अपने AI को Searchable Context दें: pgvector के साथ Postgres पर RAG का एक Crash Course
15 Concepts · Real Use का 80% · आपके agent ने बनाया, हाथ से नहीं
सोचिए आप अपने computer से कह सकें: "documents का यह folder लें, एक ऐसा database खड़ा करें जो उनके meaning को समझे, और मेरे लिए एक ऐसा search बनाएँ जहाँ 'the city that never sleeps' पूछने पर New York के बारे में quotes मिलें, वे भी जो कभी उसका नाम तक नहीं लेतीं।" और वह सच में ऐसा कर देता है।
तीन शब्द, अगर ये नए हों तो। एक database data का एक warehouse है: वह building जहाँ कोई business अपना सामान रखता है, बस यहाँ सामान का मतलब information है। SQL वह भाषा है जो आप उस warehouse से बोलते हैं: data को store, find, या change करने की हर request उसी में एक वाक्य है। Postgres (इस course के title वाला database) दुनिया में सबसे ज़्यादा इस्तेमाल होने वालों में से एक है। और एक आम warehouse किसी box को सिर्फ़ उसके exact label से ढूँढ सकता है; जो आप बनाने वाले हैं वह चीज़ों को उनके meaning से ढूँढता है।
यही meaning-से-search वाला system इस course में सिखाया जाता है, और twist यह है: आप SQL हाथ से नहीं लिखेंगे; Claude Code या OpenCode यह सब बनाता है। आपका काम इतना Postgres और pgvector (वह add-on जो उसे यह ताक़त देता है) जानना है कि आप साफ़ instructions दे सकें और judge कर सकें कि agent ने इसे सही किया या नहीं। वही दूसरा हिस्सा पूरी skill है, और आख़िर तक आप जान जाएँगे कि कौन-से knobs मायने रखते हैं और किन्हें वैसे ही छोड़ देना है।
इस course के नीचे छिपा बड़ा दावा सीधा है: ज़्यादातर applications के लिए, Postgres ही AI database है। वह अलग, specialized vector database जिसकी ज़रूरत आपको बताई गई है, ज़्यादातर teams के लिए एक और system है जिसके लिए pay करना, sync करना, और टूटना पड़ता है। आपके vectors उसी data के बग़ल में रहने चाहिए जिसे वे describe करते हैं, और आख़िर तक आप इस पर इसलिए यक़ीन नहीं करेंगे कि course ने ऐसा कहा, आप इसलिए यक़ीन करेंगे कि आपने इसे बनाया।
एक idea इस पूरे course को समझा देता है। एक AI model एक बार में सिर्फ़ इतनी ही चीज़ों पर ध्यान दे सकता है: आपको answer देने के लिए वह जो कुछ पढ़ता है, सब उसके context window में आना चाहिए, और उसमें जितनी ज़्यादा ग़ैर-ज़रूरी सामग्री होगी, answer उतना ख़राब होगा। इसलिए किसी भी AI system का मुख्य काम है model के सामने सही जानकारी सही समय पर लाना, और बाक़ी सब बाहर रखना। आप यह अपने coding agent के लिए पहले से करते हैं: एक rules file, सिर्फ़ वही files जो task को चाहिए। एक vector database आपके app के users के लिए यही काम करता है: store की हुई दस लाख rows में से, यह वही चंद ढूँढता है जो सवाल के meaning से match करती हैं और सिर्फ़ उन्हें model को देता है। इस move का एक नाम है, RAG यानी Retrieval-Augmented Generation, और यह एक layer नीचे का context management है: जो आप अपने coding agent के लिए हाथ से करते हैं, वही आपका app अपने users के लिए अपने-आप करता है। यहाँ का हर concept इसी पर वापस आकर जुड़ता है।

यह course यह मानकर चलता है कि आपने Agentic Coding Crash Course कर लिया है: आपको Claude Code या OpenCode चलाने, plan mode इस्तेमाल करने, और context manage करने में सहज होना चाहिए। यह AI Prompting in 2026 पर भी आधारित है, यानी AI से ठीक वही माँगने का हुनर जो आप चाहते हैं। अगर "embedding" और "vector" आपके लिए बिल्कुल नए हैं, तो चिंता न करें, Concept 2 इन्हें शून्य से समझाता है।
📚 शिक्षण सहायता
पूरी presentation देखें — AI Searchable Context
दो tools, एक ही discipline
driving agent करता है; आपका Postgres database वह है जिसे वह drive करता है। यह database Neon पर रहता है, एक cloud service जो आपके लिए Postgres चलाती है, कुछ install करने को नहीं, कोई machine manage करने को नहीं (serverless का बस इतना ही मतलब है: जब आप इस्तेमाल करें तब जागता है, जब न करें तब सोता है)। agent Neon MCP server के ज़रिए Neon को operate करता है: यह project बनाता है, एक branch खोलता है, SQL चलाता है, और हर बदलाव को commit करने से पहले उस branch पर preview करता है। आप कभी ख़ुद Neon console में नहीं घूमते और न ही psql खोलते हैं। और दोनों tools में discipline एक ही है: Claude Code और OpenCode यहाँ बराबर हैं, और जहाँ कोई command सच में अलग होती है, मैं वह फ़र्क़ साथ-साथ बता देता हूँ।
यह course क्या cover करता है
| Part | Topic | आप क्या सीखते हैं |
|---|---|---|
| 1 | Foundations | AI engineer के रूप में आपका काम, शून्य से vectors, meaning से search करने के लिए Postgres को क्या चाहिए, और आपका agent Neon से जुड़ा हुआ |
| 2 | आपका पहला RAG | अपना data load करें, उसे टुकड़ों में बाँटें, हर टुकड़े को एक meaning-vector में बदलें, meaning से search करें, और एक LLM से उस पर answer दिलवाएँ |
| 3 | Search को तेज़ बनाना | जब धीमी पड़ती search को index चाहिए, कौन-सा चुनें, और speed-बनाम-accuracy वाला वह एक knob जो मायने रखता है |
| 4 | Search को अच्छा बनाना | मापें कि answers सच में सही हैं या नहीं, filters जोड़ें, meaning को exact keywords के साथ मिलाएँ, हर customer का data अलग दीवार में रखें, और database से plain English में सवाल पूछें |
| 5 | पूरा Worked Example | एक complete task, ख़ाली database से चलते RAG तक, दोनों tools में driven |
| 6 | इसे एक Tool के रूप में Ship करें | अपने RAG को एक MCP server में लपेटें ताकि कोई भी agent, चाहे Claude Code, OpenCode, या आगे बनने वाला कोई Digital FTE, इसे call कर सके |
| 7 | यह कहाँ चलता है | अपने database की instant copies पर बदलाव test करें, data बदलने पर vectors को ताज़ा रखें, और production में क्या अलग होता है |
| 8 | इसे एक Agent को सौंपें | अपने RAG को एक agent (OpenAI Agents SDK) में plug करें, यानी Build AI Agents course तक का bridge |
पूरा system एक ही page पर यहाँ है: वह map जिसमें आप हर concept समझते हुए धीरे-धीरे grow करेंगे:
 |
|
आख़िर तक आपके पास एक चलता हुआ RAG project होगा: आपका docs/ folder, documents के साथ, एक Neon database में load किया हुआ जिसमें pgvector on है, एक छोटा worker जो documents बदलने पर meaning-vectors को up to date रखता है, एक search जो meaning से ढूँढता है, एक answer_question() function जो आपके अपने data से answer देता है, और एक report जो दिखाती है कि पाँच test questions सही वापस आते हैं या नहीं। और आप आसान 80% पर नहीं रुकेंगे: आपने एक HNSW index को धीमे से instant तक benchmark किया होगा, search को category से filter किया होगा, keyword और meaning को hybrid search से fuse किया होगा, और एक tenant को दूसरे से Row-Level Security के ज़रिए अलग दीवार में रखा होगा, हर एक असल में चलाया गया, आपके eval set के सामने मापा गया। वैकल्पिक रूप से, एक MCP server पूरी चीज़ किसी भी agent को सौंप देता है।
इसे कैसे पढ़ें। Parts 1 और 2 (Concepts 1 से 9) और Part 5 का worked example मिलकर पूरा system हैं, शुरू से आख़िर तक, सच्ची समझ पर लगभग 2-घंटे का read ("vector" नया हो तो ज़्यादा), साथ में build के लिए keyboard पर कुछ घंटे। Parts 3 और 4 (Concepts 10 से 15) tuning layer हैं, यानी जो search को तेज़ (Part 3) और अच्छा (Part 4) बनाता है। इन्हें "क्यों" के लिए पढ़ें, फिर इनमें से हर एक को चलाएँ: Part 5 एक hands-on loop (Steps 5 से 8) पर ख़त्म होता है जहाँ आप एक index benchmark, एक filter, hybrid search, और tenant isolation असल में बनाते हैं, उसी data पर जो आपने अभी load किया। यह गहराई कोई वैकल्पिक पढ़ाई नहीं जिस पर आप शायद बाद में लौटें, यह build का दूसरा आधा हिस्सा है, और हर कोई इसे करता है। पहले build करना और "क्यों" बाद में पढ़ना ज़्यादा पसंद है? सीधे Part 5 पर जाएँ।
अपना environment set up करें (एक बार)
इस course में आप जो कुछ बनाते हैं, सब एक छोटे folder के भीतर होता है: course base। यह पहले से wired आता है, आपका agent पहले से जानता है कि Neon (वह cloud database जो यह course इस्तेमाल करता है) और Context7 (live docs lookup, ताकि agent अंदाज़ा लगाने के बजाय मौजूदा documentation check करे) तक कैसे पहुँचे, और इसके साथ एक छोटी rules file, AGENTS.md, आती है जिसमें project के standing instructions होते हैं। आपका agent हर बार शुरू होते ही इस file को अपने-आप पढ़ता है, यही वजह है कि इस course में आपके prompts छोटे रह सकते हैं।
इसे एक बार download करें; वही folder पूरे course के काम आता है, Part 5 का worked example और Part 6 का MCP server, दोनों के लिए। अभी set up करें या बाद में, पढ़ाई के लिए ख़ुद कुछ install करने की ज़रूरत नहीं।
postgres-ai-base.zip download करें
इसे unzip करें, फिर उस folder के भीतर अपना agent खोलें:
cd postgres-ai
claude
cd postgres-ai
opencode
एक requirement: एक capable model। अगर agent का पहला plan कभी specific के बजाय vague लगे, तो आगे बढ़ने से पहले किसी मज़बूत model (Claude Sonnet या Opus, GPT-5, या ऐसा ही कोई) पर switch करें।
base तैयार करें (~3 min)। agent अपना setup ख़ुद करता है, आप एक prompt paste करते हैं और जो वह पूछे उसका जवाब देते हैं। यह paste करें:
इस base को तैयार करें: यह जो skills list करता है उन्हें install करें, मेरी
.envset up करें, और मुझे ठीक-ठीक बताएँ कि Neon और Context7 MCP servers को online लाने के लिए आपको मुझसे क्या चाहिए।
ध्यान दें: agent दो skills install करता है (neon-postgres और mcp-builder), .env बनाता है, फिर आपसे दो चीज़ें माँगता है: एक API key (वही key embeddings और answers दोनों cover करती है), और Neon को authorize करने के लिए browser में एक click। Key free है। यह course Google Gemini के free tier पर चलता है (credit card नहीं चाहिए), इसलिए agent आपको aistudio.google.com/apikey पर भेजता है; Google से sign in करें, लगभग एक minute में key बनाएँ, उसे वापस paste करें, और agent वहीं test call करके साबित कर देता है कि यह काम कर रही है। (अगर आपके पास पहले से OpenAI key है और आप वही prefer करते हैं, तो बस कह दें; agent वह इस्तेमाल कर लेगा, course में कुछ और नहीं बदलता।) Neon भी free है; अभी account नहीं? authorization screen पर ही एक बना लें। अगर अपने-आप कोई browser window न खुले, तो agent में /mcp type करें, Neon चुनें, और यह आपके लिए sign-in शुरू कर देगा।
तब पूरा जब: skills install हो गईं, .env में आपकी key है और agent ने quick test call से उसे confirm कर दिया है, Neon authorized है, और आपने agent restart कर लिया (exit, फिर relaunch) ताकि नई skills और MCP servers load हो जाएँ (इनमें से कोई भी session के बीच में load नहीं होता)।
Part 1: Foundations
1. आप असल में क्या बना रहे हैं (और इसमें आपका काम)
सबसे आम ग़लतफ़हमी: AI applications बनाने के लिए एक machine-learning team चाहिए। नहीं चाहिए। models off-the-shelf हैं। infrastructure एक database है जिसे शायद आप पहले से चलाते हों। जो बचता है वह है एक AI engineer का काम, यानी कोई जो products बनाने के लिए AI का इस्तेमाल करता है, न कि एक researcher जो models train करता है। यही वह भूमिका है जिसके लिए यह पूरी किताब आपको तैयार कर रही है, और यह बिल्कुल पहुँच के भीतर है।
