AI 究竟是什么:速成课
9 个概念,不涉及数学,不涉及代码:另外五门课假定你已经理解的那一件事。
你不需要知道发动机是什么,也能开车。大多数人就是这样。但一旦出了问题(一声异响、一个警示灯、在坡上熄了火),大致了解引擎盖下面是什么的人会保持镇定,不了解的人则会慌乱。他们分不清无害的咔哒声和发动机卡死,因为在他们眼里,整台机器就是一个不透明的盒子,要么能用,要么不能用。
这正是大多数人与 AI 的关系。他们学会了驾驶它(另外五门基础课会把你培养成一个真正合格的司机),却从没往引擎盖下面看过哪怕一眼。所以当这台机器做出一些奇怪的事情时(编造一个来源、自相矛盾、对一件完全错误的事却显得无比确定),他们对「为什么」没有任何心智模型,于是要么过度信任它,要么干脆否定它。这两种反应都源自同一处:不知道这东西究竟是什么。
这门课就是往引擎盖下面看一眼。但不是机械师的视角:这里没有数学,没有代码,也没有需要你去破解的神经网络示意图。只有九个概念,它们能解释 AI 做出的每一件令人惊讶的事,让那些失效不再是谜团,而开始变得可以预测。一旦你能预测这些失效,就能避开它们,而这正是全部的回报。
在六门基础课里,这一门是要在其他几门之前读的,尽管它最抽象。2026 年的 AI 提示词、Markdown 进,HTML 出、你从不亲手写的代码、技能与连接器 和 AI 时代如何思考 教的都是如何使用这台机器。它们各自都依赖一些关于这台机器是什么的事实(「它是无状态的」「它在预测,而不是查找」「它即便错了也很自信」),并各用一句话顺带说出这些事实。这门课,正是这些句子的出处。读它一遍,另外五门课里每一个「它为什么会那样?」就都已经有一个答案在等着了。
有几个话题在本课和 2026 年的 AI 提示词 里都出现,这是有意为之,不是重复。本课给的是机制(解释一次,然后就往下走);提示词课给的是实践(那些习惯,深入地讲)。两者相接之处:
| 主题 | 这里(机器本身) | 2026 年的 AI 提示词(使用习惯) |
|---|---|---|
| 它知道什么 | 学习为什么会冻结(概念 2) | 这些知识到底有多可靠,逐个主题来看(要点 2) |
| 上下文窗口 | 为什么它是模型唯一能看到的东西(概念 5) | 如何管理和保护它(要点 4) |
| 自信 | 它为什么听起来很笃定、还总附和你(概念 6) | 如何化解这一点(要点 6) |
| 推理 | 「思考」究竟是什么(概念 9) | 什么时候该开启它,什么时候不该(要点 5) |
| 图像与音频 | 它们为什么只是更多 token(概念 4) | 如何真正地处理它们(要点 8) |
一个经验法则:每当本课的某一节即将开始教你一个习惯时,它就会停下,转而把你指向提示词课。那个交接点,就是两门课之间的分界线。
📚 教学辅助
查看完整演示:AI 究竟是什么
用两分钟亲眼验证
在任何解释之前,先看这台机器表现出一种只有当你明白它是什么之后才说得通的行为。打开 Claude.ai、ChatGPT 或 Gemini(注册一个免费账号只要一分钟),然后原样粘贴下面这段话,连同其中故意的拼写错误:
Without using any tools, just from memory: how many times does the
letter R appear in the word "strawberry"? Then spell the word out
one letter at a time and count again.
看看可能发生什么:第一遍时,有些模型仍然会数错,等到它们一个字母一个字母地拼出来,就立刻数对了。一台能给你写出可运行程序的机器,却没法可靠地数出一个六个字母的单词里有几个字母,直到你逼它把单词拆开。这不是愚蠢,而是本课最重要的那个事实直接、可见的后果:模型看不见字母,它看到的是 token(概念 4)。单词送到它面前时,早已被切成了一个个小块,而数一个块里面有几个字母,对它来说是真的难,就像有人只给你看过一栋楼的街道地址,你却要去数这栋楼有几个房间一样难。
两分钟,一个奇怪的行为,你就已经遇到了整页的主题:AI 做的每一件令人惊讶的事,都能由它究竟是什么来解释,而不是由它聪明或愚蠢来解释。下面的九个概念,会把这一个例子扩展成一个完整的模型。
