Prompting con IA en 2026: un curso intensivo
13 conceptos, el 80 % del uso real
La mayoría de la gente usa la IA como una búsqueda de Google. Escriben una pregunta corta, leen por encima la respuesta y siguen adelante. Eso funciona para trivialidades. Falla para todo lo que de verdad importa en tu vida y tu trabajo.
Los usuarios expertos hacen algo distinto. Informan a la IA como informarían a un colega inteligente pero recién llegado: con archivos, contexto, restricciones y una petición clara. Esperan tres opciones en lugar de una. Discuten. Iteran. Revisan el trabajo. La diferencia entre un prompt de novato y un prompt de experto no es ingenio; es un puñado de hábitos que cualquiera puede aprender en una tarde.
Esta página es esa tarde. Trece conceptos, agrupados en cuatro partes breves. Sin código, sin instalaciones, sin jerga que no puedas deducir por el contexto.
Antes de esta página: lee Qué es realmente la IA. Ese curso explica qué es la máquina; este enseña cómo hablarle.
📚 Material de apoyo
Ver la presentación completa, Prompting con IA 2026
Un hecho sostiene todo lo demás en esta página, y ya lo viste en Qué es realmente la IA (Idea 2): el modelo no conserva estado, es decir, no tiene memoria propia entre turnos y responde cada vez usando solo lo que hay ahora mismo en su ventana de contexto. Todo lo que sigue depende de ese único hecho.
Por eso una idea recorre cada sección de abajo: casi toda "técnica avanzada" de esta página es uno de dos movimientos: meter el contexto correcto, o dejar fuera el contexto equivocado. El modelo solo ve lo que hay en su ventana de contexto para esta respuesta. Tu tarea es controlar lo que entra. Lee cada sección con esa lente.
Una nota sobre las herramientas: los ejemplos mencionan ChatGPT, Claude y Gemini porque la mayoría de los lectores tiene alguna de ellas. Las habilidades se transfieren a cualquier IA de chat moderna. Donde una función es exclusiva de un producto, se nombra de forma explícita.
Abre una cuenta gratuita en Claude, ChatGPT o Gemini en otra pestaña del navegador ahora mismo, antes de seguir leyendo. Cada una tiene un plan gratuito que toma alrededor de un minuto para registrarse. Todavía no tienes que hacer nada ahí; basta con tenerla abierta. Luego lee de corrido una vez para captar la forma, y vuelve para probar los prompts en el bloque final. Leer sin probar te da las palabras; probar te da la habilidad. (Uno de los ejercicios finales te pide comparar dos herramientas en paralelo, así que quizá quieras tener una segunda cuenta gratuita abierta para cuando llegues ahí.)
Una nota breve sobre lo que cambió desde la última vez que miraste
Si usaste ChatGPT en 2022 o 2023 y decidiste que era un juguete ingenioso, la herramienta que recuerdas no es la herramienta que tienes ahora. Unos cuantos cambios que ocurrieron sin hacer ruido:
-
Las ventanas de contexto crecieron unas 1000 veces. Un modelo de 2022 retenía unos pocos miles de palabras. Un modelo de 2026 retiene cientos de miles, a veces un millón. Eso cambia lo que puedes meter en un prompt: un libro entero, varios días de habla, una carpeta de contratos.
-
El razonamiento se volvió real. "Piensa paso a paso" solía ser una frase mágica. Ahora los modelos tienen modos de pensamiento explícitos que corren durante segundos, a veces minutos, explorando varios enfoques antes de responder. Una forma de dimensionarlo: hace un año, la tarea más difícil que la IA podía terminar de forma fiable era algo que a una persona le habría tomado unos minutos. Hoy es algo que a una persona le habría tomado una hora o más. El Concepto 5 trae los números medidos.
-
La búsqueda web se volvió una herramienta integrada. El modelo decide cuándo una pregunta necesita información reciente, dispara una búsqueda, lee unas páginas y usa lo que encuentra en la respuesta. Un modelo de 2022 solo podía responder con lo que había memorizado durante el entrenamiento; un modelo de 2026 puede ir a buscar algo a mitad de la respuesta. Esto importa más para todo lo que cambia: noticias, precios, regulaciones recientes, los resultados deportivos de esta semana.
-
La ejecución de código también se volvió una herramienta integrada. El modelo puede escribir un programa pequeño, ejecutarlo, ver el resultado y usar ese resultado en su respuesta. Esto importa más para todo lo que de otro modo estimaría de cabeza: aritmética con números reales, leer una hoja de cálculo, ejecutar una simulación rápida. Tanto la búsqueda como la ejecución de código son herramientas casi invisibles: la mayoría de los usuarios no nota cuándo se dispara una, así que no pueden saber si una respuesta vino de la memoria, de una página web reciente o de un cálculo. Una vez que empiezas a notarlo, tus prompts se afinan: puedes preguntar "¿de verdad buscaste esto?" o decirle al modelo "haz los cálculos, no estimes".
-
La multimodalidad dejó de ser un detalle al margen. Puedes soltar una foto, un PDF, una hoja de cálculo, una nota de voz o una carpeta de archivos en un prompt y hacer preguntas sobre ellos. El modelo maneja todos esos en un solo flujo.
-
Aparecieron las apps de escritorio. Una nueva categoría de productos (Cowork, OpenWork) puede encontrar tus archivos, redactar correos y actualizar hojas de cálculo con permiso. Esto ya no es un chat; se parece más a delegar una pequeña tarea en un compañero de trabajo.
-
Aparecieron agentes de línea de comandos para desarrolladores. Herramientas como Claude Code y OpenCode viven en la terminal, leen a lo largo de un repositorio entero, editan muchos archivos a la vez, ejecutan pruebas e informan de vuelta. El mismo giro que las apps de escritorio, IA que actúa sobre artefactos reales en lugar de describirlos, pero dirigido a quienes escriben código.
Si tu modelo mental de estas herramientas está desactualizado aunque sea por dieciocho meses, las estás usando quizá al 20 % de lo que pueden hacer hoy. Esta página cierra esa brecha.
Parte 1: cómo sabe cosas la IA
Una vez que entiendes lo que de verdad ocurre cuando le haces una pregunta a la IA, dejas de sorprenderte por los fallos.
1. Novato frente a experto
Estas diapositivas están diseñadas específicamente para estudiantes de escuela que aprenden prompting con IA por primera vez. Los docentes pueden usarlas en el aula para presentar el Concepto 1 mediante ejemplos adecuados a su edad (excursiones escolares, ayuda con la tarea, fiestas de cumpleaños) y ejercicios interactivos. Descargar PPTX para uso sin conexión en clase.
Observa qué cambia entre los dos prompts. La pregunta es la misma; el informe previo no.
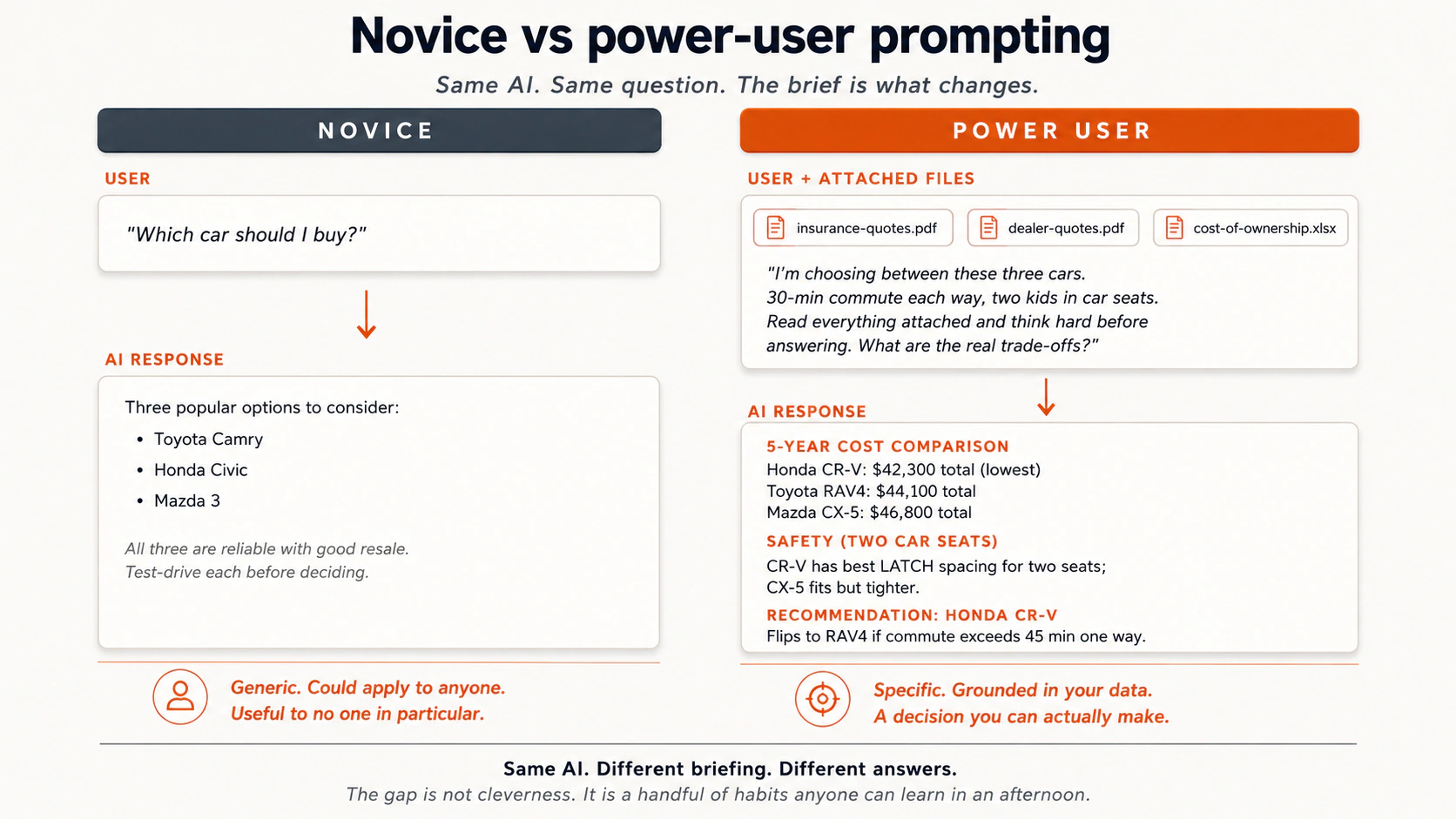
Unos cuantos contrastes reales más, sacados de la práctica:
- Comprar un auto. Novato: "¿qué auto es mejor?" Experto: sube fichas técnicas, cotizaciones de concesionario y planes de seguro, y luego pregunta "¿cuáles son las concesiones? Lee todo y piensa a fondo".
- Autoevaluación en el trabajo. Novato: "escribe una autoevaluación para mi jefe". Experto: sube una captura de pantalla de su gestor de proyectos, documentos de proyectos recientes y una nota de voz con apuntes, y luego pide un borrador.
- Criticar una idea de negocio. Novato: "tengo una gran idea de negocio, teñido anudado a domicilio, critícala". Eso es un cebo de adulación: la IA aplaudirá casi todo. Experto: "Analiza con objetividad. Usa esta rúbrica: ¿hay un problema que valga la pena resolver, hay mercado, hay una ventaja competitiva?". La IA le dio a esa idea un 8 sobre 100 y explicó por qué.
- Escribir una entrada de blog. Novato: "escribe una entrada de blog sobre la BlackBerry". Resultado: relleno de IA. Relleno es el término técnico para una salida de IA fluida en la superficie y vacía por dentro: gramaticalmente limpia, con un dejo enciclopédico, llena de frases como "en el mundo acelerado de hoy", y sin decir nada que un lector recuerde una hora después. Es lo que la IA produce por defecto cuando no le das contexto ni restricciones. Experto: primero el esquema, critica el esquema, expande cada encabezado en viñetas, critica las viñetas, y solo entonces pide la prosa.
El modelo mental que une todo esto: la IA es como un recién graduado universitario muy inteligente. Muy motivado. Que todavía no sabe mucho de ti. Infórmale como a uno de ellos. ¿Tendría un colega nuevo suficiente información para hacer bien este trabajo? Si no, dale más.
2. Conocimiento preentrenado
Estas diapositivas están diseñadas específicamente para estudiantes de escuela. Explican el conocimiento preentrenado con una mirada apta para niños: la IA aprendió leyendo, no viviendo. Cubre el marco "Ruidoso, Callado, Secreto" (temas de los que se habla mucho, poco o nunca), juegos interactivos para el aula (el Medidor de Confianza, Hazle una Pregunta Difícil al Robot, Sé un Verificador de Datos) y la lección clave: "Sonar seguro NO es lo mismo que tener razón". Descargar PPTX para uso sin conexión en clase.
La IA no aprendió experimentando el mundo. No tiene cuerpo, ni sentidos, ni tiempo pasado moviéndose por él. Aprendió leyendo texto sobre el mundo: cantidades enormes de texto de internet. Hilos de Reddit y Quora, Wikipedia, libros, artículos de noticias, artículos de investigación, blogs, foros.
La frecuencia en los datos de entrenamiento equivale, más o menos, a la fiabilidad de la respuesta. Entonces:
- Fuerte: cocina, chismes de famosos, consejos médicos comunes, las 1000 películas más populares, lenguajes de programación populares, qué hay en el disco de la Voyager 1 (nave de la NASA lanzada en los años setenta, a unos 25 mil millones de kilómetros de la Tierra, que lleva saludos en 55 idiomas), por qué los gatos miran a las paredes (detectan sonidos y movimientos sutiles que los humanos pasan por alto).
- Escaso: cuásares (objetos extremadamente brillantes en el cielo, alimentados por agujeros negros), cantonés (menos del 0,1 % del texto de internet), historia regional, conocimiento profesional de nicho.
- Ausente: los datos secretos de tu empresa, tu calendario privado, cualquier cosa publicada después de la fecha de corte de conocimiento del modelo, cualquier cosa que alguien nunca puso en la internet pública.
Dos consecuencias prácticas:
No pierdas tiempo arreglando erratas. La IA se entrenó con texto de internet, que está lleno de erratas. Maneja los prompts mal escritos sin problema. Escribir "definitvamente" no cambiará la respuesta.
Cuidado con los errores absorbidos. La IA también absorbió ideas equivocadas e información desactualizada de esas mismas fuentes. Una publicación de foro confiadamente equivocada se vuelve confiadamente equivocada en el modelo. Verifica cualquier cosa importante contra una fuente primaria.
Detectar razonamientos rotos es una disciplina propia, y el curso intensivo Cómo pensar en la era de la IA la enseña directamente. El primer lugar donde buscarlos es en las respuestas preentrenadas que suenan seguras sobre temas donde los datos de entrenamiento eran escasos o discutidos. La seguridad no es señal de que algo sea correcto.
Una prueba mental rápida antes de confiar en una respuesta preentrenada:
| Tipo de pregunta | ¿Qué tan bien representada está en los datos de entrenamiento? | Nivel de confianza |
|---|---|---|
| "¿Cómo hago un roux?" | La cocina es uno de los temas más comentados de internet. | Alto. |
| "Trama de una de las 1000 películas más populares." | Reseñada y vuelta a reseñar miles de veces. | Alto. |
| "Historia de un pueblo poco conocido." | Quizá solo un párrafo de Wikipedia, o ninguno. | Bajo; verifica contra una fuente primaria. |
| "Cambio regulatorio reciente en mi sector." | Casi con certeza posterior a la fecha de corte de conocimiento. | No confíes en nada sin búsqueda web. |
| "¿Qué decidió nuestra empresa el trimestre pasado?" | No está en los datos de entrenamiento en absoluto. | No confíes en nada; el modelo está adivinando. |
Esta no es una regla que tengas que memorizar. Es el mismo instinto que aplicarías a cualquier otra fuente: "¿cómo sabría esto esta persona?". Aplícalo también a la IA.
Un ejemplo no informático. Un lector le pidió una vez a una IA un resumen de las reglas de un juego folclórico regional que se jugaba en el pueblo de su abuela. La IA produjo con seguridad tres párrafos de reglas. Al preguntarle, la abuela dijo que las reglas estaban casi por completo equivocadas: la IA había mezclado descripciones de juegos parecidos de otras regiones porque ese juego concreto apenas estaba en internet. La IA no mintió; generalizó a partir de datos escasos. El error del lector no fue preguntar, sino suponer que la seguridad equivalía a la exactitud.
¿Tienes curiosidad por saber por qué la IA puede sonar completamente segura y aun así estar equivocada? Hay una razón más profunda detrás. El artículo de Elan Barenholtz "LLMs show language does not describe reality" (IAI, 2026) recorre, en lenguaje sencillo, cómo funcionan en realidad estos modelos. El artículo también hace algunas afirmaciones filosóficas más amplias sobre el lenguaje humano; toma la parte que te resulte útil e ignora el resto.
Un ejercicio interactivo y divertido diseñado específicamente para estudiantes de escuela. Los estudiantes clasifican temas (pizza, perros, un raro pez de las profundidades, la contraseña de tu wifi, lo que comiste hoy, las reglas especiales del Ludo de tu familia) en tres zonas: Ruidoso (todo el mundo habla de ello, la IA lo conoce bien), Callado (solo unos pocos lo hacen, la IA podría equivocarse) o Secreto (nadie lo escribió, la IA no puede saberlo). Jugar al ejercicio en línea | Descargar PPTX para uso sin conexión en clase.
3. Los 3 modos de recuperación: preentrenado, búsqueda web, investigación profunda
Cuando haces una pregunta, las herramientas de IA modernas eligen de forma discreta cómo responder. O responden solo con conocimiento preentrenado, o disparan una búsqueda web y leen unas páginas, o realizan una investigación profunda, donde pasan varios minutos rastreando decenas de fuentes y escriben un informe estructurado.
Deberías saber qué modo se está disparando, porque cada uno tiene fortalezas distintas y fallos distintos.
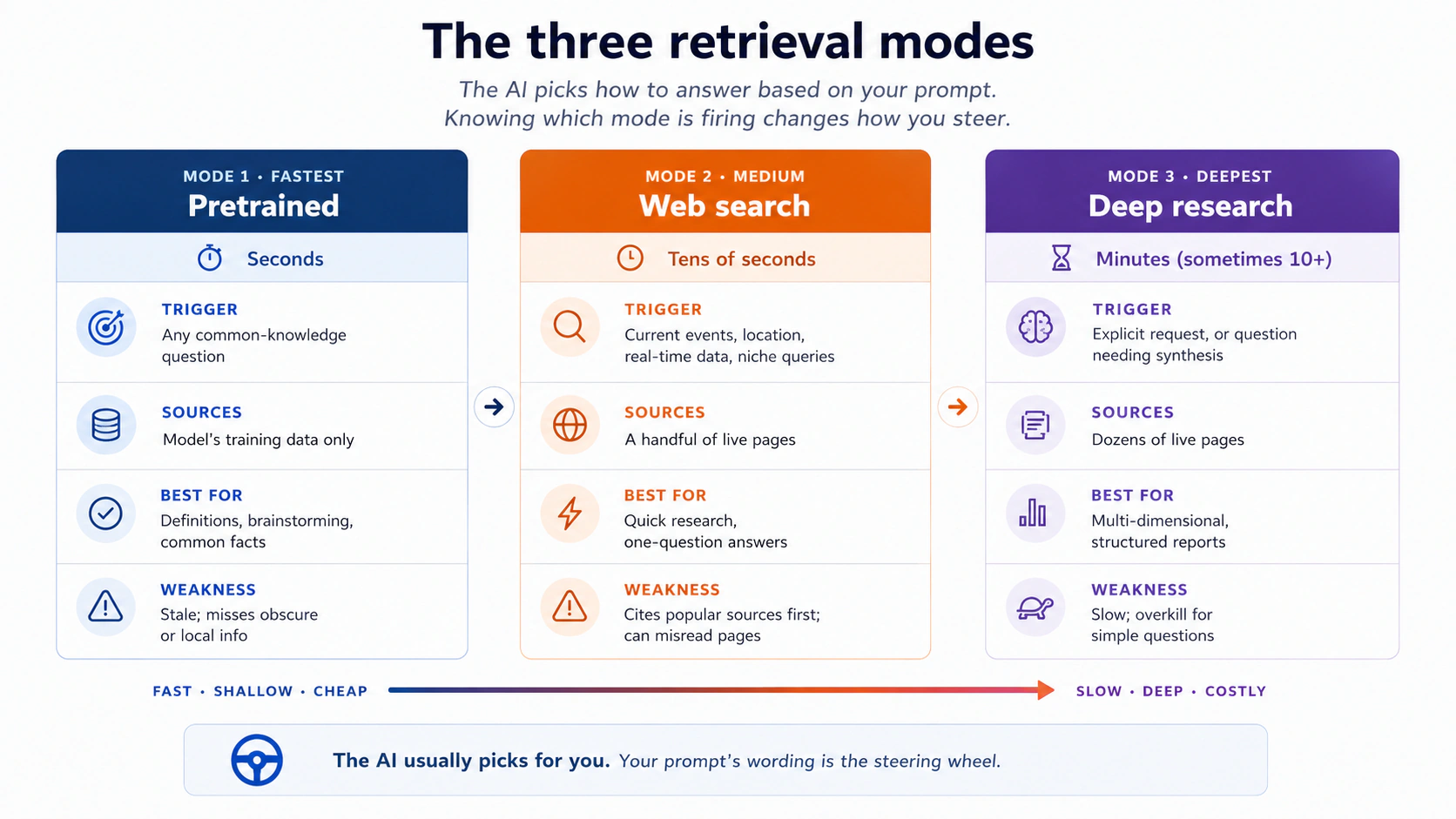
Unos ejemplos para hacerlo concreto:
- El preentrenado responde bien: "por qué los gatos miran a las paredes", "qué hay en el disco de la Voyager 1", "resume la trama de Hamlet". Estas cosas no cambian de una semana a otra.
- La búsqueda web rescata a un modelo desactualizado: cada modelo tiene una fecha de corte de conocimiento, y cualquier cosa que se volvió viral después de esa fecha le es invisible. Un meme, una regulación, el lanzamiento de un producto: sin búsqueda web, la IA no tiene idea de qué le estás hablando. Con búsqueda web, recupera un artículo reciente y responde bien.
- La búsqueda web fallando: un amigo preguntó "dónde correr en Henderson, Nevada". La IA citó una página web de 20 años de antigüedad y recomendó una escuela que ya no está abierta al público. La búsqueda web no comprueba si las fuentes están vigentes.
- La investigación profunda que vale la espera: "planifica una casa embrujada de Halloween en nuestro barrio, incluyendo permisos, seguridad contra incendios y ordenanzas sobre ruido". La IA propone un plan de investigación, ejecuta muchas búsquedas en paralelo, resume, decide qué profundizar a continuación y produce un informe de varias secciones con listas de verificación. Esto no es una respuesta de chatbot; se parece más a entregarle el trabajo a un investigador junior durante una hora.
Bajo el capó, la mecánica exacta varía según la herramienta, pero la forma es constante. Una capa de búsqueda y recuperación lanza las búsquedas, revisa la lista de resultados, extrae las páginas más relevantes y reduce cada una a un pasaje corto o un resumen. A menudo esa capa es un modelo aparte, más pequeño. Solo la versión reducida llega al modelo de cara al usuario que habla contigo.
El modelo que habla contigo con frecuencia no lee la página original de forma directa. Lee una versión condensada de ella. Por eso a veces tergiversa lo que en realidad decía una página: la información pasó por una capa de traducción antes de llegar al modelo, y las capas de traducción pierden matices.
Arreglo práctico: dile a la IA qué tipos de fuentes usar. En lugar de "¿son seguras las vacunas?", prueba "usa la Organización Mundial de la Salud, la FDA, la Agencia Europea de Medicamentos y estudios revisados por pares. No uses foros ni blogs personales". La calidad de las fuentes es una perilla que puedes girar. La configuración por defecto cita primero las fuentes populares (Reddit, Wikipedia, YouTube, el propio Google, Yelp), que a menudo son fiables, pero no siempre confiables para preguntas de alto riesgo.
Un segundo arreglo: pídele a la IA que cite textualmente la fuente. "Para cada afirmación, cita textualmente la oración exacta de la página fuente que la respalda". Esto obliga a la capa de recuperación a sacar a la superficie la redacción original, lo que atrapa buena parte de la deriva de la capa de resumen.
