے مگر speed نہیں خریدتی۔
یہ Test۔ تین sub-questions:
- کیا میں specialist کو justify کرنے والی specific expertise کا نام لے سکتا ہوں؟ "یہ cleaner ہوگا" count نہیں۔ "Reviewer کو OWASP standards apply کرنے ہیں جو coder کو نہیں سیکھنے چاہئیں" count کرتا ہے۔ اگر expertise name نہیں کر سکتے تو specialization claim غالباً aesthetic ہے۔
- کیا task کا context single agent کے effectively use کرنے سے exceed کرے گا؟ عموماً yes اگر task کو multiple distinct knowledge bases، many sources کے across long-running investigations، یا per phase specialized tool sets چاہیے ہوں۔ عموماً no اگر context ایک well-managed prompt میں fit ہو جاتا ہے۔
- کیا work genuinely parallelize ہوتا ہے، measurable throughput improvement کے ساتھ؟ اگر work sequential ہے (ہر step previous پر depend کرتا ہے)، parallel execution help نہیں کرتا۔ اگر work genuinely independent ہے (10 competitors research کریں، 10 candidates evaluate کریں، 10 documents summarize کریں)، parallelization real value دیتی ہے۔
اگر کم از کم ایک sub-question strong yes پاتا ہے تو multi-agent justified ہے۔ اگر تینوں answers "maybe" یا "organizational reasons کے لیے separate agents nice ہوں گے" ہیں، تو single-agent pattern پر رہیں۔ Coordination overhead real اور substantial ہے۔
یہ Teams یہاں کہاں غلط ہوتی ہیں۔
یہ Organizational reasons کے لیے multi-agent systems بنانا۔ "اس پر تین teams کام کر رہی ہیں؛ تین agents بنا لیتے ہیں۔" یہ agent architecture کو org chart جیسا بنا رہا ہے۔ تقریباً ہمیشہ wrong۔ Multi-agent systems کو task properties کے گرد design ہونا چاہیے، team boundaries کے گرد نہیں۔ (تین teams ایک agent پر collaborate کر سکتی ہیں؛ org structure اور agent structure کا match کرنا ضروری نہیں۔)
یہ Coordination cost underestimate کرنا۔ Agents کے درمیان ہر handoff serialization point introduce کرتا ہے (ایک agent کا output دوسرے کا input)، potential failure point (handoff format match نہ کرے)، اور debugging difficulty (کچھ غلط ہو تو کس agent نے cause کیا؟)۔ Multi-agent systems single-agent systems کے مقابلے میں roughly order of magnitude زیادہ expensive debug ہوتے ہیں: cost justify ہے یا نہیں، اس reasoning میں اسے track کریں۔
یہ Sophistication demonstrate کرنے کے لیے multi-agent بنانا۔ یہ talks-and-demos failure mode ہے۔ Multi-agent systems architecture diagrams میں impressive لگتے ہیں؛ "real AI" دکھاتے ہیں۔ اگر actual task انہیں justify نہیں کرتا، تو آپ نے impressive overhead بنایا ہے۔
یہ Route۔ اگر specialization، context، یا scale real bottleneck create کرتے ہیں → Multi-Agent Specialist System۔ System میں coordinator/routing agent plus specialists ہو سکتے ہیں، explicit handoff contracts والے specialists ہو سکتے ہیں، یا shared state کے ذریعے communicate کرتے specialists ہو سکتے ہیں۔ Core pattern (sequential workflow، ReAct، planning + ReAct) پھر بھی ہر specialist domain کے اندر apply ہوتا ہے؛ multi-agent patterns کی composition ہے، replacement نہیں۔
اگر real bottleneck نہیں → single-agent pattern رکھیں۔ Q4 کی conditions hold کریں تو reflection add کریں، مگر aesthetic reasons سے multi-agent add نہ کریں۔
یہ Q5 کے quantitative triggers: concrete metrics جو multi-agent decision fire کرتے ہیں۔ "Specialization، context، یا scale bottleneck" by default judgment-based ہے، اور judgment ہی وہ جگہ ہے جہاں pattern-overshoot creep کرتا ہے۔ جہاں ممکن ہو، judgment کو measurement سے replace کریں۔ نیچے والے triggers rules of thumb ہیں جو Q5 کو subjective ("specialists جیسا feel ہوتا ہے") سے defensible ("ہم نے X measure کیا اور X threshold سے اوپر ہے") بناتے ہیں۔
| Bottleneck claim | upgrade justify کرنے والا quantitative trigger | metric کیا measure کرتا ہے |
|---|---|---|
| Specialization | Single-agent traces specific knowledge domains میں tool-routing errors concentrated دکھائیں (rough working threshold: affected category میں تقریباً ایک third runs، اپنے baseline پر calibrate کریں)۔ مثال: unified billing+technical agent technical queries کے sizeable share پر wrong tool pick کرتا ہے کیونکہ billing terminology context dominate کرتی ہے۔ | Per-trace tool-correctness، query category کے حساب سے segmented: آپ کی eval suite کا Phoenix evaluator |
| Specialization (qualitative fallback) | Measure نہیں ہو سکتا؟ Upgrade سے پہلے specialist roles کی written specification require کریں: ہر role کی responsibilities، tools، اور acceptance criteria plain English میں۔ اگر spec vague ہو یا roles responsibility میں >40% overlap کریں، تو specialization claim aesthetic ہے، architectural نہیں۔ | Document review، metric نہیں |
| Context overflow | Holdout set پر accuracy context بڑھنے کے ساتھ materially degrade ہو (اپنی curve measure کریں؛ rough flag: 15K → 45K token sweep پر تقریباً 10 points drop investigation کے قابل ہے)۔ مثال: 25 source documents load کرنے والا research agent 15K context پر 78%، 30K پر 71%، 45K پر 62% accuracy دکھاتا ہے۔ | Golden dataset پر context-vs-accuracy curve |
| Scale (parallelizable) | work میں فی run >5 independent sub-tasks ہوں AND single-agent execution latency user-facing latency budget سے >2× exceed کرے۔ مثال: 10 competitors research → single-agent sequentially 8 minutes لیتا ہے، budget 3 minutes ہے → parallel multi-agent execution ہی fit ہونے کا راستہ ہے۔ | End-to-end latency + sub-task independence analysis |
| Scale (throughput) | Run volume single-agent design کی rate-limit ceiling سے 10× exceed کرے AND per-tenant concurrency caps fairness preserve نہ کر سکیں۔ مثال: 500 RPM OpenAI quota کے against 5K runs/day per tenant multiple agent identities یا specialist-style decomposition کے across fan-out demand کرتا ہے۔ | Production load × API rate limits: operational envelope کے flow-control dashboards میں visible |
یہ Evidence کی hierarchy۔ Multi-agent کے لیے strongest سے weakest justification:
- یہ Production trace data جو bottleneck دکھائے (best: single-agent system واقعی اس طرح fail ہوتا ہے اس کا evidence ہے)
- یہ Holdout-set measurements جو bottleneck دکھائیں (strong: controlled experiment)
- یہ Domain analysis written specialist-role specifications کے ساتھ (acceptable: کم از کم define کیا ہے کیا build کر رہے ہیں)
- "Specialists جیسا feel ہوتا ہے" (insufficient: pattern-overshoot یہی رہتا ہے)
یہ Useful self-check۔ "وہ smallest single-agent design کیا ہے جسے ہم پہلے ship کر سکتے ہیں، اور کون سا specific failure ہمیں later multi-agent پر force کرے گا؟" اگر answer ہے "production traces میں X failure pattern discover ہوگا" تو پہلے single-agent ship کریں اور upgrade trigger کو تب fire ہونے دیں جب وہ fire ہو۔ Multi-agent rarely wrong endpoint ہوتا ہے؛ تقریباً ہمیشہ wrong starting point ہوتا ہے۔
خلاصہ: Q5 پوچھتا ہے کہ specialization، context، یا scale real bottleneck create کرتے ہیں یا نہیں جو multi-agent architecture justify کرے۔ تینوں claims (specialization، context، scale) separately test ہونے چاہئیں، اور جہاں possible ہو quantitative triggers کے against (illustrative thresholds، اپنے system پر calibrated: تقریباً ایک third runs میں tool-routing errors، high context پر تقریباً 10-point accuracy drop، latency budget سے 2× سے زیادہ overrun)۔ Specialization اکثر evidence کے بغیر believe کی جاتی ہے؛ context scale پر زیادہ often genuinely true ہوتی ہے؛ scale سب سے آسان test ہے۔ سب سے بڑا failure mode organizational یا aesthetic reasons کے لیے multi-agent systems build کرنا ہے، task-property reasons کے لیے نہیں؛ coordination overhead real اور substantial ہے، اور deployed multi-agent system remove کرنا rewrite ہے، refactor نہیں۔ Single-agent سے start کریں؛ measured triggers کو upgrade force کرنے دیں۔
یہ Concept 8.5: OpenAI Agents SDK primitives، ہر pattern کیا use کرتا ہے
یہ Part 3 پانچ patterns walk کرنے سے پہلے، pattern selection سے implementation تک bridge دیکھیں۔ پہلے courses نے OpenAI Agents SDK کو anchor framework کے طور پر سکھایا تھا۔ اس course کے patterns abstract architectural shapes نہیں جنہیں آپ scratch سے reimplement کرتے ہیں؛ یہ وہ shapes ہیں جو آپ already-met SDK primitives سے compose کرتے ہیں۔ یہ concept ہر pattern کو ان specific SDK primitives سے map کرتا ہے جو اسے build کرتے ہیں۔
یہ Pattern selection کے لیے اہم پانچ primitives۔
| Primitive | یہ کیا ہے | کون سے patterns use کرتے ہیں |
|---|---|---|
Agent | core class، instructions، tools، اور optional structured output schema والی LLM-driven entity۔ ہر pattern کی atomic unit۔ | پانچوں patterns |
Runner.run(agent, input) | agent loop کو final output produce ہونے تک run کرتا ہے۔ SDK loop آپ کے لیے چلاتا ہے: hand-rolled reason-act-observe cycle نہیں۔ | Single agent + ReAct (سب سے prominent)، Planning + ReAct، Multi-agent (ہر specialist کے لیے) |
@function_tool | decorator جو Python function کو agent کے callable tool میں بدلتا ہے۔ Type signatures اور docstrings خود بخود tool schema بن جاتے ہیں۔ | Single agent + ReAct، Planning + ReAct، Multi-agent (ہر specialist)، Sequential workflow (جب LLM-step کو tools چاہئیں) |
handoff(target_agent) | multi-agent transitions کے لیے first-class SDK primitive: ایک agent conversation context preserve کرتے ہوئے control دوسرے agent کو explicitly دیتا ہے۔ coordinator hand-roll کرنے سے cleaner۔ | Multi-agent (primary use)؛ Planning + ReAct (planner-to-executor) |
output_guardrail / input_guardrail | agent input یا output پر validation/critique passes چلانے کے SDK primitives۔ Reflection کے لیے native SDK pattern۔ | Reflection (primary use)؛ input validation چاہیے ہو تو کوئی بھی pattern |
ایک اور primitive جس کا نام لینا worth ہے: Agent.as_tool()۔ یہ ایک Agent کو callable tool میں convert کرتا ہے جسے دوسرا Agent invoke کر سکتا ہے۔ یہ hierarchical multi-agent composition کے لیے SDK کا mechanism ہے (coordinator agent specialist agents کو tools کے طور پر use کرتا ہے، جیسے کوئی function tool call کر رہا ہو)۔ Agent.as_tool() والے multi-agent systems handoff() والے systems سے simpler ہیں کیونکہ coordinator control میں رہتا ہے؛ handoff() ان situations کے لیے ہے جہاں آپ واقعی specialist کو conversation take over کروانا چاہتے ہیں۔
یہ Pattern → primitive mapping ایک نظر میں۔
Sequential workflow:
Agent(output_type=...) at the LLM-steps; plain Python everywhere else
Runner.run() called once per LLM-step: no agentic loop (the agent has no tools)
Single agent + ReAct + tools:
Agent(instructions=..., tools=[@function_tool, @function_tool, ...])
Runner.run(agent, input): the SDK runs the reason-act-observe loop
Planning + ReAct execution:
planner = Agent(output_type=PlanSchema)
plan = await Runner.run(planner, task)
for stage in plan.stages:
result = await Runner.run(stage.agent, stage.input)
Single agent + reflection:
Agent(..., output_guardrails=[critic_guardrail])
OR: Agent(..., tools=[Agent.as_tool(critic_agent)])
Multi-agent specialist system:
coordinator = Agent(handoffs=[researcher, writer, reviewer])
OR: coordinator = Agent(tools=[researcher.as_tool(), writer.as_tool(), ...])
یہ Part 3 کے code blocks ان سب کو full SDK detail میں دکھاتے ہیں۔
یہ mapping pattern selection کے لیے کیوں matter کرتی ہے۔ SDK primitives صرف implementation conveniences نہیں؛ وہ architectural decisions encode کرتے ہیں۔ handoff() vs. as_tool() چننا خود pattern-composition decision ہے۔ handoff() کا مطلب ہے "specialist conversation take over کرتا ہے"؛ as_tool() کا مطلب ہے "coordinator in charge رہتا ہے اور specialist کو function کے طور پر use کرتا ہے"۔ پہلا تب appropriate ہے جب specialist کو user سے directly interact کرنا ہو؛ دوسرا تب appropriate ہے جب coordinator specialist outputs compose کر رہا ہو۔ کون سا use کرنا ہے، یہ اسی pattern-selection discipline کا downstream ہے جو یہ course سکھاتا ہے۔
یہ Worked example سے connection۔ Customer-support Worker (Maya's Tier-1 Support agent) Agent + @function_tool (lookup، refund، escalation کے لیے) + Runner.run() (FastAPI handler میں) use کرتا ہے۔ یہ single agent + ReAct + tools pattern ہے، بالکل وہی جو Concept 10 SDK detail میں walk کرے گا۔ Maya کی implementation اس course کے پانچ patterns میں سے ایک ہے؛ باقی چار variations ہیں جن کی طرف آپ task properties بدلنے پر جاتے ہیں۔
یہ Concept 8.5 کا bottom line: SDK primitives پانچوں patterns کے building blocks ہیں۔
Agentatomic unit ہے؛Runner.run()loop چلاتا ہے؛@function_toolPython functions کو tools کے طور پر expose کرتا ہے؛handoff()اورas_tool()agents کو multi-agent systems میں compose کرتے ہیں؛output_guardrailreflection implement کرتا ہے۔ Pattern → primitive mapping اس course کی architectural choices کو concrete بناتی ہے: pattern selection abstract نہیں؛ یہ choice ہے کہ کون سے SDK primitives compose کرنے ہیں اور کیسے۔
یہ Concept 8.6: ہر pattern کے operational envelope considerations (Inngest بطور concrete example)
یہ Standalone-reader note۔ یہ Concept pattern choice کے operational consequences کے بارے میں ہے، Inngest سکھانے کے بارے میں نہیں۔ Architectural argument کسی بھی durable-execution platform (Temporal، Restate، Dapr Agents، AWS Step Functions) پر generalize ہوتا ہے؛ Inngest concrete example اس لیے ہے کیونکہ operational-envelope course یہی سکھاتا ہے۔ اگر آپ کا platform different ہے، یا آپ design stage پر ہیں اور operational platform undecided ہے، تو pattern-architecture argument کے لیے پڑھیں: pattern جتنا elaborate ہوگا، operational envelope پر اتنا زیادہ depend کرے گا۔ Inngest primitives کی جگہ اپنے platform کے primitives substitute کریں۔
یہ Concept 8.5 نے patterns کو engine primitives (OpenAI Agents SDK) سے map کیا۔ Concept 8.6 patterns کو operational envelope primitives سے map کرتا ہے: وہ runtime machinery جو agent loop کو failures سے survive کراتی ہے، many concurrent users پر scale کراتی ہے، اور events fire کرنے والی world کے ساتھ integrate کرتی ہے۔ SDK agent loop چلاتا ہے؛ envelope agent loop کو production-grade بناتا ہے۔ ہر pattern different envelope primitives use کرتا ہے، اور pattern جتنا elaborate ہو envelope پر اتنا زیادہ depend کرتا ہے۔
یہ Agent Factory track میں operational envelope Inngest ہے۔ نیچے والے primitives Inngest کے ہیں؛ underlying pattern-architecture argument general ہے۔
یہ Pattern selection کے لیے اہم operational-envelope primitives۔
| Primitive | یہ کیا ہے | کون سے patterns اسے زیادہ use کرتے ہیں |
|---|---|---|
@inngest_client.create_function | decorator جو function کو durable-execution runtime کے ساتھ register کرتا ہے۔ operationally-managed work کی unit۔ | پانچوں patterns |
TriggerEvent, TriggerCron | Trigger surfaces، world کے fire کیے ہوئے events، schedules جو function کو wake کرتے ہیں۔ Agent اس لیے نہیں چلتا کہ آپ نے call کیا؛ world trigger fire کرتی ہے تو چلتا ہے۔ | پانچوں patterns؛ cron incident response اور batch workflows کے لیے خاص طور پر relevant |
ctx.step.run(name, fn, ...) | ہر call durable checkpoint ہے؛ completed steps retry پر memoized output return کرتے ہیں؛ failed steps independently retry ہوتے ہیں۔ Production reliability کے نیچے mechanic۔ | Sequential workflow (سب سے direct map)، Planning + ReAct (ہر stage پر one step.run)، Reflection (separate generator/critic steps) |
ctx.step.wait_for_event(...) | function durably suspend ہوتا ہے، zero compute consumed، جب تک matching event یا timeout نہ آئے۔ HITL gates کے پیچھے runtime primitive۔ | کوئی بھی pattern جسے human approval چاہیے؛ multi-agent (specialists کے درمیان)؛ reflection (جب human judgment critic ہو) |
concurrency, throttle, priority | per-function flow-control policies۔ Concurrency active runs cap کرتی ہے؛ throttle starts/sec cap کرتا ہے؛ priority queue order کرتی ہے؛ per-key concurrency multi-tenant fairness دیتی ہے۔ | Multi-agent (سب سے critical؛ per-specialist limits rate-limit exhaustion روکتی ہیں)؛ کوئی بھی high-volume single-agent pattern |
| Fan-out triggers | ایک event N subscribing functions کو wake کرتا ہے؛ یا parent N child events fire کرتا ہے۔ Parallel specialist execution کے پیچھے runtime primitive۔ | Multi-agent (parallel topology)؛ Planning + ReAct (جب stages parallel run ہوں) |
| Replay + dead-letter | Failed runs persist رہتے ہیں؛ fix ship کریں، replay click کریں؛ function failed step سے new code کے ساتھ resume کرتا ہے۔ Failure سے پہلے steps memoized رہتے ہیں۔ | All patterns، مگر pattern جتنا elaborate ہو replay اتنا زیادہ matter کرتا ہے کیونکہ long run partway fail ہو تو stake زیادہ ہوتا ہے |
یہ Pattern → primitive mapping ایک نظر میں۔
Sequential workflow:
@inngest_client.create_function(trigger=TriggerEvent(...))
async def workflow(ctx):
a = await ctx.step.run("extract", extractor_agent.run, ...)
b = await ctx.step.run("validate", validate, a)
c = await ctx.step.run("store", db.insert, b)
await ctx.step.run("notify", notifier_agent.run, ...)
