Founding an AI-Native Startup
From a painful workflow to a closed-loop company.
This chapter assumes you already know the machinery. You know the Agent Factory is the spec-driven, human-supervised process. You know its output is an AI-Native Company, and that the workforce inside it is made of Digital FTEs. You know the Two-Layer Model — human principals and their identic delegates at the Edge Layer, an AI Workforce Layer beneath. This chapter is not about how to build an agent. It is about how to build a company out of them, starting from nothing.
AI-Native Startup — a company designed from day one around Digital FTEs, evaluations, shared memory, and closed-loop feedback, either because it sells Digital FTEs to customers or because it runs internally on them.
Identic delegate — an AI agent that acts under a specific human principal's identity and authority. Together with the principals they answer to, identic delegates form the Edge Layer that supervises the AI Workforce Layer beneath.
This chapter builds directly on the core machinery covered elsewhere in the book — the Agent Factory process, Digital FTEs, the Two-Layer Model, the system of record, and the eval loop. If any of those are still unfamiliar, read those chapters first; everything here assumes them.
📚 Teaching Aid
View Full Presentation — Found an AI-Native Startup
1. The Founding Window
There is a window open right now, and it will not stay open.
For most of software history, the founder's job was to assemble people. You raised money so you could hire engineers, so they could write code, so the code could become a product. Headcount was the unit of production, and everything downstream — your burn rate, your org chart, your speed — was a function of how many humans you could attract and coordinate.
That equation has been rewritten. The unit of production is no longer the engineer; it is the engineer in concert with a workforce of Digital FTEs, governed by memory and evaluations. A founder who understands this can manufacture, in weeks, what once took a funded team years.
This is not merely a mood in the market. Independent trackers estimate the agent-software category is growing several-fold across the second half of the decade, and Y Combinator's own thesis, argued repeatedly on its Lightcone podcast, is blunter still: vertical AI agents could be many times larger than the SaaS market that preceded them. Treat the exact multiples with suspicion — they come from people with reasons to be optimistic — but the direction is not seriously disputed.
What the window actually rewards is narrow and specific. The strategy this chapter teaches — find one painful workflow, go deeper into it than anyone else is willing to, and deploy a Digital FTE that owns it — works because the incumbents have not yet moved. On the Five-Level AI Maturity Ladder, most of the companies you will compete against are stuck at Levels 1 and 2, handing every employee a copilot and calling it transformation. The founders who win this decade are the ones who treat that emptiness as a countdown rather than a comfort.
2. What an AI-Native Startup Actually Is
Most companies that say "AI" mean AI-assisted. They bolted a copilot onto a workflow designed for humans and left the workflow intact. The org chart did not change. The way decisions get made did not change. They got a faster horse.
An AI-Native startup is a different animal, and it shows up in two distinct forms that are easy to confuse. It is worth separating them now, because the rest of this chapter draws on both.
The first is the AI-Native company as a product: you build and sell Digital FTEs to other organizations. Your product is a worker. Salient sells a loan-servicing agent; HappyRobot sells a freight-operations agent; Reducto sells the document-processing layer that other people's agents depend on. The customer rents a workforce they could not build themselves.
The second is the AI-Native company as an operating model: you run your own company as a closed-loop intelligence, with Digital FTEs woven into how decisions actually get made internally. This is the model Jack Dorsey and Sequoia's Roelof Botha describe in their 2026 essay From Hierarchy to Intelligence — a company organized as an intelligence rather than a hierarchy, which they go so far as to call a "mini-AGI" (Block, 2026).
These are different answers to different questions — what do I sell? versus how do I operate? The reason this chapter covers both is that the same discipline underwrites each: specifications both humans and agents can read, evaluations that define quality, a system of record the workforce can query, and human accountability held at the Edge Layer. A founder who masters that discipline tends to do both at once. The company you build to sell Digital FTEs is itself run on Digital FTEs. The factory makes the product and runs the firm.
Underneath both forms sits a single architectural commitment, and it belongs at the center of your vision. The idea comes from control systems. An open loop acts and never checks the result — like a heater you switch on and leave running, whatever the room does. A closed loop senses the result and keeps adjusting — like a thermostat that reads the temperature and corrects toward the setting you want. A legacy company runs as an open loop: information lives in people's heads, in unwritten meeting notes, in side channels, in the vague institutional sense of "how we do things." Decisions are made on lossy inputs, error accumulates quietly, and the system drifts. An AI-Native company runs as a closed loop: every artifact the company produces is readable by the workforce, every outcome feeds back, and the loop corrects itself. The advantage you have as a founder is that you do not have to retrofit this. Incumbents must dismantle centuries of hierarchical habit to reach it; you can be born closed-loop.
Hold both forms in view as you read on, because they organize what follows. The wedge, the go-to-market, the pricing, and the growth curve speak first to the founder selling Digital FTEs, since that is the path most founders take first. The founding shape is where running your own company as an intelligence comes forward. The factory and the moat belong to both. Where the path forks between the two, this chapter marks the fork.
The path from here looks like this:
3. Finding the Wedge
You do not start with a market. You start with a workflow.
That workflow is your wedge: the single narrow problem you use to get your first foothold in a market — the way a thin wedge can split a heavy log, because all of its force lands in one place.
The mistake first-time AI founders make is to pick a category — "legal," "healthcare," "logistics" — and try to build a platform for it. A category is too big, too defended, and too abstract for a Digital FTE to own. What you want instead is a single, painful, unglamorous, high-friction process, the kind that today runs on phone calls, email threads, spreadsheets, and people staying late. Garry Tan describes the founders who win as acting almost like ethnographers, exploring the underserved slices of the GDP pie chart. You are not looking for a big idea; you are looking for a small, expensive, deeply annoying piece of work that nobody has bothered to automate because it was too messy to digitize.
