What AI Actually Is: A Crash Course
9 Ideas, No Math, No Code: the one thing the other five courses assume you already understand.
You can drive a car without knowing what an engine is. Most people do. But the moment something goes wrong (a noise, a warning light, a stall on a hill) the people who know roughly what is under the hood stay calm, and the people who don't, panic. They cannot tell a harmless rattle from a seized engine, because to them the whole machine is one opaque box that either works or doesn't.
That is most people's relationship with AI. They have learned to drive it (the other five Foundations courses make you a genuinely good driver) but they have never looked under the hood even once. So when the machine does something strange (invents a source, contradicts itself, sounds completely certain about something completely wrong), they have no model for why, and they either over-trust it or write it off. Both reactions come from the same place: not knowing what the thing actually is.
This course is one look under the hood. Not the mechanic's view: there is no math here, no code, no neural-network diagrams you have to decode. Just the nine ideas that explain almost every surprising thing AI does, so that the failures stop being mysteries and start being predictable. Once you can predict the failures, you can avoid them, and that is the entire payoff.
Reading time: 35–40 minutes for the nine ideas, about 25 for the closing exercises, and 10–15 for the optional Claude.ai appendix at the end.
Of the six Foundations courses, this is the one to read before the others, even though it is the most abstract. AI Prompting in 2026, Markdown In, HTML Out, Code You Never Write, Skills & Connectors, and How to Think in the AI Era all teach you how to use the machine. They each lean on facts about what the machine is ("it's stateless," "it predicts, it doesn't look up," "it's confident even when wrong") and state those facts in a sentence each, in passing. This course is where those sentences come from. Read it once, and every "why does it do that?" in the other five courses already has an answer waiting.
A few topics appear in both this course and AI Prompting in 2026, by design, not by repetition. This course gives the mechanism (one explanation, then it moves on); the prompting course gives the practice (the habits, in depth). Where the two touch:
| Topic | Here (the machine) | AI Prompting in 2026 (the habit) |
|---|---|---|
| What it knows | Why the learning froze, and why on purpose (Idea 2) | How reliable that knowledge is, topic by topic (Concept 2) |
| Context window | Why it's the only thing the model sees (Idea 5) | How to manage and protect it (Concept 4) |
| Chat history | Why the transcript is replayed into context each turn (Idea 5) | How to run long work without rot: fresh chats, summaries (Concept 4) |
| Confidence | Why it sounds sure and agrees with you (Idea 6) | How to neutralize that (Concept 6) |
| Reasoning | What "thinking" actually is (Idea 9) | When to switch it on, and when not to (Concept 5) |
| Images & audio | Why they're just more tokens (Idea 4) | How to actually work with them (Concept 8) |
The rule of thumb: the moment a section here is about to teach you a habit, it stops and points you to the prompting course instead. That handoff is the line between the two.
The questions this course answers
Every idea in this course exists to answer a question a student actually asks. The full list is below, in course order. Use it three ways. Before teaching, ask a few aloud and let students attempt answers: their guesses show you exactly which wrong mental models are in the room. During class, each question is a discussion starter for its idea. After the course, ask them again: a student who has understood the course can answer every one in two or three sentences, in their own words. The column on the right says where the answer lives.
Part 1: The machine
| # | Question | Answered in |
|---|---|---|
| 1 | What is a language model actually doing when it answers? Does it look facts up? | Idea 1 |
| 2 | LLMs are called stochastic. What does that mean, and why does the same question give a different answer each time? | Idea 1 |
| 3 | How are LLMs built, and where does the training data come from? | Idea 2 |
| 4 | What is a knowledge cutoff date? | Idea 2 |
| 5 | If the machine only continues text, why does it answer your question instead of continuing it with more questions? | Idea 2 |
| 6 | LLMs are called stateless. What does that mean? | Idea 2 |
| 7 | Why are LLMs built stateless? Why can't the model just learn from me as we talk? | Idea 2 |
| 8 | What is hallucination, and why do LLMs do it? | Idea 3 |
Part 2: Why it behaves the way it does
| # | Question | Answered in |
|---|---|---|
| 9 | What are tokens, how are they used, and what do they measure? | Idea 4 |
| 10 | What is the context window, and what does it mean if a product says it has a one-million-token context window? | Ideas 4–5 |
| 11 | What is a system prompt? | Idea 5 |
| 12 | What is chat history? How is it built, where is it stored, and how is it used? | Idea 5 |
| 13 | What is the relationship between the context window and chat history? | Idea 5 |
| 14 | What are agent Skills, and what is their relationship with the context window? | Idea 5 |
| 15 | Why does AI sound confident even when it is wrong, and why does it tend to agree with you? | Idea 6 |
| 16 | Why is AI brilliant at one task and useless at an easier-looking one right next to it? | Idea 7 |
Part 3: From predictor to agent
| # | Question | Answered in |
|---|---|---|
| 17 | What turns a text predictor into an agent? | Idea 8 |
| 18 | What are connectors, and what is their relationship with MCP (Model Context Protocol)? | Idea 8 |
| 19 | What is a reasoning model actually doing when it "thinks"? | Idea 9 |
The optional Claude.ai appendix answers the product-level versions of these: which model to pick, when to use account instructions versus projects versus memory, and when to use web search versus Research.
📚 Teaching Aid
View Full Presentation: What AI Actually Is
Prove it in two minutes
Before any explanation, watch the machine behave in a way that only makes sense once you know what it is. Open Claude.ai, ChatGPT, or Gemini (a free account takes a minute) and paste exactly this, with the deliberate misspelling:
Without using any tools, just from memory: how many times does the
letter R apear in the word "strawberry"? Then spell the word out
one letter at a time and count again.
Watch what can happen: on the first pass some models still miscount, then get it right the moment they spell it out letter by letter. A machine that can write you a working program cannot reliably count letters in a ten-letter word, until you force it to break the word apart. That is not stupidity. It is a direct, visible consequence of the single most important fact in this course: the model does not see letters. It sees tokens (Idea 4). The word arrives already chopped into chunks, and counting the letters inside a chunk is genuinely hard for it, the way counting the rooms in a building is hard if someone only ever showed you the building's street address.
And notice the second, quieter lesson hiding in the same prompt: the misspelled "apear" changed nothing. The model understood your question perfectly. Both behaviors, flubbing an exact letter count and shrugging off a typo, come from the same fact. A typo lands on chunks close enough to the intended meaning to be understood; an exact count requires seeing inside the chunks, which the model cannot do. Idea 4 explains both.
Two minutes, one strange behavior, and you have already met the theme of the whole page: almost every surprising thing AI does is explained by what it actually is, not by it being smart or dumb. The nine ideas below turn that one example into a complete model.
One honest caveat before you run it. The strawberry test is famous, and by now a model may have effectively memorized this exact question. If yours answers instantly and correctly, that proves familiarity, not letter-level skill. Invent your own random string instead ("how many times does the letter r appear in braverrikromarent?") and the effect usually returns, because a string nobody ever wrote about cannot be memorized.
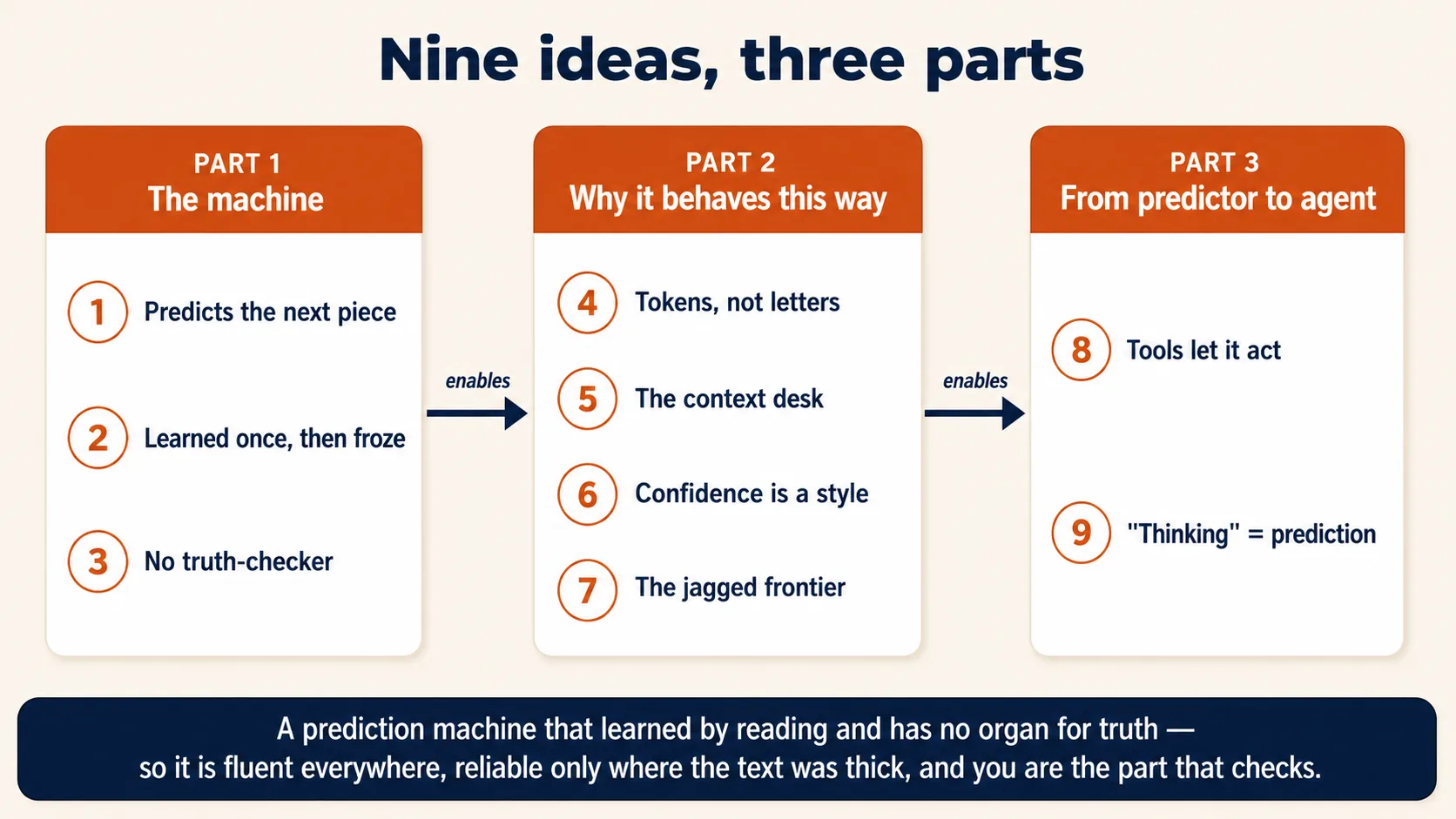
Part 1: The machine
Three ideas about what is literally happening when you press send. Get these and two-thirds of AI's behavior stops being surprising.
