人类与 Agent 团队:你的劳动力运行模型
这门课讲的是一个团队运行模型:让一组 AI 工人与人类并肩工作。它建立在一个可信的单个工人之上,也就是一个 Digital FTE:它能运行循环,基于可搜索的记忆工作,用自己的身份登录,并在边界处升级。你会在这条学习路径中构建这个工人;也可以先在纸面上写出这个运行模型,再等真实工人上线后接上去。一个可信工人是单位。运行一支由它们组成的团队,是一项不同于构建单个工人的技能;这门课讲的就是这项技能:如何把一个变成多个。
多人的团队不是一个工人的放大版。它是另一种东西,也需要另一种技能:不是构建工人,而是让这些工人与人类一起作为团队运行。
这门课就是那个运行模型。后面的四门劳动力课程是运行在它上面的机器:一个会雇用 board 的 lead agent(Workforce with Paperclip)、一个会自我扩张的劳动力(Self-Expanding Workforce)、委托式审批(Identic AI)、能赚钱的工人(Payment-Enabled Agents)。如果你还不会运行团队,这些机器都无法正常工作。因此,在自动化劳动力之前,你要先规定人类和工人如何共享同一份 roster、同一个 workspace 和同一个目标。
关于这门课类型的说明。 其他劳动力课程是边做边学。这门不是。你在这里几乎不会写代码。你会像经理一样写运行文档(roster、role cards、north star、verification rubric),区别只是由 agent 起草,你来决定。交付物是团队据以运行的协议。它们没有代码那么耀眼,却更关键:大多数人类与 agent 团队不是败在技术上,而是败在实践上。
它也是这一节里最容易进入的一门课。角色、目标、信任、谁拥有哪个部分,这些都是你从和人共事中已经理解的东西。Agent 不会改变这些基本面。它们只是提高了做错的代价。
这里的模式来自 Anthropic 对其内部运行人类与 agent 团队的描述,并映射到本书已经建立的框架上(完整链接在文末的 Sources 中)。凡是 Anthropic 报告了具体结果,都是它们的结果,并明确注明为 Anthropic 的结果。它依赖的能力(在共享团队工具中工作的 agent、带有自身凭据和记忆的 agent)正是你在这条路径中会构建的能力。
📚 教学辅助
查看完整演示文稿 — Human-Agent Teams
你将构建什么(artifact 集合)
不是一个应用,而是一组团队运行所依赖的运行文档。starter 会把每一份文档作为模板给你;你在 agent 的帮助下填完它们。
- team roster:每个成员,无论人类还是 agent,都包含角色、owner、工具和 autonomy level。
- 每个 agent 的 role card:它拥有什么、不拥有什么、它的工具、如何检查它的工作、什么时候升级。
- working agreement:什么默认公开、少数安全边界是什么、什么保持私密。
- north-star doc:团队的一个雄心目标,以及哪些 agent 可以在无需提示的情况下据此行动。
- verification rubric:如何给工作产出评分,从而不需要人类逐行阅读也能信任。
- doer-verifier setup:第二个 agent,唯一职责是检查第一个 agent。
- weekly report:「lessons and missteps」日志,让团队持续改进。
- attention budget:你审查什么、什么会被批量处理、到达你这里的内容上限是多少。
设置
- 下载 starter(
