Code You Never Write
Getting AI to do the real, tedious work of your job, and trust the result, without writing or reading a single line of code
You describe the problem. The AI picks the language, writes the code, runs it, and fixes it. You never write a line, and you never read its syntax, though you will learn to check what it did. 13 concepts, 80% of real use.
Picture a bookkeeper at a small company. She has never written a line of code, and she never will. Every month, two files are supposed to agree: what her company recorded spending, and what the bank actually charged. And every month she loses an evening hunting, line by line, for the handful that don't match.
Last month she tried something new. She opened an AI chat and typed, in plain English: "These two files should match, my own spending record and the bank statement. Find every transaction that is in one but not the other." A minute later the answer was on her screen: 23 mismatches, each with its amount and its date. The evening of hunting was gone.
Read that again and notice what is missing. She never learned to program. She never read a line of the code. She described a problem, the AI wrote the code and ran it, and the work that used to eat her evening now finishes in the time it takes to pour a coffee.
She happens to be a bookkeeper, but the move has nothing to do with accounting: describe the problem in plain words, let the AI write and run the code, then check what it did. A teacher with 200 grades, a nurse with a month of logs, a student with a chaotic folder of files, all have the same kind of problem and the same way out. This course teaches that move, for every one of them, and for you.
For seventy years, code had a gatekeeper: you had to be able to write it. That gate is now open. The most useful programming language in the world (Python, the language of spreadsheets crunched, files renamed, reports generated, and devices automated) is available to anyone who can describe a problem clearly. Not "available if you take a six-month bootcamp." Available today, in the chat tab you already have open.
If you came here from the prompting course, you already met the playful side of code: you built a small game, maybe your own web page, and shipped it to a link you could text to a friend. That was real, and it was fun, and it is not what this course is about. This is the other half, and the bigger one, what code was invented for in the first place. Not toys, but the unglamorous chores that quietly eat whole days in real work, the kind with real stakes: a grade, a paycheck, a patient's record, a client's money, totaled or merged or checked in a way you can prove is right without reading a line of it. That last part, trusting work you cannot see, is the skill this course is really about.
This course is for the accountant with two spreadsheets that should match but don't. The doctor with a year of clinic data and no time to analyze it. The marketer with exports from four platforms that refuse to combine. The teacher with 200 grade entries. The student with 300 badly named files. Even the network engineer with forty devices to log into every morning. None of you need to learn Python, or any language. All of you need to learn the thirteen concepts on this page: which problems are code problems, how to commission code the way you would commission a contractor, how to verify work you cannot read, and how to do all of it on the five surfaces where AI now writes code for you.
One sentence holds the whole course: you are not learning to write code; you are learning to be a good client for code. Good clients don't lay bricks. They write clear briefs, check the work against things they can measure, and keep what they paid for.
To be precise about the promise in the title: you will never write code, and you never have to read its syntax: the punctuation, the keywords, the line-by-line grammar that takes months to learn. (You won't even have to pick the language; the AI does that, as you'll see in Concept 2.) What you will learn to do is check what the code did: confirm the totals, inspect the steps in plain English, catch the wrong answer. Not reading the syntax is the freedom this course gives you. Verifying the result is the responsibility it asks back. Those two are not in tension; they are the whole job of a good client.
📚 Teaching Aid
View Full Presentation — Code You Never Write
Prove it in two minutes
Before any theory, feel the gate swing open. Open Claude.ai (a free account takes a minute; ChatGPT or Gemini work too) and paste this, fake data and all:
Here are my expenses for the month. Write and run code to total them by category, find my biggest category, and tell me the exact total. Show me that the code actually ran.
Groceries 4,250 Fuel 3,100 Groceries 2,890 Internet 2,499 Fuel 2,750 Eating out 1,850 Groceries 3,120 Mobile 1,200 Eating out 2,400 Fuel 2,950
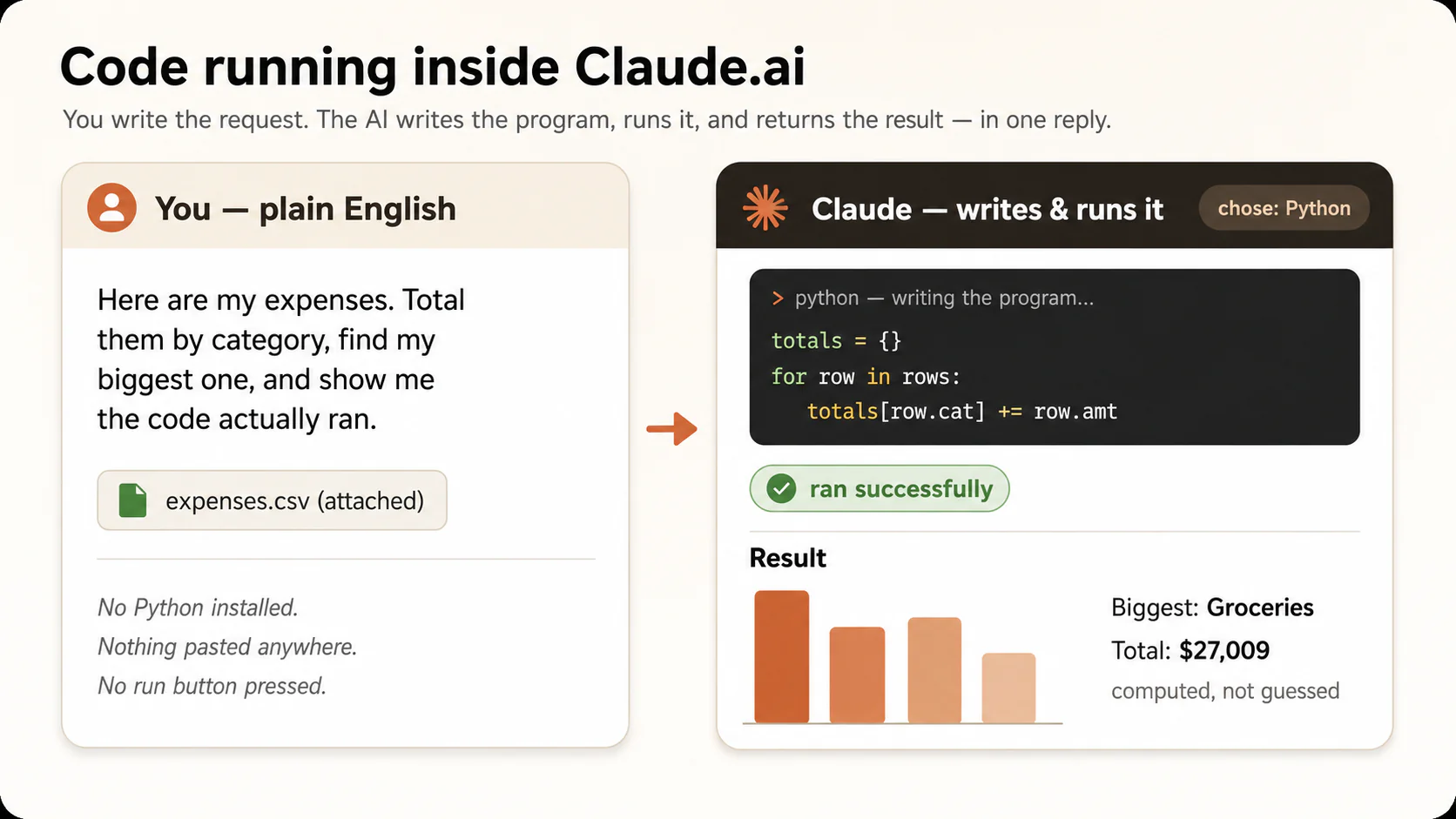
Watch what happens. The AI does not answer from a glance. It writes a small program (almost certainly Python, because that's what this kind of problem calls for, though you didn't ask for any language and didn't need to), runs it on your numbers, and reports back: the per-category totals, the biggest category, the grand total, computed, not estimated. And notice everything you did not do: you did not choose a language, did not install anything, did not copy code anywhere, did not press a run button. Choosing the tool, writing the code, and running it are all the AI's job. You just commissioned, received, and benefited from a working program without reading a character of it.
Now the move that makes this a skill instead of a trick. In the same conversation, paste:
Add up the Groceries lines yourself by hand-checking: 4,250 + 2,890 + 3,120. Does it match what your code reported?
It matches. That tiny check, verifying machine output against a calculation small enough to do yourself, is the seed of Concept 6, and it is the difference between people who can trust AI-written code and people who just hope.
Two minutes, and you have already done everything this course teaches, once, by accident: described a problem, demanded code, watched it run, and verified one slice of the answer. The thirteen concepts below make each of those steps deliberate, so they keep working when it is your own real data instead of ten fake expense lines.
This crash course assumes the Foundations before it: What AI Actually Is for the mental model of the machine, AI Prompting in 2026, especially Concept 10 (the model writes and runs code) and Concept 7 (the brainstorm-iterate loop), and Markdown In, HTML Out, because the briefs you write here are Markdown specs and the reports you demand back are HTML. This page deepens both into a single discipline: code as the thing in the middle. The full tool walkthroughs live in the Agentic Coding Crash Course and the Cowork & OpenWork Crash Course; you need neither to finish this page. Further on, Problem Solving with General Agents assumes everything here.
Haven't read those two? The 60-second version
You can follow this whole page without them; here's all you actually need carried over.
- From AI Prompting in 2026: modern AI can write a small program, run it, and use the result in its answer, but it only does this reliably when your wording asks for it; left to guess, it often just estimates. And the highest-value habit is the loop: give context, ask for options, react, iterate. Don't accept the first thing back.
- From Markdown In, HTML Out: when you write to an AI, structure beats prose, because headings and bullets remove guesswork (that's all "Markdown" means here: text with a
#for a heading and a-for a bullet). When you want a result a human will read, ask for it as an HTML page (a designed, shareable document), not a wall of text.
That's the entire dependency. If those two ideas make sense, you're ready.
You need:
- One free chat account. Claude.ai is what the examples use; the same patterns work in ChatGPT and Gemini, though exact file upload, code execution, and usage limits vary by product and plan. (Claude.ai requires an account holder 18 or older; if you are younger, use ChatGPT or Gemini, which allow ages 13+ with a parent's permission.)
- One real spreadsheet or folder from your own work or life: a bank export, a sales sheet, a grades file, a messy downloads folder. The exercises hit ten times harder on your data than on ours.
- Nothing installed. Parts 1 and 2 happen entirely in the browser. Part 3 shows the surfaces where installation pays off, but reading it requires nothing.
Reading takes about an hour, and running the 🔬 Do this now boxes as you go adds maybe thirty minutes. Do them; they are the whole point.
By the end, you'll be able to:
- Spot a code problem: tell, in seconds, whether a task is a question for the AI's mind or a job for its hands.
