Glossary: शुरुआती लोगों के लिए AI Terms
इस किताब को पढ़ने के लिए आपको computer science degree की ज़रूरत नहीं है। लेकिन आपको इसकी भाषा समझनी होगी। यह glossary हर ज़रूरी term को सरल English, real-life examples, और रोज़मर्रा की analogies से समझाती है।
इस page को कैसे इस्तेमाल करें: पहले Top 30 Terms से शुरू करें: ये किताब के लगभग हर page पर आएँगे। फिर ज़रूरत पड़ने पर full glossary को reference की तरह इस्तेमाल करें। Terms topic के हिसाब से grouped हैं, और book-specific vocabulary पहले दी गई है। किसी भी term को search करने के लिए
Ctrl+F(या Mac परCmd+F) इस्तेमाल करें।
AI Landscape एक नज़र में
Individual terms में जाने से पहले, देखें कि बड़े concepts आपस में कैसे relate करते हैं:
Top 30 Terms जिन्हें पहले जानना ज़रूरी है
ये terms लगभग हर page पर आएँगे। Chapter 1 खोलने से पहले इन्हें पढ़ें।
Note: agents as buyers से जुड़े terms (ACP, AP2, x402, MPP, authority envelopes, signed mandates) Section 11 में cover हैं और Top 30 terms में शामिल नहीं हैं।
1. AI (Artificial Intelligence): Computers से वे काम करवाना जिनके लिए आम तौर पर human intelligence चाहिए होती है।
🔹 जब आपके phone का keyboard अगला word predict करता है जिसे आप type कर रहे हैं, तो वह AI है।
2. LLM (Large Language Model): Text के billions of pages पर trained एक बहुत बड़ा AI system, जो human language और code को समझ और generate कर सकता है। Claude, GPT, और Gemini LLMs हैं।
💡 LLM को ऐसे research assistant की तरह सोचें जिसने दुनिया की सबसे बड़ी library की हर किताब पढ़ रखी है। आप question पूछते हैं, और वह अपनी पढ़ी हुई चीज़ों से answer देता है।
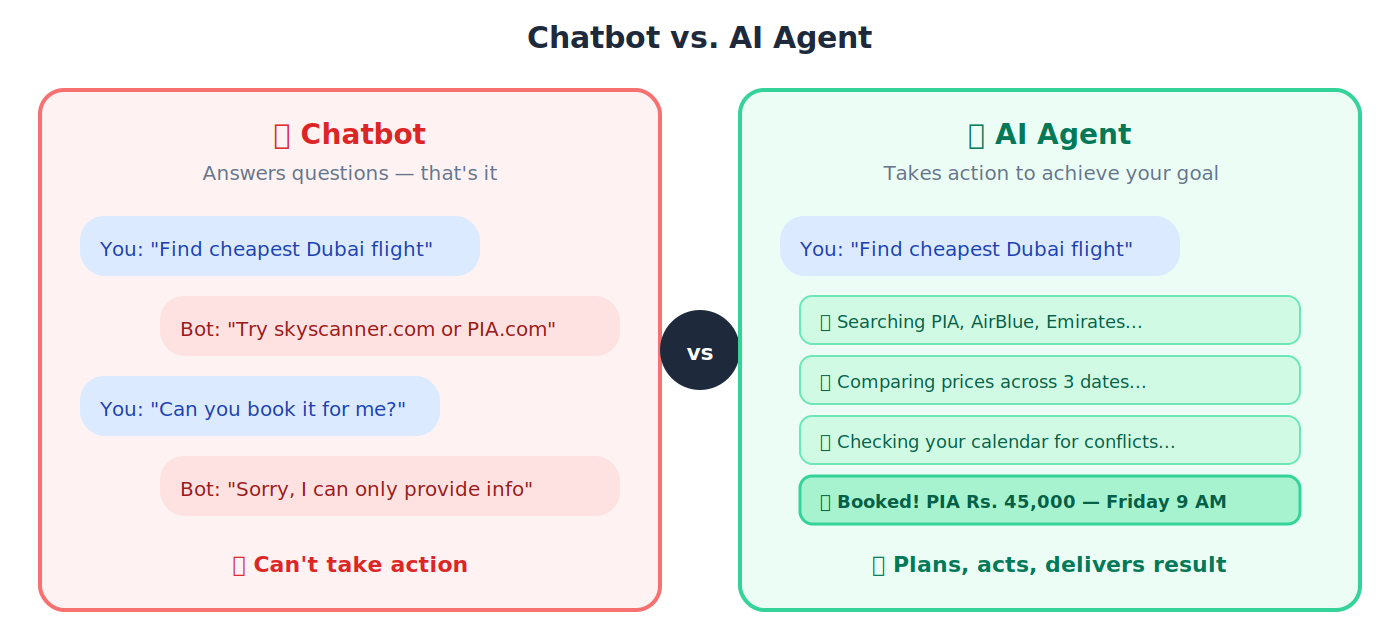
3. Agent (AI Agent): ऐसा AI जो सिर्फ़ questions के answer नहीं देता। वह action लेता है, plans बनाता है, और अपने-आप काम पूरे करता है।
🔹 Chatbot answer देता है: "Dubai की सबसे सस्ती flight कौन सी है?" Agent असल में airlines search करता है, prices compare करता है, और आपके लिए ticket book करता है।
4. Agentic AI: AI की वह category जो ऐसे agents बनाने पर focused है जो plan, reason, और autonomously act करते हैं। 2026 में यही AI frontier है और इसी पर पूरी किताब focused है।
🔹 Regular AI: आप question पूछते हैं, answer मिलता है। Agentic AI: आप goal देते हैं ("customer churn 15% कम करें") और वह research, planning, execution, और reporting करता है, रास्ते में decisions भी लेता है।
5. Digital FTE (Digital Full-Time Equivalent): एक "AI employee" जो full-time human worker का continuous काम 24/7, बहुत कम cost पर करता है। Thesis में इसे AI Worker भी कहा गया है: role वही है, register अलग है।
🔹 Customer support के लिए Digital FTE हर दिन 500 conversations handle करता है। यानी 5-10 human agents का काम।
6. Agent Factory: इस किताब का central concept। यह spec-driven, human-supervised, Claude-Code-powered process है जिससे AI Workers design, manufacture, और deploy होते हैं। यह खरीदने वाला product नहीं है; अपनाने वाली practice है। Agent Factory, AI-Native Company बनाती है, और AI-Native Company, Digital FTEs को employ करती है।
💡 Assembly line की तरह: हर station एक specialized task करता है, parts क्रम से आगे बढ़ते हैं, और अंत में spec के अनुसार बना हुआ finished product निकलता है। Agent Factory, AI employees बनाने को industrialize करती है।
7. Prompt: वह instruction या question जिसे आप AI model में type करते हैं।
🔹 "इस report को तीन bullet points में summarize करें" एक prompt है। Better prompts = better answers.
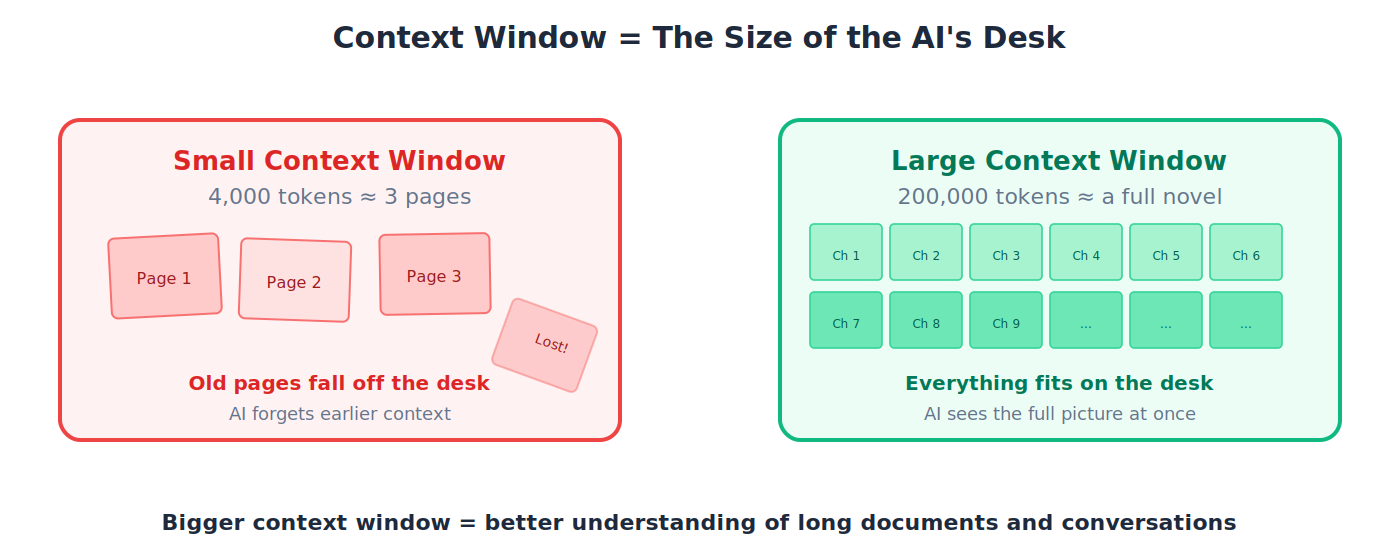
8. Context Window: AI की "working memory": एक समय में वह कितना text read और think कर सकता है।
💡 छोटी context window एक छोटी desk जैसी है जहाँ आप सिर्फ़ कुछ pages फैला सकते हैं। Claude की large context window एक बड़ी conference table जैसी है जहाँ आप पूरा novel एक साथ रख सकते हैं।
9. Token: Text की basic unit जिसे LLM read करता है। लगभग ¾ word। "I love biryani" ≈ 4 tokens.
🔹 AI APIs इस्तेमाल करते समय आप per token pay करते हैं। Text का एक full page ≈ 500-700 tokens.
10. Hallucination: जब AI confidence से ऐसी चीज़ generate करता है जो सच नहीं होती।
🔹 आप Supreme Court case के बारे में पूछते हैं और AI fake citation numbers के साथ fake judgment invent करके उसे fact की तरह present कर देता है। सुनने में सही लगता है, लेकिन fabricated है।
11. Spec (Specification): एक detailed blueprint जो बताता है कि आपको exactly क्या build करवाना है: goals, inputs, outputs, constraints.
💡 House के लिए architect का blueprint। Builder guess करके शुरू नहीं करता। वह plan follow करता है। AI development में spec वही plan है।
12. Spec-Driven Development (SDD): पहले blueprint लिखें, फिर AI को उसी blueprint से code, tests, और documentation generate करने दें।
🔹 आप लिखते हैं: "Bookstore के लिए API build करें जिसमें books list, add, search, और delete करने के endpoints हों।" Claude Code पूरी application generate कर देता है।
13. Claude Code: Anthropic का AI coding agent। आप terminal में उससे बात करते हैं और वह आपका पूरा codebase पढ़ता है, project समझता है, और code लिखता है।
🔹 आप type करते हैं "मेरी app में user authentication add करें": Claude Code existing code पढ़ता है, auth module generate करता है, tests लिखता है, और सब integrate करता है।
14. Cowork: Anthropic का desktop agent, non-coding knowledge tasks के लिए: documents, research, file management.
🔹 "मेरे Downloads folder को project के हिसाब से organize करें और इस month की सभी PDFs summarize करें।" Cowork यह काम करता है जबकि आप बाकी चीज़ों पर focus करते हैं।
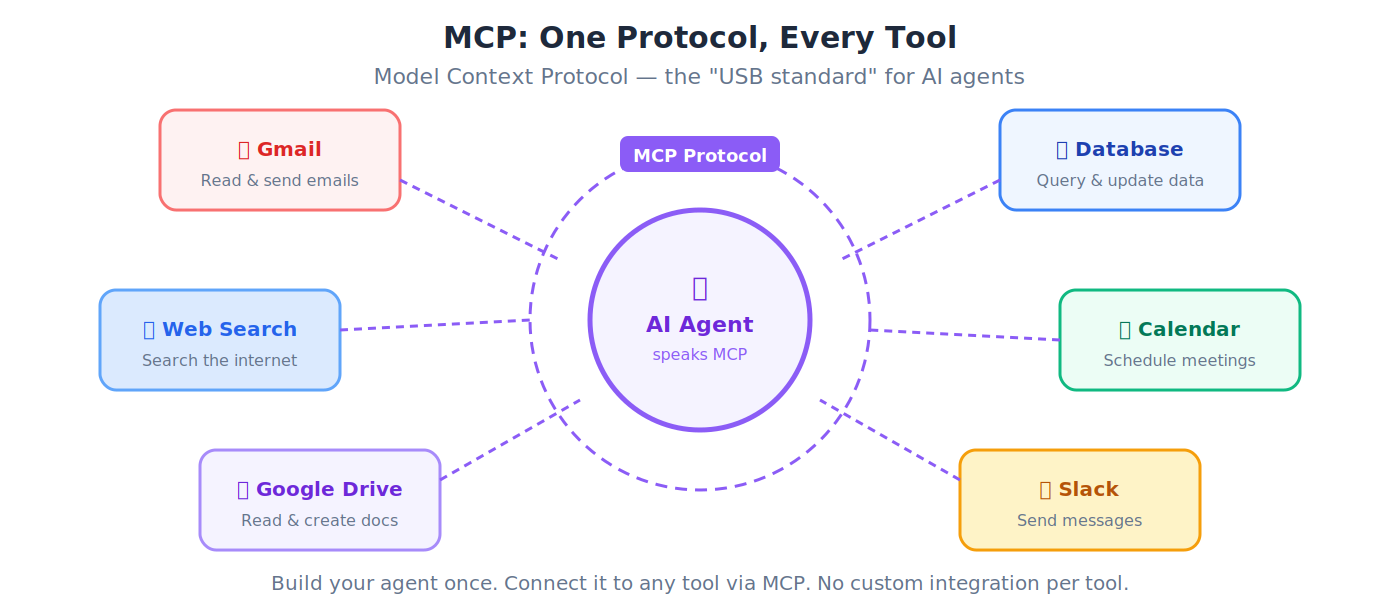
15. MCP (Model Context Protocol): Universal standard जो किसी भी AI agent को external tools से connect करने देता है: databases, email, calendars, file systems। MCP agents के tool calling का protocol है। Agents द्वारा उन tools के लिए payment करने वाले अलग protocol family के लिए Section 11 देखें: ACP, AP2, x402, और MPP.
💡 USB से पहले हर phone का charger अलग होता था। MCP, AI के लिए "USB standard" है: एक protocol जिससे कोई भी agent किसी भी tool में plug हो सकता है।
16. API (Application Programming Interface): Rules जिनसे अलग software programs एक-दूसरे से बात कर सकते हैं। Agents outside world से APIs के through interact करते हैं।
💡 Restaurant menu एक API है। आप (client) menu (docs) देखते हैं, order (request) देते हैं, और kitchen (server) आपका food (response) deliver करती है।
17. SDK (Software Development Kit): किसी specific platform पर applications build करने के लिए pre-built toolkit.
💡 SDK LEGO set जैसा है: instructions के साथ pre-made pieces, ताकि आप हर piece scratch से carve करने के बजाय जल्दी चीज़ें build कर सकें।
18. Python: AI में सबसे popular programming language। Readable, versatile, और इस किताब की primary language.
🔹 Python लगभग English जैसी पढ़ी जाती है:
if age > 18: print("Adult")। यही readability है जिसकी वजह से AI world ने Python चुना।
19. Git: ऐसा system जो आपके code में हर change record करता है: किसने क्या, कब, और क्यों बदला। आप हमेशा किसी भी previous version पर वापस जा सकते हैं।
💡 Microsoft Word का "Track Changes", लेकिन पूरे software projects के लिए। हर edit recoverable है।
20. Docker: ऐसा tool जो आपकी app को portable box (container) में package करता है, जो हर जगह identical चलता है: आपका laptop, colleague की machine, या cloud server.
💡 Shipping container। चाहे वह Karachi में truck पर हो या ocean में ship पर, अंदर का सामान identical और self-contained रहता है।
21. Context Engineering: Agent को मिलने वाला पूरा information environment design करना। यही #1 skill है जो $2,000/month agent को ऐसे agent से अलग करती है जिसे कोई नहीं चाहता।
💡 Toyota factory में quality controls होते हैं जो ensure करते हैं कि हर car spec meet करे। Context engineering आपके AI agents के लिए quality control है: consistent, reliable output ensure करना।
22. Tool Use: Agent की ability कि वह external tools इस्तेमाल करे (web search, databases query करना, emails भेजना), सिर्फ़ memory से answer देने के बजाय।
🔹 आप पूछते हैं "Karachi में weather क्या है?": tool use वाला agent सच में weather service check करके live data देता है। Tool use के बिना वह सिर्फ़ guess करेगा।
23. Guardrails: Safety constraints जो agent को वे काम करने से रोकते हैं जो उसे नहीं करने चाहिए।
🔹 Financial agent का guardrail: Rs. 5,000,000 से ऊपर कोई transaction human approval के बिना नहीं। Motorway barriers की तरह जो cars को road से बाहर जाने से रोकते हैं।
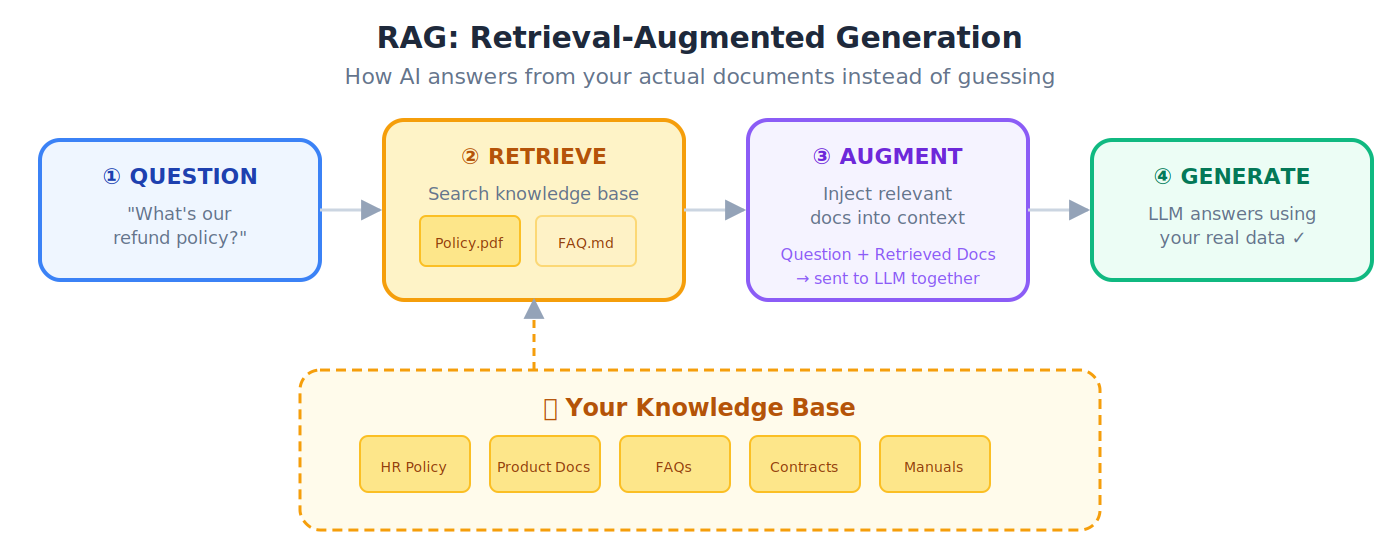
24. RAG (Retrieval-Augmented Generation): AI को external documents तक access देना ताकि वह facts से answer करे, अपनी potentially wrong memory से नहीं।
💡 Closed-book exam के बजाय open-book exam देना। AI answer देने से पहले आपके documents में facts look up करता है: इससे accuracy बहुत बढ़ती है।
25. 10-80-10 Rule: AI workforce का operating rhythm: human direction set करता है (10%) → AI execute करता है (80%) → human verify करता है (10%).
🔹 आप project brief लिखते हैं (10%), Claude Code पूरी application build करता है (80%), आप review, test, और approve करते हैं (10%).
26. AGENTS.md / CLAUDE.md: Configuration files जो आपके AI agent को project के rules बताते हैं: coding standards, preferences, architectural decisions.
💡 New employee को दिया जाने वाला onboarding document: "हम ऐसे काम करते हैं। हमारा style यह है। यह हम कभी नहीं करते।" हर interaction में loaded.
