Claude Code 与 OpenCode:速成课
15 个概念 · 覆盖 80% 的真实使用
想象一下,你可以对你的电脑说:「看一下我的论文草稿,改掉语法错误,重新调整段落顺序让论证更顺畅,然后把新版本存下来。」而它真的就照做了。不只是给你一些建议、让你自己去改,而是直接打开你的文件、动手编辑、保存结果,整个过程你都看在眼里。
这就是 Claude Code 和 OpenCode 所做的事。它们是直接在你电脑上工作的 AI 工具。你描述想要什么,它们去完成,你审查结果。
这门速成课会教你 15 个概念,覆盖你日常使用中大约 80% 的场景。读完之后,你会知道每款工具能做什么、什么时候该用哪个功能,以及如何避开常见的坑。
有一个想法能让一切都更好理解: 这些工具里大多数「高级」技巧归根结底都是一件事:在对的时间把对的信息交给 AI,并把无关的信息挡在外面。 这门课的每一节都会回到这个想法上。
前置课程:2026 年的 AI 提示词。 那门课教你如何与 AI 对话:给上下文、把话问清楚、检查 AI 的成果。这门课教你的是:当 AI 真的能动你的文件、在你电脑上运行命令时,会发生什么。
两款工具,一套技能
这门课会把两款工具并排来讲:Claude Code(由 Anthropic 出品)和 OpenCode(开源,可搭配任意 AI 模型)。我们同时教这两款,有一个很实在的理由:如果一个技巧在两款工具里都管用,那它就是一项真正的技能,而不是某款工具特有的小窍门。你学到的技能在它们之间是通用的。
| Claude Code | OpenCode | |
|---|---|---|
| 出品方 | Anthropic | 开源社区 |
| AI 模型 | 仅 Claude | Claude、GPT、Gemini、DeepSeek、本地模型 |
| 最擅长 | 开箱即用的最佳 Claude 表现 | 灵活、控制成本、免费模型 |
| 价格 | 订阅或 API | 有免费模型可用,或自带 API 密钥 |
挑一个适合你处境的就好。这门课里讲的一切,两款工具都适用。
本文内容截至 2026 年 5 月。两款工具都更新得很勤。开始任何一次会话之前,先运行
claude update或opencode upgrade,确保你用的是最新版本。如果你还没装这两款工具中的任何一个,第 1 节会讲到安装。
本页中凡是 Claude Code 与 OpenCode 有差异的小节,都带有一个切换器。选定其中一个,页面上的每个切换器都会跟着你的选择走。
这是一门速成课:一次读完覆盖 80% 的真实使用。如果你想看下面每个话题的完整讲解,请参阅 第 14 章:与通用智能体和编程智能体协作 以及 第 17 章:面向团队、CI/CD 和高级配置的 Claude Code。
这门课讲些什么
| 部分 | 主题 | 你会学到什么 |
|---|---|---|
| 1 | 基础 | 这些工具是什么、计划模式、权限、选择你的模型 |
| 2 | 上下文管理 | 为什么对话会越来越糟,以及如何修复 |
| 3 | 规则文件 | 为你的项目设置一套长期生效的指令 |
| 4 | 个性化你的工具 | 命令与技能、钩子/插件、子智能体 |
| 5 | 连接到外部世界 | 把 AI 接入外部服务(MCP) |
| 6 | 完整实战示例 | 一个完整任务,从头到尾,在两款工具里各做一遍 |
| 7 | 在哪里运行 | 终端、IDE、网页、桌面 |
| 8 | 两款工具协同 | 在同一个项目上同时使用两款工具 |
想边做边学? 直接跳到 第 6 部分 先看完整实战示例,然后再回来。
📚 教学辅助
查看完整演示文稿:智能体编程速成课
第 1 部分:基础
这四个概念是其余一切的地基。
1. 这些工具到底是什么
大多数人以为这些是「懂代码的聊天机器人」。它们不是。聊天机器人回答问题;Claude Code 和 OpenCode 会动手做事。它们读你的文件、编辑文件、在你电脑上运行命令,并一直做到任务完成。你描述想要什么,它们去做,你审查结果。
最大的思维转变是:别再问问题,开始下指令。
| 问一个问题(弱) | 下一道指令(强) |
|---|---|
| 「我该怎么整理我的笔记?」 | 「读一遍 notes/ 文件夹里的每个文件。新建一个名为 weekly-summary.md 的汇总文件,列出每一项待办事项,并按负责人分组。凡是标了 [private] 的都跳过。」 |
