Despliega tu harness de agente en la nube: curso acelerado de varias rutas
*17 conceptos • Cuatro rutas de aprendizaje. Ruta de lector: 3-4 horas de lectura conceptual pura (sin configuración, sin despliegue, para líderes de ingeniería y arquitectos que deciden si vale la pena comprometer tiempo del equipo). Rutas principiante / intermedia / avanzada: 1-2 días, 3-5 días, 7-10 días cada una (lectura conceptual más profundidad creciente de despliegue sobre el stack de cinco componentes, con observabilidad y la suite de evals conectadas). Elige tu ruta antes del laboratorio; consulta la sección "Cuatro rutas de aprendizaje" más abajo.*
Has construido agentes en los cursos anteriores, pero todos han ejecutado solo en tu portátil. Este curso toma el agente que diseñaste y lo envía como un servicio real en la nube al que los usuarios pueden acceder por internet. Alojarás el cerebro del agente en un runtime administrado en la nube, guardarás su memoria en una base de datos, almacenarás sus archivos en almacenamiento de objetos y ejecutarás su código riesgoso en un sandbox separado y bloqueado. Tu agente de programación construye y arranca todo a partir de un brief complementario que descargas. Al final, el harness está en vivo y entiendes cada pieza.
🔤 Tres términos que debes conocer antes de seguir leyendo (si hiciste los cursos anteriores, quizá ya los conozcas; salta a la versión en lenguaje claro más abajo).
Este curso tiene más infraestructura que los anteriores. Estos tres términos aparecen todo el tiempo, así que conviene verlos definidos con claridad primero:
- Harness. El "cerebro" y los controles del agente: el código que ejecuta el bucle del agente, elige qué herramienta llamar, guarda los secretos y mantiene el estado entre runs. No ejecuta por sí mismo el código generado por el agente. En este curso, el harness es una app web FastAPI que se ejecuta en la nube.
- Sandbox. Un espacio de trabajo separado y bloqueado donde se ejecuta realmente el código generado por el agente. Puede leer archivos y ejecutar comandos de shell, pero no tiene acceso a los secretos ni a la base de datos del harness. Los sandboxes son baratos de crear, se usan una vez y se descartan.
- Manifest. Una descripción breve de lo que necesita el sandbox: qué archivos montar, qué almacenamiento adjuntar y qué capacidades (shell, sistema de archivos) activar. Describes el espacio de trabajo una vez, y OpenAI Agents SDK puede ejecutarlo en cualquier proveedor de sandbox compatible.
Dos términos más que se usan mucho y que el glosario completo define: Azure Container Apps (un servicio administrado en la nube que ejecuta tu contenedor con autoscaling y una dirección web pública) y Neon Postgres (una base de datos Postgres sin servidor con branching barato). El glosario completo aparece en una sección más abajo.
Versión en lenguaje claro; empieza aquí si quieres primero la versión humana. (Los lectores técnicos pueden saltar a "Este curso enseña el despliegue de producción..." más abajo).
Los cursos anteriores construyeron una empresa AI-native en concepto. Aprendiste a diseñar un agente, darle conocimiento, ejecutarlo de forma durable, administrar muchos agentes, contratarlos y retirarlos, darle un delegado al propietario y medir si algo de eso funciona. Lo único que nunca hiciste en todos esos cursos fue desplegarlo de verdad en una nube donde usuarios reales puedan acceder. Para eso existe este curso. Tomas el agente que construiste, más la arquitectura y la suite de evals de los cursos anteriores, y los envías como un servicio vivo en la nube. Aprenderás dónde se ejecuta el cerebro del agente, dónde guarda su memoria, dónde almacena archivos y dónde se ejecuta de forma segura su código riesgoso. Es una ruta completa, de extremo a extremo, que funciona. Existen otras rutas; se aprende más rápido recorriendo una hasta el final que inspeccionándolas todas.
Este curso enseña el despliegue de producción del harness de OpenAI Agents SDK en la nube. Los cursos anteriores construyeron la arquitectura de una empresa AI-native y luego la envolvieron en la disciplina que la vuelve mediblemente confiable. Este curso envía todo eso.
Esta es la única idea a la que se reduce todo el curso. El harness es el plano de control que posees y mantienes en ejecución. El sandbox es el plano de ejecución que creas, usas una vez y descartas. El harness guarda las claves, el estado y el registro de auditoría; el sandbox no guarda nada de eso y hace el trabajo riesgoso. Cada concepto y cada decisión de este curso es una elaboración de esa división. Si interiorizas una sola frase, que sea esa.
🆕 Qué cambió en abril de 2026 y por qué este curso existe ahora. OpenAI publicó una actualización importante de Agents SDK el 15 de abril de 2026 que separa el harness del agente de la computación en sandbox como parte de primera clase del SDK. Antes de esta versión, los equipos que desplegaban agentes de producción tenían que ensamblar a mano clientes de modelos, runtimes de contenedores, aislamiento de credenciales, estado y enrutamiento de herramientas. La versión de abril convierte la división harness/sandbox en una primitiva integrada, no en un patrón que los equipos reinventan. Eso hizo que este curso se pudiera enseñar: un año antes habría sido en gran parte especulativo; ahora es una receta.
Fuente: OpenAI, "The next evolution of the Agents SDK", 15 de abril de 2026.
Ganancia rápida: arranca el harness en tu portátil en unos 15 minutos
Antes de tocar la nube, demuestra que el harness se ejecuta en tu propio equipo. El harness se ejecuta en tu portátil antes de que toques la nube. Descargarás el código complementario, lo abrirás en tu agente de programación y verás cómo arranca y responde una comprobación de salud. Esa es toda la victoria: el plano de control, vivo e informando qué piezas están conectadas.
Primero, descarga el zip complementario y descomprímelo. Abre la carpeta en tu agente de programación (Claude Code, OpenCode o similar). El agente lee el archivo AGENTS.md en la raíz, que le dice cómo está construido el proyecto y cómo arrancarlo. Luego pega el prompt de abajo.
Pega esto en tu agente de programación. Primero planifica; ejecuta con aprobación.
Lee AGENTS.md y luego arranca el harness de Maya localmente para que pueda verlo ejecutarse.
- Ejecuta el sondeo del SDK al final de AGENTS.md para confirmar la versión instalada de
openai-agentsy que los imports principales funcionen.- Instala dependencias (
make install) y copia.env.examplea.env. No agregues claves todavía; el harness debe arrancar sin ellas.- Inicia el harness (
make run, que sirve enhttp://localhost:8000).- En una segunda shell, solicita
GET /healthy muéstrame la respuesta exacta.
Terminado cuando:
- Tu agente de programación informa la versión instalada de
openai-agents(0.17.x). - El harness arranca y se mantiene en ejecución sin claves configuradas.
GET /healthdevuelve exactamente esto:
{
"status": "ok",
"model": "gpt-5.4-mini",
"backends": { "postgres": false, "sandbox": false, "r2": false }
}
Esa respuesta es el harness diciéndote la verdad: está vivo ("status": "ok"), conoce su modelo y ninguno de los backends opcionales está conectado todavía (todos false). Cada decisión posterior cambia una de esas banderas a true. El harness arranca con nada más que su propio código; luego agregas una pieza a la vez.
Cuatro rutas de aprendizaje, elige la tuya
Este curso funciona con cuatro niveles de profundidad. Elige tu ruta explícitamente antes del laboratorio; el contenido conceptual está diseñado para funcionar en las cuatro, y el laboratorio está diseñado para las rutas 2-4.
| Ruta | Tiempo requerido | Qué completas | Para quién es |
|---|---|---|---|
| Lector (conceptual puro) | ~3-4 horas, sin laboratorio | La ganancia rápida, los 17 conceptos y el cierre. Sin cuentas en la nube, sin Docker, sin configuración de Python. La arquitectura aterriza; el despliegue queda diferido. | Líderes de ingeniería, arquitectos de plataforma y responsables de plataformas de ML que deciden si comprometer tiempo del equipo con este patrón de despliegue. |
| Principiante | ~1-2 días (conceptual + lab local) | Ruta de lector más el sondeo del SDK, el scaffold y la contenerización. El harness se ejecuta localmente en Docker, hablando con OpenAI y una base de datos local. Sin despliegue en la nube todavía. | Ingenieros nuevos en el despliegue en la nube de servicios de IA. El objetivo es interiorizar la división harness/sandbox y enviar un agente contenerizado que funcione de extremo a extremo en un portátil. |
| Intermedia | ~3-5 días | Ruta principiante más despliegue a la nube, conexión de estado durable, almacenamiento de archivos y observabilidad. El harness atiende usuarios reales; el sandbox sigue simulado; la suite de evals se difiere a Avanzada. | Equipos que quieren el harness desplegado y observable, pero aún no están conectando ejecución de código ni la disciplina completa de evals. |
| Avanzada | ~7-10 días | Ruta intermedia más conexión del sandbox, la suite de evals y la checklist de producción. La disciplina completa: harness desplegado, sandbox conectado, observabilidad en vivo, suite de evals protegiendo CI y ejecutándose cada noche. | Equipos de producción que envían la disciplina completa, el despliegue completo de extremo a extremo, la observabilidad y la ruta de aseguramiento de calidad. |
Guía para elegir la ruta. Los líderes de ingeniería y arquitectos que deciden si invertir en este patrón deberían empezar con la ruta de lector: 3-4 horas, sin cuentas, sin gasto, y al final sabrán si su equipo debería comprometerse con una ruta superior. Los principiantes no deberían sentir presión por llegar a Avanzada en una primera pasada. La disciplina es iterativa; los equipos suelen graduarse de Lector a Principiante durante un fin de semana, de Principiante a Intermedia durante un sprint y de Intermedia a Avanzada durante semanas a medida que el despliegue madura. Los lectores independientes (que no vienen de los cursos anteriores) deberían empezar por defecto con la ruta de lector y luego decidir si el modo Simulado del laboratorio es el siguiente paso correcto.
Si recorres la ruta Avanzada como un sprint enfocado de dos semanas, esta es la cadencia. Supone un ingeniero con 4-6 horas productivas al día; los equipos pueden comprimirlo. El día 5 es el punto natural "enviable": el harness está desplegado y atendiendo usuarios. Los días 6-10 agregan el endurecimiento que vuelve operable el despliegue a largo plazo.
| Día | Enfoque | Artefacto acumulado |
|---|---|---|
| 1 | Conceptos 1-4 + scaffold | App FastAPI local con un endpoint /runs simulado. |
| 2 | Contenerizar + desplegar | Harness accesible en internet público desde tu teléfono. |
| 3 | Conectar Neon Postgres | Estado durable que sobrevive al reinicio de un contenedor. |
| 4 | Conectar Cloudflare R2 | Almacenamiento de archivos; el agente puede leer entradas y escribir salidas. |
| 5 | ⭐ Punto enviable | Un harness desplegado que los usuarios reales pueden usar. Detente aquí si tu único objetivo es un MVP. |
| 6 | Conectar el sandbox | Ejecución de código funcionando; el agente ejecuta código de forma segura. |
| 7 | Conectar observabilidad | Navegar rápido de una alerta de infraestructura al comportamiento del agente. |
| 8-9 | Conectar la suite de evals | Ninguna regresión del agente se envía sin que CI la note; se ejecutan informes nocturnos de comportamiento. |
| 10 | Checklist de producción + handoff | Un harness listo para producción y un equipo capaz de operarlo. |
Vocabulario que verás en este curso
Glosario, haz clic para expandir
- Harness. El plano de control del agente: el código que ejecuta el bucle del agente, guarda secretos y mantiene estado. En este curso es una app FastAPI en la nube. No ejecuta el código generado por el agente.
- Sandbox. El plano de ejecución del agente: un espacio de trabajo aislado donde se ejecuta el código generado por el agente, sin acceso a los secretos ni a la base de datos del harness.
- Plano de control / plano de ejecución. El principio de que la orquestación del agente (secretos, acceso a la base de datos, claves de modelo) vive en un límite de seguridad distinto de donde se ejecuta el código generado por el agente. Es fundacional para este curso.
- Manifest. Una descripción breve del espacio de trabajo del sandbox: montajes de archivos, almacenamiento que adjuntar, capacidades que activar. Portable entre proveedores de sandbox compatibles.
- Contenedor. Un paquete sellado de tu app más todo lo que necesita para ejecutarse, de modo que se ejecute igual en tu portátil y en la nube.
- FastAPI. Una biblioteca de Python para construir API web. Este curso la elige para la capa HTTP del harness porque encaja naturalmente con el cliente Python asíncrono del SDK.
- Azure Container Apps (ACA). Un servicio administrado en la nube que ejecuta tu contenedor con autoscale, dirección pública, secretos y revisiones. El runtime del harness en este curso.
- Neon Postgres. Una base de datos Postgres sin servidor con branching barato. El almacén de estado durable de este curso.
- Cloudflare R2. Almacenamiento de objetos compatible con S3 donde leer tus propios archivos hacia fuera es gratis. El almacén de archivos y artefactos de este curso.
- URL prefirmada. Un enlace web de vida corta que permite al sandbox leer o escribir un archivo específico en almacenamiento sin tener nunca la contraseña del almacenamiento.
- Estado durable. Memoria que sobrevive a un reinicio: sesiones, historial de runs y registro de auditoría, guardados en una base de datos en vez de en el contenedor, que olvida todo al detenerse.
- Observabilidad. Las herramientas que te dicen qué hace el harness en ejecución, cuándo algo se rompe y cómo encontrar la causa.
- OpenTelemetry (OTel). Un estándar abierto para trazar una solicitud mientras se mueve entre servicios.
- Phoenix. Una herramienta que observa trazas de agentes y convierte las malas en pruebas futuras.
- Eval. Una prueba que mide el comportamiento del agente (si la respuesta fue correcta, si la herramienta fue adecuada, si el razonamiento fue sólido), no solo si el código se ejecutó.
- Blue/green. Una forma de enviar una versión nueva sin downtime: ejecutar la versión nueva junto a la antigua y luego mover el tráfico.
- Scale-to-zero. Cuando no hay tráfico, la nube ejecuta cero copias de tu app y no pagas nada; la primera solicitud tras un período quieto espera unos segundos a que una copia despierte.
- Connection pooling. Un conjunto compartido de conexiones abiertas a la base de datos reutilizadas entre solicitudes, para que la base de datos no caiga bajo miles de conexiones simultáneas.
¿Estás listo?
📦 Antes de cualquier otra cosa: la descarga complementaria. El zip complementario es la rampa de entrada para todos, en especial para lectores independientes que no han hecho los cursos anteriores.
Descarga
deploying-agents-crash-course.zipy descomprímelo. Contiene un scaffold arrancado del harness (FastAPI más el SDK más clientes simulados), el briefAGENTS.mdque lee tu agente de programación, unschema.sqlpara las cinco tablas de base de datos, unDockerfile, un script de despliegue de Azure y unMakefilepara los comandos comunes. El agente simulado incluido (el agente de soporte de nivel 1 de Maya) es lo que permite que el laboratorio funcione incluso si no has construido Maya por tu cuenta, así que la ruta Simulada tiene algo real a lo que apuntar.Abre la carpeta en tu agente de programación antes de seguir leyendo si piensas seguir cualquier ruta más allá de Lector. La lectura sin ejecutar nada está bien para la ruta de lector.
- Has descargado el zip complementario (consulta el recuadro anterior). Sáltate esto si estás en la ruta de lector y no planeas ejecutar nada.
- Te sientes cómodo en la línea de comandos. Puedes instalar paquetes, ejecutar algunos comandos y moverte por un sistema de archivos. Si nunca has usado una terminal, la ruta de lector es el punto de entrada correcto.
- Puedes leer código Python. El harness está en Python; verás
async def,await, decoradores y sugerencias de tipos. No necesitas ser experto; basta con leerlo.- Tienes una clave de API de OpenAI con acceso a Agents SDK (ruta principiante en adelante). Es la cuenta de modelos, no solo la cuenta de chat. Revisa platform.openai.com.
- Tienes una cuenta de Azure (ruta intermedia en adelante). El laboratorio despliega en Azure Container Apps; los créditos gratuitos cubren el laboratorio. Revisa portal.azure.com.
- Tienes una cuenta de Neon (ruta intermedia en adelante). El nivel gratuito basta. Revisa console.neon.com.
- Tienes una cuenta de Cloudflare con R2 habilitado (ruta intermedia en adelante). El nivel gratuito de R2 basta para el laboratorio. El sandbox de Cloudflare necesita un plan Workers de pago, así que el laboratorio usa el nivel gratuito de E2B como la ruta gratuita realista para ejecución de código.
Si te faltan las cuentas de nube, la ruta de lector es realmente el punto de partida adecuado: lee primero, regístrate después. Si te faltan los cursos anteriores, el agente simulado del zip complementario es tu puente, así que puedes seguir el laboratorio sin haber construido Maya por tu cuenta.
Asperezas que conviene conocer desde el principio
- El código aquí es rastreable a un complemento arrancado. El código del SDK en este curso coincide con el harness de la descarga, que se instaló y arrancó contra el paquete real
openai-agentsantes de publicar el curso. No es código "ilustrativo, sin probar".- El SDK se mueve rápido. La versión de abril de 2026 es la primera que vuelve enseñable este patrón, y las API de harness/sandbox seguirán evolucionando. Por eso el primer paso del laboratorio es una decisión de sondeo: tu agente de programación instala el SDK, imprime la versión instalada, obtiene la documentación viva y reconcilia el brief complementario contra ella. Cuando el brief y los documentos vivos discrepan, ganan los documentos vivos.
- Solo Python. La versión de abril de 2026 entrega las funciones de harness y sandbox solo en Python. El soporte para TypeScript está planeado, pero sin fecha. Si tu app está en TypeScript, ejecuta el harness Python como un servicio separado al que tu app TypeScript llama por HTTP.
- Una nube, un sandbox, una base de datos, un proveedor de almacenamiento. Este curso se compromete con un stack específico para poder enseñar una ruta completa. Los principios se transfieren a otras nubes de formas obvias; el curso no inspecciona todas las sustituciones, aunque el concepto 9 y el concepto 15 nombran las principales.
