Axiom II: Knowledge is Markdown
Axiom I solved how to organize commands: the shell coordinates, programs compute. But code is only half of what a team produces. The other half is knowledge: why did we choose this database? What conventions do we follow? How is the system designed? That knowledge has to live somewhere every developer and every AI agent can find it. Should you write it in a Google Doc? A Slack message? A Confluence wiki? A markdown file in the repository? The choice of format determines whether that knowledge survives or disappears, and this axiom makes the choice for you.
Six months before Emma's rewrite, her team had made a critical architecture decision: event-driven messaging over synchronous REST. The discussion happened across four Slack threads, two Zoom calls, a Google Doc that three people edited simultaneously, and a Confluence page that nobody could find anymore. When a new developer named James joined, he looked at the codebase, saw REST calls everywhere except in the user service, and assumed it was an oversight. Nobody told him otherwise, because nobody could find the reasoning. The Google Doc had conflicting comments. The Confluence page referenced a Slack thread that had been archived. So James spent two weeks building a REST integration for the user service. Clean code. Good tests. A pull request that undid three months of deliberate architecture.
Emma caught it during code review. "We moved to event-driven for a reason," she said. "What reason?" James asked. Silence. Nobody could reconstruct the full rationale. They knew the decision was right, but the knowledge about why (the N+1 query analysis, the mobile traffic data, the RFC from the September standup) had been scattered across formats that could not be searched, versioned, or read by an AI agent.
Two weeks of James's work, discarded. Not because the decision was bad, but because the knowledge was lost.
It was James's second week. Emma had moved him from deployment scripts to architecture decisions, and the first thing he learned was that his team's knowledge was scattered everywhere.
Now consider the alternative: that same decision lives in a file called docs/adr/007-event-driven-messaging.md, committed to the repository. It has a Status, Context, Decision, Consequences, and Alternatives Considered section. Before writing a single line of code, James (or his AI agent) reads the file and understands the complete reasoning in thirty seconds. The REST integration is never built. The two weeks are never wasted. The architecture stays intact.
The difference between these two scenarios is Axiom II.
The Problem Without This Axiom
You know that knowledge must live in files. But what format should those files use?
Without a format standard, teams persist knowledge in whatever seems convenient at the moment:
| Format | Example | Problem |
|---|---|---|
| Google Docs | Architecture decisions shared via link | Can't be read by CI, can't be diffed in git, requires authentication |
| Confluence wiki | Team knowledge base | Vendor lock-in, no version control integration, search quality degrades over time |
| Slack messages | "Hey, we decided to use Postgres because..." | Disappears into archive, unsearchable after 90 days on free plans |
| Word documents | requirements_v3_FINAL_v2.docx | Binary format, merge conflicts impossible to resolve, requires specific software |
| YAML/JSON files | Configuration stored as pure data | Not human-friendly for prose, no narrative structure, poor for explaining "why" |
| Plain text | notes.txt with no structure | No headers, no hierarchy, not parseable by tools expecting structure |
Each format works in isolation. None works as a system. This is exactly the landscape James walked into: the event-driven messaging decision existed in all of these formats simultaneously, and therefore effectively existed in none of them. AI agents could not read the Slack threads. Git could not track changes to the Google Doc. New team members could not find the Confluence page. The knowledge was technically "persisted" but practically lost.
