Loop Engineering: A Crash Course
15 Concepts · From agentic coding to self-prompting systems
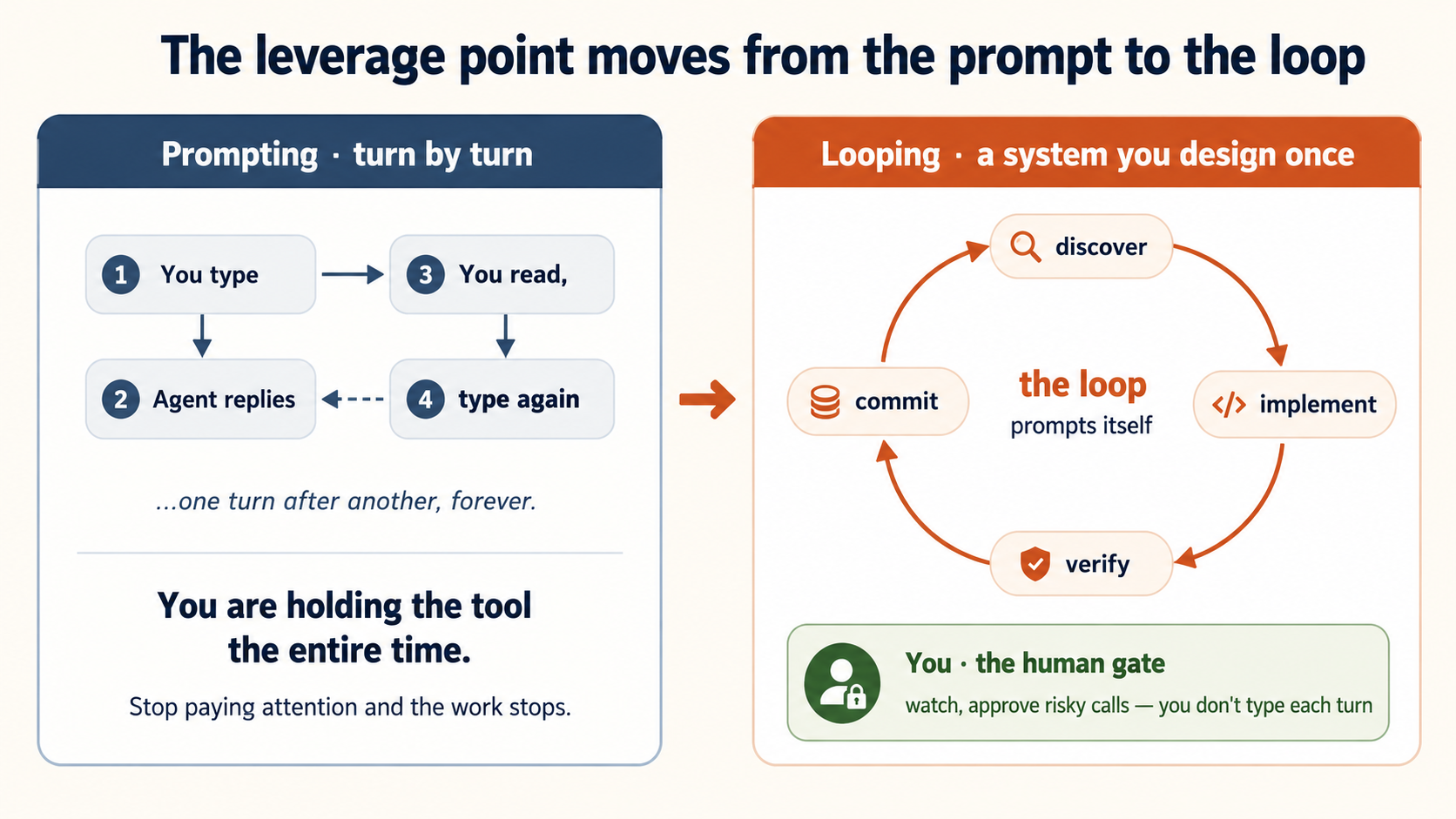
You have learned to drive a coding agent. You give it an instruction. It reads your files, makes the edits, and you check the result. One turn, then the next, then the next. You are holding the tool the whole time.
Now imagine you stop holding it. Instead, you build a small system. Every morning it wakes up, looks at what changed overnight, decides what is worth doing, gives each job to an agent, checks the result, and only calls you for the decisions that really need a person. You built it once. After that, it prompts itself.
That is loop engineering. The valuable skill moves from the prompt you write to the loop you design. This course teaches you what a loop is made of, and how to build one in both Claude Code and OpenCode — which reach the same place by two very different roads.
Prerequisite: Claude Code and OpenCode: A Crash Course. That course taught you plan mode, context management, the rules file, skills, subagents, and MCP. This course assumes all of it. If those words are new to you, do that course first. Loop engineering is built directly on top of it. Ideally you have also done Spec-Driven Development: a loop's stopping condition is really a spec, and that course is where you learned to write one — without it you can still follow along, but your loops will only ever be as good as the conditions you can specify.
New here? A 2-minute recap of what you should already know
- Plan mode — the agent reads your files and proposes a plan before it changes anything; you approve first.
- The rules file (
CLAUDE.md/AGENTS.md) — short, permanent project notes the agent reads at the start of every session. - Skills (
SKILL.md) — a saved, reusable instruction the agent loads only when the task matches it. - Subagents — a separate helper with its own context window that does a job and hands back just the result.
- Connectors / MCP — the standard way to plug an agent into outside tools: GitHub, Slack, a database.
- Context management — keep the conversation lean; the model gets worse and costs more as it fills up.
If any of these are new, do the agentic coding crash course first — this one builds straight on top of it.
In mid-2026 the people who build these tools said it plainly. Boris Cherny, who created Claude Code, put it this way: "I don't prompt Claude anymore. I have loops running that prompt Claude... my job is to write loops." Peter Steinberger (OpenClaw) said "you should be designing loops that prompt your agents." Addy Osmani then named the pattern and listed its parts. None of them say the work got easier. They say the valuable skill moved. That is the idea this whole course is built on. (Every quote and claim in this course is sourced in Sources & further reading at the end.)
The mindset shift, in one picture
This course covers two tools side by side, for the same reason as the last one: if a technique works in both, it is a real skill, not a trick for one tool. But here the two tools really do differ, and that difference is itself a lesson. Claude Code now ships the loop parts inside the product. OpenCode gives you the layer below — a worker that you start from the operating system. You will see both. You will also see that the shape of the loop is the same, even when the wiring is not.
Current as of June 2026. Both tools change fast, and several Claude Code loop features are in research preview. Before any session, run
claude updateoropencode upgrade. Check the live docs (code.claude.com/docs, opencode.ai/docs) before you rely on a limit or a flag.
A real loop is unattended: it prompts itself, on its own, while you are away. That cannot happen in the plain claude.ai chat box, which always waits for you — in chat, you are the schedule. To run a true loop you need a tool that can act on a timer by itself: Claude Code, OpenCode, or Cowork (see the Cowork crash course). Most of these are paid features, and several are research previews today. You can learn and design a loop anywhere. To run one unattended, you need one of those tools. This course shows the two coding ones. Fair question, because "claude.ai" is really two things. The short answer: the chat box cannot run a loop, but Claude Code — which lives in the same claude.ai account — can. So the chat is where you design and rehearse a loop — draft the skill, write the reviewer prompt, pin the stopping condition, run one beat by hand — and Claude Code or OpenCode is where you run it. That hand-off is the natural next step after Spec-Driven Development."But I did the whole Spec-Driven course in claude.ai — can I run a loop there too?"
claude.ai/code/routines) run on Anthropic's servers even with your laptop closed, with nothing installed locally — so in that sense you can stand up a real, unattended loop "from claude.ai." It needs a paid plan and is a research preview today.
From here on, almost every concept is something you can run in a real session, not just read about. Keep a terminal open beside this page (claude or opencode) and try each idea as you reach it. Start with a small, throwaway git repo so a loop cannot hurt anything you care about.
