AI 时代的 Python:速成班
17 个概念 · 写作前先阅读
你已经学会了在 agent 编码速成课程 中驱动 AI 编码 agent。你可以打开一个会话,向 Claude Code 或 OpenCode 发出指令,然后观看它编辑文件和运行命令。所以这就是本课程要回答的诚实问题:
如果 agent 编写 Python,为什么你还需要学习任何 Python?
因为必须有人读它。该 agent 在几秒钟内生成数百行看起来可以工作的代码。而“看起来在工作”就是一个陷阱。人工智能优化的是“合理的”,而不是“正确的”。悄悄返回错误号码、删除记录或泄露 API 密钥的代码看起来与正常运行的代码完全相同。唯一能分辨出差异的人是能够阅读agent 所写内容并证明它符合他们的意思的人。
这就是现在的全部工作。不从空白页循环输入。agent 就是这么做的。你的工作仍然需要人工完成:确定“正确”的含义,并验证生成的代码是否符合它。
这是通往 AI 时代的编程 的网关。本书的这一部分是围绕一个项目(SmartNotes)构建的为期 3-5 个月的深度课程。本速成课程是一次性阅读 80% 的版本:具备足够的 Python 知识,可以立即开始阅读 agent 代码。它位于**Agentic Coding 之后和**Build AI Agents、Postgres for AI 和 打造数字化 FTE 之前,所有三个都假设你可以读取 agent 生成的 Python。要全面了解此处的任何主题,请点击该课程的链接。
**组织以下所有内容的一个想法:**在旧世界中,你通过“编写”Python 来学习 Python。在这里,你可以通过阅读它来学习它:预测代码的作用,运行它,调查原因,然后更改它,最后构建你自己的代码。我们给这个循环起了一个名字,它是整个课程的支柱。
本课程中的所有内容都是你在“Claude Code 课程”中所做的事情,而不仅仅是阅读。保持终端打开并运行 claude,并尝试每个想法。
本课程中的所有内容都是你在 OpenCode 会话中执行的操作,而不仅仅是阅读。保持终端打开并运行 opencode,并尝试每个想法。如果你正在关注成本,请将其指向 deepseek-v4-flash 等廉价型号以进行例行运行(请参阅 agent 编码课程)。
设置你的环境(一次)
本课程有一个你下载一次的小伙伴:课程库。你并不严格需要它来阅读,但它使一切都按照课程假设的方式运行。它提供了一个简短的规则文件 AGENTS.md,可将你的 agent 变成本课程所依赖的纪律严明的导师:它在揭示之前进行预测,给出提示而不是答案,并且绝不会为了通过而悄悄削弱测试。你的 agent 每次启动时都会自动读取该文件,这就是为什么你的提示可以保持简短的原因。该底座还带有练习项目启动器和答案键,你可以检查自己的测试。
下载 python-crash-course-base.zip
解压它,然后打开文件夹中的 agent:
cd python-crash-course
claude
cd python-crash-course
opencode
请注意,该基础库故意 还没有 Python 项目。从无到有构建自己的工作台是第一个真正的技能,也是你在 Concept 3 中要做的下一步。现在,只需打开文件夹中的 agent 并确认它加载了规则:
本次会议你遵循哪些规则?
它应该描述先读后写的方法以及运行测试来验证的习惯。当你的 agent 回答这些规则时完成。(更喜欢从一个裸文件夹开始?这也有效;你只需在操作过程中自己设置规则即可。)
第 1 部分:新思维
1. 你阅读代码;agent 写的
在传统的 Python 课程中,训练的技能是“生产”:输入函数、输入循环、输入类。人工智能消除了这个瓶颈。现在重要的技能是方向和验证。
| 旧的工作(现在大部分是自动化的) | 新工作(仍然是你的) |
|---|---|
| 从空白页输入实现 | 准确描述你想要什么,用 agent 可以采取行动的语言 |
| Memorize syntax | 充分认识语法,能够批判性地阅读它 |
| 获取要运行的代码 | 证明代码是正确的,而不仅仅是可运行的 |
这就是应用于编程的10-80-10 rule。你拥有前 10%(决定构建什么以及“正确”意味着什么)和后 10%(验证它)。agent 拥有中间的 80%(生成代码)。流利地阅读才能让你两全其美。

阅读比写作容易得多。你无需从无到有地回忆列表使用方括号。当你看到它时,你只需识别 ["a", "b"] 作为一个列表。这就是整个课程的标准:识别,而不是回忆。
2. PRIMM-AI+方法
PRIMM-AI+ 是你无需盯着空白页即可学习阅读代码的方法。Python 的每个新部分都会经历五个步骤,而 agent 在每个步骤中都是你的合作伙伴:
| Step | Letter | 你做什么 | agent 的角色 |
|---|---|---|---|
| 预测 | P | 在运行任何东西之前,猜测代码会做什么 | 保持安静——这是你的猜测 |
| 运行 | R | 运行它并查看实际输出 | 为你执行代码 |
| 调查 | I | 将你的猜测与现实进行比较;问为什么 | 根据需要逐行解释 |
| 修改 | M | 改变一件事,再次预测,再次运行 | 进行你所描述的编辑 |
| 制作 | M | 从头开始指定你自己的版本;让 agent 构建它;验证 | 根据你的规范生成 |
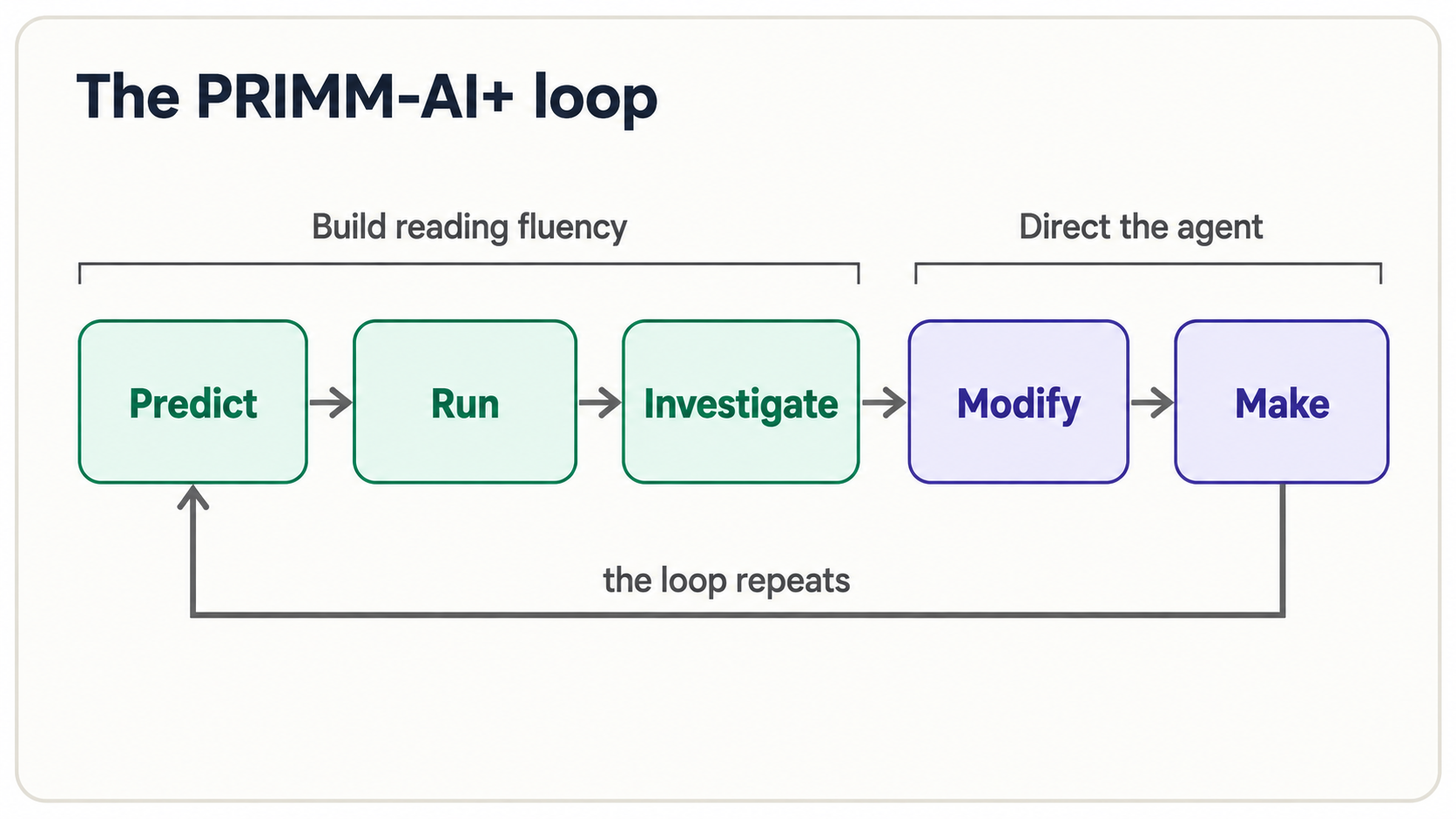 AI+ 使其成为旧教学方法的“AI 时代”版本。经典 PRIMM 之上有两件事:agent 始终可以作为阅读伙伴(“解释第 3 行”、“什么会破坏这个?”),以及 任何事情都不会被凭信心接受。 预测-运行-调查可增强你的阅读流畅性;修改-制作是你开始指导 agent 的地方。到最后,Make 感觉就像现在的 Predict 一样自然。
AI+ 使其成为旧教学方法的“AI 时代”版本。经典 PRIMM 之上有两件事:agent 始终可以作为阅读伙伴(“解释第 3 行”、“什么会破坏这个?”),以及 任何事情都不会被凭信心接受。 预测-运行-调查可增强你的阅读流畅性;修改-制作是你开始指导 agent 的地方。到最后,Make 感觉就像现在的 Predict 一样自然。
测试适合的地方:无处不在。 为调查、修改和制作提供动力的引擎是测试:一个简短的检查,确定“正确”的含义,这样计算机就可以验证 agent 的工作,而不是你目视它。这不是你最后一次执行的步骤。从你阅读的下一个函数开始,进行一个小测试:首先作为单个 assert 行(概念 5),然后作为对象(概念 8)和验证规则(概念 11),最后作为完整的 测试驱动生成 循环,你首先编写测试,然后 agent 编写代码来通过它(概念 16)。将 agent 交给你的每一段代码都视为不可信,直到你编写的测试表明情况并非如此。
本能是直接跳到“运行”:只需查看答案即可。不。你的预测与实际输出之间的差距是学习发生的地方。错误的预测可以准确地告诉你思维模型的哪一部分被破坏了,这比正确的预测要好得多。大声、书面或向 agent 进行预测。然后跑。
3.五分钟内你的工作台
本课程假设你已完成 agent 编码速成课程,你可以在其中安装并学习驱动 agent。如果你直接跳过此处并且尚未安装“任何内容”,请先设置一个编码 agent,然后再继续下一步。这个工具将为你安装其他所有内容:
- Claude Code:遵循 docs.claude.com/en/docs/claude-code 上的官方指南(通过 WSL 在 macOS、Linux 和 Windows 上运行)。