The Axiom Defined
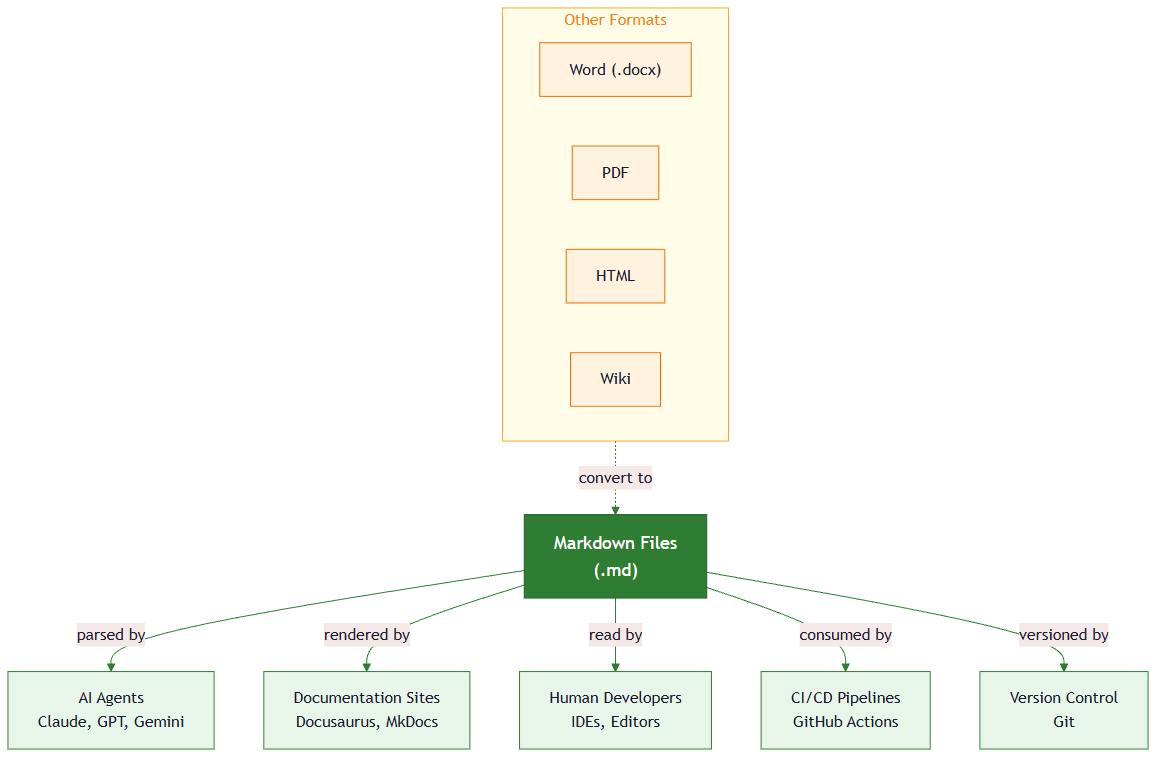
Axiom II: All persistent knowledge lives in markdown files. Markdown is the universal knowledge format because it is human-readable, version-controllable, AI-parseable, and tool-agnostic.
This axiom doesn't say "documentation should be in markdown." It says all persistent knowledge (specifications, decisions, context, guides, learning objectives, project conventions) lives in markdown. Markdown is not merely a documentation format. It is the knowledge substrate of agentic development.
From Principle to Axiom: The Format Decision
In Chapter 18, Principle 5 taught you that persisting state in files is essential for AI collaboration. You learned to create CLAUDE.md files, write ADRs, and structure projects for reproducibility. That principle answered whether to persist knowledge (yes, always) and where to persist it (in version-controlled files).
Axiom II answers the next question: how to format that knowledge.
The relationship is hierarchical:
Principle 5: "Persist state in files"
└── Axiom II: "Format that state as markdown"
└── Implementation: CLAUDE.md, ADRs, specs, README.md
The principle is about durability (ensuring knowledge survives across sessions). The axiom is about interoperability (ensuring that knowledge can be read, processed, and acted upon by every tool in the chain: humans, AI agents, linters, CI pipelines, documentation generators, and search engines).
Think of it this way. A team's knowledge is like a library.
- Markdown files in a repository are books on open shelves: anyone can walk in, find the right shelf, and read.
- A Google Doc is a book locked in someone's desk drawer: it exists, but you need their permission and their key to read it.
- A Slack message is a conversation someone overheard in the hallway last month: it happened, but good luck reconstructing it.
