De Digital FTE a Production Worker: un curso intensivo de 90 minutos
15 conceptos, ~80% del uso real: ejecución duradera, disparadores, control de flujo
Un curso intensivo de continuación. Este es el curso n.° 5 de la ruta de coding agéntico. El curso anterior, De agente a Digital FTE, terminó con un Worker de atención al cliente: la misma base de OpenAI Agents SDK, tres habilidades portátiles, un sistema de registro en Neon Postgres y un servidor MCP personalizado. Ese Worker se ejecuta solo cuando lo llamas. Abres Claude Code u OpenCode, escribes y el agente responde. Un Production Worker real no depende de que una persona escriba en el prompt.
La idea que hace que todo encaje: convertir un Digital FTE en un Production Worker requiere una sola adición arquitectónica: un motor de ejecución duradera que permite que el mundo llame al Worker (en lugar de hacerlo tú), sobrevive a fallos a mitad de ejecución y aplica límites de velocidad a escala. Inngest es la plataforma de ejecución duradera que usamos, y los patrones se transfieren uno a uno a Temporal, Restate o Dapr Agents. El nivel Hobby alojado de Inngest ofrece la entrada más sencilla: gratis, sin tarjeta de crédito, servidor de desarrollo con un solo comando y un panel que puedes explorar mientras programas.
En términos sencillos: el Digital FTE del curso n.° 4 es una función que llamas tú. El Production Worker que se construye en este curso es una función que llama el mundo: mediante trabajos cron programados, webhooks de la bandeja de entrada y el sistema de facturación, y eventos emitidos por otros Workers. Cuando se ejecuta, lo hace de forma duradera: un fallo a mitad de un flujo de reembolso de seis pasos no pierde el trabajo de los primeros tres pasos; el Worker se reanuda desde donde se interrumpió. Y cuando 500 clientes envían correos al mismo tiempo, el Worker los procesa a una velocidad controlada que no agota el límite de OpenAI ni el pool de conexiones de Postgres. No tienes que construir esa maquinaria; tu código sigue siendo un conjunto de funciones decoradas con @inngest.create_function.
Day AI, el CRM para empresas nativas de IA, llama a Inngest "el sistema nervioso" de su producto. Dos ingenieros fundadores lo describen así, de forma independiente. Su stack usa todas las primitivas que enseña este curso: flujos de trabajo duraderos con LLM, coordinación mediante espera de eventos, replay ante fallos, debounce + throttling + concurrencia y equidad multiinquilino para que el pico de una organización no ralentice a todas las demás. Este encuadre no es una marca del currículo; es el lenguaje de producción de una empresa nativa de IA que ya está en el mercado.
Un bloqueo de un solo agente en mitad del flujo de trabajo es molesto. Una fuerza laboral de cincuenta agentes que se ocupan del trabajo de cara al cliente sin un sustrato para el sistema nervioso es imposible: adoptas una plataforma que te lo brinda o pasas seis meses construyendo tú mismo una versión peor. Cuatro propiedades hacen que la ejecución duradera sea especialmente importante para los agentes:
- Cada paso cuesta dinero real. Un reintento ingenuo después de un fallo vuelve a pagar pasos que ya tuvieron éxito; la memoización de pasos (Concepto 7) paga una sola vez.
- Los flujos de trabajo acumulan fallos. Un agente de seis pasos con 95 % de confiabilidad por paso tiene un 26 % de probabilidad de fallar en algún punto. La memoización de pasos más los reintentos dirigidos elevan la confiabilidad general a ~99,7 %.
- Los efectos secundarios son reales. Los agentes envían correos a clientes, cargan tarjetas y publican en Slack. La memoización de pasos más las claves de idempotencia del proveedor hacen que esas acciones sean seguras.
- Los agentes necesitan aprobación humana en momentos de alto riesgo. Sin
step.wait_for_event(Concepto 15), tendrías que construir una cola de aprobación: tabla de base de datos, sondeo, manejo de tiempos de espera y registro de auditoría. Eso es un proyecto, no una función.
Empieza aquí: ubicación arquitectónica y hoja rápida de 15 conceptos
Dónde se ubica este curso en la arquitectura. La tesis Agent Factory describe siete invariantes que cualquier sistema de agente de producción debe satisfacer. Los cursos 3 y 4 cubrieron los invariantes 4 (motor) y 5 (sistema de registro). Este curso cubre dos más, más una parte de Invariante 1:
- Invariante 7: El mundo llama al sistema. Los disparadores (programaciones, webhooks, llamadas API entrantes, eventos de otros Workers) despiertan al Worker. Inngest es una implementación de esa idea.
- Invariante 1, en parte: el ser humano es el principal. Las puertas de aprobación son el punto donde la intención humana vuelve al runtime.
step.wait_for_eventes la expresión más limpia en cualquier plataforma: el agente se suspende, una persona emite el evento esperado y el agente se reanuda. - Ejecución duradera como invariante implícita en la tesis. La auditoría responde "¿qué pasó?"; la durabilidad responde "hazlo de nuevo desde donde se interrumpió". Se puede reproducir, reintentar y reanudar después de un fallo.
Los 15 conceptos, de un vistazo. Un fallo en producción casi siempre se debe a una de tres causas raíz: un disparador que no se activó (o se activó dos veces), una ejecución que se interrumpió y perdió estado, o una brecha de control de flujo que permitió que el tráfico de un cliente dejara sin capacidad a los demás. Los 15 conceptos se mapean a esas tres capas. Esta es la versión de primera pasada: el concepto y una idea central en una línea. La tabla de diagnóstico completa (con la pregunta que responde cada concepto) está en la Referencia rápida del final, que usarás durante la construcción.
| # | Concepto | Esencia de una línea |
|---|---|---|
| Disparadores | cómo el mundo llama al Worker | |
| 1 | Eventos vs solicitudes | Una solicitud se sincroniza y alguien espera; un evento es asíncrono y el mundo ha seguido adelante. |
| 2 | Disparadores cron | Un horario despierta la función. Una línea: TriggerCron(cron="0 9 * * *"). |
| 3 | Disparadores de webhook | Una carga útil HTTP entrante se convierte en un evento con nombre; tu función reacciona a ese nombre. |
| 4 | Idempotencia y semántica de eventos | Los ID de eventos y los nombres de los pasos hacen que un evento duplicado (o un reintento) no sea operativo. |
| 5 | Fan-out y delegación de subagentes | Un evento, N funciones de suscripción; o un padre activa N eventos secundarios. |
| Ejecución duradera | mantener el Worker correcto cuando algo se rompe | |
| 6 | step.run y el modelo de función duradera | Cada step.run es un punto de control; la función puede fallar entre pasos y reanudarse. |
| 7 | Memoización, la mecánica subyacente | Los pasos completados devuelven la salida almacenada en lugar de volver a ejecutarse. |
| 8 | step.sleep y step.wait_for_event | Ambos suspenden la función de forma duradera, por un tiempo o por un evento. |
| 9 | Reintentos, manejo de errores, dead-letter | Reintentos automáticos con backoff; después de N intentos, la ejecución fallida persiste para replay. |
| 10 | step.run para llamadas de IA en Python | Envuelve las llamadas a OpenAI en step.run; step.ai.infer descarga la inferencia (step.ai.wrap es solo TypeScript). |
| Control de flujo | mantener el Worker en buen estado bajo carga | |
| 11 | Concurrencia y limitación | concurrency limita las ejecuciones activas; throttle limita los inicios por segundo. |
| 12 | Prioridad y equidad | La prioridad ordena la cola; La concurrencia por clave le da a cada inquilino una parte justa. |
| 13 | Procesamiento por lotes | Acumula eventos en una sola llamada de función por lotes para trabajo masivo de bajo costo. |
| 14 | Replay y cancelación masiva | Reproduce ejecuciones fallidas con código nuevo; cancela en masa las ejecuciones que ya no deseas. |
| 15 | Puertas HITL con step.wait_for_event | La función se suspende hasta que un humano lo apruebe y luego se reanuda con la decisión. |
Una vez que tenga este mapeo, el resto del documento es principalmente mecánico. Un fallo en la producción se debe a uno de:
- un disparador que no coincidió (error tipográfico en el nombre del evento, programación que no se activó),
- un paso que falló sin memoización (por lo que el reintento reinicia todo el flujo),
- una brecha de control de flujo que no limitó la concurrencia (por lo que un cliente dejó sin capacidad a los demás),
- o una puerta HITL que agotó el tiempo de espera (por lo que la escalada nunca ocurrió).
La tabla de diagnóstico de la Referencia rápida te indica cuál.
Audiencia. Este es el tercer curso intensivo de nivel intermedio a avanzado de la ruta de coding agéntico. Debes haber completado los cursos 3 y 4 (o sentirte cómodo con todo lo que enseñaron), porque este curso amplía el Worker de atención al cliente del ejemplo trabajado de la Parte 4 del curso 4. OpenAI Agents SDK, sesiones, streaming, herramientas de función, sandboxing, habilidades, Neon Postgres con pgvector, servidores MCP y registro de auditoría: todo se da por sabido.
Requisitos previos. Esta página asume cinco cosas.
- Has completado De agente a Digital FTE. No negociable. Continuamos donde terminó el curso n.° 4: el mismo proyecto
chat-agent/, las mismas habilidades, el mismo servidor MCPcustomer-data.- Tienes la disciplina Curso intensivo de codificación agente. Modo de plan, archivos de reglas, comandos de barra diagonal, el flujo de trabajo de lectura primero y luego escritura.
- Has realizado al menos un ciclo PRIMM-AI+. Las indicaciones de predicción de este curso asumen el ritmo.
- Tienes Node.js 20+ disponible, incluso si tu agente es Python. El servidor de desarrollo Inngest se distribuye como un nodo CLI (
npx inngest-cli@latest dev).- Tienes un modelo mental funcional de "basado en eventos" frente a "solicitud/respuesta". Si "el mundo emite un evento y cero, una o muchas funciones reaccionan a él" te resulta familiar, estás calibrado. Si no, el Concepto 1 te da la forma.
Cómo leer esta página en la primera pasada (haz clic para expandir)
- Ampliar en la primera lectura: cualquier elemento etiquetado como "Lo que verá", "Ejecución de muestra", "Resultado esperado", "Verificar". Comportamiento ejecutable para comparar las predicciones.
- Saltar en la primera lectura: listados de archivos largos en el ejemplo resuelto de la Parte 4. La narrativa sobre cada bloque te dice qué cambió; solo necesita el contenido del archivo cuando realmente lo compila.
- Opcional durante toda la página: los bloques "Prueba con IA". Son prompts de extensión para Claude Code u OpenCode conectados al MCP del servidor de desarrollo de Inngest.
El objetivo de la primera pasada es interiorizar el modelo de tres capas: los disparadores despiertan al Worker, la ejecución duradera lo mantiene correcto y el control de flujo lo mantiene saludable. La segunda pasada, con las manos en el teclado, es donde construyes.
Glosario: términos que encontrarás (haz clic para expandir)
Cada término se explica en el contexto donde aparece por primera vez; esta lista es una referencia rápida de los términos que más probablemente dificulten una primera lectura.
- Production Worker: Un Digital FTE con una envolvente operativa: disparadores que lo despiertan, ejecución duradera que sobrevive a fallos y control de flujo que lo escala bajo carga.
- Evento: Un mensaje con nombre e inmutable que describe que algo ocurrió. Ejemplo:
{"name": "customer/email.received", "data": {"customer_id": "..."}}. Es la superficie de disparo. - Función de Inngest: Una función Python decorada con
@inngest_client.create_function, que declara disparadores y pasos. Es la unidad de trabajo duradero. - Paso: Una unidad de trabajo dentro de una función de Inngest envuelta en
ctx.step.run(),ctx.step.sleep(),ctx.step.wait_for_event()octx.step.ai.infer(). Cada paso se reintenta y se memoiza de forma independiente. - Memoización: Cuando una función falla y se reinicia, Inngest vuelve a ejecutar el código de la función desde arriba, pero devuelve salidas almacenadas para cualquier
step.runcuyo resultado ya esté en caché. La función alcanza el punto donde se interrumpió sin rehacer el trabajo. - Control de flujo: Políticas por función:
concurrency(ejecuciones activas máximas),throttle(inicios máximos por segundo),priority(orden de cola),batch_events(acumular antes de invocar). - HITL (Humano en el bucle): una función se detiene para esperar la aprobación o entrada humana antes de continuar.
step.wait_for_eventes la primitiva. - Replay: Volver a ejecutar una función fallida desde donde se interrumpió, con el código nuevo después de corregir un error.
- Servidor de desarrollo: Entorno de desarrollo local de Inngest mediante
npx inngest-cli@latest dev. Panel enhttp://127.0.0.1:8288; endpoint MCP en/mcp.
Actual al 14 de mayo de 2026. Verificado con inngest-py 0.5.18 (lanzado el 11 de marzo de 2026), Inngest CLI v1+ y Inngest Python inicio rápido. La arquitectura de ejecución duradera que este curso enseña no cambia cuando lo hace el SDK; el SDK es la interfaz de este año para esa arquitectura.
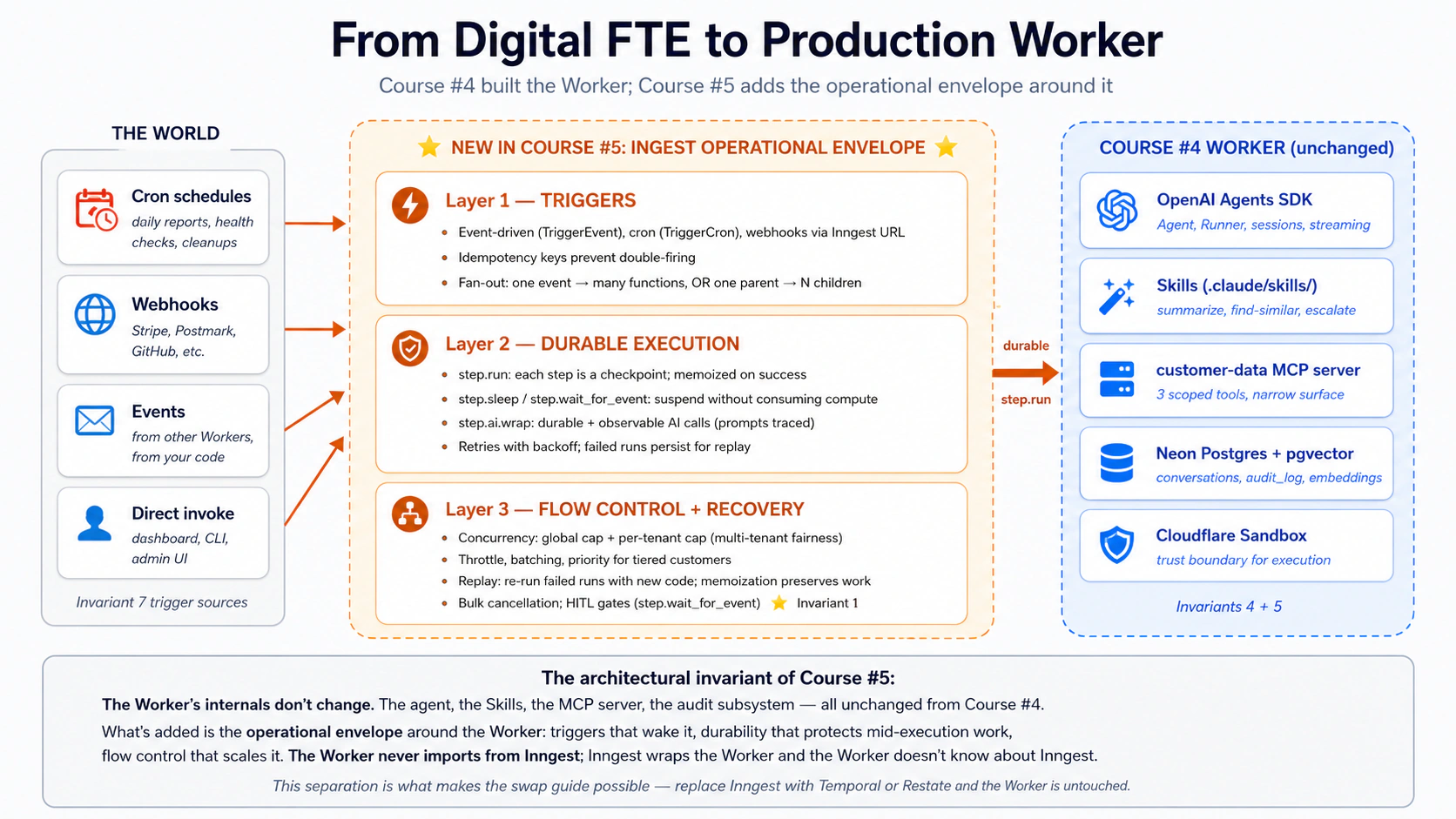
La pila de los cursos n.º 3 y n.º 4 es la base de este curso, no un escalón que dejamos atrás. El Worker de la Parte 4 todavía usa Agent, Runner, function_tool, habilidades de .claude/skills/, el servidor MCP customer-data y el esquema de seis tablas con auditoría. Lo que cambia: esas primitivas ahora se ejecutan dentro de funciones de Inngest que envuelven cada invocación del agente en step.run() para durabilidad, declaran disparadores de eventos/cron y aplican políticas de concurrencia y throttling. Las partes internas del Worker no cambian. Cambia su envolvente operativa.
Este es un curso primero Python, como sus predecesores, y usa inngest-py, el SDK de Python de Inngest. El servidor de desarrollo de Inngest es independiente del lenguaje; funciona con el SDK oficial de Python igual que con TypeScript o Go.
El patrón de herramienta dual continúa. Las secciones que divergen entre Claude Code y OpenCode tienen un conmutador; elige uno y la página se sincronizará entre visitas.
Hay un ejemplo trabajado completo en la Parte 4: el Worker de atención al cliente del curso n.° 4 envuelto en una capa de Inngest, con disparadores de eventos, comprobaciones de estado cron, puertas de escalada HITL, límites de concurrencia y soporte completo para replay. Ocho decisiones de construcción, con la misma forma que en los cursos 3 y 4. Si aprendes mejor haciendo que leyendo definiciones, hojea las Partes 1 a 3 y salta a la Parte 4.
Arquitectura en una línea. Motor = OpenAI Agents SDK + Cloudflare Sandbox (Curso #3). Capacidad + Verdad + Conector = habilidades + Neon Postgres + MCP (Curso #4). Envolvente operativa = disparadores de Inngest + ejecución duradera + control de flujo (Curso #5, este). Las partes internas del Worker no cambiaron desde el Curso #4; lo nuevo es la capa superior que permite que el mundo lo despierte, que los fallos no pierdan estado y que un Worker atienda tráfico equivalente al de toda una fuerza laboral. Si solo una frase de todo este documento se queda contigo, que sea esta.
La victoria rápida en quince minutos: comprueba la durabilidad con tus propios ojos
Antes de leer los 15 conceptos que explican por qué funciona esta arquitectura, crea la versión más pequeña posible que realmente funcione. Dos archivos, cuatro comandos uv y npx, una sesión de shell. Al final de esta sección tendrás:
- una función de Inngest con un
step.runy unstep.sleep - el servidor de desarrollo Inngest ejecutándose localmente con un panel en
http://127.0.0.1:8288 - una ejecución exitosa que activaste desde el panel
- una ejecución fallida que reprodujiste después de corregir el error, viendo cómo los pasos completados vuelven desde la memoización sin ejecutarse otra vez
Este no es el ejemplo práctico de la Parte 4; ese es el Production Worker completo, ocho Decisiones, cientos de líneas. Esta es una pantalla. Si solo tienes una sesión, haz esto y luego regresa para ver los conceptos cuando quieras saber por qué cada pieza tuvo la forma que tenía.
Paso 1. Crea un directorio de proyecto nuevo e instala el SDK junto con un framework web mínimo. (Puedes cambiar fastapi por cualquier framework ASGI compatible con Inngest; FastAPI es el más simple).
mkdir hello-inngest && cd hello-inngest
uv init
uv add inngest "fastapi[standard]"
Paso 2. Escribe un archivo con una función duradera. Guárdalo como hello.py:
# hello.py
import logging
from datetime import timedelta
import inngest
import inngest.fast_api
from fastapi import FastAPI
inngest_client = inngest.Inngest(
app_id="hello-inngest",
logger=logging.getLogger("uvicorn"),
is_production=False,
)
@inngest_client.create_function(
fn_id="greet-customer",
trigger=inngest.TriggerEvent(event="demo/greet"),
)
async def greet_customer(ctx: inngest.Context) -> dict[str, str]:
name = ctx.event.data.get("name", "friend")
greeting = await ctx.step.run("compose-greeting", lambda: f"Hello, {name}!")
await ctx.step.sleep("wait-fifteen-seconds", timedelta(seconds=15))
farewell = await ctx.step.run("compose-farewell", lambda: f"Goodbye, {name}.")
return {"greeting": greeting, "farewell": farewell}
app = FastAPI()
inngest.fast_api.serve(app, inngest_client, [greet_customer])
Tres cosas a tener en cuenta. La forma de la función es Python simple: un async def decorado con create_function. Las dos llamadas ctx.step.run envuelven operaciones que deben memoizarse. El ctx.step.sleep entre ambas suspende la función de forma duradera (el proceso puede fallar, reiniciarse o redesplegarse durante la espera; la ejecución se reanuda en la línea siguiente cuando se activa el temporizador).
Paso 3. Inicia la función host en una terminal.
uv run uvicorn hello:app --reload --port 8000
Deberías ver que uvicorn informa Started server process y Application startup complete. El host de la función ahora escucha en http://127.0.0.1:8000/api/inngest.
Paso 4. En una segunda terminal, inicia el servidor de desarrollo de Inngest.
npx inngest-cli@latest dev
El servidor de desarrollo imprime un banner y abre un panel en http://127.0.0.1:8288. Descubre automáticamente el host de funciones que iniciaste en el Paso 3.
Paso 5. Abre http://127.0.0.1:8288 en un navegador. Haz clic en Funciones en la barra lateral; deberías ver greet-customer en la lista. Haz clic en Eventos en la barra lateral y luego en Enviar evento. Pega esta carga útil y haz clic en Enviar:
{
"name": "demo/greet",
"data": { "name": "Sara" }
}
Paso 6. Haz clic en Ejecutar en la barra lateral. Verás una ejecución de greet-customer con estado En ejecución y un paso etiquetado como compose-greeting marcado como completado. Haz clic en la ejecución para ver el seguimiento de pasos.
Paso 7. Observa el paso wait-fifteen-seconds. El panel lo muestra en estado Inactivo con la hora de reanudación. No se está ejecutando nada en tu código. La terminal de uvicorn está inactiva. Después de quince segundos, la ejecución se reanuda, compose-farewell se completa y el estado de la ejecución cambia a Completado. Abre el panel Salida para ver el diccionario devuelto.
