构建数字 FTE:一门 4 小时速成课
十五个概念加一次完整构建:Skills、系统记录,以及把它们连起来的 MCP。
上一门课,你构建了一个 agent。这门课,你迈出从 agent 到 AI Worker 的第一步实质性进展。(这是 Mode 2,制造业路线 的第二门课,七步中的第二步。)那个 agent,来自 构建 AI Agent,是一个流式聊天 agent,带会话、护栏和追踪,跑在一个沙箱上用作计算。它能用。但它在你关掉终端的那一刻就把一切都忘了,而且它拥有的每个工具都写死在它的 Python 里。
只想先看它跑起来? 直接跳到下面的 15 分钟快速见效。你会创建一个真实的数据库和一个会写入它并能记住内容的小 Worker,然后再回来看那些解释它为什么是这个形态的概念。
一个 AI Worker 就是同一个聊天 agent,长大成熟后的样子。人们也叫它 AI Employee 或 数字 FTE:同一样东西,名字取决于你怎么构建它、它加入谁、以及它的成本。这门课构建它的 底座:一个你能继续成长、能记忆、且归你所有的 agent。一名完整的 Worker 还能全天候运行、自主行动、并能在任何 app 上找到你,但那是后话。上一门课里的 SDK 和 SandboxAgent 运行时保持不变;变的是它们周围的一切。
完成这个转变需要两步动作,外加把它们连起来的那根线:
- 它的 能力 变成 Skills:一个个小文件夹,agent 自己去发现并加载,而不是把工具写死在它的 Python 里。
- 那些它一重启就忘记的东西,迁入 Postgres,它的 系统记录:Worker 运行时所依据的那个唯一权威存储,企业赖以运转的真相源,就像 CRM 或一本总账。其中存放几类数据:
- 业务记录:运营层面的真相。客户、工单、订单。你查询并更新它们。
- 参考库:它按语义检索的知识。政策库、参考文档、过往案例。
- 状态:当前工作此刻的样子。哪些对话开着,哪些在等待审批。
- 轨迹:它做过什么的记录,好让公司能回放并信任它的行为。
- MCP(模型上下文协议,Model Context Protocol) 是连接 agent 与外部工具和数据的开放标准。在这里,它就是 agent 用来够到那个存储的 线。

语义召回 是人们最容易贴错标签的那一块。它指的是按意义查找,而不是按精确字词查找。它是一种 检索方式,而不是一个独立的存储:你可以在参考库上跑它、在过往对话上跑它、或者直接在业务记录本身上跑它。它来自 一名运行中的 Worker 有两个在生产中分开部署的部分。harness 是 agent 的运行时:SDK 循环本身。compute 是 agent 代码实际运行的那个 沙箱;当 agent 调用一个工具时,它把代码交给那个沙箱。这门课里两者都跑在本地。 查看完整演示 — 构建数字 FTE 底座 论点 提出了每个生产级 agent 系统都必须满足的七项不变量(Seven Invariants)。上一门课构建了 引擎(不变量 4):跑在沙箱上的 OpenAI Agents SDK。这门课增加 不变量 5:每名 Worker 都运行在一个系统记录之上。 引擎是 Worker 运行所 依托 的东西;系统记录是它运行所 依据 的东西。 两个开放标准让这一切保持可移植。Skills(最初来自 Anthropic,如今已是全生态范围,见 agentskills.io)让能力能在工具之间流转。MCP 是 agent 用来够到记录的标准线;上一门课里一个都没有,而它是这里关键的新模式。记录本身是 Neon Postgres + pgvector,之所以选它,是因为它起步免费、闲置时缩容到零、并且自带一个官方 MCP 服务器。产品是可替换的;替换指南 列出了备选项。pgvector,后者为 Postgres 增加了按意义检索的能力。一名 Worker 如何运行:harness 与 compute(这里两者你都不部署)
UnixLocalSandboxClient 把沙箱跑在你的机器上(零基础设施,一个 API key),而你可以用一行修改把它指向 Docker、Cloudflare、E2B 或 Modal(Part 5 的替换指南)。把 harness 本身作为常驻云服务来部署是它自己的一门课,把你的 Agent Harness 部署到云端。这门课在 Agent Factory 论点中的位置
📚 教学辅助
这十五个概念分布在三层:Skills、系统记录和 MCP。下面这张表就是整张地图。十五个概念一览(展开看完整地图)
# 概念 层 它回答什么问题 1 Agent Skill 是什么 Skills 可复用的能力住在哪里?住在一个文件夹里,带一个 SKILL.md 加上可选的 scripts/references。2 渐进式披露 Skills 为什么把 skills 随身带着很便宜?发现 → 激活 → 执行,只在需要时加载所需的内容。 3 编写一个 SKILL.md Skills 一个 skill 文件实际包含什么?元数据、触发描述、操作指令。 4 Skill 打包约定 Skills skills 如何在工具之间流转?同一个文件夹在 Claude Code、OpenCode 以及任何合规客户端里都能用。 5 组合 skills Skills 何时通过文件系统交接把多个小 skill 串起来,何时写一个大 skill。 6 为什么用托管 Postgres 系统记录 什么样的存储配得上「系统记录」?一个具备持久化、分支、治理,以及 agent 所需向量原语的存储。 7 Worker 的 schema 系统记录 一个 agent 实际需要哪些表?conversations、documents、embeddings、audit log、capability invocations,加上 SDK Session 用于存放回合。 8 pgvector 基础 系统记录 语义检索在 Postgres 里如何工作?embedding 列、距离运算符、索引类型。 9 embedding 流水线 系统记录 文本如何变成可查询的向量?切块、embedding 模型、何时重新 embedding。 10 审计轨迹作为纪律 系统记录 对一名 Worker 来说「读和写」意味着什么?Worker 采取的每个行动都留下一条公司能回放的轨迹。 11 MCP 是什么、不是什么 MCP 一个面向工具、资源和提示词的协议:不是框架,不是服务。 12 Neon MCP 服务器 MCP agent 通往它数据库的接口:它暴露什么,如何认证。 13 把 MCP 接到 Agents SDK MCP SDK 的 MCP 集成:如何注册一个服务器、模型看到什么、信任边界在哪里。 14 自定义 MCP 服务器 MCP 何时写自己的服务器,何时只用 @function_tool。决策树。15 负载下的 MCP MCP 传输选择、连接池、何时排队。
有了这张映射表,剩下的多半就是机械活了。生产中的一次故障可以追溯到其中之一:一个从未被发现的 Skill(描述太含糊)、两名 Worker 各执一词的系统记录(schema 竞态),或一根丢事件的 MCP 线(为该工作负载选错了传输)。诊断会告诉你是哪一种。
这门课适合谁
中级。你应当具备:
- 最好做过 构建 AI Agent,不过即便你跳过了,你的 agent 也能在 base 上脚手架出它的最终形态。
- 来自 Agentic 编程速成课 的 Plan 模式与规则文件习惯。
- 至少完成过一个 PRIMM-AI+ 循环。
这是一门 Python 优先 的续作:你不会手敲 Python 或 SQL,而是你的 agent 写代码、你来掌舵,而且 Part 2 和 Part 3 会更密集(Pydantic 模型、asyncpg 连接池、一个小型自定义 MCP 服务器),所以那两部分要预期更多来回。 数据库把信息保存在 表(tables) 里。把它想象成一张电子表格:每一 行(row) 是一样东西(一位客户、一张支持工单),每一 列(column) 是关于它的一个细节(一个名字、一个日期、一个状态)。这就是你在这里需要的全部心智模型。你从不亲自写数据库代码;你的 agent 写,而这两个词只是帮你读懂它构建出来的东西。 这门课用到的五个词,会当你已经懂它们一样:对数据库不熟?60 秒版本
截至 2026 年 5 月为最新,已对照 openai-agents 0.17.x、mcp SDK、Neon 的 MCP 文档以及 pgvector 0.8+ 核验。一旦你开始构建,就把版本钉死;如果文档与本页出现分歧,以 Cloudflare Sandbox 教程 和 Neon 文档 为准。
你来指挥,agent 来构建,而且因为 base 自带一个它在打开时就读取的 AGENTS.md,你的提示词可以保持简短:只要说接下来构建什么就行。
15 分钟快速见效:先成功一次,再研究它为什么成
在你读那解释 为什么 这套架构能成的 15 个概念之前,先构建它能真正跑起来的最小版本。读完时你将拥有:
- 一个全新的 Neon 项目,里面有两张表
notes和audit_log,是你通过 MCP 创建并在控制台里亲眼看到的, - 一个最小的 AI Worker,它通过自己的
save_note工具在一次事务里同时写入两张表, - 以及对「一个系统记录到底为我做了什么?」这个问题的一个实打实的答案:你的笔记和它的审计行,共享同一个 id。
这一整套就是一屏的提示词:你的编程 agent 通过 Neon MCP 构建存储,然后脚手架出一个写入它的小 Worker,而你看着这个 Worker 记住内容。完整的 Worker(八个决策、一个五表 schema)在 Part 4。如果你只有一次坐下来的工夫,就做这个,然后再回来看概念。
这里贯穿着两个平面,把它们分清楚就是整个心智模型。你的 编程 agent(Claude Code 或 OpenCode)用 Neon MCP 去 构建并检视 数据库。你构建的 Worker 用 它自己的工具 在运行时写入它。Worker 从不碰 Neon MCP,而 Neon 自己的文档对原因说得很直白:MCP 服务器是「仅供开发和测试」,绝不接进一个运行中的 app。

拿到 base 并打开它
下载 base 并在你的通用 agent 里打开这个文件夹。agent 会按照下面紧接着的提示词自己完成搭建。你只需搭建 一次:digital-fte/ 是你整门课的文件夹,快速见效和 Part 4 都用它。每次构建都各自开通一个全新的 Neon 项目(一个数据库),但你永远不必重新下载或重新解压。
cd digital-fte
claude
cd digital-fte
opencode
这个 base 假设你有一个有能力的通用 agent(Claude Code,或运行 Claude Sonnet/Opus、GPT-5 或类似模型的 OpenCode)。更小的模型会在构建提示词上跑偏;如果它的第一份计划看起来含糊而不是具体,就在继续之前换一个更强的。
准备 base(约 3 分钟)
base 自带规则和接线;skills 和你的 key 接下来加上。让你的 agent 自己搭好自己。粘贴这段:
读 AGENTS.md,然后把这个 base 准备好:为你所属的那种 agent 安装它列出的 skills,替我把
.env.example复制为.env,并明确告诉我你需要我提供什么,才能让 Neon 和 Context7 这两个 MCP 服务器上线。
留意: agent 安装 skill-creator、mcp-builder 和 neon-postgres(你会看到安装在跑),创建 .env,然后向你要两样东西:你要粘进 .env 的 OPENAI_API_KEY,以及一次浏览器点击以通过 OAuth 授权 Neon。Neon 是免费的;如果你还没有账号,在 neon.com 大约一分钟就能注册,或者直接在授权界面创建一个。当安装和接线都完成时,agent 会让你重启它(退出再重启),好让新的 skills 和 MCP 服务器加载;两者都不会在会话中途加载。
完成标志: skills 已安装,.env 里存着你的 key,Neon 已授权,且你已重启 agent,使新的 skills 和 MCP 服务器生效。
这道关卡:确认 agent 能够到数据库(约 1 分钟)
这门课唯一真正新增的东西,是 agent 通过 MCP 够到一个真实的系统记录。所以在你构建任何东西之前,先确认那条边界是通的。粘贴这段:
列出你能看到的 Neon 工具。
留意: 一份真实的 Neon 工具名清单(创建项目、运行 SQL、描述表,等等)。那份清单就是 agent 搭在数据库上的手,下面的一切都依赖它。
关卡通过: 回复里列出了真实的 Neon 工具名。如果没有: 你几乎肯定跳过了重启,所以工具还没加载。退出、重启、再问一次。还是没有?那是 Neon 的 OAuth 没走完:重做一遍再试。
构建存储,并取到它的连接串(约 3 分钟)
让你的编程 agent 通过 Neon MCP 创建数据库,然后把你的 Worker 稍后够到它所需的那一样东西交给它:一个连接串。
把这段粘给你的通用 agent。 先做计划;获批后再执行。
在一个全新的 Neon 项目上,创建两张表:
notes(笔记文本)和audit_log(发生了什么的记录)。然后调用get_connection_string,把那个 URL 写进我的.env作为DATABASE_URL。全程使用 Neon 工具;别写 SQL 让我去跑。
留意: agent 调用 Neon MCP 工具 来创建项目和这两张表(你看到的是那些工具调用,而不是你敲的 SQL),然后把 DATABASE_URL 写进 .env。那个串就是交接物:Neon MCP 开通了存储,而你的 Worker 将用这个串,而不是 MCP 服务器。
完成标志: 存在一个全新的 Neon 项目,带一张 notes 表和一张 audit_log 表,且 .env 里存着一个 DATABASE_URL。
亲眼看一看(约 1 分钟)
在任何代码运行之前,先在 Neon 控制台里看看这两张空表。这是「它真的在那儿」的时刻,代价不过是一个浏览器标签页。
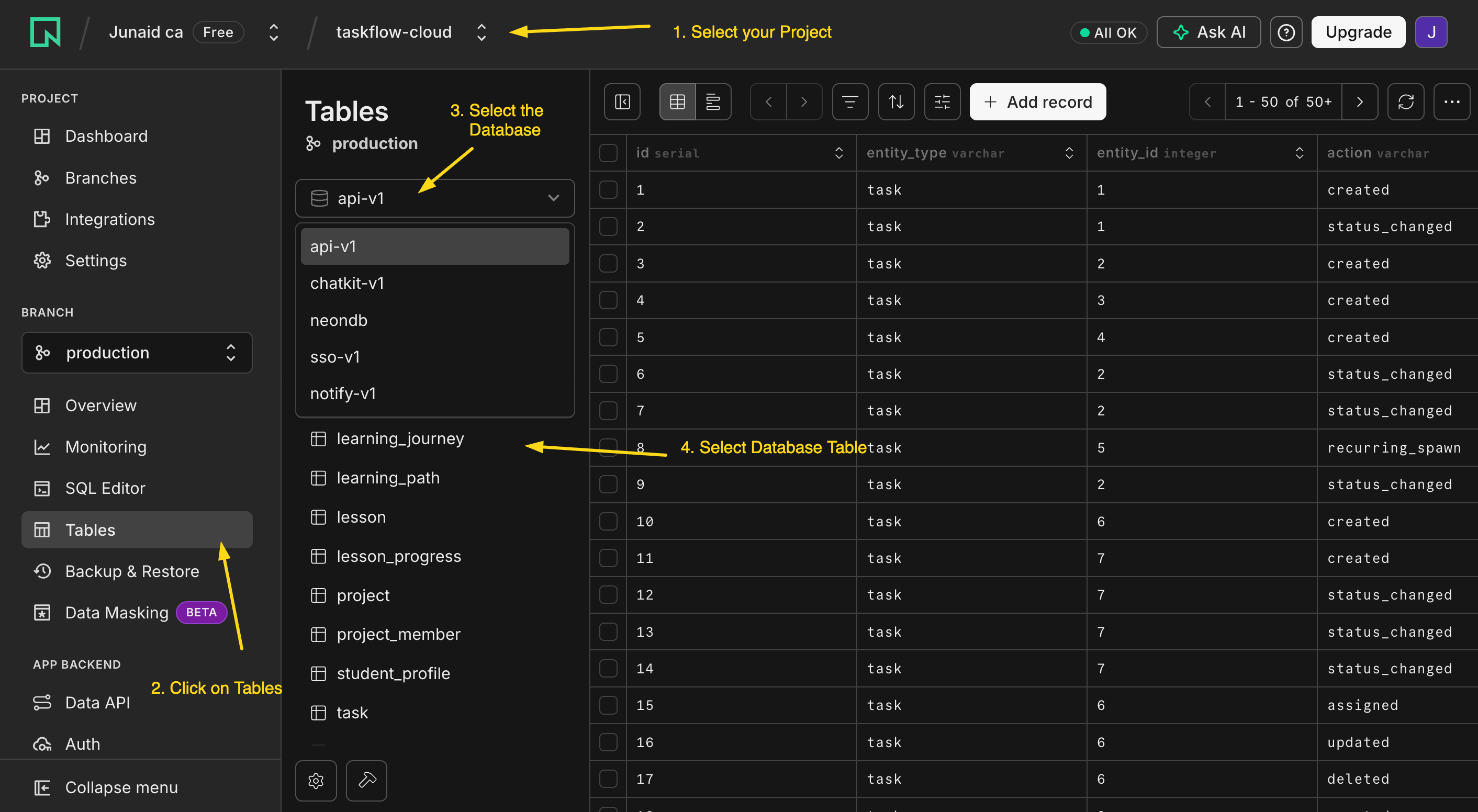
打开 console.neon.tech,挑选 agent 刚创建的那个项目,打开 Tables。那里就摆着 notes 和 audit_log,目前是空的。一张表就是一张电子表格:每行一样东西,每列一个细节。结尾时你会刷新这个视图,看着一行出现。
脚手架出 Worker 并跑它一次(约 2 分钟)
现在构建 Worker 本身:一个最小的 SandboxAgent,也就是这门课其余部分用的同一个运行时,暂时还没有工具。先让它空跑一次,证明运行时能用、你的 key 没问题,然后再加任何可能出错的东西。
用
uv在这个文件夹里脚手架出一个最小的 OpenAI Agents SDK 项目:一个跑在 gpt-5 级模型(如gpt-5-mini)上、暂时没有工具的SandboxAgent,从终端在一个本地沙箱上运行,从.env读取OPENAI_API_KEY。用 "hello" 跑它一次,让我看到它回答。
留意: agent 用 uv 搭好项目,写一个小的 SandboxAgent 加 Runner 脚本(跑在 UnixLocalSandboxClient 上,零基础设施),然后运行它。一条回复回来了。
这是你的 key 第一次被用到,所以也是一个坏 key 第一次现形的地方。如果运行返回 401,要么 key 不对,要么你的提供方不是 OpenAI:粘贴 「这次运行失败返回了 401;读一下错误,提一个我能批准的修复方案。」
完成标志: 空的 Worker 跑起来并作答。
给 Worker 它的工具,看着它记住(约 3 分钟)
现在加上那唯一的一项能力:一个工具,它在一次事务里向你刚构建的数据库写一条笔记和它对应的审计行。
给 Worker 加一个
save_note工具,写成一个@function_tool,它用.env里的DATABASE_URL,在单次事务里向notes插入一行、并向audit_log插入一行对应的行。然后运行 Worker 并发给它:"Remember this: the production deploy needs a new env var before Friday." 给我看发生了什么。
留意: 模型自己把你这句话匹配到 save_note(这个工具的描述是它唯一的路由信号),而工具用 DATABASE_URL 打开一个连接,在一次事务里写入两行。Worker 报告笔记已保存。注意它 没 做什么:它从未去够 Neon MCP。管理用的线构建了存储;Worker 用的是它自己那个窄窄的工具。
完成标志: Worker 确认笔记已保存,并向你展示是哪个 save_note 调用完成的。一句话进,一次工具调用,两行写入。
见效:读回它(约 2 分钟)
刷新刚才那个 Neon 控制台的 Tables 视图。你的笔记现在是 notes 里的一行,而 audit_log 里有一行对应的行记录着 note_saved,靠同一个 id 与之相连。(更想待在终端里?问你的编程 agent:「用 Neon 工具,把新的 notes 行和它对应的 audit_log 行并排展示给我看。」)
这就是整套架构的微缩版:一个持有真相的系统记录、一个通过自己的工具写入它的 Worker、以及一条你能回放的审计轨迹。
你构建了什么,它从哪里成长
你用了一个普通的 @function_tool,因为一名 Worker 写入一个存储,这是正确的默认选择,不是图省事。当下面三件事之一出现时,你才去用一个小型 MCP 服务器:一个需要同一个 save_note 的 第二个消费方(另一名 Worker、你的编程 agent、Claude 本身)、一个你想强制实施的 更紧的范围,或者 进程隔离。那个决策,即函数工具对自建服务器,就是概念 14,而 Part 4 会构建那个服务器。
Part 4 把同一个形态扩展到多个 Skills、五表 schema、几个工具,以及一条 embedding 流水线。形态本身不变:一个系统记录、与动作在同一事务里的审计,以及管理用的线和 Worker 自己访问之间的一条清晰界线。如果这次快速见效成了,这门课其余部分无非是在解释每一块为什么是它现在这个样子。
如果有什么没成,粘贴这个覆盖一切的恢复动作:「有东西没成。读一下错误,用大白话告诉我你看到了什么,并提一个我能批准的修复方案。」 然后回到这里。
Part 1:Skills,作为可移植文件夹的能力
你已经在 Claude Code 里用过 Skills 了。Part 1 把同样按需的、专业化的工作流,交给 你 构建的那个 agent。一个 Skill 是你交给 agent 的一项可复用能力:一个把工作流(指令,加上任何脚本或参考资料)打包起来的文件夹,agent 只在某个任务用得着时才加载它,可在各个 agent 间移植,而不是焊死在某一个 agent 的代码里。这五个概念教你写出该触发时就触发的 Skills,而 Part 1 以在你 Worker 自己的 SDK 里、在同一个 digital-fte 文件夹里跑通一个 Skill 收尾。
概念 1:Agent Skill 是什么
一个 Agent Skill 是一个带 SKILL.md 文件(加上可选的 scripts/、references/、assets/)的文件夹。SKILL.md 是入口点。它是来自 Anthropic 的开放标准,任何 agent 都能读:今天的 Claude Code 和 OpenCode,以及你正在构建的 OpenAI Agents SDK Worker。最小的 skill 就是一个文件:
---
name: hello-skill
description: Greets the user by name and time of day. Use when the user says hello or asks to be greeted.
