Digital FTE se Production Worker tak: 90-Minute Crash Course
15 concepts, real use ka taqreeban 80% - durable execution, triggers, flow control
Yeh continuation crash course hai. Agentic-coding track mein yeh Course #5 hai. Pichla course, From Agent to Digital FTE, customer-support Worker par khatam hua tha: wohi OpenAI Agents SDK foundation, teen portable Skills, Neon Postgres system of record, aur custom MCP server. Woh Worker sirf tab chalta hai jab aap usay call karte hain. Aap Claude Code ya OpenCode kholte hain, type karte hain, agent jawab deta hai. Real Production Worker mein prompt par human typing nahin hoti.
Woh single insight jo baqi sab kuch clear kar deti hai: Digital FTE ko Production Worker banane ke liye ek architectural addition chahiye: durable execution engine jo duniya ko Worker call karne deta hai (aap ke bajaye), mid-flight crashes survive karta hai, aur scale par khud ko rate-limit karta hai. Hum Inngest ko durable-execution platform ke taur par use karte hain; patterns Temporal, Restate, ya Dapr Agents par one-to-one transfer ho jate hain, lekin Inngest ka hosted Hobby tier sab se friendly on-ramp deta hai: free, credit card nahin, one-command dev server, aur dashboard jise aap code karte hue inspect kar sakte hain.
Seedhi baat: Course #4 ka Digital FTE woh function hai jise aap call karte hain. Is course ka Production Worker woh function hai jise duniya call karti hai: scheduled cron jobs se, aap ke inbox aur billing system ke webhooks se, aur dusre Workers ke fired events se. Jab yeh run karta hai to durably run karta hai: six-step refund flow ke beech crash ho jaye to pehle teen steps ka kaam lose nahin hota; Worker wahi se resume karta hai jahan break hua tha. Aur jab 500 customers ek saath email karte hain, Worker unhein controlled rate par handle karta hai jo aap ka OpenAI rate limit ya Postgres connection pool blow nahin karta. Yeh machinery aap ko khud build nahin karni; aap ka code bas @inngest.create_function se decorated functions rehta hai.
Day AI, AI-native companies ke liye CRM, Inngest ko apne product ka "nervous system" kehta hai. Do founding engineers ne independently isi tarah describe kiya. Un ka stack har woh primitive use karta hai jo yeh course sikhata hai: durable LLM workflows, wait-for-event coordination, failure par replay, debounce + throttle + concurrency, aur multi-tenant fairness taake ek organization ka spike baqi sab ko slow na kare. Yeh curriculum branding nahin; market mein chal rahi AI-native company ki production language hai.
Single agent ka mid-workflow crash annoying hai. Lekin customer-facing work handle karne wali fifty agents ki workforce, nervous-system substrate ke baghair impossible hai: ya to aap woh platform adopt karte hain jo yeh layer deta hai, ya phir chhe months laga kar us ka weaker version khud banate hain. Durable execution ko agents ke liye uniquely important banane wali chaar properties hain:
- Har step real money cost karta hai. Crash ke baad naive retry un steps ki payment dobara karta hai jo already succeed ho chuke thay; step memoization (Concept 7) ek hi dafa pay karta hai.
- Workflows failure compound karte hain. 95% per-step reliability wala six-step agent kahin na kahin fail hone ka 26% chance rakhta hai. Step memoization plus targeted retries overall reliability ko ~99.7% tak lift kar dete hain.
- Side effects real-world hain. Agents customers ko email karte hain, cards charge karte hain, Slack par post karte hain. Step memoization plus provider-level idempotency keys inhein safe banate hain.
- High-stakes moments par agents ko human approval chahiye.
step.wait_for_event(Concept 15) ke baghair aap approval queue khud build karte hain: database table, polling, timeout handling, audit trail. Yeh project hai, feature nahin.
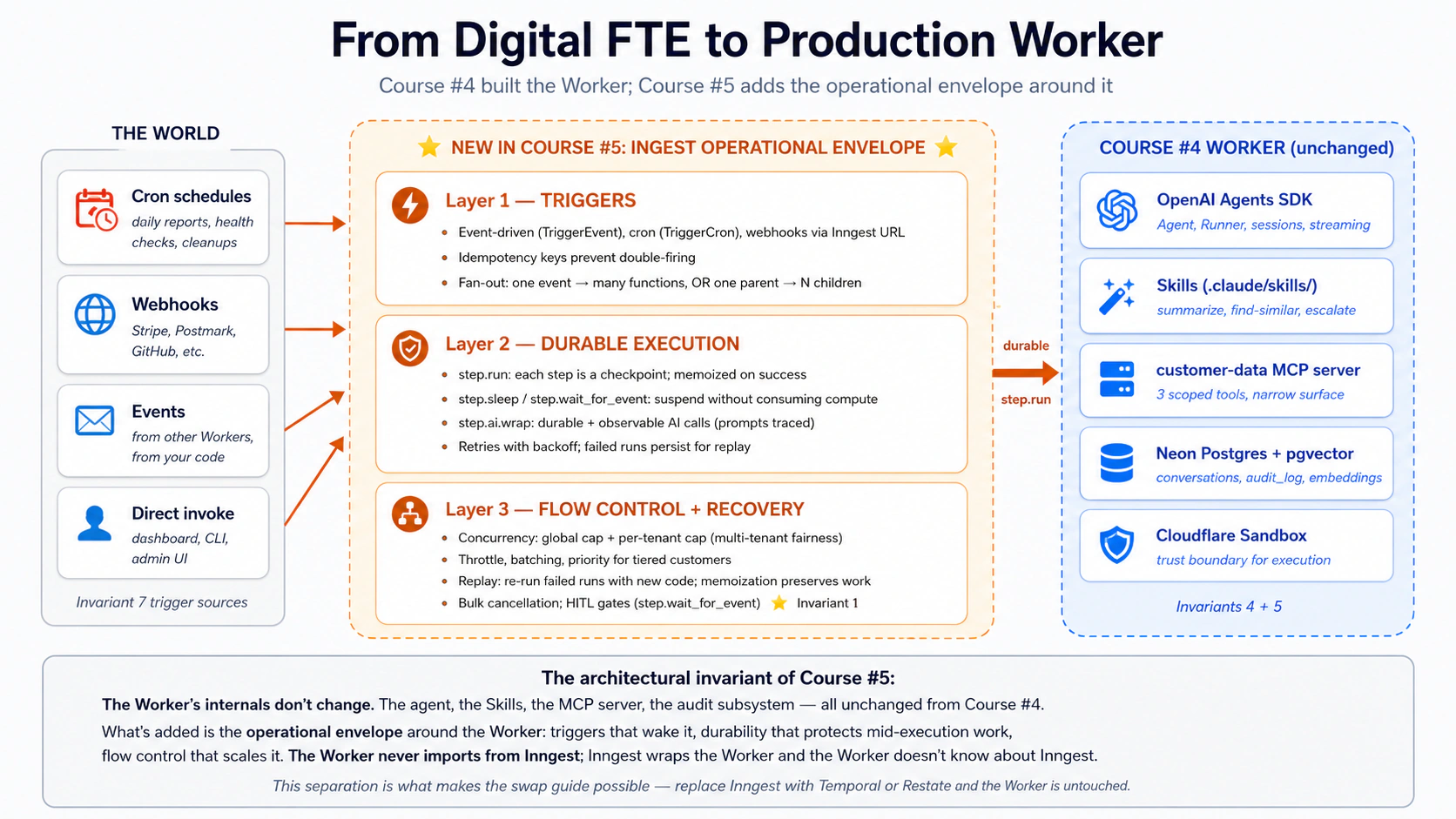
Yahan se shuru karein: architectural placement aur 15-concept cheat sheet
Yeh course architecture mein kahan fit hota hai. The Agent Factory thesis Seven Invariants describe karti hai jo kisi bhi production agent system ko satisfy karne chahiye. Courses #3 aur #4 ne Invariant 4 (engine) aur 5 (system of record) cover kiye. Yeh course do aur cover karta hai, plus Invariant 1 ka ek hissa:
- Invariant 7: Duniya system ko call karti hai. Triggers (schedules, webhooks, inbound API calls, dusre Workers ke events) Worker ko wake karte hain. Inngest is ka ek realization hai.
- Invariant 1 ka ek hissa: Human principal hai. Approval gates woh jagah hain jahan authored intent runtime mein dobara enter hota hai.
step.wait_for_eventkisi bhi platform par is ka sab se clean expression hai: agent suspend hota hai, human awaited event emit karta hai, agent resume karta hai. - Durable execution as a thesis-implicit invariant. Audit jawab deta hai "kya hua?"; durability jawab deti hai "jahan break hua tha wahan se dobara karo." Failure ke baad replayable, retriable, resumable.
15 concepts, ek nazar mein. Production failure almost hamesha teen root causes mein se kisi ek tak trace hoti hai: trigger fire nahin hua (ya do dafa fire hua), execution break hui aur state lose ho gayi, ya flow-control gap ne ek customer ke traffic ko baqi sab ko starve karne diya. 15 concepts inhi teen layers par map hote hain. Yeh first-pass version hai: concept plus one-line gist. Full diagnostic table, jahan har concept ka answered question diya hai, end mein Quick reference mein hai, jise build ke dauran use karenge.
| # | Concept | One-line gist |
|---|---|---|
| Triggers | duniya Worker ko kaise call karti hai | |
| 1 | Events vs requests | Request sync hoti hai aur koi wait karta hai; event async hota hai aur duniya aage barh chuki hoti hai. |
| 2 | Cron triggers | Schedule function ko jagata hai. Ek line: TriggerCron(cron="0 9 * * *"). |
| 3 | Webhook triggers | Inbound HTTP payload named event ban jata hai; aap ka function us name par react karta hai. |
| 4 | Idempotency and event semantics | Event IDs aur step names duplicate event (ya retry) ko no-op bana dete hain. |
| 5 | Fan-out and sub-agent delegation | Ek event, N subscribing functions; ya ek parent jo N child events fire karta hai. |
| Durable execution | jab kuch toot jaye to Worker ko correct rakhna | |
| 6 | step.run and the durable function model | Har step.run checkpoint hai; function steps ke darmiyan crash ho kar resume kar sakta hai. |
| 7 | Memoization, the mechanic underneath | Completed steps dobara execute hone ke bajaye stored output return karte hain. |
| 8 | step.sleep and step.wait_for_event | Dono function ko durably suspend karte hain, duration ke liye ya event ke liye. |
| 9 | Retries, error handling, dead-letter | Automatic backoff retries; N tries ke baad failed run replay ke liye saved rehta hai. |
| 10 | step.run for AI calls in Python | OpenAI calls ko step.run mein wrap karein; step.ai.infer inference offload karta hai (step.ai.wrap TypeScript-only hai). |
| Flow control | load ke neeche Worker ko healthy rakhna | |
| 11 | Concurrency and throttling | concurrency active runs cap karta hai; throttle starts-per-second cap karta hai. |
| 12 | Priority and fairness | Priority queue order karti hai; per-key concurrency har tenant ko fair share deti hai. |
| 13 | Batching | Saste bulk kaam ke liye events ko ek batched function call mein jama karein. |
| 14 | Replay and bulk cancellation | Failed runs ko naye code ke saath replay karein; jin runs ki zarurat nahin unhein bulk-cancel karein. |
| 15 | HITL gates with step.wait_for_event | Function human approval tak suspend rehta hai, phir decision ke saath resume karta hai. |
Jab yeh mapping clear ho jaye, baqi document zyada tar mechanics hai. Production failure aam tor par in mein se kisi ek cheez tak trace hoti hai: trigger match nahin hua (event name typo, schedule fire nahin hua), step memoization ke baghair toot gaya (is liye retry poora flow dobara shuru karta hai), flow-control gap ne concurrency cap nahin ki (is liye ek customer ne baqi sab ko drown kar diya), ya HITL gate wait karte karte timeout ho gaya (is liye escalation hui hi nahin). Quick reference ki diagnostic table batati hai kaunsa case hai.
Audience. Yeh agentic-coding track ka teesra intermediate-to-advanced crash course hai. Aap ne Courses #3 aur #4 complete kiye hon, ya un ke sikhaye hue topics se comfortable hon, kyun ke yeh course Course #4 ke Part 4 worked example wale customer-support Worker ko extend karta hai. OpenAI Agents SDK, sessions, streaming, function tools, sandboxing, Skills, Neon Postgres with pgvector, MCP servers, audit logging: sab assumed hai.
Pehle se kya chahiye. Yeh page paanch cheezen assume karta hai.
- Aap ne From Agent to Digital FTE complete kiya hai. Is par compromise nahin. Hum wahin se shuru karte hain jahan Course #4 khatam hua tha: wohi
chat-agent/project, wohi Skills, wohicustomer-dataMCP server.- Aap ke paas Agentic Coding Crash Course wali discipline hai. Plan mode, rules files, slash commands, read-first-then-write workflow.
- Aap ne kam az kam ek PRIMM-AI+ cycle kiya hai. Is course ke Predict prompts woh rhythm assume karte hain.
- Aap ke paas Node.js 20+ available hai, chahe aap ka agent Python ho. Inngest dev server Node CLI ke taur par distribute hota hai (
npx inngest-cli@latest dev).- Aap ke paas "event-driven" vs "request/response" ka working mental model hai. Agar "duniya event fire karti hai aur zero, one, ya many functions us par react karte hain" familiar lagta hai, aap calibrated hain. Agar nahin, Concept 1 shape de dega.
Is page ko pehli reading mein kaise parhein (click to expand)
- Pehli reading par expand karein: jo bhi "What you'll see," "Sample run," "Expected output," "Verify." label ke saath ho. Yeh runnable behavior hai jisse aap predictions check karte hain.
- Pehli reading par skip karein: Part 4 ke worked example ki lambi file listings. Har block ke upar narrative batata hai kya change hua; file contents tab chahiye jab aap actual build kar rahe hon.
- Throughout optional: "Try with AI" blocks. Inngest dev-server MCP se connected Claude Code ya OpenCode ke liye extension prompts.
Pehli pass ka goal three-layer model internalize karna hai: triggers Worker ko jagate hain, durable execution usay correct rakhti hai, flow control usay healthy rakhta hai. Keyboard par haath rakh kar second pass mein aap build karte hain.
Glossary: woh terms jo aap ko milengi (click to expand)
Har term us jagah context mein explain hoti hai jahan pehli baar aati hai; yeh list un terms ka quick reference hai jo first-pass reader ko sab se zyada confuse kar sakti hain.
- Production Worker: Operational envelope wala Digital FTE: triggers usay jagate hain, durable execution failures survive karwati hai, flow control load ke neeche scale karwata hai.
- Event: Named, immutable message jo batata hai ke kuch hua. Misaal:
{"name": "customer/email.received", "data": {"customer_id": "..."}}. Yeh trigger surface hai. - Inngest function: Python function jo
@inngest_client.create_functionse decorated hota hai, triggers aur steps declare karta hai. Durable work ki unit. - Step: Inngest function ke andar kaam ki unit jo
ctx.step.run(),ctx.step.sleep(),ctx.step.wait_for_event(), yactx.step.ai.infer()mein wrapped hoti hai. Har step independently retried aur memoized hota hai. - Memoization: Jab function crash ho kar restart hota hai, Inngest function code top se dobara chalata hai lekin jis
step.runka result already cached ho us ke liye stored output return karta hai. Function kaam dobara kiye baghair us jagah catch up kar leta hai jahan toota tha. - Flow control: Per-function policies:
concurrency(max active runs),throttle(max starts per second),priority(queue order),batch_events(invoke karne se pehle accumulate karna). - HITL (Human In The Loop): Function continue karne se pehle human approval ya input ka wait karne ke liye pause hota hai.
step.wait_for_eventprimitive hai. - Replay: Bug fix ke baad naye code ke saath failed function ko us jagah se dobara chalana jahan woh toota tha.
- Dev server: Inngest ka local dev environment
npx inngest-cli@latest devke zariye. Dashboardhttp://127.0.0.1:8288par; MCP endpoint/mcppar.
May 14, 2026 tak current. inngest-py 0.5.18 (released March 11, 2026), Inngest CLI v1+, aur Inngest Python quick start ke against verified. Yeh course jo durable-execution architecture sikhata hai woh SDK badalne se nahin badalta; SDK is saal us architecture ka interface hai.
Course #3 aur #4 ka stack is course ki foundation hai, koi aisi stepping stone nahin jise hum peeche chhor dete hain. Aap ka Part 4 Worker ab bhi Agent, Runner, function_tool, .claude/skills/ se Skills, customer-data MCP server, aur six-table audit-aware schema use karta hai. Jo badalta hai: yeh primitives ab Inngest functions ke andar chalte hain jo har agent invocation ko durability ke liye step.run() mein wrap karte hain, event/cron triggers declare karte hain, aur concurrency aur throttling policies apply karte hain. Worker ke internals nahin badalte. Worker ka operational envelope badalta hai.
Yeh apne predecessors ki tarah Python-first course hai, inngest-py, Inngest ke Python SDK, ko use karte hue. Inngest dev server khud language-agnostic hai; official Python SDK ke saath bilkul usi tarah kaam karta hai jaise TypeScript ya Go ke saath.
Dual-tool pattern continue hota hai. Jin sections mein Claude Code aur OpenCode alag hote hain un ke paas switcher hai; ek choose karein aur page visits ke darmiyan sync rehta hai.
Ek complete worked example Part 4 mein hai: Course #4 ka customer-support Worker Inngest layer mein wrapped hai, event triggers, cron health checks, HITL escalation gates, concurrency limits, aur full replay support ke saath. Aath build decisions, Courses #3 aur #4 jaisi shape. Agar aap definitions parhne ke bajaye kar ke behtar seekhte hain, Parts 1-3 skim karein aur Part 4 par jump karein.
Architecture ek line mein. Engine = OpenAI Agents SDK + Cloudflare Sandbox (Course #3). Capability + Truth + Connector = Skills + Neon Postgres + MCP (Course #4). Operational Envelope = Inngest ke triggers + durable execution + flow control (Course #5, yeh course). Worker ke internals Course #4 se unchanged hain; nayi cheez us ke upar wali layer hai jo duniya ko usay jagane deti hai, failures ko state lose nahin karne deti, aur ek Worker ko workforce jitna traffic serve karne deti hai. Agar is poore document ki sirf ek sentence yaad rahe, woh yahi hai.
Pandrah minute ka quick win: durability apni aankhon se dekhein
Un 15 concepts ko parhne se pehle jo explain karte hain ke yeh architecture kyun kaam karta hai, sab se chhota working version build karein. Do files, chaar uv aur npx commands, ek shell session. Is section ke end tak aap ke paas hoga:
- ek Inngest function jismein ek
step.runaur ekstep.sleephai - Inngest dev server locally running, dashboard
http://127.0.0.1:8288par - ek successful run jo aap ne dashboard se trigger kiya
- ek failed run jo aap ne bug fix karne ke baad replay kiya, aur completed steps ko re-execute hue baghair memo se wapas aate dekha
Yeh Part 4 worked example nahin; woh full Production Worker hai, aath Decisions aur hundreds of lines. Yeh one screen hai. Agar aap ke paas sirf ek sitting hai, yeh karein, phir jab har piece ki shape ka reason samajhna ho to concepts par wapas aayen.
Step 1. Fresh project directory banayein aur SDK ke saath ek chhota web framework install karein. (fastapi ki jagah aap Inngest-supported koi bhi ASGI framework use kar sakte hain; FastAPI sab se simple hai.)
mkdir hello-inngest && cd hello-inngest
uv init
uv add inngest "fastapi[standard]"
Step 2. Ek durable function wali ek file likhein. Isay hello.py ke naam se save karein:
# hello.py
import logging
from datetime import timedelta
import inngest
import inngest.fast_api
from fastapi import FastAPI
inngest_client = inngest.Inngest(
app_id="hello-inngest",
logger=logging.getLogger("uvicorn"),
is_production=False,
)
@inngest_client.create_function(
fn_id="greet-customer",
trigger=inngest.TriggerEvent(event="demo/greet"),
)
async def greet_customer(ctx: inngest.Context) -> dict[str, str]:
name = ctx.event.data.get("name", "friend")
greeting = await ctx.step.run("compose-greeting", lambda: f"Hello, {name}!")
await ctx.step.sleep("wait-fifteen-seconds", timedelta(seconds=15))
farewell = await ctx.step.run("compose-farewell", lambda: f"Goodbye, {name}.")
return {"greeting": greeting, "farewell": farewell}
app = FastAPI()
inngest.fast_api.serve(app, inngest_client, [greet_customer])
Teen cheezen note karein. Function shape plain Python hai: ek async def jo create_function se decorated hai. Do ctx.step.run calls un operations ko wrap karti hain jinhein memoized hona chahiye. Darmiyan wala ctx.step.sleep function ko durably suspend karta hai (sleep ke dauran process crash, restart, ya redeploy ho sakta hai; timer fire hone par run next line se resume karta hai).
Step 3. Ek terminal mein function host start karein.
uv run uvicorn hello:app --reload --port 8000
Aap ko uvicorn ka Started server process aur Application startup complete report dikhna chahiye. Function host ab http://127.0.0.1:8000/api/inngest par listen kar raha hai.
