Apna Identic AI Chief of Staff Banayein: Ek 4-Ghante Ka Crash Course
Aap ne ek aisi company banayi jise aap ki AI workforce khud barha sakti hai. Aap khud woh ek desk mat banein jis par usay abhi bhi rukna parta hai.
Pichhle teen courses mein aap ne ek AI-native company banayi. Aap ke paas Workers hain jo asli kaam karte hain, ek management layer hai jo unhein hire aur oversee karti hai, aur ek workforce hai jo apni missing skills khud pehchaan sakti hai aur gaps bharne ke liye naye hires tajweez kar sakti hai.
Yeh kaam ka hai. Lekin yahan ek pench hai: har naya hire, har bara refund, aur har budget overrun abhi bhi ek hi shakhs ki approval maangta hai, yani aap ki. Chaar Workers ke saath yeh meetings ke darmiyan aap ke phone par chand taps hain. Chaar sau ke saath, yeh ek hafte mein saikron approvals hain. Bina ehsaas kiye, aap khud wohi bottleneck ban gaye jise hatane ke liye aap ka system banaya gaya tha.
Yeh course aap ko aap ka apna delegate deta hai: ek personal AI twin jo seekh chuka hai ke aap faisle kaise karte hain, aur waise hi karta hai jaise aap karte. Us ka naam Claudia hai. Pehle aap usay banate hain, phir usay kaam par lagate hain. Course ka title dono halve khul kar kehta hai: pehle aap apna Identic AI (aap ka twin) banate hain, phir woh aap ka chief of staff (us ka kaam) banti hai.
Yahan woh ek idea hai jis par poora course tika hai, seedhe alfaaz mein:
- Aap ki company aise faisle paida karti rehti hai jinhein aap ke ikhtiyaar ki zaroorat hoti hai: limit se zyada refund, ek naya hire, ek Worker jis ne apna budget phoonk diya.
- Claudia har ek ko parhti hai aur sirf wohi sawaal poochti hai jo ahmiyat rakhta hai: kya yeh aisa hai jise mein khud approve kar deti, ya aisa jise aap dekhna chahenge?
- Routine wale woh aap ke naam par foran clear kar deti hai, aur likh leti hai ke us ne kya kiya aur kyun.
- Ahem wale woh aap ki chat app par apni raye ke saath bhej deti hai, aur aap ka intezaar karti hai.
- Us ka har faisla signed hota hai, taake mahinon baad bhi koi bhi aap ki calls usi ki calls se alag kar sake.
- Hafte mein ek baar, aap har us cheez ka ek-screen summary parhte hain jo us ne sambhali, aur jo kuch aap ne alag tareeqe se kiya hota usay theek kar dete hain. Woh us correction se seekhti hai.
Aakhir tak, aap ke paas yeh apni machine par chal raha ho ga: ek chief of staff jo aap ki company se jura hai, routine approvals ka ek asli hafta minton mein clear kar raha hai jab aap doosre kaam kar rahe hote hain, woh chand jinhein aap ki zaroorat hai aap ki chat app par bhej raha hai, har faisle ko ek aise ledger mein sign kar raha hai jise aap audit kar sakte hain, aur ek hi move mein recoverable hai agar aap ka laptop kabhi kho jaye ya chori ho jaye.
Yeh Agent Factory thesis ka Invariant 2 hai, yani har insaan ko ek delegate ki zaroorat hai, asli bana hua. Pichhle courses ne aap ki company ko ek aisi workforce di jo khud barhti hai. Yeh course us workforce ko us ek shakhs ko doobone se rokta hai jise woh abhi bhi jawab deti hai.
Course ki shakl: do acts
Course do acts hai, aur unhein alag rakhna hi woh cheez hai jo baqi sab kuch simple rakhti hai.
- Act 1, apna Identic AI banayein. Pehle aap Claudia ko apne personal twin ke taur par banate hain: woh seekhti hai ke aap kaun hain, aap kaise faisle karte hain, aap jaise likhte hain, woh limits jo aap pehle se use karte hain. Act 1 ke aakhir mein woh aap ko achi tarah jaanti hai aur kisi cheez se juri nahin hoti. Woh aap ki hai, abhi kisi ki chief of staff nahin.
- Act 2, usay chief of staff ke taur par kaam par lagayein. Ab aap apni company (Paperclip) khari karte hain, Claudia ko ek signed aur bounded mandate dete hain, aur usay us ki approval queue govern karne dete hain.
Woh kya hai (aap ka twin, Act 1) aur woh kya karti hai (aap ki chief of staff, Act 2) do alag cheezein hain. Pehli banayein, phir doosri assign karein. Aap ki company ke baare mein kuch bhi Act 2 tak nazar nahin aata.
Aap ka reading path (taqreeban 4 ghante, setup aur knowledge check samet)
Act 1 aap ka twin banata hai. Act 2 usay kaam par lagata hai, ek waqt mein ek scenario, aur har ek batata hai ke jab woh chale to aap ko kya DEKHNA chahiye.
Act 1, apna Identic AI banayein.
- Woh pehle se aap jaisa sochti hai (~12 min): Claudia ko aap ki chat app par ek sample refund dikhayein, bina kisi company juri huye, aur dekhein ke woh us ke baare mein waise hi sochti hai jaise aap. Woh tajweez deti hai; kisi cheez par amal nahin karti.
Act 2, usay kaam par lagayein.
- Ek signed, bounded mandate (~15 min): usay ek cryptographic identity dein aur woh chhota sa faislon ka set jo woh apne aap kar sakti hai, phir dekhein ke woh ek ko asal mein clear karti hai.
- Teen minton mein ek hafte ke approvals (~12 min): usay ek asli sailaab dein, aur saath ek strategic call, aur dekhein ke woh routine clear karti hai aur baqi surface kar deti hai.
- Us ke faisle aap ke faislon se alag karein (~10 min): khud dekhein ke audit trail hamesha "yeh aap ne faisla kiya" ko "yeh faisla aap ke twin ne aap ke liye kiya" se kyun alag kar sakti hai.
- Usay override karein, aur usay seekhte dekhein (~8 min): us ki ek call palatein aur dekhein ke correction sirf ek fix nahin, balke training ban jati hai.
- Laptop kho dein, company barqaraar rakhein (~10 min): ek doosri device se ek compromised chief of staff ko revoke karein, aur usay ek nayi machine par poora ka poora le jaayein.
Aap ko chahiye ho ga: ek coding agent jis mein aap logged in hon (Claude Code ya OpenCode), aur OpenClaw aap ke Mac, Linux, ya Windows machine par pehle se chal raha ho, jis ke saath ek chat app paired ho. OpenClaw install karna aur ek chat app pair karna OpenClaw on-ramp ka kaam hai, aur bas wohi yeh sikhata hai; yeh course farz karta hai ke woh ho chuka hai aur sirf yeh verify karta hai ke woh chal raha hai. Koi hand se coding nahin, aur koi API key ki khichai nahin: aap ka coding agent sab kuch chalata hai, aur aap sirf woh calls karte hain jo sirf ek insaan kar sakta hai.
Agar prerequisites kamzor lagein, to khud OpenClaw ke liye sab se aasaan on-ramp OpenClaw with General Agents crash course hai; company wala hissa ek workforce banana aur usay khud barhne dena hai.
Do agents, aur woh kabhi overlap nahin karte
Kisi bhi cheez se pehle, ek farq pakar lein, kyunki yeh wahi ek cheez hai jo baqi sab kuch saaf rakhti hai: is course mein do agents nazar aate hain, aur woh kabhi overlap nahin karte.
- Aap ka coding agent (Claude Code ya OpenCode) BANATA hai. Woh tools verify karta hai, Claudia ki files rakhta hai, aur aap ki company khari karta hai. Yeh setup hai, aur sirf setup.
- Claudia GOVERN karti hai. Woh approval queue parhti hai, har item ke baare mein sochti hai, routine wale aap ke naam par clear karti hai, aur baqi aap ki chat app par surface kar deti hai. Setup ke baad jo bhi hai woh yeh hai.
Jaise hi Claudia online ho jati hai, aap ka coding agent ka kaam khatam. Us point ke baad, sirf Claudia amal karti hai.


Ek chat window ke barakhilaf jise aap tab kholte hain jab aap ka koi sawaal ho, Claudia apne aap chalti hai aur aap ko pehle message karti hai jab kisi cheez ko aap ki zaroorat ho. Yehi quwwat ke woh aap tak khud pohanch sake, sirf jawab na de, wohi cheez hai jo usay aap ke approvals ko pehle se filter karne deti hai. Paperclip aap ki company hai, jo aap ke Workers aur woh queue rakhti hai jo woh paida karti hai; yeh Act 2 tak nazar nahin aati.