दूसरी ग़लतफ़हमी वही है जिसे ठीक करने के लिए यह course मौजूद है: कि आपको सारा SQL हाथ से लिखना होगा। नहीं लिखना होता। आप एक ऐसे agent को direct करते हैं जो pgvector के operators और embedding workflow पहले से अच्छी तरह जानता है। आपकी value stack में ऊपर चढ़ जाती है, CREATE INDEX type करने से लेकर यह तय करने तक कि कौन-सा index, query लिखने से लेकर यह judge करने तक कि results कुछ अच्छे हैं या नहीं।
इससे "इस सामग्री को जानने" का मतलब बदल जाता है। आप syntax याद नहीं कर रहे; आप इतना mental model बना रहे हैं कि:
- agent को एक सटीक instruction दे सकें ("embedding को उसी table में store करो, cosine distance इस्तेमाल करो, इसे HNSW से index करो"),
- उसने जो बनाया उसे पढ़कर देख सकें और पकड़ सकें कि कब वह ग़लत है,
- और वे architecture choices तय कर सकें जो agent को आपके लिए नहीं करनी चाहिए।
यह वही plan-then-execute आदत है जो coding course से आती है, और यहाँ यह और भी मायने रखती है, क्योंकि agent ऐसे फ़ैसले लेने वाला है (कौन-सा extension, कौन-सा index, कौन-सा distance function) जिन्हें data आ जाने के बाद undo करना महँगा है।
mindset shift: "semantic search के लिए SQL क्या है?" पूछना बंद करें। कहना शुरू करें "इस table पर मेरे लिए semantic search बनाएँ; ये मेरी constraints हैं; पहले मुझे plan दिखाएँ।"
इसका एक बड़ा नाम है। किताब के शब्दों में, जो database आप बनाने वाले हैं वह agent era के लिए एक system of record है, यानी वह authoritative ground truth जिससे आपके agents पढ़ते हैं, लिखते हैं, और जिसके सामने verify करते हैं। Jensen Huang का तर्क है कि agents system of record की ज़रूरत हटाते नहीं; वे उस पर निर्भर होते हैं। authoritative ground truth के बिना agent hallucinate करता है; उसके साथ, वह execute करता है। Postgres पर RAG वह तरीक़ा है जिससे आप एक agent को वह ground truth सौंपते हैं, और यही ठीक-ठीक वजह है कि बाक़ी course retrieval quality को वही चीज़ मानता है जो तय करती है कि agent पर भरोसा किया जा सकता है या नहीं।
बाक़ी course के लिए इसे शब्दशः लें: नीचे का हर SQL block इसलिए दिखाया गया है ताकि आप agent की बनाई चीज़ को पढ़ और judge कर सकें, इसलिए नहीं कि आप उसे type करें। इसे पढ़ना जानना ही वह है जो आपको ship होने से पहले एक ग़लत distance function या एक छूटा हुआ filter पकड़ने देता है।
2. Vectors और embeddings, एक मिनट में
अगर "vector" और "embedding" नए हैं, तो शुरू करने के लिए जो कुछ चाहिए वह यहाँ है।
एक vector बस numbers की एक list है, [0.021, -0.88, 0.14, …]। एक embedding model किसी content (एक वाक्य, एक paragraph, एक image) को लेता है और उसे इनमें से एक list में बदल देता है। चाल यह है कि यह list content के meaning को पकड़ती है: दो text के टुकड़े जिनका मतलब मिलता-जुलता है, उन्हें numbers की ऐसी lists मिलती हैं जो पास-पास बैठती हैं। दो phrases जिनका मतलब एक ही है, "the city that never sleeps" और "New York's restless streets", एक-दूसरे के पास आ जाती हैं भले ही उनमें कोई शब्द साझा न हो।
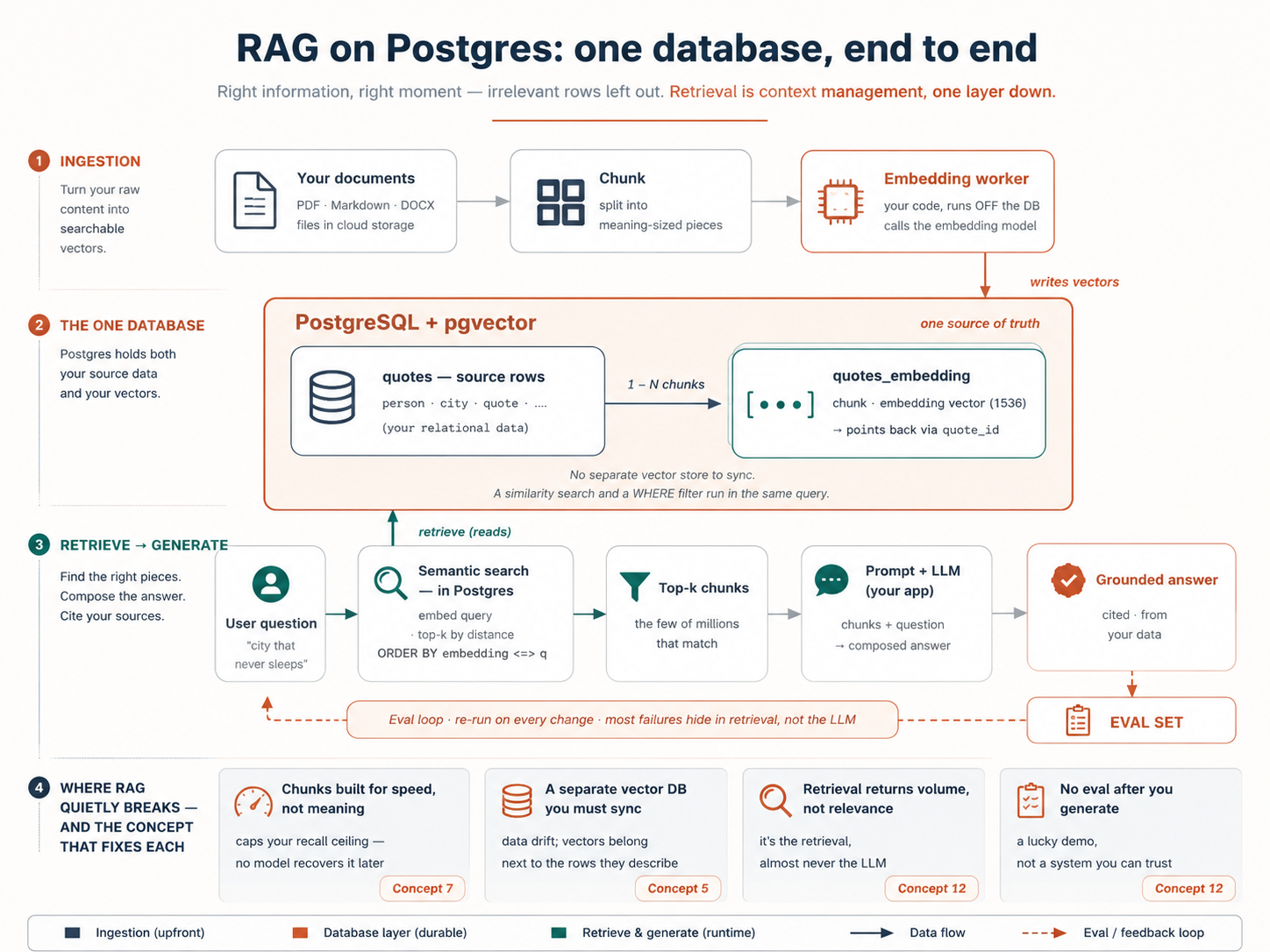
एक vector database बस एक ऐसा system है जो इन lists को store करता है और किसी दी गई list के सबसे पास वालों को तेज़ी से ढूँढ लेता है। बस इतना ही। जब कोई user कोई सवाल पूछता है, आपका app उसके सवाल को एक vector में embed करता है, फिर database से पूछता है: "कौन-से store किए vectors इसके सबसे पास हैं?" सबसे पास वाले ही सबसे ज़्यादा semantically relevant होते हैं, और यही है जिससे आपका app सही context fetch करके एक LLM को सौंपता है। (शुरुआती diagram देखें: यह आपके users के लिए context management है।)
आपको यह समझने की ज़रूरत नहीं कि embedding model अंदर से कैसे काम करता है, उतनी ही जितनी यह समझने की कि एक JPEG किसी image को कैसे compress करता है। आपको बस यह जानना है कि यह मौजूद है, कि यह content को meaning-vectors में बदलता है, और कि नज़दीकी का मतलब समानता है।
एक session खोलें और अपने agent से पूछें: "plain भाषा में समझाएँ कि embedding क्या है, फिर मुझे दो छोटे वाक्य दिखाएँ जिनके vectors पास-पास होंगे और दो जो दूर होंगे, और क्यों। फिर मज़ेदार वाला: क्या मेरे शहर का कोई मशहूर गाना या उपनाम उस शहर के नाम के पास आ जाएगा, भले ही शब्द कभी न कहें?" इसका answer पढ़ना इस section को दोबारा पढ़ने से जल्दी आपकी अपनी समझ की जाँच कर देता है।
3. वे extensions, और Neon पर आपको क्या मिलता है
Postgres extensions के ज़रिए एक vector database बन जाता है, यानी ऐसे add-ons जो उसे नई ताक़तें देते हैं बिना उसे छोड़े जो Postgres पहले से अच्छा करता है (transactions, joins, reliability, SQL)। इस पूरे course के लिए सीखने को असल में सिर्फ़ एक है: pgvector। यह तीन चीज़ें जोड़ता है, embeddings store करने के लिए एक vector type, उनकी तुलना के लिए distance operators, और उन्हें तेज़ी से search करने के लिए indexes, और Neon पर यह pre-installed आता है, इसलिए एक statement इसे on कर देता है। यही आपका पूरा RAG engine है। बस इतना पकड़ें। (दो footnotes जिन्हें आप किनारे रख सकते हैं: एक दूसरा extension, pgvectorscale, बहुत बड़े scale के लिए मौजूद है, यह वह tier है जिस पर आप graduate करते हैं, न कि जहाँ से शुरू करते हैं। और embeddings ख़ुद कोई extension हैं ही नहीं; वे एक छोटे worker से आते हैं जिसे आपका agent लिखता है, Concept 6 में बनाया गया।)
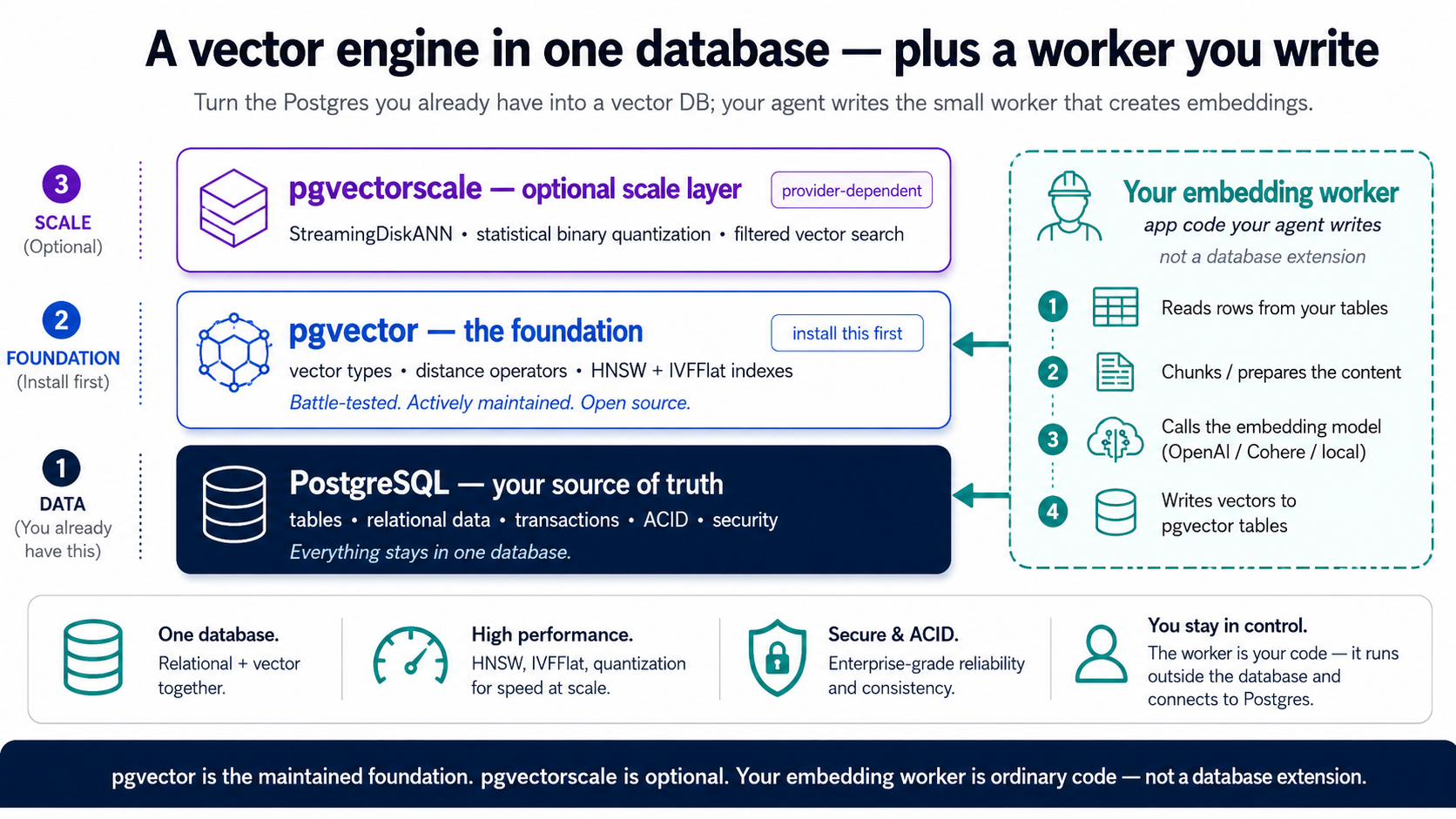
| Extension | यह क्या जोड़ता है | कब आपको चाहिए |
|---|---|---|
| pgvector | vector data type, distance operators, और HNSW + IVFFlat indexes | हमेशा, और Neon पर यह pre-installed है |
| pgvectorscale | StreamingDiskANN index, vector compression, बड़े scale पर high-accuracy filtered search | TigerData पर native; Neon पर नहीं, जहाँ यह वह tier है जिस पर आप graduate करते हैं |
इस table में index के नाम, HNSW, IVFFlat, StreamingDiskANN, अभी के लिए बस labels हैं; Part 3 सिखाता है कि वे क्या करते हैं और हर एक कब इस्तेमाल करें।
Neon पर, pgvector ही आपका पूरा stack है। यह built in आता है, और embedding के बाद यह course जो कुछ करता है, semantic search, indexing, evals, filters, hybrid search, RLS, Part 6 का MCP server, सब शुद्ध pgvector है। embeddings worker से आते हैं (Concept 6), किसी managed extension से नहीं। रही pgvectorscale: यह Neon के vetted set में नहीं है, इसलिए इसे वह host मानें जिस पर आप तभी graduate करेंगे जब HNSW से आगे बढ़ जाएँ, और pgvector साथ में एक worker आपको पहले काफ़ी दूर तक ले जाता है। पहले दिन से ही scale tier native चाहिए? वह है TigerData Cloud, पूरे में वही workflow, Concept 4 के अंत वाला एक note इसे cover करता है, और बाक़ी आप इस पूरे course को Neon-only के रूप में पढ़ सकते हैं।
one-database वाला फ़ायदा अब भी बना रहता है: आपके vectors उन्हीं rows के बग़ल में रहते हैं जिन्हें वे describe करते हैं, इसलिए एक similarity search और एक WHERE price < 2000 AND in_stock filter एक ही query में, एक ही source of truth पर होते हैं। कोई दूसरा database नहीं, कोई sync pipeline नहीं, कोई data drift नहीं। (इसे पकड़े रहें, यही पूरी वजह है कि Concept 13 में filtered search इतना आसान है।)
pgvector एक परिपक्व, व्यापक रूप से इस्तेमाल होने वाला Postgres extension है, वह स्थिर बुनियाद जिस पर यह पूरा course टिका है। embedding के बाद की हर चीज़ (semantic search, indexing, evals, filters, hybrid search, RLS, MCP server) शुद्ध pgvector है।
एक चीज़ जो pgvector आपके लिए नहीं करता वह है embeddings को बनाना, यानी एक embedding model को call करना और vectors वापस लिखना। ऐसा करने का साफ़, portable तरीक़ा एक छोटा worker है जिसे आपका agent लिखता है: source table → chunk → एक API call के ज़रिए embed → embeddings table में vectors लिखें → pgvector से search करें। उस काम को database के बाहर रखना ही असल बात है, कोई जुगाड़ नहीं, एक stateful system of record को किसी अस्थिर बाहरी API पर निर्भर नहीं होना चाहिए, इसलिए embedding (और Concept 9 में LLM calls) worker और app layers में रहते हैं, जहाँ वे आपके data को छुए बिना fail, retry, और scale कर सकते हैं, और पूरी चीज़ किसी भी host या container पर साफ़-सुथरे ढंग से port हो जाती है। (एक managed convenience layer ने कभी embedding को database में ही bake कर दिया था, pgai का Vectorizer, पर वह coupling नाज़ुक निकला, और इसके maintainer ने इसकी repository Feb 2026 में archive कर दी; यह course उस पर निर्भर नहीं है।) worker कुछ ही lines है जिसे आपका agent बनाता है और आप review करते हैं। pattern सीखें; यह किसी एक package से ज़्यादा टिकता है।
4. अपने agent को Neon से जोड़ें
हम अपना database ख़ुद install या run नहीं करते। हम Neon इस्तेमाल करते हैं, यानी serverless Postgres जिसमें pgvector पहले से built in है, और हम agent को इसे Neon MCP server के ज़रिए operate करने देते हैं। MCP वही connector तंत्र है जो coding course से आता है; यहाँ यह Claude Code और OpenCode को tools का एक set देता है (create_project, create_branch, run_sql, get_database_tables, prepare_database_migration, complete_database_migration) ताकि वे Neon को पूरी तरह natural language के ज़रिए manage कर सकें। आप कभी ख़ुद Neon console या psql shell नहीं खोलते। (यह course Neon को अपना default host मानता है; सब कुछ TigerData Cloud पर एक जैसा काम करता है, इस concept के अंत में "TigerData पसंद है?" देखें।)
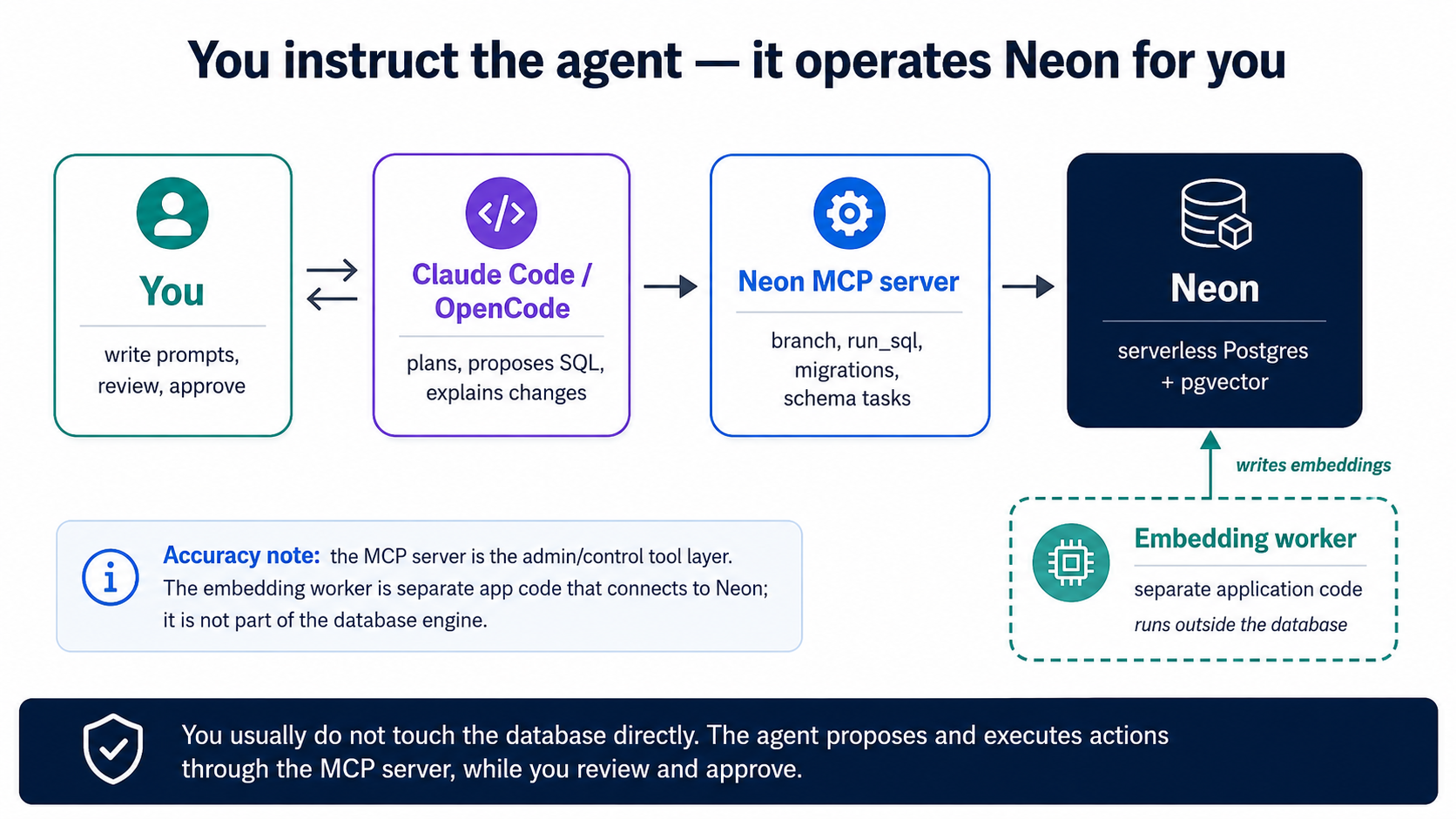
one-time wiring। अगर आपने course base से शुरू किया, तो Neon MCP server पहले से .mcp.json (Claude Code) और opencode.json (OpenCode) में declared है, आप इसे browser में OAuth के ज़रिए एक बार authorize करते हैं, manage करने को कोई API key नहीं। (इसे ख़ुद हाथ से wire करना भी वही एक step है: अपने tool में Neon MCP server जोड़ें और इसे authorize करें।) यही एकमात्र manual setup है; यहाँ से आगे, सब कुछ agent को instruct करके होता है। इसे plan mode में drive करें:
Neon MCP server का इस्तेमाल करके,
agent-factory-ragनाम का एक project बनाएँ और उस पर pgvector extension enable करें। फिर हमारे build करने के लिएdevनाम की एक branch बनाएँ, और उस branch का connection string.envमेंDATABASE_URLके रूप में save करें ताकि worker और app उसे बाद में पढ़ सकें (मेरी API key कभी print न करें)। कुछ भी चलाने से पहले मुझे plan दिखाएँ।
फिर plan पढ़ें। आप किसकी जाँच कर रहे हैं:
- यह सीधे production पर नहीं, बल्कि एक branch पर काम करता है। Branching Neon की superpower है: एक branch आपके पूरे database का एक instant clone है (copy-on-write: यह सिर्फ़ वही store करता है जो आप बदलते हैं, इसलिए cloning मुफ़्त और तुरंत है)। agent schema बदलाव एक branch पर करता है, आप उन्हें preview करते हैं, और तभी default branch पर commit करते हैं, वही plan-then-execute discipline, platform द्वारा लागू। (यही वह तरीक़ा भी है जिससे आप बाद में indexes benchmark करेंगे और evals चलाएँगे: branch बनाएँ, test करें, branch फेंक दें।)