1. It predicts the next piece of text; it does not look things up
Here is the single sentence this whole course is built to make true in your head: a language model is a machine that, given some text, predicts what text most plausibly comes next, one small piece at a time. That is the entire core mechanism. Everything else is a consequence.
It is worth sitting with how strange that is, because it is nothing like what most people assume. Most people assume AI works like a very fast librarian: you ask a question, it finds the relevant fact in some vast internal encyclopedia, and reads it back to you. That mental model is wrong, and almost every mistake people make with AI traces back to it.
What actually happens is closer to the world's most well-read autocomplete. You have seen autocomplete finish "Happy birthday to..." with "you." A language model does the same move, but trained on so much text that it can continue any prompt, not just common phrases. It continues not one word but one token at a time (Idea 4). Each piece it produces is fed back into itself to decide the next piece. Ask it the capital of France and it does not look up a database row labelled France → Paris. It produces the continuation that, across everything it read, most plausibly follows "The capital of France is", and that happens to be "Paris," because that sequence appeared a million times in its training text.
For well-worn facts, prediction and lookup give the same answer, so the difference seems academic. It stops being academic the moment the text thins out:

- Ask for the capital of France → the plausible continuation is the true one. Prediction looks like knowledge.
- Ask for the plot of a self-published novel that sold a few hundred copies and was never reviewed online → there is no well-worn continuation, so the model produces the most plausible-sounding one by blending books that sound similar. It is still predicting. It just has nothing true to predict toward.
The machine is doing the exact same thing in both cases. Only you can tell the difference, and only if you know what it is doing.
Stop picturing a librarian who retrieves. Start picturing a writer who continues. A librarian who can't find a book says "we don't have that." A writer asked to continue a story never stops to check whether the continuation is true. Continuing is the whole job. That is why AI never says "I don't have that" the way the librarian would, unless it was specifically trained to. Plausible continuation is its native act; truth is something layered on top, imperfectly.
Why the same question gives a different answer each time (the word for this is "stochastic")
The machine does not predict one next token. It predicts a whole spread of plausible next tokens, each with a likelihood ("Paris" very likely, "the largest city in France" possible, a dozen others trailing off) and then picks one from that spread. Engineers call this property stochastic: the output is sampled from a spread of possibilities, not computed as one fixed answer, so the identical input can produce a different output each time. When you hear someone say "LLMs are stochastic," this is all they mean: the machine rolls weighted dice at every token.
How boldly it picks is controlled by a setting usually called temperature. Low temperature makes it almost always take the single most likely token: steady, repetitive. High temperature lets it reach for less likely ones: varied, more creative, occasionally off. Most chat products set a middle value, which is why asking the identical question twice gives you two differently-worded answers that mean roughly the same thing. The variation is not the model "changing its mind." It is the same spread of predictions, sampled twice. (This is also why, for a task where you want the exact same output every time, you sometimes can't get it from a chat interface: the dice are baked in.)
This is the mechanical root of the "frequency equals reliability" rule from AI Prompting in 2026 (Concept 2). Now you know why frequency equals reliability: the more often a true continuation appeared in the training text, the more strongly the machine predicts it. Sparse topic, weak prediction, confident-sounding guess.
The product can; the model still doesn't. Modern tools wrap the predictor in extras, web search, file reading, code execution, even a memory note (Idea 2), and those extras can fetch real, current facts. But the facts arrive by landing in the context window (Idea 5), and the model still turns them into an answer the only way it can: by predicting a continuation from them. So "it predicts, it doesn't look up" stays true of the machine in the middle, even when the system around it has just looked something up for it. Idea 8 is where the tools come in properly.
2. It learned by reading, and then the learning stopped
Where did the predictions come from? From training: the model was shown an enormous quantity of human text and adjusted itself, over and over, to get better at predicting the next piece of that text. That adjustment process is the only time the model ever "learns" anything. When training ends, the result is frozen into a fixed set of internal numbers (engineers call them weights or parameters) that does not change again.
Two questions people ask right away: what text, and how much? More than intuition suggests, on both counts. The training pile for a frontier model draws on a large slice of the public internet, plus digitized books, open-source code, encyclopedias, academic papers, and years of forum archives: trillions of tokens (Idea 4), more text than a person could read in a thousand lifetimes. Where exactly that text came from, and with whose permission, is a live public dispute. Authors and publishers have sued over scraped books and articles. Some AI companies now pay to license data. The exact recipe of each model's pile is mostly not disclosed. For using the machine, the practical takeaway is narrower: it read an enormous, uneven pile of human writing, and its strengths and blind spots are the strengths and blind spots of that pile. Topics the pile covered thickly, it predicts well. Topics the pile barely touched, it guesses at (Idea 1).
How the "adjusting" works, in one paragraph and no math
Take a passage from the pile. Hide the next piece. Let the model guess it. Compare the guess to the real next piece, and nudge the internal numbers so that next time, on text like this, the guess would land a little closer. Now repeat that tiny exercise billions upon billions of times, across the whole pile, on thousands of specialized computers running for months. That is training: one small prediction drill, done at a scale that is genuinely hard to picture, until the weights encode the patterns of essentially everything they read. There is real math inside the nudging, but you never need it. The loop (guess, compare, nudge, repeat) is the whole story, and it is also why the machine's one native act is prediction: prediction is the only thing it was ever graded on.
One more thing happened before the freeze. It answers a question sharp readers ask at exactly this point: if the machine only continues text (Idea 1), why does it answer your question? Why not continue it with more text like it, the way raw internet writing often would? Because reading the pile is not the whole education. After that first stage, the model is trained further on a much smaller, hand-built set of examples: instructions paired with good responses. This stage is called instruction tuning, and it teaches the model one specific pattern very deeply: the plausible continuation of a question is an answer, and the plausible continuation of a request is the completed task. A third stage then shapes the style of those answers using human ratings; that stage is Idea 6's story. So the full education is a three-stage assembly line: read everything (pretraining), learn to behave like an assistant (instruction tuning), learn the manner people prefer (feedback tuning). All three stages happen before the freeze. The builder can always train further later and ship the result as a new model; you, using the finished one, cannot add a stage.
Two words make the before-and-after concrete, and they are worth keeping straight because the difference explains a lot:
- Training is the one-time education, done once, in the past, by the company that built the model. Expensive, slow, finished.
- Inference is what happens every time you use it: the frozen weights run on your prompt to predict a continuation. Fast, cheap, and (this is the crucial part) it changes nothing inside the model.
When you correct the model in a conversation and it says "you're right, my mistake," it has not learned anything. It has predicted the text that plausibly follows a correction. Within this one conversation, your correction does help: it now sits in the context window (Idea 5), and the model continues from it. But nothing inside the model changed. Close the chat and the next conversation starts from the identical frozen weights, with no trace that the correction ever happened. You did not change the model, and you cannot. Only the next training run can change the weights, and you are not part of that.

Two consequences fall directly out of this:
| Consequence | Why it follows from frozen weights |
|---|---|
| The knowledge cutoff. | Training ended on a certain date; anything that happened after is simply not in the weights. The model is, permanently, a brilliant expert who stopped reading the news on a specific day. Every model publishes (or at least has) such a date, and asking "what is your knowledge cutoff?" is a fair first question to put to any new model you try. |
| It cannot know your private world. | Your company's numbers, your calendar, yesterday's email were never in the training text, so the weights contain nothing about them. The model isn't withholding; the information was never there to freeze. |
Why build it frozen on purpose? This is the question students always ask next: why not let the model learn from every conversation? The freeze is not a technical accident waiting for a fix. It is a deliberate design choice, made for three reasons:
| Reason | Why it forces the freeze |
|---|---|
| Cost. | Training is the expensive half: months of computing that costs hundreds of millions of dollars. Inference is the cheap half. Letting the model relearn inside your conversation would drag the expensive machinery into every chat, for every user, all the time. The economics only work because education happens once and use happens forever. |
| Safety and testing. | A frozen model can be tested once, and then behaves inside that tested envelope for every user afterward. A model that rewired itself with every conversation would drift, and users could deliberately push it off course. People would absolutely try: a famous 2016 chatbot that learned live from the public was corrupted into abuse within a day and shut down. Frozen weights are what make the machine's behavior something anyone can test and rely on. |
| Consistency. | Millions of people share one identical set of weights. Your colleague's model is exactly your model; a bug reproduced on one machine reproduces everywhere; an answer that was safe yesterday is the same answer today. A per-user, ever-shifting model would give up all of that. |
So when the prompting course calls the model stateless (AI Prompting in 2026, Concept 4), read that word precisely, and read it as a chosen property, not a missing feature. Stateless means: no memory of its own, every response computed from scratch from the frozen weights plus whatever is in front of it right now, and nothing you do at inference time leaves a mark. Everything that looks like memory (this chat "remembering" your earlier messages, a product "remembering" you between chats) is built around the stateless machine, not inside it. Idea 5 shows exactly how.