- El costo es real. Un harness totalmente desplegado cuesta aproximadamente unas decenas de dólares al mes para uso personal de bajo tráfico, y puede subir a cientos con tráfico de producción moderado. Las rutas Lector y Principiante no cuestan nada; las rutas de nube tienen facturas reales. El concepto 13 contiene el desglose.
- Sin multirregión. Este curso despliega en una región. Active-active multirregión agrega una complejidad operativa que merece su propio tratamiento; el concepto 14 lo nombra con honestidad.
La forma de lo que vas a construir
Este curso introduce 17 conceptos y recorre 9 decisiones de despliegue. Antes de todo eso, aquí está toda la arquitectura en una imagen. Vuelve a ella cada vez que un concepto o una decisión se sienta abstracto.
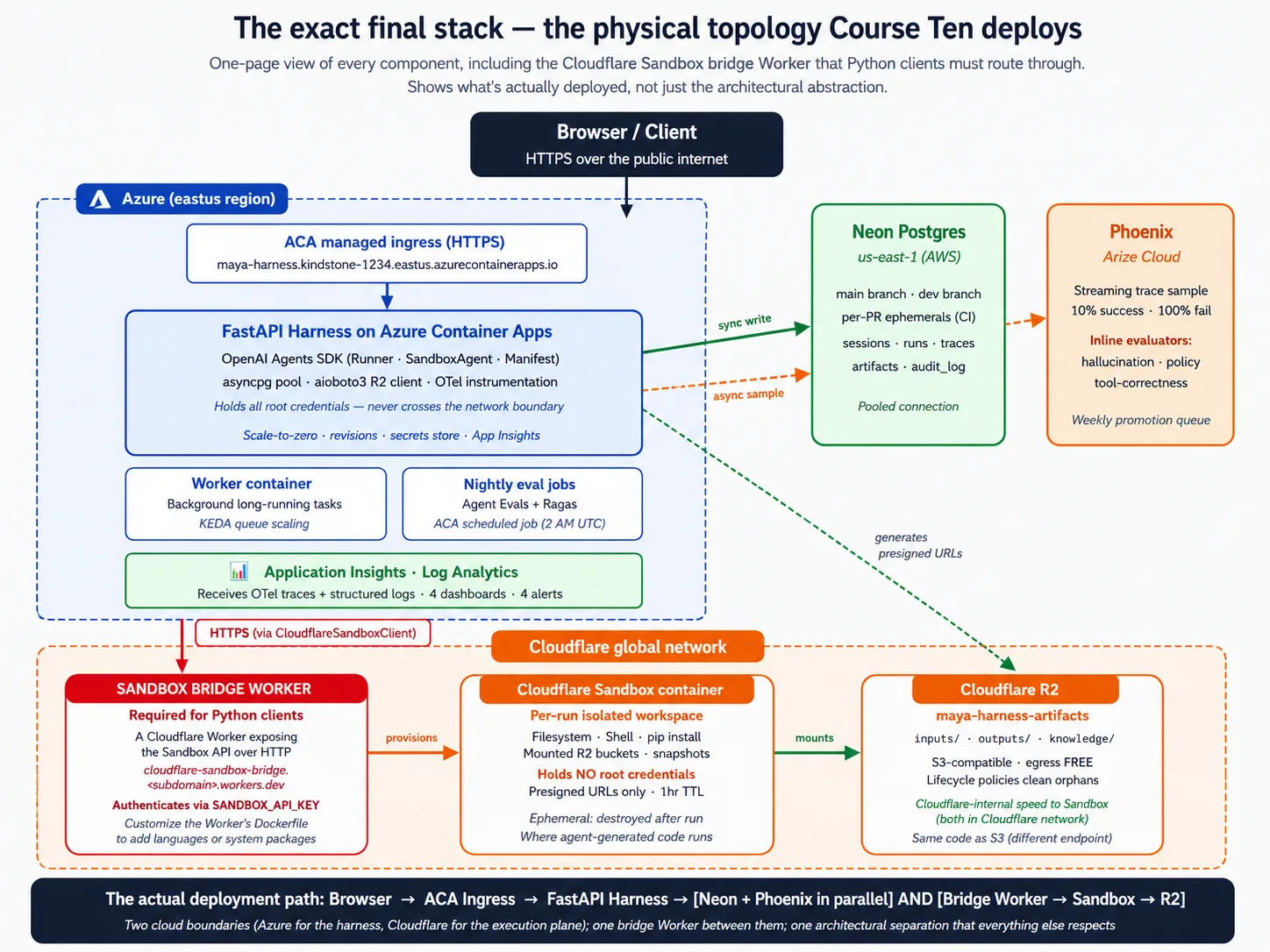
Introducción al stack: qué es realmente cada componente
Sáltate esta sección si ya has enviado servicios web de producción. Léela si los cursos anteriores son la mayor infraestructura que has hecho hasta ahora. Este curso depende de contexto que la mayoría de principiantes aún no han construido, y el laboratorio se sentirá como una serie de conjuros sin él. Cuatro piezas breves: Docker, FastAPI, Neon y Cloudflare R2. El objetivo es el modelo mental mínimo para seguir el laboratorio, no un dominio profundo.
Introducción al stack 1: Docker y contenedores
Un contenedor es un paquete sellado de tu app más todo lo que necesita para ejecutarse: tu código, sus paquetes de Python, las bibliotecas del sistema e incluso las piezas del sistema operativo de las que depende. Construyes el paquete una vez y luego lo ejecutas en cualquier lugar. El mismo paquete que se ejecuta en tu portátil se ejecuta en la nube sin cambios.
El problema que resuelve es la queja más antigua del software: "funciona en mi equipo". Un script de Python que se ejecuta en tu portátil con tus paquetes exactos probablemente no se ejecutará en el portátil de un colega ni en un servidor en la nube sin mucho ajuste. Un contenedor colapsa ese ajuste: construye la imagen una vez, ejecútala en cualquier lugar donde haya un motor de contenedores.
El vocabulario que verás en el laboratorio:
- Un Dockerfile es la receta para construir el paquete: un archivo de texto simple que dice "empieza desde esta base, copia estos archivos, ejecuta estos comandos".
- Una imagen base es el punto de partida, normalmente un sistema Linux pequeño con un lenguaje preinstalado. El harness parte de
python:3.12-slim. - Una compilación multi-stage usa una imagen para construir la app (con compiladores y herramientas) y otra imagen más pequeña para ejecutarla (con solo el resultado). La imagen de runtime se mantiene pequeña porque las herramientas de construcción no se envían en ella.
- Un registro es donde se almacenan y comparten las imágenes construidas. El flujo de despliegue es: construir la imagen, subirla a un registro, la nube la descarga y la ejecuta.
El modelo mental mínimo: piensa en un contenedor como una instantánea de una máquina funcional con tu app instalada y lista. Construir la imagen toma la instantánea; ejecutarla arranca una copia aislada. Cuando la copia se apaga, todo lo que está dentro desaparece. Por eso el estado durable necesita una base de datos externa y los archivos durables necesitan almacenamiento externo. El contenedor es desechable; los datos no.
Introducción al stack 2: FastAPI
FastAPI es una biblioteca de Python para construir API web: programas que escuchan solicitudes por una red y responden con datos, normalmente JSON. Es "Fast" porque usa las funciones asíncronas de Python para concurrencia, y "API" porque está diseñada para el patrón de solicitud y respuesta, no para renderizar páginas web.
El problema que resuelve: tu agente se ejecuta en un servidor, pero usuarios reales (u otros servicios) necesitan alcanzarlo desde otro lugar, por la red. FastAPI convierte tu código Python en algo con lo que la red puede hablar.
El vocabulario que verás en el laboratorio:
- Un endpoint es una ruta específica que tu API maneja, como
POST /runspara iniciar una tarea oGET /healthpara comprobar que el harness está vivo. - Un route handler es la función Python que se ejecuta cuando se llama a un endpoint. La marcas con un decorador, como
@app.post("/runs"). async defyawaitson las palabras clave de Python para código que espera. El harness las usa porque la mayor parte de su trabajo es esperar: al modelo, a la base de datos, al sandbox. El código asíncrono permite que un proceso maneje cientos de solicitudes en espera a la vez.- Los modelos Pydantic son clases de Python que describen la forma de los datos de solicitud y respuesta. FastAPI los usa para comprobar solicitudes entrantes automáticamente y rechazar las mal formadas antes de que tu código se ejecute.
- Uvicorn es el programa que realmente ejecuta una app FastAPI y conecta la red con tus handlers. Lo inicias con un comando como
uvicorn maya_harness.main:app.
El modelo mental mínimo: una app FastAPI es un archivo Python que crea un objeto app y decora funciones como endpoints. Cada función recibe datos comprobados, hace su trabajo (a menudo esperando otras operaciones asíncronas) y devuelve datos que FastAPI convierte en JSON. Uvicorn es el servidor delante de ella.
Introducción al stack 3: Neon Postgres
Una base de datos almacena datos en disco para que sobrevivan a reinicios, admite muchos lectores y escritores a la vez y permite consultarlos con un lenguaje llamado SQL. Postgres es una base de datos open-source específica, una de las más usadas del mundo. Neon ejecuta Postgres por ti como servicio, con dos giros: no tiene servidor (escala hacia arriba y hacia abajo por sí solo) y admite branching (puedes crear una copia de tu base de datos que comparte almacenamiento con la principal hasta que la cambias).
El problema que resuelve: tu harness necesita recordar cosas entre solicitudes y reinicios de contenedor. Estado de conversación, historial de runs, trazas, registro de auditoría. El disco local del contenedor desaparece en cada reinicio, así que el harness necesita guardar esos datos donde sobrevivan. Neon en concreto, porque su comportamiento de escala hacia arriba y hacia abajo coincide con el del harness: cuando el harness está inactivo, Neon también puede reducirse, y dejas de pagar.
El vocabulario que verás en el laboratorio:
- Una tabla es una colección nombrada de registros estructurados, como una hoja de cálculo con tipos estrictos por columna. El harness tiene cinco tablas: sesiones, runs, trazas, artefactos y un registro de auditoría.
- Un esquema es la definición de todas tus tablas y sus columnas.
- Una clave primaria es la columna que identifica de forma única cada fila; una clave externa es una columna que apunta a la clave primaria de otra tabla, lo que vuelve relacionales los datos.
- Una migración es un script SQL versionado que cambia el esquema, confirmado en el repositorio para que cada cambio quede rastreado.
- Connection pooling es un conjunto compartido de conexiones abiertas que se reutilizan entre solicitudes. Sin él, cada solicitud abre una conexión nueva, y Postgres tiene un límite. Neon proporciona un endpoint pooled que hace esta multiplexación por ti.
El modelo mental mínimo: Postgres almacena datos en tablas con formas estrictas, y los consultas con SQL. El harness habla con él mediante la biblioteca Python asyncpg. Neon aloja la base de datos y agrega scaling sin servidor y branching encima.
Introducción al stack 4: Cloudflare R2
Almacenamiento de objetos es un servicio para almacenar archivos en internet. Le das un nombre (una "clave") y unos bytes, y los guarda; más tarde pides los bytes por nombre y los recuperas. El primer servicio de este tipo fue AWS S3, y su API se convirtió en un estándar de facto que muchos proveedores implementan. Cloudflare R2 es el almacenamiento de objetos de Cloudflare. Implementa la API S3, con un giro: leer tus propios archivos hacia fuera es gratis. Sacar datos de S3 cuesta alrededor de nueve centavos por gigabyte; sacarlos de R2 no cuesta nada.
El problema que resuelve: tu agente lee archivos (documentos subidos, contenido de conocimiento) y escribe archivos (informes generados, artefactos). Estos necesitan vivir en un lugar al que puedan acceder tanto el harness como el sandbox, y son demasiado grandes o numerosos para una base de datos. Una base de datos no está hecha para archivos grandes; el disco de un contenedor no sobrevive reinicios; el almacenamiento de objetos tiene la forma correcta para archivos.
El vocabulario que verás en el laboratorio:
- Un bucket es un contenedor nombrado para archivos, como una carpeta de nivel superior. El bucket del harness guarda los artefactos del agente.
- Un objeto es un archivo almacenado, con una clave (su ruta dentro del bucket) y un valor (los bytes).
- Un prefijo es una parte de una clave que agrupa archivos relacionados, como
inputs/uoutputs/. - Compatible con S3 significa que R2 habla la misma API que inventó S3, así que cualquier biblioteca Python que hable con S3 habla con R2 cambiando una configuración: la URL del endpoint.
- Una URL prefirmada es un enlace de vida corta que concede acceso a un objeto específico. El harness guarda las credenciales raíz; cuando el sandbox necesita un archivo, el harness le entrega una URL prefirmada con expiración breve, y el sandbox solo puede llegar a ese archivo.
- Una política de ciclo de vida es una regla que elimina objetos más antiguos que cierta edad, para que el almacenamiento no se convierta en un cementerio de solo escritura.
El modelo mental mínimo: R2 es un lugar donde el harness pone archivos y lee archivos, alcanzado por la API S3. El harness guarda las credenciales raíz (leer y escribir todo); el sandbox recibe solo URL prefirmadas (un archivo, poco tiempo).
Lo que no necesitas. No necesitas Kubernetes, infraestructura como código, un service mesh ni un broker de mensajes para completar este curso. Los servicios administrados anteriores manejan la maquinaria operativa. Tampoco necesitas fluidez profunda en SQL; reconocer qué hace el código del laboratorio basta.
Parte 1: El problema de despliegue
Tres conceptos establecen por qué existe este curso y qué es realmente "el problema de despliegue". Los principiantes se benefician de aterrizar aquí; los lectores avanzados pueden hojear hasta la Parte 2.
Concepto 1: "Funciona en mi equipo" no es despliegue
Tienes un agente definido en Python, digamos el agente de soporte de nivel 1 de Maya: llama herramientas, transfiere a especialistas, respeta sus límites y pasa la suite de evals. Lo ejecutas desde tu portátil y funciona.
Esto es lo que "funciona en tu portátil" significa realmente. El agente se ejecuta como un proceso Python que iniciaste a mano. Lee sus claves de API desde un archivo en la carpeta del proyecto. Escribe su estado en un archivo local en la misma carpeta. Ejecuta código importando bibliotecas dentro del mismo proceso. El modelo se llama por internet, pero todo lo demás vive en tu equipo.
Esto es lo que significa producción, y cómo difiere cada pieza:
- Los usuarios reales llegan al agente por internet público. No solo tú, desde tu portátil.
- Muchos usuarios golpean el agente a la vez. Un solo script Python maneja uno a la vez.
- El estado del agente sobrevive al reinicio del host. Un archivo local en una carpeta temporal no.
- El código generado por el agente se ejecuta en un lugar donde no puede dañar tus datos. Ejecutarlo en tu propio proceso, junto a tus credenciales de base de datos, es un error serio de seguridad.
- Los secretos del agente están fuera del alcance del código que el agente genera. Un archivo de claves en el directorio de trabajo no.
- Cada run es observable, auditable y recuperable. Un proceso que se cae no es ninguna de esas cosas.
¿Cuántas de esas seis propiedades puedes agregar a un script de portátil con cambios menores, en uno o dos días? La respuesta honesta es una o cero. Agregar cualquiera de ellas de una forma que sobreviva a producción exige al menos una semana de trabajo enfocado de infraestructura; agregar las seis es todo el cuerpo de trabajo que enseña este curso. El despliegue de producción no es una envoltura delgada alrededor de "funciona en mi portátil". Es una arquitectura distinta.
La tentación, especialmente para equipos nuevos en desplegar servicios de IA, es saltarse esta comprensión. "Solo ejecutaremos el script en un servidor". Dos meses después el equipo tiene un servidor que se cae ocasionalmente, un agente que a veces ejecuta código influido por usuarios con acceso completo a la base de datos de producción, estado que se desvanece en cada reinicio y ningún registro de lo que hizo el agente. Ese es el resultado predecible de tratar producción como un lugar donde poner el script en vez de como una arquitectura distinta.
El problema de despliegue no es "¿dónde ejecutamos el script?". Es "¿cómo rearquitectamos el agente para que su harness tenga estas seis propiedades de producción mientras su ejecución se mantiene segura?". Este curso enseña una respuesta completa.
Concepto 2: La división harness/sandbox, plano de control frente a plano de ejecución
La idea más importante de este curso es la división entre el harness (plano de control) y el sandbox (plano de ejecución). Todos los conceptos y decisiones posteriores descansan sobre ella.
El harness es el cerebro del agente. Recibe solicitudes de usuarios por la red. Ejecuta el bucle del agente: llamar al modelo, decidir qué herramienta llamar después, manejar handoffs a agentes especialistas, aplicar guardrails. Mantiene estado durable entre muchos runs: historial de conversación, historial de runs, registro de auditoría. Guarda los secretos: la clave del modelo, las credenciales de la base de datos, las credenciales de almacenamiento. Y devuelve resultados a los usuarios.
El sandbox es las manos del agente. Recibe del harness una descripción del espacio de trabajo (el Manifest). Aprovisiona un espacio de trabajo aislado que coincide con esa descripción. Ejecuta comandos de shell, lecturas y escrituras de archivos, y código según lo solicite el agente. Devuelve resultados al harness. Y no tiene acceso a los secretos, la base de datos ni los sistemas de producción del harness más allá de lo que el Manifest monta explícitamente.
El límite entre ambos es un límite de red y seguridad. El harness habla con el sandbox por la red usando credenciales del sandbox; no comparte sus propios secretos con el sandbox. El sandbox no puede leer el entorno, la base de datos ni el sistema de archivos del harness. Esta es la disciplina de producción que la versión de abril de 2026 del SDK coloca dentro del propio SDK.
¿Por qué importa esta división? Por cuatro razones.
La razón de seguridad: un agente genera código. Ese código puede estar mal, o ser sutilmente incorrecto de formas con efectos secundarios, o, en un entorno adversarial, ser malicioso. No quieres que ese código se ejecute en el mismo proceso que guarda tus credenciales de base de datos. La división pone un límite de red y sistema operativo entre el código generado y los secretos del harness. Si el agente genera una solicitud que borraría archivos, lo único dañado es el sandbox, y el sandbox es desechable.