- यह pgvector enable करता है, वह एक extension जो इस course को चाहिए, एक ही statement से:
CREATE EXTENSION IF NOT EXISTS vector; -- pgvector is pre-installed on Neon; this just switches it on
- embeddings (Concept 6) के लिए, agent एक छोटा worker बनाता है, यानी एक छोटी Python script या service, जो नई या बदली हुई rows पढ़ती है, embedding model को call करती है, और vectors को एक embeddings table में लिखती है। यह Neon से अलग चलता है, अपने connection string के ज़रिए आपकी branch तक पहुँचता है। embedding provider की API key worker के environment में रहती है, कभी database में नहीं।
आपको MCP tool के नाम या Neon का API याद करने की ज़रूरत नहीं। plan mode का मक़सद यही है कि आप plan पढ़ें, पक्का करें कि यह एक branch पर काम कर रहा है और pgvector enable कर रहा है, और तब approve करें। अगर plan कुछ ऐसा करता है जिसे आप नहीं पहचानते, तो हाँ कहने से पहले agent से पूछें क्यों, यही सवाल आपका असली काम है।
Neon का अपना मार्गदर्शन यह है कि MCP server local development और IDE integrations के लिए है, यह शक्तिशाली operations चला सकता है, इसलिए इसे अपने dev workflow तक सीमित रखें और approve करने से पहले agent जो भी action propose करे उसे review करें। Production बदलाव अब भी आपकी सामान्य reviewed migration process से होते हैं।
course base में पहले से एक छोटी AGENTS.md / CLAUDE.md शामिल है जिसमें वे rules हैं जो इस course को चाहिए: आप किस Neon branch पर हैं, keys environment में रहती हैं (कभी commit नहीं), आपका चुना हुआ distance function, और दो सख़्त rules, "schema बदलाव हमेशा एक Neon branch पर करें और committing से पहले मुझे preview करने दें," और "मुझे पहले दिखाए बिना कभी destructive SQL (DROP, TRUNCATE, बिना WHERE के DELETE) मत चलाएँ।" base के बिना build कर रहे हैं? /init चलाएँ और ठीक उतने तक trim करें।
इस course की हर चीज़ TigerData Cloud पर बिना बदले चलती है, यानी pgvector के साथी extensions के पीछे वाली team, जो इसे "Agentic Postgres" के रूप में पेश करती है। agent-driven loop एक जैसा है; सिर्फ़ नाम बदलते हैं:
- Neon MCP server की जगह Tiger MCP। यह Tiger CLI में built है, इसे
tiger mcp installसे install करें, फिर Tiger Cloud को natural language में ठीक ऊपर जैसी drive करें ("एक service बनाएँ, उसे fork करें, extensions enable करें, पहले मुझे plan दिखाएँ")। यह Postgres Skills भी देता है जो agent को best practices सिखाती हैं। - branches की जगह Forks:
tiger service fork …एक instant, zero-copy clone बनाता है, वही fork → test → फेंक दो discipline जो आप evals और index benchmarks के लिए इस्तेमाल करेंगे। - pgvectorscale native है (pgvector के साथ-साथ), इसलिए StreamingDiskANN "graduate tier" (Concept 11) पहले दिन से ही box में है, और इसका index 16,000 dimensions तक के vectors support करता है (बड़े models जैसे
text-embedding-3-largeको फिर कोईhalfvecनहीं चाहिए)। आपका embedding worker उसी तरह चलता है जैसे Neon पर चलता है।
आपका embedding worker और generation step दोनों app code में रहते हैं, Neon जैसा ही। अंगूठे का नियम: सबसे सरल serverless शुरुआत के लिए Neon; जब आपको कभी migrate किए बिना pgvectorscale का scale और filtered-search performance चाहिए तब TigerData।
यह course Neon को दो वजहों से इस्तेमाल करता है: credit card के बिना free tier, और instant branching जिसे agent Neon MCP server के ज़रिए drive करता है। Postgres को locally (Homebrew, Docker) या किसी दूसरे host पर चलाना पसंद है? Data side बिल्कुल वही है, वही CREATE EXTENSION vector, वही schema, वही worker, वही queries; बस DATABASE_URL को अपने instance पर point कर दें। जो आप छोड़ते हैं वह MCP-driven branching है (वही "branch, test, throw away" move जिसे आप indexes और evals के लिए इस्तेमाल करेंगे), इसलिए वे steps सीधे चलाने होंगे। यहाँ जो कुछ आप सीखते हैं वह बिना बदले transfer होता है।
Part 2: आपका पहला RAG, आपके agent ने बनाया
हम एक छोटा, classic example बनाएँगे: US शहरों के बारे में ऐतिहासिक हस्तियों की quotes की एक table, फिर उसे meaning से search करेंगे, फिर एक LLM से उस पर सवालों के answer दिलवाएँगे।
5. schema: vectors आपके data के बग़ल में रहते हैं
पहले agent से source table माँगें। एक बात पकड़ें: meaning-vectors किसी अलग store में नहीं रहेंगे, वे इसी database में जाते हैं, उस companion table में जिसे आप अगले concept में बनाएँगे, ठीक उसी data के बग़ल में जिसे वे describe करते हैं।
quotesनाम की एक table बनाएँ जिसमें columns हों:person,city, औरquote। हम embeddings आगे एक companion table में जोड़ेंगे, जिसे एक छोटा worker भरेगा, इसलिए अभी के लिए बस source data। फिर New York, San Francisco, और Chicago के बारे में कुछ असली quotes insert करें ताकि हमारे पास search करने को कुछ हो।
agent जो table लिखता है वह क़रीब ऐसी दिखेगी:
CREATE TABLE quotes (
id bigint GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
person text NOT NULL,
city text NOT NULL,
quote text NOT NULL
);
पकड़ने वाला mental model: एक ही source of truth. quote, किसने कही, शहर, और (जल्द ही) उसका meaning-vector सब एक ही database में रहते हैं। यही वह है जो Part 4 में filtering को मामूली बना देता है।
6. embeddings बनाएँ: वह worker जिसे आपका agent बनाता है
आपकी quotes table text रखती है। database को उस text को meaning से search करने के लिए, उसके हर टुकड़े को एक vector चाहिए, और वे vectors बनाना ही वह एक काम है जो pgvector आपके लिए नहीं करता। इसलिए agent एक छोटा program लिखता है: embedding worker। इसका पूरा काम एक loop है, वे quotes ढूँढो जिनके अभी कोई vectors नहीं हैं → किसी लंबे text को टुकड़ों (chunks) में बाँटो → हर टुकड़े का vector embedding model से माँगो → vectors save करो। इसे एक बार चलाएँ और हर मौजूदा quote cover हो जाती है; इसे एक schedule पर दोबारा चलाएँ और नई या edited quotes भी cover हो जाती हैं। यही पूरी machine है।
vectors कहाँ save होते हैं? एक दूसरी table में, companion table में, हर chunk के लिए एक row, हर एक उसी quote की ओर इशारा करती है जहाँ से वह आई। यह उस सवाल का जवाब देता है जो यहाँ हर कोई पूछता है (एक row, एक embedding?): एक छोटी quote एक chunk है, इसलिए एक vector row; एक लंबा भाषण कई टुकड़े बनता है, इसलिए कई rows। (आख़िर बाँटें ही क्यों? वह Concept 7 है, ठीक इसके बाद।) दो tables, और वे ऐसी दिखती हैं:
quotes (your source table) quotes_embedding (companion table)
┌────┬─────────────────────┐ ┌─────┬──────────┬──────────────┬───────────┐
│ id │ quote │ │ id │ quote_id │ chunk │ embedding │
├────┼─────────────────────┤ ├─────┼──────────┼──────────────┼───────────┤
│ 7 │ a short quote │ ────→ │ 1 │ 7 │ whole quote │ [0.02, …] │
│ 8 │ a long speech… │ ──┬─→ │ 2 │ 8 │ first piece │ [0.11, …] │
└────┴─────────────────────┘ └─→ │ 3 │ 8 │ second piece │ [0.54, …] │
└─────┴──────────┴──────────────┴───────────┘
one row per quote one row per CHUNK (its own id),
pointing back via quote_id
agent के इसे बनाने से पहले एक फ़ैसला: कौन-सा embedding model text को vectors में बदलता है। यहाँ यही एकमात्र choice है जिसे उलटना झँझट है, क्योंकि models बदलने का मतलब है सब कुछ दोबारा embed करना, इसलिए इसे समझना काम आता है भले ही base ने आपके लिए sensible default पहले ही चुन लिया हो। वह default वही provider है जो आपने setup किया: free Gemini path पर Google का gemini-embedding-001, या अगर आपने OpenAI चुना तो OpenAI का text-embedding-3-small। यहाँ दोनों 1536 dimensions पर चलते हैं, दोनों ज़्यादातर RAG के लिए पर्याप्त हैं, और Gemini free है, इसलिए आप model name ख़ुद नहीं चुनते; base ने उसे आपकी दी हुई key से match कर दिया। default से हटने की दो वजहें होती हैं: आपका content English नहीं है (या गहराई से specialized है, जैसे legal, medical, code), जहाँ multilingual या domain-tuned model जीत सकता है; या आपके evals बाद में दिखाते हैं कि कोई बड़ा model सच में बेहतर retrieve करता है। worker में model एक ही setting है, इसलिए आप अंदाज़ा लगाने के बजाय विकल्पों को अपने eval set (Concept 12) पर test करते हैं: MTEB leaderboard (embedding models के लिए मानक public benchmark) से candidates shortlist करें और अपने data को winner चुनने दें।
dimension की बारीक़ बातें (तब पढ़ें जब आप default से हटें)
ज़्यादा dimensions का मतलब है ज़्यादा storage और memory और थोड़ी धीमी search। दो व्यावहारिक बातें: कई आधुनिक models आपको बिना re-training के कम dimensions माँगने देते हैं (यह course दोनों providers को 1536 पर pin करने के लिए ठीक यही करता है), और, एक असली gotcha, pgvector के HNSW/IVFFlat indexes vector type को 2,000 dimensions पर cap करते हैं (halfvec type इसे 4,000 तक बढ़ाता है), इसलिए कोई full-size 3072-dim model (OpenAI का text-embedding-3-large, या Gemini full size पर) indexable होने के लिए halfvec या reduced dimensions चाहता है। 1536 पर रहना आपको इस सबसे बाहर रखता है; अगर आप कभी dimensions बढ़ाएँ तो आपके agent को यह cap flag करना चाहिए, और जब वह करे तो आपको इसे पहचानना चाहिए। (TigerData पर, pgvectorscale का StreamingDiskANN index 16,000 dimensions तक के vectors support करता है, इसलिए यह limit शायद ही कभी अड़ती है।)
पहले, code को एक घर दें, यानी एक Python project, जिसे uv manage करता है (Python project manager; agent इसे जानता है, और हर dependency इसी के ज़रिए routing करने से project reproducible रहता है):
इस folder में uv के साथ एक Python project set up करें। यहाँ से आगे, हर dependency uv के ज़रिए जोड़ें और हर script uv के ज़रिए चलाएँ।
फिर agent से worker और उसकी table बनवाएँ:
quotesके लिए एक foreign key, chunk text, और एकembedding vector(1536)column के साथ एक companion tablequotes_embeddingबनाएँ। फिर एक छोटा embedding worker लिखें जो उन quotes को ढूँढे जिनके पास अभी कोई embedding नहीं है,quotetext को chunk करे, हर chunk को course के embedding model से embed करे, और vectors कोquotes_embeddingमें insert करे। इसे एक बार backfill करने के लिए चलाएँ, मुझे दिखाएँ कि rows आ गईं इसकी पुष्टि कैसे करूँ, और समझाएँ कि मैं इसे कैसे schedule करूँगा। API key environment से पढ़ें।
