Apne AI ko Searchable Context Dein: Postgres par pgvector ke saath RAG ka Crash Course
15 Concepts · Asal Use ka 80% · Aap ke agent ne banaya, haath se nahin
Tasawwur karein ke aap apne computer ko keh sakein: "Documents ka yeh folder lo, ek aisa database khada karo jo un ke maani ko samajhta ho, aur mere liye ek aisi search banao jahan 'the city that never sleeps' maangne par New York ke baare mein quotes wapas aayein, yahan tak ke woh bhi jo kabhi us ka naam tak nahin lete." Aur yeh waqai aisa kar deta hai.
Teen lafz, agar yeh aap ke liye naye hon. Ek database data ka godown hai: woh imarat jahan koi business apna saaman rakhta hai, sirf yahan saaman maloomat hai. SQL woh zabaan hai jo aap us godown se bolte hain: data ko store, find, ya change karne ki har request us mein ek jumla hai. Postgres (is course ke title wala database) duniya mein sab se zyada istemaal hone walon mein se ek hai. Aur ek aam godown sirf exact label se hi koi box dhoond sakta hai; jo aap banane wale hain woh cheezon ko un ke maani se dhoondta hai.
Maani se search karne wala yehi system is course ka mauzu hai, aur asal twist yeh hai: aap SQL haath se nahin likhenge; Claude Code ya OpenCode yeh sab banata hai. Aap ka kaam Postgres aur pgvector (woh add-on jo isay yeh taqat deta hai) ke baare mein itna janna hai ke aap clear instructions de sakein aur yeh judge kar sakein ke agent ne theek kiya ya nahin. Doosra hissa hi poori skill hai, aur aakhir tak aapko pata hoga ke kaunse knobs ahmiyat rakhte hain aur kaunse chhorne wale hain.
Ek idea poore course ko samajh mein la deta hai. Ek AI model ek waqt mein sirf itni hi cheez par dhyan de sakta hai: jo kuch woh aapko jawab dene ke liye parhta hai, sab us ke context window mein aana chahiye, aur jitna zyada ghair-zaroori material us mein hoga, jawab utna hi bura hoga. Is liye kisi bhi AI system mein asal kaam yeh hai: sahi maloomat ko sahi waqt par model ke saamne lana, aur baqi sab kuch bahar rakhna. Aap yeh pehle se apne coding agent ke liye karte hain: ek rules file, sirf woh files jo task ko chahiye. Ek vector database yehi kaam aap ki app ke users ke liye karta hai: lakhon stored rows mein se, woh chand aise dhoondta hai jo sawaal ke maani se match karte hain aur sirf wohi model ko deta hai. Is move ka ek naam hai, RAG yaani Retrieval-Augmented Generation, aur yeh ek layer neeche context management hi hai: jo aap apne coding agent ke liye haath se karte hain, aap ki app apne users ke liye khudkaar tareeqe se karti hai. Yahan har concept isi se wapas judta hai.

Yeh course farz karta hai ke aap ne Agentic Coding Crash Course kar liya hai: aapko Claude Code ya OpenCode chalane, plan mode use karne, aur context manage karne mein aaram hona chahiye. Yeh AI Prompting in 2026 par bhi bana hai, yani AI se theek wohi maangne ka funn jo aap chahte hain. Agar "embedding" aur "vector" aap ke liye bilkul naye hain, fikr na karein: Concept 2 inhein zero se cover karta hai.
📚 Tadreesi Madad
Poori presentation dekhein — AI Searchable Context
Do tools, ek discipline
Driving agent karta hai; aap ka Postgres database woh hai jise woh drive karta hai. Database Neon par rehta hai, ek cloud service jo aap ke liye Postgres chalati hai: kuch install karne ki zaroorat nahin, koi machine manage nahin karni (yehi serverless ka matlab hai: jab aap use karte hain to jaag jata hai, jab nahin karte to so jata hai). Agent Neon ko Neon MCP server ke zariye operate karta hai: woh project banata hai, ek branch kholta hai, SQL chalata hai, aur commit karne se pehle har change ko us branch par preview karta hai. Aap kabhi khud Neon console mein nahin ghoomte ya psql nahin kholte. Aur discipline dono tools mein bilkul ek jaisi hai: Claude Code aur OpenCode yahan barabar hain; jahan koi command waqai mukhtalif hoti hai, wahan main farq inline bata deta hoon.
Yeh course kya cover karta hai
| Part | Mauzu | Aap kya seekhenge |
|---|---|---|
| 1 | Bunyadein | AI engineer ke taur par aap ka kaam, vectors zero se, Postgres ko maani se search karne ke liye kya chahiye, aur aap ka agent Neon se juda hua |
| 2 | Aap ka Pehla RAG | Apna data load karein, isay tukron mein toren, har tukre ko ek maani-vector mein badlein, maani se search karein, aur ek LLM se us par jawab dilwayein |
| 3 | Search ko Tez Banana | Jab koi sust hoti search ko index ki zaroorat ho, kaunsa choose karein, aur woh ek speed-vs-accuracy knob jo ahmiyat rakhta hai |
| 4 | Search ko Behtar Banana | Naapein ke jawab waqai theek hain ya nahin, filters lagayein, maani ko exact keywords ke saath milayein, har customer ka data alag deewar mein band karein, aur apne database se plain English mein sawaal poochein |
| 5 | Poora Worked Example | Ek mukammal task: khaali database se chalti hui RAG tak, dono tools mein driven |
| 6 | Isay Tool ke Taur par Ship Karein | Apne RAG ko ek MCP server mein lapet dein taake koi bhi agent (Claude Code, OpenCode, ya baad mein banaya ek Digital FTE) isay call kar sake |
| 7 | Yeh Kahan Chalta Hai | Apne database ki instant copies par changes test karein, data badalne par vectors fresh rakhein, aur production mein kya alag hota hai |
| 8 | Isay Agent ke Hawale Karein | Apne RAG ko ek agent (OpenAI Agents SDK) mein plug karein: Build AI Agents course tak ka bridge |
Yahan poora system ek page par hai: woh map jis mein har concept baithne ke saath aap grow karenge:
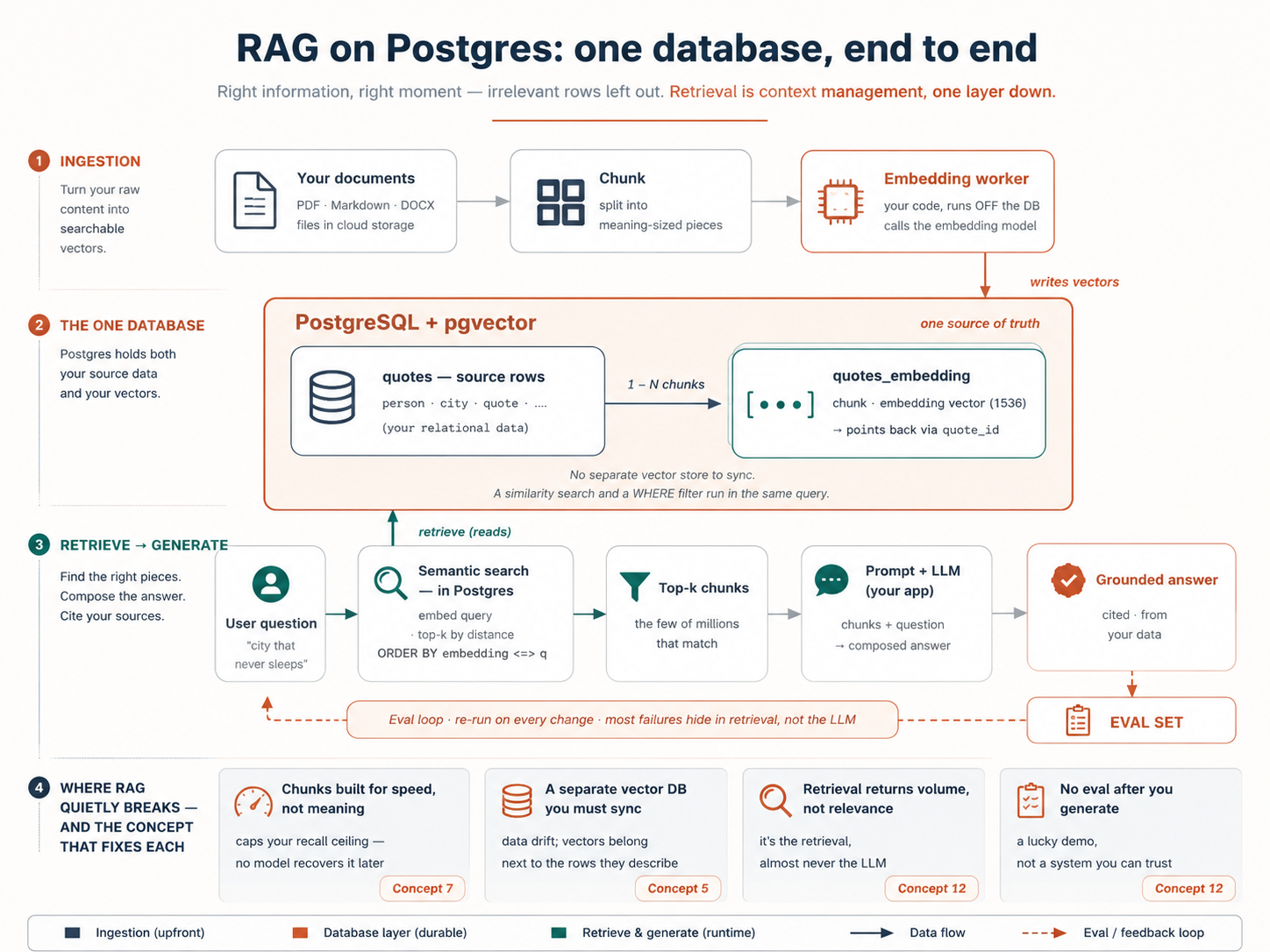 |
|
Aakhir tak aap ke paas ek chalti hui RAG project hogi: aap ka docs/ documents wala folder ek Neon database mein load kiya gaya jis par pgvector on hai, ek chhota worker jo documents badalne par maani-vectors ko up to date rakhta hai, ek search jo maani se dhoondti hai, ek answer_question() function jo aap ke apne data se jawab deta hai, aur ek report jo dikhati hai ke paanch test sawaalon ke jawab theek aate hain ya nahin. Aur aap aasaan 80% par nahin rukenge: aap ek HNSW index ko sust se instant tak benchmark kar chuke honge, search ko category se filter kar chuke honge, hybrid search ke saath keyword aur maani ko fuse kar chuke honge, aur Row-Level Security ke saath ek tenant ko doosre se deewar mein band kar chuke honge, har ek asal mein chalaya gaya, aap ke eval set ke against naapa gaya. Aur agar chahein, ek MCP server poori cheez ko kisi bhi agent ke hawale kar deta hai.
Isay kaise parhein. Parts 1 se 2 (Concepts 1 se 9) aur Part 5 ka worked example mil kar poora system hain, shuru se aakhir tak: asli samajh par lagbhag 2-ghante ka read (agar "vector" naya hai to zyada), plus build ke liye keyboard par kuch ghante. Parts 3 se 4 (Concepts 10 se 15) tuning layer hain: woh jo search ko tez (Part 3) aur behtar (Part 4) banata hai. Unhein "kyun" ke liye parhein, phir un mein se har ek ko chalayein: Part 5 ek hands-on loop (Steps 5 se 8) par khatam hota hai jahan aap ek index benchmark, ek filter, hybrid search, aur tenant isolation asal mein, abhi load kiye gaye data par banate hain. Yeh depth koi optional reading nahin jis par aap shayad baad mein wapas aayein, yeh build ka doosra half hai, aur har koi yeh karta hai. Pehle build karna aur "kyun" baad mein parhna pasand hai? Seedha Part 5 par chhalang lagayein.
Apna environment set up karein (ek baar)
Is course mein jo kuch aap banate hain woh sab ek chhote folder ke andar hota hai: course base. Yeh pehle se taiyar aata hai: aap ka agent pehle se janta hai ke Neon (woh cloud database jo yeh course use karta hai) aur Context7 (live docs lookup, taake agent andaza lagane ke bajaye maujooda documentation check kare) tak kaise pohanchna hai, aur yeh ek chhoti rules file AGENTS.md ship karta hai jis mein project ki standing instructions hain. Aap ka agent yeh file har baar start hone par khudkaar tareeqe se parhta hai, isi liye is course mein aap ke prompts chhote reh sakte hain.
Isay ek baar download karein; wohi folder poore course ko serve karta hai, Part 5 ka worked example aur Part 6 ka MCP server dono. Abhi set up karein ya baad mein, reading khud ke liye kuch installed hone ki zaroorat nahin.
postgres-ai-base.zip download karein
Isay unzip karein, phir folder ke andar apna agent kholein:
cd postgres-ai
claude
cd postgres-ai
opencode
Ek hi requirement: ek capable model. Agar agent ka pehla plan kabhi specific ke bajaye dhundla lage, to aagey barhne se pehle ek mazboot model par switch karein (Claude Sonnet ya Opus, GPT-5, ya is jaisa koi).
Base ko prep karein (~3 min). Agent apna setup khud karta hai, aap ek prompt paste karte hain aur jo woh poochta hai us ka jawab dete hain. Yeh paste karein:
Is base ko ready karein: jo skills yeh list karta hai woh install karein, mera
.envset up karein, aur mujhe theek theek batayein ke Neon aur Context7 MCP servers ko online lane ke liye aapko mujh se kya chahiye.
Is par nazar rakhein: agent do skills install karta hai (neon-postgres aur mcp-builder), .env banata hai, phir aap se do cheezein maangta hai: ek API key (wohi key embeddings aur answers dono cover karti hai), aur Neon ko authorize karne ke liye ek browser click. Key free hai. Yeh course Google Gemini ke free tier par chalta hai (credit card nahin chahiye), is liye agent aapko aistudio.google.com/apikey par bhejta hai; Google se sign in karein, lagbhag ek minute mein key banayein, usay wapas paste karein, aur agent usi waqt test call se sabit kar deta hai ke yeh kaam kar rahi hai. (Agar aap ke paas pehle se OpenAI key hai aur aap woh prefer karte hain, to bas keh dein; agent woh use kar lega, course mein kuch aur nahin badalta.) Neon bhi free hai; abhi account nahin? Authorization screen par hi ek bana lein. Agar koi browser window khud nahin khulti, to agent mein /mcp type karein, Neon chunein, aur woh aap ke liye sign-in shuru kar dega.
Kab mukammal: jab skills installed hain, .env mein aap ki key hai aur agent ne quick test call se usay confirm kar diya hai, Neon authorized hai, aur aap ne agent ko restart kar liya hai (exit, dobara launch) taake naye skills aur MCP servers load hon (in mein se koi mid-session load nahin hota).
Part 1: Bunyadein
1. Aap asal mein kya bana rahe hain (aur is mein aap ka kaam)
Sab se aam ghalat-fehmi: AI applications banane ke liye ek machine-learning team chahiye. Aisa nahin hai. Models off-the-shelf hain. Infrastructure ek database hai jo shayad aap pehle se chala rahe hon. Jo bachta hai woh ek AI engineer ka kaam hai: woh shakhs jo product banane ke liye AI ko use karta hai, na ke woh researcher jo models train karta hai. Yehi role yeh poori kitab aap ke liye taiyar kar rahi hai, aur yeh bilkul pohanch mein hai.
Doosri ghalat-fehmi wohi hai jise theek karne ke liye yeh course maujood hai: ke aapko saara SQL haath se likhna parta hai. Aisa nahin. Aap ek aise agent ko direct karte hain jo pgvector ke operators aur embedding workflow pehle se achhi tarah janta hai. Aap ki value stack mein upar chali jati hai: CREATE INDEX type karne se kaunsa index tay karne tak, query likhne se yeh judge karne tak ke results kaise hain.