La razón de durabilidad: los sandboxes están pensados para crearse y destruirse a menudo. El harness tiene que sobrevivir a la muerte de un sandbox. Una sola tarea podría aprovisionar un sandbox, ejecutarse durante diez minutos, perder el sandbox por una interrupción, restaurar desde un checkpoint en uno nuevo y terminar. El harness orquesta eso. Si el harness viviera dentro del sandbox, la muerte del sandbox lo perdería todo.
La razón de escalabilidad: un harness coordinando muchos sandboxes escala mucho mejor que un bloque harness-más-sandbox. Las necesidades del harness son modestas (manejar solicitudes, llamar al modelo, hablar con la base de datos); las del sandbox son irregulares (compilar código, ejecutar pruebas, procesar archivos). Separarlos permite que cada uno escale por su cuenta.
La razón de observabilidad: el harness posee el registro. Qué decidió el agente, qué herramientas llamó, qué traza produjo: todo vive con el harness. El sandbox es la ejecución; el harness es el registro de auditoría. Cuando algo sale mal, el registro del harness es lo que lees.
Dos antipatrones que este curso evita:
- Ejecutar el harness dentro del sandbox. Conveniente para un prototipo, incorrecto para producción. Los sandboxes son desechables; el harness necesita persistir. No se puede confiar secretos a los sandboxes; el harness debe guardarlos.
- Ejecutar código generado por el agente dentro del harness. El pecado original del despliegue de IA. El harness guarda las credenciales de base de datos, la clave del modelo y acceso a los datos de tus usuarios. No puedes ejecutar código generado por el agente con esa superficie de acceso. Con el tiempo sale mal, y cuando sale mal el daño no tiene límite.
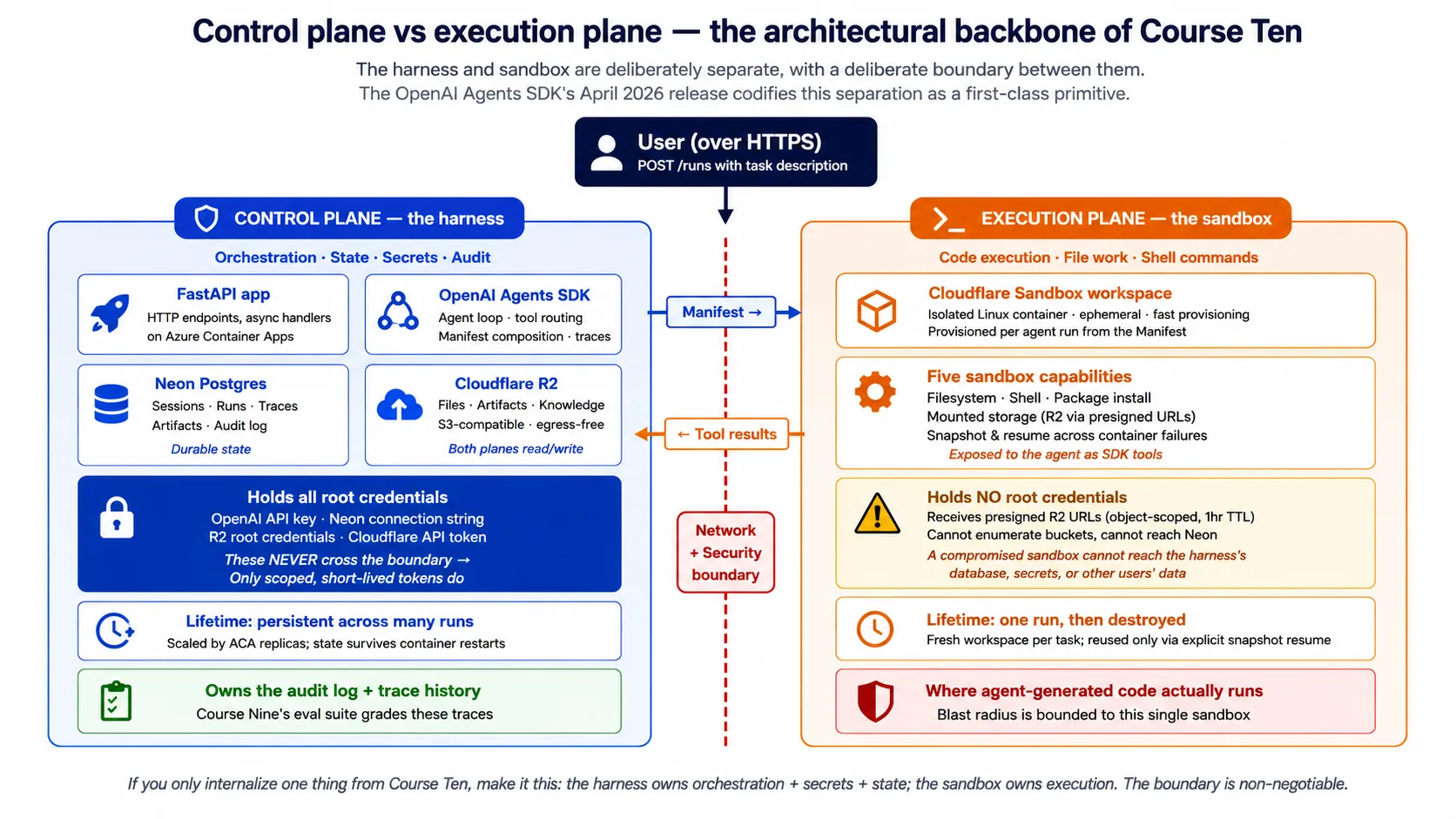
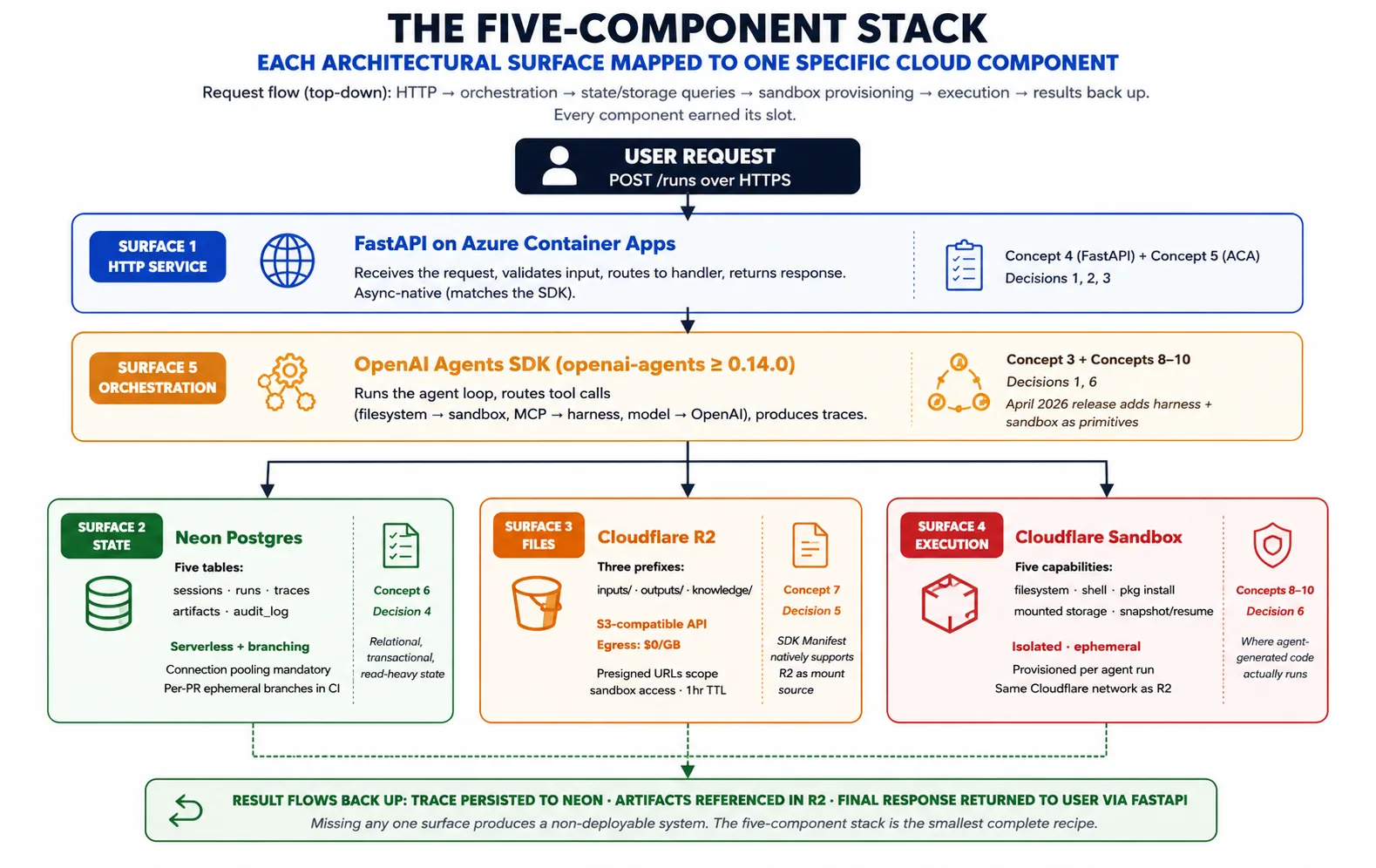
Concepto 3: Lo que el SDK necesita de la infraestructura en la nube, cinco superficies
El concepto 2 nombró el patrón. El concepto 3 pregunta: dado ese patrón, ¿qué necesita realmente OpenAI Agents SDK de la infraestructura en la nube para realizarlo? La respuesta son cinco superficies, y el stack de cinco componentes asigna un componente a cada una.
Superficie 1: un servicio HTTP de larga duración para alojar el harness. El harness es un proceso Python que debe aceptar solicitudes de usuarios, mantenerse ejecutando indefinidamente (una tarea puede tomar de segundos a horas), escalar hacia afuera cuando sube el tráfico y hacia atrás cuando baja, y sobrevivir a la falla de su host. FastAPI en Azure Container Apps proporciona esto. El concepto 4 cubre FastAPI; el concepto 5 cubre Azure Container Apps.
Superficie 2: estado durable entre runs. El harness mantiene sesiones, runs, trazas, aprobaciones y un registro de auditoría. Neon Postgres proporciona esto: Postgres porque es la base de datos transaccional mejor comprendida, Neon porque su scaling sin servidor y branching coinciden con los patrones de despliegue del harness. El concepto 6 cubre Neon.
Superficie 3: almacenamiento de archivos y artefactos al que puedan llegar ambos planos. Los agentes producen archivos (informes, código, exportaciones) y consumen archivos (subidas, datasets, contenido de conocimiento). Estos necesitan vivir en un lugar al que puedan llegar tanto el harness como el sandbox. Cloudflare R2 proporciona esto: una API compatible con S3, lecturas gratuitas de tus propios archivos hacia fuera y soporte nativo como fuente de montaje de Manifest en la versión de abril de 2026 del SDK. El concepto 7 cubre R2.
Superficie 4: ejecución aislada para código generado por agentes. Cuando el agente ejecuta un comando de shell, instala un paquete o ejecuta código, ese trabajo necesita un hogar aislado de los secretos del harness, creado bajo demanda y capaz de leer entradas desde almacenamiento y escribir salidas de vuelta. Un sandbox de ejecución de código proporciona esto. Los conceptos 8-10 cubren la capa de sandbox en profundidad.
Superficie 5: la orquestación que une las superficies 1-4. Esto es el propio SDK. Ejecuta el bucle del agente, enruta llamadas a herramientas (sistema de archivos y shell hacia el sandbox, llamadas de modelo hacia OpenAI), administra el Manifest y produce trazas. El harness importa el SDK y usa sus primitivas; no las reinventa.
La composición: una solicitud llega a FastAPI en Azure Container Apps. El harness carga el agente y el estado previo desde Neon. Compone un Manifest que describe el espacio de trabajo que necesita la tarea. Pide al proveedor de sandbox que aprovisione ese espacio de trabajo. El SDK ejecuta el bucle del agente, enviando llamadas a herramientas al sandbox y registrando la traza. Los artefactos van a R2; la traza va a Neon. El resultado vuelve al usuario. Esa composición es todo el curso; cada concepto y decisión elabora una pieza.
🚫 ¿No usas Python? Las funciones de harness y sandbox son solo para Python a partir de la versión de abril de 2026; el soporte para TypeScript está planeado, pero sin fecha. Si tu app está en TypeScript, ejecuta el harness Python como un servicio separado y haz que tu app TypeScript llame sus endpoints por HTTP. El harness que este curso construye es exactamente ese servicio.
Parte 2: El stack de cinco componentes
La Parte 1 estableció el patrón; la Parte 2 recorre el lado del harness del stack (FastAPI, Azure Container Apps, Neon, R2) y por qué cada componente ganó su lugar. El quinto componente, el sandbox, recibe su propia Parte 3.
Concepto 4: FastAPI como capa web del harness
El harness necesita ser un servicio HTTP de larga duración, y varios frameworks de Python pueden alojar uno: Flask, Django, FastAPI, Starlette. La elección de este curso es FastAPI, por razones lo bastante específicas como para nombrarlas.
La historia asíncrona: OpenAI Agents SDK está construido alrededor de asyncio de Python. Las llamadas al modelo, a herramientas y al sandbox son todas llamadas await. FastAPI es nativo asíncrono, así que escribes handlers async def que hacen await al SDK directamente, sin rodeos de thread pool. Un framework nativo sincrónico implicaría iniciar un event loop por solicitud o ejecutar el SDK en un thread pool: ambas cosas funcionan, ambas agregan fricción y pierden concurrencia. Usa el framework cuyo modelo de concurrencia coincide con tus dependencias.
La historia de esquema: FastAPI genera un esquema OpenAPI a partir de las sugerencias de tipo de tus handlers. Eso rinde en tres lugares aquí. La suite de evals puede golpear los endpoints del harness con solicitudes comprobadas porque el esquema es legible por máquina. Se pueden generar bibliotecas cliente tipadas para cualquier lenguaje, incluida la app TypeScript de la última nota. Y el esquema documenta la API para tu equipo y tu yo futuro, sin un esfuerzo separado de escritura de documentación.
La historia Pydantic: FastAPI usa Pydantic para comprobar datos de solicitud y respuesta, y el SDK también usa Pydantic internamente. La validación ocurre una vez, en el límite, con la misma biblioteca y los mismos patrones que ya usa el SDK. Otros frameworks necesitan una capa de validación separada; FastAPI elimina esa discrepancia.
La historia de comunidad: a mayo de 2026, FastAPI es el framework Python dominante para servicios de IA. Los tutoriales, ejemplos y respuestas para esta carga de trabajo lo asumen. Elegir la herramienta bien soportada reduce fricción.
Lo que FastAPI no es. No es un framework general para todo; si necesitas páginas HTML renderizadas por plantillas o un administrador estilo Django, FastAPI es la elección incorrecta. El harness es un servidor API, no una app web. Tampoco reemplaza una cola: si una tarea dura más de lo que una solicitud puede razonablemente permanecer abierta, no mantienes la conexión abierta para ella. El harness encola el trabajo y permite que el cliente vuelva a consultar; el laboratorio configura ese patrón.
En el laboratorio verás el endpoint POST /runs del harness: un handler async def que carga la sesión, ejecuta el agente, persiste el run y devuelve la respuesta. Es una función corta, porque FastAPI y Pydantic te dan gratis el manejo HTTP, la validación y la serialización, y async def te permite hacer await al SDK directamente. La versión real y arrancada de ese código está en la descarga complementaria y en la decisión del laboratorio, donde se puede rastrear a un harness que realmente ejecuta.
Concepto 5: Azure Container Apps como runtime del harness
El harness es un servicio FastAPI contenerizado que necesita ejecutarse continuamente, escalar con el tráfico, guardar secretos de forma segura y sobrevivir a la falla de su host. La elección de este curso es Azure Container Apps (ACA), que Microsoft posiciona exactamente para esta carga de trabajo.
Qué es: un servicio administrado en la nube. Le das una imagen de contenedor y una configuración; ejecuta el contenedor, le da una dirección pública, maneja autoscale, almacena secretos y rastrea revisiones. No administras servidores, no ejecutas Kubernetes a mano ni escribes código de infraestructura para la computación subyacente. Declaras lo que quieres; ACA lo hace realidad.
Las cinco capacidades que el harness necesita de él:
- Una dirección pública. ACA da a cada app una dirección HTTPS estable con certificados administrados. Sin configuración de servidor web, sin configuración de certificados, sin gimnasia de DNS.
- Autoscale. ACA escala el número de copias en ejecución según reglas que configuras, normalmente por el número de solicitudes en vuelo. Scale-to-zero es la palanca de costo: sin tráfico, ACA ejecuta cero copias y no pagas nada; la primera solicitud tras un período quieto espera unos segundos a que una copia despierte.
- Secretos. ACA almacena secretos y permite referenciarlos por nombre en variables de entorno; los valores reales nunca aparecen en tu configuración ni en la imagen. Esto supera por mucho a un archivo de claves en disco.
- Revisiones. Cada despliegue crea una revisión inmutable, y ACA puede dividir tráfico entre revisiones en cualquier porcentaje. Eso vuelve integrados los despliegues blue/green y el rollback: el rollback es un cambio de tráfico, no un redeploy.
- Observabilidad. ACA alimenta logs, métricas y trazas hacia las herramientas de monitoreo de Azure, así que obtienes gratis tasa de solicitudes, tasa de error y latencia; el harness agrega encima las trazas propias del agente.
