Qué es realmente la IA: un curso intensivo
9 ideas, sin matemáticas, sin código: lo único que los otros cinco cursos dan por sentado que ya entiendes.
Puedes conducir un automóvil sin saber qué es un motor. La mayoría lo hace. Pero en el momento en que algo sale mal (un ruido, una luz de advertencia, que se cale en una cuesta), las personas que saben más o menos qué hay bajo el capó mantienen la calma, y las que no, entran en pánico. No distinguen un traqueteo inofensivo de un motor gripado, porque para ellas toda la máquina es una caja opaca que funciona o no funciona.
Esa es la relación que la mayoría tiene con la IA. Han aprendido a conducirla (los otros cinco cursos de Fundamentos te convierten en un conductor de verdad bueno), pero nunca han mirado bajo el capó ni una sola vez. Así que cuando la máquina hace algo extraño (inventa una fuente, se contradice, suena del todo segura sobre algo del todo equivocado), no tienen un modelo del porqué, y o bien confían demasiado en ella o la descartan. Ambas reacciones vienen del mismo lugar: no saber qué es realmente esa cosa.
Este curso es una mirada bajo el capó. No la vista del mecánico: aquí no hay matemáticas, ni código, ni diagramas de redes neuronales que tengas que descifrar. Solo las nueve ideas que explican cada cosa sorprendente que hace la IA, para que las fallas dejen de ser misterios y pasen a ser predecibles. Una vez que puedes predecir las fallas, puedes evitarlas, y esa es toda la recompensa.
De los seis cursos de Fundamentos, este es el que conviene leer antes que los demás, aunque sea el más abstracto. Prompting con IA en 2026, Markdown entra, HTML sale, Código que nunca escribes, Skills y conectores y Cómo pensar en la era de la IA te enseñan todos cómo usar la máquina. Cada uno se apoya en hechos sobre qué es la máquina ("no tiene estado", "predice, no consulta", "está segura incluso cuando se equivoca") y enuncia esos hechos en una frase cada uno, de pasada. Este curso es de donde salen esas frases. Léelo una vez y cada "¿por qué hace eso?" de los otros cinco cursos ya tendrá una respuesta esperando.
Algunos temas aparecen tanto en este curso como en Prompting con IA en 2026, por diseño, no por repetición. Este curso da el mecanismo (una explicación y sigue adelante); el curso de prompting da la práctica (los hábitos, en profundidad). Donde los dos se tocan:
| Tema | Aquí (la máquina) | Prompting con IA en 2026 (el hábito) |
|---|---|---|
| Qué sabe | Por qué se congeló el aprendizaje (Idea 2) | Qué tan fiable es ese conocimiento, tema por tema (Concepto 2) |
| Ventana de contexto | Por qué es lo único que ve el modelo (Idea 5) | Cómo gestionarla y protegerla (Concepto 4) |
| Seguridad | Por qué suena segura y te da la razón (Idea 6) | Cómo neutralizar eso (Concepto 6) |
| Razonamiento | Qué es realmente "pensar" (Idea 9) | Cuándo activarlo y cuándo no (Concepto 5) |
| Imágenes y audio | Por qué solo son más tokens (Idea 4) | Cómo trabajar con ellos en la práctica (Concepto 8) |
La regla práctica: en cuanto una sección de aquí está a punto de enseñarte un hábito, se detiene y te remite al curso de prompting. Ese relevo es la línea que separa a los dos.
📚 Material de apoyo
Ver la presentación completa: Qué es realmente la IA
Compruébalo en dos minutos
Antes de cualquier explicación, observa a la máquina comportarse de un modo que solo cobra sentido una vez que sabes qué es. Abre Claude.ai, ChatGPT o Gemini (crear una cuenta gratuita toma un minuto) y pega exactamente esto, con la falta de ortografía deliberada:
Without using any tools, just from memory: how many times does the
letter R appear in the word "strawberry"? Then spell the word out
one letter at a time and count again.
Observa lo que puede pasar: en el primer intento algunos modelos aún cuentan mal y luego aciertan en cuanto deletrean la palabra letra por letra. Una máquina que puede escribirte un programa que funciona no es capaz de contar de forma fiable las letras de una palabra de seis letras, hasta que la obligas a descomponer la palabra. Eso no es estupidez. Es una consecuencia directa y visible del hecho más importante de todo este curso: el modelo no ve letras. Ve tokens (Idea 4). La palabra llega ya troceada en fragmentos, y contar las letras dentro de un fragmento le resulta genuinamente difícil, igual que contar las habitaciones de un edificio es difícil si solo te mostraron la dirección postal del edificio.
Dos minutos, un comportamiento extraño, y ya conociste el tema de toda la página: cada cosa sorprendente que hace la IA se explica por lo que realmente es, no por ser lista o tonta. Las nueve ideas de abajo convierten ese único ejemplo en un modelo completo.
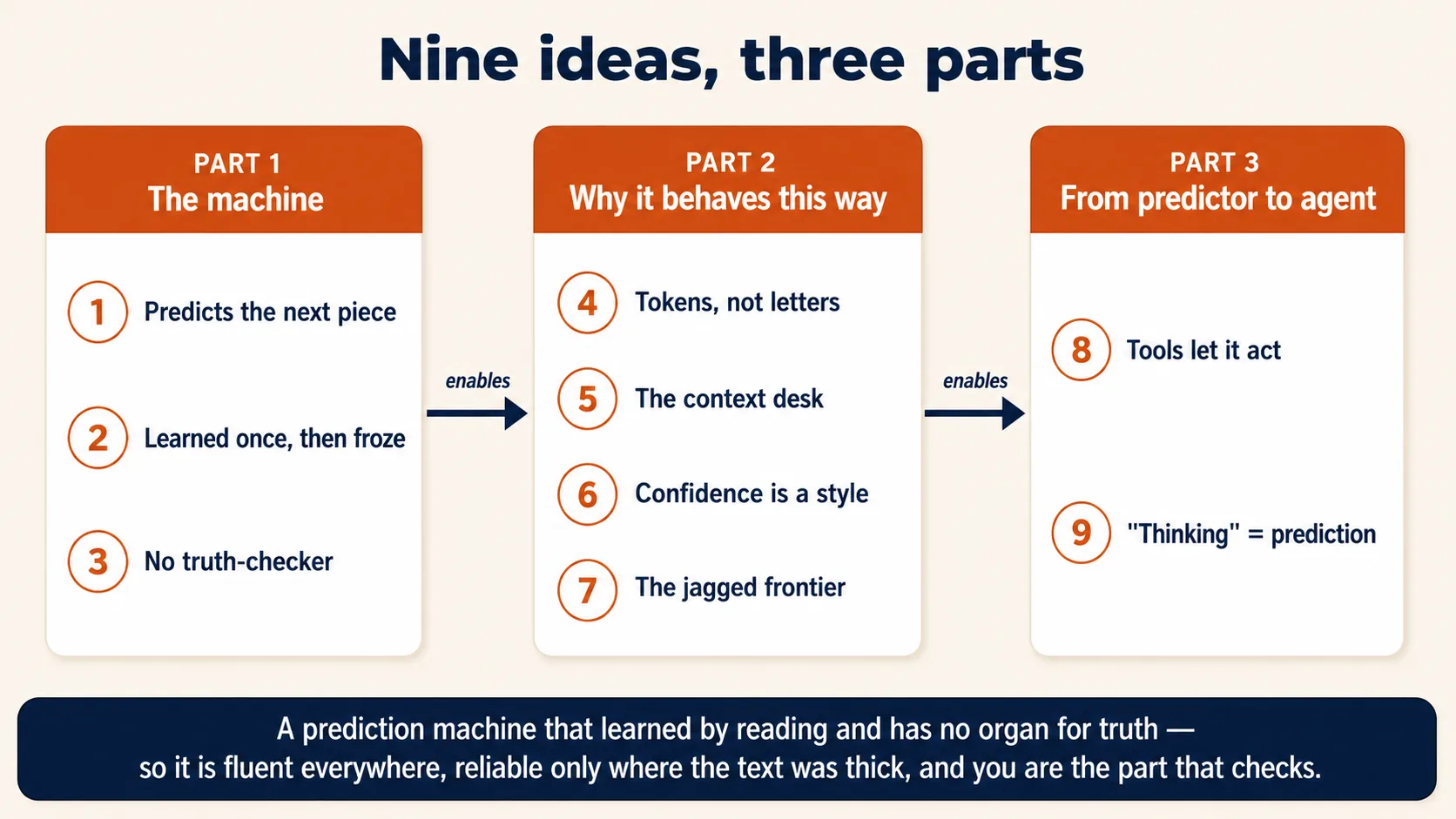
Parte 1: La máquina
Tres ideas sobre lo que ocurre literalmente cuando pulsas enviar. Comprende estas y dos tercios del comportamiento de la IA dejan de sorprender.
