Human-Agent Teams: The Operating Model for Your Workforce
This course is the operating model for a team of AI workers run alongside people. The unit it runs on is a single trustworthy worker, a Digital FTE: one that runs the loop, works from a searchable memory, signs in with its own identity, and escalates at the edges. You build that worker across this track; you can write this operating model first, on paper, then wire it to live workers as they come online. One trustworthy worker is the unit. Running a team of them is a different skill from building one, and this is it: how you turn the one into many.
A team of many is not a bigger version of one. It is a different thing, and it needs a different skill: not building a worker, but running a team of them alongside people.
This course is that operating model. The four courses after it are the machinery: a lead agent that hires a board (Workforce with Paperclip), a workforce that grows itself (Self-Expanding Workforce), delegated approval (Identic AI), workers that earn (Payment-Enabled Agents). None of that machinery works on a team you have not learned to run. So before you automate the workforce, you set how humans and workers share one roster, one workspace, and one goal.
A note on what kind of course this is. The other workforce courses are build-along. This one is not. You will write little code here. You will write operating documents (a roster, role cards, a north star, a verification rubric) the way a manager writes them, except your agent drafts them and you decide. The deliverables are the agreements a team runs on. They are less glamorous than code and more decisive: most human-agent teams fail on the practices, not the technology.
It is also the most accessible course in the section. Roles, goals, trust, and who-owns-what are things you already understand from working with people. Agents do not change those fundamentals. They raise the stakes on getting them right.
The patterns here are drawn from Anthropic's own account of running human-agent teams internally, mapped onto the frameworks this book has already built (full links in Sources, at the end). Where Anthropic reports a specific result, it is theirs, and it is named as theirs. The features it leans on (agents that work in shared team tools, agents with their own credentials and memory) are the same capabilities you build across this track.
📚 Teaching Aid
View Full Presentation — Human-Agent Teams
What you'll build (the artifact set)
Not an app: a set of operating documents your team runs on. The starter gives you each as a template; you fill them in with your agent's help.
- A team roster: every member, human and agent, with role, owner, tools, and autonomy level.
- A role card per agent: what it owns, what it does not, its tools, how its work is checked, when it escalates.
- A working agreement: what is public by default, the few security boundaries, what stays private.
- A north-star doc: the team's one ambitious goal, and which agents may act on it unprompted.
- A verification rubric: how a work product is graded, so it can be trusted without a human reading every line.
- A doer-verifier setup: a second agent whose only job is to check the first.
- A weekly report: the "lessons and missteps" log that makes the team improve.
- An attention budget: what you review, what's batched, and the cap on what reaches you.
Setup
- Download the starter (
human-agent-teams-starter.zip) and unzip it. It is a folder of templates, not code. Open them in any editor. - Ideally, have one Digital FTE (Building a Digital FTE) to run a real team around. No worker yet? That is fine: do this course in planning mode (the note below), then wire your manual to a live worker once it exists.
- Have a place where work is visible to the team: a shared channel, a doc library, a repository. Agents read from what is written there.
- Have your agent ready to draft with you (claude.ai, Cowork, or your worker). Every artifact in the starter is filled by the same rhythm: you direct, the agent drafts, you decide.
From here, each Part teaches one practice, then has you write the document that puts it in place. You will not be quizzed on theory; you will leave with a team's operating manual.
This course assumes your worker can already read your team's written record. Test it now: ask your agent to find a decision or document from last week, in a channel it doesn't own. If it can, you're ready. If it comes back empty, you haven't finished the searchable system of record from AI Searchable Context. Do that first. Without it, every practice here has nothing to read.
You can do this whole course before you have the technical stack: use claude.ai or Cowork as the drafting agent, write all the operating documents, and mark every agent role "planned" instead of "active." You'll leave with a complete operating manual on paper. Come back once your first workers are built and swap the planned roles for live ones.
