从一次性任务到 worker:向制造的交接
1 个信号 · 4 项提拔 · 1 个岔路
两个月前,在这条学习轨道的起点,Ana 看着她周一的任务(把一周的客户消息分门别类,再写一份摘要),意识到它有一个 Mode 2 的未来:一件她每周都做、做法都一样、显然值得一次性构建出来的任务。但眼下,它还是一份 Mode 1 的活儿:每个周一,她都用那七条原则手动解决一遍。每次都奏效,但也吃掉了她每个周一的上午。
她的同事 Diego 也有一份类似的周常任务。他同样每周手动解决,而且做得很好。他很擅长这件事。
一年后,Ana 几乎不再为它花费任何周一上午。她跨越了:她把自己反复打磨的 Mode 1 解决方案变成了一个 worker,由它自主处理日常部分,她只在它标记出异常时介入检查。Diego 在他那份任务上大约花掉了五十个周一(差不多一百个小时),明年还要再花五十个。同样的任务,同样的技能。唯一的区别在于:Ana 不再解决问题,而是开始制造解决方案。
这门课讲的就是那次跨越。它是 Mode 1 的最后一站,也是通往 Mode 2 的入口匝道。
适合谁
任何人,只要你有一件不断用 agent 反复解决、做法每次都一样的任务,并开始觉得每次都靠手动来做不是长久之计。这门课会告诉你:什么时候该停止「一次次解决」,把它变成一个永久 worker,以及当你这么做时,到底有什么会改变。
这本书的读者遍布全球,他们用许多不同的语言工作和学习。这里的例子使用平实的语言和日常场景,无论你住在哪里,含义都一样。遇到新词(比如 spec、eval 和 runtime)时,会在它第一次出现的地方加以解释。
请先完成 Problem Solving with General Agents:本课假设你已经能用那七条原则,在一次会话里把一个问题解决得很好。它还假设你已经做过 Is This an Agent Problem?,并且清楚 Mode 1(解决一次)和 Mode 2(构建一个永久 worker)各指什么。
📚 Teaching Aid
查看完整演示:从一次性任务到 worker
一句话规则
你不是从零构建一个 worker,而是把一个你已经验证过的解决方案提拔上来。
人们听到「构建一个 AI worker」,脑海里浮现的是从零开始:一块空白屏幕、一个艰难的工程项目、好几周的工作量。这幅画面是错的,它把人吓得不敢去做那件他们最该做的事。真相恰恰相反:当一件任务已经可以变成 worker 时,大部分工作你其实早就做完了。Ana 每个周一手动解决任务的时候,她都在不知不觉中,弄清楚这个 worker 究竟需要做什么。制造不是发明,而是把一个你已经亲手验证过的解决方案,固化成永久的形态。
这次重新框定,就是整门课的核心。接下来,你会看到:判断一个解决方案是否已准备好跨越的那一个信号、你的 Mode 1 工作中会被提拔进 worker 的四个部分,以及那一个岔路口——在那里,你要选择构建哪一种 worker。
简短版本(四点)
- 只跨越你已经验证过的东西。 只有当一个解决方案你已经亲手干净利落地解决过好几次,你才能用它来制造 worker。这些重复并不是自动化之前白白浪费的时间,而是你借以发现 worker 究竟该做什么的过程。
- 你不是从头再来。 你在 Mode 1 里已经亲手做过的四件事——你的 brief、你的检查、你驱动的那些步骤,以及会话本身——会各自被提拔成一种永久的形态。这就是全部的构建工作。
- 让它永久化时,路会分成两条岔路。 你可以自己拥有一个个人 worker(更轻量,只为你自己),也可以制造一个 Digital FTE(更重,面向一个组织)。这条岔路由一个问题决定:这个 worker 是为谁而建的?
- 回报在于:任务还是资产。 手动解决,是把劳动当作一次性任务:每一次你都要付出那些小时。而 worker 是把劳动当作一项资产:你只构建一次,之后它在你睡觉时也照样干活。
第 1 部分——信号:它真的准备好跨越了吗?