Paso 8. Ahora rómpelo a propósito. En hello.py, agrega una pequeña función auxiliar encima de greet_customer y haz que el paso la llame:
def fail_on_purpose() -> str:
raise RuntimeError("forced failure")
# ...inside greet_customer, replace the compose-farewell step:
farewell = await ctx.step.run("compose-farewell", fail_on_purpose)
Guarda el archivo; uvicorn recarga automáticamente. Envía otra vez el mismo evento demo/greet desde el panel. Observa la ejecución: compose-greeting se completa, wait-fifteen-seconds duerme y se reanuda, compose-farewell reintenta con backoff (Inngest tiene cuatro intentos de forma predeterminada) y luego la ejecución llega al estado Error con RuntimeError visible en el seguimiento de pasos.
Ahora corrige el error: revierte compose-farewell al lambda: f"Goodbye, {name}." original. Guarda. En el panel, haz clic en la ejecución fallida y luego en Replay. Observa el replay: compose-greeting se completa en milisegundos (acierto de memoización, no se vuelve a ejecutar), wait-fifteen-seconds se completa en milisegundos (acierto de memoización), compose-farewell se ejecuta de verdad con el código nuevo y tiene éxito. La ejecución se completa.
Acabas de ejecutar una función duradera, observaste un paso suspendido sin consumir cómputo, lo rompiste, lo arreglaste e hiciste replay. Los siguientes 90 minutos amplían esto:
- disparadores reales (cron, webhook, fan-out),
- durabilidad real (la invocación del agente envuelta en
step.run), - control de flujo real (concurrencia, throttling, prioridad),
- y la puerta HITL que convierte "el agente podría estropear esto" en "el agente redacta, una persona aprueba, la acción se emite".
Si algo no funcionó, los fallos más comunes de Quick Win son:
- El servidor de desarrollo no puede alcanzar el host de funciones (verifica que uvicorn se esté ejecutando en el puerto 8000).
is_production=Falsefalta en el constructor del cliente (sin él, SDK requiere una clave de firma).- La función no aparece en el panel (uvicorn no recargó automáticamente; reinícialo manualmente).
- La ejecución se bloquea sin errores ni progreso (un host desincronizado produce pausas silenciosas; reinicia juntos el host de funciones y el servidor de desarrollo, y ejecuta un host de funciones por servidor de desarrollo).
Cuatro problemas, cuatro soluciones, luego continúa.
Parte 1: Disparadores, cómo el mundo llama al Worker
El Worker del curso #4 se ejecuta cuando lo llamas. Un Production Worker real se ejecuta cuando el mundo emite eventos: llega un correo de un cliente, entra un webhook, un cron se activa a las 09:00 todos los días, otro Worker delega trabajo. Los cinco conceptos de la Parte 1 establecen el modelo mental basado en eventos, las tres superficies de disparo (cron, webhook, evento), la semántica que evita el doble procesamiento y los patrones de fan-out que permiten que un evento despierte a muchos Workers.
Concepto 1: Eventos versus solicitudes, el cambio duradero del modelo mental
Una solicitud es una conversación sincrónica. Alguien llama; tú gestionas; devuelves una respuesta; la otra parte continúa. Una conexión permanece abierta; una persona o servicio está esperando. Si falla, quien llama recibe un error. El agente de chat del Curso #4 es una solicitud: escribiste, se transmitió la respuesta, la conversación pertenecía a tu sesión de terminal.
Un evento es un mensaje asincrónico. Algo sucedió en el mundo (un cliente se registró, llegó un correo electrónico, se liquidó un pago) y el autor emite un registro con nombre de ese hecho. Cero, una o muchas funciones reaccionan al evento de forma independiente. Ninguna conexión permanece abierta. El emisor no sabe quién está escuchando, no espera resultados y no está bloqueado. El mundo ha avanzado.
# A request: I'm here, waiting, blocking
result = await agent.handle_customer_message(text=user_input)
print(result) # I unblock when the agent finishes
# An event: I fire-and-forget
await inngest_client.send(events=[
inngest.Event(
name="customer/email.received",
data={"customer_id": "c-4429", "body": email_body, "subject": subject},
),
])
# I return immediately. Somewhere else, one or more Inngest
# functions react to this event on their own schedule.
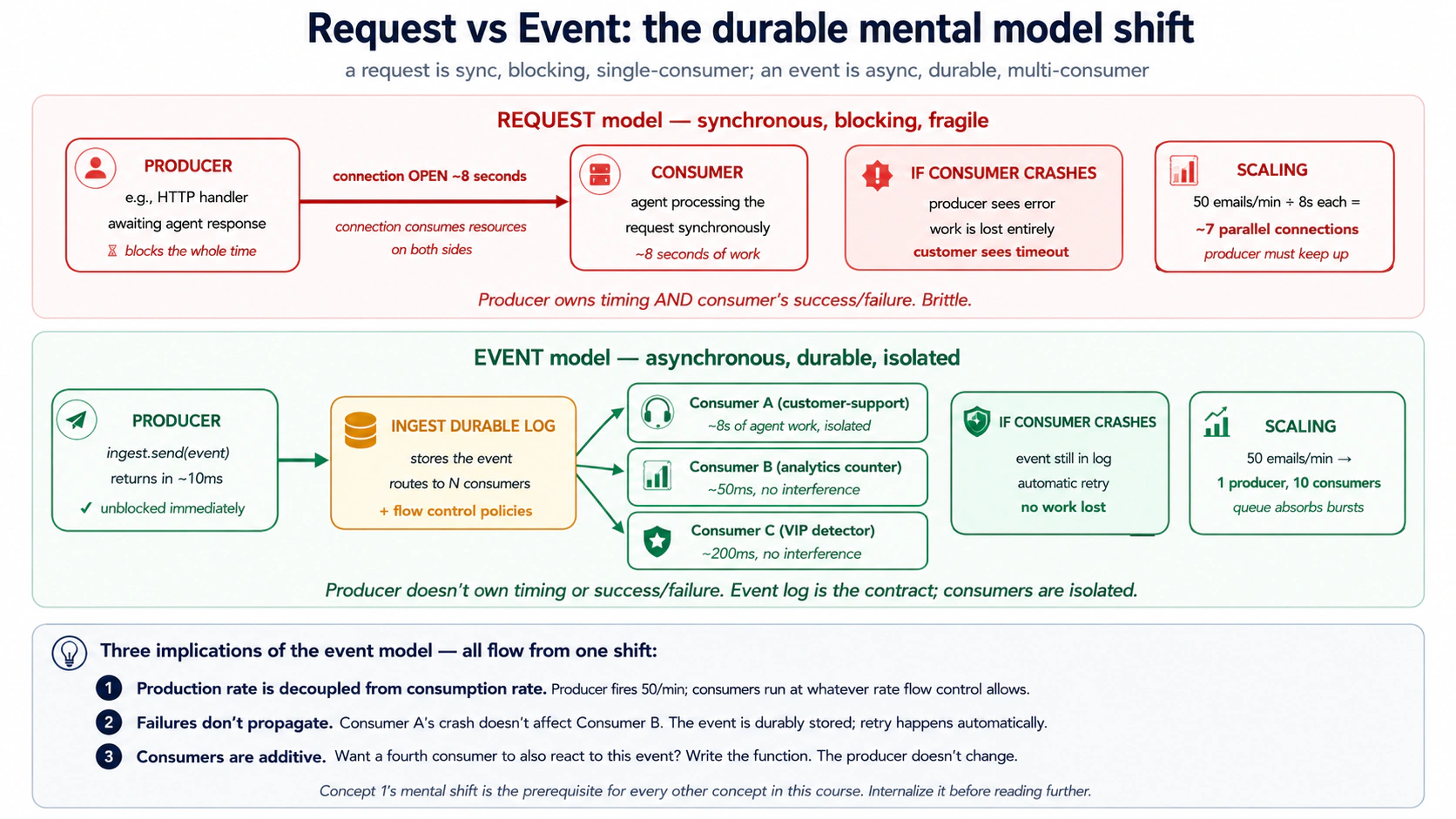
El cambio suena pequeño. No lo es. Una vez que piensas en los eventos, la durabilidad y la escala salen casi gratis, porque:
- El consumidor no puede ralentizar al productor (el receptor del correo electrónico no espera a que el agente termine de redactar una respuesta).
- El consumidor puede fallar y reiniciar sin perder el trabajo (el evento se almacena de forma duradera; Inngest lo vuelve a entregar).
- Se pueden agregar nuevos consumidores sin cambiar de productor (una segunda función, por ejemplo un contador de análisis, puede suscribirse a
customer/email.receivedsin que el destinatario del correo electrónico lo sepa). - La contrapresión se convierte en una política de control de flujo, no en un cambio de código (Inngest limita la concurrencia; el productor sigue emitiendo eventos; la cola los absorbe).
El resto de este curso son implicaciones de este único cambio mental.
PRIMM, Predict. Tu Worker de atención al cliente tarda 8 segundos en responder a un correo electrónico: tres segundos para el razonamiento del agente, cuatro segundos para dos llamadas a herramientas MCP y un segundo para la escritura en la base de datos. En la carga máxima, recibe 50 correos por minuto. Si usas el modelo de solicitud (el analizador de correo se bloquea hasta que el agente termina), ¿cuántas conexiones HTTP paralelas hacia tu analizador implica eso? Si usas el modelo de eventos (el analizador emite un evento y vuelve de inmediato), ¿cuántas? Confianza 1-5.
La respuesta: el modelo de solicitud necesita aproximadamente 7 analizadores simultáneos (50/min × 8 segundos = ~6,7 manejadores paralelos, más margen). El modelo de eventos necesita un analizador (emite el evento y vuelve en unos 10 ms; la cola de eventos absorbe el pico de 50/min; las funciones de Inngest consumen la cola con la concurrencia que se permita). El modelo de eventos desacopla la tasa de producción de la tasa de consumo. Esto no es solo un dato de escala; es una decisión arquitectónica. El evento se convierte en un límite duradero entre "lo que ocurrió en el mundo" y "lo que el Worker hace al respecto". Haz fallar al consumidor a mitad del procesamiento y el evento seguirá allí para reintentarse. Agrega tres tipos de consumidores más y el productor ni se entera. Los eventos son la forma de dejar de ser dueño del momento exacto en que se hace el trabajo.
Prueba con IA
Walk me through three scenarios. For each, classify it as REQUEST-MODEL
or EVENT-MODEL, and explain which one fits better:
A) A user clicks "Submit refund request" in the support portal and
expects to see "Refund issued: $30" within 2 seconds.
B) A nightly cron job at 02:00 runs a customer-health-check across
all 5,000 customers and writes a report to Slack.
C) A customer sends an email to support@; we want a draft response
ready within 60 seconds for the on-call agent to review and send.
For each, name (a) what the human's expectation of timing is and
(b) what failure looks like if the model crashes mid-execution.
Concepto 2: Disparadores cron, trabajo que se ejecuta porque pasó el tiempo
El disparador más simple es el reloj. Muchas cosas que hace un Production Worker no son reacciones a eventos externos; son trabajos programados: informes de salud diarios, limpiezas semanales, recálculos horarios. El disparador cron de Inngest es una línea de código.
import inngest
@inngest_client.create_function(
fn_id="daily-customer-health-check",
trigger=inngest.TriggerCron(cron="0 9 * * *"), # 09:00 every day, UTC
)
async def daily_health_check(ctx: inngest.Context) -> dict[str, int]:
"""Run a customer-health pass for every Pro/Enterprise customer."""
customers = await ctx.step.run("fetch-pro-customers", fetch_pro_customer_ids)
# fan out: one event per customer, one Worker run per event
await ctx.step.run("fan-out", fan_out_per_customer_events, customers)
return {"customers_scheduled": len(customers)}
Tres cosas a tener en cuenta:
-
La programación es solo sintaxis cron estándar.
0 9 * * *son las 09:00 UTC todos los días;*/15 * * * *es cada 15 minutos;0 9 * * 1es los lunes a las 09:00. Inngest evalúa el cron en UTC; si necesitas otra zona horaria, eso es un parámetro de función, no un concepto distinto. -
La función todavía usa
ctx.step.run. Activada por cron o por evento, la forma de la función es idéntica. Los pasos funcionan igual. La durabilidad funciona igual. El control de flujo funciona igual. El disparador es simplemente cómo se inicia la función. -
La salida cron es una ejecución normal de una función de Inngest. Aparece en el panel, tiene una ID de ejecución, tiene un seguimiento y admite replay. Si la ejecución del cron del lunes por la mañana falla en el paso 3, el cron del martes se ejecutará normalmente y el fallo del lunes seguirá disponible para replay después de corregir el error.
¿Qué sucede si tu servicio no funciona cuando se activa el cron? Esta es la pregunta que separa a los programadores reales de los temporizadores de cocina. Las ejecuciones cron de Inngest se registran de forma duradera en el momento en que se activa la programación; si no se puede alcanzar el endpoint de tu función, Inngest reintenta con backoff hasta que tenga éxito o alcance el límite de reintentos. El cron activado a las 09:00 no se "pierde" porque tu despliegue estaba en curso a las 09:00; la ejecución espera, terminas el despliegue y la ejecución se completa. Los disparadores cron en desarrollo tienen una peculiaridad útil: el servidor de desarrollo local solo activa crons mientras está en ejecución. Producción los ejecuta en la infraestructura de Inngest, que siempre está activa.
Comprobación rápida. Tres afirmaciones. Marca cada una como Verdadera o Falsa. (a) Si una función cron tarda 45 minutos en ejecutarse y se programa cada 15 minutos, se ejecutarán tres instancias concurrentes en un momento dado. (b) Puedes usar
step.sleepdentro de una función activada por cron para distribuir el trabajo a lo largo del día. (c) También se puede invocar manualmente una función activada por cron desde el panel para realizar pruebas.
Respuestas: (a) Depende de la política de concurrencia: de forma predeterminada, Inngest pondrá en cola las ejecuciones superpuestas; si configuras concurrency=1, se serializan; si configuras concurrency=10, se paralelizan. El valor predeterminado es sensato. (b) Verdadero y es un patrón común para "repartir el trabajo diario durante varias horas para suavizar la carga". (c) Verdadero: el panel de Inngest permite invocar cualquier función bajo demanda para pruebas, sin importar su disparador.
Prueba con IA
With my AI coding assistant connected to the Inngest dev server MCP,
write a cron-triggered Inngest function in Python that:
1. Runs every Monday at 09:00 UTC.
2. Queries the audit_log table for all conversations resolved in the
prior week (status='resolved' in that window).
3. Computes per-agent metrics: total conversations resolved, average
resolution time, count of escalations, count of refunds issued.
4. Returns the metrics as a JSON object.
After you write the function, use the MCP's `invoke_function` tool to
test it manually (instead of waiting for Monday). Confirm the audit
SQL is correct by using `grep_docs` to search Inngest's docs for
"step.run" examples.
Concepto 3: Disparadores de webhook, cuando llama el mundo exterior
La segunda superficie de disparo es HTTP. Un sistema externo (Stripe, tu proveedor de correo electrónico, un formulario del portal de clientes, un webhook de GitHub) quiere llamar a tu Worker. Sin Inngest, tendrías que levantar un endpoint HTTPS, analizar la carga útil, validar la fuente, escribir en una cola, escribir un Worker que consuma de la cola, manejar reintentos, manejar idempotencia y enviar telemetría. Cada elemento es una semana de trabajo de infraestructura.
Con Inngest, el endpoint ya existe. Configuras un webhook en el panel de Inngest con una URL como https://inn.gs/e/<your-key>, apuntas Stripe (o el sistema que sea) a esa URL y la carga útil del webhook se convierte en un evento en tu flujo de eventos. Entonces se activa cualquier función con un disparador de nombre de evento coincidente.
@inngest_client.create_function(
fn_id="handle-stripe-refund-failed",
trigger=inngest.TriggerEvent(event="stripe/charge.refund.failed"),
)
async def on_refund_failed(ctx: inngest.Context) -> dict[str, str]:
"""Triggered by Stripe webhook → Inngest event → this function."""
charge_id = ctx.event.data["charge_id"]
customer_id = ctx.event.data["customer_id"]
# Look up which support ticket originated this refund
ticket = await ctx.step.run(
"find-ticket-for-refund", lookup_ticket_by_charge, charge_id,
)
# Wake the customer-support Worker with the full context
await ctx.step.run(
"notify-support-agent",
notify_support_agent_of_refund_failure,
ticket_id=ticket["id"], charge_id=charge_id,
)
return {"ticket": ticket["id"], "action": "notified"}
El flujo: Stripe no puede reembolsar un cargo → Stripe hace POST a la URL del webhook de Inngest → Inngest crea un evento llamado stripe/charge.refund.failed → la función anterior (que coincide con ese nombre de evento) se activa → la función usa pasos para buscar el ticket y notificar al agente de soporte. No tienes que escribir nada del cableado HTTP: sin endpoint propio, sin analizador, sin cola, sin consumidor.
Dos patrones adyacentes que vale la pena nombrar:
- Webhooks JSON genéricos. Si la fuente no es un proveedor conocido, apunta cualquier servicio que emita JSON al mismo tipo de endpoint y elige el nombre del evento. Los nombres con namespaces separados por barra (
vendor/event.subtype) son la convención; nada la impone, pero el panel queda ordenado cuando la sigues. - Transformaciones de webhook. Si la carga útil entrante no coincide con la forma que quieres, Inngest permite definir una función de "transformación" que se ejecuta del lado del servidor en el momento de la recepción y reformatea el evento antes de que entre en tu flujo de eventos. Esto mantiene el código de la función libre de campos específicos del proveedor.
PRIMM, Predict. Un webhook de Stripe activa
stripe/charge.refund.failedexactamente en el mismo milisegundo en que tu Worker de atención al cliente también llama ainngest_client.sendpara emitir un evento diferente llamadocustomer/refund.investigation_needed. Ambos eventos llegan al sistema al mismo tiempo; la función anterior se activa solo con el evento de Stripe. ¿La función se ejecutará una o dos veces? Confianza 1-5.
La respuesta: una vez. La función está registrada para activarse solo con stripe/charge.refund.failed; el evento customer/refund.investigation_needed tiene otro nombre y coincide con otra función (o con ninguna, si no escribiste una). El nombre de un evento es su clave de enrutamiento. Dos eventos con nombres distintos nunca activan accidentalmente la misma función, incluso si llegan en el mismo instante. Por eso importa la disciplina de nombres: un error tipográfico en el nombre de un evento (customer/email_received vs customer/email.received) significa que la función nunca se activa, y el síntoma es silencioso. El panel de Inngest ayuda a detectarlo: los eventos no coincidentes aparecen en una secuencia separada que puedes auditar.
Prueba con IA
I need to handle three webhook sources for my customer-support Worker:
A) Stripe: refund failed, charge disputed
B) Postmark (email service): bounced email, complaint
C) My internal admin UI: manual "investigate this ticket" button
For each, decide:
1. What event names you'd use (vendor/event.subtype format).
2. Whether the function reacting to it should run synchronously (the
caller is waiting) or asynchronously (fire and continue).
3. Whether you'd write a webhook transform to reshape the payload, or
consume it raw.
Then write the Inngest function for the Stripe refund-failed case in
Python, using the MCP's grep_docs to find the current syntax for
TriggerEvent and the dev-server MCP's send_event tool to test it.
Concepto 4: Idempotencia y semántica de eventos, el mismo evento se dispara dos veces
Los webhooks no se entregan exactamente una vez. Son al menos una vez: el remitente vuelve a intentarlo si no recibe un acuse de recibo. Las redes descartan paquetes, los servicios se reinician, tu endpoint agota el tiempo de espera y el remitente reintenta aunque la acción anterior sí haya ocurrido. Sin idempotencia, todo sistema de webhooks termina facturando, enviando correos o reembolsando dos veces a alguien. No es una preocupación teórica; es el error de producción más común en los sistemas de eventos.
Dos capas de defensa, ambas integradas en Inngest.
Capa 1: semillas de ID de evento en el origen. Cuando envías un evento tú mismo (en lugar de recibirlo desde un webhook), puedes adjuntar una clave de idempotencia:
await inngest_client.send(events=[
inngest.Event(
name="customer/refund.requested",
data={"order_id": "o-4429", "amount_cents": 5000},
id=f"refund-request-{order_id}-{request_timestamp}", # idempotency key
),
])
Si se envía un segundo evento con el mismo id dentro de la ventana de deduplicación (24 horas de forma predeterminada), Inngest descarta el duplicado. Mismo evento lógico, mismo identificador, una sola ejecución de función.
Capa 2: Idempotencia a nivel de paso. Dentro de una función, cada step.run se identifica por su nombre. Si una función falla entre el paso 3 y el paso 4, el reintento vuelve a ejecutar el código de la función desde la parte superior, pero para los pasos 1, 2 y 3, Inngest devuelve las salidas almacenadas sin volver a ejecutar el cuerpo del paso. El paso 4 se ejecuta normalmente por primera vez. Esto es lo que hace que una función sea "duradera": los efectos secundarios de los pasos completados no vuelven a ocurrir al reintentar.
@inngest_client.create_function(
fn_id="issue-customer-refund",
trigger=inngest.TriggerEvent(event="customer/refund.requested"),
)
async def issue_refund(ctx: inngest.Context) -> dict[str, str]:
# Step 1: look up the order. If the function retries, this returns
# the SAME order data it computed the first time, from Inngest's memo.
order = await ctx.step.run(
"lookup-order", lookup_order_by_id, ctx.event.data["order_id"],
)
# Step 2: call Stripe. If the function retries AFTER this step
# succeeded, the Stripe call does NOT happen again. The refund is
# issued exactly once even if the function runs three times.
refund = await ctx.step.run(
"issue-stripe-refund", call_stripe_refund_api,
charge_id=order["stripe_charge_id"],
amount=ctx.event.data["amount_cents"],
)
# Step 3: write the audit row. Same property: runs at most once.
await ctx.step.run(
"audit-refund", write_audit_refund_issued,
order_id=order["id"], refund=refund,
)
return {"refund_id": refund["id"]}
Si esta función falla durante el paso 3, el reintento vuelve al paso 1 (obtiene datos de pedido en caché, sin llamada a la base de datos), vuelve al paso 2 (obtiene datos de reembolso en caché, sin llamada a Stripe), ejecuta el paso 3 de verdad y retorna. La tarjeta del cliente se carga una vez, incluso si la función se ejecutó tres veces. Esta es la propiedad central. Es lo que hace que Inngest sea cualitativamente distinto de una cola con un bucle de reintento.
La memoización de Inngest permite completar el paso exactamente una vez desde la perspectiva de la función: una vez que step.run registra un paso como exitoso, no se volverá a ejecutar. Pero hay una ventana estrecha. Si el cuerpo de tu paso llama a Stripe (el efecto secundario ocurre en los servidores de Stripe) y luego falla antes de que Inngest registre el resultado, el reintento volverá a llamar a Stripe. Desde la perspectiva de Inngest, el paso "no se completó". Desde la perspectiva de Stripe, el cargo ya ocurrió. El patrón de producción es memoización de pasos en Inngest más claves de idempotencia a nivel de proveedor: encabezado Idempotency-Key de Stripe, reutilización de MessageID de Postmark, contrato de idempotencia de tu propio servidor MCP. Trata step.run y las claves de idempotencia del proveedor como complementos, no como sustitutos: step.run mantiene la lógica interna de tu función exactamente una vez; la clave de idempotencia del proveedor mantiene el efecto secundario externo exactamente una vez.
