本书培养的角色
市场发明岗位名称的速度,比定义这些岗位的速度更快。 大多数名称其实是同一门纪律在不同深度上的表现:也就是本书要训练的纪律。下面是完整地图,以及本书会把你带到每个角色的哪个位置。
这里定义的是新一轮 agentic AI 时代的角色:企业开始制造、运行并治理 AI Worker 之后才出现的工作。条目按照实际工作聚类来排列,每个条目旁边的结论都是真实的范围线:本书会把你带到哪里,哪里开始由认证路径接手。结论比名称更重要。本书停下的地方,会明确说出来。
所有人都从同一组 Foundations 开始,也就是任何 agent 工作之前都需要掌握的浏览器端技能。在这一层之上,是通用 agent 的两种使用模式。Mode 1 是用通用 agent 更快地完成自己的工作,这是每个读者都需要的能力,不是一个岗位名称。Mode 2 是制造替你工作的 AI Worker,岗位名称主要就出现在这里。地图先从 Foundations 层和 Mode 1 Practitioner 开始,再转向 Mode 2 角色;后者几乎占据了整张地图。
如果你还不熟悉这些词(Digital FTE、SKILL.md、Agent Factory),先读 Thesis 和 Glossary;本页默认你已经理解它们。
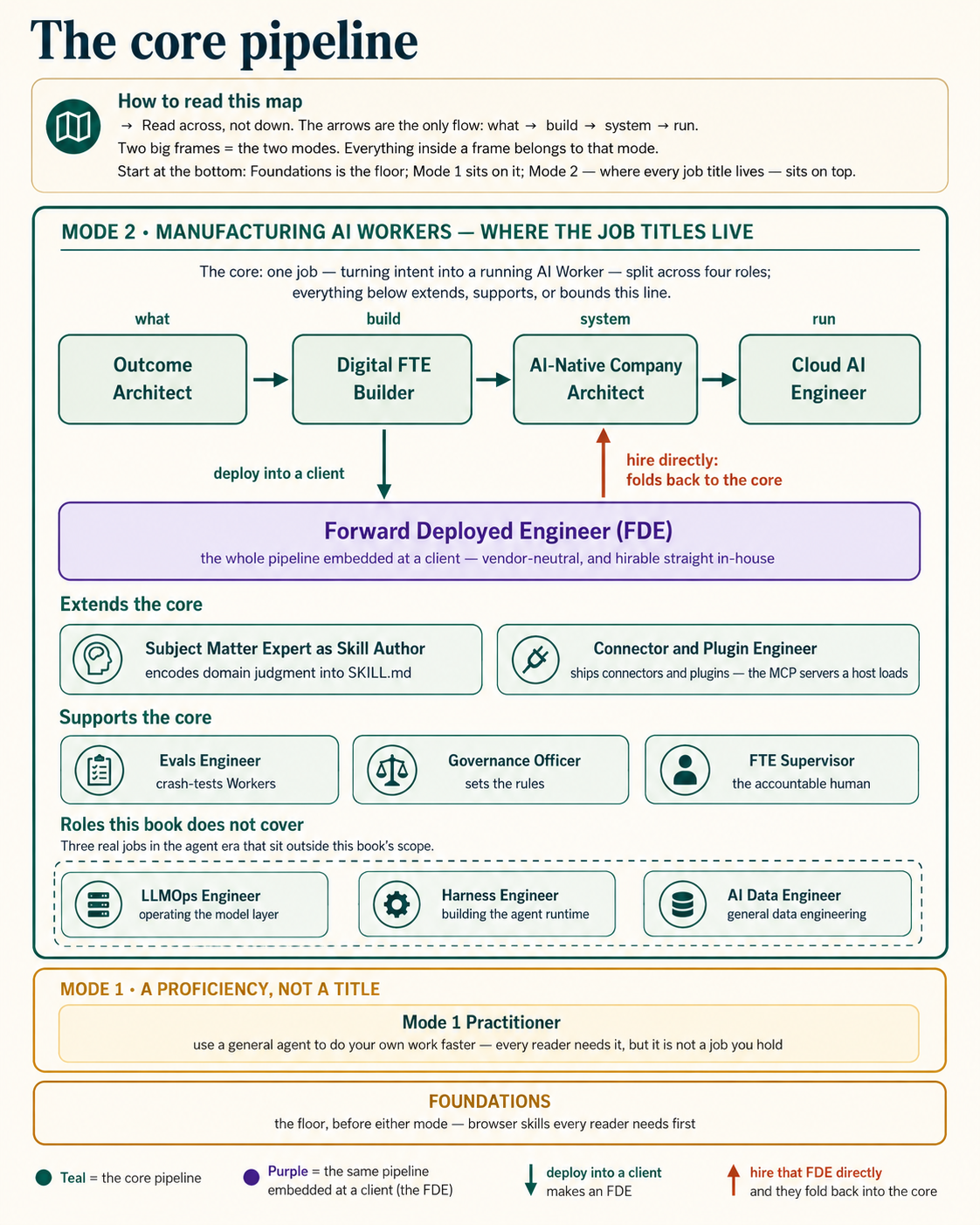
一眼看完整张地图:核心流水线、扩展和支撑它的内容、本书停下的位置,以及位于底部的共同基线。
人人都从这里出发的基线
Foundations:在任何模式之前的地板。 每位读者都以同样的方式开始:打开浏览器标签页,进入 Foundations。这里包括如何写 prompt,agentic 工作的两种文档语言,如何委托你自己不写的代码,skill 与 connector,以及如何在 AI 时代思考。没有模式,没有岗位,也没有要安装的东西。这是整张地图站立的地板。所有人从这里开始,但这不是你拥有的头衔。
Mode 1 Practitioner:不是头衔,而是一种能力。 在这层地板上,你用通用 agent 更快地完成自己的工作:推理、写作、编程、分析、规划、交付结果并结束会话。这就是 Mode 1。本书会为每个人训练这种能力:工程师通过 Claude Code 或 OpenCode,领域专家通过 Claude Cowork 或 OpenWork,并遵循通用 agent 解决问题的七项原则。这是每位读者进入下面 Mode 2 角色之前先运行的第一个模式。它让你在现有工作中更敏锐,而不是直接给你一个新头衔。所有人先运行的第一个模式,不是你拥有的头衔。