---
# Hello skill
1. Check the local time of day.
2. Greet the user warmly, by name if known, in under 25 words.
无代码,无部署,无 SDK 调用。因为它是磁盘上的一个文件,一个 skill 像任何文本一样做版本管理、流转、接受评审,而不像一个 Python 对象或一个 API 端点。
PRIMM,预测。 agent 在启动时、任何消息到来之前,加载什么?(a) 整个
SKILL.md;(b) 只有name和description;(c) 在被调用前什么都不加载。信心 1–5。
答案是 (b):启动时 agent 只读取每个 skill 的元数据;正文按需加载。那就是 渐进式披露,也就是下一个概念。
概念 2:渐进式披露,三阶段加载模型
一次性加载五十个 skills 会把模型埋在它用不上的指令里。所以一个 skill 分三阶段加载,每一阶段只在上一阶段说它相关时才触发。
阶段 1,发现。 启动时 agent 加载每个 skill 的 name 和 description,各约 100 个 token。五十个 skills 每回合约花 5,000 个 token:知道库里有什么的代价。
阶段 2,激活。 当模型把一个任务匹配到某个描述时,它加载那个完整的 SKILL.md 正文(保持在约 5,000 token 以内;多数在 500–2,000 之间)。只在用到该 skill 的回合才付出。
阶段 3,执行。 正文所引用的文件(一个 scripts/ 脚本、一份 references/ 文档)只在 agent 去够它们时才加载。
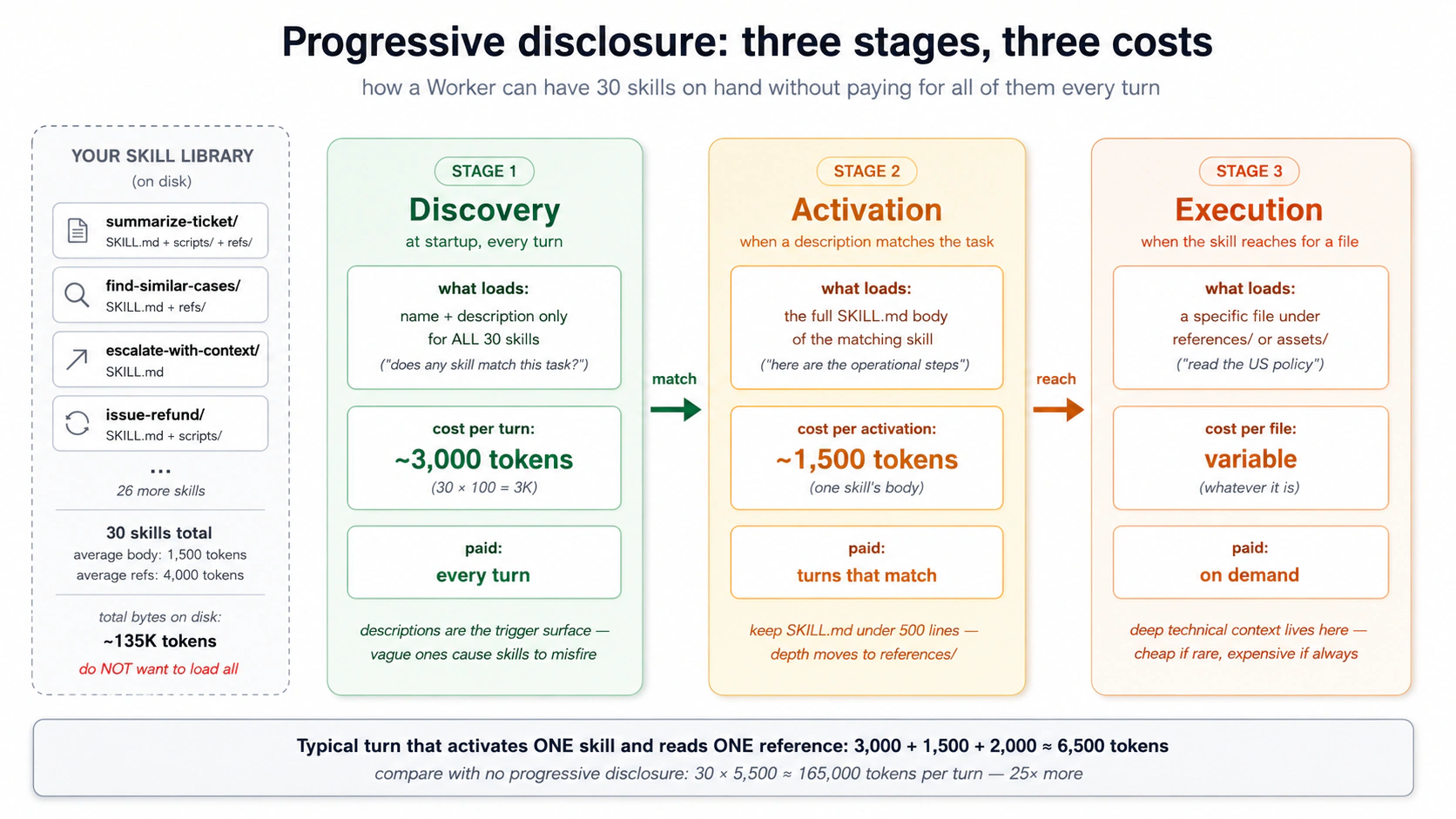
PRIMM,预测。 一名 Worker 有 30 个 skills:每个约 100 token 的描述、约 1,500 token 的正文、各带两份参考文件(共约 4,000 token)。在一个激活了一个 skill 并读取了它一份参考的回合里,大致的上下文成本是:(a) 约 3,000 token;(b) 约 6,500 token;(c) 约 135,000 token。信心 1–5。
答案是 (b),约 6,500 token:30 × 100 用于发现(3,000),加一个 1,500 token 的正文,再加一份约 2,000 token 的参考。发现随库的大小增长;激活和执行每回合保持恒定。没有渐进式披露,你每回合都要付全部 30 个正文及其参考,仅仅为了知道 agent 能做什么就约 165,000 token。没人会那么跑。
由此引出两点,它们驱动接下来的三个概念:在阶段 1 触发的是 description,所以它决定一切;以及 长正文会在每个匹配回合让你掏钱,所以让 SKILL.md 保持精炼,把深度推到 references/ 里。
概念 3:description 是触发器,也是你拥有的那一部分
一个 SKILL.md 有两部分:YAML 前置元数据(模型读取的契约)和 markdown 正文(它遵循的指令)。前置元数据只有两个字段是必填的:
| 字段 | 必填 | 它是什么 |
|---|---|---|
name | 是 | skill 的标识符(小写、连字符,与文件夹名一致)。 |
description | 是 | 触发面:agent 在发现阶段读取、用来决定是否触发此 skill 的内容。 |
(license、compatibility、metadata、allowed-tools 是可选的,很少用到;skill-creator 会替你填。)
描述是整盘棋,也是脚手架最容易写错的部分。 它会写出一个循环式的描述:「Summarizes a ticket into five sections. Use when the user wants to summarize a ticket.」 那能在「summarize this ticket」上触发,却错过了支持人员实际的说话方式:「write a handoff note for #4471」「TL;DR this thread」「give my lead the rundown before I escalate」。 这个通用版本大约能接住 8 种真实说法里的 6 种;一个手写的版本能接住全部 8 种。
一个能稳定触发的描述做三件事,外加一道护栏:
- 它产出什么(点名实际的产出:那五个小节,针对一张工单)。
- 何时去够它(真实的情形:交接、升级、向经理汇报、接手别人的线索)。
- 用户真会敲的关键词,包括那些从不说出那个显而易见的词的说法(「handoff note」「TL;DR this thread」「where does this stand」)。
- 一条 do-NOT 行,给那些必须保持安静的近似项(起草一份给客户的回复、批量分诊、报告工单量)。
一个能干掉循环式描述的自检:把那个显而易见的关键词(「summarize」)从你的描述里删掉。它还说得清何时触发吗? 如果说不清,那它就太窄了。
正文,按约定。 没有必填格式,但好的 skills 是 祈使式 的(「Read the full thread. List what was tried.」),带 一两个真实示例(在引导上大约值一份描述的 5 倍),并点名 两三个真正出过岔子的边界情况。
PRIMM,预测。 两个 skill 共用
namesummarize-document:一个在~/.claude/skills/(用户级),一个在.claude/skills/(项目级)。一个任务两者都匹配。会怎样?(a) 随机挑;(b) 项目级胜出;(c) 模型来选。信心 1–5。
(b),项目级胜出,在 Claude Code 和 OpenCode 中皆如此:更具体的上下文覆盖更宽泛的,正如一个项目规则文件覆盖一个全局规则文件。
概念 4:打包,skills 住在哪里、如何流转
一个 skill 不过是磁盘上的一个文件夹,所以你把它放在哪里就决定了哪些 agent 能找到它。一条规则覆盖整门课:把你的 skills 放在 OpenCode 先查它自己的文件夹,然后回退到 .claude/skills/ 里。 Claude Code 读那个文件夹,OpenCode 回退到它,而你 Worker 的 SDK 直接指向它(LocalDir(src=".claude/skills"),来自上面的动手部分)。写一次 skill,三者就加载同一个文件夹,逐字节一致。完整路径地图(按工具,项目级对用户级)
工具 项目级 用户级(全局) Claude Code .claude/skills/<name>/SKILL.md~/.claude/skills/<name>/SKILL.mdOpenCode .opencode/skills/<name>/SKILL.md~/.config/opencode/skills/<name>/SKILL.mdOpenCode(回退) .claude/skills/<name>/SKILL.md~/.claude/skills/<name>/SKILL.md.claude/skills/;Claude Code 只读 .claude/。这就是为什么 .claude/skills/ 是那个到处都能用的唯一位置。
一个 skill 的文件夹有一个必填文件和三个可选文件夹,各司其职:
my-skill/
├── SKILL.md # required: frontmatter + body, the entry point
├── scripts/ # optional: code the agent runs (by relative path)
├── references/ # optional: deep docs, loaded on demand, one topic per file
└── assets/ # optional: templates, schemas, lookup tables
在 SKILL.md 里,用 相对路径 指向那些文件(references/policies/us.md、scripts/extract.py);它们从 skill 自己的文件夹解析,而不是从 agent 碰巧在运行的地方。让 references/ 保持扁平,一个主题一个文件。
概念 5:组合 skills,一个大的对几个小的
一份「每周客户健康报告」既可以是一个 skill,它负责调研、起草、排版和评审,也可以是四个通过文件系统交接的 skill。两者都行,权衡相反。
- 一个大 skill: 容易被发现,一次激活。但每一步都跑在同一个上下文里,没有一块能单独复用,而中途的一次失败会让模型带着上下文里的陈旧成果去恢复。
- 多个小 skill: 每一个都能被单独测试、替换和复用;一次失败被局部隔离;每一步都从头激活,所以不会有残留上下文堆积。 代价是更多发现条目和需要某种东西把它们串起来。
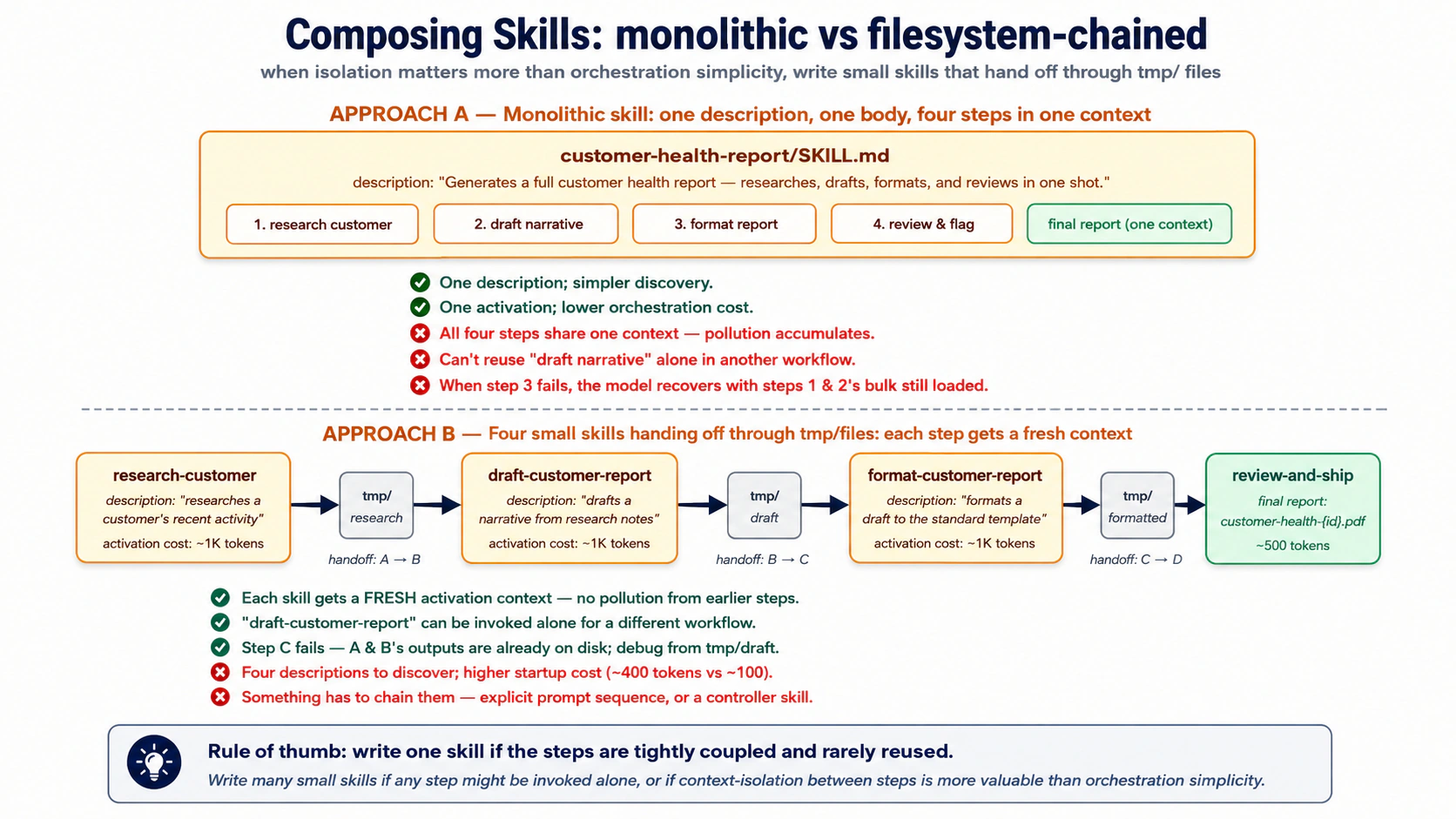
当各步紧密耦合且从不单独复用时,写一个 skill。当某一步可能被单独调用,或者保持每一步上下文干净比保持接线简单更重要时,写几个。过了两三步,分离通常胜出。
通过文件系统串联它们,而不是通过对话。 Skill A 写 tmp/research-{id}.md,Skill B 读它再写 tmp/draft-{id}.md,依此类推。对话只看到最终结果;中间各步留在磁盘上,供 agent、你和审计轨迹查看。和上一门课为子 agent 所用的隔离相同,现在缩到 skill 的尺度。
而这正是通往 Part 2 的桥:有些交接不该放进临时文件,它们该放进系统记录。 一个写入 tmp/ 的 skill 是草稿;一个写入系统记录的 skill 是一次行动。那条区别正是 Part 2 要构建的。
与 AI 一起试
Compare two designs for a customer-refund workflow:
A: one "issue-refund" skill (eligibility, policy, amount, gateway, ticket, notify).
B: five small skills chained via tmp/ handoffs.
For each, name one situation where it's the right call and one failure mode
it's vulnerable to. Then say which you'd ship, and why.
在两个运行时里触发一个 skill(约 10 分钟,动手)
你读得够多了;现在看一个 skill 在 你 构建的 agent 里触发。打开快速见效里用过的同一个 digital-fte 文件夹,你的 SandboxAgent 已经在里面运行。在一个用完即弃的 skill 上跑一次这个,好让机制变得熟悉(这正是决策 4 真刀真枪做的事),并看到你已经在 Claude Code 里用的那些 .claude/skills/ 文件在你 Worker 自己的 SDK 里同样地工作。
1. 脚手架它。 你需要一个通用 agent 和已安装的 Node(用于 npx)。粘贴这段:
Use skill-creator to scaffold a summarize-ticket skill. It turns one support ticket into a
short five-section handoff. Make it fire on how support actually asks (handoff note, TL;DR
this thread, "what's the status and next step"), including phrasings that never say
"summarize", and not on look-alikes (drafting a reply, triaging a batch). Then check it:
delete "summarize" from the description; if it no longer says when to fire, sharpen it.
正文回来得不错;读那个描述并打磨它,直到它通过删关键词检验。那次评审就是这个 skill 的精髓,也是脚手架不替你做的那部分。
2. 在一个客户端里触发它(可选,零接线)。 如果你装了 Claude Code 或 OpenCode 并已登录,在那里打开这个文件夹,让它在不说「summarize」的情况下处理一张工单(例如 「write a handoff note for case #4471 before I escalate」)。客户端发现 .claude/skills/,匹配你的描述,激活 summarize-ticket。一个注意点:如果一个请求简单到模型直接就答了,那就没有 skill 触发,而那是模型的判断,不是描述的 bug;用一次真实的交接来测,而不是一句一行的提问。只用 SDK 的读者可以跳到第 3 步。
3. 在 OpenAI Agents SDK 里触发它。 现在把这个 skill 接进你 Worker 自己的运行时,并照你在 Part 4 里做每件事的方式来做:你出提示,agent 做计划,你批准,它来构建并运行。你仍在 digital-fte 文件夹里,所以那个 uv 项目和 OPENAI_API_KEY 都延续过来。粘贴这段:
把
summarize-ticketskill 接进一个我能从这个文件夹运行的最小SandboxAgent:一个指向.claude/skills的Skills能力,保留默认能力,一个 gpt-5 级模型,跑在一个本地沙箱上。确保openai-agents已安装。先做计划。
它和快速见效里是同一个 SandboxAgent 形态,只是把 save_note 工具换成了一个 Skills 能力(用 gpt-5 级模型很重要:默认能力里包含一个文件系统工具,更小的模型会用 400 拒绝它)。当计划看起来对劲时,批准并一气呵成地做实测:
实现它,然后用 "write a handoff note for case #4471: no refund, two weeks" 运行它,并把追踪展示给我,好让我看到那个 skill 触发。
在追踪里核实它触发了。 SDK 把每次运行都追踪到你上门课用过的同一个 OpenAI 仪表盘:打开 platform.openai.com/traces,你会在这次运行里看到 summarize-ticket 的 load_skill 调用,然后是那个五小节的回复。(没有仪表盘?那个 print 循环会在你的终端里展示同样的加载。).claude/skills 是源;.agents/ 是已加载的 skill 在运行时被暂存的地方。同一个文件,两个运行时:那就是可移植的能力,而决策 8 会把它接进完整的 Worker。
这些概念假设一个强指令遵循者(Claude Sonnet/Opus、GPT-5 级)。在更小的模型上(deepseek-chat、Haiku 级、多数本地模型),有三处会跑偏:
- 多 skill 排序。 「ALWAYS run X before Y」在强模型上立得住,在弱模型上会打滑。修法:把次序放进系统提示词里一段简短的 GENERAL-FLOW 前言;让 SKILL 正文保持声明式。
- 格式漂移。 较弱的模型会加表情、表格,或转述你的输入。要明确写出 不要 做什么,而不只是要做什么。
- 触发盲点。 一个在「summarize ticket TKT-1042」上触发的描述,可能错过「what's the story on #1042」。概念 3 的纪律在弱模型上更重要,而不是更不重要。
经验法则:把强模型的功夫预算进 SKILL.md,把弱模型的功夫预算进系统提示词。架构成立;你只是在它周围多写一些脚手架。
Part 2:Neon Postgres + pgvector 作为系统记录
Part 1 给了 agent 各种能力。现在它需要一个持久的地方来存放它输不起忘记的东西:客户记录、政策库、过往已解决的案例,以及它做过的一切的轨迹。
那个存储就是你 Worker 的 系统记录,它运行所依据的那个权威存储(开篇地图里 CRM 或总账的想法,现在落到了实处)。它是带 pgvector 扩展的 Postgres;概念 6 解释为什么用它而不是一个专用向量数据库。我们用 Neon:起步免费、闲置时不花钱,而且你的编程 agent 能直接驱动它,不过任何带 pgvector 的托管 Postgres 都行。
那张地图里的四类数据中,业务记录(客户、订单、工单)是你业务特有的,所以你在 Part 4 构建它们。这一 Part 构建的是另外三类,也就是每名 Worker 共有的部分,现在映射到持有它们的真实表上:
- 参考库:Worker 按意义 检索的知识,政策库、知识库文章、过往已解决案例的摘要。它住在
documents和embeddings里(概念 8 和 9)。 - 状态:实时对话。它的回合住在 agent SDK 的 Session 里,由 SDK 替你创建并写入,所以那些表你从不设计(概念 7);一行
conversations挨着它们,靠 session id 相连,作为信封:谁、何时、一段收尾摘要。 - 轨迹:Worker 做过什么的记录,
audit_log总账(概念 10)。(一张可选的伴生表capability_invocations增加按 skill 和按工具的指标。)
概念 6:为什么用托管 Postgres,又为什么偏偏是 Neon
论点对系统记录保持产品无关:「AI 原生公司既有的数据库、工作流和运营平台(CRM、ERP、工单系统、数据仓库、总账)充当系统记录。」不过,对一个你从零构建的 agent,你总得选点什么。问题不是「Postgres 对 MongoDB 对一个向量 DB」。而是「哪一个 Postgres」。
为什么用 Postgres,而不是一个专用向量数据库。 三个即便在 2026 年依然成立的理由。
-
一个数据库,一次事务,一道认证边界。 一个单独的向量 DB 意味着两个要保持同步的存储、两套认证系统、两条备份流水线。
pgvector把向量保存在与之相关的记录 旁边,所以一次 JOIN 就还是一次 JOIN,而不是两个服务之间的一次网络跳转。每个主流的托管 Postgres(AWS RDS、Cloud SQL、Azure、Supabase、Neon)都自带它,而且它跻身 安装量最高的 Postgres 扩展 之列。对多数工作负载它足够了。 -
Postgres 早就把难的部分做了。 事务、索引、外键、行级安全、时间点恢复、查询规划。一个专用向量 DB 得从零发明这些,而且其中一些通常做得更差。那个无聊的默认选择有复利式的优势。
-
Postgres 在每一层都有 MCP 服务器。 Neon 自带一个(用于管理)。通用的 Postgres MCP 服务器存在(用于执行 SQL)。你可以写自己的(用于受限的运行时访问)。围绕 Postgres 的 MCP 生态是最成熟的。
何时一个专用向量 DB 确实胜出。 像 Pinecone、Weaviate、Qdrant 和 Milvus 这样的工具,在按意义检索 本身就是 产品、而不是挨着你业务数据的一个特性时,才值得用。信号是极端的:向量多到一个 Postgres 服务器的内存里再也装不下、检索流量重到需要一个专为向量而建的引擎,或者向量被许多彼此独立的服务单独使用。没有一个固定数字能让 pgvector 失效,所以测你自己的数据,而不要轻信某个数。一名带一张 tickets 表、把它的 embeddings 摆在旁边的 Worker,离那个点还远得很,所以 pgvector 是正确的默认。
为什么偏偏是 Neon:三个差异化点。
-
它缩容到零。 当数据库闲置时,它不花钱。一名一天处理 50 段对话的 Worker 多数时候闲着,所以它接近 $0,而不是为一台始终在线的服务器按月付费。当你运行许多各自只在突发期忙碌的 Worker 时,这一点很重要。
-
它能分支。 几秒之内,Neon 就为你的活动数据库做一份完整副本来操作,且不碰原库。与 agent 相关的用法:让 agent 在一个分支上尝试一个改动,如果出岔子,删掉那个分支就行。在一个不能分支的数据库上,撤销一个坏改动意味着从备份恢复。
-
它有一个官方 MCP 服务器。 Neon 自带一个 MCP 服务器,你的编程 agent 能跟它对话,于是它能用大白话创建项目、管理分支、运行迁移。构建时用它;概念 12 解释为什么它不适合运行中的 Worker。
与 AI 一起试
A teammate proposes splitting the stores: Postgres for the relational
data (customers, tickets, orders) AND a separate Pinecone index for the
embeddings, "because Pinecone is purpose-built for vectors."
