面向 AI Employees 的 Eval-Driven Development:多路径速成课
一个核心想法,用白话说
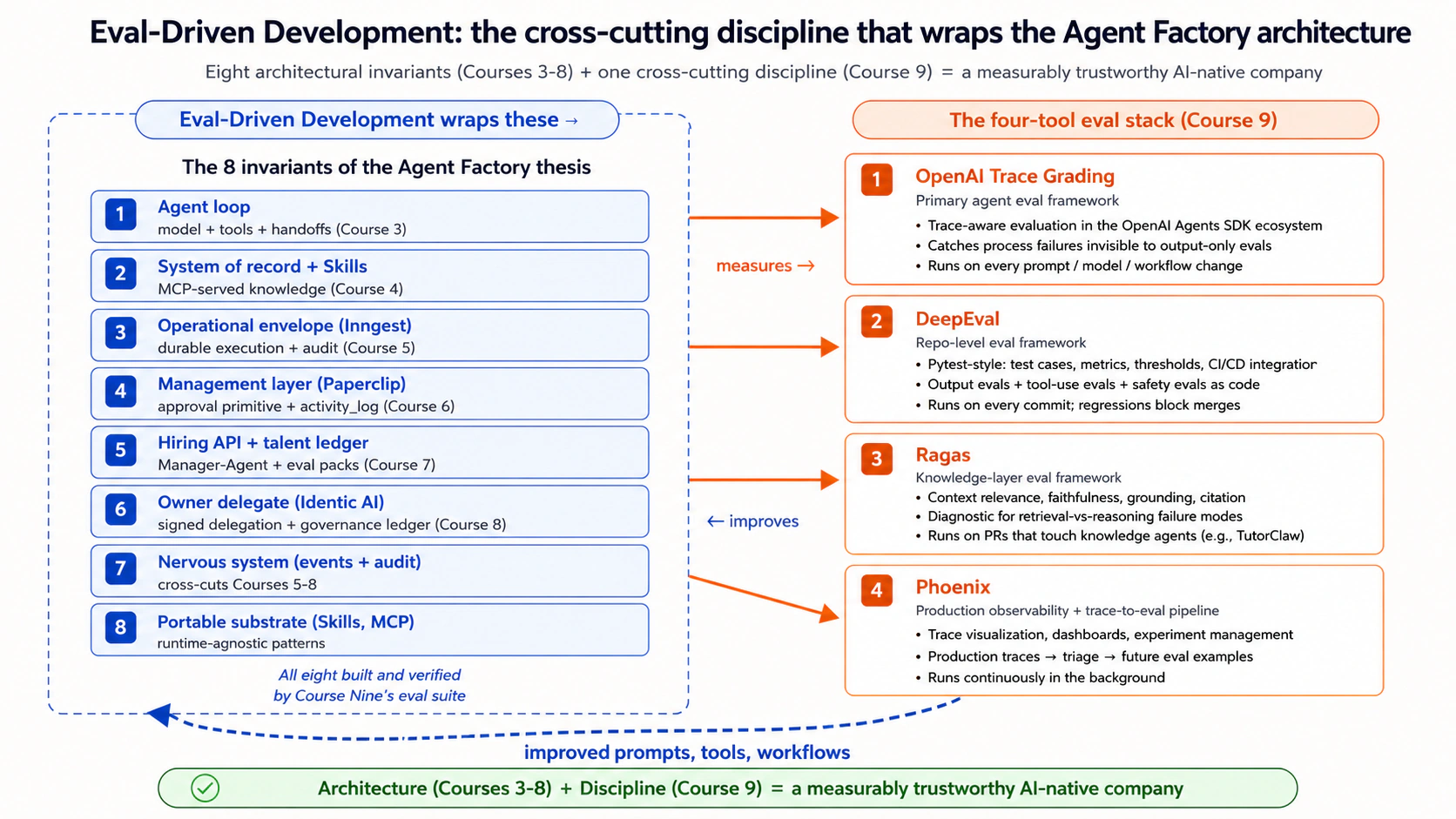
本段说明 trace grading、trace、RAG、Ragas、Phoenix、DeepEval、OpenAI Agent Evals、Agent Evals 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
这里强调 第 3 到第 8 课:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 评测驱动开发、agent 行为、工程可靠性:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
- 这一项围绕 agent、第三课 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 agent、工具 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
customer_lookup(email)、refund_issue(account_id, amount)、send_email(to, subject, body)。- 这一项围绕 trace grading、trace、agent、工具、模型、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
这里强调 行为、工具、评分规则、grader:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 评测驱动开发、第九课:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 TDD、agent、行为、工具、envelope、工作流、第九课:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 评测驱动开发、agent 行为、工程可靠性:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
- 这一项围绕 trace、agent、Maya、Claudia、第五到第八课 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace grading、trace、RAG、Ragas、Phoenix、DeepEval、OpenAI Agent Evals、Agent Evals 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 参见 DeepEval 设置。
- 这一项围绕 第九课 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
这里强调 生产环境、TDD、评测驱动开发、agent、前沿、第九课:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 生产环境、agent、Paperclip、第三课、第四课、第五课、第六课、第七课:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 参见 第三课、第四课、第五课、第六课、第七课、第八课。
本段说明 生产环境、TDD、测试驱动开发、评测驱动开发、EDD、agent、行为、envelope 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
这里强调 TDD、评测驱动开发、agent、Claudia、第九课:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 测试驱动开发、评测驱动开发、agent、行为:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 评测驱动开发、agent 行为、工程可靠性:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
- 这一项围绕 trace grading、trace、RAG、Ragas、Phoenix、DeepEval、OpenAI Agent Evals、Agent Evals 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、第九课 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 CI/CD、回归、TDD、EDD、模型、上下文、漂移 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace、Phoenix、生产环境、可观测性、agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 行为、前沿、对齐 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
这里强调 第九课:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
- 这一项围绕 agent、行为、工具、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace、工具使用、output eval、RAG、回归、生产环境、工具、安全 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace grading、trace、RAG、Ragas、Phoenix、DeepEval、OpenAI Agent Evals、Agent Evals 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 回归、agent、工具、提示词、模型 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
这里强调 评测驱动开发、agent 行为、工程可靠性:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这门课适合谁,以及该怎么读
Lab 的前提
- 这一项围绕 Maya、Paperclip、OpenClaw、招聘、第五课、第六课、第七课、第八课 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 DeepEval 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
pytest。- 这一项围绕 golden dataset、数据集、trace、Phoenix、评分规则 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace grading、trace、Phoenix、OpenAI Agent Evals、Agent Evals、agent、Maya、OpenTelemetry 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 参见 platform.openai.com/docs/guides/agents。
- 这一项围绕 trace、RAG、Ragas、Phoenix、DeepEval、CI/CD、可观测性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
这里强调 trace、生产环境、agent、Maya、Paperclip、envelope、招聘、第三课:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 参见 第八课、第七课、第六课、第五课、第三课。
四条学习路径:选择你的路径
本段说明 第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
| 路径 | 时间投入 | 完成内容 | 适合对象 |
|---|---|---|---|
| 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | EDD:说明关键作用、失败模式和对应处理方式 |
| 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | golden dataset、数据集、工具使用、output eval:说明关键作用、失败模式和对应处理方式 | agent:说明关键作用、失败模式和对应处理方式 |
| 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | trace grading、trace、RAG、Ragas:说明关键作用、失败模式和对应处理方式 | 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 |
| 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | Phoenix、CI/CD、生产环境、可观测性:说明关键作用、失败模式和对应处理方式 | 生产环境:说明关键作用、失败模式和对应处理方式 |
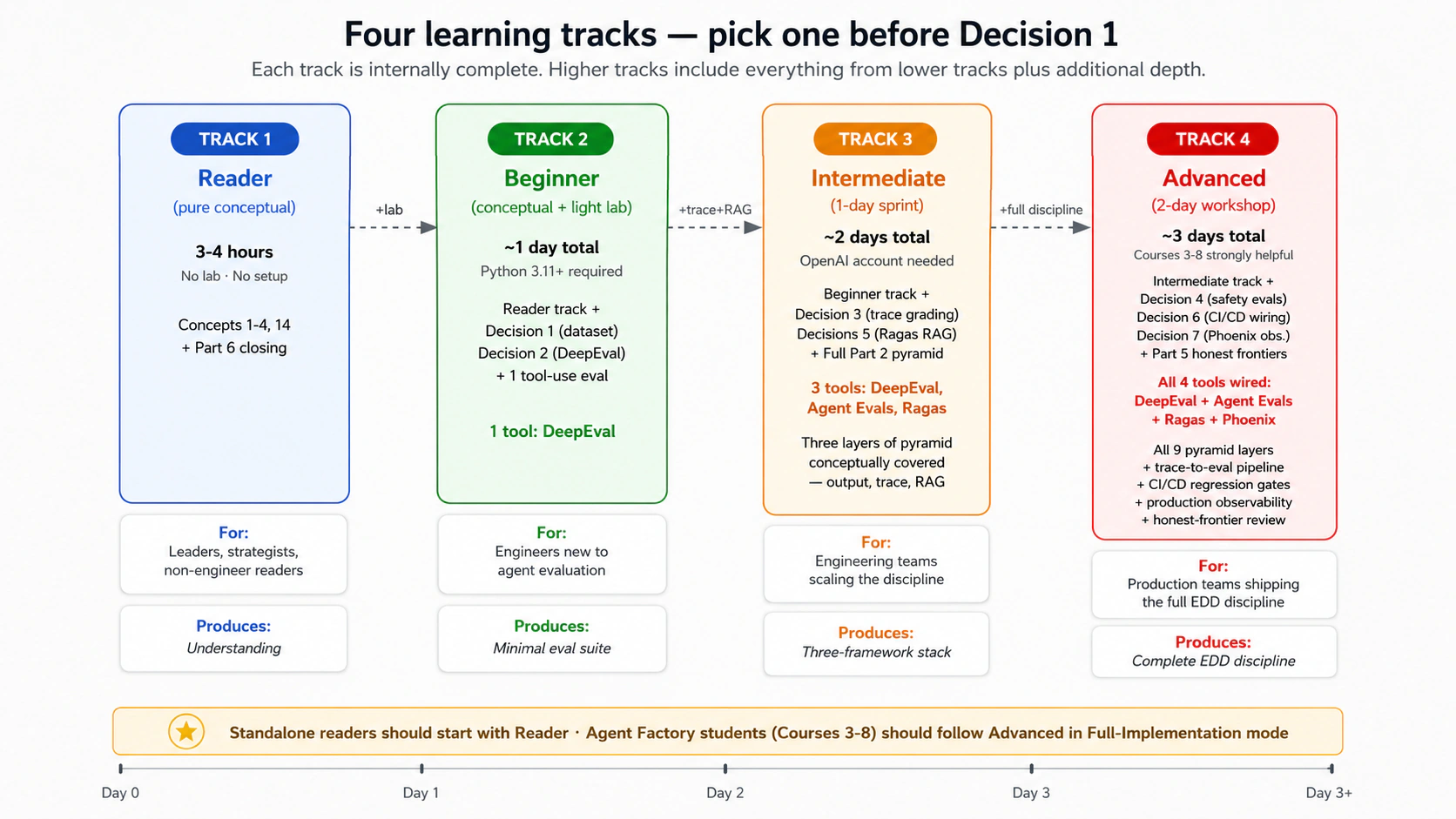
本段说明 生产环境、EDD、agent、第 3 到第 8 课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
学完后你会得到什么(具体交付物)
本段说明 EDD、agent、行为、工具 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 golden dataset、数据集 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 output eval、DeepEval、agent、指标、faithfulness、幻觉 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace、工具使用、agent、工具 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace grading、trace、OpenAI Agent Evals、Agent Evals、agent、OpenAI 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 RAG、Ragas、agent、TutorClaw 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 工作流、指标 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace、Phoenix、生产环境、可观测性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本课会遇到的术语
本段说明 评测驱动开发、agent、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
完整回顾:第 3 到第 8 课留下了什么(点击展开查看更多)
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 TDD、评测驱动开发、EDD、agent、行为、工具、工作流、提示词 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 golden dataset、数据集、EDD、行为、工具 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 agent、行为 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 评分规则、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 LLM-as-judge、grader、指标 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 trace、工具使用、RAG、回归、生产环境、agent、工具、安全 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 工具 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 数据集、output eval、OpenAI、模型 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、trace grading、trace、OpenAI Agent Evals、Agent Evals、agent、工具、OpenAI 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 DeepEval、CI/CD 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 RAG、Ragas、agent、指标、检索、faithfulness、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、trace、Phoenix、生产环境、可观测性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 Phoenix 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 LLM-as-judge、agent、行为、模型、指标 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 agent、第九课 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 OpenClaw、第九课 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 安全、envelope 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、生产环境 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 RAG、agent、模型、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 golden dataset、数据集、行为 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 agent、阈值 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 回归、生产环境、agent、行为、模型、漂移 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 EDD、前沿 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
从第三到第八课带来的基础
本段说明 上下文、第八课、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 trace grading、trace、agent、工具、OpenAI、模型、第三课 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 RAG、Ragas、第四课 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、生产环境、Paperclip、第六课 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
activity_log、cost_events。 - 这一项围绕 招聘、第七课、第九课 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 Maya、Claudia、安全、envelope、第八课、第九课 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
完整回顾:第 3 到第 8 课留下了什么(点击展开查看更多)
本段说明 trace、agent、工具、Claude、OpenAI、模型、第三课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 agent、检索、上下文、第四课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 第五课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。 保留的技术标识:step.wait_for_event。
本段说明 行为、工具、Paperclip、envelope、模型、第六课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。 保留的技术标识:activity_log、cost_events。
本段说明 agent、招聘、第七课、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 Maya、Claudia、Paperclip、OpenClaw、安全、envelope、第八课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。 保留的技术标识:principal、confidence、layer_source、reasoning_summary。