Three tests tell you whether a workflow is a real wedge.
It must be messy enough that generic models fail. If a general-purpose assistant can already do it, you have no moat. The friction — the domain rules, the edge cases, the regulatory nuance — is the thing that protects you.
It must be narrow enough that a deployed solution wins. You should be able to point at one outcome and own it end to end, rather than gesture at a category.
It must be painful enough that someone pays this quarter. Not "would be nice." The kind of pain that survives a budget review.
The domain knowledge required to find such a wedge is itself the moat, and you can acquire it deliberately. The founders of HappyRobot did not come from freight; they came from robotics and computer vision, then went into the operational guts of logistics until they understood it cold. Their CEO, Pablo Palafox, has argued that being verticalized beats general-purpose voice startups that are, in his words, clueless about the operations and intricacies of these industries. Salient's founders did not come from consumer lending either; they learned it by living in it. The lesson is not "have a background." It is to go and get one, on purpose, in a domain that is not in the training set.
To find the open ground, read the map honestly. Anthropic's Economic Index, built from real anonymized usage of Claude, shows that AI adoption is strikingly uneven — concentrated in a handful of countries and occupations. Even in the most-penetrated category, Computer and Math, observed usage covers only about a third of the tasks the models could theoretically perform, and usage across the economy still leans toward augmentation rather than full automation (Anthropic Economic Index, 2026). Translate that for founding purposes: the territory where work is genuinely being handed off to agents is small, and the white space — finance back-offices, legal operations, claims processing, customer service, and the rest — is mostly unclaimed. That gap is your opportunity map.
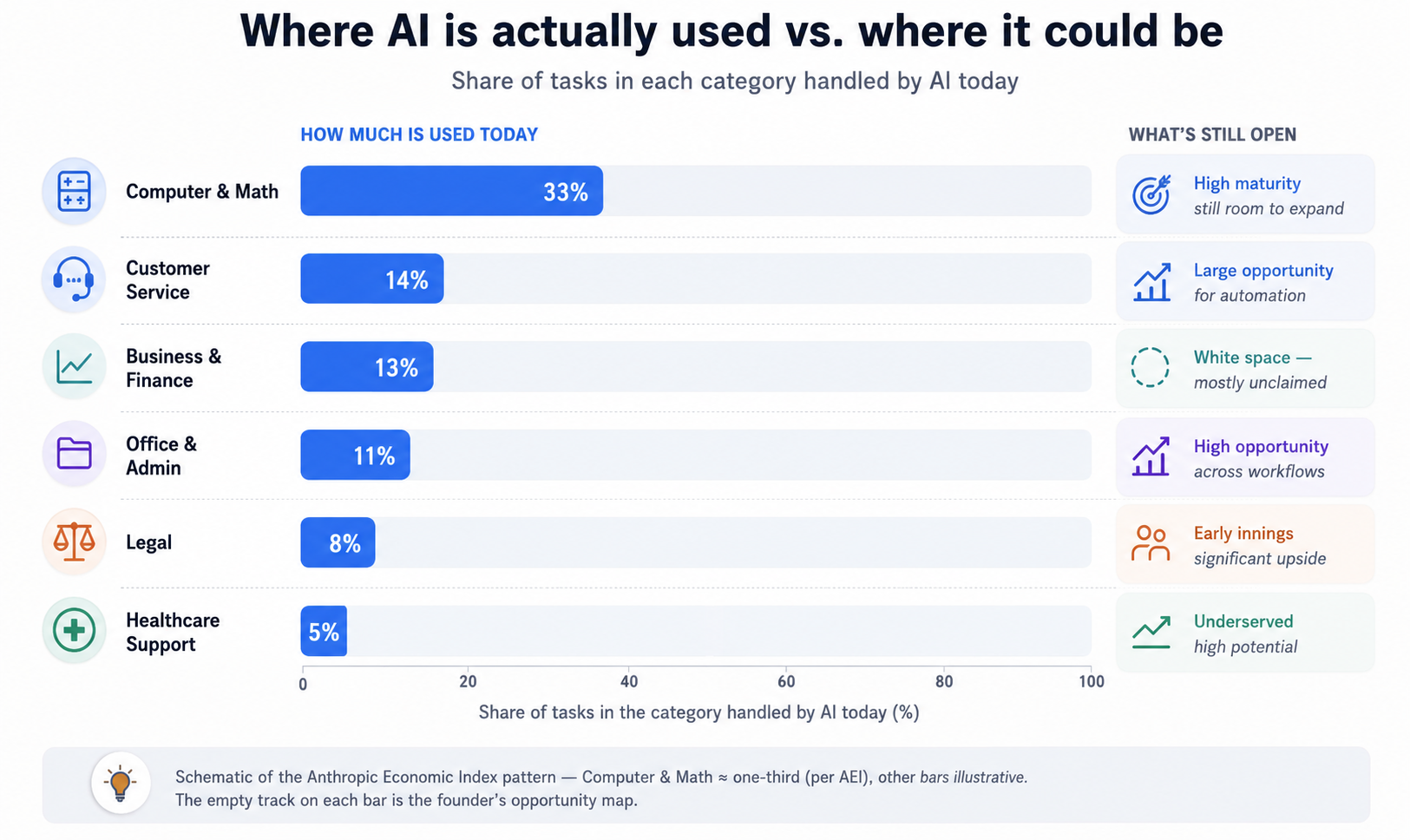 The filled bars show how little of each category's work is handed to AI today; the empty track on each bar is the founder's opportunity map.