第一个提示词给你的是一段解释,还得你自己动手去做。第二个提示词直接把活儿帮你干完了。这就是区别。(这跟 AI 提示词第 1 个概念 是同一个想法,只是这里的风险更高,因为 AI 真的会改你的文件。)
还没装这两款工具中的任何一个? 先装一个再往下读。后面的内容都假设你能打开终端、动手试一试。
# macOS / Linux / WSL —— 推荐(自动更新)
curl -fsSL https://claude.ai/install.sh | bash
# Windows PowerShell
irm https://claude.ai/install.ps1 | iex
# macOS Homebrew(不自动更新 —— 需定期运行 `brew upgrade claude-code`)
brew install --cask claude-code
# npm 兜底方案
npm install -g @anthropic-ai/claude-code
完整参考:code.claude.com/docs。
# 所有平台 —— 推荐
curl -fsSL https://opencode.ai/install | bash
# macOS Homebrew
brew install opencode
# npm / bun / pnpm / yarn
npm install -g opencode-ai
完整参考:opencode.ai/docs。
装好之后,在任何你想干活的文件夹里打开终端,输入 claude(或 opencode)。这会把你带进第一次会话。
先确认一下:你现在用的是哪个模型? 在深入之前,先弄清你实际对话的是哪个模型 —— 免得你在简单工作上悄悄烧掉一个昂贵的模型,或者纳闷为什么一个便宜的模型那么吃力。
输入 /status 可以看到当前模型,连同你的套餐、工作目录和上下文用量。想看完整列表并切换,就输入 /model 从菜单里选 —— 改动立即生效,无需重启。
输入 /models 可以看到你已连接的各个供应商下的每一个模型并在它们之间切换;当前激活的模型也会显示在 TUI 里。(在命令行里,opencode models 会打印出可用的 provider/model 名称 —— 在配置里设默认模型时很方便。)
当你运行 /models 时,免费选项里有几个是 隐身模型 —— 以代号发布、出品方未公开(比如写作本文时 OpenCode Zen 的 Big Pickle)。它们值得了解,但有两个注意点:
- 它们是临时的、未经预告的。 隐身模型是某家厂商在正式公开之前悄悄做的测试。它可能改变行为、被改名,或在毫无通知的情况下消失 —— 所以别围绕它养成习惯、设默认、或搭建课程/项目环境。
- 「免费」可能意味着你才是产品。 在一个模型的免费测试窗口期内,你的提示词和代码可能被用来训练和改进它。绝不要把隐身模型对准任何机密内容 —— 客户工作、私有仓库、任何受 NDA 约束的东西。
它们用来做一次性实验、试试工作流是没问题的。但凡你要靠它干正事,就选一个稳定、私下计费的模型(见下方的 DeepSeek V4 提示框),那里的供应商、定价和数据政策都是已知的,而且不会在你脚底下悄悄变动。
从这里开始,本页上的每个概念都是你可以在那次会话里动手试的,而不只是读一读。 在这一页旁边开着一个终端,每碰到一个想法就跑一遍。
本文内容截至 2026 年。两款工具都更新得很勤。开始任何一次会话之前,先运行
claude update或opencode upgrade,确保你用的是最新版本。
因为 OpenCode 不挑模型,你可以把它指向任何性价比最好的选择。在托管模型里,截至 2026 年中性价比最强的是 DeepSeek V4,它分两档:
deepseek-v4-flash—— 经济款默认选择。大约 每 100 万输入 token $0.14(命中缓存时低至 $0.0028),每 100 万输出 token $0.28,带 100 万 token 的上下文窗口 和工具调用支持。学生和高频量大的工作就以这一档为标准。deepseek-v4-pro—— 当你需要更强推理时的进阶档。更能干,但仍只是前沿模型定价的一个零头。
设置方法(约 1 分钟): 运行 opencode → 输入 /connect → 输入 deepseek → 粘贴你的 API 密钥(在那里创建密钥,并充一点预付余额 —— DeepSeek 是按量付费的,所以账户没有余额时密钥还用不了)→ 选好模型。DeepSeek 自己的指南默认选 V4-Pro,所以如果你想要最便宜的选项,请改选 deepseek-v4-flash。