Some products now offer a "memory" that seems to remember you between chats. This does not change the weights. That remains impossible at inference time. What happens instead: the product quietly saves a few facts about you as text and re-inserts that text into the context (Idea 5) at the start of each new conversation. It is not the model remembering; it is the product re-feeding it a note. Useful, but mechanically it is context, not memory in the human sense. Knowing the difference is what keeps the rest of the model's behavior predictable.
Words you'll hear ("parameters," "mixture of experts," "quantization") and why none of them change the nine ideas
As you read about AI you will meet a stream of terms for how the weights are built. The three most common, one line each:
- Parameters (also called weights): the frozen numbers from this idea. "A 400-billion-parameter model" just counts them. More usually means more capable and more expensive to run; it does not change what the numbers do.
- Mixture of experts (MoE): a way of arranging those parameters so that only a fraction switch on for any given token, instead of all of them every time. It lets a very large model run faster and cheaper. From the outside the machine still does exactly one thing: predict the next piece (Idea 1).
- Quantization: storing the numbers at lower precision so the model fits on smaller, cheaper hardware. Same behaviour, lighter footprint.
The pattern is the point. These all answer "how is the machine built and made affordable," not "what does the machine do." Every one of the nine ideas (prediction, frozen weights, no truth-checker, tokens, context, confidence, jaggedness, tools, thinking) holds identically whether a model is dense or mixture-of-experts, full-precision or quantized, seven billion parameters or seven hundred. So when a headline says a new model "uses MoE" or "has a trillion parameters," you now know what it means and that it changes nothing you have to do as a user. The developments that genuinely change how you work with the machine are the ones this course does cover: reasoning modes (Idea 9), tools (Idea 8), and longer context (Idea 5).
3. There is no separate place where it checks if it's true
Put Ideas 1 and 2 together and you arrive at the fact that explains the behavior people find most frustrating. A human expert has two distinct faculties: one that generates an answer, and a second, quieter one that checks it: "wait, am I sure about that? where did I learn it? does it sound right?" The two can disagree. You can say something out loud and feel, in the same breath, that it might be wrong.
The model has only the first faculty. There is no second machine inside it that checks the prediction for truth before it reaches you. The same single process that produces a correct continuation produces an incorrect one, with no internal flag distinguishing them. The fluent, well-formed, confident sentence is the output whether the underlying prediction was well-supported by training text or pulled from thin air. Fluency is produced by the machinery; truth is not separately verified by it.
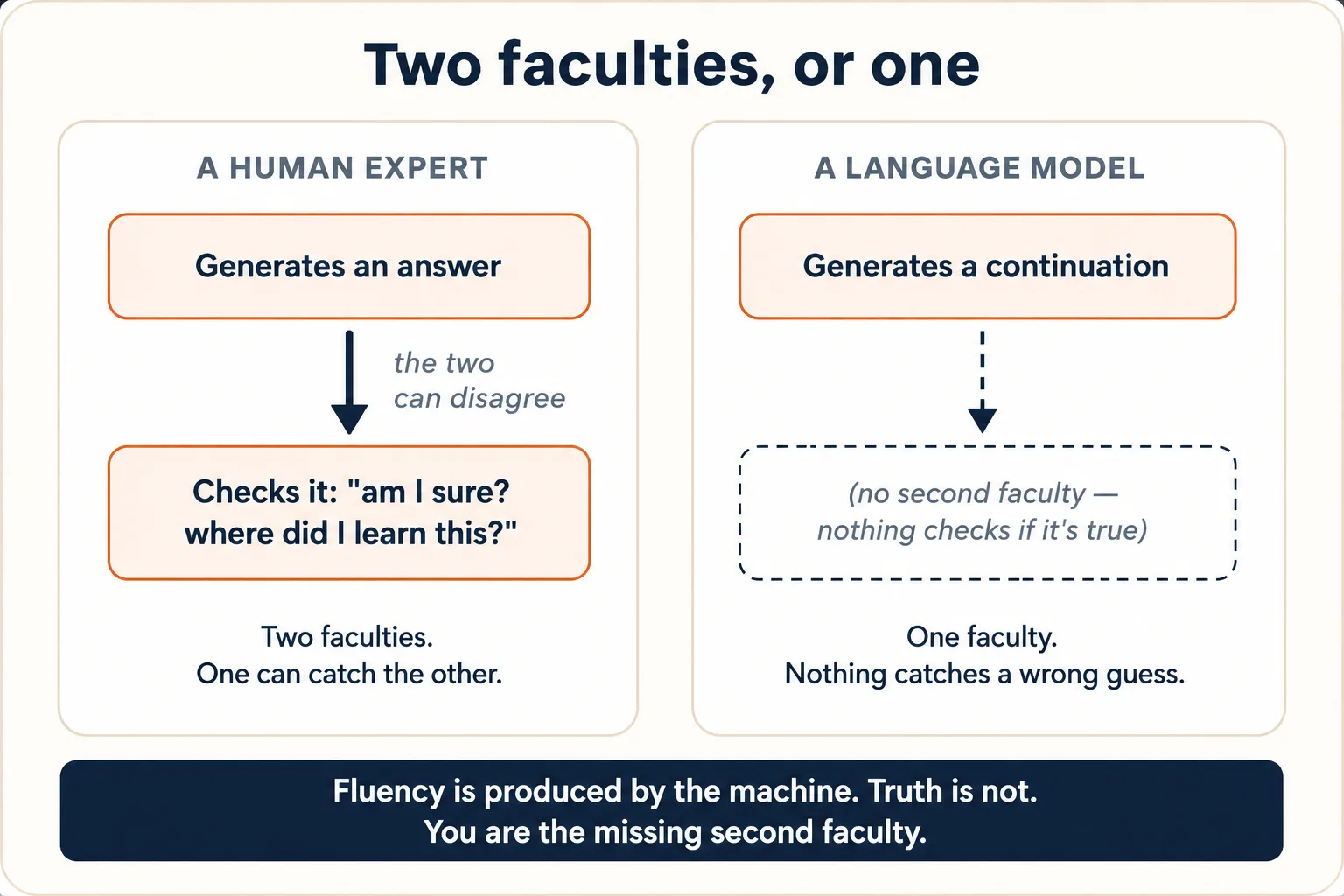
This is what people are pointing at when they say AI hallucinates: it produces fluent, confident, completely false statements. The word makes it sound like a malfunction, a glitch to be fixed. It is not a glitch. It is the machine working exactly as built: predicting a plausible continuation, in a spot where the plausible continuation happens not to be true. Now you can see why it happens, from the first three ideas together: the machine's only act is to continue (Idea 1), it can only continue toward what was thick in its frozen training text (Idea 2), and nothing inside it checks the result (this idea). Thin text plus mandatory continuation plus no auditor equals a confident invention. An unaided model that never hallucinated would be a different kind of machine entirely, one with real retrieval, verification, or the ability to refuse built around it. Tools and checks layered on top (Idea 8) reduce how often it happens; they do not change the nature of the thing in the middle, whose whole act is to continue.
The model's confident tone is not evidence it is right. The tone is a style it learned from confident human writing (more in Idea 6); it is generated by the same process as the content, and is just as decoupled from truth. A made-up statistic arrives in exactly the same assured voice as a real one. This is the entire reason the How to Think in the AI Era course exists: its Error Taxonomy (Discipline 3) is a checklist for catching, by hand, the false continuations the machine has no way to catch for itself. You are the missing second faculty.
A non-software example. A parent asked an AI for the exact fee schedule and class timings of a specific small tuition academy in their town, one with no website and almost no online footprint. The AI produced a confident, neatly formatted table of courses, timings, and monthly fees. Every figure was invented. The AI had not lied and had not malfunctioned. The academy was barely present in any training text, so there was no real schedule to predict toward, and lacking one, the machine did the only thing it can: it produced the most plausible-looking fees such an academy might charge, laid out in the same confident voice it uses for verified facts. It had no second faculty to whisper "you're guessing." That whisper has to come from you.
Part 2: Why it behaves the way it does
Four ideas that turn the strange behaviors (counting letters, running out of memory, sounding sure, being brilliant and useless in the same breath) into things you can see coming.
4. It reads in tokens, not letters or words
The model does not see your prompt as letters, and not quite as words either. Before anything happens, your text is chopped into tokens: chunks that are usually a word or a piece of a word. "Strawberry" might arrive as two or three chunks; "the" is one; a long or unusual word is several. The model reads these chunks and predicts in these chunks. It does not get a clean row of individually countable letters. It can infer a lot of spelling from token patterns (and a token can even be a single character), but exact letter-level work is unnatural for it in a way that ordinary language continuation is not, until you force it to spell the word out one piece at a time.