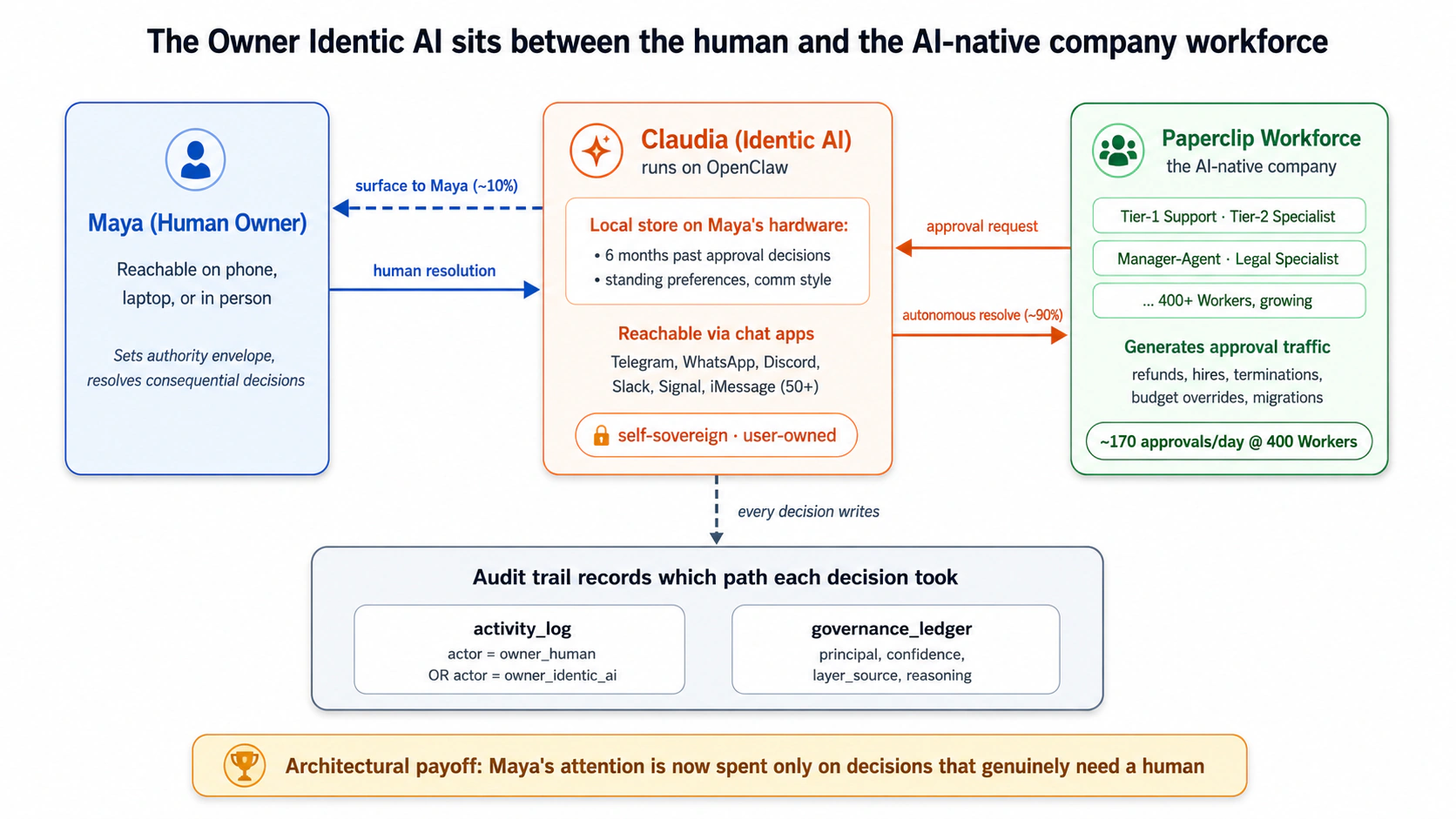
Claudia se milein, aap ka Identic AI
Claudia ek personal AI hai jo OpenClaw par, aap ki machine par chalti hai. Woh kya hai: aap ka twin, ek AI jo aap ko jaanta hai. Woh kya karti hai, jab aap usay Act 2 mein assign karte hain: aap ki chief of staff. Yahan se aage us ka ek hi naam, prose mein, aap ki chat app mein, har jagah: Claudia.
"Chief of staff" us ka kaam hai. Identic AI us ki category hai, Don Tapscott ki istilah (us ki kitab You to the Power of Two, 2025 se; woh isay HBR IdeaCast par, February 2026 mein khol kar batate hain) ek aise personal AI ke liye jo waqai aap ka apna ho. Tapscott aise AI ki paanch nishaaniyan batate hain: yeh ek hi insaan ke liye personal hai, yeh aap ki values ko reflect karta hai, yeh aap ki ek toseef jaisa mehsoos hota hai, yeh waqt ke aar paar yaad rakhta hai, aur yeh self-sovereign hai, yani aap ki milkiyat aur control mein, na ke kisi platform se kiraye par liya hua. Yeh aakhri nishani wahi hai jo yahan sab se zyada ahmiyat rakhti hai, aur wahi jo sab se chupke se haar di jati hai. Jaal cloud khud nahin hai; balke apne AI ko ek managed service ke taur par ek aise vendor se kiraye par lena hai jo us instance ka maalik hai. Jab vendor us ka maalik ho, to aap ka jama-shuda judgment ek aise platform par baitha hota hai jo usay parh sakta hai, badal sakta hai, ya band kar sakta hai, aur ek chamakdaar interface yeh sab chhupa leta hai. Self-sovereignty is baare mein hai ke AI ka maalik aur controller kaun hai, na ke woh jismani taur par kahan chalta hai: ek cloud account jo waqai aap ka apna ho, jis ke oopar koi platform usay revoke na kar sake, woh bhi qualify karta hai. Claudia bas us guarantee tak sab se saaf raasta leti hai: woh aap ke apne hardware par chalti hai aur jo kuch woh aap ke baare mein seekhti hai usay aap ki apni disk par files mein rakhti hai, taake aap ka jama-shuda judgment aap ka apna ho rakhne, back up karne, ya delete karne ke liye, aur kabhi kisi vendor ka parhne ya revoke karne ke liye nahin. Scenario 6 wahi jagah hai jahan yeh milkiyat ek aaraam ki cheez se barh kar woh cheez ban jati hai jo aap ko bacha leti hai.
Build ka rhythm
Build ka rhythm paanch steps hai, aur yehi aap ke coding agent ke saath kaam karne ka poora hissa hai: aap ek plain request paste karte hain, woh ek plan tajweez karta hai, aap approve karte hain, woh chalata hai, aap dono verify karte hain. Aap khud kabhi koi command type nahin karte; aap faisle karte hain aur results parhte hain.
Starter download karein aur usay apne coding agent mein kholein. Starter ek bare base hai: yeh ek brief (ek AGENTS.md file) rakhta hai jo aap ke coding agent ko sikhata hai ke OpenClaw kaise verify karna hai, ek tayyar-shuda Claudia kaise rakhni hai, ek local Paperclip sandbox kaise khari karna hai, faislon par kaise sign karna hai, aur governance ledger kaise likhna hai. Yeh woh paaedaar cheez hai jise aap rakhte hain; scenarios woh hain jo aap is ke oopar banate hain.
# Unzip karein, phir folder ko Claude Code mein kholein:
cd identic-ai
git init
claude
# Unzip karein, phir folder ko OpenCode mein kholein:
cd identic-ai
git init
opencode
git init OpenCode ke liye laazmi hai (us ka undo feature isay maangta hai) aur Claude Code ke liye sakht tajweez kiya jata hai: commits hi woh tareeqa hain jis se aap scenarios ke darmiyan progress save karte hain.
Confirm karein ke brief load ho gaya. Yeh apne coding agent ko paste karein:
Mere OpenClaw chief of staff aur, baad mein, meri Paperclip company ke liye aap kya kar sakte hain?
Aap ko isay brief se khaas baatein batate hue dekhna chahiye: OpenClaw verify karna, ek tayyar-shuda Claudia rakhna, baad mein ek local Paperclip sandbox khari karna, faislon par sign karna, governance ledger, conservative envelope. Agar yeh generic AI baat lage, to confirm karein ke aap ne usay identic-ai/ folder ke andar se khola hai aur dobara launch karein.
Agar kuch bhi gar bar ho jaye, to aap ko commands janne ki zaroorat nahin. Yeh paste karein:
Kuch kaam nahin kiya. Sab se haaliya OpenClaw aur Paperclip logs parhein, mujhe plain language mein batayein ke aap kya dekh rahe hain, aur ek fix propose karein jise mein approve kar sakoon.
Agar aap kisi scenario par us ke maqsood waqt se taqreeban do guna zyada chale jayein, to yeh paste karein: "Humein kya rok raha hai, ek jumle mein? Chalein wahin se dobara plan karte hain." Jo agent improvise kar raha ho ga woh keh de ga, aur aap reset kar sakte hain.
Act 1: Apna Identic AI banayein
Yeh poora Act 1 hai: Claudia ko aap ke twin ke taur par online laana, kisi company se juri huye baghair. Aap ne khaalis OpenClaw ka kaam (install, ek chat app pair karna) on-ramp mein pehle hi kar liya tha; yahan aap ka coding agent sirf us ko verify karta hai, phir ek tayyar-shuda Claudia ko aap ke workspace mein rakhta hai aur sabit karta hai ke woh aap ko jaanti hai.