ध्यान दें: agent companion table बनाता है (ऊपर diagram वाला ठीक आकार), worker एक बार चलाता है, और आपको vector rows दिखाता है जो आईं। अगर worker अपने पहले embedding call पर 401 या 429 के साथ मर जाए, तो आपके code में कुछ टूटा नहीं है; मामला key का है, और शायद आप इसे setup में पहले ही पकड़ चुके होंगे, जहाँ agent ने test call की थी। Gemini पर free key को aistudio.google.com/apikey से फिर copy करें; OpenAI पर बिल्कुल नए account को अक्सर embed करने से पहले payment method चाहिए। 429 rate limit है, इसलिए थोड़ा इंतज़ार करें और फिर चलाएँ। key ठीक करें, फिर दोबारा चलाएँ। अगर इसके बजाय expected 1536 dimensions, got 3072 दिखे, तो embedding call ने 1536 dims request नहीं किए; दोनों providers default रूप से बड़ा vector देते हैं, इसलिए call को vector(1536) column से match करने के लिए 1536 माँगना ज़रूरी है। base worker यह पहले ही करता है, इसलिए यह error बताता है कि हाथ से edit की गई call से वह setting हट गई। तब पूरा जब: हर quote की quotes_embedding में कम से कम एक row है, और आप वह एक command जानते हैं जो worker को दोबारा चलाती है।
सबसे सरल version poll करता है: worker एक schedule पर दोबारा चलता है और उन rows को दोबारा embed करता है जिनका text बदला। इसके बजाय change-driven updates चाहिए? एक INSERT/UPDATE trigger किसी row को dirty mark कर सकता है, यानी यह झंडी लगा सकता है कि "इसे एक ताज़ा embedding चाहिए", और worker अपने अगले pass में उन flagged rows को उठा लेता है। अगर आप कभी worker की एक से ज़्यादा copy चलाएँ ताकि गति बनी रहे, तो उन्हें एक ही row दो बार नहीं पकड़नी चाहिए; Postgres यह आपके लिए संभाल लेता है, हर worker को unclaimed rows का एक अलग batch देता हुआ (SKIP LOCKED वाली तरकीब)। तो embedding-चाहने-वाली rows की वह to-do list बस एक साधारण Postgres table है, चलाने को कोई अलग queue service नहीं, वही one-database फ़ायदा जो आपके vectors के साथ है। किसी भी तरह trigger सिर्फ़ flag करता है; embedding call फिर भी worker में out-of-band होता है, और database ख़ुद कभी embedding API call नहीं करता।
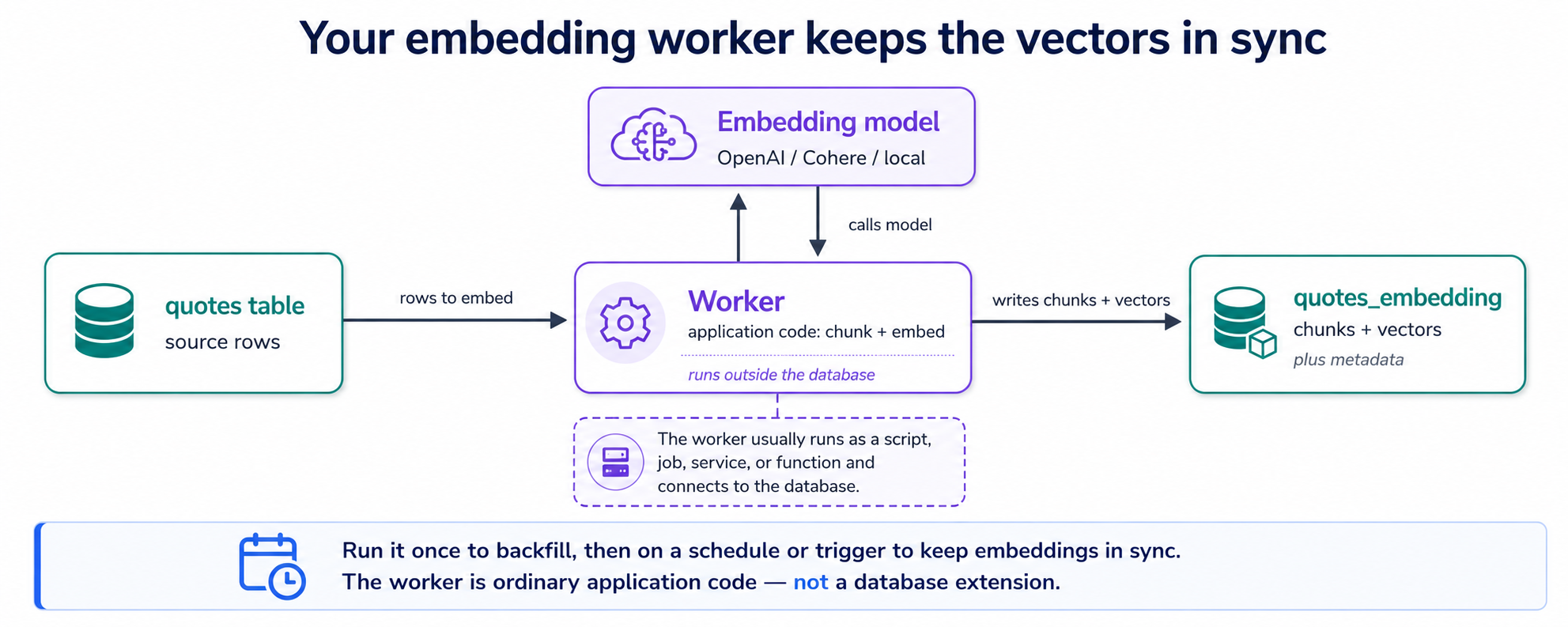
वही worker pattern documents को embed करता है, न कि सिर्फ़ छोटे fields, इसे PDFs, DOCX, या cloud storage की files (मसलन एक Amazon S3 bucket) की ओर इंगित करें और उनसे उन्हें parse, chunk, और उसी companion table में embed करवाएँ। और चूँकि model worker में एक ही setting है, आप providers swap कर सकते हैं (Gemini, OpenAI, Cohere, Voyage, एक local model) यह test करने के लिए कि आपके data पर कौन सबसे अच्छा retrieve करता है, यानी ऊपर वाला model experiment।
worker एक बाहरी embedding provider को call करता है, इसलिए उसे उस provider की API key चाहिए। key worker के environment की है (या आपके cloud provider के secret store की), कभी SQL में hard-coded या आपके repo में committed नहीं। अपने agent को साफ़-साफ़ बताएँ: "API key एक environment variable से पढ़ो, इसे कभी किसी ऐसी file में मत लिखो जिसे हम commit करते हैं।" फिर approve करने से पहले diff verify करें। बाद में embedding providers बदलना (Gemini और OpenAI के बीच, या Cohere, Voyage, एक local model पर) worker में एक line का बदलाव है; आपके app का बाक़ी हिस्सा हिलता नहीं।
7. Chunking: वह lever जो आपकी ceiling तय करता है
Chunking आपके worker के भीतर एक step है, और चुपचाप, सबसे अहम। एक लंबा document अगर एक ही vector के रूप में embed हो जाए तो लुगदी बन जाता है, यानी वह जो कुछ कहता है उस सबका एक धुँधला औसत, इसलिए आप उसे छोटे chunks में बाँटते हैं, और हर chunk को अपना vector मिलता है। chunk किसे माना जाए, यही तय करता है कि आपका search कभी क्या retrieve कर सकता है।
दो dials:
- Size. बहुत बड़ा हो तो एक chunk कई topics तक फैल जाता है, इसलिए उसका vector बेफ़ोकस होता है और आप near-misses retrieve करते हैं। बहुत छोटा हो तो chunk वह context खो देता है जिसने उसे meaningful बनाया था। कुछ सौ tokens एक आम शुरुआती बिंदु है; सही जवाब आपके content पर निर्भर करता है।
- Overlap. chunks को थोड़ा overlap करने देना (मान लें 10 से 20%) उस वाक्य को अनाथ होने से बचाता है जो किसी boundary पर बँटा हो। थोड़ा overlap लगभग हमेशा मदद करता है; बहुत ज़्यादा storage बर्बाद करता है और near-duplicates retrieve करता है।
एक strategy भी है: character count से बाँटें (सरल default), structure से (markdown headings, paragraphs), या semantically (वे वाक्य समूहित करें जो साथ चलते हैं)। structured docs के लिए, headings पर बाँटना आम तौर पर अंधे character counts से बेहतर होता है।
यह अपने अलग concept का हक़ क्यों रखता है: chunking आपकी recall ceiling तय करता है, recall का मतलब बस यह कि आपके search ने पहली जगह सही chunks वापस खींचे या नहीं। अगर सही जवाब कभी एक ही chunk में साफ़-साफ़ नहीं आता, तो कोई embedding model और कोई चतुर prompt उसे recover नहीं कर सकता, यही वजह है कि ख़राब chunking उन सबसे आम कारणों में से एक है जिनसे कोई RAG system चुपचाप कमज़ोर निकलता है। इसलिए आप अंदाज़ा नहीं लगाते: एक बार जब आप असली documents के साथ काम कर रहे हों और आपका eval set मौजूद हो (Concept 12), तो आप agent से कुछ chunking setups Neon branches पर आज़मवाते हैं, हर एक को अपने eval questions के सामने मापते हैं, और winner रखते हैं, वही test-and-discard move जो आप Part 3 में indexes के लिए इस्तेमाल करेंगे। आप ठीक यही move worked example (Part 5) में करेंगे।
8. Semantic search: distance से order करें
अब intro वाला जादू। किसी phrase के meaning में मिलती-जुलती quotes ढूँढने के लिए, आपका app उस phrase को अपना एक vector बना लेता है, यानी query vector, और database store किए chunks को इस आधार पर sort करता है कि उनके vectors उसके कितने पास बैठते हैं।
SQL का एक ही नया टुकड़ा है एक distance operator, यानी वह चिह्न जो पूछता है "कितना पास?"। आपको सिर्फ़ <=> चाहिए, cosine distance: text embeddings के लिए default, और यही पूरा course इस्तेमाल करता है। (pgvector के पास दो और हैं, <-> सीधी-रेखा distance के लिए, <#> inner product के लिए, जिनसे आपका सामना तभी होगा जब किसी model के docs ख़ास तौर पर किसी एक की माँग करें; आपका agent जान जाएगा।)
मुझे एक query लिखकर दें जो किसी search phrase के meaning में सबसे मिलती-जुलती top 5 quotes लौटाए। phrase का embedding application code से एक parameter के रूप में पास किया जाएगा, इसे SQL के भीतर embed न करें।
जो query यह वापस सौंपता है (आपके पढ़ने के लिए, type करने के लिए नहीं):
SELECT q.person, q.city, q.quote
FROM quotes_embedding e -- the table your worker populates: chunks + vectors
JOIN quotes q ON q.id = e.quote_id -- each chunk points back to its source quote
ORDER BY e.embedding <=> $1 -- $1 = the query phrase, embedded in app code
LIMIT 5;
"the city that never sleeps" search करें और top results New York के बारे में quotes होते हैं, उनमें वे भी जिनमें "New York" शब्द कभी नहीं आते, क्योंकि meanings पास हैं। यही, आख़िरकार ठोस रूप में, semantic search है।
user के phrase को एक vector में बदलना आपके application code में होता है, यानी कुछ lines जो agent लिखता है, और नतीजा query में $1 parameter के रूप में पास होता है। model call आपके app में रहता है, जहाँ आप model, retries, और caching control करते हैं; Postgres वही करता है जिसमें वह सबसे अच्छा है, यानी vectors store करना, सबसे पास वाले ढूँढना।
9. RAG: retrieve करें, फिर generate करें
Semantic search relevant text ढूँढता है। RAG (Retrieval-Augmented Generation) एक क़दम आगे जाता है: यह उन retrieved chunks को लेता है, उन्हें एक prompt में context के रूप में भरता है, और एक LLM से कहता है कि आपके data में grounded एक answer रचे। यह customer-support bot है, docs assistant है, "chat with my files" feature है, ये सब यही loop हैं।
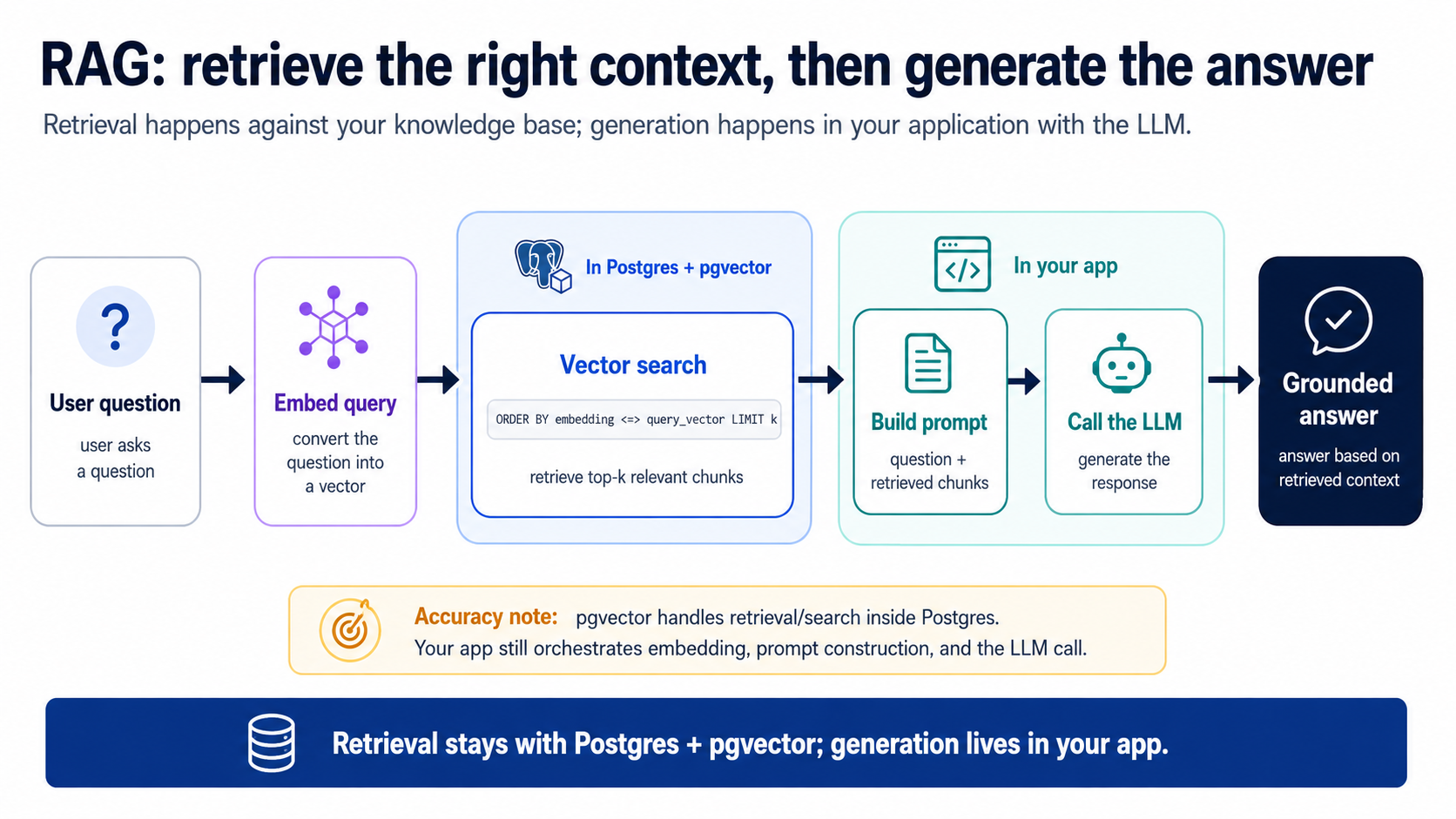
loop के दो stages हैं, और यही बँटवारा असल बात है:
- Retrieve (Postgres में): सबसे relevant top k chunks खींचने के लिए Concept 8 वाली query चलाएँ (k बस यह है कि आप कितने माँगते हैं; 5 अच्छी शुरुआत है)। यही context-management step है, signal fetch करें, दस लाख ग़ैर-relevant rows बाहर छोड़ दें।
- Generate (आपके app में): एक prompt बनाएँ = system instructions + retrieved chunks + user का सवाल, इसे एक LLM को भेजें, answer लौटाएँ। agent यह app-side glue आपके लिए लिखता है; यह छोटा है।
इसे दो steps में बनाएँ, ताकि generation के लपेटने से पहले आप retrieval को अकेले काम करता देख सकें। पहले, एक housekeeping prompt ताकि code का एक घर हो, अगर आपने Concept 6 में worker बनाया था तो यह पहले से सच है, और उस सूरत में agent बस इसकी पुष्टि कर देगा:
पक्का करें कि यह folder एक uv-managed Python project है, अगर नहीं है तो इसे set up करें, और हर dependency और script को uv के ज़रिए ही रखें।
अब search वाला आधा:
application code में एक
search_quotes(question)function बनाएँ: सवाल को embed करें,quotes_embeddingके विरुद्ध हमारा top-k semantic search चलाएँ, और matching chunks उनकी source quotes के साथ लौटाएँ। फिर इसे "the city that never sleeps" पर चलाएँ और मुझे दिखाएँ कि क्या वापस आता है।
जो वापस आता है वह अकेले stage 1 है, यानी सही chunks, meaning से ढूँढे गए, कोई answer लिखे जाने से पहले। अब इसके चारों ओर stage 2 लपेटें:
अब इसके ऊपर
answer_question(question)बनाएँ:search_quotesको call करें, उन chunks को एक prompt में context के रूप में format करें, LLM को call करें, और grounded answer लौटाएँ, retrieval SQL में रहे, generation app code में। फिर इससे एक सवाल पूछें और मुझे retrieved chunks final answer के बग़ल में दिखाएँ।
ग़ौर करें stage 1 क्या कर रहा है: LLM को ठीक वही context सौंप रहा है जो उसे चाहिए और कुछ नहीं, यानी context management, ठीक जैसा शुरुआती diagram ने वादा किया था। अगर retrieval ढीला है, ग़लत chunks, बहुत ज़्यादा, ग़ैर-relevant, तो LLM ख़राब answer देता है और लोग "AI" को दोष देते हैं। यह लगभग हमेशा retrieval होता है। यही वजह है कि Part 4 मौजूद है।
फिर अगली ही साँस में उन्होंने ऐसा system describe किया जो documents index करता है, queries embed करता है, और answer generate करने से पहले relevant chunks retrieve करता है। सम्मान के साथ: वह अभी भी RAG है।
अब आपने इसका हर step build कर लिया है। पूरी machine एक card पर:
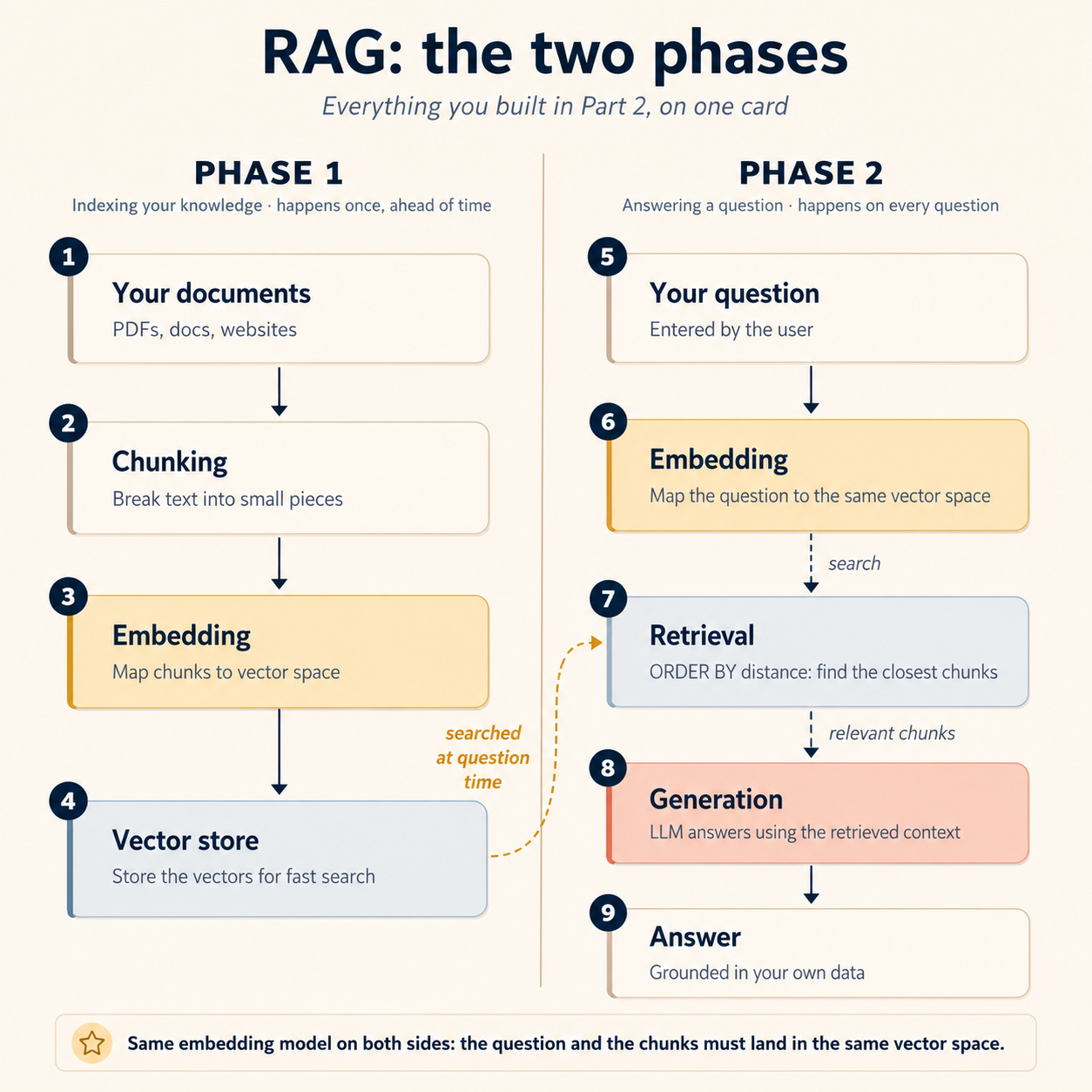
Phase 1: indexing (एक बार, पहले से होती है):
- आपके documents chunks में टूटते हैं (Concept 7)
- हर chunk आपका worker vector space में embed करता है (Concept 6)
- vectors Postgres में land करते हैं, उस data के बग़ल में जिसे वे describe करते हैं (Concept 5)
Phase 2: answering (हर question पर होती है):
- user का question उसी same vector space में embed होता है
- Retrieval question के सबसे closest chunks खींचता है (Concept 8)
- वे chunks model को pass होते हैं, जो उन पर grounded answer generate करता है (यह concept)
