Construir un Digital FTE: curso intensivo de 4 horas
Quince conceptos y una construcción guiada: Skills, el sistema de registro y el cable MCP que los conecta.
En el curso anterior construiste un agente. En este curso das el primer paso real de agente a Worker de IA. (Este es el segundo curso de Modo 2, la ruta de fabricación, el segundo movimiento de siete.) Ese agente, de Construir agentes de IA, era un agente de chat con streaming, con sesiones, guardrails y trazas, ejecutado en un sandbox para el cómputo. Funcionaba. También olvidaba todo en cuanto cerrabas la terminal, y todas las herramientas que tenía estaban escritas dentro de su Python.
¿Solo quieres verlo funcionar primero? Salta a la Quick Win de 15 minutos más abajo. Crearás una base de datos real y un Worker pequeño que escribe en ella y recuerda; después vuelve por los conceptos que explican por qué tiene esa forma.
Un Worker de IA es ese mismo agente de chat, pero ya maduro. También se le llama empleado de IA o Digital FTE: una sola cosa, nombrada según cómo la construyes, a qué equipo se suma y cómo aparece en los costos. Este curso construye su base: un agente que puedes hacer crecer, que recuerda y que te pertenece. Un Worker completo también funciona las veinticuatro horas, actúa por cuenta propia y te alcanza en cualquier app, pero eso llega después. El SDK y el runtime SandboxAgent del curso anterior se mantienen iguales; lo que cambia es todo lo que los rodea.
Hacer ese cambio requiere dos movimientos, más el cable que los conecta:
- Sus capacidades se convierten en Skills: carpetas pequeñas que el agente encuentra y carga por su cuenta, en lugar de herramientas fijadas dentro de su Python.
- Las cosas que antes olvidaba al reiniciar pasan a Postgres, su sistema de registro: el único almacén autoritativo contra el que trabaja el Worker, la fuente de verdad sobre la que opera una empresa, como un CRM o un libro contable. Allí viven varios tipos de datos:
- Registros de negocio: la verdad operativa. Clientes, tickets, pedidos. Los consultas y los actualizas.
- Biblioteca de referencia: conocimiento que busca por significado. La biblioteca de políticas, documentos de referencia, casos anteriores.
- Estado: cómo se ve el trabajo ahora mismo. Qué chats están abiertos, qué espera aprobación.
- Traza: un registro de lo que hizo, para que la empresa pueda reproducir sus acciones y confiar en ellas.
- MCP (el Model Context Protocol) es el estándar abierto para conectar agentes con herramientas y datos externos. Aquí es el cable que el agente usa para llegar a ese almacén.

La recuperación semántica es la pieza que la gente etiqueta mal. Significa encontrar cosas por significado, no por palabras exactas. Es una forma de buscar, no un almacén propio: puedes ejecutarla sobre la biblioteca de referencia, sobre conversaciones anteriores o sobre los propios registros de negocio. Viene de Un Worker en ejecución tiene dos partes que producción despliega por separado. El arnés es el runtime del agente: el bucle del SDK en sí. El cómputo es el sandbox donde realmente se ejecuta el código del agente; cuando el agente llama a una herramienta, entrega el código a ese sandbox. En este curso ambos permanecen locales. Ver presentación completa: Construir la base del Digital FTE La tesis nombra Siete Invariantes que todo sistema de agentes en producción debe satisfacer. El curso anterior construyó el motor (Invariante 4): el OpenAI Agents SDK sobre un sandbox. Este curso agrega el Invariante 5: todo Worker trabaja contra un sistema de registro. El motor es aquello sobre lo que se ejecuta un Worker; el sistema de registro es aquello contra lo que trabaja. Dos estándares abiertos mantienen eso portátil. Las Skills (originalmente de Anthropic, ahora de todo el ecosistema en agentskills.io) permiten que las capacidades viajen entre herramientas. MCP es el cable estándar que el agente usa para llegar al registro; el curso anterior no tenía ninguno, y es el patrón nuevo clave aquí. El registro en sí es Neon Postgres + pgvector, elegido porque es gratis para empezar, escala a cero cuando está inactivo y trae un servidor MCP oficial. El producto es reemplazable; la guía de intercambio lista alternativas.pgvector, que agrega búsqueda por significado a Postgres.Cómo se ejecuta un Worker: arnés frente a cómputo (aquí no despliegas ninguno)
UnixLocalSandboxClient ejecuta el sandbox en tu equipo (cero infraestructura, una clave de API), y puedes apuntarlo a Docker, Cloudflare, E2B o Modal con un cambio de una línea (guía de intercambio de la Parte 5). Desplegar el arnés en sí como un servicio en la nube siempre activo es su propio curso, Despliega tu arnés de agente en la nube.Dónde se sitúa este curso en la tesis de Agent Factory
📚 Material didáctico
Estos quince conceptos se reparten en tres capas: Skills, sistema de registro y MCP. La tabla de abajo es el mapa completo.Los 15 conceptos de un vistazo (expande para ver el mapa completo)
# Concepto Capa Qué pregunta responde 1 Qué es una Agent Skill Skills ¿Dónde vive la capacidad reutilizable? En una carpeta, con SKILL.md más scripts/referencias opcionales.2 Divulgación progresiva Skills ¿Por qué es barato tener skills a mano? Descubrimiento → activación → ejecución carga solo lo necesario cuando se necesita. 3 Escribir un SKILL.md Skills ¿Qué contiene en realidad un archivo de skill? Metadatos, descripción de disparo, instrucciones operativas. 4 Convenciones de empaquetado de skills Skills ¿Cómo viajan las skills entre herramientas? La misma carpeta funciona en Claude Code, OpenCode y cualquier cliente compatible. 5 Componer skills Skills Cuándo encadenar skills pequeñas por traspaso de archivos frente a escribir una skill grande. 6 Por qué Postgres gestionado Sistema de registro ¿Qué almacén se gana el título de "sistema de registro"? Uno con persistencia, ramificación, gobernanza y las primitivas de vectores que un agente necesita. 7 El esquema del Worker Sistema de registro ¿Qué tablas necesita de verdad un agente? Conversaciones, documentos, embeddings, registro de auditoría, invocaciones de capacidades, más la Session del SDK para los turnos. 8 Fundamentos de pgvector Sistema de registro ¿Cómo funciona la búsqueda semántica en Postgres? Columna de embedding, operadores de distancia, tipos de índice. 9 El pipeline de embeddings Sistema de registro ¿Cómo se convierte el texto en un vector consultable? Fragmentación, el modelo de embedding, cuándo volver a generar embeddings. 10 La auditoría como disciplina Sistema de registro ¿Qué significa "leer y escribir" para un Worker? Cada acción que toma un Worker deja una traza que la empresa puede reproducir. 11 Qué es MCP y qué no es MCP Un protocolo para herramientas, recursos y prompts: no es un framework, no es un servicio. 12 El servidor MCP de Neon MCP La interfaz del agente con su base de datos: qué expone, cómo se autentica. 13 Conectar MCP con el Agents SDK MCP La integración de MCP del SDK: cómo registrar un servidor, qué ve el modelo, dónde vive la frontera de confianza. 14 Servidores MCP personalizados MCP Cuándo escribir el tuyo propio frente a solo usar @function_tool. El árbol de decisión.15 MCP bajo carga MCP Elecciones de transporte, pooling de conexiones, cuándo encolar.
Una vez que tienes este mapeo, lo demás es casi todo mecánica. Una falla en producción se rastrea a una de tres cosas: una Skill que nunca se descubrió (descripción demasiado vaga), un sistema de registro sobre el que dos Workers no se ponen de acuerdo (carrera de esquema), o un cable MCP que pierde eventos (transporte equivocado para la carga). El diagnóstico te dice cuál.
Para quién es este curso
Nivel intermedio. Deberías tener:
- Idealmente haber hecho Construir agentes de IA, aunque tu agente puede generar su estado final sobre la base si te lo saltaste.
- Los hábitos de Plan Mode y archivos de reglas del Curso intensivo de programación con agentes.
- Un ciclo PRIMM-AI+ en tu haber.
Esta es una secuela centrada en Python: no escribirás Python ni SQL a mano, tu agente escribe el código mientras tú diriges, y las Partes 2 y 3 se vuelven más densas (modelos de Pydantic, pools de asyncpg, un pequeño servidor MCP personalizado), así que espera más idas y vueltas ahí. Una base de datos guarda información en tablas. Imagina una hoja de cálculo: cada fila es una cosa (un cliente, un ticket de soporte) y cada columna es un detalle sobre ella (un nombre, una fecha, un estado). Ese es todo el modelo mental que necesitas aquí. Nunca escribes código de base de datos tú mismo; lo hace tu agente, y estas dos palabras solo te ayudan a leer lo que construye. Cinco palabras que este curso usa como si las conocieras:¿Eres nuevo en bases de datos? La versión de 60 segundos
Vigente a mayo de 2026, verificado contra openai-agents 0.17.x, el SDK mcp, la documentación de MCP de Neon y pgvector 0.8+. Fija tus versiones una vez que construyas; si la documentación y esta página alguna vez no coinciden, mandan el tutorial de Cloudflare Sandbox y la documentación de Neon.
Tú diriges, el agente construye, y como la base trae un AGENTS.md que lee al abrirse, tus prompts pueden quedarse cortos: solo di qué construir a continuación.
The fifteen-minute quick win: succeed once, then study why it worked
Antes de leer los 15 conceptos que explican por qué funciona esta arquitectura, construye la versión más pequeña de ella que de verdad funcione. Al terminar tendrás:
- un proyecto Neon nuevo con dos tablas,
notesyaudit_log, que creaste por MCP y viste en la consola, - un Worker de IA mínimo que escribió en ambas en una sola transacción a través de su propia herramienta
save_note, - y una respuesta concreta a "¿un sistema de registro hizo algo de verdad por mí?": tu nota y su fila de auditoría, compartiendo un mismo id.
Esto es una sola pantalla de prompts: tu agente de programación construye el almacén sobre Neon MCP, luego genera un Worker pequeño que escribe en él, y tú ves cómo el Worker recuerda. El Worker completo (ocho decisiones, un esquema de cinco tablas) llega en la Parte 4. Si solo tienes una sesión, haz esto y después vuelve por los conceptos.
Por aquí corren dos planos, y tenerlos claros es todo el modelo mental. Tu agente de programación (Claude Code u OpenCode) usa Neon MCP para construir e inspeccionar la base de datos. El Worker que construyes usa su propia herramienta para escribir en ella en tiempo de ejecución. El Worker nunca toca Neon MCP, y la propia documentación de Neon es tajante sobre por qué: el servidor MCP es "solo para desarrollo y pruebas", nunca conectado a una app en ejecución.

Obtén la base y ábrela
Descarga la base y abre la carpeta en tu agente general. El agente hace la configuración por sí mismo, a partir de los prompts de abajo. Esto se configura una sola vez: digital-fte/ es tu carpeta para todo el curso, lo mismo para la Quick Win que para la Parte 4. Cada construcción provisiona su propio proyecto Neon nuevo (una base de datos), pero nunca vuelves a descargar ni a descomprimir nada.
cd digital-fte
claude
cd digital-fte
opencode
Esta base asume un agente general capaz (Claude Code, u OpenCode ejecutando Claude Sonnet u Opus, GPT-5 o similar). Un modelo más pequeño se desviará con el prompt de construcción; si su primer plan se ve vago en lugar de específico, cambia a uno más fuerte antes de seguir.
Prepara la base (~3 min)
La base trae reglas y cableado; las skills y tu clave vienen después. Haz que tu agente se configure a sí mismo. Pega esto:
Lee AGENTS.md, luego deja esta base lista: instala las skills que lista para el agente que seas, copia
.env.examplea.envpor mí, y dime exactamente qué necesitas de mí para poner en línea los servidores MCP de Neon y Context7.
Fíjate en: que el agente instale skill-creator, mcp-builder y neon-postgres (ves ejecutarse la instalación), cree .env y luego te pida dos cosas: tu OPENAI_API_KEY para pegarla en .env, y un clic en el navegador para autorizar Neon por OAuth. Neon es gratis; si todavía no tienes cuenta, regístrate en neon.com en cerca de un minuto, o crea una justo en la pantalla de autorización. Cuando la instalación y el cableado terminen, el agente te pide reiniciarlo (salir y relanzar) para que las nuevas skills y servidores MCP carguen; ninguno carga a mitad de sesión.
Listo cuando: las skills están instaladas, .env tiene tu clave, Neon está autorizado, y reiniciaste el agente para que las nuevas skills y servidores MCP estén activos.
La compuerta: confirma que el agente puede llegar a la base de datos (~1 min)
Lo único genuinamente nuevo que agrega este curso es que el agente llegue a un sistema de registro real por MCP. Así que antes de construir nada, confirma que esa frontera está activa. Pega esto:
Lista las herramientas de Neon que puedes ver.
Fíjate en: una lista real de nombres de herramientas de Neon (crear un proyecto, ejecutar SQL, describir tablas y cosas así). Esa lista es la mano del agente sobre la base de datos, y todo lo de abajo se apoya en ella.
Compuerta abierta: la respuesta lista nombres reales de herramientas de Neon. Si no lo hace: casi seguro te saltaste el reinicio, así que las herramientas aún no están cargadas. Sal, relanza y pregunta de nuevo. ¿Sigue sin haber nada? El OAuth de Neon no terminó: vuelve a hacerlo y reintenta.
Construye el almacén y toma su cadena de conexión (~3 min)
Haz que tu agente de programación cree la base de datos sobre Neon MCP, y luego entrégale a tu Worker lo único que necesitará para llegar a ella más tarde: una cadena de conexión.
Pega esto a tu agente general. Planifica primero; ejecuta tras la aprobación.
En un proyecto Neon nuevo, crea dos tablas:
notes(el texto de la nota) yaudit_log(un registro de lo que pasó). Luego llama aget_connection_stringy escribe esa URL en mi.envcomoDATABASE_URL. Usa las herramientas de Neon para todo; no me escribas SQL para que lo ejecute yo.
Fíjate en: el agente llamando a las herramientas MCP de Neon para crear el proyecto y las dos tablas (ves esas llamadas a herramientas, no SQL que tú tecleaste), y luego escribiendo DATABASE_URL en .env. Esa cadena es el traspaso: Neon MCP provisionó el almacén, y tu Worker usará la cadena, no el servidor MCP.
Listo cuando: existe un proyecto Neon nuevo con una tabla notes y una tabla audit_log, y .env tiene un DATABASE_URL.
Velo con tus propios ojos (~1 min)
Antes de que corra cualquier código, mira las tablas vacías en la consola de Neon. Este es el momento de "está ahí de verdad", y te cuesta una pestaña del navegador.
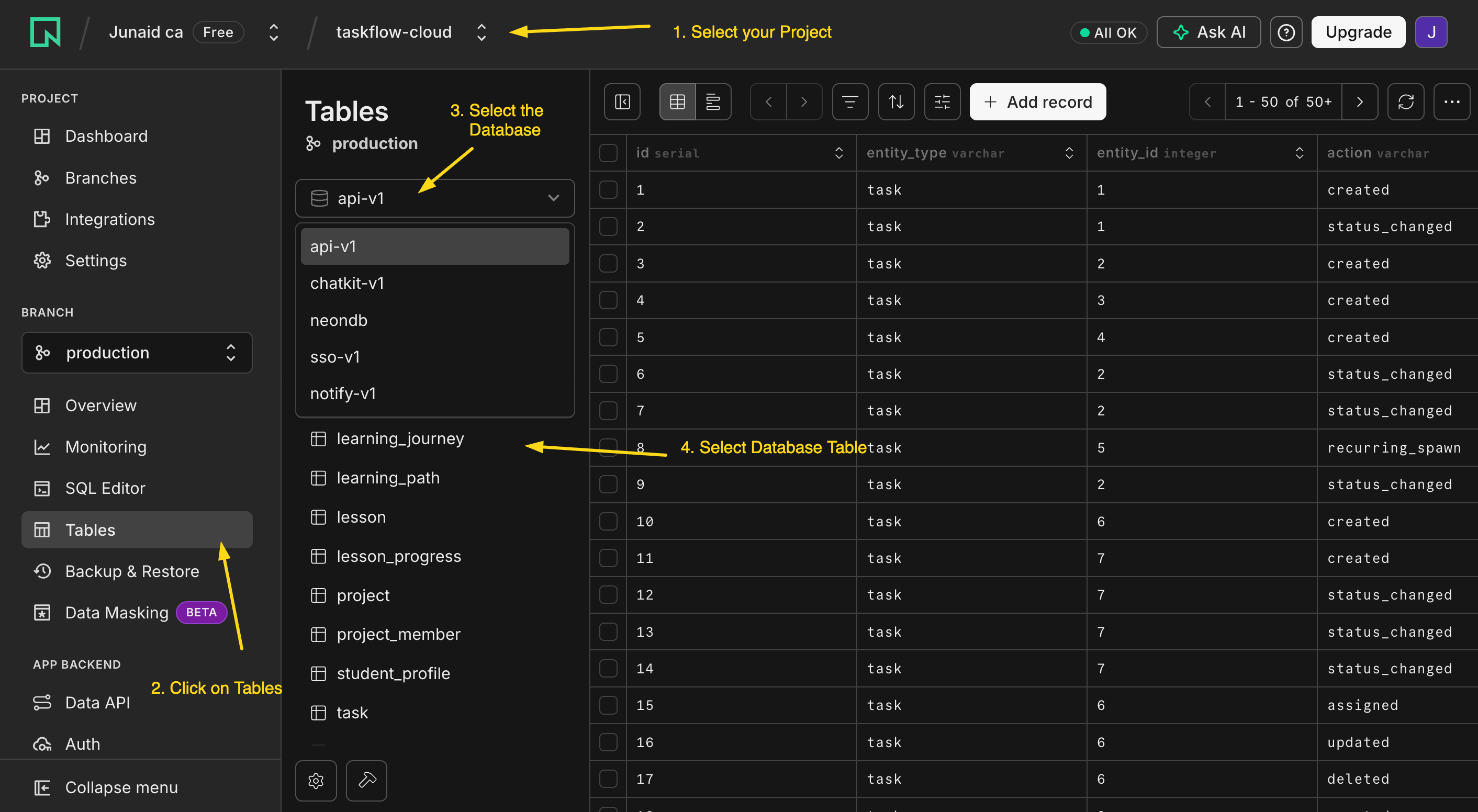
Abre console.neon.tech, elige el proyecto que el agente acaba de crear, y abre Tables. Ahí están notes y audit_log, vacías por ahora. Una tabla es solo una hoja de cálculo: cada fila una cosa, cada columna un detalle. Actualizarás esta vista al final y verás aparecer una fila.
Genera el Worker y ejecútalo una vez (~2 min)
Ahora construye el Worker en sí: un SandboxAgent mínimo, el mismo runtime que usa el resto del curso, todavía sin herramientas. Ejecutarlo vacío primero prueba que el runtime funciona y que tu clave sirve, antes de agregar cualquier otra cosa que pueda fallar.
Con
uv, genera un proyecto mínimo de OpenAI Agents SDK en esta carpeta: unSandboxAgentsobre un modelo de clase gpt-5 (por ejemplogpt-5-mini) todavía sin herramientas, ejecutado desde la terminal en un sandbox local, leyendoOPENAI_API_KEYde.env. Ejecútalo una vez con "hello" para que lo vea responder.
Fíjate en: el agente configurando el proyecto con uv, escribiendo un pequeño script con SandboxAgent más Runner (sobre UnixLocalSandboxClient, cero infraestructura), y ejecutándolo. Llega una respuesta.
Esta es la primera vez que se usa tu clave, así que es el primer lugar donde aparece una clave mala. Si la ejecución da un 401, la clave está mal o tu proveedor no es OpenAI: pega "la ejecución falló con un 401; lee el error y propón una sola corrección que pueda aprobar."
Listo cuando: el Worker vacío se ejecuta y responde.
Dale al Worker su herramienta, y míralo recordar (~3 min)
Ahora agrega la única capacidad: una herramienta que escribe una nota y su fila de auditoría, en una sola transacción, en la base de datos que construiste.
Agrega al Worker una herramienta
save_note, escrita como@function_tool, que inserte una fila ennotesy una fila correspondiente enaudit_logen una sola transacción, usando elDATABASE_URLde.env. Luego ejecuta el Worker y mándale: "Recuerda esto: el deploy de producción necesita una nueva variable de entorno antes del viernes." Muéstrame qué pasó.
Fíjate en: el modelo asociando tu frase con save_note por su cuenta (la descripción de la herramienta es su única señal de enrutamiento), y la herramienta abriendo una conexión con DATABASE_URL y escribiendo ambas filas en una transacción. El Worker informa que la nota se guardó. Fíjate en lo que no hizo: nunca recurrió a Neon MCP. El cable de administración construyó el almacén; el Worker usa su propia herramienta estrecha.
Listo cuando: el Worker confirma que la nota se guardó y te muestra la llamada a save_note que lo hizo. Una frase de entrada, una llamada a herramienta, dos filas escritas.
El logro: léelo de vuelta (~2 min)
Actualiza la vista Tables de la consola de Neon de hace un momento. Tu nota es ahora una fila en notes, y una fila correspondiente en audit_log registra note_saved, ligada a ella por el mismo id. (¿Prefieres quedarte en la terminal? Pídele a tu agente de programación: "usando las herramientas de Neon, muéstrame la nueva fila de notes y su fila correspondiente de audit_log lado a lado.")
Esa es toda la arquitectura en miniatura: un sistema de registro que sostiene la verdad, un Worker que escribió en él a través de su propia herramienta, y una traza de auditoría que puedes reproducir.
Qué construiste, y por dónde crece
Usaste un @function_tool simple porque un Worker escribe en un almacén, que es la opción correcta por defecto, no un atajo. Recurres a un pequeño servidor MCP cuando aparece una de tres cosas: un segundo consumidor que necesita el mismo save_note (otro Worker, tu agente de programación, el propio Claude), un alcance más estricto que quieras imponer, o aislamiento de procesos. Esa decisión, una herramienta de función frente a tu propio servidor, es el Concepto 14, y la Parte 4 construye el servidor.
La Parte 4 escala esta misma forma a varias Skills, el esquema de cinco tablas, unas cuantas herramientas y un pipeline de embeddings. La forma no cambia: un sistema de registro, auditoría en la misma transacción, y una línea limpia entre el cable de administración y el acceso propio del Worker. Si esta Quick Win funcionó, el resto del curso es solo explicar por qué cada pieza tiene la forma que tiene.
Si algo no funcionó, pega la única jugada de recuperación que lo cubre todo: "Algo no funcionó. Lee el error, dime en lenguaje claro qué ves, y propón una sola corrección que pueda aprobar." Luego vuelve aquí.
Parte 1: Skills, la capacidad como carpetas portátiles
Ya usaste Skills dentro de Claude Code. La Parte 1 le da los mismos flujos de trabajo profesionales y bajo demanda al agente que tú construyes. Una Skill es una capacidad reutilizable que le entregas a un agente: una carpeta que empaqueta un flujo de trabajo (instrucciones, más cualquier script o referencia) que el agente carga solo cuando una tarea lo pide, portátil entre agentes en lugar de cocida dentro del código de un agente. Estos cinco conceptos te enseñan a escribir Skills que se disparan cuando deben, y la Parte 1 termina ejecutando una en el propio SDK de tu Worker, en la misma carpeta digital-fte.
Concepto 1: Qué es una Agent Skill
Una Agent Skill es una carpeta con un archivo SKILL.md (más scripts/, references/, assets/ opcionales). SKILL.md es el punto de entrada. Es un estándar abierto de Anthropic que cualquier agente puede leer: Claude Code y OpenCode hoy, y el Worker de OpenAI Agents SDK que estás construyendo. La skill más pequeña es un solo archivo:
---
name: hello-skill
description: Greets the user by name and time of day. Use when the user says hello or asks to be greeted.