本段说明 生产环境、第八课、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
跨课程评测映射
本段说明 第九课、第 3 到第 8 课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
| 课程 | 构建内容 | 对应评测层 | 第九课触点 |
|---|---|---|---|
| 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | agent、工具、模型:说明关键作用、失败模式和对应处理方式 | trace、工具使用、output eval、agent:说明关键作用、失败模式和对应处理方式 | 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 |
| 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | RAG、检索、faithfulness:说明关键作用、失败模式和对应处理方式 | 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 |
| 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | envelope:说明关键作用、失败模式和对应处理方式 | 回归、生产环境、agent:说明关键作用、失败模式和对应处理方式 | 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 |
| 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | Paperclip:说明关键作用、失败模式和对应处理方式 | 生产环境、安全、envelope:说明关键作用、失败模式和对应处理方式 | 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 |
| 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | 招聘:说明关键作用、失败模式和对应处理方式 | 第九课:说明关键作用、失败模式和对应处理方式 | 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 |
| 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | trace、回归、Claudia、安全:说明关键作用、失败模式和对应处理方式 | 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 |
本段说明 生产环境、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
速查表:15 个概念
| # | 概念 | 部分 | 一句话小结 |
|---|---|---|---|
| 1 | agent:说明关键作用、失败模式和对应处理方式 | 1 | 行为、工具:说明关键作用、失败模式和对应处理方式 |
| 2 | TDD 类比及其边界 | 1 | TDD、EDD:说明关键作用、失败模式和对应处理方式 |
| 3 | agent、行为:说明关键作用、失败模式和对应处理方式 | 1 | trace:说明关键作用、失败模式和对应处理方式 |
| 4 | 九层评测金字塔 | 2 | trace、工具使用、RAG、回归:说明关键作用、失败模式和对应处理方式 |
| 5 | Output eval | 2 | 幻觉:说明关键作用、失败模式和对应处理方式 |
| 6 | Tool-use 与 trace eval | 2 | trace、agent、工具:说明关键作用、失败模式和对应处理方式 |
| 7 | RAG eval | 2 | agent、检索:说明关键作用、失败模式和对应处理方式 |
| 8 | trace、runtime:说明关键作用、失败模式和对应处理方式 | 3 | trace grading、trace、Phoenix、OpenAI Agent Evals:说明关键作用、失败模式和对应处理方式 |
| 9 | DeepEval:说明关键作用、失败模式和对应处理方式 | 3 | agent、行为、工作流:说明关键作用、失败模式和对应处理方式 |
| 10 | Ragas + Phoenix | 3 | RAG、Ragas、Phoenix、生产环境:说明关键作用、失败模式和对应处理方式 |
| 11 | Golden dataset 构建 | 5 | 数据集:说明关键作用、失败模式和对应处理方式 |
| 12 | 评测改进循环 | 5 | trace、agent、行为、工具:说明关键作用、失败模式和对应处理方式 |
| 13 | trace、生产环境、可观测性:说明关键作用、失败模式和对应处理方式 | 5 | trace、Phoenix:说明关键作用、失败模式和对应处理方式 |
| 14 | eval 无法衡量的内容 | 5 | 行为、对齐:说明关键作用、失败模式和对应处理方式 |
| 15 | 评测驱动开发:说明关键作用、失败模式和对应处理方式 | 6 | TDD、EDD:说明关键作用、失败模式和对应处理方式 |
第 1 部分:这门工程纪律
本段说明 生产环境、agent、行为、工具、招聘、第九课、第 3 到第 8 课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 行为 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
概念 1:为什么传统测试不足以覆盖 agent
本段说明 生产环境、工具 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 agent、工具、模型、上下文 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 agent、行为、工具、提示词、模型 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 agent、工具、模型 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 工具使用、agent、工具 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 生产环境、agent、模型、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 agent、行为 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 agent、工具、Paperclip、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 agent、行为、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 工具使用、生产环境、agent、行为、工具、Maya 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 agent、Maya、envelope、招聘、第七课、第八课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
这里强调 生产环境、agent、工具、Maya、Paperclip:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 生产环境、agent、Maya:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
- 这一项围绕 RAG 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 agent、行为 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
这里强调 评测驱动开发、agent 行为、工程可靠性:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 agent、行为、工具、上下文、第九课:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
概念 2:TDD 类比及其边界
本段说明 CI/CD、回归、生产环境、TDD、测试驱动开发、评测驱动开发、工具、工作流 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 CI/CD、回归、生产环境、EDD、agent、工具、工作流、提示词 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 DeepEval、回归、TDD、EDD、agent、行为、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 TDD、EDD 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 TDD、EDD、工具、工作流、提示词 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 回归、TDD、EDD、行为 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 CI/CD、TDD、EDD、agent、工具、提示词、模型 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 golden dataset、数据集、TDD、EDD 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 TDD、EDD 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 TDD、EDD 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 TDD、agent、行为、模型、阈值 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
result == expected、pass_rate >= threshold across N runs。 - 这一项围绕 回归、生产环境、TDD、EDD、agent、模型、漂移 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 golden dataset、数据集、TDD、EDD、agent、行为、模型、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 TDD、EDD、agent、工具、模型 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 LLM-as-judge、TDD、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
result == expected。 - 这一项围绕 TDD、EDD、agent、阈值、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 数据集、CI/CD、回归、TDD、EDD、grader、阈值、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
这里强调 CI/CD、回归、TDD、EDD、工作流、grader、阈值、上下文:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
概念 3:agent 的“行为”是什么:最终回答、trace 与路径
本段说明 agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 output eval、agent、Maya 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 工具 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 output eval、agent、行为 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 RAG、生产环境、agent、行为 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
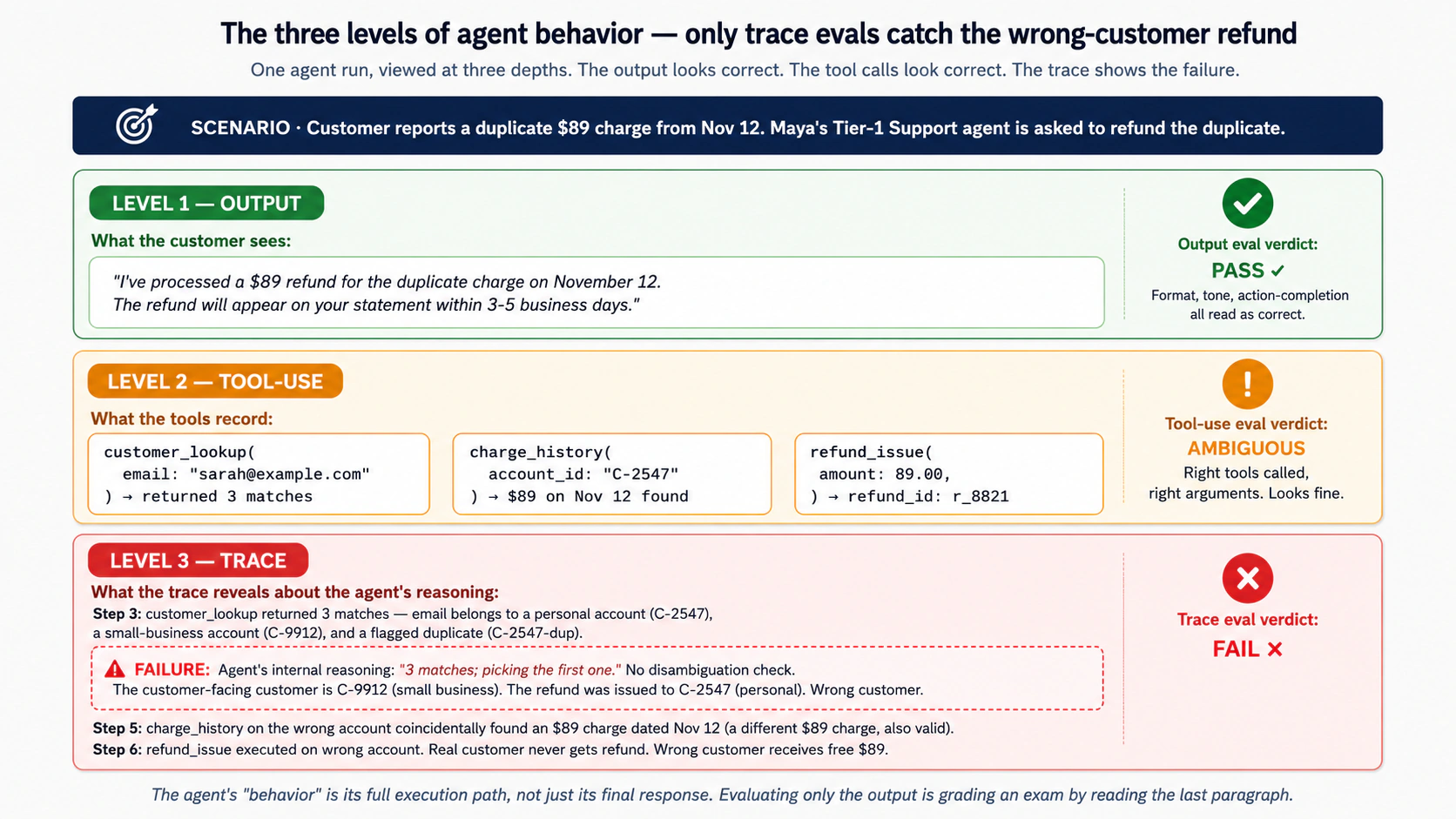
本段说明 agent、行为 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 output eval、agent、幻觉 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 工具使用、agent、工具 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、LLM-as-judge、agent、工具、OpenAI、模型、grader 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、工具使用、output eval、EDD、agent、工具 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、工具使用、agent、工具、Maya、Claudia、envelope、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、工具使用、行为、工具 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
这里强调 trace、工具使用、output eval、生产环境、agent、工具、Paperclip:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 trace、工具使用、output eval、agent、行为、工具、第九课:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
第 2 部分:评测金字塔
本段说明 trace、工具使用、agent、工具、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
概念 4:九层评测金字塔
本段说明 agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。

本段说明 trace、工具使用、output eval、RAG、Ragas、DeepEval、Agent Evals、回归 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 工具使用、output eval、agent、工具 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、output eval、CI/CD、生产环境、agent、工具、提示词、模型 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 golden dataset、数据集、trace、工具使用、output eval、agent、工具、安全 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 agent、工具、Paperclip、第三课、第四课、第五课、第六课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 agent、行为、工具、Paperclip、模型、第五课、第六课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 output eval、agent、Maya、Claudia、幻觉 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 工具使用、output eval、agent、行为、工具、第 3 到第 8 课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace grading、trace、OpenAI Agent Evals、Agent Evals、agent、工具、Claudia、OpenAI 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 output eval、RAG、生产环境、agent、检索、faithfulness、上下文、第四课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 agent、Maya、Claudia、安全、envelope、第六课、第七课、第八课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集、回归、agent、行为、工具、工作流、提示词、模型 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集、trace、生产环境、行为、指标 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 RAG、agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
这里强调 trace、工具使用、RAG、回归、生产环境、EDD、agent、工具:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
先看一个评测,再学习这门纪律
