术语表:面向初学者的 AI 词汇
读这本书不需要计算机科学学位。 但你确实需要听懂这门语言。本术语表用简明中文、真实案例和日常类比,解释你会遇到的每个重要术语。
如何使用本页: 先读 前 30 个术语,它们几乎出现在本书的每一页。然后把完整术语表当作参考来查阅。术语按主题分组,本书专有词汇排在最前。用
Ctrl+F(Mac 上是Cmd+F)搜索任意术语。
AI 全景速览
在深入单个术语之前,先看看这些主要概念之间是如何关联的:
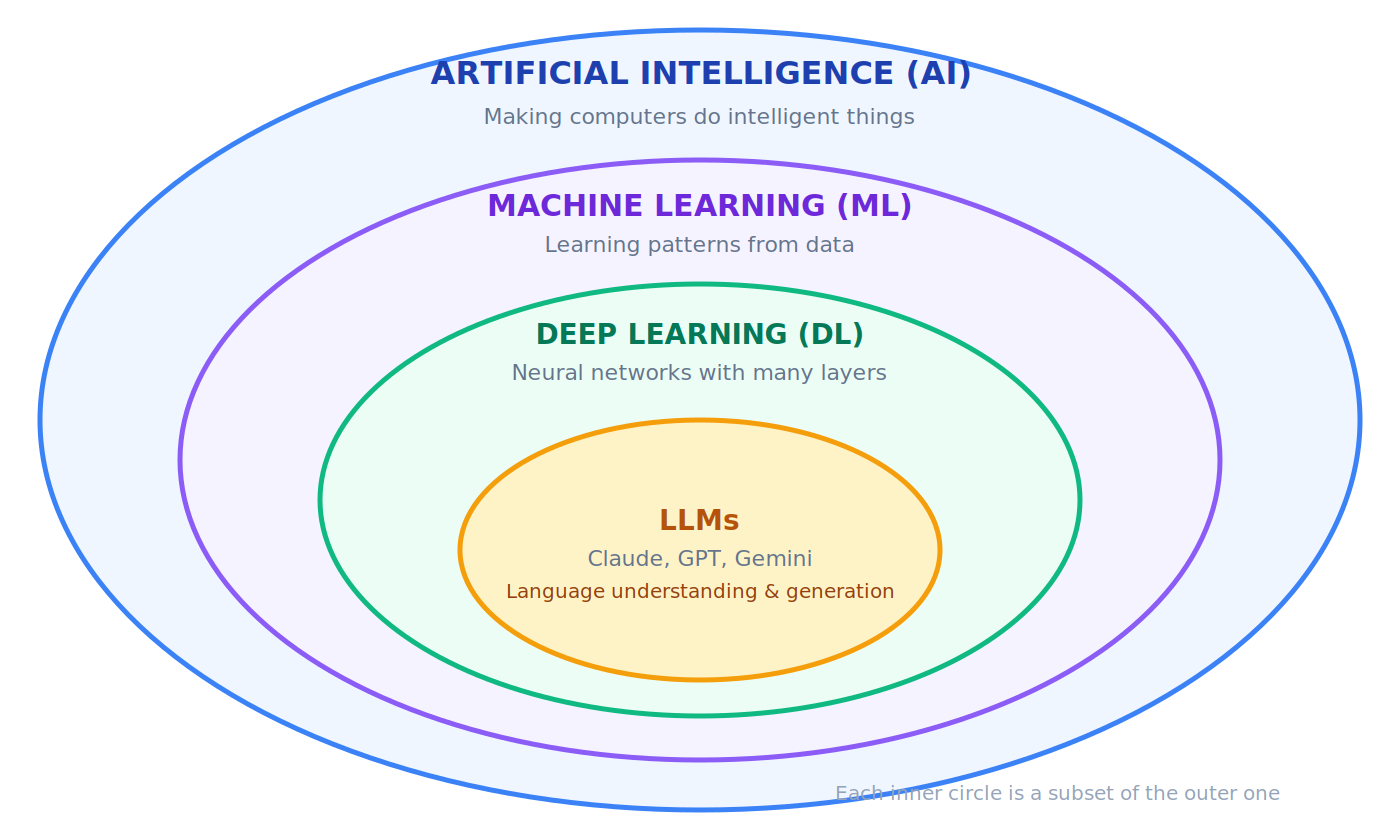
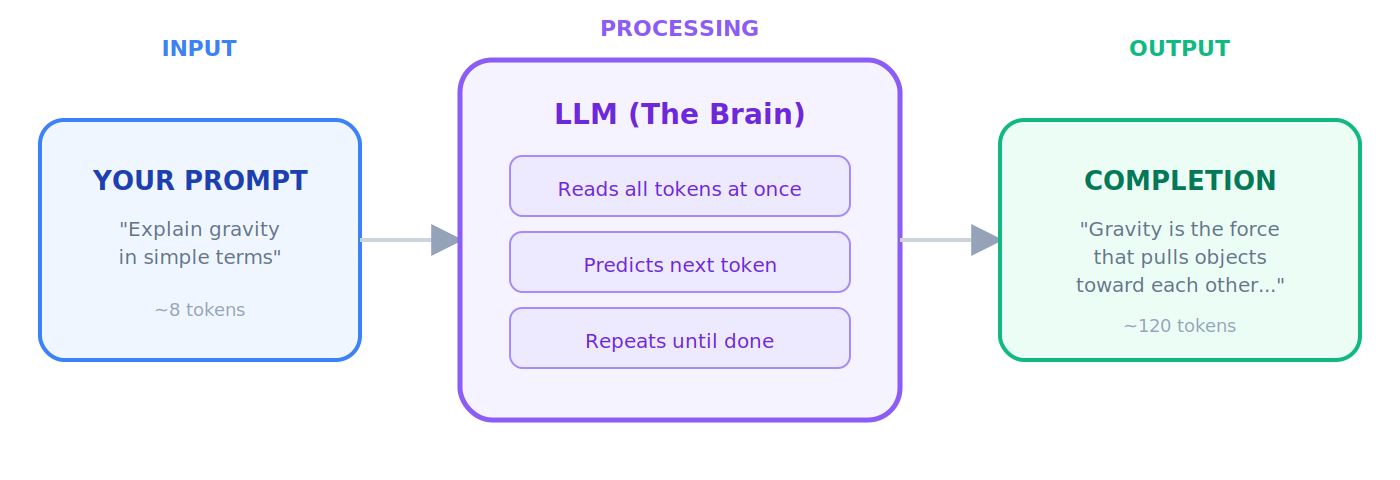
必须先掌握的前 30 个术语
这些词几乎出现在每一页。打开第 1 章之前,先把它们读完。
说明:与「agent 作为买方」相关的术语(ACP、AP2、x402、MPP、authority envelope、signed mandate)放在第 11 节,不计入前 30 个术语。
1. AI(人工智能):让计算机去做那些通常需要人类智能才能完成的事情。
🔹 当你手机的键盘预测你接下来要打的词时,那就是 AI。
2. LLM(大语言模型):在数十亿页文本上训练出来的巨型 AI 系统,能够理解和生成人类语言与代码。Claude、GPT 和 Gemini 都是 LLM。
💡 把 LLM 想象成一位读遍了世界上最大图书馆里每一本书的研究助理。你提一个问题,它就从读过的一切中给你答案。
3. Agent(AI 智能体):一种不只是回答问题的 AI。它会采取行动、制定计划,并自己把事情做成。
🔹 聊天机器人会回答「飞迪拜最便宜的航班是哪个?」而 agent 会真的去搜索各家航空公司、比较价格,并替你把机票订下来。
4. Agentic AI(智能体式 AI):专注于构建能够自主规划、推理和行动的 agent 的那一类 AI。这是 2026 年 AI 的前沿,也是整本书的焦点。
🔹 普通 AI:你问一个问题,得到一个答案。Agentic AI:你给它一个目标(「把客户流失率降低 15%」),它就去做调研、制定计划、执行并汇报,一路上自己做决策。
5. Digital FTE(数字全职当量):一名「AI 员工」,全天候完成一名全职人类员工的持续性工作,成本只是其中一小部分。在论点中也称为 AI Worker,同一角色,不同的语域。
🔹 一名做客户支持的 Digital FTE 每天处理 500 次对话,天天如此,相当于 5 到 10 名人类客服的工作量。
6. Agent Factory(智能体工厂):本书的核心概念。它是一套以规格驱动、由人类监督、以 Claude Code 为动力的流程,用来设计、制造和部署 AI Worker。它不是一件你购买的产品,而是一套你采纳的实践。Agent Factory 建造 AI-Native Company,而 AI-Native Company 雇用 Digital FTE。
💡 就像一条装配线:每个工位完成一项专门任务,零件按顺序流过,最后产出一件按规格打造好的成品。Agent Factory 把「制造 AI 员工」这件事工业化了。
7. Prompt(提示词):你输入给 AI 模型的指令或问题。
🔹 「把这份报告总结成三个要点」就是一条提示词。更好的提示词等于更好的答案。
8. Context Window(上下文窗口):AI 的「工作记忆」,也就是它一次能读取和思考的文本量。
💡 小的上下文窗口就像一张很小的桌子,你只能摊开几页纸。Claude 巨大的上下文窗口就像一张巨大的会议桌,你可以一次铺开一整本小说。
9. Token(词元):LLM 读取文本的基本单位,大约相当于四分之三个英文单词。「I love biryani」约等于 4 个 token。
🔹 使用 AI API 时,你按 token 付费。一整页文本约等于 500 到 700 个 token。
10. Hallucination(幻觉):AI 自信满满地生成出不真实的内容。
🔹 你问一个最高法院的案件,AI 编造了一份假判决、配上假的引用编号,然后当作事实呈现给你。它听起来很对,其实全是捏造的。
11. Spec(规格):一份详细蓝图,准确描述你想要构建什么:目标、输入、输出、约束。
💡 就像建筑师为一栋房子画的蓝图。没有哪个建筑工会一上来就靠猜,他们照着图纸来。在 AI 开发里,规格就是那份图纸。
12. Spec-Driven Development(规格驱动开发,SDD):先写好蓝图,再让 AI 从这份蓝图生成代码、测试和文档。
🔹 你写下:「为一家书店构建一个 API,提供列出、添加、搜索和删除图书的接口。」Claude Code 就会生成整个应用。
13. Claude Code:Anthropic 的 AI 编码 agent。你在终端里和它对话,它会读取你的整个代码库,理解你的项目并编写代码。
🔹 你输入「给我的应用加上用户身份认证」:Claude Code 读取你现有的代码,生成认证模块,编写测试,并把一切集成好。
14. Cowork:Anthropic 的桌面 agent,专门处理非编码类的知识工作:文档、调研、文件管理。
🔹 「按项目整理我的下载文件夹,并总结本月所有的 PDF。」Cowork 替你完成,而你可以专注于别的事。
15. MCP(Model Context Protocol,模型上下文协议):一个通用标准,让任意 AI agent 连接到任意外部工具:数据库、邮件、日历、文件系统。MCP 是 agent 调用工具的协议。至于处理「agent 为这些工具付费」的另一套协议族,参见第 11 节:ACP、AP2、x402 和 MPP。
💡 在 USB 出现之前,每部手机都有不同的充电器。MCP 就是 AI 的「USB 标准」:一套协议,让任意 agent 都能插入任意工具。
16. API(应用程序接口):让不同软件程序彼此对话的一套规则。Agent 就是通过 API 与外部世界交互的。
💡 餐厅的菜单就是一个 API。你(客户端)看菜单(文档),下单(请求),厨房(服务器)把菜端给你(响应)。
17. SDK(软件开发工具包):在某个特定平台上构建应用的一套预制工具箱。
💡 SDK 就像一套乐高积木:预制好的零件加上说明书,让你能快速搭建,而不必从零雕刻每一个零件。
18. Python:AI 领域最流行的编程语言。可读性强、用途广泛,也是本书的主力语言。
🔹 Python 读起来几乎像英语:
if age > 18: print("Adult")。正是这种可读性,让 AI 世界选择了 Python。
19. Git:一套记录代码每次改动的系统:谁、在何时、为什么改了什么。你随时可以回到任意一个历史版本。
💡 就像 Microsoft Word 里的「修订追踪」,但针对的是整个软件项目。每一次编辑都可恢复。
20. Docker:一种工具,把你的应用打包进一个可移植的盒子(容器),让它在任何地方都以相同方式运行:你的笔记本、同事的机器,或一台云服务器。
💡 就像一个航运集装箱。无论它在卡拉奇的卡车上,还是在海上的轮船里,箱内的东西都完全一致、自成一体。
21. Context Engineering(上下文工程):设计 agent 所接收的完整信息环境。它是把一个月费 2000 美元的 agent 与一个无人问津的 agent 区分开来的头号技能。
💡 丰田工厂有一整套质量管控,确保每辆车都达标。上下文工程就是给你 AI agent 做的质量管控:确保输出稳定、可靠。
22. Tool Use(工具使用):agent 使用外部工具(搜索网页、查询数据库、发送邮件)的能力,而不是只凭记忆作答。
🔹 你问「卡拉奇现在天气如何?」:具备工具使用能力的 agent 会真的去查天气服务,给你实时数据。没有工具使用,它就只能靠猜。
23. Guardrails(护栏):阻止 agent 去做它不该做的事的安全约束。
🔹 一个金融 agent 有这样一条护栏:未经人工批准,不得进行超过 500 万卢比的交易。就像高速公路两侧的护栏,防止车辆冲出路面。
24. RAG(检索增强生成):让 AI 能够访问外部文档,从而依据事实作答,而不是凭(可能出错的)记忆。
💡 就像参加一场开卷考试而非闭卷考试。AI 在作答前先在你的文档里查证事实:准确得多。
25. 10-80-10 法则:AI 劳动力的运转节奏:人类设定方向(10%)→ AI 执行(80%)→ 人类验证(10%)。
🔹 你写好一份项目简报(10%),Claude Code 构建出整个应用(80%),你审阅、测试并批准(10%)。
26. AGENTS.md / CLAUDE.md:告诉你的 AI agent 项目规则的配置文件:编码规范、偏好、架构决策。
💡 就像你交给新员工的入职文档:「我们这样工作。这是我们的风格。这是我们绝不会做的事。」它会被载入每一次交互。
27. Orchestration(编排):协调多个 agent 协同完成一项任务。
💡 板球队长会布置外场员、安排投球轮次、调整战术。他不会事事亲为,而是协调各路专才奔向同一个目标。
28. Stateless(无状态):AI 在两次对话之间会忘掉一切。每次新对话都从绝对的零开始。
💡 一位健忘的店主:每次你走进店里,他都把你当陌生人招呼,哪怕你 5 分钟前才来过。聊天应用靠每次重新发送整段对话,制造出记忆的_假象_。
29. Deployment(部署):让你的应用上线,供互联网上的真实用户访问。
🔹 你的应用在自己笔记本上能跑。部署把它放到云服务器上,让 1 万人能同时使用。
30. CI/CD(持续集成 / 持续交付):每当开发者改动代码,就自动测试并部署。
🔹 开发者下午 2 点推送代码。测试在 3 分钟内自动跑完,全部通过。新版本在 2 点 10 分就上线了:零手动步骤。
架构:运行时栈
这些术语命名了由 Agent Factory 制造出来的 AI-Native Company 的各个组成部分。它们贯穿于架构相关章节和论点之中。在这里读一遍,你在每一次构建中都会再次遇到它们。
💡 各部分如何拼到一起: Agent Factory(流程)建造 AI-Native Company(产出)。在这家公司内部,人类从 Edge Layer 设定方向,Digital FTE 在 AI Workforce Layer 执行。Paperclip 管理这支劳动力。每个 Digital FTE 都运行在自己选定的运行时引擎上。触发器从外部世界唤醒整个系统。
AI Worker
AI-Native Company 的劳动力。基于角色的 agent,会被招聘、分派、排班和退役。与 Digital FTE 和 Digital Worker 是同一个概念:论点用 AI Worker,本书用 Digital FTE。挑一个适合你受众的说法即可。
📌 劳动力 vs. 常驻人员(关键区分): 只有 AI Worker 才属于劳动力。代理人(OpenClaw)和经理(Paperclip)是常驻人员,不是劳动力。运行时引擎根本不算人员,它们是劳动力所运行其上的技能。当论点说 agent 时,指的是这栋楼里的任何人(常驻人员或劳动力)。当它说 AI Worker 时,特指劳动力。
🔹 示例: 一个筛简历的 AI Worker 每天读 200 份简历,按岗位规格打分,把前 10 名交给一位人类招聘官。它是 AI-Native Company 人力资源劳动力中的一名 Digital FTE,由 Paperclip 招聘,可排班、可退役。
AI-Native Company(AI 原生公司)
Agent Factory 的产出。一家正在运转的企业:由 AI Worker(Digital FTE)担任员工,由一个管理平面协调,并由位于边缘的人类指挥。AI-Native Company 就是你最终要运营的东西。本书也把它称作 Agentic Enterprise,同一个概念的面向业务的叫法。
💡 类比: Agent Factory 是流程,就像一套建造摩天楼的方法。AI-Native Company 是这套方法造出来的摩天楼,是你真正去运营的那个东西。
📌 三元组: Agent Factory(流程)→ AI-Native Company(产出)→ AI Worker(产出内部的劳动力)。三个术语,三种不同的角色。不可互换。
Two-Layer Model(双层模型)
让 Agent Factory 论点得以完整的架构模式:人类从 Edge Layer 设定意图,AI Worker 在 AI Workforce Layer 执行,而规格是二者之间的契约语言。
🔹 示例: 一位 CEO 告诉自己的 OpenClaw 代理人(Edge Layer)「跑一下本周的客户流失报告」。代理人把任务交给 AI Workforce Layer 里的一名 Digital FTE。Digital FTE 拉取数据、生成报告,再通过代理人把它交回给 CEO 验证。
Principal(委托人)
位于运行时栈顶端的那个人:设定意图、定义预算、划定权限边界并对结果负责的人。论点的不变量 1。每一条合法的行动链都源自一位委托人;没有委托人就行动的系统不是自主的,而是无主的(没有责任主体、没有对齐目标、没有预算负责人、没有结果裁判)。
🔹 示例: 一位 CFO 写下一份规格:「在 3 万美元预算内、不改变付款条件的前提下,把应收账款账龄降低 20%。」这份规格承载着意图、预算和约束,是委托人层的具体形态。代理人(OpenClaw)读取它,把工作中介给劳动力;委托人随后回来验证结果。
📌 它能被什么替代: 什么都不能。其他每一层的参考实现都可以更换;委托人层不可转移。
Edge Layer(边缘层)
AI-Native Company 中服务于单个人的那一层。每个人在边缘都有一个 agent,即一个 personal identic agent(比如 OpenClaw),它了解此人的上下文,代表此人发声,并把工作向下游分派。
💡 类比: Edge Layer 就是参谋长那一层。每位高管配一个 agent,在整个公司里代表他本人。
AI Workforce Layer(AI 劳动力层)
AI-Native Company 中服务于整个企业的那一层。这是 AI Worker(Digital FTE)生活和执行的地方:由 Paperclip 管理,运行在各种运行时引擎上,通过规格相互协调。
💡 类比: AI Workforce Layer 就是生产车间。许多 Digital FTE,各做专门工作,全部由管理平面协调。
Delegate(代理人)
位于 Edge Layer 的那个 personal agent,它持有委托人的上下文,代表其判断,携带其权限边界,并代表他中介一切下游工作。论点的不变量 2。没有代理人,人类瓶颈就会回归,规模便会塌缩到打字速度。OpenClaw 是其参考实现;任何持有身份、上下文和权限、且会说 MCP 的 personal agent 都符合条件。
💡 类比: 一位 CEO 的参谋长。每位高管一名,了解其优先事项,替他发声,把工作分给合适的专才。
另见: 下文的 OpenClaw(作为代理人) 了解其参考实现,以及第 1 节的 Identic AI 了解人类主权的框定。
OpenClaw(作为代理人)
OpenClaw 是 Edge Layer 上代理人的参考实现,也就是那个代表人类、了解其上下文、代其发声的「参谋长」agent。AI-Native Company 中的每个人都需要一个代理人;OpenClaw 就是我们构建它的方式。
🔹 示例: 当你问 OpenClaw「总结我这一周,并为周一草拟三个优先事项」时,它会从你的日历、邮件和 Slack(它被授权访问的工具)中拉取信息,用你的口吻综合出一个答案,然后等你批准后才会去执行任何动作。它就是你,只不过以机器的速度运转。
另见: 术语表前文的 OpenClaw 词条,了解这个框架本身。
Manager(管理平面)
