为你的 AI 接入可检索的上下文:用 pgvector 在 Postgres 上构建 RAG 速成课
15 个概念 · 覆盖 80% 的真实用途 · 由你的 agent 构建,而非手工编写
设想一下,你可以对电脑说:「把这个文件夹里的文档拿过去,建一个能理解它们含义的数据库,再给我做一个搜索,让我搜『不夜城』时返回的是关于纽约的引文,哪怕那些引文从没提过纽约。」而它真的做到了。
万一下面三个词对你是新的,先解释一下。数据库是数据的仓库:就像一家企业存放货物的厂房,只不过这里的货物是信息。SQL 是你对这座仓库说话的语言,每一次存取、查找或修改数据的请求都是一句 SQL。Postgres(本课标题里的那个数据库)是全世界使用最广泛的数据库之一。普通仓库只能凭精确的标签去找一个箱子;而你即将构建的这座仓库,能凭事物的含义去找。
这套按含义检索的系统正是本课要教的,而其中的转折在于:**你不会手写 SQL;所有 SQL 都由 Claude Code 或 OpenCode 来构建。**你的任务是对 Postgres 和 pgvector(赋予它这种能力的扩展)了解到足以给出清晰的指令,并判断 agent 做得对不对。后面这一点才是真正的本事,到课程结束时,你会知道哪些旋钮重要、哪些该放着别动。
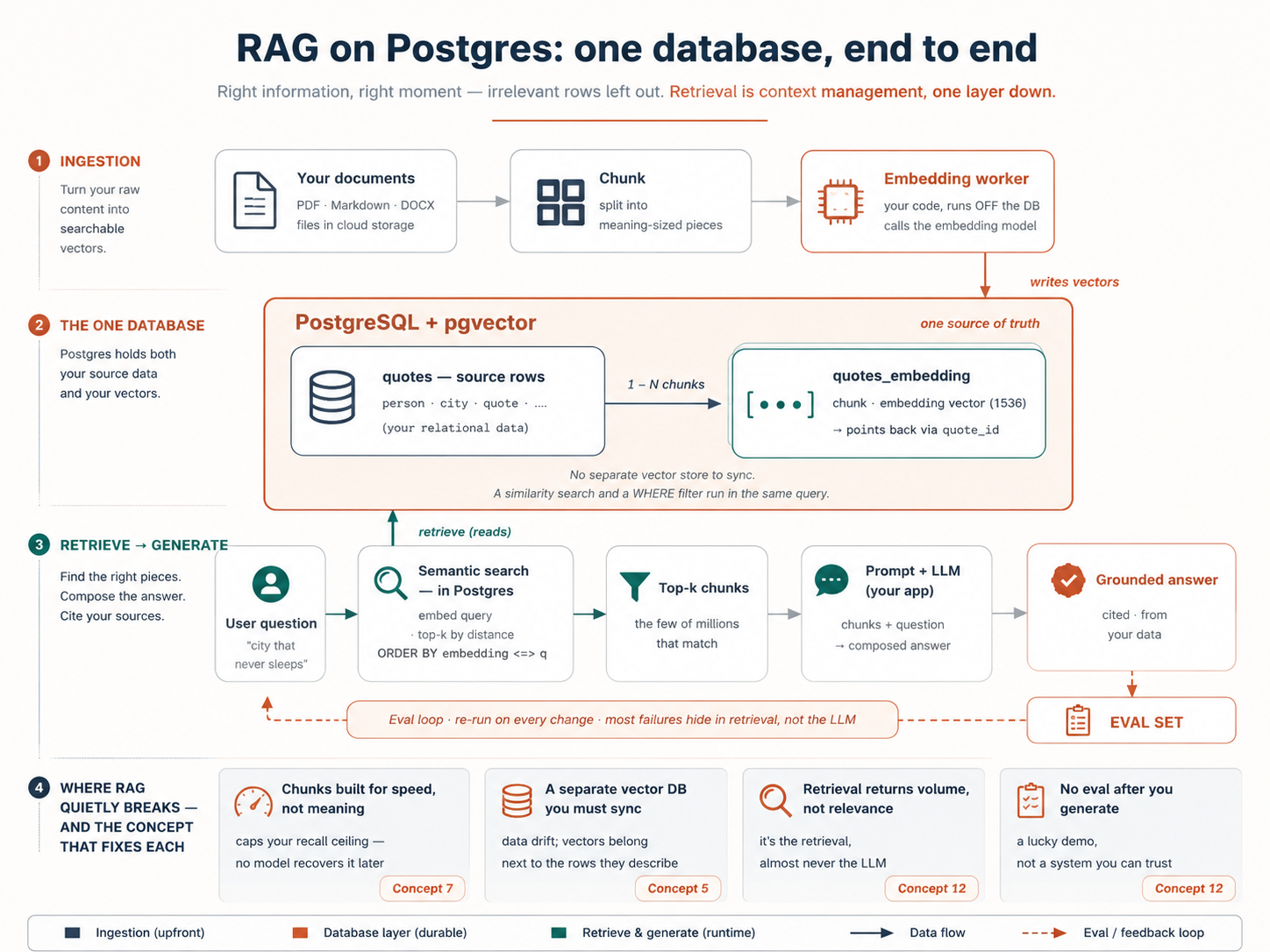
有一个想法能让整门课豁然开朗。一个 AI 模型一次只能关注这么多内容:它为了回答你而读到的一切,都得装进它的上下文窗口,而里面无关的材料越多,答案就越差。所以任何 AI 系统的核心工作都是在恰当的时刻把恰当的信息摆到模型面前,把其余一切挡在外面。你已经在为自己的编码 agent 做这件事了:一个规则文件,只给任务需要的那几个文件。向量数据库为你应用的用户做的是同一件事:从上百万行存储数据里,找出与问题含义匹配的那几行,只把它们交给模型。**这个动作有个名字,叫 RAG,即检索增强生成(Retrieval-Augmented Generation),它就是低一层的上下文管理:**你为编码 agent 手工做的事,你的应用为它的用户自动地做。这里的每个概念都会回到这一点上。

本课假定你已经做完了 Agentic Coding 速成课,你应当能够熟练地驾驭 Claude Code 或 OpenCode、使用 plan 模式、管理上下文。它还建立在 2026 年的 AI 提示词 之上,也就是向 AI 精确表达你想要什么的手艺。如果「embedding」和「向量」对你完全是新词,别担心,概念 2 会从零讲起。
📚 教学辅助资料
查看完整演示文稿 — AI 可检索上下文
两个工具,一套方法
由 agent 来驾驶;你的 Postgres 数据库就是它驾驶的对象。这个数据库托管在 Neon 上,这是一项为你运行 Postgres 的云服务,无需安装,也没有机器要管理(这正是 serverless 的全部含义:你用它时它就醒来,不用时它就休眠)。agent 通过 Neon MCP 服务器 来操作 Neon:它创建项目、开一个分支、运行 SQL,并在提交前先在那个分支上预览每一处改动。你从不需要自己在 Neon 控制台里点来点去,也不用打开 psql。这套方法在两个工具里完全一致:Claude Code 和 OpenCode 在这里地位相同,凡是命令真有差别的地方,我都会就地指出。
这门课涵盖什么
| 部分 | 主题 | 你会学到什么 |
|---|---|---|
| 1 | 基础 | 你作为 AI 工程师的职责、从零理解向量、Postgres 要按含义检索还缺什么,以及把你的 agent 连上 Neon |
| 2 | 你的第一个 RAG | 加载你的数据、把它切成小块、把每一块变成一个含义向量、按含义检索,再让一个 LLM 据此作答 |
| 3 | 让检索变快 | 检索变慢时什么时候该上索引、怎么选索引,以及那个唯一重要的速度与精度的旋钮 |
| 4 | 让检索变好 | 衡量答案是否真的正确、加过滤条件、把含义和精确关键词结合起来、把每个客户的数据隔离开,以及用大白话向你的数据库提问 |
| 5 | 完整实战示例 | 一个完整的任务,从空数据库到能用的 RAG,在两个工具里都跑一遍 |
| 6 | 作为工具发布 | 把你的 RAG 包进一个 MCP 服务器,让任何 agent(Claude Code、OpenCode,或你日后会构建的 Digital FTE)都能调用它 |
| 7 | 它运行在哪里 | 在数据库的即时副本上测试改动、随着数据变化让向量保持最新,以及生产环境里有什么不同 |
| 8 | 交给一个 agent | 把你的 RAG 接入一个 agent(OpenAI Agents SDK),通往「构建 AI Agent」课程的桥梁 |
下面是一页看完整个系统:随着每个概念落地,你会一步步长到这张地图上:
 |
|
读到最后,你会拥有一个能用的 RAG 项目:你的 docs/ 文档文件夹被加载进一个开启了 pgvector 的 Neon 数据库、一个随文档变化而让含义向量保持更新的小 worker、一个按含义检索的搜索、一个据你自己的数据作答的 answer_question() 函数,以及一份显示五个测试问题是否都答对的报告。而你不会止步于轻松的那 80%:你还会把一个 HNSW 索引从慢调到快、按类别过滤检索、用混合检索融合关键词与含义,并用行级安全(Row-Level Security)把一个租户与另一个隔离开,每一项都真刀真枪地跑一遍,并以你的评测集为准来衡量。可选地,再用一个 MCP 服务器把这整套东西交给任何 agent。
**怎么读这门课。**第 1 到第 2 部分(概念 1 到 9)加上 第 5 部分 的实战示例,就是端到端的完整系统,大约 90 分钟读完,再加上几个小时的动手构建。第 3 到第 4 部分(概念 10 到 15)是调优层,讲的是什么让检索变快(第 3 部分)和变好(第 4 部分)。先读懂其中的「为什么」,然后把每一项都跑一遍:第 5 部分 以一个动手循环(第 5 到第 8 步)收尾,你会在那里真刀真枪地构建一个索引基准、一个过滤器、混合检索和租户隔离,就用你刚加载的数据。这些深度内容不是可选的、你日后也许会回头看的部分,而是构建的下半场,人人都要做。更想先构建、之后再读原理?直接跳到 第 5 部分。
配置你的环境(一次即可)
你在本课里构建的一切,都发生在一个小文件夹内:课程基座。它已经预先接好线,你的 agent 已经知道怎么连上 Neon(本课使用的云数据库)和 Context7(实时文档查询,这样 agent 会去查当前文档而不是凭记忆猜),它还附带一个简短的规则文件 AGENTS.md,里面是这个项目的常设指令。你的 agent 每次启动时都会自动读取那个文件,这也是为什么你在本课里的提示词能保持简短。
下载一次即可;同一个文件夹服务整门课,第 5 部分 的实战示例和 第 6 部分 的 MCP 服务器都用它。现在配置还是稍后配置都行,阅读本身不需要安装任何东西。
解压它,然后在该文件夹内打开你的 agent:
cd postgres-ai
claude
cd postgres-ai
opencode
只有一个要求:一个能力够强的模型。如果 agent 的第一份计划看起来含糊而不够具体,先换一个更强的模型(Claude Sonnet 或 Opus、GPT-5,或同级别的),再往下走。
**准备基座(约 3 分钟)。**agent 会自己完成配置,你只需粘贴一个提示词,并回答它问你的问题。粘贴这个:
把这个基座准备好:安装它列出的 skills、配置我的
.env,并明确告诉我你需要我做什么才能让 Neon 和 Context7 的 MCP 服务器上线。
**注意观察:**agent 会安装两个 skills(neon-postgres 和 mcp-builder),创建 .env,然后向你要两样东西:一个 API key(同一个 key 覆盖 embedding 和作答),以及在浏览器里点一下授权 Neon。**这个 key 是免费的。**本课运行在 Google Gemini 的免费层上(无需信用卡),所以 agent 会指向 aistudio.google.com/apikey;用 Google 登录,大约一分钟创建一个 key,粘贴回来,agent 会当场测试并证明它可用。(已经有 OpenAI key,而且更想用它?直接说明即可,agent 会改用那个;本课其余内容不变。)Neon 也是免费的;还没有账号?直接在授权页面上创建一个。如果浏览器窗口没有自动打开,在 agent 里输入 /mcp,选 Neon,它就会替你启动登录。
**完成标志:**skills 已安装、.env 里有你的 key,并且 agent 已通过一次快速测试调用确认它可用;Neon 已授权,并且你已经重启了 agent(退出、再启动),好让新的 skills 和 MCP 服务器加载进来(这两样都不会在会话中途加载)。
第 1 部分:基础
1. 你到底在构建什么(以及你在其中的角色)
最常见的误解是:构建 AI 应用需要一支机器学习团队。其实不需要。模型是现成的。基础设施是一个你可能本来就在运行的数据库。剩下的,是 AI 工程师 的工作,这种人是用 AI 来构建产品,而不是训练模型的研究员。这正是整本书在为你准备的角色,而且它完全触手可及。
第二个误解,正是本课存在的理由:你必须手写所有 SQL。你不必。你指挥的这个 agent,早已把 pgvector 的运算符和 embedding 工作流烂熟于心。你的价值往上层移动,从敲 CREATE INDEX 变成决定用哪一个索引,从写查询变成判断结果到底好不好。
这改变了「掌握这门内容」的含义。你不是在背语法;你是在建立足够的心智模型,以便:
- 给 agent 一条精确的指令(「把 embedding 存在同一张表里、用余弦距离、用 HNSW 给它建索引」),
- 读回它产出的东西,并在它错的时候看出来,
- 还能拍板那些不该让 agent 替你做的架构选择。
这跟编码课里那套先计划再执行的习惯是同一个,而在这里它更要紧,因为 agent 即将做出一些决定(用哪个扩展、哪个索引、哪个距离函数),一旦有了数据,这些决定撤销起来代价高昂。