The filled bars show how little of each category's work is handed to AI today; the empty track on each bar is the founder's opportunity map.
Here is the chapter's first fork. If your aim is the operating-model company rather than a product to sell, run the same exercise inward. Your first wedge is the most painful workflow inside your own walls, and the first Digital FTE you deploy is one you will never invoice for. The discipline is identical; only the customer changes.
4. The Founding Shape
The AI-Native company can be flatter from the first day, and the flattening is structural rather than cultural. It does not remove leadership, governance, compliance, product judgment, or customer ownership — those stay firmly at the Edge Layer. What it removes are the layers that exist only to route information.
Hierarchy exists to move information. For two thousand years — Dorsey and Botha trace it to the Roman army — organizations have inserted layers of middle management whose real job is to route information, pre-compute decisions, and hold alignment across a group too large for any one person to see. When the workforce becomes a closed loop with a shared world model, that routing function can be performed by the system itself. The middle layer is not cut to save money. Once the system moves the information on its own, that layer is simply no longer needed.
In practice this collapses the company into three roles, and they map almost exactly onto your Two-Layer Model. There is the individual contributor, a deep specialist who takes direction from the model rather than a manager, and who is rarely working alone — even a salesperson now orchestrates a pipeline of Digital FTEs. There is the directly responsible individual — the DRI, borrowed from Apple — who owns a cross-functional outcome end to end and has standing permission to pull whatever the workforce can provide. And there are the human principals who live, in Dorsey and Botha's phrase, "at the edge" of the organization, handling the creative, cultural, and ethical decisions that cannot be delegated while the AI Workforce Layer handles coordination.
That last role is your Edge Layer, named by someone else and arrived at independently. When a payments company restructuring under duress and a startup blueprint built from first principles converge on the same shape, it is a strong sign the architecture is right.
The mechanism that makes this work is a system of record. Dorsey and Botha describe it as a world model that tracks every decision, discussion, plan, and problem, paired with a strong customer signal that defines success. This is the same instinct that makes a queryable, agent-readable system of record the spine of an AI-Native company: the DRI orchestrates, the world model remembers, the customer signal judges, and there is no manager in between because none is needed.
This is also where the new headcount math becomes a design constraint rather than a slogan. Salient reportedly reached meaningful scale with roughly forty employees, weighting its hiring toward engineering and, by its CEO's emphasis, prioritizing real revenue over a paper valuation. Reducto, in its early days, ran with a famously small team. Revenue per employee stops being a vanity metric and becomes a number you set: you are not trying to grow the org chart, you are trying to keep it small while the workforce beneath it scales. Block treated this as more than theory — in early 2026 it cut roughly four thousand of more than ten thousand employees and framed the move not as cost-cutting but as a permanent restructuring to replace middle management with intelligence. That is an incumbent paying, in pain, for a transition you can skip.
5. Build: The Factory Is the Company
The mechanics of manufacturing a Digital FTE — the spec-driven, human-supervised loop of Manufacture, Package, and Monetize — are the subject of the rest of this book (see the Agent Factory build chapters), and the founding context does not change them. What it changes is their scope. For a single agent, the skill–resolver–memory–evaluation loop is how you build one reliable worker. For a company, that same loop is the operating system of the entire business: it is how the product gets made and how the firm runs itself.
This has a consequence founders underrate. The factory is not a phase you complete before going to market; it is the thing you are selling and the thing you are becoming, simultaneously. Your evaluation suite is both your quality gate and your moat. Your system of record is both the product's memory and the company's. When you treat the factory as infrastructure rather than a build step, the two forms of AI-Native company from Section 2 stop being separate projects and become one.
Before going further, internalize the one line that separates a company from a science fair: the line between a demo and a deployment. A demo is easy, and the market is now drowning in them. Getting a Digital FTE to production — reliable on real data, on the customer's worst day, inside their actual systems — is the hard, unglamorous, company-defining work. The penalty for skipping it is well documented: Gartner predicts that more than 40% of agentic AI projects will be canceled by the end of 2027, citing escalating costs, unclear business value, and inadequate risk controls (Gartner, 2025). Read the figure as a forecast, but read the pattern as real. The failures are rarely failures of model quality; they are failures of discipline — shipping the demo, calling it done, and watching it fall over. The eval-gated, test-covered rigor the Agent Factory imposes is the direct answer. A demo proves the model can; a deployment proves the workforce will, repeatably.
6. The Moat: Taste, Evals, and the Closed Loop
When the cost of writing code falls toward zero, every founder has to answer one question: what is left to defend?
The increasingly agreed-upon answer is taste expressed as evaluations. An evaluation — an eval — is a repeatable test that checks whether an agent's output is genuinely good: correct, compliant, and useful, not merely plausible-sounding. Garry Tan has called evals the real moat for AI startups — not the model, not the prompt, but the capacity to measure quality systematically. OpenAI's Greg Brockman has said that evals are often all you need, and the investor Anjney Midha has pointed out the tell: the best AI product leaders publicly credit "taste" as their differentiator, while behind the scenes it is relentless evals. Tan connects the two directly — taste is the thing the model has not solved and may never fully solve, and it shows up operationally as the question of whether a given prompt, model, and Digital FTE actually hold up across the scenarios a real customer will throw at them.
This is why generic benchmarks are a trap. A high score on a public benchmark tells you nothing about whether your Digital FTE preserved a customer's trust, followed the domain's rules, or hit the business goal. The only judge that matters is the user, in your specific domain, on your specific workflow — and because that judgment differs in every vertical, it cannot be commoditized away by the next model release.