这个做法能避免的错误:「我为一件其实还没真正想清楚的任务,构建了一个永久 worker,结果花了一周做出了错的东西,然后只能重做。」
在 Is This an Agent Problem? 里,Gate 2 已经给了你信号的前半部分:当三个旋钮全部拉满时,一件任务就是 Mode 2——你经常做它、它每次的形状相同,而且它值得你投入。触发条件很简单:当你第三次用同样的方式做同一件任务时,停下来检查一下。
但还有一个 Gate 2 无法检查的后半部分,而它恰恰是人们会跳过的那个:你真的已经把它解决好了吗?
你只能从一个经过验证的解决方案出发去制造。如果你用一套自己还在摸索的方法去构建 worker,你构建出来的就是错的 worker,而且要等到你已经付出了努力之后才会发现。所以,跨越的完整信号有两个部分:
- Gate 2 判定为 Mode 2(经常、相同、值得),并且
- 你已经在 Mode 1 里干净利落地解决过这件任务足够多次,多到方法已经不再变化。
第二个部分才是真正的考验。问问自己:「我最近三次做这件事,做法都一样吗?」如果一样,形状就是稳定的——你已经找到那个 worker 了。如果你每周还是会做得略有不同(不同的步骤、不同的检查、临时的新决定),那你就还没找到稳定的形状。继续在 Mode 1 里解决它,直到它稳定下来。这些重复并不代表你没能完成自动化,而是你在做调研,告诉 worker 该做什么。
一旦你知道某件任务属于 Mode 2,还继续手动去做,会让人觉得效率低下。其实不然。每解决一次,你都会发现一个边缘情况、一种更好的步骤顺序、一项真正重要的检查。在第一周就构建的 worker,会错过所有这些。在第五周构建的 worker,则建立在五周来之不易的知识之上。等学习速度慢下来再跨越,而不是更早。
第 2 部分——重新框定:worker 就藏在工作里
下面这一点,会改变整件事给你的感觉。你每一次在 Mode 1 里把任务解决好,都留下了一条痕迹,而这条痕迹,就是构建 worker 的原材料。
想想一次好的 Mode 1 会话究竟产出了什么。你写了一份 brief(基于什么来做、你想要什么、「完成」意味着什么)。你要求输出有清晰的形状。你跑了一遍检查,确认它没错。你把结果保存到了文件里。这些都不是用完即弃的东西。所以,制造是两个动作,而不是从零开始构建:先收集这些零件,再把每一件加固,让它能在没有你的情况下运行。对第二个动作要看得清楚:加固是实打实的工作——设计出口、构建一个能自我打分的 eval、搭起一个 runtime,这些都是真正的工程,而不只是把你已经在做的事写下来。重新框定为你省去了那张空白页,但它并不会让构建变得轻松。