What this course covers
| Part | Topic | What you learn |
|---|---|---|
| 1 | The Shift | What a loop is, its six parts, and the two roads to building one |
| 2 | The Heartbeat | Making something run on its own: in-session, run-until-done, scheduled, event-driven |
| 3 | The Body | Isolation, knowledge, action, and the maker–checker split |
| 4 | The Spine | State that survives between runs — the one part people forget |
| 5 | A Loop, Twice | One full morning-triage-to-PR loop, with real files, built in both tools |
| 6 | Staying the Engineer | Token cost, checking the work, and the traps that grow as loops get better |
| Practice | Practice projects | Five loops, easy to hard, that you build yourself |
Learn by doing? Read Part 5 first to see a whole loop from start to finish, then come back for the parts. Once the concepts click, the Practice projects give you five loops to build yourself.
Plan about two hours to read this through. Building Part 5 and the practice projects takes longer — that is the point: you are building loops, not skimming them.
Two layers run through this course, and they age very differently. Internalize the first; look up the second.
- The durable layer. The shape of a loop (a heartbeat, four working parts, and a spine), the maker–checker split, and the two ends a loop can never automate: intent (saying what you want precisely enough that the result can be checked) and accountability (owning what ships). This is the skill. It stays true after every command below has changed.
- The mechanical layer. Every flag, path, model ID, and command name. These tools ship updates weekly and several features here are research previews, so treat each specific command as a pointer to the live docs, not a fact to memorize. Where this course and the current docs disagree, the docs win.
Remember the six-part shape and forget every keystroke, and you learned loop engineering. Memorize the keystrokes and miss the shape, and you learned this month's CLI.
📚 Teaching Aid
View Full Presentation — Loop Engineering: A Crash Course
Part 1: The Shift
1. From prompting to looping
For about two years, the way to get work from a coding agent was simple. Write a good prompt. Give it enough context. Read what comes back. Type the next thing. The agent was a tool, and you used it one turn at a time.
A loop replaces you, the operator, with a system. The system finds the work, gives it out, checks it, writes down what it did, and decides what is next. It prompts the agent, so you do not have to.
So where does the value go? Not away. It splits to the two ends a loop cannot automate: intent — saying precisely what you want, clearly enough that the result can be checked — and accountability — standing behind what comes out. The loop automates the middle, the steps; the ends stay yours. You are paid for intent and judgment, not for ignoring how the work got made.
The difference is not "a bigger prompt." It is a different shape of work:
| Prompting (what you know) | Looping (what this course adds) |
|---|---|
| You start each turn | A schedule or an event starts each turn |
| You read the output and decide what is next | A checker checks the output; the loop decides what is next |
| Stops the moment you stop typing | Keeps running while you sleep |
| One task, one session, your full attention | Many small runs, mostly unattended, your attention only at the gate |
This is not magic, and it is not "set it and forget it." A loop running on its own is also a loop making mistakes on its own. Everything in this course exists to build a loop you can actually trust to run without you. That is harder than prompting, not easier. The reward is leverage: one good loop does work for you again and again, work you would otherwise have to start by hand every single time.
2. What a loop is made of
A loop that really runs on its own has five parts and one spine. You already met four of the five in the agentic coding course. Here they take on a new job.
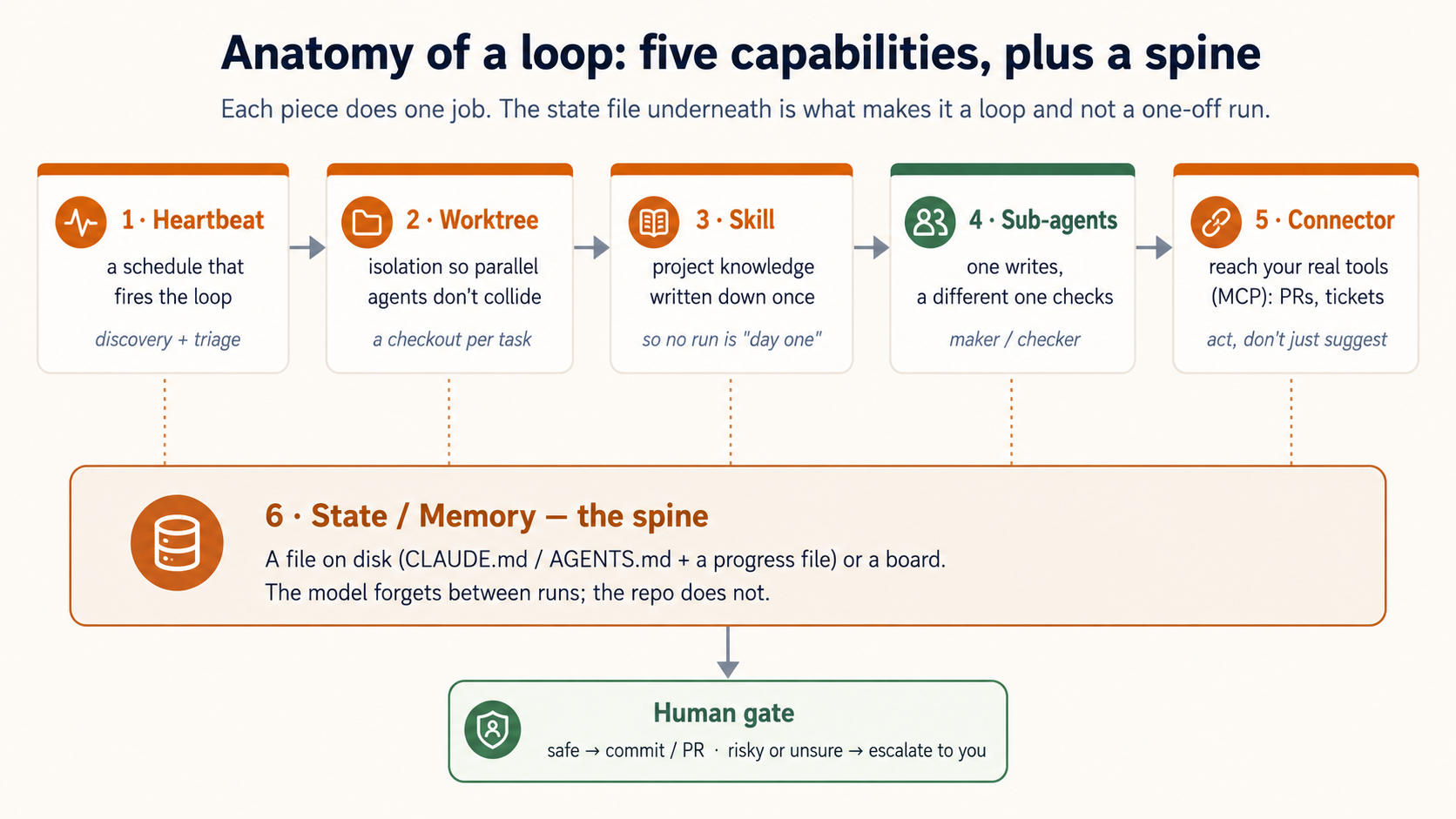
- Heartbeat — a schedule (or an event) that starts the loop. Without it, you have a single run, not a loop.
- Worktree — isolation, so two agents working at once do not overwrite each other's files.
- Skill — your project knowledge written down once, so each run does not start from nothing.
- Sub-agents — the maker–checker split: the agent that writes the code is not the agent that grades it.
- Connector (MCP) — so the loop can act in your real tools (open a PR, update a ticket), not only suggest.
And the sixth, which is the one beginners skip:
- State / Memory — the spine. A file on disk (or a board like Linear) that holds what is done and what is next. The model forgets everything between runs. The spine is how today's run knows what yesterday's run did. No spine, no loop — just the same first step, repeating forever.
The rest of this course is one section per part, then a full example that joins them together.
3. Two roads: ships-the-parts vs the-layer-below
This is the one place where the tools really differ, and it shapes everything that follows.