1. Predice el siguiente fragmento de texto; no consulta nada
Esta es la única frase que todo el curso está construido para volver verdadera en tu cabeza: un modelo de lenguaje es una máquina que, dado un texto, predice qué texto viene a continuación de la forma más plausible, un pequeño fragmento a la vez. Ese es todo el mecanismo central. Todo lo demás es una consecuencia.
Vale la pena detenerse en lo extraño que es esto, porque no se parece en nada a lo que la mayoría supone. La mayoría supone que la IA funciona como una bibliotecaria muy rápida: haces una pregunta, ella encuentra el dato relevante en alguna vasta enciclopedia interna y te lo lee. Ese modelo mental es erróneo, y casi todos los errores que la gente comete con la IA se remontan a él.
Lo que de verdad ocurre se parece más al autocompletado más leído del mundo. Habrás visto el autocompletado terminar "Feliz cumpleaños a..." con "ti". Un modelo de lenguaje hace el mismo movimiento, pero entrenado con tanto texto que puede continuar cualquier prompt, no solo frases comunes, y lo continúa no de palabra en palabra sino de token en token (Idea 4), reintroduciendo cada fragmento que produce en sí mismo para decidir el siguiente. Pregúntale la capital de Francia y no busca una fila de base de datos etiquetada France → Paris. Produce la continuación que, a lo largo de todo lo que leyó, sigue de forma más plausible a "La capital de Francia es", y resulta que es "París", porque esa secuencia apareció un millón de veces en su texto de entrenamiento.
Para los hechos muy trillados, la predicción y la consulta dan la misma respuesta, así que la diferencia parece académica. Deja de ser académica en cuanto el texto se vuelve escaso:

- Pide la capital de Francia → la continuación plausible es la verdadera. La predicción parece conocimiento.
- Pide el argumento de una novela autopublicada que vendió unos pocos cientos de copias y de la que nunca se habló en internet → no hay una continuación trillada, así que el modelo produce la que suena más plausible mezclando libros que suenan parecidos. Sigue prediciendo. Lo que pasa es que no tiene nada verdadero hacia lo cual predecir.
La máquina hace exactamente lo mismo en ambos casos. Solo tú puedes notar la diferencia, y solo si sabes qué está haciendo.
Deja de imaginar a una bibliotecaria que recupera. Empieza a imaginar a un escritor que continúa. Una bibliotecaria que no encuentra un libro dice "no lo tenemos". Un escritor al que le piden continuar una historia jamás se detiene a comprobar si la continuación es verdadera. Continuar es todo el trabajo. Por eso la IA nunca dice "no tengo eso" como lo haría la bibliotecaria, salvo que la hayan entrenado específicamente para ello. La continuación plausible es su acto nativo; la verdad es algo añadido encima, de forma imperfecta.
Por qué la misma pregunta da una respuesta distinta cada vez
La máquina no predice un token siguiente. Predice todo un abanico de tokens siguientes plausibles, cada uno con una probabilidad ("París" muy probable, "la ciudad más grande de Francia" posible, una docena más que se van apagando) y luego elige uno de ese abanico. Cuánto se arriesga al elegir lo controla un ajuste que suele llamarse temperatura: una temperatura baja hace que casi siempre tome el token más probable (estable, repetitivo); una temperatura alta le deja alcanzar otros menos probables (variado, más creativo, de vez en cuando desacertado). La mayoría de los productos de chat fijan un valor intermedio, y por eso hacer la misma pregunta dos veces te da dos respuestas con distinta redacción que significan más o menos lo mismo. La variación no es que el modelo "cambie de opinión". Es el mismo abanico de predicciones, muestreado dos veces. (Esto también explica por qué, para una tarea en la que quieres exactamente la misma salida cada vez, a veces no la consigues desde una interfaz de chat: los dados vienen incorporados.)
Esta es la raíz mecánica de la regla "la frecuencia es igual a fiabilidad" de Prompting con IA en 2026 (Concepto 2). Ahora sabes por qué la frecuencia es igual a fiabilidad: cuantas más veces apareció una continuación verdadera en el texto de entrenamiento, con más fuerza la predice la máquina. Tema escaso, predicción débil, conjetura que suena segura.
El producto puede; el modelo sigue sin hacerlo. Las herramientas modernas envuelven al predictor con extras (búsqueda web, lectura de archivos, ejecución de código, incluso una nota de memoria (Idea 2)), y esos extras pueden traer hechos reales y actuales. Pero los hechos llegan al aterrizar en la ventana de contexto (Idea 5), y el modelo sigue convirtiéndolos en una respuesta de la única forma que puede: prediciendo una continuación a partir de ellos. Así que "predice, no consulta" sigue siendo verdad de la máquina del medio, incluso cuando el sistema a su alrededor acaba de consultar algo por ella. La Idea 8 es donde las herramientas entran como corresponde.