Part 1: From one worker to a team
Concept 1: Single-player is over
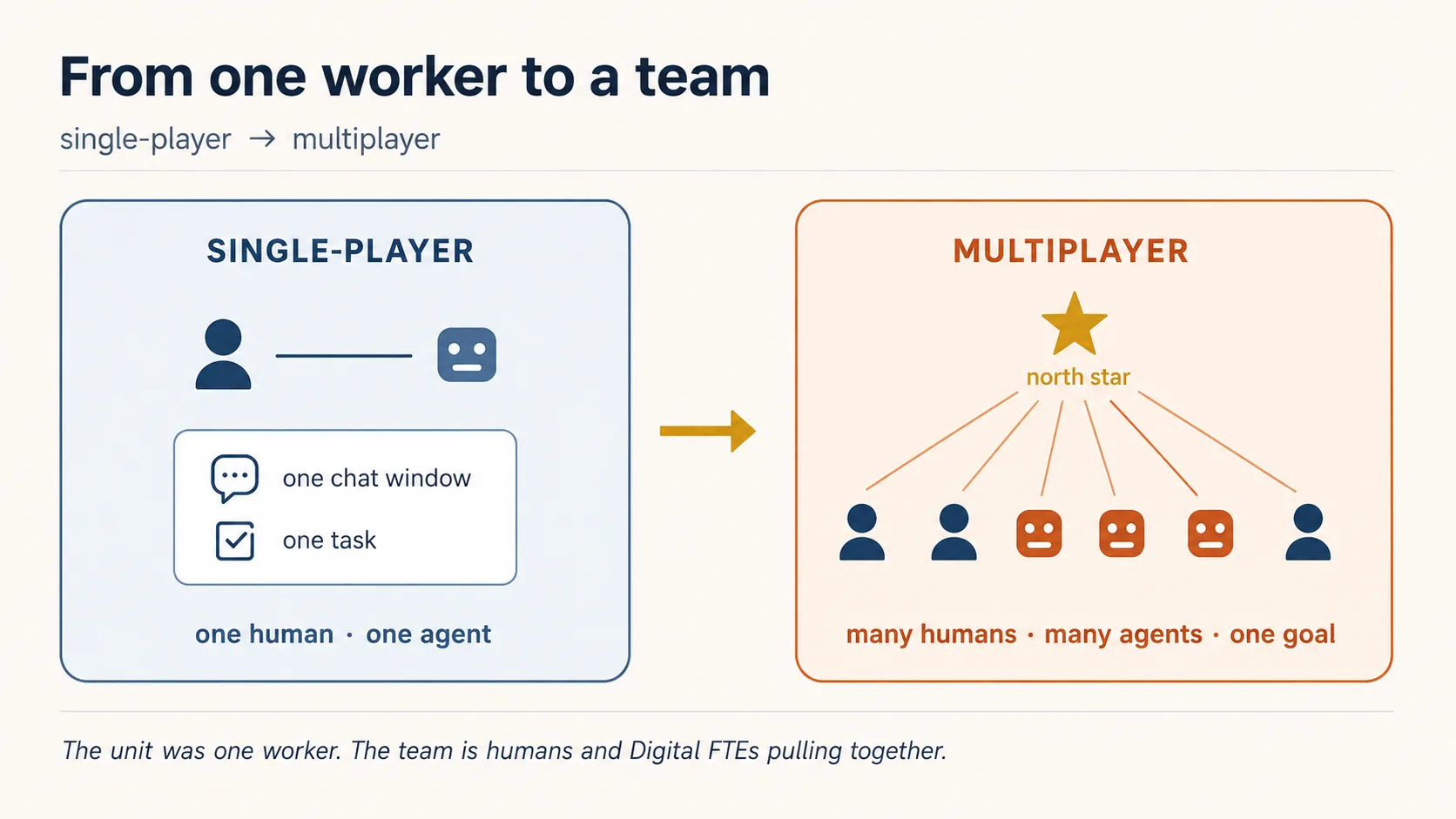
Working with AI used to be single-player: one person, one chat window, one task. A Digital FTE already does more than that. The shift this course is built on is to multiplayer: many people and many agents in one workspace, pulling toward shared goals. Humans set the strategy; the agents execute.
A multiplayer agent is one that works with many humans at once. Like a Digital FTE, it has its own memory and skills. Unlike a chat window, it has its own credentials (not borrowed from a person) and it lives where the work happens: the team's channels and docs, not a private session.
The unit is a Digital FTE. The team is humans and Digital FTEs sharing one roster. The team is the business.
Concept 2: The parts a worker needs
A team does not work until each agent has three things, and this track builds all three:
- Persistent memory: so it holds the goal across days, not just one prompt (AI Searchable Context).
- Its own identity: credentials not tied to a human, so it acts inside guardrails you set instead of borrowing someone's logins (AI Identity).
- Broad, searchable access: so it learns how the organisation works from what is written down (your Postgres system of record and RAG: retrieval, the searchable memory you gave it).
Without these, "add an agent to the team" means a person sharing their password with a script. With them, it means a worker that belongs on the roster. You can design the operating model now and wire it to live workers as those three come online; the human practices sit on top either way.
✓ Checkpoint: you know the unit. A worker with memory, identity, and access is the thing a team is made of. Now you make many of them work with people.
Concept 3: The scarce resource is human judgment
The whole operating model protects one thing: human attention and judgment. Agents are fast and many; people are the bottleneck and the authority. Every practice in this course exists to keep humans deciding the things only humans should decide, and out of everything else.
Name the failure mode first, because it is the common one. Without an operating model, people run fleets of personal AIs on the side. Work is duplicated. The team's context shatters into private windows that no one else (human or agent) can see. The metric everyone needs gets computed five different ways. The fix is not more agents; it is to run one team in the open.
The rest of the course is four practices that do exactly that.