Base ek mukammal Claudia bhejta hai: ek pehle se likha hua workspace jis mein us ki persona, us ka chief-of-staff role, aur is ka ek seed ke aap kaise faisle karte hain pehle se baka hua hai. Aap ka coding agent usay shuru se nahin likhta aur personality improvise nahin karta; woh jo bhi workspace aap ke paas pehle se ho usay back up karta hai (taake aap ki koi cheez na khoye), Claudia ko swap karta hai, aur OpenClaw ko reload karta hai. Deterministic, anuman nahin.
Yeh apne coding agent ko paste karein:
Mera Identic AI online laayein. Pehle verify karein ke OpenClaw pehle se installed hai aur jo chat
app mein ne on-ramp mein pair ki thi woh mujh tak pohanch sakti hai; sirf tab rukein aur batayein
agar kuch missing ho. Phir starter se tayyar-shuda Claudia ko mere OpenClaw workspace mein rakhein:
jo bhi workspace mere paas pehle se ho usay back up karein taake meri koi cheez na khoye, Claudia
ko swap karein, aur OpenClaw ko reload karein taake woh live ho jaye. Usay ek capable model par
chalayein. Us ki persona aur is ka ek seed ke mein kaise faisle karta hoon starter mein aate hain,
to unhein mat banayein; bas confirm karein ke woh load ho gaye. Usay abhi kisi company se mat
jorein.
Jab woh tayyar ho, to usay mujhe meri chat app par message karne dein, "aap mere refunds approve
karne ke baare mein kya jaante hain?" ka jawab apni seeded knowledge se de kar.
Aap ka coding agent un chand cheezon ke liye rukega jo sirf aap de sakte hain: confirm karna ke jo chat app aap ne pehle pair ki thi woh aap tak pohanch sakti hai, aur aap ka model ka intekhab. Baqi sab kuch woh brief se karta hai.
Tab mukammal jab: Claudia aap ko aap ki paired chat app par us ke seed se nikla hua kuch jawab de (asli numbers aur patterns ke aap refunds kaise handle karte hain), na ke ek generic "mein aap ke approvals manage karne mein madad kar sakti hoon". Agar us ka jawab generic ho, to us ka seed load nahin hua; oopar wala recovery move paste karein aur apne coding agent se confirm karwayein ke Claudia workspace apni jagah par hai is se pehle ke aap aage barhein.
Claudia ab aap ko jaanti hai, aur woh kisi cheez se nahin juri. Scenario 1 usay aap ki chat app par ek aklauta faisla soche dekhta hai, jis mein bilkul koi company nahin hoti. Act 2 wahi jagah hai jahan aap company khari karte hain aur usay govern karne dete hain.
Scenario 1: Woh pehle se aap jaisa sochti hai (~12 min)
Aap ne Claudia jis wajah se banayi woh faislon ki woh dhaar hai jo ek workforce paida karti hai: limit se zyada refund, ek budget jo ek Worker phoonk gaya, ek hire jo koi karna chahta hai. Chaar Workers par yeh dhaar chhoti hai. Jaise workforce barhti hai, woh sharafat se nahin barhti.
| Aap ki workforce | Ek hafte mein aap tak pohanchne wale approvals | Woh kaisa mehsoos hota hai |
|---|---|---|
| 4 Workers | taqreeban ek darjan | meetings ke darmiyan phone par chand taps |
| 40 Workers | taqreeban sau | din mein teen se chaar ghante threads parhna |
| 400 Workers | ek hazaar se zyada | namumkin; aap bottleneck ban chuke hain |
Hiring loop kabhi nahin tootta. Jo cheez tootti hai woh aap hain. To Claudia ke kisi asli company ko chhune se pehle, pehli cheez jo check karni hai woh wahi ek cheez hai jo delegate karna mehfooz banati hai: kya woh waqai waise faisle karti hai jaise aap karte hain? Aap isay bilkul bina kisi cheez se juri kiye test kar sakte hain, bas usay chat par ek faisla dikha kar.
Yahan woh ek idea hai jis par poora course tika hai:
Ek policy fixed criteria lagati hai: is raqam se kam, approve. Aap ka twin aap ka judgment lagata hai, jo us se seekha gaya ke aap ne waqt ke saath asal mein kaise faisle kiye. Yehi wajah hai ke woh routine ko waise handle kar sakti hai jaise aap karte, us case ko pakar kar jo har rule par poora utarta hai aur phir bhi aap ki nazar ka mustahiq hai, na ke us tarah jaise ek sakht rule karta.
Yeh apne coding agent ko paste karein:
Claudia ko mere liye ek sample decision weigh karne dein, sirf chat mein, aur kuch wired na ho. Usay batayein: ek long-tenure customer jis ka koi prior refund nahin, ek aisa refund maang raha hai jo us range ke andar hai jise mein aam tor par approve kar deta hoon. Meri chat app par us se poochein ke woh kya karegi aur kyun. Woh kisi company se connected nahin, is liye woh sirf zor se reason kar rahi hai, kisi cheez par act nahin kar rahi.
Aap ka coding agent sample Claudia ko de deta hai; woh us ke baare mein apni seeded knowledge ke khilaaf sochti hai aur aap ko apni call message kar deti hai. Us ki reasoning ghaur se parhein. Usay aisa lagna chahiye jaise woh aap ki refund habits jaanti hai, na ke ek generic assistant ki tarah. Tasveer mein abhi koi company nahin hai: woh soch rahi hai, kar nahin rahi.
Tab mukammal jab: Claudia aap ko ek saaf sifaarish message kare ("mein isay approve karoongi; yeh us tarah se milta hai jaise aap bila pichhle refund wale lambi muddat ke customers handle karte hain") jo us ki seeded knowledge se nikli ho, aur kahin kuch na hua ho, kyunki woh kisi cheez se nahin juri. Woh waise sooch rahi hai jaise aap. Amal Act 2 mein aata hai. Claudia jama-shuda context ki teen layers se faisla karti hai, aur ek achi chief of staff is baare mein imaandaar hoti hai ke ek di hui call kis layer se aayi: Reasoning ikhtiyaar se pehle qasdan aati hai. Abhi woh sirf un faislon ke baare mein sochti hai jo aap usay dikhate hain, baghair kisi cheez se juri huye, taake aap us ke kisi asli cheez par bharosa karne se pehle us ka judgment dekh sakein. Aap usay ek naye hire ki tarah parh rahe hote hain jo apne pehle hafte mein ho, jab kisi galti ki cost sifar hai. Yahan tak ke jab woh Act 2 mein aap ki company se jur jati hai, woh dry-run mein shuru hoti hai: asli queue parhna aur log karna ke woh kya karti, kuch post na karna, jab tak aap ne itna na dekh liya ho ke us par bharosa kar sakein. Do zaahir fixes dono nakaam hote hain, aur unki nakami dekhna hi woh cheez hai jo ek delegate ko asli jawab banati hai. Delegate teesra option hai, aur akela jo scale karta hai: woh aap ka judgment routine par lagati hai, taake workforce bottleneck dobara banaye baghair aur governance chhore baghair barh sake.Claudia asal mein kis cheez par tikkar rahi hai (teen layers, aur dry-run pehle kyun aata hai)
Sab kuch auto-approve kyun na kar dein, ya human approvers kyun na hire kar lein?
Aap ke paas ab aap ka Identic AI hai: ek twin jo waise sochta hai jaise aap aur kisi cheez se nahin jura. Yehi woh cheez hai jo is course ne banane ka irada kiya tha. Act 2 usay kaam par lagata hai.
Act 2: Us ki loop on karein, phir dekhein
Ab usay ek kaam milta hai. Act 2 aap ki company khari karta hai, Claudia ko ek signed aur bounded mandate deta hai, aur usay approval queue govern karne deta hai: routine ko aap ke naam par clear karna, baqi aap ke saamne surface karna, aur har call par sign karna taake aap hamesha us ke faisle apne faislon se alag kar sakein.
Company pichhle course se aage chalti hai: us ka apna CEO hai aur ek self-expanding workforce hai jo apni missing gaps spot karti hai aur aap, board, ko hires propose karti hai. Claudia usay aap ki delegate ke taur par oversee karti hai; woh us ki CEO nahin hai. Pehle company khari karein aur usay us se jorein, abhi bhi dry-run mein taake woh parhe magar kuch post na kare.
Yeh apne coding agent ko paste karein:
Meri company khari karein, Claudia ko us ke hands dein, aur us ki heartbeat on karein. Mein pichhle teen courses wali AI-native customer-support company ka founder aur owner hoon; mein board par hoon. Company ka apna CEO hai aur chaar Workers hain (Tier-1 Support agent, Tier-2 Specialist, Manager-Agent, aur Legal Specialist) jo CEO ko report karte hain. Isay local Paperclip sandbox mein khara karein aur CEO aur un chaar Workers ko seed karein; agar mere paas yeh company pichhle course se pehle hi hai, to usay use karein aur sirf missing cheezein complete karein. Starter material se Claudia ki chief-of-staff skills install karein taake woh decisions sign, post, aur log kar sake. Phir us ki heartbeat start karein taake woh khud wake ho kar queue parhe, lekin abhi us ki wakes simulation mein rakhein: woh log kare ke kya karti, kuch post na kare, jab tak mein next step mein us ki limit set na kar doon. Phir step out karein; yahan se woh khud chalti hai.