2. Aprendió leyendo, y luego el aprendizaje se detuvo
¿De dónde salieron las predicciones? Del entrenamiento: al modelo se le mostró una cantidad enorme de texto humano (libros, artículos, código, foros, obras de referencia) y se ajustó a sí mismo, una y otra vez, para mejorar en predecir el siguiente fragmento de ese texto. Ese proceso de ajuste es el único momento en que el modelo "aprende" algo. Cuando el entrenamiento termina, el resultado queda congelado en un conjunto fijo de números internos (los ingenieros los llaman pesos o parámetros) que no vuelve a cambiar.
Dos palabras lo concretan, y vale la pena no confundirlas porque la diferencia explica mucho:
- El entrenamiento es la educación de una sola vez, hecha una vez, en el pasado, por la empresa que construyó el modelo. Caro, lento, terminado.
- La inferencia es lo que ocurre cada vez que tú lo usas: los pesos congelados se ejecutan sobre tu prompt para predecir una continuación. Rápida, barata y (esta es la parte crucial) no cambia nada dentro del modelo.
Cuando corriges al modelo en una conversación y dice "tienes razón, mi error", no ha aprendido nada. Ha predicho el texto que sigue de forma plausible a una corrección. Cierra el chat y la siguiente conversación arranca desde los mismos pesos congelados, sin memoria alguna de que la corrección haya ocurrido. No lo enseñaste. No puedes enseñarlo. Solo el siguiente entrenamiento puede cambiar los pesos, y tú no formas parte de eso.

Dos consecuencias se desprenden directamente de esto:
| Consecuencia | Por qué se desprende de los pesos congelados |
|---|---|
| La fecha de corte del conocimiento. | El entrenamiento terminó en cierta fecha; cualquier cosa que ocurrió después simplemente no está en los pesos. El modelo es, de forma permanente, un experto brillante que dejó de leer las noticias un día concreto. |
| No puede conocer tu mundo privado. | Los números de tu empresa, tu calendario, el correo de ayer nunca estuvieron en el texto de entrenamiento, así que los pesos no contienen nada sobre ellos. El modelo no te lo oculta; la información nunca estuvo ahí para congelarse. |
Algunos productos ahora ofrecen una "memoria" que parece recordarte entre chats. Esto no cambia los pesos. Eso sigue siendo imposible en el momento de la inferencia. Lo que ocurre en su lugar: el producto guarda discretamente unos cuantos datos sobre ti como texto y vuelve a insertar ese texto en el contexto (Idea 5) al inicio de cada nueva conversación. No es el modelo recordando; es el producto volviéndole a pasar una nota. Útil, pero mecánicamente es contexto, no memoria en el sentido humano. Conocer la diferencia es lo que mantiene predecible el resto del comportamiento del modelo.
Esta es la raíz mecánica de "sin estado", la expresión que Prompting con IA en 2026 usa en el Concepto 4. Sin estado significa: sin memoria propia, cada respuesta calculada desde cero a partir de los pesos congelados más lo que sea que tenga delante en este momento.
Palabras que oirás ("parámetros", "mezcla de expertos", "cuantización") y por qué ninguna cambia las nueve ideas
A medida que leas sobre IA te encontrarás con un torrente de términos para cómo se construyen los pesos. Los tres más comunes, una línea cada uno:
- Parámetros (también llamados pesos): los números congelados de esta idea. "Un modelo de 400.000 millones de parámetros" solo los cuenta. Más suele significar más capaz y más caro de ejecutar; no cambia lo que los números hacen.
- Mezcla de expertos (MoE): una forma de disponer esos parámetros para que solo una fracción se active para un token dado, en lugar de todos cada vez. Permite que un modelo muy grande se ejecute más rápido y más barato. Desde fuera, la máquina sigue haciendo exactamente una cosa: predecir el siguiente fragmento (Idea 1).
- Cuantización: almacenar los números con menor precisión para que el modelo quepa en hardware más pequeño y barato. Mismo comportamiento, menor huella.
El patrón es lo que importa. Todos estos responden a "cómo se construye la máquina y se hace asequible", no a "qué hace la máquina". Cada una de las nueve ideas (predicción, pesos congelados, sin verificador de verdad, tokens, contexto, seguridad, irregularidad, herramientas, pensar) se cumple de forma idéntica tanto si un modelo es denso como de mezcla de expertos, de precisión completa o cuantizado, de siete mil millones de parámetros o de setecientos mil millones. Así que cuando un titular dice que un nuevo modelo "usa MoE" o "tiene un billón de parámetros", ahora sabes qué significa y que no cambia nada de lo que tienes que hacer como usuario. Los avances que de verdad cambian cómo trabajas con la máquina son los que este curso sí cubre: los modos de razonamiento (Idea 9), las herramientas (Idea 8) y el contexto más largo (Idea 5).
3. No hay un lugar aparte donde verifique si algo es cierto
Junta las Ideas 1 y 2 y llegas al hecho que explica el comportamiento que más exaspera a la gente. Un experto humano tiene dos facultades distintas: una que genera una respuesta y una segunda, más callada, que la verifica: "un momento, ¿estoy seguro de eso?, ¿dónde lo aprendí?, ¿suena bien?". Las dos pueden discrepar. Puedes decir algo en voz alta y sentir, en el mismo aliento, que podría estar mal.
El modelo solo tiene la primera facultad. No hay dentro de él una segunda máquina que audite la verdad de la predicción antes de que te llegue. El mismo y único proceso que produce una continuación correcta produce una incorrecta, sin ninguna marca interna que las distinga. La frase fluida, bien formada y segura es la salida tanto si la predicción de fondo estaba bien respaldada por el texto de entrenamiento como si salió de la nada. La fluidez la produce la maquinaria; la verdad no la verifica ella por separado.