价格和分档经常变 —— 做预算前先看实时页面。
📘 DeepSeek + OpenCode 集成指南 · 💰 DeepSeek 模型与定价
这与 「计划 / 执行」分工 天然搭配:用前沿模型做计划,再让一个由 DeepSeek 驱动的便宜 OpenCode 会话去执行。
Claude Code 默认对接 Anthropic 的模型,但你也可以把它指向 DeepSeek V4。有两条路:
- 简单的原生路线。 DeepSeek 提供了一个兼容 Anthropic 的端点,所以你可以在启动
claude之前,设置ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic和你的 DeepSeek 密钥作为鉴权令牌,直接让 Claude Code 跑在它上面。无需额外工具。 - 路由器路线 —— claude-code-router。 一个社区代理,挡在 Claude Code 前面,让你把请求路由到 DeepSeek(以及其他供应商),甚至可以按任务用不同模型 —— 比如用前沿模型做计划、用
deepseek-v4-flash做执行。你用ccr code而不是claude来启动。安装与配置见该仓库。
两条诚实的提醒:两者都是 第三方 / 非官方 的搭法,所以 Claude Code 更新时它们可能会失效,而且你会失去 Claude Code 专门调校出来的「开箱即用的最佳 Claude 表现」。如果你的主要目标是低成本、由 DeepSeek 驱动的编程,那 OpenCode 是更顺的路(它天生就不挑模型)—— 这些路线是留给那种你专门想要 Claude Code 的界面 又 想要 DeepSeek 的定价的情况。
2. 计划模式(最被低估的功能)
通常,当你给这些工具一道指令,它们会立刻开干:读文件、改代码、运行命令。计划模式改变了这一点。它把 AI 置于一种「只看不动」的状态。AI 可以读你的文件、思考任务,但不能改动任何东西。它不去做,而是写出一份它 打算 怎么做的分步计划。你读这份计划、提出修改,然后才让它开始真正动手。
两款工具都支持这个。打开它的方式略有不同,但想法是一样的。
按 Shift+Tab 在各权限模式之间循环。第一次按进入自动接受模式;第二次按进入计划模式。在计划模式里,模型能读但不能写:不改文件,不运行 shell 命令。
按 Tab 在 Build 模式(AI 什么都能做)和 Plan 模式(AI 只能读、不能改任何东西)之间切换。在 Plan 模式里,如果你让它写或改什么,它会告诉你它做不到,并等你切回 Build。和 Claude Code 是同一个想法:先看,再动手。
它在实际中是什么样子。 你进入计划模式,然后输入一道普通的指令:
写一首关于我妈妈的诗,存成
for-mom.md。
它不直接写,而是先给你一份计划:
计划
- 以经典十四行诗的风格写一首五节的诗。
- 使用正式、老派的语言。
- 层层铺垫,推向一个宏大、戏剧化的结尾。
- 存为
for-mom.md。尚未写出任何内容。批准即可继续,或告诉我要调整什么。
这不是你想要的 —— 你要的是短小、温暖、朴实的东西,而不是一首正式的十四行诗。于是你提出异议:
写得短而温暖 —— 四行,日常用语,不要宏大。能写进一张生日卡片里的那种。
AI 更新了计划。这时 你再批准,它就写出你真正想要的那首诗 —— 而不是甩给你一首你还得费口舌解释清楚的正式十四行诗。
为什么要费这个劲做计划?两个理由:
- 你能在错误发生之前抓住它。 上面发生的正是这件事 —— 错误的假设暴露在计划里,而不是暴露在一份你还得费劲争辩才能推翻的成稿里。在一首四行诗上,这只是个小小的省事;可当 AI 即将编辑 10 个文件时,这就是「快速纠正」和「漫长清理」之间的差别。
- AI 先做计划时干得更好。 写计划逼着 AI 在动手之前把任务想清楚。没有计划,它就一边想一边写,结果通常更糟。
经验法则: 如果任务会花超过 10 分钟,先用计划模式。对更大的任务,让 AI 把计划存到一个文件里(比如 docs/plans/my-plan.md),这样你以后可以回头看,或者分享给一次全新的会话。
把它想成写论文前先列提纲。你不会在不知道结构的情况下就动笔写一篇 10 页的论文。这里也是同一个道理:先计划,再动手。
3. 权限纪律