- A Confluence page is a book in a private library across town: you need a membership card, a login, and the hope that nobody has rearranged the shelves since your last visit.
The markdown repository is the only library where every reader (human developers, AI agents, CI pipelines, new hires on their first day) can walk in and find what they need without asking anyone for access.
Why Markdown?
After the incident, Emma told James: "We need to write down every decision."
"We did write it down," James said. "It was in a Google Doc. With comments. And a Confluence page. And three Slack threads. The problem wasn't that we didn't document; it was that we documented in too many places."
"And what happened when you needed to find it?"
James thought about it. He had searched the repository first (nothing). He had asked his AI assistant to check the codebase (nothing, because the AI could not read Google Docs or archived Slack threads). He had eventually found the Confluence page, but it referenced a Slack thread behind the archive wall.
"The format was the problem," he said slowly. "The decision existed. It just didn't exist anywhere a developer, or an AI, would naturally look."
If the team had written docs/adr/007-event-driven-messaging.md on the day they made the decision, James would have found his answer in thirty seconds. But why markdown specifically? Why not a JSON file, a YAML config, or a well-organized text file?
Markdown wins not because it is the most powerful format, but because it satisfies all four requirements simultaneously (no other format does).
The Four Properties
| Property | What It Means | Why It Matters for Agents |
|---|---|---|
| Human-readable | You can read raw markdown without any special tool | Developers edit knowledge directly; no rendering step required |
| Version-controllable | Plain text diffs cleanly in git | Every knowledge change has a commit, author, and timestamp |
| AI-parseable | LLMs process markdown natively: headers, lists, tables, code blocks | AI agents extract structured information without custom parsers |
| Tool-agnostic | Works with any editor, any platform, any operating system | No vendor lock-in; knowledge survives tool migrations |
The Comparison
Every alternative format fails on at least one property. This is not a matter of taste; it is a testable claim:
| Format | Human-Readable | Version-Controllable | AI-Parseable | Tool-Agnostic |
|---|---|---|---|---|
| Markdown | Yes | Yes | Yes | Yes |
| YAML | Partial (data only, not prose) | Yes | Yes | Yes |
| JSON | No (noise from braces/quotes) | Yes | Yes | Yes |
| Word (.docx) | Yes (rendered) | No (binary) | Partial | No (requires Office) |
| Google Docs | Yes (rendered) | No (proprietary history) | No (requires API auth) | No (requires Google) |
| Confluence | Yes (rendered) | No (database-backed) | No (requires API auth) | No (requires Atlassian) |
| Plain text | Yes | Yes | Partial (no structure) | Yes |
| HTML | Partial (tag noise) | Yes | Yes | Yes |
Markdown is the only format that scores "Yes" on all four. HTML comes close but fails human-readability; raw HTML is cluttered with tags that obscure the content. Plain text fails AI-parseability; without headers and structure, an agent cannot distinguish a section title from body text.
Historical Background: Why Markdown Scores "Yes" on All Four (click to expand)
This is not an accident. Markdown was created in 2004 by John Gruber, a writer and blogger, with substantial contributions from Aaron Swartz (who was seventeen years old at the time and had already created atx, a precursor format, two years earlier).
Their design goal was radical in its simplicity: create a format that reads as well before rendering as it does after. Unlike HTML, where <h1>Title</h1> obscures the content behind tags, markdown's # Title is immediately legible. The format drew directly from conventions people had already been using for decades in plain-text email: asterisks for emphasis, dashes for lists, blank lines for paragraphs. Gruber and Swartz did not invent a new syntax. They formalized the one that humans had already converged on naturally.
This origin explains the comparison table above. Markdown was designed for human readability first, and machines turned out to be able to parse it too. Twenty years later, that design decision is what makes markdown the natural interface between human developers and AI agents: both can read the same file with the same ease, because readability was the original and only design constraint.
The Structure Advantage
The code blocks in this lesson show markdown formatting examples and project file structures. You do not need to memorize any syntax. Focus on why structured text is better than unstructured conversation for preserving knowledge.