human-agent-teams-starter.zip)并解压。它是一组模板,不是代码。用任意编辑器打开。 - 最好已经有一个 Digital FTE(Building a Digital FTE),可以围绕它运行真实团队。还没有工人?没关系:用规划模式完成这门课(见下面的说明),等工人存在后再把手册接到真实工人上。
- 准备一个团队能看见工作的位置:共享频道、文档库或仓库。Agent 会从那里写下来的内容中读取。
- 准备好和你一起起草的 agent(claude.ai、Cowork 或你的工人)。starter 中每个 artifact 都按同一节奏填写:你指挥,agent 起草,你决定。
从这里开始,每一部分都会讲一个实践,然后让你写出把它落地的那份文档。你不会只在理论上被测验;你会带走一份团队操作手册。
这门课假设你的工人已经能读取团队的书面记录。现在测试一下:让你的 agent 找到上周某个不属于它的频道里的决定或文档。如果能找到,你就准备好了。如果返回空结果,说明你还没有完成 AI Searchable Context 中的可搜索 system of record。先完成它。没有它,这里的每个实践都没有东西可读。
即使还没有技术栈,你也可以完成整门课:用 claude.ai 或 Cowork 作为起草 agent,写出所有运行文档,并把每个 agent 角色标记为 "planned" 而不是 "active"。你会得到一份纸面上的完整操作手册。等第一个工人构建完成后,再回来把 planned 角色换成 live 角色。
第 1 部分:从一个工人到一支团队
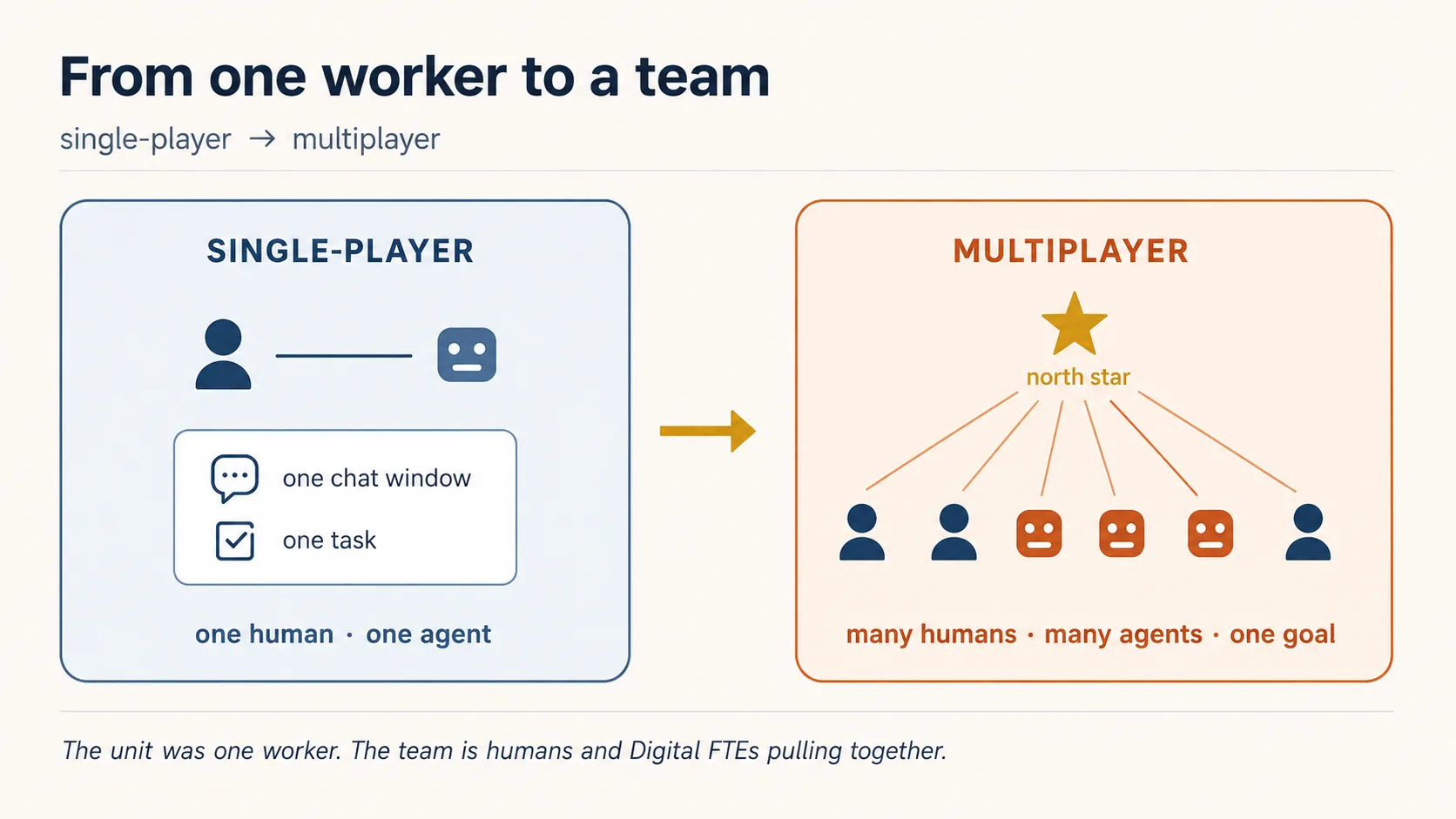
概念 1:Single-player 已经结束
过去,与 AI 共事是 single-player:一个人、一个聊天窗口、一个任务。Digital FTE 已经不止如此。这门课建立在一个转变之上:走向 multiplayer,也就是很多人和很多 agent 在同一个 workspace 中,朝共同目标拉动。人类制定战略,agent 执行。
multiplayer agent 是能同时与多个人协作的 agent。像 Digital FTE 一样,它有自己的记忆和技能。不同于聊天窗口,它有自己的凭据(不是借用某个人的凭据),并且生活在工作发生的地方:团队频道和文档里,而不是某个私有会话里。
单位是 Digital FTE。团队是人类和 Digital FTEs 共享同一份 roster。团队就是业务本身。
概念 2:一个工人需要的组成部分
只有当每个 agent 都具备三样东西时,团队才真正能工作,而这条路径会构建这三样:
- 持久记忆:让它能跨天持有目标,而不是只在一个 prompt 里记住(AI Searchable Context)。
- 自己的身份:不绑定到人类的凭据,让它在你设置的 guardrails 内行动,而不是借用某个人的登录(AI Identity)。
- 广泛、可搜索的访问:让它从写下来的内容中学习组织如何运作(你的 Postgres system of record 和 RAG:retrieval,也就是你给它的可搜索记忆)。
没有这些,「给团队增加一个 agent」就等于某个人把自己的密码分享给一个脚本。有了这些,它才是属于 roster 的工人。你现在就可以设计运行模型,等这三样能力上线后再接到真实工人上;人类实践无论如何都在其上运行。
✓ 检查点:你知道单位是什么。 具有记忆、身份和访问的工人,正是组成团队的东西。现在要让多个这样的工人与人一起工作。
概念 3:稀缺资源是人类判断
整个运行模型只保护一件事:人类注意力和判断。Agent 快而多;人类既是瓶颈,也是权威。这门课中的每个实践,都是为了让人类只决定那些只有人类该决定的事,并远离其他一切。
先给失败模式命名,因为它最常见。没有运行模型时,人们会在旁边各自运行一支个人 AI 小队。工作被重复。团队上下文碎裂成别人(无论人类还是 agent)都看不见的私有窗口。所有人都需要的指标被算出五种不同版本。修复方法不是更多 agent,而是运行一个公开工作的团队。
