AI असल में क्या है: एक crash course
9 Ideas, No Math, No Code: वह एक चीज़ जो बाकी पाँच courses मान लेते हैं कि आप पहले से समझते हैं।
Engine क्या है, यह जाने बिना भी आप car चला सकते हैं। ज़्यादातर लोग ऐसे ही चलाते हैं। लेकिन जिस पल कुछ गड़बड़ होता है (कोई आवाज़, कोई warning light, पहाड़ी पर गाड़ी का रुक जाना) तब वे लोग जो मोटे तौर पर जानते हैं कि hood के नीचे क्या है, शांत रहते हैं, और जो नहीं जानते, वे घबरा जाते हैं। वे एक मामूली खड़खड़ाहट और seize हुए engine में फ़र्क नहीं बता पाते, क्योंकि उनके लिए पूरी machine एक बंद डिब्बा है जो या तो चलता है या नहीं।
ज़्यादातर लोगों का AI के साथ यही रिश्ता है। उन्होंने इसे चलाना सीख लिया है (बाकी पाँच Foundations courses आपको सचमुच एक अच्छा driver बना देते हैं) लेकिन उन्होंने एक बार भी hood के नीचे नहीं झाँका। इसलिए जब machine कुछ अजीब करती है (कोई source गढ़ देती है, ख़ुद का विरोध कर बैठती है, या किसी पूरी तरह ग़लत बात पर पूरी तरह confident लगती है), तब उनके पास कोई model नहीं होता कि ऐसा क्यों हुआ, और वे या तो उस पर ज़रूरत से ज़्यादा भरोसा कर लेते हैं या उसे पूरी तरह खारिज कर देते हैं। दोनों ही प्रतिक्रियाएँ एक ही जगह से आती हैं: यह न जानना कि यह चीज़ असल में है क्या।
यह course hood के नीचे एक झाँक है। mechanic वाला नज़रिया नहीं: यहाँ कोई math नहीं है, कोई code नहीं, कोई neural-network diagram नहीं जिसे आपको समझना पड़े। बस वे नौ ideas जो AI के हर हैरान करने वाले व्यवहार को समझाते हैं, ताकि failures रहस्य रहना बंद कर दें और predictable बन जाएँ। एक बार आप failures predict कर पाएँ, तो आप उनसे बच सकते हैं, और बस यही पूरा फ़ायदा है।
छह Foundations courses में से, यही वह है जिसे बाकियों से पहले पढ़ना चाहिए, भले ही यह सबसे abstract है। 2026 में AI Prompting, Markdown In, HTML Out, Code You Never Write, Skills & Connectors, और AI युग में कैसे सोचें सब आपको सिखाते हैं कि machine को कैसे use करें। ये सब machine क्या है इसके बारे में कुछ तथ्यों पर टिके हैं ("यह stateless है," "यह predict करता है, look up नहीं करता," "यह ग़लत होने पर भी confident रहता है") और इन तथ्यों को एक-एक वाक्य में, गुज़रते हुए बता देते हैं। यह course वह जगह है जहाँ से वे वाक्य आते हैं। इसे एक बार पढ़ें, और बाकी पाँच courses का हर "यह ऐसा क्यों करता है?" का जवाब पहले से तैयार मिलेगा।
कुछ topics इस course और 2026 में AI Prompting दोनों में आते हैं, यह जान-बूझकर है, दोहराव नहीं। यह course mechanism देता है (एक explanation, फिर आगे बढ़ जाता है); prompting course practice देता है (आदतें, गहराई में)। जहाँ दोनों छूते हैं:
| Topic | यहाँ (machine) | AI Prompting in 2026 (habit) |
|---|---|---|
| यह क्या जानता है | learning क्यों froze हुई (Idea 2) | वह knowledge कितनी reliable है, topic by topic (Concept 2) |
| Context window | model को दिखने वाली यह एकमात्र चीज़ क्यों है (Idea 5) | इसे manage और protect कैसे करें (Concept 4) |
| Confidence | यह sure क्यों लगता है और आपसे agree क्यों करता है (Idea 6) | उसे neutralize कैसे करें (Concept 6) |
| Reasoning | "thinking" असल में क्या है (Idea 9) | इसे कब on करें, और कब नहीं (Concept 5) |
| Images और audio | ये बस और tokens क्यों हैं (Idea 4) | इनके साथ असल में काम कैसे करें (Concept 8) |
मोटा नियम: जिस पल यहाँ कोई section आपको कोई आदत सिखाने वाला होता है, वह रुक जाता है और आपको prompting course की ओर भेज देता है। वही handoff दोनों के बीच की रेखा है।
📚 Teaching Aid
पूरा Presentation देखें: AI असल में क्या है
दो मिनट में इसे साबित करें
किसी भी explanation से पहले, machine को ऐसे व्यवहार करते देखें जो तभी समझ आता है जब आप जानते हों कि यह है क्या। Claude.ai, ChatGPT, या Gemini खोलें (free account बनाने में एक मिनट लगता है) और जान-बूझकर की गई spelling की ग़लती के साथ बिलकुल यही paste करें:
Without using any tools, just from memory: how many times does the
letter R appear in the word "strawberry"? Then spell the word out
one letter at a time and count again.
देखें क्या हो सकता है: पहले pass में कुछ models अभी भी ग़लत गिनते हैं, फिर जिस पल वे word को एक-एक letter करके spell करते हैं, सही गिन लेते हैं। एक machine जो आपके लिए चलता हुआ program लिख सकती है, वह छह अक्षरों वाले एक word में letters भरोसे से नहीं गिन पाती, जब तक आप उसे word को टुकड़ों में तोड़ने पर मजबूर न करें। यह बेवक़ूफ़ी नहीं है। यह इस course के सबसे ज़रूरी एक तथ्य का सीधा, दिखने वाला नतीजा है: model letters नहीं देखता। वह tokens देखता है (Idea 4)। Word उस तक पहले से चंक्स में कटा हुआ पहुँचता है, और किसी चंक के अंदर के letters गिनना उसके लिए सचमुच मुश्किल है, ठीक वैसे ही जैसे किसी इमारत के कमरे गिनना मुश्किल है अगर किसी ने आपको सिर्फ़ इमारत का street address दिखाया हो।
दो मिनट, एक अजीब व्यवहार, और आप पूरे page की theme से मिल चुके हैं: AI की हर हैरान करने वाली चीज़ इस बात से समझाई जाती है कि यह असल में है क्या, इससे नहीं कि यह smart है या dumb। नीचे दिए नौ ideas उसी एक example को एक पूरे model में बदल देते हैं।
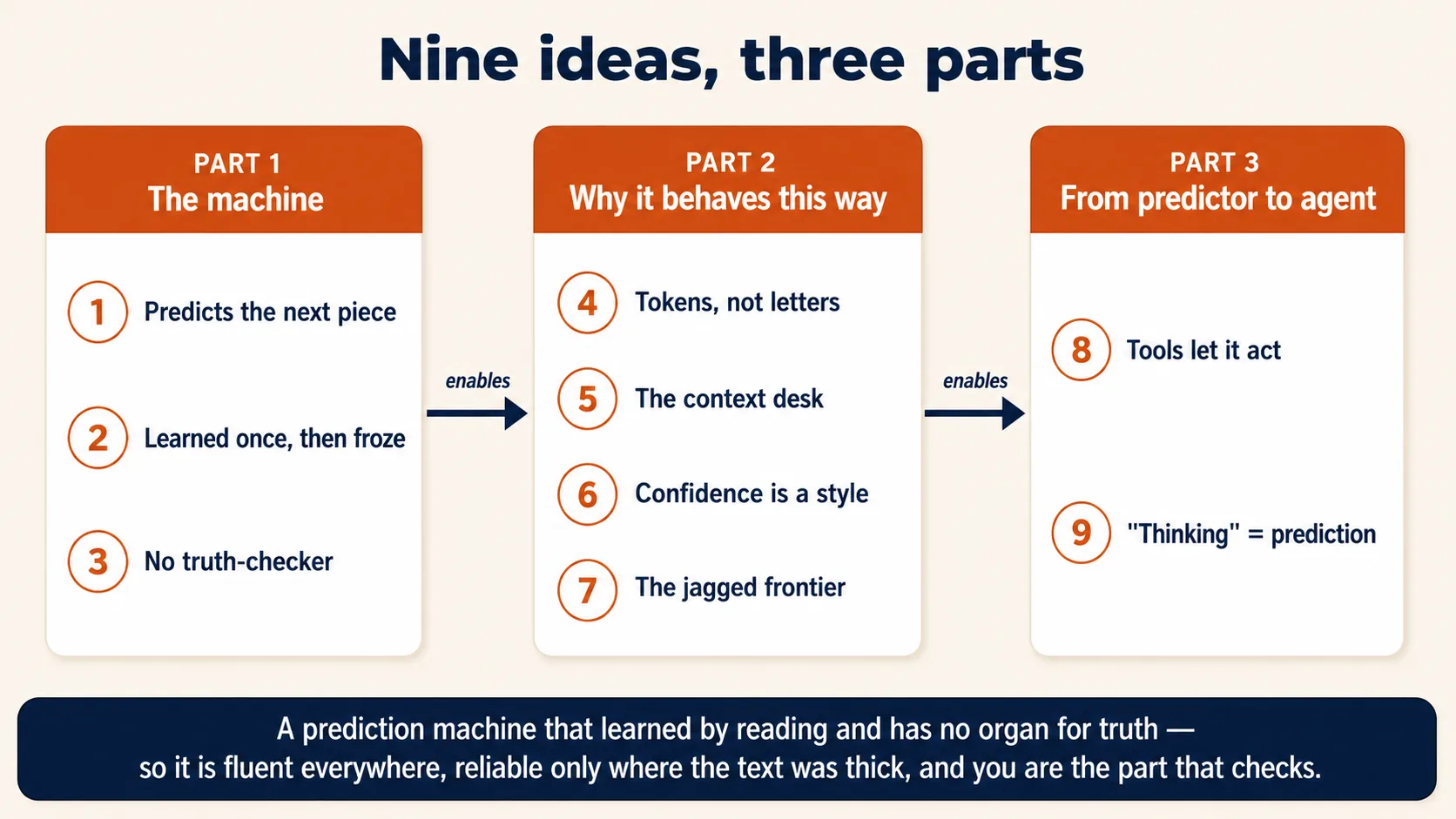
Part 1: The machine