Step 4. Doosre terminal mein Inngest dev server start karein.
npx inngest-cli@latest dev
Dev server banner print karta hai aur http://127.0.0.1:8288 par dashboard kholta hai. Yeh Step 3 mein start kiya hua function host auto-discover karta hai.
Step 5. Browser mein http://127.0.0.1:8288 open karein. Sidebar mein Functions click karein; aap ko greet-customer listed dikhna chahiye. Sidebar mein Events click karein, phir Send event. Yeh payload paste karein aur Send click karein:
{
"name": "demo/greet",
"data": { "name": "Sara" }
}
Step 6. Sidebar mein Runs click karein. Aap greet-customer ke liye ek run dekhenge jiska status Running hai aur compose-greeting label wala step complete mark hai. Step trace dekhne ke liye run ke andar click karein.
Step 7. wait-fifteen-seconds step dekhein. Dashboard usay resume time ke saath Sleeping state mein dikhata hai. Aap ke code mein kuch run nahin ho raha. uvicorn terminal idle hai. Pandrah seconds ke baad run resume hota hai, compose-farewell complete hota hai, aur run status Completed mein flip ho jata hai. Returned dict dekhne ke liye Output panel open karein.
Step 8. Ab isay jaan boojh kar break karein. hello.py mein greet_customer ke upar ek chhota helper add karein aur step se woh call karwa dein:
def fail_on_purpose() -> str:
raise RuntimeError("forced failure")
# ...inside greet_customer, replace the compose-farewell step:
farewell = await ctx.step.run("compose-farewell", fail_on_purpose)
File save karein; uvicorn auto-reload karega. Dashboard se wahi demo/greet event dobara send karein. Run dekhein: compose-greeting complete hota hai, wait-fifteen-seconds sleep aur resume karta hai, compose-farewell backoff ke saath retry karta hai (Inngest default mein four attempts karta hai), phir run Failed state mein land karta hai aur RuntimeError step trace mein visible hota hai.
Ab bug fix karein: compose-farewell ko original lambda: f"Goodbye, {name}." par revert karein. Save karein. Dashboard mein failed run click karein, phir Replay click karein. Replay dekhein: compose-greeting milliseconds mein complete hota hai (memo hit, no re-execution), wait-fifteen-seconds milliseconds mein complete hota hai (memo hit), compose-farewell naye code ke saath real execute hota hai aur succeed karta hai. Run complete ho jata hai.
Aap ne abhi ek durable function run kiya, step ko compute consume kiye baghair sleep karte dekha, usay break kiya, fix kiya, aur replay kiya. Agle 90 minutes isay scale up karte hain: real triggers (cron, webhook, fan-out), real durability (agent invocation jo step.run mein wrapped hai), real flow control (concurrency, throttle, priority), aur HITL gate jo "agent shayad yeh bigar de" ko "agent draft karta hai, human approve karta hai, action issue hota hai" mein badalta hai.
Agar kuch kaam nahin hua, sab se common Quick Win failures yeh hain: (1) dev server function host tak nahin pahunch raha (check karein uvicorn port 8000 par running hai); (2) client constructor mein is_production=False missing hai (is ke baghair SDK signing key maangta hai); (3) function dashboard mein appear nahin ho raha (uvicorn auto-reload nahin hua; manually restart karein); (4) run error aur progress ke baghair hang ho gaya (de-synced host silent stalls paida karta hai; function host aur dev server dono saath restart karein, aur ek function host ko ek dev server ke against run karein). Chaar problems, chaar fixes, phir aage barhein.
Part 1: Triggers, duniya Worker ko kaise call karti hai
Course #4 ka Worker tab run hota hai jab aap usay call karte hain. Real Production Worker tab run hota hai jab duniya events fire karti hai: customer email karta hai, webhook aata hai, cron daily 09:00 par fire hota hai, doosra Worker kaam hand off karta hai. Part 1 ke paanch concepts event-driven mental model, teen trigger surfaces (cron, webhook, event), double-processing rokne wali semantics, aur fan-out patterns establish karte hain jo ek event se many Workers jaga sakte hain.
Concept 1: Events vs requests, durable mental model ka shift
Request synchronous conversation hoti hai. Koi call karta hai; aap handle karte hain; aap return karte hain; woh continue karte hain. Connection open rehta hai; koi human ya service wait kar rahi hoti hai. Agar aap crash kar jayein, caller ko error milta hai. Course #4 ka chat agent request hai: aap ne type kiya, us ne stream back kiya, conversation aap ke terminal session ki thi.
Event asynchronous message hota hai. Duniya mein kuch hua (customer sign up hua, email aayi, payment clear hui), aur originator us fact ka named record emit karta hai. Zero, one, ya many functions event par independently react karte hain. Koi connection open nahin rehta. Originator ko nahin pata kaun listen kar raha hai, woh results ka wait nahin karta, aur block nahin hota. Duniya aage barh chuki hoti hai.
# A request: I'm here, waiting, blocking
result = await agent.handle_customer_message(text=user_input)
print(result) # I unblock when the agent finishes
# An event: I fire-and-forget
await inngest_client.send(events=[
inngest.Event(
name="customer/email.received",
data={"customer_id": "c-4429", "body": email_body, "subject": subject},
),
])
# I return immediately. Somewhere else, one or more Inngest
# functions react to this event on their own schedule.
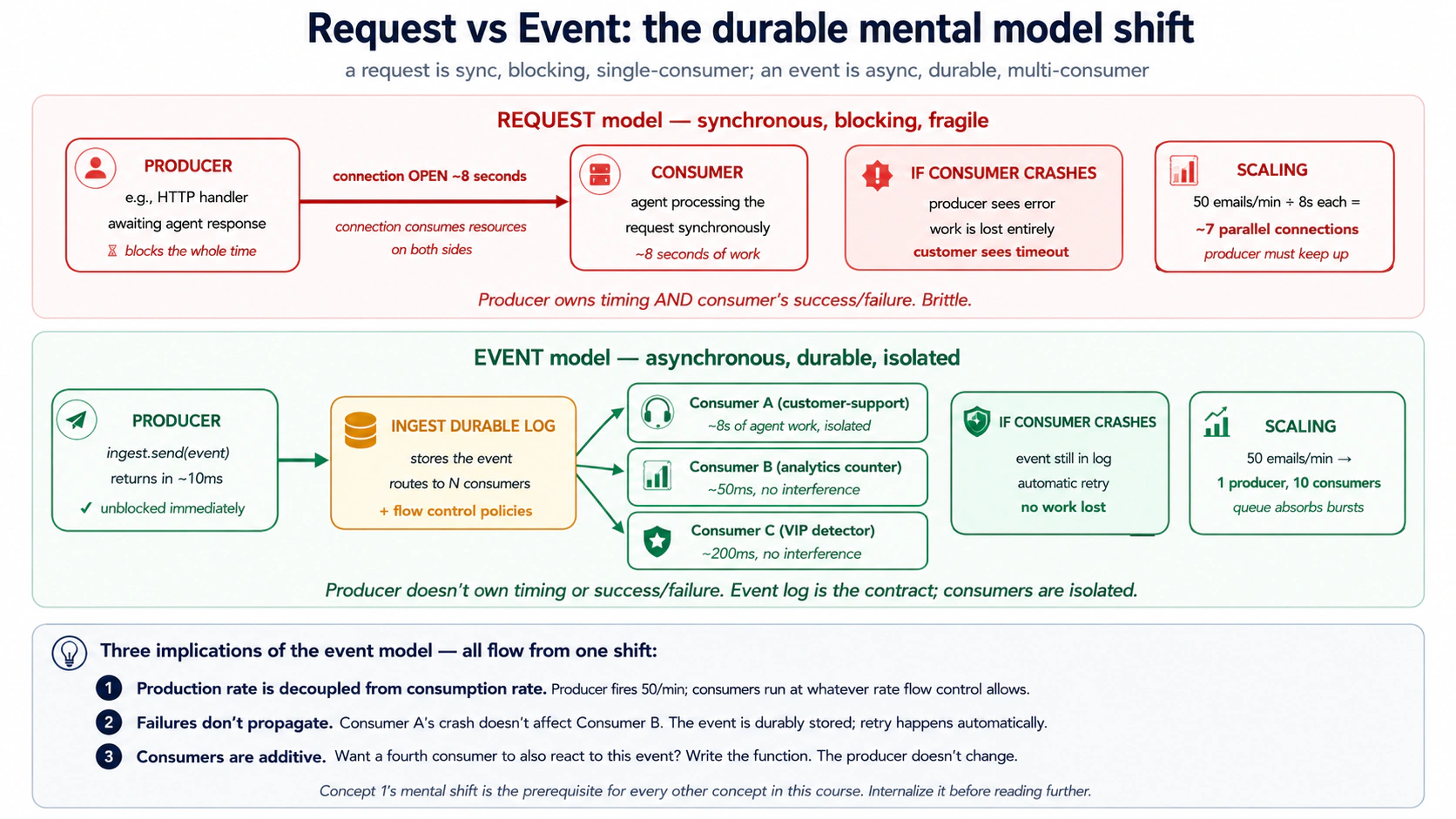
Shift chhota lagta hai. Chhota nahin hai. Jab aap events mein sochte hain, durability aur scale lagbhag free milne lagte hain, kyun ke:
- Producer ko consumer slow nahin kar sakta (email-receiver agent ke reply draft karne ka wait nahin karta).
- Consumer kaam lose kiye baghair crash aur restart kar sakta hai (event durably stored hai; Inngest usay re-deliver karta hai).
- Producers change kiye baghair naye consumers add kiye ja sakte hain (maan lein analytics counter wala doosra function
customer/email.receivedsubscribe kar sakta hai, email-receiver ko pata bhi nahin chalega). - Backpressure code change ke bajaye flow-control policy ban jata hai (Inngest concurrency cap karta hai; producer fire karta rehta hai; events queue hote hain).
Is course ka poora baqi hissa isi ek mental shift ke implications hain.
PRIMM, Predict. Aap ka customer-support Worker email ka jawab dene mein 8 seconds leta hai: agent reasoning ke liye three seconds, do MCP tool calls ke liye four seconds, database write ke liye one second. Peak load par aap 50 emails per minute receive karte hain. Agar aap request model use karte hain (email parser agent ke finish hone tak block hota hai), to aap ke email parser ke liye kitne parallel HTTP connections imply hote hain? Agar event model use karte hain (email parser event fire kar ke immediately return hota hai), to kitne? Confidence 1-5.
Jawab: request model ko taqreeban 7 concurrent parsers chahiye hote hain (50/min × 8 seconds = ~6.7 parallel handlers, plus headroom). Event model ko ek parser chahiye hota hai (woh event fire karta hai aur ~10ms mein return ho jata hai; event queue 50/min spike absorb karti hai; Inngest functions queue ko utni concurrency par consume karte hain jitni aap allow karte hain). Event model production rate ko consumption rate se decouple karta hai. Yeh sirf scaling fact nahin; architectural fact hai. Event "duniya mein kya hua" aur "Worker us ke baare mein kya karta hai" ke darmiyan durable boundary ban jata hai. Consumer mid-processing crash kare to event retry ke liye ab bhi maujood hai. Teen aur consumer types add karein aur producer notice nahin karta. Events woh tareeqa hain jisse aap kaam ke timing ke owner rehna chhor dete hain.
Try with AI
Walk me through three scenarios. For each, classify it as REQUEST-MODEL
or EVENT-MODEL, and explain which one fits better:
A) A user clicks "Submit refund request" in the support portal and
expects to see "Refund issued: $30" within 2 seconds.
B) A nightly cron job at 02:00 runs a customer-health-check across
all 5,000 customers and writes a report to Slack.
C) A customer sends an email to support@; we want a draft response
ready within 60 seconds for the on-call agent to review and send.
For each, name (a) what the human's expectation of timing is and
(b) what failure looks like if the model crashes mid-execution.
Concept 2: Cron triggers, waqt guzarne par chalne wala kaam
Sab se simple trigger clock hai. Production Worker ke bahut se kaam outside events ka reaction nahin hote; woh scheduled work hote hain: daily health reports, weekly cleanups, hourly recalculations. Inngest ka cron trigger ek line ka code hai.
import inngest
@inngest_client.create_function(
fn_id="daily-customer-health-check",
trigger=inngest.TriggerCron(cron="0 9 * * *"), # 09:00 every day, UTC
)
async def daily_health_check(ctx: inngest.Context) -> dict[str, int]:
"""Run a customer-health pass for every Pro/Enterprise customer."""
customers = await ctx.step.run("fetch-pro-customers", fetch_pro_customer_ids)
# fan out: one event per customer, one Worker run per event
await ctx.step.run("fan-out", fan_out_per_customer_events, customers)
return {"customers_scheduled": len(customers)}
Teen cheezen note karein:
-
Schedule standard cron syntax hi hai.
0 9 * * *har din 09:00 UTC hai;*/15 * * * *har 15 minutes hai;0 9 * * 1Mondays at 09:00 hai. Inngest cron ko UTC mein evaluate karta hai; agar aap ko different timezone chahiye, woh function parameter hai, different concept nahin. -
Function ab bhi
ctx.step.runuse karta hai. Cron-triggered ho ya event-triggered, function shape identical hoti hai. Steps wahi kaam karte hain. Durability wahi kaam karti hai. Flow control wahi kaam karta hai. Trigger bas yeh hai ke function kaise start hota hai. -
Cron output regular Inngest function run hota hai. Woh dashboard mein dikhta hai, run ID rakhta hai, trace rakhta hai, replay support karta hai. Agar aap ka Monday-morning cron run step 3 par fail ho, Tuesday ka cron normally run karega aur Monday ki failure bug fix ke baad replay ke liye available rahegi.
Agar cron fire hone ke waqt aap ki service down ho to kya hota hai? Yeh sawal real schedulers ko kitchen-timer schedulers se alag karta hai. Schedule fire hote hi Inngest ke cron runs durably record ho jate hain; agar aap ka function endpoint unreachable ho, Inngest backoff ke saath retry karta hai jab tak woh succeed kare ya retry ceiling hit kare. 09:00 par fire hua cron is liye "miss" nahin hota ke aap ka deploy 09:00 par rolling tha; run wait karta hai, aap deploy finish karte hain, run complete hota hai. Development mein cron triggers ki ek quirk jaan leni chahiye: local dev server sirf tab crons fire karta hai jab woh running ho. Production unhein Inngest infrastructure par run karta hai, jo hamesha running hota hai.
Quick check. Teen claims. Har ek ko True ya False mark karein. (a) Agar cron function run hone mein 45 minutes leta hai aur har 15 minutes schedule hai, to kisi bhi waqt teen concurrent instances running honge. (b) Aap cron-triggered function ke andar
step.sleepuse kar ke kaam ko din bhar spread kar sakte hain. (c) Cron-triggered function ko testing ke liye dashboard se manually invoke bhi kiya ja sakta hai.
Answers: (a) Concurrency policy par depend karta hai: default mein Inngest overlapping runs queue karega; agar aap concurrency=1 set karein to woh serialize honge; agar concurrency=10 set karein to parallelize honge. Default sane hai. (b) True, aur "daily work ko hours mein spread kar ke load smooth karna" common pattern hai. (c) True: Inngest dashboard testing ke liye kisi bhi function ko on demand invoke karne deta hai, trigger kuch bhi ho.
Try with AI
With my AI coding assistant connected to the Inngest dev server MCP,
write a cron-triggered Inngest function in Python that:
1. Runs every Monday at 09:00 UTC.
2. Queries the audit_log table for all conversations resolved in the
prior week (status='resolved' in that window).
3. Computes per-agent metrics: total conversations resolved, average
resolution time, count of escalations, count of refunds issued.
4. Returns the metrics as a JSON object.
After you write the function, use the MCP's `invoke_function` tool to
test it manually (instead of waiting for Monday). Confirm the audit
SQL is correct by using `grep_docs` to search Inngest's docs for
"step.run" examples.
Concept 3: Webhook triggers, jab bahar ki duniya call karti hai
Doosra trigger surface HTTP hai. Koi external system (Stripe, aap ka email provider, customer-portal form, GitHub webhook) aap ke Worker ko call karna chahta hai. Inngest ke baghair aap ko HTTPS endpoint khara karna, payload parse karna, source validate karna, queue mein likhna, queue consume karne wala worker likhna, retries handle karna, idempotency handle karna, aur telemetry ship karni padti. Har item ek week ka infrastructure work hai.
Inngest ke saath endpoint provided hota hai. Aap Inngest dashboard mein https://inn.gs/e/<your-key> jaisi URL ke saath webhook configure karte hain, Stripe (ya jo bhi provider ho) ko us URL par point karte hain, aur webhook payload aap ke event stream mein event ban jata hai. Matching event-name trigger wala koi bhi function fire ho jata hai.
@inngest_client.create_function(
fn_id="handle-stripe-refund-failed",
trigger=inngest.TriggerEvent(event="stripe/charge.refund.failed"),
)
async def on_refund_failed(ctx: inngest.Context) -> dict[str, str]:
"""Triggered by Stripe webhook → Inngest event → this function."""
charge_id = ctx.event.data["charge_id"]
customer_id = ctx.event.data["customer_id"]
# Look up which support ticket originated this refund
ticket = await ctx.step.run(
"find-ticket-for-refund", lookup_ticket_by_charge, charge_id,
)
# Wake the customer-support Worker with the full context
await ctx.step.run(
"notify-support-agent",
notify_support_agent_of_refund_failure,
ticket_id=ticket["id"], charge_id=charge_id,
)
return {"ticket": ticket["id"], "action": "notified"}
Flow yeh hai: Stripe charge refund karne mein fail hota hai -> Stripe Inngest webhook URL par POST karta hai -> Inngest stripe/charge.refund.failed naam ka event banata hai -> upar wala function (jo us event name se match karta hai) fire hota hai -> function steps use kar ke ticket lookup karta hai aur support agent ko notify karta hai. HTTP plumbing mein se kuch bhi aap ko likhna nahin. Na endpoint, na parser, na queue, na consumer.
Do related patterns naam se yaad rakhne ke laiq hain:
- Generic JSON webhooks. Agar source known vendor nahin, to aap kisi bhi JSON-emitting service ko isi type ke endpoint par point karte hain aur event name choose karte hain. Slash-namespaced names (
vendor/event.subtype) convention hain; kuch enforce nahin karta, lekin follow karne par dashboard clean sort hota hai. - Webhook transforms. Agar incoming payload aap ki required shape se match nahin karta, Inngest aap ko "transform" function define karne deta hai jo receipt time par server-side run hota hai aur event stream mein enter hone se pehle event ko reshape kar deta hai. Is se aap ka function code provider-specific fields se clean rehta hai.
PRIMM, Predict. Stripe webhook bilkul usi millisecond par
stripe/charge.refund.failedfire karta hai jab aap ka customer-support Workercustomer/refund.investigation_needednaam ka different event emit karne ke liyeinngest_client.sendbhi call kar raha hai. Dono events system mein simultaneous arrive karte hain; upar wala function sirf Stripe event par trigger hota hai. Function ek dafa run hoga ya do dafa? Confidence 1-5.
Jawab: ek dafa. Function sirf stripe/charge.refund.failed par trigger hone ke liye registered hai; customer/refund.investigation_needed event ka name different hai aur woh different function se match karta hai (ya kisi se nahin, agar aap ne function likha hi nahin). Event ka name us ki routing key hai. Different names wale do events kabhi ghalti se same function trigger nahin karte, chahe ek hi instant par arrive hon. Isi liye naming discipline matter karti hai: event name mein typo (customer/email_received vs customer/email.received) ka matlab hai function kabhi fire nahin hoga, aur symptom silent hota hai. Inngest dashboard isay catch karne mein madad karta hai: unmatched events separate stream mein appear hote hain jise aap audit kar sakte hain.
Try with AI
I need to handle three webhook sources for my customer-support Worker:
A) Stripe: refund failed, charge disputed
B) Postmark (email service): bounced email, complaint
C) My internal admin UI: manual "investigate this ticket" button
For each, decide:
1. What event names you'd use (vendor/event.subtype format).
2. Whether the function reacting to it should run synchronously (the
caller is waiting) or asynchronously (fire and continue).
3. Whether you'd write a webhook transform to reshape the payload, or
consume it raw.
Then write the Inngest function for the Stripe refund-failed case in
Python, using the MCP's grep_docs to find the current syntax for
TriggerEvent and the dev-server MCP's send_event tool to test it.
Concept 4: Idempotency aur event semantics, wahi event do dafa fire hona
Webhooks exactly-once nahin hote. Woh at-least-once hote hain: sender acknowledgment na mile to retry karta hai. Networks packets drop karte hain, services restart hoti hain, aap ka endpoint timeout hota hai aur sender retry karta hai, chahe aap asal mein succeed kar chuke hon. Idempotency ke baghair har webhook system aakhir kar kisi ko double-bill, double-email, ya double-refund karta hai. Yeh theoretical concern nahin; event systems ka sab se common production bug hai.
Defense ki do layers hain, dono Inngest mein built-in.
