Dale a tu IA un contexto consultable: RAG en Postgres con pgvector (curso acelerado)
15 conceptos · 80% de uso real · Lo construye tu agente, no tú a mano
Imagina que pudieras decirle a tu PC: "Toma esta carpeta de documentos, levanta una base de datos que entienda su significado y créame una búsqueda donde pedir 'the city that never sleeps' devuelva citas sobre Nueva York, incluso las que nunca la nombran". Y que de verdad lo haga.
Tres palabras, por si son nuevas para ti. Una base de datos es un almacén de datos: el edificio donde un negocio guarda sus mercancías, solo que aquí las mercancías son información. SQL es el idioma que hablas con ese almacén: cada petición para guardar, encontrar o cambiar datos es una frase en él. Postgres (la base de datos del título de este curso) es una de las más usadas del mundo. Y un almacén corriente solo puede encontrar una caja por su etiqueta exacta; el que estás a punto de construir encuentra cosas por lo que significan.
Ese sistema de búsqueda por significado es lo que enseña este curso, y aquí está el giro: no escribirás el SQL a mano; Claude Code u OpenCode lo construyen todo. Tu trabajo es saber lo suficiente sobre Postgres y pgvector (el complemento que le da ese poder) para dar instrucciones claras y para juzgar si el agente lo hizo bien. Esa segunda parte es toda la habilidad, y para el final sabrás qué perillas importan y cuáles dejar quietas.
La afirmación más grande que hay debajo de este curso es simple: para la mayoría de las aplicaciones, Postgres es la base de datos de IA. La base de datos vectorial separada y especializada que te han dicho que necesitas es, para la mayoría de los equipos, un sistema más que pagar, sincronizar y romper. Tus vectores pertenecen junto a los datos que describen, y para el final no lo creerás porque este curso lo dijo, lo creerás porque lo construiste.
Una sola idea hace que todo este curso encaje. Un modelo de IA solo puede prestar atención a una cantidad limitada a la vez: todo lo que lee para responderte tiene que caber en su ventana de contexto, y cuanto más material irrelevante haya ahí, peor será la respuesta. Por eso el trabajo central de cualquier sistema de IA es poner la información correcta frente al modelo en el momento correcto, y dejar todo lo demás fuera. Ya haces esto con tu agente de programación: un archivo de reglas, solo los archivos que la tarea necesita. Una base de datos vectorial hace el mismo trabajo para los usuarios de tu app: de un millón de filas guardadas, encuentra las pocas que coinciden con el significado de la pregunta y le entrega solo esas al modelo. Ese movimiento tiene nombre: RAG, generación aumentada por recuperación (Retrieval-Augmented Generation), y es gestión del contexto, un nivel más abajo: lo que tú haces a mano para tu agente de programación, tu app lo hace por sus usuarios automáticamente. Cada concepto aquí se conecta con eso.

Este curso asume que ya hiciste el Curso acelerado de codificación agentic: deberías sentirte cómodo dirigiendo a Claude Code u OpenCode, usando el modo plan y gestionando el contexto. También se apoya en Prompting con IA en 2026: el arte de pedirle a una IA exactamente lo que quieres. Si "embedding" y "vector" son completamente nuevos para ti, no te preocupes: el Concepto 2 los cubre desde cero.
📚 Ayuda didáctica
Ver presentación completa — Contexto consultable para IA
Dos herramientas, una disciplina
El agente conduce; tu base de datos Postgres es lo que conduce. La base de datos vive en Neon, un servicio en la nube que ejecuta Postgres por ti: nada que instalar, ninguna máquina que administrar (eso es todo lo que significa serverless: se despierta cuando lo usas y duerme cuando no). El agente opera Neon a través del servidor MCP de Neon: crea el proyecto, abre una rama, ejecuta el SQL y previsualiza cada cambio en esa rama antes de confirmarlo. Nunca andas haciendo clic por la consola de Neon ni abres psql tú mismo. Y la disciplina es idéntica en ambas herramientas: Claude Code y OpenCode son equivalentes aquí; donde un comando difiere de verdad, señalo la diferencia en línea.
Qué cubre este curso
| Parte | Tema | Qué aprendes |
|---|---|---|
| 1 | Fundamentos | Tu trabajo como ingeniero de IA, los vectores desde cero, qué necesita Postgres para buscar por significado y tu agente conectado a Neon |
| 2 | Tu primer RAG | Carga tus datos, divídelos en piezas, convierte cada pieza en un vector de significado, busca por significado y haz que un LLM responda a partir de ahí |
| 3 | Acelerar la búsqueda | Cuándo una búsqueda que se ralentiza necesita un índice, cómo elegir uno y la única perilla de velocidad-vs-precisión que importa |
| 4 | Hacer la búsqueda buena | Mide si las respuestas son realmente correctas, añade filtros, mezcla el significado con palabras clave exactas, aísla los datos de cada cliente y hazle preguntas a tu base de datos en lenguaje natural |
| 5 | Ejemplo completo paso a paso | Una tarea completa, de base de datos vacía a RAG funcional, dirigida en ambas herramientas |
| 6 | Publícalo como herramienta | Envuelve tu RAG en un servidor MCP para que cualquier agente (Claude Code, OpenCode o un Digital FTE que construyas más adelante) pueda llamarlo |
| 7 | Dónde se ejecuta | Prueba cambios en copias instantáneas de tu base de datos, mantén los vectores al día a medida que cambian los datos y qué cambia en producción |
| 8 | Entrégaselo a un agente | Conecta tu RAG a un agente (OpenAI Agents SDK): el puente hacia el curso Construye agentes de IA |
Aquí está todo el sistema en una sola página: el mapa hacia el que crecerás a medida que cada concepto encaje:
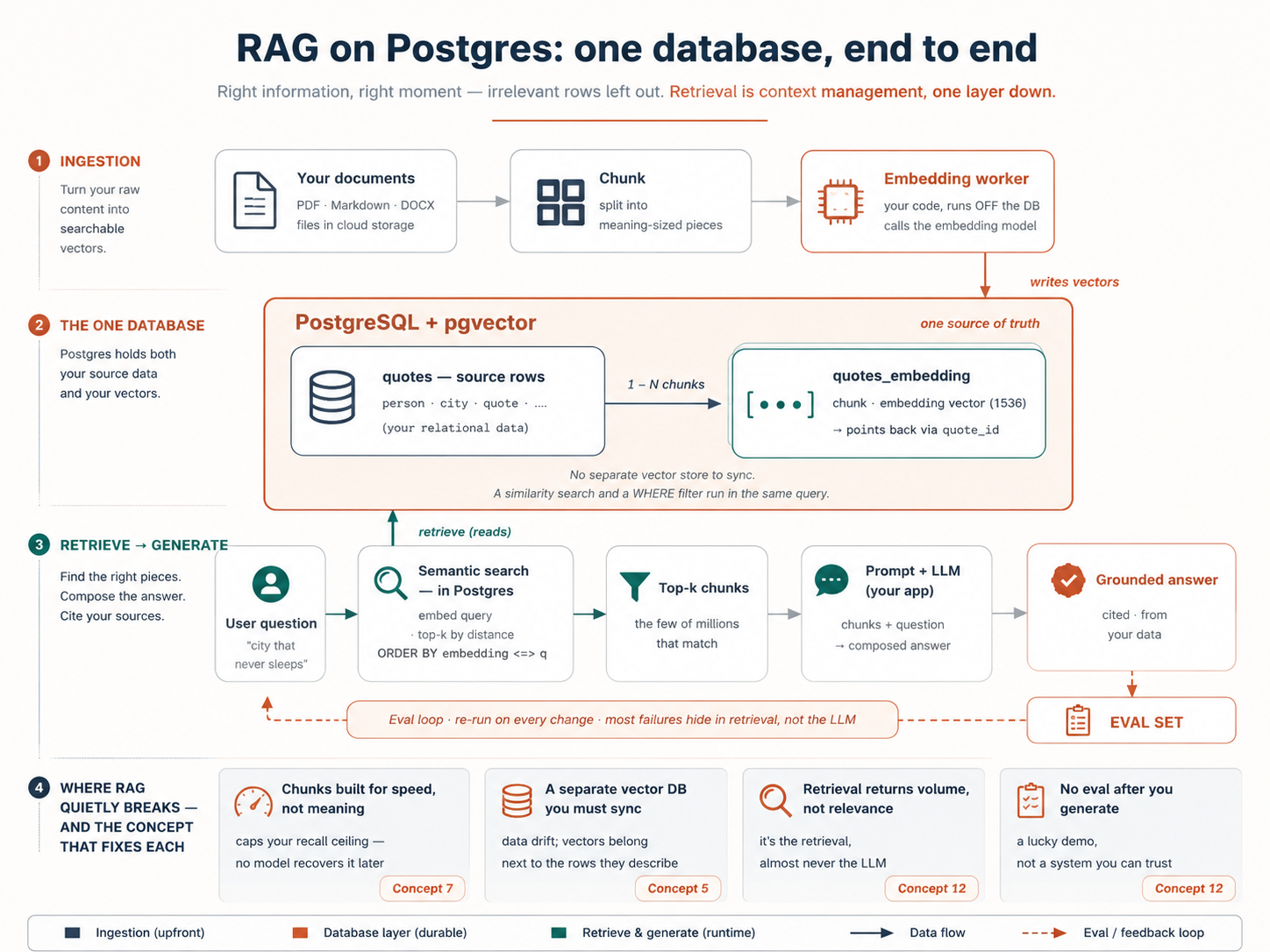 |
|
Para el final tendrás un proyecto RAG funcional: tu carpeta docs/ de documentos cargada en una base de datos Neon con pgvector activado, un pequeño worker que mantiene los vectores de significado actualizados a medida que cambian los documentos, una búsqueda que encuentra por significado, una función answer_question() que responde a partir de tus propios datos y un informe que muestra si cinco preguntas de prueba regresan correctas. Y no te detendrás en el 80% fácil: habrás medido un índice HNSW pasando de lento a instantáneo, filtrado la búsqueda por categoría, fusionado palabras clave y significado con búsqueda híbrida y aislado un inquilino de otro con seguridad a nivel de fila (Row-Level Security), cada uno ejecutado de verdad y medido contra tu conjunto de evaluación. De forma opcional, un servidor MCP entrega todo el conjunto a cualquier agente.
Cómo leer esto. Las Partes 1 y 2 (Conceptos 1 a 9) más el ejemplo paso a paso de la Parte 5 son el sistema completo, de principio a fin: una lectura de unas 2 horas con comprensión real (más si "vector" es nuevo para ti), más unas horas de teclado para la construcción. Las Partes 3 y 4 (Conceptos 10 a 15) son la capa de ajuste: lo que hace la búsqueda rápida (Parte 3) y buena (Parte 4). Léelas por el porqué y luego ejecuta cada una de ellas: la Parte 5 termina con un bucle práctico (Pasos 5 a 8) donde construyes de verdad un benchmark de índice, un filtro, búsqueda híbrida y aislamiento de inquilinos, sobre los datos que acabas de cargar. La profundidad no es lectura opcional a la que quizá vuelvas: es la segunda mitad de la construcción, y todo el mundo la hace. ¿Prefieres construir primero y leer el porqué después? Salta directo a la Parte 5.
Configura tu entorno (una sola vez)
Todo lo que construyes en este curso ocurre dentro de una sola carpeta pequeña: la base del curso. Viene precableada (tu agente ya sabe cómo llegar a Neon, la base de datos en la nube que usa este curso, y a Context7, consulta de documentación en vivo, para que el agente revise la documentación actual en lugar de adivinar) y trae un breve archivo de reglas, AGENTS.md, con las instrucciones permanentes del proyecto. Tu agente lee ese archivo automáticamente cada vez que arranca, y por eso tus prompts en este curso pueden ser cortos.
Descárgala una vez; la misma carpeta sirve para todo el curso, tanto el ejemplo paso a paso de la Parte 5 como el servidor MCP de la Parte 6. Configúrala ahora o después; la lectura en sí no necesita nada instalado.
Descargar postgres-ai-base.zip
Descomprímela y luego abre tu agente dentro de la carpeta:
cd postgres-ai
claude
cd postgres-ai
opencode
Un requisito: un modelo capaz. Si el primer plan del agente alguna vez se ve vago en lugar de específico, cambia a uno más fuerte (Claude Sonnet u Opus, GPT-5 o similar) antes de seguir.
Prepara la base (~3 min). El agente hace su propia configuración: pegas un prompt y respondes lo que te pida. Pega esto:
Deja lista esta base: instala las skills que enumera, configura mi
.envy dime exactamente qué necesitas de mí para poner en línea los servidores MCP de Neon y Context7.
Fíjate en: el agente instala dos skills (neon-postgres y mcp-builder), crea .env y luego te pide dos cosas: una clave de API (la misma clave cubre tanto los embeddings como las respuestas) y un clic en el navegador para autorizar Neon. La clave es gratis. Este curso se ejecuta sobre el nivel gratuito de Google Gemini (sin tarjeta de crédito), así que el agente te dirige a aistudio.google.com/apikey; inicia sesión con Google, crea una clave en alrededor de un minuto, pégala de vuelta y el agente comprueba en el acto que funciona. (¿Ya tienes una clave de OpenAI y la prefieres? Solo dilo, y el agente usará esa en su lugar; nada más del curso cambia.) Neon también es gratis; ¿todavía no tienes cuenta? Crea una justo en la pantalla de autorización. Si no se abre ninguna ventana del navegador por sí sola, escribe /mcp en el agente, elige Neon y este iniciará el inicio de sesión por ti.
Listo cuando: las skills están instaladas, .env contiene tu clave y el agente la confirmó con una llamada rápida de prueba, Neon está autorizado y reiniciaste el agente (sal y vuelve a abrir) para que se carguen las nuevas skills y los servidores MCP (ninguno de los dos se carga a mitad de sesión).
Parte 1: Fundamentos
1. Qué estás construyendo en realidad (y cuál es tu papel)
El error más común: construir aplicaciones de IA requiere un equipo de aprendizaje automático. No es así. Los modelos vienen listos para usar. La infraestructura es una base de datos que quizá ya ejecutas. Lo que queda es el trabajo de un ingeniero de IA: alguien que usa la IA para construir productos, no un investigador que entrena modelos. Ese es el papel para el que te prepara todo este libro, y está totalmente a tu alcance.
El segundo error es el que este curso existe para corregir: que debes escribir todo el SQL a mano. No es así. Diriges a un agente que ya conoce al dedillo los operadores de pgvector y el flujo de trabajo de embeddings. Tu valor sube en la pila: de teclear CREATE INDEX a decidir qué índice, de escribir la consulta a juzgar si los resultados sirven de algo.
Eso cambia lo que significa "saber este material". No memorizas sintaxis; construyes suficiente modelo mental para:
- darle al agente una instrucción precisa ("guarda el embedding en la misma tabla, usa distancia coseno, indéxalo con HNSW"),
- leer lo que produjo y detectar cuándo está mal,
- y decidir las elecciones de arquitectura que el agente no debería tomar por ti.
Este es el mismo hábito de planificar y luego ejecutar del curso de codificación, y aquí importa aún más, porque el agente está a punto de tomar decisiones (qué extensión, qué índice, qué función de distancia) que son caras de deshacer una vez que tienes datos.