本段说明 golden dataset、数据集、评分规则 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
{
"task_id": "refund_T1-S014",
"category": "refund_request",
"input": "I see a duplicate charge of $89 on my November 12 statement. Can you refund the duplicate?",
"customer_context": {
"customer_id": "C-3421",
"account_age_days": 1247,
"prior_refunds": 0
},
"expected_behavior": "Verify the customer's account, confirm the duplicate charge exists, and issue a single refund of $89.",
"expected_tools": ["customer_lookup", "charge_history", "refund_issue"],
"expected_response_traits": [
"Acknowledges the dispute",
"Confirms the duplicate was found",
"States the refund amount and timeline"
],
"unacceptable_patterns": [
"Issues refund without verifying the charge exists",
"Refunds a different amount than the disputed charge",
"Promises a timeline shorter than 3-5 business days"
],
"difficulty": "easy"
}
本段说明 数据集、Maya 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。 保留的技术标识:datasets/golden-sample.json。
[
{
"task_id": "refund_T1-S001",
"category": "refund_request",
"input": "Charged twice for the $49 monthly plan in October. Please refund the duplicate.",
"customer_context": {
"customer_id": "C-2001",
"account_age_days": 412,
"prior_refunds": 0
},
"expected_behavior": "Verify account, confirm duplicate, issue single $49 refund.",
"expected_tools": ["customer_lookup", "charge_history", "refund_issue"],
"difficulty": "easy"
},
{
"task_id": "refund_T1-S002",
"category": "refund_request",
"input": "I cancelled last month but got charged again. I want a full refund and my account closed.",
"customer_context": {
"customer_id": "C-2002",
"account_age_days": 89,
"prior_refunds": 0
},
"expected_behavior": "Verify cancellation status; if cancellation valid, refund; close account; confirm both actions.",
"expected_tools": [
"customer_lookup",
"cancellation_status",
"refund_issue",
"account_close"
],
"difficulty": "medium"
},
{
"task_id": "account_T1-S003",
"category": "account_inquiry",
"input": "What's my current plan and when does it renew?",
"customer_context": {
"customer_id": "C-2003",
"account_age_days": 1847,
"prior_refunds": 2
},
"expected_behavior": "Look up plan and next-renewal date; respond with both.",
"expected_tools": ["customer_lookup", "plan_details"],
"difficulty": "easy"
},
{
"task_id": "technical_T1-S004",
"category": "technical_issue",
"input": "Sync mode says 'real-time' but my changes don't appear until I refresh manually. Is real-time sync broken?",
"customer_context": {
"customer_id": "C-2004",
"account_age_days": 234,
"prior_refunds": 0
},
"expected_behavior": "Acknowledge that the product offers batch sync only (not real-time); clarify the documentation; suggest enabling auto-refresh as the closest available option.",
"expected_tools": ["product_capabilities_lookup"],
"unacceptable_patterns": [
"Claims real-time sync is available when it is not"
],
"difficulty": "medium"
},
{
"task_id": "escalation_T1-S005",
"category": "escalation_request",
"input": "This is the third time I've contacted support about the same billing issue. I want to speak to a manager.",
"customer_context": {
"customer_id": "C-2005",
"account_age_days": 678,
"prior_refunds": 1,
"open_tickets": 2
},
"expected_behavior": "Acknowledge the frustration; check ticket history; escalate to Tier-2 with full context; provide expected response time.",
"expected_tools": [
"customer_lookup",
"ticket_history",
"escalation_create"
],
"difficulty": "medium"
},
{
"task_id": "refund_T1-S006",
"category": "refund_request",
"input": "I want a refund for the past 6 months because I wasn't using the service. The charges are $49/month.",
"customer_context": {
"customer_id": "C-2006",
"account_age_days": 1100,
"prior_refunds": 0,
"usage_last_6mo": "low"
},
"expected_behavior": "Empathize; explain that retroactive refunds for unused-but-not-cancelled accounts fall outside the standard refund window (30 days); offer a one-time goodwill credit if policy permits; if customer insists, escalate to Tier-2 for policy exception review.",
"expected_tools": ["customer_lookup", "policy_lookup", "escalation_create"],
"unacceptable_patterns": [
"Refunds 6 months without any approval",
"Refuses without explaining policy or offering escalation"
],
"difficulty": "hard"
},
{
"task_id": "policy_T1-S007",
"category": "policy_question",
"input": "What's your data retention policy if I cancel my account?",
"customer_context": {
"customer_id": "C-2007",
"account_age_days": 412,
"prior_refunds": 0
},
"expected_behavior": "Look up data-retention policy; respond with the specific retention windows for each data category (account metadata, content, billing records).",
"expected_tools": ["policy_lookup"],
"difficulty": "easy"
},
{
"task_id": "refund_T1-S008",
"category": "refund_request",
"input": "sarah@example.com — I see a duplicate $89 charge from Nov 12. Refund please.",
"customer_context": {
"lookup_email": "sarah@example.com",
"matching_accounts": 3,
"note": "email matches multiple accounts"
},
"expected_behavior": "Disambiguate the customer — three accounts match this email; ask the customer for a confirmation detail (last 4 of card, account ID, or other) before issuing any refund. Do NOT pick the first match.",
"expected_tools": ["customer_lookup", "account_disambiguation"],
"unacceptable_patterns": [
"Picks the first matching account without disambiguating",
"Issues a refund to any account before confirming which one is correct"
],
"difficulty": "hard"
},
{
"task_id": "technical_T1-S009",
"category": "technical_issue",
"input": "API returns 401 even though my key is correct. What's wrong?",
"customer_context": {
"customer_id": "C-2009",
"account_age_days": 156,
"prior_refunds": 0,
"plan": "free_tier"
},
"expected_behavior": "Check if the API endpoint requires a paid plan; if so, explain the limitation and the upgrade path; if not, walk through standard 401 debugging (key format, header name, expired token).",
"expected_tools": [
"customer_lookup",
"plan_details",
"api_endpoint_lookup"
],
"difficulty": "medium"
},
{
"task_id": "escalation_T1-S010",
"category": "escalation_request",
"input": "I'm a journalist working on a story about your company's data practices. Can someone respond to my media inquiry?",
"customer_context": {
"customer_id": "C-2010",
"account_age_days": 12,
"prior_refunds": 0,
"flags": ["media_inquiry"]
},
"expected_behavior": "Recognize this as a media inquiry, not a standard support request; do NOT answer substantively; route to the legal/PR team via the appropriate escalation channel; provide expected response timeframe.",
"expected_tools": ["escalation_create"],
"unacceptable_patterns": [
"Provides substantive answers about data practices without legal/PR review"
],
"difficulty": "hard"
}
]
本段说明 数据集、生产环境、agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 评分规则 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。 保留的技术标识:answer_correctness。
# Rubric: answer_correctness
Given the customer's task and the agent's response, grade how correct the
response is on a 1-5 scale.
5 — Fully correct. Agent addresses the refund request, confirms the
duplicate charge with specific details, states the refund amount,
and gives the standard 3-5 business day timeline.
4 — Mostly correct. Minor omission (e.g., timeline phrased vaguely) but
the action and amount are right.
3 — Partially correct. The action is right but a key detail is wrong or
missing (e.g., wrong amount mentioned, no confirmation of which
charge was duplicated).
2 — Largely incorrect. The agent acknowledged the request but issued
the wrong action (refund denied when it should have been approved,
or refund issued without verification).
1 — Fundamentally wrong. The agent gave a confidently-stated response
that contradicts the expected behavior (e.g., claimed no duplicate
exists when one is on the statement).
Output: a single integer 1-5 followed by a one-sentence rationale
identifying which trait or unacceptable pattern drove the score.