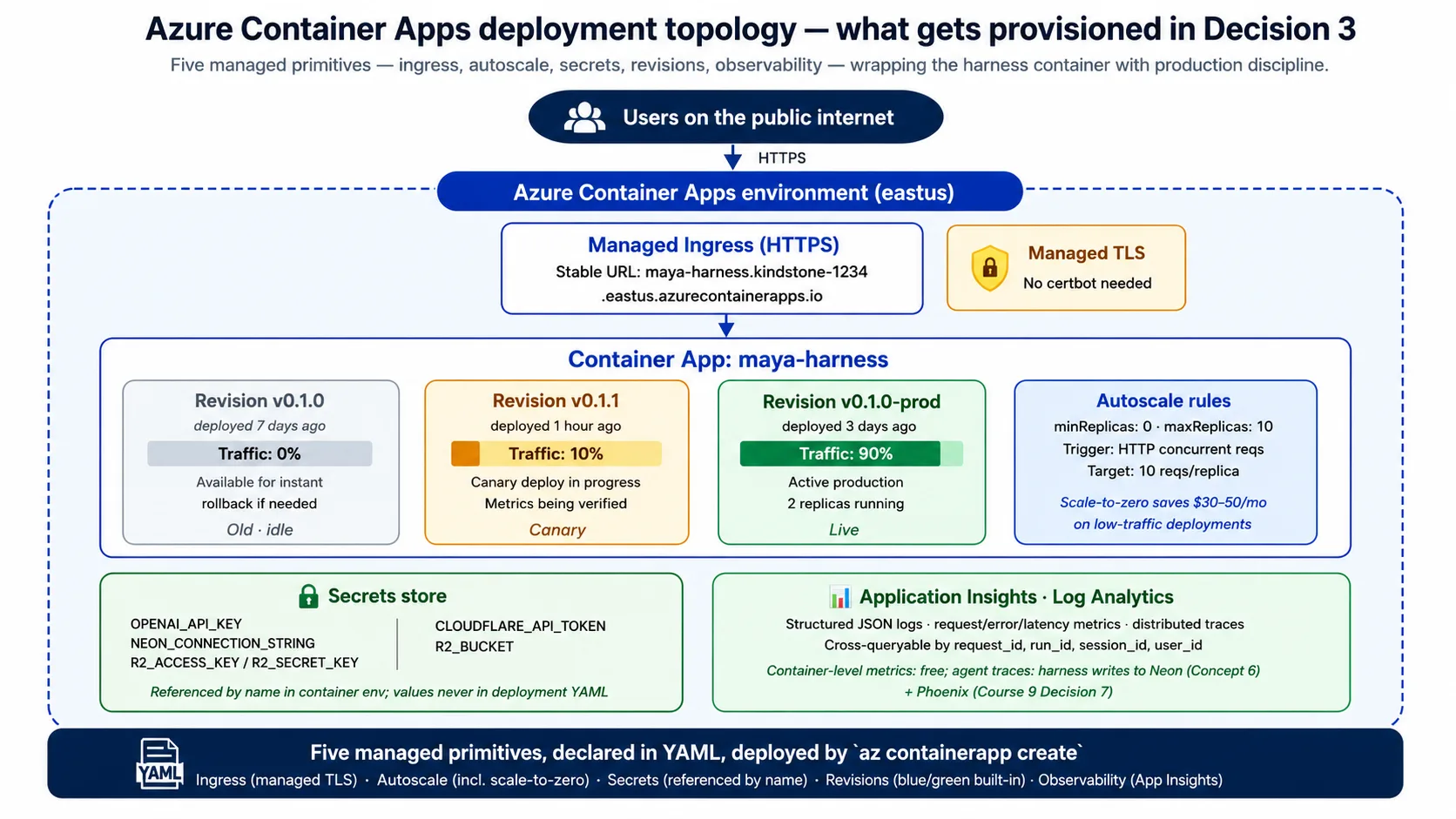
¿Por qué ACA específicamente, y no Cloud Run, Fly.io o Kubernetes directo? Tres razones honestas. Microsoft posiciona ACA para este perfil exacto: API contenerizadas, trabajos en segundo plano y microservicios. Sus revisiones y división de tráfico son de primera clase, mientras que muchos servicios tratan blue/green como un añadido. Y su scale-to-zero es honesto: realmente ejecuta cero copias y no factura nada, mientras algunos servicios "administrados" mantienen una copia caliente y la facturan. Otras nubes tienen equivalentes limpios (Google Cloud Run, AWS App Runner); la forma arquitectónica es idéntica, y el concepto 9 y el concepto 15 cubren las sustituciones.
Cuándo ACA es la elección incorrecta: si necesitas más de unas 25 copias en pico, sus límites por app se vuelven incómodos y Kubernetes completo encaja mejor; si necesitas active-active multirregión, su historia multirregión está menos madura (el concepto 14 lo nombra). El contenedor que despliega el harness es pequeño, construido desde python:3.12-slim con una compilación multi-stage, iniciado por uvicorn y comprobado con el mismo endpoint GET /health que golpeaste en la ganancia rápida.
La decisión 3 del laboratorio produce una configuración corta de ACA que declara la dirección pública, los secretos referenciados por nombre, el tamaño de recursos y la regla de escala (de cero a unas pocas copias según volumen de solicitudes). La leerás y reconocerás cada línea de este concepto.
Concepto 6: Neon Postgres para estado durable
El harness necesita recordar cosas entre runs: historial de conversación, registros de runs, trazas, registro de auditoría. Todo debe sobrevivir a que el contenedor se reinicie, escale o sea reemplazado. La elección de este curso es Neon Postgres.
¿Por qué Postgres, y no Redis o un almacén de documentos? El estado del harness tiene tres propiedades que apuntan a una base de datos relacional y transaccional. Tiene forma relacional: las sesiones tienen muchos runs, los runs tienen trazas y artefactos, así que las claves externas y los joins se mapean limpiamente. Necesita integridad transaccional: "marca este run como completo, inserta su traza y actualiza el timestamp de la sesión" debería ocurrir todo o no ocurrir nada, cosa que las transacciones de Postgres te dan gratis. Y sus lecturas son relacionales: "dame los últimos diez runs de esta sesión, con sus trazas" es una consulta SQL de manual. Una caché como Redis es más rápida para búsquedas por clave, pero tiene la forma incorrecta para el sistema de registro.
¿Por qué Neon específicamente, y no RDS o una base de datos en una VM? La historia sin servidor: Neon escala su computación hacia arriba y hacia abajo por sí solo, y puede escalar casi a cero cuando el harness está inactivo, coincidiendo con el modelo de costo del resto del stack. Una instancia administrada tradicional te factura consultes o no. La historia de branching: Neon te permite crear una rama de tu base de datos, una copia que comparte almacenamiento con la principal hasta que la cambias, lo que te da copias por desarrollador y bases de datos de prueba desechables por PR en segundos. Y es Postgres, no una aproximación: el mismo SQL, las mismas bibliotecas cliente, así que moverte dentro o fuera de Neon es un cambio de cadena de conexión.
El esquema del harness tiene cinco tablas: sessions (el contexto continuo de un usuario), runs (cada tarea de agente), traces (la traza completa del SDK para un run), artifacts (punteros a archivos en R2) y un audit log (un registro inmutable de lo ocurrido, para la suite de evals y para cumplimiento). La decisión 4 del laboratorio crea este esquema desde un archivo schema.sql en la descarga complementaria.
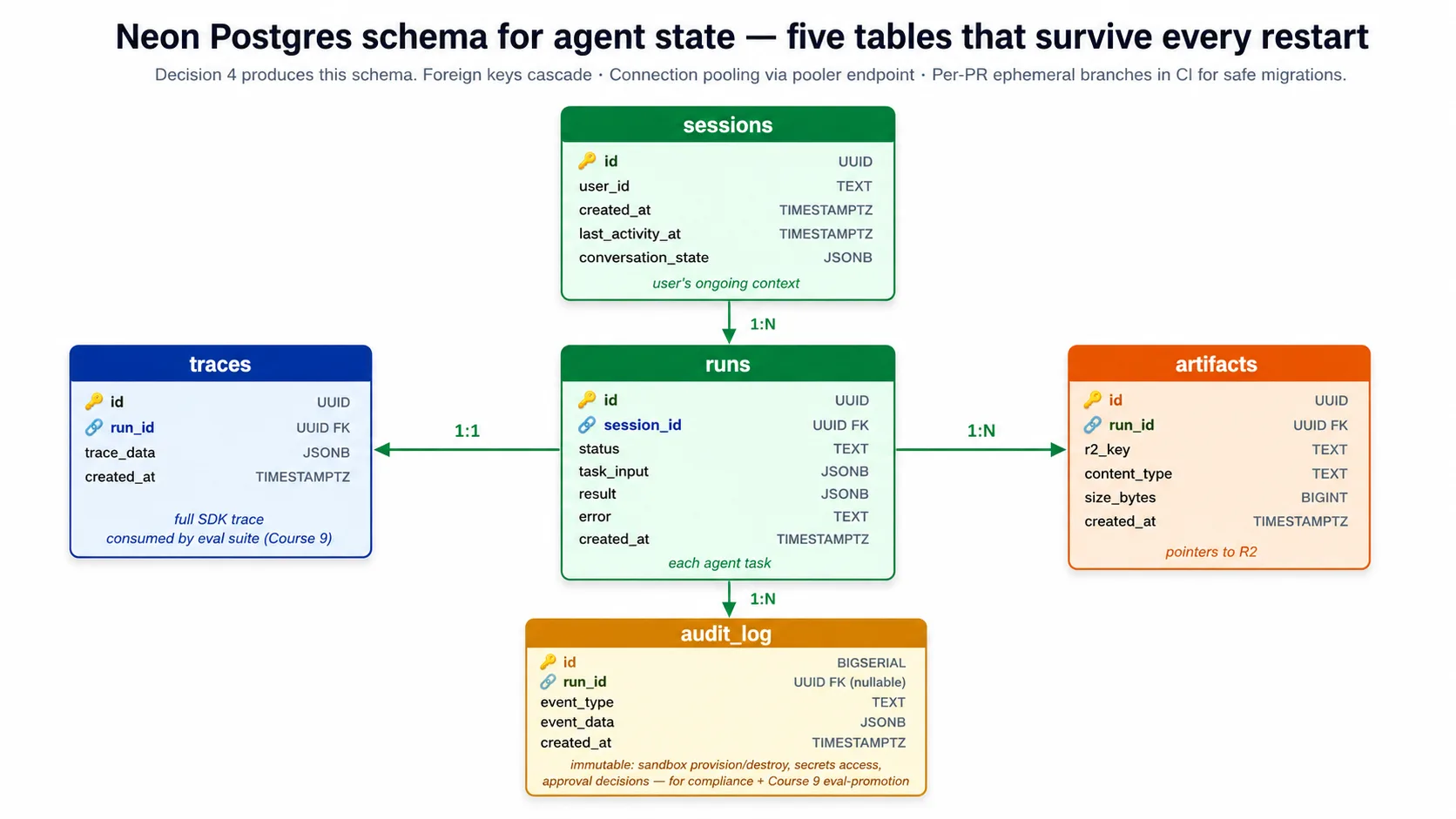
⚠️ Dos trampas de Neon que el laboratorio corrige por ti. La cadena de conexión que Neon copia y pega incluye
channel_binding=require. El driverasyncpgno reconoce eso y falla contra el endpoint pooled, así que el harness eliminachannel_bindingantes de conectarse (mantienesslmode=require). Por separado, el endpoint pooled descarta silenciosamente la configuración de servidorsearch_path, así que el harness califica cada statement con esquema (public.runs,public.sessions), y ejecutas el esquema contra el endpoint directo, no pooled. Ambas son trampas reales, y el código complementario las maneja; el laboratorio las nombra como criterios de aceptación explícitos.
Connection pooling no es opcional. El harness escala a muchas copias, cada una abriendo conexiones, y Postgres cae por encima de unas pocas cientos simultáneas. Neon proporciona un endpoint pooled que multiplexa miles de conexiones del harness en un número pequeño de conexiones reales a Postgres. El harness se conecta al endpoint pooled para trabajo normal y al endpoint directo solo para cambios de esquema.
Concepto 7: Cloudflare R2 para archivos y artefactos
El harness y el sandbox necesitan archivos: documentos de entrada que el agente lee, artefactos de salida que produce, contenido de conocimiento que recupera. La elección de este curso es Cloudflare R2, por tres razones específicas.
¿Por qué almacenamiento de objetos, y no la base de datos o el disco del contenedor? Los archivos tienen la forma incorrecta para una base de datos relacional: Postgres puede guardar un archivo grande en una columna, pero te arrepentirás cuando los backups crezcan y la conexión se vuelva el cuello de botella. Usa la base de datos para estado relacional y guarda punteros a archivos; los bytes del archivo viven en almacenamiento de objetos. Los archivos también tienen la forma incorrecta para el disco local de un contenedor, que desaparece al reiniciar y no se comparte fácilmente entre copias. El almacenamiento de objetos tiene la forma correcta cuando los archivos necesitan sobrevivir a cualquier contenedor individual y ser accesibles por muchos a la vez.
¿Por qué R2 específicamente, y no S3 o GCS? La historia de egreso es la razón principal. Leer tus propios archivos hacia fuera de R2 es gratis. S3, Google Cloud Storage y Azure Blob cobran por datos transferidos hacia fuera, normalmente entre cinco y doce centavos por gigabyte. Para un agente que mueve archivos entre el harness y el sandbox repetidamente, eso crece rápido. Un harness que mueve unos terabytes al mes pagaría cientos de dólares de egreso en S3 y cero en R2; los costos de almacenamiento y solicitudes son más o menos comparables entre ellos, así que la línea de egreso simplemente desaparece. Para un harness de bajo tráfico la diferencia es pequeña, pero con volumen real, el egreso gratuito es la diferencia entre viable e inviable en costos de nube.
R2 también habla la API S3, así que cualquier biblioteca S3 de Python habla con él cambiando una configuración, la URL del endpoint, sin reescritura del cliente si alguna vez migras. Y la versión de abril de 2026 del SDK lista R2 como fuente de montaje de Manifest compatible junto a S3, GCS y Azure Blob, así que el harness declara buckets R2 en el Manifest y el sandbox los monta sin código puente personalizado.
El harness usa tres prefijos en su bucket: inputs/ para archivos que suben usuarios, outputs/ para archivos que produce el agente y knowledge/ para contenido de conocimiento de larga vida. La decisión 5 del laboratorio lo configura.
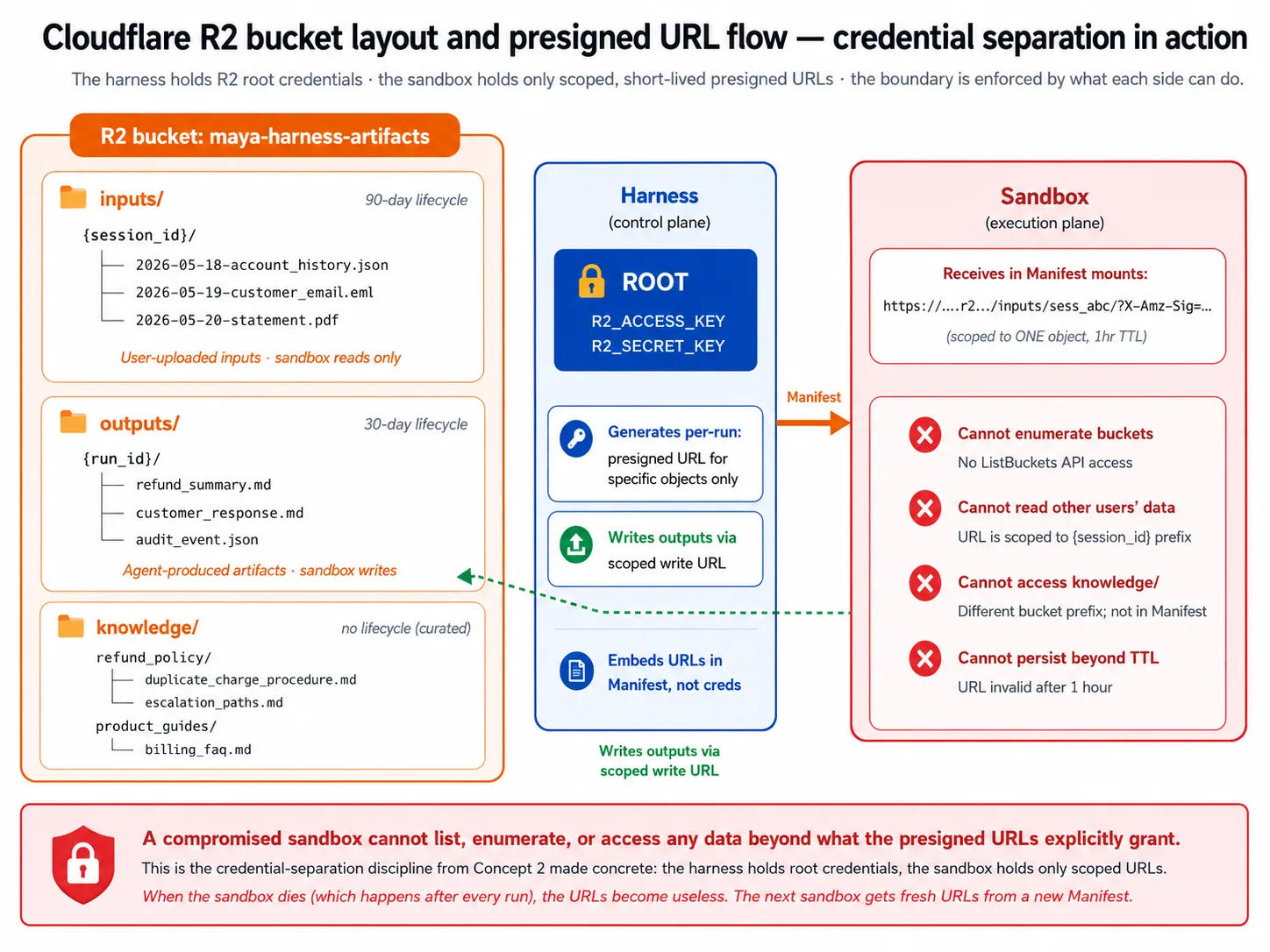
Las URL prefirmadas son la forma en que el sandbox obtiene acceso sin las credenciales raíz. El harness guarda las credenciales raíz que pueden leer o escribir cualquier cosa. No las comparte con el sandbox. En cambio, acuña una URL prefirmada para un objeto específico, con expiración breve, y se la entrega al sandbox. El sandbox solo puede alcanzar lo que la URL permite; cuando muere, la URL deja de servir, y el siguiente sandbox recibe URL frescas. Esta es la separación de credenciales del concepto 2 hecha concreta: un sandbox comprometido no puede listar buckets ni llegar a datos de otro usuario.