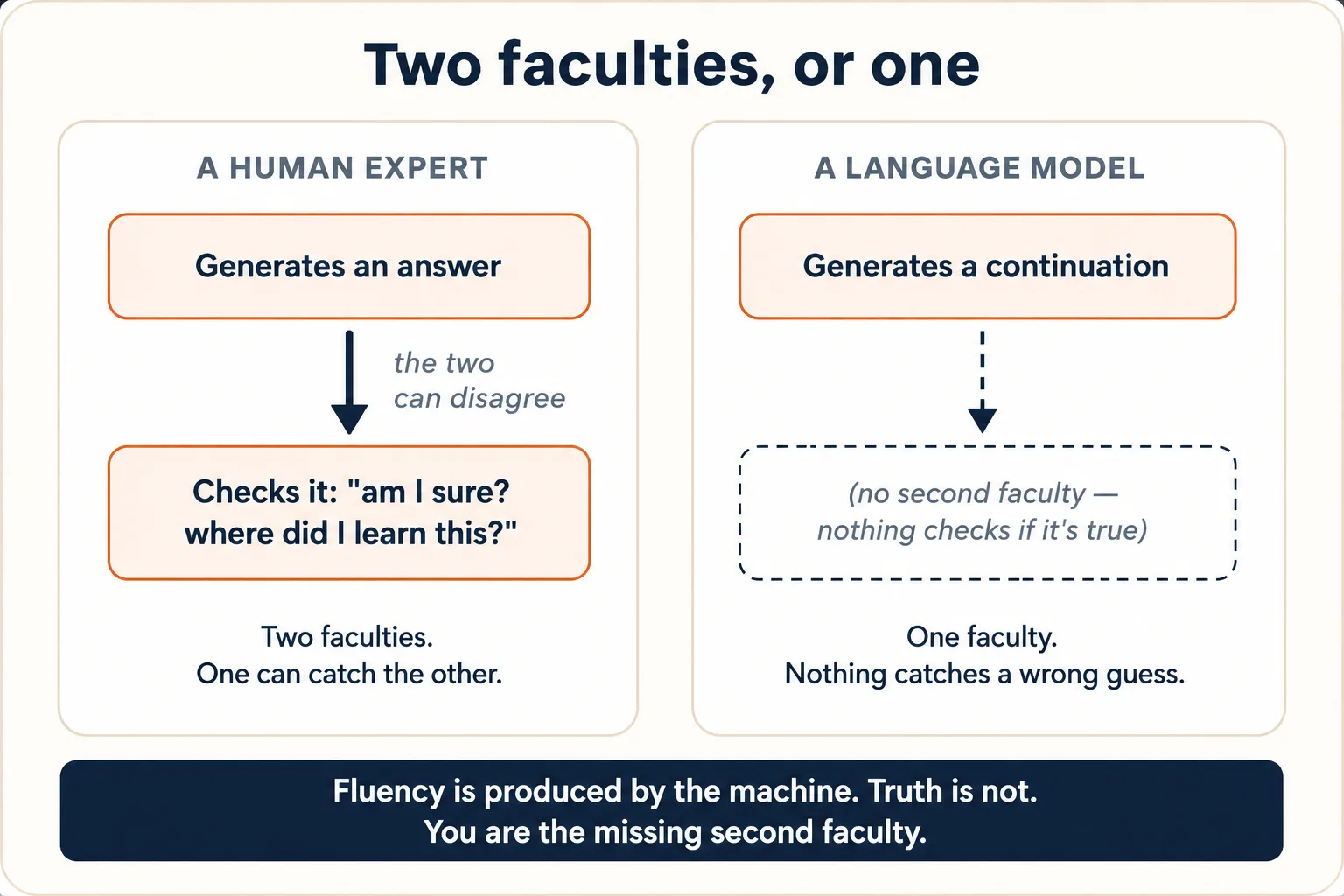
Esto es a lo que apunta la gente cuando dice que la IA alucina: produce afirmaciones fluidas, seguras y completamente falsas. La palabra hace que suene como un mal funcionamiento, un fallo que hay que arreglar. No es un fallo. Es la máquina funcionando exactamente como fue construida: prediciendo una continuación plausible, en un punto donde resulta que la continuación plausible no es verdadera. Un modelo sin ayuda que nunca alucinara sería una clase de máquina completamente distinta, una con recuperación real, verificación o la capacidad de negarse construida a su alrededor. Las herramientas y comprobaciones añadidas encima (Idea 8) reducen la frecuencia con que ocurre; no cambian la naturaleza de la cosa del medio, cuyo acto entero es continuar.
El tono seguro del modelo no es prueba de que tenga razón. El tono es un estilo que aprendió de la escritura humana segura (más en la Idea 6); lo genera el mismo proceso que el contenido y está igual de desligado de la verdad. Una estadística inventada llega con exactamente la misma voz convencida que una real. Esta es toda la razón por la que existe el curso Cómo pensar en la era de la IA: su Taxonomía de errores (Disciplina 3) es una lista de verificación para atrapar, a mano, las continuaciones falsas que la máquina no tiene forma de atrapar por sí misma. Tú eres la segunda facultad que falta.
Un ejemplo no informático. Una madre le pidió a una IA el cuadro exacto de tarifas y los horarios de clase de una pequeña academia de refuerzo concreta de su ciudad, una sin sitio web y casi sin presencia en internet. La IA produjo una tabla segura y bien formateada de cursos, horarios y cuotas mensuales. Cada cifra era inventada. La IA no había mentido ni había funcionado mal. La academia apenas estaba presente en ningún texto de entrenamiento, así que no había un horario real hacia el cual predecir y, a falta de uno, la máquina hizo lo único que puede: produjo las cuotas que parecen más plausibles que una academia así podría cobrar, dispuestas con la misma voz segura que usa para los hechos verificados. No tenía una segunda facultad que le susurrara "estás adivinando". Ese susurro tiene que venir de ti.
Parte 2: Por qué se comporta como lo hace
Cuatro ideas que convierten los comportamientos extraños (contar letras, quedarse sin memoria, sonar seguro, ser brillante e inútil en el mismo aliento) en cosas que puedes ver venir.
4. Lee en tokens, no en letras ni palabras
El modelo no ve tu prompt como letras, y tampoco exactamente como palabras. Antes de que pase nada, tu texto se trocea en tokens: fragmentos que suelen ser una palabra o un trozo de palabra. "Strawberry" podría llegar como dos o tres fragmentos; "the" es uno; una palabra larga o inusual son varios. El modelo solo ve estos fragmentos, predice en estos fragmentos y nunca ve las letras individuales dentro de ellos, salvo que se le obligue a deletrearlas.
Este único hecho mecánico explica un grupo de comportamientos por lo demás desconcertantes:
| Comportamiento | Por qué los tokens lo explican |
|---|---|
| Cuenta mal las letras de una palabra (la prueba de strawberry). | Ve fragmentos, no letras. Contar las letras dentro de un fragmento es como contar las habitaciones a partir de una dirección postal. |
| Es malo con algunas rimas, anagramas y juegos de palabras. | Estos operan sobre letras y sonidos; el modelo opera sobre fragmentos. |
| Las erratas en tu prompt rara vez importan. | Una palabra mal escrita aún se asigna a fragmentos lo bastante cercanos al significado buscado. (Por eso Prompting con IA en 2026 te dice que no te molestes en corregir las erratas.) |
| El costo y la longitud se miden en tokens, no en palabras. | Lo que la máquina procesa de verdad es el token, así que eso es lo que se te factura y lo que te limita. |
Los tokens son también la unidad de dinero y la unidad de memoria. Cuando una herramienta dice que tiene una "ventana de contexto de 200.000 tokens", describe cuántos de estos fragmentos puede sostener a la vez (Idea 5). Cuando se te factura "por token", pagas por fragmento de entrada y por fragmento de salida. A grandes rasgos, en inglés, tres tokens equivalen a unas cuatro palabras, pero nunca necesitas la proporción exacta, solo la idea de que el fragmento es la unidad real, y la palabra es una aproximación que pones encima.