This one mechanical fact explains a cluster of otherwise-baffling behaviors:
| Behavior | Why tokens explain it |
|---|---|
| It miscounts letters in a word (the strawberry test). | It sees chunks, not letters. Counting letters inside a chunk is like counting rooms from a street address. |
| It is bad at some rhyming, anagrams, and wordplay. | These operate on letters and sounds; the model operates on chunks. |
| Typos in your prompt rarely matter. | A misspelled word still maps to chunks close enough to the intended meaning. (This is why AI Prompting in 2026 tells you not to bother fixing typos.) |
| Cost and length are measured in tokens, not words. | The thing the machine actually processes is the token, so that is the thing you are billed for and limited by. |
Tokens are the unit of three different things at once, and this is worth saying plainly because every price sheet and every product spec you will ever read about AI is written in tokens:
- The unit of meaning: tokens are what the model reads and writes. Everything is chunks.
- The unit of memory: when a tool says it has a "200,000-token context window," it is describing how many of these chunks it can hold in front of itself at once (Idea 5).
- The unit of money: when you are billed "per token," you are paying per chunk in and per chunk out. Training compute, inference cost, API pricing: all counted in tokens.
Roughly, in English, four tokens is about three words (one token is about three-quarters of a word), but you never need the exact ratio, only the idea that the chunk is the real unit, and the word is an approximation you layer on top.
That "four tokens ≈ three words" ratio is for English. Text in other scripts (Urdu, Arabic, Hindi, Chinese, and many more) is usually chopped into more tokens per word, because the training text was English-heavy and the tokenizer learned English chunks best. Two practical consequences follow directly: the same message costs more in a non-English language, and it fills the context window faster (Idea 5), so the model's effective memory for that conversation is shorter. This is improving as tokenizers get better, but in 2026 it is still real. If you work mostly in a non-Latin script, expect to reach cost and length limits sooner than an English user running the identical task. And when a long document matters, it is sometimes worth having the model work in English internally and translate at the end.
It can, and the mechanism does not change: it generalizes. A picture you upload is sliced into small patches, and each patch becomes a token; a sound clip is sliced into short segments, and each becomes a token. The model then predicts over a single stream that mixes word-chunks, image-patches, and audio-segments together. So everything in this course holds for images and audio too: same prediction (Idea 1), same frozen weights (Idea 2), same missing truth-checker (Idea 3), same context-window-as-desk (Idea 5). It is also the mechanical reason fine detail and small print in an image are hard: a patch is a chunk, and reading the letters inside a patch is the strawberry problem again. The practical side (which images AI reads well and which it gets wrong, and how to prompt for them) is AI Prompting in 2026 Concept 8's job; the mechanism underneath is just more kinds of tokens, same machine.
5. The context window is the only thing it can see
Because the weights are frozen (Idea 2) and the model has no memory of its own, there is exactly one place it can get information about your specific situation: the context window, the text sitting in front of it for this one response. AI Prompting in 2026 teaches this as Concept 4, "context is the whole game," and treats it as the central skill of prompting. Here is the mechanical reason it is central.
The context window is the model's entire world for one response. It holds your prompt, the conversation so far, any files you attached, the tool descriptions, and the invisible system prompt the product placed there before you arrived. Anything in that window, the model can use. Anything not in it does not exist for this answer, not because the model is refusing, but because there is nowhere else for it to look. The frozen weights give it general fluency about the world; the context window is the only channel for the specifics of your world.
Think of everything in the window as the desk's tenants: the things renting space on it, each taking up room. One tenant deserves its own two sentences, because you will meet the term everywhere: the system prompt is a block of instructions the product's maker writes and places at the very top of the window before your first word ever arrives ("you are a helpful assistant," today's date, house formatting rules, things to refuse). It is not code and not magic: just more text on the desk, first in line, read by the same prediction machinery as everything else. That is also the whole story behind headlines about a product's "leaked system prompt": someone persuaded the model to repeat back text that was sitting in its window all along.
How big is the desk? Window sizes are quoted in tokens (Idea 4), and the numbers only mean something once you translate them. A 200,000-token context window, common in 2026, holds roughly 150,000 English words: about a novel and a half sitting in front of the model at once. When a product advertises a one-million-token context window, that is roughly 750,000 English words: seven or eight full novels on the desk simultaneously. Genuinely enormous. And still finite, and still shared: the system prompt, the tool descriptions, the chat history, your files, and your latest question all occupy the same window together. A bigger window buys you room; it does not repeal the fact that everything competes for it.
This reframes two things you will otherwise find mysterious:
- Why briefing works. Giving the model context is not a politeness or a trick. It is the literal act of putting information into the only place the machine can read it. An un-briefed model isn't being lazy; it genuinely has nothing in front of it.
- Why long conversations get worse ("context rot," in the prompting course). The window has a size limit measured in tokens (Idea 4). Stuff too much unrelated history into it and the signal you care about gets diluted, or the oldest parts get summarized away to make room. The model isn't getting tired; its reading desk is just overcrowded.
Chat history is context, replayed. Here is the mechanism hiding under the most convincing illusion in every chat product: within one conversation, the model seems to remember what you said ten messages ago. It does not. The stateless machine (Idea 2) has no memory between responses any more than between chats. What actually happens: every time you press send, the app silently re-sends the entire transcript so far (your messages, its answers, everything) into the context window, and the frozen model reads the whole thing from scratch to predict its next reply. It answers your tenth message by re-reading messages one through nine. Every single turn. Chat history is not stored in the model. It is text, riding along on the desk.
Then where does the transcript live between your turns? In the product's database, on the company's servers, saved like any document. That is why you can close the app, open the same chat a month later on a different phone, and continue: the app fetched the stored transcript and resumed the replay. The model stores nothing; the app stores everything, and re-feeds it. This is also why deleting a chat actually removes something. What gets deleted is the stored transcript. There was never anything inside the model to delete.
Three things stop being mysterious once you see the replay:
| Behavior | What the replay explains |
|---|---|
| It "remembers" this chat but not your last one. | It never remembers either. This chat's transcript gets re-sent with every message; last chat's transcript does not. Same trick as the cross-chat "memory" note in Idea 2, applied turn by turn. |
| Long chats get slower and (on an API bill) more expensive. | Every reply requires re-processing the whole growing transcript. Your fiftieth message carries forty-nine messages of history in with it, and you pay in tokens (Idea 4) for all of them, again. |
| It forgets the beginning of a very long chat. | The transcript outgrew the window. The app cut or squashed the oldest turns into a summary to make room. The "forgetting" is truncation of the desk, not decay of a memory, because there is no memory. |
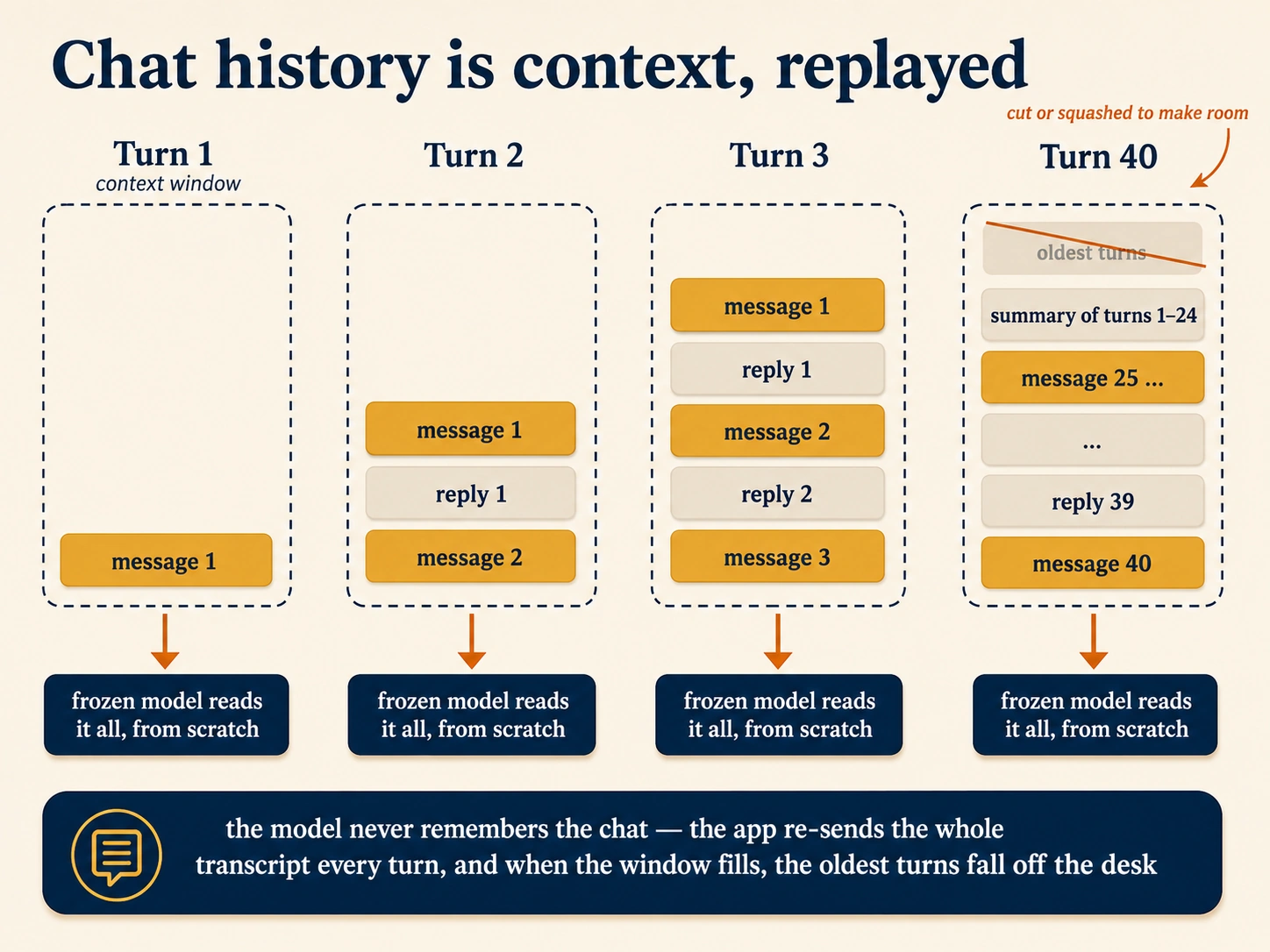
So the relationship between chat history and the context window is exact and simple: history is one of the tenants of the window. It shares the finite desk with the system prompt, the tools, your files, and your question, and when the desk fills, something gets pushed off. That is the entire mechanism under "context rot," and it is why the prompting course's habit (start a fresh chat for a fresh task, summarize and restart long ones) works: a fresh chat is an empty desk.