Context for you, the assistant: keeping vectors in Postgres (via the
pgvector extension) next to the relational data means one query can
filter by business state, rank by similarity, and return the full
record in a single transaction. Splitting the stores forces the agent
to round-trip between two services, denormalize and sync metadata
across them, and give up cross-store transactional consistency.
1. Make the case against the split as concretely as you can on ONE
request: a support Worker gets a message and must answer "have we
seen this before, and what did we tell them?" Show exactly what that
request costs when the vectors live in Pinecone and the tickets live
in Postgres. Name the join, what happens to ranking at the LIMIT
boundary when you filter in application code, and how an embedding
goes stale after a resolution is updated.
2. Name the ONE condition under which the teammate is actually right and
a dedicated vector DB is the better call. Be specific about the scale
at which the crossover happens.
3. Neon adds two properties a plain Postgres box doesn't: scale-to-zero
(an idle Worker's database costs nothing) and branching (the agent
forks a production-fidelity copy of the data, experiments or migrates
on it in isolation, then verifies before merging). Which matters more
for an AI Worker specifically, and why? Defend your pick in two
sentences.
概念 7:Worker 的 schema,一个 agent 实际需要哪些表
一个数据库 schema 不过是你保留的那些表以及每张表里的列,也就是你数据的形状。worked example 构建的五张表,是系统记录中每名 Worker 都需要的共享部分;业务记录本身在 Part 4 才来。它们分成两组,这样你能看清什么是必需、什么是可选。
每名 Worker 都保留的四张表,共享脊梁。 它们持有这一 Part 开篇讲的 状态、参考库 和 轨迹,现在落为表:
conversations(状态):每段对话一行,它是和谁、何时进行的,以及结尾的一段简短摘要。(逐回合的消息单独存放,由 SDK 负责;见下。)documents和embeddings(参考库):documents持有文本(政策、过往案例);embeddings是让它能 按意义 被检索的东西。一个 embedding 把一段文本变成一串数字,捕捉它的主题,于是相关的文本最终彼此靠近,就像把便签钉在一块板上、相似的扎成一堆,而「找出相关的」就变成了「找出最近的」。(概念 9 构建这个;这里只需知道embeddings是那个按意义检索的层。)audit_log(轨迹):Worker 做过什么的一份流水记录,每个动作按顺序排列,包括像签发一笔退款这样的业务事件。
当你需要时再加的一张,使用情况分析。
capability_invocations:Worker 每次跑一个 skill 或调一个工具就写一行(两者共用这一张表;一列标明是哪种,于是你永远不会每个工具长一张表),带上它花了多久、成功还是失败,以及一个粗略成本。当你想在 SQL 里做能力使用分析时再加它:一个 skill 触发的频率、它的错误率、什么往往出现在一次升级之前。
还有两张表住在这一组之外,都在 Part 4:你的 业务特定表(customers、tickets、orders),以及 run_states,后者在某个人稍后或在另一个进程里、而不是当场签批时,存放一次暂停的审批。两者都不属于共享脊梁。
消息本身去哪里? 想象一份逐字记录和一张封面。逐字记录 是每一条消息,你的提问、模型的回复、每次工具调用,各自保存为它自己的一行;SDK 替你写并保留它(在决策 3 里接好),所以你从不构建它。封面 是你写的那一行 conversations:谁、何时、一段摘要,加上像 user_id 这样的业务细节,那些是 SDK 自己的表所不携带的。你保留它,是因为逐字记录回答不了「展示这位客户最近的五段对话」;那是 conversations 上的一次快速查找,靠它们共享的 session id 与逐字记录连接。它是可选的:如果你从不需要按用户列表或摘要,仅凭逐字记录就够了。
全部五张表的完整 SQL 在下面的方框里。你的编程 agent 会按决策 3 里的计划写它,所以你可以略过;要紧的是知道每张表是干什么的。完整 schema(四张共享表加上可选的 capability_invocations)
-- 1. CONVERSATIONS: business metadata per conversation (your app writes this row)
CREATE TABLE conversations (
session_id TEXT PRIMARY KEY, -- the SAME id you pass to SQLAlchemySession
user_id TEXT NOT NULL,
started_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
ended_at TIMESTAMPTZ,
metadata JSONB NOT NULL DEFAULT '{}'::jsonb,
-- searchable summary; your app writes it at conversation end
summary TEXT
);
CREATE INDEX idx_conversations_user ON conversations(user_id, started_at DESC);
-- The turns themselves live in the SDK Session's tables (agent_sessions /
-- agent_messages, via SQLAlchemySession), created automatically on this same
-- database and keyed by this session_id; you do not hand-build them.
-- 2. DOCUMENTS: the agent's reference library
CREATE TABLE documents (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
source TEXT NOT NULL, -- 'policy_library', 'kb_article', 'past_case', etc.
title TEXT NOT NULL,
body TEXT NOT NULL,
metadata JSONB NOT NULL DEFAULT '{}'::jsonb,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
updated_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE INDEX idx_documents_source ON documents(source);
-- 3. EMBEDDINGS: vector representations of documents AND past conversations
CREATE TABLE embeddings (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
-- one of these is populated; the other is NULL
document_id UUID REFERENCES documents(id) ON DELETE CASCADE,
conversation_id TEXT REFERENCES conversations(session_id) ON DELETE CASCADE,
chunk_text TEXT NOT NULL,
chunk_index INT NOT NULL,
embedding VECTOR(1536) NOT NULL,
model TEXT NOT NULL, -- 'text-embedding-3-small', etc.
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
CHECK (
(document_id IS NOT NULL)::int + (conversation_id IS NOT NULL)::int = 1
)
);
-- the key index for semantic search; see Concept 8
CREATE INDEX idx_embeddings_hnsw
ON embeddings USING hnsw (embedding vector_cosine_ops);
-- 4. AUDIT_LOG: replayable trace of how the Worker changed or used the record
CREATE TABLE audit_log (
id BIGSERIAL PRIMARY KEY,
conversation_id TEXT REFERENCES conversations(session_id) ON DELETE SET NULL,
actor TEXT NOT NULL, -- 'worker:customer-support', 'system', etc.
action TEXT NOT NULL CHECK (action IN (
'message_received', 'message_sent', 'skill_activated',
'capability_invoked', 'refund_issued', 'refund_blocked',
'guardrail_tripped', 'corpus_seeded'
)), -- closed vocabulary; widening it is a migration (Concept 10)
target TEXT, -- table name, skill name, etc.
payload JSONB NOT NULL, -- the data of the action
result JSONB, -- what happened
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE INDEX idx_audit_conv ON audit_log(conversation_id, created_at);
CREATE INDEX idx_audit_action ON audit_log(action, created_at);
-- 5. CAPABILITY_INVOCATIONS: every skill or tool call, for replay and metrics
CREATE TABLE capability_invocations (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
conversation_id TEXT NOT NULL REFERENCES conversations(session_id) ON DELETE CASCADE,
capability TEXT NOT NULL, -- 'skill:summarize-ticket', 'tool:search_docs', etc.
arguments JSONB NOT NULL,
result JSONB,
status TEXT NOT NULL CHECK (status IN ('ok', 'error', 'blocked', 'timeout')), -- 'blocked' = approval rejected
latency_ms INT,
cost_cents INT, -- approximate cost in 1/100 cents
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE INDEX idx_cap_conv ON capability_invocations(conversation_id, created_at);

几个值得理解的设计选择:
-
一张
embeddings表同时管 documents 和 conversations。 一个CHECK约束让每一行恰好指向其中之一,一份 document 或一段 conversation。于是一次检索就能同时覆盖政策和过往对话,而「我们以前回答过这个吗?」用一个索引,而不是两个。 -
audit_log用BIGSERIAL(一个自增数字),而不是UUID。 审计行堆积得很快,而一个普通整数键让写入保持快、次序保持显而易见。其他表用UUID(随机的、全局唯一的 id),因为它们的行会出现在 API 响应和 URL 里,而UUID掩盖了你有多少行。 -
Skills 和 tools 共用
capability_invocations。 一次 skill 调用和一次 tool 调用相似但不相同(不同的代码、不同的成本、不同的失败方式)。把两者放进一张表、用一列说明是哪种,让你既能跨两者问「agent 做了什么?」,也能拆开来问「哪些 skill 慢或在失败?」。 -
metadataJSONB 列是逃生口。 没有哪个 schema 能猜中某个特定业务会需要的每个字段,所以一个 JSONB 列让你不改表就能加字段。省着用:任何你经常查询的东西都应当成为它自己的一列。
你会为你的业务再加些表:一张 customers 表、一张 tickets 表、一张 orders 表,都是 agent 通过 MCP 读写的普通关系表。
PRIMM,预测。 一名 Worker 一天处理 200 段对话,每段平均 10 个回合,其中 30% 触发一次 skill 调用、50% 在 skill 行之外再写两行审计。一个月(30 天)后,哪个存储增长最快?三个选项:(a) 全部以相近的量增长;(b)
audit_log以大幅领先增长最快;(c) embeddings 表,因为每个回合都被 embedding。信心 1–5。
答案是 (b):在你构建的表里,audit_log 增长最快,因为一次交互能写好几行动作(一次 skill 或 tool 调用、一次对记录的写入、有时一笔退款),同时它只增加一行 conversations、不增加新的 documents。所以随着你扩张,它是你最先要为之规划留存和索引的那张表。(SDK 自己的回合存储增长还要更快,但你不管它。)
与 AI 一起试
I'm building a customer-support Worker. Its database already
has the four shared tables from Concept 7: `conversations` (one row per
conversation, plus a summary), `documents` and `embeddings` (a
searchable reference library), and `audit_log` (the record of what it
did). The turn-by-turn messages are held by the agent SDK's Session,
not a table I built.
I want to extend this for a Worker that handles software bug reports
specifically. What three additional tables would you add, and what
columns would they have? For each, say what the agent will use it for
(read access? write access? both?) and what foreign keys connect it to
the tables above.
概念 8:pgvector 基础,类型、距离运算符、索引
embeddings 表是让 Worker 能按 意义 而不只是按字词匹配来查找文本的东西。回想那块板:每段文本(一条政策、一个过往案例、一条记录)都得到一枚钉子,相关的彼此靠近。一枚钉子的位置 就是 那个 embedding,一串数字。pgvector(一个 Postgres 扩展)是让 Postgres 能存这些钉子并找出最近那些的东西,于是你不需要一个单独的向量数据库(概念 6 讲了为什么)。
向量类型。 VECTOR(n) 是一个持有一枚钉子的列:一串固定的 n 个数字。生成 embedding 的那个模型决定 n,OpenAI 的 text-embedding-3-small 是 1536,text-embedding-3-large 是 3072,其他模型各异。会咬人的那条规则:你存储的文本和你的检索查询必须来自 同一个 模型。 两个模型就像按不同比例尺画的两张地图,在其中一张上意味着「市中心」的位置,在另一张上却落到了海里。用一个模型 embedding 你的文档、用另一个 embedding 你的查询,那么即便查询能无错运行,「最近的」结果回来也是一堆胡话。这是最常见的 pgvector 错误。
对很大的 embedding(超过 2,000 个数字),一个 halfvec 列以一半的精度存每个数字:这大致把存储减半,还能被索引(最多 4,000 个数字),代价是少许精度损失。我们这 1536 个数字的情形不需要它;普通的 vector(1536) 就行。
三种「衡量有多近」的方式。 一旦文本被钉好,「相似」无非就是「靠近」。pgvector 给出三种衡量两枚钉子之间距离的方式。挑一种并坚持用它;在一个项目中途切换只会让结果变乱。
| 运算符 | 名称 | 它衡量什么 | 何时用 |
|---|---|---|---|
<=> | 余弦 | 两枚钉子对齐程度,忽略长度 | 文本,我们的默认 |
<-> | 直线距离 | 两点之间的普通距离 | 图像检索及其他几何数据 |
<#> | 点积 | 方向和长度合在一起 | 罕见:仅当你的向量长度不一致时 |
对文本,用余弦(<=>)。 它不管向量多长都比较意义,这正是你想要的,而且它是标准选择(它的索引名为 vector_cosine_ops)。
要检索,你把用户的问题变成一个 embedding,向 Postgres 要那些到它的 <=> 距离最小的行,最近的在前,取前几条。你的 agent 写那段 SQL;你会在下面的「感受它跑起来」里看到一条真实查询运行。
索引:让检索变快的东西。 一旦你有了成千上万枚钉子,逐枚核对会变慢。一个 索引 解决这个,就像书后的索引让你直接跳到某个主题,而不是逐页读。pgvector 能用两种方式建这个索引,名为 HNSW 和 IVFFlat;你不需要知道那些字母代表什么,只需知道每个做什么。截至 2026 年建议已成定论:
- 从 HNSW 起步。 它把每枚钉子链到它的邻居,于是一次检索能径直跳向最近的那些:检索快,构建慢,更耗内存。正确的默认。
- 只有当构建速度比检索速度更重要时才用 IVFFlat。 它把钉子分进若干桶、检索最近的几个桶:构建更快、更省内存,但检索更慢,而且你只能在表里有了数据之后才能建它(它从已有的行里学出那些桶)。如果你经常重建索引,它就值。
- DiskANN(一个独立的附加组件)是给大到内存装不下的索引用的。你几乎肯定不需要它。
上面 schema 里的那个 HNSW 索引:
CREATE INDEX idx_embeddings_hnsw
ON embeddings USING hnsw (embedding vector_cosine_ops);
HNSW 有两个旋钮,m 和 ef_construction。默认值对多数工作负载都够用;除非你测出了改它们的理由,否则别碰。
快速核对。 对还是错?(a) 你可以在同一列上放不止一个 HNSW 索引,每个距离运算符一个。(b) 向一张带 HNSW 索引的表加一行,比向一张没有向量索引的表加一行代价更高。(c) 你可以在加载任何数据之前就创建一个 HNSW 索引。三个都 对:你可以为多个运算符建索引(很少需要),行到来时让索引保持最新有实打实的代价(所以有些团队先批量加载、再建索引),而 HNSW 不需要训练数据,这和 IVFFlat 不同。
与 AI 一起试
Two scenarios. For each, pick HNSW or IVFFlat and justify with one
specific property of the index:
Scenario A: A research index of 10M scientific papers. Built once,
queried millions of times. Build time is "whatever it takes,
overnight is fine." Query latency directly affects user experience.
Scenario B: A live index of customer support tickets that's
re-indexed every 4 hours because thousands of new tickets stream in.
Query patterns are simple (top-5 nearest neighbors). The current
HNSW build takes 20 minutes, a third of the re-index cycle.
After you answer: name ONE thing that would change your answer for
each scenario. Be specific about what you'd need to see in
production metrics before switching.