जब आप send दबाते हैं तब असल में क्या हो रहा है, इसके बारे में तीन ideas। इन्हें समझ लें और AI के दो-तिहाई व्यवहार हैरान करना बंद कर देते हैं।
1. यह text का अगला टुकड़ा predict करता है; चीज़ें look up नहीं करता
यह वह एक वाक्य है जिसे आपके दिमाग़ में सच बनाने के लिए यह पूरा course बना है: language model एक machine है जो, कुछ text दिए जाने पर, predict करती है कि सबसे संभावित तौर पर आगे क्या text आता है, एक बार में एक छोटा टुकड़ा। यही पूरा core mechanism है। बाकी सब एक नतीजा है।
यह कितना अजीब है, इस पर थोड़ा रुकना ज़रूरी है, क्योंकि यह उससे बिलकुल अलग है जो ज़्यादातर लोग मान लेते हैं। ज़्यादातर लोग मानते हैं कि AI एक बहुत तेज़ librarian की तरह काम करता है: आप कोई सवाल पूछते हैं, यह किसी विशाल internal encyclopedia में से सही तथ्य ढूँढता है, और आपको पढ़कर सुना देता है। वह mental model ग़लत है, और लोग AI के साथ जो ग़लतियाँ करते हैं उनमें से लगभग हर एक का सिरा यहीं जुड़ता है।
असल में जो होता है वह दुनिया के सबसे ज़्यादा पढ़े-लिखे autocomplete के क़रीब है। आपने autocomplete को "Happy birthday to..." को "you" से पूरा करते देखा है। Language model वही चाल चलता है, बस इतने सारे text पर trained है कि वह किसी भी prompt को आगे बढ़ा सकता है, सिर्फ़ आम वाक्यांश नहीं, और वह उसे एक word नहीं बल्कि एक बार में एक token आगे बढ़ाता है (Idea 4), अपने बनाए हर टुकड़े को वापस ख़ुद में डालकर अगला टुकड़ा तय करता है। इससे France की राजधानी पूछिए और यह France → Paris लेबल वाली कोई database row look up नहीं करता। यह वह continuation बनाता है जो, उसने जो कुछ पढ़ा उस सब में, "The capital of France is" के बाद सबसे संभावित तौर पर आता है, और वह संयोग से "Paris" होता है, क्योंकि वह क्रम उसके training text में दस लाख बार आया।
जाने-पहचाने तथ्यों के लिए, prediction और lookup एक ही जवाब देते हैं, इसलिए फ़र्क academic लगता है। जिस पल text पतला होता है, यह academic रहना बंद कर देता है:

- France की राजधानी पूछिए → संभावित continuation ही सच वाला है। Prediction knowledge जैसी दिखती है।
- ऐसे self-published novel का plot पूछिए जो कुछ सौ copies बिका और online कभी review नहीं हुआ → कोई जाना-पहचाना continuation है ही नहीं, इसलिए model एक जैसी लगने वाली किताबों को मिलाकर सबसे संभावित-लगने वाला plot बना देता है। यह अब भी predict ही कर रहा है। बस इसके पास predict करने के लिए कोई सच्ची चीज़ नहीं है।
Machine दोनों ही मामलों में ठीक वही एक काम कर रही है। सिर्फ़ आप फ़र्क बता सकते हैं, और तभी जब आप जानते हों कि यह क्या कर रही है।
एक librarian की तस्वीर बनाना बंद करें जो ढूँढकर लाता है। एक writer की तस्वीर बनाना शुरू करें जो आगे बढ़ाता है। एक librarian जो किताब नहीं ढूँढ पाता, कहता है "वह हमारे पास नहीं है।" किसी कहानी को आगे बढ़ाने को कहा गया writer कभी रुककर यह नहीं जाँचता कि continuation सच है या नहीं। आगे बढ़ाना ही पूरा काम है। इसीलिए AI कभी "मेरे पास वह नहीं है" वैसे नहीं कहता जैसे librarian कहता, जब तक उसे ख़ास तौर पर ऐसा सिखाया न गया हो। संभावित continuation इसका सहज काम है; truth ऊपर से जोड़ी गई चीज़ है, अधूरी तरह से।
एक ही सवाल हर बार अलग जवाब क्यों देता है
Machine एक अगला token predict नहीं करती। यह संभावित अगले tokens का एक पूरा फैलाव predict करती है, हर एक के साथ एक likelihood ("Paris" बहुत संभावित, "the largest city in France" संभव, एक दर्जन और घटते हुए) और फिर उस फैलाव में से एक चुन लेती है। यह कितने adventurous ढंग से चुनती है, यह आमतौर पर temperature कहलाने वाली एक setting से तय होता है: low temperature इसे लगभग हमेशा सबसे संभावित token चुनवाती है (steady, दोहराव वाली), high temperature इसे कम संभावित tokens की ओर पहुँचने देती है (varied, ज़्यादा creative, कभी-कभी पटरी से उतरी हुई)। ज़्यादातर chat products एक बीच की value रखते हैं, इसीलिए एक ही सवाल दो बार पूछने पर आपको दो अलग-अलग शब्दों में लिखे जवाब मिलते हैं जिनका मतलब मोटे तौर पर एक ही होता है। यह बदलाव model का "मन बदलना" नहीं है। यह predictions का वही एक फैलाव है, दो बार sample किया गया। (इसीलिए, ऐसे task के लिए जहाँ आप हर बार बिलकुल वही output चाहते हों, आपको कभी-कभी वह chat interface से नहीं मिल पाता: पासे अंदर ही set हैं।)
यह 2026 में AI Prompting (Concept 2) के "frequency equals reliability" नियम की mechanical जड़ है। अब आप जानते हैं कि क्यों frequency का मतलब reliability है: कोई सच्चा continuation training text में जितनी बार आया, machine उसे उतनी ही मज़बूती से predict करती है। पतला topic, कमज़ोर prediction, confident-लगने वाला अंदाज़ा।
Product कर सकता है; model अब भी नहीं करता। आधुनिक tools predictor को कुछ extras में लपेट देते हैं, web search, file reading, code execution, यहाँ तक कि एक memory note (Idea 2), और ये extras असली, ताज़ा तथ्य ला सकते हैं। लेकिन तथ्य context window (Idea 5) में आकर ही पहुँचते हैं, और model अब भी उन्हें जवाब में बदलने का एकमात्र तरीका जानता है: उनमें से एक continuation predict करके। तो "यह predict करता है, look up नहीं करता" बीच वाली machine के बारे में सच बना रहता है, तब भी जब उसके चारों ओर का system अभी-अभी उसके लिए कुछ look up कर चुका हो। Idea 8 वह जगह है जहाँ tools ठीक से सामने आते हैं।
2. यह पढ़कर सीखा, और फिर सीखना रुक गया