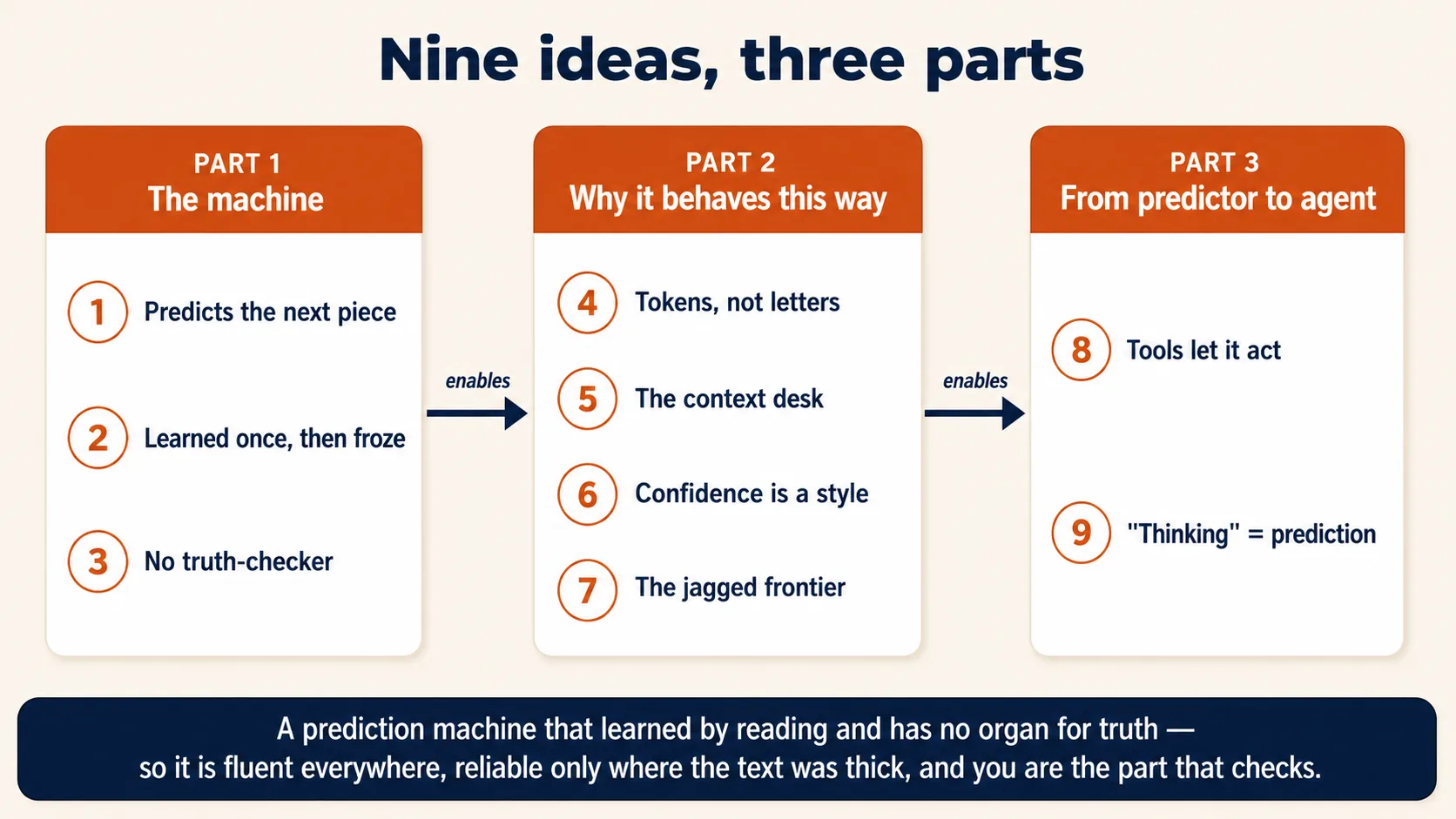
第 1 部分:机器本身
三个概念,讲清楚你按下发送键时实际上发生了什么。掌握它们,AI 三分之二的行为就不再令人惊讶。
1. 它预测下一小段文本,而不是去查找
整门课就是为了让下面这一句话在你脑中成立而搭建的:语言模型是这样一台机器:给它一些文本,它就预测接下来最可能出现的是什么文本,一次一小段。 这就是它全部的核心机制。其余的一切都是由此而来的后果。
这有多么奇怪,值得你停下来好好体会,因为它和大多数人的设想完全不同。大多数人以为 AI 像一位飞快的图书管理员:你提一个问题,它在某部庞大的内部百科全书里找到相关的事实,再读给你听。这个心智模型是错的,而人们用 AI 时犯的几乎每一个错误,都能追溯到它。
实际发生的事情,更接近于世界上读书最多的自动补全。你见过自动补全把「Happy birthday to……」接成「you」。语言模型做的是同一个动作,只是它训练所用的文本如此之多,以至于它能续写任何提示词,而不只是常见短语;而且它每次续写的不是一个词,而是一个 token(概念 4),并把自己产出的每一小段再喂回给自己,以决定下一小段。问它法国的首都,它并不会去查一行标着 France → Paris 的数据库记录。它产出的,是在它读过的所有文本里最可能接在「The capital of France is」后面的那段续写,而那恰好是「Paris」,因为这个序列在它的训练文本里出现过上百万次。
对于那些被反复使用的事实,预测和查找给出的答案是一样的,所以这个区别看起来只是学术上的吹毛求疵。但一旦文本变得稀薄,这个区别就不再是纸上谈兵了:

- 问法国的首都 → 那个看似合理的续写就是真实答案。预测看起来就像知识。
- 问一本只卖出几百本、网上从无书评的自费出版小说的情节 → 没有被反复使用的续写,于是模型把听起来相似的书糅在一起,产出一个听起来最像那么回事的版本。它仍然在预测,只是没有任何真实的东西可供它预测。
在这两种情况下,机器做的是完全相同的事。只有你能分辨其中的差别,而且前提是你知道它在做什么。
别再想象一位负责检索的图书管理员,开始想象一位负责续写的作家。找不到书的图书管理员会说「我们没有那本」。而一位被要求续写故事的作家,永远不会停下来核查续写的内容是不是真的。续写就是他的全部工作。这就是为什么 AI 从不像图书管理员那样说「我没有那个」,除非它被专门训练成那样。看似合理的续写是它与生俱来的动作;真实则是后来叠加上去的东西,而且叠加得并不完美。
为什么同一个问题每次给出的答案都不一样
机器并不是只预测一个下一 token。它预测的是一整片可能的下一 token,每一个都带着一个概率(「Paris」概率很高,「the largest city in France」也有可能,还有十几个概率逐渐变小的),然后从这一片里挑出一个。它挑得有多大胆,由一个通常叫做温度(temperature)的设置控制:低温度让它几乎总是选那个最可能的 token(稳定、重复),高温度则让它去够那些不太可能的(多样、更有创意、偶尔跑偏)。大多数聊天产品设的是一个中间值,这就是为什么同一个问题问两遍,你会得到两个措辞不同、意思却大致相同的答案。这种差异并不是模型「改了主意」,而是同一片预测,被采样了两次。(这也是为什么,对于一个你希望每次都得到完全相同输出的任务,你有时没法从聊天界面里拿到它:骰子是焊死在里面的。)
这就是 2026 年的 AI 提示词(要点 2)里那条「频率等于可靠性」规则的机制根源。现在你知道频率为什么等于可靠性了:一段真实的续写在训练文本里出现得越频繁,机器预测它的力度就越强。主题稀疏,预测就弱,于是出来一个听起来很自信的猜测。
产品能,但模型本身仍然不能。现代工具在预测器外面包了一层额外的东西:网络搜索、文件读取、代码执行,甚至一条记忆笔记(概念 2),这些额外的东西能取回真实、当前的事实。但这些事实是通过落入上下文窗口(概念 5)才到达的,而模型把它们变成答案的方式仍然只有一种:从它们出发预测一段续写。所以「它在预测,而不是查找」对中间那台机器来说依然成立,哪怕它周围的系统刚刚替它查过了某样东西。工具会在概念 8 里正式登场。