Comprobación rápida. Verdadero o falso. (a)
step.runhace que el paso sea idempotente solo si la función interna también es idempotente. (b) Un evento con un ID duplicado fuera de la ventana de desduplicación se tratará como un evento nuevo. (c) Sistep.runfalla en mitad de la ejecución (el código del paso genera una excepción), Inngest almacena el error y vuelve a intentar el paso en el siguiente intento sin volver a ejecutar los pasos anteriores.
Respuestas: (a) Falso: step.run hace que la invocación del paso sea idempotente (se ejecutará como máximo una vez si tiene éxito), pero si la función interna no es idempotente (como llamar a Stripe), esa garantía de como máximo una vez es exactamente lo que quieres. El punto es que no tienes que hacer idempotente por tu cuenta la llamada a Stripe. (b) Verdadero: la ventana de deduplicación de Inngest es de 24 horas de forma predeterminada; los eventos con el mismo ID después de esa ventana se tratan como nuevos. (c) Verdadero: el replay del fallo conserva la memoización; Inngest sabe que el paso 3 falló en el intento 1 y vuelve a intentar solo el paso 3 en el intento 2. Los pasos anteriores exitosos no se vuelven a ejecutar.
Prueba con IA
Here are three scenarios. For each, decide: idempotency PROBLEM or
NO PROBLEM, and if it's a problem, what's the fix:
A) Stripe sends the same charge.refund.failed webhook three times
in 90 seconds (because their first two attempts timed out at
your endpoint). Your function emails the customer.
B) A customer clicks "Issue refund" three times because the page
was slow. Your function calls Stripe and writes audit_log.
C) Your nightly cron at 09:00 sends a customer-health-check event
to each Pro customer. If two crons fire at the same time (a deploy
bug), what happens?
For each problem case, propose ONE specific fix: event ID seed
inside the function, idempotency key in inngest_client.send, or
function-level deduplication on the trigger.
Concepto 5: Fan-out y delegación de subagente, un evento, muchos Workers
A menudo, un único evento debe activar el trabajo en muchos lugares. Es posible que el evento Stripe charge.refund.failed deba: notificar al agente de soporte, escribir para auditar, actualizar la puntuación de riesgo del cliente, alertar a las operaciones financieras y publicar en Slack. Cinco reacciones, todas independientes, todas de un solo evento.
El patrón Inngest: suscribir muchas funciones al mismo evento. Sin código de distribución; solo varios decoradores @inngest_client.create_function con el mismo TriggerEvent. Cada función se ejecuta de forma independiente, tiene sus propios reintentos, tiene su propio seguimiento de pasos y falla independientemente de las demás.
@inngest_client.create_function(
fn_id="refund-failed-notify-support",
trigger=inngest.TriggerEvent(event="stripe/charge.refund.failed"),
)
async def notify_support(ctx: inngest.Context) -> dict[str, str]:
# ... runs the customer-support Worker to draft a response ...
return {"status": "drafted"}
@inngest_client.create_function(
fn_id="refund-failed-update-risk-score",
trigger=inngest.TriggerEvent(event="stripe/charge.refund.failed"),
)
async def update_risk_score(ctx: inngest.Context) -> dict[str, float]:
# ... runs the risk-scoring Worker ...
return {"new_risk_score": 0.42}
@inngest_client.create_function(
fn_id="refund-failed-post-slack",
trigger=inngest.TriggerEvent(event="stripe/charge.refund.failed"),
)
async def post_to_slack(ctx: inngest.Context) -> None:
# ... posts a Slack notification ...
return None
Llega un webhook Stripe. Inngest crea un evento. Se activan tres funciones, cada una en su propia ejecución. Si post_to_slack falla porque Slack está inactivo, los otros dos no se ven afectados y se completan normalmente. La ejecución fallida se guarda en el panel para reproducirse una vez que Slack se recupere. Este es el núcleo de la coordinación multi-Worker y es el patrón arquitectónico que su futura capa de administrador (un curso posterior) compondrá a escala.
El otro patrón de distribución: un padre dispara N hijos. A veces, la distribución es dinámica. Tu cron diario debe activar un evento de salud del cliente para cada cliente Pro, que puede ser 500 o 5000 según la semana. La función principal envía N eventos:
from datetime import date
async def fan_out_per_customer_events(
customers: list[str],
) -> int:
events = [
inngest.Event(
name="customer/health_check.requested",
data={"customer_id": cid},
id=f"daily-health-{cid}-{date.today().isoformat()}", # idempotency
)
for cid in customers
]
await inngest_client.send(events=events)
return len(events)
Se envían 5000 eventos en una sola llamada send. Se ejecutan 5.000 funciones, cada una con su propio customer_id, cada una aislada y cada una reintentable de forma independiente. El control de flujo (Concepto 11) limita la cantidad de aplicaciones que se ejecutan simultáneamente para no derretir las API posteriores. La función cron regresa en segundos; la distribución se ejecuta a cualquier velocidad que permitan las políticas de control de flujo de Inngest.
La delegación de subagentes es un caso especial de distribución. Dentro de una ejecución de Worker, puede llamar a await inngest_client.send(...) para delegar subtareas a otros tipos de Worker. El padre no espera a los hijos a menos que utilice explícitamente step.invoke para ejecutarlos sincrónicamente y recopilar sus resultados.
PRIMM, Predict. Tienes tres funciones, todas activadas por
customer/email.received: el agente de atención al cliente que redacta una respuesta (15 segundos), un contador de análisis (50 ms) y un "detector VIP" que verifica si el cliente es de alto valor (200 ms). Cuando llega un correo electrónico, ¿cómo es la latencia visible para el usuario para cada una? Tres opciones: (a) las tres suman ~15 segundos; (b) las tres se ejecutan en paralelo, la latencia total es de ~15 segundos (la más lenta); (c) cada una se ejecuta de forma independiente sin ninguna latencia compartida. Confianza 1-5.
La respuesta: (c). Cada función es su propia ejecución, en su propia ranura de proceso. El agente de atención al cliente no bloquea el contador de análisis; el detector VIP no bloquea al agente. Desde fuera, la latencia de cualquier función en particular es simplemente el tiempo de esa función. Ninguna función espera nunca a una función hermana. Esta es la razón por la que se produce una distribución en abanico: los consumidores están aislados. Si el agente falla, el contador de análisis no se ve afectado.
Prueba con IA
Design the fan-out architecture for these three scenarios. For each,
sketch the event names and the functions that subscribe:
A) New customer signs up. Need to: send welcome email, create
Stripe customer, post to Slack #new-customers, write to
audit_log, schedule a 7-day follow-up.
B) Customer support email arrives. Need to: draft a reply (agent),
detect sentiment, check if VIP, update customer's "last contact"
timestamp, attach to the right ticket thread.
C) Daily cron at 09:00 needs to run customer-health-check on
~5,000 Pro customers. Each check takes ~30 seconds. We want
the whole batch to complete by 11:00 (a 2-hour window).
For each, decide: how many event types, how many subscriber
functions, what the idempotency story is, and one specific failure
mode this design protects against.
Parte 2: Ejecución duradera, qué sucede cuando algo se rompe
Los disparadores despiertan al Worker. La ejecución duradera hace que el Worker sobreviva a lo que viene después. El Worker del Curso #4 llama a un agente, el agente llama a tres herramientas, y las herramientas llaman a Postgres, Stripe y OpenAI: seis llamadas externas en una sola conversación, cualquiera de las cuales puede fallar. Sin durabilidad, un único fallo transitorio a mitad de la conversación reinicia todo el flujo desde arriba. La durabilidad es la propiedad que dice: cuando algo falla a mitad de ejecución, el trabajo ya completado permanece completo y la ejecución se reanuda desde donde se interrumpió. Inngest ofrece esto con una primitiva (step.run) y una mecánica de memoización por debajo. La Parte 2 explica ambas, además de las variantes basadas en tiempo (step.sleep, step.wait_for_event), la semántica de reintentos y las primitivas step.ai.
Nota para una primera lectura rápida. Si estás escaneando, los conceptos que cargan más peso son el 6 (
step.run) y el 7 (memoización). Los conceptos 8 a 10 se apoyan en ellos. Lee con atención el 6 y el 7; el resto se leerá rápido cuando tengas esos dos claros.
Concepto 6: step.run y el modelo de función duradera
Una función normal de Python se ejecuta una vez, de arriba a abajo. Si falla a la mitad, empieza desde arriba. Si hace tres llamadas API antes de fallar, el siguiente intento vuelve a hacer esas tres llamadas, las pagas de nuevo y posiblemente cobras dos veces a alguien.
Una función de Inngest es duradera. Cada operación que quieres controlar se envuelve en step.run(name, fn, ...). La función todavía se ejecuta de arriba a abajo en cada intento, pero los pasos que ya se completaron devuelven sus resultados almacenados en lugar de ejecutarse otra vez. La función "alcanza" el punto donde se interrumpió y luego continúa.
@inngest_client.create_function(
fn_id="customer-support-conversation",
trigger=inngest.TriggerEvent(event="customer/email.received"),
)
async def handle_email(ctx: inngest.Context) -> dict[str, str]:
customer_id = ctx.event.data["customer_id"]
# Step 1: load the customer record (one DB call)
customer = await ctx.step.run(
"load-customer", load_customer_by_id, customer_id,
)
# Step 2: load the conversation thread (one DB call)
thread = await ctx.step.run(
"load-thread", load_thread_for_customer, customer_id,
)
# Step 3: run the OpenAI Agents SDK agent (the Course Four Worker)
response = await ctx.step.run(
"run-agent",
run_customer_support_agent,
customer=customer,
thread=thread,
email_body=ctx.event.data["body"],
)
# Step 4: write the draft reply to the database
await ctx.step.run(
"save-draft-reply", save_reply,
customer_id=customer_id, text=response.draft,
)
# Step 5: notify the on-call human reviewer via Slack
await ctx.step.run(
"notify-reviewer", post_slack_for_review, response=response,
)
return {"status": "drafted", "reviewer_notified": True}
Cinco pasos. Cada uno tiene controles independientes.
Lo que la durabilidad te ofrece aquí, en tres escenarios de fallo:
-
Escenario A: el paso del agente agota el tiempo de espera. Sin
step.runenvolviendo la llamada del agente, el siguiente reintento de esta función vuelve a cargar el cliente, vuelve a cargar el hilo y vuelve a ejecutar el agente desde cero, pagando tokens de OpenAI dos veces por trabajo que el agente ya hizo parcialmente. Constep.run, las cargas del cliente y del hilo se memoizan (los pasos 1 y 2 no se vuelven a ejecutar); solo se reintenta el paso 3. Los reintentos automáticos de Inngest manejan errores transitorios de OpenAI sin que tu código tenga que saberlo. -
Escenario B: el proceso de la función se elimina entre el paso 3 y el paso 4 (un despliegue está en curso, se reinicia un nodo, el contenedor se queda sin memoria). Sin durabilidad, la respuesta del agente se pierde y el correo del cliente queda sin respuesta hasta que alguien lo nota. Con durabilidad, la función se reanuda después del reinicio: los pasos 1, 2 y 3 devuelven sus resultados almacenados en milisegundos, el paso 4 se ejecuta de verdad, el paso 5 se ejecuta de verdad y el cliente recibe la respuesta redactada.
-
Escenario C: Slack devuelve un 503 en el paso 5. Sin
step.run, perderías el trabajo o escribirías a mano lógica de reintento y backoff específicamente para la llamada a Slack. Constep.run, Inngest vuelve a intentar el paso 5 con backoff exponencial hasta que Slack se recupere; mientras tanto, los pasos 1 a 4 permanecen completos y no se vuelven a ejecutar. El borrador de respuesta ya está en la base de datos; la notificación es lo único pendiente.
No escribes ningún bucle de reintento, ninguna comprobación de "¿ya hice esto?" ni ninguna máquina de estados. La máquina de estados es la secuencia de llamadas step.run. Cada paso es un nodo; cada transición es duradera.
La única regla de step.run. La función pasada a step.run debe ser determinista dadas sus entradas: llamarla dos veces con los mismos argumentos debería producir el mismo resultado.
- Eso es automático para funciones puras.
- Es automático para llamadas API idempotentes (
idempotency_keyde Stripe, tus propias herramientas del servidor MCP). - Requiere atención para cosas como "generar una ID aleatoria" o "llamar a un LLM con la temperatura predeterminada" (un reintento podría producir un resultado diferente al intento original, lo que a veces es importante).
Cuando la operación no es determinista, conviértela en determinista: pasa una semilla, genera antes el valor aleatorio fuera del paso o acepta que el reintento puede diferir del original (a menudo está bien para una respuesta de agente).
Comprobación rápida. Verdadero o falso. (a) El cuerpo de la función se vuelve a ejecutar desde arriba en cada reintento, incluidas todas las importaciones y asignaciones de variables fuera de las llamadas
step.run. (b) Si un paso tarda 30 segundos en completarse y la función falla a los 25 segundos, el reintento continúa ese paso desde el segundo 25. (c) Las salidas destep.runse almacenan en la infraestructura de Inngest, no en tu aplicación.
Respuestas: (a) Verdadero y por eso mantienes el trabajo dentro de step.run. El código fuera de step.run se vuelve a ejecutar en cada reintento; el código interno se ejecuta una vez por intento y se memoiza si tiene éxito. (b) Falso: step.run es la unidad atómica; si se interrumpe un paso, el reintento vuelve a ejecutar el paso completo. Si tu paso es tan largo que no puedes permitir que se reinicie, divídelo en pasos más pequeños. (c) Verdadero: el almacén de salidas de pasos es parte de Inngest, no de tu base de datos. Por eso puedes hacer replay de ejecuciones incluso después de que cambie el esquema de tu base de datos.
La Decisión 4 del curso intensivo build-agents documenta un bug del SDK en la ruta de streaming de openai-agents==0.17.2 con los modelos de razonamiento de DeepSeek en turnos de llamada a herramientas: aparece un mensaje de asistente vacío falso entre el mensaje tool_calls y el resultado tool, y el analizador estricto de DeepSeek lo rechaza. Si tu Worker del Curso Cuatro transmite DeepSeek con @function_tool, aplica la alternativa de OpenAI de ese curso antes de envolver Runner.run_streamed en step.run más abajo.
Prueba con IA
With my AI coding assistant connected to the Inngest dev server MCP,
re-shape my Course Four customer-support Worker into an Inngest
durable function. Take the existing Runner.run_streamed invocation
that processes a customer email and wrap each of these inside its
own step.run:
1. Load the customer from the customer-data MCP server
2. Load the related conversation thread
3. Run the agent (the OpenAI Agents SDK Runner)
4. Persist the draft reply
5. Notify the on-call reviewer in Slack
Use grep_docs to find the current Python SDK syntax. Use
invoke_function to test it with a synthetic email payload. Then
deliberately raise an exception in step 4 and use get_run_status
to confirm steps 1-3 don't re-execute on retry.
Concepto 7: Memoización, la mecánica detrás de la reanudación
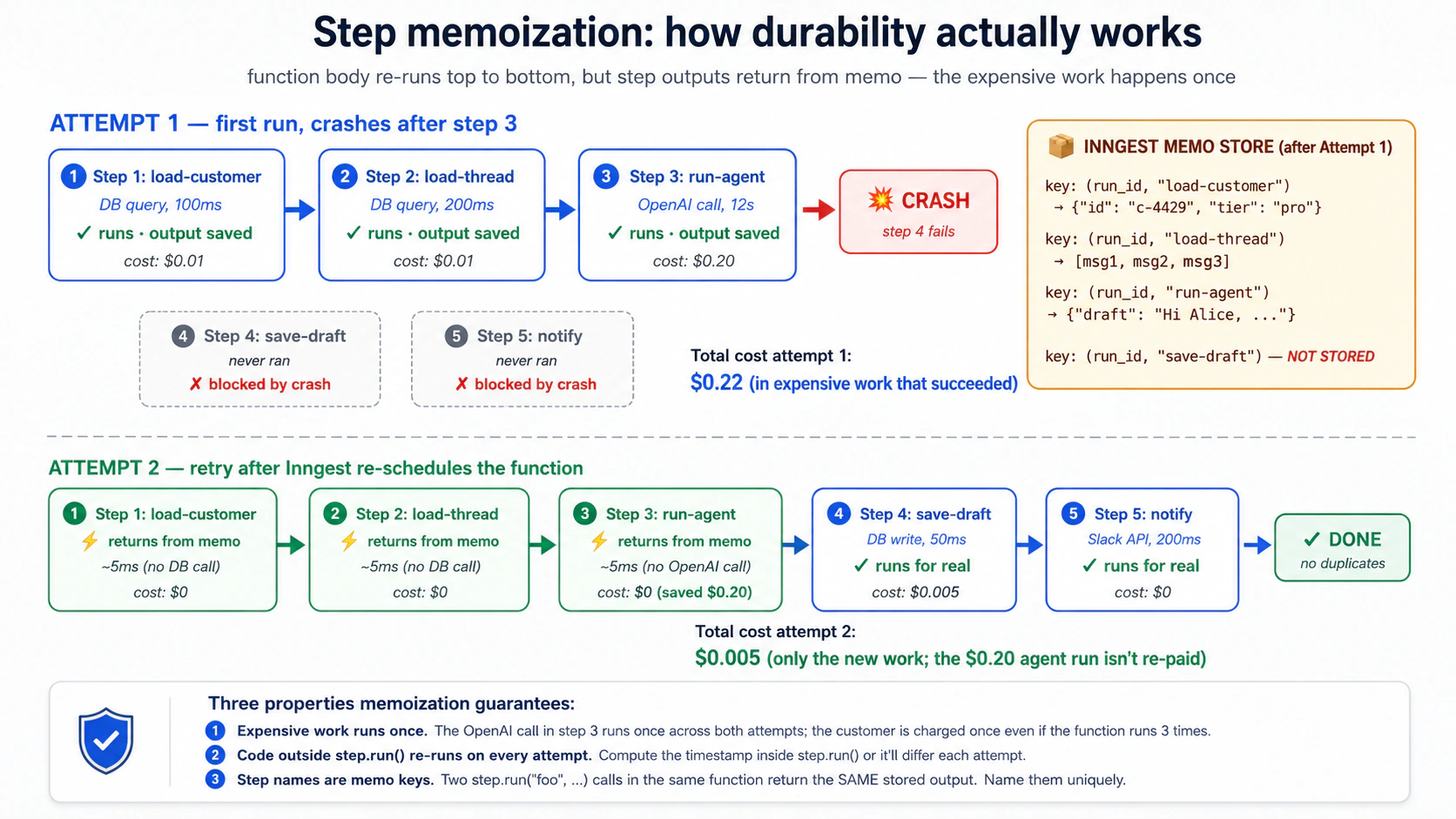
El Concepto 6 decía que "los pasos que ya se completaron devuelven sus resultados almacenados en lugar de ejecutarse otra vez". Ese mecanismo es memoización, y vale la pena entenderlo porque todas las demás primitivas de Inngest lo usan.
Cuando llamas a await ctx.step.run("load-customer", load_customer_by_id, "c-4429"), suceden tres cosas en el primer intento:
- Inngest comprueba su almacén de memoización: "¿hay un resultado almacenado para el paso
load-customeren esta ejecución?" No lo hay. - Se ejecuta la función
load_customer_by_id("c-4429"). Devuelve{"id": "c-4429", "tier": "pro", ...}. - Inngest escribe ese resultado en el almacén de memoización, con la clave
(run_id, step_name="load-customer"). Luego devuelve el resultado a tu código.
Si la función falla después del paso 3 y Inngest vuelve a intentarlo, en el segundo intento, el cuerpo de la función se vuelve a ejecutar desde arriba. Cuando la ejecución llega a la misma línea, suceden tres cosas diferentes:
- Inngest comprueba su almacén de memoización: "¿hay un resultado almacenado para el paso
load-customeren esta ejecución?" Sí, se almacenó en el intento 1. - La función
load_customer_by_id("c-4429")no se ejecuta. La llamada a la base de datos no se produce. - Inngest devuelve el resultado almacenado a tu código en milisegundos.
Esta es la razón por la que los reintentos son baratos: el trabajo costoso ya está almacenado en caché. Por eso la durabilidad es correcta: el trabajo costoso no se repite dos veces. Y por eso "el cuerpo de la función se vuelve a ejecutar de arriba a abajo" está bien aunque parezca un desperdicio: el trabajo dentro de los pasos en realidad no se vuelve a ejecutar; solo lo hace el código de orquestación entre pasos.
La implicación que sorprende a los nuevos usuarios. El código externo step.run se ejecuta en cada intento. Si haces esto:
async def handle_email(ctx: inngest.Context) -> dict[str, str]:
# ANTI-PATTERN: this runs on every retry. Don't do this.
expensive_thing: dict = await fetch_expensive_data(ctx.event.data["id"])
await ctx.step.run("do-something", do_something_with, expensive_thing)
return {"status": "done"}
fetch_expensive_data se ejecuta en cada reintento. Si cuesta $0,10 una llamada y la función lo reintenta 5 veces, acabas de gastar $0,50 obteniendo los mismos datos cinco veces. La solución es envolver lo caro en su propio paso:
async def handle_email(ctx: inngest.Context) -> dict[str, str]:
expensive_thing: dict = await ctx.step.run(
"fetch-expensive-data", fetch_expensive_data, ctx.event.data["id"],
)
await ctx.step.run("do-something", do_something_with, expensive_thing)
return {"status": "done"}
Ahora se memoriza fetch_expensive_data; Los reintentos no vuelven a pagar por ello.
El nombre del paso es la clave de memoización. Por eso los nombres de los pasos deben ser únicos dentro de una función. Si tienes dos llamadas step.run("load-customer", ...) en la misma función, Inngest devolverá la salida almacenada de la primera para ambas llamadas. Eso casi nunca es lo que quieres. Si tienes un bucle que llama a un paso N veces, asígnale un nombre exclusivo (step.run(f"load-customer-{i}", ...)) para que cada iteración tenga su propia ranura de memoización.
PRIMM, Predict. Tu función tiene tres pasos. El paso 1 (
load-customer) cuesta $0,01 en llamadas a la base de datos y tarda 100 ms. El paso 2 (run-agent) cuesta $0,20 en tokens OpenAI y tarda 12 segundos. El paso 3 (save-draft) cuesta $0,005 en llamadas a la base de datos y tarda 50 ms. El paso 2 falla el 30 % de las veces debido a los límites de velocidad de OpenAI; Inngest reintenta con retroceso. ¿Cuál es la diferencia de costo entre (a) envolver los tres enstep.runy (b) envolver solo el paso 2 enstep.run? Confianza 1-5.
La respuesta: con (a), un solo reintento cuesta solo el costo del paso 2 ($0,20). El cliente y el borrador se memoizan; no se vuelven a ejecutar. Con (b), cada reintento cuesta los pasos 1 y 3 más el paso 2: $0,215 por reintento. En mil correos con una tasa de reintento del 30 %, eso es una diferencia de aproximadamente $4,50 en desperdicio puro, más la complejidad operativa de descubrir qué se escribió parcialmente cuando el paso 3 se ejecutó dos veces. Envuelve en step.run todo lo que no quieres que se vuelva a ejecutar. No es opcional cuando entiendes la mecánica.