---
# Hello skill
1. Check the local time of day.
2. Greet the user warmly, by name if known, in under 25 words.
Sin código, sin deploy, sin llamada al SDK. Como es un archivo en disco, una skill se versiona, viaja y se revisa como cualquier texto, no como un objeto de Python o un endpoint de API.
PRIMM, predice. ¿Qué carga el agente al arrancar, antes de que llegue ningún mensaje? (a) todo el
SKILL.md; (b) solo elnamey ladescription; (c) nada hasta que se invoca. Confianza 1–5.
La respuesta es (b): al arrancar, el agente lee solo los metadatos de cada skill; el cuerpo carga bajo demanda. Eso es la divulgación progresiva, el siguiente concepto.
Concepto 2: Divulgación progresiva, el modelo de carga en tres etapas
Cargar cincuenta skills de golpe enterraría al modelo en instrucciones que no necesita. Por eso una skill carga en tres etapas, y cada una se dispara solo cuando la anterior dice que es relevante.
Etapa 1, Descubrimiento. Al arrancar, el agente carga el name y la description de cada skill, unos 100 tokens cada una. Cincuenta skills cuestan unos 5.000 tokens por turno: el precio de saber qué hay en la biblioteca.
Etapa 2, Activación. Cuando el modelo asocia una tarea con una descripción, carga el cuerpo completo de ese SKILL.md (mantenlo por debajo de ~5.000 tokens; la mayoría se sitúa en 500–2.000). Se paga solo en los turnos que usan la skill.
Etapa 3, Ejecución. Los archivos a los que el cuerpo hace referencia (un script de scripts/, un documento de references/) cargan solo cuando el agente los necesita.
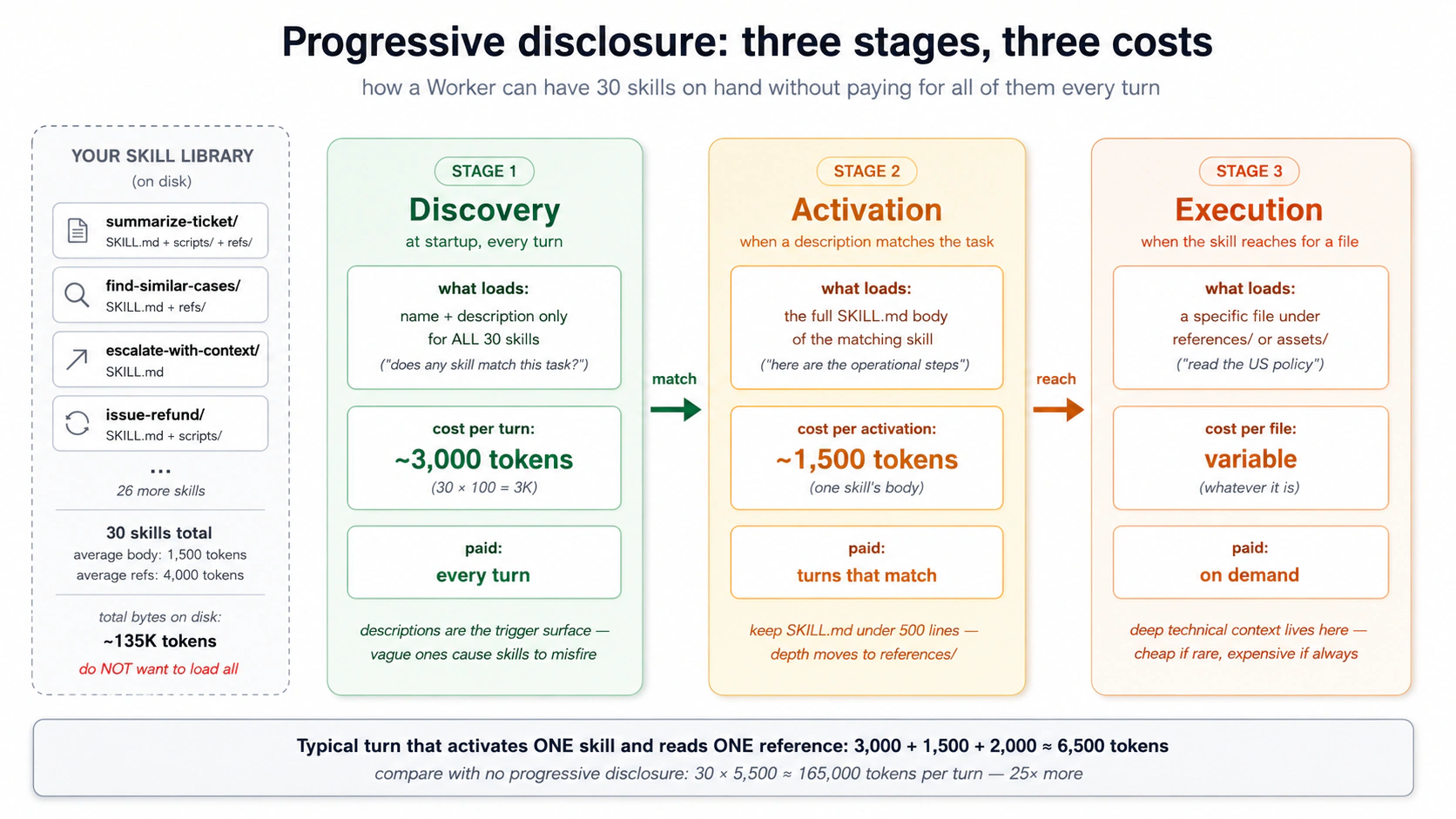
PRIMM, predice. Un Worker tiene 30 skills: descripciones de ~100 tokens cada una, cuerpos de ~1.500 tokens, dos archivos de referencia (~4.000 tokens en total) cada una. En un turno que activa una skill y lee una de sus referencias, el costo aproximado de contexto es: (a) ~3.000 tokens; (b) ~6.500 tokens; (c) ~135.000 tokens. Confianza 1–5.
La respuesta es (b), ~6.500 tokens: 30 × 100 para descubrimiento (3.000), más un cuerpo de 1.500 tokens, más una referencia de ~2.000 tokens. El descubrimiento escala con el tamaño de la biblioteca; la activación y la ejecución se mantienen constantes por turno. Sin divulgación progresiva pagarías los 30 cuerpos y sus referencias cada turno, ~165.000 tokens solo para saber lo que el agente puede hacer. Nadie ejecuta eso.
De ahí se siguen dos cosas, y dirigen los siguientes tres conceptos: la description es lo que se dispara en la Etapa 1, así que lo decide todo; y los cuerpos largos te cuestan en cada turno que coincide, así que mantén el SKILL.md ajustado y empuja la profundidad hacia references/.
Concepto 3: La description es el disparador, y la única parte que te pertenece
Un SKILL.md tiene dos partes: el YAML frontmatter (el contrato que lee el modelo) y el cuerpo en markdown (las instrucciones que sigue). Solo dos campos del frontmatter son obligatorios:
| Campo | Obligatorio | Qué es |
|---|---|---|
name | Sí | El identificador de la skill (minúsculas, guiones, coincide con el nombre de la carpeta). |
description | Sí | La superficie de disparo: lo que el agente lee en el descubrimiento para decidir si dispara esta skill. |
(license, compatibility, metadata, allowed-tools son opcionales y rara vez se necesitan; skill-creator los rellena.)
La descripción es todo el juego, y es la parte que el andamiaje se equivoca. Escribe una circular: "Resume un ticket en cinco secciones. Úsalo cuando el usuario quiera resumir un ticket." Eso se dispara con "resume este ticket" pero se pierde cómo habla en realidad el soporte: "escribe una nota de traspaso para #4471", "TL;DR de este hilo", "dale el resumen a mi líder antes de que escale". La versión genérica atrapa unas 6 de 8 formulaciones reales; una escrita a mano atrapa las 8.
Una descripción que se dispara de forma fiable hace tres cosas, más una salvaguarda:
- Qué produce (nombra la salida real: las cinco secciones, sobre un ticket).
- Cuándo recurrir a ella (las situaciones reales: traspaso, escalada, informar a un gerente, retomar el hilo de otra persona).
- Palabras clave que los usuarios realmente teclean, incluyendo las que nunca dicen la palabra obvia ("nota de traspaso", "TL;DR de este hilo", "en qué quedó esto").
- Una línea de NO disparar para los casos parecidos que deben quedarse callados (redactar una respuesta al cliente, triaje de un lote, informar sobre el volumen de tickets).
Una autocomprobación que mata las descripciones circulares: borra la palabra clave obvia ("resume") de tu descripción. ¿Sigue diciendo cuándo dispararse? Si no, es demasiado estrecha.
El cuerpo, por convención. No hay formato obligatorio, pero las buenas skills son imperativas ("Lee el hilo completo. Lista lo que se intentó."), llevan uno o dos ejemplos reales (valen unas 5× una descripción para guiar), y nombran dos o tres casos límite que de verdad han roto algo.
PRIMM, predice. Dos skills comparten el
namesummarize-document: una en~/.claude/skills/(nivel de usuario), otra en.claude/skills/(nivel de proyecto). Una tarea coincide con ambas. ¿Qué pasa? (a) elección al azar; (b) gana la de nivel de proyecto; (c) el modelo elige. Confianza 1–5.
(b), gana la de nivel de proyecto tanto en Claude Code como en OpenCode: el contexto más específico anula al más general, igual que un archivo de reglas de proyecto anula uno global.
Concepto 4: Empaquetado, dónde viven las skills y cómo viajan
Una skill no es más que una carpeta en disco, así que dónde la pones decide qué agentes la encuentran. Una sola regla cubre todo este curso: pon tus skills en OpenCode revisa su propia carpeta primero, luego recurre a .claude/skills/. Claude Code lee esa carpeta, OpenCode recurre a ella, y el SDK de tu Worker apunta directo a ella (LocalDir(src=".claude/skills"), del ejercicio práctico de arriba). Escribe la skill una vez y las tres cargan la misma carpeta, byte por byte.El mapa completo de rutas (por herramienta, proyecto frente a usuario)
Herramienta Nivel de proyecto Nivel de usuario (global) Claude Code .claude/skills/<name>/SKILL.md~/.claude/skills/<name>/SKILL.mdOpenCode .opencode/skills/<name>/SKILL.md~/.config/opencode/skills/<name>/SKILL.mdOpenCode (respaldo) .claude/skills/<name>/SKILL.md~/.claude/skills/<name>/SKILL.md.claude/skills/; Claude Code solo lee .claude/. Por eso .claude/skills/ es la única ubicación que funciona en todas partes.
La carpeta de una skill tiene un archivo obligatorio y tres carpetas opcionales, cada una con un trabajo:
my-skill/
├── SKILL.md # required: frontmatter + body, the entry point
├── scripts/ # optional: code the agent runs (by relative path)
├── references/ # optional: deep docs, loaded on demand, one topic per file
└── assets/ # optional: templates, schemas, lookup tables
Dentro de SKILL.md, apunta a esos archivos por ruta relativa (references/policies/us.md, scripts/extract.py); se resuelven desde la propia carpeta de la skill, no desde donde el agente esté ejecutándose. Mantén references/ poco profunda, un tema por archivo.
Concepto 5: Componer skills, una grande frente a varias pequeñas
Un "informe semanal de salud del cliente" podría ser una skill que investiga, redacta, da formato y revisa, o cuatro skills que se traspasan a través del sistema de archivos. Ambas funcionan, con compromisos opuestos.
- Una skill grande: fácil de descubrir, una sola activación. Pero cada paso corre en un mismo contexto, nada es reutilizable por sí solo, y una falla a mitad de camino deja al modelo recuperándose con trabajo rancio en el contexto.
- Muchas skills pequeñas: cada una puede probarse, reemplazarse y reutilizarse por su cuenta; una falla queda localizada; cada paso se activa en limpio, así que no se acumula contexto sobrante. El costo son más entradas de descubrimiento y algo que las encadene.
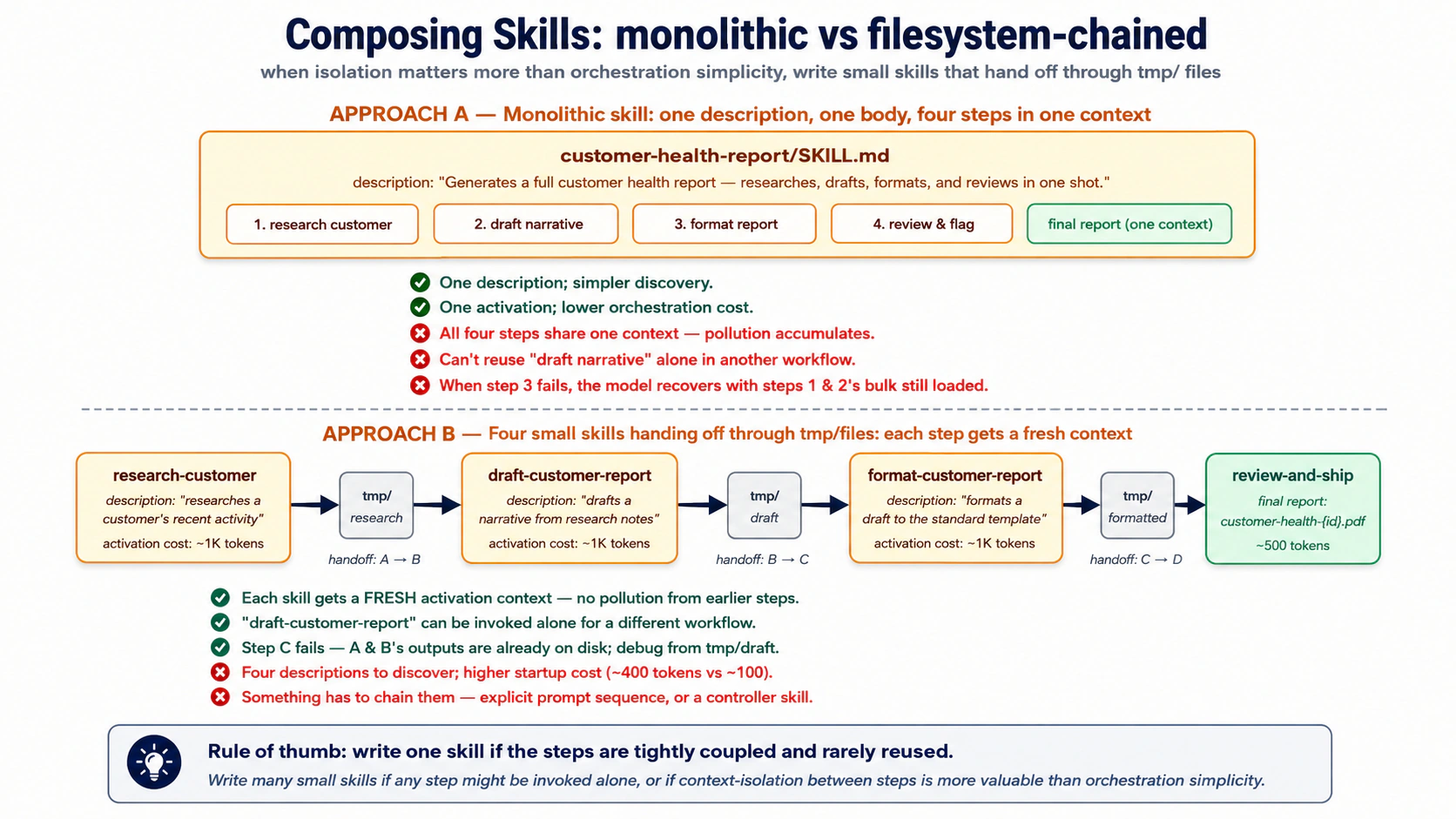
Escribe una sola skill cuando los pasos están fuertemente acoplados y nunca se reutilizan por separado. Escribe varias cuando un paso podría llamarse por su cuenta, o cuando mantener limpio el contexto de cada paso importa más que mantener simple el cableado. La separación suele ganar pasados dos o tres pasos.
Encadénalas a través del sistema de archivos, no de la conversación. La Skill A escribe tmp/research-{id}.md, la Skill B la lee y escribe tmp/draft-{id}.md, y así sucesivamente. La conversación solo ve el resultado final; los pasos intermedios quedan en disco para el agente, para ti y para la traza de auditoría. El mismo aislamiento que el curso anterior usaba para los subagentes, ahora a tamaño de skill.
Y es el puente hacia la Parte 2: algunos traspasos no van en un archivo temporal, van en el sistema de registro. Una skill que escribe en tmp/ es un borrador; una skill que escribe en el sistema de registro es una acción. Esa distinción es lo que construye la Parte 2.
Try with AI
Compare two designs for a customer-refund workflow:
A: one "issue-refund" skill (eligibility, policy, amount, gateway, ticket, notify).
B: five small skills chained via tmp/ handoffs.
For each, name one situation where it's the right call and one failure mode
it's vulnerable to. Then say which you'd ship, and why.
Dispara una skill en ambos runtimes (~10 min, práctico)
Ya has leído suficiente; ahora mira una skill dispararse dentro del agente que tú construyes. Abre la misma carpeta digital-fte de la Quick Win, donde tu SandboxAgent ya corre. Ejecuta esto una vez sobre una skill desechable para que la mecánica te resulte familiar (es la jugada que la Decisión 4 hace de verdad), y observa que los archivos de .claude/skills/ que ya usas en Claude Code funcionan igual en el propio SDK de tu Worker.
1. Genérala. Necesitas un agente general y Node instalado (para npx). Pega esto:
Use skill-creator to scaffold a summarize-ticket skill. It turns one support ticket into a
short five-section handoff. Make it fire on how support actually asks (handoff note, TL;DR
this thread, "what's the status and next step"), including phrasings that never say
"summarize", and not on look-alikes (drafting a reply, triaging a batch). Then check it:
delete "summarize" from the description; if it no longer says when to fire, sharpen it.
El cuerpo vuelve bien; lee la descripción y afínala hasta que pase la comprobación de borrar la palabra clave. Esa revisión es la skill, y la parte que ningún andamiaje hace por ti.
2. Dispárala en un cliente (opcional, cero cableado). Si tienes Claude Code u OpenCode instalado y con sesión iniciada, abre la carpeta ahí y pídele que maneje un ticket sin decir "resume" (por ejemplo, "escribe una nota de traspaso para el caso #4471 antes de que escale"). El cliente descubre .claude/skills/, asocia tu descripción, y activa summarize-ticket. Una salvedad: si una petición es lo bastante simple como para que el modelo la responda directamente, no se dispara ninguna skill, y eso es decisión del modelo, no un fallo de la descripción; prueba con un traspaso real, no con una pregunta de una línea. Quienes solo usen el SDK pueden saltar al paso 3.
3. Dispárala en el OpenAI Agents SDK. Ahora conecta la skill al propio runtime de tu Worker, y hazlo como harás todo en la Parte 4: tú pides, el agente planifica, tú apruebas, él construye y ejecuta. Sigues en la carpeta digital-fte, así que el proyecto uv y OPENAI_API_KEY se mantienen. Pega esto:
Conecta la skill
summarize-ticketa unSandboxAgentmínimo que pueda ejecutar desde esta carpeta: una capacidadSkillsapuntada a.claude/skills, las capacidades por defecto conservadas, un modelo de clase gpt-5, en un sandbox local. Asegúrate de queopenai-agentsesté instalado. Planifica primero.
Es la misma forma de SandboxAgent que la Quick Win, con la herramienta save_note cambiada por una capacidad Skills (un modelo de clase gpt-5 importa: las capacidades por defecto incluyen una herramienta de sistema de archivos que los modelos más pequeños rechazan con un 400). Cuando el plan se vea bien, aprueba y pruébalo en vivo de una sola vez:
Impleméntalo, luego ejecútalo con "write a handoff note for case #4471: no refund, two weeks" y muéstrame la traza para que vea dispararse la skill.
Verifica que se disparó, en la traza. El SDK traza cada ejecución al mismo panel de OpenAI que usaste el curso pasado: abre platform.openai.com/traces y verás la llamada load_skill de summarize-ticket en la ejecución, y luego la respuesta de cinco secciones. (¿Sin panel? El bucle print muestra la misma carga en tu terminal.) .claude/skills es la fuente; .agents/ es donde una skill cargada se prepara en tiempo de ejecución. El mismo archivo, dos runtimes: eso es capacidad portátil, y la Decisión 8 la conecta al Worker completo.
Estos conceptos asumen un buen seguidor de instrucciones (Claude Sonnet/Opus, clase GPT-5). En un modelo más pequeño (deepseek-chat, clase Haiku, la mayoría de los modelos locales), tres cosas se desvían:
- Secuenciación de varias skills. "SIEMPRE ejecuta X antes de Y" aterriza en modelos fuertes, se resbala en los débiles. Solución: pon el orden en un breve preámbulo GENERAL-FLOW en el system prompt; mantén los cuerpos de SKILL declarativos.
- Desviación de formato. Un modelo más débil agrega emojis, tablas o parafrasea tus entradas. Sé explícito sobre lo que NO debe hacer, no solo sobre lo que debe hacer.
- Ceguera al disparo. Una descripción que se dispara con "resume el ticket TKT-1042" puede perderse "qué onda con el #1042". La disciplina del Concepto 3 importa más, no menos, en un modelo débil.
Regla práctica: invierte el esfuerzo del modelo fuerte en el SKILL.md, y el del modelo débil en el system prompt. La arquitectura se mantiene; solo escribes más andamiaje a su alrededor.
Parte 2: Neon Postgres + pgvector como sistema de registro
La Parte 1 le dio capacidades al agente. Ahora necesita un lugar duradero donde guardar lo que no puede permitirse olvidar: el registro del cliente, la biblioteca de políticas, casos resueltos en el pasado, y una traza de todo lo que hizo.
Ese almacén es el sistema de registro de tu Worker, el almacén autoritativo contra el que trabaja (la idea de CRM-o-libro-contable del mapa de apertura, ahora hecha concreta). Es Postgres con la extensión pgvector; el Concepto 6 explica por qué frente a una base de datos vectorial dedicada. Usamos Neon: gratis para empezar, no cuesta nada mientras está inactiva, y tu agente de programación puede manejarla directamente, pero cualquier Postgres gestionado con pgvector sirve.
De los cuatro tipos de datos de aquel mapa, los registros de negocio (clientes, pedidos, tickets) son específicos de tu negocio, así que esos los construyes en la Parte 4. Lo que esta Parte construye son los otros tres, las partes que todo Worker comparte, ahora mapeadas a las tablas reales que las contienen:
- Biblioteca de referencia: conocimiento que el Worker busca por significado, la biblioteca de políticas, artículos de la base de conocimiento, resúmenes de casos resueltos en el pasado. Vive en
documentsyembeddings(Conceptos 8 y 9). - Estado: la conversación en vivo. Sus turnos viven en la Session del agent SDK, que el SDK crea y escribe por ti, así que nunca diseñas esas tablas (Concepto 7); una fila de
conversationsse sienta al lado, ligada por el id de sesión, como el sobre: quién, cuándo, un resumen de cierre. - Traza: el registro de lo que hizo el Worker, el libro mayor
audit_log(Concepto 10). (Una tabla compañera opcional,capability_invocations, agrega métricas por skill y por herramienta.)
Concepto 6: Por qué Postgres gestionado, y por qué Neon en concreto
La tesis se mantiene agnóstica de producto sobre los sistemas de registro: "las bases de datos, los flujos de trabajo y las plataformas operativas existentes de la empresa nativa de IA (CRMs, ERPs, sistemas de tickets, almacenes de datos, libros contables) sirven como sistema de registro." Sin embargo, para un agente que construyes desde cero, tienes que elegir algo. La pregunta no es "Postgres frente a MongoDB frente a una base de datos vectorial". Es "cuál Postgres".
Por qué Postgres, no una base de datos vectorial dedicada. Tres razones que se sostienen incluso en 2026.