- Write a five-section code brief (Goal, Input, Output, Rules, Edge cases) with no technical language in it.
- Force computation over estimation: make the AI actually run code instead of guessing, and prove that it did.
- Verify a result you can't read: check AI-written work against things you independently know, without touching the Python.
- Run scripts safely on real files: backups, dry runs, scoped folders, so a mistake is a shrug, not a disaster.
- Keep what you build: turn a one-time solution into a reusable script you, or a colleague, can run forever.
The full page is worth it, but if the length intimidates you, this gets you the core skill fast: read Concepts 3–6 (which problems need code, how to force computation, how to brief, how to verify) and run each one's 🔬 Do this now box as you go. Come back later for the surfaces (Part 3), the safety rules (Concept 12), and the Projects. Those few pieces alone make you a competent client for code.
Part 1: The deal
Three concepts that change what you believe you are allowed to ask for.
1. Code is no longer gated by coding
Why does the bookkeeper's lost evening matter so much? Because for her entire career, the deal was the same brutal either/or: either learn to program, or do it by hand. Reconciling two files meant an evening of manual hunting, or begging a developer for a script, waiting two weeks, and getting something that almost fit.
The new deal: AI is the developer, you are the client, and the developer works in seconds, for free, and never gets tired of your revisions.
What changed is not that AI can write code; it could in 2022, badly. Three things matured together:
- AI writes working code for well-described small problems. For the scale of problem this course covers (one file, one folder, one repetitive task), modern models succeed on the first or second try most of the time.
- AI runs the code itself. You don't copy code into some tool you don't have. The AI executes it, in the chat's own sandbox (Claude.ai, ChatGPT, Gemini) or on your machine with permission (Claude Code, OpenCode, Cowork, OpenWork), sees the result, and fixes its own errors.
- AI repairs the code itself. When something breaks, the error message goes back into the loop and the AI corrects course. The debugging skill that took programmers years to build is now part of the service.
(Those are the places AI can write and run code for you, and Part 3 walks through each one. The short version: Claude.ai is the chat website you may already use, and ChatGPT and Gemini work the same way; Claude Code and OpenCode are tools that work directly inside a folder on your computer; Cowork and OpenWork are desktop apps that do the same for non-programmers. That is five surfaces grouped into three kinds of place (browser, folder, desktop app); within the folder pair and the desktop pair, the first tool is a commercial product and the second a free, open-source alternative. You don't need to know more than that yet.)
Back then, the AI handed you a block of code and walked away, and unless you had Python installed and knew where to paste the block, the conversation ended there. That era is over. Today you describe the problem, and the AI writes the code and runs it, in the same response, with nothing installed on your side. There is no step where code is handed to you to deal with. The only things that ever reach you are the things you actually wanted: the answer, the chart, the cleaned file, the report.
Put those together and the unit of work changes. You no longer ask "can I write this?" You ask "can I describe this?" Description is a skill you already have. You describe problems to colleagues, contractors, and tailors every week.
From the field, six professions:
| Who | The problem they described | What the AI's Python did |
|---|---|---|
| Bookkeeper | "These two sheets should match: my ledger and the bank statement. Find every transaction in one but not the other." | Reconciled 1,400 rows in seconds; flagged 23 mismatches with amounts and dates. |
| Doctor (clinic owner) | "A year of appointment exports. Which days and slots have the worst no-show rates?" | Computed no-show rates by weekday and hour; Monday 9 a.m. was 3× worse than average. |
| Marketer | "Four platform exports, four different column layouts. One table: spend, leads, cost-per-lead by campaign." | Merged the formats, normalized the currencies, produced the table and a chart. |
| Teacher | "200 students, three assessment columns. Compute weighted finals, letter grades, and a personalized one-line comment per student." | Did all three; the comment merge alone saved an evening. |
| Student | "300 scanned files named IMG_4501.jpg onward. Rename them using the date stored inside each photo file." | Renamed all 300 in under a minute. |
| Network engineer | "Log into these devices each morning, pull interface status and error counters, write a health report." | The script from the opening message, running daily before he reaches his desk. |
Six professions, zero lines of code read. The pattern in every row: a problem that was always describable but never commissionable, until now.
Stop asking "do I know how to do this?" Start asking "can I describe what done looks like?" If you can describe done, you can commission code.
🔬 Do this now (1 min). Feel the new deal: you describe a real chore, the AI does it. Open Claude.ai and paste this:
Here are eight students, one per line: their average score, then how many days their final project is overdue. Tell me which students are BOTH below 50 AND more than 30 days late, so I know who to contact, and how many that is. Write and run code so the count is exact.
72, 12 41, 45 88, 60 35, 8 47, 38 29, 90 51, 33 44, 5
You did not sort or tally anything by hand. You described which students matter and what to find; the AI wrote a small program, ran it, and handed back the answer (three students: the ones scoring 41, 47, and 29). That is the new deal, start to finish: describe done, receive done, with the arithmetic guaranteed.
2. What code actually is (the 60-second version)
(Already write code yourself? Skim this one. The course really begins for you at Concept 3, and Concepts 6 and 12, verification and blast radius, are the parts even seasoned programmers get burned by.) You will never read code in this course, but you need to know what you are commissioning, the way a homeowner who never lays bricks still knows what a wall is.
Code is a list of exact instructions that a computer follows perfectly, at any speed, any number of times. That's it. "Open the file. For each row, read the category and the amount. Add the amount to that category's running total. When done, print every total." Written in English, that's a procedure. Written in a programming language, it's code, and the machine executes it a million times without one slip of attention.
Code comes in many languages, the way contracts come in many human languages, and just as you'd let a translator pick the right one, you let the AI pick the right code language for the job. You will meet two on your screen:
- Python is the one you'll see most, and the protagonist of this course. It is the default language for exactly your kind of problem (files, spreadsheets, data, charts, reports, automation), and, decisively, it is the language AI knows best. More Python exists in AI training data than any other language, so when an AI writes Python it is writing in its mother tongue. For the kind of real-data problems the next concept pins down, the AI reaches for Python almost every time.
- JavaScript / TypeScript is the one you'll see when you ask for something to click: a web tool, a small game, a calculator you share by link. That is the world the prompting course lived in, the games and pages you built there. (TypeScript is just JavaScript with extra safety checks; for your purposes they're the same thing in slightly different clothes.) This course barely visits that world. The work here, real data handled reliably, is Python's home turf.
Here is the part that keeps your job simple: you never choose between them. Picking the language is a technical judgment, and technical judgments are exactly what you're delegating. A good client describes the building and lets the architect decide between steel and timber; you describe the problem and let the AI decide between Python and JavaScript. It chooses based on what your problem needs, a number from a spreadsheet (Python) versus a button someone can click (JavaScript), and it's right about that choice far more reliably than a beginner would be. The only reason to know the two names at all is so you recognize what's scrolling past and aren't surprised when a "make me a tool" request comes back in a different language than a "total my expenses" request.

What does code look like when it scrolls past? A scrap of Python looks like this:
totals = {}
for row in rows:
totals[row.category] = totals.get(row.category, 0) + row.amount
Did your eyes slide right off that? Perfectly fine. That is all the attention code ever asks of you here. And yet you can half-read it anyway: "for each row, add the amount to that category's total" shows through the punctuation. That's the level of reading this course asks of you, and no more.
(Are there other languages? Many: Go, Rust, SQL, and more, each suited to technical work outside this course. You may glimpse one someday, but the rule never changes: for the everyday data problems this course is about, it's Python or JavaScript, and either way you describe the outcome and the AI picks the language.)
You are allowed to look at it. You are not required to. This course's promise is that every skill you need (commissioning, steering, verifying, keeping) works without parsing a single line. Treat scrolling code the way you treat a mechanic's open engine bay: evidence that real work is happening, not a test you have to pass.
The one property of code worth memorizing: code is exact, in both directions. It will compute your totals to the last cent with zero arithmetic errors, and it will also do exactly what it was told, including the wrong thing, perfectly, at scale. A script with a misunderstanding renames 300 files wrongly just as fast as it renames them rightly. That is why Concept 6 (verification) and Concept 12 (blast radius) exist. Power and danger come from the same property.
A non-software analogy. A recipe is code for a human. "Simmer 20 minutes" executed by an attentive cook produces dinner; executed by a perfectly obedient robot that was accidentally told "simmer 20 hours" produces charcoal, flawlessly. The robot didn't fail. The brief did. Everything in Part 2 is about writing briefs that don't burn the kitchen down.
🔬 Do this now (1 min). See what "the AI writes the code and runs it" actually looks like. Paste this:
Write and run code to total these numbers, then tell me the average and how many are above 40: 12, 47, 8, 93, 21, 56. Show me the code you ran.
Back comes a short Python program, a "ran successfully" result, and the answers (total 237, average 39.5, three above 40). You asked for no language; Python is simply what this kind of work calls for, and what you'll see for the rest of the course. (It writes JavaScript too, for clickable things, but those were the prompting course's games and pages. Here, we do the work.)
3. The dividing line: which problems are code problems
This is the concept the whole course turns on, because it is the one decision you make before any prompt: is this a question for the AI's mind, or a job for the AI's hands?
AI has two ways to help you. It can answer (draft, advise, summarize, explain, brainstorm) from its own reasoning. And it can compute: write and run code that operates on your actual data. Most people only ever use the first, then wonder why the AI's "analysis" of their spreadsheet had wrong totals. The totals were wrong because the AI answered when it should have computed: it described your data from a glance, the way a human skims, instead of processing it, the way a machine counts.
Four signals tell you a problem is a code problem. Any one of them is enough:

| Signal | The test | Examples |
|---|---|---|
| Volume | More items than you'd comfortably do by hand. | 300 files to rename, 5,000 rows to total, 80 PDFs to scan for a clause. |
| Precision | A wrong digit has consequences. | Invoices, payroll, grades, dosage tables, reconciliations, anything with money. |
| Repetition | You'll face this same task again next week or next month. | Month-end reports, daily device health checks, weekly campaign rollups. |
| Files | The problem lives in files, not in sentences. | Spreadsheets, exported data files, folders of images, logs. |
Volume, Precision, Repetition, Files: VPRF for short, the four-letter test this course keeps coming back to. If a task trips none of the four, it is an answer problem: use the skills from AI Prompting in 2026 and never think about code. If it trips even one, it is a code problem, and the rest of this course is the playbook.