把一堆 AI Worker 变成一支劳动力的编排者:分派工作、强制执行预算、批准高风险动作、审计执行、记账,并把「招聘」暴露成一个可调用的 API。论点的不变量 3。没有它,agent 会相互冲突、预算会渗漏,没有人能说清这支劳动力花了多少、产出了什么。Paperclip 是其参考实现;任何满足管理契约的编排者都符合条件。
💡 类比: 如果代理人是参谋长,那么经理就是首席运营官。与人类一对一;与劳动力一对多。
另见: 下文的 Paperclip 了解其参考实现。
Paperclip
AI-Native Company 的管理平面。Paperclip 是 COO:它招聘 Digital FTE、分派工作、强制执行预算、批准高风险动作并记账。它把「招聘」暴露成一个 API,任何被授权的 agent 都可以调用,这正是劳动力得以按需扩张的方式。
💡 类比: 如果 OpenClaw 是参谋长,那么 Paperclip 就是首席运营官。与人类一对一;与劳动力一对多。
🔹 示例: 一位客户用印尼语写来消息。在岗名单上没有 Digital FTE 会这门语言。Paperclip 检测到这个能力缺口,并在自己的权限边界内调用它自己的招聘 API,制造出一名会说印尼语的新 Digital FTE。新 worker 读取消息并回复。没有任何人被吵醒。
Meta-Layer(把招聘作为可调用能力)
把「招聘」暴露成一个 API 的那一层:任何被授权的 agent 都能调用它,在委托人的权限边界内、无需吵醒任何人,于运行时即刻配置出一名新的 AI Worker。论点的不变量 5。它解决了「在岗名单冻结」的问题:当能力缺口出现时(一位客户用某个现有 worker 都不会的语言写来消息),劳动力就在政策约束下按需扩编。Claude Managed Agents 是其参考实现;任何能在运行时生成 agent 并配置其环境的托管 agent API 都符合条件。
🔹 示例: 上文 Paperclip 词条里那段印尼语的踪迹,就是元层在动作。Paperclip 检测到缺口;元层的招聘 API 制造出新 worker;新 worker 被注册到经理处并留在在岗名单上。
📌 双重角色: Claude Managed Agents 既是一个引擎选项(不变量 4),又是元层(不变量 5)。同一套运行时配置能力,既能运行一个 worker,也能创建新的 worker,这正是元层之所以可调用、而非批量预置的原因。
Runtime Engine(运行时引擎)
Digital FTE 运行其上的执行底座。每个 Digital FTE 都根据工作需要挑选自己的引擎,而不是全公司一个引擎。可选项包括 Dapr Agents(用于关键任务的持久化执行)、Claude Managed Agents(为你托管和运维)、OpenAI Agents SDK(自托管、可移植)和 OpenClaw-native(轻量、部署快)。在内部,每个引擎都有两个平面:一个 harness(控制平面)和一个 compute plane(执行平面 / 沙箱)。参见接下来的两个词条。
💡 类比: 运行时引擎就是员工带到岗位上的技能组合。心脏外科团队里的护士所需的技能,和诊所里的护士不同。同样的角色,不同的引擎。
Harness(Agent Harness,智能体框架)
agent 引擎的控制平面:围绕模型、把它变成一个可工作系统的一切。包括 agent 循环、工具分发、审批、追踪、上下文管理、恢复、指令、技能和校验器。从业者用一句简写概括它:Agent = Model + Harness:模型是你从前沿实验室租来的大脑,而 harness 是围绕它建起来的身体、工作场所和标准作业流程。compute plane(沙箱)紧挨着 harness,而非在其内部。凭据留在 harness 里,模型生成的代码则在沙箱里运行。
💡 类比: 如果模型是 CPU、上下文窗口是内存,那么 harness 就是操作系统:它负责引导启动、分发驱动(工具)、整理上下文,并管理 agent 的生命周期。你的 agent 代码就是跑在其上的应用。
🔹 示例: Claude Agent SDK 是一个你自己组装的 harness。OpenClaw 是一个你通过技能去扩展的 harness。Claude Code、Cursor 和 Codex 是为编码工作调校过的 harness。Claude Managed Agents 是 Anthropic 替你运行、藏在稳定接口背后的 harness。
📌 词源: 这个词从 test harness(软件工程里驱动被测代码的脚手架)演化到 eval harness(lm-eval-harness,驱动模型跑完一套基准的脚手架),再到 agent harness(驱动模型完成真实世界工作的脚手架)。三者都是围绕「真正干活的东西」搭起来的脚手架。
Compute Plane / Sandbox Runtime(计算平面 / 沙箱运行时)
紧挨着 harness 的执行平面:模型生成的代码真正运行(读文件、执行命令、写产物)的安全沙箱。它既不同于其下方的云基础设施(裸机、Kubernetes、网络),也不同于其旁边的 harness(编排逻辑)。这道切分对安全和可移植至关重要:凭据留在 harness 里,由模型指挥的代码在沙箱里运行,而沙箱厂商(E2B、Cloudflare、Daytona、Modal、Runloop、Vercel、Blaxel,或你自己的 Kubernetes)可以更换,无需重写 agent。
🔹 示例: OpenAI Agents SDK 是 harness;compute plane 由你另行选择。Claude Managed Agents 把两者融合在一个 API 背后。Dapr Agents 默认以 Kubernetes 作为它的 compute plane。
📌 三种叫「运行时」的东西: 语言运行时(Node.js、Python 解释器)是纯粹的基础设施。执行运行时 / 沙箱就是本词条所指。Agent 运行时有时被当作 harness 本身的同义词。读厂商文档时要留意这种混用。
Trigger(触发器)
外部世界唤醒 AI-Native Company、让它动起来的方式:一个排程到点、一个 webhook 到达、一次 API 调用落地、一位客户上门。Claude Code Routines 是其参考实现:它把每个外部事件变成一个会话,唤醒代理人并点燃整条链。没有触发器,系统就只在人类敲下提示词时才动一动,那其实算不上一家公司,只是个多了几道手续的助手。
🔹 示例: 每周一早上 9 点,一个排程触发器唤醒 OpenClaw,由它请 Paperclip 跑本周的客户健康报告。一名 Digital FTE 拉取数据、生成报告,并发邮件给高管团队。人类只配置过一次触发器;此后系统便自行运转。
小结
一句话分类法,背下来:
Agent Factory(流程)建造 AI-Native Company(产出)。AI-Native Company 雇用 AI Worker(劳动力),他们跨越 Two-Layer Model 工作:人类在 Edge Layer(通过代理人 OpenClaw),Digital FTE 在 AI Workforce Layer(由 Paperclip 管理),各自运行在自己选定的 运行时引擎 上,由外部世界的 触发器 唤醒。
你可以把这句话当作最后一行加上去。
你现在已经懂得足够多,可以开始阅读了。 下面的完整术语表会更深入地讲解每个术语,并涵盖另外 250 多个词。
1. Agent Factory:本书专有术语
这些是本书独有的概念和词汇。你从第 1 章起就会遇到它们,所以把它们放在最前面。
Agent Factory
流程。以规格驱动、由人类监督、以 Claude Code 为动力的方法,用来设计、制造和部署 AI Worker。原材料是人类意图;成品是一个经过验证的结果。Agent Factory 建造 AI-Native Company,而 AI-Native Company 雇用 AI Worker(Digital FTE)。
📌 是实践,不是产品。 Agent Factory 不是你购买或安装的东西,而是你学会去运作的东西。本书教你这套实践;一旦你运作起来,最终运营的就是 AI-Native Company。
💡 类比: 汽车工厂把原始钢材变成成品汽车。Agent Factory 把你的业务意图(「我需要一个全天候的客户支持 agent」)变成一个成品的、可工作的 Digital FTE。
Industrialized Stack(工业化栈)
论点对「价值如何流经 Agent Factory」的三层框定:Intent(意图)(目标、约束、预算和权限的高层蓝图)→ Production Engine(生产引擎)(把意图转化为结果的架构)→ Outcome(结果)(高保真的动作和产物,经准确性验证,并通过反馈回路持续改进)。
🔹 示例: 一位 CFO 的指令(「在 3 万美元内把应收账款账龄降低 20%」)是意图。OpenClaw → Paperclip → 运行在引擎上的 AI Worker 这条链是生产引擎。那个经过验证、已记入账本的「销售未收款天数」下降,就是结果。
Production Engine(生产引擎)
在 Industrialized Stack 内部,把意图转化为结果的机制。它不是一个你下载的应用,而是一套架构:规格驱动的指令喂给基于角色的 AI Worker,他们带到岗位上的打包技能,用于连接工具的 MCP,以及随时间收窄质量差距的反馈回路。论点称它为「整篇论点中最重要的想法」。
💡 类比: 汽车工厂的装配线。原始钢材从一头进,一辆成品车从另一头出。每个工位干一项专门活,零件按顺序流动,成品在交付前经过验证。生产引擎同理:意图进、经验证的结果出,AI Worker 就是那些专门工位。
Six Invariants(六大不变量)
让 AI-Native Company 得以运转的结构性规则:(1) Principal(委托人):人是委托人;(2) Delegate(代理人):每个人都需要一个代理人;(3) Manager(经理):劳动力需要一个经理;(4) Engine(引擎):每个 worker 自选引擎;(5) Meta(元):劳动力可在政策下扩编;(6) Trigger(触发器):世界来呼叫系统。每一条都是关于「公司如何运转」的规则;今天实现它们的那些具名产品(OpenClaw、Paperclip、Claude Managed Agents、Inngest)明天都可以更换,而架构不变。
📌 完整的主张、缺失时的失效模式,以及每个不变量当下的实现,参见论点。
Invariant vs. Reference Implementation(不变量 vs. 参考实现)
论点的框定技巧。不变量是一项结构性要求,它在系统的每个版本中都成立,无论由哪个具体产品来实现。参考实现是 2026 年用来实现某个不变量的具体产品。不变量是论点本身;具名产品是今年最契合的那一个。当某个产品被点名(OpenClaw、Paperclip、Claude Managed Agents、Inngest)时,不变量是规则,而产品只是其中一个实例。
💡 类比: 「一栋房子必须有进出的途径」是不变量。「带黄铜把手的红木双开门」是参考实现。明年换掉门,房子照样能用;去掉「进出」这个不变量,它就不再是房子了。
🔹 示例: 不变量 4 说「每个 AI Worker 自选引擎」。2026 年的参考实现是 Dapr Agents、Claude Managed Agents、OpenAI Agents SDK 和 OpenClaw-native。明年换掉其中任何一个,不变量依然成立。
Digital FTE(数字全职当量)
一名「AI 员工」,全天候完成一名全职人类员工的持续性工作,成本只是其中一小部分。一个 Digital FTE 每周工作 168 小时,毫不疲倦。与论点中的 AI Worker(AI-Native Company 的劳动力)是同一角色:被招聘、分派、排班、退役。它有别于代理人(OpenClaw)和经理(Paperclip),后两者是常驻人员,不是劳动力。Digital FTE 如何嵌入运行时栈,参见架构小节。
🔹 示例: 一名做客户支持的 Digital FTE 每天处理 500 次对话,天天如此,相当于 5 到 10 名人类客服的工作量。
Digital Worker / AI Employee(数字工人 / AI 员工)
Digital FTE 的同义词。一个在组织内执行持续性、基于角色工作的 AI agent;不是一次性的聊天机器人,而是一名长期的团队成员。
Spec / Specification(规格)
一份详细的书面描述,准确说明需要构建什么:目标、约束、输入、预期输出和行为。这就是 AI 所遵循的「蓝图」。
💡 类比: 规格就像建筑师的蓝图。建筑工不会靠猜就开工,他们照着详图施工。在 AI 开发里,规格是图纸,AI 是施工方。
Spec-Driven Development(规格驱动开发,SDD)
一种开发方法论:你先写好详细规格,再让 AI 从这份规格生成代码、测试和文档。规格是真理之源,代码不是。
📌 四个阶段: 调研 → 规格 → 精化 → 实现。
🔹 示例: 你想要一个书店的 REST API。你不去写代码,而是写一份规格:「该 API 必须提供列出图书、添加图书、按作者搜索、按 ISBN 删除的接口。每本书有标题、作者、ISBN、价格和库存数。所有输入都必须校验。返回 JSON。」你把这份规格交给 Claude Code,它就生成整个 FastAPI 应用、测试和文档。
💡 类比: 规格就像建筑师的蓝图。没有哪家建筑公司会靠猜房子该是什么样就动工。他们照着详图来。在 SDD 里,规格是图纸,AI 是施工队。
Test-Driven Generation(测试驱动生成,TDG)
SDD 针对 Python 的具体形式。你先写测试(定义代码_应当_做什么),再让 Claude Code 生成能通过这些测试的代码。
💡 类比: 烤蛋糕之前,你先准确写下完美蛋糕的样子:高度、口感、味道。然后试一个配方。如果蛋糕不符合你的标准,就再试。标准是测试;配方是生成的代码。
10-80-10 法则
AI 劳动力的运转节奏:人类提供最初的 10%(意图与方向),AI 处理中间的 80%(执行),人类回来收尾最后的 10%(验证与判断)。
📌 由来: 史蒂夫·乔布斯在苹果就遵循这个模式:定下愿景(10%),让团队去做(80%),回来打磨并发布(10%)。现在把「团队」换成「AI 员工」。

AGENTS.md / CLAUDE.md
给 AI 编码 agent 提供持久上下文的配置文件。它们包含你项目的规则、编码规范、架构决策和偏好,会被载入每一次交互。
💡 类比: 新员工加入团队时,你会给他一份入职文档:「我们这样工作。这是我们的编码风格。这是我们绝不会做的事。」AGENTS.md 就是给你 AI agent 的那份入职文档。
SPEC.md
一个具体文件,包含某个项目的详细规格。它是「软件该做什么」唯一的真理之源。
🔹 示例: 你的 SPEC.md 可能这样写:「为一家餐厅构建一个 WhatsApp 聊天机器人。它必须能展示菜单、接受点单、确认配送地址、含 GST 计算总价,并发送订单确认。最长响应时间:2 秒。语言:乌尔都语和英语。」
SKILL.md
一个文件,把一项可复用能力(技能)打包给 AI agent,包含针对某类任务(如生成 PDF、部署 Docker 容器)的指令、最佳实践和模板。
🔹 示例: 一个 Docker SKILL.md 可能包含:「容器化 FastAPI 应用时,始终使用多阶段构建。基础镜像:python:3.12-slim。始终包含一个健康检查端点。绝不以 root 运行。」agent 读取这个技能文件,每次做 Docker 工作时都会自动遵循这些实践。
Skill Library(技能库)