- OpenCode(开源替代方案):OpenCode.ai。
- uv(Python 本身 + 软件包):docs.astral.sh/uv;或者让 agent 在下一步中为你安装它。
你不需要深入了解这些工具中的任何一个。安装一个 agent,在文件夹中将其打开,然后继续。本节的其余部分让 agent 进行设置。
你需要三样东西:运行 Python 的方法、一些高质量的工具和你的 agent。一个安装程序涵盖了前两个:uv,一个快速的包管理器,可以安装 Python 本身并管理你的项目。
不要根据记忆手动安装它们——这正是 agent 所擅长的那种繁琐的设置。在你打开 agent 的文件夹中,为其提供说明:
使用
uv在这里设置一个新的 Python 项目。添加pytest用于测试,pyright用于类型检查,ruff用于格式化。创建一个打印“ready”的hello.py。然后运行它并显示输出。
agent 将运行 uv 命令、创建文件并运行脚本。你观看并批准每一步。那是你的工作台。你一个命令都没记住。
不要根据记忆手动安装它们——这正是 agent 所擅长的那种繁琐的设置。在你打开 agent 的文件夹中,为其提供说明:
使用
uv在这里设置一个新的 Python 项目。添加pytest用于测试,pyright用于类型检查,ruff用于格式化。创建一个打印“ready”的hello.py。然后运行它并显示输出。
OpenCode 将运行 uv 命令、创建文件并运行脚本。你观看并批准每一步。那是你的工作台。你一个命令都没记住。
它实际上是什么样子
你不会默默地观看。agent 会叙述每个步骤并在运行任何操作之前进行询问。真实的会话大致如下所示(显示了 Claude Code;OpenCode 几乎相同):
> Set up a new Python project here using uv. Add pytest, pyright, ruff.
Create a hello.py that prints "ready", run it, and show the output.
● I'll initialize the project with uv.
$ uv init . ← the agent proposes a command
Allow? (y/n) y ← you approve
Initialized project
● $ uv add --dev pytest pyright ruff
Allow? (y/n) y
+ pytest + pyright + ruff
● Created hello.py:
print("ready")
● $ uv run hello.py ← this is how a Python file gets run
ready ← the output prints right here
Done. Your workbench is ready.
需要注意三件事,因为它们是你将重复所有课程的物理循环:
- 代码位于文件中 (
hello.py),而不是聊天窗口中。 - 你使用
uv run hello.py运行一个文件:该命令执行本课程中的每个脚本和示例。 - agent 在每个命令之前都会请求许可,然后在下面打印输出。你批准,你阅读结果。
因此,每当下面的示例说“运行它”时,你就有两个简单的选择:将代码粘贴到文件中并告诉 agent“运行此文件并向我显示输出”,或者只是将代码片段粘贴到聊天中并说“运行此文件并向我显示它打印的内容”。无论哪种方式,你都不会手动输入 Python。
如果任何步骤抛出红色错误,你不需要需要理解它。复制红色文本,将其粘贴回来,然后说:“此失败。阅读错误并修复它。” 如果 agent 报告未安装 uv,请要求它先安装 uv。摆脱困境是 agent 的工作;注意到自己陷入困境是你自己的事。
以下是每个工具的作用,一行。从这里开始,你将不断看到提到的所有四个:
| Tool | 它对你有什么作用 |
|---|---|
| 紫外线 | 快速安装 Python 和项目的包 |
| py 测试 | 运行你的测试并报告哪些通过,哪些失败 |
| 皮赖特 | 在运行代码之前读取代码中的类型标签并标记不匹配的情况 |
| 拉夫 | 检查样式和格式——代码的拼写检查器 |
Pyright 和 Ruff 是阅读机器。当 agent 生成代码时,这些工具会为你读取代码并立即捕获一整类错误:错误的类型、未使用的变量、拼写错误的名称。在你自己阅读一行之前,它们是你的第一行验证。(完整设置演练:人工智能时代的编程,第一阶段:工作台。)
看看你的阅读机捕捉到了什么
这些工具并不抽象。要求 agent 编写一个小函数,然后使用错误类型的值调用它:
def total_with_tax(price: float, tax_rate: float) -> float:
return price + (price * tax_rate)
total_with_tax("100", 0.15) # oops — "100" is text, not a number
在其上运行 pyright,在代码执行之前你会得到以下结果:
error: Argument of type "Literal['100']" cannot be assigned to
parameter "price" of type "float" (reportArgumentType)
Pyright 阅读了类型提示,发现文本已传递到承诺 float 的位置,并立即发现了不匹配的情况。Ruff 发现了不同类型的失误:agent 有时留下的剩余杂物:
F401 `os` imported but unused
你不会记住这些消息。你可以像阅读拼写检查器的下划线一样阅读它们:*这里的某些内容不适合,它指向确切的行。*当 agent 生成一百行时,这两个工具会在一秒钟内读取所有内容,这正是它们在你开始阅读自己之前运行的原因。
第 2 部分:随处可见的形状
这些是核心形状,它们可能构成了你所读过的所有 Python 语言的 70%。使用 预测 → 运行 → 调查 浏览每一个:阅读它,猜测输出,然后在会话中运行它进行检查。
4. 值、变量和四种类型
变量是一个保存值的标记框。= 符号的意思是“将右侧的值放入左侧的框中”:从数学意义上来说,它不“等于”。每个值都有一个类型,目前你只需要识别四个。我们将类型写在名称后面,如 name: type,这样你和 agent 就可以一目了然地看到每个盒子的用途:
name: str = "Ayesha" # str — text, always in quotes
age: int = 30 # int — a whole number
price: float = 19.99 # float — a number with a decimal point
is_active: bool = True # bool — only ever True or False
: str、: int、: float、: bool 部分是 类型提示。它们在 Python 中是可选的,但在本课程中,我们始终包含它们:部分是因为它们使代码更易于阅读,部分是因为,正如你将在概念 10 中看到的,它们是你告诉 agent 确切要构建什么的方式。现在,将 name: str 读为简单的英语:“盒子 name 包含文本。”
预测: 你认为这会打印什么?