This is where markdown's design genius (and its relevance to James's situation) becomes concrete. It provides just enough structure to be parseable without becoming a data format that sacrifices readability:
# Decision Title ← Parseable as section boundary
## Context ← Parseable as subsection
We needed a database... ← Prose that explains reasoning
## Alternatives ← Another parseable subsection
| Option | Pros | Cons | ← Structured data within prose
|--------|------|------|
| Postgres | ACID | Scale |
## Decision ← The conclusion, identifiable by header
We chose Postgres.
An AI agent reading this file can:
- Identify the decision by finding the
## Decisionheader - Extract alternatives from the table
- Understand reasoning from the
## Contextprose - All without a custom parser (markdown structure is the parser)
Markdown as Knowledge System
Once Emma's team committed to markdown, something unexpected happened. The ADR that would have saved James's two weeks was just the beginning. Axiom II is not about individual files. A single ADR in markdown is useful. A complete knowledge system in markdown (where specs, decisions, context, and documentation all share the same format, the same repository, and the same version history) is transformative. Different knowledge types serve distinct purposes but use identical infrastructure.
Specifications: What to Build
A spec file contains the goal, success criteria (as checkboxes), and constraints. The person responsible writes it, the AI agent implements against it, and the team can check off the boxes as each criterion is met. One file, three audiences, zero format translation.
Decisions: Why We Built It This Way
This is an Architecture Decision Record (ADR), the kind of file that would have saved James two weeks:
# ADR-007: Use Event-Driven Messaging Over REST
## Status
Accepted
## Context
Our user service sends notifications to three other services whenever
a user updates their profile. The current approach (direct REST calls)
means the user service must know about all three services and wait
for each one to respond before confirming the update.
## Decision
Switch to event-driven messaging: the user service publishes an event,
and each downstream service listens for it independently.
## Consequences
- Positive: User service no longer needs to know about downstream services
- Positive: Adding a new listener does not require changing existing code
- Negative: Harder to debug when an event is lost or delayed
- Negative: Team needs to learn a new messaging tool
## Alternatives Considered
- Keep REST: Simpler, but creates tight coupling between services
- Shared database: Services read from the same table, but creates contention
You do not need to understand REST, events, or messaging yet. Focus on the structure: Status, Context, Decision, Consequences, Alternatives. That structure is what makes the reasoning findable six months later. The specific technology does not matter; the format does.
Context: How to Work Here
# CLAUDE.md
## Project Overview
A to-do list app where users can create, complete, and delete tasks.
## How to Run
- `python app.py` → Start the app
- `python -m pytest` → Run the tests
## Project Rules
- Each feature gets its own file in `src/`
- Every feature has a matching test file in `tests/`
- Write a test before writing the feature code
Documentation: How It Works
Setup guides, how-to instructions, reference pages: all markdown, all in the repo. A docs/guides/setup.md file with headers, code blocks, and tables serves the same purpose as a Confluence page but without the vendor lock-in, authentication walls, or staleness that plagues wiki platforms.
All four knowledge types (spec, decision, context, documentation) use the same format. They live in the same repository. They are tracked by the same version control. They are readable by the same AI agents. This is what makes markdown a system, not just a file format.
YAML Frontmatter: The Metadata Layer
As Emma's team migrated their knowledge into markdown, James noticed a gap. The ADR captured the reasoning behind a decision, but he also wanted to record when it was made, who approved it, and what status it had: structured data that did not belong in prose paragraphs. Raw markdown provides structure through headers, lists, and tables. But some knowledge is better expressed as structured data: lesson duration, skill proficiency levels, creation dates, taxonomy categories. This is where YAML frontmatter adds a metadata layer on top of markdown content.
---
title: "Axiom II: Knowledge is Markdown"
chapter: 43
lesson: 2
duration_minutes: 20
skills:
- name: "Knowledge Format Selection"
proficiency_level: "A2"
bloom_level: "Understand"
---
# Axiom II: Knowledge is Markdown
The lesson content begins here...