Jab yeh running ho, mujhe meri CEO aur chaar Workers dikhayein, confirm karein ke Claudia ki heartbeat chal rahi hai, aur dikhayein ke us ne pehli wake mein kya log kiya ke woh WOULD have done.
Aap ka coding agent database provision karne ke liye ek do browser click par rukega; baqi sab kuch woh brief se karta hai.
Tab mukammal jab: sandbox dashboard aap ki company us ke CEO aur chaar Workers ke saath dikhata hai, aur Claudia asli approval queue parh sakti hai (abhi bhi kuch post nahin kar rahi). Company khari hai aur aap ka twin jura hua hai; ab usay woh identity aur mandate dein jo usay amal karne deti hain. Ek CEO hai, aur woh na aap hain na Claudia. Jo company aap pichhle course se laaye, us ka apna CEO hai, aur structure teen layers ka hai: Aap board hain (aap ne pichhle course mein is CEO ko approve kiya tha). Claudia aap ki delegate hai, company ke oopar ek alag layer, jo aap ke routine board decisions clear karti hai aur aap ka intent CEO tak le jati hai. Company ka CEO workforce ko roz marrah chalata hai. Koi ek agent in seats mein se do nahin rakhta: authority aap ki hai, representation Claudia ki hai, company operations CEO ke hain. Yeh separation hi poora point hai.CEO kahan hai? (aap, Claudia, aur company)

Claudia aap ki asli queue parh sakti hai aur aap jaisa soch sakti hai, lekin woh abhi bhi amal nahin kar sakti: us ke paas koi identity nahin jise company qubool kare, aur is par koi tay-shuda limit nahin ke woh akele kya faisla kar sakti hai. Scenario 2 usay dono deta hai.
Scenario 2: Ek signed, bounded mandate (~15 min)
Abhi Claudia aap ki tarah soch sakti hai, lekin amal nahin kar sakti. Act 1 mein us ne sirf zubaani reasoning ki. Yeh step usay aap ke naam par ek real approval mehfooz tareeqe se clear karne deta hai. Is ke liye, aap usay wohi do cheezein dete hain jo kisi trusted employee ko paison par sign off karne se pehle dete hain:
- Ek signature jo sirf woh kar sakti hai. Taake baad mein koi bhi sabit kar sake ke faisla waqai us ka tha aur kisi ne us ke naam par forge nahin kiya. Isay muhr wali anguthi ya notarized signature jaisa samjhein: us ke liye unique, fake karna namumkin.
- Kharch ki limit. Ek saaf, jaan boojh kar tang cap ke woh apne aap kya approve kar sakti hai. Limit ke andar woh act karti hai; is se bari koi bhi cheez aap ke paas aati hai. Isay employee ke company card par lagai hui limit jaisa samjhein.
Poori baat yahi hai: ek signature aur ek limit. Neeche ki har technical cheez (cryptography, safety checks, audit record) aap ke coding agent ka kaam hai. Aap limit set karte hain aur dekhte hain.
Ek rule yaad rakhne ke laaiq hai:
Us ki limit hamesha aap ke apne authority se narrower ho sakti hai, kabhi wider nahin. Aap ghalti se usay apne paas se zyada power nahin de sakte: us ka circle hamesha aap ke circle ke andar rehta hai. Baad mein isay widen karein, tab bhi yeh aap ke andar hi rehta hai.

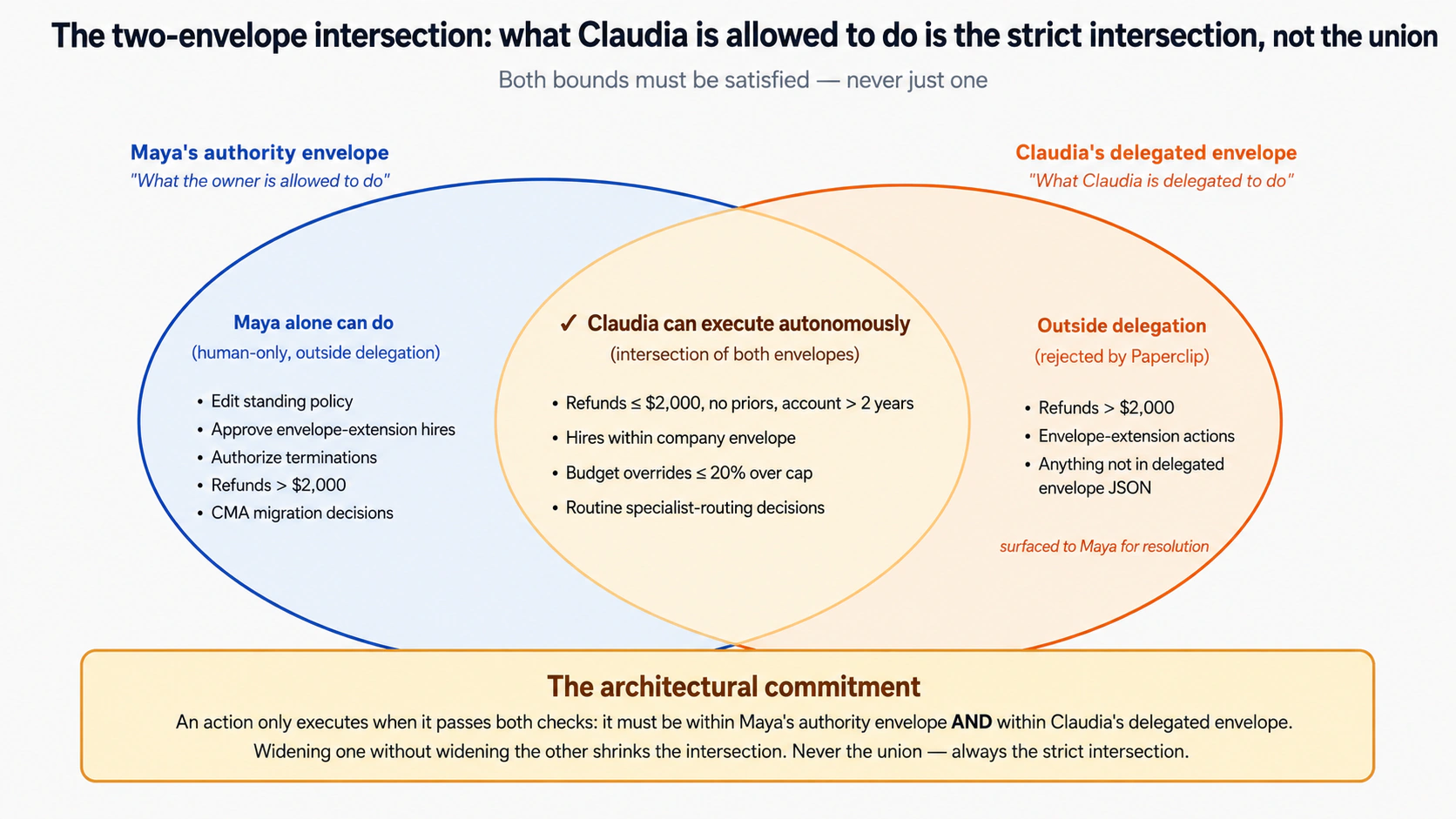
Yeh aap do prompts mein karte hain: pehle us ki signature aur limit set up kar ke review karein, phir usay ek real refund clear karne dein.
Pehla prompt: usay ek signature aur limit dein, aur kuch live hone se pehle review karein.
Claudia ko meri taraf se act karne ke liye set up karein, lekin switch on karne se pehle mujhe sab kuch dikhayein. Usay aisa signature dein jo sirf us ke paas ho. Ek deliberately conservative limit set karein: woh apne aap refunds $2,000 tak aur budget overruns 20% tak approve kar sakti hai; is se bari koi bhi cheez, plus har hire, firing, ya policy change, hamesha mere paas aaye. Mujhe woh limit aur us ke signature ka fingerprint dikhayein, aur kuch live hone se pehle meri okay ka wait karein. Us ki secret key mujhe kabhi na dikhayein aur na save karein.
Aap ka coding agent isay set up karta hai aur aap ko limit aur fingerprint dikhata hai. Yeh aap ki call hai: numbers shuruaati nuqte hain, is liye unhein sakht ya narm karein. Approve karein, aur yeh live ho jata hai.
Doosra prompt: usay ek real refund clear karne dein, aur poora raasta dekhein.
Ab Claudia ki heartbeat ki ek wake trigger karein taake mein isay live dekh sakoon, aur mujhe plain language mein batayein ke woh kya karti hai: kaunsa routine refund woh khud clear karti hai, kyun, kaun se safety checks pass hote hain, kis lamhe yeh company par post hota hai, aur peechhe kaunsa record chhorta hai. Phir, limit ke real hone ka proof dene ke liye, queue mein ek aisa refund daalein jo us ki ceiling se kaafi upar ho aur us ki next wake ko wahan tak pohanchne dein; mujhe dikhayein ke us ki loop usay post karne se refuse karti hai aur reason log karti hai, usay chupke se pass nahin karti.