age: int = 30
age = age + 1
print(age)
**运行它。**输出为 31。**调查:**如果将 = 读作“等于”,则 age = age + 1 行看起来不可能:30 不能等于 31。但 = 的意思是分配:取 age 的当前值 (30),加 1,然后将结果 (31) 放回框中。右侧首先运行,然后更新框。(请注意,我们仅在“第一次”出现 age 时编写了类型提示 : int;一旦该框具有类型,你就不必在每次重新分配时都重复它。)这个想法几乎一开始就让每个人都感到困惑,这就是你首先预测它的原因。
当你看到 x = something 时,从右到左读:“计算 something,然后将其存储在 x 中。”左边的名字只是一个标签。
5. 函数及其签名
函数是具有名称的可重用代码块。你给它输入(称为参数),它给你一个输出。第一行,签名,是你将学习阅读的最重要的一行,因为它是一个合同:
def total_with_tax(price: float, tax_rate: float) -> float:
return price + (price * tax_rate)
逐段阅读签名:
def:“我正在定义一个函数。”total_with_tax:其名称。(price: float, tax_rate: float):它需要两个输入,均为小数。: float部分是一个类型提示(概念 10 中有更多相关内容)。-> float:返回一个小数。
一口气说:“给我一个价格和税率,都是小数,我会给你一个小数。”*你可以理解一个函数的承诺无需阅读其正文的一行。这就是为什么签名在验证人工智能代码时如此重要。身体可能会出错;签名告诉你它“应该”做什么。
预测,然后运行:
def total_with_tax(price: float, tax_rate: float) -> float:
return price + (price * tax_rate)
print(total_with_tax(100.0, 0.15))
输出:115.0。如果你预测了 115.0,那么你已经可以读取一个函数了。
通过测试固定它
函数是你可以“证明”正确的第一件事,因为它有一个明确的契约:给定这些输入,它必须返回该输出。你可以用 assert 来锁定它:这是一个单行声明,当为真时什么也不做,当它为假时就会大声崩溃:
assert total_with_tax(100.0, 0.15) == 115.0 # "I claim this must equal 115.0"
assert total_with_tax(0.0, 0.15) == 0.0 # a free item costs nothing
运行这两行,你将看到什么也没有。沉默意味着每一个主张都被保留。将 115.0 更改为 999.0,立即崩溃。这就是测试背后的整个想法:**你一次写下正确的含义,然后计算机每次都会重新检查它。**这两行已经是一个很小的规范。抓住他们。在概念 16 中,你将把这些确切的断言交给 agent,并让它编写函数来满足它们。(这并非偶然:与整个 TDG 周期相同的税收功能再次出现。)
6.集合:对数据进行分组
在实际代码中单个值很少见。大多数数据都是成组的,你会反复看到四个容器:
notes: list[str] = ["buy milk", "call Sara", "finish report"] # list — ordered, can change
note: dict[str, str | bool] = {"title": "Meeting", "done": False} # dict — labeled pairs (key: value)
tags: set[str] = {"work", "urgent"} # set — unique items, no duplicates
point: tuple[int, int] = (3, 5) # tuple — ordered, cannot change
这些提示描述容器内部是什么:list[str] 是“文本列表”,dict[str, str | bool] 是“键为文本、值为文本或 true/false 的 dict”(| 表示“或”),set[str] 是“文本集合”,tuple[int, int] 是“一对整数”。你不需要凭记忆写出这些,只需要读懂它们。
你最常遇到的两个是 list (可以添加和重新排序的序列)和 dict (一组标记值:AI agent 传递的几乎每条数据的主干,因为它直接映射到 JSON)。
预测,然后运行:
note: dict[str, str | bool] = {"title": "Meeting", "done": False}
print(note["title"])
note["done"] = True
print(note)
Output:
Meeting
{'title': 'Meeting', 'done': True}
调查: note["title"] 进入字典并提取标记为 "title" 的值。第二行更改标记为 "done" 的值。字典是 agent 向你提供注释、用户、API 响应的方式:任何带有命名字段的内容。
7. 控制流程和理解
代码使用 if 做出决策,并使用 for 重复。缩进(行首的空格)是 Python 知道 if 或 for 内部内容的方式。它不是装饰,而是结构。
prices: list[int] = [10, 250, 50, 400]
for price in prices: # do this once for each price in the list
if price > 100: # decision
print(f"{price} is expensive")
else:
print(f"{price} is fine")
在运行之前预测哪些行打印“昂贵”。(答案:250 和 400。)
其中两行使用 f-string:前面带有 f 的文本,其中 {...} 内的任何内容都将替换为其值。因此 f"{price} is expensive" 将当前的 price 放入句子中。你会不断地看到 f 弦;只需认识到 {name} 的意思是“将此值的文本放在这里”。
当决策有“两个以上”结果时,elif(“else if”的缩写)会将它们链接起来。Python 从上到下检查每个分支并运行第一个正确的分支:
def grade_for(score: int) -> str:
if score >= 90:
return "A"
elif score >= 70:
return "B"
elif score >= 50:
return "C"
else:
return "F"
预测 grade_for(72),然后运行。它是 "B":72 >= 90 为假,所以它落到下一个分支,72 >= 70 为真,并在那里停止。将 if/elif/else 链读取为 “按顺序检查这些;取第一个匹配项。” 你还将看到与 and 和 or 组合的条件 — if score >= 70 and attended: 意味着两者都必须为真 — 这就是你阅读“多条件”决策所需的全部内容。
一旦你可以读取 for 循环,你就可以读取 Python 中最常见的单行代码:推导式。它只是一个 for 循环折叠到一行以构建一个新列表:
prices: list[int] = [10, 250, 50, 400]
# The long way:
expensive: list[int] = []
for price in prices:
if price > 100:
expensive.append(price)
# The comprehension — exactly the same result:
expensive = [price for price in prices if price > 100]
长版本中的 .append(price) 将 price 添加到列表末尾;thing.action() 形状是你将在概念 8 中遇到的方法调用。从左到右阅读推导式:“给我 price,对于 prices 中的每个 price,如果 price > 100。” 两者都会产生 [250, 400]。你会在人工智能代码中随处看到推导式,因为数据清理和重塑是大部分工作。熟悉这种形状后,你就可以阅读大量真实的 Python 内容。
将你不理解的任何行粘贴到你的会话中:*“解释这一行,就像我从未编码过一样:[n['text'] for n in notes if n['done']]。”*这是 PRIMM-AI+ 按需的 调查 步骤。不断地使用它。它比任何参考都快。
8. 类和对象——阅读蓝图
到目前为止,你的数据是松散的:note 是一个字典,price 是一个浮点数。类允许你将相关数据和属于它的操作捆绑到一个命名形状中。将类视为蓝图,将对象(也称为实例)视为根据该蓝图构建的事物:一个 Note 蓝图,根据它构建的许多实际注释。
这是一个模拟单个音符的类:
class Note:
def __init__(self, title: str, body: str) -> None:
self.title = title # an attribute — data this note carries
self.body = body
self.done = False
def mark_done(self) -> None: # a method — an action this note can perform
self.done = True
分段阅读:
class Note:,定义蓝图,命名为Note。__init__:设置方法。当你构建新笔记时,它会自动运行一次并存储起始数据。(-> None意味着它什么也不返回;它只是配置对象。)self:这个特定对象。在蓝图中,self.title表示“此注释的标题”。每个方法首先采用self,这样它就知道它正在处理哪个对象。self.title、self.body、self.done— 属性:每个音符携带的数据。mark_done,一个方法:一个位于类*内部并作用于对象的函数。
现在构建一个并使用它。在运行之前预测输出:
n: Note = Note(title="Groceries", body="milk, eggs")
print(n.done)
n.mark_done()
print(n.done)
Output:
False
True
调查: Note(title="Groceries", body="milk, eggs") 运行 __init__ 并返回一个完成的对象,存储在 n 中。n.done 读取一个属性;n.mark_done() 调用更改它的方法。点 (.) 始终表示同一件事:“进入该对象以获取以其命名的事物。”
这种模式——object.attribute 读取数据,object.method() 要求对象做某事——解锁了最真实的 Python。你在 agent 代码中读到的几乎所有内容都是对象:Pydantic 模型是一个类,agent 是一个对象,数据库连接是一个对象。当你看到 agent.run(task) 或 db.save(note) 时,你正在阅读“要求此对象运行其方法之一”。(完整的对象模型是 人工智能时代的编程,第五阶段。)
通过测试固定它
你验证对象的方式与概念 5 中验证函数的方式完全相同:断言方法运行之前和之后其状态必须是什么:
n: Note = Note(title="Groceries", body="milk, eggs")
assert n.done is False # a fresh note starts unfinished
n.mark_done()
assert n.done is True # ...and is finished after mark_done()
同样的举动,新的目标:方法只是附加到对象的函数,因此相同的一行 assert 证明了它的行为。当 agent 为你编写一个类时,你可以通过以下方式检查它是否符合你的意思。
与本课程中的所有内容一样,这里的目标是认可。当 agent 生成一个类时,你希望能够指向它并说“这是设置方法,这些是它的属性,这是更改其状态的方法。”这足以验证它是否符合你的要求。
9. 你将在生成的代码中遇到更多形状:while、切片、try/except 和 input()
你很少“写”这四个,但 agent 经常使用它们,因此你在阅读和验证其输出时需要识别它们。快速预测→运行→调查每一个就足够了。
while:重复直到条件发生变化。 for 循环对集合中的每个项目运行一次,而 while 循环只要其条件保持为真,就会继续运行:
count: int = 3
while count > 0: # keep looping while this is true
print(count)
count = count - 1
print("done")
预测,然后运行。 输出:3、2、1、done。将其读作*“在 count > 0 时继续执行此操作。”* 在生成的代码中值得认识的一个危险:如果条件永远不会变为假,则循环将永远运行,因此当你看到 while 时,请看一下最终使其停止的原因。
**切片:抓取列表或字符串的一部分。**方括号内的冒号表示“位置范围”:
letters: list[str] = ["a", "b", "c", "d", "e"]
print(letters[1:3]) # from position 1 up to (not including) 3
print(letters[:2]) # the first two
print(letters[-1]) # the last one
预测,然后运行。 输出:['b', 'c']、['a', 'b']、e。从 0 开始计数;[1:3] 是“从 1 到但不包括 3”;-1 的意思是“最后一个”。相同的语法适用于文本:"hello"[:3] 是 "hel"。
**try / except:尝试可能会失败的操作。**某些操作可能会失败:除以零、读取丢失的文件、网络调用超时。try/except 运行有风险的代码并捕获错误而不是崩溃:
def safe_divide(a: float, b: float) -> float:
try:
return a / b
except ZeroDivisionError: # if dividing by zero is attempted...
return 0.0 # ...do this instead of crashing
预测 safe_divide(10.0, 2.0) 和 safe_divide(10.0, 0.0),然后运行。输出:5.0 和 0.0。将其读作“尝试这个;如果以这种特定方式失败,则改为这样做。”* 你将看到 try/except 包裹了 agent 代码中可能失败的任何内容。
**input():暂停并阅读用户键入的内容。**交互式脚本和命令行工具使用 input() 向用户询问问题并等待答案:
name: str = input("What's your name? ") # waits here until the user types and presses Enter
print(f"Hello, {name}!")