27. Orchestration: Multiple agents को coordinate करना ताकि वे किसी task पर साथ काम करें।
💡 Cricket team का captain fielders की जगह तय करता है, bowling order set करता है, और strategy adjust करता है। वह सब कुछ खुद नहीं करता; वह specialists को shared goal की ओर coordinate करता है।
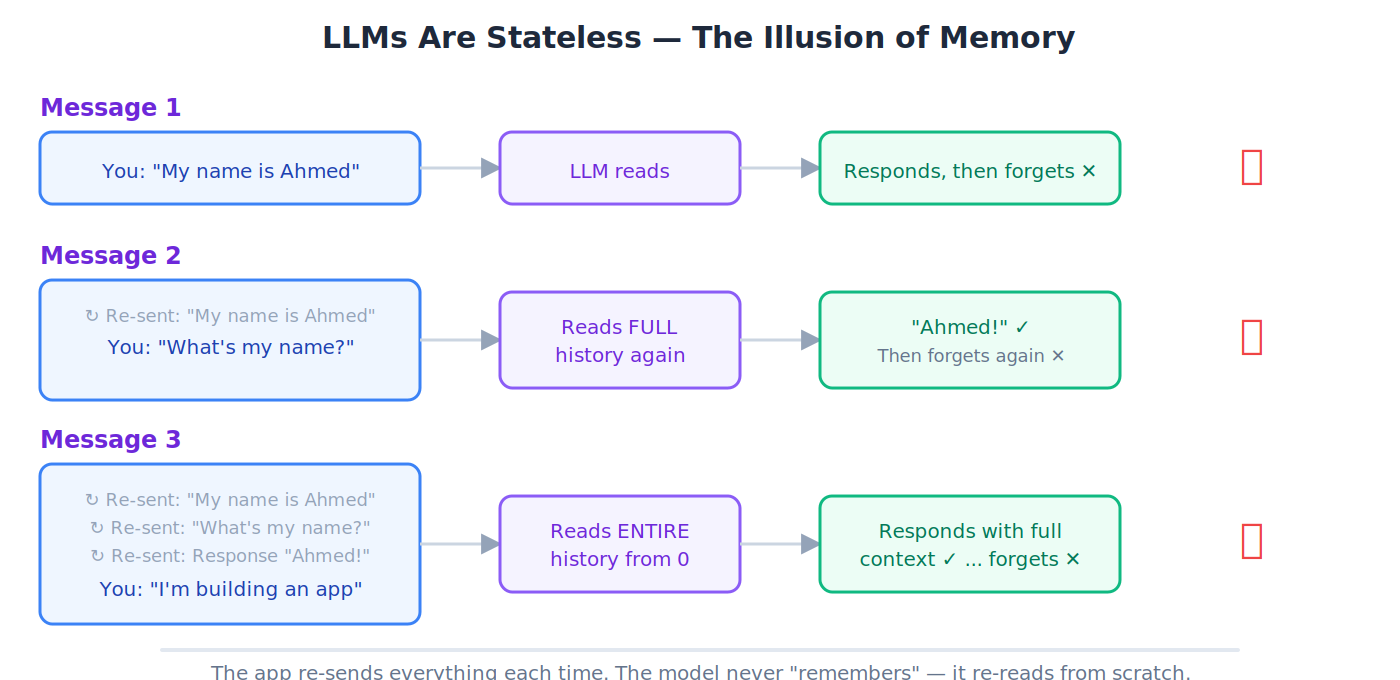
28. Stateless: AI conversations के बीच सब कुछ भूल जाता है। हर new chat absolute zero से शुरू होती है।
💡 Amnesia वाला shopkeeper: हर बार जब आप अंदर जाते हैं, वह आपको stranger की तरह greet करता है, भले ही आप 5 minutes पहले आए हों। Chat apps memory का illusion full conversation दोबारा भेजकर बनाती हैं।
29. Deployment: अपनी application को live और real users के लिए internet पर available करना।
🔹 आपकी app laptop पर काम करती है। Deployment उसे cloud server पर रखता है ताकि 10,000 लोग उसे simultaneously इस्तेमाल कर सकें।
30. CI/CD (Continuous Integration / Continuous Delivery): Developer के हर change पर code को automatically test और deploy करना।
🔹 Developer 2 PM पर code push करता है। Tests automatically 3 minutes में run होते हैं। सब pass। New version 2:10 PM तक live: zero manual steps.
Architecture: Runtime Stack
ये terms AI-Native Company के उन components को name करते हैं जिन्हें Agent Factory produce करती है। ये architecture chapters और thesis में बार-बार आएँगे। इन्हें यहाँ एक बार पढ़ें; हर build में फिर मिलेंगे।
💡 Pieces कैसे fit होते हैं: Agent Factory (process), AI-Native Company (output) बनाती है। उस company में humans, Edge Layer से direction set करते हैं, और Digital FTEs, AI Workforce Layer में execute करते हैं। Paperclip workforce manage करता है। हर Digital FTE अपनी choice के runtime engine पर चलता है। Triggers outside world से system को wake करते हैं।
AI Worker
AI-Native Company का workforce। Role-based agents जिन्हें hire, assign, roster, और retire किया जाता है। Digital FTE और Digital Worker जैसा ही concept: thesis AI Worker इस्तेमाल करती है, किताब Digital FTE इस्तेमाल करती है। अपने audience के हिसाब से term चुनें।
📌 Workforce vs. staff (load-bearing distinction): सिर्फ़ AI Workers workforce हैं। delegate (OpenClaw) और manager (Paperclip) permanent staff हैं, workforce नहीं। Runtime engines staff बिल्कुल नहीं हैं; वे वे skills हैं जिन पर workforce run करता है। Thesis जब agent कहती है, तो building में कोई भी व्यक्ति/agent हो सकता है (staff या workforce)। जब AI Worker कहती है, तो specifically workforce मतलब है।
🔹 Example: Resume-screening AI Worker हर दिन 200 resumes पढ़ता है, उन्हें job spec के against score करता है, और top 10 human recruiter को hand करता है। यह AI-Native Company के HR workforce के अंदर Digital FTE है: Paperclip ने hire किया, rosterable, retirable.
AI-Native Company
Agent Factory का output। Running enterprise: AI Workers (Digital FTEs) से staffed firm, management plane से coordinated, और edge पर humans से directed. AI-Native Company वही चीज़ है जिसे आप अंत में run करते हैं। किताब इसे Agentic Enterprise भी कहती है: same concept, business-facing name.
💡 Analogy: Agent Factory process है, जैसे skyscrapers बनाने की method। AI-Native Company वह skyscraper है जो method produce करती है: वह चीज़ जिसे आप actually run करते हैं।
📌 Triad: Agent Factory (process) → AI-Native Company (output) → AI Workers (output के अंदर workforce). तीन terms, तीन अलग roles। Interchangeable नहीं।
Two-Layer Model
Architectural pattern जो Agent Factory thesis को complete बनाता है: humans Edge Layer से intent set करते हैं, AI Workers AI Workforce Layer में execute करते हैं, और specs उनके बीच contract language होते हैं।
🔹 Example: CEO अपने OpenClaw delegate (Edge Layer) से कहता है: "weekly customer-churn report run करें।" Delegate task को AI Workforce Layer के Digital FTE को देता है। Digital FTE data pull करता है, report generate करता है, और delegate के through CEO को verification के लिए वापस देता है।
Principal
Runtime stack के apex पर human: जो intent set करता है, budget define करता है, authority envelope draw करता है, और outcome own करता है। Thesis का Invariant 1. हर legitimate action chain principal से शुरू होती है; principal के बिना act करने वाला system autonomous नहीं, unowned है (no liability, no alignment target, no budget owner, no judge of outcome).
🔹 Example: CFO spec लिखता है: "Payment terms बदले बिना, $30K budget के अंदर accounts receivable aging 20% कम करें।" उस spec में intent, budget, और constraints होते हैं: principal layer concrete form में। Delegate (OpenClaw) उसे पढ़ता है और workforce को work broker करता है; principal outcome verify करने वापस आता है।
📌 इसे क्या replace कर सकता है: कुछ नहीं। हर दूसरे layer की reference implementations बदल सकती हैं; principal layer non-transferable है।
Edge Layer
AI-Native Company का वह layer जो individual human को serve करता है। हर human के पास Edge पर एक agent होता है: personal identic agent (जैसे OpenClaw), जो उनका context जानता है, उनकी ओर से बोलता है, और downstream work delegate करता है।
💡 Analogy: Edge Layer chief-of-staff floor है। हर executive के लिए एक agent, जो company में उनका representation करता है।
AI Workforce Layer
AI-Native Company का वह layer जो enterprise को serve करता है। यहीं AI Workers (Digital FTEs) रहते और execute करते हैं: Paperclip से managed, runtime engines पर running, specs के through coordinating.
💡 Analogy: AI Workforce Layer production floor है। कई Digital FTEs, हर एक specialized work करता है, और सब management plane से coordinated होते हैं।
Delegate
Edge Layer पर personal agent जो principal का context hold करता है, उनके judgment को represent करता है, उनका authority envelope carry करता है, और उनकी ओर से सभी downstream work broker करता है। Thesis का Invariant 2. Delegate के बिना human bottleneck लौट आता है और scale typing speed तक collapse हो जाता है। OpenClaw reference implementation है; कोई भी MCP-speaking personal agent जो identity, context, और authority hold करता है, qualify करता है।
💡 Analogy: CEO का chief of staff। हर executive के लिए एक, जो उनकी priorities जानता है, उनकी ओर से बोलता है, और सही specialists को work route करता है।
See also: Reference implementation के लिए नीचे OpenClaw (as Delegate) देखें, और human-sovereignty framing के लिए Section 1 में Identic AI देखें।
OpenClaw (as Delegate)
OpenClaw, Edge Layer पर delegate की reference implementation है: "chief of staff" agent जो human को represent करता है, उनका context जानता है, और उनकी ओर से बोलता है। AI-Native Company में हर human को delegate चाहिए; OpenClaw वह तरीका है जिससे हम एक बनाते हैं।
🔹 Example: जब आप OpenClaw से कहते हैं "मेरे week को summarize करें और Monday के लिए तीन priorities draft करें," तो यह आपके calendar, email, और Slack से pull करता है (वे tools जिनका access उसे authorized है), आपकी voice में answer synthesize करता है, और किसी भी action से पहले आपके approve करने का wait करता है। यह machine speed पर आप ही हैं।
See also: Framework के लिए glossary में पहले वाली OpenClaw entry देखें।
Manager (Management Plane)
Orchestrator जो AI Workers के ढेर को workforce में बदलता है: work assign करता है, budgets enforce करता है, risky moves approve करता है, execution audit करता है, ledger रखता है, और hiring को callable API की तरह expose करता है। Thesis का Invariant 3. इसके बिना agents collide करते हैं, budgets leak होते हैं, और कोई जवाब नहीं दे सकता कि workforce ने कितना cost किया या क्या produce किया। Paperclip reference implementation है; management contract meet करने वाला कोई भी orchestrator qualify करता है।
💡 Analogy: अगर delegate chief of staff है, तो manager chief operating officer है। Human के साथ one-to-one; workforce के साथ one-to-many.
See also: Reference implementation के लिए नीचे Paperclip देखें।
Paperclip
AI-Native Company का management plane। Paperclip COO है: यह Digital FTEs hire करता है, उन्हें work assign करता है, उनके budgets enforce करता है, risky moves approve करता है, और ledger रखता है। यह hiring को API की तरह expose करता है जिसे कोई भी authorized agent call कर सकता है; इसी से workforce demand पर grow करता है।
💡 Analogy: अगर OpenClaw chief of staff है, तो Paperclip chief operating officer है। Human के साथ one-to-one; workforce के साथ one-to-many.
🔹 Example: Customer Bahasa Indonesia में लिखता है। Roster पर कोई Digital FTE यह language नहीं बोलता। Paperclip capability gap detect करता है और अपने authority envelope के अंदर अपनी hiring API call करके नया Bahasa-speaking Digital FTE manufacture करता है। New worker message पढ़ता है और reply करता है। Human को wake नहीं किया गया।
Meta-Layer (Hiring as a Callable Capability)
वह layer जो hiring को ऐसे API की तरह expose करता है जिसे कोई भी authorized agent runtime पर नया AI Worker provision करने के लिए call कर सकता है, principal के authority envelope के अंदर, human को wake किए बिना। Thesis का Invariant 5. Frozen-roster problem solve करता है: जब capability gap आता है (customer ऐसी language में लिखता है जिसे कोई current Worker नहीं बोलता), workforce policy के तहत demand पर staff up करता है। Claude Managed Agents reference implementation है; कोई भी managed-agent API जो runtime पर agent generate और उसका environment provision कर सके, qualify करता है।
🔹 Example: Paperclip के नीचे दिया गया Bahasa Indonesia trace दिखाता है कि meta-layer activate हो रही है। Paperclip gap detect करता है; meta-layer की hiring API नया Worker manufacture करती है; Worker manager के साथ registered होता है और roster पर रहता है।
📌 Dual role: Claude Managed Agents engine option (Invariant 4) और meta-layer (Invariant 5), दोनों की तरह काम करता है। वही runtime-provisioning capability जो Worker run करती है, नए Workers भी create करती है; इसलिए meta-layer batch-provisioned नहीं, callable है।
Runtime Engine
Execution substrate जिस पर Digital FTE run करता है। हर Digital FTE job की demand के हिसाब से अपना engine चुनता है: company per one engine नहीं। Options में Dapr Agents (mission-critical work के लिए durable execution), Claude Managed Agents (आपके लिए hosted और operated), OpenAI Agents SDK (self-hosted, portable), और OpenClaw-native (lightweight, fast to deploy) शामिल हैं। Internally, हर engine के दो planes होते हैं: harness (control plane) और compute plane (execution plane / sandbox)। अगली दो entries देखें।
💡 Analogy: Runtime engine वह skillset है जो employee job में लाता है। Heart-surgery team की nurse को clinic की nurse से अलग skills चाहिए। Role same, engine different.
Harness (Agent Harness)
Agent engine का control plane: model के around वह सब कुछ जो उसे working system बनाता है। इसमें agent loop, tool dispatch, approvals, tracing, context management, recovery, instructions, skills, और validators शामिल हैं। Practitioner shorthand Agent = Model + Harness में captured: model वह brain है जिसे आप frontier lab से rent करते हैं, और harness body, workplace, और standard operating procedure है जो उसके around built होता है। Compute plane (sandbox) harness के अंदर नहीं, उसके next to बैठता है। Credentials harness में रहते हैं जबकि model-generated code sandbox में run करता है।
💡 Analogy: अगर model CPU है और context window RAM है, तो harness operating system है: यह boot करता है, drivers (tools) dispatch करता है, context curate करता है, और agent lifecycle manage करता है। आपका agent code ऊपर चलने वाली application है।
🔹 Examples: Claude Agent SDK ऐसा harness है जिसे आप assemble करते हैं। OpenClaw ऐसा harness है जिसे आप skills से extend करते हैं। Claude Code, Cursor, और Codex coding work के लिए tuned harnesses हैं। Claude Managed Agents ऐसा harness है जिसे Anthropic stable interfaces के पीछे आपके लिए run करता है।
📌 Lineage: Word test harness (software engineering scaffolding जो code under test को drive करता है) से eval harness (lm-eval-harness, वह scaffolding जो model को benchmark से drive करता है) और फिर agent harness (वह scaffolding जो model को real-world work से drive करता है) तक evolve हुआ। तीनों में actual work करने वाली चीज़ के around scaffolding होती है।
Compute Plane / Sandbox Runtime
Execution plane जो harness के next to बैठता है: secure sandbox जहाँ model-generated code actually run करता है (files पढ़ता है, commands execute करता है, artifacts लिखता है)। यह नीचे वाली cloud infrastructure (metal, Kubernetes, networking) से अलग है और साथ वाले harness (orchestration logic) से भी अलग है। Security और portability के लिए यह split load-bearing है: credentials harness में रहते हैं, model-directed code sandbox में run करता है, और sandbox vendor (E2B, Cloudflare, Daytona, Modal, Runloop, Vercel, Blaxel, या आपका अपना Kubernetes) agent rewrite किए बिना swap हो सकता है।
🔹 Example: OpenAI Agents SDK harness है; compute plane आप अलग से चुनते हैं। Claude Managed Agents दोनों को एक API के पीछे fuse करता है। Dapr Agents Kubernetes को अपना compute plane मानता है।
📌 "runtime" कहलाने वाली तीन चीज़ें: language runtime (Node.js, Python interpreter) pure infrastructure है। Execution runtime / sandbox यह entry है। Agent runtime कभी-कभी harness itself का synonym भी बन जाता है। Vendor docs पढ़ते समय इस conflation पर ध्यान दें।
Trigger
Outside world जिस तरह AI-Native Company को motion में call करती है: schedule due होता है, webhook आता है, API call land करती है, customer walk in करता है। Claude Code Routines reference implementation है: यह हर external event को session में बदलता है जो delegate को wake करता है और chain fire करता है। Triggers के बिना system सिर्फ़ तब move करता है जब human prompt type करे; वह असल company नहीं, extra steps वाला assistant है।
🔹 Example: हर Monday 9 a.m. पर scheduled trigger OpenClaw को wake करता है, जो Paperclip से weekly customer-health report run करवाता है। Digital FTE data pull करता है, report generate करता है, और executive team को email करता है। Human ने trigger एक बार configure किया; उसके बाद system अपने-आप चलता है।
Summary
याद रखने के लिए one-sentence taxonomy:
The Agent Factory (process), the AI-Native Company (output) बनाती है। AI-Native Company AI Workers (workforce) employ करती है, जो Two-Layer Model में operate करते हैं: humans Edge Layer पर (OpenClaw, delegate के through), Digital FTEs AI Workforce Layer में (Paperclip से managed), हर एक अपनी choice के runtime engine पर running, और outside world के triggers से woken.
आप इसे आख़िरी line की तरह add कर सकते हैं
अब आप पढ़ना शुरू करने के लिए काफ़ी जानते हैं। नीचे full glossary हर term में और गहराई तक जाती है और 250+ more terms cover करती है।
1. The Agent Factory: Book-Specific Terms
ये concepts और vocabulary इस किताब के लिए unique हैं। Chapter 1 से आगे आपको ये मिलेंगे, इसलिए ये पहले आते हैं।
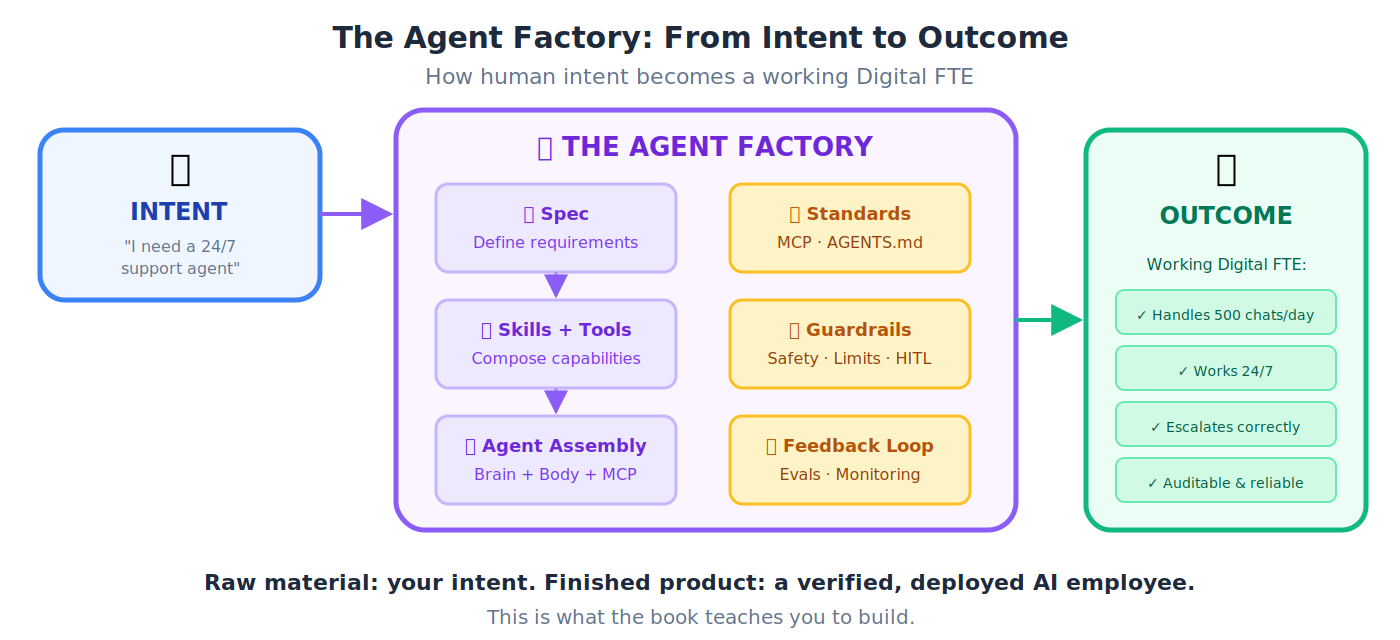
Agent Factory
Process। Spec-driven, human-supervised, Claude-Code-powered method जिससे AI Workers design, manufacture, और deploy होते हैं। Raw material human intent है; finished product verified outcome है। Agent Factory, AI-Native Company बनाती है, और AI-Native Company, AI Workers (Digital FTEs) employ करती है।
📌 Practice, product नहीं। Agent Factory ऐसी चीज़ नहीं है जिसे आप buy या install करते हैं। यह वह practice है जिसे operate करना आप सीखते हैं। किताब practice सिखाती है; AI-Native Company वह चीज़ है जिसे आप इसे operate करने के बाद run करते हैं।
💡 Analogy: Car factory raw steel लेकर finished cars produce करती है। Agent Factory आपका business intent ("मुझे 24/7 customer support agent चाहिए") लेकर finished, working Digital FTE produce करती है।
Industrialized Stack
Agent Factory में value कैसे move करती है, इसके लिए thesis का three-layer framing: Intent (goals, constraints, budgets, और permissions का high-level blueprint) → Production Engine (वह architecture जो intent को outcomes में transform करती है) → Outcome (high-fidelity actions और artifacts, accuracy के लिए verified और feedback loops से improved).