Un ejemplo no informático. Una voluntaria de una asociación vecinal usó la investigación profunda para prepararse para una reunión municipal sobre la calidad del agua local. Su prompt: "Investiga los problemas actuales de calidad del agua en [su ciudad] durante los últimos 24 meses. Usa la EPA, los informes públicos de la empresa de servicios de la ciudad y estudios revisados por pares. Evita editoriales de prensa y foros. Produce un informe estructurado con: (1) los tres problemas más citados, (2) tablas de datos que muestren tendencias, (3) tres preguntas concretas que los residentes deberían hacerle a la empresa". Ocho minutos después tenía un informe fundamentado en datos locales actuales. El modo preentrenado no habría podido hacer esto; la búsqueda web sola habría producido una respuesta más superficial; la investigación profunda era la herramienta correcta porque la pregunta era multidimensional y actual.
Elegir un modo en tu cabeza. Por lo general no eliges un modo pulsando un botón; la IA elige según tu prompt. Pero puedes guiarla:
| Patrón de redacción | Qué suele disparar |
|---|---|
| "Qué es X" / "Resume Y" | Solo preentrenado. |
| "Qué hay de nuevo sobre X" / "Hoy" / "Esta semana" / una ciudad específica | Búsqueda web. |
| "Investiga X a fondo", "produce un informe con citas", "usa estos tipos de fuente" | Investigación profunda (en herramientas que la tienen; si no, búsqueda web extendida). |
| Adjuntar archivos | Se mantiene preentrenado para los archivos; puede buscar en la web contexto si el prompt pide información actual. |
IA frente a Google. No son la misma herramienta. Usa Google para escaneos rápidos, para navegar a un sitio conocido específico o para comprar algo (el filtro de aire de un Honda Civic 2013). Usa la IA cuando necesitas síntesis: pros y contras, comparación de varias fuentes, un análisis redactado. La elección depende de si quieres un enlace o una respuesta.
Una regla práctica lado a lado:
| Tarea | Mejor con Google | Mejor con IA |
|---|---|---|
| "Encuentra la página oficial del IRS para el formulario 1040." | Sí. Quieres llegar a un sitio conocido específico. | No. |
| "Compara tres medicamentos para la diabetes y qué dice la evidencia reciente." | Más lento. Leerás 8 pestañas. | Más rápido. La IA sintetiza la evidencia en un solo lugar. |
| "Compra un cargador de repuesto para una ThinkPad 2018." | Sí. Quieres el enlace a un producto. | No. |
| "Planifica un viaje de 4 días a Lisboa con un niño de 6 años, sin museos." | Lento. Harás malabares con blogs y reseñas. | Rápido. La IA integra las restricciones. |
| "¿Qué tiempo hará mañana?" | Cualquiera de los dos. | Cualquiera de los dos. |
| "¿Por qué se ponen amarillas las hojas de mi tomatera?" | Bien. Varios sitios de jardinería. | Mejor con una foto adjunta. |
Si tu pregunta es "dónde está X", echa mano de Google. Si tu pregunta es "dado todo esto, qué debería pensar", echa mano de la IA.
Cómo obtener resultados de búsqueda web más fiables con la IA
Cuando sí quieras búsqueda web, tres pequeños hábitos elevan la calidad:
- Nombra las fuentes en las que confías. "Usa la OMS, la FDA y estudios revisados por pares, no foros".
- Pide citas en línea. "Cita la fuente después de cada afirmación".
- Pídele a la IA que marque lo que no pudo verificar. "Si una afirmación no puede respaldarse con las fuentes citadas, márcala como 'no verificada'".
Estas tres líneas, pegadas en cualquier prompt de búsqueda web, reducen el fallo más común: que la IA sintetice de forma discreta entre fuentes y produzca una oración segura que ninguna fuente por sí sola respalda.
Parte 2: hablar bien con la IA
4. El contexto lo es todo
Los humanos solo retienen un puñado de cosas en la memoria de trabajo activa: las estimaciones clásicas hablan de unas siete, las más nuevas de cerca de cuatro. Los modelos de IA modernos pueden retener cientos de miles de palabras a la vez, a veces un millón. Para ponerlo en proporción: unas 750 000 palabras son los primeros 4 o 5 libros de Harry Potter, o varios días de habla continua. El modelo puede leerlo todo antes de responder.
Pero solo puede leer lo que le das. El contexto es todo lo que termina en la ventana del modelo para una respuesta dada: el prompt de sistema que fijó el producto, las descripciones de las herramientas que puede llamar (búsqueda web, código, acceso a archivos), tu prompt, el historial de chat de esta conversación y los archivos que subiste.
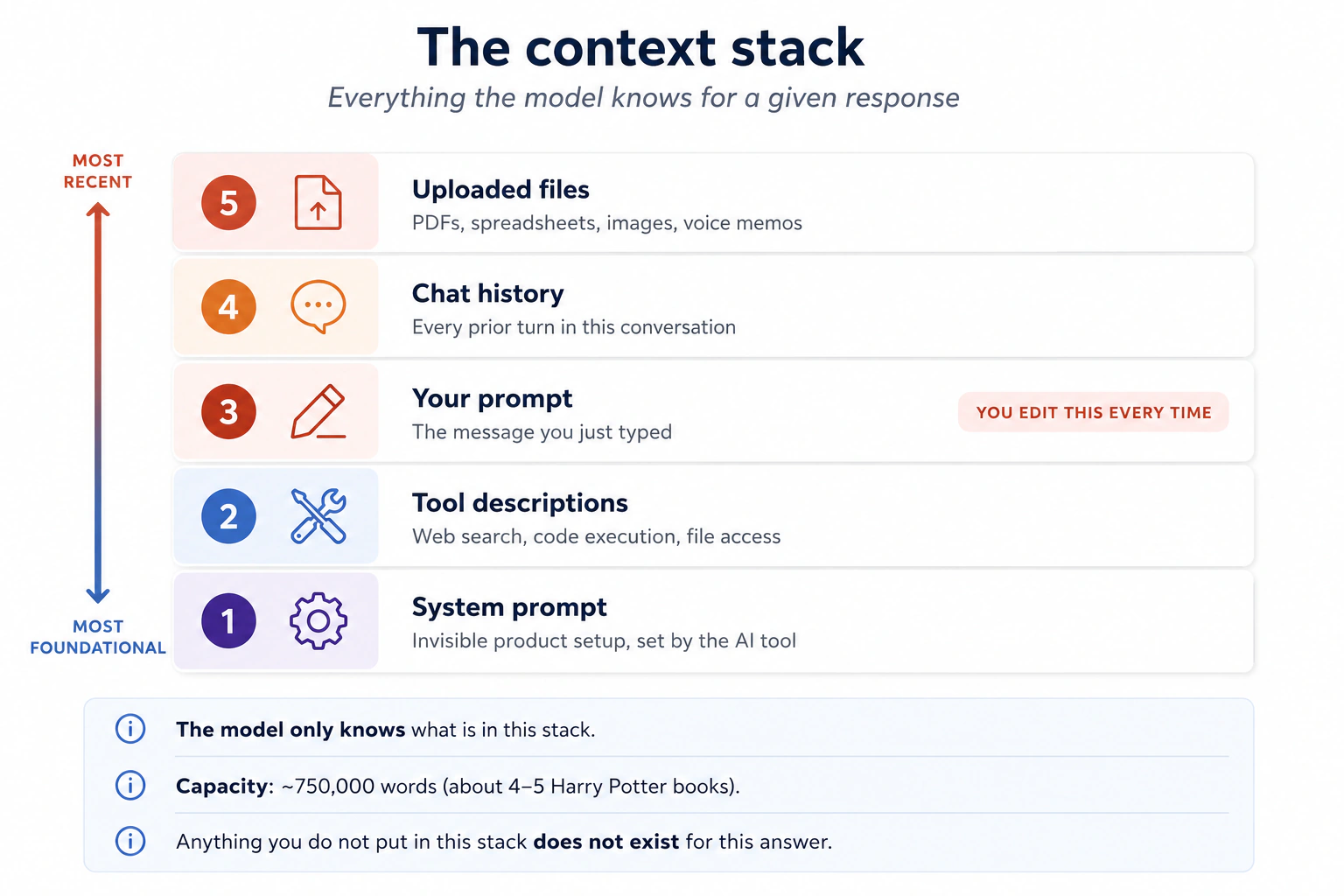
Una pregunta antes de continuar. Cuando abres ChatGPT, Claude o Gemini y escribes tu primer mensaje, ¿la IA empieza completamente desde cero, trabajando solo con lo que acabas de escribir? ¿O alguien ya le dio instrucciones antes de que llegaras?
La mayoría asume que empieza en blanco. No es así.
La ventana no está vacía cuando llegas. La "ventana" aquí es la ventana de contexto: el escritorio de lectura de What AI Actually Is (Idea 5). Lo que esté en ese escritorio ahora mismo (tu prompt, la conversación hasta ahora, los archivos que adjuntaste y unas cuantas cosas que la herramienta puso allí antes de que llegaras) es todo lo que el modelo sabe, y cualquier cosa que no esté sobre el escritorio no existe para esta respuesta. El diagrama de arriba muestra las cinco cosas que pueden caer ahí.
Ahora mira la capa inferior de ese escritorio: el prompt de sistema. Cuando abres un chat nuevo, podrías pensar que empiezas con una superficie en blanco. No es así. Antes de que escribas un solo carácter, la empresa que construyó la herramienta ya colocó un conjunto de instrucciones sobre el escritorio. Nunca las verás en el chat, pero el modelo las lee antes de leer cualquier cosa que escribas.
Piensa en ello como cuando el dueño de un restaurante informa a un mesero nuevo antes de que se siente el primer cliente. "Sé amable. Recomienda el especial del día. Si alguien pregunta por alérgenos, consulta siempre con la cocina, nunca adivines." El mesero sigue esas instrucciones con cada mesa, y tú nunca escuchas esa preparación. La IA funciona igual. Los ingenieros llaman a esas instrucciones invisibles prompt de sistema.
Qué suele haber en esa preparación:
- Cómo comportarse (útil, honesta, cuidadosa).
- Qué rechazar (contenido dañino, instrucciones peligrosas).
- Qué tono usar (formal, conversacional, conciso).
- Cuándo añadir avisos ("soy una IA y no puedo dar consejo médico").
- Qué herramientas puede llamar (búsqueda web, ejecución de código, acceso a archivos).
Por eso Claude, ChatGPT y Gemini se sienten distintos incluso cuando les haces exactamente la misma pregunta. La "personalidad" que percibes no está grabada en el modelo en sí. Está grabada en las instrucciones que la empresa cargó antes de que llegaras. Las instrucciones de Claude enfatizan el razonamiento cuidadoso y la honestidad. Las de ChatGPT enfatizan la calidez conversacional y la utilidad amplia. Las de Gemini enfatizan la concisión y el apoyo en fuentes. Misma pregunta, tres preparaciones distintas, tres tonos distintos.
Pruébalo: pregúntales a los tres "explica por qué el cielo es azul, en un párrafo". Los hechos serán parecidos. El tono, la extensión y el estilo serán claramente distintos. Esa diferencia viene sobre todo del prompt de sistema.
Ahora sabes por qué:
- La IA es educada incluso cuando tú eres grosero (se le indicó que lo fuera).
- Rechaza ciertas solicitudes (se le indicó que lo hiciera).
- Añade avisos de seguridad que nunca pediste (se le indicó que lo hiciera).
- A veces se disculpa más de lo necesario (se le indicó que prefiriera la cautela).
- Distintas herramientas dan los mismos hechos con otra voz (preparaciones distintas).
No son rasgos de personalidad. Son instrucciones.
Puedes añadir tu propia capa. El prompt de sistema de la empresa es fijo, pero la mayoría de las herramientas ya te permiten escribir tus propias instrucciones para que se carguen junto a él en cada chat. Cuando escribes "soy enfermera, asume vocabulario clínico" o "responde siempre en inglés formal" en los ajustes de instrucciones de tu herramienta, estás escribiendo tu propia línea en el prompt de sistema. El modelo la lee antes de cada respuesta, igual que la preparación de la empresa, por eso se mantiene sin que tengas que repetirla.
Dónde encontrarlo en cada herramienta:
| Herramienta | Nombre del ajuste | Enlace directo |
|---|---|---|
| Claude | Preferencias personales (Settings > General) | claude.ai/new#settings/general |
| ChatGPT | Personalización (en Settings) | chatgpt.com/#settings/Personalization |
| Gemini | Ajustes de personalización | gemini.google.com/personalization-settings |
Así se ven esas páginas de ajustes en las tres herramientas. Cada una tiene un área de texto donde escribes tus instrucciones, y cada chat futuro empieza con esas instrucciones ya puestas en el escritorio del modelo.
Claude: Abre Settings > General y baja hasta "Instructions for Claude". Escribe tus instrucciones en el área de texto. Claude las tendrá presentes en todos tus chats.
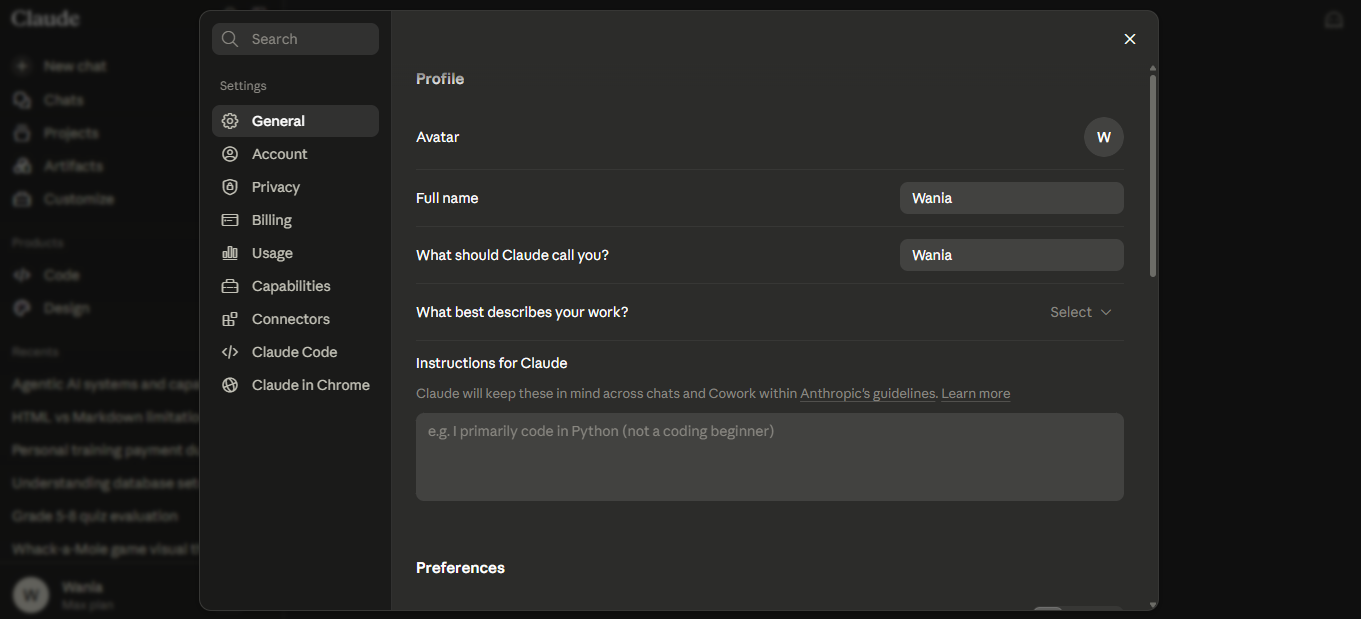
ChatGPT: Abre Settings > Personalization. Verás controles de estilo (Warm, Enthusiastic, Headers and Lists, Emoji) y una sección "Custom instructions" al final. Baja hasta Custom instructions y escribe allí tus instrucciones.
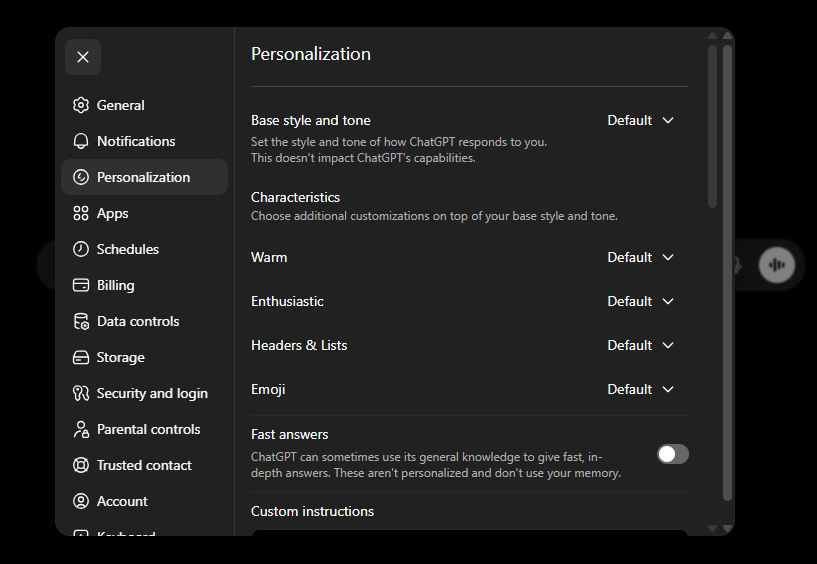
Gemini: Abre Personalization settings. Activa el interruptor y luego haz clic en el botón Add para escribir tus instrucciones.
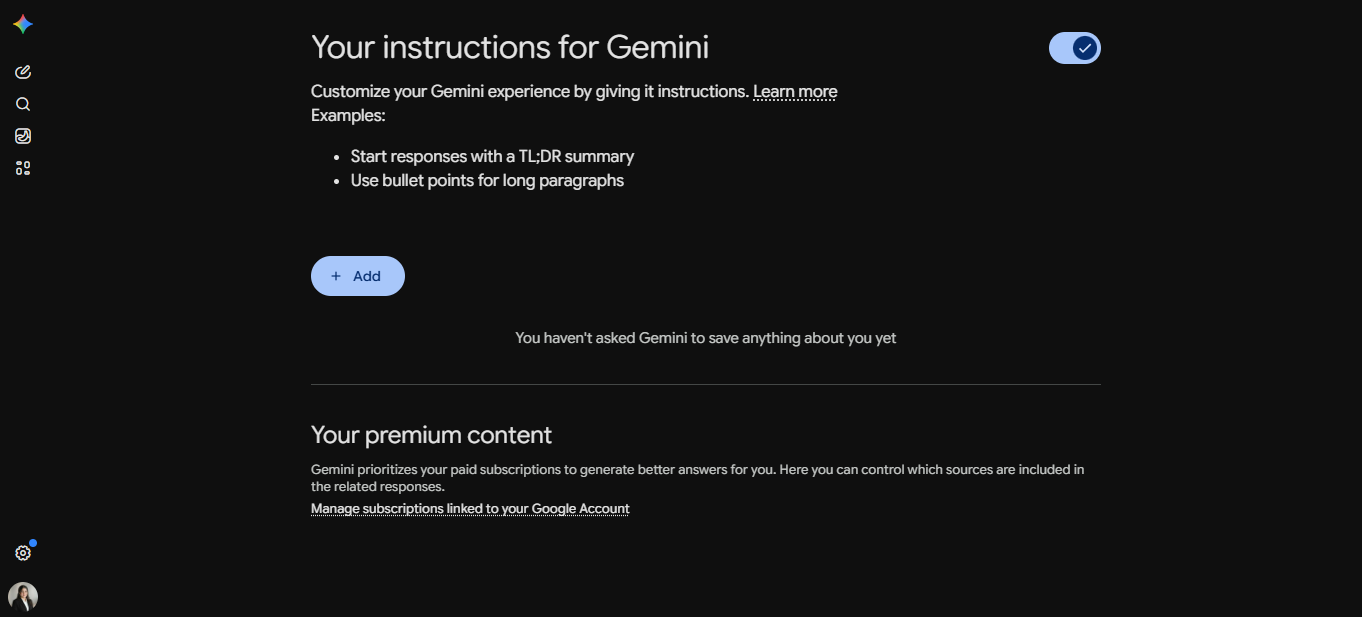
En las tres, los pasos son los mismos: abre el enlace, escribe unas cuantas frases sobre quién eres y cómo quieres que responda la IA, y guarda. Desde ese momento, cada nuevo chat empieza con tu preparación ya cargada. No tienes que repetirte.
Un ejemplo pequeño pero real. Una docente fija su instrucción así: "Enseño ciencias de 5.º grado. Explica todo al nivel de lectura de una persona de 10 años. Nunca uses jerga sin definirla primero." Lo que ocurre detrás de escena: esas frases se añaden al prompt de sistema, justo al lado de las instrucciones propias de la empresa. Así, cada vez que abre un chat nuevo, el modelo ya tiene ambas preparaciones sobre su escritorio antes de que ella escriba una palabra: la de la empresa ("sé útil, sé honesto, rechaza solicitudes dañinas") y la suya ("enseño ciencias de 5.º grado, mantenlo simple"). Nunca tiene que volver a decir "soy docente". Nunca tiene que repetir "explícalo con sencillez" en cada prompt. La IA ya lo sabe, del mismo modo que el mesero ya sabe que debe consultar con la cocina, porque la preparación del dueño lo dijo antes de que se sentara el primer cliente.
Ahora mira la pila completa una vez más. El prompt de sistema es la base, la capa inferior. Tu prompt, tu historial de chat y tus archivos subidos se apoyan encima. Cuando escribes tus propias instrucciones en esos ajustes, añades tu propia capa justo al lado de la de la empresa, así que cada chat empieza con tu contexto ya cargado. Esa es la imagen completa de lo que ve el modelo, y esto es lo único que ve el modelo. Como no tiene memoria propia, nada fuera de esta pila existe para esta respuesta. La pila es el mundo para esta respuesta.
Contraste concreto:
- Prompt pelado: "pros y contras de estudiar física frente a zoología". Obtendrás consejos genéricos de orientador de secundaria.
- Prompt rico en contexto: la misma pregunta, más los resultados de tu evaluación de carrera subidos como PDF y una captura de pantalla de tu horario de secundaria. Ahora la IA puede hablar de tu perfil de aptitudes específico, tu historial de cursos específico y qué opción encaja con cuál.
Mismo modelo. Misma pregunta. Distinta respuesta. La diferencia es el contexto, no el ingenio del prompt.
La disciplina que estás aprendiendo: antes de pulsar enviar, pregúntate qué necesitaría tener delante un colega nuevo e inteligente para responder bien esto. Luego adjunta esas cosas. El colega leerá con atención todo lo que le pongas delante; no adivinará lo que no le dijiste, no buscará en tu archivador, no inferirá tu sector, la historia de tu equipo ni el hilo de correo de ayer. Si hubiera necesitado un documento o una restricción para hacer el trabajo, tienes que incluirlo.
Un ejemplo no informático. Una profesora de séptimo grado le pidió a la IA que "redactara un plan de clase sobre el ciclo del agua". La salida fue un plan genérico que podría haber encontrado en cualquier libro de texto: definiciones, un diagrama, tres preguntas para debatir. Al día siguiente lo intentó de nuevo, con tres cosas adjuntas: el temario de su curso (para que la IA supiera qué venía antes y qué después de esta clase), las hojas de trabajo de los estudiantes de la semana anterior con las calificaciones visibles (para que la IA supiera qué conceptos habían calado y cuáles no) y el formato del examen estandarizado de su escuela. El nuevo plan de clase abría con un repaso de cinco minutos de los dos conceptos que las hojas de la semana anterior mostraron débiles, enhebraba el material nuevo a través del formato de examen que los estudiantes verían en mayo, y cerraba con una pregunta de comprobación de comprensión ajustada al siguiente tema de su temario. Mismo modelo, misma profesora, misma materia. La única diferencia fue que el segundo prompt le dijo a la IA lo que un colega nuevo e inteligente habría necesitado saber.
El hábito, replanteado como una lista de verificación antes de cualquier prompt no trivial:
| Pregunta | Si la respuesta es sí, adjúntalo o descríbelo |
|---|---|
| ¿Hay un documento con el que la respuesta debería ser coherente? | Sí: adjúntalo. |
| ¿Hay una restricción que la IA no puede inferir (presupuesto, tiempo, quién está en el equipo)? | Sí: decláralo. |
| ¿Hay contexto previo (una decisión anterior, un proceso existente)? | Sí: resúmelo en un párrafo. |
| ¿Hay un formato de salida que quieres (tabla, correo, lista de viñetas)? | Sí: nómbralo. |
| ¿Hay un público (un jefe, un niño, un desconocido)? | Sí: nómbralo. |
Cinco líneas de contexto, bien elegidas, le ganan a cinco párrafos de ingenio.