需要认识到的一件事,也是生成代码经常出错的地方,是 input() 始终返回文本,即使用户键入数字也是如此。要使用它进行数学运算,代码必须首先对其进行转换:
age_text: str = input("Your age? ") # "30" comes back as text, not a number
age: int = int(age_text) # int(...) converts text to a whole number
print(f"Next year you'll be {age + 1}")
如果你看到 input() 直接输入算术而没有 int(...) 或 float(...) 围绕它,那么这是一个需要标记的错误:程序要么崩溃,要么将文本粘合在一起而不是添加。
通过测试固定它
错误情况正是值得关注的事情:断言危险输入已得到处理,而不是崩溃:
def test_safe_divide() -> None:
assert safe_divide(10.0, 2.0) == 5.0
assert safe_divide(10.0, 0.0) == 0.0 # handled, not a crash
每一个都是生成代码容易出错的常见地方:永远不会结束的 while、相差 1 的切片([1:3] 为你提供两项,而不是三项)、默默地吞下你需要了解的错误的 except,或者其文本在数学之前从未转换为数字的 input()。认识到形状可以让你停下来仔细观察这些点。
第三部分:AI 时代的电源概念
这些概念将“hello world”Python 与你在 agent 和机器学习代码中实际看到的 Python 区分开来。其中大多数你还不会从头开始编写;agent 会这样做,而你的目标纯粹是识别:当一个人出现时,你知道它的用途以及大致的作用。唯一的例外是第一个,类型提示(概念 10):你“确实”学会编写的提示,因为它们是你告诉 agent 确切要构建什么的方式。(其中一些直接取自生产人工智能工程师日常使用的内容。)
这里的节奏是故意跳跃的。两页前你正在阅读 age = age + 1;现在你将看到生成器、验证器和 async。没关系。**你不需要写任何内容。**概念 11-15 的唯一任务是识别每个形状并用简单的英语说出它的用途。如果一个块看起来很密集,请阅读一行“将其读为……”摘要并继续。没有人记住这些;你学会发现它们。
10. 类型提示——引导 agent 的标签
你已经在概念 5 中遇到过一个:price: float。类型提示是一个标签,说明变量或函数需要什么类型的数据。Python 并不“需要”它们,但在人工智能时代,它们是最强大的工具,原因之一:
类型提示是对 agent 的说明。 当你在之前要求 agent 填写这样的签名时 -
def summarize_notes(notes: list[dict], max_words: int) -> str:
... # the agent writes this part
- 你已经准确无误地告诉它,输入是一个字典列表,有一个整数的字数限制,输出是一个字符串。agent 现在更频繁地生成“正确”的东西,因为你消除了猜测。Pyright 会在代码运行之前读取这些标签并标记任何不匹配的情况。
在 TDG 术语中(在 AI 时代的编程中有完整介绍),编写类型是编写规范的一部分。 前 10% 是属于你的。
由于类型是指令,因此最强的代码请求会向 agent 提供三件事并要求第四件事:
- 签名,类型:
summarize_notes(notes: list[dict], max_words: int) -> str。这固定了输入和输出,因此无需猜测。 - 输入→输出的一两个例子。(这些都是你的测试。)
- 任何限制:“必须处理空列表”、“不要调用网络”、“保持在 20 行以下”。
- 要求它验证:“然后运行
pytest和pyright并向我显示结果。”
模糊的请求(“写一些东西来总结笔记”)会得到模糊的代码。输入的签名加上示例即可获得你可以实际检查的代码。当结果错误时,不要只是重试:粘贴失败的输出并说出问题所在:“它在空列表上崩溃。处理这个问题。” 一次明智的更正胜过十次盲目重投。
11. Dataclasses 和 Pydantic — 结构化、经过验证的数据
原始字典 ({"learning_rate": 0.001}) 很灵活,但很危险:输入错误的密钥或错误的类型会默默地传递并破坏下游的所有内容。有两个工具可以解决这个问题。
Pydantic 未内置于 Python 中,因此下面的示例需要将其添加到你的项目一次:告诉你的 agent “将 pydantic 添加到此项目”(它运行 uv add pydantic)。dataclass 是内置的,不需要任何东西。
数据类为你的数据提供定义的形状。这与概念 8 中的 Note 相同。但请注意,没有 __init__:@dataclass 行为你编写设置方法,因此你只需列出属性及其类型。
from dataclasses import dataclass
@dataclass
class Note:
title: str
body: str
done: bool = False # default value
Pydantic 更进一步:它在运行时“验证”数据并拒绝任何不适合的内容:
from pydantic import BaseModel, Field
class ModelConfig(BaseModel):
learning_rate: float = Field(gt=0.0, lt=1.0) # must be between 0 and 1
batch_size: int = Field(gt=0) # must be positive
如果你尝试使用 learning_rate=-0.05 构建 ModelConfig,Pydantic 立即会引发明显的错误,而不是让损坏的值在数小时后毒害训练运行。这就是 Pydantic 在 agent 代码中无处不在的原因:它还会自动生成 LLM 用于工具调用的 JSON 模式。当你启动building agents的那一刻你就会再次遇到它。
通过测试固定它
Pydantic 模型本质上是每次程序执行时都会运行的测试。但你仍然应该固定你关心的行为,包括错误情况。到目前为止,你已经断言某件事是“真实的”;在这里,你断言必须“拒绝”错误的输入,使用 pytest.raises:
import pytest
from pydantic import ValidationError
def test_rejects_negative_learning_rate() -> None:
with pytest.raises(ValidationError): # the block below MUST raise this error
ModelConfig(learning_rate=-0.05, batch_size=32)
仅当错误配置被拒绝时,此测试才会通过。测试失败与测试成功一样重要:agent 会很高兴地生成“看起来”严格的验证,但会悄悄地让坏数据通过,而“必须引发”测试就是你捕获该数据的方法。
@dataclass 行是一个装饰器函数或类上方一行中的 @ 符号是一个 装饰器:一个标签,可以将行为添加到其后面的内容中,而无需你自己编写该行为。@dataclass 自动为类提供构造函数和可读的打印输出。你还不需要编写装饰器;只需要认识到 @something 的意思是“用额外的能力包裹下一个事物”。
12. 生成器和 yield — 流式传输而不会耗尽内存
当代码需要处理一百万条记录时,一次将所有记录加载到列表中可能会耗尽计算机的内存。生成器通过按需一次返还物品来解决这个问题。要查找的信号是关键字 yield 而不是 return:
from collections.abc import Iterator
def stream_notes(lines: list[str]) -> Iterator[str]:
for line in lines:
yield line.strip().lower() # hand back one item, then pause
返回类型 Iterator[str] 是生成器的明显标志:它不承诺 list[str] (完成的一堆)。它承诺有一个“迭代器”,即一次从一项中提取的流。
使用 return 的普通函数会构建整个结果并将其一次性移交。具有 yield 的生成器会在每个项目后暂停,仅在被要求时才执行下一部分工作。回报是真实的:通过生成器流式传输大型数据集而不是将其加载到列表中可以显着减少峰值内存,因为你永远不会一次保存整个数据集。当你看到 yield 时,请将其读作:“这会产生一个流,而不是一堆。”
13. with — 安全地打开和关闭东西
文件、数据库连接、网络会话——任何必须“打开”然后可靠地“关闭”的东西,即使中间发生崩溃——使用 with 语句:
with open("notes.txt") as file:
contents: str = file.read()
# the file is automatically closed here, even if an error happened above
当缩进块结束时,保证清理正在管理的事物(此处为文件)。在 AI 代码中,你将看到 with 包含 GPU 状态、模型评估模式和计时器。当你看到 with 时,请将其读作:“设置一些内容,在该块内使用它,并无论如何安全地将其拆除。”
14. async / await — 同时处理很多事情
当一个 agent 进行 20 次 API 调用时,一次又一次地调用意味着等待 20 次。异步代码让程序触发所有请求并在响应到达时对其进行处理:一一站在 20 个队列中与一次加入所有 20 个队列之间的区别。信号是关键字 async 和 await:
async def query_llm(prompt: str) -> str:
response = await call_the_api(prompt) # pause here, let other work proceed
return response
举例来说:如果 20 个 API 调用每个大约需要 0.1 秒,那么依次运行它们大约需要 2 秒,而与 async 同时运行它们可以在大约最慢的单次调用的时间内完成,因为总数受到最慢调用的限制,而不是总和。你还不需要编写异步代码。只需要认识到:async/await 的意思是“此代码是为了同时执行许多缓慢的操作而构建的。”* 当你使用 build agents 时,你将严重依赖它。
15. Dunder 方法——为什么 model(x) 有效
你将读到的最奇怪的东西是两边都有双下划线的方法,例如 __init__ 或 __call__。这些被昵称为 “dunders”(双下划线),你已经遇到过一个:Concept 8 中的 __init__ 设置方法就是一个 dunder。它们是特殊的方法,可以让你自己的对象表现得像内置对象一样。
class Pipeline:
def __init__(self, factor: float) -> None: # runs when you create the object
self.factor = factor
def __call__(self, x: float) -> float: # runs when you "call" the object like a function
return x * self.factor
pipeline = Pipeline(2.5)
print(pipeline(10.0)) # prints 25.0 — the object is called like a function
__init__ 设置一个新对象;__call__ 使 pipeline(10.0) 工作起来就像对象是一个函数一样。这正是为什么在 PyTorch 和类似库中编写 model(x) 而不是 model.forward(x) 的原因:框架定义 __call__ 在运行之前进行重要设置。当你看到 dunders 时,请将其读作:“这个对象正在被教导像原生 Python 一样运行。”
停下来注意发生了什么。你还不能从空白页“编写”生成器或异步函数。你不需要这样做。但是你现在可以打开 agent 生成的文件并识别:“这是一个具有属性和方法的类,这是一个类型提示,这是一个定义工具模式的 Pydantic 模型,这是一个流数据生成器,with 块管理资源,那些 dunders 制作自定义数据集。”这种认识是整本书所依赖的验证技能。
第 4 部分:端到端的 TDG 循环
你已经在第 2 部分和第 3 部分中完成了预测-运行-调查。现在 PRIMM-AI+ 的最后两个字母,修改和 制作,它们一起构成了测试驱动生成 (TDG) 周期:定义 AI 时代编程的方法。
16. 在你的工具中完成一个完整的循环
TDG 颠倒了旧秩序。你可以:**编写一个定义“正确”的失败测试→让 agent 生成代码→运行测试进行验证,而不是编写代码→也许测试它。**测试不是事后的想法;它是*规格。它必须来自你,因为如果你让 agent 编写代码和测试,你就会根据人工智能自己的期望来检查人工智能的工作:根本没有独立的信号。
这是概念 5 中的税务功能循环。按照你的会话进行操作。
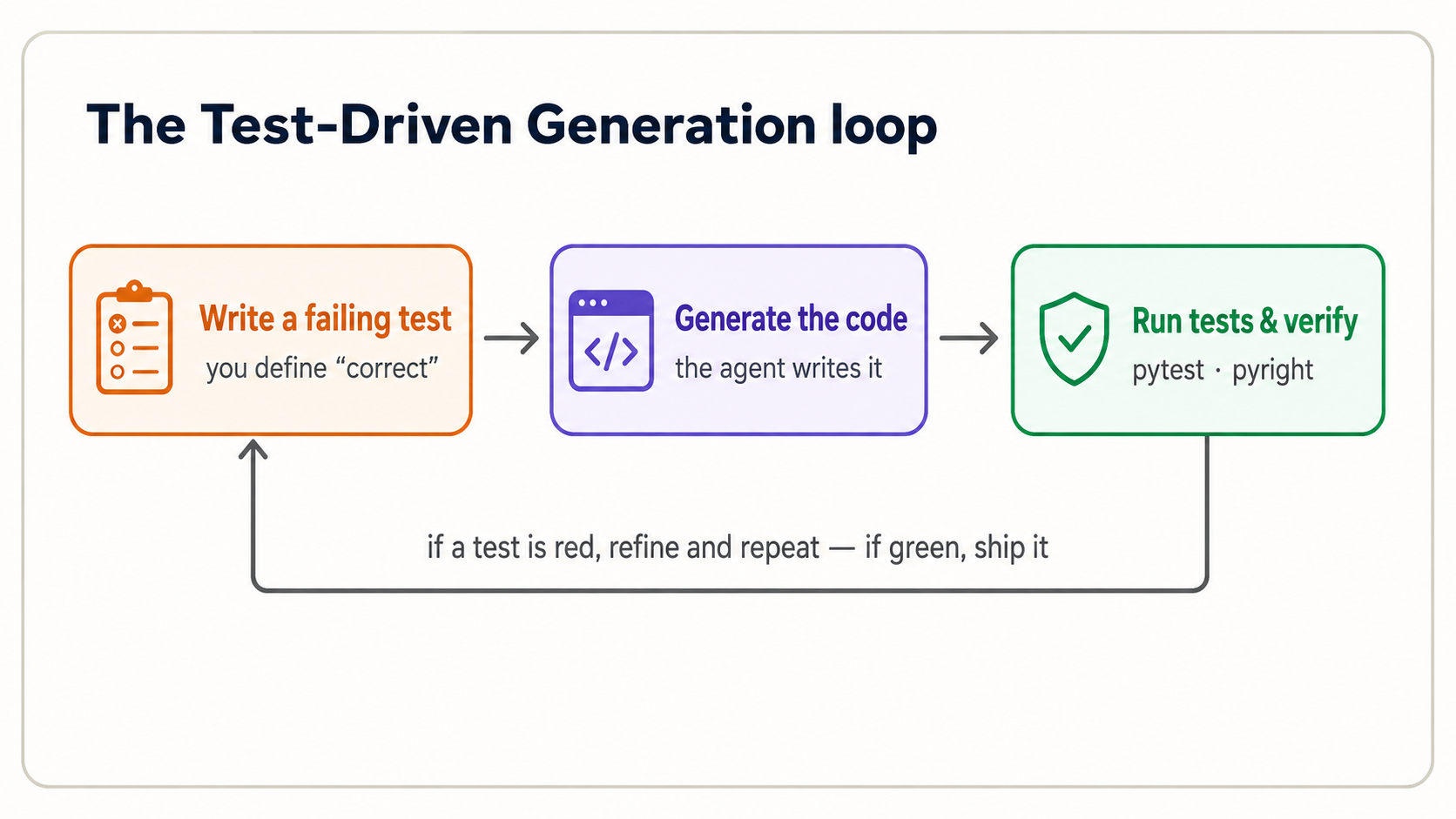
步骤 1:将需求编写为失败测试。 创建 test_tax.py:
from tax import total_with_tax
def test_basic() -> None:
assert total_with_tax(100.0, 0.15) == 115.0
def test_zero_price() -> None:
assert total_with_tax(0.0, 0.15) == 0.0
你以前已经见过这些确切的断言。它们是你在概念 5 中编写的两行,现在已移至 test_*.py 文件中,以便 pytest 可以自动运行它们。assert X == Y 的意思是“我声明 X 必须等于 Y;如果不等于,请大声失败。”这两行定义了任何代码存在之前的正确含义。现在运行 pytest,但失败:还没有 tax.py。失败才是重点。 你对完成有一个精确的、可执行的定义。
这里唯一的新内容是顺序:在概念 5、8 和 11 中,你为已经存在的代码编写了测试。在真正的 TDG 中,你首先编写失败的测试,然后让 agent 生成代码以通过它。测试不再是你之后运行的检查,而是成为 agent 构建所依据的“规范”。
第 2 步:agent 生成实施。 现在向你的工具发出指令:
读取
test_tax.py。使用total_with_tax(price: float, tax_rate: float) -> float函数创建tax.py,使两个测试都通过。然后运行 pytest并显示结果。
Claude Code 读取你的测试,写入 tax.py,并运行 pytest。因为你编写了测试,所以你可以对其生成的内容进行独立检查。
读取
test_tax.py。使用total_with_tax(price: float, tax_rate: float) -> float函数创建tax.py,使两个测试都通过。然后运行 pytest并显示结果。
OpenCode 读取你的测试,写入 tax.py,并运行 pytest。因为你编写了测试,所以你可以对其生成的内容进行独立检查。
步骤 3:验证并迭代。 读取 pytest 输出。两个绿色勾号 (2 passed) 表示代码符合你定义的规范。如果它是红色的,你将阅读失败(下一个概念),然后进行改进。你不只是盲目地重新提示和希望。并仔细观察一件事:如果 agent 通过编辑 test 而不是 code 使测试通过失败,请停止它。测试就是你的规格;通过削弱它而将其变成绿色只是隐藏了错误。
这就是整个循环,它清晰地映射到 PRIMM-AI+ 和 10-80-10 rule:
| TDG step | Who leads | PRIMM-AI+ |
|---|---|---|
| 编写需求+失败的测试 | 你(前 10%) | 制造 |
| 生成实施 | agent(80%) | — |
| 运行测试、验证、迭代 | 你(最后 10%) | Investigate / Modify |
该 agent 擅长建议你错过的测试,询问它,“我应该测试哪些边缘情况来进行税收计算?”。但是关于哪些情况定义“正确”的决定仍然由你决定。负价?零税?非常大的数字?你添加的每一项都是更清晰的规范。
TDG 并不是为大型活动举办的仪式。在 agent 生产的每个具有可检查合同的单元上运行它:每个函数、每个方法、每个验证规则。来自概念 5、8 和 11 的单行 assert 是种子;不断增长的 tests/ 文件夹中充满了这些内容,让你可以在 agent 更改项目时继续信任该项目。一条实用的规则:如果你不能为某件事编写测试,那么你还不明白“正确”对它意味着什么。agent 也不知道。 编写测试即可找到答案。随着你的项目不断发展,这也可以保护你免受回归的影响:agent 修复一件事并默默地破坏另一件事。你的测试套件是捕获它的警报。
读取回溯(当它中断时)
当 Python 失败时,它会打印一个回溯:一堵红色的文字墙,看起来很吓人,实际上是一份礼物。自下而上阅读它:最后行命名了错误,其上方的行跟踪了错误发生的位置。
Traceback (most recent call last):
File "tax.py", line 2, in total_with_tax
return price + (price * tax_rate)
TypeError: can't multiply sequence by non-int of type 'float'
底线是整个故事:某个东西应该是一个数字,但它是一个字符串(str):price 作为 "100"(文本)而不是 100.0 出现。你不需要自己解决这个问题;你需要仔细阅读它以告诉 agent 出了什么问题:“价格以文本形式出现,而不是数字。处理这个问题。”精确的描述可以获得精确的修复。(调试有自己的阶段:人工智能时代的编程,第四阶段。)
人工智能编码中最昂贵的习惯是在你没有读到的失败时点击“重试”。agent 会很高兴地生成一个“不同的”错误答案。阅读回溯,了解实际问题,然后进行描述。一个明智的提示胜过十个盲目的提示。
你实际上会遇到的少数错误
你不记得修复。你从最后一行中识别出了类别,并向 agent 描述了它。这六个几乎涵盖了初学者在运行生成的代码时看到的所有内容:
| 最后一行说…… | 通常意味着什么 | 应该告诉 agent 什么 |
|---|---|---|
ModuleNotFoundError / ImportError | 未安装软件包或名称拼写错误 | “X 未安装 — 使用 uv 添加” |
NameError | 使用从未定义过的名称(通常是拼写错误) | “使用了 y 但从未定义 - 拼写错误?” |
TypeError | 错误的“种类”值——需要数字的文本等。 | “数字以文本形式到达 - 转换它” |
AttributeError | 向对象索要它没有的东西 (note.titel) | “该对象没有属性 titel — 可能是拼写错误” |
KeyError | 向字典请求一个不在其中的密钥 | “密钥 'x' 不在字典中 — 处理丢失的情况” |
IndexError | 向列表询问超出其末尾的位置 | “列表比代码假设的要短” |
元技能与设置相同(概念 3):你不是修复错误的人,你是*阅读错误并准确命名它的人。*精确的名称可以获得精确的修复;“它坏了”得到了另一种猜测。
17.从模糊的目标到具体的目标