这里也是经济账翻转的地方,而这正是全书的核心。当你手动解决一件任务时,你的劳动是一项任务:你花掉时间,得到一个结果,时间就这么没了。当你把那个解决方案提拔成 worker 时,同样的劳动就变成了一项资产:你只花一次时间把它构建出来,之后它会一次又一次地产出结果,而你可以去做别的事。这就是 Diego 和 Ana 之间的全部差别:前者一年花掉一百个小时,后者只花过几个小时。
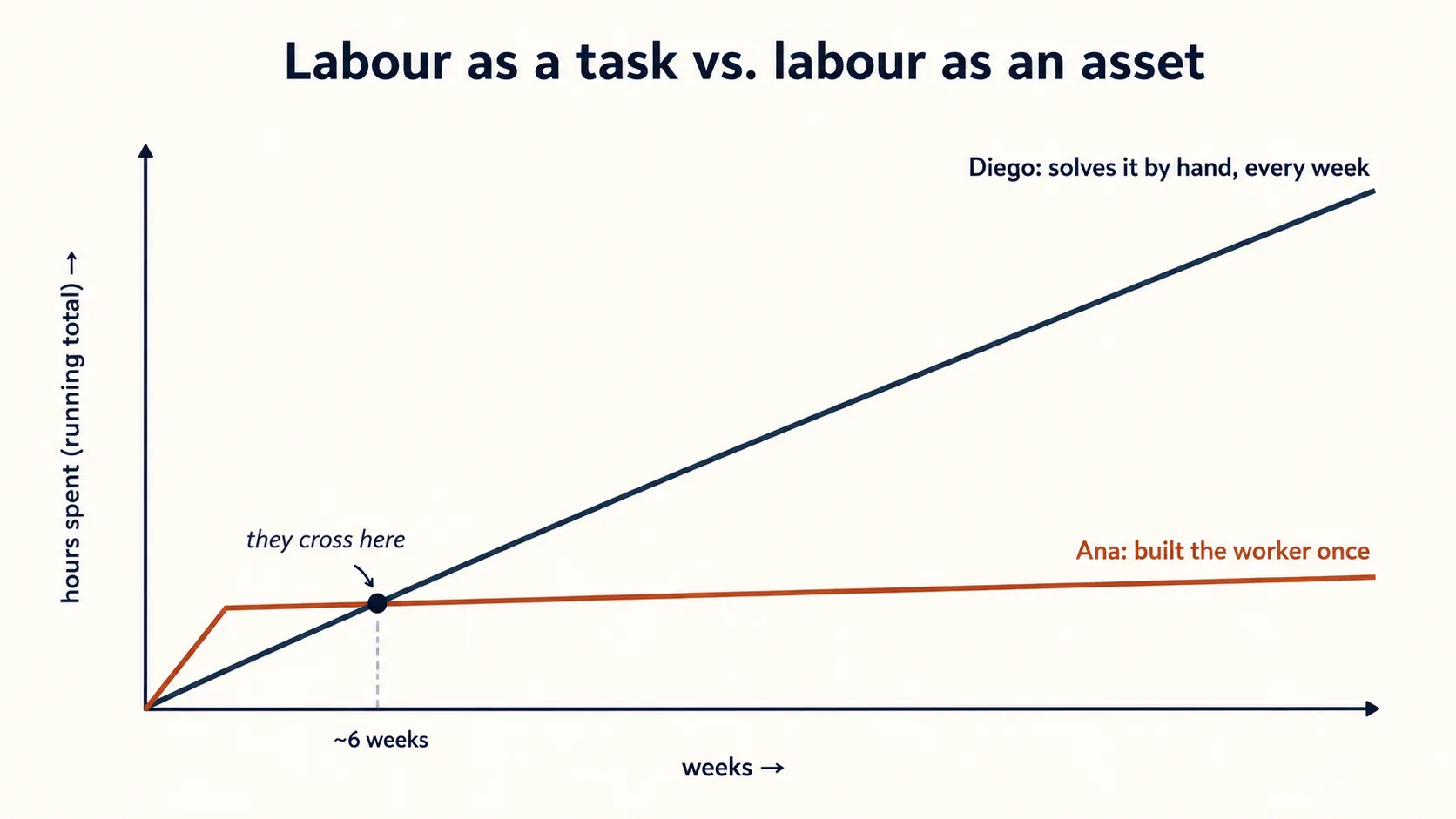 把劳动当作任务,会一直消耗你。把劳动当作资产,只消耗一次,之后就开始回报你。两条线交叉的时间,比人们预想的要早。
把劳动当作任务,会一直消耗你。把劳动当作资产,只消耗一次,之后就开始回报你。两条线交叉的时间,比人们预想的要早。
第 3 部分——四项提拔
跨越不是一次大工程,而是四项具体的升级——而且每一项的硬思考,你都已经在 Mode 1 里做过了。每一次提拔,都是把一件你亲手做的事,变成 worker自己就能做的事。每一项也会把你交接给那门完整讲解它的 Mode 2 课程。
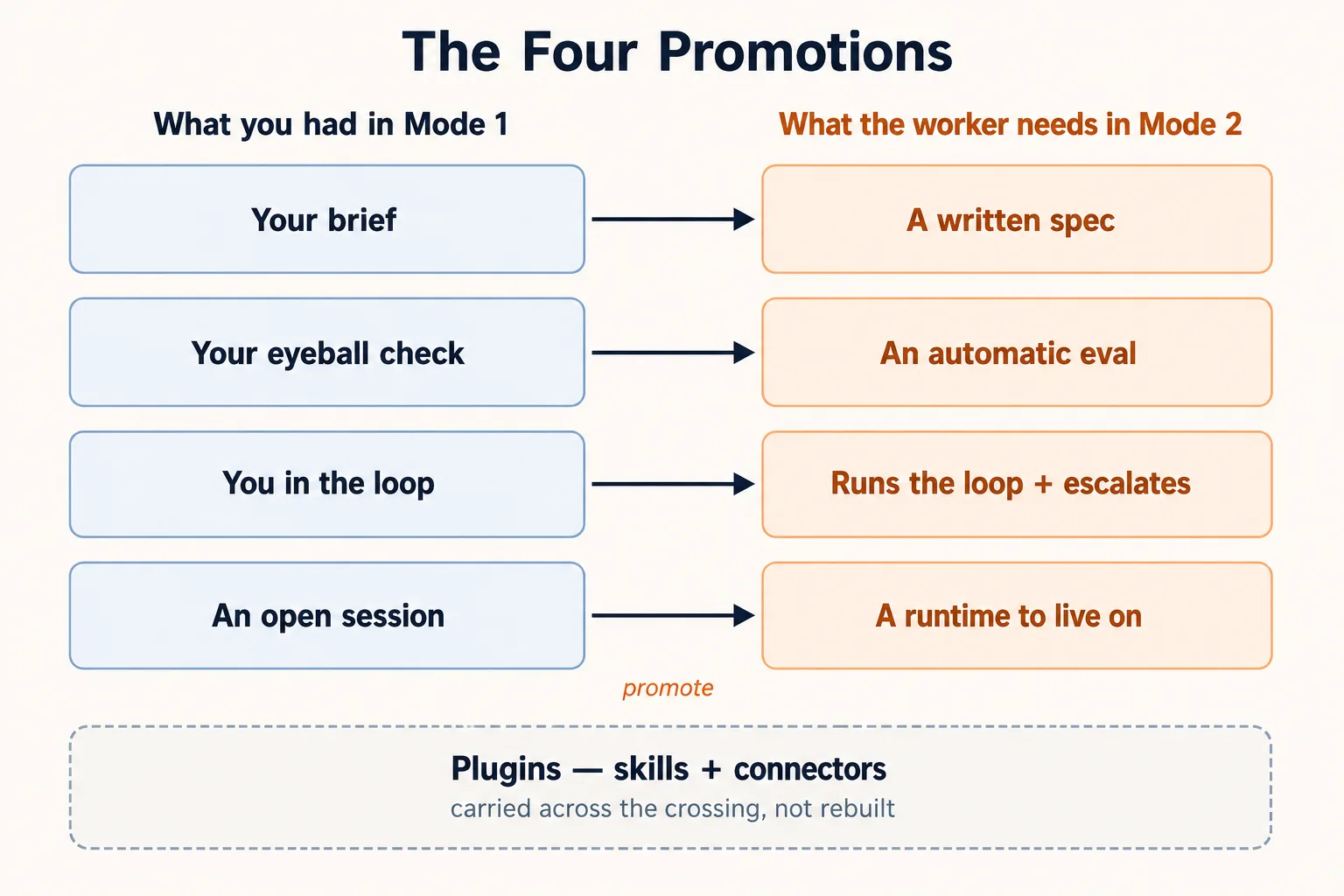 你不是在添加四样新东西,而是在升级四样你已经拥有的东西。
你不是在添加四样新东西,而是在升级四样你已经拥有的东西。
提拔 1:你的 brief 变成 spec
在 Mode 1 里,你每次都会写一份简短的 brief:基于什么、最终想要什么、何时算完成(来自 Gate 3 的那三行)。它存在你的脑子里,或者一张草稿便笺上,你可以随手调整。
worker 读不懂你的心思,也不会问你是什么意思,所以那份 brief 必须变成一份 spec(specification 的简称,即一份写下来的规格说明)——worker 每一次运行都会读它,里面准确写明它要做什么、对什么做、做到什么标准。spec 就是你已经写过的那三行,只是被写得明确、完整、永久。省掉它,worker 就会用猜测来填补空白,而且每次运行都略有不同。
在这门课里学:Spec-Driven Development。
提拔 2:你的检查变成 eval
在 Mode 1 里,你自己验证输出(第三条原则):你读它、把数字和来源逐一核对,你信任它,是因为你亲眼看过。
worker 在你不盯着的情况下运行,往往一天好多次。「每次都靠你读」是没法规模化的,也抓不住 worker 悄悄开始出错的那一刻。所以你的检查会变成一套 eval(evaluation 的简称,即一组保存下来的示例输入,配上它们各自已知正确的答案)。(对于更模糊的工作,「已知正确的答案」可能是一个标签、一个评分量表的分数,或者输出必须满足的一份清单,并不总是一段完美的文本。)worker 的结果会自动拿去和它们比对打分,于是检查无需你在场就能进行,并在 worker 开始漂移的那一刻就向你示警。你那次一次性的阅读,变成了一个永远运行的测试。省掉它,漂移就是无声的——你会从一个不满的客户那里听说,而不是从一次检查里。