Run your own week through the filter:
| Task | Code problem? | Why |
|---|---|---|
| "Draft a polite email declining a meeting." | No | No volume, no precision stakes, no files. Pure answer problem. |
| "Summarize this one contract." | No | One document, judgment-heavy. The AI reads it directly. |
| "Which of these 80 contracts have a non-standard termination clause?" | Yes | Volume + files. Code scans all 80; a glance-based answer would miss some. |
| "Is my business idea good?" | No | Judgment. Use the rubric pattern from the prompting course. |
| "What did I spend on fuel this year?" | Yes | Precision + files. The number must come from computation, not impression. |
| "Explain what a mutual fund is." | No | Knowledge question. |
| "Rename these vacation photos by date taken." | Yes | Volume + files. |
| "Every Monday I combine three exports into one report." | Yes | Repetition, the strongest signal of all, because the script becomes an asset (Concept 8). |
The trap to watch for: problems that look like answer problems but trip Precision. "Roughly how did my sales trend this year?" feels conversational, so people ask conversationally and get a conversational (that is, approximated) answer. If a decision rests on the number, it is a code problem no matter how casually you'd phrase it. The phrasing fix is Concept 4.
Which language does each of these get? (Curious only; you never choose it)
Recall from Concept 2 that the AI picks the language, and the choice follows the output, not the task:
| If the result you want is… | The AI usually writes… | Examples from above |
|---|---|---|
| A number, a cleaned file, a report, a renamed folder | Python | Fuel total, contract scan, photo rename, Monday rollup |
| A thing someone clicks, types into, or opens in a browser | JavaScript / TypeScript | A shareable expense calculator, an interactive quiz, a little dashboard with buttons |
Almost everything in this course (the VPRF problems, the projects, your real working week) produces a number or a file, so you'll see Python almost every time. The clickable tools are the prompting course's territory, not ours.
A non-software example. A school administrator asked an AI to "look at this fee spreadsheet and tell me which families are behind on payments." The AI listed eight families, confidently. The real number, computed later, was eleven. Nobody was lying; the AI had answered (pattern-matched from a skim) rather than computed. The three missed families had partial payments that a skim reads as paid. One sentence would have prevented it: "write and run code to find them." She now ends every data question with that sentence, which is exactly where Part 2 begins.
🔬 Do this now (2 min). Make the one decision the whole course turns on, eight times in a row. Paste this:
Sort these 8 tasks into ANSWER problems (you just reply) or CODE problems (you write and run code). Give one short reason each, and name which signal fires: Volume, Precision, Repetition, or Files.
- Draft a polite email declining a meeting.
- Add up 2,000 rows of sales and break the total down by month.
- Is my business idea any good?
- Rename 300 photos using the date stored inside each one.
- Explain what a mutual fund is.
- Find which of 80 contracts have a non-standard cancellation clause.
- Summarize this one news article.
- Every Monday, combine three exported files into one report.
Check its answers against your gut before you read its reasons. The odd-numbered tasks are answer problems; the even-numbered ones are code problems. You just sorted mind-work from hands-work, which is the move you will make before every prompt for the rest of your life.
Part 2: Commissioning code
You've decided it's a code problem. Five concepts cover the full client-side craft: making sure code actually runs, writing the brief, verifying work you can't read, handling failure, and keeping what you paid for.
4. Make the AI's hands move: automatic vs. explicit
Modern AI tools decide whether to write code based on how your prompt sounds. Upload a spreadsheet and ask "which products grew fastest?" and most will compute it. But on anything that sounds answerable from a glance, the AI may skip the code and estimate, and an estimate is formatted exactly like a computation: same confident tone, same tidy numbers. This is the silent failure mode, and for this course it is enemy number one.
You neutralize it with one habit: never leave the decision to the AI on anything that trips the Precision signal. Say the words.
The three-line incantation, worth pinning above your desk:
Write and run code to answer this. Show me the code you ran. Before analyzing anything, tell me the exact row count, the column names, and the date range of the file.
Line one forces computation. Line two gives you proof: if no code block appears, no code ran, whatever the prose claims. Line three is the cheapest lie detector in this course: if the AI is actually reading your file, the row count and column names will be exactly right; if it is making things up, you'll get a suspiciously round number and plausible-but-wrong column names, and you'll know to stop before the "analysis" begins.
Notice the incantation says "code," not "Python." That is deliberate, and it is the rule for every prompt in this course: you tell the AI to compute; you never tell it which language to compute in. "Write and run code" lets the AI pick the right tool for your problem (Concept 2). Adding "in Python" would force its hand based on a guess you're not equipped to make, and on the rare problem where Python is the wrong choice, you'd have quietly steered it wrong. Describe the job, demand code, leave the language to the AI.
How your phrasing steers the AI, side by side:
| Your phrasing | What usually happens | Risk |
|---|---|---|
| "What does this data show?" | Glance-based summary, maybe code. | Estimates dressed as facts. |
| "Roughly how did costs trend?" | Almost always a glance. "Roughly" tells the AI precision doesn't matter. | Fine only if you truly don't care. |
| "Write and run code to compute cost by month." | Code, every time. | Minimal. |
| "Are you running code on this file, or estimating? If estimating, stop and run code instead." | The AI declares its method, then computes. | The strongest single move when you suspect a glance. |
And the converse discipline: don't demand code for answer problems. "Write and run code to tell me if my essay is persuasive" wastes the tool. The dividing line from Concept 3 cuts both ways.
A response about your data that contains no visible code block, no row counts, and no "here's what I computed" is an opinion about your data, not an analysis of it. Treat it the way you'd treat a contractor's invoice for work you never saw happen.
🔬 Do this now (2 min). Make the AI prove it computed instead of guessed. Paste this small file and the three-line incantation together:
Here is a small commute log.
Date,Mode,Minutes 2025-03-03,Bus,35 2025-03-03,Walk,10 2025-03-04,Bike,20 2025-03-05,Bus,40 2025-03-06,Walk,15 2025-03-07,Bike,25 2025-03-10,Bus,30 2025-03-11,Walk,12
Write and run code to total the minutes by mode. Show me the code you ran. Before anything else, tell me the exact number of rows, the column names, and the date range.
You can check the answer yourself: 8 rows, columns Date / Mode / Minutes, all in March 2025. It will report exactly that, then a code block, then the totals (Bus comes to 105). On a file of hundreds of rows you could never eyeball, that same opening question is what catches the AI inventing numbers.
5. Brief the problem, not the program
Here is the most liberating fact in this course: the best code briefs contain no technical language at all. You do not specify loops, libraries, file-handling, or even which programming language to use. You specify what a good outcome looks like, exactly as you would for a human assistant, and the AI translates intent into implementation, language included. People who half-know programming often write worse briefs than total beginners, because they micromanage the how and under-specify the what. "Write this in Python" is exactly that kind of micromanagement: you've now constrained the AI's choice based on a preference you can't actually justify, when describing the outcome ("a tool I can click" vs. "a number from my spreadsheet") would have let it pick correctly on its own.
A complete brief answers five questions. You met the first three in the prompting course's app recipe (Goal, Input, Output); code problems add two more:

# Brief: [name the task]
## Goal
What problem is solved when this works?
## Input
What am I giving you? (files, their format, roughly how many rows/items)
## Output
What exactly do I want back? (a number, a table, a chart, a cleaned
file, an HTML report)
## Rules
The constraints a stranger wouldn't know. (The school year starts in
August. "Pending" means not yet submitted. Ignore rows before 2024.)
## Edge cases
What should happen when the data is imperfect? (blank rows, duplicates,
a date in the wrong format, an amount with a currency symbol)
Yes, that's a Markdown spec, exactly the kind Markdown In, HTML Out trained you to write. Code briefs are where that skill starts paying compound interest: every heading is a thing the AI no longer has to guess.
The two sections beginners skip are the two that matter most:
Rules is where your professional knowledge lives. The AI knows Python; it does not know that your school year starts in August, that "Pending" means not-yet-submitted in your system, or that the downtown store closed in March and should be excluded. Every wrong analysis you'll ever get traces back to a Rule you knew and didn't state. The school administrator's missed partial payments in Concept 3? A missing Rule: "a family with any unpaid balance counts as behind."
Edge cases is where you decide, in advance, what imperfect data should do, because your data is imperfect; everyone's is. The professional move is one sentence: "If you hit a row you can't interpret, don't guess; skip it, and list every skipped row at the end." That sentence converts silent corruption into a visible report.
A worked brief, teacher edition (the inputs here are .csv files, just spreadsheets saved as plain text; more on that in Part 3):
# Brief: Who hasn't turned in the essay
## Goal
Find which students on my class list have NOT submitted the essay,
so I know exactly who to chase before grades are due.
## Input
Two files, attached. "class-list.csv": Name, Student ID (about 180
students). "submissions.csv": one row per file turned in, with
Student Name, Filename, Date.
## Output
A list of students with no matching submission, and a count, then a
one-line summary. Format it as an HTML page I can print for class.
## Rules
- Match on student name; names in the submissions may have extra
spaces or different capitalization than the class list.
- A student who submitted twice still counts as submitted (once).
## Edge cases
- A submission whose name matches nobody on the class list: list it
separately (a typo or a wrong upload), don't silently drop it.
- Any row you can't read: skip it and list it at the end.
No programming words anywhere, and this brief will succeed on the first run far more often than "find who hasn't submitted," because every guess has been removed. (Notice the Output line quietly applying the previous course: the human-facing result is HTML.)
The honest truth: you often won't know what's lurking in your data. So make discovery the first prompt: "Before doing anything, examine the files and tell me: what could be ambiguous, inconsistent, or surprising in here? List the questions you'd want answered before processing." The AI inspects, comes back with "there are 14 rows with blank dates and two currency formats. What should I do with each?", and now you write the Edge cases section with knowledge instead of imagination. Inspect, ask, then brief. This is the brainstorm-iterate loop from the prompting course, applied to data.
🔬 Do this now (3 min). Write your first brief, on data that fights back. This little file is deliberately messy: a stray unit, a comma inside a number, a row entered twice, and a row with no date. Paste the file and the brief together, exactly as shown:
Here is my data, and my brief for it.
Date,Meal,Calories
2025-03-02,Breakfast,420
2025-03-02,Lunch,650 kcal
2025-03-02,Lunch,650 kcal
2025-03-05,Dinner,"1,100"
,Snack,200
2025-03-06,Breakfast,380
# Brief: Total my March calories by meal
## Goal
A clean total for each meal, so I can see where the calories went.
## Output
A table of meal and total, biggest first, then the grand total.
## Rules
- Calories may have a unit like "kcal" or a comma; treat them as plain numbers.
- The exact same row appearing twice is a double-entry; count it once.
## Edge cases
- A row with no date: do not guess. Skip it, and list it at the end.
Write and run code to do this, and tell me which rows you skipped or
treated as duplicates.
Watch it strip the kcal and the comma, drop the repeated Lunch row, set the blank-date row aside (and tell you it did), and total the rest. The Rules and Edge cases lines are what made that happen. Delete those two sections, run it again, and the mess walks straight back in. That is the whole power of a brief, in one before-and-after. Six messy rows here; a few hundred in your real export, where one wrong number hides easily. The brief is what makes the big version safe to trust.