Predictions आईं कहाँ से? Training से: model को इंसानी text की एक बहुत बड़ी मात्रा दिखाई गई (किताबें, articles, code, forums, reference works) और इसने ख़ुद को बार-बार adjust किया, ताकि उस text का अगला टुकड़ा predict करने में बेहतर हो जाए। वह adjustment process ही एकमात्र समय है जब model कभी कुछ "सीखता" है। जब training ख़त्म होती है, नतीजा internal numbers के एक तय set में freeze हो जाता है (engineers इन्हें weights या parameters कहते हैं) जो फिर कभी नहीं बदलता।
दो शब्द इसे ठोस बनाते हैं, और इन्हें अलग-अलग रखना ज़रूरी है क्योंकि यह फ़र्क बहुत कुछ समझाता है:
- Training एक बार की पढ़ाई है, एक बार, अतीत में, model बनाने वाली company द्वारा की गई। महँगी, धीमी, ख़त्म हो चुकी।
- Inference वह है जो हर बार होता है जब आप इसे use करते हैं: frozen weights आपके prompt पर चलकर एक continuation predict करते हैं। तेज़, सस्ता, और (यही असली बात है) यह model के अंदर कुछ नहीं बदलता।
जब आप किसी conversation में model को सुधारते हैं और यह कहता है "आप सही हैं, मेरी ग़लती," तब इसने कुछ सीखा नहीं है। इसने वह text predict किया है जो संभावित तौर पर एक सुधार के बाद आता है। Chat बंद करें और अगली conversation ठीक उन्हीं frozen weights से शुरू होती है, बिना किसी याद के कि वह सुधार कभी हुआ था। आपने इसे सिखाया नहीं। आप इसे सिखा नहीं सकते। सिर्फ़ अगला training run weights बदल सकता है, और आप उसका हिस्सा नहीं हैं।

दो नतीजे सीधे इसी से निकलते हैं:
| नतीजा | यह frozen weights से क्यों निकलता है |
|---|---|
| Knowledge cutoff. | Training एक तय तारीख़ पर ख़त्म हुई; उसके बाद जो कुछ हुआ वह weights में है ही नहीं। Model हमेशा के लिए एक brilliant expert है जिसने एक ख़ास दिन news पढ़ना बंद कर दिया। |
| यह आपकी private दुनिया नहीं जान सकता। | आपकी company के numbers, आपका calendar, कल का email training text में कभी थे ही नहीं, इसलिए weights में उनके बारे में कुछ नहीं है। Model छुपा नहीं रहा; वह जानकारी freeze होने के लिए वहाँ थी ही नहीं। |
कुछ products अब एक "memory" देते हैं जो chats के बीच आपको याद रखता लगता है। यह weights को नहीं बदलता। वह inference time पर असंभव ही रहता है। इसके बजाय जो होता है: product चुपचाप आपके बारे में कुछ तथ्य text के रूप में save कर लेता है और वह text हर नई conversation की शुरुआत में context (Idea 5) में दोबारा डाल देता है। यह model का याद रखना नहीं है; यह product का उसे एक note दोबारा खिलाना है। उपयोगी, लेकिन mechanically यह context है, इंसानी मतलब वाली memory नहीं। यह फ़र्क जानना ही model के बाकी व्यवहार को predictable रखता है।
यह "stateless" की mechanical जड़ है, वह शब्द जो 2026 में AI Prompting Concept 4 में use करता है। Stateless का मतलब: अपनी कोई memory नहीं, हर response शून्य से, frozen weights और जो कुछ अभी इसके सामने है उससे, गिना जाता है।
जो शब्द आप सुनेंगे ("parameters," "mixture of experts," "quantization") और इनमें से कोई नौ ideas क्यों नहीं बदलता
जैसे-जैसे आप AI के बारे में पढ़ेंगे, आपको weights कैसे बने हैं इसके लिए शब्दों की एक धारा मिलेगी। तीन सबसे आम, एक-एक line में:
- Parameters (जिन्हें weights भी कहते हैं): इस idea के frozen numbers। "A 400-billion-parameter model" बस उन्हें गिनता है। ज़्यादा का मतलब आमतौर पर ज़्यादा capable और चलाने में ज़्यादा महँगा होता है; यह नहीं बदलता कि numbers करते क्या हैं।
- Mixture of experts (MoE): उन parameters को इस तरह सजाने का एक तरीका कि किसी एक token के लिए सब के बजाय बस एक हिस्सा on हो। इससे एक बहुत बड़ा model तेज़ और सस्ता चलता है। बाहर से machine अब भी ठीक एक ही काम करती है: अगला टुकड़ा predict करना (Idea 1)।
- Quantization: numbers को कम precision पर store करना ताकि model छोटे, सस्ते hardware पर fit हो जाए। वही व्यवहार, हल्का footprint।
Pattern ही असली बात है। ये सब "machine कैसे बनी है और affordable कैसे बनाई गई" का जवाब देते हैं, "machine करती क्या है" का नहीं। नौ ideas में से हर एक (prediction, frozen weights, कोई truth-checker नहीं, tokens, context, confidence, jaggedness, tools, thinking) एक जैसा ही टिका रहता है, चाहे model dense हो या mixture-of-experts, full-precision हो या quantized, सात अरब parameters हो या सात सौ। तो जब कोई headline कहती है कि एक नया model "MoE use करता है" या "एक trillion parameters रखता है," अब आप जानते हैं कि उसका मतलब क्या है और यह कि user के तौर पर आपको जो करना है उसमें यह कुछ नहीं बदलता। जो developments machine के साथ आपके काम करने का तरीका सचमुच बदलती हैं, वे वही हैं जिन्हें यह course cover करता है: reasoning modes (Idea 9), tools (Idea 8), और लंबा context (Idea 5)।
3. कोई अलग जगह नहीं है जहाँ यह जाँचता हो कि बात सच है या नहीं
Ideas 1 और 2 को साथ रखें और आप उस तथ्य तक पहुँचते हैं जो लोगों को सबसे ज़्यादा परेशान करने वाले व्यवहार को समझाता है। एक इंसानी expert के पास दो अलग faculties होती हैं: एक जो जवाब बनाती है, और एक दूसरी, शांत वाली जो उसे जाँचती है: "रुको, क्या मुझे इसका यक़ीन है? मैंने यह कहाँ सीखा? क्या यह सही लगता है?" दोनों असहमत हो सकती हैं। आप कुछ ज़ोर से कह सकते हैं और उसी साँस में महसूस कर सकते हैं कि यह ग़लत हो सकता है।