概念 16 展示了如何规范和验证一个单元。但你自己的项目并不是作为一项整洁的功能而实现的。它们以一个模糊的句子形式出现:“为我构建一个总结我笔记的工具。”你无法为此编写一个测试。将句子转化为生成代码的技巧是分解:将目标分解成小块,每个小块足以提供键入的签名和测试。这是 agent 无法为你做的部分,因为这是你决定事情实际上是什么的地方。
这是动作,每次都是一样的。
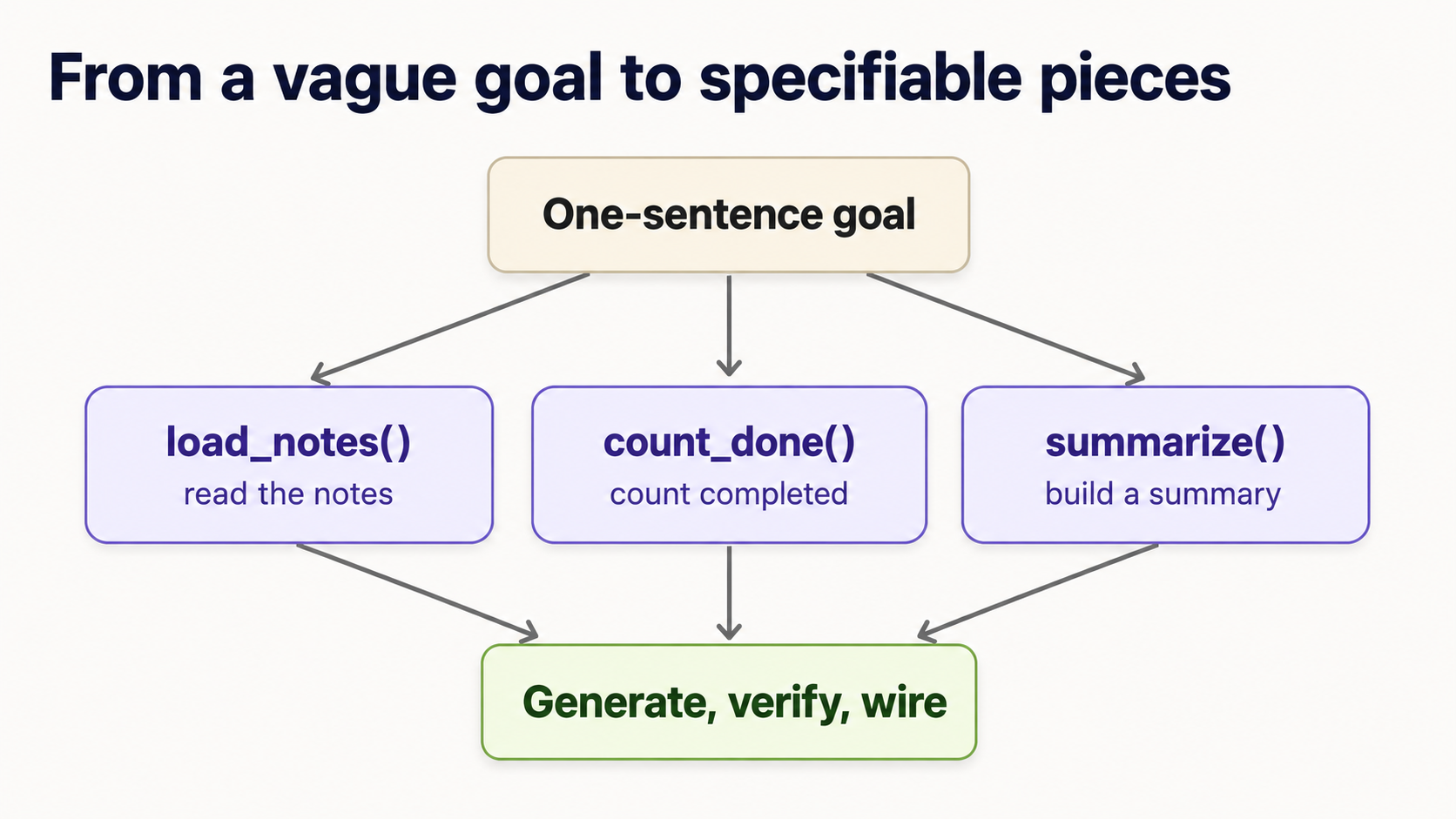 1.用一句话说出目标。 “阅读我的笔记并打印完成了多少,哪些没有完成。”
1.用一句话说出目标。 “阅读我的笔记并打印完成了多少,哪些没有完成。”
2.列出你要手动执行的步骤。 写下动词:加载笔记→计数已完成的笔记→查找待处理的标题→*将它们总结为一行→打印它。每个动词都是一个候选单元。
**3.为每个单元提供一个键入的签名:输入到输出。**这是规范。还没有尸体;agent 写这些。
def load_notes(path: str) -> list[Note]: ... # text file -> list of notes
def count_done(notes: list[Note]) -> int: ... # notes -> how many are done
def pending_titles(notes: list[Note]) -> list[str]: ... # notes -> titles not done
def summarize(notes: list[Note]) -> str: ... # notes -> one summary line
4. TDG 每个单元,按顺序。 上面的每一行现在正是一个概念 16 循环:编写失败的测试,让 agent 生成主体,验证。例如,summarize 很小且可测试:
def test_summarize() -> None:
notes = [Note(title="groceries", done=True), Note(title="call sara", done=False)]
assert summarize(notes) == "1 of 2 done; pending: call sara"
5.将它们连接在一起并测试整个流程。 要求 agent 编写一个按顺序调用各部分的 main(),然后为端到端结果编写一个测试。完毕。
请注意发生了什么:一个模糊的句子变成了四个小的、可独立验证的合同。agent 编写了每一行实际代码。但“你”找到了这些碎片并定义了每个碎片的承诺。前端分解是人类的 10%,使得 agent 的 80% 值得信赖。
你可以要求 agent 帮助你找到单位:“我想构建一个总结我的笔记的工具。我需要什么 3-5 个函数及其输入和输出?” 这是一个很好的起始列表。但你决定最终签名并你编写测试。永远不要让 agent 既分解问题又验证自己的答案,否则你就失去了独立检查的机会。
一个可靠的启发式:如果一个单元很难编写测试,那么它就做得太多了。拆分它。 无法测试的函数就是无法验证的函数,这意味着你也不能信任 agent 为其生成的内容。可测试性和良好的分解是相同的技能。
这是从“我可以验证一个功能”到“我可以用人工智能构建一个完整的东西”的桥梁。这正是本书的 SmartNotes 项目的发展方式:一次分解、测试一个部分。你将在 项目 5 小型顶点 中进行练习,然后在 项目 6 中从头开始,不使用任何脚手架。
一旦你分解了目标,你就可以每次将这个模板粘贴到 Claude Code 或 OpenCode 中。它体现了本课程的整个原则:首先测试,在代码之前获得批准,最后进行验证:
I want to build: [your one-sentence goal]
First, break it into 3–5 small functions or classes.
For each unit, propose ONLY:
1. a typed signature (inputs and output)
2. expected behavior in one line
3. edge cases to consider
4. pytest tests
Do NOT write any implementation yet. Wait for me to approve the tests.
After I approve, generate the implementation to pass those tests.
Then run pytest, pyright, and ruff, and show me only the
changed files and the test results.
这两个承载词是 ONLY 和 NOT:在你决定“正确”的含义之前,它们会阻止 agent 继续前进并编写代码(及其自己的测试)。你可以掌控规范;agent 负责打字。
Part 5: Judgment
何时不应该依赖人工智能——以及如何验证你无法完全阅读的内容
阅读流畅度是有上限的,而诚实地阅读本身就是一种技能。
- 安全敏感代码是不可协商的。 任何涉及密码、API 密钥、付款或用户数据的内容都会被仔细阅读,最好由了解该领域的人进行审查。人工智能可以自信地编写不安全的代码。如果无法验证,请勿发货。(安全审查请参见AI 时代的编程,第 8 阶段。)
- 当你真的无法阅读它时,更加依赖测试,而不是信仰。 如果生成的函数超出了你当前的水平,你的
pytest检查变得“更”重要,而不是更少:它们是你“可以”验证的部分。对你选择的投入进行的绿色测试是真实的证据;“看起来不错”不是。 - 微小而明显的更改有时手动会更快。 自己动手重命名一个变量或修复一个数字可能比描述更快。认识这些时刻需要练习。
红队你自己的测试
你的测试是你完全控制的唯一验证,因此弱测试比没有测试更糟糕,因为它会产生错误的信心。当 agent 生成你无法完全阅读的代码(一个棘手的 Pydantic 验证器、一个 async 块)时,你的测试将承担全部负载。让他们成为敌对的:
- **永远不要让 agent 编写自己的代码必须通过的测试。**这是一种反模式,它悄悄地击败了本课程中的其他所有内容:如果人工智能同时编写代码和检查,那么你就没有独立的信号:只有 agent 与自己达成一致。你编写测试,或者至少你阅读并拥有每个断言。无论如何都要问“我错过了哪些边缘情况?”*。然后自己决定哪些是重要的。
- 永远不要让 agent 削弱测试以使其通过。 当测试失败时,agent 有时会通过更改测试而不是代码来“修复”它:放松断言,删除边缘情况,降低预期值。它会从红色变为绿色,同时将错误留在原处。留意它,除非你认为测试本身确实是错误的,否则不要允许它发生。测试就是规范;agent 无法重写规范以适应其代码。
- **测试失败,而不仅仅是快乐的路径。**询问每个单元:*什么输入会破坏这个?*空列表,零,负数,缺少键,需要数字的文本。项目 4 中的错误隐藏在无人测试的情况下。
- 如果你想不出一个测试来测试它,那么你还没有理解它。而且你当然无法验证 agent 的版本。这是你进一步分解(概念 17)或要求 agent 在你接受代码之前逐行解释代码的信号。
保留一个模糊的启发式:绿色测试证明你的代码符合你的测试所说的内容。不再。验证的质量就是测试的质量。(文件、标准库、软件包生态系统、更深入的调试和真正的安全审查故意留给 AI 时代的编程。这个速成课程给你判断力;这部分给你深度。)
在接受之前检查差异
当你使用 Claude Code 或 OpenCode 时,agent 不仅仅会回答。它更改文件。阅读代码是工作的一半;另一半正在阅读发生了什么变化。在接受任何一批生成的更改之前,请运行此列表:
- 哪些文件发生了变化? 修复一项功能的请求不应悄悄触及五个文件。
- 它是否改变了测试? 如果你的测试被编辑,请先找出原因(请参阅上面的反模式)。
- 它是否添加了依赖项? 新包意味着你未编写的新代码在你的计算机上运行。确保每一项都是真实且必要的。
- 它是否触及任何敏感内容? 秘密、密钥、身份验证、付款、用户数据:这些内容会由了解该领域的人仔细阅读或审查。
pytest、Pyright 和 Ruff 都通过了吗? 三者中的绿色是地板,而不是天花板。- 你能用简单的英语解释一下主要函数或类吗? 如果你不能,你就无法验证它:在你接受之前要求 agent 逐行引导你完成它。
这是一个快速的习惯,而不是一个仪式。但是,在不阅读差异的情况下“接受全部”是一个小的错误更改如何在不被注意的情况下溜进工作项目的原因。
整个课程的主线是:**agent 带来代码;你提出关于它是否正确的判断。**该判断取决于流利的阅读和你自己编写的测试。两者都不是可选的,一旦你练习了循环,也就不难了。
第六部分:实践项目
阅读循环与运行循环不同。这六个项目将按顺序引导你完成 PRIMM-AI+:从“阅读”代码,到“测试”代码,到“制作”自己的代码,到“验证”隐藏在其中的错误的真实 agent 式代码,到构建一个可以同时使用每个概念的小型端到端工具,最后到从一句话目标构建一个完全没有脚手架的工具。在你的 Claude Code 或 OpenCode 会话中按顺序执行这些操作;每个人都继承了前一个人的技能。
每个项目都会告诉你目标及其所练习的技能,然后为你提供入门。首先自己尝试一下:写下你的预测,编写你的测试,提示 agent。然后才打开解决方案。解决方案不可复制:agent 无论如何都可以为你生成代码。它们就在那里,以便你可以检查你的规格和测试是否正确。这就是被评分的技能。
参考代码是每个解决方案中“最不”重要的部分。重要的是:你的测试是否捕获了“正确”的含义?你正确预测了输出吗?你能读一下结果并判断它是正确的吗?如果你的测试通过了参考代码,则说明你很好地指出了问题。这就是胜利。
项目 1 — 阅读和预测*(预测·运行·调查)*
**技能:**阅读函数、推导式和 len;运行前预测输出。
启动程序。 先不要运行它。阅读它并写下三个 print 行中的每一行将产生的内容:
def shout(text: str) -> str:
return text.upper() + "!"