El cambio de mentalidad: deja de preguntar "¿cuál es el SQL para la búsqueda semántica?". Empieza a decir "constrúyeme una búsqueda semántica sobre esta tabla; estas son mis restricciones; muéstrame el plan primero".
Hay un nombre más grande para esto. En los términos del libro, la base de datos que estás a punto de construir es un sistema de registro para la era de los agentes: la verdad de referencia autorizada de la que tus agentes leen, en la que escriben y contra la que verifican. El argumento de Jensen Huang es que los agentes no eliminan la necesidad de un sistema de registro; dependen de uno. Sin una verdad de referencia autorizada, un agente alucina; con ella, ejecuta. RAG en Postgres es cómo le entregas a un agente esa verdad de referencia, que es justo por lo que el resto de este curso trata la calidad de la recuperación como lo que decide si se puede confiar en el agente.
Tómalo literalmente durante el resto del curso: cada bloque de SQL de abajo se muestra para que puedas leer y juzgar lo que produjo el agente, no para que lo teclees. Saber leerlo es lo que te permite atrapar una función de distancia equivocada o un filtro faltante antes de que llegue a producción.
2. Vectores y embeddings, en un minuto
Si "vector" y "embedding" son nuevos, aquí tienes todo lo que necesitas para empezar.
Un vector es simplemente una lista de números: [0.021, -0.88, 0.14, …]. Un modelo de embeddings toma un fragmento de contenido (una oración, un párrafo, una imagen) y lo convierte en una de estas listas. El truco es que la lista captura el significado del contenido: dos fragmentos de texto que significan cosas parecidas obtienen listas de números que quedan cerca una de la otra. Dos frases que significan lo mismo, "the city that never sleeps" y "New York's restless streets", caen cerca aunque no compartan ninguna palabra.
Una base de datos vectorial es solo un sistema que guarda estas listas y encuentra las más cercanas a una lista dada, rápido. Eso es todo. Cuando un usuario hace una pregunta, tu app convierte su pregunta en un vector y luego le pregunta a la base de datos: "¿qué vectores guardados están más cerca de este?". Los más cercanos son los más relevantes en cuanto a significado, y así es como tu app obtiene el contexto correcto para entregárselo a un LLM. (Mira el diagrama inicial: esto es gestión del contexto para tus usuarios.)
No necesitas entender cómo funciona el modelo de embeddings por dentro, igual que no necesitas entender cómo un JPEG comprime una imagen. Necesitas saber que existe, que convierte contenido en vectores de significado y que cercanía equivale a similitud.
Abre una sesión y pídele a tu agente: "En lenguaje sencillo, explica qué es un embedding, luego muéstrame dos oraciones cortas que tendrían vectores cercanos y dos que estarían lejos, y por qué. Y luego la divertida: ¿una canción famosa o un apodo de mi ciudad caería cerca del nombre de la ciudad, aunque las palabras nunca lo digan?" Leer su respuesta es una verificación más rápida de tu propia comprensión que releer esta sección.
3. Las extensiones, y qué obtienes en Neon
Postgres se convierte en una base de datos vectorial mediante extensiones: complementos que le dan poderes nuevos sin renunciar a lo que Postgres ya hace bien (transacciones, joins, fiabilidad, SQL). Para todo este curso realmente solo hay una que aprender: pgvector. Añade tres cosas (un tipo vector para guardar embeddings, operadores de distancia para compararlos e índices para buscarlos rápido) y en Neon viene preinstalada, así que una sola sentencia la activa. Ese es tu motor RAG completo. Quédate solo con eso. (Dos notas al pie que puedes aparcar: existe una segunda extensión, pgvectorscale, para escala muy grande; es el nivel al que asciendes, no donde empiezas. Y los embeddings en sí no son una extensión: vienen de un pequeño worker que escribe tu agente, que se construye en el Concepto 6.)
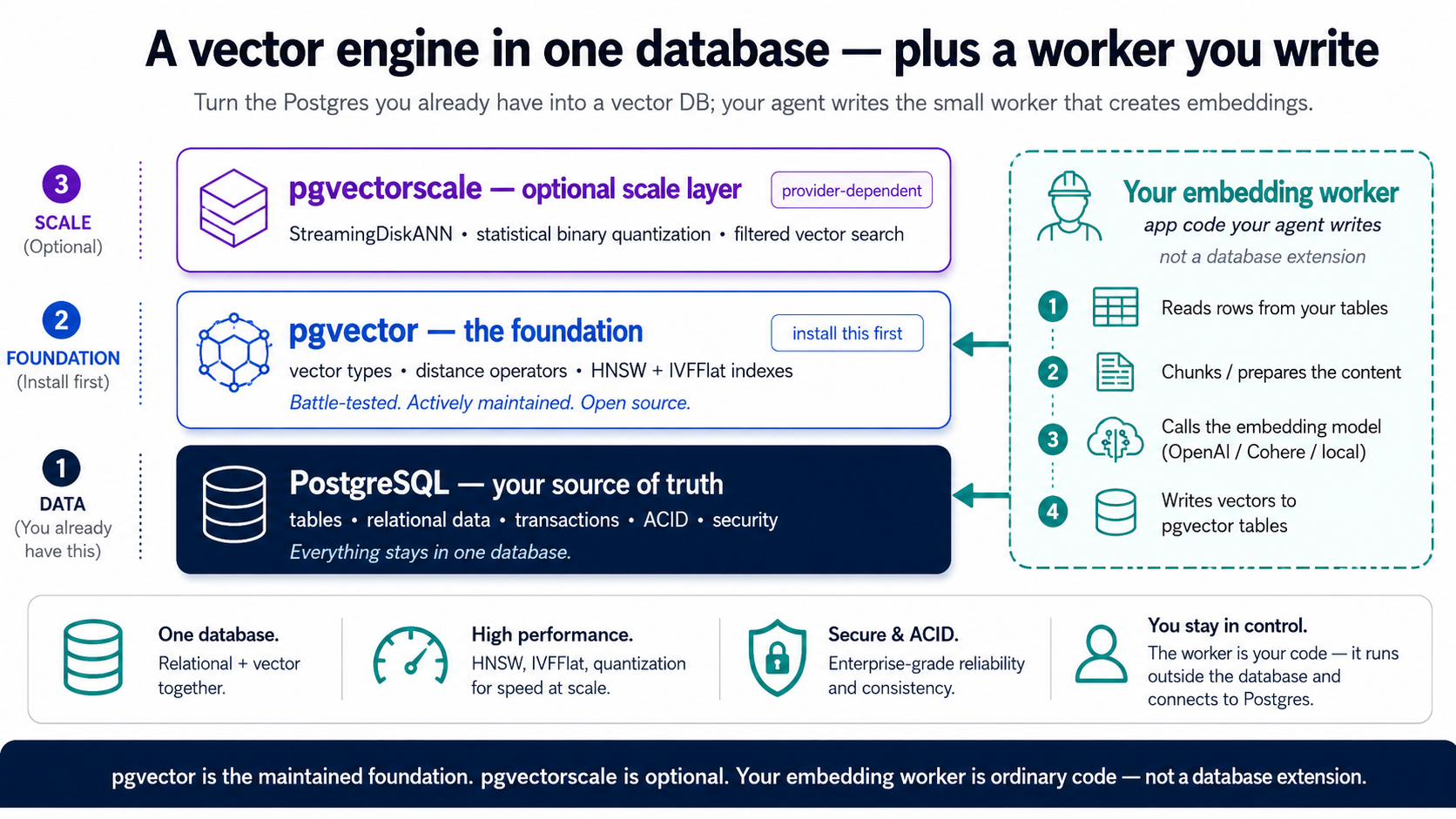
| Extensión | Qué añade | Cuándo la necesitas |
|---|---|---|
| pgvector | El tipo de dato vector, los operadores de distancia y los índices HNSW + IVFFlat | Siempre, y en Neon viene preinstalada |
| pgvectorscale | El índice StreamingDiskANN, compresión de vectores y búsqueda filtrada de alta precisión a gran escala | Nativo en TigerData; no en Neon, donde es el nivel al que asciendes |
Los nombres de los índices de esta tabla (HNSW, IVFFlat, StreamingDiskANN) son por ahora solo etiquetas; la Parte 3 enseña qué hacen y cuándo usar cada uno.
En Neon, pgvector es toda tu pila. Viene integrada, y todo lo que este curso hace después del embedding (búsqueda semántica, indexación, evaluaciones, filtros, búsqueda híbrida, RLS, el servidor MCP de la Parte 6) es pgvector puro. Los embeddings vienen del worker (Concepto 6), no de una extensión administrada. En cuanto a pgvectorscale: no está en el conjunto verificado de Neon, así que trátala como el host al que ascenderías solo si te quedas pequeño con HNSW, y pgvector más un worker te llevan muy lejos primero. ¿Quieres el nivel de escala nativo desde el primer día? Eso es TigerData Cloud, el mismo flujo de principio a fin; la única nota al final del Concepto 4 lo cubre, y por lo demás puedes leer todo este curso como si fuera solo de Neon.
La ventaja de una sola base de datos se mantiene: tus vectores viven junto a las filas que describen, así que una búsqueda por similitud y un filtro WHERE price < 2000 AND in_stock ocurren en la misma consulta, sobre la misma fuente de verdad. Ninguna segunda base de datos, ningún canal de sincronización, ninguna deriva de datos. (Quédate con eso: es toda la razón por la que la búsqueda filtrada del Concepto 13 es tan fácil.)
pgvector es una extensión de Postgres madura y ampliamente usada: la base estable sobre la que se apoya todo este curso. Todo lo que viene después del embedding (búsqueda semántica, indexación, evaluaciones, filtros, búsqueda híbrida, RLS, el servidor MCP) es pgvector puro.
La única cosa que pgvector no hace por ti es crear los embeddings: llamar a un modelo de embeddings y escribir los vectores de vuelta. La forma limpia y portable de hacerlo es un pequeño worker que escribe tu agente: tabla de origen → chunk → embeber mediante una llamada a la API → escribir vectores en una tabla de embeddings → buscar con pgvector. Mantener ese trabajo fuera de la base de datos es el objetivo, no un parche: un sistema de registro con estado no debería depender de una API externa volátil, así que el embedding (y las llamadas al LLM del Concepto 9) viven en las capas del worker y de la app, donde pueden fallar, reintentar y escalar sin tocar tus datos, y todo el conjunto se traslada limpiamente a cualquier host o contenedor. (Una capa de conveniencia administrada una vez horneó el embedding dentro de la base de datos, el Vectorizer de pgai, pero ese acoplamiento resultó frágil, y su repositorio fue archivado por el mantenedor en febrero de 2026; este curso no depende de él.) El worker son unas pocas líneas que produce tu agente y que tú revisas. Aprende el patrón; sobrevive a cualquier paquete concreto.
4. Conecta tu agente a Neon
No instalamos ni ejecutamos nuestra propia base de datos. Usamos Neon, Postgres serverless con pgvector ya integrado, y dejamos que el agente lo opere a través del servidor MCP de Neon. MCP es el mismo mecanismo de conexión del curso de codificación; aquí le entrega a Claude Code y OpenCode un conjunto de herramientas (create_project, create_branch, run_sql, get_database_tables, prepare_database_migration, complete_database_migration) para que puedan administrar Neon enteramente en lenguaje natural. Nunca abres la consola de Neon ni una shell psql tú mismo. (Este curso usa Neon como host por defecto; todo funciona de forma idéntica en TigerData Cloud; mira "¿Prefieres TigerData?" al final de este concepto.)
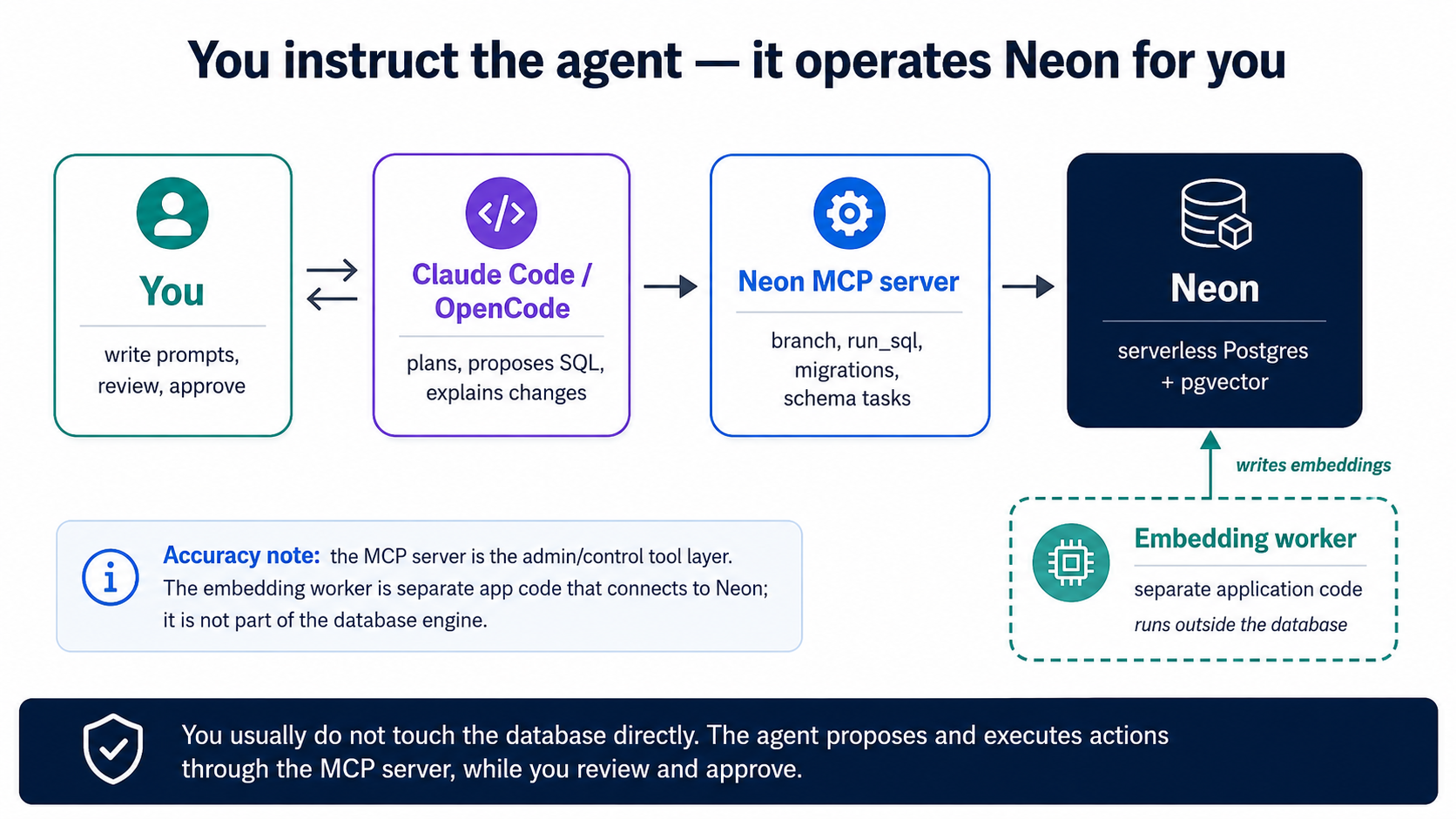
Cableado de una sola vez. Si arrancaste desde la base del curso, el servidor MCP de Neon ya está declarado en .mcp.json (Claude Code) y opencode.json (OpenCode): lo autorizas una vez en el navegador por OAuth, sin ninguna clave de API que administrar. (Cablearlo a mano es el mismo paso único: añade el servidor MCP de Neon a tu herramienta y autorízalo.) Esa es la única configuración manual; de aquí en adelante, todo ocurre instruyendo al agente. Condúcelo en modo plan:
Usando el servidor MCP de Neon, crea un proyecto llamado
agent-factory-ragy activa la extensión pgvector en él. Luego crea una rama llamadadevpara que construyamos sobre ella, y guarda la cadena de conexión de esa rama en.envcomoDATABASE_URLpara que el worker y la app puedan leerla después (nunca imprimas mi clave de API). Muéstrame el plan antes de ejecutar nada.