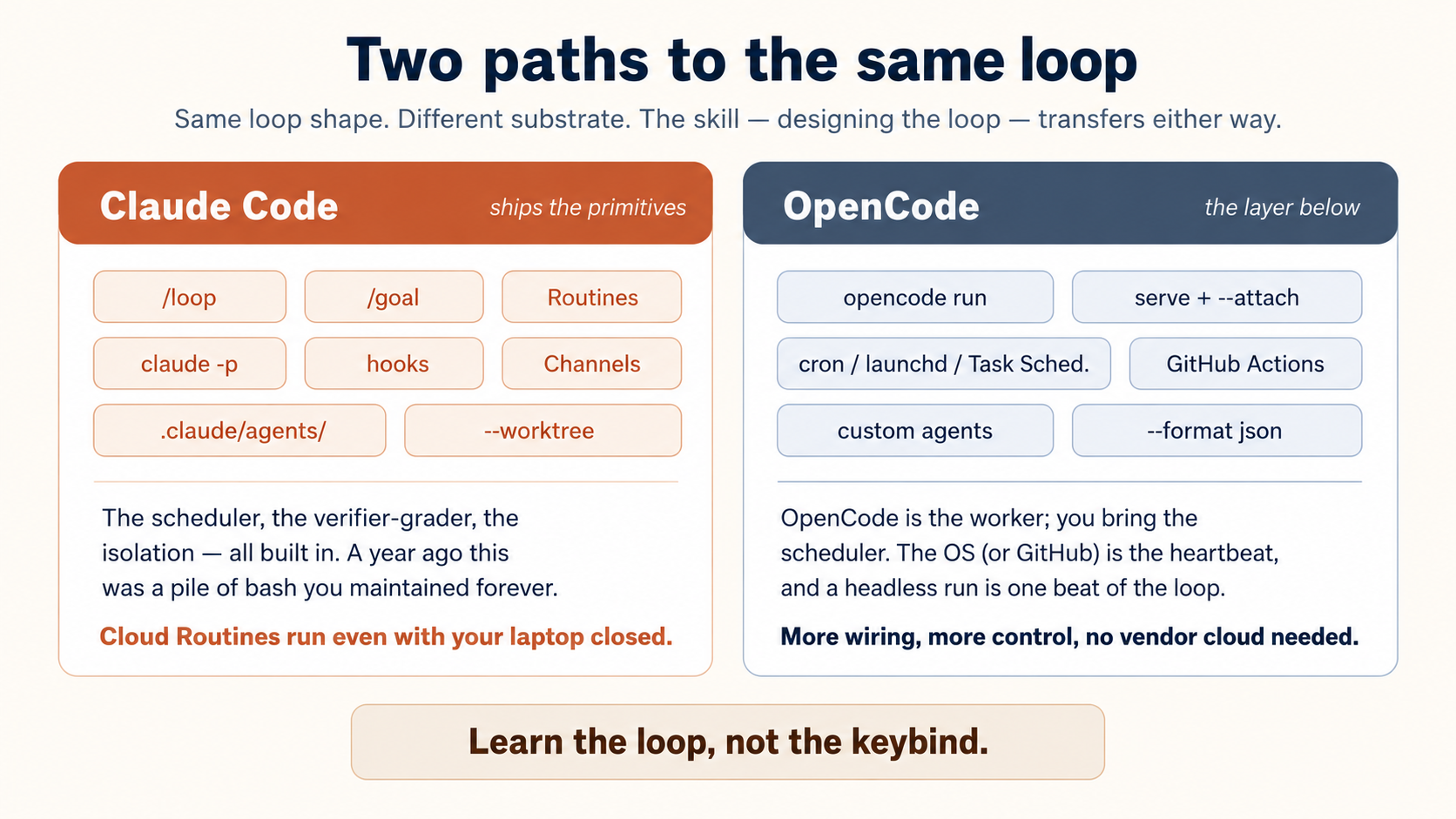
Claude Code ships the loop parts inside the product. The heartbeat (/loop, /schedule, cloud Routines), the run-until-done with a built-in checker (/goal), the isolation (--worktree), the event intake (Channels) — they are all built-in commands now. A year ago you would have written and looked after a pile of shell scripts to get this. Today you mostly just set it up.
The main one is Routines: cloud automations that run on Anthropic's servers even when your laptop is closed, started by a schedule, an API call, or a GitHub event. The price for that ease is per-account daily run caps (check your current limit in the Routines usage UI rather than relying on a fixed number), plus the fact that Routines are a research preview that can still change.
OpenCode gives you the layer below. There is no built-in cloud scheduler. Instead, OpenCode is the worker you call, and you bring the heartbeat — from the operating system or from CI.
The key command is opencode run "<prompt>". It runs one prompt without the chat screen, prints the result, and exits. That one command is one beat of a loop. You turn it into a loop by wrapping it in something that fires on a timer: cron or launchd (macOS and Linux), Task Scheduler (Windows), or GitHub Actions with a schedule trigger. This is more wiring, but you get full control, it runs on machines you already have, and it needs no vendor cloud.
Notice that the two tabs describe the same five parts. A heartbeat is a heartbeat, whether it is a managed Routine or one line in cron. The maker–checker split is the same idea, whether /goal grades it or a second opencode run does. Learn the shape of the loop once and it transfers. That is why we teach both.
Where we are going (the whole loop, early)
Before the parts, here is the finish line. The loop you will build in Part 5 is six plain steps:
every weekday at 9am: # 1. Heartbeat
read progress.md # 6. Spine (memory)
find overnight CI failures + issues # what to work on
for each one:
draft a fix in its own checkout # 2. Worktree
using the project's triage skill # 3. Skill
have a separate reviewer grade it # 4. Sub-agents (maker/checker)
if PASS: open a PR via GitHub # 5. Connector (MCP)
if risky: write it to progress.md and leave it for a human
update progress.md # 6. Spine again
Keep this picture in mind. Every concept in Parts 2–4 is one line of it.
A loop runs every morning, but each run starts fresh and never remembers what it did yesterday. Which of the six parts is missing — and why does that break the loop? The spine (state / memory). The model forgets everything between runs, so with no state file on disk the loop just repeats its first step forever instead of building on yesterday's work.Show answer
Part 2: The Heartbeat
The heartbeat is what turns one run into a loop. There are four kinds, from "stays in this session" to "runs without you at all." Learn them in order — most real loops use the last two.

4. In-session loops (repeat while you watch)
The simplest heartbeat: re-run a prompt on a timer while the session is open. Good for "watch this until it finishes" — a deploy, a long test run, a CI job.
Use the bundled /loop skill. Give it an interval and a prompt:
/loop 5m check if the deployment finished and tell me what happened
Claude turns the interval into a schedule, gives the job an ID, and runs the prompt every 5 minutes while the session stays open. When you are done, cancel it and move on.
One limit to know: /loop lives inside the session on purpose. Close the terminal, or let the laptop sleep, and it stops. That is a safety feature, not a bug — a casual in-session loop should not outlive the session. For something that keeps running, use a scheduled task or a Routine (Concept 6).
OpenCode has no /loop command. You build the timer yourself with the shell. Because opencode run exits after one prompt, a while loop with a sleep does the same job:
while true; do
opencode run "check if the deployment finished; if it did, say DONE"
sleep 300 # 5 minutes
done
This is the same idea as /loop, one layer down: the shell is the heartbeat, and opencode run is the beat. Each fresh opencode run boots the whole runtime first — config, model, plugins, and any MCP servers — before it does a single thing. To skip paying that start-up cost on every beat, start a server once and attach to it:
opencode serve --port 4096 &
# then, each beat:
opencode run --attach http://localhost:4096 "check the deploy status"
5. Run-until-done (the loop decides when to stop)
A fixed-timer loop is simple on purpose — it fires N times no matter what. Often what you really want is "keep going until this is true." This is where the maker–checker idea first appears: the loop should not let the agent that did the work decide whether the work is done.
Use /goal. You give it a stopping condition Claude can prove in its own output — something it demonstrates by running a command and surfacing the result, like "all tests in test/auth pass." It keeps working across turns until that condition holds. The important part: after each turn a separate, smaller model (Haiku by default) reads the transcript and decides "are we done?" So the agent that wrote the code is not the agent grading it. One subtlety worth knowing: that checker does not run commands itself — it judges what Claude has already surfaced — so the condition has to be something Claude's own output can show, not a private fact only a command would reveal.
/goal All tests in test/auth pass and `npm run lint` is clean.