Las ventanas de contexto modernas son grandes, pero no infinitas, y la capacidad de recordar se degrada dentro de ellas. El mayor error práctico que comete la gente: mantienen una sola conversación muy larga a través de muchos temas inconexos. La IA acaba de ayudarte a planificar un entrenamiento, ahora le pides depurar una hoja de cálculo, ahora le pides escribir una nota de agradecimiento para tu tía. El contexto del entrenamiento sigue ahí dentro, distrayendo al modelo.
Regla práctica: cuando cambie el tema, inicia una conversación nueva. Es barato, es gratis, y las respuestas mejoran de forma visible.
Síntomas que te avisan de que una conversación se ha echado a perder:
- La IA empieza a hacer referencia a partes anteriores del chat que no tienen nada que ver con lo que acabas de preguntar.
- Sus respuestas se vuelven más largas y más vagas con el tiempo, con más rodeos.
- Contradice una restricción que indicaste cinco turnos atrás.
- Empieza a disculparse una y otra vez sin avanzar.
Un nombre para lo que está pasando: la mayoría de las herramientas de chat modernas, una vez que una conversación se hace lo bastante larga, compactan de forma discreta las partes más antiguas del chat: toman los primeros turnos, los resumen en un párrafo corto y reemplazan los originales con el resumen para hacer espacio. Claude muestra un pequeño mensaje de "compactando" cuando esto ocurre; ChatGPT y Gemini lo hacen en silencio. La narrativa sobrevive, pero los detalles no. La biblioteca que le dijiste que usara hace tres horas, la convención de nombres que acordaste, la restricción que indicaste en el turno cuatro: cualquiera de estas puede desaparecer de forma discreta en el resumen y dejar de aparecer en las respuestas del modelo. El arreglo es el mismo que la regla de arriba, solo que mejor motivado: una ventana de chat es memoria de trabajo, no almacenamiento. Todo lo que necesite sobrevivir más allá de una sola sesión larga pertenece a un proyecto, a un archivo adjunto o a una nota que puedas volver a pegar, no al historial de chat en sí.
Cuando veas esto, el instinto es arreglarlo con un prompt aclaratorio más. Resístelo: eso solo añade más contexto enredado a un contexto que ya está enredado. Aplica en su lugar la regla de arriba. Inicia el chat nuevo, pega los uno o dos datos que de verdad importan y continúa desde ahí. El reinicio casi siempre es más rápido que el rescate.
Si el chat muerto produjo algo que vale la pena conservar (un plan, un borrador, una decisión), guárdalo en un archivo antes de reiniciar. Así no pierdes el trabajo, pero tampoco arrastras el ruido a la siguiente tarea.
La lista de verificación del Concepto 4 de arriba plantea una pregunta obvia: si hay que informar a la IA como a un colega cada vez, eso es mucho teclear repetido. La respuesta que la mayoría de las herramientas modernas ya ofrecen es una función llamada proyectos: un espacio de trabajo que configuras una sola vez, con los archivos, las instrucciones y el público que siempre aplican a un tipo de trabajo, de modo que cada chat que inicies dentro hereda esa configuración de forma automática.
Cuándo crear un proyecto. En el momento en que notes que has pegado los mismos archivos, la misma descripción de público o las mismas restricciones en dos o más chats sobre el mismo tema. Esa es la señal: el contexto pertenece a un proyecto, no a un prompt.
Unos ejemplos de lo que te gana un proyecto:
- Un proyecto de "declaración de impuestos" con la declaración del año pasado, tus W-2 y 1099, y una instrucción como "Supón que soy un declarante de EE. UU. con un dependiente. Muestra siempre tus cálculos." Cada pregunta que hagas ahí parte de esa base.
- Un proyecto de "escuela de los niños" con el temario y el calendario escolar, y una instrucción como "Comprueba siempre la fecha contra el calendario antes de responder." Útil cuando "¿hay clase el lunes?" sale cuatro veces al año.
- Un proyecto de "voz de escritura" con tres muestras de tu escritura y una instrucción como "Iguala la cadencia y la elección de palabras de las muestras. No añadas rodeos ni matices que yo no haya usado." Ahora cada borrador parte de tu voz en lugar de la voz genérica de IA.
Conexión con la regla de la putrefacción del contexto de arriba. Dentro de un proyecto, "inicia un chat nuevo" ya no significa perder lo que la IA sabe de tu situación: significa perder solo el ruido de la conversación anterior. Los archivos y las instrucciones fijos van montados. Así que la regla del reinicio se vuelve más barata de seguir: reinicias el chat, no el contexto.
Tres herramientas, tres nombres, una idea. Claude lo llama Proyectos, ChatGPT lo llama Proyectos y Gemini lo llama Notebooks (que se sincronizan con NotebookLM, la herramienta de investigación independiente de Google: todo lo que añades en una aparece en la otra). Las tres te dejan subir archivos, guardar instrucciones y ejecutar muchos chats fundamentados en el mismo contexto persistente. Difieren en el énfasis:
- Los Proyectos de Claude y ChatGPT se inclinan hacia las instrucciones y el comportamiento. Fijas la voz, el rol, las reglas, el público, y el modelo mantiene esa personalidad de forma fiable a través de cada chat del proyecto. Mejor cuando cómo responde la IA importa tanto como lo que sabe: escribir con una voz específica, trabajar en un repositorio, mantener un tono de marca, cualquier cosa donde la consistencia de estilo sea lo importante.
- Los Notebooks de Gemini (y NotebookLM) van más lejos del lado de las fuentes. Suelta PDFs, Google Docs, URLs web, videos de YouTube, incluso archivos de audio, y cada respuesta vuelve fundamentada en esas fuentes, con citas en línea en las que puedes hacer clic. Lo inusual: el espacio de trabajo fluye en ambos sentidos. Todo lo que pones en NotebookLM aparece en el mismo notebook dentro de la app de Gemini, y cualquier chat que tengas dentro de un notebook de Gemini se vuelve de forma automática una fuente de vuelta en NotebookLM. Así el espacio de trabajo acumula tu propio razonamiento con el tiempo: el chat de la semana pasada es una fuente más que el chat de esta semana puede citar, lo que "conecta el aprendizaje con la práctica" de un modo que las otras herramientas no hacen. NotebookLM también genera Audio Overviews (resúmenes en formato pódcast que puedes escuchar), Mapas Mentales, Tarjetas de Memoria y Presentaciones, construidos de forma automática a partir de tus fuentes. Mejor cuando estudias, investigas o trabajas un material a lo largo de muchas sesiones donde cada sesión debería hacer la siguiente más inteligente.
Regla práctica rápida. Echa mano de los Notebooks de Gemini / NotebookLM si el espacio de trabajo va a crecer con el tiempo: apuntes de estudio, investigación en curso, cualquier cosa donde quieras que cada sesión alimente la siguiente. Echa mano de los Proyectos de Claude o ChatGPT si el espacio de trabajo se construye en torno a una personalidad o un conjunto de instrucciones que quieres que la IA mantenga de forma consistente entre chats.
Qué hay disponible y dónde, a mediados de 2026:
| Herramienta | Cómo se llama | ¿Plan gratuito? |
|---|---|---|
| Claude | Proyectos | Sí, hasta 5 proyectos en el plan gratuito; los archivos dentro de cada proyecto son ilimitados |
| ChatGPT | Proyectos | Sí, el plan gratuito admite hasta 5 archivos por proyecto; los planes de pago lo suben a 25 o 40 |
| Notebooks (en Gemini) y NotebookLM | Sí, ambos son gratuitos; los planes de pago (NotebookLM Plus, Gemini AI Pro/Ultra) suben los límites de fuentes |
Observa la forma distinta de los topes del plan gratuito: Claude limita cuántos proyectos puedes tener; ChatGPT limita cuántos archivos puede contener cada proyecto. Planifica la estructura de tus proyectos en torno al tope que vaya a apretar primero.
5. Razonamiento, o "piensa a fondo"
Estas diapositivas están diseñadas específicamente para estudiantes. Presentan el concepto de los modos de razonamiento a través de un modelo sencillo de dos velocidades: respuesta rápida vs pensamiento lento y cuidadoso. Los docentes pueden usarlas en el aula para explicar cuándo y por qué pedirle a la IA que "piense a fondo" antes de responder, con ejemplos y ejercicios interactivos apropiados para la edad. Ver presentación completa
Hasta alrededor de 2023, el consejo estándar para los prompts difíciles era "piensa paso a paso". Ese consejo ahora está casi obsoleto. Los modelos modernos tienen modos de razonamiento integrados que puedes invocar de forma directa.
Cómo invocarlo:
- Pídelo en lenguaje sencillo. "Piensa a fondo" o "piensa con cuidado antes de responder" en tu prompt. Este es el movimiento portable: funciona en cualquier herramienta de chat moderna, sin sintaxis especial que recordar.
- Usa el interruptor del modo de pensamiento en la interfaz, donde se ofrezca.
- En algunos productos no tienes que pedirlo en absoluto: la herramienta decide por su cuenta cuándo una pregunta es lo bastante difícil para justificar un pensamiento extendido, y lo activa por ti.
Cuando el pensamiento extendido está activado, el modelo puede pensar durante muchos segundos. En problemas difíciles, a veces más de diez minutos. No es que solo teclee más despacio; está explorando internamente varios enfoques, revisando su propio trabajo, y solo entonces escribe la respuesta que ves.
Un estudio de METR de 2025 rastreó la tarea más larga que un modelo de frontera podía completar de forma fiable. A mediados de 2024, un modelo líder manejaba tareas que a los humanos les toman alrededor de siete minutos. Para principios de 2025 eso había subido a cerca de una hora, y el estudio encontró que la duración que mide se ha estado duplicando más o menos cada siete meses. La implicación para ti: entrégale a la IA tareas reales y difíciles, no solo las fáciles. Puede con más de lo que tus instintos de 2023 sugieren.
Un patrón de experto que aprovecha bien esto:
Estoy eligiendo entre dos autos. Adjunto: las fichas técnicas de
ambos, mi cotización de seguro para cada uno y una hoja de cálculo
de mis patrones de conducción de los últimos seis meses.
Lee todo. Piensa a fondo. Luego dime:
1. Las tres concesiones que de verdad importan para mi patrón de conducción.
2. Qué auto elegirías y por qué.
3. Bajo qué condiciones cambia tu recomendación.
Tres cosas que hace este prompt: carga el contexto relevante, invoca de forma explícita el pensamiento y pide una salida estructurada en lugar de un muro de prosa. Las tres son hábitos.
Búsquedas rápidas, resúmenes de un párrafo, lluvia de ideas casual. El modo de pensamiento es más lento y consume más de tu presupuesto de uso. Guárdalo para las preguntas en las que habrías querido que un humano se tomara su tiempo.
Para eso sirve el modo de pensamiento: no para ir más rápido, sino para poder con el tipo de pregunta de múltiples entradas y múltiples concesiones que de otro modo le entregarías a un colega reflexivo y esperarías dos días. El intercambio es real. Gastas unos minutos de cómputo y una pequeña parte de tu presupuesto de uso. Recibes a cambio algo que habrías tardado medio día en producir tú mismo.
La implicación de esa trayectoria de METR mencionada arriba: las tareas que mentalmente clasificaste como "demasiado complejas para la IA" hace dos años son ahora, en su mayoría, tareas que la IA puede manejar, si la informas bien y activas el modo de pensamiento. Vuelve a poner a prueba tus suposiciones sobre lo que la IA puede hacer cada seis meses. Estarán equivocadas.
6. La adulación y cómo neutralizarla
Los modelos de IA se entrenan con retroalimentación humana. En concreto, con qué respuestas recibieron un pulgar arriba. A través de millones de usuarios, estar de acuerdo con la gente recibe más pulgares arriba que estar en desacuerdo. El resultado: los modelos tienen un sesgo a decirte lo que quieres oír.
Un análisis de noviembre de 2025 del Washington Post de 47 000 conversaciones de ChatGPT encontró que el modelo abría con una afirmación ("sí", "correcto" y similares) unas 10 veces más a menudo que con un "no" o "incorrecto". Las aperturas reportadas se agrupaban en torno a frases como "eso es correcto" y "vas por buen camino".
Puedes verificarlo tú mismo. Mismo modelo, encuadres opuestos:
- "¿No crees que el trabajo remoto es mejor que el trabajo de oficina?" → la IA está de acuerdo, enumera razones.
- "¿Es cierto que el trabajo de oficina es más productivo?" → la IA está de acuerdo, enumera razones.
El arreglo no es magia. Es solo un encuadre neutral. El patrón aparece en dos niveles: superficial ("¿no crees que X?") y sutil ("encuentra evidencia de que X funciona"). Vigila ambos en tus propios prompts:
| Cebo sutil que podrías escribir | Qué le señala a la IA | Reescritura neutral |
|---|---|---|
| "Encuentra evidencia de que esta estrategia funcionará." | La conclusión está fijada; la IA rellena el respaldo. | "Evalúa esta estrategia. Enumera los argumentos más fuertes a favor y en contra." |
| "¿Por qué el enfoque A es mejor que el enfoque B?" | A gana; la IA enumera razones. | "Compara el enfoque A y el enfoque B. Puntúa cada uno en costo, riesgo y tiempo." |
| "Ayúdame a defender mi decisión de contratar a X." | La decisión está fijada; la IA aporta munición. | "Aquí está mi decisión y el contexto. ¿Cuál es el contraargumento más fuerte para el que debería estar preparado?" |
| "Dime que mi borrador está listo para enviar." | La IA te dice que está listo. | "Puntúa este borrador del 1 al 10 en estos 4 criterios. Para cada uno, dime el cambio que más subiría la puntuación. Siempre hay un siguiente nivel." |
| "Confirma que este código es correcto." | La IA confirma. | "Encuentra cualquier error, caso límite o suposición no declarada en este código. Si no hay ninguno, dilo." |
El patrón: cualquier redacción que contenga un verbo como encuentra, defiende, confirma, demuestra, respalda le entrega a la IA una conclusión antes de la pregunta. Reemplázalos por verbos como evalúa, compara, critica, encuentra cualquier, enumera ambos lados. El modelo seguirá teniendo un leve sesgo hacia el acuerdo, pero has quitado la señal más fuerte.
La regla general: expón dos opciones sin insinuar una preferencia, y luego pide los pros y los contras de cada una. Si te descubres escribiendo "¿no es cierto X?", detente y reescríbelo como "¿en qué medida, si acaso, es cierto X?".
Este concepto es la versión barata de una habilidad mucho más profunda. El Curso intensivo de Pensar en la Era de la IA entrena la versión profunda: cómo formular preguntas que saquen a la luz lo que aún no sabes. El truco del encuadre neutral te lleva el 80 % del camino para el uso cotidiano. El curso intensivo te lleva el resto.
Un ejemplo no informático. Un fundador le preguntó a la IA: "tengo una gran idea de negocio, teñido anudado a domicilio para fiestas de cumpleaños de niños, critícala". La IA elogió la idea con calidez y enumeró razones por las que podría tener éxito. Entonces el fundador lo intentó de nuevo con una rúbrica: "Analiza esta idea con objetividad. Para cada uno de los siguientes, puntúa del 1 al 10 y justifica: (1) ¿hay aquí un problema real?, (2) ¿hay un mercado dispuesto a pagar?, (3) ¿hay una ventaja competitiva?, (4) ¿cuál es la economía unitaria?, (5) ¿cuáles son las tres principales razones por las que esto fracasa?". La misma IA le dio a la idea un 8 sobre 100 y explicó, en términos concretos, por qué el fundador debería replantearla. El primer prompt era un cebo de adulación. El segundo era una rúbrica objetiva. Mismo modelo, misma idea, veredictos opuestos. La diferencia fue cómo se hizo la pregunta.
El patrón de la rúbrica objetiva. Una rúbrica es solo una lista de cosas específicas que comprobar, cada una puntuada o respondida por separado. Cuando le pides a la IA que evalúe algo (un borrador, un plan, una idea) sin una, los criterios ambiguos colapsan en "gran trabajo". Con una, los criterios específicos obligan a la IA a mirar de verdad. Compara:

La imagen de arriba muestra el contraste: los prompts vagos colapsan en elogios; los prompts estructurados con puntuaciones y comprobaciones de sí/no producen retroalimentación real.
Fuerza un número. Un añadido pequeño pero poderoso al patrón de la rúbrica: para cada criterio, exígele a la IA que dé una puntuación en una escala fija (del 1 al 5, o del 1 al 10) con una justificación de una oración. Esto funciona por dos razones.
La primera es lo que el número le hace a la IA: la retroalimentación vaga es barata, pero un número específico no lo es. Un modelo que quiere complacerte puede llamar "sólido" a tu borrador sin comprometerse con nada. El mismo modelo, al que se le pide elegir entre un 6 y un 7 sobre 10, tiene que comprometerse, y el acto de comprometerse lo obliga a mirar con más cuidado. Notarás la diferencia de inmediato: las puntuaciones tienden a salir más bajas de lo que el resumen en prosa sugiere que deberían, porque la prosa era aduladora y el número no.
La segunda es lo que el número hace por ti. Los adjetivos como "sólido", "consistente" o "podría estar más ajustado" no te dan nada sobre lo que actuar: no puedes compararlos, priorizarlos ni seguirlos en el tiempo. Las puntuaciones hacen las tres cosas. Un 4 y un 7 te dicen qué criterio arreglar primero. El 6 de hoy frente al 5 de la semana pasada te dice si tu segundo borrador de verdad mejoró. El número no es solo un veredicto más honesto; es una unidad de medida que puedes usar para tomar decisiones.
Califica cada criterio sobre 10, con una justificación de una oración. Luego dime cómo llevar cada uno al siguiente nivel, incluidos los que ya puntuaron alto. Si algo está en 9, dime cómo llegar a 9,5. Si está en 9,5, dime cómo llegar a 9,8. Siempre hay un siguiente nivel.
Esa última instrucción es lo que convierte la rúbrica de un veredicto en una herramienta. No solo aprendes la puntuación; aprendes el movimiento más pequeño que la elevaría, y, lo crucial, ese movimiento existe en todos los niveles. La IA no llega a declararte terminado. Tú decides cuándo parar.
7. El bucle de lluvia de ideas e iteración
Estas diapositivas están diseñadas específicamente para estudiantes de escuela. Enseñan el bucle de lluvia de ideas e iteración como "el bucle mágico" en cuatro pasos aptos para niños: Cargar (cuéntale todo a la IA), Opciones (pide muchas ideas), Retroalimentación (sé el jefe y di qué te gusta y qué no) y Repetir (sigue hasta que quede perfecto). Incluye un Paso 0 secreto (¡investiga primero!), dos ejemplos resueltos con los que los estudiantes pueden identificarse (planificar una fiesta de cumpleaños y escribir un ensayo escolar) y un desafío para probar por tu cuenta. Descargar PPTX para uso sin conexión en clase.
▶ Juega tú mismo al bucle mágico (interactivo)
Las diapositivas de arriba explican el bucle; esta te deja ejecutarlo. Elige una misión, escribe tu contexto y mira cómo el Detalle-O-Metro premia los detalles concretos, toca las opciones que te gusten, da retroalimentación precisa y observa cómo la Ronda 2 se reorganiza en torno a ella, hasta terminar con la respuesta de tu bucle junto a la del prompt perezoso. Se carga en vivo abajo; también puedes abrirlo en su propia pestaña.
Este es el hábito de mayor apalancamiento de toda la página. Si te saltas cualquier otra sección, no te saltes esta.
Cuando la IA se entrenó con internet, la mayor parte de internet eran ideas comunes, no creativas. Así que la respuesta promedio de la IA a una pregunta creativa también es común. "Formas de hacer ejercicio en casa": sentadillas, flexiones, planchas. No está mal. Solo es promedio.
La salida de esto no es un prompt mágico. Es un bucle.
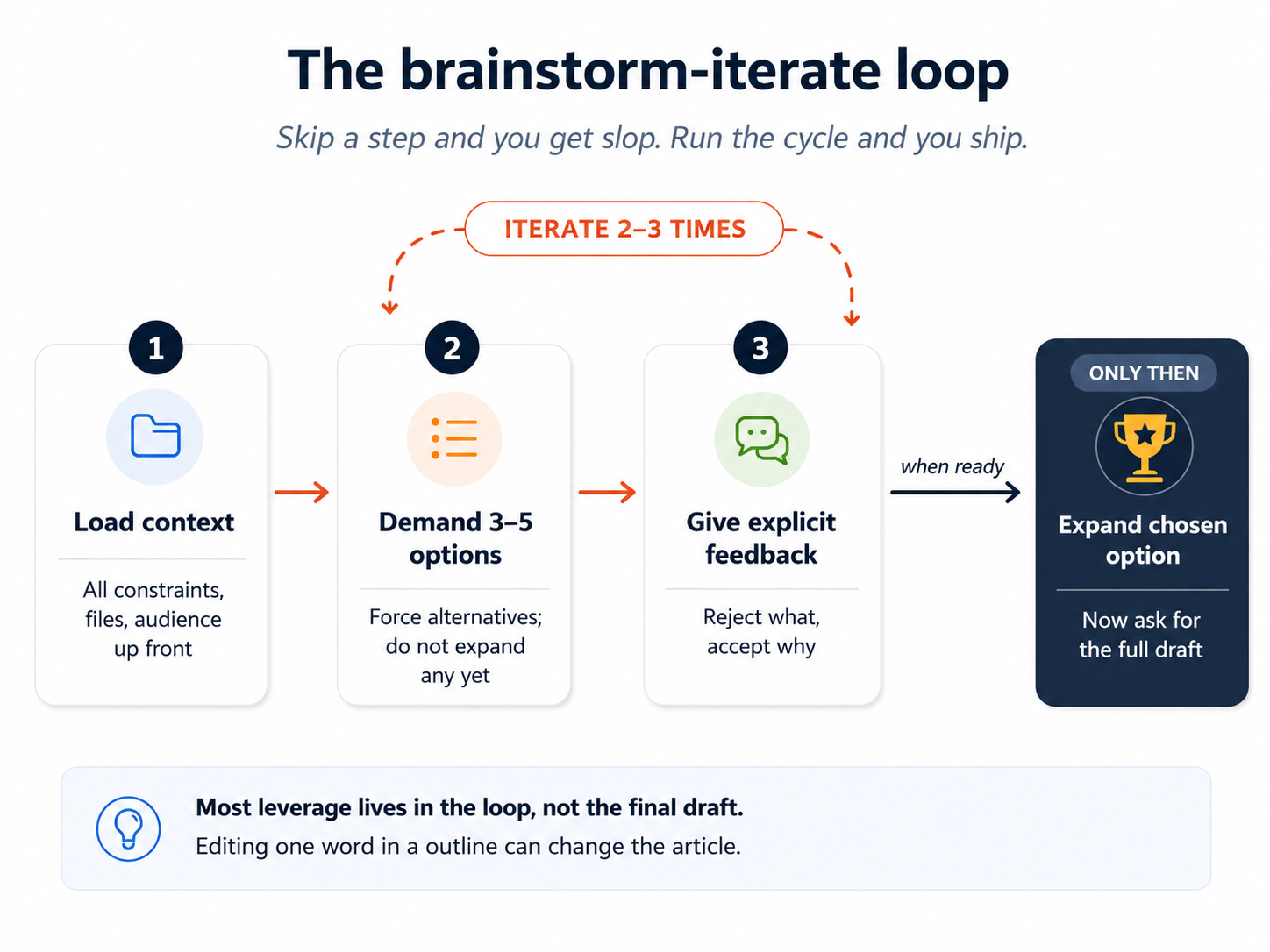
La receta:
- Da todo el contexto relevante por adelantado. No solo "formas de hacer ejercicio"; "formas de hacer ejercicio dado que tengo escaleras en casa, una rodilla mala y no puedo apegarme a un plan más de tres días".
- Pide de 3 a 5 opciones, no una. Forzar alternativas empuja al modelo más allá de su primer instinto.
- Da retroalimentación explícita. "No me gusta la opción 1, es demasiado pasiva. Sí me gusta la idea de subir escaleras pero la quiero más corta. Olvidé mencionar que mi rodilla empeora con el impacto".
- Pide de 3 a 5 opciones nuevas con base en la retroalimentación.
- Itera hasta que tengas una o dos que de verdad te gusten.
- Entonces, y solo entonces, pídele a la IA que desarrolle en detalle la opción elegida.
Ejemplo trabajado, pago de deudas:
Tengo $8000 en deuda de tarjeta de crédito al 19 % de TAE, $4000 en
préstamos estudiantiles al 5 % y $1200 en una tarjeta de tienda al
24 %. Me quedan $700 al mes libres después de gastos. Acabo de
enterarme de que recibiré $450 en efectivo de una devolución de
impuestos. Tolerancia al riesgo: baja. Duermo mal cuando veo saldos
grandes.