The frontmatter block (between --- delimiters) contains machine-processable metadata. The body contains human-readable prose. Together, they give you the best of both worlds:
| Layer | Format | Purpose | Processed By |
|---|---|---|---|
| Frontmatter | YAML | Structured metadata (dates, tags, numbers) | Build tools, CI, search indexes |
| Body | Markdown | Narrative content (explanations, examples, decisions) | Humans, AI agents, documentation generators |
This pattern appears throughout professional tooling: Jekyll blogs, Docusaurus documentation, Hugo sites, Obsidian notes, and Astro pages all use YAML frontmatter on markdown files. The pattern works because it respects the boundary between data and narrative.
Anti-Patterns: Knowledge Trapped Outside Markdown
Every team has a Knowledge Graveyard. It is the Google Doc with forty-seven comments, twelve of which contradict each other. It is the Confluence page that starts with "This document is a living document," last updated eight months ago. It is the Slack thread where the CTO explained exactly why the team chose one technology over another, and those messages disappeared behind the archive wall while nobody noticed.
The knowledge existed. It was written down. It was even shared. But it was scattered across formats that could not be searched together, versioned together, or read by an AI agent. When a new developer asked their AI assistant to "explain why we use this technology," the agent searched the repository, found nothing, and hallucinated an answer. The developer believed it, and a wrong decision followed.
Here are the most common ways knowledge gets trapped:
| Anti-Pattern | What Happens | The Fix |
|---|---|---|
| Decisions in Slack | Knowledge archived after 90 days; unsearchable; no structure | Write an ADR in docs/adr/ and commit it |
| Specs in Google Docs | AI can't read without authentication; merge conflicts impossible to resolve | Write specs as markdown in the repo |
| Docs in Confluence | Vendor lock-in; pages go stale; separate from the code they describe | Co-locate docs with code as markdown |
| Notes without headers | AI can't parse sections; search returns the whole file instead of the relevant part | Use # headers to create parseable structure |
The common thread: every anti-pattern breaks at least one of the four properties. Slack breaks version-controllability. Google Docs breaks tool-agnosticism. Plain text without headers breaks AI-parseability. Proprietary formats break all four.
The Knowledge Architecture
After Emma's Makefile rewrite from Axiom I, her team adopted Axiom II. They migrated every decision from Slack, every spec from Google Docs, and every convention from tribal knowledge into markdown files in the repository. Within a month, the project looked like this:
project/
├── CLAUDE.md ← Context: How to work here
├── README.md ← Context: What this project is
├── docs/
│ ├── adr/
│ │ ├── 001-database.md ← Decision: Why Postgres
│ │ ├── 002-framework.md ← Decision: Why FastAPI
│ │ └── 003-orm.md ← Decision: Why SQLModel
│ ├── specs/
│ │ ├── auth-spec.md ← Spec: Authentication requirements
│ │ └── api-spec.md ← Spec: API design
│ └── guides/
│ ├── setup.md ← Documentation: Getting started
│ └── deployment.md ← Documentation: How to deploy
├── src/ ← Implementation
└── tests/ ← Verification
Every knowledge type has a place. Every file is markdown. Every change is tracked. Every agent can read everything. When the next James joins the team and asks "why event-driven messaging?", the answer is one grep away (or one question to an AI agent that can read every file in the repository).
The Openness Trade-Off
During the migration, James almost committed the team's database connection string into CLAUDE.md. Emma caught it in review. "That's the other side of this axiom," she said. Markdown's greatest strength (plain text that anyone and anything can read) is also its greatest risk. A markdown file committed to a repository is visible to every person and every tool with access. This openness is exactly what makes it the universal knowledge format. It is also exactly what makes it dangerous for secrets.
Never store API keys, passwords, tokens, or customer data in markdown files, even in private repositories. An AI agent reading your CLAUDE.md should find instructions like DATABASE_URL is set via environment variable, not the actual connection string. A spec file should reference Use the Stripe API key from .env, not embed the key itself.