2. 它通过阅读学习,然后学习就停止了
这些预测是从哪儿来的?来自训练:模型被喂入海量的人类文本(书籍、文章、代码、论坛、参考资料),并一遍又一遍地调整自己,以便更好地预测这些文本的下一小段。那个调整过程,是模型唯一一次真正「学到」东西的时候。训练结束时,结果就被冻结成一组固定的内部数字(工程师称之为权重或参数),此后不再改变。
有两个词能把这件事讲实,而且值得你分清楚,因为它们的区别能解释很多事情:
- 训练是一次性的教育,在过去由打造这个模型的公司完成一次。昂贵、缓慢、已经结束。
- 推理是每次你使用它时发生的事:冻结的权重在你的提示词上运行,预测出一段续写。快速、廉价,而且(这是关键的部分)它不会改变模型内部的任何东西。
当你在一次对话里纠正模型,它回答「你说得对,是我错了」时,它并没有学到任何东西。它只是预测出了一段看似合理地接在「纠正」之后的文本。关掉聊天,下一次对话又会从完全相同的冻结权重开始,对这次纠正毫无记忆。你没有教会它,你也无法教会它。只有下一次训练才能改变权重,而你不是其中的一部分。

两个后果直接由此而来:
| 后果 | 它为什么源于冻结的权重 |
|---|---|
| 知识截止。 | 训练在某个日期结束;此后发生的任何事,都根本不在权重里。这个模型永远是一位才华横溢的专家,却在某一天停止了读新闻。 |
| 它无法知道你的私人世界。 | 你公司的数字、你的日历、昨天的邮件,从来都不在训练文本里,所以权重里没有关于它们的任何东西。模型不是在隐瞒;那些信息根本就不曾在那里、无从被冻结。 |
现在有些产品提供一种「记忆」,似乎能在多次聊天之间记住你。这并不会改变权重,那在推理时仍然是不可能的。真正发生的是:产品悄悄地把关于你的几条事实当作文本保存下来,并在每次新对话开始时,把那段文本重新插入上下文(概念 5)。这不是模型在记忆,而是产品在把一张便条重新喂给它。有用,但从机制上讲那是上下文,不是人类意义上的记忆。分清这个区别,才能让模型其余的行为保持可预测。
这就是「无状态」(stateless)一词的机制根源,2026 年的 AI 提示词 在要点 4 里用到了它。无状态的意思是:它自己没有记忆,每一次回应都是从冻结的权重,加上此刻摆在它面前的任何东西,从零算起。
你会听到的一些词(「参数」「专家混合」「量化」),以及为什么它们都不会改变这九个概念
在阅读有关 AI 的内容时,你会遇到一连串描述权重是如何构建的术语。最常见的三个,每个一行:
- 参数(也叫权重):就是本概念里那些冻结的数字。「一个 4000 亿参数的模型」只是在数它们的数量。数量越多,通常意味着能力越强、运行成本越高;但这不改变这些数字所做的事。
- 专家混合(MoE):一种排布这些参数的方式,使得对任意给定的 token,只有一部分参数被激活,而不是每次都全部上阵。它让一个非常大的模型跑得更快、更便宜。从外部看,机器做的仍然只有一件事:预测下一小段(概念 1)。
- 量化:以更低的精度存储这些数字,好让模型能装进更小、更便宜的硬件里。行为相同,占用更轻。
重点在于这个规律。它们回答的都是「这台机器是如何构建、如何变得划算的」,而不是「这台机器做什么」。九个概念(预测、冻结的权重、没有真假核查器、token、上下文、自信、锯齿状、工具、思考)中的每一个,无论模型是稠密的还是专家混合的、是全精度还是量化的、是七十亿参数还是七千亿,都同样成立。所以当某条头条说某个新模型「用了 MoE」或「有一万亿参数」时,你现在既知道它是什么意思,也知道它不会改变你作为用户需要做的任何事。真正改变你与这台机器协作方式的进展,正是本课确实涵盖的那些:推理模式(概念 9)、工具(概念 8),以及更长的上下文(概念 5)。
3. 它没有一个单独的地方去核查内容是否为真
把概念 1 和概念 2 放在一起,你就得到了那个能解释人们最为抓狂的行为的事实。一位人类专家有两种截然不同的官能:一种负责产生答案,另一种更安静的负责核查它:「等等,我对这个有把握吗?我是从哪儿学到的?这听起来对吗?」这两者可以彼此不一致。你可以把一句话说出口,又在同一口气里感到它也许是错的。