Prueba con IA
With my AI coding assistant: review the Inngest function we built
in Concept 6's Try-with-AI and identify any code BETWEEN step.run
calls that should be wrapped in its own step but isn't. Common
candidates:
- Computed values (timestamps, IDs, formatting) that we want to be
stable across retries
- Calls to logging or metrics services
- Reads from Redis, environment variables, secret managers
Then propose a refactor that moves each of these into its own step
with a meaningful name. For each, explain whether the side effect
is one you want to happen once (use step.run) or every retry
(leave it outside).
Concepto 8: step.sleep y step.wait_for_event, durabilidad en el tiempo
Algunos trabajos tienen que esperar. Una canalización de correo electrónico de bienvenida envía un correo electrónico inmediatamente, luego espera tres días y luego envía un seguimiento. Una investigación de reembolso debe esperar a que un humano la apruebe. Un flujo de conversión de prueba busca "usuarios actualizados a pagos" dentro de los 7 días y envía un correo electrónico diferente dependiendo de lo que ve.
En una función normal de Python, "esperar tres días" significa mantener abierto un proceso durante tres días. Eso es insostenible: el proceso se reinicia, el hosting factura 72 horas de cómputo inactivo y el temporizador se pierde. En Inngest, "esperar tres días" es una línea:
from datetime import timedelta
@inngest_client.create_function(
fn_id="trial-welcome-series",
trigger=inngest.TriggerEvent(event="user/trial.started"),
)
async def welcome_series(ctx: inngest.Context) -> dict[str, str]:
user_id = ctx.event.data["user_id"]
await ctx.step.run("send-welcome-email", send_welcome_email, user_id)
# Wait three days. The function gets paged out of memory. Nothing
# is consuming compute. Three days later, Inngest pages it back in
# and resumes execution at the next line.
await ctx.step.sleep("wait-three-days", timedelta(days=3))
await ctx.step.run("send-followup", send_followup_email, user_id)
return {"status": "completed"}
step.sleep es duradero. La función se suspende; Inngest almacena el tiempo de reanudación; nada consume cómputo mientras esperas; la función se reanuda en el momento adecuado, con todas las salidas de los pasos anteriores todavía memorizadas. step.sleep (y step.sleep_until) pueden esperar hasta un año en planes pagos, hasta siete días en el plan Hobby gratuito (límites de uso de Inngest). El límite máximo de Hobby de siete días es lo suficientemente amplio para cada sueño que se utiliza en este curso.
El hermano más poderoso es step.wait_for_event. En lugar de esperar tiempo, espera otro evento. La función se suspende hasta que llega un evento coincidente o hasta que vence el tiempo de espera establecido. Esto es lo que hace que Inngest sea la expresión más limpia de HITL (Concepto 15) y de los patrones de coordinación entre agentes:
@inngest_client.create_function(
fn_id="refund-with-approval",
trigger=inngest.TriggerEvent(event="customer/refund.requested"),
)
async def refund_with_approval(ctx: inngest.Context) -> dict[str, str]:
request = ctx.event.data
request_id = request["request_id"]
# If amount is over $500, require approval before issuing
if request["amount_cents"] >= 50_000:
# Notify a human via Slack/email/whatever
await ctx.step.run("notify-approver", notify_human_approver, request)
# Wait for an approval event. Up to 24 hours; expires otherwise.
approval = await ctx.step.wait_for_event(
"wait-for-approval",
event="refund/approval.decided",
timeout=timedelta(hours=24),
if_exp=f"async.data.request_id == '{request_id}'",
)
if approval is None or not approval.data.get("approved"):
return {"status": "rejected_or_timeout"}
# Either it was under $500, or it was approved
refund = await ctx.step.run(
"issue-stripe-refund", call_stripe_refund_api, request,
)
return {"status": "issued", "refund_id": refund["id"]}
Qué está pasando:
- La función llega a
wait_for_event. Se suspende. Computación cero consumida. - Una persona revisa la notificación de Slack, hace clic en "Aprobar" en la interfaz de administración, y esa interfaz llama a
inngest_client.send(events=[Event(name="refund/approval.decided", data={"request_id": "...", "approved": True})]). - Inngest hace coincidir el evento con la función de espera (el
if_expgarantiza que solo los eventos para esta coincidencia de request_id) y reanuda la función con el evento como valor de retornoapproval. - La función continúa con el paso de reembolso. El reembolso Stripe se produce después de que el ser humano lo apruebe.
step.sleep y step.wait_for_event son esperas por las que no pagas. La función parece sincrónica en tu código ("espera tres días y luego envía el correo"), pero la semántica del runtime es asíncrona y duradera. Esta es una de las dos cosas por las que Inngest es conocido (la otra son los reintentos duraderos). Sin esto, la alternativa es una cola más una máquina de estados más una base de datos más un sondeador, y escribirías mil líneas en lugar de tres.
Comprobación rápida. Tres afirmaciones. Marca cada una como Verdadera o Falsa. (a) Si
step.sleepestá configurado para 30 días y tu servicio se redespliega cinco veces en esos 30 días, la suspensión continúa sin interrupción en un plan pago. (b) Si se agota el tiempo de espera destep.wait_for_event, la función genera una excepción. (c) Dos llamadasstep.wait_for_eventen la misma función pueden esperar el mismo evento simultáneamente.
Respuestas: (a) Verdadero en un plan pago: las suspensiones se almacenan en la infraestructura de Inngest, no en la memoria de tu servicio, por lo que los redespliegues no las pierden. Ten en cuenta el límite del nivel: una suspensión de 30 días está bien en un plan pago, pero excede el límite de siete días del plan Hobby gratuito. (b) Falso: cuando se agota el tiempo, wait_for_event devuelve None. Tu código lo verifica y decide qué hacer (rechazo, escalamiento, aprobación predeterminada o la política que corresponda). (c) Cierto, pero sospechoso: ambas llamadas se activarán cuando llegue un evento coincidente. Si las dos llamadas wait_for_event tienen filtros if_exp distintos, está bien. Si son idénticas, probablemente hay una oportunidad de refactorización.
Prueba con IA
Build a delayed-investigation flow with my AI coding assistant.
Specification:
1. Triggered by event 'customer/refund.failed'.
2. Immediately notify the on-call human via Slack with the refund
details and a "Investigate" button.
3. Wait for the human to click the button (which fires
'customer/refund.investigation_started') for up to 4 hours.
4. If the click arrives in time: run the agent to draft an
investigation summary.
5. If 4 hours pass without a click: escalate to a senior reviewer
by firing 'customer/refund.escalated'.
Use the dev-server MCP's send_event tool to simulate the
human-click event during testing. Use get_run_status to inspect
how the suspended function shows up in the dashboard. Before
writing, use list_docs to scan the Inngest documentation tree
for the right page on wait_for_event semantics, then
read_doc on the page you find to get the exact syntax for
the if_exp filter expression.
Concepto 9: Reintentos, manejo de errores, mensajes no entregados
De forma predeterminada, Inngest reintenta los pasos fallidos. Los valores predeterminados son sensatos: ~4 reintentos con backoff exponencial, desde unos pocos segundos hasta unos minutos entre intentos. Después de que falla el último reintento, la ejecución entra en estado fallido y permanece allí para inspección y, opcionalmente, replay. Puedes ajustar esto por función: retries=10, retries=0 (no reintentar), tipos de excepción específicos que no se deben reintentar.
@inngest_client.create_function(
fn_id="charge-customer",
trigger=inngest.TriggerEvent(event="order/checkout.completed"),
retries=2, # only retry twice; this involves Stripe; don't keep hammering
)
async def charge_customer(ctx: inngest.Context) -> dict[str, str]:
try:
charge = await ctx.step.run(
"call-stripe", call_stripe_charge, ctx.event.data,
)
return {"status": "charged", "charge_id": charge["id"]}
except StripeCardDeclinedError as e:
# A declined card is not a transient failure. Don't retry.
# Mark the order as failed in our database and emit an event
# for the dunning flow.
await ctx.step.run(
"mark-failed", mark_order_failed,
ctx.event.data["order_id"], reason=str(e),
)
await ctx.step.run(
"emit-dunning-event", emit_dunning, ctx.event.data["order_id"],
)
return {"status": "card_declined"}
Tres patrones importan.
Patrón 1: fallos transitorios frente a permanentes. Inngest reintenta todo de forma predeterminada, pero algunos errores no son transitorios. Una tarjeta rechazada por Stripe volverá a rechazarse al reintentar. Un 401 no autorizado de tu API aguas abajo no se convertirá en 200 solo por esperar. Tu función debe detectarlos y manejarlos específicamente: escribir en tu base de datos, emitir un evento posterior o retornar limpiamente, para no desperdiciar el presupuesto de reintentos en intentos condenados. NonRetriableError de Inngest le dice explícitamente a Inngest que omita los reintentos para una excepción lanzada.
Patrón 2: errores a nivel de paso frente a errores a nivel de función. Un paso que lanza una excepción se reintenta. Una vez agotados los reintentos del paso, la función falla. A veces quieres que una función sobreviva a un paso fallido: registrar el error, marcar el trabajo como "parcial" y continuar. Envuelve el step.run en try/except. El paso todavía recibe reintentos; si todos fallan, la excepción se propaga a tu bloque catch, donde puedes decidir qué hacer.
Patrón 3: dead-letter y replay. Cuando una función falla por completo, no desaparece. Entra en la vista de "ejecuciones fallidas" del panel de Inngest, con el seguimiento completo, todas las salidas de los pasos, la excepción y un botón Replay. Después de enviar una corrección, puedes hacer replay de las ejecuciones fallidas: se reanudan desde donde se interrumpieron, con la corrección implementada. Es el patrón de "cola de mensajes fallidos" de las colas tradicionales, pero sin escribir el controlador de mensajes fallidos. Simplemente corriges el error y haces replay.
PRIMM, Predict. Tu función llama a Stripe en el paso 2 y a tu servidor MCP de datos de cliente en el paso 4. Stripe devuelve 503 (servicio no disponible, transitorio) en el primer intento del paso 2. El paso 2 reintenta 4 veces con backoff exponencial (~1s, ~2s, ~5s, ~12s); en el cuarto intento, Stripe responde y el cargo se realiza correctamente. Ahora se ejecuta el paso 4 y el servidor MCP de datos de cliente está caído con un 500. ¿Inngest reintenta toda la función o solo el paso 4? ¿Cuántas veces? Confianza 1-5.
La respuesta: solo el paso 4, y tendrá su propio presupuesto de reintentos. Los pasos no comparten reintentos. Los cuatro reintentos del paso 2 son independientes de los del paso 4. Inngest reintentará el paso 4 (predeterminado: ~4 veces) y, si el servidor MCP vuelve, el paso 4 se completará y la función tendrá éxito. El cargo de Stripe del paso 2 no se vuelve a emitir, porque el resultado del paso 2 se memoizó después de su reintento exitoso. Al cliente se le cobra exactamente una vez, aunque la función haya pasado 20 segundos entre reintentos.
Prueba con IA
With my AI coding assistant: extend the customer-support Worker
function from Concept 6 with explicit retry and failure handling.
Specification:
1. The OpenAI Agents SDK call should retry 3 times on transient
failures (rate limit, timeout), but NOT retry on a content-policy
refusal from the model.
2. The Slack notification should retry up to 10 times (Slack is
often flaky; don't lose the notification).
3. The Postgres write should retry once; if it fails again, log the
failure and continue (don't fail the whole function over a
transient DB blip).
For each step, decide what's transient vs permanent and structure
the try/except accordingly. Use grep_docs to find the Python SDK's
NonRetriableError equivalent.
Concepto 10: step.run para llamadas AI en Python (step.ai.wrap es solo TypeScript)
Los conceptos 6-9 de funcionan para cualquier código con efectos secundarios: escrituras de bases de datos, llamadas API, escrituras de archivos, invocaciones de agentes. Inngest también incluye primitivas de pasos específicas de IA que manejan los patrones a los que son propensas las llamadas LLM: reintentos de límite de velocidad, observabilidad en mensajes y respuestas y (opcionalmente) proxy de inferencia que reduce los costos de computación sin servidor.
Nota importante sobre Python frente a TypeScript desde el principio. El módulo
step.aide Inngest tiene dos métodos y admiten diferentes idiomas.step.ai.infer()está disponible en TypeScript y Python (Python SDK v0.5+): descarga la inferencia a la infraestructura de Inngest y rastrea la llamada.step.ai.wrap()es solo TypeScript: por ahora no existe ningún equivalente en Python. Para proyectos Python (como el Worker de este curso), el patrón correcto para envolver una llamada a OpenAI Agents SDK esctx.step.run(...), que ya te da durabilidad completa, reintentos y observabilidad de las entradas y salidas del paso envuelto. Simplemente no obtienes la telemetría de solicitud/respuesta específica de LLM que agrega TypeScriptstep.ai.wrap. (Verificado con los documentos de inferencia de IA a partir de mayo de 2026.)
step.run para llamadas a OpenAI en Python (el patrón recomendado). Tu función realiza la llamada a OpenAI dentro de ctx.step.run("name", fn, ...). Inngest rastrea las entradas y salidas del paso (los argumentos pasados y lo que se devolvió), reintenta fallos transitorios y memoiza el resultado para que los reintentos de pasos posteriores no paguen otra vez el costo de OpenAI. El prompt y la respuesta se registran como entrada/salida del paso en el panel:
from openai import AsyncOpenAI
oai = AsyncOpenAI()
async def call_openai_summary(thread_text: str) -> str:
"""A normal async function. Inngest doesn't care that this is an LLM call."""
response = await oai.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "Summarize this support thread in 3 sentences."},
{"role": "user", "content": thread_text},
],
)
return response.choices[0].message.content
@inngest_client.create_function(
fn_id="summarize-customer-thread",
trigger=inngest.TriggerEvent(event="customer/thread.summary_requested"),
)
async def summarize_thread(ctx: inngest.Context) -> dict[str, str]:
thread: list = await ctx.step.run(
"load-thread", load_thread, ctx.event.data["thread_id"],
)
# The OpenAI call is wrapped in step.run. Inngest sees this as a step:
# the inputs (formatted thread text) are recorded, the output (summary
# string) is recorded, the call is memoized on success, and retries are
# automatic on transient failures.
summary: str = await ctx.step.run(
"openai-summary", call_openai_summary, format_thread(thread),
)
return {"summary": summary}
En el panel, esta ejecución muestra el seguimiento de pasos de la función (load-thread seguido de openai-summary) con las entradas y salidas de cada paso. Si OpenAI devolvió un 429 (límite de velocidad), Inngest reintenta openai-summary con backoff automático: la misma semántica de memoización del Concepto 7, por lo que los reintentos no facturan dos veces el paso anterior load-thread. Lo que no obtienes (en comparación con el step.ai.wrap de TypeScript) es telemetría automática específica de LLM, como recuentos de tokens, nombre de modelo y seguimientos específicos del proveedor desglosados en la vista de IA del panel. Para la mayoría de las cargas de trabajo de producción en Python, el seguimiento estándar de pasos más tu propia telemetría del cliente OpenAI (por ejemplo, el seguimiento de OpenAI Agents SDK) cubren esta brecha.
Como step.run registra las entradas y salidas de cada paso en el almacén de observabilidad de Inngest, el contenido que pasa por un paso se almacena y es visible en el panel. Si tu prompt incluye PII (nombres, correos electrónicos, direcciones), secretos (claves API, tokens internos), datos contractuales o financieros o contenido regulado (HIPAA, datos con alcance GDPR, PCI), no pases el contenido sin procesar al cuerpo del paso. Redacta, aplica hash, resume o pasa una referencia (un customer_id y un ticket_id, no el texto completo del ticket) y vuelve a cargar el contenido confidencial dentro del cuerpo del paso desde tu almacén autorizado, donde tú configuras los controles de retención y acceso. La misma disciplina se aplica al rastreo propio del OpenAI Agents SDK si lo habilitas. Trata los seguimientos de pasos como tratarías cualquier registro de producción: útil por defecto, regulado por política.
step.ai.infer: una herramienta especializada para reducir costos sin servidor (compatible con Python). Rara vez recurrirás a esto; step.run es el valor predeterminado para cada llamada de IA en este curso. step.ai.infer existe para una situación específica: en lugar de llamar a OpenAI desde tu proceso de función, le pides a la infraestructura de Inngest que haga la llamada, de modo que tu proceso pueda desasignarse mientras la solicitud está en curso. En plataformas sin servidor (Vercel, Cloudflare Workers, AWS Lambda) que facturan por tiempo en vuelo, esto ahorra costos de cómputo durante la espera. Para inferencias de larga duración (investigación profunda, grandes lotes de embeddings), los ahorros son reales. Para llamadas de menos de un segundo, agrega latencia sin mucho beneficio. Esta es la forma concreta a la que apunta el árbol de decisión de la Referencia rápida:
import os
from inngest.experimental.ai.openai import Adapter as OpenAIAdapter
@inngest_client.create_function(
fn_id="long-research-call",
trigger=inngest.TriggerEvent(event="customer/research.requested"),
)
async def long_research(ctx: inngest.Context) -> dict[str, str]:
response = await ctx.step.ai.infer(
"call-openai",
adapter=OpenAIAdapter(
auth_key=os.environ["OPENAI_API_KEY"],
model="gpt-4o",
),
body={
"messages": [
{"role": "user", "content": ctx.event.data["prompt"]},
],
},
)
return {"response": response["choices"][0]["message"]["content"]}
Dos detalles hacen tropezar a la gente. La palabra clave es adapter=, no model=: pasa una instancia de Adapter importada de inngest.experimental.ai.<provider> (los adaptadores se envían para openai, anthropic, gemini, grok y deepseek). Y el espacio de nombres inngest.experimental.ai está marcado como experimental en inngest-py 0.5.18, así que fija la versión del SDK si dependes de él. El valor de retorno es un dict simple, por lo que el subíndice response["choices"][0]["message"]["content"] anterior es correcto. El tiempo de cálculo de la función es aproximadamente el tiempo entre activar la solicitud y procesar la respuesta, no la llamada OpenAI en sí; en sistemas sin servidor, esto puede reducir en segundos el tiempo facturable por invocación.
Comprobación rápida. Verdadero o falso. (a) En Python,
ctx.step.run("name", call_openai, ...)hace que la llamada OpenAI sea duradera, se reintente en caso de fallas transitorias y se memorice en caso de éxito. (b)step.ai.inferes un requisito estricto para usar Inngest con OpenAI Agents SDK en Python. (c) Reemplazarstep.runconstep.ai.inferen el ejemplo anterior siempre haría que la función fuera más económica de ejecutar.
Respuestas: (a) Verdadero: este es el patrón Python recomendado. La llamada OpenAI va dentro del cuerpo del paso; Inngest trata todo el paso como una unidad de trabajo. (b) Falso: step.run es suficiente para la mayoría de los casos. step.ai.infer es una optimización para el costo de computación sin servidor, no un requisito. La integración OpenAI Agents SDK en el ejemplo resuelto utiliza step.run simple. (c) Falso: step.ai.infer ahorra dinero solo cuando (i) está en una plataforma sin servidor que factura por el tiempo de vuelo Y (ii) la llamada es lo suficientemente larga como para que los ahorros en la descarga de solicitudes dominen la sobrecarga adicional de orquestación. Para llamadas de menos de un segundo en servidores siempre activos, gana el simple step.run.
Ten en cuenta la misma advertencia anterior del curso: si tu Worker del curso cuatro transmite DeepSeek con @function_tool, el error de ruta de streaming del SDK en openai-agents==0.17.2, documentado en la Decisión 4 de build-agents, se aplica a la Versión A de abajo. Aplica la alternativa con OpenAI de ese curso antes de envolver Runner.run_streamed en step.run.
Prueba con IA
With my AI coding assistant: take the Course Four customer-support
agent invocation and produce TWO versions of the Inngest function
that calls it:
Version A: Wrap the Runner.run_streamed call in step.run (the
recommended Python pattern: durable, retried on transient failures,
memoized; you get the standard step trace).
Version B: For comparison, write a SEPARATE small Inngest function
that calls a single OpenAI completion via step.ai.infer (the
Python-supported step.ai primitive that offloads inference to
Inngest's infrastructure to save serverless compute cost).
For each version, explain (a) what the dashboard trace shows for a
successful run, (b) what happens when the OpenAI call hits a 429
rate limit, (c) whether the Course Four SQLiteSession state gets
corrupted by a mid-run crash, and (d) on which kind of deployment
(always-on server vs serverless) Version B's offload saves real money.
Parte 3: Control y recuperación de flujo, escala de producción
El control de flujo es la tercera capa: mantiene el Worker en buen estado bajo carga. La concurrencia evita que Worker fusione los sistemas posteriores. La limitación lo mantiene fuera de los límites de velocidad. La prioridad y la justicia evitan que un cliente locuaz mate a todos de hambre. El procesamiento por lotes convierte "10.000 eventos a medianoche" en "100 ejecuciones de funciones manejables". La repetición convierte "el error de ayer nos costó 200 interacciones fallidas" en "lo arreglamos; se reanudaron 200 conversaciones". Las puertas HITL suspenden al agente hasta que un humano lo apruebe. Los cinco conceptos de la Parte 3 le brindan las políticas de producción que convierten un Worker funcional en uno que puede presentar a los clientes que pagan.
Concepto 11: Concurrencia y throttling
La concurrencia es el número máximo de ejecuciones de una función que pueden ejecutarse al mismo tiempo. El throttling es el número máximo de ejecuciones que pueden iniciar por unidad de tiempo. Ambos se configuran por función con una línea cada uno. Ambas son de las brechas de producción más comunes cuando los equipos pasan del prototipo a la escala.
from datetime import timedelta
@inngest_client.create_function(
fn_id="customer-support-conversation",
trigger=inngest.TriggerEvent(event="customer/email.received"),
concurrency=[inngest.Concurrency(limit=10)],
throttle=inngest.Throttle(limit=100, period=timedelta(minutes=1)),
)
async def handle_email(ctx: inngest.Context) -> dict[str, str]:
...
concurrency=10 dice: como máximo 10 de estas funciones se están ejecutando en cualquier momento. El undécimo evento espera en cola hasta que finalice uno de los 10. throttle=100/minute dice: como máximo se inician 100 ejecuciones nuevas por minuto. El evento 101 espera incluso si hay margen de concurrencia.
Por qué ambos son importantes en la práctica. La concurrencia protege los sistemas posteriores: si tu Worker de atención al cliente habla con OpenAI y Postgres, tener 1000 ejecuciones simultáneas significa 1000 llamadas simultáneas a OpenAI y 1000 conexiones simultáneas a Postgres. Agotarás el límite de velocidad de OpenAI, el pool de conexiones o ambos. El throttling protege contra ráfagas: si llegan 500 correos electrónicos de clientes exactamente a las 9:00 a. m., no querrás que 500 funciones comiencen en el mismo segundo; el throttling suaviza la tasa de inicio.
Concurrencia por clave. Se aplica un único límite concurrency a la función de forma global. Un patrón más interesante es la concurrencia por clave: límite por alguna propiedad del evento.
