这件事该交给 agent 吗?速成课
3 道关卡 · 3 次走错 · 一条清晰路径
两个人经营着一家小网店。周一,两人接到同样一份活:积压了 400 条客户消息,他们需要把这些消息分成几组(投诉、问题、订单、其他),并在周五前写一份简短的摘要。
Ana 在打开任何工具之前,先停下来想了 10 分钟。她问自己三个简单的问题。第一:这到底算不算 AI 的活,还是消息应用自带的搜索和筛选就能搞定?分组需要判断(判定什么才算「投诉」,不是一个简单的筛选器能做的事),所以,是的,这是一件 AI 的活。第二:这件事她是做一次,还是每周都做?每周。于是她记下一笔,打算以后搭一个能自己完成这件事的东西,眼下先手动做个快速版本,赶上周五。第三:做完的成果该长什么样?一份每条消息一行的电子表格,外加一页纸的摘要。她打开 AI 工具时,已经清楚地知道自己想要什么。
Yusuf 立刻打开 AI 工具,输入「帮我处理一下这些客户消息」。工具问他想要什么。他自己也不确定,于是边做边想。两个小时后,他得到一份自己也拿不准能否信任的摘要,没有办法在下周重复这项工作,而同样一堆消息又会在下个周一等着他,到时候,他还是只能手动分。
同样的活。同样的工具。Ana 在敲下任何字之前,先让这份工作过了三道关卡。Yusuf 则径直走进工具,让工具来提问。 这门课教的就是这三道关卡。
这门课适合谁
任何拥有这几款 AI 工具之一(Claude Code、OpenCode、Cowork 或 OpenWork)、手头有一堆真实工作、却不总能确定这件工作该不该交给工具的人。这门课处在中间地带:在你已经认识这些工具、见识过它们能做什么之后,但在你学会用它们解决真实问题之前。它讲的是,决定该把什么交给工具,以及工作该去往哪里。
这本书的读者遍布全球,他们用许多不同的语言工作和学习。本页的例子使用平实的语言和日常的场景(一家小店、一个装满文件的文件夹、一堆消息),无论你住在哪里,它们的含义都一样。你不需要了解任何一个国家的工具、法律或货币,也能跟得上。
general agent 是一种不只会说、还会做事的 AI 工具。它能打开你的文件、读取它们、写出新文件、运行小程序,还能替你使用其他应用。本书里的四个 general agent 是 Claude Code、OpenCode、Cowork 和 OpenWork:Claude Code 和 OpenCode 面向需要和代码打交道的人,Cowork 和 OpenWork 则面向其他所有人。一句话记住它:chatbot 回答你的问题,agent 去把任务做掉。整门课就建立在这一个差别之上。
读这一页之前,有两件事。第一,先完成 AI 时代如何思考:它教你在与 AI 协作时如何守住自己的判断。这门课不会重复那些内容。第二,至少完成一门工具课程,Claude Code & OpenCode 或 Cowork & OpenWork 都可以,这样你才见识过 agent 能做什么。在你弄清 agent 是什么之前,你没法判断「这是不是一件该交给 agent 的事」。
📚 教学辅助
查看完整演示文稿:这件事该交给 agent 吗?速成课
一句话原则
最便宜的错误,是你动手之前就发现的那一个。