So the founder's non-delegable work is to sit with the traces: to read what the workforce actually did, label it right or wrong, and feed that judgment back into the loop. This is the closed loop made personal — the human at the Edge Layer supplies the taste, the eval suite encodes it, and the workforce inherits it. It is tedious, it is the moat, and it is one of the Seven Invariants made concrete. Human accountability does not get automated, even in a company built of automated workers.
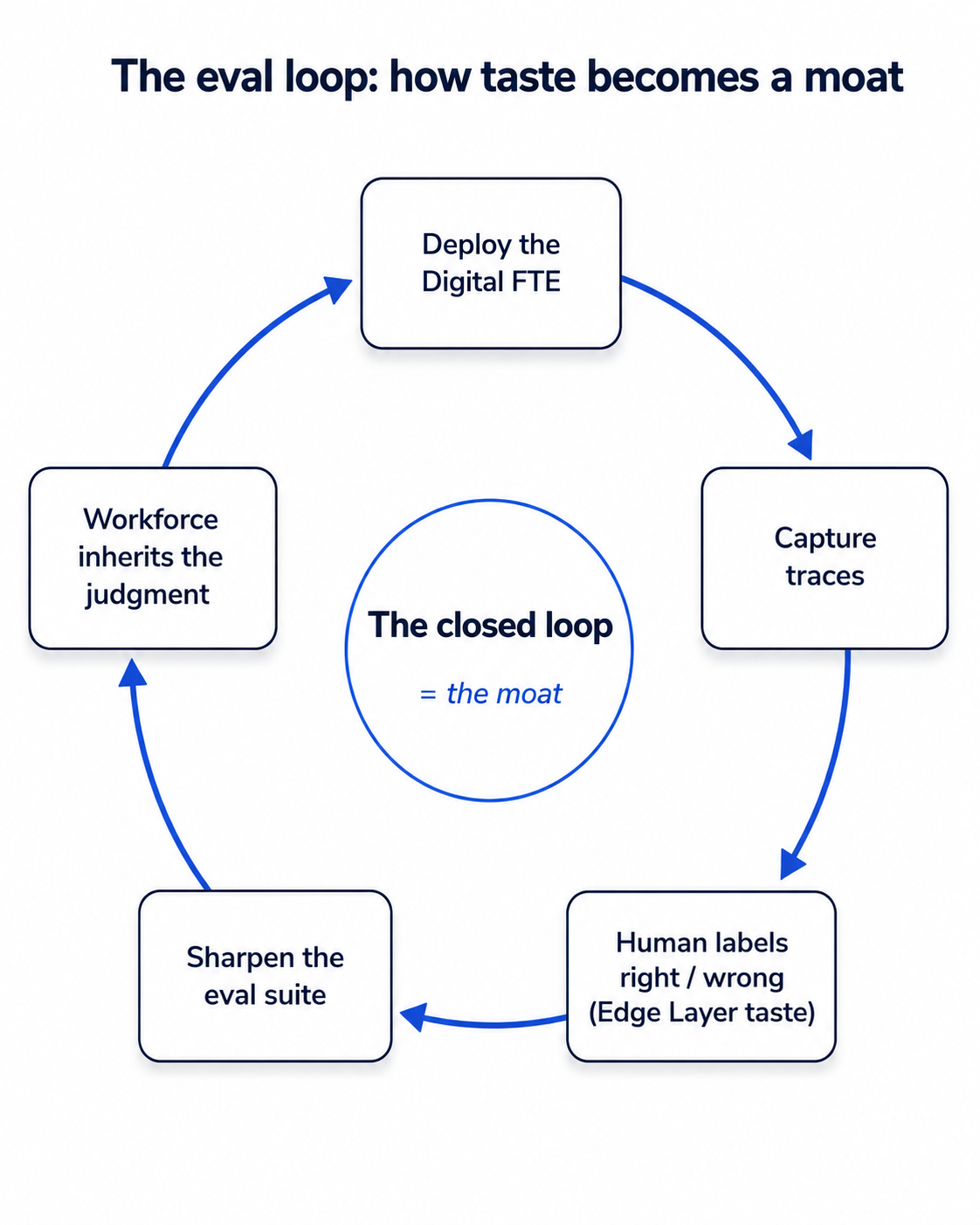 Taste becomes a moat when it is encoded as evaluations and fed back through a loop the workforce inherits.
Taste becomes a moat when it is encoded as evaluations and fed back through a loop the workforce inherits.
7. Go-to-Market: Deploy, Don't Demo
The most important strategic word in this chapter is deploy.
The companies posting growth numbers that sound impossible are not selling AI in the abstract; they are deploying full solutions inside a customer's messiest workflow and owning the outcome. The motion that makes this work has a name and a lineage: the forward-deployed engineer.
Put plainly: a forward-deployed engineer is an engineer you send to work inside the customer's own company — sitting with their team, on their own systems — building the solution together with them, instead of shipping them software and leaving them to install it alone.
Palantir — a data-software company known for its work with governments and large enterprises — invented it in the early 2010s, when its intelligence-community customers could not even articulate their problems in a product brief. The only way to solve them was to embed engineers — Palantir called them "Deltas" and "Echoes" — directly inside the customer's organization, sometimes for months, to learn the domain, stitch the systems together, and ship working software on the customer's own ground. The internal philosophy was "gravel road to paved highway": the embedded engineer builds a fast, rough, customer-specific solution, and the core team studies it, finds the pattern across customers, and turns it into product. a16z now calls the forward-deployed engineer one of the hottest roles in tech (a16z, 2026), and in May 2026 both OpenAI and Anthropic formalized the model at scale — OpenAI launching its own Deployment Company, capitalized at more than four billion dollars and seeded with roughly 150 forward-deployed engineers through its acquisition of Tomoro, and Anthropic standing up a parallel forward-deployed venture and co-building embedded agent systems with enterprises such as FIS (OpenAI, 2026).