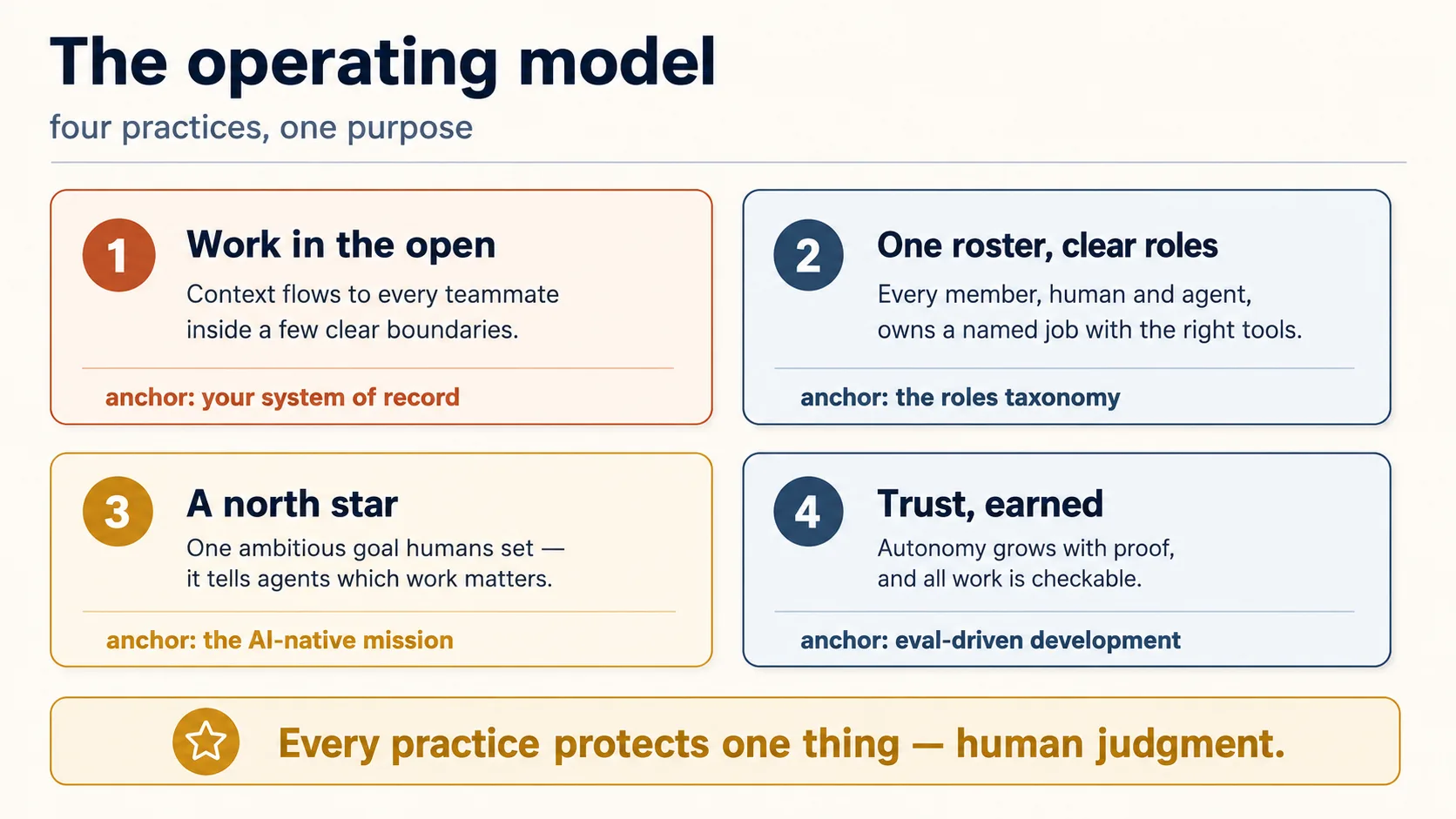
✓ Checkpoint: you know the shape. Four practices, one purpose. Next, the first one.
Part 2: Work in the open
Concept 4: If it isn't written down, it doesn't exist
An agent builds its understanding entirely from what the team makes searchable: channels, code, docs, notes. Private messages, hallway conversations, and restricted files do not reach it. For an agent, unwritten is invisible.
So the first practice is cultural before it is technical: work in public. Decisions land in channels and docs, not direct messages and meetings without notes. Write artifacts so an agent can find them: the agent is now a primary reader of your documentation, not an afterthought.
The payoff is real, and Anthropic reports it plainly. An agent that can read a team's decisions will not pitch work you already killed. One that can read another team's specs will reuse a pattern that worked. And because an agent reads far faster than any human, it routinely surfaces relevant work people would have missed. Transparency stops being a virtue and becomes leverage.
Concept 5: Boundaries at the workspace, not the document
There is a wrong way to decide what an agent can see: one document, one channel at a time. That is decision fatigue, for humans and agents both: should this be private? can I share that doc? is this agent allowed in that thread? Soft, per-item lines are exhausting and easy to get wrong.