在这门课里学:Eval-Driven Development。
提拔 3:你退出回路,并设计好出口
在 Mode 1 里,你身处回路之中(第六和第七条原则):你盯着每一步,在它跑偏时纠偏,在它进入下一步前批准。你就是那张安全网。
worker 自己跑这些步骤,没有人盯着。人们容易搞错的正是这一点:日常部分是容易的,你的 Mode 1 方法本来就能搞定。难的是边缘:那些异常的输入、那些你的方法从来不必处理的情况。你必须提前决定:当 worker 撞上一个它处理不了的情况时,它该怎么办。答案几乎总是:停下来,叫一个人来。 设计这些出口(什么时候上报、上报给谁、带上哪些信息)才是这次提拔真正的工作,也正是这份工作,让一个 worker 安全到值得信任。而且每一件任务都有边缘,哪怕是那些看起来很简单的:一个写代码的 worker,会在它的改动让测试挂掉时停下来问你;一个支付发票的 worker,会把任何超过设定金额的发票标记出来,而不是直接付掉;一个归档文件的 worker,会把它没法有把握分类的那一份单独放到一边,而不是瞎猜。形状从不改变:处理日常,上报例外。省掉它,那么迟早有一天,worker 会去处理那个它本该标记出来的情况,而且会自信地、错误地处理。
在这门课里学:Build AI Agents 和 Building a Digital FTE。
提拔 4:你的会话变成 runtime
在 Mode 1 里,工作存在于一个你打开的会话中。你合上笔记本,它就不复存在了。要为下一次保存任何东西(第五条原则),靠的是你亲手把东西放进文件里。
worker 必须在你不在的时候继续存在。这就需要一个 runtime(运行时,即让 worker 持续存活、自行运行的软件),以及一个供它栖身的地方,好让它可被触达、可靠运行。它的记忆会自行留存,而不是因为你记得去保存。省掉它,就没有 worker——只剩你自己,亲手打开一个会话,而这恰恰是你最初出发的地方。
在这门课里学:Deploy the Agent Harness。(如果这个 worker 只为你自己,还有一条更轻量的路——见下面的岔路。)
四项提拔一览:
| 你在 Mode 1 里有的 | 它在 Mode 2 里变成什么 | 在哪里学 |
|---|---|---|
| 你的 brief(基于什么 / 最终想要什么 / 何时算完成) | 一份 worker 每次运行都读取的 spec | Spec-Driven Development |
| 你自己用眼睛做的检查 | 一套自动给 worker 打分的 eval | Eval-Driven Development |
| 你盯着并纠偏 | worker 自己跑回路,并在边缘上报 | Build AI Agents · Building a Digital FTE |