-
Una base de datos, una transacción, una frontera de autenticación. Una base de datos vectorial aparte significa dos almacenes que mantener en sincronía, dos sistemas de autenticación, dos pipelines de respaldo.
pgvectormantiene los vectores junto a los registros con los que se relacionan, así que un JOIN sigue siendo un JOIN, no un salto de red entre dos servicios. Todo Postgres gestionado importante (AWS RDS, Cloud SQL, Azure, Supabase, Neon) la trae, y está entre las extensiones de Postgres más instaladas. Para la mayoría de las cargas es suficiente. -
Postgres ya hace las partes difíciles. Transacciones, índices, claves foráneas, seguridad a nivel de fila, recuperación a un punto en el tiempo, planificación de consultas. Una base de datos vectorial dedicada tiene que inventar esto desde cero y normalmente hace algunas peor. La opción aburrida por defecto tiene ventajas que se acumulan.
-
Existen servidores MCP para Postgres en cada capa. Neon trae uno (para gestión). Existen servidores MCP de Postgres generales (para ejecución de SQL). Puedes escribir el tuyo propio (para acceso de runtime con alcance acotado). El ecosistema MCP alrededor de Postgres es el más maduro.
Cuándo gana una base de datos vectorial dedicada. Herramientas como Pinecone, Weaviate, Qdrant y Milvus valen la pena cuando la búsqueda por significado es el producto, no una funcionalidad que se sienta junto a tus datos de negocio. Las señales son extremas: tantos vectores que ya no caben en la memoria de un servidor Postgres, tráfico de búsqueda lo bastante pesado como para necesitar un motor construido solo para vectores, o vectores usados por su cuenta por muchos servicios separados. No hay un número fijo donde pgvector se quede corto, así que prueba con tus propios datos en vez de fiarte de una cifra. Un Worker con una tabla tickets y sus embeddings al lado está muy lejos de ese punto, así que pgvector es la opción correcta por defecto.
Por qué Neon en concreto: tres diferenciadores.
-
Escala a cero. Cuando la base de datos está inactiva, no cuesta nada. Un Worker que maneja 50 conversaciones al día está inactivo la mayor parte del tiempo, así que se queda cerca de $0 en lugar de pagar mensualmente por un servidor siempre encendido. Eso importa cuando ejecutas muchos Workers que solo están ocupados a ráfagas.
-
Se ramifica. En segundos, Neon hace una copia completa de tu base de datos en vivo para trabajar sobre ella, sin tocar la original. El uso relevante para el agente: deja que el agente pruebe un cambio en una rama, y si sale mal, solo borras la rama. En una base de datos que no puede ramificarse, deshacer un cambio malo significa restaurar desde un respaldo.
-
Tiene un servidor MCP oficial. Neon trae un servidor MCP con el que tu agente de programación puede hablar, así que puede crear proyectos, gestionar ramas y ejecutar migraciones en lenguaje natural. Úsalo mientras construyes; el Concepto 12 explica por qué no es para el Worker en ejecución.
Try with AI
A teammate proposes splitting the stores: Postgres for the relational
data (customers, tickets, orders) AND a separate Pinecone index for the
embeddings, "because Pinecone is purpose-built for vectors."
Context for you, the assistant: keeping vectors in Postgres (via the
pgvector extension) next to the relational data means one query can
filter by business state, rank by similarity, and return the full
record in a single transaction. Splitting the stores forces the agent
to round-trip between two services, denormalize and sync metadata
across them, and give up cross-store transactional consistency.
1. Make the case against the split as concretely as you can on ONE
request: a support Worker gets a message and must answer "have we
seen this before, and what did we tell them?" Show exactly what that
request costs when the vectors live in Pinecone and the tickets live
in Postgres. Name the join, what happens to ranking at the LIMIT
boundary when you filter in application code, and how an embedding
goes stale after a resolution is updated.
2. Name the ONE condition under which the teammate is actually right and
a dedicated vector DB is the better call. Be specific about the scale
at which the crossover happens.
3. Neon adds two properties a plain Postgres box doesn't: scale-to-zero
(an idle Worker's database costs nothing) and branching (the agent
forks a production-fidelity copy of the data, experiments or migrates
on it in isolation, then verifies before merging). Which matters more
for an AI Worker specifically, and why? Defend your pick in two
sentences.
Concepto 7: El esquema del Worker, qué tablas necesita de verdad un agente
Un esquema de base de datos no es más que las tablas que mantienes y las columnas en cada una, la forma de tus datos. Las cinco tablas que construye el ejemplo guiado son las partes compartidas del sistema de registro que todo Worker necesita; los registros de negocio en sí llegan en la Parte 4. Caen en dos grupos, para que veas qué es esencial y qué es opcional.
Cuatro tablas que todo Worker mantiene, la espina dorsal compartida. Sostienen el estado, la biblioteca de referencia y la traza del inicio de la Parte, ahora como tablas:
conversations(estado): una fila por conversación, con quién fue, cuándo, y un resumen corto al final. (Los mensajes turno a turno se almacenan aparte, por el SDK; ver más abajo.)documentsyembeddings(la biblioteca de referencia):documentscontiene el texto (políticas, casos pasados);embeddingses lo que lo hace buscable por significado. Un embedding convierte un fragmento de texto en una lista de números que captura su tema, así que el texto relacionado termina cerca, como prender notas en un tablero donde las parecidas se agrupan, y "encontrar lo relevante" se vuelve "encontrar lo más cercano". (El Concepto 9 lo construye; aquí, solo ten claro queembeddingses la capa de búsqueda por significado.)audit_log(la traza): un registro continuo de lo que hizo el Worker, cada acción en orden, incluyendo eventos de negocio como la emisión de un reembolso.
Una más que agregas cuando la necesitas, analítica de uso.
capability_invocations: una fila cada vez que el Worker ejecuta una skill o llama a una herramienta (ambas comparten esta única tabla; una columna marca cuál, así que nunca creces una tabla por herramienta), con cuánto tardó, si tuvo éxito o falló, y un costo aproximado. Agrégala cuando quieras analítica de uso de capacidades en SQL: con qué frecuencia se dispara una skill, su tasa de error, qué suele preceder a una escalada.
Dos tablas más viven fuera de este conjunto, ambas en la Parte 4: tus tablas específicas del negocio (customers, tickets, orders), y run_states, que almacena una aprobación pausada cuando un humano firma más tarde o en otro proceso en lugar de en el acto. Ninguna es parte de la espina dorsal compartida.
¿Dónde van los mensajes en sí? Imagina una transcripción y una portada. La transcripción es cada mensaje, tu pregunta, la respuesta del modelo, cada llamada a herramienta, cada una guardada como su propia fila; el SDK la escribe y la mantiene por ti (cableado en la Decisión 3), así que nunca la construyes. La portada es la única fila de conversations que escribes: quién, cuándo, un resumen, más detalles de negocio como user_id que las propias tablas del SDK no llevan. La mantienes porque la transcripción no puede responder "muéstrame las últimas cinco conversaciones de este cliente"; eso es una consulta rápida sobre conversations, unida a la transcripción por el id de sesión que comparten. Es opcional: si nunca necesitas listas por usuario ni resúmenes, la transcripción sola basta.
El SQL completo de las cinco tablas está en el cuadro de abajo. Tu agente de programación lo escribe a partir del plan de la Decisión 3, así que puedes pasarlo por encima; lo que importa es saber para qué sirve cada tabla.El esquema, completo (cuatro tablas compartidas más la opcional capability_invocations)
-- 1. CONVERSATIONS: business metadata per conversation (your app writes this row)
CREATE TABLE conversations (
session_id TEXT PRIMARY KEY, -- the SAME id you pass to SQLAlchemySession
user_id TEXT NOT NULL,
started_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
ended_at TIMESTAMPTZ,
metadata JSONB NOT NULL DEFAULT '{}'::jsonb,
-- searchable summary; your app writes it at conversation end
summary TEXT
);
CREATE INDEX idx_conversations_user ON conversations(user_id, started_at DESC);
-- The turns themselves live in the SDK Session's tables (agent_sessions /
-- agent_messages, via SQLAlchemySession), created automatically on this same
-- database and keyed by this session_id; you do not hand-build them.
-- 2. DOCUMENTS: the agent's reference library
CREATE TABLE documents (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
source TEXT NOT NULL, -- 'policy_library', 'kb_article', 'past_case', etc.
title TEXT NOT NULL,
body TEXT NOT NULL,
metadata JSONB NOT NULL DEFAULT '{}'::jsonb,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
updated_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE INDEX idx_documents_source ON documents(source);
-- 3. EMBEDDINGS: vector representations of documents AND past conversations
CREATE TABLE embeddings (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
-- one of these is populated; the other is NULL
document_id UUID REFERENCES documents(id) ON DELETE CASCADE,
conversation_id TEXT REFERENCES conversations(session_id) ON DELETE CASCADE,
chunk_text TEXT NOT NULL,
chunk_index INT NOT NULL,
embedding VECTOR(1536) NOT NULL,
model TEXT NOT NULL, -- 'text-embedding-3-small', etc.
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
CHECK (
(document_id IS NOT NULL)::int + (conversation_id IS NOT NULL)::int = 1
)
);
-- the key index for semantic search; see Concept 8
CREATE INDEX idx_embeddings_hnsw
ON embeddings USING hnsw (embedding vector_cosine_ops);
-- 4. AUDIT_LOG: replayable trace of how the Worker changed or used the record
CREATE TABLE audit_log (
id BIGSERIAL PRIMARY KEY,
conversation_id TEXT REFERENCES conversations(session_id) ON DELETE SET NULL,
actor TEXT NOT NULL, -- 'worker:customer-support', 'system', etc.
action TEXT NOT NULL CHECK (action IN (
'message_received', 'message_sent', 'skill_activated',
'capability_invoked', 'refund_issued', 'refund_blocked',
'guardrail_tripped', 'corpus_seeded'
)), -- closed vocabulary; widening it is a migration (Concept 10)
target TEXT, -- table name, skill name, etc.
payload JSONB NOT NULL, -- the data of the action
result JSONB, -- what happened
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE INDEX idx_audit_conv ON audit_log(conversation_id, created_at);
CREATE INDEX idx_audit_action ON audit_log(action, created_at);
-- 5. CAPABILITY_INVOCATIONS: every skill or tool call, for replay and metrics
CREATE TABLE capability_invocations (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
conversation_id TEXT NOT NULL REFERENCES conversations(session_id) ON DELETE CASCADE,
capability TEXT NOT NULL, -- 'skill:summarize-ticket', 'tool:search_docs', etc.
arguments JSONB NOT NULL,
result JSONB,
status TEXT NOT NULL CHECK (status IN ('ok', 'error', 'blocked', 'timeout')), -- 'blocked' = approval rejected
latency_ms INT,
cost_cents INT, -- approximate cost in 1/100 cents
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE INDEX idx_cap_conv ON capability_invocations(conversation_id, created_at);

Vale la pena entender algunas decisiones de diseño:
-
Una sola tabla
embeddingspara documentos y conversaciones. Una restricciónCHECKhace que cada fila apunte exactamente a uno, un documento o una conversación. Así una sola búsqueda puede cubrir políticas y conversaciones pasadas a la vez, y "¿ya respondimos esto antes?" usa un índice, no dos. -
audit_logusaBIGSERIAL(un número autoincremental), no unUUID. Las filas de auditoría se acumulan rápido, y una clave entera simple mantiene las escrituras veloces y el orden obvio. Las otras tablas usanUUIDs (ids aleatorios, globalmente únicos) porque sus filas aparecen en respuestas de API y URLs, donde unUUIDoculta cuántas filas tienes. -
Skills y herramientas comparten
capability_invocations. La llamada a una skill y la llamada a una herramienta son parecidas pero no idénticas (distinto código, distintos costos, distintas formas de fallar). Mantener ambas en una tabla, con una columna que dice cuál, te deja preguntar "¿qué hizo el agente?" entre las dos, o separarlas para preguntar "¿qué skills son lentas o están fallando?". -
Las columnas JSONB
metadatason válvulas de escape. Ningún esquema puede adivinar cada campo que un negocio dado necesitará, así que una columna JSONB te deja agregar campos sin cambiar la tabla. Úsala con moderación: lo que consultes a menudo debería volverse su propia columna.
Agregarás más tablas para tu negocio: una tabla customers, una tabla tickets, una tabla orders, tablas relacionales ordinarias que el agente lee y escribe a través de MCP.
PRIMM, predice. Un Worker maneja 200 conversaciones/día, cada una con 10 turnos en promedio, con un 30 % que dispara una invocación de skill y un 50 % que escribe dos filas de auditoría más allá de la fila de la skill. Tras un mes (30 días), ¿qué almacén crece más rápido? Tres opciones: (a) todos a un volumen similar; (b)
audit_logcrece más rápido por amplio margen; (c) la tabla de embeddings, porque cada turno se embebe. Confianza 1–5.
La respuesta es (b): entre las tablas que construyes, audit_log crece más rápido, porque una interacción puede escribir varias filas de acción (una llamada a skill o herramienta, una escritura al registro, a veces un reembolso) mientras agrega solo una fila de conversations y ningún documents nuevo. Así que es la tabla cuya retención e indexación planificas primero a medida que creces. (El propio almacén de turnos del SDK crece aún más rápido, pero tú no lo gestionas.)
Try with AI
I'm building a customer-support Worker. Its database already
has the four shared tables from Concept 7: `conversations` (one row per
conversation, plus a summary), `documents` and `embeddings` (a
searchable reference library), and `audit_log` (the record of what it
did). The turn-by-turn messages are held by the agent SDK's Session,
not a table I built.
I want to extend this for a Worker that handles software bug reports
specifically. What three additional tables would you add, and what
columns would they have? For each, say what the agent will use it for
(read access? write access? both?) and what foreign keys connect it to
the tables above.
Concepto 8: Fundamentos de pgvector, tipos, operadores de distancia, índices
La tabla embeddings es lo que le permite al Worker encontrar texto por significado, no solo por coincidencia de palabras. Vuelve al tablero: cada fragmento de texto (una política, un caso pasado, un registro) recibe una chincheta, y las cosas relacionadas quedan cerca unas de otras. La posición de una chincheta es el embedding, una lista de números. pgvector (una extensión de Postgres) es lo que le permite a Postgres almacenar esas chinchetas y encontrar las más cercanas, así que no necesitas una base de datos vectorial aparte (el Concepto 6 explica por qué).
El tipo de vector. VECTOR(n) es una columna que contiene una chincheta: una lista fija de n números. El modelo que hace los embeddings decide n, 1536 para text-embedding-3-small de OpenAI, 3072 para text-embedding-3-large, otros modelos difieren. La regla que muerde a la gente: tu texto almacenado y tu consulta de búsqueda deben venir del mismo modelo. Dos modelos son como dos mapas dibujados a escalas distintas, un punto que significa "centro de la ciudad" en uno cae en el océano en el otro. Embebe tus documentos con un modelo y tus consultas con otro, y los resultados "más cercanos" vuelven como un sinsentido aunque la consulta corra sin error. Es el error de pgvector más común.
Para embeddings muy grandes (más de 2.000 números), una columna halfvec almacena cada número a la mitad de la precisión: eso reduce aproximadamente a la mitad el almacenamiento y todavía puede indexarse (hasta 4.000 números), a un pequeño costo de exactitud. Nuestro caso de 1536 números no lo necesita; vector(1536) simple está bien.
Tres maneras de medir "qué tan cerca". Una vez que el texto está prendido con chincheta, "similar" solo significa "cerca". pgvector da tres maneras de medir la distancia entre dos chinchetas. Elige una y quédate con ella; cambiar entre ellas a mitad del proyecto solo confunde los resultados.
| Operador | Nombre | Qué mide | Cuándo usarlo |
|---|---|---|---|
<=> | Coseno | qué tan alineadas están dos chinchetas, sin tener en cuenta su longitud | texto, nuestro valor por defecto |
<-> | Línea recta | la distancia simple entre dos puntos | búsqueda de imágenes y otros datos geométricos |
<#> | Producto punto | dirección y longitud juntas | raro: solo cuando tus vectores no son todos de una longitud |
Para texto, usa coseno (<=>). Compara el significado sin importar cuán largos sean los vectores, que es lo que quieres, y es la opción estándar (su índice se llama vector_cosine_ops).
Para buscar, conviertes la pregunta del usuario en un embedding y le pides a Postgres las filas cuya distancia <=> a él sea la más pequeña, las más cercanas primero, las primeras pocas. Tu agente escribe ese SQL; verás ejecutarse una consulta real en "Siéntelo funcionar" más abajo.
Índices: lo que hace rápida la búsqueda. Revisar cada chincheta una por una se vuelve lento una vez que tienes miles. Un índice lo arregla, igual que el índice al final de un libro te deja saltar a un tema en vez de leer cada página. pgvector puede construir este índice de dos maneras, llamadas HNSW e IVFFlat; no necesitas saber qué significan las letras, solo qué hace cada una. A fecha de 2026 el consejo está asentado:
- Empieza con HNSW. Enlaza cada chincheta con sus vecinas para que una búsqueda pueda saltar directo hacia las más cercanas: búsquedas rápidas, más lento de construir, más memoria. El valor correcto por defecto.
- Usa IVFFlat solo si la velocidad de construcción importa más que la de búsqueda. Ordena las chinchetas en cubetas y busca en las cubetas más cercanas: más rápido de construir y más liviano en memoria, pero búsquedas más lentas, y solo puedes construirlo después de que la tabla tenga datos (aprende las cubetas de las filas que ya hay). Vale la pena si reconstruyes el índice a menudo.
- DiskANN (un complemento aparte) es para índices demasiado grandes para caber en memoria. Casi con seguridad no lo necesitas.
El índice HNSW del esquema de arriba:
CREATE INDEX idx_embeddings_hnsw
ON embeddings USING hnsw (embedding vector_cosine_ops);
HNSW tiene dos perillas, m y ef_construction. Los valores por defecto están bien para la mayoría de las cargas; déjalos en paz a menos que hayas medido una razón para cambiarlos.
Comprobación rápida. ¿Verdadero o falso? (a) Puedes poner más de un índice HNSW sobre la misma columna, uno por operador de distancia. (b) Agregar una fila a una tabla con un índice HNSW cuesta más que agregar una a una sin índice de vectores. (c) Puedes crear un índice HNSW antes de cargar cualquier dato. Las tres son verdaderas: puedes indexar para varios operadores (rara vez se necesita), mantener el índice al día a medida que llegan las filas tiene un costo real (así que algunos equipos cargan en bloque primero y luego construyen el índice), y HNSW no necesita datos de entrenamiento, a diferencia de IVFFlat.
Try with AI
Two scenarios. For each, pick HNSW or IVFFlat and justify with one
specific property of the index:
Scenario A: A research index of 10M scientific papers. Built once,
queried millions of times. Build time is "whatever it takes,
overnight is fine." Query latency directly affects user experience.
Scenario B: A live index of customer support tickets that's
re-indexed every 4 hours because thousands of new tickets stream in.
Query patterns are simple (top-5 nearest neighbors). The current
HNSW build takes 20 minutes, a third of the re-index cycle.
After you answer: name ONE thing that would change your answer for
each scenario. Be specific about what you'd need to see in
production metrics before switching.
Concepto 9: El pipeline de embeddings, texto que entra, vector consultable que sale
Un embedding convierte un fragmento de texto en un punto en el espacio. El texto sobre reembolsos aterriza cerca de otro texto sobre reembolsos; el texto sobre errores de inicio de sesión aterriza en otro lado. Así "encontrar tickets similares" se vuelve "encontrar los puntos más cercanos". Esa es toda la idea. El resto es plomería.
La plomería son cuatro pasos, y cada uno tiene una decisión que importa:
- Fragmenta el documento en piezas lo bastante pequeñas para cargar una idea cada una.
- Embebe cada pieza llamando al modelo; recibes su punto de vuelta.
- Almacena el texto, su punto y unos pocos metadatos en la tabla
embeddings. - Consulta convirtiendo la pregunta del usuario también en un punto, y luego encontrando los puntos almacenados más cercanos.
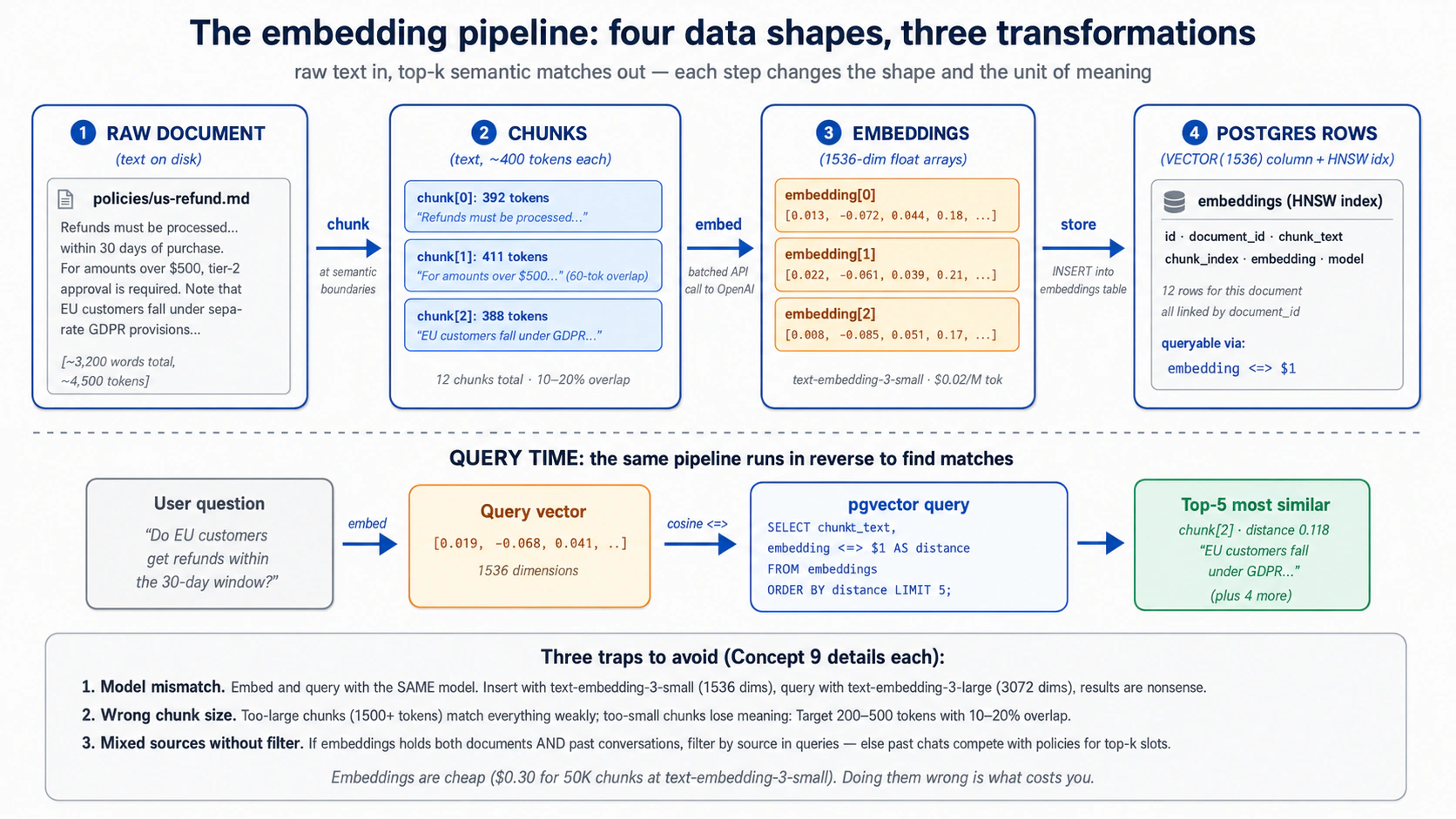
Fragmentar: divide el texto largo primero. Un documento largo no debería volverse un solo embedding gigante. Lo divides en fragmentos, y el tamaño del fragmento es la única decisión que importa:
- Divide en cortes naturales (encabezados, párrafos). Un fragmento que se detiene a media frase busca mal.