每当这些工具想做点什么(编辑一个文件、运行一条命令),它们都会先向你请求许可。你可以跳过这一步,让它们不问就什么都做,但 刚上手的时候千万别这么做。 你要在 AI 动手之前看清它在做什么。
用过几次会话之后,你会注意到有些操作总是安全的(比如读文件或运行测试)。你可以告诉工具,对这些特定操作别再问了,自动批准。方法如下:
你不需要看懂每一行。每段代码后面的解释会告诉你它的作用。随着你用这款工具,这些设置自然会越来越清楚。
.claude/settings.json:
{
"permissions": {
"allow": [
"Read",
"Edit",
"Write",
"Bash(npm test)",
"Bash(npm run lint)",
"Bash(npm run build)",
"Bash(git status)",
"Bash(git diff *)",
"Bash(git log *)"
],
"deny": ["Bash(rm -rf *)", "Bash(npm publish *)", "Bash(git push *)"]
}
}
opencode.json:
{
"$schema": "https://opencode.ai/config.json",
"permission": {
"*": "ask",
"read": "allow",
"edit": "allow",
"bash": {
"*": "ask",
"npm test": "allow",
"npm run lint": "allow",
"npm run build": "allow",
"git status*": "allow",
"git diff*": "allow",
"git log*": "allow",
"rm -rf*": "deny",
"npm publish*": "deny",
"git push*": "deny"
}
}
}
OpenCode 在权限上给你更细的控制。你可以为每一类操作(读取、编辑、运行命令)分别设规则。它还有一个内置的安全特性:如果 AI 连着三次尝试同一个操作却毫无进展,它会自动停下来。
提示:设好通知。 这些工具可以在你做别的事时去处理更长的任务。让这件事真正好用的窍门是:当 AI 完成或需要你介入时,能收到一条通知。这样你就可以启动一个任务、切去做别的工作,需要你时再回来。
- Claude Code: 像
cc-notify这样的社区工具可以给你发桌面通知。 - OpenCode: 桌面应用会自动发通知。终端版本可以加一个插件来通知你。
4. 让模型与任务匹配
两款工具都让你选择 由哪个 AI 模型来干活 —— 而切换只要一条命令。大多数新手从不碰这个设置,这是两头都吃亏的错误:他们要么在琐碎杂务上烧掉一个昂贵模型,要么在一个难题上跟一个弱模型死磕,还为糟糕的结果责怪自己。
这个选择背后有一个简单的权衡。最能干的模型是最好的 思考者 —— 它们做计划、对棘手代码做推理、应对模糊地带 —— 但它们最贵,也最快地耗掉你的额度。更便宜(以及免费)的模型在 照着一份清晰的计划做 这件事上完全够用:编辑文件、运行测试、重新格式化、重复性改动。本事就在于把每一种工作派给对的那个。
| 这类工作 | 该用 |
|---|---|
| 做计划、设计架构、「想清楚这事该怎么做」、调试某个搞不懂的东西 | 你手上最能干的模型 |
| 照着你已批准的计划做 —— 常规编辑、格式化、运行测试、样板代码 | 一个更便宜或免费的模型 |
| 一个快速的问题或一行小修补 | 当前已经加载的那个,别多想 |
你在概念 1 里已经学过怎么 查看和切换 你的模型。有意识地去选它,才是要养成的习惯:
输入 /model 在一个更能干的 Claude(用于硬思考)和一个更快、更便宜的(用于常规工作)之间切换;改动立即生效,无需重启。一个常见的搭法是:让强模型处理计划模式,让一个更快的模型做执行 —— 这样昂贵的思考只在前期发生一次。
因为 OpenCode 不挑模型,你的选择面更宽:输入 /models 在你连接的每一个供应商之间切换 —— 用一个前沿模型做计划,用一个便宜的托管模型如 deepseek-v4-flash(见概念 1 里的 DeepSeek V4 提示)甚至一个免费/本地模型做执行。你也可以在 opencode.json 里设一个默认模型,并给子智能体配它们自己更便宜的模型。