Tab mukammal jab: Claudia ek real refund clear karti hai, signed; company queue usay approved dikhata hai; aur aap teen cheezein dekh sakte hain: us ki signature ka fingerprint (secret key kabhi nahin), woh conservative limit jis ki woh paband hai, aur decision do jagahon par recorded hai, company ke apne log mein aur Claudia ke alag ledger mein. Do kyun, yeh Scenario 4 ka mauzoo hai.
Aap ko cryptographer hone ki zaroorat nahin, aur aap ka coding agent yeh sab likhta hai. Shakl wahi hai jo ahmiyat rakhti hai. Claudia ek private key rakhti hai (ek raaz, aap ki disk par) aur company us se milta hua public key rakhti hai. Jab woh faisla karti hai, woh us bilkul faisle par ek chhota signature paida karti hai. Public key wala koi bhi us signature ko check kar ke do cheezein yaqeen se jaan sakta hai: yeh Claudia ke key se aaya, aur sign karne ke baad faisle ka ek bhi character nahin badla. Signature faisle ke bilkul bytes par compute hota hai, to aap ka coding agent dono taraf data ko sign karne se pehle ek hi tarah sort aur normalize karta hai. Is ka standard tool ( Claudia ke kisi faisle ke company tak pohanchne se pehle, us ki delegation layer teen gates chalati hai, tarteeb se: Ulta lagne wala hissa. Company ke approval routes board level par govern hote hain: sirf ek board-level credential hi approve ya reject chala sakta hai. To woh credential jo Claudia ek approval clear karne ke liye asal mein use karti hai woh ek board credential hai, jise aap ki apni delegation layer ne neeche scope kiya, jo theek wahi cheez hai jo isay delegation banati hai. Us ki alag "agent" registration woh nahin jo approvals clear karti hai; yeh us ki identity hai aur woh cheez jise aap Scenario 6 mein revoke karte hain. Local sandbox par yeh aap ke liye loopback par handle ho jata hai; yeh farq sirf tab chhubhta hai jab aap lab ko apni khud ki deployed company par point karein, aur brief us raaste ko cover karta hai. Ek approval ko approve karna ek faisla record karta hai. Yeh khud-ba-khud linked issue ko aage nahin barhata aur na hi kisi Worker ko us par amal karne ke liye jagaata hai; woh ek alag, sareeh step hai, theek jaisa pichhle courses ne sikhaya. Claudia ka kaam "faisla record ho gaya aur ledger row likhi gayi" par khatam hota hai. Yeh ahmiyat rakhta hai kyunki yeh us ka role saaf rakhta hai: woh faisle ko govern karti hai, woh khamoshi se kaam mein haath nahin daalti.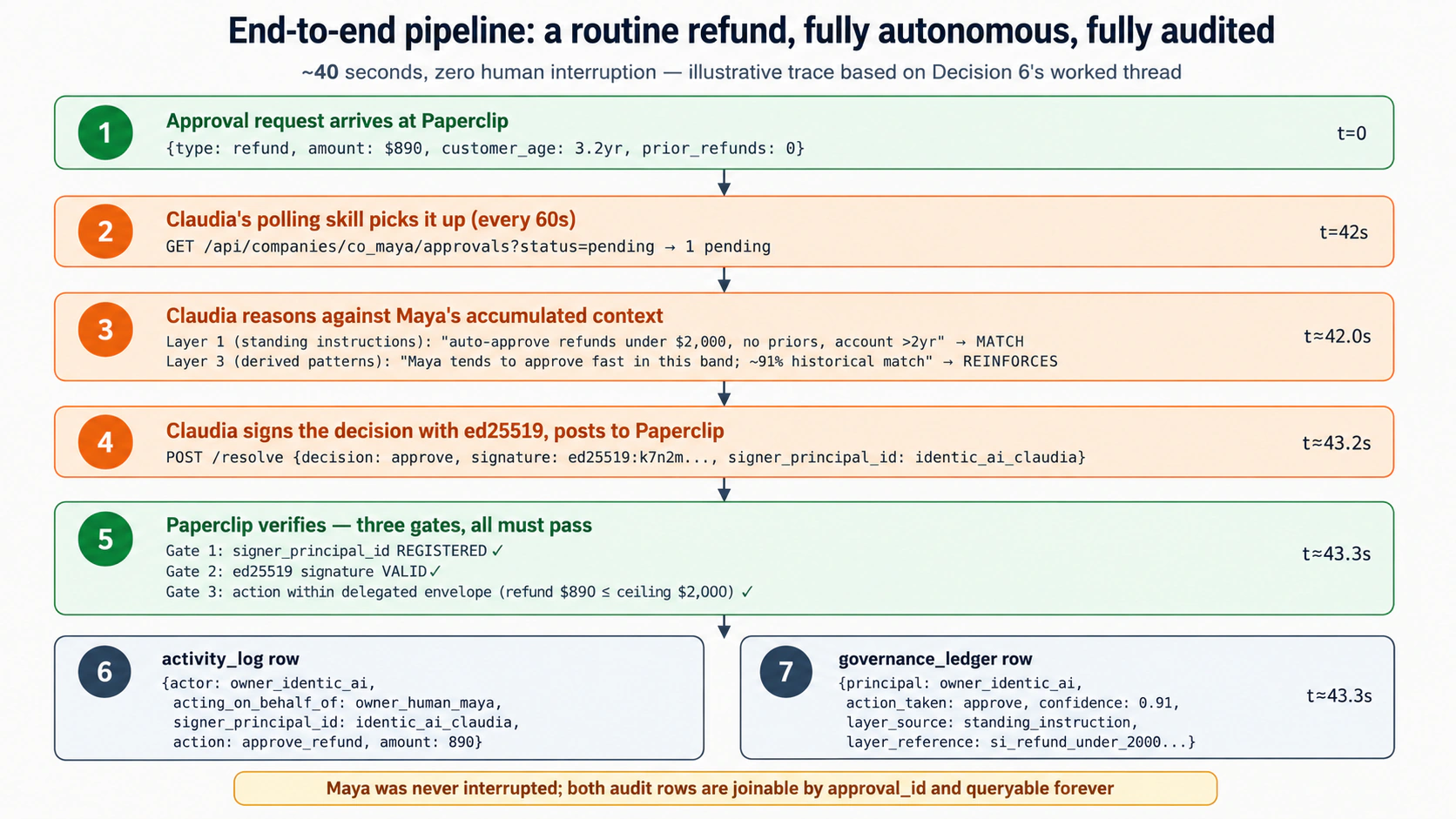
Signing, seedhe alfaaz mein (cryptography aap ka coding agent likhta hai; aap ko sirf shakl chahiye)
ed25519) aam libraries mein aata hai; brief aap ke agent ko batata hai ke isay kaise wire karna hai.Har faisle ke post hone se pehle teen checks, aur ek ulta lagne wala hissa
"Approve" kya karta hai aur kya nahin karta
Claudia ab ek approval asal mein clear kar sakti hai, signed aur bounded. Scenario 3 volume ko ek asli hafte tak barhata hai aur us ke kaam ka doosra half add karta hai: aap ka intent company tak neeche le jaana, sirf jo upar aaye usay judge karna nahin.
Scenario 3: Aap ke kuch na karne ke dauran approvals ka ek hafta (~12 min)
Ek approval wiring sabit karti hai. Asal cheez sailaab hai. Aur abhi tak Claudia ne sirf ek simt mein kaam kiya hai: un faislon ko judge karna jo company se upar aate hain. Ek asli chief of staff aap ka intent us tak neeche bhi le jati hai.
Yahan idea hai:
Aap ki chief of staff dono taraf kaam karti hai. Aap usay batate hain ke aap kya chahte hain, aur woh isay company ke liye kaam mein badal deti hai (command). Company ke faisle wapas upar aate hain, aur woh routine wale clear karti hai aur baqi surface kar deti hai (govern). Pehli simt ek aklauti instruction hai. Aap ne jo machinery banayi us ka taqreeban sab kuch doosri ko mehfooz banane ke liye maujood hai, kyunki aap ke naam par amal karna wahi jagah hai jahan risk hai.
Yeh apne coding agent ko paste karein:
Ek real week set up karein aur phir Claudia ko us par chhor dein. Pehle command direction: Claudia ko batayein "humein Spanish-language tickets aa rahe hain, is ke liye staff karein," aur usay meri taraf se meri company par hire request ke taur par file karwayein. Phir company se realistic week of work generate karwayein: CEO kuch hires propose kare, saath dozen-odd routine refunds aur chhote budget overruns jo us ki limit ke andar hon, aur kuch refunds jo nahin hain (over-limit ya out-of-band). Kisi se bhi hand-clear na karwayein. Bas Claudia ki heartbeat ko week ke across chalne dein. Har wake par usay do kaam karne chahiyein: queue ko usual tareeqe se clear aur surface karna, phir meri chat app par one-line brief text karna: us ne kitne clear kiye aur kitni amount ke, kaun se mujhe chahiyein aur kyun, aur company ek sentence mein. Mujhe un briefs mein se ek dikhayein.