Las políticas de ciclo de vida evitan que el almacenamiento se convierta en un cementerio de solo escritura: el laboratorio configura limpieza a 30 días en outputs/, y ninguna en el knowledge/ curado.
Parte 3: El plano de ejecución
La Parte 2 cubrió el lado del harness: orquestación, estado y almacenamiento. La Parte 3 cubre el lado de ejecución, el sandbox donde realmente se ejecuta el código generado por el agente. Tres conceptos: qué proporciona un sandbox, qué proveedor elegir y cómo funciona el handoff entre harness y sandbox.
Concepto 8: Capacidades de ejecución del sandbox
El concepto 2 nombró el sandbox como plano de ejecución: el lugar donde el código se ejecuta sin acceso a los secretos del harness. El concepto 8 lo vuelve concreto. ¿Qué necesita realmente un agente de un sandbox?
Cinco capacidades:
- Sistema de archivos. El agente lee y escribe archivos: entradas, artefactos intermedios, salidas. El sandbox proporciona un sistema de archivos tipo Unix con operaciones de lectura, escritura, edición y listado expuestas como herramientas. Sin él, el agente no puede hacer trabajo con archivos.
- Shell. El agente ejecuta comandos: un runner de pruebas, una instalación de paquetes, un clone, una herramienta personalizada. El sandbox proporciona una shell donde eso se ejecuta. Sin ella, el agente se limita a lo que el harness envuelve explícitamente.
- Instalación de paquetes. El agente instala paquetes bajo demanda: "instala esta biblioteca, luego lee el archivo que subió el usuario, luego resúmelo". Sin esto, la capacidad del agente queda bloqueada a lo que venía en la imagen base.
- Almacenamiento montado. El agente necesita archivos demasiado grandes para el disco local: subidas, contenido de conocimiento, datasets. El sandbox monta almacenamiento externo (R2, S3, GCS) como rutas normales, y el Manifest declara qué montar y dónde. Sin esto, el agente solo puede tocar archivos lo bastante pequeños como para enviarse dentro de la imagen.
- Snapshot y reanudación. Los sandboxes son desechables y pueden fallar a mitad de run. El sandbox puede hacer checkpoint de su estado y reanudar desde ese checkpoint en un espacio de trabajo nuevo, que es como el SDK hace que las tareas largas sobrevivan a la muerte de un workspace. Sin esto, cualquier tarea más larga que la vida de un sandbox es un fallo esperando ocurrir.
Tres propiedades separan un sandbox de producción de un prototipo. Aislamiento: el sandbox no puede alcanzar la red del harness, su sistema de archivos ni otros sandboxes, aplicado por la infraestructura del proveedor y no por confianza, así que un sandbox comprometido solo se daña a sí mismo. Efimeralidad: cada tarea recibe un sandbox fresco, destruido cuando termina, así que incluso un sandbox comprometido no se arrastra a la siguiente tarea. Aprovisionamiento rápido: el sandbox empieza en pocos segundos, porque un arranque de treinta segundos convierte cada tarea en una operación de más de treinta segundos y hace que los agentes estilo chat se sientan lentos.
Lo que un sandbox no es. No es una VM de larga vida que mantienes ejecutándose entre tareas; eso reinventa el problema, acumulando estado y enredo con los secretos del harness. No es una función serverless, que ejecuta una función y devuelve; un sandbox es un espacio de trabajo que persiste a través de muchas llamadas a herramientas dentro de un run, mantiene estado en su sistema de archivos durante el run y da acceso a shell. Y no es Kubernetes; un proveedor de sandbox abstrae la orquestación de contenedores por completo, así que obtienes aislamiento y efimeralidad sin ejecutar un clúster.
Concepto 9: Elegir un proveedor de sandbox
El concepto 8 nombró las capacidades; el concepto 9 elige el proveedor. Este curso es honesto sobre la elección y sobre la ruta gratuita realista.
Empieza con el tradeoff que decide para la mayoría de lectores. El sandbox de Cloudflare necesita un plan Workers de pago, y también necesita un pequeño Worker puente entre tu harness Python y el sandbox. E2B tiene un nivel Hobby gratuito, un cliente nativo en el SDK y ningún puente que desplegar. Así que si quieres completar el laboratorio sin gastar dinero, E2B es la ruta gratuita realista; si ya estás en un plan Cloudflare de pago y usas R2, el sandbox de Cloudflare vale la pena por su beneficio de proximidad. El laboratorio está escrito para que cualquiera de los dos funcione, y el código complementario usa E2B por defecto porque es el que realmente puedes probar gratis.
Por qué el sandbox de Cloudflare es el primario nombrado del curso cuando eliges usarlo: se ejecuta en la red de Cloudflare, y R2 también, así que montar buckets R2 ocurre a velocidades internas de Cloudflare en vez de por internet público. Ningún otro proveedor tiene esa proximidad a R2. También tiene soporte de primera clase en el SDK y una estructura de costos que no factura tiempo inactivo (y un agente espera al modelo mucho más de lo que ejecuta). El inconveniente es el plan de pago y el Worker puente: clientes que no son Workers, como un harness Python, no pueden crear sandboxes de Cloudflare directamente, así que un pequeño Worker desplegado por separado traduce las llamadas del harness a operaciones de sandbox. Otros proveedores, incluido E2B, exponen una API Python directamente y no necesitan puente.
Las alternativas honestas, cada una con un caso donde gana:
- E2B. La ruta realista de nivel gratuito y un proveedor general pulido. Funciona igual de bien con S3, GCS o Azure Blob, y el SDK tiene un cliente nativo para él. Usa E2B cuando eres agnóstico de almacenamiento, no estás en R2 o quieres completar el laboratorio gratis.
- Modal. Fuerte en cargas de Python ML; trivial ejecutar tareas de agente junto a inferencia respaldada por GPU. Usa Modal si tu agente incluye serving de modelos personalizados.
- Daytona. Se ejecuta en tu propia cuenta de nube. Úsalo para industrias reguladas donde la residencia de datos exige que el sandbox viva en tu nube específica, al costo de mayor complejidad operativa.
- Vercel. Úsalo si tu equipo ya está profundamente dentro del ecosistema Vercel; menos maduro para cargas que no son JavaScript.
- Trae el tuyo. El SDK admite implementar el cliente de sandbox contra tu propia infraestructura de contenedores. Vale la pena solo cuando tu equipo de seguridad exige sandboxes en tu nube, punto; la complejidad operativa sube mucho.
La sustitución entre proveedores es mayormente mecánica. El Manifest es agnóstico del proveedor, así que declaras la misma forma de workspace en cualquier caso. Cambia la clase de cliente del proveedor (un cliente Cloudflare en uno, un cliente E2B en otro). El montaje de almacenamiento difiere por proximidad de red (R2 con el sandbox de Cloudflare es rápido; R2 con E2B viaja por internet público, lo cual sigue funcionando). Y el patrón de credenciales es idéntico: el harness guarda las credenciales del proveedor y entrega al sandbox solo acceso de vida corta.
La recomendación, en una línea: usa el sandbox de Cloudflare si estás en un plan Workers de pago y usas R2; usa E2B en caso contrario, especialmente si quieres la ruta gratuita; elige uno y envía en vez de inspeccionarlos todos.
Concepto 10: El handoff de harness a sandbox
El harness orquesta; el sandbox ejecuta. El concepto 10 recorre el handoff: cómo el harness le dice al sandbox qué aprovisionar, cómo cruzan las credenciales el límite de forma segura y cómo se administra el ciclo de vida del sandbox durante un run.
El Manifest es el contrato de handoff. El harness compone un Manifest que describe qué necesita el workspace; el proveedor lo recibe y aprovisiona un workspace correspondiente. En el SDK de abril de 2026, un Manifest se construye a partir de un conjunto de entries: cada entry es una ruta en el workspace mapeada a lo que va allí, un archivo, un directorio, un repositorio git o un montaje de almacenamiento. Los montajes (R2Mount, S3Mount y el resto) viven en agents.sandbox.entries y van dentro de esas entries. No hay una lista separada de montajes ni campos de imagen base o límites de recursos en el Manifest; las entries describen el workspace.
from agents.sandbox import Manifest
from agents.sandbox.entries import R2Mount
from agents.sandbox.entries.mounts.base import DockerVolumeMountStrategy
# Mounts go inside entries, keyed by their path in the workspace. An R2Mount
# attaches a bucket; it has no per-prefix field, so object-level scoping is
# the harness's job (the presigned URLs it mints, from Concept 7), not a mount.
manifest = Manifest(
entries={
"/workspace/inputs": R2Mount(
mount_path="/workspace/inputs",
bucket="maya-harness-artifacts",
account_id=R2_ACCOUNT_ID,
mount_strategy=DockerVolumeMountStrategy(driver="rclone"),
),
"/workspace/outputs": R2Mount(
mount_path="/workspace/outputs",
bucket="maya-harness-artifacts",
account_id=R2_ACCOUNT_ID,
mount_strategy=DockerVolumeMountStrategy(driver="rclone"),
),
}
)
Las capacidades se eligen desde los valores por defecto del SDK, y una lista pasada las reemplaza. Capabilities.default() devuelve el conjunto estándar (sistema de archivos, shell y compactación). Si pasas tu propia lista, reemplaza el valor por defecto en vez de sumarse a él, así que para conservar los valores por defecto y agregar una capacidad más, concatenas:
from agents.sandbox.capabilities import Capabilities, Memory
# Keep the defaults and add one: a passed list REPLACES the default,
# so concatenate rather than passing [Memory()] alone.
capabilities = Capabilities.default() + [Memory()]
Esto es una trampa real: escribir capabilities=[Shell()] elimina silenciosamente el sistema de archivos y la compactación incluidos por defecto. Conserva el valor por defecto y agrega encima.
El sandbox se adjunta mediante RunConfig, no como argumento de Runner.run. No existe un parámetro Runner.run(..., sandbox=...). Construyes un SandboxRunConfig con el cliente del proveedor y su objeto de opciones, lo colocas en un RunConfig y pasas el RunConfig al run. Cada cliente de proveedor se empareja con su propio objeto de opciones, y las opciones viajan en SandboxRunConfig, no en el constructor del cliente:
from agents import Runner
from agents.run import RunConfig
from agents.sandbox import SandboxRunConfig
from agents.extensions.sandbox.e2b import E2BSandboxClient, E2BSandboxClientOptions
# The client reads E2B_API_KEY from the environment; the options carry the
# required sandbox_type. The sandbox rides on RunConfig, not a Runner kwarg.
sandbox = SandboxRunConfig(
client=E2BSandboxClient(),
options=E2BSandboxClientOptions(sandbox_type="e2b"),
)
result = await Runner.run(agent, message, run_config=RunConfig(sandbox=sandbox))
Para el sandbox de Cloudflare la forma es la misma; solo cambian el cliente y las opciones (un CloudflareSandboxClient con CloudflareSandboxClientOptions(worker_url=...)). Este es exactamente el código en sandbox.py y runner.py de la descarga complementaria, arrancado contra el SDK instalado.
La disciplina de credenciales es el punto de seguridad más importante. El harness guarda las credenciales raíz de almacenamiento y las credenciales del proveedor. Acuña URL prefirmadas para objetos específicos, con expiración breve, y esas entran en el workspace, no las credenciales raíz. El sandbox recibe solo esas URL limitadas: no puede enumerar buckets, no puede alcanzar la base de datos del harness (ninguna cadena de conexión cruza el límite) y no puede alcanzar los demás servicios del harness (la política de red lo restringe a lo que necesita, como la API del modelo y registros de paquetes). Cualquier otra cosa, incrustar credenciales raíz o una cadena de base de datos en el workspace, es el error de seguridad que la versión de abril de 2026 fue diseñada para evitar.
El ciclo de vida de un run individual: el harness recibe la solicitud y carga el estado de sesión; compone el Manifest para la tarea; pide al proveedor que aprovisione el workspace; el SDK ejecuta el bucle del agente, enrutando llamadas de sistema de archivos y shell al sandbox y registrando la traza; si el workspace falla y los snapshots están habilitados, el SDK aprovisiona uno nuevo desde el último snapshot y continúa; al completar, el harness lee cualquier salida desde R2, persiste la traza y los punteros de artefactos en Neon, destruye el sandbox para que nada quede inactivo y devuelve el resultado al usuario.
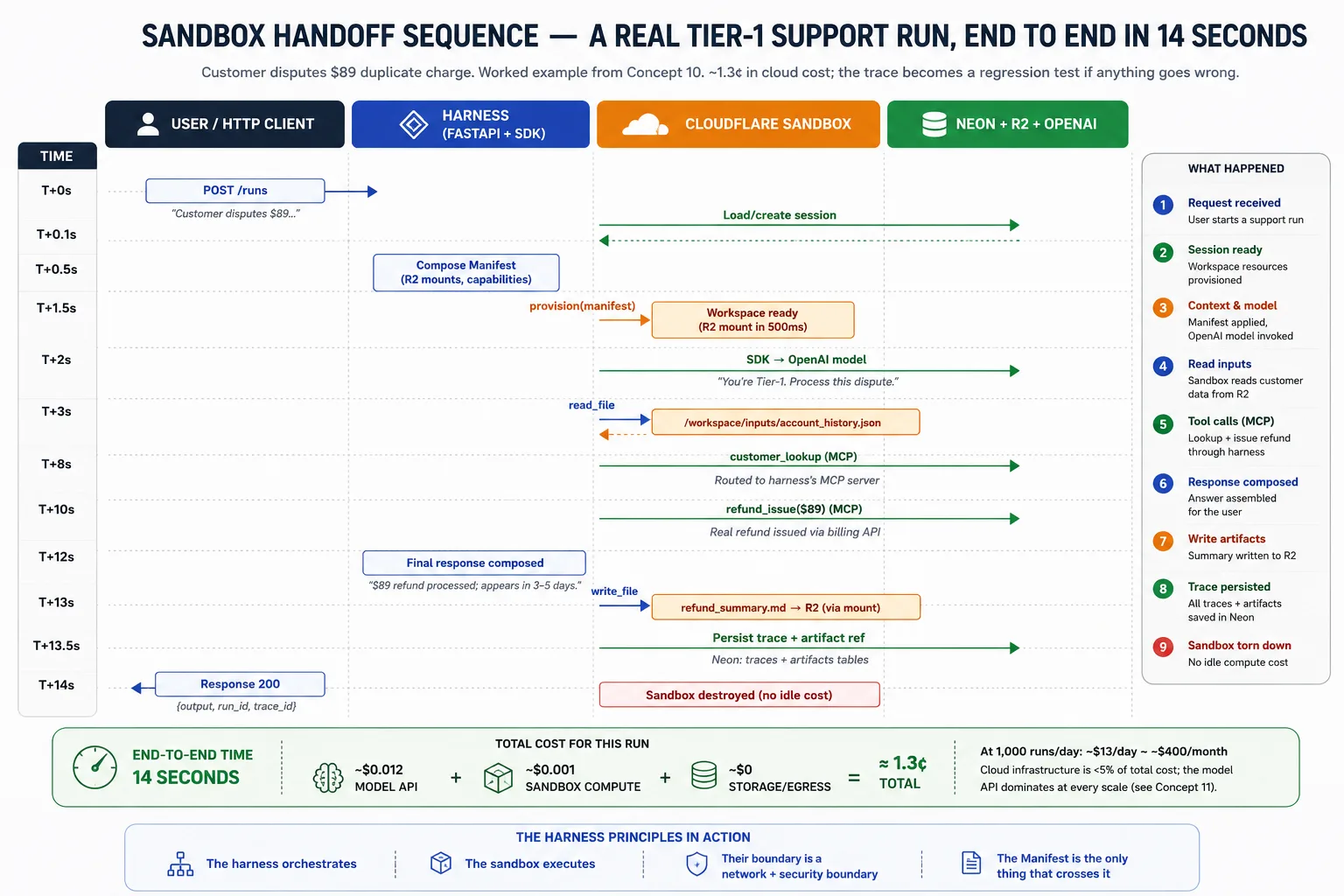
Parte 4: Observabilidad y evals como superficies arquitectónicas
Las partes 1-3 desplegaron el harness. El laboratorio de la Parte 5 lo construirá. La Parte 4 se sienta entre ambas y nombra las dos superficies que la división harness/sandbox de la Parte 1 todavía necesita: los sistemas que te dicen qué está haciendo el harness en ejecución, y los sistemas que miden si todavía hace lo correcto. Los equipos que se saltan esto envían un harness que funciona el primer día y se degrada en silencio después. Dos conceptos, luego el laboratorio.
Concepto 11: Observabilidad como superficie arquitectónica
Observabilidad: las herramientas que te dicen qué está haciendo el harness en ejecución, cuándo algo se rompe y cómo encontrar la causa. La mayoría de los fallos de IA de producción son fallos de observabilidad. El agente hace algo mal, nadie lo nota durante días, y el costo de la demora crece. Por eso la observabilidad no es una función que atornillas al final. Es una superficie arquitectónica más, planificada desde el principio. La decisión 7 la conecta.
Cuando el harness se ejecuta, cuatro superficies lo observan a la vez. Se parecen. Cada una posee una pregunta distinta.
| Superficie | Posee la pregunta |
|---|---|
| Application Insights | ¿Está sana la infraestructura del harness? |
| Trazas OpenTelemetry | ¿Cómo fluyó una solicitud entre servicios? |
| Trazas de OpenAI Agents SDK | ¿Qué hizo el agente durante este run? |
| Phoenix | ¿Cómo cambia el comportamiento del agente con el tiempo? |
Application Insights es el monitor integrado de Azure. Posee la vista del contenedor: tasa de solicitudes, tasa de errores, latencia, CPU y memoria, recuentos de reinicio, flujos de logs. Cuando una réplica se cae, lo nota primero. No puede ver el comportamiento del agente. Para él, cada solicitud es "POST /runs devolvió 200 en 12 segundos"; si la respuesta fue correcta es invisible.