接下来的课程就是四个实践,正是为了做到这一点。
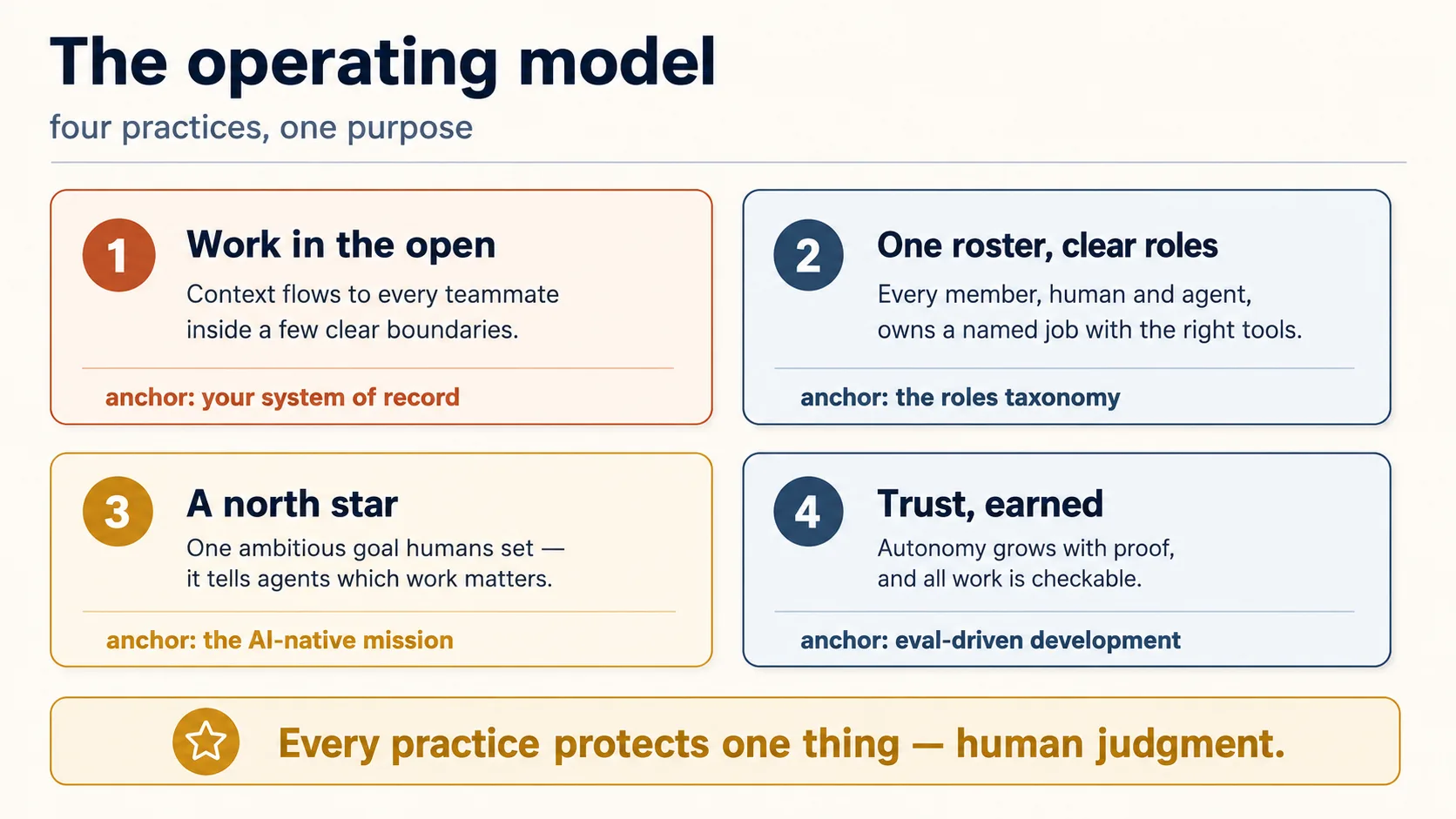
✓ 检查点:你知道形状了。 四个实践,一个目的。接下来是第一个实践。
第 2 部分:公开工作
概念 4:没写下来,就不存在
Agent 完全从团队变得可搜索的内容中建立理解:频道、代码、文档、笔记。私信、走廊对话和受限文件不会到达它那里。对 agent 来说,没写下来的东西就是不可见的。
因此,第一个实践先是文化问题,然后才是技术问题:公开工作。决定落在频道和文档里,而不是私信和没有记录的会议里。写 artifact 时要让 agent 能找到:agent 现在是你文档的主要读者,而不是事后才考虑的对象。
回报是真实的,Anthropic 说得很直白。能读取团队决定的 agent 不会再提你已经杀掉的工作。能读取另一个团队 specs 的 agent 会复用已经奏效的模式。又因为 agent 读得远比任何人快,它会经常浮现人们本来会错过的相关工作。透明不再只是美德,而是杠杆。
概念 5:边界在 workspace,而不是文档
有一种错误方式来决定 agent 能看什么:逐个文档、逐个频道判断。这会让人类和 agent 都产生决策疲劳:这个该私密吗?我能分享那个文档吗?这个 agent 能进那个 thread 吗?按条目划软线,既累人又容易出错。
正确方式是:在 workspace 层画出少数清晰的安全边界:安全边界就是一堵围住一组信息的墙,并带有谁在墙内的规则。在一个边界内,上下文流向每个队友,无论人类还是 AI。少数清晰线条胜过大量柔软线条,并且移除每天「我能分享这个吗?」的税。
这正是你的 system of record 证明价值的地方。边界是墙;来自 AI Searchable Context 的可搜索存储,是在墙内自由流动的东西。只画一次墙;剩下交给 retrieval。
把例外说清楚,因为 public-by-default 不等于 everything-is-public。有些工作很敏感,只属于一个人类和一个 agent 之间。那就是发给 agent 的私信,或通过个人 connectors 进入的私有应用(claude.ai、Cowork),对话保持私密。默认开放;为不能开放的东西保留一条清晰、狭窄的通道。
起草它。 打开 01-working-agreement.md,把下面内容粘贴给你的 agent:
为我的团队起草一份 working agreement。说明什么默认公开。列出我们需要的少数安全边界(不要超过几个)以及谁在每个边界内。列出什么保持私密(一个人类,一个 agent)。对每个边界,写一句新队友能照着执行的话。
检查它。 你能用一句话说清每个边界吗?如果不能,边界就太多了。必须少而清晰,否则守不住。
✓ 检查点:上下文可以流动。 你的团队在 agent 能读取的地方工作,并位于任何人都能说清的少数墙之后。现在给工作命名。
第 3 部分:一份 roster,清晰角色
概念 6:团队有 roster
人类与 agent 团队共享一份 roster、一组 artifacts 和一个工作空间。因此,把 roster 写下来:每个成员,无论人类还是 agent,以及每个人拥有什么。
Agent 持有不同角色。一个拥有数据分析,一个持有并执行设计标准,一个负责 research synthesis。当项目开始时,人类会和 agent 交谈,决定要分配哪些角色以及它们如何一起工作:roster 是那场对话的输出,而不是提前猜出来的东西。
这是你的 Roles Taxonomy 和 Digital FTE taxonomy,在一个团队中变得具体。catalog 说明可能存在什么种类的工人;roster 说明哪些工人在这个团队里,以及谁拥有什么。