6. Verifying work you cannot read
Remember from What AI Actually Is (Idea 3) that the model has no truth-checker of its own. With code you have one it doesn't: you can run it. That is why verification here is running and reading, not trusting.
Here is the question every skeptic asks, and they are right to ask it: if you can't read the code, how do you know it's correct?
The answer is older than computers: the same way you check any expert whose craft you can't audit. You don't verify your accountant by re-deriving tax law; you check totals against your records. You don't verify a builder by testing the cement yourself; you check whether the wall is straight and the door closes. You verify outputs against independent knowledge, and you, the domain expert, have independent knowledge the AI never will.
Five checks, in escalating order of effort. The first three cover most situations:

1. The known-answer test. Before trusting the script on 5,000 rows, feed it a slice whose answer you already know. Run it on one month you've already closed by hand. Pick one student and compute her weighted grade on paper. If the script reproduces every answer you can check, your confidence in the answers you can't check is earned, not hoped. This is the single most powerful move on this page.
Before running on the full file, run the code on just March. I already know March's correct total is $184,250. Show me what the code gets.
2. The reality questions. Interrogate the output with what you know about your world. Row counts in versus rows out: if 1,400 went in and the report covers 1,381, where are the missing 19? Do the totals land in a plausible range? Does the "biggest customer" match the one you know is biggest? Any answer that contradicts your professional gut is either a data surprise or a code bug, and both deserve the next prompt: "Your report says X. Walk me through, in plain English, exactly how you computed that number, and show me three of the underlying rows."
3. The plain-English replay. Make the AI explain the code's behavior as a procedure:
Explain, step by step in plain English, what this code does, as if describing it to a colleague who will check the logic but can't read code. Include what it does with blank rows and duplicates.
You can't audit Python, but you can absolutely audit "I matched on amount and date within two days, treated debits as negative, and skipped 14 unparseable rows (listed below)." If the procedure is wrong (wrong rule, wrong assumption), it will be wrong in English too, and you'll catch it. Most real errors are procedure errors, not typo errors, which is why this works.
4. The adversarial pass. Borrowed straight from the prompting course's rubric habit: "Find any way this analysis could be wrong or misleading. What assumptions did the code make? What's the weakest link? Score your own confidence 1–10 per claim and justify each score." The AI is genuinely good at attacking its own work when explicitly invited to.
5. The cross-model check. For high-stakes outputs (the reconciliation going to an auditor, the analysis going to a board), take the brief and data to a second model from a different family (prompting course, Concept 13) and compare the computed numbers. Two independently written programs agreeing on 23 mismatches is the strongest signal this technology offers.
| Stakes | Minimum verification |
|---|---|
| Personal curiosity (your own spending) | Reality questions. |
| Work product a colleague relies on | Known-answer test + plain-English replay. |
| Money, grades, health, anything signed | All five, and a human reviews the load-bearing claims. |
A non-software example. A pharmacist commissioned a script to cross-check her dispensing log against stock counts. Before trusting it, she planted a trap: she manually inserted one fake discrepancy into a copy of the data, a 10-unit gap she knew about because she created it. The script caught her plant, plus four real discrepancies she didn't know about. The plant is what let her believe the four. Salt your data with one known error and see if the code finds it, a known-answer test in its most elegant form, and it costs ninety seconds.
There is a worry sitting under this whole course, and it deserves a straight answer: is not reading the code a beginner's compromise? Something a real programmer would never accept?
Robert C. Martin, Uncle Bob to a generation of programmers, wrote Clean Code, one of the most widely read programming books ever published. For forty years he taught that reading code carefully is the job. In July 2026 he posted that he no longer reads the code his agents write, and that this is the only way he gets real speed out of them. Instead, he surrounds them with what he calls "extreme constraints": layers of automated checks the code has to survive before he believes a word of it.
So no, it is not a compromise. It is where the most experienced people in the field have arrived, by the same road you are walking: stop reading, start checking.
But notice the order, because this is what most people online missed. He did not stop reading and then hope for the best. He built the checks first. Not reading was what the checks allowed. His confidence is not a feeling. It is the size of his checks, and he can name every one of them.
And here is the part that should make you feel at home. One item on his list is mutation testing: you break the code on purpose, one small change at a time, and see whether any test notices. A test that stays quiet while the code is quietly wrong has just told you it proves nothing.
Now look at the pharmacist again, one paragraph up. She planted a fake discrepancy in a copy of her data and checked that the script found it. She had never heard of mutation testing. She invented it anyway, because it is the obvious move the moment you take verification seriously: put in a fault you know about, and see whether the check catches it.
His version runs on code you cannot read. Yours runs on something he will never have: you already know what March's total was. Different tools, same discipline. You are not doing a simplified version of his job. You are doing the same job, from the other side.
You may skip any check on this list except one: never act on a precision-critical number you haven't tested against at least one answer you independently know. Code is exact (Concept 2), including exactly wrong. The known-answer test is your firewall.
🔬 Do this now (2 min). Run the one check you never skip, on a slice small enough to verify by hand. First add these three numbers yourself: 8,000 + 6,500 + 9,000 = 23,500. Now make the AI prove its code lands there:
Here are my steps for three days, one per line: Monday 8000 Tuesday 6500 Wednesday 9000 Write and run code to total the steps. I worked it out by hand and it should be 23,500. Show me the code and the total it gets.
If the code returns 23,500, you have watched the known-answer test work: you checked a slice you could verify yourself, so you can trust the same code on a full year of steps you could never add in your head. If it returns anything else, you just caught a bug for free, in thirty seconds.
7. When it breaks: errors are dialogue, not failure
Something will go wrong. The script stops; red text appears; or worse, it finishes and the output looks bizarre. Here is the mindset shift that separates people who push through from people who give up: an error is not the project failing; it is the computer describing, very precisely, what it needs. And you have an expert on staff, already in the conversation, who reads that language fluently.
The entire skill, for red-text errors:
It stopped and showed this error. Diagnose it, fix the code, and run it again:
[paste the red text, all of it]
That's it. You don't interpret the error; you forward it. The AI reads its own error messages the way a mechanic reads engine noise, fixes the script, and reruns. Most errors die on the first paste. On the surfaces in Part 3 where the AI runs code in its own loop, it usually sees the error itself and fixes it before you even notice: you'll watch it try, fail, adjust, and succeed in a single response.
The subtler case is wrong-but-running: no red text, but the numbers smell off. Don't say "it's wrong, fix it"; the AI doesn't know which part offends. Report it like a symptom to a doctor:
The output shows total sales of 4.2 million, but I know this year was around 12 million. Something is being dropped or misread. Investigate: show me the row count you processed, the date range you found, and the first 5 rows as the code sees them.
Specific symptom, expected value, request to inspect before re-fixing. Nine times out of ten the culprit surfaces immediately: the code read only the first sheet (tab) of a three-sheet Excel file, or treated "1,200" with its comma as text, or your export quietly cut off halfway. Notice this is just Concept 6's reality questions, now used as a repair tool.
Three patterns cover nearly every breakdown:
| Symptom | The prompt |
|---|---|
| Red text, script stopped | Paste the full error: "diagnose, fix, rerun." |
| Runs, but a number contradicts what you know | State the symptom and your expected value; ask it to show row counts and sample rows before fixing. |
| Same fix fails three times in a row | Stop digging. "We've tried this three times. Step back, restate the problem fresh, and propose two completely different approaches." Three strikes means the approach is wrong, not the typing, and if the conversation has gotten long and confused, start a clean chat with the brief and the lesson learned (context rot, prompting course Concept 4). |
A non-software example. A marketer's campaign-merge script crashed with an error mentioning a "codec." She pasted it without understanding a syllable of it. The AI replied, in effect: one of your exports is saved in a different text encoding (common with files from older systems), adjusting the code to detect it. Reran; worked. Total downtime: forty seconds. She never learned what a codec is, and never needed to. Fluency in errors is not required. Willingness to paste them is.
🔬 Do this now (2 min). Crash it on purpose, today, while nothing is at stake, so a real crash next month feels routine. Paste this, deliberate typo and all:
Here is a tiny reading log: Title,Genre,Pages Dune,SciFi,412 Hamlet,Drama,150 Sapiens,History,498 First write and run code to total the Pages by Genre. Then misspell the 'Pages' column as 'Pagse' in the data, rerun the same code WITHOUT fixing it, and show me the exact error.
Red text appears. (If the AI helpfully fixes the typo instead of showing the error, tell it: "no, run it exactly as written so I can see the failure.") You will not understand a word of it, and that is exactly the point. Now do the only thing the skill asks:
Here is the error. Diagnose it, fix the code, and run it again.
It reads its own error, repairs the column name, and finishes. You just survived your first crash, and the whole skill was: paste the red text back. You never had to know what it meant.
8. Keep the script: a solved problem becomes a button
The Repetition signal from Concept 3 has a payoff the other three don't: a script written once is an asset you own forever. The teacher's submission-check brief takes effort the first time you write it. The next assignment, the same job is one sentence: "Run my submission-check script on this new class list." The marginal cost of every future round rounds to zero. This is the moment you stop using AI and start accumulating with it, the first humble step toward the AI Workers this book builds in later parts.
The habit has three parts:
Ask for the script as a file. When a code-built result is one you'll want again, end with: "Save this as a script file, named clearly, with a plain-English description at the top of what it does, what files it expects, and the rules it applies." On Claude.ai you download the file; on the Part 3 surfaces it's already sitting in your folder.
Keep the brief next to the script. Save your Markdown brief from Concept 5 alongside it. The script is the how (for machines); the brief is the what and why (for humans and future AI sessions). Six months from now, when something needs changing, you won't re-explain from scratch; you'll hand any AI the brief plus the script and say "the late-cutoff rule changed; update it." The previous course called this the Intent Layer. This pair of files, brief.md and submissions.py, is your first piece of it.
Give them a home. One folder, my-scripts/, one subfolder per task. Inside each: the brief, the script, and one small sample input file. That sample is tomorrow's known-answer test, pre-packaged.
my-scripts/
essay-submissions/
brief.md ← what & why, in your words
submissions.py ← the code (you still never read it)
sample-class/ ← inputs whose correct answer you know
monthly-campaign-rollup/
brief.md
rollup.py
sample-april/
Rerunning, by surface. On Claude.ai, you re-upload the script with the new month's files and say "run this on these": workable, slightly manual. On the Part 3 surfaces, the script lives on your machine, so rerunning is a single sentence in a tool that can already see your folder. This asymmetry is, frankly, the best argument for reading Part 3: chat is where scripts are born; your machine is where they live.
| Without the keep-the-script habit | With it |
|---|---|
| Every month, re-explain the task from memory. | Every month: "run the script on the new files." |
| Subtle rule drift: May's logic isn't quite June's. | The rules are frozen in the script; identical logic every run. |
| Your AI skill helps only you. | Hand the folder to a colleague: brief, script, sample. They're productive in minutes. |
A non-software example. A clinic manager built her no-show analysis in March and kept the script. By August, "run the no-show script on this month's export" was a 30-second Friday ritual, and when a new branch opened, she handed the folder to its manager, who ran it on day one without a single question. One afternoon of describing, six people's recurring work automated. That multiplication (describe once, run forever, hand to anyone) is the entire economic argument of this course in one anecdote.