AI agent 可以取用的一批 SKILL.md 文件,让它在许多领域都具备专长,就像员工可以查阅的参考资料库。
Agent Skills(智能体技能)
AI agent 所拥有的具体能力,由它的工具、知识和 SKILL.md 文件定义。
🔹 示例: 人类员工有「Excel 熟练」或「合同谈判」这样的技能。AI agent 有「生成 PDF」「查询数据库」或「起草邮件」这样的技能。
Agent Triangle(智能体三角)
本书提出的一个框架,描述每个高效 agent 都需要的三个组成部分:(1) 清晰的角色、(2) 具体的工具、(3) 明确定义的约束。缺了任何一个,agent 都会表现不佳。
Body + Brain(身体 + 大脑)
一种 agent 架构模式。**Brain(大脑)**是负责推理和决策的 LLM。**Body(身体)**是执行层(工具、API、基础设施),负责把那些决策落地。
💡 类比: 你的大脑决定「我要去拿那个杯子」。你的手(身体)执行这个动作。在 AI agent 里,Claude(大脑)决定「我需要查询数据库」,而 NanoClaw(身体)执行这次查询。
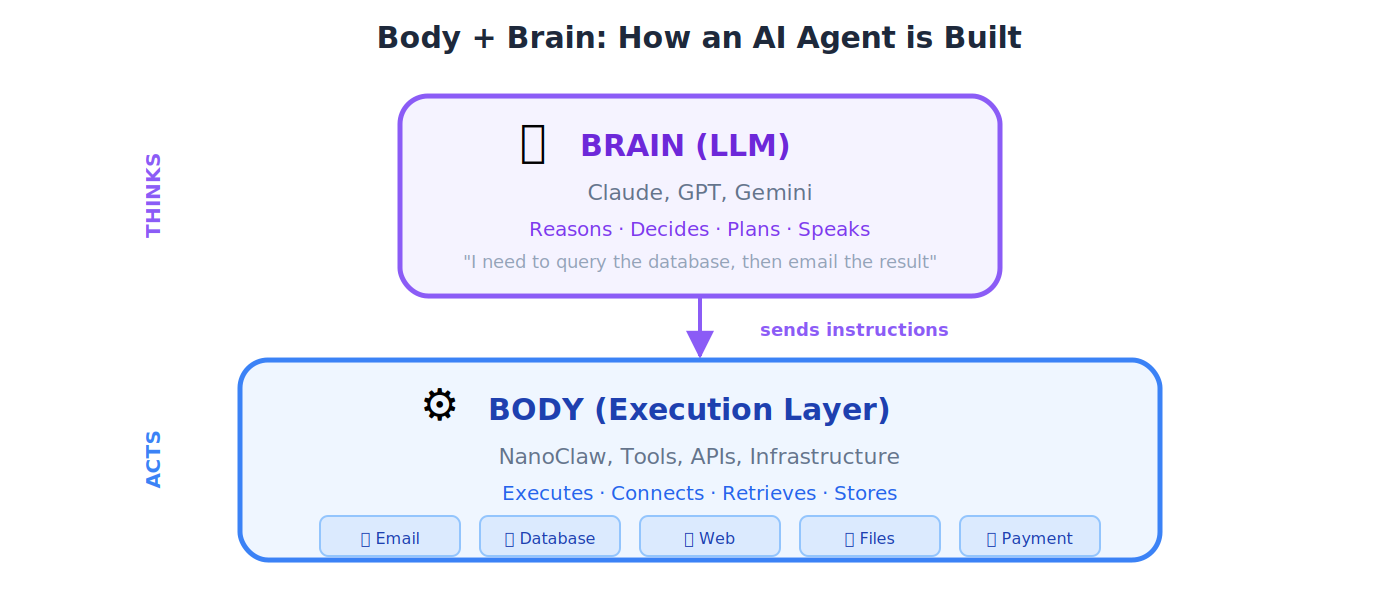
NanoClaw
一种轻量级容器运行时,在 OpenClaw 架构中充当 agent 的「身体」,负责执行任务、运行工具和管理 agent 的环境。
💡 类比: 如果 LLM(大脑)是决定往哪飞的飞行员,那么 NanoClaw(身体)就是真正完成飞行的飞机:引擎、机翼、操纵装置,一应俱全。
OpenClaw
一个用于构建 agent 驱动应用的开源应用框架。在论点的架构里,OpenClaw 是 Edge Layer 上的代理人,那个代表人类、了解其上下文、代其发声的「参谋长」agent。NanoClaw 是它基于容器的执行层。
TutorClaw
一个通过 WhatsApp 提供的全天候 AI 导师,建立在 Agent Factory 架构之上。TutorClaw 把这本书当作它的记录系统来阅读:依据已验证的知识来教学,而非概率性生成。它是本书的第一个 Digital FTE,也是「Agent Factory 如何制造 AI Worker」的一个活生生的例子。
Claude Code
Anthropic 的 AI 编码 agent,在终端(命令行)里运行。它读取你的整个代码库,理解你的项目上下文,并根据你的规格生成代码。本书的主力开发工具。
Cowork
Anthropic 的桌面 agent,专门处理非编码类的知识工作:文档管理、调研和文件整理。把它当作你的 AI 办公助理。
Dispatch
一项功能,让你从手机上把工作分派给 Cowork。你在通勤途中发出一项任务;Claude 在你的桌面上工作。完成后,你会收到一条推送通知。
💡 类比: Dispatch 把 Cowork 从一个你坐在旁边用的工具,变成一个你远程管理的员工,就像你在开会时给助理发消息「把报告准备好」。
Computer Use
一项研究预览功能,Claude 可以在 macOS 上看到并操控你的屏幕(点击按钮、在应用里输入、浏览界面),就像一个远程员工在用你的电脑。
🔹 示例: 你告诉 Claude:「打开我桌面上的电子表格,用这些数字更新第三季度营收那一列,然后把它发邮件给财务团队。」Claude 看着你的屏幕,打开 Excel,录入数据,打开你的邮件客户端并发送,就像一位人类助理坐在你的电脑前。
Claude Desktop
与 Claude 交互的桌面应用,承载着 Cowork、Computer Use 和 Dispatch 等功能。
Hooks(钩子)
在 Claude Code 执行某些操作之前或之后自动触发的动作,比如每次保存文件后自动格式化代码,或每次提交前运行测试。
💡 类比: Hooks 就像给助理的常驻指令:「每次写完一封信,先做拼写检查,再拿给我看。」
Subagents(子智能体)
Claude Code 可以派生出来、处理大项目中某些子任务的专门 agent,每个都有自己专注的上下文。
💡 类比: 项目经理(主 agent)把设计工作分给平面设计师(子 agent),把记账工作分给簿记员(子 agent)。各自专注于自己的专长。
Tasks System(任务系统)
Claude Code 的一项内置功能,用于跨会话管理持久状态,追踪一个多步骤项目里已完成、待处理和下一步要做的事。
Context Engineering(上下文工程)
Digital FTE 制造的质量管控学科。设计 agent 所接收的完整信息环境,以确保输出稳定、高质量。它是把一个月费 2000 美元、可售卖的 agent 与一个无人问津的 agent 区分开来的头号技能。
💡 类比: 丰田工厂有系统化的质量管控,确保每辆车都达到规格。上下文工程确保你的 Digital FTE 交付稳定、可售卖的价值。
Context Injection(上下文注入)
在 AI 生成回答之前,把相关的外部信息插入它的上下文窗口,在恰当的时机给它恰当的信息。
💡 类比: 律师走进法庭之前,助理递给他一个夹子,里面装着所有相关的案卷。上下文注入对 AI 做的就是同样的事。
Context Isolation(上下文隔离)
用干净的上下文开启一个全新会话,而不是把一个冗长的旧会话里可能已经混乱或自相矛盾的状态带过来。
💡 类比: 当你的桌子乱到没法思考时,你会把上面的东西全清掉,重新开始。上下文隔离对 AI 是一样的;有时一张白纸比一段杂乱的历史能产出更好的结果。
Harness Engineering(框架工程)
设计并持续改进 AI agent 周围环境的学科,让它无需监督也能可靠地干有用的活。它处于一个递进序列的第三层:提示词工程优化一次交互,上下文工程管理模型一次能看到什么,而框架工程构建 agent 跨越数百次决策所处的执行环境。这一具名实践由 Mitchell Hashimoto 在 2026 年初提炼成形,他描述了自己每天的习惯:每当 agent 犯一次错,就把一个永久性的修复工程化进 agent 的环境里。OpenAI 和 Anthropic 在数周内陆续发表了展开论述的文章。口号版本是:别去修 agent,去修 agent 所生活的那个世界。
💡 类比: 修提示词是创可贴;修框架是疫苗。修提示词只解决一次失败实例。修框架(加一个工具、一个校验器、一个技能、一个检查、一条指令)则一劳永逸地封死那一类失败,对此后每一个在同一框架里运行的 agent 都有效。
🔹 示例: TutorClaw 给出的反馈对初学者来说太严厉了。幼稚的修法是重写提示词。框架式修法是加一个语气检查技能,让输出经过一套评分标准过滤。此后每一个 TutorClaw 的回答都会经过它,无需改动提示词。
📌 在 OpenClaw 中: 框架扩展的单元是 SKILL.md 文件。你学生写的每一个技能都是一件框架工程产物,同样的 Hashimoto 回路(观察失败 → 追问它为何可能 → 工程化永久修复 → 验证它会复利累积)都适用。
Progress Files(进度文件)
跨多个 Claude Code 会话追踪一个长期项目状态的文件,记录已完成的事、做出的决策,以及下一步是什么。
💡 类比: 一个建筑工地的日志本。每天工头都记下盖了什么、出了什么问题、明天计划做什么。新班组到岗(新会话)时,读一遍日志就能无缝接着干。
Session Architecture(会话架构)
为一个大项目设计你如何在多个会话间组织和排序与 AI agent 的交互:决定何时另起炉灶、何时承上启下、保留哪些上下文。
🔹 示例: 对一个 30 章的写书项目,你不会把整本书一股脑塞进一个会话。你设计一套架构:会话 1 做大纲,会话 2 写第 1 章(带上大纲作为上下文),会话 3 写第 2 章(带上大纲 + 第 1 章摘要),以此类推。每个会话拿到它恰好需要的上下文,不多也不少。
Five Powers(五大能力)
让「从传统用户界面转向自主 AI agent」成为可能的五项能力:(1) 自然语言理解、(2) 推理、(3) 工具使用、(4) 记忆、(5) 规划。合在一起,它们让 agent 能够理解意图并独立执行。
💡 类比: 想象一位能干的人类助理。他能 (1) 听懂你说什么、(2) 想透问题、(3) 用手机电脑这些工具、(4) 记住你的偏好、(5) 规划多步骤项目。一个集齐五大能力的 AI agent 也能做到同样的事:这正是从「你操作的软件」转向「为你操作的软件」的关键。
Agent Maturity Model(智能体成熟度模型)
一个五级框架,描述一个组织采纳 AI 的各个阶段:
| 级别 | 名称 | 描述 |
|---|---|---|
| 1 | 试验型 | 个别开发者在尝试 AI 编码工具 |
| 2 | 标准化 | 全组织采纳,并配有治理 |
| 3 | AI 驱动 | 规格成为活文档;工作流被重新设计 |
| 4 | AI 原生 | AI/LLM 是核心组件的产品 |
| 5 | 自主 | 整个组织 AI 原生;自我改进的系统 |
AI-Assisted Development(AI 辅助开发)
把 AI 当作助手或副驾驶:代码补全、缺陷检测、文档生成。大部分代码仍由人来写。
🔹 示例: GitHub Copilot 在你打字时建议下一行代码。
AI-Driven Development(AI 驱动开发)
AI 从人写的规格生成大量代码。人扮演架构师、导演和审阅者的角色,而不是打字员。
🔹 示例: 你写一份描述某 REST API 的 SPEC.md,Claude Code 就生成整个 FastAPI 应用、测试和文档。
AI-Native Development(AI 原生开发)
从一开始就围绕 AI 能力设计的应用:AI 不是作为一项功能加上去的,而是产品的核心。
🔹 示例: TutorClaw 不是一本外挂了聊天机器人的教科书。AI 导师_本身_就是产品。整个架构都是围绕 LLM 的能力构建的。
Nine Pillars of AIDD(AIDD 九大支柱)
本书所定义的 AI 驱动开发的九条基础原则:从「规格优先」的设计一直涵盖到「持续验证」。
OODA Loop(观察、定向、决策、行动)
一个应用于与 AI agent 协作的快速决策循环。你 观察 agent 的输出,通过检查它是否符合规格来给自己 定向,决策 是接受还是改道,然后通过批准或下达新指令来 行动。
📌 由来: 一个由战斗机飞行员 John Boyd 提出的军事战略框架,如今被用于 AI 驱动工作的快速迭代循环。
PRIMM-AI+
本书使用的一个教学框架:预测(Predict) 代码会做什么 → 运行(Run) 它 → 调查(Investigate) 输出 → 修改(Modify) 它 → 创造(Make) 你自己的版本。「AI+」意味着 AI 嵌入了每一步。
AI Gravity(AI 引力)
一种持续的拉力:让你把越来越多的思考交给 AI。这个名字来自 MIT Sloan 教授 Eric So。它同时来自三个方向:你的大脑想节省能量,你希望自己的工作看起来像专家水平,而且你看不见同伴到底用了多少 AI。这正是 How to Think in the AI Era 速成课训练你抵抗的力量。
💡 类比: 真实的引力:你看不见它,它从不关闭,而且它拉着每个人。你不会注意到它正在拉你;你只会在几个月后发现,自己已经不再先形成观点再打开 AI。
🔹 例子: 两个人拿到同一项任务和同一套 AI 工具。一个人先写自己的答案,再和 AI 的答案比较。另一个人打开 AI、提问、接受;不是因为懒,而是因为三股安静的力量把她推向同一个方向。那股拉力就是 AI gravity。
Cognitive Capital(认知资本)
你的思考肌肉:一步步处理问题、识别错误答案、看出一个自信答案遗漏了什么的累积能力。Eric So 用这个词描述 AI gravity 在你不检查就接受答案时慢慢消耗的东西。
🔹 例子: MIT Media Lab 的一项早期研究中,100 个用 ChatGPT 写作文的人里有 83 个,刚交完作文就无法复述其中任何一句。文字从屏幕到了作业,却没有经过写作者的大脑;这就是认知资本没有被使用,直到慢慢退化。
📌 为什么它对本书重要: 10-80-10 Rule 只有在人类的两个 10 仍然敏锐时才有效。认知资本让它们保持敏锐。一个已经看不出 agent 何时出错的监督者,守不住最后那个 10%。
Identic AI
一个概念:每个人都有一个 personal AI agent,它反映此人的判断、偏好和权限,代其在多个 AI 系统之间分派任务。在本书的参考架构里,OpenClaw 就是那个 identic AI,即 Edge Layer 上的代理人。
💡 类比: 一位 CEO 有一名行政助理,对他的优先事项和决策风格了如指掌,以至于能代表 CEO 行事。Identic AI 就是其 AI 版本:你在 Agent Factory 里的私人代表。
System of Record / Source of Truth(记录系统 / 真理之源)
那个唯一的、人人都信其准确的权威数据源。当出现相互矛盾的版本时,记录系统说了算。
🔹 示例: 如果你公司的 HR 系统说某员工月薪 20 万卢比,而一张电子表格说 18 万卢比,那么 HR 系统就是记录系统。
Bounded Workflow(有界工作流)
一个有清晰起点、终点和约束的工作流:agent 确切知道自己能做什么、不能做什么。没有模糊地带,没有范围蔓延。
Escalation Protocol(上报协议)
一条预先定义的规则,规定 agent 在何时应当停下并把任务交给人:因为太复杂、太冒险,或超出了 agent 的权限。
🔹 示例: 一个客服 agent 处理常规问题,但如果某位客户威胁要采取法律行动,上报协议就把对话转给人类经理。
Tool Interface(工具接口)
agent 连接并使用某个外部工具的既定契约,规定该工具期望什么输入、返回什么输出。
Vertical Intelligence(垂直智能)
把某个特定行业的术语、法规、工作流和痛点的深度专长,打包进一个 agent。
🔹 示例: 一个面向巴基斯坦纺织出口商的 AI agent,懂 SRO 通知、HS 编码、信用证单据和 SBP 法规,而不只是泛泛的商业知识。
Agentic Enterprise(智能体式企业)
一个把 AI agent 嵌入核心运营的组织,Digital FTE 与人类员工并肩,作为一种标准工作方式。在论点里,这被称作 AI-Native Company,即 Agent Factory 制造出来的那家正在运转的企业。两个术语指的是同一个东西。
🔹 示例: 一家物流公司,AI agent 全天候处理订单追踪、路线优化和客户通知,而人类员工专注于合作关系、异常处理和战略。这些 agent 不是一个副业项目,而是组织架构图的一部分。
Custom-Built AI Employee(定制 AI 员工)
你为某个具体业务需求从零构建的 AI agent,完全贴合你的工作流和领域。
🔹 示例: 一家纺织出口商构建一个 agent,读取传入的信用证(LC)单据,对照 SBP 法规检查,标出不符之处,并起草修改请求。没有任何现成工具能做到这一点;它是为他们精确的工作流定制的。
Pre-Built AI Employee(预制 AI 员工)
一个现成的 AI agent,无需定制开发即可立即使用,比如使用 ChatGPT、Claude 或现成的客服机器人。
🔹 示例: 直接用 Claude 来起草邮件、总结文档或回答问题。无需开发;你立刻就能上手。权衡在于:它对通用任务管用,但没有为你独特的业务流程做专门优化。
Build vs. Buy(自建 vs. 购买)
那个战略性决策:自建你自己的定制 AI agent(控制更强、成本更高、耗时更久),还是用一个现成的(部署更快、定制更少)?