概念 7:角色是一张卡,也是一份 skill 文件
每个 agent 都得到一张 role card:它拥有什么、不拥有什么、需要的工具和访问、如何检查它的工作、什么时候升级给人类。Scope 既关乎「owns」,也关乎「does not own」:边界模糊的 agent 会滑进别人的工作。
把工具命名出来,因为没有工具的角色只是没有手的头衔。analyst 需要 database。QA agent 需要 browser tool。列出每个角色需要的访问,并且只授予那些访问(least privilege 是你在委托审批中还会再次遇到的同一条规则)。
然后把角色写成一份 skill file。这是让本书框架真正扣上的动作:在 skill 中定义一个 agent 的角色,该角色就变得可移植。组织中任何人都可以从它站起另一个同类型 agent。角色不再是组织结构图上的方框,而变成了可以复制的技能。(技能是贯穿整本书的可移植杠杆;角色只是 skill 可以承载的又一样东西。)
把 human-only 角色保持明确。人类和 agent 在同样的 threads 中工作,但人类持有只有人类能持有的角色:有后果的决定、有成本的判断。Roster 是你把人类判断留在需要它的决定上,并从不需要它的决定中移开的方式。
当一个 agent 需要另一个 agent 时
有时一项工作对一个工人来说太大,lead agent 会生成带有正确上下文的队友来处理子任务:这里一个 researcher,那里一个 reviewer。这个直觉是对的,也正是下一门课要自动化的内容:Workforce with Paperclip 把「lead hires a board」变成一个在预算和审批下运行的托管劳动力。你的 roster 和 role cards 是它的输入。在这里,你先手写角色,好理解 Paperclip 之后会替你做什么。
关于底层功能,截至 2026 年中有两点要诚实说明:Claude Code agent teams 仍是实验性功能,默认禁用(需要通过设置开启),并且只有 lead 能生成队友;队友不能再嵌套生成自己的队友。所以「agents spinning up agents」实际上是「一个 lead 生成一个扁平团队」。把它当作早期功能,并在生产环境依赖它之前阅读最新文档。
起草它。 打开 02-roster.md 和一份 03-role-cards/role-card.template.md,粘贴:
为 [team] 起草一份 team roster。列出每个成员,人类和 agent 都要列出。对每个成员写出:role、谁拥有它、它需要的 tools 和 access,以及 autonomy level。标出只有人类应该持有的角色。然后为 [my worker] 写一张完整 role card:owns、does NOT own、tools/access、如何验证它的工作、什么会触发升级给人类。
检查它。 每个成员都有 owner 和「does not own」。每个 agent 都有工具和一个清晰的升级触发器。如果两个成员都可能声称同一项任务属于自己,scope 还不够锋利。
✓ 检查点:每个人都有自己的 lane。 人类和 agent 在同一份 roster 上,每个都拥有一项命名工作,并带着完成它所需的工具。现在给团队方向。
第 4 部分:north star
概念 8:让 agent 主动起来的目标
上下文和角色会让 agent 做你分配的工作。north star 会让它提出正确的工作。north star 是一个雄心大、覆盖广的目标,告诉团队哪些任务和 workstreams 值得做:其他所有东西都用来衡量的那一句话。它始终由人类设定,并扎根在业务使命中。