पहली pipeline में लोगों को जो हिस्सा उलझाता है वह ऊपर एक word में छिपा है: same. Question और documents को same vector space में land करना होता है: same embedding model, same dimensions, same settings, दोनों sides पर। Documents एक model से embed करें और queries दूसरे से, तो retrieval चुपचाप टूट जाता है, कहीं कोई error नहीं: दो models के vector spaces बस अलग coordinate systems हैं, इसलिए "closest" का मतलब "most similar" रहना बंद हो जाता है। कोई leaderboard ranking इस mismatch से नहीं बचाती। (यह Concept 6 वाले expected 1536 dimensions, got 3072 error का model-level cousin है, बस यह version loud fail भी नहीं करता।)
तो "RAG is dead" headlines के बाद सच में क्या बदला? Mechanism नहीं, packaging. Agents, tool calls, और multi-step reasoning अब उसी retrieve-then-generate loop के ऊपर बैठते हैं। आप Part 6 में इसी exact loop को agent tool के रूप में wrap करेंगे और Part 8 में उसे agent को देंगे: loop मरता नहीं, promote होता है।
answer_question() सिर्फ़ एक chatbot backend नहीं है, यह एक tool है जिसे agent call करता है। agent वाले chapters में, retrieval उन tools में से एक बन जाता है जिन तक एक बड़ा agent तब पहुँचता है जब उसे grounded facts चाहिए, ठीक उसी तरह जैसे वह एक calculator या एक web search तक पहुँचता है। RAG वह searchable context है जिस पर एक agent टिकता है।
Part 3: search को तेज़ बनाना, यानी indexes
यहाँ से Intermediate। Parts 3 और 4 tuning layer हैं: आप सिर्फ़ Parts 1 और 2 पर ship कर सकते थे, पर आप वहाँ नहीं रुकेंगे, इन्हें "क्यों" के लिए पढ़ें, फिर इन सबको Part 5, Steps 5 से 8 में असल में चलाएँ। तेज़ (Part 3) और पैना (Part 4) ऐसी skills हैं जो आपने करके देखी होंगी, सिर्फ़ पढ़ी नहीं।
10. आपको एक vector index की ज़रूरत क्यों है (और कब नहीं)
index के बिना, एक similarity search query vector की तुलना हर row से करता है, यानी एक exact nearest-neighbor scan। यह पूरी तरह accurate है, और जब तक आप छोटे हैं तब तक बिल्कुल ठीक है। जैसे-जैसे table बढ़ती है, यह धीमा पड़ जाता है।
इसका हल एक approximate search है: हर vector न जाँचकर थोड़ी-सी accuracy के बदले बड़ी speed पाएँ। एक vector index वह data structure है जो उस approximation को अच्छा बनाता है।
वह threshold जो आपको over-engineering से बचाता है: लगभग 100,000 vectors से नीचे, exact search अक्सर काफ़ी तेज़ होता है, और हमेशा सही। पर असली threshold dimensions, compute size, speed target, filters, concurrency, और vectors कितनी बार दोबारा लिखे जाते हैं, इन सबके साथ खिसकता है, इसलिए default से index माँगने के बजाय agent से पहले benchmark करवाएँ; इसे तब जोड़ें जब searches सच में धीमी पड़ें, उससे पहले नहीं। (यह coding course के "जब कुछ ग़लत हो तब एक rule जोड़ो, उससे पहले नहीं" की ही नक़ल है।)
11. indexes, कौन-सा इस्तेमाल करें, और उन्हें कैसे tune करें

Neon पर, असल choice बीच वाला card है: HNSW आपका workhorse है (IVFFlat एक legacy विकल्प के रूप में)। StreamingDiskANN card TigerData पर native है; Neon से, उस तक पहुँचने का मतलब है एक ऐसे host पर जाना जो pgvectorscale देता है।
agent आपके लिए index बनाता है, आपका काम यह पहचानना है कि उसने क्या बनाया और पुष्टि करना कि यह आपकी queries पर फ़िट बैठता है। एक constraint जो cards नहीं दिखाते: एक column सिर्फ़ एक vector index type रख सकता है, इसलिए यह एक असली या-यह-या-वह है। हर एक ऐसा दिखता है:
-- HNSW — your default on Neon
CREATE INDEX ON quotes_embedding USING hnsw (embedding vector_cosine_ops);
-- IVFFlat — also on Neon; legacy, needs a lists parameter; recall drifts as data grows, so periodic rebuilds
CREATE INDEX ON quotes_embedding USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);
-- StreamingDiskANN — native on TigerData; on Neon only via a pgvectorscale host
CREATE INDEX ON quotes_embedding USING diskann (embedding vector_cosine_ops);
vector_cosine_ops पर ग़ौर करें, index को आपकी queries के इस्तेमाल किए distance function से match करना चाहिए (<=> → cosine)। इसे mismatch करें और index चुपचाप मदद नहीं करेगा।
असल में फ़ैसला कैसे करें: इसे benchmark करें। HNSW के दो build-time settings हैं, m और ef_construction, जो index बनते समय graph को आकार देते हैं। ये ठीक उसी तरह की चीज़ें हैं जिन्हें आप कभी याद नहीं करते: अपना असली workload बताएँ, और एक फेंक देने लायक़ branch को experiment की क़ीमत चुकाने दें। दो prompts (यहाँ row counts एक real-scale stand-in हैं, आप ठीक यही benchmark Part 5, Step 5 में असल में चलाएँगे, scale तक seed की गई एक throwaway branch पर, ताकि यह एक skill के रूप में बैठे, सिर्फ़ एक कहानी नहीं):
हमारे पास लगभग 2 million quote-vectors हैं और हम ज़्यादातर searches को city से filter करते हैं। एक ताज़ा Neon branch पर, HNSW index इसकी default settings के साथ बनाएँ, दस प्रतिनिधि searches चलाएँ, और p95 latency तथा यह बताएँ कि top results सही दिखते हैं या नहीं।
अब
mऔरef_constructiontune करें: कुछ settings आज़माएँ, हर एक पर वही दस searches दोबारा चलाएँ, और एक की सिफ़ारिश करें, एक paragraph में tradeoff समझाएँ। फिर branch फेंक दें।
यही AI-engineer move है: आप यह याद नहीं करते कि कौन-सी settings तेज़ हैं, आप agent से एक Neon branch पर measure करवाते हैं और एक सिफ़ारिश लाते हैं जिसे आप ऊपर वाले cards के सामने sanity-check कर सकते हैं, फिर branch बिना किसी क़ीमत के फेंक दें। (p95 latency का बस इतना मतलब है कि वह speed जिसके नीचे 95% queries आती हैं, यानी एक समझदार worst-case जिस पर लकीर खींची जाए।)
Row count अकेली धुरी नहीं, churn दूसरी है। आपके vectors कितनी बार दोबारा लिखे जाते हैं (re-chunking, embedding models बदलना, time-decay re-indexing) यह अपने आप में एक cost है। HNSW incremental inserts और updates बिना full rebuild के लेता है, पर भारी rewrite volume समय के साथ graph को फुला देता है, recall खिसकती है और आपको आख़िरकार एक REINDEX चाहिए, और re-embedding ख़ुद compute है जिसकी आप क़ीमत चुकाते हैं। इसलिए लगातार दोबारा लिखा जाने वाला data बड़ा होने से बहुत पहले महँगा हो सकता है। agent को सिर्फ़ अपनी row count नहीं, अपना असली update pattern बताएँ, और उसे उसी के विरुद्ध benchmark करवाएँ।
रोज़मर्रा में जानने लायक़ एकमात्र knob: ef_search। ऊपर वाली build-time settings index बन जाने के बाद बेक हो जाती हैं; जो dial आप असल में छुएँगे वह query time पर है, ef_search control करता है कि search कितनी मेहनत से देखता है: ज़्यादा का मतलब बेहतर recall और धीमी queries, कम का मतलब तेज़ और कम accurate। agent इसे per query set करता है; यह वह line है जो आप इसे चलाते देखेंगे:
SET LOCAL hnsw.ef_search = 100; -- raise for more recall, lower for more speed
तो move यह है: agent को बताएँ कि आपको असल में कितनी recall चाहिए और उससे ef_search को वहाँ पहुँचने के लिए tune करवाएँ, इसे आँख मूँदकर max न करें। फिर उससे साबित करवाएँ कि index अपना काम कर रहा है: EXPLAIN ANALYZE चलाएँ, एक sequential scan के बजाय एक index scan की जाँच करें, और वापस रिपोर्ट करें। यह रहा फ़र्क़, output के उस हिस्से में जिसे आप असल में पढ़ते हैं (वही 2M-vector table, एक usable index के साथ और बिना):
✅ GOOD — the index is doing the work
-> Index Scan using quotes_embedding_hnsw_idx on quotes_embedding
Order By: (embedding <=> $1)
Execution Time: 0.8 ms
❌ BAD — no index used; every row got scanned and sorted
-> Seq Scan on quotes_embedding (rows=2000000)
Sort Key: (embedding <=> $1)
Execution Time: 52.4 ms
दो lines बता देती हैं कि आपको कौन-सा मिला: operator line (Index Scan using …hnsw… बनाम Seq Scan on …) और execution time (उसी data पर sub-millisecond बनाम दसियों millisecond)। Seq Scan का मतलब है index इस्तेमाल नहीं हो रहा, आम तौर पर इसलिए कि query का distance operator index से match नहीं करता, या इसलिए कि अभी कोई index है ही नहीं। यही वह एक चीज़ है जिसे indexing को "हो गया" कहने से पहले आप agent से पुष्ट करवाएँ।
ये वे बार-बार आने वाले तरीक़े हैं जिनसे vector search चुपचाप टूटता है, और चूँकि आपका काम agent के काम को judge करना है, ये ठीक वही हैं जिन पर नज़र रखें:
- Dimension mismatch, column के dimensions embedding model के output से match नहीं करते।
- Vector type client में register नहीं, worker (और search code) को हर database connection पर pgvector register करना चाहिए जो
embeddingcolumn को छूता है (register_vector), वरना vectors चुपचाप plain text के रूप में round-trip होते हैं: फिर inserts और searches बिना किसी error के ग़लत बर्ताव करते हैं। यही एकमात्र silent-corruption mode है जो SQL में दिखता नहीं, इसलिए agent से पुष्टि करवाएँ कि उसने type register किया। - No index उस बिंदु के बाद जहाँ आपको एक चाहिए था, एक silent slowdown, कोई error नहीं।
- Operator / index mismatch, query
<->इस्तेमाल करती है पर index cosine है, इसलिए index नज़रअंदाज़ हो जाता है। - chunks के बजाय पूरे documents, Concept 7 वाली ग़लती; retrieval कभी कुछ सटीक नहीं ढूँढ सकता।
EXPLAIN ANALYZEछोड़ना, ताकि ऊपर वाली कोई भी चीज़ तब तक कोई न पकड़े जब तक users न पकड़ें।
अगर आपकी ज़्यादातर searches एक WHERE clause ढोती हैं (tenant से, date से, category से), तो HNSW को filter columns पर साधारण B-tree indexes (dates और categories जैसे plain columns के लिए Postgres का standard index) के साथ जोड़ें ताकि Postgres set को कुशलता से सँकरा कर सके। (StreamingDiskANN, ऊपर वाला तीसरा card, बहुत बड़े scale पर भारी filtered search के लिए बना है।) Neon पर, HNSW और अच्छे filter indexes आपको पहले काफ़ी दूर तक ले जाते हैं।
Part 4: search को अच्छा बनाना, यानी advanced layer
एक चलता हुआ RAG कोई अच्छा RAG नहीं होता। यहीं ज़्यादातर projects अटक जाते हैं, और यहीं इन moves को जानना आपको उस किसी से अलग करता है जो सिर्फ़ एक demo बना सकता है।
12. Eval-driven development
वही आदत जो एक shippable system को एक भाग्यशाली demo से अलग करती है। ज़्यादातर लोग build करके शुरू करते हैं, फिर आँख से देखते हैं कि output "सही लगता है" या नहीं। इसके बजाय, सवालों से शुरू करें। कुछ भी लिखने से पहले, एक दर्जन सवाल लिख डालें जो आपके users सच में पूछेंगे और उन्हें एक file में रखें। वह file आपका evaluation set है, यानी आपका वह पैमाना कि किसी बदलाव ने चीज़ें बेहतर कीं या बदतर।
फिर, जब भी आप system बदलें, एक नया embedding model, एक अलग chunking strategy, एक जोड़ा गया filter, आप eval set दोबारा चलाते हैं और असर देखते हैं, अंदाज़ा लगाने के बजाय। जैसे-जैसे app बढ़ता है, set भी उसके साथ बढ़ता है (20, 50 सवाल), और आप regressions अपने users से पहले पकड़ लेते हैं।
दूसरा आधा है समस्या को decompose करना। जब कोई answer ख़राब हो, यह नतीजा न निकालें कि "AI बेवक़ूफ़ है।" stages का पता लगाएँ:
- Retrieval: क्या semantic search ने सही chunks लौटाए भी? (अक्सर असली समस्या एक inventory gap होती है, users किसी ऐसी चीज़ के बारे में पूछते हैं जो आपने database में कभी डाली ही नहीं।)
- Context: क्या सही chunks LLM को पास किए गए, या बहुत ज़्यादा/बहुत कम?