通才核心
这些核心角色像一条流水线一样运行,从意图到生产:Outcome Architect(定义要做什么)→ Digital FTE Builder(构建)→ AI-Native Company Architect(系统)→ Cloud AI Engineer(运行)。如果在自己的公司内部运行,就是这四个角色;如果在客户公司内部运行,由一位嵌入式、厂商中立的工程师端到端承载,就是 Forward Deployed Engineer。地图上的其他内容,要么支撑这条线,要么扩展这条线,要么为它划定边界。
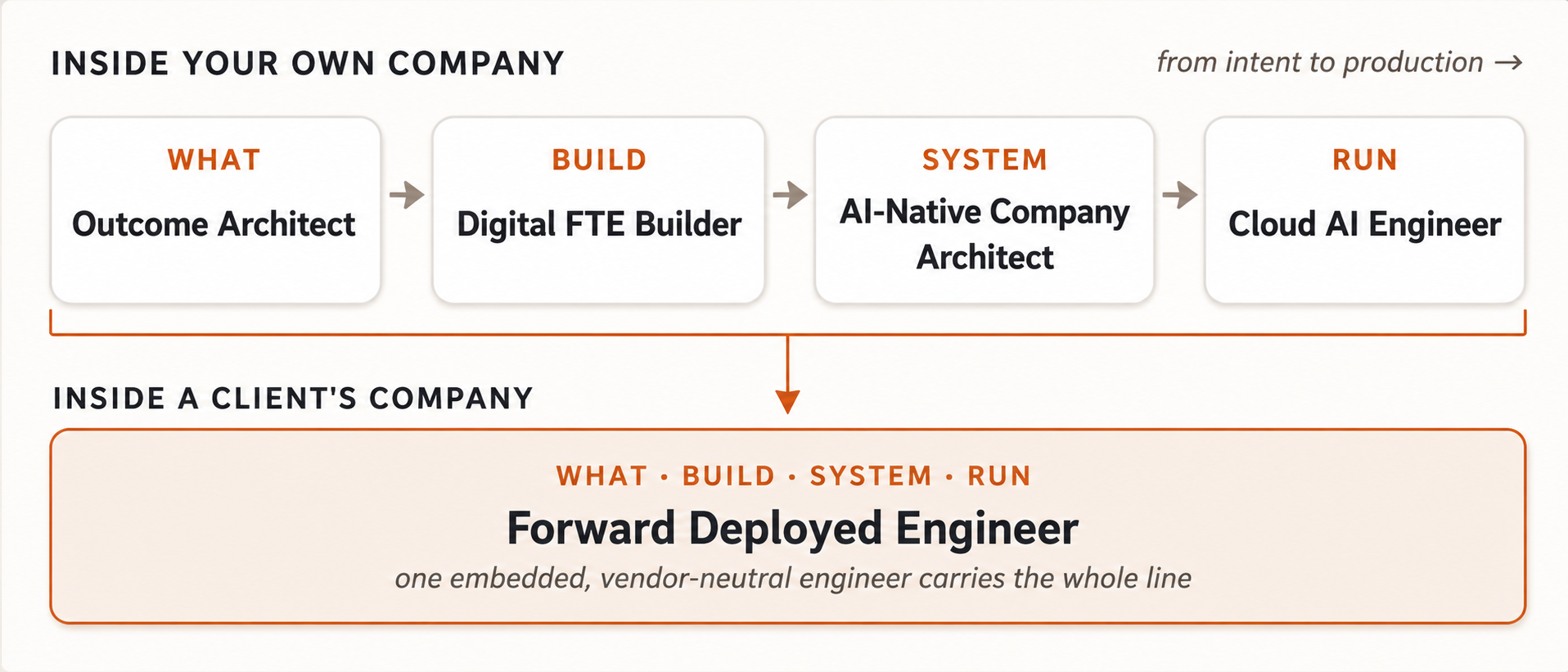
四个角色在你自己的公司内部跑通这条线;一位嵌入式工程师在客户公司内部承载同一条线。
Outcome Architect:拥有意图,而不是执行。 Agent 时代的工作分成三部分:意图、执行、验证。Worker 拥有执行;这个角色拥有意图。它决定一个 Worker 应该达成什么,编写把目标钉住的 spec,设定什么叫「正确」,并决定哪些 Worker 值得先被构建。也就是说,在 Builder 回答「怎么做」之前,由这个人先回答「做什么」和「为什么」。Strategist 路径负责面向客户的发现和 ROI;Outcome Architect 负责内部 Worker 路线图,以及支撑路线图的 spec。本书会直接训练这一点:spec-driven development 的核心,就是把意图写到 Worker 可以被约束和评估的程度。本书训练它:这是整个方法赖以成立的纪律。
Digital FTE Builder:端到端构建的单位产品。 市场通常把这个叫作 AI Engineer,用来笼统描述一个能用 AI 组件构建应用、并驱动 AI coding agent 的人。本书的名称更锋利,因为你构建的东西也更明确:Digital FTE,也就是整家公司被组装起来的单位。本书最主要的毕业角色就是它。它训练完整主干:spec-driven development、SKILL.md 编写、agent 架构、工具和 MCP 接口、评测与人的监督;同时包含足够的部署能力,让你可以交付上线,至于更深的生产运行能力,则留给 Cloud AI Engineer。本书端到端训练它。
AI-Native Company Architect:设计公司,而不是单个 Worker。 这里关注的是整个企业:双层模型、管理层、劳动力、在两者之间传递事件的神经系统,以及这一切所依托的记录系统。Agent Factory 是这位架构师实践的过程;AI-Native Company 是他们交付的产品。本书是它的权威来源。为期五个季度的 Certified Agentic AI Architect 项目是它的认证凭证。完整训练;由 Architect 路径认证。