The right way: a few clear security boundaries drawn at the workspace level: a security boundary is just a wall around a set of information, with a rule for who is inside it. Within a boundary, context flows to every teammate, human or AI. A small number of clear lines beats a large number of soft ones, and it removes the daily "can I share this?" tax.
This is where your system of record earns its place. The boundary is the wall; the searchable store from AI Searchable Context is what flows freely inside it. Draw the wall once; let retrieval do the rest.
Say the exception plainly, because public-by-default is not everything-is-public. Some work is sensitive and belongs between one human and one agent. That is a direct message to the agent, or the private apps (claude.ai, Cowork) over your personal connectors, where the conversation stays private. Default to open; keep a clear, narrow lane for what must not be.
Draft it. Open 01-working-agreement.md and paste into your agent:
Draft a working agreement for my team. State what is public by default. List the few security boundaries we need (no more than a handful) and who is inside each. List what stays private (one human, one agent). For each boundary, write one sentence a new teammate could follow.
Check it. Can you state every boundary in a single sentence? If you cannot, you have too many. Few and clear, or it will not hold.
✓ Checkpoint: context flows. Your team works where agents can read, behind a few walls anyone can name. Now put names to the work.
Part 3: One roster, clear roles
Concept 6: A team has a roster
A human-agent team shares one roster, one set of artifacts, one working space. So write the roster down: every member, human and agent, and what each one owns.
Agents hold different roles. One owns the data analysis; one holds and enforces the design standard; one runs research synthesis. When a project starts, the humans chat with the agents to decide which roles to assign and how they will work together: the roster is the output of that conversation, not a guess made in advance.
This is your Roles Taxonomy and Digital FTE taxonomy, made concrete for one team. The catalog says what kinds of workers can exist; the roster says which ones are on this team and who owns what.
Concept 7: A role is a card, and a skill file
Each agent gets a role card: what it owns, what it does not own, the tools and access it needs, how its work is checked, and when it escalates to a human. Scope is as much about the "does not own" as the "owns": an agent with fuzzy edges drifts into other people's work.
Name the tools, because a role without them is a title with no hands. The analyst needs the database. The QA agent needs the browser tool. List the access each role requires, and grant only that (least privilege is the same rule you will meet again with delegated approval).
Then write the role as a skill file. This is the move that makes the book's frameworks click: define an agent's role in a skill, and the role becomes portable: anyone in the org can stand up another agent of the same type from it. Roles stop being boxes on an org chart and become skills you can copy. (Skills are the portable lever across this whole book; a role is one more thing a skill can carry.)
Keep the human-only roles explicit. Humans work in the same threads the agents do, but they hold the roles only humans can hold: the consequential calls, the judgment with a cost. The roster is how you keep human judgment on the decisions that need it and off the ones that don't.
When an agent needs another agent
Sometimes a job is too big for one worker, and a lead agent spawns teammates with the right context for a sub-task: a researcher here, a reviewer there. That instinct is correct, and it is what the next course automates: Workforce with Paperclip turns "a lead hires a board" into a managed workforce under budgets and approvals. Your roster and role cards are its inputs. Here, you write the roles by hand so you understand what Paperclip will later do for you.
Two honest notes on the underlying feature, as of mid-2026: Claude Code agent teams are experimental and disabled by default (you turn them on with a setting), and only the lead spawns teammates; teammates can't nest their own. So "agents spinning up agents" is really "a lead spawns a flat team." Treat it as early, and read the current docs before you lean on it in production.
Draft it. Open 02-roster.md and a copy of 03-role-cards/role-card.template.md and paste:
Draft a team roster for [team]. List every member, human and agent. For each: role, who owns it, the tools and access it needs, and its autonomy level. Mark the roles only a human should hold. Then write a full role card for [my worker]: owns, does NOT own, tools/access, how its work is verified, and what triggers an escalation to a human.
Check it. Every member has an owner and a "does not own." Every agent has its tools and one clear escalation trigger. If two members could both claim the same task, the scopes are not sharp enough yet.
✓ Checkpoint: everyone has a lane. Humans and agents on one roster, each owning a named job with the tools to do it. Now give the team a direction.
Part 4: The north star
Concept 8: A goal that makes an agent proactive
Context and roles get an agent doing the work you assign. A north star gets it proposing the right work. A north star is an ambitious, wide-reaching goal that tells the team which tasks and workstreams are worth doing: the one sentence everything else is measured against. Humans always set it, grounded in the business's mission.
Once it is written, you share it with the agents on the team. Then (and this is the part people skip) you name which agents may act on it unprompted. Not every agent should propose work. Only the ones with the skills and the earned trust to do it well.
Anthropic's example is small and exact: a team whose north star was "make product onboarding more helpful" had an agent proactively recommend rewrites to onboarding error messages: changes that measurably raised onboarding success the next week. The agent did not wait to be asked. The north star told it the rewrite was on-mission.
This is your AI-Native Company mission, pushed down to one team. The company has a mission; the team has a north star that serves it; the agent has work that serves the north star. The line runs straight from the goal to the task.