OpenTelemetry (OTel) es un estándar abierto para trazar una solicitud entre servicios. Una traza es el registro completo de un run. Cuando una sola solicitud se abre en una llamada de modelo, tres llamadas a herramientas y cuatro consultas de base de datos, OTel muestra el timing padre-hijo de todo eso. No ve el razonamiento del agente entre llamadas a herramientas; registra que se llamó al modelo, no por qué.
OpenAI Agents SDK emite su propia traza: qué decisiones de modelo se tomaron, qué herramientas se llamaron con qué argumentos, adónde fueron los handoffs. Posee la vista de comportamiento del agente. No ve nada fuera de la ejecución del agente.
Phoenix observa trazas de agentes con el tiempo y convierte las malas en pruebas futuras. Muestrea trazas del SDK, las puntúa y marca las peores para promoción a la suite de evals. Posee la vista de tendencia: no solo qué hizo el agente, sino qué runs deberían convertirse en las pruebas de regresión de mañana. No ve cortes transitorios de infraestructura.
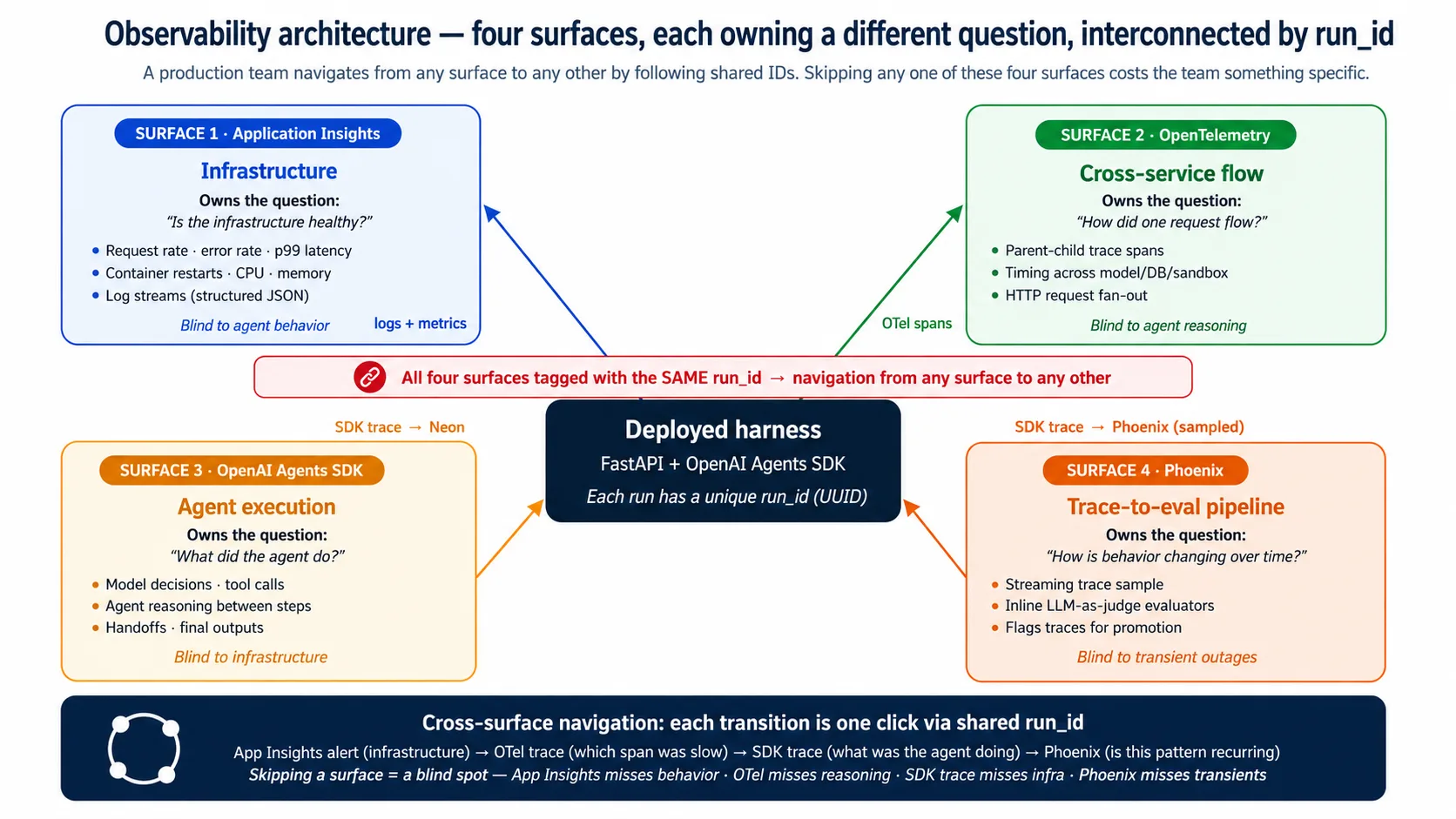
Las superficies se superponen; no se reemplazan. Se interconectan mediante un run_id compartido, para que un equipo pueda empezar en cualquier superficie y saltar a cualquier otra en un clic. Una alerta de Application Insights marca un pico de infraestructura; la traza OTel muestra qué span fue lento; la traza del SDK muestra qué hacía el agente; Phoenix muestra si el mismo patrón se repite. Si omites una superficie, pierdes uno de esos pasos: omite Application Insights y pierdes cortes, omite OTel y pierdes el span lento, omite la traza del SDK y pierdes la decisión del agente, omite Phoenix y tu suite de evals se vuelve obsoleta.
Una quinta superficie aparece solo si envuelves runs en una capa de ejecución durable. El dashboard propio de esa capa agrega linaje operativo a nivel de run (qué paso falló, reintentó y luego tuvo éxito). Es territorio del curso de Worker de producción, no de este. Si lo construyes, consulta Worker de producción con sistema nervioso.
Concepto 12: Evals como superficie arquitectónica
Eval: una prueba que mide el comportamiento del agente (si la respuesta fue correcta, si la herramienta fue adecuada, si el razonamiento fue sólido), no solo si el código se ejecutó. El curso de desarrollo guiado por evals construyó cuatro frameworks de eval. Este concepto nombra dónde se adjuntan al harness desplegado. El adjunto es todo el punto: sin él, la suite de evals es teoría.
El límite está en un lugar: las trazas. Todo lo que la suite de evals califica lee desde una traza, y las trazas viven en dos almacenes. Neon guarda el registro durable, consultado por jobs programados y auditoría. Phoenix guarda la muestra en tiempo real, mostrada en el dashboard vivo. Si recuerdas una cosa de este concepto, recuerda que la integración está mediada por trazas, y que las trazas viven en Neon y Phoenix.
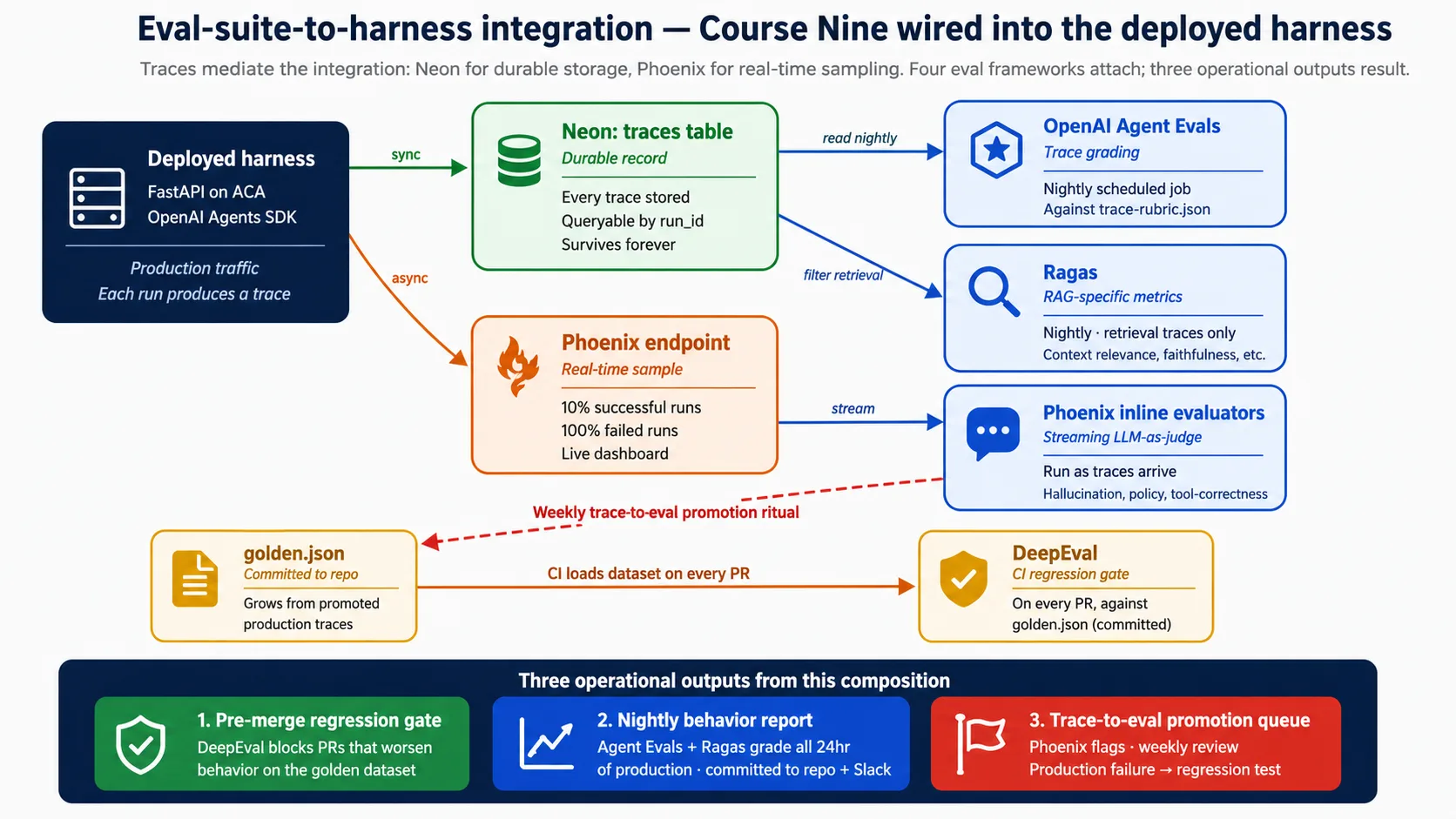
Cuando termina un run, el harness escribe la traza en Neon de forma sincrónica (el registro durable) y transmite una muestra a Phoenix de forma asíncrona (la vista en vivo). Desde ahí, los frameworks de eval se adjuntan en puntos específicos: una puerta de CI se ejecuta en cada pull request, jobs programados califican las trazas del día anterior cada noche, y las comprobaciones inline de Phoenix se ejecutan cuando llegan las trazas. La decisión 8 conecta todo eso por completo. La razón para planificarlo ahora, no después, es simple: las trazas producidas antes de cablear la observabilidad se pierden, y la suite de evals solo crece a partir de trazas que realmente vio.
Parte 5: El laboratorio de despliegue
Las partes 1-4 cubrieron la arquitectura y las superficies. La Parte 5 construye todo: diez decisiones que te llevan de una carpeta vacía a un harness desplegado, observable y protegido por evals. La forma es la que usan los cursos anteriores. Diriges a un agente de programación; el agente escribe y ejecuta el código. Cada decisión es un brief corto que pegas, una línea "Terminado cuando:" que puedes observar y una nota de una línea para lectores que siguen sin desplegar.
La descarga complementaria contiene el contexto compartido. Dentro, AGENTS.md contiene las reglas del proyecto, la arquitectura y las formas de API verificadas, así que cada brief se mantiene corto: el agente lee AGENTS.md para los detalles y tú pegas solo el objetivo. Descarga ahora: deploying-agents-crash-course.zip.
Vuelve a este diagrama mientras trabajas. Cada decisión agrega una pieza etiquetada.
Dos formas de completar el laboratorio.
Construcción completa (rutas intermedia y avanzada): despliegas en la nube. Destruye los recursos después de cada sesión y la factura de extremo a extremo se mantiene pequeña; déjalos ejecutando y crece. El concepto 13 tiene el desglose de costos.
Simulado (rutas Lector y Principiante): lees el código complementario en vez de aprovisionar nada. El harness todavía arranca localmente con solo
OPENAI_API_KEYconfigurada, así que puedes ejecutar cada paso que no necesita una cuenta en la nube. La nota Simulado de cada decisión dice qué leer en su lugar.
Decisión 0: sondear el SDK y reconciliar el brief
En una línea: instala el SDK, imprime la versión instalada, obtiene los documentos vivos del sandbox y reconcilia el AGENTS.md complementario contra ellos. Ganan los documentos vivos.
OpenAI Agents SDK se mueve rápido. Nombres, firmas y valores por defecto cambian entre versiones. El AGENTS.md complementario es lo conocido-bueno de hoy, no lo conocido-bueno para siempre. Así que la primera decisión es un sondeo: confirma cada símbolo del que depende el laboratorio contra el SDK realmente instalado en tu equipo y escribe cualquier deriva. Cinco minutos aquí ahorran una hora de "¿por qué no existe este atributo?" después.
Pega esto en tu agente de programación. Primero planifica; ejecuta con aprobación.
Abre la descarga complementaria. Ejecuta el sondeo del SDK desde el final de
AGENTS.md:uv sync, luego las comprobaciones de import paraagents,agents.sandbox,agents.sandbox.entriesy el cliente E2B. Imprime la versión instalada deopenai-agents. Consulta la referencia viva de la API de sandbox en los documentos oficiales. Compara cada símbolo del SDK nombrado enAGENTS.mdcontra lo que importaste realmente. Si algo difiere, ganan los documentos vivos: escribe una nota corta "Qué cambió desde el brief" al inicio deAGENTS.mdque enumere cada diferencia, y usa el nombre vivo en adelante. No cambies ningún código todavía.
Terminado cuando:
- El agente informa la versión instalada de
openai-agents(espera 0.17.x). - El agente informa cualquier nombre del SDK que difiera de
AGENTS.md, y los documentos vivos ganan en cada diferencia. - Una nota corta "What changed since the brief" queda al inicio de
AGENTS.md, o el agente declara que el brief coincidía con el SDK instalado.
Ruta simulada. Lee la sección de sondeo del SDK al final de
AGENTS.md. No necesitas ejecutarla; el punto es ver el hábito de resistencia a deriva: confirmar el brief contra el SDK vivo antes de confiar en cualquier símbolo, y dejar que los documentos vivos ganen.
Decisión 1: construir el scaffold del harness
En una línea: una app FastAPI con el agente, la capa de estado y la capa de almacenamiento, todas degradando con gracia cuando falta una clave, que arranca localmente solo con OPENAI_API_KEY.
Esta decisión configura el proyecto sobre el que construyen las siguientes nueve. El agente (soporte de nivel 1 de Maya) y sus dos herramientas vienen de los cursos anteriores; esta decisión es el harness que los envuelve, no el agente en sí.
Pega esto en tu agente de programación. Primero planifica; ejecuta con aprobación.
Construye el scaffold del harness a partir del
AGENTS.mdcomplementario. Sigue exactamente sus reglas de proyecto y su arquitectura. Fijaopenai-agents>=0.17,<0.18. Construye la app FastAPI conGET /health(informa qué backends están activos) yPOST /runs(carga la sesión, ejecuta el agente de Maya, persiste el run y la traza, y opcionalmente escribe un artefacto). Conecta degradación gradual: la app debe importar y arrancar solo conOPENAI_API_KEYconfigurada, con fallback a SQLite cuandoDATABASE_URLno esté definida y a un directorio local cuando no haya claves de R2. Agrega las dos herramientas (lookup_account,draft_reply) como funciones@function_toolcuyos cuerpos se ejecuten en el harness, no en el sandbox. Confirma el lockfile.
Terminado cuando:
uv run uvicorn maya_harness.main:apparranca el harness sin errores.GET /healthdevuelve{"status": "ok", ...}conpostgres,sandboxyr2reportados comofalseen un arranque desnudo solo conOPENAI_API_KEY.GET /docsmuestra la API autogenerada para los dos endpoints.
Ruta simulada. El complemento ya contiene este scaffold. Lee
src/maya_harness/main.py,agent.pyysettings.py, y observa cómo cada backend es opcional: cada clave faltante apaga un componente y el harness sigue arrancando.
Ese arranque es la victoria temprana que promete todo este curso. Antes de cualquier cuenta de nube, Docker o base de datos, tienes un harness de agente real respondiendo en /health desde tu propio portátil. La división harness/sandbox ya no es un diagrama; se está ejecutando en tu equipo. Todo lo posterior agrega un backend durable a la vez.
Decisión 2: contenerizar el harness
En una línea: una imagen de contenedor pequeña y reproducible del harness que se ejecuta igual en tu portátil y en la nube.
Contenedor: un paquete sellado de tu app más todo lo que necesita para ejecutarse, para que se comporte igual en todas partes. La decisión 3 despliega esta imagen; la decisión 2 la construye.
Pega esto en tu agente de programación. Primero planifica; ejecuta con aprobación.
Construye el contenedor del harness a partir de la forma del
Dockerfileen el complemento. Usapython:3.12-slimconuvpara una instalación reproducible desde el lockfile confirmado. Instala dependencias en una capa cacheada antes de copiar el código fuente. Expón el puerto 8000 y ejecutauvicorn maya_harness.main:app --host 0.0.0.0 --port 8000 --proxy-headers(la bandera--proxy-headersimporta porque la nube termina TLS en su ingress). Agrega un.dockerignoreque excluya el entorno virtual, cachés y archivos.env. Construye la imagen y ejecútala localmente con tu.envmontado.
Terminado cuando:
- La imagen se construye sin errores.