Layer 1: Source par Event ID seeds. Jab aap event khud send karte hain (webhook se receive karne ke bajaye), aap idempotency key attach kar sakte hain:
await inngest_client.send(events=[
inngest.Event(
name="customer/refund.requested",
data={"order_id": "o-4429", "amount_cents": 5000},
id=f"refund-request-{order_id}-{request_timestamp}", # idempotency key
),
])
Agar same id ke saath doosra event dedup window ke andar send ho (default 24 hours), Inngest duplicate drop kar deta hai. Same logical event, same id, sirf ek function run.
Layer 2: Step-level idempotency. Function ke andar har step.run apne name se identify hota hai. Agar function step 3 aur step 4 ke darmiyan crash ho, retry function code ko top se dobara run karta hai, lekin steps 1, 2, aur 3 ke liye Inngest step body re-execute kiye baghair stored outputs return karta hai. Step 4 pehli dafa normally run hota hai. Isi se function "durable" banta hai: completed steps ke side effects retry par dobara nahin hote.
@inngest_client.create_function(
fn_id="issue-customer-refund",
trigger=inngest.TriggerEvent(event="customer/refund.requested"),
)
async def issue_refund(ctx: inngest.Context) -> dict[str, str]:
# Step 1: look up the order. If the function retries, this returns
# the SAME order data it computed the first time, from Inngest's memo.
order = await ctx.step.run(
"lookup-order", lookup_order_by_id, ctx.event.data["order_id"],
)
# Step 2: call Stripe. If the function retries AFTER this step
# succeeded, the Stripe call does NOT happen again. The refund is
# issued exactly once even if the function runs three times.
refund = await ctx.step.run(
"issue-stripe-refund", call_stripe_refund_api,
charge_id=order["stripe_charge_id"],
amount=ctx.event.data["amount_cents"],
)
# Step 3: write the audit row. Same property: runs at most once.
await ctx.step.run(
"audit-refund", write_audit_refund_issued,
order_id=order["id"], refund=refund,
)
return {"refund_id": refund["id"]}
Agar yeh function step 3 ke dauran crash ho, retry step 1 mein dobara enter karta hai (cached order data milta hai, DB call nahin hoti), step 2 mein dobara enter karta hai (cached refund data milta hai, Stripe call nahin hoti), step 3 real run karta hai, phir return karta hai. Customer ka card ek hi dafa charge hota hai, chahe function teen dafa run hua ho. Yeh killer feature hai. Isi se Inngest retry loop wali queue se qualitatively different banta hai.
Inngest memoization function ke perspective se exactly-once step completion deti hai: jab step.run kisi step ko successful record kar le, woh re-execute nahin hoga. Lekin ek narrow window hoti hai. Agar aap ke step ki body Stripe call kare (side effect Stripe ke servers par hota hai), phir Inngest ke result record karne se pehle crash ho jaye, retry Stripe ko dobara call karega. Inngest ke perspective se step "complete nahin hua." Stripe ke perspective se charge pehle hi ho chuka hai. Production-grade pattern Inngest step memoization plus provider-level idempotency keys hai: Stripe ka Idempotency-Key header, Postmark ka MessageID reuse, aap ke apne MCP server ka idempotency contract. step.run aur provider idempotency keys ko complementary samjhein, substitutes nahin: step.run aap ke function ki internal logic ko exactly-once rakhta hai; provider ki idempotency key external side effect ko exactly-once rakhti hai.
Quick check. True ya false. (a)
step.runstep ko idempotent sirf tab banata hai jab andar wala function bhi idempotent ho. (b) Dedup window ke bahar duplicate ID wala event new event ke taur par treat ho ga. (c) Agarstep.runmid-execution fail hota hai (step ka code exception throw karta hai), Inngest failure store karta hai aur next attempt par prior steps re-run kiye baghair step retry karta hai.
Answers: (a) False: step.run step invocation ko idempotent banata hai (success par zyada se zyada ek dafa run hoga), lekin agar andar wala function non-idempotent ho (jaise Stripe call), at-most-once guarantee exactly wohi hai jo aap chahte hain. Point yeh hai ke Stripe-calling ko aap ko khud idempotent nahin banana parta. (b) True: Inngest ki dedup window default mein 24 hours hai; us window ke baad same ID wale events new treat hote hain. (c) True: failure replay khud memoized hota hai; Inngest janta hai step 3 attempt 1 par fail hua tha aur attempt 2 par sirf step 3 retry karta hai. Pehle successful steps re-execute nahin hote.
Try with AI
Here are three scenarios. For each, decide: idempotency PROBLEM or
NO PROBLEM, and if it's a problem, what's the fix:
A) Stripe sends the same charge.refund.failed webhook three times
in 90 seconds (because their first two attempts timed out at
your endpoint). Your function emails the customer.
B) A customer clicks "Issue refund" three times because the page
was slow. Your function calls Stripe and writes audit_log.
C) Your nightly cron at 09:00 sends a customer-health-check event
to each Pro customer. If two crons fire at the same time (a deploy
bug), what happens?
For each problem case, propose ONE specific fix: event ID seed
inside the function, idempotency key in inngest_client.send, or
function-level deduplication on the trigger.
Concept 5: Fan-out aur sub-agent delegation, ek event many Workers
Aksar ek single event ko many places par kaam trigger karna hota hai. Stripe charge.refund.failed event ko shayad support agent notify karna ho, audit likhna ho, customer ka risk score update karna ho, finance ops alert karni ho, Slack par post karna ho. Paanch reactions, sab independent, sab ek event se.
Inngest pattern: same event ko many functions subscribe karte hain. Fan-out code nahin; bas same TriggerEvent ke saath multiple @inngest_client.create_function decorators. Har function independently run hota hai, apni retries rakhta hai, apna step trace rakhta hai, aur doosron se independently fail hota hai.
@inngest_client.create_function(
fn_id="refund-failed-notify-support",
trigger=inngest.TriggerEvent(event="stripe/charge.refund.failed"),
)
async def notify_support(ctx: inngest.Context) -> dict[str, str]:
# ... runs the customer-support Worker to draft a response ...
return {"status": "drafted"}
@inngest_client.create_function(
fn_id="refund-failed-update-risk-score",
trigger=inngest.TriggerEvent(event="stripe/charge.refund.failed"),
)
async def update_risk_score(ctx: inngest.Context) -> dict[str, float]:
# ... runs the risk-scoring Worker ...
return {"new_risk_score": 0.42}
@inngest_client.create_function(
fn_id="refund-failed-post-slack",
trigger=inngest.TriggerEvent(event="stripe/charge.refund.failed"),
)
async def post_to_slack(ctx: inngest.Context) -> None:
# ... posts a Slack notification ...
return None
Ek Stripe webhook aata hai. Inngest ek event banata hai. Teen functions fire hote hain, har ek apne run mein. Agar Slack down hone ki wajah se post_to_slack fail ho, baqi do unaffected rehte hain aur normally complete hote hain. Failed run Slack recover hone par replay ke liye dashboard mein baitha rehta hai. Yeh multi-Worker coordination ka core hai, aur yahi architectural pattern aap ka future manager layer (later course) scale par compose karega.
Doosra fan-out pattern: parent-fires-N-children. Kabhi fan-out dynamic hota hai. Aap ke daily cron ko har Pro customer ke liye customer-health event fire karna hota hai, jo week ke hisab se 500 ya 5,000 ho sakte hain. Parent function N events send karta hai:
from datetime import date
async def fan_out_per_customer_events(
customers: list[str],
) -> int:
events = [
inngest.Event(
name="customer/health_check.requested",
data={"customer_id": cid},
id=f"daily-health-{cid}-{date.today().isoformat()}", # idempotency
)
for cid in customers
]
await inngest_client.send(events=events)
return len(events)
5,000 events ek single send call mein send hote hain. 5,000 function runs fire hote hain, har ek apne customer_id ke saath, har ek isolated, har ek independently retryable. Flow control (Concept 11) cap karta hai ke kitne concurrently run hon taake aap downstream APIs melt na kar dein. Cron function seconds mein return karta hai; fan-out us rate par run hota hai jo Inngest ki flow-control policies allow karti hain.
Sub-agent delegation fan-out ka special case hai. Worker run ke andar aap await inngest_client.send(...) call kar ke sub-tasks doosri Worker types ko delegate kar sakte hain. Parent children ka wait nahin karta jab tak woh explicitly step.invoke use kar ke unhein synchronously run aur results collect na kare.
PRIMM, Predict. You have three functions all triggered by
customer/email.received: the customer-support agent that drafts a reply (15 seconds), an analytics counter (50ms), and a "VIP detector" that checks if the customer is high-value (200ms). When an email arrives, what does user-visible latency look like for each? Three options: (a) all three add up to ~15 seconds; (b) all three run in parallel, total latency is ~15 seconds (the slowest); (c) each runs independently with no shared latency at all. Confidence 1-5.
Jawab: (c). Har function apna run hai, apne process slot mein. Customer-support agent analytics counter ko block nahin karta; VIP detector agent ko block nahin karta. Bahar se kisi bhi particular function ki latency bas us function ka apna time hai. Koi function sibling function ka wait nahin karta. Isi liye fan-out scale hota hai: consumers isolated hain. Agar agent crash kare, analytics counter unaffected rehta hai.
Try with AI
Design the fan-out architecture for these three scenarios. For each,
sketch the event names and the functions that subscribe:
A) New customer signs up. Need to: send welcome email, create
Stripe customer, post to Slack #new-customers, write to
audit_log, schedule a 7-day follow-up.
B) Customer support email arrives. Need to: draft a reply (agent),
detect sentiment, check if VIP, update customer's "last contact"
timestamp, attach to the right ticket thread.
C) Daily cron at 09:00 needs to run customer-health-check on
~5,000 Pro customers. Each check takes ~30 seconds. We want
the whole batch to complete by 11:00 (a 2-hour window).
For each, decide: how many event types, how many subscriber
functions, what the idempotency story is, and one specific failure
mode this design protects against.
Part 2: Durable execution, jab kuch toot jaye to kya hota hai
Triggers Worker ko jagate hain. Durable execution Worker ko agle failures se survive karwati hai. Course #4 ka Worker agent call karta hai, agent teen tools call karta hai, tools Postgres, Stripe, aur OpenAI call karte hain: ek conversation mein six external calls, jin mein se koi bhi fail ho sakti hai. Durability ke baghair mid-conversation ek transient failure poore flow ko top se restart kar deta hai. Durability woh property hai jo kehti hai: jab mid-execution kuch fail ho, jo kaam already complete ho chuka hai woh complete hi rehta hai, aur execution us jagah se resume hoti hai jahan tooti thi. Inngest yeh ek primitive (step.run) aur neeche memoization mechanic se deliver karta hai. Part 2 dono explain karta hai, plus time-based variants (step.sleep, step.wait_for_event), retry semantics, aur step.ai primitives.
First-pass compression note. Agar aap scan kar rahe hain, load-bearing concepts 6 (
step.run) aur 7 (memoization) hain. Concepts 8-10 un par build karte hain. 6 aur 7 dhyan se parhein; jab yeh dono aap ke head mein aa jayein to baqi fast read hoga.
Concept 6: step.run and the durable function model
Normal Python function ek dafa top to bottom run hota hai. Agar halfway crash ho jaye, aap top se dobara start karte hain. Agar crash se pehle teen API calls kar chuka ho, next attempt woh teen calls dobara karta hai, un ka cost dobara pay karta hai, aur shayad kisi ko dobara charge bhi kar de.
Inngest function durable hota hai. Jis operation ko aap checkpoint karna chahte hain woh step.run(name, fn, ...) mein wrap hota hai. Function har attempt par ab bhi top to bottom run hota hai, lekin jo steps already complete ho chuke hain woh re-execute hone ke bajaye apne stored outputs return karte hain. Function us jagah tak "catch up" karta hai jahan toota tha, phir aage continue karta hai.
@inngest_client.create_function(
fn_id="customer-support-conversation",
trigger=inngest.TriggerEvent(event="customer/email.received"),
)
async def handle_email(ctx: inngest.Context) -> dict[str, str]:
customer_id = ctx.event.data["customer_id"]
# Step 1: load the customer record (one DB call)
customer = await ctx.step.run(
"load-customer", load_customer_by_id, customer_id,
)
# Step 2: load the conversation thread (one DB call)
thread = await ctx.step.run(
"load-thread", load_thread_for_customer, customer_id,
)
# Step 3: run the OpenAI Agents SDK agent (the Course Four Worker)
response = await ctx.step.run(
"run-agent",
run_customer_support_agent,
customer=customer,
thread=thread,
email_body=ctx.event.data["body"],
)
# Step 4: write the draft reply to the database
await ctx.step.run(
"save-draft-reply", save_reply,
customer_id=customer_id, text=response.draft,
)
# Step 5: notify the on-call human reviewer via Slack
await ctx.step.run(
"notify-reviewer", post_slack_for_review, response=response,
)
return {"status": "drafted", "reviewer_notified": True}
Paanch steps. Har step independently checkpoint hota hai.
Yahan durability aapko teen failure scenarios mein kya deti hai:
-
Scenario A: agent step timeout throw karta hai. Agar agent call
step.runmein wrapped na ho, to function ki next retry customer reload karegi, thread reload karegi, aur agent ko scratch se dobara run karegi, yani jis kaam ka hissa agent pehle kar chuka tha us ke OpenAI tokens dobara pay honge.step.runke saath customer aur thread loads memoized hoti hain (steps 1-2 re-execute nahin hote); sirf step 3 retry hota hai. Transient OpenAI errors Inngest ke automatic retries handle kar lete hain, aap ke code ko pata bhi nahin chalta. -
Scenario B: function process step 3 aur step 4 ke darmiyan kill ho jata hai (deploy roll out hua, node restart hua, container OOM ho gaya). Durability ke baghair agent ka response lose ho jata hai aur customer ki email unanswered rehti hai jab tak koi notice na kare. Durability ke saath function restart ke baad resume hota hai: steps 1, 2, 3 milliseconds mein apne stored outputs return karte hain, step 4 real run hota hai, step 5 real run hota hai, aur customer ko drafted reply mil jata hai.
-
Scenario C: Slack step 5 par 503 return karta hai.
step.runke baghair aap ya to work lose karte, ya Slack call ke liye specially retry-and-backoff logic haath se likhte.step.runke saath Inngest step 5 ko exponential backoff ke saath retry karta hai jab tak Slack recover na ho; is dauran steps 1-4 completed rehte hain aur re-execute nahin hote. Draft reply database mein already hai; sirf notification pending hai.
Aap koi retry loops, koi "kya main yeh pehle kar chuka hun" checks, koi state machines nahin likhte. State machine khud step.run calls ki sequence hai. Har step ek node hai; har transition durable hai.
step.run ka ek rule. step.run ko pass kiya gaya function apne inputs ke hisaab se deterministic hona chahiye: same arguments ke saath do dafa call karein to same result nikalna chahiye. Pure functions ke liye yeh automatic hai; idempotent API calls ke liye bhi automatic hai (Stripe ka idempotency_key, aap ke apne MCP server tools); lekin "random ID generate karna" ya "default temperature ke saath LLM call karna" jaisi cheezon mein care chahiye (retry original attempt se different output de sakti hai, jo kabhi kabhi matter karta hai). Jab operation deterministic na ho, to aap usay deterministic banate hain: seed pass karein, random value step ke bahar pre-generate karein, ya accept karein ke retry original se differ kar sakti hai (agent response ke liye aksar fine).
Quick check. True ya false. (a) Har retry par function body top se re-execute hoti hai, including imports aur
step.runcalls ke bahar variable assignments. (b) Agar step complete hone mein 30 seconds leta hai aur function 25 seconds par crash ho jaye, to retry us step ko second 25 se continue karti hai. (c)step.runoutputs Inngest infrastructure mein store hote hain, aap ki application mein nahin.
Answers: (a) True, aur isi liye kaam inside step.run rakha jata hai. step.run ke bahar code har retry par re-run hota hai; andar wala code har attempt par run hota hai aur success par memoized hota hai. (b) False: step.run atomic unit hai; agar aap ka step itna long hai ke restart tolerate nahin kar sakta, to usay smaller steps mein break karein. (c) True: step output store Inngest ka part hai, aap ka DB nahin. Isi liye database schema change hone ke baad bhi runs replay ho sakte hain.
build-agents crash course ka Decision 4 openai-agents==0.17.2 ke streamed-path SDK bug ko document karta hai jo DeepSeek reasoning models ke tool-calling turns par aata hai: tool_calls message aur tool result ke darmiyan spurious empty assistant message, jise DeepSeek ka strict parser reject karta hai. Agar aap ka Course Four Worker @function_tool ke saath DeepSeek stream karta hai, to neeche Runner.run_streamed ko step.run mein wrap karne se pehle us course ka OpenAI-fallback resolution apply karein.
Try with AI
With my AI coding assistant connected to the Inngest dev server MCP,
re-shape my Course Four customer-support Worker into an Inngest
durable function. Take the existing Runner.run_streamed invocation
that processes a customer email and wrap each of these inside its
own step.run:
1. Load the customer from the customer-data MCP server
2. Load the related conversation thread
3. Run the agent (the OpenAI Agents SDK Runner)
4. Persist the draft reply
5. Notify the on-call reviewer in Slack
Use grep_docs to find the current Python SDK syntax. Use
invoke_function to test it with a synthetic email payload. Then
deliberately raise an exception in step 4 and use get_run_status
to confirm steps 1-3 don't re-execute on retry.
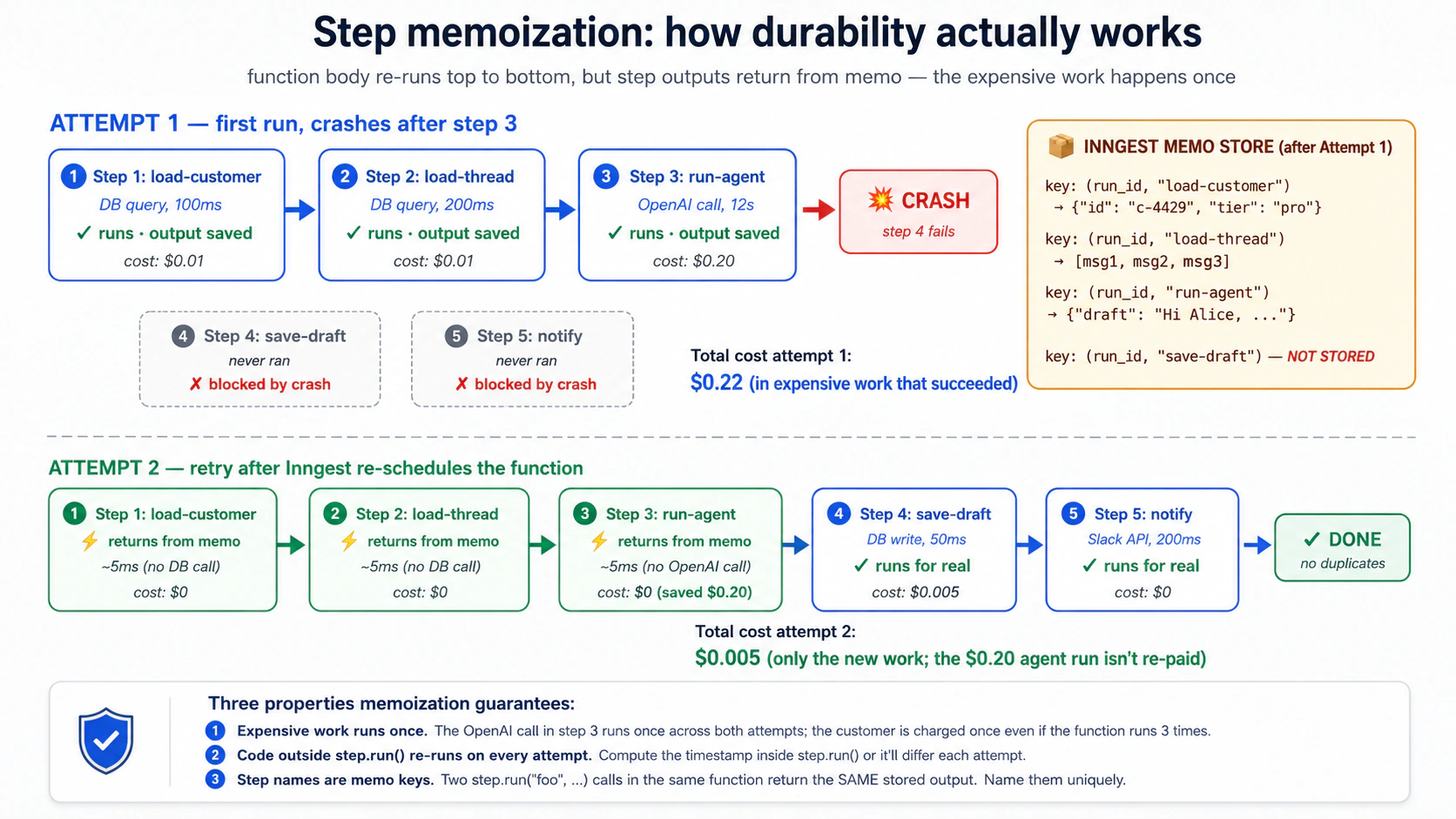
Concept 7: Memoization, resumability ke neeche wali mechanic
Concept 6 ne kaha tha: "jo steps already complete ho chuke hain woh re-execute hone ke bajaye apne stored outputs return karte hain." Yeh mechanism memoization hai, aur is mechanic ko samajhna zaroori hai kyun ke har doosra Inngest primitive isay use karta hai.