概念 9:embedding 流水线,文本进,可查询的向量出
一个 embedding 把一段文本变成空间中的一个点。关于退款的文本落在其他关于退款的文本附近;关于登录 bug 的文本落在别处。于是「找出相似的工单」就变成了「找出最近的点」。这就是全部的想法。其余的都是管道活。
管道是四步,每一步都有一个要紧的决策:
- 切块(Chunk),把文档切成小到每块只承载一个想法的片段。
- Embed,调模型给每个片段做 embedding;你拿回它的点。
- 存储(Store),把文本、它的点和一点元数据存进
embeddings表。 - 查询(Query),把用户的问题也变成一个点,然后找出最近的那些已存的点。
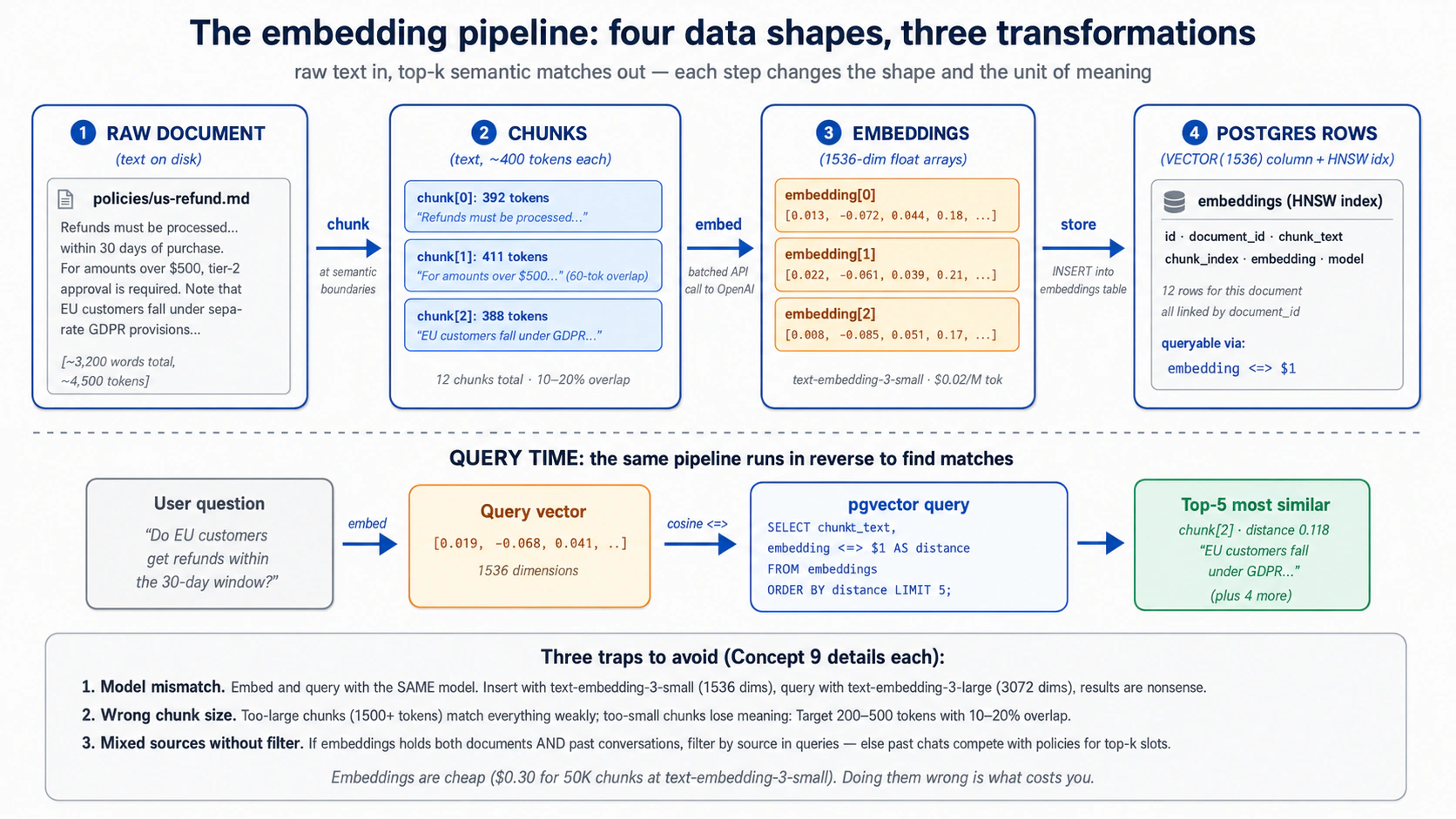
切块:先切分长文本。 一份长文档不该变成一个巨大的 embedding。你把它切成若干块,而块的大小是那个要紧的决策:
- 在自然断点处切分(标题、段落)。一个在句子中途停下的块检索效果很差。
- 每块瞄准几百个词。 太大它就「什么都弱弱地匹配」;太小它就丢掉了使它有意义的那点上下文。
- 让块之间稍微重叠,这样一个跨在边界上的想法仍能被找到。
- 别去切本来就短的东西。 一张单独的已解决工单或一条简短的 FAQ 条目本身就是一块;照原样 embedding 它。
你的 agent 写切分代码;你决定的是块大小和重叠。
Embedding:把每一块变成一个点。 你把每一块交给 embedding 模型,把它给回的点存起来(成批做,比一块一调便宜得多)。让概念 8 的那条规则继续生效:用 同一个 模型 embedding 你存的文本和你的检索查询,否则匹配回来就是噪声。一个值得知道的搭建坑(你的 agent 会处理):必须告诉数据库驱动那个向量类型,否则你的插入可能静默失败。
如果你不在 OpenAI 上怎么办? OpenAI 是唯一也提供一流 embeddings API 的主流提供方,所以如果你通过 DeepSeek、Anthropic、Gemini 或一个本地模型做推理,你就单独挑一个 embedding 模型,而要紧的是维度得对上。常见的逃生口是一个本地的 sentence-transformers 模型,比如 all-MiniLM-L6-v2(384 维):不调 API,也没有文本离开你的机器。无论哪种,embedding 都是账单上最便宜的一行,所以这个选择移动的是你的架构,不是你的预算。
何时重新 embedding。 三个触发条件:
- 源文本变了,重新 embedding 那些行。
- 你换了 embedding 模型,每个旧的点现在都住在一张不同的地图上、而且很可能尺寸也不同,所以你重建那一列并重新 embedding 每一行(或在切换期间两者都留着)。没有「差不多就行」。
- 你改了块大小,重新切块并重新 embedding。
PRIMM,预测。 你已用
text-embedding-3-smallembedding 了 100,000 块。随后你决定也 embedding 你的 过往对话(不只是文档),好让 agent 能做「我们以前讨论过这个吗?」的查找。你把对话的 embedding 写进同一张embeddings表、同一列。一条语义检索查询(找出与某个用户问题最近的 5 个邻居,不过滤)回来时混着文档和对话的结果。这是你想要的吗?正确的查询形态是什么?信心 1–5。
答案:几乎肯定不是你想要的。当结果里混着文档和过往对话,agent 就可能把一段旧聊天的片段当作权威政策来对待。修法是 在检索时按来源过滤:只要文档,或者跑两次检索再加权,好让两类永远不糊到一起。
当结果看起来不对时,原因几乎总是三者之一:查询和存储的文本走了不同的模型(匹配是噪声)、你忘了按来源类型过滤,或者你的块太小、承载不了意义。先查这三样。
检索质量是 Worker 准确性的隐形杀手。最终答案听上去可以完全合理,却引用了错误的证据。唯一能逮住它的办法,是在答案之前先核对检索。
与 AI 一起试
I'm chunking a corpus of legal contracts (each averaging 8,000 words)
for semantic search. The user will query things like "what's the
termination clause in this contract", phrases that map cleanly to
specific sections. Walk me through three chunking strategies:
A) Fixed 400-token chunks with 60-token overlap (the default)
B) Chunk at section headings only, with no overlap
C) A two-level approach: store both 400-token chunks AND
whole-section chunks, search both, combine results
For each, name (1) when it wins and (2) when it loses.
感受它跑起来:十分钟里的语义检索
你读完了 pgvector 和 embedding 流水线,却还没看到任何一个返回过一条结果。在 schema 的最后一块、也就是审计轨迹之前,花十分钟看语义检索真的按意义排序一次。这是个用完即弃的东西,不是那个 Worker:一张草稿表、五句话、一条查询。Part 4 才构建真东西。
你的 Neon 在快速见效时就已接好,所以这是一条提示词:
在我 Neon 项目的一个全新草稿分支上,创建一张小小的
notes(id, text, embedding vector(1536))表,带一个 HNSW 索引。用text-embedding-3-smallembedding 下面这五句话并插入它们:"the refund hasn't arrived"、"my package is late"、"how do I reset my password"、"the charge appears twice"、"I was billed for something I didn't buy"。然后 embedding 查询 "I never got my money back",跑一次余弦距离检索,把按距离排序的行展示给我。
留意: 关于账单和退款的句子排在 "my package is late" 之上、远在 "reset my password" 之上,尽管查询和它们中的任何一句几乎不共享任何字词。按意义排序、而不是按关键词重叠排序,正是 embeddings 表存在的全部理由。
完成标志: 你看到了那个排序列表,退款和账单的句子在最上面。告诉你的 agent 删掉那个草稿分支;真正的 schema 在 Part 4。
如果退款的句子 没有 胜出,常见原因是概念 9 里的模型不一致:插入和查询走了不同的 embedding 模型。两端用同一个模型,否则那些距离就是噪声。
概念 10:审计轨迹作为纪律,对一名 Worker 来说「读和写」意味着什么
agent 采取的每个有意义的行动,都应当在数据库里留下一行。没有那一行,你后来就回答不了「agent 做了什么,何时做的?」那条轨迹正是把一次真实行动和一句听上去靠谱的回复区分开的东西。
这里有两样东西挨得很近、容易被混淆,所以把它们分开:
- 真相本身:当前是什么情况,一位客户的等级、一张工单的状态、一条政策的文本。它住在业务记录和参考库里,Worker 读取并更新它。
- 审计轨迹:Worker 对那个真相 做过什么 的可回放记录,它调了哪个工具、它改了什么、它返回了什么、谁批准的。它住在
audit_log里、在同一个数据库里,而且它回答一个不同的问题,不是「什么是真的?」而是「Worker 做了什么,你能证明吗?」它不是对话的第二份副本(Session 已经持有每一条消息);它记录那些有类型的行动及其结果,包括那些从不作为一条消息出现的,一次数据库写入、一笔退款、一次护栏拦截。(一张单独的、可选的capability_invocations表在它旁边,用于按 skill 和按工具的指标;见概念 7。)
所以每个有意义的行动都写它自己的审计行,即便它触及的数据存在别处。行动发生了这一事实 住在 audit_log 里;两者靠外键连接。
里面放什么。 那些有意义的行动,带上足以回放它们的细节:每次工具或 skill 调用(名称、输入、结果、它花了多久、是否成功)、每次对记录的改动(哪张表、改了什么、在哪段对话之下)、每个护栏决策,以及每次模型调用连同它的 token 成本。
什么不放进去。 完整的对话文本,Session 已经持有它,所以再存一遍只是让你的存储翻倍。人能读的一行里的原始敏感数据,留一个哈希或一段摘要,把完整的东西锁起来。还有模型的私密推理。
让它成为审计轨迹、而不只是日志的那个检验: 给定一段对话和一个时间,你能不重跑模型就重建出 Worker 做了什么、为什么。如果你不能,你拥有的是日志。
把行动和它的记录一起写。 无论哪段代码签发退款,都在一次事务里写退款 以及 它的审计行:要么都落地,要么都不落。一条写了一半的审计轨迹比没有更糟,它看上去完整却不是。(你的 agent 在 Part 4 里写这个。)
给每个行动起一个来自一个小的、约定好的集合的名字(refund_issued、message_sent,诸如此类),别让这些名字漂移。半年后同一个事件有三个不同的名字,就是让那条轨迹没法查询的原因。像 refund_issued 这样的领域事件得到它自己的名字,于是那一行读起来像那个业务事件的收据,而不只是触发它的那次工具调用的收据。
因为那个集合小而固定,用 audit_log.action 上的一个 CHECK 约束来强制它(概念 7 的 schema 就是这么做的)。几周后一次构建撞上的坑:那个词表现在是 封闭 的,所以引入一个新动词(决策 9 里的一行 guardrail_tripped、决策 5 为它自己那次播种运行写的 corpus_seeded 行)是一行 ALTER TABLE ... DROP/ADD CONSTRAINT 的迁移,而不只是新代码,而且那个错误表现为一个 DB 约束违例,它指向的地方离「你忘了规划你的词表」十万八千里。所以一开始就把整个集合定下来;概念 7 的那个 CHECK 已经列出了这门课用到的那八个。
审计轨迹不是什么。 不只是日志:它是你自己数据库里可查询的 SQL(「上个月 agent 跟客户 X 说了什么,引用了哪条政策?」就是一条查询),不是在文本文件上 grep,而且它和你的业务数据一起被备份、被访问控制。不是事件溯源:它是一条 挨着 你状态的、只追加的轨迹,而不是你用来重建状态的那个东西(你的工单、文档和 Session 才是状态)。不是你的 traces:tracing(OpenTelemetry、OpenAI 仪表盘)是给调试用的飞行记录器,它住在一个单独的系统里、能被关掉、在零数据留存下不可用;审计日志是那张收据,和动作在同一事务里提交、需要留多久就留多久。两者都跑:trace 用来调试,总账用来证明。
这就是论点的意思:「只有当一本总账让 Worker 可被读取时,它们才作为一支劳动力变得可治理。」你的 audit_log 就是 那本总账。而可被读取正是让一名 Worker 可售卖 的东西:你不能为一个你证明不了发生过的结果收费。按席位定价数的是登录次数;按结果定价数的是 Worker 做了什么,每解决一张工单、每处理一张发票、每起草一份回复。那些 refund_issued 和 ticket_resolved 行 就是 那些结果,和底层事件坐在同一本日志里,是你能指给客户看、并据以开票的东西。所以一名 Worker 需要一个系统记录,不只是为了让它在两次运行之间不再忘记,更是为了让它的工作成为一件可证明、可计费的资产。那就是把一个 agent 接到数据库、和构建一名你真能售卖的 Worker 之间的那条界线。
与 AI 一起试
Here's a customer support scenario: a customer claims the Worker told
them they would receive a $50 refund, but the actual refund issued was
$30. The Worker handled the conversation 19 days ago.
Walk me through the audit-trail query path to resolve this:
1. Find the conversation. (Which columns of which tables?)
2. Find the message where the refund amount was promised. (How do you
distinguish "discussed" from "promised"?)
3. Find the capability invocation that issued the refund.
4. Find the database write that recorded the $30 amount.
For each step, name the table you'd query and the WHERE clauses.
Then say what's MISSING from the five-table schema that would make
this query easier.
Part 3:MCP,把 agent 接到系统记录
Part 1 给了 agent 一个 Skills 库。Part 2 给了它一个 Postgres 系统记录。Part 3 用模型上下文协议把两者连起来:关于 agent 如何够到外部状态和外部能力的开放标准。论点对 MCP 的位置说得很直接:「MCP 是这支劳动力够到 [它的系统记录] 的方式:每个权威存储都通过一个 MCP 服务器、在策略之下,对任何 Worker 变得可寻址。」 这一 Part 把它变成可操作的。
概念 11:MCP 是什么、不是什么
模型上下文协议(modelcontextprotocol.io)是一个开放的客户端/服务器协议(最初来自 Anthropic,现作为开放标准被治理),规定一个 AI agent 如何连接到外部工具、数据和提示词。被反复提起的那个说法是「AI 工具的 USB-C」:一个协议,多个实现,换任一边都不破坏另一边。这个说法是准确的;像所有比喻一样,它有值得点明的局限。
MCP 是什么。 一个协议。一份规范。服务器能向客户端暴露的三种原语。
- 工具(Tools):模型能调用的函数。客户端把它们列出来,模型挑一个,服务器执行它。概念上类似上一门课里的一个
@function_tool装饰器,但实现住在 MCP 服务器进程里,而不是 agent 的进程里。这是用得最多的原语,遥遥领先。 - 资源(Resources):agent 能取的只读数据。文件、数据库查询结果、API 响应。把它们想象成 MCP 里只读 GET 的那一面。实践中没工具那么常见,但对「让 agent 按需读这份文档」很有用。
- 提示词(Prompts):服务器提供的可复用提示词模板。一个团队可以发布标准化的提示词(「summarize-incident-report」),任何连到该服务器的 agent 都能调用。和工具、资源相比很少用。
三种传输,连同截至 2026 年的当前推荐:
| 传输 | 何时用 | 状态 |
|---|---|---|
stdio | 本地子进程;agent 和服务器在同一台机器上 | 成熟。本地工具的默认。 |
streamable HTTP | 远程服务器;生产部署 | 新的远程工作推荐用它。 走普通 HTTPS 的单一端点。 |
SSE | 远程服务器;较旧的部署 | 遗留。许多服务器仍暴露它;新的越来越多地默认用 streamable HTTP。 |
Streamable HTTP 有两种风味,部署时这个区别就要紧了。无状态(Stateless) 是该首选的默认:每次调用都是一个独立的请求和响应,和一次普通 API 调用一模一样,于是你能在一个负载均衡器后面跑许多份服务器副本,任何一份都能作答。有状态(Stateful) 保持一个活跃会话打开,于是服务器能把部分结果流式回送、或在任务中途推送通知,这是长时间运行的工作所需要的,但它把每个客户端钉死在一份服务器实例上、运维起来也更费事。用无状态,除非你有一个具体理由(实时流、服务器主动发起的消息)需要那个打开的会话。
MCP 不是什么。
- 不是框架。 它是一个协议。你的 agent 不像用 Agents SDK 那样「用 MCP」;是你 agent 的 MCP 客户端对一个 MCP 服务器讲 MCP。Agents SDK 包含一个 MCP 客户端;那就是集成点。
- 不是服务。 没有「MCP 云」。MCP 服务器是你运行(或厂商替你运行)的程序。Neon MCP 服务器托管在
mcp.neon.tech;文件系统 MCP 服务器作为一个本地子进程运行;你写的一个自定义 MCP 服务器跑在你部署它的任何地方。 - 不是安全边界。 MCP 定义传输和协议;一个 MCP 服务器暴露什么工具、那些工具能做什么,是服务器的责任。一个恶意 MCP 服务器能做它服务端代码所能做的任何事。信任边界仍然是 agent 循环决定调用哪些工具,以及工具执行所在的那个沙箱。
- 不是
@function_tool的替代品。 两者都仍有各自的位置。决策树是概念 14。
快速核对。 对还是错:(a) 一个 MCP 客户端一次只对恰好一个 MCP 服务器讲话。(b) 同一个
@function_tool风格的函数,如果你愿意,既能作为一个 MCP 工具暴露、也能保留为一个函数工具,而模型察觉不出差别。(c) MCP 服务器和 OpenAI Agents SDK 紧耦合,所以要用 MCP 你就必须用这个 SDK。答案:(a) 错:一个 agent 能连到多个 MCP 服务器,看到它们工具的并集。(b) 对:对模型来说,两者都像是带 schema 的可调用工具。区别在于实现住在哪里。(c) 错:MCP 与模型无关。Claude、Gemini 和其他模型都有它们自己的 MCP 客户端。OpenAI Agents SDK 只是众多客户端之一。
与 AI 一起试
For each item, say which MCP primitive fits best (tool, resource, or
prompt), and why in one line:
A) The agent reads the current text of a policy document on demand,
but never writes it.
B) The agent issues a refund through the payment gateway.
C) Every Worker on the team should summarize incidents the same way,
from one shared, versioned template.
Then a judgment question. A teammate says: "We put the refund logic
behind an MCP server, so the agent can't do anything dangerous." Using
this concept's "what MCP is NOT," explain why that sentence is false,
and name where the real trust boundary actually lives.
概念 12:Neon MCP 服务器,开发平面,而非运行时
这个概念里的具体细节会过时。模式不会。 Neon 的 MCP 服务器工具、认证流程和确切的工具面每隔几个月就变。不变的是:一家托管数据库厂商通过 MCP 暴露它的 管理 API 以做自然语言操作,而运行时的生产流量用直连或受限的自定义服务器。在钉死具体细节前,对照 Neon 的文档 核验。
你在搭建时已经把 Neon MCP 服务器 连到了你的编程 agent,而且从那以后你一直靠着它:用大白话要 schema、查表里有什么、拉一个连接串。那个十五分钟的连接值得停下来想想,因为它教会整个这一 Part 里最重要的那一句话:Neon MCP 服务器是干什么的,以及它绝不能被接到什么上。
它把 Neon 的 管理 API(项目、分支、schema、迁移、临时 SQL)作为工具暴露出来,让你的 agent 能用大白话调用。那使它成为一个开发工具,而不是一个生产工具。 Neon 自己的文档很直白:「绝不要把 MCP agent 连到生产数据库。」
这条界线为什么这么难,原因在此。服务器的 run_sql 工具运行模型写的 任何 SQL。当你在构建时,那正是它的全部意义:你说「展示上周注册却从未登录的用户」,模型写出查询,服务器跑它,你拿到答案。把那同一个工具指向你的活动数据库,它就成了一扇门。任何能把指令塞进你 Worker 的人(一位敲一句措辞巧妙的消息的客户)都能让它读你的整个数据库,因为那个工具的活儿就是运行交给它的任何 SQL。
所以在它出彩的地方继续用它,开发期间的全部:
- Schema 和迁移。 「给 tickets 表加一个
priority列。」服务器先在一个用完即弃的分支上测这个改动,然后合并它。那个分支优先的习惯是演进 schema 的安全方式。 - 探索你自己的数据。 「里面有多少个 embedding,按来源分组?」比为一个一次性问题手写 SQL 更快。
- 查东西。 连接串、项目设置、表的形状,不必打开 Neon 控制台。
你在搭建时见过这个:你让你的 agent 创建项目、打开 pgvector、跑 schema、并报告连接串,它就通过这些工具把这一切都做了,在碰 main 之前先在一个分支上测那个迁移。没有手敲一行 SQL。
PRIMM,预测。 你做好的客户支持 Worker 需要:(a) 查一位客户的订单;(b) 查他们等级的退款政策;(c) 签发一笔退款;(d) 写一行它做了什么、为什么的审计行。它应当通过这同一个 MCP 服务器够到 Neon,还是用别的方式?信心 1–5。
答案:用别的方式,四个全部都是。 一名活动 Worker 绝不该持有一个 run_sql 风格的工具,那是一扇你锁不严的门。它需要的是几项窄能力,而不是运行任意 SQL 的权力。两个生产模式是一个只暴露它所需具体操作的 自定义 MCP 服务器(概念 14),或者一个把它们包起来的直连 Postgres。Part 4 两者都用:一个用于业务操作的自定义 customer-data 服务器,以及一个 只 给审计子系统的直连(决策 7 解释为什么审计要待在它所审计的那条 MCP 边界之外)。
这正是不变量 5:劳动力通过 受治理的 存储来读写。一个宽泛的 run_sql 工具不是治理,它是给「毫无治理」贴的一张友好的脸。Neon MCP 服务器是 你 构建那个存储的方式。它不是你的 Worker 触及它的方式。
与 AI 一起试
Read Neon's MCP server documentation page and answer three questions:
1. List THREE management operations the Neon MCP server exposes that
would be useful while you're building a customer-support Worker.
2. List THREE things a running Worker NEEDS to do that you should NOT
use the Neon MCP server for, and why.
3. For each of the three in (2), say what the Worker should use instead
(direct Postgres connection? custom MCP server? function_tool?).