**心态的转变:**别再问「语义检索的 SQL 怎么写?」开始这样说:「在这张表上给我做语义检索;这是我的约束条件;先把计划给我看。」
这件事还有个更大的名字。用本书的话说,你即将构建的这个数据库,是一个 面向 agent 时代的记录系统,是你的 agent 从中读取、向其写入、并据以验证的权威事实基准。黄仁勋的观点是:agent 并没有消除对记录系统的需求,反而依赖于它。没有权威的事实基准,agent 就会产生幻觉;有了它,agent 才能执行。在 Postgres 上做 RAG,正是你把这份事实基准交给 agent 的方式,这也正是本课其余部分把检索质量当作决定 agent 能否被信任的关键的原因。
本课其余部分请照字面理解:**下面每一段 SQL 都摆出来,是为了让你读懂并判断 agent 产出了什么,而不是让你照着敲。**会读它,才能让你在错误的距离函数或缺失的过滤条件上线之前抓住它。
2. 一分钟搞懂向量和 embedding
如果「向量」和「embedding」对你是新词,这里有你起步所需的一切。
向量就是一串数字,比如 [0.021, -0.88, 0.14, …]。embedding 模型接受一段内容(一句话、一个段落、一张图片),把它变成这样一串数字。诀窍在于,这串数字捕捉了内容的含义:两段意思相近的文本,会得到坐落得很近的两串数字。两个意思相同的短语,比如「不夜城」和「纽约那躁动不眠的街道」,即便一个字都不重合,也会落在彼此附近。
向量数据库就是这样一个系统:它存储这些数字串,并快速找出离给定数字串最近的那些。就这么简单。当用户提问时,你的应用把他们的问题 embedding 成一个向量,然后问数据库:「哪些存储的向量离这个最近?」最近的那些就是语义上最相关的,而这就是你的应用如何取出恰当的上下文交给一个 LLM。(看开篇那张图:这就是为你的用户做上下文管理。)
你不需要弄懂 embedding 模型内部是怎么工作的,就像你不需要弄懂 JPEG 是怎么压缩图片的一样。你只需要知道它存在、它把内容转成含义向量,以及「近」就等于「相似」。
打开一个会话,问你的 agent:*「用大白话解释一下 embedding 是什么,然后给我两句会有相近向量的短句,再给两句会相距很远的,并说明为什么。然后来个有意思的:我所在城市的一首名曲或一个别称,会不会落在这座城市名字的附近,哪怕歌词里从来没出现过这个名字?」*读它的回答,比重读本节更能快速验证你自己的理解。
3. 扩展,以及你在 Neon 上能得到什么
Postgres 通过扩展成为一个向量数据库,这些扩展是给它添新能力的附加组件,同时不放弃 Postgres 本来就擅长的东西(事务、连接查询、可靠性、SQL)。整门课真正要学的扩展只有一个:pgvector。它添了三样东西,一个用来存 embedding 的 vector 类型、一组用来比较向量的距离运算符,以及一些用来快速检索的索引,而在 Neon 上它是预装好的,一条语句就能开启。这就是你完整的 RAG 引擎。记住这一点就够了。(有两个脚注可以先搁一边:还有第二个扩展 pgvectorscale,是为超大规模而生的,是你毕业升级才去用的层级,而不是起步的地方。另外,embedding 本身根本不是一个扩展;它来自一个由你的 agent 编写的小 worker,在 概念 6 里构建。)
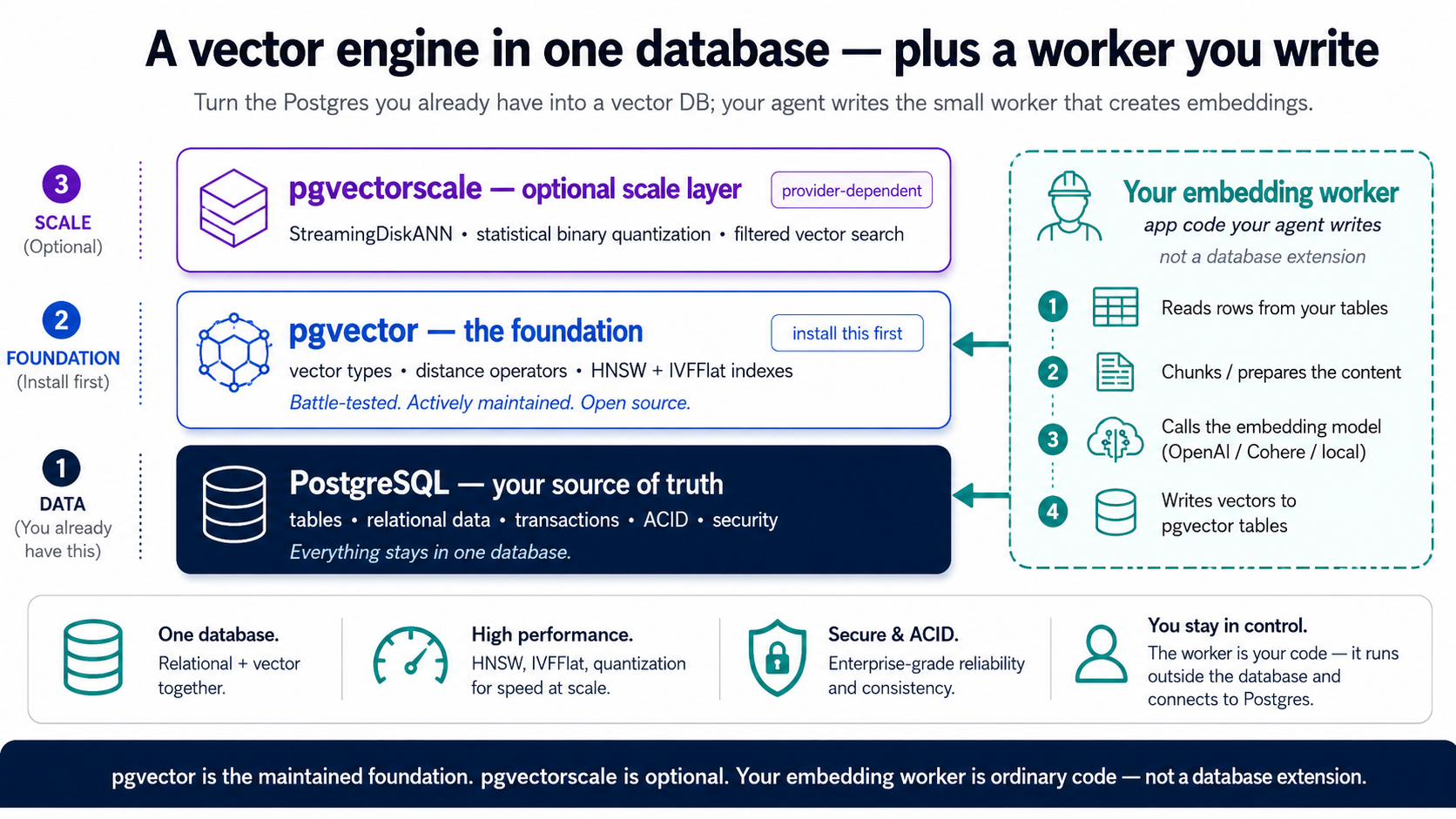
| 扩展 | 它添了什么 | 你什么时候需要它 |
|---|---|---|
| pgvector | vector 数据类型、距离运算符,以及 HNSW + IVFFlat 索引 | 总是需要,而且在 Neon 上它是预装的 |
| pgvectorscale | StreamingDiskANN 索引、向量压缩,以及大规模下的高精度过滤检索 | 在 TigerData 上原生支持;Neon 上没有,在 Neon 上它是你毕业才升级到的层级 |
这张表里的索引名字,HNSW、IVFFlat、StreamingDiskANN,目前只是标签;第 3 部分 会教它们各自做什么、什么时候用哪一个。
**在 Neon 上,pgvector 就是你的整套技术栈。**它内置,而且本课在 embedding 之后做的一切,语义检索、建索引、评测、过滤、混合检索、RLS、第 6 部分的 MCP 服务器,全都是纯 pgvector。embedding 来自那个 worker(概念 6),而不是某个托管扩展。至于 pgvectorscale:它不在 Neon 的审核集里,所以把它当作你只有用尽了 HNSW 才会毕业升级到的主机,而 pgvector 加一个 worker 先带你走很远。想从第一天起就原生用上规模层?那就选 TigerData Cloud,从头到尾工作流一样,概念 4 末尾那条注释会讲到它,除此之外你完全可以把整门课当成只用 Neon 来读。
单一数据库的好处依然成立:你的向量就住在它们所描述的那些行旁边,所以一次相似度检索和一个 WHERE price < 2000 AND in_stock 过滤,发生在同一个查询里、同一份事实来源上。没有第二个数据库、没有同步管道、没有数据漂移。(记住这一点,这正是 概念 13 里过滤检索如此轻松的全部原因。)
pgvector 是一个成熟、广泛使用的 Postgres 扩展,是整门课所依托的稳固基石。embedding 之后的一切(语义检索、建索引、评测、过滤、混合检索、RLS、MCP 服务器)都是纯 pgvector。
pgvector 唯一不替你做的,是创建 embedding,也就是调用 embedding 模型并把向量写回去。干净、可移植的做法,是由你的 agent 编写一个小 worker:**源表 → 切块 → 通过一次 API 调用 embedding → 把向量写入一张 embedding 表 → 用 pgvector 检索。**把这部分工作放在数据库外面是有意为之,而非权宜之计,一个有状态的记录系统不应依赖一个易变的外部 API,所以 embedding(以及 概念 9 里的 LLM 调用)都住在 worker 和应用层,在那里它们可以失败、重试、扩容,而不触碰你的数据,整套东西也能干净地移植到任何主机或容器。(曾经有一个托管的便利层把 embedding 烤进了数据库,即 pgai 的 Vectorizer,但那种耦合被证明很脆弱,其仓库已被维护者于 2026 年 2 月归档;本课不依赖它。)这个 worker 只是几行你的 agent 产出、你来审阅的代码。学会这个模式;它比任何单一的软件包都长命。
4. 把你的 agent 连接到 Neon
我们不安装、也不运行自己的数据库。我们用 Neon,这是一个已经内置 pgvector 的 serverless Postgres,我们让 agent 通过 Neon MCP 服务器 来操作它。MCP 就是编码课里那同一套连接器机制;在这里它给 Claude Code 和 OpenCode 递了一套工具(create_project、create_branch、run_sql、get_database_tables、prepare_database_migration、complete_database_migration),好让它们完全通过自然语言来管理 Neon。你从不需要自己打开 Neon 控制台或一个 psql shell。(本课默认用 Neon 作为主机;一切在 TigerData Cloud 上同样运行,见本概念末尾的「更想用 TigerData?」。)
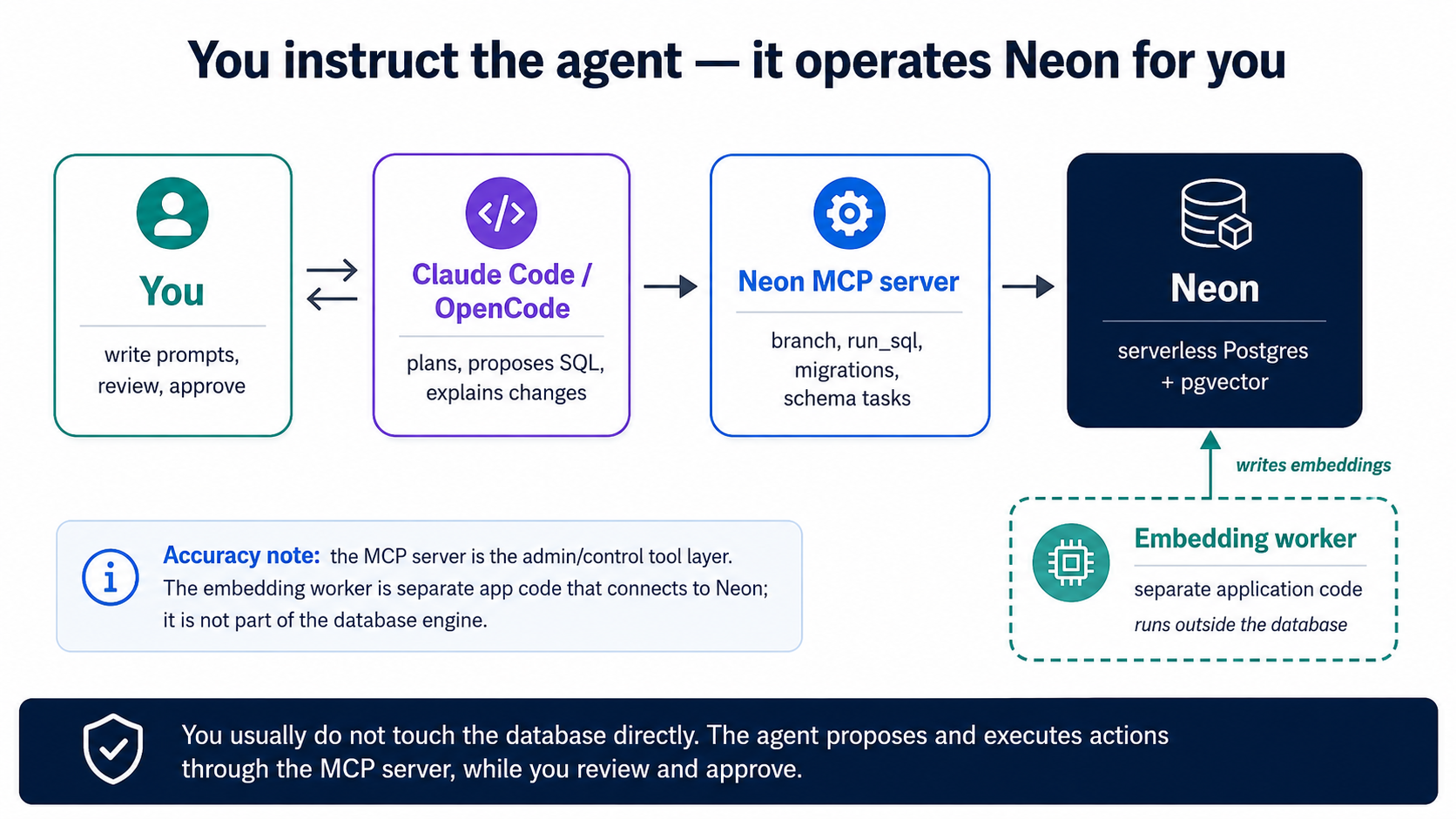
**一次性接线。**如果你从 课程基座 起步,Neon MCP 服务器已经在 .mcp.json(Claude Code)和 opencode.json(OpenCode)里声明好了,你只需在浏览器里通过 OAuth 授权一次,没有 API key 要管。(改为手工接线也是同样这一步:把 Neon MCP 服务器加进你的工具并授权。)这是唯一的手工配置;从此往后,一切都靠指挥 agent 来完成。在 plan 模式下驱动它:
用 Neon MCP 服务器,创建一个叫
agent-factory-rag的项目,并在上面启用 pgvector 扩展。然后创建一个叫dev的分支供我们在上面构建,并把那个分支的连接字符串存进.env里的DATABASE_URL,这样 worker 和应用稍后能读到它(绝不要打印我的 API key)。在你运行任何东西之前,先把计划给我看。
然后读那份计划。你要核对的是:
- 它在一个分支上工作,而不是直接在生产上。分支是 Neon 的超能力:一个分支是你整个数据库的即时克隆(写时复制:它只存储你改动的部分,所以克隆既免费又即时)。agent 在一个分支上改动表结构,你来预览,然后才提交到默认分支,这就是同一套先计划再执行的方法,由平台强制执行。(这也是你稍后做索引基准和跑评测的方式:开分支、测试、扔掉分支。)
- 它用一条语句启用 pgvector,这门课唯一需要的扩展:
CREATE EXTENSION IF NOT EXISTS vector; -- pgvector is pre-installed on Neon; this just switches it on
- 对于 embedding(概念 6),agent 会构建一个小 worker,一个简短的 Python 脚本或服务,它读取新增或改动过的行、调用 embedding 模型,并把向量写入一张 embedding 表。它在 Neon 之外运行,通过连接字符串去够到你的分支。embedding 提供方的 API key 住在 worker 的环境里,绝不进数据库。
你不需要去背 MCP 工具的名字或 Neon 的 API。plan 模式的意义在于,你读计划、确认它在一个分支上工作并启用了 pgvector,然后再批准。如果计划里有你认不出的动作,在说「行」之前先问 agent 为什么,那个问题才是你真正的工作。
Neon 自己的指引是,这个 MCP 服务器面向的是本地开发和 IDE 集成,它能执行一些威力很大的操作,所以把它限制在你的开发工作流里,并在批准前审阅 agent 提议的每一个动作。生产环境的改动仍然走你正常的、经过审阅的迁移流程。
课程基座 已经包含一个简短的 AGENTS.md / CLAUDE.md,里面是这门课需要的规则:你在哪个 Neon 分支上、key 住在环境里(绝不提交)、你选定的距离函数,以及两条硬规则,「永远在 Neon 分支上改动表结构,并让我在提交前预览」,以及*「在没先给我看的情况下,绝不运行破坏性 SQL(DROP、TRUNCATE、不带 WHERE 的 DELETE)」*。不用基座来构建?运行 /init,然后精简到正好这些内容。