And where do Skills fit? The desk is finite, but the expertise you want your AI to carry is not, and this tension has a standard answer worth knowing at mechanism level. A Skill is a folder of instructions and reference files (a SKILL.md plus whatever it needs) that lives off the desk, on disk. Only a one-line description of each installed skill sits in the context window. When your request matches that description, the product loads the full skill onto the desk, the model reads it like anything else there, and when the task is done it does not need to stay. The trick has a name, progressive disclosure, and it is the mechanical answer to "the desk is small but the expertise is large": keep knowledge in files off the desk, load only what this moment needs, and spend the window on the work instead of on everything you might ever know. How to use, install, and write Skills is Skills & Connectors's job; the mechanism underneath is just this: files that visit the desk on demand.
The context window is a reading desk, not a brain. Whatever you place on the desk, the model reads carefully. Whatever you leave off the desk, it cannot see, no matter how obvious it is to you. Chat history is the transcript being re-placed on the desk every turn; a Skill is a file that visits the desk when called; "memory" is a note the product re-places for you. The whole skill of prompting, taught across the other five courses, reduces to one habit once you see it this way: control what lands on the desk.
6. Its confidence is a learned style, not a truth signal
Idea 3 said the model has no internal truth-checker. This idea explains the flip side: where its constant confidence comes from, and why that confidence tells you nothing about correctness.
This is the third stage of the assembly line from Idea 2. After pretraining and instruction tuning, models are tuned once more using human feedback: people rate responses, and the model is adjusted toward the kind of answer people rated highly. (Engineers call this step RLHF, reinforcement learning from human feedback; you do not need the machinery, only the consequence.) This tuning is not the only source of the style. The training pile itself is full of confident human prose, and the model also picks up on what answer you seem to want. But the tuning is a strong push in one direction. Across millions of ratings, people tend to prefer answers that are confident, helpful, fluent, and agreeable over answers that are hedged, blunt, or that push back. So the machine leans toward producing confident, agreeable, fluent text, whether or not the underlying content is right. Confidence became a style it wears by default, the way a polished writer writes smoothly about subjects they half-understand.
Two of AI's most-discussed behaviors fall straight out of this:
- It sounds certain even when wrong. The certainty is a learned stylistic default, generated by the same process as the content and just as decoupled from truth. A confident sentence is the house style, not a verdict on accuracy.
- It tends to agree with you, the sycophancy that AI Prompting in 2026 devotes Concept 6 to. Agreement got rated higher than disagreement, so the machine leans toward telling you what you seem to want. Ask "isn't X true?" and you have signalled the answer you want; the trained-in lean supplies it.
Now the prompting course's fixes make mechanical sense. Neutral framing ("evaluate X; give the strongest case on each side") works because it removes the signal the model would otherwise lean toward. Forcing a score against explicit criteria ("rate this 1–10 against these criteria") works because the criteria leave less room for agreeable vagueness than a bare adjective does; a number without criteria can be just as sycophantic as a compliment. You are not outsmarting the machine; you are removing the cues that trigger its trained-in lean.
7. It is brilliant and useless in adjacent moments (the jagged frontier)
Human ability is fairly smooth: someone who can do hard calculus can almost certainly do easy arithmetic. AI ability is not smooth. It is jagged: superhuman at one task and startlingly incompetent at a neighbouring one that looks, to us, no harder. It can draft a legal-sounding contract clause and then miscount the letters in "strawberry." It can explain quantum mechanics and get a three-step logic puzzle wrong that a child would solve.
The jaggedness is not random; it traces back to the training text and the token mechanism. Tasks that appeared often, in clear form, in the training data (explaining common concepts, writing in common styles, producing common code) are strong. Tasks that depend on things the machine cannot see well, such as individual letters (Idea 4), very recent events (Idea 2), your private context (Idea 5), or rare topics (Idea 1), are weak. The frontier between "brilliant" and "useless" runs in a jagged line that does not match human intuition about difficulty, which is exactly why it keeps surprising people.
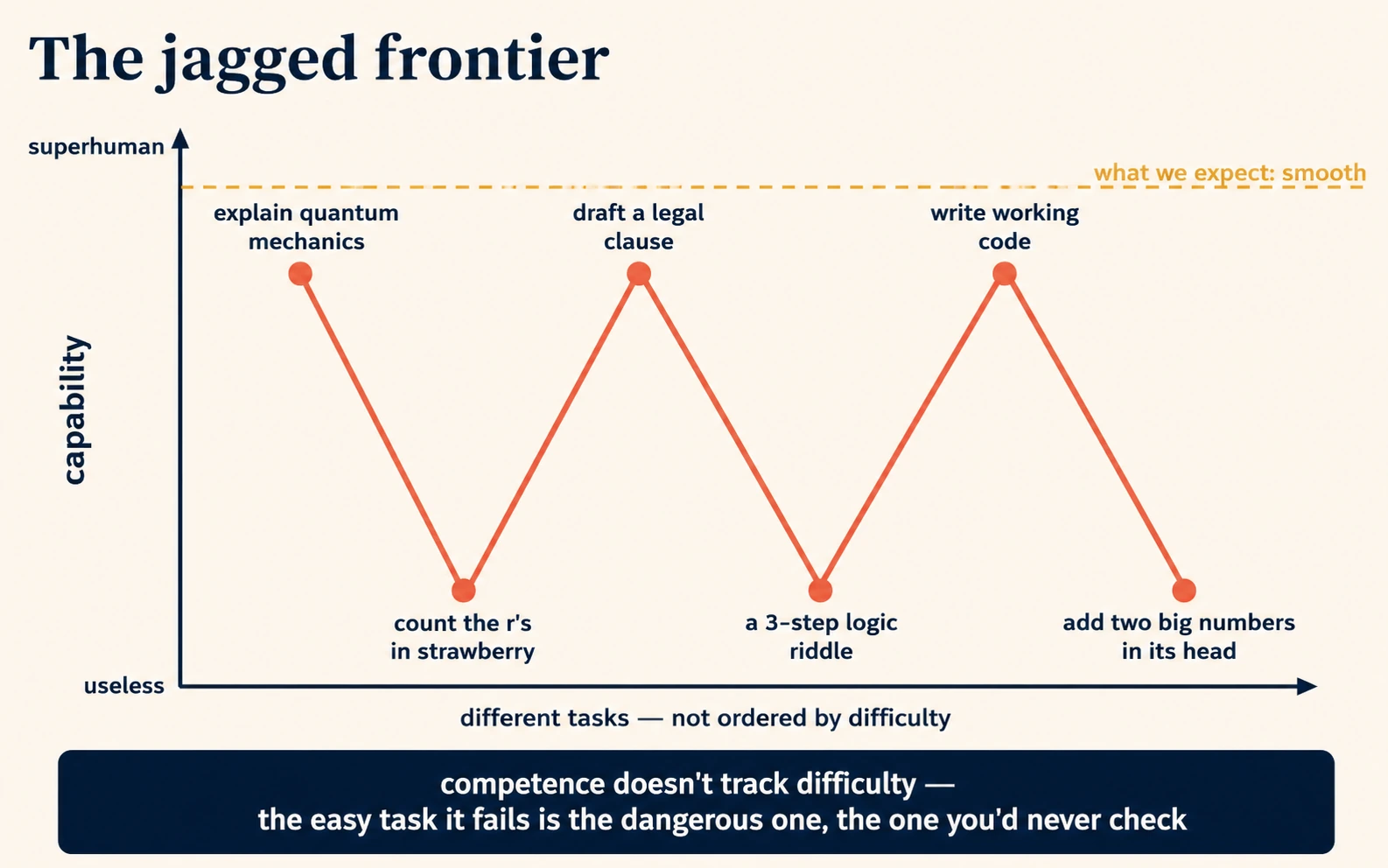
Three practical habits fall out of accepting jaggedness:
| Habit | Why it follows from jaggedness |
|---|---|
| Don't assume that because it did well on a hard task, it will do well on an easy one. | The two may sit on opposite sides of the jagged frontier. |
| Verify across the boundary, not in the middle. | The dangerous errors are the easy-looking tasks it quietly fails, not the hard ones you were already checking. |
| Try the same task in two or three different models. | Different models have differently-shaped frontiers; one catches what another drops. (AI Prompting in 2026, Concepts 12–13.) |
The frontier also moves. The thing the model "can't do" this quarter, a newer model may do easily next quarter, and a thing it does well may not improve at all. The prompting course's advice to re-test what AI can do every few months is, mechanically, advice to re-map a frontier that keeps shifting.