Yeh badal deta hai ke "yeh material janna" ka matlab kya hai. Aap syntax yaad nahin kar rahe; aap itna mental model bana rahe hain ke:
- agent ko ek theek instruction de sakein ("embedding ko usi table mein store karo, cosine distance use karo, isay HNSW se index karo"),
- jo woh banaye usay parh kar dekh sakein aur pakad sakein ke kab woh ghalat hai,
- aur woh architecture choices tay kar sakein jo agent ko aap ke liye nahin karne chahiyein.
Yeh wohi plan-then-execute aadat hai jo coding course se aati hai, aur yahan yeh aur bhi ahmiyat rakhti hai, kyunke agent aise faisle karne wala hai (kaunsi extension, kaunsa index, kaunsa distance function) jo data hone ke baad undo karna mehnga hota hai.
Mindset shift: yeh poochna chhor dein ke "semantic search ke liye SQL kya hai?" Yeh kehna shuru karein: "is table par mere liye semantic search banao; yeh mere constraints hain; pehle mujhe plan dikhao."
Is ka ek bara naam bhi hai. Kitab ki istilaah mein, jo database aap banane wale hain woh agent era ka system of record hai: woh authoritative ground truth jis se aap ke agents parhte hain, jis mein likhte hain, aur jis ke against verify karte hain. Jensen Huang ki daleel yeh hai ke agents system of record ki zaroorat khatam nahin karte; woh us par depend karte hain. Authoritative ground truth ke baghair ek agent hallucinate karta hai; us ke saath, woh execute karta hai. Postgres par RAG woh tareeqa hai jis se aap ek agent ko woh ground truth dete hain, aur isi liye is course ka baqi hissa retrieval quality ko us cheez ke taur par treat karta hai jo tay karti hai ke agent par bharosa kiya ja sakta hai ya nahin.
Course ke baqi hisse ke liye isay lafzi lein: Neeche har SQL block is liye dikhaya gaya hai ke aap jo agent ne banaya usay parh aur judge kar sakein, na is liye ke aap usay type karein. Isay parhna janna hi woh cheez hai jo aapko ek ghalat distance function ya ek missing filter ship hone se pehle pakadne deti hai.
2. Vectors aur embeddings, ek minute mein
Agar "vector" aur "embedding" naye hain, to shuru karne ke liye aapko jo kuch chahiye sab yahan hai.
Ek vector sirf numbers ki ek list hai: [0.021, -0.88, 0.14, …]. Ek embedding model content ka koi tukra (ek jumla, ek paragraph, ek image) leta hai aur usay in mein se ek list mein badal deta hai. Khaas baat yeh hai ke yeh list content ke maani ko pakadti hai: text ke do tukre jo aisi cheezon ka matlab dete hain jo milti julti hain, aise numbers ki lists paate hain jo paas paas baithti hain. Do faqre jo wohi matlab dete hain ("the city that never sleeps" aur "New York's restless streets") ek doosre ke qareeb utarte hain chahe un mein ek bhi lafz mushtarak na ho.
Ek vector database sirf ek system hai jo in lists ko store karta hai aur kisi di gayi list ke sab se qareeb walon ko, tezi se, dhoondta hai. Bas itna hi. Jab koi user koi sawaal poochta hai, aap ki app us ke sawaal ko ek vector mein embed karti hai, phir database se poochti hai: "kaunse stored vectors is ke sab se qareeb hain?" Sab se qareeb wale sab se zyada semantically relevant hote hain, aur yehi tareeqa hai jis se aap ki app ek LLM ko dene ke liye sahi context laati hai. (Shuruaati diagram dekhein: yeh aap ke users ke liye context management hai.)
Aapko yeh samajhne ki zaroorat nahin ke embedding model andar se kaise kaam karta hai, jaise aapko yeh samajhne ki zaroorat nahin ke ek JPEG image ko kaise compress karta hai. Aapko bas yeh janna hai ke yeh maujood hai, ke yeh content ko maani-vectors mein badalta hai, aur ke qareeb hona similarity ke barabar hai.
Ek session kholein aur apne agent se poochein: "Aasaan zabaan mein samjhao ke embedding kya hai, phir mujhe do chhote jumle dikhao jin ke vectors qareeb honge aur do jo door honge, aur kyun. Phir maze wala: kya mere shehar ka koi mashhoor gaana ya nickname us shehar ke naam ke qareeb utrega, chahe lafz kabhi yeh na kahein?" Us ka jawab parhna aap ki apni samajh ka, is section ko dobara parhne se zyada tez, gut-check hai.
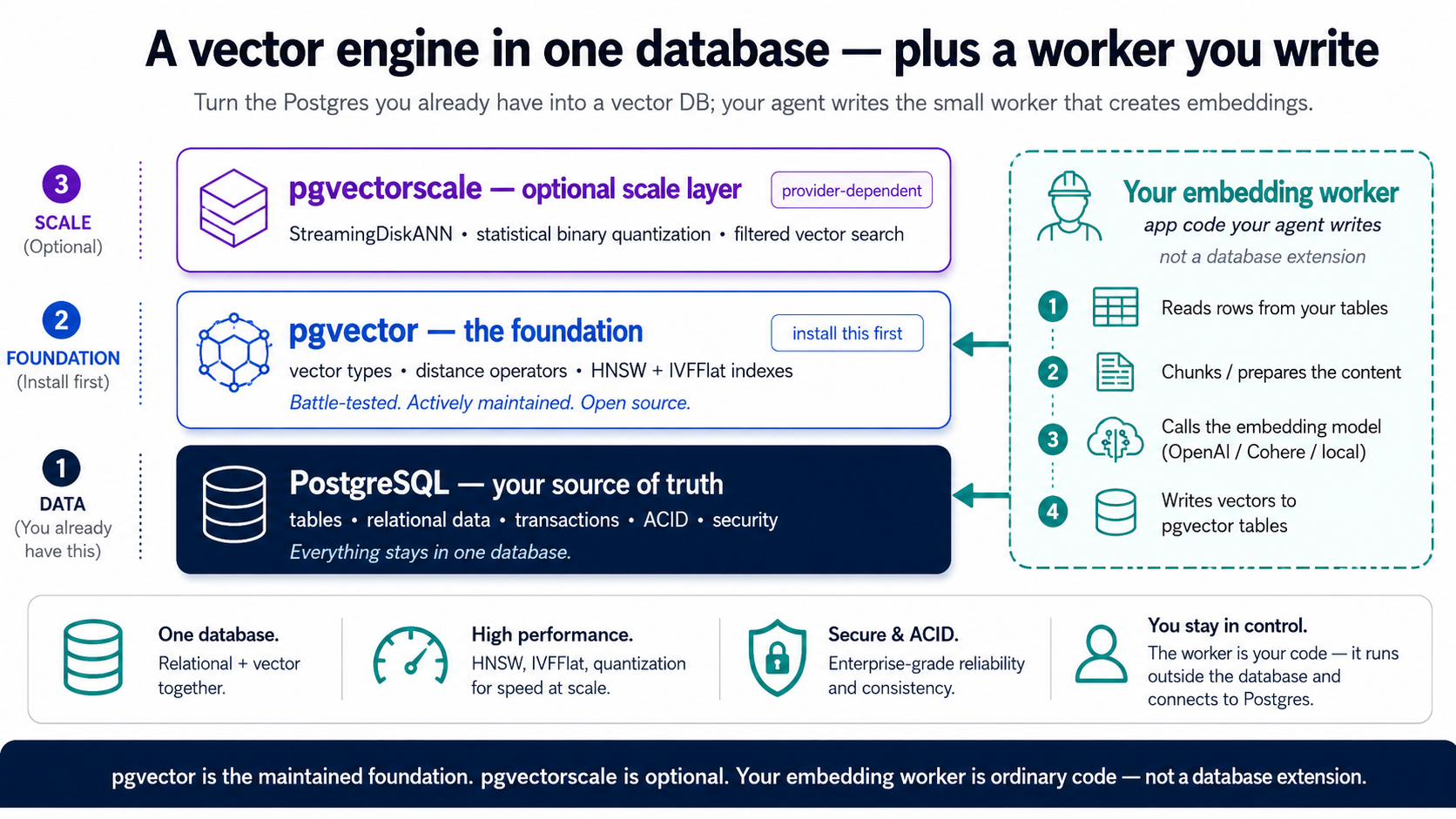
3. Extensions: aur Neon par aapko kya milta hai
Postgres extensions ke zariye ek vector database banta hai: aise add-ons jo isay nayi taqatein dete hain bina us cheez ko chhore jo Postgres pehle se achha karta hai (transactions, joins, reliability, SQL). Is poore course ke liye seekhne ke liye waqai sirf ek hai: pgvector. Yeh teen cheezein add karta hai: embeddings store karne ke liye ek vector type, unhein compare karne ke liye distance operators, aur unhein tezi se search karne ke liye indexes, aur Neon par yeh pehle se installed ship hota hai, to ek statement isay on kar deta hai. Yehi aap ka mukammal RAG engine hai. Bas itna pakad lein. (Do footnotes jinhein aap park kar sakte hain: ek doosri extension, pgvectorscale, bohat bare scale ke liye maujood hai, yeh woh tier hai jis par aap graduate karte hain, na ke jahan aap shuru karte hain. Aur embeddings khud koi extension hain hi nahin; woh ek chhote worker se aate hain jo aap ka agent likhta hai, jo Concept 6 mein banta hai.)
| Extension | Yeh kya add karta hai | Aapko iski zaroorat kab hai |
|---|---|---|
| pgvector | vector data type, distance operators, aur HNSW + IVFFlat indexes | Hamesha, aur Neon par yeh pehle se installed hai |
| pgvectorscale | StreamingDiskANN index, vector compression, bare scale par high-accuracy filtered search | TigerData par native; Neon par nahin, jahan yeh woh tier hai jis par aap graduate karte hain |
Is table ke index naam (HNSW, IVFFlat, StreamingDiskANN) abhi ke liye sirf labels hain; Part 3 sikhata hai ke yeh kya karte hain aur har ek kab use karna hai.
Neon par, pgvector hi aap ka poora stack hai. Yeh built in ship hota hai, aur embedding ke baad yeh course jo kuch karta hai (semantic search, indexing, evals, filters, hybrid search, RLS, Part 6 ka MCP server) woh pure pgvector hai. Embeddings worker (Concept 6) se aate hain, kisi managed extension se nahin. Jahan tak pgvectorscale ka taalluq hai: yeh Neon ke vetted set mein nahin, to isay woh host samjhein jis par aap sirf tab graduate karein jab aap HNSW se aagey barh jayein, aur pgvector plus ek worker pehle aapko kaafi door tak le jata hai. Scale tier pehle din se native chahiye? Woh TigerData Cloud hai, shuru se aakhir tak wohi workflow; Concept 4 ke aakhir wala ek note isay cover karta hai, aur warna aap is poore course ko sirf Neon ke taur par parh sakte hain.
Ek-database ka faida abhi bhi qaaim hai: aap ke vectors un rows ke saath rehte hain jin ko woh describe karte hain, to ek similarity search aur ek WHERE price < 2000 AND in_stock filter ek hi query mein, ek hi source of truth par hote hain. Koi doosra database nahin, koi sync pipeline nahin, koi data drift nahin. (Isay pakad lein, yehi poori wajah hai ke Concept 13 mein filtered search itni aasaan hai.)
pgvector ek mature, vasi paimane par istemaal hone wali Postgres extension hai: woh stable bunyad jis par yeh poora course tika hai. Embedding ke baad ki har cheez (semantic search, indexing, evals, filters, hybrid search, RLS, MCP server) pure pgvector hai.
Ek cheez jo pgvector aap ke liye nahin karta woh hai embeddings ko banana: embedding model ko call karna aur vectors wapas likhna. Isay karne ka saaf, portable tareeqa ek chhota worker hai jo aap ka agent likhta hai: source table → chunk → ek API call ke zariye embed → embeddings table mein vectors likho → pgvector se search. Us kaam ko database ke bahar rakhna hi maqsad hai, koi workaround nahin: ek stateful system of record ko ek volatile external API par depend nahin karna chahiye, to embedding (aur Concept 9 ke LLM calls) worker aur app layers mein rehte hain, jahan woh fail, retry, aur scale kar sakte hain bina aap ke data ko chhuye, aur poori cheez kisi bhi host ya container par saaf port ho jati hai. (Ek managed convenience layer ne kabhi embedding ko database ke andar baked kiya tha, pgai ka Vectorizer, lekin woh coupling brittle saabit hui, aur us ka repository maintainer ne Feb 2026 mein archive kar diya; yeh course us par depend nahin karta.) Worker chand lines hain jo aap ka agent banata hai aur aap review karte hain. Pattern seekhein; yeh kisi bhi ek package se zyada zinda rehta hai.
4. Apne agent ko Neon se connect karein
Hum apna database khud install ya run nahin karte. Hum Neon use karte hain: serverless Postgres jis mein pgvector pehle se built in hai, aur hum agent ko isay Neon MCP server ke zariye operate karne dete hain. MCP wohi connector mechanism hai jo coding course se aata hai; yahan yeh Claude Code aur OpenCode ko tools ka ek set deta hai (create_project, create_branch, run_sql, get_database_tables, prepare_database_migration, complete_database_migration) taake woh Neon ko poori tarah natural language ke zariye manage kar sakein. Aap kabhi khud Neon console ya psql shell nahin kholte. (Yeh course Neon ko apne default host ke taur par use karta hai; sab kuch TigerData Cloud par bilkul ek jaisa kaam karta hai, is concept ke aakhir mein "TigerData pasand hai?" dekhein.)
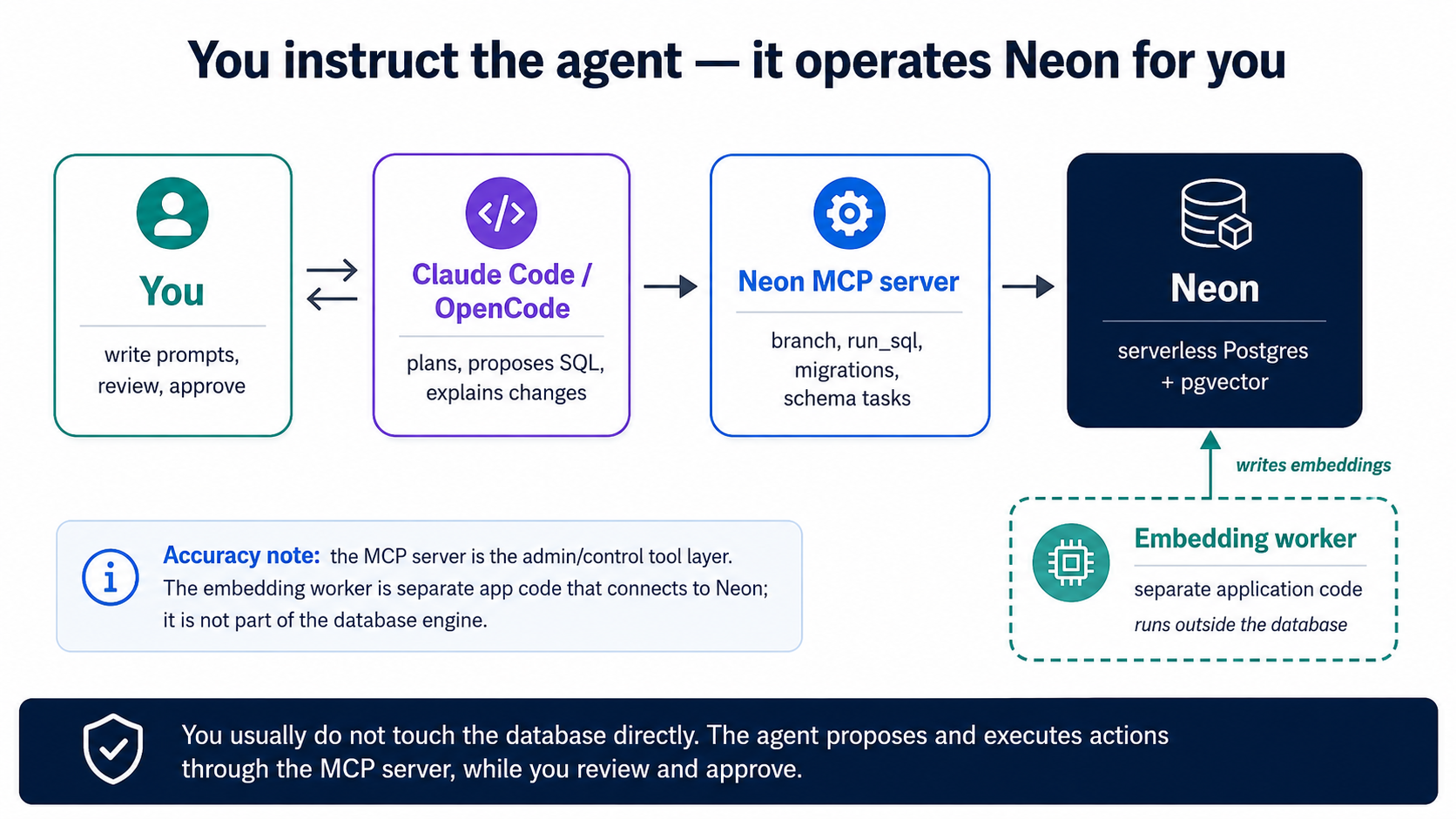
One-time wiring. Agar aap ne course base se shuru kiya, to Neon MCP server pehle se .mcp.json (Claude Code) aur opencode.json (OpenCode) mein declared hai: aap isay ek baar browser mein OAuth ke zariye authorize karte hain, koi API key manage karne ki zaroorat nahin. (Iske bajaye isay haath se wire karna bhi wohi single step hai: Neon MCP server ko apne tool mein add karein aur authorize karein.) Yehi ek manual setup hai; ab se sab kuch agent ko instruct kar ke hota hai. Isay plan mode mein drive karein:
Neon MCP server use karte hue,
agent-factory-ragnaam ka ek project banao aur us par pgvector extension enable karo. Phir hamare build karne ke liyedevnaam ki ek branch banao, aur us branch ki connection string ko.envmeinDATABASE_URLke taur par save karo taake worker aur app baad mein use parh sakein (meri API key kabhi print mat karna). Kuch bhi chalane se pehle mujhe plan dikhao.