The rule is simple: markdown is for knowledge, not for secrets. Knowledge wants to be readable. Secrets need to be hidden. These are opposite requirements, and they belong in opposite systems: markdown files for the first, environment variables and secret managers for the second.
Try With AI
Prompt 1: Knowledge Audit
I want to audit where my project's knowledge currently lives.
Help me categorize my project knowledge into these buckets:
1. Decisions (why we chose X over Y)
2. Specifications (what we're building and the success criteria)
3. Context (how to work on this project, conventions, patterns)
4. Documentation (how things work, API references, guides)
For each piece of knowledge I identify, help me determine:
- Where does it currently live? (Slack, Google Docs, someone's head, README, etc.)
- Is it in markdown in the repo? If not, what's the migration path?
- What breaks if this knowledge disappears tomorrow?
Start by asking me about my project and where I keep information today.
What you're learning: How to identify knowledge that is currently trapped in non-markdown, non-version-controlled locations. You are building the skill of recognizing when the four properties (human-readable, version-controllable, AI-parseable, tool-agnostic) are violated, and understanding the operational cost of each violation.
Prompt 2: Markdown Knowledge Migration
I have a decision that currently lives outside any document:
[Paste or describe a decision from a chat, a call, meeting notes, or memory.
For example: "We decided to use Google Slides instead of PowerPoint because..." or
"Our study group agreed to meet on Tuesdays because..." or
"The team chose Python over JavaScript for this project because..."]
Help me convert this into a proper Architecture Decision Record (ADR) in markdown format.
Include: Status, Context, Decision, Consequences (positive and negative), Alternatives Considered.
Then explain:
- What information was I about to lose by not writing this down?
- How would an AI agent use this ADR when suggesting changes to my project?
- What would happen if someone proposed a change that contradicts this decision?
What you're learning: The practical mechanics of converting knowledge from ephemeral formats into durable, structured markdown. You are experiencing how the act of writing an ADR forces you to articulate reasoning that was previously implicit, making it available to both future humans and AI agents.
Prompt 3: YAML Frontmatter Design
I'm organizing my project's knowledge into markdown files. I need to decide
what metadata belongs in YAML frontmatter versus what belongs in the markdown body.
My project involves [describe your project (it could be a class assignment,
a personal app, a study group, a club website, or a team project)].
Help me design a frontmatter schema for my most common document types
(for example: meeting notes, decisions, project specs, how-to guides).
For each type, help me decide:
- What fields go in frontmatter? (things tools need to process: dates, tags, status)
- What stays in the body? (things humans and AI need to read: explanations, reasoning)
- What's the boundary between "data about the document" and "the document itself"?
Give me a concrete template for each document type with example frontmatter
and explain why each field is in frontmatter rather than the body.
What you're learning: The design principle behind YAML frontmatter (separating machine-processable metadata from human-readable content). You are learning to draw the boundary between structured data (dates, tags, numbers, categories) and narrative content (explanations, reasoning, examples), and understanding how build tools, CI pipelines, and AI agents use each layer differently.
PRIMM-AI+ Practice: Knowledge is Markdown
Predict [AI-FREE]
Enter Plan Mode in Claude Code (Shift+Tab). Your team made a big decision last month about which tool to use for a group project. The discussion happened in three places:
- A WhatsApp group chat
- A phone call between two team members
- A shared Google Doc
Six months later, a new member joins and asks: "Why did you pick that tool?"
Consider these four properties: (1) human-readable, (2) version-controllable, (3) AI-parseable, (4) tool-agnostic. For each format (WhatsApp, phone call, Google Doc), predict which of the four properties it violates. Write your answer down and rate your confidence from 1 to 5.
Run
In Claude Code, type: "Evaluate WhatsApp group chats, phone calls, and Google Docs against these four properties: human-readable, version-controllable, AI-parseable, and tool-agnostic. Which properties does each format violate?"