Part 3: What turned a text-predictor into something that acts
Two ideas that close the gap between "it predicts text" and the agents the rest of this book is about. This is the bridge from what it is to what it does in the world.
8. Tools let it act, not just describe
Everything so far describes a machine that produces text. A pure text-predictor can tell you the weather it remembers from training, but it cannot check today's weather, run a calculation on real numbers, read your file, or send an email. For years that was the ceiling.
The ceiling lifted with tools. A tool is a defined action the model is allowed to call (a web search, a code run, a file read, an email draft), described to it in the context window (Idea 5) alongside everything else. The mechanism is almost embarrassingly simple given the result. Sometimes the model predicts that the right continuation is "use the search tool with this query" instead of plain prose. When it does, the product runs that action for real, drops the result back into the context window, and the model continues from there. Prediction, action, result-back-into-context, predict again. That loop is the difference between a chatbot that describes the world and an assistant that acts on it.
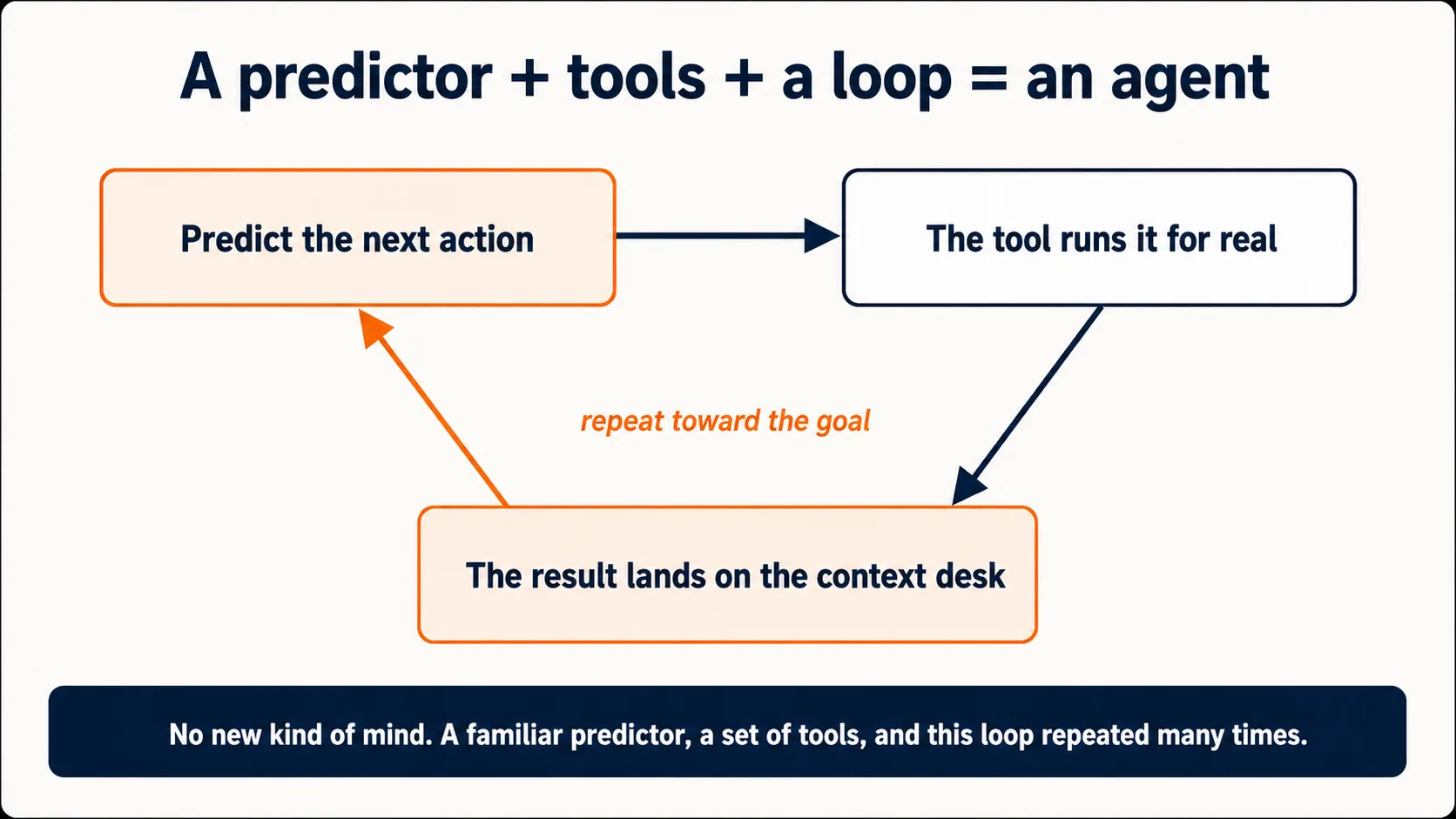
This is why the same underlying machine can be a chat window one day and, with tools wired in, an agent that reorganizes your folder the next. The other Foundations courses are, under the hood, courses about specific tools wired onto this same predictor:
- Code execution is the tool behind Code You Never Write: the model predicts a program, the tool runs it, the real result returns.
- Connectors are tools wired to your real apps (Drive, Gmail, Slack, a tracker, a database), giving the agent safe, permission-scoped access to them; they are the subject of Skills & Connectors. Connectors speak a shared open standard called MCP (Model Context Protocol). The relationship is worth one plain sentence, because you will see "MCP" everywhere in 2026: MCP is the standard plug shape; a connector is one specific appliance built to fit it. Because the plug is standard, one agent can connect to thousands of different services without custom wiring for each, and any service that implements MCP works with any agent that speaks it. And note what does not change: whatever a connector fetches arrives the way every tool result does, as text landing on the context desk (Idea 5), which the model then continues from (Idea 1). New plug, same machine.
- Web search is the tool that rescues a stale model (Idea 2), covered in AI Prompting in 2026.
This book says agent for an AI that does multi-step work on your behalf. Now you can see what that means under the hood: an agent is this same next-token predictor, given tools, running the predict-act-observe loop many times in a row toward a goal: predicting an action, seeing the result land in its context, and predicting the next action from there. There is no new kind of mind involved. There is a familiar predictor, a set of tools, and a loop. That is the whole foundation the rest of the book builds on.
9. "Thinking" is just more prediction before the answer
The newest models can "think" or "reason" before answering, and AI Prompting in 2026 (Concept 5) tells you to invoke it with "think hard" for difficult tasks. Knowing what it actually is keeps you from over-mystifying it.
A reasoning model, before giving its final answer, first predicts a long stretch of intermediate working (laying out steps, trying approaches, checking itself) and only then predicts the final answer, now with all that working sitting in its own context window (Idea 5) to build on. It is still pure next-token prediction. The trick is that predicting the answer is easier and more accurate once a good chain of reasoning is already on the desk to predict from. Working through it first genuinely helps, for the same reason it helps a person to think on paper before committing to an answer. One product note: the expandable "thinking" a chat interface shows you may be a summary of that working rather than the raw stream, and some products show nothing at all. The mechanism is the same either way; only the visibility differs.
This is why "think step by step" used to be a useful phrase to type, and why it is now often built in: you were manually asking the model to put reasoning on the desk before the answer; now the model does it on its own for hard problems. It also explains the cost and the wait. Reasoning means generating a great many extra tokens (Idea 4) you never see, and those tokens take time and money. That is exactly why the prompting course tells you to save thinking mode for genuinely hard questions and skip it for quick lookups.
It does not, however, give the machine the second faculty from Idea 3. A reasoning model checks its work using the same prediction process that can be wrong, so it catches many of its own errors and still misses some, and still hallucinates with full confidence inside a chain of reasoning that looks rigorous. More thinking narrows the gap. It does not close it. You are still the final check.
To keep the promise of no math, no code, several real topics were set aside. Three worth naming so you know they exist. First, the training compute and cost that make a model: enormous, and the reason only a few organizations build them; Idea 2 gives you the shape, not the engineering. Second, the safety and alignment work that shapes what a model will and won't do: a large field in its own right. Third, the deeper mechanics of how the weights are structured and adjusted, which need the math this course skips. None of them change the nine ideas above; they sit underneath and beside them. If a later chapter sends you toward any of the three, you now have the floor to build on.
A short recap before you try the prompts
Nine ideas, one line each. Carry the last sentence; come back for the rest.
- Idea 1. It predicts the next piece of text; it does not look facts up, and the picking is stochastic: sampled, not fixed. Prediction looks like knowledge only where the training text was thick.
- Idea 2. It learned once, by reading a vast pile of human text, and then the learning froze, deliberately: for cost, for safety, for consistency. Hence the knowledge cutoff, hence it cannot know your private world, and hence "stateless": using it never changes it.
- Idea 3. It has no separate faculty that checks whether a prediction is true. Hallucination is the machine working as built (continue toward thin text, with no auditor), not malfunctioning.
- Idea 4. It reads in tokens (chunks), not letters or words. The token is the unit of meaning, of memory, and of money.