# Each step independently checkpointed; failure → memoized resume
Single agent + ReAct + tools:
@inngest_client.create_function(
trigger=TriggerEvent(event="customer/email.received"),
concurrency=[Concurrency(limit=10, key="event.data.customer_id")],
)
async def support(ctx):
result = await ctx.step.run("agent-loop", Runner.run, support_agent, ctx.event.data["query"])
# If agent needs HITL escalation, use step.wait_for_event inside the agent's tool
return result.final_output
Planning + ReAct execution:
@inngest_client.create_function(trigger=TriggerEvent(event="research/started"))
async def planning(ctx):
plan = await ctx.step.run("plan", Runner.run, planner, ctx.event.data["task"])
results = {}
for stage in plan.stages:
# Each stage = one step.run. Crash mid-stage → only that stage retries.
results[stage.id] = await ctx.step.run(f"stage-{stage.id}", Runner.run, stage.agent, ...)
return await ctx.step.run("synthesize", Runner.run, synthesizer, results)
Single agent + reflection:
@inngest_client.create_function(trigger=TriggerEvent(...))
async def reflective(ctx):
output = await ctx.step.run("generate", Runner.run, generator, ctx.event.data["task"])
critique = await ctx.step.run("critique", Runner.run, critic, output)
if not critique.final_output.is_safe:
output = await ctx.step.run("refine", Runner.run, generator, refine_prompt(output, critique))
return output
Multi-agent specialist system:
# Coordinator triggers fan-out of specialist events
@inngest_client.create_function(trigger=TriggerEvent(event="research/landscape.requested"))
async def coordinator(ctx):
plan = await ctx.step.run("plan", Runner.run, planner, ctx.event.data["topic"])
await ctx.step.run("fan-out", fan_out_specialist_events, plan.competitors)
# Each specialist runs independently as its own function:
@inngest_client.create_function(
trigger=TriggerEvent(event="research/competitor.research"),
concurrency=[Concurrency(limit=5, key="event.data.tenant_id")], # per-tenant cap
)
async def competitor_research(ctx):
return await ctx.step.run("research", Runner.run, researcher, ctx.event.data["target"])
یہ Part 3 کی sidebars ہر pattern کے لیے explicit operational-envelope section کے ساتھ ان mappings کو دکھاتی ہیں۔
یہ mapping pattern selection کے لیے کیوں matter کرتی ہے۔ دو production failure modes architecture diagram پر visible نہیں ہوتے مگر production میں hard bite کرتے ہیں:
- یہ Crash mid-flight۔ چھ-step planning + ReAct execution اگر step 4 پر crash کرے (durable execution کے بغیر) تو first three steps دوبارہ pay ہوتے ہیں۔ Operational-envelope course اسے quantify کرتا ہے: GPT-5-class pricing پر multi-stage agent flow crash per run تقریباً $0.10-$2.00 lost work repay کر سکتا ہے۔ 1000 runs/day پر صرف crashes سے تقریباً $30-$600/month lost work بنتا ہے۔ Sequential workflows crashes cheaply survive کرتے ہیں کیونکہ retries short ہیں؛ multi-agent + reflection systems crashes expensively survive کرتے ہیں کیونکہ retries long ہیں۔ Pattern جتنا elaborate ہو، operational envelope کی
step.runmemoization اتنی dollars میں valuable ہوتی ہے۔ - یہ Scale پر coordination۔ پانچ specialists، دس tenants، اور 100 events/minute کے bursts والا multi-agent system per-specialist concurrency caps کے بغیر rate limits exhaust کرے گا۔ Operational envelope اسے one line بناتا ہے:
concurrency=[Concurrency(limit=5, key="event.data.tenant_id")]۔ یہ course کا decision tree pattern pick کرتا ہے؛ operational envelope کے flow-control primitives chosen pattern کو scale پر healthy رکھتے ہیں۔
تعیناتی کی composition۔ Operational envelope (Inngest) اور آپ کی cloud deployment compose ہوتے ہیں؛ compete نہیں کرتے۔ Cloud deployment course cloud topology سکھاتا ہے: ACA + Neon + R2 + Cloudflare Sandbox + Phoenix۔ Operational-envelope course وہ layer سکھاتا ہے جو اس topology کے اندر SDK runner کو wrap کرتی ہے۔ Real production system دونوں use کرتا ہے: ACA پر deployed Inngest functions، Runner.run() calls کو step.run() blocks کے اندر کرتے ہوئے، Neon agent traces store کرتا ہے اور sandbox tool code execute کرتا ہے۔ Part 3 کی deployment-composition sidebars دونوں layers کو explicitly name کرتی ہیں۔
یہ Eval composition۔ Inngest کی structured trace (ہر step کا input، output، retry count، latency) Phoenix میں اسی طرح flow کرتی ہے جیسے SDK کی agent trace، OpenTelemetry کے ذریعے۔ Eval suite کے failure-detection patterns (trace-length anomalies، plan-execution divergence، rubber-stamping) Inngest-instrumented runs پر بھی work کرتے ہیں؛ operational envelope add ہونے سے eval suite change نہیں ہوتی۔
یہ Concept 8.6 کا bottom line: operational envelope (Inngest) پانچوں patterns کا production substrate ہے۔ Triggers function کو wake کرتے ہیں؛
step.runاسے durable بناتا ہے؛step.wait_for_eventHITL gates implement کرتا ہے؛ concurrency، throttle، اور priority load کے تحت shape دیتے ہیں؛ fan-out multi-agent specialists coordinate کرتا ہے؛ replay bug-fix recovery handle کرتا ہے۔ Pattern جتنا elaborate ہو envelope اتنا valuable ہے: sequential workflows اس کے بغیر survive کر سکتے ہیں؛ multi-agent + reflection systems کو اس کی ضرورت ہوتی ہے۔ Envelope cloud deployment اور eval suite کے ساتھ alternatives کے طور پر نہیں بلکہ production architecture کی parallel layers کے طور پر compose ہوتا ہے۔
تین layers، side by side۔ Concepts 8.5 اور 8.6 مل کر establish کرتے ہیں کہ کوئی بھی production agentic pattern تین layers کی composition ہے: operational envelope (Inngest)، engine (OpenAI Agents SDK)، اور cloud deployment۔ World top پر triggers fire کرتی ہے (customer emails، billing یا Slack یا CRM سے webhooks، cron schedule، دوسرے Workers سے fan-out events، human approvals)؛ یہ triggers تین layers سے نیچے flow کرتے ہیں۔ نیچے diagram ہر layer کے primitives اور ان کے کام map کرتا ہے۔ جب Part 3 کی operational-envelope sidebars abstract لگیں، اس پر واپس آئیں۔

یہ Takeaway: تینوں layers stack ہوتی ہیں۔ Inngest (envelope) SDK (engine) کو wrap کرتا ہے، اور دونوں cloud deployment کے اندر run کرتے ہیں۔ یہ course pattern choose کرتا ہے؛ تین layers chosen pattern کو production reality بناتی ہیں۔ Part 3 کے پانچوں patterns انہی تین layers کی compositions ہیں؛ pattern-to-pattern فرق یہ ہے کہ ہر layer کے کون سے primitives use ہوتے ہیں۔ Pattern جتنا elaborate ہو (reflection والا multi-agent)، operational-envelope layer اتنی critical ہوتی ہے، کیونکہ coordination، durability، اور HITL optional نہیں رہتے۔
یہ Part 2 کے بعد AI کے ساتھ try کریں۔ آپ کے پاس پانچ questions ہیں۔ Patterns depth میں پڑھنے سے پہلے انہیں کسی real چیز پر use کریں۔ اپنی Claude Code یا OpenCode session کھولیں اور paste کریں:
"I'm learning to choose agentic architectures. Pick one real task from my actual work that I might build an agent for. Ask me to describe it, then walk me through the five questions: Q1 (is the solution path known?), Q2 (is the workflow fixed and stable?), Q3 (is the task structure articulable?), Q4 (does quality outweigh speed, with checkable criteria?), Q5 (is there a specialization, context, or scale bottleneck?). Push back when my answer is vague or when I'm reaching for a more elaborate pattern than the task needs. At the end, tell me which starting pattern the answers point to."
آپ کیا سیکھ رہے ہیں۔ پانچ questions تب reflex بنتے ہیں جب آپ انہیں کسی ایسے task پر run کرتے ہیں جس کی آپ کو واقعی پروا ہے۔ weak answers پر pushback دینے والی چیز کے ساتھ ایک بار یہ کام loud کرنا اگلے دس pages پڑھنے سے زیادہ valuable ہے۔
یہ Part 3: پانچ patterns کی گہری سمجھ
یہ Part 2 نے decision tree کو question level پر walk کیا۔ Part 3 اسے pattern level پر walk کرتا ہے۔ پانچ terminal patterns میں سے ہر ایک کے لیے: pattern کیا ہے، اس کی characteristic implementation کیسی لگتی ہے، یہ آپ کی deployment topology کے لیے کیا معنی رکھتا ہے، اور آپ کی eval suite کیا watch کرتی ہے تاکہ detect کر سکے کہ pattern misapplied ہے۔
یہ Deployment-and-eval composition وہ چیز ہے جو یہ course اوپر add کرتا ہے۔ Agentic patterns پر کم courses یہ layer سکھاتے ہیں، کیونکہ اس کے لیے deployment اور eval courses foundation کے طور پر چاہیے ہوتے ہیں۔ اگر آپ نے وہ courses نہیں کیے، sidebars کو آنے والی چیزوں کا preview سمجھیں؛ اگر کیے ہیں، composition pattern selection کو operational بنا دیتی ہے۔
یہ Patterns ایک ایک کر کے walk کرنے سے پہلے، یہ matrix پورے part کا summary ہے۔ ہر pattern cloud stack کا different subset use کرتا ہے؛ deployment cost differences real اور substantial ہیں۔ Concepts 9-13 جب ہر pattern detail میں walk کریں تو اس matrix پر واپس آتے رہیں۔
یہ Matrix ہر pattern (columns) کو اس کے required cloud deployment components (rows) کے against map کرتا ہے۔ Check کا مطلب needed؛ cross کا مطلب not needed؛ tilde کا مطلب conditional۔
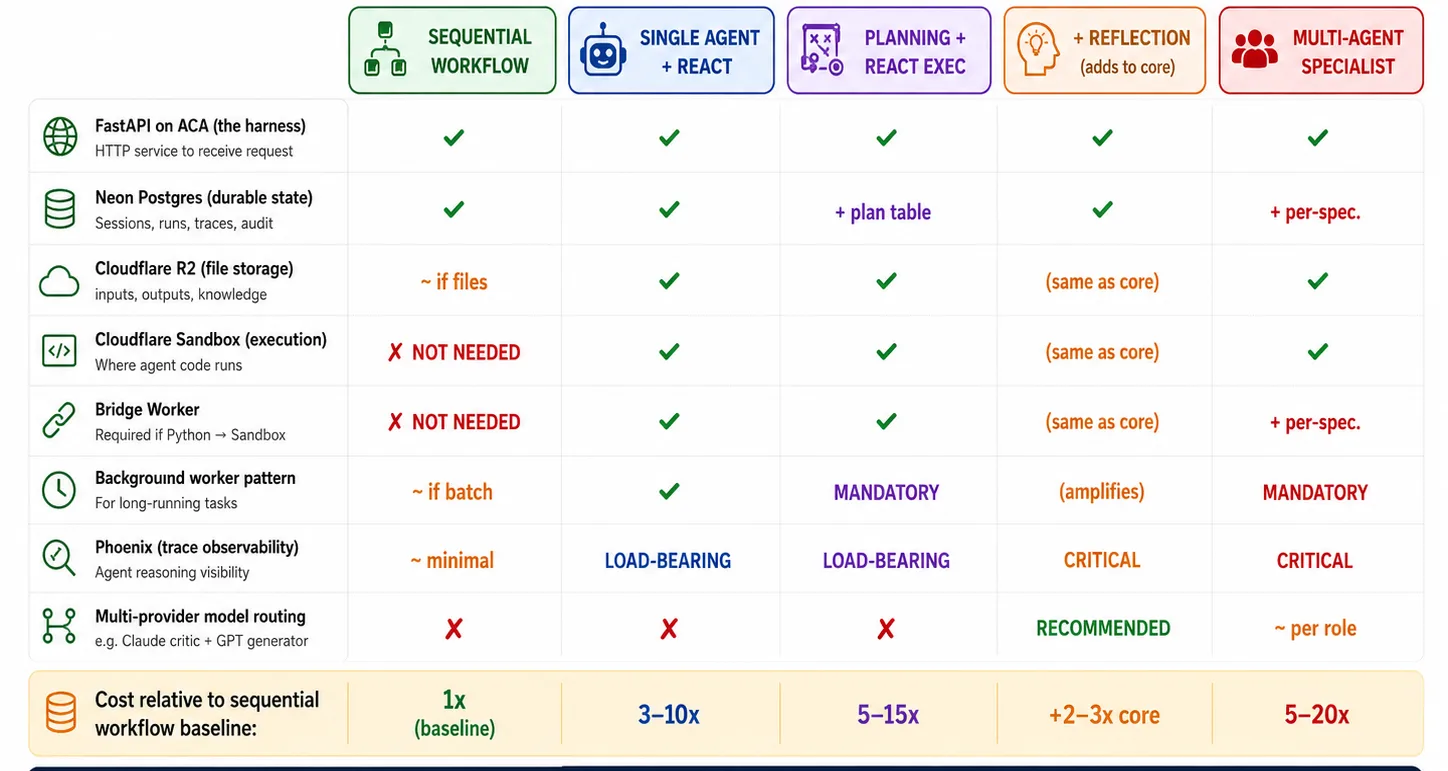
یہ Pattern selection میں encoded cost discipline: reflection کے ساتھ multi-agent system same task volume کے لیے sequential workflow سے بہت بڑے multiple پر cost کر سکتا ہے (illustrative ratio، tens of times کے order پر، measured benchmark نہیں)۔ Sequential workflow sandbox اور bridge-Worker tiers entirely skip کرتا ہے، اس لیے infrastructure کا بڑا حصہ avoid کرتا ہے؛ justification کے بغیر ReAct یا multi-agent کی طرف جانا ایسی capability کے لیے pay کرنا ہے جس کی task کو ضرورت نہیں۔
یہ Takeaway: sequential workflow کو دو clear "not needed" markers ملتے ہیں (sandbox اور bridge Worker)، جو agentic patterns کے مقابلے میں meaningfully less infrastructure بن جاتا ہے۔ Multi-agent کو سب سے زیادہ expansion markers ملتے ہیں (per-specialist tracing، per-specialist bridge-Worker config)۔ Matrix decision tree کی cost discipline کو visible بناتا ہے۔
یہ Concept 9: Sequential workflow، characteristic shape، deployment، eval signals
یہ کیا ہے۔ steps کی fixed pipeline جہاں ہر step کا output next step کو feed کرتا ہے۔ Path known اور stable ہے (Q1=yes، Q2=yes)۔ LLM calls صرف ان steps کے لیے reserved ہیں جنہیں واقعی interpretation یا generation، extraction، summarization، classification چاہیے؛ next step decide کرنے کے لیے نہیں۔
یہ OpenAI Agents SDK میں characteristic implementation:
from agents import Agent, Runner
from pydantic import BaseModel
class Invoice(BaseModel):
vendor: str
amount_cents: int
due_date: str
line_items: list[dict]
class NotificationMessage(BaseModel):
subject: str
body: str
# Two narrow agents: each does ONE LLM-step in the workflow.
# Notice: no tools, no agentic loop. Just structured-output extraction.
extractor = Agent(
name="invoice_extractor",
instructions="Extract structured invoice fields from the email body. Be strict about field types.",
output_type=Invoice,
)
notifier = Agent(
name="notification_writer",
instructions="Write a brief notification message to the requester, referencing the invoice details.",
output_type=NotificationMessage,
)
async def invoice_intake_workflow(email_content: str) -> ProcessingResult:
# Step 1: extraction (SDK Agent with structured output)
extraction = await Runner.run(extractor, email_content)
invoice: Invoice = extraction.final_output
# Step 2: validation (plain Python, no LLM)
validation = validate_against_db(invoice)
if not validation.ok:
return ProcessingResult(status="rejected", reason=validation.reason)
# Step 3: store (plain Python, no LLM)
record_id = db.insert(invoice)
# Step 4: notify (SDK Agent with structured output)
notif = await Runner.run(notifier, f"Invoice {record_id} from {invoice.vendor} stored. Notify {invoice.requester}.")
email.send(invoice.requester, notif.final_output.subject, notif.final_output.body)
return ProcessingResult(status="completed", record_id=record_id)
یہ SDK shape notice کریں: دو narrow Agent instances، ہر ایک صرف ایک LLM-only job کر رہا ہے (extraction، notification writing)۔ ہر agent کے پاس output_type= کے ذریعے structured output ہے، free-form text parsing نہیں۔ Runner.run() دو بار call ہوتا ہے، ہر LLM-step کے لیے ایک بار۔ Tools نہیں، @function_tool decorators نہیں، handoffs نہیں، کیونکہ workflow کو agentic reasoning نہیں چاہیے؛ plain Python میں embedded LLM calls چاہیے۔
یہ SDK کا نکتہ جو ذہن میں بٹھانا چاہیے: Agent کا ہر use "agentic" نہیں ہوتا۔ Tools کے بغیر ایک Agent جس کے پاس output_type= ہے، SDK کا idiomatic طریقہ ہے کہ "typed response کے ساتھ LLM call" کی جائے، جو sequential workflow کے interpretation steps کو بالکل یہی چاہیے۔ آپ SDK use کر رہے ہیں مگر agent loop use نہیں کر رہے۔
تعیناتی کی composition۔ Sequential workflows cloud stack کا smallest subset use کرتے ہیں:
- یہ SDK primitives used:
Agent(structured extraction/generation کے لیےoutput_type=کے ساتھ)، ہر LLM-step کے لیےRunner.run()۔@function_toolنہیں،handoff()نہیں،as_tool()نہیں،output_guardrailنہیں۔ Agent loop unused ہے؛Runner.run()ایک LLM call کے بعد return کرتا ہے کیونکہ agent کے پاس tools نہیں۔ - یہ FastAPI harness on Azure Container Apps: yes، requests receive کرنے کے لیے HTTP service پھر بھی چاہیے۔
- یہ Durable state کے لیے Neon Postgres: yes، workflow record-keeping اور idempotency کے لیے۔
- یہ LLM calls کے لیے OpenAI API: yes، مگر صرف specific steps کے لیے جنہیں ضرورت ہے۔
- یہ Files کے لیے Cloudflare R2: شاید، صرف اگر workflow file artifacts handle کرتا ہو۔
- یہ Execution کے لیے Cloudflare Sandbox: نہیں۔ Sequential workflows agent-generated code نہیں چلاتے؛ deterministic code embedded LLM calls کے ساتھ چلاتے ہیں۔ Sandbox layer (اور bridge Worker) needed نہیں۔
یہ Sequential workflows کے بارے میں سب سے under-appreciated finding یہ ہے: انہیں cloud-deployment course کی سکھائی ہوئی deployment complexity کے زیادہ تر حصے کی ضرورت نہیں۔ اگر آپ کا task sequential workflow میں fit ہوتا ہے، تو FastAPI + Postgres + OpenAI stack پر ship کریں اور sandbox infrastructure entirely skip کریں۔ Cost savings: full agentic deployment سے meaningfully less infrastructure، کیونکہ sandbox اور bridge-worker tiers entirely skip ہوتے ہیں۔ ایسی capability کے لیے pay نہ کریں جس کی pattern کو ضرورت نہیں۔
تشخیصی signals۔ Sequential workflows کے لیے eval suite خاص طور پر کیا watch کرتی ہے:
| Failure mode | eval اسے کس صورت catch کرتا ہے |
|---|---|
| Extraction step input misread کرتا ہے | Output schema validation fail ہوتی ہے؛ DeepEval structured-output mismatch catch کرتا ہے |
| Validation logic میں gap ہے | Production case slip through ہوتا ہے؛ trace valid-but-wrong record کو storage تک پہنچتا دکھاتی ہے |
| Notification message off-tone یا factually wrong ہے | Generated message پر Phoenix inline evaluator اسے catch کرتا ہے؛ golden dataset میں promotion |
| Workflow ایسا case handle کرتا ہے جس کے لیے designed نہیں تھا | DeepEval test suite "edge case inputs" شامل کرتی ہے؛ failures workflow کی assumption boundary expose کرتے ہیں |
اہم نکتہ: sequential workflow evals step-level correctness کے بارے میں ہیں، agent reasoning quality کے بارے میں نہیں۔ آپ ہر LLM-using step independent test کرتے ہیں (کیا extraction right schema return کرتا ہے؟ کیا generation right tone produce کرتی ہے؟)۔ آپ workflow کے branching points test کرتے ہیں (کیا validation وہ cases catch کرتا ہے جو catch کرنے چاہئیں؟)۔ "کیا agent نے right path pick کیا" test کرنے کی ضرورت نہیں کیونکہ path fixed ہے۔
یہ Production میں teams یہاں کہاں غلط ہوتی ہیں۔ LLM-embedded workflows کو agentic سمجھ لینا۔ Teams workflows میں agent-loop observability (tool-call tracing، reasoning-step inspection) add کرتی ہیں جن میں نہ tool calls ہیں نہ reasoning steps۔ آپ کو بس standard request/response tracing plus per-step structured-output validation چاہیے۔ Phoenix کے agent-reasoning dashboards overkill ہیں؛ App Insights کی standard request tracing right level ہے۔
عملی envelope۔ Sequential workflow Inngest کے durable-execution model کے لیے most direct fit ہے۔ Pattern کی structure، fixed steps، each potentially failing، deterministic dependencies، بالکل وہی ہے جس کے لیے Inngest functions built ہیں۔
- یہ Inngest primitives used: workflow register کرنے کے لیے
@inngest_client.create_function؛ wake signal کے لیےTriggerEventیاTriggerCron؛ ہر workflow step کے لیے ایکctx.step.run("step-name", fn, args)۔step.wait_for_eventنہیں (routine workflow کو HITL needed نہیں)، fan-out نہیں (workflow linear ہے)، complex flow control نہیں۔ - 1:1 mapping: sequential workflow کا ہر step Inngest function میں ایک
ctx.step.runcall بن جاتا ہے۔ Concept 9 کے code کا five-step invoice intake (extract → validate → store → notify) پانچstep.runcalls بنتا ہے۔ Step 3 پر crash → steps 1-2 memoized output return کرتے ہیں، step 3 retry ہوتا ہے۔ - یہ Cost benefit: $0.001-$0.05 فی LLM call پر، step 5 پر crash ہونے والا workflow memoization کے بغیر steps 1-4 دوبارہ pay کرتا ہے۔ Memoization کے ساتھ صرف step 5 retry ہوتا ہے۔ Operational-envelope course اسے quantify کرتا ہے؛ workflows lengthen ہونے پر savings compound ہوتی ہیں۔
یہ Sequential workflow plus Inngest curriculum میں simplest production-ready agentic deployment ہے۔ بہت سے real workflows جنہیں mistakenly "agentic systems" سمجھا جاتا ہے، step.run checkpoints والی Inngest functions ہونی چاہئیں۔ Decision tree کا Q1 ("کیا path known ہے؟") essentially یہی پوچھ رہا ہے کہ کیا آپ کو agent loop کے بغیر Inngest use کرنا چاہیے۔
خلاصہ، Concept 9: sequential workflow درست pattern ہے جب path known اور stable ہو۔ یہ cloud stack کا smallest subset use کرتا ہے (sandbox needed نہیں)، LLM calls interpretation-only steps کے لیے reserve کرتا ہے، اور agent-reasoning level کے بجائے step level پر evaluated ہوتا ہے۔ سب سے common production mistake workflows کو ایسے agent-grade observability سے over-instrument کرنا ہے جس کی انہیں ضرورت نہیں۔
یہ Concept 10: ایک agent + ReAct + tools، characteristic shape، deployment، eval signals
یہ کیا ہے۔ ایسا agent جو اپنی current state پر reasoning اور action (tool call) کے درمیان alternate کرتا ہے، result observe کرتا ہے، اور repeat کرتا ہے۔ Path unknown ہے (Q1=no) اور structure articulable نہیں (Q3=no)۔ defining property: agent ابھی observe کی ہوئی چیز کی بنیاد پر decide کرتا ہے کہ next کیا کرنا ہے۔
یہ OpenAI Agents SDK میں characteristic implementation:
from agents import Agent, Runner, function_tool
# Tools: plain async Python functions, exposed to the agent via the decorator.
# Type hints and docstrings become the tool's schema automatically.
@function_tool
async def lookup_account(account_id: str) -> dict:
"""Look up an account's current state including balance, plan, and billing status."""
return await db.accounts.find_by_id(account_id)
@function_tool
async def lookup_transactions(account_id: str, since_days: int = 90) -> list[dict]:
"""Return recent transactions for an account; defaults to last 90 days."""
return await db.transactions.find(account_id=account_id, since=since_days)
@function_tool
async def issue_refund(transaction_id: str, amount_cents: int, reason: str) -> dict:
"""Issue a refund. Fails if amount exceeds agent's authority ($500). Returns refund_id."""
return await refund_service.create(transaction_id, amount_cents, reason)
@function_tool
async def escalate_to_human(reason: str, context: dict) -> str:
"""Hand the case to a human reviewer. Returns the escalation ticket id."""
return await escalation_service.create_ticket(reason, context)
# One Agent with all the tools. The SDK runs the reason-act-observe loop.
support_agent = Agent(
name="tier1_support",
instructions=(
"You are a Tier-1 customer support agent. Investigate the customer's issue "
"using your tools. Issue refunds only when policy clearly allows and the "
"amount is under $500. Escalate any ambiguous case. If you cannot determine "
"the right action within 3 lookups, escalate. State when you are done."