- Generation: अच्छा context मिलने पर भी, क्या model ने फिर भी ख़राब answer दिया?
दस में से नौ बार failure retrieval होती है, LLM नहीं। उस stage को ठीक करें जो सच में टूटा है।
अपना अभी बनाएँ, जो भी आपने load किया उसके विरुद्ध, Part 2 की quotes, या आपका अपना data। पहले सवाल, agent draft करता है, आप curate करते हैं:
हमारी source table पढ़ें और 12 eval सवाल draft करें जो एक user वाक़ई पूछ सकता है, कुछ जिनकी एक साफ़ source row हो, कुछ जिनका answer कई पर फैला हो, और दो-तीन जिनका हमारा data जवाब दे ही न सके। हर एक के लिए अपेक्षित answer नोट करें (या "जवाब नहीं दे सकते"), और उन्हें मेरे edit करने के लिए
evals/questions.mdमें save करें।
उस file को bless करने से पहले edit करें, आप अपने users को जानते हैं; agent नहीं जानता। फिर harness wire करें:
एक छोटा harness बनाएँ जो
evals/questions.mdके हर सवाल को हमारे retrieve-then-generate pipeline से चलाए, और हर एक के लिए दिखाए: retrieve किए chunks, final answer, और यह कि वह मेरी अपेक्षा से match करता है या नहीं। संक्षेप में बताएँ कि यह कहाँ fail हो रहा है, retrieval या generation।
अब से, हर बदलाव इसके विरुद्ध मापा जाता है:
evals चलाएँ और नतीजों को आज की baseline के रूप में save करें। हमारे अगले बदलाव के बाद, दोबारा चलाएँ और मुझे diff दिखाएँ, कौन-से सवाल बेहतर हुए, कौन-से बदतर।
429 free-tier cap है, bug नहींहर eval run हर सवाल के लिए एक model call करता है, और आप set को कई बार दोबारा चलाएँगे। Free tier पर आप आख़िरकार provider के daily request cap से टकराएँगे और बीच में 429 देखेंगे। यह cap है, आपने कुछ नहीं तोड़ा: इंतज़ार करके retry करें, harness को back off और automatic retry करवाएँ, routine runs के लिए छोटा free model इस्तेमाल करें, या billing enable करें। exact limits बदलती रहती हैं, इसलिए किसी number पर भरोसा करने के बजाय provider का dashboard देखें।
Eval-driven development भरोसेमंद agents की रीढ़ है, सिर्फ़ RAG की नहीं। इसका समर्पित treatment है Eval-Driven Development Crash Course, इसे इसके बाद करें।
13. Filtered search: WHERE clause आपका दोस्त है
शुद्ध semantic search वैश्विक रूप से सबसे मिलती-जुलती rows लौटाता है। अक्सर आप चाहते हैं वे सबसे मिलती-जुलती rows जो किसी शर्त को भी पूरा करती हों। चूँकि आपके vectors आपके data के बग़ल में रहते हैं (Concept 5), यह बस उसी query पर एक WHERE clause है, कोई दूसरा system नहीं, कोई जुगलबंदी नहीं। पाँच patterns लगभग सब कुछ cover कर लेते हैं:
| Pattern | उदाहरण use case | जोड़ा गया clause (खाका) |
|---|---|---|
| Metadata filter | कई products में docs search | WHERE product = 'CRM' AND doc_type = 'api-reference' |
| Composite filter | E-commerce recommendations | WHERE category = 'electronics' AND price BETWEEN 500 AND 2000 AND in_stock |
| Time filter | News recommender, सिर्फ़ हाल के articles | WHERE published_at > now() - interval '7 days' |
| Permissions filter | Internal RAG जहाँ users सिर्फ़ वही देखें जिसके वे cleared हों | WHERE clearance_level <= $user_level |
| Geospatial filter | "5 km के भीतर चीज़ें recommend करें" (PostGIS जोड़ें) | WHERE ST_DWithin(location, $point, 5000) |
हर एक का आकार वही है: ORDER BY embedding <=> $1 के आगे एक WHERE। permissions वाला ठहरकर सोचने लायक़ है, यही वह तरीक़ा है जिससे आप tenant A को कभी tenant B के documents retrieve करने से रोकते हैं, जो application code में आशा करने के बजाय database में लागू होता है।
हमारे semantic search में एक optional city filter जोड़ें। एक Neon branch पर,
citycolumn पर एक B-tree index जोड़ें, पक्का करें कि filtered queries तेज़ रहें, और मुझे हमारे eval set पर before/after latency दिखाएँ।
14. Hybrid search: meaning और keywords
2026 तक hybrid search गंभीर retrieval के लिए सबसे मज़बूत candidate upgrade है, ऐसा candidate जिसे आप अपने eval set पर confirm करते हैं, आँख बंद करके default के रूप में ship नहीं करते। idea यह है: keyword search और vector search चलाएँ, फिर merge करें। हर एक दूसरे का अंधा कोना ढक देता है, vector search paraphrase समझता है पर exact दुर्लभ terms (एक product code, किसी का नाम) को कम तौलता है; keyword search exact term पकड़ लेता है पर meaning से चूक जाता है। Postgres दोनों natively करता है, keyword search full-text search (tsvector) के ज़रिए, vectors pgvector के ज़रिए, इसलिए यह एक database और, अक्सर, एक query बना रहता है।
जो आकार standard बन गया है:
- दोनों से retrieve करें, ज़रूरत से ज़्यादा खींचते हुए, मान लें keyword से top 20 और vector से top 20, ताकि merge के पास काम करने को signal हो।
- Reciprocal Rank Fusion (RRF) से fuse करें। RRF दोनों ranked lists को position से merge करता है, score से नहीं, जो उस असली सिरदर्द को किनारे कर देता है कि keyword scores और cosine distances बिल्कुल अलग scales पर रहते हैं और उन्हें समझदारी से औसत नहीं किया जा सकता। यह SQL की कुछ lines है और इसे किसी model की ज़रूरत नहीं।
- (वैकल्पिक) top candidates को एक cross-encoder से rerank करें, एक छोटा model जो हर query–chunk जोड़े को सीधे score करता है। यह precision step है: RRF लगभग 100 का एक अच्छा pool चुनता है, cross-encoder उस आख़िरी मुट्ठी भर को क्रम देता है जो आप LLM को सौंपते हैं। इसे तभी जोड़ें जब आपके evals कहें कि अतिरिक्त latency के बदले फ़ायदा सही है।
जो आकार agent बनाता है (आपके पढ़ने के लिए, type के लिए नहीं), यह पहले vectors के बग़ल में एक ts full-text column जोड़ चुका होगा, दो ranked lists, RRF से fused, सब एक query में:
WITH kw AS ( -- keyword side: full-text search, ranked
SELECT id, row_number() OVER (ORDER BY ts_rank_cd(ts, plainto_tsquery($1)) DESC) AS rank
FROM quotes_embedding WHERE ts @@ plainto_tsquery($1) LIMIT 20
),
vec AS ( -- vector side: semantic search, ranked
SELECT id, row_number() OVER (ORDER BY embedding <=> $2) AS rank
FROM quotes_embedding ORDER BY embedding <=> $2 LIMIT 20
)
SELECT id, SUM(1.0 / (60 + rank)) AS score -- RRF: k = 60, summed across both lists
FROM (SELECT * FROM kw UNION ALL SELECT * FROM vec) r
GROUP BY id ORDER BY score DESC LIMIT 10; -- $1 = query text, $2 = query vector
इसे पढ़ना: kw keyword match से top 20 लौटाता है और vec meaning से top 20, हर row उस list में अपने rank से tagged (1 = सबसे अच्छा)। final query दोनों lists में हर row के लिए 1 / (60 + rank) जोड़ती है, इसलिए किसी भी list के top के पास वाली row अच्छा score करती है, और जो row दोनों में आती है वह जीतती है। 60 (standard RRF constant) किसी एक ऊँचे rank को हावी होने से रोकता है, और चूँकि यह positions पर काम करता है, आपको कभी keyword scores और cosine distances को अलग scales पर मिलाना नहीं पड़ता।
हमारे vector search के साथ-साथ
quotecolumn पर full-text search जोड़ें, दोनों को RRF से fuse करें, और हमारे eval set को vector-only बनाम hybrid चलाएँ। मुझे बताएँ कि कौन-से सवाल बेहतर हुए और कितना।
Hybrid search सबसे ज़्यादा उन queries पर जीतता है जो किसी concept को एक ख़ास term के साथ मिलाती हैं, "Truman Capote ने शहर के बारे में क्या कहा" को नाम exactly match होना और meaning समझा जाना, दोनों चाहिए। यह आपके data पर सच में मदद करता है या नहीं, और कितनी, यह एक ऐसा सवाल है जिसका जवाब सिर्फ़ आपका eval set दे सकता है, इसलिए अतिरिक्त चलते-पुर्ज़े लेने से पहले vector-only बनाम hybrid मापें।
15. Multi-tenancy और text-to-SQL
दो और जिन्हें आपको पहचानना चाहिए, भले ही आप उन्हें आज न बनाएँ।
Multi-tenancy. अगर आप SaaS बना रहे हैं, तो हर customer का data हर दूसरे से दीवार के पीछे रहना चाहिए। isolation की एक सीढ़ी है, सबसे ढीली से सबसे सख़्त तक:
| तरीक़ा | Isolation | Cost / complexity | आम तौर पर फ़िट |
|---|---|---|---|
Shared table + tenant_id filter | सबसे कमज़ोर | सबसे सस्ता | Internal tools, low-risk data |
| Schema per tenant | अच्छा | मध्यम | ज़्यादातर SaaS के लिए sweet spot |
| Database per tenant | सबसे मज़बूत | सबसे ज़्यादा (backups, ops) | High-security / regulated clients |
Schema-per-tenant आम संतुलन है: असली isolation, चलाने को एक database। किसी भी तरह, Concept 13 वाला नियम क़ायम है, सीमा को database में लागू करें, सिर्फ़ अपने app code में नहीं। सबसे साफ़ Postgres तंत्र है Row-Level Security (RLS): आप agent से एक policy एक बार लिखवाते हैं (rows सिर्फ़ वहाँ दिखें जहाँ, मसलन, tenant_id = current_setting('app.tenant')) और फिर Postgres इसे हर query पर अपने-आप लागू करता है, इसलिए एक भूला हुआ WHERE clause एक tenant के vectors दूसरे को leak नहीं कर सकता। एक पेच जानने लायक़ है, क्योंकि यह पहली बार सबको काटता है: RLS को superusers और table के owner bypass कर देते हैं, इसलिए आपके app को एक साधारण, non-owner role के रूप में connect करना चाहिए (Part 6 वाला read-only role बिल्कुल सही है), policy को उसी role के रूप में test करें, वरना आपको कोई isolation नहीं दिखेगा और आप ग़लत नतीजा निकालेंगे कि यह काम नहीं करता।
Text-to-SQL. Postgres structured data भी रखता है, numbers, dates, relations। Text-to-SQL एक user को plain English में पूछने देता है ("Q3 sales region के हिसाब से क्या थीं?") और एक agent से उसे आपकी असली tables के विरुद्ध एक सही SQL query में translate करवाता है। जो चीज़ इसे accurate बनाती है वह है एक अच्छी तरह वर्णित schema: साफ़ table और column नाम, COMMENTs जो समझाएँ कि हर एक का क्या मतलब है, और कुछ उदाहरण सवाल→query जोड़े जिनसे agent सीख सके। agent को वह context दें, SQL के चलने से पहले उसे review करने के लिए एक इंसान को loop में रखें, और इसे semantic search (आपके documents के लिए) के साथ मिलाएँ, एक agent जो हर सवाल के लिए सही tool चुनता है, एक असली data assistant की बुनियाद है।
इसे हमारे schema पर दो prompts में असली बनाएँ। पहले, agent से ज़मीन तैयार करवाएँ:
हमारी tables को document करें ताकि English सवाल अच्छी तरह translate हों: tables और columns में comments जोड़ें कि हर एक क्या रखता है, और कुछ उदाहरण सवाल उस SQL के साथ save करें जो उन्हें पैदा करनी चाहिए।
फिर बस पूछें, plain English में:
किस person की सबसे ज़्यादा quotes हैं, और उनकी quotes शहरों में कैसे फैली हैं? मुझे पहले वह SQL दिखाएँ जो आप चलाएँगे, मेरे approve करने के बाद ही execute करें।
Text-to-SQL एक और नाम से plan mode है: agent से पहले SQL दिखवाएँ, ख़ासकर कुछ भी जो लिखता है। एक ग़लत SELECT एक सेकंड बर्बाद करता है; एक ग़लत UPDATE आपकी दोपहर बर्बाद कर देता है।
Part 5: एक complete worked example
एक task, शुरू से आख़िर तक: एक ख़ाली Neon project से एक चलते Q&A तक जो आपके documents से answer देता है। नीचे के prompts ही पूरा काम हैं, इन्हें किसी भी tool में type करें। तरीक़ा वही coding course का एक move है पूरे आकार में: एक मज़बूत model के साथ plan करें, plan review करें, फिर एक सस्ते model से routine build करवाएँ।
यह दोनों ही तरह से काम करता है जैसे भी आप पहुँचें। आप उसी postgres-ai/ folder में रहते हैं, पर build एक बिल्कुल नया Neon project बनाता है, इसलिए quotes वाले build की कोई चीज़ नहीं छूती, चाहे आपने Concepts 5 से 9 किए हों या सीधे यहाँ कूदे हों। अगर plan आपके पहले से बने functions दोबारा इस्तेमाल करने का सुझाव दे, तो ठीक है; review में judge करें।
0. build को documents और एक घर दें, base कोई नहीं देता, इसलिए कुछ बनाएँ (और अगर यह folder अभी uv project नहीं है, तो यह वह भी ठीक कर देता है)। Paste करें:
इस folder को एक uv-managed Python project के रूप में set up करें अगर यह पहले से नहीं है। फिर दस छोटी markdown files के साथ एक