| 一个你打开又关上的会话 | 一个 worker 赖以存活的 runtime | Deploy the Agent Harness |
这就是整个跨越。四项升级,每一项都是你通过亲手去做、早已理解了的东西。
四项提拔,是你跨越时会改变的东西。有一样重要的东西却几乎不改变:你的插件,也就是你在 Mode 1 里解决问题时已经用过的技能(agent 可复用的打包知识)和连接器(连接你其他应用和数据的通道)。因为它们建立在开放、跨 runtime 的格式之上,同一批技能和连接器可以贯穿 claude.ai、你驱动过的那些 general agent(Claude Code、OpenCode、Cowork、OpenWork)以及 personal harness,而且往往只需轻微改动,就能进入你制造的 worker。只要一个插件坚持使用那些开放格式,它就能基本原样地随跨越一起带过去,这也是构建 worker 大多是提拔、而不是发明的又一个理由。第一次接触这些?请看 Skills & Connectors。
为什么这样行得通(背后的研究)——可选阅读
有两个老想法,解释了为什么「先提拔,别从零构建」是正确的顺序。
第一个来自 Fred Brooks。他领导了 1960 年代最大的软件项目之一,并在《人月神话》(The Mythical Man-Month,1975)中写下了这段经历。他那句著名的建议是:「准备好扔掉第一个版本——反正你早晚都会扔。」你构建的第一样东西,会告诉你本该构建的是什么;真正值得留下的是第二个版本,用你学到的东西做出来。你在 Mode 1 里反复解决的那些次,正是这些「被扔掉的版本」。你不是在自动化之前白白浪费几周,而是在做那个实验,它会告诉你那个永久 worker 应该是什么样。在第一周就构建 worker,意味着你构建的正是那个本来就注定要扔掉的版本。
第二个来自 Lisanne Bainbridge 的《自动化的反讽》(Ironies of Automation,1983),这是关于工作自动化被引用最多的论文之一。她的发现是:当你把一份工作里的日常部分自动化时,你并没有移除人,而是恰恰把人留下来,去负责自动化处理不了的那些罕见、困难的情况;而且自动化越可靠,这些罕见的人为干预就越重要(也越难)。这正是为什么提拔 3 讲的是设计出口,而不是日常。日常是容易自动化的那一部分;价值和危险都住在边缘,所以你要刻意地设计上报,而不是寄希望于它永远不会发生。
来源:Brooks, F. P. (1975). The Mythical Man-Month. Addison-Wesley. Bainbridge, L. (1983). "Ironies of Automation," Automatica, 19(6), 775–779.