Luego lee el plan. Esto es lo que estás comprobando:
- Que trabaje sobre una rama, no directamente sobre producción. La ramificación es el superpoder de Neon: una rama es un clon instantáneo de toda tu base de datos (copy-on-write, copia al escribir: solo guarda lo que cambias, así que clonar es gratis e inmediato). El agente hace cambios de esquema en una rama, tú los previsualizas y solo entonces los confirmas en la rama por defecto: la misma disciplina de planificar y luego ejecutar, impuesta por la plataforma. (También es como medirás índices y ejecutarás evaluaciones después: ramificas, pruebas y descartas la rama.)
- Que active pgvector (la única extensión que este curso necesita) con una sola sentencia:
CREATE EXTENSION IF NOT EXISTS vector; -- pgvector is pre-installed on Neon; this just switches it on
- Para los embeddings (Concepto 6), el agente construye un pequeño worker (un breve script o servicio en Python) que lee las filas nuevas o cambiadas, llama al modelo de embeddings y escribe los vectores en una tabla de embeddings. Se ejecuta fuera de Neon, llegando a tu rama a través de su cadena de conexión. La clave de API del proveedor de embeddings vive en el entorno del worker, nunca en la base de datos.
No necesitas memorizar los nombres de las herramientas MCP ni la API de Neon. El punto del modo plan es que lees el plan, confirmas que trabaja sobre una rama y activa pgvector, y entonces apruebas. Si el plan hace algo que no reconoces, pregúntale al agente por qué antes de decir que sí: esa pregunta es tu verdadero trabajo.
La propia guía de Neon es que el servidor MCP está pensado para el desarrollo local y las integraciones de IDE: puede ejecutar operaciones potentes, así que mantenlo en tu flujo de desarrollo y revisa cada acción que proponga el agente antes de aprobarla. Los cambios en producción siguen pasando por tu proceso normal de migración revisada.
La base del curso ya incluye un breve AGENTS.md / CLAUDE.md con las reglas que este curso necesita: en qué rama de Neon estás, que las claves viven en el entorno (nunca se confirman), tu función de distancia elegida y dos reglas duras: "siempre haz los cambios de esquema en una rama de Neon y déjame previsualizar antes de confirmar" y "nunca ejecutes SQL destructivo (DROP, TRUNCATE, DELETE sin WHERE) sin mostrármelo primero". ¿Construyes sin la base? Ejecuta /init y recórtalo exactamente a eso.
Todo en este curso se ejecuta sin cambios en TigerData Cloud, el equipo detrás de las extensiones compañeras de pgvector, que lo posicionan como "Agentic Postgres". El bucle dirigido por el agente es idéntico; solo cambian los nombres:
- Tiger MCP en lugar del servidor MCP de Neon. Viene integrado en la CLI de Tiger: instálalo con
tiger mcp instally luego conduce Tiger Cloud en lenguaje natural exactamente como arriba ("crea un servicio, bifúrcalo, activa las extensiones, muéstrame el plan primero"). Incluso trae Skills de Postgres que le enseñan al agente las buenas prácticas. - Forks en lugar de ramas:
tiger service fork …crea un clon instantáneo sin copia (zero-copy), la misma disciplina de bifurcar → probar → descartar que usarás para las evaluaciones y los benchmarks de índices. - pgvectorscale es nativo (junto a pgvector), así que el "nivel de ascenso" StreamingDiskANN (Concepto 11) viene en la caja desde el primer día, y su índice admite vectores de hasta 16.000 dimensiones (los modelos grandes como
text-embedding-3-largeya no necesitanhalfvec). Tu worker de embeddings se ejecuta igual que en Neon.
Tu worker de embeddings y el paso de generación viven ambos en el código de la app, idéntico a Neon. Regla general: Neon para el arranque serverless más simple; TigerData cuando quieres la escala de pgvectorscale y el rendimiento de la búsqueda filtrada sin tener que migrar nunca.
Este curso usa Neon por dos razones: un nivel gratuito sin tarjeta de crédito y ramificación instantánea que el agente maneja mediante el servidor MCP de Neon. ¿Prefieres ejecutar Postgres localmente (Homebrew, Docker) o en otro host? El lado de los datos es idéntico: el mismo CREATE EXTENSION vector, el mismo esquema, el mismo worker, las mismas consultas; solo apunta DATABASE_URL a tu instancia. Lo que pierdes es la ramificación dirigida por MCP (el movimiento de "crear rama, probar, descartar" que usarás para índices y evaluaciones), así que ejecutarías esos pasos directamente. Todo lo que aprendes aquí se transfiere sin cambios.
Parte 2: Tu primer RAG, construido por tu agente
Construiremos un ejemplo pequeño y clásico: una tabla de citas de figuras históricas sobre ciudades de Estados Unidos, luego la buscaremos por significado y luego haremos que un LLM responda preguntas sobre ella.
5. El esquema: los vectores viven junto a tus datos
Pídele al agente la tabla de origen primero. Una cosa con la que quedarte: los vectores de significado no vivirán en algún almacén aparte; van en esta misma base de datos, en la tabla complementaria que construirás en el siguiente concepto, justo al lado de los datos que describen.
Crea una tabla
quotescon columnas:person,cityyquote. Añadiremos los embeddings en una tabla complementaria a continuación, poblada por un pequeño worker, así que por ahora solo los datos de origen. Luego inserta un puñado de citas reales sobre Nueva York, San Francisco y Chicago para que tengamos algo que buscar.
La tabla que escriba el agente se verá más o menos así:
CREATE TABLE quotes (
id bigint GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
person text NOT NULL,
city text NOT NULL,
quote text NOT NULL
);
El modelo mental con el que quedarte: una sola fuente de verdad. La cita, quién la dijo, la ciudad y (pronto) su vector de significado viven todos en la misma base de datos. Eso es lo que hace que el filtrado de la Parte 4 sea trivial.
6. Crea embeddings: el worker que construye tu agente
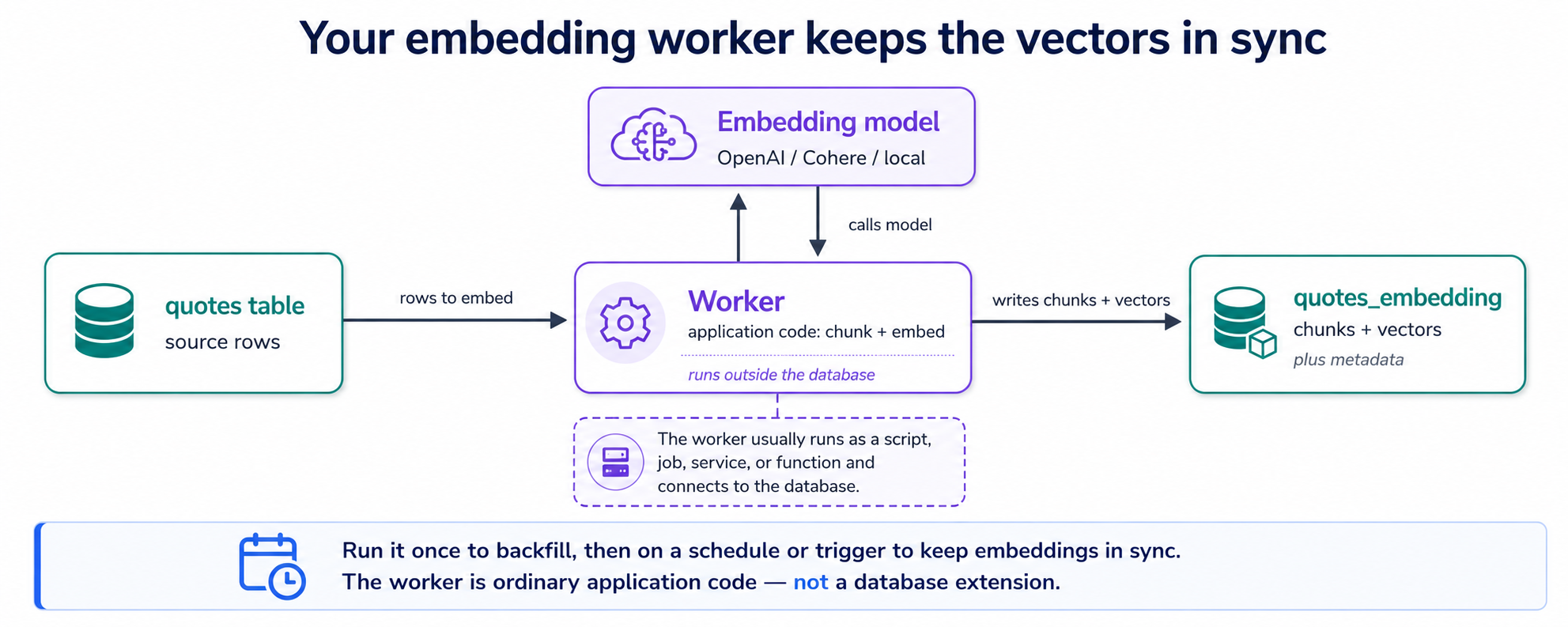
Tu tabla quotes contiene texto. Para que la base de datos busque ese texto por significado, cada fragmento de él necesita un vector, y crear esos vectores es el único trabajo que pgvector no hace por ti. Así que el agente escribe un pequeño programa: el worker de embeddings. Todo su trabajo es un bucle: encuentra citas que aún no tienen vectores → divide cualquier texto largo en piezas (chunks) → pídele al modelo de embeddings el vector de cada pieza → guarda los vectores. Ejecútalo una vez y cada cita existente queda cubierta; vuelve a ejecutarlo según una programación y las citas nuevas o editadas también quedan cubiertas. Esa es toda la máquina.
¿Dónde se guardan los vectores? En una segunda tabla, la tabla complementaria: una fila por chunk, cada una apuntando de vuelta a la cita de la que vino. Eso responde la pregunta que todos hacen aquí (¿una fila, un embedding?): una cita corta es un chunk, así que una fila de vector; un discurso largo se vuelve varias piezas, así que varias filas. (¿Por qué dividir? Eso es el Concepto 7, justo después de este.) Dos tablas, y se ven así:
quotes (your source table) quotes_embedding (companion table)
┌────┬─────────────────────┐ ┌─────┬──────────┬──────────────┬───────────┐
│ id │ quote │ │ id │ quote_id │ chunk │ embedding │
├────┼─────────────────────┤ ├─────┼──────────┼──────────────┼───────────┤
│ 7 │ a short quote │ ────→ │ 1 │ 7 │ whole quote │ [0.02, …] │
│ 8 │ a long speech… │ ──┬─→ │ 2 │ 8 │ first piece │ [0.11, …] │
└────┴─────────────────────┘ └─→ │ 3 │ 8 │ second piece │ [0.54, …] │
└─────┴──────────┴──────────────┴───────────┘
one row per quote one row per CHUNK (its own id),
pointing back via quote_id
Una decisión antes de que el agente lo construya: qué modelo de embeddings convierte el texto en vectores. Es la única elección aquí que resulta molesta de revertir, ya que cambiar de modelo significa volver a embeber todo, así que vale la pena entenderla aunque la base ya haya elegido un valor por defecto sensato por ti. Ese valor por defecto es el proveedor que configuraste: gemini-embedding-001 de Google en la ruta gratuita de Gemini, o text-embedding-3-small de OpenAI si elegiste OpenAI. Ambos se ejecutan aquí con 1536 dimensiones, ambos sobran para la mayoría del RAG y Gemini es gratis, así que nunca eliges tú el nombre del modelo; la base lo configuró para que coincida con la clave que diste. Dos razones por las que alguna vez te desviarías del valor por defecto: tu contenido no está en inglés (o es muy especializado, como legal, médico o código), donde un modelo multilingüe o ajustado al dominio puede ganar; o tus evaluaciones después muestran que un modelo más grande recupera genuinamente mejor. En el worker, el modelo es un solo ajuste, así que pruebas alternativas sobre tu conjunto de evaluación (Concepto 12) en lugar de adivinar: preselecciona candidatos del ranking de MTEB (el benchmark público estándar para modelos de embeddings) y deja que tus datos elijan al ganador.
La letra pequeña de las dimensiones (léela cuando te desvíes del valor por defecto)
Más dimensiones significa más almacenamiento y memoria y una búsqueda un poco más lenta. Dos notas prácticas: muchos modelos modernos te permiten solicitar menos dimensiones sin reentrenar (este curso usa exactamente eso para fijar ambos proveedores en 1536), y, una trampa real, los índices HNSW/IVFFlat de pgvector limitan el tipo vector a 2000 dimensiones (el tipo halfvec lo extiende a 4000), así que un modelo de tamaño completo de 3072 dimensiones (text-embedding-3-large de OpenAI, o Gemini a tamaño completo) necesitaría halfvec o dimensiones reducidas para poder indexarse. Mantenerte en 1536 te evita todo esto; tu agente debería señalar el límite si alguna vez subes las dimensiones, y tú deberías reconocerlo cuando lo haga. (En TigerData, el índice StreamingDiskANN de pgvectorscale admite vectores de hasta 16.000 dimensiones, así que el límite rara vez molesta.)
Primero, dale al código un hogar: un proyecto Python, administrado por uv (el administrador de proyectos de Python; el agente lo conoce, y enrutar cada dependencia a través de él mantiene el proyecto reproducible):
Configura un proyecto Python en esta carpeta con uv. De aquí en adelante, añade cada dependencia y ejecuta cada script a través de uv.
Luego haz que el agente construya el worker y su tabla:
Crea una tabla complementaria
quotes_embeddingcon una clave foránea aquotes, el texto del chunk y una columnaembedding vector(1536). Luego escribe un pequeño worker de embeddings que encuentre las citas sin embedding actual, divida en chunks el texto dequote, embeba cada chunk con el modelo de embeddings del curso e inserte los vectores enquotes_embedding. Ejecútalo una vez para hacer el relleno inicial, muéstrame cómo confirmar que las filas llegaron y explícame cómo lo programaría. Lee la clave de API desde el entorno.
Fíjate en: el agente crea la tabla complementaria (la forma exacta del diagrama de arriba), ejecuta el worker una vez y te muestra las filas de vectores que llegaron. Si el worker muere en su primera llamada de embedding con un 401 o un 429, nada en tu código está roto; es la clave, y probablemente ya lo detectaste en la configuración, donde el agente la probó con una llamada. En Gemini, vuelve a copiar la clave gratuita desde aistudio.google.com/apikey; en OpenAI, una cuenta recién creada a menudo necesita un método de pago antes de poder embeber. Un 429 es un límite de velocidad, así que espera un momento y vuelve a ejecutar. Arregla la clave y vuelve a ejecutar. Si en cambio ves expected 1536 dimensions, got 3072, la llamada de embedding no pidió 1536 dimensiones; ambos proveedores devuelven por defecto un vector más grande, así que la llamada debe pedir 1536 para coincidir con la columna vector(1536). El worker base ya lo hace, así que ese error significa que una llamada editada a mano lo perdió. Listo cuando: cada cita tiene al menos una fila en quotes_embedding, y conoces el único comando que vuelve a ejecutar el worker.