这话的意思是:计划里的错误,改起来不花你一分钱,你只需改变主意。而等 agent 已经花了一小时做错事,你才事后发现的错误,会赔上你那一整个小时。所以,花功夫最聪明的地方,就是最开头,在你敲下任何字之前。
几乎所有和 agent 有关的差错,都是在这里、在最开头出的:
- 你用 agent 去做一件电子表格一步就能完成的事。
- 你每周手动做同一件事,连做了两个月,其实本可以搭一个东西替你做。
- 你打开 agent 时,对自己想要什么只有一个模糊的念头,于是它把活干得很漂亮,却干在了错的事情上。
这些都不是因为字打得不好。它们是因为从错误的地方起步。再多巧妙的措辞也救不了它们,因为对错误问题的完美回答,依然是错的。这门课给你三个检查(我们把它们叫作关卡),让你在动手之前,先让工作从中穿过。每道关卡都拦住一个常见的错误。
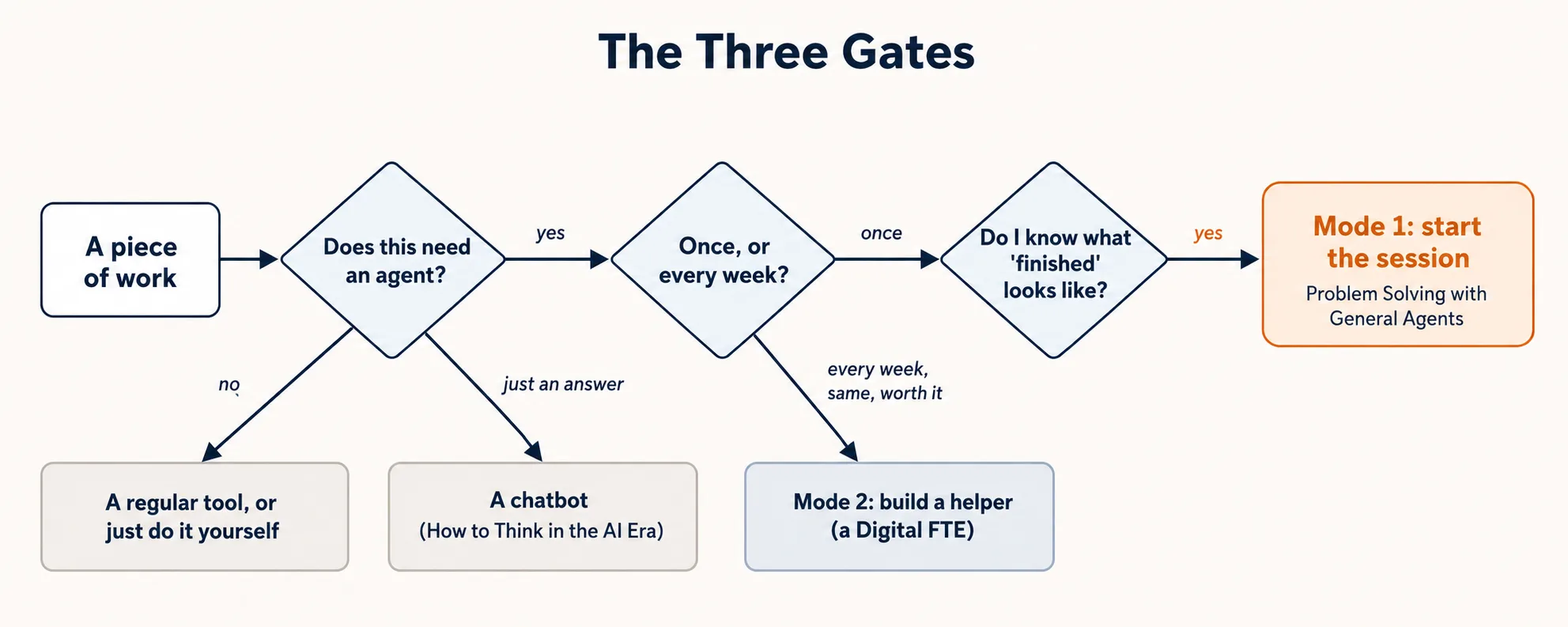 三道关卡,以及每个答案把你送往何处。大多数被浪费的时间,都来自直接跳到最后。
三道关卡,以及每个答案把你送往何处。大多数被浪费的时间,都来自直接跳到最后。
三道关卡,按顺序:
| 关卡 | 要问的问题 | 它拦住的错误 |
|---|---|---|
| 1 | 这件事到底需不需要 agent? | 用大工具做小事,或者用小工具做大事 |
| 2 | 一次,还是每周? | 为一次性的活搭帮手,或者把重复的活永远手动做下去 |
| 3 | 「完成」长什么样? | 漂亮的活,却瞄准了错误的目标 |
按顺序走。只有当关卡 1 说「需要 agent」时,关卡 2 才有意义;只有当关卡 2 说「现在就做」时,关卡 3 才有意义。跳过一道关卡,你就会犯它对应的那个错误。
这一页怎么读
| 你有多少时间 | 该读什么 |
|---|---|
| 15 分钟 | 一句话原则、上面那张图,以及每道关卡下的简短小结。足够你给下一个任务分类。 |
| 45 分钟 | 三道关卡连同例子,只读不练。 |
| 一整个工作日(最佳) | 全部内容,并用你自己这一周里的真实任务做每一个「轮到你了」。 |
只有把这些关卡用在你自己的工作上,它们才会真正留下来。阅读让你看清招式;在三个真实任务上做一遍,才能让它们变成习惯。
精简版(三条)
如果你只记住这三条,就已经抓住了大部分要点:
- 不是每件事都是 AI 的活,也不是每件 AI 的活都需要 agent。 如果一份电子表格、一个搜索框,或者你自己花 30 秒就能搞定,那就这么做。如果你只需要一个答案,那是 chatbot 的活。agent 适合的是那种模糊的、横跨不同类型文件、并且需要工具真的对你的文件、数据或应用动手做点什么的活,而不只是嘴上说说。
- 你多频繁做这件事,决定了一切。 只做一次的任务 → 打开 agent,解决,结束。每周都做、做法都一样的任务 → 别再手动做了,搭一个帮手替你做。世界上最常见的浪费,就是把一件「该搭帮手」的活,一遍又一遍地手动做。
- 在打开 agent 之前,先想清楚「完成」长什么样。 说清三件事:它从什么开始、你最终想要什么、以及那个能告诉你结果正确的检查。目标清晰,agent 就能命中;目标模糊,agent 会做出一个漂亮却错误的东西。
本页接下来的内容,会把这三条变成你真正能运行的关卡。
关卡 1:这件事到底需不需要 agent?