Concept 9: Proactivity is a privilege you grant
The risk in a proactive agent is an agent proposing work it should not touch. So proactivity is named, not assumed. You say which agents may suggest workstreams, and the north star is the test each proposal must pass. An agent without that grant still does its assigned job: it just does not freelance.
Draft it. Open 04-north-star.md and paste:
Help me write a north star for [team]. It should be one ambitious goal, grounded in our mission. State why it matters. Name which agents on the roster may propose new work against it, and the guardrails on those proposals. Write it so an agent, given only this doc, could judge whether a new idea is on-mission.
Check it. Read it as the named agent would. Given only this doc, could it tell an on-mission idea from an off-mission one? If not, the star is too vague to steer by.
✓ Checkpoint: the team has a direction. One goal, humans' to set, with a named few allowed to chase it. Now decide how much you let them run.
Part 5: Trust, earned
Concept 10: Autonomy grows with reliability
You do not hand a new colleague the keys on their first day. You do not hand an agent 500 bug fixes on its first day either. Anthropic's engineers got there (agents dispatched to handle hundreds of fixes on their own) but it did not start that way. Grant autonomy in proportion to demonstrated reliability, then widen it deliberately, per task type.
It takes feedback cycles to externalise the tacit knowledge of how a task is done well: for a new human, and for an agent. And retest as the models change: a guardrail that helped a weaker model can shackle a stronger one, and a prompt may need rewording when the model improves. Trust is not set once; it is tuned.
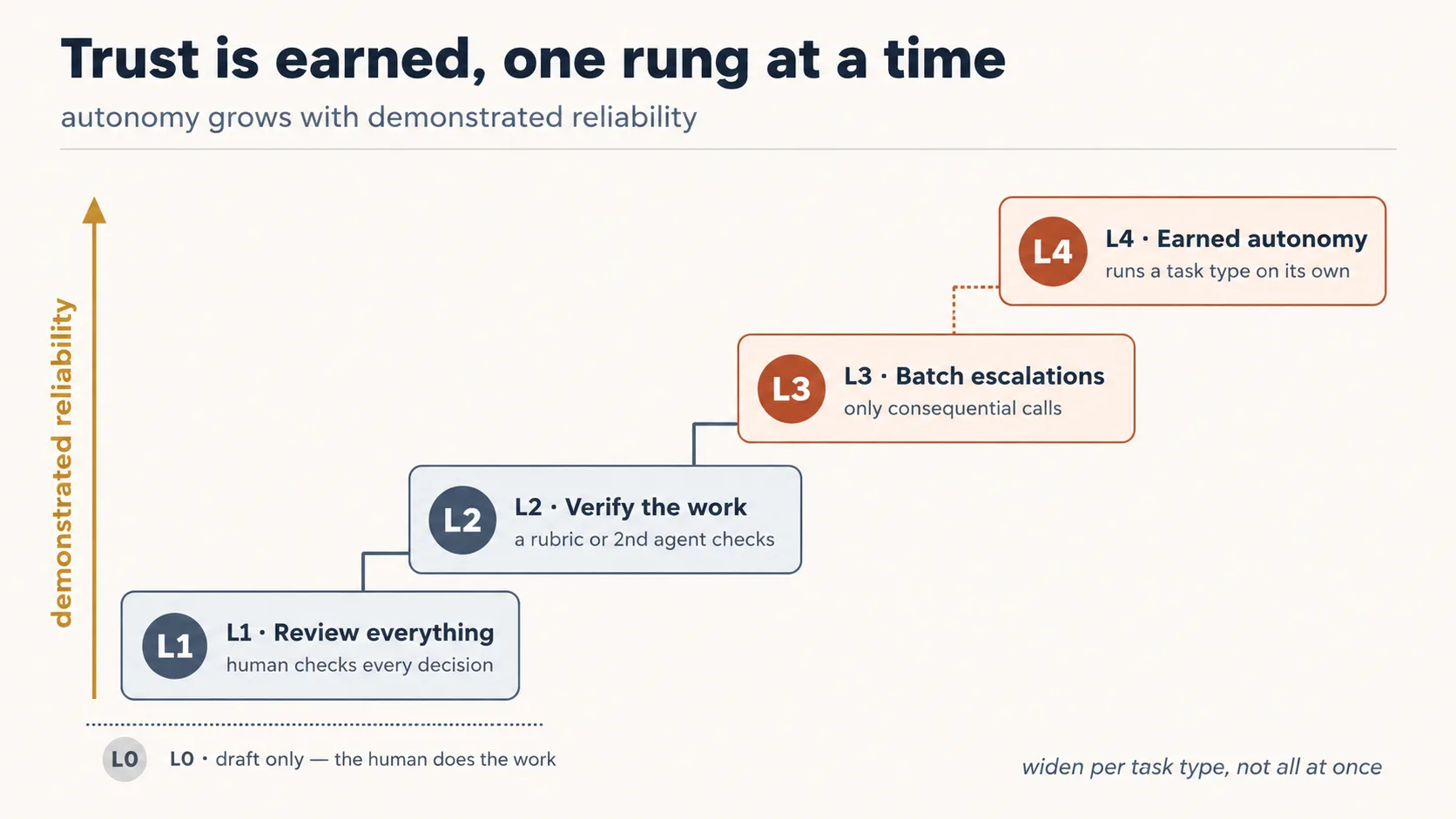
Make the ladder operational by giving it fixed rungs. Set an autonomy level per agent per task type in the roster, not one level for the whole agent:
| Level | What the agent does | Where the human is |
|---|---|---|
| L0 | Drafts only; the human does the work | human does everything |
| L1 | Acts, but a human reviews every output | human reviews all |
| L2 | Acts; a verifier checks; human reviews only exceptions | human reviews exceptions |
| L3 | Acts within limits; batches escalations to the human | human reviews batched escalations |
| L4 | Runs the task type on its own, within approved scope | human reviews the weekly report |
A new agent starts at L1 on a task type and earns its way up after repeated, verified wins. The same agent can sit at L4 on one task type and L1 on another: autonomy is granted to a worker-on-a-job, never to a worker in general.