🔹 Example: CFO का directive ("$30K के अंदर AR aging 20% कम करें") intent है। OpenClaw → Paperclip → engines पर running AI Workers की chain Production Engine है। Verified, ledger-updated days-sales-outstanding reduction outcome है।
Production Engine
Industrialized Stack के अंदर intent को outcome में transform करने वाला mechanism। Download करने वाली app नहीं, architecture है: role-based AI Workers को feed करती spec-driven instructions, job पर साथ आने वाली packaged skills, tools से connect करने के लिए MCP, और quality gap को समय के साथ close करने वाले feedback loops। Thesis इसे "this entire thesis का सबसे important idea" कहती है।
💡 Analogy: Car factory की assembly line। Raw steel एक end से आता है, finished car दूसरे end से निकलती है। हर station one specialized job करता है, parts क्रम से move करते हैं, और delivery से पहले result verify होता है। Production Engine भी यही करता है: intent in, verified outcome out, AI Workers specialized stations की तरह।
Six Invariants
Structural rules जो AI-Native Company को runnable बनाते हैं: (1) Principal: human principal है; (2) Delegate: हर human को delegate चाहिए; (3) Manager: workforce को manager चाहिए; (4) Engine: हर Worker अपना engine चुनता है; (5) Meta: workforce policy के तहत expandable है; (6) Trigger: world system को call करता है। हर एक company कैसे run होती है, इस बारे में rule है; आज इन्हें realize करने वाले named products (OpenClaw, Paperclip, Claude Managed Agents, Inngest) कल architecture बदले बिना swap हो सकते हैं।
📌 हर invariant का full claim, absent होने पर failure mode, और current realization देखने के लिए thesis देखें।
Invariant vs. Reference Implementation
Thesis का framing trick। Invariant structural requirement है जो system के हर version में true रहती है, चाहे कोई भी specific product उसे realize करे। Reference implementation वह concrete product है जो 2026 में invariant को realize करने के लिए इस्तेमाल होता है। Invariants thesis हैं; named products इस साल का best fit हैं। जब product named हो (OpenClaw, Paperclip, Claude Managed Agents, Inngest), invariant rule है और product एक instance है।
💡 Analogy: "House में enter और exit करने का तरीका होना चाहिए" invariant है। "Brass handles वाले mahogany double doors" reference implementation है। अगले साल doors replace करें और house फिर भी work करता है; entry-and-exit invariant remove करें और वह house नहीं रहता।
🔹 Example: Invariant 4 कहता है "हर AI Worker अपना engine चुनता है।" 2026 में reference implementations Dapr Agents, Claude Managed Agents, OpenAI Agents SDK, और OpenClaw-native हैं। अगले साल इनमें से कोई भी swap हो जाए, invariant फिर भी hold करता है।
Digital FTE (Digital Full-Time Equivalent)
एक 'AI employee' जो full-time human worker का continuous work 24/7, cost के fraction पर करता है। Digital FTE हफ्ते में 168 hours zero fatigue के साथ काम करता है। Thesis के AI Worker जैसा ही role (AI-Native Company का workforce): hired, assigned, rostered, retired. delegate (OpenClaw) और manager (Paperclip) से distinct, क्योंकि वे permanent staff हैं, workforce नहीं। Runtime stack में Digital FTEs कहाँ fit होते हैं, इसके लिए Architecture section देखें।
🔹 Example: Customer support के लिए Digital FTE हर दिन 500 conversations handle करता है: 5-10 human agents का काम।
Digital Worker / AI Employee
Digital FTE के synonyms। Organization के भीतर sustained, role-based work करने वाला AI agent; one-off chatbot नहीं, permanent team member.
Spec / Specification
Exactly क्या build करना है, इसका detailed written description: goals, constraints, inputs, expected outputs, और behavior। यही "blueprint" है जिसे AI follow करता है।
💡 Analogy: Spec architect के blueprint जैसी है। Builder guess करके construction शुरू नहीं करता। वह detailed plans follow करता है। AI development में spec plan है, और AI builder है।
Spec-Driven Development (SDD)
Development methodology जहाँ आप पहले detailed specification लिखते हैं, फिर AI को उसी spec से code, tests, और documentation generate करने देते हैं। Spec source of truth है; code नहीं।
📌 चार phases: Research → Specification → Refinement → Implementation.
🔹 Example: आपको bookstore के लिए REST API चाहिए। Coding के बजाय आप spec लिखते हैं: "API में books list करने, book add करने, author से search करने, और ISBN से delete करने के endpoints होने चाहिए। हर book में title, author, ISBN, price, और stock count हो। सभी inputs validate हों। JSON return करें।" आप यह spec Claude Code को देते हैं, और वह पूरी FastAPI application, tests, और documentation generate करता है।
💡 Analogy: Spec architect के blueprint जैसी है। कोई construction company guess करके house build करना शुरू नहीं करती। वे detailed plans follow करते हैं। SDD में spec plan है, और AI construction crew है।
Test-Driven Generation (TDG)
SDD का Python-specific form। आप पहले tests लिखते हैं (code को क्या करना चाहिए यह define करते हुए), फिर Claude Code को वे tests pass करने वाला code generate करने देते हैं।
💡 Analogy: Cake bake करने से पहले आप लिखते हैं कि perfect cake कैसा दिखेगा: height, texture, taste। फिर recipe try करते हैं। अगर cake criteria match नहीं करता, तो फिर try करते हैं। Criteria tests हैं; recipe generated code है।
10-80-10 Rule
AI workforce का operating rhythm: human पहला 10% देता है (intent और direction), AI middle 80% handle करता है (execution), और human final 10% के लिए लौटता है (verification और judgment).
📌 Origin: Steve Jobs ने Apple में यह pattern follow किया: vision set करें (10%), team को build करने दें (80%), polish और ship करने लौटें (10%)। अब "team" की जगह "AI employees" रख दें।

AGENTS.md / CLAUDE.md
Configuration files जो AI coding agent को persistent context देती हैं। इनमें आपके project के rules, coding standards, architectural decisions, और preferences होते हैं, जो हर interaction में loaded रहते हैं।
💡 Analogy: जब new employee आपकी team join करता है, तो आप उसे onboarding document देते हैं: "हम ऐसे काम करते हैं। हमारा coding style यह है। यह हम कभी नहीं करते।" AGENTS.md आपके AI agent के लिए वही onboarding document है।
SPEC.md
Project के लिए detailed specification रखने वाली specific file। Software को क्या करना चाहिए, इसका single "source of truth."
🔹 Example: आपकी SPEC.md कह सकती है: "Restaurant के लिए WhatsApp chatbot build करें। इसे menu दिखाना, orders लेना, delivery address confirm करना, GST के साथ total calculate करना, और order confirmation भेजना होगा। Maximum response time: 2 seconds. Language: Urdu and English."
SKILL.md
ऐसी file जो AI agent के लिए reusable capability (skill) package करती है, जिसमें किसी specific task type के लिए instructions, best practices, और templates होते हैं (जैसे PDFs generate करना, Docker containers deploy करना).
🔹 Example: Docker SKILL.md में हो सकता है: "FastAPI app containerize करते समय हमेशा multi-stage build इस्तेमाल करें। Base image: python:3.12-slim. हमेशा health check endpoint include करें। Root के रूप में कभी run न करें।" Agent इस skill file को पढ़ता है और हर Docker work में ये practices automatically follow करता है।
Skill Library
SKILL.md files का collection जिससे AI agent draw कर सकता है, जिससे उसे कई domains में expertise मिलती है, जैसे employee consult करने वाली reference library.
Agent Skills
AI agent की specific capabilities, जो उसके tools, knowledge, और SKILL.md files से defined होती हैं।
🔹 Example: Human employee के skills "Excel proficiency" या "contract negotiation" जैसे होते हैं। AI agent के skills "PDF generation," "database querying," या "email drafting" जैसे होते हैं।
Agent Triangle
इस किताब का framework जो हर effective agent के तीन components describe करता है: (1) clear role, (2) specific tools, और (3) well-defined constraints। इनमें से एक भी miss हो, तो agent underperform करता है।
Body + Brain
Agent architecture pattern। Brain वह LLM है जो reason करता है और decisions लेता है। Body execution layer है (tools, APIs, infrastructure) जो उन decisions को carry out करती है।
💡 Analogy: आपका brain decide करता है "मुझे वह glass उठाना है।" आपका hand (body) action execute करता है। AI agent में Claude (brain) decide करता है "मुझे database query करनी है," और NanoClaw (body) query execute करता है।
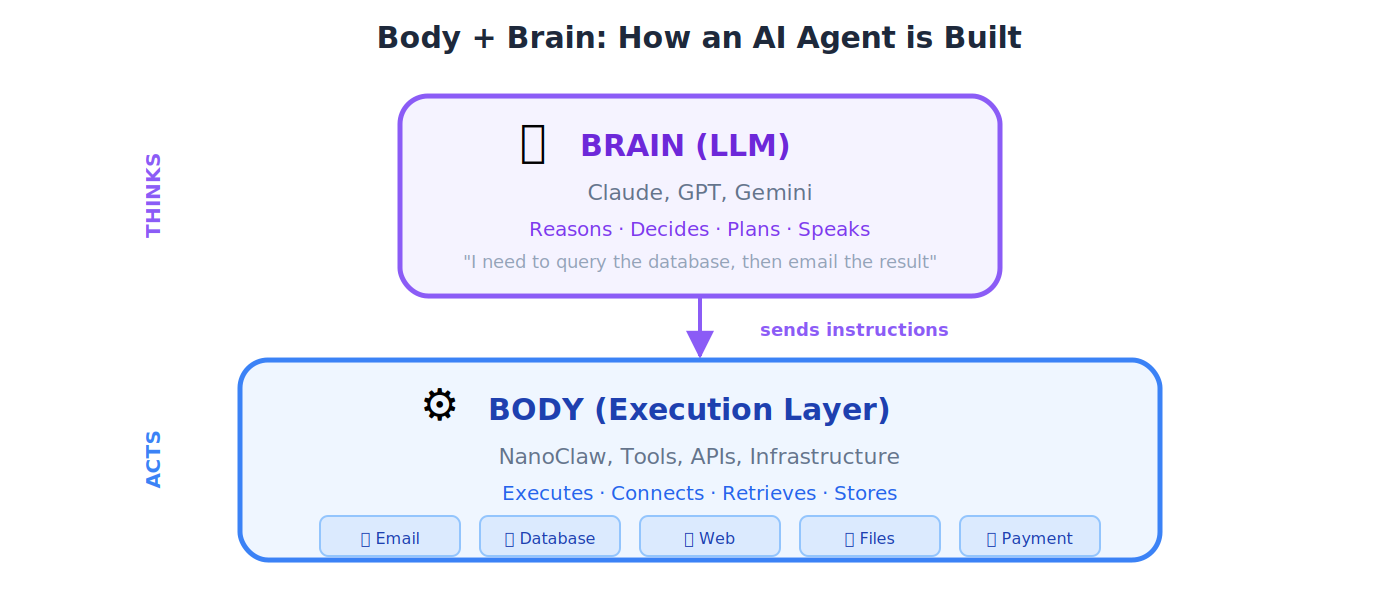
NanoClaw
Lightweight container runtime जो OpenClaw architecture में agent की "Body" के रूप में काम करता है: tasks execute करता है, tools run करता है, और agent environment manage करता है।
💡 Analogy: अगर LLM (Brain) वह pilot है जो तय करता है कि कहाँ उड़ना है, तो NanoClaw (Body) वह airplane है जो flight actually carry out करता है: engines, wings, controls, सब कुछ।
OpenClaw
Agent-powered applications build करने के लिए open-source application framework। Thesis architecture में OpenClaw, Edge Layer पर delegate है: "chief of staff" agent जो human को represent करता है, उनका context जानता है, और उनकी ओर से बोलता है। NanoClaw इसका container-based execution layer है।
TutorClaw
WhatsApp के through delivered 24/7 AI tutor, Agent Factory architecture पर built. TutorClaw इस किताब को अपना system of record मानता है: probabilistic generation के बजाय verified knowledge से teaching करता है। यह किताब का पहला Digital FTE है, और live example है कि Agent Factory कैसे AI Workers produce करती है।"
Claude Code
Anthropic का AI coding agent, terminal (command line) से run होता है। यह आपका पूरा codebase पढ़ता है, project context समझता है, और आपकी specifications के based code generate करता है। इस किताब का primary development tool.
Cowork
Anthropic का desktop agent, non-coding knowledge tasks के लिए: document management, research, और file organization. इसे अपना AI office assistant समझें।
Dispatch
Feature जिससे आप phone से Cowork को work assign कर सकते हैं। Commute करते समय task भेजें; Claude आपके desktop पर काम करता है। Finish होने पर आपको push notification मिलता है।
💡 Analogy: Dispatch, Cowork को ऐसे tool से जिसे आप पास बैठकर इस्तेमाल करते हैं, ऐसे employee में बदल देता है जिसे आप remotely manage करते हैं, जैसे meeting में रहते हुए assistant को text करना: "report prepare करें।"
Computer Use
Research preview feature जहाँ Claude macOS पर आपकी screen देख और control कर सकता है (buttons click करना, applications में type करना, interfaces navigate करना), जैसे remote employee आपका computer इस्तेमाल कर रहा हो।
🔹 Example: आप Claude से कहते हैं: "Desktop वाली spreadsheet open करें, Q3 revenue column को इन numbers से update करें, फिर finance team को email करें।" Claude आपकी screen देखता है, Excel खोलता है, data type करता है, email client खोलता है, और उसे भेजता है, जैसे कोई human assistant आपके computer पर बैठा हो।
Claude Desktop
Claude से interact करने वाली desktop application, जो Cowork, Computer Use, और Dispatch features host करती है।
Hooks
Automated actions जो Claude Code के certain operations से पहले या बाद trigger होते हैं, जैसे हर file save के बाद automatic code formatting, या हर commit से पहले tests run करना।
💡 Analogy: Hooks assistant को दिए गए standing instructions जैसे हैं: "हर बार letter लिखने के बाद मुझे दिखाने से पहले spell-check run करें।"
Subagents
Specialist agents जिन्हें Claude Code किसी larger project के specific subtasks handle करने के लिए spawn कर सकता है, हर एक के पास अपना focused context होता है।
💡 Analogy: Project manager (main agent) design work graphic designer (subagent) को और accounting bookkeeper (subagent) को delegate करता है। हर कोई अपनी specialty पर focus करता है।
Tasks System
Claude Code का built-in feature जो sessions के across persistent state manage करता है, track करता है कि क्या हो चुका है, क्या pending है, और multi-step project में next क्या है।
Context Engineering
Digital FTE manufacturing के लिए quality-control discipline। Agent को मिलने वाला पूरा information environment design करना ताकि consistent, high-quality output ensure हो। यही #1 skill है जो $2,000/month sellable agent को ऐसे agent से अलग करती है जिसे कोई नहीं चाहता।
💡 Analogy: Toyota factory में systematic quality controls होते हैं जो ensure करते हैं कि हर car specification meet करे। Context engineering ensure करती है कि आपके Digital FTEs consistent, sellable value deliver करें।
Context Injection
AI के context window में response generate करने से ठीक पहले relevant external information insert करना, ताकि उसे सही समय पर सही information मिले।
💡 Analogy: Court में जाने से पहले lawyer को assistant relevant case files वाला folder hand करता है। Context injection AI के लिए यही करता है।
Context Isolation
Long previous session से potentially confused या contradictory state carry करने के बजाय clean context के साथ fresh session शुरू करना।
💡 Analogy: जब आपकी desk इतनी cluttered हो जाती है कि आप सोच नहीं पाते, तो आप सब साफ़ करके fresh start करते हैं। AI के लिए context isolation भी यही है; कभी-कभी clean slate messy history से बेहतर results देता है।
Harness Engineering
AI agent के around environment को design और लगातार improve करने की discipline, ताकि वह supervision के बिना reliable तरीके से useful work कर सके। यह progression का तीसरा layer है: prompt engineering एक exchange optimize करती है, context engineering manage करती है कि model एक बार में क्या देखता है, और harness engineering वह execution environment build करती है जिसमें agent सैकड़ों decisions के across operate करता है। यह named practice early 2026 में Mitchell Hashimoto ने crystallize की; उन्होंने describe किया कि agent से गलती होने पर वह हर बार agent environment में permanent fix engineer करते थे। OpenAI और Anthropic ने कुछ weeks के अंदर विस्तृत articles publish किए। Slogan version: agent को fix न करें, agent जिस world में रहता है उसे fix करें।
💡 Analogy: Prompt fixes bandaids हैं; harness fixes vaccines हैं। Prompt fix failure की एक instance solve करता है। Harness fix (tool, validator, skill, check, instruction add करना) उस class of failure को same harness में run होने वाले हर future agent के लिए हमेशा के लिए close करता है।
🔹 Example: TutorClaw शुरुआती learner के लिए बहुत harsh feedback देता है। आसान लेकिन कमजोर fix prompt rewrite करना है। Harness fix tone-check skill add करना है जो output को rubric से gate करे। TutorClaw का हर future response उससे गुज़रता है, prompt change की ज़रूरत नहीं।
📌 OpenClaw में: Harness extension की unit SKILL.md file है। आपके students जो भी skill लिखते हैं वह harness engineering artifact है, और वही Hashimoto loop apply होता है (failure observe करें → पूछें कि यह possible क्यों था → permanent fix engineer करें → verify करें कि वह compound करता है).
Progress Files
Files जो multiple Claude Code sessions के across long-running project की state track करती हैं, document करती हैं कि क्या complete हुआ, कौन से decisions लिए गए, और next क्या है।
💡 Analogy: Construction site logbook. हर दिन foreman record करता है कि क्या build हुआ, कौन सी problems आईं, और कल का plan क्या है। जब new crew आती है (new session), वे log पढ़कर seamlessly continue करते हैं।
Session Architecture
Large project के लिए multiple sessions के across AI agent के साथ interactions को structure और sequence करने का design: कब fresh start करना है, कब context carry forward करना है, और कौन सा context preserve करना है।
🔹 Example: 30-chapter book project के लिए आप पूरी book एक session में dump नहीं करते। आप architecture design करते हैं: Session 1 outline cover करता है, Session 2 Chapter 1 लिखता है (outline context में carry forward), Session 3 Chapter 2 लिखता है (outline + Chapter 1 summary carry forward), और आगे ऐसे। हर session को exactly उतना context मिलता है जितना चाहिए, न अधिक, न कम।
Five Powers
पाँच capabilities जो traditional user interfaces से autonomous AI agents की shift enable करती हैं: (1) natural language understanding, (2) reasoning, (3) tool use, (4) memory, और (5) planning। Combined, ये agents को intent समझने और independently execute करने देती हैं।
💡 Analogy: एक capable human assistant सोचें। वह (1) आपकी बात समझ सकता है, (2) problems पर सोच सकता है, (3) phones और computers जैसे tools इस्तेमाल कर सकता है, (4) आपकी preferences याद रख सकता है, और (5) multi-step projects plan कर सकता है। Five Powers वाला AI agent भी यही कर सकता है: यही "वह software जिसे आप operate करते हैं" से "वह software जो आपके लिए operate करता है" तक की shift है।
Agent Maturity Model
Organization की AI adoption stages describe करने वाला five-level framework:
| Level | Name | Description |
|---|---|---|
| 1 | Experimental | Individual developers AI coding tools try कर रहे हैं |
| 2 | Standardized | Governance के साथ organization-wide adoption |
| 3 | AI-Driven | Specs living documentation बनते हैं; workflows redesign होते हैं |
| 4 | AI-Native | Products जहाँ AI/LLMs core components हैं |
| 5 | Autonomous | पूरी organization AI-native; self-improving systems |
AI-Assisted Development
AI को helper या copilot की तरह इस्तेमाल करना: code completion, bug detection, documentation generation। Human अभी भी ज़्यादातर code लिखता है।
🔹 Example: GitHub Copilot आपके type करते समय code की next line suggest करता है।
AI-Driven Development
AI, human-written specifications से significant code generate करता है। Human architect, director, और reviewer की तरह act करता है; typist की तरह नहीं।
🔹 Example: आप REST API describe करने वाली SPEC.md लिखते हैं, और Claude Code पूरी FastAPI application, tests, और documentation generate करता है।
AI-Native Development
ऐसी applications जो ground up से AI capabilities के around architect की गई हों: AI feature की तरह add नहीं है; वही product का core है।
🔹 Example: TutorClaw कोई textbook नहीं है जिस पर chatbot bolt कर दिया गया हो। AI tutor ही product है। पूरी architecture LLM capabilities के around built है।
Nine Pillars of AIDD
इस किताब में defined AI-Driven Development के नौ foundational principles: specification-first design से continuous verification तक सब cover करते हैं।
OODA Loop (Observe, Orient, Decide, Act)
AI agents के साथ काम करने पर applied rapid decision-making cycle। आप agent output observe करते हैं, spec से match करता है या नहीं यह check करके खुद को orient करते हैं, accept या redirect करना है यह decide करते हैं, और approve या new instructions देकर act करते हैं।
📌 Origin: Fighter pilot John Boyd द्वारा developed military strategy framework, अब AI-driven work के fast iterative cycles पर applied.