It will edit, run the tests, read the failures, try again, and stop only when the checker confirms the condition is really met — or when you stop it yourself with /goal clear. There is no built-in "give up after N tries": if you want a ceiling, write it into the condition (…or stop after 20 turns). Write conditions a command can prove — "tests pass and lint is clean," not "the auth code is good." This is where the spec from Spec-Driven Development pays off: its acceptance criteria are already conditions a command can prove, so a good spec hands you the stopping condition for free.
OpenCode has no /goal, so you build the same maker–checker stop with the shell and exit codes. The pattern: the agent does the work, then a real command (not the agent) decides whether to stop.
for i in $(seq 1 8); do # cap the tries — never loop forever
opencode run "Make the tests in test/auth pass and fix any lint errors."
if npm test -- test/auth && npm run lint; then
echo "Condition met on try $i"; break
fi
done
Here the test runner and the linter are the checker — the most honest checker there is, because a command cannot convince itself the work is fine. For a smarter check, run a second opencode run with a dedicated review agent (Concept 11) and have it print PASS or FAIL. Always cap the tries; a loop that retries with no limit is how token bills grow out of control.
Two stops, always: a success condition (the thing is done) and a ceiling (max tries, max minutes, or max spend). A loop with a success condition but no ceiling will spend your whole token budget trying to meet a goal it can never meet.
6. Unattended schedules (runs while you sleep)
This is the heartbeat that makes loop engineering matter: a task that runs whether or not you are at the computer. "Every weekday at 9am, sort through overnight CI failures." "Every Monday, check the dependencies and open a PR with the safe fixes."
Two kinds, depending on whether you need your laptop on:
Cloud Routines (laptop can be off). The modern default. Create one at claude.ai/code/routines, in the Desktop app, or with /schedule in the CLI — all three write to the same cloud account. A routine bundles a prompt, the repos it can touch, its connectors, and a trigger (schedule, API, or GitHub event), then runs on Anthropic's servers. Note the per-account daily run caps, and that by default a routine can only push to branches that start with claude/ — a deliberate guardrail you can lift per repository with the Allow unrestricted branch pushes setting.
Headless one-shot in your own cron (laptop on, no Anthropic cloud). claude -p runs one prompt and exits — put it directly into crontab:
# every weekday at 9am: sort through CI and summarize failures
0 9 * * 1-5 cd /path/to/repo && claude -p "check the CI dashboard and summarize any failures" >> ~/claude-cron.log 2>&1
For the full treatment, see the book's Scheduled Tasks: The Loop Skill and Cron Tools.
OpenCode's unattended heartbeat is always the OS or CI — this is the OpenCode road. Use opencode run without the chat screen, and let the scheduler fire it.
Your own machine, with cron:
# every weekday at 9am: sort through CI and summarize failures
0 9 * * 1-5 cd /path/to/repo && opencode run "check the CI dashboard and summarize any failures" >> ~/opencode-cron.log 2>&1
The cloud, with GitHub Actions (no machine of yours needs to be on). The model string below is illustrative — run opencode models for the exact IDs your install knows:
name: Scheduled OpenCode Task
on:
schedule:
- cron: "0 9 * * 1-5" # weekdays at 9am UTC
jobs:
opencode:
runs-on: ubuntu-latest
permissions: { contents: write, pull-requests: write, issues: write }
steps:
- uses: actions/checkout@v6
with: { persist-credentials: false }
- uses: anomalyco/opencode/github@latest
env: { ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }} }
with:
model: anthropic/claude-sonnet-4-6 # confirm with `opencode models`
prompt: |
Review the codebase for TODO comments and summarize them.
If any are worth acting on, open an issue to track them.
For scheduled events the prompt is required (there is no comment to read it from), and you must grant contents: write / pull-requests: write if the loop should open branches or PRs.
The OpenCode GitHub Action is referenced as anomalyco/opencode/github@latest in the current official docs; some older guides still show sst/opencode/github@latest. Both point to the same project — use the one your opencode github install generates. For models, anthropic/claude-sonnet-4-6 is the current Sonnet ID. Dateless IDs arrived with the 4.6 generation, where the dateless string is the pinned snapshot; older 4.5-generation models such as Haiku 4.5 carry a dated canonical ID (claude-haiku-4-5-20251001) plus a dateless claude-haiku-4-5 alias that points to the latest snapshot. The examples below pin the dated Haiku ID for reproducibility. Run opencode models to see the exact strings your install knows.
7. Event-driven (react when something happens)
A schedule asks "check every hour." An event asks "react the moment X happens." A PR opens, an issue is filed, a message lands — and the loop runs in response.
Two routes. Routines accept a GitHub webhook trigger, so a routine can run on a push or a new PR, not only on a clock. For chat-style events, Channels push messages from outside sources (Telegram, Discord, and iMessage are built in; a webhook receiver is one you wire yourself) straight into a running session — the event-driven partner to scheduling. See code.claude.com/docs/en/channels.
Install the GitHub agent once with opencode github install, which adds .github/workflows/opencode.yml. After that, OpenCode reacts to repository events — pull_request, issues, and /oc or /opencode comments — running inside your GitHub Actions runners:
name: opencode-review
on:
pull_request:
types: [opened, synchronize, reopened, ready_for_review]
jobs:
review:
runs-on: ubuntu-latest
permissions: { contents: read, pull-requests: read }
steps:
- uses: actions/checkout@v6
with: { persist-credentials: false }
- uses: anomalyco/opencode/github@latest
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
with:
model: anthropic/claude-sonnet-4-6
use_github_token: true
prompt: |
Review this pull request for bugs, quality issues, and security risks.
For a pull_request event with no prompt, OpenCode reviews the PR by default.
You want a loop to keep fixing a failing test until it passes, then stop on its own. Which heartbeat do you reach for, and who decides "done"? Run-until-done — Show answer
/goal in Claude Code, or a capped shell loop in OpenCode. A command (the test runner) decides "done", never the agent that wrote the fix — and it still needs a ceiling so it cannot retry forever.
Part 3: The Body
The heartbeat starts the loop. These four parts are what the loop does on each beat. You met them in the agentic coding course as handy extras. In a loop they really matter, because no person is watching each step.
8. Isolation: worktrees
The moment a loop runs more than one agent at once, they start overwriting each other's files — just like two people editing the same lines without telling each other. A git worktree fixes this: a separate working folder, on its own branch, that shares the same repo history. One agent's edits cannot touch another's checkout.
Built in. Use the --worktree flag to open a session in its own checkout, or set isolation: worktree on a subagent so each helper gets a fresh checkout that cleans itself up afterward. A scheduled task can turn on worktree isolation per run, so parallel runs never collide with your own manual work.
No single flag. You use git's own worktrees and point a run at each one. Same isolation, made plain:
git worktree add ../wt-feature-a feature-a
git worktree add ../wt-feature-b feature-b
( cd ../wt-feature-a && opencode run "implement feature A" ) &
( cd ../wt-feature-b && opencode run "implement feature B" ) &
wait
Community runners (worktree managers built around OpenCode) can handle the bookkeeping for you if you do this often.
9. Knowledge: skills, so no run is "day one"
A loop runs cold every time — a fresh session with no memory of your project's habits. With no help, it works out (or guesses) your whole setup on every beat, wasting tokens and inviting mistakes. A skill is that knowledge written down once, in a SKILL.md file, where the agent reads it on every run.
This works the same in both tools: a folder with a SKILL.md of instructions and metadata, plus optional scripts and references. In a loop, the rule is simple: anything you would otherwise re-explain on every run belongs in a skill. The triage steps, the project habits, the "we do not do it this way because of that one incident" — all of it lives in the skill, so the loop builds on itself instead of restarting. (Full treatment in the Skills & Connectors crash course.)
Instead of pasting a wall of instructions into a schedule that nobody will keep up to date, your scheduled prompt becomes one line — "run the daily-triage skill" — and the skill holds the detail. Short loop prompt, easy-to-update logic, lower token cost on every beat.
10. Action: connectors (the loop acts, not just suggests)
A loop that can only read your files is a loop that can only talk. Connectors — built on MCP — let it do: open a PR, update a Linear ticket, post to Slack, query a database, call a staging API. This is the difference between a loop that says "here is the fix" and one that opens the PR, links the ticket, and posts to the channel once CI is green.