),
tools=[lookup_account, lookup_transactions, issue_refund, escalate_to_human],
)
# The FastAPI handler: exactly the customer-support Worker's shape.
async def handle_support_request(customer_id: str, query: str) -> str:
result = await Runner.run(
support_agent,
input=f"Customer {customer_id} asks: {query}",
max_turns=25, # explicit step budget: non-optional in production
)
return result.final_output
یہ SDK shape notice کریں: multiple tools والا ایک Agent، Runner.run() کے ذریعے called۔ SDK reason-act-observe loop internally چلاتا ہے: آپ for step in range(max_steps): response = llm.chat(...); for tool_call in response.tool_calls: ... نہیں لکھتے۔ max_turns parameter step budget ہے؛ hit ہونے پر SDK MaxTurnsExceeded raise کرتا ہے۔
یہ SDK کا نکتہ جو ذہن میں بٹھانا چاہیے: canonical ReAct loop ایک Runner.run() call ہے۔ Complexity tool definitions اور agent instructions میں ہے؛ loop machinery SDK کی responsibility ہے۔ یہی pattern Maya کے Tier-1 Support agent، customer-support Worker، کے پیچھے ہے۔
تعیناتی کی composition۔ Single-agent ReAct cloud stack کا زیادہ تر حصہ use کرتا ہے:
- یہ SDK primitives used:
Agent(tools=اورinstructions=کے ساتھ)، ہر exposed Python function پر@function_tooldecorator، agentic loop کے لیےRunner.run(agent, input, max_turns=N)۔ یہی canonical SDK shape ہے، بالکل وہی جو customer-support Worker deploy کرتا ہے۔handoff()یاas_tool()نہیں (وہ multi-agent primitives ہیں)؛output_guardrailنہیں (وہ reflection ہے)۔ - یہ FastAPI harness on Azure Container Apps: yes، HTTP service کے لیے۔
- یہ Durable state کے لیے Neon Postgres: yes، sessions، runs، traces کے لیے۔ Critical کیونکہ agent کی reasoning trace primary debugging artifact ہے۔
- یہ Files کے لیے Cloudflare R2: yes، اگر agent file inputs/outputs handle کرتا ہے۔
- یہ Execution کے لیے Cloudflare Sandbox: yes، اگر agent code-executing tools رکھتا ہے۔ Agent
apply_patch، shell commands، یا arbitrary Python run کرتا ہے؛ وہ code sandbox میں جاتا ہے۔ Bridge Worker required ہے۔ - یہ Background worker pattern: yes، کیونکہ ReAct loops 30+ seconds لے سکتے ہیں اور HTTP request block نہیں کرنی چاہیے۔
تشخیصی signals۔ ReAct کے failure modes reasoning-level ہیں، اس لیے eval signals بھی reasoning-level ہیں:
| Failure mode | eval اسے کس صورت catch کرتا ہے |
|---|---|
| Agent loops، solved work revisit کرتا ہے | Trace-length anomaly: same tool similar arguments کے ساتھ repeatedly called۔ Phoenix flag |
| Agent nonexistent tools invoke کرتا ہے (hallucinated tools) | SDK میں tool-call validation؛ structured trace invalid call دکھاتی ہے؛ CI eval DeepEval کے ذریعے catch کرتا ہے |
| Agent solve کرنے سے پہلے give up کرتا ہے (premature termination) | final output کو expected behavior سے compare کریں؛ trace few steps دکھاتی ہے؛ DeepEval catch کرتا ہے |
| Agent کی reasoning actions سے diverge کرتی ہے | Phoenix tool-correctness evaluator: کیا agent کا stated reason called tool سے match کرتا ہے؟ |
| Tool call latency cascade کرتی ہے (ہر step slow ہے) | OTel timing aggregate runtime کو latency budget سے exceed دکھاتا ہے |
اہم نکتہ: ReAct evals کو reasoning trace capture کرنی چاہیے، صرف input/output نہیں۔ Trace ہی data ہے۔ اگر آپ صرف check کریں کہ agent نے right answer دیا یا نہیں، تو آپ وہ cases miss کریں گے جہاں lucky tool calls سے right answer ملا، اور وہ cases بھی miss کریں گے جہاں single bad decision کی وجہ سے right answer نہیں مل سکا۔ Phoenix کے inline trace evaluators ReAct کے لیے load-bearing observability layer ہیں۔
یہ Production میں teams یہاں کہاں غلط ہوتی ہیں۔ Step budgets کو infinity default رہنے دینا۔ Step cap کے بغیر ReAct loop eventually ایسا input دیکھے گا جو اسے indefinitely loop کرائے، tokens burn ہوں گے، workers block ہوں گے، rate limits exhaust ہوں گی۔ ہمیشہ steps explicitly cap کریں (25 reasonable default ہے؛ کچھ tasks کو 50 چاہیے؛ بہت کم کو 100 چاہیے)۔ Cap hit ہو تو یہ investigate کرنے کا signal ہے، remove کرنے کا workaround نہیں۔
عملی envelope۔ Single agent + ReAct Inngest میں cleanly wrap ہوتا ہے، ایک structural decision کے ساتھ جسے right کرنا ضروری ہے: کیا پورے agent loop کو one step.run بنائیں یا multiple steps میں decompose کریں؟
- یہ Inngest primitives used: event trigger کے ساتھ
@inngest_client.create_function(TriggerEvent(event="customer/email.received")، Maya کا exact setup)؛ SDK call کو wrap کرنے والاctx.step.run("agent-loop", Runner.run, agent, input)، یعنی SDK کےRunner.run()call کے گرد durable step؛ downstream systems protect کرنے کے لیےconcurrencyاورthrottle؛ optionally escalation tool کے اندر HITL implement کرنے کے لیےctx.step.wait_for_event۔ - یہ Structural choice: پورے agent loop کے لیے one
step.runstandard pattern ہے۔ SDK reason-act-observe loop internally چلاتا ہے؛ Inngest کے perspective سے یہ ایک durable step ہے۔ Crash mid-loop → پورا loop retry ہوتا ہے (SDK traces lost ہو سکتی ہیں، مگر function recover کرتا ہے)۔ Alternatively decomposed، ہر tool call کو اپنےstep.runمیں wrap کرنا finer-grained durability دیتا ہے مگر SDK loop کوRunner.run()سے باہر lift کرنا پڑتا ہے، جو fragile ہے۔ Specific reason نہ ہو تو per agent loop onestep.rundefault رکھیں۔ - یہ HITL via wait_for_event: Concept 10 کے code کا escalation tool Inngest pattern بن جاتا ہے۔ Agent جب
escalate_to_humancall کرتا ہے، tool event fire کرتا ہے (refund/approval.requested) اور functionstep.wait_for_eventکے ذریعے suspend ہو جاتا ہے جب تک human respond نہ کرے۔ Agent code clean رہتا ہے، وہ بس tool call کرتا ہے، durability envelope handle کرتا ہے۔ - یہ Concurrency caps:
concurrency=[Concurrency(limit=10, key="event.data.customer_id")]ایک customer's burst کو others کو starve کرنے سے روکتا ہے۔ یہ operational envelope کا per-key concurrency pattern ہے، Maya کی deployment پر directly applied۔
یہ Maya کا Tier-1 Support agent implicitly یہی composition ہے: engine کے لیے SDK Agent + Runner.run()، deployment کے لیے ACA + Neon + R2 + sandbox، plus Inngest envelope (جب present ہو) triggers، durability، اور flow control کے لیے۔ Part 5 میں Decision 1 composition explicit بناتا ہے۔
خلاصہ، Concept 10: single-agent ReAct درست pattern ہے جب path unknown ہو اور structure articulable نہ ہو۔ یہ cloud stack کا زیادہ تر حصہ use کرتا ہے (اگر agent code run کرتا ہے تو sandbox required؛ Python harnesses کے لیے bridge Worker required)۔ Eval discipline reasoning trace capture کرتی ہے، صرف final output نہیں: Phoenix ReAct کے لیے load-bearing observability ہے کیونکہ trace-level signals ہی characteristic failures (looping، hallucinated tools، premature termination، reasoning-action divergence) catch کرتے ہیں۔
یہ Concept 11: Planning + ReAct execution، characteristic shape، deployment، eval signals
یہ کیا ہے۔ دو-layer pattern: execution شروع ہونے سے پہلے planning agent explicit plan produce کرتا ہے (dependencies والے stages)؛ ہر stage کے اندر ReAct + tools work handle کرتے ہیں۔ Step level پر path unknown ہے (Q1=no) مگر stage level پر structure articulable ہے (Q3=yes)۔
یہ OpenAI Agents SDK میں characteristic implementation:
from agents import Agent, Runner, function_tool
from pydantic import BaseModel
from typing import Literal
class Stage(BaseModel):
id: str
description: str
agent_role: Literal["researcher", "analyzer", "synthesizer"]
depends_on: list[str] # other stage ids
step_budget: int
class Plan(BaseModel):
task_summary: str
stages: list[Stage]
success_criteria: str
# Planner: an Agent that produces a structured plan, no tools.
planner = Agent(
name="market_research_planner",
instructions=(
"Given a research task, produce a plan with 3-7 stages. Each stage has clear "
"dependencies and a step budget. Prefer fewer broader stages over many narrow ones."
),
output_type=Plan,
)
# Three execution specialists: each with its own tools and instructions.
researcher = Agent(
name="researcher",
instructions="Investigate the assigned topic using your tools. Return a structured brief.",
tools=[web_search, fetch_url, read_document],
)
analyzer = Agent(
name="analyzer",
instructions="Analyze the briefs from researchers. Identify patterns, contradictions, gaps.",
tools=[compute_metrics, compare_briefs],
)
synthesizer = Agent(
name="synthesizer",
instructions="Synthesize the analyzed findings into a coherent report.",
tools=[draft_report, format_citations],
)
ROLE_TO_AGENT = {"researcher": researcher, "analyzer": analyzer, "synthesizer": synthesizer}
async def planning_then_react(task: str, session_id: str) -> str:
# Stage 1: Generate the plan via the planner Agent
plan_result = await Runner.run(planner, task)
plan: Plan = plan_result.final_output
await db.runs.persist_plan(session_id, plan) # cloud deployment: plan persistence
# Stage 2: Execute each stage via the matching specialist Agent
stage_results: dict[str, str] = {}
for stage in topological_order(plan.stages):
agent = ROLE_TO_AGENT[stage.agent_role]
stage_input = compose_stage_input(stage, stage_results, task)
stage_run = await Runner.run(agent, stage_input, max_turns=stage.step_budget)
stage_results[stage.id] = stage_run.final_output
await db.runs.persist_stage(session_id, stage.id, stage_run.final_output)
# Stage 3: Final synthesis via the synthesizer one more time
final = await Runner.run(
synthesizer,
f"Compose the final report. Plan: {plan.model_dump_json()}. Results: {stage_results}",
)
return final.final_output
یہ SDK shape پر غور کریں: planner ایک Agent ہے جس کے پاس output_type=Plan ہے اور tools نہیں ہیں؛ وہ صرف structured output بناتا ہے۔ ہر execution stage اپنے role کے مطابق specialist Agent استعمال کرتی ہے، جسے Runner.run() کے ذریعے call کیا جاتا ہے۔ Plan Pydantic سے structured ہے، اس لیے SDK اسے type level پر validate کرتا ہے: JSON parse کر کے امید لگانے والی بات نہیں۔ Plan persistence cloud deployment کے Neon-Postgres runs table میں ہوتی ہے، جسے customer-support Worker wire کرتا ہے۔
یہ SDK کا نکتہ جو ذہن میں بٹھانے کے قابل ہے: structured-output Agent + tool-using Agent ہی planning + ReAct execution کے دو halves ہیں۔ SDK کا output_type= plans کو first-class artifacts بناتا ہے؛ باقی Runner.run() calls کے اوپر plain orchestration code ہے۔
تعیناتی کی composition۔ Planning + ReAct وہی components استعمال کرتا ہے جو single-agent ReAct کرتا ہے، ساتھ ایک اضافی discipline:
- یہ SDK primitives used: planner
Agentwithoutput_type=PlanSchema(tools نہیں، صرف structured output)؛ ہر role کے لیے ایک executionAgentwithtools=[...]اور@function_tooldecorators؛ planner کے لیے ایک بار اور ہر stage کے لیے ایک بارRunner.run()call ہوتا ہے۔ Plan persistence cloud deployment کےrunstable میں رہتی ہے، SDK میں نہیں؛ SDKRunner.run()calls کے درمیان stateless رہتا ہے۔ - یہ Concept 10 سے تمام ReAct deployment requirements: وہی harness، sandbox، R2، background worker۔
- یہ Neon میں plan persistence۔ Plan خود ایک artifact ہے جسے audit اور resumability کے لیے store کرنا چاہیے۔ ایک نئی table یا
runstable کی schema extensionplan_id، plan content، اور stage-by-stage progress track کرتی ہے۔ - یہ Long-running runs زیادہ common ہیں۔ Plans اکثر 5-10 stages رکھتے ہیں، اور ہر stage ممکنہ طور پر 20-30 ReAct steps چلا سکتی ہے۔ End-to-end 5-10 minute runs normal ہیں۔ Background worker pattern mandatory ہے، optional نہیں۔
تشخیصی signals۔ Planning + ReAct pure ReAct سے آگے نئے failure modes add کرتا ہے:
| Failure mode | eval اسے کس صورت catch کرتا ہے |
|---|---|
| Planner ایسا plan بناتا ہے جس سے execution diverge کر جاتی ہے | Plan کو actual stage execution سے compare کریں؛ skipped، reordered، یا mid-run substantively redefined stages flag کریں |
| Plan میں missing stages ہیں، یعنی obvious step شامل نہیں | Similar tasks کے golden-dataset plans سے compare کریں؛ DeepEval structural divergence flag کرتا ہے |
| Stage handoffs context کھو دیتے ہیں | ہر stage کے input inspect کریں؛ اگر stage N stage M کے critical output کو reference نہیں کر سکتی تو handoff نے information کھو دی |
| Plan over-detailed ہے، ہر stage ایک single tool call ہے | Plan-stage size analysis؛ اگر ہر stage 1-2 ReAct steps میں execute ہو تو planning layer کام نہیں کر رہی |
| Plan under-detailed ہے، ایک stage بہت وسیع scope cover کرتی ہے | Plan-stage size analysis؛ اگر ایک stage 50+ ReAct steps چلے تو planning نے واقعی decompose نہیں کیا |
اہم نکتہ: planning + ReAct evals کو plan quality کو execution quality سے الگ measure کرنا چاہیے۔ اچھا plan مگر خراب execution، اور خراب plan مگر اچھی execution، دو مختلف diagnoses ہیں؛ انہیں mix کرنے سے false diagnoses بنتی ہیں۔ Eval signal "plan-execution divergence" سب سے informative ہے، کیونکہ یہ بتاتا ہے کہ planner ایسی structure produce کر رہا ہے جو task میں actually موجود نہیں۔
یہ Production میں teams یہاں کہاں غلط ہوتی ہیں۔ Plan کو contract سمجھ کر trust کرنا۔ Plan starting structure ہے؛ stages کے اندر execution legitimately discover کر سکتی ہے کہ اگلی stage کو planned کام سے مختلف work چاہیے۔ Divergence کو ہمیشہ bad سمجھنے سے rigidity آتی ہے؛ اسے ہمیشہ fine سمجھنے سے planning کی value ختم ہوتی ہے۔ درست discipline یہ ہے: ہر divergence log کریں، recurring patterns کے لیے periodically review کریں (recurring divergence کا مطلب planner کو improve کرنا ہے)، اور small in-stage adaptations کو alarm کے بغیر ہونے دیں۔
عملی envelope۔ Planning + ReAct execution Inngest کے step.run model کے لیے سب سے صاف fit ہے؛ ہر stage ایک step.run سے map ہوتی ہے، اور durability benefits multi-stage run میں compound ہوتے ہیں۔
- یہ Inngest primitives used: parent function کے لیے
@inngest_client.create_function؛ ہر stage کے لیے ایکctx.step.run(step.run("plan", Runner.run, planner, task)، پھر ہر execution stage کے لیے ایکstep.run)؛ اگر کچھ stages کے non-transient failure modes ہیں توretries=per stage configure؛ parallel runs cap کرنے کے لیےconcurrency۔ - یہ Plan-then-execute mapping:
step.run("plan", ...)plan produce کرتا ہے؛ پھر function plan.stages پر iterate کر کے ہر stage کے لیےstep.run(f"stage-{stage.id}", ...)call کرتا ہے۔ اگر function mid-execution crash ہو جائے، مثلاً 6 میں سے stage 4 پر، Inngest memoization سے plan اور stages 1-3 restore کرتا ہے؛ صرف stage 4 retry ہوتی ہے۔ Plan persistence مفت ملتی ہے، Inngest اسے "plan" step کے output کے طور پر store کرتا ہے۔ - یہ Cost impact: یہاں savings کسی بھی pattern سے زیادہ ہیں۔ Planning + ReAct run 5-10 minutes لے سکتا ہے اور 20-30 tool calls involve کر سکتا ہے؛ minute 8 پر durability کے بغیر crash ہو تو سب کچھ دوبارہ pay کرنا پڑتا ہے۔ Operational envelope کی memoization GPT-5-class pricing پر ہر crashed run میں $0.50-$2.00 بچا سکتی ہے۔ 1000 ایسے runs/day اور transient infrastructure issues سے 1-5% crash rates والے systems میں یہ directly saved LLM costs میں $150-$1000/month ہے۔
- یہ Parallel stage execution: جن stages کی ایک دوسرے پر dependencies نہیں، انہیں operational envelope کے fan-out pattern سے fan out کیا جا سکتا ہے، یعنی ہر stage کے لیے ایک event، ہر event اپنی function trigger کرے؛ اس سے execution parallel ہوتی ہے مگر per-stage durability برقرار رہتی ہے۔
یہ Concept 11 کی deployment composition میں "Neon میں plan persistence" requirement جزوی طور پر unnecessary ہے اگر envelope میں Inngest ہے، کیونکہ Inngest plan کو "plan" step کے output کے طور پر store کرتا ہے۔ Neon پھر بھی OTel کے ذریعے audit اور observability کے لیے run track کرتا ہے، مگر plan-recovery story Inngest handle کرتا ہے، application code نہیں۔
خلاصہ، Concept 11: planning + ReAct execution درست pattern ہے جب structure articulable ہو مگر step-level work adaptation مانگتا ہو۔ یہ full ReAct deployment stack plus plan persistence اور background-worker pattern استعمال کرتا ہے۔ Eval discipline plan quality کو execution quality سے الگ رکھتی ہے؛ plan-execution divergence سب سے informative signal ہے، جو بتاتا ہے کہ planner ایسی structure produce کر رہا ہے جو task میں actually موجود نہیں۔
یہ Concept 12: Single agent + reflection، characteristic shape، deployment، eval signals
یہ کیا ہے۔ کسی بھی core pattern کے اوپر ایک layer: agent output produce کرے، پھر critique pass اسے explicit criteria کے خلاف evaluate کرے؛ defects identify ہوں تو agent refine یا regenerate کرے۔ Reflection Q4 سے justify ہوتی ہے: quality speed سے زیادہ اہم ہو، اور checkable criteria موجود ہوں۔
یہ OpenAI Agents SDK میں characteristic implementation۔ SDK reflection کے لیے دو الگ primitives دیتا ہے؛ choice اس پر ہے کہ آپ validation چاہتے ہیں (bad outputs block کرنا) یا refinement چاہتے ہیں (borderline outputs improve کرنا)۔
یہ Flavor 1، output_guardrail for validation-style reflection (lightweight SDK-native pattern):
from agents import Agent, Runner, output_guardrail, GuardrailFunctionOutput, RunContextWrapper
from pydantic import BaseModel
class SQLReview(BaseModel):
is_safe: bool
issues: list[str]
reasoning: str
# A critic Agent: uses a different model from the generator to avoid blind-spot overlap.
sql_critic = Agent(
name="sql_critic",
model="claude-opus-4-5", # different model family from the generator
instructions=(
"Review the SQL query. Check that it parses, hits only allowed tables, "
"does not use SELECT *, and has appropriate WHERE clauses. Flag any issues."