docs/folder बनाएँ: एक काल्पनिक company के लिए एक mini employee handbook: leave policy, expenses, security, onboarding, equipment।
1. पहले plan करें, एक मज़बूत model के साथ plan mode में जाएँ (Claude Code में Shift+Tab, OpenCode में Tab), फिर paste करें:
मेरे पास markdown files का एक folder
./docsहै। Neon पर एक RAG system बनाएँ: Neon MCP server का इस्तेमाल करके, एक project और एकdevbranch बनाएँ, pgvector enable करें, docs को एक table में load करें, एक छोटा embedding worker बनाएँ जो उन्हें chunk और embed करके एक companionchunkstable में डाले, और मुझे एकanswer_question()function दें जो retrieve करके फिर generate करता है। कुछ भी चलाने से पहले मुझे पूरा plan और schema दिखाएँ।
2. approve करने से पहले plan पढ़ें। जाँचें: क्या यह एक Neon branch पर काम कर रहा है? क्या pgvector enabled है? क्या embedding worker API key environment से पढ़ता है (और key repo से बाहर रखी गई है)? क्या generation app code में है? अगर सब हाँ, तो approve करें।
3. execute करें, तीन checkpoints में, routine build के लिए एक सस्ते model पर switch करें (किसी भी tool में /model), और पूरा plan आँख मूँदकर न दागें: इसे चरणों में चलाएँ, हर एक के बाद देखने को कुछ रहे। पहले database:
सही लगता है। database और worker के साथ आगे बढ़ें: project और
devbranch बनाएँ, pgvector enable करें, docs load करें, और worker एक बार चलाएँ। फिर मुझे दिखाएँ कि हर document ने कितने chunks पैदा किए, ताकि मैं देख सकूँ कि documents आ गए।
retrieval अगला, answers से पहले chunks, Concept 9 जैसा ही:
अब search वाला आधा। retrieval function बनाएँ और इसे तीन सवालों पर चलाएँ जो एक नया employee पूछ सकता है, मुझे सिर्फ़ वे chunks दिखाएँ जो वापस आते हैं, अभी कोई answers नहीं।
अगर सही chunks वापस आ रहे हैं, तो generation आसान हिस्सा है:
इसके चारों ओर
answer_question()लपेटें। फिर पाँच सवाल पूछें जो एक नया employee वाक़ई पूछेगा और मुझे हर answer के बग़ल में retrieve किए chunks दिखाएँ।
4. evaluate करें, फिर iterate करें, कुछ answers दूसरों से कमज़ोर होंगे; वह loop की शुरुआत है, कोई failure नहीं। Paste करें:
सबसे कमज़ोर answers ने ग़ैर-relevant chunks इस्तेमाल किए। निदान करें: यह retrieval है या generation? अगर retrieval, तो एक ताज़ा branch पर एक अलग chunking strategy आज़माएँ और वही पाँच सवाल दोबारा चलाएँ।
अब आपके पास एक चलता हुआ RAG है। अगले चार steps tuning layer (Parts 3 और 4) हैं, और आप हर एक को चलाने वाले हैं, सिर्फ़ उसके बारे में पढ़ने वाले नहीं। हर learner ये करता है, उसी data पर जो आपके पास पहले से है, ताकि गहराई एक skill के रूप में बैठे। ये स्वतंत्र हैं: इन्हें किसी भी क्रम में करें, कोई न छोड़ें।
5. इसे तेज़ बनाएँ, और index को अपनी कमाई कमाते देखें (Concept 11)। दस docs index की ज़रूरत के लिए बहुत छोटे हैं, इसलिए आप scale ख़ुद बनाएँगे, एक branch पर जिसे आप फेंक देते हैं, और search को उसी data पर धीमे से instant होते देखेंगे। Paste करें:
एक throwaway Neon branch पर, एक benchmark table बनाएँ और उसे इतने random vectors से भरें कि वह ~100k वाली निशानी पार कर जाए जहाँ एक index जीतना शुरू करता है, किसी embeddings या असली text की ज़रूरत नहीं, यह सिर्फ़ scale बनाने के लिए है। पक्का करें कि हर row को अपना अलग random vector मिले (आम गलती हर row में वही vector भर देती है, agent से
count(distinct embedding)के साथ verify करवाएँ)। इसका आकार ऐसा रखें कि यह Neon के free storage के भीतर रहे; अगर इससे फ़िट होने में मदद मिले तो इस synthetic table के लिए एक छोटा vector dimension इस्तेमाल करें।EXPLAIN ANALYZEके साथ एक nearest-neighbour search चलाएँ और मुझे plan व समय दिखाएँ। फिर HNSW index बनाएँ, build के लिएmaintenance_work_memबढ़ाएँ ताकि यह रेंगता न रहे, और वही search दोबारा चलाएँ। दोनों को बग़ल-बग़ल रखें: operator line और execution time, पहले और बाद में। फिरef_searchबढ़ाएँ और घटाएँ और मुझे दिखाएँ कि latency कैसे हिलती है। काम पूरा होने पर branch delete कर दें, इससे storage वापस मिल जाता है।
तब पूरा जब: अपनी आँखों से आपने Seq Scan को Index Scan using …hnsw… बनते देखा है और identical data पर execution time गिरते देखी है, और आपने ef_search को latency हिलाते देखा है। यही Concept 11 का speed वाला आधा हिस्सा, हो गया। (तीन चीज़ें जो समस्या जैसी दिखती हैं पर हैं नहीं: 100k+ vectors पर HNSW index बनने में कुछ मिनट लगते हैं, सेकंड नहीं, यह अपेक्षित है, कोई hang नहीं, और build के लिए maintenance_work_mem बढ़ाने से यह काफ़ी घटता है; इस throwaway table के लिए छोटा dimension इस्तेमाल करना lesson के बारे में कुछ नहीं बदलता, क्योंकि index-scan-बनाम-seq-scan और ef_search latency dial किसी भी dimension पर एक जैसा बर्ताव करते हैं; और ये random vectors ईमानदारी से speed दिखाते हैं, पर real recall नहीं दिखा सकते, क्योंकि random points में neighbourhood structure नहीं होता, इसलिए यहाँ poor recall number का कोई अर्थ नहीं। recall को real embeddings पर अपने eval set के विरुद्ध judge करें, synthetic data पर कभी नहीं। आप index benchmark कर रहे हैं, retrieval नहीं।)
6. meaning और एक शर्त से filter करें (Concept 13)। आपके handbook docs प्राकृतिक categories में आते हैं (leave, expenses, security, onboarding, equipment), इसलिए आप असल में filter कर सकते हैं:
हर chunk को उस doc की category से tag करें जहाँ से वह आया। हमारे search में एक optional
categoryfilter जोड़ें। "मुझे कितने दिन की leave मिलती है?" दो बार पूछें, एक बार सब पर, एक बार leave category तक filtered, और मुझे दिखाएँ कि retrieve किए chunks कैसे बदलते हैं।categoryपर एक B-tree index जोड़ें औरEXPLAIN ANALYZEसे पुष्टि करें कि filter उसका इस्तेमाल करता है।
तब पूरा जब: filtered query सँकरे, विषय पर टिके chunks लौटाती है, और आपने plan में B-tree index देखा है, Concept 5 वाला उसी-query-पर-WHERE-clause फ़ायदा, असली बना हुआ।
7. वह exact term पकड़ें जो अकेला meaning चूक जाता है (Concept 14)। यहीं आप महसूस करते हैं कि hybrid search default क्यों बना:
किसी एक doc में एक दुर्लभ exact code डालें, मान लें expenses file में
EXP-2031। "EXP-2031 क्या है?" vector-only search से पूछें और मुझे दिखाएँ कि यह कहाँ rank करता है। अब chunk text पर full-text search जोड़ें, दोनों lists को RRF से fuse करें, और दोबारा पूछें, exact match का rank कैसे बदलता है यह दिखाएँ। फिर हमारे पाँच eval सवाल vector-only बनाम hybrid दोबारा चलाएँ और बताएँ कि कौन-सा बेहतर हुआ।
तब पूरा जब: आपने compare कर लिया कि code vector-only बनाम hybrid में कहाँ rank करता है और अपने eval set को net effect दिखाने दिया, इसलिए आपने hybrid का फ़ैसला सबूत पर किया, किसी headline की वजह से नहीं। (इतने छोटे corpus में vector search rare code को पहले से top के पास ला सकती है; hybrid जिस gap को बंद करता है वह corpus बढ़ने और rare token के कई chunks में dilute होने पर चौड़ा होता है। अगर hybrid यहाँ साफ़ move न करे, तो यह scale effect है, failure नहीं, RRF query चलती है यह confirm करें और eval comparison को verdict बनने दें।)
8. एक tenant को दूसरे से दीवार में बंद करें (Concept 15)। वही isolation जो इसे ऐसी चीज़ बना देता है जिसे आप एक साथ दो customers को बेच सकते हैं:
हमारे chunks को दो दिखावटी tenants से tag करें, docs को आधा-आधा बाँट दें। एक Row-Level Security policy लिखें ताकि tenant A पर set एक session सिर्फ़ tenant A के chunks ही retrieve कर सके। फिर इसे एक साधारण, non-owner database role से साबित करें (RLS को superusers और table owner bypass कर देते हैं, इसलिए table बनाने वाले admin role के रूप में test करने पर कोई isolation नहीं दिखता, इसके बजाय एक plain read-only role इस्तेमाल करें): agent से वह role आपके लिए बनवाएँ (एक
CREATE ROLE+GRANT SELECT,SET ROLEया अलग Neon role और connection string से connected, हाथ से setup नहीं), session को tenant A पर set करें और एक ऐसी search चलाएँ जो वरना किसी tenant-B chunk से match करती, दिखाएँ कि वह कभी वापस नहीं आती, फिर tenant B पर switch करें और उल्टी छवि दिखाएँ।
तब पूरा जब: वही identical query अलग rows लौटाती है, सिर्फ़ उस tenant के आधार पर जिस पर session set है, और आपने इसे एक non-owner role के रूप में चलाया (ताकि दीवार असली हो)। यही Concept 15 का "इसे database में लागू करो" ठोस बना, RLS, कोई WHERE clause नहीं जिसे आप भूल सकें।
लय पर ग़ौर करें, और ग़ौर करें कि यह कठिन हिस्सों के लिए बदली नहीं: plan → review → execute → evaluate → iterate। Indexes, filters, hybrid, और tenant isolation पहले RAG build जैसा ही loop हैं, हर बार नई चीज़ बस यह है कि आप क्या review कर रहे हैं (schema, worker, index plan, RLS policy)। उस loop में महारत हासिल करें और ख़ास SQL मायने रखना बंद कर देता है, क्योंकि आप हमेशा agent से वह बनवा सकते हैं और आप हमेशा बता सकते हैं कि यह सही है या नहीं, किसी भी गहराई पर, सिर्फ़ आसान वाली पर नहीं।
Part 6: अपने RAG को एक MCP tool के रूप में Ship करें
आपने search_quotes() और answer_question() बनाए (Concept 9), और Part 5 में, उनके document जुड़वाँ; यह part उसे लपेटता है जिसे भी आप serve करना चाहें। अभी सिर्फ़ आपका code उन्हें call कर सकता है। उन्हें एक Model Context Protocol (MCP) server में लपेटें और वही retrieval एक tool बन जाता है जिसे कोई भी agent discover और call कर सकता है, Claude Code, OpenCode, Claude Desktop, Cursor, या आगे बनने वाला कोई Digital FTE। MCP वह open standard है जिस पर यह किताब बार-बार लौटती है: capability एक बार लिखें, और हर agent उससे एक ही तरह बात करता है।
यह Concept 9 का वादा है, कि retrieval वह searchable context है जिस पर एक agent टिकता है, असली बना हुआ। आपका vector search एक app में दबा हुआ feature रहना बंद कर देता है और एक पुनः-इस्तेमाल योग्य capability बन जाता है: कुछ ऐसा जिस तक एक agent उसी तरह पहुँचता है जैसे वह एक calculator तक पहुँचता है।
अब आप दोनों से मिल चुके हैं, और वे उल्टे काम करते हैं:
- Neon MCP server (Concept 4) एक dev-time admin tool है। यह आपके agent को build करते समय database operate करने देता है, branches बनाना, SQL चलाना, migrations preview करना। यह production या end users के लिए नहीं है।
- RAG MCP server (यह part) runtime पर आपकी product surface है। यह read-only retrieval expose करता है, "मेरा knowledge search करो," "मेरे data से answer दो", जिस किसी agent की ओर आप इसे इंगित करें उसके लिए।
पहला वाला system को बनाता है। दूसरा वाला system है, जो agents को पेश किया गया। Neon admin server कभी end users को मत सौंपें।
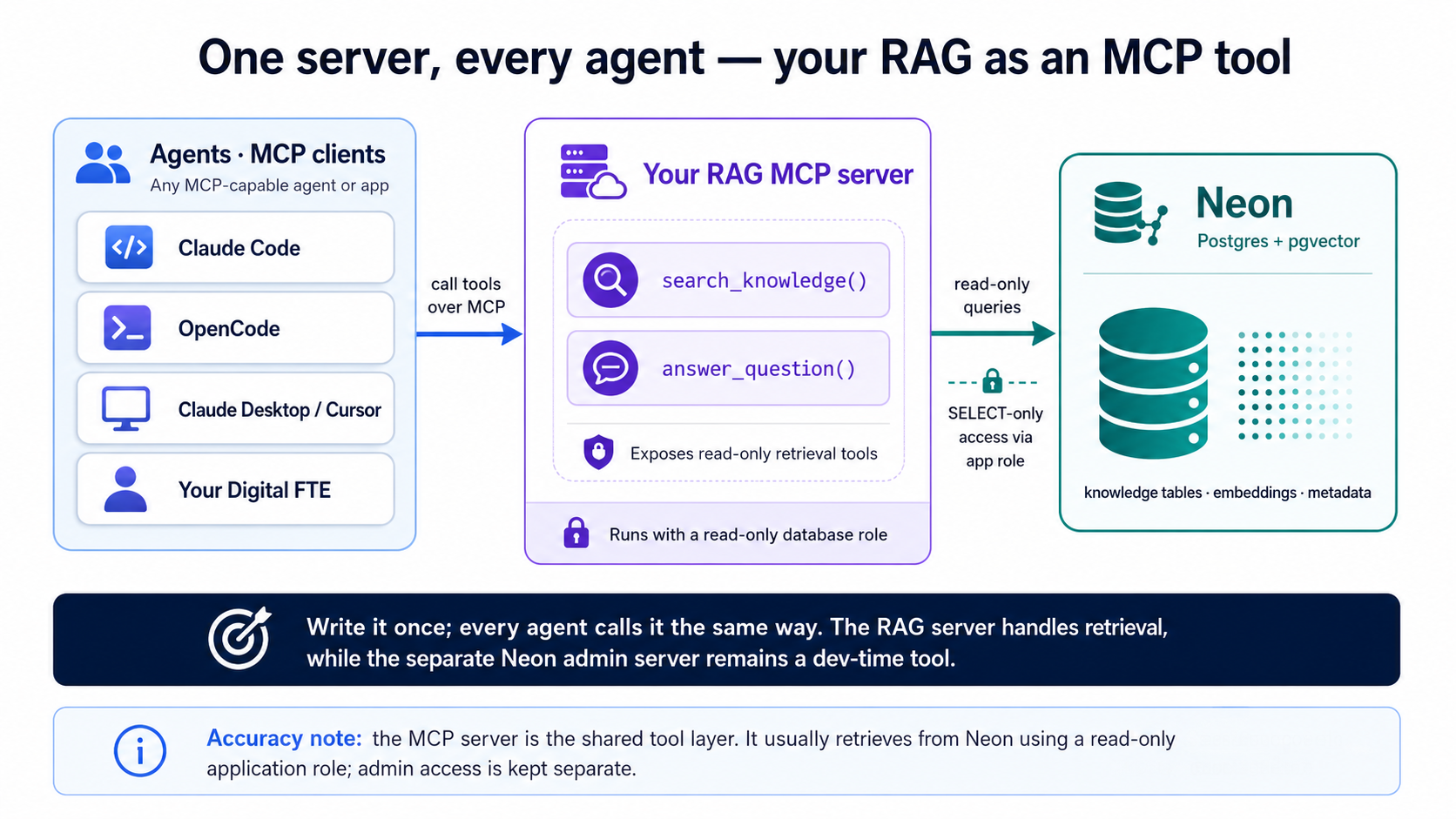
server कैसा दिखता है
एक MCP server एक छोटा program है जो tools की एक list विज्ञापित करता है जिन्हें एक agent call कर सकता है। FastMCP के साथ, standard Python library, official MCP SDK के ऊपर एक पतली decorator layer, हर tool बस एक docstring वाला typed function है; आप कोई भी JSON-RPC plumbing नहीं लिखते। हमेशा की तरह, agent यह लिखता है, इसे इसलिए दिखाया गया है ताकि आप इसे judge कर सकें:
# server.py — your RAG, exposed as MCP tools (review material, not to type)
import os
from fastmcp import FastMCP
from rag import search_quotes, answer_question as rag_answer # your Concept 9 functions —
# renamed on import so the MCP tool below can keep the public name "answer_question"
mcp = FastMCP("agent-factory-rag")
@mcp.tool()
def search_knowledge(query: str, limit: int = 5) -> list[dict]:
"""Search the knowledge base by meaning and return the closest chunks.
Use this when you need grounded facts from the user's own data."""