names: list[str] = ["ada", "alan", "grace"]
greetings: list[str] = [shout(n) for n in names if len(n) > 3]
print(len(names))
print(greetings)
print(shout("hi"))
现在在你的会话中运行它并进行比较。如果你的预测错误,请询问 agent*“为什么 X 线会产生这样的结果?”*。这个差距就是教训。
解决方案
3
['ALAN!', 'GRACE!']
HI!
len(names)→3:列表中的三项。greetings→ 只有长度超过 3 个字母的名称才能通过if len(n) > 3过滤器。"ada"正好是 3(失败),"alan"是 4,"grace"是 5(通过)。每个人都喊出['ALAN!', 'GRACE!']。shout("hi")→"HI!":大写,添加!。
如果你将理解理解为*“对于名称中的每个名称,如果长度超过 3 个字母,请喊出每个名称”*,那么你就读对了。
项目 2 — 你的第一个 TDG 循环功能 (Make)
技能: 将 assert 测试编写为规范,提示 agent,使用 pytest 进行验证。
目标。 构建一个函数 initials(full_name: str) -> str,返回名称的大写首字母:"ada lovelace" → "AL"。
**入门。**在任何实现存在之前,首先在 test_initials.py 中编写测试。涵盖正常情况和至少两个边缘情况(单个名称;额外空格)。然后提示你的 agent:
读取
test_initials.py。使用使每个测试通过的initials(full_name: str) -> str函数创建initials.py。然后运行 pytest并显示结果。
在你信任绿色支票之前,请阅读它生成的代码。
解决方案
你的测试(重要部分)可能如下所示:
from initials import initials
def test_two_names() -> None:
assert initials("ada lovelace") == "AL"
def test_many_names() -> None:
assert initials("grace brewster murray hopper") == "GBMH"
def test_single_name() -> None:
assert initials("alan") == "A"
def test_extra_spaces() -> None:
assert initials(" extra spaces ") == "ES"
通过所有这些的参考实现:
def initials(full_name: str) -> str:
return "".join(part[0].upper() for part in full_name.split())
full_name.split() 在空格上断开文本(并忽略多余的),part[0] 取每个部分的第一个字母,.upper() 将其大写,"".join(...) 将它们粘合在一起。如果你编写了 extra_spaces 测试,你就自己验证了棘手的情况:这正是 agent 无法提供的判断。
项目 3 — 班级上的 TDG (制作)
技能: 读取和指定类、更改对象状态的方法、测试对象行为。
目标。 构建一个小型 TaskList:类似于本书 SmartNotes 的种子。它可以添加任务、将一项标记为已完成,并报告有多少任务尚未完成。
入门。 首先编写测试。决定方法的调用内容以及它们返回的内容。这就是设计。一个起点:
def test_task_flow() -> None:
tasks = TaskList()
tasks.add("write tests")
tasks.add("call agent")
assert tasks.remaining() == 2
tasks.complete("write tests")
assert tasks.remaining() == 1
然后提示 agent 实现一个使测试通过的 TaskList 类,并进行验证。
解决方案
A reference implementation:
class TaskList:
def __init__(self) -> None:
self.tasks: dict[str, bool] = {} # task name -> done?
def add(self, name: str) -> None:
self.tasks[name] = False
def complete(self, name: str) -> None:
if name in self.tasks: # only complete a task that exists
self.tasks[name] = True
def remaining(self) -> int:
return sum(1 for done in self.tasks.values() if not done)
该类将任务存储在一个字典中,将每个名称映射到 done 标志。remaining() 计数仍设置为 False 的。请注意“测试”如何驱动设计:它在任何代码存在之前就决定了方法名称以及 remaining() 返回的内容。
自己捕获无声错误。 complete("a task I never added") 应该做什么?agent 的第一个版本通常会编写没有 if name in self.tasks 防护的 self.tasks[name] = True,这会默默“添加”标记为已完成的全新任务,从而发明没人要求的数据。这正是测试所暴露的看似合理但错误的行为:
def test_completing_unknown_task_does_nothing() -> None:
tasks = TaskList()
tasks.add("real task")
tasks.complete("typo task") # not a real task
assert tasks.remaining() == 1 # still one; nothing was invented
**扩展:**要求你的 agent 将每个任务制作为具有 created_at 时间戳的 Pydantic Task 模型,然后添加一个测试,即全新的 TaskList 具有 remaining() == 0。
项目 4 — 查找 agent 代码中的错误*(调查·修改)*
技能: 识别电源概念(Pydantic、生成器)、批判性阅读、编写捕获真正错误的测试。
这是最接近你实际工作的事情:agent 向你提供看起来合理的代码,你必须找出问题所在。下面的函数应该只返回完成的笔记标题。但它有一个错误。
from collections.abc import Iterator
from pydantic import BaseModel
class Note(BaseModel):
title: str
done: bool
def completed_titles(notes: list[Note]) -> Iterator[str]:
for note in notes:
yield note.title
你的任务,按顺序:
- 调查。 用简单的英语,说出每一行的含义。(
Note型号是什么?Iterator[str]告诉你什么?yield做什么?) - 测试。 编写一个
pytest测试来确定预期的行为:仅返回已完成的笔记。运行它。它应该失败,捕获错误。 - 修改。 既然你的测试定义正确,请提示 agent 修复
completed_titles,然后重新运行,直到你的测试变为绿色。
解决方案
错误: 该函数生成每个注释的标题,完全忽略 done。它从不检查标志。
抓住它的测试:
def test_only_completed() -> None:
notes = [Note(title="a", done=True), Note(title="b", done=False)]
assert list(completed_titles(notes)) == ["a"]
针对有错误的代码,此操作会失败,因为它返回 ["a", "b"]:证明该错误是真实的,而不是预感。
修复是一行:在产生之前进行 done 检查:
def completed_titles(notes: list[Note]) -> Iterator[str]:
for note in notes:
if note.done:
yield note.title
这个项目的要点是:这个 bug 乍一看是看不见的,但在测试中却是显而易见的。*“看起来不错”*会发货。你写的一个测试发现了它。这就是整个课程的一次练习。
项目 5 — Mini-capstone:一个 Notes 工具,端到端*(整个循环)*
技能: 一切、一个 Pydantic 模型、一个带有状态的类、一个生成器、类型提示、一个 f 字符串摘要和一个测试套件,构建为一个 TDG 循环。这是本书 SmartNotes 的缩小版。
目标。 构建一个小型 NoteBook,其中包含注释(每个注释都有标题、正文和完成标志),允许你添加注释并将其标记为完成,流式传输仍待处理的注释,并打印一行摘要,如 2 notes, 1 done, pending: call sara。
入门:通过测试进行设计。 这是真正的练习:在编写或生成任何实现之前,编写一个 test_notebook.py 来确定你想要的行为。决定方法名称以及 summary() 应该说的内容。一个要反应的骨架:
from notebook import NoteBook
def test_summary_flow() -> None:
nb = NoteBook()
nb.add("groceries", "milk, eggs")
nb.add("call sara", "about the trip")
assert nb.summary() == "2 notes, 0 done, pending: groceries, call sara"
nb.complete("groceries")
assert nb.summary() == "2 notes, 1 done, pending: call sara"
def test_pending_is_a_stream() -> None:
nb = NoteBook()
nb.add("a", "x")
nb.add("b", "y")
nb.complete("a")
assert [n.title for n in nb.pending()] == ["b"] # pending() yields, like a generator
然后运行完整循环:
- 运行
pytest。它失败了(还没有notebook.py)。好:这就是你的规格,故意失败。 - 提示你的 agent:“阅读
test_notebook.py。使用NotePydantic 模型(标题、正文、完成)和NoteBook类创建notebook.py,该类使每个测试通过:add、complete、pending()生成器和summary()返回测试期望的确切字符串,然后运行 pytest 并显示结果。" - 阅读它生成的内容。 你能指出 Pydantic 模型、类状态、