Phir plan parhein. Aap kis cheez ke liye check kar rahe hain:
- Yeh ek branch par kaam karta hai, seedha production par nahin. Branching Neon ki superpower hai: ek branch aap ke poore database ki instant clone hai (copy-on-write: yeh sirf woh store karti hai jo aap badalte hain, to cloning free aur foran hai). Agent schema changes ek branch par karta hai, aap unhein preview karte hain, aur sirf tab default branch par commit karte hain, wohi plan-then-execute discipline, platform ke zariye enforce ki gayi. (Yehi tareeqa hai jis se aap baad mein indexes benchmark karenge aur evals chalayenge: branch banao, test karo, branch phenk do.)
- Yeh pgvector enable karta hai (woh ek extension jo is course ko chahiye) ek single statement ke saath:
CREATE EXTENSION IF NOT EXISTS vector; -- pgvector is pre-installed on Neon; this just switches it on
- embeddings (Concept 6) ke liye, agent ek chhota worker banata hai (ek chhota Python script ya service) jo nayi ya badli hui rows parhta hai, embedding model ko call karta hai, aur vectors ko ek embeddings table mein likhta hai. Yeh Neon se bahar chalta hai, apni branch tak us ki connection string ke zariye pohanchta hai. Embedding provider ki API key worker ke environment mein rehti hai, kabhi database mein nahin.
Aapko MCP tool naam ya Neon ka API yaad karne ki zaroorat nahin. Plan mode ka maqsad yeh hai ke aap plan parhein, tasdeeq karein ke yeh ek branch par kaam kar raha hai aur pgvector enable kar raha hai, aur phir approve karein. Agar plan koi aisi cheez karta hai jise aap nahin pehchante, to haan kehne se pehle agent se wajah poochein, yeh sawaal hi aap ka asal kaam hai.
Neon ki apni guidance yeh hai ke MCP server local development aur IDE integrations ke liye hai: yeh powerful operations chala sakta hai, to isay apne dev workflow tak rakhein aur agent jo bhi action propose kare usay approve karne se pehle review karein. Production changes abhi bhi aap ke normal reviewed migration process se hote hain.
course base mein pehle se ek chhoti AGENTS.md / CLAUDE.md shamil hai jis mein woh rules hain jo is course ko chahiyein: aap kaunsi Neon branch par hain, ke keys environment mein rehti hain (kabhi committed nahin), aap ka chuna hua distance function, aur do hard rules: "schema changes hamesha ek Neon branch par karo aur commit karne se pehle mujhe preview karne do," aur "kabhi destructive SQL (DROP, TRUNCATE, WHERE ke baghair DELETE) bina mujhe pehle dikhaye mat chalao." Bina base ke build kar rahe hain? /init chalayein aur isay theek isi tak trim karein.
Is course ki har cheez TigerData Cloud par bina kisi tabdeeli ke chalti hai: woh team jo pgvector ki companion extensions ke peeche hai, jo isay "Agentic Postgres" ke taur par position karti hai. Agent-driven loop bilkul wohi hai; sirf naam badalte hain:
- Neon MCP server ki jagah Tiger MCP. Yeh Tiger CLI mein built hai: isay
tiger mcp installse install karein, phir Tiger Cloud ko natural language mein bilkul upar ki tarah drive karein ("ek service banao, isay fork karo, extensions enable karo, pehle mujhe plan dikhao"). Yeh Postgres Skills bhi ship karta hai jo agent ko best practices sikhati hain. - branches ki jagah Forks:
tiger service fork …ek instant, zero-copy clone banata hai, wohi fork → test → phenk do discipline jo aap evals aur index benchmarks ke liye use karenge. - pgvectorscale native hai (pgvector ke saath saath), to StreamingDiskANN "graduate tier" (Concept 11) pehle din se box mein hai, aur us ka index 16,000 dimensions tak ke vectors support karta hai (
text-embedding-3-largejaise bare models ko phir koihalfvecnahin chahiye). Aap ka embedding worker usi tarah chalta hai jaise Neon par.
Aap ka embedding worker aur generation step dono app code mein rehte hain, Neon ke bilkul jaisa. Asool: sab se aasaan serverless shuruaat ke liye Neon; jab aap kabhi migrate kiye baghair pgvectorscale ki scale aur filtered-search performance chahein to TigerData.
Yeh course Neon ko do wajhon se use karta hai: credit card ke baghair free tier, aur instant branching jise agent Neon MCP server ke zariye drive karta hai. Postgres locally (Homebrew, Docker) ya kisi aur host par chalana pasand hai? Data side bilkul wohi hai, wohi CREATE EXTENSION vector, wohi schema, wohi worker, wohi queries; bas DATABASE_URL ko apne instance par point kar dein. Jo cheez aap chhorte hain woh MCP-driven branching hai (woh "branch, test, throw away" move jo aap indexes aur evals ke liye use karenge), is liye woh steps seedhe chalane honge. Yahan jo kuch aap seekhte hain woh bina badle transfer hota hai.
Part 2: Aap ka pehla RAG, jo aap ke agent ne banaya
Hum ek chhota, classic example banayenge: US cities ke baare mein historical figures ke quotes ki ek table, phir isay maani se search karenge, phir ek LLM se us par sawaalon ke jawab dilwayenge.
5. Schema: vectors aap ke data ke saath rehte hain
Agent se pehle source table maangein. Ek cheez pakad lein: maani-vectors kisi alag store mein nahin rahenge, woh isi database mein jaate hain, us companion table mein jo aap agle concept mein banayenge, theek us data ke saath jise woh describe karte hain.
Ek
quotestable banao jis mein columns hon:person,city, aurquote. Hum agle qadam mein embeddings ek companion table mein add karenge, jise ek chhota worker populate karega, to abhi ke liye sirf source data. Phir New York, San Francisco, aur Chicago ke baare mein kuch asli quotes insert karo taake hamare paas search karne ke liye kuch ho.
Jo table agent likhega woh lagbhag aisi dikhegi:
CREATE TABLE quotes (
id bigint GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
person text NOT NULL,
city text NOT NULL,
quote text NOT NULL
);
Pakadne wala mental model: ek source of truth. Quote, jis ne kaha, city, aur (jald hi) us ka maani-vector sab ek hi database mein rehte hain. Yehi cheez Part 4 mein filtering ko trivial bana deti hai.
6. Embeddings banayein: woh worker jo aap ka agent banata hai
Aap ki quotes table text rakhti hai. Database ko us text ko maani se search karne ke liye, us ke har tukre ko ek vector chahiye, aur woh vectors banana hi woh ek kaam hai jo pgvector aap ke liye nahin karta. To agent ek chhota program likhta hai: embedding worker. Iska poora kaam ek loop hai: woh quotes dhoondo jin ke abhi tak koi vectors nahin → kisi bhi lambe text ko tukron (chunks) mein toren → embedding model se har tukre ka vector maango → vectors save karo. Isay ek baar chalao aur har maujooda quote cover ho jata hai; isay schedule par dobara chalao aur nayi ya edit ki gayi quotes bhi cover ho jati hain. Yehi poori machine hai.
Vectors kahan save hote hain? Ek doosri table mein, companion table mein: har chunk ke liye ek row, har ek us quote ki taraf wapas ishara karti hui jis se woh aaya. Yeh us sawaal ka jawab deta hai jo yahan har koi poochta hai (ek row, ek embedding?): ek chhota quote ek chunk hai, to ek vector row; ek lamba speech kayi tukron mein badalta hai, to kayi rows. (Kyun toren bhi? Woh Concept 7 hai, theek is ke baad.) Do tables, aur woh aisi dikhti hain:
quotes (your source table) quotes_embedding (companion table)
┌────┬─────────────────────┐ ┌──────────┬──────────────┬────────────┐
│ id │ quote │ │ quote_id │ chunk │ embedding │
├────┼─────────────────────┤ ├──────────┼──────────────┼────────────┤
│ 7 │ a short quote │ ────→ │ 7 │ whole quote │ [0.02, …] │
│ 8 │ a long speech… │ ──┬─→ │ 8 │ first piece │ [0.11, …] │
└────┴─────────────────────┘ └─→ │ 8 │ second piece │ [0.54, …] │
└──────────┴──────────────┴────────────┘
one row per quote one row per CHUNK, pointing back
Agent ke isay banane se pehle ek faisla: kaunsa embedding model text ko vectors mein badalta hai. Yeh yahan ek hi choice hai jise palatna takleef-deh hai, kyunke models switch karne ka matlab hai sab kuch dobara embed karna, is liye isay samajhna kaam aata hai bhale base ne aap ke liye sensible default pehle hi chun liya ho. Woh default wohi provider hai jo aap ne set up kiya: free Gemini path par Google ka gemini-embedding-001, ya agar aap ne OpenAI chuna to OpenAI ka text-embedding-3-small. Yahan dono 1536 dimensions par chalte hain, dono zyada-tar RAG ke liye kaafi hain, aur Gemini free hai, is liye aap model name khud nahin chunte; base ne usay aap ki di hui key se match kar diya. Default se hatne ki do wajhein hoti hain: aap ka content English nahin (ya gehra specialized hai, jaise legal, medical, code), jahan multilingual ya domain-tuned model jeet sakta hai; ya baad mein aap ke evals dikhayein ke ek bara model waqai behtar retrieve karta hai. Worker mein model ek single setting hai, to aap alternatives apne eval set (Concept 12) par test karte hain, andaza lagane ke bajaye: MTEB leaderboard (embedding models ke liye standard public benchmark) se candidates ki shortlist banayein aur apne data ko winner chunne dein.
Dimension ki baareek baatein (jab aap default se hatein to parhein)
Zyada dimensions ka matlab zyada storage aur memory aur thori sust search. Do amali notes: kayi modern models aapko bina dobara train kiye kam dimensions request karne dete hain (yeh course dono providers ko 1536 par pin karne ke liye yahi karta hai), aur (ek asli gotcha) pgvector ke HNSW/IVFFlat indexes vector type ko 2,000 dimensions par cap karte hain (halfvec type isay 4,000 tak barhata hai), to koi full-size 3072-dim model (OpenAI ka text-embedding-3-large, ya Gemini full size par) indexable hone ke liye halfvec ya reduced dimensions chahega. 1536 par rehna aapko is sab se bachata hai; agar aap kabhi dimensions barhayein to aap ke agent ko yeh cap flag karni chahiye, aur jab woh kare to aapko isay pehchanna chahiye. (TigerData par, pgvectorscale ka StreamingDiskANN index 16,000 dimensions tak ke vectors support karta hai, to yeh limit shaaz hi pareshan karti hai.)
Pehle, code ko ek ghar dein: ek Python project, uv se managed (Python project manager; agent isay janta hai, aur har dependency ko us ke zariye route karna project ko reproducible rakhta hai):
Is folder mein uv ke saath ek Python project set up karo. Ab se, har dependency add karo aur har script uv ke zariye chalao.
Phir agent se worker aur us ki table banwayein:
quoteski ek foreign key, chunk text, aur ekembedding vector(1536)column ke saath ek companion tablequotes_embeddingbanao. Phir ek chhota embedding worker likho jo aise quotes dhoondta hai jin ka koi current embedding nahin,quotetext ko chunk karta hai, har chunk ko course ke embedding model se embed karta hai, aur vectorsquotes_embeddingmein insert karta hai. Backfill ke liye isay ek baar chalao, mujhe dikhao ke rows aane ki tasdeeq kaise karoon, aur samjhao ke main isay kaise schedule karoonga. API key environment se parho.
Is par nazar rakhein: agent companion table banata hai (upar diagram wali theek shakal), worker ek baar chalata hai, aur aapko woh vector rows dikhata hai jo aayein. Agar worker apne pehle embedding call par 401 ya 429 ke saath mar jata hai, to aap ke code mein kuch toota nahin; masla key ka hai, aur mumkin hai aap ne isay setup mein pehle hi pakar liya ho, jahan agent ne test call ki thi. Gemini par free key ko aistudio.google.com/apikey se dobara copy karein; OpenAI par bilkul naye account ko aksar embed karne se pehle payment method chahiye. 429 rate limit hai, is liye thora ruk kar dobara chalayein. Key theek karein, phir dobara chalayein. Agar is ke bajaye expected 1536 dimensions, got 3072 dikhe, to embedding call ne 1536 dims request nahin kiye; dono providers default mein bara vector dete hain, is liye call ko vector(1536) column se match karne ke liye 1536 maangna zaroori hai. Base worker yeh pehle hi karta hai, is liye yeh error batata hai ke haath se edit ki gayi call se woh setting gir gayi. Kab mukammal: jab har quote ki quotes_embedding mein kam az kam ek row ho, aur aap woh ek command jante hon jo worker ko dobara chalati hai.
Sab se simple version poll karta hai: worker ek schedule par dobara chalta hai aur un rows ko dobara embed karta hai jin ka text badal gaya. Iske bajaye change-driven updates chahte hain? Ek INSERT/UPDATE trigger ek row ko dirty mark kar sakta hai, "isay ek fresh embedding chahiye" flag kar ke, aur worker un flagged rows ko apne agle pass par utha leta hai. Agar aap kabhi keep up karne ke liye worker ki ek se zyada copy chalayein, to unhein wohi row do baar nahin pakadni chahiye; Postgres yeh aap ke liye sambhalta hai, har worker ko unclaimed rows ka ek alag batch de kar (SKIP LOCKED trick). To embedding-darkaar rows ki to-do list bas ek aam Postgres table hai, koi alag queue service chalane ko nahin, wohi ek-database faida jo aap ke vectors ka hai. Kisi bhi tareeqe se trigger sirf flag karta hai; embedding call abhi bhi worker mein out mein hota hai, aur database khud kabhi embedding API ko call nahin karta.