Jab aap await ctx.step.run("load-customer", load_customer_by_id, "c-4429") call karte hain, first attempt par teen cheezein hoti hain:
- Inngest apna memo store check karta hai: "kya is run mein step
load-customerka stored result hai?" Nahin hota. - Function
load_customer_by_id("c-4429")run hota hai. Yeh{"id": "c-4429", "tier": "pro", ...}return karta hai. - Inngest woh result memo store mein write karta hai,
(run_id, step_name="load-customer")se keyed. Phir result aap ke code ko return karta hai.
Agar function step 3 ke baad crash ho jaye aur Inngest retry kare, to second attempt par function body top se re-run hoti hai. Jab execution same line tak pohanchti hai, teen different cheezein hoti hain:
- Inngest apna memo store check karta hai: "kya is run mein step
load-customerka stored result hai?" Yes, woh attempt 1 par stored tha. - Function
load_customer_by_id("c-4429")run nahin hota. DB call nahin hoti. - Inngest milliseconds mein stored result aap ke code ko return karta hai.
Isi liye retries cheap hoti hain: expensive work already cached hai. Isi liye durability correct hai: expensive work do dafa nahin hota. Aur isi liye "function body top to bottom re-run hoti hai" wasteful lagne ke bawajood fine hai: steps ke andar wala kaam asal mein re-run nahin hota; sirf steps ke darmiyan orchestration code re-run hota hai.
Woh implication jo new users ko surprise karta hai. step.run ke outside code har attempt par run hota hai. Agar aap yeh karte hain:
async def handle_email(ctx: inngest.Context) -> dict[str, str]:
# ANTI-PATTERN: this runs on every retry. Don't do this.
expensive_thing: dict = await fetch_expensive_data(ctx.event.data["id"])
await ctx.step.run("do-something", do_something_with, expensive_thing)
return {"status": "done"}
fetch_expensive_data runs on every retry. If it costs $0.10 a call and the function retries 5 times, you just spent $0.50 fetching the same data five times. The fix is to wrap the expensive thing in its own step:
async def handle_email(ctx: inngest.Context) -> dict[str, str]:
expensive_thing: dict = await ctx.step.run(
"fetch-expensive-data", fetch_expensive_data, ctx.event.data["id"],
)
await ctx.step.run("do-something", do_something_with, expensive_thing)
return {"status": "done"}
Ab fetch_expensive_data memoized hai; retries is ke liye dobara pay nahi karte.
Step name memo key hai. Isi liye step names function ke andar unique hone chahiye. Agar same function mein do step.run("load-customer", ...) calls hon, Inngest dono calls ke liye pehle wale ka stored output return kare ga. Yeh almost kabhi woh nahi jo aap chahte hain. Agar aap ke paas loop hai jo step N dafa call karta hai, unhein uniquely name karein (step.run(f"load-customer-{i}", ...)) taake har iteration ka apna memo slot ho.
PRIMM, Predict. aap ka function has three steps. Step 1 (
load-customer) costs $0.01 in DB calls and takes 100ms. Step 2 (run-agent) costs $0.20 in OpenAI tokens and takes 12 seconds. Step 3 (save-draft) costs $0.005 in DB calls and takes 50ms. Step 2 fails 30% of the time due to OpenAI rate limits; Inngest retries with backoff. What is the cost difference between (a) wrapping all three instep.runand (b) wrapping only step 2 instep.run? Confidence 1-5.
Answer: (a) ke saath single retry sirf step 2 ka cost leta hai ($0.20). Customer aur save-draft memoized hain; woh re-execute nahi hote. (b) ke saath har retry steps 1 aur 3 plus step 2 cost karta hai: $0.215 per retry. 30% retry rate ke saath thousand emails par yeh pure waste mein roughly $4.50 ka difference hai, plus yeh operational complexity ke step 3 do dafa run hone par kya partially written hua. Jis cheez ko aap re-execute nahi karwana chahte usay step.run mein wrap karein. Mechanic samajhne ke baad yeh optional nahi.
Try with AI
With my AI coding assistant: review the Inngest function we built
in Concept 6's Try-with-AI and identify any code BETWEEN step.run
calls that should be wrapped in its own step but isn't. Common
candidates:
- Computed values (timestamps, IDs, formatting) that we want to be
stable across retries
- Calls to logging or metrics services
- Reads from Redis, environment variables, secret managers
Then propose a refactor that moves each of these into its own step
with a meaningful name. For each, explain whether the side effect
is one you want to happen once (use step.run) or every retry
(leave it outside).
Concept 8: step.sleep aur step.wait_for_event, waqt ke paar durability
Some work has to wait. A welcome-email pipeline sends an email immediately, then waits three days, then sends a follow-up. A refund-investigation ko human approval ka wait karna hota hai. A trial-conversion flow watches for "user upgraded to paid" within 7 days and sends a different email depending on what it sees.
Normal Python function mein "wait three days" ka matlab process ko teen din khula rakhna hota hai. Yeh untenable hai: aap ka process restart hota hai, hosting aap se 72 hours idle compute ka bill leti hai, timer kho jata hai. Inngest mein "wait three days" aik line hai:
from datetime import timedelta
@inngest_client.create_function(
fn_id="trial-welcome-series",
trigger=inngest.TriggerEvent(event="user/trial.started"),
)
async def welcome_series(ctx: inngest.Context) -> dict[str, str]:
user_id = ctx.event.data["user_id"]
await ctx.step.run("send-welcome-email", send_welcome_email, user_id)
# Wait three days. The function gets paged out of memory. Nothing
# is consuming compute. Three days later, Inngest pages it back in
# and resumes execution at the next line.
await ctx.step.sleep("wait-three-days", timedelta(days=3))
await ctx.step.run("send-followup", send_followup_email, user_id)
return {"status": "completed"}
step.sleep is durable. The function suspends; Inngest stores the resume time; nothing consumes compute while you wait; the function resumes at the right time, with all prior step outputs still memoized. step.sleep (and step.sleep_until) can wait up to one year on paid plans, up to seven days on the free Hobby plan (Inngest usage limits). The seven-day Hobby ceiling is wide enough for every sleep this course uses.
Zyada powerful sibling step.wait_for_event hai. Time ka wait karne ke bajaye doosre event ka wait karein. Function tab tak suspend hota hai jab tak matching event arrive na ho, ya aap ka set kiya timeout expire na ho. Yahi Inngest ko HITL (Concept 15) aur inter-agent coordination patterns ki cleanest expression banata hai:
@inngest_client.create_function(
fn_id="refund-with-approval",
trigger=inngest.TriggerEvent(event="customer/refund.requested"),
)
async def refund_with_approval(ctx: inngest.Context) -> dict[str, str]:
request = ctx.event.data
request_id = request["request_id"]
# If amount is over $500, require approval before issuing
if request["amount_cents"] >= 50_000:
# Notify a human via Slack/email/whatever
await ctx.step.run("notify-approver", notify_human_approver, request)
# Wait for an approval event. Up to 24 hours; expires otherwise.
approval = await ctx.step.wait_for_event(
"wait-for-approval",
event="refund/approval.decided",
timeout=timedelta(hours=24),
if_exp=f"async.data.request_id == '{request_id}'",
)
if approval is None or not approval.data.get("approved"):
return {"status": "rejected_or_timeout"}
# Either it was under $500, or it was approved
refund = await ctx.step.run(
"issue-stripe-refund", call_stripe_refund_api, request,
)
return {"status": "issued", "refund_id": refund["id"]}
What is happening:
- Function
wait_for_eventtak pahunchta hai. Yeh suspend hota hai. Zero compute consume hota hai. - Human Slack notification dekhta hai, aap ke admin UI mein "Approve" click karta hai, aur aap ka UI
inngest_client.send(events=[Event(name="refund/approval.decided", data={"request_id": "...", "approved": True})])call karta hai. - Inngest event ko waiting function se match karta hai (
if_expensure karta hai ke sirf is request_id ke events match hon) aur event koapprovalreturn value ke taur par de kar function resume karta hai. - Function refund step tak continue karta hai. Stripe refund human approval ke baad hota hai.
step.sleep and step.wait_for_event are timeouts you do not pay for. The function looks synchronous in aap ka code ("wait three days, then send the email"), but the runtime semantics are async and durable. This is one of the two things Inngest is famous for (durable retries being the other). Without it, the alternative is a queue plus a state machine plus a database plus a poller, and you would write a thousand lines instead of three.
Quick check. Three claims. Mark each True or False. (a) If
step.sleepis set for 30 days and aap ka service is redeployed five times in those 30 days, the sleep continues uninterrupted on a paid plan. (b) Ifstep.wait_for_eventtimes out, the function raises an exception. (c) Twostep.wait_for_eventcalls in the same function can wait for the same event simultaneously.
Answers: (a) True on a paid plan: sleeps are stored in Inngest's infrastructure, not in aap ki service memory, so redeploys do not lose them. Note the tier ceiling: a 30-day sleep is fine on a paid plan but exceeds the free Hobby plan's seven-day sleep cap. (b) False: on timeout, wait_for_event returns None. aap ka code checks for it and decides what to do (rejection, escalation, default-approval, whatever the policy is). (c) True, but suspicious: both will fire when a matching event arrives. If the two wait_for_event calls have different if_exp filters, this is fine. If they are identical, yeh shayad refactor opportunity hai.
Try with AI
Build a delayed-investigation flow with my AI coding assistant.
Specification:
1. Triggered by event 'customer/refund.failed'.
2. Immediately notify the on-call human via Slack with the refund
details and a "Investigate" button.
3. Wait for the human to click the button (which fires
'customer/refund.investigation_started') for up to 4 hours.
4. If the click arrives in time: run the agent to draft an
investigation summary.
5. If 4 hours pass without a click: escalate to a senior reviewer
by firing 'customer/refund.escalated'.
Use the dev-server MCP's send_event tool to simulate the
human-click event during testing. Use get_run_status to inspect
how the suspended function shows up in the dashboard. Before
writing, use list_docs to scan the Inngest documentation tree
for the right page on wait_for_event semantics, then
read_doc on the page you find to get the exact syntax for
the if_exp filter expression.
Concept 9: Retries, error handling, dead-letter
By default, Inngest retries failed steps. The defaults are sensible: ~4 retries with exponential backoff, ranging from a few seconds to a few minutes between attempts. After the final retry fails, the run enters a failed state and stays there for inspection and (optionally) replay. Aap isay per function tune kar sakte hain: retries=10, retries=0 (do not retry at all), specific exception types that should not be retried.
@inngest_client.create_function(
fn_id="charge-customer",
trigger=inngest.TriggerEvent(event="order/checkout.completed"),
retries=2, # only retry twice; this involves Stripe; don't keep hammering
)
async def charge_customer(ctx: inngest.Context) -> dict[str, str]:
try:
charge = await ctx.step.run(
"call-stripe", call_stripe_charge, ctx.event.data,
)
return {"status": "charged", "charge_id": charge["id"]}
except StripeCardDeclinedError as e:
# A declined card is not a transient failure. Don't retry.
# Mark the order as failed in our database and emit an event
# for the dunning flow.
await ctx.step.run(
"mark-failed", mark_order_failed,
ctx.event.data["order_id"], reason=str(e),
)
await ctx.step.run(
"emit-dunning-event", emit_dunning, ctx.event.data["order_id"],
)
return {"status": "card_declined"}
Three patterns matter.
Pattern 1: Transient vs permanent failures. Inngest retries everything by default, but some errors are not transient. A card-declined error from Stripe will be declined again on retry. A 401-unauthorized from aap ka downstream API will not become a 200 just because you wait. aap ka function should catch these specifically and handle them: write to aap ka DB, emit a downstream event, return cleanly, so they do not waste retry budget on hopeless attempts. Inngest's NonRetriableError explicitly tells Inngest to skip retries for a thrown exception.
Pattern 2: Step-level vs function-level errors. A step that throws is retried. After step-level retries are exhausted, the function fails. Sometimes you want a function to survive a failing step: log the failure, mark the work as "partial," continue. Wrap the step.run in try/except. The step still gets its retries; if all retries fail, the exception aap ke catch block tak propagate hoti hai, jahan aap decide kar sakte hain kya karna hai.
Pattern 3: Dead-letter and replay. When a function fully fails, it does not disappear. It enters the Inngest dashboard's "failed runs" view, with the full trace, all step outputs, the exception, and a Replay button. Bug fix ship karne ke baad aap failed runs replay kar sakte hain: woh fix ke saath wahi se resume karte hain jahan break hue the. This is the "dead-letter queue" pattern from traditional queues, except you do not write the dead-letter handler. You just fix the bug and replay.
PRIMM, Predict. aap ka function calls Stripe in step 2 and aap ka customer-data MCP server in step 4. Stripe returns 503 (service unavailable, transient) on the first attempt of step 2. Step 2 retries 4 times with exponential backoff (~1s, ~2s, ~5s, ~12s); on the 4th retry, Stripe is back, the charge succeeds. Now step 4 runs, and the customer-data MCP server is down with a 500. Does Inngest retry the whole function, or just step 4? How many times? Confidence 1-5.
Answer: sirf step 4, aur usay apna retry budget milta hai. Steps retries share nahi karte. Step 2 ke four retries step 4 se independent hain. Inngest step 4 retry kare ga (default ~4 dafa) aur agar MCP server wapas aa jaye, step 4 complete hota hai, function succeed ho jata hai. Step 2 ka Stripe charge dobara issue nahi hota, kyun ke successful retry ke baad step 2 ka output memoized tha. Customer exactly aik dafa charge hota hai chahe function ne retries ke across 20 seconds spend kiye.
Try with AI
With my AI coding assistant: extend the customer-support Worker
function from Concept 6 with explicit retry and failure handling.
Specification:
1. The OpenAI Agents SDK call should retry 3 times on transient
failures (rate limit, timeout), but NOT retry on a content-policy
refusal from the model.
2. The Slack notification should retry up to 10 times (Slack is
often flaky; don't lose the notification).
3. The Postgres write should retry once; if it fails again, log the
failure and continue (don't fail the whole function over a
transient DB blip).
For each step, decide what's transient vs permanent and structure
the try/except accordingly. Use grep_docs to find the Python SDK's
NonRetriableError equivalent.
Concept 10: Python mein AI calls ke liye step.run (step.ai.wrap TypeScript-only hai)
Concepts 6-9 har side-effecting code ke liye kaam karte hain: DB writes, API calls, file writes, agent invocations. Inngest AI-specific step primitives bhi ship karta hai jo un patterns ko handle karte hain jin par LLM calls prone hoti hain: rate-limit retries, prompts aur responses ki observability, aur (optionally) inference proxying jo serverless compute costs reduce karti hai.
aham Python-vs-TypeScript note up front. Inngest's
step.aimodule has two methods, and they have different language support.step.ai.infer()is available in both TypeScript and Python (Python SDK v0.5+): it offloads inference to Inngest's infrastructure and traces the call.step.ai.wrap()is TypeScript only: there is no Python equivalent today. For Python projects (like this course's Worker), the correct pattern for wrapping an OpenAI agents SDK call isctx.step.run(...), which already gives you full durability, retries, and observability of the wrapped step's inputs and outputs. You just do not get the LLM-specific prompt/response telemetry that the TypeScriptstep.ai.wrapadds. (Verified against the AI Inference docs as of May 2026.)
step.run for OpenAI calls in Python (the recommended pattern). aap ka function makes the OpenAI call inside ctx.step.run("name", fn, ...). Inngest traces the inputs and outputs of the step (the arguments you passed and what was returned), retries on transient failures, and memoizes the result so retries of later steps do not re-pay the OpenAI cost. The prompt and response are recorded as the step's input/output in the dashboard:
from openai import AsyncOpenAI
oai = AsyncOpenAI()
async def call_openai_summary(thread_text: str) -> str:
"""A normal async function. Inngest doesn't care that this is an LLM call."""
response = await oai.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "Summarize this support thread in 3 sentences."},
{"role": "user", "content": thread_text},
],
)
return response.choices[0].message.content
@inngest_client.create_function(
fn_id="summarize-customer-thread",
trigger=inngest.TriggerEvent(event="customer/thread.summary_requested"),
)
async def summarize_thread(ctx: inngest.Context) -> dict[str, str]:
thread: list = await ctx.step.run(
"load-thread", load_thread, ctx.event.data["thread_id"],
)
# The OpenAI call is wrapped in step.run. Inngest sees this as a step:
# the inputs (formatted thread text) are recorded, the output (summary
# string) is recorded, the call is memoized on success, and retries are
# automatic on transient failures.
summary: str = await ctx.step.run(
"openai-summary", call_openai_summary, format_thread(thread),
)
return {"summary": summary}
Dashboard mein yeh run function ka step trace dikhata hai (load-thread ke baad openai-summary) har step ke inputs aur outputs ke saath. Agar OpenAI ne 429 return kiya (rate limited), Inngest openai-summary ko backoff ke saath automatically retry karta hai: Concept 7 jaisi same memoization semantics, is liye retries pichle load-thread step ko double-bill nahi karti. Jo cheez aap ko nahi milti (TypeScript ke step.ai.wrap ke muqable mein): automatic LLM-specific telemetry, jaise token counts, model name, aur dashboard ke AI view mein provider-specific traces ka breakdown. Zyada tar Python production workloads ke liye standard step trace plus aap ki apni OpenAI client telemetry (misaal OpenAI Agents SDK tracing) yeh gap cover kar deti hai.
Because step.run records each step's inputs and outputs to Inngest's observability store, the content you pass through a step is stored and visible in the dashboard. If aap ka prompt includes PII (names, emails, addresses), secrets (API keys, internal tokens), contractual or financial data, or regulated content (HIPAA, GDPR-scoped data, PCI), do not pass the raw content into the step body. Redact, hash, summarize, or pass a reference (a customer_id and ticket_id, not the full ticket text) and reload the sensitive content inside the step body from aap ke authoritative store, jahan retention aur access controls aap configure karte hain. The same discipline applies to the OpenAI Agents SDK's own tracing if you enable it. Treat step traces as you would treat any production log: useful by default, regulated by policy.
step.ai.infer: a niche tool for serverless cost reduction (Python-supported). aap rarely reach for this; step.run is the default for every AI call in this course. step.ai.infer exists for one specific situation: instead of calling OpenAI from aap ka function process, you ask Inngest's infrastructure to make the call, so while the request is in flight aap ka function process can deallocate. On serverless platforms (Vercel, Cloudflare workers, AWS Lambda) that bill for in-flight time, this saves compute cost during the wait. For long-running inferences (deep research, large embedding batches) the savings are real. For sub-second calls, it adds latency without much benefit. The one shape, so the Quick reference decision-tree has a concrete referent:
import os
from inngest.experimental.ai.openai import Adapter as OpenAIAdapter
@inngest_client.create_function(
fn_id="long-research-call",
trigger=inngest.TriggerEvent(event="customer/research.requested"),
)
async def long_research(ctx: inngest.Context) -> dict[str, str]:
response = await ctx.step.ai.infer(
"call-openai",
adapter=OpenAIAdapter(
auth_key=os.environ["OPENAI_API_KEY"],
model="gpt-4o",
),
body={
"messages": [
{"role": "user", "content": ctx.event.data["prompt"]},
],
},
)
return {"response": response["choices"][0]["message"]["content"]}
Two details that trip people up. The keyword is adapter=, not model=: you pass an Adapter instance imported from inngest.experimental.ai.<provider> (adapters ship for openai, anthropic, gemini, grok, and deepseek). And the inngest.experimental.ai namespace is flagged experimental in inngest-py 0.5.18, so pin aap ka SDK version if you depend on it. The return value is a plain dict, so the response["choices"][0]["message"]["content"] subscript above is correct. The function's compute time is roughly the time between firing the request and processing the response, not the OpenAI call itself; on serverless, this can shave seconds off aap ka billable time per invocation.
Quick check. True ya false. (a) Python mein
ctx.step.run("name", call_openai, ...)OpenAI call ko durable banata hai, transient failures par retry karta hai, aur success par memoize karta hai. (b) Python mein OpenAI agents SDK ke saath Inngest use karne ke liyestep.ai.inferhard requirement hai. (c) Upar example meinstep.runkostep.ai.inferse replace karna hamesha function ko cheaper bana de ga.
Answers: (a) True: this is the recommended Python pattern. The OpenAI call goes inside the step body; Inngest treats the whole step as the unit of work. (b) False: step.run is enough for most cases. step.ai.infer is an optimization for serverless compute cost, not a requirement. The OpenAI Agents SDK integration in the worked example uses plain step.run. (c) False: step.ai.infer sirf tab money save karta hai jab (i) aap serverless platform par hon jo in-flight time ka bill karta hai AND (ii) call itni long ho ke request-offload savings added orchestration overhead se zyada hon. Sub-second calls on always-on servers ke liye plain step.run wins.
See the same caveat from earlier in this course: if aap ka course Four Worker streams DeepSeek with @function_tool, the openai-agents==0.17.2 streamed-path SDK bug documented in build-agents Decision 4 applies to Version A below. Apply that course's OpenAI-fallback resolution before wrapping Runner.run_streamed in step.run.