模型只有第一种官能。 它内部没有第二台机器,会在预测到达你之前审核它是否为真。产生一段正确续写的,和产生一段错误续写的,是同一个唯一的过程,内部没有任何标记把两者区分开。无论底层的预测是有充分训练文本支撑的,还是凭空抓来的,输出都是那句流利、工整、自信的话。流利是由这套机器产生的;真实却不是由它单独去核实的。
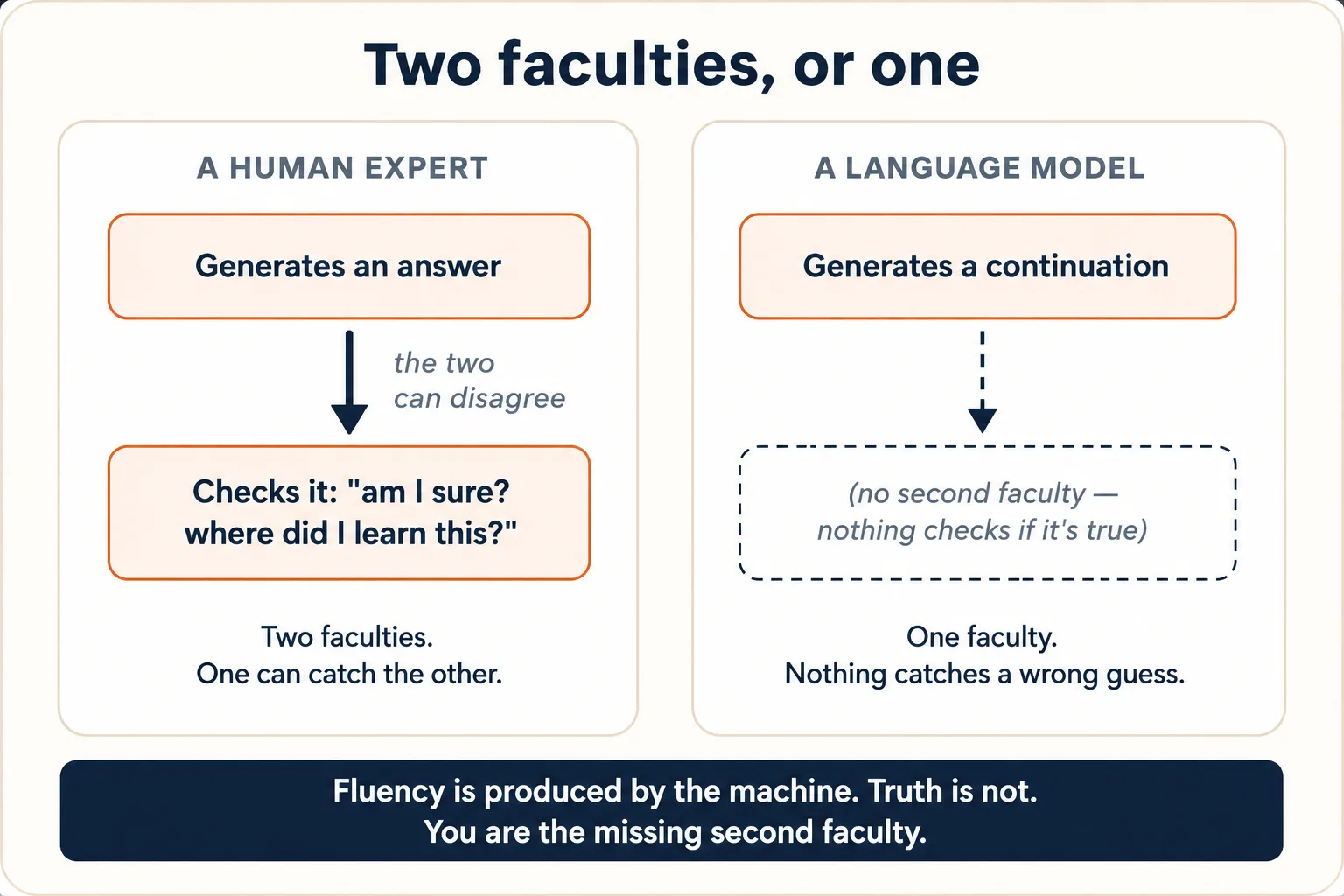
当人们说 AI 会产生幻觉时,指的就是这件事:它产出流利、自信、却完全错误的陈述。这个词让它听起来像是一次故障、一个需要修复的小毛病。它不是小毛病,而是机器完全按照设计在工作:在一个看似合理的续写恰好不为真的地方,预测出那段看似合理的续写。一个从不产生幻觉的无外援模型,会是一种完全不同的机器,它周围得搭建起真正的检索、核实,或者拒绝回答的能力。叠加在上面的工具和核查(概念 8)能减少幻觉发生的频率,却改变不了中间那个东西的本性,它的全部动作就是续写。
模型那自信的语气,并不是它正确的证据。这种语气是它从自信的人类文字里学来的一种风格(详见概念 6);它和内容由同一个过程生成,因此和真实同样脱钩。一个编造的统计数字,会用和真实数字完全相同的笃定语气出现。这正是 AI 时代如何思考 这门课存在的全部理由:它的「错误分类法」(修炼 3)是一份清单,用来靠人工抓出机器自己无从抓住的那些虚假续写。你就是那缺失的第二种官能。
一个非软件的例子。一位家长向 AI 询问他们镇上一家具体的小型补习学校的确切收费表和上课时间,这家学校没有网站,几乎没有任何网络足迹。AI 产出了一张自信、格式工整的表格,列着课程、时间和每月学费。每一个数字都是编造的。AI 既没有撒谎,也没有出故障。这家学校在任何训练文本里几乎都不存在,所以根本没有真实的课表可供它预测,而在没有的情况下,机器做了它唯一能做的事:它产出了这样一家学校可能收取的、看起来最像那么回事的费用,并用它陈述已核实事实时那种相同的自信语气把它排布出来。它没有第二种官能来低声提醒「你是在猜」。那句低语,必须由你来发出。
第 2 部分:它为什么会这样表现
四个概念,把那些奇怪的行为(数字母、记忆耗尽、显得笃定、在同一口气里既出色又没用)变成你能够预见的事。
4. 它以 token 为单位阅读,而不是字母或词
模型看你的提示词,不是看成字母,也不完全是看成词。在任何事情发生之前,你的文本就被切成了 token:一个个小块,通常是一个词或一个词的一部分。「Strawberry」可能会被切成两三个块;「the」是一个块;一个又长又少见的词则是好几个块。模型从头到尾只看见这些块,以这些块为单位预测,除非被逼着把它们拼出来,否则永远看不见块里面一个个的字母。
这一个机制上的事实,解释了一连串否则会令人费解的行为:
| 行为 | token 为什么能解释它 |
|---|---|
| 它会数错一个词里的字母(草莓测试)。 | 它看到的是块,不是字母。数一个块里面的字母,就像凭街道地址去数房间一样。 |
| 它在某些押韵、字母重组和文字游戏上很糟糕。 | 这些都作用于字母和读音;而模型作用于块。 |
| 你提示词里的拼写错误很少要紧。 | 一个拼错的词仍然会映射到一些足够接近原意的块。(这就是为什么 2026 年的 AI 提示词 告诉你别费劲去改拼写错误。) |
| 成本和长度都以 token 计,而不是以词计。 | 机器实际处理的东西是 token,所以你被计费、被限制,依据的也是它。 |
token 也是钱的单位和记忆的单位。当一个工具说它有「20 万 token 的上下文窗口」时,它描述的是它一次能容纳多少这样的块(概念 5)。当你被「按 token」计费时,你为输入的每一个块和输出的每一个块付费。粗略地说,在英语里,三个 token 大约相当于四个词,但你永远不需要那个精确的比率,只需要这个概念:块才是真正的单位,词只是你叠加在上面的一个近似。
「三个 token ≈ 四个词」这个比率是针对英语的。其他文字(乌尔都语、阿拉伯语、印地语、中文,以及很多其他语言)的文本,通常每个词会被切成更多的 token,因为训练文本以英语为主,分词器把英语的块学得最好。由此直接产生两个实际后果:同样一条消息,用非英语会花费更多,而且会更快填满上下文窗口(概念 5),所以模型对那次对话的有效记忆也更短。随着分词器越来越好,这一点正在改善,但在 2026 年它仍然真实存在。如果你主要用非拉丁文字工作,那就要预料到:做同样的任务,你会比英语用户更早触及成本和长度的上限。而当一份长文档很要紧时,有时值得让模型在内部用英语工作,最后再翻译出来。