Cloud AI Engineer:在生产环境中运行 AI Worker 和 AI-Native Company 的人。 构建 Digital FTE 只是工作的一半;可靠地运行它是另一半。运行它所属的整家 AI-Native Company 也是如此。AI-Native Company Architect 设计企业,而这个角色运营企业:在真实云基础设施上部署并扩展 Worker、管理层和神经系统,用 Azure Container Apps 交付,用 Inngest 做持久执行,用 Dapr 和 Kubernetes 扩展。这是系统从原型变成组织可以依赖的一家公司之处。本书端到端训练它。
几乎没有其他人训练的两个角色
Subject Matter Expert as Skill Author:市场还没有命名的角色。 会计、律师或供应链专家把判断力编码进 SKILL.md,成为 Digital FTE 的知识引擎。大多数市场清单会漏掉这个角色,因为它们仍然把 AI 工作想象成只属于工程。本书把领域判断本身视为可以编写、测试和部署的东西。这是几乎没有其他人训练的两个角色之一。完整训练它:判断力进入,工作 agent 出来。
Forward Deployed Engineer (FDE):市场找不到的厂商中立版本
FDE 实际做什么。 大多数软件工程师在总部构建产品,甚至从未见过使用产品的客户。FDE 正好相反。他们去到客户真实的工作现场,坐在真正做事的人旁边,理解这些人面对的真实问题,并在那里用自家公司平台直接构建解决方案。不是 demo。不是幻灯片。是在客户真实环境中运行的软件。
可以把它想成两种医生的区别:一种医生在另一个城市读你的病历;另一种医生坐在诊室里,检查你,并当场开始治疗。FDE 是第二种医生。
Palantir 是一家为政府和大型企业构建软件的大型数据分析公司,它在 2010 年代初创造了这个角色,最早把这些人称为 "Deltas"。1 到大约 2016 年以前,Palantir 的 FDE 数量甚至多于普通软件工程师,因为它的客户(政府机构和大型传统企业)需要有人在现场,用 startup 心态穿透内部官僚结构。Palantir 对这一区别的解释最清楚:普通开发者关注「一个能力,很多客户」(构建一个功能,发给所有人),而 FDE 关注「一个客户,很多能力」(嵌入一个客户,解决客户需要的一切)。这个岗位描述捕捉到了范围:它看起来像 startup CTO 的工作。你在高风险项目上从头到尾拥有一切。