第 4 部分——岔路:让它永久化的两条路
一旦你决定跨越,「构建一个持久的 worker」就分成两条不同的路。它们用的是同样的四项提拔,但服务的是不同的人,而这个区别很重要。
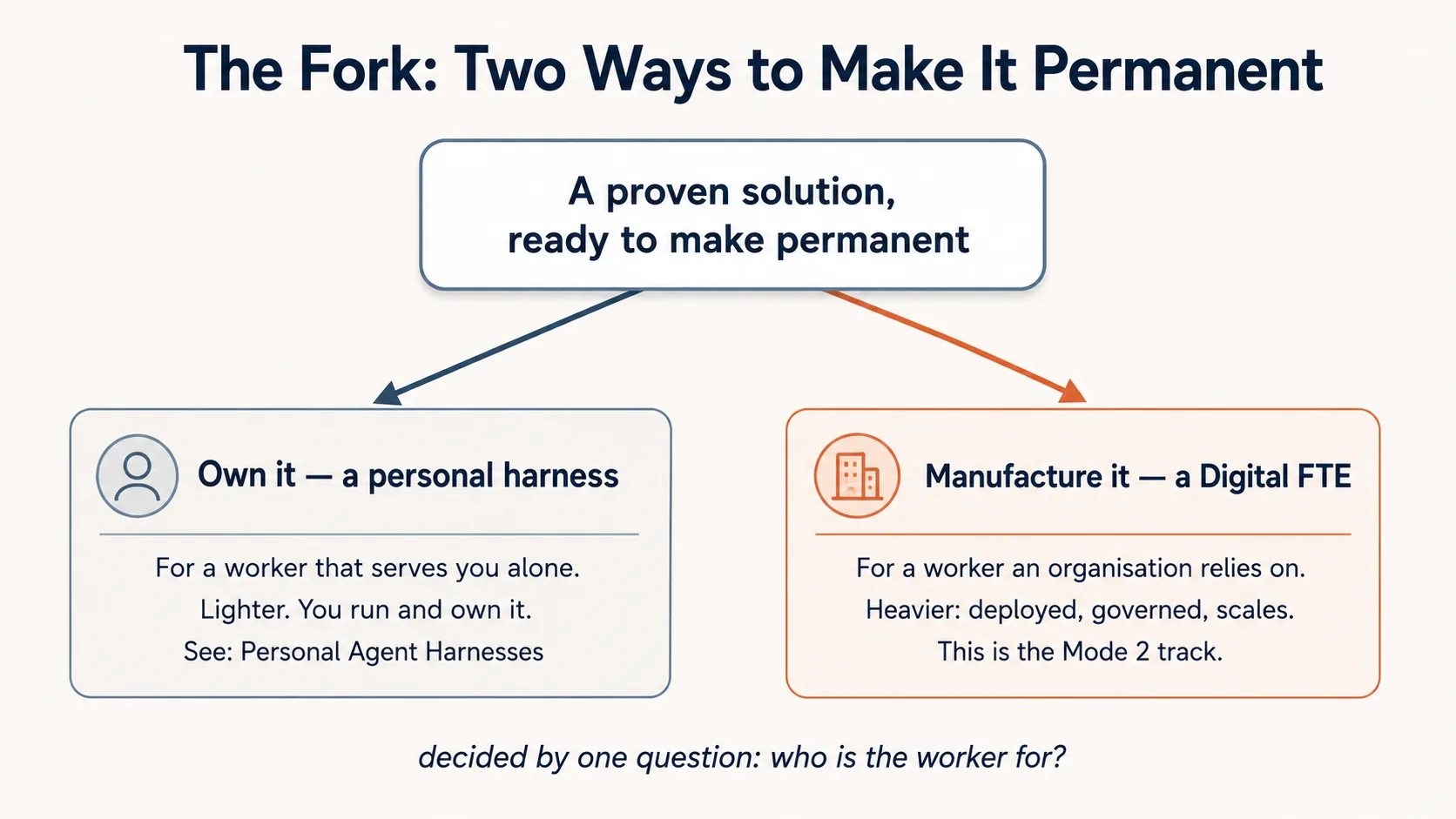 同一个经过验证的解决方案,两个目的地。决定性的问题是:谁依赖这个 worker。
同一个经过验证的解决方案,两个目的地。决定性的问题是:谁依赖这个 worker。
自己拥有它:personal harness。 如果这个 worker 是为你服务的(你的收件箱、你的代码、你要跑的杂事),更轻量的那条路就是 personal harness(一种你自己运行并拥有、为你让一个 worker 持续存活的软件)。四项提拔你照样要做,但做得很轻:spec 就是你自己的笔记,eval 就是你自己的少数几个示例,上报就是 worker 给你发消息。你也许永远都用不上完整的 Mode 2 轨道。这正是 Personal Agent Harnesses 这一节所教的路,用的是 OpenClaw 和 Hermes。
制造它:Digital FTE。 如果这个 worker 是为一个组织服务的(一种别人会依赖、必须可靠运行、受到治理、能够规模化,也许还能卖钱的东西),那它就是一个 Digital FTE(「数字全职员工」,digital full-time employee),而你要严格地做这四项提拔:spec 是共享并经过评审的,eval 是整个团队都信任的一道关卡,上报会送到一个指定的人或团队那里,runtime 则是真正的生产环境基础设施。这就是完整的 Mode 2——制造轨道。
决定性的问题只有一句:这个 worker 是为谁而建的,又是谁在依赖它? 只为你一个人 → personal harness。为一个组织 → Digital FTE。同一次跨越,两种严格程度。
你用什么来构建。 两条路是不变量;工具是变量,而且它们经常变。下面是 2026 年时的变量——你既然已经选好了路,那就只需要看与它对应的那一列:
| 这条路 | 你用什么来构建(2026) | 在哪里学 |
|---|---|---|
| 自己拥有它:personal harness | OpenClaw 或 Hermes——你自己运行并拥有的开源 harness | Personal Agent Harnesses |
| 制造它:Digital FTE | OpenAI Agents SDK,或一套托管式 Claude agent 方案 | Mode 2 轨道;Choosing Agentic Architectures 帮你挑选 |
你在 Mode 1 里一直驱动的那个 general agent(Claude Code、OpenCode、Cowork 或 OpenWork)在这里不会消失——在两条路上,它都是你用来构建并安装 worker 的工具。它只是不再是每次去做任务的那个东西,而变成了「制造那个去做任务的东西」的东西。