本课的一切在 TigerData Cloud 上原封不动地运行,这家团队正是 pgvector 配套扩展背后的团队,他们把它定位为「Agentic Postgres」。这套由 agent 驱动的循环一模一样;只是名字变了:
- 用 Tiger MCP 代替 Neon MCP 服务器。它内置在 Tiger CLI 里,用
tiger mcp install安装,然后就像上面那样用自然语言驱动 Tiger Cloud(「创建一个服务、把它 fork 出来、启用扩展,先把计划给我看」)。它甚至附带 Postgres Skills,教 agent 各种最佳实践。 - 用 fork 代替分支:
tiger service fork …制作一个即时、零拷贝的克隆,就是你做评测和索引基准时会用到的同一套 fork → 测试 → 扔掉 的方法。 - pgvectorscale 是原生的(与 pgvector 并存),所以 StreamingDiskANN 那个「毕业层级」(概念 11)从第一天起就在盒子里,而且它的索引支持高达 16,000 维的向量(像
text-embedding-3-large这样的大模型于是就不需要halfvec)。你的 embedding worker 运行方式和在 Neon 上一样。
你的 embedding worker 和生成那一步都住在应用代码里,跟 Neon 完全一致。经验法则:Neon 用于最简单的 serverless 起步;TigerData 用于你想要 pgvectorscale 的规模和过滤检索性能、又永远不必迁移的时候。
本课选择 Neon 有两个原因:免费层无需信用卡,以及 agent 可通过 Neon MCP 服务器驱动即时分支。更想在本地运行 Postgres(Homebrew、Docker),或放在另一家主机上?数据这一侧完全相同,还是同一个 CREATE EXTENSION vector、同一套 schema、同一个 worker、同样的查询;只要把 DATABASE_URL 指向你的实例即可。你失去的是 MCP 驱动的分支能力,也就是做索引和评测时会用到的「开分支、测试、扔掉」动作,所以那些步骤要直接运行。你在这里学到的东西仍然原样迁移。
第 2 部分:你的第一个 RAG,由你的 agent 构建
我们会构建一个小而经典的例子:一张表,装着历史人物谈论美国城市的引文,然后按含义检索它,再让一个 LLM 据此回答问题。
5. 表结构:向量就在你的数据旁边
先向 agent 要那张源表。有一点要记住:含义向量不会住在某个独立的存储里,它们就进同一个数据库,进你下一个概念里要构建的配套表,正好挨着它们所描述的数据。
创建一张
quotes表,字段有:person、city和quote。接下来我们会在一张配套表里加 embedding,由一个小 worker 来填充,所以现在只要源数据。然后插入几条关于纽约、旧金山和芝加哥的真实引文,好让我们有东西可以检索。
agent 写出来的表大致长这样:
CREATE TABLE quotes (
id bigint GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
person text NOT NULL,
city text NOT NULL,
quote text NOT NULL
);
要记住的心智模型是:**单一事实来源。**引文、说话的人、城市,以及(很快就有的)它的含义向量,全住在同一个数据库里。正是这一点,让第 4 部分里的过滤变得轻而易举。
6. 生成 embedding:你的 agent 构建的 worker
你的 quotes 表装的是文本。要让数据库按含义检索那些文本,其中的每一片都需要一个向量,而生成这些向量,正是 pgvector 不替你做的那一件事。所以 agent 会写一个小程序:embedding worker。它的全部工作就是一个循环:**找出还没有向量的引文 → 把任何长文本切成小片(块)→ 向 embedding 模型要每一片的向量 → 保存这些向量。**跑一次,每一条现有引文就都覆盖到了;按计划重跑,新增或编辑过的引文也会被覆盖。这就是整台机器。
向量保存在哪里?保存在第二张表里,即配套表,每块一行,每一行都指回它来自的那条引文。这回答了人人在此都会问的那个问题(一行,一个 embedding?):一条短引文是一块,所以一个向量行;一段长演讲会变成好几片,所以好几行。(为什么要切块?那是 概念 7,紧接在这之后。)两张表,长这样:
quotes (your source table) quotes_embedding (companion table)
┌────┬─────────────────────┐ ┌─────┬──────────┬──────────────┬───────────┐
│ id │ quote │ │ id │ quote_id │ chunk │ embedding │
├────┼─────────────────────┤ ├─────┼──────────┼──────────────┼───────────┤
│ 7 │ a short quote │ ────→ │ 1 │ 7 │ whole quote │ [0.02, …] │
│ 8 │ a long speech… │ ──┬─→ │ 2 │ 8 │ first piece │ [0.11, …] │
└────┴─────────────────────┘ └─→ │ 3 │ 8 │ second piece │ [0.54, …] │
└─────┴──────────┴──────────────┴───────────┘
one row per quote one row per CHUNK (its own id),
pointing back via quote_id
在 agent 构建它之前,有一个决定:用哪个 embedding 模型把文本变成向量。这是这里唯一一个反悔起来很麻烦的选择,因为换模型意味着把一切重新 embedding,所以即便基座已经替你选了一个合理默认值,也值得理解它。默认值取决于你配置的是哪家提供方:走免费 Gemini 路径时是 Google 的 gemini-embedding-001;如果你选择 OpenAI,则是 OpenAI 的 text-embedding-3-small。本课里二者都以 1536 维运行,都足以应付大多数 RAG,而且 Gemini 是免费的,所以你不必自己挑模型名;基座会按你给的 key 设置好。你只有两个理由会偏离默认值:你的内容不是英文(或者高度专业,例如法律、医疗、代码),这时多语言或领域调优模型可能更胜;或者你稍后的评测显示一个更大的模型确实检索得更好。在 worker 里,模型只是一个设置,所以你在你的评测集(概念 12)上去测试备选项,而不是靠猜:从 MTEB 排行榜(embedding 模型的标准公开基准)上挑出候选名单,让你的数据来选出赢家。
维度的细则(当你偏离默认时再读)
维度越多,意味着越多的存储和内存,以及略慢的检索。两条实用的提醒:许多现代模型让你在不重新训练的情况下请求更少的维度(本课正是用这一点把两家提供方都固定在 1536 维);还有一个真正的坑,pgvector 的 HNSW/IVFFlat 索引把 vector 类型的上限卡在 2,000 维(halfvec 类型把这个上限扩到 4,000),所以完整尺寸的 3072 维模型(OpenAI 的 text-embedding-3-large,或完整尺寸的 Gemini)需要 halfvec 或降维才能建索引。保持在 1536 维会让你避开这些问题;如果你以后提高维度,你的 agent 应当点出这个上限,它点出来时,你也应当认得出来。(在 TigerData 上,pgvectorscale 的 StreamingDiskANN 索引支持高达 16,000 维的向量,所以这个上限很少咬到你。)
首先,给代码一个家,一个 Python 项目,由 uv 管理(那个 Python 项目管理器;agent 认得它,把每个依赖都经由它来走,能让项目可复现):
在这个文件夹里用 uv 配置一个 Python 项目。从现在起,所有依赖都经由 uv 添加,所有脚本都经由 uv 运行。
然后让 agent 构建这个 worker 和它的表:
创建一张配套表
quotes_embedding,带一个指向quotes的外键、块文本,以及一个embedding vector(1536)列。然后写一个小的 embedding worker,它找出当前没有 embedding 的引文、把quote文本切块、用本课的 embedding 模型 embedding 每一块,并把向量插入quotes_embedding。跑一次来回填,告诉我怎么确认这些行落进去了,并解释我该怎么给它排定时任务。从环境里读取 API key。
**注意观察:**agent 创建配套表(就是上面那张图里的确切形状)、跑一次 worker,并把落进去的向量行给你看。如果 worker 在第一次 embedding 调用时以 401 或 429 挂掉,你的代码没有任何毛病;问题在 key,而且你很可能已经在配置阶段通过 agent 的测试调用发现了它。在 Gemini 上,从 aistudio.google.com/apikey 重新复制那个免费 key;在 OpenAI 上,一个全新的账户通常需要先绑付款方式才能 embedding。429 是速率限制,等一会儿再重跑即可。修好 key,然后重跑。若你看到的是 expected 1536 dimensions, got 3072,说明 embedding 调用没有请求 1536 维,两家提供方默认都会返回更大的向量,所以调用必须请求 1536 来匹配 vector(1536) 列;基座 worker 已经这样做了,因此这个错误意味着手工改过的调用把它漏掉了。**完成标志:**每条引文在 quotes_embedding 里至少有一行,而且你知道那条重跑 worker 的命令。
最简单的版本是轮询:worker 按计划重跑,并对文本变过的行重新 embedding。想要由变更驱动的更新?一个 INSERT/UPDATE 触发器可以把一行标记为脏,也就是标出「这一行需要一个新鲜的 embedding」,worker 在它下一趟里把那些被标记的行取走。如果你为了跟上节奏跑了不止一个 worker 副本,它们绝不能抢到同一行两次;Postgres 替你处理这件事,给每个 worker 递上一批互不相同的、还没被认领的行(这就是 SKIP LOCKED 的把戏)。于是那张「待 embedding 的行」的清单,就只是一张普通的 Postgres 表,没有单独的队列服务要运行,跟你的向量是同一个单一数据库的好处。无论哪种方式,触发器都只负责打标记;embedding 调用仍然在 worker 里带外发生,数据库本身从不调用 embedding API。