这不同于 Solutions Architect 或 Sales Engineer。Solutions Architect 提供建议:做 demo,在白板上设计方案,用样例数据构建 proof-of-concept 原型,说服潜在客户签约。交易关闭后,他们的参与通常会逐渐结束。FDE 接上 Solutions Architect 停下的地方。他们直接在客户基础设施上、用真实数据写生产代码,并留下来直到客户获得真实价值。简单测试是:如果这个角色要对客户专属工作在生产环境中真正运行负责,它更接近 FDE;如果它要对证明或解释产品负责,它更接近 solutions architect。
一个真实例子:OpenAI 的 deployment team 嵌入 John Deere,这家接近 190 年历史的农业公司,在现场解决种植季问题。他们从每位农民过去的使用情况出发,帮助构建 AI 驱动的推荐,判断农民使用 John Deere 的定向除草系统 See & Spray 时可以少用多少化学品。John Deere 认为这项工作让化学品用量下降约 70%,并把客户参与度提高了 6 倍。2 截止日期是种植日历,而不是产品路线图。这句话就能概括 FDE 的工作:真实生产软件,在客户世界里构建,并在客户真正需要时交付。
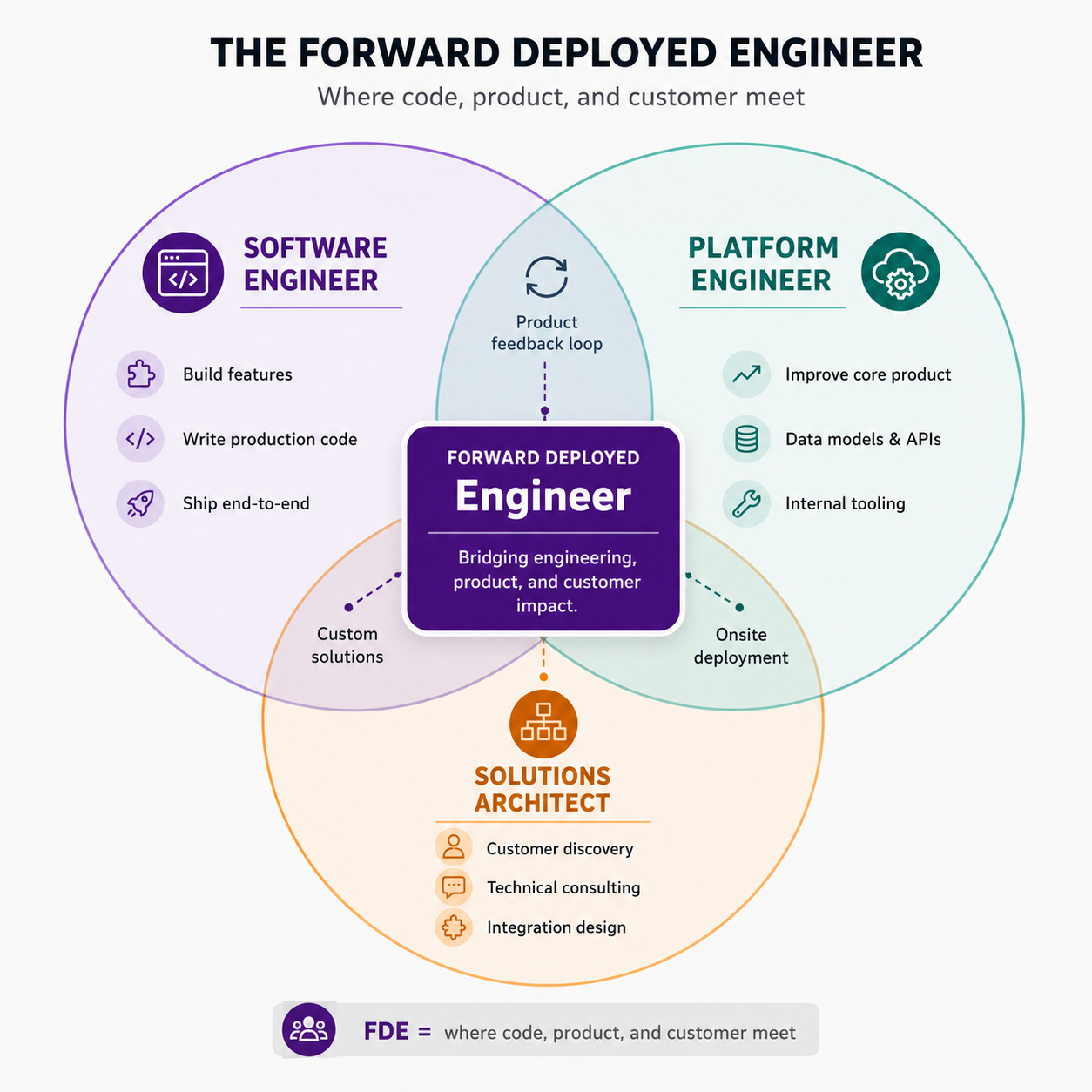
FDE 是代码、产品和客户相遇的地方:software engineer 的构建能力、platform engineer 的产品直觉,以及 solutions architect 对客户的理解,集中在一个在客户世界里构建而不是在总部构建的人身上。
为什么现在每家 AI 公司都想要 FDE。 2025 年前三个季度,FDE 岗位发布量增长超过 800%。3 Salesforce 建立了专门的 FDE 团队来支持 Agentforce 平台。4 OpenAI 创建了 "Deployment Company",这是一家由 OpenAI 控股、由投资者联盟支持约 40 亿美元的子公司,核心就是为企业配备 FDE。5 背后的原因很简单:MIT Media Lab 2025 年的一项研究(Project NANDA)发现,约 95% 的企业定制生成式 AI 试点没有可衡量回报。6 不是因为 AI 不工作,而是因为把 AI 塞进企业混乱的真实系统里极其困难。FDE 就是为弥合这道鸿沟而存在。它们是 Palantir 到 2024 年底市值超过 1360 亿美元、超过 Lockheed Martin 的原因之一,7 现在每家 AI 公司都想复制这个模型。