Try with AI
With my AI coding assistant: take the Course Four customer-support
agent invocation and produce TWO versions of the Inngest function
that calls it:
Version A: Wrap the Runner.run_streamed call in step.run (the
recommended Python pattern: durable, retried on transient failures,
memoized; you get the standard step trace).
Version B: For comparison, write a SEPARATE small Inngest function
that calls a single OpenAI completion via step.ai.infer (the
Python-supported step.ai primitive that offloads inference to
Inngest's infrastructure to save serverless compute cost).
For each version, explain (a) what the dashboard trace shows for a
successful run, (b) what happens when the OpenAI call hits a 429
rate limit, (c) whether the Course Four SQLiteSession state gets
corrupted by a mid-run crash, and (d) on which kind of deployment
(always-on server vs serverless) Version B's offload saves real money.
Part 3: Flow control aur recovery, production scale
Flow control is the third layer: it keeps the Worker healthy under load. Concurrency stops the Worker from melting downstream systems. Throttling keeps you off rate-limit walls. Priority and fairness prevent one chatty customer from starving everyone. Batching turns "10,000 events at midnight" into "100 manageable function runs." Replay turns "yesterday's bug cost us 200 failed interactions" into "we fixed it; 200 conversations resumed." HITL gates agent ko human approval tak suspend karte hain. Part 3 ke five concepts woh production policies dete hain jo working Worker ko paying customers ke saamne rakhne laiq banati hain.
Concept 11: Concurrency aur throttling
Concurrency function ke simultaneous execute hone wale runs ki maximum number hai. Throttling per unit time start hone wale runs ki maximum number hai. Dono per function aik aik line se configured hote hain. Jab teams prototype se scale par move karti hain, dono sab se common production gap hote hain.
from datetime import timedelta
@inngest_client.create_function(
fn_id="customer-support-conversation",
trigger=inngest.TriggerEvent(event="customer/email.received"),
concurrency=[inngest.Concurrency(limit=10)],
throttle=inngest.Throttle(limit=100, period=timedelta(minutes=1)),
)
async def handle_email(ctx: inngest.Context) -> dict[str, str]:
...
concurrency=10 says: at most 10 of these functions are running at any moment. The 11th event waits in queue until one of the 10 finishes. throttle=100/minute says: at most 100 new runs start per minute. The 101st event waits even if there is concurrency headroom.
Why both matter in practice. Concurrency protects downstream systems: if aap ka customer-support Worker talks to OpenAI and Postgres, having 1,000 concurrent runs means 1,000 simultaneous OpenAI calls and 1,000 simultaneous Postgres connections. aap exhaust aap ka OpenAI rate limit, exhaust aap ka connection pool, or both. Throttle protects against bursts: if 500 customer emails arrive at 9:00am sharp, you do not want 500 functions starting in the same second; throttle smooths the start rate.
Per-key concurrency. Single concurrency limit function par globally apply hoti hai. Zyada interesting pattern per-key concurrency hai: event ki kisi property ke hisaab se limit.
@inngest_client.create_function(
fn_id="customer-support-conversation",
trigger=inngest.TriggerEvent(event="customer/email.received"),
concurrency=[
inngest.Concurrency(limit=10), # global cap
inngest.Concurrency(limit=2, key="event.data.customer_id"), # per-customer cap
],
)
async def handle_email(ctx: inngest.Context) -> dict[str, str]:
...
Is ka matlab hai: globally at most 10 functions running, AUR per customer at most 2 at a time. Agar single customer aik minute mein 100 emails bheje, sirf 2 emails simultaneously process hon gi; baqi 98 peeche queue hon gi. Meanwhile, doosre customers ki emails normally flow karti hain; woh chatty customer se blocked nahi. Yeh do lines of code mein multi-tenant fairness hai. Concept 12 pattern ko aur develop karta hai.
Quick check. Teen claims, True ya False. (a) Agar aap
concurrency=10set karein aur 1,000 events aik saath arrive hon, 990 drop ho jate hain. (b) Throttling aur concurrency limits dono total throughput reduce karti hain. (c) Per-key concurrency ko event data se deterministic key chahiye.
Answers: (a) False: events are not dropped; they queue. Inngest's queue is durable; the 990 events wait until concurrency slots open up. (b) False. Throttling caps start-rate; concurrency caps in-flight runs. Neither drops work; both shape when work executes. Throughput over a long window is unchanged if aap ka average load is below the limits. Throughput over a peak is shaped: bursts are absorbed by the queue. (c) True: the key expression is evaluated on the event data; it has to produce a stable string for the same logical scope (customer_id is fine; current_timestamp is not).
Try with AI
With my AI coding assistant: design the concurrency and throttling
policy for the customer-support Worker. Constraints:
- OpenAI rate limit: 30 requests per minute, hard cap.
- Postgres connection pool: 20 max connections (the Worker takes 1 per run).
- Some customers send bursts of 30+ emails in a minute (an angry
customer); these shouldn't starve other customers.
- We expect ~1,000 emails per day, with peaks around 9am and 2pm.
Propose:
1. A global concurrency value
2. A per-customer concurrency value
3. A throttle (limit and period)
For each, explain what production failure it protects against and
what the cost is (in queue latency at peak).
Concept 12: Priority aur fairness, multi-tenant scaling
Concurrency limits work. Per-key concurrency adds basic fairness. production-grade multi-tenant systems need more: priorities (enterprise customers should not wait behind hobbyists for the same compute) and fair-share scheduling (no single tenant can monopolize system even within their concurrency cap).
Priority. Inngest har event par priority expression evaluate karta hai; higher priority wale runs lower priority runs se pehle queue jump karte hain.
@inngest_client.create_function(
fn_id="customer-support-conversation",
trigger=inngest.TriggerEvent(event="customer/email.received"),
concurrency=[inngest.Concurrency(limit=10)],
priority=inngest.Priority(
# Enterprise tier = high priority; Pro = 0; Free = low priority
run="100 - (event.data.customer_tier_priority * 100)",
),
)
async def handle_email(ctx: inngest.Context) -> dict[str, str]:
...
Jab concurrency queue mein 50 runs waiting hon, enterprise customers ke runs pehle jate hain, phir Pro, phir Free. Same tier ke andar FIFO order apply hota hai. Priority concurrency ya throttle limits override nahi karti; yeh sirf decide karti hai waiting runs mein se kaunsa next free slot lega. Enterprise customer ab bhi slot open hone ka wait karta hai; bas woh next slot leta hai.
Fair-share scheduling. Jab hundreds of tenants same global concurrency pool ke liye compete kar rahe hon, FIFO plus priority enough nahi. Single tenant ka burst minutes ke liye most slots occupy kar sakta hai. Fair-share scheduling, concurrency par key parameter ke zariye thoughtful sizing ke saath implemented, har tenant ko guaranteed slice deti hai:
concurrency=[
inngest.Concurrency(limit=50), # global pool
inngest.Concurrency(limit=3, key="event.data.tenant_id"), # max 3 per tenant
],
Is ke saath: 50 total slots, koi tenant 3 se zyada nahi leta. Agar 20 tenants active hain, at most 60 slots requested hain lekin available sirf 50. Fair-share unhein rotate karta hai, har tenant ko kuch share milta hai, koi shut out nahi hota.
PRIMM, Predict. Aap ke paas customer-support function hai jisme
concurrency=10aur per-customerconcurrency=2hai. Priority bhi configured hai: enterprise = high, Free = low. 9:00am par queue mein yeh hai: Customer A (Free) se 5 events, Customer B (enterprise) se 5 events, aur single new Customer C (Free, just bought their first plan) se 10 events. Yeh kis order mein execute hon ge? Confidence 1-5.
Jawab: yeh multi-level decision hai. Pehle, per-customer cap 2 ka matlab hai ke har customer ke zyada se zyada 2 events aik waqt mein run ke eligible hain. To pool of candidates hai: A se 2, B se 2, C se 2: six runs immediately eligible. Doosra, priority decide karti hai ke in six mein se pehle slots kaun fill kare: B ke do pehle run hotay hain (enterprise), phir A ke do aur C ke do (Free, FIFO). To t=0 par: B ke 2 run, phir A ke 2 start, phir C ke 2 start. Total: 6 active. Jaise har aik finish hota hai, us customer ka next queued event eligible hota hai aur next slot priority se fill hota hai. Yeh woh policy hai jo Inngest mein feature hai aur aap ke apne code mein thousand-line scheduler.
Try with AI
With my AI coding assistant: extend the customer-support Worker
configuration with a priority and fair-share scheme. Requirements:
1. Three customer tiers: Enterprise, Pro, Free.
2. Enterprise customers should never wait more than 5 seconds at
peak load.
3. Free tier customers should get fair access: no Free customer
should be starved for more than 60 seconds, even when the
global queue is full.
4. A single noisy customer (regardless of tier) should not occupy
more than 3 slots.
Write the concurrency + priority configuration. For each line of
config, explain which requirement it satisfies.
Concept 13: Batching, cost-effective bulk processing
Kuch work naturally batched hota hai. Aap 10,000 customer conversations ko independently summarize nahi karte; aap LLM ko aik waqt mein 50 ke batch ke saath call karte hain. Aap 10,000 audit rows aik aik kar ke nahi likhte; aap unhein COPY karte hain. Inngest ka batch trigger aap ko events accumulate karne aur batch ko input bana kar single function invoke karne deta hai.
@inngest_client.create_function(
fn_id="batch-embed-tickets",
trigger=inngest.TriggerEvent(event="ticket/resolved"),
batch_events=inngest.Batch(
max_size=50, # invoke when 50 events accumulated, OR
timeout=timedelta(seconds=30), # invoke when 30 seconds pass, whichever first
),
)
async def batch_embed_resolved_tickets(ctx: inngest.Context) -> dict[str, int]:
# ctx.events (plural) instead of ctx.event
ticket_ids = [e.data["ticket_id"] for e in ctx.events]
tickets = await ctx.step.run(
"load-tickets", load_tickets_by_ids, ticket_ids,
)
# One embedding call for 50 tickets, not 50 calls for 1 ticket each
embeddings = await ctx.step.run(
"embed-batch", embed_texts_batch,
[t["text"] for t in tickets],
)
await ctx.step.run(
"store-embeddings", store_embeddings_batch,
ticket_ids, embeddings,
)
return {"batched": len(ctx.events)}
Jo change hota hai: ctx.events list hai, single event nahi. Function har event ke bajaye har batch par aik dafa run hota hai. OpenAI embedding API 50 single-text calls ke bajaye 50-text batch ke saath call hoti hai, jo dramatically cheaper hai (aap per token pay karte hain, lekin per-request overhead khatam) aur zyada tez hai (50 ke bajaye aik API round-trip).
Batching right tool tab hai jab kaam naturally bulkable ho (embeddings, bulk DB writes, bulk emails) aur kaam hone se pehle aap timeout jitni latency tolerate kar sakte hon. Yeh wrong tool hai jab har event ko interactive response chahiye ya events ke darmiyan ordering unpredictable tareeqe se matter karti ho.
Quick check. True or false. (a) Batched functions still get retries and memoization; the batch as a whole is durably memoized. (b) If the batch timeout expires with only 3 events accumulated, the function will not run until the next 47 arrive. (c) Aap
batch_eventskoconcurrencyke saath combine kar ke cap kar sakte hain ke kitne batches parallel run hon.
Answers: (a) True: the batch is the unit of work; retries replay the whole batch with all its events still in scope. (b) False: that is the whole point of the timeout. After 30 seconds the function runs with whatever is accumulated, even if it is 1 event. (c) True: this is the production pattern. Batch plus concurrency together cap aap ka downstream load nicely.
Try with AI
With my AI coding assistant: convert the Course Four embedding
pipeline (the one that embeds resolved tickets) from a per-ticket
event handler into a batched Inngest function.
Triggers: 'ticket/resolved' event, batched at 50 events or 30 seconds.
The function should:
1. Load the ticket bodies in one query
2. Call OpenAI embeddings API with a 50-text batch (faster + cheaper)
3. Store the embeddings via the customer-data MCP server
4. Emit a 'ticket/embedded' event per ticket for downstream consumers
Use grep_docs to find the OpenAI batch-embedding pattern.
Concept 14: Replay aur bulk cancellation, production recovery
Sometimes everything goes wrong at once. You shipped a bug; a thousand runs failed in the last six hours. Or aap ka downstream API was down for 30 minutes; everything that tried to call it during that window died. Or you discovered a logic error and want to redo a day's work after fixing it.
Do opposite recovery primitives. Replay kehta hai "yeh work fail hua, main chahta hoon yeh succeed ho." Bulk cancellation kehta hai "yeh work queued tha lekin ab main nahi chahta yeh ho." Same dashboard surface, opposite intent. Most teams real traffic chalane ke pehle teen mahino mein dono need karte hain.
Replay recovery primitive hai. Failed runs apni full step history, input event, successful steps ke partial outputs, aur failed step ki exception ke saath persist karte hain. Dashboard se Functions view open karein, us function par filter karein jiske failed runs hain, time window aur failure pattern select karein (koi specific error message ya sirf "all failures"), Replay click karein. Inngest un runs ko is tarah re-schedule karta hai jaise woh freshly arrive hue hon, lekin aik crucial difference ke saath: previously memoized step outputs cache hits ke taur par wapas aate hain.
Replay ke baare mein teen cheezen samajhni hain.
- Replay uses the same function code as the original run, after aap ka deploy. If you deployed a fix between when the runs failed and when you replay them, the replayed runs use the new code. This is the whole point.
- Replay respects memoization. Steps that succeeded in the original run do not re-execute on replay. If aap ka customer-support Worker spent $0.20 on OpenAI tokens at step 3 before failing at step 4, you do not re-spend that $0.20: only step 4 onwards runs. For a 47-run recovery scenario, this means the dollar cost of replaying after a bug fix is roughly the cost of the failed step × 47, not the cost of the whole function × 47.
- Replay opt-in hai. Failed runs dashboard mein rehte hain jab tak aap un par act na karein. Woh forever retry nahi karte; woh disappear nahi hote. Woh aap ka wait karte hain.
Bulk cancellation inverse hai. Kabhi aap ke paas thousands of queued ya sleeping runs hotay hain jo aap ab nahi chahte: campaign cancel ho gayi, customer churn ho gaya aur aap follow-up emails nahi bhejna chahte, feature rollback ho gaya. Dashboard se function aur time window ya event filter select karein, phir Cancel click karein. Matching runs cleanly terminate hote hain: un ke step.sleep aur step.wait_for_event calls resume nahi hote, queued runs start nahi hote, in-flight runs cancellation check kar ke next step boundary par exit karte hain. Cancellation step boundary respect karti hai; in-flight step.run terminate hone se pehle apna current step finish karta hai, is liye half-completed Stripe charges ya torn DB writes nahi milte.
Replay vs cancellation as a decision. When something has gone wrong with a population of runs, ask one question: do I want this work to succeed or do I want it to not happen? If the work should succeed (bug-fix recovery), replay. If the work should not happen (cancelled campaign, churned customer, rolled-back feature), cancel. Agar aap unsure hon (for example, failed runs mein kuch recover karne laiq aur kuch aise hon jo pehle fire hi nahin hone chahiye the), to dashboard query zyada narrowly filter karein taake har subset ko right treatment mile.
Practice mein yeh teen patterns enable karta hai:
- "Hum ne bug ship kiya" recovery. Bad deploy ke time window mein failed runs find karein, bug fix karein, fix ship karein, failures replay karein. Customer experience: un ki email ko aik hour tak reply nahi mila lekin eventually mil gaya, bina aap ke recovery code likhe.
- "Campaign canceled" rollback. Welcome series 14 days mein teen follow-up emails fire karti hai; customer day 4 par churn ho jata hai. Aap day-7 aur day-14 follow-ups nahi bhejna chahte. Matching
wait-for-eventaursleepruns bulk-cancel karein. - The "schema migration" replay. You changed how agent formats summaries; you want yesterday's tickets re-summarized with the new format. Find the runs, force-replay even the successful ones (the dashboard offers this as a separate option: replay-failures-only is the default; replay-all is the schema-migration mode), and agent re-runs with the new code.

Dev-server MCP replay ko Claude Code chhore baghair accessible banata hai. Development ke dauran jab aap replay scenario test karna chahte hain, dashboard mein manually click karne ki zaroorat nahi; aap AI se keh sakte hain ke get_run_status use kar ke failed run inspect kare, phir dashboard se replay trigger kare ya same idempotency key ke saath event re-fire kare (jo Concept 4 ki idempotency semantics ki wajah se testing ke liye functionally equivalent hai).
Quick check. True or false. (a) Replay re-runs failed steps with the new deployed code. (b) Replay re-runs successful steps too, to make sure everything is consistent. (c) A run in
step.sleepfor 30 days can be canceled before the sleep expires. (d) Bulk-canceling a function that is in flight will mid-step abort the currently-executingstep.runto terminate tezer.
Answers: (a) True: this is why replay is kaam ka for bug-fix recovery. (b) False, with a footnote: by default replay only re-executes failed-and-onwards steps; successful steps are returned from memo. There is an opt-in mode (sometimes called "force replay" or "replay all") that re-executes every step from the top, which is what you want for schema migrations or "the function logic itself changed and I want to redo even the successful work." (c) True: sleeping runs are first-class objects in the dashboard and can be canceled, modified, or replayed. (d) False: cancellation respects the step boundary; the current step.run finishes (or fails) before the run terminates. This prevents torn writes.
Try with AI
Walk through a recovery scenario with my AI coding assistant:
Yesterday at 14:00 we deployed a change to the Worker's
escalate-with-context Skill. The new SKILL.md description had a
typo that made the model fail to recognize the trigger phrases.
From 14:00 to 18:00, 47 customer-support runs failed at the
escalation step.
At 18:30 we noticed, fixed the SKILL.md typo, and re-deployed.
Use the dev-server MCP's grep_docs to find Inngest's replay docs,
then:
1. Outline the exact dashboard steps to identify the 47 failed runs.
2. Explain what replay will do (step-by-step) for one of those runs:
which steps return from memo, which run for real, what the
dollar cost is.
3. Confirm whether the customers will see one reply or multiple
(the durability + memoization story).
4. Identify ONE scenario in this story where you'd prefer to
bulk-cancel instead of replay, and explain why.
Concept 15: step.wait_for_event ke saath HITL gates, runtime mein Invariant 1
Agent Factory's Invariant 1 says the human is the principal: authored intent, not agent's autonomous judgment, is what the runtime must honor on high-stakes decisions. This shows up in production as approval gates: agent analysis karta hai, action draft karta hai, lekin action execute nahin karta jab tak human approve na kare.
Inngest's step.wait_for_event (Concept 8) is the cleanest expression of this on any platform today. Agent decision point tak run karta hai, suspend hota hai, aur approval event ka wait karta hai. Human review karta hai (Slack, admin UI, ya email mein) aur approve ya reject click karta hai. Event fire hota hai. Function human verdict ke saath resume hota hai aur us ke mutabiq act karta hai.
@inngest_client.create_function(
fn_id="refund-with-hitl-gate",
trigger=inngest.TriggerEvent(event="customer/refund.investigated"),
concurrency=[inngest.Concurrency(limit=5)],
)
async def refund_with_gate(ctx: inngest.Context) -> dict[str, str]:
request_id = ctx.event.data["request_id"]
amount_cents = ctx.event.data["amount_cents"]
# Step 1: the agent's analysis (Course Four Worker)
analysis = await ctx.step.run(
"agent-investigates",
run_refund_investigation_agent,
request_id=request_id,
)
# Step 2: if the agent thinks refund is warranted AND amount > $100,
# gate behind human approval
needs_approval = analysis.recommends_refund and amount_cents >= 10_000
if needs_approval:
await ctx.step.run(
"notify-approver",
send_slack_approval_request,
request_id=request_id,
analysis=analysis,
amount_cents=amount_cents,
)
# === THE HITL GATE ===
approval = await ctx.step.wait_for_event(
"wait-for-human-approval",
event="refund/approval.decided",
timeout=timedelta(hours=24),
if_exp=f"async.data.request_id == '{request_id}'",
)
if approval is None:
# Timeout: no human responded in 24h. Escalate.
await ctx.step.run(
"escalate-timeout",
escalate_to_senior_reviewer,
request_id=request_id,
)
return {"status": "escalated_timeout"}
if not approval.data["approved"]:
await ctx.step.run(
"notify-rejected", notify_customer_rejected,
request_id=request_id,
)
return {"status": "rejected_by_human"}
# Either it was approved, or it didn't need approval
refund = await ctx.step.run(
"issue-refund", call_stripe_refund,
request_id=request_id, amount_cents=amount_cents,
)
await ctx.step.run(
"audit-approved-refund", audit_refund,
request_id=request_id, refund=refund,
approved_by="human" if needs_approval else "auto",
)
return {"status": "issued", "refund_id": refund["id"]}
Code mein jo aap dekhte hain: steps ki sequence, beech mein aik wait_for_event. Runtime par kya ho raha hai:
- agent runs (step 1, durably).
- Function decide karta hai ke gate apply hota hai ya nahi (in-code logic, side effects se free).
- Agar gated ho: Slack notification fire hoti hai (step 2, durable). Function suspend hota hai. 24 hours tak zero compute consume hota hai.