一旦写好,就把它分享给团队中的 agent。然后(这正是很多人跳过的部分)你要点名哪些 agent 可以在未被提示时据此行动。不是每个 agent 都应该提出工作。只有具备技能并赢得信任、能够把这件事做好的那些才可以。
Anthropic 的例子很小也很精确:一个团队的 north star 是「让产品 onboarding 更有帮助」,于是一个 agent 主动建议重写 onboarding 错误消息,而这些改动在下一周可衡量地提高了 onboarding 成功率。Agent 没有等别人来要求。North star 告诉它这次重写符合任务。
这是你的 AI-Native Company mission 下推到一个团队。公司有 mission;团队有服务于它的 north star;agent 有服务于 north star 的工作。从目标到任务是一条直线。
概念 9:主动性是你授予的特权
主动 agent 的风险在于,它可能提出不该触碰的工作。因此,主动性是点名的,不是默认假设的。你说清哪些 agent 可以建议 workstreams,而 north star 是每个建议必须通过的测试。没有这项授权的 agent 仍然做自己被分配的工作:它只是不自由接活。
起草它。 打开 04-north-star.md,粘贴:
帮我为 [team] 写一个 north star。它应该是一个雄心目标,扎根在我们的 mission 中。说明它为什么重要。点名 roster 上哪些 agent 可以针对它提出新工作,以及这些建议的 guardrails。写成这样:一个 agent 只拿到这份文档,也能判断一个新想法是否 on-mission。
检查它。 像那个被点名的 agent 一样阅读它。只拿这份文档,它能分辨 on-mission idea 和 off-mission idea 吗?如果不能,这颗 star 就太模糊,无法导航。
✓ 检查点:团队有方向。 一个目标,由人类设定,少数被点名的 agent 可以追逐它。现在决定你让它们跑多远。
第 5 部分:信任,要赢得
概念 10:Autonomy 随可靠性增长
你不会在新同事第一天就把钥匙交给他。也不要在 agent 第一天就把 500 个 bug fix 交给它。Anthropic 的工程师确实走到了那一步(agent 被派去独立处理数百个修复),但一开始不是这样。按已证明的可靠性授予 autonomy,然后按任务类型有意扩大。
无论对新人还是 agent,都需要反馈循环来外化「一项任务怎样才算做好」这种 tacit knowledge。并且要随着模型变化重新测试:曾经帮助弱模型的 guardrail,可能会束缚更强的模型;模型变好后,prompt 也可能需要重写。信任不是一次设定,而是持续调校。
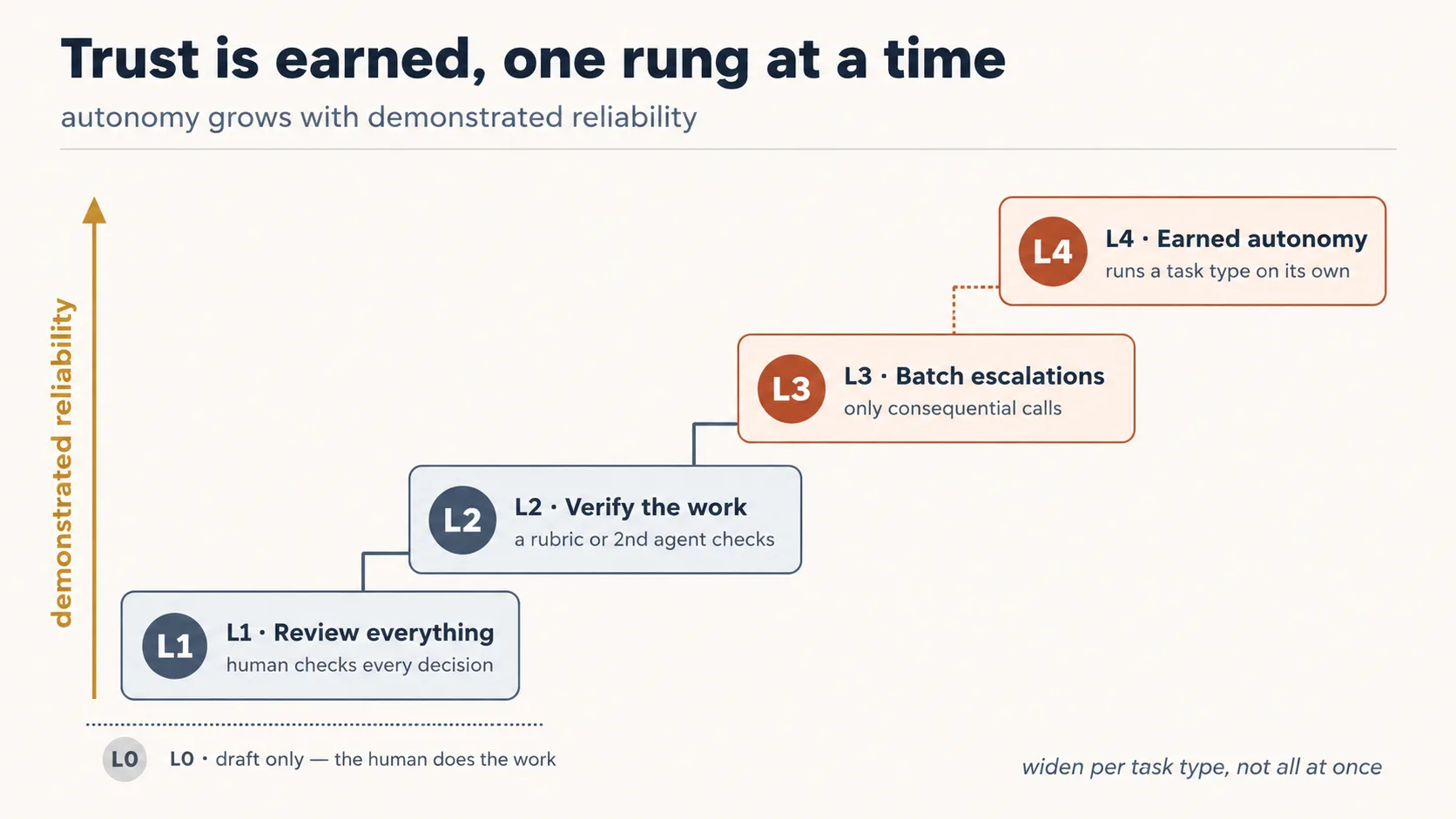
给梯子固定的横档,让它可操作。在 roster 中为每个 agent 按任务类型设置 autonomy level,而不是给整个 agent 一个统一等级:
| Level | What the agent does | Where the human is |
|---|---|---|
| L0 | Drafts only; the human does the work | human does everything |
| L1 | Acts, but a human reviews every output | human reviews all |
| L2 | Acts; a verifier checks; human reviews only exceptions | human reviews exceptions |