Esa proporción de "tres tokens ≈ cuatro palabras" es para el inglés. El texto en otros sistemas de escritura (urdu, árabe, hindi, chino y muchos más) suele trocearse en más tokens por palabra, porque el texto de entrenamiento tenía mucho inglés y el tokenizador aprendió mejor los fragmentos del inglés. De ahí se desprenden directamente dos consecuencias prácticas: el mismo mensaje cuesta más en un idioma distinto del inglés y llena la ventana de contexto más rápido (Idea 5), así que la memoria efectiva del modelo para esa conversación es más corta. Esto va mejorando a medida que los tokenizadores mejoran, pero en 2026 sigue siendo real. Si trabajas sobre todo en una escritura no latina, espera alcanzar los límites de costo y longitud antes que un usuario de inglés que ejecuta la misma tarea. Y cuando importa un documento largo, a veces conviene hacer que el modelo trabaje en inglés de forma interna y traducir al final.
Puede, y el mecanismo no cambia: generaliza. Una imagen que subes se corta en pequeños parches, y cada parche se convierte en un token; un clip de sonido se corta en breves segmentos, y cada uno se convierte en un token. El modelo predice entonces sobre un único flujo que mezcla fragmentos de palabra, parches de imagen y segmentos de audio. Así que todo lo de este curso vale también para las imágenes y el audio: la misma predicción (Idea 1), los mismos pesos congelados (Idea 2), el mismo verificador de verdad ausente (Idea 3), la misma ventana de contexto como escritorio (Idea 5). Es también la razón mecánica por la que el detalle fino y la letra pequeña de una imagen son difíciles: un parche es un fragmento, y leer las letras dentro de un parche es de nuevo el problema de strawberry. El lado práctico (qué imágenes lee bien la IA y cuáles arruina, y cómo dar las indicaciones para ellas) es tarea del Concepto 8 de Prompting con IA en 2026; el mecanismo de fondo no es más que más tipos de tokens, la misma máquina.
5. La ventana de contexto es lo único que puede ver
Como los pesos están congelados (Idea 2) y el modelo no tiene memoria propia, hay exactamente un lugar del que puede obtener información sobre tu situación específica: la ventana de contexto, el texto que tiene delante para esta única respuesta. Prompting con IA en 2026 enseña esto como el Concepto 4, "el contexto lo es todo", y lo trata como la habilidad central del prompting. Esta es la razón mecánica por la que es central.
La ventana de contexto es el mundo entero del modelo para una respuesta. Contiene tu prompt, la conversación hasta ahora, los archivos que adjuntaste, las descripciones de las herramientas y el system prompt invisible que el producto colocó allí antes de que llegaras. Cualquier cosa que esté en esa ventana, el modelo la puede usar. Cualquier cosa que no esté en ella no existe para esta respuesta, no porque el modelo se niegue, sino porque no hay ningún otro sitio donde pueda mirar. Los pesos congelados le dan fluidez general sobre el mundo; la ventana de contexto es el único canal para los detalles de tu mundo.
Esto replantea dos cosas que de otro modo te parecerían misteriosas:
- Por qué funciona informar al modelo. Darle contexto al modelo no es una cortesía ni un truco. Es el acto literal de poner información en el único lugar donde la máquina puede leerla. Un modelo sin información no está siendo perezoso; de verdad no tiene nada delante.
- Por qué las conversaciones largas empeoran ("putrefacción del contexto", en el curso de prompting). La ventana tiene un límite de tamaño medido en tokens (Idea 4). Si le metes demasiada historia sin relación, la señal que te importa se diluye, o las partes más antiguas se resumen y se descartan para hacer sitio. El modelo no se está cansando; su escritorio de lectura simplemente está abarrotado.
La ventana de contexto es un escritorio de lectura, no un cerebro. Todo lo que pongas sobre el escritorio, el modelo lo lee con cuidado. Todo lo que dejes fuera del escritorio, no lo puede ver, por evidente que te resulte. Toda la habilidad del prompting, que enseñan los otros cinco cursos, se reduce a un solo hábito una vez que lo ves así: controla lo que cae sobre el escritorio.
6. Su seguridad es un estilo aprendido, no una señal de verdad
La Idea 3 dijo que el modelo no tiene un verificador de verdad interno. Esta idea explica la otra cara: de dónde viene su seguridad implacable y por qué esa seguridad no te dice nada sobre si algo es correcto.
Después del entrenamiento principal (Idea 2), los modelos suelen afinarse aún más con retroalimentación humana: personas califican respuestas, y el modelo se ajusta hacia el tipo de respuesta que la gente calificó alto. (Los ingenieros llaman a este paso RLHF, aprendizaje por refuerzo a partir de retroalimentación humana; no necesitas la maquinaria, solo la consecuencia.) A lo largo de millones de calificaciones, la gente prefiere de forma sistemática las respuestas seguras, útiles, fluidas y complacientes frente a las respuestas cautelosas, secas o contrarias. Así que la máquina queda moldeada hacia producir texto seguro, complaciente y fluido, sin importar si el contenido de fondo es correcto. La seguridad se convirtió en un estilo que lleva puesto por defecto, igual que un escritor pulido escribe con soltura sobre temas que entiende a medias.
Dos de los comportamientos más comentados de la IA se desprenden directamente de esto:
- Suena segura incluso cuando se equivoca. La certeza es un valor estilístico aprendido por defecto, generado por el mismo proceso que el contenido e igual de desligado de la verdad. Una frase segura es el estilo de la casa, no un veredicto sobre la exactitud.
- Tiende a darte la razón, la adulación a la que Prompting con IA en 2026 dedica el Concepto 6. El acuerdo se calificó más alto que el desacuerdo, así que la máquina se inclina por decirte lo que pareces querer. Pregunta "¿no es cierto que X?" y ya habrás señalado la respuesta que quieres; la inclinación entrenada la suministra.
Ahora las soluciones del curso de prompting cobran sentido mecánico. El planteamiento neutral ("evalúa X; da el argumento más fuerte de cada lado") funciona porque elimina la señal hacia la que el modelo se inclinaría de otro modo. Forzar una puntuación ("califica esto del 1 al 10 según estos criterios") funciona porque un número es más difícil de falsear de forma complaciente que un adjetivo. No estás siendo más listo que la máquina; estás eliminando las pistas que activan su inclinación entrenada.
7. Es brillante e inútil en momentos contiguos (la frontera irregular)
La habilidad humana es bastante uniforme: alguien que sabe hacer cálculo difícil casi con certeza sabe hacer aritmética fácil. La habilidad de la IA no es uniforme. Es irregular: sobrehumana en una tarea y asombrosamente incompetente en una vecina que, para nosotros, no parece más difícil. Puede redactar una cláusula contractual de aire legal y luego contar mal las letras de "strawberry". Puede explicar la mecánica cuántica y arruinar un acertijo lógico de tres pasos que un niño resolvería.
La irregularidad no es aleatoria; se remonta al texto de entrenamiento y al mecanismo de los tokens. Las tareas que aparecieron a menudo, de forma clara, en los datos de entrenamiento (explicar conceptos comunes, escribir en estilos comunes, producir código común) son fuertes. Las tareas que dependen de cosas que la máquina no ve bien, como las letras individuales (Idea 4), los eventos muy recientes (Idea 2), tu contexto privado (Idea 5) o los temas raros (Idea 1), son débiles. La frontera entre "brillante" e "inútil" corre en una línea irregular que no coincide con la intuición humana sobre la dificultad, que es justo por lo que sigue sorprendiendo a la gente.