🔹 示例: 一家医院需要一个患者排班 agent。购买: 用一个现成的医疗 AI 平台(数周内部署完成,但定制有限)。自建: 创建一个与他们特定 EMR 系统、医生偏好和乌尔都语/英语支持集成的定制 agent,需要数月但完美契合。正确的选择取决于预算、时间线,以及工作流有多独特。
FTE Development Plugin(FTE 开发插件)
一个辅助 Digital FTE 开发和部署的工具或扩展,让 Agent Factory 工作流更顺畅。
Skill Shim(技能垫片)
一个薄薄的适配层,在不同的 agent 技能格式之间做转换,实现跨平台的兼容。
💡 类比: 一个旅行电源转换头。你的巴基斯坦插头插不进英国插座,但一个垫片(转换头)不必动任何线路就让它们兼容。
Gateway Proxy Pattern(网关代理模式)
一种架构模式:单一入口(网关)把请求路由到正确的后端 agent 或服务,并管理认证、限流和负载分配。
💡 类比: 一家大医院的接待台。所有患者从接待处进入,由它核对预约、核实身份,并引导到正确的科室。
Piggyback Protocol(搭车策略)
本书提到的一种创业策略:把你的产品建在某个现有平台的分发渠道之上,以便快速触达用户,之后再去建立自己独立的渠道。
🔹 示例: 与其为了交付 TutorClaw 而自建一个消息应用,不如把它建在 WhatsApp 之上,后者在巴基斯坦已有 1 亿多用户。你「搭」WhatsApp 分发的「车」,即刻触达学生,无需说服任何人去下载一个新应用。
2. 核心 AI 与机器学习
这些是本书一切内容背后的基础概念。
AI ⊃ ML ⊃ DL ⊃ LLMs
(每一个都是前一个的子集)
AI(人工智能)
让计算机去做那些通常需要人类智能才能完成的事,比如理解语言、识别图像、做决策、解决问题。
🔹 示例: 当你手机的键盘用乌尔都语或英语预测你的下一个词时,那就是 AI。当 Careem 根据路况估算你的行程时间时,那也是 AI。
ML(机器学习)
一种教计算机的方式:给它看例子,而不是写下明确的规则。计算机在数据中找出模式并从中学习。
🔹 示例: YouTube 推荐你可能喜欢的视频。没有人编写一条「如果用户看了板球集锦,就推荐更多板球」的规则。系统是从数十亿次观看习惯里学到这个模式的。
💡 类比: 想象教一个孩子认芒果。你不会去解释生物学。你给他看几十个芒果,说「芒果」。最终,他能认出从没见过的芒果,甚至像 Chaunsa 和 Sindhri 这样不同的品种。这就是机器学习。
DL(深度学习)
机器学习的一个更强大的版本,使用带许多层的「神经网络」。它能学到极其复杂的模式,比如理解语音、生成图像或在不同语言之间翻译。
🔹 示例: 当 Google 翻译把一段乌尔都语转成流畅的英语时,背后是深度学习在驱动这次翻译。
💡 类比: 如果说 ML 是学会认简单形状,那么 DL 就是学会在拥挤的 Saddar 集市里认出人脸:复杂得多,但同样是「从例子中学习」这个原理。
Model(模型)
一个在数据上训练过、现在能做预测或生成输出的程序。人们说「GPT-4」或「Claude」时,指的就是模型。
💡 类比: 模型就像一个读了数百万本教科书的学生。你提问,它依据读过的一切作答。不同的模型就像不同的学生:有的更擅长数学,有的更擅长创意写作。
Foundation Model(基础模型)
一个在海量数据上训练出来的、非常大的通用模型。无需从零重新训练,就能适配到许多不同任务。Claude、GPT-4 和 Gemini 都是基础模型。
💡 类比: 基础模型就像一个受过广博教育的大学毕业生。他还没专精某一行,但能迅速适应许多工作:会计、写作、调研、管理。
Neural Network(神经网络)
一种受人脑启发的计算系统,由一层层相互连接的「节点」组成,它们处理信息,每一层都提取越来越复杂的模式。
💡 类比: 想象一系列网眼大小不同的筛子。你把原始数据倒过第一层筛子(筛住大模式),再倒过下一层(筛住更细的模式),再下一层(筛住最细的细节)。神经网络的工作方式类似,每一层都在精炼信息。
Transformer
驱动所有现代 LLM 的那种特定神经网络架构。2017 年发明,它尤其擅长理解词与词之间的关系,知道「bank」在「river bank(河岸)」和「bank account(银行账户)」里意思不同。
💡 类比: 老一代 AI 一个词一个词地读句子,就像透过钥匙孔看(一次看到一个词,靠猜意思)。Transformer 一次读完整个句子,就像把整扇门打开(它同时看到每个词,并理解每个词和其他每个词的关系)。这正是它们如此擅长理解语言的原因。
💡 为什么重要: 本书里的每个 AI 模型(Claude、GPT、Gemini)都建立在 transformer 之上。你不需要懂背后的数学,但你会经常见到这个术语。
Multimodal Model(多模态模型)
一个能处理多种输入类型(文本、图像、音频、视频)而不只一种的模型。
🔹 示例: 你拍下一张餐厅账单,问 Claude「总共多少?」模型同时理解了图像和你的文字问题。这就是多模态能力。
Reasoning Model(推理模型)
一个被设计成在作答前先一步步「想透」复杂问题、而非即刻应答的模型。在难题上往往更准确。
💡 类比: 在一场板球比赛里,有的击球手凭本能挥拍(快,有时鲁莽)。另一些则研究场上布局、读懂投球手,并刻意计划每一击。推理模型属于后者:更慢,但在难球面前更可靠。
Training(训练)
给模型喂入海量数据、让它学到模式的过程。这发生在你与模型交互之前;它是「受教育」的阶段。
💡 类比: 训练就像一位厨师在烹饪学校待上数年:尝过成千上万道菜,学会各种技法,反复练习菜谱。等他开自己的餐厅时(也就是你使用模型时),学习早已完成。
Pretraining(预训练)
训练中第一个、也是最昂贵的阶段。模型读入海量文本(书籍、网站、代码、对话),学到关于语言和世界的通用知识。
Post-Training(后训练)
预训练之后的额外训练,让模型变得有用、安全,并与人类期望对齐。模型正是在这里学会遵循指令、保持礼貌、拒绝有害请求。
💡 类比: 预训练就像接受通识教育(中学和大学)。后训练就像入职培训:学习公司文化、沟通方式和职业规范。
Fine-Tuning(微调)
在一个更小的特定数据集上进一步训练一个已有模型,让它成为某个领域的专家。
🔹 示例: 拿一个通用模型,在数千份巴基斯坦税务裁决上微调,让它尤其擅长税务咨询。
💡 类比: 一位全科医生完成额外培训,成为心脏病专家。同样的基础教育,如今专精了。
Parameters(参数)
模型内部在训练中被调整的那些数值。参数越多,通常意味着模型越强大。现代 LLM 有数十亿乃至数万亿个参数。
💡 类比: 参数就像一张巨大地毯里的一根根线。训练时,每根线都被调整(颜色、松紧、位置),直到完整的图案浮现。一个有 1000 亿参数的模型,就有 1000 亿根线,编织出一个极其复杂的图案。
Weights(权重)
训练之后参数的那些具体数值。当有人说「下载权重」时,指的是那个包含所有训练好的数值的文件:模型学到的知识。
Dataset(数据集)
用来训练或评测 AI 模型的一批数据。
🔹 示例: 训练垃圾邮件过滤器的数据集,可能包含 100 万封邮件,每封都标注了「垃圾」或「非垃圾」。训练翻译模型的数据集,可能包含数百万对英语-乌尔都语句子。
Benchmark(基准测试)
一项标准化测试,用来衡量并比较不同 AI 模型的表现好坏。
🔹 示例: 就像 CSS 或剑桥考试让你能比较学生一样,MMLU(通用知识)或 HumanEval(编码能力)这样的基准让研究者能公平地比较 AI 模型。
Inference(推理)
一个训练好的模型对你的输入生成回答的过程。每次你问 Claude 一个问题并得到答案,那就是推理。
💡 类比: 训练是为考试复习。推理是上考场。学习早已完成,现在模型把学到的应用出来。你为推理付费(每次 API 调用都要花钱),而不是为训练付费。
3. LLM 基础
LLM 是驱动本书每一个 AI agent 的引擎。本节从实用层面讲解它们如何工作。
LLM(大语言模型)
一个在海量文本上训练出来、能够理解和生成类人语言与代码的非常大的 AI 模型。Claude、GPT-4 和 Gemini 都是 LLM。
💡 类比: LLM 就像一位博览群书到惊人的研究助理,读过每一篇维基百科文章、数百万本书和数十亿个网页。你几乎可以问他任何事,他都能从那些阅读中调取来帮你:写作、分析、代码、翻译,等等。
Prompt(提示词)
你给 AI 模型的输入:你的问题、指令或请求。提示词的质量直接影响回答的质量。
🔹 示例: 「写点关于市场营销的东西」是个糟糕的提示词。「为什么巴基斯坦纺织出口商应当使用 AI agent 来做订单追踪,写一篇 500 字的 LinkedIn 帖子,语气专业而对话化」则是个有力的提示词。
System Prompt(系统提示词)
在你的对话开始之前就给 AI 的隐藏指令。由开发者设定,而非用户。它们塑造模型的人格、行为和约束。
🔹 示例: 一个银行聊天机器人的系统提示词可能写着:「你是 HBL 的得力助手。根据客户的语言用乌尔都语或英语作答。未经 OTP 验证,绝不透露账户余额。若被问及贷款,引导至贷款页面。」
💡 类比: 系统提示词就像经理在第一天给新员工的简报:「我们是谁,我们如何与客户交谈,你绝不能做什么。」
User Prompt(用户提示词)
你(用户)实际打出的那条消息。这是你在对话中的一方。
Instruction(指令)
提示词里的一条具体指示,告诉模型该做什么。
🔹 示例: 「把这个总结成三个要点」「翻译成乌尔都语」「修复这段代码里的 bug」,每一条都是清晰的指令。
Context(上下文)
一次对话中模型可获得的全部信息:系统提示词、对话历史、上传的文档,以及你当前的消息,合在一起。
💡 类比: 当你向同事征询一笔交易的建议时,「上下文」就是他知道的一切:客户历史、过往邮件、合同条款、你公司的政策。相关上下文越多,建议越好。
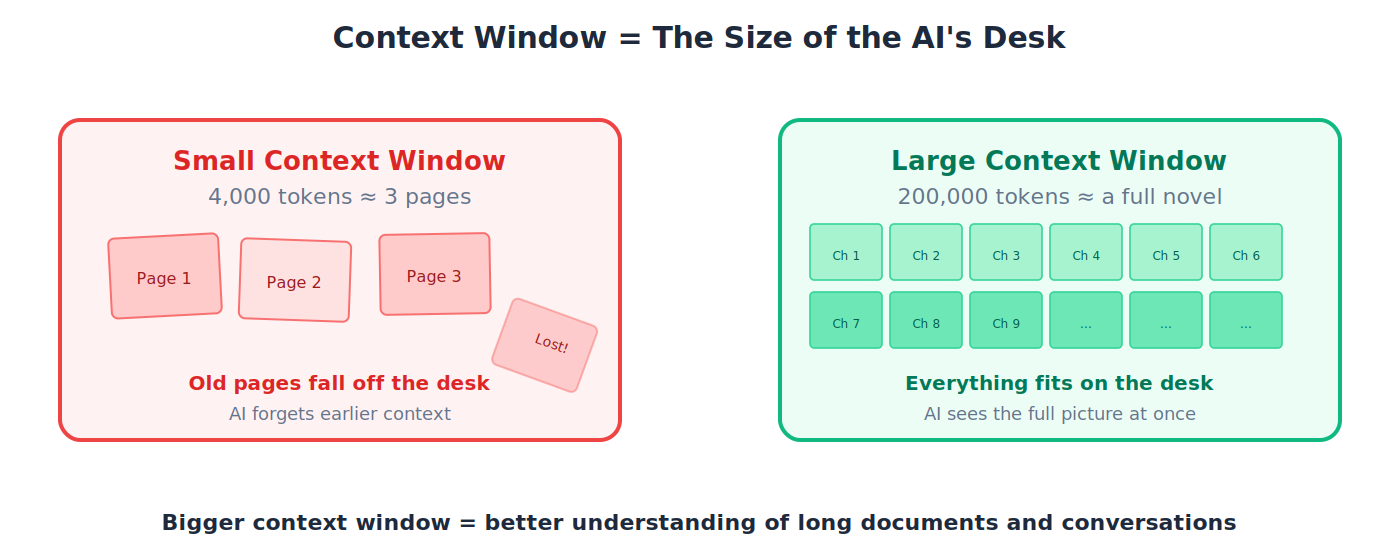
Context Window(上下文窗口)
一个 LLM 一次能处理的最大文本量,以 token 计量。把它当作模型的「工作记忆」。
🔹 示例: Claude 模型提供从 20 万到 100 多万 token 的上下文窗口。即便是 20 万 token,也大约相当于 15 万个英文单词(一整本小说)。老一代模型也许只能处理 4000 token(几页纸)。
💡 类比: 上下文窗口就像桌子的大小。小桌子只放得下几页纸,你得不断撤掉旧的来腾地方。大桌子让你铺开一整个项目、一眼看全。更大的上下文窗口等于更大的桌子。
Token(词元)
LLM 处理文本的基本单位。一个 token 大约相当于四分之三个英文单词。像「the」这样的短词是一个 token。像「unbelievable」这样的长词会被拆成 3 到 4 个 token。空格和标点也消耗 token。
🔹 示例: 「I love biryani」约等于 4 个 token。一整页文本约等于 500 到 700 个 token。使用 AI API 时,你按 token 计费。
Completion / Generation(补全 / 生成)
LLM 对你的提示词生成的输出。当模型「补全」你的请求时,那个回答就是补全。
Structured Output(结构化输出)
当 LLM 把回答生成为某种特定的、机器可读的格式(比如 JSON),而非对话式文本,好让其他软件能轻松处理。
🔹 示例: 与其说「卡拉奇的气温是 35 度,晴天」,结构化输出会是:
{"city": "Karachi", "temp": 35, "condition": "sunny"}。软件读这种格式毫不费力。
Hallucination(幻觉)
当 AI 模型自信满满地生成虚假、不准确或捏造的信息,并把它当作事实呈现。
🔹 示例: 你问一个最高法院的判决,模型编造出一个案件(配上假的引用编号和假的合议庭),还当作真事呈现。
💡 类比: 一个考试时不知道答案、却照样写出非常自信、非常详尽的回答的学生。读起来像是对的,其实全是编的。
Grounding(落地 / 接地)
把 AI 模型连到事实性的、已验证的数据源上,让它给出准确答案而不是产生幻觉。
💡 类比: 落地就像允许学生在考试时翻教科书。现在他的答案基于真实信息,而非靠不住的记忆。
Temperature(温度)
一个控制 LLM 回答里「创造性 vs 可预测性」的设置。低温度(0)= 非常稳定。高温度(1 以上)= 更有创意、更多变。
💡 类比: 温度就像厨师在厨房里的自由度。温度 0:「严格照菜谱来,不许替换。」温度 1:「自由发挥。」给药剂量你想要精确的菜谱,做一道新菜则想要创意的自由。
Latency(延迟)
从发出请求到收到回答之间的时间间隔。延迟越低 = 越快。以毫秒或秒计量。
🔹 示例: 如果 Claude 在 1 秒内响应,那是低延迟。如果要 15 秒,那是高延迟。超过 2 到 3 秒,用户就不耐烦了。
Throughput(吞吐量)
一个系统单位时间内能处理多少请求。高吞吐量 = 能同时服务许多用户。
💡 类比: 延迟是一辆车通过收费站有多快。吞吐量是收费站每小时能处理多少辆车。你想要低延迟和高吞吐量兼得。
Deterministic vs. Non-Deterministic(确定性 vs 非确定性)
确定性: 相同输入总是产生完全相同的输出(就像计算器:2+2 永远等于 4)。非确定性: 相同输入每次可能产生不同的输出。
LLM 是非确定性的:同一个问题问两次,你可能得到略有不同(但同样有效)的答案。这不是 bug,而是这项技术运作方式的根本所在。
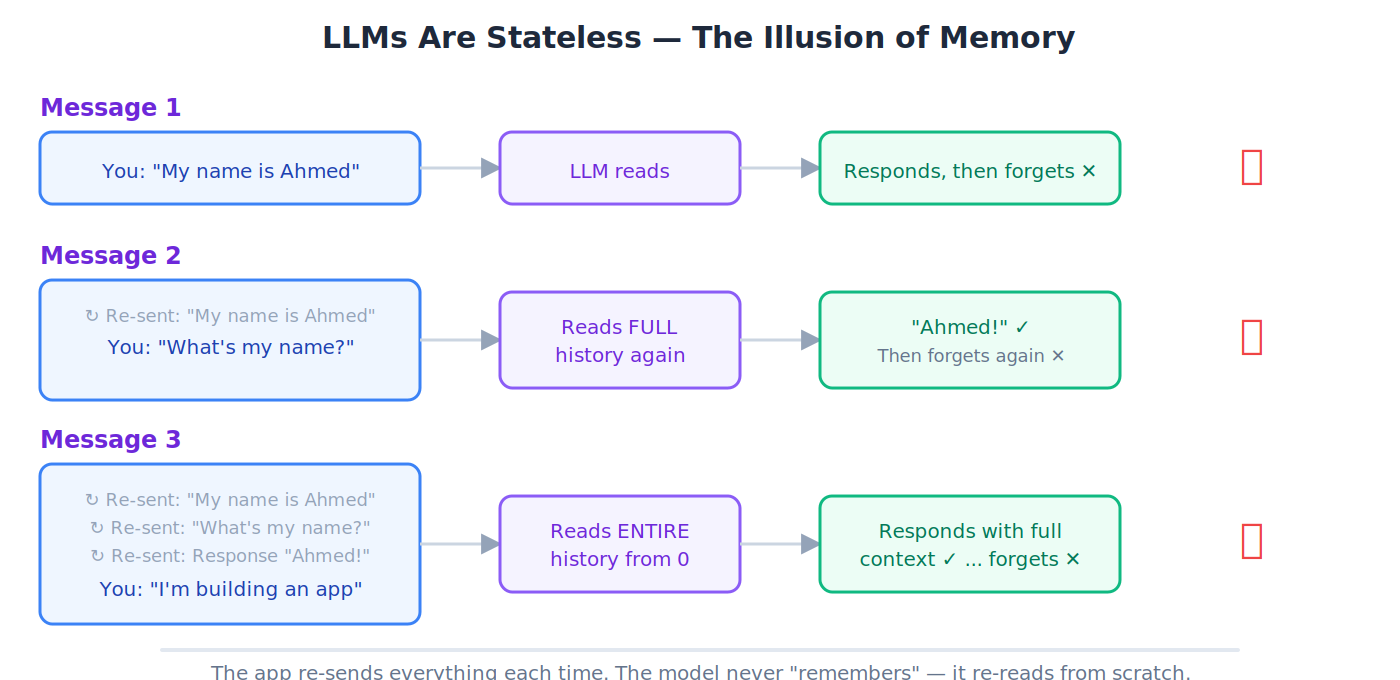
Stateless(无状态)
在两次独立交互之间没有记忆。与 LLM 的每一次新对话都从绝对的零开始:模型对此前任何对话一无所知。
💡 类比: 一位健忘的店主。每次你走进店里,他都把你当陌生人招呼,哪怕你 5 分钟前才来过。聊天应用靠每条消息都重新发送整段对话历史,制造出记忆的_假象_。
Prompt Engineering(提示词工程)
打磨清晰、具体的指令、从 AI 模型获取尽可能好的输出的技能。不只是「你问什么」,还包括「你怎么问」。
🔹 示例: 与其说「写写 AI」,一位提示词工程师会写:「你是一名为《黎明报》撰稿的科技记者。写一篇 600 字的文章,讲巴基斯坦的银行如何用 AI agent 做欺诈检测。包含一个真实例子。用非技术背景的商业读者也能看懂的简单语言。」
NLP(自然语言处理)
AI 中处理「理解、解读和生成人类语言」的分支,是让 LLM 成为可能的基础。
🔹 示例: 当你用蹩脚的英语打一个搜索词、Google 仍能明白你的意思时,那就是 NLP 在起作用。
Copilot(副驾驶)
一个集成在软件环境(比如代码编辑器)里的 AI 助手,与你并肩工作以提升效率,在你工作时给出建议、自动补全和审阅。
🔹 示例: GitHub Copilot 在你打字时建议代码。它就像一位知识渊博的同事在你肩后看着,替你把句子写完。
4. 知识、检索与上下文
这些术语描述 AI agent 如何访问和使用外部知识,以给出更好、更准确的答案。
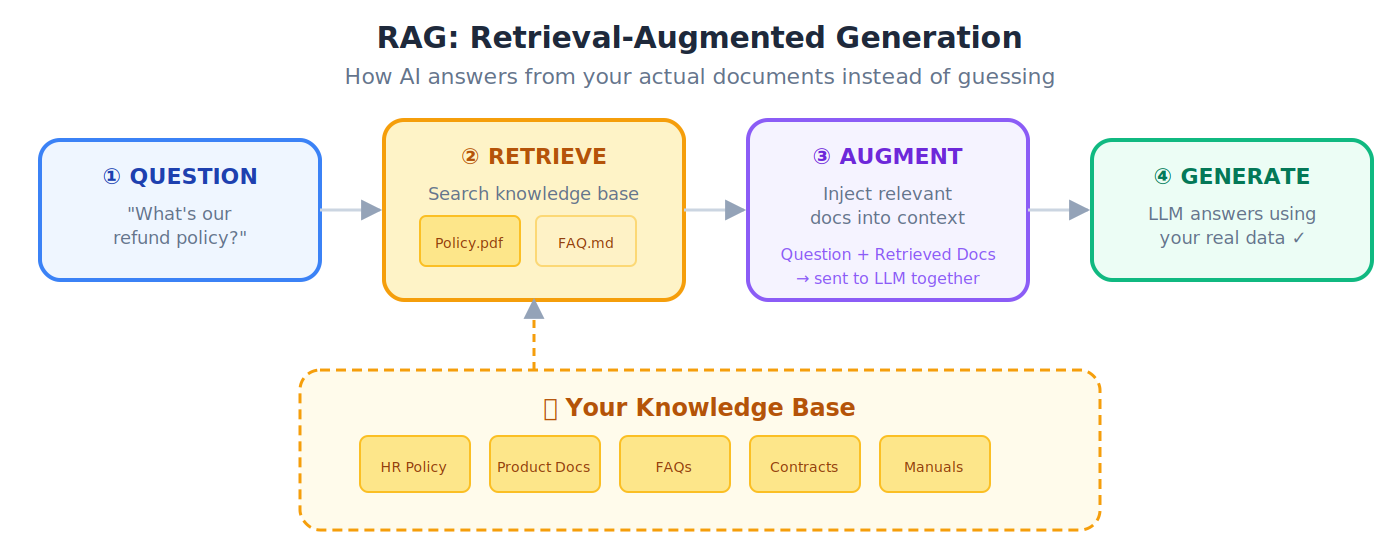
RAG(检索增强生成)
一种技术:AI 先从外部文档或数据库检索相关信息,再用这些信息生成更准确的回答。
💡 类比: 参加一场开卷考试。与其只靠记下来的(可能出错的)知识,你在写答案前先在参考资料里查证具体事实。RAG 给了 AI 它自己的参考资料库。
Embedding(嵌入)
把文本转成数值坐标,好让计算机能衡量不同文本片段有多相似,捕捉的是含义而不只是关键词。