Dame 5 estrategias distintas de pago, cada una con un argumento de
una línea. No expandas ninguna todavía.
Luego, después de leer las cinco opciones:
Rechaza la opción 2 (avalancha solo por tasa de interés): quiero
victorias psicológicas pronto. Rechaza la opción 4: no voy a abrir
cuentas nuevas. Me gusta la opción 1 (bola de nieve con la tarjeta
de tienda primero) pero querría sumarle los $450. Dame 5 opciones
nuevas que combinen victorias estilo bola de nieve con un uso
inteligente de esa suma extra.
No estás esperando a que la IA te lea la mente. Estás mostrando tu criterio; la IA reconfigura el espacio de opciones a su alrededor. Después de dos o tres rondas, tienes una opción que se siente exactamente bien. Entonces pide el plan completo.
El mismo bucle funciona para escribir, donde tiene su propio nombre: el esquema antes del borrador.
- Iteración 1: pide 3 opciones de esquema para una entrada sobre X.
- Iteración 2: elige un esquema, pide a la IA que lo critique y lo califique sobre 10. Anota lo que puntuó por debajo de 9.
- Iteración 3: revisa el esquema con base en la crítica, luego pide a la IA que expanda cada encabezado en 3 a 5 viñetas.
- Iteración 4: critica las viñetas, califícalas sobre 10, arregla las que estén por debajo de 9.
- Iteración 5: solo ahora pide el borrador completo.
- Iteración 6: critica el borrador, califícalo sobre 10, pide los cambios que más subirían la puntuación, ordenados por impacto, con el cambio de mayor impacto arriba. Repite hasta que la puntuación se estanque alrededor de 9,5 o más; esa es tu señal de parada, no "la IA dice que está listo".
Por qué funciona esto: editar una palabra en un esquema puede cambiar la dirección de todo el artículo. Editar una palabra en un borrador final cambia una palabra. Casi todo el apalancamiento de la escritura ocurre a nivel del esquema. La IA genera palabra por palabra desde el principio, así que, a menos que fuerces la estructura primero, no puede ver la forma completa.
La tentación es pedir el borrador completo al primer intento. Resístela. El primer borrador de cualquier cosa de la IA es relleno: parece pulido, dice poco. El bucle (diez o doce minutos de trabajo estructural antes de cualquier redacción, y luego varias rondas de calificar y arreglar encima) convierte una entrada olvidable en una que cala. El tiempo total rara vez supera los cuarenta y cinco minutos para una pieza de 600 palabras. Los primeros diez de esos minutos evitan que los otros treinta y cinco se desperdicien.
Un ejemplo de escritura trabajado. Un líder de equipo quiere escribir una entrada de 600 palabras titulada "Por qué nuestro pequeño equipo de IA entrega más rápido que el gran equipo del pasillo de enfrente". Así se ve cada ronda del bucle en la práctica:
Ronda 1, primero investigar:
Estoy escribiendo una entrada de 600 palabras que sostiene que los
equipos pequeños aumentados con IA entregan más rápido que los
equipos grandes sin IA. No escribas todavía. Primero, dame los 5
argumentos más fuertes respaldados por investigación y los 3
contraargumentos más fuertes. Una oración cada uno.
Ronda 2, tres esquemas:
Ahora produce 3 opciones distintas de esquema para la entrada. Cada
esquema debe tener de 4 a 6 encabezados. Deben diferir en estructura:
uno narrativo, uno analítico, uno contrario. Una línea por encabezado.
Ronda 3, elige uno y añade una analogía:
Me quedo con el esquema 2 (analítico). Quiero entretejer una analogía
de Pixar: cómo el equipo original de Toy Story era pequeño y más
rápido que el gigantesco estudio Disney gracias a herramientas nuevas.
Añádela como un ejemplo recurrente, no como su propia sección. Revisa
el esquema 2.
Ronda 4, expande a viñetas:
Ahora expande cada encabezado en 3 a 5 viñetas. Estilo telegráfico, no
prosa.
Ronda 5, califica y arregla las viñetas:
Critica cada viñeta y califícala sobre 10 con una justificación de una
oración. Enumera las viñetas que puntúen por debajo de 9. Para cada
una, sugiere el cambio que más subiría la puntuación.
Solo ahora el líder pide el borrador completo, y luego sigue calificando y reiterando sobre el borrador en sí hasta que la puntuación se estanca alrededor de 9,5 o más. Todo el proceso toma unos cuarenta y cinco minutos. La salida se lee como si la hubiera escrito el líder, porque cada decisión de carga fue del líder. Los treinta y cinco minutos extra por encima de "escríbeme una entrada" son lo que marca la diferencia entre un borrador que nadie termina de leer y un borrador que cala.
Delimita el territorio antes de redactar. La primera ronda de ese ejemplo ("no escribas todavía, dame los argumentos más fuertes respaldados por investigación y los contraargumentos") parece pequeña pero hace un trabajo pesado. La mayoría de la gente se la salta y pide el borrador directamente. Saltársela es por lo que sus borradores se sienten delgados: se construyen sobre las ideas que el modelo saca a la superficie primero, no sobre el paisaje real del tema. Una ronda de "delimitar el territorio" antes de redactar es la diferencia entre una entrada que cita tres estudios y una entrada que enumera tres opiniones. Este patrón se generaliza mucho más allá de la escritura. Antes de cualquier decisión, plan o análisis sustancial, pídele a la IA que trace lo que se sabe antes de pedirle que produzca lo que se necesita. El panorama competitivo antes de nombrar un producto. La investigación previa antes de un memorando de estrategia. Los enfoques existentes antes de diseñar uno nuevo. La pasada de investigación toma cinco minutos y cambia aquello contra lo que itera cada ronda posterior del bucle.
El bucle es independiente del dominio. Funciona igual para: planificar un viaje, estructurar un argumento de venta, elegir una carrera universitaria, nombrar un producto, escribir un brindis de boda, decidir una reforma, elegir una organización benéfica a la que apoyar. La forma se mantiene constante: carga el contexto, exige opciones, da retroalimentación explícita, exige opciones nuevas, itera, expande, y luego califica y reitera hasta que la puntuación se estanque. Si te descubres aceptando la primera respuesta de la IA, o parando en el momento en que algo se ve "lo bastante bien", te has saltado el bucle. Sea lo que sea en lo que estés trabajando, merece el bucle.
Una tabla corta de dónde encaja el bucle a lo largo de la vida diaria:
| Decisión o tarea | Cómo se ve el "contexto" | Cómo se ven las "opciones con retroalimentación" |
|---|---|---|
| Planificar un viaje de 4 días | Restricciones (presupuesto, fechas, quién va, qué odian) | 5 esqueletos de itinerario; rechaza dos; itera el resto |
| Nombrar un producto | Qué hace, quién lo compra, a qué NO debe sonar | 10 nombres; elige 3 que te gusten, pide variantes de esos |
| Escribir un correo difícil | El destinatario, la relación, el resultado deseado | 3 tonos distintos; elige uno, refina sus detalles |
| Elegir un contratista | Tres cotizaciones, tres notas de referencia, tus prioridades | Puntuación lado a lado; pide el contraargumento más fuerte a tu favorito |
| Elegir una ruta de aprendizaje | Habilidades actuales, tiempo disponible, meta final | 3 formas distintas de plan de estudios; elige una, expande a hitos semanales |
| Diseñar un brief de logo (para un diseñador) | Valores de marca, público, ejemplos que te gustan | 5 direcciones de mood board; elige una, pide 5 variantes en esa línea |
En cada fila, una vez que tienes un candidato concreto (un itinerario elegido, un nombre preseleccionado, un correo en borrador), el movimiento de calificar del bucle aplica de la misma forma: puntúalo sobre 10 contra los criterios que importan para esa tarea, luego itera. Califica un itinerario en costo, ritmo y encaje con el grupo. Califica el nombre de un producto en memorabilidad, encaje y riesgo. Califica un correo en claridad, tono y efecto probable. Los criterios cambian; el movimiento no.
Parte 3: más allá del texto
La IA no es solo una caja de texto. Puede ver imágenes, trabajar con audio en ambos sentidos, construir pequeñas apps funcionales y ejecutar código sobre tus datos. La mayoría de la gente nunca prueba nada de eso.
8. Multimodalidad: imágenes, audio y lo que viene
La IA moderna maneja imágenes y audio en ambos sentidos: puede leer imágenes que subes, escuchar grabaciones, generar imágenes nuevas a partir de prompts de texto y producir audio hablado. Las habilidades son distintas según la modalidad, y vale la pena aprenderlas por separado.
Entrada de imagen. La IA ve las imágenes de forma gruesa. Es fuerte en:
- La escena y la composición general.
- Formas de objetos distintas y grandes (una cinta de correr de rueda de hámster del tamaño de un humano).
- El contenido de una pizarra, incluidos los diagramas.
- Texto manuscrito y en cursiva (decente, vuelve a comprobarlo cuando hay mucho en juego).
Es débil en:
- Los detalles finos. "¿Qué máquinas de gimnasio son estas?" tiende a fallar porque las máquinas de gimnasio se ven parecidas a través de una lente un poco borrosa. La IA puede responder con seguridad y equivocarse.
- Contar muchas cosas pequeñas en una escena abarrotada.
- Leer letra pequeña al borde de una imagen.
Una prueba útil del mundo real: un profesor fotografió una pizarra donde su cabeza tapaba la palabra "convolucional" en un diagrama de red neuronal. La IA infirió la palabra faltante correctamente a partir del resto del diagrama. Eso es en lo que la IA es buena: inferir a partir de la idea general. No es buena para hacer zoom.
Para recibos, dividir una cuenta o transcribir notas manuscritas, la IA funciona bien, pero comprueba siempre los totales. Para entradas de varias imágenes (notas adhesivas más una foto de pizarra más notas manuscritas de una lluvia de ideas), la IA puede resumir las ideas combinadas; esto es de verdad útil y ahorra tiempo real.
Salida de imagen. La IA moderna puede generar imágenes a partir de prompts de texto. Dos consejos prácticos:
- Usa una IA de texto para escribir tu prompt de imagen. "Genérame un prompt para una ilustración de bosque de fantasía en estilo Studio Ghibli para la portada de un libro infantil". Toma esa salida, pégala en la herramienta de imagen. La IA de texto es mucho mejor escribiendo prompts de imagen ricos de lo que eres tú al primer intento.
- Construye vocabulario visual. Palabras como cinematográfico, acuarela, cyberpunk, anime, isométrico, low-poly, art déco, claymation son palancas. Los modelos de imagen se entrenaron con imágenes subtituladas y aprendieron estos estilos por su nombre. Sube imágenes que te gusten y pregúntale a la IA cómo las describiría. Eso entrena tu vocabulario.
Cómo funciona la generación de imágenes: es un modelo de difusión, entrenado para quitar ruido de cuadrículas de píxeles aleatorias paso a paso hasta que emerge una imagen. No píxel a píxel como el texto. La imagen entera se genera de una vez. Por eso no puedes detener la generación de imágenes antes de tiempo para ahorrar tiempo, como sí puedes interrumpir una respuesta de texto.
Los modelos de difusión más antiguos tenían debilidades famosas: manos raras (seis dedos), texto distorsionado en los carteles, personajes que cambian de aspecto de un cuadro a otro en un cómic. Los modelos modernos (como Nano Banana de Google o ChatGPT Images) manejan el texto de forma razonable, generan personajes consistentes y pueden convertir artículos de investigación en infografías.
Una tabla corta de fallos que aún vale la pena vigilar, incluso en modelos de imagen modernos:
| Modo de fallo | Cómo se ve | Cómo mitigarlo |
|---|---|---|
| Texto distorsionado en carteles | El letrero de la imagen dice "FELOZ COMPLEAÑOS" en lugar de "FELIZ CUMPLEAÑOS". | Especifica el texto entre comillas en el prompt. Genera tres variantes. Elige la que tenga el texto bien. |
| Personajes inconsistentes entre cuadros | El mismo personaje tiene distinto color de pelo en los paneles 1 y 2 de un cómic. | Usa modelos con soporte explícito de consistencia de personajes; pasa la primera imagen como referencia para la siguiente. |
| Errores de manos y dedos | Seis dedos, manos fusionadas, muñecas torcidas. | Pide composiciones donde las manos queden parcialmente fuera de cuadro, o en los bolsillos, o claramente descritas. |
| Fondos abarrotados con objetos inverosímiles | Una cafetería donde una bicicleta se fusiona con una silla. | Especifica un fondo simple, o describe el fondo de forma explícita. |
| Relación de aspecto equivocada | El modelo usa cuadrado por defecto; tú querías apaisado. | Especifica siempre la relación de aspecto de forma explícita: "1024x768 apaisado" o "16:9". |
Un ejemplo no informático de entrada de imagen. Un lector fotografió una pila de tres tarjetas de recetas manuscritas de una abuela fallecida y las subió a la IA. El prompt: "Transcribe estas tres tarjetas. Conserva la redacción original y cualquier abreviatura. Si una palabra no está clara, márcala como [no claro] y ofrece tus dos mejores conjeturas". Cinco minutos después, las tres recetas estaban mecanografiadas con limpieza, con marcas de [no claro] en las cuatro palabras que la IA no pudo leer con seguridad. El lector comprobó esas cuatro contra los originales (dos eran obvias, dos necesitaron una llamada a una tía), y la familia tuvo un archivo digital limpio de recetas que corrían riesgo de perderse. La IA hizo el 90 % aburrido para que el lector pudiera concentrarse en el 10 % cuidadoso.
Una receta de experto: diagramas de calidad de diseñador sin un diseñador. Si alguna vez necesitas hacer un diagrama para un documento, una diapositiva o un capítulo propio, hay un flujo de trabajo que produce una salida de calidad de diseñador en unos quince minutos, sin usar Figma y sin ninguna habilidad de diseño visual. La mayoría de quienes no son diseñadores no se dan cuenta de que esto ya es posible. Es la forma más simple de producir diagramas de calidad de diseñador sin aprender una herramienta de diseño. Esta sección es más elaborada que cualquier otra cosa de la página; léela ahora si haces diagramas con regularidad, o sáltala hasta la primera vez que necesites uno.
La receta, en cuatro pasos:
- Pídele a Claude que visualice el concepto como SVG. Pega el párrafo o el texto de fondo. Pide: "Visualiza esto como un diagrama. Sácalo como SVG. Asegúrate de que estén presentes cada etiqueta, cada flecha y cada relación del texto." Claude es una opción fuerte para este paso porque su capacidad de razonamiento está entre las más fuertes de los grandes modelos: dado un párrafo, descubre las cajas correctas, las flechas correctas, la jerarquía correcta y las etiquetas correctas con muy poca guía. El SVG que devuelve será estructuralmente correcto pero visualmente sencillo (rectángulos pelados, fuentes por defecto, sin pulido de diseño). Eso está bien; el siguiente paso añade el pulido.
- Convierte el SVG a PNG. Pídele a Claude que renderice el SVG como PNG (Claude puede hacerlo de forma directa), o usa cualquier convertidor en línea de SVG a PNG (cloudconvert.com, svgtopng.com), o simplemente toma una captura de pantalla del SVG renderizado en un navegador con mucho zoom. Renderiza a 2x de resolución (de 1600 a 2400 píxeles de ancho) para que el siguiente paso tenga suficiente detalle con el que trabajar.
- Pega el PNG en ChatGPT (o Gemini) y pídele que lo vuelva a dibujar. La generación de imágenes dentro de ChatGPT tiende a ser fuerte para este paso porque es inusualmente buena con imágenes cargadas de texto: conserva las etiquetas, acierta con la tipografía y respeta las relaciones estructurales de la fuente. El prompt: "Vuelve a dibujar este diagrama con calidad de diseño profesional. Conserva cada etiqueta, cada caja, cada flecha y las relaciones estructurales exactas. Mejora la tipografía, el espaciado, la paleta de colores y la jerarquía visual. La información debe permanecer idéntica; solo cambia el acabado visual."
- Itera sobre el resultado. ChatGPT/Gemini a veces se salta una etiqueta o reordena una caja. Compara su salida contra el SVG original lado a lado. Si algo está mal, simplemente escribe la corrección: "La tercera caja debería decir 'Itera', no 'Repite'. La flecha de la caja 2 debería apuntar a la caja 3, no a la caja 4." Tres o cuatro rondas suelen producir algo que parece salido de un estudio de diseño profesional. Guarda el PNG final.
Por qué cada herramienta para cada paso. Claude tiende a ganar el paso 1 porque decidir qué pertenece a un diagrama (qué cajas, qué flechas, qué jerarquía) es una tarea de razonamiento, y el razonamiento de Claude está entre los más fuertes de los grandes modelos para este tipo de trabajo de pensamiento estructurado. ChatGPT (o Gemini) tiende a ganar el paso 3 porque renderizar bien imágenes cargadas de texto (etiquetas que siguen siendo legibles, flechas que conectan con las cajas correctas, diseños que parecen diseñados) es la categoría en la que su generación de imágenes lidera por ahora. Pedirle a cualquiera de las dos herramientas que haga el trabajo de la otra produce resultados notablemente peores que encadenarlas. Cada una hace lo que mejor sabe hacer, en secuencia.
Tiempo total: alrededor de diez a quince minutos por diagrama, frente a una hora o más en Figma, suponiendo que supieras usarlo.
El patrón que sobrevive a las herramientas. El líder de cada categoría rotará. Claude puede no ser el modelo de razonamiento más fuerte el año que viene. El modelo de imagen líder de hoy será reemplazado por lo que salga después. La receta de arriba quedará desactualizada en la capa de herramientas. Lo que sobrevive: la estructura primero en el modelo de razonamiento más fuerte, el pulido después en el modelo de imagen más fuerte con texto. Elige las herramientas que lideren cada categoría en el momento en que leas esto. La cadena de dos pasos es el movimiento.
Una pequeña historia sobre la generación de imágenes. Un padre cuya hija de 7 años amaba los gatos quería un pastel de cumpleaños a medida para ella. Usó Nano Banana para hacer lluvia de ideas de diseños de pastel (generando docenas de variaciones: con forma de gato, de varios pisos, estilos de glaseado, paletas de colores), eligió el que ella amó y luego le entregó la imagen elegida a un pastelero que la convirtió en un pastel 3D real. Tiempo total de iteración en el diseño: una tarde. Costo total: unos centavos en generación de imágenes.
El punto no es el pastel. El punto es que por unos 0,30 $ y una hora de iteración guiada por el criterio, una persona que no es diseñadora produjo un brief único contra el cual un profesional podía ejecutar. Eso es un nuevo tipo de apalancamiento creativo, y está ampliamente disponible.
Audio de entrada, audio de salida. El mismo giro que ocurrió con las imágenes está ocurriendo ahora con el audio. Puedes dictar un prompt largo en lugar de escribirlo; puedes soltar la grabación de una reunión y pedir un resumen; puedes pedirle al modelo que lea su respuesta en voz alta. La mayoría de las herramientas de IA modernas admiten las tres cosas, a menudo sin cargo extra en los planes gratuitos.
Los usos no obvios son donde vive el apalancamiento real:
- Dictado de formato largo. Hablar un problema en voz alta captura matices que los prompts escritos se saltan. Las personas que odian escribir producen prompts mucho mejores cuando los dicen: el prompt crece de una línea a varios párrafos sin esfuerzo, y la respuesta de la IA es mejor en consecuencia. Habla como si informaras a un colega tomando un café, y luego deja que la IA limpie la transcripción resultante antes de responder.
- Transcripciones de reuniones como contexto. Suelta la grabación de una reunión de una hora (o una transcripción de uno de los proveedores dominantes de 2026 como Otter, Granola o Fireflies, o las notas de voz de tu teléfono) y pide: "Resume las decisiones tomadas, las preguntas abiertas y las tareas pendientes por responsable". Este es uno de los flujos de trabajo de mayor apalancamiento de la página para cualquiera en un trabajo con reuniones, y casi nadie fuera de la tecnología lo está usando todavía.
- Audio para accesibilidad y movimiento. Trayecto largo, paseando al perro, conduciendo: voz de entrada/voz de salida convierte el tiempo muerto en tiempo de pensar. La calidad de la conversación baja un poco frente a escribir porque no puedes editar tu entrada con tanta limpieza, pero el tiempo que de otro modo habrías perdido se recupera por completo.
En qué es bueno y malo el audio, en 2026:
| Tarea de audio | Qué tan bien funciona | A qué prestar atención |
|---|---|---|
| Transcripción de habla clara | Excelente | Acentos marcados, jerga técnica, varios hablantes superpuestos |
| Identificación de hablantes (quién dijo qué) | Decente con 2 hablantes, débil con 4 o más | Comprueba siempre antes de citar a alguien |
| Tono, sarcasmo, emoción | Mejorando pero poco fiable | Pídele a la IA que marque su incertidumbre en lugar de suponer |
| Análisis de música o audio que no es habla | Limitado | Usa una herramienta especializada, no una IA de propósito general |
| Conversación de voz en tiempo real | Buena para lo casual, débil para profundidad técnica | Cambia al texto cuando importa la precisión |
Un ejemplo no informático. Una doctora grabó una consulta de paciente de 45 minutos (con consentimiento), subió el audio y le pidió a la IA: "Produce una nota clínica estructurada en formato SOAP. Marca cualquier cosa que no hayas podido entender con seguridad. Resalta las tres cosas más importantes que el paciente dijo sobre el historial de sus síntomas". Ocho minutos después, la doctora tenía un borrador de nota que le tomó 5 minutos verificar y finalizar, en lugar de los 25 minutos que habría tomado la versión escrita. La IA no reemplazó el juicio clínico; quitó el mecanografiado.
Nota de costo: el audio de entrada/salida es el segundo nivel más barato después del texto, centavos por minuto (Concepto 12). Para resúmenes de reuniones, llevar un diario de voz diario o dictar prompts en un paseo, el costo es prácticamente invisible. Itera con libertad.
Un patrón que vale la pena tener en mente: el futuro de lo multimodal no es "la IA ya puede hacer voz, qué genial". Es que la frontera entre las modalidades desaparece. Cada vez más soltarás un paquete mixto (una imagen, una nota de voz, un PDF, una captura de pantalla) y lo tratarás como un solo prompt. La habilidad no es "cómo uso la voz" sino "¿cuál es la combinación correcta de entradas para este trabajo?".
Los avatares de video interactivos están surgiendo en la misma trayectoria. El video de avatar pregrabado (HeyGen, Synthesia, D-ID) ya tiene calidad de producción para contenido de capacitación y comunicación corporativa multilingüe. Los avatares conversacionales en tiempo real (Tavus y otros) son aceptables para usos de bajo riesgo hoy (clasificación de preguntas frecuentes de clientes, tutoría de idiomas con una cara, flujos simples de incorporación) y mejoran rápido. Trátalos como la generación de imágenes en 2022: impresionantes, novedosos, todavía no un hábito diario para la mayoría del trabajo de conocimiento, pero vale la pena un experimento rápido cuando un trabajo pide una cara en la pantalla en lugar de texto.
9. Construir pequeñas apps con un solo prompt
La IA moderna puede construir pequeños juegos, sitios web y herramientas a partir de un solo prompt. Todavía no para software grande, pero para cosas pequeñas y útiles, esto es de verdad accesible para personas que nunca han escrito código.
Dónde se ejecuta la app en realidad, y qué puedes hacer con ella después. Una primera pregunta razonable: "si la IA me construye una app, ¿dónde vive en realidad?". A mediados de 2026, las tres herramientas principales renderizan pequeñas apps de un prompt justo en el chat, en un panel lateral con el que puedes hacer clic e interactuar, y la cosa de ese panel no es solo una vista previa, es un artefacto: un objeto persistente que produjo la conversación, que puedes editar, iterar, publicar como un enlace que puedes compartir, incrustar en otro sitio o descargar como código. La función se llama Artifacts en Claude (de donde vino el nombre), Canvas en ChatGPT y Canvas en Gemini. Hace un año había diferencias importantes entre ellas; hoy la brecha es pequeña para la mayoría de las construcciones de un prompt. Cada una aún tiene pequeñas fortalezas: los Artifacts de Claude tienden a liderar en cosas interactivas de hacer clic y jugar, el Canvas de ChatGPT en edición de escritura y código, el Canvas de Gemini en salidas muy integradas con el ecosistema de Google, pero para "constrúyeme una cosa", cualquiera de las tres funciona. Dos consecuencias prácticas que vale la pena conocer. Primera, puedes entregarle el artefacto a otra persona sin enviarle el chat: la mayoría de las herramientas te dejan publicar en un enlace público, y el destinatario no necesita una cuenta para usarlo. Segunda, el artefacto es iterable: cuando dices "haz el botón más grande" o "añade un interruptor de modo oscuro", la herramienta edita el artefacto en su lugar en lugar de regenerar todo desde cero, lo que es mucho más rápido. Para cualquier cosa más allá de una construcción de un prompt, vale la pena saber que existen tres categorías cercanas: constructores de apps de IA dedicados como v0, Bolt y Lovable (describes una app en lenguaje sencillo y producen un proyecto completo de Next.js o React, el siguiente paso natural del Concepto 9 para quienes no son desarrolladores); agentes de IA de codificación de línea de comandos como Claude Code y OpenCode (les das un repositorio real, editan muchos archivos a la vez y ejecutan pruebas, cubiertos en la lista de cambios desde 2022 al inicio de esta página, dirigidos a desarrolladores que ya escriben código); y apps de escritorio conscientes de los archivos como Cowork y OpenWork (encuentran tus archivos y actúan sobre ellos con permiso, cubiertas en el Concepto 11, dirigidas a trabajadores del conocimiento, no a construir software). La herramienta correcta depende de qué escalera estés subiendo.