- Apunta a unos cientos de palabras por fragmento. Demasiado grande y "coincide con todo débilmente"; demasiado pequeño y pierde el contexto que lo hacía significativo.
- Solapa los fragmentos un poco, para que una idea que cruza un límite todavía se encuentre.
- No fragmentes lo que ya es corto. Un solo ticket resuelto o una entrada de FAQ corta ya es un fragmento; embébelo tal cual.
Tu agente escribe el código de la división; lo que tú decides es el tamaño del fragmento y el solapamiento.
Embeber: convierte cada fragmento en un punto. Le entregas cada fragmento al modelo de embedding y almacenas el punto que devuelve (en lotes, lo que es mucho más barato que una llamada por fragmento). Mantén en vigor la regla del Concepto 8: embebe tu texto almacenado y tus consultas de búsqueda con el mismo modelo, o las coincidencias vuelven como ruido. Una trampa de configuración que conviene conocer (tu agente la maneja): hay que avisarle al driver de la base de datos sobre el tipo de vector, o tus inserciones pueden fallar en silencio.
¿Y si no estás en OpenAI? OpenAI es el único proveedor importante que además trae una API de embeddings de primera clase, así que si ejecutas la inferencia a través de DeepSeek, Anthropic, Gemini o un modelo local, eliges un modelo de embedding por separado, y la dimensión es lo que tiene que coincidir. La válvula de escape habitual es un modelo local de sentence-transformers como all-MiniLM-L6-v2 (384 dimensiones): sin llamada a API, y ningún texto sale de tu equipo. De cualquier forma, los embeddings son la línea más barata de la factura, así que esta elección mueve tu arquitectura, no tu presupuesto.
Cuándo volver a embeber. Tres disparadores:
- El texto fuente cambió, vuelve a embeber esas filas.
- Cambiaste de modelo de embedding, cada punto viejo ahora vive en un mapa distinto y probablemente de un tamaño distinto, así que reconstruyes la columna y vuelves a embeber cada fila (o mantienes ambos durante el cambio). No hay un "suficientemente cerca".
- Cambiaste el tamaño del fragmento, vuelve a fragmentar y a embeber.
PRIMM, predice. Embebiste 100.000 fragmentos con
text-embedding-3-small. Luego decides embeber también tus conversaciones pasadas (no solo documentos) para que el agente pueda hacer búsquedas de "¿ya hablamos de esto antes?". Escribes los embeddings de las conversaciones en la misma tablaembeddingscon la misma columna. Una consulta de búsqueda semántica (encuentra los 5 vecinos más cercanos a la pregunta de un usuario, sin filtro) vuelve con resultados mezclados de documentos y conversaciones. ¿Es lo que querías? ¿Cuál es la forma correcta de la consulta? Confianza 1–5.
La respuesta: casi con seguridad no es lo que querías. Con documentos y conversaciones pasadas mezclados en los resultados, el agente puede tratar un fragmento de un chat viejo como si fuera política autoritativa. La solución es filtrar por fuente cuando buscas: pide solo documentos, o ejecuta dos búsquedas y pondéralas, para que los dos tipos nunca se confundan entre sí.
Cuando los resultados se ven mal, la causa es casi siempre una de tres: la consulta y el texto almacenado pasaron por modelos distintos (las coincidencias son ruido), olvidaste filtrar por tipo de fuente, o tus fragmentos son demasiado pequeños para cargar significado. Revisa esas primero.
La calidad de la recuperación es el asesino silencioso de la precisión de un Worker. La respuesta final puede sonar perfectamente razonable mientras cita la evidencia equivocada. La única forma de atraparlo es revisar la recuperación antes de la respuesta.
Try with AI
I'm chunking a corpus of legal contracts (each averaging 8,000 words)
for semantic search. The user will query things like "what's the
termination clause in this contract", phrases that map cleanly to
specific sections. Walk me through three chunking strategies:
A) Fixed 400-token chunks with 60-token overlap (the default)
B) Chunk at section headings only, with no overlap
C) A two-level approach: store both 400-token chunks AND
whole-section chunks, search both, combine results
For each, name (1) when it wins and (2) when it loses.
Siéntelo funcionar: búsqueda semántica en diez minutos
Has leído sobre pgvector y el pipeline de embeddings sin ver a ninguno devolver un solo resultado. Antes de la última pieza del esquema, la traza de auditoría, tómate diez minutos para ver la búsqueda semántica ordenar de verdad por significado. Esto es desechable, no el Worker: una tabla improvisada, cinco frases, una consulta. La Parte 4 construye lo real.
Tu Neon ya está cableado desde la Quick Win, así que esto es un solo prompt:
En una rama de borrador nueva de mi proyecto Neon, crea una tablita
notes(id, text, embedding vector(1536))con un índice HNSW. Embebe estas cinco frases context-embedding-3-smalle insértalas: "the refund hasn't arrived", "my package is late", "how do I reset my password", "the charge appears twice", "I was billed for something I didn't buy". Luego embebe la consulta "I never got my money back", ejecuta una búsqueda por distancia coseno, y muéstrame las filas ordenadas por distancia.
Fíjate en: las frases de facturación y reembolso quedan por encima de "my package is late" y muy por encima de "reset my password", aunque la consulta casi no comparte palabras con ninguna de ellas. Ordenar por significado, no por solapamiento de palabras clave, es toda la razón por la que existe la tabla embeddings.
Listo cuando: has visto la lista ordenada con las frases de reembolso y facturación arriba. Dile a tu agente que borre la rama de borrador; el esquema real es la Parte 4.
Si las frases de reembolso no ganaron, la causa habitual es el desajuste de modelo del Concepto 9: la inserción y la consulta pasaron por modelos de embedding distintos. El mismo modelo en ambos extremos, o las distancias son ruido.
Concepto 10: La auditoría como disciplina, qué significa "leer y escribir" para un Worker
Cada acción significativa que toma el agente debería dejar una fila en la base de datos. Sin esa fila, no puedes responder después "¿qué hizo el agente, y cuándo?". Esa traza es lo que separa una acción real de una respuesta que suena plausible.
Dos cosas se sientan cerca aquí y se confunden, así que mantenlas separadas:
- La verdad en sí: lo que es el caso ahora mismo, el nivel de un cliente, el estado de un ticket, el texto de una política. Vive en los registros de negocio y la biblioteca de referencia, y el Worker la lee y la actualiza.
- La traza de auditoría: el registro reproducible de lo que el Worker hizo con esa verdad, qué herramienta llamó, qué cambió, qué devolvió, quién lo aprobó. Vive en
audit_log, en la misma base de datos, y responde una pregunta distinta, no "¿qué es verdad?" sino "¿qué hizo el Worker, y puedes probarlo?". No es una segunda copia de la conversación (la Session ya contiene cada mensaje); registra las acciones tipadas y sus resultados, incluidas las que nunca aparecen como un mensaje, una escritura a la base de datos, un reembolso, un bloqueo de guardrail. (Una tablacapability_invocationsaparte y opcional se sienta a su lado para métricas por skill y por herramienta; ver el Concepto 7.)
Así que cada acción significativa escribe su propia fila de auditoría aunque los datos que tocó estén almacenados en otra parte. El hecho de que la acción ocurrió vive en audit_log; las dos se unen por clave foránea.
Qué va en ella. Las acciones significativas, con suficiente detalle para reproducirlas: cada llamada a herramienta o skill (nombre, entradas, resultado, cuánto tardó, si tuvo éxito), cada cambio al registro (qué tabla, qué cambió, bajo qué conversación), cada decisión de guardrail, y cada llamada al modelo con su costo en tokens.
Qué se queda fuera. El texto completo de la conversación, la Session ya lo contiene, así que almacenarlo de nuevo solo duplica tu almacenamiento. Datos sensibles en bruto en una fila que los humanos puedan leer, guarda un hash o un resumen y resguarda lo completo bajo llave. Y el razonamiento privado del modelo.
La prueba que la convierte en traza de auditoría, no solo en logs: dada una conversación y una hora, puedes reconstruir lo que el Worker hizo y por qué, sin volver a ejecutar el modelo. Si no puedes, tienes logs.
Escribe la acción y su registro juntos. Sea cual sea el código que emite un reembolso, escribe el reembolso y su fila de auditoría en una sola transacción: ambos aterrizan o ninguno lo hace. Una traza de auditoría a medio escribir es peor que ninguna, parece completa y no lo está. (Tu agente escribe esto en la Parte 4.)
Dale a cada acción un nombre de un conjunto pequeño y acordado (refund_issued, message_sent, y así) y no dejes que esos nombres se desvíen. Tres nombres distintos para el mismo evento, seis meses después, es lo que hace imposible consultar la traza. Los eventos de dominio como refund_issued reciben su propio nombre para que la fila se lea como un recibo del evento de negocio, no solo de la llamada a herramienta que lo disparó.
Como ese conjunto es pequeño y fijo, imponlo con una restricción CHECK sobre audit_log.action (el esquema del Concepto 7 lo hace). La trampa que un build encuentra semanas después: el vocabulario ahora está cerrado, así que introducir un nuevo verbo (una fila guardrail_tripped en la Decisión 9, la fila corpus_seeded que la Decisión 5 escribe para su propia ejecución de siembra) es una migración ALTER TABLE ... DROP/ADD CONSTRAINT de una línea, no solo código nuevo, y el error aparece como una violación de restricción de la base de datos que no apunta para nada a "olvidaste planificar tu vocabulario". Así que decide el conjunto completo por adelantado; el CHECK del Concepto 7 ya lista los ocho que usa este curso.
Qué no es la traza de auditoría. No son solo logs: es SQL consultable en tu propia base de datos ("¿qué le dijo el agente al cliente X el mes pasado, y qué política citó?" es una consulta), no grep sobre archivos de texto, y está respaldada y con control de acceso junto a tus datos de negocio. No es event sourcing: es una traza de solo-anexar al lado de tu estado, no la cosa a partir de la cual reconstruyes el estado (tus tickets, documentos y la Session son el estado). No son tus trazas: el trazado (OpenTelemetry, el panel de OpenAI) es el registrador de vuelo para depurar, vive en un sistema aparte, puede apagarse, y no está disponible bajo Zero-Data-Retention; el registro de auditoría es el recibo, confirmado en la misma transacción que la acción y conservado mientras lo necesites. Ejecuta ambos: la traza para depurar, el libro mayor para probar.
Esto es lo que quiere decir la tesis: "los Workers solo se vuelven gobernables como fuerza de trabajo cuando un libro mayor los hace legibles." Tu audit_log es ese libro mayor. Y ser legible es lo que hace que un Worker sea vendible: no puedes cobrar por un resultado que no puedes probar que ocurrió. El precio por puesto cuenta inicios de sesión; el precio por resultado cuenta lo que el Worker hizo, por ticket resuelto, por factura procesada, por respuesta redactada. Las filas refund_issued y ticket_resolved son esos resultados, sentados en el mismo registro que los eventos de bajo nivel, algo a lo que puedes apuntar a un cliente y por lo que facturar. Así que un Worker necesita un sistema de registro no solo para dejar de olvidar entre ejecuciones, sino para que su trabajo se vuelva un artefacto demostrable y facturable. Esa es la línea entre conectar un agente a una base de datos y construir un Worker que de verdad puedes vender.
Try with AI
Here's a customer support scenario: a customer claims the Worker told
them they would receive a $50 refund, but the actual refund issued was
$30. The Worker handled the conversation 19 days ago.
Walk me through the audit-trail query path to resolve this:
1. Find the conversation. (Which columns of which tables?)
2. Find the message where the refund amount was promised. (How do you
distinguish "discussed" from "promised"?)
3. Find the capability invocation that issued the refund.
4. Find the database write that recorded the $30 amount.
For each step, name the table you'd query and the WHERE clauses.
Then say what's MISSING from the five-table schema that would make
this query easier.
Parte 3: MCP, cableando el agente al sistema de registro
La Parte 1 le dio al agente una biblioteca de Skills. La Parte 2 le dio un sistema de registro en Postgres. La Parte 3 conecta ambos con el Model Context Protocol: el estándar abierto para cómo los agentes llegan a estado y capacidades externos. La tesis es directa sobre el lugar de MCP: "MCP es cómo la fuerza de trabajo llega a [sus sistemas de registro]: cada almacén autoritativo se vuelve direccionable para cualquier Worker a través de un servidor MCP, bajo política." Esta Parte vuelve eso operativo.
Concepto 11: Qué es MCP y qué no es
El Model Context Protocol (modelcontextprotocol.io) es un protocolo abierto cliente/servidor (originalmente de Anthropic, ahora gobernado como estándar abierto) para cómo un agente de IA se conecta a herramientas, datos y prompts externos. El encuadre que se repite es "USB-C para herramientas de IA": un protocolo, muchas implementaciones, intercambia cualquier lado sin romper el otro. El encuadre es exacto; como toda metáfora, tiene límites que conviene nombrar.
Qué es MCP. Un protocolo. Una especificación. Tres primitivas que el servidor puede exponer al cliente.
- Herramientas: funciones que el modelo puede invocar. El cliente las lista, el modelo elige una, el servidor la ejecuta. Conceptualmente parecido a un decorador
@function_tooldel curso anterior, pero la implementación vive en el proceso del servidor MCP, no en el proceso del agente. Esta es la primitiva más usada con diferencia. - Recursos: datos de solo lectura que el agente puede obtener. Archivos, resultados de consultas a la base de datos, respuestas de API. Piénsalos como el lado solo-GET de MCP. Menos común que las herramientas en la práctica, pero útil para "deja que el agente lea este documento bajo demanda".
- Prompts: plantillas de prompt reutilizables que el servidor provee. Un equipo puede publicar prompts estandarizados ("summarize-incident-report") que cualquier agente conectado al servidor puede invocar. Rara vez se usan comparados con herramientas y recursos.
Tres transportes, con recomendaciones actuales a fecha de 2026:
| Transporte | Cuándo usarlo | Estado |
|---|---|---|
stdio | Subproceso local; agente y servidor en el mismo equipo | Maduro. Por defecto para herramientas locales. |
streamable HTTP | Servidor remoto; despliegues de producción | Recomendado para nuevo trabajo remoto. Un solo endpoint sobre HTTPS plano. |
SSE | Servidor remoto; despliegues más antiguos | Heredado. Muchos servidores aún lo exponen; los nuevos cada vez más toman por defecto streamable HTTP. |
Streamable HTTP viene en dos sabores, y la diferencia importa cuando despliegas. Sin estado es el valor por defecto al que recurrir: cada llamada es una petición y respuesta independiente, exactamente como una llamada de API ordinaria, así que puedes ejecutar muchas copias del servidor detrás de un balanceador de carga y cualquiera de ellas puede responder. Con estado mantiene una sesión viva abierta para que el servidor pueda transmitir resultados parciales de vuelta o enviar notificaciones a mitad de tarea, que es lo que necesitas para trabajo de larga duración, pero fija cada cliente a una instancia del servidor y es más para operar. Usa sin estado a menos que tengas una razón específica (transmisión en vivo, mensajes iniciados por el servidor) para necesitar la sesión abierta.
Qué no es MCP.
- No es un framework. Es un protocolo. Tu agente no "usa MCP" de la forma en que usa el Agents SDK; el cliente MCP de tu agente habla MCP con un servidor MCP. El Agents SDK incluye un cliente MCP; ese es el punto de integración.
- No es un servicio. No existe una "nube MCP". Los servidores MCP son programas que ejecutas (o que los proveedores ejecutan por ti). El servidor MCP de Neon está alojado en
mcp.neon.tech; el servidor MCP del sistema de archivos corre como un subproceso local; un servidor MCP personalizado que escribes corre donde sea que lo despliegues. - No es una frontera de seguridad. MCP define el transporte y el protocolo; qué herramientas expone un servidor MCP y qué pueden hacer es responsabilidad del servidor. Un servidor MCP malicioso puede hacer cualquier cosa que haga su código del lado del servidor. La frontera de confianza sigue siendo el bucle del agente decidiendo qué herramientas llamar, y el sandbox en el que las herramientas se ejecutan.
- No es un reemplazo de
@function_tool. Ambos siguen teniendo su lugar. El árbol de decisión es el Concepto 14.
Comprobación rápida. Verdadero o falso: (a) Un cliente MCP habla con exactamente un servidor MCP a la vez. (b) La misma función de estilo
@function_tool, si quisieras, podría exponerse como una herramienta MCP o mantenerse como una herramienta de función, y el modelo no notaría la diferencia. (c) Los servidores MCP y el OpenAI Agents SDK están fuertemente acoplados, así que para usar MCP debes usar el SDK. Respuestas: (a) Falso: un agente puede conectarse a varios servidores MCP y ver la unión de sus herramientas. (b) Verdadero: para el modelo, ambas se ven como herramientas invocables con esquemas. La diferencia es dónde vive la implementación. (c) Falso: MCP es agnóstico del modelo. Claude, Gemini y otros tienen sus propios clientes MCP. El OpenAI Agents SDK es un cliente entre muchos.
Try with AI
For each item, say which MCP primitive fits best (tool, resource, or
prompt), and why in one line:
A) The agent reads the current text of a policy document on demand,
but never writes it.
B) The agent issues a refund through the payment gateway.
C) Every Worker on the team should summarize incidents the same way,
from one shared, versioned template.
Then a judgment question. A teammate says: "We put the refund logic
behind an MCP server, so the agent can't do anything dangerous." Using
this concept's "what MCP is NOT," explain why that sentence is false,
and name where the real trust boundary actually lives.
Concepto 12: El servidor MCP de Neon, plano de desarrollo, no de runtime
Los detalles de este concepto envejecerán. El patrón no. El conjunto de herramientas del servidor MCP de Neon, el flujo de autenticación y la superficie exacta de herramientas cambian cada pocos meses. Lo que se mantiene cierto: un proveedor de base de datos gestionada expone su API de gestión a través de MCP para operaciones en lenguaje natural, mientras que el tráfico de producción en tiempo de ejecución usa conexiones directas o servidores personalizados con alcance acotado. Verifica contra la documentación de Neon antes de fijar detalles.
Ya conectaste el servidor MCP de Neon a tu agente de programación durante la configuración, y te has estado apoyando en él desde entonces: pidiendo el esquema en inglés llano, revisando qué hay en las tablas, sacando una cadena de conexión. Esa conexión de quince minutos vale la pena detenerse en ella, porque enseña la línea más importante de toda esta Parte: para qué sirve el servidor MCP de Neon, y a qué nunca debe conectarse.
Expone la API de gestión de Neon (proyectos, ramas, esquema, migraciones, SQL ad hoc) como herramientas que tu agente puede llamar en lenguaje natural. Eso lo hace una herramienta de desarrollo, no de producción. La propia documentación de Neon es tajante: "Nunca conectes agentes MCP a bases de datos de producción."
Aquí está por qué esa línea es tan difícil. La herramienta run_sql del servidor ejecuta cualquier SQL que el modelo escriba. Mientras construyes, ese es todo el punto: dices "muéstrame los usuarios que se registraron la semana pasada y nunca iniciaron sesión", el modelo escribe la consulta, el servidor la ejecuta, obtienes tu respuesta. Apunta esa misma herramienta a tu base de datos en vivo y se vuelve una puerta. Cualquiera que pueda colar instrucciones en tu Worker (un cliente que teclea un mensaje hábilmente formulado) puede pedirle que lea toda tu base de datos, porque el trabajo de la herramienta es ejecutar el SQL que se le entregue.
Así que sigue usándolo donde brilla, todo durante el desarrollo:
- Esquema y migraciones. "Agrega una columna
prioritya la tabla de tickets." El servidor prueba el cambio en una rama desechable primero, luego lo fusiona. Ese hábito de rama-primero es la forma segura de evolucionar un esquema. - Explorar tus propios datos. "¿Cuántos embeddings hay ahí, agrupados por fuente?" Más rápido que escribir SQL a mano para una pregunta puntual.
- Buscar cosas. Cadenas de conexión, configuración del proyecto, formas de tablas, sin abrir la consola de Neon.
Lo viste en la configuración: le pediste a tu agente que creara el proyecto, encendiera pgvector, ejecutara el esquema e informara la cadena de conexión, y lo hizo todo a través de estas herramientas, probando la migración en una rama antes de tocar main. Nada de SQL tecleado a mano.
PRIMM, predice. Tu Worker de soporte terminado necesita: (a) consultar los pedidos de un cliente; (b) revisar la política de reembolsos para su nivel; (c) emitir un reembolso; (d) escribir una fila de auditoría de lo que hizo y por qué. ¿Debería llegar a Neon a través de este mismo servidor MCP, o de alguna otra forma? Confianza 1–5.
La respuesta: de alguna otra forma, para las cuatro. Un Worker en vivo nunca debería tener una herramienta de estilo run_sql, esa es una puerta que no puedes cerrar del todo. Necesita unas pocas habilidades estrechas, no el poder de ejecutar SQL arbitrario. Los dos patrones de producción son un servidor MCP personalizado que expone solo las operaciones específicas que necesita (Concepto 14), o una conexión directa a Postgres que las envuelve. La Parte 4 usa ambos: un servidor customer-data personalizado para las operaciones de negocio, y una conexión directa solo para el subsistema de auditoría (la Decisión 7 explica por qué la auditoría se mantiene fuera de la frontera MCP que audita).
Esto es exactamente el Invariante 5: la fuerza de trabajo lee y escribe a través de almacenes gobernados. Una herramienta run_sql amplia no es gobernanza, es una cara amable sobre la ausencia total de gobernanza. El servidor MCP de Neon es cómo tú construyes el almacén. No es cómo tu Worker lo toca.
Try with AI
Read Neon's MCP server documentation page and answer three questions:
1. List THREE management operations the Neon MCP server exposes that
would be useful while you're building a customer-support Worker.
2. List THREE things a running Worker NEEDS to do that you should NOT
use the Neon MCP server for, and why.
3. For each of the three in (2), say what the Worker should use instead
(direct Postgres connection? custom MCP server? function_tool?).
Concepto 13: Conectar MCP con el OpenAI Agents SDK
Has estado manejando el servidor MCP de Neon desde tu agente de programación. Tu Worker, el que construyes en la Parte 4, es un programa distinto: un agente de OpenAI Agents SDK. Así que la pregunta que responde este concepto es simple: ¿cómo habla ese agente con un servidor MCP? No escribirás la plomería de la conexión a mano, el SDK la trae. Lo que vale la pena entender es la forma, para que puedas dirigir el build y depurarlo cuando se porte mal.
Aquí está la imagen completa. El SDK tiene un cliente MCP incorporado con un conector por transporte: uno local para stdio, uno moderno para streamable HTTP remoto, y uno heredado para SSE (evita SSE para cualquier cosa nueva). Abres una conexión a un servidor, se la entregas a tu agente, y de ahí el SDK hace todo: le pregunta al servidor qué herramientas tiene, pone esas herramientas frente al modelo justo al lado de los @function_tool que escribiste tú mismo, y cuando el modelo elige una, enruta la llamada al servidor correcto y trae la respuesta de vuelta. El modelo no puede distinguir una herramienta MCP de una herramienta de función local, y no le hace falta. Esa igualdad es el punto: MCP es solo otra forma de entregarle al modelo una capacidad.