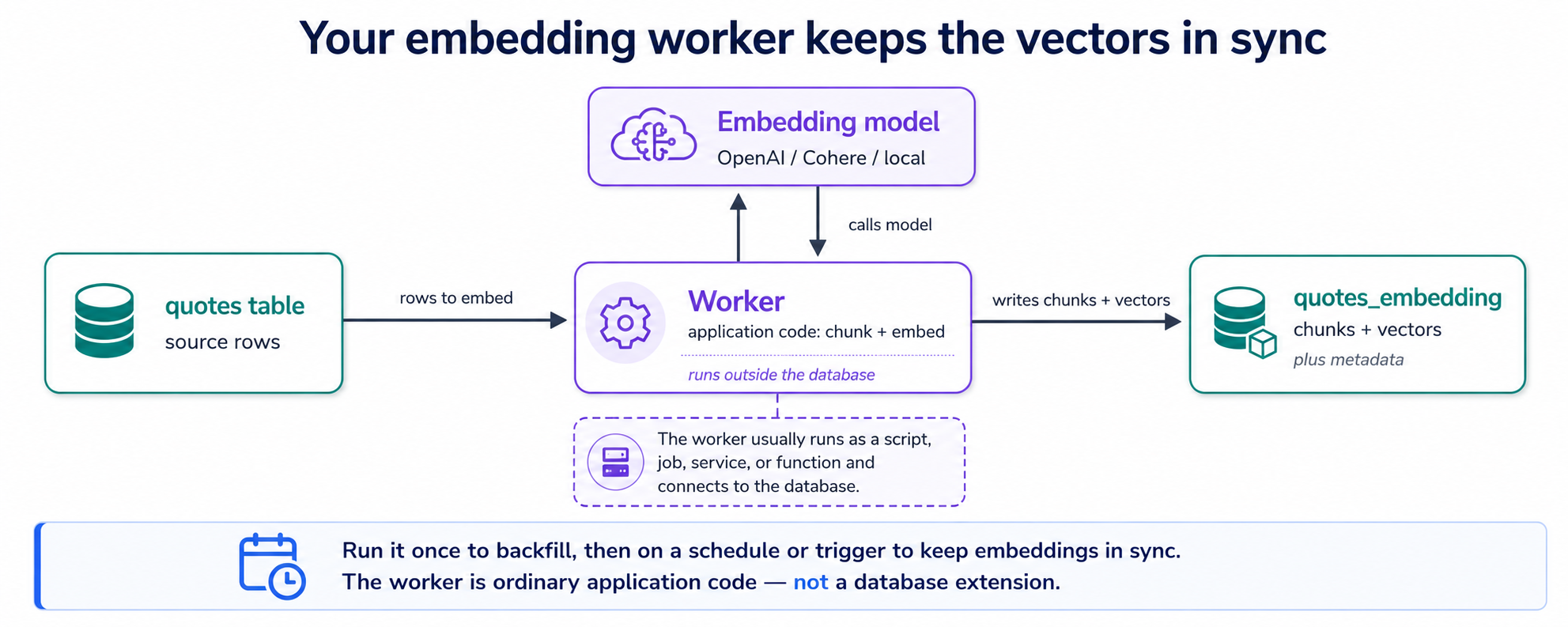
Wohi worker pattern documents embed karta hai, na ke sirf chhote fields: isay PDFs, DOCX, ya cloud storage (maslan ek Amazon S3 bucket) ki files par point karein aur isay parse, chunk, aur unhein usi companion table mein embed karne dein. Aur chunke model worker mein ek setting hai, aap providers swap kar sakte hain (Gemini, OpenAI, Cohere, Voyage, ek local model) yeh test karne ke liye ke aap ke data par kaunsa behtar retrieve karta hai, woh upar wala model experiment.
Worker ek external embedding provider ko call karta hai, to usay us provider ki API key chahiye. Key worker ke environment ki hai (ya aap ke cloud provider ke secret store ki), kabhi SQL mein hard-coded ya aap ke repo mein committed nahin. Apne agent ko sareehan batayein: "API key ek environment variable se parho, isay kabhi kisi aisi file mein mat likho jo hum commit karte hain." Phir approve karne se pehle diff verify karein. Baad mein embedding providers switch karna (Gemini aur OpenAI ke darmiyan, ya Cohere, Voyage, ek local model par) worker mein ek one-line change hai; aap ki baqi app nahin hilti.
7. Chunking: woh lever jo aap ki ceiling tay karta hai
Chunking aap ke worker ke andar ek qadam hai, aur khamoshi se, sab se ahem. Ek lamba document ek single vector ke taur par embed kiya jaye to woh dalia ban jata hai: us ne jo kuch kaha us sab ka ek dhundla average, to aap isay chhote chunks mein toren, aur har chunk ko apna vector milta hai. Jo cheez ek chunk shumar hoti hai, woh tay karti hai ke aap ki search kabhi kya retrieve kar sakti hai.
Do dials:
- Size. Bohat bara to ek chunk kayi topics par phailta hai, to us ka vector unfocused hota hai aur aap near-misses retrieve karte hain. Bohat chhota to ek chunk woh context kho deta hai jis ne usay ba-maani banaya tha. Kuch sau tokens ek aam shuruaati point hai; sahi jawab aap ke content par mauqoof hai.
- Overlap. Chunks ko thora overlap karne dena (kahein 10 se 20%) ek aise jumle ko orphan hone se bachata hai jo kisi boundary par parta hai. Thora overlap lagbhag hamesha madad karta hai; bohat zyada storage zaaya karta hai aur near-duplicates retrieve karta hai.
Ek strategy bhi hai: character count se toren (simple default), structure se (markdown headings, paragraphs), ya semantically (woh jumle group karo jo ek saath taalluq rakhte hain). Structured docs ke liye, headings par torna aksar andhe character counts se behtar hota hai.
Yeh apna alag concept kyun kamata hai: chunking aap ki recall ceiling tay karta hai: recall ka matlab sirf yeh ke aap ki search ne pehle hi sahi chunks wapas laaye ya nahin. Agar sahi jawab kabhi ek single chunk mein saaf nahin utarta, to koi embedding model aur koi chalaak prompt usay recover nahin kar sakta, isi liye bura chunking un sab se aam wajhon mein se ek hai jin se ek RAG system khamoshi se kam performance deta hai. To aap andaza nahin lagate: jab aap asal documents ke saath kaam kar rahe hon aur aap ka eval set maujood ho (Concept 12), to aap agent se chand chunking setups Neon branches par try karwate hain, har ek ko apne eval sawaalon ke against naapte hain, aur winner rakhte hain, wohi test-and-discard move jo aap Part 3 mein indexes ke liye use karenge. Aap theek wohi move worked example (Part 5) mein karenge.
8. Semantic search: distance ke hisab se order
Ab intro wala jaadu. Kisi faqre se maani mein milti julti quotes dhoondne ke liye, aap ki app us faqre ko apne ek vector mein badalti hai (query vector) aur database stored chunks ko is hisab se sort karta hai ke un ke vectors us ke kitne qareeb baithte hain.
Ek hi naya SQL ka tukra ek distance operator hai: woh symbol jo poochta hai "kitne qareeb?". Aapko sirf <=> ki zaroorat hai, cosine distance: text embeddings ke liye default, aur jo yeh poora course use karta hai. (pgvector ke do aur hain, <-> straight-line distance ke liye, <#> inner product ke liye, jin se aap sirf tab milenge jab kisi model ke docs sareehan kisi ek ko maangein; aap ka agent yeh jaanega.)
Mujhe ek query likho jo ek search phrase se maani mein sab se milti julti top 5 quotes wapas kare. Phrase ka embedding application code se ek parameter ke taur par pass hoga, isay SQL ke andar embed mat karna.
Jo query woh wapas deta hai (aap ke parhne ke liye, type karne ke liye nahin):
SELECT q.person, q.city, q.quote
FROM quotes_embedding e -- the table your worker populates: chunks + vectors
JOIN quotes q ON q.id = e.quote_id -- each chunk points back to its source quote
ORDER BY e.embedding <=> $1 -- $1 = the query phrase, embedded in app code
LIMIT 5;
"the city that never sleeps" search karein aur top results New York ke baare mein quotes hain, woh bhi shamil jin mein kabhi "New York" lafz nahin aate, kyunke maani qareeb hain. Yeh, aakhirkar thos shakal mein, semantic search hai.
$1 ke taur par kyun aata haiUser ke faqre ko ek vector mein badalna aap ke application code mein hota hai (chand lines jo agent likhta hai) aur nateeja query mein $1 parameter ke taur par pass hota hai. Model call aap ki app mein rehti hai, jahan aap model, retries, aur caching control karte hain; Postgres woh karta hai jis mein woh sab se behtar hai: vectors store karna, sab se qareeb wale dhoondna.
9. RAG: pehle retrieve, phir generate
Semantic search relevant text dhoondti hai. RAG (Retrieval-Augmented Generation) ek qadam aur aagey jata hai: yeh un retrieved chunks ko leta hai, unhein ek prompt mein context ke taur par bharta hai, aur ek LLM se aap ke data mein grounded jawab tarteeb dene ko kehta hai. Yeh customer-support bot hai, docs assistant hai, "chat with my files" feature hai, yeh sab yehi loop hain.
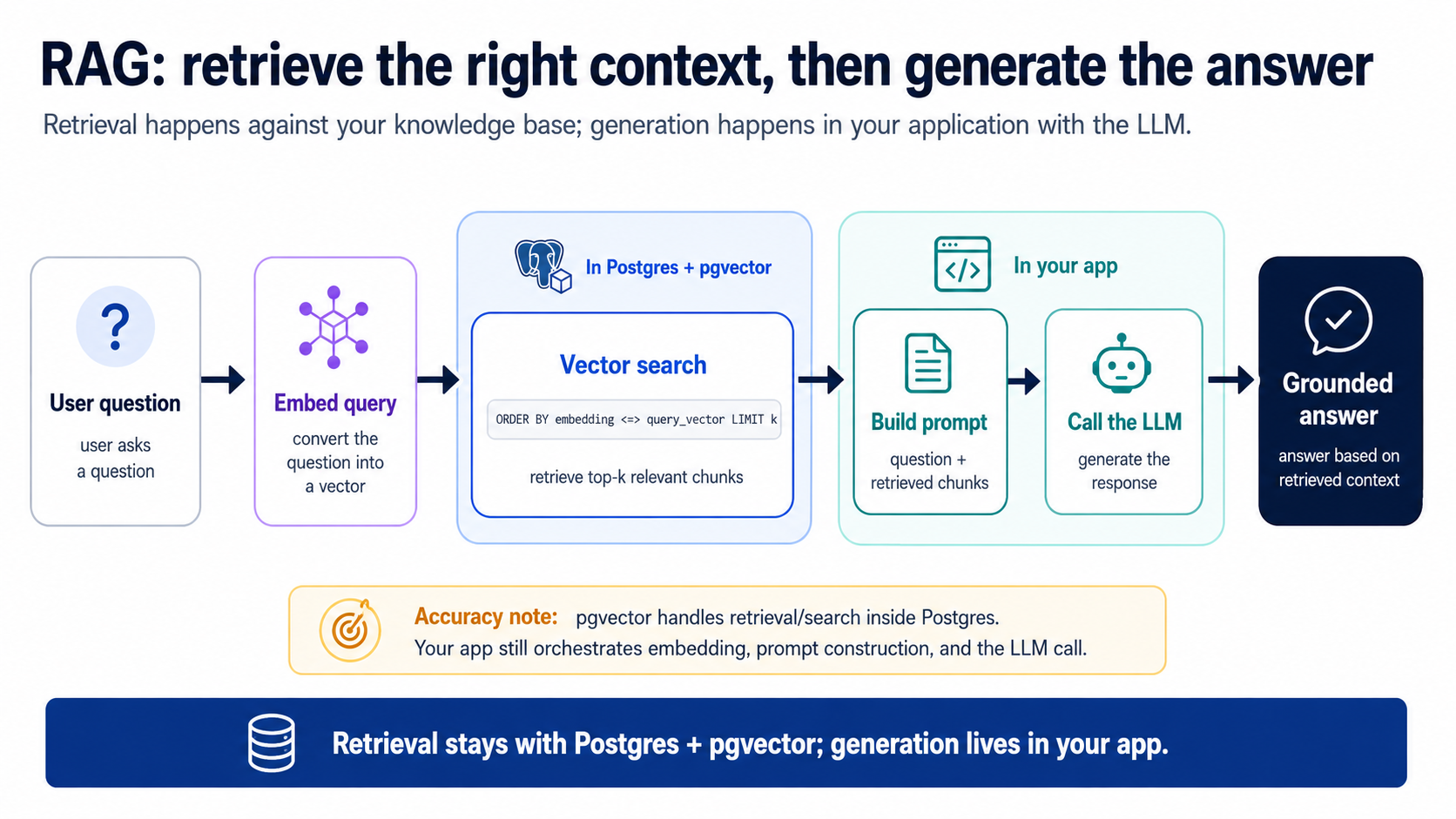
Loop ke do stages hain, aur yeh taqseem hi poora point hai:
- Retrieve (Postgres mein): sab se relevant top k chunks nikalne ke liye Concept 8 wali query chalao (k bas yeh hai ke aap kitne maangte hain; 5 ek theek shuruaat hai). Yeh context-management qadam hai: signal nikalo, das lakh ghair-zaroori rows chhor do.
- Generate (aap ki app mein): ek prompt banao = system instructions + retrieved chunks + user ka sawaal, isay ek LLM ko bhejo, jawab wapas karo. Agent yeh app-side glue aap ke liye likhta hai; yeh chhota hai.
Isay do qadmon mein banayein, taake aap retrieval ko generation se lapetne se pehle akela kaam karte dekhein. Pehle, ek housekeeping prompt taake code ka ek ghar ho (agar aap ne Concept 6 mein worker banaya to yeh pehle hi sach hai, jis surat mein agent bas is ki tasdeeq kar dega):
Is baat ko yaqeeni banao ke yeh folder ek uv-managed Python project hai, agar nahin to set up karo, aur har dependency aur script uv ke zariye chalti rahe.
Ab search wala half:
Application code mein ek
search_quotes(question)function banao: sawaal ko embed karo, hamari top-k semantic searchquotes_embeddingke against chalao, aur source quotes ke saath matching chunks wapas karo. Phir isay "the city that never sleeps" par chalao aur mujhe dikhao ke kya wapas aata hai.
Jo wapas aata hai woh akela stage 1 hai: sahi chunks, maani se dhoonde gaye, kisi jawab ke likhe jaane se pehle. Ab is ke gird stage 2 lapetein:
Ab us ke upar
answer_question(question)banao:search_quotesko call karo, un chunks ko ek prompt mein context ke taur par format karo, LLM ko call karo, aur grounded jawab wapas karo, retrieval SQL mein rahe, generation app code mein. Phir isay ek sawaal poocho aur mujhe retrieved chunks final jawab ke saath dikhao.
Ghor karein ke stage 1 kya kar raha hai: LLM ko theek woh context dena jo usay chahiye aur kuch nahin, context management, jaisa shuruaati diagram ne wada kiya tha. Agar retrieval laaparwah hai (ghalat chunks, bohat zyada, ghair-zaroori) to LLM bura jawab deta hai aur log "AI" ko ilzaam dete hain. Yeh lagbhag hamesha retrieval hota hai. Isi liye Part 4 maujood hai.
Phir agle hi jumle mein unhon ne aisa system describe kiya jo documents index karta hai, queries embed karta hai, aur answer generate karne se pehle relevant chunks retrieve karta hai. Respectfully: yeh ab bhi RAG hai.