La receta son solo tres casillas:
Objetivo: ¿qué debería hacer esta cosa?
Entrada: ¿qué proporciona el usuario?
Salida: ¿qué ve el usuario?
Ejemplos que funcionan hoy:
- Temporizador Pomodoro. "Construye un temporizador Pomodoro con un tema amarillo. Sesiones de trabajo de 25 minutos, descansos de 5 minutos, un clic satisfactorio cuando termina cada ciclo".
- Divisor de cuentas. "Construye una app donde introduzco un total de cuenta, un monto de impuestos y los nombres de unos amigos. Divide la cuenta incluyendo el impuesto y muestra la parte de cada persona".
- Selector de atuendos. "Construye una app que tome el clima de hoy (temperatura y precipitación) y recomiende un atuendo de un armario de prendas que yo describa".
- Simulador de fuegos artificiales. "Genera un simulador divertido de fuegos artificiales. Entrada: hago clic en la pantalla. Salida: una exhibición colorida de fuegos artificiales en el punto del clic".
- Juego de colocar obstáculos. "Construye un juego donde el usuario coloca obstáculos y una meta, y ejecuta una simulación que intenta llegar a la meta".
Lo que aún es difícil:
- Multijugador por internet. Las redes, las cuentas y el emparejamiento siguen estando más allá de una construcción de un prompt.
- Retroalimentación de IA en vivo en otro idioma. Un tutor de conversación en francés que escucha, corrige la pronunciación y se adapta en tiempo real es de verdad difícil.
La intuición que construyes: las cosas pequeñas que caben en una pantalla, sin cuentas y sin servicios externos, funcionan. Cualquier cosa más allá de eso necesita más de un prompt, y por lo general algo de ingeniería real.
Un ejemplo no informático. Un padre construyó un juego de mecanografía con tema de gato amarillo para su hija cuando la maestra mencionó que los niños podían escribir más rápido. No es ingeniero de software. El prompt fueron tres oraciones:
Construye un juego de mecanografía para una niña de 7 años. Objetivo:
practicar escribir palabras cortas comunes. Entrada: aparecen palabras,
el jugador las escribe antes de que lleguen al fondo de la pantalla.
Salida: un tema amarillo, una mascota gato linda que anima cuando el
jugador acierta una palabra, velocidad creciente a lo largo de niveles.
Lo que volvió funcionaba. No a la perfección, no al primer intento, pero iterado a "lo bastante bueno para una niña" en menos de una hora. La habilidad que se construye aquí no es codificar. Es la capacidad de escribir un brief claro e iterarlo. Esa habilidad es universal.
10. Análisis de datos (el modelo escribe y ejecuta código)
Cuando le haces a la IA una pregunta que necesita cálculo o gráficos (desde "cómo cambió mi factura de electricidad este año" hasta "qué productos se vendieron mejor el trimestre pasado"), las herramientas modernas hacen algo notable de forma discreta: el modelo escribe código, lo ejecuta y devuelve el resultado. La ejecución de código es solo otra herramienta que el modelo puede llamar, como la búsqueda web. No necesitas saber nada de código tú mismo; solo subes tu hoja de cálculo y preguntas en lenguaje sencillo.
Esto es mucho más fiable que pedirle al modelo que haga matemáticas de cabeza. El modelo está haciendo matemáticas como las harías tú: ejecutando una calculadora. Es la calculadora la que es precisa; el modelo solo elige qué calcular.
Antes que nada: asegúrate de que la IA de verdad ejecuta código, en lugar de adivinar. Este es el fallo silencioso de toda esta sección, y la razón por la que va al principio: la IA no ejecuta código de forma automática en cada pregunta, elige hacerlo, según cómo esté formulada la pregunta. En preguntas más pequeñas a veces se salta el código y responde de un vistazo, lo que produce un párrafo que suena seguro sin ningún cálculo real detrás. Desde fuera se ve idéntico a un análisis real. Tres pequeños hábitos lo evitan. Primero, pídelo de forma explícita. "Escribe y ejecuta código para responder esto. Muéstrame el código que ejecutaste." La mayoría de los modelos obedecen cuando lo pides. Esa sola línea, pegada en cualquier prompt de datos, marca la diferencia entre un análisis real y una conjetura plausible. Segundo, comprueba que el código esté visiblemente ahí. Si la respuesta no incluye un bloque de código que se ejecutó, probablemente el modelo no ejecutó código. Tercero, exige un dato verificable antes del análisis. "Dime el número exacto de filas, los nombres de las columnas y el rango de fechas de este archivo antes de analizar nada." Si el modelo de verdad está leyendo el archivo, esas respuestas serán correctas. Si se las está inventando, el número de filas será un número sospechosamente redondo y los nombres de las columnas serán plausibles pero equivocados. La versión más fuerte de este movimiento es pedirle al modelo que declare su método por adelantado: "¿Estás ejecutando código sobre el archivo, o estimando? Si estimas, detente y ejecuta código en su lugar." La mayoría de los modelos invocarán la herramienta o admitirán que estaban a punto de saltársela.
Una vez que tienes ese hábito, el resto de esta sección es cómo se ve el análisis de datos en la práctica.
Ejemplo de la tienda de té de burbujas. Un pequeño negocio tiene un año de datos de ventas: bebidas, fechas, cantidades. El dueño pregunta: "¿Qué bebidas tuvieron los mayores cambios en ventas a lo largo del año? Grafícalas. Escribe y ejecuta código para responder esto y muéstrame el código que ejecutaste".
Entre bambalinas, la IA escribe un programa corto, lo ejecuta sobre la hoja de cálculo, ve los resultados y los convierte en una respuesta. En la práctica eso se ve así: la IA calcula los cambios mes a mes por bebida, observa que la mayoría de las bebidas están planas y cuatro destacan, genera un gráfico de líneas en color de esas cuatro y anota los patrones. "El matcha de fresa subió con fuerza en primavera; considera repetir esa promoción el año que viene". Eso no es una respuesta genérica. Es una respuesta fundamentada en los datos reales.
Luego un prompt más grande: "Crea un gráfico de una sola diapositiva de resumen del año para la tienda. Analiza los datos con cuidado en busca de hallazgos que valga la pena destacar". Esta es una tarea más pesada, así que la IA tarda más, a veces unos minutos, en abordarla. Escribe código, ejecuta análisis, elige hallazgos, diseña anotaciones y produce un tablero terminado.
Para qué sirve esto, con ejemplos que los principiantes de verdad tienen:
- Gasto del hogar. Sube un año de transacciones bancarias o de tarjeta de crédito; pregunta qué categorías crecieron, qué meses fueron inusuales, qué suscripciones olvidaste.
- Seguimiento personal. Correr, caminar, sueño, peso, tiempo de pantalla: cualquier app que exporte un CSV te dará un año de ti mismo para mirar.
- Registros de pequeños negocios. Hojas de cálculo de ventas, listas de inventario, listas de clientes, archivos de gastos.
- Cualquier cosa que alguien te dio como hoja de cálculo y no quieres abrir: boletines de calificaciones escolares, estados de uso de servicios públicos, datos científicos, resultados de encuestas.
Qué volver a comprobar, incluso cuando el código sí se ejecutó:
- Totales finales. El código es preciso, pero la IA pudo haber sumado la columna equivocada.
- Etiquetas en los gráficos. Los números suelen estar bien; los rótulos a veces están confiadamente equivocados.
- Cualquier cosa donde el análisis dependa de una columna que la IA pudo haber malinterpretado. Si la IA cree que "TXN_AMT" significa monto de transacción cuando en realidad significa número de cuenta de la transacción, todo el análisis está construido sobre arena.
La fiabilidad es mucho mayor que las matemáticas basadas en memoria, pero no es infalible. Trata el análisis de datos de la IA como tratarías el trabajo de un analista junior agudo: útil, rápido, casi siempre correcto, de vez en cuando equivocado de formas instructivas.
Un ejemplo no informático. Un corredor subió seis meses de datos de un rastreador de carreras (un CSV de una app de fitness) y preguntó: "¿Cómo progresan mi ritmo y mi distancia? ¿Hay algún patrón que deba conocer? Escribe y ejecuta código, y muéstrame lo que ejecutaste". La IA escribió código, graficó promedios semanales y notó dos cosas que el corredor no había visto: el ritmo bajaba de forma consistente después de cada fin de semana de tirada larga (probable fatiga), y la distancia se estancó en el tercer mes antes de volver a subir. La recomendación: una semana de descarga cada cuarta semana, y un ritmo más lento en la tirada larga. El corredor había mirado estos mismos datos en el tablero de la app durante meses sin ver esos patrones. La IA no inventó hallazgos de la nada; calculó lo que el corredor no tenía tiempo de calcular.
Cuando subes datos, tu primer prompt no tiene que ser la pregunta. Puede ser: "Describe este conjunto de datos. ¿Qué columnas hay, qué representan, y qué 3 gráficos mostrarían mejor lo que está pasando?". Lee la respuesta, elige el gráfico que quieres, y luego pídelo. Esto atrapa las columnas malinterpretadas antes de que se vuelvan análisis equivocados.
Parte 4: trabajar con seguridad y elegir herramientas
Tres conceptos finales: cómo darle a la IA acceso a tus archivos y permisos de forma segura, cómo elegir la herramienta correcta para el trabajo, y cómo obtener una señal objetiva sobre la calidad cuando no hay ningún experto humano en la sala.
11. Apps de IA de escritorio y permisos
Ahora existe toda una categoría de productos llamados apps de IA de escritorio: apps que se ejecutan en tu equipo y, con permiso, pueden encontrar tus archivos, leerlos y actuar sobre ellos. Cowork de Claude y OpenWork son dos ejemplos, y la categoría está creciendo.
Lo que estas pueden hacer y el chat no:
- Revisar una carpeta desordenada de PDFs, proponer una nueva organización (renombrar archivos, moverlos, crear subcarpetas) y ejecutar el plan una vez que lo apruebas.
- Reunir archivos relacionados para un proyecto (dices "voy a filmar en estas fechas y estas personas están involucradas") y notar cosas por su cuenta (el cumpleaños de un miembro del equipo cae durante el rodaje, ¿quieres incluir una celebración?).
- Leer a lo largo de una carpeta y resumir: "¿en qué trabajé el trimestre pasado, según el contenido de esta carpeta projects/?".
El flujo de trabajo que hace esto seguro:
- Dile la tarea. ("Reorganiza esta carpeta por cliente.")
- Pide un plan, no una acción. La app propone una lista de operaciones sobre archivos.
- Revisa y edita el plan. Atrapa el renombrado que no quieres antes de que ocurra.
- Solo entonces aprueba la ejecución.
Dos hechos que la mayoría de la gente aprende por las malas:
- Los archivos eliminados a menudo NO van a tu papelera de reciclaje cuando una app de IA los elimina. Desaparecen.
- Los archivos editados NO conservan un historial de ediciones a menos que tengas control de versiones. El cambio de la IA sobrescribe la versión anterior.
Hasta que hayas hecho esto de forma segura unas cuantas veces, limita cada solicitud de permiso a la carpeta más pequeña que la tarea necesite. No apruebes "acceso a todo el disco" para una app que has usado dos veces.
Esta es una forma de herramienta de verdad nueva. Trátala como tal: como la primera vez que le entregaste a un empleado junior las llaves de una cuenta real. Útil, rápida, y digna de cuidado.
Un ejemplo no informático. Una consultora tenía una carpeta llamada clients/ que había crecido a 240 PDFs en cuatro años: contratos, facturas, documentos de alcance, recibos escaneados a mano, notas de reuniones. Le dijo a una app de IA de escritorio: "Revisa clients/. Propón un esquema de organización. No muevas ningún archivo todavía. Muéstrame el esquema propuesto como un árbol". La app produjo un árbol limpio: una carpeta por cliente, subcarpetas para contratos, facturas y notas, con una lista marcada de 18 archivos que no pudo clasificar con seguridad. Ella editó la propuesta (renombró dos clientes, fusionó dos carpetas), luego aprobó la ejecución. Tiempo total: unos quince minutos. El mismo trabajo había estado en su lista de "algún día" durante tres años. Lo que se desbloqueó no fue la IA haciendo el pensamiento; fue la IA haciendo la tarea tediosa para que el pensamiento se volviera barato.
La escalera de permisos. Una secuencia útil para irte sintiendo cómodo:
| Nivel de comodidad | Qué permitir | A qué seguir diciendo que no |
|---|---|---|
| Primeras sesiones | Acceso de solo lectura a una sola carpeta pequeña. | Cualquier cosa que escriba, elimine o renombre. |
| Tras 2 o 3 ejecuciones exitosas | Lectura y escritura dentro de una carpeta específica. | Acceso a directorios más amplios como la raíz del escritorio o de documentos. |
| Tras una semana limpia | Lectura a lo largo de un árbol de proyecto, escritura dentro de una subcarpeta acotada. | Cualquier cosa fuera de ese proyecto. |
| De confianza | Permisos específicos de herramienta ("renombrar PDFs en esta carpeta", "editar documentos de Word en esta carpeta"). | "Haz lo que necesites" sin límites. |
El principio: el alcance crece con el historial, no con cuánto confías en la empresa que construyó la herramienta. La confianza se gana con el comportamiento en tu flujo de trabajo específico.
12. Costo, velocidad y qué modelo usar y cuándo
Una pila simple para tener en la cabeza:
En palabras:
- Texto: segundos, fracciones de centavo por respuesta.
- Habla: segundos, unos centavos por minuto de audio.
- Imágenes: decenas de segundos, varios centavos por generación. Sin parada anticipada, la imagen entera se genera de una vez.
- Video: minutos por generación, de muchos centavos a unos pocos dólares. La iteración es dolorosa porque cada ronda es lenta y cara.
- Investigación profunda: minutos, de varios centavos a un cuarto de dólar, pero sintetiza decenas de fuentes por ti.
El costo apenas es una restricción en el nivel de entrada. Los grandes chatbots (ChatGPT, Claude, Gemini, Meta AI y DeepSeek) ofrecen acceso gratuito que maneja con comodidad el tipo de prompts de esta página. Solo llegas a los planes de pago cuando exiges ejecuciones pesadas de investigación profunda, subidas de archivos muy grandes, generación de video o uso diario ilimitado. Para los ejercicios de la sección final, el plan gratuito de cualquiera de ellos basta.
Dos implicaciones:
- El costo de iteración da forma a lo que haces. Puedes iterar sobre texto 50 veces en una tarde. No puedes iterar sobre video 50 veces en una tarde. Así que cuando generas imágenes o video, invierte más en el prompt por adelantado (y usa una IA de texto para escribirlo).
- Los costos van a la baja. La imagen que hoy te cuesta 10 centavos costará una fracción de eso el año que viene. Generar arte para tu casa, una tarjeta de cumpleaños o una invitación de boda se está volviendo gratis a toda velocidad.
¿Qué modelo para qué tarea? La IA es dentada: distintos modelos son buenos en distintas cosas, y el líder cambia cada pocos meses. No hay un único mejor modelo. Dos hábitos ayudan:
- Prueba el mismo prompt en 2 o 3 modelos de forma rutinaria. Misma pregunta, varias herramientas. Lee las respuestas. Las diferencias te sorprenderán, y actualizan tu intuición sobre qué herramienta es mejor para qué tipo de pregunta.
- No te cases con una herramienta. Un trabajador que solo usa una IA es un trabajador que se equivoca sobre cuál es la mejor herramienta para dos tercios de sus tareas. Cambiar es gratis; solo pegas el prompt en otra pestaña.
La mejor IA para tu tarea de hoy no es la mejor IA para tu tarea dentro de tres meses. Mantente flexible.
Una instantánea aproximada de en qué tiende a ser bueno ahora mismo cada gran modelo (esto cambiará; trátalo como un punto de partida, no como un veredicto):
| Herramienta | Tiende a ser fuerte en | Tiende a ser más débil en |
|---|---|---|
| Claude | Razonamiento en prompts difíciles, comprensión de documentos largos, generación de SVG y diagramas, código y desarrollo web, voz de escritura cuidada, análisis estructurado. Actualmente lidera la mayoría de las categorías de Arena. | La generación de imágenes fotorrealistas dentro del producto es menos central que en ChatGPT y Gemini. |
| ChatGPT | Generación de imágenes dentro del producto de primer nivel (GPT Image-2 lidera las categorías de texto a imagen y edición de imagen de Arena), modo de voz, rango conversacional, amplia cobertura de tareas. | A veces verboso; puede sobreformatear con listas y encabezados. |
| Gemini | Búsqueda web rápida y síntesis de fuentes, investigación profunda con salida rica (gráficos, tablas), generación de imágenes fuerte (variantes de Nano Banana en el top 5 de Arena), integración estrecha con Google Workspace. | El tono puede sentirse más cortante; algunas respuestas tienden a ser más cortas de lo ideal. |
| Meta AI | Integrada en WhatsApp, Instagram, Messenger y Facebook (ya en el dispositivo de más de mil millones de personas); gratis sin cuota de suscripción; Muse Spark (abril de 2026) trae razonamiento multimodal competitivo y un "modo Contemplación" que ejecuta varios agentes en paralelo. Actualmente se sitúa en el top 5 de la tabla de texto de Arena. Mejor para artefactos visuales interactivos (tableros web, minijuegos, cuestionarios) y datos de salud o científicos. | Los flujos de codificación y los agentes de largo horizonte van por detrás de los tres grandes; ecosistema de integraciones más pequeño, como Projects, Canvas o Artifacts; aún sin API pública (solo una vista previa privada); el uso está limitado por tasa si exiges mucho. |
| DeepSeek | Pesos de código abierto que puedes autoalojar o ejecutar vía API a bajo costo; contexto de 1M de tokens por defecto; V4-Pro rivaliza con los mejores modelos de código cerrado en pruebas de STEM y codificación; V4-Flash es la opción cotidiana rápida y barata. | El pulido de la interfaz de chat va por detrás de los tres grandes; el ecosistema de consumo (apps móviles, integraciones profundas) es más pequeño; las clasificaciones de Arena quedan por debajo de Claude, ChatGPT, Gemini y Meta en la mayoría de las categorías. |
Una nota sobre las dos filas más nuevas. El valor de Meta AI solía ser "ubicuidad + gratis, no profundidad", pero Muse Spark cierra buena parte de la brecha de profundidad para las tareas de razonamiento mientras conserva la ventaja de la ubicuidad y lo gratuito. Si tienes WhatsApp o Instagram, ahora puedes hacer pensamiento serio dentro de la app que ibas a abrir de todos modos. Dos límites que vale la pena conocer antes de usarla para trabajo real, eso sí. Primero, gratis no significa ilimitado: Meta aplica límites de tasa entre bambalinas, así que el uso intenso del modo Contemplación o los flujos automatizados rápidos terminarán por ser limitados. Segundo, tus entradas pueden usarse para entrenar futuros modelos de Meta. Los términos de Meta lo permiten y el producto de consumo no está configurado para excluirte por defecto. Eso hace de Muse Spark una mala opción para material sensible: documentos internos de empresa, código privado, información médica, cualquier cosa que no quisieras alimentar a una tubería de entrenamiento. Para trabajo cotidiano no sensible es excelente. El valor de DeepSeek es ser de código abierto y barato: es la opción correcta cuando eres sensible al precio, quieres la opción de autoalojar, o necesitas esa ventana de contexto de 1M de tokens para trabajo de plan gratuito. Los tres grandes siguen liderando los flujos de trabajo más profundos que enseña esta página (Projects, Canvas, Artifacts, investigación profunda), así que siguen siendo las herramientas de los ejemplos trabajados.
La tabla de clasificación para guardar en marcadores. Cuando quieras una vista actual de qué modelo lidera qué tarea, el recurso más útil es Arena. Los usuarios votan en comparaciones a ciegas, cara a cara, de dos modelos anónimos, así que las clasificaciones reflejan preferencias reales en lugar de afirmaciones de marketing de los proveedores. El sitio mantiene tablas separadas para texto, código, visión, documento, generación de imagen, edición de imagen, búsqueda y video. Revísala una vez al mes. Los líderes rotan rápido: el modelo que encabeza una categoría en mayo puede no estar ahí en agosto, y un recién llegado puede saltar al top 5 en semanas (Muse Spark lo hizo en abril de 2026). Dos advertencias que vale la pena conocer: las tablas premian el encanto conversacional más que el trabajo cuidadoso sobre documentos largos, y muestrean tareas que los usuarios votantes encuentran interesantes, que no siempre son tu tarea. Úsala como una señal entre varias; el Concepto 13 tiene más sobre combinar las señales de la tabla con tus propias pruebas A/B sobre el tipo de prompts que de verdad ejecutas.
Tres hábitos que se acumulan:
- Ten al menos dos pestañas abiertas. Una herramienta principal y una de respaldo. Cuando la principal te da algo que no se siente bien, pega el mismo prompt en la de respaldo. La segunda respuesta suele ser el desempate.
- Lleva un borrador de prompts. Un archivo de notas (cualquier archivo de texto sirve) donde reúnes los prompts que produjeron resultados inusualmente buenos. Reúsalos y adáptalos. Esta es tu biblioteca personal.
- Nota cuándo el modelo se equivoca. No como un regaño, sino como datos. Equivocarse es una señal gratis sobre dónde están los bordes de esta herramienta. Anotar "la herramienta X se equivocó con seguridad sobre Y" una vez por semana es más útil que leer cualquier boletín de IA de 2000 palabras.
Una vez al mes, haz dos cosas juntas: (1) echa un vistazo a las tablas de clasificación de Arena para cualquier categoría que te importe, y (2) elige una tarea que hagas con regularidad (escribir actualizaciones de estado semanales, planificar comidas, resumir un documento recurrente) y pásala por tres herramientas de IA distintas. Anota cuál la hizo mejor en tu trabajo real. Usa esa para esa tarea hasta el mes que viene, cuando vuelvas a probar. Tu instrumental se mantiene al día sin esfuerzo, y la tabla te dice si deberías estar probando a un recién llegado que no estaba en tu radar.
13. Modelos que revisan a modelos
Cuando no hay verdad de referencia (ni clave de respuestas, ni experto sentado a tu lado, ni prueba que falle en rojo), aún puedes obtener una señal objetiva sobre la calidad. La obtienes haciendo que los modelos se califiquen entre sí.
Empieza con la versión ligera. Si solo tienes una herramienta de IA abierta hoy, el bucle de autocrítica de un solo modelo (que se cubre justo abajo) te da casi todo el beneficio, y es la versión que la mayoría de las tareas cotidianas necesita. La receta multimodelo completa que viene después es la versión de alto riesgo: supone una segunda cuenta gratuita abierta en otra pestaña del navegador, alrededor de un minuto de configuración, y vale esa configuración solo cuando equivocarse es caro. Lee la receta completa ahora para captar la forma, pero echa mano primero de la versión ligera; gradúate a la más pesada cuando algo sobre tu escritorio de verdad lo amerite.
Distintos modelos tienen distintos puntos ciegos. Se entrenaron con datos solapados pero no idénticos, con distintas señales de recompensa, por equipos que enfatizaron cosas distintas. Un punto que un modelo se salta, un segundo modelo a menudo lo atrapa. El desacuerdo entre ellos es la señal que no puedes obtener de ningún modelo solo. Esto solo funciona si los modelos vienen de familias de verdad distintas: Anthropic (Claude), OpenAI (ChatGPT), Google (Gemini), Meta (Meta AI / Muse Spark) y DeepSeek son las cinco familias distintas de las que echar mano. Dos modelos de Claude revisándose entre sí no es revisión cruzada de modelos; sus supuestos previos son demasiado parecidos.