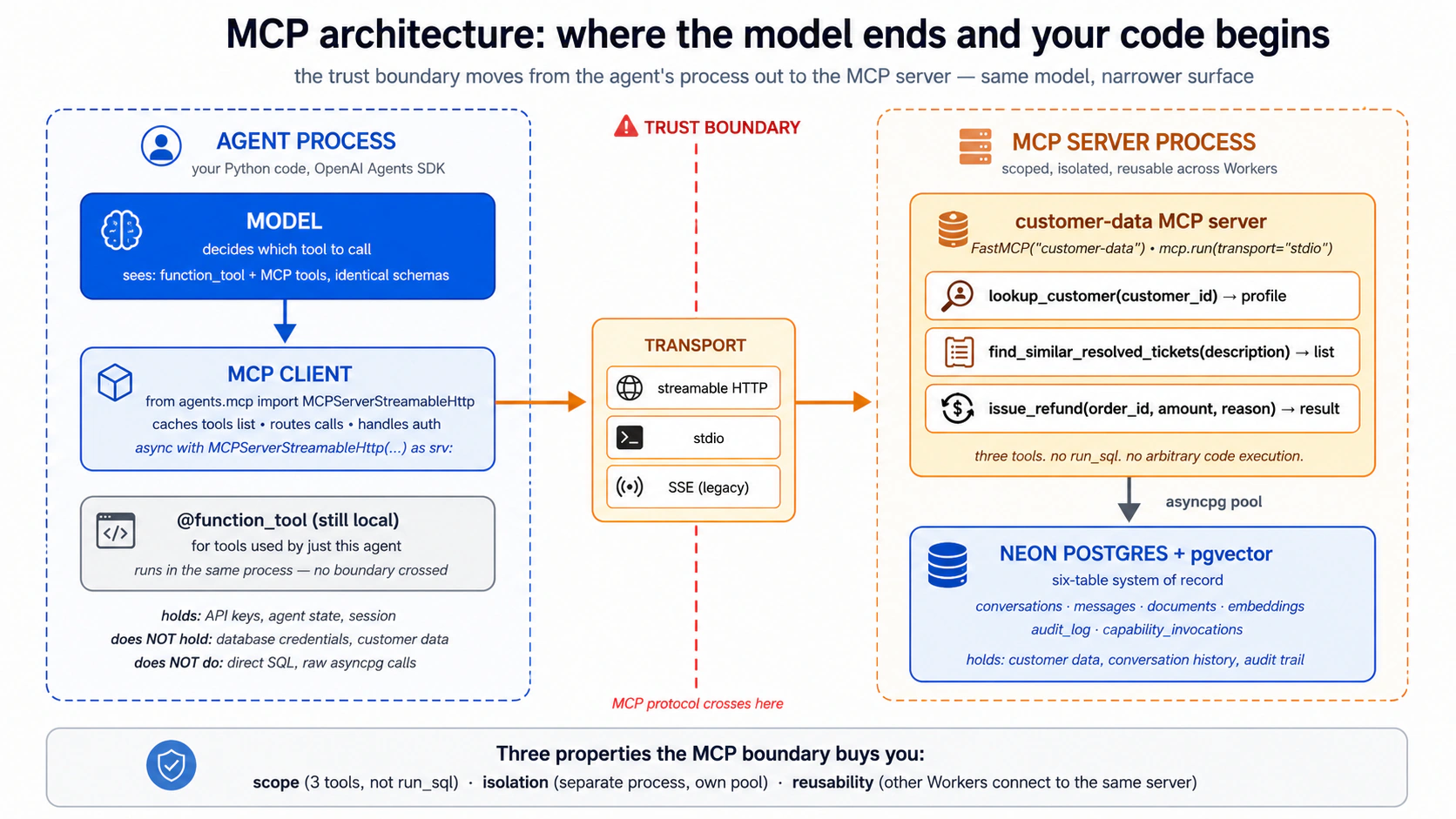
Cuatro cosas que tener en mente, todas las cuales tu agente maneja por ti una vez que se las pides:
- Abre la conexión limpiamente, y ciérrala limpiamente. Una conexión MCP mantiene algo abierto: un subproceso para stdio, una sesión HTTPS para remoto. Si no se cierra bien, la conexión se fuga. Los objetos de conexión del SDK están hechos para abrirse y cerrarse como un bloque gestionado, así que esto se maneja siempre que no lo pelees.
- Cachea la lista de herramientas en producción. Por defecto, el agente vuelve a preguntarle al servidor "¿qué herramientas tienes?" en cada ejecución, un viaje de red desperdiciado. Encender el caché hace que pregunte una vez. La única salvedad: si cambias las herramientas del servidor, le dices al agente que refresque el caché (o lo reinicias). Mientras construyes, deja el caché apagado para que los cambios aparezcan de inmediato.
- Los servidores se apilan. Puedes entregarle a tu agente varios servidores MCP a la vez, y el modelo simplemente ve el conjunto combinado de herramientas. El Worker de la Parte 4 se conecta a su servidor
customer-datapersonalizado de esta forma. - Pon las herramientas peligrosas detrás de aprobación. Por defecto, las llamadas a herramientas corren sin confirmación. Para las sensibles puedes exigir que un humano apruebe cada llamada. Esta es la perilla práctica para la brecha desarrollo-frente-a-runtime del Concepto 12: incluso mientras usas el servidor MCP de Neon a mano, poner sus herramientas destructivas (cualquier cosa que elimine o reescriba) detrás de un aviso de aprobación es una ganancia de seguridad real.
Una trampa que conviene archivar: si un servidor MCP carga algo pesado al arrancar (un modelo de aprendizaje automático, por ejemplo), la ventana por defecto del agente de "¿respondió el servidor a tiempo?" puede ser demasiado corta y verás un error de fallo de conexión confuso. La solución es un solo ajuste que alarga esa ventana. Solo te toparás con esto si un servidor hace trabajo real en el momento en que arranca.
Práctico, solo para entender. Esta es la forma más rápida de hacer concreta la forma. Pega el prompt de abajo en tu agente de programación. Construye un pequeño script desechable que apunta un agente de OpenAI Agents SDK al servidor MCP de Neon que ya tienes conectado, y te deja ver al agente listar tus proyectos en lenguaje llano. Este es un ejercicio de aprendizaje, no el camino de producción: un Worker real nunca se conecta al servidor MCP de Neon (Concepto 12). Lo haces una vez, aquí, para ver a un agente del Agents SDK manejar un servidor MCP de extremo a extremo.
Write me a small throwaway Python script (call it scratch_neon_agent.py)
that uses the OpenAI Agents SDK to connect to the Neon MCP server over
its remote streamable-HTTP transport, then runs one agent turn asking it
to "list my Neon projects and show the schema of the largest one."
Use the current OpenAI Agents SDK MCP classes (check the docs for the
exact import and class name). Open the connection as a managed block so
it closes cleanly, turn on tool-list caching, and print the final output.
Then run it and show me what the agent did, step by step. Remind me in a
comment that this is for understanding only and a real Worker should
never connect to the Neon MCP server.
Mira qué pasa: el agente se conecta, el SDK trae las herramientas de Neon, el modelo elige list_projects por su cuenta, y obtienes una respuesta en inglés. Acabas de ver el mismo cableado que usará tu Worker de la Parte 4, solo que apuntado a un servidor que no debería usar en producción, que es exactamente por qué estás desechando este script.
Try with AI
Explain, in plain language and without writing code, how you would
connect one OpenAI Agents SDK agent to TWO MCP servers at once: the
Neon MCP server (remote) and a local filesystem MCP server for reading
project files. Cover:
1. Which transport each server would use, and why.
2. How the model decides which server's tool to call.
3. Which tools you'd put behind human approval, and why.
4. One thing that could go wrong with two servers connected, and how
you'd notice it.
Concepto 14: Servidores MCP personalizados, cuándo escribir el tuyo propio y cuándo no
El servidor MCP de Neon es genérico: puede hacer cualquier cosa que pueda hacer la API de Neon. Esa es su fuerza para el desarrollo y su debilidad para el runtime. Un servidor MCP personalizado invierte el compromiso: superficie estrecha, sin un run_sql de propósito general, solo las operaciones específicas que tu Worker de verdad necesita.
El árbol de decisión, en orden de prioridad.
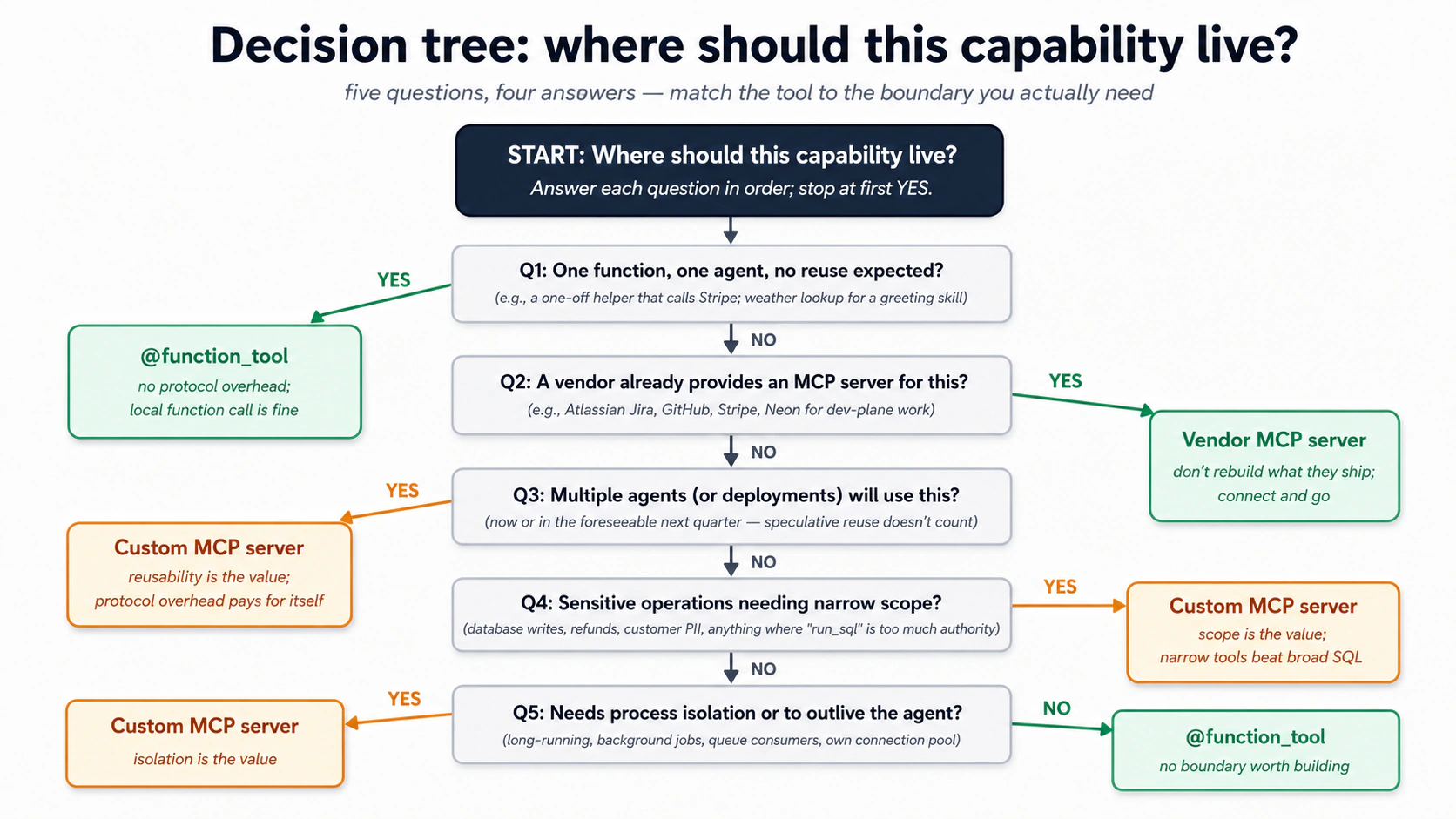
La misma lógica en una tabla de vistazo rápido:
| Quieres exponer... | Usa esto | Por qué |
|---|---|---|
| Una función con una entrada, usada por un agente | @function_tool | No hace falta la sobrecarga del protocolo. Una llamada a función local basta. |
| Varias funciones fuertemente acopladas al código de tu agente | @function_tool | Si comparten estado con el agente y viven en el mismo repo, son parte del agente. |
| Una capacidad que varios agentes (o varios despliegues) usarán | Servidor MCP personalizado | El protocolo es lo que la hace reutilizable. |
| Una capacidad que necesita sobrevivir al proceso del agente | Servidor MCP personalizado | Conexiones de larga duración, trabajos en segundo plano, consumidores de colas. |
| Funcionalidad provista por el proveedor (Neon, GitHub, Linear) | Servidor MCP del proveedor | No reconstruyas lo que ellos traen. |
| Operaciones sensibles que necesitan un alcance estrecho | Servidor MCP personalizado | Define exactamente las herramientas que necesitas; nada más. |
La forma de un servidor MCP personalizado es más simple de lo que suena. Es un programa pequeño que declara un puñado de herramientas con nombre. Cada herramienta tiene una descripción en inglés llano (el mismo tipo de texto de disparo que lleva un SKILL.md) que le dice al modelo cuándo recurrir a ella, y una lista corta de entradas tipadas para que el modelo sepa qué pasar. Eso es todo: unas pocas herramientas bien descritas y estrechas, y nada más. Sin un run_sql general, sin válvula de escape.
Y no escribes ese programa a mano. De la misma forma en que has instalado skills y dejado que tu agente haga el trabajo, hay una skill mcp-builder que convierte una descripción de alcance en un servidor funcional y probado. Tu criterio va en el alcance, qué herramientas existen, qué puede hacer cada una, y cuáles deliberadamente no, no en la plomería. El flujo del prompt se ve así:
/mcp-builder Let's design a custom MCP server called "customer-data"
on the streamable-HTTP transport, stateless flavor (each call an
independent request, no open session, so it scales). Plan the
implementation first, then build it.
Scope: exactly three tools, nothing else.
- lookup_customer(customer_id): return id, email, tier, open-ticket count
- find_similar_resolved_tickets(description, limit): semantic search over
past resolved tickets
- issue_refund(order_id, amount_cents, reason): issue a refund (amount in
integer cents, never a float) AND write an audit row in the same transaction
No general SQL tool. Each tool gets a clear description so the model
knows when to call it. Start a fresh project with uv, walk me through
the plan before writing code, then build and verify it.
El agente genera un nuevo proyecto uv, planifica las herramientas, construye el servidor y verifica que corre. Una vez que existe, lo conectas de las mismas dos formas en que ya has visto conectarse servidores MCP: a tu agente de programación general (Claude Code u OpenCode, para que puedas probarlo a mano) y a tu Worker de OpenAI Agents SDK (para que el Worker pueda usarlo de verdad). La Decisión 6 de la Parte 4 recorre este build de extremo a extremo.
Tres cosas que este servidor te da que @function_tool no.
-
Aislamiento de procesos. El servidor MCP corre en su propio proceso (subproceso para stdio, servicio aparte para streamable HTTP). Un fallo en el servidor no tumba al agente; una fuga de memoria en el servidor no se fuga en el agente.
-
Alcance. El servidor expone solo el puñado de herramientas que defines (el servidor
customer-datadel ejemplo guiado tiene tres). Sinrun_sql. Sin "ejecutar código arbitrario". El modelo no puede escapar de este alcance porque el protocolo no expone nada más. Esto es una verdadera defensa en profundidad: aunque el modelo decidiera hacer algo estúpido, la superficie por la que hacerlo son esas pocas funciones. -
Reutilización entre agentes. Un segundo agente (un Worker de Ventas, un Worker de Reportes) puede hablar con el mismo servidor MCP
customer-data. Mismo alcance, mismo protocolo, misma frontera de confianza. La capacidad se vuelve una pieza de infraestructura compartida en lugar de un copia-y-pega entre agentes.
El compromiso es real. Los servidores MCP personalizados agregan complejidad operativa: otro proceso que desplegar, otro conjunto de logs, otro salto de red (si es remoto), otra versión que gestionar. No escribas uno para una sola función usada por un solo agente. Escribe uno cuando la capacidad se va a reutilizar, cuando el alcance importa, o cuando el aislamiento te compra seguridad.
PRIMM, predice. Estás diseñando el Worker de soporte. Necesitas: (1) búsqueda semántica sobre tickets resueltos en el pasado; (2) escribir una fila de auditoría de reembolso; (3) leer el clima actual (usado en una skill de saludo que dice "buenos días desde la soleada Karachi"); (4) llamar a la pasarela de pago para emitir un reembolso. Para cada uno predice:
@function_tool, servidor MCP personalizado, o servidor MCP del proveedor (por ejemplo, el de Stripe, si existe)?
Las respuestas destilan el marco:
- Servidor MCP personalizado (
customer-data). Reutilizado entre agentes; datos sensibles; herramientas acotadas le ganan a unrun_sqlamplio. - Servidor MCP personalizado (
customer-data) o@function_tool. Cualquiera sirve; si el Worker es el único que escribe, una herramienta de función está bien. Si varios Workers escribirán filas de auditoría, servidor MCP. @function_tool. Un agente, una función diminuta, ninguna superficie de seguridad que defender. No construyas un servidor para eso.- Servidor MCP del proveedor (Stripe MCP) si existe, o
@function_toolque llama a la API de Stripe. No envuelvas APIs de terceros en tu propio servidor MCP a menos que necesites agregar política encima.
El marco se aclara una vez que lo rastreas: el valor de MCP sube con el valor de la frontera que crea. Una frontera que no necesitas es sobrecarga.
Try with AI
Paste this into your coding agent. It applies the decision tree to the customer-support Worker you're actually building, so every choice is one you could ship, not a guess about infrastructure you don't have.
Here are five capabilities I'm thinking of adding to my customer-support
Worker. For each, walk the Concept 14 decision tree with me and recommend
one: a @function_tool, my custom customer-data MCP server, or a vendor
MCP server (if a credible one exists). Justify each choice with ONE of
the three properties (isolation, scope, reusability), or say plainly why
no boundary is worth building.
1. Look up a customer by email (the gap Decision 8 leaves open).
2. Issue the real refund through Stripe (actual money, third-party API).
3. Send the drafted reply as an email through our mail provider.
4. Convert a UTC timestamp to the customer's local time for a greeting.
5. Let a second Worker (a sales assistant) reuse the customer lookups.
Then push back on me: which TWO of these would you deliberately NOT put
behind a custom MCP server, and what does that say about when the
boundary earns its cost?
Concepto 15: MCP bajo carga: transportes, pooling y qué pasa a escala
Una demo con un agente y un servidor simplemente funciona. El tráfico real, muchas conversaciones por minuto, agrega tres presiones. No necesitas actuar sobre estas para un primer Worker, pero saber que existen te ahorra una tarde confundido más adelante. Cada una tiene una solución sencilla.
- El cable entre el agente y el servidor. Un subproceso local (stdio) está bien mientras todo corre en un equipo. En cuanto más de un agente comparte el servidor, o el servidor se muda a su propio hardware, cambia al transporte remoto (streamable HTTP). Eso es un cambio de despliegue, no una reescritura.
- No pagues el mismo costo de configuración una y otra vez. Tres pequeños hábitos convierten costos repetidos en costos de una sola vez: conéctate a cada servidor una vez cuando el Worker arranca y mantén esa conexión abierta, en lugar de reconectar en cada petición; deja que el agente recuerde la lista de herramientas del servidor en vez de volver a preguntar "¿qué puedes hacer?" en cada ejecución (refréscala cuando cambies las herramientas); y mantén un pool listo de conexiones a la base de datos dentro del servidor, para que una consulta no espere a abrir una nueva cada vez. Una rareza que un Worker de larga vida encuentra en un Postgres con escala a cero o con pooler (Neon): el pooler cierra las conexiones inactivas, así que si el proceso se bloquea (un aviso de terminal
input()congela el bucle de eventos de asyncio), la siguiente escritura falla con "connection was closed in the middle of operation". Ejecuta los avisos bloqueantes fuera del bucle (asyncio.to_thread) y haz que el pool vuelva a adquirir una vez ante ese error. - Pon un techo a todo, y mantén la traza entera. Limita cuántos pasos puede tomar una petición, reintenta una llamada a herramienta fallida un par de veces antes de rendirte, y limita la tasa del servidor para que una ráfaga no lo desborde. Y asegúrate de que tu traza siga la llamada a través de la frontera MCP: cuando el Worker llama a una herramienta, quieres que el trabajo de base de datos propio del servidor aparezca en la misma imagen. De otro modo, una consulta lenta dentro del servidor es invisible desde afuera, y perseguirás la latencia en el lugar equivocado.
Las perillas más profundas (topes de concurrencia por inquilino, ajuste fino del transporte) están más allá de lo que un primer Worker necesita. Estas tres son las que muerden primero.
Comprobación rápida. Verdadero o falso: (a) Mover un servidor del transporte heredado SSE a streamable HTTP te obliga a reescribir las herramientas del servidor. (b) Dejar que el agente cachee la lista de herramientas de un servidor es seguro en producción, siempre que refresques el caché después de cambiar las herramientas. (c) Exponer cinco habilidades como herramientas MCP siempre cuesta al modelo más presupuesto de contexto que exponer las mismas cinco como herramientas de función locales. Respuestas: (a) Mayormente falso: las herramientas no cambian; el servidor solo necesita hablar el transporte más nuevo, que la mayoría de los modernos ya hace. (b) Verdadero: ese es el patrón previsto. (c) Falso: para el modelo una herramienta es una herramienta. Cinco descripciones de herramientas cuestan más o menos lo mismo en cualquiera de los dos lados en que vivan.
Try with AI
My customer-support Worker is in production. It runs 80 conversations/minute
at peak. Each conversation makes 2-4 MCP tool calls on average. I'm seeing
intermittent latency spikes: most calls return in 200ms, but a small
percentage take 5-15 seconds.
Walk me through five places I'd investigate, in order of priority:
1. The agent-side MCP client connection management.
2. The transport choice between agent and MCP server.
3. The MCP server's internal connection pool to Postgres.
4. Postgres-side query performance (slow queries blocking the pool).
5. Network or DNS issues between agent and MCP server.
For each, name the specific signal I'd look for and the rough fix.
Parte 4: El ejemplo guiado, un Worker de soporte al cliente
Una construcción realista que usa cada concepto de arriba. Empiezas con un agente de chat mínimo (un prompt, cerca de un minuto), luego haces crecer ese mismo worker hasta volverlo un Worker de soporte al cliente, una pieza a la vez. Cada Decisión agrega una pieza, el sistema de registro, luego las Skills, luego la capa MCP, luego la traza de auditoría, y vuelves a ejecutar el worker cada vez para ver funcionar la nueva pieza antes de seguir. Ocho Decisiones construyen el worker; una novena pone un humano frente a la única acción que mueve dinero.

Paso 0: levanta el agente de chat (un prompt, ~1 minuto). Para que todos empiecen la Decisión 1 desde el mismo lugar. (¿Hiciste Construir agentes de IA? Abre ese proyecto en su lugar, es el mismo agente, y salta a la Decisión 1.)
In this digital-fte folder, build me a small terminal chat agent with the
OpenAI Agents SDK: a uv project, a gpt-5-class model, on a local sandbox.
Check the current SDK docs for the API. Get it answering "hi", then stop,
we grow it in the steps below.
Crea: el archivo del worker (por ejemplo worker.py) más su proyecto uv.
Comprobación. Mandas "hi" y responde. Esa es la línea de salida; la Decisión 1 le enseña la nueva arquitectura a través de
AGENTS.md.
El encargo
Evoluciona el agente de chat mínimo del Paso 0 a un Worker de soporte al cliente que:
- Carga tres Skills bajo demanda:
summarize-ticket,find-similar-casesyescalate-with-context. - Lee de y escribe en un sistema de registro Neon Postgres con las cinco tablas del Concepto 7 (los turnos de la conversación viven en la Session del SDK en la misma base de datos).
- Usa pgvector para búsqueda semántica sobre una pequeña biblioteca de casos resueltos en el pasado.