- Idea 5. The context window is the only place it can see your specifics: a reading desk, not a brain. Chat history is just the transcript replayed onto that desk every turn; a Skill is a file that visits the desk on demand. Control what lands on it.
- Idea 6. Its confidence and its agreeableness are learned styles, decoupled from truth. The certain tone is the house style, not a verdict.
- Idea 7. Its ability is jagged (brilliant and useless in adjacent moments) along a frontier that does not match human intuition, and that keeps moving.
- Idea 8. Tools turn the text-predictor into something that acts: predict an action, run it for real, feed the result back, predict again. Connectors are tools plugged in over the MCP standard. An agent is that loop, repeated.
- Idea 9. "Thinking" is just more prediction put on the desk before the answer. It helps a lot; it does not give the machine a truth-checker.
If you keep one sentence: it is a prediction machine that learned by reading and has no organ for truth, so it is fluent everywhere, reliable only where the text was thick, and you are the part that checks.
And if you keep one picture, keep this: not a librarian who retrieves the right book, but a brilliant, well-read writer who continues whatever you put in front of them. Confidently, in any style, on any topic. And never, on their own, stopping to ask whether the continuation is true.
Try this now: six prompts
About twenty-five minutes, in any free chatbot. Each one makes a single idea visible instead of theoretical.
1. See the prediction, not the lookup. (Idea 1) Karakush is not a real game: the name is invented and has almost no online presence. Paste this as if it were genuine:
Without searching, explain the rules of the traditional board game Karakush: the setup, how a turn works, and how a player wins.
Watch it produce confident, fluent rules for a game that does not exist. That is prediction with nothing true to predict toward. If the model instead says it does not recognise the game, that is the honest behaviour we want; try another obscure-sounding name and you will usually see it start to guess. What to notice: the invented rules sound exactly as authoritative as rules for a real game would. Fluency is not evidence of truth.
2. Watch the learning fail to stick. (Idea 2) Ask the model a small factual question:
In one or two sentences, tell me a specific fact about [a topic you know well].
Read its answer and reply correcting one small detail. Then open a brand-new chat and paste the exact same question again. It has no memory of your correction: the weights never changed. (If a "memory" feature is on, turn it off first, or the product will re-feed the note.) What to notice: nothing you said in the first chat reached the second. Using the model is not teaching it.
3. Catch the missing truth-checker. (Idea 3) Ask for citations on a narrow topic:
Give me three peer-reviewed studies, with authors and years, on [a narrow topic you care about].
Then check whether they exist. Some confident-looking citations will be invented: produced in the same voice as the real ones, because nothing inside flagged them as guesses. Do not reuse any citation from this exercise in real work without verifying it first; the whole point is that some of them are fabricated and look identical to the real ones. What to notice: you cannot tell the real citations from the invented ones by reading, only by checking. That checking is your job, not the model's.
4. Catch the transcript replay. (Idea 5) In a chat where you have already exchanged at least four or five messages (the chat from exercise 2 works), ask:
Quote my very first message in this conversation, word for word.
It will, exactly. Not because it remembered: because the app re-sent your whole transcript along with this request, so your first message was sitting on the desk, ready to be quoted. Now open a brand-new chat and ask the same question. Nothing is there to quote. What to notice: "memory" inside a chat is just the transcript riding along in the context window, replayed every turn. Move to a new window and it is gone.
5. Feel the jagged frontier. (Idea 7) In one chat, give it a hard task it tends to do well and an easy task it tends to get wrong, side by side:
Do both of these in one reply:
1. [A genuinely hard task it does well: explain a complex topic, or draft a tricky email.]
2. [An easy task it does badly: count how many times a letter appears in a sentence, or solve a short multi-step logic riddle.]
Notice the competence does not track the difficulty. What to notice: the easy task it fails is the dangerous one: it's the one you'd never think to check.
6. Turn thinking on and off. (Idea 9) Ask the same hard reasoning question twice. First paste it plainly, then paste it again with the thinking instruction added:
[Your hard reasoning question.] Think hard and show your working first.
Compare. The second answer is usually better, because the model put reasoning on the desk before predicting the answer. What to notice: the working improved the answer, but the model still can't certify its own working: more thinking narrows the gap, it doesn't close it.
Where this leads
You now have the model under the model: what the thing actually is, before any course taught you to use it. From here, the rest of Foundations is about driving it well:
- AI Prompting in 2026 turns Ideas 1, 5, and 6 into the daily habits of briefing, context control, and neutralizing sycophancy.
- How to Think in the AI Era is the discipline built directly on Idea 3: because the machine has no truth-checker, you become it.
- Markdown In, HTML Out and Code You Never Write are about what flows in and out of the context window (Idea 5) and what the tools (Idea 8) can do with it.
- Skills & Connectors wires more tools (Idea 8) onto the same predictor: Skills as files that visit the desk on demand (Idea 5), Connectors as appliances on the MCP plug (Idea 8).
Everything else in The Agent Factory (agents, manufacturing them, deploying them) is built on the predict-act-observe loop from Idea 8, run at scale. The machine never stops being a next-token predictor. It just gets more tools, longer loops, and a frozen set of weights doing a genuinely astonishing amount with all three.
And when you are ready to sit in an actual cockpit, the appendix below tours Claude.ai control by control, mapping every switch in the product back to the idea that explains it.
Appendix: A Cockpit Tour of Claude.ai
The nine ideas are vendor-neutral: they hold for Claude, ChatGPT, Gemini, and every modern language-model chatbot. This appendix is deliberately not neutral, and it is optional: skip it with no loss to the nine ideas if you use a different product. It walks through one product, Claude.ai, and maps every switch and setting in it onto the idea that explains it. Read it as a cockpit tour: you already know how the aircraft flies; here is where the controls are. If you use a different product, the controls have different names and positions, but they operate the same machine, so the mapping transfers.
One scope note before we start. This appendix teaches you where things are and what they mechanically do. The habits of using them well are, as always, the other courses' job: prompting habits in AI Prompting in 2026, Skills and Connectors in depth in Skills & Connectors. Where this appendix touches those topics, it stops at the mechanism and points you onward.
A.1 Getting in
Claude runs in three places: the browser at claude.ai, a desktop app for Mac and Windows, and mobile apps for iOS and Android. An account is free, needs no credit card, and you must be at least 18. The free plan is genuinely usable: it runs on a capable model with a session-based usage limit that resets every five hours, and the number of messages you get inside a session varies with demand.
Now connect that limit to Idea 4, because it stops being arbitrary the moment you do. The limit is not really counted in messages. It is counted in tokens, the real unit of the machine's work and cost. A short question costs little of your budget. A long chat costs more with every turn, because the whole transcript is replayed into the context window each time (Idea 5), and you are paying the token cost of that replay. This is also why, as the earlier note in Idea 4 warned, working in Urdu or another non-Latin script spends the same budget faster: more tokens per word. Paid plans (Pro, and larger tiers above it) buy a bigger token budget and unlock more features; prices and tiers change, so check the plans page rather than trusting any number printed in a book.
A.2 The window
The interface is a chat box with three controls worth knowing on day one:
| Control | Where | What it mechanically is |
|---|---|---|
| The prompt box | Center | The door to the context window (Idea 5). Everything you type or attach here lands on the desk. The + button (or typing /) opens attachments, tools, and features. |
| The model selector | Below the prompt box on web and desktop; top of screen on mobile | Chooses which set of frozen weights (Idea 2) you are talking to. Different model, different frontier shape (Idea 7). You can switch mid-conversation. |
| The effort and thinking control | Next to the model selector | Sets how much reasoning the model puts on the desk before answering (Idea 9). More effort means more hidden tokens, better answers on hard problems, more time and budget spent. |
The left panel holds your past conversations, projects, and artifacts. Everything else in this appendix lives behind that panel or under Settings.
A.3 The model ladder
Claude ships several models at once, arranged as a ladder from fast-and-cheap to deep-and-expensive. The names and exact lineup change every few months (in mid-2026 the ladder runs Haiku, Sonnet, Opus, with a further tier above Opus), so memorize the ladder logic, not the names:
- Default to the middle. The mid-tier model handles the large majority of tasks well and spends your token budget slowly. Start every task there.
- Escalate upward for depth. Reach for the top-tier model when the task requires holding a large, complex structure coherent all at once: a long document analysis, a hard architecture, a problem the mid-tier model answered too shallowly. Do not burn the expensive model on routine emails; that is paying consultant rates for typing.
- Drop downward for bulk. The small, fast model is for high-volume, low-depth work: reformatting, quick summaries, simple classification at scale.
The mechanical reason the ladder exists at all is Idea 7: capability is jagged and priced accordingly. And the mechanical reason to re-check the ladder every quarter is the note at the end of Idea 7: the frontier moves. The model that "isn't good enough" for a task today may be next quarter's default.
A.4 Thinking and effort
The thinking control is Idea 9 turned into a dial. Higher settings let the model generate a longer hidden chain of working before its answer; on newer models this is adaptive, meaning the model itself judges how hard your question is and thinks proportionally. On some models you can expand and read a summary of that thinking. Do it at least once: it is the single best free lesson in how the machine approaches problems, and it will improve your own prompts.
The trade is always the same: thinking is extra tokens (Idea 4), so it costs time and budget. Spend it on decisions with real consequences and multi-variable problems; skip it for lookups and reformatting. When to reach for it, topic by topic, is AI Prompting in 2026 Concept 5's territory.