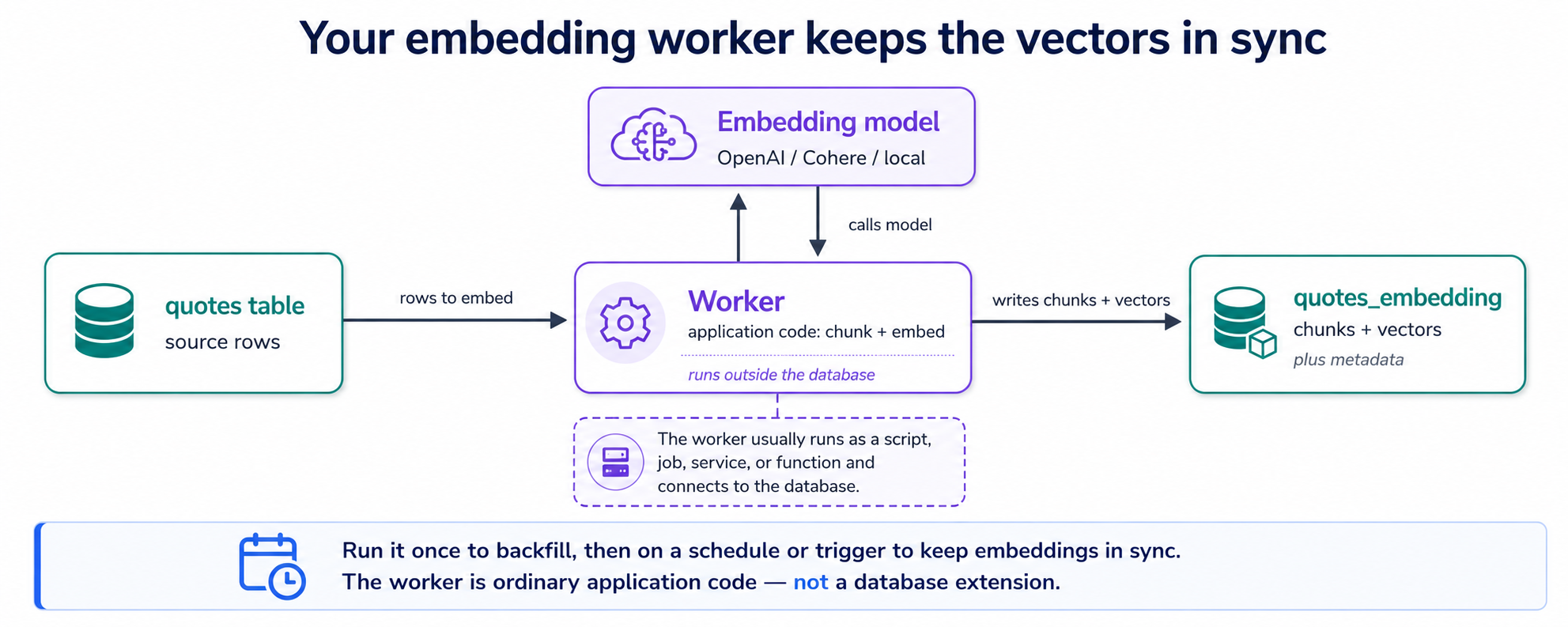
同一个 worker 模式可以 embedding 文档,而不只是短字段,把它对准 PDF、DOCX,或云存储里的文件(比如一个 Amazon S3 桶),让它解析、切块,并把它们 embedding 进同一张配套表。而且因为模型在 worker 里只是一个设置,你可以更换提供方(Gemini、OpenAI、Cohere、Voyage、一个本地模型),来测试哪个在你的数据上检索得最好,也就是上面那个模型实验。
worker 调用一个外部 embedding 提供方,所以它需要那个提供方的 API key。这个 key 属于 worker 的环境(或者你云服务商的密钥库),绝不硬编码在 SQL 里、也绝不提交进你的仓库。明确告诉你的 agent:*「从一个环境变量里读取 API key,绝不要把它写进我们会提交的文件里。」*然后在批准前核对 diff。日后更换 embedding 提供方(在 Gemini 和 OpenAI 之间切换,或换到 Cohere、Voyage、一个本地模型)在 worker 里是一行的改动,你应用的其余部分纹丝不动。
7. 分块:决定你上限的那根杠杆
分块是你 worker 内部的一步,而且悄悄地,是最重要的一步。一篇长文档若作为单个向量来 embedding,就糊成一团,变成它所说一切的一个模糊平均,所以你把它切成更小的块,每一块得到自己的向量。什么算作一块,决定了你的检索究竟能取回什么。
两个旋钮:
- **大小。**太大,一块就横跨好几个话题,于是它的向量不聚焦,你取回的是擦肩而过的近似。太小,一块就丢掉了让它有意义的那点上下文。几百个 token 是常见的起点;正确答案取决于你的内容。
- **重叠。**让块之间稍微重叠一点(比如 10–20%),能让一句横跨边界的话不至于成为孤儿。一些重叠几乎总有帮助;太多则浪费存储,并取回近乎重复的内容。
还有策略:按字符数切(简单的默认)、按结构切(markdown 标题、段落),或按语义切(把彼此相关的句子归到一起)。对于结构化文档,按标题切通常胜过盲目数字符。
为什么它配得上单独一个概念:分块决定了你的召回率上限,而召回率的意思很简单,就是你的检索一开始有没有把对的那些块取回来。如果正确答案从来没有干净地落进单独一块里,那么再好的 embedding 模型、再巧的提示词也救不回来,这也正是为什么糟糕的分块是 RAG 系统悄悄表现不佳最常见的原因之一。所以你不靠猜:一旦你在处理真实文档、并且你的评测集已经存在(概念 12),你就让 agent 在 Neon 分支上试几种分块配置、用你的评测问题逐一衡量,留下赢家,就是你在 第 3 部分 给索引用的那同一个测试即弃的动作。你会在实战示例(第 5 部分)里正好做这个动作。
8. 语义检索:按距离排序
现在轮到开篇说的那个魔法了。要找出在含义上与一个短语相近的引文,你的应用先把这个短语变成它自己的一个向量,即查询向量,然后数据库按存储的块的向量离它有多近来排序。
唯一新出现的那一片 SQL,是一个距离运算符,也就是那个发问「有多近?」的符号。你需要的只有一个:<=>,余弦距离,文本 embedding 的默认选择,也是整门课所用的。(pgvector 还有另外两个,<-> 表示直线距离,<#> 表示内积,你只有在某个模型的文档明确要用其中之一时才会碰到它们;你的 agent 会知道。)
给我写一个查询,返回与一个搜索短语在含义上最相近的前 5 条引文。这个短语的 embedding 会作为参数从应用代码传进来,别在 SQL 里面 embedding 它。
它递回来的查询(供你读,不是供你敲):
SELECT q.person, q.city, q.quote
FROM quotes_embedding e -- the table your worker populates: chunks + vectors
JOIN quotes q ON q.id = e.quote_id -- each chunk points back to its source quote
ORDER BY e.embedding <=> $1 -- $1 = the query phrase, embedded in app code
LIMIT 5;
搜索「不夜城」,排在最前面的结果是关于纽约的引文,包括那些从不含「纽约」二字的,因为含义是相近的。这,终于落到了实处,就是语义检索。
$1 传进来的把用户的短语变成一个向量,发生在你的应用代码里,是 agent 写的几行,其结果作为 $1 参数传进查询。模型调用留在你的应用里,你在那里掌控模型、重试和缓存;Postgres 做它最擅长的,存向量、找出最近的那些。
9. RAG:先检索,再生成
语义检索找到相关的文本。RAG(检索增强生成)更进一步:它把那些检索到的块拿过来,塞进一个提示词当上下文,再请一个 LLM 写出一个扎根于你的数据的答案。这就是客服机器人、文档助手、「和我的文件聊天」功能,它们全都是这个循环。
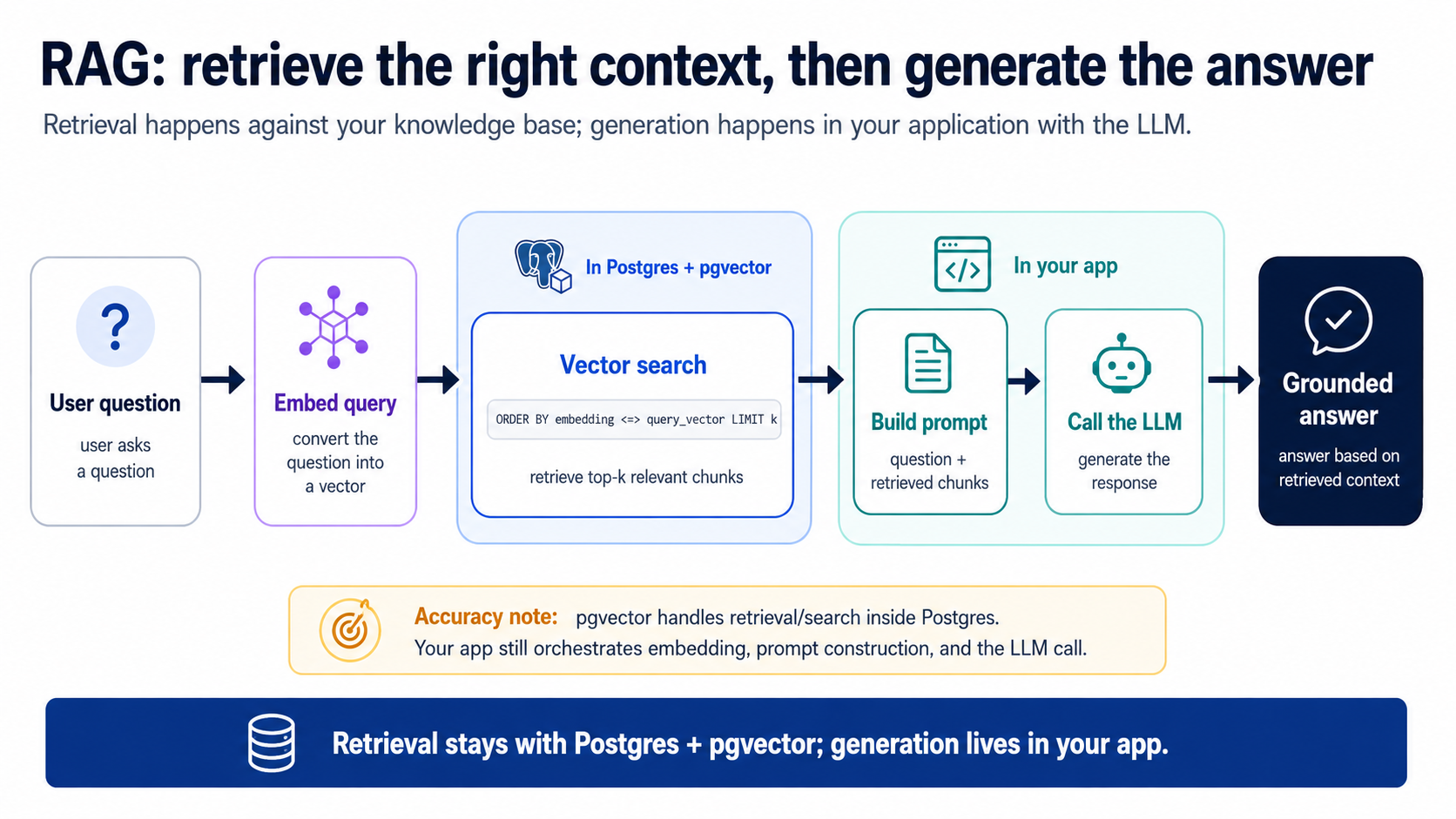
这个循环有两个阶段,而这个拆分正是全部要点:
- 检索(在 Postgres 里):运行 概念 8 那个查询,拉出前 k 个最相关的块(k 就是你要多少个;5 是个不错的起点)。这就是上下文管理那一步,取出信号,把上百万行无关的挡在外面。
- **生成(在你的应用里):**构建一个提示词 = 系统指令 + 检索到的块 + 用户的问题,把它发给一个 LLM,返回答案。这段应用侧的胶水代码由 agent 替你写;它很小。
分两步构建,这样你能在生成把检索包起来之前,先看到检索单独工作。首先,一个收尾性的提示词,好让代码有个家,如果你在 概念 6 里已经构建了 worker,那这就已经成立,这时 agent 只会确认一下:
确认这个文件夹是一个 uv 管理的 Python 项目,如果不是就配置好,并让每个依赖和脚本都继续经由 uv 走。
现在是检索那一半:
在应用代码里构建一个
search_quotes(question)函数:embedding 这个问题、对quotes_embedding跑我们的前 k 语义检索,并返回匹配的块连同它们的源引文。然后在「不夜城」上跑它,把返回的东西给我看。
返回的是单独的阶段 1,凭含义找到的那些对的块,在写出任何答案之前。现在把阶段 2 包在它外面:
现在在它之上构建
answer_question(question):调用search_quotes、把那些块格式化进一个提示词当上下文、调用 LLM,并返回那个扎根的答案,检索留在 SQL 里,生成在应用代码里。然后问它一个问题,把检索到的块挨着最终答案给我看。
注意阶段 1 在做什么:把正好它需要的上下文、别无其他地交给 LLM,这就是上下文管理,正如开篇那张图所许诺的。如果检索马虎,块不对、太多、或者无关,LLM 就给出一个糟糕的答案,然后人们怪「这 AI」。几乎总是检索的问题。这正是第 4 部分存在的理由。
然后下一口气,他们描述了一个系统:index documents、embed queries,并在生成答案前 retrieve relevant chunks。尊重地说:这仍然是 RAG。
你现在已经 built 它的每一步。整台机器就在这一张 card 上:
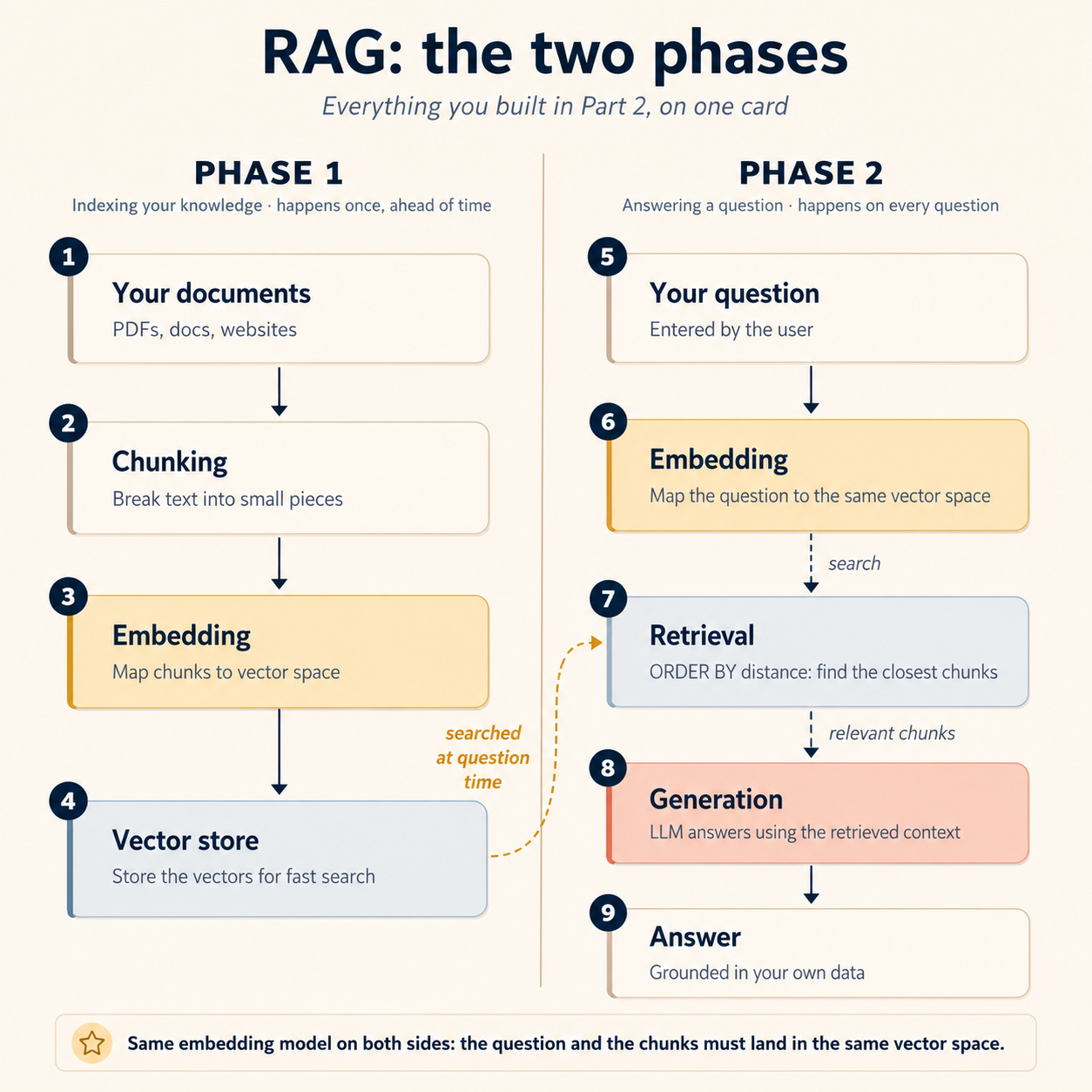
Phase 1:indexing(提前发生一次):
- 你的 documents 被切成 chunks(Concept 7)
- 每个 chunk 由你的 worker embed 到 vector space(Concept 6)
- vectors 落进 Postgres,挨着它们描述的数据(Concept 5)
Phase 2:answering(每个 question 都会发生):
- user 的 question 被 embed 到那个 same vector space
- Retrieval 拉回最接近 question 的 chunks(Concept 8)
- 那些 chunks 被传给 model,model 基于它们生成 grounded answer(本 concept)
第一次做 pipeline 时最容易绊倒人的部分,藏在上面一个词里:same。Question 和 documents 必须落进 同一个 vector space:两边使用相同 embedding model、相同 dimensions、相同 settings。用一个 model embed documents,再用另一个 model embed queries,retrieval 会悄悄坏掉,哪里都不报错:两个 model 的 vector spaces 只是不同坐标系,于是 "closest" 不再等于 "most similar"。任何 leaderboard ranking 都救不了这个 mismatch。(它是 Concept 6 中 expected 1536 dimensions, got 3072 error 的 model-level cousin,只是这个版本甚至不会 loud fail。)
所以,从 “RAG is dead” 那些 headlines 之后,真正改变了什么?不是 mechanism,而是 packaging。Agents、tool calls、multi-step reasoning 现在坐在同一个 retrieve-then-generate loop 上面。你会在 Part 6 把这个 exact loop 包成 agent tool,并在 Part 8 交给一个 agent:这个 loop 不会死,它会被 promoted。
answer_question() 不只是一个聊天机器人的后端,它是 一个 agent 调用的工具。在讲 agent 的那些章节里,检索成为一个更大的 agent 在需要扎根的事实时会去够的工具之一,就像它去够一个计算器或一次网络搜索那样。RAG 就是一个 agent 所凭借的可检索的上下文。