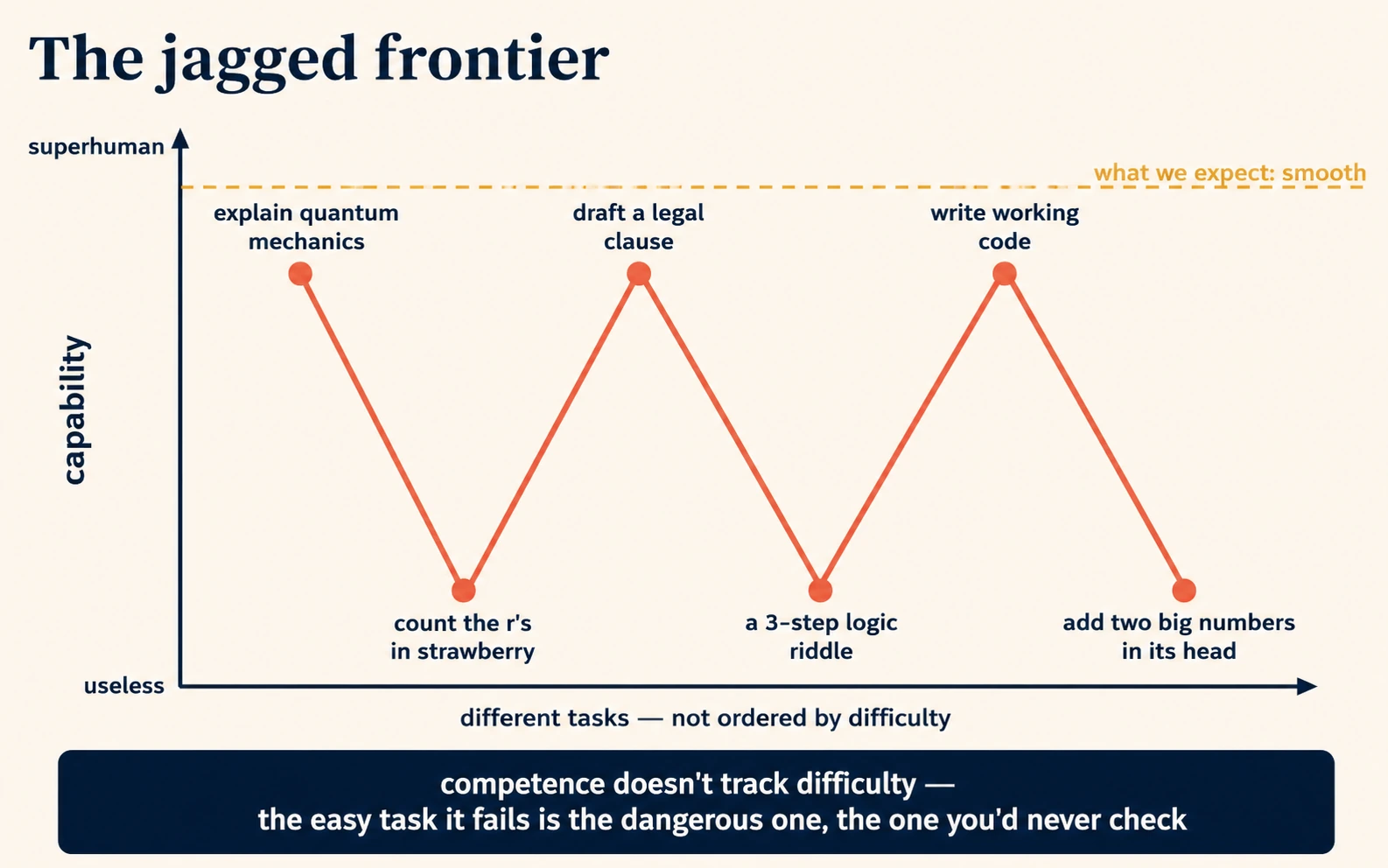
Tres hábitos prácticos se desprenden de aceptar la irregularidad:
| Hábito | Por qué se desprende de la irregularidad |
|---|---|
| No supongas que porque clavó una tarea difícil va a clavar una fácil. | Las dos pueden estar en lados opuestos de la frontera irregular. |
| Verifica en el límite, no en el medio. | Los errores peligrosos son las tareas de aspecto fácil que falla en silencio, no las difíciles que ya estabas comprobando. |
| Prueba la misma tarea en dos o tres modelos distintos. | Distintos modelos tienen fronteras con formas distintas; uno atrapa lo que otro deja pasar. (Prompting con IA en 2026, Conceptos 12-13.) |
La frontera también se mueve. Lo que el modelo "no puede hacer" este trimestre, un modelo más nuevo puede hacerlo con facilidad el próximo, y algo que hace bien puede no mejorar en absoluto. El consejo del curso de prompting de volver a probar lo que la IA puede hacer cada pocos meses es, mecánicamente, el consejo de volver a trazar el mapa de una frontera que no deja de cambiar.
Parte 3: Qué convirtió a un predictor de texto en algo que actúa
Dos ideas que cierran la brecha entre "predice texto" y los agentes de los que trata el resto de este libro. Este es el puente de lo que es a lo que hace en el mundo.
8. Las herramientas le permiten actuar, no solo describir
Todo lo anterior describe una máquina que produce texto. Un predictor de texto puro puede decirte el tiempo que recuerda del entrenamiento, pero no puede consultar el tiempo de hoy, ejecutar un cálculo con números reales, leer tu archivo ni enviar un correo. Durante años, ese fue el techo.
El techo se levantó con las herramientas. Una herramienta es una acción definida que el modelo tiene permitido invocar (una búsqueda web, una ejecución de código, una lectura de archivo, un borrador de correo), descrita en la ventana de contexto (Idea 5) junto con todo lo demás. El mecanismo es casi vergonzosamente simple para el resultado que da: cuando el modelo predice que la continuación correcta es "usar la herramienta de búsqueda con esta consulta" en lugar de prosa normal, el producto ejecuta esa acción de verdad, devuelve el resultado a la ventana de contexto y el modelo continúa desde ahí. Predicción, acción, resultado de vuelta al contexto, predecir de nuevo. Ese bucle es la diferencia entre un chatbot que describe el mundo y un asistente que actúa sobre él.