厂商 lock-in 问题。 关键就在这里。Palantir 的每位 FDE 都构建在 Palantir 平台上。OpenAI 的每位 FDE 都构建在 OpenAI 模型上。Salesforce 的每位 FDE 都构建在 Salesforce 工具上。工程师深入客户公司,把某个厂商的产品接入一切,然后离开。之后再切换会很痛苦、很昂贵,就像只安装一种品牌管道的水管工:水管能用,但你若想请另一个水管工,就得拆墙。正如 Andrew Ng 在 The Batch 中指出的,8 客户很难找到不绑定单一厂商的 FDE,因为从厂商角度看,这个角色本来就是为了把客户锁住。
本书训练市场一直想要却找不到的 FDE。 这里的方法不绑定任何厂商。本书的毕业者会把完整 pipeline(spec 意图、构建 Worker、设计系统、在生产环境中运行)带进客户组织,同时不把客户锁进任何单一平台。下个季度出现更好的模型,或者明年出现更便宜的 runtime,你就切换。客户保留选择自由,而你保留适用于任何 stack 的纪律。这里要诚实说出一个 tradeoff:厂商的 FDE 往往被高度补贴,有时甚至免费,因为厂商会通过 lock-in 赚回来;厂商中立的 FDE 则由客户或独立公司付费。这不是 bug,而是 feature:客户现在购买的是选择权,而不是以后支付切换成本。
这就是几乎没有其他人训练的第二个角色。更准确地说,本书训练的是厂商中立 FDE 的技术核心,也就是市场找不到的一半。另一半(客户发现、优先级排序、ROI 框定,以及对不现实要求说不的纪律)属于 Certified Agentic AI Business Strategist 路径。本书训练技术核心;咨询层属于 Strategist 路径。
连接器与插件工程师
Connector and Plugin Engineer:扩展别人已经在运行的 agent host。 在你构建一个拥有自己 loop 的 Worker 之前,还有一整套 discipline,是构建 agent 会 伸手调用 的东西,而市场正在同时用五种名字称呼它:MCP engineer、integrations engineer、connector developer、plugin developer、agent-tooling engineer。它是同一份工作,落在两个地址上。