💡 类比: 想象把图书馆里的每一本书放到一张巨大的地图上,相似的书聚到一起。菜谱书彼此挨着,远离物理教科书。嵌入就在数学空间里创造出这张「相似度地图」。
Vector(向量)
在数学空间里表示一段文本的一串数字。当文本被转成嵌入时,结果就是一个向量。
🔹 示例: 「cricket」这个词可能变成
[0.8, 0.3, 0.7, 0.1, ...]:一长串数字,同时捕捉了「板球运动」和「蟋蟀」两种含义,靠上下文来区分。
Vector Database(向量数据库)
一种专门用来存储并快速检索向量的数据库,按含义而非精确关键词匹配来查找相似内容。

🔹 示例: 你把 1 万份公司文档存为向量。当有人问「我们的退货政策是什么?」时,向量数据库即刻找出最相关的文档,哪怕它们里头一个都没出现「退货政策」这个确切短语。
💡 类比: 传统数据库按精确关键词检索(像在电话簿里按名字查)。向量数据库按含义检索(像问图书管理员「帮我找和这本类似的书」)。
Semantic Search(语义检索)
按含义而非精确关键词来检索。「我怎么退一件商品?」能匹配到一篇标题为「退款流程」的文档,哪怕用词完全不同。
🔹 示例: 一名员工在公司知识库里搜「怎么请假」。语义检索找到标题为「年假政策与流程」的文档,哪怕标题里一个搜索词都没出现。传统关键词检索会一无所获。
Retrieval(检索)
从数据源(数据库、文档集合、网络)取出相关信息,供 AI 在生成回答时使用。
🔹 示例: 一位客户问你的支持 agent「你们笔记本的保修是怎样的?」agent 从你的知识库里检索保修政策文档,读取相关段落,并依据你真实的政策生成准确回答,而不是靠猜。
Reranking(重排序)
在检索出多个结果之后,按相关性重新排序,让最有用的结果排在最前:在初次检索之后再加一道质量过滤。
Chunking / Chunk(分块 / 块)
把一份大文档拆成更小的片段,好让它们能被单独存储和检索。
🔹 示例: 一份 200 页的 HR 手册被拆成段落大小的块。当有人问起请假政策时,系统只检索最相关的 3 到 4 个段落,而不是整本手册。
Knowledge Base(知识库)
一批有组织的信息(文档、常见问题、手册、政策),供 AI 检索和参考。
🔹 示例: 一个公司内部 wiki,包含产品文档、HR 政策和培训资料,组织成 AI agent 能即刻找到答案的结构。
Grounding Data(落地数据)
连接到 AI 模型、用以确保回答准确、基于事实而非幻觉式猜测的那些具体事实数据。
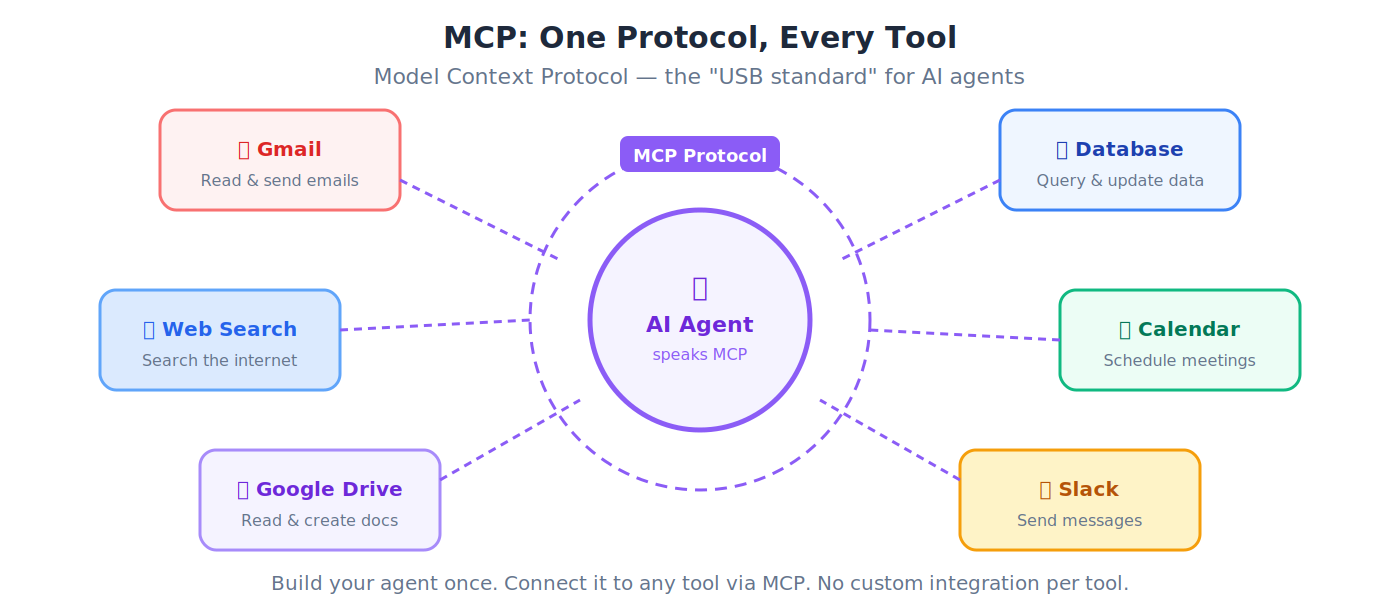
MCP(Model Context Protocol,模型上下文协议)
一个开放标准(由 Anthropic 创建,现由 Linux 基金会治理),让任意 AI agent 用一套通用协议连接到任意外部工具:搜索、数据库、邮件、日历、文件系统。MCP 是 agent 调用工具的协议。至于处理「agent 为这些工具付费」的另一套协议族,参见第 11 节:ACP、AP2、x402 和 MPP。
💡 类比: 在 USB 出现之前,每部手机都有不同的充电器。USB 成了通用接口。MCP 就是 AI agent 的「USB 标准」:一套协议,让任意 agent 都能插入任意工具。把你的 agent 构建一次,就能连接一切。
Connector(连接器)
用 MCP 或另一种协议,把 AI agent 接到某个外部服务的具体集成。
🔹 示例: 一个「Gmail 连接器」让 AI agent 能读取、搜索和发送邮件。一个「Google Drive 连接器」让它能读取和创建文档。
System Integration(系统集成)
把不同的软件系统连起来,让它们共享数据、无缝协作:任何企业级 agent 部署背后的「管道工程」。
🔹 示例: 你的 Digital FTE 需要从 Salesforce 读取客户数据、在 SAP 里查库存、通过 JazzCash 处理付款,并通过邮件发送确认。系统集成把这四个系统连起来,让 agent 能在单个工作流里跨越它们工作。
5. Agentic AI 概念
本书的核心:不只回答问题、还会采取行动的 AI 系统。
Agent(或 AI Agent,智能体)
一个能独立感知所处环境、做决策并采取行动以达成目标的 AI 系统,无需人类在每一步加以引导。
🔹 示例: 聊天机器人只是回答问题。一个 AI agent 收到一个目标,比如「帮我找下周五卡拉奇飞迪拜最便宜的航班」,然后就去搜索各家航空公司、比较价格、查看你的日历并订票,全都自己来。
💡 类比: 聊天机器人是坐在柜台后回答问题的图书管理员。agent 是接过你的请求、走进现实世界把事情办成的私人助理。
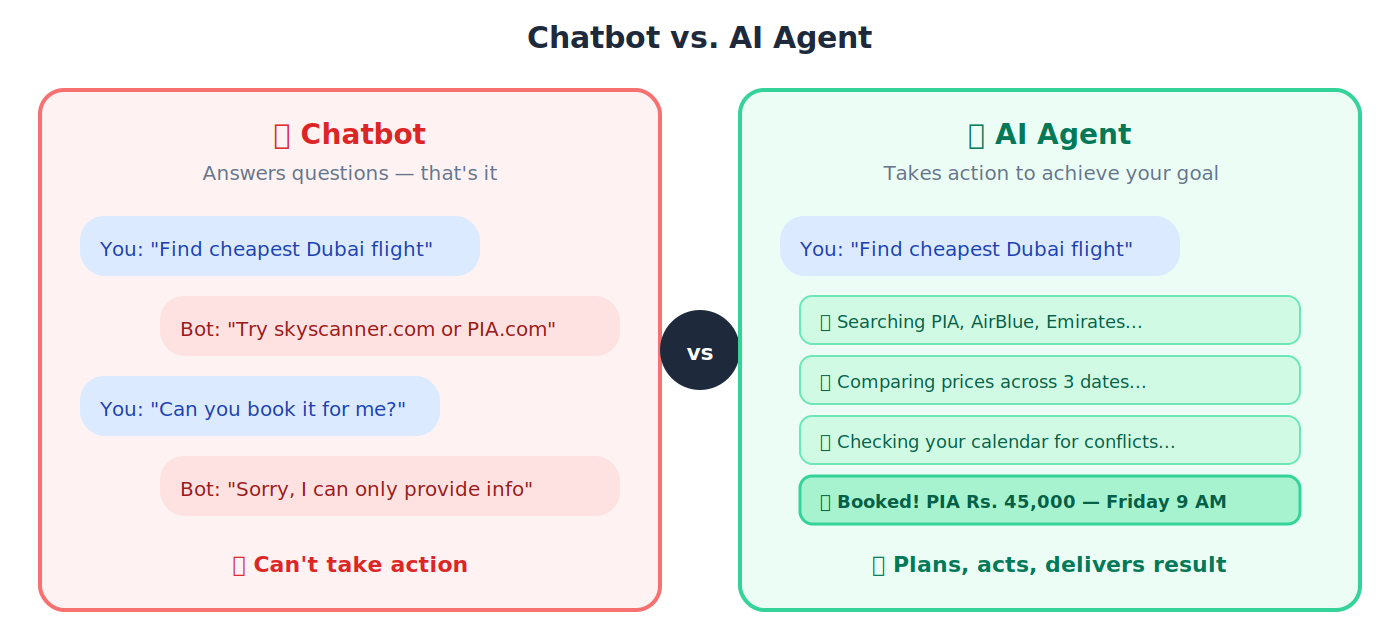
Agentic AI(智能体式 AI)
专注于构建能自主规划、推理、行动和适应的 agent 的那一类 AI。这是 2026 年 AI 的前沿。
General Agent(通用智能体)
一个通过自然语言用于广泛任务的 AI agent。它不是为某一项具体工作打造的;它是一把多才多艺的「瑞士军刀」,能帮你做编码、写作、调研、文件管理,等等。
🔹 示例: Claude Code 就是一个通用 agent:你可以让它整理文件、写一个 API、分析一张电子表格,或调试一个 Python 错误。它用自然语言指令适应你的任何需求。
💡 类比: 通用 agent 就像一位能力极强的行政助理。你不是为某一项任务才雇他;你每天给他不同的差事,他自己想办法把每一件办成。
Autonomy(自主性)
一个 AI agent 能够在多大程度上独立运作、而不必每一步都得到人类批准。
💡 类比: 一个每封邮件都要请示的初级员工自主性低。一个独立做决策的资深总监自主性高。agent 处在同一条谱系上:有的每个动作都需人类批准;有的在既定边界内完全独立运作。
Reasoning(推理)
agent 在行动之前合乎逻辑地想透一个问题的能力:分析信息、权衡选项、得出结论。
🔹 示例: 你问一个 agent:「我们应该先在拉合尔还是伊斯兰堡开张?」一个不会推理的 agent 也许就随便挑一个。一个会推理的 agent 则分析:「拉合尔人口是两倍,但伊斯兰堡人均收入更高。你的产品面向专业人士,所以伊斯兰堡的人群画像更契合。我建议先伊斯兰堡,第 3 个月再拉合尔。」
Acting(行动)
当 agent 真的在现实世界里做了某件事:发一封邮件、写一个文件、查询一个 API、下一个订单、订一个预约。
Planning(规划)
agent 把一个复杂目标拆成一连串步骤、并确定执行顺序的能力。
🔹 示例: 你告诉一个 agent:「准备一份关于巴基斯坦水泥出口的市场分析报告。」agent 这样规划:(1) 搜索出口数据,(2) 收集竞争对手信息,(3) 分析趋势,(4) 撰写报告,(5) 排版并导出为 PDF。
Task Decomposition(任务分解)
把一个庞大、复杂的任务拆成更小、更可控、能够各个击破的子任务。
💡 类比: 「筹办一场婚礼」作为单个任务令人望而生畏。分解之后:找场地、选餐饮、设计请柬、布置鲜花、雇摄影师。每个子任务都可解决。AI agent 用同样的方式分解复杂目标。
Orchestration(编排)
协调多个 agent 或工具协同工作,管理它们之间的信息流动。
💡 类比: 一位板球队长不会同时投球、击球和守场。他布置外场员、安排投球轮次,并根据赛况调整战术。Agent 编排同理:协调各路专才奔向同一个目标。
Multi-Agent System(多智能体系统)
一个由多个 AI agent 协作(各自处理任务的不同部分)的系统,去完成任何单个 agent 都做不成的事。
🔹 示例: 一个 agent 调研竞争对手定价,另一个起草分析,第三个排版幻灯片,第四个准备演讲备注。他们作为一个团队工作。
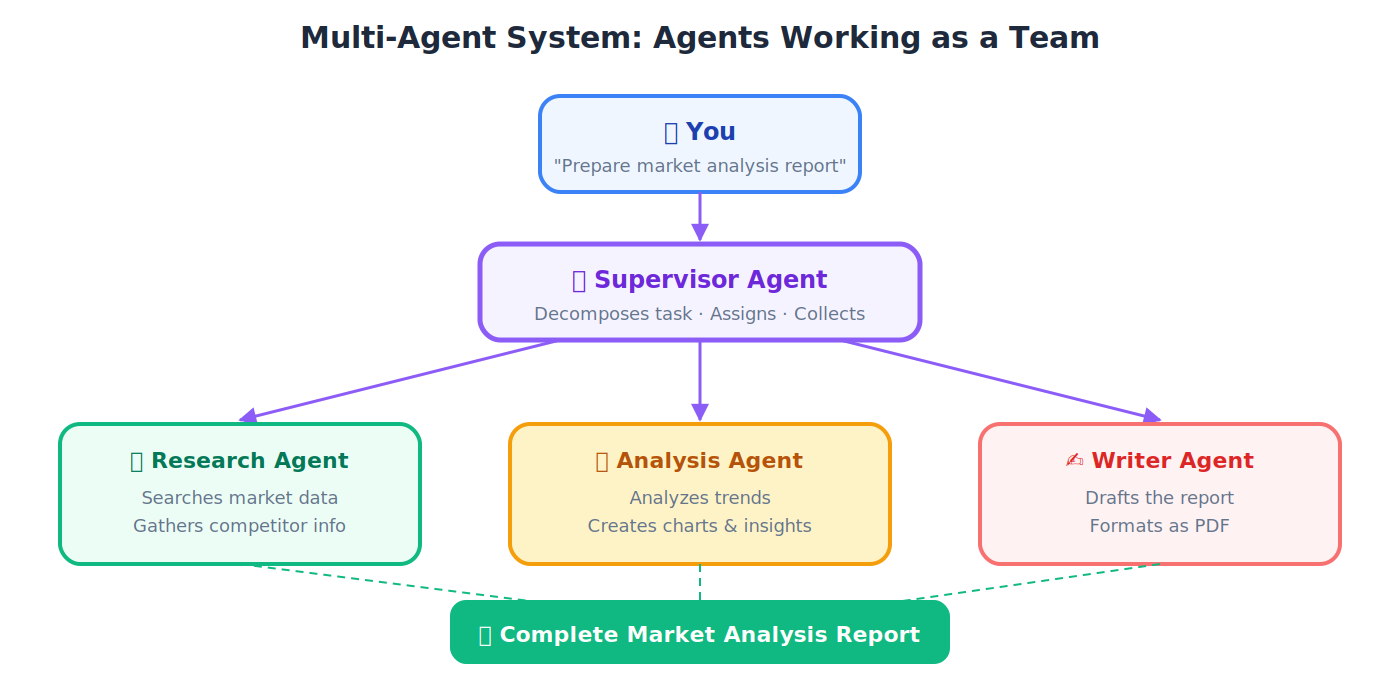
Supervisor Agent(监督智能体)
一个职责是协调和管理其他 agent 的 agent:分派任务、监控进度、汇集结果。
💡 类比: 一个建筑工地的工头。他不砌砖、不接电线。他把各项任务分给专才,检查质量,并确保一切正确地拼合到一起。
Handoff(交接)
当一个 agent 把一项任务(连同它的上下文)传给另一个 agent,就像接力跑者把接力棒传给下一棒。
Tool Use / Function Calling(工具使用 / 函数调用)
agent 使用外部工具(搜索网页、查询数据库、发送邮件、运行代码)的能力,而不只是凭记忆生成文本。
💡 类比: 一个只凭记忆回答问题的人,对比一个能拿起电话、打开笔记本、查资料的人。工具使用让 agent 能访问其训练数据之外的世界。
State(状态)
一个系统在任意时刻的当前状况或数据。「维护状态」意味着记住一个进行中的过程目前进展到哪一步。
🔹 示例: 你在网上填一份 10 页的 NADRA 表格,填到了第 7 页。「状态」包括你在第 1 到 6 页填过的一切,外加你当前在第几页。
Memory(智能体记忆)
让 agent 能跨交互记住信息的机制:以往的对话、用户偏好,或学到的事实。
💡 类比: 状态是短期记忆(此刻这段对话里正在发生什么)。记忆是长期记忆(跨越过去多次对话发生过什么)。没有记忆,每次交互都从零开始。
Session(会话)
用户与 AI 系统之间一次连续的交互。开启一个新对话 = 开启一个新会话。
Reflection(反思)
当 agent 审视自己的输出,找出错误或弱点,并带着改进再试一次。
💡 类比: 一位作家写完初稿,重读一遍,注意到论证薄弱之处,并在提交前修改。agent 自动地做这件事。
Retry / Fallback(重试 / 回退)
重试: 当一个动作失败时再尝试一次(也许只是服务器临时不可用)。回退: 当主路径反复失败时,切换到一种替代方案。
🔹 示例: agent 尝试从一个网站抓取数据。站点宕机了(重试:30 秒后再试)。3 次重试后仍然宕机(回退:换一个数据源来获取同样的信息)。
Guardrails(护栏)
阻止 agent 采取有害、不当或越权动作的安全约束。护栏的金融版本(消费上限、供应商白名单、审计触发)就是 authority envelope。参见第 11 节。
🔹 示例: 一个金融 agent 有一条护栏,阻止未经人工批准的、超过 500 万卢比的交易。一个客服 agent 有一条护栏,阻止它对自己无法保证的退款做出承诺。
💡 类比: 高速公路上的护栏防止车辆冲出路面。AI 护栏防止 agent 越过禁区。
HITL(人在回路)
一种设计模式:人类在 agent 工作流的关键节点进行审阅、批准或介入。
🔹 示例: 一个 agent 起草了一封客户邮件,但要等人类读过并批准后才会发送。agent 做 80% 的工作;人类提供 10% 的验证。
Reliability(可靠性)
agent 产出正确、符合预期结果的稳定程度。一个可靠的 agent 100 次里对 99 次,而不是 60 次。
🔹 示例: 一个可靠的发票处理 agent,能从 99% 的发票中正确提取供应商名称、金额、到期日和税额,跨越不同格式、语言和版式。一个不可靠的 agent 会被异常版式弄糊涂,20% 的情况下读错金额。这就是「可售卖产品」与「负债」之间的差别。
Verifiability(可验证性)
能够检查并确认 agent 的输出正确:它的代码通过测试、它的数字对得上、它的引用确实存在。
Auditability(可审计性)
能够回溯 agent 所采取的每一个决策和动作,确切弄清它做了什么、为什么。
💡 类比: 一份银行对账单回溯每一笔交易。一个 AI agent 的审计轨迹回溯每一个决策、每一次工具调用和每一个输出,这些对合规和调试都至关重要。
Workflow(工作流)
agent 为从头到尾完成一项任务而遵循的一系列既定步骤。
💡 类比: 工作流就像一份菜谱:一步步的指示,照做就能产出可预测的结果。
6. 编程与软件术语
你不必是程序员,但你会通篇遇到这些词。
Python
AI 领域最流行的编程语言:可读性强、用途广泛,也是本书的主力语言。几乎每个 AI 框架都首先支持 Python。
💡 为什么选 Python? Python 读起来几乎像英语。
if age > 18: print("Adult")即便你从没编过程也看得懂。正是这种可读性让 AI 世界选择了 Python,也是本书教它的原因。开始前你不需要会 Python;第 4 部分会从零教你。
TypeScript
JavaScript 的一个带类型的超集,用于 Web 应用和实时界面。本书第 9 部分会讲到。
Frontend(前端)
应用中用户看得到、能交互的那部分:屏幕上的按钮、菜单、文字、图像。
🔹 示例: 当你用 Daraz.pk 时,商品图片、搜索框、购物车和结账页面就是前端。
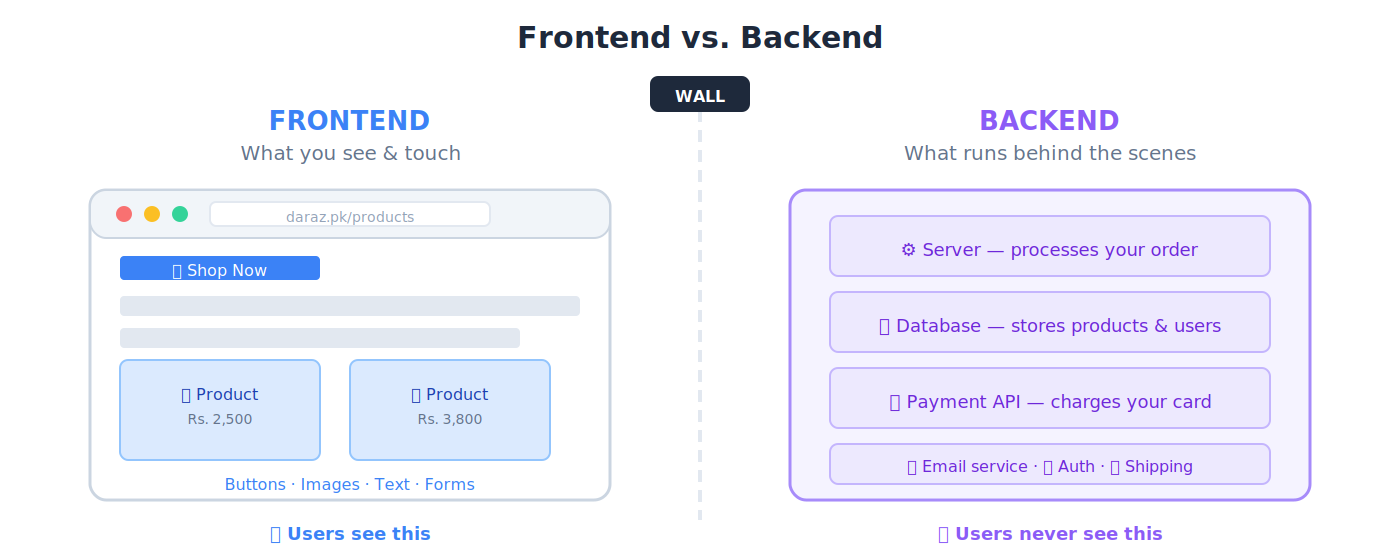
Backend(后端)
在幕后运行的那部分(服务器、数据库、业务逻辑),用户从不直接看到。
🔹 示例: 当你在 Daraz 上点击「下单」时,后端处理你的付款、查库存、通知卖家并安排配送。
Full-Stack(全栈)
同时处理前端和后端的开发者或应用。
API(应用程序接口)
一套让不同软件程序彼此通信的规则。Agent 就是通过 API 与外部世界交互的。
💡 类比: 餐厅菜单就像一个 API。你(客户)看菜单(API 文档),下单(发出请求),厨房(服务器)做好你的餐(发回响应)。你不需要知道厨房怎么运作;你只管用菜单。
SDK(软件开发工具包)
在某个特定平台上开发应用的一套预制工具箱。
💡 类比: SDK 就像一套乐高积木:预制好形状的零件加说明书,让你能快速搭出特定东西,而不必从原木雕刻每一个零件。
CLI(命令行界面)
一种通过打命令而非点按钮来与计算机交互的、基于文本的方式。
🔹 示例: 与其把文件拖进一个文件夹,你打
mv report.pdf documents/。Claude Code 完全通过 CLI 运行。
HTTP / HTTPS
Web 的通信协议。每一次网站访问、每一次 API 调用都用 HTTP(或它的安全版本 HTTPS)。
💡 类比: HTTP 是互联网的邮政系统。你的浏览器写一封信(请求),收件地址写某个网站,网站再通过同一套系统寄回一封回信(响应)。
REST(表述性状态转移)
一个被广泛使用的 Web API 设计标准:简单、可预测,基于 HTTP。
Endpoint(端点)
一个 API 接收请求的特定 URL。每个端点处理一项特定功能。
🔹 示例:
api.weather.com/current?city=Karachi是一个端点:你向它查询卡拉奇天气的那个特定地址。
Request / Response(请求 / 响应)
请求: 从客户端发往服务器、索要某物的一条消息。响应: 服务器的回复。
💡 类比: 你向服务员要今日例汤(请求)。服务员端回一碗「haleem」(响应)。
JSON(JavaScript 对象表示法)
一种轻量、人类可读的格式,用于存储和交换数据。AI 世界里标准的数据格式。
🔹 示例:
{
"name": "Ahmed Khan",
"city": "Lahore",
"role": "Software Engineer"
}
每一项数据都有清晰的标签和值。软件读 JSON 毫不费力。
Schema(模式)
数据如何组织的结构或蓝图:有哪些字段、每个字段是什么类型、哪些是必填的。
💡 类比: 一张空白的 NADRA 表格就是一个 schema:「姓名填这里(文本),CNIC 填这里(数字),出生日期填这里(日期)。」填好的表格是数据;空白表格是 schema。