第 3 部分:让检索变快,索引
从这里开始进入中级。第 3、第 4 部分是调优层:你单凭第 1、第 2 部分就能上线,但你不会止步于此,先读这些内容的「为什么」,然后在 第 5 部分,第 5 到第 8 步 里把它们全都真刀真枪地跑一遍。更快(第 3 部分)和更准(第 4 部分)是你做过的本事,而不只是读过的。
10. 为什么你需要向量索引(以及什么时候不需要)
没有索引时,一次相似度检索会把查询向量与每一行比较,这是一次精确的最近邻扫描。它完全准确,在你规模还小时也完全没问题。可表一大,它就变慢。
解法是一次近似检索:不去检查每一个向量,用一丝精度换取大幅提速。一个向量索引,就是让那种近似变得好用的数据结构。
**这个阈值能救你免于过度工程:**低于大约 100,000 个向量时,精确检索往往已经够快,而且永远正确。但真正的阈值会随维度、计算规模、速度目标、过滤条件、并发量,以及向量被重写的频率而移动,所以在加索引之前,让 agent 先做基准测试,而不是默认就上一个;等检索真的变慢了再加,别提前加。(这呼应了编码课那句「出了问题再加规则,别提前加」。)
11. 各种索引、该用哪个、以及怎么调优

在 Neon 上,真正在选的是中间那张卡:HNSW 是你的主力(IVFFlat 作为遗留选项)。StreamingDiskANN 那张卡在 TigerData 上是原生的;从 Neon 出发要够到它,意味着搬到一个自带 pgvectorscale 的主机。
索引由 agent 替你构建,你的工作是认出它构建了什么、并确认它适配你的查询。卡片上没显示的一条约束:一个列只能持有一种向量索引类型,所以这是一个真正的二选一。下面是各自的样子:
-- HNSW — your default on Neon
CREATE INDEX ON quotes_embedding USING hnsw (embedding vector_cosine_ops);
-- IVFFlat — also on Neon; legacy, needs a lists parameter; recall drifts as data grows, so periodic rebuilds
CREATE INDEX ON quotes_embedding USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);
-- StreamingDiskANN — native on TigerData; on Neon only via a pgvectorscale host
CREATE INDEX ON quotes_embedding USING diskann (embedding vector_cosine_ops);
注意 vector_cosine_ops,索引必须与你查询所用的距离函数匹配(<=> → 余弦)。这一处错配,索引就会悄无声息地帮不上忙。
**到底怎么决定:做基准测试。**HNSW 有两个构建期设置,m 和 ef_construction,它们在索引构建时塑造那张图。它们正是那种你永远不该去背的东西:描述你真实的工作负载,让一个用完即弃的分支替这场实验买单。两个提示词(这里的行数是一个真实规模的替身,你会在 第 5 部分,第 5 步 里、在一个填充到规模的用完即弃分支上,真刀真枪地跑这个完全相同的基准,好让它落成一项本事,而不是一个故事):
我们有大约 200 万条引文向量,而且我们的大多数检索按城市过滤。在一个全新的 Neon 分支上,用默认设置构建一个 HNSW 索引、跑十次有代表性的检索,并报告 p95 延迟。
现在调
m和ef_construction:试几组设置、在每一组上重跑那同样的十次检索,并推荐一组,用一段话解释其中的权衡。然后扔掉这个分支。
这就是 AI 工程师的动作:你不去背哪组设置更快,你让 agent 在一个 Neon 分支上去测量,并带给你一个推荐,你再对照上面那些卡片来做一次常识校验,然后零成本地丢弃那个分支。这个基准衡量的是速度,不是召回率:别在这里用眼睛去瞄结果「看起来对不对」,召回率要用诚实的办法来判断,用真实 embedding 对照你的评测集(概念 12),绝不靠瞥一眼一次合成的运行。(p95 延迟的意思就是 95% 的查询能落在其下的那个速度,是一个稳妥的、用来守住底线的最坏情况,但前提是查询数量够多:想的是几百次,不是十次,而且要在几次预热检索把分支的缓存热起来之后,因为一个全新的 Neon 分支头几次读取是从存储里冷启的。在十次冷采样上,p95 基本上就是你那一个最差的查询。)
**行数不是唯一的维度,变动量是另一个。**你的向量被重写的频率(重新切块、更换 embedding 模型、按时间衰减重建索引)本身就是一项成本。HNSW 能接受增量的插入和更新而无需整体重建,但重写量一大,这张图就会随时间膨胀,召回率漂移,最终你需要一次 REINDEX,而重新 embedding 本身又是你要付的算力。所以一份不停被重写的数据,可能在它变大之前就已经变贵了。把你真实的更新模式告诉 agent,而不只是行数,并让它对照那个模式来做基准测试。
**日常真正值得知道的那一个旋钮:ef_search。**上面那些构建期设置在索引一旦存在就烤定了;你真正会去拨的那个旋钮在查询期,ef_search 控制一次检索找得多卖力:越高意味着召回率越好、查询越慢,越低意味着越快、越不准。agent 会按查询来设它;这是你会看到它跑的那一行:
SET LOCAL hnsw.ef_search = 100; -- raise for more recall, lower for more speed
所以这个动作是:把你真正需要的召回率告诉 agent,让它调 ef_search 去命中那个值,而不是盲目地把它拉满。然后让它证明索引在干它的活:跑 EXPLAIN ANALYZE、检查是一次索引扫描而不是顺序扫描,并回报。下面是其中的差别,就在你真正会读的那部分输出里(同一张 200 万向量的表,有和没有一个可用索引):
✅ GOOD — the index is doing the work
-> Index Scan using quotes_embedding_hnsw_idx on quotes_embedding
Order By: (embedding <=> $1)
Execution Time: 0.8 ms
❌ BAD — no index used; every row got scanned and sorted
-> Seq Scan on quotes_embedding (rows=2000000)
Sort Key: (embedding <=> $1)
Execution Time: 52.4 ms
两行就告诉你拿到的是哪一种:运算符那一行(Index Scan using …hnsw… 对比 Seq Scan on …)和执行时间(在同一份数据上,亚毫秒对比几十毫秒)。Seq Scan 意味着索引没在被用,通常是因为查询的距离运算符与索引不匹配,或者根本还没有索引。这就是你在把建索引这件事称为「完成」之前,该让 agent 确认的那一件事。
这些是向量检索悄悄出错的几种反复出现的方式,而既然你的工作是判断 agent 的活,它们正是你该盯的:
- 维度不匹配,列的维度和 embedding 模型的输出对不上。
- 客户端没注册向量类型,worker(以及检索代码)必须在每一个触碰
embedding列的数据库连接上注册 pgvector(register_vector),否则向量会悄悄地以纯文本来回传送:插入和检索于是出错,却完全没有报错。这是唯一一种在 SQL 里看不见的静默损坏模式,所以要让 agent 确认它注册了类型。 - 过了该上索引的临界点却没有索引,这是一次静默的变慢,不是一个报错。
- 运算符与索引不匹配,查询用
<->但索引是余弦的,于是索引被忽略。 - 用整篇文档而不是块,就是 概念 7 那个错误;检索永远找不到任何精确的东西。
- 跳过
EXPLAIN ANALYZE,于是上面这些没人抓得到,直到用户抓到。
过滤有一个值得知道的陷阱,而它正是上面基准里那个「大多数检索按城市过滤」的情形。一个 HNSW 索引是在它扫完自己那个固定的候选预算(ef_search,默认 40)之后才应用你的 WHERE 子句的,所以一个选择性强的过滤可能让你剩下的行比你的 LIMIT 还少,悄悄丢掉真正的匹配,在你验证那些检索时,留意结果数低于 LIMIT 的情况。把召回率撑住的那些杠杆在查询期,而不是一张更密的图:调高 ef_search、打开迭代扫描(SET hnsw.iterative_scan = strict_order,默认关闭),或者按每个过滤值构建一个部分 HNSW 索引。给过滤列配一个普通的 B-tree 索引也有帮助,但不是靠预先缩窄 HNSW 扫描,Postgres 每次扫描只用一个索引,所以那个 B-tree 只是给 planner 一个精确距离的备选,在过滤足够有选择性时它可以挑这个(满召回率,没有过滤后的损失)。(StreamingDiskANN,上面第三张卡片,正是为超大规模下的重过滤检索而生的。)在 Neon 上,这些杠杆加上好的过滤索引先带你走很远。
第 4 部分:让检索变好,进阶层
一个能用的 RAG 不等于一个好的 RAG。这里是大多数项目卡住的地方,也是懂这些招式把你和一个只会做 demo 的人区分开的地方。
12. 评测驱动开发
这是把一个可上线的系统和一个走运的 demo 区分开的那个习惯。大多数人一开始就埋头构建,然后用眼睛去瞄输出「看起来对不对」。换个做法,从问题开始。在写任何东西之前,先写下十几个你的用户真的会问的问题,把它们放进一个文件。那个文件就是你的评测集,是你衡量一次改动让事情变好还是变坏的标尺。
然后,每当你改动系统,新的 embedding 模型、不同的分块策略、加一个过滤,你就重跑评测集,看见那个效果,而不是靠猜。随着应用长大,这个集合也跟着长(20 个、50 个问题),你就能在你的用户之前抓住回归。
下半截是**拆解问题。**当一个答案糟糕时,别下结论说「这 AI 真笨」。去追踪各个阶段:
- **检索:**语义检索究竟有没有返回对的块?(很多时候真正的问题是一个库存缺口,用户问的东西你压根没放进数据库。)
- **上下文:**对的块被传给 LLM 了吗,还是太多 / 太少?
- **生成:**给了好的上下文,模型是不是还是答得很差?