For a founder, the actionable claim is that the forward-deployed engineer belongs in your first handful of hires, ahead of your first salesperson. The reason is the compounding loop. A sales-led motion produces a closed deal and a note in a CRM. A forward-deployed motion produces a closed deal and a piece of product and a piece of domain knowledge that makes the next deployment faster. Proponents put the iteration advantage at several times a traditional sales motion; even if you discount that, the structural point holds — every engagement feeds the product instead of dead-ending in an account record.
The case studies are the playbook. HappyRobot funds a dedicated forward-deployed engineering team that works on-site to tailor its agents to each freight operator's reality. Salient lands customers through a deliberately narrow pilot — one loan portfolio, one agent, clear guardrails, measurable outcomes in weeks — and then expands. That is your template: win one workflow inside one customer completely before widening by an inch.
One honest caveat, and it comes from a16z itself: the forward-deployed model works only when there is a real platform underneath the bespoke work. Embed without a product engine behind you and you do not become an AI-Native company; you become a consulting shop that happens to use AI, trading hours for money with no compounding asset. The forward-deployed engineer is a flywheel for the product, not a substitute for it.
Forward deployment is not consulting if every engagement improves the product, the eval suite, and a reusable workflow specification. If each customer instead requires a one-off rebuild that compounds into nothing, you are running an agency with extra steps.
Picture a team that builds a sharp claims-processing agent for one insurer, then rebuilds it almost from scratch for the next because none of the first build became a reusable spec. Three customers in, they have three fragile codebases, no product, and a calendar consumed by maintenance — busy, paid, and going nowhere.
8. Monetizing the Workforce
Here the two forms of AI-Native company part ways, and the fork is worth naming. If you are selling Digital FTEs, monetization is your revenue model — the price a customer pays to rent a worker. If you are running your own company on Digital FTEs, "monetization" is really margin: the worker shows up not as a line of revenue but as a cost that never arrives — a profit margin that a competitor carrying many human salaries cannot match. Both are real business models. This section is about the first; the second is simply the discipline of the founding shape, expressed on the income statement.
Whichever you are building, the anchoring principle is the same: price against headcount, not against software. A Digital FTE that replaces or augments human labor should be valued against the fully loaded cost of that labor, not benchmarked against a per-seat SaaS comparison. The case studies justify it. Salient's agents reportedly automate the large majority of outbound calls while measurably improving payment rates, and one public deployment cited a reduction in call handle times of more than sixty percent. Those are outcome metrics, and they support a value-based contract far better than a seat license can.