# embeds `query` in app code, runs the Concept 8 search on Neon,
# returns [{text, source, score}, ...] — retrieval only, read-only role
return search_quotes(query, limit)
@mcp.tool()
def answer_question(question: str) -> str:
"""Answer a question grounded in the knowledge base (retrieve, then generate)."""
return rag_answer(question) # the Concept 9 pipeline
if __name__ == "__main__":
mcp.run() # start the server; the calling agent connects to it
दो चीज़ें बाक़ी सबसे ज़्यादा मायने रखती हैं। docstring ही interface है, यह वह text है जिसे calling agent पढ़ता है ताकि तय कर सके कि tool कब इस्तेमाल करना है, इसलिए इसे साफ़-साफ़ कहना चाहिए कि tool क्या करता है और इसके लिए कब पहुँचना है। और retrieval read-only रहता है: tool Concept 8 वाला parameterized search एक read-only database role के तहत चलाता है, इसलिए कोई tool argument आपके data को कभी बदल या leak नहीं कर सकता।
इसे अपने agent के साथ बनाएँ
बाक़ी हर जगह जैसी ही discipline, plan, review, execute। यही वह पल भी है जब आपके setup वाली mcp-builder skill अपनी कमाई कमाती है, इसका नाम लें, और agent server को वैसे बनाता है जैसे skill सिखाती है। plan mode में:
mcp-builder skill का इस्तेमाल करके, हमारे retrieval को
agent-factory-ragनाम के एक FastMCP server में लपेटें। दो tools expose करें:search_knowledge(query, limit)जो top matching chunks उनके source और similarity score के साथ लौटाए, औरanswer_question(question)जो एक grounded answer लौटाए। हमारे मौजूदाsearch_quotesऔरanswer_questionfunctions दोबारा इस्तेमाल करें। Neon pooled connection string और model API keys environment से पढ़ें, और एक read-only database role से connect करें। साफ़, action-oriented tool docstrings लिखें, यही वह है जिसे calling agent पढ़कर तय करता है कि हर tool कब इस्तेमाल करना है। कोई code लिखने से पहले मुझे plan और tool list दिखाएँ।
plan पढ़ें, tool list और read-only role की पुष्टि करें, फिर approve करें और इसे build करने दें।
इसे चलाएँ, फिर connect करें
यहाँ Neon admin server से फ़र्क़ आता है: वह वाला client आपके लिए launch करता है; यह वाला आप start करते हैं, और agents इसके URL से connect होते हैं। यही production वाली शक्ल है, चाहे यह आपके laptop पर चले या cloud में, एक जैसी। इसे start करें:
uv run server.py
यह चलता रहता है और बताता है कि कहाँ serve हो रहा है, आप banner में http://0.0.0.0:8000/mcp देखेंगे (0.0.0.0 का बस मतलब है "हर interface पर सुन रहा है"; आप इससे localhost के रूप में connect होते हैं)। इसे इस terminal में चलता छोड़ें, अपने agent के लिए एक और खोलें, और इसे localhost पर register करें:
claude mcp add --transport http rag http://localhost:8000/mcp
इसे claude mcp list से जाँचें; session के बीच में /mcp से दोबारा connect करें।
opencode.json में एक remote block जोड़ें:
{
"$schema": "https://opencode.ai/config.json",
"mcp": {
"rag": {
"type": "remote",
"url": "http://localhost:8000/mcp",
"enabled": true
}
}
}
फिर बस किसी prompt में कहें "rag tool इस्तेमाल करो", यही वह add → check → use flow है जो आप Concept 4 के Neon server से जानते हैं, सिर्फ़ यहाँ आप किसी command के बजाय एक URL की ओर इंगित करते हैं। इसे आज़माएँ:
rag tool का इस्तेमाल करके answer दें: लोगों ने New York के बारे में क्या कहा? मुझे दिखाएँ कि इसने पहले कौन-से chunks retrieve किए।
agent को search_knowledge call करते, आपके chunks वापस पाते, और अपने answer को उनमें ground करते देखें। वही round-trip पूरी बात है: आपका data अब कुछ ऐसा है जिस पर कोई भी agent तर्क कर सकता है।
इसे cloud पर ship करें
एक local server जिस तक सिर्फ़ आप पहुँच सकें अभी product नहीं है, और एक MCP tool का मक़सद वहाँ चलना है जहाँ कोई भी agent इसे call कर सके। यहीं इसे शुरू से stateless बनाने का फ़ायदा मिलता है: इसे deploy करने के लिए server में कुछ नहीं बदलता। आप वही server.py किसी भी ऐसे host पर push करते हैं जो Python service चलाए (Cloud Run, Render, Railway, Fly पर एक container, या आपकी अपनी VM), वहाँ वही environment variables set करते हैं, और localhost के बजाय public URL register करते हैं:
claude mcp add --transport http rag https://your-host/mcp
उस .mcp.json को commit करें और हर वह व्यक्ति जो repo clone करता है उसी एक hosted server तक पहुँचता है (Claude Code उन्हें एक बार इसे approve करने को कहता है); OpenCode में, वही "type": "remote" block public URL की ओर मोड़ें। जिस पल एक से ज़्यादा व्यक्ति connect करें तब OAuth जोड़ें।
stateless ही इसे safe क्यों बनाता है: हर request अपना context ख़ुद साथ लाती है, calls के बीच कोई session नहीं रखा जाता, इसलिए server serverless cold-starts को नज़रअंदाज़ कर देता है और बिना sticky sessions के एक load balancer के पीछे कई replicas के रूप में चलता है, और एक retrieval tool, जो per-user कोई conversation नहीं रखता, इससे कुछ नहीं खोता। जिस transport पर आप बना रहे हैं, यानी Streamable HTTP, वह stable production target है; एक तेज़ बदलती detail बस ठीक FastMCP keyword है, इसलिए जब agent इसे लिखे तो mcp-builder skill या live docs से transport="http" और stateless_http की पुष्टि कराएँ। Neon admin server किसी भी तरह एक local dev tool ही रहता है।
कुछ rules जो agent से मनवाएँ, और review में पुष्ट करें:
- Read-only role. retrieval tools कभी सिर्फ़
SELECTकरते हैं। एक ऐसे database role से connect करें जो लिख न सके, ताकि कोई tool argument data delete या alter न कर सके। - Parameterized queries. query text एक bound parameter के रूप में आता है, कभी string-concatenated होकर SQL में नहीं, वही नियम जो Concept 8 में था।
- Multi-tenancy: एक plain tool argument के रूप में पास किए गए
tenant_idपर कभी भरोसा न करें। इसे authenticated session से निकालें और इसे RLS (Concept 15) से लागू करें, ताकि एक tenant का agent दूसरे के vectors न पढ़ सके। अगर आपने RLS exercise (Part 5, Step 8) उसी table पर चलाई है जिसे यह server पढ़ता है, तो एक gotcha याद रखें: read-only role को हर request पर tenant set करना होगा, वरना RLS सही ढंग से zero rows लौटाएगा, जो बिना error के empty results जैसा दिखता है। हर request पर tenant set करें, या सीखते समय server को non-RLS table पर point करें। - config पर भरोसा। एक local MCP server एक command है जिसे दूसरी machine चलाती है। सिर्फ़ वही servers register करें, और सिर्फ़ वही
.mcp.json/opencode.jsonfiles खोलें, जिन पर आप भरोसा करते हैं; एक project config आपकी machine पर एक process launch कर सकती है।
और retrieval हमेशा उतना ही अच्छा होता है जितना उसके पीछे का data, इसलिए आपका eval set अब भी राज करता है: इसे MCP tool की ओर इंगित करें और आप ठीक वही चीज़ माप रहे हैं जो आपके agents अनुभव करेंगे।
Part 7: यह कहाँ चलता है
ईमानदार जवाब: आम तौर पर आपको सिर्फ़ Postgres चाहिए। अगर आप पहले से Postgres चलाते हैं, pgvector आपको vectors को उसी data के साथ रखने देता है जिसे वे describe करते हैं: joins, filters, transactions, backups, permissions, एक source of truth। Neon इसे serverless Postgres plus branching बनाता है। TigerData उसी pattern को बड़े-vector और heavy-filter workloads तक बढ़ाता है। Local Postgres भी सीखने और कई real apps के लिए वही pattern है, बस MCP branching के बिना।
| कहाँ | किसके लिए best | Notes |
|---|---|---|
| Neon (यह course) | पहले build से production तक | Serverless Postgres, pgvector built in, instant branching, autoscaling. आप कुछ भी operate नहीं करते। |
| Neon branches | Dev, preview, evals, benchmarks | हर branch एक instant clone है, dev पर build करें, preview करें, default branch पर commit करें। |
| TigerData Cloud | Neon का एक full-stack विकल्प | "Agentic Postgres": pgvector + pgvectorscale native, Tiger MCP, instant zero-copy forks. इसे StreamingDiskANN scale और filtered search के लिए चुनें, बिना कभी migrate किए। |
कुछ production हक़ीक़तें जिन्हें अपने agent को पहले ही बता देना सही है:
- embedding worker एक असली process है, embeddings के sync में रहने के लिए इसका चलते रहना ज़रूरी है। production में यह एक service है जिसे आप deploy और monitor करते हैं, ऐसा कुछ नहीं जिसे आप हाथ से शुरू करें।
- Migrations: schema और worker बदलाव एक Neon branch पर करें, उन्हें preview करें, फिर default branch पर commit करें, agent इसे Neon MCP के migration tools के ज़रिए चलाता है। Versioned, reviewed, reversible, और कभी production के विरुद्ध एक ad-hoc edit नहीं।
- Cost embedding calls और generation calls में रहती है, जो दोनों बाहरी model APIs पर जाती हैं। जहाँ हो सके batch करें, जहाँ हो सके cache करें, और model-matching आदत इस्तेमाल करें, routine generation के लिए एक सस्ता model, और जहाँ quality मायने रखती है वहाँ एक मज़बूत।
- Scale-to-zero बनाम worker. Neon idle होने पर database को zero तक scale कर देता है पैसे बचाने के लिए, पर एक embedding worker जो लगातार poll करता है उसे जगाए रखता है, चुपचाप उसी बचत को मात देता है। low-traffic apps के लिए, agent से worker को एक schedule पर चलवाएँ (या embeddings batch करवाएँ) बजाय tight-polling के, ताकि आपको सच में बचत मिले।
- app traffic के लिए pooled connection string इस्तेमाल करें. Neon का pooled endpoint (
-poolerhost, transaction mode में PgBouncer) उन कई अल्पकालिक connections के लिए बना है जो serverless और high-concurrency apps खोलते हैं। agent से अपने RAG-serving app को उस पर इंगित करवाएँ; migrations और worker direct string इस्तेमाल कर सकते हैं। - worker Neon से अलग चलता है. आप Neon के managed compute पर sidecar processes नहीं चला सकते, इसलिए embedding worker आपके app host, एक छोटे VM, या एक scheduled job पर रहता है, अपने connection string के ज़रिए Neon तक पहुँचता हुआ। अपने agent को बताएँ कि इसे कहाँ चलना चाहिए।
यही hype के पीछे का असली सवाल है, और ईमानदार जवाब है आम तौर पर नहीं। अगर आप पहले से Postgres चलाते हैं, तो pgvector आपके vectors को उसी data के बग़ल में रखता है जिसे वे describe करते हैं, एक ही source of truth, उसी query में filters और joins, sync, secure, और pay करने को कोई दूसरा system नहीं। HNSW आराम से ~100k से 10M की range cover करता है, और pgvectorscale का StreamingDiskANN एक अरब से ज़्यादा vectors तक फैलता है, इसलिए raw scale शायद ही कभी वह तय करने वाला कारक रहा जो कभी था। ज़्यादातर applications के लिए, Postgres ही vector database है।
एक dedicated store (Pinecone, Weaviate, Qdrant, Milvus, और दूसरे) तब अपनी जगह कमाता है जब आपने एक ऐसी ज़रूरत माप ली हो जिसे वह पूरा करता है और Postgres नहीं कर सकता, मसलन, एक अरब से ज़्यादा scale पर बहुत ऊँचा query throughput, एक ख़ास recall/latency target जिसे आपके benchmarks pgvector से चूकते दिखाते हैं, या एक पूरी तरह managed vector service जिसे आप operate करने के बजाय किराए पर लेना पसंद करेंगे। वे असली मामले हैं; वे बस अल्पसंख्यक हैं। जाल यह है कि किसी एक के लिए by default पहुँच जाना क्योंकि किसी tutorial या headline ने ऐसा किया। इसे वैसे तय करें जैसे आप indexes तय करते हैं (Concept 11): अपने eval set और अपने असली workload पर एक benchmark को, उसके churn समेत, फ़ैसला करने दें, और एक दूसरे system की standing cost को उस फ़ायदे के विरुद्ध तौलें जो वह सच में देता है।
Part 8: इसे एक agent को सौंपें
आपने retrieval बनाया और उसे एक tool के रूप में लपेटा (Part 6)। स्वाभाविक अगला क़दम एक agent है जो असली काम पूरा करने के लिए उस tool को इस्तेमाल करता है, और ठीक यहीं से Build AI Agents crash course उठाता है। आप वहाँ इसमें से कुछ भी दोबारा नहीं बनाते; आप agent को वही tool सौंपते हैं जो आपके पास पहले से है।
पूरा bridge एक idea में यह रहा। वह course OpenAI Agents SDK के साथ agent loop सिखाता है: एक Agent एक model है जो instructions और tools से लैस है, और एक Runner model → tool → model loop को तब तक चलाता है जब तक काम पूरा न हो जाए। आपका RAG उन्हीं tools में से एक है। जहाँ यह course ख़त्म होता है, एक callable search_knowledge / answer_question, वहीं वह शुरू होता है।
जो आपने बनाया उसे जोड़ने के दो तरीक़े (agents course loop को cover करता है; आप बस tool देते हैं):
- Part 6 वाले MCP server के रूप में. Agents SDK MCP servers को सीधे consume कर सकता है, इसलिए आप agent को अपने
agent-factory-ragserver की ओर इंगित करते हैं और इसके tools agent के toolbox में अपने-आप दिख जाते हैं, वही server जो आपने Claude Code और OpenCode में पहले से register किया। - एक function tool के रूप में. अगर आप इसे in-process रखना पसंद करें, तो वही read-only query SDK के
@function_toolमें लपेटें, उस course की native tool शैली। वही retrieval, एक Python function के रूप में व्यक्त जिसे agent call कर सकता है।
गहरा bridge: memory बनाम knowledge. agents course हर agent को दो सवालों के इर्द-गिर्द ढालता है: यह किस पर टिक सकता है (state) और इसे क्या करने की अनुमति है (trust)। state की एक क़िस्म है memory, जो यह चलती बातचीत से याद रखता है, जिसे वह course sessions से संभालता है। आपका RAG दूसरी क़िस्म देता है: knowledge, टिकाऊ, searchable context जिसे यह देख सकता है, उससे कहीं ज़्यादा data में जितना किसी window में आता है। sessions chat रखती हैं; आपका Postgres + pgvector वह सब रखता है जो agent को retrieve करने की ज़रूरत पड़ सकती है। दोनों से जुड़ा एक agent वह भी याद रख सकता है जो अभी कहा गया और वह भी देख सकता है जो उसने कभी जाना ही नहीं, और इस course की "सिर्फ़ relevant chunks fetch करो, दस लाख ग़ैर-relevant rows बाहर छोड़ दो" वाली discipline ठीक वही है जो उस retrieved context को window में बाढ़ लाने से रोकती है। वही throughline, अब किसी app के बजाय एक agent की सेवा में।
किताब की भाषा में, वह knowledge वाला आधा agent का system of record है, वह ground truth जिससे यह पढ़ता है (retrieval), लिखता है (worker इसे ताज़ा रखता है), और जिसके विरुद्ध verify करता है (आपका eval set)। यही वह है जो एक धाराप्रवाह अंदाज़ा लगाने वाले को एक ऐसे agent में बदलता है जो execute करता है।
इसे वैसे ही wire करें जैसे आपने बाक़ी सब बनाया, agent के ज़रिए। plan mode में:
Build AI Agents crash course वाला न्यूनतम agent scaffold करें (OpenAI Agents SDK, एक
Agentऔर एकRunnerloop)। इसे ठीक एक tool दें: हमारा retrieval। या तो इसे Part 6 वालेagent-factory-ragMCP server से connect करें ताकिsearch_knowledgeऔरanswer_questiontools के रूप में दिखें, या वही read-only query एक@function_toolके रूप में लपेटें, सिफ़ारिश करें कि कौन-सा फ़िट बैठता है और क्यों। agent की अपनी मशीनरी (sessions, guardrails, model routing) उस course के लिए छोड़ दें; यहाँ, बस साबित करें कि agent हमारा retrieval call कर सकता है और उसमें एक answer ground कर सकता है। मुझे पहले plan दिखाएँ।
इसे approve करें, एक ऐसा सवाल चलाएँ जो tool call को मजबूर करे, और agent को अपने Neon (या TigerData) database से retrieve करते और उससे answer देते देखें। यही वह handoff है: Build AI Agents loop, guardrails, sessions, और deployment सिखाता है; इस course ने agent को कहने के लिए कुछ सच्चा दिया। आपका eval set बरक़रार पार चला जाता है, यह अब भी उस retrieval को मापता है जिस पर agent अब निर्भर है।
आगे कहाँ जाएँ
अब आपके पास 80% है: आप Neon को एक vector database में बदल सकते हैं, एक grounded RAG system बना सकते हैं, सबूत पर एक index चुन सकते हैं, और filters, hybrid search, और evals से retrieval बेहतर कर सकते हैं, यह सब एक agent को direct करके और उसके काम को judge करके।
- इसे भरोसेमंद बनाएँ: Eval-Driven Development Crash Course
- इसे एक agent बनाएँ: Part 8 आपके RAG tool को एक agent में bridge करता है; पूरा loop, guardrails, sessions, और deployment Build AI Agents में हैं
- इसे एक product बनाएँ: assistant को एक deployable Digital FTE में बदलें
throughline कभी नहीं बदलती: सही जानकारी, सही समय, ग़ैर-relevant जानकारी बाहर। आपने इसे अपने agent के लिए सीखा। अब आप इसे बाक़ी सबके लिए बना सकते हैं।