有一件事要列进预算。一个持久的 worker 跑在 API 上,在那里每一次模型调用都会被计量并计费,而且这在两条路上都成立:personal harness(OpenClaw、Hermes)跑在 API 上的程度,丝毫不亚于一个制造出来的 Digital FTE。这和在网页应用 claude.ai 里用 AI 不同:在那里,一个插件的调用是从你的订阅或免费额度里扣的,没有单独的按次账单。所以跨越会把「思考」从一种打包进你套餐里的东西,变成一笔实打实的、按次计费的成本。这又是一个理由,说明「值不值得?」这个信号为什么重要:一个 worker 不仅要偿还你的构建时间,还要偿还它每次工作都会产生的模型账单。(personal harness 的这笔账由你自己付;Digital FTE 的则由你或组织来付;而如果你把这个 worker 卖出去,那笔按次成本就是你定价时要围绕的那个数字。)
自己拥有一个 personal harness,并不是夹在 Mode 1 和 Mode 2 之间的一种新模式,而是同一个「构建持久 worker」的活动,只是缩小到了一个人的规模。模式问的是:你只解决一次,还是构建一个能长期存在的东西;所有权问的是:这个 worker 是你的,还是一个组织的。这是两个不同的问题。无论哪种模式,你都可以跑在一个你自己拥有的 harness 上。
Ana 的蓝图,已填好
在你动手做自己的之前,先看看 Ana 那份周一任务跨越后的样子——同样的四项提拔,已经填好。这就是「完成」长什么样,并且注意:每一行都只不过是她过去两个月里已经亲手做过的事。
- Brief → spec。 每个周一,读取 Support 文件夹里的新消息。把每一条恰好归入一个分组(投诉、咨询、订单或其他),再写一份一页纸的摘要,附上每组的数量和最常见的三类投诉。(她那 Gate 3 的三行,永久地写了下来。)
- Check → eval。 十二条她过去已经手动分好类的消息,每一条都和它正确的分组一起保存着。每当她改动 worker 的指令时,都会先拿它在这十二条上跑一遍;如果错分超过一条,她就会先修好,之后才让它去碰真实邮件。
- You → exits。 如果一条消息使用的是 worker 处理不了的语言,或者要求的退款超过了她设定的上限,worker 不会乱猜——它会把这条消息标记出来,并提醒 Ana。其余的一切,它都自己处理。
- Session → runtime。 这个 worker 每个周一上午都在一台常开的小机器上运行,并自己维护一份它已经处理过的内容清单——于是 Ana 什么都不用打开,什么都不用记。
这些没有一样是在跨越那天发明出来的。它们是两个月的周一,被固化成了永久。
轮到你了
拿一件你已经在用 agent、以同样方式、不止一次解决过的真实任务。让它走一遍跨越,把下面三个步骤填好。