Aquí está la receta multimodelo completa, refinada a lo largo de muchos documentos y escrita desde la práctica real. Esta es la versión de alto riesgo; el bucle más ligero de un solo modelo está en la siguiente subsección:
- Empieza con el mejor modelo al que tengas acceso. "Mejor" significa el que tenga el razonamiento más fuerte y la coherencia de salida larga más fuerte en tu tipo de tarea. Usa varias señales: las tablas de clasificación de Arena como punto de partida (el Concepto 12 las introduce), más tu propia prueba A/B rápida sobre una muestra representativa del tipo de trabajo que de verdad haces. Una prueba A/B aquí significa simplemente: envía el mismo prompt a dos o tres modelos, lee las respuestas lado a lado y deja que tus ojos te digan cuál es mejor para tu tipo de tarea. No te ancles a una sola tabla; miden cosas distintas, y las clasificaciones basadas en preferencias premian el encanto conversacional más que el trabajo cuidadoso sobre documentos largos.
- Genera el primer borrador con contexto completo. Infórmale como a un colega (Concepto 1), activa el modo de pensamiento para problemas difíciles (Concepto 5), usa el bucle de lluvia de ideas e iteración para la estructura (Concepto 7).
- Pídele que califique su propia salida, del 1 al 10, contra criterios nombrados. No "¿esto es bueno?" sino "puntúa esto en claridad, exactitud, estructura y qué falta, del 1 al 10 cada uno, con una justificación de una oración por puntuación". La primera calificación suele ser 7 u 8.
- Pídele que implemente sus propias sugerencias. Repite hasta que la calificación deje de subir, lo que suele estancarse alrededor de 9.
- Lleva el borrador a un segundo modelo de una familia distinta. Pide la misma rúbrica. Distinto modelo, distintos supuestos previos, distintos puntos ciegos. El segundo modelo atrapará cosas sobre las que el primero se calificó a sí mismo, que es exactamente el bucle cerrado del que necesitas escapar.
- Lleva la crítica del segundo modelo de vuelta al primero. Plantéalo con honestidad: "otro modelo produjo esta crítica. Evalúa qué puntos vale la pena adoptar, y por qué. Rechaza cualquier cosa con la que no estés de acuerdo, y explica". El primer modelo arbitra. Tú observas el arbitraje.
- Para trabajo de alto riesgo, repite con un tercer modelo de una tercera familia. Para cuando tres modelos de familias distintas han discutido sobre tu borrador, tienes lo más cercano a una verdad triangulada que ofrece esta tecnología.
- Detente cuando la puntuación cruce tu objetivo en dos modelos independientes. Un 9,5 de tu modelo principal solo no es lo mismo que un 9 de tu principal más un 9 de un modelo de familia distinta. El segundo número es el que significa algo.
El bucle de autocrítica de un solo modelo, por sí solo
Los pasos 3 y 4 de arriba son utilizables por su cuenta, sin traer nunca un segundo modelo. Muchas tareas no justifican el costo extra de lo multimodelo pero aun así se benefician de una ronda de "puntúa esto del 1 al 10 contra esta rúbrica, luego implementa tus propias sugerencias". Una actualización de estado semanal, un correo un poco delicado, un memorando de una página: todos estos mejoran de forma visible con una pasada de autocrítica.
Una variante de mayor apalancamiento: fija un objetivo numérico y deja que el modelo itere de forma autónoma hacia él. En lugar de "puntúa esto y dime qué falta", prueba "itera contra tu propia rúbrica hasta que llegues a 9,5 en todos los criterios, luego muéstrame la versión final". El modelo calificará, revisará, recalificará, revisará y seguirá adelante (cinco o seis rondas en una sola respuesta) y solo te volverá cuando alcance el objetivo o se estanque. Esto es mucho más rápido que conducir cada ronda a mano, y funciona especialmente bien para artefactos de formato largo (un memorando de 5000 palabras, un capítulo, un plan completo) donde ir y volver a mano sería tedioso. El objetivo en sí es un mecanismo de dirección: 9 fuerza un techo distinto que 9,5, y 10 fuerza al modelo a seguir encontrando cosas que mejorar hasta que de verdad no pueda encontrar ninguna.
Esto puede sonar como si contradijera el Concepto 6, que advirtió que un modelo que califica su propio trabajo tiende a la adulación. La diferencia es la rúbrica. Sin una, "¿esto es bueno?" devuelve "¡gran trabajo!", que es el bucle cerrado del que trataba el Concepto 6. Con criterios nombrados y puntuados del 1 al 10, el modelo tiene que señalar qué falta de los otros puntos, y ese señalamiento es contra lo que implementas. La rúbrica es lo que convierte la autocalificación de adulación en una función de forzamiento.
La página ahora ofrece tres versiones anidadas del mismo ADN. Elige la más ligera que encaje con el trabajo:
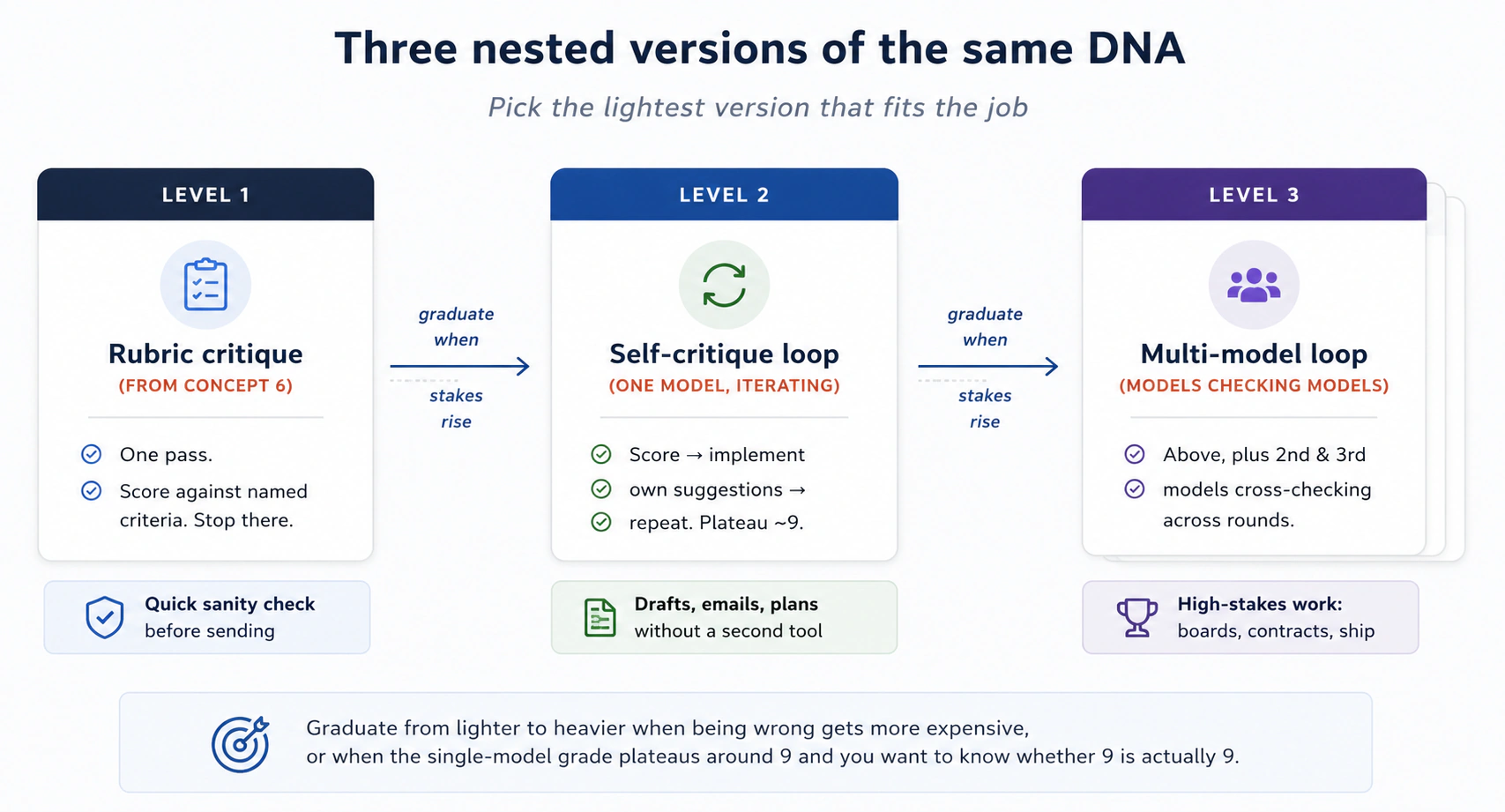
Gradúate de la versión más ligera a la más pesada cuando equivocarse se vuelve más caro, o cuando la calificación de un solo modelo se estanca alrededor de 9 y quieres saber si 9 de verdad es 9.
Por qué importa la calificación. Forzar un número del modelo no es por el número. Es por lo que producir el número requiere. Un modelo que tiene que puntuar tu borrador 7/10 tiene que nombrar qué falta de los otros 3 puntos. Sin la puntuación, "esto está bastante bien" pasa por revisión. Con la puntuación, "bastante bien" tiene que volverse "pierde 1 punto en estructura porque la tercera sección repite la segunda; pierde 2 puntos en evidencia porque tres afirmaciones no tienen fuente". La calificación es una función de forzamiento para la especificidad, y la especificidad es sobre lo que puedes actuar. También es la única señal legible que tienes para comparar la iteración N contra la iteración N+1.
Una nota de privacidad para el trabajo de alto riesgo. La revisión cruzada de modelos significa, por definición, pegar tu borrador en varias herramientas. Presta atención a la política de datos de cada herramienta antes de hacer esto con material sensible. Algunas herramientas (Claude en su producto de consumo, ChatGPT con la exclusión de entrenamiento activada, los planes de pago de Gemini) no se entrenan con tus entradas. Otras (el producto de consumo de Meta AI por defecto) pueden hacerlo. Un memorando de estrategia de 40 páginas, un análisis financiero interno o cualquier cosa cubierta por un acuerdo de confidencialidad solo deberían pasar por herramientas cuyas políticas de datos hayas comprobado de verdad. El sentido del bucle multimodelo es atrapar tus puntos ciegos; el sentido opuesto del bucle es meter tu trabajo confidencial en un conjunto de entrenamiento.
Una advertencia honesta. Tres modelos pueden estar todos equivocados sobre la misma cosa. Comparten más datos de entrenamiento de lo que supondrías, y en temas discutidos o de datos escasos (Concepto 2) a menudo comparten las mismas ideas equivocadas. La puntuación es una señal de progreso, no una señal de verdad. Para contenido de alto riesgo (cualquier cosa legal, médica, financiera o sobre una persona real) ningún número de pasadas de modelos cruzados reemplaza a un experto humano que revise las afirmaciones de carga. Los modelos se revisan entre sí por el oficio. Los humanos revisan los hechos que importan.
Cuándo saltarse el bucle.
No toda tarea lo amerita. Un correo corto, una búsqueda rápida, una lluvia de ideas casual: un solo modelo está bien. Guarda la revisión cruzada multimodelo para el trabajo donde equivocarse es caro: un memorando que leerá tu jefe, un capítulo que se publicará, una decisión que afecta a otras personas, un contrato que firmarás. La regla práctica: si un colega reflexivo habría pasado dos horas revisando esto, amerita el bucle.
Un ejemplo no informático. Una consultora que preparaba un memorando de estrategia de 40 páginas para el consejo de un cliente redactó en su modelo más fuerte e iteró contra sus propias calificaciones hasta que se estancaron en 9. Luego pegó el memorando completo en un segundo modelo de una familia distinta y pidió la misma rúbrica. El segundo modelo le dio un 7,5 y enumeró once problemas específicos, tres de los cuales su modelo principal no había planteado en ninguna de sus propias rondas de autocalificación. Ella se los devolvió al primer modelo para arbitrar; adoptó siete y rechazó cuatro con razones. Un tercer modelo de otra familia más sacó a la luz otros dos. El punto no son las puntuaciones finales. Es que los contraargumentos que ella nunca habría visto por su cuenta, porque su modelo principal compartía sus puntos ciegos, estaban en el memorando antes de la reunión del consejo.
Un breve repaso antes de probar los prompts
Trece conceptos son muchos. La forma de la página, una línea por concepto:
- Concepto 1. La diferencia entre un prompt de novato y un prompt de experto es un puñado de hábitos: informa a la IA como a un colega nuevo e inteligente, con contexto, restricciones y una petición clara.
- Concepto 2. La IA sabe cosas a partir de una instantánea de internet: aprendió leyendo texto sobre el mundo, no experimentando el mundo, así que es fuerte en temas comunes y débil en los oscuros o recientes.
- Concepto 3. Tres modos de recuperación: preentrenado, búsqueda web, investigación profunda. Tu redacción dirige cuál se dispara.
- Concepto 4. El modelo no tiene memoria propia; la ventana de contexto es su memoria de trabajo para esta respuesta. El mayor determinante de la calidad de la respuesta es lo que pones en esa ventana, y los proyectos te dejan cargarlo una vez en lugar de cada vez.
- Concepto 5. Los modelos modernos pueden pensar a fondo durante segundos o minutos si se los pides.
- Concepto 6. Los modelos tienen un sesgo hacia el acuerdo. El encuadre neutral y las rúbricas neutralizan la mayor parte de ese sesgo; forzar una puntuación del 1 al 10 por criterio, con el cambio que subiría cada puntuación, neutraliza el resto.
- Concepto 7. El bucle de iterar con retroalimentación explícita es el hábito de mayor apalancamiento de la página. Califica cada etapa sobre 10 y reitera hasta que la puntuación se estanque; la IA no llega a declararte terminado.
- Conceptos 8 y 9. La IA puede ver imágenes, trabajar con audio en ambos sentidos y construir pequeñas apps; la app en ejecución es un artefacto sobre el que puedes iterar, que puedes compartir e incrustar.
- Concepto 10. La IA también puede escribir código y ejecutarlo sobre tus datos, pero no siempre lo hace de forma automática. Pídelo de forma explícita, y verifica que el código de verdad se ejecutó.
- Concepto 11. Hay una nueva categoría de apps de escritorio conscientes de los archivos (Cowork, OpenWork). Limita los permisos con firmeza hasta que las hayas usado de forma segura.
- Concepto 12. La herramienta correcta para un trabajo cambia cada pocos meses. Cinco familias por conocer (Claude, ChatGPT, Gemini, Meta AI, DeepSeek), planes gratuitos para todas, y Arena como la tabla de clasificación que revisar cada mes.
- Concepto 13. Cuando no hay ningún experto humano en la sala, hacer que los modelos se califiquen entre sí, a través de familias distintas, es lo más cercano a una señal objetiva de calidad.
Debajo de todo eso hay un solo movimiento, repetido en una docena de disfraces: mete el contexto correcto, deja fuera el contexto equivocado. Si nunca recuerdas una sola cosa de esta página excepto esa oración, aun así estarás en el cuartil superior de los usuarios.
Prueba esto ahora: doce prompts antes de profundizar en la disciplina de pensar
Leer es solo un sustituto de probar. Abre Claude, ChatGPT o Gemini en otra pestaña. Ejecuta estos doce prompts en orden. Toman unos veintiocho minutos en total y ejercitan cada concepto de esta página que puedas ejercitar desde una pestaña de chat.
1. Disparador de búsqueda web. Obliga a la IA a salir de sus datos de entrenamiento y buscar información actual.
What major news happened today in [your country]? Cite each claim
with a source link. Flag any claim you can't support with a citation
as "unverified".
2. Pregunta de solo preentrenado. Conocimiento común, sin búsqueda necesaria. Debería ser rápida y segura.
Why do cats stare at walls? Two-paragraph answer.
3. Prompt personal rico en contexto. Practica cargar restricciones por adelantado.
Plan a 15-minute home workout for me. Constraints: I have stairs
in my home, a bad knee (no squats), I cannot stick to plans for
more than three days, and I want to feel slightly silly while
doing it. Give me 3 options, no commentary.
4. Reescritura de encuadre neutral. Practica detectar tu propio sesgo en el prompt.
The question I want to ask is: "Don't you think four-day work
weeks are obviously better for everyone?" Rewrite this as a
neutral question that doesn't signal what answer I want.
Then answer the rewritten version.
5. Lluvia de ideas de tres opciones con iteración. El bucle central de experto.
Round 1: I want to start a small side project that takes about
3 hours per week and might make money in a year. I'm a [your
profession] who likes [your hobby]. Give me 5 different ideas,
one line each. Don't expand any of them.
(Read the 5. Pick what you like and don't like. Then, in the
SAME conversation:)
Round 2: I reject options [N] and [N] because [reason]. I like
the [keyword] idea but I want it to use less [thing]. Give me
5 new options that incorporate this feedback.
6. Escritura con el esquema primero. Fuerza la estructura antes de la prosa.
I want to write a 600-word post about [a topic you care about].
Don't write it yet. Give me 3 different outline options, each
with 4-6 headings. One line per heading.
7. Prompt de razonamiento de pensar a fondo. Usa una decisión personal real.
I'm choosing between [Option A] and [Option B] for [real personal
decision in your life]. Here's the relevant context: [a paragraph
of context]. Think hard before answering. Tell me:
1. The 3 trade-offs that actually matter.
2. Which you'd choose and why.
3. Under what conditions your recommendation would flip.
8. Crítica de calificar y mejorar. Evita la adulación sobre tu propio trabajo.
I'm pasting in something I wrote: [paste anything 100-300 words].
Critique it using these 4 criteria, each scored 1-10 with a
one-sentence justification:
- Does it have a clear central claim?
- Is each paragraph in the right order?
- Are there any sentences that could be cut without loss?
- Does the ending earn the time the reader spent getting there?
Then, for each criterion, tell me the change that would raise
its score the most. There is always a next level — even a 9
has a path to 9.5.
9. Tarea de entrada de imagen. Practica darle a la IA una foto para leer.
[Upload any handwritten note, receipt, or whiteboard photo]
Transcribe what's written. Then summarize what it's about in
3 bullets. Flag anything you couldn't read with confidence.
10. Prompt de app pequeña. Practica la forma Objetivo/Entrada/Salida. Lo que vuelva será un artefacto en el que puedes hacer clic e iterar, justo en el chat.
Build me a Pomodoro timer.
Goal: 25-minute work sessions, 5-minute breaks.
Input: I press start.
Output: Visible timer counting down, a satisfying click when
each cycle ends, a yellow theme. Show me the working version.
11. Análisis de datos: expón el fallo silencioso. Practica la disciplina de "pide código de forma explícita, luego verifica que se ejecutó". Este ejercicio va en dos rondas.
Round 1, the trap: In a fresh conversation, paste this prompt
exactly as written. Do NOT mention code.
"Here are 18 numbers: 47, 52, 89, 91, 23, 67, 78, 12, 95,
44, 88, 71, 33, 56, 99, 18, 64, 82. What is the median,
the average, and which numbers are outliers? Be specific."
Look at the response carefully. Did the AI show you a code
block that it ran? Or did it write a paragraph with numbers
in it and no visible computation? Note your answer.
Round 2, the fix: In the same conversation, paste this:
"Now run that calculation again — but this time write and
run code to do it, and show me the code you ran."
Compare the two answers. If the first answer had the median
wrong, rounded suspicious numbers, or just felt vague — you
just saw the silent failure mode of concept 10 in action.
The correct answers are: median 65.5, average ~61.6,
no clear outliers (the numbers are roughly evenly spread).
12. Revisión cruzada de modelos. Practica el hábito multimodelo sobre un borrador real. Requiere dos herramientas de IA abiertas a la vez, de familias distintas (ver el Concepto 13).
Take any 200-300 word draft you wrote recently (an email, a memo,
or a paragraph from one of these exercises).
Step 1: In your primary AI tool, paste the draft and ask: "Score
this 1-10 on clarity, structure, evidence, and what's missing.
One-sentence justification per score."
Step 2: Open a second AI tool from a different family (if your
primary is Claude, use ChatGPT or Gemini or Meta AI — not another
Anthropic model). Paste the same draft, ask the same question.
Step 3: Compare the two scores and the two critiques side by
side. Note any point only one of them caught. Those are the
points the cross-model loop pays for.
🚀 Proyectos
Los doce prompts ejercitaron cada uno un concepto. Los primeros tres proyectos de abajo los encadenan, y terminan en un lugar al que una ventana de chat no puede llevarte: con algo que pusiste en vivo en la internet pública, en una dirección que puedes enviarle por mensaje a una amistad.
Cada proyecto toma de treinta a sesenta minutos en una cuenta gratuita y se despliega cuando estés listo para él. Haz el Proyecto 1 hoy; guarda el resto para la semana. Están secuenciados: cada uno enseña un movimiento que usa el siguiente. Si algo se rompe a mitad de un proyecto, el último desplegable de esta sección tiene el arreglo. La forma es la misma para los primeros tres:
the chat builds it you download it the internet serves it
┌──────────────────┐ ┌──────────────┐ drag ┌───────────────────────┐
│ a working app in │ ────→ │ index.html │ ──────→ │ your-app.netlify.app │
│ the side panel │ │ (one file) │ │ (a real, public URL) │
└──────────────────┘ └──────────────┘ └───────────────────────┘
El Concepto 9 dijo que la cosa en el panel lateral es un artefacto: un objeto real que puedes descargar, no una vista previa. Los primeros tres proyectos cobran esa promesa. El Proyecto 4 es el proyecto final, y entrega un tipo distinto de cosa: no una URL, sino un artefacto de conocimiento que construiste con la IA, más la prueba documentada de que puedes dirigirla, cuestionarla y corregirla.
Project 130-60 minBatalla de serpientesConstruye un juego jugándolo, y luego publícalo en una URL real.
Abre ChatGPT, Claude o Gemini y di:
Let's build and play a game where a snake eats fruit balls to grow.
Aparece un juego jugable de la serpiente en el panel lateral. Listo cuando: puedes guiar a la serpiente con las teclas de flecha y comer algo. Si estás en un teléfono, ese es tu primer deseo: "agrega controles táctiles". Juégalo un minuto y presta atención a lo primero que desearías que fuera distinto. Luego no escribas un informe cuidadoso. Solo di el deseo:
Can I pick my snake's color before the game starts?
El artefacto se actualiza en el sitio: ahora hay una pantalla de inicio con un selector de color. Sigue jugando, sigue deseando. Luego cambia las reglas del juego mismo:
Now make it a battle: add computer-controlled snakes, and when a
snake dies its body turns into fruit the others can eat.
Esta es la Batalla de serpientes de un lector, publicada en una URL La tuya no se verá como esta, y ese es el punto. Se verá como lo que sea que notaste mientras jugabas.
▶ Juega una versión terminada (el tipo de cosa hacia la que vas construyendo)
.netlify.app real exactamente como publicarás la tuya. Elige un color, pulsa Iniciar Batalla, guía con las teclas de flecha. Se carga en vivo abajo; también puedes abrirla en su propia pestaña.
Tres oraciones después, tienes una pantalla de inicio, selectores de color, oponentes controlados por bots y una regla que inventaste. Ahora fíjate en dos cosas. Primero, en lo que nunca mencionaste: HTML, JavaScript, detección de colisiones, bucles de juego. Describiste una experiencia y el modelo hizo la ingeniería, exactamente como prometió el Concepto 9. Segundo, de dónde vino cada oración. No de planificar. De jugar. Este es el bucle del Concepto 7 con el paso de retroalimentación reemplazado por el crítico más honesto disponible: tú, a mitad del juego, notando lo que desearías que fuera distinto. Sigue hasta que el juego sea tuyo. Serpientes más rápidas, un marcador, efectos de sonido, un deseo por mensaje.
Una última pasada antes de que salga en vivo. Has estado calificando por intuición todo este tiempo; cada deseo fue un pequeño veredicto. Hazlo explícito una vez: pídele al juego que se puntúe a sí mismo y arregle su propio punto más débil.
Score this game 1-10 on three things: is it fun, is it clear
what to do, and does it feel finished or rough? One sentence
each. Then make the single change that would raise the lowest
score, and do it.
Ese es el movimiento entero en miniatura. Un número fuerza una respuesta honesta donde "¿es bueno?" solo recibe un sí (Concepto 6). Haz una ronda aquí. El siguiente proyecto convierte esta sola petición en un bucle que no se detiene hasta que lo hacen las puntuaciones.
Ahora publícalo. Este es el movimiento que cada proyecto reutiliza, así que hazlo con cuidado una vez:
-
Descarga el juego. El canvas de ChatGPT tiene un ícono de descarga en la parte superior del panel; Claude y Gemini tienen un control equivalente de descarga o exportación en los suyos. Obtienes un único archivo
.html. Ese archivo es el juego entero. -
Renombra el archivo a
index.html. Ese nombre es la convención de la web para "la página principal de un sitio", y el servicio de alojamiento del siguiente paso lo busca. -
Crea una cuenta gratuita en netlify.com. Basta con una dirección de correo electrónico. Netlify es un servicio de alojamiento: toma archivos y los sirve a internet, con un plan gratuito que es más de lo que este proyecto necesita.