- Habla con Postgres para los datos de negocio en tiempo de ejecución a través de un servidor MCP personalizado y acotado (
customer-data), nunca el servidor MCP de Neon y nuncaasyncpgdirecto en el código del agente. - Escribe una fila de auditoría por cada acción significativa (cada skill invocada, cada escritura a la base de datos, cada reembolso considerado) a través de su propia conexión directa, el único camino que deliberadamente esquiva la frontera MCP, para que la traza de auditoría no pueda ser asfixiada por el sistema que audita.
La prueba de "verificación al final": un cliente escribe "I haven't received my refund from order #4429, it's been two weeks." El Worker encuentra tres casos pasados similares vía búsqueda vectorial, redacta una respuesta que cita la resolución del caso más similar, y escribe una fila de auditoría de lo que hizo (y, en un despliegue real, escala si el cliente es de nivel Pro). Resolver el cliente o el pedido exacto a partir del mensaje necesita una herramienta de búsqueda que agregas más tarde; la Decisión 8 muestra dónde está esa brecha.
Cómo leer los prompts que siguen. Haces crecer este Worker pidiéndole a tu agente de programación una tarea pequeña a la vez, y cada Decisión termina igual: la nueva pieza se conecta al único worker y lo ejecutas, para que la veas funcionar antes de que la siguiente Decisión construya encima. No tecleas SQL, Python ni configuración: el agente lo escribe, tú diriges y revisas. Tu agente ya leyó
AGENTS.mdcuando abrió la carpeta, así que conoce el proyecto; tus prompts se quedan cortos. Dos hábitos:
- Un paso, una tarea. Pega el prompt de ese paso y nada más. Para cualquier cosa que escriba código real, el prompt dice "planifica primero": lee el plan, objeta, aprueba, y luego déjalo construir.
- Revisa antes del siguiente paso. Cada paso termina con una Comprobación: una pregunta en lenguaje llano que haces ("muéstrame X"). No avances hasta que pase, o estarás cuatro pasos adentro antes de descubrir que el paso uno estaba mal.
Decisión 1: Actualiza el archivo de reglas con la nueva arquitectura
Dónde estás: un agente de chat mínimo que responde "hi"; esta Decisión agrega las tres reglas de arquitectura a AGENTS.md; al terminar verás esas reglas en el diff del archivo.
Tu agente ya conoce este proyecto por AGENTS.md. Lo que todavía no conoce son las pocas reglas que agrega la arquitectura de este curso, así que las escribes en AGENTS.md ahora, y cada prompt posterior puede quedarse corto. Una tarea.
Paso 1: Agrega las nuevas reglas a AGENTS.md.
Add a short "Rules" section to AGENTS.md so a fresh session follows these:
- business data is read and written only through the customer-data MCP
server, never raw SQL from the running worker
- the audit log uses its own direct database connection, and each action
and its audit row are committed together
- embeddings use the same model to store and to search
Show me the diff before you write it.
Edita: AGENTS.md.
Comprobación. Lee el diff. Esas tres reglas están ahí, en lenguaje llano, sobre todo la primera: es lo que impide que el modelo rodee la frontera MCP en silencio más adelante. Si el agente suavizó o eliminó alguna, vuelve a pedírselo.
Por qué. Un archivo de reglas débil falla en silencio semanas después, cuando el modelo toma el atajo que la regla pretendía prohibir. Escribirlo ahora es lo que mantiene cortos todos los prompts posteriores a este.
Decisión 2: Planifica el esquema y el conjunto de Skills
Dónde estás: un AGENTS.md que enuncia la arquitectura pero sin un diseño todavía; esta Decisión agrega un plan escrito y revisado; al terminar verás un plan en markdown que objetaste y aprobaste.
Terminas esta Decisión con un plan escrito que revisaste, antes de que exista una línea de código. Una tarea. Presiona Shift+Tab dos veces para entrar en Plan Mode (en OpenCode, presiona Tab para cambiar al agente Plan): el modelo puede leer tu proyecto pero no puede editar nada.
Paso 1: Obtén el plan.
Plan the customer-support Worker evolution of this project. The
foundation (OpenAI Agents SDK, your sandbox runtime, sessions, streaming,
guardrails) stays. We're adding:
1. Three Skills: summarize-ticket, find-similar-cases, escalate-with-context.
For each, propose: the description, the operational shape (script-driven
or instruction-driven), and what reference files it needs.
2. The five-table schema from Part 2 Concept 7, plus any tables specific
to a customer-support domain (probably: customers, orders, tickets, refunds).
3. The custom MCP server (customer-data), with exactly the runtime tools
our agent will need. Propose the tool list and signatures. No run_sql.
4. The audit-logging plan: what writes an audit row, what doesn't.
Output the plan as a markdown file at plans/customer-support-worker-plan.md.
Do not write code yet.
For reference the part 2 here: https://agentfactory.panaversity.org/docs/digital-fte-crash-course
Crea: plans/customer-support-worker-plan.md.
Comprobación. Lee el plan y objeta las dos cosas que el primer borrador suele equivocar: descripciones de Skill vagas ("Resume tickets", una descripción que nunca se dispara bien, Concepto 3) y entradas de herramientas MCP demasiado amplias ("query: string", que es solo
run_sqldisfrazado;lookup_customerdebería tomar uncustomer_id, no texto libre con el que construyes SQL). No apruebes el plan hasta que ambas estén ajustadas.
Por qué un plan primero. Ambos modos de falla cuestan horas una vez construidos y minutos para arreglarse en un plan de markdown. Este es el lugar más barato de toda la Parte para equivocarse.
Estás a punto de tocar la base de datos por primera vez, y verás mucho SQL a lo largo de las Decisiones 3 a 8. Nunca lo tecleas ni lo ejecutas a mano. Tres componentes lo poseen, y hay dos servidores MCP distintos haciendo dos trabajos distintos.
| Ruta de SQL / datos | Quién lo escribe | Quién lo ejecuta | Cuándo |
|---|---|---|---|
| Esquema + migraciones (esta Decisión) | Tú lo describes; el agente lo redacta | Servidor MCP de Neon (una herramienta de dev que conectas a tu agente) | Una vez, en la configuración |
| Consultas de verificación (las comprobaciones "Listo cuando") | Mostradas en la lección | Servidor MCP de Neon run_sql, manejado por ti en inglés llano | Para confirmar que un paso funcionó |
| SQL de negocio en runtime: búsquedas, búsqueda vectorial, reembolsos (D6) | mcp-builder lo genera | El servidor MCP customer-data que construyes | Cada interacción con un cliente |
| Escrituras de auditoría (D7) | El código del subsistema de auditoría | Un pool de asyncpg aparte (sin MCP) | Cada acción |
Dos servidores MCP, nunca confundidos. El servidor MCP de Neon (que autenticaste en el paso de configuración de arriba) es una herramienta de desarrollo: lo usas para provisionar y verificar la base de datos en inglés llano, y nunca lo usas en tiempo de ejecución. El servidor MCP customer-data es el servidor acotado que construyes en la Decisión 6; el Worker en ejecución habla con ese, y solo con ese, para los datos de negocio. El Concepto 12 explica por qué un run_sql de propósito general en producción es un agujero de inyección de prompts.
Leer, escribir y eliminar no tienen la misma autoridad. Las herramientas del Worker en ejecución se dividen por riesgo:
- Lectura (
lookup_customer,find_similar_resolved_tickets, construidas en D6): corre libremente, sin compuerta. Las lecturas son baratas de permitir. - Escritura (
issue_refund, construida en D6): la única herramienta que mueve dinero. La pones detrás de aprobación humana en la Decisión 9, después de que el Worker funcione de extremo a extremo, para que un humano firme antes de que cualquier reembolso pase. Las escrituras de auditoría son de solo-anexar: insertadas, nunca actualizadas ni eliminadas. - Eliminar / cambio de esquema (
CREATE/DROP TABLE, DDL): no invocable en runtime para nada. El servidor personalizado nunca expone una herramienta DDL, así que no hay nada que aprobar. Los cambios de esquema ocurren solo en tiempo de desarrollo (esta Decisión), a través del servidor MCP de Neon, en una rama temporal antes de que toquenmain.
La regla práctica: las lecturas corren libres, las escrituras están con compuerta, y los cambios estructurales nunca llegan a producción a través del agente.
Decisión 3: Provisiona Neon y ejecuta la migración del esquema
El nivel gratuito de Neon cubre un solo Worker al volumen que asume la Parte 5 (~200 conversaciones/día). Cuenta con $0/mes aquí. Los límites del plan gratuito son 0,5 GB de almacenamiento y 100 horas de cómputo por proyecto (precios de Neon); por encima de eso, el nivel Launch es de pago por uso (aproximadamente $0,11/CU-hora + $0,35/GB-mes), y un Worker de ejemplo guiado normalmente se mantiene por debajo de $25/mes. Consulta la tabla de forma del costo de la Parte 5 para el desglose completo.
Dónde estás: un plan aprobado pero sin base de datos; esta Decisión agrega una base de datos Neon en vivo con tu esquema y una Session persistente; al terminar verás nueve tablas en Postgres y un worker que recuerda turnos anteriores.
Terminas esta Decisión con una base de datos Neon en vivo que contiene tu esquema, más una Session que persiste los turnos de la conversación en ella. Cuatro pasos pequeños, y revisas cada uno antes del siguiente, porque un paso de base de datos roto es invisible hasta que algo más abajo no lee nada. Presiona Shift+Tab para salir de Plan Mode y asegúrate de que el servidor MCP de Neon esté conectado (Concepto 12). El agente ejecuta todo esto a través de las herramientas MCP de Neon; nunca abres una consola de base de datos.
Paso 1: Crea el proyecto.
Create a fresh Neon project called "chat-agent" and give me the
connection string for its main branch.
Comprobación. Pídele al agente que confirme que el proyecto existe y te pegue de vuelta la cadena de conexión de
main. (También puedes verla en la consola de Neon.) No continúes sin una cadena de conexión en mano.
Paso 2: Enciende pgvector.
Enable the pgvector extension on the chat-agent database.
Comprobación. "Confirm the
vectorextension is now listed on the database." Si no lo está, nada más abajo que almacene embeddings funcionará, así que detente aquí hasta que lo esté.
Paso 3: Aplica el esquema, rama-primero.
Apply our schema to chat-agent: the five-table core from Concept 7
(conversations, documents, embeddings, audit_log, capability_invocations)
plus four domain tables, customers, orders, tickets, refunds. Build the
audit_log and capability_invocations columns EXACTLY as Concept 7 prints
them: audit_log keeps its `target` column and the closed `action` CHECK
set, capability_invocations keeps its `status` CHECK set, so Decision 8's
replay query matches the schema you built. Test it on a temporary branch
first, then merge to main. Plan the DDL first; I'll approve before you merge.
Comprobación. "Count the tables in the public schema, I expect nine, and confirm the embeddings index exists." Nueve tablas significa que la migración aterrizó. Si quedan menos, la fusión no se aplicó limpiamente: haz que el agente la vuelva a ejecutar en una rama nueva. (Este es exactamente el caso de uso de desarrollo del Concepto 12: trabajo de esquema en inglés llano, probado en una rama, fusionado a
mainsolo después de tu "adelante".)
Aproximadamente lo que deberías ver:
table_count = 9
embeddings index: present
Paso 4: Dale al worker su Session, y prueba que recuerda.
Write the connection string to .env as NEON_DATABASE_URL, then give the
worker a SQLAlchemySession on that database so it remembers across turns.
Install what the session needs (the sqlalchemy extra, asyncpg, pgvector,
and greenlet), and use the postgresql+asyncpg:// form of the URL for it.
Edita: el archivo del worker (agrega la Session); escribe NEON_DATABASE_URL en .env.
Comprobación. Ejecuta una conversación de dos turnos: dile al worker tu nombre y un número de pedido, luego en un segundo turno pídele que te los repita. Recuerda ambos, eso es la Session haciendo su trabajo, no solo una fila sentada en una tabla. Luego pregunta: "show me those turns in the
agent_messagestable." Verlos en Postgres prueba que el estado ahora vive en el sistema de registro, no solo en memoria. (Dos cosas que el agente suele pasar por alto: el extra[sqlalchemy]no traegreenlet, así que necesitauv add greenlet; y el motor async necesita la formapostgresql+asyncpg://de la URL, no elpostgresql://pelado.SQLAlchemySessioncreaagent_sessionsyagent_messagespor ti.)
Decisión 4: Define y prueba la primera Skill, summarize-ticket, luego conéctala
Dónde estás: un worker que recuerda pero no tiene capacidad portátil; esta Decisión agrega tres Skills en disco y las conecta al worker; al terminar verás una dispararse en una ejecución real.
Terminas esta Decisión con tres Skills en disco, la primera probada contra criterios que tú estableces, y la capacidad Skills conectada al worker para que la veas dispararse. Aquí está el cambio respecto a cómo la gente suele escribir skills: no escribes la skill a mano y la revisas a ojo. Le dices a skill-creator cuándo debe dispararse la skill y cómo se ve un buen resultado, y él la construye, la prueba y la afina contra esos criterios. Definir el éxito y juzgar los resultados es el trabajo que un experto de dominio hace en el mundo real; la autoría de debajo es de la herramienta.
Paso 1: Confirma que skill-creator está disponible. Ya lo instalaste (con mcp-builder y neon-postgres) en la preparación de la base, así que está en .claude/skills/ y no lo reinstalas aquí. Vuelve a agregarlo solo si de algún modo desapareció:
npx skills add https://github.com/anthropics/skills --skill skill-creator --agent claude-code -y
Comprobación.
skill-creatorestá presente en.claude/skills/. (Una sola instalación sirvió a ambas herramientas: OpenCode lee.claude/skills/como respaldo, así que nunca hubo una instalación--agent opencodeaparte que ejecutar.)
Paso 2: Define qué hace la skill y cuándo se dispara. skill-creator te pide las dos cosas que solo tú puedes decidir, el disparador y la salida. Dáselas ambas por adelantado, en lenguaje llano, y déjalo redactar.
Use skill-creator to build a summarize-ticket skill. Here is the spec.
Output: turn one support ticket into a five-section handoff (Customer
Context, Issue, Resolution Steps Taken, Current Status, Recommended Next
Action). It SHOULD fire on phrasings like "write a handoff note for #4471",
"TL;DR this thread", and "where does this stand before I escalate",
including ones that never say "summarize". It should NOT fire on drafting a
customer reply, triaging a batch, or reporting on ticket volume. Draft the
skill from that, then we'll test it.
Crea: .claude/skills/summarize-ticket/.
Comprobación. Existe un borrador bajo
.claude/skills/summarize-ticket/, y sudescriptionrefleja TU lista de disparar / no disparar, no un genérico "resume tickets". Esa descripción es la única entrada que decide si la skill llega a ejecutarse (Concepto 3); la entregaste como criterios comprobables en vez de adivinar el texto.
Paso 3: Deja que skill-creator la pruebe y la afine. Esta es la parte que reemplaza revisar la descripción a ojo. skill-creator convierte tu lista de disparar / no disparar en evals de disparo, las ejecuta, y mejora la descripción hasta que la skill se dispara cuando debe y se queda callada cuando no.
Test summarize-ticket against the fire and don't-fire cases I gave you:
turn them into trigger evals, run them, and tighten the description until
it passes. Show me which cases pass and which fail, before and after.
Comprobación. Lees los resultados de las evals, no la descripción en bruto: la skill se dispara en las formulaciones de traspaso, TL;DR y estado, y se queda callada en los casi-aciertos (redactar una respuesta, triaje de lote). Esa tabla de aprobado / fallado es la versión rigurosa del instinto del Concepto 3 de "borra la palabra clave y mira si sigue diciendo cuándo dispararse". El modelo decide si ejecutar esta skill solo a partir de su descripción, así que dejar esa tabla en verde es todo el juego.
Ambas herramientas, una disciplina. En Claude Code, skill-creator ejecuta esto como un bucle automatizado: divide tus casos en un conjunto de entrenamiento y uno reservado, ejecuta cada uno unas cuantas veces para una tasa de disparo fiable, y optimiza durante varias rondas, conservando la descripción que mejor puntúa en los casos en los que no entrenó. En OpenCode ejecutas el mismo bucle a mano: define casos, prueba, afina, repite. La automatización difiere; la disciplina de probar el disparador contra formulaciones reales es idéntica.
Paso 4: Define las otras dos Skills de la misma forma. La misma jugada: define cuándo se dispara cada una y qué produce, y deja que skill-creator las construya. No necesitas el bucle de prueba completo en las tres; ejecutarlo una vez sobre summarize-ticket te enseñó el ciclo. Dale el disparador y la forma de salida de cada una; las descripciones a las que llegue deberían leerse como las de abajo. El Worker necesita las tres.
# .claude/skills/find-similar-cases/SKILL.md (frontmatter only)
---
name: find-similar-cases
description: Searches the resolved-tickets library for tickets semantically similar to a customer's described issue, returning the top 3-5 with their resolutions, ranked by how closely each matches. Use when the user describes a problem, complaint, or symptom and you need to check whether the team has handled something similar before. Calls the find_similar_resolved_tickets MCP tool. Always run this BEFORE drafting a response, so the response can reference proven prior resolutions rather than inventing a new approach.
---
El cuerpo recorre estos pasos:
- Extrae la descripción del problema del contexto.
- Llama a
find_similar_resolved_ticketsconlimit=5. - Presenta los tres primeros con sus valores de distancia en una tabla de markdown.
- Marca explícitamente las coincidencias de baja confianza (distancia por encima de ~0,3, donde menor significa más similar) como "no se encontró precedente sólido previo".
La instrucción "always run this BEFORE drafting" hace un trabajo real; sin ella, el modelo a veces redacta una respuesta a partir de conocimientos previos y nunca mira la biblioteca.
# .claude/skills/escalate-with-context/SKILL.md (frontmatter only)
---
name: escalate-with-context
description: Packages a customer conversation for handoff to a tier-2 support agent. Produces a structured escalation note with customer profile, issue summary, what was already tried, why escalation is recommended, and the suggested specialist team. Use when (a) the customer is on the Pro or Enterprise tier AND the issue is unresolved after one round of investigation, (b) the customer's sentiment is clearly negative, (c) the issue involves billing >$500 or a refund decision, or (d) the user explicitly asks for a human.
---
El cuerpo invoca summarize-ticket primero para obtener el contexto estructurado, luego escribe una nota de escalada de seis secciones (contexto del cliente, problema, resoluciones intentadas, señales de sentimiento, equipo recomendado, SLA sugerido). Las cuatro condiciones de disparo explícitas en la descripción son lo que impide que esta skill se dispare de más; un Worker con lógica de escalada vaga escala todo, lo que anula el propósito.
Comprobación. Ambas descripciones nombran disparadores explícitos y específicos, no "úsalo cuando sea relevante".
escalate-with-contextsobre todo: sus cuatro condiciones son lo que la mantiene sin dispararse en cada mensaje. Las tres Skills ahora viven en.claude/skills/.
Crea: .claude/skills/find-similar-cases/ y .claude/skills/escalate-with-context/.
Paso 5: Conecta la capacidad Skills al worker, y mira una dispararse. Las tres Skills están en disco; ahora el worker en sí tiene que cargarlas. Dale la capacidad Skills encima de sus capacidades por defecto, luego ejecútalo.
Give the worker the Skills capability pointed at .claude/skills, on top of
its default capabilities, and run it from the project root with: "write a
handoff note for ticket #4471, refund delayed two weeks, customer Sam."
Show me the run so I can see the skill load.
Edita: el archivo del worker (agrega la capacidad Skills).
Comprobación. La ejecución muestra una llamada
load_skillparasummarize-tickety la respuesta vuelve en las cinco secciones: eso es la skill disparándose dentro de tu propio worker, no solo sentada en disco. Si en cambio el worker escribe un resumen libre y no aparece ningúnload_skill, la ruta se resolvió mal: las Skills cargan desde una ruta relativa a donde el worker se ejecuta, así que ejecuta desde la raíz del proyecto con un.claude/skillsrelativo, no uno absoluto. (En macOS una ruta absoluta bajo/tmpcarga cero skills en silencio, sin error alguno, que es la forma más confusa en que esto puede fallar.) Una más: agregas Skills a las capacidades por defecto, no las reemplazas, o el worker pierde el sistema de archivos y el shell de los que depende.
Aproximadamente lo que deberías ver en la ejecución:
tool call: load_skill(name="summarize-ticket")
reply: Customer Context / Issue / Resolution Steps Taken / Current Status / Recommended Next Action
Por qué conectarla ahora. Este es el momento en que las Skills dejan de ser archivos y se vuelven capacidad: el siguiente mensaje que mencione un ticket dispara esta skill solo a partir de su descripción. Las otras dos Skills se apoyan en las herramientas MCP que construyes a continuación, así que summarize-ticket, que se sostiene por sí sola, es la honesta para verificar aquí.
Decisión 5: Construye el pipeline de embeddings y siembra la biblioteca de documentos
Un corpus de siembra de unas pocas docenas de tickets resueltos a ~300 tokens cada uno se embebe por una fracción de centavo al precio de text-embedding-3-small de $0,02 por 1M de tokens de entrada. El embedding continuo de nuevos tickets y conversaciones normalmente se mantiene por debajo de $3/mes al volumen del ejemplo guiado. La palanca del costo es el presupuesto de inferencia, no el presupuesto de embedding.
Dónde estás: un esquema con tablas vacías y skills que no tienen nada que buscar; esta Decisión agrega una biblioteca sembrada y embebida de tickets resueltos en el pasado; al terminar verás una búsqueda por similitud devolver coincidencias ordenadas.
Terminas esta Decisión con una pequeña biblioteca de tickets resueltos en el pasado, embebidos y buscables. Dos pasos.
Paso 1: Genera la biblioteca de siembra en código. La "biblioteca" del Worker es un conjunto de tickets resueltos en el pasado: lo bastante pequeña para ejecutarse rápido, lo bastante variada como para que la búsqueda tenga algo que distinguir. No la escribes a mano, y no rellenas un CSV; el agente la genera.
Have the worker's own SDK generate a dozen-plus varied resolved tickets as
structured data (a Pydantic model is the clean way): each with a customer
email, a one-line summary, and the resolution. Vary the issues across
refunds, logins, duplicate charges, and shipping, so semantic search has
something to tell apart. Write the generator and run it; don't hand me a CSV.
Crea: el script generador de tickets.
Comprobación. Una docena y pico de tickets generados sobre problemas genuinamente distintos (reembolsos, inicios de sesión, cargos, envíos), no reformulaciones de tres. Nunca tecleaste una fila a mano, y ese es el punto: los datos de siembra de un Worker son algo que el Worker puede producir.
Paso 2: Siembra y embebe. Cada ticket generado lleva un customer_email, lo que le permite al sembrador buscar-o-crear una fila de customers antes de insertar el ticket (la clave foránea tickets.customer_id es NOT NULL). Luego:
Seed the generated resolved tickets so the Worker can search them later.
For each one: find-or-create the customer by email, insert a resolved
ticket, store the case text as a documents row tagged source='past_case'
with the ticket id at metadata->>'ticket_id' (there is no ticket_id column
on documents), then embed that text with
text-embedding-3-small and link the embedding to the document. Write one
audit_log row for the whole seed run. Plan first.
Crea: el script de siembra y embedding.
Esa forma no es arbitraria, y es la parte que el agente no puede adivinar: el find_similar_resolved_tickets de la Decisión 6 busca uniendo embeddings a documents (donde source='past_case') a tickets. Si la siembra no coloca las filas de esa forma, la búsqueda de la Decisión 8 devuelve nada en silencio y no tendrás idea de por qué. El agente escribe el sembrador real; tú estás especificando la forma que tiene que producir. Dos reglas que confirmar en el resultado, ambas del Concepto 9 y ambas ya en tu AGENTS.md: embebe con el mismo modelo con el que consultarás después, y registra pgvector en la conexión (o los vectores se escriben de vuelta como basura).