- El contenedor se ejecuta localmente y
GET /healthdevuelveokdesde dentro. - Cambiar un archivo fuente y reconstruir es rápido (la capa de dependencias queda cacheada).
Ruta simulada. Lee el
Dockerfilecomplementario. El ejercicio es la idea multi-stage: las dependencias se instalan en una capa cacheada, el código fuente se copia después y la imagen se mantiene pequeña. No necesitas Docker instalado.
Decisión 3: desplegar en Azure Container Apps
En una línea: aprovisiona un runtime administrado en la nube, construye la imagen en la nube y despliega el harness para que responda desde internet público por HTTPS.
Azure Container Apps (ACA): un servicio administrado que ejecuta tu contenedor en la nube con autoscale e ingress, para que no ejecutes servidores por tu cuenta. Esta decisión es donde el harness sale de tu portátil.
Pega esto en tu agente de programación. Primero planifica; ejecuta con aprobación.
Despliega el harness en Azure Container Apps usando la forma de
infra/deploy.shdel complemento. Crea un grupo de recursos y un registro de contenedores. Construye la imagen en la nube conaz acr build(sin necesitar Docker local). Crea el entorno de Container Apps y luego crea la app con--ingress external,--target-port 8000y--min-replicas 0para scale-to-zero. GuardaOPENAI_API_KEYcomo secreto con nombre y referéncialo consecretref:, nunca horneado dentro de la imagen. Confirma la URL pública de la app y que/healthresponda por HTTPS. Pasa el entorno actual a cualquier subproceso para que las claves sobrevivan.
Terminado cuando:
- El script de despliegue termina e imprime una URL pública
*.azurecontainerapps.io. - Abrir
https://<that-url>/healthdesde tu teléfono devuelve{"status": "ok", ...}. - Tras un período quieto la app escala a cero, y la siguiente solicitud despierta una copia en pocos segundos (un cold start de scale-to-zero).
Ruta simulada. Lee
infra/deploy.sheinfra/containerapp.yaml. La forma que debes entender es: construir en la nube, desplegar con ingress externo y scale-to-zero, y guardar secretos por nombre. No necesitas una cuenta de Azure.
Ahora tienes una app de Container Apps desplegada y su URL pública de la decisión 3. Las decisiones 4 a 9 redepliegan sobre esta misma app para agregar cada backend. Consérvala; no ejecutes az group delete hasta terminar el laboratorio o cerrar una sesión a propósito.
Decisión 4: conectar Neon Postgres para estado durable
En una línea: aprovisiona una base de datos Postgres sin servidor y apunta el harness a ella, para que sesiones, runs y trazas sobrevivan a un reinicio.
Estado durable: memoria que sobrevive a un reinicio, guardada en una base de datos en vez de en el contenedor, que olvida todo cuando se detiene. Neon Postgres: una base de datos Postgres sin servidor con branching barato. Después de esta decisión, reinicias el contenedor y el historial de runs sigue ahí.
Pega esto en tu agente de programación. Primero planifica; ejecuta con aprobación.
Conecta Neon Postgres como estado durable del harness, siguiendo los archivos complementarios
state.pyyschema.sql. Crea un proyecto Neon en console.neon.com. Aplica el esquema de cinco tablas (sessions, runs, traces, artifacts, audit_log), calificado por esquema comopublic.*. Conecta el harness medianteasyncpg. Dos reglas de aceptación delnormalize_neon_dsncomplementario no son opcionales y evitan fallos silenciosos contra el pooler:
- Elimina
channel_bindingde la cadena de conexión de Neon antes de entregarla a asyncpg; conservasslmode=require. asyncpg no reconocechannel_bindingy falla contra el pooler si lo dejas.- Usa el endpoint pooled para la app en ejecución y el endpoint directo (non-pooled) para migraciones. El endpoint pooled descarta
search_pathsilenciosamente, por eso cada statement está calificado por esquema.Agrega
DATABASE_URLcomo valor local de.envy como secreto de ACA, luego redepliega. Confirma que un run persista después de un reinicio.
Terminado cuando:
/healthreporta"postgres": truedespués del redeploy.- Un
POST /runsescribe una fila que puedes leer de vuelta desde la tablarunsde Neon. - Reiniciar el contenedor conserva el historial de runs (el estado es durable, no está en el contenedor).
- La cadena de conexión no tiene
channel_binding, y las migraciones se ejecutaron contra el endpoint directo.
Ruta simulada. Lee
state.pyyschema.sql. Observa dos cosas: la funciónnormalize_neon_dsnque eliminachannel_binding, y que cada tabla se escribe comopublic.runs,public.sessions, etc., porque el endpoint pooled ignorasearch_path.
Ahora tienes un proyecto Neon y dos cadenas de conexión de la decisión 4: pooled para la app, directa para migraciones. El sandbox de la decisión 6 y la observabilidad de la decisión 7 escriben en esta base de datos. Consérvala.
Decisión 5: conectar Cloudflare R2 para archivos y artefactos
En una línea: aprovisiona almacenamiento de objetos y entrega al harness enlaces de vida corta a archivos específicos, para que las salidas del agente se puedan descargar sin compartir nunca la contraseña del almacenamiento.
Cloudflare R2: almacenamiento de objetos compatible con S3 donde leer tus archivos hacia fuera es gratis. URL prefirmada: un enlace de vida corta que permite leer o escribir un archivo específico, sin tener nunca la contraseña del almacenamiento. Después de esta decisión, una respuesta del agente se puede guardar como archivo y devolver como enlace de descarga.
Pega esto en tu agente de programación. Primero planifica; ejecuta con aprobación.
Conecta Cloudflare R2 como almacén de artefactos del harness, siguiendo el archivo complementario
storage.py. Crea un bucket R2 y credenciales de API con alcance limitado. Apunta un cliente boto3 S3 al endpoint de R2https://<account_id>.r2.cloudflarestorage.comconregion_name="auto". En un run dondesave_artifactsea true, escribe la respuesta en el bucket y devuelve una URL de descarga prefirmada con expiración corta (una hora). Agrega los cuatro valoresR2_*a.envy a los secretos de ACA, luego redepliega.
Terminado cuando:
/healthreporta"r2": truedespués del redeploy.- Un
POST /runsconsave_artifacttrue devuelve unartifact_urlque descarga la respuesta. - La URL prefirmada deja de funcionar después de expirar (es limitada y de vida corta, no una contraseña permanente).
Ruta simulada. Lee
storage.py. Observa el detalle que hace que R2 funcione con boto3: apunta el cliente S3 al endpoint de R2 conregion_name="auto", y el resto de la API S3 no cambia. El fallback a directorio local es lo que se ejecuta cuando no hay claves de R2 configuradas.
Ahora tienes un bucket R2 y credenciales limitadas de la decisión 5. El sandbox de la decisión 6 lee y escribe archivos mediante URL prefirmadas en este bucket. Consérvalo.
Decisión 6: conectar ejecución en sandbox
En una línea: adjunta un espacio de trabajo aislado donde se pueda ejecutar el código del agente, sin acceso a los secretos ni a la base de datos del harness.
Sandbox: un espacio de trabajo separado y bloqueado donde se ejecuta el código generado por el agente, sin guardar ninguna de las claves del harness. Manifest: una descripción breve de lo que necesita el sandbox (qué archivos montar, qué capacidades activar). Esta decisión agrega el plano de ejecución; el agente sigue respondiendo sin él, así que el harness sigue siendo útil en cada paso.
Una nota de costo antes de construir. El proveedor primario de sandbox del curso, Cloudflare, necesita un plan Workers de pago y un pequeño Worker puente entre el harness Python y el sandbox. E2B es la ruta gratuita realista: tiene un nivel Hobby gratuito, un cliente de primera clase en el SDK y ningún Worker puente. El complemento usa E2B por defecto exactamente por esa razón. Usa E2B a menos que quieras Cloudflare específicamente.
Pega esto en tu agente de programación. Primero planifica; ejecuta con aprobación.
Conecta la ejecución en sandbox siguiendo el archivo complementario
sandbox.pyy las formas verificadas enAGENTS.md. Usa E2B por defecto (nivel gratuito). Construye unSandboxRunConfigsolo cuando haya una clave de sandbox configurada, y adjúntalo medianteRunConfig, nunca como kwarg deRunner.run. Dos formas verificadas del complemento que el borrador anterior tenía mal:
- La ruta de E2B es
SandboxRunConfig(client=E2BSandboxClient(), options=E2BSandboxClientOptions(sandbox_type="e2b")). El objeto de opciones es obligatorio y lleva el campo requeridosandbox_type; el constructor del cliente no recibeoptions=.- Si alguna vez construyes un Manifest, es
Manifest(entries={...})con mounts (R2Mount,S3Mount) importados desdeagents.sandbox.entries. No existenbase_image=,mounts=[]niMountSpec. Una lista de capacidades pasada reemplaza el valor predeterminado, así que conservaCapabilities.default()o concaténala.Agrega
E2B_API_KEYa.envy a los secretos de ACA, luego redepliega. Ruta de nivel gratuito: deja Cloudflare intacto, configura soloE2B_API_KEY, y no necesitas Worker puente ni plan de pago.
Terminado cuando:
/healthreporta"sandbox": truedespués de configurar la clave de E2B y redeplegar.- Un
POST /runsdevuelve"used_sandbox": true. - El sandbox importa desde
agents.extensions.sandbox.e2b, y el agente sigue respondiendo cuando no hay clave de sandbox configurada (el harness sigue siendo útil sin él).
Ruta simulada. Lee
sandbox.py. Observa los imports diferidos (el módulo carga incluso sin los extras de sandbox instalados), el valor por defecto E2B-first con Cloudflare como alternativa de pago, y que la función devuelveNonecuando no hay clave configurada, que es lo que mantiene el harness ejecutándose con el sandbox desactivado.
El plano de ejecución está conectado (decisión 6) sobre el harness (decisión 1), su runtime en la nube (decisión 3), su estado (decisión 4) y su almacenamiento (decisión 5). El agente de Maya ya está desplegado de extremo a extremo sobre el stack de cinco componentes. Las decisiones 7 a 9 lo endurecen.
Decisión 7: conectar observabilidad
En una línea: conecta las cuatro superficies de observabilidad con un run_id compartido para navegar desde infraestructura hasta comportamiento del agente.
El concepto 11 nombró cuatro superficies. Esta decisión las conecta y las reconcilia. Después, un equipo puede empezar en Application Insights, OpenTelemetry, la traza del SDK o Phoenix, y llegar a cualquiera de las otras tres siguiendo un ID.
Pega esto en tu agente de programación. Primero planifica; ejecuta con aprobación.
Conecta las cuatro superficies de observabilidad del Concepto 11. Instrumenta el harness con OpenTelemetry (FastAPI, asyncpg y spans HTTP) y exporta a Application Insights. Etiqueta cada superficie con el mismo
run_id: adjúntalo al span padre de OTel, inclúyelo en cada línea de log estructurado, llévalo en la traza del SDK y envíalo con la muestra de Phoenix. Transmite las trazas completadas del SDK a Phoenix como fire-and-forget (si Phoenix está caído, regístralo y continúa; Neon es el registro durable). Muestrea aproximadamente el 10% de runs exitosos y el 100% de runs fallidos, de forma determinista sobrerun_idpara que el muestreo sea estable. Redepliega con las claves de observabilidad como secretos de ACA.
Terminado cuando:
- Una traza OTel de una solicitud aparece en Application Insights en alrededor de un minuto.
- Buscar un
run_iden cualquier superficie devuelve el registro correspondiente en las demás. - Phoenix muestra trazas recientes, con muestreo de todos los fallos y una fracción de los éxitos.
Ruta simulada. Lee el cableado de observabilidad en el complemento. El patrón que debes aprender es el
run_idcompartido: es el hilo que permite que un clic vaya de una alerta de infraestructura al razonamiento del agente y luego a la tendencia en el tiempo. Sin él, las cuatro superficies son cuatro dashboards desconectados.
Decisión 8: conectar la suite de evals
En una línea: conecta los cuatro frameworks del curso de desarrollo guiado por evals a las trazas del harness, produciendo una puerta de regresión en CI, un informe nocturno de comportamiento y un ritual semanal de promoción de traza a eval.
El concepto 12 fijó el límite: trazas en Neon y Phoenix. Esta decisión conecta los cuatro frameworks de eval a esas dos superficies. Aquí se enseña el cableado completo de evals; si no has construido la suite de evals en sí, haz primero el curso de desarrollo guiado por evals, porque esta decisión adjunta esa suite al despliegue.
Pega esto en tu agente de programación. Primero planifica; ejecuta con aprobación.
Conecta los cuatro frameworks de eval del curso de desarrollo guiado por evaluaciones a las trazas del harness desplegado. Adjunta cada uno en su punto:
- DeepEval como puerta de regresión en CI. En cada pull request que toque el agente o los prompts, ejecuta DeepEval contra el conjunto de datos dorado confirmado llamando a un
POST /runsde staging, y bloquea el merge si un caso que antes pasaba ahora falla.- Un job programado nocturno (Container Apps Jobs) que lea las trazas de las 24 horas previas desde Neon, las califique con OpenAI Agent Evals contra la rúbrica del equipo, ejecute Ragas en las trazas que usaron retrieval, escriba un informe en el repo y publique el resumen en Slack.
- Evaluadores inline de Phoenix que se ejecuten cuando lleguen las trazas (alucinación, política, corrección de herramientas), etiquetando puntuaciones sin bloquear runs.
- Un ritual semanal, documentado en un runbook: revisar las trazas marcadas por Phoenix y promover al conjunto de datos dorado las que merezcan convertirse en eval, para que cada una se vuelva una prueba de regresión futura.
Terminado cuando:
- Un pull request que empeora intencionalmente el comportamiento queda bloqueado por la puerta DeepEval.
- El job nocturno produce un informe de comportamiento en el repo y lo publica en Slack.
- Phoenix muestra puntuaciones de evaluadores inline en trazas recientes, y el ritual de promoción está documentado y se ejecutó una vez de extremo a extremo.
Ruta simulada. Lee las configuraciones del pipeline de evals y los workflows de CI en el complemento. La forma que debes interiorizar son los tres productos operativos: una puerta previa al merge que captura regresiones, un informe nocturno que captura deriva y una cola de promoción que convierte fallos de producción en pruebas nuevas.
Decisión 9: checklist de producción
En una línea: completa la disciplina operativa: rotación de secretos, despliegues blue/green, runbook de guardia, backup y recuperación, y rate limits.
Con el harness observable (decisión 7) y medido (decisión 8), esta decisión agrega lo que necesitas para dejarlo ejecutándose sin miedo. Blue/green: envía una versión nueva sin downtime ejecutándola junto a la antigua y luego moviendo el tráfico.
Pega esto en tu agente de programación. Primero planifica; ejecuta con aprobación.
Completa la disciplina de producción para el harness, documentada en un runbook. Cubre:
- Rotación de secretos: un procedimiento para agregar una credencial nueva junto a la anterior, redeplegar, verificar y luego revocar la anterior.
- Despliegues blue/green: un script que cree una revisión nueva con 0% de tráfico, verifique
/healthen ella, mueva 10% y observe Application Insights, luego mueva a 100% y conserve la revisión anterior durante un día para rollback.- Un runbook de guardia con cinco escenarios (tasa alta de errores, latencia alta, proveedor de sandbox caído, Neon inaccesible, R2 inaccesible), cada uno con pasos de investigación y remediación.
- Backup y recuperación: recuperación point-in-time de Neon, versionado de R2 y rollback de revisión de ACA.
- Per-user rate limits at the middleware layer, returning 429 with
Retry-Afterwhen exceeded.- Cost alerts that fire when daily spend jumps well above the recent average.
Terminado cuando:
- Todos los secretos tienen un procedimiento de rotación documentado y probado.
- Un despliegue blue/green se ejecuta de extremo a extremo: nueva revisión verificada, tráfico movido, revisión antigua conservada para rollback.
- El rate limiting funciona (la solicitud que supera el límite devuelve 429), y las alertas de costo están configuradas.
Ruta simulada. Lee el runbook y los scripts de despliegue y rotación en el complemento. La disciplina que debes absorber es que cada modo de fallo tiene una respuesta nombrada y ensayada, y que rate limiting y alertas de costo no son opcionales: son lo que se interpone entre tú y una factura descontrolada después de un pico de tráfico.
Parte 6: Fronteras honestas
El laboratorio produce un despliegue funcional. La Parte 6 nombra lo que no resuelve, dónde cuesta más de lo esperado y dónde está su límite. Cuatro conceptos y cinco antipatrones.
Concepto 13: Economía de costos de un harness de agente en la nube
El costo en la nube es la dimensión que la mayoría de cursos omiten. Esta receta tiene una economía específica, y un equipo que se compromete con ella debería conocerla a escala pequeña, mediana y grande.
La factura tiene cinco capas, una por componente, y una capa domina todas las demás.
| Capa | Participación en la factura |
|---|---|
| API del modelo (OpenAI) | 90-98% en todas las escalas |
| Ejecución del sandbox | La mayor del resto con volumen alto |
| Cómputo del harness (ACA) | Pequeña; scale-to-zero la mantiene cerca de cero cuando está inactivo |
| Estado durable (Neon) | Pequeña; el nivel gratuito cubre uso ligero |
| Almacenamiento de archivos (R2) | Pequeña; el egreso es gratuito |
Toma las cifras como rangos aproximados, no como números precisos. A escala pequeña (alrededor de 100 runs al día), la factura total está en el orden de unos ciento y tantos dólares al mes, y la API del modelo es aproximadamente nueve décimas partes. A escala mediana (alrededor de 10.000 runs al día), la factura está en las decenas de miles bajas al mes, y la API del modelo ronda el 98%. A escala grande (alrededor de un millón de runs al día), la factura entra en siete cifras mensuales, casi toda API del modelo. Las capas de infraestructura también crecen, pero se mantienen por debajo del 5% del total en todo momento.