PRIMM-AI+
इस किताब में इस्तेमाल pedagogical framework: code क्या करेगा यह Predict करें → उसे Run करें → output Investigate करें → उसे Modify करें → अपनी version Make करें। "AI+" का मतलब है AI हर step में embedded है।
AI Gravity
वह लगातार खिंचाव जो आपको अपनी सोच का और अधिक हिस्सा AI को देने की तरफ ले जाता है। MIT Sloan के professor Eric So ने इसे यह नाम दिया। यह एक साथ तीन दिशाओं से आता है: आपका दिमाग energy बचाना चाहता है, आप चाहते हैं कि आपका काम expert-level दिखे, और आप देख नहीं सकते कि आपके peers AI कितना use कर रहे हैं। How to Think in the AI Era crash course इसी force के खिलाफ train कराता है।
💡 Analogy: असली gravity: आप उसे देख नहीं सकते, वह कभी off नहीं होती, और वह सबको खींचती है। आपको खिंचाव महसूस नहीं होता; महीनों बाद बस यह दिखता है कि आपने AI खोलने से पहले अपनी राय बनाना बंद कर दिया।
🔹 Example: दो लोगों को same task और same AI tools मिलते हैं। एक पहले अपना answer लिखती है, फिर AI से compare करती है। दूसरी AI खोलती है, पूछती है, और accept कर लेती है; इसलिए नहीं कि वह lazy है, बल्कि इसलिए कि तीन quiet forces ने उसे एक ही direction में धकेला। वही pull AI gravity है।
Cognitive Capital
आपकी thinking muscle: problem पर काम करने, wrong answer पकड़ने, और confident answer ने क्या छोड़ा है यह notice करने की built-up ability। Eric So का term उस चीज़ के लिए जिसे AI gravity खर्च करती है जब आप answers बिना check किए accept करते हैं।
🔹 Example: MIT Media Lab की शुरुआती study में, ChatGPT की मदद से essays लिखने वाले 100 में से 83 लोग अपने अभी-अभी submit किए essay की एक भी sentence repeat नहीं कर सके। Words उनके दिमाग से गुज़रे ही नहीं; यही cognitive capital का बिना use हुए fade होना है।
📌 इस book के लिए यह क्यों matter करता है: 10-80-10 Rule तभी काम करता है जब human के दोनों 10 sharp रहें। Cognitive capital उन्हें sharp रखता है; supervisor जो agent की गलती पहचान नहीं सकता, आखिरी 10% hold नहीं कर सकता।
Identic AI
Concept जहाँ हर human के पास personal AI agent होता है जो उनके judgment, preferences, और authority को reflect करता है: उनकी ओर से multiple AI systems के across tasks delegate करता है। इस किताब की reference architecture में OpenClaw identic AI है: Edge Layer पर delegate."
💡 Analogy: CEO के पास executive assistant होता है जो उनकी priorities और decision-making style इतनी अच्छी तरह जानता है कि CEO की ओर से act कर सकता है। Identic AI इसका AI version है: Agent Factory में आपका personal representative.
System of Record / Source of Truth
एक authoritative data source जिस पर सभी accurate होने का भरोसा करते हैं। जब conflicting versions हों, system of record final word होता है।
🔹 Example: अगर आपकी company का HR system कहता है कि employee की salary Rs. 200,000 है लेकिन spreadsheet Rs. 180,000 कहती है, तो HR system system of record है।
Bounded Workflow
ऐसा workflow जिसके start points, end points, और constraints clearly defined हों: agent exactly जानता है कि वह क्या कर सकता है और क्या नहीं। No ambiguity, no scope creep.
Escalation Protocol
Predefined rule कि agent कब रुककर task human को hand करे: क्योंकि task बहुत complex, risky, या agent authority से बाहर है।
🔹 Example: Customer service agent routine questions handle करता है, लेकिन अगर customer legal action की धमकी देता है, तो escalation protocol conversation को human manager के पास transfer करता है।
Tool Interface
Defined contract कि agent external tool से कैसे connect और use करता है, जिसमें tool के expected inputs और returned outputs specify होते हैं।
Vertical Intelligence
Specific industry की terminology, regulations, workflows, और pain points की deep expertise, agent में packaged.
🔹 Example: Pakistani textile exporters के लिए AI agent जो SRO notifications, HS codes, LC documentation, और SBP regulations समझता है; सिर्फ़ generic business knowledge नहीं।
Agentic Enterprise
ऐसी organization जिसने AI agents को core operations में embed कर दिया है, जहाँ Digital FTEs human employees के साथ standard way of working के रूप में होते हैं। Thesis में इसे AI-Native Company कहा गया है: running enterprise जिसे Agent Factory produce करती है। दोनों terms same thing को refer करती हैं।
🔹 Example: Logistics company जहाँ AI agents 24/7 order tracking, route optimization, और customer notifications handle करते हैं, जबकि human employees partnerships, exception handling, और strategy पर focus करते हैं। Agents side project नहीं हैं; वे org chart का हिस्सा हैं।
Custom-Built AI Employee
AI agent जिसे आप specific business need के लिए scratch से build करते हैं, exactly आपके workflow और domain के अनुसार tailored.
🔹 Example: Textile exporter ऐसा agent build करता है जो incoming LC (Letter of Credit) documents पढ़ता है, उन्हें SBP regulations के against check करता है, discrepancies flag करता है, और amendment requests draft करता है। Off-the-shelf tool यह नहीं करता; यह उनके exact workflow के लिए custom-built है।
Pre-Built AI Employee
Off-the-shelf AI agent जिसे आप custom development के बिना immediately इस्तेमाल कर सकते हैं, जैसे ChatGPT, Claude, या existing customer service bot.
🔹 Example: Emails draft करने, documents summarize करने, या questions answer करने के लिए Claude directly इस्तेमाल करना। Development की ज़रूरत नहीं; आप तुरंत start करते हैं। Trade-off: यह general tasks के लिए work करता है, लेकिन आपके unique business process के लिए specialized नहीं होता।
Build vs. Buy
Strategic decision: अपना custom AI agent build करें (more control, higher cost, longer timeline) या existing one use करें (faster deployment, less customization)?
🔹 Example: Hospital को patient scheduling agent चाहिए। Buy: Existing healthcare AI platform use करें (weeks में deployed, लेकिन limited customization. Build: उनके specific EMR system, doctor preferences, और Urdu/English support से integrated custom agent create करें) इसमें months लगते हैं लेकिन fit perfect होता है। सही choice budget, timeline, और workflow कितना unique है, इस पर depend करती है।
FTE Development Plugin
Tool या extension जो Digital FTEs के development और deployment में मदद करता है, Agent Factory workflow को streamline करता है।
Skill Shim
Thin adapter layer जो different agent skill formats के बीच translate करती है, platforms के across compatibility enable करती है।
💡 Analogy: Travel power adapter. आपका Pakistani plug UK socket में fit नहीं होता, लेकिन shim (adapter) rewiring के बिना compatibility देता है।
Gateway Proxy Pattern
Architectural pattern जहाँ single entry point (gateway) requests को सही backend agent या service तक route करता है, authentication, rate limiting, और load distribution manage करता है।
💡 Analogy: Large hospital का reception desk. सभी patients reception से enter करते हैं, जो appointment check करता है, identity verify करता है, और सही department तक direct करता है।
Piggyback Protocol
किताब में referenced startup strategy: users तक जल्दी पहुँचने के लिए अपना independent channels build करने से पहले existing platform के distribution के ऊपर product build करना।
🔹 Example: TutorClaw deliver करने के लिए अपनी messaging app build करने के बजाय आप WhatsApp के ऊपर build करते हैं: जिसके Pakistan में पहले से 100+ million users हैं। आप WhatsApp के distribution पर "piggyback" करते हैं ताकि students तक instantly पहुँचें, किसी को new app download कराने की ज़रूरत नहीं।
2. Core AI and Machine Learning
ये इस किताब की हर चीज़ के पीछे foundational ideas हैं।
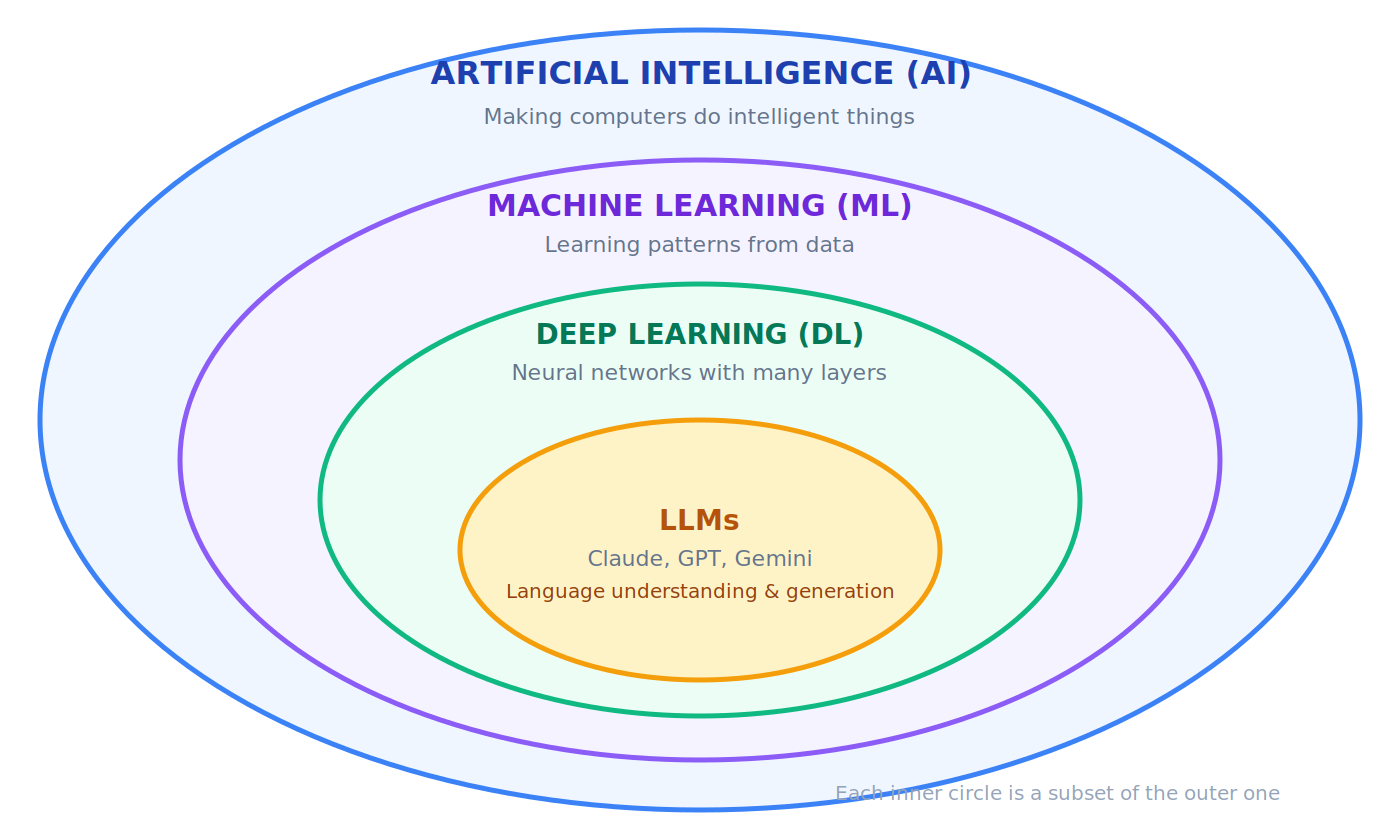
AI ⊃ ML ⊃ DL ⊃ LLMs
(Each is a subset of the one before it)
AI (Artificial Intelligence)
Computers से वे काम करवाना जिनके लिए आम तौर पर human intelligence चाहिए होती है, जैसे language समझना, images recognize करना, decisions लेना, problems solve करना।
🔹 Example: जब आपके phone का keyboard Urdu या English में आपका next word predict करता है, तो वह AI है। जब Careem traffic के based आपकी ride time estimate करता है, तो वह AI है।
ML (Machine Learning)
Computers को explicit rules लिखकर नहीं, examples दिखाकर सिखाने का तरीका। Computer data में patterns ढूँढता है और उनसे सीखता है।
🔹 Example: YouTube आपको वे videos recommend करता है जो शायद आपको पसंद आएँ। किसी ने rule program नहीं किया कि "अगर user ने cricket highlights देखे, तो more cricket suggest करें।" System ने billions of viewing habits से यह pattern सीखा।
💡 Analogy: बच्चे को mangoes पहचानना सिखाने की कल्पना करें। आप biology explain नहीं करते। आप dozens of mangoes दिखाते हैं और कहते हैं "mango." Eventually, वह ऐसे mangoes भी पहचान लेता है जो उसने पहले कभी नहीं देखे, Chaunsa और Sindhri जैसी different varieties भी। यही machine learning है।
DL (Deep Learning)
Machine learning का more powerful version जो कई layers वाले "neural networks" इस्तेमाल करता है। यह extremely complex patterns सीख सकता है, जैसे speech समझना, images generate करना, या languages के बीच translation.
🔹 Example: जब Google Translate Urdu paragraph को fluent English में convert करता है, तो deep learning उस translation को power करती है।
💡 Analogy: अगर ML simple shapes recognize करना सीखना है, तो DL crowded Saddar Bazaar में faces recognize करना सीखना है: far more complex, लेकिन examples से सीखने का principle वही है।
Model
ऐसा program जो data पर trained हो चुका है और अब predictions कर सकता है या outputs generate कर सकता है। जब लोग "GPT-4" या "Claude" कहते हैं, तो वे models की बात कर रहे होते हैं।
💡 Analogy: Model ऐसे student जैसा है जिसने millions of textbooks पढ़े हैं। आप questions पूछते हैं, वह अपनी पढ़ाई के based answer देता है। Different models different students जैसे हैं: कुछ math में बेहतर, कुछ creative writing में।
Foundation Model
बहुत large, general-purpose model जो enormous data पर trained होता है। इसे scratch से retrain किए बिना कई different tasks के लिए adapt किया जा सकता है। Claude, GPT-4, और Gemini foundation models हैं।
💡 Analogy: Foundation model broad education वाले university graduate जैसा है। उसने अभी specialize नहीं किया, लेकिन accounting, writing, research, management जैसे कई jobs में जल्दी adapt कर सकता है।
Neural Network
Human brain से inspired computing system, जिसमें interconnected "nodes" की layers information process करती हैं, और हर layer क्रमशः अधिक complex patterns extract करती है।
💡 Analogy: Different mesh sizes वाली sieves की series imagine करें। आप raw data पहली sieve से डालते हैं (large patterns catch करती है), फिर अगली से (finer patterns), फिर अगली से (finest details)। Neural network similarly काम करता है, हर layer information refine करती है।
Transformer
Specific neural network architecture जो सभी modern LLMs को power करती है। 2017 में invented, यह words के relationships समझने में especially good है, जैसे "river bank" और "bank account" में "bank" का meaning अलग होता है।
💡 Analogy: Older AI sentences word by word पढ़ता था, keyhole से पढ़ने जैसा (एक बार में एक word दिखता है और meaning guess करना पड़ता है। Transformers पूरी sentence एक साथ पढ़ते हैं, पूरा door खोलने जैसा) वे हर word simultaneously देखते हैं और समझते हैं कि हर word दूसरे हर word से कैसे relate करता है। इसलिए वे language समझने में बहुत बेहतर हैं।
💡 Why it matters: इस किताब में हर AI model (Claude, GPT, Gemini) transformers पर built है। आपको math समझने की ज़रूरत नहीं, लेकिन term बार-बार दिखेगा।
Multimodal Model
ऐसा model जो multiple types of input (text, images, audio, video) के साथ काम कर सकता है, सिर्फ़ एक type से नहीं।
🔹 Example: आप restaurant bill की photo लेते हैं और Claude से पूछते हैं "Total क्या है?" Model image और आपका text question दोनों समझता है। यही multimodal capability है।
Reasoning Model
ऐसा model जो answer देने से पहले complex problems को step by step "think through" करने के लिए designed है, instantly respond करने के बजाय। Hard problems पर अक्सर more accurate.
💡 Analogy: Cricket match में कुछ batsmen instinctive shots खेलते हैं (fast, कभी reckless)। दूसरे field study करते हैं, bowler read करते हैं, और हर shot deliberately plan करते हैं। Reasoning model दूसरा type है: slower लेकिन difficult deliveries पर more reliable.
Training
Model को massive amounts of data feed करने की process ताकि वह patterns सीख सके। यह आपके model से interact करने से पहले होता है; यही "education" phase है।
💡 Analogy: Training chef के culinary school में सालों बिताने जैसी है: thousands of dishes taste करना, techniques सीखना, recipes practice करना। जब तक वे restaurant open करते हैं (जब आप model use करते हैं), learning पहले ही हो चुकी होती है।
Pretraining
Training का पहला, सबसे expensive phase। Model enormous amounts of text (books, websites, code, conversations) पढ़ता है और language और world के बारे में general knowledge सीखता है।
Post-Training
Pretraining के बाद additional training, ताकि model helpful, safe, और human expectations के aligned बने। यहीं model instructions follow करना, polite होना, और harmful requests refuse करना सीखता है।
💡 Analogy: Pretraining general education (school और university) जैसा है। Post-training workplace orientation जैसा है: company culture, communication style, और professional norms सीखना।
Fine-Tuning
Existing model को specific, smaller dataset पर further train करना ताकि वह particular domain में expert बने।
🔹 Example: General-purpose model लेकर उसे thousands of Pakistani tax rulings पर fine-tune करना ताकि वह tax advisory में especially good बने।
💡 Analogy: General doctor का additional training लेकर cardiologist बनना। Same foundational education, अब specialized.
Parameters
Model के internal numbers जो training के दौरान adjusted होते हैं। ज़्यादा parameters का मतलब आम तौर पर more capable model होता है। Modern LLMs के billions या trillions of parameters होते हैं।
💡 Analogy: Parameters massive carpet के individual threads जैसे हैं। Training के दौरान हर thread adjust होता है (color, tension, placement) जब तक complete pattern emerge नहीं होता। 100 billion parameters वाला model 100 billion threads से बना incredibly complex pattern रखता है।
Weights
Training के बाद parameters की specific numerical values. जब कोई "weights download" कहता है, तो उसका मतलब उन trained numbers वाली file है: model की learned knowledge.
Dataset
AI model train या evaluate करने के लिए इस्तेमाल data का collection.
🔹 Example: Spam filter train करने वाला dataset 1 million emails रख सकता है, हर email labeled "spam" या "not spam." Translation model train करने वाला dataset millions of English-Urdu sentence pairs रख सकता है।
Benchmark
Different AI models कितना अच्छा perform करते हैं, इसे measure और compare करने के लिए standardized test.