),
output_type=SQLReview,
)
@output_guardrail
async def critic_guardrail(ctx: RunContextWrapper, agent: Agent, output: str) -> GuardrailFunctionOutput:
review_result = await Runner.run(sql_critic, output)
review: SQLReview = review_result.final_output
return GuardrailFunctionOutput(
output_info={"issues": review.issues, "reasoning": review.reasoning},
tripwire_triggered=not review.is_safe,
)
# The generator Agent: uses output_guardrails to invoke the critic.
sql_generator = Agent(
name="sql_generator",
model="gpt-5", # different model family from the critic
instructions="Generate a SQL query that answers the user's question.",
tools=[fetch_schema, list_tables],
output_guardrails=[critic_guardrail],
)
# When tripwire fires, Runner.run raises OutputGuardrailTripwireTriggered.
# Catch it and decide: retry with critique context, escalate, or fail loudly.
یہ Flavor 2، separate critic-and-refiner loop for refinement-style reflection (جب آپ generator سے output fix کروانا چاہتے ہوں، صرف bad output block نہیں کرنا):
async def with_reflection(task: str, max_refinements: int = 2) -> str:
output = (await Runner.run(sql_generator, task)).final_output
for refinement in range(max_refinements):
critique = (await Runner.run(sql_critic, output)).final_output
if critique.is_safe and not critique.issues:
return output
# Refinement: feed the critique back to the generator
refine_prompt = f"Original query:\n{output}\n\nCritic flagged: {critique.issues}\n\nRevise the query."
output = (await Runner.run(sql_generator, refine_prompt)).final_output
return output # max refinements reached; output is best-effort
دو SDK shapes پر غور کریں: output_guardrail SDK کا native pattern ہے "bad outputs block" کرنے کے لیے؛ declarative، agent definition سے tied، ہر Runner.run() پر automatically run ہوتا ہے۔ Separate critic-and-refiner loop "borderline outputs improve" کرنے کا SDK idiom ہے؛ زیادہ flexible ہے، مگر orchestration آپ لکھتے ہیں۔ دونوں patterns critic اور generator کے لیے different models استعمال کرتے ہیں۔ یہی Concept 7 والی discipline ہے، SDK کے model= parameter کو ہر Agent پر set کر کے concrete ہو گئی۔
یہ SDK کا نکتہ جو ذہن میں بٹھانے کے قابل ہے: reflection SDK میں separate framework primitive نہیں؛ یہ Agent + Agent کی composition ہے۔ output_guardrail decorator بس SDK convention ہے جو second agent کو first agent کے output path میں wire کرتا ہے۔
تعیناتی کی composition۔ Reflection core pattern کے اوپر layer ہوتی ہے، اس لیے deployment composition نیچے والے pattern پر depend کرتی ہے:
- یہ SDK primitives used: block-bad-outputs reflection کے لیے
output_guardrail(SDK کا native validation primitive)؛ یا refinement-style reflection کے لیے دوAgentinstances (generator + critic) جن پر فی agentRunner.run()call ہوتا ہے۔ Critical بات: critic کو generator سے differentmodel=استعمال کرنا چاہیے، same SDK مگر different model family۔ - اگر core sequential workflow ہے تو reflection 1-2 LLM calls add کرتی ہے؛ deployment structurally نہیں بدلتا۔
- اگر core ReAct + tools ہے تو reflection agent loop complete ہونے کے بعد 1-2 LLM calls add کرتی ہے؛ deployment structurally نہیں بدلتا۔
- اگر core planning + ReAct ہے تو reflection اکثر stages کے درمیان آتی ہے (stage N کا output critique کریں before stage N+1 starts) اور final synthesis پر بھی؛ اس سے latency add ہوتی ہے۔
یہ New deployment consideration: model variety۔ اگر critic generator سے different model use کرتا ہے (Claude GPT کو critique کر رہا ہو، یا vice versa) تو harness کو multiple model providers support کرنے پڑتے ہیں۔ Cloud deployment course single-provider deployment سکھاتا ہے؛ reflection add کرنا اکثر multi-provider کو real need بنا دیتا ہے۔ Secrets-management اور routing accordingly plan کریں۔
تشخیصی signals۔ Reflection کے اپنے characteristic failure modes ہیں:
| Failure mode | eval اسے کس صورت catch کرتا ہے |
|---|---|
| Reflection output کو بدلتی نہیں، یعنی rubber-stamping | Pre-reflection اور post-reflection outputs compare کریں؛ اگر وہ 80% سے زیادہ time nearly identical ہوں تو reflection کام نہیں کر رہی |
| Reflection غلط سمت میں refine کرتی ہے، output خراب ہوتا ہے | Golden dataset کے خلاف pre- اور post-reflection score کریں؛ net negative impact critic misfire دکھاتا ہے |
| Critic اور generator blind spots share کرتے ہیں | A/B test: same generator، دو different critics (different models یا prompts)؛ اگر critique content strongly correlate کرے تو critics کافی independent نہیں |
| Criteria drift over time، یعنی criteria list ad-hoc grow/shrink ہوتی ہے | Criteria list کو version-control کریں؛ جب changes documented decisions سے match نہ کریں تو flag کریں |
| Refinement loops budget exceed کرتے ہیں | Refinement counter threshold سے اوپر جائے؛ investigate کریں کہ critic ایسے defects کیوں ڈھونڈتا رہتا ہے جنہیں generator fix نہیں کر سکتا |
اہم نکتہ: reflection evals کو یہ measure کرنا چاہیے کہ reflection net-positive ہے یا نہیں، صرف یہ نہیں کہ وہ run ہوئی۔ ایسا reflection pass جو output نہیں بدلتا overhead ہے؛ ایسا reflection pass جو output worse کر دے harmful ہے۔ "Rubber-stamp" failure mode detect کرنا سب سے مشکل ہے کیونکہ surface metric healthy لگتی ہے (latency بڑھی، errors flat رہے) مگر system اپنی cost earn نہیں کر رہا۔
یہ Production میں teams یہاں کہاں غلط ہوتی ہیں۔ Reflection اس لیے add کرنا کہ وہ rigorous سنائی دیتی ہے۔ Teams "generate, then critique" pattern لگا دیتی ہیں مگر measure نہیں کرتیں کہ critique واقعی وہ چیزیں catch کر رہی ہے جو generator miss کرتا ہے۔ مہینوں بعد reflection pass extra LLM calls میں $X خرچ کر چکا ہوتا ہے اور measurable quality improvement $0 ہوتا ہے۔ Discipline یہ ہے: first month کے اندر reflection کی net contribution measure کریں، اور اگر contribution threshold سے کم ہو تو اسے remove کریں۔
عملی envelope۔ Reflection Inngest کے step model کے ساتھ اچھی compose ہوتی ہے؛ ہر pass (generate، critique، refine) اپنا step.run بنتا ہے، اور durability benefits اس بات کے proportional ہیں کہ کسی individual failure سے پہلے کتنے passes مکمل ہو چکے تھے۔
- یہ Inngest primitives used: فی run تین یا چار
ctx.step.runcalls،step.run("generate", ...)،step.run("critique", ...)، اور refinement attempts کے لیے 0-2step.run("refine-N", ...)۔ Optionally: جب critic human ہو توctx.step.wait_for_event(function suspend رہتا ہے جب تک human reviewer approval event fire نہ کرے، وہی HITL-gate primitive جو operational envelope دیتا ہے)۔ - یہ Durability win: اگر generator step successfully complete ہو جائے (سب سے expensive step، output produce کرتا ہے جسے critique ہونا ہے) اور critic step transiently fail ہو جائے (rate limit، network blip)، تو صرف critic step retry ہوتا ہے۔ Generator کا output memoized رہتا ہے اور regenerate نہیں ہوتا۔ Operational envelope کی
step.rundiscipline reflection کی added latency کو crashes پر double-cost میں compound ہونے سے روکتی ہے۔ - یہ HITL reflection۔ جب evaluation criteria کسی دوسرے LLM سے checkable نہ ہوں (Concept 7 کا "subjective domains" caveat)، تو اکثر right answer human reflection ہے۔ Inngest کا
step.wait_for_eventاسے clean بناتا ہے:step.run("generate", ...)→step.run("send-to-reviewer", ...)→step.wait_for_event("await-human-decision", timeout=timedelta(hours=4))→step.run("act-on-decision", ...)۔ Function zero compute consumed کے ساتھ suspend رہتا ہے while human reviews۔ Operational-envelope course HITL pattern کو detail میں walk کرتا ہے۔ - یہ Reflection کی cost-per-output discipline: Inngest کی run-level cost tracking (per
step.runکی LLM cost) reflection کی net contribution measure کرنا trivial بناتی ہے۔ Per-run cost comparison (with-reflection vs. without-reflection) Phoenix dashboard query سے ایک step دور ہے۔
یہ Concept 12 کے reflection کے دو SDK flavors (output_guardrail vs. separate critic-and-refiner loop) دونوں Inngest envelope کے ساتھ naturally compose ہوتے ہیں۔ SDK flavor reflection style کے حساب سے pick کریں؛ envelope discipline دونوں صورتوں میں same ہے۔
خلاصہ، Concept 12: reflection درست additive layer ہے جب quality speed سے زیادہ اہم ہو اور criteria checkable ہوں۔ یہ کسی بھی core pattern کے اوپر layer ہوتی ہے۔ Eval discipline measure کرتی ہے کہ reflection net-positive ہے یا نہیں؛ rubber-stamping سب سے insidious failure mode ہے کیونکہ surface metrics healthy لگتی ہیں۔ اگر deployment کے ایک مہینے کے اندر reflection measurably outputs improve نہیں کر رہی، اسے remove کریں۔
یہ Concept 13: Multi-agent specialist system، characteristic shape، deployment، eval signals
یہ کیا ہے۔ Multiple agents distinct roles کے ساتھ task پر collaborate کرتے ہیں۔ Q5 سے justify ہوتا ہے: specialization، context، یا scale واقعی bottleneck create کرے۔ Pattern composition اہم ہے: ہر specialist کی internal architecture sequential workflow، ReAct، یا planning + ReAct ہو سکتی ہے۔ Multi-agent دوسرے patterns کا replacement نہیں؛ ان کی composition ہے۔
تین SDK-native topologies، ہر ایک different SDK primitive استعمال کرتی ہے۔
یہ Topology 1، Coordinator with specialists as tools (SDK کا Agent.as_tool() pattern)۔ Coordinator control میں رہتا ہے؛ specialists function tools کی طرح invoke ہوتے ہیں۔
from agents import Agent, Runner, function_tool
# Three specialists, each with its own tools and instructions.
researcher = Agent(name="researcher", instructions="...", tools=[web_search, fetch_url])
writer = Agent(name="writer", instructions="...", tools=[draft_document])
reviewer = Agent(name="reviewer", instructions="...", tools=[lint_check, fact_check])
# The coordinator uses specialists as_tool(): calling them like functions.
coordinator = Agent(
name="coordinator",
instructions=(
"Decompose the task into research, writing, and review phases. "
"Use the specialist tools in order. Compose their outputs into a final report."
),
tools=[
researcher.as_tool(tool_name="research_topic", tool_description="Investigate a topic and return a brief"),
writer.as_tool(tool_name="draft_document", tool_description="Draft a document from research notes"),
reviewer.as_tool(tool_name="review_document", tool_description="Review a draft and return critique"),
],
)
async def coordinator_topology(task: str) -> str:
result = await Runner.run(coordinator, task, max_turns=30)
return result.final_output
یہ Topology 2: Sequential handoff (SDK کا handoff() pattern)۔ Specialists conversation take over کرتے ہیں؛ SDK ان کے درمیان context pass کرتا ہے۔
from agents import Agent, Runner, handoff
# Define specialists; each one declares which agents it can hand off TO.
final_reviewer = Agent(name="reviewer", instructions="Review the draft and produce the final output.")
writer = Agent(
name="writer",
instructions="Draft from the research. When the draft is ready, hand off to the reviewer.",
handoffs=[handoff(final_reviewer)],
)
researcher = Agent(
name="researcher",
instructions="Investigate the topic. When research is complete, hand off to the writer.",
tools=[web_search, fetch_url],
handoffs=[handoff(writer)],
)
async def handoff_topology(task: str) -> str:
# Start with the researcher; the SDK threads control through handoffs.
result = await Runner.run(researcher, task, max_turns=50)
return result.final_output # whoever ended up holding the conversation
یہ Topology 3، Parallel specialists composed by a synthesizer۔ SDK ہر specialist کو independently Runner.run() کے ذریعے چلاتا ہے؛ synthesizer ان کے outputs compose کرتا ہے۔
import asyncio
from agents import Agent, Runner
# Five domain specialists running in parallel: one per competitor to research.
competitor_specialist = Agent(
name="competitor_research",
instructions="Research one competitor in depth: pricing, product, positioning, recent news.",
tools=[web_search, fetch_url, read_document],
)
synthesizer = Agent(
name="synthesizer",
instructions="Compose competitor briefs into a single comparative landscape report.",
)
async def parallel_topology(competitors: list[str]) -> str:
# Each specialist runs independently: different Runner.run() calls.
parallel_briefs = await asyncio.gather(*[
Runner.run(competitor_specialist, f"Research: {c}", max_turns=15)
for c in competitors
])
briefs_text = "\n\n".join(r.final_output for r in parallel_briefs)
final = await Runner.run(synthesizer, briefs_text)
return final.final_output
یہاں تین SDK primitives کام کر رہے ہیں:
- یہ
Agent.as_tool()agent کو callable tool کے طور پر wrap کرتا ہے؛ coordinator control میں رہتا ہے اور specialists کو functions کی طرح call کرتا ہے۔ Best جب coordinator کو outputs compose کرنے اور next step decide کرنے کی ضرورت ہو۔ - یہ
handoff()conversation دوسرے agent کو pass کرتا ہے؛ control transfer ہوتا ہے، اور SDK context manage کرتا ہے۔ Best جب specialist کو user-facing interaction take over کرنا ہو۔ - یہ Parallel
Runner.run()+asyncio.gather()specialists کو independently چلاتا ہے: shared conversation نہیں، handoff نہیں۔ Best جب specialists isolation میں کام کریں اور outputs synthesizer compose کرے۔
یہ SDK کا نکتہ جو ذہن میں بٹھانے کے قابل ہے: SDK multi-agent composition کے لیے native primitives دیتا ہے۔ Routing logic hand-roll کرنے کی ضرورت نہیں۔ as_tool() hierarchical composition کے لیے؛ handoff() sequential takeover کے لیے؛ parallel Runner.run() fan-out کے لیے۔ ان کے درمیان انتخاب خود ایک pattern-selection decision ہے، اور یہ Q5 میں سامنے آنے والی task properties کے downstream ہے۔
تعیناتی کی composition۔ Multi-agent systems full cloud stack استعمال کرتے ہیں، plus ایک critical additional discipline:
- یہ SDK primitives used: hierarchical composition کے لیے
Agent.as_tool()(coordinator control میں رہتا ہے)؛ sequential takeover کے لیےhandoff()(specialist conversation take over کرتا ہے)؛ fan-out کے لیے parallelRunner.run()+asyncio.gather()۔ ہر specialist اپناAgentہے، اپنیtools=list اورinstructions=کے ساتھ۔ SDK handoffs میں context-passing manage کرتا ہے؛ routing hand-roll نہ کریں۔ - یہ Single-agent ReAct کی تمام requirements ہر specialist کے لیے (harness، ضرورت ہو تو sandbox، R2، background worker)۔
- یہ Neon میں per-specialist runs/traces۔ ہر specialist execution اپنی run ہے؛ multi-agent system parent run ہے جو child runs کو reference کرتا ہے۔ Schema کو
parent_run_idاورagent_rolecolumns چاہییں۔ - یہ Routing audit logs۔ ہر routing decision log کریں: کون سا specialist؟ کون سا handoff format؟ Multi-agent failures عموماً wrong-routing-decision یا lost-context-on-handoff کی صورت نکلتے ہیں؛ explicit routing logs کے بغیر debugging تقریباً impossible ہے۔
- یہ Cost tracking per specialist۔ Multi-agent systems میں یہ بھولنا آسان ہے کہ کون سا specialist tokens burn کر رہا ہے۔ Per-specialist cost attribution runaway costs کو aggregate metrics میں چھپنے سے روکتی ہے۔
یہ Bridge Worker plus specialists۔ اگر multiple specialists code run کرتے ہیں، تو آپ کو multiple bridge-Worker configurations چاہیے ہو سکتی ہیں (different specialists کی tooling needs کے لیے different Manifests) یا ایک bridge Worker جو specialist identity کے حساب سے route کرے۔ Complexity توقع سے زیادہ تیزی سے بڑھتی ہے: یہی وہ جگہ ہے جہاں deployment-topology costs dominate کرنا شروع کرتی ہیں۔
تشخیصی signals۔ Multi-agent failures evaluate کرنا سب سے مشکل ہے کیونکہ failure تین layers پر ہو سکتا ہے: specialist کے اندر، routing/coordination میں، یا integration میں:
| Failure mode | eval اسے کس صورت catch کرتا ہے |
|---|---|
| Specialist غلط output produce کرتا ہے | ہر specialist کے role پر standard per-agent eval؛ evaluation کے لیے ہر specialist کو standalone agent سمجھیں |
| Coordinator غلط specialist کو route کرتا ہے | Routing-accuracy eval: task given ہو تو کیا right specialist تک گیا؟ Golden dataset میں labeled routing examples چاہییں |
| Handoff information کھو دیتا ہے، specialist B specialist A کا output use نہیں کر سکتا | Handoff-completeness eval: کیا specialist B کے پاس specialist A سے needed material تھا؟ شروع میں manual labels؛ patterns clear ہوں تو automate کریں |
| Integration specialists کے outputs غلط combine کرتی ہے | Golden dataset کے خلاف end-to-end eval؛ اگر specialists individually pass مگر integrated output fail ہو، problem integration ہے |
| Specialists disagreement بغیر resolution کے چھوڑ دیتے ہیں | Inconsistency detector: parallel specialists conflicting answers produce کرتے ہیں؛ aggregator conflict explicitly resolve کرے یا surface کرے |
| Coordination overhead work value سے بڑھ جاتا ہے | Cost-per-correct-output: اگر multi-agent costs single-agent سے 3× اوپر اور quality improvement 20% سے کم ہو تو architecture overhead earn نہیں کر رہی |
اہم نکتہ: multi-agent evals کو تین الگ scoreboards چاہیے: specialist quality، routing accuracy، integration quality۔ انہیں mix کرنے سے meaningless aggregate scores بنتے ہیں۔ Specialist individual quality 95%، routing accuracy 90%، integration quality 80% ہو سکتی ہے، اور end-to-end system تقریباً 68% perform کرے گا۔ Separation نہ ہو تو معلوم نہیں ہوتا کون سی layer improve کرنی ہے۔
یہ Production میں teams یہاں کہاں غلط ہوتی ہیں۔ Multi-agent system کو single unit سمجھنا۔ کچھ fail ہو تو team پوری system debug کرتی ہے، layer localize نہیں کرتی۔ Solution: day one سے per-specialist tracing اور per-handoff logging enforce کریں۔ اس کے بغیر multi-agent debugging single-agent debugging سے بہت زیادہ مشکل اور slow ہو جاتی ہے، اور یہی pattern کی سب سے بڑی hidden costs میں سے ایک ہے۔
عملی envelope۔ Multi-agent وہ pattern ہے جو Inngest کے operational envelope پر سب سے زیادہ depend کرتا ہے۔ تقریباً ہر envelope primitive role ادا کرتا ہے: parallel specialists کے لیے fan-out، tenant fairness کے لیے per-key concurrency، tier-based queueing کے لیے priority، specialists کے درمیان HITL gates، partial-failure recovery کے لیے replay۔