@inngest_client.create_function(
fn_id="customer-support-conversation",
trigger=inngest.TriggerEvent(event="customer/email.received"),
concurrency=[
inngest.Concurrency(limit=10), # global cap
inngest.Concurrency(limit=2, key="event.data.customer_id"), # per-customer cap
],
)
async def handle_email(ctx: inngest.Context) -> dict[str, str]:
...
Esto dice: como máximo 10 funciones ejecutándose globalmente, Y como máximo 2 por cliente a la vez. Si un solo cliente envía 100 correos electrónicos en un minuto, solo 2 de sus correos electrónicos se procesan simultáneamente; los otros 98 quedan en cola. Mientras tanto, los correos electrónicos de otros clientes fluyen con normalidad; no quedan bloqueados por el cliente más activo. Esto es equidad multiinquilino en dos líneas de código. El concepto 12 desarrolla aún más el patrón.
Comprobación rápida. Tres afirmaciones, verdaderas o falsas. (a) Si configuras
concurrency=10y llegan 1000 eventos a la vez, 990 de ellos se descartan. (b) Los límites de throttling y concurrencia reducen el rendimiento total. (c) La concurrencia por clave requiere una clave que sea determinista a partir de los datos del evento.
Respuestas: (a) Falso: los eventos no se eliminan; hacen cola. La cola de Inngest es duradera; los 990 eventos esperan hasta que se abran espacios de concurrencia. (b) Falso. El throttling limita la tasa de inicio; la concurrencia limita las ejecuciones en vuelo. Ninguno descarta trabajo; ambos moldean cuándo se ejecuta. El rendimiento durante una ventana larga no cambia si la carga promedio está por debajo de los límites. Durante un pico, el rendimiento sí queda moldeado: la cola absorbe las ráfagas. (c) Verdadero: la expresión clave se evalúa sobre los datos del evento; debe producir una cadena estable para el mismo alcance lógico (customer_id está bien; current_timestamp no).
Prueba con IA
With my AI coding assistant: design the concurrency and throttling
policy for the customer-support Worker. Constraints:
- OpenAI rate limit: 30 requests per minute, hard cap.
- Postgres connection pool: 20 max connections (the Worker takes 1 per run).
- Some customers send bursts of 30+ emails in a minute (an angry
customer); these shouldn't starve other customers.
- We expect ~1,000 emails per day, with peaks around 9am and 2pm.
Propose:
1. A global concurrency value
2. A per-customer concurrency value
3. A throttle (limit and period)
For each, explain what production failure it protects against and
what the cost is (in queue latency at peak).
Concepto 12: Prioridad y equidad, escalamiento multiinquilino
Los límites de concurrencia funcionan. La concurrencia por clave añade equidad básica. Los sistemas multiinquilino de producción necesitan más: prioridades (los clientes Enterprise no deben esperar detrás de clientes Free para obtener el mismo cómputo) y programación de reparto justo (ningún inquilino puede monopolizar el sistema, incluso dentro de su límite de concurrencia).
Prioridad. Inngest evalúa una expresión de prioridad en cada evento; las ejecuciones con mayor prioridad saltan la cola por delante de las ejecuciones con menor prioridad.
@inngest_client.create_function(
fn_id="customer-support-conversation",
trigger=inngest.TriggerEvent(event="customer/email.received"),
concurrency=[inngest.Concurrency(limit=10)],
priority=inngest.Priority(
# Enterprise tier = high priority; Pro = 0; Free = low priority
run="100 - (event.data.customer_tier_priority * 100)",
),
)
async def handle_email(ctx: inngest.Context) -> dict[str, str]:
...
Cuando la cola de concurrencia tiene 50 ejecuciones en espera, las ejecuciones de clientes Enterprise van primero, luego Pro y luego Free. Dentro del mismo nivel, se aplica el orden FIFO. La prioridad no anula los límites de concurrencia ni de throttling; simplemente decide cuál de las ejecuciones en espera obtiene el siguiente espacio libre. Un cliente Enterprise todavía espera a que se abra un espacio; simplemente obtiene el siguiente.
Programación de reparto justo. Cuando hay cientos de inquilinos compitiendo por el mismo grupo de concurrencia global, la prioridad más FIFO no es suficiente. Un solo inquilino que envía una ráfaga aún puede ocupar la mayoría de los espacios durante minutos. La programación de reparto justo, implementada mediante el parámetro key en concurrencia con un dimensionamiento bien pensado, da a cada inquilino una porción garantizada:
concurrency=[
inngest.Concurrency(limit=50), # global pool
inngest.Concurrency(limit=3, key="event.data.tenant_id"), # max 3 per tenant
],
Con esto: 50 espacios en total, ningún inquilino ocupa más de 3. Si hay 20 inquilinos activos, son como máximo 60 espacios solicitados, pero solo 50 están disponibles. La participación justa los rota, cada inquilino recibe una parte, nadie queda excluido.
PRIMM, Predict. Tienes una función de atención al cliente con
concurrency=10yconcurrency=2por cliente. También tienes configurada la prioridad: Enterprise = alta, Free = baja. A las 9:00 a. m., la cola tiene: 5 eventos del cliente A (Free), 5 eventos del cliente B (Enterprise) y 10 eventos de un cliente C nuevo (Free, acaba de comprar su primer plan). ¿En qué orden se ejecutan? Confianza 1-5.
La respuesta: es una decisión de varios niveles. Primero, el límite por cliente de 2 significa que como máximo 2 eventos de cada cliente son elegibles para ejecutarse a la vez. Entonces, el grupo de candidatos es: 2 de A, 2 de B y 2 de C: seis ejecuciones elegibles de inmediato. En segundo lugar, la prioridad decide cuáles de esas seis ocupan los primeros espacios: las dos de B se ejecutan primero (Enterprise), luego las dos de A y las dos de C (Free, FIFO). Entonces, en t = 0: se ejecutan 2 de B, luego comienzan 2 de A y luego comienzan 2 de C. Total: 6 activas. Cuando cada una finaliza, el siguiente evento en cola de su cliente se vuelve elegible y el siguiente espacio se llena según la prioridad. Este es el tipo de política que en Inngest es una función integrada y en tu propio código sería un programador de mil líneas.
Prueba con IA
With my AI coding assistant: extend the customer-support Worker
configuration with a priority and fair-share scheme. Requirements:
1. Three customer tiers: Enterprise, Pro, Free.
2. Enterprise customers should never wait more than 5 seconds at
peak load.
3. Free tier customers should get fair access: no Free customer
should be starved for more than 60 seconds, even when the
global queue is full.
4. A single noisy customer (regardless of tier) should not occupy
more than 3 slots.
Write the concurrency + priority configuration. For each line of
config, explain which requirement it satisfies.
Concepto 13: Procesamiento por lotes para trabajo masivo rentable
Algunos trabajos se hacen naturalmente por lotes. No resumes cada una de las 10.000 conversaciones de clientes de forma independiente; llamas al LLM con un lote de 50 a la vez. No escribes 10.000 filas de auditoría una por una; usas COPY. El disparador por lotes de Inngest permite acumular eventos e invocar una única función con el lote como entrada.
@inngest_client.create_function(
fn_id="batch-embed-tickets",
trigger=inngest.TriggerEvent(event="ticket/resolved"),
batch_events=inngest.Batch(
max_size=50, # invoke when 50 events accumulated, OR
timeout=timedelta(seconds=30), # invoke when 30 seconds pass, whichever first
),
)
async def batch_embed_resolved_tickets(ctx: inngest.Context) -> dict[str, int]:
# ctx.events (plural) instead of ctx.event
ticket_ids = [e.data["ticket_id"] for e in ctx.events]
tickets = await ctx.step.run(
"load-tickets", load_tickets_by_ids, ticket_ids,
)
# One embedding call for 50 tickets, not 50 calls for 1 ticket each
embeddings = await ctx.step.run(
"embed-batch", embed_texts_batch,
[t["text"] for t in tickets],
)
await ctx.step.run(
"store-embeddings", store_embeddings_batch,
ticket_ids, embeddings,
)
return {"batched": len(ctx.events)}
Qué cambia: ctx.events es una lista, no un solo evento. La función se ejecuta una vez por lote en lugar de una vez por evento. La API de embeddings de OpenAI se llama con un lote de 50 textos en lugar de 50 llamadas de un solo texto, lo cual es mucho más barato (pagas por token, pero desaparece la sobrecarga por solicitud) y más rápido (una ida y vuelta de API en lugar de 50).
El procesamiento por lotes es la herramienta adecuada cuando el trabajo es naturalmente agrupable (embeddings, escrituras masivas en base de datos, correos electrónicos masivos) y puede tolerar la latencia del timeout antes de ejecutarse. Es la herramienta equivocada cuando cada evento requiere una respuesta interactiva o cuando el orden entre eventos importa de forma impredecible.
Comprobación rápida. Verdadero o falso. (a) Las funciones por lotes aún reciben reintentos y memoización; el lote completo se memoiza de forma duradera. (b) Si el tiempo de espera del lote expira con solo 3 eventos acumulados, la función no se ejecutará hasta que lleguen los siguientes 47. (c) Puedes combinar
batch_eventsconconcurrencypara limitar el número de lotes que se ejecutan en paralelo.
Respuestas: (a) Verdadero: el lote es la unidad de trabajo; los reintentos reproducen todo el lote con todos sus eventos aún dentro del alcance. (b) Falso: ese es el objetivo del timeout. Después de 30 segundos, la función se ejecuta con lo acumulado, aunque sea 1 evento. (c) Verdadero: este es el patrón de producción. El lote más la concurrencia limitan muy bien la carga aguas abajo.
Prueba con IA
With my AI coding assistant: convert the Course Four embedding
pipeline (the one that embeds resolved tickets) from a per-ticket
event handler into a batched Inngest function.
Triggers: 'ticket/resolved' event, batched at 50 events or 30 seconds.
The function should:
1. Load the ticket bodies in one query
2. Call OpenAI embeddings API with a 50-text batch (faster + cheaper)
3. Store the embeddings via the customer-data MCP server
4. Emit a 'ticket/embedded' event per ticket for downstream consumers
Use grep_docs to find the OpenAI batch-embedding pattern.
Concepto 14: Reproducción y cancelación masiva, recuperación de producción
A veces todo sale mal a la vez. Enviaste un bug; mil ejecuciones fallaron en las últimas seis horas. O tu API aguas abajo estuvo inactiva durante 30 minutos; todo lo que intentó llamarla durante esa ventana murió. O descubriste un error lógico y quieres rehacer un día de trabajo después de corregirlo.
Dos primitivas de recuperación opuestas. La reproducción dice "este trabajo falló, quiero que se complete correctamente". La cancelación masiva dice "este trabajo estaba en cola pero ya no quiero que suceda". Misma superficie del panel, intención opuesta. La mayoría de los equipos necesitan ambas dentro de los primeros tres meses de tráfico real.
Replay es la primitiva de recuperación. Las ejecuciones fallidas persisten con su historial de pasos completo, el evento de entrada, las salidas parciales de los pasos exitosos y la excepción del paso fallido. Desde el panel, abre la vista Funciones, filtra por una función con ejecuciones fallidas, selecciona una ventana de tiempo y un patrón de fallo (un mensaje de error específico o simplemente "todas las fallas") y haz clic en Replay. Inngest reprograma esas ejecuciones como si acabaran de llegar, pero con una diferencia crucial: las salidas de los pasos previamente memoizados vuelven como aciertos de caché.
Tres cosas que debes entender sobre el replay.
- La reproducción usa el mismo código de función que la ejecución original, después de tu despliegue. Si desplegaste una solución entre el momento en que las ejecuciones fallaron y el momento en que las reprodujiste, las ejecuciones repetidas usan el código nuevo. Ese es el punto.
- El replay respeta la memoización. Los pasos que tuvieron éxito en la ejecución original no se vuelven a ejecutar en el replay. Si tu Worker de atención al cliente gastó $0,20 en tokens de OpenAI en el paso 3 antes de fallar en el paso 4, no volverá a gastar esos $0,20: solo se ejecuta el paso 4 en adelante. Para un escenario de recuperación de 47 ejecuciones, esto significa que el costo en dólares de hacer replay después de corregir un error es aproximadamente el costo del paso fallido × 47, no el costo de la función completa × 47.
- La reproducción es opcional. Las ejecuciones fallidas permanecen en el panel hasta que actúas. No se reintentan para siempre; no desaparecen. Te esperan.
La cancelación masiva es lo inverso. A veces tienes miles de ejecuciones en cola o inactivas que ya no deseas: se canceló una campaña, se fue un cliente y ya no quieres enviarle correos de seguimiento, se revirtió una función. Desde el panel, seleccionas una función y una ventana de tiempo o filtro de evento y haces clic en Cancelar. Las ejecuciones coincidentes terminan limpiamente: sus llamadas step.sleep y step.wait_for_event no se reanudan, las ejecuciones en cola no se inician, las ejecuciones en curso verifican la cancelación y salen en el límite del siguiente paso. La cancelación respeta el límite del paso; un step.run en vuelo finaliza el paso en el que está antes de terminar, por lo que no obtienes cargos de Stripe a medio completar ni escrituras de base de datos rotas.
Replay versus cancelación como decisión. Cuando algo salió mal con una población de ejecuciones, haz una pregunta: ¿quiero que este trabajo tenga éxito o no quiero que suceda? Si el trabajo debe tener éxito (recuperación tras corregir un error), haz replay. Si el trabajo no debe realizarse (campaña cancelada, cliente perdido, función revertida), cancela. Si no estás seguro (por ejemplo, las ejecuciones fallidas incluyen algunas que quieres recuperar y otras que no debieron activarse), filtra la consulta del panel con más precisión para que cada subconjunto reciba el tratamiento correcto.
Tres patrones que esto permite en la práctica:
- La recuperación "enviamos un bug". Encuentra las ejecuciones fallidas en la ventana de tiempo del despliegue incorrecto, corrige el error, envía la solución y reproduce los fallos. La experiencia del cliente: su correo electrónico no recibió respuesta durante una hora, pero finalmente recibió una, sin que escribieras código de recuperación.
- La reversión de "campaña cancelada". Una serie de bienvenida envía tres correos electrónicos de seguimiento durante 14 días; el cliente abandona el día 4. No quieres enviar los seguimientos del día 7 ni del día 14. Cancelación masiva de ejecuciones coincidentes de
wait-for-eventysleep. - La repetición de "migración de esquema". Cambiaste la forma en que el agente formatea los resúmenes; quieres que los tickets de ayer se vuelvan a resumir con el nuevo formato. Encuentra las ejecuciones, fuerza la reproducción incluso de las exitosas (el panel ofrece esto como una opción separada: solo reproducir fallos es el modo predeterminado; reproducir todo es el modo de migración de esquema) y el agente vuelve a ejecutarse con el código nuevo.

El servidor de desarrollo MCP hace que la reproducción sea accesible sin salir de Claude Code. Durante el desarrollo, cuando desee probar un escenario de repetición, no es necesario hacer clic manualmente en el panel. Puede pedirle a la IA que use get_run_status para inspeccionar una ejecución fallida y luego activar una repetición a través del tablero o reactivando el evento con la misma clave de idempotencia (que, debido a la semántica de idempotencia de Concept 4, es funcionalmente equivalente para fines de prueba).
Comprobación rápida. Verdadero o falso. (a) El replay vuelve a ejecutar los pasos fallidos con el nuevo código implementado. (b) El replay también repite los pasos exitosos para asegurarse de que todo sea coherente. (c) Una ejecución en
step.sleepdurante 30 días se puede cancelar antes de que expire el período de suspensión. (d) La cancelación masiva de una función que está en ejecución abortará en mitad del paso elstep.runen curso para terminar más rápido.
Respuestas: (a) Verdadero: esta es la razón por la que la reproducción es útil para la recuperación de corrección de errores. (b) Falso, con una nota al pie: de forma predeterminada, la reproducción solo vuelve a ejecutar los pasos fallidos y posteriores; Los pasos exitosos se devuelven desde la nota. Hay un modo de participación voluntaria (a veces llamado "forzar repetición" o "reproducir todo") que vuelve a ejecutar cada paso desde arriba. Eso es lo que desea para las migraciones de esquemas o "la lógica de la función en sí cambió y quiero rehacer incluso el trabajo exitoso". (c) Verdadero: las ejecuciones inactivas son objetos de primera clase en el tablero y se pueden cancelar, modificar o reproducir. (d) Falso: la cancelación respeta el límite del paso; el step.run actual finaliza (o falla) antes de que finalice la ejecución. Esto evita escrituras rotas.
Prueba con IA
Walk through a recovery scenario with my AI coding assistant:
Yesterday at 14:00 we deployed a change to the Worker's
escalate-with-context Skill. The new SKILL.md description had a
typo that made the model fail to recognize the trigger phrases.
From 14:00 to 18:00, 47 customer-support runs failed at the
escalation step.
At 18:30 we noticed, fixed the SKILL.md typo, and re-deployed.
Use the dev-server MCP's grep_docs to find Inngest's replay docs,
then:
1. Outline the exact dashboard steps to identify the 47 failed runs.
2. Explain what replay will do (step-by-step) for one of those runs:
which steps return from memo, which run for real, what the
dollar cost is.
3. Confirm whether the customers will see one reply or multiple
(the durability + memoization story).
4. Identify ONE scenario in this story where you'd prefer to
bulk-cancel instead of replay, and explain why.
Concepto 15: Puertas HITL con step.wait_for_event, Invariante 1 en tiempo de ejecución
La Invariante 1 del Agent Factory dice que el ser humano es el principal: la intención del autor, no el juicio autónomo del agente, es lo que el tiempo de ejecución debe respetar en las decisiones de alto riesgo. Esto se muestra en producción como puertas de aprobación: el agente hace el análisis, redacta la acción, pero no ejecuta la acción hasta que un humano la apruebe.
Inngest step.wait_for_event (Concepto 8) es la expresión más limpia de esto en cualquier plataforma actual. El agente se ejecuta hasta el punto de decisión, se suspende y espera un evento de aprobación. El humano revisa (en Slack, en una interfaz de usuario de administrador, en un correo electrónico) y selecciona aprobar o rechazar. El evento se dispara. La función se reanuda con el veredicto del ser humano y actúa en consecuencia.
@inngest_client.create_function(
fn_id="refund-with-hitl-gate",
trigger=inngest.TriggerEvent(event="customer/refund.investigated"),
concurrency=[inngest.Concurrency(limit=5)],
)
async def refund_with_gate(ctx: inngest.Context) -> dict[str, str]:
request_id = ctx.event.data["request_id"]
amount_cents = ctx.event.data["amount_cents"]
# Step 1: the agent's analysis (Course Four Worker)
analysis = await ctx.step.run(
"agent-investigates",
run_refund_investigation_agent,
request_id=request_id,
)
# Step 2: if the agent thinks refund is warranted AND amount > $100,
# gate behind human approval
needs_approval = analysis.recommends_refund and amount_cents >= 10_000
if needs_approval:
await ctx.step.run(
"notify-approver",
send_slack_approval_request,
request_id=request_id,
analysis=analysis,
amount_cents=amount_cents,
)
# === THE HITL GATE ===
approval = await ctx.step.wait_for_event(
"wait-for-human-approval",
event="refund/approval.decided",
timeout=timedelta(hours=24),
if_exp=f"async.data.request_id == '{request_id}'",
)
if approval is None:
# Timeout: no human responded in 24h. Escalate.
await ctx.step.run(
"escalate-timeout",
escalate_to_senior_reviewer,
request_id=request_id,
)
return {"status": "escalated_timeout"}
if not approval.data["approved"]:
await ctx.step.run(
"notify-rejected", notify_customer_rejected,
request_id=request_id,
)
return {"status": "rejected_by_human"}
# Either it was approved, or it didn't need approval
refund = await ctx.step.run(
"issue-refund", call_stripe_refund,
request_id=request_id, amount_cents=amount_cents,
)
await ctx.step.run(
"audit-approved-refund", audit_refund,
request_id=request_id, refund=refund,
approved_by="human" if needs_approval else "auto",
)
return {"status": "issued", "refund_id": refund["id"]}
Lo que ves en el código: una secuencia de pasos, con un wait_for_event en el medio. Qué sucede en tiempo de ejecución:
- El agente se ejecuta (paso 1, de forma duradera).
- La función decide si se aplica la puerta (lógica en código, libre de efectos secundarios).
- Si está cerrado: se activa una notificación Slack (paso 2, duradero). La función se suspende. Cero cálculo consumido durante un máximo de 24 horas.
- A humano en Slack hace clic en Aprobar o Rechazar. El backend de administración llama a
inngest_client.sendconrefund/approval.decidedyrequest_id. - Inngest hace coincidir el evento con la función suspendida (el filtro
if_expgarantiza que solo coincidan los ID de solicitud coincidentes). La función se reanuda en la siguiente línea. - La función utiliza la decisión del ser humano para emitir el reembolso o notificar el rechazo. Ambas rutas auditan la decisión y al aprobador.
Esto es lo que hace que Inngest sea cualitativamente diferente de una máquina de cola más estado. El patrón HITL es un primitivo. El código de la función se lee de arriba a abajo, con la puerta en línea. No hay devolución de llamada, ni restauración del estado, ni envío de if state == waiting_for_approval: .... El tiempo de ejecución maneja la mecánica de suspensión/reanudación; su código expresa la política.