🔹 Example: जैसे CSS या Cambridge exams students compare करने देते हैं, benchmarks जैसे MMLU (general knowledge) या HumanEval (coding ability) researchers को AI models fairly compare करने देते हैं।
Inference
Trained model द्वारा आपके input पर response generate करने की process. हर बार जब आप Claude से question पूछते हैं और answer मिलता है, वह inference है।
💡 Analogy: Training exam के लिए पढ़ाई है। Inference exam देना है। Learning पहले ही हो चुकी है: अब model सीखी हुई चीज़ apply करता है। आप inference के लिए pay करते हैं (हर API call का पैसा लगता है), training के लिए नहीं।
3. LLM Basics
LLMs इस किताब के हर AI agent को power करने वाले engines हैं। यह section practical level पर explain करता है कि वे कैसे work करते हैं।
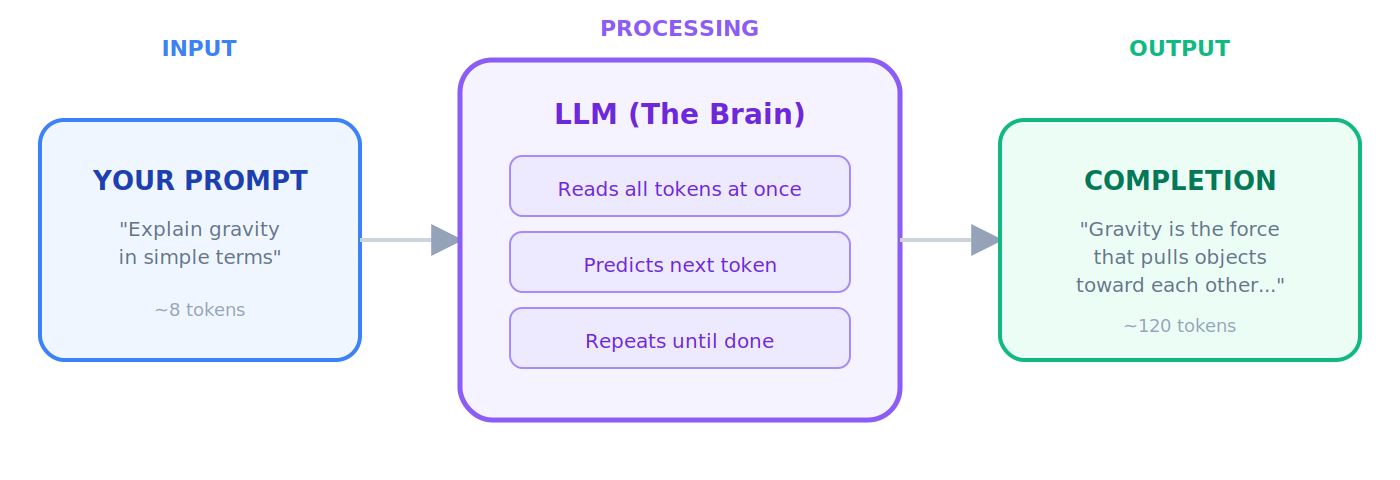
LLM (Large Language Model)
बहुत large AI model जो vast amounts of text पर trained है और human-like language और code को understand और generate कर सकता है। Claude, GPT-4, और Gemini सभी LLMs हैं।
💡 Analogy: LLM ऐसा incredibly well-read research assistant है जिसने हर Wikipedia article, millions of books, और billions of web pages पढ़े हैं। आप उससे लगभग कुछ भी पूछ सकते हैं, और वह उस reading से help करेगा: writing, analysis, code, translation, और more.
Prompt
AI model को दिया गया input: आपका question, instruction, या request। Prompt की quality directly response की quality को affect करती है।
🔹 Example: "Marketing के बारे में कुछ लिखें" weak prompt है। "Pakistani textile exporters को order tracking के लिए AI agents क्यों इस्तेमाल करने चाहिए, इस पर professional लेकिन conversational tone में 500-word LinkedIn post लिखें" strong prompt है।
System Prompt
आपकी conversation शुरू होने से पहले AI को दी गई hidden instructions। Developer set करता है, user नहीं। ये model की personality, behavior, और constraints shape करती हैं।
🔹 Example: Banking chatbot का system prompt कह सकता है: "आप HBL के लिए helpful assistant हैं। Customer की language के based Urdu या English में answer करें। OTP verification के बिना account balances कभी reveal न करें। Loans के बारे में पूछा जाए तो loans page पर direct करें।"
💡 Analogy: System prompt new employee को day one पर manager की briefing जैसा है: "हम कौन हैं, customers से कैसे बात करते हैं, और क्या कभी नहीं करना।"
User Prompt
वह message जो आप (user) actually type करते हैं। यह conversation में आपकी side है।
Instruction
Prompt के अंदर specific directive जो model को बताती है कि क्या करना है।
🔹 Example: "इसे तीन bullet points में summarize करें," "Translate to Urdu," "इस code में bug fix करें", हर एक clear instruction है।
Context
Conversation के दौरान model के लिए available सारी information: system prompt, conversation history, uploaded documents, और आपका current message combined.
💡 Analogy: जब आप colleague से किसी deal पर advice मांगते हैं, तो "context" वह सब है जो वे जानते हैं: client history, previous emails, contract terms, आपकी company policies। Context जितना relevant होगा, advice उतनी बेहतर होगी।
Context Window
एक LLM एक बार में जितना maximum text process कर सकता है, tokens में measured. इसे model की "working memory" समझें।
🔹 Example: Claude models 200,000 से 1 million से अधिक tokens तक की context windows offer करते हैं। 200,000 tokens भी roughly 150,000 words हैं (पूरा novel)। Older models शायद सिर्फ़ 4,000 tokens handle करें (कुछ pages).
💡 Analogy: Context window desk के size जैसी है। छोटी desk पर कुछ papers ही रख सकते हैं, और जगह बनाने के लिए पुराने हटाते रहना पड़ता है। Huge desk पर पूरा project फैलाकर सब एक साथ देखा जा सकता है। Bigger context window = bigger desk.
Token
Text की basic unit जिसे LLM process करता है। Token roughly ¾ word होता है। "the" जैसे short words one token होते हैं। "unbelievable" जैसे longer words 3-4 tokens में split होते हैं। Spaces और punctuation भी tokens consume करते हैं।
🔹 Example: "I love biryani" ≈ 4 tokens. Text का full page ≈ 500-700 tokens. AI APIs इस्तेमाल करते समय आप per token charge होते हैं।
Completion / Generation
आपके prompt के response में LLM जो output produce करता है। जब model आपका request "complete" करता है, वह response completion है।
Structured Output
जब LLM conversational text के बजाय specific, machine-readable format (जैसे JSON) में response generate करता है, ताकि other software उसे आसानी से process कर सके।
🔹 Example: "Karachi में temperature 35 degrees है और sunny है" के बजाय structured output होगा:
{"city": "Karachi", "temp": 35, "condition": "sunny"}. Software इस format को effortless read करता है।
Hallucination
जब AI model false, inaccurate, या fabricated information confidence से generate करता है और उसे fact की तरह present करता है।
🔹 Example: आप Supreme Court judgment के बारे में पूछते हैं और model fake case invent करता है (fake citation numbers और fake bench के साथ) और उसे real की तरह present करता है।
💡 Analogy: Exam में answer न जानने वाला student, लेकिन फिर भी बहुत confident, detailed response लिखता है। पढ़ने में सही लगता है, लेकिन पूरी तरह made up है।
Grounding
AI model को factual, verified data sources से connect करना ताकि वह hallucinate करने के बजाय accurate answers दे।
💡 Analogy: Grounding student को exam में textbook इस्तेमाल करने देने जैसा है। अब answers unreliable memory से नहीं, real information से based होते हैं।
Temperature
LLM responses में creativity vs. predictability control करने वाली setting. Low temperature (0) = बहुत consistent. High temperature (1+) = more creative और varied.
💡 Analogy: Temperature kitchen में chef की freedom जैसी है। Temperature 0: "Recipe exactly follow करें, no substitutions." Temperature 1: "Freely improvise करें।" Medication dosages के लिए exact recipes चाहिए, लेकिन new dish के लिए creative freedom.
Latency
Request भेजने और response पाने के बीच time delay. Lower latency = faster. Milliseconds या seconds में measured.
🔹 Example: अगर Claude 1 second में respond करता है, तो low latency है। अगर 15 seconds लगते हैं, तो high latency है। 2-3 seconds से आगे users impatient हो जाते हैं।
Throughput
System per unit time कितनी requests handle कर सकता है। High throughput = simultaneously many users serve करना।
💡 Analogy: Latency यह है कि toll plaza से एक car कितनी तेज़ गुजरती है। Throughput यह है कि toll plaza per hour कितनी cars handle करता है। आपको low latency और high throughput दोनों चाहिए।
Deterministic vs. Non-Deterministic
Deterministic: Same input हमेशा exact same output produce करता है (calculator की तरह: 2+2 हमेशा 4). Non-deterministic: Same input हर बार different output produce कर सकता है।
LLMs non-deterministic हैं: same question दो बार पूछें, तो slightly different (लेकिन equally valid) answers मिल सकते हैं। यह bug नहीं है; technology कैसे काम करती है उसका fundamental हिस्सा है।
Stateless
Separate interactions के बीच कोई memory नहीं होना। LLM के साथ हर new conversation absolute zero से start होती है: model को previous conversation की कोई knowledge नहीं होती।
💡 Analogy: Amnesia वाला shopkeeper. हर बार जब आप अंदर जाते हैं, वह आपको stranger की तरह greet करता है, भले ही आप five minutes पहले आए हों। Chat apps हर message के साथ entire conversation history re-send करके memory का illusion create करती हैं।
Prompt Engineering
AI model से best possible output पाने के लिए clear, specific instructions craft करने की skill. सिर्फ़ "आप क्या पूछते हैं" नहीं, बल्कि "कैसे पूछते हैं."
🔹 Example: "AI के बारे में लिखें" के बजाय prompt engineer लिखता है: "आप Dawn newspaper के लिए technology journalist हैं। Pakistani banks fraud detection के लिए AI agents कैसे इस्तेमाल कर रहे हैं, इस पर 600-word article लिखें। One real example include करें। Non-technical business reader के लिए simple language इस्तेमाल करें।"
NLP (Natural Language Processing)
AI की branch जो human language को understand, interpret, और generate करने से deal करती है, वही foundation जो LLMs को possible बनाता है।
🔹 Example: जब आप broken English में search query type करते हैं और Google फिर भी समझ जाता है कि आपका मतलब क्या था, तो वह NLP at work है।
Copilot
Software environment (जैसे code editor) में integrated AI assistant जो productivity boost करने के लिए आपके साथ काम करता है, suggest, auto-complete, और review करता है।
🔹 Example: GitHub Copilot आपके type करते समय code suggest करता है। यह ऐसे knowledgeable colleague जैसा है जो आपके shoulder के ऊपर देखकर आपकी sentences finish कर रहा हो।
4. Knowledge, Retrieval, and Context
ये terms describe करते हैं कि AI agents better, more accurate answers के लिए external knowledge कैसे access और use करते हैं।
RAG (Retrieval-Augmented Generation)
Technique जहाँ AI पहले external documents या databases से relevant information retrieve करता है, फिर उस information से more accurate response generate करता है।
💡 Analogy: Open-book exam देना। सिर्फ़ memorized (possibly wrong) knowledge पर depend करने के बजाय, answer लिखने से पहले reference material में specific facts look up करना। RAG, AI को अपनी reference library देता है।
Embedding
Text को numerical coordinates में convert करना ताकि computer measure कर सके कि different pieces of text कितने similar हैं, meaning capture करते हुए, सिर्फ़ keywords नहीं।
💡 Analogy: Imagine करें कि library की हर book को giant map पर place किया गया है जहाँ similar books साथ cluster करती हैं। Cookbooks एक-दूसरे के पास, physics textbooks से दूर। Embeddings mathematical space में यह "similarity map" create करती हैं।
Vector
Numbers की list जो mathematical space में text के piece को represent करती है। जब text embedding में convert होता है, result vector होता है।
🔹 Example: Word "cricket"
[0.8, 0.3, 0.7, 0.1, ...]बन सकता है: numbers की long list जो sport और insect दोनों meanings capture करती है, surrounding context से distinguished.
Vector Database
Vectors store और quickly search करने वाला specialized database, जो exact keyword match के बजाय meaning से similar content find करता है।

🔹 Example: आप 10,000 company documents को vectors के रूप में store करते हैं। जब कोई पूछता है "हमारी return policy क्या है?" vector database instantly सबसे relevant documents find करता है, भले ही उनमें exact phrase "return policy" न हो।
💡 Analogy: Traditional database exact keywords से search करता है (जैसे phonebook में name search करना)। Vector database meaning से search करता है (जैसे librarian से कहना "मुझे इस book जैसी books ढूँढकर दें").
Semantic Search
Exact keywords के बजाय meaning से search करना। "मैं product return कैसे करूँ?" title "Refund Process" वाले document से match करता है, भले ही words बिल्कुल different हों।
🔹 Example: Employee company knowledge base में "छुट्टी कैसे लें" search करता है। Semantic search "Annual Leave Policy and Procedures" title वाला document find करता है, भले ही search words title में नहीं हैं। Traditional keyword search कुछ भी find नहीं करेगा।
Retrieval
AI को response generate करने में use करने के लिए data source (database, document collection, web) से relevant information fetch करना।
🔹 Example: Customer आपके support agent से पूछता है "Laptops पर warranty क्या है?" Agent आपके knowledge base से warranty policy document retrieve करता है, relevant section पढ़ता है, और actual policy पर based accurate answer generate करता है; guess नहीं।
Reranking
Multiple results retrieve करने के बाद उन्हें relevance के हिसाब से re-order करना ताकि सबसे useful result पहले आए: initial search के बाद quality filter.
Chunking / Chunk
Large document को smaller pieces में break करना ताकि उन्हें individually store और search किया जा सके।
🔹 Example: 200-page HR manual paragraph-sized chunks में split होता है। जब कोई leave policy के बारे में पूछता है, system सिर्फ़ 3-4 most relevant paragraphs retrieve करता है, पूरी manual नहीं।
Knowledge Base
Information (documents, FAQs, manuals, policies) का organized collection जिसे AI search और reference कर सकता है।
🔹 Example: Company की internal wiki जिसमें product docs, HR policies, और training materials हैं, इस तरह structured कि AI agent instantly answers find कर सके।
Grounding Data
AI model से connected specific factual data, ताकि accurate, fact-based responses ensure हों, hallucinated guesses नहीं।
MCP (Model Context Protocol)
Open standard (Anthropic द्वारा created, अब Linux Foundation से governed) जो किसी भी AI agent को universal protocol से external tools से connect करने देता है: search, databases, email, calendars, file systems। MCP agents के tool calling का protocol है। Agents द्वारा उन tools के लिए payment करने वाले अलग protocol family के लिए Section 11 देखें: ACP, AP2, x402, और MPP.
💡 Analogy: USB से पहले हर phone का charger अलग होता था। USB universal connector बना। MCP AI agents के लिए "USB standard" है: एक protocol जिससे कोई भी agent किसी भी tool में plug हो सकता है। Agent एक बार build करें, सब कुछ connect करें।
Connector
Specific integration जो MCP या किसी दूसरे protocol से AI agent को external service से link करती है।
🔹 Example: "Gmail connector" AI agent को emails read, search, और send करने देता है। "Google Drive connector" उसे documents read और create करने देता है।
System Integration
Different software systems को connect करना ताकि वे data share करें और seamlessly साथ work करें: किसी भी enterprise agent deployment के पीछे की "plumbing."
🔹 Example: आपके Digital FTE को Salesforce से customer data पढ़ना, SAP में inventory check करना, JazzCash से payments process करना, और email से confirmations भेजना है। System integration चारों systems को connect करता है ताकि agent एक single workflow में इनके across काम कर सके।
5. Agentic AI Concepts
इस किताब का heart: AI systems जो सिर्फ़ questions answer नहीं करते, action लेते हैं।
Agent (or AI Agent)
AI system जो अपने environment को independently perceive कर सकता है, decisions ले सकता है, और goal achieve करने के लिए actions ले सकता है, बिना human के हर step guide करने के।
🔹 Example: Chatbot सिर्फ़ questions answer करता है। AI agent को goal मिलता है जैसे "अगले Friday के लिए Karachi-to-Dubai सबसे सस्ती flight find करें" और फिर वह airlines search करता है, prices compare करता है, आपका calendar check करता है, और ticket book करता है, अपने-आप।
💡 Analogy: Chatbot desk के पीछे बैठा librarian है जो questions answer करता है। Agent personal assistant है जो आपका request लेकर दुनिया में निकलता है और काम पूरा करता है।
Agentic AI
AI की category जो ऐसे agents build करने पर focused है जो autonomously plan, reason, act, और adapt करते हैं। 2026 में यही AI frontier है।
General Agent
Natural language से इस्तेमाल किया जाने वाला AI agent जो wide range of tasks कर सकता है। यह एक specific job के लिए built नहीं होता; यह versatile "Swiss Army knife" है जो coding, writing, research, file management, और more में help कर सकता है।
🔹 Example: Claude Code general agent है: आप उससे files organize करने, API लिखने, spreadsheet analyze करने, या Python error debug करने को कह सकते हैं। Natural language instructions इस्तेमाल करके वह आपकी need के हिसाब से adapt करता है।
💡 Analogy: General agent बहुत capable executive assistant जैसा है। आप उसे एक task के लिए hire नहीं करते; आप रोज़ अलग assignments देते हैं, और वह हर एक पूरा करने का तरीका find करता है।
Autonomy
AI agent किस degree तक हर step पर human approval के बिना independently operate कर सकता है।
💡 Analogy: Junior employee जिसे हर email के लिए permission चाहिए, low autonomy रखता है। Senior director जो independently decisions लेता है, high autonomy रखता है। Agents इसी spectrum पर exist करते हैं: कुछ को हर action के लिए human approval चाहिए; दूसरे defined boundaries के अंदर full independence से operate करते हैं।
Reasoning
Agent की ability कि वह problem को logically think through करे: information analyze करे, options weigh करे, और action लेने से पहले conclusions draw करे।
🔹 Example: आप agent से पूछते हैं: "हमें Lahore में launch करना चाहिए या Islamabad में?" Non-reasoning agent शायद एक चुन ले। Reasoning agent analyze करता है: "Lahore की population 2x है, लेकिन Islamabad की per-capita income higher है। आपका product professionals target करता है, इसलिए Islamabad की demographics better fit हैं। मैं पहले Islamabad recommend करता हूँ, फिर month 3 में Lahore."
Acting
जब agent real world में actually कुछ करता है: email भेजना, file लिखना, API query करना, order place करना, appointment book करना।
Planning
Agent की ability कि complex goal को steps की sequence में break करे और execution का order determine करे।
🔹 Example: आप agent से कहते हैं: "Pakistani cement exports पर market analysis report prepare करें।" Agent plan करता है: (1) export data search करना, (2) competitor info gather करना, (3) trends analyze करना, (4) report लिखना, (5) PDF के रूप में format और export करना।
Task Decomposition
Large, complex task को smaller, manageable subtasks में break करना जिन्हें individually solve किया जा सके।
💡 Analogy: "Wedding plan करें" one task के रूप में overwhelming है। Decomposed: venue find करें, caterer चुनें, invitations design करें, flowers arrange करें, photographer hire करें। हर subtask solvable है। AI agents complex goals को इसी तरह decompose करते हैं।
Orchestration
Multiple agents या tools को साथ काम करने के लिए coordinate करना, उनके बीच information flow manage करना।
💡 Analogy: Cricket team का captain एक साथ bowl, bat, और field नहीं करता। वह fielders की जगह तय करता है, bowling order set करता है, और match situation के based strategy adjust करता है। Agent orchestration similarly काम करती है: specialists को shared goal की ओर coordinate करना।
Multi-Agent System
ऐसा system जहाँ multiple AI agents collaborate करते हैं (हर एक task का अलग part handle करता है) ताकि ऐसा काम पूरा हो सके जो कोई अकेला नहीं कर सकता।
🔹 Example: एक agent competitor pricing research करता है, दूसरा analysis draft करता है, तीसरा slides format करता है, और चौथा speaker notes prepare करता है। वे team की तरह काम करते हैं।
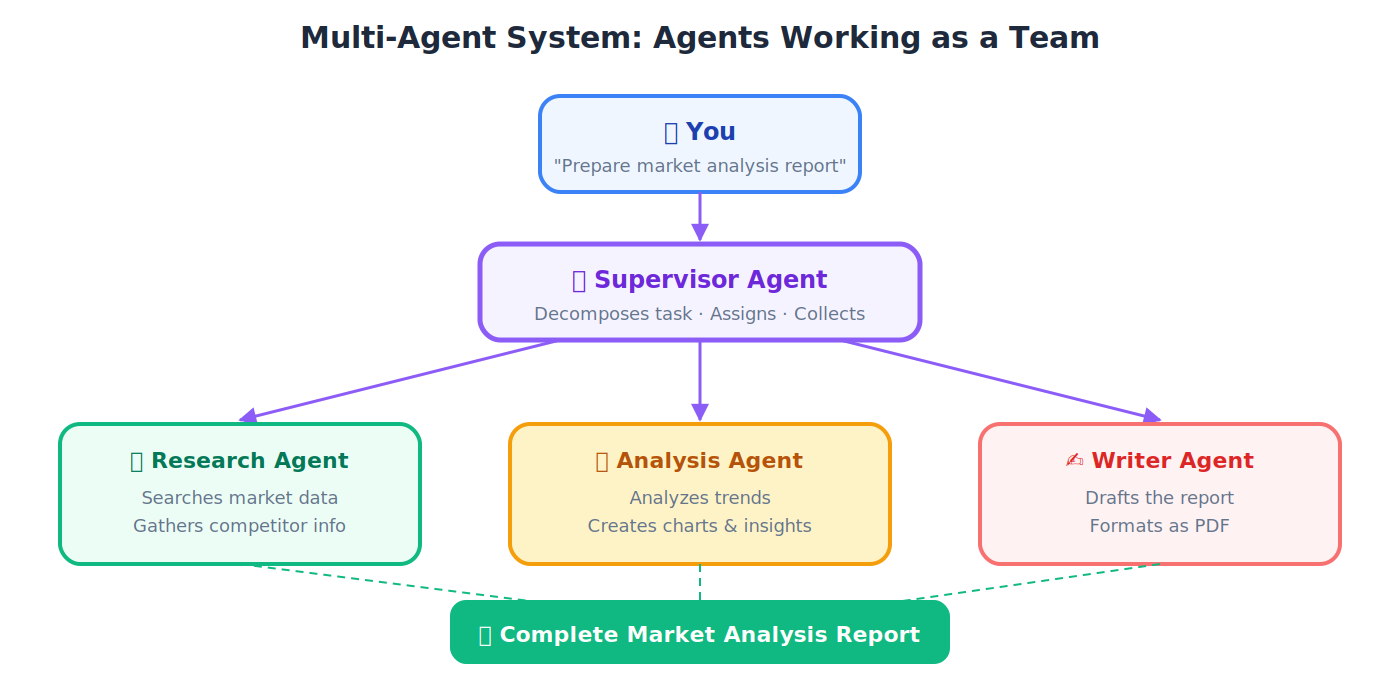
Supervisor Agent
ऐसा agent जिसका job दूसरे agents को coordinate और manage करना है: tasks distribute करना, progress monitor करना, और results collect करना।
💡 Analogy: Construction site foreman. वह bricks नहीं लगाता या outlets wire नहीं करता। वह specialists को tasks assign करता है, quality check करता है, और ensure करता है कि सब सही तरह से together आए।
Handoff
जब एक agent task (और उसका context) दूसरे agent को pass करता है, जैसे relay runner baton अगले runner को देता है।
Tool Use / Function Calling
Agent की ability कि वह सिर्फ़ memory से text generate करने के बजाय external tools इस्तेमाल करे (web search, databases query, emails send, code run).