-
یہ Inngest primitives used (curriculum کی سب سے extensive composition):
- یہ Fan-out trigger pattern parallel specialist execution کے لیے: coordinator function N specialist events fire کرتا ہے؛ ہر specialist اپنی
@inngest_client.create_functionاور اپنیTriggerEventکے ساتھ separate function ہے۔ ایک event N functions جگاتا ہے؛ وہ parallel چلتی ہیں؛ Inngest ہر ایک کو independently track کرتا ہے۔ - یہ
step.runper specialist run ہر specialist function کے اندر، durability story single-agent ReAct (Concept 10) جیسی، مگر N سے multiplied۔ - یہ Per-key concurrency caps تاکہ کوئی single tenant specialist capacity monopolize نہ کرے:
concurrency=[Concurrency(limit=5, key="event.data.tenant_id")]۔ Per-key concurrency یہاں load-bearing pattern ہے۔ - یہ Priority expressions tier-based fairness کے لیے: Enterprise tenant runs queue میں Free tier سے آگے jump کرتے ہیں۔
- یہ
step.wait_for_eventbetween specialists جب handoffs کو human approval چاہیے ہو، مثلاً research → human-vetted research → analysis۔ - یہ Replay partial-failure recovery کے لیے: جب 5 میں سے 3 specialists fail اور 2 succeed ہوں، failing-specialist کا code fix کریں اور replay کریں؛ 2 successful specialists کے outputs memoized رہتے ہیں۔
- یہ Fan-out trigger pattern parallel specialist execution کے لیے: coordinator function N specialist events fire کرتا ہے؛ ہر specialist اپنی
-
یہ Coordination-cost insight: Concept 13 نے بتایا کہ multi-agent کا coordination overhead اس کی سب سے بڑی hidden cost ہے۔ Inngest کے primitives اس overhead کا زیادہ حصہ absorb کرتے ہیں: routing logic events + triggers بن جاتی ہے (hand-rolled router نہیں)؛ handoff contracts event schemas بن جاتے ہیں (SDK سے validated Pydantic models)؛ integration failures replay candidates بنتے ہیں (lost work نہیں)؛ per-specialist cost tracking per-function dashboard metrics بن جاتی ہے۔
-
یہ Quantified savings۔ Inngest کے بغیر multi-agent system عموماً یہ مانگتا ہے:
- یہ Custom routing/dispatch layer (~500-2000 lines of code)
- یہ Custom retry/dead-letter handler (~200-1000 lines)
- یہ Custom HITL approval queue with timeouts (~500-1500 lines)
- یہ Per-tenant rate limiting (~300-800 lines)
- یہ Custom replay/recovery tooling (~500-2000 lines)
یہ Together: 2,000-7,000 lines of operational-envelope code جسے test، debug، maintain کرنا پڑتا ہے۔ Inngest کے ساتھ یہ ~50-200 lines of trigger declarations اور
step.runcalls بن جاتا ہے۔ Production multi-agent system کی lifetime میں total-cost difference compound ہوتا رہتا ہے۔ -
یہ Three-scoreboard observability رہتی ہے۔ Eval suite کے per-specialist quality، routing accuracy، اور integration quality scoreboards (Concept 13 کے eval signals سے) اب بھی apply کرتے ہیں؛ Inngest کی structured traces OTel کے ذریعے Phoenix میں flow کرتی ہیں، اس لیے eval discipline change نہیں ہوتی۔
یہ Cloud deployment کی "per-specialist tracing، routing audit logs، cost tracking per specialist" requirement جزوی طور پر Inngest absorb کر لیتا ہے۔ Application-level traces (Phoenix) پھر بھی چاہییں، مگر audit logs اور cost tracking Inngest dashboard میں function-runs کے functions بن جاتے ہیں۔ Composition یہ ہے: run-level operational data کے لیے Inngest، trace-level evaluation data کے لیے Phoenix، application-level audit کے لیے Neon۔ تین layers، ہر ایک وہی own کرتی ہے جو وہ best کرتی ہے۔
یہ Concept 13 کا خلاصہ: multi-agent specialist systems full cloud stack plus per-specialist tracing، routing audit logs، اور cost-per-specialist tracking استعمال کرتے ہیں۔ Eval discipline تین الگ scoreboards مانگتی ہے (specialist quality، routing accuracy، integration quality) کیونکہ aggregate scores چھپا دیتے ہیں کہ کون سی layer fail ہوئی۔ Coordination overhead سب سے زیادہ under-estimated cost ہے؛ rigorous per-specialist instrumentation کے بغیر debugging single-agent debugging سے کہیں زیادہ مشکل اور slow ہوتی ہے۔
یہ Part 3 کے بعد AI کے ساتھ آزمائیں۔ آپ دیکھ چکے ہیں کہ ہر pattern deploy کرنے میں کیا cost آتی ہے اور وہ کیسے fail ہوتا ہے۔ اسے اپنے actual likely pattern کے لیے concrete بنائیں۔ Claude Code یا OpenCode session کھولیں اور paste کریں:
"وہ agentic pattern pick کریں جو میں سب سے زیادہ likely next build کروں گا (sequential workflow، single agent with ReAct and tools، planning with ReAct، یا multi-agent specialist system)۔ اس pattern کے لیے مجھے دو چیزیں walk through کرائیں۔ پہلے deployment topology: اسے کون سے components چاہییں (HTTP service، durable state، file storage، sandboxed code execution، background workers، trace observability) اور کون سے skip ہو سکتے ہیں؟ دوسرا، production میں پہلے کون سا single failure signal watch کرنا چاہیے، اور architecture بدلنے سے پہلے کون سا specific cheap fix try کرنا چاہیے۔ میرے pattern کے بارے میں concrete رہیں، generic نہیں۔"
آپ کیا سیکھ رہے ہیں۔ Pattern choice real نہیں جب تک آپ یہ نہ بتا سکیں کہ اسے run کرنے کی cost کیا ہے اور آپ کیسے جانیں گے کہ یہ broken ہے۔ یہ deployment-and-eval composition کو reading material سے whiteboard sketch میں بدل دیتا ہے۔
یہ Part 4: Failure signals and pattern revision
آپ starting pattern choose کر چکے ہیں۔ System run ہو رہا ہے۔ کیا چیز بتاتی ہے کہ pattern غلط تھا، اور پھر آپ کو کیا کرنا چاہیے؟ Part 4 Bala Priya C کے article کے پانچ characteristic failure signals cover کرتا ہے، انہیں آپ کی eval suite کے specific eval اور observability signals سے map کرتا ہے، اور ایسے targeted fixes دیتا ہے جو architecture چھوڑنے کا تقاضا نہیں کرتے۔
یہ Concept 14: پانچ failure signals، اور ہر ایک کا مطلب
یہ Article پانچ runtime symptoms identify کرتا ہے جو pattern-task mismatch دکھاتے ہیں۔ ہر ایک کی characteristic shape ہے؛ دو بار دیکھ لیں تو فوراً recognize ہو جاتی ہے۔
یہ Signal 1: ReAct loops یا solved work revisit کرتا ہے۔ Agent ایک run میں similar arguments کے ساتھ same tool multiple times call کرتا ہے۔ یا partial outputs produce کر کے انہیں scratch سے دوبارہ derive کرتا ہے۔ Pattern میں structure یا stop conditions missing ہیں۔ Agent کے پاس یہ جاننے کا way نہیں کہ کام done ہے۔
یہ Observability میں یہ کہاں دکھتا ہے: trace-length anomalies (run 40 steps لیا جبکہ اکثر runs 15 لیتے ہیں)؛ duplicate-tool-call patterns (same customer_lookup پانچ بار call ہوا)؛ reasoning-loop signals (model کی reasoning text میں "let me try this again" یا equivalent)۔
یہ Likely meanings، frequency کے order میں:
- یہ Agent کا prompt define نہیں کرتا کہ work کب "done" ہے
- یہ Tool contracts loose ہیں (multiple tools plausibly same کام کر سکتے ہیں؛ agent ان کے درمیان oscillate کرتا ہے)
- یہ Task کو واقعی planning چاہیے تھی (Q3 should have been yes)
یہ Signal 2، Planner plan بناتا ہے مگر execution diverge کرتی ہے۔ Plan کہتا ہے "stage 1: research; stage 2: draft; stage 3: review"۔ Execution stage 1 کرتی ہے، پھر stage 3 پر jump، پھر stage 2 پر واپس۔ یا execution وہ stages add کرتی ہے جو planner نے include نہیں کیں۔ Task planning bet سے کم predictable تھا۔
یہ Observability میں یہ کہاں دکھتا ہے: plan-execution divergence metric (planned stages اور executed stages کے درمیان edit distance compute کریں)؛ reordering signals (stages dependency order سے باہر run ہوتی ہیں)؛ inserted-stage signals (execution میں وہ stages شامل ہیں جو plan میں نہیں تھیں)۔
یہ Likely meanings، frequency کے order میں:
- یہ Task structure partially articulable ہے، fully نہیں؛ planner major phases correctly identify کرتا ہے مگر adaptive sub-phases miss کرتا ہے (lightweight planning use کریں)
- یہ Planner کی training اس task domain سے match نہیں کرتی (domain examples کے ساتھ planning prompt improve کریں)
- یہ Task میں genuinely articulable structure نہیں (Q3 should have been no؛ pure ReAct پر downgrade کریں)
یہ Signal 3، Reflection answer improve نہیں کرتی۔ Critique pass run ہوتا ہے، critique produce کرتا ہے، agent refine کرتا ہے، اور refined output original سے indistinguishable ہے۔ یا refined output worse ہے۔ Reflection bet fail ہو رہی ہے: criteria vague ہیں، یا critic اور generator blind spots share کرتے ہیں، یا دونوں۔
یہ Observability میں یہ کہاں دکھتا ہے: pre/post-reflection comparison scores (statistically indistinguishable ہوں تو reflection کام نہیں کر رہی)؛ criterion-firing rates (کون سے criteria refinement trigger کرتے ہیں؟ اگر ہمیشہ ایک ہی criterion ہو تو وہی useful ہے)؛ critic-generator agreement rate (critic تقریباً ہمیشہ pass کرے تو rubber-stamping ہے)۔
یہ Likely meanings، frequency کے order میں:
- یہ Criteria refinement drive کرنے کے لیے بہت vague ہیں (انہیں more specific اور checkable بنائیں)
- یہ Critic اور generator same model with similar prompts ہیں (different model یا fundamentally different critic framing use کریں)
- یہ Task کو actually reflection نہیں چاہیے تھی (Q4 should have been no؛ quality matter کر سکتی ہے مگر criteria checkable نہیں)
یہ Signal 4، Multi-agent routing fail ہوتا ہے۔ Coordinator task کو wrong specialist تک بھیجتا ہے۔ یا دو specialists conflicting outputs produce کرتے ہیں جنہیں aggregator reconcile نہیں کر سکتا۔ یا specialists کے درمیان handoff critical information کھو دیتا ہے۔ Coordination overhead work پر dominate کر رہا ہے۔
یہ Observability میں یہ کہاں دکھتا ہے: routing accuracy metric (coordinator decisions کو golden-dataset labels سے compare کریں)؛ handoff-completeness signals (specialist B کے input میں specialist A کے output کا critical content reference نہیں)؛ integration-failure rate (specialists individually pass، end-to-end fails)۔
یہ Likely meanings، frequency کے order میں:
- یہ Specialists کے roles overlap کرتے ہیں (boundaries clarify کریں؛ overlapping specialists merge کریں)
- یہ Handoff contracts implicit ہیں (explicit بنائیں؛ structured handoff formats require کریں)
- یہ Task کو actually multi-agent نہیں چاہیے تھا (Q5 should have been no؛ single agent پر collapse کریں)
یہ Signal 5، System complex لگتا ہے مگر بہتر نہیں۔ Diagnose کرنا سب سے مشکل کیونکہ کوئی single eval signal اسے catch نہیں کرتا۔ Architecture کے multiple layers ہیں (مثلاً planning + reflection + multi-agent) مگر output quality simpler baseline سے measurably better نہیں۔ Architecture task bottleneck نہیں بلکہ aesthetic problem solve کر رہی ہے۔
یہ Observability میں یہ کہاں دکھتا ہے: single observability signal نہیں۔ Detection baseline comparison مانگتی ہے: same task کا simpler version implement کریں (single agent + ReAct + tools، reflection نہیں، multi-agent نہیں) اور golden dataset پر quality measure کریں۔ اگر simpler version complex version کے تقریباً 10% کے اندر perform کرے تو complex architecture اپنی cost earn نہیں کر رہی۔
یہ Likely meaning، تقریباً ہر case میں:
- یہ Team نے ہر layer justified ہے یا نہیں test کیے بغیر patterns layer کیے؛ multiple decisions میں overshoot accumulate ہوا
یہ Concept 14 کا خلاصہ: پانچ characteristic failure signals pattern-task mismatch دکھاتے ہیں: ReAct loops/revisits (missing structure)، plan-execution divergence (overstructured)، reflection not improving (vague criteria)، multi-agent routing failures (overpartitioned)، system-feels-complex-but-not-better (cumulative overshoot)۔ ہر signal کی characteristic observability shape ہے۔ Signal recognize کرنا first step ہے؛ fix ہمیشہ architectural نہیں، کبھی prompt tightening یا contract clarification ہوتی ہے۔
یہ Concept 15: Targeted fixes جن کے لیے architecture چھوڑنا ضروری نہیں
یہ Failure signal recognize کرنے کا مطلب ہمیشہ architecture rewrite نہیں ہوتا۔ زیادہ تر fixes prompt، contract، یا instrumentation level پر ہوتے ہیں، architectural level پر نہیں۔ یہ concept ہر signal کو fix-first cheapest option سے map کرتا ہے۔
| Signal | پہلے try کرنے کے لیے cheapest fix | اگر یہ کام نہ کرے | Required architectural change |
|---|---|---|---|
| ReAct loops/revisits | Explicit stop conditions add کریں ("you have completed the task when…") اور tool boundaries ("use X for purpose Y; do not use X for Z") | Tool contracts improve کریں (better descriptions، clearer return types) | Planning layer add کریں (Concept 11 کے pattern پر upgrade) |
| Plan-execution divergence | Lightweight planning پر switch کریں (fewer، broader stages) | Domain-specific examples کے ساتھ planner prompt improve کریں | Pure ReAct پر downgrade کریں (Concept 10) |
| Reflection not improving | Criteria زیادہ specific اور checkable بنائیں (numeric thresholds، schema validation، explicit rules) | Critic کے لیے different model use کریں؛ یا explicit checking tools (parser، validator) use کریں | اگر improvement materialize نہ ہو تو reflection entirely remove کریں |
| Multi-agent routing fails | Known cases کے لیے coordinator کو LLM-based routing سے deterministic routing پر switch کریں | Handoff contracts explicit اور structured بنائیں (Pydantic models، free-text نہیں) | Overlapping specialists merge کریں؛ اگر Q5 actually hold نہیں کرتا تو single agent پر collapse کریں |
| Complex-but-not-better | Topmost layer remove کریں (recently added pattern) اور measure کریں | Next layer up remove کریں؛ iterate کریں | Strong baseline کے ساتھ single agent پر واپس جائیں؛ evidence کے ساتھ ہی rebuild کریں |
یہ Principle: سب سے چھوٹے scope پر fix کریں جو کام کر جائے۔ Prompt tightening tool-contract changes سے cheaper ہے۔ Tool-contract changes architectural changes سے cheaper ہیں۔ Architectural changes rewrites سے cheaper ہیں۔ زیادہ تر failure signals prompt یا contract level پر address ہو سکتے ہیں؛ پہلے architecture knob تک نہ جائیں۔
یہ Exception: اگر prompt اور contract fixes کے بعد failure signal recur ہو، تو یہ evidence ہے کہ architecture genuinely wrong ہے۔ "میں اسے patch کر سکتا ہوں" کو "میں اسے patch کرتا رہتا ہوں اور یہ نئے طریقوں سے fail ہوتا رہتا ہے" سے الگ رکھیں۔ دوسری صورت pattern selection revisit کرنے کا signal ہے۔
یہ Concept 15 کا خلاصہ: failure signals ہمیشہ architectural changes require نہیں کرتے۔ زیادہ تر prompt level (stop conditions، criteria specification، role boundaries) یا contract level (tool descriptions، handoff structures، routing logic) پر fix ہوتے ہیں۔ Architectural change last resort ہے، first move نہیں۔ Exception: prompt اور contract fixes کے بعد recurrent failures indicate کرتے ہیں کہ pattern itself wrong ہے؛ تب decision tree دوبارہ walk کریں۔
یہ Concept 16: جب decision tree غلط ہو
یہ Decision tree اچھا ہے۔ Infallible نہیں۔ تین situations جہاں tree کا first answer غلط ہو سکتا ہے، اور کیا کرنا ہے:
یہ Situation 1، Task properties deployment کے بعد change ہو جاتی ہیں۔ Stable workflow adaptive بن جاتا ہے (business 20 edge cases add کر دیتا ہے)۔ Specialized expertise commodity بن جاتی ہے (LLM بہتر ہو جاتا ہے اور generalist وہ کام handle کر لیتا ہے جس کے لیے specialist چاہیے تھا)۔ Real example: customer-support workflow جو sequential pipeline سے شروع ہوا (extract → classify → route → respond) personalization، history-awareness، اور tone-matching add ہونے کے بعد adaptive بن گیا۔ Original pattern اب غلط ہے، مگر system production میں ہے۔
یہ The fix: Concept 14 کی failure-signal observability اسے catch کرے۔ جب workflow paths اس لیے fail ہونے لگیں کہ real inputs expected workflow shape سے match نہیں کرتے، یہی signal ہے۔ نئی task properties کے ساتھ decision tree دوبارہ walk کریں۔ Deployed ہونے کی وجہ سے original choice کو right pretend نہ کریں۔
یہ Situation 2، Different sub-tasks کو different patterns چاہیے۔ Maya کا Tier-1 Support agent routing، lookups، refunds، escalations handle کرتا ہے۔ کچھ workflow-shaped ہیں (lookup deterministic)۔ کچھ ReAct-shaped ہیں (refund investigation adaptive)۔ Single-agent ReAct pattern سب کو handle کر لیتا ہے، مگر adequately rather than well۔ Fix: recognize کریں کہ یہ multi-pattern composition opportunity ہے۔ Top-level coordinator pattern-specific sub-systems کو route کرتا ہے: lookups کے لیے sequential workflow، investigations کے لیے ReAct + tools، complex multi-step disputes کے لیے planning۔ Composition multi-agent ہے، مگر specialists role-based نہیں، pattern-based ہیں۔
یہ Situation 3، Constraints answer بدل دیتے ہیں۔ Decision tree assume کرتا ہے کہ آپ جو pattern fit ہو وہ pick کر سکتے ہیں۔ کبھی آپ نہیں کر سکتے۔ Hard latency budget reflection rule out کرتا ہے۔ Hard cost budget multi-agent rule out کرتا ہے۔ Hard simplicity requirement planning rule out کرتی ہے۔ جب constraints tree کے picked pattern کو exclude کریں، تو یا constraints بدلیں، یا task scope بدلیں، یا worse fit accept کریں۔
یہ The fix: constraint-driven pattern choices کو separate decision کے طور پر explicitly track کریں۔ Document کریں: "decision tree نے multi-agent دکھایا، مگر cost ceiling کی وجہ سے ہم نے single-agent choose کیا۔ Known limitation: specialization-driven failures زیادہ common ہوں گے۔" اس سے constraint-driven choice visible اور revisitable رہتی ہے؛ constraints change ہوں تو معلوم ہوتا ہے کیا reconsider کرنا ہے۔
یہ Concept 16 کا خلاصہ: decision tree starting point ہے، permanent answer نہیں۔ تین situations tree revisit مانگتی ہیں: task properties deployment کے بعد change ہوں (failure-signal observability سے catch کریں)، different sub-tasks different patterns مانگیں (multiple patterns compose کریں)، اور constraints tree کا answer exclude کریں (constraint-driven choice explicitly document کریں)۔ Pattern selection iterative ہے، one-shot نہیں۔
یہ Concept 16.5: Anti-pattern gallery، common wrong choices اور بہتر alternatives
یہ Part 5 correct pattern selection کے worked examples سے پہلے inverse دیکھیں: common wrong choices کی quick gallery اور ہر ایک کا بہتر alternative۔ Anti-patterns recognize کرنا اپنی skill ہے: decision tree internalize کرنے والے students بھی pattern-overshoot یا pattern-undershoot میں fall ہو سکتے ہیں جب architectural temptation strong ہو۔