🔬 Do this now (1 min). Turn a result into something you own. Paste this, data and all:
Total this study log by subject, then save the code as a script file I can download: Math 3 History 2 Math 1.5 Science 2 At the very top of the script, put a plain-English note: what it does, what file it expects, and the rules it follows. Name it something I will recognize in a year.
You now hold a real file. Next time you paste new numbers and say "run this on these." The work you did once has become a button you press forever. This is the exact moment using AI turns into owning something, the first brick of every AI Worker later in this book.
Part 3: One problem, five surfaces
Everything in Parts 1 and 2 (the dividing line, the brief, the verification, the loop, the kept script) works identically everywhere. What changes across surfaces is where the code runs and what it can touch. There are five surfaces, but only three kinds of place code can run: a browser sandbox (Claude.ai, with ChatGPT and Gemini working the same way), a terminal that sits inside your folder (Claude Code, OpenCode), and a desktop app (Cowork, OpenWork). The next three concepts walk those three places, using one running job so the differences stand out:
A folder of twelve monthly expense CSVs. Merge them, total by category, flag duplicate transactions, and produce a one-page HTML report with a chart.
(One word before we start, if "CSV" is new to you: a CSV is the simplest kind of spreadsheet file: plain rows of values separated by commas. Your bank, your school portal, your fitness app, and almost every system with an "export" or "download" button produces them, and Excel opens and saves them like any other spreadsheet. And if your data is a regular Excel file instead, nothing changes: every prompt in this course works the same on it.)
9. Claude.ai: the home surface (and ChatGPT, Gemini)
The browser chat is where this course lives, where every prompt so far ran, and where most of your code problems will be solved for a long time. When you ask Claude.ai to write and run code, the code executes in a sandbox: a temporary computer on Anthropic's side, created for your conversation. Your uploads go in; results, files, and charts come out; nothing on your computer is touched, which makes this the zero-risk surface to learn on. ChatGPT (its data-analysis capability) and Gemini work the same way: upload, demand code, verify. Every prompt in this course transfers unchanged.
The running job on Claude.ai:
Attached are 12 CSV files, one per month of my 2025 expenses (columns: Date, Description, Category, Amount).
Write and run code to:
- Merge all 12 into one dataset. Tell me the total row count and confirm all 12 months are present before going further.
- Total spending by category and by month.
- Flag likely duplicate transactions (same date, amount, and description); list them, don't delete anything.
- Produce a one-page HTML report: monthly trend chart, category table, duplicates list, and three observations worth my attention.
Rules: amounts use commas as thousand separators. Refunds are negative. If any row can't be parsed, skip it and list it at the end.
A few minutes later: a rendered HTML artifact, exactly as the Markdown In, HTML Out course promised: your Markdown-shaped brief in, a designed page out, with Python invisibly in the middle. Run the Concept 6 checks (does the row count match? does one month you know well look right?), then publish or download the report.
This is what "the AI runs the code" looks like: the program and its result appear together in one reply. You wrote none of it and pressed no run button.
What the home surface is best at, and where it ends:
| Strength | Limit |
|---|---|
| Zero installation, zero risk to your machine. | The sandbox sees only what you upload. Forty files means forty uploads, and "log into my network devices" is impossible from here. |
| Perfect for one-off and exploratory jobs. | The sandbox is temporary. Scripts must be downloaded (Concept 8) or they effectively die with the chat. |
| The full brief → code → verify → iterate loop, all visible. | Recurring jobs mean re-uploading every time. Fine monthly; tedious daily. |
The boundary, in one line: the chat sandbox is a workshop you visit; it is not where your files live. The moment your problem is about your computer (its folders, its hundreds of files, its daily rhythms), you've outgrown the visit, and the next two surfaces exist.
🔬 Do this now (2 min). Every exercise so far ran on Claude.ai, so you already live on the home surface. Here is its signature move, the designed report. Paste this, data and all:
Here is last month's screen time, hours per app: Instagram,28 YouTube,41 Messages,12 Maps,6 Games,19 Produce a one-page HTML report: a headline with the total hours, a simple bar chart by app, the full table, and two observations worth my attention. Make it look good enough to send to someone.
A designed page appears, not a wall of text: your plain words in, a real report out, code working unseen in between. That is "Markdown in, HTML out" from the last course, now powered by code you never wrote.
10. Claude Code & OpenCode: the agent in your folder
Claude Code (Anthropic) and OpenCode (open-source, works with many AI models; this book pairs every commercial tool with an open alternative on principle) live in the terminal: the plain text window that has lived in every computer since before graphical screens. If the word makes you flinch, hold this reframe: the terminal is just a chat box that sits inside a folder. You type sentences; the agent answers. The difference from the browser is everything around the chat: the agent can see the files already there (no uploading), run code directly on them, save scripts that persist forever, and fix its own errors in a tight loop without you ferrying messages.
(The terminal is the clearest way to picture these tools, and the place this course teaches them, but both have grown beyond it. Claude Code also runs inside code editors, a desktop app, and the browser; OpenCode runs in editors and a desktop app too. The "chat box in a folder" idea holds in every one of them: wherever it lives, it's an agent that can see and act on your files. Pick whichever entry point your tool offers; the skills are identical.)
The running job again, and notice what's missing:
The expenses-2025 folder contains 12 monthly CSVs. Merge them, total by category and month, flag duplicates (same date, amount, description), and produce report.html with a trend chart, category table, duplicates list, and three observations. Amounts use comma separators; refunds are negative; skip and list unparseable rows. Save the merge-and-report code as a reusable script named monthly-report (you choose the right file type) so I can rerun it next year.
No attachments: the files are simply there. The agent reads them, writes the code (Python, for a merge-and-total job like this), runs it, hits the comma-separator snag, fixes it itself, and finishes. Open the folder: report.html, ready to send, and monthly-report.py, yours forever. Next January: "run the monthly-report script on the 2026 folder." Concept 8's keep-the-script habit, with the keeping done for you.
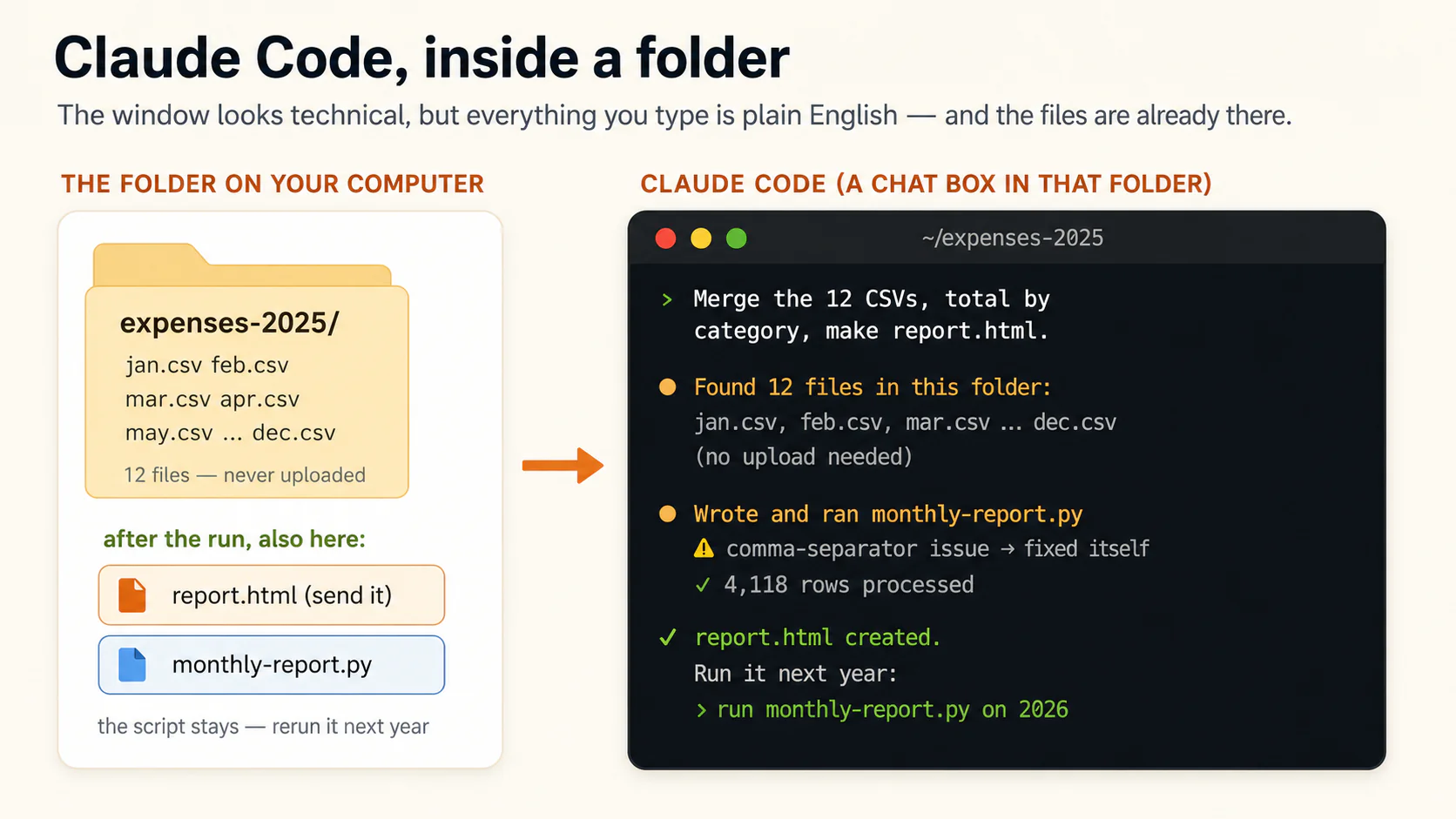
Claude Code in a folder. Notice it lists files you never uploaded; they were already there. The window looks technical, but everything you type is plain English.
This is the surface for the most demanding jobs: code that must run on your own machine, on a schedule, touching systems a browser tab can never reach. Picture a network engineer who logs into forty devices every morning to pull health reports. That work needs code running from his machine, on his network, before he reaches his desk. No browser sandbox can do that. His entire workflow is: open the terminal, describe, verify, schedule. He has never read the scripts either, and he never learned to write them.
Claude Code or OpenCode? Same chat-in-a-folder experience. Claude Code is Anthropic's, polished, runs Claude. OpenCode is open-source and lets you pick your model, including free and self-hosted ones. Learn on either; the skills are identical. The Agentic Coding Crash Course covers installing and operating both; what you've learned here (brief, verify, iterate, keep) is exactly what you'll do inside them.