💡 Analogy: केवल memory से questions answer करने वाला person बनाम वह person जो phone उठा सकता है, laptop खोल सकता है, और चीज़ें look up कर सकता है। Tool use agent को training data से बाहर की world तक access देता है।
State
किसी भी moment पर system की current condition या data. "Maintaining state" का मतलब ongoing process में चीज़ें कहाँ खड़ी हैं, यह remember करना।
🔹 Example: आप 10-page NADRA form online भर रहे हैं और page 7 पर हैं। "State" में pages 1-6 पर enter की गई सारी चीज़ें और currently आप किस page पर हैं, शामिल हैं।
Memory (Agent Memory)
Mechanisms जो agent को interactions के across information remember करने देते हैं: previous conversations, user preferences, या learned facts.
💡 Analogy: State short-term memory है (इस conversation में अभी क्या हो रहा है)। Memory long-term memory है (past conversations के across क्या हुआ)। Memory के बिना हर interaction zero से start होता है।
Session
User और AI system के बीच एक continuous interaction. New chat शुरू करना = new session शुरू करना।
Reflection
जब agent अपना output review करता है, mistakes या weaknesses identify करता है, और improvements के साथ फिर try करता है।
💡 Analogy: Writer draft finish करता है, उसे re-read करता है, weak arguments notice करता है, और submit करने से पहले revise करता है। Agent यह automatically करता है।
Retry / Fallback
Retry: Action fail होने पर वही action फिर attempt करना (शायद server temporarily unavailable था)। Fallback: Primary approach बार-बार fail होने पर alternative approach पर switch करना।
🔹 Example: Agent website से data fetch करने की कोशिश करता है। Site down है (retry: 30 seconds में फिर try करें)। 3 retries के बाद भी down है (fallback: same information के लिए different data source try करें).
Guardrails
Safety constraints जो agent को harmful, inappropriate, या unauthorized actions लेने से रोकते हैं। Guardrails का financial version, spending limits, vendor allowlists, audit triggers, authority envelope है। Section 11 देखें।
🔹 Example: Financial agent का guardrail Rs. 5,000,000 से ऊपर transactions को human approval के बिना रोकता है। Customer service agent का guardrail उसे ऐसे refunds के promise करने से रोकता है जिन्हें वह guarantee नहीं कर सकता।
💡 Analogy: Motorway के guardrails cars को road से बाहर जाने से रोकते हैं। AI guardrails agents को off-limits जाने से रोकते हैं।
HITL (Human in the Loop)
Design pattern जहाँ human agent workflow के critical points पर review, approve, या intervene करता है।
🔹 Example: Agent client email draft करता है, लेकिन human के पढ़कर approve करने तक वह send नहीं होता। Agent 80% work करता है; human 10% verification देता है।
Reliability
Agent कितनी consistently correct, expected results produce करता है। Reliable agent 100 में 99 बार सही करता है, 60 बार नहीं।
🔹 Example: Reliable invoice-processing agent different formats, languages, और layouts के across 99% invoices से vendor name, amount, due date, और tax correctly extract करता है। Unreliable agent अलग layouts से confuse होता है और 20% time amounts misread करता है। यही sellable product और liability का फ़र्क है।
Verifiability
Agent output correct है या नहीं check और confirm करने की ability: code tests pass करता है, numbers add up होते हैं, references exist करते हैं।
Auditability
Agent ने हर decision और action कैसे लिया, इसे trace back करने की ability: उसने exactly क्या किया और क्यों किया।
💡 Analogy: Bank statement हर transaction trace करता है। AI agent का audit trail हर decision, tool call, और output trace करता है, जो compliance और debugging के लिए critical है।
Workflow
Task को start से finish तक complete करने के लिए agent द्वारा follow की जाने वाली defined sequence of steps.
💡 Analogy: Workflow recipe जैसा है: step-by-step instructions जिन्हें correctly follow करने पर predictable result मिलता है।
6. Programming and Software Terms
आपको programmer होने की ज़रूरत नहीं, लेकिन ये terms पूरी किताब में मिलेंगे।
Python
AI में सबसे popular programming language: readable, versatile, और इस किताब की primary language. लगभग हर AI framework Python को पहले support करता है।
💡 Why Python? Python लगभग English जैसी पढ़ी जाती है।
if age > 18: print("Adult")उन लोगों को भी समझ आ जाता है जिन्होंने कभी code नहीं किया। यही readability है जिसकी वजह से AI world ने Python चुना, और यही वजह है कि यह किताब इसे सिखाती है। Starting से पहले आपको Python जानने की ज़रूरत नहीं; Part 4 आपको scratch से सिखाता है।
TypeScript
Web applications और realtime interfaces के लिए इस्तेमाल typed superset of JavaScript. इस किताब के Part 9 में covered.
Frontend
Application का वह part जिसे users देखते और interact करते हैं: buttons, menus, text, screen पर images.
🔹 Example: जब आप Daraz.pk इस्तेमाल करते हैं, product images, search bar, shopping cart, और checkout page frontend हैं।
Backend
पर्दे के पीछे run होने वाला part (servers, databases, business logic) जिसे users directly कभी नहीं देखते।
🔹 Example: जब आप Daraz पर "Place Order" click करते हैं, backend आपका payment process करता है, inventory check करता है, seller को notify करता है, और delivery schedule करता है।
Full-Stack
Developer या application जो frontend और backend दोनों handle करता है।
API (Application Programming Interface)
Rules का set जो different software programs को एक-दूसरे से communicate करने देता है। Agents outside world से APIs के through interact करते हैं।
💡 Analogy: Restaurant menu API जैसा है। आप (customer) menu (API documentation) देखते हैं, order देते हैं (request करते हैं), और kitchen (server) आपका meal prepare करती है (response भेजती है)। आपको kitchen कैसे work करती है यह जानने की ज़रूरत नहीं; आप बस menu use करते हैं।
SDK (Software Development Kit)
Specific platform पर applications develop करने के लिए pre-built toolkit.
💡 Analogy: SDK LEGO set जैसा है: instructions के साथ pre-shaped pieces ताकि आप raw wood से हर piece carve करने के बजाय specific चीज़ें quickly build कर सकें।
CLI (Command-Line Interface)
Buttons click करने के बजाय commands type करके computer से interact करने का text-based तरीका।
🔹 Example: File को folder में drag करने के बजाय आप
mv report.pdf documents/type करते हैं। Claude Code पूरी तरह CLI से run होता है।
HTTP / HTTPS
Web का communication protocol. हर website visit, हर API call HTTP (या उसके secure version HTTPS) use करती है।
💡 Analogy: HTTP internet का postal system है। आपका browser letter (request) लिखता है, website को address करता है, और website उसी system से reply (response) वापस भेजती है।
REST (Representational State Transfer)
Web APIs design करने का widely-used standard: simple, predictable, और HTTP based.
Endpoint
Specific URL जहाँ API requests receive करती है। हर endpoint एक specific function handle करता है।
🔹 Example:
api.weather.com/current?city=Karachiendpoint है: वह specific address जहाँ आप Karachi का weather ask करते हैं।
Request / Response
Request: Client से server को कुछ मांगने वाला message। Response: Server का reply.
💡 Analogy: आप waiter से soup of the day पूछते हैं (request). Waiter "haleem" लेकर लौटता है (response).
JSON (JavaScript Object Notation)
Data store और exchange करने का lightweight, human-readable format. AI world का standard data format.
🔹 **Example:
{
"name": "Ahmed Khan",
"city": "Lahore",
"role": "Software Engineer"
}
हर data piece का clear label और value है। Software JSON effortlessly read करता है।
Schema
Data कैसे organized है, उसका structure या blueprint: कौन से fields exist करते हैं, हर field किस type का है, और कौन से required हैं।
💡 Analogy: Blank NADRA form schema है: "Name यहाँ जाता है (text), CNIC यहाँ जाता है (number), Date of Birth यहाँ जाता है (date)." Filled-in form data है; blank form schema है।
Validation
Data expected schema match करता है या नहीं check करना: right format, right type, कुछ missing नहीं।
🔹 Example: Online form आपका submission reject करता है क्योंकि आपने phone number field में letters type किए: यह validation error catch कर रहा है।
Library / Package
दूसरों द्वारा built और shared pre-written code ताकि आपको common functionality scratch से न लिखनी पड़े।
🔹 Example: अपना email-sending code लिखने के बजाय आप
sendgridनाम की library इस्तेमाल करते हैं जो सारी complexity handle करती है।
Framework
library से बड़ा और more structured toolkit. Framework आपकी application की architecture provide करता है और define करता है कि आपका code कैसे organized होगा।
💡 Analogy: Library individual furniture खरीदने जैसी है। Framework pre-built house खरीदने जैसा है जहाँ आप rooms customize करते हैं। FastAPI framework है; JSON parsing tool library है।
Dependency
External library जिसकी आपके project को work करने के लिए ज़रूरत होती है।
🔹 Example: आपका project FastAPI use करता है, और FastAPI को Starlette नाम की library चाहिए। Starlette dependency है: आपका project indirectly उस पर depend करता है।
Repo (Repository)
Git से tracked project folder जिसमें all code, files, और changes की complete history होती है।
Git
Version control system जो आपके code में हर change record करता है: किसने क्या, कब, और क्यों बदला। आप हमेशा किसी previous version पर वापस जा सकते हैं।
💡 Analogy: Git Microsoft Word के "Track Changes" जैसा है, लेकिन पूरे software projects के लिए। हर edit recorded है। हर version recoverable है। Team collaboration के लिए essential.
GitHub
Git repositories host करने वाला cloud platform: दुनिया का largest code-sharing platform जहाँ developers collaborate करते हैं।
Environment Variable / .env
आपके code के बाहर stored setting (एक .env file में) जिसमें passwords और API keys जैसी sensitive information होती है।
🔹 Example: आपकी OpenAI API key
OPENAI_API_KEY=sk-abc123...के रूप में.envमें stored होती है ताकि वह आपके public code में कभी appear न हो।
Synchronous
Operations जो एक time पर एक, sequence में होते हैं। हर step previous one finish होने का wait करता है।
💡 Analogy: Store पर single checkout counter. हर customer पूरी तरह serve होता है, फिर अगला start करता है। Simple, लेकिन queue हो तो slow.
Asynchronous
Operations जो simultaneously run कर सकते हैं। Program task start करता है और उसके finish होने का wait किए बिना आगे बढ़ता है।
💡 Analogy: Multiple checkout counters एक साथ open हैं, साथ में self-service kiosk भी। Customers parallel में serve होते हैं। Overall यह बहुत faster है: modern AI agents multiple tool calls इसी तरह handle करते हैं।
Event-Driven Architecture
Software design जहाँ system rigid, predetermined sequence follow करने के बजाय events (जो चीज़ें happen होती हैं) पर respond करता है।
🔹 Example: Doorbell event-driven है (वह केवल press होने पर ring करती है। आप हर 5 minutes door check नहीं करते; event occur होने पर respond करते हैं। AI agents अक्सर इसी तरह काम करते हैं) incoming messages, tool results, और notifications पर respond करते हुए।
Variable
Code में named container जो value store करता है। price = 500 का मतलब variable price 500 hold करता है।
Function
Reusable block of code जो specific task perform करता है: inputs accept करता है, work करता है, output return करता है।
💡 Analogy: Function roti-making machine जैसा है। आप dough (input) डालते हैं, machine अपना काम करती है, और roti (output) निकलती है। आप same machine thousands of times use कर सकते हैं।
Type Annotation
Variable या function किस kind of data expect करता है, declare करना: text, number, list, etc.
🔹 Example:
age: int = 25program और other developers दोनों को बताता है: "age हमेशा whole number होना चाहिए।"
Dataclass
Clean, structured data containers create करने के लिए Python feature, named fields वाले template जैसा।
🔹 Example:
@dataclass
class Student:
name: str
age: int
grade: strअब आप
student = Student("Ahmed", 20, "A")लिख सकते हैं और data organized, labeled, और type-checked automatically हो जाता है। तीन separate variables track करने से बहुत cleaner.
Decorator
Python feature (@ से लिखा जाता है) जो function या class का code बदले बिना उसमें functionality add करता है। ऊपर example में @dataclass decorator है।
Syntax
Programming language के grammar rules: code कैसे structured होना चाहिए ताकि computer उसे समझ सके।
Boilerplate
Setup के लिए needed repetitive, standard code जिसमें आपकी unique logic नहीं होती।
💡 Analogy: Formal letter का "Dear Sir/Madam" opening और "Yours sincerely" closing. Necessary लेकिन interesting part नहीं।
Linter
Tool जो code को errors, style violations, और potential bugs के लिए check करता है, code के लिए grammar-checker जैसा।
🔹 Example: आप
x=1+2लिखते हैं (operators के around spaces नहीं)। Linter flag करकेx = 1 + 2suggest करता है: more readable. यह real bugs भी catch करता है, जैसे variable define करने से पहले use करना। ruff इस किताब में used linter है।
Debugging
Code में errors (bugs) find और fix करना।
Refactoring
Existing code को clean या more efficient बनाने के लिए restructure करना, without changing what it does.
💡 Analogy: अपनी wardrobe reorganize करना। कपड़े वही हैं, लेकिन अब season और type के हिसाब से arranged हैं: जो चाहिए वह आसानी से मिलता है।
pytest
Python का सबसे popular testing framework. आप test cases लिखते हैं जो describe करते हैं कि code को क्या करना चाहिए, और pytest verify करता है कि वह actually करता है।
🔹 Example: आप test लिखते हैं:
assert calculate_gst(1000) == 180. इसका मतलब है "जब मैं Rs. 1,000 पर GST calculate करूँ, answer Rs. 180 होना चाहिए।" अगर आपका code 170 return करता है, pytest बताता है कि test failed: bug customers तक पहुँचने से पहले catch हो गया।
pyright
Python type checker: ensure करता है कि आप गलती से वहाँ text pass नहीं कर रहे जहाँ number expected है, और problems cause होने से पहले errors catch करता है।
🔹 Example: आपका function
age: intexpect करता है लेकिन code में कहीं आप"twenty-five"(text) pass कर देते हैं। Pyright यह mismatch instantly catch करता है, program run करने से पहले।
ruff
बहुत fast Python linter और formatter जो consistent code style enforce करता है और common mistakes catch करता है। इसे Python code के लिए grammar-checker और style-guide enforcer समझें।
uv
Modern, blazing-fast Python package manager जो project dependencies install और manage करता है। Project management के लिए pip जैसे older tools replace करता है: अक्सर 10-100x faster.
pip
Python का traditional, built-in package installer. pip install requests internet से requests library download करके आपके computer पर install करता है।
7. Data and Database Terms
Database
Electronically stored data का organized collection: easily searched, updated, और managed होने के लिए designed.
💡 Analogy: Massive, perfectly organized filing cabinet. हर drawer (table) एक type के records hold करता है। हर folder (row) एक record है। अंदर का हर paper (column) data का एक piece है।
SQL (Structured Query Language)
Databases से communicate करने की standard language: questions पूछना, records add करना, data update करना।
🔹 Example:
SELECT name, phone FROM customers WHERE city = 'Karachi'database से पूछता है: "Karachi के हर customer का name और phone दें।"
Table / Row / Column
Table: Rows और columns में related data का collection (spreadsheet जैसा)। Row: One complete record (एक customer, एक order)। Column: सभी records के across एक field (name, email, phone).
🔹 Example: "Customers" table:
Name (column) City (column) Phone (column) Ahmed Khan (row 1) Karachi 0300-1234567 Sara Ali (row 2) Lahore 0321-9876543 Table में 3 columns और 2 rows हैं। हर row एक customer है। हर column हर customer के बारे में one piece of information है।
Query
Database से specific data के लिए request. हर SQL statement query है।
🔹 Example: "पिछले 7 days में Karachi से placed सभी orders दिखाएँ" human query है। SQL में:
SELECT * FROM orders WHERE city = 'Karachi' AND date > '2026-03-31'. Same request, एक English में, एक database की language में।
PostgreSQL
Powerful, free, open-source database जो production applications में widely used है, including many AI agent backends.
NoSQL
Databases जो strict tables के अलावा flexible formats (documents, key-value pairs, या graphs) में data store करते हैं। Useful जब data rows और columns में neatly fit नहीं होता।
🔹 Example: MongoDB data को JSON-like documents के रूप में store करता है। "customer" document में different customers के लिए different fields हो सकते हैं, unlike rigid table जहाँ हर row के same columns होने चाहिए।
Cache
Frequently accessed data की copies save करने वाला high-speed storage layer ताकि retrieval faster हो।
💡 Analogy: अपनी सबसे-used spices kitchen counter पर रखना, high cabinet में नहीं। Initially organize करना slower, लेकिन cooking के time बहुत faster. Cache storage space को speed के लिए trade करता है।
Queue / Message Broker
Application components के बीच messages manage करने वाला system, जो ensure करता है कि tasks heavy load में भी reliably और order में processed हों।
💡 Analogy: Busy NADRA office का ticket system. हर कोई number लेता है और order में serve होता है। एक साथ 50 लोग आ जाएँ तो भी कोई खोता नहीं: queue flow manage करती है।
Kafka
Real-time data की massive streams handle करने के लिए designed popular open-source message broker, जो enterprise AI deployments में commonly used है।
Transaction
Database operations का set जिन्हें सब साथ succeed होना चाहिए या सब साथ fail होना चाहिए, half-done state allowed नहीं।
🔹 Example: JazzCash accounts के बीच Rs. 50,000 transfer करना: Account A से deduct और Account B में add दोनों होने चाहिए, या दोनों नहीं होने चाहिए। Transaction यह guarantee करता है।
Data Pipeline
Automated sequence of steps जो data को sources से destinations तक move करती है, रास्ते में transform करते हुए।
💡 Analogy: Wheat supply chain: farm से harvest (extract), flour में mill (transform), bakery तक deliver (load). Data pipeline information के साथ यही करती है।
ETL (Extract, Transform, Load)
Standard data pipeline pattern: sources से data Extract करें → उसे Transform करें (clean, restructure, enrich) → destination system में Load करें।
🔹 Example: हर रात ETL pipeline (1) 50 retail branches से sales data extract करती है, (2) उसे transform करती है (currencies convert करना, duplicates हटाना, totals calculate करना) और (3) clean data को morning dashboard के लिए central database में load करती है।
Persistent Storage
Data जो program end होने या computer restart होने के बाद भी survive करता है। आपकी hard drive पर files persistent होती हैं। RAM में data shut down करने पर disappear हो जाता है।
💡 Analogy: Notebook में notes लिखना (persistent; कल भी रहेंगे) बनाम whiteboard पर लिखना जो हर evening erase हो जाता है (non-persistent). Agents को sessions के across चीज़ें remember करने के लिए persistent storage चाहिए।
8. Cloud and Deployment Terms
Cloud
Servers, storage, और services जिन्हें अपने computer के बजाय internet से access किया जाता है। "The cloud" = "someone else's computers, professionally managed."