Ab aap ne is ka har step build kar liya hai. Puri machine aik card par:
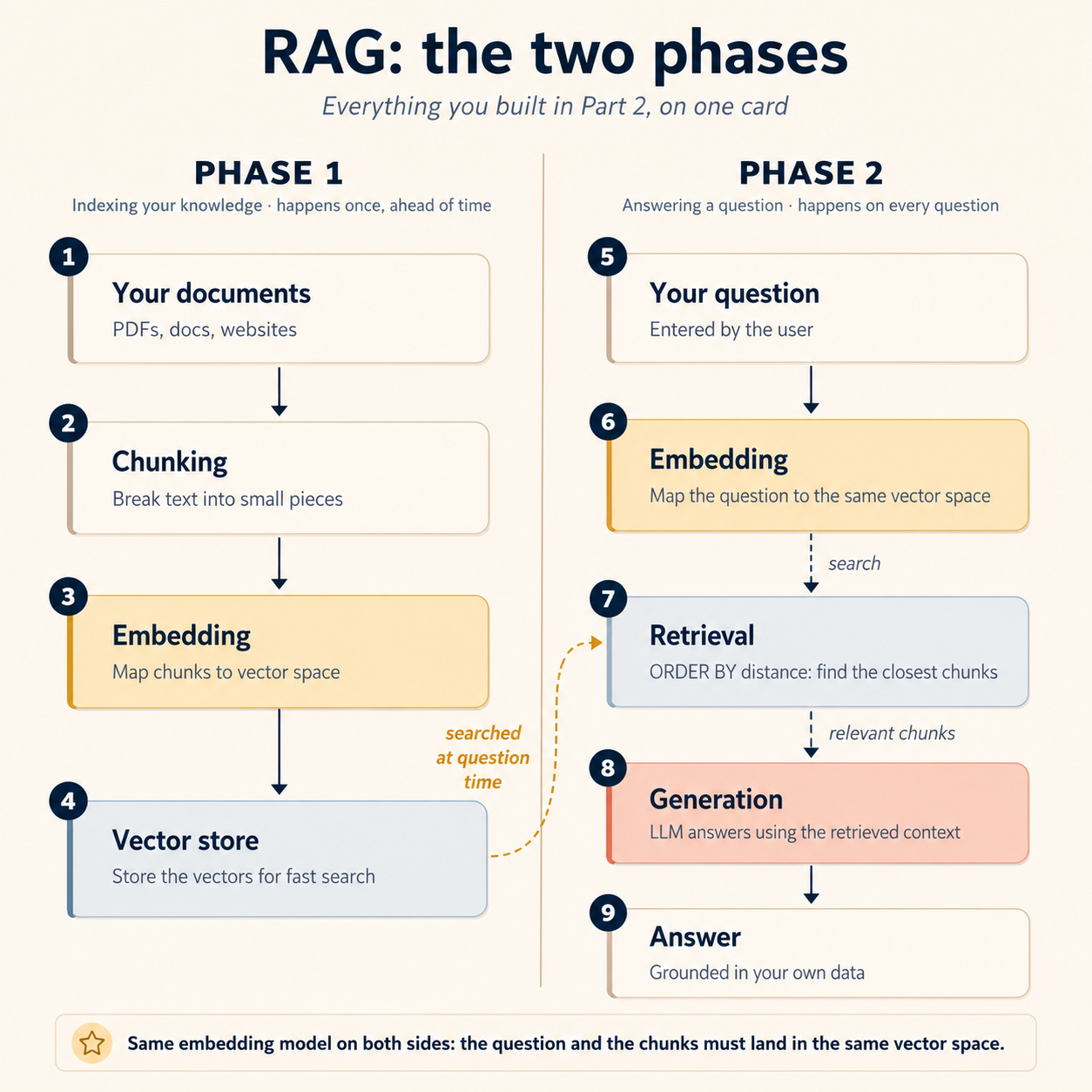
Phase 1: indexing (aik dafa, pehle se hoti hai):
- Aap ke documents chunks mein toot-te hain (Concept 7)
- Har chunk aap ka worker vector space mein embed karta hai (Concept 6)
- Vectors Postgres mein land karte hain, us data ke saath jise woh describe karte hain (Concept 5)
Phase 2: answering (har question par hoti hai):
- User ka question us same vector space mein embed hota hai
- Retrieval question ke closest chunks kheenchta hai (Concept 8)
- Woh chunks model ko pass hote hain, jo un par grounded answer generate karta hai (yeh concept)
Pehli pipeline mein logon ko jo hissa uljhata hai woh upar aik word mein chhupa hai: same. Question aur documents ko same vector space mein land karna hota hai: same embedding model, same dimensions, same settings, dono sides par. Documents aik model se embed karein aur queries doosre se, to retrieval chup chap toot jata hai, kahin koi error nahin: do models ke vector spaces bas alag coordinate systems hain, is liye "closest" ka matlab "most similar" rehna band ho jata hai. Koi leaderboard ranking is mismatch se nahin bachati. (Yeh Concept 6 wale expected 1536 dimensions, got 3072 error ka model-level cousin hai, bas yeh version loud fail bhi nahin karta.)
To "RAG is dead" headlines ke baad asal mein kya badla? Mechanism nahin, packaging. Agents, tool calls, aur multi-step reasoning ab usi retrieve-then-generate loop ke upar baithte hain. Aap Part 6 mein isi exact loop ko agent tool ke taur par wrap karein ge aur Part 8 mein agent ko dein ge: loop marta nahin, promote hota hai.
answer_question() sirf ek chatbot backend nahin, yeh ek tool hai jise ek agent call karta hai. Agent chapters mein, retrieval un tools mein se ek ban jata hai jin tak ek bara agent tab pohanchta hai jab usay grounded facts chahiyein, usi tarah jaise woh ek calculator ya web search tak pohanchta hai. RAG woh searchable context hai jis par ek agent inhisaar karta hai.
Part 3: Search ko tez banana: indexes
Yahan se intermediate. Parts 3 aur 4 tuning layer hain: aap sirf Parts 1 se 2 par ship kar sakte hain, lekin aap wahan nahin rukenge, inhein "kyun" ke liye parhein, phir un sab ko Part 5, Steps 5 se 8 mein asal mein chalayein. Tez (Part 3) aur teez (Part 4) aisi skills hain jo aap ne ki hongi, sirf parhi nahin.
10. Aapko vector index ki zaroorat kyun hai (aur kab nahin)
Bina index ke, ek similarity search query vector ko har row se compare karti hai: ek exact nearest-neighbor scan. Yeh bilkul accurate hai, aur jab aap chhote hain to bilkul theek. Jaise jaise table barhti hai, yeh sust ho jati hai.
Hal ek approximate search hai: har vector check na kar ke accuracy ka ek zarra de kar ek bara speed-up le lo. Ek vector index woh data structure hai jo us approximation ko achha banata hai.
Woh threshold jo aapko over-engineering se bachata hai: lagbhag 100,000 vectors se kam, exact search aksar kaafi tez hoti hai, aur hamesha durust. Lekin asal threshold dimensions, compute size, speed target, filters, concurrency, aur vectors kitni baar dobara likhe jate hain, in ke saath khiskti hai, to index add karne se pehle agent se benchmark karwayein, default tor par ek ki taraf na lapkein; isay tab add karein jab searches waqai sust ho jayein, pehle nahin. (Yeh coding course ke "rule tab add karo jab kuch ghalat ho, pehle nahin" ka aks hai.)
11. Indexes, kaunsa use karein, aur unhein tune kaise karein

Neon par, live choice darmiyan wala card hai: HNSW aap ka workhorse hai (IVFFlat ek legacy option ke taur par). StreamingDiskANN card TigerData par native hai; Neon se, us tak pohanchne ka matlab ek aise host par jana hai jo pgvectorscale ship karta hai.
Agent aap ke liye index banata hai, aap ka kaam yeh pehchanna hai ke us ne kya banaya aur tasdeeq karna ke yeh aap ki queries mein fit hota hai. Ek constraint jo cards nahin dikhate: ek column sirf ek vector index type rakh sakta hai, to yeh ek asli either/or hai. Yeh dekhein ke har ek kaisa dikhta hai:
-- HNSW — your default on Neon
CREATE INDEX ON quotes_embedding USING hnsw (embedding vector_cosine_ops);
-- IVFFlat — also on Neon; legacy, needs a lists parameter and rebuilds on change
CREATE INDEX ON quotes_embedding USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);
-- StreamingDiskANN — native on TigerData; on Neon only via a pgvectorscale host
CREATE INDEX ON quotes_embedding USING diskann (embedding vector_cosine_ops);
vector_cosine_ops par ghor karein: index ko us distance function se match karna chahiye jo aap ki queries use karti hain (<=> → cosine). Isay mismatch karein aur index khamoshi se madad nahin karega.
Asal mein faisla kaise karein: isay benchmark karein. HNSW ke do build-time settings hain, m aur ef_construction, jo index bante waqt graph ki shakal banate hain. Yeh bilkul woh cheez hain jo aap kabhi yaad nahin karte: apne asli workload ko bayan karein, aur ek throwaway branch ko experiment ki qeemat ada karne dein. Do prompts (yahan row counts ek real-scale stand-in hain, aap yeh exact benchmark asal mein Part 5, Step 5 mein chalayenge, ek throwaway branch par jo scale tak seed ki gayi, taake yeh ek skill ban kar utre, kahani nahin):
Hamare paas lagbhag 2 million quote-vectors hain aur hum zyada-tar searches ko city se filter karte hain. Ek taaza Neon branch par, default settings ke saath ek HNSW index banao, das representative searches chalao, aur p95 latency report karo.
Ab
mauref_constructiontune karo: chand settings try karo, har ek par wohi das searches dobara chalao, aur ek recommend karo, ek paragraph mein tradeoff samjhao. Phir branch phenk do.
Yehi AI-engineer move hai: aap yaad nahin karte ke kaunse settings tez hain, aap agent se ek Neon branch par naapwate hain aur ek recommendation lwate hain jise aap upar diye cards ke against sanity-check kar sakein, phir branch ko bina kisi qeemat ke phenk dein. Yeh benchmark speed naapta hai, recall nahin: yahan aankh se yeh mat dekhein ke results "theek lagte hain" ya nahin, recall ko imandari se real embeddings par apne eval set (Concept 12) ke against judge karein, kabhi kisi synthetic run par sarsari nazar daal kar nahin. (p95 latency ka matlab bas woh speed jis ke neeche 95% queries aati hain, ek samajhdaar worst-case jis par deewar khichni hai, lekin sirf kaafi queries par: sainkron sochein, das nahin, aur sirf chand warm-up searches ke baad jo branch ka cache garam kar dein, kyunke ek taaza Neon branch apni pehli reads storage se thandi serve karta hai. Das thandi samples par, p95 lagbhag aap ki akeli sab se buri query hi hai.)
Row count akela axis nahin, churn doosra hai. Aap ke vectors kitni baar dobara likhe jate hain (re-chunking, embedding models swap karna, time-decay re-indexing) yeh apni alag cost hai. HNSW incremental inserts aur updates bina full rebuild ke leta hai, lekin bhaari rewrite volume waqt ke saath graph ko phula deta hai, recall khiskti hai aur aakhirkar aapko ek REINDEX chahiye, aur re-embedding khud compute hai jo aap ada karte hain. To woh data jo musalsal dobara likha jata hai, bara hone se bohat pehle mehnga ho sakta hai. Agent ko apna asli update pattern batayein, sirf apna row count nahin, aur us ke against benchmark karwayein.
Roz-marra janne layaq ek hi knob: ef_search. Upar wale build-time settings index banne ke baad baked ho jate hain; jo dial aap asal mein chhuyenge woh query time par hai: ef_search control karta hai ke ek search kitni mehnat se dekhti hai: zyada ka matlab behtar recall aur sust queries, kam ka matlab tez aur kam accurate. Agent isay per query set karta hai; yeh woh line hai jo aap isay chalate dekhenge:
SET LOCAL hnsw.ef_search = 100; -- raise for more recall, lower for more speed
To move yeh hai: agent ko woh recall batayein jo aapko waqai chahiye aur us se ef_search tune karwayein taake woh us tak pohanche, isay andha-dhund max mat karwayein. Phir us se sabit karwayein ke index apna kaam kar raha hai: EXPLAIN ANALYZE chalao, sequential scan ke bajaye ek index scan ke liye check karo, aur report karo. Yeh raha farq, output ke us hisse mein jo aap asal mein parhte hain (wohi 2M-vector table, ek usable index ke saath aur baghair):
✅ GOOD — the index is doing the work
-> Index Scan using quotes_embedding_hnsw_idx on quotes_embedding
Order By: (embedding <=> $1)
Execution Time: 0.8 ms
❌ BAD — no index used; every row got scanned and sorted
-> Seq Scan on quotes_embedding (rows=2000000)
Sort Key: (embedding <=> $1)
Execution Time: 52.4 ms
Do lines aapko batati hain ke aapko kaunsa mila: operator line (Index Scan using …hnsw… ke muqable Seq Scan on …) aur execution time (usi data par sub-millisecond ke muqable dasiyon milliseconds). Seq Scan ka matlab index istemaal nahin ho raha, aksar is liye ke query ka distance operator index se match nahin karta, ya is liye ke abhi tak koi index maujood nahin. Yeh woh ek cheez hai jis ki agent se tasdeeq karwa lein is se pehle ke aap indexing ko "ho gaya" kahein.
Yeh woh baar baar aane wale tareeqe hain jin se vector search khamoshi se toot ti hai, aur chunke aap ka kaam agent ke kaam ko judge karna hai, yeh bilkul woh hain jin par nazar rakhni hai:
- Dimension mismatch: column ke dimensions embedding model ke output se match nahin karte.
- Vector type client mein register nahin: worker (aur search code) ko pgvector har database connection par register karna chahiye jo
embeddingcolumn ko chhuti hai (register_vector), warna vectors khamoshi se plain text ki tarah round-trip ho jate hain: inserts aur searches phir bina kisi error ke ghalat behave karte hain. Yeh woh ek silent-corruption mode hai jo SQL mein nazar nahin aata, to agent se poochein ke us ne type register kiya ya nahin. - No index us point ke baad jahan aapko ek ki zaroorat thi: ek silent slowdown, koi error nahin.
- Operator / index mismatch: query
<->use karti hai lekin index cosine hai, to index nazar-andaz ho jata hai. - Whole documents chunks ke bajaye: woh Concept 7 wali ghalti; retrieval kabhi koi theek cheez nahin dhoond sakti.
EXPLAIN ANALYZEskip karna: to koi bhi upar wali kisi cheez ko nahin pakadta jab tak users na pakdein.
Agar aap ki zyada-tar searches ek WHERE clause uthati hain (tenant se, date se, category se), to HNSW ko filter columns par aam B-tree indexes (Postgres ka standard index plain columns jaise dates aur categories ke liye) ke saath pair karein taake Postgres set ko efficiently narrow kar sake. (StreamingDiskANN, upar wala teesra card, bohat bare scale par bhaari filtered search ke liye bana hai.) Neon par, HNSW plus achhe filter indexes pehle aapko kaafi door tak le jate hain.
Part 4: Search ko behtar banana: advanced layer
Ek chalti hui RAG ek achhi RAG nahin. Yahan zyada-tar projects atak jate hain, aur yahan in moves ko janna aapko us shakhs se alag karta hai jo sirf ek demo bana sakta hai.
12. Eval-driven development
Woh aadat jo ek shippable system ko ek khushqismat demo se alag karti hai. Zyada-tar log build kar ke shuru karte hain, phir aankh se dekhte hain ke output "theek lagta hai" ya nahin. Iske bajaye, sawaalon se shuru karein. Kuch bhi likhne se pehle, ek darjan sawaal likh lein jo aap ke users asal mein poochenge aur unhein ek file mein daal dein. Woh file aap ka evaluation set hai: aap ka woh paimana ke kisi change ne cheezein behtar ki ya badtar.