Comprobación. Pídele al agente que lea el resultado de vuelta: "Count the documents tagged as past cases (should match the number of tickets you generated), count the embeddings (should match too), confirm only one embedding model is present, and run one similarity search to show the closest match to 'refund delayed two weeks' comes back ranked." Dos formas de falla: si informa dos modelos de embedding, la siembra mezcló modelos a medio camino, reinicia y vuelve a ejecutar; si los conteos vuelven en cero, el sembrador se tragó un error, haz que lea de vuelta la fila de
audit_logque escribió para la ejecución de siembra (que es exactamente por qué el sembrador escribe una). No avances a la Decisión 6 hasta que una búsqueda por similitud devuelva resultados ordenados.
Aproximadamente lo que la búsqueda por similitud debería devolver:
query: "refund delayed two weeks"
1. "refund not received after 14 days" distance 0.08
2. "duplicate charge, awaiting reversal" distance 0.24
Por qué esto es una conexión directa, no MCP. Un script de siembra es infraestructura: corre una vez, a mano, por ti, no es algo que el Worker hace por su cuenta. La frontera MCP es para lo que el agente hace de forma autónoma; el script de siembra es algo que haces tú. No pongas una frontera entre ti y tu propia base de datos cuando tú eres quien está al teclado.
Decisión 6: Define, construye y conecta el servidor MCP customer-data
El servidor MCP personalizado corre como un pequeño servicio junto a tu Worker; co-ubicado en el mismo host no agrega un costo de hospedaje significativo (solo si lo empujas a hardware aparte aparece una línea de cómputo). Donde la factura de verdad aparece es en la inferencia: cada llamada a lookup_customer o find_similar_resolved_tickets agrega un viaje de ida y vuelta de tokens al siguiente turno del modelo. El Concepto 15 cubre el lado de la latencia y el tamaño del pool de MCP bajo carga.
Dónde estás: una biblioteca sembrada que el worker aún no puede alcanzar en runtime; esta Decisión agrega el servidor MCP acotado customer-data y lo conecta; al terminar verás al worker llamar a una de sus herramientas en un mensaje real.
Terminas esta Decisión con el servidor acotado customer-data corriendo y conectado a tu worker, sus tres herramientas invocables desde una ejecución real. Es la misma forma que las Skills de la Decisión 4: defines qué debe hacer el conector y cuán estrecho se mantiene, mcp-builder lo construye, y lo pruebas usándolo. Tú diriges el alcance; no escribes a mano nada del boilerplate de FastMCP. (Poner compuerta a la única herramienta peligrosa, issue_refund, llega en la Decisión 9, después de que todo funcione.)
Paso 1: Confirma que mcp-builder está disponible. Como skill-creator, lo instalaste en la preparación de la base, así que ya está aquí. Vuelve a agregarlo solo si desapareció:
npx skills add https://github.com/anthropics/skills --skill mcp-builder --agent claude-code -y
Comprobación.
mcp-builderestá presente en.claude/skills/.
Paso 2: Define el contrato de herramientas y el alcance. Esta es la versión de definir los criterios de una Skill para el conector: dices exactamente qué herramientas existen, qué toma cada una, y cuán estrecho se mantiene el servidor (sin SQL general), y mcp-builder lo planifica. Constrúyelo sobre streamable HTTP, sabor sin estado (el valor por defecto del Concepto 11): cada llamada es una petición independiente, así que el servidor es un servicio direccionable real al que el Worker llega por URL, y puedes ejecutar más de una copia si el tráfico crece. (Un build puramente local de un solo Worker podría usar stdio; el servicio sin estado coincide con lo que de verdad enviarías a producción.)
/mcp-builder Plan a custom MCP server called "customer-data" on the
streamable-HTTP transport, stateless flavor, with exactly three scoped
tools and no general SQL tool:
- lookup_customer(customer_id): return id, email, tier, open-ticket count.
Tier lives in customers.metadata->>'tier' (COALESCE to 'standard'); there
is no tier column.
- find_similar_resolved_tickets(description, limit): semantic search over
past resolved cases. Embed the description with text-embedding-3-small
(the SAME model the seed used) and register pgvector on the connection.
The search joins embeddings -> documents -> tickets, where the
documents->tickets link is documents.metadata->>'ticket_id' (there is no
ticket_id column on documents).
- issue_refund(order_id, amount_cents, reason): insert the refund (amount in
integer cents), set the order to refunded, AND write the audit_log row,
all in ONE transaction.
Give each tool a clear description so the model knows when to call it.
Show me the plan before any code.
Comprobación. Lee el plan antes de cualquier código: exactamente tres herramientas, sin herramienta SQL general, y
issue_refundescribiendo el reembolso, el cambio de estado del pedido y la fila de auditoría en una transacción. Objeta si falta alguna. (Una trampa de Neon que solo le pasas al agente si moviste el esquema fuera delpublicpor defecto: califica con el esquema los nombres de las tablas, porque el endpoint con pooler de Neon reiniciasearch_pathal liberar la conexión, así queSET search_pathno sobrevivirá. En la migración por defecto del curso simplemente funciona.) Una trampa de Neon que siempre aplica, aquí y en la Decisión 7: el endpoint con pooler (PgBouncer, modo transacción) rompe las prepared statements de asyncpg, así que tanto el pool de este servidor como el pool de auditoría deben pasarstatement_cache_size=0aasyncpg.create_pool(...), o la primerísima consulta da error.
Paso 3: Constrúyelo, y deja que mcp-builder pruebe las herramientas. Una vez que el plan esté bien: "Build the server exactly as we planned, three tools and no more, then start it and confirm it boots cleanly. Don't add tools I didn't ask for." mcp-builder puede ir un paso más allá y generar evaluaciones, tareas realistas que las herramientas tienen que satisfacer de extremo a extremo, que es la versión del conector de la eval de disparo que ejecutaste sobre la Skill. Para el curso la prueba decisiva es el siguiente paso, llamar a una herramienta desde el worker, así que un arranque limpio aquí basta para avanzar.
Crea: el servidor customer-data-mcp/.
Comprobación. Lee la descripción de cada herramienta en el servidor construido: es lo que el modelo lee para decidir cuándo llamar a la herramienta (el mismo papel que juega una descripción de
SKILL.md), y una vaga se dispara en el momento equivocado. Luego confirma lo que el agente más suele equivocar sutilmente: el cuerpo deissue_refundhace las tres escrituras en una sola transacción. La mayoría de estas disciplinas también viven en tuAGENTS.md, así que un agente cuidadoso las aplica; estás confirmando que sobrevivieron.
El servidor customer-data es un servicio streamable-HTTP, así que tiene que estar corriendo antes de que el worker pueda alcanzarlo. De aquí en adelante, las ejecuciones en vivo (esta Decisión, y las Decisiones 8 y 9) necesitan dos terminales: inicia el servidor en una, ejecuta el worker en la otra, el servidor primero. Detén el servidor y las llamadas a herramientas del worker fallan con un error de conexión, no con una respuesta equivocada.
Paso 4: Conéctalo al worker y llama a una herramienta. Conecta el servidor al worker que ya tiene su Session y sus Skills, y prueba que una herramienta de verdad corre. Esta es la versión del conector de ver dispararse la Skill en la Decisión 4:
Register the customer-data server with the worker as a remote
streamable-HTTP server at its URL, alongside the Session and Skills it
already has. Check the current SDK docs for the exact registration API.
Edita: el archivo del worker (registra el servidor customer-data).
Comprobación. Es un servicio streamable-HTTP, así que inicia el servidor primero, luego ejecuta el worker sobre un mensaje real: "Start the customer-data server, then run the worker on 'I'm Sam, and I haven't had my refund for order #4429 in two weeks.'" El worker debería llamar a
find_similar_resolved_ticketsy volver con casos pasados ordenados, no con un resultado vacío y no con una respuesta inventada. Eso es el cable MCP funcionando: el worker alcanzó los datos de negocio a través del servidor acotado, y solo ese servidor. Dos banderas rojas: una herramienta de estilorun_sqlgeneral en la lista significa que el worker sigue conectado al servidor MCP de Neon en runtime, sácala (Concepto 12); un resultado vacío de la búsqueda significa que la siembra de la Decisión 5 no aterrizó en la forma que lee el join (embeddingsadocumentsdondesource='past_case'atickets). Si el servidor en sí no arranca, haz que el agente lea sus logs (la nota de importación de arranque del Concepto 13 es la causa habitual).
Por qué un servidor personalizado, no solo asyncpg en el código del agente. Las tres razones del Concepto 14, en el orden en que importan aquí: alcance (el agente puede hacer exactamente tres cosas a la base de datos, no cualquier cosa que SQL permita), aislamiento (el servidor corre en su propio proceso con su propio pool que el agente no puede agotar), y reutilización (un segundo Worker que necesita lookup_customer habla con este mismo servidor). Esa superficie estrecha es todo el argumento de seguridad, que es por qué la comprobación del Paso 3 es sobre la frontera, no sobre la plomería.
Decisión 7: Conecta el registro de auditoría en todas partes
Dónde estás: un worker que actúa pero solo registra la única escritura de reembolso; esta Decisión agrega las acciones propias del agente a la traza de auditoría; al terminar verás una traza message_received / skill_activated / capability_invoked / message_sent para una conversación.
Esta es una de las dos Decisiones donde un primer build normalmente choca con un error; los avisos de abajo nombran cada uno antes de que te lo encuentres, así que léelos primero.
Terminas esta Decisión con las acciones propias del agente registradas en audit_log. El servidor MCP ya registra una cosa, issue_refund escribe su fila de auditoría dentro de la transacción del reembolso (Decisión 6); lo que queda son las escrituras del lado del agente: invocaciones de skills, llamadas al modelo, llamadas a herramientas, disparos de guardrails. Una tarea, usando el helper log_capability del Concepto 10.
Paso 1: Conecta el helper de auditoría en cada frontera.
Wire the audit helper around the agent's own actions, at three points:
the start and end of each skill invocation, after each MCP tool call,
and around any guardrail trip. Use the separate audit connection (its
own pool), not the customer-data MCP boundary. Plan first.
Edita: el archivo del worker (agrega el cableado de auditoría en cada frontera).
Las tres "fronteras" de arriba no se mapean a tres hooks que coincidan, y el cableado ingenuo tumba la ejecución. La realidad:
- No hay hook de skill. En el modo lazy de Skills que usa este curso, una skill se activa cuando el modelo llama a la herramienta
load_skill, así que observa el inicio/fin de la skill enon_tool_start/on_tool_enddondetool.name == "load_skill". Las llamadas a herramientas MCP llegan por ese mismoon_tool_end. - Los disparos de guardrail son excepciones lanzadas, no un hook. Captura
InputGuardrailTripwireTriggered(y las variantes de salida/herramienta) contry/exceptalrededor deRunner.run, y escribe ahí la filaguardrail_tripped. - El
resultdeon_tool_endestá tipado comostrpero te entrega el objeto en bruto de la herramienta (un modelo de Pydantic o un dict). Cortarlo o hacer operaciones de cadena sobre él lanza una excepción, y una excepción no manejada dentro de un hook mata todo el turno (aparece como un confusoUserError: Error running tool ...). Conviértelo constr(...)Y envuelve el cuerpo del hook entry/exceptpara que un bug de auditoría nunca pueda abortar el turno del usuario. on_tool_endtambién se dispara cuando una herramienta falla, entregándote un resultado"Error executing tool ...". Detéctalo (una comprobación de subcadena, nostartswith) y registrastatus="error", o un reembolso fallido queda registrado como un éxito.
Escribe la fila de conversations primero. audit_log.conversation_id es una clave foránea a conversations(session_id). Si una fila de auditoría hace referencia a una sesión que aún no tiene fila de conversations, la FK se viola y revierte toda la transacción, incluido el reembolso que estaba registrando. Haz upsert de la fila de conversations en message_received, antes de que cualquier fila de auditoría apunte a ella (la Decisión 3 crea la tabla pero nunca dice cuándo se escribe la fila: es aquí).
Un input guardrail con una Session ve toda la transcripción. No solo el mensaje nuevo: toda la historia preparada más el nuevo turno. Así que una palabra marcada de cualquier turno anterior dispara cada turno posterior (un benigno "say hello" queda bloqueado porque un token de prueba sigue en la historia). Filtra solo el último elemento role: user, no toda la entrada.
Comprobación. Ejecuta una conversación desechable, luego: "Using the Neon tools, find the most recent conversation and show me every
audit_logrow for it, in order." Deberías ver al menos unmessage_received, unskill_activated(el worker tiene sus Skills desde la Decisión 4), uncapability_invokedpor la llamada MCP, y unmessage_sent. Dos formas de falla: si ves solo las propias filas del servidor MCP (capability_invoked,refund_issued) y ninguna del lado del agente, el helper está cableado pero nunca se dispara, haz que el agente confirme que corre desde dentro del bucle de streaming, no solo una vez al arrancar; si ves cero filas, la conexión de auditoría no está llegando a la base de datos, haz que revise el pool de auditoría contra tu URL de base de datos.
Aproximadamente lo que deberías ver (una conversación, en orden):
message_received
skill_activated
capability_invoked
message_sent
Por qué el pool de auditoría es aparte. Usa su propia conexión, no el pool MCP de customer-data, por dos razones: la auditoría debe tener éxito incluso cuando el pool de datos está saturado, y las escrituras de auditoría no deberían competir con las escrituras de negocio por las conexiones. Un subsistema de auditoría que puede ser asfixiado por el sistema que audita no es un subsistema de auditoría. La mecánica es pequeña (el Concepto 7 trae las tablas, el Concepto 10 trae el helper); la disciplina es llamarlo en cada frontera, de forma consistente. (Idéntico en OpenCode: es Python plano.)
Decisión 8: Verifica el worker completo en un escenario
Dónde estás: cada capa cableada y revisada en aislamiento; esta Decisión no agrega nada nuevo, prueba que funcionan juntas en un escenario y lo reproduce desde el registro; al terminar verás una sola traza ordenada que cruza todas las capas.
A estas alturas el worker tiene las tres capas cableadas y cada una revisada por su cuenta: la Session (Decisión 3), las Skills (Decisión 4) y el servidor MCP (Decisión 6), con la auditoría debajo (Decisión 7). Esta Decisión prueba que funcionan juntas en un escenario real, luego lo reproduce solo desde el registro de auditoría.
Paso 1: Ejecuta el escenario y lee su traza. Haz que tu agente ejecute el Worker contra el único mensaje que ejercita todo el stack (el servidor en una terminal, el worker en otra, el servidor primero; ver la Decisión 6):
Run the Worker and send it this customer message, then show me the
audit_log rows that conversation produced, in order:
"I haven't received my refund from order #4429, it's been two weeks."
Deberías ver estas filas en pocos segundos:
action=message_received: el mensaje llega, se crea la fila de la conversación.action=skill_activated(solo si una skill carga): el worker puede cargar una Skill (find-similar-casesosummarize-ticket) para manejar la petición. El modelo también puede alcanzarfind_similar_resolved_ticketsdirectamente sin cargar una skill primero, en cuyo caso esta fila simplemente está ausente y la traza va directo acapability_invoked. Ambos son builds correctos, así que no trates unskill_activatedausente como un bug.action=capability_invoked, target=mcp:find_similar_resolved_tickets: la skill maneja una búsqueda vectorial a través del servidor MCP, y el worker lee la resolución pasada más cercana para redactar a partir de ella.action=message_sent: la respuesta redactada, registrada.
Una quinta condicional, action=capability_invoked, target=mcp:lookup_customer, aparece solo si el worker ya tiene un id de cliente. El primer turno normalmente no lo tiene (el cliente dio un número de pedido y un email, no un UUID), así que se omite hasta que algo aguas arriba resuelva al cliente: la autenticación, el orquestador, o una herramienta lookup_customer_by_email que agregues después. Eso está bien; la respuesta todavía puede citar el caso pasado.
Comprobación. Las filas centrales están presentes y en orden (con
skill_activatedsolo si una skill cargó), y cruzan las capas en una sola traza: una herramienta MCP corrió contra el sistema de registro, la conversación se registró, y una Skill pudo activarse. Eso es el worker completo funcionando junto. Si faltacapability_invokedomessage_sent, vuelve a la Decisión que lo cableó y vuelve a ejecutar la comprobación propia de esa Decisión.
message_received, skill_activated y message_sent los escribe el cableado de auditoría del lado del agente de la Decisión 7; las filas capability_invoked vienen de ese mismo cableado alrededor de cada llamada MCP. El servidor MCP escribe su propia fila solo cuando una herramienta cambia datos (la fila refund_issued dentro de issue_refund). Así que un escenario de solo lectura como este deja filas del lado del agente más las lecturas capability_invoked, y ninguna fila de escritura de negocio hasta que un reembolso de verdad ocurra, en la Decisión 9.
Ahora que las Skills corren dentro del worker, el scripts/ de una skill es código ejecutable en el sandbox. UnixLocalSandboxClient no da aislamiento; Docker, E2B, Cloudflare o Modal lo contienen. Trata el acceso de escritura a tu biblioteca de skills como acceso de despliegue, y aísla el sandbox antes de cargar skills que no escribiste.
Memory, y qué no esLa misma lista de capacidades acepta un Memory() junto a Skills() (ambos de agents.sandbox.capabilities). Vale la pena conocerlo con precisión, porque suena como lo que acabas de construir y no lo es. Memory() le permite a un Worker aprender de sus propias ejecuciones pasadas: destila la conversación de cada ejecución en archivos del workspace (un MEMORY.md y un resumen) cuando la sesión del sandbox se cierra, y las ejecuciones posteriores los leen de vuelta, así que el agente explora menos y repite menos correcciones. Eso es el recuerdo del Concepto 3 de "¿hemos visto una pregunta como esta antes?", manejado por el runtime, así que no lo construyes a mano.
Lo que no es es el registro de negocio duradero. La memoria del sandbox está basada en archivos, poda sus entradas más viejas por antigüedad, y está en beta; un sandbox nuevo empieza vacío, y al agente se le dice que la trate como guía, no como almacenamiento autoritativo. Tus tablas de Neon son lo opuesto en cada punto: duraderas, completas, estables, consultables en SQL. Así que quieres ambas, para trabajos distintos. Memory() hace al agente más listo entre ejecuciones; el sistema de registro hace su trabajo duradero, demostrable y vendible: el activo que te pertenece. Las cuatro páginas bajo Sandbox agents en la documentación del SDK son la fuente de toda esta capa; el AGENTS.md compañero enlaza las cuatro.
Paso 2: Ejecuta la consulta de reproducción. Esta es la prueba para la que sirvió toda la capa de auditoría. Pídele al agente que saque la traza de la conversación que acabas de ejecutar:
Using the Neon tools, take the most recent conversation and show me its full
audit_logtrace, in order: created_at, action, target, payload, result.
Comprobación. Leyendo esa salida, puedes reconstruir línea por línea lo que el agente hizo y por qué, sin volver a ejecutar el modelo. Si no puedes, si pasó un paso que no está en el registro, o una fila afirma una acción que las tablas de negocio no reflejan, hay un bug de cableado. Arréglalo antes de dar el Worker por terminado.
Aproximadamente cómo debería leerse la reproducción:
created_at action target result
10:02:11 message_received conversation:abc ok
10:02:12 capability_invoked mcp:find_similar_resolved_tickets ok
10:02:14 message_sent conversation:abc ok
Por qué este escenario. Ejercita cada pieza arquitectónica que agrega este curso, en una sola pasada: una Skill se activa, una herramienta respaldada por MCP ejecuta una búsqueda semántica contra el sistema de registro, y la traza de auditoría registra todo el camino, reproducible en SQL. Nada de eso existía en el agente de chat mínimo con el que empezaste. Lo que todavía no hace es mover dinero; esa es la única acción frente a la que pones un humano a continuación.
Decisión 9: Endurece la única acción que mueve dinero
Dónde estás: un worker que corre de extremo a extremo pero emite reembolsos sin ninguna revisión; esta Decisión agrega una compuerta de aprobación humana sobre issue_refund; al terminar verás un reembolso pausarse para firma, luego pasar al aprobar y detenerse al rechazar.
Esta es la otra Decisión donde un primer build normalmente choca con un error; los avisos de abajo nombran cada uno antes de que te lo encuentres, así que léelos primero.
El worker funciona de extremo a extremo. Ahora agrega lo único que dejaste fuera a propósito: un humano frente a issue_refund, la única herramienta que mueve dinero. Construyes esto último, a propósito, porque una compuerta de aprobación solo tiene sentido una vez que la cosa que protege de verdad corre.
Paso 1: Pon compuerta a la herramienta de reembolso.
Gate issue_refund behind human approval: register the customer-data server
so that tool needs sign-off before it runs, and leave lookup_customer and
find_similar_resolved_tickets un-gated. Check the current SDK docs for the
exact approval API.
Edita: el archivo del worker (pone compuerta a issue_refund en el registro del servidor).
Comprobación. Las dos herramientas de lectura siguen corriendo sin tocar; solo
issue_refundtiene compuerta. La compuerta vive en cómo se registra el servidor, no dentro de la herramienta. (Dentro de Claude Code u OpenCode el propio aviso de permiso del cliente es la misma compuerta; en el worker independiente es el ajuste de aprobación en el registro del servidor.)
Paso 2: Ejecuta un reembolso y míralo pausarse. (El servidor en una terminal, el worker en otra, el servidor primero; ver la Decisión 6.)
Run the worker on a message that should lead to a refund on order #4429,
and show me what happens when it tries to issue it.
Comprobación. La ejecución se pausa en lugar de emitir el reembolso: el worker informa que está esperando la aprobación de
issue_refund(en términos del SDK, la ejecución vuelve con una interrupción en lugar de una respuesta final), y nada se ha escrito todavía en la tablarefunds. Esa pausa es el modelo de autoridad funcionando: el modelo propuso una acción, y el sistema se detuvo en la frontera.
La compuerta solo se activa una vez que el modelo de verdad llama a issue_refund. Un system prompt cauteloso (como "solo emite un reembolso una vez aprobado") puede hacer que el modelo siga pidiendo aprobación en prosa y nunca invoque la herramienta, así que nada se pausa y ningún reembolso ocurre, lo que parece una compuerta rota pero no lo es. Para forzar a la compuerta a mostrarse, empuja la llamada explícitamente: "Supervisor approved the refund for order #4429. Call issue_refund now: 2999 cents, reason 'arrived damaged'. Invoke the tool, don't ask again." La compuerta del SDK es el respaldo duro sobre la ejecución; no puede hacer que el modelo enrute a través de una herramienta en primer lugar.
Paso 3: Aprueba una vez, luego rechaza una vez. Prueba ambas mitades de la compuerta:
Approve the pending refund and let the run finish, then show me the refunds
table and the audit_log row. Then run the same scenario again, reject it,
and show me that no refund was written.
Comprobación. Al aprobar: la fila del reembolso aparece, el pedido cambia a refunded, y
issue_refundescribe su fila de auditoríarefund_issued, todo en la misma transacción. Al rechazar: ninguna fila de reembolso, y la traza muestra que la acción fue declinada. Una trampa que pasarle al agente, porque es la diferencia entre "funciona" y "parece que debería": reanudar una ejecución aprobada es un bucle, no una sola llamada. Una ejecución puede tener más de una aprobación pendiente, así que el agente sigue reanudando mientras la ejecución todavía tenga aprobaciones esperando (aprueba o rechaza cada una, luego reanuda), no solo una vez. Reanuda una sola vez y puedes obtener una respuesta vacía con el reembolso aún sin escribir.
Aproximadamente lo que cada mitad debería producir:
approve -> refunds: 1 new row | orders.status = refunded | audit: refund_issued
reject -> refunds: no new row | audit: action declined
Por qué esto es lo último. Una compuerta de aprobación agregada antes de que el worker corra es teatro no comprobable: no puedes distinguir una compuerta que funciona de una rota cuando nada fluye a través de ella. Agregada aquí, sobre un worker que has visto buscar, redactar y auditar, puedes probar ambas mitades: aprobar deja pasar el reembolso, rechazar lo detiene, y la auditoría registra cuál. Eso es todo el modelo de autoridad, el agente propone y un humano dispone.