The book's four models are not interchangeable; each fits a different shape of wedge. The managed subscription is the easiest to sell and the easiest to forecast, but it caps your upside at a number the buyer can rationalize against a salary line — reach for it when the workflow is continuous and the value is steady. The success fee can capture far more of the value you create and puts your incentives on the same side as the customer's, which is why it often closes fastest in a high-trust enterprise wedge; but it works only when the outcome is measurable and attributable, which means it rests entirely on the evaluation and instrumentation discipline from the moat. It also transfers risk onto you, so reserve it for wedges where you are genuinely confident in the worker's reliability. Licensing the recipe — selling the specification and letting the customer run it inside their own walls — is the model for regulated, security-sensitive, or sovereignty-conscious buyers in defense, finance, and healthcare who will not let an outside agent touch their data. The skill marketplace is for niche expertise at volume, where no single customer justifies a bespoke deployment.
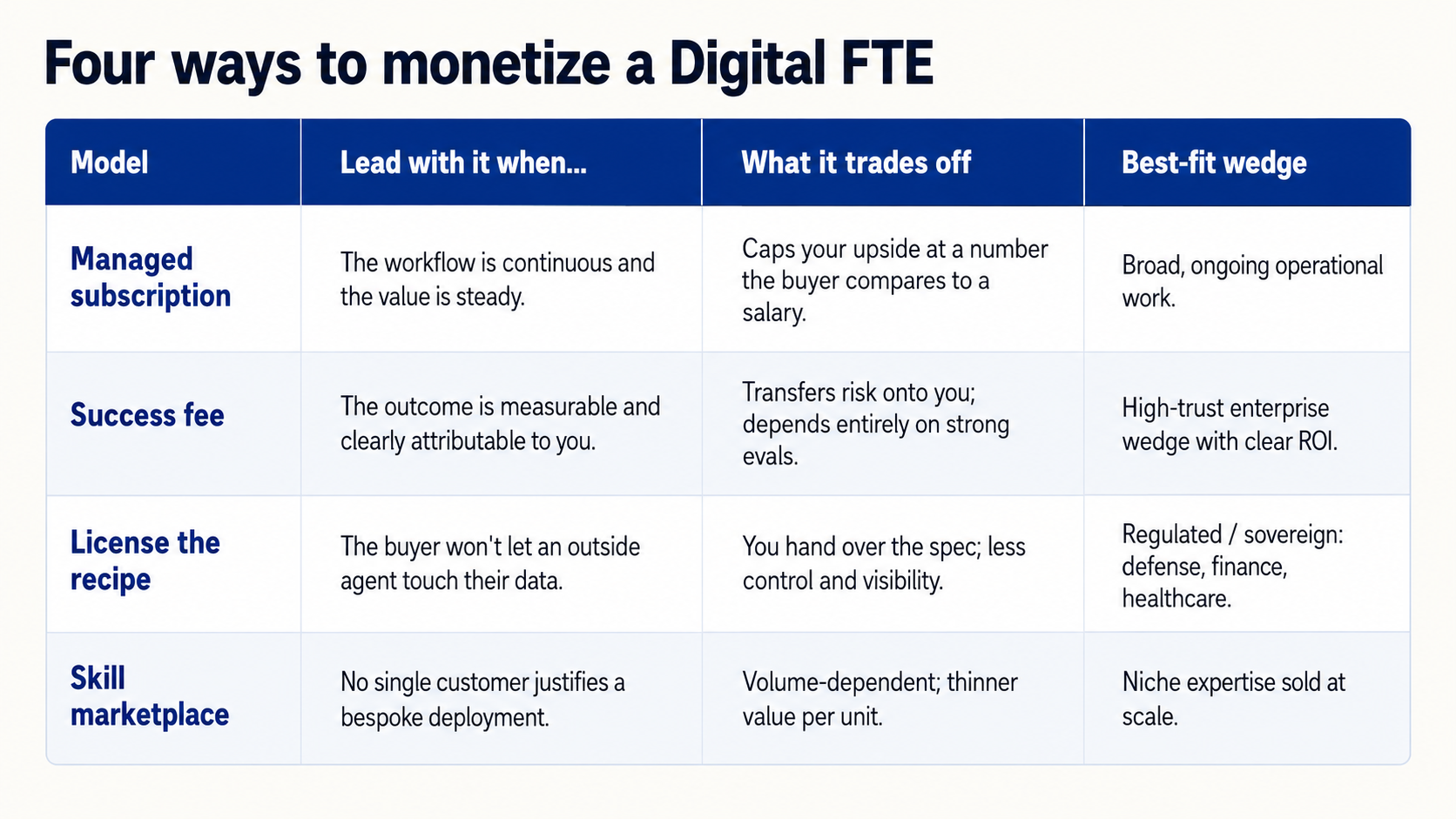 Each model fits a different shape of wedge; lead with the simplest one the wedge will bear.
Each model fits a different shape of wedge; lead with the simplest one the wedge will bear.
Lead with the simplest model the wedge will bear, and let the relationship — and your accumulating eval evidence — earn you the right to value-based pricing over time. The most common founding mistake is the opposite instinct: anchoring low against the human comparison out of fear, charging for the seat, and only later discovering that the buyer would gladly have paid for the outcome.
9. Growth and Scaling
The growth curve of an AI-Native company looks wrong to anyone trained on the old math, because it decouples revenue from the size of the team producing it.
The trajectories are now a matter of record. Salient reportedly reached roughly twenty-five million dollars in annual recurring revenue in about two years, and did so without losing a customer along the way. HappyRobot grew its revenue more than tenfold between funding rounds, well into the eight figures, while expanding to more than seventy enterprise customers — DHL, Ryder, Schneider, Werner — within roughly a year of going to production (Reuters, 2025). Reducto raised about $108 million across two rounds in a single year (a $24.5M Series A and a $75M Series B) as the document layer that other AI companies build on, its monthly processing volume multiplying more than sixfold between rounds as it processed close to a billion pages (Reducto, 2025).
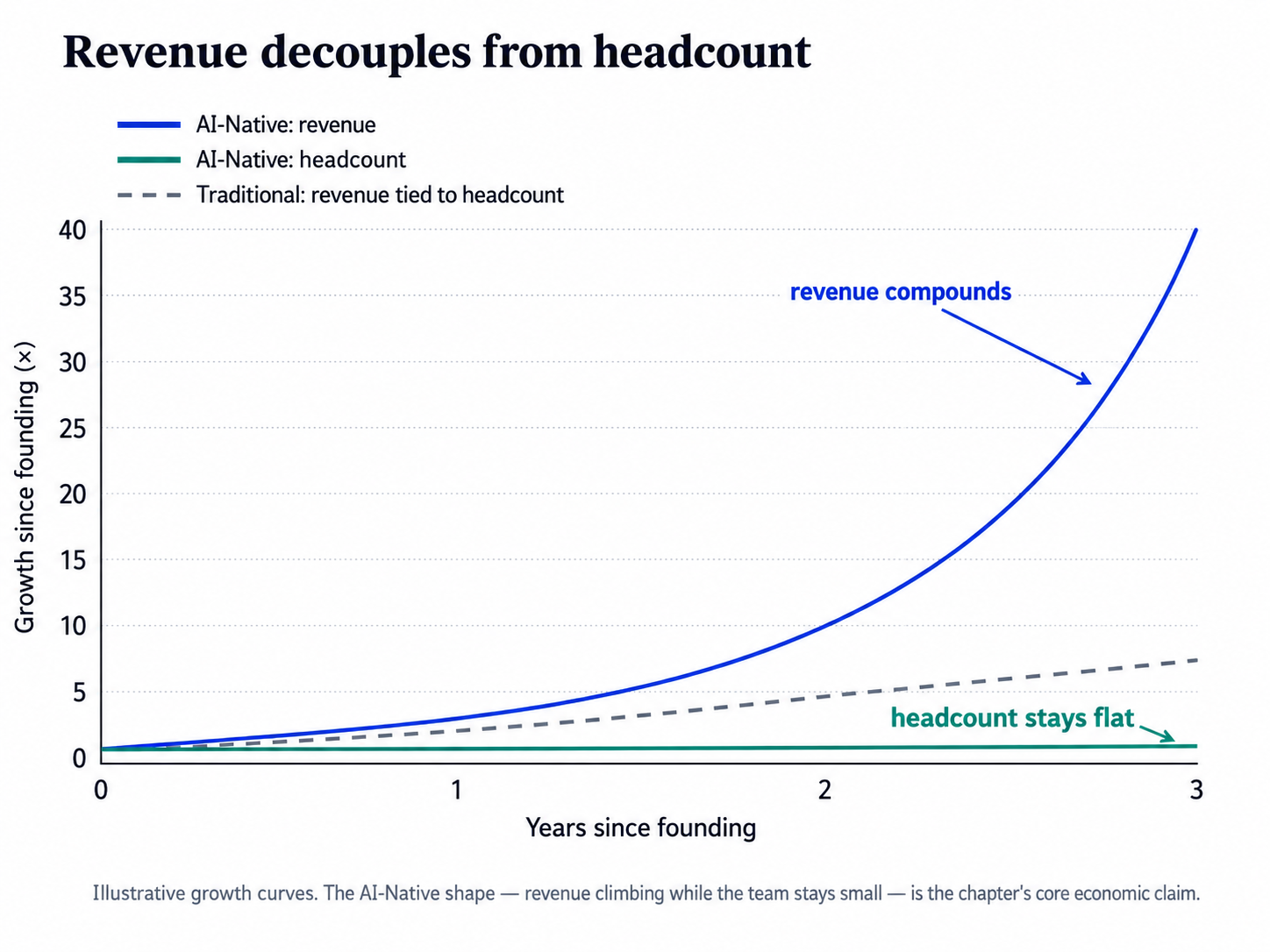 Illustrative growth curves. The AI-Native shape — revenue climbing while the team stays small — is the chapter's core economic claim.