这与计划模式(概念 2)直接搭配。 任何任务里昂贵的部分都是思考 —— 读项目、定方案、看出哪里可能出错。一旦这变成一份写好的计划,剩下的就是「照这些步骤做」,一个便宜模型干得很好。所以:用强模型做计划,用便宜模型做执行。 这一招就是大部分成本节省的来源,而且不损失质量 —— 它也是第 8 部分里 「计划 / 执行」分工 的主心骨。
两条诚实的提醒。 第一,更便宜的模型需要更清晰的指令 —— 它们照着好计划做得不错,但即兴发挥很差,所以模型越弱,计划就得讲得越细。第二,别过度优化:每隔几分钟换一次模型,是拿你的注意力去省几分钱。默认用一个强模型,对那些显而易见的杂务降到便宜模型,然后就让它待在那儿。
经验法则: 用强模型决定 做什么,用便宜模型去 做。当一个便宜模型开始原地打转时,那就是信号 —— 这个任务本该用更强的模型,切上去,别一直重试。
第 2 部分:上下文管理
这是这门课里最重要的一个想法:在任何时刻,模型只能基于此刻摆在它面前的东西去行动 —— 也就是它的 上下文。而这个上下文不是一个你随手往里扔东西的大桶。它是一摞层,而且每一轮,每一层你都要为之付费。
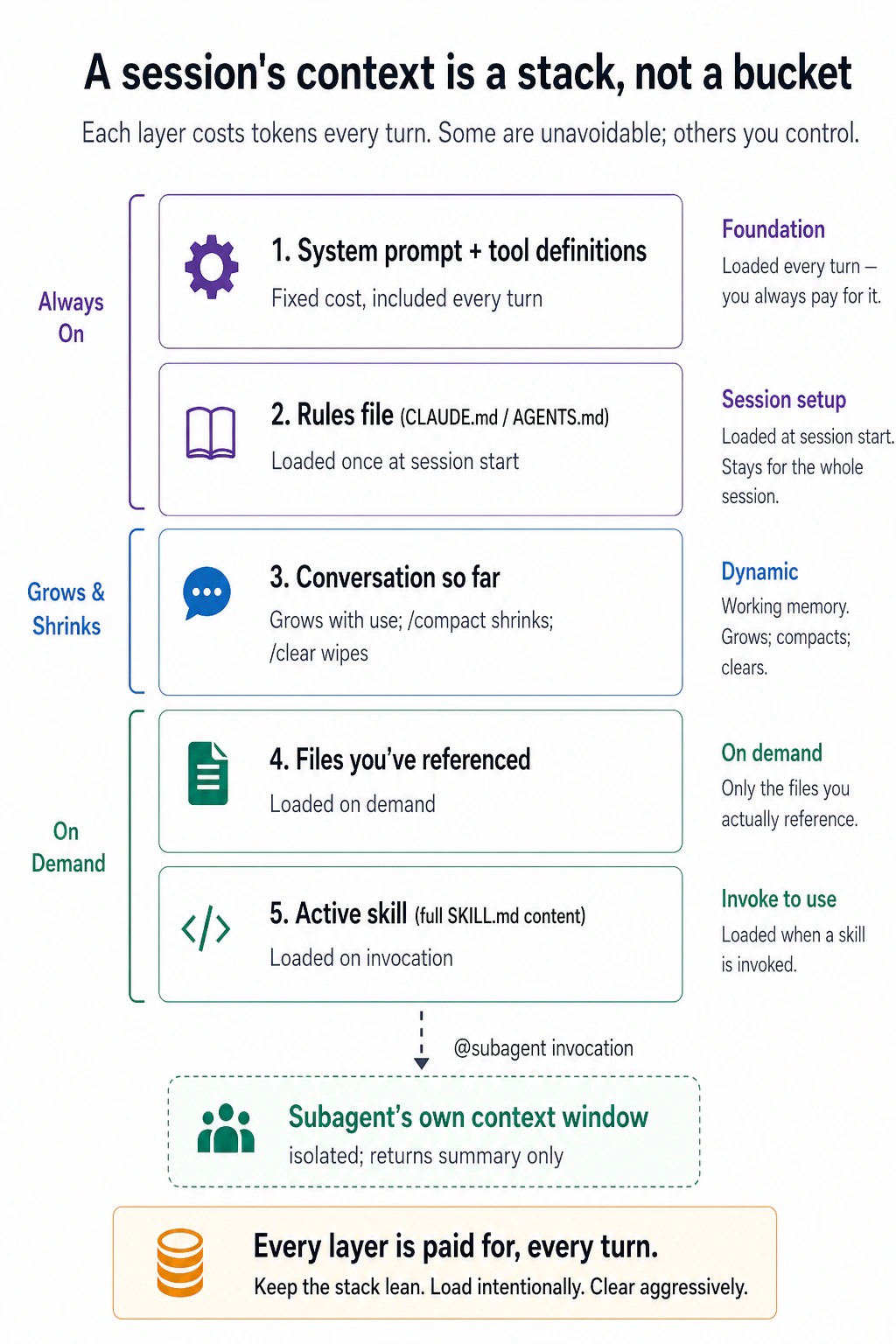
要记住的不是那五个标签 —— 而是左侧那道分界线。上面的几层是 固定的:系统提示词和你的规则文件,不管你愿不愿意都会加载。下面的一切都 归你管 —— 对话会一直长大,直到你 /compact 或 /clear 它;文件只在你指明时才加载;技能只在被调用时才加载;而一个子智能体会在另一个窗口里做它繁重的阅读,只递回一份摘要。
整个游戏就这么回事。好的上下文管理不是什么花招;它是一种习惯,就是让那摞东西保持精简 —— 加载任务需要的,清掉它不需要的。臃肿的堆叠花更多 token,但更糟的是:它把要紧的部分埋掉了 —— 窗口里的垃圾越多,模型就越费劲才能找到信号,它的回答也越容易跑偏。
在 AI 提示词课 里你学到,你给 AI 什么,比你怎么问更要紧。 这里的赌注更高:在聊天里,糟糕的上下文给你一个糟糕的答案;用这些工具,糟糕的上下文意味着 AI 把糟糕的代码 直接写进你的项目里。这就是为什么第 2 部分余下的一切,都只是控制这几层之一的某个具体方法 —— 也是为什么,如果这门速成课你只记住一节,那就该记这一节。它在两款工具里的运作方式是一样的。
5. 上下文腐烂是真的
AI 一次只能记住有限的信息量。这叫做 上下文窗口。把它想成一个群聊:AI 只能看到 这个 群里的消息。如果你在群里早些时候提过某件事,AI 可以往上翻、看到它。如果你从没说过,AI 就不知道。现代 AI 能应付很长的聊天(几十万字),但它仍然有上限。
为什么这件事要紧:
问题 1:聊天变长的速度比你以为的快。
你发的每条消息、你让 AI 读的每个文件、AI 给的每条回复,全都会加进聊天历史。来回二三十条消息,再加上你让它看的几个文件,这聊天就已经很长了。
棘手之处在于:没有任何警告告诉你「这段对话太长了」。它只是在背景里悄悄地不停长大。
问题 2:随着对话变长,AI 越来越记不住东西。
这里有个出人意料的地方。哪怕还没到上限,AI 就已经开始吃力。当对话很长时,AI 更难找到要紧的部分。你可能会注意到:
- AI 忽略了你 20 条消息前告诉它的东西(你确实说了,但太久之前,AI 跟丢了)
- AI 重做它已经做完的活儿(它忘了自己已经做过了)
- AI 把之前明明搞对的名字或细节弄混了
这叫做 上下文腐烂。对话还在继续,但 AI 成果的质量在慢慢变差,因为堆积的旧信息太多了。
问题 3:更长的对话花更多钱。
每次你发消息,AI 不只读你的新消息。它会把 整段 对话从第一条消息开始重读一遍。所以如果你已经来回了 30 条消息,那么你每发出第 31 条,AI 都会把这 30 条全部再读一遍。
如果你是按量付费(大多数 OpenCode 的搭法都是),这意味着更长的对话会贵得多。如果你用的是订阅套餐(比如 Claude Code Pro),你会更快撞上每日用量上限。无论哪种,一段又长又乱的对话都在耗你的预算。
要点:让你的对话保持短小、聚焦。 只给 AI 当前任务需要的信息,而不是你手头的一切。一段干净、聚焦的对话,远比一段冗长、杂乱的对话好用。

查看你的上下文有多满。 你看不见这摞东西,就没法让它保持精简。两款工具都让你读到当前用量 —— 只是呈现方式不同。
输入 /context 看一份完整明细:在窗口总量里已用了多少 token(比如 25.6k/1m tokens (3%)),并按类别拆分 —— 系统提示词、工具、记忆/规则文件、技能,以及你的对话。它甚至会标出哪些值得精简。你工作时,输入框附近还会有一个实时百分比,省得你老去问。