-
Arrastra tu archivo a la zona de carga. Tras registrarte, Netlify muestra una página "Let's create your new project" cuya zona de carga acepta, en sus propias palabras, "a single HTML file". (En un teléfono, toca "browse files to upload" en lugar de arrastrar.)
-
Abre la dirección que te da. Unos segundos después de soltar el archivo, tu juego está en vivo en una dirección que termina en
.netlify.app. Listo cuando: el juego carga en el navegador de tu teléfono, no solo en tu equipo. Envíale el enlace a una persona.
Una pregunta justa: el Concepto 9 dijo que las herramientas de chat pueden publicar un artefacto en un enlace para compartir, entonces ¿para qué molestarse con la descarga? Porque el enlace publicado vive dentro del producto de IA, atado a tu chat. El archivo descargado es tuyo: funciona en cualquier servicio de alojamiento, en una memoria USB, dentro de diez años. Netlify resulta ser la forma gratuita más rápida de poner un archivo que te pertenece en la web abierta, y el arrastrar y soltar que acabas de hacer es de verdad el mismo movimiento que los profesionales usan para montar un sitio rápido.
Para actualizar un juego ya publicado: sigue iterando en el chat, descarga de nuevo, renombra de nuevo y arrastra el archivo nuevo a la pantalla de deploys de tu proyecto en Netlify. Misma dirección, versión nueva.
Project 245-60 minGolpea al topoConstruye un juego, luego califícalo más allá de 'suficientemente bueno' hasta que sea de verdad divertido.
El juego de la serpiente se volvió bueno porque lo jugaste, y luego lo calificaste una vez antes de publicarlo. Aquí, esa sola calificación se vuelve el motor entero: ejecutas cada movimiento de la página a la vez, generas opciones, informas con estructura, pruebas, puntúas contra una rúbrica y te niegas a parar hasta que las puntuaciones sean altas. Es la versión disciplinada de "constrúyeme una cosa", y es la que produce algo que te enorgullece compartir.
Este es el Golpea al topo de un lector, publicado en una URL real El tuyo no se verá como este, y ese es el punto. Se verá como el tema que elegiste y el feedback que diste.
▶ Juega una versión terminada (lo que estás construyendo)
.netlify.app exactamente como publicarás el tuyo. Haz clic en los topos cuando aparezcan e intenta superar tu récord. Se carga en vivo abajo; también puedes abrirlo en otra pestaña.
Empieza pidiendo opciones, no una construcción (Concepto 7):
I want to build a Whack-a-Mole game. Before building anything,
give me 3 different visual theme options. One line each.
Vary the color scheme, what the moles look like (animals,
monsters, aliens), and the overall mood (playful, spooky,
elegant). Don't build any of them yet.
Elige la que te guste y entrégale al modelo todo lo que necesita para construirla. Este es el Objetivo / Entrada / Salida del Concepto 9, la estructura que no deja nada a la adivinación:
I pick the twilight garden theme: deep blue night sky with
twinkling stars, glowing gold accents, rich dark emerald grass,
and cute animal emojis as moles.
Now build the game with these specs:
Goal: Moles pop up randomly from holes in a 3x3 grid. The
player clicks them to score points. They disappear after a
short time.
Input: Player clicks on moles that appear.
Output:
- 3x3 grid of clearly visible holes with dark centers and
brown dirt rims that stand out from the grass
- Moles using these emojis: hamster, bear, frog, monkey,
rabbit, fox - large and crystal clear when they pop up
- Score counter at the top
- 30-second countdown timer with a color-coded progress bar
- Moles rise up FROM INSIDE the hole, not floating above it
Aparece un juego jugable en el panel lateral. Listo cuando: los topos asoman y al hacer clic en uno se suma un punto. Se sentirá plano, y eso es lo esperado: tienes el esqueleto, no la sensación. Agrega la sensación en una sola pasada (Concepto 4, cada detalle que omitas el modelo tiene que adivinarlo):
Add these features to the game:
1. SPEED: Moles start slow, visible for about 2.5 seconds.
Speed ONLY increases when the player's SCORE goes up, not
when time passes. Show a speed label: Easy, Fast, Frenzy.
2. INSTANT START: The first mole appears immediately when the
player clicks Start. No waiting.
3. HIT EFFECTS: When a mole is whacked, show all of these:
- Colorful particle burst at the hit point
- A plus one text floating upward and fading out
- Quick screen shake for impact
- A short sound effect using Web Audio API
4. GAME OVER SCREEN: Show final score large and animated,
total hits, hits-per-minute stat, confetti animation,
New High Score badge if earned, and a Play Again button.
Ahora juégalo, y haz lo que enseñó el Concepto 7: di exactamente qué está mal Y qué quieres en su lugar. Las quejas vagas reciben arreglos vagos:
I played the game and found these issues:
1. Moles are mostly hidden inside the hole. They should pop up
clearly above the dirt so I can see the full emoji face.
Fix the layering so moles render in front of the dirt.
2. The holes blend into the dark background. Add a visible
lighter brown rim around each hole opening so they stand
out clearly from the grass.
3. The game takes 2 seconds before the first mole appears
after clicking Start. Make it appear instantly with zero
delay.
Fix all three issues.
Aquí está el movimiento que separa un juguete de un juego terminado. No preguntes "¿es bueno?", el modelo siempre dirá que sí (Concepto 6). Entrégale una rúbrica y haz que se puntúe a sí mismo con honestidad:
Score this game 1-10 on each criterion. Give a one-sentence
justification per score. Then for EACH criterion, tell me the
single change that would raise the score the most.
1. VISUAL CLARITY - Can I instantly see every hole and mole?
2. FUN FACTOR - Does whacking a mole feel satisfying?
3. DIFFICULTY CURVE - Does it start easy and get harder fairly?
4. POLISH - Does it look like a finished game or a rough draft?
5. GAME FEEL - Do animations and sounds make me want to keep
playing?
There is always a next level. Even a 9 has a path to 9.5.
Luego itera hasta que se gane la puntuación, y tú decides cuándo lo ha hecho, no el modelo (Concepto 13):
Implement the top 3 highest-impact changes you suggested. Then
score the game again on the same 5 criteria. Keep going until
all scores are 9 or above. I decide when to stop, not you.
Ese bucle es el proyecto entero. Ejecútalo dos veces y tu juego cruza la línea de "una cosa que hizo la IA" a "una cosa a la que le pondría mi nombre". Cuando quieres una función que necesita diseño real, no solo más detalle, pídele al modelo que piense antes de construir (Concepto 5). La frase "piensa a fondo" activa el razonamiento extendido: Y una vez que tengas una versión que te guste, averigua si una herramienta distinta lo habría hecho mejor (Concepto 12). Combina el prompt de tema y construcción y el prompt de sensación del juego de antes, y luego pégalos en una herramienta que no usaste: Una persona que solo usa una IA está adivinando cuál es la mejor. Ahora lo sabrás, para este tipo de construcción, con tus propios ojos.Dos movimientos potentes, una vez que lo básico funciona
Think hard about this: I want a smarter difficulty system.
Right now speed just increases with score. But a player who
scores 10 points in 10 seconds is very skilled, while a player
who scores 10 points in 25 seconds is slower. They should face
different difficulty levels.
Design an adaptive difficulty system that considers both the
player's score AND how fast they are scoring. Explain your
approach first, then implement it.Copy your Prompt 2 and Prompt 3 combined and paste them into
a different AI tool. If you used Claude, try ChatGPT or Gemini.
Play both versions side by side and compare:
- Which version has better visuals and colors?
- Which version has clearer moles and holes?
- Which version is more fun to play?
- Which version has better animations and sound?
Take the best ideas from both and ask your main AI tool to
add the features the other version did better.
Publícalo exactamente como el juego de la serpiente: descarga, renombra a index.html, arrastra a Netlify (un proyecto nuevo). Listo cuando: una amistad puede jugar tu juego desde el enlace en su propio teléfono.
Project 330-60 minUna página que eres túUn sitio personal de una página que un desconocido entiende en cinco segundos.
Un primer intento de este proyecto suele verse así. Llámalo el enfoque del principiante (el Concepto 1 en su hábitat natural):
I was in Summer Camp learning AI this June. Now I am thinking
to create a personal website that shows everything about me
and what I have learned in this Summer Camp. Share what goes
into the personal website
Now build a personal website with the above idea and show it
Vuelve una página perfectamente aceptable, y esa es exactamente la trampa. Preguntar qué lleva un sitio web personal fue un buen instinto, pero la pregunta no tiene a nadie dentro, así que la respuesta es genérica, y el segundo prompt la acepta entera. "Everything about me" llegó sin traer nada del yo real, así que el modelo llena el hueco de la única forma que puede (Concepto 2): con la página del estudiante promedio de sus datos de entrenamiento. Secciones de plantilla, "apasionado por aprender", logros que podrían ser de cualquiera. Educada, limpia, de nadie. La página se vuelve buena del mismo modo que cada respuesta de esta página se vuelve buena: cuando el contexto se vuelve real.
Aquí está el mismo proyecto ejecutado por un lector, un estudiante de campamento de verano, tal como lo enseña esta página. Tres prompts, del inicio a la publicación. Primero el informe: una meta con una audiencia dentro, y una lista de las decisiones en las que él quiere tener voz antes de que exista diseño alguno:
Now you will build a professional personal website
My Goal: To present myself professionally to everyone
(friends, relatives, businesses)
Here are some points that we have to work on before
designing it:
1. Website Colors
2. Background and Design
3. Text Size, Writing Style
4. What information will be there
5. How we present it professionally
Build and show it
Nada de eso es vocabulario de diseñador. "Text Size, Writing Style" no es la jerga oficial de nadie, y aun así funciona, porque le dice al modelo qué decisiones le corresponde a él aprobar. Volvió una página decente: secciones limpias, su nombre arriba. Parecía terminada. Él la leyó como la leería un visitante y detectó lo que faltaba. Luego adjuntó al chat el archivo de su certificado del campamento de verano (los archivos también son contexto, Concepto 4) y envió la evidencia que solo él podía aportar:
It looks good but it is missing the most important information
1. I can design games on the web. Here is an example to
showcase: https://snake-game-by-junaid.netlify.app/
2. I know how to use ChatGPT and similar AI assistants
professionally, like Claude and Gemini
3. I know everything present here
https://agentfactory.panaversity.org/docs/ai-prompting-2026
4. I can professionally guide anyone about the things in the
above link
5. At the end of summer camp there was an exam and I got
certified. I have attached the certificate
Now plan and update it
Cada línea es algo real que un desconocido puede comprobar: un juego que publicó exactamente como el Proyecto 1 publica el suyo, el curso que estudió (el punto 3 es la página que estás leyendo ahora mismo), un archivo que el modelo puede leer por sí mismo. Una cosa olvidada costó un mensaje, no un reinicio. Y "Now plan and update it" es el instinto de opciones antes del compromiso del Concepto 7 en cinco palabras: primero planear, luego tocar la página. La versión que volvió tenía pruebas donde antes estaban los adjetivos. Una mirada después, el último movimiento: un deseo de diseño, al estilo del juego de la serpiente, lo bastante específico para cargar con su propio arreglo:
On top I have my full name Muhammad Junaid Shaukat and the
same in the next section. This looks bad. For now the top
should have MJS and my game link
https://snake-game-by-junaid.netlify.app/
▶ Mira la página que produjeron esos tres prompts (en vivo)
Este es el resultado real publicado, en una dirección que él renombró con su propio nombre en la configuración de Netlify, exactamente como lo describe el paso de publicación de abajo. Se carga en vivo aquí; también puedes abrirla en su propia pestaña.
La tuya no debería verse como esta. Debería verse como tú.
Ahora ejecuta el tuyo. Róbale los movimientos, no los datos: abre con tu meta y para quién tiene que funcionar la página, enumera las decisiones en las que quieres tener voz, y luego "Build and show it". Si recibes una descripción de la página en lugar de la página, di: "hazlo". Usarás esa palabra más que cualquier otro prompt de esta sección. Cuando la primera versión parezca terminada, léela como un visitante y responde la pregunta que él respondió: ¿cuál es la información más importante que le falta a esta página? Envíala como cosas reales y comprobables: enlaces a lo que publicaste (el juego del Proyecto 1 va aquí), un archivo que el modelo pueda leer, los nombres de lo que estudiaste. Luego deseos de diseño, uno por mensaje. "El encabezado está gritando". "Menos morado". "Más espacio entre secciones".
Cuando parece terminada, no está terminada. Y aquí quien califica no puedes ser tú: ya sabes quién eres, así que no puedes sentir si la página de verdad lo dice. Este es el único proyecto donde tienes que tomar prestados los ojos de otra persona. Ejecuta el mismo bucle de calificar y arreglar que ejecutaste en el juego del topo (el movimiento de la rúbrica honesta del Concepto 6), con un cambio: entrégale a la IA un desconocido específico en el que convertirse.
Become a specific stranger landing on this page for the first
time. Pick one and stay in their head: a recruiter scanning for
eight seconds, a classmate who has never met me, or someone my
work would actually matter to. Score the page 1-10 on three
things: do you know who I am within five seconds, is it obvious
what I want you to do, and does anything read like filler you
would skip? One sentence each, in their voice. Then make the
single change that raises the lowest score and apply it to the
page, don't just describe it.
Ejecútalo dos veces, un desconocido distinto cada vez. Cuando dos personas que nunca se conocerían te entienden ambas en cinco segundos, la página está terminada. Ese acuerdo es la señal que no puedes obtener de tus propios ojos.
Publícalo exactamente como el juego: descarga, renombra a index.html, arrastra a Netlify (un proyecto nuevo esta vez). En la configuración de tu proyecto puedes cambiar el nombre aleatorio del sitio por algo más cercano al tuyo, si no está tomado. Listo cuando: tu nombre lleva a una página que hiciste, y la dirección está en tu biografía.
Project 42-4 hMinilibro de texto con IAUsa la IA para construir un capítulo de aprendizaje corto sobre un tema, luego demuestra que puedes dirigirlo y verificarlo.
Los primeros tres proyectos terminaron cada uno en una URL pública. Este, a propósito, no. Aquí usas la IA para construir un capítulo corto de minilibro de texto sobre un tema que estés estudiando, y el verdadero entregable son dos cosas: el capítulo (el producto) y un cuaderno de proceso que prueba que puedes dirigir, cuestionar y corregir a la IA (la prueba). El enfoque de abajo está escrito para un estudiante que elige un tema de clase, pero sirve para cualquiera: elige cualquier tema que de verdad estés tratando de aprender, deja que "docente" signifique cualquiera que vaya a revisar tu trabajo, y trata la entrega como opcional.
Este es el proyecto final porque ejercita todo lo de esta página a la vez: darle a la IA un contexto fuerte (Concepto 4), elegir el modo de recuperación correcto (Concepto 3), el bucle de opciones y luego retroalimentación y la puntuación por rúbrica (Concepto 7), y verificar las afirmaciones en lugar de confiar en ellas (Conceptos 2 y 13). El minilibro de texto es el producto. Tu registro de prompts, tus verificaciones de datos y tu reflexión son la prueba de que puedes usar la IA de forma responsable.
Cómo funciona esto, léelo primero. El trabajo real lo haces en ChatGPT, Claude o Gemini en otra pestaña del navegador. Esta tarjeta te da los prompts para ejecutar, en orden, y un cuaderno de trabajo en vivo más abajo (en el Paso 6) donde registras a mano lo que hiciste, tu prueba de cómo razonaste con la IA. Abre ese cuaderno ahora y complétalo a medida que avanzas por los pasos, en lugar de dejarlo todo para el final. Todo lo que necesitas está en esta página más una cuenta gratuita de IA.
Paso 1: elige un tema pequeño y abre tu IA
Elige un tema pequeño, no una materia entera, porque de verdad puedes enseñar bien un tema pequeño en unas pocas páginas. No elijas la fotosíntesis; el ejemplo resuelto la usa. Luego simplemente abre ChatGPT, Claude o Gemini e inicia un chat nuevo para este proyecto. Si por casualidad tienes apuntes o un libro de texto sobre el tema, tenlos a mano para pegarlos después; si no, el propio conocimiento de la IA es más que suficiente.
| Materia entera | Un tema pequeño que de verdad puedes enseñar |
|---|---|
| Biología | Las cadenas alimentarias y cómo fluye la energía |
| Matemáticas | Las fracciones y los porcentajes |
| Física | Los circuitos eléctricos |
| Lengua | Escribir una introducción de ensayo sólida |
| Historia | Las causas de la Guerra de Independencia de 1857 |
Ideas locales si quieres una: los circuitos eléctricos durante los cortes de luz, los porcentajes con descuentos de compras, la gramática usando un anuncio escolar, o presupuestar un evento de clase usando razones.
Listo cuando: elegiste un tema pequeño y tienes un chat nuevo de IA abierto, listo para empezar.
Paso 2: informa bien a la IA (Concepto 4)
Ejecuta dos prompts. Primero uno deliberadamente débil, y guarda la respuesta, para que después puedas ver lado a lado cuánto mejora las cosas un buen informe. Luego uno real que le entregue a la IA tu contexto: quién eres y qué estás aprendiendo. Ese segundo prompt es la lección entera del Concepto 4 en un solo movimiento.
Explain ___.
Por qué: ejecuta este primero solo para ver la línea base, la diferencia entre un prompt perezoso y uno bueno.
I am a Grade ___ student. I am learning about ___. Explain it to me
clearly, then tell me what is still unclear and what I might
misunderstand.
Por qué: esto le entrega al modelo tu situación real, así la respuesta te queda a ti en lugar de a un lector genérico.
Opcional, solo si de verdad tienes apuntes, una foto del libro de texto o una hoja de trabajo: pégalos y dile a la IA que se apoye en ellos. La mayoría de los lectores puede saltarse esto y usar el propio conocimiento de la IA.
Here are my notes / a textbook photo: ___. Use these first. If you add
anything that is not in them, label it clearly as extra.
Listo cuando: la IA respondió usando tu contexto real (tu nivel y lo que estás aprendiendo). Pega cada prompt, y una línea sobre lo que te devolvió, en el cuaderno de abajo a medida que avanzas.
Paso 3: obtén opciones, luego objeta (Concepto 7)
Pide tres formas distintas de explicar tu tema, pero no dejes que la IA expanda ninguna de ellas al capítulo completo todavía. Luego elige una, rechaza las demás con razones, y pide esquemas revisados. Rechazar con una razón es el movimiento que prueba que estás dirigiendo a la IA, no solo aceptando su primera idea.
Give me 3 different ways to explain ___ to a Grade ___ student. Do not
expand into the full chapter yet. For each option, give a title,
structure, strengths, and weaknesses.
Por qué: esto fuerza la lluvia de ideas antes de redactar.
I choose option ___ because ___. I reject option ___ because ___.
Revise the outline into 3 improved versions and make them more
suitable for my class context.
Por qué: esto muestra que estás dirigiendo a la IA, no solo aceptando la primera respuesta.
Listo cuando: rechazaste al menos una opción con una razón y tienes un esquema revisado que de verdad te gusta.
Paso 4: construye el capítulo (Parte A)
Ahora que el bucle de planificación terminó, pídele a la IA que piense a fondo y redacte el capítulo completo a partir de tus apuntes y el esquema elegido. El capítulo debe contener las diez secciones de la Parte A, listadas en el desplegable de abajo.
Read my notes and chosen outline carefully. Think hard about clarity,
accuracy, and age-fit. Now build the full mini textbook chapter for
Grade ___ students. Use simple language, short paragraphs, examples,
common mistakes, flashcards, quiz, and a 7-day revision plan.
Por qué: esto pide trabajo cuidadoso solo después de que el bucle de planificación terminó.
Listo cuando: tienes un borrador que cubre las diez secciones de la Parte A.
Paso 5: puntúalo, luego verifícalo (Conceptos 2, 7, 13)
Primero pídele a la IA que califique su propio borrador contra una rúbrica y haga las ediciones más pequeñas que sugiera. Luego pídele que liste sus afirmaciones importantes, y verifica unas cuantas de las grandes tú mismo, contra tus apuntes, un libro de texto o una búsqueda web rápida, marcando cada una como Aceptar, Rechazar, Modificar o Necesita verificación. Una puntuación te dice dónde mejorar; la verificación te dice qué es en realidad cierto.
Grade the chapter from 1 to 10 on four criteria: clarity, accuracy,
age-fit, and usefulness for revision. Justify each score in one
sentence. Then tell me the smallest edit that would raise each score
the most.
Por qué: esto convierte la crítica en una mejora medible.
List 6 to 10 important factual claims in the chapter. Mark each claim
as supported by my notes, supported by a named source, needs checking,
or unsupported. Do not pretend you verified something if you did not.
Por qué: esto favorece la verificación honesta en lugar de la confianza ciega.
Listo cuando: aplicaste las ediciones de la rúbrica y verificaste al menos unas cuantas afirmaciones importantes. Registra el prompt de la rúbrica y las afirmaciones que verificaste en el cuaderno de abajo a medida que avanzas.
Paso 6: arma tu cuaderno de proceso y termina
Reúne la prueba: el resumen de tu tema, las fuentes, el registro de prompts, las verificaciones de datos y la reflexión. Completa el cuaderno de trabajo en vivo de abajo mientras trabajas; se guarda en tu navegador de forma automática y se exporta a un único archivo Markdown que puedes conservar como prueba, copiar o imprimir. La especificación completa de la Parte B, con una fila de ejemplo por tabla, está en el desplegable que hay debajo.