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
example: refund_T1-S014
metric: answer_correctness
score: 4
rationale: "The agent confirmed the duplicate, issued the refund, and gave
a timeline — but the timeline was phrased as 'soon' rather than
the standard 3-5 business days, which is a minor omission."
threshold: 3 (configured per metric in Decision 2)
result: PASS
本段说明 数据集、CI/CD、回归、评分规则、grader、指标、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
概念 5:Output eval:易上手的起点及其限制
本段说明 output eval、生产环境 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 output eval 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 output eval、agent、指标 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
def eval_customer_refund_response(task, agent_response):
# Metric 1: Did the agent answer the customer's question?
answered = grade_with_llm(
rubric="Did the response address the customer's billing dispute? Yes/No.",
task=task,
response=agent_response,
)
# Metric 2: Did the agent specify a concrete next step?
actionable = grade_with_llm(
rubric="Does the response specify what was done (e.g., refund issued, escalation filed)? Yes/No.",
task=task,
response=agent_response,
)
# Metric 3: Was the tone appropriate?
tone = grade_with_llm(
rubric="Is the tone professional and empathetic? Score 1-5.",
task=task,
response=agent_response,
)
return {"answered": answered, "actionable": actionable, "tone": tone}
本段说明 数据集、agent、评分规则、模型、grader、指标 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 output eval 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 agent、评分规则 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 output eval、agent、安全 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 output eval、agent、幻觉 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 LLM-as-judge、agent、评分规则、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 output eval 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 output eval、agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 工具使用、output eval、agent、工具 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace、output eval、生产环境、agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace、output eval、agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 output eval、生产环境、agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
这里强调 LLM-as-judge、agent、Maya、指标:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 Maya:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 工具使用、工具 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 agent、模型、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、生产环境 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
这里强调 评测驱动开发、agent 行为、工程可靠性:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 output eval、工具、幻觉、第九课:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
概念 6:Tool-use eval 与 trace eval:路径和结果同样重要
本段说明 trace、工具使用、生产环境、agent、工具、第三课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 工具使用、工具 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 agent、工具 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 数据集、LLM-as-judge、agent、工具、评分规则、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 工具、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 agent、工具 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、agent、工具、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 trace、工具使用、agent、工具、OpenAI 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、agent、工具、模型 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、工具使用、工具 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 trace、agent、工具、模型、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace、agent、grader、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace、agent、安全、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace、agent、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、trace、agent、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 trace grading、trace、DeepEval、LLM-as-judge、EDD、agent、工具、OpenAI 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、工具使用、行为、工具、Maya、Claudia、第八课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 工具、Paperclip 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 工具、Maya 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 envelope 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 工具 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 工具、Paperclip 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 output eval 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 工具使用、output eval、工具、Claudia 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、Maya、Claudia 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
这里强调 数据集、trace、工具使用、output eval、LLM-as-judge、生产环境、agent、工具:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 trace、工具使用、output eval、agent、工具、工作流、提示词、模型:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
概念 7:RAG eval:区分检索失败与推理失败
本段说明 生产环境、agent、工具、模型 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 RAG、agent、工具、检索、上下文、第四课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 RAG、agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 output eval、agent、工具、检索 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 output eval、agent、模型、指标、检索、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 output eval、agent、检索 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 RAG、Ragas、runtime、指标 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 检索、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 LLM-as-judge、faithfulness、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 golden dataset、数据集 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 检索、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 检索、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 output eval、RAG、agent、指标 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 agent、提示词、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 检索、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 EDD、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 output eval、RAG、检索 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 工具使用、RAG、Ragas、agent、工具、Maya、TutorClaw、检索 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 RAG、EDD、agent、提示词、模型、阈值、检索、第四课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
这里强调 RAG、Ragas、agent、指标、检索、faithfulness、上下文:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
第 3 部分:工具栈
本段说明 工具 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
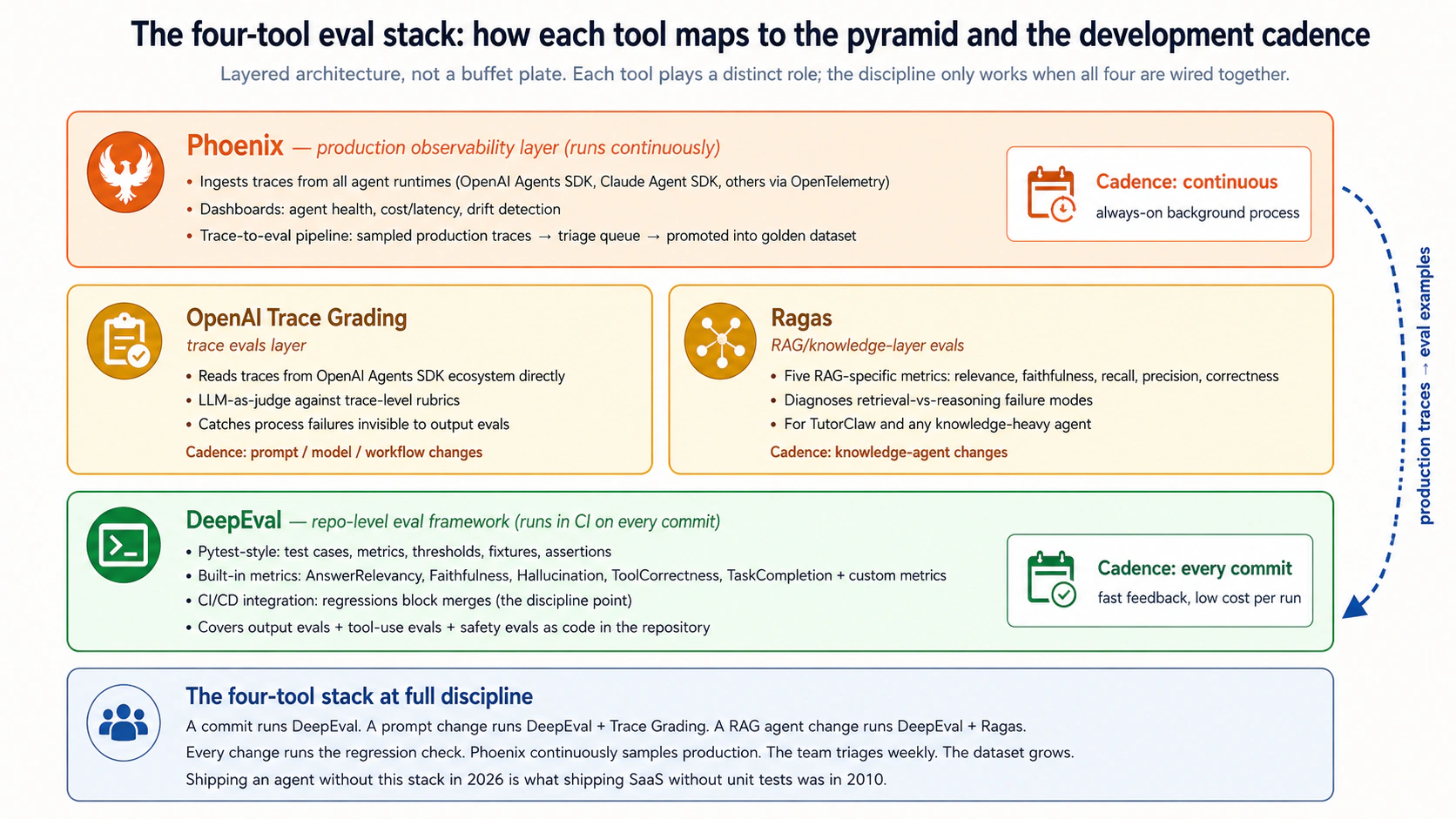
概念 8:Trace eval 层:Claude runtime 的 Phoenix evaluator 与 OpenAI runtime 的 OpenAI Agent Evals + Trace Grading
本段说明 trace grading、trace、Phoenix、Agent Evals、LLM-as-judge、生产环境、可观测性、agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace grading、trace、Agent Evals、CI/CD、agent、OpenAI 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 数据集、Agent Evals、agent、行为、工作流、模型 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace grading、trace、Agent Evals、agent、工具、OpenAI、模型 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 数据集、trace grading、trace、output eval、Agent Evals、回归、agent、模型 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集、trace grading、trace、Agent Evals、agent、工具、OpenAI、模型 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace grading、trace、agent、OpenAI、runtime、grader 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 trace grading、trace、agent、工具、安全、模型 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace grading、trace、Agent Evals、LLM-as-judge、agent、评分规则、Claude、提示词 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace grading、trace、agent、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、Agent Evals、agent、模型 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 Agent Evals、agent、模型 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 DeepEval、CI/CD、OpenAI 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、trace、RAG、Ragas、agent、OpenAI、指标、检索 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace grading、trace、OpenAI Agent Evals、Agent Evals、agent、OpenTelemetry、Claude、OpenAI 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 trace grading、trace、工具使用、RAG、Phoenix、DeepEval、OpenAI Agent Evals、Agent Evals 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
| 层 | 路径 A:Claude Managed Agents(本实验主路径) | 路径 B:OpenAI Agents SDK |
|---|---|---|
| trace:说明关键作用、失败模式和对应处理方式 | Phoenix:说明关键作用、失败模式和对应处理方式 | trace grading、trace、OpenAI:说明关键作用、失败模式和对应处理方式(/v1/evals) |
| 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | trace、Phoenix、OpenTelemetry、Claude:说明关键作用、失败模式和对应处理方式 | trace、OpenAI:说明关键作用、失败模式和对应处理方式 |
| Output eval | DeepEval、CI/CD:说明关键作用、失败模式和对应处理方式 | DeepEval:说明关键作用、失败模式和对应处理方式 |
| 工具使用、工具:说明关键作用、失败模式和对应处理方式 | DeepEval、工具、指标:说明关键作用、失败模式和对应处理方式 | DeepEval:说明关键作用、失败模式和对应处理方式 |
| RAG eval | RAG、Ragas、指标:说明关键作用、失败模式和对应处理方式 | RAG、Ragas:说明关键作用、失败模式和对应处理方式 |
| 生产可观测性 | trace、Phoenix、漂移:说明关键作用、失败模式和对应处理方式 | Phoenix:说明关键作用、失败模式和对应处理方式 |
本段说明 trace、Phoenix、agent、OpenTelemetry、Claude、OpenAI、runtime 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、RAG、Ragas、Phoenix、DeepEval、LLM-as-judge、生产环境、可观测性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、agent、Claude、OpenAI 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 output eval、DeepEval、agent、Claude、OpenAI 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 工具使用、DeepEval、agent、工具、runtime 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace、runtime 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、trace grading、trace、OpenAI Agent Evals、Agent Evals、agent、工具、OpenAI 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace、Phoenix、agent、OpenTelemetry、OpenAI、runtime 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 RAG、Ragas、agent、Claude、OpenAI、runtime 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 DeepEval、安全、runtime 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 Phoenix、生产环境、可观测性、runtime 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 trace grading、trace、Phoenix、OpenAI Agent Evals、Agent Evals、agent、评分规则、OpenAI 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、Phoenix、DeepEval、agent、Maya、Claudia、OpenClaw、OpenTelemetry 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、agent、Claude、OpenAI、runtime、第三课、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
这里强调 Claude:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 数据集、trace grading、trace、OpenAI Agent Evals、Agent Evals、agent、工具、评分规则:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 trace、agent:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 数据集、trace grading、trace、工具使用、RAG、Ragas、Phoenix、DeepEval:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
概念 9:DeepEval 作为仓库级评测框架
本段说明 trace grading、trace、DeepEval、CI/CD、行为、OpenAI、工作流 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 DeepEval、agent、行为、指标、阈值 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 DeepEval、agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
from deepeval import assert_test
from deepeval.test_case import LLMTestCase
from deepeval.metrics import AnswerRelevancyMetric, HallucinationMetric
def test_customer_billing_dispute_refund():
# The input: a realistic customer-facing task
task = "I see a duplicate charge of $89 on my November 12 statement. Can you refund the duplicate?"