OpenCode 在它的界面里(那个全屏终端视图)实时显示你的用量 —— 当前模型、已用 token,以及占窗口的百分比。它具体落在屏幕的哪个位置,会随版本和终端宽度而变,所以找那个滚动的 token/百分比读数就行。目前还没有内置的类似 /context 那样的明细命令,所以你是从界面上读那个仪表,而不是去调用它。(如果你想要,社区插件可以加一个带完整明细的 /context 命令。)
不管你在哪款工具里,做法都一样:瞥一眼仪表,别等它填满。 质量往往在窗口技术上还没满之前就开始滑坡 —— 一旦一次会话用过了大约一半窗口,那就是你该 /compact 或 /clear(下一节)的信号,而不是等它到 100%。
6. /clear 与 /compact
当聊天变得太长时,你有两个选择。务必挑对那一个:
选择 1:开一段全新的聊天。 当你做完了一个任务、想开始一件完全不同的事时用它。旧聊天会被抹掉。
- Claude Code:输入
/clear - OpenCode:输入
/new(或/clear)
选择 2:缩小当前的聊天。 当你还在做同一个任务、但聊天已经变得太长时用它。AI 读完整段对话,写一份简短摘要,把其余的全扔掉。你从这份摘要接着干。
- 两款工具:输入
/compact
你可以告诉它保留什么:/compact 保留文件名和我们做的决定。
别把这两个搞混了。 /clear 删除一切、从头开始。/compact 保留要紧的部分、去掉其余的。如果你在一个任务中途用了 /clear,你会丢掉所有进度。如果你在本该开新会话时用了 /compact,你会把旧的杂物带进新任务。
7. 恢复会话
你进行的每一段对话都会自动保存。你可以关掉工具、关掉电脑,过会儿回来,从你停下的地方原封不动地继续。
- Claude Code: 在终端里运行
claude --resume。你会看到一份过往对话的列表。挑一个继续。 - OpenCode: 在工具里输入
/sessions(或/resume)来查看你保存的对话。
为什么这有用:
- 明天接着做。 大任务常常一次坐下来做不完。不必从头来过,直接从停下的地方恢复。
- 同时做多件事。 你可以让一段对话做一个任务、另一段对话做另一个任务,想什么时候切换就什么时候切换。
提示: 如果你之前存过一个计划文件(比如 docs/plans/my-plan.md),你也可以开一段全新的对话,告诉它:「读 docs/plans/my-plan.md,从第 4 步继续。」这个计划文件就是一份备份,万一你恢复不了旧对话时用得上。(更多细节见 第 17 章 § 会话管理。)
万一 AI 出错了呢?你可以撤销。
有时 AI 会改错文件、写出糟糕的代码,或者误解了你的要求。别慌 —— 两款工具都让你回退,方式略有不同:
- Claude Code: 按两次
Esc(在输入框为空时),或输入/rewind。你会得到本次会话中每一条提示词的菜单;挑一条,再选要恢复什么 —— 代码、对话,或两者。注意这撤销的是 AI 自己改的文件,而不是它通过运行 shell 命令做的事(被删掉或移动的文件,这样找不回来)。没有「重做」 —— rewind 是把你跳到一个选定的点,而不是来回单步走,所以要谨慎地 rewind。 - OpenCode: 输入
/undo撤销 AI 上一次改动,/redo在你改主意时用。它的底层用的是 git,所以你的项目得是一个 git 仓库。
无论哪种,把它当成做实验时的安全网,而不是 git 的替代品。任何你想留住的东西,都提交它;检查点和撤销是会话级别的便利,不是永久的历史记录。
Claude Code 的撤销管文件编辑,但不管终端命令。举例来说,如果 AI 运行了一条删除某个文件的命令,撤销不会把它找回来。OpenCode 的撤销管一切(文件编辑 和 终端命令),因为它用 git 来追踪所有改动。
三个命令的快速判断规则:

诊断:上下文变坏时
你怎么知道聊天已经太长了?留意这些迹象:
- AI 一直在道歉,却没真正修好任何东西。
- AI 把同一段代码改来改去,却没让它变好。
- AI 提到一些在你项目里并不存在的文件或名字。
- AI 忘了你在同一段对话里早先告诉它的某条规则。
- AI 的回复越来越长、越来越空泛,而不是越来越有用。
当你看到任何一条时,停止发消息。 你的第一反应会是再把问题解释一遍。别这么做。往一段已经过载的对话里再发消息,只会让它更糟。