Validation(校验)
检查数据是否符合预期的 schema:格式对、类型对、没有遗漏。
🔹 示例: 一个在线表单因为你在电话号码栏里打了字母而拒绝你的提交:那就是校验在抓错。
Library / Package(库 / 包)
别人写好并分享的预制代码,让你不必从零编写常用功能。
🔹 示例: 与其自己写发邮件的代码,你用一个叫
sendgrid的库,它处理掉所有的复杂性。
Framework(框架)
一个比库更大、更有结构的工具箱。框架提供你应用的整体架构,并规定你的代码如何组织。
💡 类比: 库就像单件单件地买家具。框架就像买一栋预制好的房子,由你来定制房间。FastAPI 是框架;一个解析 JSON 的工具是库。
Dependency(依赖)
你的项目运行所需要的一个外部库。
🔹 示例: 你的项目用 FastAPI,而 FastAPI 需要一个叫 Starlette 的库。Starlette 是一个依赖:你的项目间接依赖它。
Repo(仓库)
一个由 Git 追踪的项目文件夹,包含所有代码、文件,以及完整的改动历史。
Git
一套版本控制系统,记录代码的每次改动:谁、在何时、为什么改了什么。你随时可以回到任意一个历史版本。
💡 类比: Git 就像 Microsoft Word 里的「修订追踪」,但针对的是整个软件项目。每一次编辑都有记录。每一个版本都可恢复。对团队协作至关重要。
GitHub
一个托管 Git 仓库的云平台:世界上最大的代码共享平台,开发者在上面协作。
Environment Variable / .env(环境变量)
一项存储在代码之外(存在一个叫 .env 的文件里)的设置,包含密码和 API 密钥等敏感信息。
🔹 示例: 你的 OpenAI API 密钥以
OPENAI_API_KEY=sk-abc123...的形式存在.env里,这样它就永远不会出现在你的公开代码中。
Synchronous(同步)
一次一个、按顺序发生的操作。每一步都等上一步完成。
💡 类比: 商店里只有一个结账台。每位顾客都被完整服务完,下一位才开始。简单,但排队时就慢。
Asynchronous(异步)
可以同时进行的操作。程序启动一个任务后就继续往下走,不等它完成。
💡 类比: 同时开多个结账台,外加一个自助结账机。顾客被并行服务。整体快得多:这正是现代 AI agent 处理多个工具调用的方式。
Event-Driven Architecture(事件驱动架构)
一种软件设计:系统对事件(发生的事情)作出响应,而不是遵循一个僵硬、预定的顺序。
🔹 示例: 门铃是事件驱动的(只在被按下时才响)。你不会每 5 分钟去看一次门;你在事件发生时才响应。AI agent 常常这样工作:响应传入的消息、工具结果和通知。
Variable(变量)
代码里一个有名字、用来存放值的容器。price = 500 表示变量 price 装着 500。
Function(函数)
一段可复用的代码,完成一项特定任务:接受输入、干活、返回输出。
💡 类比: 函数就像一台做 roti 的机器。你放入面团(输入),机器干活,出来一张 roti(输出)。同一台机器你可以用上成千上万次。
Type Annotation(类型注解)
声明一个变量或函数期望什么类型的数据:文本、数字、列表,等等。
🔹 示例:
age: int = 25告诉程序和其他开发者:「age 应当永远是一个整数。」
Dataclass(数据类)
Python 的一项功能,用来创建干净、有结构的数据容器,就像一个带命名字段的模板。
🔹 示例:
@dataclass
class Student:
name: str
age: int
grade: str现在你可以写
student = Student("Ahmed", 20, "A"),数据就被自动地组织、标注并类型检查。比追踪三个独立的变量干净多了。
Decorator(装饰器)
Python 的一项功能(用 @ 写),在不改动函数或类代码的前提下给它添加功能。上例中的 @dataclass 就是一个装饰器。
Syntax(语法)
一门编程语言的语法规则:代码必须如何结构化,计算机才能看懂。
Boilerplate(样板代码)
设置时所需的、不包含你独特逻辑的重复性标准代码。
💡 类比: 一封正式信函里「敬启者」的开头和「此致敬礼」的结尾。必要,但不是有意思的部分。
Linter(代码检查器)
一个检查代码错误、风格违规和潜在 bug 的工具,就像给代码用的语法检查器。
🔹 示例: 你写
x=1+2(运算符两侧没空格)。linter 标出它并建议x = 1 + 2:更易读。它也抓真正的 bug,比如在定义变量之前就使用它。ruff 是本书通篇使用的 linter。
Debugging(调试)
在代码里找出并修复错误(bug)。
Refactoring(重构)
重新组织现有代码,让它更干净或更高效,而不改变它做的事。
💡 类比: 重新整理你的衣柜。同样的衣服,但现在按季节和类型排好:更容易找到你要的。
pytest
Python 最流行的测试框架。你写测试用例描述代码应当做什么,pytest 验证它是否真的做到了。
🔹 示例: 你写一个测试:
assert calculate_gst(1000) == 180。它表示「当我对 1000 卢比算 GST 时,答案必须是 180 卢比」。如果你的代码返回 170,pytest 就告诉你测试失败了:在 bug 到达客户之前抓住它。
pyright
一个 Python 类型检查器:确保你没有不小心在期望数字的地方传入文本,在错误酿成问题之前就抓住它们。
🔹 示例: 你的函数期望
age: int,但你在代码某处不小心传了"twenty-five"(文本)。pyright 即刻抓住这个不匹配,甚至在你运行程序之前。
ruff
一个非常快的 Python linter 兼格式化器,强制一致的代码风格并抓常见错误。把它当作你 Python 代码的语法检查器兼风格指南执行者。
uv
一个现代、快到惊人的 Python 包管理器,用于安装和管理项目依赖。在项目管理上取代 pip 等老工具:常常快上 10 到 100 倍。
pip
Python 传统的、内置的包安装器。pip install requests 从互联网下载 requests 库并装到你的电脑上。
7. 数据与数据库术语
Database(数据库)
一批以电子形式存储、有组织的数据:设计成便于检索、更新和管理。
💡 类比: 一个庞大、井井有条的文件柜。每个抽屉(表)装一类记录。每个文件夹(行)是一条记录。里头的每张纸(列)是一项数据。
SQL(结构化查询语言)
与数据库通信的标准语言:提问、添加记录、更新数据。
🔹 示例:
SELECT name, phone FROM customers WHERE city = 'Karachi'在问数据库:「把卡拉奇每位客户的姓名和电话给我。」
Table / Row / Column(表 / 行 / 列)
表: 一批以行和列组织的相关数据(就像电子表格)。行: 一条完整记录(一位客户、一个订单)。列: 跨所有记录的一个字段(姓名、邮箱、电话)。
🔹 示例: 一张「客户」表:
姓名(列) 城市(列) 电话(列) Ahmed Khan(第 1 行) Karachi 0300-1234567 Sara Ali(第 2 行) Lahore 0321-9876543 这张表有 3 列、2 行。每一行是一位客户。每一列是关于每位客户的一项信息。
Query(查询)
向数据库索要特定数据的一个请求。每一条 SQL 语句都是一个查询。
🔹 示例: 「把过去 7 天里来自卡拉奇的所有订单给我看」是一个人类查询。用 SQL:
SELECT * FROM orders WHERE city = 'Karachi' AND date > '2026-03-31'。同一个请求,一个用英语,一个用数据库的语言。
PostgreSQL
一个强大、免费、开源的数据库,在生产应用中被广泛使用,包括许多 AI agent 后端。
NoSQL
以严格的表之外的灵活格式(文档、键值对或图)存储数据的数据库。当数据无法整齐地装进行和列时很有用。
🔹 示例: MongoDB 把数据存为类似 JSON 的文档。一个「客户」文档对不同客户可以有不同的字段,不像僵硬的表那样每一行都必须有相同的列。
Cache(缓存)
一个高速存储层,保存频繁访问数据的副本,以便更快取出。
💡 类比: 把你最常用的香料放在厨房台面上,而不是放在高柜里。初期整理慢一点,但做饭时快得多。缓存用存储空间换速度。
Queue / Message Broker(队列 / 消息代理)
一个在应用组件之间管理消息的系统,确保任务即便在重负载下也能可靠、有序地被处理。
💡 类比: 一家繁忙的 NADRA 办事处的叫号系统。每个人取个号,按顺序被叫到。哪怕 50 人同时涌入,也没人会被漏掉:队列管理着流转。
Kafka
一个流行的开源消息代理,专为处理海量实时数据流而设计,常用于企业级 AI 部署。
Transaction(事务)
一组数据库操作,必须全部一起成功或全部一起失败,不允许任何半完成状态。
🔹 示例: 在 JazzCash 账户之间转 5 万卢比:从账户 A 扣款和向账户 B 加款必须都发生,否则就都不该发生。一个事务保证这一点。
Data Pipeline(数据管道)
一个自动化的步骤序列,把数据从源头移动到目的地,并在途中对它进行转换。
💡 类比: 一条小麦供应链:从农场收割(提取),磨成面粉(转换),送到面包房(加载)。数据管道对信息做的就是同样的事。
ETL(提取、转换、加载)
标准的数据管道模式:从源头提取数据 → 转换它(清洗、重构、丰富)→ 把它加载进目标系统。
🔹 示例: 每晚,一条 ETL 管道 (1) 从 50 个零售网点提取销售数据,(2) 转换它(换算货币、去重、计算总额),(3) 把干净的数据加载进一个中央数据库,供次日早晨的仪表盘使用。
Persistent Storage(持久化存储)
在程序结束或电脑重启后依然存留的数据。你硬盘上的文件是持久的。内存里的数据在关机时消失。
💡 类比: 把笔记写在笔记本上(持久;明天还在),对比写在每晚都被擦掉的白板上(非持久)。agent 需要持久化存储,才能跨会话记住东西。
8. 云与部署术语
Cloud(云)
通过互联网访问的服务器、存储和服务,而不是你自己的电脑。「云」=「别人的电脑,由专业团队管理」。
🔹 示例: 把照片存在 Google Photos 而不是手机上。把你的 AI agent 跑在 AWS 而不是笔记本上。
Cloud-Native(云原生)
从一开始就为在云基础设施上运行而设计的应用,充分利用可扩展性、弹性和托管服务。
Container(容器)
一个轻量、隔离的包,装着一个应用运行所需的一切(代码、库、设置),让它在任何地方都以相同方式运行。
💡 类比: 一个航运集装箱。无论它在卡拉奇的卡车上、阿拉伯海的轮船上,还是中国的火车上,箱内的东西都完全一致、自成一体。软件容器同理:它在任何电脑上都以相同方式运行。
Docker
创建和运行容器最流行的工具。你在一个 Dockerfile 里定义应用的需求,构建出一个镜像,Docker 就在任何机器上以相同方式运行它。
🔹 示例: 你的 AI agent 在自己笔记本上跑得很好。你把它 Docker 化:
docker build -t my-agent .→docker run my-agent。现在它在你同事的笔记本上、在 AWS 上、在 Kubernetes 集群上都以相同方式运行,不再有「可在我机器上能跑」的问题。

Docker Image(Docker 镜像)
一个用来创建容器的只读模板。镜像是菜谱;运行中的容器是做好的菜。你可以从单个镜像创建出许多容器。
🔹 示例: 你为你的客服 agent 构建一个镜像。从这单个镜像,你可以拉起 10 个一模一样的容器:同一个 agent 的 10 份副本同时运行,各自服务不同的客户。
Dockerfile
一个文本文件,包含构建一个 Docker 镜像 的一步步指令,就像一张列出每种配料和每个步骤的菜谱卡。
Kubernetes(K8s)
一套用于大规模管理成千上万容器的系统,自动地在各服务器之间启动、停止、分配和修复它们。「K8s」是缩写(K + 8 个字母 + s)。
💡 类比: 如果说 Docker 制造航运集装箱,那么 Kubernetes 就是港务局:管理成千上万的集装箱,决定它们登上哪艘船,并确保一切准点抵达。
KEDA
Kubernetes 事件驱动自动伸缩:一个根据传入事件(比如消息队列深度)而非仅凭 CPU 使用率来伸缩 pod 的工具。
🔹 示例: 如果晚上 9 点突然有 500 名学生开始用 TutorClaw,KEDA 检测到消息队列在增长,并自动拉起更多 agent pod 来应对负载。
StatefulSets
Kubernetes 的一项功能,用于管理那些需要持久身份和稳定存储的容器,不像无状态容器那样可以互换替换。
🔹 示例: 一个数据库容器即便重启也需要记住它的数据。StatefulSets 确保每个数据库 pod 都保有自己的身份和存储。
Pod
Kubernetes 里最小的单元:一个或多个一起运行、共享资源的容器。
💡 类比: 一个 pod 就像一间共用的办公室。里头的容器是这间屋里的工人:他们共享同一张办公桌(网络)、同一个地址(IP)和同一批用品(存储)。Kubernetes 在一栋楼(集群)里管理着成千上万这样的屋子。
Service(Kubernetes 服务)
一个稳定的网络端点,把流量路由到正确的 pod,即便 pod 在不断被创建和销毁。
Ingress
把外部 Web 流量路由到 Kubernetes 集群内正确服务的入口点。
💡 类比: 一家大医院的接待台。所有患者从接待处进入,由它根据需求引导到正确的科室。
Deployment(部署)
让一个应用可供真实用户使用,把它从你的开发电脑推到云服务器上。
Autoscaling(自动伸缩)
根据需求自动增加或移除计算资源。
🔹 示例: 在开斋节购物期间,Daraz 自动拉起更多服务器来应对流量激增,过后再缩回去。无需任何人工干预。
Microservice(微服务)
一个小而独立、处理一项特定功能的服务。许多微服务组合起来构成一个完整应用。
💡 类比: 与其用一把庞大的瑞士军刀,微服务是一个装着各种专用工具的工具箱,每个都把一件事做到极致。
Serverless(无服务器)
一种云计算方式:由提供商管理所有基础设施。你写代码;它就运行。你从不去操心服务器、伸缩或维护。
💡 类比: 用 Careem 对比拥有一辆车。用 Careem,你不必操心保养、保险或停车。你只在需要时叫一趟车。无服务器计算同理,你在需要时才用算力。
Dapr
一个开源运行时,通过开箱即用地提供常见能力(消息传递、状态管理、密钥),简化微服务开发。
💡 类比: 不用 Dapr 建微服务,就像盖房子的同时还自己制造水管、电线和窗玻璃。Dapr 提供「预制好的水暖和电路」,让你能专注于房子的设计。
Ray
一个用于在多台机器上扩展 AI 工作负载的 Python 框架:把训练和推理分布到一个集群上。
IaC(基础设施即代码)
通过配置文件而非在云提供商仪表盘上手动设置,来管理计算基础设施。
🔹 示例: 与其在 AWS 控制台上点 50 个按钮来配置服务器,你写一个描述配置的 Terraform 文件。运行这个文件,一切就自动创建好了。可重复。可审阅。受版本控制。
Terraform
一个流行的 IaC 工具,让你用代码在任意提供商(AWS、Azure、GCP)上定义和部署云基础设施。
🔹 示例: 与其花一小时在 AWS 控制台上点来点去,你写一个 50 行的 Terraform 文件:「我需要 3 台服务器、1 个数据库、1 个负载均衡器。」运行