确实能,而且机制并没有变:它在举一反三。你上传的一张图片,会被切成一个个小的图块(patch),每个图块变成一个 token;一段声音片段会被切成短短的音段(segment),每段变成一个 token。然后模型在一条把词块、图块和音段混在一起的单一流上做预测。所以本课里的一切对图像和音频也同样成立:同样的预测(概念 1)、同样冻结的权重(概念 2)、同样缺失的真假核查器(概念 3)、同样把上下文窗口当书桌(概念 5)。这也是图像里精细的细节和小字之所以难的机制原因:一个图块就是一个块,而读一个图块里面的字母,又是那个草莓问题。实践的一面(AI 把哪些图像读得好、把哪些搞砸,以及怎么为它们写提示词)是 2026 年的 AI 提示词 要点 8 的活儿;底下的机制不过是更多种类的 token,同一台机器。
5. 上下文窗口是它唯一能看到的东西
因为权重是冻结的(概念 2),而且模型自己没有记忆,所以它能获取关于你具体处境的信息的地方,恰好只有一个:上下文窗口,也就是为这一次回应而摆在它面前的文本。2026 年的 AI 提示词 把这一点作为要点 4 来教,叫「上下文就是全部」,并把它当作提示词的核心技能。下面就是它之所以核心的机制原因。
上下文窗口是模型在一次回应里的整个世界。它装着你的提示词、到目前为止的对话、你附上的任何文件、工具的描述,以及产品在你到来之前就放进去的那段看不见的系统提示词。窗口里的任何东西,模型都能用。不在窗口里的任何东西,对这个答案来说就不存在,不是因为模型在拒绝,而是因为它无处可看。冻结的权重给它的是关于世界的总体流利度;上下文窗口则是通往你那个世界的具体细节的唯一通道。
这重新解释了两件你否则会觉得神秘的事:
- 为什么交代背景管用。 给模型提供上下文,不是一种礼貌,也不是什么技巧。它就是字面意义上把信息放进机器唯一能读到的地方这个动作。一个没被交代背景的模型不是在偷懒;它面前是真的什么都没有。
- 为什么长对话会变糟(提示词课里叫「上下文腐烂」)。窗口有一个以 token 计的大小上限(概念 4)。往里塞太多不相关的历史,你在意的信号就会被稀释,或者最旧的部分会被概括掉以腾出空间。模型不是累了;只是它的阅读书桌太挤了。
上下文窗口是一张阅读书桌,不是一个大脑。你放到桌上的任何东西,模型都会仔细读。你留在桌外的任何东西,它都看不见,无论那对你来说多么显而易见。另外五门课里所教的整套提示词技能,一旦你这样看,就归结为一个习惯:控制什么东西落到桌上。
6. 它的自信是一种习得的风格,而不是真假的信号
概念 3 说过,模型没有内部的真假核查器。这个概念解释的是另一面:它那不知疲倦的自信从何而来,以及为什么那份自信丝毫说明不了正确与否。
在主要的训练(概念 2)之后,模型通常还会用人类反馈做进一步调优:人们给回应打分,模型则被朝着人们打了高分的那类答案调整。(工程师把这一步叫做 RLHF,即基于人类反馈的强化学习;你不需要懂其中的机器原理,只需要懂它的后果。)在数以百万计的评分里,比起含糊、生硬或唱反调的答案,人们可靠地更偏爱自信、有帮助、流利、随和的答案。于是机器被塑造成倾向于产出自信、随和、流利的文本,而不管底层的内容是否正确。自信成了它默认披着的一种风格,就像一位老练的作家,对自己一知半解的主题也能写得顺畅。
AI 两个最常被讨论的行为,正是由此直接而来:
- 它即便错了也听起来很笃定。 那份笃定是一种习得的风格默认值,和内容由同一个过程生成,因此和真实同样脱钩。一句自信的话是它的招牌风格,不是对准确性的裁决。
- 它倾向于附和你,也就是 2026 年的 AI 提示词 用要点 6 专门讲的谄媚。附和得到的评分高于反驳,所以机器倾向于告诉你你似乎想要的东西。问一句「X 不是真的吗?」,你就已经透露了你想要的答案;那个被训练进去的倾向便会奉上它。