为你自己的任务填好这三个步骤。评分会检查:这件任务是否真的经过验证、你的四项提拔是否具体,以及最重要的——你的出口是否是一个真实的上报情况,而不是被略过的边缘。
Discuss with an AI. Question your scores.
Come back when you have your BEST evaluation.
如果你能把这三个步骤都填好,那你就不是在「琢磨着哪天也许要构建一个 agent」,而是已经手握一份它的蓝图了。Mode 2 轨道,无非就是把这四项提拔,认真地做一遍。
这门课把你交接到哪里
这就是那次跨越。Mode 1 是把劳动当作一项任务:每一次你都要付出那些小时。Mode 2 是把劳动当作一项资产:你只构建一次,它就会在你睡觉时也照样干活。这门课,正是其中一者变成另一者的地方。
现在,你带着一份蓝图、而不是一张空白页,进入 Mode 2——制造轨道。那里的每一门课,都会把四项提拔中的一项真正构建出来:
- Python in the AI Era——制造所用的语言(你来指挥,agent 写其中大部分)。
- Build AI Agents——那个跑回路并上报的 worker。
- Eval-Driven Development——给它打分的那套 eval。
- Building a Digital FTE——把四项提拔全部组装成一个组织能够信任的 worker。
- Deploy the Agent Harness——它赖以存活的那个 runtime。
带着一个经过验证的 Mode 1 解决方案和一份填好的蓝图走进去,你就不是从零开始。你是在提拔一个已经管用的东西。
参考资料
本课各项主张背后的想法,供想读原始出处的人参考。
- Brooks, F. P. (1975). The Mythical Man-Month: Essays on Software Engineering. Addison-Wesley. 那个「准备好扔掉第一个版本」的论点——为什么你那些经过验证的 Mode 1 解决方案,正是真正的 worker 据以构建的原型——就在同名的那一章里。(概览)
- Bainbridge, L. (1983). "Ironies of Automation." Automatica, 19(6), 775–779. doi:10.1016/0005-1098(83)90046-8. 为什么把日常自动化之后,人反而要负责那些罕见、困难的情况——这正是提拔 3 讲设计出口、而不是日常的原因。(易读的摘要)
- Munroe, R. "Is It Worth the Time?" xkcd 1205。任务与资产那张图背后的盈亏平衡逻辑:一件任务重复的频率,决定了构建这个 worker 是否值得。
抽认卡学习辅助
知识自测
对你刚刚走过的这些想法,做一次快速的闯关式自测。