十有八九,失败出在检索,而不是 LLM。去修真正坏掉的那个阶段。
现在就构建你自己的,针对你已经加载的任何东西,第 2 部分的引文,或你自己的数据。先是问题,agent 起草,你来甄选:
读我们的源表,起草 12 个用户可能现实地会问的评测问题,有些有一个明显的源行、有些的答案横跨好几行、还有几个是我们的数据根本答不了的。为每一个标注期望的答案(或「无法回答」),并把它们存到
evals/questions.md让我编辑。
在你认可它之前先编辑那个文件,你了解你的用户,agent 不了解。然后接好那套测试装置:
构建一个小的测试装置,把
evals/questions.md里的每个问题都过一遍我们的「先检索再生成」流水线,并为每一个显示:检索到的块、最终答案,以及它是否与我期望的相符。汇总它在哪里失败,检索还是生成。
从此往后,每一次改动都拿它来衡量:
跑一遍评测,把结果存为今天的基线。等我们下次改动之后,重跑并把 diff 给我看,哪些问题变好了、哪些变差了。
429 是免费层上限,不是 bug每次评测都会为每个问题发起一次模型调用,而你会反复重跑这套评测。在免费层上,你最终会撞到提供方的每日请求上限,并在中途看到 429。这是额度上限,不是你把什么弄坏了:等一等再试,让测试装置自动退避并重试,把日常评测切到一个更小的免费模型,或者启用计费。具体限制会变化,所以请看你提供方的 dashboard,不要相信某个固定数字。
评测驱动开发是可靠 agent 的脊梁,而不只是 RAG 的。专门的讲解是 评测驱动开发速成课,在这一门之后再做。
13. 过滤检索:WHERE 子句是你的好帮手
纯语义检索返回全局上最相似的那些行。很多时候你想要的是*那些既最相似、又满足某个条件的行。*因为你的向量就住在你的数据旁边(概念 5),这只不过是同一个查询上的一个 WHERE 子句,没有第二个系统、没有手忙脚乱。五种模式几乎覆盖了一切:
| 模式 | 示例用例 | 加上的那个子句(示意) |
|---|---|---|
| 元数据过滤 | 跨多个产品的文档检索 | WHERE product = 'CRM' AND doc_type = 'api-reference' |
| 复合过滤 | 电商推荐 | WHERE category = 'electronics' AND price BETWEEN 500 AND 2000 AND in_stock |
| 时间过滤 | 新闻推荐,只要近期文章 | WHERE published_at > now() - interval '7 days' |
| 权限过滤 | 内部 RAG,用户只看到自己被授权的内容 | WHERE clearance_level <= $user_level |
| 地理空间过滤 | 「推荐 5 公里内的东西」(加 PostGIS) | WHERE ST_DWithin(location, $point, 5000) |
每一个都是同一个形状:ORDER BY embedding <=> $1,前面加一个 WHERE。权限那一个值得多说一句,它正是你如何让租户 A 永远无法取到租户 B 的文档,这道边界在数据库里强制执行,而不是在应用代码里寄希望于运气。
给我们的语义检索加一个可选的城市过滤。在一个 Neon 分支上,给
city列加一个 B-tree 索引、确保带过滤的查询依然快,并把我们评测集上前后的延迟给我看。
14. 混合检索:既懂语义又懂关键词
到 2026 年,混合检索是认真做检索时最强的候选升级,一个你要在评测集上确认的候选,而不是一个盲目就上线的默认。它的想法是:同时跑关键词检索和向量检索,然后合并。两者各自补上对方的盲点,向量检索懂同义改写,却低估精确的稀有词(一个产品编号、一个人名);关键词检索精准命中确切词,却抓不住含义。Postgres 两者都原生支持,关键词检索靠全文检索(tsvector)、向量靠 pgvector,所以它依旧是一个数据库,而且往往是一个查询。
(关于关键词那一侧的一点说明:本课用的是 Postgres 内置的关键词检索(tsvector),它本来就在那里,对大多数数据也足够好。一个更新的扩展 pg_textsearch 做更强的 BM25 排名,也就是 Elasticsearch 用的那套方法,并在 TigerData 上预装。只有当你的评测显示内置检索漏掉了好结果时,才切到它。下面那个 RRF 步骤无论用哪一种都完全一样。)
已成标准的那个形状:
- 从两边都取、并多取一些,比如关键词取前 20、向量取前 20,好让合并有信号可用。
- **用倒数排名融合(Reciprocal Rank Fusion,RRF)来融合。**RRF 按位置而非分数来合并两个排好序的列表,这绕开了真正棘手的地方:关键词分数和余弦距离活在完全不同的量纲上,没法合理地求平均。它是几行 SQL,而且不需要模型。
- (可选)用一个 cross-encoder 重排顶部候选,这是一个直接给每个「查询–块」对打分的小模型。这是精度那一步:RRF 挑出大约 100 个的好池子,cross-encoder 给你最终交给 LLM 的那一小撮排序。只有当你的评测说这点提升值得那额外的延迟时,才加它。
agent 产出的那个形状(供你读,不是供你敲),它会先在向量旁边加一个 ts 全文列,两个排好序的列表由 RRF 融合,全在一个查询里:
WITH kw AS ( -- keyword side: full-text search, ranked
SELECT id, row_number() OVER (ORDER BY ts_rank_cd(ts, plainto_tsquery($1)) DESC) AS rank
FROM quotes_embedding WHERE ts @@ plainto_tsquery($1) LIMIT 20
),
vec AS ( -- vector side: semantic search, ranked
SELECT id, row_number() OVER (ORDER BY embedding <=> $2) AS rank
FROM quotes_embedding ORDER BY embedding <=> $2 LIMIT 20
)
SELECT id, SUM(1.0 / (60 + rank)) AS score -- RRF: k = 60, summed across both lists
FROM (SELECT * FROM kw UNION ALL SELECT * FROM vec) r
GROUP BY id ORDER BY score DESC LIMIT 10; -- $1 = query text, $2 = query vector
读它:kw 按关键词匹配返回前 20、vec 按含义返回前 20,每一行都标上它在那个列表里的排名(1 = 最佳)。最后那个查询把两个列表里每一行的 1 / (60 + rank) 加起来,于是一行只要在任一列表里靠前就得分不错,而一行若在两个列表里都出现就胜出。那个 60(标准的 RRF 常数)防止任何单个高排名一家独大,而且因为它作用在位置上,你永远不必在不同量纲上去调和关键词分数和余弦距离。
在我们的向量检索旁边,给
quote列加上全文检索,用 RRF 融合两者,并把我们的评测集跑一遍「只用向量」对比「混合」。告诉我哪些问题变好了、好了多少。
混合检索在那种把一个概念和一个具体词混在一起的查询上赢得最多,「杜鲁门·卡波特关于这座城市说了什么」既需要精确匹配那个名字、又需要理解那层含义。它在你的数据上到底有没有帮助、帮助多少,这个问题只有你的评测集能回答,所以在你扛起那些额外的零件之前,先衡量「只用向量」对比「混合」。
15. 多租户与 text-to-SQL
还有两个,你即便今天不构建也该认得。
**多租户。**如果你在做 SaaS,每个客户的数据都必须与其他每一个隔离开。隔离有一道从最松到最严的阶梯:
| 做法 | 隔离度 | 成本 / 复杂度 | 典型适配场景 |
|---|---|---|---|
共享表 + tenant_id 过滤 | 最弱 | 最便宜 | 内部工具、低风险数据 |
| 每租户一个 schema | 良好 | 中等 | 大多数 SaaS 的甜点区 |
| 每租户一个数据库 | 最强 | 最高(备份、运维) | 高安全 / 受监管的客户 |
每租户一个 schema 是通常的平衡点:真正的隔离,只要运维一个数据库。无论哪种方式,概念 13 那条规则都成立,在数据库里强制这道边界,而不只在你的应用代码里。最干净的 Postgres 机制是行级安全(Row-Level Security,RLS):你让 agent 写一次策略(行只在比如 tenant_id = current_setting('app.tenant') 处才可见),Postgres 此后就把它自动应用到每一个查询上,于是一个被遗忘的 WHERE 子句也不可能把一个租户的向量泄漏给另一个。有一个值得知道的坑,因为它头一回就咬到每个人:RLS 会被超级用户和表的所有者绕过,所以你的应用必须以一个普通的、非所有者的角色来连接(第 6 部分 那个只读角色正好合适),以那个角色来测试策略,否则你会看不到任何隔离,从而错误地下结论说它不管用。
**text-to-SQL。**Postgres 也持有结构化数据,数字、日期、关系。text-to-SQL 让用户用大白话提问(「第三季度各地区的销售额是多少?」),让一个 agent 把它翻译成一个针对你真实表的、正确的 SQL 查询。让它准确的关键,是一个描述良好的表结构:清晰的表名和列名、解释每一个含义的 COMMENT,以及几对供 agent 学习的「问题→查询」示例。把那份上下文给 agent、保留一个人在回路里、在 SQL 运行前审阅它,再把它和语义检索(针对你的文档)结合起来,一个能为每个问题挑对工具的 agent,就是一个真正的数据助手的基础。
用两个提示词在我们的表结构上把它做实。首先,让 agent 把地基打好:
把我们的表描述清楚,好让英文问题能翻译得当:给表和列加注释,说明每一个持有什么,并存几个示例问题连同它们应该产出的 SQL。
然后就直接用大白话问:
哪个人的引文最多,他的引文又是怎样分布在各个城市的?先把你会运行的 SQL 给我看,等我批准后再执行。
text-to-SQL 是 plan 模式换了个名字:让 agent 先把 SQL 给你看,尤其是任何会写入的。一个错的 SELECT 浪费你一秒;一个错的 UPDATE 毁掉你一下午。
第 5 部分:一个完整的实战示例
一个任务,从头到尾:从一个空的 Neon 项目到一个能据你的文档作答的、可用的问答。**下面的提示词就是整个活,把它们敲进任一个工具。**方法就是 编码课 那一个动作的全尺寸版:用一个强模型来计划、审阅计划,然后让一个更便宜的模型去做例行的构建。
你从哪条路来都行得通。你待在同一个 postgres-ai/ 文件夹里,但这次构建会创建一个全新的 Neon 项目,所以引文那次构建的任何东西都不会被碰到,不管你是走完了概念 5 到 9 还是直接跳到这里。如果计划提议复用你已经构建过的函数,那没问题;在审阅里判断它。
0. 给这次构建准备文档和一个家,基座一份都不带,所以造几个(而且如果这个文件夹还不是一个 uv 项目,这一步也把它修好)。粘贴:
如果这个文件夹还不是一个 uv 管理的 Python 项目,就把它配置成。然后创建一个
docs/文件夹,放十个简短的 markdown 文件:一个虚构公司的迷你员工手册,休假、报销、安全、入职、设备。
1. 先计划,用一个强模型进入 plan 模式(Claude Code 里是 Shift+Tab,OpenCode 里是 Tab),然后粘贴:
我有一个 markdown 文件的文件夹
./docs。在 Neon 上构建一个 RAG 系统:用 Neon MCP 服务器创建一个项目和一个dev分支、启用 pgvector、把这些文档加载进一张表、构建一个小的 embedding worker 把它们切块并 embedding 进一张配套的chunks表,再给我一个先检索后生成的answer_question()函数。在运行任何东西之前,先把完整的计划和表结构给我看。
**2. 在你批准之前读那份计划。**核对:它是在一个 Neon 分支上工作吗?pgvector 启用了吗?embedding worker 是从环境里读 API key 吗(而且这个 key 被挡在仓库之外吗)?生成在应用代码里吗?如果全是,就批准。
3. 分三个检查点执行,切到一个更便宜的模型(任一工具里都是 /model)来做例行构建,而且别盲目地把整份计划一股脑放出去:分阶段跑,每个阶段后都有东西可看。先是数据库:
看起来对。继续做数据库和 worker:创建项目和
dev分支、启用 pgvector、加载文档,并跑一次 worker。然后告诉我每个文档产生了多少块,好让我看到文档落进去了。
接下来是检索,先块后答案,和 概念 9 一样:
现在是检索那一半。构建检索函数,在一个新员工可能会问的三个问题上跑它,只把返回的块给我看,先别给答案。
如果对的块正在回来,生成就是容易的部分了:
把
answer_question()包在它外面。然后问五个新员工真的会问的问题,把检索到的块挨着每个答案给我看。
4. 评测,然后迭代,有些答案会比另一些弱;那是循环的开始,不是失败。粘贴:
最弱的那些答案用了不相关的块。诊断一下:是检索还是生成?如果是检索,在一个全新的分支上试一种不同的分块策略,重跑那同样的五个问题。