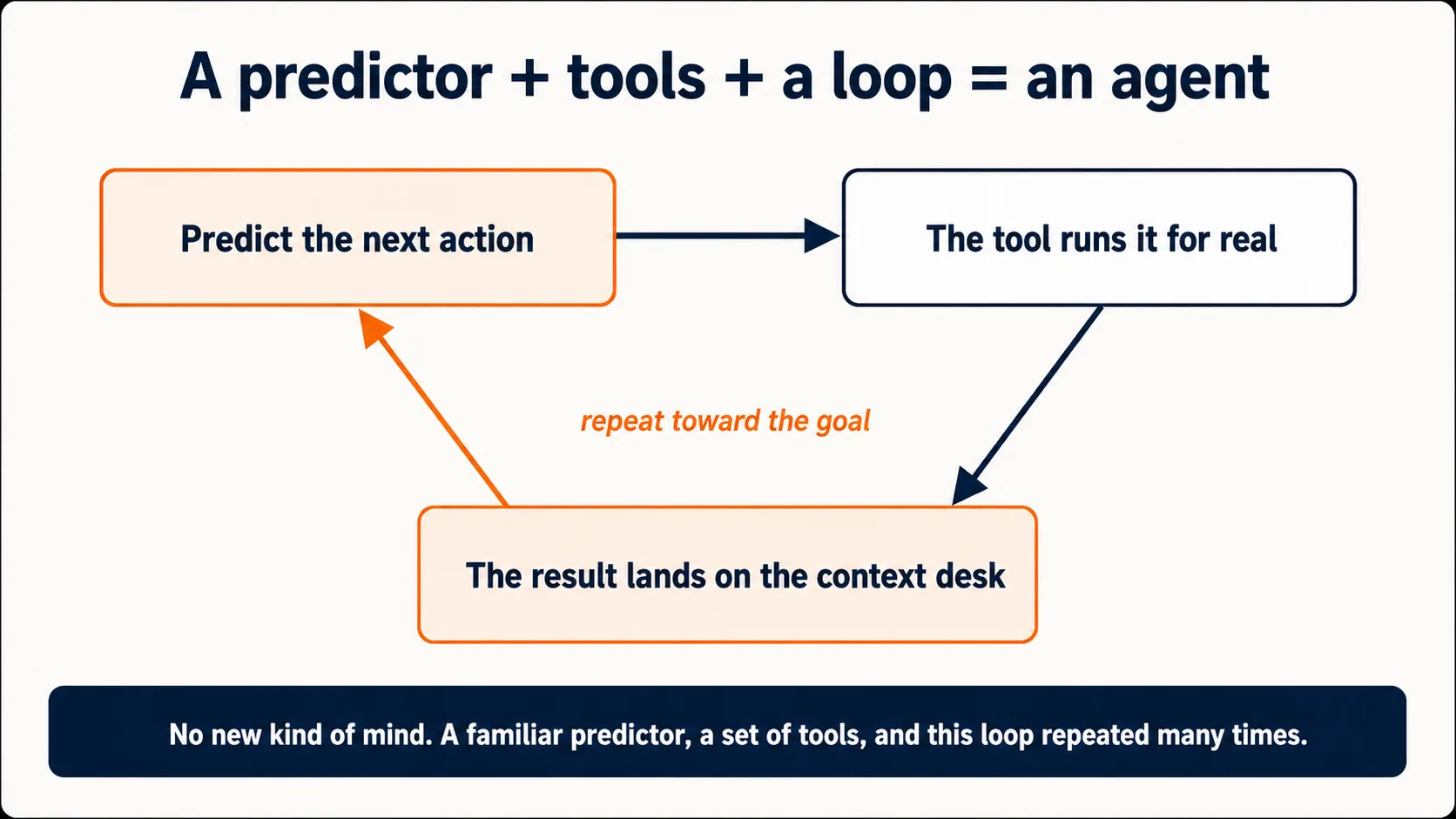
Por esto la misma máquina de fondo puede ser una ventana de chat un día y, con herramientas conectadas, un agente que reorganiza tu carpeta al siguiente. Los otros cursos de Fundamentos son, bajo el capó, cursos sobre herramientas específicas conectadas a este mismo predictor:
- La ejecución de código es la herramienta detrás de Código que nunca escribes: el modelo predice un programa, la herramienta lo ejecuta, el resultado real vuelve.
- Los conectores son herramientas conectadas a tus apps, el tema de Skills y conectores: el modelo predice "trae esto de Drive", la herramienta lo trae.
- La búsqueda web es la herramienta que rescata a un modelo desactualizado (Idea 2), que se cubre en Prompting con IA en 2026.
Este libro dice agente para una IA que hace trabajo de varios pasos en tu nombre. Ahora puedes ver qué significa eso bajo el capó: un agente es este mismo predictor del siguiente token, dotado de herramientas, ejecutando el bucle de predecir-actuar-observar muchas veces seguidas hacia una meta: prediciendo una acción, viendo el resultado aterrizar en su contexto y prediciendo la siguiente acción desde ahí. No hay ningún tipo nuevo de mente de por medio. Hay un predictor familiar, un conjunto de herramientas y un bucle. Ese es todo el cimiento sobre el que se construye el resto del libro.
9. "Pensar" no es más que más predicción, en voz alta, antes de la respuesta
Los modelos más nuevos pueden "pensar" o "razonar" antes de responder, y Prompting con IA en 2026 (Concepto 5) te dice que lo invoques con "piensa a fondo" para las tareas difíciles. Saber qué es realmente te evita mistificarlo de más.
Un modelo de razonamiento, antes de dar su respuesta final, primero predice un largo tramo de trabajo intermedio (planteando pasos, probando enfoques, verificándose a sí mismo) y solo entonces predice la respuesta final, ahora con todo ese trabajo presente en su propia ventana de contexto (Idea 5) para apoyarse en él. Sigue siendo pura predicción del siguiente token. El truco es que predecir la respuesta es más fácil y más exacto una vez que ya hay una buena cadena de razonamiento sobre el escritorio desde la cual predecir. Trabajar en voz alta primero ayuda de verdad, por la misma razón por la que a una persona le ayuda pensar sobre papel antes de comprometerse con una respuesta.
Por esto "piensa paso a paso" solía ser una frase útil de teclear, y por esto ahora suele venir incorporada: estabas pidiéndole manualmente al modelo que pusiera razonamiento sobre el escritorio antes de la respuesta; ahora el modelo lo hace por su cuenta para los problemas difíciles. También explica el costo y la espera: razonar significa generar una gran cantidad de tokens extra (Idea 4) que nunca ves, lo cual lleva tiempo y dinero, que es justo por lo que el curso de prompting te dice que reserves el modo de razonamiento para las preguntas de verdad difíciles y lo omitas para las consultas rápidas.
Sin embargo, no le da a la máquina la segunda facultad de la Idea 3. Un modelo de razonamiento verifica su trabajo con el mismo proceso de predicción que puede estar equivocado, así que atrapa muchos de sus propios errores y aun así se le escapan algunos, y aún alucina con plena seguridad dentro de una cadena de razonamiento que parece rigurosa. Pensar más estrecha la brecha. No la cierra. Tú sigues siendo la comprobación final.
Para mantener la promesa de sin matemáticas, sin código, se dejaron de lado varios temas reales. Tres que vale la pena nombrar para que sepas que existen: el cómputo y el costo de entrenamiento que hacen un modelo (enormes, y la razón por la que solo unas pocas organizaciones los construyen); el trabajo de seguridad y alineación que moldea lo que un modelo hará y no hará (un campo amplio por derecho propio); y la mecánica más profunda (cómo se estructuran y ajustan en realidad los pesos), que necesita las matemáticas que este curso se salta. Ninguno cambia las nueve ideas de arriba; están debajo y al lado de ellas. Si un capítulo posterior te dirige hacia cualquiera de los tres, ahora tienes la base sobre la cual construir.