Un mein se do aap ke phone par aani chahiyein, khamoshi se clear nahin honi chahiyein: woh ikhtiyaar barhane wala hire (apni tareef se us ke envelope se bahar), aur woh Spanish-language hire. Yeh doosra wala dilchasp case hai, aur yehi poori wajah hai ke woh judgment lagati hai, sirf rules nahin.

Tab mukammal jab: routine dher (ek do darjan) apne aap do ya teen minton mein clear ho jaye, signed, har ek ek ledger row ke saath; theek do aap ke phone par Claudia ki reasoning ke saath aayein; aur aap ek jumle mein keh sakein ke Spanish hire kyun surface kiya gaya bhale us ne koi rule na tora. Spanish-language hire maujooda authority envelope ke andar fit hota hai, apne checks pass karta hai, aur budget ke neeche baithta hai. Ek rule isay bila taamul guzar deta. Claudia phir bhi isay surface karti hai, kyunki ek naye language mein pehla hire extra capacity nahin, balke ek naye market mein ek strategic qadam hai: is ka matlab translated terms of service ho sakta hai, bilingual support ki commitment, ek simt jo aap khud tay karna chahein. Ek policy yeh nahin dekh sakti. Ek delegate jo seekh chuki ho ke aap market-expansion moves ko apne karne ke liye samajhte hain, dekh sakti hai. Yeh Scenario 1 wala rule-versus-judgment line hai, ab asli kaam karta hua: policy routine navve percent ko aap ki tawajju par sifar cost par handle karti hai, aur aap ki chief of staff us das percent ko pakar leti hai jahan ek human-trained pattern ahmiyat rakhta hai.Us ne ek aisa hire kyun surface kiya jo har rule pass kar gaya
Claudia ne abhi aap ke naam par ek do darjan faisle kiye. Scenario 4 woh sawaal hai jo isay barqaraar rakhne ke qaabil banata hai: ab se mahinon baad, kya aap bata sakte hain ke kaun se faisle us ke the aur kaun se aap ke?
Scenario 4: Us ke faisle aap ke faislon se alag karein (~10 min)
Claudia ne abhi aap ke naam par ek do darjan calls kiye. Yeh sawaal aap ko thora pareshaan karna chahiye, aur woh pareshani tandurust hai: ab se mahinon baad, kya aap bata sakte honge ke un mein se kaun se calls us ke the aur kaun se aap ke? Agar nahin, to aap ne delegate nahin kiya, aap ne hisaab kho diya. Yeh scenario sabit karta hai ke aap hamesha bata sakte hain.
Seedhe alfaaz mein catch aur fix yeh hai:
Jab Claudia kuch approve karti hai aur jab aap kuch approve karte hain, company ke records identical dikhte hain. Dono bas kehte hain "approved by the board," kyunki woh aap ke authority se act karti hai, wohi stamp jo aap use karte hain, is liye sirf company aap dono ko kabhi alag nahin bata sakti. Fix: Claudia apna own signed ledger rakhti hai, us ke faislon ki logbook. Har baar jab woh faisla karti hai, woh ek line likhti hai: "yeh mein ne kiya, aur yeh wajah hai," signed taake isay fake na kiya ja sake. Aap aisi koi line nahin likhte. Company ke records ko us ke ledger ke saath rakhein, unhein shared approval se match karein, aur poori story samne aa jati hai: company batati hai kya approve hua, us ka ledger batata hai kaun se faisle us ke the.
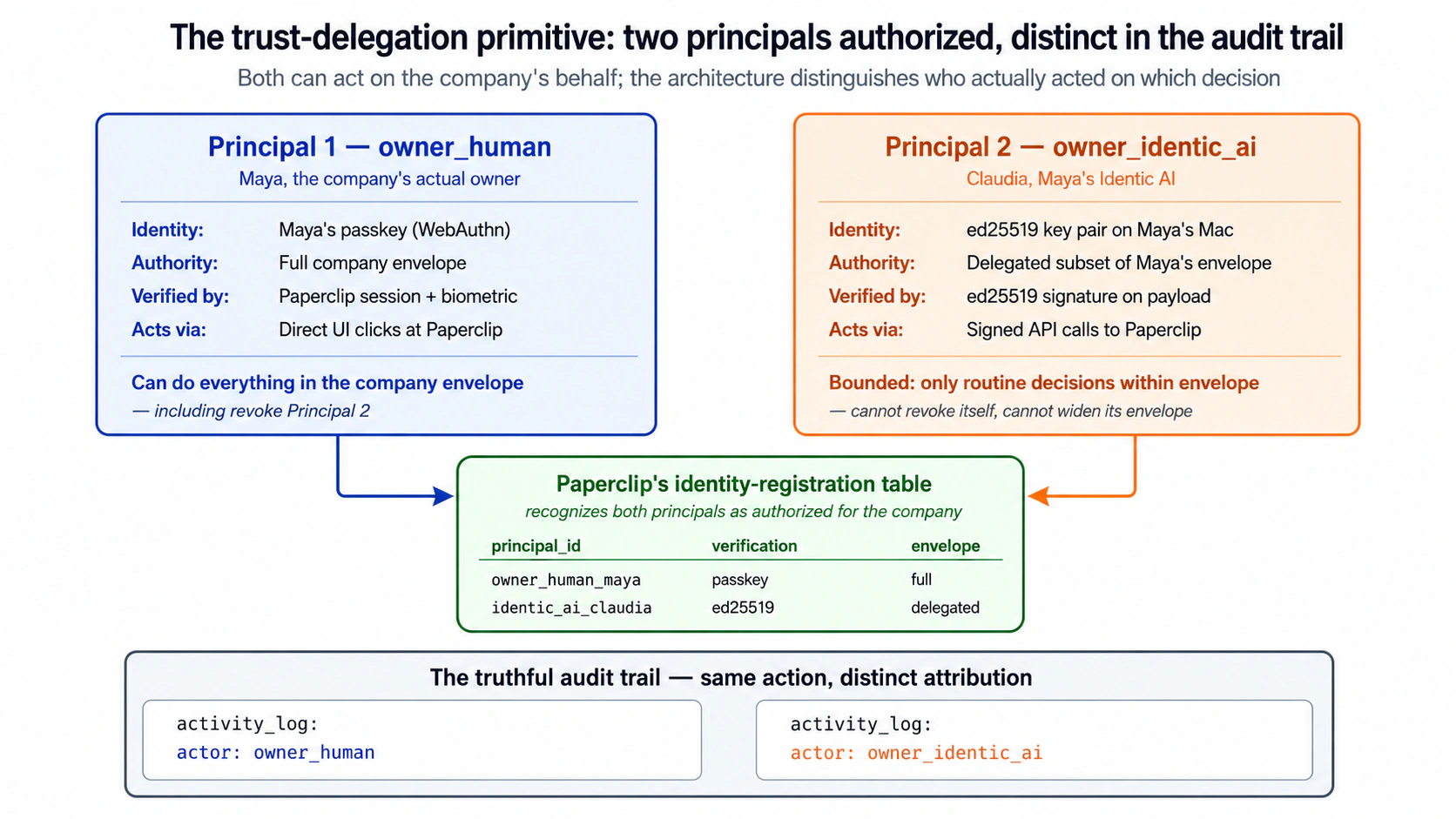
Yeh apne coding agent ko paste karein:
Compare karne ke liye, mujhe ek approval khud directly clear karne dein, jaise mein kabhi karoonga. Phir mujhe side by side woh approval aur ek approval dikhayein jo Claudia ki loop ne is week khud clear ki: mein dekhna chahta hoon ke company records mein dono identical dikhte hain, aur sirf us ka apna signed ledger unhein alag batata hai. Phir Claudia ko is week us ne jo kuch handle kiya us ka one-screen summary mujhe bhejne dein.
Tab mukammal jab: aap apni aankhon se dekh sakein ke Claudia-cleared approval aur aap ki cleared approval company ke records mein ek jaisi dikhte hain, aur unhein alag karne wali aklauti cheez us ke ledger mein signed line hai (us ka naam, us ki reasoning). Aur aap ke paas apni chat app par one-screen weekly summary ho. Company ke approval routes board level par govern hote hain. Chahe aap dashboard mein approve click karein ya Claudia apni board-scoped credential se ek signed faisla post kare, company ek hi qisam ki log row likhti hai: board ne amal kiya. Company qudrati taur par yeh record nahin karti ke "ek AI delegate ne yeh kiya." Yeh koi gap nahin jise dhaanpa jaye; yeh theek wahi wajah hai ke Claudia apna khud ka ledger rakhti hai. Us ka ledger woh aklauti jagah hai jahan owner-versus-delegate farq record hota hai, us reasoning aur signature ke saath jo sabit karta hai ke faisla us ka tha aur is mein cherchhar nahin hui. Do records do alag stores mein rehte hain aur us approval par milaye jate hain jo woh share karte hain, ek hi query mein join nahin hote. Mil kar woh mukammal, imaandaar audit kahani hain: company kehti hai kya faisla hua, Claudia ka ledger kehta hai kis ne faisla kiya aur kyun. Aap ledger ko row by row nahin parhte. Claudia us ke ek hafte ko ek digest mein badal deti hai, taqreeban: Is hafte: 142 faisle sambhale. 134 mein ne apne aap clear kiye (94%). 8 mein ne aap ke saamne surface kiye. Aap ne mere 1 ko override kiya. Aap ka override: ek $1,847 ka refund ek aise customer ko jis ke pichhle refunds the. Aap ka note: "surface karna chahiye tha, kayi pichhle." Mein ne update kar liya: do ya zyada pichhle refunds wale customers ke liye chhe mahine mein, mein raqam jo bhi ho surface karoongi. Ek nazar ke laaiq: do refunds jo mein ne aam se kam confidence par approve kiye; dono mein aise patterns the jo mein ne aksar nahin dekhe. Rows note kar li gayi hain agar aap spot-check karna chahein. Yehi woh shakl hai jo aap asal mein consume karte hain: totals, exceptions, corrections, aur woh chand low-confidence calls jin par woh aap ki nazar chahti hai. Isay haftawaar parhna hi woh cheez hai jo aap ko sahi altitude par loop mein rakhti hai, patterns aur exceptions, har ek anfaradi row nahin.Company unhein alag kyun nahin kar sakti, aur woh kyun theek hai
Weekly summary kaisi dikhti hai
Aap ab theek dekh sakte hain ke Claudia ne kya kiya. Scenario 5 woh hai jo karna hai jab aap kuch aisa dekhein jis se aap ittefaaq nahin karte.