Compare the AI's evaluation to your predictions. Did you catch all the violations? Were there any you missed?
Answer Key (check after comparing with AI)
| Format | Human-Readable | Version-Controllable | AI-Parseable | Tool-Agnostic |
|---|---|---|---|---|
| WhatsApp group | Yes (you can read it) | No (no change history, no diffs) | No (requires app login, no API for agents) | No (requires WhatsApp) |
| Phone call | No (nothing written down) | No (no record exists) | No (nothing for AI to read) | No (no artifact at all) |
| Google Doc | Yes (rendered text) | Partial (proprietary version history, not diffable in git) | No (requires Google authentication) | No (requires Google account) |
The phone call is the worst: it violates all four properties because no artifact exists at all. WhatsApp is slightly better (the text exists) but still fails three properties. Google Docs is the best of the three but still fails version-controllability (you cannot diff it in git), AI-parseability (an AI agent cannot read it without API authentication), and tool-agnosticism (you need a Google account).
A markdown file in the repository would score "Yes" on all four.
Investigate
Think back to James's story. He spent two weeks building a REST integration, work that contradicted a decision his team had already made. Here is the critical detail: the team DID write the decision down. It existed in Slack threads, a Google Doc, and a Confluence page. The knowledge was not unwritten; it was written in the wrong formats.
Write in your own words, without asking AI, the answer to this question: Why didn't the existing written records save James? The decision was documented in three different places. That is more documentation than most teams produce. So what specifically failed? Which of the four properties did each format violate, and which violation is the one that actually caused James to miss the decision?
Apply the Error Taxonomy: knowledge stored in the wrong format = specification error. The decision was specified (people wrote it down), but the specification was unfindable when it mattered. The distinction matters: this is not a case of "nobody wrote it down." It is a case of "everyone wrote it down and it still did not work." That is what makes format (not just existence) the issue.
Modify
Your team writes the ADR in a markdown file (good). But instead of committing it to the repository, they save it in a shared Google Drive folder. A new team member joins and asks their AI coding assistant: "What architecture decisions has this team made?" The AI searches the repository and finds nothing.
What went wrong? Which of the four properties did the Google Drive location break? What would change if the same file were committed to docs/adr/ in the repo?
Make [Mastery Gate]
Pick a real decision you made recently (which phone to buy, which course to take, which approach for an assignment). Write it in this structured format:
- Title: The decision in one sentence
- Context: Why you needed to decide (2-3 sentences)
- Decision: What you chose
- Why: Your reasoning (2-3 sentences)
- Alternatives: What else you considered and why you rejected each
This structured document is your mastery gate. You should be able to hand it to someone who was not part of the decision and have them understand the full reasoning in under a minute.
James stared at the project's new docs/adr/ folder. Seven decisions, all findable, all diffable. "It's like when I ran inventory audits," he said. "We had three warehouses, and every warehouse kept records differently. One used a spreadsheet, one used a whiteboard, one used a binder. Every quarter, someone had to fly between sites and reconcile everything by hand. The day we standardized on one system, reconciliation went from three days to thirty minutes."
"Four properties," Emma said. "Human-readable, version-controllable, AI-parseable, tool-agnostic. Markdown hits all four. Your warehouse spreadsheet probably hit two."
"Maybe one and a half. The whiteboard hit zero." James paused. "So the YAML frontmatter at the top of each file, that's the structured metadata? Dates, tags, status?"
"Right. The frontmatter is for machines. The body is for humans and AI. Same file, two layers."
James nodded. "One thing I'm not sure about, though. How far does this scale? Like, is there a point where markdown isn't enough?"
Emma hesitated. "Honestly? I don't know where the ceiling is. I've seen it work for teams of fifty. Beyond that... I haven't tested it. But the format hasn't been the bottleneck yet." She tapped the screen. "What I do know is that your knowledge now has a home. Next question: when an AI builds something from that knowledge, should it produce a quick script or a real program?"