它拦住的错误: 「我花了 20 分钟让 agent 去做一件电子表格一步就能完成的事;或者我为了回答一个 chatbot 5 秒就能答上来的问题,竟然动用了一整个 agent。」
这道关卡有两个小检查,按顺序来。
检查 1a:它需要 AI,还是你手头已有的普通工具?
agent 擅长模糊的活:需要判断、混合了不同类型文件、而且没有哪个普通应用是为之而生的活。对于普通工具已经做得很完美的活,它们并不是最佳选择。
有一个简单的判断方法。如果你能把任务描述成每次都一样的、精确的一步,那普通工具多半更快、更可靠:
- 「把这一列数字加起来。」→ 这是电子表格的活。不是 AI。
- 「在我的联系人里找出所有姓 Khan 的人。」→ 这是联系人应用里的搜索框。不是 AI。
- 「把这份文档里的每个『2024』都改成『2025』。」→ 这是查找替换。不是 AI。
一旦任务需要判断(比如「按主题给这些消息分组」,你得自己决定每个主题到底是什么意思),或者混合了没有哪个应用能一并打开的不同类型文件(照片、PDF、截图),又或者根本没有应用能做它,那你就越过了检查 1a。这是一件 AI 的活。
检查 1b:它需要 agent,还是只要一个 chatbot?
这是人们最常跳过的检查。记住提醒框里那条规则:chatbot 回答,agent 动手做。
所以要问:这个任务需要工具去碰我真实的东西吗?
- 「解释一下借方和贷方有什么区别。」→ 这需要一个答案。它不碰你任何东西。这是 chatbot 的活。想从 chatbot 那里得到好答案,靠的是 AI 时代如何思考,而不是这门课。
- 「过一遍我那 400 条客户消息,把每一条放进一个分组。」→ 这需要工具去打开并处理你真实的文件。这是 agent 的活。
全部的区别就在于答案与行动。如果你只是想知道点什么,或者想要一份草稿、一些想法,那是「答案」类的活,交给 chatbot。如果你需要工具去打开你的文件、修改它们、运行某些东西,或者替你使用另一个应用,那是「行动」类的活,交给 agent。