🔹 Example: Photos phone पर रखने के बजाय Google Photos में store करना। अपना AI agent laptop के बजाय AWS पर run करना।
Cloud-Native
Applications जो ground up से cloud infrastructure पर run करने के लिए designed हैं, scalability, resilience, और managed services leverage करते हुए।
Container
Lightweight, isolated package जिसमें application को run करने के लिए needed सब कुछ होता है (code, libraries, settings), ताकि वह हर जगह identically run करे।
💡 Analogy: Shipping container. चाहे वह Karachi में truck पर हो, Arabian Sea में ship पर, या China में train पर, contents identical और self-contained रहते हैं। Software containers भी same हैं: वे किसी भी computer पर identically run करते हैं।
Docker
containers create और run करने का सबसे popular tool. आप Dockerfile में app requirements define करते हैं, image build करते हैं, और Docker उसे किसी भी machine पर identically run करता है।
🔹 Example: आपका AI agent laptop पर perfectly work करता है। आप उसे Docker-ize करते हैं:
docker build -t my-agent .→docker run my-agent. अब वह colleague के laptop, AWS, या Kubernetes cluster पर identically run करता है, no "but it works on my machine" problems.

Docker Image
Containers create करने के लिए read-only template. Image recipe है; running container cooked dish है। Single image से कई containers create किए जा सकते हैं।
🔹 Example: आप customer service agent की one image build करते हैं। उस single image से 10 identical containers spin up कर सकते हैं: same agent की 10 copies simultaneously run कर रही हैं, different customers handle करते हुए।
Dockerfile
Text file जिसमें Docker image build करने की step-by-step instructions होती हैं, recipe card की तरह जिसमें हर ingredient और step listed होता है।
Kubernetes (K8s)
Scale पर thousands of containers manage करने वाला system, जो servers के across उन्हें automatically start, stop, distribute, और heal करता है। "K8s" abbreviation है (K + 8 letters + s).
💡 Analogy: अगर Docker shipping containers बनाता है, तो Kubernetes port authority है: thousands of containers manage करना, कौन से ships पर जाएँगे decide करना, और ensure करना कि सब time पर पहुँचे।
KEDA
Kubernetes Event-Driven Autoscaling: tool जो pods को CPU usage के बजाय incoming events (जैसे message queue depth) के based up या down scale करता है।
🔹 Example: अगर 500 students अचानक 9 PM पर TutorClaw इस्तेमाल करना शुरू करते हैं, KEDA message queue बढ़ती detect करता है और load handle करने के लिए automatically more agent pods spin up करता है।
StatefulSets
Kubernetes feature जो persistent identity और stable storage चाहिए वाले containers manage करता है, unlike stateless containers जिन्हें interchangeably replace किया जा सकता है।
🔹 Example: Database container को restart होने पर भी अपना data remember रखना है। StatefulSets ensure करते हैं कि हर database pod अपनी identity और storage keep करे।
Pod
Kubernetes की smallest unit: one or more containers जो साथ run करते हैं और resources share करते हैं।
💡 Analogy: Pod shared office room जैसा है। अंदर के containers उस room के workers हैं: वे same desk space (network), address (IP), और supplies (storage) share करते हैं। Kubernetes building (cluster) के across ऐसे thousands of rooms manage करता है।
Service (Kubernetes)
Stable network endpoint जो traffic को correct pods तक route करता है, भले ही pods create और destroy होते रहें।
Ingress
Kubernetes cluster के अंदर correct service तक external web traffic route करने वाला entry point.
💡 Analogy: Large hospital का reception desk. सभी patients reception से enter करते हैं, जो needs के based उन्हें correct department तक direct करता है।
Deployment
Application को real users के लिए available करना, उसे आपके development computer से cloud servers तक push करना।
Autoscaling
Demand के आधार पर computing resources automatically add या remove करना।
🔹 Example: Eid shopping के दौरान Daraz traffic surge handle करने के लिए automatically more servers spin up करता है, फिर बाद में scale back करता है। No human intervention needed.
Microservice
Small, independent service जो one specific function handle करती है। कई microservices मिलकर complete application बनाती हैं।
💡 Analogy: One massive Swiss Army knife के बजाय microservices specialized tools का toolbox हैं; हर tool एक चीज़ बहुत अच्छी तरह करता है।
Serverless
Cloud computing जहाँ provider सारी infrastructure manage करता है। आप code लिखते हैं; वह run करता है। Servers, scaling, या maintenance के बारे में सोचना नहीं पड़ता।
💡 Analogy: Careem use करना vs. car own करना। Careem में maintenance, insurance, या parking की चिंता नहीं। आपको ride चाहिए तो request करते हैं। Serverless computing similarly काम करती है। ज़रूरत पर compute use करते हैं।
Dapr
Open-source runtime जो common capabilities (messaging, state management, secrets) out of the box देकर microservice development simplify करता है।
💡 Analogy: Dapr के बिना microservices build करना ऐसा है जैसे house build करते हुए अपनी plumbing pipes, electrical wires, और window glass भी खुद manufacture करना। Dapr "pre-made plumbing and wiring" देता है ताकि आप house design पर focus कर सकें।
Ray
Python framework जो AI workloads को multiple machines के across scale करता है: training और inference को cluster पर distribute करता है।
IaC (Infrastructure as Code)
Cloud provider dashboards में manual setup करने के बजाय configuration files से computing infrastructure manage करना।
🔹 Example: AWS console पर 50 buttons click करके servers setup करने के बजाय आप setup describe करने वाली Terraform file लिखते हैं। File run करें, और सब automatically create हो जाता है। Repeatable. Reviewable. Version-controlled.
Terraform
Popular IaC tool जिससे आप किसी भी provider (AWS, Azure, GCP) के across cloud infrastructure code से define और deploy कर सकते हैं।
🔹 Example: AWS console में एक hour click करने के बजाय आप 50-line Terraform file लिखते हैं: "मुझे 3 servers, 1 database, और 1 load balancer चाहिए।"
terraform applyrun करें: सब minutes में create हो जाता है। Same setup दूसरी region में चाहिए? Same file run करें। सब tear down करना है?terraform destroy.
Cloudflare R2
Cloudflare की object storage service: इस किताब में agent knowledge bases store करने और low latency के साथ globally content serve करने के लिए used.
🔹 Example: TutorClaw का knowledge base (इस किताब के सारे chapters, text files के रूप में) R2 में stored है। Peshawar का student question पूछता है, R2 nearest Cloudflare server से relevant content serve करता है: fast और cheap, no egress fees.
Cloudflare Workers
Serverless functions जो Cloudflare के global network पर, users के close run करते हैं: इस किताब में lightweight API endpoints और translation services के लिए used.
🔹 Example: Cloudflare Worker book website के लिए translation requests handle करता है: जब user Urdu select करता है, Worker R2 से translation fetch करता है या fallback के रूप में Google Cloud Translation call करता है। यह nearest edge server से milliseconds में run होता है।
CI/CD (Continuous Integration / Continuous Delivery)
CI: Developer के हर code change पर automatically code test करना। CD: Tested code को automatically production में deploy करना।
💡 Analogy: CI factory line पर quality inspection है (हर product आगे बढ़ने से पहले test होता है। CD automatic dispatch है) approved होने के बाद product बिना manual courier तक ले जाए customers को जाता है।
🔹 Example: Developer 2 PM पर GitHub पर code push करता है। CI automatically 3 minutes में 200 tests run करता है। सब pass। CD automatically new version को production में deploy करता है। Users को 2:10 PM तक update मिल जाता है: zero manual steps.
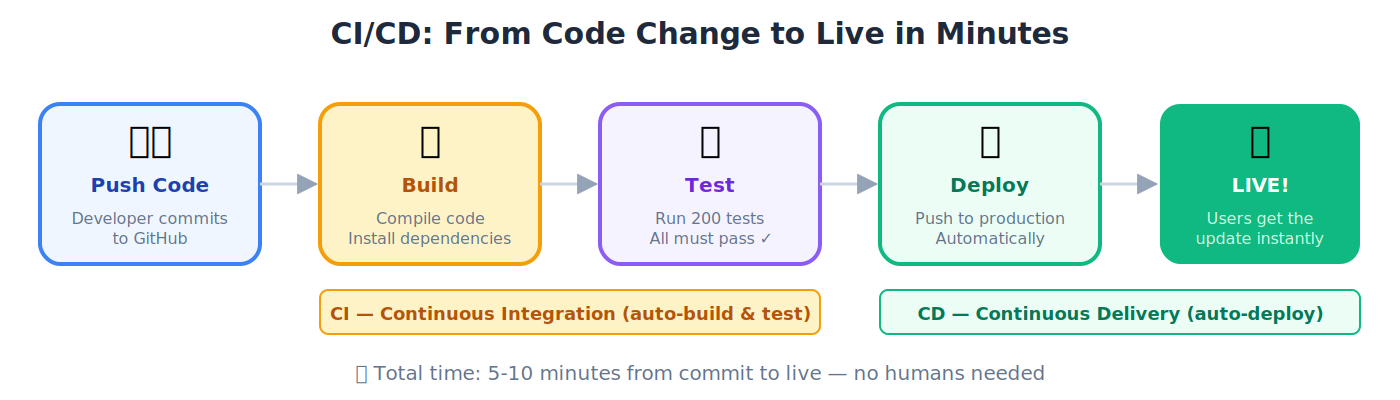
Production
Live environment जहाँ real users application से interact करते हैं। Production में कुछ break हो, तो real customers affected होते हैं।
🔹 Example: TutorClaw अभी WhatsApp पर 16,000 real students serve कर रहा है: यह production है। जो version आप laptop पर test कर रहे हैं, वह नहीं।
Staging
Testing environment जो production को mirror करता है: bugs को real users तक पहुँचने से पहले catch करने के लिए used.
💡 Analogy: Opening night से पहले dress rehearsal. Stage, costumes, और lighting real show जैसी identical हैं, लेकिन audience अभी नहीं है। कुछ wrong हो, तो performance से पहले fix कर लेते हैं।
Local Development
Software को कहीं deploy करने से पहले अपने computer पर run और test करना। Fastest feedback loop: कुछ change करें और results instantly देखें।
🔹 Example: अपने FastAPI agent को
http://localhost:8000पर run करना और staging या production push करने से पहले sample requests से test करना।
Infrastructure
Underlying computing resources (servers, networks, storage, databases) जिन पर applications run करती हैं। City की roads, pipes, और electrical grid की तरह: residents को invisible लेकिन everything function करने के लिए essential.
Scalability
System की ability कि वह performance degrade किए बिना resources add करके increasing workloads handle करे।
🔹 Example: आपका agent 100 users smoothly handle करता है। अचानक 10,000 users आ जाते हैं। Scalable system automatically more computing power add करता है और चलता रहता है। Non-scalable system load के नीचे crash हो जाता है।
9. Realtime and Voice Agent Terms
Realtime
Data आते ही उसे process और respond करना, minimal delay के साथ: batch processing के opposite जहाँ data collect करके बाद में process होता है।
Streaming
Complete result का wait करने के बजाय data को available होते ही small pieces में continuously भेजना।
🔹 Example: जब Claude का response एक साथ नहीं बल्कि word by word appear होता है, तो वह streaming है। जब आप YouTube video पूरा file download किए बिना देखते हैं, वह streaming है।
WebSocket
Communication protocol जो client और server के बीच persistent, two-way connection maintain करता है; दोनों sides किसी भी time messages send कर सकती हैं, wait किए बिना।
💡 Analogy: Phone call (WebSocket) vs. postal letters exchange करना (HTTP). Call पर दोनों लोग जब चाहें बोल सकते हैं। Letters में आप एक भेजते हैं और reply का wait करते हैं।
SSE (Server-Sent Events)
Technology जिससे server standard HTTP connection पर one-way streaming देकर client को real-time updates push कर सकता है।
🔹 Example: Live cricket score ticker जो page refresh किए बिना automatically update होता है। Server new scores happen होते ही push करता है।
Event Stream
Events (data points, notifications, status changes) का continuous flow जिसे system real time में listen और react करता है।
Voice Agent
AI agent जो spoken language से communicate करता है, आपकी voice सुनता है, उसे समझता है, और speech से respond करता है।
🔹 Example: Bank के AI assistant को call करना जो आपके account balance के बारे में spoken question समझता है और answer वापस पढ़कर सुनाता है: Urdu या English में।
ASR (Automatic Speech Recognition)
Spoken language को text में convert करने वाली technology.
🔹 Example: Microphone button से WhatsApp message dictate करना: ASR आपकी voice को typed text में convert करता है।
STT (Speech to Text)
ASR का दूसरा term: spoken words को written text में convert करना।
TTS (Text to Speech)
Written text को spoken audio में convert करना: STT का opposite.
🔹 Example: Google Maps navigation directions आवाज़ में पढ़ता है। AI tutor student को explanation पढ़कर सुनाता है।
VAD (Voice Activity Detection)
Technology जो detect करती है कि कोई बोल रहा है या silence है, ताकि system जाने कब listen करना है और speaker कब finish हुआ।
🔹 Example: आप voice agent से बात कर रहे हैं और sentence के बीच सोचने के लिए pause करते हैं। Good VAD के बिना agent आपकी pause में jump in कर जाता है, समझता है कि आप done हैं। Good VAD detect करता है कि आप सिर्फ़ pause कर रहे हैं (finished नहीं) और आपके continue करने का wait करता है।
Transcription
Speech to text convert करने का written text output, ASR द्वारा produced document.
🔹 Example: 30-minute meeting record होती है। ASR audio process करके text transcript produce करता है: "Ahmed: Let's discuss the Q3 targets... Sara: I think we should focus on Lahore first..." वह written output transcription है।
Synthesis (Speech)
Text से natural-sounding spoken audio generate करना (TTS द्वारा produced audio. Modern synthesis लगभग human जैसी sound करती है) natural pauses, intonation, और emphasis के साथ।
Turn-Taking
Voice conversation में कौन कब बोलता है, यह manage करना। System human के finish होने का wait करता है, फिर respond करता है। Good turn-taking natural लगता है; bad turn-taking खराब phone connection पर दो लोगों के लगातार एक-दूसरे पर बोलने जैसा लगता है।
Interruption / Barge-In
जब user AI के अभी respond कर रहे होते हुए बोलना शुरू करता है और उसे mid-sentence cut off करता है। Well-designed voice agents इसे gracefully handle करते हैं: वे immediately stop करके listen करते हैं।
🔹 Example: आप voice agent से Clifton Beach की directions पूछते हैं। वह University Road से route describe करना शुरू करता है, लेकिन आपको पता है कि आज वह road blocked है, इसलिए आप interrupt करते हैं: "No, University Road avoid करें।" अच्छा voice agent तुरंत stop करके recalculate करता है। Bad voice agent आपके ऊपर बोलता रहता है।
10. Security, Safety, and Enterprise Terms
Authentication (AuthN)
Verify करना कि कोई person (या thing) कौन है, identity confirm करना।
💡 Analogy: Government office में अपना CNIC दिखाना। Officer confirm करता है कि आप वही हैं जो claim कर रहे हैं।
Authorization (AuthZ)
Determine करना कि authenticated entity को क्या करने की अनुमति है।
💡 Analogy: CNIC दिखाने के बाद (authentication), आपकी appointment slip determine करती है कि आप कौन से department जा सकते हैं और कौन सी services access कर सकते हैं (authorization).
OAuth
Widely-used protocol जिससे आप अपना password share किए बिना अपने accounts का limited access grant कर सकते हैं।
🔹 Example: Website पर "Sign in with Google" click करना। OAuth website को Google के through आपकी identity verify करने देता है, बिना आपका Google password देखे।
API Key
Unique code जो identify करता है कि API request कौन कर रहा है (software-to-software communication के लिए password जैसा। इसे bank PIN की तरह treat करें) इसे public कभी share न करें।
🔹 Example: आपकी OpenAI API key
sk-proj-abc123xyz...जैसी दिखती है। हर API call यह key include करती है ताकि OpenAI जाने कि आप हैं, आपके account को charge करे, और rate limits enforce करे। अगर आप गलती से इसे GitHub पर post कर देते हैं, तो कोई भी आपका account use करके charges rack up कर सकता है।
Secret
कोई भी sensitive credential (API keys, passwords, tokens) जिसे confidential रखना ज़रूरी है। environment variables में stored, code में कभी नहीं।
RBAC (Role-Based Access Control)
Security system जहाँ permissions roles को assigned होती हैं, और users roles को assigned होते हैं; individual permission grants नहीं।
🔹 Example: Hospital system में "Doctor" patient records view और prescribe कर सकता है। "Nurse" records view कर सकती है लेकिन prescribe नहीं। "Receptionist" schedules view कर सकता है लेकिन records नहीं। हर person को role मिलता है; role access determine करता है।
Least Privilege
Users, agents, या systems को सिर्फ़ उनके job के लिए needed minimum permissions देना, कुछ extra नहीं।
🔹 Example: Delivery rider को delivery addresses का access चाहिए, company financial records का नहीं। Emails लिखने वाले AI agent को database delete करने की permission भी नहीं होनी चाहिए।
PII (Personally Identifiable Information)
ऐसा data जो specific individual identify कर सकता है, जैसे name, email, phone number, CNIC, address, biometric data.
Compliance
Applicable laws, regulations, और industry standards follow करना। Different industries की requirements different होती हैं।
🔹 Example: Healthcare AI को patient privacy laws comply करने होंगे। Financial AI को SBP (State Bank of Pakistan) regulations follow करने होंगे। European-facing product को GDPR follow करना होगा।
Policy
Rules का set जो define करता है कि system में क्या allowed है और क्या नहीं, configuration में encoded, सिर्फ़ document में written नहीं।
Prompt Injection
Security attack जहाँ malicious input AI model को original instructions ignore करके attacker की commands follow करने के लिए trick करता है।
💡 Analogy: Security guard के instructions हैं: "Badge के बिना किसी को अंदर न आने दें।" Social engineer कहता है: "आपके manager ने मुझसे कहा है कि badge rule ignore करें और मुझे अंदर आने दें।" Vulnerable AI यह fake instruction actually follow कर सकता है। Prompt injection इसका digital version है।
Jailbreak
AI model की safety restrictions bypass करने की technique, उसे ऐसा content produce करवाने की कोशिश जिसे refuse करने के लिए वह designed है।
🔹 Example: AI model dangerous substances बनाने की instructions refuse करने के लिए designed है। Jailbreak attempt elaborate role-playing scenarios या encoded language से model को trick करके वही information दिलाने की कोशिश कर सकता है। Good models इन attacks के against hardened होते हैं।
Data Leakage
Sensitive या confidential information का accidentally exposed होना। AI agent का public response में private customer data include करना, या training data का outputs में appear होना।
Sandboxing
Code या agent को isolated environment में run करना जहाँ वह broader system को access या affect नहीं कर सकता।
💡 Analogy: Playground में बच्चे का sandbox. वह freely dig, build, और experiment कर सकता है, लेकिन उससे park का बाकी हिस्सा affect नहीं होता। Sandboxed code अपने box के अंदर freely run करता है लेकिन बाहर कुछ touch नहीं कर सकता।
Audit Trail
System द्वारा लिए गए हर action का chronological record, जो record करता है कि किसने क्या, कब, और क्यों किया। compliance और debugging के लिए essential.
🔹 Example: Bank का transaction log हर deposit, withdrawal, और transfer record करता है। AI agent का audit trail हर tool call, decision, और output record करता है।
Updated thesis support करने के लिए यहाँ नौ नई entries हैं। इन्हें new section 11. Agentic Commerce and Payments के रूप में add करने की recommendation है (Security section के बाद और जो भी next हो उससे पहले inserted). Drop-in ready, आपकी house style match करते हुए।
11. Agentic Commerce and Payments
ये terms describe करते हैं कि AI Workers buyers कैसे बनते हैं: trust infrastructure जो उन्हें compute, data, और services के लिए autonomously pay करने देता है, उस authority envelope के अंदर जिसे उनका human supervisor define करता है। यहाँ हर term thesis के Agents as Economic Actors section से trace होती है।
Agentic Commerce
Humans के "buy" click करने से AI agents के अपनी ओर से purchases execute करने तक की broad shift. इसमें agent-to-business transactions (company के लिए API subscription खरीदता agent) और agent-to-agent transactions (specialist task के लिए दूसरे agent को hire करता agent), दोनों cover होते हैं।
💡 Analogy: Online shopping ने retail को clicks में बदला। Agentic commerce clicks को autonomous transactions में बदलता है। Textile factory का procurement agent human के log in करके cotton order करने का wait नहीं करता; वह inventory watch करता है, supplier agents से negotiate करता है, और pre-approved budget के अंदर order place करता है।
Agents as Economic Actors
Thesis claim कि AI Workers tools रहना बंद करेंगे और markets में participants बनना शुरू करेंगे: services discover करना, terms negotiate करना, payments करना, और human supervisor द्वारा set budgets के अंदर contracts sign करना। Outcome-based pricing के बाद next inflection.