Illustrative growth curves. The AI-Native shape — revenue climbing while the team stays small — is the chapter's core economic claim.
What matters more than the numbers is understanding which parts of the machine scale and which do not. The Digital FTE workforce clones almost instantly and almost for free — that is the exponential, and it is real. The founder's taste and the eval suite that encodes it do not clone; they are the bottleneck, and they are supposed to be. The discipline of scaling an AI-Native company is to scale the loop — more deployments feeding more traces feeding a sharper eval suite — without letting the org chart underneath it grow in proportion. The workforce expands; the Edge Layer stays small and sharp.
10. Staying on the Right Side of the Line
Everything above describes how these companies win. Intellectual honesty — the kind this book has insisted on since its preface — requires the other half.
Most of these companies will fail, and the ways they fail are predictable. They ship slop and call it a product. They skip the eval suite because reading traces is tedious, and they never learn their Digital FTE is wrong until a customer does. They fake the closed loop with a dashboard that looks like feedback but changes nothing. They let the forward-deployed motion curdle into consulting because the product engine was never really there. Or they pick a wedge with no real pain and discover that "would be nice" does not survive a renewal conversation.
There is a survivorship trap in every chapter like this one, this one included. The winners are visible because they are loud; the majority who quietly abandoned their AI initiatives are invisible because failure does not issue press releases. The lectures and founder threads that inspired this material are, in the end, encouragements delivered to rooms full of people about to try. Read them as fuel, not as forecast.
The same skepticism belongs on the productivity numbers you will be tempted to quote. When Garry Tan claims he is hundreds of times more productive than he was a decade ago, he footnotes it carefully — the figure is measured in logical code change rather than raw lines, which AI inflates, across his own repositories, with AI writing most of it. Cite it as an illustration of a genuine shift, not as a law of nature.
The deepest line is accountability, which is why a founding chapter's risk section circles back to the idea of the right side of the line. A founder owns every outcome their Digital FTEs produce, and in regulated wedges that ownership is the entire game. Salient is not built with compliance added afterward; it is built compliance-first, with real-time monitoring against the alphabet of consumer-lending regulation — CFPB, FCRA, TILA, UDAAP, TCPA. In those markets, compliance is not a feature you bolt on after product-market fit. It is the wedge, and the founder who treats the rules as the moat rather than the obstacle is the one standing on the right side of the line.
11. The First 90 Days
If you want a place to begin on Monday, here is the sequence. It is deliberately concrete.