La versión más simple hace sondeo (polling): el worker se vuelve a ejecutar según una programación y vuelve a embeber las filas cuyo texto cambió. ¿Quieres en cambio actualizaciones impulsadas por el cambio? Un trigger de INSERT/UPDATE puede marcar una fila como sucia (señalar "esta necesita un embedding fresco") y el worker recoge esas filas marcadas en su siguiente pasada. Si alguna vez ejecutas más de una copia del worker para no quedarte atrás, no deben tomar la misma fila dos veces; Postgres se encarga de eso por ti, entregándole a cada worker un lote distinto de filas no reclamadas (el truco SKIP LOCKED). Así que la lista de tareas de filas-que-necesitan-embedding es simplemente una tabla ordinaria de Postgres: ningún servicio de cola aparte que ejecutar, la misma ventaja de una sola base de datos que tienes con tus vectores. De cualquier forma el trigger solo marca; la llamada de embedding aún ocurre fuera en el worker, y la base de datos en sí nunca llama a la API de embeddings.
El mismo patrón del worker embebe documentos, no solo campos cortos: apúntalo a PDF, DOCX o archivos en almacenamiento en la nube (un bucket de Amazon S3, por ejemplo) y haz que los analice, los divida en chunks y los embeba en la misma tabla complementaria. Y como el modelo es un solo ajuste en el worker, puedes cambiar de proveedor (Gemini, OpenAI, Cohere, Voyage, un modelo local) para probar cuál recupera mejor sobre tus datos, el experimento de modelos de arriba.
El worker llama a un proveedor de embeddings externo, así que necesita la clave de API de ese proveedor. La clave pertenece al entorno del worker (o al almacén de secretos de tu proveedor de nube), nunca escrita a mano en SQL ni confirmada en tu repositorio. Dile a tu agente explícitamente: "lee la clave de API desde una variable de entorno, nunca la escribas en un archivo que confirmemos". Luego verifica el diff antes de aprobar. Cambiar de proveedor de embeddings después (entre Gemini y OpenAI, o a Cohere, Voyage, un modelo local) es un cambio de una línea en el worker; el resto de tu app no se mueve.
7. Chunking: la palanca que fija tu techo
El chunking es un paso dentro de tu worker y, calladamente, el más importante. Un documento largo embebido como un solo vector se convierte en una masa informe (un promedio borroso de todo lo que dice), así que lo divides en chunks más pequeños, y cada chunk obtiene su propio vector. Lo que cuenta como un chunk decide lo que tu búsqueda podrá llegar a recuperar.
Dos diales:
- Tamaño. Demasiado grande y un chunk abarca varios temas, así que su vector queda desenfocado y recuperas casi-aciertos. Demasiado pequeño y un chunk pierde el contexto que lo hacía significativo. Unos pocos cientos de tokens es un punto de partida común; la respuesta correcta depende de tu contenido.
- Solapamiento. Dejar que los chunks se solapen un poco (digamos un 10-20%) evita que una oración que cruza un límite quede huérfana. Algo de solapamiento casi siempre ayuda; demasiado desperdicia almacenamiento y recupera casi-duplicados.
También está la estrategia: dividir por conteo de caracteres (el valor por defecto simple), por estructura (encabezados de markdown, párrafos) o semánticamente (agrupar oraciones que van juntas). Para documentos estructurados, dividir por encabezados suele ganarle al conteo ciego de caracteres.
Por qué esto se gana su propio concepto: el chunking fija tu techo de recall (donde recall significa simplemente si tu búsqueda trajo de vuelta los chunks correctos en primer lugar). Si la respuesta correcta nunca cae limpia en un solo chunk, ningún modelo de embeddings ni ningún prompt ingenioso puede recuperarla, y por eso un mal chunking es una de las razones más comunes de que un sistema RAG rinda por debajo de lo esperado en silencio. Así que no adivinas: una vez que trabajes con documentos reales y tu conjunto de evaluación exista (Concepto 12), haces que el agente pruebe unas pocas configuraciones de chunking en ramas de Neon, mide cada una contra tus preguntas de evaluación y se queda con la ganadora: el mismo movimiento de probar-y-descartar que usarás para los índices en la Parte 3. Harás exactamente ese movimiento en el ejemplo paso a paso (Parte 5).
8. Búsqueda semántica: ordena por distancia
Ahora la magia de la introducción. Para encontrar citas similares en significado a una frase, tu app convierte la frase en un vector propio (el vector de consulta) y la base de datos ordena los chunks guardados por lo cerca que sus vectores quedan de él.
La única pieza nueva de SQL es un operador de distancia: el símbolo que pregunta "¿qué tan cerca?". El único que necesitas es <=>, la distancia coseno: el valor por defecto para los embeddings de texto, y lo que usa todo este curso. (pgvector tiene otros dos: <-> para la distancia en línea recta, <#> para el producto interno, que solo encontrarás si la documentación de un modelo pide uno específicamente; tu agente lo sabrá.)
Escríbeme una consulta que devuelva las 5 citas más similares en significado a una frase de búsqueda. El embedding de la frase se pasará como parámetro desde el código de la aplicación; no lo embebas dentro del SQL.
La consulta que te entrega (para que la leas, no la teclees):
SELECT q.person, q.city, q.quote
FROM quotes_embedding e -- the table your worker populates: chunks + vectors
JOIN quotes q ON q.id = e.quote_id -- each chunk points back to its source quote
ORDER BY e.embedding <=> $1 -- $1 = the query phrase, embedded in app code
LIMIT 5;
Busca "the city that never sleeps" y los mejores resultados son citas sobre Nueva York, incluidas las que nunca contienen las palabras "New York", porque los significados están cerca. Eso, por fin hecho concreto, es la búsqueda semántica.
$1Convertir la frase del usuario en un vector ocurre en el código de tu aplicación (unas pocas líneas que escribe el agente) y el resultado se pasa a la consulta como el parámetro $1. La llamada al modelo se queda en tu app, donde tú controlas el modelo, los reintentos y el cacheo; Postgres hace lo que mejor sabe: guardar vectores y encontrar los más cercanos.
9. RAG: recupera y luego genera
La búsqueda semántica encuentra el texto relevante. RAG (Retrieval-Augmented Generation, generación aumentada por recuperación) va un paso más allá: toma esos chunks recuperados, los mete en un prompt como contexto y le pide a un LLM que componga una respuesta fundamentada en tus datos. Este es el bot de atención al cliente, el asistente de documentación, la función de "chatea con mis archivos": todos son este bucle.
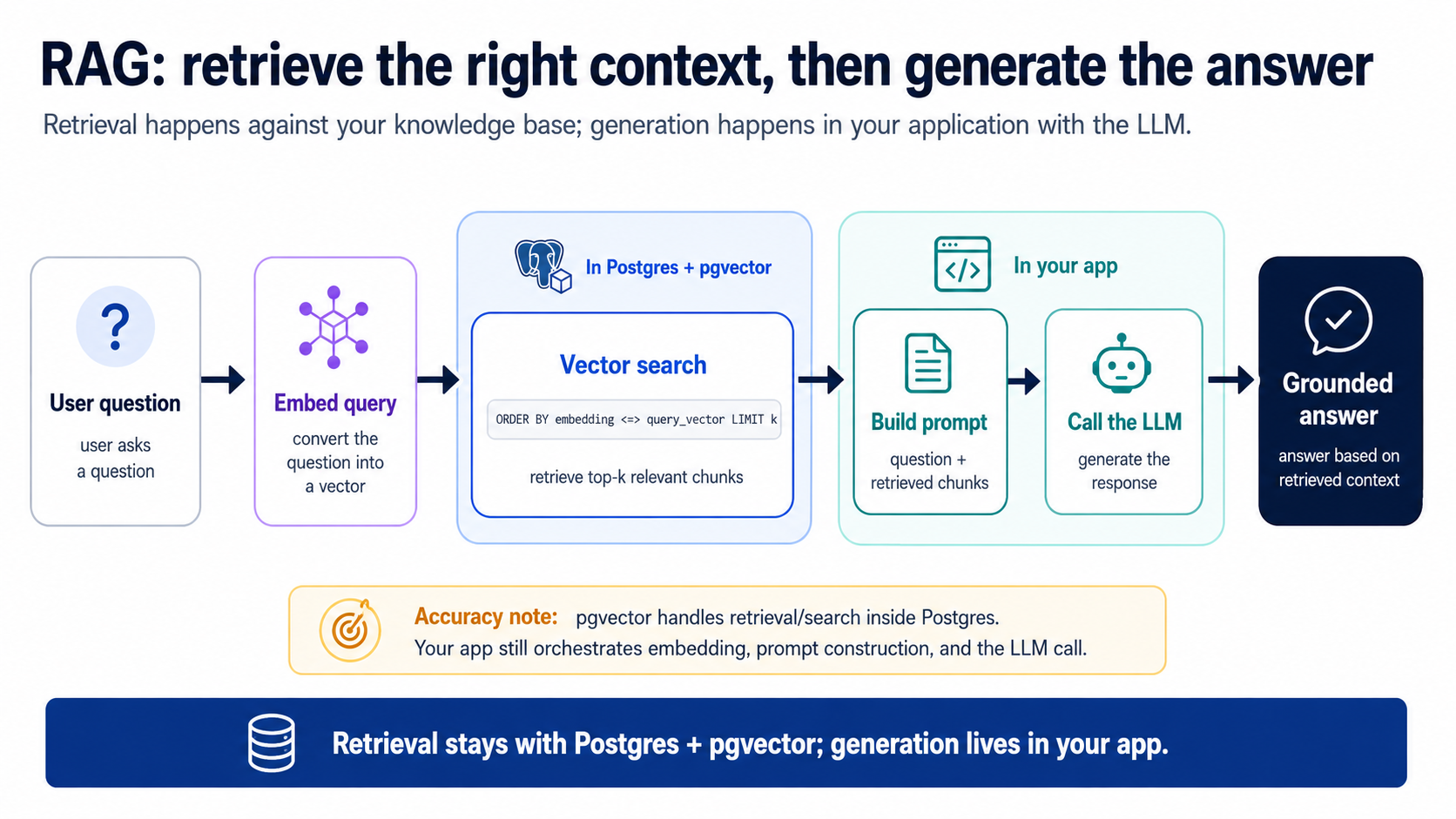
El bucle tiene dos etapas, y la división es todo el punto:
- Recuperar (en Postgres): ejecuta la consulta del Concepto 8 para sacar los k chunks principales más relevantes (k es simplemente cuántos pides; 5 es un buen comienzo). Este es el paso de gestión del contexto: trae la señal, deja fuera el millón de filas irrelevantes.
- Generar (en tu app): construye un prompt = instrucciones de sistema + chunks recuperados + la pregunta del usuario, envíalo a un LLM, devuelve la respuesta. El agente escribe este código de unión del lado de la app por ti; es pequeño.
Constrúyelo en dos pasos, para que veas la recuperación funcionando por su cuenta antes de que la generación la envuelva. Primero, un prompt de preparación para que el código tenga un hogar (ya es verdad si construiste el worker en el Concepto 6, en cuyo caso el agente solo lo confirmará):
Asegúrate de que esta carpeta sea un proyecto Python administrado por uv (configúralo si no lo es) y mantén cada dependencia y script pasando por uv.
Ahora la mitad de la búsqueda:
Construye una función
search_quotes(question)en el código de la aplicación: embebe la pregunta, ejecuta nuestra búsqueda semántica de k principales contraquotes_embeddingy devuelve los chunks coincidentes con sus citas de origen. Luego ejecútala con "the city that never sleeps" y muéstrame qué regresa.
Lo que regresa es la etapa 1 sola: los chunks correctos, encontrados por significado, antes de que se escriba ninguna respuesta. Ahora envuelve la etapa 2 a su alrededor:
Ahora construye
answer_question(question)encima: llama asearch_quotes, formatea esos chunks en un prompt como contexto, llama al LLM y devuelve la respuesta fundamentada; la recuperación se queda en SQL, la generación en el código de la app. Luego hazle una pregunta y muéstrame los chunks recuperados junto a la respuesta final.
Fíjate en lo que hace la etapa 1: entregarle al LLM exactamente el contexto que necesita y nada más; gestión del contexto, justo como prometió el diagrama inicial. Si la recuperación es descuidada (chunks equivocados, demasiados, irrelevantes), el LLM da una mala respuesta y la gente culpa a "la IA". Casi siempre es la recuperación. Y por eso existe la Parte 4.
Y acto seguido describieron un sistema que indexa documentos, embebe consultas y recupera chunks relevantes antes de generar una respuesta. Con respeto: eso sigue siendo RAG.