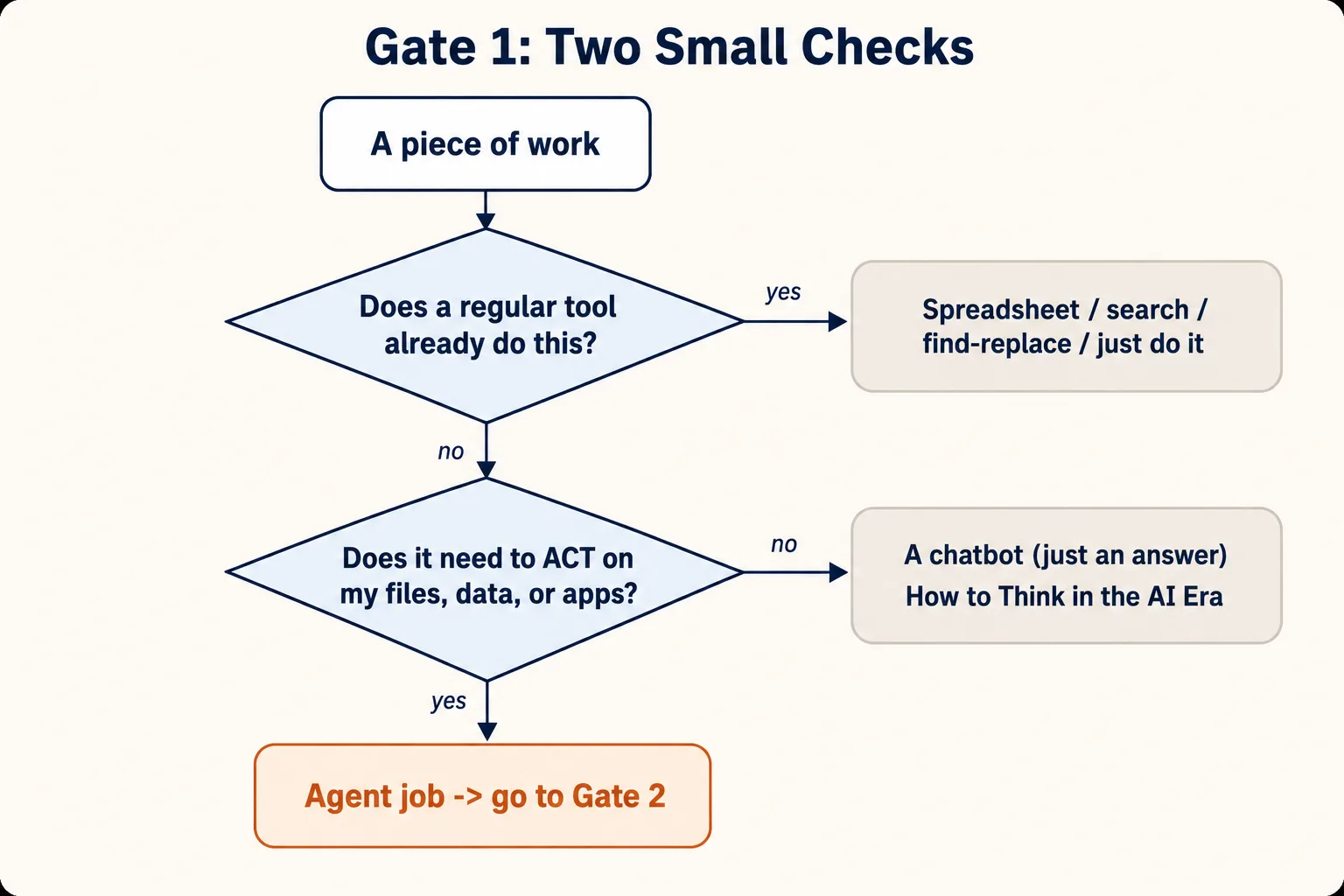 两个小问题,三个出口。只有最底下那个才是 agent。
两个小问题,三个出口。只有最底下那个才是 agent。
先看一个日常的例子
想想做饭。「鸡蛋要煮多久?」是一个答案:你问,得到一个数字,结束。这是 chatbot。但「看看我冰箱里有什么,帮我列一张这周三顿晚饭的购物清单」,需要有人真的去做好几件事。这才是 agent 该上场的那类任务。而「把我这张食品杂货小票上的价格加起来」两者都不是,那只是个计算器的活。
一个工作中的例子
Mei 在一家小公司帮忙打理办公室事务。同一个早上来了四份活。她把每一份都过一遍关卡 1:
- 「这份开支清单的总额是多少?」→ 电子表格加一下就好。连 AI 都算不上。停在 1a。
- 「解释一下什么是采购订单。」→ 她只需要一个答案,不碰她任何东西。chatbot。停在 1b。
- 「翻一遍这个账单文件夹,找出缺少签名的那些。」→ 这需要判断(逐一阅读),而且会处理她的文件。agent。通过关卡 1。
- 「把银行的付款清单和我们自己的清单对一下,告诉我哪些对不上。」→ 两份不同的文件,需要判断,会处理她的数据。agent。通过关卡 1。
她那四件「AI 任务」里,有两件根本不是 agent 的活。这很正常,也很好。关卡 1 的作用不是把活推向 agent,而是把不属于 agent 的活挡在门外。
轮到你了
从你自己这一周里挑五项任务,任何你曾想过「问问 AI」的事都行。给每一项写下它走哪个出口:普通工具、chatbot,还是 agent。然后用一句话写清为什么。
在下面列出你的五项任务。评分器会评估你的分类,并标出你最可能弄错的那一项,尤其是那些被送到「agent」、其实只需要一个答案的任务。
Discuss with an AI. Question your scores.
Come back when you have your BEST evaluation.