Las conclusiones honestas se siguen directamente. La infraestructura en la nube casi siempre está por debajo del 5% de la factura, así que la palanca de costo de mayor impacto es el modelo, no la infraestructura: usa un modelo más barato para decisiones simples, cachea prompts donde el SDK lo admita y mantén cortos los prompts de sistema. El costo de infraestructura es predecible y aproximadamente lineal con el tráfico; no recibes facturas sorpresa por él. El egreso gratuito de R2 importa más para cargas con muchos archivos y casi no aparece en cargas de texto como la de Maya. El costo del sandbox escala con el tiempo de ejecución activo, así que los agentes intensivos en computación cuestan más allí, mientras que los agentes que sobre todo esperan al modelo siguen siendo baratos.
Concepto 14: Consideraciones multirregión
Esta receta despliega en una sola región a propósito. Active-active multirregión es un problema mucho más difícil, y la mayoría de despliegues no lo necesitan. Lo necesitas por una de tres razones: latencia, cuando tus usuarios están repartidos por el mundo y una sola región agrega una demora de ida y vuelta perceptible; disponibilidad, cuando tu compromiso de uptime es 99,99% o superior y una caída de una sola región es inaceptable; o cumplimiento, cuando las reglas de residencia de datos exigen que los datos de usuarios permanezcan en una región específica.
Los componentes difieren en cuán difícil es hacerlos multirregión. R2 y el sandbox ya son globales en la red de Cloudflare, así que no necesitan trabajo adicional. ACA es de una sola región por entorno, así que multirregión significa varios entornos detrás de un balanceador de carga global. Neon admite réplicas de lectura en otras regiones, pero las escrituras siguen yendo al primario, así que el estado de agente con muchas escrituras necesita un diseño de base de datos más complejo. La receta honesta es más entornos, réplicas de lectura y una puerta frontal global, con el costo operativo creciendo con cada región. Si tus usuarios están mayormente en una región, tu objetivo de uptime es 99,9% y una región satisface tus reglas de datos, una sola región es la respuesta correcta; no pagues por complejidad que no necesitas.
Concepto 15: Cuándo migrar fuera de la receta
La receta de este curso cubre entornos de desarrollo hasta producción de tráfico medio en una sola región. Cinco disparadores te dicen cuándo migrar un componente específico.
Los disparadores: concurrencia pesada sostenida por encima de unas 25 réplicas ACA, donde la economía y la matemática de conexiones favorecen mover el harness a Kubernetes (el código de app permanece igual). Active-active multirregión, según el concepto 14. Computación especializada como trabajo con GPU, donde encaja mejor un proveedor de sandbox nativo para GPU y el Manifest portable se mueve contigo. Una regla de cumplimiento que exige que el sandbox se ejecute dentro de tu propia nube, lo que descarta un sandbox SaaS y te empuja a un proveedor bring-your-own. Y superar Postgres como almacén principal a volúmenes de escritura muy altos, lo que apunta a SQL distribuido o almacenamiento dividido y es el cambio más invasivo de los cinco.
Concepto 16: Lo que el despliegue no resuelve
El laboratorio produce una disciplina real de producción, pero no resuelve todo. Nombrar las brechas evita una falsa confianza y te dice qué trabajo las cerraría.
No produce certificación de cumplimiento. Obtienes los controles técnicos que espera un marco como SOC2, pero la certificación necesita una auditoría de terceros y meses de evidencia; planéala como un flujo de trabajo separado. No te da un programa de respuesta a incidentes. El runbook cubre remediación técnica, no quién recibe la alerta, cómo se declaran incidentes ni cómo se hacen post-mortems; esa capa de personas y proceso debes construirla. No resuelve la responsabilidad legal por las acciones del agente. El audit log registra lo ocurrido, pero el marco legal alrededor de decisiones de agentes aún se está formando. No detiene prompt injection a nivel de comportamiento. La división harness/sandbox mantiene el código inyectado lejos de tus secretos, pero no evita que un mensaje diseñado dirija la respuesta del agente; eso necesita guardrails, comprobaciones de entrada y red-teaming, gran parte de ello trabajo de la suite de evals. No maneja actualizaciones de modelos por ti; la suite de evals es la disciplina para probar un modelo nuevo antes de cambiar. Y no previene el descontrol de costos; el monitoreo detecta un pico en horas, pero los topes diarios y kill switches son defensas adicionales que agregas encima.
Cinco cosas que no debes hacer
La receta evita cinco antipatrones. Nombrarlos ayuda a un equipo a no retroceder después de que el despliegue se envía.
- No ejecutes código generado por el agente dentro del harness. Una llamada como
exec(model_output)en el proceso del harness es peor que una SQL injection, porque la superficie de ataque es todo el razonamiento del modelo. El límite del sandbox no es negociable; el harness guarda las claves, el código del agente no puede tocarlas. - No pongas credenciales raíz en el Manifest. Todo lo que está en el Manifest cruza al sandbox. Solo cruzan el límite URL prefirmadas y tokens de vida corta; las cadenas de base de datos y claves de API permanecen en el harness.
- No omitas scale-to-zero en desarrollo. Una app de desarrollo mantenida caliente todo el día, multiplicada por personas y servicios, cuesta silenciosamente cientos al mes por computación inactiva casi todo el tiempo. Acepta el cold start en desarrollo.
- No despliegues sin la suite de evals conectada. Saltarla es el atajo más caro en despliegue de agentes: envías cambios que pasan revisión de código, hacen regresionar el comportamiento y aparecen como quejas semanas después. La puerta de evals es la diferencia entre desplegar agentes y desplegar agentes que se mantienen buenos.
- No ejecutes el harness sin rate limiting. Los despliegues del primer día sin eso son la forma en que los equipos descubren, después de una mención viral, que pagaron una fortuna a un proveedor de modelos en un solo día. Los límites generosos están bien; ningún límite es el ajuste peligroso.
Parte 7: Cierre
Concepto 17: El harness desplegado como realización
La ruta de fabricación construyó y midió una empresa AI-native: el bucle del agente, el sistema de registro, la capa de fuerza laboral, el delegado y la disciplina que vuelve medible el comportamiento. Este curso la envía. El harness desplegado es donde todo eso se convierte en un servicio que los usuarios reales pueden alcanzar, observado en cuatro superficies y calificado continuamente contra una suite de evals que aprende del tráfico de producción.
Todo el curso descansa en una idea: el harness es el plano de control y el sandbox es el plano de ejecución, y esa sola separación es lo que vuelve seguro, durable y escalable el despliegue. Todo lo que conectaste en el laboratorio la sirve. El harness guarda las claves, el estado y la orquestación; el sandbox ejecuta el código riesgoso sin ninguna de las claves; las URL prefirmadas limitan acceso a archivos a través del límite; la observabilidad muestra qué ocurre; la suite de evals te dice si sigue siendo correcto. Desviarte de la receta está bien. Desviarte de la arquitectura no. Ejecuta el harness y el sandbox en planos separados, observa en las cuatro superficies y califica comportamiento contra una suite de evals que crece desde producción, y la arquitectura funciona sin importar qué componentes de nube elijas.
Lo que viene después es la disciplina de diseño que se ejecuta antes de construir: elegir qué forma de agente encaja con la tarea en primer lugar. Si quieres eso, lee Elección de arquitecturas agénticas, el tejido conectivo entre diseño de agentes y despliegue de producción. Vale la pena nombrar con honestidad tres fronteras más, ninguna enviada todavía: comercio agente a agente, donde los agentes actúan como actores económicos mediante protocolos de pago; detalles de despliegue para un agente delegado del propietario, cuyo mandato firmado y ledger de gobernanza son más pesados que los de un Worker; y multicloud active-active multirregión más profundo, que es su propio tema sustancial.
Prueba con IA. Abre tu agente de programación. Pega:
"Completé la ruta de fabricación hasta este curso de despliegue. Enumera las tres cosas que aprendí y que aplicaré con más frecuencia durante el próximo año construyendo agentes, y las tres que aplicaré rara vez pero que serán críticas cuando las necesite. Explica cada una brevemente. Luego, para la composición que conectó este curso (la suite de evals del curso de desarrollo guiado por evaluaciones adjunta a un harness desplegado), nombra cuál esperas que sea la parte más difícil de operarla en la práctica: ¿qué disciplina será tentador omitir cuando el equipo esté bajo presión de despliegue?"
Lo que estás aprendiendo. La ruta es amplia, y usarás la mayor parte de ella de forma desigual: algunas partes a diario, otras raramente pero de forma crítica. Esta reflexión fuerza una lectura honesta de qué partes encajan con tu trabajo real, y saca a la superficie el modo de fallo de producción más común, que es que la disciplina de evals se despriorice bajo presión de despliegue hasta que el harness deriva.
Variante de taller de un día
Si ejecutas esto como taller de un día, el conjunto completo de conceptos y decisiones es demasiado para un solo día. Usa esta tabla para ajustar el curso al tiempo disponible.
| Tiempo disponible | Mantén | Recorta |
|---|---|---|
| 8 horas (intensivo de 1 día) | Introducción al stack (solo Docker y FastAPI) · Conceptos 1-3 (la columna arquitectónica) · Decisiones 0-5 (del sondeo a R2) · Concepto 13 (costo) · Cierre de Parte 7 | Introducción a Neon y R2 (leer por cuenta propia) · Conceptos 4-12 (usar como referencia) · Decisión 6 (sandbox: demo, no construir) · Decisiones 7-9 (diferir) · Conceptos 14-16 (diferir) |
| 2 días | Agrega decisiones 6-7 (sandbox y observabilidad) · Conceptos 8-11 | Decisiones 8-9 diferidas · Conceptos 12, 14-16 diferidos |
| 3-4 días | Agrega decisión 8 (suite de evals) · Concepto 12 | Decisión 9 diferida · Conceptos 14-16 diferidos |
| Semana completa (5-7 días) | Todo: la ruta Avanzada completa | Nada |
Para talleres cortos, conserva la columna arquitectónica (la división harness/sandbox y el stack de cinco componentes) y la ruta mínima de despliegue (decisiones 0-5). El endurecimiento y el material de fronteras honestas pueden quedar como autoestudio posterior. La comprensión arquitectónica es aquello con lo que los estudiantes deben salir; la profundidad de implementación es aquello hacia lo que crecen.
Chuleta
| # | Concepto | Idea clave |
|---|---|---|
| 1 | "Funciona en mi equipo" no es despliegue | Producción significa rearquitectar el agente en un harness (plano de control) más un sandbox (plano de ejecución), no envolver un script de portátil |
| 2 | Separación harness/sandbox | La columna: el harness orquesta con secretos y estado; el sandbox ejecuta código; el límite es de red y seguridad |
| 3 | Lo que el SDK necesita de la infraestructura | Cinco superficies (servicio HTTP, estado durable, almacenamiento de archivos, ejecución aislada, orquestación), cada una mapeada a un componente del stack |
| 4 | FastAPI como capa web del harness | Nativo asíncrono para coincidir con el SDK, esquemas API autogenerados, modelos Pydantic |
| 5 | Azure Container Apps como runtime | Ingress, autoscale incluido scale-to-zero, secretos y revisiones como primitivas administradas |
| 6 | Neon Postgres para estado durable | Postgres para estado relacional; Neon para scaling sin servidor y branching barato |
| 7 | Cloudflare R2 para archivos | Sin egreso, compatible con S3, URL prefirmadas limitan acceso a un archivo a la vez |
| 8 | Capacidades de ejecución del sandbox | Sistema de archivos, shell, instalación de paquetes, almacenamiento montado, todo aislado y efímero |
| 9 | Elegir un proveedor de sandbox | E2B es la ruta gratuita; Cloudflare es el primario de pago; otros encajan con necesidades específicas |
| 10 | Handoff de harness a sandbox | El Manifest declara el workspace; las URL prefirmadas limitan archivos; las credenciales raíz nunca cruzan |
| 11 | Observabilidad como superficie | Cuatro superficies (Application Insights, OpenTelemetry, traza del SDK, Phoenix), unidas por un run_id compartido |
| 12 | Evals como superficie | Mediadas por trazas en Neon (durable) y Phoenix (tiempo real); los frameworks de eval se adjuntan en puntos específicos |
| 13 | Economía de costos | La infraestructura es menos del 5% de la factura; la API del modelo es 90-98%; optimiza el modelo, no la infraestructura |
| 14 | Multirregión | Una sola región por defecto; multirregión solo por latencia global, uptime 99,99%+ o residencia de datos |
| 15 | Cuándo migrar fuera de la receta | Concurrencia pesada, multirregión, GPU, sandbox solo dentro de tu nube o volumen extremo de escritura |
| 16 | Lo que el despliegue no resuelve | Certificación de cumplimiento, proceso de incidentes, responsabilidad legal, prompt injection a nivel de comportamiento, upgrades de modelos, descontrol de costos |
| 17 | El harness desplegado como realización | Este curso envía lo que construyó la ruta de fabricación, con observabilidad y la suite de evals conectadas operativamente |
| # | Decisión | Entregable |
|---|---|---|
| 0 | Sondear el SDK | Versión instalada impresa, brief reconciliado con documentos vivos, nota "What changed" |
| 1 | Construir el scaffold del harness | App FastAPI, agente, estado y almacenamiento opcionales, arranca solo con OPENAI_API_KEY |
| 2 | Contenerizar | Imagen pequeña y reproducible que se ejecuta igual localmente y en la nube |
| 3 | Desplegar en Azure Container Apps | URL HTTPS pública, scale-to-zero, secretos guardados por nombre |
| 4 | Conectar Neon Postgres | Esquema de cinco tablas, pooled para la app y directo para migraciones, channel_binding eliminado |
| 5 | Conectar Cloudflare R2 | Bucket, credenciales limitadas, URL de descarga prefirmadas de vida corta |
| 6 | Conectar ejecución en sandbox | Cliente E2B de nivel gratuito adjunto por RunConfig; Cloudflare como alternativa de pago |
| 7 | Conectar observabilidad | Cuatro superficies unidas por un run_id compartido; muestra Phoenix fire-and-forget |
| 8 | Conectar la suite de evals | Puerta de regresión en CI, informe nocturno de comportamiento, promoción semanal de trace a eval |
| 9 | Checklist de producción | Rotación de secretos, despliegues blue/green, runbook de guardia, backup y recuperación, rate limits |
Referencia rápida: comandos de despliegue
# Local dev (Beginner track)
uv sync # install from the lockfile
uv run uvicorn maya_harness.main:app --reload # boot the harness locally
# Pin: openai-agents>=0.17,<0.18
# Cloud deployment (Intermediate / Advanced): Azure Container Apps
az group create --name maya-rg --location eastus
az acr create --resource-group maya-rg --name <acr-name> --sku Basic --admin-enabled true
az acr build --registry <acr-name> --image maya-harness:latest . # build in the cloud
az containerapp env create --name maya-env --resource-group maya-rg --location eastus
az containerapp create --name maya-harness --resource-group maya-rg \
--environment maya-env --image <acr-name>.azurecr.io/maya-harness:latest \
--target-port 8000 --ingress external --min-replicas 0 --max-replicas 3 \
--secrets "openai-api-key=$OPENAI_API_KEY" \
--env-vars "OPENAI_API_KEY=secretref:openai-api-key"
# Tear-down (cost discipline)
az group delete --name maya-rg --yes
# Neon Postgres (console.neon.com)
# asyncpg ignores channel_binding (not a libpq client), so the DSN works with it left in.
# Use the pooled endpoint for the app; the direct (non-pooled) endpoint for migrations.
psql "$DIRECT_BRANCH_URL" -f schema.sql # migrations on the direct endpoint
Descarga complementaria
El zip complementario contiene el harness arrancado, AGENTS.md (el brief, reglas del proyecto, arquitectura y sondeo del SDK), el código verificado para cada backend, el Dockerfile, las formas de despliegue en Azure y schema.sql: deploying-agents-crash-course.zip.
Referencias
URL vigentes a mayo de 2026; verifica antes de citarlas en tu propio trabajo.
La ruta agent-factory:
- El bucle del agente y el SDK: Construye agentes de IA.
- La suite de evals que este curso conecta al harness: Desarrollo guiado por evals.
- El sobre operativo (ejecución durable, la quinta superficie de observabilidad): Worker de producción con sistema nervioso.
- La disciplina de diseño que viene antes de construir: Elección de arquitecturas agénticas.
- La tesis detrás de la ruta: /spanish/docs/thesis.
El stack de cinco componentes:
- OpenAI Agents SDK (Python): paquete
openai-agents>=0.17,<0.18; docs en https://openai.github.io/openai-agents-python; la referencia de Manifest y proveedor de sandbox vive en la misma fuente. La separación harness/sandbox se envió como parte integrada del SDK en la versión del 15 de abril de 2026: https://openai.com/index/the-next-evolution-of-the-agents-sdk/. - FastAPI: manejo asíncrono de solicitudes y esquemas API autogenerados. https://fastapi.tiangolo.com
- Azure Container Apps: ingress, autoscale, secretos, revisiones. https://learn.microsoft.com/en-us/azure/container-apps/
- Neon Postgres: Postgres sin servidor con branching; el endpoint pooled y la trampa de
channel_bindingson detalles clave de la decisión 4. https://neon.com - Cloudflare R2: almacenamiento compatible con S3 y egreso gratuito; el SDK admite R2 como montaje de Manifest. https://developers.cloudflare.com/r2/
- Sandbox de ejecución de código: E2B (https://e2b.dev, nivel Hobby gratuito, cliente SDK nativo) es la ruta gratuita; Cloudflare Sandbox (parte de la plataforma Workers) es el primario de pago. Modal y Daytona encajan con necesidades de GPU y dentro de tu propia nube.
Referencias operativas y de seguridad:
- OpenTelemetry: el estándar de trazado que exporta el harness. https://opentelemetry.io
- OWASP API Security Top 10: la checklist de seguridad que la decisión 9 cubre en gran parte. https://owasp.org/API-Security/editions/2023/en/0x11-t10/
Curso 30 de la ruta de primeros pasos: el curso acelerado de despliegue de extremo a extremo para la ruta agent-factory. Harness, sandbox, observabilidad y suite de evals compuestos, con una introducción al stack para lectores nuevos en Docker, FastAPI, Neon y R2.