Ya construiste cada paso. Aquí está toda la máquina en una sola tarjeta:
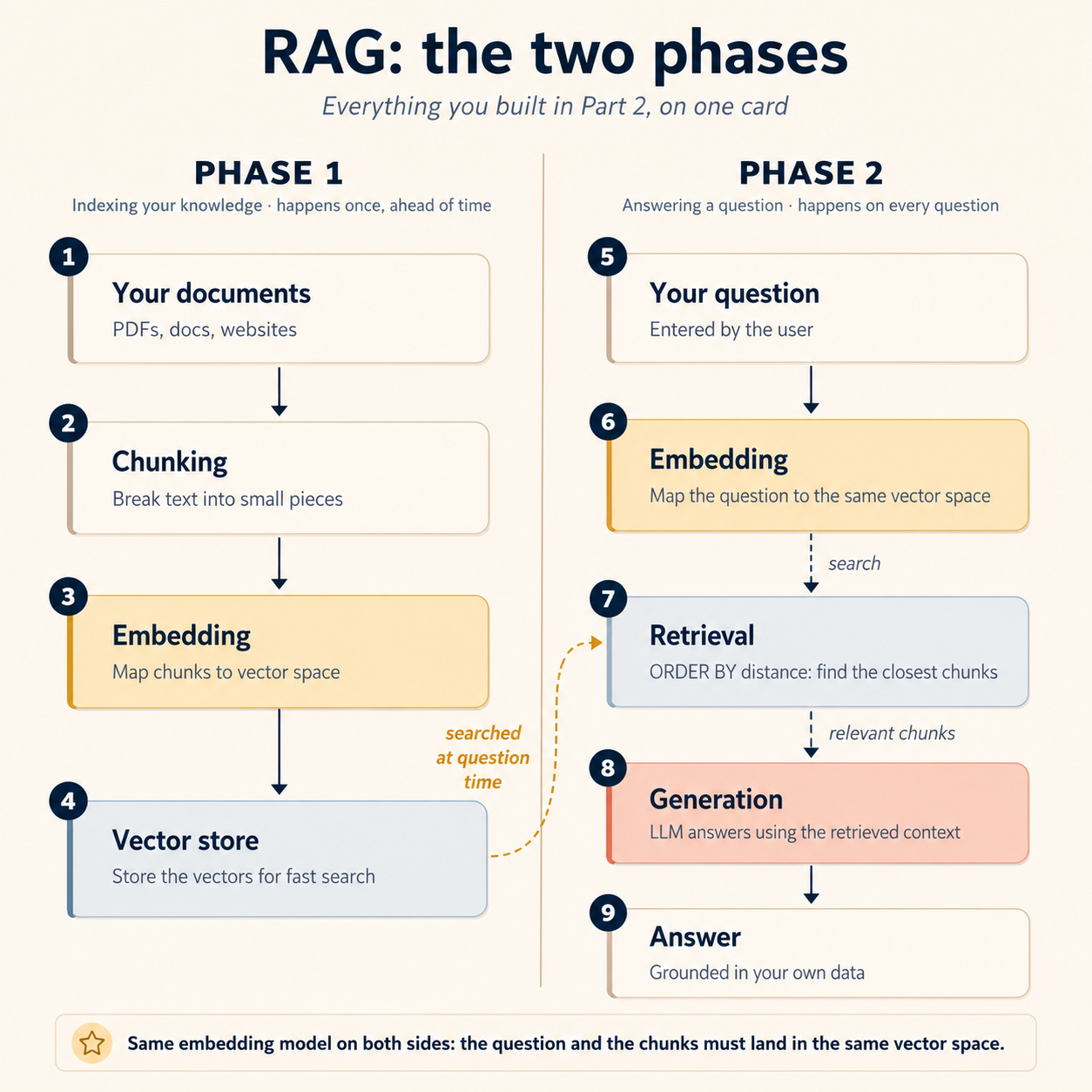
Fase 1: indexación (ocurre una vez, por adelantado):
- Tus documentos se dividen en chunks (Concepto 7)
- Cada chunk se embebe en el espacio vectorial mediante tu worker (Concepto 6)
- Los vectores aterrizan en Postgres, junto a los datos que describen (Concepto 5)
Fase 2: respuesta (ocurre con cada pregunta):
- La pregunta del usuario se embebe en ese mismo espacio vectorial
- Retrieval trae los chunks más cercanos a la pregunta (Concepto 8)
- Esos chunks se pasan al modelo, que genera una respuesta fundamentada en ellos (este concepto)
La parte que confunde a la gente en su primer pipeline está escondida en una palabra de arriba: mismo. La pregunta y los documentos tienen que caer en el mismo espacio vectorial: mismo modelo de embeddings, mismas dimensiones, mismos ajustes, en ambos lados. Embebe tus documentos con un modelo y tus consultas con otro y retrieval se rompe en silencio, sin error en ningún lugar: los espacios vectoriales de dos modelos son simplemente sistemas de coordenadas distintos, así que "más cercano" deja de significar "más similar". Ningún ranking de leaderboard te salva de ese desajuste. (Es el primo a nivel de modelo del error expected 1536 dimensions, got 3072 del Concepto 6, salvo que esta versión ni siquiera falla en voz alta).
Entonces, ¿qué cambió realmente desde los titulares de "RAG está muerto"? No el mecanismo: el empaquetado. Agentes, tool calls y razonamiento de varios pasos ahora se sientan encima del mismo ciclo retrieve-then-generate. Envolverás este mismo ciclo como una herramienta de agente en la Parte 6 y se la entregarás a un agente en la Parte 8: el ciclo no muere, asciende.
answer_question() no es solo el backend de un chatbot: es una herramienta que un agente llama. En los capítulos sobre agentes, la recuperación se vuelve una de las herramientas a las que recurre un agente más grande cuando necesita hechos fundamentados, igual que recurre a una calculadora o a una búsqueda web. RAG es el contexto consultable del que se nutre un agente.
Parte 3: Acelerar la búsqueda: los índices
De aquí en adelante, nivel intermedio. Las Partes 3 y 4 son la capa de ajuste: podrías lanzar solo con las Partes 1 y 2, pero no te detendrás ahí; léelas por el porqué y luego ejecútalas todas de verdad en la Parte 5, Pasos 5 a 8. Más rápido (Parte 3) y más fino (Parte 4) son habilidades que habrás practicado, no solo leído.
10. Por qué necesitas un índice vectorial (y cuándo no)
Sin un índice, una búsqueda por similitud compara el vector de consulta con cada fila: un escaneo exacto del vecino más cercano. Eso es perfectamente preciso, y perfectamente válido mientras seas pequeño. A medida que la tabla crece, se vuelve lento.
El arreglo es una búsqueda aproximada: cambias una pizca de precisión por una gran aceleración al no comprobar cada vector. Un índice vectorial es la estructura de datos que hace que esa aproximación sea buena.
El umbral que te salva de la sobreingeniería: por debajo de unos 100.000 vectores, la búsqueda exacta suele ser lo bastante rápida, y siempre correcta. Pero el umbral real cambia con las dimensiones, el tamaño de cómputo, el objetivo de velocidad, los filtros, la concurrencia y cuán a menudo se reescriben los vectores, así que haz que el agente mida con un benchmark antes de añadir un índice en lugar de recurrir a uno por defecto; añádelo cuando las búsquedas de verdad se vuelvan lentas, no antes. (Esto refleja el "añade una regla cuando algo sale mal, no antes" del curso de codificación.)
11. Los índices, cuál usar y cómo ajustarlos

En Neon, la opción real es la tarjeta del medio: HNSW es tu caballo de batalla (con IVFFlat como opción heredada). La tarjeta de StreamingDiskANN es nativa en TigerData; desde Neon, llegar a ella significa mudarte a un host que trae pgvectorscale.
El agente construye el índice por ti; tu trabajo es reconocer lo que construyó y confirmar que encaja con tus consultas. Una restricción que las tarjetas no muestran: una columna solo puede tener un tipo de índice vectorial, así que esto es un verdadero o-lo-uno-o-lo-otro. Así se ve cada uno:
-- HNSW — your default on Neon
CREATE INDEX ON quotes_embedding USING hnsw (embedding vector_cosine_ops);
-- IVFFlat — also on Neon; legacy, needs a lists parameter; recall drifts as data grows, so periodic rebuilds
CREATE INDEX ON quotes_embedding USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);
-- StreamingDiskANN — native on TigerData; on Neon only via a pgvectorscale host
CREATE INDEX ON quotes_embedding USING diskann (embedding vector_cosine_ops);
Nota vector_cosine_ops: el índice debe coincidir con la función de distancia que usan tus consultas (<=> → coseno). Si te equivocas en esto, el índice silenciosamente no ayudará.
Cómo decidir de verdad: mídelo con un benchmark. HNSW tiene dos ajustes de tiempo de construcción, m y ef_construction, que dan forma al grafo a medida que se construye el índice. Son exactamente el tipo de cosa que nunca memorizas: describe tu carga de trabajo real y deja que una rama desechable pague el experimento. Dos prompts (los conteos de filas de aquí son un sustituto a escala real: ejecutarás este mismo benchmark de verdad en la Parte 5, Paso 5, sobre una rama desechable sembrada a escala, para que quede como una habilidad y no como un cuento):
Tenemos unos 2 millones de vectores de citas y filtramos la mayoría de las búsquedas por ciudad. En una rama nueva de Neon, construye un índice HNSW con sus ajustes por defecto, ejecuta diez búsquedas representativas e informa la latencia p95.
Ahora ajusta
myef_construction: prueba unos pocos ajustes, vuelve a ejecutar las mismas diez búsquedas en cada uno y recomienda uno; explica el compromiso en un párrafo. Luego descarta la rama.
Ese es el movimiento del ingeniero de IA: no memorizas qué ajustes son más rápidos, haces que el agente mida en una rama de Neon y te traiga una recomendación que puedes verificar contra las tarjetas de arriba, y luego descartas la rama sin costo. Este benchmark mide velocidad, no recall: no evalúes a ojo si los resultados "se ven bien" aquí; juzgas el recall de la forma honesta, con embeddings reales contra tu conjunto de evaluación (Concepto 12), nunca echando un vistazo a una ejecución sintética. (Latencia p95 significa simplemente la velocidad por debajo de la cual entra el 95% de las consultas: un peor caso sensato donde poner el límite, pero solo sobre suficientes consultas: piensa en cientos, no en diez, y solo después de que unas pocas búsquedas de calentamiento calienten la caché de la rama, ya que una rama nueva de Neon sirve sus primeras lecturas en frío desde el almacenamiento. Sobre diez muestras en frío, la p95 es básicamente tu peor consulta a secas.)
El conteo de filas no es el único eje; la reescritura es el otro. Cuán a menudo se reescriben tus vectores (re-chunking, cambiar de modelo de embeddings, reindexar por decaimiento temporal) es un costo en sí mismo. HNSW acepta inserciones y actualizaciones incrementales sin una reconstrucción completa, pero un volumen alto de reescrituras infla el grafo con el tiempo (el recall deriva y al final necesitas un REINDEX), y el re-embedding en sí es cómputo que pagas. Así que datos que se reescriben constantemente pueden volverse caros mucho antes de ser grandes. Dile al agente tu patrón de actualización real, no solo tu conteo de filas, y haz que lo mida contra eso.
La única perilla que vale la pena conocer en el día a día: ef_search. Los ajustes de tiempo de construcción de arriba quedan fijados una vez que existe el índice; la perilla que de verdad tocarás está en tiempo de consulta: ef_search controla cuán fuerte busca una búsqueda: más alto significa mejor recall y consultas más lentas, más bajo significa más rápido y menos preciso. El agente lo ajusta por consulta; esta es la línea que lo verás ejecutar:
SET LOCAL hnsw.ef_search = 100; -- raise for more recall, lower for more speed
Así que el movimiento es: dile al agente el recall que de verdad necesitas y haz que ajuste ef_search para alcanzarlo, no que lo maximice a ciegas. Luego haz que demuestre que el índice hace su trabajo: ejecuta EXPLAIN ANALYZE, comprueba que haya un escaneo de índice en lugar de un escaneo secuencial e informa. Aquí está la diferencia, en la parte de la salida que de verdad lees (la misma tabla de 2M de vectores, con y sin un índice utilizable):
✅ GOOD — the index is doing the work
-> Index Scan using quotes_embedding_hnsw_idx on quotes_embedding
Order By: (embedding <=> $1)
Execution Time: 0.8 ms
❌ BAD — no index used; every row got scanned and sorted
-> Seq Scan on quotes_embedding (rows=2000000)
Sort Key: (embedding <=> $1)
Execution Time: 52.4 ms
Dos líneas te dicen cuál obtuviste: la línea del operador (Index Scan using …hnsw… frente a Seq Scan on …) y el tiempo de ejecución (submilisegundo frente a decenas de milisegundos sobre los mismos datos). Seq Scan significa que el índice no se está usando, normalmente porque el operador de distancia de la consulta no coincide con el índice, o porque aún no existe ningún índice. Eso es lo único que debes hacer que el agente confirme antes de dar la indexación por "lista".
Estas son las formas recurrentes en que la búsqueda vectorial se rompe en silencio, y como tu trabajo es juzgar el trabajo del agente, son exactamente lo que debes vigilar:
- Desajuste de dimensiones: las dimensiones de la columna no coinciden con la salida del modelo de embeddings.
- Tipo de vector no registrado en el cliente: el worker (y el código de búsqueda) deben registrar pgvector en cada conexión a la base de datos que toque la columna
embedding(register_vector), o los vectores silenciosamente van y vuelven como texto plano: las inserciones y búsquedas entonces se comportan mal sin ningún error. Este es el único modo de corrupción silenciosa que no es visible en el SQL, así que pídele al agente que confirme que registró el tipo. - Sin índice pasado el punto en que lo necesitabas: una ralentización silenciosa, no un error.
- Desajuste de operador / índice: la consulta usa
<->pero el índice es coseno, así que el índice se ignora. - Documentos enteros en lugar de chunks: el error del Concepto 7; la recuperación nunca podrá encontrar nada preciso.
- Saltarse
EXPLAIN ANALYZE: así nadie atrapa nada de lo anterior hasta que lo hacen los usuarios.
El filtrado tiene una trampa que vale la pena conocer, y es exactamente el caso de "filtrar la mayoría de las búsquedas por ciudad" del benchmark de arriba. Un índice HNSW aplica tu cláusula WHERE después de escanear su presupuesto fijo de candidatos (ef_search, 40 por defecto), así que un filtro selectivo puede dejarte con menos filas que tu LIMIT y descartar en silencio coincidencias reales; vigila los recuentos de resultados por debajo del LIMIT cuando valides esas búsquedas. Las palancas que mantienen alto el recall son de tiempo de consulta, no un grafo más denso: sube ef_search, o activa los escaneos iterativos (SET hnsw.iterative_scan = strict_order, desactivado por defecto), o construye un índice HNSW parcial por valor de filtro. Un índice B-tree ordinario sobre la columna de filtro también ayuda, pero no acotando de antemano el escaneo HNSW: Postgres usa un índice por escaneo, así que el B-tree solo le da al planificador una alternativa de distancia exacta que puede elegir cuando el filtro es lo bastante selectivo (recall completo, sin pérdida por postfiltrado). (StreamingDiskANN, la tercera tarjeta de arriba, está hecho para búsqueda filtrada intensa a muy gran escala.) En Neon, estas palancas más buenos índices de filtro te llevan muy lejos primero.
Parte 4: Hacer la búsqueda buena: la capa avanzada
Un RAG que funciona no es un buen RAG. Aquí es donde se atascan la mayoría de los proyectos, y donde conocer los movimientos te separa de alguien que solo puede producir una demo.
12. Desarrollo guiado por evaluaciones
El hábito que separa un sistema lanzable de una demo con suerte. La mayoría empieza construyendo y luego mira a ojo si la salida "se ve bien". En cambio, empieza por las preguntas. Antes de escribir nada, anota una docena de preguntas que tus usuarios harán de verdad y ponlas en un archivo. Ese archivo es tu conjunto de evaluación: tu vara de medir para saber si un cambio mejoró o empeoró las cosas.
Luego, cada vez que cambies el sistema (un nuevo modelo de embeddings, una estrategia de chunking distinta, un filtro añadido) vuelves a ejecutar el conjunto de evaluación y ves el efecto, en lugar de adivinar. A medida que la app crece, el conjunto crece con ella (20, 50 preguntas) y atrapas las regresiones antes que tus usuarios.
La segunda mitad es descomponer el problema. Cuando una respuesta es mala, no concluyas "la IA es tonta". Rastrea las etapas:
- Recuperación: ¿la búsqueda semántica siquiera devolvió los chunks correctos? (A menudo el problema real es un hueco de inventario: los usuarios preguntan por algo que nunca pusiste en la base de datos.)
- Contexto: ¿se le pasaron los chunks correctos al LLM, o demasiados/demasiado pocos?
- Generación: dado un buen contexto, ¿el modelo aun así respondió mal?
Nueve de cada diez veces el fallo es la recuperación, no el LLM. Arregla la etapa que de verdad está rota.
Construye el tuyo ahora, contra lo que sea que hayas cargado: las citas de la Parte 2 o tus propios datos. Primero las preguntas; el agente las borra, tú las curas:
Lee nuestra tabla de origen y redacta 12 preguntas de evaluación que un usuario podría hacer de forma realista: algunas con una fila de origen obvia, algunas cuya respuesta abarca varias y un par que nuestros datos no pueden responder en absoluto. Anota la respuesta esperada de cada una (o "no respondible") y guárdalas en
evals/questions.mdpara que yo las edite.