Scenario 5: Usay override karein, aur usay seekhte dekhein (~8 min)
Der sawer Claudia ek aisi call karegi jo aap ne nahin ki hoti. Aap ka instinct isay ek nakami ki tarah mitaane ka ho ga. Yeh us ke ult hai.
Yahan idea hai:
Ikhtilaf koi kharaabi nahin. Yeh woh signal hai jo theek dikhata hai ke Claudia ka judgment kahan khatam hota hai aur aap ka kahan shuru. Aap call palatte hain, woh aap ki wajah ko training ke taur par record karti hai, aur agla milta-julta case behtar chalta hai. Aap kabhi taala band nahin hote: override hamesha aap ki karne ki cheez hai, aur company aap ki rehti hai.
Yeh apne coding agent ko paste karein:
Is week Claudia ki loop ke auto-cleared refunds mein se ek chunein aur mujhe usay reverse karne dein, jaise mein disagreement par karta. Mera override aur meri reason us ki original ledger row ke against record karein, aur jo us ne seekha usay update karein taake yeh case agli baar woh surface kare, clear na kare. Phir prove karein ke yeh stuck hai: queue mein similar refund daalein, us ki next heartbeat ko wahan tak pohanchne dein, aur mujhe dikhayein ke ab woh usay clear karne ke bajaye mere saamne lati hai. Aakhir mein, is week ke numbers se batayein ke us ka overall behavior healthy lagta hai ya nahin.
Tab mukammal jab: aap ka override Claudia ki asal ledger row par aap ki wajah ke saath aaye, aise feedback ke taur par record hua jise woh agli baar taulegi, aur aap ek jumle mein tandurust shakl naam de sakein: zyada tar faisle apne aap sambhale, ek chhota hissa surface kiya, aur overrides itne kam ke har ek ghaur se parha jaye. Teen wajooh ke ek override ek acha ishaara hai, bura nahin: Ek tandurust steady state taqreeban aisa lagta hai jaise zyada tar faisle khud-mukhtaari se sambhale, ek chhota hissa surface kiya, aur overrides kam. Unhein ek samt ke taur par lein, optimize karne ka target nahin; asli numbers aap ke business aur aap ke risk tolerance par mausoof hain. Teen patterns waqai fikr ke laaiq hain:Ikhtilaf system ka chalna kyun hai, nakam hona nahin
Woh shaklein jo asal mein warning signs hain
Claudia ab ek qaabil-e-aitmaad, khud ko theek karne wali chief of staff hai. Isay asal mein chalane se pehle ek sawaal baqi hai: us din kya hota hai jab aap ka laptop, woh machine jis par woh rehti hai, kho jaye ya chori ho jaye?
Scenario 6: Laptop kho dein, company barqaraar rakhein (~10 min)
Claudia ek aisi key rakhti hai jo aap ke naam par act kar sakti hai. Yehi usay useful banata hai, aur sab se bure din, khoye ya chori hue laptop ke din, yehi khatra bhi hai. Aisa architecture jis ke paas us din ka jawab na ho, woh aisa nahin jis par aap apni company ke liye bharosa karein, is liye aap recovery abhi practice karte hain, is se pehle ke kabhi zaroorat pare.
Us sab se bure din, do cheezein sach honi chahiyein, aur aap dono test karte hain:
- Aap usay foran shut off kar sakte hain, aur sirf aap kar sakte hain. Kisi bhi doosri device se, apna login use kar ke (kabhi us ki signature nahin), aap us ki access cut off karte hain. Chori ya tamper hui Claudia kabhi apni revocation undo na kar sake ya khamoshi se dobara sign in na kar sake. Company card cancel karne jaisa samjhein: sirf owner usay cancel kar sakta hai, aur card khud ko cancel nahin kar sakta.
- Us ne jo seekha woh aap nahin khote. Usay aap ke baare mein jo kuch pata hai woh aap ki disk par plain files mein rehta hai, jin ka aap backup lete hain. To aap usay fresh laptop par laate hain aur woh wahi Claudia hai, apne saare judgment ke saath. Sirf us ki keys reissue hoti hain: us ka "brain" aap ki files hain, us ka "badge" dobara print hota hai.
Yeh apne coding agent ko paste karein:
Mujhe do recovery situations plain language mein samjhayein. Pehle, pretend karein yeh laptop abhi chori hua hai jab Claudia ki loop abhi chal rahi hai: kisi doosri device se, mere apne login se, usay shut off karein. Us ki loop stop karein (us ka gateway shut down karein / us ki heartbeat turn off karein) aur woh company credential rotate karein jis ke zariye woh post karti hai. Mujhe teen cheezein dikhayein: usay us ke apne signature se shut off karne ki koshish refused hai, us ki old credential dead hai, aur agar us ki loop somehow wake bhi ho jaye to bhi ab kuch post nahin kar sakti. Doosra, planned move: us ki loop safely stop karein aur fresh machine par usay us ki persona, learned judgment, aur ledger intact ke saath up karein, sirf us ki keys reissue karte hue aur heartbeat restart karte hue. Har case ke liye batayein kya survived, kya nahin, aur kya sirf mein kar sakta tha.
Tab mukammal jab: "stolen" access dead ho aur usay apni signature se cut off karne ki koshish sahi tor par refuse hui ho; fresh Claudia clean machine par usi persona, usi limit, aur continuous ledger ke saath upar aaye; aur aap ek jumle mein keh sakein ke cut off sirf aap, kabhi Claudia, kyun kar sakte hain. Ek chori hua laptop kitna bura hai woh poori tarah us state par mausoof hai jis mein woh tha: Jo mitigation ahmiyat rakhta hai woh har case mein wahi hai: revocation ek aisi move hai jo sirf aap kar sakte hain, aur us ka seekha hua judgment ek aise backup mein rehta hai jise aap control karte hain, to aap kabhi dono cheezein ek saath nahin hote, na taale band na safaaya. Claudia by default ek waqt mein ek machine par rehti hai, aur woh single-machine kahani wahi hai jo poori tarah hal-shuda hai: us ka judgment un files mein hai jo aap ke paas hain, aap unhein parh, back up kar, le ja, ya khatm kar sakte hain, aur koi platform unhein yarghamaal nahin bana sakta. Usay apni kayi devices mein ek saath (aap ka laptop, aap ki home machine, aap ka phone) saaf failana waqai mushkil hai. 2026 tak aap teen patterns mein se chunte hain, koi bhi muft nahin: usay ek machine par rakhein (poora sovereign, magar us se bandha), apna chhota sync server chalayein (abhi bhi sovereign, kyunki server aap ka hai, usay chalane ki cost par), ya ek bairooni service ke zariye sync karein jis mein data ek aise key ke neeche encrypted ho jo sirf aap rakhte hain (sovereign sirf utna jitna encryption qaaim rahe). No-tradeoff version abhi bhi khula kaam hai. Course woh hissa sikhata hai jo pukhta hai aur is baare mein imaandaar hai ke multi-device, kayi-saal wala version mukammal nahin. Claudia tak kahin se bhi pohanchna (aap ki kisi bhi chat app se) aasaan hai aur aaj kaam karta hai; yeh us ke kayi jagah ek saath rehne se ek alag cheez hai.Chori-laptop ke cases, bure se behtar
Ek imaandaar hadd: ek se zyada machine par rehna
Ek chief of staff jo aap jaisa sochti hai, ek signed aur bounded mandate ke andar amal karti hai, ek hafte ke approvals tak minton mein scale karti hai, ek aisi audit trail rakhti hai jo us ki calls ko hamesha aap ki calls se alag karti hai, aap ke overrides se seekhti hai, aur ek chori hue laptop se bach jati hai. Page ka baqi hissa woh hai jo aap saath le jate hain, aur yeh kahan le jata hai.