La comprobación de arriba asume que hay un humano ahí mismo. Si la firma llega una hora después, en otro proceso, la ejecución pausada tiene que serializarse (el RunState del SDK), almacenarse y reanudarse cuando la decisión llegue. Su hogar duradero es una pequeña tabla run_states (una fila por pausa: el estado serializado más awaiting/approved/rejected), no audit_log (de solo-anexar) y no una columna en conversations (una conversación puede pausarse más de una vez). Las llamadas de serializar-y-reanudar son parte de la superficie cambiante del SDK, así que confírmalas a través de Context7.
Qué acaba de pasar
Nueve Decisiones, y el agente de chat mínimo del Paso 0 ahora tiene la base de un Worker. Mira atrás a lo que cambió:
- La capacidad salió del código. Tres Skills están en
.claude/skills/, con control de versiones, compartibles entre agentes. - Los almacenes duraderos salieron del proceso. Un esquema Postgres real (el núcleo de cinco tablas más una capa de dominio para customers, orders, tickets y refunds) ahora contiene el sistema de registro del Worker y la biblioteca de referencia que busca con pgvector, mientras la Session del SDK mantiene el estado de la conversación del Worker en la misma base de datos.
- El acceso de negocio en runtime está mediado. El agente alcanza los datos de negocio en Postgres solo a través de un servidor MCP acotado que expone exactamente tres herramientas; cada lectura y escritura de negocio cruza esa única frontera. El subsistema de auditoría es la única excepción deliberada, en su propia conexión directa, para que no pueda ser asfixiado por la frontera que audita.
- Cada acción deja una traza. El registro de auditoría puede reproducir la traza de razonamiento completa de cualquier conversación, semanas o meses después, en SQL.
- La acción peligrosa tiene un dueño. La única herramienta que mueve dinero se pausa para un humano antes de ejecutarse; aprobar la deja pasar, rechazar la detiene, y de cualquier forma el registro de auditoría guarda la decisión. Ese es el modelo de autoridad que un Worker necesita antes de que alguien confíe en él acciones reales.
El OpenAI Agents SDK sigue ahí. El sandbox sigue siendo tu cómputo, y el streaming, los guardrails y el trazado con los que el agente empezó siguen todos ahí. Lo que cambió es la arquitectura encima: las Skills contienen las capacidades, el sistema de registro contiene la verdad, MCP los conecta, y un humano se queda en el bucle sobre las acciones que importan.
Esa es la base de un Worker. Lo que todavía no es es siempre activo, proactivo, ni parte de una fuerza de trabajo gestionada. Esos son los movimientos que agregan los siguientes cursos.
Decisión 10 (reto opcional): haz que la aprobación pausada sobreviva a un reinicio
En la Decisión 9 el aprobador estaba sentado justo en la terminal, así que un [y/N] bastaba. Las aprobaciones reales rara vez funcionan así: el gerente que firma un reembolso podría responder una hora después, desde otra app, en otra máquina. Tu worker todavía no puede manejar eso. Cuando un reembolso se pausa, la ejecución pausada vive solo en la memoria del worker, así que si el proceso se cierra antes de que el humano responda, el reembolso pendiente se pierde.
Ya has movido tres tipos de estado a Postgres: los turnos de la conversación, los registros de negocio y la biblioteca de referencia, y la traza de auditoría. La ejecución pausada es el único tipo que sigue atrapado en memoria. Este capstone opcional la mueve también a la base de datos, para que una pausa pueda aprobarse después, desde cualquier lugar. Es un reto calificado, no un build guiado: cada paso te da la idea y el prompt, y deja el cableado a tu agente.
Meta: aprobar o rechazar un reembolso pausado desde un proceso distinto al que lo inició.
Paso 1: Dale a cada ejecución pausada un hogar en la base de datos. Una pausa necesita su propia fila: a qué conversación y herramienta pertenece, la ejecución guardada en sí, y un estado que pasa de awaiting a approved, rejected o resumed. Es su propia tabla, no el registro de auditoría (eso es historia terminada) y no una columna en conversations (una conversación puede pausarse más de una vez).
Add a run_states table that stores one paused run per row: the conversation
and tool it belongs to, the saved run, and a status that defaults to
"awaiting" and can become approved, rejected, or resumed. Plan the DDL first;
I'll approve before you apply it on a branch.
Comprobación. Existe una tabla
run_statesy una pausa nueva toma por defectoawaiting. Nunca tecleaste el SQL: dijiste para qué sirve la tabla, tu agente la escribió, igual que el esquema aterrizó en la Decisión 3.
Paso 2: Cuando un reembolso se pausa, guárdalo y sigue. Ahora mismo el worker espera en la terminal; en su lugar debería registrar la pausa y liberarse para el siguiente turno.
When a run comes back waiting for approval instead of with a final answer, do
not block on input. Save the paused run as a run_states row marked "awaiting"
and return, so the worker is free for the next turn. One turn is one request
that either finishes or parks. Check the current Agents SDK docs for the exact
"save the paused run" call before you write it.
Comprobación. Un turno de reembolso ahora vuelve pronto, dejando atrás una fila
awaiting, y nada se bloquea esperando a un humano.
Paso 3: Aprueba o rechaza desde un comando aparte. La decisión sale del bucle de chat a su propio pequeño punto de entrada, para que pueda ejecutarse en otro proceso por completo.
Build a small "decide" command, separate from the chat loop: it lists the
awaiting rows, takes my approve or reject on one, then reloads that saved run
and finishes it. Keep resuming in a loop while the run still has approvals
pending, since resuming once can come back empty with the refund unwritten
(the loop gotcha from Decision 9). Confirm the reload call through Context7.
Comprobación. Aprobar una fila desde el comando decide lleva ese reembolso a completarse; rechazarla no escribe ningún reembolso y registra el rechazo.
Paso 4: Haz el reembolso seguro de reintentar. En una configuración distribuida, un reintento de red puede disparar el mismo reembolso aprobado dos veces.
Make issue_refund idempotent: dedupe on the order plus a request id, so the
same approved refund cannot run twice.
Comprobación. Reanuda la misma aprobación dos veces a propósito: obtienes exactamente una fila de
refunds, no dos.
Paso 5: Un turno activo por conversación. Dos turnos en la misma conversación a la vez corromperán su sesión.
Add a per-conversation lock (a Postgres advisory lock on the session id, or a
status guard) so only one turn is active per conversation at a time.
Comprobación. Un segundo turno en la misma conversación espera o es rechazado, en lugar de competir con el primero.
Las llamadas que guardan una ejecución pausada y la recargan después son parte de la superficie beta del SDK que cambia entre versiones. La disciplina del curso aplica a su propio reto: pega las llamadas exactas de guardar y recargar de la documentación actual del Agents SDK o de Context7 en vez de recordarlas. La idea, que una ejecución pausada se vuelve una fila que retomas después, es estable; los nombres de los métodos no.
Listo cuando:
- Inicias un reembolso en un proceso; sale con la ejecución estacionada en
run_states(estadoawaiting), y todavía sin fila derefunds.- En un segundo proceso, lo apruebas; el reembolso se confirma (fila de reembolso, el pedido cambia, fila de auditoría
refund_issued), y la fila estacionada se vuelveresumed.- El camino de rechazo deja cero escrituras de negocio y una fila de auditoría
refund_blocked.- Aprobar la misma ejecución estacionada dos veces no emite un segundo reembolso.
- Todo el episodio es reproducible desde
audit_logmásrun_statessin volver a ejecutar el modelo.
Estiramiento (distribuido completo). Pon el servidor customer-data detrás de una URL real con autenticación y apunta el worker a ella; cambia el sandbox local por uno alojado sin cambiar el agente en sí (cambia el cliente, conserva el agente); y saca tus secretos del archivo .env a un gestor de secretos. El mismo worker, ahora capaz de ejecutarse entre máquinas.
El estado en la base de datos es necesario pero no suficiente: lo último con estado que mover es la propia ejecución pausada, y una vez que vive en run_states tu worker deja de estar atado a un solo proceso.
Parte 5: Dónde termina este curso
Forma del costo de un Worker: cómo estimarlo
Aquí no hay totales en dólares a propósito: los precios por token y los límites del nivel gratuito cambian cada mes, así que cualquier número impreso estaría desactualizado para cuando lo leas, y un número viejo es peor que ninguno. Lo que perdura es el método. Aquí está, con el tráfico del propio ejemplo guiado como las entradas que conectas: 200 conversaciones/día, unos 10 turnos cada una, unos 8K tokens de entrada por turno.
Una línea es casi toda la factura; las otras tres son errores de redondeo. Trabájalas en orden.
1. Inferencia del modelo. Tu volumen mensual de tokens por el precio por token de tu modelo. El volumen viene de tu propio tráfico:
input tokens/month ≈ conversations/day × turns/conversation × tokens/turn × 30
Para el ejemplo: 200 × 10 × 8,000 × 30 ≈ 480M input tokens/month. Multiplica eso por el precio de entrada de tu modelo (de su página de precios), luego suma los tokens de salida de la misma forma (muchos menos, pero a un precio por token más alto). Esa única multiplicación es tu factura.
La mayor palanca sobre ella es el prompt caching. Tu AGENTS.md, el system prompt y los metadatos de las Skills son idénticos en cada turno, así que cuando el proveedor cachea ese prefijo estable, esos tokens facturan a una fracción de la tarifa normal. Mantener el prefijo estable (no cambies AGENTS.md a mitad del día) es la jugada de costo de mayor valor que tienes. Enrutar los turnos fáciles a un modelo más pequeño y solo los difíciles a un modelo de frontera es la segunda.
2. Embeddings. tokens embebidos × el precio del modelo de embedding. Embebes el corpus de siembra una vez y los nuevos tickets a medida que llegan; a la tarifa de un modelo de embedding pequeño eso son centavos, no dólares, a menos que vuelvas a embeber continuamente historiales de conversación completos. La misma página de precios.
3. Postgres (Neon). A menudo $0: el nivel gratuito cubre un solo Worker de bajo volumen, y la escala a cero significa que las horas inactivas no cuestan nada. Pagas solo después de cruzar los límites gratuitos de almacenamiento / horas de cómputo, y entonces es almacenamiento más cómputo activo, ambos en la página de precios de Neon.
4. Cómputo del sandbox. $0 aquí, porque el ejemplo guiado corre en UnixLocalSandboxClient, tu propio equipo. En producción son minutos-de-contenedor donde sea que despliegues (Docker, Cloudflare, E2B, Modal): duración de la sesión × concurrencia × la tarifa de ese proveedor.
Todo el método en una línea: calcula tu volumen mensual de tokens a partir de tus propios números de conversación, multiplica por el precio por token de hoy, y lee las otras tres líneas de las páginas de precios. Escalar a muchos Workers no cambia la fórmula, multiplica la línea de inferencia por cuántos Workers y cuán ocupados están; las líneas de infraestructura se mantienen más o menos planas, así que la factura del modelo es la que crece, y los dos hábitos de arriba (prefijo cacheado estable, modelo más barato para los turnos fáciles) son lo que la mantiene a raya.
Guía de intercambio: la arquitectura es invariante, los productos no
Este curso nombra proveedores específicos en cada capa (OpenAI Agents SDK, el sandbox local del SDK, Neon, embeddings de OpenAI, el SDK de Python de MCP). Eso es porque un ejemplo de enseñanza necesita respuestas concretas, no "usa cualquier runtime de LLM que te guste". Pero la arquitectura funciona con cualquier alternativa compatible. Cinco intercambios que el diseño del curso anticipa explícitamente:
- Host de Postgres: Neon → Supabase, AWS RDS, autoalojado. Cualquier cosa con
pgvectorfunciona. Pierdes la ramificación y la escala a cero (esas son específicas de Neon), pero el esquema de cinco tablas, el pipeline de embeddings, la disciplina de la traza de auditoría y el patrón del servidor MCP personalizado son todos transferibles byte por byte. El único cambio es la cadena de conexión y posiblemente la configuración de SSL. - Almacenamiento de vectores: pgvector → Pinecone, Weaviate, Qdrant. Si rechazas el argumento de "una base de datos para datos relacionales y vectoriales" del Concepto 6, cambia la tabla
embeddingspor un cliente de base de datos vectorial. El costo: dos almacenes que mantener consistentes (el Concepto 6 sostiene que rara vez vale la pena). El beneficio: mejor recall a escalas muy grandes (10M+ vectores), y la simplicidad operativa de un servicio gestionado. - Modelo de embedding: OpenAI → Cohere, Voyage, BGE-small (local). Cambia una constante (
EMBEDDING_MODEL) y una dimensión de columna (VECTOR(n)). Ejecuta un re-embedding de una sola vez de los datos existentes. El pipeline del Concepto 9 no cambia. - Sandbox: el sandbox local → Cloudflare, E2B, Modal, Daytona, tu propio Docker. Cualquier cosa con fronteras de proceso aisladas y un reinicio limpio funciona. El runtime
SandboxAgentes agnóstico del backend; el ejemplo guiado corre enUnixLocalSandboxClient, y producción cambia a cualquiera de estos. Losscripts/de las Skills se ejecutan de la misma forma. El diagrama de frontera de confianza del curso anterior todavía aplica. - Runtime del agente: OpenAI Agents SDK → LangGraph, CrewAI, Pydantic AI, tu propio bucle. La frontera MCP es lo que sobrevive; cada framework de agentes moderno tiene un cliente MCP. Las Skills funcionan en cualquier agente que pueda cargar archivos
SKILL.md(Claude Code, OpenCode, Goose, y cada vez más Cursor/Windsurf). La disciplina de la traza de auditoría es Python agnóstico del framework.
Qué no se intercambia con facilidad. El protocolo MCP en sí, la especificación del formato de Skills, y el hábito de la traza de auditoría. Estas son las partes que llevas entre productos; los productos son las partes que intercambias. La misma forma arquitectónica debajo, implementaciones reemplazables encima.
Una palabra sobre "invariante" y "propio". Ambas son heurísticas que vale la pena apostar, no hechos asentados. "Invariante" nombra los mejores estándares abiertos disponibles en 2026: MCP tiene cerca de dieciocho meses y la especificación de Skills es más joven, y algún día el cable o el propio formato de capacidad podría ser lo que se reemplace, no solo los productos enchufados a él. Apostar por protocolos abiertos en lugar de propietarios es cómo envejeces bien, pero trata la arquitectura como duradera-por-diseño, no eterna. Y "propio" en realidad significa propio-por-composición: este Worker corre sobre la nube de Neon, los modelos de un proveedor, un cliente de agente de programación, y skills sacadas de repos de terceros. Lo que te pertenece es la libertad de intercambiar cualquiera de ellos sin reescribir el resto. Eso es real y vale muchísimo, y es menos de lo que sugiere la palabra completa. Te pertenecen las costuras, no el sustrato.
Qué no cubre este curso (todavía)
Ahora tienes un Worker que satisface dos de los Siete Invariantes que plantea la tesis. En concreto: corre sobre un motor (Invariante 4, del curso anterior), y trabaja contra un sistema de registro (Invariante 5, de este curso). Los otros cinco Invariantes son lo que las empresas nativas de IA en producción requieren, y lo que cubren los cursos siguientes. Cada uno es una viñeta aquí, no una sección.
- Invariante 1: El humano es el principal. Specs autoradas, compuertas de aprobación, declaraciones de presupuesto. La arquitectura para fijar la intención y ser dueño de los resultados, cubierta en la Parte 6 del libro.
- Invariante 2: Cada humano necesita un delegado. Un agente personal en el borde que sostiene tu contexto, representa tu criterio, y reparte trabajo a la fuerza de trabajo. La tesis nombra a OpenClaw como la realización actual.
- Invariante 3: La fuerza de trabajo necesita un gerente. Un orquestador que asigna trabajo, impone presupuestos, audita la ejecución, expone la contratación como una capacidad invocable. La tesis nombra a Paperclip.
- Invariante 6: La fuerza de trabajo es expandible bajo política. Una metacapa donde un agente autorizado genera un prompt, provisiona un runtime, y registra un nuevo Worker, sin despertar a un humano. Claude Managed Agents es una realización.
- Invariante 7: La fuerza de trabajo corre sobre un sistema nervioso. Disparadores (horarios, webhooks, llamadas de API entrantes) despiertan al agente bajo el sobre de autoridad. Inngest (funciones duraderas y trabajos en segundo plano) es una realización para los eventos generales de la fuerza de trabajo; Claude Code Routines es el camino específico del agente de programación.
Cómo volverte bueno en esto de verdad
Leer este curso intensivo no te vuelve bueno construyendo Workers. Usarlo sí. El camino se ve igual que para el curso anterior: empiezas manual, sientes la fricción, y dejas que cada pieza de fricción te enseñe a qué Concepto pertenece.
El mapeo para este curso:
- "¿Por qué no se dispara mi skill cuando debería?" → calidad de la descripción (Concepto 3). Reescríbela. Pruébala inventando cinco formas distintas en que un usuario podría formular el disparador.
- "¿Por qué el agente inventa datos que la base de datos no tiene?" → el agente no está llamando de verdad al servidor MCP. Revisa la traza; revisa el registro
mcp_servers=[...]. - "¿Por qué mi registro de auditoría está incompleto?" → la escritura de auditoría no está en el mismo camino de código que la acción (Concepto 10). Muévela junto a la acción, en la misma transacción.
- "¿Por qué mis resultados de pgvector son irrelevantes?" → o la fragmentación está mal (Concepto 9), o el modelo de embedding al insertar no coincide con el modelo de embedding al consultar. Vuelve a embeber.
- "¿Por qué mi servidor MCP es lento bajo carga?" → el pool de conexiones dentro del servidor es demasiado pequeño, o la lista de herramientas no está cacheada en el cliente. Concepto 15.
- "¿Por qué el servidor MCP de Neon da miedo en producción?" → porque la propia documentación de Neon dice que no es para producción. Escribe un servidor MCP personalizado (Concepto 14). El primero toma 30 minutos; el segundo toma 10.
Construye la arquitectura una pieza a la vez. No intentes agregar Skills, sistema de registro y MCP todo en un fin de semana. Empieza desde el agente de chat del Paso 0. Agrega un sistema de registro primero (Decisiones 3–5) y mira cómo cambia tu experiencia de depuración. Agrega una Skill (Decisión 4) y mira cómo el modelo decide usarla. Agrega la frontera MCP al final (Decisión 6). Cada paso es su propio aprendizaje; hacer los tres a la vez es un muro.
El dividendo de la portabilidad es real: las Skills, los esquemas y los servidores MCP que escribes aquí se mueven todos a otros productos. La guía de intercambio lista las alternativas por capa.
El cambio en aquello en lo que inviertes tu tiempo
Después de la Decisión 4, tu trabajo cambia de forma. Escribir código se vuelve instruir al agente; revisar la descripción (un campo de archivo de configuración que normalmente leerías por encima) se vuelve la artesanía clave. Una descripción que pasaste 30 minutos redactando y refinando hace más trabajo arquitectónico que las 200 líneas de código del servidor MCP que el agente generó debajo, porque la descripción es la superficie de enrutamiento que el modelo lee en cada turno.
Dos cambios prácticos. Primero, dejas de preguntar "¿cómo implemento esto?" y empiezas a preguntar "¿cuáles son las cinco formas distintas en que un usuario real podría formular el disparador?". El código es aguas abajo; si la descripción está mal, el agente nunca alcanza el código y la calidad del código es irrelevante. Segundo, la revisión reemplaza a la autoría como la habilidad clave. El agente redacta; tú decides si el borrador funciona en los casos de disparo para los que escribiste la descripción. La parte más difícil es resistir el impulso de reescribir cuando podrías resolverlo tú mismo en tres minutos: la misma disciplina que te impide rodear la frontera MCP.
Referencia rápida
Los 15 conceptos en una línea cada uno
- Una Agent Skill es una carpeta. SKILL.md más scripts/referencias/assets opcionales.
- Divulgación progresiva. Metadatos al arrancar → cuerpo completo al activarse → referencias bajo demanda.
- Un SKILL.md es frontmatter + cuerpo. Nombre, descripción, metadatos opcionales, luego instrucciones operativas.
- Las Skills viajan como archivos. El mismo SKILL.md funciona en Claude Code y OpenCode sin modificación.
- Compón skills pequeñas por traspaso de archivos cuando el aislamiento importa más que la simplicidad de la orquestación.
- Postgres + pgvector le gana a una base de datos vectorial aparte para casi todas las cargas de agentes. Neon agrega ramificación, escala a cero, y un servidor MCP.
- Cinco tablas son el esquema operativo mínimo: conversations, documents, embeddings, audit_log, capability_invocations; los turnos de la conversación viven en la Session del SDK (
SQLAlchemySessionen la misma base de datos). - Fundamentos de pgvector:
VECTOR(1536)+ distancia coseno<=>+ índice HNSW. Usa el mismo modelo de embedding en ambos extremos. - El pipeline de embeddings: fragmenta en límites semánticos (~400 tokens con solapamiento), embebe en lote, almacena con metadatos del modelo.
- La auditoría no es logging. Cada acción significativa escribe una fila en la misma transacción que la acción que registra.
- MCP es un protocolo, no un servicio. Tres primitivas (herramientas, recursos, prompts), tres transportes (stdio, streamable HTTP, SSE heredado).
- El servidor MCP de Neon es para desarrollo. Diseño de esquema, migraciones basadas en ramas. No para el runtime de producción.
- El OpenAI Agents SDK tiene un cliente MCP incorporado.
from agents.mcp import MCPServerStdio, MCPServerStreamableHttp. Usaasync with. Cachealist_toolsen producción. - Los servidores MCP personalizados se ganan su lugar vía alcance, aislamiento y reutilización. No escribas uno para una sola función usada por un solo agente.
- MCP bajo carga: streamable HTTP para remoto, cachea herramientas, reutiliza conexiones, haz pool dentro del servidor, propaga el contexto de la traza vía
_meta.
Cuando algo se siente mal
Skill not firing when it should
→ Description too vague. Rewrite with "Use when..." and specific keywords (Concept 3).
Skill firing when it shouldn't
→ Description too broad. Add explicit constraints in the description.
pgvector returning irrelevant results
→ Embedding model mismatch (insert vs. query). Verify the model column in
the embeddings table. Re-embed if needed.
MCP tool not appearing in agent
→ Server not registered, or list_tools cache stale. Check mcp_servers=[...]
and try cache_tools_list=False temporarily.
Audit log has gaps
→ Action and audit write are in different code paths. Move them next to
each other, ideally same transaction.
Agent timing out on Postgres operations under load
→ MCP server's connection pool too small. Check asyncpg.create_pool(max_size=...).
MCP server hangs on startup with torch / sentence-transformers / large imports
→ Default client_session_timeout_seconds=5 is too short for servers that
load ML models at import. Bump to 60. See Concept 13's callout.
CREATE TABLE fails: relation "notes" already exists
→ You're pointing at a database that already has tables. Use a fresh
database or Neon project; the Quick Win's build prompt makes a fresh one.
Non-OpenAI key getting 401 against api.openai.com
→ Set OPENAI_BASE_URL to your provider's OpenAI-compatible endpoint
(e.g., https://api.deepseek.com/v1) before running the agent.
Agent fails partway with a 401 / auth / BadRequestError
→ Wrong key, wrong provider, or expired key. Have your agent confirm
OPENAI_API_KEY is set and test a model call before the full run; it
fails in one second instead of four files deep.
Neon MCP server returning errors in production agent code
→ You're using it wrong. Neon's docs are explicit: development only.
Write a custom MCP server instead (Concept 14, ~30 minutes).
Ayuda de estudio con flashcards
Comprobación de conocimientos
Una autoevaluación rápida y guiada sobre las ideas que acabas de recorrer.