Edita ese archivo antes de darle el visto bueno: tú conoces a tus usuarios; el agente no. Luego conecta el arnés:
Construye un pequeño arnés que ejecute cada pregunta de
evals/questions.mda través de nuestro pipeline de recuperar-y-luego-generar, y para cada una muestre: los chunks recuperados, la respuesta final y si coincide con lo que yo esperaba. Resume dónde está fallando: recuperación o generación.
De ahora en adelante, cada cambio se mide contra él:
Ejecuta las evaluaciones y guarda los resultados como la línea base de hoy. Después de nuestro próximo cambio, vuelve a ejecutar y muéstrame el diff: qué preguntas mejoraron y cuáles empeoraron.
Cada ejecución de evaluaciones hace una llamada al modelo por pregunta, y volverás a ejecutar el conjunto muchas veces. En un nivel gratuito, tarde o temprano llegarás al límite diario de solicitudes del proveedor y verás un 429 a mitad de camino. Ese es el límite, no algo que rompiste: espera y vuelve a intentar, haz que el arnés retroceda y reintente automáticamente, cambia a un modelo gratuito más pequeño para las ejecuciones rutinarias o activa la facturación. Los límites exactos se mueven, así que revisa el panel de tu proveedor en lugar de confiar en un número.
El desarrollo guiado por evaluaciones es la columna vertebral de los agentes fiables, no solo del RAG. El tratamiento dedicado es el Curso acelerado de desarrollo guiado por evaluaciones: hazlo después de este.
13. Búsqueda filtrada: la cláusula WHERE es tu amiga
La búsqueda semántica pura devuelve las filas globalmente más similares. A menudo quieres las filas más similares que además cumplan alguna condición. Como tus vectores viven junto a tus datos (Concepto 5), esto es simplemente una cláusula WHERE sobre la misma consulta: ningún segundo sistema, ningún malabarismo. Cinco patrones cubren casi todo:
| Patrón | Caso de uso de ejemplo | La cláusula añadida (boceto) |
|---|---|---|
| Filtro de metadatos | Búsqueda de documentación en varios productos | WHERE product = 'CRM' AND doc_type = 'api-reference' |
| Filtro compuesto | Recomendaciones de comercio electrónico | WHERE category = 'electronics' AND price BETWEEN 500 AND 2000 AND in_stock |
| Filtro temporal | Recomendador de noticias: solo artículos recientes | WHERE published_at > now() - interval '7 days' |
| Filtro de permisos | RAG interno donde los usuarios solo ven lo que tienen permitido | WHERE clearance_level <= $user_level |
| Filtro geoespacial | "Recomienda cosas a menos de 5 km" (añade PostGIS) | WHERE ST_DWithin(location, $point, 5000) |
Cada uno tiene la misma forma: ORDER BY embedding <=> $1 con un WHERE delante. El de permisos vale la pena detenerse en él: es cómo evitas que el inquilino A llegue a recuperar los documentos del inquilino B, impuesto en la base de datos en lugar de esperado en el código de la aplicación.
Añade un filtro opcional de ciudad a nuestra búsqueda semántica. En una rama de Neon, añade un índice B-tree sobre la columna
city, asegúrate de que las consultas filtradas se mantengan rápidas y muéstrame la latencia antes/después sobre nuestro conjunto de evaluación.
14. Búsqueda híbrida: significado y palabras clave
Para 2026, la búsqueda híbrida es la mejora candidata más fuerte para la recuperación seria: una candidata que confirmas con tu conjunto de evaluación, no un valor por defecto que lanzas a ciegas. La idea: ejecutar búsqueda por palabras clave y búsqueda vectorial, luego fusionarlas. Cada una cubre el punto ciego de la otra: la búsqueda vectorial entiende el parafraseo pero subestima los términos raros exactos (un código de producto, el nombre de una persona); la búsqueda por palabras clave clava el término exacto pero se pierde el significado. Postgres hace ambas de forma nativa (búsqueda por palabras clave mediante búsqueda de texto completo con tsvector, vectores mediante pgvector), así que sigue siendo una sola base de datos y, a menudo, una sola consulta.
La forma que se ha vuelto estándar:
- Recupera de ambas, recuperando de más: digamos los 20 principales por palabras clave y los 20 principales por vector, para que la fusión tenga señal con la que trabajar.
- Fusiona con Reciprocal Rank Fusion (RRF, fusión de rangos recíprocos). RRF combina las dos listas ordenadas por posición, no por puntuación, lo que esquiva el verdadero dolor de cabeza de que las puntuaciones de palabras clave y las distancias coseno viven en escalas completamente distintas y no se pueden promediar con sensatez. Son unas pocas líneas de SQL y no necesita ningún modelo.
- (Opcional) reordena (rerank) los mejores candidatos con un cross-encoder: un modelo pequeño que puntúa cada par consulta-chunk directamente. Este es el paso de precisión: RRF elige un buen grupo de ~100, el cross-encoder ordena el puñado final que le entregas al LLM. Añádelo solo si tus evaluaciones dicen que la mejora vale la latencia extra.
La forma que produce el agente (para que la leas, no la teclees), tras haber añadido primero una columna ts de texto completo junto a los vectores: dos listas ordenadas fusionadas por RRF, todo en una consulta:
WITH kw AS ( -- keyword side: full-text search, ranked
SELECT id, row_number() OVER (ORDER BY ts_rank_cd(ts, plainto_tsquery($1)) DESC) AS rank
FROM quotes_embedding WHERE ts @@ plainto_tsquery($1) LIMIT 20
),
vec AS ( -- vector side: semantic search, ranked
SELECT id, row_number() OVER (ORDER BY embedding <=> $2) AS rank
FROM quotes_embedding ORDER BY embedding <=> $2 LIMIT 20
)
SELECT id, SUM(1.0 / (60 + rank)) AS score -- RRF: k = 60, summed across both lists
FROM (SELECT * FROM kw UNION ALL SELECT * FROM vec) r
GROUP BY id ORDER BY score DESC LIMIT 10; -- $1 = query text, $2 = query vector
Leyéndolo: kw devuelve los 20 principales por coincidencia de palabras clave y vec los 20 principales por significado, cada fila etiquetada con su rank en esa lista (1 = el mejor). La consulta final suma 1 / (60 + rank) para cada fila a través de ambas listas, así que una fila cerca de la cima de cualquiera de las listas puntúa bien, y una fila que cae en ambas gana. El 60 (la constante estándar de RRF) evita que un solo rango alto domine, y como trabaja sobre posiciones, nunca tienes que reconciliar las puntuaciones de palabras clave y las distancias coseno en escalas distintas.
Añade búsqueda de texto completo sobre la columna
quotejunto a nuestra búsqueda vectorial, fusiona ambas con RRF y ejecuta nuestro conjunto de evaluación solo-vector frente a híbrido. Dime qué preguntas mejoraron y cuánto.
La búsqueda híbrida gana más en consultas que mezclan un concepto con un término específico: "qué dijo Truman Capote sobre la ciudad" necesita que el nombre coincida exactamente y que se entienda el significado. Si de verdad ayuda con tus datos, y cuánto, es una pregunta que solo tu conjunto de evaluación puede responder, así que mide solo-vector frente a híbrido antes de asumir las piezas móviles extra.
15. Multitenencia y text-to-SQL
Dos más que deberías reconocer aunque no las construyas hoy.
Multitenencia. Si construyes SaaS, los datos de cada cliente deben quedar aislados de los de todos los demás. Hay una escalera de aislamiento, de la más laxa a la más estricta:
| Enfoque | Aislamiento | Costo / complejidad | Encaje típico |
|---|---|---|---|
Tabla compartida + filtro tenant_id | El más débil | El más barato | Herramientas internas, datos de bajo riesgo |
| Un esquema por inquilino | Bueno | Moderado | El punto dulce para la mayoría del SaaS |
| Una base de datos por inquilino | El más fuerte | El más alto (respaldos, operaciones) | Clientes de alta seguridad / regulados |
Un esquema por inquilino es el equilibrio habitual: aislamiento real, una sola base de datos que operar. De cualquier forma, la regla del Concepto 13 se mantiene: impón la frontera en la base de datos, no solo en el código de tu app. El mecanismo más limpio de Postgres es la seguridad a nivel de fila (Row-Level Security, RLS): haces que el agente escriba una política una vez (las filas son visibles solo donde, digamos, tenant_id = current_setting('app.tenant')) y Postgres la aplica entonces a cada consulta automáticamente, así que una sola cláusula WHERE olvidada no puede filtrar los vectores de un inquilino a otro. Una trampa que vale la pena conocer, porque muerde a todo el mundo la primera vez: los superusuarios y el dueño de la tabla saltan la RLS, así que tu app debe conectarse como un rol ordinario que no sea dueño (el rol de solo lectura de la Parte 6 es justo el indicado); prueba la política como ese rol, o no verás ningún aislamiento y concluirás erróneamente que no funciona.
Text-to-SQL. Postgres también contiene datos estructurados: números, fechas, relaciones. Text-to-SQL permite que un usuario pregunte en lenguaje natural ("¿cuáles fueron las ventas del T3 por región?") y que un agente lo traduzca a una consulta SQL correcta contra tus tablas reales. Lo que lo hace preciso es un esquema bien descrito: nombres claros de tablas y columnas, COMMENTs que explican lo que significa cada uno y un puñado de pares de ejemplo pregunta→consulta de los que el agente pueda aprender. Dale al agente ese contexto, mantén a un humano en el bucle para revisar el SQL antes de que se ejecute y combínalo con la búsqueda semántica (para tus documentos): un agente que elige la herramienta correcta por pregunta es la base de un verdadero asistente de datos.
Hazlo real sobre nuestro esquema en dos prompts. Primero, haz que el agente prepare el terreno:
Documenta nuestras tablas para que las preguntas en lenguaje natural se traduzcan bien: añade comentarios a las tablas y columnas diciendo qué contiene cada una, y guarda unas pocas preguntas de ejemplo junto con el SQL que deberían producir.
Luego simplemente pregunta, en lenguaje natural:
¿Qué persona tiene más citas, y cómo se reparten sus citas entre ciudades? Muéstrame el SQL que ejecutarías primero; ejecútalo solo después de que yo lo apruebe.
Text-to-SQL es el modo plan con otro nombre: haz que el agente muestre el SQL primero, especialmente cualquier cosa que escriba. Un SELECT equivocado desperdicia un segundo; un UPDATE equivocado te arruina la tarde.
Parte 5: Un ejemplo completo paso a paso
Una tarea, de principio a fin: de un proyecto Neon vacío a un sistema de preguntas y respuestas funcional que responde a partir de tus documentos. Los prompts de abajo son todo el trabajo: tecléalos en cualquiera de las dos herramientas. El método es el único movimiento del curso de codificación a tamaño completo: planifica con un modelo fuerte, revisa el plan y luego deja que un modelo más barato haga la construcción rutinaria.
Funciona sin importar cómo llegues. Te quedas en la misma carpeta postgres-ai/, pero la construcción crea un proyecto Neon completamente nuevo, así que nada de la construcción de citas se toca, hayas trabajado los Conceptos 5 a 9 o saltado directo aquí. Si el plan propone reutilizar funciones que ya construiste, está bien; júzgalo en la revisión.
0. Dale a la construcción documentos y un hogar: la base no trae ninguno, así que crea algunos (y si esta carpeta aún no es un proyecto uv, esto también lo arregla). Pega:
Configura esta carpeta como un proyecto Python administrado por uv si aún no lo es. Luego crea una carpeta
docs/con diez archivos markdown cortos: un mini manual del empleado para una empresa ficticia: permisos, gastos, seguridad, onboarding, equipamiento.
1. Planifica primero: entra en modo plan (Shift+Tab en Claude Code, Tab en OpenCode) con un modelo fuerte y luego pega:
Tengo una carpeta
./docsde archivos markdown. Construye un sistema RAG en Neon: usando el servidor MCP de Neon, crea un proyecto y una ramadev, activa pgvector, carga los documentos en una tabla, construye un pequeño worker de embeddings que los divida en chunks y los embeba en una tabla complementariachunks, y dame una funciónanswer_question()que recupere y luego genere. Muéstrame el plan completo y el esquema antes de ejecutar nada.
2. Lee el plan antes de aprobar. Comprueba: ¿está trabajando sobre una rama de Neon? ¿Está activado pgvector? ¿El worker de embeddings lee la clave de API desde el entorno (y la clave se mantiene fuera del repositorio)? ¿La generación está en el código de la app? Si todo es sí, aprueba.
3. Ejecuta, en tres puntos de control: cambia a un modelo más barato (/model en cualquiera de las herramientas) para la construcción rutinaria, y no dispares todo el plan a ciegas: ejecútalo por etapas, con algo que mirar después de cada una. La base de datos primero:
Se ve correcto. Procede con la base de datos y el worker: crea el proyecto y la rama
dev, activa pgvector, carga los documentos y ejecuta el worker una vez. Luego muéstrame cuántos chunks produjo cada documento, para que pueda ver que los documentos llegaron.
La recuperación a continuación, chunks antes que respuestas, igual que en el Concepto 9:
Ahora la mitad de la búsqueda. Construye la función de recuperación y ejecútala sobre tres preguntas que un nuevo empleado podría hacer; muéstrame solo los chunks que regresan, todavía sin respuestas.
Si los chunks correctos están regresando, la generación es la parte fácil:
Envuelve
answer_question()a su alrededor. Luego haz cinco preguntas que un nuevo empleado haría de verdad y muéstrame los chunks recuperados junto a cada respuesta.
4. Evalúa, luego itera: algunas respuestas serán más débiles que otras; eso es el bucle empezando, no un fallo. Pega:
Las respuestas más débiles usaron chunks irrelevantes. Diagnostica: ¿es recuperación o generación? Si es recuperación, prueba una estrategia de chunking distinta en una rama nueva y vuelve a ejecutar las mismas cinco preguntas.
Ahora tienes un RAG funcional. Los siguientes cuatro pasos son la capa de ajuste (Partes 3 y 4), y vas a ejecutar cada uno, no solo leer sobre él. Todo el que aprende hace estos, sobre los datos que ya tienes, para que la profundidad quede como una habilidad. Son independientes: hazlos en cualquier orden, no te saltes ninguno.
5. Hazlo rápido y observa cómo el índice se gana el sustento (Concepto 11). Diez documentos son demasiado pequeños para necesitar un índice, así que crearás la escala tú mismo, en una rama que descartas, y verás la búsqueda pasar de lenta a instantánea sobre los mismos datos. Pega:
En una rama desechable de Neon, crea una tabla de benchmark y llénala con suficientes vectores aleatorios para cruzar la marca de ~100k donde un índice empieza a ganar; no se necesitan embeddings ni texto real, esto es puramente para crear escala. Asegúrate de que cada fila tenga su propio vector aleatorio distinto (un error común llena todas las filas con el mismo vector; haz que el agente lo verifique con
count(distinct embedding)). Dimensiónala para que quepa dentro del almacenamiento gratuito de Neon; usa una dimensión de vector más pequeña para esta tabla sintética si eso ayuda a que quepa. Ejecuta una búsqueda del vecino más cercano conEXPLAIN ANALYZEy muéstrame el plan y el tiempo. Luego construye un índice HNSW (subemaintenance_work_mempara la construcción, de modo que no se arrastre) y ejecuta la búsqueda idéntica otra vez. Pon las dos lado a lado: la línea del operador y el tiempo de ejecución, antes y después. Luego sube y bajaef_searchy muéstrame cómo se mueve la latencia. Borra la rama cuando terminemos: eso recupera el almacenamiento.