如果五项全都归到了「agent」,那你多半是在硬套,再看一遍,找出其中真正属于电子表格或 chatbot 的那一项。如果一项都没归到「agent」,这同样是一个真实的发现。也许这一周里就是没有 agent 形状的活。这没关系。
这为什么有效(背后的研究)(选读)
凡事都伸手去拿同一个心爱工具的本能,是有名字的。Abraham Kaplan 在 1964 年称之为工具定律(law of the instrument),两年后 Abraham Maslow 给了它那个著名的说法:如果你手里唯一的工具是一把锤子,那每个问题看起来都像钉子。agent 是一个强大又令人兴奋的工具,于是它成了新的锤子;而关卡 1 就是那个让你别拿它去敲螺丝的习惯。
同一个想法还有一个更量化的版本。Goodhue 和 Thompson 的任务-技术匹配(Task-Technology Fit)模型(1995)研究的是:为什么有些软件真的能改善人们的工作,有些却不能。他们发现,收益的大小,更多取决于工具是否匹配任务,而不是它有多好、多受欢迎。一个广受好评的工具用在错误的任务上,作用甚微;一个更朴素但匹配的工具,却能带来很多。关卡 1,就是把任务-技术匹配压缩成两个你 10 秒内就能回答的问题。
来源:Kaplan, A. (1964). The Conduct of Inquiry. Maslow, A. (1966). The Psychology of Science. Goodhue, D. L., & Thompson, R. L. (1995). "Task-Technology Fit and Individual Performance," MIS Quarterly, 19(2), 213–236.
关卡 2:一次,还是每周?
它拦住的错误: 「我为一件只会做一次的事,搭了一整个长期帮手;又或者,更常见的是,我每周手动做同一件事,做了好几个月,却从没意识到本可以搭一个帮手替我做。」
一旦关卡 1 说「需要 agent」,下一个问题就是:这是哪一类 agent 的活。这是全书最重要的一个想法,所以我们给这两类各起了个名字。
- Mode 1:解决一次。 你打开一个 agent,做完任务,拿走结果,然后走人。什么都不留下。大多数时候、大多数工作都是这一类。
- Mode 2:搭一个帮手。 你搭建一个长期的 AI worker,它会一次又一次地自己完成任务,不需要你每次亲自动手。(本书把这种 worker 称为 Digital FTE,即「数字全职员工」。)这需要更多的搭建功夫,只有当任务频繁回来时才值得。
怎么判断你面对的是哪一类?查三件事。把每一件都想象成一个可以调高或调低的旋钮。只有当三个旋钮全部调高时,一项任务才是 Mode 2:
- 多频繁? 这件事你只做一次或偶尔做(旋钮调低 → Mode 1),还是一遍又一遍、每周甚至每天都做(旋钮调高 → Mode 2)?
- 多一致? 它每次都是同样的形态吗?也就是同样类型的输入、同样的步骤、同样的成品(旋钮调高 → Mode 2);还是每次都不一样、需要重新思考(旋钮调低 → Mode 1)?
- 值不值得? 这件活够不够大,能不能抵回搭建帮手的功夫(旋钮调高 → Mode 2)?要权衡的不止是它多久发生一次,还有:每跑一次花你多少时间、它处理多少条目、出错的代价有多高、以及为了做它而中断其他工作的麻烦。一件你每周都做、但每次只花 4 分钟、只处理两个条目、就算耽误了也没什么损失的活,可能并不值得搭建。(这就是为什么这道关卡那个朗朗上口的名字「一次还是每周」只是一个触发器,真正的决定,藏在这个旋钮里。)
只要有一个旋钮处于低位(你很少做它,或者它每次都在变,或者它小到不值得折腾),就留在 Mode 1。只有当任务重复、每次一样、而且值得时,才去搭帮手。
 Mode 2 需要三个旋钮全部调高。任何一个处于低位,都会把你留在 Mode 1。
Mode 2 需要三个旋钮全部调高。任何一个处于低位,都会把你留在 Mode 1。
最昂贵的错误
关卡 2 有两种错法。为一件一次性的活搭一个长期帮手,是其中较小的错误:你浪费一个下午,然后察觉到,再继续往前走。
昂贵的那种很安静,而且几乎每个人都会犯:把一件 Mode 2 的活,一遍又一遍,永远手动做下去。
它之所以藏得住,是因为每一次都感觉很小。每个周一,你花 25 分钟让 agent 收集这一周的消息、分类、写一份摘要。每次都跑得挺好。你从没把它们加起来算过。但一年下来,那就是 20 多个小时,手动花在一件重复、每次一样、显然值得一次性搭建的活上。你之所以一直没搭那个帮手,是因为没有哪一个单独的周一,大到足以让你停下来做决定。