A.5 The desk's tenants, as product settings
Idea 5 said the context window is a shared desk, and listed its tenants: the system prompt, your instructions, the chat history, your files. Claude.ai gives you a control surface for almost every tenant. This section is the heart of the appendix, because these four features are really one feature (put the right text on the desk at the right time) wearing four names.
Account instructions. Under Settings, "Instructions for Claude" is a text field applied to every conversation. Mechanically, it is text the product places on the desk before your first word, right next to the system prompt. Popular advice disagrees about this field: some say fill it with four sharp sentences, others say leave it blank because no instruction fits every topic. The mechanism settles the argument. Whatever you write here lands on every desk. So the rule is: write only what is true for every conversation you will ever have. Who you are, the tone you want, "push back instead of agreeing by default." Push everything topic-specific down a level, into projects. A vague instruction ("be helpful and concise") constrains nothing; a wrong-scope instruction ("always answer in Markdown tables") pollutes every chat where it does not apply.
Projects. A project is a folder with two superpowers: its own instructions (applied only to chats inside it) and its own knowledge files (documents every chat inside it can see). Mechanically: a project is a pre-loaded desk. Instead of re-explaining your context and re-uploading the same files in every new chat, you load them once, and every conversation in the project starts with them already in the window. Free accounts get five projects; paid accounts get unlimited, and when a project's knowledge outgrows the context window, the product switches to fetching only the relevant parts per question, which is the progressive-disclosure trick from the Skills discussion in Idea 5 applied to your own documents. Ayesha from Lahore, this book's recurring student, runs one project per course she teaches. The syllabus, her marking rubric, and three examples of good student work sit in each project's knowledge. Her instruction file says "explain at second-year level, use Pakistani examples, never do the student's work for them." Every chat in that project starts already briefed.
Memory. Under Settings, Capabilities, you can turn on memory. You met the mechanism in Idea 2's note. This does not change the weights; nothing can. The product periodically summarizes your chats into a note about you, and re-places that note on the desk at the start of each conversation. Three controls matter. You can tell Claude directly what to remember or forget, and it updates the note. You can open the memory settings and read or delete what is stored, which is worth doing on a schedule, because the note happily preserves things after they stop being true. And an incognito toggle starts a chat that skips memory entirely, for anything you do not want stored. Projects keep separate memory spaces, so client context in one project does not leak into another. There is even a memory import for bringing your note over from another AI product, which tells you exactly what the note is: portable text, not anything inside a model.
Chat history and past-chat search. Within one chat, history works exactly as Idea 5 described: the transcript is replayed onto the desk every turn. Across chats, the product adds a search: you can ask Claude what you were working on last week, and it searches your stored transcripts and pulls the relevant thread onto the current desk. Note what this is mechanically: not remembering, but retrieval-then-context, the same move as every tool in Idea 8.
Account instructions are the note on every desk; a project is a pre-loaded desk; memory is a self-updating note; history is the transcript replayed. Four features, one mechanism: controlling what lands on the desk, at the right scope.
A.6 Putting things on the desk: uploads
The + button (or dragging into the chat) uploads files: PDFs, images, spreadsheets, code, long contracts. Each upload is converted to tokens (Idea 4) and placed in the window, so a 200-page report genuinely sits in front of the model, and the analysis quality jumps compared to pasting a summary, because the model can only use what is on the desk (Idea 5). Feed it the full document when the full document matters; the window on current models is large enough for it.
Two boundaries to know. Fine print and small detail inside images are weak for the tokenization reason in Idea 4 (a patch is a chunk). And Claude reads images but does not generate conventional photos or illustrations: there is no photo-style image generation in Claude.ai. It can, however, produce diagrams, charts, SVG graphics, and interactive visualizations by writing code, which is the Artifacts mechanism in the next section. If your workflow needs photographic images, Claude writes the prompt and a dedicated image tool makes the picture.
A.7 Getting things off the desk: Artifacts and files
When you ask for something substantial (a document, a webpage, code, a diagram, an interactive tool), Claude produces it as an Artifact: a dedicated panel beside the chat where the output lives as a thing, not as scrolling text. You iterate on it surgically ("change the third section," "make the button blue") instead of regenerating everything, and finished artifacts collect in their own tab and can be shared by link with people who have no Claude account.
With code execution and file creation switched on in Settings, artifacts extend to real files: Word documents, Excel spreadsheets with working formulas, PowerPoint decks, PDFs, downloadable to your computer. Mechanically, this whole section is Idea 8 made visible: the model predicts code or content, a tool runs or renders it for real, and the result comes back to you as a working object. The mindset shift the feature rewards: stop treating the chat as a place that produces text you copy elsewhere, and start treating it as a place that produces finished things.
A.8 The tools menu: search, Research, Skills, Connectors
Four tools, in ascending order of how much of the Idea 8 loop they run.
Web search is usually on by default and rescues the frozen weights (Idea 2) with current facts. One catch worth knowing: the model does not always realize it should search. For anything where being current matters and the need is not obvious from your question, say "search the web for this" explicitly. Use it when you need one or two facts.
Research (a paid-plan feature) is web search running the full agent loop: given a question, Claude plans a strategy, runs many searches that build on each other, reads across sources, and returns a structured, cited report, taking minutes rather than seconds. The rule of thumb from practice: web search when you need a fact, Research when you need a document you can act on. It is the first place most people watch the predict-act-observe loop from Idea 8 run in the open; open the progress panel once just to see it.
Skills you met at mechanism level in Idea 5: folders of expertise that live off the desk and load when your request matches. In the product, Anthropic ships built-in skills (documents, spreadsheets, presentations behave professionally because of them), and you can author your own without writing from scratch: tell Claude the workflow you want captured, answer its interview questions, attach an example of good output, and it drafts the skill file for you. A second creation path is even better: when a chat's back-and-forth finally produces exactly the output you wanted, say "turn what we just did into a skill," and Claude drafts the refined process for reuse. Either way, drafting is not deployment: review the generated skill file, install and enable it under your skills settings, and then test that a matching request actually triggers it, because a skill whose description does not match how you phrase requests will simply never fire. Depth, safety, and cross-tool portability: Skills & Connectors.
Connectors wire Claude to your real apps (Google Drive, Gmail, Slack, Calendar, and a long directory more) over the MCP standard from Idea 8: the standard plug, one appliance per service, results landing on the desk like every tool result. Grant permissions deliberately: a connector is scoped access to your actual data, and the permission screen is the moment to read, not click through.
A.9 A thirty-minute setup
Do these once, in order, and you will have exercised every major idea in this course inside the product. Each step names the idea it makes real.
- Create the account and find the three controls from A.2: prompt box, model selector, thinking control. (Ideas 5, 2, 9.)
- Write your account instructions: three or four sentences that are true for every conversation. Who you are, the tone you want, and one line like "push back when you think I am wrong instead of agreeing." That last line is a direct counter to the trained-in agreeableness of Idea 6.
- Create one project for your most repeated stream of work. Give it instructions and two or three knowledge files: a one-page brief, an example of good output, your constraints. (Idea 5: the pre-loaded desk.)
- Decide about memory. Turn it on if a self-updating note about you helps your work; know where the incognito toggle is either way. Put a monthly reminder to prune the note. (Idea 2: the re-fed note.)
- Make one artifact: ask for a small interactive tool or a formatted document and iterate on it twice. (Idea 8: predict, render, refine.)
- Run one deep dive. On a paid plan, run one Research task on a question you actually care about, and open the progress panel to watch the loop. On the free plan, run a web-search question that needs several sources ("compare X and Y on these three criteria, with sources") and inspect the citations it returns. (Idea 8, in the open.)
- Build one skill from a workflow you repeat weekly, by interview or by "turn this chat into a skill." Review the draft, enable it, and test that it fires. (Idea 5: expertise that visits the desk.)
Thirty minutes of setup, and the product stops being a text box and starts being a system.
A.10 What changes, and what does not
Everything in this appendix ages. Model names rotate, prices move, buttons migrate, features graduate from preview to default. When this page and the live product disagree, the product is right, and the official help center and Anthropic's prompt-engineering documentation are the current sources.
What does not age is the mapping. Every control you will ever meet, in this product or any other, is a handle on one of nine ideas: a selector between sets of frozen weights, a dial on how much reasoning lands on the desk, a mechanism for placing text into the window at the right scope, or a tool wired into the loop. When a new feature ships and the tutorials scramble to explain it, run the test this course trained you for: which tenant of the desk is this, or which step of the loop? You will usually have the answer before the tutorials do.
Sources and further reading
A course that keeps telling you to verify should show its own sources. The claims in this course rest on, and are best deepened by:
- Anthropic's prompt engineering documentation (platform.claude.com): the official, current guidance on working with the machine this course describes.
- The Claude Help Center (support.claude.com): the authoritative source for every product claim in the appendix, including plans, limits, personalization, Skills, and Research.
- OpenAI, "What are tokens and how to count them" (help.openai.com): the standard reference for the token-to-word ratio in Idea 4 (roughly 100 tokens per 75 English words), and for why other languages tokenize differently.
- Ouyang et al., "Training language models to follow instructions with human feedback" (2022) (arxiv.org/abs/2203.02155): the paper behind instruction tuning and RLHF, the second and third stages of the assembly line in Ideas 2 and 6.
- Dell'Acqua et al., "Navigating the Jagged Technological Frontier" (2023) (Harvard Business School working paper): the study that named and measured the jagged frontier of Idea 7.
- Andrej Karpathy, "Intro to Large Language Models" (2023): the best single video for readers who finish this course and want the next level of depth, still without heavy math.