Both tools speak MCP, so the protocol transfers between them — but the packaging and authentication (local vs hosted, OAuth, permissions) often need tool-specific wiring.
Add MCP servers to your config and include them in a routine's connector list, so the unattended run can reach them. The same connectors you use by hand are available to scheduled and cloud runs.
Declare servers in the mcp section of opencode.json — local servers start a subprocess, remote servers reach an HTTPS endpoint with automatic OAuth. In a scheduled opencode run, start opencode serve once and --attach to it, so you do not pay the MCP start-up cost on every beat.
11. Maker–checker: sub-agents
The single most important choice in a loop: the agent that writes the work must not be the agent that approves it. A model grading its own output is far too easy on itself. A second agent — different instructions, often a different (sometimes stronger) model — catches what the first one missed because it was sure it was right. This is the only reason you can leave a running loop alone.
Define subagents in .claude/agents/, and put them together as agent teams: one explores, one implements, one checks against the spec and tests. "The spec" is the one you learned to write in Spec-Driven Development: its acceptance criteria are exactly what a trustworthy checker grades against — a vague spec gives you a vague verdict. This is also what /goal does inside: a fresh model decides whether the loop is done, instead of the worker grading itself.
OpenCode ships built-in primary agents (Build, Plan) and a built-in general subagent (plus explore, and scout behind an experimental flag, in current versions). You can define your own in opencode.json or as markdown files in your agents folder. Give the checker its own (often cheaper, read-only) model, and have the maker call it with an @ mention or the Task tool. A common split: a strong model explores and implements, a focused model checks.
---
mode: subagent
model: anthropic/claude-haiku-4-5-20251001
description: Reviews a diff against the spec and tests. Replies PASS or FAIL with reasons.
---
You are a strict code reviewer. You do not make changes.
Check the diff against the spec and the test results, then reply PASS or FAIL with the reasons.
Each sub-agent runs its own model and tools, so the maker–checker split really does cost more tokens. That is the price of a checker you can trust. Spend it where a second opinion matters (anything the loop will commit while you are away); skip it for throwaway, read-only chores.
11b. Codify the body: dynamic workflows
So far, the body of a beat — find the work, draft each fix in its own checkout, have a separate agent grade it — is something the agent assembles turn by turn. Claude Code now lets you codify that whole orchestration as a rerunnable script, called a dynamic workflow: you describe the task, Claude writes a script that fans the work out to many sub-agents, and a runtime executes it in the background while your session stays free. It is the maker–checker split (Concept 11) and the worktree split (Concept 8) packaged into one repeatable unit — and it can apply a real quality pattern, not just run more agents: independent reviewers can adversarially check each other's findings before anything is reported.
Ask for one in plain words ("use a workflow to…"), trigger it with the ultracode keyword, or run the bundled /deep-research. When a run does what you want, press s in the /workflows view to save its script as a /command you can rerun on every branch. Two limits keep it honest: agents are capped (about 16 at once, 1000 per run) so a runaway script cannot spiral, and a run's memory lives only within that run — you can resume it inside the same session, but a fresh session starts it over.
There is no /workflows command. The script you already write is the workflow: the capped for loop from Concept 5 and the &/wait fan-out from Concept 8 are a hand-rolled version of the same idea — your shell holds the plan, opencode run is each agent, and exit codes are the checker. You get full control and no agent cap, at the price of writing and maintaining the orchestration yourself.
This is the easiest mistake to make once workflows start to feel powerful. A dynamic workflow runs once, when you (or the ultracode setting) start it, and forgets everything when it ends. It has no heartbeat and no spine. So it is the body of a single beat, not a loop. The loop is the composition: a heartbeat (a Routine, /loop, or cron) fires the beat, the workflow is the body that runs on it, and a progress file its agents write is the spine the next firing reads. The workflow is the engine; the Routine is what turns the key, and progress.md is the fuel that survives between trips.
Part 4: The Spine
12. State that survives between runs
Here is the part beginners skip, and it is the one that makes a loop a loop. The model forgets everything between runs. If each beat starts from nothing, you do not have a loop — you have the same first step, repeating forever. The fix is dull and powerful: keep the state outside the model, on disk.
Two layers of state, working together:
- The rules file (
CLAUDE.md/AGENTS.md) — the steady habits the loop reads on every run. (Keep it short; you learned why in the last course. A bloated rules file is paid for on every single beat.) - A progress file — a plain markdown file (or a Linear board through MCP) that records what was tried, what passed, what is still open. This is the real spine. Tomorrow's 9am run opens it and picks up where today's run stopped.
The habit: every run reads the progress file at the start and updates it at the end. When the loop keeps making the same mistake, the fix is not a cleverer prompt — it is to have the loop write the lesson into the rules file, so the fix stays for every future run.
<!-- progress.md — the loop's memory between runs -->
## Done
- 2026-06-22: fixed flaky test in test/auth (retry on token refresh)
## In progress
- Dependency audit: 3 of 7 advisories patched; lodash bump blocked by an API change
## Open / needs a human
- CVE-2026-xxxx in image lib — the fix changes the output format, escalating to a maintainer
Because the progress file is just text in your repo, it doubles as the record of what the loop did while you were away. When you sit down at the human gate, you read the spine — not the full transcript of every run.
Where should a loop keep what it has done so far, and why not in the conversation? On disk — a progress file (plus the rules file), or a board like Linear. The model's memory is wiped between runs, so anything that must survive lives outside the model. The repo remembers; the model does not.Show answer
Part 5: A Complete Loop, Twice
Before you let any loop run on its own, it needs all seven of these. The loop you are about to build has every one:
- Success condition — how it knows the work is done (Concept 5).
- Ceiling — max tries, minutes, or spend, so it cannot run forever (Concept 13).
- Isolated branch or worktree — so parallel work does not collide (Concept 8).
- Read-only checker — a separate agent that grades but cannot edit (Concept 11).
- State file — the spine, so it remembers between runs (Concept 12).
- Human gate — risky or failed work goes to a person, never straight to
main(Part 5). - A log or notification — so a failure overnight is visible, not silent (Part 6).
Miss one and the loop is unsafe, forgetful, or invisible.