解决办法,是把这个决定变成一个刻意的检查,而不是一件你等着「感觉到」的事。Randall Munroe 有一幅很有名的老漫画,叫「Is It Worth the Time?」(xkcd 漫画 1205)。它画了一张简单的表:如果一件任务经常重复,你可以花上相当多的时间去搭一个东西来做它,整体上仍然省时间。你不需要那些精确的数字,你只需要这个习惯。所以,简单的规则是:
当你用同样的方法第三次做同一件任务时,停下来,运行关卡 2。 如果三个旋钮都调高了,那你其实已经不再是在解决一个问题,而是在充当那个你还没搭出来的帮手。这就是把它升级成 worker 的信号。
一个工作中的例子
David 在一家 12 人的公司打理日常事务。有两件看起来都在重复的任务:
- 为新员工设置账号和访问权限。 这件事大概每隔几个月才发生一次,而且每个新人都有点不一样:不同的岗位、不同的应用、不同的特殊情况。多频繁?低。多一致?低。 两个旋钮处于低位。这件事留在 Mode 1:每次都用 agent 重新解决。一个僵化的帮手,第一次碰到不寻常的入职者就会崩。
- 周一的消息摘要。 每周一次,同样类型的输入,同样的成品,每次花 25 分钟。多频繁?高。多一致?高。值不值得?值。 三个旋钮都调高。这是 Mode 2。David 的做法,是把它升级成 worker:先持续手动解决,直到方法被验证成熟,再把它提升上去,让它不需要他也能运行。From One-Off to Worker 会教你怎么做。
同一个人,同一周,两个相反的答案。新员工那件事看起来在重复,但它没过「多一致?」这个旋钮。周一摘要则三个都过。关卡 2 正是把两者区分开的东西:在你为第一件事过度搭建、或者为第二件事手动做满一年之前。
轮到你了
列出三项你用 agent 做过不止一次的任务。给每一项设好三个旋钮(多频繁、多一致、值不值得),并写出答案:Mode 1 还是 Mode 2。
在下面列出你的三项任务,连同它们的旋钮和结论。评分器会检查你的旋钮设置是否真的支撑每一个 Mode 1 或 Mode 2 的判断,并标出任何其实每次变化太大、不适合交给僵化 worker 的「Mode 2」任务。
Discuss with an AI. Question your scores.
Come back when you have your BEST evaluation.
那个让你意外的任务,也就是你一直手动做、结果发现其实是 Mode 2 的那个,是你在整页里能找到的最有价值的东西。那些,是你即将拿回来的时间。
这为什么有效(背后的研究)(选读)
关卡 2 是一条穿了新衣服的老规则。在软件领域,Martin Fowler 的《重构》(Refactoring,1999)让三次法则(Rule of Three)广为人知,他把这条法则归功于 Don Roberts:第一次做某件事,你就直接做;第二次,尽管它重复了,你还是再做一遍;第三次,你才停下来,构建可复用的版本。第三次重复才是信号,而不是第一次,因为太早动手意味着在你还没看清模式之前就构建了错误的东西。这正是关卡 2 的触发器:当你用同样的方法第三次做同一件任务时,停下来,决定要不要搭那个帮手。
「值不值得?」这个旋钮呼应了第二条广为人知的告诫。Donald Knuth 那句「过早优化是万恶之源」(1974)真正讲的是功夫:在你确定某件事值得自动化之前,别把功夫都倒进去让它自动化。为一件你只会做一次的任务搭一个长期帮手,正是这个错误的反面。而自动化到底什么时候划算,那套粗略的算术,被 Randall Munroe 的「Is It Worth the Time?」表格(xkcd 1205)概括了:一件任务重复得越频繁,你能花在搭帮手上、并且整体仍然省时间的时间就越多。
来源:Fowler, M. (1999). Refactoring: Improving the Design of Existing Code (Rule of Three, attributed to Don Roberts). Knuth, D. E. (1974). "Structured Programming with go to Statements," ACM Computing Surveys, 6(4). Munroe, R. "Is It Worth the Time?", xkcd 1205.
关卡 3:「完成」长什么样?