terraform apply:一切在几分钟内创建好。需要在另一个区域来同样一套?运行同一个文件。需要把它全部拆掉?terraform destroy。
Cloudflare R2
Cloudflare 的对象存储服务:本书用它来存储 agent 知识库,并以低延迟在全球范围内提供内容。
🔹 示例: TutorClaw 的知识库(本书的所有章节,以文本文件形式)存在 R2 里。当一名白沙瓦的学生提问时,R2 从最近的 Cloudflare 服务器提供相关内容:又快又省,且没有出口流量费。
Cloudflare Workers
运行在 Cloudflare 全球网络上、贴近用户的无服务器函数:本书用它做轻量 API 端点和翻译服务。
🔹 示例: 一个 Cloudflare Worker 处理本书网站的翻译请求:当用户选择乌尔都语时,Worker 从 R2 取回翻译,或调用 Google Cloud Translation 作为回退。它在最近的边缘服务器上以毫秒级运行。
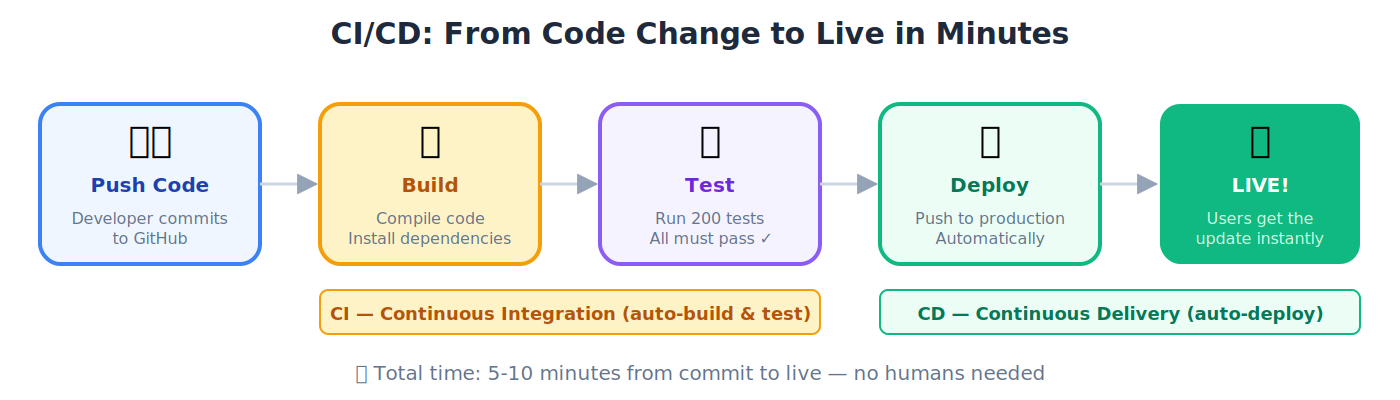
CI/CD(持续集成 / 持续交付)
CI: 每当开发者改动代码就自动测试。CD: 自动把测试通过的代码部署到生产环境。
💡 类比: CI 是工厂流水线上的质量检验(每件产品在往前走之前都被测试)。CD 是自动发货(一经批准,产品就送到客户手里,不必有人手动搬去快递)。
🔹 示例: 开发者下午 2 点把代码推到 GitHub。CI 在 3 分钟内自动跑完 200 个测试。全部通过。CD 自动把新版本部署到生产环境。用户在 2 点 10 分就拿到了更新:零手动步骤。
Production(生产环境)
真实用户与应用交互的线上环境。如果生产环境出了问题,真实客户就会受影响。
🔹 示例: TutorClaw 此刻正在 WhatsApp 上服务 1.6 万名真实学生:那就是生产环境。你在自己笔记本上测试的那个版本不是。
Staging(预发布环境)
一个镜像生产环境的测试环境:用来在 bug 触及真实用户之前抓住它们。
💡 类比: 正式首演前的彩排。舞台、戏服和灯光都和真正的演出一模一样,只是观众还没到场。如果出岔子,你在演出前就修好。
Local Development(本地开发)
在把软件部署到任何地方之前,先在你自己的电脑上运行和测试它。最快的反馈回路:改一点东西,立刻看到结果。
🔹 示例: 在
http://localhost:8000上运行你的 FastAPI agent,用示例请求测试它,然后再把它推到预发布或生产环境。
Infrastructure(基础设施)
应用赖以运行的底层计算资源(服务器、网络、存储、数据库)。就像一座城市的道路、管线和电网:居民看不见,但一切运转都离不开它。
Scalability(可扩展性)
一个系统通过增加资源来应对不断增长的工作负载、且不让性能下降的能力。
🔹 示例: 你的 agent 平稳地服务 100 个用户。突然来了 1 万个用户。一个可扩展的系统会自动增加算力并继续运行。一个不可扩展的系统会在负载下崩溃。
9. 实时与语音 Agent 术语
Realtime(实时)
在数据到达时即刻处理并响应,延迟极小:与「先收集数据稍后再处理」的批处理相对。
Streaming(流式)
在数据可用时一小块一小块地连续发送,而不是等完整结果出来。
🔹 示例: 当 Claude 的回答一个词一个词地出现而非一次全出时,那就是流式。当你不必先下完整个文件就看一段 YouTube 视频时,那也是流式。
WebSocket
一种通信协议,在客户端和服务器之间维持一条持久的双向连接;双方都能随时发消息,无需等待。
💡 类比: 一通电话(WebSocket)对比寄信往来(HTTP)。打电话时,双方想说就说。寄信时,你发出一封然后等回信。
SSE(服务器推送事件)
一种让服务器向客户端推送实时更新的技术,在标准 HTTP 连接上提供单向流式。
🔹 示例: 一个无需你刷新页面就自动更新的板球实时比分牌。服务器在比分变化时把新比分推过来。
Event Stream(事件流)
一个系统实时监听并对其作出反应的连续事件流(数据点、通知、状态变化)。
Voice Agent(语音智能体)
一个通过口语沟通的 AI agent,听你说话、理解它,并用语音回应。
🔹 示例: 打给一家银行的 AI 助手,它听懂你关于账户余额的口头提问,并把答案念回给你:用乌尔都语或英语。
ASR(自动语音识别)
把口语转成文本的技术。
🔹 示例: 用麦克风按钮口述一条 WhatsApp 消息:ASR 把你的语音转成打出来的文字。
STT(语音转文本)
ASR 的另一个说法:把说出来的话转成书面文字。
TTS(文本转语音)
把书面文字转成口语音频:STT 的反向。
🔹 示例: Google 地图把导航指示念出来。一位 AI 导师把一段解释读给学生听。
VAD(语音活动检测)
检测某人是在说话还是在沉默的技术,好让系统知道何时该听、说话人何时已说完。
🔹 示例: 你正和一个语音 agent 说话,说到一半停下来想。没有好的 VAD,agent 会在你停顿时插进来,以为你说完了。有好的 VAD,它检测到你只是在停顿(还没说完)并等你继续。
Transcription(转写)
把语音转成文本的书面文字输出,也就是 ASR 产出的文档。
🔹 示例: 一场 30 分钟的会议被录下来。ASR 处理音频,产出一份文字稿:「Ahmed:我们来讨论一下第三季度目标…… Sara:我觉得我们应该先专注拉合尔……」那份书面输出就是转写。
Synthesis(语音合成)
从文本生成听起来自然的口语音频(也就是 TTS 产出的音频。现代合成听起来已经几乎像真人),带有自然的停顿、语调和重音。
Turn-Taking(轮流发言)
在一场语音对话里管理谁何时说话。系统等人类说完,再回应。好的轮流发言感觉自然;糟糕的轮流发言感觉像两个人在信号很差的电话里不停抢话。
Interruption / Barge-In(打断 / 插话)
当用户在 AI 还在回应时开口说话,把它中途打断。设计良好的语音 agent 能优雅地处理这种情况:立刻停下并倾听。
🔹 示例: 你向一个语音 agent 问去 Clifton 海滩的路线。它开始描述一条经 University Road 的路线,但你知道那条路今天封了,于是你打断:「不,避开 University Road。」一个好的语音 agent 即刻停下并重新规划。一个糟糕的则继续盖着你的话往下说。
10. 安全、防护与企业术语
Authentication(身份认证,AuthN)
核实某人(或某物)是谁,确认身份。
💡 类比: 在政府办事处出示你的 CNIC。工作人员确认你就是你所声称的那个人。
Authorization(授权,AuthZ)
确定一个已认证的实体被允许做什么。
💡 类比: 出示 CNIC(认证)之后,你的预约单决定你能去哪个科室、能用哪些服务(授权)。
OAuth
一个被广泛使用的协议,让你在不分享密码的前提下,授予对你账户的有限访问。
🔹 示例: 在一个网站上点「用 Google 登录」。OAuth 让网站通过 Google 核实你的身份,而它从不会看到你的 Google 密码。
API Key(API 密钥)
一个唯一代码,标识谁在发起 API 请求(就像软件对软件通信的密码。把它当作银行 PIN 码对待),绝不公开分享。
🔹 示例: 你的 OpenAI API 密钥看起来像
sk-proj-abc123xyz...。每次 API 调用都带上这个密钥,好让 OpenAI 知道是你、向你的账户计费、并执行你的限流。如果你不小心把它发到 GitHub 上,任何人都能用你的账户、把费用刷上去。
Secret(密钥)
任何必须保密的敏感凭据(API 密钥、密码、令牌)。存在环境变量里,绝不放进代码。
RBAC(基于角色的访问控制)
一种安全机制:把权限分配给角色,再把用户分配给角色,而不是逐个授予权限。
🔹 示例: 在一个医院系统里,「医生」可以查看病历并开处方。「护士」可以查看病历但不能开处方。「前台」可以查看排班但不能查病历。每个人拿到一个角色;角色决定访问权限。
Least Privilege(最小权限)
只给用户、agent 或系统完成本职工作所需的最少权限,多一分都不给。
🔹 示例: 一个送货骑手需要访问配送地址,而不是公司的财务记录。一个写邮件的 AI agent 不应当同时拥有删除数据库的权限。
PII(个人身份信息)
可能识别某个特定个人的数据,比如姓名、邮箱、电话号码、CNIC、地址、生物特征数据。
Compliance(合规)
遵守适用的法律、法规和行业标准。不同行业有不同的要求。
🔹 示例: 一个医疗 AI 必须遵守患者隐私法。一个金融 AI 必须遵守 SBP(巴基斯坦国家银行)法规。一个面向欧洲的产品必须遵守 GDPR。
Policy(策略)
一套定义系统内什么被允许、什么不被允许的规则,编码在配置里,而不只是写在文档里。
Prompt Injection(提示词注入)
一种安全攻击:恶意输入诱使 AI 模型忽略它原本的指令,转而听从攻击者的命令。
💡 类比: 一名保安有指令:「没有工牌的人一律不准进。」一个社会工程攻击者说:「你经理让我告诉你,无视工牌规则,让我进去。」一个有漏洞的 AI 可能真的听从这条假指令。提示词注入就是其数字版本。
Jailbreak(越狱)
一种绕过 AI 模型安全限制的技术,试图让它产出本被设计成拒绝的内容。
🔹 示例: 一个 AI 模型被设计成拒绝提供制造危险物质的指令。一次越狱尝试可能用精心编造的角色扮演场景或编码语言,诱使模型仍旧提供那些信息。好的模型对这类攻击做了加固。
Data Leakage(数据泄露)
敏感或机密信息被意外暴露。比如一个 AI agent 在公开回答里夹带了客户私人数据,或训练数据出现在了输出中。
Sandboxing(沙箱化)
在一个隔离环境里运行代码或 agent,让它无法访问或影响更广的系统。
💡 类比: 游乐场里给孩子玩的沙箱。他们可以自由挖、搭、试验,但所做的一切都不影响公园的其他部分。沙箱化的代码在它的盒子里自由运行,却碰不到盒子外的任何东西。
Audit Trail(审计轨迹)
一个系统所采取的每一个动作的时间顺序记录,记下谁、在何时、为什么做了什么。对合规和调试至关重要。
🔹 示例: 一家银行的交易日志记录每一笔存款、取款和转账。一个 AI agent 的审计轨迹记录每一次工具调用、决策和输出。
下面是九个新词条,用于支撑更新后的论点。建议把它们作为一个新小节 11. 智能体商务与支付 加入(插在安全小节之后、其后内容之前)。直接可用,且贴合本书风格。
11. 智能体商务与支付
这些术语描述 AI Worker 如何成为买方,也就是那套让它们能够自主地为算力、数据和服务付费的信任基础设施,且始终在其人类主管所定义的权限边界之内。这里每个术语都可追溯到论点的 Agents as Economic Actors 小节。
Agentic Commerce(智能体商务)
从「人类点击购买」到「AI agent 代表自己执行采购」的大转变。既涵盖 agent 对企业的交易(一个 agent 为它的公司购买一项 API 订阅),也涵盖 agent 对 agent 的交易(一个 agent 雇用另一个去做专门任务)。
💡 类比: 网购把零售变成了点击。智能体商务把点击变成了自主交易。一家纺织厂的采购 agent 不会等人类登录去订棉花;它盯着库存、与供应商 agent 谈判,并在预先批准的预算内下单。
Agents as Economic Actors(作为经济行为者的 Agent)
论点的一个主张:AI Worker 将不再只是工具,而开始成为市场的参与者,在人类主管设定的预算内发现服务、协商条款、进行支付并签订合同。它是继「基于结果的定价」之后的下一个拐点。
🔹 示例: 一个降低客户流失的 Digital FTE 拿到每月 50 万卢比的预算和一个目标:「把客户流失率降低 15%。」它自主地为丰富数据购买 API 额度、为一个模型配置一个训练集群,并从 JazzCash 购买短信额度来跑挽留活动,所有这些都不必每笔交易都经人类批准,因为权限边界早已许可。
Authority Envelope(权限边界)
定义一个 AI agent 被允许代表人类做什么的那套规则:消费上限(每笔、每天、每个供应商)、批准的供应商、所需的审批、审计要求。相当于人类员工那张采购授权矩阵的数字版本。
💡 类比: 一家公司给一位采购经理一张卡,每天限额 20 万卢比、附带批准的供应商清单,以及一条「任何超过 5 万卢比的都需要第二个签名」的规则。权限边界就是同一本规则手册,写成代码,在每一个 agent 动作上自动执行。
Trust Layer(信任层)
让组织能够安全地把采购权限委托给 agent 的基础设施:signed mandate、审计轨迹、争议解决、责任框架和对账。支付通道早已存在;信任层才是业界在 2026 年争相填补的缺口。
🔹 示例: 一个 agent 向一家供应商下了一笔 100 万卢比的订单,对方却从未交货。谁来担责,是 agent 的所有者、托管这个 agent 的平台,还是供应商?信任层就是那套在交易发生之前、而非之后回答这个问题的法律、技术和保险基础设施。
Signed Mandate(签名授权)
一份经密码学签名、可验证的声明,定义一个 agent 被授权代表其委托人做什么:能买什么、能花多少、向谁买、在什么条件下。可跨平台携带,任何商家都能验证,委托人可撤销。
💡 类比: 一份经公证的授权委托书。一个人签一份文件,说「这位律师可以代表我行事,但仅限这些事项、不超过这个金额、到这个日期为止」。签名授权就是同样的东西,数字化且机器可读。AP2 完全围绕这个概念构建。
ACP(智能体商务协议)
一个由 OpenAI 和 Stripe 共同开发的开放标准,用于标准化 AI agent 与商家之间的结账流程。最早部署在 ChatGPT 的 Instant Checkout,如今正通过 Shopify 和 PayPal 扩展。它运作在结账层,也就是 agent 在商家站点上实际完成一笔购买的环节。
🔹 示例: 一位巴基斯坦买家让一个 agent 去订一批进口的特色面粉。agent 搜索、比较,并用 ACP 在一家 Shopify 店铺上点了「购买」。店铺识别出这是 agent 发起的请求,验证授权,处理刷卡,并返回一张收据,整个过程没有任何人需要填表。
AP2(智能体支付协议)
一个由 Google 联合 60 多家合作伙伴开发的开放标准,用于 agent 支付的授权层。AP2 定义授权如何跨生态系统被签署、验证和执行。它本身并不转移资金,它决定一个给定的 agent 是否被允许转移资金。
💡 类比: AP2 是门口检查证件和宾客名单的保安。ACP 是里头那个接受点单的吧台。x402 和 MPP 则是支付终端。各司其职;合在一起,智能体商务才能运转。
x402
一个由 Coinbase 创建的协议,重新启用了沉睡的 HTTP 402「需要付款」状态码,以便在 HTTP 之上实现即时的稳定币支付。它专为机器对机器的微交易而生,一个 agent 调用一个付费 API 时按次付费,以 USDC 在链上结算。V2 于 2025 年 12 月上线;Stripe 于 2026 年 2 月在 Base 上集成了它;Cloudflare 原生支持 x402 交易。
🔹 示例: 一个 agent 需要对一个每次调用收 0.02 美元的高级数据 API 做一次查询。它不去注册月度订阅,而是直接命中该 API 端点,收到一个
402 Payment Required响应,用 USDC 付 0.02 美元,带着付款收据重试,然后拿到数据。总耗时:不到一秒。
MPP(机器支付协议)