Phir, jab bhi aap system badlein (ek naya embedding model, ek mukhtalif chunking strategy, ek add kiya gaya filter) to aap eval set dobara chalate hain aur asar dekhte hain, andaza lagane ke bajaye. Jaise app barhti hai, set us ke saath barhta hai (20, 50 sawaal), aur aap regressions ko apne users se pehle pakad lete hain.
Doosra half hai masle ko decompose karna. Jab koi jawab bura ho, yeh nateeja mat nikalein ke "AI bewaqoof hai." Stages trace karein:
- Retrieval: kya semantic search ne sahi chunks bhi wapas kiye? (Aksar asal masla ek inventory gap hai: users kisi aisi cheez ke baare mein poochte hain jo aap ne kabhi database mein dali hi nahin.)
- Context: kya sahi chunks LLM ko pass hue, ya bohat zyada/bohat kam?
- Generation: achha context milne par bhi, kya model ne phir bhi bura jawab diya?
Das mein se nau baar failure retrieval hota hai, LLM nahin. Woh stage theek karein jo asal mein toota hai.
Apna ab banayein, jo kuch bhi aap ne load kiya us ke against, Part 2 ke quotes, ya aap ka apna data. Pehle sawaal, agent draft karta hai, aap curate karte hain:
Hamari source table parho aur 12 eval sawaal draft karo jo ek user waqaiyatan poochh sakta hai, kuch ek waazeh source row ke saath, kuch jin ka jawab kayi par phaila ho, aur ek do jin ka jawab hamara data de hi nahin sakta. Har ek ke liye expected jawab note karo (ya "not answerable"), aur unhein mere edit karne ke liye
evals/questions.mdmein save karo.
Us file ko bless karne se pehle edit karein, aap apne users ko jante hain; agent nahin. Phir harness wire karein:
Ek chhota harness banao jo
evals/questions.mdke har sawaal ko hamari retrieve-then-generate pipeline se chalata hai, aur har ek ke liye dikhata hai: retrieve hue chunks, final jawab, aur kya yeh us se match karta hai jo main ne expect kiya. Khulasa karo ke yeh kahan fail ho raha hai, retrieval ya generation.
Ab se, har change is ke against naapa jata hai:
Evals chalao aur results ko aaj ki baseline ke taur par save karo. Hamare agle change ke baad, dobara chalao aur mujhe diff dikhao, kaunse sawaal behtar hue, kaunse badtar.
429 free-tier cap hai, bug nahinHar eval run har sawaal ke liye ek model call karta hai, aur aap set ko kayi baar dobara chalayenge. Free tier par aap aakhirkar provider ke daily request cap se takrayenge aur beech mein 429 dekhenge. Yeh cap hai, aap ne kuch nahin toda: intezar kar ke retry karein, harness ko back off aur automatic retry karwayein, routine runs ke liye chhota free model use karein, ya billing enable karein. Exact limits badalti rehti hain, is liye kisi number par bharosa karne ke bajaye provider ka dashboard dekhein.
Eval-driven development bharosemand agents ki reedh ki haddi hai, sirf RAG ki nahin. Iska makhsoos ilaaj Eval-Driven Development Crash Course hai, isay is ke baad karein.
13. Filtered search: WHERE clause aap ka dost hai
Khaalis semantic search globally sab se milte julte rows wapas karti hai. Aksar aap woh sab se milte julte rows chahte hain jo kisi shart ko bhi poora karte hain. Chunke aap ke vectors aap ke data ke saath rehte hain (Concept 5), yeh bas usi query par ek WHERE clause hai, koi doosra system nahin, koi jugglery nahin. Paanch patterns lagbhag har cheez ko cover karte hain:
| Pattern | Misaal use case | Add ki gayi clause (khaaka) |
|---|---|---|
| Metadata filter | Kayi products mein docs search | WHERE product = 'CRM' AND doc_type = 'api-reference' |
| Composite filter | E-commerce recommendations | WHERE category = 'electronics' AND price BETWEEN 500 AND 2000 AND in_stock |
| Time filter | News recommender: sirf haali articles | WHERE published_at > now() - interval '7 days' |
| Permissions filter | Internal RAG jahan users sirf woh dekhein jis ke woh cleared hon | WHERE clearance_level <= $user_level |
| Geospatial filter | "5 km ke andar cheezein recommend karo" (PostGIS add karein) | WHERE ST_DWithin(location, $point, 5000) |
Har ek wohi shakal hai: ORDER BY embedding <=> $1 jis ke aagey ek WHERE. Permissions wale par thodi der rukna faiday-mand hai, yeh woh tareeqa hai jis se aap tenant A ko kabhi tenant B ke documents retrieve karne se rokte hain, database mein enforce kiya gaya na ke application code mein ummeed kiya gaya.
Hamari semantic search mein ek optional city filter add karo. Ek Neon branch par,
citycolumn par ek B-tree index add karo, yaqeeni banao ke filtered queries tez rehti hain, aur mujhe hamare eval set par before/after latency dikhao.
14. Hybrid search: maani aur keywords
2026 tak hybrid search serious retrieval ke liye sab se mazboot candidate upgrade hai, aisa candidate jise aap apne eval set par confirm karte hain, andha default bana kar ship nahin karte. Idea yeh hai: keyword search aur vector search chalao, phir merge karo. Har ek doosre ke blind spot ko cover karta hai: vector search paraphrase samajhti hai lekin exact rare terms (ek product code, ek shakhs ka naam) ko kam weight deti hai; keyword search exact term ko theek pakadti hai lekin maani chook jati hai. Postgres dono natively karta hai: full-text search (tsvector) ke zariye keyword search, pgvector ke zariye vectors, to yeh ek hi database aur aksar ek hi query rehti hai.
Woh shakal jo standard ban gayi hai:
- Dono se retrieve karo, over-fetching ke saath: kahein keyword se top 20 aur vector se top 20, taake merge ke paas kaam karne ke liye signal ho.
- Reciprocal Rank Fusion (RRF) se fuse karo. RRF do ranked lists ko position se merge karta hai, score se nahin, jo us asli sirdard se bachata hai ke keyword scores aur cosine distances bilkul mukhtalif scales par rehte hain aur unhein samajhdaari se average nahin kiya ja sakta. Yeh chand lines SQL hai aur koi model nahin maangta.
- (Optional) top candidates ko ek cross-encoder se rerank karo: ek chhota model jo har query-chunk pair ko seedha score karta hai. Yeh precision qadam hai: RRF lagbhag 100 ka ek achha pool chunta hai, cross-encoder us aakhri muthhi bhar ko order karta hai jo aap LLM ko dete hain. Isay sirf tab add karein jab aap ke evals kahein ke lift extra latency ke layaq hai.
Woh shakal jo agent banata hai (aap ke parhne ke liye, type karne ke liye nahin), pehle us ne vectors ke saath ek ts full-text column add ki hogi, do ranked lists RRF se fuse ki gayi, sab ek hi query mein:
WITH kw AS ( -- keyword side: full-text search, ranked
SELECT id, row_number() OVER (ORDER BY ts_rank_cd(ts, plainto_tsquery($1)) DESC) AS rank
FROM quotes_embedding WHERE ts @@ plainto_tsquery($1) LIMIT 20
),
vec AS ( -- vector side: semantic search, ranked
SELECT id, row_number() OVER (ORDER BY embedding <=> $2) AS rank
FROM quotes_embedding ORDER BY embedding <=> $2 LIMIT 20
)
SELECT id, SUM(1.0 / (60 + rank)) AS score -- RRF: k = 60, summed across both lists
FROM (SELECT * FROM kw UNION ALL SELECT * FROM vec) r
GROUP BY id ORDER BY score DESC LIMIT 10; -- $1 = query text, $2 = query vector
Isay parhna: kw keyword match se top 20 wapas karti hai aur vec maani se top 20, har row us list mein apne rank ke saath tagged (1 = best). Final query dono lists mein har row ke liye 1 / (60 + rank) jorti hai, to woh row jo kisi bhi list ke top ke qareeb ho achha score karti hai, aur woh row jo dono mein utre jeet jati hai. 60 (standard RRF constant) kisi bhi single high rank ko ghaalib hone se rokta hai, aur chunke yeh positions par kaam karta hai, aap ko kabhi keyword scores aur cosine distances ko mukhtalif scales par reconcile nahin karna parta.
quotecolumn par hamari vector search ke saath full-text search add karo, dono ko RRF se fuse karo, aur hamara eval set vector-only vs hybrid chalao. Mujhe batao ke kaunse sawaal behtar hue aur kitne.
Hybrid search un queries par sab se zyada jeet ti hai jo ek concept ko ek makhsoos term ke saath milati hain: "Truman Capote ne city ke baare mein kya kaha" ko naam exact match hona aur maani samjha jana, dono chahiye. Yeh aap ke data par waqai madad karti hai ya nahin, aur kitni, yeh ek sawaal hai jis ka jawab sirf aap ka eval set de sakta hai, to extra moving parts uthane se pehle vector-only vs hybrid naapein.
15. Multi-tenancy aur text-to-SQL
Do aur jinhein aapko pehchanna chahiye chahe aap aaj na banayein.
Multi-tenancy. Agar aap SaaS bana rahe hain, to har customer ka data har doosre se deewar mein band rehna chahiye. Isolation ki ek seerhi hai, sab se dheeli se sab se sakht tak:
| Tareeqa | Isolation | Cost / complexity | Aam fit |
|---|---|---|---|
Shared table + tenant_id filter | Sab se kamzor | Sab se sasta | Internal tools, low-risk data |
| Schema per tenant | Achhi | Mutawassit | Zyada-tar SaaS ke liye sweet spot |
| Database per tenant | Sab se mazboot | Sab se zyada (backups, ops) | High-security / regulated clients |
Schema-per-tenant aam balance hai: asli isolation, operate karne ke liye ek database. Kisi bhi tarah, Concept 13 ka asool qaaim hai: boundary ko database mein enforce karein, sirf apne app code mein nahin. Sab se saaf Postgres mechanism Row-Level Security (RLS) hai: aap agent se ek baar ek policy likhwate hain (rows sirf wahan nazar aati hain jahan, kahein, tenant_id = current_setting('app.tenant')) aur Postgres phir isay har query par khudkaar tareeqe se apply karta hai, to ek bhoola hua WHERE clause ek tenant ke vectors doosre ko leak nahin kar sakta. Ek baat janne layaq hai, kyunke yeh har kisi ko pehli baar pakadti hai: RLS superusers aur table ke owner se bypass ho jati hai, to aap ki app ko ek aam, non-owner role ke taur par connect karna chahiye (Part 6 ka read-only role bilkul theek hai), policy ko us role ke taur par test karein, warna aapko koi isolation nazar nahin aayega aur aap ghalat nateeja nikalenge ke yeh kaam nahin karti.
Text-to-SQL. Postgres structured data bhi rakhta hai: numbers, dates, relations. Text-to-SQL ek user ko plain English mein poochne deta hai ("Q3 mein region ke hisaab se sales kya thi?") aur ek agent se isay aap ki asli tables ke against ek durust SQL query mein tarjuma karwata hai. Jo cheez isay accurate banati hai woh ek achhi tarah describe ki gayi schema hai: clear table aur column names, COMMENTs jo samjhayein ke har ek ka matlab kya hai, aur muthhi bhar example question→query pairs jin se agent seekh sake. Agent ko woh context dein, SQL chalne se pehle review karne ke liye ek insaan loop mein rakhein, aur isay semantic search (aap ke documents ke liye) ke saath milayein, ek agent jo har sawaal ke liye sahi tool chunta hai woh ek asli data assistant ki bunyad hai.
Isay do prompts mein hamari schema par asli banayein. Pehle, agent se zameen taiyar karwayein:
Hamari tables ko document karo taake English sawaal achhe tarjuma hon: tables aur columns mein comments add karo jo batayein ke har ek kya rakhta hai, aur SQL ke saath chand example sawaal save karo jo unhein produce karne chahiyein.
Phir bas poochein, plain English mein:
Kis shakhs ke sab se zyada quotes hain, aur un ke quotes cities mein kaise phaile hain? Mujhe woh SQL dikhao jo tum pehle chalaoge, sirf mere approve karne ke baad execute karna.
Text-to-SQL ek doosre naam se plan mode hi hai: agent se pehle SQL dikhwayein, khaas tor par koi bhi cheez jo likhti ho. Ek ghalat SELECT ek second zaaya karti hai; ek ghalat UPDATE aap ki shaam barbaad kar deti hai.
Part 5: Ek mukammal worked example
Ek task, shuru se aakhir tak: ek khaali Neon project se ek chalti hui Q&A tak jo aap ke documents se jawab deti hai. Neeche diye prompts hi poora kaam hain, unhein kisi bhi tool mein type karein. Tareeqa coding course ka ek hi move poore size par hai: ek mazboot model ke saath plan karo, plan review karo, phir ek saste model ko routine build karne do.
Yeh dono tarah kaam karta hai chahe aap kaise bhi pohanchein. Aap usi postgres-ai/ folder mein rehte hain, lekin build ek bilkul naya Neon project banata hai, to quotes wale build se kuch bhi nahin chhua jata, chahe aap ne Concepts 5 se 9 kiye ya seedha yahan aaye. Agar plan un functions ko dobara istemaal karne ki tajweez de jo aap pehle bana chuke hain, woh theek hai; review mein judge karein.
0. Build ko documents aur ek ghar do: base koi nahin ship karta, to kuch banao (aur agar yeh folder abhi tak ek uv project nahin, to yeh woh bhi theek kar deta hai). Paste karein:
Is folder ko ek uv-managed Python project ke taur par set up karo agar yeh pehle se nahin hai. Phir ten chhoti markdown files ke saath ek
docs/folder banao: ek farzi company ka mini employee handbook, leave policy, expenses, security, onboarding, equipment.
1. Pehle plan karo: ek mazboot model ke saath plan mode mein dakhil hon (Claude Code mein Shift+Tab, OpenCode mein Tab), phir paste karein:
Mere paas markdown files ka ek folder
./docshai. Neon par ek RAG system banao: Neon MCP server use karte hue, ek project aur ekdevbranch banao, pgvector enable karo, docs ko ek table mein load karo, ek chhota embedding worker banao jo unhein chunk aur embed kar ke ek companionchunkstable mein dale, aur mujhe ekanswer_question()function do jo retrieve karta hai aur phir generate karta hai. Kuch bhi chalane se pehle mujhe poora plan aur schema dikhao.
2. Approve karne se pehle plan parho. Check karein: kya yeh ek Neon branch par kaam kar raha hai? Kya pgvector enabled hai? Kya embedding worker API key environment se parhta hai (aur kya key repo se bahar rakhi gayi hai)? Kya generation app code mein hai? Agar sab haan, to approve karein.
3. Execute karo, teen checkpoints mein: routine build ke liye ek saste model par switch karein (kisi bhi tool mein /model), aur poora plan andha mat chalayein: isay stages mein chalayein, har ek ke baad dekhne ke liye kuch. Pehle database:
Theek lagta hai. Database aur worker ke saath aagey barho: project aur
devbranch banao, pgvector enable karo, docs load karo, aur worker ek baar chalao. Phir mujhe dikhao ke har document ne kitne chunks banaye, taake main dekh sakoon ke documents aa gaye.
Retrieval agle, jawabon se pehle chunks, Concept 9 ki tarah:
Ab search wala half. Retrieval function banao aur isay teen sawaalon par chalao jo ek naya employee poochh sakta hai, mujhe sirf woh chunks dikhao jo wapas aate hain, abhi koi jawab nahin.
Agar sahi chunks wapas aa rahe hain, to generation aasaan hissa hai:
Is ke gird
answer_question()lapeto. Phir paanch sawaal poocho jo ek naya employee waqai poochega aur mujhe har jawab ke saath retrieved chunks dikhao.
4. Evaluate karo, phir iterate karo: kuch jawab doosron se kamzor honge; yeh loop ka shuru hona hai, koi failure nahin. Paste karein:
Sab se kamzor jawabon ne ghair-zaroori chunks istemaal kiye. Diagnose karo: yeh retrieval hai ya generation? Agar retrieval hai, to ek taaza branch par ek mukhtalif chunking strategy try karo aur wohi paanch sawaal dobara chalao.