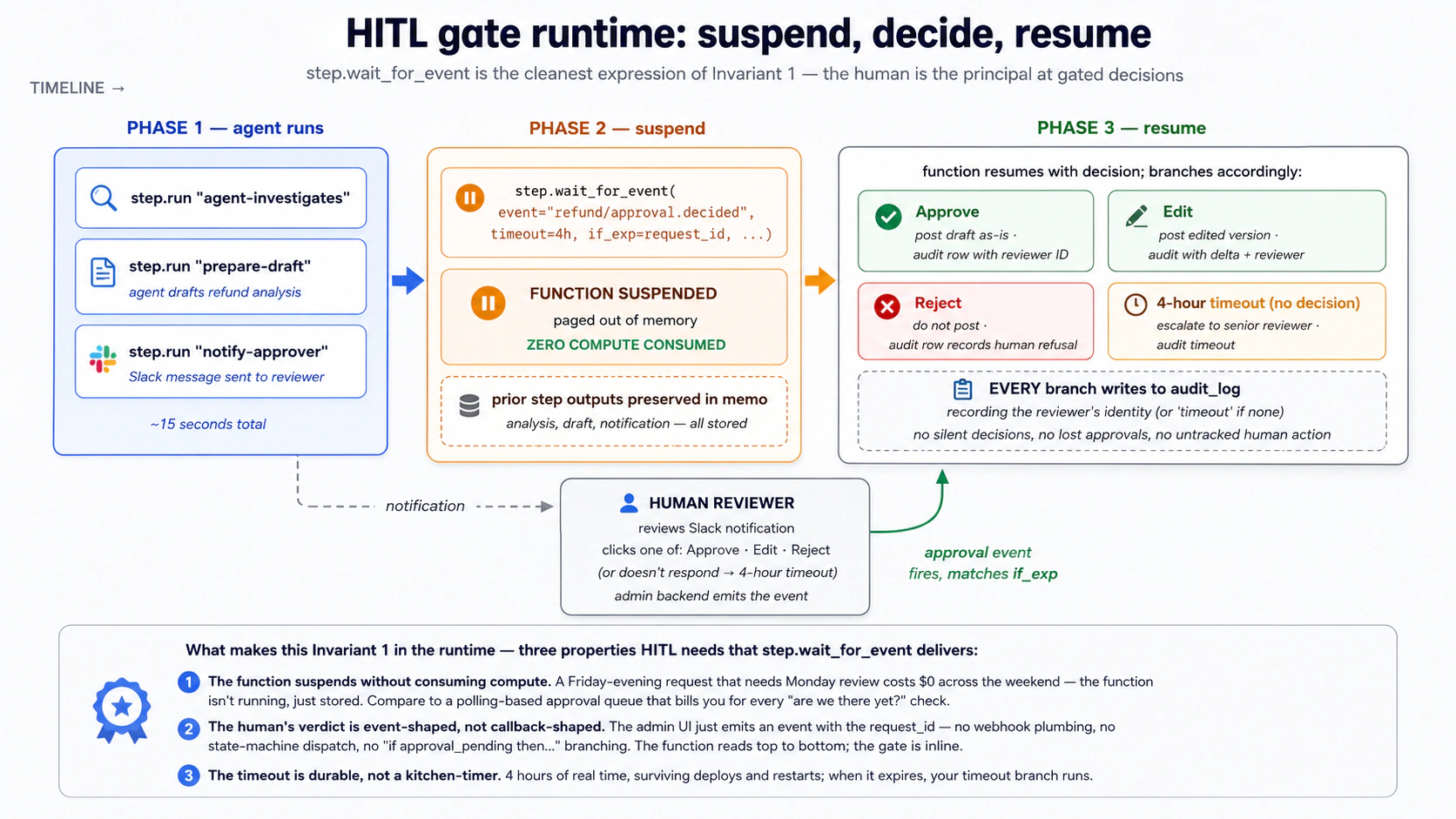
Un curso posterior desarrolla la arquitectura del Invariante 1: intención de autor, flujos de trabajo basados en especificaciones, la capa de administrador de Workers que decide qué puertas se aplican a qué acciones. Este curso le brinda la primitiva de tiempo de ejecución. Cuando llegue esa capa de administrador, la puerta que implemente será exactamente este patrón wait_for_event, recién compuesto a escala de flota. Conocer lo primitivo ahora significa que el patrón arquitectónico se lee más tarde como "una composición sensata" en lugar de "mágica".
PRIMM, Predict. Tienes una puerta HITL configurada con
timeout=timedelta(hours=24). La solicitud de reembolso de un cliente llega a las 17:00 un viernes. Ningún ser humano está en línea durante el fin de semana. El timeout de la puerta se activa a las 17:00 del sábado. Tu controlador de timeout pasa el caso a un revisor senior. El revisor senior lee la escalada el lunes a las 9:00 a. m. Recorre la línea de tiempo: ¿cuántas funciones estuvieron activas durante el fin de semana? ¿Por cuánto cómputo cobró Inngest? Confianza 1-5.
La respuesta: no hay una función activa ejecutándose durante el fin de semana. La función quedó suspendida: Inngest almacenó su estado, la sacó de memoria y quedó esperando el evento o el timeout. Inngest no factura por tiempo suspendido. Cuando llegó el sábado a las 17:00 y se activó el timeout, la función se reanudó durante los pocos cientos de milisegundos que tomó llamar al controlador de timeout y luego volvió a suspenderse (o se completó si el controlador terminó). Que el revisor senior se tome hasta el lunes es, desde la perspectiva del Worker, solo otro ciclo de wait_for_event. La economía de los flujos HITL en Inngest es radicalmente distinta de la de las colas basadas en sondeo que te facturan cada segundo de "¿ya está aprobado?".
Prueba con IA
With my AI coding assistant: design the HITL gate for the
customer-support Worker's escalate-with-context Skill. Specification:
1. When the agent decides to escalate (the Skill fires), pause for
human approval before posting the escalation summary to the
senior support channel.
2. The approval gate should:
- Notify the on-call reviewer via Slack with the agent's draft
- Wait up to 4 hours for the reviewer to approve, edit, or reject
- On approve: post the draft as-is.
- On edit: incorporate the reviewer's edits, then post.
- On reject: do not post; mark the escalation as canceled.
- On 4-hour timeout: post the draft with a "no human review"
warning header.
3. Every branch (approve/edit/reject/timeout) writes to audit_log
with the human reviewer's identity (or "timeout" if none).
Use the dev-server MCP's send_event to simulate each branch of
the reviewer's decision during testing.
Parte 4: El ejemplo resuelto, atención al cliente Production Worker
Una evolución realista, todos los conceptos anteriores, ambas herramientas. Tomamos el proyecto chat-agent/ del Curso #4 y le agregamos el sobre operativo que lo convierte en un Production Worker:
Funciones
- Inngest que envuelven el agente,
- un activador de evento para correos electrónicos entrantes,
- un cron diario para controles de estado proactivos,
- límites de concurrencia,
- an HITL puerta de escalada,
- y una ruta de error probada con repetición.
Ocho decisiones de construcción, la misma forma que los cursos 3 y 4.
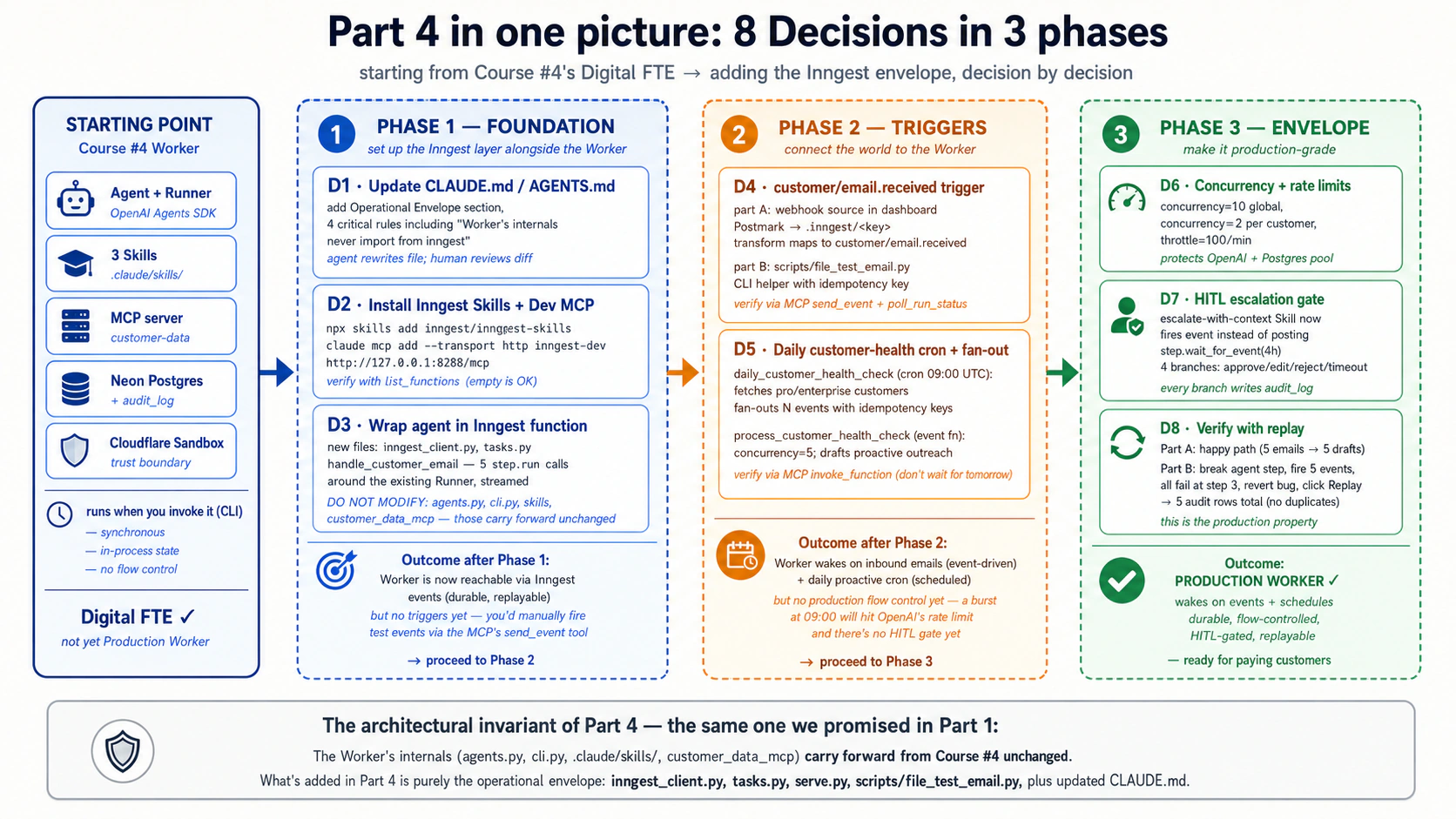
Antes de comenzar: la configuración que necesita no está en los requisitos previos. Cuatro cosas que esta parte supone ya están hechas. Lee esta lista de verificación; Si falta algún elemento, corríjalo antes de la Decisión 1.
- El ejemplo trabajado del Curso #4 está construido, no solo leído. Tienes un proyecto
chat-agent/en funcionamiento:cli.py,agents.py, tres.claude/skills/(resumir ticket, buscar casos similares, escalar con contexto), el esquema Neon Postgres conaudit_logy el servidor MCP personalizadocustomer-data. Esta parte amplía esos archivos; no los reemplaza. Un lector que leyó el curso n.° 4 pero no desarrolló el ejemplo práctico de la Parte 4 llegará a la Decisión 3 sin ningún agente que finalizar.- Node.js 20+ está instalado, por lo que se puede ejecutar el servidor de desarrollo Inngest (
npx inngest-cli@latest dev).- Tienes una cuenta Inngest gratuita en el nivel Hobby (siempre $0, sin tarjeta de crédito). El nivel Hobby cubre todo lo que este curso ejercita: 50 000 ejecuciones por mes, 5 pasos simultáneos, panel completo con repetición y cancelación masiva. Dos límites que debes conocer: el límite de 5 pasos simultáneos y un límite
step.sleepde siete días en el plan gratuito (un año en el plan pago). Ninguno le impide completar el curso; dan forma a la escala de producción (consulte la sección de costos en la Parte 5).- Claude Code o OpenCode están instalados y autenticados.
El resumen
evolucione el curso #4 chat-agent Digital FTE en un Production Worker de atención al cliente que:
- Se activa en eventos
customer/email.received(webhook de matasellos en producción, llamadassend_eventsimuladas en desarrollo). - Ejecuta el agente de atención al cliente existente de forma duradera: cada invocación de agente está empaquetada en
step.runpara que sobreviva fallas, vuelva a intentar fallas transitorias y obtenga una observabilidad completa de los mensajes/respuestas. - Ejecuta un cron diario a las 09:00 UTC que distribuye un evento
customer/health_check.requestedpara cada cliente Pro/Enterprise; cada evento desencadena una ejecución Worker que redacta un mensaje de divulgación proactivo. - Limita la concurrencia a 10 globalmente y 2 por cliente, con throttling de 100 inicios por minuto (protegiendo los límites de velocidad de OpenAI y el pool de conexiones de Postgres).
- Gate las escaladas detrás de una ventana HITL de 4 horas: el agente redacta la escalada, se envía una notificación Slack al revisor de guardia, la función se suspende hasta que el revisor aprueba/rechaza/edita, luego completa en consecuencia.
- Mantiene una ruta de reproducción: cuando algo falla, las ejecuciones fallidas persisten en estado completo; Después de corregir el error, los reproduces y se reanudan desde donde se rompieron.
Los internos del Worker (el agente, las Habilidades, el servidor MCP, el audit_log) no cambian. Agregamos Inngest alrededor de ellos.
Una nota sobre las indicaciones que siguen. Cada Decisión muestra una pregunta estructurada como una indicación entre comillas. El patrón que funciona mejor en la práctica es preceder cada pregunta con un movimiento de orientación ("Lee
CLAUDE.mdy los archivos relevantes, dígame lo que ve y haga 1 o 2 preguntas antes de comenzar"_) y luego envíe la pregunta estructurada una vez que el agente haya cargado el contexto y haya aclarado las ambigüedades. Las preguntas estructuradas a continuación son el destino, no el primer movimiento. Pegarlos en frío funciona; pegarlos después de la orientación funciona mejor, especialmente a medida que el proyecto crece.
Decisión 1: Actualizar el archivo de reglas con la capa Inngest
Qué haces (Claude Code). Abre Claude Code en su proyecto chat-agent/ existente. Oriente primero: pídale al agente que lea CLAUDE.md, el diseño existente de src/chat_agent/ y las Habilidades del Curso #4 y que le diga lo que ve, además de una o dos preguntas aclaratorias sobre las adiciones al Curso Cinco. Una vez que se establezca el intercambio, informe al agente sobre la adición arquitectónica y pídale que actualice CLAUDE.md:
We're adding the Inngest operational envelope around the Course Four
Digital FTE. The Worker's internals don't change. What's NEW:
1. inngest-py SDK installed and configured (an inngest_client in
src/chat_agent/inngest_client.py).
2. A new module src/chat_agent/tasks.py containing Inngest
functions that wrap the agent: one for inbound emails, one for
the daily health-check cron, one for the HITL escalation gate.
3. A dev-only entry point src/chat_agent/serve.py that runs an
ASGI server hosting the Inngest functions so the local dev
server can discover them.
4. The Inngest dev server is launched separately with
`npx inngest-cli@latest dev`; the Inngest dev-server MCP at
http://127.0.0.1:8288/mcp is added to Claude Code's MCP config.
Update CLAUDE.md to add:
- A new "Operational envelope" section describing where Inngest
functions live, what triggers each one has, and the rule that
the Worker's internal code never depends on Inngest's API:
agents, skills, MCP server are unchanged.
- A new critical rule: every Inngest function wraps its agent
invocation in step.run so failures don't lose state.
- A new critical rule: every inngest_client.send from inside agent
code uses an idempotency key (event ID seed) to prevent
double-firing on retry.
- A new critical rule: HITL gates use step.wait_for_event with
an explicit timeout AND a timeout handler that writes to
audit_log. No silent timeouts.
- Update the Commands section with the two new commands:
`npx inngest-cli@latest dev` (dev server) and
`uv run uvicorn chat_agent.serve:app --reload` (function host).
Keep the file focused (well under 3,000 tokens). Show me the diff before writing.
Claude Code redacta la actualización. Lee la diferencia con atención. Las nuevas reglas críticas son las piezas que admiten la carga: cualquier cosa débil allí no logra prevenir el modo de falla de producción que se supone debe prevenir.
Por qué. La regla "Las partes internas de Worker nunca se importan desde inngest" es la invariante arquitectónica de este curso. Al intercambiar Inngest por Temporal o Restate posteriormente se cambia solo la capa de orquestación; el Worker está intacto. La regla de clave de idempotencia evita que los eventos posteriores se activen dos veces al reintentar. La regla HITL sin tiempo de espera silencioso evita que una solicitud del viernes por la noche no se apruebe ni se escale porque nadie notó el tiempo de espera activado durante el fin de semana.
Qué cambios en OpenCode. Mismo flujo: informar al agente, revisar la diferencia. Usa AGENTS.md si le cambió el nombre en el curso n.º 3; mismo contenido.
Decisión 2: Instalar las habilidades Inngest y conectar el servidor de desarrollo MCP
Qué hacer (Claude Code). Empieza con la orientación: pide al agente que lea la configuración actual de MCP y pyproject.toml, informe qué piezas de Inngest ya están conectadas y cuáles necesitan instalación, y solicite confirmación antes de cambiar algo. Luego indícale que configure el plano de desarrollo de Inngest:
::::pestañas de herramientas
:: código-claude
Set up the Inngest development plane for this project. Three things
to do:
1. Install the Inngest Python SDK as a dependency:
`uv add inngest`
2. Install the Inngest Agent Skills into .claude/skills/ via the
official installer:
`npx skills add inngest/inngest-skills`
These six skills (inngest-setup, inngest-events,
inngest-durable-functions, inngest-steps, inngest-flow-control,
inngest-middleware) are TypeScript-focused in their code examples
but the conceptual content transfers to Python. They'll help you
write correct Inngest code when I ask for new functions.
3. Add the Inngest dev-server MCP to Claude Code's MCP config so you
can interact with the running dev server:
`claude mcp add --transport http inngest-dev http://127.0.0.1:8288/mcp`
After installing, start the dev server in a separate terminal:
`npx inngest-cli@latest dev`
Verify the setup by using the MCP's list_functions tool to confirm
the dev server is reachable. (It'll be empty; we haven't written
any functions yet. That's expected. The point is to confirm the
MCP connection works.)
::código abierto
Set up the Inngest development plane for this project. Three things
to do:
1. Install the Inngest Python SDK as a dependency:
`uv add inngest`
2. Install the Inngest Agent Skills into .claude/skills/ via the
official installer:
`npx skills add inngest/inngest-skills`
OpenCode reads .claude/skills/ as a fallback, so no duplication
in .opencode/skills/ is needed.
3. Add the Inngest dev-server MCP to OpenCode's MCP config via
opencode.json:
{
"$schema": "https://opencode.ai/config.json",
"mcp": {
"inngest-dev": {
"type": "remote",
"url": "http://127.0.0.1:8288/mcp"
}
}
}
After installing, start the dev server in a separate terminal:
`npx inngest-cli@latest dev`
Verify the setup by using the MCP's list_functions tool to confirm
the dev server is reachable.
::::
Lee atentamente la diferencia. El paso de verificación es importante: si se produce un error en list_functions, el servidor de desarrollo no se está ejecutando o el MCP no está configurado y esto se detecta antes de la Decisión 3 en lugar de depurarlo más tarde.
Este es el único lugar donde Claude Code y OpenCode realmente divergen en este curso (la mecánica de configuración de MCP cambia: un comando CLI para Claude Code, un bloque JSON para OpenCode). Las demás decisiones son independientes de la herramienta; los prompts que pegas son los mismos en ambas.
Por qué. Las habilidades de Inngest dan a tu agente de coding el conocimiento actualizado de API que necesita. MCP le da la capacidad de interactuar con tu servidor de desarrollo en ejecución: enviar eventos, monitorear ejecuciones y buscar documentación. Juntos aceleran mucho las Decisiones 3 a 8, porque el modelo escribe el código correcto en el primer intento (habilidades) y puede verificarlo sin que tengas que cambiar de contexto (MCP).
Una nota sobre el enfoque TypeScript de las Habilidades: el contenido conceptual (eventos, funciones duraderas, pasos, control de flujo, middleware) es independiente del idioma. Cuando los ejemplos de código TypeScript de Skills entran en conflicto con la sintaxis de Python, la IA usa grep_docs y read_doc en MCP para encontrar la sintaxis específica de Python. Este es el flujo de trabajo recomendado según la documentación de habilidades del agente de Inngest.
"El modelo escribe el código correcto en el primer intento" supone un agente de coding de primera línea: Claude Sonnet u Opus, un modelo de clase GPT-5 o Gemini 2.5 Pro. La arquitectura Inngest que enseña este curso (eventos, pasos, memoización, control de flujo) es de nivel SDK y no depende del modelo: contiene a cualquier modelo que impulse tu agente de coding. Pero la experiencia de construcción de la Parte 4 sí depende de un seguimiento sólido de instrucciones: los prompts estructurados de Decisión y el paso de la Decisión 7, donde se reescribe la descripción de una habilidad para emitir un evento, esperan que el agente siga instrucciones de varios pasos de forma confiable. Con un modelo más débil, tendrás que repetir más los prompts estructurados y hacer que las descripciones de las habilidades sean más concretas y explícitas. La arquitectura no está rota; el prompt solo necesita más andamiaje para un modelo más pequeño.
Decisión 3: empaquetar el agente de atención al cliente existente en una función Inngest
Qué haces (Claude Code). Empieza con un movimiento de orientación: pide al agente que lea src/chat_agent/agents.py, cli.py y tools.py, y que informe qué espera el agente como entrada y qué devuelve Runner.run_streamed. Luego indícale que envuelva el agente del Curso n.° 4 sin modificar el agente en sí:
Create the Inngest client and the first Inngest function. Two files.
File 1: src/chat_agent/inngest_client.py
- Import inngest
- Create a single inngest.Inngest() instance with app_id="chat-agent"
and the appropriate env vars
- Export it so tasks.py can import it
File 2: src/chat_agent/tasks.py
- Import the inngest_client from file 1
- Define handle_customer_email: an async function decorated with
inngest_client.create_function, triggered by event
'customer/email.received'
- Inside the function:
- step.run "load-customer": call the customer-data MCP server
to load the customer record
- step.run "load-thread": load the conversation thread for
that customer
- step.run "run-agent": call Runner.run_streamed with the
existing Course Four agent, passing the customer, thread, and
email body. The entire agent invocation is durably memoized.
- step.run "save-draft-reply": persist the agent's draft to
Postgres
- step.run "audit-handled": write an audit_log row with the
run_id, customer_id, action='email_drafted'
- Return {"status": "drafted", "draft_id": draft["id"]}
DO NOT MODIFY:
- src/chat_agent/agents.py (the agent definition)
- src/chat_agent/cli.py (the original CLI)
- src/customer_data_mcp/server.py (the MCP server)
- any .claude/skills/ files
The Inngest layer is purely additive. After writing, run
`uv run uvicorn chat_agent.serve:app --reload` in one terminal and
`npx inngest-cli@latest dev` in another. Then use the MCP's
list_functions to confirm handle_customer_email shows up.
Claude Code escribe los dos archivos, revisa los errores de importación y verifica que la función sea detectable. Lee atentamente la diferencia.
Por qué. La lista "no modificar" es lo que hace que este sea un cambio aditivo. El Worker del curso n.º 4 sigue funcionando exactamente como antes a través de python -m chat_agent.cli; la capa Inngest es un nuevo punto de entrada al mismo Worker. Esto es lo que quieren los equipos de producción: la opción de migrar gradualmente el tráfico entrante de la ruta anterior a la nueva, sin bifurcar el código Worker.
Decisión 4: Agregar el disparador de evento de correo recibido
Qué haces (Claude Code). Orienta primero: pide al agente que lea la documentación de webhooks existente en el MCP del servidor de desarrollo de Inngest y que resuma cómo se relacionan los webhooks configurados en el panel con las funciones activadas por eventos. Luego indícale que configure la integración del webhook entrante:
Configure the inbound webhook trigger for customer emails. In
production this connects to Postmark (your email service); in
development we simulate it with send_event from the dev-server MCP.
Two parts:
PART A, webhook configuration (Inngest dashboard, manual).
Walk me through configuring a webhook source in the Inngest
dashboard that:
- Has the URL inn.gs/e/<key> (Inngest provides the key)
- Transforms incoming Postmark JSON into our event shape:
name: 'customer/email.received'
data:
customer_id: lookup from Postmark's 'From' email
body: Postmark's 'TextBody'
subject: Postmark's 'Subject'
received_at: Postmark's 'Date' (ISO 8601)
idempotency: derived from Postmark's MessageID
You don't write the webhook config in code; it's dashboard UI.