Listo cuando: con tus propios ojos viste Seq Scan convertirse en Index Scan using …hnsw… y el tiempo de ejecución caer sobre datos idénticos, y observaste a ef_search mover la latencia. Esa es la mitad de velocidad del Concepto 11, hecha. (Tres cosas que parecen problemas pero no lo son: construir el índice HNSW sobre más de 100k vectores toma unos minutos, no segundos; eso es lo esperado, no un cuelgue, y subir maintenance_work_mem para la construcción lo recorta mucho; usar una dimensión más pequeña para esta tabla desechable no cambia nada de la lección, ya que escaneo-de-índice-frente-a-secuencial y el dial de latencia ef_search se comportan igual en cualquier dimensión; y estos vectores aleatorios sí muestran honestamente velocidad, pero no pueden mostrar recall real, porque los puntos aleatorios no tienen estructura de vecindad. Si aquí aparece un mal número de recall, no significa nada. Juzga el recall con embeddings reales contra tu conjunto de evaluación, nunca con datos sintéticos. Estás midiendo el índice, no tu recuperación.)
6. Filtra por significado y una condición (Concepto 13). Tus documentos del manual caen en categorías naturales (permisos, gastos, seguridad, onboarding, equipamiento), así que puedes filtrar de verdad:
Etiqueta cada chunk con la categoría del documento del que vino. Añade un filtro opcional de
categorya nuestra búsqueda. Pregunta "¿cuántos días de permiso me corresponden?" dos veces, una sobre todo y otra filtrada a la categoría de permisos, y muéstrame cómo cambian los chunks recuperados. Añade un índice B-tree sobrecategoryy confirma conEXPLAIN ANALYZEque el filtro lo usa.
Listo cuando: la consulta filtrada devuelve chunks más ajustados y al tema, y viste el índice B-tree en el plan: la ventaja de la-cláusula-WHERE-sobre-la-misma-consulta del Concepto 5, hecha real.
7. Atrapa el término exacto que el significado solo no encuentra (Concepto 14). Aquí es donde sientes por qué la búsqueda híbrida se volvió el valor por defecto:
Pon un código exacto y raro en un documento, digamos
EXP-2031en el archivo de gastos. Pregunta "¿qué es EXP-2031?" con búsqueda solo-vector y muéstrame en qué posición queda. Ahora añade búsqueda de texto completo sobre el texto de los chunks, fusiona las dos listas con RRF y pregunta otra vez; muéstrame cómo cambia el rango de la coincidencia exacta. Luego vuelve a ejecutar nuestras cinco preguntas de evaluación solo-vector frente a híbrido y dime cuáles mejoraron.
Listo cuando: comparaste dónde queda el código con solo-vector frente a híbrido y dejaste que tu conjunto de evaluación mostrara el efecto neto, así que decidiste híbrido por evidencia, no porque un titular te lo dijera. (En un corpus tan pequeño, la búsqueda vectorial quizá ya coloque un código raro cerca de la cima; la brecha que cierra la búsqueda híbrida crece cuando el corpus aumenta y el token raro se diluye entre muchos chunks. Si la híbrida no mueve algo de forma visible aquí, ese es el efecto de escala, no un fallo: confirma que la consulta RRF se ejecuta y deja que la comparación de evaluaciones sea el veredicto.)
8. Aísla un inquilino de otro (Concepto 15). El aislamiento que convierte esto en algo que podrías venderle a dos clientes a la vez:
Etiqueta nuestros chunks con dos inquilinos de mentira: divide los documentos por la mitad. Escribe una política de seguridad a nivel de fila para que una sesión fijada al inquilino A solo pueda recuperar los chunks del inquilino A. Luego demuéstralo desde un rol de base de datos ordinario que no sea dueño (la RLS la saltan los superusuarios y el dueño de la tabla, así que probar como el rol de administrador que construyó la tabla no muestra ningún aislamiento; usa en cambio un rol simple de solo lectura): haz que el agente cree ese rol por ti (un
CREATE ROLE+GRANT SELECT, conectado conSET ROLEo con un rol y cadena de conexión separados en Neon, no algo que configures a mano), fija la sesión al inquilino A y ejecuta una búsqueda que de otro modo coincidiría con un chunk del inquilino B, muestra que nunca regresa, luego cambia al inquilino B y muestra la imagen espejo.
Listo cuando: la consulta idéntica devuelve filas distintas dependiendo solo del inquilino al que está fijada la sesión, y la ejecutaste como un rol que no es dueño (para que la muralla sea real). Eso es el "impónlo en la base de datos" del Concepto 15 hecho concreto: RLS, no una cláusula WHERE que podrías olvidar.
Fíjate en el ritmo, y fíjate en que no cambió para las partes difíciles: planifica → revisa → ejecuta → evalúa → itera. Los índices, los filtros, la búsqueda híbrida y el aislamiento de inquilinos son el mismo bucle que la primera construcción de RAG; lo único nuevo cada vez es qué estás revisando (el esquema, el worker, el plan del índice, la política de RLS). Domina ese bucle y el SQL concreto deja de importar, porque siempre puedes hacer que el agente lo produzca y siempre puedes decir si está bien, a cualquier profundidad, no solo en la fácil.
Parte 6: Publica tu RAG como una herramienta MCP
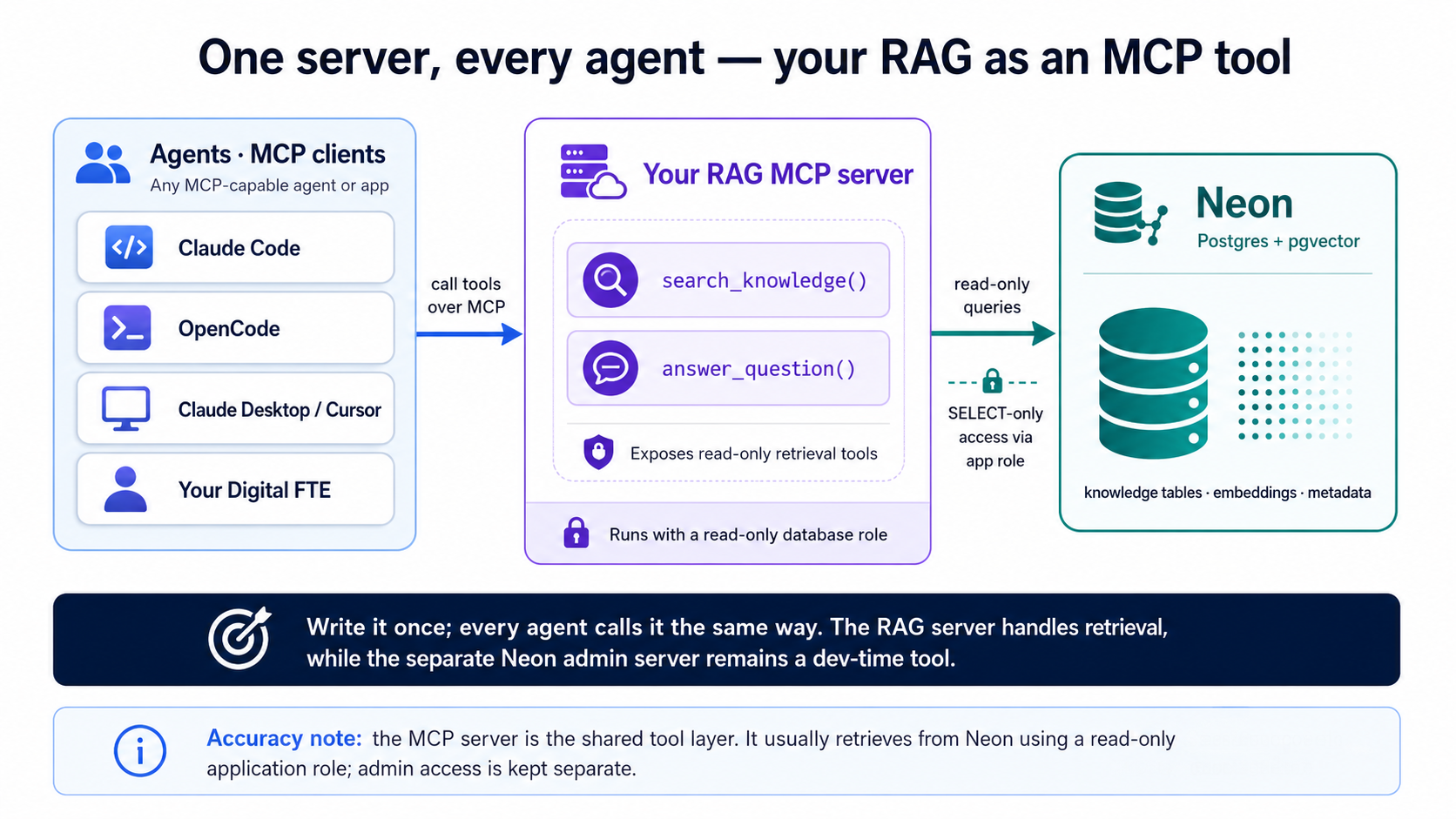
Construiste search_quotes() y answer_question() (Concepto 9), y en la Parte 5, sus gemelos para documentos; esta parte envuelve el que quieras servir. Ahora mismo solo tu código puede llamarlos. Envuélvelos en un servidor MCP (Model Context Protocol) y la misma recuperación se vuelve una herramienta que cualquier agente puede descubrir y llamar: Claude Code, OpenCode, Claude Desktop, Cursor o un Digital FTE que construyas después. MCP es el estándar abierto al que este libro vuelve una y otra vez: escribe la capacidad una vez, y cada agente le habla de la misma forma.
Esta es la promesa del Concepto 9, que la recuperación es el contexto consultable del que se nutre un agente, hecha real. Tu búsqueda vectorial deja de ser una característica enterrada en una sola app y se vuelve una capacidad reutilizable: algo a lo que un agente recurre igual que recurre a una calculadora.
Ya conociste ambos, y hacen trabajos opuestos:
- El servidor MCP de Neon (Concepto 4) es una herramienta de administración en tiempo de desarrollo. El cliente lo lanza localmente por stdio mientras construyes: crear ramas, ejecutar SQL, previsualizar migraciones. No es para producción ni para usuarios finales.
- El servidor MCP de RAG (esta parte) es tu superficie de producto en tiempo de ejecución: un servicio Streamable HTTP que ejecutas tú mismo y alojas en la nube, donde cualquier agente lo alcanza por URL. Expone recuperación de solo lectura ("busca en mi conocimiento", "responde a partir de mis datos") al agente que sea al que lo apuntes.
El primero construye el sistema. El segundo es el sistema, ofrecido a los agentes. El transporte sigue al papel: una herramienta de desarrollo local que el cliente lanza habla stdio; un producto alojado que despliegas habla HTTP. Nunca le entregues el servidor de administración de Neon a los usuarios finales.
Cómo es el servidor
Un servidor MCP es un pequeño programa que anuncia una lista de herramientas que un agente puede llamar. Con FastMCP (la biblioteca estándar de Python, una fina capa de decoradores sobre el SDK oficial de MCP) cada herramienta es simplemente una función tipada con un docstring; no escribes nada de la fontanería JSON-RPC. Como siempre, el agente escribe esto; se muestra para que lo juzgues:
# server.py — your RAG, exposed as MCP tools (review material, not to type)
import os
from fastmcp import FastMCP
from rag import search_quotes, answer_question as rag_answer # your Concept 9 functions —
# renamed on import so the MCP tool below can keep the public name "answer_question"
mcp = FastMCP("agent-factory-rag")
@mcp.tool()
def search_knowledge(query: str, limit: int = 5) -> list[dict]:
"""Search the knowledge base by meaning and return the closest chunks.
Use this when you need grounded facts from the user's own data."""
# embeds `query` in app code, runs the Concept 8 search on Neon,
# returns [{text, source, score}, ...] — retrieval only, read-only role
return search_quotes(query, limit)
@mcp.tool()
def answer_question(question: str) -> str:
"""Answer a question grounded in the knowledge base (retrieve, then generate)."""
return rag_answer(question) # the Concept 9 pipeline
if __name__ == "__main__":
# Streamable HTTP, stateless — the production shape. The same file runs on
# your laptop and in the cloud; stateless means no session is held between
# requests, so it scales behind a load balancer. (host="0.0.0.0" binds all
# interfaces so a container can route to it; locally you reach it on localhost.)
mcp.run(transport="http", host="0.0.0.0", port=8000, stateless_http=True)
Dos cosas importan más que el resto. El docstring es la interfaz: es el texto que lee el agente que llama para decidir cuándo usar la herramienta, así que debe decir con claridad qué hace la herramienta y cuándo recurrir a ella. Y la recuperación se queda de solo lectura: la herramienta ejecuta la búsqueda parametrizada del Concepto 8 bajo un rol de base de datos de solo lectura, así que un argumento de la herramienta nunca puede mutar ni filtrar tus datos. La tercera línea que vale la pena mirar es la última, mcp.run(transport="http", …, stateless_http=True), que convierte esto en un servicio que puedes alojar en lugar de un subproceso local; lo ejecutarás a continuación y luego desplegarás ese mismo archivo.
Constrúyelo con tu agente
La misma disciplina que en todas partes: planifica, revisa, ejecuta. Este es también el momento en que la skill mcp-builder de tu configuración se gana el sustento: nómbrala, y el agente construye el servidor como enseña la skill. En modo plan:
Usando la skill mcp-builder, envuelve nuestra recuperación en un servidor FastMCP llamado
agent-factory-rag. Expón dos herramientas:search_knowledge(query, limit)que devuelva los mejores chunks coincidentes con su origen y puntuación de similitud, yanswer_question(question)que devuelva una respuesta fundamentada. Reutiliza nuestras funciones existentessearch_quotesyanswer_question. Lee la cadena de conexión agrupada de Neon y las claves de API del modelo desde el entorno, y conéctate con un rol de base de datos de solo lectura. Sírvelo por Streamable HTTP en modo sin estado, para que el mismo archivo se ejecute localmente ahora y se despliegue en la nube después. Escribe docstrings de herramienta claros y orientados a la acción: eso es lo que lee el agente que llama para decidir cuándo usar cada herramienta. Muéstrame el plan y la lista de herramientas antes de escribir nada de código.
Lee el plan, confirma la lista de herramientas y el rol de solo lectura, luego aprueba y déjalo construir.
Ejecútalo y luego conéctate
Aquí está el cambio respecto al servidor de administración de Neon: aquel lo lanza el cliente por ti; este lo arrancas tú, y los agentes se conectan a su URL. Esa es la forma de producción, idéntica tanto si se ejecuta en tu portátil como en la nube. Arráncalo:
uv run server.py
Sigue ejecutándose e imprime dónde está sirviendo: verás http://0.0.0.0:8000/mcp en el banner (0.0.0.0 solo significa "escuchando en todas las interfaces"; te conectas a él como localhost). Déjalo levantado en esta terminal, abre otra para tu agente y regístralo en localhost:
claude mcp add --transport http rag http://localhost:8000/mcp
Compruébalo con claude mcp list; reconéctate a mitad de sesión con /mcp.