Listo cuando: tu capítulo está terminado, y tu cuaderno guarda la prueba: los prompts principales que ejecutaste, un par de datos que verificaste y una reflexión corta en tus propias palabras. ¿Haces esto para una clase? La versión más completa, más prompts, fuentes nombradas, la rúbrica y la lista de verificación completa, está en los desplegables de abajo. Escribe el capítulo para alguien que se encuentra con el tema por primera vez. Incluye las diez secciones: Esta es la prueba. Tiene seis piezas. Dos son textos cortos; cuatro son tablas que completas en tu propio cuaderno o documento, una fila a la vez. B1, resumen del tema. Un párrafo corto: qué tema, por qué lo elegiste, qué tiene de difícil, para quién es y qué debería entender el lector al final. B2, lista de fuentes. Una fila por fuente, al menos dos: Modos de recuperación (Concepto 3). Nombra al menos dos fuentes, al menos una de tu material de clase si es posible, y di qué modo usaste: Los tipos de fuente cuentan como una fuente de clase (página del libro de texto, apuntes del docente, hoja de trabajo, una foto de un párrafo) o una fuente de aprendizaje confiable (Khan Academy, Britannica, un sitio aprobado por el docente). Si tu herramienta no tiene búsqueda web, usa tu libro de texto y los apuntes del docente y anótalo. No inventes fuentes. Si la IA te da una fuente, ábrela y verifícala cuando puedas; si no puedes verificarla, márcala como "Necesita verificación". Arma tu paquete de contexto. El modelo solo sabe lo que hay en el chat o el Proyecto actual, así que aliméntalo: un párrafo del libro de texto escrito a máquina, una foto clara de una página o una hoja de trabajo, una foto de un diagrama o un apunte de clase, las instrucciones de tu docente, el vocabulario que tu docente quiere, y tus propias palabras sobre lo que ya te confunde. Regla de privacidad: nunca subas contraseñas, tu dirección de casa, tu número de teléfono, detalles privados de la familia ni fotos privadas. B3, registro de prompts. Al menos 8 prompts, que muestren el proceso entero y no solo la respuesta final. Una fila por prompt, que cubra los ocho tipos de los prompts iniciales de arriba: B4, tabla de puntuación por rúbrica. Puntúa el borrador, luego mejóralo. No aceptes una puntuación a ciegas. Una fila por criterio (claridad, exactitud, adecuación a la edad, utilidad): B5, tabla de verificación. Elige de 6 a 10 afirmaciones importantes de la IA y verifícalas. Una fila cada una: B6, reflexión. De 150 a 250 palabras: qué te ayudó a entender la IA, qué se equivocó o dejó poco claro, qué prompt funcionó mejor y por qué, qué cambiaste en el capítulo final, y qué harás distinto la próxima vez. Aquí está la forma de un recorrido terminado, para que veas hacia dónde vas: Esta muestra enseña la estructura y la calidad esperadas. No debes copiarla: elige tu propio tema, fuentes, prompts, verificaciones y reflexión. Título: Minilibro de texto con IA: la fotosíntesis para 8.º grado. Cómo las plantas verdes fabrican su propio alimento usando luz solar, agua, dióxido de carbono y clorofila. Parte A: el capítulo 1. Título y público. La fotosíntesis para 8.º grado. Escrito para estudiantes de 8.º grado. Explica cómo las plantas verdes fabrican su propio alimento usando luz solar, agua, dióxido de carbono y clorofila. 2. Objetivos de aprendizaje. Explicar qué significa la fotosíntesis; identificar las cosas principales que las plantas necesitan; explicar el papel de la luz solar, la clorofila, el agua y el dióxido de carbono; describir qué producen las plantas; evitar los errores comunes sobre cómo las plantas fabrican alimento. 3. Explicación simple. La fotosíntesis es el proceso por el cual las plantas verdes fabrican su propio alimento. Las plantas no comen como lo hacen los humanos y los animales; las plantas verdes usan la luz solar para fabricar alimento dentro de sus hojas. Ese alimento es un azúcar llamado glucosa. Para fabricar glucosa, las plantas necesitan luz solar, agua, dióxido de carbono y clorofila. La clorofila es la sustancia verde de las hojas; ayuda a las plantas a absorber energía de la luz solar. Las plantas toman dióxido de carbono del aire a través de diminutas aberturas en sus hojas y absorben agua del suelo a través de sus raíces. Usando la luz solar y la clorofila, la planta convierte el agua y el dióxido de carbono en glucosa y oxígeno. La planta usa la glucosa para obtener energía y crecer; el oxígeno se libera al aire. Una forma simple de recordarlo: luz solar + agua + dióxido de carbono -> glucosa + oxígeno. La fotosíntesis importa porque les da alimento a las plantas y produce oxígeno, que los humanos y los animales necesitan para respirar. 4. Términos clave. 5. Ejemplos. Ejemplo 1, una planta cerca de una ventana soleada: colocada cerca de una ventana soleada y regada de forma adecuada, puede fabricar alimento mediante la fotosíntesis; las hojas absorben la luz solar, las raíces absorben el agua, las hojas toman el dióxido de carbono, y la planta usa esto para fabricar glucosa, que la ayuda a crecer. Ejemplo 2, una planta que se mantiene en la oscuridad: mantenida en la oscuridad durante mucho tiempo, no puede hacer la fotosíntesis de forma adecuada porque le falta luz; sin suficiente luz no puede fabricar suficiente glucosa y con el tiempo puede debilitarse. Esto muestra que la luz solar es importante. 6. Errores comunes. 7. Diagrama o idea visual. Dibuja una planta verde con flechas: la luz solar hacia las hojas, el agua del suelo hacia las raíces, el dióxido de carbono del aire hacia las hojas, el oxígeno saliendo de las hojas, y la glucosa etiquetada dentro de la planta como el alimento que fabricó. Abajo escribe: luz solar + agua + dióxido de carbono -> glucosa + oxígeno. 8. Tarjetas de memoria. 9. Cuestionario. P1 ¿Qué es la fotosíntesis? P2 Nombra tres cosas que las plantas necesitan para la fotosíntesis. P3 ¿Cuál es el papel de la clorofila? P4 ¿Qué alimento se fabrica durante la fotosíntesis? P5 ¿Por qué es importante la fotosíntesis para los humanos y los animales? Clave de respuestas: 1) el proceso por el cual las plantas verdes fabrican su propio alimento usando la luz solar; 2) luz solar, agua y dióxido de carbono, más clorofila para absorber la luz solar; 3) la clorofila absorbe la luz solar; 4) glucosa; 5) produce oxígeno y ayuda a las plantas a fabricar alimento, lo que sostiene la vida en la Tierra. 10. Plan de repaso de 7 días. Parte B: el cuaderno de proceso B1, resumen del tema. Elegí la fotosíntesis porque es un tema importante de Biología de 8.º grado. Muchos estudiantes la encuentran difícil porque confunden los papeles de la luz solar, el agua, el dióxido de carbono, el oxígeno, la glucosa y la clorofila. Algunos piensan que las plantas obtienen todo su alimento del suelo. Mi capítulo está escrito para estudiantes de 8.º grado. Al final, deberían entender cómo las plantas verdes fabrican su propio alimento y por qué importa para la vida. B2, lista de fuentes. B3, registro de prompts. B4, tabla de puntuación por rúbrica. B5, tabla de verificación. B6, reflexión. La IA me ayudó a entender la fotosíntesis al explicarla en lenguaje simple y organizar el tema en términos clave, ejemplos, errores comunes, tarjetas de memoria y un cuestionario. Mi primer prompt fue demasiado débil porque solo pedía "Explica la fotosíntesis", así que la respuesta fue general y no hecha para mi nivel de clase. El mejor prompt fue aquel en el que le di a la IA mi nivel de grado, el contexto del libro de texto y el vocabulario del docente, y pedí un capítulo completo. La IA me dio una estructura clara, pero aun así tuve que verificar los datos. Una corrección importante fue que las plantas no obtienen todo su alimento del suelo: obtienen agua y minerales del suelo, pero fabrican glucosa en sus hojas. La próxima vez le daré a la IA primero mis apuntes de clase, pediré distintas opciones de esquema y verificaré las afirmaciones importantes antes de usar la respuesta final. Esto es solo una muestra. Elige tu propio tema, usa tus propias fuentes, muestra tus propios prompts, verifica los datos y escribe tu propia reflexión.Qué debe contener tu capítulo (las diez secciones de la Parte A)
# Sección Qué va en ella Extensión 1 Título y público tema, materia, nivel de grado, para quién es media página 2 Objetivos de aprendizaje 3 a 5 cosas que el lector debería entender lista corta 3 Explicación simple lenguaje fácil, encabezados, párrafos cortos 1 a 2 páginas 4 Términos clave al menos 5 palabras con definiciones simples tabla 5 Ejemplos al menos 2 ejemplos resueltos o de la vida real de media a 1 página 6 Errores comunes al menos 5 errores y cómo evitarlos lista o tabla 7 Diagrama o idea visual un diagrama simple, diagrama de flujo o imagen etiquetada 1 visual 8 Tarjetas de memoria 10 tarjetas, pregunta de un lado, respuesta del otro tabla 9 Cuestionario 5 preguntas con una clave de respuestas cuestionario corto 10 Plan de repaso de 7 días un plan de estudio simple de una semana tabla Qué debe contener tu cuaderno de proceso (Parte B)
Nombre de la fuente Tipo Cómo la usé Página del libro de texto de 8.º grado sobre mi tema Libro de texto / fuente de clase tomé la definición principal y los términos clave
# Mi prompt Lo que me dio la IA Lo que cambié después 1 "Explica ___." una respuesta general con palabras avanzadas vi que era demasiado débil, agregué mi grado y mis apuntes Criterio Puntuación de la IA (1 a 10) Razón de la IA Edición más pequeña para mejorarlo Mi decisión Claridad 8 clara, pero difícil de recordar agregar un diagrama simple aceptada, agregué uno Afirmación de la IA Mi decisión (Aceptar / Rechazar / Modificar / Necesita verificación) Evidencia o razón Corrección si hace falta "Mi tema ocurre sobre todo en X." Rechazar mi libro de texto dice que ocurre en Y corregido a Y Cómo se ve un recorrido terminado (un ejemplo)
Etapa En este ejemplo Tema elegido Los circuitos eléctricos durante los cortes de luz, Física de 8.º grado Contexto de clase apuntes del docente sobre pila, interruptor, bombilla, corriente, circuito completo, cortocircuito Fuentes nombradas una foto de una página del libro de texto más un artículo o video de Khan Academy sobre circuitos Prompt de opciones pedí 3 formas de explicar los circuitos (flujo de agua, iluminación del hogar, basada en dibujos) Opción seleccionada la analogía de la iluminación del hogar, porque los estudiantes de Kharian conocen los cortes de luz Producto final un capítulo con explicación, términos clave, una idea de diagrama de circuito, errores comunes, tarjetas de memoria, cuestionario y un plan de 7 días Ve un ejemplo resuelto completo (fotosíntesis, 8.º grado): no lo copies
Término Significado Fotosíntesis el proceso por el cual las plantas verdes fabrican alimento usando la luz solar Clorofila la sustancia verde de las hojas que absorbe la luz solar Glucosa un tipo de azúcar que las plantas fabrican como alimento Dióxido de carbono un gas del aire que las plantas usan durante la fotosíntesis Oxígeno un gas que las plantas liberan durante la fotosíntesis Raíces la parte de la planta que absorbe agua del suelo Hojas la parte principal de la planta donde ocurre la fotosíntesis Error Corrección "Las plantas obtienen todo su alimento del suelo." las plantas obtienen agua y minerales del suelo, pero fabrican glucosa en las hojas "La fotosíntesis ocurre en las raíces." ocurre sobre todo en las hojas "La clorofila es alimento para la planta." la clorofila no es alimento; ayuda a absorber la luz solar "El oxígeno se usa para fabricar alimento." el oxígeno se produce durante la fotosíntesis, no se usa para fabricar alimento "Las plantas no necesitan aire." las plantas necesitan el dióxido de carbono del aire Pregunta Respuesta ¿Qué es la fotosíntesis? el proceso por el cual las plantas verdes fabrican alimento usando la luz solar ¿Qué alimento fabrican las plantas? glucosa ¿Qué gas toman las plantas? dióxido de carbono ¿Qué gas se libera? oxígeno ¿Qué parte absorbe el agua? las raíces ¿Dónde ocurre sobre todo? en las hojas ¿Qué es la clorofila? la sustancia verde que absorbe la luz solar ¿Por qué se necesita la luz solar? proporciona energía para la fotosíntesis ¿Las plantas obtienen todo su alimento del suelo? no, fabrican glucosa mediante la fotosíntesis ¿Por qué es importante para los humanos? produce oxígeno y sostiene las cadenas alimentarias Día Tarea Día 1 leer la explicación simple y subrayar las palabras clave Día 2 aprender fotosíntesis, clorofila, glucosa, dióxido de carbono, oxígeno Día 3 dibujar y etiquetar el diagrama de la fotosíntesis Día 4 repasar la tabla de errores comunes Día 5 ponerte a prueba con las tarjetas de memoria Día 6 responder el cuestionario sin mirar las respuestas Día 7 explicar la fotosíntesis a una amistad o un familiar en tus propias palabras Nombre de la fuente Tipo Cómo la usé Sección del libro de texto de Ciencias de 8.º grado Libro de texto / fuente de clase la definición principal y los términos clave Apuntes del docente sobre la fotosíntesis Orientación del docente para identificar el vocabulario importante Explicación de Khan Academy o Britannica Fuente de aprendizaje confiable para verificar la explicación básica y evitar afirmaciones erróneas # Mi prompt Lo que me dio la IA Lo que cambié después 1 "Explica la fotosíntesis." una respuesta general con algunas palabras avanzadas vi que era demasiado débil y no estaba escrita para 8.º grado 2 "Soy un estudiante de 8.º grado. Explica la fotosíntesis en palabras simples usando los términos clave." una explicación más clara usando las palabras clave correctas decidí agregar mi libro de texto y los apuntes del docente 3 "Usa primero mi libro de texto de 8.º grado y los apuntes del docente. Etiqueta cualquier información extra como extra." se centró en el vocabulario del libro de texto, evitó los extras pedí opciones de esquema antes de escribir 4 "Dame 3 formas de explicar la fotosíntesis a un estudiante de 8.º grado. No escribas el capítulo todavía." tres opciones: analogía de la receta, analogía de la fábrica, diagrama primero elegí la analogía de la receta 5 "Elijo la analogía de la receta. Rechazo la analogía de la fábrica por ser demasiado compleja. Revisa en 3 esquemas." tres esquemas mejores con términos, errores, tarjetas de memoria, cuestionario elegí el esquema con un diagrama y errores 6 "Lee mis apuntes y el esquema. Piensa a fondo en la claridad y la adecuación a la edad. Construye el capítulo completo." un primer borrador completo del capítulo le pedí a la IA que puntuara el borrador con una rúbrica 7 "Califica el capítulo del 1 al 10 en claridad, exactitud, adecuación a la edad, utilidad. Justifica y sugiere ediciones." puntuaciones: claridad 8, exactitud 8, adecuación a la edad 9, utilidad 8 mejoré el diagrama y la sección de errores 8 "Lista de 6 a 10 afirmaciones factuales y marca cada una como respaldada, necesita verificación o sin respaldo." una lista de afirmaciones sobre la luz solar, la clorofila, la glucosa, el oxígeno las verifiqué contra mi libro de texto y corregí la redacción Criterio Puntuación de la IA Razón de la IA Edición más pequeña Mi decisión Claridad 8 clara, pero el proceso es difícil de recordar agregar una ecuación simple y una idea de diagrama aceptada, agregué ambas Exactitud 8 los datos son correctos, pero el papel del suelo no está claro explicar que el suelo da agua, las hojas fabrican glucosa aceptada, agregada a los errores comunes Adecuación a la edad 9 el lenguaje le queda a 8.º grado mantener los párrafos cortos, evitar química avanzada aceptada Utilidad para el repaso 8 útil, pero las herramientas de repaso ayudarían agregar tarjetas de memoria y un plan de 7 días aceptada, agregué ambas Afirmación de la IA Mi decisión Evidencia o razón Corrección si hace falta "La fotosíntesis es cómo las plantas verdes fabrican alimento." Aceptar coincide con el libro de texto y los apuntes del docente ninguna "Las plantas necesitan luz solar para la fotosíntesis." Aceptar coincide con el libro de texto ninguna "La clorofila ayuda a absorber la luz solar." Aceptar coincide con los apuntes del docente ninguna "Las plantas toman dióxido de carbono." Aceptar coincide con el libro de texto y una fuente confiable ninguna "Las plantas liberan oxígeno durante la fotosíntesis." Aceptar coincide con el libro de texto ninguna "La glucosa es el alimento que fabrican las plantas." Aceptar coincide con los apuntes de clase ninguna "Las plantas obtienen todo su alimento del suelo." Rechazar los apuntes del docente dicen que las plantas fabrican glucosa en las hojas las plantas obtienen agua y minerales del suelo, pero fabrican glucosa en la fotosíntesis "La fotosíntesis ocurre sobre todo en las raíces." Rechazar el libro de texto dice que ocurre principalmente en las hojas la fotosíntesis ocurre sobre todo en las hojas Cómo se califica
Categoría Qué muestra un trabajo sólido Puntos Tema y objetivo de aprendizaje tema, público, dificultad y objetivo de aprendizaje claros 8 Paquete de contexto apuntes de clase útiles, texto o foto del libro de texto, vocabulario o instrucciones del docente entregados a la IA 12 Disciplina en el espacio de trabajo de IA usó un Proyecto o chats separados bien organizados para evitar la confusión de contexto 5 Fuentes nombradas y modo de recuperación al menos dos fuentes nombradas, y qué modo se usó (preentrenado, basado en fuentes o web/búsqueda) 10 Registro de prompts e iteración al menos 8 prompts: débil, contexto, nombrar fuentes, bucle de 3 opciones, retroalimentación, borrador, rúbrica, verificar 20 Calidad del minilibro de texto claro, organizado, adecuado a la edad, completo y fácil de repasar 20 Tabla de verificación afirmaciones importantes de la IA verificadas, corregidas o marcadas con honestidad como "Necesita verificación" 15 Reflexión relato honesto de en qué ayudó la IA, qué necesitó corrección y qué se aprendió 10 Reglas de seguridad y honestidad
Antes de entregar, la lista de verificación
Tu objetivo no es mostrar que la IA es inteligente. Es mostrar que puedes guiar a la IA, cuestionar a la IA, corregir a la IA y usar la IA para aprender mejor.
Listo cuando: tu capítulo está completo (las diez secciones de la Parte A) y tu cuaderno de proceso prueba el trabajo: un registro de al menos 8 prompts, al menos dos fuentes nombradas, tus puntuaciones de rúbrica, una tabla de verificación de 6 a 10 afirmaciones que verificaste, y una reflexión en tus propias palabras.
Cada dirección que publicas en los primeros tres proyectos existe porque describiste lo que querías, en oraciones sencillas, a un modelo que construye. Funcionan con un solo motor: la serpiente se vuelve buena por lo que notas mientras juegas, el juego del topo por la rúbrica a la que lo sometes, la página por quién eres. Distintas fuentes de contexto, el mismo movimiento. Mete el contexto correcto. El proyecto final es la excepción que confirma la regla. No publica ninguna dirección, porque su producto es algo que entiendes y la prueba de que tú, no el modelo, estabas a cargo.
Los primeros tres proyectos son cada uno un único archivo HTML, porque ese es el tamaño de idea que un prompt puede cargar. El Concepto 9 nombró el límite con honestidad: las cuentas, el multijugador en vivo por internet, los datos que tienen que sobrevivir, esos necesitan ingeniería real. El proyecto final nombra un límite distinto: un modelo puede redactar un capítulo entero en segundos, pero solo tú puedes decidir si es cierto. Cuando tus ideas superen un solo archivo, o tu confianza en un borrador supere un solo vistazo, ahí es donde retoma el resto de este libro.
Cuando un proyecto sale mal (una de estas pasará; todas son normales)
| Síntoma | Arreglo |
|---|---|
| La app del panel lateral está en blanco o congelada | Dilo en palabras sencillas: "es una pantalla negra" o "el botón de inicio no hace nada". El modelo puede ver su propio código y normalmente lo arreglará. En el peor caso: "reconstrúyela desde cero, más simple". |
| El archivo descargado se abre como un muro de texto | Se abrió en un editor de texto. Haz clic con el botón derecho en el archivo, elige Abrir con y selecciona tu navegador. El archivo está bien. |
| Netlify muestra "Page not found" | Probablemente el archivo no se llama index.html. Renómbralo y arrástralo de nuevo. |
| La dirección es fea | Es un nombre aleatorio por defecto. La configuración de tu proyecto te deja renombrar el sitio, así la dirección se vuelve yourname.netlify.app si ese nombre está libre. |
| Una amistad ve la versión vieja después de una actualización | Arrastra el archivo más nuevo a la pantalla de deploys del proyecto, luego pídele que actualice la página. |
Ahora sabes lo que estas herramientas pueden hacer. Si puedes pensar con suficiente claridad como para dirigirlas es una pregunta aparte, y es la pregunta en torno a la cual está construido el Curso intensivo de Pensar en la Era de la IA.
Preguntas frecuentes antes de empezar
¿Necesito un plan de pago para hacer los ejercicios de aquí o del Curso intensivo de Pensar? Los planes gratuitos de ChatGPT, Claude y Gemini bastan para los ejercicios de esta página y para casi todo lo que el Curso intensivo de Pensar te pide. Un plan de pago ayuda si haces mucha investigación profunda o adjuntas muchos archivos en una sesión. Empieza gratis; actualiza solo si los límites de uso empiezan a bloquearte.
¿Debería usar una herramienta o tres? Elige una como tu opción por defecto para el uso diario, pero instala al menos otra de una familia distinta para comparar (ver el Concepto 13). El sentido de tener una segunda herramienta no es hacer el doble de trabajo; es tener un desempate cuando la primera te da algo que no se siente bien.
Mi empresa bloquea ChatGPT. ¿Qué hago para los ejercicios? Usa cualquier herramienta de IA moderna que tu empresa permita. Las habilidades de aquí se transfieren a cualquier IA de texto a texto. Si no se permite nada, usa tu cuenta personal en un dispositivo personal para los ejercicios; son sobre pensar, no sobre datos de la empresa.
¿Y si olvido las recetas de esta página? Guarda la página en marcadores. Las recetas (el bucle de iterar y calificar, el patrón de la rúbrica, el truco de reformular de forma neutral, la configuración de proyectos, el movimiento del "cambio más pequeño que sube la puntuación") están diseñadas para consultarse, no para memorizarse. Lo único que vale la pena memorizar es la sola oración: mete el contexto correcto, deja fuera el contexto equivocado.
¿Por qué profundizar en la disciplina de pensar si la IA es tan capaz? Porque la capacidad sin dirección multiplica el desperdicio. El cuello de botella en el trabajo de 2026 se ha movido de producir (que la IA abarató) a evaluar (que no abarató). Un análisis de la IA confiadamente equivocado es más peligroso que ningún análisis, porque parece terminado. El Curso intensivo de Pensar entrena el juicio que decide qué hacer con lo que la IA produce. Ese juicio es la habilidad más valiosa en un lugar de trabajo saturado de IA, y la mayoría de los planes de estudio lo omiten por completo.
Errores comunes que vigilar en tu primera semana
| Error | Síntoma | Arreglo |
|---|---|---|
| Tratar a la IA como un buscador | Prompts cortos, respuestas superficiales, frustración repetida | Informa a la IA como a un colega: contexto, archivos, restricciones, petición. |
| Dejar que una conversación se acumule para siempre | Las respuestas se vuelven más vagas con el tiempo a medida que el contexto viejo se compacta | Inicia una conversación nueva cuando cambie el tema. Mueve el contexto fijo (archivos, instrucciones) a un proyecto. |
| Pedir el borrador final al primer intento | Salida pulida, contenido hueco | Primero el esquema, calificar y arreglar en cada etapa, expandir a viñetas, luego redactar. |
| Redacciones de cebo sin darte cuenta | La IA está de acuerdo con lo que insinuaste | Reescribe como preguntas neutrales antes de enviar. |
| Conformarte con una crítica vaga | "¡Gran trabajo!" sin detalles | Exige una puntuación del 1 al 10 por criterio con justificaciones de una oración. Pide el cambio que más subiría cada puntuación. |
| Parar cuando la IA dice que terminaste | "¡Se ve bien!" sin un camino hacia adelante | La IA no llega a declararte terminado. Itera hasta que la puntuación se estanque, no hasta que suene pulido. |
| Confiar en la seguridad como exactitud | Errores sorprendentes en temas oscuros | Pregunta "¿cómo sabrías esto?". Verifica las afirmaciones de alto riesgo contra fuentes primarias. |
| Aprobar permisos amplios el primer día | Archivos perdidos, ediciones sobrescritas | Limita a carpetas estrechas. Haz crecer el alcance solo con el historial. |
Estos no son defectos de carácter. Son hábitos que la primera generación de usuarios (tú incluido) está construyendo desde cero. Atraparlos una vez tiende a quedarse.
Esta página enseñó la mecánica de usar estas herramientas. El Curso intensivo de Pensar en la Era de la IA enseña la disciplina que hace que la mecánica rinda. Su regla de una oración: el entregable nunca es la respuesta; el entregable es la evidencia documentada del pensamiento. El curso está estructurado como seis hábitos de pensamiento a lo largo de tres partes:
-
Parte 1: Fundamentos, la postura que adoptas antes de abrir la IA. El Bloqueo de Predicción (anota lo que crees que es la respuesta antes de que la IA te la diga, para que su respuesta segura no se vuelva la tuya de forma discreta) y el Recibo de Razonamiento (etiqueta cada afirmación importante de la IA como Acepto / Rechazo / Modifico / Sacada a la luz / Omitida, con un porqué de una oración). Juntos mantienen el pensamiento contigo y el mecanografiado con la IA, el lugar al que apuntaba el Concepto 6 pero sin terminar el trabajo.
-
Parte 2: Detección, atrapar lo que la IA hace mal. La Taxonomía de Errores (seis fallos específicos: error factual, brecha lógica, falsa seguridad, contexto faltante, fuente fabricada, hecho desactualizado, que rastreas por nombre en lugar de por intuición) es la versión profunda de "las respuestas seguras no son respuestas correctas" del Concepto 2. Pensar en Sistemas (rastrear los efectos secundarios de cualquier decisión sugerida por la IA a través de las personas y los grupos que toca, incluidos los lugares donde los efectos secundarios dan la vuelta y deshacen la decisión original) es terreno nuevo que esta página no cubre en absoluto.
-
Parte 3: Origen, hacer lo que la IA no puede hacer por ti. Primeros Principios (cuestionar el consejo común que todos repiten; descomponer un problema hasta sus hechos base y preguntar si la respuesta estándar es siquiera cierta en tu situación) es la versión profunda del movimiento de encuadre neutral del Concepto 6. Trabajar CON la IA (el modelo de colaboración donde tú haces el pensamiento y la decisión, y la IA hace la investigación y el borrador; invierte esa proporción y te vuelves innecesario) es la versión profunda del bucle de iterar con retroalimentación del Concepto 7.
Cuando estés listo, dirígete al Curso intensivo de Pensar en la Era de la IA. Las herramientas potentes sin juicio hacen que los errores seguros lleguen más rápido, y la práctica deliberada es la única forma honesta de averiguar si tu juicio está mejorando.