| L3 | Acts within limits; batches escalations to the human | human reviews batched escalations |
| L4 | Runs the task type on its own, within approved scope | human reviews the weekly report |
新 agent 在某类任务上从 L1 开始,在反复、已验证的成功之后向上赢得等级。同一个 agent 可以在一种任务类型上处于 L4,在另一种任务类型上处于 L1:autonomy 授予的是某个工人在某项工作上的权限,绝不是笼统授予某个工人。
概念 11:让工作可检查
让 autonomy 安全增长的东西是这一点:工作可以在人类看到之前被验证。代码当然有 tests。但大多数其他工作也可以评分:文档对照 rubric 和 style guide,报告对照 checklist。当你设定标准,并让每项 assignment 都可验证时,质量会保持高水平,并且不会偏离你的意图。
这是团队层面的 Eval-Driven Development(Eval-Driven Development)。在那里,eval 自动给工人评分。在这里,rubric 是这个 eval 应用到某个工人的输出上:同一个想法,写成一份队友可以运行的 checklist。
然后是 doer-verifier:一个 agent 做任务,第二个 agent 的唯一职责是检查它。(Anthropic 称之为 doer-verifier harness。)这是便宜的保险,用一个 agent 的时间来节省人类时间:verifier 会在你稀缺的注意力花进去之前捕捉偏移。
起草它。 打开 05-verification-rubric.md 和 06-doer-verifier.md,粘贴:
为 [my worker] 的主要输出写一份 verification rubric:用清晰的 pass/fail 条款列出决定这项工作是否足以 ship 的具体检查。然后描述一个 doer-verifier setup:第二个 agent 的唯一职责是按照这份 rubric 给第一个 agent 的输出打分,并带理由返回 pass/fail。
检查它。 第二个 agent 能否只用这份 rubric 给第一个 agent 的工作评分,并且你会信任那个 pass 吗?如果一个「pass」仍让你想逐行阅读,rubric 就还不够具体。
概念 12:像花钱一样花人类注意力
一旦 agent 独立起来,新的失败模式就会出现:人类淹没在输出里。因此,把人类注意力当作稀缺资源来对待。最好的团队会让 agent 把问题批量合并到一次处理里,重复关键上下文让人类快速进入状态,并限制人类一次看到的条目数量。
有些团队会让一个 agent 专门负责决定什么要升给人类。有些团队会限制一个 agent 每天做多少工作:不是为了减慢它,而是为了让人类仍能有意义地参与工作,并保留那些对自己重要的技能。
把 reflection 纳入循环。让团队提交一份每周 "lessons and missteps" 报告,跟踪错误,让它们停止重复。记录每个 agent 已经在哪些任务类型上赢得 autonomy,并且只在反复成功后扩大 scope。团队通过这份报告有意变好,而不是靠运气变好。
起草它。 打开 07-weekly-report.md 和 08-attention-budget.md,粘贴:
起草一份 weekly team report template,针对每个 agent 捕捉:它 ship 了什么、本周的 lessons and missteps,以及它在哪些任务类型上赢得了更多 autonomy。然后为我提出一份 attention budget:我会审查什么,什么会被批量处理,一次到达我这里的数量上限是多少。