你现在有了一个能用的 RAG。接下来这四步是调优层(第 3 到第 4 部分),而你要把每一步都跑一遍,不只是读它。每个学习者都做这些,就在你已经有的数据上,好让那份深度落成一项本事。它们彼此独立:任意顺序做、一个都别跳。
**5. 让它变快,看着索引挣回它的身价(概念 11)。**十个文档太小,小到不需要索引,所以你要自己造出规模,在一个用完即弃的分支上,看着检索在同一份数据上从慢翻转到快。粘贴:
在一个用完即弃的 Neon 分支上,创建一张基准表,往里填足够多的随机向量,越过约 10 万这个索引开始占优的门槛,不需要 embedding 或真实文本,这纯粹是为了造出规模。确保每一行都有自己独立的随机向量(常见错误是给每一行填入同一个向量,让 agent 用
count(distinct embedding)验证)。把它的体积控制在 Neon 免费存储之内;如果有助于装下,就给这张合成表用一个更小的向量维度。用EXPLAIN ANALYZE跑一次最近邻检索,把执行计划和耗时给我看。然后构建一个 HNSW 索引,为了不让构建慢到爬,先调高maintenance_work_mem,再跑一遍完全相同的检索。把两者并排放:运算符那一行和执行时间,前后对比。然后把ef_search调高调低,给我看延迟如何变化。我们做完后删掉这个分支,那能把存储回收回来。
完成标志:你亲眼看到 Seq Scan 变成 Index Scan using …hnsw…、执行时间在同一份数据上下降,而且你看着 ef_search 拨动了延迟。那就是 概念 11 的速度那一半,做完了。(有三件事看着像问题其实不是:在 10 万以上向量上构建 HNSW 索引要花几分钟,而不是几秒,那是预期之内,不是卡住,而调高 maintenance_work_mem 会明显缩短构建时间;给这张用完即弃的表用一个更小的维度,丝毫不改变这一课,因为索引扫描对顺序扫描、以及 ef_search 的延迟旋钮,在任何维度上行为都一样;这些随机向量能诚实展示速度,但不能展示真实召回率,因为随机点没有邻域结构,所以这里召回率数字不好不代表什么。召回率要用真实 embedding 对照你的评测集来判断,绝不要靠合成数据。你在做基准测试的是那个索引,不是你的检索质量。)
**6. 按含义和一个条件来过滤(概念 13)。**你那些手册文档落进自然的类别里(休假、报销、安全、入职、设备),所以你能真刀真枪地过滤:
给每一块标上它所来自文档的类别。给我们的检索加一个可选的
category过滤。把「我有多少天休假?」问两遍,一遍跨所有内容、一遍过滤到休假这个类别,把检索到的块怎么变化给我看。给category加一个 B-tree 索引,并用EXPLAIN ANALYZE确认那个过滤用到了它。
**完成标志:**带过滤的查询返回更紧凑、更切题的块,而且你在执行计划里看到了那个 B-tree 索引,概念 5 那个「同一个查询上的 WHERE 子句」的好处,被做实了。
**7. 抓住那个单凭含义会漏掉的精确词(概念 14)。**这里就是你亲身感受到混合检索为什么成了默认的地方:
在一个文档里放一个稀有的精确编号,比如在报销文件里放
EXP-2031。用只有向量的检索问「EXP-2031 是什么?」,把它排在第几给我看。现在给块文本加上全文检索、用 RRF 融合这两个列表,再问一遍,给我看精确匹配的排名怎么变化。然后把我们的五个评测问题再跑一遍「只用向量」对比「混合」,告诉我哪些变好了。
**完成标志:**你已经比较了那个编号在只用向量和混合检索里的排名,并让评测集显示净效果,于是你是凭证据决定用混合,而不是因为某个标题这么说。(在这么小的语料库上,向量检索可能已经把稀有编号排得很靠前;随着语料库变大、稀有 token 被更多块稀释,混合检索能弥合的差距会扩大。如果这里看不到明显移动,那是规模效应,不是失败;确认 RRF 查询能运行,再让评测对比给出最终判定。)
**8. 把一个租户与另一个隔开(概念 15)。**正是这道隔离,把它变成你可以同时卖给两个客户的东西:
给我们的块标上两个假装的租户,把文档对半分。写一条行级安全策略,让一个设为租户 A 的会话只能取到租户 A 的块。然后用一个普通的、非所有者的数据库角色来证明它(RLS 会被超级用户和表所有者绕过,所以用那个构建了表的管理员角色来测试会显示不出隔离,改用普通的只读角色):让 agent 替你创建这个角色(
CREATE ROLE+GRANT SELECT,通过SET ROLE或单独的 Neon 角色和连接字符串连接,不要手工配置),把会话设为租户 A、跑一个本来会匹配到租户 B 某个块的检索,显示它永远不回来,然后切到租户 B、显示出镜像的另一面。
**完成标志:**完全相同的查询,仅仅因为会话被设成哪个租户就返回不同的行,而且你是以一个非所有者角色来跑的(所以这道墙是真的)。那就是 概念 15 那句「在数据库里强制它」被做实,是 RLS,而不是一个你可能会忘的 WHERE 子句。
注意那个节奏,也注意它在那些难的部分上并没有变:**计划 → 审阅 → 执行 → 评测 → 迭代。**索引、过滤、混合、租户隔离,和第一次 RAG 构建是同一个循环,每一次唯一新的东西,是你在审阅什么(表结构、worker、索引计划、RLS 策略)。掌握那个循环,具体的 SQL 就不再要紧了,因为你总能让 agent 产出它,而你也总能判断它对不对,在任何深度上,而不只是那个轻松的深度。
第 6 部分:把你的 RAG 作为 MCP 工具发布
你已经构建了 search_quotes() 和 answer_question()(概念 9),并在 第 5 部分 里构建了它们的文档版孪生;这一部分把你想服务的那个包起来。现在只有你的代码能调用它们。把它们包进一个 模型上下文协议(Model Context Protocol,MCP)服务器,同一套检索就变成一个任何 agent 都能发现并调用的工具,Claude Code、OpenCode、Claude Desktop、Cursor,或你日后构建的一个 Digital FTE。MCP 是本书一再回到的那个开放标准:把能力写一次,每个 agent 都用同样的方式跟它说话。
这就是 概念 9 的承诺,检索是一个 agent 所凭借的可检索的上下文,被做实了。你的向量检索不再是埋在某一个应用里的一个功能,而成了一个可复用的能力:一个 agent 会去够的东西,就像它去够一个计算器那样。
你现在两个都见过了,它们做的是相反的活:
- Neon MCP 服务器(概念 4)是一个开发期的管理工具。它让你的 agent 在你构建时操作数据库,创建分支、运行 SQL、预览迁移。它不是给生产或终端用户用的。
- RAG MCP 服务器(这一部分)是你运行期的产品界面。它对外提供只读的检索,「搜索我的知识」、「据我的数据作答」,提供给你指向它的任何 agent。
第一个构建这个系统。第二个就是这个系统,提供给 agent。永远别把 Neon 的管理服务器交给终端用户。
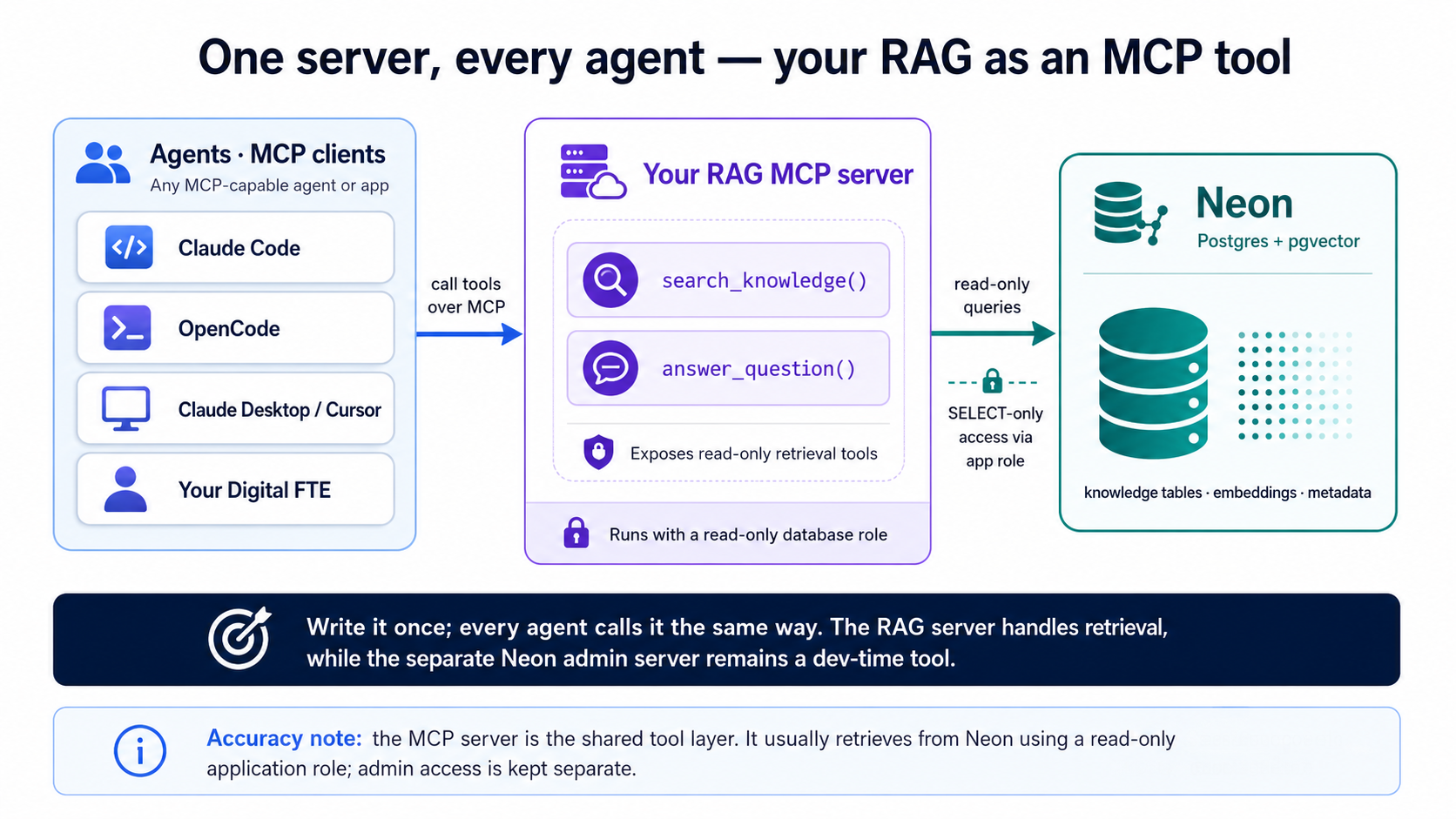
服务器长什么样
一个 MCP 服务器是一个小程序,它对外公布一份 agent 可以调用的工具清单。有了 FastMCP(那个标准的 Python 库,是官方 MCP SDK 之上一个薄薄的装饰器层),每个工具就只是一个带类型标注和文档字符串的函数;你不用写任何 JSON-RPC 的管道代码。一如既往,这由 agent 来写,摆出来是供你判断:
# server.py — your RAG, exposed as MCP tools (review material, not to type)
import os
from fastmcp import FastMCP
from rag import search_quotes, answer_question as rag_answer # your Concept 9 functions —
# renamed on import so the MCP tool below can keep the public name "answer_question"
mcp = FastMCP("agent-factory-rag")
@mcp.tool()
def search_knowledge(query: str, limit: int = 5) -> list[dict]:
"""Search the knowledge base by meaning and return the closest chunks.
Use this when you need grounded facts from the user's own data."""
# embeds `query` in app code, runs the Concept 8 search on Neon,
# returns [{text, source, score}, ...] — retrieval only, read-only role
return search_quotes(query, limit)
@mcp.tool()
def answer_question(question: str) -> str:
"""Answer a question grounded in the knowledge base (retrieve, then generate)."""
return rag_answer(question) # the Concept 9 pipeline
if __name__ == "__main__":
# Streamable HTTP, stateless — the production shape. The same file runs on
# your laptop and in the cloud; stateless means no session is held between
# requests, so it scales behind a load balancer. (host="0.0.0.0" binds all
# interfaces so a container can route to it; locally you reach it on localhost.)
mcp.run(transport="http", host="0.0.0.0", port=8000, stateless_http=True)
有两件事比其余的更要紧。文档字符串就是接口,它是发起调用的那个 agent 用来决定何时使用该工具的文字,所以它必须明白地说出这个工具做什么、何时该去够它。还有,检索始终只读:这个工具在一个只读的数据库角色下,跑 概念 8 那个参数化的检索,所以一个工具参数永远无法篡改或泄漏你的数据。第三行也值得看一眼,就是最后那一行,mcp.run(transport="http", …, stateless_http=True),它让这成为一个你可以托管的服务,而不是一个本地子进程;你接下来会先跑它,然后再把那同一个文件部署出去。
用你的 agent 来构建
和别处一样的方法,计划、审阅、执行。这也是你 配置 时那个 mcp-builder skill 挣回身价的时刻,点它的名,agent 就会照那个 skill 教的方式构建服务器。在 plan 模式下:
用 mcp-builder skill,把我们的检索包进一个叫
agent-factory-rag的 FastMCP 服务器。对外提供两个工具:search_knowledge(query, limit)返回最匹配的那些块连同它们的来源和相似度分数,以及answer_question(question)返回一个扎根的答案。复用我们现有的search_quotes和answer_question函数。从环境里读取 Neon 的池化连接字符串和模型 API key,并以一个只读数据库角色来连接。写清晰、面向动作的工具文档字符串,那正是发起调用的 agent 用来决定何时使用每个工具的依据。在写任何代码之前,先把计划和工具清单给我看。
读那份计划、确认工具清单和那个只读角色,然后批准并让它构建。
跑它,然后连接
这里和 Neon 管理服务器有一处不同:那个是客户端替你启动的;而这一个**由你启动,agent 连到它的 URL。**这就是生产形态,无论它跑在你的笔记本上还是云端都一模一样。启动它:
uv run server.py
它会持续运行,并打印出它在哪里提供服务,你会在那段横幅里看到 http://0.0.0.0:8000/mcp(0.0.0.0 只是表示「监听每一个网络接口」;你连它时用 localhost)。把它留在这个终端里开着,再开一个给你的 agent,并在 localhost 上注册它:
claude mcp add --transport http rag http://localhost:8000/mcp
用 claude mcp list 检查它;会话中途用 /mcp 重新连接。
往 opencode.json 里加一段 remote 块:
{
"$schema": "https://opencode.ai/config.json",
"mcp": {
"rag": {
"type": "remote",
"url": "http://localhost:8000/mcp",
"enabled": true