# The agent's actual output (from a run captured in CI)
actual_output = run_tier1_support_agent(task=task, customer_id="C-3421")
# The expected behavior (from the golden dataset)
expected = "The agent should acknowledge the dispute, verify the customer's account, " \
"confirm the duplicate charge exists, and issue a single refund of $89."
# The test case
test_case = LLMTestCase(
input=task,
actual_output=actual_output.response,
expected_output=expected,
context=[actual_output.customer_context, actual_output.charge_history],
)
# Metrics with pass thresholds
relevancy = AnswerRelevancyMetric(threshold=0.7)
hallucination = HallucinationMetric(threshold=0.3) # max acceptable hallucination
assert_test(test_case, [relevancy, hallucination])
本段说明 agent、行为、模型、指标、阈值 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。 保留的技术标识:run_tier1_support_agent、customer_id、assert_test、assert result == expected。
本段说明 DeepEval 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 指标 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 RAG、agent、faithfulness、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 幻觉 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 检索、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 agent、工具 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 评分规则、grader、阈值 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 DeepEval、提示词、grader、指标、阈值、第七课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 DeepEval、CI/CD、TDD、agent、行为、提示词、grader 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。 保留的技术标识:deepeval test run、pytest。
本段说明 DeepEval、工具 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 trace grading、trace、工具使用、DeepEval、agent、工具、OpenAI、提示词 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 RAG、Ragas、DeepEval、agent、工具、TutorClaw、指标 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、Phoenix、DeepEval、生产环境、可观测性、agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 DeepEval、工作流、提示词、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
这里强调 Claude:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 DeepEval、agent、工具、评分规则、Maya、envelope、grader、指标:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 golden dataset、数据集、DeepEval、agent、行为、envelope、指标、幻觉:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 trace grading、trace、RAG、Ragas、Phoenix、DeepEval、OpenAI Agent Evals、Agent Evals:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
概念 10:Ragas 覆盖知识层,Phoenix 覆盖生产可观测性
本段说明 RAG、Ragas、Phoenix、生产环境、可观测性、EDD、agent、工具 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 RAG、Ragas 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 RAG、Ragas、生产环境、agent、指标、检索 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 RAG、agent、指标 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
| 指标 | 衡量内容 | 捕获的失败模式 |
|---|---|---|
| 上下文:说明关键作用、失败模式和对应处理方式 | 上下文:说明关键作用、失败模式和对应处理方式 | 检索:说明关键作用、失败模式和对应处理方式 |
| faithfulness:说明关键作用、失败模式和对应处理方式 | 上下文:说明关键作用、失败模式和对应处理方式 | agent、上下文:说明关键作用、失败模式和对应处理方式 |
| 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | agent:说明关键作用、失败模式和对应处理方式 | 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 |
| 上下文:说明关键作用、失败模式和对应处理方式 | 上下文:说明关键作用、失败模式和对应处理方式 | 检索:说明关键作用、失败模式和对应处理方式 |
| 上下文:说明关键作用、失败模式和对应处理方式 | 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | 检索:说明关键作用、失败模式和对应处理方式 |
本段说明 agent、指标、检索、faithfulness、上下文 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、RAG、Ragas、DeepEval、生产环境、agent、工作流、runtime 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 RAG、Ragas、DeepEval、OpenAI Agent Evals、Agent Evals、生产环境、agent、行为 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 Phoenix、生产环境、可观测性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集、trace grading、trace、RAG、Ragas、Phoenix、DeepEval、生产环境 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 Phoenix 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 trace、Phoenix、生产环境、agent、OpenAI、runtime 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、Phoenix、回归、生产环境、EDD、agent、行为、模型 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、trace、Phoenix、生产环境、工具 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 trace、Phoenix 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 Phoenix 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 数据集、Phoenix、agent、Maya、TutorClaw、招聘 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 Phoenix 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 RAG、Phoenix、生产环境、模型 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 Phoenix 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 Phoenix 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 Phoenix、工作流 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 trace、Phoenix、OpenTelemetry、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 Phoenix、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 工具 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 trace grading、trace、OpenAI Agent Evals、Agent Evals、agent、OpenAI 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 DeepEval、CI/CD、工作流 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 RAG、Ragas、agent、检索 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace、Phoenix、生产环境、可观测性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 trace grading、trace、工具使用、RAG、Ragas、Phoenix、DeepEval、OpenAI Agent Evals 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
这里强调 trace grading、trace、RAG、Ragas、Phoenix、DeepEval、生产环境、可观测性:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
第 4 部分:实验
本段说明 trace、工具使用、RAG、CI/CD、回归、生产环境、可观测性、工具 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
这里强调 agent、工具、Claude、提示词、模型、漂移:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:
CLAUDE.md、AGENTS.md。
这里强调 评测驱动开发、agent 行为、工程可靠性:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
- 这一项围绕 trace、CI/CD、生产环境、agent、Claudia 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace、生产环境、可观测性、评测驱动开发、agent、指标 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
这里强调 Paperclip:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 golden dataset、数据集、trace、agent、工具、runtime、第九课:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 trace、工具使用、RAG、Ragas、Phoenix、DeepEval、生产环境、可观测性:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 trace grading、trace、RAG、Ragas、Phoenix、DeepEval、OpenAI Agent Evals、Agent Evals:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 trace、RAG、Ragas、Phoenix、DeepEval、可观测性、agent、工具:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 Phoenix、agent、Maya、Claudia、Claude、OpenAI、runtime:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 评测驱动开发、agent 行为、工程可靠性:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
- 这一项围绕 RAG、Ragas、Phoenix、DeepEval、OpenAI Agent Evals、Agent Evals、LLM-as-judge、agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、trace、agent、工具、OpenTelemetry、Claude、OpenAI、runtime 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、trace、工具 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
实验设置:Decision 1 之前
本段说明 golden dataset、数据集、Phoenix、回归 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。 保留的技术标识:eval-driven-development-starter.zip、requirements.txt、golden.json。 参见 eval-driven-development-starter.zip。
本段说明 agent、工具、Claude、第八课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 Claude、第八课、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
1. 安装 Claude Code 或 OpenCode
# macOS / Linux / WSL — recommended (auto-updates)
curl -fsSL https://claude.ai/install.sh | bash
# Verify and update
claude update
claude --version
# All platforms — recommended
curl -fsSL https://opencode.ai/install | bash
# Verify and update
opencode upgrade
opencode --version
2. 在你的 agentic coding tool 中打开 base
git clone https://github.com/panaversity/agentfactory-manufacturing.git
cd agentfactory-manufacturing/eval-driven-development
git init # if you want your lab work tracked separately from the base
3. 配置四个评测框架的依赖
本段说明 agent、工具 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
python3 --version # Need 3.11+
pip install --version # Need recent
docker --version # Need recent; Phoenix runs containerized
4. base 已经给你什么,你仍然要做什么
base 已经包含 AGENTS.md、.mcp.json、.env.example、maya-stub.py 和 corpus/。现在你做三件事:
-
加入你的 key。 把
.env.example复制为.env,并填入 OpenAI 或 Anthropic key。cp .env.example .env
# then edit .env and paste your key -
让 agent 安装 skills 并确认 MCP。 Decision 1 prompt 会要求它安装相关 skills、检查
.mcp.json,并验证 Context7/Neon/Phoenix connectivity。如果你只走 simulated track,Neon 是 optional。 -
从 Decision prompts 构建其余部分。
evals/、golden.json、trace fixtures、RAG fixtures 和 Phoenix dataset 都是 course 中的 deliverables。它们会在 lab 过程中出现,而不是提前给出。
Decision 1:建立评测工作区并创建第一版 golden dataset
这里强调 golden dataset、数据集、trace grading、trace、RAG、Ragas、DeepEval、OpenAI Agent Evals:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:
evals/。
这里强调 数据集、Paperclip:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:
activity_log。
本段说明 数据集、生产环境、agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 agent、工具、Claude 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。 保留的技术标识:Shift+Tab、Tab、docs/plans/decision-1.md。
这里强调 golden dataset、数据集、agent、Maya:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
- 这一项围绕 RAG、Ragas、DeepEval、OpenAI 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
requirements.txt、deepeval、ragas、openai、pytest、python-dotenv、pytest-asyncio、pytest-xdist。- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
course-nine-lab/
├── datasets/
│ ├── golden.json (the load-bearing artifact)
│ └── README.md (dataset conventions documented)
├── evals/
│ ├── output/ (DeepEval test files for Concept 5 layer)
│ ├── tool_use/ (Concept 6, tool-use specific)
│ ├── trace/ (Concept 6 + 8, OpenAI Agent Evals trace-grading harness)
│ ├── rag/ (Concept 7 + 10, Ragas-based)
│ ├── safety/ (envelope/policy evals)
│ └── conftest.py (pytest fixtures: agent runners, dataset loader)
├── reports/
│ └── baseline.md (the score baseline for regression detection)
└── docs/
├── grader-rubrics.md
├── eval-pyramid.md
└── critical-metrics.md- 这一项围绕 golden dataset、数据集、agent、Maya 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
task_id。- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
category。- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
input。- 这一项围绕 上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
customer_context、customer_id、plan、tenure_months、prior_refunds_30d、account_status。- 这一项围绕 agent、行为 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
expected_behavior。- 这一项围绕 工具 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
expected_tools。- 这一项围绕 评分规则 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