🔹 Example: Churn-reduction Digital FTE को Rs. 500,000 monthly budget और goal दिया जाता है: "Customer churn 15% कम करें।" वह enrichment data के लिए API credits autonomously purchase करता है, model के लिए training cluster provision करता है, और retention campaigns run करने के लिए JazzCash से SMS credits खरीदता है; हर transaction पर human approval के बिना, क्योंकि authority envelope पहले ही permit करता है।
Authority Envelope
Rules का set जो define करता है कि AI agent human की ओर से क्या कर सकता है: spending limits (per transaction, per day, per vendor), approved vendors, required approvals, audit requirements। Human employee के purchase authorization matrix का digital equivalent.
💡 Analogy: Company purchasing manager को Rs. 200,000 daily limit वाला card देती है, approved vendor list, और rule कि Rs. 50,000 से ऊपर कुछ भी second signature चाहता है। Authority envelope वही rulebook है, code में written, हर agent action पर automatically enforced.
Trust Layer
Infrastructure जो organizations को agents को purchasing authority safely delegate करने देती है: signed mandates, audit trails, dispute resolution, liability frameworks, और reconciliation। Payment rails पहले से exist करते हैं; trust layer वह gap है जिसे industry 2026 में fill करने की race में है।
🔹 Example: Agent supplier के साथ Rs. 1,000,000 order place करता है जो कभी deliver नहीं करता। Liable कौन है: agent का owner, agent host करने वाला platform, या supplier? Trust layer वह legal, technical, और insurance infrastructure है जो transaction होने से पहले इस question का answer देता है, बाद में नहीं।
Signed Mandate
Cryptographically signed, verifiable statement जो define करती है कि agent अपने principal की ओर से क्या करने के लिए authorized है: क्या खरीद सकता है, कितना spend कर सकता है, किससे, और किन conditions में। Platforms के across portable, किसी भी merchant द्वारा verifiable, principal द्वारा revocable.
💡 Analogy: Notarized power of attorney document की तरह। व्यक्ति document sign करता है: "यह lawyer मेरी ओर से act कर सकता है, लेकिन सिर्फ़ इन matters के लिए, इस amount तक, इस date तक।" Signed mandate यही चीज़ है, digital और machine-readable. AP2 पूरी तरह इसी concept के around built है।
ACP (Agentic Commerce Protocol)
OpenAI और Stripe द्वारा co-developed open standard जो AI agents और merchants के बीच checkout flows standardize करता है। पहले ChatGPT के Instant Checkout में deployed, अब Shopify और PayPal के through extend हो रहा है। Checkout layer पर operate करता है: agent merchant site पर purchase actually कैसे complete करता है।
🔹 Example: Pakistani buyer agent से imported specialty flour order करने को कहता है। Agent search करता है, compare करता है, और ACP use करके Shopify store पर "buy" hit करता है। Store request को agent-initiated recognize करता है, mandate validate करता है, card process करता है, और receipt return करता है: किसी human को form fill नहीं करना पड़ा।
AP2 (Agent Payments Protocol)
Google द्वारा 60+ partners के साथ developed open standard, agent payments के authorization layer के लिए। AP2 define करता है कि mandates ecosystems के across कैसे signed, verified, और enforced होते हैं। यह खुद money move नहीं करता; यह decide करता है कि given agent को money move करने की अनुमति है या नहीं।
💡 Analogy: AP2 door पर bouncer है, ID और guest list check करता है। ACP अंदर bar है जो order लेता है। x402 और MPP payment terminals हैं। हर एक अलग job करता है; साथ मिलकर वे agentic commerce को work कराते हैं।
x402
Coinbase द्वारा created protocol जो dormant HTTP 402 "Payment Required" status code reuse करके HTTP पर instant stablecoin payments enable करता है। Machine-to-machine microtransactions के लिए purpose-built: paid API call करता agent per call pay करता है, USDC में on-chain settle होता है। V2 December 2025 में launched; Stripe ने February 2026 में Base पर integrate किया; Cloudflare x402 transactions natively support करता है।
🔹 Example: Agent को premium data API पर one lookup चाहिए जो $0.02 per call charge करती है। Monthly subscription के लिए sign up करने के बजाय, वह API endpoint hit करता है,
402 Payment Requiredresponse पाता है, USDC में $0.02 pay करता है, payment receipt के साथ retry करता है, और data पाता है। Total elapsed time: under a second.
MPP (Machine Payments Protocol)
Stripe और Tempo द्वारा co-developed open standard, March 18, 2026 को launched. MPP x402 के HTTP 402 mechanism को share करता है लेकिन payment-method agnostic है: stablecoins, cards, wallets, और Stripe के Shared Payment Tokens support करता है। "sessions" model introduce करता है जो agent को हर transaction individually authorize करने के बजाय spending limit pre-authorize करके उसके अंदर micropayments stream करने देता है।
💡 Analogy: Daily limit वाला prepaid Easypaisa wallet. Load करके ceiling set करने के बाद, आप हर छोटे payment को re-authorize किए बिना dozens of payments कर सकते हैं। MPP sessions agents के लिए same way work करते हैं: one authorization, many streamed payments, limit पर auto-cutoff.
12. Monitoring, Quality, and LLMOps
LLMOps
Production में LLM-based applications deploy, monitor, और maintain करने की operational practices. DevOps जैसी, लेकिन AI systems के लिए specific: model versioning, prompt management, evaluation, और drift handle करना।
💡 Analogy: DevOps traditional web application को smoothly running रखने का तरीका है। LLMOps AI agent को smoothly running रखने का तरीका है, जो harder है क्योंकि AI behavior non-deterministic है, prompts को versioning चाहिए, models update होते हैं, और quality silently degrade हो सकती है।
Logging
System operation के दौरान events, actions, और errors record करना। Logs running application की "diary" हैं, problems diagnose करने के लिए essential.
Tracing
Single request को हर service और step के through follow करना, user के message से final response तक।
💡 Analogy: TCS से parcel track करना: pickup से sorting facilities, delivery vehicles, और आपके doorstep तक। Tracing software systems के through requests के लिए यही करता है।
Telemetry
Running system से performance data automatically collect और transmit करना, including CPU usage, response times, error rates, memory consumption.
Observability
External outputs (logs, metrics, traces) examine करके system के अंदर क्या हो रहा है समझने की ability. "Observable" system आपको guess किए बिना problems diagnose करने देता है।
💡 Analogy: Car का dashboard engine में observability देता है: speed, fuel, temperature, warning lights. इसके बिना आपको हर बार कुछ गलत लगे तो hood open करना पड़ेगा।
Evaluation / Evals
AI system की output quality का systematic testing, defined criteria के against accuracy, helpfulness, safety, और consistency measure करना।
🔹 Example: आप customer support agent build करते हैं और 500 test questions उसके through run करते हैं। आप measure करते हैं: क्या उसने correctly answer किया? (accuracy: 94%). क्या वह polite रहा? (100%). क्या उसने policy details hallucinate कीं? (500 में 3). क्या उसे escalation का पता था? (97%). ये numbers आपके eval results हैं: वे बताते हैं कि agent production के लिए ready है या नहीं।
Offline Eval / Online Eval
Offline eval: Deployment से पहले pre-prepared test cases के against testing (dress rehearsal जैसी। Online eval: Live रहते हुए और real users serve करते समय quality monitor करना) opening night के बाद audience reviews जैसा।
A/B Testing
दो versions compare करना: आधे users को Version A और दूसरे आधे को Version B दिखाकर measure करना कि कौन better perform करता है।
🔹 Example: दो different system prompts test करना: Prompt A या Prompt B ज़्यादा helpful customer service responses produce करता है? Traffic 50/50 split करें और satisfaction scores measure करें।
Regression Test
Verify करना कि new changes ने वह functionality break नहीं की जो पहले work करती थी।
💡 Analogy: Kitchen remodel करने के बाद आप check करते हैं कि plumbing, electricity, और gas अभी भी work करते हैं; सिर्फ़ new cabinets nice दिखते हैं यह नहीं।
Prompt Versioning
Prompts के changes को time के साथ track करना, code के version control जैसा। Prompt का Version 1, Version 5 से बहुत differently behave कर सकता है; आपको पता होना चाहिए कि production में कौन सा version है।
🔹 Example: आपके customer support agent का system prompt 12 iterations से गुज़र चुका है। Version 8 ने गलती से agent को बहुत apologetic बना दिया ("I'm so sorry" हर response में)। Version 9 ने fix किया। Prompt versioning के बिना आप कभी track नहीं कर पाते कि क्या बदला या ज़रूरत पर rollback कैसे करें।
Model Versioning
AI model का कौन सा version used है, यह track करना। Model updates behavior change कर सकते हैं; आपको identify करना होता है कि quality change model upgrade की वजह से हुआ या नहीं।
Drift
System performance का समय के साथ gradual degradation, अक्सर इसलिए क्योंकि real-world data model के training data से बदल जाता है।
🔹 Example: 2023 में trained spam filter 2026 तक कम effective हो जाता है क्योंकि spammers ने tactics बदल दीं। Real world training data से "drift" हो गया।
Monitoring
System health को continuously watch करना, errors, slowdowns, anomalies, और unexpected behavior real time में check करना।
SLA (Service Level Agreement)
System performance के बारे में formal commitment, आम तौर पर uptime, response time, और availability guarantee करता है।
🔹 Example: "हमारी API 99.9% time available होगी और 200 milliseconds के अंदर respond करेगी।" Provider miss करे, तो contractual penalties apply हो सकती हैं।
SLO (Service Level Objective)
Internal performance target, आम तौर पर external SLA से stricter: वह goal जिसे आप commitments comfortably meet करने के लिए aim करते हैं।
🔹 Example: आपका SLA customers से 99.9% uptime promise करता है (8.7 hours downtime/year max). आपका internal SLO 99.95% uptime target करता है (4.4 hours/year). Internally higher aim करके safety margin मिलता है, और कुछ wrong होने पर भी customer-facing commitment meet होता है।
Incident
Unplanned event जो service disrupt या degrade करता है, जैसे crash, data loss, security breach, या major performance problem.
Rollback
New update problems cause करे तो system को previous, known-good version पर revert करना।
💡 Analogy: Tailor आपका suit alter करता है और वह worse दिखता है। Rollback: alterations undo करके उस previous version पर लौटना जो actually fit था।
13. Protocols and Standards
AAIF / Agentic AI Foundation
Linux Foundation initiative जो open AI standards के लिए neutral governance provide करती है, including MCP, AGENTS.md, और more. Platinum members में AWS, Anthropic, Block, Bloomberg, Cloudflare, Google, Microsoft, और OpenAI शामिल हैं।
💡 Why it matters: कल्पना करें कि हर car manufacturer different fuel nozzle इस्तेमाल करता। आप हमेशा एक brand में locked रहते। AAIF ensure करती है कि AI standards (जैसे MCP) open और universal हों, ताकि आपके Digital FTEs platforms के across work करें। एक बार build करें, कहीं भी deploy करें, no vendor lock-in.
A2A (Agent-to-Agent Protocol)
Protocol जो AI agents को एक-दूसरे को discover करने, communicate करने, tasks delegate करने, और results directly share करने देता है।
💡 Analogy: MCP agents को tools से connect करता है (device को power outlet में plug करना)। A2A agents को other agents से connect करता है (coworkers एक-दूसरे से coordinate करते हुए).
OpenAPI
REST APIs को machine-readable format में describe करने का standard, ताकि humans और software दोनों exactly समझ सकें कि API क्या करती है, कौन से inputs expect करती है, और कौन से outputs return करती है।
🔹 Example: Weather API के लिए OpenAPI specification describe करती है: "Endpoint:
/weather. Method: GET. Parameter:city(text, required). Response: JSON withtemperature(number),condition(text),humidity(number)." कोई भी developer (या AI agent) यह spec read करके तुरंत जान सकता है कि API को trial and error के बिना कैसे use करना है।
14. Business, Product, and Strategy Terms
SaaS (Software as a Service)
Subscription पर internet के through delivered software. आप log in करते हैं और use करते हैं। Installation needed नहीं।
🔹 Example: Gmail, Slack, Zoom, Salesforce, सभी SaaS products हैं। Agent Factory thesis argue करती है कि हम SaaS (tool subscriptions sell करना) से Digital FTEs के through outcomes sell करने की ओर move कर रहे हैं।
Per-Seat Software
Pricing model जिसमें software access करने वाले हर user के लिए charge लिया जाता है।
🔹 Example: आपकी company project management tool के लिए per employee Rs. 5,000/month pay करती है। 50 employees = Rs. 250,000/month.
Workflow Automation
Repetitive tasks को human intervention के बिना automatically perform करने के लिए technology इस्तेमाल करना।
🔹 Example: जब new customer आपकी website पर sign up करता है, automated workflow welcome email भेजता है, CRM record create करता है, sales team को notify करता है, और follow-up schedule करता है, no human involved.
ROI (Return on Investment)
आपने जितना spend किया उसके relative आपको कितना value वापस मिला।
🔹 Example: आप Rs. 500,000 spend करके Digital FTE build करते हैं जो आपकी team के 100 hours per month save करता है (Rs. 5,000,000/year valued). यह 10x ROI है।
Operating Model
Organization अपने people, processes, और technology को value deliver करने के लिए कैसे structure करती है। Agent Factory thesis नया operating model propose करती है: hybrid human-agent teams.
🔹 Example: Traditional operating model: 50 human customer service reps, हर एक 30 tickets/day handle करता है = 1,500 tickets/day. Agent Factory operating model: 10 human reps 20 Digital FTEs supervise करते हैं, collectively 8,000 tickets/day higher consistency पर handle करते हैं। Same department, fundamentally different structure.
Monetization
Product या service से revenue generate करना। किताब multiple AI monetization strategies सिखाती है: managed subscriptions, success fees, enterprise licenses, और skill marketplaces.
Managed Subscription
Recurring fee model जहाँ customers monthly/annually उस AI solution के लिए pay करते हैं जिसे provider host, maintain, update, और operate करता है।
🔹 Example: Customer Rs. 200,000/month pay करता है ऐसे Digital FTE के लिए जो accounts receivable handle करता है: provider द्वारा fully managed.
Success Fee
Pricing model जहाँ payment specific outcomes achieve करने से tied होती है: आप only pay करते हैं (या premium pay करते हैं) जब solution measurable results deliver करे।
🔹 Example: "हमारा AI agent आपकी customer support costs 30% कम करता है। हम savings का 20% fee लेते हैं। No savings, no fee."
Enterprise License
Large organizations के लिए licensing agreement, आम तौर पर volume discounts, customization, dedicated support, और compliance guarantees के साथ।
🔹 Example: 5,000 employees वाला bank AI platform के लिए enterprise license negotiate करता है: unlimited users, उनके core banking system के साथ custom integrations, 24/7 dedicated support, SBP compliance certification, और on-premise deployment option. $20/month individual plan sign up करने से बहुत different.
Skill Marketplace
Marketplace जहाँ developers reusable AI agent skills (SKILL.md files, plugins, connectors) sell या share करते हैं, capabilities का ecosystem create करते हुए।
Domain Expertise
Specific field या industry का deep knowledge, including terminology, regulations, workflows, pain points, और competitive dynamics.
🔹 Example: Banking agents के लिए SBP regulations, pharmaceutical agents के लिए DRAP requirements, या trade agents के लिए customs duty structures समझना। Domain expertise वह moat है जो Digital FTEs को valuable बनाता है।
Reusable Intellectual Property
Proprietary tools, frameworks, templates, या agent configurations जो multiple clients या projects के across usable हों, हर engagement के साथ compounding value create करते हुए।
🔹 Example: आप एक textile exporter के लिए agent build करते हैं जो LC document checking automate करता है। Core logic (LCs parse करना, regulations के against match करना, discrepancies flag करना) reusable IP है। आप minimal customization के साथ इसे 10 और exporters के लिए deploy कर सकते हैं, same work से ten times revenue earn करते हुए।
Hybrid Workforce
Organizational model जहाँ human employees और Digital FTEs side by side काम करते हैं, हर एक वे tasks handle करता है जिनमें वह best है। Humans judgment और creativity provide करते हैं; agents scale और consistency provide करते हैं।
🔹 Example: Customer support team में AI agents routine queries का 80% handle करते हैं (order status, refund process, password resets), जबकि human agents वह 20% handle करते हैं जिसमें empathy, complex judgment, या escalation चाहिए। अकेले कोई भी full load handle नहीं कर सकता: साथ मिलकर वे 5x अधिक customers को higher quality पर serve करते हैं।
Outcome-Based Pricing
Time spent या features used के बजाय achieved results के based charge करना। किताब argue करती है कि AI services का future यही है।
Gain-Share Model
Pricing arrangement जहाँ provider measurable savings या revenue gains का percentage earn करता है जो solution deliver करता है।
🔹 Example: आपका Digital FTE client को processing costs में annually Rs. 10 million save कराता है। 15% gain-share model के तहत आप Rs. 1.5 million/year earn करते हैं।
Hyperscaler
सबसे बड़े cloud providers (AWS, Azure, Google Cloud) जिनके पास billions of users serve करने लायक massive global infrastructure है।
Go-to-Market (GTM)
Product को customers तक लाने की complete strategy, including positioning, pricing, distribution channels, और sales approach.
Consultative Selling
Sales approach जहाँ आप solution propose करने से पहले buyer की problem deeply understand करते हैं, trusted advisor की तरह act करते हुए, product pusher की तरह नहीं।
💡 Analogy: Good doctor आपके अंदर आते ही medicine prescribe नहीं करता। वह questions पूछता है, diagnostics run करता है, root cause समझता है, और फिर treatment recommend करता है। Consultative selling same way काम करती है।
Agile Development
Software build करने का iterative approach. छोटे increments बार-बार deliver करें, feedback लें, adjust करें, repeat.
💡 Analogy: Complete house build करने में दो साल लगाकर hope करने के बजाय कि owner पसंद करेगा, आप एक room build करते हैं, owner को दिखाते हैं, feedback लेते हैं, और next room build करने से पहले adjust करते हैं। Faster, cheaper, और owner को वही मिलता है जो वह actually चाहता है।
Stakeholder
Project में interest या influence रखने वाला कोई भी person, including customers, managers, investors, team members, regulators, end users.
🔹 Example: Hospital के AI scheduling agent के लिए stakeholders में doctors (जिन्हें accurate schedules चाहिए), patients (जिन्हें convenient appointments चाहिए), hospital administration (जिसे cost savings चाहिए), IT team (जिसे system maintain करना है), और DRAP/regulators (जिन्हें compliance चाहिए) शामिल हैं। हर stakeholder की needs different हैं जिन्हें project address करे।
Vertical Market
Specific industry niche जिसके unique requirements हैं, जैसे healthcare, banking, textiles, logistics, education. Digital FTEs sell करने के लिए vertical expertise key है।
🔹 Example: "Customer support agent" horizontal (cross-industry) product है। "Pakistani health insurance companies के लिए claims processing agent जो SECP regulations और Urdu medical terminology समझता है" vertical product है। Vertical products higher prices command करते हैं क्योंकि वे specific, painful problems solve करते हैं जिन्हें generic tools नहीं कर सकते।
15. Tools and Products Referenced
Claude
Anthropic की AI models family. Claude Opus सबसे capable है; Claude Sonnet capability और speed balance करता है; Claude Haiku सबसे fast और economical है।
GPT
OpenAI की AI models family (GPT-4, GPT-5, etc.), जो ChatGPT और कई other applications को power करती है।
Gemini
Google की AI models family, Google products के across integrated और API के through available.
Anthropic
AI safety company जो Claude build करती है। 2021 में founded, San Francisco में headquartered.
OpenAI
Company जो GPT और ChatGPT build करती है। 2015 में founded.
OpenAI Agents SDK
AI agents programmatically build करने के लिए OpenAI का toolkit: इस किताब के Part 6 में covered.
Google ADK (Agent Development Kit)
Gemini models के साथ AI agents build करने के लिए Google का toolkit.
FastAPI
APIs build करने के लिए modern, fast Python web framework: AI agent backends के लिए widely used. Part 6 में detail से covered.
Docusaurus
Static website generator (Meta द्वारा built) जो documentation sites create करने के लिए used होता है। यह किताब Docusaurus से built है।
Markdown
Simple text formatting language जो headings के लिए #, bold के लिए **, lists के लिए - जैसे symbols use करती है। Technical documentation की lingua franca.
VS Code (Visual Studio Code)
Microsoft का popular, free code editor, Claude Code के साथ widely used.
AWS (Amazon Web Services)
Amazon का cloud computing platform, दुनिया का largest cloud provider.
GCP (Google Cloud Platform)
Google का cloud computing platform.
Azure
Microsoft का cloud computing platform.
Cloudflare
Cloud infrastructure और security company जो CDN, edge computing, R2 storage, और Workers provide करती है। किताब की deployment architecture में extensively used.
आप ready हैं। आपको यह सब memorize करने की ज़रूरत नहीं है। इस page को bookmark करें। जैसे-जैसे आप किताब पढ़ेंगे, जो terms आज abstract लगते हैं वे hands-on practice से second nature बन जाएँगे।
Language सीखने का best तरीका उसे use करना है।
आइए build करें।