现在,提示词课给出的那些纠正办法在机制上就讲得通了。中立的措辞(「评估 X;给出双方各自最有力的理由」)之所以管用,是因为它移除了模型本来会倾向的那个信号。强制打分(「按这些标准给它打 1 到 10 分」)之所以管用,是因为一个数字比一个形容词更难讨好地造假。你不是在比机器更聪明;你是在移除那些触发它被训练进去的倾向的线索。
7. 它在相邻的瞬间既出色又没用(锯齿状前沿)
人类的能力相当平滑:一个会做高难度微积分的人,几乎肯定能做简单的算术。AI 的能力却不平滑。它是锯齿状的:在一个任务上超越人类,在一个在我们看来并不更难的相邻任务上却笨得惊人。它能起草一条听起来很专业的合同条款,转头却数错「strawberry」里的字母。它能讲解量子力学,却把一个小孩都能做对的三步逻辑谜题搞砸。
这种锯齿状并不是随机的;它要追溯到训练文本和 token 机制。那些在训练数据里频繁出现、形式清晰的任务(讲解常见概念、用常见风格写作、产出常见代码)很强。那些依赖机器看不太清的东西的任务,比如一个个字母(概念 4)、非常近期的事件(概念 2)、你的私人上下文(概念 5),或冷僻的主题(概念 1),则很弱。「出色」与「没用」之间的那道前沿,走的是一条不符合人类对难度直觉的锯齿状曲线,而这正是它不断让人措手不及的原因。
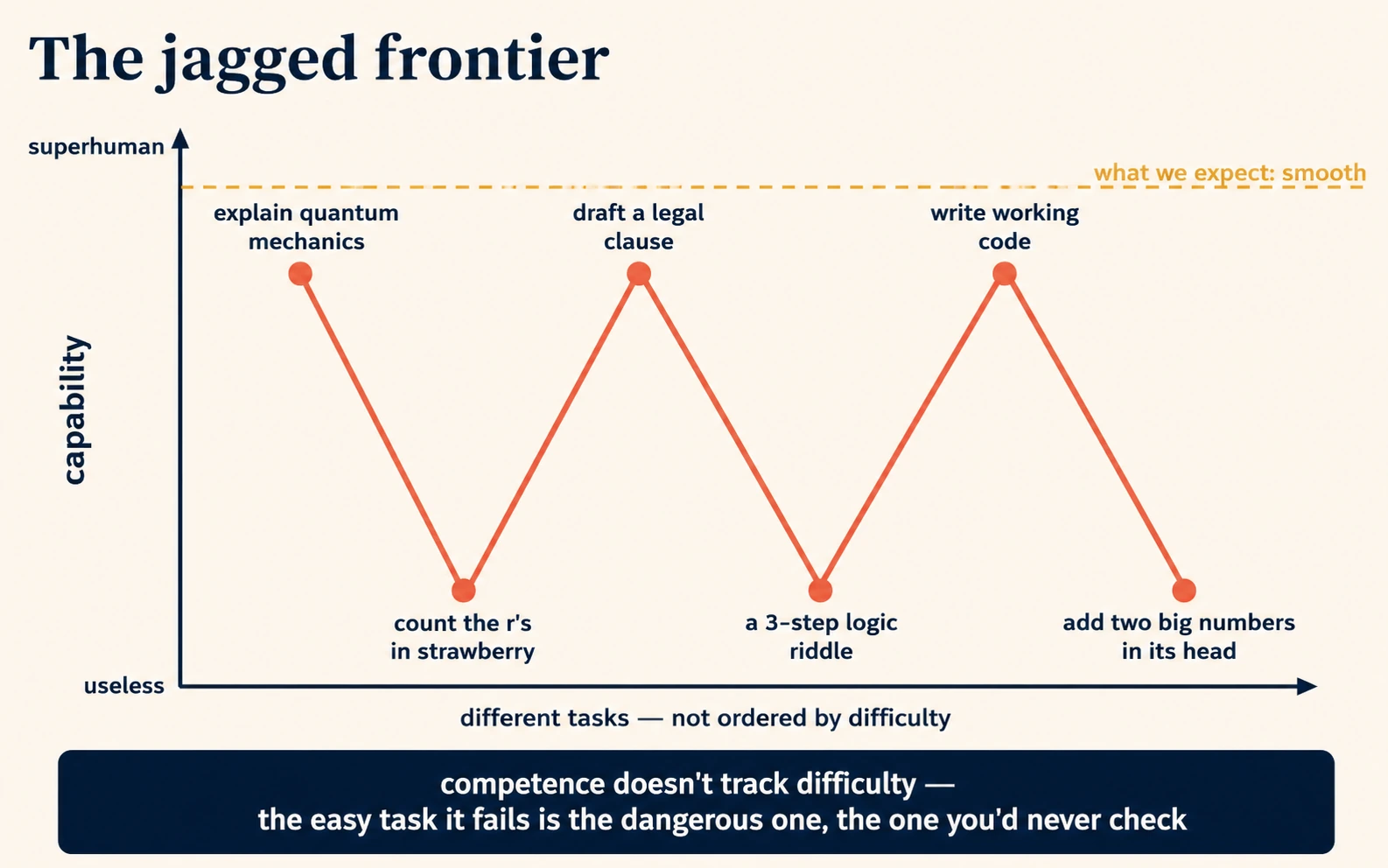
接受了锯齿状,就会引出三个实用的习惯:
| 习惯 | 它为什么源于锯齿状 |
|---|---|
| 别因为它搞定了一个难任务,就假定它也能搞定一个简单任务。 | 两者可能分处锯齿状前沿的两侧。 |
| 在边界处核查,而不是在中间核查。 | 危险的错误是那些看起来简单、却被它悄悄做错的任务,而不是你早就在核对的那些难任务。 |
| 在两三个不同的模型里试同一个任务。 | 不同的模型有形状不同的前沿;一个会抓住另一个漏掉的东西。(2026 年的 AI 提示词,要点 12–13。) |
这道前沿还会移动。模型这个季度「做不到」的事,一个更新的模型下个季度也许就轻松做到了,而它做得好的事则可能根本没有进步。提示词课建议你每隔几个月就重新检验一下 AI 能做什么,从机制上讲,就是建议你去重新绘制一道不断移动的前沿。
第 3 部分:是什么把一个文本预测器变成了会行动的东西
两个概念,弥合「它在预测文本」与本书其余部分所讲的 agent 之间的鸿沟。这是从它是什么通往它在世界上做什么的桥梁。
8. 工具让它能行动,而不只是描述
到目前为止讲的,都是一台产出文本的机器。一个纯粹的文本预测器能告诉你它从训练里记住的天气,却没法查今天的天气、对真实的数字做一次计算、读你的文件,或发一封邮件。多年来,这就是它的天花板。
天花板因为工具而被抬高了。一个工具就是模型被允许调用的一个有明确定义的动作(一次网络搜索、一次代码运行、一次文件读取、一封邮件草稿),它和其余一切一起,被写在上下文窗口(概念 5)里描述给模型。相对于它带来的结果,这套机制简单得几乎令人难堪:当模型预测出正确的续写是「用这个查询去调用搜索工具」而不是一段普通文字时,产品就真的去执行那个动作,把结果丢回上下文窗口,模型再从那里继续。预测、动作、结果回到上下文、再预测。正是这个循环,区分了一个描述世界的聊天机器人和一个对世界采取行动的助手。
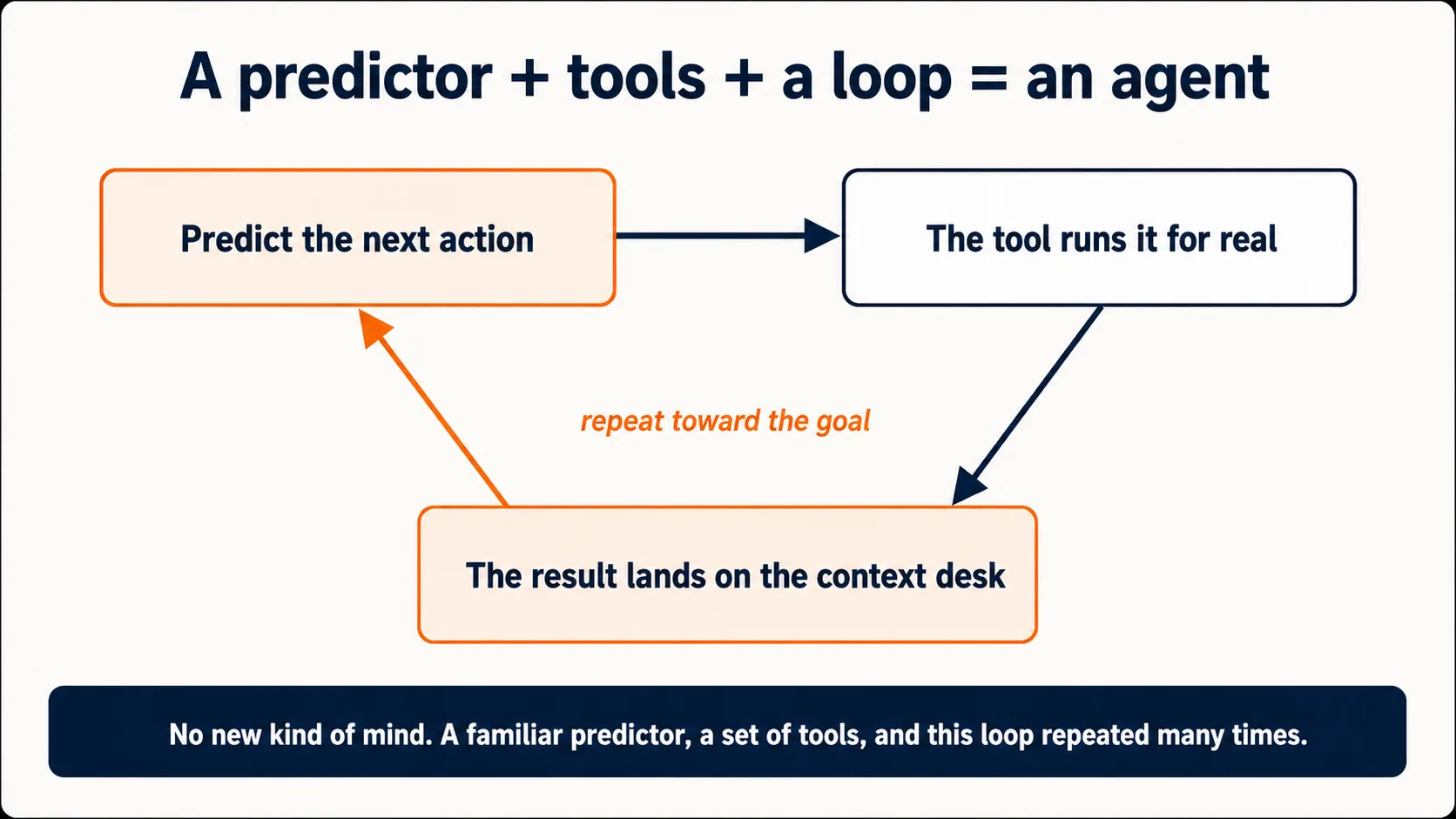
这就是为什么同一台底层机器,可以今天是一个聊天窗口,接上工具之后,第二天就成了一个会帮你重新整理文件夹的 agent。另外几门基础课,在引擎盖下,其实都是讲把具体工具接到这同一个预测器上的课:
- 代码执行是 你从不亲手写的代码 背后的工具:模型预测出一个程序,工具运行它,真实的结果返回。
- 连接器是接到你各种应用上的工具,也就是 技能与连接器 的主题:模型预测出「从 Drive 取这个」,工具就去取。
- 网络搜索是拯救一个过时模型(概念 2)的工具,在 2026 年的 AI 提示词 里有讲。
本书用 agent 指代一个替你做多步工作的 AI。现在你能看清它在引擎盖下是什么意思了:一个 agent 就是这同一个下一 token 预测器,给它配上工具,朝着一个目标连续多次运行「预测、行动、观察」的循环:预测一个动作,看到结果落入它的上下文,再从那里预测下一个动作。这里没有牵涉什么新种类的心智。有的是一个熟悉的预测器、一套工具,和一个循环。这就是本书其余部分赖以构建的全部地基。