检查它。 在忙碌的一周里,这能让人类只决定重要的事,而不决定其他事吗?如果人类仍然必须阅读所有内容,这份 budget 就没有保护稀缺资源。
✓ 检查点:信任是旋钮,不是开关。 工作可检查,autonomy 随证据扩大,人类注意力花在真正有用的地方。你已经拥有完整运行模型。
第 6 部分:站起你的团队
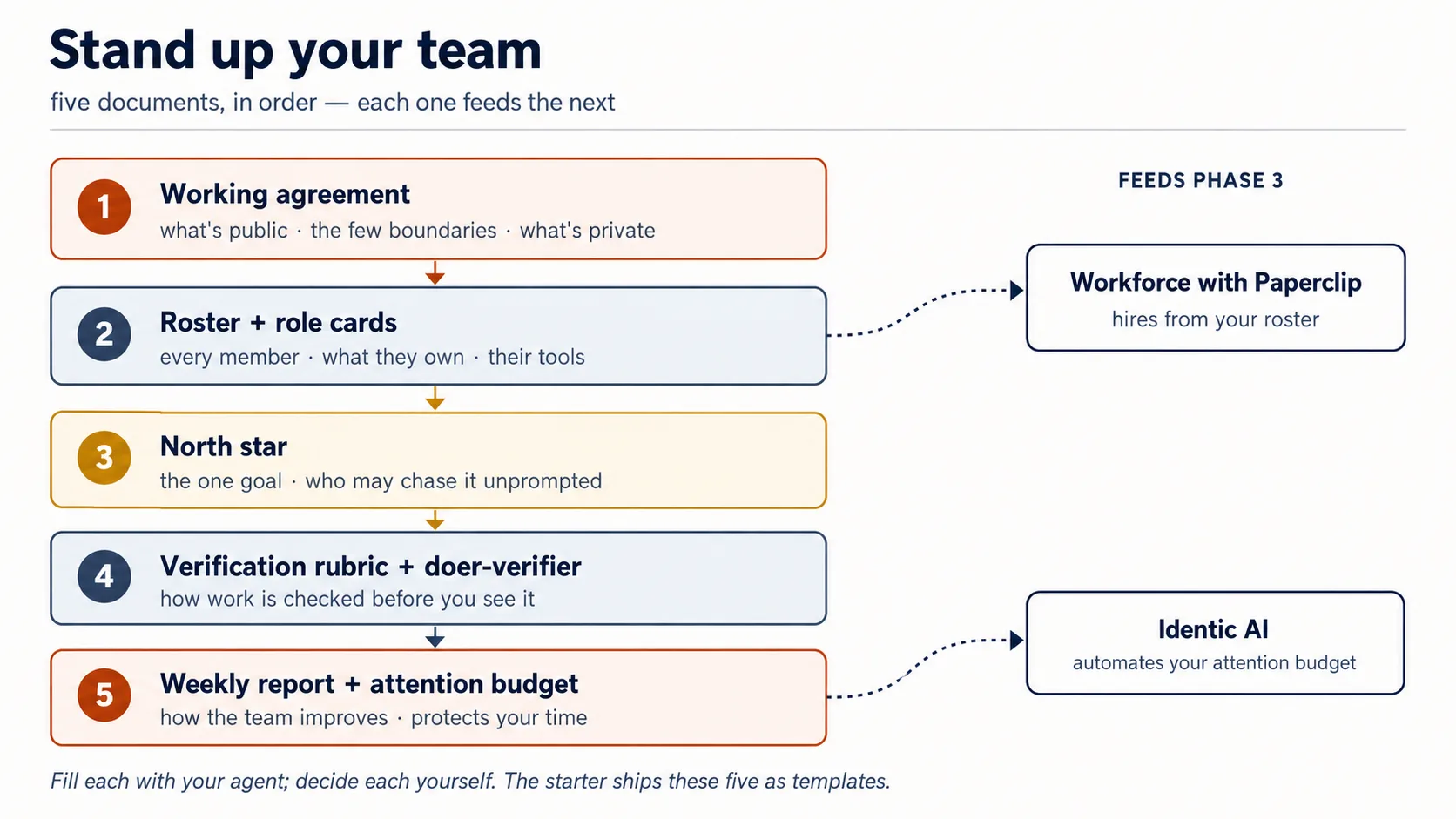
你已经学了四个实践,并为每个实践起草了一份文档。现在把它们组装成一个团队的操作手册。
操作手册:一个文件夹,八个文件
手册是一个文件夹,按你填写的顺序编号。starter 正是这样提供的:
human-agent-team/
01-working-agreement.md few clear boundaries · what's public · what's private
02-roster.md every member · owner · tools · autonomy level (L0–L4)
03-role-cards/ one card per agent (copy the template)
role-card.template.md
reconciler.md (filled example)
04-north-star.md the one goal · which agents may act on it unprompted
05-verification-rubric.md the pass/fail checks a verifier can apply
06-doer-verifier.md which agent checks which, and what happens on fail
07-weekly-report.md shipped · lessons & missteps · autonomy changes
08-attention-budget.md what you review · what's batched · the cap
每个文件都有一个简短的必需 checklist(在模板中,也会在每个 Part 末尾的「Check it」中重复)。只有所有项都是 yes,文件才算完成。只有 8 个文件全都完成,手册才算完成。
按顺序填写
这个顺序就是依赖顺序。四个实践映射成 5 个填写步骤(信任实践拆成 verification 和 attention),并产出 8 个文件:一份手册的 3 个缩放层级。
- Working agreement:什么公开、少数边界、什么保持私密。(先有上下文;没有它,其他都无法工作。)
- Roster + role cards:每个成员、他们拥有什么、他们的工具、他们的升级触发器。
- North star:目标,以及谁可以在无需提示的情况下追逐它。
- Verification rubric + doer-verifier:工作在人类看到前如何被检查。
- Weekly report + attention budget:团队如何改进,以及如何保护你的时间。
每一份都用同样的节奏跑:粘贴对应 Part 的 prompt,阅读 agent 起草的内容,然后决定:删减、磨尖、批准。你是权威;agent 是起草者。
用 Anthropic 的 5 个问题作为完成测试。当每个答案都是 yes 时,团队就准备好了:
- agent 和人类需要的信息与访问是否都公开且广泛可搜索?
- 你能否写出团队的 roster,包括人类和 agent,并说明每个成员拥有什么?
- 每个人类和 agent 是否都有完成工作所需的正确工具?
- 你是否有 rubrics 或 tests 来验证关键工作产出?