Walk me through the steps with written instructions.
PART B, local development testing.
We need to test handle_customer_email without an actual email
arriving. Write a small CLI helper at scripts/fire_test_email.py
that:
- Takes --customer-id and --body arguments
- Sends an Inngest event via inngest_client.send(...) matching
customer/email.received
- Uses an idempotency key derived from customer_id + timestamp so
repeated test runs don't cause duplicate processing
- Prints the resulting run_id so we can inspect it in the dashboard
After writing both parts, use the MCP's send_event tool to fire
a test email payload directly, and poll_run_status to watch the
function execute end-to-end. Confirm:
- The function picks up the event
- The customer-data MCP server is called
- The agent runs (you'll see prompt/response in the trace)
- The audit_log gets a new row
Lee atentamente la diferencia.
Por qué. Separar la configuración del webhook (panel, sin código) de las pruebas locales (ayudante CLI) refleja cómo funciona esto en producción real. El panel de Inngest posee el enrutamiento del webhook; tu código posee el consumo de eventos. Mezclarlos en un solo lugar es lo que vuelve tan complicado el manejo tradicional de webhooks.
Decisión 5: Agregar el cron diario de verificación del estado del cliente con distribución
Qué haces (Claude Code). Orienta primero: pide al agente que lea tasks.py e informe cómo extendería el archivo con una función activada por cron más un consumidor independiente activado por evento. Luego indícale que agregue el trabajo programado:
Add a daily cron-triggered Inngest function that runs at 09:00 UTC
and fires a customer-health-check event per Pro/Enterprise customer.
In src/chat_agent/tasks.py, add:
1. daily_customer_health_check, a cron-triggered function:
- Schedule: 09:00 UTC daily (cron expression: "0 9 * * *")
- step.run "fetch-eligible-customers": query the customer-data
MCP for all customers where tier IN ('pro', 'enterprise')
AND last_proactive_outreach < NOW() - INTERVAL '7 days'
- step.run "fan-out-events": for each customer, build an Event
with name='customer/health_check.requested', data={'customer_id':
id, 'date': today.isoformat()}, and id=f'health-check-{id}-{date}'
(idempotency key prevents same-day duplicates if the cron fires
twice). Call inngest_client.send(events=[...]) in one batch.
- Return {'customers_scheduled': N}
2. process_customer_health_check, an event-triggered function:
- Trigger: event 'customer/health_check.requested'
- concurrency: limit=5 globally (it's batch work; don't melt OpenAI)
- step.run "load-customer": from customer-data MCP
- step.run "load-recent-activity": last 30 days of conversations
and refunds from audit_log
- step.run "run-health-agent": run the Course Four agent with a
specialized system prompt: "draft a proactive outreach for
this customer based on their recent activity"
- step.run "save-draft" and step.run "audit-drafted"
- Return {'status': 'drafted', 'customer_id': id}
After writing both, use the MCP's invoke_function to manually
trigger daily_customer_health_check (don't wait for 09:00 tomorrow).
Use poll_run_status to watch the fan-out happen. You should see
the parent function complete in seconds, and N child runs appear in
the dashboard. Confirm one of those child runs succeeds end-to-end.
Lee atentamente la diferencia. Claude Code escribe las funciones, ejecuta el disparador manual a través de MCP y observa cómo se propagan las ejecuciones.
Por qué. Esto es fan-out (Concepto 5) con idempotencia (Concepto 4) en acción. La función cron vuelve rápidamente; el trabajo real ocurre en ejecuciones hijas paralelas (según el límite de concurrencia en process_customer_health_check). Si el cron se activa dos veces el mismo día (error, redespliegue, invocación manual desde el panel), las claves de idempotencia evitan el procesamiento duplicado. Este es el patrón que un curso posterior compondrá a escala de fuerza laboral.
Decisión 6: Agregar límites de concurrencia y throttling
Las configuraciones de concurrencia y throttling de abajo son configuración, no consumo. Por sí mismas no cuestan dinero; protegen los sistemas posteriores que sí lo cuestan (tokens con límite de velocidad de OpenAI, pool de conexiones de Postgres, recursos de tu propio servidor MCP). Escribe la configuración para escala de producción; solo recuerda que el límite de 5 pasos concurrentes del nivel Hobby mantiene la concurrencia observada en 5 (consulta "Límites máximos del nivel Hobby" en la Parte 5).
Qué haces (Claude Code). Orienta primero: pide al agente que lea el tasks.py actual e informe qué funciones ya tienen alguna configuración de control de flujo. Luego indícale que agregue control de flujo de producción:
Add concurrency and throttling configuration to the customer-support
functions so we protect OpenAI's rate limit and Postgres' connection
pool. Apply these specific policies:
For handle_customer_email:
- concurrency: 10 globally
- concurrency: 2 per customer (key="event.data.customer_id")
- throttle: 100 starts per minute
- Rationale to capture in comments: OpenAI has 30 rpm hard cap;
Postgres pool is 20; we want a noisy customer to not occupy
more than 2 slots.
For process_customer_health_check (already has concurrency=5):
- Add: throttle of 30 starts per minute
- Rationale: this is batch work; the cron fires 500+ events at once;
the throttle smooths the start-rate.
For daily_customer_health_check (the cron):
- No concurrency change needed; it runs at most once a day at 09:00
with the global default concurrency.
After making the changes, simulate a burst: use the MCP's
send_event to fire 20 customer/email.received events for 5 different
customers in quick succession (4 events per customer). Then use
list_functions and get_run_status to confirm:
- Only 10 are running concurrently (global cap)
- Only 2 per customer are running (per-customer cap)
- The remaining events queue
- All eventually complete
Lee atentamente la diferencia. Claude Code agrega la configuración, ejecuta la prueba de ráfaga a través de MCP e informa los resultados.
Por qué. El límite de concurrencia de dos capas es el patrón de equidad multiinquilino del Concepto 12. Sin él, un cliente ruidoso puede ocupar los 10 espacios globales y dejar sin capacidad a todos los demás. El throttling es la protección contra el límite de velocidad de OpenAI del Concepto 11; sin él, una ráfaga de las 09:00 impulsada por cron alcanzaría el límite de 30 rpm de OpenAI en los primeros 2 segundos y haría fallar muchas ejecuciones.
Decisión 7: Agregar la puerta de escalada HITL
Qué haces (Claude Code). Orienta primero: pide al agente que lea escalate-with-context/SKILL.md y tasks.py, y que informe qué sucede ahora cuando se activa la habilidad de escalamiento. Luego indícale que agregue la puerta de aprobación humana:
Add the HITL escalation gate per Concept 15. When the agent's
escalate-with-context Skill fires, we want a human to approve
before the escalation actually posts to the senior support channel.
Add to src/chat_agent/tasks.py:
escalate_with_human_approval, an event-triggered function:
- Trigger: event 'customer/escalation.requested'
(the Course Four escalate-with-context Skill emits this event
instead of posting directly; we need to update the Skill to do so,
see below)
- concurrency: 5 (escalations are rare)
Inside the function:
1. step.run "notify-reviewer": Slack message to on-call reviewer
with the agent's escalation draft and three buttons (Approve,
Edit, Reject). Buttons POST to our admin backend which calls
inngest_client.send with event 'escalation/decision.made' and data
including request_id, decision, and optional edited_text.
2. THE GATE:
approval = await ctx.step.wait_for_event(
"wait-for-decision",
event="escalation/decision.made",
timeout=timedelta(hours=4),
if_exp=f"async.data.request_id == '{request_id}'",
)
3. Branch on the result:
- approval is None (timeout): step.run "audit-timeout" + post
the draft with a "no human review" warning header. Audit row
includes action='escalation_posted_via_timeout'.
- approval.data.decision == 'reject': step.run "audit-rejected" +
do not post. Audit row includes the reviewer's identity.
- approval.data.decision == 'edit': step.run "audit-edited" with
reviewer's edited_text + post the edited version.
- approval.data.decision == 'approve': step.run "audit-approved" +
post the original draft.
Also: update .claude/skills/escalate-with-context/SKILL.md to
instruct the agent to fire 'customer/escalation.requested' (via
inngest_client.send with an idempotency key) instead of posting
directly. The actual posting now happens in the Inngest function
after the gate.
After writing, test all four branches by using the MCP's send_event
to manually fire 'escalation/decision.made' with each decision
type, and one scenario where no decision is sent and you let the
4-hour timeout fire (use a 30-second timeout for the test, then
revert to 4 hours).
Lee atentamente la diferencia. Claude Code escribe la función, actualiza la descripción y el cuerpo de SKILL.md y recorre la prueba de cuatro ramas a través de MCP.
Por qué. Este es el patrón HITL del Concepto 15 conectado al subsistema de auditoría del curso n.º 4. Cada rama (aprobar, editar, rechazar, tiempo de espera) escribe en audit_log con la identidad del revisor (o "tiempo de espera" si no hay ninguno). La actualización de la habilidad cierra el círculo: el agente ya no publica directamente; solicita una escalada y la función de Inngest decide si publicar según la entrada humana. Esta es la Invariante 1 en el runtime: la autoridad del agente está restringida, la intención humana vuelve al sistema y el registro de auditoría conserva quién decidió qué.
Decisión 8: Verificar de un extremo a otro con el escenario de reproducción
Qué haces (Claude Code). Orienta primero: pide al agente que lea el estado actual del panel mediante MCP (list_functions, ejecuciones recientes) y que resuma qué verificará antes de enviar cualquier evento. Luego indícale que ejecute el escenario de verificación:
Run the end-to-end verification. Two parts.
PART A, the happy path.
1. Fire a customer/email.received event via the MCP's send_event
for customer 'c-test-1' with body "Hi, my refund hasn't arrived
and I'm getting worried about my upcoming bill."
2. Use poll_run_status to watch handle_customer_email run end-to-end.
3. Confirm in the dashboard trace:
- All 5 steps completed
- The agent's prompt and response are visible in the trace
- The audit_log has a new row with action='email_drafted'
4. Query the customer-data MCP to confirm the draft reply is
persisted in the customer's conversation thread.
PART B, the failure-and-replay path (this is the production scenario).
1. Deliberately break the run-agent step: edit src/chat_agent/tasks.py
to raise a ValueError("simulated agent failure") inside the
run-agent step.
2. Fire 5 customer/email.received events via send_event for 5
different customers.
3. Watch all 5 runs fail at the run-agent step. Confirm in the
dashboard:
- Each run has steps 1 and 2 marked successful
- Step 3 (run-agent) shows the ValueError after the retries
exhaust
- Steps 4 and 5 (save-draft, audit) never ran
4. Now fix the bug: revert the deliberate ValueError. Save the file
(uvicorn auto-reloads).
5. In the dashboard, select the 5 failed runs and click Replay.
6. Watch each replayed run:
- Steps 1 and 2 return immediately from memo (no re-execution)
- Step 3 (run-agent) executes for real and succeeds
- Steps 4 and 5 execute for real
- The customer's draft is persisted; the audit row is written
7. Query audit_log to confirm:
- Each customer has exactly ONE row with action='email_drafted'
- No duplicates (memoization prevented re-running the
audit-writing step on replay)
Report back: did Part A succeed cleanly? Did Part B produce exactly
one audit row per customer (5 total)?
Lee atentamente la diferencia. Claude Code ejecuta ambas partes e informa el resultado. Si la Parte B produce 5 filas de auditoría (una por cliente) sin duplicados, la arquitectura Production Worker queda verificada. Si produce 10 (algunas duplicadas) o 4 (una faltante), algo en la historia de durabilidad o memoización está roto y la consulta de auditoría es el diagnóstico.
Por qué. La Parte A demuestra que el camino feliz funciona. La Parte B demuestra que la historia de fallo y replay funciona, que es la propiedad arquitectónica de Inngest que justifica adoptarlo. Un Worker que puede recuperarse de un despliegue incorrecto sin perder interacciones con clientes es un Production Worker; un Worker que las pierde es un Digital FTE. Este escenario de verificación marca la línea clara entre los dos.
Qué acaba de pasar
Tomaste el documento de atención al cliente Digital FTE del curso n.° 4 y le agregaste una envolvente operativa. Las partes internas del agente no cambiaron: mismo Agent, mismo Runner.run_streamed, mismas habilidades, mismo servidor MCP, mismo audit_log. Lo que cambió es todo lo que rodea al agente. Ahora se activa con eventos (correos entrantes controlados por webhook) y programaciones (cron diario), se ejecuta de manera duradera (step.run envuelve la invocación del agente), respeta el control de flujo de producción (concurrencia, throttling, equidad por cliente), admite puertas HITL (aprobación en Slack antes de publicaciones de escalada) y se recupera de fallos (replay desde el panel).
El código de agente es el mismo; el alcance del agente es fundamentalmente diferente. Una función que alguien tiene que llamar es ahora una función que el mundo puede despertar, con la resiliencia y el control de flujo que exige la producción.
Las preocupaciones restantes son la observabilidad a escala, la coordinación multi-Worker y la capa de administrador que decide qué Workers maneja qué tráfico. Ese es el siguiente curso en la pista. El curso cinco cubre la unidad de ejecución lista para producción; el siguiente compone esas unidades en la fuerza laboral.
Parte 5: Dónde termina este curso
La forma de costo de un Production Worker
Dos superficies de costos importan: costo de infraestructura (Inngest, Postgres, cómputo de sandbox) y costo de inferencia (tokens de OpenAI). La infraestructura se mantiene más o menos estable a medida que aumenta la carga; la inferencia escala linealmente. Los números de abajo son de mayo de 2026; consulta las páginas de precios actuales antes de usarlos en un presupuesto.
Precios de Inngest. Cargos de Inngest por ejecución: cada ejecución de función, más cada reintento a nivel de paso, cuenta como una ejecución.
| Nivel | Precio | Ejecuciones / mes | Pasos simultáneos | Destacados |
|---|---|---|---|---|
| Afición | $0 | 50.000 | 5 | 3 usuarios, 50 conexiones en tiempo real, sin tarjeta de crédito |
| Pro | desde $75 / mes | 1.000.000 | 100+ | Más de 1000 conexiones en tiempo real, más de 15 usuarios, retención de seguimiento de 7 días |
| Empresa | personalizado | personalizado | 500-50.000 | SAML/RBAC, retención de seguimiento de 90 días, soporte dedicado |
Capas de precios de eventos en la parte superior: se incluyen los primeros 1 a 5 millones de eventos por día; el nivel 1M-5M anterior cuesta alrededor de $0,0005 por evento. Pro agrega $50 por cada 1 millón de ejecuciones adicionales cuando superas el límite de 1 millón.
Los límites máximos del nivel Hobby son los que importan aquí. El límite de 5 pasos simultáneos significa que, aunque declares concurrency=Concurrency(limit=10) en el código, el límite de cuenta de la plataforma lo mantiene en 5. Tu código es correcto para producción; la concurrencia observada en el nivel gratuito es 5. step.sleep y step.sleep_until también están limitados por nivel: hasta siete días en el plan Hobby gratuito y hasta un año en planes pagos (límites de uso de Inngest).
El costo de inferencia domina. Una ejecución típica de Worker de atención al cliente utiliza entre 3000 y 10 000 tokens de GPT-4o por conversación. Al precio ilustrativo de GPT-4o, es de $ 0,01 a $ 0,50 por correo electrónico, según el tamaño del contexto y la elección del modelo. Por 1000 correos electrónicos al día, entre 10 y 500 dólares al día en inferencia. Esto es lo que optimizas. Todo lo demás es un error de redondeo.
Tres palancas de costos específicas de Inngest una vez que esté en la zona de optimización:
- No incluya funciones puras en
step.run. Si una función no tiene efectos secundarios, no necesita durabilidad; envolverlo agrega un cargo por paso sin ningún beneficio. Guardastep.runpara E/S y efectos secundarios. - Usa
batch_eventspara rutas masivas. Un lote de 50 eventos es una ejecución de función, no 50. - Suspender económicamente con
step.sleepystep.wait_for_event. Las funciones suspendidas no facturan por el tiempo de suspensión. Un seguimiento diferido de 3 días cuesta lo mismo que uno de 3 segundos.
Escalar a 50 Workers cuesta aproximadamente entre $3000 y $15 000/mes para inferencia, entre $50 y $200 para Inngest, entre $50 y $200 para Neon y entre $100 y $500 para computación sandbox. La infraestructura escala plana; la factura de inferencia aumenta con el tráfico.
Guía de intercambio: la envolvente operativa es invariante, la plataforma no
Este curso nombra Inngest en cada capa. Esto se debe a que un ejemplo de enseñanza necesita respuestas concretas, no "usa el orquestador que quieras". Pero la arquitectura funciona con cualquier alternativa compatible. Cinco cambios que el diseño del curso anticipa explícitamente:
-
Superficie de activación: eventos Inngest → señales Temporal, controladores Restate, AWS EventBridge + Lambda. Cada plataforma tiene una manera de expresar "este código se ejecuta cuando sucede algo con nombre". Los nombres de los eventos, las formas de la carga útil y la disciplina de idempotencia se transfieren. Qué cambia: la sintaxis del decorador del SDK y el tablero.
-
Ejecución duradera: actividades Inngest
step.run→ Temporal, handlers de Restate, máquinas de estado personalizadas respaldadas por Postgres. Cada una ofrece la opción "memoiza esto": semántica de llamada con efectos secundarios, reintento ante fallo transitorio y reanudación después de un fallo. Temporal es la opción análoga más cercana, antigua y probada en empresas. Restate es más nuevo y tiene un modelo de programación más funcional. Las máquinas de estado personalizadas son lo que escriben los equipos cuando no pueden adoptar una plataforma administrada; normalmente son entre 1000 y 10 000 líneas de código que recrean aproximadamente el 70 % de lo que Inngest ofrece gratis. -
HITL primitiva:
step.wait_for_event→await Workflow.execute_activity(approval_signal)de Temporal, activables de Restate, personalizados Colas de aprobación de Redis/Postgres. El patrón es el mismo: la función se suspende, la señal externa la reanuda, la auditoría captura la decisión. La expresión de Inngest es la más limpia al escribir; El de Temporal es más detallado pero ha sido probado en batalla a gran escala. -
Programación cron: disparadores cron de Inngest → Kubernetes CronJobs + cola, programaciones de GitHub Actions, programaciones de AWS EventBridge. Los disparadores cron son básicos. La ventaja de Inngest no es tener cron; es que las funciones activadas por cron obtienen automáticamente la misma durabilidad, replay y control de flujo que las activadas por eventos. Otras plataformas te obligan a conectarlo por tu cuenta.
-
Control de flujo: concurrencia + throttling de Inngest → colas de tareas de Temporal con concurrencia de Workers, limitadores de velocidad respaldados por Redis, tiempos de espera de visibilidad de mensajes de AWS SQS. Otras plataformas pueden hacer esto; Inngest lo hace con la densidad de configuración que vimos (un argumento de decorador).
Dapr como compañero abierto a escala de producción. Un reemplazo más ambicioso que vale la pena nombrar: Dapr Agents como compañero estructural de Inngest a escala de producción, de la misma manera que OpenCode lo es para Claude Code. Dapr Agents alcanzó la versión 1.0 GA el 23 de marzo de 2026 bajo la gobernanza de CNCF (anuncio de CNCF, conceptos básicos de Dapr Agents). DurableAgent es la clase lista para producción; la clase anterior Agent está en desuso. Elige Dapr cuando la implementación nativa de Kubernetes y los SDK en varios idiomas sean más importantes que la experiencia de desarrollo local de Inngest. Inngest es la mejor herramienta de aprendizaje (el panel hace visible el modelo mental); Dapr es la mejor herramienta de escalamiento cuando ha alcanzado los niveles máximos de Inngest o necesita una implementación multilingüe nativa de K8.
Inngest también es de código abierto (github.com/inngest/inngest; la versión 1.0 se agregó soporte de autohospedaje en septiembre de 2024) y se puede autohospedar a través de Helm + KEDA. Los ejes que importan a escala son la gobernanza, el soporte y la madurez: Inngest está gobernado por un único proveedor con una joven historia de autohospedaje; Dapr está gobernado por CNCF y tiene un historial de producción más largo.
| Concepto del curso cinco | Inngest primitivo | Análogo de producción Dapr | Nota didáctica |
|---|---|---|---|
| Trabajo programado | TriggerCron | Enlace de entrada cron / Programador Dapr | Misma idea: el tiempo despierta el Worker. Dapr normalmente requiere la configuración de componentes. |
| Webhook/ingreso de evento | Punto final del webhook Inngest → evento | Punto final HTTP, enlaces de entrada o ingreso de publicación/sub | Inngest oculta más cableado; Dapr brinda control de infraestructura. |
| Eventos internos | inngest_client.send() | Dapr publicación/suscripción | El mismo modelo mental basado en eventos; El corredor se puede conectar en Dapr. |
| Distribución en abanico | Un evento desencadena muchas funciones | Un tema/evento consumido por muchos servicios | Misma arquitectura; Dapr utiliza la composición de agente/tema/suscriptor. |
| Pasos duraderos | step.run() + memoización | Flujos de trabajo + actividades de Dapr | Propósito de producción similar, modelo de desarrollador diferente. |
| Esperando sin cálculo | step.sleep() | Temporizadores de flujo de trabajo duraderos | Ambos evitan mantener abierto un proceso mientras se espera. |
| Puerta de aprobación humana | step.wait_for_event() | Flujo de trabajo de eventos/señales externos, pub/sub, actores | La expresión Inngest es más simple; Dapr es más componible. |
| Reintentos | Reintentos de función/paso | Reintentos de flujo de trabajo/actividad + políticas de resiliencia | Dapr convierte la resiliencia en una política de tiempo de ejecución, así como en un comportamiento del flujo de trabajo. |
| Mensajes fallidos/ejecuciones fallidas | Ejecuciones fallidas del panel de Inngest + replay | Broker DLQ + estado del flujo de trabajo/reinicio/herramientas manuales | Inngest es más llave en mano aquí; Dapr es más nativo de infraestructura. |
| Control de flujo | Concurrencia, throttling, prioridad, procesamiento por lotes | Escalado de Kubernetes, concurrencia de aplicaciones, controles de intermediarios, políticas de resiliencia, publicación/suscripción masiva | Dapr puede hacerlo, pero no es un argumento de decorador. Inngest es más denso. |
| Coordinación con estado | wait_for_event, claves de eventos, estado de paso | Actores + almacén estatal + flujos de trabajo | Dapr Los actores son más fuertes para la coordinación de identidad/estado de larga duración. |
| Tiempo de ejecución del agente | Tu agente dentro de la función Inngest | DurableAgent / Dapr Agents v1.0 GA | Dapr Agents explícitamente hace que el agente esté respaldado por el flujo de trabajo y sea reanudable. |
Esta tabla es una guía de traducción, no una afirmación de API idénticas. Inngest enseña el patrón de producción con una experiencia de desarrollador compacta: disparadores, pasos, esperas, replay y control de flujo en una sola superficie de producto. Dapr implementa la misma arquitectura de producción mediante bloques de construcción de sistemas distribuidos: enlaces, publicación/suscripción, flujos de trabajo, actores, estado, resiliencia y operaciones nativas de Kubernetes. Los conceptos se transfieren directamente; el estilo de implementación cambia. Verificado con la descripción general de enlaces de Dapr y los conceptos principales de Dapr Agents a partir de mayo de 2026.