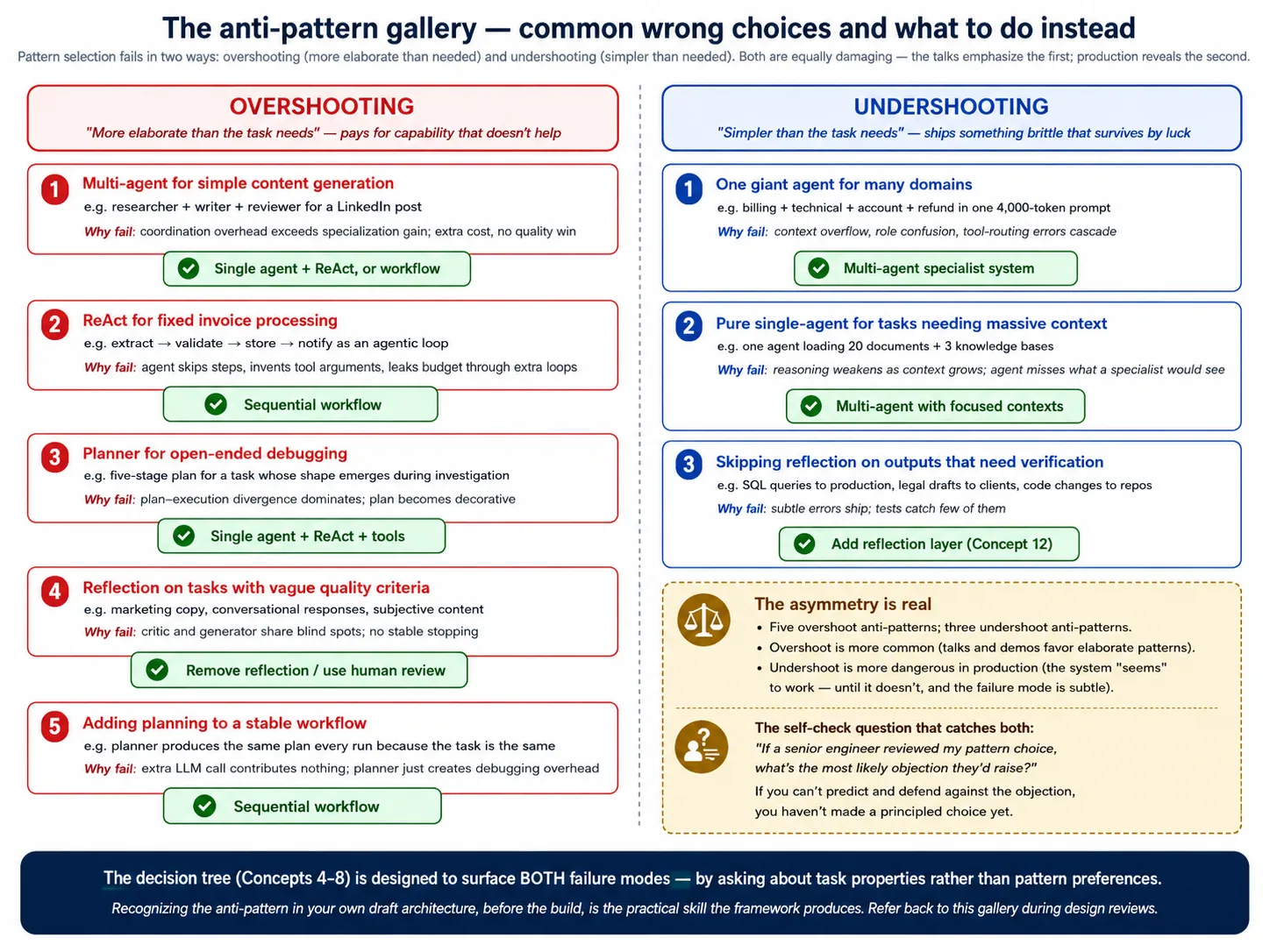
یہ Visual asymmetry، 5 overshoot anti-patterns vs. 3 undershoot، production systems کی real frequency reflect کرتی ہے۔ Overshoot زیادہ visible ہے کیونکہ elaborate patterns بہتر demos بناتے ہیں؛ undershoot زیادہ dangerous ہے کیونکہ failure modes subtle ہوتے ہیں۔ Design-review time پر دونوں catch کرنے کے قابل ہیں۔ نیچے table gallery کا full text دیتی ہے:
| Bad choice | Why it fails | Better starting pattern |
|---|---|---|
| Simple content generation کے لیے multi-agent (مثلاً ایک LinkedIn post کے لیے تین agents: researcher + writer + reviewer) | Coordination overhead specialization gain سے بہت زیادہ ہے۔ "Researcher" output ایک paragraph ہے جسے "writer" summarize کرتا ہے۔ Routing failures، handoff format mismatches، measurable quality improvement کے بغیر تین گنا tokens۔ | Single agent + ReAct + tools (Concept 10)، یا sequential workflow (Concept 9) اگر content shape fixed ہے۔ Multi-agent صرف تب اٹھائیں جب Q5 genuinely fire کرے۔ |
| Fixed invoice processing کے لیے ReAct (extract → validate → store → notify) | Agent کبھی steps skip کرتا ہے، کبھی already done work re-validate کرتا ہے، کبھی tool calls invent کرتا ہے۔ 5% runs میں step-budget exhaustion۔ Team prompt میں "stop conditions" add کرتی ہے، architectural mismatch کے symptoms treat کرتی ہے۔ | Sequential workflow (Concept 9)۔ Path known اور stable ہے؛ LLM-driven loop غلط tool ہے۔ |
| Open-ended debugging کے لیے planner (planner 5-stage plan produce کرتا ہے؛ execution فوراً diverge کرتی ہے) | Task structure advance میں articulable نہیں۔ Planner ایسا plan produce کرتا ہے جو stage 2 تک غلط ہو جاتا ہے۔ Trace پر plan-execution divergence dominate کرتی ہے۔ Team یا planner endlessly tighten کرتی ہے یا plan کو decorative سمجھتی ہے۔ | Single agent + ReAct + tools (Concept 10)۔ Pure ReAct ان tasks کو handle کرتا ہے جہاں shape اور content دونوں unknown ہوں۔ |
| Vague quality criteria والی tasks پر reflection (marketing copy، conversational responses، subjective content) | Critic اور generator blind spots share کرتے ہیں۔ Critique rubber-stamping بن جاتی ہے۔ Latency double؛ quality flat۔ Worse: team کو false confidence ملتی ہے کہ "AI نے check کر لیا"۔ | Reflection entirely remove کریں (اکثر right answer) یا LLM reflection کو human review سے replace کریں (Concept 12)۔ LLM reflection صرف checkable criteria پر کام کرتی ہے۔ |
| Many domains کے لیے one giant agent (billing + technical + account + refund + sales، سب ایک agent میں 4,000-token system prompt کے ساتھ) | Context overflow، role confusion، tool-routing errors cascade کرتے ہیں۔ Reflection marginally help کرتی ہے مگر root cause fix نہیں کرتی۔ Agent technical questions کا جواب billing policy سے اور vice versa دیتا ہے۔ | Multi-agent specialist system (Concept 13)، ہر domain کے لیے specialist، coordinator intent classification سے route کرے۔ Q5 کی specialization claim واقعی fire کرتی ہے۔ |
| Stable workflow میں planning add کرنا (planner ہر بار same plan produce کرتا ہے کیونکہ task same ہے) | ہر run ایک extra LLM call pay کرتا ہے جو کچھ contribute نہیں کرتی۔ Input ذرا unusual ہو تو planner slightly different plan produce کرتا ہے، اور team debug کرتی ہے کہ planner نے different path کیوں لیا۔ | Sequential workflow (Concept 9)۔ جب path fixed ہے تو planning کی ضرورت نہیں؛ path directly لکھ دیں۔ |
| Massive context مانگنے والی tasks کے لیے pure single-agent (ایک agent 20 source documents، تین knowledge bases، اور database schema prompt میں load کرتا ہے) | Context window degradation۔ Context بڑھنے پر agent کی reasoning weak ہوتی ہے؛ model وہ چیزیں miss کرتا ہے جو obvious لگتی ہیں۔ | Focused contexts کے ساتھ multi-agent specialist system (Concept 13)۔ ہر specialist صرف اپنی needed context load کرتا ہے؛ synthesizer outputs compose کرتا ہے۔ Q5 کی context claim genuinely fire کرتی ہے۔ |
| Verification کی genuinely ضرورت والے outputs پر reflection skip کرنا (production SQL queries، clients کے لیے legal drafts، repos میں code changes) | Subtle errors ship ہو جاتے ہیں۔ Team بعد میں tests add کرتی ہے، جو generation time پر catch کرنے کے مقابلے میں کم errors catch کرتے ہیں۔ | Core pattern کے اوپر reflection layer (Concept 12)۔ جب criteria checkable ہوں، reflection genuinely valuable ہے۔ Q4 fire کرتا ہے؛ اسے skip نہ کریں۔ |
یہ Anti-pattern gallery کا pattern: زیادہ تر bad choices aesthetic appeal سے driven pattern-overshoot ہیں (multi-agent impressive لگتا ہے، planning rigorous لگتی ہے، reflection careful لگتی ہے)۔ چھوٹا مگر equally important subset simplicity bias سے driven pattern-undershoot ہے (one big agent، workflow tasks پر pure ReAct، checkable outputs پر no reflection)۔ Decision tree دونوں mistakes surface کرنے کے لیے design کیا گیا ہے: pattern preferences کے بجائے task properties پوچھ کر۔
یہ Pattern choice lock کرنے سے پہلے useful self-check: "اگر senior engineer میری choice review کرے تو وہ سب سے likely کون سا objection raise کرے گا؟" اگر آپ objection predict اور defend نہیں کر سکتے تو غالباً choice principled نہیں۔
یہ Concept 16.5 کا خلاصہ: pattern selection سب سے زیادہ overshoot سے fail ہوتی ہے (needed سے زیادہ elaborate) اور کم مگر equally damagingly undershoot سے (needed سے زیادہ simple)۔ Anti-pattern gallery دونوں failure modes کی common shapes name کرتی ہے۔ انہیں internalize کرنا decision tree کی discipline کو تیز کرتا ہے؛ اپنی draft architecture میں anti-pattern recognize کرنا framework کی practical skill ہے۔ Course کے end پر one-page design-review template دیکھیں۔ اس میں explicit anti-pattern check شامل ہے ("اگر senior engineer یہ choice review کرے تو وہ کیا objection کرے گا؟") جو team design reviews میں اس discipline کو operationalize کرتا ہے۔
یہ Part 5: The decision lab
یہ Part 5 decision tree کو پانچ real tasks پر walk کرتا ہے۔ ہر Decision ایک worked classification ہے: task، پانچ سوالات کے answers، resulting pattern، deployment topology sketch، اور watch کرنے کے eval signals۔ Point right answer نہیں؛ discipline applied دیکھنا ہے۔
ہر Decision same shape follow کرتا ہے:
- یہ Task (ایک paragraph)
- یہ Tree walk (task-specific reasoning کے ساتھ پانچ questions answered)
- یہ Pattern choice and justification
- یہ Deployment topology sketch (کون سے cloud components، Neon میں کون سی new tables، bridge-Worker config کیا)
- یہ Eval signals to watch for (کون سے eval patterns، کون سے Phoenix evaluators)
- یہ Simulated track callout ان readers کے لیے جنہوں نے deployment اور eval courses نہیں کیے
یہ Decision 1: Maya کا Tier-1 Support agent
یہ Task۔ Customer-support agent incoming queries handle کرتا ہے۔ Agent account information lookup کر سکتا ہے، transaction history دیکھ سکتا ہے، policy rules lookup کر سکتا ہے، knowledge base search کر سکتا ہے، authority limits کے اندر refunds issue کر سکتا ہے، اور authority exceed ہو یا case ambiguous ہو تو human review کو escalate کر سکتا ہے۔ Agent customer کے ساتھ conversational interaction maintain کرتا ہے۔
آپ کی باری۔ Worked answer پڑھنے سے پہلے اس task پر پانچ questions walk کریں۔ Pattern پر commit کریں، پھر worked answer سے خود کو check کریں۔ یا task اپنے AI میں paste کریں اور اسے کہیں کہ Q1 سے Q5 تک آپ کو quiz کرے، جہاں reasoning thin ہو وہاں push back کرے۔
پہلے خود walk کریں، پھر worked answer کھولیں۔
یہ Tree walk۔
یہ Q1: کیا solution path advance میں define ہو سکتا ہے؟ نہیں۔ Customer queries بہت vary کرتی ہیں: "میرا refund کہاں ہے؟" lookup مانگتا ہے؛ "مجھ سے دو بار charge ہوا" investigation مانگتا ہے؛ "میں cancel کرنا چاہتا ہوں" account changes مانگ سکتا ہے؛ "میرا bill explain کریں" policy lookup اور explanation مانگتا ہے۔ Path unknown ہے۔
یہ Q2: N/A (Q1 no تھا، اس لیے Q2 skip)۔
یہ Q3: کیا task structure execution سے پہلے articulable ہے؟ نہیں۔ Articulable stages نہیں؛ investigation complete ہوتی ہے جب complete ہو۔ Agent ایک lookup کر کے respond کر سکتا ہے، یا پانچ lookups اور تین policy checks کر سکتا ہے۔ Clear stage structure نہیں۔
یہ Q4: کیا quality speed سے زیادہ اہم ہے؟ Mixed۔ Speed اہم ہے کیونکہ customers live conversation میں wait کر رہے ہیں؛ quality بھی اہم ہے کیونکہ wrong refund decisions business کو cost دیتے ہیں۔ مگر "good response" کے evaluation criteria real time میں checkable نہیں۔ ان میں nuanced judgment ہے کہ customer's situation اچھی طرح handle ہوئی یا نہیں۔ Reflection یہاں fit نہیں ہوتی۔
یہ Q5: کیا specialization، context، یا scale bottleneck ہے؟ Borderline۔ Agent کو billing، technical، account، اور refund issues handle کرنے ہیں، جو specialization کا case لگتا ہے۔ مگر overlap بہت ہے (زیادہ customers categories cross کرتے ہیں)، اس لیے specialist routing specialization benefit سے زیادہ handoff friction create کرے گی۔ Single agent right call ہے۔
یہ Pattern choice: Single agent + ReAct + tools۔ Concept 10 کا pattern۔
یہ Deployment topology sketch۔ یہی customer-support Worker کی cloud deployment نے build کیا۔ Full stack: ACA پر FastAPI، sessions، runs، traces کے لیے Neon، attached documents کے لیے R2، bridge Worker کے ذریعے Cloudflare Sandbox تاکہ agent کبھی refund-documentation files generate کرنے کے لیے apply_patch tool use کرے، اور 30 seconds سے longer runs کے لیے background worker۔ اس deployment سے کوئی deployment change نہیں۔
یہ Watch کرنے کے eval signals۔ ReAct کی characteristic failures:
- یہ Trace-length anomalies (Phoenix dashboard)
- یہ Tool-call duplication (agent same account تین بار lookup کرے)
- یہ Reasoning-action divergence (Phoenix tool-correctness evaluator)
- یہ Premature termination (agent بہت جلد "I can't help" کہہ دے)
- یہ Step-budget exhaustion (agent 25 steps سے آگے loop کرے مگر output نہ دے)
یہ Production میں most likely failure mode: agent ambiguous refund cases پر loop کرے گا۔ Fix: explicit stop conditions add کریں ("اگر 3 lookups کے اندر right refund amount determine نہ ہو تو escalate کریں") اور "investigate further" اور "human کو escalate" کے درمیان boundary clarify کریں۔
عملی envelope۔ Maya کا setup customer-support agent کے لیے canonical Inngest composition ہے:
- یہ Trigger:
TriggerEvent(event="customer/email.received")، email-ingestion webhook event fire کرتا ہے؛ function ہر customer email پر wake ہوتی ہے۔ - یہ Durability:
Runner.run(support_agent, ...)کو singlestep.run("agent-loop", ...)میں wrap کریں۔ Crash mid-loop → whole agent run retry؛ loop کے اندر sub-steps SDK-internal ہیں اور separately durable نہیں۔ - یہ HITL on escalation:
escalate_to_humantoolrefund/approval.requestedfire کرتا ہے اور functionstep.wait_for_eventکے ذریعے 4 hours تک suspend رہتا ہے۔ Waiting کے دوران zero compute consumed۔ Human Slack سے approve کرتا ہے؛ function verdict کے ساتھ resume ہوتی ہے۔ - یہ Concurrency:
concurrency=[Concurrency(limit=10, key="event.data.customer_id"), Concurrency(limit=50)]، فی customer زیادہ سے زیادہ 2-3 concurrent runs (angry customer everyone کو starve نہیں کر سکتا) اور globally 50 (OpenAI rate limit اور Neon connection pool protect ہوتے ہیں)۔
یہ Decision 1 کے لیے simulated track callout۔ Deployment اور eval courses کے بغیر بھی آپ یہ exercise paper پر کر سکتے ہیں: Maya کے task کے لیے five questions walk کریں، pattern choice justify کریں، اور sketch کریں کہ agent کو کون سے tools چاہییں (account lookup، transaction lookup، policy search، refund issuance، escalation)۔ Decision 1 classification discipline سکھاتا ہے؛ deployment specifics اسے deepen کرتے ہیں مگر framework internalize کرنے کے لیے required نہیں۔
یہ Decision 2: Incident response agent
یہ Task۔ On-call agent alerts receive کرتا ہے (monitoring systems، customer reports، یا internal teams سے) اور initial incident response چلاتا ہے: service health check، recent deploys سے correlate، likely root cause identify، applicable ہو تو remediation runbook run، situation novel یا severe ہو تو human on-call کو escalate۔ Agent کو clear incident report produce کرنی ہے۔
آپ کی باری۔ Worked answer پڑھنے سے پہلے اس task پر پانچ questions walk کریں۔ Pattern پر commit کریں، پھر worked answer سے خود کو check کریں۔ یا task اپنے AI میں paste کریں اور اسے کہیں Q1 سے Q5 تک quiz کرے، جہاں reasoning thin ہو وہاں push back کرے۔
پہلے خود walk کریں، پھر worked answer کھولیں۔
یہ Tree walk۔
یہ Q1: کیا solution path advance میں define ہو سکتا ہے؟ Partially۔ Standard structure ہے: "service health check، deploys correlate، cause identify، remediation try، needed ہو تو escalate"۔ مگر specific path actual incident پر depend کرتا ہے۔ Service A میں latency spike شاید "rollback recent deploy" تک لے جائے؛ service B میں 500-error spike "restart pod" تک؛ customer-reported issue user-specific data flow investigation تک۔ Path step level پر unknown مگر stage level پر structured ہے۔
یہ Q2: N/A.
یہ Q3: کیا task structure execution سے پہلے articulable ہے؟ Yes۔ Stages clear ہیں: triage → diagnose → remediate → report۔ ہر incident ان stages سے گزرتا ہے، چاہے ہر stage کے اندر specific work vary کرے۔ Articulable structure۔
یہ Q4: کیا quality speed سے زیادہ اہم ہے؟ Incident response میں speed بہت اہم ہے: ہر minute business کو cost کرتا ہے۔ مگر quality بھی اہم ہے کیونکہ wrong remediation situation worsen کر سکتی ہے۔ Remediation steps execute کرنے سے پہلے reflection justified ہے۔ Quick critique pass جو پوچھے "کیا یہ remediation safe ہے؟ کیا یہ actual symptoms سے match کرتی ہے؟" latency worth ہے۔ Remediation decisions پر reflection add کریں۔
یہ Q5: کیا specialization، context، یا scale bottleneck ہے؟ نہیں۔ Monitoring، deploy history، runbook library، اور remediation tools کے ساتھ ایک agent handle کر سکتا ہے۔ Multi-agent نہ کریں۔
یہ Pattern choice: Planning + ReAct execution، remediation steps پر reflection کے ساتھ۔ Concepts 11 + 12 layered۔
یہ Deployment topology sketch۔ ReAct deployment (Concept 10) plus plan persistence (Concept 11) پر built۔ Specific additions:
- یہ New Neon table:
incidents(incident_id، severity، plan، current_stage، remediation_history) - یہ Plan explicitly store ہوتا ہے اور stages complete ہونے پر update ہوتا ہے
- یہ Remediation پر reflection separate agent کے طور پر run ہوتی ہے (different model recommended، Claude-instance GPT-instance کو critique کرے یا vice versa، blind-spot overlap سے بچنے کے لیے)
- یہ Background worker pattern mandatory ہے (incident runs 5-15 minutes لے سکتے ہیں)
یہ Watch کرنے کے eval signals۔
- یہ Plan-execution divergence (کیا plan actual execution سے match کرتا ہے؟)
- یہ Remediation پر reflection effectiveness (کیا critique نے unsafe remediations catch کیں؟ اگر مہینوں تک نہیں تو reflection rubber-stamping ہو سکتی ہے)
- یہ Time-to-resolution metric (incident response speed سے judge ہوتا ہے؛ regression track اور alert کریں)
- یہ Escalation accuracy (کیا agent نے جہاں چاہیے تھا escalate کیا؟ جہاں remediate کرنا تھا وہاں کیا؟)
یہ Production میں most likely failure mode: planner simple incidents کے لیے overly-detailed plans produce کرے گا، latency add ہو گی۔ Fix: planner کو appropriate plan granularity کی examples پر train کریں: clear incidents کے لیے short plans، ambiguous ones کے لیے longer plans۔ Plan کی value comprehensive ہونے میں نہیں؛ situation کے لیے right-sized ہونے میں ہے۔
عملی envelope۔ Incident response تقریباً ہر Inngest primitive use کرتا ہے: cron، events، fan-out، durability، HITL، replay:
- یہ Triggers: dual triggers، proactive health checks کے لیے
TriggerCron(cron="*/5 * * * *")اور reactive incidents کے لیےTriggerEvent(event="incident/alert.fired")۔ Same function shape دونوں handle کرتی ہے۔ - یہ Durability per stage: ہر planning stage اور ہر remediation step کے لیے ایک
step.run؛ remediation midway fail ہو تو previous stages memoized رہتی ہیں۔ - یہ HITL on remediation: planner output اور execution کے درمیان
step.wait_for_event("await-remediation-approval", timeout=timedelta(minutes=15))human reviewer gate کرتا ہے۔ Tight timeout کیونکہ incidents time-sensitive ہیں۔ - یہ Replay for false-positive bug fixes: remediation script میں bug ہو جو incidents کو particular way میں fail کرے، script fix کریں اور Inngest dashboard سے failed incidents bulk-replay کریں۔ Manual incident re-triage نہیں۔
یہ Decision 2 کے لیے simulated track callout۔ یہ پہلا Decision ہے جو pattern composition introduce کرتا ہے (planning + reflection)۔ Paper پر بھی exercise useful ہے: note کریں کہ reflection add کرنے کا choice صرف Q4 سے نہیں آیا؛ Q4 remediation step پر specifically apply ہوا۔ Reflection rarely all-or-nothing ہوتی ہے؛ اکثر specific high-stakes outputs پر layer ہوتی ہے۔
یہ Decision 3: Market research agent
یہ Task۔ Topic ("competitive landscape in agentic AI middleware") اور research brief (key questions، depth requirements، deadline) given ہو تو agent research report produce کرتا ہے۔ Work میں relevant sources identify کرنا، multiple databases search کرنا، documents read/extract کرنا، sources کے claims compare کرنا، findings draft کرنا، اور final report produce کرنا شامل ہے۔
آپ کی باری۔ Worked answer پڑھنے سے پہلے اس task پر پانچ questions walk کریں۔ Pattern پر commit کریں، پھر worked answer سے خود کو check کریں۔ یا task اپنے AI میں paste کریں اور اسے Q1 سے Q5 تک quiz کرنے دیں، جہاں reasoning thin ہو وہاں push back کرے۔
پہلے خود walk کریں، پھر worked answer کھولیں۔
یہ Tree walk۔
یہ Q1: کیا solution path advance میں define ہو سکتا ہے؟ نہیں۔ کون سے sources consult کرنے ہیں، کون سے competitors investigate کرنے ہیں، کون سے analyses run کرنے ہیں، یہ سب discovery کے دوران معلوم ہوتا ہے۔ Unknown path۔
یہ Q2: N/A.