These tools are marketed at developers, and the marketing is wrong about the boundary. Nothing about "chat with an agent that can see this folder" requires knowing code; it requires knowing your files and your problem, which is the part you bring. Some of the heaviest non-programmer users of these tools are accountants and researchers who simply got tired of uploading.
11. Cowork & OpenWork: delegation with a safety ritual
Claude Cowork (Anthropic) and OpenWork (open-source, from Different AI) are desktop apps: the same file-touching power as the terminal surface, wrapped in a normal application window, built for knowledge workers rather than developers. You met the category in the prompting course's Concept 11. What's new here is realizing what these apps are underneath: when Cowork reorganizes your folder or builds your report, it is very often writing and running code to do it. Same Python, different costume.
Their defining feature is a built-in working rhythm the other surfaces leave to your discipline: plan first, act after approval. Give Cowork the running job and it typically responds with a plan ("I'll read the 12 CSVs, merge on these columns, treat refunds as negative, flag duplicates without deleting, produce report.html; here's what I'll create") and waits. You read the plan in plain English, catch the wrong assumption before it executes, and approve. The plan-review step is Concept 6's plain-English replay, moved before the work instead of after: verification by default, built into the surface.
Choosing among the five, by the problem in front of you:
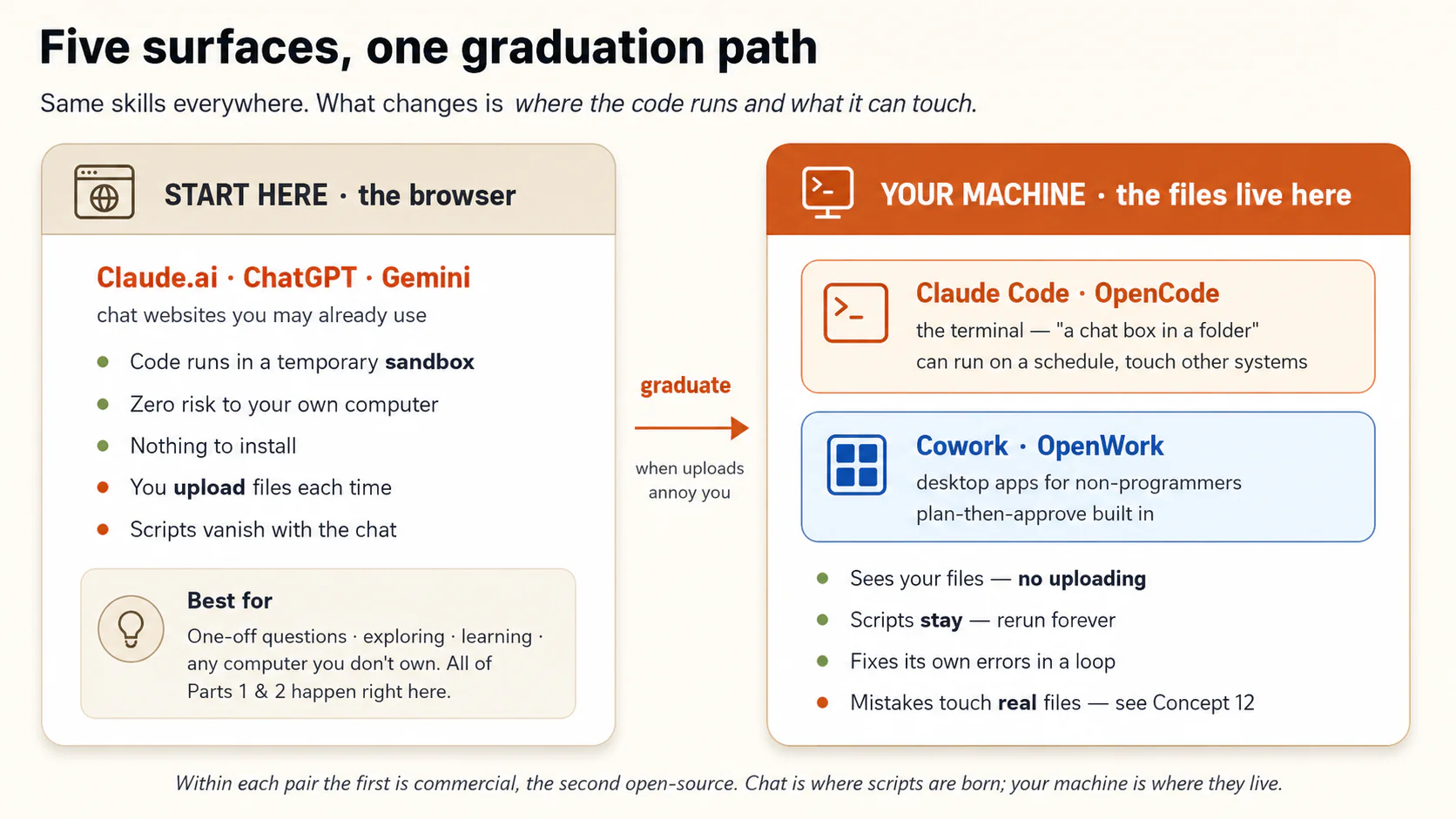
| Your situation | Reach for | Why |
|---|---|---|
| One-off question about a file or a few files | Claude.ai (or ChatGPT / Gemini) | Upload, compute, verify, done. Nothing to install, nothing at risk. |
| Learning, exploring, or working on a borrowed computer | Claude.ai | The sandbox can't hurt anything. |
| The problem lives in your folders; you'll repeat it; scripts should persist | Claude Code or OpenCode | No uploading, scripts stay, errors self-heal, automation possible. |
| Same, but you want an app, not a terminal, and a plan to approve before anything moves | Cowork or OpenWork | Plan-then-approve is verification built into the surface. |
| The task must run on a schedule, or touch other systems (the network engineer's case) | Claude Code or OpenCode | Only code living on your machine can run while you sleep. |
And the honest sequencing advice: stay on Claude.ai until uploading becomes the annoying part of your week. That annoyance is the graduation signal. Most readers feel it within a month of applying this course to real work; the tool-pair crash courses are waiting when you do.
You cannot try the terminal or the desktop app inside a browser tab; they live on your computer, and trying them means a short install, which is exactly what the Agentic Coding and Cowork & OpenWork courses are for. Here is the reassuring part: you have already practiced the real skills (brief, force code, verify, keep) with your own hands on Claude.ai. These surfaces change where the code runs, not what you do. Same job, bigger room.
Part 4: Power, safely held
Two closing concepts: the safety rules for code that can touch real things, and an honest map of where one-prompt code ends.
12. Blast radius: the rules for code that touches your files
On Claude.ai, mistakes are free: the sandbox is disposable and your computer is untouchable. The moment you move to surfaces where code runs on your machine, Concept 2's warning stops being theoretical: code does exactly what it was told, perfectly, at scale, including the wrong thing. A script with a misunderstood brief renames 300 files wrongly in the same four seconds it would have taken to rename them rightly. And two facts from the prompting course bear repeating because people learn them the expensive way: files deleted by an agent often skip the recycle bin, and files edited by a script keep no undo history.
So: four rules, cheap to follow, that remove nearly all of the risk. Together they shrink the blast radius, the worst thing that can happen if a run goes wrong.

Rule 1: Work on copies until a script has earned trust. Before any run that modifies files: "First copy the folder to expenses-2025-backup, then work only on the original." One sentence. When (not if) something goes sideways during a script's first runs, the incident becomes a shrug instead of a disaster. After a script has run cleanly several times on real data, relax this for that script.
Rule 2: Demand a dry run before any destructive act. Renaming, moving, deleting, overwriting: "Don't change anything yet. Show me the full list of operations you would perform (every rename, old name → new name) and wait for my approval." Reading that list takes two minutes and catches the misunderstanding ("wait, why is it touching the 2024 folder?") while it is still words instead of actions. Cowork and OpenWork do this by design; on the terminal surface, you enforce it.
Rule 3: Scope the territory. Point the agent at the smallest folder that contains the problem: never your home directory, never "Documents," never the whole disk. A script confused inside expenses-2025/ can damage twelve CSVs you backed up under Rule 1. A script confused at the top of your drive can damage your life.
Rule 4: Output to new files; never overwrite inputs. "Write results to a new file; leave the originals untouched." The original data stays pristine; every run is reversible by deletion. Make it a standing line in every brief's Output section.
The combined ritual costs three sentences per brief and roughly ninety seconds per run:
Copy the folder to a backup first. Show me your plan of operations before changing anything, and wait for approval. Write all output to new files; never modify the originals.
This is the same permission ladder the prompting course gave for desktop apps, translated for code: trust is granted to specific scripts with track records, not to the technology, and the scope of what code may touch grows only as fast as the evidence that it behaves.
A non-software example. A researcher asked an agent to "clean up" a folder of interview recordings by removing duplicates. The dry-run list showed 40 proposed deletions, including six files the matching logic had wrongly grouped, because two different interviews had identical lengths and similar names. She corrected the rule ("match on content, not name and size"), reran the dry run, approved 34 true deletions. The six interviews that would have silently vanished (past the recycle bin, unrecoverable) survived because of a two-minute read of a plan. That is what the ritual buys.
🔬 Do this now (2 min). Practice the move that prevents disasters: demand the plan before any change. Paste:
I have six files: report-jan.pdf, report-feb.pdf, notes.txt, report-mar.pdf, photo.jpg, report-apr.pdf. I want to rename only the "report-" PDFs to report-01.pdf, report-02.pdf, and so on, in date order. Before doing anything, show me your exact plan: every old name next to its new name. Change nothing yet, and wait for my approval.
It shows you a list, old name next to new name, and stops. Read it. Check that it leaves notes.txt and photo.jpg untouched. That two-minute read, before a single file moves, is the entire safety habit. On your real files, it is the difference between a shrug and a catastrophe.
13. The edge of the map, and what's across it
This course has been deliberately confident, because within its territory the confidence is justified: for problems that fit in a brief and live in your files, AI-written code whose syntax you never read (but whose result you always verify) is not a compromise. It is simply how this work is done now. But you should know exactly where the territory ends, both to avoid frustration and to see where this book goes next.
Across the edge, needs more than one-prompt code:
- Software other people log into. Accounts, payments, simultaneous users, a service that must stay up at 3 a.m.: products, not scripts. Buildable with AI, but with the engineering discipline of Part 4 of this book, not a chat prompt.
- Always-on automation with real-world consequences. "Email my clients automatically every week" runs unattended, where Concept 6's checks can't reach. The gap between a script you run and verify and a worker that runs itself is the gap between this course and the Digital FTEs this book exists to teach: crossable, but with eval-driven discipline, not optimism.