Model के पास सिर्फ़ पहली faculty है। इसके अंदर कोई दूसरी machine नहीं है जो आप तक पहुँचने से पहले prediction को truth के लिए audit करे। वही एक process जो सही continuation बनाती है, ग़लत वाली भी बनाती है, बिना किसी internal flag के जो दोनों में फ़र्क बताए। Fluent, सही ढंग से बना, confident वाक्य वही output है, चाहे अंदरली prediction training text से अच्छी तरह समर्थित थी या हवा से खींची गई। Fluency machinery बनाती है; truth उससे अलग verify नहीं होती।
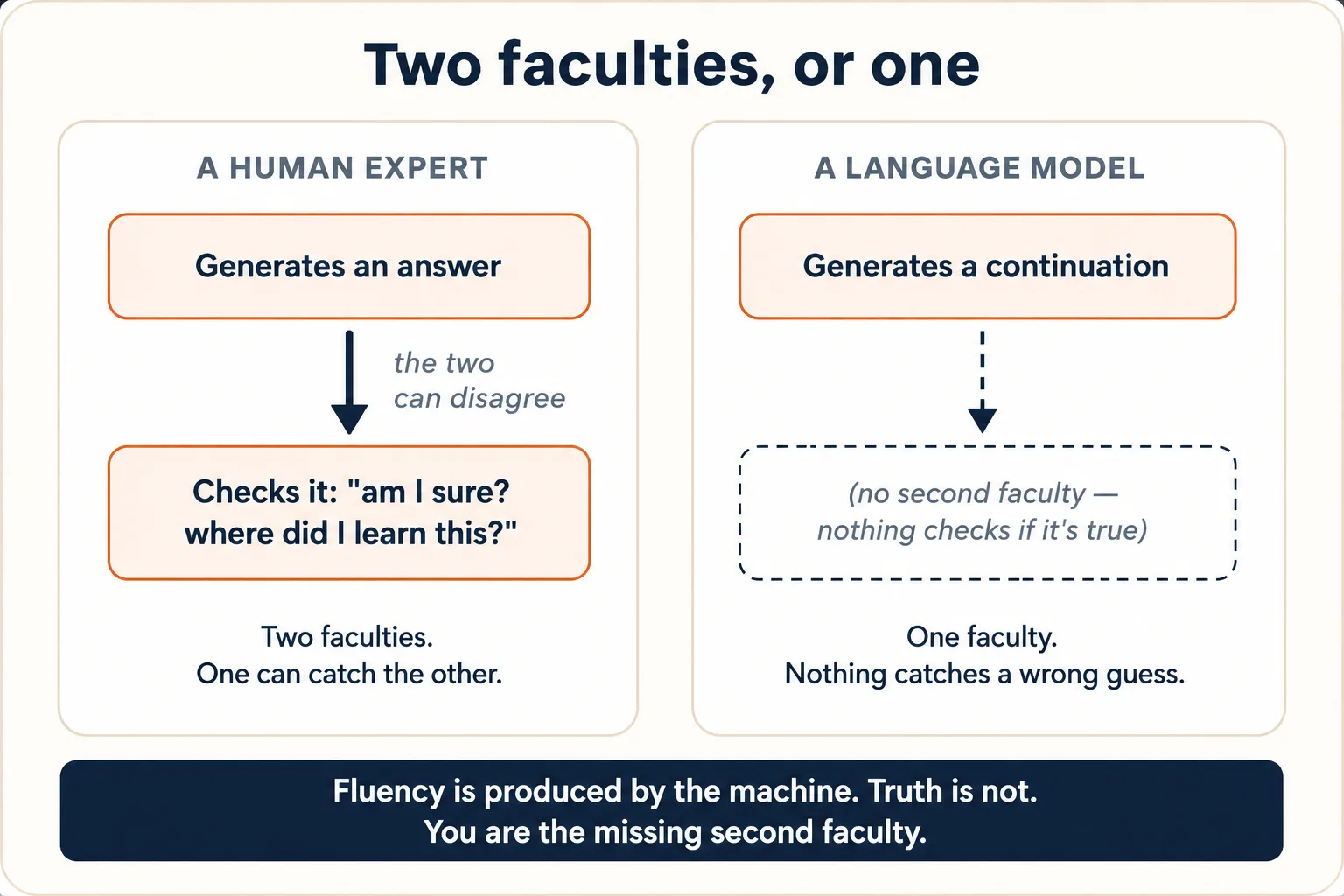
लोग जब कहते हैं कि AI hallucinate करता है तो वे इसी की ओर इशारा कर रहे होते हैं: यह fluent, confident, पूरी तरह झूठे statements बनाता है। शब्द ऐसा लगवाता है जैसे यह कोई ख़राबी हो, ठीक की जाने वाली कोई glitch। यह glitch नहीं है। यह machine का ठीक वैसे काम करना है जैसे बनी है: एक संभावित continuation predict करना, ऐसी जगह जहाँ संभावित continuation संयोग से सच नहीं होता। एक unaided model जो कभी hallucinate न करता, वह एक पूरी तरह अलग किस्म की machine होती, जिसके चारों ओर असली retrieval, verification, या मना करने की क्षमता बनी होती। ऊपर से जोड़े गए tools और checks (Idea 8) कम करते हैं कि यह कितनी बार होता है; वे बीच वाली चीज़ की fitrat नहीं बदलते, जिसका पूरा काम आगे बढ़ाना है।
Model का confident अंदाज़ इस बात का सबूत नहीं है कि वह सही है। यह अंदाज़ एक style है जो इसने confident इंसानी लेखन से सीखा (Idea 6 में और); यह content की तरह उसी process से बनता है, और truth से उतना ही कटा हुआ है। एक गढ़ा हुआ आँकड़ा ठीक उसी भरोसेमंद आवाज़ में आता है जिसमें एक असली आँकड़ा। यही पूरी वजह है कि AI युग में कैसे सोचें course मौजूद है: इसकी Error Taxonomy (Discipline 3) उन झूठे continuations को हाथ से पकड़ने की checklist है जिन्हें machine के पास ख़ुद पकड़ने का कोई तरीका नहीं। गुम दूसरी faculty आप हैं।
एक non-software example। एक माता-पिता ने AI से अपने शहर की एक ख़ास छोटी tuition academy का सटीक fee schedule और class timings पूछीं, ऐसी academy जिसकी कोई website नहीं थी और online लगभग कोई मौजूदगी नहीं थी। AI ने courses, timings, और मासिक fees की एक confident, सुथरी तरह formatted table बना दी। हर आँकड़ा गढ़ा हुआ था। AI ने न झूठ बोला था और न ख़राब हुआ था। वह academy किसी भी training text में बमुश्किल मौजूद थी, इसलिए predict करने के लिए कोई असली schedule था ही नहीं, और एक के अभाव में machine ने वही किया जो वह कर सकती है: इसने वे सबसे संभावित-दिखने वाली fees बना दीं जो ऐसी academy ले सकती हो, उसी confident आवाज़ में रखी हुई जिसमें यह verified तथ्य देती है। इसके पास कोई दूसरी faculty नहीं थी जो फुसफुसाती "यह तो अंदाज़ा है।" वह फुसफुसाहट आपकी ओर से आनी होती है।
Part 2: यह ऐसा व्यवहार क्यों करता है
चार ideas जो अजीब व्यवहारों (letters गिनना, memory ख़त्म हो जाना, sure लगना, एक ही साँस में brilliant और बेकार होना) को ऐसी चीज़ों में बदल देते हैं जिन्हें आप आते हुए देख सकते हैं।
4. यह tokens में पढ़ता है, letters या words में नहीं
Model आपके prompt को letters के रूप में नहीं देखता, और ठीक words के रूप में भी नहीं। कुछ भी होने से पहले, आपका text tokens में कटता है: चंक्स जो आमतौर पर एक word या किसी word का एक टुकड़ा होते हैं। "Strawberry" शायद दो या तीन चंक्स के रूप में आए; "the" एक है; एक लंबा या असामान्य word कई है। Model सिर्फ़ इन्हीं चंक्स को देखता है, इन्हीं चंक्स में predict करता है, और इनके अंदर के अलग-अलग letters कभी नहीं देखता जब तक उसे spell करने पर मजबूर न किया जाए।
यह एक mechanical तथ्य कई और-नाहीं-समझ-आने वाले व्यवहारों का समूह समझाता है:
| व्यवहार | Tokens इसे क्यों समझाते हैं |
|---|---|
| यह किसी word में letters ग़लत गिनता है (strawberry test)। | यह चंक्स देखता है, letters नहीं। किसी चंक के अंदर letters गिनना street address से कमरे गिनने जैसा है। |
| यह कुछ rhyming, anagrams, और wordplay में कमज़ोर है। | ये letters और ध्वनियों पर चलते हैं; model चंक्स पर चलता है। |
| आपके prompt की typos शायद ही मायने रखती हैं। | एक ग़लत spell किया word अब भी ऐसे चंक्स में बदलता है जो इच्छित मतलब के काफ़ी क़रीब हैं। (इसीलिए 2026 में AI Prompting आपको typos ठीक करने की चिंता न करने को कहता है।) |
| Cost और length tokens में नापे जाते हैं, words में नहीं। | जो चीज़ machine असल में process करती है वह token है, इसलिए वही चीज़ है जिसके लिए आपसे पैसे लिए जाते हैं और जिसकी सीमा बँधती है। |
Tokens पैसे की इकाई भी हैं और memory की इकाई भी। जब कोई tool कहता है कि उसके पास "200,000-token context window" है, तो वह बता रहा है कि वह एक बार में इनमें से कितने चंक्स पकड़ सकता है (Idea 5)। जब आपसे "per token" पैसे लिए जाते हैं, तो आप हर आते चंक और हर जाते चंक के पैसे दे रहे हैं। मोटे तौर पर, English में, तीन tokens लगभग चार words के बराबर हैं, लेकिन आपको कभी सटीक अनुपात की ज़रूरत नहीं, बस यह idea कि चंक असली इकाई है, और word एक approximation है जिसे आप ऊपर से जोड़ते हैं।