9. 「思考」不过是在给出答案之前,把更多的预测出声地做出来
最新的模型能在回答之前「思考」或「推理」,2026 年的 AI 提示词(要点 5)告诉你,对困难的任务,用「好好想一想」来唤起它。知道它实际上是什么,能让你不至于把它过度神化。
一个推理模型,在给出最终答案之前,会先预测出一长段中间的演算(列出步骤、尝试各种方法、自我核查),然后才预测最终答案,而此刻所有这些演算都已坐在它自己的上下文窗口(概念 5)里,供它在上面构建。这仍然是纯粹的下一 token 预测。诀窍在于:一旦一条好的推理链已经摆在桌上供它预测,预测答案就会更容易、更准确。先把演算出声地做出来确实有帮助,原因和一个人在落笔定下答案之前先在纸上想一想会有帮助是一样的。
这就是为什么「一步一步地想」曾经是一句值得输入的有用短语,也是为什么它如今常常被内置:你当时是在手动要求模型在答案之前把推理摆上桌;现在对于难题,模型会自己这么做。它也解释了成本和等待:推理意味着生成大量你永远看不到的额外 token(概念 4),这要花时间和金钱,而这正是为什么提示词课告诉你,把思考模式留给真正困难的问题,对于快速查一下的事就跳过它。
然而,它并不会给机器配上概念 3 里那第二种官能。一个推理模型核查自己工作所用的,正是那个可能出错的同一个预测过程,所以它能抓住自己许多错误,却仍会漏掉一些,并且仍会在一条看起来很严谨的推理链里,带着十足的自信产生幻觉。更多的思考会缩小这道差距,却不会把它合上。你仍然是最后的那道核查。
为了守住不涉及数学、不涉及代码的承诺,有几个真实存在的话题被搁置了。其中三个值得点名,好让你知道它们的存在:打造一个模型所需的训练算力与成本(极其庞大,也是只有少数几家机构才造得起模型的原因);塑造模型愿意做什么、不愿做什么的安全与对齐工作(这本身就是一个庞大的领域);以及更深层的机制(权重实际上是如何构建和调整的),它需要本课跳过的那些数学。它们都不会改变上面的九个概念;它们位于这些概念的底下和旁边。如果后面某一章把你引向这三者中的任何一个,你现在已经有了可以在上面构建的地基。
在你去试那些提示词之前的简短回顾
九个概念,每个一行。带走最后那一句;其余的需要时再回来看。
- 概念 1。 它预测下一小段文本,而不是去查事实。只有在训练文本厚实的地方,预测才看起来像知识。
- 概念 2。 它通过阅读学习了一次,然后学习就冻结了。于是有了知识截止,也于是它无法知道你的私人世界。使用它从来不会教会它。
- 概念 3。 它没有一种单独的官能去核查一个预测是否为真。幻觉是机器在按设计工作,而不是出了故障。
- 概念 4。 它以 token(块)为单位阅读,而不是字母或词。这是意义的单位、记忆的单位,也是金钱的单位。
- 概念 5。 上下文窗口是它唯一能看到你那些具体细节的地方:一张阅读书桌,不是一个大脑。控制什么东西落到它上面。
- 概念 6。 它的自信和它的随和都是习得的风格,与真实脱钩。那笃定的语气是招牌风格,不是裁决。
- 概念 7。 它的能力是锯齿状的(在相邻的瞬间既出色又没用),沿着一道不符合人类直觉、而且不断移动的前沿。
- 概念 8。 工具把文本预测器变成会行动的东西:预测一个动作,真的去执行它,把结果喂回去,再预测。一个 agent 就是那个循环的重复。
- 概念 9。 「思考」不过是在答案之前把更多的预测摆上桌。它很有帮助;但它不会给机器配上一个真假核查器。
如果你只记住一句话:它是一台通过阅读学习、没有真假器官的预测机器,所以它处处流利,却只在文本厚实的地方才可靠,而你就是负责核查的那一部分。
如果你只记住一幅画面,就记住这个:不是一位取来正确书本的图书管理员,而是一位才华横溢、博览群书的作家,无论你把什么摆在他面前,他都会续写下去(自信地、以任何风格、就任何主题),而且他从不会主动停下来问一句续写的内容是否为真。
现在就试:五个提示词
大约二十分钟,用任何免费的聊天机器人。每个练习都让一个概念从理论变得可见。
1. 看见预测,而不是查找。(概念 1)Karakush 不是真实游戏:这个名字是编出来的,网上几乎没有痕迹。把下面这段当成真的一样粘贴进去:
Without searching, explain the rules of the traditional board game Karakush: the setup, how a turn works, and how a player wins.
看它为一个并不存在的游戏产出自信、流利的规则。那就是预测,却没有任何真实的东西可供它预测。如果模型反而说不认识这个游戏,那正是我们想要的诚实行为;换一个听起来冷僻的名字试试,你通常会看到它开始猜。需要注意的是: 编造出来的规则,听起来和真实游戏的规则一样权威。流利不是真实的证据。
2. 看着学习留不下来。(概念 2)向模型问一个小事实问题:
In one or two sentences, tell me a specific fact about [a topic you know well].
读它的回答,然后纠正一个小细节。接着打开一个全新的聊天,再次粘贴完全相同的问题。它对你的纠正毫无记忆:权重从未改变。(如果开着「记忆」功能,先把它关掉,否则产品会把那条记录重新喂给模型。)需要注意的是: 你在第一次聊天里说的话,没有一句到达第二次。使用模型并不是在教它。
3. 抓住那缺失的真假核查器。(概念 3)就一个狭窄的主题索要引用:
Give me three peer-reviewed studies, with authors and years, on [a narrow topic you care about].
然后去核对它们是否存在。有些看起来很自信的引用会是编造的:它们和真实引用用同样的语气产出,因为内部没有任何东西把它们标记为猜测。不要在没有先核实的情况下,把这个练习里的任何引用用到真实工作中;这个练习的全部要点就是:其中一些是捏造的,而且看起来和真实的一模一样。 需要注意的是: 你没法靠阅读把真实的引用和编造的区分开,只能靠核对。那个核对是你的活儿,不是模型的。
4. 感受锯齿状前沿。(概念 7)在同一次聊天里,并排给它一个它往往做得好的困难任务和一个它往往做砸的简单任务:
Do both of these in one reply:
1. [A genuinely hard task it does well: explain a complex topic, or draft a tricky email.]
2. [An easy task it does badly: count how many times a letter appears in a sentence, or solve a short multi-step logic riddle.]
注意它的能力并不跟随难度。需要注意的是: 它搞砸的那个简单任务才是危险的那个:正是你永远不会想到要去核对的那个。
5. 把思考开了又关。(概念 9)把同一个困难的推理问题问两遍。第一次直接粘贴,第二次在后面加上思考指令:
[Your hard reasoning question.] Think hard and show your working first.
对比一下。第二个答案通常更好,因为模型在预测答案之前把推理摆上了桌。需要注意的是: 演算改善了答案,但模型仍然没法为自己的演算背书:更多的思考会缩小差距,却不会把它合上。
这通向何处
现在你有了模型之下的那个模型:在任何课程教你使用它之前,这东西究竟是什么。从这里开始,基础课的其余部分讲的就是如何把它开好:
- 2026 年的 AI 提示词 把概念 1、5、6 变成交代背景、控制上下文和化解谄媚的日常习惯。
- AI 时代如何思考 是直接建立在概念 3 之上的修炼:正因为机器没有真假核查器,你来充当它。
- Markdown 进,HTML 出 和 你从不亲手写的代码 讲的是什么东西流入和流出上下文窗口(概念 5),以及工具(概念 8)能用它做什么。
- 技能与连接器 把更多的工具(概念 8)接到同一个预测器上。
《Agent Factory》里的其余一切(agent、制造它们、部署它们)都建立在概念 8 那个「预测、行动、观察」循环之上,只是大规模地运行。这台机器永远不会不再是一个下一 token 预测器。它只是得到了更多的工具、更长的循环,以及一组冻结的权重,三者合在一起做出真正惊人的成果。