- Slack mein human Approve ya Reject click karta hai. Admin backend
refund/approval.decidedaurrequest_idke saathinngest_client.sendcall karta hai. - Inngest event ko suspended function se match karta hai (
if_expfilter ensure karta hai ke sirf matching request IDs match hon). Function next line par resume hota hai. - Function human decision use kar ke refund issue karta hai ya rejection notify karta hai. Dono paths decision aur approver audit karte hain.
Yahi Inngest ko queue-plus-state-machine se qualitatively different banata hai. HITL pattern aik primitive hai. Function ka code top to bottom read hota hai, gate inline hota hai. Koi callback nahi, koi state restoration nahi, koi if state == waiting_for_approval: ... dispatching nahi. Runtime suspend/resume mechanic handle karta hai; aap ka code policy express karta hai.
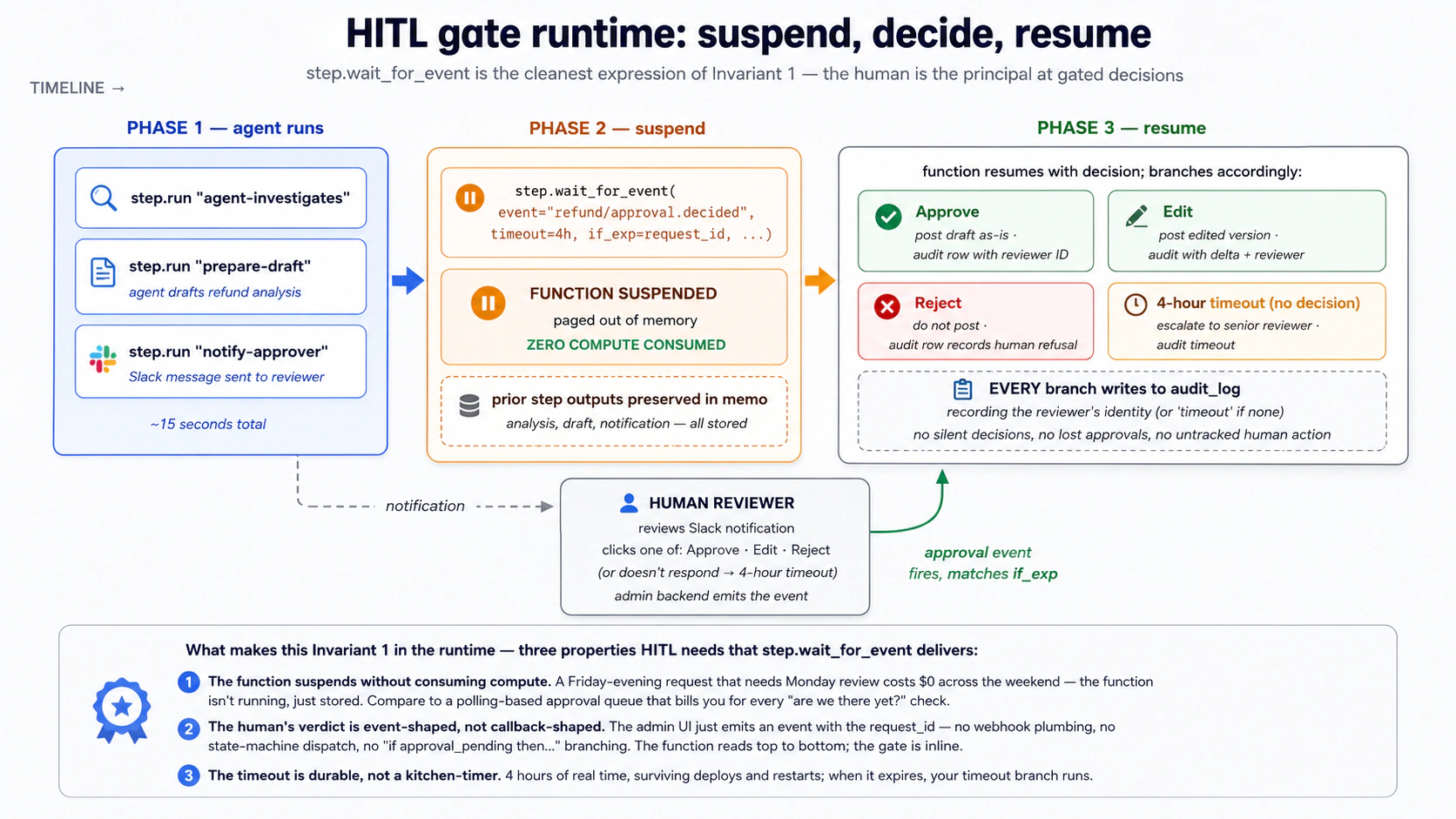
Later course Invariant 1 ko architecturally develop karta hai: authored intent, spec-driven workflows, manager-of-workers layer jo decide karti hai ke kaun se gates kaun se actions par apply hon. Yeh course aap ko runtime primitive deta hai. Jab woh manager layer aayegi, jo gate woh implement kare gi woh exactly yahi wait_for_event pattern ho ga, bas fleet scale par composed. Primitive ko ab samajhna ka matlab hai ke later architectural pattern "magic" ke bajaye "sensible composition" lage ga.
PRIMM, Predict. You have an HITL gate set with
timeout=timedelta(hours=24). A customer's refund request comes in at 17:00 on a Friday. Weekend par koi human online nahin. Gate ka timeout Saturday 17:00 par fire hota hai. Aap ka timeout handler senior reviewer ko escalate karta hai. Senior reviewer Monday 9:00am par escalation parhta hai. Timeline walk through karein: weekend ke dauran kitne function runs active the? Inngest ne kitna compute charge kiya? Confidence 1-5.
Answer: weekend ke dauran zero active function runs. Function suspended tha: Inngest ne us ki state store ki, function ko memory se page out kiya, aur event ya timeout ka wait kar raha tha. Inngest suspended time ke liye bill nahi karta. Jab Saturday 17:00 aaya aur timeout fire hua, function kuch hundred milliseconds ke liye resume hua jisme timeout handler call hua, phir dobara suspend ho gaya (ya handler complete hua to complete ho gaya). Senior reviewer ka Monday tak lena, Worker ke perspective se, bas aik aur wait_for_event cycle hai. Inngest par HITL workflows ki economics polling-based queues se dramatically different hain jo har second ke "kya yeh approve hua?" polling ke liye bill karti hain.
Try with AI
With my AI coding assistant: design the HITL gate for the
customer-support Worker's escalate-with-context Skill. Specification:
1. When the agent decides to escalate (the Skill fires), pause for
human approval before posting the escalation summary to the
senior support channel.
2. The approval gate should:
- Notify the on-call reviewer via Slack with the agent's draft
- Wait up to 4 hours for the reviewer to approve, edit, or reject
- On approve: post the draft as-is.
- On edit: incorporate the reviewer's edits, then post.
- On reject: do not post; mark the escalation as canceled.
- On 4-hour timeout: post the draft with a "no human review"
warning header.
3. Every branch (approve/edit/reject/timeout) writes to audit_log
with the human reviewer's identity (or "timeout" if none).
Use the dev-server MCP's send_event to simulate each branch of
the reviewer's decision during testing.
Part 4: Worked example, customer-support Production Worker
One realistic evolution, every concept above, both tools. We take the chat-agent/ project from course #4 and add the operational envelope that turns it into a production Worker: Inngest functions wrapping agent, an event trigger for inbound emails, a daily cron for proactive health checks, concurrency limits, an HITL escalation gate, and a replay-tested failure path. Eight build decisions, same shape as courses #3 and #4.
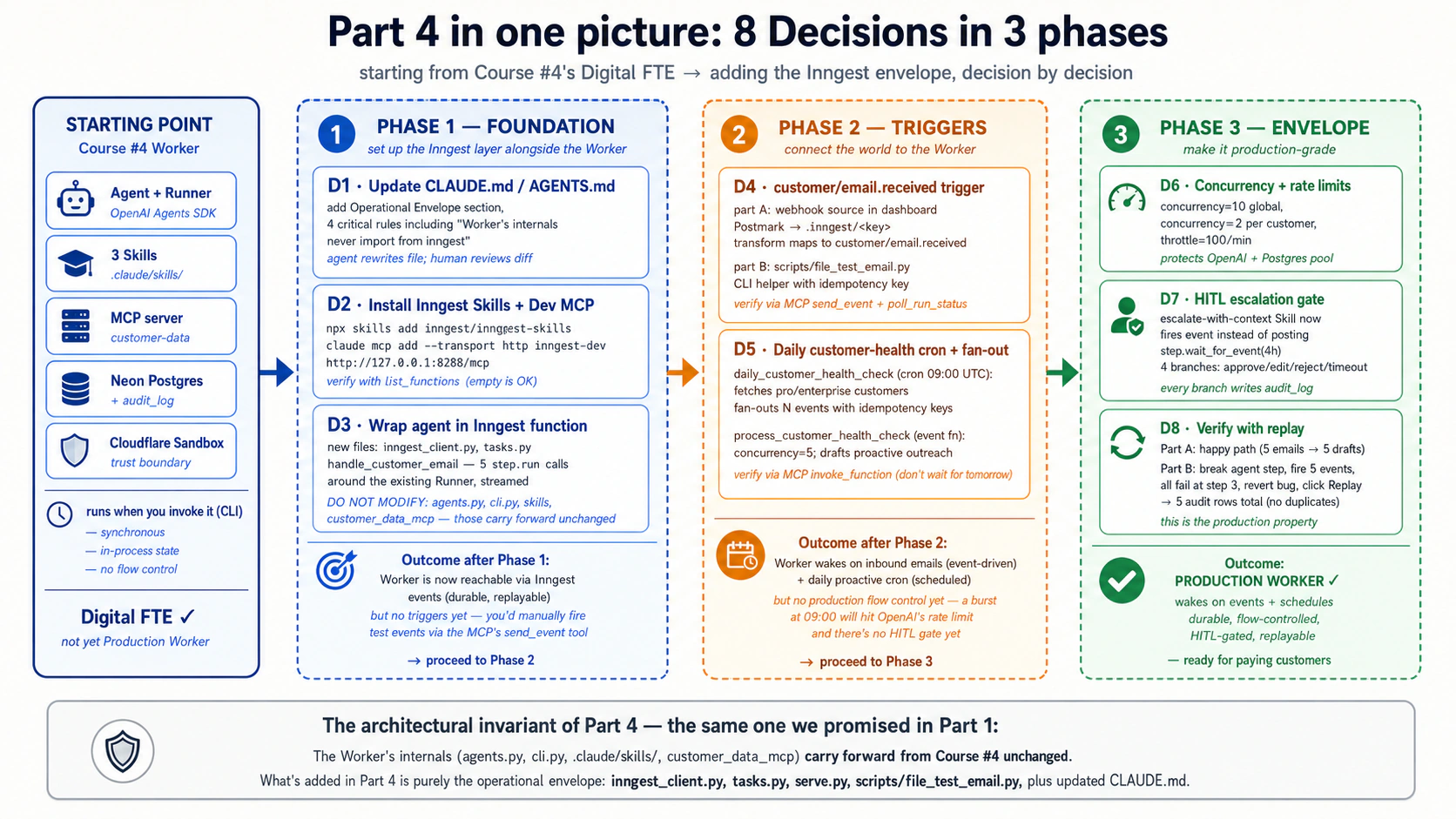
Before you start: setup aap ko chahiye that is not in the prereqs. Four things this Part assumes are already done. Run down this checklist; if any item is missing, fix it before Decision 1.
- Course #4 ka worked example built hai, sirf read nahi. Aap ke paas working
chat-agent/project hai:cli.py,agents.py, teen.claude/skills/(summarize-ticket, find-similar-cases, escalate-with-context), Neon Postgres schema withaudit_log, aur customcustomer-dataMCP server. Yeh Part un files ko extend karta hai; replace nahi karta. Jo reader course #4 read karta hai lekin Part 4 worked example build nahi karta, woh Decision 3 par wrap karne ke liye agent ke baghair hit kare ga.- Node.js 20+ installed hai, taake Inngest dev server (
npx inngest-cli@latest dev) run kar sake.- Aap ke paas Hobby tier par free Inngest account hai (hamesha $0, no credit card). Hobby tier is course ki har exercised cheez cover karta hai: 50,000 executions per month, 5 concurrent steps, replay aur bulk-cancel ke saath full dashboard. Do ceilings jaanne laayiq hain: 5-concurrent-step cap, aur free plan par seven-day
step.sleepceiling (paid par one year). Dono aap ko course complete karne se nahi rokte; woh production scale ki shape banate hain (Part 5 ke cost section dekhein).- Claude Code ya OpenCode mein se aik installed aur authenticated hai.
Brief
Course #4 ke chat-agent Digital FTE ko evolve kar ke aisa customer-support production Worker banayein jo:
customer/email.receivedevents par wake hota hai (production mein Postmark webhook, dev mein simulatedsend_eventcalls).- Existing customer-support agent ko durably run karta hai: har agent invocation
step.runmein wrapped, taake crashes survive kare, transient failures par retry ho, aur full prompt/response observability mile. - Daily 09:00 UTC cron run karta hai jo har Pro/enterprise customer ke liye
customer/health_check.requestedevent fan out karta hai; har event Worker run trigger karta hai jo proactive outreach message draft karta hai. - Globally concurrency 10 aur per customer 2 par cap karta hai, starts ko 100 per minute throttle karta hai (OpenAI rate limits aur Postgres connection pool protect karte hue).
- Gates escalations behind a 4-hour HITL window: agent drafts the escalation, a Slack notification goes to the on-call reviewer, the function suspends until the reviewer approves/rejects/edits, then completes accordingly.
- Replay path maintain karta hai: jab kuch fail ho, failed runs full state ke saath persist karte hain; bug fix ke baad aap unhein replay karte hain aur woh jahan broken thay wahin se resume karte hain.
Worker ke internals (agent, skills, MCP server, audit_log) change nahi hotay. Hum un ke around Inngest add karte hain.
A note on the prompts that follow. Each Decision shows a structured ask as a block-quoted prompt. The pattern that works best in practice is to precede each ask with one orient move ("Read
CLAUDE.mdand the relevant files, tell me what you see, and ask 1-2 questions before we start") and then send the structured ask once agent has loaded context and clarified ambiguities. The structured asks below are the destination, not the first move. Pasting them cold works; pasting them after orientation works better, especially as the project grows.
Decision 1: Rules file ko Inngest layer ke saath update karein
What you do (Claude Code). Open Claude Code in aap ka existing chat-agent/ project. Orient first: ask agent to read CLAUDE.md, the existing src/chat_agent/ layout, and the course #4 skills, and to tell you back what it sees plus one or two clarifying questions about the course Five additions. Once that exchange settles, brief agent on the architectural addition and ask it to update CLAUDE.md:
We're adding the Inngest operational envelope around the Course Four
Digital FTE. The Worker's internals don't change. What's NEW:
1. inngest-py SDK installed and configured (an inngest_client in
src/chat_agent/inngest_client.py).
2. A new module src/chat_agent/tasks.py containing Inngest
functions that wrap the agent: one for inbound emails, one for
the daily health-check cron, one for the HITL escalation gate.
3. A dev-only entry point src/chat_agent/serve.py that runs an
ASGI server hosting the Inngest functions so the local dev
server can discover them.
4. The Inngest dev server is launched separately with
`npx inngest-cli@latest dev`; the Inngest dev-server MCP at
http://127.0.0.1:8288/mcp is added to Claude Code's MCP config.
Update CLAUDE.md to add:
- A new "Operational envelope" section describing where Inngest
functions live, what triggers each one has, and the rule that
the Worker's internal code never depends on Inngest's API:
agents, skills, MCP server are unchanged.
- A new critical rule: every Inngest function wraps its agent
invocation in step.run so failures don't lose state.
- A new critical rule: every inngest_client.send from inside agent
code uses an idempotency key (event ID seed) to prevent
double-firing on retry.
- A new critical rule: HITL gates use step.wait_for_event with
an explicit timeout AND a timeout handler that writes to
audit_log. No silent timeouts.
- Update the Commands section with the two new commands:
`npx inngest-cli@latest dev` (dev server) and
`uv run uvicorn chat_agent.serve:app --reload` (function host).
Keep the file focused (well under 3,000 tokens). Show me the diff before writing.
Claude Code update draft karta hai. Diff carefully parhein. New critical rules load-bearing pieces hain: wahan kuch bhi weak ho to woh production failure mode prevent nahi kar sake ga jise prevent karna tha.
Kyun. "Worker ke internals kabhi inngest se import nahi karte" rule is course ka architectural invariant hai. Baad mein Inngest ko Temporal ya Restate se swap karna sirf orchestration layer change karta hai; Worker untouched rehta hai. Idempotency-key rule downstream events ko retry par do dafa fire hone se rokta hai. HITL no-silent-timeout rule Friday-evening request ko na approve aur na escalate hone se rokta hai sirf is liye ke kisi ne weekend par timeout fire hona notice nahi kiya.
What changes in OpenCode. Same flow: brief agent, review the diff. Use AGENTS.md if you renamed it in course #3; same content.
Decision 2: Inngest Skills install karein aur dev-server MCP connect karein
What you do (Claude Code). Start with orientation: ask agent to read the current MCP config and pyproject.toml, report which Inngest pieces are already wired and which need installing, and ask for confirmation before changing anything. Then brief it to set up the Inngest development plane:
Set up the Inngest development plane for this project. Three things
to do:
1. Install the Inngest Python SDK as a dependency:
`uv add inngest`
2. Install the Inngest Agent Skills into .claude/skills/ via the
official installer:
`npx skills add inngest/inngest-skills`
These six skills (inngest-setup, inngest-events,
inngest-durable-functions, inngest-steps, inngest-flow-control,
inngest-middleware) are TypeScript-focused in their code examples
but the conceptual content transfers to Python. They'll help you
write correct Inngest code when I ask for new functions.
3. Add the Inngest dev-server MCP to Claude Code's MCP config so you
can interact with the running dev server:
`claude mcp add --transport http inngest-dev http://127.0.0.1:8288/mcp`
After installing, start the dev server in a separate terminal:
`npx inngest-cli@latest dev`
Verify the setup by using the MCP's list_functions tool to confirm
the dev server is reachable. (It'll be empty; we haven't written
any functions yet. That's expected. The point is to confirm the
MCP connection works.)
Read the diff carefully. The verify step is aham: if list_functions errors out, the dev server is not running or the MCP is not configured, and you catch this before Decision 3 instead of debugging it later.
Is course mein yahi single jagah hai jahan Claude Code aur OpenCode genuinely diverge karte hain (MCP-config mechanic different hai: Claude Code ke liye CLI command, OpenCode ke liye JSON block). Baqi har Decision tool-agnostic hai; jo prompts aap paste karte hain woh dono tools mein same hain.
Why. The Inngest Agent skills aap ke coding agent ko up-to-date API knowledge dete hain. MCP agent ko aap ke running dev server se interact karne ki ability deta hai: events send karna, runs monitor karna, docs search karna. Dono mil kar Decisions 3-8 dramatically faster bana dete hain, kyun ke model first try par correct code likhta hai (skills) aur aap ke context switch kiye baghair verify kar sakta hai (MCP).
Skills ke TypeScript focus par note: conceptual content (events, durable functions, steps, flow control, middleware) language-agnostic hai. Jahan skills ke TypeScript code examples Python syntax se conflict karte hain, AI MCP par grep_docs aur read_doc use karta hai taake Python-specific syntax find kare. Inngest ki Agent Skills documentation ke mutabiq recommended workflow yahi hai.
"model writes correct code on the first try" assumes a frontier-class coding agent: Claude Sonnet or Opus, a GPT-5-class model, or Gemini 2.5 Pro. The Inngest architecture this course teaches (events, steps, memoization, flow control) is SDK-level and model-independent: it holds whatever model drives aap ka coding agent. But the Part 4 build experience leans on strong instruction-following: the structured Decision prompts and the Decision 7 step where you rewrite a Skill's description to emit an event both expect agent to follow multi-step instructions reliably. On a weaker model, expect to iterate on the structured prompts more, and to make the Skill descriptions more concrete and explicit. The architecture is not broken; the prompting just needs more scaffolding for a smaller model.
Decision 3: Existing customer-support agent ko Inngest function mein wrap karein
What you do (Claude Code). Begin with an orient move: ask agent to read src/chat_agent/agents.py, cli.py, and tools.py and to report what agent expects as input and what Runner.run_streamed returns. Then brief it to wrap the course #4 agent without modifying agent itself:
Create the Inngest client and the first Inngest function. Two files.
File 1: src/chat_agent/inngest_client.py
- Import inngest
- Create a single inngest.Inngest() instance with app_id="chat-agent"
and the appropriate env vars
- Export it so tasks.py can import it
File 2: src/chat_agent/tasks.py
- Import the inngest_client from file 1
- Define handle_customer_email: an async function decorated with
inngest_client.create_function, triggered by event
'customer/email.received'
- Inside the function:
- step.run "load-customer": call the customer-data MCP server
to load the customer record
- step.run "load-thread": load the conversation thread for
that customer
- step.run "run-agent": call Runner.run_streamed with the
existing Course Four agent, passing the customer, thread, and
email body. The entire agent invocation is durably memoized.