Concept 11: Make the work checkable
The thing that lets autonomy grow safely is this: the work can be verified before a human looks at it. Code has tests, of course. But most other work can be graded too: a document against a rubric and a style guide, a report against a checklist. When you set the bar and make every assignment vettable, quality stays high and does not drift from what you intended.
This is Eval-Driven Development at the team level (Eval-Driven Development). There, the eval grades the worker automatically. Here, the rubric is that eval applied to one worker's output: the same idea, written as a checklist a teammate could run.
Then the doer-verifier: one agent does the task, a second agent's only job is to check it. (Anthropic calls this the doer-verifier harness.) It is cheap insurance, and it spends an agent's time to save a human's: the verifier catches drift before your scarce attention is spent on it.
Draft it. Open 05-verification-rubric.md and 06-doer-verifier.md and paste:
Write a verification rubric for [my worker]'s main output: the concrete checks that decide whether the work is good enough to ship, in plain pass/fail terms. Then describe a doer-verifier setup: a second agent whose only job is to grade the first's output against this rubric and return pass/fail with reasons.
Check it. Could a second agent grade the first's work using only this rubric, and would you trust the pass? If a "pass" still leaves you wanting to read every line, the rubric is not specific enough.
Concept 12: Spend human attention like money
Once agents are independent, a new failure mode appears: drowning humans in output. So treat human attention as the scarce resource it is. The best teams have their agents batch questions into a single pass, repeat key context so a human gets up to speed fast, and limit how many items a human sees at once.
Some teams give one agent the sole job of deciding what to elevate to humans. Some cap how much an agent does per day: not to slow it down, but so humans can still meaningfully engage with the work, and keep the skills that matter to them.
Build reflection into the cycle. Ask the team for a weekly "lessons and missteps" report, so mistakes get tracked and stop repeating. Track which task types each agent has earned autonomy on, and widen scope only after repeated wins. The report is how a team gets better on purpose instead of by luck.
Draft it. Open 07-weekly-report.md and 08-attention-budget.md and paste:
Draft a weekly team report template that captures, for each agent: what it shipped, its lessons and missteps this week, and which task types it has earned more autonomy on. Then propose an attention budget for me: what I will review, what gets batched, and the cap on how much reaches me at once.
Check it. In a busy week, does this keep a human deciding the important things, and nothing else? If a human still has to read everything, the budget is not protecting the scarce resource.
✓ Checkpoint: trust is a dial, not a switch. Work is checkable, autonomy widens with proof, and human attention is spent where it counts. You have the whole operating model.
Part 6: Stand up your team
You have learned four practices and drafted a document for each. Now assemble them into one team's operating manual.