- High-stakes acts with no undo. Code that submits the tax filing, sends the mass email, executes the trade. Let code prepare these and a human fire them. The day you remove the human is the day you need the reliability engineering of the book's later parts.
- Judgment wearing a computation costume. "Compute which employees to promote": the arithmetic is trivial; the criteria are the entire problem, and they are yours, not Python's. Code computes; you decide.
Inside the territory, yours as of today: every reconciliation, rollup, rename, merge, clean, cross-check, flag, chart, and report in your working life that trips Volume, Precision, Repetition, or Files. For most professionals that is hundreds of hours a year, gated until now behind a skill you were told you had to learn first.
Remember the bookkeeper who got her evening back? Multiply her by every reconciliation, rollup, rename, and report in your working life, and you have the whole promise of this course. The people who learn this are not being replaced; they are getting hours of their week back. That is not magic; it is commissioned code: problems described once, computed perfectly, kept forever, rerun for free. None of them became programmers. They became good clients. Now so are you.
Where the book goes from here. You now hold both of the two great levers this Foundations track is built on: precise documents (taught in Markdown In, HTML Out) and computation commissioned through them (this page). What remains is the discipline that decides when to reach for them: How to Think in the AI Era, knowing when to call on an agent and when not to. After it, Problem Solving with General Agents takes both levers onto the agent surfaces from Part 3 and adds the operating discipline (decomposition, constraints, the autonomy ladder) that turns "AI wrote me a script" into "AI and I shipped the engagement." The tool-pair walkthroughs (Agentic Coding, Cowork & OpenWork) are there the day uploading starts to annoy you.
A short recap before you try the prompts
Thirteen concepts, one line each:
- Concept 1. Code is no longer gated by the ability to write it. The AI writes the code and runs it: nothing installed, nothing pasted. You ask "can I describe this?", not "can I build this?"
- Concept 2. Code is exact instructions executed perfectly, in both directions. The AI picks the language; for the real data work of this course, that means Python almost every time. You never write or read its syntax.
- Concept 3. Four signals mark a code problem: Volume, Precision, Repetition, Files. Any one is enough. None means it's an answer problem.
- Concept 4. The AI sometimes estimates when it should compute. Say the words: "Write and run code. Show me that the code ran. Give me row counts first."
- Concept 5. Brief the problem, not the program: Goal, Input, Output, Rules (your professional knowledge), Edge cases (what imperfect data should do). Let the AI inspect the data first and tell you what to decide.
- Concept 6. Verify outputs against independent knowledge: known-answer tests, reality questions, plain-English replays, adversarial passes, cross-model checks. Never act on an untested precision-critical number.
- Concept 7. Errors are dialogue. Paste the red text; report wrong numbers as symptoms with expected values; after three failed fixes, demand a fresh approach.
- Concept 8. Repetition turns scripts into assets: keep the brief, the script, and a known-answer sample together in a folder. Describe once, run forever, hand to anyone.
- Concept 9. Claude.ai (and ChatGPT, Gemini) runs code in a zero-risk sandbox: the home surface for one-off jobs and all of your learning.
- Concept 10. Claude Code and OpenCode put the agent inside your folder: no uploads, persistent scripts, self-healing errors, scheduled runs. The terminal is a chat box that lives in a folder.
- Concept 11. Cowork and OpenWork wrap the same power in a desktop app with plan-then-approve: verification built into the surface.
- Concept 12. When code can touch real files: copies first, dry runs before destruction, smallest folder possible, output to new files. Three sentences per brief.
- Concept 13. The edge of the map: multi-user software, unattended automation, no-undo actions, and judgment calls need the rest of this book. Everything else is yours today.
Underneath all of it, one identity and one skill. The identity: you are the client, not the contractor. The skill, the one the prompting course never needed: you can trust work you cannot see, because you tested it against something you already knew. Clients who brief clearly, verify against what they independently know, and keep what they paid for win back a real day of their week, on work that actually matters. That is the whole course.
You have already done it, ten times over
If you ran the do-this-now boxes above, you did not just read this course; you used it. You spotted code problems, forced the AI to compute, wrote a brief that tamed messy data, ran a known-answer test, survived a crash, kept a script, and demanded a dry run. All of it with your own eyes, on data that sat right there in the page.
Now take the training wheels off. These three projects run the same moves on your data, where the answers actually matter.
🚀 Projects
Those ten do-this-now boxes were rehearsals on data we handed you. These four projects are the real thing: your data, your stakes, and a catch at the end.
A catch is a true thing the AI's code finds that you did not already know, and that you can do something about: a subscription to cancel, a charge to dispute, a grade to rescue, a friend to chase for money owed. So notice what these projects are not. They are not about making a screen to show off. There is no link to send, no page to publish. The thing you walk away with is a sentence you can tell a real person ("the AI found a subscription I forgot, 796 gone so far, plus a double charge I can dispute") and a small script you keep. The catch is the demo.
Before you point a project at some data, ask: has a company already built an app for exactly this? If yes (Splitwise for splitting a bill, a budgeting app for tracking spend, your phone's year-in-review), it is the wrong problem for here. An app exists only when the rules are the same for everybody. And if the rules are universal, there is nothing of yours to brief, and no private answer only you hold for verification to check against.
The right problems are the opposite: a market of one. Your rules, your mess, an answer only you can confirm. That is exactly where commissioned code beats every app on the store, and where every project below lives.
Start with Money Detective; it teaches every move the others reuse. The first three hunt for a catch in data you can only read; the fourth turns the same discipline on your files, where the stakes are higher because code there can delete. Each takes under an hour on a free account.
Project 145 minMoney DetectiveDon't track your money going forward. Hunt the leak hiding in your own real history.
"Money just disappears and I don't know where it goes." Everyone has said it. A budgeting app answers it going forward, which is why one already exists for everybody and why tracking fails the off-the-shelf-app test. This is the opposite move, and the reason no app does it: you are hunting backward through your own real history for the specific leak only you would recognize.
Rehearse the hunt once on a sample wallet whose answer you can check, then turn it loose on your own real export. Paste this into the chat as your "file." It is a few months of a student's wallet, one transaction per line. A positive amount is money in, a negative amount is money out.No export of your own yet? Rehearse on this wallet first
Date,What,Amount
2025-06-01,Pocket money,+5000
2025-06-04,PrimeVideo subscription,-199
2025-06-05,Spotify,-299
2025-06-07,Foodpanda,-650
2025-06-09,Careem ride,-300
2025-06-15,Tutoring received,+1500
2025-06-18,Foodpanda,-700
2025-06-28,Bank service fee,-50
2025-07-01,Pocket money,+5000
2025-07-04,PrimeVideo subscription,-199
2025-07-05,Spotify,-299
2025-07-08,Foodpanda,-650
2025-07-08,Foodpanda,-650
2025-07-14,Careem ride,-300
2025-07-28,Bank service fee,-50
2025-08-01,Pocket money,+5000
2025-08-04,PrimeVideo subscription,-199
2025-08-05,Spotify,-299
2025-08-10,Foodpanda,-700
2025-08-16,Careem ride,-350
2025-08-20,Tutoring received,+1500
2025-08-28,Bank service fee,-50
2025-09-01,Pocket money,+5000
2025-09-04,PrimeVideo subscription,-199
2025-09-05,Spotify,-299
2025-09-12,Foodpanda,-700
2025-09-17,Careem ride,-300
2025-09-28,Bank service fee,-50
Paste the wallet, then this brief:
Here's a few months of my wallet (a plus is money in, a minus is money out). Money keeps disappearing and I can't see where. Be my money detective: write and run code, and show me it ran, to find where it actually goes, anything quietly charging me every month, and any charge billed twice on the same day. Then tell me what I'll have left by my next pocket money.
Earn your trust backstage first. Before you believe anything it found, confirm two numbers you can check yourself: total money IN should be 23,000 (four months of 5,000 pocket money, plus tutoring twice at 1,500), and PrimeVideo should show up every month, 796 taken so far (199 times four). If the code reproduces both, then the things it found that you could not pre-check have earned your trust. That quiet check is Concept 6's known-answer test doing its real job, out of sight.
Now make it explain itself. The numbers you could check came back right, so the next move is to make the AI walk you through its own thinking in words you can actually read.
Now explain it like I can't read code. Which language did you use, and how did you actually get these numbers, especially how you decided something was a duplicate?
This is Concept 6's plain-English replay. You cannot read the Python, but you can check the logic in plain English: "I summed by category, I counted a charge as recurring only when the same amount hit every month, I flagged same-day same-amount as a possible duplicate." If that logic is wrong, it reads wrong in English, and you catch it without reading a single line of code. Notice too that you never told it to use Python (Concept 2): it picked the language itself, because this is data work and choosing the right tool was its job, not yours.
What the detective catches. On this wallet it surfaces three true things you did not hand it: a PrimeVideo subscription quietly taking 199 a month, 796 so far, that you forgot you had; a Foodpanda charge that hit twice on the same day, 8 July, a double charge you can dispute; and the real leak, food delivery at roughly 4,050, more than every subscription combined. The forecast rides honestly on top: you are actually net positive, you just feel broke because food delivery nibbles you in small bites. (And the detective is honest about its own footing: that forecast assumes your tutoring income keeps coming, and here it arrived only two months of four. A good detective shows you the number and what it leaned on.)
Your one sentence: "the AI found a subscription I forgot, 796 gone so far, plus a double charge I can dispute." That sentence ends in a verb. You cancel, you dispute, you eat in twice a week.
Keep the tool. Ask it to save the whole thing as a script with a plain-English header (Concept 8), named something like "my monthly money check." Next month you paste a fresh export and say "run this," and the hunt is a thirty-second habit instead of an evening.
If the catch is going to drive a real decision (a refund worth chasing, a budget you'll show someone), run the identical brief in a second AI from a different family and see if the two agree on the leak before you act. That is Concept 6's strongest check, performed for real.
Optional: keep the receipt. The catch is the real deliverable, and you already have it. But if you want to keep a copy or show someone (a parent, your own records), you can package what you found using the very skill from the last course, Markdown In / HTML Out.
For keeping or showing someone: turn what you found into one clean page I can save, with the leak, the forgotten subscription, the double charge, and your one-line verdict.
On Claude the report appears inline as an artifact you can save; on ChatGPT it downloads as an .html file you open in your browser, same result either way. This is packaging the catch, not the point, and it is for you: a report of your own forgotten subscriptions is for your eyes or a parent's, never a link you publish. It is also the honest sense in which this project uses code both ways: Python to compute and catch the leak, the HTML markup from the last course to package it, and never a clickable app to build. This one is built from the practice wallet above, not anyone's real money, so it is safe to show. Yours would carry your own catches, and your real report stays yours, never a link you publish. You can also open the sample in its own tab.▶ See a sample report (what your saved page can look like)
Done when: the code reproduces the two numbers you already knew, and it hands you at least one true thing you did not know (the forgotten subscription, the double charge) that you can act on this week, plus a saved script you can rerun next month.