Ab aap ke paas ek chalti hui RAG hai. Agle chaar steps tuning layer (Parts 3 se 4) hain, aur aap un mein se har ek ko chalayenge, sirf un ke baare mein parhenge nahin. Har seekhne wala yeh karta hai, usi data par jo aap ke paas pehle se hai, taake depth ek skill ban kar utre. Yeh independent hain: unhein kisi bhi order mein karein, koi mat chhoren.
5. Isay tez banao, aur index ko apni keemat kamate dekho (Concept 11). Ten docs ek index maangne ke liye bohat chhote hain, to aap khud scale banayenge, ek branch par jise aap phenk dein, aur search ko usi data par sust se instant tak palatte dekhenge. Paste karein:
Ek throwaway Neon branch par, ek benchmark table banao aur usay itne random vectors se bharo ke woh lagbhag 100k ke mark ko cross kar jaye jahan ek index jeetna shuru karta hai, koi embeddings ya asli text ki zaroorat nahin, yeh khaalis scale banane ke liye hai. Yaqeeni banao ke har row ko apna distinct random vector mile (aam ghalti har row ko wohi vector bhar deti hai, agent se
count(distinct embedding)ke saath verify karwayein). Isay itna size do ke yeh Neon ki free storage ke andar rahe; agar fit hone mein madad ho to is synthetic table ke liye ek chhota vector dimension use karo. Ek nearest-neighbour searchEXPLAIN ANALYZEke saath chalao aur mujhe plan aur time dikhao. Phir HNSW index banao, build ke liyemaintenance_work_membarhao taake yeh rengta na rahe, aur wohi search dobara chalao. Dono ko saath rakho: operator line aur execution time, pehle aur baad mein. Phiref_searchbarhao aur ghatao aur mujhe dikhao ke latency kaise move karti hai. Jab hum khatam kar lein to branch delete kar do, woh storage wapas reclaim karta hai.
Kab mukammal: apni aankhon se aap ne Seq Scan ko Index Scan using …hnsw… ban te dekha aur usi data par execution time girta dekha, aur aap ne ef_search ko latency hilate dekha. Yeh Concept 11 ka speed wala half ho gaya. (Teen cheezein jo masle lagti hain magar nahin: 100k+ vectors par HNSW index banane mein chand minute lagte hain, seconds nahin, yeh expected hai, koi hang nahin, aur build ke liye maintenance_work_mem barhane se yeh kaafi kam ho jata hai; is throwaway table ke liye chhota dimension use karna sabaq ke baare mein kuch nahin badalta, kyunke index-scan-vs-seq-scan aur ef_search latency dial kisi bhi dimension par ek jaisa behave karte hain; aur yeh random vectors imandari se speed dikhate hain, lekin real recall nahin dikha sakte, kyunke random points mein neighbourhood structure nahin hota, is liye yahan poor recall number ka koi matlab nahin. Recall ko real embeddings par apne eval set ke against judge karein, synthetic data par kabhi nahin. Aap index benchmark kar rahe hain, retrieval nahin.)
6. Maani aur ek shart se filter karo (Concept 13). Aap ke handbook docs qudrati categories mein aate hain (leave, expenses, security, onboarding, equipment), to aap asal mein filter kar sakte hain:
Har chunk ko us doc ki category se tag karo jis se woh aaya. Hamari search mein ek optional
categoryfilter add karo. "Mujhe kitne din ki leave milti hai?" do baar poocho, ek baar har cheez par, ek baar leave category par filtered, aur mujhe dikhao ke retrieved chunks kaise badalte hain.categorypar ek B-tree index add karo aurEXPLAIN ANALYZEse tasdeeq karo ke filter isay use karta hai.
Kab mukammal: filtered query tighter, on-topic chunks wapas karti hai, aur aap ne plan mein B-tree index dekha, Concept 5 ka WHERE-clause-on-the-same-query faida, asli ban gaya.
7. Woh exact term pakado jo akeli maani chook jati hai (Concept 14). Yahan aap mehsoos karte hain ke hybrid search default kyun ban gayi:
Ek rare exact code ek doc mein daalo, kahein expenses file mein
EXP-2031. "EXP-2031 kya hai?" vector-only search ke saath poocho aur mujhe dikhao ke yeh kahan rank karta hai. Ab chunk text par full-text search add karo, dono lists ko RRF se fuse karo, aur dobara poocho, exact match ka rank kaise badalta hai yeh dikhao. Phir hamare paanch eval sawaal vector-only vs hybrid dobara chalao aur batao ke kaunse behtar hue.
Kab mukammal: aap compare kar chuke hon ke code vector-only vs hybrid mein kahan rank karta hai aur apne eval set ko net effect dikhane diya ho, to aap ne hybrid ka faisla saboot par kiya, kisi headline ki wajah se nahin. (Itne chhote corpus mein vector search rare code ko pehle hi top ke qareeb rank kar sakti hai; hybrid jis gap ko band karta hai woh corpus barhne aur rare token ke kayi chunks mein dilute hone par chora hota hai. Agar hybrid yahan saaf move na kare, to yeh scale effect hai, failure nahin, RRF query chalti hai yeh confirm karein aur eval comparison ko verdict banne dein.)
8. Ek tenant ko doosre se deewar mein band karo (Concept 15). Woh isolation jo isay aisi cheez bana deta hai jo aap ek saath do customers ko bech sakein:
Hamare chunks ko do farzi tenants se tag karo, docs ko aadhe aadhe mein baant do. Ek Row-Level Security policy likho taake tenant A par set ek session sirf kabhi tenant A ke chunks retrieve kar sake. Phir isay ek aam, non-owner database role se sabit karo (RLS superusers aur table owner se bypass ho jati hai, to us admin role ke taur par test karna jis ne table banayi koi isolation nahin dikhata, iske bajaye ek plain read-only role use karo): agent se woh role aap ke liye banwayein (ek
CREATE ROLE+GRANT SELECT,SET ROLEya alag Neon role aur connection string se connected, haath se setup nahin), session ko tenant A par set karo aur ek aisi search chalao jo warna ek tenant-B chunk se match karti, dikhao ke woh kabhi wapas nahin aati, phir tenant B par switch karo aur aks-e-tasveer dikhao.
Kab mukammal: wohi query sirf is par mauqoof alag rows wapas karti hai ke session kis tenant par set hai, aur aap ne isay ek non-owner role ke taur par chalaya (to deewar asli hai). Yeh Concept 15 ka "isay database mein enforce karo" thos ban gaya, RLS, na ke ek WHERE clause jo aap bhool sakte hain.
Rhythm par ghor karein, aur ghor karein ke yeh mushkil hisson ke liye nahin badla: plan → review → execute → evaluate → iterate. Indexes, filters, hybrid, aur tenant isolation wohi loop hain jo pehli RAG build thi, har baar sirf ek nayi cheez hai: aap kya review kar rahe hain (schema, worker, index plan, RLS policy). Us loop mein maharat hasil karein aur makhsoos SQL ahmiyat khona shuru kar deti hai, kyunke aap hamesha agent se isay banwa sakte hain aur aap hamesha bata sakte hain ke yeh theek hai ya nahin, kisi bhi depth par, sirf aasaan wali par nahin.
Part 6: Apne RAG ko ek MCP tool ke taur par ship karein
Aap ne search_quotes() aur answer_question() (Concept 9) banaye hain, aur Part 5 mein, un ke document twins; yeh part jise bhi aap serve karna chahein usay lapeta hai. Abhi sirf aap ka code unhein call kar sakta hai. Unhein ek Model Context Protocol (MCP) server mein lapet dein aur wohi retrieval ek aisa tool ban jata hai jise koi bhi agent discover aur call kar sakta hai, Claude Code, OpenCode, Claude Desktop, Cursor, ya ek Digital FTE jo aap baad mein banayein. MCP woh khula standard hai jis ki taraf yeh kitab baar baar lautti hai: capability ek baar likho, aur har agent us se ek hi tarah baat karta hai.
Yeh Concept 9 ka wada hai, ke retrieval woh searchable context hai jis par ek agent inhisaar karta hai, asli ban gaya. Aap ki vector search ek app mein dabi hui feature hona chhor kar ek dobara istemaal hone wali capability ban jati hai: aisi cheez jis tak ek agent us tarah pohanchta hai jaise woh ek calculator tak pohanchta hai.
Aap ab dono se mil chuke hain, aur woh ulte kaam karte hain:
- Neon MCP server (Concept 4) ek dev-time admin tool hai. Client isay build ke dauran locally stdio par chalata hai, yani branches banao, SQL chalao, migrations preview karo. Yeh production ya end users ke liye nahin hai.
- RAG MCP server (yeh part) runtime par aap ka product surface hai, yani ek Streamable HTTP service jo aap khud chalate aur cloud mein host karte hain, jahan koi bhi agent isay URL se pohanchta hai. Yeh read-only retrieval expose karta hai, "meri knowledge search karo," "mere data se jawab do," us agent ke liye jis par bhi aap isay point karein.
Pehla wala system ko banata hai. Doosra wala system hi hai, agents ko pesh kiya gaya. Transport kirdaar ke peeche chalta hai: ek local dev tool jise client chalata hai stdio bolta hai; ek hosted product jise aap deploy karte hain HTTP bolta hai. Neon admin server kabhi end users ke hawale na karein.
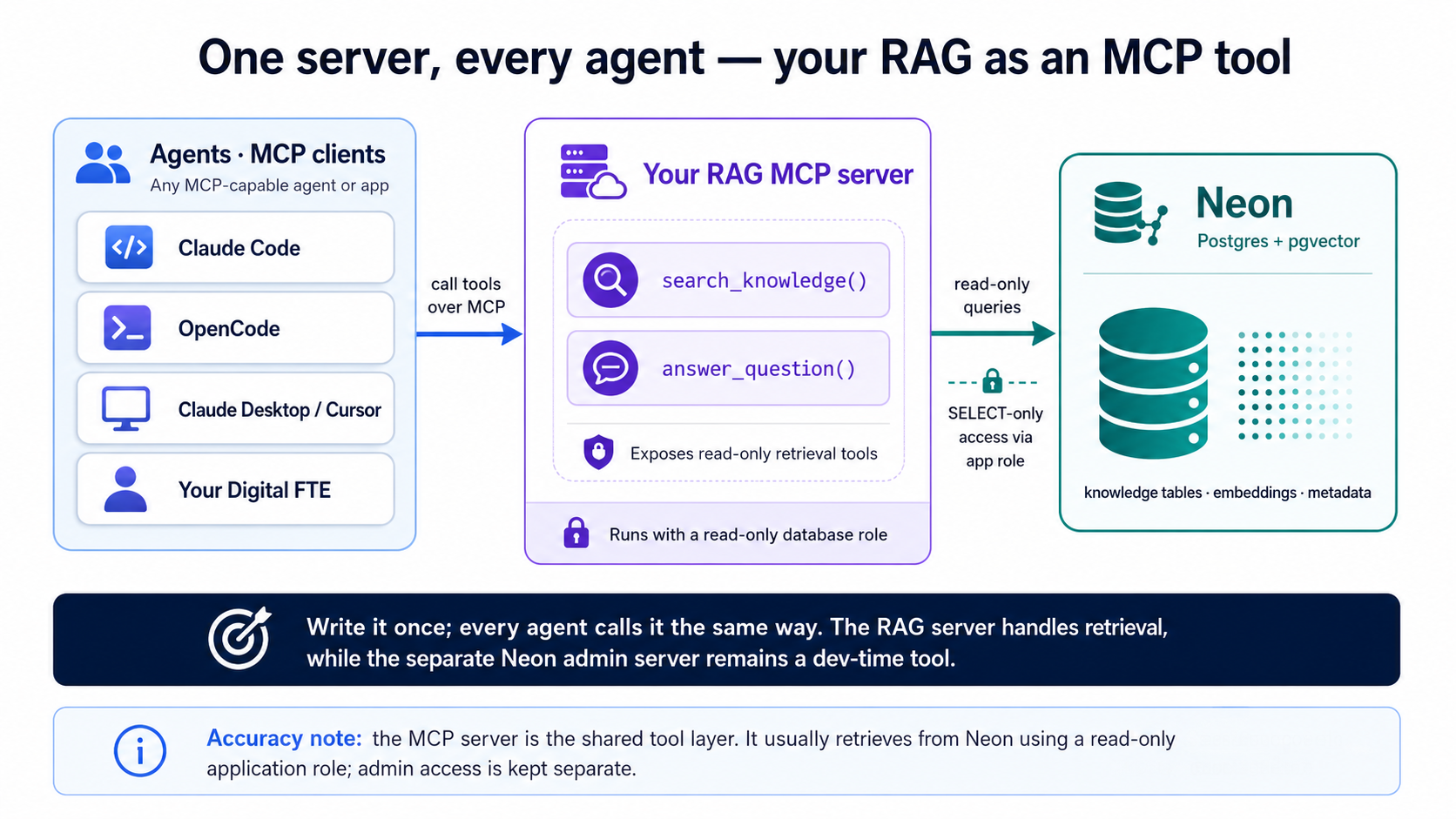
Server kaisa dikhta hai
Ek MCP server ek chhota program hai jo tools ki ek list ka ishtihaar karta hai jise ek agent call kar sakta hai. FastMCP ke saath (standard Python library, official MCP SDK par ek patli decorator layer) har tool bas ek typed function with a docstring hai; aap koi JSON-RPC plumbing nahin likhte. Hamesha ki tarah, agent yeh likhta hai, yeh isi liye dikhaya gaya hai ke aap isay judge kar sakein:
# server.py — your RAG, exposed as MCP tools (review material, not to type)
import os
from fastmcp import FastMCP
from rag import search_quotes, answer_question as rag_answer # your Concept 9 functions —
# renamed on import so the MCP tool below can keep the public name "answer_question"
mcp = FastMCP("agent-factory-rag")
@mcp.tool()
def search_knowledge(query: str, limit: int = 5) -> list[dict]:
"""Search the knowledge base by meaning and return the closest chunks.
Use this when you need grounded facts from the user's own data."""
# embeds `query` in app code, runs the Concept 8 search on Neon,
# returns [{text, source, score}, ...] — retrieval only, read-only role
return search_quotes(query, limit)
@mcp.tool()
def answer_question(question: str) -> str:
"""Answer a question grounded in the knowledge base (retrieve, then generate)."""
return rag_answer(question) # the Concept 9 pipeline
if __name__ == "__main__":
# Streamable HTTP, stateless — the production shape. The same file runs on
# your laptop and in the cloud; stateless means no session is held between
# requests, so it scales behind a load balancer. (host="0.0.0.0" binds all
# interfaces so a container can route to it; locally you reach it on localhost.)
mcp.run(transport="http", host="0.0.0.0", port=8000, stateless_http=True)
Do cheezein baqi sab se zyada ahmiyat rakhti hain. Docstring hi interface hai: yeh woh text hai jise calling agent yeh tay karne ke liye parhta hai ke tool kab use karna hai, to isay saaf saaf kehna chahiye ke tool kya karta hai aur kab is tak pohanchna hai. Aur retrieval read-only rehti hai: tool Concept 8 wali parameterized search ek read-only database role ke tehat chalata hai, to ek tool argument kabhi aap ka data mutate ya leak nahin kar sakta. Teesri line bhi dekhne ke laayaq hai, yani aakhri, mcp.run(transport="http", …, stateless_http=True), jo isay ek aisi service bana deti hai jise aap host kar sakte hain, na ke koi local subprocess; aap isay aage chalayenge, phir bil-kul wohi file deploy karenge.