pending()中的yield以及summary()中的 f 字符串吗?如果是,那么你已经阅读了一段真正的 agent 代码。也运行pyright和ruff。 - 通过阅读来迭代任何失败,而不是盲目地重新提示。
解决方案
通过这两项测试的参考实现:
from collections.abc import Iterator
from pydantic import BaseModel
class Note(BaseModel):
title: str
body: str
done: bool = False
class NoteBook:
def __init__(self) -> None:
self.notes: list[Note] = []
def add(self, title: str, body: str) -> None:
self.notes.append(Note(title=title, body=body))
def complete(self, title: str) -> None:
for note in self.notes:
if note.title == title:
note.done = True
def pending(self) -> Iterator[Note]: # a generator: yields one note at a time
for note in self.notes:
if not note.done:
yield note
def summary(self) -> str:
total = len(self.notes)
done = sum(1 for n in self.notes if n.done)
pending_titles = [n.title for n in self.pending()]
return f"{total} notes, {done} done, pending: {', '.join(pending_titles)}"
课程中的每个概念都显示在这里:一个Pydantic 模型(Note),带有类型提示和默认值,一个类(NoteBook)保持状态,一个方法,它改变对象的属性(complete),一个生成器(pending) yields,理解和 sum(...),以及构建摘要的 f 字符串。
**让它成为一个真正的 CLI(通往 AI 时代编程课程的桥梁)。**上面测试的核心是最难的部分;将其变成命令行工具是顶部的一个薄壳。要求你的 agent 添加一个 main(),它从终端读取 add、done 和 list 等命令并调用这些方法。然后要求它为任何新逻辑编写一个测试。最后一步,即一个工作 CLI 及其后面的通过测试套件,与 SmartNotes 的形状完全相同,只是更小。
自己决定一个边缘情况。 当没有待处理时,summary() 应该说什么?该引用留下尾随 pending: 。这是正确的吗?编写一个测试来编码你的决定,然后让 agent 满足它。确定“正确”在这里的含义,并通过测试来确定它,就是整个工作。
项目 6 - 自己完成:没有启动器,没有测试 (自己分解)
技能: 关闭辅助轮的概念 17。到目前为止,每个项目都会向你提供测试框架或签名。这个只给你一句话。
目标。 “构建一个工具,可以获取一段文本并打印三个最常见的单词。”
这就是你得到的全部。没有签名,没有测试,没有关于作品的提示。你的工作就是整个前面的 10%:
- 分解。 手工写下你要执行的步骤,并将每个步骤转换为打印的签名。(如何将文本拆分为单词?去掉标点符号?数数?对它们进行排名?)
- 规范 对于每个部分,编写一个失败的
pytest测试来定义“正确”:在生成任何内容之前。 - 生成并验证。 让 agent 根据你的测试实施每个单元;运行
pytest、pyright、ruff;迭代。 - 将其连接在一起到
report()并测试整个流程。
没有单一的正确答案:只有每个部分都很小且可测试的分解。这就是正在评分的技能。
解决方案(一种有效的分解 - 你的分解可能有所不同)
合理细分为四个小的、可独立测试的单元:
def clean(text: str) -> list[str]:
# lowercase, drop punctuation, split into words
cleaned = "".join(c.lower() if c.isalnum() or c.isspace() else " " for c in text)
return cleaned.split()
def tally(words: list[str]) -> dict[str, int]:
counts: dict[str, int] = {}
for word in words:
counts[word] = counts.get(word, 0) + 1
return counts
def top_n(counts: dict[str, int], n: int) -> list[tuple[str, int]]:
return sorted(counts.items(), key=lambda pair: pair[1], reverse=True)[:n]
def report(text: str, n: int) -> str:
pairs = top_n(tally(clean(text)), n)
return ", ".join(f"{word} ({count})" for word, count in pairs)
以及你应该首先编写的测试类型:
def test_clean_strips_punctuation() -> None:
assert clean("Hi, hi! Bye.") == ["hi", "hi", "bye"]
def test_tally_counts() -> None:
assert tally(["hi", "hi", "bye"]) == {"hi": 2, "bye": 1}
def test_report_picks_top_two() -> None:
assert report("the cat sat on the mat the cat", 2) == "the (3), cat (2)"
有目的地值得做出一个决定:当两个单词具有相同的计数时,哪个先出现?Python 的 sorted 是稳定的,因此这里的关系回落到首次出现的顺序。但你应该慎重地决定并通过测试来确定它,而不是偶然发现它。(如果你根本没有考虑关系,那么你的测试应该会出现这种差距。)
如果你的分解有不同的部分(例如,单个 word_frequencies 函数),但每个部分都是可独立测试的,并且你的测试通过了,你做对了。 等级与此代码不匹配:它是你是否将一句话目标变成了你自己的可测试合约。这正是你在此之后使用人工智能构建的每个项目所依赖的技能。
这些都是热身活动。真正的实践项目是AI 时代的编程中的SmartNotes。你使用这个精确的循环跨九个阶段开发一个应用程序,然后从头开始构建第二个应用程序(QuizForge),而无需任何指导来证明你拥有该技能。
接下来是什么
现在,你可以阅读构成大多数 Python 的核心形状(值、函数、集合、控制流和类),识别填充 agent 和 ML 代码的五个强大概念,在 Claude Code 或 OpenCode 中运行完整的测试驱动生成周期,将模糊的目标分解为可指定的部分,并且你已经在六个项目中实践了所有这些。这就是本书其余部分所假设的读写能力。
你通过了吗?自查一次
如果你现在可以在没有笔记的情况下完成所有这七个内容,那么本课程就有效了。如果有人感到不稳定,请在继续之前重新审视括号中的概念:
- 阅读函数签名并用简单的英语解释其输入和输出。(概念 5)
- 在任何代码存在之前为一个单元编写至少三个
pytest测试。(概念 5、16) - 要求 AI agent 使用键入的签名来针对这些测试实施代码。(概念 10、16)
- 运行
pytest、Pyright 和 Ruff,并阅读每个内容告诉你的内容。(概念 3) - 自下而上阅读回溯并准确描述问题。(概念 16)
- 在人工智能生成的代码中发现一个看似合理但错误的错误。(项目 4)
- 将一个模糊的、一句话的目标分解为可测试的单元。(概念 17,项目 6)
如果你能完成这七个任务,你就可以坐下来使用 Claude Code 或 OpenCode,并发布一个你真正理解的、经过测试的小型 Python 程序。这就是整个目标。
From here:
- Build AI Agents:其中 Pydantic 模型、
async/await和你刚刚学会识别的类型提示成为 agent 代码的日常材料。 - Postgres for AI:读取存储和检索 agent 数据的代码。
- 打造数字化 FTE:将所有东西组装成一个工作的人工智能工作者。
- AI 时代的编程:完整的深度课程。你可以跨九个阶段构建 SmartNotes,从读者到架构师,在每个步骤中拥有更多的 TDG 周期。
你不是在学习输入代码。你正在学习指导和验证编写它的系统。阅读总是更难的一半。而你才刚刚开始。
60-second glossary
| Term | Plain English |
|---|---|
| PRIMM-AI+ | 预测·运行·调查·修改·制作——本课程的先读方法,以 agent 为伙伴,以测试为真相 |
| TDD→TDG | 测试驱动开发:编写失败的测试,然后编写代码。在人工智能时代,它变成了测试驱动的一代——你编写失败的测试,agent编写代码,你验证它通过 |
| TDG | 测试驱动生成——首先编写失败的测试,agent 生成代码,你进行验证 |
assert | 像 assert x == 5 这样的一行声明 - 如果为真则不会执行任何操作,如果为假则会严重崩溃。每个测试都是由原子构建的 |
| 类型/类型提示 | 数据类型的标签(str、int、float、bool)——以及给 agent 的精确指令 |
| 功能/签名 | 一个命名的、可重用的块;它的第一行是输入和输出的契约 |
| 列表/字典/集合/元组 | 对数据进行分组的四个容器;dict(标记对)是你读得最多的一个 |
| 类/对象 | 一个类是一个蓝图;对象(实例)是由它构建的东西。object.attribute 读取其数据;object.method() 要求其采取行动 |
self /属性/方法 | self 是类内的“这个对象”;属性是它携带的数据;方法是存在于类中并作用于对象的函数 |
| 理解力 | for 循环折叠成一行以构建新列表 |
| f 字符串 | 前面带有 f 的文字;{...} 中的任何内容都将被其值替换 (f"{name}") |
发电机/yield | 一次交还一个项目以保持记忆平坦——一条流,而不是一堆 |
with(上下文管理器) | 打开某些内容、使用它,甚至在出现错误时也安全地关闭它 |
async / await | 为同时执行许多缓慢的操作(例如 API 调用)而构建的代码 |
邓德(__call__、__init__) | 双下划线方法使你的对象表现得像原生 Python 东西 |
装饰器(@name) | 函数或类上方的标签,用于向其添加行为 |
| 尾饰 | 验证结构化数据并自动生成 LLM 用于工具调用的 JSON 模式 |
| pytest / Pyright / Ruff / uv | 你的验证工具:运行测试/检查类型/检查样式/管理 Python |
| 回溯 | Python 的错误报告——自下而上阅读;最后一行指出了问题的名称 |