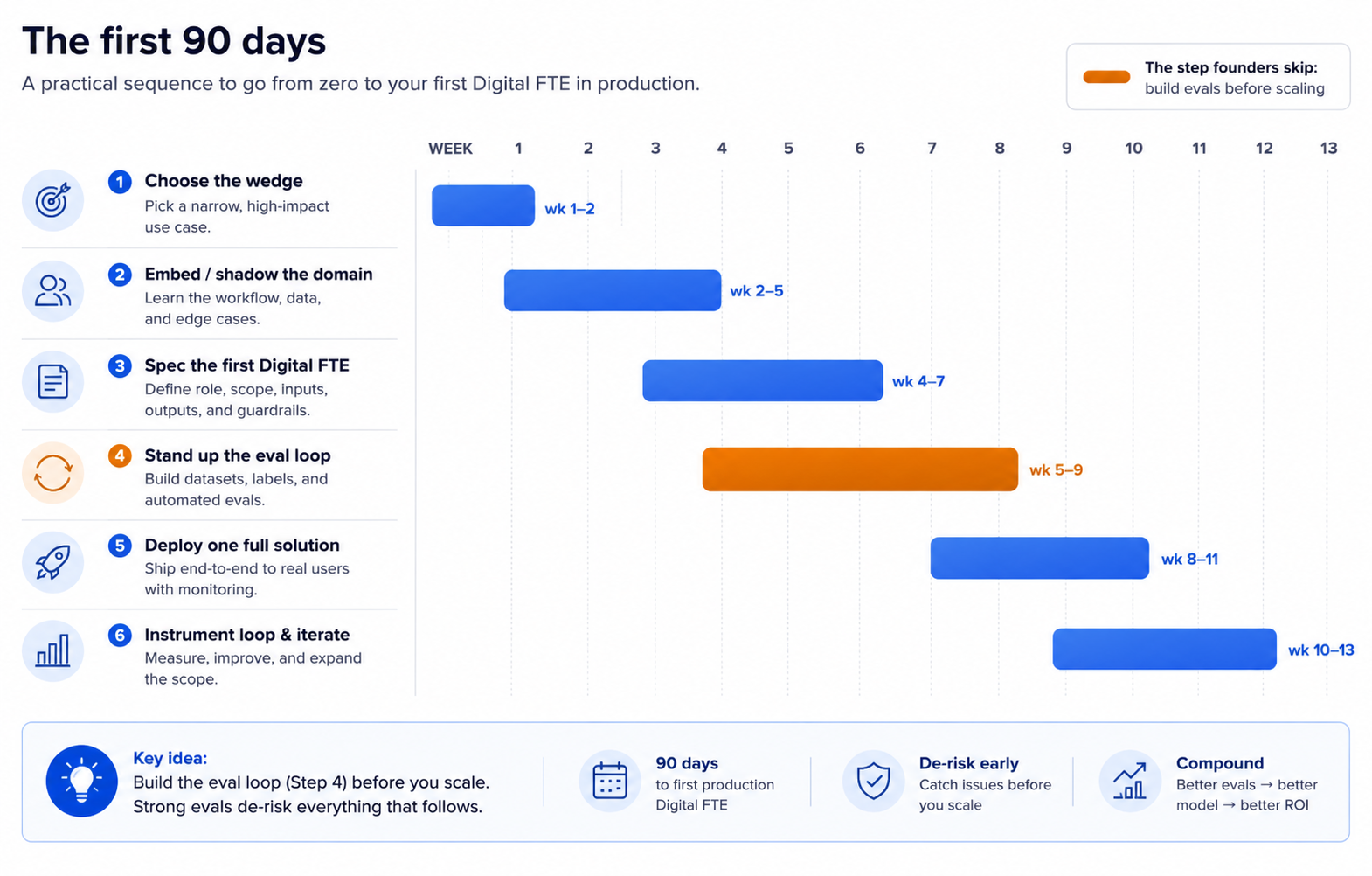 The phases overlap on purpose. Note that the eval loop is stood up before scaling, not after.
The phases overlap on purpose. Note that the eval loop is stood up before scaling, not after.
Weeks 1–2 — Choose the wedge. Find one painful workflow that fails the three tests only by being too painful to ignore. Resist the urge to pick a category.
Weeks 2–5 — Embed. Go into the domain. Shadow the people who do the work. Learn what is not in the training set — the edge cases, the unwritten rules, the reason it is still done by phone.
Weeks 4–7 — Spec the first Digital FTE. Use the Agent Factory. Write the specification before you write the agent, and define the single outcome it owns.
Weeks 5–9 — Stand up the eval loop first. Before scaling anything, build the harness that tells you when the worker is wrong. This is the step the failures skip.
Weeks 8–11 — Deploy one full solution to one customer. Run the narrow pilot: one portfolio, one agent, clear guardrails, a measurable outcome in weeks.
Weeks 10–13 — Instrument the closed loop and iterate on traces. Read what the worker actually did, label it, feed it back, sharpen the evals. This is the work, and it does not end.
Ongoing — Price against headcount, and expand inside the customer before widening across customers.
The arc of this book runs from a one-person frontier lab to a manufactured, supervised workforce. This chapter is where that lab becomes a company — not a metaphor and not a deck, but a closed-loop AI-Native Company that a single founder can stand up and a small Edge Layer can run. The window is open and the map still has white space on it.
Flashcards Study Aid
Test Your Understanding
Sources and Further Reading
The factual claims, figures, and named examples in this chapter are drawn from public reporting and primary sources current as of early 2026. Funding figures, revenue, and company details change quickly; verify specifics before publication, and treat market-size projections and self-reported productivity multiples as estimates from interested parties.
- Anthropic Economic Index — task coverage by occupation, augmentation versus automation, and the unevenness of adoption. (anthropic.com/research)
- Jack Dorsey & Roelof Botha, From Hierarchy to Intelligence (2026) — the company-as-intelligence model, the three-role org, the "humans at the edge" framing, and Block's 2026 restructuring.
- a16z, The Palantirization of Everything (2026) — the forward-deployed engineer model and the conditions under which it breaks down.
- OpenAI, OpenAI launches the OpenAI Deployment Company (May 2026), and Anthropic's parallel forward-deployed engineering venture — the frontier labs formalizing the embedded-FDE model at scale.
- Salient (trysalient.com; Crunchbase; Fortune; the Consumer Portfolio Services deployment announcement) — loan-servicing voice agents, revenue, team size, compliance posture, and pilot motion.
- HappyRobot (happyrobot.ai; Reuters; FreightWaves; Tech.eu) — freight automation, funding, customer roster, forward-deployed team, and the verticalization thesis.
- Reducto (reducto.ai; PRNewswire; Fortune) — the document-intelligence layer, funding, processing scale, and lean team.
- Garry Tan / Y Combinator (the Lightcone podcast; public statements on evals as moat; the gstack repository and its productivity-measurement caveats).
- Gartner, Over 40% of Agentic AI Projects Will Be Canceled by End of 2027 (June 2025) — the project-cancellation forecast; cited as a forecast, not a measured outcome.