Tres razones por las que Dapr es importante específicamente para un plan de estudios, no solo para una implementación de producción:
- Regido por CNCF, proveedor neutral según estatuto. Un plan de estudios que enseña en una plataforma controlada por el proveedor conlleva el riesgo de que las decisiones comerciales del proveedor reformen lo que los estudiantes aprendieron.
- Polyglot con Python de primera clase. Dapr Agents es el primero en Python; el mismo código de agente se puede ejecutar junto con servicios escritos en JavaScript, Go,.NET, Java o PHP sin que nadie aprenda un segundo marco.
- Escalable horizontalmente en Kubernetes por diseño. Ejecútalo en tu propio clúster, en una oferta administrada (Diagrid Catalyst) o localmente mediante
dapr init. La historia de escala es la misma arquitectura en todos los entornos.
La advertencia honesta: Dapr no es una plataforma para principiantes. Ejecutarlo en producción implica Kubernetes, almacén de estado, broker de pub/sub, servicio de colocación, observabilidad, componentes YAML y sidecars. Para un alumno cuyo objetivo es interiorizar qué son realmente los disparadores, la ejecución duradera y las puertas HITL, esa sobrecarga operativa ahoga los conceptos. La experiencia de Inngest "un comando, aparece el panel" es la herramienta didáctica adecuada. Dapr se convierte en la herramienta adecuada cuando los conceptos ya aterrizaron y la pregunta cambia a "cómo ejecuto esto a escala organizacional, en la infraestructura que controlo".
El recorrido del plan de estudios va por etapas. Los cursos 3, 4 y 5 desarrollan los conceptos sobre Inngest y OpenAI Agents SDK: ciclo de retroalimentación rápido, infraestructura mínima, enfoque en los patrones. Cuando se alcanza la escala en la que la gobernanza de Kubernetes, los equipos políglotas o la neutralidad de proveedores se vuelven no negociables, los mismos patrones arquitectónicos se elevan a Dapr con la tabla de traducción de 12 filas anterior como clave. Los patrones se transfieren; el sustrato cambia; lo que aprendiste en este curso sigue siendo conocimiento central.
Lo que este curso no cubre (aún)
Ahora tienes un Worker que satisface cuatro de las Siete Invariantes que establece la tesis. Específicamente: se ejecuta en un motor (Invariante 4, del Curso #3), contra un sistema de registro (Invariante 5, del Curso #4), con el mundo capaz de llamarlo (Invariante 7, de este curso) y con el ser humano como principal en las decisiones controladas (Invariante 1, parcial: mecanismo de tiempo de ejecución aquí, patrón arquitectónico en cursos posteriores). Los tres invariantes restantes y la arquitectura más amplia que constituye una fuerza laboral a partir de Workers son cursos posteriores. Una bala cada uno:
- Invariante 2: Cada ser humano necesita un delegado. Un agente personal en el borde que mantiene su contexto, representa su juicio e intermedia trabajo para la fuerza laboral. La tesis nombra OpenClaw como la implementación actual.
- Invariante 3: La fuerza laboral necesita un gerente. Un orquestador que asigna trabajo, hace cumplir los presupuestos, audita la ejecución y expone la contratación como una capacidad exigible. Los nombres de la tesis Paperclip.
- Invariante 6: la fuerza laboral se puede expandir según la política. Una metacapa donde un agente autorizado genera un mensaje, aprovisiona un tiempo de ejecución y registra un nuevo Worker, sin despertar a un humano. Claude Managed Agents es una realización.
Un solo Worker que se activa ante eventos, se ejecuta de manera duradera y se bloquea ante decisiones humanas es la unidad más pequeña de la arquitectura que enseña este curso. El próximo curso extiende ese Worker a una fuerza laboral: múltiples Workers coordinados por un gerente, ampliables según demanda, activados por disparadores y gobernados por especificaciones. Misma base OpenAI Agents SDK, mismo formato de habilidades, mismo sistema de registro Neon, misma envolvente Inngest. La arquitectura es invariante.
Cómo ser realmente bueno en esto
Leer este curso intensivo no te hace bueno en la construcción de Production Workers. Usarlo sí. El camino es el mismo que en los cursos anteriores: comienzas de forma manual, sientes la fricción y dejas que cada fricción te enseñe a qué concepto pertenece.
El mapeo para este curso:
- "¿Por qué mi función no se activa cuando llega el evento?" → error tipográfico en el nombre del evento o discrepancia en el namespace (Concepto 3). Compara byte por byte la cadena de nombre de evento en tu
TriggerEventcon la deinngest_client.send. - "¿Por qué mi función se activó dos veces para el mismo evento lógico?" → falta la clave de idempotencia (Concepto 4). Agrega un
id=al evento con una semilla determinista. - "¿Por qué mi función 'perdió trabajo' después de una implementación?" → código fuera de
step.runhaciendo el trabajo (Concepto 7). Envuelve las E/S y los efectos secundarios en pasos con nombre. - "¿Por qué se le cobró dos veces al cliente?" → la llamada a Stripe estaba fuera de
step.run, o el nombre del paso no era único (Conceptos 6 y 7). Mueve la llamada a unstep.runcon nombre; haz que el nombre del paso sea globalmente único dentro de la función. - "¿Por qué OpenAI devuelve errores 429 en el pico de las 9:00?" → falta throttling (Concepto 11). Agrega
throttle=Throttle(limit=N, period=timedelta(minutes=1)). - "¿Por qué las ráfagas de un cliente dejan sin capacidad a otros clientes?" → falta concurrencia por clave (Concepto 12). Agrega un segundo
Concurrency(limit=2, key="event.data.customer_id"). - "¿Por qué mi puerta HITL se disparó silenciosamente durante el fin de semana?" → falta un controlador de timeout que escriba en auditoría (Concepto 15). Ramifica con
approval is Noney escribe explícitamente la fila de auditoría.
Construye la arquitectura pieza por pieza. Toma el Worker del curso n.º 4. Agrega primero un disparador de evento (Decisión 4). Agrega step.run alrededor del agente (Decisión 3). Observa lo que cambia cuando provocas deliberadamente un fallo a mitad de ejecución. Agrega límites de concurrencia (Decisión 6) solo cuando hayas alcanzado realmente un límite de velocidad descendente. Agrega la puerta HITL (Decisión 7) cuando una escalada necesite de verdad aprobación humana. Cada paso es su propio aprendizaje. Combinarlos en una gran reescritura los convierte en un muro.
La disciplina que enseña este curso (despertar ante eventos, ejecutar de forma duradera, controlar a humanos, reproducir errores) es la invariante arquitectónica. Cualquiera que sea la plataforma que lo implemente, ese contrato de cuatro propiedades es con lo que realmente se está comprometiendo. El producto es reemplazable; la disciplina no lo es.
Referencia rápida
Un separador entre el curso narrativo y la referencia durante la construcción. Las secciones siguientes están destinadas a ser buscadas, no leídas de arriba a abajo.
Los 15 conceptos en una línea cada uno
- Eventos frente a solicitudes. Una solicitud es sincrónica, bloqueante y de un solo consumidor; un evento es asíncrono, duradero y multiconsumidor. Una vez que piensas en eventos, la durabilidad y la escala aparecen casi gratis.
- Disparadores cron.
TriggerCron(cron="0 9 * * *")activa una función según una programación. Misma forma de función que la activada por evento. - Disparadores de webhook. Inngest proporciona el endpoint; la carga útil entrante se convierte en un evento con nombre; tu función reacciona al nombre del evento.
- Idempotencia. Dos capas: las semillas de ID de evento evitan entregas duplicadas; la memoización de pasos evita ejecuciones duplicadas de pasos.
- Fan-out. Múltiples funciones pueden suscribirse a un evento; o una función principal puede enviar N eventos para la delegación de subagente.
step.run. Cada paso es un punto de control. Al reintentar, los pasos completados devuelven resultados memoizados en lugar de volver a ejecutarse.- Memoización. El mecanismo detrás de la durabilidad de
step.run. El código fuera de los pasos se vuelve a ejecutar al reintentar; el código dentro de los pasos no lo hace. step.sleepystep.wait_for_event. Ambos suspenden la función de forma duradera (no se consume ningún proceso durante la espera) por tiempo o eventos, respectivamente.- Reintentos y dead-letter. Por defecto, ~4 reintentos con backoff. Las ejecuciones fallidas persisten en el panel para replay después de corregir errores.
step.runpara llamadas de IA en Python (step.ai.wrapes solo TypeScript). Envuelve las llamadas a OpenAI Agents SDK enctx.step.run(...)para durabilidad y reintentos. Usastep.ai.infer(compatible con Python) para descargar la inferencia a la infraestructura de Inngest y ahorrar cómputo sin servidor.- Concurrencia y throttling.
concurrency=10limita las ejecuciones activas;throttle=100/minlimita los inicios por minuto. Ambos protegen los sistemas aguas abajo. - Prioridad y equidad. La prioridad decide qué ejecución en cola obtiene el siguiente espacio libre. La concurrencia por clave da a cada inquilino una parte justa.
- Procesamiento por lotes. Acumula eventos en una única llamada de función por lotes para procesamiento masivo rentable (embeddings, correos masivos).
- Replay y cancelación masiva. Las ejecuciones fallidas persisten con su estado; el replay las vuelve a ejecutar con código nuevo. Cancela en masa ejecuciones en cola o inactivas.
- Puertas HITL.
step.wait_for_eventes la expresión más limpia del Invariante 1 en cualquier plataforma: la función se suspende hasta que una persona aprueba y se reanuda con una decisión.
La tabla de diagnóstico de 15 conceptos
Un fallo de producción casi siempre se debe a una de tres causas raíz: un disparador que no se activó (o se activó dos veces), una ejecución que se interrumpió y perdió estado, o una brecha de control de flujo que permitió que el tráfico de un cliente dejara sin capacidad a los demás. Cuando algo se rompe, encuentra el concepto cuya pregunta coincida con tu síntoma.
| # | Concepto | Capa | ¿Qué pregunta responde? |
|---|---|---|---|
| 1 | Eventos vs solicitudes | Disparadores | ¿Qué es el cambio de modelo mental? Una solicitud es sincrónica y alguien está esperando; un evento es asincrónico y el mundo ha seguido adelante. |
| 2 | Disparadores cron | Disparadores | ¿Cómo se activa el Worker según un horario? @inngest_client.create_function(trigger=TriggerCron(cron="0 9 * * *")). |
| 3 | Disparadores de webhook | Disparadores | ¿Cómo despierta el mundo exterior al Worker? Un endpoint HTTP se convierte en un evento; un evento dispara una función. |
| 4 | Idempotencia y semántica de eventos | Disparadores | ¿Qué pasa si el mismo evento se activa dos veces? Los ID de eventos y las claves de idempotencia hacen que el segundo no funcione. |
| 5 | Fan-out y delegación de subagentes | Disparadores | ¿Cómo dispara un evento muchos Workers? Un evento, N funciones que coinciden con su nombre; o una función padre invoca N hijas mediante inngest_client.send. |
| 6 | step.run y el modelo de función duradera | Ejecución duradera | ¿Qué hace que una función sea "duradera"? Cada step.run es un punto de control; la función puede fallar entre dos pasos cualesquiera y reanudarse. |
| 7 | Memoización, la mecánica subyacente | Ejecución duradera | ¿Cómo sabe Inngest dónde reanudar? Reutiliza la salida almacenada de cada paso en lugar de volver a ejecutarlo. |
| 8 | step.sleep y step.wait_for_event | Ejecución duradera | ¿Cómo puede esperar un Worker sin consumir cómputo? Ambas primitivas suspenden la función y la reanudan más tarde. |
| 9 | Reintentos, manejo de errores, dead-letter | Ejecución duradera | ¿Qué sucede cuando un paso sigue fallando? Reintentos automáticos con backoff; después de N intentos, la ejecución pasa a un estado dead-letter que puedes inspeccionar y reproducir. |
| 10 | step.run para llamadas de IA en Python | Ejecución duradera | ¿Cómo haces duraderas las llamadas a OpenAI Agents SDK? En Python, envuelve cada llamada en step.run. step.ai.infer descarga la inferencia; step.ai.wrap es solo TypeScript. |
| 11 | Concurrencia y throttling | Control de flujo | ¿Cómo evitas que el Worker inunde OpenAI en el pico? concurrency=10 limita las ejecuciones activas; throttle limita los inicios por segundo. |
| 12 | Prioridad y equidad | Control de flujo | ¿Cómo evitas que un cliente deje sin capacidad a los demás? Concurrencia por clave, colas de prioridad, programación de reparto justo. |
| 13 | Procesamiento por lotes | Control de flujo | ¿Cómo se procesan 10.000 eventos sin 10.000 invocaciones de funciones? Los disparadores por lotes acumulan eventos en una llamada de función. |
| 14 | Replay y cancelación masiva | Control de flujo | ¿Qué haces cuando todas las ejecuciones de ayer fallaron? Corrige el error y reproduce las ejecuciones fallidas desde donde se interrumpieron. Cancela en masa las ejecuciones que ya no deseas. |
| 15 | Puertas HITL con step.wait_for_event | Control de flujo | ¿Cómo aparece el Invariante 1 (el humano es el principal) en el runtime? La función se suspende; una persona aprueba mediante Slack/email/UI; se emite el evento esperado; la función se reanuda. |
Árbol de decisión: selecciona la superficie de disparo
Cuando sucede algo nuevo en el mundo, ¿de dónde viene el despertar?
- Un sistema externo nos envió una solicitud HTTP. → Disparador de webhook. Configura la fuente en el panel de Inngest; remodela la carga útil mediante la transformación; consume el evento resultante.
- Una programación dice que es hora. → Disparador cron.
TriggerCron(cron="..."). Usa UTC; los crons de producción se activan incluso cuando tu servicio está a mitad de despliegue. - Otra función de Inngest emitió un evento durante su ejecución. → Disparador de evento.
TriggerEvent(event="ns/name.subtype"). Suscribe una o varias funciones al mismo nombre. - Un usuario interactivo espera una respuesta inmediata. → No es un disparador de Inngest. Mantén la solicitud/respuesta en tu endpoint web normal; si la respuesta implica trabajo pesado, emite un evento desde dentro de la solicitud y vuelve de inmediato para que Inngest maneje el trabajo de forma asincrónica.
Árbol de decisión: elige la primitiva de paso
Dado que una función se está ejecutando y necesitas hacer algo, ¿a qué llamada step.* recurres?
- Una llamada con efectos secundarios (API, base de datos, escritura de archivos, invocación de agente). →
ctx.step.run("name", fn, ...). Es el valor predeterminado. Memoizada en caso de éxito, reintentada en caso de fallo transitorio. - Una llamada a OpenAI de larga duración en una plataforma sin servidor que factura por tiempo en vuelo. →
ctx.step.ai.infer(...). Descarga la inferencia a la infraestructura de Inngest para que el proceso de tu función pueda desasignarse. - Esperar un tiempo fijo antes de continuar. →
ctx.step.sleep("name", timedelta(...)). Durable; cero cómputo durante la espera (hasta siete días en el plan gratuito, un año en el plan pago). - Esperar un evento externo (aprobación humana, finalización de la función entre hermanos). →
ctx.step.wait_for_event("name", event="...", timeout=..., if_exp=...). Durable; se reanuda cuando llega el evento o devuelveNonecuando se agota el tiempo de espera. - Cálculo determinista puro (formatear una cadena, calcular una fecha). → Simplemente escribe el código. No se necesita
step.run; sin cargo.
Referencia rápida de ubicación de archivos
chat-agent/
├── .claude/
│ └── skills/ # Course Four + Inngest's installed skills
│ ├── summarize-ticket/SKILL.md
│ ├── find-similar-cases/SKILL.md
│ ├── escalate-with-context/SKILL.md # updated in Decision 7
│ ├── inngest-setup/SKILL.md
│ ├── inngest-events/SKILL.md
│ ├── inngest-durable-functions/SKILL.md
│ ├── inngest-steps/SKILL.md
│ ├── inngest-flow-control/SKILL.md
│ └── inngest-middleware/SKILL.md
├── src/
│ ├── chat_agent/
│ │ ├── agents.py # Course Three, unchanged
│ │ ├── cli.py # Course Three, unchanged
│ │ ├── tools.py # Course Three, unchanged
│ │ ├── guardrails.py # Course Three, unchanged
│ │ ├── inngest_client.py # NEW Course Five (Decision 3)
│ │ ├── tasks.py # NEW Course Five (Decisions 3,5,7)
│ │ └── serve.py # NEW Course Five (Decision 1)
│ ├── customer_data_mcp/ # Course Four, unchanged
│ └── chat_agent/embedding/ # Course Four, unchanged
├── scripts/
│ └── fire_test_email.py # NEW Course Five (Decision 4)
├── migrations/ # Course Four, unchanged
└── CLAUDE.md # updated in Decision 1
Tabla de diagnóstico, síntoma → causa raíz → concepto
| Síntoma | Primer sospechoso | Concepto para releer |
|---|---|---|
| La función nunca se activa cuando llega el evento esperado | Error tipográfico en el nombre del evento, no coincide el espacio de nombres | C3 (webhooks), C5 (desplegado) |
| La función se activa dos veces para el mismo evento lógico | Falta clave de idempotencia | C4 (idempotencia) |
| La función "perdió trabajo" después de la implementación | Código fuera de step.run haciendo el trabajo | C7 (memoización) |
| La programación cron no se activó durante una implementación | Solo servidor de desarrollo local, la producción se ejecuta en Inngest infra | C2 (cron) |
| Se cobró dos veces al cliente por un reembolso | Llamada a Stripe fuera de step.run, o nombre de paso no único | C6 (step.run), C7 (memoización) |
| Errores de límite de velocidad de OpenAI durante el pico de las 9:00 | Falta throttling | C11 (concurrencia + throttling) |
| Las ráfagas de un cliente dejan sin capacidad a otros clientes | Falta concurrencia por clave | C12 (prioridad + equidad) |
| Función suspendida para siempre, nunca reanudada | El nombre del evento en wait_for_event no coincide con el evento que se envía | C8 (wait_for_event), C15 (HITL) |
| HITL el tiempo de espera se disparó silenciosamente durante el fin de semana | Falta un controlador de tiempo de espera que escribe en auditoría | D7 (decisión HITL), C15 (HITL) |
| Las ejecuciones fallidas de ayer desaparecieron del panel | Las ejecuciones persisten hasta que haces replay manualmente o hasta que pasa la ventana de retención | C14 (replay) |
| El replay volvió a cobrar a clientes | Colisión de nombres de pasos que provoca que la búsqueda de memoización encuentre una entrada incorrecta | C7 (regla de memoización sobre nombres únicos) |
| El seguimiento de la función no muestra el mensaje OpenAI | El seguimiento de pasos muestra entradas/salidas de funciones, pero no hay telemetría de token/indicador específico de LLM | C10 (Python usa step.run; la telemetría específica de LLM necesita su propio rastreo de cliente OpenAI; los rastreos a nivel de solicitud de step.ai.wrap son solo para TypeScript) |
Apéndice: repaso de requisitos previos (no es un sustituto)
Este curso asume material previo sustancial. Dos breves repasos para alguien que llega de la búsqueda y ha realizado algún trabajo adyacente pero no los requisitos previos exactos.
A.1: Lo que le enseñó el curso n.º 4 y que este curso supone
Curso completo: De agente a Digital FTE. Tres propiedades críticas de tu Worker del Curso #4 en las que este curso se apoya con fuerza:
- Tus habilidades están operativas.
.claude/skills/summarize-ticket/,.claude/skills/find-similar-cases/,.claude/skills/escalate-with-context/. La tercera,escalate-with-context, se modifica en la Decisión 7. Si tus tres habilidades aún no se cargan correctamente mediante Claude Code u OpenCode, corrígelo antes de comenzar este curso. - Tu esquema de Neon incluye
audit_log. Cada decisión en este curso supone queaudit_loges una tabla escribible con al menos:id,action,customer_id,payload (JSONB),created_at. Si tu subsistema de auditoría de la Decisión 7 del Curso #4 no está conectado, los pasos de escritura de auditoría de este curso fallarán silenciosamente. - Tu servidor MCP
customer-dataes accesible como proceso Python. Desde la Decisión 3 en adelante se lo llama (load-customer,load-thread). Si el servidor MCP no se ejecuta medianteuv run python -m customer_data_mcp.server, tienes un hueco de configuración del curso n.° 4.
Señal de parada. Si "el Worker lee y escribe en un sistema de registro Postgres mediante un servidor MCP personalizado y acotado, y cada acción significativa escribe una fila audit_log en la misma transacción" te suena a repaso, continúa. Si te parece material nuevo, detente y haz primero el Curso n.° 4. El ejemplo trabajado de este curso evoluciona el Worker del curso n.° 4; leer sin esa base agrega fricción.
A.2: Conceptos básicos específicos de Inngest que utiliza este curso
Si algo de lo siguiente no te resulta familiar, lee la página de documentación correspondiente antes de entrar en la Parte 4.
- Instanciación del cliente de Inngest. Una única instancia de
inngest.Inngest(app_id=...)por proyecto Python, exportada desde un módulo e importada donde decores funciones. Inicio rápido de Python. - Decoración funcional.
@inngest_client.create_function(fn_id=..., trigger=...). El disparador puede serTriggerEvent,TriggerCrono una lista de ambos para funciones de disparador múltiple. ctx.step.run,ctx.step.sleep,ctx.step.wait_for_event,ctx.step.ai.infer. Las primitivas de cuatro pasos que constituyen el 90% de lo que escribirás en Python. (TypeScript tiene un quinto,step.ai.wrap, para el seguimiento específico de LLM; los proyectos Python usanstep.runpara llamadas de IA).inngest_client.send(events=[...]). Emite eventos desde cualquier lugar del código (dentro de funciones, dentro de herramientas del agente, desde scripts CLI). Usa unid=para idempotencia.- Arranque del servidor de desarrollo.
npx inngest-cli@latest dev. Se ejecuta en:8288. Panel de control enhttp://127.0.0.1:8288. MCP enhttp://127.0.0.1:8288/mcp.
A.3: Lo que este apéndice NO reemplaza
Aún necesitas la Parte 3 del Curso n.° 3 (Cloudflare Sandbox) para comprender el límite de confianza dentro del cual se ejecuta el agente, y el ejemplo práctico completo de la Parte 4 del Curso n.° 4 para comprender el Worker que envuelve este curso. Si esos conceptos están borrosos, vuelve a ellos; el ejemplo trabajado de este curso asume ambos.
Lo más difícil de este curso no es la sintaxis de Inngest. Es el cambio mental de solicitud a evento (Concepto 1) y de ejecución en proceso a ejecución duradera (Concepto 6). La sintaxis es mecánica una vez que esos dos aterrizan. Vuelve a leer primero los Conceptos 1 y 6 si algo más se siente más difícil de lo que debería.