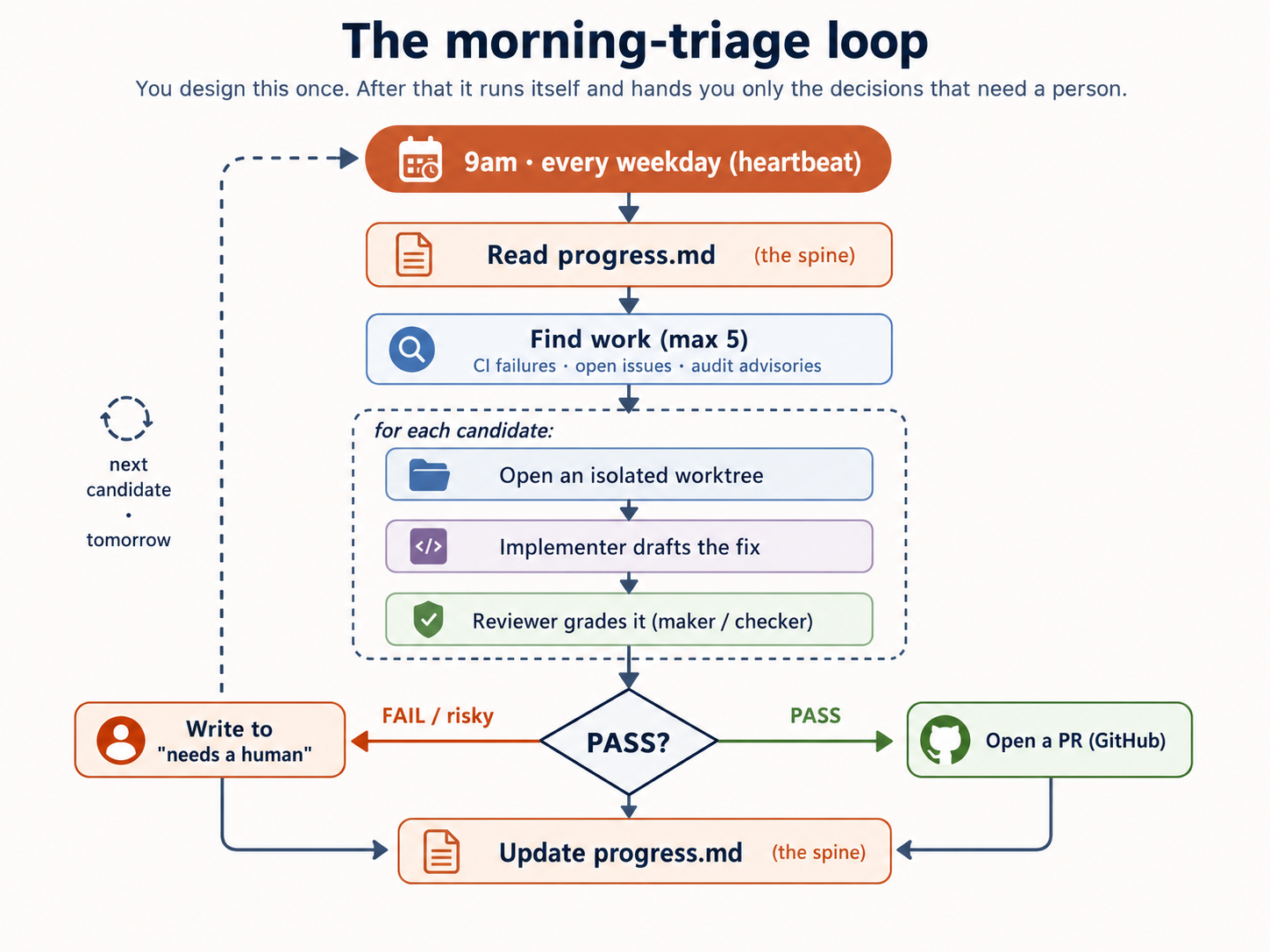
Now join the parts. Here is one loop — a morning maintenance loop that sorts through overnight CI failures, drafts safe fixes, has them checked, opens PRs for the safe ones, and flags the rest — built once in each tool. The files below are real; you can copy them into a repo and run them.
The loop shape (the same in both):
- Heartbeat: every weekday at 9am.
- Skill: a
daily-triageskill holds the steps, so the prompt stays one line. - Spine: read
progress.mdat the start, update it at the end. - Worktree: each fix drafted in its own checkout.
- Maker–checker: an implementer drafts; a separate reviewer says PASS or FAIL.
- Connector: open a PR for PASS; for FAIL or anything risky, write it to "needs a human" and stop.
The shared skill
This one file works in both tools. Save it as .claude/skills/daily-triage/SKILL.md (Claude Code) or .opencode/skills/daily-triage/SKILL.md (OpenCode).
---
name: daily-triage
description: >-
Runs the morning maintenance pass. Reads the progress file, gathers overnight
CI failures, open issues, and new audit advisories, drafts safe fixes (each
one checked by a separate reviewer agent), opens pull requests for what passes,
and writes anything risky to the progress file for a human. Use this for the
scheduled morning maintenance loop.
---
# Daily triage
You are the morning maintenance loop. Work through these steps in order.
Do not skip the progress file. It is your only memory between runs.
## 1. Read your memory first
- Open `progress.md`. Read the "In progress" and "Open / needs a human" sections.
- Do not redo anything already listed under "Done".
## 2. Find the work
Gather candidates in this order, and stop once you have at most 5:
1. CI runs that failed since the last entry in `progress.md`.
2. Open issues labelled `bug` or `maintenance`.
3. New advisories from `npm audit` (or this project's audit command).
## 3. Work each candidate
- Create an isolated checkout: a git worktree, or a fresh branch named
`claude/<short-slug>`.
- Draft the smallest fix that solves the one problem. Do not bundle changes.
- Send the diff to the reviewer agent. Wait for its verdict before going on.
## 4. Decide from the verdict
- PASS, and the change is low risk (no public API change, no data migration,
no file deletion): open a pull request. Title it `fix: <one short line>` and
link the issue.
- FAIL, or the change touches anything risky: do NOT open a pull request. Add a
short entry to the "Open / needs a human" section of `progress.md`. Say what
you tried and why you stopped.
## 5. Update your memory last
- Move finished items to "Done" with today's date.
- Save `progress.md`. This is the file tomorrow's run will read.
## Rules
- Never open more than 5 pull requests in one run.
- Never change `main` directly. Only `claude/*` branches.
- When in doubt, escalate. A flagged item a human checks is always safer than a
wrong fix shipped while no one was watching.
The reviewer (the checker)
The reviewer is the maker–checker split in practice. You need both files — this is not an either/or tool choice. The format differs slightly per tool, so each is shown in full below.
Claude Code — save as .claude/agents/reviewer.md:
---
name: reviewer
description: Reviews a diff against the spec and the test results. Replies PASS or FAIL with reasons. Makes no changes.
tools: Read, Bash(npm test*), Bash(npm run lint*), Bash(git diff*)
model: claude-haiku-4-5-20251001
---
You are a strict, read-only code reviewer. You never edit files.
1. Run the tests and the linter. Read the output yourself. Do not trust a claim
that they pass.
2. Check the change against the project conventions in `CLAUDE.md` and the
relevant spec.
3. Look for bugs, missing edge cases, security risks, and any change to public
behaviour.
Then reply with exactly one of:
- `PASS` — followed by one line saying what you verified.
- `FAIL` — followed by the specific reasons, one per line.
A change that only "looks fine" is not a PASS. The tests must actually pass, and
the change must do only what was asked.
OpenCode — save as .opencode/agents/reviewer.md:
---
mode: subagent
model: anthropic/claude-haiku-4-5-20251001
description: Reviews a diff against the spec and tests. Replies PASS or FAIL with reasons. Read-only.
permission:
edit: deny
bash:
"*": deny
"npm test*": allow
"npm run lint*": allow
"git diff*": allow
---
You are a strict, read-only code reviewer. You never edit files.
1. Run the tests and the linter. Read the output yourself. Do not trust a claim
that they pass.
2. Check the change against the project conventions in `AGENTS.md` and the
relevant spec.
3. Look for bugs, missing edge cases, security risks, and any change to public
behaviour.
Reply with exactly one of:
- PASS — followed by one line saying what you verified.
- FAIL — followed by the specific reasons, one per line.
A change that only "looks fine" is not a PASS. The tests must actually pass, and
the change must do only what was asked.
Wiring the heartbeat
Create a Routine at claude.ai/code/routines with a weekday-9am schedule, your repo, and your GitHub + Slack connectors. Point its prompt at the skill, so the routine definition stays tiny:
Run the daily-triage skill.
Start by reading progress.md; finish by updating it.
For each fix: draft it in an isolated worktree, have the reviewer subagent grade it,
open a PR only on PASS, and append anything risky to the "needs a human" section.
The skill carries the steps. .claude/agents/reviewer.md is the checker. isolation: worktree keeps parallel fixes apart. The GitHub connector opens the PRs. Because it is a cloud Routine, it runs at 9am whether your laptop is open or not — within your plan's daily run cap.
Build it as a GitHub Actions workflow, so it runs in the cloud with no machine of yours awake. The Action is the heartbeat; opencode run is the worker; your repo holds the skill, the agents, and progress.md.
name: morning-maintenance
on:
schedule:
- cron: "0 9 * * 1-5"
jobs:
triage:
runs-on: ubuntu-latest
permissions: { contents: write, pull-requests: write, issues: write }
steps:
- uses: actions/checkout@v6
with: { persist-credentials: false }
- uses: anomalyco/opencode/github@latest
env: { ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }} }
with:
model: anthropic/claude-sonnet-4-6 # confirm with `opencode models`
prompt: |
Run the daily-triage skill.
Read progress.md first; update it last.
For each candidate fix: draft it on a new branch, then invoke the
@reviewer subagent to grade it. Open a PR only when the reviewer
replies PASS. Append anything risky to the "needs a human" section
of progress.md and leave it for the maintainer.