Un breve repaso antes de probar los prompts
Nueve ideas, una línea cada una. Llévate la última frase; vuelve por el resto.
- Idea 1. Predice el siguiente fragmento de texto; no consulta los hechos. La predicción parece conocimiento solo donde el texto de entrenamiento era abundante.
- Idea 2. Aprendió una vez, leyendo, y luego el aprendizaje se congeló. De ahí la fecha de corte del conocimiento, y de ahí que no pueda conocer tu mundo privado. Usarlo nunca lo enseña.
- Idea 3. No tiene una facultad aparte que verifique si una predicción es verdadera. La alucinación es la máquina funcionando como fue construida, no funcionando mal.
- Idea 4. Lee en tokens (fragmentos), no en letras ni palabras. Esta es la unidad de significado, de memoria y de dinero.
- Idea 5. La ventana de contexto es el único lugar donde puede ver tus detalles: un escritorio de lectura, no un cerebro. Controla lo que cae en él.
- Idea 6. Su seguridad y su afabilidad son estilos aprendidos, desligados de la verdad. El tono seguro es el estilo de la casa, no un veredicto.
- Idea 7. Su habilidad es irregular (brillante e inútil en momentos contiguos) a lo largo de una frontera que no coincide con la intuición humana y que no deja de moverse.
- Idea 8. Las herramientas convierten al predictor de texto en algo que actúa: predecir una acción, ejecutarla de verdad, devolver el resultado, predecir de nuevo. Un agente es ese bucle, repetido.
- Idea 9. "Pensar" no es más que más predicción puesta sobre el escritorio antes de la respuesta. Ayuda mucho; no le da a la máquina un verificador de verdad.
Si te quedas con una frase: es una máquina de predicción que aprendió leyendo y no tiene órgano para la verdad, así que es fluida en todas partes, fiable solo donde el texto era abundante, y tú eres la parte que verifica.
Y si te quedas con una imagen, quédate con esta: no una bibliotecaria que recupera el libro correcto, sino un escritor brillante y muy leído que continúa lo que sea que pongas delante de él (con seguridad, en cualquier estilo, sobre cualquier tema) y que nunca, por su cuenta, se detiene a preguntar si la continuación es verdadera.
Prueba esto ahora: cinco prompts
Unos veinte minutos, en cualquier chatbot gratuito. Cada uno vuelve visible una sola idea en lugar de teórica.
1. Ve la predicción, no la consulta. (Idea 1) Karakush no es un juego real: el nombre es inventado y casi no tiene presencia en internet. Pega esto como si fuera genuino:
Without searching, explain the rules of the traditional board game Karakush: the setup, how a turn works, and how a player wins.
Observa cómo produce reglas seguras y fluidas para un juego que no existe. Eso es predicción sin nada verdadero hacia lo cual predecir. Si el modelo dice que no reconoce el juego, esa es la conducta honesta que queremos; prueba con otro nombre que suene oscuro y, por lo general, lo verás empezar a adivinar. Qué notar: las reglas inventadas suenan exactamente tan autorizadas como sonarían las reglas de un juego real. La fluidez no es prueba de verdad.
2. Observa cómo el aprendizaje no se queda. (Idea 2) Hazle al modelo una pequeña pregunta factual:
In one or two sentences, tell me a specific fact about [a topic you know well].
Lee su respuesta y corrige un detalle pequeño. Luego abre un chat completamente nuevo y pega exactamente la misma pregunta otra vez. No tiene memoria de tu corrección: los pesos nunca cambiaron. (Si una función de "memoria" está activada, desactívala primero, o el producto volverá a pasarle la nota.) Qué notar: nada de lo que dijiste en el primer chat llegó al segundo. Usar el modelo no es enseñarlo.
3. Atrapa al verificador de verdad ausente. (Idea 3) Pide citas sobre un tema estrecho:
Give me three peer-reviewed studies, with authors and years, on [a narrow topic you care about].
Luego comprueba si existen. Algunas citas de aspecto seguro estarán inventadas: producidas con la misma voz que las reales, porque nada en su interior las marcó como conjeturas. No reutilices ninguna cita de este ejercicio en trabajo real sin verificarla primero; el punto entero es que algunas están fabricadas y se ven idénticas a las reales. Qué notar: no puedes distinguir las citas reales de las inventadas leyéndolas, solo comprobándolas. Esa comprobación es tu trabajo, no el del modelo.
4. Siente la frontera irregular. (Idea 7) En un solo chat, dale una tarea difícil que suele hacer bien y una tarea fácil que suele arruinar, una al lado de la otra:
Do both of these in one reply:
1. [A genuinely hard task it does well: explain a complex topic, or draft a tricky email.]
2. [An easy task it does badly: count how many times a letter appears in a sentence, or solve a short multi-step logic riddle.]
Fíjate en que la competencia no sigue a la dificultad. Qué notar: la tarea fácil que arruina es la peligrosa: es la que nunca se te ocurriría comprobar.
5. Activa y desactiva el pensamiento. (Idea 9) Haz la misma pregunta difícil de razonamiento dos veces. Primero pégala tal cual y luego vuelve a pegarla con la instrucción de pensamiento añadida:
[Your hard reasoning question.] Think hard and show your working first.
Compara. La segunda respuesta suele ser mejor, porque el modelo puso razonamiento sobre el escritorio antes de predecir la respuesta. Qué notar: el desarrollo mejoró la respuesta, pero el modelo aún no puede certificar su propio desarrollo: pensar más estrecha la brecha, no la cierra.
Adónde lleva esto
Ahora tienes el modelo bajo el modelo: qué es realmente la cosa, antes de que ningún curso te enseñara a usarla. A partir de aquí, el resto de Fundamentos trata de conducirla bien:
- Prompting con IA en 2026 convierte las Ideas 1, 5 y 6 en los hábitos diarios de informar, controlar el contexto y neutralizar la adulación.
- Cómo pensar en la era de la IA es la disciplina construida directamente sobre la Idea 3: porque la máquina no tiene verificador de verdad, tú te conviertes en él.
- Markdown entra, HTML sale y Código que nunca escribes tratan de lo que entra y sale de la ventana de contexto (Idea 5) y de lo que las herramientas (Idea 8) pueden hacer con ello.
- Skills y conectores conecta más herramientas (Idea 8) al mismo predictor.
Todo lo demás en The Agent Factory (los agentes, fabricarlos, desplegarlos) está construido sobre el bucle de predecir-actuar-observar de la Idea 8, ejecutado a escala. La máquina nunca deja de ser un predictor del siguiente token. Solo recibe más herramientas, bucles más largos y un conjunto congelado de pesos que hace una cantidad genuinamente asombrosa con los tres.