Isay apne agent ke saath banayein
Wohi discipline jo har jagah hai: plan, review, execute. Yeh woh lamha bhi hai jab aap ke setup wali mcp-builder skill apni keemat kamati hai, isay naam dein, aur agent server usi tarah banata hai jaise skill sikhati hai. Plan mode mein:
mcp-builder skill use karte hue, hamari retrieval ko ek FastMCP server mein lapeto jise
agent-factory-ragkaha jaye. Do tools expose karo:search_knowledge(query, limit)jo top matching chunks unke source aur similarity score ke saath wapas kare, auranswer_question(question)jo ek grounded jawab wapas kare. Hamare maujoodasearch_quotesauranswer_questionfunctions dobara istemaal karo. Neon pooled connection string aur model API keys environment se parho, aur ek read-only database role ke saath connect karo. Saaf, action-oriented tool docstrings likho, yehi woh hai jo calling agent har tool kab use karna hai tay karne ke liye parhta hai. Koi code likhne se pehle mujhe plan aur tool list dikhao.
Plan parhein, tool list aur read-only role ki tasdeeq karein, phir approve karein aur isay banane dein.
Isay chalayein, phir connect karein
Yahan Neon admin server se farq aata hai: woh wala client aap ke liye chalata hai; yeh wala aap shuru karte hain, aur agents us ke URL se connect karte hain. Yehi production wali shakl hai, chahe yeh aap ke laptop par chale ya cloud mein, ek jaisi. Isay shuru karein:
uv run server.py
Yeh chalta rehta hai aur batata hai ke kahan serve ho raha hai, aap banner mein http://0.0.0.0:8000/mcp dekhenge (0.0.0.0 ka bas matlab hai "har interface par sun raha hai"; aap is se localhost ke taur par connect karte hain). Isay is terminal mein chalta chhorein, apne agent ke liye ek aur kholein, aur isay localhost par register karein:
claude mcp add --transport http rag http://localhost:8000/mcp
Isay claude mcp list se check karein; mid-session /mcp se dobara connect karein.
opencode.json mein ek remote block add karein:
{
"$schema": "https://opencode.ai/config.json",
"mcp": {
"rag": {
"type": "remote",
"url": "http://localhost:8000/mcp",
"enabled": true
}
}
}
Phir bas kisi prompt mein kahein "rag tool use karo", yehi woh add → check → use flow hai jo aap Concept 4 ke Neon server se jante hain, sirf yahan aap kisi command ke bajaye ek URL ki taraf ishara karte hain. Isay try karein:
rag tool use kar ke jawab do: logon ne New York ke baare mein kya kaha? Mujhe dikhao ke us ne pehle kaunse chunks retrieve kiye.
Agent ko search_knowledge call karte, aap ke chunks wapas paate, aur apna jawab un mein ground karte dekhein. Woh round-trip hi poora point hai: aap ka data ab aisi cheez hai jis par koi bhi agent reasoning kar sakta hai.
Isay cloud par ship karein
Ek local server jis tak sirf aap pohanch sakein abhi product nahin, aur ek MCP tool ka maqsad wahan chalna hai jahan koi bhi agent isay call kar sake. Yahin isay shuru se stateless banane ka faida milta hai: isay deploy karne ke liye server mein kuch nahin badalta. Aap wohi server.py kisi bhi aise host par push karte hain jo Python service chalaye (Cloud Run, Render, Railway, Fly par ek container, ya aap ki apni VM), wahan wohi environment variables set karte hain, aur localhost ke bajaye public URL register karte hain:
claude mcp add --transport http rag https://your-host/mcp
Us .mcp.json ko commit karein aur har woh shakhs jo repo clone karta hai usi ek hosted server tak pohanchta hai (Claude Code unhein ek baar isay approve karne ka kehta hai); OpenCode mein, wohi "type": "remote" block public URL ki taraf mor dein. Jis lamhe ek se zyada shakhs connect karein OAuth add karein.
Stateless hi isay mehfooz kyun banata hai: har request apna context khud saath laati hai, calls ke darmiyan koi session nahin rakha jata, to server serverless cold-starts ko nazar-andaaz kar deta hai aur bina sticky sessions ke ek load balancer ke peeche kayi replicas ke taur par chalta hai, aur ek retrieval tool, jo per-user koi conversation nahin rakhta, is se kuch nahin khota. Jis transport par aap bana rahe hain, yani Streamable HTTP, woh mustaqil production target hai; ek tez badalti tafseel bas ain FastMCP keyword hai, to jab agent isay likhe to mcp-builder skill ya live docs se transport="http" aur stateless_http ki tasdeeq karwayein. Neon admin server kisi bhi tarah ek local dev tool hi rehta hai.
Chand rules jo agent se follow karwayein, aur review mein tasdeeq karein:
- Read-only role. Retrieval tools sirf kabhi
SELECTkarte hain. Ek aise database role ke saath connect karein jo likh na sake, taake koi tool argument data delete ya alter na kar sake. - Parameterized queries. Query text ek bound parameter ke taur par aata hai, kabhi string-concatenated SQL mein nahin, wohi asool jo Concept 8 ka hai.
- Multi-tenancy: ek
tenant_idpar kabhi bharosa na karein jo ek plain tool argument ke taur par pass kiya gaya ho. Isay authenticated session se derive karein aur RLS (Concept 15) se enforce karein, taake ek tenant ka agent doosre ke vectors na parh sake. Agar aap ne RLS exercise (Part 5, Step 8) usi table par chalayi hai jise yeh server parhta hai, to ek gotcha yaad rakhein: read-only role ko har request par tenant set karna hoga, warna RLS sahi tareeqe se zero rows wapas karega, jo bina error ke empty results jaisa dikhta hai. Har request par tenant set karein, ya seekhte waqt server ko non-RLS table par point karein. - Config par bharosa karo. Ek local MCP server ek command hai jise doosri machine chalati hai. Sirf woh servers register karein, aur sirf woh
.mcp.json/opencode.jsonfiles kholein, jin par aap bharosa karte hain; ek project config aap ki machine par ek process launch kar sakta hai.
Aur retrieval hamesha sirf utni hi achhi hai jitna us ke peeche ka data, to aap ka eval set abhi bhi raj karta hai: isay MCP tool par point karein aur aap theek wohi cheez naap rahe hain jo aap ke agents experience karenge.
Part 7: Yeh kahan chalta hai
Imandaar jawab: aam tor par aapko sirf Postgres chahiye. Agar aap pehle se Postgres chala rahe hain, pgvector aapko vectors usi data ke saath rakhne deta hai jise woh describe karte hain: joins, filters, transactions, backups, permissions, ek source of truth. Neon isay serverless Postgres plus branching banata hai. TigerData usi pattern ko bare-vector aur heavy-filter workloads tak phelata hai. Local Postgres bhi learning aur kayi real apps ke liye yehi pattern hai, bas MCP branching ke baghair.
| Kahan | Kis ke liye behtar | Notes |
|---|---|---|
| Neon (yeh course) | Pehle build se production tak | Serverless Postgres, pgvector built in, instant branching, autoscaling. Aap kuch operate nahin karte. |
| Neon branches | Dev, preview, evals, benchmarks | Har branch ek instant clone hai, dev par build karo, preview karo, default branch par commit karo. |
| TigerData Cloud | Neon ka ek full-stack alternative | "Agentic Postgres": pgvector + pgvectorscale native, Tiger MCP, instant zero-copy forks. Isay StreamingDiskANN scale aur filtered search ke liye chunein bina kabhi migrate kiye. |
Chand production haqaiq jinhein agent ko pehle se flag karna faiday-mand hai:
- Embedding worker ek asli process hai: embeddings ko sync mein rehne ke liye isay chalte rehna chahiye. Production mein yeh ek service hai jise aap deploy aur monitor karte hain, na ke aisi cheez jo aap haath se start karte hain.
- Migrations: schema aur worker changes ek Neon branch par karo, unhein preview karo, phir default branch par commit karo, agent isay Neon MCP ke migration tools ke zariye drive karta hai. Versioned, reviewed, reversible, aur kabhi production ke against koi ad-hoc edit nahin.
- Cost embedding calls aur generation calls mein rehti hai, dono external model APIs ko hit karte hain. Jahan ho sake batch karein, jahan ho sake cache karein, aur model-matching aadat use karein, routine generation ke liye ek sasta model, jahan quality ahmiyat rakhti hai wahan ek mazboot.
- Scale-to-zero vs worker. Neon idle hone par database ko zero tak scale karta hai paisa bachane ke liye, lekin ek embedding worker jo musalsal poll karta hai usay jagaye rakhta hai, khamoshi se us ko shikast deta hai. Low-traffic apps ke liye, agent se worker ko ek schedule par chalwayein (ya embeddings batch karwayein) tight-polling ke bajaye, taake aapko waqai bachat mile.
- App traffic ke liye pooled connection string use karein. Neon ka pooled endpoint (
-poolerhost, transaction mode mein PgBouncer) un bohat se short-lived connections ke liye bana hai jo serverless aur high-concurrency apps kholti hain. Agent se apni RAG-serving app ko us par point karwayein; migrations aur worker direct string use kar sakte hain. - Worker Neon se bahar chalta hai. Aap Neon ki managed compute par sidecar processes nahin chala sakte, to embedding worker aap ke app host, ek chhote VM, ya ek scheduled job par rehta hai, Neon tak us ki connection string ke zariye pohanchta hua. Apne agent ko batayein ke isay kahan chalna chahiye.
Yeh hype ke peeche asli sawaal hai, aur imaandaar jawab aksar nahin hai. Agar aap pehle se Postgres chalate hain, to pgvector aap ke vectors un ke describe kiye data ke saath rakhta hai, ek source of truth, usi query mein filters aur joins, koi doosra system sync, secure, aur pay karne ko nahin. HNSW aaraam se lagbhag 100k se 10M ki range cover karta hai, aur pgvectorscale ka StreamingDiskANN ek billion vectors se aagey barhta hai, to khaalis scale shaaz hi woh deciding factor hota hai jo kabhi tha. Zyada-tar applications ke liye, Postgres hi vector database hai.
Ek dedicated store (Pinecone, Weaviate, Qdrant, Milvus, aur doosre) apni jagah tab kamata hai jab aap ne ek aisi zaroorat naap li ho jo woh poora karta hai aur Postgres nahin kar sakta, kahein, billion-plus scale par bohat high query throughput, ek makhsoos recall/latency target jo aap ke benchmarks dikhayein ke pgvector chook raha hai, ya ek poori tarah managed vector service jise aap operate karne ke bajaye rent par lena chahein. Yeh asli cases hain; bas yeh aqaliyat mein hain. Jaal yeh hai ke ek ki taraf default tor par lapkein kyunke kisi tutorial ya headline ne lapka. Isay usi tarah tay karein jaise aap indexes tay karte hain (Concept 11): apne eval set aur apne asli workload par ek benchmark ko, us ke churn samet, faisla karne dein, aur ek doosre system ki khari cost ko us faiday ke against tolein jo woh asal mein deta hai.
Part 8: Isay ek agent ke hawale karein
Aap ne retrieval bana li hai aur isay ek tool ke taur par lapet diya hai (Part 6). Qudrati agla move ek agent hai jo us tool ko use kar ke asli kaam karwata hai, jo theek wahi hai jahan Build AI Agents crash course uthata hai. Aap wahan is mein se kuch dobara nahin banate; aap agent ko woh tool dete hain jo aap ke paas pehle se hai.
Yeh raha poora bridge ek idea mein. Woh course agent loop ko OpenAI Agents SDK ke saath sikhata hai: ek Agent ek model hai jo instructions aur tools se lais hai, aur ek Runner model → tool → model loop ko us waqt tak drive karta hai jab tak kaam ho na jaye. Aap ka RAG un tools mein se ek hai. Jahan yeh course khatam hota hai, ek callable search_knowledge / answer_question, wahan woh shuru hota hai.
Jo aap ne banaya usay connect karne ke do tareeqe (agents course loop cover karta hai; aap bas tool supply karte hain):
- Part 6 ke MCP server ke taur par. Agents SDK MCP servers ko seedha consume kar sakta hai, to aap agent ko apne
agent-factory-ragserver par point karte hain aur us ke tools agent ke toolbox mein khudkaar tareeqe se aa jate hain, wohi server jo aap pehle hi Claude Code aur OpenCode mein register kar chuke hain. - Ek function tool ke taur par. Agar aap isay in-process rakhna pasand karein, to wohi read-only query SDK ke
@function_toolmein lapet dein, us course ka native tool style. Wohi retrieval, ek Python function ke taur par bayan ki gayi jise agent call kar sakta hai.
Gehra bridge: memory vs. knowledge. Agents course har agent ko do sawaalon ke gird frame karta hai: woh kis par draw kar sakta hai (state) aur usay kya karne ki ijazat hai (trust). State ki ek qism memory hai, woh jo yeh chalti hui conversation se yaad karta hai, jise woh course sessions ke saath handle karta hai. Aap ka RAG doosri qism faraham karta hai: knowledge, paaedaar, searchable context jise yeh dhoondh sakta hai, kahin zyada data par jitna kisi window mein fit hota hai. Sessions chat rakhti hain; aap ka Postgres + pgvector woh sab kuch rakhta hai jise agent retrieve karna chahe. Dono se juda hua ek agent yaad rakh sakta hai ke abhi kya kaha gaya aur woh dhoondh sakta hai jo usay kabhi pata hi nahin tha, aur is course wali "sirf relevant chunks laao, das lakh ghair-zaroori rows chhor do" discipline theek wohi hai jo us retrieved context ko window mein bharne se rokti hai. Wohi throughline, ab ek app ke bajaye ek agent ki khidmat mein.
Kitab ki zabaan mein, woh knowledge half agent ka system of record hai, woh ground truth jis se yeh parhta hai (retrieval), jis mein likhta hai (worker isay current rakhta hai), aur jis ke against verify karta hai (aap ka eval set). Yehi woh hai jo ek fluent guesser ko ek aise agent mein badalta hai jo execute karta hai.
Isay usi tarah wire karein jaise aap ne baqi sab banaya, agent ke zariye. Plan mode mein:
Build AI Agents crash course ka minimal agent scaffold karo (OpenAI Agents SDK, ek
Agentplus ekRunnerloop). Isay bilkul ek tool do: hamari retrieval. Ya to isay Part 6 keagent-factory-ragMCP server se connect karo taakesearch_knowledgeauranswer_questiontools ke taur par nazar aayein, ya wohi read-only query ek@function_toolke taur par lapeto, recommend karo ke kaunsa fit hai aur kyun. Agent ki apni mechanics (sessions, guardrails, model routing) us course par chhor do; yahan, bas sabit karo ke agent hamari retrieval call kar sakta hai aur us mein ek jawab ground kar sakta hai. Pehle mujhe plan dikhao.
Isay approve karein, ek aisa sawaal chalayein jo tool call ko majboor kare, aur agent ko apne Neon (ya TigerData) database se retrieve karte aur us se jawab dete dekhein. Yeh handoff hai: Build AI Agents loop, guardrails, sessions, aur deployment sikhata hai; is course ne agent ko kehne ke liye kuch sach diya. Aap ka eval set saheeh-salaamat cross over karta hai, yeh abhi bhi us retrieval ko naapta hai jis par agent ab inhisaar karta hai.
Aagey kahan jayein
Aap ke paas ab 80% hai: aap Neon ko ek vector database mein badal sakte hain, ek grounded RAG system bana sakte hain, saboot par ek index chun sakte hain, aur filters, hybrid search, aur evals ke saath retrieval behtar kar sakte hain, yeh sab ek agent ko direct kar ke aur us ke kaam ko judge kar ke.
- Isay bharosemand banayein: Eval-Driven Development Crash Course
- Isay ek agent banayein: Part 8 aap ke RAG tool ko ek agent mein bridge karta hai; poora loop, guardrails, sessions, aur deployment Build AI Agents mein hain
- Isay ek product banayein: assistant ko ek deployable Digital FTE mein badlein
Throughline kabhi nahin badalta: sahi maloomat, sahi lamha, ghair-zaroori maloomat bahar. Aap ne yeh apne agent ke liye seekha. Ab aap isay har kisi aur ke liye bana sakte hain.