connector-native app 为最终用户扩展 chat app(claude.ai):你交付一个 remote MCP server,里面有 tools、stored state、真正的 sign-in 和 fail-closed session gate;陌生人只要粘贴一个 URL 就能添加它,从那以后,model 本身就是你的客户。plugin 为 builders 扩展 coding agent(Claude Code、OpenCode):skills、subagents、hooks 和 MCP servers 被包在一次安装后面,其中 deterministic hook 是 model 可能跳过的建议和每次都会运行的规则之间的分界线。同一个动作,两个 hosts;而两者下面都是同一个 artifact:MCP server,所以本书把它们背靠背讲。贯穿线来自 thesis 的一个想法:你交付一个 host 会加载的 unit,你拥有 extension,而 host 拥有 loop。两者都会从头到尾训练到一个已部署 artifact;签发身份,也就是你自己的 sign-in server 和 agents 的 identity,属于 AI Identity 课程;构建 runtime 本身仍然不在范围内,见本书停止的位置。
支撑角色
每条流水线都需要有人检查工作、制定规则并承担责任。下面三个角色做的就是这些事。
Evals Engineer:AI Worker 上线前做压力和碰撞测试的人。 你不会在没有碰撞测试的情况下交付汽车。你不会在没有临床试验的情况下发布药物。一个会影响真实的人和真实的钱的 AI Worker,也需要同样的纪律。Evals Engineer 设计这些测试:Worker 给出的答案对吗?遇到从未见过的情况时,会优雅地失败吗?会留在被给定的边界内吗?这不是最后才补上的东西。它被嵌入每一章。核心课程,不是附加内容。
AI Governance Officer:决定 AI 被允许做什么。 公司里的每个员工都有边界。初级会计可以批准 500 美元以内的费用,超过这个数字就需要经理签字。银行柜员可以处理存款,但不能批准贷款。AI Worker 也需要同样的结构。Governance Officer 在公司层面写下这些规则:AI 可以自己决定什么,什么必须交给人审批,什么永远不能碰。他们还负责映射到公司必须遵守的法规:银行的公平借贷规则,医院的患者隐私,欧洲的数据驻留法律。AI-Native Company Architect 构建执行这些规则的系统;Governance Officer 决定规则应该写成什么。本书直接训练这种治理框架纪律;你所在行业的具体法规,是你带进来的输入。本书训练治理框架;你所在司法辖区的规则由你提供。