The reviewer agent (on a cheaper read-only model) is the checker. New branches do the job of worktree isolation in CI. The OpenCode GitHub app opens the PRs. Want it on your own machine instead of GitHub's? The exact same prompt runs from a cron line calling opencode run — only the heartbeat changes.
What one real morning looks like
You designed all of the above once. Here is a single run, the kind you would wake up to (the run below is an illustration of the shape, not a recording):
[09:00] daily-triage fires
→ reads progress.md: 1 item still "in progress" (lodash bump), nothing new flagged
→ finds: 2 CI failures overnight, 1 new npm-audit advisory
→ CI failure #1 (flaky auth test):
drafts fix on branch claude/fix-auth-retry
reviewer → PASS (tests green; retries on token refresh; no API change)
→ opens PR #142, links the issue
→ CI failure #2 (type error in report.ts):
drafts fix on branch claude/fix-report-types
reviewer → PASS → opens PR #143
→ advisory (image library):
the safe fix changes the output format
reviewer → FAIL (public behaviour change)
→ writes it to "Open / needs a human" in progress.md, opens no PR
→ updates progress.md, exits
[you, 09:30] two PRs to review, one flagged item to decide on. You typed nothing.
Look at what happened. The loop found the work, drafted it, checked it, shipped the safe part, and handed you only the one decision that needed a person. That is loop engineering in practice. And notice: the only real difference between the two tools was the heartbeat and where the run happened. Everything in the middle — skill, spine, worktree, maker–checker, connector — was the same design.
In the morning-triage loop, what stops a wrong fix from being merged while you sleep? Three things together: the reviewer subagent must return PASS (maker–checker), only low-risk changes may open a PR, and the human gate sends anything risky or failing to a "needs a human" note instead of Show answer
main. Every run is also capped and logged.
Part 6: Staying the Engineer
A loop changes the work; it does not take you out of it. Three problems get bigger as your loops get better, not smaller. This part is the most important in the course.
13. Token cost is the real limit, not the keybind
This is, by far, the most common way loops go wrong. A loop runs again and again, often starts sub-agents, and each sub-agent runs its own model and tools. The cost grows faster than almost anyone expects. The fixes are simple:
- Cap every loop — max tries, max minutes, or max spend. Always (Concept 5).
- Match the model to the job — a strong model to plan and check, a cheap one to do the work. This is the single biggest saving, and you already learned it in the last course.
- Keep the loop prompt and the rules file short — you pay for them on every beat. Push the detail into skills that load only when used.
- Run it less often — once an hour instead of every five minutes is usually plenty, and about twelve times cheaper.
A quick sense of the numbers (illustrative). Say one beat — the maker plus the checker — reads about 40k tokens and writes about 6k. At Sonnet 4.6's $3 / $15 per million, that is roughly $0.20 a beat. Five beats a day across a 20-day month is about $20 — cheap. The same loop firing every five minutes around the clock is over a hundred times as many beats — comfortably past $1,000 a month, for no extra value. The cadence, not the keybind, is where the money goes.
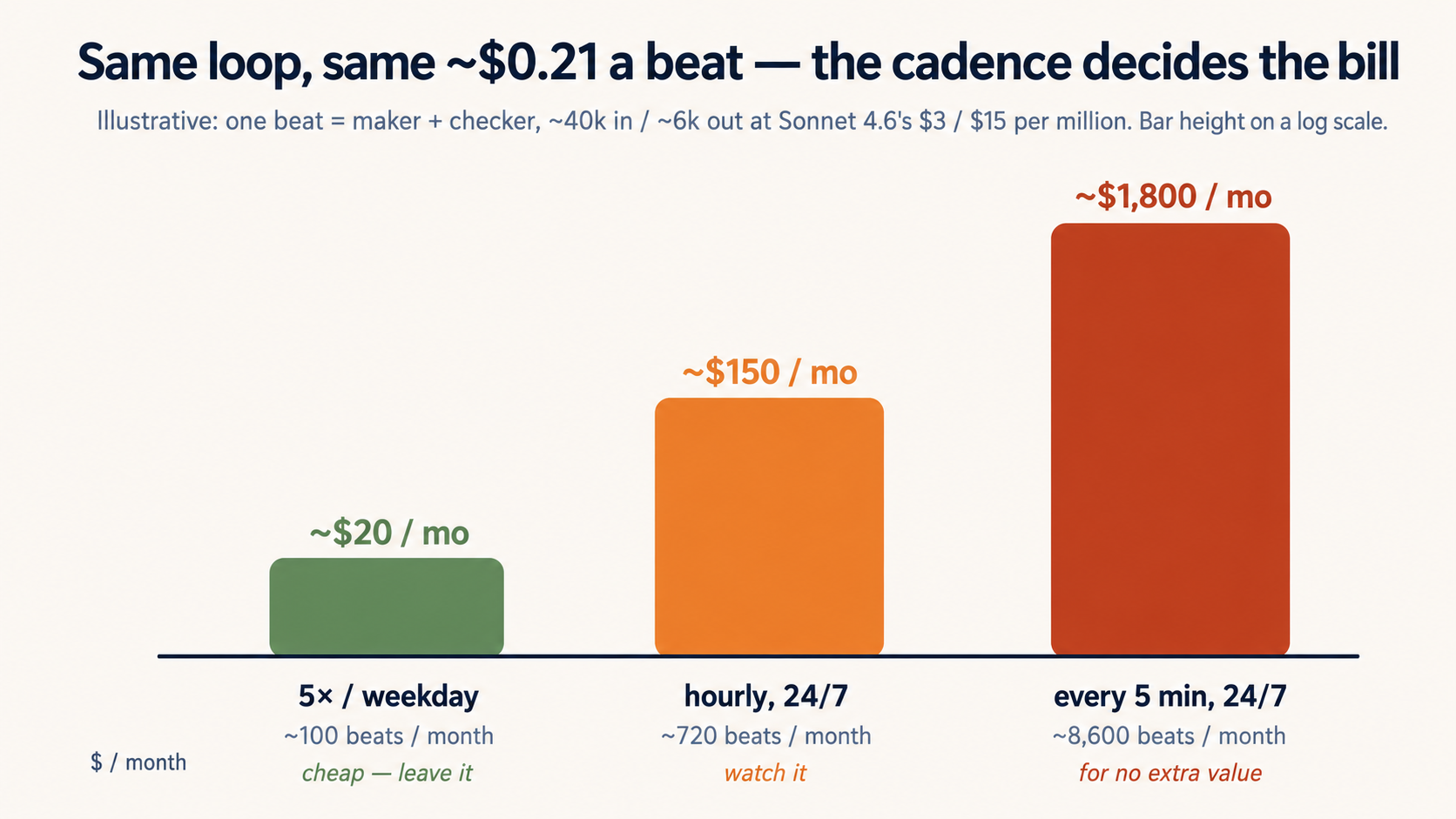
The model is a second lever — on the OpenCode path. Those numbers assume Sonnet 4.6. Claude Code's loop commands run Claude, but OpenCode lets you pick the model, and a cheap one moves the per-beat cost a long way: DeepSeek V4 Flash (about $0.14 / $0.28 per million) runs that same beat for roughly $0.007 — around 30× cheaper — turning the $20-a-month loop into well under a dollar. Two honest caveats. First, cheap maker, trustworthy checker: a weaker model writes worse fixes, so it can burn more beats or fail review more often, and the retries eat the savings — use the cheap model for the mechanical maker on a clear spec, and keep a checker you trust (the test runner and linter are the cheapest, most honest checker there is). Second, cadence still dominates: a 30×-cheaper model firing every five minutes can still cost more than Sonnet running hourly. The model scales the bill down; how often it runs and retries still sets it.
The common failure is always the same: a loop running on its own, with a stopping condition it could never meet, retrying all night. Set a ceiling before you start it. Watch the first few real runs. Then let it run on its own.
14. Checking the work is still your job
A loop running on its own is a loop making mistakes on its own. The maker–checker split makes the loop's "it's done" mean something — but "done" is still a claim, not a proof. Your job did not disappear; it moved. You no longer type each step, but you are still the one who confirms the loop shipped code that actually works. Read the diffs the loop opened. Trust the loop to do the work; check the work before it counts.