概念 13:把 MCP 接到 OpenAI Agents SDK
你一直在从你的编程 agent 驱动 Neon MCP 服务器。你的 Worker,那个你在 Part 4 里构建的,是一个不同的程序:一个 OpenAI Agents SDK agent。所以这个概念回答的问题很简单:那个 agent 怎么跟一个 MCP 服务器讲话?你不会手写那些连接管道,SDK 自带它们。值得理解的是它的形态,好让你能掌舵这次构建、并在它出岔子时调试它。
整幅图景在此。SDK 有一个内置的 MCP 客户端,每种传输一个连接器:一个给 stdio 的本地连接器、一个给远程 streamable HTTP 的现代连接器,以及一个给 SSE 的遗留连接器(任何新东西都避开 SSE)。你打开一个到服务器的连接、把它交给你的 agent,从那以后 SDK 包办一切:它问服务器有哪些工具、把那些工具摆在模型面前、紧挨着你自己写的那些 @function_tool,而当模型挑了一个时,它把调用路由到正确的服务器、再把答案取回来。模型分不清一个 MCP 工具和一个本地函数工具,而它也不需要分清。 那种一致性正是关键:MCP 不过是把一项能力交给模型的又一种方式。
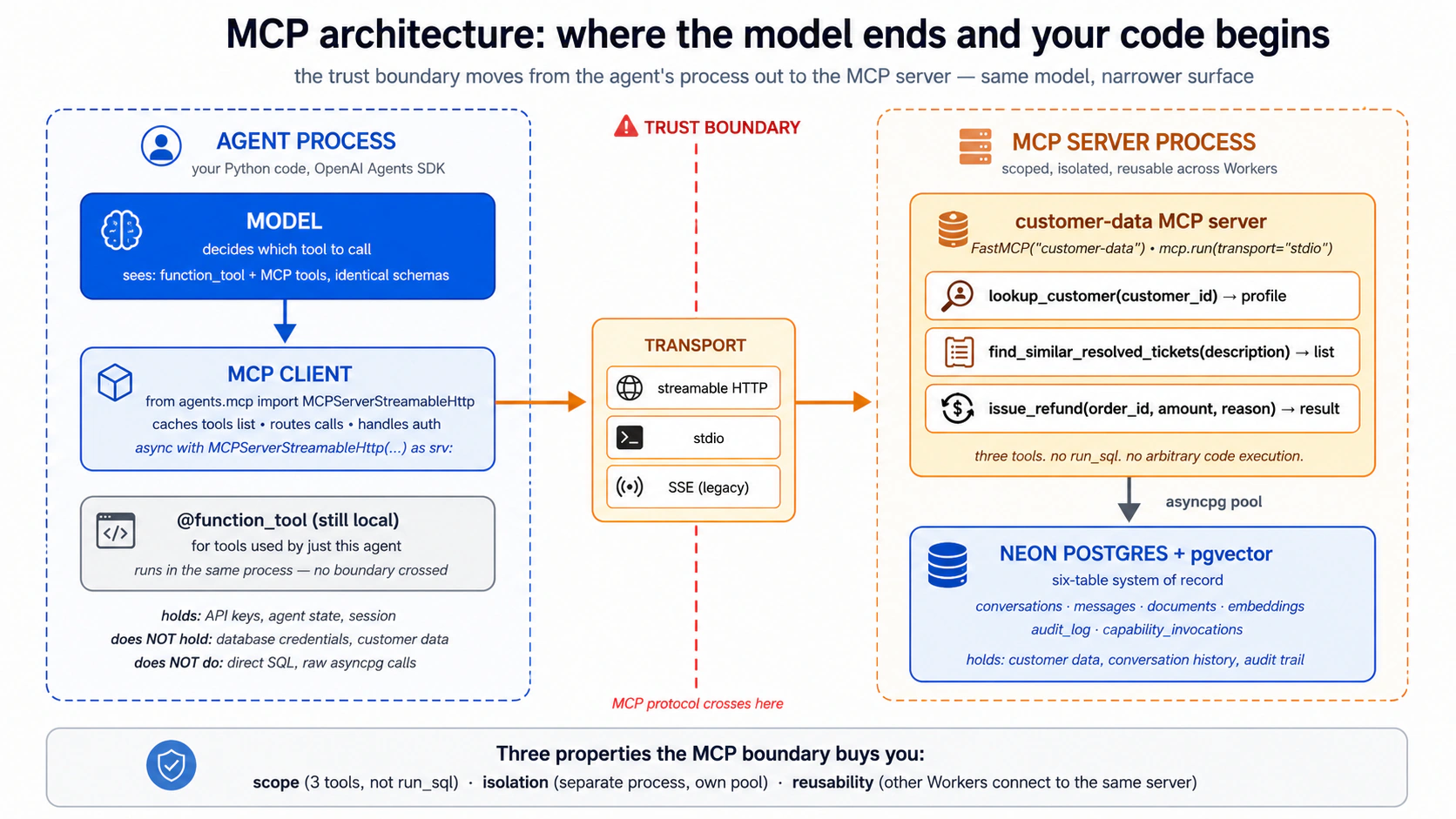
四件要记住的事,一旦你提出要求,你的 agent 全都替你处理:
- 干净地打开连接,干净地关闭它。 一个 MCP 连接持着某样打开的东西:stdio 的一个子进程、远程的一个 HTTPS 会话。如果不被正确关闭,连接就泄漏。SDK 的连接对象被设计成作为一个受管理的代码块来打开和关闭,所以只要你不跟它对着干,这就被处理好了。
- 在生产中缓存工具列表。 默认情况下 agent 每一次运行都重新问服务器「你有哪些工具?」,一次白白浪费的网络往返。打开缓存让它只问一次。唯一的注意点:如果你改了服务器的工具,你就告诉 agent 刷新缓存(或重启它)。构建时让缓存关着,好让改动立刻显现。
- 服务器可以叠加。 你能一次把好几个 MCP 服务器交给你的 agent,模型就只看到那些工具合并起来的集合。Part 4 的 Worker 就这样连到它的自定义
customer-data服务器。 - 把危险工具挡在审批后面。 默认情况下工具调用不经确认就跑。对敏感的那些,你可以要求一个人逐次批准每个调用。这是概念 12 里开发与运行时那道鸿沟的实际旋钮:即便你手动使用 Neon MCP 服务器,把它的破坏性工具(任何会删或重写的)挡在一个审批提示后面,也是一次实打实的安全收益。
一个值得记下的坑:如果一个 MCP 服务器在启动时加载某样重的东西(比如一个机器学习模型),agent 默认的「服务器及时应答了吗?」的窗口可能太短,你就会看到一个令人困惑的连接失败错误。修法是一个延长那个窗口的单一设置。只有当一个服务器在它启动那一刻就做实活时,你才会碰到这个。
动手,仅供理解。 这是把那个形态变具体的最快方式。把下面的提示词粘进你的编程 agent。它构建一个小小的、用完即弃的脚本,把一个 OpenAI Agents SDK agent 指向你已经连好的那个 Neon MCP 服务器,让你看着 agent 用大白话列出你的项目。这是个学习练习,不是生产路径:一名真实的 Worker 绝不连 Neon MCP 服务器(概念 12)。你只在这里、只这一次做它,为的是看一个 Agents SDK agent 端到端地驱动一个 MCP 服务器。
Write me a small throwaway Python script (call it scratch_neon_agent.py)
that uses the OpenAI Agents SDK to connect to the Neon MCP server over
its remote streamable-HTTP transport, then runs one agent turn asking it
to "list my Neon projects and show the schema of the largest one."
Use the current OpenAI Agents SDK MCP classes (check the docs for the
exact import and class name). Open the connection as a managed block so
it closes cleanly, turn on tool-list caching, and print the final output.
Then run it and show me what the agent did, step by step. Remind me in a
comment that this is for understanding only and a real Worker should
never connect to the Neon MCP server.
看会发生什么:agent 连上,SDK 拉进 Neon 的工具,模型自己挑了 list_projects,你拿到一个英文答案。你刚看到的,正是你 Part 4 的 Worker 将要用的同一套接线,只不过指向了一个它在生产中不该用的服务器,而那正是你把这个脚本扔掉的原因。
与 AI 一起试
Explain, in plain language and without writing code, how you would
connect one OpenAI Agents SDK agent to TWO MCP servers at once: the
Neon MCP server (remote) and a local filesystem MCP server for reading
project files. Cover:
1. Which transport each server would use, and why.
2. How the model decides which server's tool to call.
3. Which tools you'd put behind human approval, and why.
4. One thing that could go wrong with two servers connected, and how
you'd notice it.
概念 14:自定义 MCP 服务器,何时写自己的、何时不写
Neon MCP 服务器是 通用 的:它能做 Neon 的 API 能做的任何事。那是它在开发上的强项,也是它在运行时的弱点。一个自定义 MCP 服务器把这个权衡反过来:窄窄的面、没有通用的 run_sql,只有你 Worker 实际需要的那些具体操作。
决策树,按优先级排序。
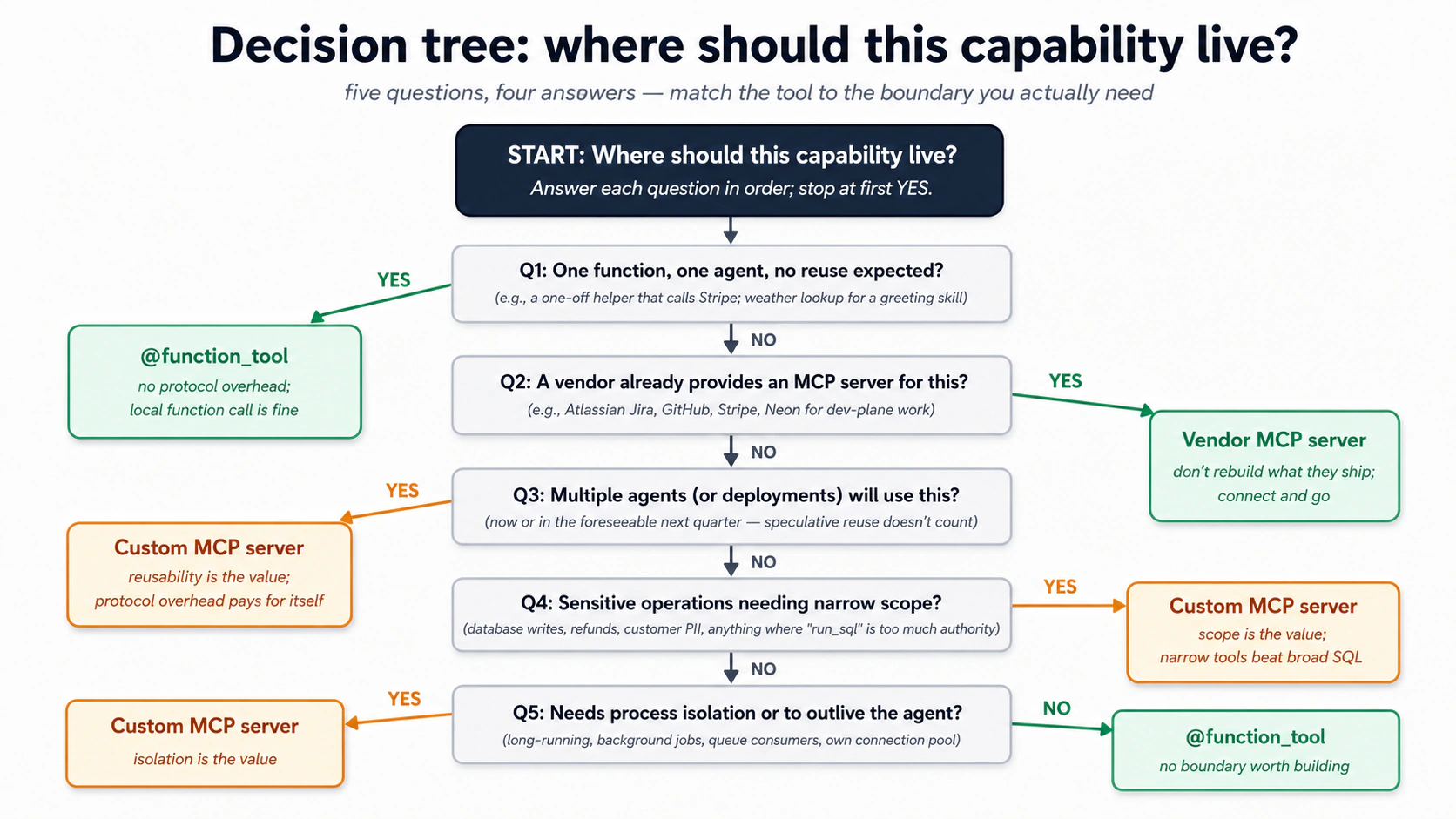
同样的逻辑,用一张速查表:
| 你想暴露…… | 用这个 | 为什么 |
|---|---|---|
| 一个函数、一个输入、一个 agent 用 | @function_tool | 不需要协议开销。一次本地函数调用就行。 |
| 几个与你 agent 代码紧密耦合的函数 | @function_tool | 如果它们和 agent 共享状态、住在同一个仓库里,它们就是 agent 的一部分。 |
| 一项多个 agent(或多个部署)会用的能力 | 自定义 MCP 服务器 | 协议正是让它可复用的东西。 |
| 一项需要比 agent 进程活得更久的能力 | 自定义 MCP 服务器 | 长连接、后台作业、队列消费者。 |
| 厂商提供的功能(Neon、GitHub、Linear) | 厂商的 MCP 服务器 | 别重建他们已交付的东西。 |
| 需要窄范围的敏感操作 | 自定义 MCP 服务器 | 恰好定义你需要的工具;别的都没有。 |
一个自定义 MCP 服务器的形态比听上去简单。 它是一个声明少数几个命名工具的小程序。每个工具有一段大白话描述(和一个 SKILL.md 携带的那种触发文本同一类),告诉模型何时去够它,以及一份简短的有类型输入列表,好让模型知道要传什么。就这样:几个描述清晰的窄工具,别的没有。没有通用 run_sql,没有逃生口。
而你不手写那个程序。和你已经安装 skills、让你的 agent 干活同一个方式,有一个 mcp-builder skill,它把一段范围描述变成一个可用的、测过的服务器。你的判断花在 范围 上,哪些工具存在、每个被允许做什么、以及哪些故意不存在,而不花在管道上。提示词流程长这样:
/mcp-builder Let's design a custom MCP server called "customer-data"
on the streamable-HTTP transport, stateless flavor (each call an
independent request, no open session, so it scales). Plan the
implementation first, then build it.
Scope: exactly three tools, nothing else.
- lookup_customer(customer_id): return id, email, tier, open-ticket count
- find_similar_resolved_tickets(description, limit): semantic search over
past resolved tickets
- issue_refund(order_id, amount_cents, reason): issue a refund (amount in
integer cents, never a float) AND write an audit row in the same transaction
No general SQL tool. Each tool gets a clear description so the model
knows when to call it. Start a fresh project with uv, walk me through
the plan before writing code, then build and verify it.
agent 脚手架出一个新的 uv 项目、规划工具、构建服务器、并验证它能跑。一旦它存在,你就用你已经见过 MCP 服务器被连接的同样两种方式连接它:连到你的 通用编程 agent(Claude Code 或 OpenCode,好让你手动测它)和连到你的 OpenAI Agents SDK Worker(好让 Worker 真能用它)。Part 4 的决策 6 端到端走这次构建。
这个服务器给你三样 @function_tool 给不了的东西。
-
进程隔离。 MCP 服务器跑在它自己的进程里(stdio 的子进程、streamable HTTP 的独立服务)。服务器里的一次崩溃不会崩掉 agent;服务器里的一处内存泄漏不会泄漏到 agent 里。
-
范围。 服务器只暴露你定义的那少数几个工具(worked example 的
customer-data服务器有三个)。没有run_sql。没有「执行任意代码」。模型逃不出这个范围,因为那个 协议 不暴露别的任何东西。这是一道实打实的纵深防御:即便模型决定做某件蠢事,能让它得逞的面积也就那几个函数。 -
跨 agent 复用。 第二个 agent(一名销售 Worker、一名报告 Worker)能跟同一个
customer-dataMCP 服务器讲话。同样的范围、同样的协议、同样的信任边界。那项能力成了一块共享的基础设施,而不是 agent 之间的一次复制粘贴。
这个权衡是真实的。 自定义 MCP 服务器增加运维复杂度:又一个要部署的进程、又一套日志、又一次网络跳转(如果是远程的)、又一个要管理的版本。别为一个 agent 用的一个函数写一个。当那项能力将被复用、当范围要紧、或当隔离为你买到安全时,才写一个。
PRIMM,预测。 你在设计那个客户支持 Worker。你需要:(1) 在过往已解决工单上做语义检索;(2) 写一行退款审计行;(3) 读当前天气(用在一个说「good morning from sunny Karachi」的问候 skill 里);(4) 调支付网关签发一笔退款。对每一个,预测:
@function_tool、自定义 MCP 服务器,还是厂商 MCP 服务器(例如 Stripe 的,如果存在的话)?
那些答案把这个框架带了出来:
- 自定义 MCP 服务器(
customer-data)。 跨 agent 复用;敏感数据;受限工具胜过一个宽泛的run_sql。 - 自定义 MCP 服务器(
customer-data)或@function_tool。 都行;如果 Worker 是唯一的写入者,函数工具就行。如果多名 Worker 都会写审计行,那就用 MCP 服务器。 @function_tool。 一个 agent、一个小函数、没有要防的安全面。别为它建一个服务器。- 厂商 MCP 服务器(Stripe MCP)如果存在,否则一个调 Stripe API 的
@function_tool。 别把第三方 API 包进你自己的 MCP 服务器,除非你需要在上面加一层策略。
一旦你顺着它走,这个框架就很清楚:MCP 的价值随它所创造的那条边界的价值而上升。 一条你不需要的边界就是开销。
与 AI 一起试
把这段粘进你的编程 agent。它把决策树套用到你正在真实构建的那个客户支持 Worker 上,于是每个选择都是你能交付的,而不是对你手头没有的基础设施的一次猜测。
Here are five capabilities I'm thinking of adding to my customer-support
Worker. For each, walk the Concept 14 decision tree with me and recommend
one: a @function_tool, my custom customer-data MCP server, or a vendor
MCP server (if a credible one exists). Justify each choice with ONE of
the three properties (isolation, scope, reusability), or say plainly why
no boundary is worth building.
1. Look up a customer by email (the gap Decision 8 leaves open).
2. Issue the real refund through Stripe (actual money, third-party API).
3. Send the drafted reply as an email through our mail provider.
4. Convert a UTC timestamp to the customer's local time for a greeting.
5. Let a second Worker (a sales assistant) reuse the customer lookups.
Then push back on me: which TWO of these would you deliberately NOT put
behind a custom MCP server, and what does that say about when the
boundary earns its cost?
概念 15:负载下的 MCP:传输、连接池,以及规模上发生什么
一个 agent、一个服务器的演示就是能跑。真实流量,一分钟许多段对话,会带来三种压力。对第一名 Worker 你不需要为这些采取行动,但知道它们存在能省你以后一个困惑的下午。每一个都有一个朴素的修法。
- agent 和服务器之间的那根线。 当一切都跑在一台机器上时,一个本地子进程(stdio)就行。一旦不止一个 agent 共享那个服务器、或者服务器搬到它自己的硬件上,就切到远程传输(streamable HTTP)。那是一次部署改动,不是一次重写。
- 别一遍又一遍付同一份搭建成本。 三个小习惯把重复成本变成一次性成本:在 Worker 启动时连每个服务器一次并保持那个连接打开,而不是每次请求都重连;让 agent 记住服务器的工具列表,而不是每次运行都重问「你能做什么?」(改了工具时刷新它);在服务器内部保持一个就绪的数据库连接池,于是一次查询不必每次都等着打开一个新的。一个长寿命 Worker 在一个缩容到零或带连接池的 Postgres(Neon)上会撞到的怪事:连接池会关掉空闲连接,所以如果进程阻塞了(一个终端
input()提示冻住了 asyncio 事件循环),下一次写入就会以 "connection was closed in the middle of operation" 失败。把阻塞式提示挪出事件循环(asyncio.to_thread),并让连接池在那个错误上重新获取一次。 - 给一切设一个上限,并让 trace 保持完整。 给一次请求最多能走多少步设上限、给一次失败的工具调用在放弃前重试一两次、并给服务器限流,好让一次突发不能把它淹没。还要确保你的 trace 跨过 MCP 边界跟住那次调用:当 Worker 调一个工具时,你想要服务器 自己的 数据库工作出现在同一幅图里。否则服务器内部一条慢查询从外面看不见,你就会在错误的地方追那个延迟。
更深的旋钮(按租户的并发上限、精细的传输调优)超出了第一名 Worker 所需。上面这三个是最先咬人的。
快速核对。 对还是错:(a) 把一个服务器从遗留的 SSE 传输换到 streamable HTTP,迫使你重写服务器的工具。(b) 让 agent 缓存一个服务器的工具列表在生产中是安全的,只要你在改了工具之后刷新缓存。(c) 把五项能力作为 MCP 工具暴露,总是比把同样五项作为本地函数工具暴露花模型更多的上下文预算。答案:(a) 多半错:工具没变;服务器只需讲那个更新的传输,多数现代服务器已经会了。(b) 对:那正是预期的模式。(c) 错:对模型来说一个工具就是一个工具。五个工具描述无论住在哪一边都花差不多的量。
与 AI 一起试
My customer-support Worker is in production. It runs 80 conversations/minute
at peak. Each conversation makes 2-4 MCP tool calls on average. I'm seeing
intermittent latency spikes: most calls return in 200ms, but a small
percentage take 5-15 seconds.
Walk me through five places I'd investigate, in order of priority:
1. The agent-side MCP client connection management.
2. The transport choice between agent and MCP server.
3. The MCP server's internal connection pool to Postgres.
4. Postgres-side query performance (slow queries blocking the pool).
5. Network or DNS issues between agent and MCP server.
For each, name the specific signal I'd look for and the rough fix.