Digital FTE Supervisor:名字写在责任线上的人。 当 AI Worker 处理理赔、起草合同或标记交易时,必须有人负责。那个人就是 Supervisor。他们是 human-in-the-loop:检查工作的人、批准输出的经理、审计轨迹在出错时指向的名字。这不是构建 Worker 的人,而是每天运行它的人,就像班组经理运行一个团队。本书训练它。
本书刻意停下的地方
LLMOps Engineer:到模型为止,不构建模型本身。 在生产环境中运行 agent 是 Cloud AI Engineer 的工作,本书会训练它。本书也会训练实际 fine-tuning,但把它作为最后手段,而不是默认选择。Fine-tune 会把你的系统绑定到某个模型快照上,并牺牲整个方法要保护的可选择性,所以只有在 prompting、context、tools 和 retrieval 真正不够时才使用。硬边界是构建模型本身:从零开始预训练 foundation model 不在范围内,因为这种能力正在商品化。本书训练 fine-tuning 和模型周边 ops,不训练 foundation model 的构建。
Harness Engineer:你使用的 runtime,不是你构建的 runtime。 Harness 是 agent runtime,例如 OpenAI Agents SDK、Claude 的托管 agent 等。它运行 agent loop、管理状态并执行 tool calls。本书训练你熟练使用这些 runtime,并在它们之间保持可移植性,因为你的纪律会比任何获胜的 runtime 更长寿。构建 runtime 本身不是这份工作。本书训练使用任何 runtime 的 operator,不训练构建 runtime 的工程师。
AI Data Engineer:面向 agent 的数据层。 system-of-record 工作会触及面向 agent 的数据层:Postgres、pgvector 和 MCP 是 agent 读取数据的主干。经典 pipeline 和数据仓库工程是相邻能力,但不是中心。本书训练面向 agent 的数据层,不训练通用数据工程。
模式本身就是信号。Agent 时代把工作展开为许多角色,而不是一个角色:构建 Worker、运行和治理 Worker、教会 Worker 判断。地图才是重点:找到你已经站在哪里,以及本书会把你从那里带到多远。