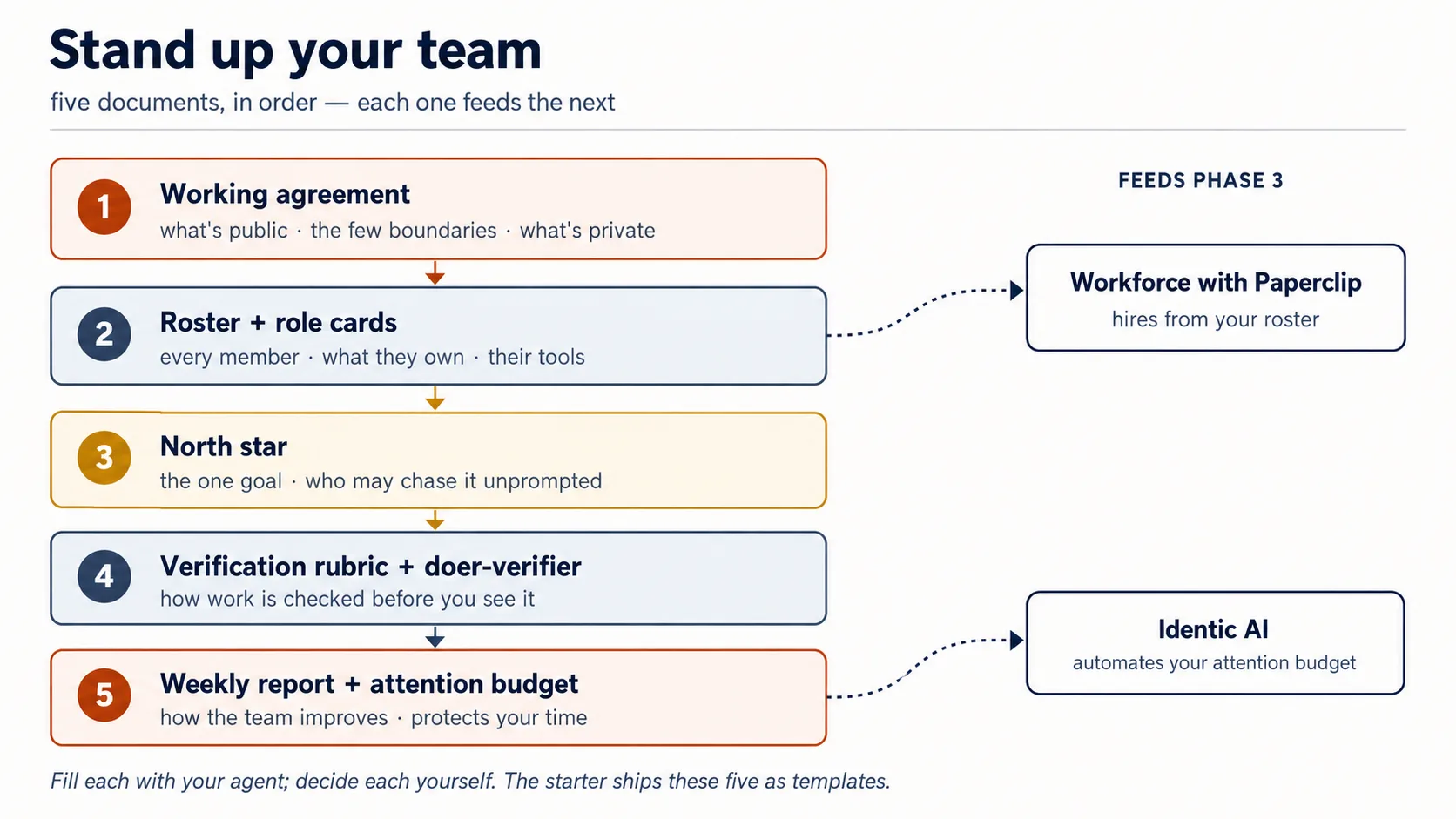
The operating manual: one folder, eight files
The manual is a folder, numbered in the order you fill it. The starter ships exactly this:
human-agent-team/
01-working-agreement.md few clear boundaries · what's public · what's private
02-roster.md every member · owner · tools · autonomy level (L0–L4)
03-role-cards/ one card per agent (copy the template)
role-card.template.md
reconciler.md (filled example)
04-north-star.md the one goal · which agents may act on it unprompted
05-verification-rubric.md the pass/fail checks a verifier can apply
06-doer-verifier.md which agent checks which, and what happens on fail
07-weekly-report.md shipped · lessons & missteps · autonomy changes
08-attention-budget.md what you review · what's batched · the cap
Each file has a short required checklist (in the template, and repeated as the "Check it" at the end of each Part). A file isn't done until its checklist is all yes. The manual isn't done until all eight are.
Fill it in order
The order is the dependency order. The four practices map to five fill-steps (the trust practice splits into verification and attention), and those produce the eight files: one manual seen at three zoom levels.
- Working agreement: what is public, the few boundaries, what stays private. (Context first; nothing else works without it.)
- Roster + role cards: every member, what they own, their tools, their escalation triggers.
- North star: the goal, and who may chase it unprompted.
- Verification rubric + doer-verifier: how the work gets checked before you see it.
- Weekly report + attention budget: how the team improves and how it protects your time.
Run each through the same rhythm: paste the Part's prompt, read what the agent drafts, and decide: cut, sharpen, approve. You are the authority; the agent is the drafter.
Use Anthropic's five questions as your done-test. The team is ready when every answer is yes:
- Is the information and access agents and humans need both public and broadly searchable?
- Can you write your team's roster, humans and agents, and say what each member owns?
- Does every human and agent have the right tools to do their job?
- Do you have rubrics or tests to verify the key work products?
- Does the team have a clear north star everyone can reference?
A worked example: a finance close team
Templates are abstract until you see one filled. Here is a small finance team that runs the monthly close (a human controller and three agents) with the parts that matter made concrete. (The starter ships this as examples/finance-close-team.md.)