- step.run "save-draft-reply": persist the agent's draft to
Postgres
- step.run "audit-handled": write an audit_log row with the
run_id, customer_id, action='email_drafted'
- Return {"status": "drafted", "draft_id": draft["id"]}
DO NOT MODIFY:
- src/chat_agent/agents.py (the agent definition)
- src/chat_agent/cli.py (the original CLI)
- src/customer_data_mcp/server.py (the MCP server)
- any .claude/skills/ files
The Inngest layer is purely additive. After writing, run
`uv run uvicorn chat_agent.serve:app --reload` in one terminal and
`npx inngest-cli@latest dev` in another. Then use the MCP's
list_functions to confirm handle_customer_email shows up.
Claude Code do files likhta hai, koi import errors hon to walk through karta hai, aur verify karta hai ke function discoverable hai. Diff carefully parhein.
Kyun. "Do not modify" list hi isay additive change banati hai. Course #4 ka Worker python -m chat_agent.cli ke zariye exactly pehle jaisa kaam karta rehta hai; Inngest layer same Worker ka new entry point hai. Production teams yahi chahte hain: Worker code fork kiye baghair inbound traffic ko old path se new path par gradually migrate karne ka option.
Decision 4: Email-received event trigger add karein
What you do (Claude Code). Orient first: ask agent to read the existing webhook documentation in the Inngest dev-server MCP and to summarize how dashboard-configured webhooks relate to event-triggered functions. Then brief it to set up the inbound webhook integration:
Configure the inbound webhook trigger for customer emails. In
production this connects to Postmark (your email service); in
development we simulate it with send_event from the dev-server MCP.
Two parts:
PART A, webhook configuration (Inngest dashboard, manual).
Walk me through configuring a webhook source in the Inngest
dashboard that:
- Has the URL inn.gs/e/<key> (Inngest provides the key)
- Transforms incoming Postmark JSON into our event shape:
name: 'customer/email.received'
data:
customer_id: lookup from Postmark's 'From' email
body: Postmark's 'TextBody'
subject: Postmark's 'Subject'
received_at: Postmark's 'Date' (ISO 8601)
idempotency: derived from Postmark's MessageID
You don't write the webhook config in code; it's dashboard UI.
Walk me through the steps with written instructions.
PART B, local development testing.
We need to test handle_customer_email without an actual email
arriving. Write a small CLI helper at scripts/fire_test_email.py
that:
- Takes --customer-id and --body arguments
- Sends an Inngest event via inngest_client.send(...) matching
customer/email.received
- Uses an idempotency key derived from customer_id + timestamp so
repeated test runs don't cause duplicate processing
- Prints the resulting run_id so we can inspect it in the dashboard
After writing both parts, use the MCP's send_event tool to fire
a test email payload directly, and poll_run_status to watch the
function execute end-to-end. Confirm:
- The function picks up the event
- The customer-data MCP server is called
- The agent runs (you'll see prompt/response in the trace)
- The audit_log gets a new row
Read the diff carefully.
Why. Splitting webhook configuration (dashboard, no code) from local testing (CLI helper) reflects how this works in real production. The Inngest dashboard owns webhook routing; aap ka code owns event consumption. Mixing them in one place is what makes traditional webhook handling so messy.
Decision 5: Fan-out ke saath daily customer-health-check cron add karein
What you do (Claude Code). Orient first: ask agent to read tasks.py and report how it would extend file with a cron-triggered function plus a separate event-triggered consumer. Then brief it to add scheduled work:
Add a daily cron-triggered Inngest function that runs at 09:00 UTC
and fires a customer-health-check event per Pro/Enterprise customer.
In src/chat_agent/tasks.py, add:
1. daily_customer_health_check, a cron-triggered function:
- Schedule: 09:00 UTC daily (cron expression: "0 9 * * *")
- step.run "fetch-eligible-customers": query the customer-data
MCP for all customers where tier IN ('pro', 'enterprise')
AND last_proactive_outreach < NOW() - INTERVAL '7 days'
- step.run "fan-out-events": for each customer, build an Event
with name='customer/health_check.requested', data={'customer_id':
id, 'date': today.isoformat()}, and id=f'health-check-{id}-{date}'
(idempotency key prevents same-day duplicates if the cron fires
twice). Call inngest_client.send(events=[...]) in one batch.
- Return {'customers_scheduled': N}
2. process_customer_health_check, an event-triggered function:
- Trigger: event 'customer/health_check.requested'
- concurrency: limit=5 globally (it's batch work; don't melt OpenAI)
- step.run "load-customer": from customer-data MCP
- step.run "load-recent-activity": last 30 days of conversations
and refunds from audit_log
- step.run "run-health-agent": run the Course Four agent with a
specialized system prompt: "draft a proactive outreach for
this customer based on their recent activity"
- step.run "save-draft" and step.run "audit-drafted"
- Return {'status': 'drafted', 'customer_id': id}
After writing both, use the MCP's invoke_function to manually
trigger daily_customer_health_check (don't wait for 09:00 tomorrow).
Use poll_run_status to watch the fan-out happen. You should see
the parent function complete in seconds, and N child runs appear in
the dashboard. Confirm one of those child runs succeeds end-to-end.
Diff carefully read karein. Claude Code functions likhta hai, MCP ke zariye manual trigger run karta hai, aur runs ko propagate hota dekhta hai.
Kyun. Yeh fan-out (Concept 5) idempotency (Concept 4) ke saath action mein hai. Cron function jaldi return karta hai; actual work parallel child runs mein hota hai (process_customer_health_check par concurrency limit ke mutabiq). Agar cron same day do dafa fire ho (bug, redeploy, dashboard manual-invoke), idempotency keys duplicate processing prevent karte hain. Yahi pattern later course workforce scale par compose kare ga.
Decision 6: Concurrency limits aur rate limiting add karein
Neeche concurrency aur throttle settings configuration hain, consumption nahi. Yeh khud paisa cost nahi karti; yeh un downstream systems ko protect karti hain jo cost karte hain (OpenAI ke rate-limited tokens, Postgres connection pool, aap ke apne MCP server resources). Production scale ke liye config likhein; bas yaad rakhein ke Hobby-tier 5-concurrent-step cap aap ki observed concurrency ko 5 par hold karta hai (Part 5 ka "Hobby-tier ceilings" dekhein).
What you do (Claude Code). Orient first: ask agent to read the current tasks.py and report which functions currently have any flow-control configuration. Then brief it to add production flow control:
Add concurrency and throttling configuration to the customer-support
functions so we protect OpenAI's rate limit and Postgres' connection
pool. Apply these specific policies:
For handle_customer_email:
- concurrency: 10 globally
- concurrency: 2 per customer (key="event.data.customer_id")
- throttle: 100 starts per minute
- Rationale to capture in comments: OpenAI has 30 rpm hard cap;
Postgres pool is 20; we want a noisy customer to not occupy
more than 2 slots.
For process_customer_health_check (already has concurrency=5):
- Add: throttle of 30 starts per minute
- Rationale: this is batch work; the cron fires 500+ events at once;
the throttle smooths the start-rate.
For daily_customer_health_check (the cron):
- No concurrency change needed; it runs at most once a day at 09:00
with the global default concurrency.
After making the changes, simulate a burst: use the MCP's
send_event to fire 20 customer/email.received events for 5 different
customers in quick succession (4 events per customer). Then use
list_functions and get_run_status to confirm:
- Only 10 are running concurrently (global cap)
- Only 2 per customer are running (per-customer cap)
- The remaining events queue
- All eventually complete
Diff carefully read karein. Claude Code configuration add karta hai, MCP ke zariye burst test run karta hai, aur results report karta hai.
Kyun. Two-layer concurrency cap Concept 12 ka multi-tenant fairness pattern hai. Is ke baghair aik chatty customer tamam 10 global slots occupy kar sakta hai aur baqi sab ko starve kar sakta hai. Throttle Concept 11 ka OpenAI rate-limit protection hai; is ke baghair cron-driven fan-out ka 09:00 burst pehle 2 seconds mein OpenAI ke 30-rpm cap ko hit kare ga aur bohat se runs fail hon ge.
Decision 7: HITL escalation gate add karein
What you do (Claude Code). Orient first: agent se escalate-with-context/SKILL.md aur tasks.py parhne ko kahen, phir report karne ko kahen ke escalate Skill fire hone par currently kya hota hai. Phir usay human-approval gate add karne ka brief dein:
Add the HITL escalation gate per Concept 15. When the agent's
escalate-with-context Skill fires, we want a human to approve
before the escalation actually posts to the senior support channel.
Add to src/chat_agent/tasks.py:
escalate_with_human_approval, an event-triggered function:
- Trigger: event 'customer/escalation.requested'
(the Course Four escalate-with-context Skill emits this event
instead of posting directly; we need to update the Skill to do so,
see below)
- concurrency: 5 (escalations are rare)
Inside the function:
1. step.run "notify-reviewer": Slack message to on-call reviewer
with the agent's escalation draft and three buttons (Approve,
Edit, Reject). Buttons POST to our admin backend which calls
inngest_client.send with event 'escalation/decision.made' and data
including request_id, decision, and optional edited_text.
2. THE GATE:
approval = await ctx.step.wait_for_event(
"wait-for-decision",
event="escalation/decision.made",
timeout=timedelta(hours=4),
if_exp=f"async.data.request_id == '{request_id}'",
)
3. Branch on the result:
- approval is None (timeout): step.run "audit-timeout" + post
the draft with a "no human review" warning header. Audit row
includes action='escalation_posted_via_timeout'.
- approval.data.decision == 'reject': step.run "audit-rejected" +
do not post. Audit row includes the reviewer's identity.
- approval.data.decision == 'edit': step.run "audit-edited" with
reviewer's edited_text + post the edited version.
- approval.data.decision == 'approve': step.run "audit-approved" +
post the original draft.
Also: update .claude/skills/escalate-with-context/SKILL.md to
instruct the agent to fire 'customer/escalation.requested' (via
inngest_client.send with an idempotency key) instead of posting
directly. The actual posting now happens in the Inngest function
after the gate.
After writing, test all four branches by using the MCP's send_event
to manually fire 'escalation/decision.made' with each decision
type, and one scenario where no decision is sent and you let the
4-hour timeout fire (use a 30-second timeout for the test, then
revert to 4 hours).
Diff carefully read karein. Claude Code function likhta hai, SKILL.md description aur body update karta hai, aur MCP ke zariye four-branch test walk karta hai.
Why. This is Concept 15's HITL pattern wired into the course #4 audit subsystem. Every branch (approve, edit, reject, timeout) writes to audit_log with the reviewer's identity (or "timeout" if none). Skill update loop close karta hai: agent ab directly post nahin karta; woh escalation request karta hai aur Inngest function human input ki bunyaad par decide karta hai ke post karna hai ya nahin. This is Invariant 1 in the runtime: agent authority constrained hai, human authored intent system mein dobara enter hota hai, aur audit trail record karta hai kis ne kya decide kiya.
Decision 8: Replay scenario ke saath end-to-end verify karein
What you do (Claude Code). Orient first: ask agent to read the dashboard's current state via the MCP (list_functions, recent runs) and to summarize what the verification will exercise before any events are sent. Then brief it to run the verification scenario:
Run the end-to-end verification. Two parts.
PART A, the happy path.
1. Fire a customer/email.received event via the MCP's send_event
for customer 'c-test-1' with body "Hi, my refund hasn't arrived
and I'm getting worried about my upcoming bill."
2. Use poll_run_status to watch handle_customer_email run end-to-end.
3. Confirm in the dashboard trace:
- All 5 steps completed
- The agent's prompt and response are visible in the trace
- The audit_log has a new row with action='email_drafted'
4. Query the customer-data MCP to confirm the draft reply is
persisted in the customer's conversation thread.
PART B, the failure-and-replay path (this is the production scenario).
1. Deliberately break the run-agent step: edit src/chat_agent/tasks.py
to raise a ValueError("simulated agent failure") inside the
run-agent step.
2. Fire 5 customer/email.received events via send_event for 5
different customers.
3. Watch all 5 runs fail at the run-agent step. Confirm in the
dashboard:
- Each run has steps 1 and 2 marked successful
- Step 3 (run-agent) shows the ValueError after the retries
exhaust
- Steps 4 and 5 (save-draft, audit) never ran
4. Now fix the bug: revert the deliberate ValueError. Save the file
(uvicorn auto-reloads).
5. In the dashboard, select the 5 failed runs and click Replay.
6. Watch each replayed run:
- Steps 1 and 2 return immediately from memo (no re-execution)
- Step 3 (run-agent) executes for real and succeeds
- Steps 4 and 5 execute for real
- The customer's draft is persisted; the audit row is written
7. Query audit_log to confirm:
- Each customer has exactly ONE row with action='email_drafted'
- No duplicates (memoization prevented re-running the
audit-writing step on replay)
Report back: did Part A succeed cleanly? Did Part B produce exactly
one audit row per customer (5 total)?
Diff carefully read karein. Claude Code dono parts run karta hai aur outcome report karta hai. Agar Part B 5 audit rows produce kare (har customer ke liye aik) with no duplicates, production Worker architecture verified hai. Agar yeh 10 (some duplicated) ya 4 (aik missed) produce kare, durability ya memoization story mein kuch broken hai, aur audit query diagnostic hai.
Kyun. Part A prove karta hai happy path works. Part B failure-and-replay story prove karta hai, jo Inngest ki woh architectural property hai jo isay adopt karne ko justify karti hai. Jo Worker bad deploy se customer interactions lose kiye baghair recover kar sakta hai woh production Worker hai; jo unhein lose karta hai woh Digital FTE hai. Yeh verification scenario dono ke darmiyan bright line hai.
Abhi kya hua
Aap ne course #4 ke customer-support Digital FTE ko liya aur us ke around operational envelope add ki. Agent ke internals change nahi hue: same Agent, same Runner.run_streamed, same skills, same MCP server, same audit_log. Jo change hua woh agent ke around sab kuch hai. Ab yeh events (webhook-driven inbound emails) aur schedules (daily cron) par wake hota hai, durably run karta hai (step.run wrapping agent invocation), production flow control respect karta hai (concurrency, throttle, per-customer fairness), HITL gates support karta hai (escalation posts se pehle Slack approval), aur failures se recover karta hai (dashboard replay).
agent code is the same; agent's reach is fundamentally different. A function someone has to call is now a function the world can wake, with the resilience and flow control that production demands.
Remaining concerns observability at scale, multi-Worker coordination, aur manager layer hain jo decide karta hai kaun se workers kaunsa traffic handle karte hain. Yeh track ka next course hai. Course Five production-ready execution ki unit cover karta hai; next course un units ko workforce mein compose karta hai.
Part 5: Yeh course kahan chhorta hai
Production Worker ki cost shape
Do cost surfaces matter karte hain: infrastructure cost (Inngest, Postgres, sandbox compute) aur inference cost (OpenAI tokens). Load increase hone par infrastructure roughly flat rehta hai; inference linearly scale hoti hai. Neeche numbers May 2026 ke hain; budget mein quote karne se pehle current pricing pages check karein.
Inngest pricing. Inngest per execution charge karta hai: har function run, plus har step-level retry, aik execution count hota hai.
| Tier | Price | Executions / month | Concurrent steps | Notable |
|---|---|---|---|---|
| Hobby | $0 | 50,000 | 5 | 3 users, 50 realtime connections, no credit card |
| Pro | from $75 / month | 1,000,000 | 100+ | 1000+ realtime connections, 15+ users, 7-day trace retention |
| enterprise | custom | custom | 500-50,000 | SAML / RBAC, 90-day trace retention, dedicated support |
Events pricing upar layer hoti hai: pehle 1-5M events per day included hain; upar 1M-5M tier roughly $0.0005 per event chalta hai. Jab aap 1M cap cross karte hain to Pro additional 1M executions par $50 add karta hai.
Hobby-tier ceilings that matter here. The 5-concurrent-step cap means that even if you declare concurrency=Concurrency(limit=10) in code, the platform's account-level cap holds you at 5. aap ka code is correct for production; observed concurrency on the free tier is 5. step.sleep and step.sleep_until are also tier-bounded: up to seven days on the free Hobby plan, up to one year on paid plans (Inngest usage limits).
Inference cost dominate karta hai. Typical customer-support Worker run per conversation GPT-4o ke ~3,000-10,000 tokens use karta hai. Illustrative GPT-4o pricing par yeh context size aur model choice ke hisaab se $0.01-$0.50 per email hai. 1,000 emails per day ke liye inference mein $10-$500/day. Yahi cheez optimize karni hai. Baqi sab rounding error hai.
Three Inngest-specific cost levers jab aap optimization zone mein hon:
- Pure functions ko
step.runmein wrap na karein. Agar function ke side effects nahi, usay durability nahi chahiye; wrap karne se benefit ke baghair step-run charge add hota hai.step.runko I/O aur side effects ke liye save karein. - Bulk paths ke liye
batch_eventsuse karein. 50-event batch aik function run hai, 50 nahi. step.sleepaurstep.wait_for_eventse cheaply suspend karein. Suspended functions suspension time ke liye bill nahi karte. 3-day delayed-followup 3-second delayed-followup jaisa cost karta hai.
50 workers tak scale karna inference ke liye roughly $3,000-$15,000/month, Inngest ke liye $50-$200, Neon ke liye $50-$200, sandbox compute ke liye $100-$500 hai. Infrastructure flat scale hoti hai; inference bill traffic ke saath scale hota hai.
Swap guide: operational envelope invariant hai, platform nahin
Yeh course names Inngest at every layer. That is because a teaching example needs concrete answers, not "use any orchestrator you like." But the architecture works with any compliant alternative. Five swaps the course's design explicitly anticipates:
-
Trigger surface: Inngest events → Temporal signals, Restate handlers, AWS EventBridge + Lambda. Har platform ke paas "yeh code tab run hota hai jab yeh named thing hoti hai" express karne ka tareeqa hai. Event names, payload shapes, aur idempotency discipline sab transfer hote hain. Jo change hota hai: SDK ka decorator syntax aur dashboard.
-
Durable execution: Inngest
step.run→ Temporal activities, Restate handlers, custom Postgres-backed state machines. Har aik aap ko "is side-effecting call ko memoize karo, transient failure par retry karo, crash ke baad resume karo" semantics deta hai. Temporal closest analog aur older, more enterprise-tested option hai. Restate newest hai aur functional-programming flavor zyada rakhta hai. Custom state machines teams tab likhti hain jab managed platform adopt nahi kar sakti; usually 1,000-10,000 lines of code jo Inngest ki ~70% free value recreate karta hai. -
HITL primitive:
step.wait_for_event→ Temporal kaawait Workflow.execute_activity(approval_signal), Restate ke awakeables, custom Redis/Postgres approval queues. Pattern same hai: function suspend hota hai, external signal usay resume karta hai, audit decision capture karta hai. Inngest ki expression writing mein sab se clean hai; Temporal zyada verbose hai lekin large scale par battle-tested. -
Cron scheduling: Inngest cron triggers → Kubernetes CronJobs + queue, GitHub Actions schedules, AWS EventBridge schedules. Cron triggers are commodity. The Inngest advantage is not having cron; it is that cron-triggered functions get the same durability/replay/flow-control as event-triggered ones, automatically. Other platforms make you wire that aap khud.
-
Flow control: Inngest concurrency + throttle → worker concurrency ke saath Temporal task queues, Redis-backed rate limiters, AWS SQS message visibility timeouts. Doosre platforms bhi yeh kar sakte hain; Inngest isay us configuration density se karta hai jo hum dekh chuke hain (aik decorator argument).
Production scale par Dapr open companion ke taur par. Aik zyada ambitious replacement worth naming: Dapr agents production scale par Inngest ka structural companion, jaisay OpenCode Claude Code ka companion hai. Dapr agents CNCF governance ke under March 23, 2026 ko v1.0 GA tak pahunchay (CNCF announcement, Dapr Agents core concepts). DurableAgent production-ready class hai; purani Agent class deprecated hai. Dapr tab choose karein jab Kubernetes-native deployment aur multi-language SDKs Inngest ke local dev experience se zyada matter karte hon. Inngest better learning tool hai (dashboard mental model visible banata hai); Dapr better scale tool hai jab aap Inngest tier ceilings hit kar chuke hon ya K8s-native multi-language deployment chahiye.