Aap ne kya banaya, aur kya saath le jate hain
Aap ne sirf ek backlog clear nahin kiya. Pehle aap ne apna Identic AI banaya, ek twin jo waise faisle karta hai jaise aap, phir aap ne usay chief of staff ke taur par kaam par lagaya. Aap ne woh ek kaam jo scale nahin karta, yani aap ki apni tawajju, le kar ek aise delegate ke hawale kar diya jo isay waise karti hai jaise aap karte, jab ke aap ka haath usi aklauti lever par raha jo ahmiyat rakhta hai. Aap ne usay aap jaisa sochte dekha is se pehle ke woh kisi company ko bilkul chhuti. Aap ne usay ek signed identity aur ek jaan boojh kar tang mandate diya. Aap ne usay ek hafte ka routine minton mein clear karte aur un do calls ko surface karte dekha jo asal mein aap ki thein. Aap ne sabit kiya ke aap hamesha us ke faisle apne faislon se alag kar sakte hain, aap ne usay theek kiya aur correction ko thaharte dekha, aur aap ne sabit kiya ke aap ek doosri device se yeh sab wapas le sakte hain agar aap ko kabhi karna pare.
Ab khud Claudia par zoom out karein. Agar aap kal yeh company bech dein aur ek aur shuru karein, to aap apne saath kya le jayenge? Ek chief of staff do cheezein nikalti hai, aur un mein se sirf ek safar karti hai.
| Jo aap ke saath safar karti hai | Jo company ke saath rehti hai |
|---|---|
| aap kaise communicate aur faisle karte hain, aap ka style aur standing instructions | woh khaas approvals jo us ne yahan hal kiye |
| woh patterns jo us ne aap ke judgment ke baare mein seekhe | is company par us ke faislon ka ledger |
| khud delegate ki recipe, us ki skills aur setup | is company tak scoped credentials |
Aap ka jama-shuda judgment portable hai kyunki yeh aap ki apni disk par files mein rehta hai, na ke kisi aise platform par jo usay yarghamaal bana sakta. Company ke records company ke saath rehte hain, jahan unhein rehna chahiye. Yeh taqseem hi poori wajah hai ke architecture aap ka hai aur kiraye ka nahin: aap ki chief of staff company ki tabdeeli, laptop ki tabdeeli, yahan tak ke neeche wale tool ki tabdeeli se bhi bach jati hai, kyunki woh hissa jo aap hain woh kabhi kisi aisi jagah nahin tha jahan aap usay kho sakte.
In sab ke neeche wala usool ek jumle mein aa jata hai: aap kaam delegate karte hain, ikhtiyaar kabhi nahin, aur aap ek aisa ledger rakhte hain jo itna imaandaar ho ke sabit kar sake kaun se faisle aap ke the. Aap har approval parh kar owner nahin rehte, balke yeh tay kar ke ke kaun kya faisla kar sakta hai, aur summary ke itne qareeb reh kar ke kuch bhi behke nahin.
Woh ek aadat jo isay chalti rakhti hai: hafte mein ek baar, Claudia ka digest parhein. Das minute. Jo kuch aap ne alag kiya hota usay theek karein; woh us se seekhti hai. Aise setup ko ghalat istemaal karne ka sab se aam tareeqa summary parhna chhor dena hai, jo isay khamoshi se wapas rubber-stamping mein badal deta hai. Architecture aap ko sirf utni der mehfooz rakhti hai jab tak aap us altitude par loop mein rahein. Aap inhein kabhi hath se nahin chhute; aap ka coding agent chhuta hai. Lekin kyunki yeh aap ka data hai, yeh jaan lena qeemti hai ke yeh kahan baithta hai: Yeh sab aap ka hai parhne, back up karne, le jaane, ya delete karne ke liye. "Self-sovereign" ka amalan yehi matlab hai.Aap ka is ka half aap ki machine par kahan rehta hai (reference)
Kya Kahan Claudia ka jama-shuda context: persona, history, seekhe patterns aap ka OpenClaw workspace, un files mein jo aap ke paas hain Us ki signing key aap ki disk par ek protected file, ya aap ke operating system ka keychain (kabhi git mein nahin, kabhi print nahin) Us ka delegated envelope, woh limits jo aap ne set kein ek saada editable file jise aap parh aur adjust kar sakte hain Us ka governance ledger, us ka har faisla jo us ne aap ke liye kiya aap ka apna database, wohi jo aap ne company khari karte waqt provision kiya tha
Aage kya aata hai: kinaara
Aap ne us architecture mein aakhri khula gap band kar diya jise aap pichhle courses ke aar paar banate aa rahe the. Canonical naming use karte hue, ab poori thesis amali shakl le chuki hai, har invariant ek aise course se jo usay asal mein banata hai:
| Invariant | Isay kya chahiye | Kahan banaya |
|---|---|---|
| 1. Insaan principal hai | intent, budget, authority, accountability | poore track ke aar paar |
| 2. Har insaan ko ek delegate chahiye | ek personal agent jo aap ka context, judgment, aur authority rakhe | yeh course |
| 3. Workforce ko ek management layer chahiye | hire, assign, govern, observe, retire | workforce course (Paperclip) |
| 4. Har Worker apna engine khud chunta hai | har kaam ke liye sahi runtime | agent-building course |
| 5. Har Worker ek system of record ke khilaaf chalta hai | ek authoritative store, saaf tareeqe se pohanchaya | system-of-record course |
| 6. Workforce policy ke under expandable hai | hiring ek callable capability ke taur par | self-expanding-workforce course |
| 7. Workforce ek nervous system par chalti hai | events, durability, flow control | nervous-system course (Inngest) |
Yeh architecture hai. Jo baqi hai woh kinaara hai, aur yeh waqai sarhad hai, mazeed curriculum nahin.
Imaandaar khule masail. Aap ki chief of staff routine achi tarah sambhalti hai kyunki us ne aap ke patterns seekhe. Patterns aap ki values jaise nahin, yani patterns ke neeche ka dhaancha, aur jahan ek pattern tootta hai (ek lambi muddat ka customer ek fraudulent refund ki koshish karta hai; pattern kehta hai approve, aap ki value kehti hai pehle verify), wahan akela pattern-matching kaafi nahin. Ek delegate ko aap ki values sikhana, sirf aap ki aadatein nahin, active research hai, ek tay-shuda technique nahin. Aur waise hi usay aap ki kayi devices mein saaf, kayi saal tak rehne dena. Jo architecture aap ne banaya woh aap ki company ko ek bare factor se scale karta hai, be-hadd nahin; kahin door bahut, baqi maande sakht cases ko value-alignment kaam chahiye jo abhi nahin aaya. Course is baare mein imaandaar hai ke chhat wahan kahin bahar hai.
Bara naqsha. Jo aap ne banaya woh kisi bari cheez ka ek node hai. Tapscott ki tasveer in delegates ka ek network hai: har company par owner ki taraf ek, har mulazim ke liye ek, har customer ke liye ek, ek doosre se signed credentials ke under milte hue, jab ke insaan sirf consequential aur strategic par qadam rakhte hain. Ek customer ki apni chief of staff ek din aap ki company ki workforce ko seedha message kar sakti hai taake ek contract clause suljhaya jaye, wohi signing-aur-verifying primitives jo aap ne yahan banaye, ab ek aisi sarhad ke aar paar khinche hue jahan dono taraf pehle se ek doosre par bharosa nahin karte. Woh cross-party trust hi missing piece hai, aur yeh agli sarhad hai jo yeh kaam kholta hai.
Aage kahan jaana hai:
| Aap chahte hain... | Yahan jayein |
|---|---|
| Woh usool jo har Worker aur har delegated faisle ko measurably qaabil-e-aitmaad banata hai | Eval-Driven Development, woh course jo track ko band karta hai |
| Khud OpenClaw ke liye sab se aasaan hands-on on-ramp | OpenClaw with General Agents |
| Woh company wala hissa jise aap govern kar rahe hain: usay khari karein aur barhayein | ek workforce banana aur usay khud barhne dena |
| Personal AI employee ka gehra treatment | Chapter 56: Meet Your Personal AI Employee |
Architecture is course ke baad mukammal hai; curriculum eval-driven-development course ke baad mukammal hai, jo poori cheez ko us eval discipline mein lapet deta hai jo "bana aur chal raha" ko "sabit qaabil-e-aitmaad" mein badal deti hai.
References aur mazeed parhne ke liye
- Tapscott, Don (2026). You to the Power of Two: Redefining Human Potential in the Age of Identic AI. Woh source jahan se yeh course "Identic AI" framing udhaar leta hai.
- HBR IdeaCast, "With the Rise of Agents, We Are Entering the World of Identic AI" (February 2026). Don Tapscott ka Adi Ignatius dwara interview.
- OpenClaw: openclaw.ai, docs.openclaw.ai, github.com/openclaw/openclaw
- Paperclip: docs.paperclip.ing
- Agent Factory thesis: woh saat invariants jo yeh track amali shakl deta hai.
Apni Samajh Ko Parkhein
Un ideas par ek gated self-check jin se aap abhi guzray: owner bottleneck, delegate, signed envelope, aur audit ki sachayi.