Project 230-45 minWhat's My Grade, ReallyEncode the one set of grading rules no app has, your teacher's, and find out where you really stand.
No gradebook app knows that your teacher drops your two lowest homeworks, counts the best 8 of 10 quizzes, lets a strong final replace a weak midterm, and caps the late penalty. That exact bundle of rules exists on one syllabus in the world, which is precisely why it passes the off-the-shelf-app test: the rules are not universal, they are your teacher's, so only a brief you write can encode them. This is "brief the problem, not the program" (Concept 5) at its purest, because here the Rules section is the syllabus, copied into plain English.
Gather your real scores (copy-pasted straight from the portal, messy is fine) and your teacher's actual rules. Rehearse on the sample if you don't have them in front of you.No scores handy? Rehearse on this, then do it for real
My homework scores: 60, 92, 88, 45, 90, 85
My quiz scores (best 8 of 10 count): 70, 95, 88, 100, 0, 91, 84, 77, 93, 80
Midterm: 72
Final: 86
My teacher's exact rules:
- Homework is 20% of the grade. Drop my two lowest homework scores, average the rest.
- Quizzes are 20%. Only my best 8 of 10 count (a 0 means I missed one).
- Midterm is 25%.
- Final is 35%. If my final percentage is higher than my midterm, the final replaces the midterm too.
Paste your scores and rules, then this brief:
Here are my scores and my teacher's exact grading rules. Write and run code, and show me it ran, to work out my real grade right now following every rule, and show each part's subtotal so I can check one by hand. Then tell me what I need on the final to reach 90 percent.
Earn your trust backstage first. Check one category yourself before you trust the whole grade. Drop the two lowest homeworks (45 and 60) and average what's left, 92, 88, 90, 85, which is 88.75. If the code's homework subtotal reads 88.75, its arithmetic on the categories you can't easily hand-check just earned your trust. (On your own data, pick whichever single category is easiest to compute on paper. That is the known-answer test, and it costs a minute.)
The catch. The number that comes back is almost never the number in your head. The catch is a true, stakes-bearing figure you did not have, with a plan attached: "I'm actually sitting at a 79, not the 85 I assumed, and I need an 88 on the final for an A." That sentence ends in a verb too. It changes what you study tonight, which is the entire point of running it.
Keep the tool. Save it as a "what do I need on the final" script. Re-run it every time a grade posts, and you always know exactly where you stand and exactly what the final has to clear.
Done when: the code reproduces the one category you hand-checked, and it hands you a real grade you did not know plus the exact score you need next, specific enough to change tonight's study plan.
Project 345 minThe Books Don't MatchTwo records that should agree: your counted total and the messy digital one. Find the gap, name the person.
Remember the bookkeeper who opened this course, losing an evening every month hunting the handful of transactions where two records disagreed? You have her problem at teen scale. You collected money for a class trip, a club, a group gift. You counted what came in, so you know the true total, and that count is your known answer, the thing no app can give you because no app was in the room.
Now reconcile it against the messy digital record: JazzCash or Venmo or Easypaisa memos full of free text, plus your paper list of who owes. Your private knowledge is the rules no app has: "pizza in the memo isn't dues, that's a friend paying me back"; "Ali's 1,000 covers him and his brother"; "a stray 500 from a number I don't recognize is probably someone's dues, but whose?" That bundle of rules lives in your head alone, which is exactly why this is a market of one and Splitwise is not.No collection of your own to settle? Rehearse on this one
Everyone owes 500 for the class trip. Eight people: Ali, Omar, Sara,
Bilal, Hina, Zoya, Ayesha, Usman. So the books should show 4,000.
Digital record (JazzCash), exactly as it came in, messy memos and all:
Date,From,Amount,Memo
2025-09-02,Ali,1000,trip me + my brother Omar
2025-09-02,Sara,500,trip dues
2025-09-03,Bilal,500,
2025-09-03,Hina,500,class trip
2025-09-05,0300-unknown,500,
2025-09-05,Usman,300,pizza
2025-09-06,Zoya,500,dues
2025-09-08,Ayesha,500,trip
What only I know (the rules):
- Ali's 1,000 covers Ali AND his brother Omar. Count it for both.
- Usman's 300 with "pizza" is NOT dues; he was paying me back. Ignore it.
- The 500 from "0300-unknown" has no name I recognize. Do not assume; flag it.
Paste the dues list, the digital record, and your rules, then this brief:
Here's what everyone owes, the messy payment record, and the rules only I know. Write and run code, and show me it ran, to reconcile them: who's paid, who still owes, and how much is unaccounted for. List any payment you can't match to a person; don't guess. My counted total is [your number]; show me how it stacks against that.
Earn your trust backstage first. Your counted figure, 4,000 owed across eight people, is the known answer here, the same role the closed-by-hand month plays in Concept 6. If the code's "expected" total comes back as anything but 4,000, something is off in the brief before you even look at the catch.
The catch. On this sample the books come out 500 short on paper. Applying your rules, seven people are covered (Ali and Omar by the 1,000, plus Sara, Bilal, Hina, Zoya, Ayesha), Usman's only payment was pizza so he still owes, and there's one unplaceable 500 from a number you don't recognize. So the catch is a real, actionable mismatch: either that mystery 500 is Usman paying under a handle you didn't know, or you are genuinely still owed, and one message settles it. The deliverable is the sentence you can send to the group chat tonight: "everyone's accounted for except Usman, and there's a mystery 500, so I'll message him before I close the books." A mismatch like that is either a bug in your brief or a true discrepancy worth chasing, which is exactly the bookkeeper's craft.
Keep the tool. Save it as your reconciliation script. The next trip, the next gift, the next collection: paste the new record and the new dues list, and an evening of hunting becomes a one-prompt check.
Done when: the code reconciles against your counted total, and it hands you a specific name to chase or a specific payment to place, the one true mismatch, in a sentence you could send to the group chat tonight.
Project 445 minPhoto Gallery RescueYour photo gallery is hiding duplicates eating real space. Find them, delete them safely, then sort what's left by date.
The other three projects read your data. This one changes it, which is exactly why it teaches the safety habit the others can't. Your photo gallery is two messes in one: it is full of duplicates (the same shot saved twice, near-identical bursts, a screenshot you copied around), and whatever survives sits in no real order. You fix both here: find and safely delete the duplicates, then sort what is left by date. The catch is the space the duplicates waste; the safety lesson is deleting them without losing a real photo; the payoff is a gallery that is finally in order.
First, find the duplicates, and notice the AI never "looks" at your photos. Telling two photos apart is an algorithm, not an AI job: the code shrinks each image to a tiny fingerprint and compares fingerprints. You ask for exactly that:
Write and run code to find duplicate and near-duplicate photos in this folder. Fingerprint each image with a perceptual hash, group the ones that match, and tell me how many duplicates there are and how much space they take. Don't delete anything yet.
The catch arrives as a number: "47 duplicates across 18 sets, 2.1 GB." That alone is worth the project.
Then the safety gate, because this step deletes (Concept 12). Deleted files skip the recycle bin, and a fingerprint match can be wrong, since two different sunsets look alike. So you make the code show its plan before it touches anything:
For each set, keep the largest copy and list the ones you would delete, with names and sizes. Change nothing yet. Copy the originals to a backup first, then wait for my approval.
Read the list. There is almost always one "duplicate" that is really a different moment: spare it, then approve the rest. That review, before a single file is deleted, is the whole safety lesson, and it is the one move the read-only projects above never made you practice.
Finally, sort what's left, so the cleanup sticks. A gallery with the duplicates gone is still only half-tidy if it is a thousand photos in upload order. One more instruction puts it in shape:
Now take the photos that are left and sort them by date, newest first, into a copy I can scan at a glance. Leave my originals untouched.
You end with your own gallery, deduped and in order: nothing published, nothing sent, just your files finally tidy. This is what the code does, made interactive. Drop a pile of photos in (try the same one twice): it fingerprints each one to catch duplicates, lets you review before removing any, then sorts the rest by date. No AI, nothing uploaded, all in your browser. It loads live below; you can also open it in its own tab.▶ Try it yourself (live)
Done when: the code hands you a real number (the duplicates found and the space they waste), you caught at least one false match before approving, a backup of the originals exists so deleting was safe, and the survivors are sorted by date. Keep the script, and your photo gallery never piles up again.
🛟 If you get stuck mid-project
Every stall we've seen lands in one of these. Find your symptom, paste the fix. None of them asks you to understand what went wrong; that's the AI's job.
1. "It can't open or read my export." Usually the file, not the AI. Paste: "Tell me exactly what's wrong with this file: its format, what you can and can't read from it, and what I should re-export or save it as instead." If the download screen offered both CSV and Excel, try the other one. Nine times out of ten this is a re-export.
2. "It answered, but I never saw a code block." The silent estimate from Concept 4. Say the words again, firmly: "Stop. Write and run code to answer this, show me the code, and give me the row count first." No code block means no code ran, whatever the prose claims.
3. "The number doesn't match what I counted or what I know." Don't say "it's wrong." Report it as a symptom (Concept 7): "Your total is X but I counted Y. Show me the row count you processed, the date range, and the first five rows as the code sees them." The culprit (a skipped row, a comma read as text, a half-finished export) almost always surfaces in that inspection. And remember: in these projects a mismatch might be the catch, not a bug.
4. "The same fix keeps failing." Three strikes means the approach is wrong, not the typing. Paste: "We've tried this three times. Forget the current code. Restate the problem fresh and propose two completely different approaches."
5. "My file has private data and I'm nervous uploading it." Good instinct; act on it. These projects all touch real money and real names, so this one matters. Paste: "Before any analysis, make a cleaned copy with the names and account numbers removed, work only on that copy, and confirm what you removed." Or delete those columns yourself first; the totals rarely need them. Check your tool's data policy before uploading anything sensitive, and if your data genuinely can't leave (a workplace or school rule), practice on the sample and apply the moves only inside an approved tool.
6. "I ran out of free-tier usage mid-project." Every project here fits a free tier, but heavy iteration can hit a daily cap. Wait for the reset (your saved brief means resuming costs nothing), or re-paste the brief into a different model family and keep going; the skill transfers either way.
The pattern under all six: when stuck, describe the stuckness to the AI. The same skill that commissions the code rescues the project.
You now commission code. The next course teaches you to run the engagement: Problem Solving with General Agents →
Flashcards Study Aid
Test Your Understanding
Thirteen concepts, one identity: you are the client, not the contractor. These thirty-two scenarios drop you into other people's spreadsheets, folders, and broken runs and ask the one question each concept turns on. None reward memorizing a definition; every one rewards knowing what to actually do. Answer from the reasoning, not the longest option.