Añade un bloque remoto a opencode.json:
{
"$schema": "https://opencode.ai/config.json",
"mcp": {
"rag": {
"type": "remote",
"url": "http://localhost:8000/mcp",
"enabled": true
}
}
}
Luego simplemente di "usa la herramienta rag" en un prompt: el mismo flujo de añadir → comprobar → usar que conoces del servidor de Neon en el Concepto 4, solo que aquí apuntas a una URL en lugar de a un comando. Pruébalo:
Usa la herramienta rag para responder: ¿qué dijo la gente sobre Nueva York? Muéstrame qué chunks recuperó primero.
Observa al agente llamar a search_knowledge, recuperar tus chunks y fundamentar su respuesta en ellos. Ese ida y vuelta es todo el punto: tus datos son ahora algo sobre lo que cualquier agente puede razonar.
Despliégalo en la nube
Un servidor local que solo tú puedes alcanzar todavía no es un producto, y una herramienta MCP está pensada para ejecutarse donde cualquier agente pueda llamarla. Aquí es donde construirlo sin estado desde el principio rinde frutos: nada del servidor cambia para desplegarlo. Subes el mismo server.py a cualquier host que ejecute un servicio de Python (un contenedor en Cloud Run, Render, Railway, Fly o tu propia VM), defines allí las mismas variables de entorno y registras la URL pública en lugar de localhost:
claude mcp add --transport http rag https://your-host/mcp
Confirma ese .mcp.json y todo el que clone el repositorio alcanza el único servidor alojado (Claude Code les pide aprobarlo una vez); en OpenCode, apunta el mismo bloque "type": "remote" a la URL pública. Añade OAuth en cuanto se conecte más de una persona.
Por qué lo sin estado es lo que hace eso seguro: cada solicitud lleva su propio contexto, sin sesión mantenida entre llamadas, así que el servidor sortea los arranques en frío serverless y se ejecuta como varias réplicas detrás de un balanceador de carga sin sesiones pegajosas, y una herramienta de recuperación, que no guarda ninguna conversación por usuario, no pierde nada con ello. El transporte sobre el que construyes, Streamable HTTP, es el objetivo de producción estable; el único detalle que se mueve rápido es la palabra clave exacta de FastMCP, así que deja que la skill mcp-builder o la documentación en vivo confirmen transport="http" y stateless_http cuando el agente lo escriba. El servidor de administración de Neon se queda como herramienta de desarrollo local de cualquier forma.
Unas pocas reglas que el agente debe seguir, y que debes confirmar al revisar:
- Rol de solo lectura. Las herramientas de recuperación solo hacen
SELECT. Conéctate con un rol de base de datos que no pueda escribir, para que ningún argumento de herramienta pueda borrar ni alterar datos. - Consultas parametrizadas. El texto de la consulta llega como un parámetro vinculado, nunca concatenado como cadena dentro del SQL: la misma regla que el Concepto 8.
- Multitenencia: nunca confíes en un
tenant_idpasado como un simple argumento de herramienta. Derívalo de la sesión autenticada e imponlo con RLS (Concepto 15), para que el agente de un inquilino no pueda leer los vectores de otro. Una trampa si hiciste el ejercicio de RLS (Parte 5, Paso 8) sobre la tabla que lee este servidor: el rol de solo lectura debe fijar el inquilino en cada solicitud, o la RLS devolverá correctamente cero filas, lo que parece resultados vacíos sin error. Fija el inquilino por solicitud, o apunta este servidor a una tabla sin RLS mientras sigues aprendiendo. - Confía en la configuración. Un servidor MCP local es un comando que ejecuta otra máquina. Registra solo servidores, y abre solo archivos
.mcp.json/opencode.json, en los que confíes; una configuración de proyecto puede lanzar un proceso en tu máquina.
Y la recuperación es solo tan buena como los datos que tiene detrás, así que tu conjunto de evaluación sigue mandando: apúntalo a la herramienta MCP y estarás midiendo exactamente lo que experimentarán tus agentes.
Parte 7: Dónde se ejecuta
| Dónde | Mejor para | Notas |
|---|---|---|
| Neon (este curso) | De la primera construcción a producción | Postgres serverless, pgvector integrado, ramificación instantánea, autoescalado. No operas nada. |
| Ramas de Neon | Desarrollo, vista previa, evaluaciones, benchmarks | Cada rama es un clon instantáneo: construye sobre dev, previsualiza, confirma en la rama por defecto. |
| TigerData Cloud | Una alternativa full-stack a Neon | "Agentic Postgres": pgvector + pgvectorscale nativos, Tiger MCP, forks instantáneos sin copia. Elígelo para la escala de StreamingDiskANN y la búsqueda filtrada sin tener que migrar nunca. |
No estás encerrado en ninguna de estas opciones. Lo que aprendiste es Postgres normal más pgvector, con el trabajo de embeddings en un worker que se ejecuta fuera de la base de datos, así que la habilidad no es específica de Neon. El mismo esquema, el mismo worker y las mismas consultas se ejecutan en cualquier host de Postgres: Supabase, Xata (también Postgres con pgvector), Amazon RDS, Azure Database for PostgreSQL (pgvector más un índice vectorial DiskANN administrado para escalar) o tu propio clúster CloudNativePG sobre hardware que controlas.
Cómo elegir realmente un host (cuando superes el nivel gratuito)
No elijas por el precio por gigabyte de un tutorial; elige según la forma de tu carga de trabajo y luego compara la factura con tu tráfico.
- Tráfico en ráfagas o mucho tiempo inactivo (un proyecto paralelo, un asistente de bajo tráfico, ramas de desarrollo y evaluación): un host serverless medido que escala a cero, como Neon, solo cobra mientras de verdad estás ejecutando. Los tramos largos de inactividad cuestan casi nada.
- Tráfico constante, siempre activo (un servicio que nunca duerme): un precio de instancia plana suele ser más simple y más barato que un medidor que no se detiene nunca. El escalado a cero deja de ayudar en cuanto algo mantiene despierta la base de datos, incluido un worker de embeddings que sondea constantemente (mira la nota sobre el worker arriba).
- Una flota de bases de datos o necesidades de soberanía de datos: el autoalojamiento (CloudNativePG en tu propio clúster) hace que el costo marginal de la siguiente base de datos sea casi cero, al precio de operarla tú.
Dos cosas pesan más que la tarifa de cartel: si el nivel gratuito exige tarjeta de crédito (a menudo no, y eso importa para estudiantes) y si la ruta de actualización es una rampa suave o un precipicio (saltar de unos pocos dólares a varios cientos en el siguiente nivel es un costo real, no un detalle). Verifica ambas en la página de precios actual del proveedor; estos números se mueven, así que este curso no da cifras a propósito.
Unas pocas realidades de producción que vale la pena señalarle a tu agente desde el principio:
- El worker de embeddings es un proceso real: tiene que estar ejecutándose para que los embeddings se mantengan sincronizados. En producción es un servicio que despliegas y monitoreas, no algo que arrancas a mano.
- Migraciones: haz los cambios de esquema y de worker en una rama de Neon, previsualízalos y luego confírmalos en la rama por defecto; el agente conduce esto a través de las herramientas de migración de MCP de Neon. Versionado, revisado, reversible y nunca una edición improvisada contra producción.
- El costo vive en las llamadas de embedding y las llamadas de generación, ambas pegan a APIs de modelos externos. Agrupa en lotes donde puedas, cachea donde puedas y usa el hábito de emparejar modelos: un modelo barato para la generación rutinaria, uno fuerte donde la calidad importa.
- El escalado a cero frente al worker. Neon escala la base de datos a cero cuando está inactiva para ahorrar dinero, pero un worker de embeddings que sondea constantemente la mantiene despierta, derrotando ese ahorro en silencio. Para apps de poco tráfico, haz que el agente configure el worker para ejecutarse según una programación (o agrupe los embeddings en lotes) en lugar de sondear sin parar, para que de verdad obtengas el ahorro.
- Usa la cadena de conexión agrupada (pooled) para el tráfico de la app. El endpoint agrupado de Neon (el host
-pooler, PgBouncer en modo transacción) está hecho para las muchas conexiones efímeras que abren las apps serverless y de alta concurrencia. Haz que el agente apunte tu app que sirve el RAG a él; las migraciones y el worker pueden usar la cadena directa. - El worker se ejecuta fuera de Neon. No puedes ejecutar procesos sidecar en el cómputo administrado de Neon, así que el worker de embeddings vive en tu host de app, una VM pequeña o un trabajo programado, llegando a Neon a través de su cadena de conexión. Dile a tu agente dónde debería ejecutarse.
Esta es la verdadera pregunta detrás de todo el bombo, y la respuesta honesta es normalmente no. Si ya ejecutas Postgres, pgvector mantiene tus vectores junto a los datos que describen: una sola fuente de verdad, filtros y joins en la misma consulta, ningún segundo sistema que sincronizar, asegurar y pagar. HNSW cubre cómodamente el rango de ~100k a 10M, y el StreamingDiskANN de pgvectorscale se extiende más allá de mil millones de vectores, así que la escala bruta rara vez es el factor decisivo que alguna vez fue. Para la mayoría de las aplicaciones, Postgres es la base de datos vectorial.
El dinero grande está de acuerdo: en 2025 más de mil millones de dólares fueron a parar a empresas de Postgres, y tanto Databricks como Snowflake compraron su entrada al mercado: Databricks se quedó con Neon y Snowflake con CrunchyData. Eso es una buena señal, pero no es una prueba: las empresas que defienden este argumento también se benefician de él. Las cifras que reportan son llamativas: el índice DiskANN de pgvectorscale aparece en benchmarks con alrededor de 28 veces menos latencia p95 y un 75% menos de costo que Pinecone con el mismo recall, y unas 11,4 veces más rendimiento que Qdrant con 50 millones de vectores; pgvector con HNSW sirve decenas de millones de vectores con un p99 por debajo de 100 ms; y un equipo que consolidó cuatro bases de datos en un solo Postgres midió consultas 350 veces más rápidas. Trata estas como cifras de proveedores y casos de estudio, no como garantías: te dicen que el techo es alto, no lo que hará tu carga de trabajo. Confía en tu propio benchmark por encima del titular de cualquiera.
Un almacén dedicado (Pinecone, Weaviate, Qdrant, Milvus y otros) se gana su lugar cuando has medido una necesidad que él cubre y Postgres no: digamos un rendimiento de consultas muy alto a escala de miles de millones, un objetivo específico de recall/latencia que tus benchmarks muestran que pgvector no alcanza, o un servicio vectorial totalmente administrado que prefieres alquilar en lugar de operar. Esos son casos reales; simplemente son la minoría. La trampa es recurrir a uno por defecto porque un tutorial o un titular lo hizo. Decídelo como decides los índices (Concepto 11): deja que tu conjunto de evaluación y un benchmark sobre tu carga de trabajo real (incluida su reescritura) tomen la decisión, y pesa el costo permanente de un segundo sistema contra la ganancia que de verdad aporta.
Parte 8: Entrégaselo a un agente
Construiste la recuperación y la envolviste como una herramienta (Parte 6). El siguiente movimiento natural es un agente que use esa herramienta para hacer trabajo real, que es justo donde retoma el curso acelerado Construye agentes de IA. Allí no reconstruyes nada de esto; le entregas al agente la herramienta que ya tienes.
Aquí está todo el puente en una idea. Ese curso enseña el bucle del agente con el OpenAI Agents SDK: un Agent es un modelo equipado con instrucciones y herramientas, y un Runner conduce el bucle modelo → herramienta → modelo hasta que el trabajo está hecho. Tu RAG es una de esas herramientas. Donde termina este curso (un search_knowledge / answer_question invocable) es donde empieza aquel.
Dos formas de conectar lo que construiste (el curso de agentes cubre el bucle; tú solo aportas la herramienta):
- Como el servidor MCP de la Parte 6. El Agents SDK puede consumir servidores MCP directamente, así que apuntas el agente a tu servidor
agent-factory-ragy sus herramientas aparecen en la caja de herramientas del agente automáticamente: el mismo servidor que ya registraste en Claude Code y OpenCode. - Como una herramienta de función. Si prefieres mantenerlo en proceso, envuelve la misma consulta de solo lectura en el
@function_tooldel SDK: el estilo de herramienta nativo de ese curso. La misma recuperación, expresada como una función Python que el agente puede llamar.
El puente más profundo: memoria frente a conocimiento. El curso de agentes enmarca cada agente alrededor de dos preguntas: de qué puede nutrirse (estado) y qué tiene permitido hacer (confianza). Un tipo de estado es la memoria: lo que recuerda de la conversación en curso, que ese curso maneja con sesiones. Tu RAG aporta el otro tipo: conocimiento, contexto duradero y consultable que puede buscar, sobre muchos más datos de los que caben en cualquier ventana. Las sesiones contienen el chat; tu Postgres + pgvector contiene todo lo que el agente podría necesitar recuperar. Un agente conectado a ambos puede recordar lo que se acaba de decir y buscar lo que nunca supo, y la disciplina de "trae solo los chunks relevantes, deja fuera el millón de filas irrelevantes" de este curso es exactamente lo que evita que ese contexto recuperado inunde la ventana. El mismo hilo conductor, ahora al servicio de un agente en lugar de una app.
En el lenguaje del libro, esa mitad de conocimiento es el sistema de registro del agente: la verdad de referencia de la que lee (recuperación), en la que escribe (el worker la mantiene al día) y contra la que verifica (tu conjunto de evaluación). Es lo que convierte a un adivinador elocuente en un agente que ejecuta.
Conéctalo igual que construiste todo lo demás: a través del agente. En modo plan:
Arma el agente mínimo del curso acelerado Construye agentes de IA (OpenAI Agents SDK: un
Agentmás un bucleRunner). Dale exactamente una herramienta: nuestra recuperación. O conéctalo al servidor MCPagent-factory-ragde la Parte 6 para quesearch_knowledgeyanswer_questionaparezcan como herramientas, o envuelve la misma consulta de solo lectura como un@function_tool; recomienda cuál encaja y di por qué. Deja la mecánica propia del agente (sesiones, salvaguardas, enrutamiento de modelos) para ese curso; aquí, solo demuestra que el agente puede llamar a nuestra recuperación y fundamentar una respuesta en ella. Muéstrame el plan primero.
Apruébalo, ejecuta una pregunta que fuerce la llamada a la herramienta y observa al agente recuperar de tu base de datos Neon (o TigerData) y responder a partir de ella. Ese es el traspaso: Construye agentes de IA enseña el bucle, las salvaguardas, las sesiones y el despliegue; este curso le dio al agente algo verdadero que decir. Tu conjunto de evaluación cruza intacto: sigue midiendo la recuperación de la que el agente ahora depende.
A dónde ir después
Ahora tienes el 80%: puedes convertir Neon en una base de datos vectorial, construir un sistema RAG fundamentado, elegir un índice por evidencia y mejorar la recuperación con filtros, búsqueda híbrida y evaluaciones, todo dirigiendo a un agente y juzgando su trabajo.
- Hazlo fiable: Curso acelerado de desarrollo guiado por evaluaciones
- Conviértelo en un agente: la Parte 8 tiende el puente de tu herramienta RAG hacia un agente; el bucle completo, las salvaguardas, las sesiones y el despliegue están en Construye agentes de IA
- Conviértelo en un producto: transforma el asistente en un Digital FTE desplegable
El hilo conductor nunca cambia: información correcta, momento correcto, información irrelevante fuera. Lo aprendiste para tu agente. Ahora puedes construirlo para el de todos los demás.