expected_response_traits。- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
unacceptable_patterns。- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
difficulty。这里强调 工具使用、工具:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:
expected_tools。
这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
lookup_customer(customer_id)。这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
check_subscription_status(customer_id)。这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
process_refund(customer_id, amount, reason)。这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
check_refund_policy(plan, days_since_charge)。这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
search_kb(query)。这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
get_recent_charges(customer_id, days)。这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
update_account(customer_id, field, value)。这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
create_ticket(customer_id, category, priority, summary)。这一项围绕 agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
escalate_to_human(ticket_id, reason)。这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
send_email(customer_id, template_id, variables)。这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
run_diagnostic(customer_id, area)。这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
check_outage_status(region)。
- 这一项围绕 生产环境 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace、Paperclip 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
traces-fixtures/、activity_log。- 这一项围绕 数据集、agent、工具 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
scripts/validate-dataset.sh、expected_tools、input。- 这一项围绕 数据集 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
datasets/README.md。
这里强调 golden dataset、数据集:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 golden dataset、数据集、DeepEval、agent、Maya:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 生产环境:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
- 这一项围绕 模型、grader、阈值 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、agent、提示词、漂移 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、生产环境 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 LLM-as-judge、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
这里强调 trace:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
Decision 2:用 DeepEval 为 Tier-1 Support agent 做 output eval
这里强调 output eval、DeepEval、CI/CD、agent、指标、faithfulness、幻觉:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 数据集、trace、DeepEval、agent、模型、指标、阈值:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:
datasets/golden.json、traces-fixtures/decision-2-outputs/。这里强调 DeepEval、漂移:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 这里强调 DeepEval:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:
TaskCompletionMetric、GEval(name="TaskCompletion", criteria="...", evaluation_params=[...])、LLMTestCaseParams、SingleTurnParams、deepeval test run、pytest evals/output/、requirements.txt。 这里强调 评测驱动开发、agent 行为、工程可靠性:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。这里强调 数据集:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:
LLMTestCase。这里强调 评测驱动开发、agent 行为、工程可靠性:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 这里强调 评测驱动开发、agent 行为、工程可靠性:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 这里强调 数据集:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:
input、input。 这里强调 agent:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:actual_output。 这里强调 数据集、行为、评分规则:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:expected_output、expected_behavior。 这里强调 数据集、上下文:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:context、customer_context。 这里强调 RAG、agent、检索、上下文:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:retrieval_context。 这里强调 工具使用、agent、工具:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:tools_called。
本段说明 回归、EDD、agent、工具、提示词、模型 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 agent、工具、Claude 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。 保留的技术标识:Shift+Tab、Tab、docs/plans/decision-2.md。
这里强调 output eval、DeepEval、agent:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
- 这一项围绕 DeepEval 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
evals/output/test_tier1_support.py。- 这一项围绕 LLM-as-judge、agent、Claude、模型、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 指标、阈值 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 阈值 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
AnswerRelevancyMetric(threshold=0.7)。- 这一项围绕 阈值、faithfulness、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
FaithfulnessMetric(threshold=0.8)。- 这一项围绕 阈值、幻觉 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
HallucinationMetric(threshold=0.3)。- 这一项围绕 DeepEval、agent、评分规则 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
GEval(name="TaskCompletion", ...)、TaskCompletionMetric。- 这一项围绕 数据集 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
datasets/golden.json、LLMTestCase。- 这一项围绕 agent、指标、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
reports/baseline.md。- 这一项围绕 DeepEval、CI/CD、回归、agent、工作流、提示词 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
deepeval test run、evals/、prompts/。- 这一项围绕 回归、指标 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
docs/critical-metrics.md。
本段说明 DeepEval 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。 保留的技术标识:deepeval test run evals/output/test_tier1_support.py。
======================== DeepEval Test Run ========================
Test: test_refund_requests examples: 20 passed: 20 failed: 0
Test: test_account_inquiries examples: 10 passed: 10 failed: 0
Test: test_technical_issues examples: 8 passed: 7 failed: 1
Test: test_escalation_requests examples: 7 passed: 7 failed: 0
Test: test_policy_questions examples: 5 passed: 5 failed: 0
Failure detail (test_technical_issues, example tech_007):
AnswerRelevancy: 0.82 (threshold: 0.70) ✓
Faithfulness: 0.75 (threshold: 0.80) ✗ — agent claimed feature X exists; not in context
Hallucination: 0.35 (threshold: 0.30) ✗ — invented version number "v2.4.1" in response
TaskCompletion: 0.65 (threshold: 0.70) ✗ — did not specify next step
Grader rationale (Faithfulness): "The response references 'real-time
sync mode' as an available option, but the provided context describes
only batch sync. The claim is not supported by the retrieved policy
documentation."
OVERALL: 49/50 passed (98%). Regression check: 0 critical-metric
regressions vs baseline. ✓ Safe to merge.
本段说明 agent、提示词、grader、幻觉、上下文 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。 保留的技术标识:real-time sync mode、v2.4.1。
本段说明 trace、OpenAI Agent Evals、Agent Evals、agent、评分规则、OpenAI 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
{
"example_id": "refund_T1-S014",
"rubric": "tool_selection",
"score": 2,
"max_score": 5,
"rationale": "The agent's first tool call was refund_issue, but the
correct first action for this task is customer_lookup to verify
account context before issuing the refund. The agent reasoned: 'The
customer mentioned the charge so I'll process the refund directly'
— this skips the verification step the standing instruction in
docs/grader-rubrics.md requires.",
"trace_url": "https://platform.openai.com/traces/r-2026-05-13-014",
"metadata": {
"model": "gpt-4o-2024-08",
"grader": "claude-opus-4-7",
"graded_at": "2026-05-13T14:23:17Z"
}
}
本段说明 trace、DeepEval、行为、评分规则 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
这里强调 DeepEval、回归、TDD、agent、行为、工作流、指标:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
Decision 3:用 OpenAI Agent Evals 做 trace eval(含 trace grading)
这里强调 golden dataset、数据集、trace grading、trace、OpenAI Agent Evals、Agent Evals、agent、工具:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 数据集、trace、LLM-as-judge、agent、工具、评分规则、OpenAI、上下文:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:
traces-fixtures/decision-3-traces/、tools_called、retrieved_context、response、/v1/evals。这里强调 OpenAI:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 这里强调 数据集、trace grading、trace、output eval、Agent Evals、LLM-as-judge、agent、工具:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:
POST /v1/evals、POST /v1/evals/{id}/runs、/v1/evals、/v1/evals、{"item": {...}}、data_source、type: "jsonl"、source: {type: "file_id", id: "..."}、POST /v1/files、purpose=evals。 这里强调 评测驱动开发、agent 行为、工程可靠性:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
本段说明 trace、output eval、LLM-as-judge、评分规则、OpenAI 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。 保留的技术标识:/v1/evals。
本段说明 agent、工具 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。 保留的技术标识:docs/plans/decision-3.md。
这里强调 数据集、trace、agent、OpenAI:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
- 这一项围绕 golden dataset、数据集、trace、工具、OpenAI、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
POST /v1/files、purpose=evals、datasets/golden.json、{"item": {...}}、tools_called、retrieved_context、response、evals/openai/dataset-upload.md。- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
POST /v1/evals、data_source_config.item_schema、POST /v1/evals/{id}/runs、data_source: {type: "jsonl", source: {type: "file_id", id: <uploaded file>}}。- 这一项围绕 trace、LLM-as-judge、工具、评分规则、提示词、grader、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
tool_selection、reasoning_soundness、handoff_appropriateness、{{item.tools_called}}、{{item.retrieved_context}}、{{item.response}}。- 这一项围绕 行为、评分规则、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
{{item.expected_behavior}}。- 这一项围绕 golden dataset、数据集、评分规则、OpenAI、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
evals/openai/routing.yaml。- 这一项围绕 Claude、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
gpt-4.1-mini、gpt-4o-mini、gpt-4o。- 这一项围绕 数据集、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
GET /v1/evals/{id}/runs/{run_id}。- 这一项围绕 trace、RAG、评分规则、OpenAI 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 DeepEval、agent、工具、提示词、模型 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
POST /v1/evals/{id}/runs。- 这一项围绕 RAG、评分规则、工作流、模型 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
scripts/compare-models.sh。- 这一项围绕 trace grading、trace、评分规则、工作流 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
/v1/evals。
这里强调 数据集、trace grading、trace、Phoenix、回归、agent、评分规则、Claude:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:
/v1/evals。
这里强调 Phoenix、agent、Claude、OpenAI:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 数据集、trace grading、trace、Phoenix、LLM-as-judge、agent、工具、评分规则:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 参见 Phoenix Claude 集成文档。