یہ Q3: کیا task structure execution سے پہلے articulable ہے؟ Yes۔ Standard research-report shape: gather data → analyze → synthesize → draft → review۔ Specific sources اور analyses unknown ہیں، مگر major phases clear ہیں۔ Articulable structure۔
یہ Q4: کیا quality speed سے زیادہ اہم ہے؟ Yes، strongly۔ Research reports decision-makers پڑھتے ہیں؛ factual errors اور weak analysis کے real consequences ہیں۔ Quality criteria partially checkable ہیں: "all claims are sourced"، "competitor analysis covers each major player"، "synthesis answers the brief's questions"۔ Reflection justified ہے، especially synthesis اور final draft پر۔
یہ Q5: کیا specialization، context، یا scale bottleneck ہے؟ Context کے لیے likely yes۔ Deep research large source material load کرتی ہے؛ اسے one agent کے context window میں ڈالنا reasoning degradation risk کرتا ہے۔ Research-and-summarize-per-source agents میں split کر کے focused briefs produce کرنا، پھر briefs compose کرنا، right pattern ہے۔ Context-management reasons سے multi-agent۔
یہ Pattern choice: Multi-agent specialist system، top layer پر planning، research specialists کے اندر ReAct، اور final synthesis پر reflection۔ Concepts 11، 13، اور 12 کی composition۔
یہ Deployment topology sketch۔ Full cloud stack plus multi-agent additions (Concept 13):
- یہ Neon میں parent-run + per-specialist run structure (
parent_run_id،agent_role) - کون سا specialist کون سا source لے گیا، اس کے routing audit logs
- یہ Per-specialist cost tracking (research agents 50-page PDFs پڑھ کر tokens تیزی سے burn کر سکتے ہیں)
- یہ Bridge Worker specialists میں shared document-reading tools handle کرتا ہے
- یہ Aggregator agent shared Neon table سے reads کرتا ہے جہاں specialists اپنی summaries deposit کرتے ہیں
یہ Watch کرنے کے eval signals۔
- یہ Three separate scoreboards: per-specialist research quality، routing accuracy (کیا right specialist کو right source ملا؟)، integration quality (کیا final report specialists کی findings اچھی synthesize کرتی ہے؟)
- یہ Top-level plan پر plan-execution divergence
- یہ Final synthesis پر reflection effectiveness
- یہ Cost-per-correct-output (multi-agent + reflection expensive ہے؛ track اور justify کریں)
یہ Production میں most likely failure mode: specialists excellent individual briefs produce کرتے ہیں مگر aggregator انہیں cleanly synthesize نہیں کر پاتا کیونکہ briefs inconsistent formats یا terminology use کرتے ہیں۔ Fix: structured handoff formats enforce کریں (brief structure کے لیے Pydantic schemas)، تاکہ aggregator uniformly-shaped inputs receive کرے۔
عملی envelope۔ Market research اس course کا premier fan-out example ہے، وہ pattern جس کے لیے Inngest کے flow-control primitives designed ہیں:
- یہ Fan-out trigger pattern: coordinator function ہر competitor کے لیے ایک
research/competitor.researchevent fire کرتا ہے؛ ہر event independent function run fire کرتا ہے۔ N competitors → N parallel function runs، سب separately tracked، سب independently durable۔ - یہ Per-tenant concurrency cap: competitor-research function پر
concurrency=[Concurrency(limit=5, key="event.data.tenant_id")]، ایک tenant کی "research 50 competitors" request system monopolize نہیں کرتی۔ - یہ Durability per specialist: ہر competitor-research run اپنی
step.runcalls رکھتا ہے (web search، document fetch، brief generation)؛ mid-research crash صرف failing step retry کرتا ہے، پوری research run نہیں۔ - یہ Aggregation as a separate function: جب تمام specialist runs complete ہوں (Inngest "all done" events emit کرتا ہے)،
research/landscape.synthesizeسے triggered synthesizer function briefs read کر کے final report compose کرتی ہے۔ Events کے ذریعے decoupled؛ shared state نہیں۔ - یہ Cost-per-specialist visibility: Inngest کا per-function dashboard token spend per competitor دکھاتا ہے؛ outliers (competitor X others سے 5× زیادہ cost کرے) فوراً visible ہیں۔
یہ Decision 3 کے لیے simulated track callout۔ یہ Decision pattern composition دکھاتا ہے: multi-agent دوسرے patterns کا replacement نہیں، composition ہے۔ Planning agent planning use کرتا ہے؛ research specialists ReAct use کرتے ہیں؛ synthesis agent reflection use کرتا ہے۔ Multi-agent topology ہے؛ topology کے اندر patterns وہی پانچ patterns ہیں۔
یہ Decision 4: Enterprise onboarding agent
یہ Task۔ New enterprise customer sign up کرے تو agent onboarding workflow چلاتا ہے: tenant provision کرنا (accounts، databases، configuration create)، seed data populate، administrators invite، kickoff meetings schedule، welcome materials send۔ Work میں multiple deterministic provisioning steps اور چند personalized communications شامل ہیں۔
آپ کی باری۔ Worked answer پڑھنے سے پہلے اس task پر پانچ questions walk کریں۔ Pattern پر commit کریں، پھر worked answer سے خود کو check کریں۔ یا task اپنے AI میں paste کریں اور اسے Q1 سے Q5 تک quiz کرنے دیں، جہاں reasoning thin ہو وہاں push back کرے۔
پہلے خود walk کریں، پھر worked answer کھولیں۔
یہ Tree walk۔
یہ Q1: کیا solution path advance میں define ہو سکتا ہے؟ Yes۔ Onboarding کا fixed sequence ہے: provision → configure → seed → invite → schedule → send-welcome۔ ہر onboarding اسی order میں ان steps سے گزرتی ہے۔ کچھ steps کا content personalized ہے (welcome message customer کے name اور industry کو reference کرتا ہے) مگر step sequence invariant ہے۔ Known path۔
یہ Q2: کیا workflow fixed اور stable across runs ہے؟ Yes۔ ہر enterprise customer same onboarding workflow follow کرتا ہے۔ Stable۔
یہ Q3، Q4، Q5: N/A یا no۔ Decision tree Q2 پر terminate ہو جاتا ہے کیونکہ workflow fixed ہے۔
یہ Pattern choice: Sequential workflow۔ Concept 9۔
یہ Deployment topology sketch۔ Minimal cloud stack:
- یہ ACA پر FastAPI
- یہ Onboarding state کے لیے Neon (کون سے customers کس step میں ہیں)
- یہ Documents کے لیے R2 (welcome PDFs، onboarding guides)
- یہ Personalization steps میں embedded LLM calls (welcome message generation، customer request کرے تو account-name suggestions)
- یہ Sandbox needed نہیں۔ Bridge Worker نہیں۔ Long-running agentic reasoning کے لیے background-worker pattern needed نہیں (اگرچہ workflow itself scale کے لیے background job ہو سکتی ہے)۔
یہ deployment باقی deployments سے meaningfully cheaper ہے، کیونکہ task کو cloud deployment کی زیادہ complexity نہیں چاہیے۔
یہ Watch کرنے کے eval signals۔
- یہ Step-level correctness (ہر provisioning step succeed ہوا؛ extraction نے valid schemas return کیے)
- یہ Workflow completion rate (onboardings کا کتنا fraction successfully complete ہوتا ہے؟)
- یہ Personalization quality (LLM-generated welcome messages؛ Phoenix tone اور factual accuracy grade کر سکتا ہے)
- یہ Failure mode: workflow steps wrong inputs پر apply ہو گئے (validation gaps)
یہ Production میں most likely failure mode: edge-case enterprise (unusual industry، special compliance requirements) standard workflow میں fit نہیں ہوتا۔ Fix: یا edge case کے لیے explicit branching add کریں (اگر edge cases few ہیں)، یا recognize کریں کہ workflow variable ہو رہا ہے اور ReAct + tools پر upgrade consider کریں (اگر edge cases proliferate ہوں)۔ اس transition کو time کے ساتھ watch کریں: workflows اکثر stable start ہوتے ہیں اور gradually adaptive بن جاتے ہیں۔
عملی envelope۔ Enterprise onboarding اس course کا cleanest Inngest sequential workflow example ہے: ہر step ایک step.run ہے، agentic complexity نہیں:
- یہ Trigger:
TriggerEvent(event="customer/enterprise.signed_up")، CRM میں deal close ہونے پر fire۔ - یہ One step.run per onboarding step:
step.run("provision-tenant", ...)،step.run("configure-defaults", ...)،step.run("seed-data", ...)،step.run("invite-admins", ...)،step.run("schedule-kickoff", ...)،step.run("send-welcome", ...)۔ ہر step durable ہے؛ step 4 پر crash → steps 1-3 memoized ہیں۔ - یہ No HITL needed: onboarding fully automated ہے؛ standard path میں
step.wait_for_eventcalls نہیں۔ - یہ
step.sleepfor delayed actions:step.sleep("wait-2-days-before-followup", timedelta(days=2))follow-up schedule کرتا ہے جو onboarding complete ہونے کے بعد fire ہوتا ہے، wait کے دوران zero compute consumed۔ - یہ Cron pairing: separate cron-triggered function (
TriggerCron("0 9 * * *")) روز customer database sweep کرتی ہے ان onboardings کے لیے جو stalled ہیں (step fail ہوا اور retries ختم ہو گئیں)؛ cron function stuck cases کے لیے recovery events fire کرتی ہے۔
یہ deployment دوسروں سے substantially cheaper ہے، اور Inngest cost discipline visible کرتا ہے: function dashboard step-by-step success rates اور step-by-step costs دکھاتا ہے، تاکہ آپ exact onboarding bottleneck دیکھ سکیں۔
یہ Decision 4 کے لیے simulated track callout۔ یہ Decision اہم ہے کیونکہ یہ agentic patterns کا negative example ہے۔ Task کو agentic reasoning نہیں چاہیے۔ Embedded LLM calls والا workflow cheaper، more reliable، اور easier to debug ہے۔ Workflow کام کرے تو ReAct تک نہ جائیں۔ Decision tree کی سب سے اہم discipline یہی ہے۔
یہ Decision 5: Coding agent (advanced track)
یہ Task۔ Coding agent feature request receive کرتا ہے اور working implementation produce کرتا ہے: existing codebase read، change design، code write، tests write، tests run، failures fix، اور human review کے لیے ready PR produce۔ Codebase large ہے، changes complex ہو سکتے ہیں، اور correctness matter کرتی ہے۔
آپ کی باری۔ Worked answer پڑھنے سے پہلے اس task پر پانچ questions walk کریں۔ Pattern پر commit کریں، پھر worked answer سے خود کو check کریں۔ یا task اپنے AI میں paste کریں اور اسے Q1 سے Q5 تک quiz کرنے دیں، جہاں reasoning thin ہو وہاں push back کرے۔
پہلے خود walk کریں، پھر worked answer کھولیں۔
یہ Tree walk۔
یہ Q1: کیا solution path advance میں define ہو سکتا ہے؟ نہیں۔ Coding work continuous discovery involve کرتا ہے: codebase میں کیا موجود ہے، existing code کیسے structured ہے، tests کون سے edge cases reveal کرتے ہیں۔ Unknown path۔
یہ Q2: N/A.
یہ Q3: کیا task structure execution سے پہلے articulable ہے؟ Partially۔ Clear high-level shape ہے: requirement سمجھنا → codebase سمجھنا → change design کرنا → implement → test → fix → PR produce۔ مگر complex changes میں design phase iterate کر سکتی ہے (design → constraint discover → design revise → constraint rediscover)۔ Articulable مگر internal adaptation needs کے ساتھ۔
یہ Q4: کیا quality speed سے زیادہ اہم ہے؟ Yes، بہت۔ Production میں ship ہونے والا code real consequences رکھتا ہے۔ Quality criteria checkable ہیں: tests pass/fail، type checks pass/fail، linter pass/fail، code review specific issues identify کرتا ہے۔ Reflection highly justified ہے۔
یہ Q5: کیا specialization، context، یا scale bottleneck ہے؟ Genuinely yes، specialization اور context دونوں کے لیے۔ Coding میں کم از کم تین distinct skill sets ہیں: code generation (اچھا code لکھنا)، security review (vulnerabilities catch کرنا)، documentation (change explain کرنا)۔ ہر ایک focused agent سے benefit کرتا ہے۔ Multi-agent justified ہے۔
یہ Pattern choice: Multi-agent specialist system، top پر planning، specialists کے اندر ReAct + tools، اور code outputs پر explicit reflection۔ باقی چار patterns کی composition۔
یہ Deployment topology sketch۔ Full cloud stack plus multi-agent extensions:
- یہ Coordinator agent: feature request receive کرتا ہے، stages کے ساتھ plan produce کرتا ہے (design → code → review → document)
- یہ Coder specialist: ReAct + tools (codebase read، files write، tests run)۔ Heavy sandbox use (tests run کرنا، code execute کرنا)۔ Bridge Worker mandatory۔
- یہ Reviewer specialist: ReAct + tools (coder output read، security checks run، linters run)۔ Lighter sandbox use۔
- یہ Documentation specialist: simpler، possibly sequential (changes extract → docs generate)۔
- یہ Coder کی final PR پر reflection layer (کیا all tests pass ہیں؟ کیا requirement match ہے؟)
- یہ Neon میں per-specialist runs؛ routing audit logs؛ per specialist cost tracking (coder costs dominate کرے گا)
یہ Watch کرنے کے eval signals۔ Multi-agent کے تینوں scoreboards، plus reflection metrics۔ Particular focus:
- یہ Code-correctness eval (کیا generated code tests pass کرتا ہے؟)
- یہ Security-review effectiveness (کیا reviewer vulnerabilities catch کرتا ہے؟ false-positive rate بھی matter کرتی ہے)
- یہ Plan-execution divergence (coordinator کا plan vs. actually shipped work)
- یہ Cost-per-PR (یہ expensive pattern ہے؛ ensure کریں کہ cost earn ہو رہی ہے)
یہ Production میں most likely failure mode: reviewer specialist bottleneck بن جاتا ہے، یا too strict (valid code minor style issues پر reject) یا too permissive (real bugs والا code pass)۔ Fix: reviewer decisions کے لیے explicit criteria، اور separate eval جو same code پر reviewer judgments کو human reviewer judgments کے خلاف grade کرے۔
عملی envelope۔ Coding agent ہر Inngest primitive use کرتا ہے؛ یہی pattern full operational envelope justify کرتا ہے:
- یہ Triggers:
TriggerEvent(event="github/issue.assigned_to_agent")، issue assign ہونے پر fire؛ یا Slack میں chat command event fire کرے۔ - یہ Fan-out coordination: coordinator function feature کو stages میں decompose کرتی ہے، پھر specialist functions کو events fire کرتی ہے (
coding/specialist.code،coding/specialist.review،coding/specialist.docs)۔ ہر specialist اپنی function ہے، اپنی concurrency اور durability کے ساتھ۔ - یہ
step.runper file edit: coder specialist ہر file modification کوstep.run("edit-{path}", ...)میں wrap کرتا ہے تاکہ multi-file edit کے دوران crash completed edits lose نہ کرے۔ Memoization یہاں especially valuable ہے؛ partial completion کے بعد LLM-generated code change دوبارہ run کرنا expensive ہے اور original plan سے divergence risk کرتا ہے۔ - یہ
step.wait_for_eventon PR merge: agent PR produce کرنے کے بعد functionstep.wait_for_event("await-human-merge-approval", timeout=timedelta(days=2))سے suspend ہوتی ہے۔ Human GitHub پر review/approve کرتا ہے؛ function post-merge cleanup کے لیے resume ہوتی ہے۔ - یہ Per-tenant concurrency: coder specialist پر
concurrency=[Concurrency(limit=2, key="event.data.tenant_id")]ایک tenant کو coding capacity monopolize کرنے سے روکتا ہے۔ Coding expensive ہے؛ per-tenant caps critical ہیں۔ - یہ Priority for tier-based fairness: Enterprise tenants کی coding tasks Free-tier سے queue میں آگے jump کرتی ہیں (
priority=Priority(run="100 - (event.data.tier_priority * 100)"))۔ - یہ Replay for partial failure: reviewer specialist fixable reason سے code reject کرے تو coder fix کرتا ہے اور review event دوبارہ fire کرتا ہے؛ function dashboard per PR iteration history دکھاتا ہے۔
- یہ
step.sleepfor safety windows: merge کے بعدstep.sleep("await-tests-stable", timedelta(hours=2))، CI runs کے 2 hours wait کریں تاکہ downstream tests break نہ ہوں before agent work complete mark کرے۔
یہ Decision 5 کے لیے simulated track callout۔ یہ hardest Decision ہے کیونکہ task genuinely ہر pattern کو compose کرنے کی ضرورت رکھتا ہے۔ Exercise یہ یاد رکھنا نہیں کہ کون سے patterns apply کرتے ہیں؛ اصل بات یہ دیکھنا ہے کہ decision tree systematically identify کیسے کرتا ہے کہ کون سے patterns compose کرنے ہیں اور کہاں۔ Coding agent "advanced" اس لیے نہیں کہ complex ہے؛ advanced اس لیے ہے کہ pattern composition کی discipline practice مانگتی ہے۔
یہ Part 6: Honest frontiers
یہ Concept 17: Cost اور latency architectural constraints ہیں، afterthoughts نہیں
اب تک course نے pattern selection کو اس طرح treat کیا جیسے cost اور latency secondary ہوں۔ Production میں وہ اکثر primary ہوتے ہیں۔ Concept 17 ہر pattern کا cost اور latency profile explicitly name کرتا ہے، تاکہ decision tree budget constraints سامنے رکھ کر walk ہو سکے۔
ہر pattern کا cost profile (rough orders of magnitude، GPT-5-class pricing assume کرتے ہوئے):
| Pattern | Cost per task | Cost driver |
|---|---|---|
| Sequential workflow | 1× (baseline) | LLM calls کی تعداد (اکثر 1-3 per workflow) |
| Single agent + ReAct | 3-10× | ReAct iterations کی تعداد (model ہر loop پر ایک بار call) |
| Planning + ReAct execution | 5-15× | Planning call + per-stage ReAct loops |
| Single agent + reflection | underlying pattern کا 2-3× | Critique + refinement passes |
| Multi-agent specialist | 5-20× | Specialist runs + coordinator + integration کی تعداد |
یہ Numbers illustrative ہیں، precise نہیں۔ اہم ratios ہیں: same task volume کے لیے reflection کے ساتھ multi-agent system sequential workflow سے 30-60× زیادہ cost کر سکتا ہے۔ جب multiplier quality سے justified ہو تو fine۔ جب aesthetics سے justified ہو تو budget catastrophe waiting to happen۔
ہر pattern کا latency profile:
| Pattern | Latency | Driver |
|---|---|---|
| Sequential workflow | Lowest (~1-5s) | Deterministic steps + LLM calls in sequence |
| Single agent + ReAct | Medium (~10-30s) | Loop پر one model call؛ loops stretch ہو سکتے ہیں |
| Planning + ReAct | Medium-high (~30-90s) | Planning call + sequential stage execution |
| Single agent + reflection | underlying pattern کا 2-3× | Critique + refinement multiplicative latency add کرتے ہیں |
| Multi-agent specialist | Variable | Parallel execution help کرتی ہے؛ coordination overhead add کرتا ہے |
یہ Decision tree کے ساتھ integration۔ Q4 (quality vs. speed) implicitly latency address کرتا ہے۔ Q5 (specialization/scale) implicitly cost address کرتا ہے۔ مگر decision tree explicitly یہ نہیں کہتا کہ "answer tree کے suggest کردہ pattern سے ایک less elaborate pattern ہے، کیونکہ latency budget hard ہے"۔ یہ tree کے اوپر constraint-layer decision ہے۔
یہ Practical discipline: decision tree walk کرنے سے پہلے latency اور cost budgets لکھیں۔ اگر tree کا chosen pattern کسی budget کو violate کرے تو تین options ہیں:
- یہ Constraints change کریں۔ More budget لیں، latency tolerance raise کریں، یا slower delivery accept کریں۔
- یہ Scope change کریں۔ System کو جو کرنا ہے اسے reduce کریں، تاکہ less elaborate pattern handle کر سکے۔
- یہ Worse fit accept کریں۔ Less elaborate pattern use کریں اور accept کریں کہ کچھ failure modes آئیں گے جنہیں more elaborate pattern catch کر لیتا۔
آپ نے کون سا option choose کیا اور کیوں، document کریں۔ جب system وہ failure modes دکھائے گا جنہیں elaborate pattern prevent کر سکتا تھا، تو آپ کو یاد رکھنا ہو گا کہ کون سا trade-off کیا تھا۔
یہ Concept 17 کا خلاصہ: cost اور latency architectural constraints ہیں، afterthoughts نہیں۔ ہر pattern کا characteristic cost اور latency profile ہے، اور patterns compose ہوں تو multipliers compound ہوتے ہیں۔ Same task volume کے لیے reflection کے ساتھ multi-agent sequential workflow سے 30-60× cost کر سکتا ہے (illustrative ratio)۔ Decision tree Q4 اور Q5 کے ذریعے انہیں implicitly address کرتا ہے، مگر explicit budget constraints کبھی tree کا answer override کرتے ہیں؛ override document کریں اور resulting failure modes consciously accept کریں۔
یہ Concept 18: Pattern composition، different layers پر multiple patterns
یہ Course نے زیادہ تر patterns کو اس طرح treat کیا جیسے ایک pick کرنا ہے۔ Real systems often different layers پر patterns compose کرتے ہیں: top پر planning agent، ہر plan stage کے اندر ReAct + tools، final output پر reflection۔ Decisions 3 اور 5 already یہ دکھا چکے ہیں؛ Concept 18 اسے first-class architectural move کے طور پر name کرتا ہے۔
یہ Recognize کرنے کے قابل تین composition shapes:
یہ Hierarchical composition۔ Higher-level pattern lower-level patterns کو wrap کرتا ہے۔ Examples:
- یہ Planning agent (top) + ReAct + tools (ہر stage کے اندر)
- یہ Multi-agent coordinator (top) + sequential workflows (specialists کے اندر)
- یہ ReAct (top) + sequential workflow (tool کے طور پر جسے ReAct agent deterministic work کے لیے call کرتا ہے)
یہ Sequential composition۔ Patterns one after another run ہوتے ہیں، first کا output second کو feed کرتا ہے۔ Examples:
- یہ Sequential workflow (structured data extract) → ReAct agent (structured data investigate)
- یہ ReAct agent (output generate) → reflection layer (critique اور refine)
یہ Conditional composition۔ Different cases different patterns handle کرتے ہیں، router pattern select کرتا ہے۔ Examples:
- یہ Known-shape requests کو sequential workflow پر route کریں؛ unknown-shape requests کو ReAct پر
- یہ High-stakes outputs پر reflection apply کریں؛ low-stakes outputs پر skip
یہ Composition کا pragmatic rule: ہر layer کا pattern choice اسی five questions سے justify ہونا چاہیے، مگر اس layer کے scope پر applied۔ Top-level pattern overall task پر tree walk کر کے choose ہوتا ہے۔ ہر sub-component کا pattern اس sub-component کے کام پر tree walk کر کے choose ہوتا ہے۔ Composition اس لیے نہ کریں کہ sophisticated لگتی ہے؛ اس لیے کریں کہ ہر layer کی task properties demand کرتی ہیں۔
یہ Most common composition mistake: layers add کرنا کیونکہ layers اچھی engineering لگتی ہیں۔ Coding agent جو multi-agent + planning + ہر output پر reflection + everything کے گرد circuit breaker pattern رکھتا ہے، rigorous لگتا ہے؛ اکثر unnecessary ہوتا ہے۔ Composition test کریں: topmost layer remove کریں۔ Outputs degrade نہ ہوں تو layer اپنی cost earn نہیں کر رہی تھی۔
یہ Concept 18 کا خلاصہ: real systems different layers پر patterns compose کرتے ہیں: hierarchical (ایک pattern دوسرے کو wrap کرے)، sequential (ایک کا output دوسرے کو feed کرے)، conditional (different cases کے لیے different patterns)۔ ہر layer کا pattern choice اسی layer کے scope پر decision tree walk کر کے justify ہونا چاہیے۔ Common mistake layered architectures کو sophisticated سمجھ کر layers add کرنا ہے؛ topmost layer remove کر کے quality degradation check کریں۔
یہ Part 7: Closing
یہ Concept 19: Agent Factory curriculum میں pattern selection connective tissue ہے
یہ course اس چیز کے درمیان bridge ہے کہ agent کیا ہے (agent-building course: agent loops and tools) اور اسے ship کرنے کے لیے کیا چاہیے (production deployment پر cloud deployment course، operational evaluation پر eval-driven course)۔