它拦住的错误: 「agent 干得很漂亮,只是那不是我需要的活,而我直到它已经做完才发现。」
你已经判定这是 agent 的活(关卡 1),而且你会解决一次(关卡 2)。打开 agent 前的最后一道关卡:用文字写下完成意味着什么,三行就够。
- 处理对象(输入)。 agent 到底该看什么:哪个文件夹、哪些文件、哪些消息。要具体。「我的邮件」太模糊,「我 Support 文件夹里最近 7 天的 400 条消息」才清楚。
- 最终产出(输出)。 完成时你希望存在的那个东西:一份电子表格、一页纸的摘要、一个重命名好的文件夹。说清它的形态,而不只是主题。
- 判定完成的那个检查(完成判定)。 你看一眼就能知道任务已完成且正确的那一件事。例如:「每条消息都只属于一个分组,各分组的数量加起来正好是 400。」为真,你就完成了;不为真,就还没完成。
就这些,三行而已。你还没有在写完整的指令,也没有在告诉 agent 怎么做这件活。你只是在确定目标,这样当 agent 命中它时,你能知道。
关卡 3 决定的是完成长什么样,也就是目标。你在 agent 干活时真正给它的指令(怎么措辞、要求表格、检查结果)会在下一门课 使用 General Agents 解决问题 里讲。可以这样想:关卡 3 是选定目标,下一门课是学会命中它。在这里选好目标,然后去那门课学怎么瞄准。
 动手之前,先写三行。agent 能命中一个它看得见的目标。
动手之前,先写三行。agent 能命中一个它看得见的目标。
一个工作中的例子
回到开篇的 Ana,还有她那 400 条客户消息。(她的任务有一个 Mode 2 的未来,但在那个 worker 还没出现之前,她每周仍然要解决它一次,所以关卡 3 对每一次运行都适用。)打开 agent 之前,她写下这三行:
处理对象: 我 Support 文件夹里最近 7 天的 400 条消息。
最终产出: 一份电子表格,每条消息一行,列包括:发件人、日期、分组(投诉、问题、订单、其他之一)、一行摘要。另外再加一页纸的说明,写明每个分组的数量,以及最常见的三类投诉。
完成判定: 每条消息都只属于一个分组,各分组的数量加起来正好是 400,而且说明里的数字和电子表格对得上。
现在她打开 agent。当结果回来时,她有一个精确的办法去检查它是否真的完成了,而那个完成判定(「数量加起来正好是 400」)是她或 agent 几秒钟内就能确认的。Yusuf 当初打开 agent 时只说「帮我处理一下这些消息」,这些他一样都没有。这正是为什么他的结果是一个他既无法信任、也无法检查的东西。
轮到你了
拿出你最近一次交给 agent 的真实任务,或者你接下来正要交给它的那一个。写下这三行:处理对象、最终产出、完成判定。然后,认真盯着那条完成判定:你真的能检查它吗?你或 agent 能在一分钟内确认它吗?如果你的完成判定是「摘要写得不错」这种模糊的说法,那它还不是一个真正的检查。把它磨得更锋利,直到它变成一个你能清楚验证的东西。
在下面写出你的三行。评分器最锋利的检验,是你的「完成判定」那一行:它是你真的能在一分钟内检查的东西,还是一个伪装过的模糊意见?
Discuss with an AI. Question your scores.
Come back when you have your BEST evaluation.
这为什么有效(背后的研究)(选读)
几十年来关于目标的研究都指向同一个方向。Edwin Locke 和 Gary Latham 的目标设定理论(在他们 2002 年发表于《American Psychologist》的论文中有总结)通过数百项研究发现:具体、可衡量的目标,比模糊的「尽力而为」目标带来好得多的表现,因为一个具体的目标会精确地告诉你该瞄准什么、以及你究竟在什么时候命中了它。给 agent 一个模糊的指令(「写一份好摘要」)就是一个「尽力而为」的目标。这三行,把它变成了一个具体的目标。
软件团队在实践中得出了同样的结论,并给它起了个名字:完成的定义(Definition of Done)。在工作开始之前,团队先就「一项任务算完成」的确切清单达成一致,这样「完成」就成了一个共享的、可检查的事实,而不是事后争来争去的意见。关卡 3 就是你为单个任务准备的个人版「完成的定义」:在 agent 动手之前写好,让它有一个看得见的目标。
来源:Locke, E. A., & Latham, G. P. (2002). "Building a Practically Useful Theory of Goal Setting and Task Motivation," American Psychologist, 57(9), 705–717. "Definition of Done" — standard practice in Agile/Scrum software development.