वह "तीन tokens ≈ चार words" वाला अनुपात English के लिए है। दूसरी scripts (Urdu, Arabic, Hindi, Chinese, और कई और) में text आमतौर पर प्रति word ज़्यादा tokens में कटता है, क्योंकि training text English-भारी था और tokenizer ने English चंक्स सबसे अच्छे सीखे। दो व्यावहारिक नतीजे सीधे निकलते हैं: एक ही message किसी non-English भाषा में ज़्यादा महँगा पड़ता है, और यह context window (Idea 5) तेज़ी से भरता है, इसलिए उस conversation के लिए model की असरदार memory छोटी होती है। यह सुधर रहा है क्योंकि tokenizers बेहतर हो रहे हैं, लेकिन 2026 में यह अब भी असली है। अगर आप ज़्यादातर किसी non-Latin script में काम करते हैं, तो वही task चलाने वाले English user से जल्दी cost और length की सीमाओं तक पहुँचने की उम्मीद रखें। और जब कोई लंबा document मायने रखता हो, तो कभी-कभी model से अंदर-अंदर English में काम करवाना और आख़िर में translate करवाना फ़ायदेमंद होता है।
यह कर सकता है, और mechanism नहीं बदलता: यह generalize करता है। आपकी upload की एक तस्वीर छोटे patches में काटी जाती है, और हर patch एक token बन जाता है; एक sound clip छोटे segments में काटा जाता है, और हर एक token बनता है। फिर model एक ही stream पर predict करता है जो word-चंक्स, image-patches, और audio-segments को साथ मिला देती है। तो इस course की हर बात images और audio के लिए भी टिकती है: वही prediction (Idea 1), वही frozen weights (Idea 2), वही गुम truth-checker (Idea 3), वही context-window-as-desk (Idea 5)। यह वह mechanical वजह भी है कि किसी image में बारीक detail और छोटी छपाई पढ़ना मुश्किल है: एक patch एक चंक है, और किसी patch के अंदर के letters पढ़ना फिर वही strawberry वाली समस्या है। व्यावहारिक पहलू (AI किन images को अच्छा पढ़ता है और किन्हें बिगाड़ता है, और इनके लिए prompt कैसे करें) 2026 में AI Prompting Concept 8 का काम है; नीचे का mechanism बस और किस्मों के tokens, वही machine है।
5. Context window ही एकमात्र चीज़ है जो यह देख सकता है
क्योंकि weights frozen हैं (Idea 2) और model के पास अपनी कोई memory नहीं, ठीक एक ही जगह है जहाँ से यह आपकी ख़ास स्थिति के बारे में जानकारी पा सकता है: context window, वह text जो इस एक response के लिए इसके सामने रखा है। 2026 में AI Prompting इसे Concept 4 के तौर पर सिखाता है, "context is the whole game," और इसे prompting का केंद्रीय हुनर मानता है। यहाँ वह mechanical वजह है कि यह केंद्रीय क्यों है।
Context window एक response के लिए model की पूरी दुनिया है। इसमें आपका prompt, अब तक की conversation, आपके जोड़े गए कोई भी files, tool descriptions, और वह अदृश्य system prompt होता है जिसे product ने आपके आने से पहले वहाँ रखा। उस window में जो भी है, model उसका use कर सकता है। जो उसमें नहीं है, वह इस जवाब के लिए मौजूद ही नहीं है, इसलिए नहीं कि model मना कर रहा है, बल्कि इसलिए कि देखने के लिए और कोई जगह ही नहीं। Frozen weights इसे दुनिया के बारे में सामान्य fluency देते हैं; context window आपकी दुनिया की ख़ासियतों के लिए एकमात्र channel है।
यह दो चीज़ों को नए सिरे से समझाता है जो वरना आपको रहस्यमय लगेंगी:
- Briefing क्यों काम करती है। Model को context देना कोई शिष्टाचार या चाल नहीं है। यह सचमुच जानकारी को उस एकमात्र जगह रखने का काम है जहाँ machine उसे पढ़ सकती है। बिना briefing वाला model आलस नहीं कर रहा; उसके सामने सचमुच कुछ है ही नहीं।
- लंबी conversations बदतर क्यों होती हैं ("context rot," prompting course में)। Window की एक size सीमा है जो tokens में नापी जाती है (Idea 4)। इसमें बहुत सारा ग़ैर-ज़रूरी इतिहास ठूँस दें और जो signal आपको चाहिए वह पतला पड़ जाता है, या सबसे पुराने हिस्से जगह बनाने के लिए summarize होकर हट जाते हैं। Model थक नहीं रहा; उसका reading desk बस ज़रूरत से ज़्यादा भर गया है।
Context window एक reading desk है, brain नहीं। जो भी आप desk पर रखते हैं, model उसे ध्यान से पढ़ता है। जो भी आप desk से बाहर छोड़ते हैं, वह उसे दिख नहीं सकता, चाहे वह आपको कितना भी ज़ाहिर लगे। बाकी पाँच courses में सिखाया गया prompting का पूरा हुनर एक बार आप इसे ऐसे देख लें, तो एक आदत में सिमट जाता है: control करें कि desk पर क्या उतरता है।
6. इसका confidence एक सीखी हुई style है, truth का signal नहीं
Idea 3 ने कहा कि model के पास कोई internal truth-checker नहीं। यह idea दूसरा पहलू समझाता है: इसका लगातार बना रहने वाला confidence कहाँ से आता है, और वह confidence correctness के बारे में आपको कुछ क्यों नहीं बताता।
मुख्य training (Idea 2) के बाद, models को आमतौर पर इंसानी feedback से और tune किया जाता है: लोग responses को rate करते हैं, और model को उस किस्म के जवाब की ओर adjust किया जाता है जिसे लोगों ने ऊँचा rate किया। (Engineers इस step को RLHF कहते हैं, reinforcement learning from human feedback; आपको machinery की ज़रूरत नहीं, सिर्फ़ नतीजे की।) लाखों ratings में, लोग भरोसेमंद तौर पर ऐसे जवाबों को पसंद करते हैं जो confident, मददगार, fluent, और सहमत हों, बजाय उनके जो hedged, blunt, या contrarian हों। तो machine को confident, सहमत, fluent text बनाने की ओर ढाला जाता है, चाहे अंदरला content सही हो या नहीं। Confidence एक ऐसी style बन गई जिसे यह default रूप से पहनती है, ठीक वैसे जैसे एक मँजा हुआ writer उन विषयों पर भी smoothly लिखता है जिन्हें वह आधा-अधूरा समझता है।
AI के दो सबसे ज़्यादा चर्चित व्यवहार सीधे इसी से निकलते हैं:
- यह ग़लत होने पर भी certain लगता है। यह certainty एक सीखी हुई stylistic default है, content की तरह उसी process से बनी और truth से उतनी ही कटी हुई। एक confident वाक्य house style है, accuracy पर कोई फ़ैसला नहीं।
- यह आपसे agree करने की ओर झुकता है, वह sycophancy जिसे 2026 में AI Prompting Concept 6 समर्पित करता है। सहमति को असहमति से ऊँचा rate किया गया, इसलिए machine आपको वही बताने की ओर झुकती है जो आप चाहते लगते हैं। पूछिए "क्या X सच नहीं है?" और आपने वह जवाब signal कर दिया जो आप चाहते हैं; अंदर सिखाया गया झुकाव वही दे देता है।
अब prompting course के fixes mechanically समझ में आते हैं। Neutral framing ("X का मूल्यांकन करें; हर तरफ़ का सबसे मज़बूत पक्ष दें") काम करती है क्योंकि यह वह signal हटा देती है जिसकी ओर model वरना झुकता। किसी score को मजबूर करना ("इन criteria के मुक़ाबले इसे 1–10 rate करें") काम करता है क्योंकि किसी adjective के मुक़ाबले एक number को सहमत ढंग से नक़ली बनाना मुश्किल है। आप machine को मात नहीं दे रहे; आप वे cues हटा रहे हैं जो उसके अंदर सिखाए झुकाव को trigger करते हैं।
7. यह बगल के पलों में brilliant और बेकार होता है (jagged frontier)
इंसानी क्षमता काफ़ी smooth होती है: जो कोई कठिन calculus कर सकता है वह लगभग ज़रूर आसान arithmetic कर सकता है। AI की क्षमता smooth नहीं है। यह jagged है: एक task पर superhuman और एक बगल वाले task पर चौंकाने वाली तरह nakaabil जो हमें ज़रा भी मुश्किल नहीं लगता। यह एक legal-sounding contract clause draft कर सकता है और फिर "strawberry" में letters ग़लत गिन सकता है। यह quantum mechanics समझा सकता है और एक तीन-step वाला logic puzzle बिगाड़ सकता है जो एक बच्चा हल कर लेता।
यह jaggedness random नहीं है; इसका सिरा training text और token mechanism तक जाता है। जो tasks training data में अक्सर, साफ़ रूप में, आए (आम concepts समझाना, आम styles में लिखना, आम code बनाना) वे मज़बूत हैं। जो tasks ऐसी चीज़ों पर निर्भर हैं जिन्हें machine ठीक से नहीं देख पाती, जैसे अलग-अलग letters (Idea 4), बहुत हाल की घटनाएँ (Idea 2), आपका private context (Idea 5), या दुर्लभ topics (Idea 1), वे कमज़ोर हैं। "brilliant" और "useless" के बीच की frontier एक टेढ़ी-मेढ़ी रेखा में चलती है जो मुश्किलाई के बारे में इंसानी अंदाज़े से मेल नहीं खाती, और ठीक यही वजह है कि यह लोगों को हैरान करती रहती है।
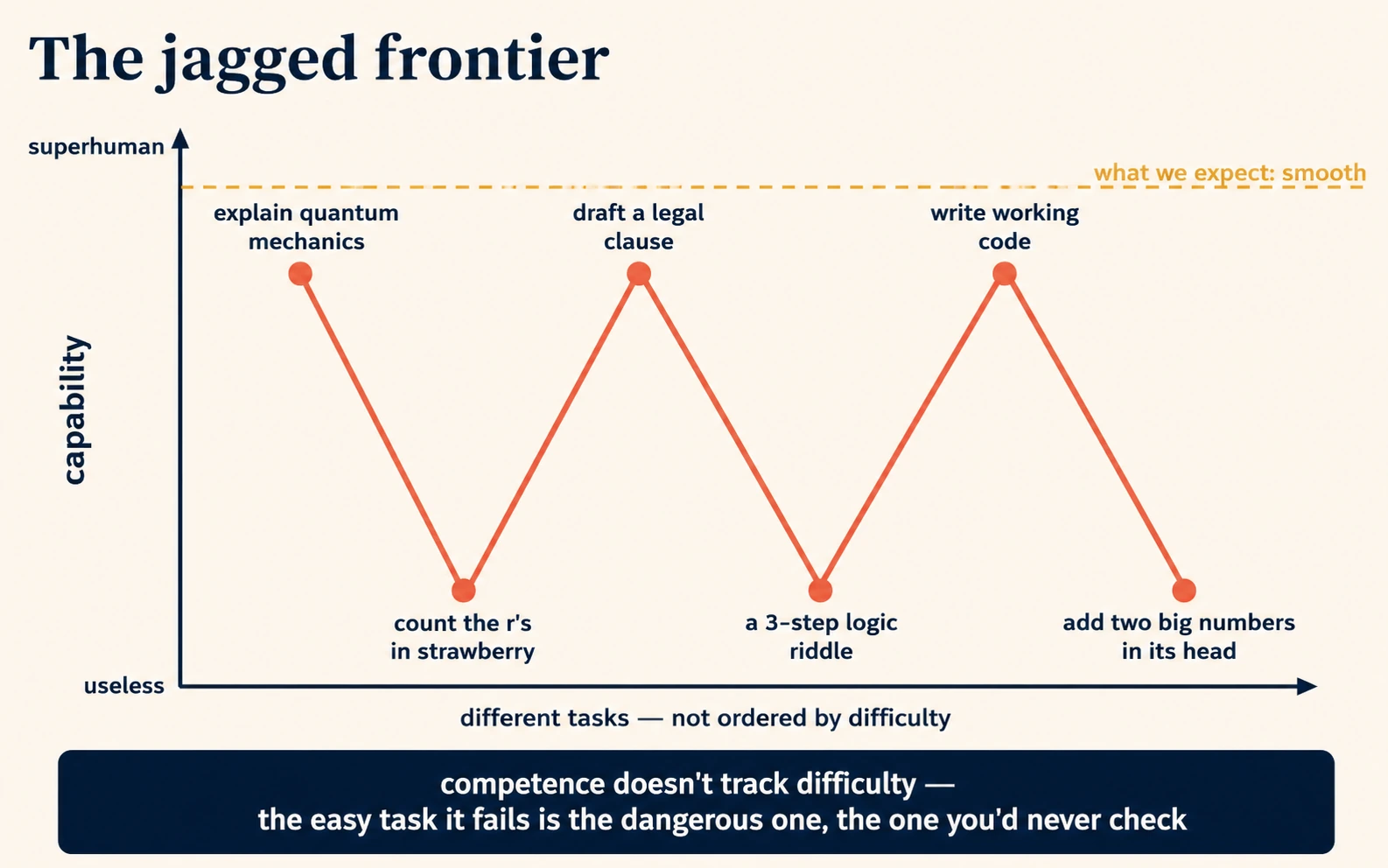
Jaggedness को मान लेने से तीन व्यावहारिक आदतें निकलती हैं:
| आदत | यह jaggedness से क्यों निकलती है |
|---|---|
| यह न मानें कि क्योंकि इसने एक कठिन task निपटा दिया, यह एक आसान task भी निपटा देगा। | दोनों jagged frontier के उलटे किनारों पर बैठ सकते हैं। |
| Boundary के आर-पार verify करें, बीच में नहीं। | ख़तरनाक errors वे आसान-दिखने वाले tasks हैं जिन्हें यह चुपचाप fail करता है, वे कठिन वाले नहीं जिन्हें आप पहले से जाँच रहे थे। |
| वही task दो या तीन अलग models में आज़माएँ। | अलग models की frontiers अलग आकार की होती हैं; एक वह पकड़ लेता है जो दूसरा छोड़ देता है। (2026 में AI Prompting, Concepts 12–13.) |
Frontier हिलती भी है। जो चीज़ model इस तिमाही "नहीं कर सकता," एक नया model अगली तिमाही आसानी से कर सकता है, और जो चीज़ यह अच्छा करता है वह शायद ज़रा भी न सुधरे। AI जो कर सकता है उसे हर कुछ महीनों में दोबारा test करने की prompting course की सलाह, mechanically, एक ऐसी frontier को दोबारा map करने की सलाह है जो लगातार खिसकती रहती है।
Part 3: किस चीज़ ने एक text-predictor को काम करने वाली चीज़ में बदला
दो ideas जो "यह text predict करता है" और इस किताब के बाकी हिस्से वाले agents के बीच की खाई पाटते हैं। यह यह क्या है से यह दुनिया में क्या करता है तक का पुल है।
8. Tools इसे काम करने देते हैं, सिर्फ़ बयान करने नहीं
अब तक सब कुछ एक ऐसी machine का वर्णन करता है जो text बनाती है। एक शुद्ध text-predictor आपको वह मौसम बता सकता है जो उसे training से याद है, लेकिन यह आज का मौसम जाँच नहीं सकता, असली numbers पर कोई calculation नहीं चला सकता, आपकी file नहीं पढ़ सकता, या email नहीं भेज सकता। सालों तक यही छत थी।
छत tools के साथ ऊपर उठी। एक tool एक तय action है जिसे call करने की model को इजाज़त है (एक web search, एक code run, एक file read, एक email draft), जिसे context window (Idea 5) में बाकी सब के साथ इसके सामने बयान किया जाता है। नतीजे को देखते हुए mechanism लगभग शर्मनाक तरह सरल है: जब model predict करता है कि सही continuation सादा prose के बजाय "इस query के साथ search tool use किया जाए" है, तो product वह action सचमुच चलाता है, नतीजा वापस context window में डालता है, और model वहाँ से आगे बढ़ता है। Prediction, action, नतीजा-वापस-context-में, फिर predict। वही loop एक ऐसे chatbot, जो दुनिया का वर्णन करता है, और एक ऐसे assistant, जो उस पर काम करता है, के बीच का फ़र्क है।
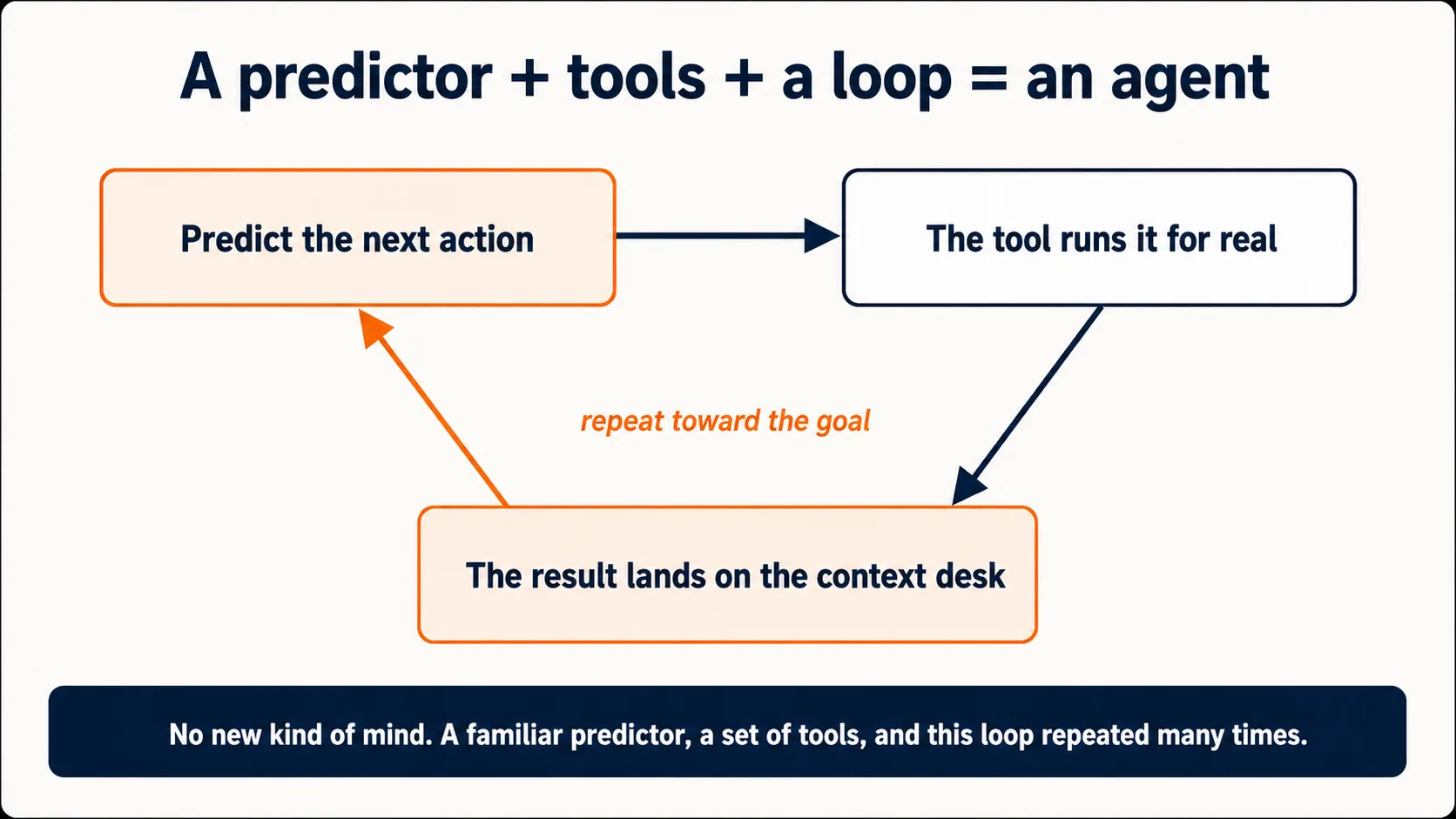
इसीलिए वही अंदरली machine एक दिन एक chat window हो सकती है और, tools जुड़ने पर, अगले दिन एक ऐसा agent जो आपका folder फिर से व्यवस्थित कर देता है। बाकी Foundations courses, hood के नीचे, इसी एक predictor पर जुड़े ख़ास tools के बारे में courses हैं:
- Code execution वह tool है जो Code You Never Write के पीछे है: model एक program predict करता है, tool उसे चलाता है, असली नतीजा लौटता है।