North star: every number that leaves the building is right and traceable to its source.
| Member | Human/Agent | Owns | Tools / access | Autonomy |
|---|---|---|---|---|
| Controller | Human | Sign-off on anything that leaves the company | none | human-only |
| Puller | Agent | Pulling figures from the source systems | ERP / GL read-only | L2 (verified) |
| Reconciler | Agent | Matching figures across sources, flagging variances | the ledger, the system of record | L3 on routine ties; L1 on new accounts |
| Checker | Agent | Grading the reconciliation against the rubric | the rubric | doer-verifier only |
The detail that makes it safe is the escalation trigger, written plainly on the Reconciler's role card.
Escalate to the Controller when: any variance exceeds 1% of the account balance or $10,000, whichever is smaller (deliberately conservative, so even small accounts escalate on small swings), or any figure has no source in the system of record. Otherwise, tie it and log it.
And the verification rubric the Checker applies. The reconciliation passes only if:
- every balance ties to its source within threshold; 2. every variance has a reason code; 3. every source document is linked in the system of record; 4. every exception is listed in the escalation queue.
That escalation line is the whole operating model in miniature. The Reconciler runs routine ties on its own (L3), the Checker verifies against the rubric before anyone looks (doer-verifier), the unsourced or material numbers stop and reach a human (attention spent only where it counts), and the Controller holds the only role that ships a number to the outside world. Note the Reconciler is L3 on routine ties but L1 on new accounts: autonomy per task type, not per agent. Swap the thresholds and the sources, and the same shape runs accounts payable, payroll, or board reporting.
✓ Checkpoint: you can run a team. A working agreement, a roster with clear roles, a north star, a way to verify work, and a budget for your own attention. That is an operating model, and it is what the rest of the workforce courses run on.
Part 7: The ceiling, where it grows
The operating model does not, by itself, scale the team. It sets the rules; the next four courses are the machinery that runs on them, and each one takes an artifact you just wrote as its input:
- Workforce with Paperclip automates the roster: a lead agent hires and runs a board of workers under budgets, approvals, and a full audit trail. Your roster and role cards are what it hires from.
- Self-Expanding Workforce grows the team as the work grows, instead of you adding every worker by hand.
- Identic AI is your attention budget, automated: a signed identity that clears the routine approvals inside limits you set and surfaces only the consequential ones.
- Payment-Enabled Agents lets a worker transact: the step from a team that saves cost to one that earns.
Build the operating model first, and that machinery has something sound to run on. Skip it, and you are automating a team that was never coherent to begin with.
And the ceiling on the practices themselves: none of this is new, for humans. A clear north star, defined roles, working in the open, a shared bar for quality, room to learn from mistakes: these are healthy team habits we have known for decades. Agents do not introduce them. They make skipping them fatal, because an agent will scale a bad practice as fast as a good one. The teams getting the most from their agents are the ones most disciplined about the fundamentals.
This is the line the book has been walking toward: a workforce of Digital FTEs, run on this operating model, inside an AI-native company. You arrive at this operating model thinking about one worker. You leave able to run a team of them with people, and to scale, govern, and sell what that team produces.
The same manual, other teams
The artifact set is one shape; the team changes, the documents don't:
- A research team: analyst, synthesiser, and fact-checker agents under a "answer the question, with sources" north star.
- A delivery team: a planner, a doer, and a doer-verifier under a quality rubric, with a human holding the ship decision.
- A finance team: a data-pull agent, a reconciliation agent, and a human who owns every number that leaves the building.
Same five documents. Different roster, different north star, different rubric.
Capstone: stand up a real team
Pick a real goal at your organisation and produce the full artifact set for it: working agreement, roster, role cards, north star, verification rubric, doer-verifier, weekly report, attention budget.
Discuss with an AI. Question your scores.
Come back when you have your BEST evaluation.
The starter ships a graded example (examples/finance-close-team-graded.md), a complete finance manual scored 15/16 against these eight checks, with the one weak check named and the fix shown. Read it before you grade your own: it shows what the rubric catches and what a strong manual looks like.
Sources
This course teaches from Anthropic's account of running human-agent teams, mapped onto the frameworks this book has already built. The primary source and the Anthropic material it draws on:
- Anthropic, "Lessons from Anthropic on building effective human-agent teams" (June 2026): the primary source. The four practices, and the specific results named in the text (the onboarding error-message rewrite, the 500-bug-fix trust arc, the workspace-level security boundaries), are from here.
- "Equipping agents for the real world with Agent Skills" and the Agent Skills overview: defining an agent's role as a portable skill file.
- "Managed agents" and agent memory: credentials not tied to humans, and persistent memory (Concept 2).
- "Effective context engineering for AI agents": broad, searchable context (Part 2).
- "Harness design for long-running agents": the doer-verifier harness (Concept 11).
- Agent teams in Claude Code and Claude Tag: agents working in shared team spaces with their own identity.