یہ Pattern selection کے بغیر connective tissue missing ہے۔ آپ agent build بھی کر سکتے ہیں اور deploy بھی، مگر درمیان کا design decision، یعنی اس task کے لیے کس قسم کا agent، unprincipled رہتا ہے۔ یہ course اسی gap کو fill کرتا ہے۔
یہ Five questions simple لگتے ہیں۔ کیا path known ہے؟ کیا workflow stable ہے؟ کیا structure articulable ہے؟ کیا quality speed سے outweigh کرتی ہے؟ کیا specialization bottleneck ہے؟ مگر یہی وہ architectural distinctions encode کرتے ہیں جن پر field نے پانچ سال کام کیا ہے۔ Pattern catalogs (ReAct، planning، reflection، multi-agent) موجود ہیں؛ missing چیز ان کے درمیان choose کرنے کی decision logic تھی۔ Bala Priya C کا article یہ gap fill کرتا ہے؛ یہ course اسے deployment اور evaluation composition کے ساتھ extend کرتا ہے جو Agent Factory students کو چاہیے۔
یہ Deployment composition اس course کی وہ contribution ہے جو اسے الگ بناتی ہے۔ Agentic patterns پر few courses سکھاتے ہیں کہ ہر pattern cloud stack کے لیے کیا مطلب رکھتا ہے:
- یہ Sequential workflows sandbox layer entirely skip کرتے ہیں
- یہ Single-agent ReAct full stack use کرتا ہے
- یہ Planning + ReAct plan persistence اور longer background workers add کرتا ہے
- یہ Reflection اکثر multi-provider model routing introduce کرتی ہے
- یہ Multi-agent per-specialist tracing، routing audit logs، اور per-role cost attribution demand کرتا ہے
یہ abstract concerns نہیں۔ یہی difference ہے ایک deployment میں جو small workload کے لیے $130/month cost کرے اور دوسری میں جو same workload کے لیے $400/month cost کرے کیونکہ pattern over-elaborate تھا۔ Pattern selection cost discipline بھی ہے اور architecture discipline بھی۔
یہ Evaluation composition دوسری contribution ہے۔ ہر pattern کے characteristic failure modes ہیں جنہیں آپ کی eval suite differently catch کرتی ہے:
- یہ Sequential workflows: DeepEval سے step-level correctness
- یہ ReAct: Phoenix سے reasoning traces
- یہ Planning + ReAct: custom metric کے طور پر plan-execution divergence
- یہ Reflection: pre/post comparison اور rubber-stamp detection
- یہ Multi-agent: specialist quality، routing، integration کے لیے تین الگ scoreboards
یہ Pattern-aware evaluation کے بغیر eval suite generic رہتی ہے اور ہر pattern کی specific failures miss کرتی ہے۔ یہ course pattern by pattern بتاتا ہے کہ کیا دیکھنا ہے، تاکہ eval suite pattern-aware بن جائے۔
یہ Agent Factory track کا closing thesis sentence اب تھوڑا different read ہوتا ہے۔ Agent-building course نے start کیا تھا کہ agent loop AI-native company کا engine ہے۔ Cloud deployment course نے close کیا تھا کہ production scale پر right architectural separation کے ساتھ deployed، right surfaces پر observed، اور living eval suite کے خلاف continuously graded agent loop ہی AI-native company actually run کرتی ہے۔ یہ course missing prefix add کرتا ہے: task کے لیے right agent loop ہی وہ چیز ہے جس پر AI-native company run کرتی ہے۔ Wrong shape pick کرنا، overshoot یا undershoot، ایسے systems produce کرتا ہے جو slow ship ہوتے ہیں، زیادہ cost کرتے ہیں، اور زیادہ failure modes میں break ہوتے ہیں۔ Pattern selection first design decision ہے؛ باقی سب اس کے downstream ہے۔
اس course کے بعد کیا آتا ہے۔ Cloud deployment course کی closing نے تین frontiers name کیے تھے: agent-to-agent commerce، identic-AI deployment specifics، multi-region active-active۔ وہ future courses کے طور پر برقرار ہیں۔ یہ course ایک اور frontier add کرتا ہے: pattern-specific testing harnesses۔ Eval suite generic ہے؛ future course pattern-specific test generators build کر سکتا ہے ("sequential workflow tester" جو workflow branches cover کرنے والے inputs generate کرے؛ "multi-agent routing tester" جو coordinator routing logic probe کرنے والے inputs generate کرے)۔ یہ real frontier ہے، اور prerequisite کے طور پر اس course کی pattern taxonomy پر depend کرتا ہے۔
یہ AI کے ساتھ آخری exercise آزمائیں۔ Claude Code یا OpenCode session کھولیں۔ Paste کریں:
"میں نے ابھی agentic pattern selection کا course complete کیا ہے۔ کوئی real task pick کریں جس کے لیے میں next quarter agent build کرنا چاہوں، میرے actual job سے، toy example نہیں۔ اس پر میرے ساتھ five-question decision tree walk کریں، ہر question پر مجھ سے answer مانگیں اور اگر reasoning weak ہو تو push back کریں۔ پھر بتائیں کہ آپ کون سا pattern recommend کریں گے، مجھے کون سی cloud deployment topology چاہیے ہو گی، اور کون سے eval signals watch کرنے چاہییں۔ Task properties کے بارے میں specific رہیں، generic نہیں۔"
آپ کیا سیکھ رہے ہیں۔ Decision tree صرف textbook examples پر نہیں، آپ کے tasks پر apply ہو تو stick کرتا ہے۔ یہ exercise discipline کو ایسے concrete decision میں force کرتی ہے جو آپ واقعی کریں گے۔ AI کا response save کریں؛ agent build شروع کرتے وقت revisit کریں۔
خلاصہ: یہ course agent design (agent loops and tools) اور agent deployment (cloud deployment اور eval courses) کے درمیان connective tissue ہے۔ Five-question decision tree وہ architectural distinctions encode کرتا ہے جن پر literature نے years work کیا؛ composition layer ہر pattern کو specific deployment اور evaluation discipline سے map کرتی ہے۔ Closing thesis: task کے لیے right agent loop ہی AI-native company run کرتی ہے، اور pattern selection first design decision ہے جس کے downstream ہر چیز flow کرتی ہے۔ اس course کا actionable artifact final section before References میں one-page design-review template ہے: printable، team-shareable، اور ہر architecture proposal کے لیے تقریباً 15-20 minutes میں same five questions walk کرواتا ہے۔
یہ Cheat sheet: تمام 22 Concepts اور 5 Decisions، Part کے حساب سے grouped
دونوں friend reviews نے cheat sheet کو dense کہا؛ نیچے grouping ہر row کو اس Part سے map کرتی ہے جس سے وہ belong کرتی ہے، تاکہ آپ 22 rows scroll کرنے کے بجائے section کے حساب سے navigate کر سکیں۔
یہ Part 1: Pattern-selection problem
| # | Concept | Key takeaway |
|---|---|---|
| 1 | Pattern selection build سے پہلے design work ہے | Patterns well-documented ہیں؛ ان کے درمیان choose کرنے کی decision logic نہیں۔ Wrong choice production میں expensive compound ہوتی ہے۔ |
| 2 | ہر pattern task کے بارے میں ایک bet ہے | Sequential workflow known paths پر bet؛ ReAct unknown paths پر؛ planning articulable structure پر؛ reflection checkable criteria پر؛ multi-agent real specialization needs پر۔ |
| 3 | دو failure modes: overshoot اور undershoot | Overshoot (needed سے زیادہ elaborate) famous mode ہے؛ undershoot (needed سے زیادہ simple) equally common اور subtler ہے۔ |
یہ Part 2: Five-question decision tree
| # | Concept | Key takeaway |
|---|---|---|
| 4 | Q1: کیا solution path advance میں define ہو سکتا ہے؟ | Known paths workflows کو route ہوتے ہیں؛ unknown paths agentic reasoning کو۔ "LLM calls کے بغیر Python function" heuristic سے test کریں۔ |
| 5 | Q2: کیا workflow fixed اور stable ہے؟ | Stable paths sequential workflow کو route ہوتے ہیں؛ known-but-variable routes یا branched workflow کو یا agentic patterns کو۔ |
| 6 | Q3: کیا task structure articulable ہے؟ | Articulable → planning + ReAct execution؛ not articulable → pure ReAct۔ Shape-vs-content distinction۔ Q2/Q3 disambiguation sidebar boundary cases walk کرتا ہے۔ |
| 7 | Q4: Quality > speed AND criteria checkable؟ | Reflection value add کرنے کے لیے دونوں conditions hold کریں۔ Common failures: rubber-stamping، vague criteria، latency budget violations۔ |
| 8 | Q5: Specialization، context، یا scale bottleneck؟ | تین claims separately test کریں، جہاں possible ہو quantitative triggers کے against: >30% tool-routing errors (specialization)، higher context پر >10% accuracy drop (overflow)، >2× latency budget overrun (scale)۔ |
یہ Bridge concepts: pattern selection سے implementation تک
| # | Concept | Key takeaway |
|---|---|---|
| 8.5 | SDK primitives: ہر pattern کیا use کرتا ہے | Agent atomic unit ہے۔ Runner.run() loop run کرتا ہے۔ @function_tool tools expose کرتا ہے۔ Specialist takeover کے لیے handoff()؛ coordinator-in-charge کے لیے as_tool()۔ Reflection کے لیے output_guardrail۔ Pattern selection primitives compose کرنے کا choice ہے۔ |
| 8.6 | Operational envelope per pattern (concrete example کے طور پر Inngest) | Triggers function wake کرتے ہیں (TriggerEvent، TriggerCron)؛ step.run durability دیتا ہے؛ step.wait_for_event HITL gates implement کرتا ہے؛ concurrency/throttle/priority load shape کرتے ہیں؛ fan-out multi-agent specialists coordinate کرتا ہے؛ replay bug-fix recovery handle کرتا ہے۔ Pattern جتنا elaborate ہو، envelope اتنا critical۔ |
یہ Part 3: Five patterns in depth
| # | Concept | Key takeaway |
|---|---|---|
| 9 | Sequential workflow، pattern، deployment، evals، envelope | Cloud stack کا smallest subset use کرتا ہے (sandbox needed نہیں)۔ Step-level evals، agent-reasoning evals نہیں۔ Inngest functions سے سب سے direct map۔ |
| 10 | Single agent + ReAct، pattern، deployment، evals، envelope | Bridge Worker سمیت full cloud stack۔ Phoenix trace evals load-bearing ہیں۔ Whole agent loop کے لیے ایک step.run۔ |
| 11 | Planning + ReAct execution، pattern، deployment، evals، envelope | Plan persistence add؛ longer background workers۔ Plan-execution divergence key eval signal۔ ہر stage کے لیے ایک step.run۔ |
| 12 | Single agent + reflection (additive layer)، pattern، deployment، evals، envelope | کسی بھی core pattern کے اوپر layer۔ اکثر multi-provider model routing introduce کرتی ہے۔ Rubber-stamping سب سے insidious failure۔ SDK output_guardrail یا separate generator/critic۔ |
| 13 | Multi-agent specialist system، pattern، deployment، evals، envelope | Full stack plus per-specialist tracing۔ تین الگ scoreboards required۔ ہر Inngest primitive use کرتا ہے (fan-out، per-tenant concurrency، priority، HITL)۔ Coordination overhead real ہے۔ |
یہ Part 4: Failure signals and revision
| # | Concept | Key takeaway |
|---|---|---|
| 14 | Five failure signals | ReAct loops (missing structure)، plan-execution divergence (overstructured)، reflection no-improve (vague criteria)، multi-agent routing fail (overpartitioned)، complex-but-not-better (cumulative overshoot)۔ |
| 15 | پہلے smallest scope پر fixes | Prompt-level fixes (stop conditions، criteria specs) before contract-level (tool descriptions، handoff structures) before architectural changes۔ |
| 16 | جب decision tree غلط ہو | Task properties post-deploy change ہوں، different sub-tasks different patterns مانگیں، constraints tree کا answer exclude کریں۔ Tree دوبارہ walk کریں۔ |
| 16.5 | Anti-pattern gallery، common wrong choices | Five overshoot anti-patterns + three undershoot۔ Content کے لیے multi-agent (→ single agent)؛ invoice کے لیے ReAct (→ workflow)؛ debugging کے لیے planner (→ ReAct)؛ vague criteria پر reflection (→ remove)؛ one giant agent (→ multi-agent)؛ checkable output پر reflection skip (→ add)۔ |
یہ Part 5: Decision lab (پانچ Decisions، separate table below)
یہ Part 6: Honest frontiers
| # | Concept | Key takeaway |
|---|---|---|
| 17 | Cost اور latency architectural constraints | Multi-agent + reflection sequential workflow سے 30-60× cost کر سکتا ہے (illustrative ratio)۔ Constraint-driven pattern choices explicitly document کریں۔ |
| 18 | Different layers پر pattern composition | Hierarchical، sequential، conditional۔ ہر layer کا pattern choice اسی scope پر same five questions سے justified۔ |
یہ Part 7: Closing
| # | Concept | Key takeaway |
|---|---|---|
| 19 | Pattern selection connective tissue ہے | Agent design (agent loops and tools) اور deployment (cloud deployment course) کے درمیان bridge۔ Task کے لیے right agent loop ہی AI-native company run کرتی ہے۔ |
پانچ Decisions (Part 5)
| # | Decision | Core pattern + additive layers |
|---|---|---|
| 1 | Maya کا Tier-1 Support agent | Core: Single agent + ReAct + tools (Concept 10)۔ Additive layers نہیں۔ |
| 2 | Incident response agent | Core: Planning + ReAct execution (Concept 11)۔ + Reflection layer remediation steps پر (Concept 12)۔ |
| 3 | Market research agent | Core: Multi-agent specialist system (Concept 13)، specialists کے اندر planning + ReAct کے ساتھ۔ + Reflection layer synthesis پر۔ |
| 4 | Enterprise onboarding agent | Core: Sequential workflow (Concept 9)۔ Additive layers نہیں۔ Agentic patterns کے لیے negative example۔ |
| 5 | Coding agent | Core: Multi-agent specialist system (Concept 13)، specialists کے اندر planning + ReAct کے ساتھ۔ + Reflection layer coder output پر۔ Advanced case: ہر architectural decision composed۔ |
فوری reference: پانچ questions، پانچ patterns
Q1: Can the solution path be defined in advance?
Yes → Q2
No → Q3 (need agentic reasoning)
Q2: Is the workflow fixed and stable across runs?
Yes → SEQUENTIAL WORKFLOW
No → Q3 (or branched workflow if few stable variants)
Q3: Is the task structure articulable before execution?
Yes → PLANNING + REACT EXECUTION
No → SINGLE AGENT + REACT + TOOLS
Q4: Quality > speed AND criteria are checkable?
Yes → Add REFLECTION on top of the chosen pattern
No → Skip reflection
Q5: Specialization, context, or scale bottleneck?
Yes → MULTI-AGENT SPECIALIST SYSTEM
No → Keep single-agent pattern
یہ Design-review template (one-page، printable)
یہ Team-shareable worksheet جو design reviews میں اس course کا framework apply کرنے کے لیے ہے۔ ہر architecture proposal کے لیے ایک print کریں۔ Template same five questions walk کرتا ہے اور same compositional decisions surface کرتا ہے؛ value اسے solo fill کرنے میں نہیں، بلکہ discussion کے دوران questions visible رکھنے میں ہے۔
═══════════════════════════════════════════════════════════════════════
COURSE ELEVEN: Agentic Architecture Design Review
═══════════════════════════════════════════════════════════════════════
Task name: _______________________________________________________
Task description (1-3 sentences):
________________________________________________________________
________________________________________________________________
________________________________________________________________
Reviewer(s): __________________________ Date: ____________________
───────────────────────────────────────────────────────────────────────
CORE PATTERN (Q1-Q3)
───────────────────────────────────────────────────────────────────────
Q1. Can the solution path be defined in advance?
[ ] YES, known → go to Q2
[ ] NO, adaptive → skip to Q3
Evidence:
______________________________________________________________
Q2. Is the workflow fixed and stable across runs?
[ ] YES, stable → CORE = Sequential Workflow → skip to Q4
[ ] NO, variable → continue to Q3
Evidence:
______________________________________________________________
Q3. Is the task's high-level structure articulable before execution?
[ ] YES, articulable → CORE = Planning + ReAct execution
[ ] NO, emergent → CORE = Single Agent + ReAct + tools
Evidence:
______________________________________________________________
→ CORE PATTERN CHOSEN: ________________________________________
───────────────────────────────────────────────────────────────────────
ADDITIVE LAYERS (Q4-Q5)
───────────────────────────────────────────────────────────────────────
Q4. Quality > speed AND criteria are checkable?
[ ] YES: both → ADD Reflection layer
[ ] NO: vague criteria → DO NOT add reflection
[ ] NO: latency budget → DO NOT add reflection (consider human review)
Checkable criteria (if YES):
______________________________________________________________
______________________________________________________________
Q5. Specialization, context, or scale bottleneck?
[ ] YES: specialization (name it): _______________________________
[ ] YES: context overflow (describe): ____________________________
[ ] YES: parallelizable scale (quantify): ________________________
[ ] NO: keep single agent
→ If Q5 is YES → upgrade CORE to: Multi-Agent Specialist System
Specialist roles: ____________________________________________
───────────────────────────────────────────────────────────────────────
FINAL ARCHITECTURE
───────────────────────────────────────────────────────────────────────
Core pattern: ________________________________________________
+ Reflection (Y/N): ________________________________________________
+ Multi-agent (Y/N): ________________________________________________
───────────────────────────────────────────────────────────────────────
IMPLEMENTATION & DEPLOYMENT
───────────────────────────────────────────────────────────────────────
SDK primitives used (Concept 8.5):
[ ] Agent (with output_type if structured)
[ ] Runner.run(agent, input, max_turns=__)
[ ] @function_tool decorators on N tools (N = __)
[ ] handoff() between agents
[ ] Agent.as_tool() for coordinator composition
[ ] output_guardrail (if reflection layer)
Operational envelope primitives (Concept 8.6, if applicable):
[ ] Trigger: ___________________________________________________
[ ] step.run per: _____________________________________________
[ ] step.wait_for_event for: __________________________________
[ ] Concurrency cap: ______ per ______________________________
[ ] Fan-out for: ______________________________________________
[ ] Priority/fairness rule: ___________________________________
Cloud deployment subset needed (Concept 9-13 sidebars):
[ ] FastAPI on ACA (always)
[ ] Neon Postgres
[ ] R2 (if files in/out)
[ ] Sandbox + Bridge Worker (if agent runs code)
[ ] Phoenix (if agentic: any pattern except pure sequential workflow)
───────────────────────────────────────────────────────────────────────
RISK ANALYSIS
───────────────────────────────────────────────────────────────────────
Cost class (Concept 17):
[ ] 1× baseline (Sequential workflow)
[ ] 3-10× (Single agent + ReAct)
[ ] 5-15× (Planning + ReAct)
[ ] +2-3× core (with Reflection)
[ ] 5-20× (Multi-agent)
Latency budget check:
Expected latency: ___________________________________________
User-facing budget: _________________________________________
[ ] Fits [ ] Tight [ ] Will not fit
Most likely failure signal to watch (Concept 14):
[ ] ReAct loops / revisits solved work
[ ] Plan-execution divergence
[ ] Reflection not improving output
[ ] Multi-agent routing failures
[ ] System feels complex but not better
Mitigation if it appears:
______________________________________________________________
Eval signals to wire (Concept 9-13 sidebars):
______________________________________________________________
______________________________________________________________
───────────────────────────────────────────────────────────────────────
ANTI-PATTERN CHECK (Concept 16.5)
───────────────────────────────────────────────────────────────────────
If a senior engineer reviewed this choice, what would they object to?
______________________________________________________________
______________________________________________________________
Counter-argument (why our choice is right despite the objection):
______________________________________________________________
______________________________________________________________
───────────────────────────────────────────────────────────────────────
SIGN-OFF
───────────────────────────────────────────────────────────────────────
Architecture approved for: [ ] Prototype [ ] Pilot [ ] Production
Approved by: ______________________________________________________
Re-review date: ______________________________________________________
═══════════════════════════════════════════════════════════════════════
یہ Template deliberately ہر architecture proposal کے لیے 15-20 minutes میں walkable ہے۔ اسے fill کرنا discipline ہے؛ value team conversation کے دوران questions visible رکھنے میں ہے۔ ہر major architecture decision کے لیے ایک print کریں؛ filled-out versions اپنی team کے design-decision archive میں رکھیں۔
حوالہ جات
- یہ حوالہ Bala Priya C، "Choosing the Right Agentic Design Pattern: A Decision-Tree Approach،" Machine Learning Mastery، May 15, 2026، machinelearningmastery.com/choosing-the-right-agentic-design-pattern-a-decision-tree-approach۔ اس course کی spine میں decision tree انہی کا ہے۔
- یہ حوالہ Yao et al.، "ReAct: Synergizing Reasoning and Acting in Language Models" (2022)، original ReAct paper۔
- یہ حوالہ Wang et al.، "Voyager: An Open-Ended Embodied Agent with Large Language Models" (2023)، planning + execution composition کی early example۔
- یہ حوالہ Shinn et al.، "Reflexion: Language Agents with Verbal Reinforcement Learning" (2023)، reflection pattern کی formalization۔
- یہ حوالہ OpenAI، "The next evolution of the Agents SDK" (April 2026)، SDK update (model-native harness plus native sandbox execution) جو patterns کو shippable بناتا ہے۔
- یہ حوالہ agent-building course (Panaversity Agent Factory): agent loops اور AI-native company کا engine۔
- یہ حوالہ eval-driven course (Panaversity Agent Factory): eval-driven development اور trace-to-eval discipline۔
- یہ حوالہ cloud deployment course (Panaversity Agent Factory): cloud میں OpenAI Agents SDK harness deploy کرنا۔
یہ Agent Factory track کے لیے pattern-selection crash course: پانچ questions، پانچ patterns، failure signals، اور آپ کی deployment، eval suite، اور operational envelope (Inngest) کے ساتھ composition۔ Anchor article: Bala Priya C، Machine Learning Mastery، May 15, 2026۔ یہ agent design (agent loops and tools) اور deployment/eval courses کی production discipline کے درمیان pattern-selection gap close کرتا ہے، operational envelope کے ساتھ throughout composed، اور translation table کے ذریعے کسی بھی agentic stack پر portable۔