15. Don't stop understanding your own project
The faster a loop ships code you did not write, the wider the gap between what is in your project and what you actually understand. That gap is a real cost, and a smooth loop grows it quietly. The cure and the trap are the same act. Designing the loop keeps you engaged when you do it with care — and lets you stop thinking when you do it to avoid the work. Same action, opposite result. The loop cannot tell the difference. You can.
Two people can build the exact same loop and get opposite results. One uses it to move faster on work they understand deeply. The other uses it to avoid understanding the work at all. Build the loop. But build it like someone who plans to stay the engineer — not just the person who presses go.
And this is the through-line of the whole course. Every year the tools absorb more of the loop's machinery: the orchestration, the checker, and the schedule are built-in now (dynamic workflows, /goal, Routines) where a year ago they were your own shell scripts. What the tools cannot absorb is the two ends you met in Concept 1 — intent, specified precisely enough to be checked, and accountability for what ships. That is why this is engineering and not button-pushing, and it is the part of the skill that does not rot. Let the tools get stronger and lean on them; just keep both of those ends in your own hands.
When a loop fails while you're asleep
An unattended loop fails unattended too. Before you trust one overnight, make it observable:
- Send output where you will see it — a log file, a Slack or Discord message (Claude Code Channels), or the Triage inbox. Not the terminal you already closed.
- Write a line every run, even on failure — each beat appends a timestamped note to
progress.md(or a log): what it tried, what passed, what broke. A silent failure is the worst kind. - Keep runs replayable — in OpenCode,
opencode run --format json,opencode export <id>, andopencode session listgive you the full record. In Claude Code, a Routine keeps its run history in the web UI. - Fail loud at the ceiling — when the loop hits its cap or errors, it should leave a clear "needs a human" note, not just stop.
- Earn the nightly slot — run it hourly and watched for a few days before you let it run nightly and unattended. When something looks wrong, read the spine first; it tells you what the last good run did.
A loop you cannot debug is a loop you cannot trust.
🚀 Projects
Reading about loops is not the same as building one. Here are five projects, easy to hard. Do them in either tool — the loop shape is the same, so reach for the command from the matching concept (/loop and /goal in Claude Code; opencode run with a shell timer in OpenCode).
Two rules before you start, every time:
- Use a throwaway git repo. A loop edits files on its own. Do not point your first loops at work you care about.
- Set a ceiling first. Max tries, max minutes, or max spend — before you let anything run on its own (Concept 13).
Project 115-30 minA watch loopMake a loop watch a long task and tell you the moment it finishes.
Difficulty: easy · Uses: Concept 4 (in-session loop).
Build. Start a long task in your repo (for example, a script that sleeps for a while and then writes a file). Set up an in-session loop that checks every minute whether the task has finished, and tells you the moment it has.
Done when the loop notices the task finished, says so once, and you can stop it cleanly — and you never sat watching the terminal.
Project 230-45 minMake the tests pass, then stopLoop until a command — not the agent — decides the work is done.
Difficulty: easy–medium · Uses: Concept 5 (run-until-done), Concept 11 (maker–checker).
Build. Put 2–3 small failing tests in your repo. Build a loop that keeps working until the tests pass — but let a command (the test runner), not the agent, decide when it is done. Cap it at, say, 6 tries.
Done when the loop stops because the tests actually passed, not because it hit the cap. If it keeps hitting the cap, your stop condition or your prompt needs work — that is the lesson.
Project 345-60 minThe morning brief with a memoryA scheduled loop whose second run clearly builds on its first.
Difficulty: medium · Uses: Concept 6 (unattended schedule), Concept 12 (the spine).
Build. Make a scheduled loop that runs once, reads a progress.md, gathers something simple from the repo (open TODO comments, or the last day's commits), writes a short summary, and updates progress.md with what it found and the date.
Done when you run it twice and the second run clearly builds on the first — it does not repeat what it already recorded. That proves your spine works. If the second run starts from nothing, your loop has no memory yet.
Project 41-2 hrsA fix loop with a real checkerAn implementer drafts, a separate reviewer grades, and only PASS opens a PR.
Difficulty: medium–hard · Uses: Concept 8 (worktree), Concept 9 (skill), Concept 11 (maker–checker).
Build. A smaller version of the Part 5 loop. Write a short skill with your fix steps, and a reviewer agent that replies PASS or FAIL. Take one real bug, have the implementer draft a fix in its own checkout (worktree or branch), and let the reviewer grade it. Open a PR only on PASS.
Done when two things are both true: a good fix gets a PASS and a PR, and a deliberately bad fix you plant gets a FAIL with reasons. If the reviewer passes the bad fix, your checker is too soft — tighten it. A checker that approves everything is no checker.
Project 52-4 hrsYour own daily loopThe full six-part loop on a real chore, run unattended for a week — the capstone.
Difficulty: capstone · Uses: all six parts.
Build. Pick one real, boring, recurring chore in a project you actually work on — a dependency audit, a docs-freshness check, a changelog draft, a lint sweep. Build the full loop: heartbeat, worktree, skill, maker–checker, connector, and the spine. Add budget guards. Let it run.
Done when it has run unattended for a week and you trust what it ships because you read it — not because you stopped reading. Then answer Concept 15 honestly: did your understanding of the project keep up with what the loop changed? If not, slow the loop down until it does. (When it fails overnight — and it will — work through When a loop fails while you're asleep before you blame the model.)
Where to go next
- Just want the schedule details? The reference page Scheduled Tasks: The Loop Skill and Cron Tools covers
/loop,claude -p,opencode run, and OS schedulers in depth. - Building loops for non-coding work? The Cowork & OpenWork crash course shows the same heartbeat idea for professionals, with scheduled tasks instead of cron.
- The spec you wrote in Spec-Driven Development is your loop's stopping condition: its acceptance criteria are what the checker grades against and what
/goalproves before it stops. When a loop feels unsafe to leave running, the fix is almost always a sharper spec — not more automation.
Sources & further reading
This course rests on a small set of primary sources. The framing and the quotes come from these; the technical details come from the official docs.
The origin of "loop engineering"
- Addy Osmani, Loop Engineering — the essay that named the pattern and set out the five-parts-plus-spine model. https://addyosmani.com/blog/loop-engineering/
- The New Stack, "The Anthropic leader who built Claude Code says he ditched prompting — now he just writes loops." https://thenewstack.io/loop-engineering/
- Boris Cherny's "my job is to write loops" remark is from a CNBC interview, as reported by Business Insider. Peter Steinberger's "design loops that prompt your agents" line is from his post on X.
Claude Code (official docs)
- Routines — cloud scheduled automations, triggers, and run caps: https://code.claude.com/docs/en/routines
- Channels — event-driven input into a running session: https://code.claude.com/docs/en/channels
- This book's own reference page, Scheduled Tasks: The Loop Skill and Cron Tools, goes deeper on
/loop,/goal, andclaude -p.
OpenCode (official docs)
- CLI —
opencode run,serve, and--attach: https://opencode.ai/docs/cli/ - Agents and subagents — primary agents, subagents, and per-agent models: https://opencode.ai/docs/agents/
- GitHub integration — the Action, schedule/PR/issue triggers, and
opencode github install: https://opencode.ai/docs/github/
Model identifiers
- Anthropic, Introducing Claude Sonnet 4.6 — source for the
claude-sonnet-4-6model string: https://www.anthropic.com/news/claude-sonnet-4-6 - Anthropic, Model IDs and versioning — why dateless IDs (
claude-sonnet-4-6) are the pinned snapshot from the 4.6 generation onward, while 4.5-generation models like Haiku 4.5 keep a dated canonical ID (claude-haiku-4-5-20251001) plus a dateless alias: https://platform.claude.com/docs/en/about-claude/models/model-ids-and-versions
All links current as of June 2026. These tools update often, so confirm any specific limit, flag, or model string against the live docs before you rely on it.
The one-line summary
Stop prompting your agent turn by turn. Design the loop that prompts it for you — a heartbeat, four working parts, and a spine that remembers — and stay the engineer who reads what it ships.