- 团队是否有一个所有人都能引用的清晰 north star?
worked example:一个财务结账团队
模板在你看到填好的版本之前都是抽象的。这里有一个运行月度结账的小型财务团队(一个人类 controller 和 3 个 agent),关键部分已经变得具体。(starter 会把它作为 examples/finance-close-team.md 提供。)
North star: 离开公司的每个数字都是正确的,并且能追溯到其来源。
| Member | Human/Agent | Owns | Tools / access | Autonomy |
|---|---|---|---|---|
| Controller | Human | Sign-off on anything that leaves the company | none | human-only |
| Puller | Agent | Pulling figures from the source systems | ERP / GL read-only | L2 (verified) |
| Reconciler | Agent | Matching figures across sources, flagging variances | the ledger, the system of record | L3 on routine ties; L1 on new accounts |
| Checker | Agent | Grading the reconciliation against the rubric | the rubric | doer-verifier only |
让它安全的细节,是写在 Reconciler role card 上的升级触发器。
在以下情况升级给 Controller:任何 variance 超过账户余额的 1% 或 $10,000,取较小者(有意保守,因此即使小账户出现小幅波动也会升级),或任何数字在 system of record 中没有来源。否则,完成对账并记录日志。
以及 Checker 应用的 verification rubric。只有满足以下条件,reconciliation 才通过:
- every balance ties to its source within threshold; 2. every variance has a reason code; 3. every source document is linked in the system of record; 4. every exception is listed in the escalation queue.
这条升级线就是整个运行模型的缩影。Reconciler 独立运行 routine ties(L3),Checker 在任何人查看前按 rubric 验证(doer-verifier),无来源或重要的数字会停下并到达人类那里(注意力只花在真正有用处),Controller 持有唯一能把数字发到外部世界的角色。注意 Reconciler 是 routine ties 上的 L3,但 new accounts 上的 L1:autonomy 按任务类型授予,不按 agent 授予。换掉 thresholds 和 sources,同样的形状就能运行 accounts payable、payroll 或 board reporting。
✓ 检查点:你能运行一支团队。 一个 working agreement、一份带清晰角色的 roster、一个 north star、一种验证工作的方法,以及一份给你自己注意力的 budget。这就是运行模型,也是其他劳动力课程运行其上的东西。
第 7 部分:天花板,以及它如何升高
运行模型本身不会扩展团队。 它设定规则;后面的四门课程是运行在这些规则之上的机器,并且每一门都会拿你刚写出的一个 artifact 作为输入:
- Workforce with Paperclip 自动化 roster:lead agent 在预算、审批和完整审计轨迹下雇用并运行一组工人。你的 roster 和 role cards 就是它雇用的来源。
- Self-Expanding Workforce 随工作增长而扩张团队,而不是让你手动添加每个工人。
- Identic AI 是自动化的 attention budget:一个签名身份,在你设定的限制内清理日常审批,只浮现有后果的审批。
- Payment-Enabled Agents 让工人能够交易:从节省成本的团队,走向能赚钱的团队。
先构建运行模型,那些机器才有一个可靠的东西可运行。跳过它,你自动化的就是一支从一开始就不连贯的团队。
实践本身的天花板也在这里: 对人类来说,这一切并不新。清晰的 north star、定义好的角色、公开工作、共同的质量标准、从错误中学习的空间:这些都是我们几十年来已知的健康团队习惯。Agent 没有发明它们。Agent 只是让跳过它们变得致命,因为一个 agent 会以放大好实践同样快的速度放大坏实践。最能从 agent 中获益的团队,正是最严肃对待基本功的团队。
这就是本书一直走向的那条线:一支 Digital FTE 劳动力,在这个运行模型上运行,位于一家 AI-native company 内。你带着一个工人的视角来到这个运行模型。离开时,你已经能和人类一起运行一支由它们组成的团队,并且能够扩展、治理和销售这支团队生产的东西。
同一份手册,其他团队
artifact 集合是一种形状;团队会变,文档不变:
- 研究团队:analyst、synthesiser 和 fact-checker agents,在「answer the question, with sources」的 north star 下工作。
- 交付团队:planner、doer 和 doer-verifier,在质量 rubric 下工作,由人类持有 ship decision。
- 财务团队:data-pull agent、reconciliation agent,以及一个拥有每个离开公司数字的人类。
同样的 5 份文档。不同的 roster,不同的 north star,不同的 rubric。
Capstone:站起一支真实团队
在你的组织中选择一个真实目标,并为它产出完整 artifact 集合:working agreement、roster、role cards、north star、verification rubric、doer-verifier、weekly report、attention budget。
Discuss with an AI. Question your scores.
Come back when you have your BEST evaluation.
starter 会提供一个已评分示例(examples/finance-close-team-graded.md),这是一份完整的财务手册,按这 8 项检查得到 15/16,并点名了唯一弱项和修复方式。在给自己的手册评分前先读它:它展示了 rubric 会捕捉什么,也展示了强手册是什么样子。
Sources
这门课基于 Anthropic 关于运行人类与 agent 团队的说明,并映射到本书已经构建的框架。主要来源和所引用的 Anthropic 材料如下:
- Anthropic, "Lessons from Anthropic on building effective human-agent teams" (June 2026):主要来源。文中提到的四个实践和具体结果(onboarding 错误消息重写、500 个 bug fix 的信任路径、workspace-level security boundaries)都来自这里。
- "Equipping agents for the real world with Agent Skills" 和 Agent Skills overview:把 agent 角色定义为可移植 skill file。
- "Managed agents" 和 agent memory:不绑定到人类的凭据,以及持久记忆(概念 2)。
- "Effective context engineering for AI agents":广泛、可搜索的上下文(第 2 部分)。
- "Harness design for long-running agents":doer-verifier harness(概念 11)。
- Agent teams in Claude Code 和 Claude Tag:agent 以自己的身份在共享团队空间中工作。