Part 4:worked example,客户支持 Worker
一次真实的构建,用上上面每一个概念。你从一个最小的聊天 agent 起步(一条提示词,约一分钟),然后把同一个 worker 一块一块地长成一名客户支持 Worker。每个决策加一块,先是系统记录,再是 Skills,然后是 MCP 层,最后是审计轨迹,而你每次都重跑那个 worker,于是你在往下走之前先看到新的一块跑起来。八个决策构建那个 worker;第九个把一个人放在那唯一一个动钱的动作前面。

第 0 步:立起聊天 agent(一条提示词,约 1 分钟)。 好让每个人都从同一个地方开始决策 1。(做过 构建 AI Agent?打开那个项目就行,它是同一个 agent,直接跳到决策 1。)
In this digital-fte folder, build me a small terminal chat agent with the
OpenAI Agents SDK: a uv project, a gpt-5-class model, on a local sandbox.
Check the current SDK docs for the API. Get it answering "hi", then stop,
we grow it in the steps below.
创建:worker 文件(例如 worker.py)连同它的 uv 项目。
核对。 你发 "hi",它回答。那就是起跑线;决策 1 通过
AGENTS.md教它这套新架构。
任务简报
把第 0 步那个最小聊天 agent 演进成一名 客户支持 Worker,它要:
- 按需加载三个 Skills:
summarize-ticket、find-similar-cases和escalate-with-context。 - 从一个带概念 7 那五张表的 Neon Postgres 系统记录读取并写入(对话回合住在同一数据库上的 SDK Session 里)。
- 用 pgvector 在一个由过往已解决案例组成的小库上做语义检索。
- 在运行时通过一个受限的自定义 MCP 服务器(
customer-data)跟 Postgres 谈 业务数据,绝不用 Neon MCP 服务器、也绝不在 agent 代码里直接用asyncpg。 - 为每个有意义的动作写一行审计行(每次调 skill、每次数据库写入、每次考虑退款),通过它 自己的直连,那条故意绕开 MCP 边界的路径,好让审计轨迹不会被它所审计的那个系统饿死。
「结尾验证」的检验:一位客户发来「I haven't received my refund from order #4429, it's been two weeks.」Worker 通过向量检索找到三个相似的过往案例,起草一份引用最相似案例处理方式的回复,并写一行它做了什么的审计行(而且,在一次真实部署里,如果客户是 Pro 等级就升级)。从消息里解析出确切的客户或订单记录,需要一个你稍后才加的查找工具;决策 8 会指出那个缺口在哪里。
如何读接下来的提示词。 你通过一次只给你的编程 agent 一个小任务来长这个 Worker,而每个决策都以同样的方式收尾:新的一块被接进那一个 worker、你跑它,于是你在下一个决策建立其上之前先看到它跑起来。你不会敲 SQL、Python 或配置:agent 写它,你掌舵并核对。你的 agent 在打开文件夹时就已读过
AGENTS.md,所以它懂这个项目;你的提示词保持简短。两个习惯:
- 一步,一个任务。 粘那一步的提示词,别的什么都不粘。对任何写真实代码的,提示词都说「先做计划」:读计划、回推、批准,然后让它构建。
- 下一步之前先核对。 每一步都以一个 核对 收尾:一个你问的大白话问题(「show me X」)。在它通过之前别往下走,否则你会在发现第一步错了之前已经走出去四步。
决策 1:用新架构更新规则文件
你在哪里:一个回答 "hi" 的最小聊天 agent;这个决策把三条架构规则加进 AGENTS.md;到结尾你会在那个文件的 diff 里看到那些规则。
你的 agent 已经从 AGENTS.md 懂了这个项目。它还不知道的,是这门课的架构所加的那几条规则,所以你现在就把它们写进 AGENTS.md,于是后面每条提示词都能保持简短。一个任务。
第 1 步:把新规则加进 AGENTS.md。
Add a short "Rules" section to AGENTS.md so a fresh session follows these:
- business data is read and written only through the customer-data MCP
server, never raw SQL from the running worker
- the audit log uses its own direct database connection, and each action
and its audit row are committed together
- embeddings use the same model to store and to search
Show me the diff before you write it.
编辑:AGENTS.md。
核对。 读那个 diff。那三条规则都在,用大白话写着,尤其是第一条:正是它后来挡住模型悄悄绕过 MCP 边界。如果 agent 软化或丢了某一条,重新提示。
为什么。 一个弱的规则文件几周后会静默失败,就在模型走了那条规则本要禁止的捷径之时。现在就写它,正是让这之后每条提示词都保持简短的原因。
决策 2:规划 schema 和 Skill 集
你在哪里:一个陈述了架构但还没有为它做任何设计的 AGENTS.md;这个决策加一份评审过的书面计划;到结尾你会看到一份你回推过并批准的 markdown 计划。
你以一份在一行代码存在之前你就评审过的书面计划结束这个决策。一个任务。按 Shift+Tab 两次进入 Plan 模式(在 OpenCode 里,按 Tab 切到 Plan agent):模型能读你的项目但不能编辑任何东西。
第 1 步:拿到计划。
Plan the customer-support Worker evolution of this project. The
foundation (OpenAI Agents SDK, your sandbox runtime, sessions, streaming,
guardrails) stays. We're adding:
1. Three Skills: summarize-ticket, find-similar-cases, escalate-with-context.
For each, propose: the description, the operational shape (script-driven
or instruction-driven), and what reference files it needs.
2. The five-table schema from Part 2 Concept 7, plus any tables specific
to a customer-support domain (probably: customers, orders, tickets, refunds).
3. The custom MCP server (customer-data), with exactly the runtime tools
our agent will need. Propose the tool list and signatures. No run_sql.
4. The audit-logging plan: what writes an audit row, what doesn't.
Output the plan as a markdown file at plans/customer-support-worker-plan.md.
Do not write code yet.
For reference the part 2 here: https://agentfactory.panaversity.org/docs/digital-fte-crash-course
创建:plans/customer-support-worker-plan.md。
核对。 读那份计划,并对第一版草稿通常会弄错的两样东西回推:含糊的 Skill 描述(「Summarizes tickets」,一个永远不会正确触发的描述,概念 3)和 过宽的 MCP 工具输入(「query: string」,那不过是伪装的
run_sql;lookup_customer应当接受一个customer_id,而不是你拿来拼 SQL 的自由文本)。在这两样都收紧之前别批准那份计划。
为什么先做计划。 这两种失败模式一旦构建出来就要花几小时,而在一份 markdown 计划里改只要几分钟。这是整个这一 Part 里出错代价最低的地方。
你正要第一次碰数据库,而你会在决策 3 到 8 里看到大量 SQL。你从不手敲它或手动跑它。 三个组件拥有它,而且有 两个不同的 MCP 服务器 在做两件不同的活。
| SQL / 数据路径 | 谁写它 | 谁跑它 | 何时 |
|---|---|---|---|
| Schema + 迁移(这个决策) | 你描述它;agent 起草它 | Neon MCP 服务器(一个你连到 agent 的开发工具) | 一次,搭建时 |
| 验证查询(「完成标志」核对) | 课里给出 | Neon MCP 服务器 的 run_sql,由你用大白话驱动 | 确认一步成了 |
| 运行时业务 SQL:查找、向量检索、退款(D6) | mcp-builder 生成它 | 你构建的 customer-data MCP 服务器 | 每次客户交互 |
| 审计写入(D7) | 审计子系统代码 | 一个单独的 asyncpg 连接池(无 MCP) | 每个动作 |
两个 MCP 服务器,从不混淆。 Neon MCP 服务器(你在上面搭建步骤里认证过的那个)是一个开发工具:你用它来用大白话开通并验证数据库,而你从不在运行时用它。customer-data MCP 服务器 是你在决策 6 里构建的那个受限服务器;运行中的 Worker 跟那一个、而且只跟那一个谈业务数据。概念 12 解释为什么生产中一个通用 run_sql 是一个 prompt 注入漏洞。
读、写、删不是同等权限。 运行中 Worker 的工具按风险分开:
- 读(
lookup_customer、find_similar_resolved_tickets,在 D6 构建):自由跑,无关卡。读放行起来很便宜。 - 写(
issue_refund,在 D6 构建):那唯一一个动钱的工具。你在决策 9 里、在 Worker 端到端跑通之后,把它挡在人工审批后面,好让一个人在任何退款放行前签字。审计写入是只追加的:只插入,从不更新或删除。 - 删 / schema 变更(
CREATE/DROP TABLE、DDL):运行时根本不可调用。 自定义服务器从不暴露一个 DDL 工具,所以没有任何东西要审批。Schema 变更只在开发时(这个决策)发生,通过 Neon MCP 服务器、在一个临时分支上,在它们碰main之前。
经验法则:读自由跑,写被关卡挡着,结构性变更从不经由 agent 抵达生产。
决策 3:开通 Neon 并跑 schema 迁移
Neon 的免费层覆盖一名 Part 5 所假设那个量级(约 200 段对话/天)的单一 Worker。在这里就按 $0/月 来打算。免费计划的限额是每个项目 0.5 GB 存储和 100 个计算小时(Neon 定价);超过之后,Launch 层是按量付费(大约 $0.11/CU 小时 + $0.35/GB 月),而一个 worked-example Worker 通常保持在 $25/月 以下。完整拆解见 Part 5 的成本形态表。
你在哪里:一份批准过的计划但还没有数据库;这个决策加一个带你 schema 的活动 Neon 数据库和一个持久的 Session;到结尾你会在 Postgres 里看到九张表、以及一个能回忆起先前回合的 worker。
你以一个持有你 schema 的活动 Neon 数据库、加上一个把对话回合持久化进它的 Session 结束这个决策。四个小步,而且你在下一步之前核对每一步,因为一个坏掉的数据库步骤是看不见的,直到下游某样东西读到空。按 Shift+Tab 退出 Plan 模式,并确保 Neon MCP 服务器已连接(概念 12)。agent 通过 Neon MCP 工具跑这一切;你从不打开一个数据库控制台。
第 1 步:创建项目。
Create a fresh Neon project called "chat-agent" and give me the
connection string for its main branch.
核对。 让 agent 确认项目存在,并把
main连接串粘回来给你。(你也能在 Neon 控制台里看到它。)在手里没有一个连接串之前别继续。
第 2 步:打开 pgvector。
Enable the pgvector extension on the chat-agent database.
核对。 「确认
vector扩展现在列在数据库上。」如果没有,下游任何存 embedding 的东西都没法工作,所以在它列上之前就停在这里。
第 3 步:应用 schema,分支优先。
Apply our schema to chat-agent: the five-table core from Concept 7
(conversations, documents, embeddings, audit_log, capability_invocations)
plus four domain tables, customers, orders, tickets, refunds. Build the
audit_log and capability_invocations columns EXACTLY as Concept 7 prints
them: audit_log keeps its `target` column and the closed `action` CHECK
set, capability_invocations keeps its `status` CHECK set, so Decision 8's
replay query matches the schema you built. Test it on a temporary branch
first, then merge to main. Plan the DDL first; I'll approve before you merge.
核对。 「数一数 public schema 里的表,我预期九张,并确认 embeddings 索引存在。」九张表意味着迁移落地了。如果少了,说明合并没干净地应用:让 agent 在一个全新分支上重跑。(这正是概念 12 的开发用例:用大白话做 schema 活、在一个分支上测、只在你「放行」之后才合并到
main。)
大致你应当看到:
table_count = 9
embeddings index: present
第 4 步:给 worker 它的 Session,并证明它记得。
Write the connection string to .env as NEON_DATABASE_URL, then give the
worker a SQLAlchemySession on that database so it remembers across turns.
Install what the session needs (the sqlalchemy extra, asyncpg, pgvector,
and greenlet), and use the postgresql+asyncpg:// form of the URL for it.
编辑:worker 文件(加上 Session);把 NEON_DATABASE_URL 写进 .env。
核对。 跑一段两回合对话:告诉 worker 你的名字和一个订单号,然后在第二回合让它把它们复述回来。它把两个都回忆起来,那就是 Session 在干它的活,而不只是一行坐在一张表里。然后问:「在
agent_messages表里把那些回合展示给我看。」 在 Postgres 里看到它们,就证明了状态现在住在系统记录里,而不只是在内存里。(agent 常漏的两件事:[sqlalchemy]extra 不会带进greenlet,所以它需要uv add greenlet;而那个异步引擎需要 URL 的postgresql+asyncpg://形式,不是裸的postgresql://。SQLAlchemySession替你创建agent_sessions和agent_messages。)
决策 4:定义并验证第一个 Skill,summarize-ticket,然后把它接进来
你在哪里:一个记得但还没有可移植能力的 worker;这个决策把三个 Skills 加到磁盘上、并把它们接进 worker;到结尾你会看到一个在一次真实运行里触发。
你以三个在磁盘上的 Skills 结束这个决策,第一个对照你设定的标准被 验证 过,而 Skills 能力被接进 worker,于是你看着它触发。这里有一个相对人们通常怎么写 skills 的转变:你不手写那个 skill 再用眼睛过一遍。你告诉 skill-creator 这个 skill 该何时触发、一个好结果长什么样,而它对照那些标准来构建、测试并收紧这个 skill。定义成功并评判结果,是一位领域专家在现实世界里做的活;下面的撰写是工具的活。
第 1 步:确认 skill-creator 可用。 你早在 base 准备里就装过它(连同 mcp-builder 和 neon-postgres),所以它就坐在 .claude/skills/ 里,你在这里不重装它。只有当它不知怎么不见了才重新加它:
npx skills add https://github.com/anthropics/skills --skill skill-creator --agent claude-code -y
核对。
skill-creator在.claude/skills/里就位。(一次安装服务了两个工具:OpenCode 把.claude/skills/当作回退来读,所以从来不存在一个单独的--agent opencode安装要跑。)
第 2 步:定义这个 skill 做什么、何时触发。 skill-creator 向你要那两样只有你能决定的东西,触发器和产出。把两样都用大白话一开始就给它,让它起草。
Use skill-creator to build a summarize-ticket skill. Here is the spec.
Output: turn one support ticket into a five-section handoff (Customer
Context, Issue, Resolution Steps Taken, Current Status, Recommended Next
Action). It SHOULD fire on phrasings like "write a handoff note for #4471",
"TL;DR this thread", and "where does this stand before I escalate",
including ones that never say "summarize". It should NOT fire on drafting a
customer reply, triaging a batch, or reporting on ticket volume. Draft the
skill from that, then we'll test it.
创建:.claude/skills/summarize-ticket/。
核对。
.claude/skills/summarize-ticket/下存在一份草稿,而它的description反映出 你的 触发 / 不触发列表,而不是一个通用的「summarizes tickets」。那个描述是那唯一一个决定这个 skill 是否会跑的输入(概念 3);你把它作为可测试的标准交了出去,而不是去猜措辞。
第 3 步:让 skill-creator 测它并收紧它。 这是取代用眼睛过描述的那部分。skill-creator 把你的触发 / 不触发列表变成触发 eval、跑它们,并改进描述,直到这个 skill 该触发时触发、不该时保持安静。
Test summarize-ticket against the fire and don't-fire cases I gave you:
turn them into trigger evals, run them, and tighten the description until
it passes. Show me which cases pass and which fail, before and after.
核对。 你读的是那些 eval 结果,而不是原始描述:这个 skill 在交接、TL;DR 和状态那些说法上触发,在那些近似项(起草一份回复、批量分诊)上保持安静。那张通过 / 失败表,是概念 3 那个「删掉关键词、看它是否还说得清何时触发」直觉的严谨版本。模型仅凭它的描述就决定是否跑这个 skill,所以把那张表弄绿就是整盘棋。
两个工具,一套纪律。 在 Claude Code 里,skill-creator 把这跑成一个自动化循环:它把你的案例分成一个训练集和一个留出集、每个跑几次以得到一个可靠的触发率、并在数轮里优化,保留在它没训练过的案例上得分最高的那个描述。在 OpenCode 里你手动跑同一个循环:定义案例、测、收紧、重复。自动化不同;对照真实说法验证触发器的那套纪律是相同的。
第 4 步:用同样方式定义另外两个 Skills。 同样的动作:定义每个何时触发、产出什么,让 skill-creator 构建它们。你不需要在三个上都跑完整的测试循环;在 summarize-ticket 上跑过一次就教会了你这个周期。给它每个的触发器和产出形态;它落定的描述应当读起来像下面这些。Worker 需要这三个都有。
# .claude/skills/find-similar-cases/SKILL.md (frontmatter only)
---
name: find-similar-cases
description: Searches the resolved-tickets library for tickets semantically similar to a customer's described issue, returning the top 3-5 with their resolutions, ranked by how closely each matches. Use when the user describes a problem, complaint, or symptom and you need to check whether the team has handled something similar before. Calls the find_similar_resolved_tickets MCP tool. Always run this BEFORE drafting a response, so the response can reference proven prior resolutions rather than inventing a new approach.
---
正文走这些步骤:
- 从上下文里抽取问题描述。
- 用
limit=5调find_similar_resolved_tickets。 - 在一张 markdown 表里把前三个连同它们的距离值展示出来。
- 把低置信度的匹配(距离高于约 0.3,越低越相似)明确标记为「no strong prior precedent found」。
指令「always run this BEFORE drafting」在干实活;没有它,模型有时会凭先验起草一份回复、根本不去看那个库。
# .claude/skills/escalate-with-context/SKILL.md (frontmatter only)
---
name: escalate-with-context
description: Packages a customer conversation for handoff to a tier-2 support agent. Produces a structured escalation note with customer profile, issue summary, what was already tried, why escalation is recommended, and the suggested specialist team. Use when (a) the customer is on the Pro or Enterprise tier AND the issue is unresolved after one round of investigation, (b) the customer's sentiment is clearly negative, (c) the issue involves billing >$500 or a refund decision, or (d) the user explicitly asks for a human.
---
正文先调 summarize-ticket 拿到结构化上下文,然后写一份六小节的升级说明(客户上下文、问题、已尝试的处理、情绪信号、推荐团队、建议 SLA)。描述里那四个明确的触发条件,正是阻止这个 skill 过度触发的东西;一个升级逻辑含糊的 Worker 会把一切都升级,那就违背了初衷。
核对。 两份描述都点名明确、具体的触发器,而不是「use when relevant」。尤其是
escalate-with-context:它那四个条件正是让它不在每条消息上都触发的东西。三个 Skills 现在都住在.claude/skills/里。
创建:.claude/skills/find-similar-cases/ 和 .claude/skills/escalate-with-context/。
第 5 步:把 Skills 能力接进 worker,看一个触发。 三个 Skills 在磁盘上了;现在 worker 自己得加载它们。在它的默认能力之上给它 Skills 能力,然后跑它。
Give the worker the Skills capability pointed at .claude/skills, on top of
its default capabilities, and run it from the project root with: "write a
handoff note for ticket #4471, refund delayed two weeks, customer Sam."
Show me the run so I can see the skill load.
编辑:worker 文件(加上 Skills 能力)。
核对。 这次运行展示出一个
summarize-ticket的load_skill调用,而回复以那五个小节回来:那就是 skill 在你自己的 worker 里触发,而不只是坐在磁盘上。如果 worker 反而自由写了一段摘要、没有load_skill出现,说明路径解析错了:Skills 从一个 相对于 worker 运行处 的路径加载,所以从项目根用一个相对的.claude/skills跑,而不是一个绝对路径。(在 macOS 上,/tmp下的一个绝对路径会静默加载零个 skills,完全没有错误,这是它能失败的最令人困惑的方式。)还有一个:你把 Skills 加到 默认能力上,你不替换它们,否则 worker 就丢了它依赖的文件系统和 shell。
大致你应当在这次运行里看到:
tool call: load_skill(name="summarize-ticket")
reply: Customer Context / Issue / Resolution Steps Taken / Current Status / Recommended Next Action
为什么现在就接。 这是 Skills 不再是文件、成为能力的时刻:下一条提到工单的消息就仅凭它的描述触发这个 skill。另外两个 Skills 倚靠你接下来构建的 MCP 工具,所以 summarize-ticket 因为它能自立,是这里诚实可验证的那一个。
决策 5:构建 embedding 流水线并播种文档库
一个由几十张已解决工单、每张约 300 token 组成的种子语料,在 text-embedding-3-small 的每 1M 输入 token $0.02 下,embedding 起来花 不到一分钱。在 worked-example 的量级下,对新工单和对话的持续 embedding 通常保持在 $3/月 以下。成本的杠杆是推理预算,不是 embedding 预算。
你在哪里:一个表都空着的 schema 和一些没东西可搜的 skills;这个决策加一个播种过、embedding 过的过往已解决工单库;到结尾你会看到一次相似度检索返回排序过的匹配。
你以一个小小的、过往已解决工单库,已 embedding 且可检索,结束这个决策。两步。
第 1 步:用代码生成种子库。 Worker 的「库」是一组过往已解决工单:小到跑得快,又多样到检索有东西可分辨。你不手写它,也不去填一个 CSV;agent 生成它。
Have the worker's own SDK generate a dozen-plus varied resolved tickets as
structured data (a Pydantic model is the clean way): each with a customer
email, a one-line summary, and the resolution. Vary the issues across
refunds, logins, duplicate charges, and shipping, so semantic search has
something to tell apart. Write the generator and run it; don't hand me a CSV.
创建:工单生成脚本。
核对。 十几张以上生成的工单,跨越真正不同的问题(退款、登录、重复扣款、配送),而不是三种问题的换词版。你从没手敲过一行,而那正是关键:一名 Worker 自己的种子数据是这名 Worker 能生产的东西。
第 2 步:播种并 embedding。 每张生成的工单都带一个 customer_email,这让播种器在插入工单之前先找到或创建一行 customers(tickets.customer_id 外键是 NOT NULL)。然后:
Seed the generated resolved tickets so the Worker can search them later.