现在,用一件真实任务跑完全部三道关卡
在你一口气把一件真实任务推过全部三道关卡之前,这些关卡都只是理论。
挑一件你现在就需要做的事。把它走一遍:
- 关卡 1。 普通工具、chatbot,还是 agent?如果它在到达「agent」之前就停下了,你刚刚为自己省下了一整次会话:用对的工具,继续往前。
- 关卡 2。 如果这是 agent 的活:做一次(Mode 1),还是搭一个帮手(Mode 2)?如果三个旋钮都调高了,那它就是一件 Mode 2 任务:先持续手动解决,直到方法不再变化,再把它升级成 worker。From One-Off to Worker 会告诉你它什么时候算成熟、以及如何把它提升上去。
- 关卡 3。 如果这是一件解决一次的 agent 活:写下那三行。处理对象、最终产出、完成判定。
如果这件任务一路走到尽头时是 agent、是 Mode 1、三行也写好了,那就这时候才打开 agent。然后,你就带着一件已经分好类、清晰明确的任务,走进 使用 General Agents 解决问题,去学真正解决它的七条原则。
这为什么重要。 这些关卡大约花 10 分钟。它们避免的错误,要花掉一个个下午,而 Mode 2 那类错误,要花掉一个个月。这就是全部的交换:动手前花一点心思去想,换回你本来会因为从错误的地方起步而损失的那些时间。
第一个决定,从来都不是怎样和 agent 对话。而是要不要、这是哪一类活、以及朝着什么。把这一步做对,和 agent 对话的那部分就变得简单了。
每个答案把你送去哪里(一张参考卡)
这三道关卡为你的工作指了路,却自始至终没点名任何一个工具,这是有意的。你落到哪道关卡是不变量,你用哪个工具是变量,而工具每隔几个月就会变。下面是这个变量在 2026 年的样子。请从你落到的那道关卡读起,而不是反过来读。
| 关卡把你送到了哪里 | 它意味着什么 | 该用的工具(2026) |
|---|---|---|
| 只要一个答案(关卡 1 → chatbot) | 你需要的是知识、一份草稿,或一些想法。你的东西不会被碰到。 | claude.ai、ChatGPT 或 Gemini。这方面的本领,靠的是 AI 时代如何思考。 |
| 解决一次(关卡 1 → agent,再到关卡 2 → Mode 1) | 一个你在会话里驾驭的 agent:它动手,你看着,你交付,然后走人。 | Claude Code 或 OpenCode(终端或代码编辑器);Cowork 或 OpenWork(桌面应用)。这正是 使用 General Agents 解决问题 所教的。 |
| 拥有这个 worker(一个关于所有权的选择,而不是一种 mode) | 你想要一个自己运行、自己拥有的长期 worker:它能跨越数周记住事情,还能在你睡着时替你回应。 | 一个个人 harness(一种让 worker 持续运行、并为你保持记忆的软件):OpenClaw,它能在许多聊天应用里找到你;或者 Hermes,它能深度记住你的工作。参见 Personal Agent Harnesses。 |
| 制造它(关卡 2 → Mode 2) | 一个为组织而造的 worker:一个 Digital FTE(「数字全职员工」),被部署来可靠地、大规模地运行。 | OpenAI Agents SDK,或一套托管的 Claude agent 配置。这就是整条 Mode 2 — Manufacturing 路线;Choosing Agentic Architectures 能帮你挑选。 |
唯一容易混淆的地方。 第三行和第四行都是「一个不需要你也能运行的长期 worker」。把两者区分开的,是这个 worker 是为谁服务的。如果它是为你自己服务的(你的收件箱、你的代码、你的日常杂事),那是一个个人 harness,你并不需要整条 Mode 2 路线就能搭出它。如果它是为一个组织服务的(被部署、被治理、为规模化而生),那就是 Mode 2。同样的活动,不同的所有者。
而且,拥有一个个人 harness 并不是第三种 mode。它是一个独立的所有权问题:在你拥有的 harness 之上,你既可以跑 Mode 1(解决一次性的活),也可以跑 Mode 2(构建能长期使用的东西)。这是两个独立的问题,而且它们永不冲突:所有权问的是「我是驾驭它,还是拥有它?」;mode 问的是「我是解决一次,还是构建一个能长期使用的东西?」。
还是拿不准哪个工具合适?本书在 2026 年你应该使用哪些 AI Employees 里持续维护着一份对比。
Flashcards 学习辅助
知识检查
对你刚刚走过的这些想法,做一次快速的分关自测。