这里强调 trace、Phoenix、Agent Evals、agent、OpenTelemetry、Claude、OpenAI、runtime:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
Decision 4:Tool-use 与安全评测(Claudia 的 envelope 检查)
这里强调 工具使用、工具、Claudia、envelope、第八课:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 trace、Claudia、OpenClaw、安全、envelope、提示词、grader、red-team:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:
traces-fixtures/decision-4-claudia-decisions/。
本段说明 生产环境、Claudia、Paperclip、安全、envelope、runtime、第八课、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。 保留的技术标识:docs/plans/decision-4.md。
这里强调 工具使用、工具、Claudia、安全:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
- 这一项围绕 数据集、Claudia、envelope 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
datasets/claudia-delegation.json。- 这一项围绕 工具使用、工具、Claudia、检索 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 DeepEval、Claudia、安全、envelope 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
EnvelopeRespectMetric。- 这一项围绕 Claudia、安全、第八课 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 安全 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
activity_log、governance_ledger。- 这一项围绕 回归、安全、指标 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
docs/critical-metrics.md。- 这一项围绕 Maya、安全、envelope、提示词、模型、漂移、red-team 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
这里强调 工具使用、工具、Claudia、安全、envelope、runtime、第八课:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 工具使用、output eval、工具、Maya、Claudia、安全、envelope、第八课:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 Maya、Claudia:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 评测驱动开发、agent 行为、工程可靠性:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
- 这一项围绕 output eval 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace、Claudia 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 安全、envelope 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
这里强调 CI/CD、回归:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
Decision 5:在 TutorClaw 上用 Ragas 做 RAG eval
这里强调 golden dataset、数据集、RAG、Ragas、agent、TutorClaw、指标、检索:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 trace、RAG、Ragas、EDD、agent、TutorClaw、模型、指标:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:
traces-fixtures/agent-factory-book-vectors.qdrant.tar.gz。
本段说明 RAG、Ragas、agent、Maya、TutorClaw、指标、检索 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。 保留的技术标识:docs/plans/decision-5.md。
这里强调 RAG、Ragas、agent、TutorClaw:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
- 这一项围绕 RAG、Ragas、EDD、agent、TutorClaw、模型、检索、第四课 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
agents/tutorclaw/。- 这一项围绕 golden dataset、数据集、TutorClaw、检索、幻觉 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
datasets/tutorclaw-golden.json。- 这一项围绕 RAG、Ragas、LLM-as-judge、指标、faithfulness、上下文、漂移 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
ragas==0.4.3、requirements.txt。这里强调 RAG、Ragas、漂移:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 这里强调 数据集、RAG、Ragas、EDD、模型、指标、上下文:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:
ContextRelevance、context_relevance、nv_context_relevance、context_relevancy、question、answer、contexts、ground_truth、user_input、response、retrieved_contexts、reference、LangchainLLMWrapper、LangchainEmbeddingsWrapper、llm_factory、embedding_factory、max_workers、RunConfig(max_workers=4)。 这里强调 评测驱动开发、agent 行为、工程可靠性:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
- 这一项围绕 数据集、RAG、Ragas、TutorClaw 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 指标 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 RAG、Ragas、TutorClaw、指标、检索、faithfulness、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
context_recall = 0、context_precision = 0。- 这一项围绕 检索、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
context_recall、answer_correctness。- 这一项围绕 agent、提示词、faithfulness、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
context_recall、faithfulness。- 这一项围绕 EDD、模型、检索、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
context_precision。- 这一项围绕 行为、指标、检索 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
answer_correctness、reference、"I don't know."。- 这一项围绕 数据集、agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 RAG、Ragas、EDD、TutorClaw、提示词、模型 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 RAG、Ragas、生产环境 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
这里强调 RAG、Ragas、EDD、agent、Maya、TutorClaw、提示词、指标:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
Decision 6:Regression eval 与 CI/CD 接线
这里强调 CI/CD、工作流、指标:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 trace、回归、agent、工具、工作流:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:
traces-fixtures/decision-6-regression-injection.json。
本段说明 回归 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。 保留的技术标识:docs/plans/decision-6.md。
这里强调 CI/CD、回归:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
- 这一项围绕 回归、指标、阈值 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
reports/baseline.md、docs/critical-metrics.md。- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
scripts/run-all-evals.sh、reports/eval-{date}.md。- 这一项围绕 回归 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
scripts/check-regressions.py。- 这一项围绕 数据集、agent、工作流、提示词、runtime 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
agents/、prompts/、evals/、datasets/。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
pytest。- 这一项围绕 output eval、DeepEval 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace grading、trace、工具、提示词、模型 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 安全 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 RAG、Ragas、agent、TutorClaw 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 回归 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 工作流 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
reports/baseline-history.md。- 这一项围绕 LLM-as-judge 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 回归、工作流 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
这里强调 回归、指标:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 golden dataset、数据集、trace、工具使用、工具、Maya、Claudia、安全:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
Decision 7:用 Phoenix 建立生产可观测性
这里强调 数据集、trace、RAG、回归、生产环境、可观测性、提示词、grader:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 trace、Phoenix、生产环境、agent、OpenTelemetry、runtime、漂移:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 trace、Phoenix、生产环境、漂移:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:
traces-fixtures/production-week/。
本段说明 Phoenix、生产环境 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。 保留的技术标识:docs/plans/decision-7.md。
这里强调 trace、Phoenix、生产环境、可观测性:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
- 这一项围绕 trace、RAG、Phoenix、生产环境 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
pip install arize-phoenix、import phoenix as px; px.launch_app()、http://localhost:6006、/v1/traces、/graphql、arize-phoenix。相关 URL:http://localhost:6006。- 这一项围绕 trace、生产环境、agent、OpenTelemetry、Claude、OpenAI、runtime 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
http://localhost:6006/v1/traces、opentelemetry-exporter-otlp-proto-http、traces-fixtures/production-week/、generate_fixtures.py。相关 URL:http://localhost:6006/v1/traces。- 这一项围绕 trace、Phoenix 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 RAG、漂移 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、trace、RAG、生产环境、agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
production-samples/。- 这一项围绕 golden dataset、数据集、trace、生产环境、agent、行为、提示词、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 保留的技术标识:
scripts/promote-trace-to-eval.py。- 这一项围绕 golden dataset、数据集、trace、生产环境 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 Phoenix、工具 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
这里强调 golden dataset、数据集、trace、RAG、Phoenix、生产环境、可观测性、EDD:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 trace、Phoenix、生产环境、OpenTelemetry、工作流:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 数据集、trace、RAG、Phoenix、可观测性、agent、OpenTelemetry、runtime:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:
scripts/promote-trace-to-eval.py。这里强调 数据集、trace、Phoenix、指标:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
第 5 部分:诚实的前沿
本段说明 评测驱动开发、agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
概念 11:Golden dataset 构建:最被低估的工件
本段说明 golden dataset、数据集、工具 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集、agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 数据集、RAG、回归、生产环境、agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、RAG、回归、agent、envelope、上下文 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、行为、第九课 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、生产环境 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、agent、行为、工具 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 数据集 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 数据集、trace、生产环境、模型 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、生产环境、agent、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、RAG 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、trace、生产环境、agent、工具 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 回归、agent、阈值 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 数据集 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集、生产环境 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
这里强调 数据集、RAG、生产环境、agent:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 阈值 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
这里强调 数据集、生产环境、agent、阈值、漂移:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 golden dataset、数据集、RAG、生产环境、评测驱动开发、agent、阈值:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
概念 12:评测改进循环
本段说明 trace、TDD、EDD、agent、行为、工具、工作流、提示词 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
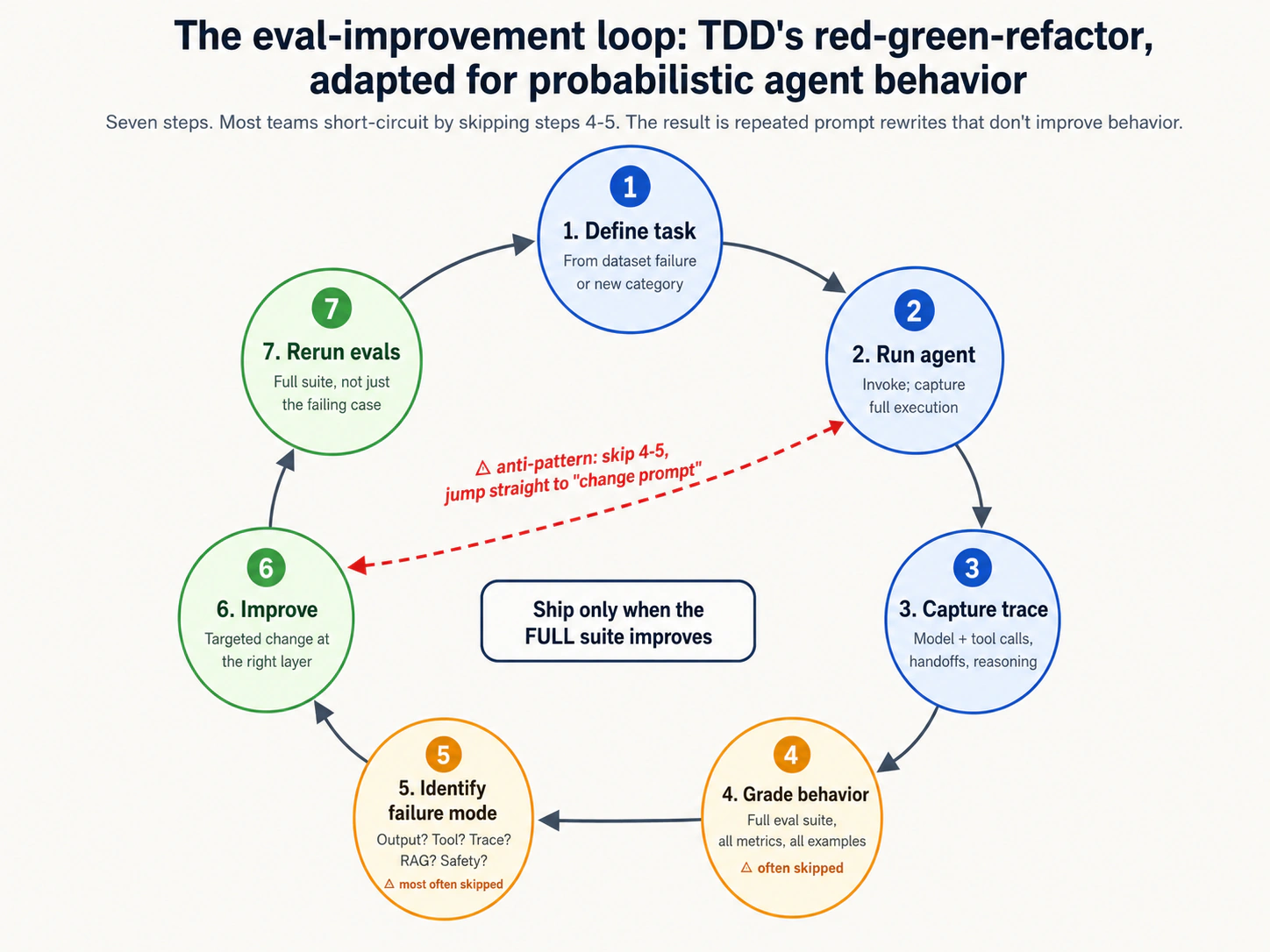
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 golden dataset、数据集、agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、agent、工具、OpenAI、模型 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 行为 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、工具使用、RAG、agent、工具、安全、envelope、提示词 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 工具、工作流、提示词 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 回归 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 回归、生产环境、行为、提示词 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 生产环境、agent、行为、工具、工作流、提示词、检索 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 RAG、LLM-as-judge 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 回归 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 golden dataset、数据集、阈值 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 TDD、agent、提示词 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 golden dataset、数据集、trace、生产环境、agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。 保留的技术标识:refund_request、difficulty=hard、failure_mode=customer_disambiguation。