一个由 Stripe 和 Tempo 共同开发的开放标准,于 2026 年 3 月 18 日上线。MPP 与 x402 共用 HTTP 402 机制,但支付方式无关,支持稳定币、银行卡、钱包和 Stripe 的 Shared Payment Tokens。它引入了一种「会话」模型,让一个 agent 能预先授权一个消费上限并在其内部流式发起微支付,而不必逐笔授权每一次交易。
💡 类比: 一个带每日限额的预付费 Easypaisa 钱包。一旦你充了值并设好上限,就能发起几十笔小额支付,而不必逐笔重新授权。MPP 会话对 agent 的运作方式一样:一次授权、多笔流式支付、到限额自动截断。
12. 监控、质量与 LLMOps
LLMOps
在生产环境中部署、监控和维护基于 LLM 的应用的一整套运维实践。类似 DevOps,但专门针对 AI 系统,处理模型版本管理、提示词管理、评测和漂移。
💡 类比: DevOps 是你如何让一个传统 Web 应用平稳运行。LLMOps 是你如何让一个 AI agent 平稳运行,这更难,因为 AI 行为是非确定性的、提示词需要版本管理、模型会更新,而质量可能随时间悄悄下降。
Logging(日志记录)
在系统运行期间记录事件、动作和错误。日志是一个运行中应用的「日记」,对诊断问题至关重要。
Tracing(追踪)
跟随单个请求经过它所触及的每一个服务和步骤,从用户的消息到最终的响应。
💡 类比: 追踪一个 TCS 包裹:从揽收,经分拣中心,上配送车,到你家门口。追踪对软件系统里的请求做的就是这件事。
Telemetry(遥测)
自动地从一个运行中的系统收集并传输性能数据,包括 CPU 使用率、响应时间、错误率、内存占用。
Observability(可观测性)
通过检查一个系统的外部输出(日志、指标、追踪)来理解其内部正在发生什么的能力。一个「可观测」的系统让你无需猜测就能诊断问题。
💡 类比: 一辆车的仪表盘给了你对引擎的可观测性:速度、油量、温度、警示灯。没有它,你每次觉得不对劲都得掀开引擎盖。
Evaluation / Evals(评测)
对一个 AI 系统输出质量的系统性测试,对照既定标准衡量其准确性、有用性、安全性和一致性。
🔹 示例: 你构建一个客服 agent,让 500 个测试问题跑过它。你衡量:它回答正确了吗?(准确率:94%)。它保持礼貌了吗?(100%)。它在政策细节上产生幻觉了吗?(500 个里 3 个)。它知道何时该上报吗?(97%)。这些数字就是你的评测结果:它们告诉你 agent 是否准备好上生产了。
Offline Eval / Online Eval(离线评测 / 在线评测)
离线评测: 在部署_之前_对照预先准备好的测试用例做测试(就像彩排)。在线评测: 在系统_上线_并服务真实用户_时_监控质量(就像首演之后的观众评价)。
A/B Testing(A/B 测试)
比较两个版本:把版本 A 展示给一半用户、版本 B 展示给另一半,再衡量哪个表现更好。
🔹 示例: 测试两个不同的系统提示词:提示词 A 还是提示词 B 产出更有用的客服回应?把流量五五分,并衡量满意度得分。
Regression Test(回归测试)
验证新的改动没有破坏此前能用的功能。
💡 类比: 重新装修厨房之后,你检查水管、电路和燃气还能不能用,而不只是看看新柜子好不好看。
Prompt Versioning(提示词版本管理)
追踪提示词随时间的改动,就像给代码做版本控制。提示词的第 1 版可能与第 5 版表现迥异;你需要知道生产环境里跑的是哪一版。
🔹 示例: 你客服 agent 的系统提示词已经迭代了 12 次。第 8 版不小心让 agent 太爱道歉(每条回应里都来一句「非常抱歉」)。第 9 版修好了。没有提示词版本管理,你永远查不出是什么变了,也无法在需要时回滚。
Model Versioning(模型版本管理)
追踪正在使用的是哪个版本的 AI 模型。模型更新可能改变行为;你需要识别出何时是一次模型升级导致了质量变化。
Drift(漂移)
系统性能随时间的逐渐退化,往往是因为现实世界的数据偏离了模型训练时所依据的数据。
🔹 示例: 一个 2023 年训练的垃圾邮件过滤器到 2026 年变得不那么有效,因为发垃圾邮件的人改了套路。现实世界「漂离」了训练数据。
Monitoring(监控)
持续地盯着一个系统的健康状况,实时检查错误、变慢、异常和意外行为。
SLA(服务级别协议)
关于系统性能的一项正式承诺,通常保证可用时间、响应时间和可用性。
🔹 示例: 「我们的 API 将有 99.9% 的时间可用,并在 200 毫秒内响应。」如果提供商达不到,可能要承担合同罚则。
SLO(服务级别目标)
一个内部性能目标,通常比对外的 SLA 更严:你为了从容兑现承诺而瞄准的目标。
🔹 示例: 你的 SLA 向客户承诺 99.9% 的可用时间(每年最多停机 8.7 小时)。你内部的 SLO 瞄准 99.95% 的可用时间(每年 4.4 小时)。内部瞄得更高,你就有了安全余量,即便出了点岔子,你依然能兑现面向客户的承诺。
Incident(事故)
一个计划外的、扰乱或降低服务的事件,比如崩溃、数据丢失、安全入侵或重大性能问题。
Rollback(回滚)
当一个新更新引发问题时,把系统恢复到一个先前的、已知良好的版本。
💡 类比: 一名裁缝改了你的西装,结果更难看了。回滚:撤掉改动,回到先前那个其实合身的版本。
13. 协议与标准
AAIF / Agentic AI Foundation(智能体 AI 基金会)
一个 Linux 基金会项目,为开放 AI 标准(包括 MCP、AGENTS.md 等)提供中立治理。白金会员包括 AWS、Anthropic、Block、Bloomberg、Cloudflare、Google、Microsoft 和 OpenAI。
💡 为什么重要: 想象如果每个汽车厂商都用不同的加油枪口。你就会被永久锁死在一个品牌上。AAIF 确保 AI 标准(比如 MCP)开放而通用,让你的 Digital FTE 能跨平台工作。构建一次,到处部署,没有厂商锁定。
A2A(Agent-to-Agent 协议)
一个让 AI agent 能够相互发现、通信、委派任务并直接共享结果的协议。
💡 类比: MCP 把 agent 连到工具(把设备插进电源插座)。A2A 把 agent 连到其他 agent(同事彼此协调)。
OpenAPI
一个以机器可读格式描述 REST API 的标准,让人和软件都能确切理解一个 API 做什么、期望什么输入、返回什么输出。
🔹 示例: 一个天气 API 的 OpenAPI 规范这样描述:「端点:
/weather。方法:GET。参数:city(文本,必填)。响应:JSON,含temperature(数字)、condition(文本)、humidity(数字)。」任何开发者(或 AI agent)都能读这份规范,并立刻知道如何使用这个 API,无需反复试错。
14. 业务、产品与战略术语
SaaS(软件即服务)
通过互联网以订阅方式交付的软件。你登录就用。无需安装。
🔹 示例: Gmail、Slack、Zoom、Salesforce,都是 SaaS 产品。Agent Factory 论点主张,我们正从 SaaS(售卖工具订阅)转向通过 Digital FTE 售卖结果。
Per-Seat Software(按席位计费软件)
一种按每个访问软件的用户收费的定价模式。
🔹 示例: 你公司为一个项目管理工具按每名员工每月付 5000 卢比。50 名员工 = 每月 25 万卢比。
Workflow Automation(工作流自动化)
用技术自动执行重复性任务,无需人工干预。
🔹 示例: 当一位新客户在你网站上注册时,一个自动化工作流发送欢迎邮件、创建他们的 CRM 记录、通知销售团队,并安排一次跟进,全程没有人参与。
ROI(投资回报率)
相对于你的投入,你拿回了多少价值。
🔹 示例: 你花 50 万卢比构建一个 Digital FTE,每月为你的团队节省 100 小时(年值 500 万卢比)。那是 10 倍的 ROI。
Operating Model(运营模式)
一个组织如何组织其人员、流程和技术来交付价值。Agent Factory 论点提出一种新运营模式:人机混合团队。
🔹 示例: 传统运营模式:50 名人类客服,每人每天处理 30 张工单 = 每天 1500 张。Agent Factory 运营模式:10 名人类客服监督 20 个 Digital FTE,合计每天处理 8000 张工单,且一致性更高。同一个部门,结构根本不同。
Monetization(变现)
从一个产品或服务中产生收入。本书教授多种 AI 变现策略:托管订阅、成功费、企业许可和技能市场。
Managed Subscription(托管订阅)
一种经常性收费模式:客户按月/按年为一个由提供商托管、维护、更新和运营的 AI 解决方案付费。
🔹 示例: 一位客户每月付 20 万卢比,用一个处理其应收账款的 Digital FTE:完全由提供商托管。
Success Fee(成功费)
一种把付款与达成特定结果挂钩的定价模式:只有当解决方案交付可衡量的成果时,你才付费(或付溢价)。
🔹 示例: 「我们的 AI agent 把你的客户支持成本降低 30%。我们从节省额中抽 20% 作为费用。没有节省,就不收费。」
Enterprise License(企业许可)
一份面向大型组织的许可协议,通常带有批量折扣、定制、专属支持和合规保证。
🔹 示例: 一家有 5000 名员工的银行,为一个 AI 平台谈下一份企业许可:用户无限、与其核心银行系统的定制集成、7×24 专属支持、SBP 合规认证,以及本地部署选项。这和注册一个月费 20 美元的个人套餐截然不同。
Skill Marketplace(技能市场)
一个开发者出售或分享可复用 AI agent 技能(SKILL.md 文件、插件、连接器)的市场,催生出一个能力生态。
Domain Expertise(领域专长)
对某个特定领域或行业的深度知识,包括术语、法规、工作流、痛点和竞争态势。
🔹 示例: 懂银行 agent 的 SBP 法规、药企 agent 的 DRAP 要求,或贸易 agent 的关税结构。领域专长是让 Digital FTE 有价值的护城河。
Reusable Intellectual Property(可复用知识产权)
可跨多个客户或项目使用的专有工具、框架、模板或 agent 配置,每一次承接都带来复利累积的价值。
🔹 示例: 你为一家纺织出口商构建一个自动化信用证单据核查的 agent。其核心逻辑(解析信用证、对照法规、标出不符)是可复用的 IP。你可以只做极少定制就为另外 10 家出口商部署它,靠同一份活把收入挣上十遍。
Hybrid Workforce(混合劳动力)
一种组织模式:人类员工与 Digital FTE 并肩工作,各自处理自己最擅长的任务。人类提供判断和创造力;agent 提供规模和一致性。
🔹 示例: 在一个客户支持团队里:AI agent 处理 80% 的常规咨询(订单状态、退款流程、密码重置),而人类客服处理那需要共情、复杂判断或上报的 20%。任何一方都无法独自扛下全部负载:合在一起,他们以更高质量服务多出 5 倍的客户。
Outcome-Based Pricing(基于结果的定价)
按取得的成果而非花费的时间或使用的功能来收费。本书主张这是 AI 服务的未来。
Gain-Share Model(收益分成模式)
一种定价安排:提供商从解决方案带来的可衡量节省或收入增长中赚取一定百分比。
🔹 示例: 你的 Digital FTE 每年为一位客户节省 1000 万卢比的处理成本。在 15% 的收益分成模式下,你每年赚 150 万卢比。
Hyperscaler(超大规模云厂商)
最大的那几家云提供商(AWS、Azure、Google Cloud),拥有能服务数十亿用户的庞大全球基础设施。
Go-to-Market(市场进入策略,GTM)
把一个产品推向客户的完整战略,包括定位、定价、分销渠道和销售方式。
Consultative Selling(顾问式销售)
一种销售方式:在提出任何解决方案之前,先深入理解买家的问题,扮演可信赖的顾问,而非推销产品的人。
💡 类比: 一位好医生不会在你一进门就开药。他会问诊、做检查、弄清病根,_然后_才推荐治疗。顾问式销售同理。
Agile Development(敏捷开发)
一种迭代式的软件构建方式。频繁交付小的增量,获取反馈,调整,重复。
💡 类比: 与其花两年盖一整栋房子、再指望房主喜欢,不如先盖一间房,给房主看,获取反馈,调整后再盖下一间。更快、更省,房主也得到他真正想要的。
Stakeholder(利益相关方)
任何对一个项目有兴趣或有影响力的人,包括客户、经理、投资人、团队成员、监管方、终端用户。
🔹 示例: 对一个医院的 AI 排班 agent 来说,利益相关方包括:医生(需要准确的排班)、患者(需要便利的预约)、医院管理层(需要降本)、IT 团队(需要维护系统),以及 DRAP/监管方(需要合规)。每个利益相关方都有项目必须照顾到的不同需求。
Vertical Market(垂直市场)
一个有独特需求的特定行业细分,比如医疗、银行、纺织、物流、教育。垂直专长是售卖 Digital FTE 的关键。
🔹 示例: 「客服 agent」是一个水平(跨行业)产品。「面向巴基斯坦健康保险公司、懂 SECP 法规和乌尔都语医学术语的理赔处理 agent」则是一个垂直产品。垂直产品能卖更高的价,因为它们解决通用工具解决不了的、具体而棘手的问题。
15. 提到的工具与产品
Claude
Anthropic 的 AI 模型家族。Claude Opus 能力最强;Claude Sonnet 在能力和速度之间取得平衡;Claude Haiku 最快、最经济。
GPT
OpenAI 的 AI 模型家族(GPT-4、GPT-5 等),驱动 ChatGPT 和许多其他应用。
Gemini
Google 的 AI 模型家族,集成在 Google 的各类产品中,也通过 API 提供。
Anthropic
构建 Claude 的 AI 安全公司。成立于 2021 年,总部位于旧金山。
OpenAI
构建 GPT 和 ChatGPT 的公司。成立于 2015 年。
OpenAI Agents SDK
OpenAI 用于以编程方式构建 AI agent 的工具包:本书第 6 部分会讲到。
Google ADK(Agent Development Kit)
Google 用于以 Gemini 模型构建 AI agent 的工具包。
FastAPI
一个现代、快速的 Python Web 框架,用于构建 API:被广泛用于 AI agent 后端。第 6 部分会详讲。
Docusaurus
一个静态网站生成器(由 Meta 构建),用于创建文档站点。本书就是用 Docusaurus 构建的。
Markdown
一种简单的文本格式语言,用 # 表示标题、** 表示加粗、- 表示列表等符号。技术文档的通用语。
VS Code(Visual Studio Code)
Microsoft 出品的一个流行、免费的代码编辑器,常与 Claude Code 搭配使用。
AWS(Amazon Web Services)
亚马逊的云计算平台,世界上最大的云提供商。
GCP(Google Cloud Platform)
Google 的云计算平台。
Azure
Microsoft 的云计算平台。
Cloudflare
一家云基础设施和安全公司,提供 CDN、边缘计算、R2 存储 和 Workers。在本书的部署架构中被大量使用。
你准备好了。 你不需要把这些都背下来。把这一页加入书签。随着你读这本书,今天看起来抽象的术语,会通过动手实践变成第二天性。
学会这门语言最好的办法,就是去用它。
我们开始构建吧。