For each one: find-or-create the customer by email, insert a resolved
ticket, store the case text as a documents row tagged source='past_case'
with the ticket id at metadata->>'ticket_id' (there is no ticket_id column
on documents), then embed that text with
text-embedding-3-small and link the embedding to the document. Write one
audit_log row for the whole seed run. Plan first.
创建:播种与 embedding 脚本。
那个形态不是随意的,而且它是 agent 猜不出的那部分:决策 6 的 find_similar_resolved_tickets 通过把 embeddings 连到 documents(其中 source='past_case')再连到 tickets 来检索。如果种子没有照那个样子把行铺下来,决策 8 里的检索就静默返回空,而你将毫无头绪。agent 写实际的播种器;你在指定它必须产出的形态。结果里要确认的两条规则,都来自概念 9、也都已在你的 AGENTS.md 里:用你稍后查询时会用的 同一个 模型来 embedding,并在连接上注册 pgvector(否则向量会以垃圾写回)。
核对。 让 agent 把结果读回来:「数一数标记为 past case 的文档(应当与你生成的工单数相符),数一数 embeddings(也应当相符),确认只有一个 embedding 模型在场,并跑一次相似度检索,展示与 'refund delayed two weeks' 最接近的匹配排序回来。」 两种失败形态:如果它报告 两个 embedding 模型,说明种子中途混了模型,重置并重跑;如果计数回来是 零,说明播种器吞了一个错误,让它把它为这次播种运行写的那行
audit_log读回来(这正是播种器写一行的原因)。在一次相似度检索返回排序结果之前别走到决策 6。
大致那次相似度检索应当返回:
query: "refund delayed two weeks"
1. "refund not received after 14 days" distance 0.08
2. "duplicate charge, awaiting reversal" distance 0.24
为什么这是直连,而不是 MCP。 一个种子脚本是基础设施:它跑一次、手动地、由你来跑,不是 Worker 自己做的事。MCP 边界是给 agent 自主做的事用的;种子脚本是你做的事。 当坐在键盘前的是你自己时,别在你和你自己的数据库之间放一条边界。
决策 6:定义、构建并连接 customer-data MCP 服务器
那个自定义 MCP 服务器作为一个小服务和你的 Worker 一起跑;和它同主机时它不增加任何有意义的托管成本(只有当你把它推到独立硬件上时才出现一行计算费用)。账单真正显现的地方是推理:每次 lookup_customer 或 find_similar_resolved_tickets 调用都给下一个模型回合加上一个往返量的 token。概念 15 讲了负载下 MCP 的延迟和连接池大小那一面。
你在哪里:一个 worker 还在运行时够不到的播种库;这个决策加上那个受限的 customer-data MCP 服务器并把它接进来;到结尾你会看到 worker 在一条真实消息上调用它的一个工具。
你以那个受限的 customer-data 服务器跑起来、并接进你 worker,它三个工具能从一次真实运行里被调用,结束这个决策。它和决策 4 里的 Skills 是同一个形态:你定义这个连接器必须做什么、它保持多窄,mcp-builder 构建它,而你通过使用它来验证它。你掌舵范围;你不手写任何 FastMCP 样板。(给那唯一一个危险工具 issue_refund 加关卡,在决策 9,在整个东西跑通之后。)
第 1 步:确认 mcp-builder 可用。 和 skill-creator 一样,你在 base 准备里装过它,所以它已经在这里。只有当它不见了才重新加它:
npx skills add https://github.com/anthropics/skills --skill mcp-builder --agent claude-code -y
核对。
mcp-builder在.claude/skills/里就位。
第 2 步:定义工具契约和范围。 这是定义一个 Skill 标准的连接器版本:你说清楚哪些工具存在、每个接受什么、以及服务器保持多窄(没有通用 SQL),而 mcp-builder 来规划它。把它构建在 streamable HTTP、无状态风味 上(概念 11 的默认):每次调用都是一个独立请求,于是这个服务器是 Worker 靠 URL 够到的一个真实可寻址服务,而且流量增长时你能跑不止一份副本。(一个纯本地的单 Worker 构建可以用 stdio;那个无状态服务才匹配你实际会交付的东西。)
/mcp-builder Plan a custom MCP server called "customer-data" on the
streamable-HTTP transport, stateless flavor, with exactly three scoped
tools and no general SQL tool:
- lookup_customer(customer_id): return id, email, tier, open-ticket count.
Tier lives in customers.metadata->>'tier' (COALESCE to 'standard'); there
is no tier column.
- find_similar_resolved_tickets(description, limit): semantic search over
past resolved cases. Embed the description with text-embedding-3-small
(the SAME model the seed used) and register pgvector on the connection.
The search joins embeddings -> documents -> tickets, where the
documents->tickets link is documents.metadata->>'ticket_id' (there is no
ticket_id column on documents).
- issue_refund(order_id, amount_cents, reason): insert the refund (amount in
integer cents), set the order to refunded, AND write the audit_log row,
all in ONE transaction.
Give each tool a clear description so the model knows when to call it.
Show me the plan before any code.
核对。 在任何代码之前读那份计划:恰好三个工具、没有通用 SQL 工具,而
issue_refund在 一次 事务里写退款、订单状态变更和审计行。如果有任何一个缺了就回推。(一个只在你把 schema 从默认的public挪走时才递给 agent 的 Neon 坑:给表名加 schema 限定,因为 Neon 的 带连接池 端点在连接释放时重置search_path,所以SET search_path撑不过去。在这门课的默认迁移上它就是能用。)一个总是适用的 Neon 坑,这里和决策 7 都是:那个带连接池的端点(PgBouncer,事务模式)破坏 asyncpg 的预备语句,所以这个服务器的连接池和审计连接池都必须给asyncpg.create_pool(...)传statement_cache_size=0,否则第一条查询就报错。
第 3 步:构建它,让 mcp-builder 测那些工具。 一旦计划对了:「Build the server exactly as we planned, three tools and no more, then start it and confirm it boots cleanly. Don't add tools I didn't ask for.」 mcp-builder 还能再进一步、生成 evaluation,即那些工具必须端到端满足的真实任务,那是你在 Skill 上跑过的触发 eval 的连接器版本。对这门课,决定性的测试是下一步、从 worker 调一个工具,所以这里一次干净的启动就够往下走了。
创建:customer-data-mcp/ 服务器。
核对。 读构建出的服务器里每个工具的描述:它是模型用来决定何时调那个工具的东西(和一个
SKILL.md描述扮演同一个角色),而一个含糊的会在错误的时刻触发。然后确认那唯一一件 agent 最常微妙弄错的事:issue_refund的正文在单次事务里做全部三个写入。这些纪律多数也在你的AGENTS.md里,所以一个细心的 agent 会应用它们;你在确认它们活了下来。
customer-data 服务器是一个 streamable-HTTP 服务,所以它必须在 worker 能够到它之前先跑起来。从这里往后,那些实时运行(这个决策,以及决策 8 和 9)需要 两个终端:在一个里启动服务器,在另一个里跑 worker,服务器在先。停掉服务器,worker 的工具调用就以一个连接错误失败,而不是一个错误答案。
第 4 步:把它连到 worker 并调一个工具。 把这个服务器接进那个已经有它 Session 和 Skills 的 worker,并证明一个工具真的跑起来。这是决策 4 里看 Skill 触发的连接器版本:
Register the customer-data server with the worker as a remote
streamable-HTTP server at its URL, alongside the Session and Skills it
already has. Check the current SDK docs for the exact registration API.
编辑:worker 文件(注册 customer-data 服务器)。
核对。 它是一个 streamable-HTTP 服务,所以先启动服务器、再在一条真实消息上跑 worker:「Start the customer-data server, then run the worker on 'I'm Sam, and I haven't had my refund for order #4429 in two weeks.'」 worker 应当 调用
find_similar_resolved_tickets、回来带着排序过的过往案例,而不是一个空结果、也不是一个编造的答案。那就是 MCP 线在工作:worker 通过那个受限服务器、而且只通过那个服务器,够到了业务数据。两个红旗:列表里出现一个通用run_sql风格的工具,意味着 worker 在运行时仍接着 Neon MCP 服务器,把它去掉(概念 12);检索回来一个空结果,意味着决策 5 的种子没按那个 join 读取的形态落地(embeddings连到documents(其中source='past_case')连到tickets)。如果服务器本身起不来,让 agent 读它的日志(概念 13 那条启动导入的提示是常见原因)。
为什么用一个自定义服务器,而不只是 agent 代码里的 asyncpg。 概念 14 的三个理由,按它们在这里要紧的次序:范围(agent 对数据库恰好能做三件事,而不是 SQL 允许的任何事)、隔离(服务器跑在它自己的进程里、带它自己的、agent 耗不尽的连接池)和 可复用性(一个需要 lookup_customer 的第二名 Worker 跟这同一个服务器讲话)。那个窄窄的面就是整个安全论点,这正是为什么第 3 步的核对是关于那条边界、而不是关于管道。
决策 7:把审计日志接到处处
你在哪里:一个会行动、但只记录那一次退款写入的 worker;这个决策把 agent 自己的动作加进审计轨迹;到结尾你会看到一段对话的 message_received / skill_activated / capability_invoked / message_sent 轨迹。
这是两个第一版构建通常会撞上一个错误的决策之一;下面的旁注在你碰到每个之前点名它,所以先读它们。
你以 agent 自己的 动作被记录进 audit_log 结束这个决策。MCP 服务器已经记录了一样东西,issue_refund 在退款事务内部写它的审计行(决策 6);剩下的是 agent 端的写入:skill 调用、模型调用、工具调用、护栏触发。一个任务,用概念 10 里的 log_capability 辅助函数。
第 1 步:在每条边界处接上审计辅助函数。
Wire the audit helper around the agent's own actions, at three points:
the start and end of each skill invocation, after each MCP tool call,
and around any guardrail trip. Use the separate audit connection (its
own pool), not the customer-data MCP boundary. Plan first.
编辑:worker 文件(在每条边界处加上审计接线)。
上面那三条「边界」并不映射到三个对应的钩子,而朴素的接线会崩掉这次运行。现实是:
- 没有 skill 钩子。 在这门课用的惰性 Skills 模式里,一个 skill 通过模型调用
load_skill工具 来激活,所以在on_tool_start/on_tool_end里、当tool.name == "load_skill"时观察 skill 的开始/结束。MCP 工具调用通过那同一个on_tool_end到来。 - 护栏触发是被抛出的异常,不是一个钩子。 用
try/except在Runner.run周围捕获InputGuardrailTripwireTriggered(以及输出/工具变体),并在那里写guardrail_tripped行。 on_tool_end的result类型标注为str,却把工具的原始对象递给你(一个 Pydantic 模型或字典)。在它上面切片或做字符串操作会抛错,而一个钩子内部未处理的异常 会杀掉整个回合(它表现为一个令人困惑的UserError: Error running tool ...)。用str(...)强转 并且 把钩子正文裹进try/except,好让一个审计 bug 永远不能中止用户的回合。on_tool_end在一个工具失败时也会触发,递给你一个"Error executing tool ..."结果。检测它(一个子串检查,不是startswith)并记录status="error",否则一笔失败的退款会被记成成功。
先写 conversations 行。 audit_log.conversation_id 是一个指向 conversations(session_id) 的外键。如果一行审计引用了一个还没有 conversations 行的 session,外键就违例并回滚整个事务,包括它正在记录的那笔退款。在 message_received 时 upsert 那行 conversations,在任何审计行指向它之前(决策 3 创建那张表,却从没说何时写那一行:就是这里)。
一个带 Session 的输入护栏看到整段逐字记录。 不只是新消息:完整的已准备历史加上新回合。所以任何更早回合里的一个被标记词会触发之后每一个回合(一句无害的「say hello」被挡,因为一个测试 token 还在历史里)。只筛查最新那条 role: user 项,不要整段输入。
核对。 跑一段用完即弃的对话,然后:「用 Neon 工具,找到最近的那段对话,把它的每一行
audit_log按顺序展示给我。」 你应当至少看到一个message_received、一个skill_activated(worker 自决策 4 起就有它的 Skills)、一个给那次 MCP 调用的capability_invoked,以及一个message_sent。两种失败形态:如果你只看到 MCP 服务器自己的行(capability_invoked、refund_issued)、却一个 agent 端的都没有,说明辅助函数接好了但从不触发,让 agent 确认它从流式循环内部运行、而不只是在启动时跑一次;如果你看到零行,说明审计连接没够到数据库,让它对照你的数据库 URL 检查审计连接池。
大致你应当看到(一段对话,按顺序):
message_received
skill_activated
capability_invoked
message_sent
为什么审计连接池是独立的。 它用它自己的连接,而不是 customer-data 的 MCP 连接池,有两个理由:即便数据连接池饱和,审计也必须成功;而且审计写入不该和业务写入争连接。一个能被它所审计的系统饿死的审计子系统,不是一个审计子系统。 机制很小(概念 7 交付那些表、概念 10 交付那个辅助函数);纪律在于一致地、在每条边界上调用它。(在 OpenCode 里完全相同:它就是普通的 Python。)
决策 8:在一个场景上验证整个 worker
你在哪里:每一层都接好并各自核对过;这个决策不加任何新东西,它证明它们在一个场景上协同工作、并从日志里回放它;到结尾你会看到一段跨越所有层的、有序的轨迹。
到现在 worker 接好了三层、每一层都各自核对过:Session(决策 3)、Skills(决策 4)和 MCP 服务器(决策 6),底下垫着审计(决策 7)。这个决策证明它们在一个真实场景上 协同 工作,然后仅从审计日志回放它。
第 1 步:跑这个场景并读它的轨迹。 让你的 agent 在那条调动整个栈的消息上跑 Worker(服务器在一个终端、worker 在另一个,服务器在先;见决策 6):
Run the Worker and send it this customer message, then show me the
audit_log rows that conversation produced, in order:
"I haven't received my refund from order #4429, it's been two weeks."
几秒之内你应当看到这些行:
action=message_received:消息到达,conversation 行被创建。action=skill_activated(仅当一个 skill 加载时):worker 可能 加载一个 Skill(find-similar-cases或summarize-ticket)来处理这个请求。模型也可以直接够到find_similar_resolved_tickets、不先加载一个 skill,那种情况下这一行就是缺席,轨迹直接走到capability_invoked。两者都是正确的构建,所以别把一个缺失的skill_activated当作一个 bug。action=capability_invoked, target=mcp:find_similar_resolved_tickets:skill 通过 MCP 服务器驱动一次向量检索,worker 读取最接近的过往处理来据以起草。action=message_sent:起草的回复,被记录。
一个有条件的第五行,action=capability_invoked, target=mcp:lookup_customer,只在 worker 已经有一个客户 id 时出现。第一回合通常没有(客户给了一个订单号和一个邮箱,不是一个 UUID),所以它被跳过,直到上游某样东西解析出客户:认证、编排器,或一个你稍后才加的 lookup_customer_by_email 工具。那没问题;回复仍能引用那个过往案例。
核对。 核心行都在、且按顺序(
skill_activated仅当一个 skill 加载时),它们在一段轨迹里跨越各层:一个 MCP 工具对着系统记录跑了、对话被记录了、一个 Skill 可能激活了。那就是整个 worker 协同工作。如果capability_invoked或message_sent缺了,回到接好它的那个决策、重跑那个决策自己的核对。
message_received、skill_activated 和 message_sent 由 决策 7 的 agent 端审计接线 写入;那些 capability_invoked 行来自围绕每次 MCP 调用的那同一套接线。MCP 服务器只在一个工具改动数据时才写它自己的行(issue_refund 内部的那行 refund_issued)。所以一个像这样的只读场景,留下 agent 端的行加上 capability_invoked 的读,没有业务写入行,直到一笔退款真的发生,在决策 9。
现在 Skills 在 worker 内部运行,一个 skill 的 scripts/ 就是沙箱里的可执行代码。UnixLocalSandboxClient 不给任何隔离;Docker、E2B、Cloudflare 或 Modal 把它框住。把对你 skill 库的写访问当作部署访问,并在你加载不是你写的 skills 之前隔离那个沙箱。
Memory 能力,以及它不是什么那同一个能力列表也接受一个 Memory(),和 Skills() 并列(两者都来自 agents.sandbox.capabilities)。值得精确地认识它,因为它听起来像你刚构建的那个东西、而它不是。Memory() 让一名 Worker 从它自己的过往运行里学习:它在沙箱会话关闭时把每次运行的对话提炼成工作区文件(一个 MEMORY.md 和一段摘要),而后来的运行把那些读回来,于是 agent 探索得更少、重复更少的纠正。那就是概念 3 那个 「我们见过类似的问题吗?」 的召回,由运行时处理,于是你不手工构建它。
它 不是 那个持久的业务记录。沙箱记忆是基于文件的、按近期把它最旧的条目剪掉、且在 beta 中;一个全新的沙箱从空开始,而 agent 被告知把它当作指引、不是权威存储。你的 Neon 表在每一项上都正相反:持久、完整、稳定、可在 SQL 里查询。所以你两个都想要,用于不同的活。Memory() 让 agent 跨运行 更聪明;系统记录让它的工作 持久、可证明、可售卖:那件归你所有的资产。SDK 文档里 Sandbox agents 下的那四页是这一整层的来源;配套的 AGENTS.md 把四页都链上。
第 2 步:跑那条回放查询。 这是整个审计层的存在之证。让 agent 拉出你刚跑那段对话的轨迹:
Using the Neon tools, take the most recent conversation and show me its full
audit_logtrace, in order: created_at, action, target, payload, result.
核对。 读那份输出,你能逐行重建出 agent 做了什么、为什么,而不重跑模型。 如果你不能,如果发生了某一步却不在日志里、或某一行声称了一个业务表并不反映的动作,那就有一个接线 bug。在你把 Worker 称为完成之前修好它。
大致那次回放读起来应当像:
created_at action target result
10:02:11 message_received conversation:abc ok
10:02:12 capability_invoked mcp:find_similar_resolved_tickets ok
10:02:14 message_sent conversation:abc ok
为什么是这个场景。 它在一趟里调动这门课所加的每一个架构件:一个 Skill 激活、一个 MCP 支撑的工具对系统记录跑一次语义检索、而审计轨迹记录整条路径,可在 SQL 里回放。这些在你起步那个最小聊天 agent 里一个都没有。它还没做的,是动钱;那是你接下来把一个人放在它前面的那唯一一个动作。
决策 9:加固那唯一一个动钱的动作
你在哪里:一个端到端跑通、但签发退款不带任何检查的 worker;这个决策给 issue_refund 加一道人工审批关卡;到结尾你会看到一笔退款停下等签字,然后在批准时通过、在拒绝时停下。
这是另一个第一版构建通常会撞上一个错误的决策;下面的旁注在你碰到每个之前点名它,所以先读它们。
worker 端到端跑通了。现在加上那唯一一件你故意留出的东西:一个人在 issue_refund 前面,那唯一一个动钱的工具。你故意把这个最后构建,因为一道审批关卡只有在它所守护的东西真的会跑时才有意义。
第 1 步:给退款工具加关卡。
Gate issue_refund behind human approval: register the customer-data server
so that tool needs sign-off before it runs, and leave lookup_customer and
find_similar_resolved_tickets un-gated. Check the current SDK docs for the
exact approval API.
编辑:worker 文件(在服务器注册处给 issue_refund 加关卡)。
核对。 两个读工具仍原封不动地跑;只有
issue_refund被加了关卡。这道关卡住在服务器如何被 注册 上,而不在工具内部。(在 Claude Code 或 OpenCode 内部,客户端自己的权限提示就是同一道关卡;在独立 worker 里,它是服务器注册上的那个审批设置。)
第 2 步:跑一笔退款,看它暂停。(服务器在一个终端、worker 在另一个,服务器在先;见决策 6。)
Run the worker on a message that should lead to a refund on order #4429,
and show me what happens when it tries to issue it.
核对。 这次运行 暂停 而不是签发退款:worker 报告它在等
issue_refund的审批(用 SDK 的话说,这次运行回来时带着一个中断、而不是一个最终答案),而refunds表里还什么都没写。那次暂停就是权限模型在工作:模型提议了一个动作,而系统在那条边界处停住了。
这道关卡只在模型 真的调用 issue_refund 时才介入。一个谨慎的系统提示词(像「only issue a refund once approved」)会让模型在散文里不停地要审批、却从不调那个工具,于是没有东西暂停、也没有退款发生,那看上去像一道坏掉的关卡却不是。要逼这道关卡现身,明确地把那次调用推过去:「Supervisor approved the refund for order #4429. Call issue_refund now: 2999 cents, reason 'arrived damaged'. Invoke the tool, don't ask again.」 SDK 的关卡是对 执行 的硬后盾;它不能让模型一开始就经由一个工具走。
第 3 步:批准一次,然后拒绝一次。 证明这道关卡的两半:
Approve the pending refund and let the run finish, then show me the refunds
table and the audit_log row. Then run the same scenario again, reject it,
and show me that no refund was written.