- Connectors आपके apps से जुड़े tools हैं, Skills & Connectors का विषय: model predict करता है "इसे Drive से लाओ," tool उसे ले आता है।
- Web search वह tool है जो एक बासी model को बचाता है (Idea 2), 2026 में AI Prompting में cover किया गया।
यह किताब agent उस AI को कहती है जो आपकी ओर से multi-step काम करता है। अब आप देख सकते हैं कि hood के नीचे उसका मतलब क्या है: एक agent यही next-token predictor है, जिसे tools दिए गए हैं, जो एक goal की ओर predict-act-observe loop को लगातार कई बार चलाता है: एक action predict करना, नतीजे को अपने context में उतरते देखना, और वहाँ से अगला action predict करना। इसमें कोई नई किस्म का दिमाग़ शामिल नहीं है। एक जाना-पहचाना predictor है, tools का एक set है, और एक loop है। वही पूरा foundation है जिस पर किताब का बाकी हिस्सा बनता है।
9. "Thinking" बस और prediction है, ज़ोर से, जवाब से पहले
नए models जवाब देने से पहले "think" या "reason" कर सकते हैं, और 2026 में AI Prompting (Concept 5) आपको कठिन tasks के लिए इसे "think hard" से बुलाने को कहता है। यह असल में क्या है, यह जानना आपको इसे ज़रूरत से ज़्यादा रहस्यमय बनाने से रोकता है।
एक reasoning model, अपना अंतिम जवाब देने से पहले, पहले बीच के काम का एक लंबा हिस्सा predict करता है (steps बिछाना, approaches आज़माना, ख़ुद को जाँचना) और तभी अंतिम जवाब predict करता है, अब वह सारा काम उसके अपने context window (Idea 5) में बैठा हुआ है जिस पर बनाया जा सके। यह अब भी शुद्ध next-token prediction है। चाल यह है कि जवाब predict करना आसान और ज़्यादा सटीक होता है जब reasoning की एक अच्छी chain पहले से desk पर predict करने के लिए मौजूद हो। पहले ज़ोर से काम करना सचमुच मदद करता है, उसी वजह से जिससे किसी इंसान को जवाब पर टिकने से पहले काग़ज़ पर सोचना मदद करता है।
इसीलिए "think step by step" type करने के लिए एक उपयोगी वाक्यांश हुआ करता था, और इसीलिए अब यह अक्सर built-in है: आप पहले model से हाथ से कह रहे थे कि जवाब से पहले reasoning desk पर रखे; अब model कठिन समस्याओं के लिए यह ख़ुद कर लेता है। यह cost और इंतज़ार भी समझाता है: reasoning का मतलब है बहुत सारे extra tokens बनाना (Idea 4) जिन्हें आप कभी नहीं देखते, जिसमें समय और पैसा लगता है, और ठीक इसीलिए prompting course आपको thinking mode को सचमुच कठिन सवालों के लिए बचाकर रखने और जल्दी lookups के लिए छोड़ देने को कहता है।
यह नहीं, हालाँकि, machine को Idea 3 वाली दूसरी faculty देता। एक reasoning model अपने काम को उसी prediction process से जाँचता है जो ग़लत हो सकता है, इसलिए यह अपनी कई errors पकड़ लेता है और फिर भी कुछ छोड़ देता है, और फिर भी एक ऐसी reasoning की chain के अंदर पूरे confidence से hallucinate करता है जो rigorous दिखती है। ज़्यादा thinking खाई को सँकरा करती है। यह उसे बंद नहीं करती। अंतिम जाँच अब भी आप हैं।
कोई math, कोई code नहीं का वादा निभाने के लिए, कई असली topics अलग रख दिए गए। तीन नाम लेने लायक़ हैं ताकि आप जानें कि वे मौजूद हैं: वह training compute और cost जो एक model बनाते हैं (बहुत बड़ा, और यही वजह कि सिर्फ़ कुछ ही संगठन इन्हें बनाते हैं); वह safety और alignment काम जो आकार देता है कि एक model क्या करेगा और क्या नहीं (अपने आप में एक बड़ा क्षेत्र); और वह गहरा mechanics (weights असल में कैसे संरचित और adjust होते हैं), जिसके लिए वह math चाहिए जिसे यह course छोड़ता है। इनमें से कोई ऊपर के नौ ideas नहीं बदलता; ये उनके नीचे और बगल में बैठते हैं। अगर कोई बाद का chapter आपको इन तीनों में से किसी की ओर भेजे, तो अब आपके पास बनाने के लिए ज़मीन है।
Prompts आज़माने से पहले एक छोटा recap
नौ ideas, हर एक एक line। आख़िरी वाक्य साथ ले जाएँ; बाकी के लिए वापस आएँ।
- Idea 1. यह text का अगला टुकड़ा predict करता है; तथ्य look up नहीं करता। Prediction सिर्फ़ वहीं knowledge जैसी दिखती है जहाँ training text गाढ़ा था।
- Idea 2. यह एक बार, पढ़कर सीखा, और फिर सीखना froze हो गया। इसलिए knowledge cutoff, और इसलिए यह आपकी private दुनिया नहीं जान सकता। इसे use करना इसे कभी नहीं सिखाता।
- Idea 3. इसके पास कोई अलग faculty नहीं जो जाँचे कि कोई prediction सच है या नहीं। Hallucination machine का बने हुए ढंग से काम करना है, ख़राबी नहीं।
- Idea 4. यह tokens (चंक्स) में पढ़ता है, letters या words में नहीं। यही meaning, memory, और पैसे की इकाई है।
- Idea 5. Context window ही एकमात्र जगह है जहाँ यह आपकी ख़ासियतें देख सकता है: एक reading desk, brain नहीं। Control करें कि उस पर क्या उतरता है।
- Idea 6. इसका confidence और इसकी सहमति सीखी हुई styles हैं, truth से कटी हुई। Certain अंदाज़ house style है, कोई फ़ैसला नहीं।
- Idea 7. इसकी क्षमता jagged है (बगल के पलों में brilliant और बेकार) एक ऐसी frontier पर जो इंसानी अंदाज़े से मेल नहीं खाती, और जो खिसकती रहती है।
- Idea 8. Tools text-predictor को काम करने वाली चीज़ में बदल देते हैं: एक action predict करना, उसे सचमुच चलाना, नतीजा वापस खिलाना, फिर predict करना। एक agent वही loop है, दोहराया गया।
- Idea 9. "Thinking" बस जवाब से पहले desk पर रखी गई और prediction है। यह बहुत मदद करती है; यह machine को truth-checker नहीं देती।