}
}
}
然后在一个提示词里直接说*「用 rag 工具」*就行,就是你从 概念 4 里 Neon 服务器那里熟悉的那套 添加 → 检查 → 使用 流程,只是这里你指向的是一个 URL 而不是一条命令。试试:
用 rag 工具来回答:大家关于纽约说了什么?把它最先检索到的块给我看。
看着 agent 调用 search_knowledge、把你的块取回来,并把它的答案扎根在那些块上。那个来回正是全部要点:你的数据现在成了任何 agent 都能据以推理的东西。
把它发布到云端
一个只有你能够到的本地服务器还算不上一个产品,而一个 MCP 工具本就该跑在任何 agent 都能调用它的地方。这正是从一开始就把它构建成无状态的回报所在:**把它部署出去,服务器本身不用改任何东西。**你把那同一个 server.py 推到任何能跑 Python 服务的主机上(Cloud Run、Render、Railway、Fly 上的一个容器,或你自己的 VM),在那里设好那同一批环境变量,并注册那个公开的 URL 而不是 localhost:
claude mcp add --transport http rag https://your-host/mcp
提交那个 .mcp.json,每个克隆了仓库的人都连到那同一个托管的服务器(Claude Code 会提示他们批准一次);在 OpenCode 里,把那同一段 "type": "remote" 块指向那个公开 URL。一旦不止一个人连接,就立刻加上 OAuth。
为什么无状态正是让这变安全的东西:每个请求都自带它自己的上下文,调用之间不保留任何会话,所以这个服务器能从容应对 serverless 的冷启,并作为负载均衡器后面的几个副本运行而不需要黏性会话,而一个不保留任何按用户对话的检索工具,在这上面分毫不损。你所构建于其上的那个传输,Streamable HTTP,是稳定的生产目标;唯一一处变动很快的细节是 FastMCP 那个确切的关键字,所以当 agent 写它时,让 mcp-builder skill 或实时文档来确认 transport="http" 和 stateless_http。无论哪种方式,Neon 的管理服务器始终是一个本地开发工具。
有几条规则要让 agent 遵守,并在审阅里确认:
- **只读角色。**检索工具永远只
SELECT。用一个不能写的数据库角色来连接,这样没有任何工具参数能删除或更改数据。 - **参数化查询。**查询文本作为一个绑定参数到达,从不被字符串拼接进 SQL,和 概念 8 是同一条规则。
- 多租户:永远别信任一个作为普通工具参数传进来的
tenant_id。从已认证的会话里推导它,并用 RLS(概念 15)来强制它,这样一个租户的 agent 就读不到另一个租户的向量。如果你在这个服务器读取的表上做过 RLS 练习(第 5 部分,第 8 步),还有一个坑:只读角色必须在每次请求中设置租户,否则 RLS 会正确返回零行,看起来像是没有结果也没有报错。请在每次请求里设置租户,或者在仍在学习时先让这个服务器指向一张未启用 RLS 的表。 - **信任那份配置。**一个本地 MCP 服务器*是另一台机器运行的一条命令。*只注册你信任的服务器,也只打开你信任的
.mcp.json/opencode.json文件;一份项目配置能在你的机器上启动一个进程。
而检索永远只和它背后的数据一样好,所以你的 评测集 依旧主宰全局:把它对准那个 MCP 工具,你衡量的就正是你的 agent 将会经历的那件事。
第 7 部分:它运行在哪里
| 在哪里 | 最适合 | 备注 |
|---|---|---|
| Neon(本课) | 从第一次构建到生产 | serverless Postgres、内置 pgvector、即时分支、自动扩缩。你什么都不用运维。 |
| Neon 分支 | 开发、预览、评测、基准 | 每个分支都是一个即时克隆,在 dev 上构建、预览、提交到默认分支。 |
| TigerData Cloud | Neon 的一个全栈替代品 | 「Agentic Postgres」:原生的 pgvector + pgvectorscale、Tiger MCP、即时零拷贝 fork。当你想要 StreamingDiskANN 的规模和过滤检索、又永远不必迁移时,选它。 |
**你不会被锁死在这些选择里。**你学到的是普通的 Postgres 加 pgvector,而 embedding 工作在数据库外部的 worker 里运行,所以这项技能并不专属于 Neon。同一套 schema、同一个 worker、同样的查询,可以跑在任何 Postgres 主机上:Supabase、Xata(也是带 pgvector 的 Postgres)、Amazon RDS、Azure Database for PostgreSQL(pgvector 加上一个为规模而设的托管 DiskANN 向量索引),或者你自己控制硬件上的 CloudNativePG 集群。
真正该如何选择主机(当你用完免费层之后再读)
不要按教程里的每 GB 价格选;先按工作负载形状选,再用你的流量去核账单。
- 突发或大量空闲(副项目、低流量助手、开发和评测分支):像 Neon 这样的按量计费 serverless 主机可以缩容到零,只在实际运行时收费。长时间空闲几乎不花钱。
- 持续在线、稳定流量(永不休眠的服务):固定实例价格通常比一个永不停表的计量表更简单、更便宜。一旦有什么东西让数据库一直醒着,缩容到零就不再有帮助,其中也包括一个持续轮询的 embedding worker(见上面的 worker 提示)。
- 一组数据库,或数据主权需求:自托管(在你自己的集群上跑 CloudNativePG)让下一个数据库的边际成本接近零,代价是你要自己运维它。
比标价更能决定选择的有两件事:免费层是否需要信用卡(很多时候不需要,这对学生很重要),以及升级路径是平滑斜坡还是悬崖(从几美元跳到下一档数百美元,是真成本,不是细节)。请在提供方当前的定价页上核实二者,这些数字会变,所以本课故意不写具体金额。
有几条值得提前向你的 agent 点明的生产现实:
- embedding worker 是一个真实的进程,它必须在运行,embedding 才能保持同步。在生产里,它是一个你部署并监控的服务,而不是你手工启动的东西。
- 迁移:在一个 Neon 分支 上做表结构和 worker 的改动、预览它们、然后提交到默认分支,agent 通过 Neon MCP 的迁移工具来驱动这件事。有版本、经审阅、可回退,绝不是一次针对生产的临时编辑。
- 成本住在 embedding 调用和生成调用里,两者都会打到外部模型 API。能批处理就批处理、能缓存就缓存,并用 模型匹配那个习惯,例行的生成用便宜模型,质量要紧的地方用强模型。
- **缩容到零对上 worker。**Neon 在空闲时把数据库缩容到零来省钱,但一个不停轮询的 embedding worker 会让它一直醒着,悄悄抵消了那份节省。对于低流量的应用,让 agent 把 worker 设成按计划运行(或批量 embedding),而不是密集轮询,这样你才真的拿到那份节省。
- **应用流量用池化连接字符串。**Neon 的池化端点(那个
-pooler主机,事务模式下的 PgBouncer)是为 serverless 和高并发应用打开的那许多短命连接而建的。让 agent 把你那个提供 RAG 服务的应用指向它;迁移和 worker 可以用直连字符串。 - **worker 在 Neon 之外运行。**你没法在 Neon 的托管计算上跑边车进程,所以 embedding worker 住在你的应用主机、一台小 VM,或一个定时任务上,通过连接字符串够到 Neon。告诉你的 agent 它该在哪里运行。
这是炒作背后真正的问题,而诚实的答案是通常不需要。如果你本来就在运行 Postgres,pgvector 让你的向量就在它们所描述的数据旁边,单一事实来源、过滤和连接查询都在同一个查询里、没有第二个系统要去同步、加固、付费。HNSW 从容覆盖约 10 万到 1000 万这个区间,而 pgvectorscale 的 StreamingDiskANN 延伸到超过十亿向量,所以纯粹的规模,已经很少再是它当年那个决定性因素了。对于大多数应用,Postgres 就是那个向量数据库。
一个专门的存储(Pinecone、Weaviate、Qdrant、Milvus 等)在你衡量出一个它能满足而 Postgres 不能的需求时,才挣得它的位置,比如十亿以上规模下极高的查询吞吐、你的基准显示 pgvector 没达到的某个特定的召回率 / 延迟目标,或者一个你宁愿租而不愿运维的全托管向量服务。那些是真实的情形;只是它们是少数。陷阱在于默认就去够一个,因为某个教程或某个标题这么做了。像你决定索引那样去决定它(概念 11):让你的评测集和一次在你真实工作负载(连同它的变动量)上的基准来拍板,并把第二个系统的常设成本与它实际带来的收益放在一起掂量。
第 8 部分:把它交给一个 agent
你已经构建了检索、并把它包成了一个工具(第 6 部分)。自然的下一步,是一个使用那个工具去完成真实工作的 agent,而那正是 构建 AI Agent 速成课接手的地方。你不会在那里重建这里的任何东西;你把你已经有的那个工具交给 agent。
整座桥就在一个想法里。那门课用 OpenAI Agents SDK 教那个 agent 循环:一个 Agent 是一个配备了指令和工具的模型,一个 Runner 驱动「模型 → 工具 → 模型」的循环,直到活干完。**你的 RAG 就是那些工具之一。**这门课结束的地方,一个可调用的 search_knowledge / answer_question,正是那门课开始的地方。
把你构建的东西接进去的两种方式(agent 课程负责那个循环;你只管提供工具):
- **作为 第 6 部分 的那个 MCP 服务器。**Agents SDK 能直接消费 MCP 服务器,所以你把 agent 指向你的
agent-factory-rag服务器,它的那些工具就自动出现在 agent 的工具箱里,就是你已经在 Claude Code 和 OpenCode 里注册过的那同一个服务器。 - **作为一个函数工具。**如果你更想把它留在进程内,就把那同一个只读查询包进 SDK 的
@function_tool,那门课原生的工具风格。同一套检索,表达成一个 agent 能调用的 Python 函数。
更深的那座桥:记忆对上知识。agent 课程把每个 agent 都围绕两个问题来构建:它能凭借什么(状态),以及它被允许做什么(信任)。一种状态是记忆,它从正在进行的对话里回想起的东西,那门课用**会话(sessions)**来处理。你的 RAG 提供的是另一种:知识,持久、可检索的上下文,它可以查阅,跨越远比任何窗口装得下的更多数据。会话保存聊天;你的 Postgres + pgvector 保存 agent 可能需要检索的一切。一个同时接上两者的 agent,既能记住刚说过的话,又能查阅它从不知道的东西,而本课那条「只取相关的块、把上百万行无关的挡在外面」的方法,正是让那些检索到的上下文不至于淹没窗口的东西。同一条主线,如今服务的是一个 agent 而不是一个应用。
用本书的话说,知识那一半就是 agent 的 记录系统,它从中读取(检索)、向其写入(worker 让它保持最新)、并据以验证(你的评测集)的事实基准。正是它,把一个流利的猜测者变成一个会执行的 agent。
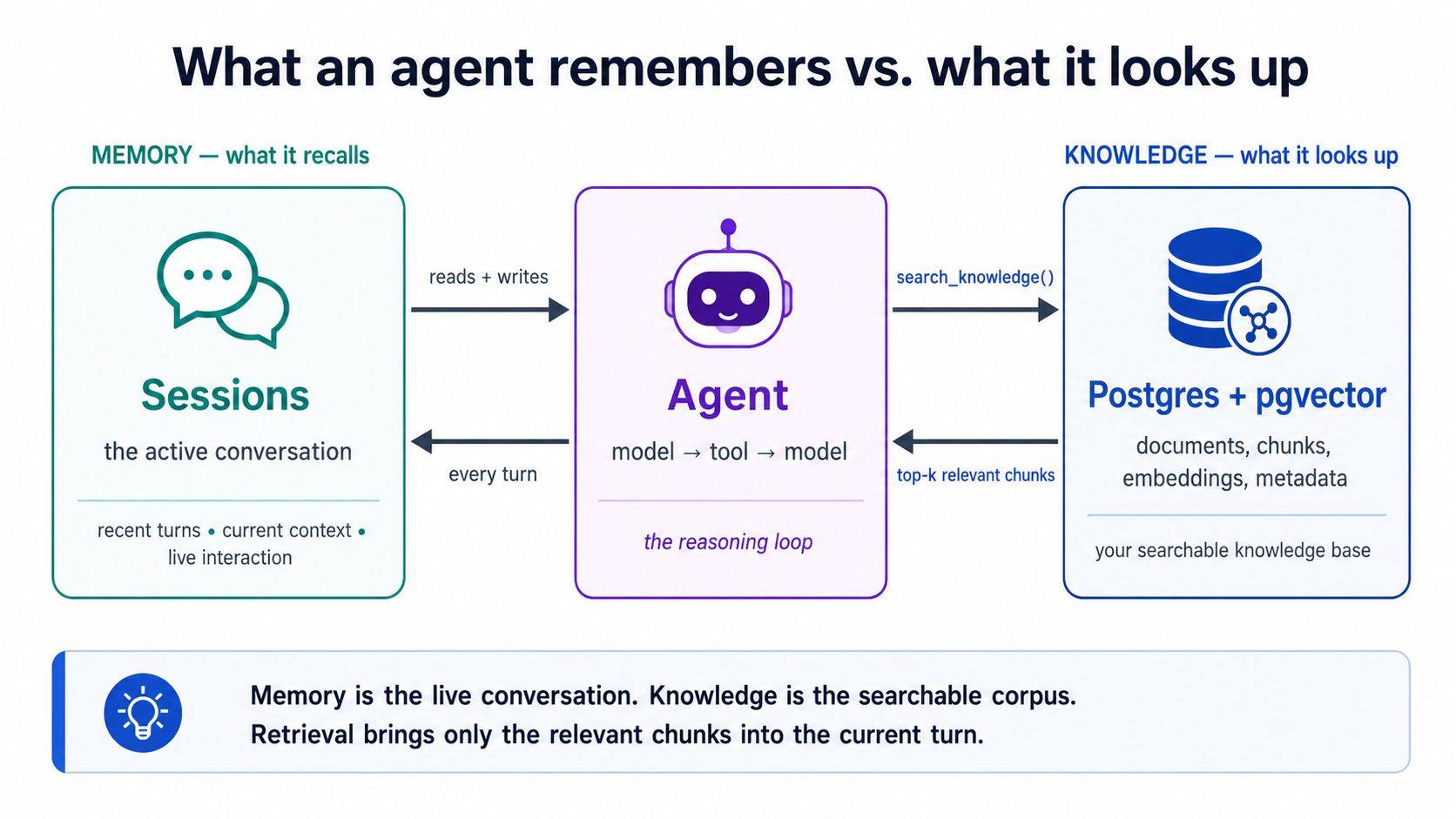
**像你构建别的一切那样把它接好,通过 agent。**在 plan 模式下:
搭一个出自「构建 AI Agent」速成课的最小 agent(OpenAI Agents SDK,一个
Agent加一个Runner循环)。只给它一个工具:我们的检索。要么把它连到 第 6 部分 的agent-factory-ragMCP 服务器,让search_knowledge和answer_question作为工具出现,要么把那同一个只读查询包成一个@function_tool,推荐哪个更合适并说明为什么。agent 自身的那套机制(会话、护栏、模型路由)留给那门课;在这里,只证明这个 agent 能调用我们的检索、并把一个答案扎根在它上面。先把计划给我看。
批准它、跑一个会逼出工具调用的问题,看着 agent 从你的 Neon(或 TigerData)数据库里检索、并据此作答。那就是这次交接:构建 AI Agent 教那个循环、那些护栏、那些会话和那次部署;这门课给了 agent 一些真实可说的东西。你的 评测集 完好地跨了过去,它依旧衡量着 agent 如今所依赖的那套检索。
接下来去哪里
你现在拥有了那 80%:你能把 Neon 变成一个向量数据库、构建一个扎根的 RAG 系统、凭证据选一个索引,并用过滤、混合检索和评测来改进检索,全都靠指挥一个 agent 并判断它的活。
- 让它可靠:评测驱动开发速成课
- 让它成为一个 agent:第 8 部分 把你的 RAG 工具接进一个 agent;完整的循环、护栏、会话和部署都在 构建 AI Agent 里
- **让它成为一个产品:**把这个助手变成一个可部署的 Digital FTE
那条主线从不改变:**恰当的信息、恰当的时刻、把无关的信息挡在外面。**你为你的 agent 学会了它。现在你能为别人的 agent 构建它。