正确的做法是 重置:
- 如果你想接着做同一个任务,用
/compact(它保留要紧的部分、清掉其余的)。 - 如果你想完全从头开始,用
/clear(OpenCode 里是/new)。
花五分钟重置,好过花一个小时跟一个再也跟不上对话的 AI 死磕。
诊断:上下文成本飙升时
记住:一段又长又乱的对话不只让 AI 把活儿干得更差 —— 它也让你花更多钱。随着对话变长,AI 在每条消息上要处理的文本就更多。
一个重要的微妙之处:缓存。 你可能以为每发一条消息都要付全价去重读整段对话。通常你不用 —— 但这个折扣来自 模型的供应商,而不是工具。大多数主流模型 API(Anthropic、DeepSeek 等)都支持 提示词缓存:它们把你上下文里稳定的前段 —— 系统提示词、你的规则文件、更早的几轮 —— 存起来,以很大的折扣复用(常常约为正常价的十分之一,有时远低于此),于是你只为自上一条消息以来 新增 的内容付全价。Claude Code 和 OpenCode 都被设计成让那个前段保持稳定,好让缓存持续生效 —— 但缓存本身是供应商的功能,一个不支持它的模型就拿不到折扣。问题在于:这个折扣只在上下文的前段保持不变时才成立。改你的规则文件,或者在历史里跳来跳去,缓存就从那一点开始重置,你又得付全价。(缓存在一次会话闲置一段时间后也会过期。)这就是为什么下面这些飙升是以那样的方式发生的。
| 你注意到什么 | 为什么会这样 | 怎么修 |
|---|---|---|
| 你的用量在对话中途突然跳高 | 你改了设置文件(CLAUDE.md 或 AGENTS.md),这会重置缓存折扣,逼 AI 把一切从头重新处理 | 把设置文件改回去,或者接受这一次性的飙升 |
| 每条消息都比上一条贵 | 对话一直在长大。AI 在读越来越多的文件,却没清掉旧的 | 用 /compact 缩小对话。告诉它保留什么:/compact 保留文件名和决定 |
| AI 在写极长的回复 | 你问了个简单问题,AI 却在过度解释。或者 AI 的思考模式相对任务设得太高了 | 让它「只给代码,不要解释」。或者在设置里调低推理力度 |
| 你的月度账单远高于预期 | 你对每个任务都在用最强(也最贵)的 AI 模型,连简单的也是 | 用昂贵模型做计划和难题。用更便宜的模型做格式化、运行测试这类简单任务(概念 4) |
所有这些背后的规律是同一个:更短、更聚焦、更稳定的对话,比又长又乱的更省钱、也更好用。
第 3 部分:规则文件
8. 把 CLAUDE.md / AGENTS.md 写好
两款工具都让你创建一个特殊文件,AI 会在每段对话开始时读它。把它想成一套为你项目长期生效的指令。每次你开新会话,AI 先读这个文件,好让它知道规矩。
- Claude Code 把这个文件叫
CLAUDE.md - OpenCode 把这个文件叫
AGENTS.md
你不需要自己写这个文件。 在任一工具里运行 /init,AI 会扫描你的项目文件夹、替你创建这个文件。之后,你的任务是 删掉你不需要的部分。 AI 倾向于生成一个很长的文件。其中大部分是多余的。
(完整的逐步讲解见 第 14 章 § CLAUDE.md 和 AGENTS.md。高级的团队搭法见 第 17 章 § CLAUDE.md 配置层级。)
如果你已经有一个 CLAUDE.md、然后切到 OpenCode,你不必重写它。当不存在 AGENTS.md 时,OpenCode 会自动读取 CLAUDE.md。如果两个文件都存在,OpenCode 用 AGENTS.md,忽略 CLAUDE.md。
人们犯的最大错误: 他们把这个文件当成一本完整手册,把项目的一切都塞进去:架构、编码规则、命名约定、团队偏好。问题在哪?AI 每发一条消息都会读这个文件。 一个巨大的规则文件拖慢 AI、耗掉你的对话空间,哪怕其中大部分信息跟当前任务无关。
让它保持简短。 只写 AI 没法通过看你的文件就弄明白的东西。把它想成一份目录,而不是一部百科全书。细节指向别的文件,让 AI 只在需要时才加载那些文件:
CLAUDE.md。@filename 语法会在相关时自动加载被引用的文件:
# Project: my-app
## Stack
Next.js 14, TypeScript, Postgres, Drizzle ORM.
## Commands
- `npm run dev`: start local server
- `npm test`: run vitest