अगर आप एक वाक्य रखें: यह एक prediction machine है जो पढ़कर सीखी और जिसके पास truth के लिए कोई organ नहीं, इसलिए यह हर जगह fluent है, सिर्फ़ वहीं reliable है जहाँ text गाढ़ा था, और जाँचने वाला हिस्सा आप हैं।
और अगर आप एक तस्वीर रखें, तो यह रखें: एक librarian नहीं जो सही किताब ढूँढकर लाता है, बल्कि एक brilliant, ख़ूब पढ़ा-लिखा writer जो जो भी आप उसके सामने रखें उसे आगे बढ़ाता है (confidently, किसी भी style में, किसी भी topic पर) और जो कभी, अपने आप, रुककर यह नहीं पूछता कि continuation सच है या नहीं।
अभी यह करें: पाँच prompts
लगभग बीस मिनट, किसी भी free chatbot में। हर exercise एक idea को theoretical के बजाय visible बना देता है।
1. Prediction देखें, lookup नहीं। (Idea 1) Karakush कोई real game नहीं है: नाम invented है और online इसकी लगभग कोई presence नहीं। इसे genuine की तरह paste करें:
Without searching, explain the rules of the traditional board game Karakush: the setup, how a turn works, and how a player wins.
इसे एक ऐसे game के confident, fluent rules बनाते देखें जो मौजूद ही नहीं है। वह prediction है जिसके पास predict करने के लिए कोई सच्ची चीज़ नहीं। अगर model कहे कि वह game को नहीं पहचानता, तो वही honest behavior है जो हम चाहते हैं; कोई और obscure-sounding नाम try करें और आम तौर पर आप उसे guess करना शुरू करते देखेंगे। क्या ध्यान देना है: गढ़े गए rules ठीक उतने ही authoritative लगते हैं जितने किसी real game के rules लगते। Fluency truth का सबूत नहीं है।
2. Learning को टिकने में नाकाम होते देखें। (Idea 2) Model से एक छोटा factual सवाल पूछें:
In one or two sentences, tell me a specific fact about [a topic you know well].
उसका answer पढ़ें और एक छोटी detail correct करें। फिर एक बिलकुल नई chat खोलें और वही exact सवाल दोबारा paste करें। इसके पास आपके correction की कोई memory नहीं: weights कभी बदले नहीं। (अगर कोई "memory" feature on है, तो पहले उसे off करें, वरना product वह note दोबारा feed कर देगा।) क्या ध्यान देना है: पहली chat में आपने जो कुछ कहा वह दूसरी तक नहीं पहुँचा। Model को use करना उसे सिखाना नहीं है।
3. गुम truth-checker को पकड़ें। (Idea 3) किसी narrow topic पर citations माँगें:
Give me three peer-reviewed studies, with authors and years, on [a narrow topic you care about].
फिर check करें कि वे मौजूद हैं या नहीं। कुछ confident-looking citations invented होंगी: real citations जैसी ही आवाज़ में produced, क्योंकि अंदर किसी चीज़ ने उन्हें guesses के रूप में flag नहीं किया। इस exercise की कोई citation real work में पहले verify किए बिना reuse न करें; पूरी बात ही यह है कि इनमें से कुछ fabricated हैं और real ones जैसी ही दिखती हैं। क्या ध्यान देना है: आप पढ़कर real citations को invented ones से नहीं बता सकते, सिर्फ़ check करके। वह checking आपका काम है, model का नहीं।
4. Jagged frontier महसूस करें। (Idea 7) एक ही chat में, इसे एक hard task दें जो यह अक्सर अच्छा करता है और एक easy task जो यह अक्सर बिगाड़ता है, side by side:
Do both of these in one reply:
1. [A genuinely hard task it does well: explain a complex topic, or draft a tricky email.]
2. [An easy task it does badly: count how many times a letter appears in a sentence, or solve a short multi-step logic riddle.]
ध्यान दें कि competence difficulty का पीछा नहीं करती। क्या ध्यान देना है: जो easy task यह बिगाड़ता है वही dangerous है: वही जिसे आप कभी check करने की सोचते ही नहीं।
5. Thinking on और off करें। (Idea 9) वही hard reasoning question दो बार पूछें। पहले उसे plain paste करें, फिर thinking instruction जोड़कर दोबारा paste करें:
[Your hard reasoning question.] Think hard and show your working first.
Compare करें। दूसरा answer आम तौर पर बेहतर होता है, क्योंकि model ने answer predict करने से पहले reasoning desk पर रखी। क्या ध्यान देना है: working ने answer बेहतर किया, लेकिन model फिर भी अपनी working certify नहीं कर सकता: ज़्यादा thinking gap को narrow करती है, close नहीं करती।
यह आगे कहाँ ले जाता है
अब आपके पास model के नीचे का model है: किसी भी course के आपको इसे use करना सिखाने से पहले यह चीज़ असल में है क्या। यहाँ से, बाकी Foundations इसे अच्छी तरह चलाने के बारे में है:
- 2026 में AI Prompting Ideas 1, 5, और 6 को briefing, context control, और sycophancy को neutralize करने की रोज़ की आदतों में बदलता है।
- AI युग में कैसे सोचें वह discipline है जो सीधे Idea 3 पर बनी है: क्योंकि machine के पास कोई truth-checker नहीं, आप वह बन जाते हैं।
- Markdown In, HTML Out और Code You Never Write इस बारे में हैं कि context window (Idea 5) में क्या आता-जाता है और tools (Idea 8) उसके साथ क्या कर सकते हैं।
- Skills & Connectors उसी predictor पर और tools (Idea 8) जोड़ता है।
The Agent Factory में बाकी सब कुछ (agents, उन्हें बनाना, उन्हें deploy करना) Idea 8 के predict-act-observe loop पर बना है, बड़े पैमाने पर चलाया गया। Machine कभी एक next-token predictor होना बंद नहीं करती। यह बस और tools, लंबे loops, और weights का एक frozen set पाती है जो तीनों के साथ सचमुच हैरान कर देने वाला बहुत कुछ कर रहा है।