核对。 批准时:退款行出现、订单翻成 refunded、而
issue_refund写它的refund_issued审计行,全在那一次事务里。拒绝时:没有退款行,而轨迹显示那个动作被回绝了。一个要递给 agent 的坑,因为它是「能用」和「看上去该能用」之间的差别:恢复一次批准过的运行是一个循环,不是一次调用。 一次运行能持有不止一个待审批,所以 agent 在运行还有审批待处理时持续恢复(批准或拒绝每一个,然后恢复),而不只是一次。只恢复一次,你可能拿回一个空答案、退款却还没写。
大致每一半应当产出:
approve -> refunds: 1 new row | orders.status = refunded | audit: refund_issued
reject -> refunds: no new row | audit: action declined
为什么这是最后一个。 一道在 worker 跑通之前就加上的审批关卡是不可测的演戏:当没有东西流过它时,你分不清一道能用的关卡和一道坏掉的。加在这里、在一个你已看着它检索、起草和审计的 worker 上,你能证明两半:批准放退款过去、拒绝把它停下,而审计日志记录是哪个。那就是整个权限模型,agent 提议、一个人定夺。
上面的核对假设一个人就在跟前。如果签字一小时后、在另一个进程里到来,那次暂停的运行就得被序列化(SDK 的 RunState)、存起来、并在决定到达时恢复。它持久的家是一张小小的 run_states 表(每次暂停一行:序列化的状态加上 awaiting/approved/rejected),不是 audit_log(只追加)、也不是 conversations 上的一列(一段对话能暂停不止一次)。那些序列化与恢复的调用是移动中的 SDK 面的一部分,所以通过 Context7 核实它们。
刚才发生了什么
九个决策,而第 0 步那个最小聊天 agent 现在有了一名 Worker 的 底座。回看变了什么:
- 能力移出了代码。 三个 Skills 坐在
.claude/skills/里,做版本管理、可在 agent 间共享。 - 那些持久的存储移出了进程。 一个真实的 Postgres schema(五表核心加上一个为 customers、orders、tickets 和 refunds 而设的领域层)现在持有 Worker 的系统记录和它用 pgvector 检索的参考库,而 SDK Session 把 Worker 的对话状态保在同一数据库上。
- 运行时的业务访问是被中介的。 agent 只通过一个恰好暴露三个工具的受限 MCP 服务器够到 Postgres 里的业务数据;每次业务读和写都跨过那唯一一条边界。审计子系统是那个故意的例外,在它自己的直连上,于是它不会被它所审计的那条边界饿死。
- 每个动作都留下一条轨迹。 审计日志能在事后几周或几个月、在 SQL 里回放任何一段对话的完整推理轨迹。
- 那个危险的动作有了一个主人。 那唯一一个动钱的工具在它跑之前为一个人暂停;批准放它过去、拒绝把它停下,而无论哪种审计日志都记录那个决定。那就是一名 Worker 在任何人信任它去做真实动作之前所需的权限模型。
OpenAI Agents SDK 还在那里。沙箱还是你的计算,而 agent 起步时就带的流式、护栏和追踪都还在。变的是上面那层架构:Skills 持有能力、系统记录持有真相、MCP 把它们连起来,而一个人在要紧的那些动作上留在回路里。
那就是一名 Worker 的底座。它还不是常驻、主动,或一支受管理劳动力的一部分。那些是接下来几门课所加的动作。
决策 10(可选挑战):让暂停的审批熬过一次重启
在决策 9 里,审批者就坐在终端跟前,所以一个 [y/N] 就够了。真实审批很少这样:那个为一笔退款签字的经理可能一小时后、从另一个 app、在另一台机器上回答。你的 worker 还处理不了那个。当一笔退款暂停时,那次暂停的运行只活在 worker 的内存里,所以如果进程在那个人回答之前关闭,那笔待处理的退款就没了。
你已经把三类状态移进了 Postgres:对话回合、业务记录和参考库,以及审计轨迹。那次暂停的运行是仍困在内存里的那唯一一类。这个可选的综合项目把它也移进数据库,于是一次暂停能稍后、从任何地方被批准。它是一个评分挑战,不是一次带引导的构建:每一步给你想法和提示词,把接线留给你的 agent。
目标: 从一个 不同的 进程,而非启动它的那个,批准或拒绝一笔暂停的退款。
第 1 步:给每次暂停的运行在数据库里一个家。 一次暂停需要它自己的一行:它属于哪段对话和哪个工具、那次保存的运行本身,以及一个从 awaiting 走向 approved、rejected 或 resumed 的状态。它是它自己的一张表,不是审计日志(那是已完成的历史)、也不是 conversations 上的一列(一段对话能暂停不止一次)。
Add a run_states table that stores one paused run per row: the conversation
and tool it belongs to, the saved run, and a status that defaults to
"awaiting" and can become approved, rejected, or resumed. Plan the DDL first;
I'll approve before you apply it on a branch.
核对。 一张
run_states表存在,而一次全新的暂停默认为awaiting。你从没敲过那段 SQL:你说了那张表是干什么的,你的 agent 写了它,和 schema 在决策 3 里落地同一个方式。
第 2 步:当一笔退款暂停时,保存它并往下走。 现在 worker 在终端等着;它该改成记录那次暂停、并为下一回合腾出自己。
When a run comes back waiting for approval instead of with a final answer, do
not block on input. Save the paused run as a run_states row marked "awaiting"
and return, so the worker is free for the next turn. One turn is one request
that either finishes or parks. Check the current Agents SDK docs for the exact
"save the paused run" call before you write it.
核对。 一个退款回合现在迅速返回,留下一行
awaiting,而没有任何东西阻塞着等一个人。
第 3 步:从一个单独的命令批准或拒绝。 这个决定移出聊天循环、进它自己那个小入口,于是它能完全在另一个进程里跑。
Build a small "decide" command, separate from the chat loop: it lists the
awaiting rows, takes my approve or reject on one, then reloads that saved run
and finishes it. Keep resuming in a loop while the run still has approvals
pending, since resuming once can come back empty with the refund unwritten
(the loop gotcha from Decision 9). Confirm the reload call through Context7.
核对。 从 decide 命令批准一行,把那笔退款驱动到完成;拒绝它则不写退款、并记录那次拒绝。
第 4 步:让退款可以安全重试。 在一个分布式设置里,一次网络重试能把同一笔批准过的退款触发两次。
Make issue_refund idempotent: dedupe on the order plus a request id, so the
same approved refund cannot run twice.
核对。 故意把同一次批准恢复两次:你恰好得到一行
refunds,不是两行。
第 5 步:每段对话一个活动回合。 同一段对话上同时两个回合会损坏它的会话。
Add a per-conversation lock (a Postgres advisory lock on the session id, or a
status guard) so only one turn is active per conversation at a time.
核对。 同一段对话上的第二个回合等待或被拒绝,而不是和第一个赛跑。
那些保存一次暂停的运行、并稍后重新加载它的调用,是 beta SDK 面的一部分、在版本间会变。这门课的纪律适用于它自己的挑战:从当前 Agents SDK 文档或 Context7 粘贴确切的保存和重载调用,而不是凭记忆。那个想法,即一次暂停的运行成为一行你稍后接手的行,是稳定的;方法名不是。
完成标志:
- 你在一个进程里开始一笔退款;它退出时那次运行停在
run_states里(状态awaiting),而还没有refunds行。- 在第二个进程里,你批准它;退款提交(退款行、订单翻转、
refund_issued审计行),而那行停泊的行变成resumed。- 拒绝路径留下零次业务写入和一行
refund_blocked审计行。- 把同一次停泊的运行批准两次,不签发第二笔退款。
- 整个过程可从
audit_log加run_states回放,而不重跑模型。
伸展(完整分布式)。 把 customer-data 服务器放到一个带认证的真实 URL 后面、并把 worker 指向它;把本地沙箱换成一个托管的、而不改 agent 本身(换客户端,留 agent);并把你的 secret 从 .env 文件移进一个 secret 管理器。同一个 worker,现在能跨机器运行。
状态在数据库里是必要的、但还不充分:最后一样要移的有状态东西,是那次暂停的运行本身,而一旦它住进 run_states,你的 worker 就不再被绑在一个单一进程上。
Part 5:这门课在哪里收尾
一名 Worker 的成本形态:如何估算它
这里故意不给任何美元总额:每 token 价格和免费层限额每月都变,所以任何印出来的数字到你读它时就已陈旧,而一个陈旧的数字比没有更糟。持久的是那个 方法。它在此,以 worked example 自己的流量作为你代入的输入:200 段对话/天、每段约 10 个回合、每回合约 8K 输入 token。
一行几乎就是整张账单;另外三行是凑整误差。 按顺序算它们。
1. 模型推理。 你每月的 token 量乘以你模型每 token 的价格。量来自你自己的流量:
input tokens/month ≈ conversations/day × turns/conversation × tokens/turn × 30
对这个例子:200 × 10 × 8,000 × 30 ≈ 480M input tokens/month。把它乘以你模型的输入价(从它的 定价页),然后用同样方式加上输出 token(它们少得多,但每 token 价更高)。那一次乘法就是你的账单。
它上面最大的杠杆是 prompt 缓存。你的 AGENTS.md、系统提示词和 Skills 元数据在每一回合都相同,所以当提供方缓存那个稳定前缀时,那些 token 就按正常价的一个零头计费。保持那个前缀稳定(别在白天中途搅动 AGENTS.md)是你拥有的最高价值的成本动作。把容易的回合路由到一个更小的模型、只把难的路由到一个前沿模型,是第二个。
2. Embeddings。 embedding 的 token 数 × embedding 模型的价。你 embedding 一次种子语料、并在新工单到来时 embedding 它们;在一个小 embedding 模型的费率下那是几分钱、不是几美元,除非你持续地重新 embedding 整段对话历史。同一个定价页。
3. Postgres(Neon)。 常常是 $0:免费层覆盖一名低流量的单一 Worker,而缩容到零意味着空闲小时不花钱。你只在越过免费的存储 / 计算小时限额之后才付费,那时是存储加上活动计算,两者都在 Neon 的定价页 上。
4. 沙箱计算。 这里是 $0,因为 worked example 跑在 UnixLocalSandboxClient、你自己的机器上。在生产中它是你部署之处的容器分钟(Docker、Cloudflare、E2B、Modal):会话时长 × 并发 × 那个提供方的费率。
整个方法一句话: 从你自己的对话数字算出你每月的 token 量、乘以今天的每 token 价、再从定价页读出另外三行。扩展到许多 Worker 不改这个公式,它把推理那一行乘以有多少 Worker、它们有多忙;基础设施那几行大致保持平坦,所以模型账单是会增长的那个,而上面那两个习惯(稳定的缓存前缀、给容易的回合用更便宜的模型)正是把它管住的东西。
替换指南:架构不变,产品会变
这门课在每一层都点名具体厂商(OpenAI Agents SDK、SDK 的本地沙箱、Neon、OpenAI embeddings、MCP Python SDK)。那是因为一个教学示例需要具体答案,而不是「用你喜欢的任何 LLM 运行时」。但这套架构和任何合规的替代品都能用。这门课的设计明确预期了五种替换:
- Postgres 主机:Neon → Supabase、AWS RDS、自托管。 任何带
pgvector的都行。你失去分支和缩容到零(那些是 Neon 特有的),但五表 schema、embedding 流水线、审计轨迹纪律和自定义 MCP 服务器模式全都逐字节可移植。唯一的改动是连接串、可能还有 SSL 配置。 - 向量存储:pgvector → Pinecone、Weaviate、Qdrant。 如果你拒绝概念 6 那个「关系数据和向量数据共用一个数据库」的论点,就把
embeddings表换成一个向量 DB 客户端。代价:两个要保持一致的存储(概念 6 主张这很少值得)。好处:在非常大的规模上(1000 万以上向量)更好的召回,以及托管服务的运维简洁性。 - embedding 模型:OpenAI → Cohere、Voyage、BGE-small(本地)。 改一个常量(
EMBEDDING_MODEL)和一个列维度(VECTOR(n))。对已有数据跑一次性的重新 embedding。概念 9 的流水线不变。 - 沙箱:本地沙箱 → Cloudflare、E2B、Modal、Daytona、你自己的 Docker。 任何有隔离进程边界和干净重启的都行。
SandboxAgent运行时与后端无关;worked example 跑在UnixLocalSandboxClient上,而生产换到这些里的任何一个。Skills 的scripts/以同样方式执行。上一门课那张信任边界图仍然适用。 - agent 运行时:OpenAI Agents SDK → LangGraph、CrewAI、Pydantic AI、你自己的循环。 存活下来的是那条 MCP 边界;每个现代 agent 框架都有一个 MCP 客户端。Skills 在任何能加载
SKILL.md文件的 agent 里都能用(Claude Code、OpenCode、Goose,以及越来越多的 Cursor/Windsurf)。审计轨迹纪律是与框架无关的 Python。
什么不容易换。 MCP 协议本身、Skills 格式规范,以及审计轨迹的习惯。这些是你跨产品携带的部分;产品是你替换的部分。底下同样的架构形态,上面可替换的实现。
关于「不变」和「拥有」一句话。 两者都是值得押注的启发式,不是已成定论的事实。「不变」点名的是 2026 年可得的最好的开放标准:MCP 大约十八个月大、Skills 规范更年轻,而有朝一日那根线或那个能力格式本身就可能是那个被替换的东西,而不只是插进它的产品。押注开放协议而非专有协议,是你优雅老去的方式,但把这套架构当作「设计上耐久」、而非「永恒」。而「拥有」其实意味着「以组合方式拥有」:这名 Worker 跑在 Neon 的云、一家厂商的模型、一个编程 agent 客户端,以及从第三方仓库拉来的 skills 上。你拥有的是不重写其余部分就能替换其中任何一个的自由。那是真实的、值很多钱,而它也少于这个词所暗示的全部。拥有那些接缝,而不是那个基底。
这门课(暂时)没覆盖什么
你现在有了一名满足论点提出的 七项不变量 中两项的 Worker。具体来说:它跑在一个引擎上(不变量 4,来自上一门课),而它运行在一个系统记录之上(不变量 5,来自这门课)。另外五项不变量是生产级 AI 原生公司所要求的,也是后续几门课所覆盖的。每一项在这里是一个要点,不是一节。
- 不变量 1:人是主体。 撰写的 spec、审批关卡、预算声明。设定意图并对结果负责的架构,在 本书 Part 6 里覆盖。
- 不变量 2:每个人都需要一个代表。 一个在边缘、持有你上下文、代表你判断、并把工作经纪给劳动力的个人 agent。论点点名 OpenClaw 为当前的实现。
- 不变量 3:劳动力需要一个管理者。 一个分派工作、强制预算、审计执行、把招聘作为一个可调用能力暴露的编排器。论点点名 Paperclip。
- 不变量 6:劳动力在策略下可扩张。 一个元层,在其中一个被授权的 agent 生成一条提示词、开通一个运行时、并注册一名新 Worker,而不惊动一个人。Claude Managed Agents 是一种实现。
- 不变量 7:劳动力跑在一套神经系统上。 触发器(调度、webhook、入站 API 调用)在权限信封下唤醒 agent。Inngest(持久函数和后台作业)是面向通用劳动力事件的一种实现;Claude Code Routines 是编程 agent 专属的那条路径。
如何真正把这件事做好
读这门速成课不会让你擅长构建 Worker。用它才会。路径和上一门课一样:你从手动起步、感受摩擦,让每一处摩擦教你它属于哪个概念。
这门课的映射:
- 「为什么我的 skill 该触发时不触发?」→ 描述质量(概念 3)。重写。用你能想到的五种不同用户说法来测那个触发器。
- 「为什么 agent 在编造数据库里没有的数据?」→ agent 其实没在调那个 MCP 服务器。查 trace;查
mcp_servers=[...]注册。 - 「为什么我的审计日志不完整?」→ 那个审计写入不在和动作同一条代码路径上(概念 10)。把它挪到动作旁边、在同一事务里。
- 「为什么我的 pgvector 结果不相关?」→ 要么切块不对(概念 9),要么插入时的 embedding 模型和查询时的不匹配。重新 embedding。
- 「为什么我的 MCP 服务器在负载下慢?」→ 服务器内部的连接池太小,或者工具列表没在客户端缓存。概念 15。
- 「为什么 Neon MCP 服务器在生产里让人发怵?」→ 因为 Neon 自己的文档说它不是给生产用的。写一个自定义 MCP 服务器(概念 14)。第一个花 30 分钟;第二个花 10 分钟。
一块一块地构建这套架构。 别试图在一个周末里把 Skills、系统记录和 MCP 都加上。从第 0 步那个聊天 agent 起步。先加一个系统记录(决策 3–5),看你的调试体验怎么变。加一个 Skill(决策 4),看模型怎么决定使用它。把 MCP 边界最后加(决策 6)。每一步都是它自己的一份学习;三个一起做是一堵墙。
那份可移植性红利是真实的: 你在这里写的 Skills、schema 和 MCP 服务器全都能移到其他产品。替换指南 列出每一层的替代品。
你花时间在什么上的转变
决策 4 之后,你的活儿换了形态。写代码变成给 agent 做简报;评审那个描述(一个你平常会略读的配置文件字段)变成那门关键手艺。一份你花 30 分钟起草并精修的描述,比 agent 在它底下生成的 200 行 MCP 服务器代码做更多的架构活,因为那个描述是模型每一回合都读的路由面。
两个实际的转变。第一,你不再问「我怎么实现这个?」、而开始问「一个真实用户可能用哪五种不同方式说出这个触发器?」代码是下游;如果描述错了,agent 永远够不到代码,而代码的质量无关紧要。第二,评审取代撰写、成为关键技能。agent 起草;你判断那份草稿在你为之写描述的那些触发案例里是否管用。最难的部分是抵住那股在你三分钟就能自己解决时想要重写的冲动:和那条让你不绕过 MCP 边界的纪律是同一条。
快速参考
15 个概念,每个一句话
- 一个 Agent Skill 是一个文件夹。 SKILL.md 加上可选的 scripts/references/assets。
- 渐进式披露。 启动时元数据 → 激活时完整正文 → 按需引用文件。
- 一个 SKILL.md 是前置元数据 + 正文。 name、description、可选元数据,然后是操作指令。
- Skills 以文件形式流转。 同一个 SKILL.md 在 Claude Code 和 OpenCode 里不加修改就能用。
- 当隔离比编排简洁更要紧时,通过文件系统交接组合小 skills。
- 对几乎所有 agent 工作负载,Postgres + pgvector 胜过一个单独的向量 DB。 Neon 增加分支、缩容到零和一个 MCP 服务器。
- 五张表是最小的运营 schema: conversations、documents、embeddings、audit_log、capability_invocations;对话回合住在 SDK Session 里(同一数据库上的
SQLAlchemySession)。 - pgvector 基础:
VECTOR(1536)+<=>余弦距离 + HNSW 索引。两端用同一个 embedding 模型。 - embedding 流水线: 在语义边界处切块(约 400 token 带重叠)、批量 embedding、连同模型元数据一起存。
- 审计不是日志。 每个有意义的动作在和它所记录的动作同一事务里写一行。
- MCP 是一个协议,不是一个服务。 三个原语(工具、资源、提示词),三种传输(stdio、streamable HTTP、遗留 SSE)。
- Neon MCP 服务器是给开发的。 Schema 设计、基于分支的迁移。不是给生产运行时的。
- OpenAI Agents SDK 有一个内置 MCP 客户端。
from agents.mcp import MCPServerStdio, MCPServerStreamableHttp。用async with。在生产中缓存list_tools。 - 自定义 MCP 服务器靠范围、隔离和可复用性挣得它们的价值。 别为一个 agent 用的一个函数写一个。
- 负载下的 MCP: 远程用 streamable HTTP、缓存工具、复用连接、在服务器内部用连接池、通过
_meta传播 trace 上下文。
当某样东西感觉不对时
Skill not firing when it should
→ Description too vague. Rewrite with "Use when..." and specific keywords (Concept 3).
Skill firing when it shouldn't
→ Description too broad. Add explicit constraints in the description.
pgvector returning irrelevant results
→ Embedding model mismatch (insert vs. query). Verify the model column in
the embeddings table. Re-embed if needed.
MCP tool not appearing in agent
→ Server not registered, or list_tools cache stale. Check mcp_servers=[...]
and try cache_tools_list=False temporarily.
Audit log has gaps
→ Action and audit write are in different code paths. Move them next to
each other, ideally same transaction.
Agent timing out on Postgres operations under load
→ MCP server's connection pool too small. Check asyncpg.create_pool(max_size=...).
MCP server hangs on startup with torch / sentence-transformers / large imports
→ Default client_session_timeout_seconds=5 is too short for servers that
load ML models at import. Bump to 60. See Concept 13's callout.
CREATE TABLE fails: relation "notes" already exists
→ You're pointing at a database that already has tables. Use a fresh
database or Neon project; the Quick Win's build prompt makes a fresh one.
Non-OpenAI key getting 401 against api.openai.com
→ Set OPENAI_BASE_URL to your provider's OpenAI-compatible endpoint
(e.g., https://api.deepseek.com/v1) before running the agent.
Agent fails partway with a 401 / auth / BadRequestError
→ Wrong key, wrong provider, or expired key. Have your agent confirm
OPENAI_API_KEY is set and test a model call before the full run; it
fails in one second instead of four files deep.
Neon MCP server returning errors in production agent code
→ You're using it wrong. Neon's docs are explicit: development only.
Write a custom MCP server instead (Concept 14, ~30 minutes).
闪卡学习辅助
知识检测
对你刚走过的那些想法的一次快速、有关卡的自检。