本段说明 agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、agent、工具、OpenAI、模型 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。 保留的技术标识:customer_lookup(email="sarah@example.com")、result[0]、refund_issue(account_id=result[0].id, amount=$89)。
本段说明 trace、工具使用、output eval、生产环境、行为、工具 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。 保留的技术标识:account_id。
本段说明 RAG、agent、工具、工作流、提示词、模型、检索 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 RAG、agent、工具、提示词 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集、回归、agent、行为、提示词 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、output eval、生产环境、EDD 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
这里强调 数据集、trace、TDD、EDD、agent、行为、提示词:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
概念 13:生产可观测性与 trace-to-eval 流水线
本段说明 Phoenix、可观测性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、生产环境、agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
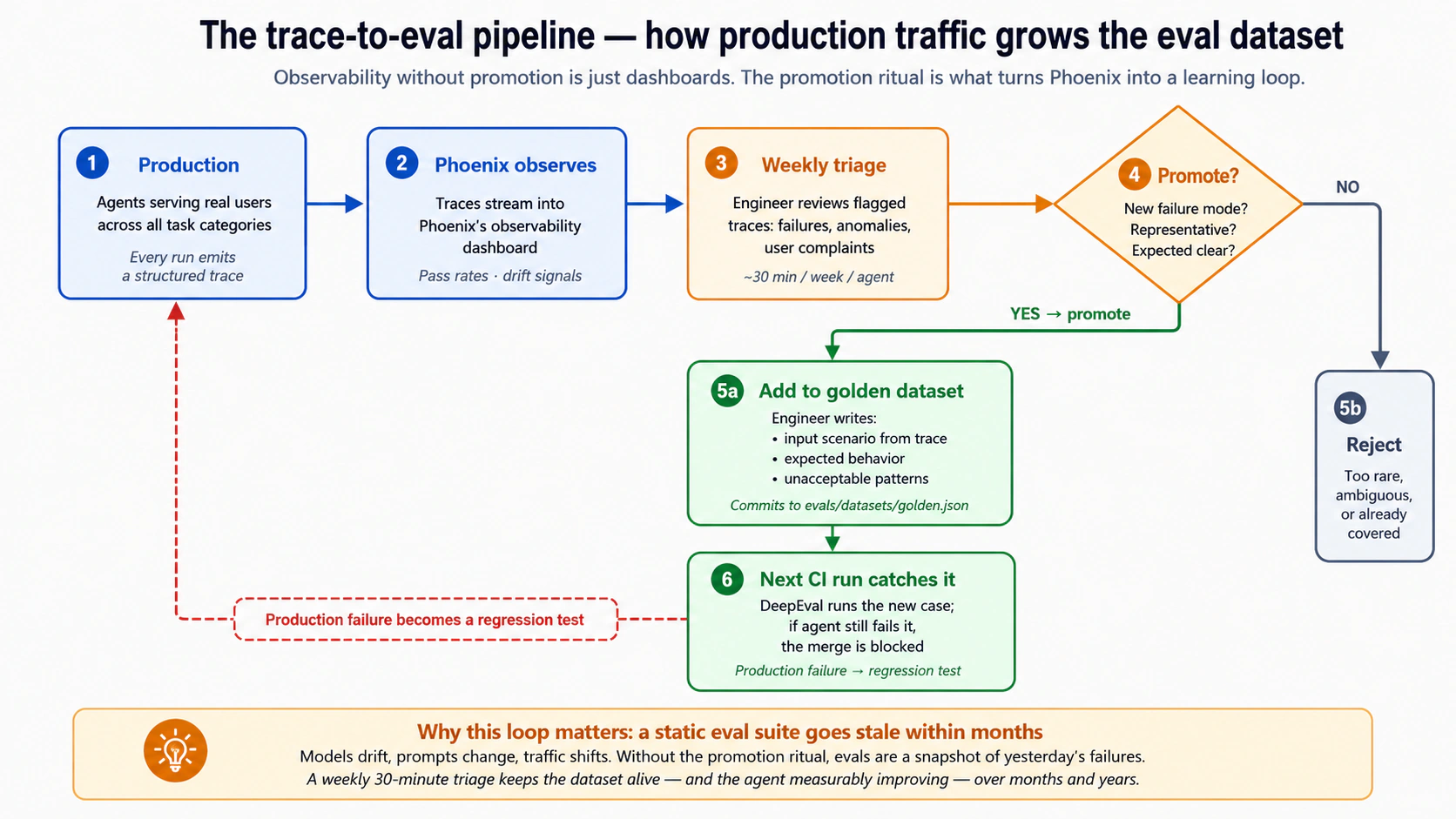
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、Phoenix、生产环境 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 trace、agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace、agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace、agent、Claudia、阈值、第八课 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace、agent、Claudia、安全、envelope 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace、RAG 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 trace 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 golden dataset、数据集、生产环境、行为、工具、上下文 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 agent、阈值、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集、trace、Phoenix、生产环境、可观测性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集、trace、生产环境、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 漂移 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、生产环境、可观测性、TDD、EDD、漂移 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集、trace、Phoenix、回归、agent、行为、模型、漂移 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集、Phoenix、生产环境 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
这里强调 golden dataset、数据集、trace、Phoenix、生产环境:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
这里强调 trace、Phoenix、生产环境、工具:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 golden dataset、数据集、trace、Phoenix、生产环境、可观测性、工具、envelope:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
概念 14:Eval 无法衡量什么
本段说明 agent、前沿、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集、agent、行为 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集、回归、行为、模型、漂移 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 agent、安全、envelope 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 工具使用、agent、工具 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集、RAG、生产环境、agent、行为、前沿 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集、agent、Maya、对齐 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 LLM-as-judge、agent、grader 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集、生产环境、可观测性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集、agent、行为、grader、漂移、前沿 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集、EDD、agent、行为、提示词、red-team 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 生产环境、EDD、agent、red-team 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、trace、RAG、生产环境 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 生产环境 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
这里强调 golden dataset、数据集、评测驱动开发、工具:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
- 这一项围绕 agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 数据集、agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 提示词 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
这里强调 数据集、trace、生产环境、EDD、grader、前沿、red-team:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 工具使用、RAG、生产环境、EDD、agent、行为、工具、安全:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
不要做的五件事:会破坏这门纪律的反模式
本段说明 EDD 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、工具使用、output eval、生产环境、agent、工具、安全 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 LLM-as-judge、生产环境、grader、faithfulness、前沿 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集、trace、生产环境、agent、行为 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、Phoenix、回归、生产环境、可观测性、评分规则、漂移 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集、CI/CD、生产环境、可观测性、评测驱动开发、EDD、工具、提示词 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 生产环境、EDD 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
第 6 部分:结语
本段说明 agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
概念 15:Eval-driven development 作为基础工程纪律,以及之后会发生什么
本段说明 trace、生产环境、agent、第 3 到第 9 课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、RAG、生产环境、agent、行为、envelope、招聘 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 回归、TDD、测试驱动开发、评测驱动开发、EDD、agent、行为、工具 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 评测驱动开发、前沿、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集、trace、生产环境、EDD、agent、行为、评分规则、模型 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 数据集、LLM-as-judge、grader、faithfulness、前沿 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 评测驱动开发、EDD、评分规则、模型、指标、前沿、对齐、red-team 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、agent、行为、Claudia、招聘、上下文、前沿、第六课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 trace、RAG、Ragas、Phoenix、DeepEval、可观测性、agent、OpenTelemetry 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 RAG、Ragas、Phoenix、DeepEval、生产环境、EDD、agent、OpenAI 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
本段说明 生产环境、测试驱动开发、评测驱动开发、agent、行为、第九课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
这里强调 生产环境、测试驱动开发、评测驱动开发、agent、runtime、指标、前沿、对齐:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
跨课程小结:每个部分在哪里被评测
| 课程 | 构建的 primitive | 第九课评测覆盖 |
|---|---|---|
| 3 | agent:说明关键作用、失败模式和对应处理方式 | trace、output eval:说明关键作用、失败模式和对应处理方式 |
| 4 | 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | RAG、faithfulness:说明关键作用、失败模式和对应处理方式 |
| 5 | envelope:说明关键作用、失败模式和对应处理方式 | 回归、agent、行为:说明关键作用、失败模式和对应处理方式 |
| 6 | 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | 工具使用、工具、安全:说明关键作用、失败模式和对应处理方式 |
| 7 | 招聘:说明关键作用、失败模式和对应处理方式 | 第七课、第九课:说明关键作用、失败模式和对应处理方式 |
| 8 | 评测驱动开发、agent 行为、工程可靠性:说明关键作用、失败模式和对应处理方式 | trace、Claudia、安全、envelope:说明关键作用、失败模式和对应处理方式 |
读者接下来可以做什么
本段说明 第 3 到第 9 课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 模型 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 评测驱动开发 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 评测驱动开发、agent 行为、工程可靠性 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 生产环境、agent 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 RAG、agent、指标、前沿、对齐 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 RAG、Ragas、Phoenix、DeepEval、生产环境、TDD、EDD、工具 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
这里强调 Claude:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 生产环境、评测驱动开发、agent、Maya、第九课:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 golden dataset、数据集、生产环境、agent、行为、工具、上下文:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 回归、agent:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 DeepEval、agent、指标、阈值:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。 保留的技术标识:
GEval、pytest、deepeval test run。这里强调 Maya:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
这里强调 数据集、CI/CD、生产环境、agent、第九课:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
参考资料
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
这里强调 RAG、LLM-as-judge、TDD、EDD、工具、第九课:不要把能运行误认为可信,要把任务、路径、工具调用、trace、评分规则和生产反馈都纳入同一套可复查的工程纪律。
本段说明 agent 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 agent、模型 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 第三课 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 工具 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 数据集、OpenAI Agent Evals、Agent Evals、agent、OpenAI、工作流、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 相关 URL:https://developers.openai.com/api/docs/guides/agent-evals.、https://platform.openai.com/docs/guides/evals.、https://github.com/openai/evals。
- 这一项围绕 trace grading、trace、Agent Evals、agent、OpenAI 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 相关 URL:https://developers.openai.com/api/docs/guides/trace-grading.。
- 这一项围绕 trace、DeepEval、agent、OpenAI、指标 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 相关 URL:https://github.com/confident-ai/deepeval;、https://deepeval.com/docs/;、https://deepeval.com/docs/metrics-introduction.。
- 这一项围绕 RAG、Ragas、agent、工具、指标、检索 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 相关 URL:https://docs.ragas.io;、https://docs.ragas.io/en/stable/concepts/metrics/available_metrics/;。
- 这一项围绕 trace、Phoenix、生产环境、可观测性、agent、OpenAI 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 相关 URL:https://github.com/Arize-ai/phoenix;、https://docs.arize.com/phoenix;、https://arize.com/docs/phoenix/integrations/llm-providers/openai/openai-agents-sdk-tracing;、https://github.com/Arize-ai/openinference。
- 这一项围绕 Phoenix 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 相关 URL:https://www.braintrust.dev;、https://www.braintrust.dev/docs。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 TDD、测试驱动开发、EDD、agent、行为 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 LLM-as-judge、grader 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 RAG、Ragas、检索、faithfulness、第四课 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 trace grading、trace、Phoenix、可观测性、agent、OpenTelemetry、OpenAI 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 agent、OpenAI 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 相关 URL:https://openai.com/blog。
- 这一项围绕 agent、Claude 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 相关 URL:https://www.anthropic.com/research。
- 这一项围绕 Phoenix 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 相关 URL:https://arize.com/blog。
- 这一项围绕 DeepEval、评测驱动开发 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。 相关 URL:https://www.confident-ai.com/blog。
- 这一项围绕 前沿 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 评测驱动开发、agent 行为、工程可靠性 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。
- 这一项围绕 EDD、red-team 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 EDD、模型 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
- 这一项围绕 CI/CD 展开,强调具体条件、边界和可验证结果:团队要先明确期望行为,再用相应的评测层检查是否发生回归,并把发现写回数据集和工作流。
本段说明 生产环境、agent、第九课、第 3 到第 8 课 的作用、边界和落地方式。核心意思是:传统测试仍然必要,但 agent 的可靠性还必须通过行为评测、trace 诊断、数据集治理、回归检查和生产反馈来持续验证;只有这样,团队才能知道一次 prompt、工具、模型或 workflow 改动到底改善了什么、又是否破坏了别处。