Inngest bhi open source hai (github.com/inngest/inngest; 1.0 release ne September 2024 mein self-hosting support add ki) aur Helm + KEDA ke zariye self-hostable hai. Scale par jo axes matter karte hain woh governance, support, aur maturity hain: Inngest single vendor ke zariye governed hai aur self-hosting story young hai; Dapr CNCF-governed hai aur production track record longer hai.
| course Five concept | Inngest primitive | Dapr production analogue | Teaching note |
|---|---|---|---|
| Scheduled work | TriggerCron | Cron input binding / Dapr Scheduler | Same idea: time wakes the Worker. Dapr usually requires component configuration. |
| Webhook/event ingress | Inngest webhook endpoint → event | HTTP endpoint, input bindings, or pub/sub ingress | Inngest hides more plumbing; Dapr gives infrastructure control. |
| Internal events | inngest_client.send() | Dapr pub/sub | Same event-driven mental model; broker is pluggable in Dapr. |
| Fan-out | One event triggers many functions | One topic/event consumed by many services | Same architecture; Dapr uses broker/topic/subscriber composition. |
| durable steps | step.run() + memoization | Dapr workflows + activities | Similar production purpose, different developer model. |
| Waiting without compute | step.sleep() | durable workflow timers | Both avoid holding a process open while waiting. |
| human approval gate | step.wait_for_event() | workflow external events/signals, pub/sub, actors | Inngest expression clean hai; Dapr zyada composable hai. |
| Retries | Function/step retries | workflow/activity retries + resiliency policies | Dapr makes resiliency a runtime policy as well as workflow behavior. |
| Dead-letter / failed runs | Inngest dashboard failed runs + replay | Broker DLQ + workflow status/restart/manual tooling | Inngest is more turnkey here; Dapr is more infrastructure-native. |
| Flow control | Concurrency, throttling, priority, batching | Kubernetes scaling, app concurrency, broker controls, resiliency policies, bulk pub/sub | Dapr can do it, but it is not one decorator argument. Inngest is denser. |
| Stateful coordination | wait_for_event, event keys, step state | Actors + state store + workflows | Dapr Actors are stronger for long-lived identity/stateful coordination. |
| Agent runtime | aap ka agent inside Inngest function | DurableAgent / Dapr agents v1.0 GA | Dapr agents explicitly makes agent workflow-backed and resumable. |
Yeh table translation guide hai, identical APIs ka claim nahi. Inngest compact developer experience ke saath production pattern teach karta hai: triggers, steps, waits, replay, aur flow control aik product surface mein. Dapr same production architecture ko distributed-systems building blocks ke through implement karta hai: bindings, pub/sub, workflows, actors, state, resiliency, aur Kubernetes-native operations. Concepts directly transfer hote hain; implementation style change hoti hai. May 2026 tak Dapr bindings overview aur Dapr agents core concepts ke against verified.
Teen reasons jin ki wajah se Dapr specifically curriculum ke liye matter karta hai, sirf production deployment ke liye nahi:
- CNCF-governed, charter ke mutabiq vendor-neutral. Vendor-controlled platform par teach karne wala curriculum yeh risk carry karta hai ke vendor ke business decisions students ki learned cheez ko reshape kar dein.
- First-class Python ke saath polyglot. Dapr agents Python-first hai; same agent code JavaScript, Go, .NET, Java, ya PHP mein written services ke saath run kar sakta hai bina kisi ko second framework seekhne ke.
- Horizontally scalable on Kubernetes by design. Aap ke apne cluster mein run karein, managed offering (Diagrid Catalyst) mein, ya locally
dapr initke zariye. Scaling story har environment mein same architecture hai.
Honest caveat: Dapr getting-started platform nahi. Isay production mein chalane ka matlab Kubernetes, state store, pub/sub broker, placement service, observability, YAML components, sidecars. Jis learner ka goal triggers, durable execution, aur HITL gates actually kya hain internalize karna hai, us ke liye yeh operational overhead concepts ko drown kar deta hai. Inngest ka "one command, dashboard appears" experience right teaching tool hai. Dapr tab right tool banta hai jab concepts land ho chuke hon aur question shift ho kar "main isay organizational scale par, apni controlled infrastructure par kaise run karun" ban jaye.
Curriculum ka path staged hai. Courses #3, #4, #5 concepts ko Inngest aur OpenAI Agents SDK par build karte hain: fast feedback loop, minimal infrastructure, patterns par focus. Jab aap us scale par pahunchte hain jahan Kubernetes governance, polyglot teams, ya vendor-neutrality non-negotiable ho jaye, same architectural patterns Dapr par lift hote hain aur upar wali 12-row translation table aap ki key hoti hai. Patterns transfer hote hain; substrate badalta hai; is course mein jo seekha woh load-bearing knowledge rehta hai.
Yeh course abhi kya cover nahin karta
Ab aap ke paas aik Worker hai jo thesis ke set kiye hue Seven Invariants mein se four satisfy karta hai. Specifically: yeh engine par run karta hai (Invariant 4, Course #3 se), system of record ke against (Invariant 5, Course #4 se), duniya isay call kar sakti hai (Invariant 7, is course se), aur gated decisions par human principal rehta hai (Invariant 1, partial: runtime mechanism yahan, architectural pattern subsequent courses mein). Baqi teen Invariants, aur woh broader architecture jo Workers se workforce banati hai, subsequent courses hain. Har aik aik bullet:
- Invariant 2: Every human needs a delegate. Edge par personal agent jo aap ka context hold karta hai, aap ke judgment ko represent karta hai, aur workforce ko work broker karta hai. Thesis OpenClaw ko current realization ke taur par name karti hai.
- Invariant 3: Workforce ko manager chahiye. Aisa orchestrator jo work assign kare, budgets enforce kare, execution audit kare, hiring ko callable capability ke taur par expose kare. Thesis Paperclip ko name karti hai.
- Invariant 6: The workforce is expandable under policy. Meta-layer jahan authorized agent prompt generate karta hai, runtime provision karta hai, aur human ko jagaye baghair naya Worker register karta hai. Claude Managed agents is ki ek realization hai.
Single Worker jo events par wake hota hai, durably run hota hai, aur human gates use karta hai, is course ki architecture ki smallest unit hai. Next course us Worker ko workforce mein extend karta hai: multiple Workers manager ke through coordinated, demand par expandable, triggers se woken, spec se governed. Same OpenAI Agents SDK foundation, same Skills format, same Neon system of record, same Inngest envelope. Architecture invariant hai.
Is mein waqai achha kaise hona hai
Yeh crash course padhne se aap production workers build karne mein achhe nahi bante. Isay use karne se bante hain. Path previous courses jaisa hi hai: aap manual start karte hain, friction mehsoos karte hain, aur har friction piece se seekhte hain ke woh kis Concept se belong karta hai.
The mapping for this course:
- "Why does my function not fire when the event arrives?" → event name typo or namespace mismatch (Concept 3). Compare the event name string in aap ka
TriggerEventto the one ininngest_client.sendbyte-for-byte. - "Mera function same logical event ke liye do dafa kyun fire hua?" → missing idempotency key (Concept 4). Event mein deterministic seed ke saath
id=add karein. - "Mera function deploy ke baad 'work lose' kyun kar gaya?" →
step.runke outside code work kar raha hai (Concept 7). I/O aur side effects ko named steps mein wrap karein. - "Customer do dafa charge kyun hua?" → Stripe call
step.runke outside thi, ya step name unique nahi tha (Concepts 6 aur 7). Call ko namedstep.runmein move karein; step name ko function ke andar globally unique banayein. - "9am peak par OpenAI 429 errors kyun return karta hai?" → missing throttle (Concept 11).
throttle=Throttle(limit=N, period=timedelta(minutes=1))add karein. - "Aik customer ke bursts doosre customers ko starve kyun karte hain?" → missing per-key concurrency (Concept 12). Doosra
Concurrency(limit=2, key="event.data.customer_id")add karein. - "Mera HITL gate weekend par silently fire kyun hua?" → missing timeout handler jo audit likhta hai (Concept 15).
approval is Nonepar branch karein aur audit row explicitly likhein.
Architecture ek piece at a time build karein. Course #4 Worker lein. Pehle ek event trigger add karein (Decision 4). Agent ke gird step.run add karein (Decision 3). Dekhein jab aap deliberately mid-run crash karte hain to kya badalta hai. Concurrency limits (Decision 6) tab add karein jab aap actual downstream rate limit hit kar chuke hon. HITL gate (Decision 7) tab add karein jab escalation ko waqai human approval chahiye. Har step apni learning hai. Ek big rewrite mein combine hon to wall ban jate hain.
Yeh course jo discipline sikhata hai (wake on events, run durably, gate on human, replay on bugs) wahi architectural invariant hai. Jo bhi platform isay implement kare, aap asal mein isi four-property contract par commit karte hain. Product replaceable hai; discipline nahin.
Quick reference
Narrative course aur during-build reference ke darmiyan separator. Neeche ke sections search karne ke liye hain, top to bottom read karne ke liye nahi.
15 concepts, har ek ek line mein
- Events vs requests. Request sync, blocking, single-consumer hoti hai; event async, durable, multi-consumer hota hai. Jab aap events mein sochte hain, durability aur scale almost free nikal aate hain.
- Cron triggers.
TriggerCron(cron="0 9 * * *")function ko schedule par wake karta hai. Same function shape as event-triggered. - Webhook triggers. Inngest provides the endpoint; the inbound payload becomes a named event; aap ka function reacts to the event name.
- Idempotency. Do layers: event ID seeds duplicate event delivery prevent karte hain; step memoization duplicate step execution prevent karti hai.
- Fan-out. Multiple functions aik event ko subscribe kar sakte hain; ya aik parent function sub-agent delegation ke liye N events send kar sakta hai.
step.run. Har step checkpoint hai. Retry par completed steps re-execute hone ke bajaye memoized outputs return karte hain.- Memoization.
step.runki durability ke peeche mechanism. Steps ke outside code retry par re-run hota hai; steps ke inside code nahi. step.sleepaurstep.wait_for_event. Dono function ko durably suspend karte hain (wait ke dauran no compute consumed), respectively time ya events ke liye.- Retries aur dead-letter. Default ~4 retries with backoff. Failed runs bug fixes ke baad replay ke liye dashboard mein persist karte hain.
- Python mein AI calls ke liye
step.run(step.ai.wrapTypeScript-only hai). Durability aur retries ke liye OpenAI agents SDK calls koctx.step.run(...)mein wrap karein. Serverless compute savings ke liye inference ko Inngest infrastructure par offload karne ke liyestep.ai.infer(Python-supported) use karein. - concurrency aur throttling.
concurrency=10caps active runs;throttle=100/mincaps starts-per-minute. Both protect downstream systems. - Priority aur fairness. Priority decide karti hai queued runs mein se next free slot kaun leta hai. Per-key concurrency har tenant ko fair share deti hai.
- Batching. Cost-effective bulk processing (embeddings, bulk emails) ke liye events ko single batched function call mein accumulate karein.
- Replay aur bulk cancellation. Failed runs apni state ke saath persist karte hain; replay unhein new code ke saath re-run karta hai. Queued/sleeping runs ko bulk mein cancel karein.
- HITL gates.
step.wait_for_eventkisi bhi platform par Invariant 1 ka cleanest expression hai: function human approval tak suspend hota hai, decision ke saath resume karta hai.
15-concept diagnostic table
Production failure taqreeban hamesha teen root causes mein se kisi ek tak trace hoti hai: trigger fire nahin hua (ya do dafa fire hua), execution break hui aur state lose ho gayi, ya flow-control gap ne ek customer ke traffic ko baqi sab ko starve karne diya. Jab kuch break ho, woh concept dhoondein jiska question aap ke symptom se match karta ho.
| # | Concept | Layer | What question it answers |
|---|---|---|---|
| 1 | Events vs requests | Triggers | What's the mental model shift? A request is synchronous and someone is waiting; an event is asynchronous and the world has moved on. |
| 2 | Cron triggers | Triggers | How does the Worker wake on a schedule? @inngest_client.create_function(trigger=TriggerCron(cron="0 9 * * *")). |
| 3 | Webhook triggers | Triggers | How does the outside world wake the Worker? An HTTP endpoint becomes an event; an event triggers a function. |
| 4 | Idempotency and event semantics | Triggers | What if the same event fires twice? Event IDs and idempotency keys make the second one a no-op. |
| 5 | Fan-out and sub-agent delegation | Triggers | How does one event trigger many workers? One event, N functions matching its name; or one parent invoking N children via inngest_client.send. |
| 6 | step.run and the durable function model | durable execution | What makes a function "durable"? Each step.run is a checkpoint; the function can crash between any two steps and resume. |
| 7 | Memoization, the mechanic underneath | durable execution | How does Inngest know where to resume? It re-plays each step's stored output instead of re-executing. |
| 8 | step.sleep and step.wait_for_event | durable execution | How can a Worker wait without consuming compute? Both primitives suspend the function and resume it later. |
| 9 | Retries, error handling, dead-letter | durable execution | What happens when a step keeps failing? Automatic retries with backoff; N tries ke baad run dead-letter state mein move hota hai jise aap inspect aur replay kar sakte hain. |
| 10 | step.run for AI calls in Python | durable execution | How do you make OpenAI agents SDK calls durable? In Python, wrap each call in step.run. step.ai.infer offloads inference; step.ai.wrap is TypeScript-only. |
| 11 | concurrency aur throttling | Flow control | How do you stop the Worker from flooding OpenAI at peak? concurrency=10 caps active runs; throttle caps starts-per-second. |
| 12 | Priority and fairness | Flow control | How do you keep one customer from starving everyone? Per-key concurrency, priority queues, fair-share scheduling. |
| 13 | Batching | Flow control | How do you process 10,000 events without 10,000 function invocations? Batch triggers accumulate events into one function call. |
| 14 | Replay and bulk cancellation | Flow control | What do you do when yesterday's runs all failed? Fix the bug, replay the failed runs from where they broke. Bulk-cancel runs you no longer want. |
| 15 | HITL gates with step.wait_for_event | Flow control | How does Invariant 1 (the human is the principal) show up in the runtime? Function suspend hota hai; human Slack/email/UI ke through approve karta hai; awaited event fire hota hai; function resume hota hai. |
Decision tree: trigger surface choose karein
Jab duniya mein nayi cheez hoti hai, wake-up kahan se aata hai?
- External system ne humein HTTP request bheji. → Webhook trigger. Inngest dashboard mein source configure karein; transform ke zariye payload reshape karein; resulting event consume karein.
- A schedule says it is time. → Cron trigger.
TriggerCron(cron="..."). Use UTC; production crons fire even when aap ka service is mid-deploy. - Doosre Inngest function ne apne run ke dauran event emit kiya. → Event trigger.
TriggerEvent(event="ns/name.subtype"). Same name ko aik ya many functions subscribe karein. - An interactive user is waiting for an immediate response. → Not an Inngest trigger. Keep the request/response in aap ka normal web endpoint; if the response involves heavy work, fire an event from inside the request and return immediately, letting Inngest handle the work asynchronously.
Decision tree: step primitive choose karein
Given a function is running and aap ko chahiye to do something, which step.* call do you reach for?
- Side-effecting call (API, DB, file write, agent invocation). →
ctx.step.run("name", fn, ...). Default. Success par memoized, transient failure par retried. - A long-running OpenAI call on a serverless platform that bills for in-flight time. →
ctx.step.ai.infer(...). Offloads the inference to Inngest's infrastructure so aap ka function process can deallocate. - Continue karne se pehle fixed duration ka wait. →
ctx.step.sleep("name", timedelta(...)). Durable; wait ke dauran zero compute (free plan par seven days tak, paid par one year). - Wait for an external event (human approval, sibling-function completion). →
ctx.step.wait_for_event("name", event="...", timeout=..., if_exp=...). Durable; event arrive hone par resume hota hai ya timeout parNonereturn karta hai. - Pure deterministic computation (formatting a string, computing a date). → Just write code. No
step.runneeded; no charge.
File-location quick-ref
chat-agent/
├── .claude/
│ └── skills/ # Course Four + Inngest's installed skills
│ ├── summarize-ticket/SKILL.md
│ ├── find-similar-cases/SKILL.md
│ ├── escalate-with-context/SKILL.md # updated in Decision 7
│ ├── inngest-setup/SKILL.md
│ ├── inngest-events/SKILL.md
│ ├── inngest-durable-functions/SKILL.md
│ ├── inngest-steps/SKILL.md
│ ├── inngest-flow-control/SKILL.md
│ └── inngest-middleware/SKILL.md
├── src/
│ ├── chat_agent/
│ │ ├── agents.py # Course Three, unchanged
│ │ ├── cli.py # Course Three, unchanged
│ │ ├── tools.py # Course Three, unchanged
│ │ ├── guardrails.py # Course Three, unchanged
│ │ ├── inngest_client.py # NEW Course Five (Decision 3)
│ │ ├── tasks.py # NEW Course Five (Decisions 3,5,7)
│ │ └── serve.py # NEW Course Five (Decision 1)
│ ├── customer_data_mcp/ # Course Four, unchanged
│ └── chat_agent/embedding/ # Course Four, unchanged
├── scripts/
│ └── fire_test_email.py # NEW Course Five (Decision 4)
├── migrations/ # Course Four, unchanged
└── CLAUDE.md # updated in Decision 1
Diagnostic table, symptom → root cause → concept
| Symptom | First suspect | Concept to re-read |
|---|---|---|
| Function never fires when expected event arrives | Event name typo, namespace mismatch | C3 (webhooks), C5 (fan-out) |
| Function fires twice for the same logical event | Missing idempotency key | C4 (idempotency) |
| Function "lost work" after deploy | Code outside step.run doing the work | C7 (memoization) |
| Cron schedule did not fire over a deploy | Local dev server only, production runs on Inngest infra | C2 (cron) |
| Customer charged twice for one refund | Stripe call outside step.run, or step name not unique | C6 (step.run), C7 (memoization) |
| OpenAI rate-limit errors during 9am peak | Missing throttle | C11 (concurrency + throttle) |
| One customer's bursts starve other customers | Missing per-key concurrency | C12 (priority + fairness) |
| Function suspended forever, never resumed | Event name in wait_for_event does not match the event being sent | C8 (wait_for_event), C15 (HITL) |
| HITL timeout fired silently over the weekend | Missing timeout handler that writes to audit | D7 (HITL decision), C15 (HITL) |
| Yesterday's failed runs disappeared from dashboard | Runs persist until manually replayed or after retention window | C14 (replay) |
| Replay re-charged customers | Step name collision causing memo lookup to find wrong entry | C7 (memoization rule about unique names) |
| Function trace does not show OpenAI prompt | Step trace shows function inputs/outputs but no LLM-specific prompt/token telemetry | C10 (Python uses step.run; LLM-specific telemetry needs aap ke apne OpenAI client tracing; step.ai.wrap's prompt-level traces are TypeScript-only) |
Appendix: prerequisites refresher (substitute nahin)
Yeh course assumes substantial preceding material. Two short refreshers for someone landing from search who has done some adjacent work but not the exact prereqs.
A.1: Course #4 ne kya sikhaya jo yeh course assume karta hai
Full course: From Agent to Digital FTE. Three load-bearing properties of aap ka course #4 Worker that this course leans on hard:
- aap ka skills are operational.
.claude/skills/summarize-ticket/,.claude/skills/find-similar-cases/,.claude/skills/escalate-with-context/. The third,escalate-with-context, gets modified in Decision 7. If aap ka three skills are not already loading correctly via Claude Code or OpenCode, fix that before starting this course. - aap ka Neon schema includes
audit_log. Every Decision in this course assumesaudit_logis a writable table with at minimum:id,action,customer_id,payload (JSONB),created_at. If aap ka audit subsystem from course #4's Decision 7 is not wired, the audit-writing steps in this course will fail silently. - Aap ka
customer-dataMCP server Python process ke taur par reachable hai. Decision 3 onwards usay call karta hai (load-customer,load-thread). Agar MCP serveruv run python -m customer_data_mcp.serverse run nahin hota, to aap ke setup mein Course #4 ka gap hai.
Stop signal. If "the Worker reads from and writes to a Postgres system of record through a scoped custom MCP server, and every meaningful action writes an audit_log row in the same transaction" reads as review, continue. If it feels like new material, stop and do course #4 first. Yeh course's worked example evolves course #4's Worker; reading without that foundation is friction.
A.2: Inngest-specific essentials jo yeh course use karta hai
Agar neeche kuch unfamiliar lage, Part 4 mein dive karne se pehle corresponding doc page skim karein.
- Inngest client instantiation. Har Python project mein single
inngest.Inngest(app_id=...)instance, aik module se exported aur jahan functions decorate karte hain wahan imported. Python quick start. - Function decoration.
@inngest_client.create_function(fn_id=..., trigger=...). TriggerTriggerEvent,TriggerCron, ya multi-trigger functions ke liye dono ki list ho sakta hai. ctx.step.run,ctx.step.sleep,ctx.step.wait_for_event,ctx.step.ai.infer. The four step primitives that make up 90% of what aap write in Python. (TypeScript has a fifth,step.ai.wrap, for LLM-specific tracing; Python projects usestep.runfor AI calls.)inngest_client.send(events=[...]). Emit events from anywhere in aap ka code (inside functions, inside agent tools, from CLI scripts). Use anid=for idempotency.- Dev server startup.
npx inngest-cli@latest dev.:8288par runs. Dashboardhttp://127.0.0.1:8288par; MCPhttp://127.0.0.1:8288/mcppar.
A.3: Yeh appendix kya replace nahin karta
Aap ko ab bhi course #3 ka Part 3 (Cloudflare Sandbox) chahiye taake samajh sakein agent kis trust boundary ke andar run karta hai, aur course #4 ka full Part 4 worked example chahiye taake woh Worker samajh sakein jise yeh course wrap karta hai. Agar yeh foggy hain, wapas un par jayen; is course ka worked example dono assume karta hai.
Is course ki sab se hard cheez Inngest syntax nahi. Yeh request se event tak mental shift (Concept 1) aur in-process execution se durable execution tak shift (Concept 6) hai. Jab yeh dono land ho jayen to syntax mechanical hai. Agar koi aur cheez expected se hard lage to pehle concepts 1 aur 6 dobara read karein.