- `npm run db:migrate`: apply migrations
## Critical rules
- Never edit files in `src/generated/`. They're rebuilt by codegen.
- All API routes use the auth middleware in `src/lib/auth.ts`.
- See @docs/conventions.md for naming and folder rules.
- See @docs/db-schema.md for table structure.
AGENTS.md。结构相同。有一点不同:在 Claude Code 里,写 @docs/conventions.md 会在需要时自动加载那个文件。在 OpenCode 里,这不会自动生效。你有两个选择:要么在你的 AGENTS.md 里写「相关时加载 docs/conventions.md」,要么在 opencode.json 里列出这些文件:
# Project: my-app
## Stack
Next.js 14, TypeScript, Postgres, Drizzle ORM.
## Commands
- `npm run dev`: start local server
- `npm test`: run vitest
- `npm run db:migrate`: apply migrations
## Critical rules
- Never edit files in `src/generated/`. They're rebuilt by codegen.
- All API routes use the auth middleware in `src/lib/auth.ts`.
## External references
When you encounter @docs/conventions.md or @docs/db-schema.md, load them
on a need-to-know basis with the read tool. Do not preemptively load all
references; only load what's relevant to the current task.
或者,更干净的做法,在 opencode.json 里列出它们:
{
"$schema": "https://opencode.ai/config.json",
"instructions": ["docs/conventions.md", "docs/db-schema.md"]
}
这不只是给代码项目用的。 你可以把同一套规则文件用于任何工作:写论文、整理研究、打理博客、策划活动。这里有一个写作项目的例子:
# Project: blog-and-newsletter
## What this is
A folder of drafts, research, and published posts. I write a weekly newsletter and occasional long-form posts.
## Where things live
- `drafts/`: in-progress posts, one per file
- `research/`: source notes and clippings, organized by topic
- `published/`: shipped posts (do not edit)
## Critical rules
- Never edit anything in `published/`. Fixes go in a new draft with a correction note.
- Footnotes go in `[brackets]` inline; we resolve them to numbered footnotes only at publish time.
- Tone: conversational, no bullet lists in body copy.
跟上面那个代码例子是同一个想法:保持简短,只放 AI 自己弄不明白的东西。
给你要加的每一行做一个简单测试: 问自己「如果我删掉这一行,AI 会出错吗?」如果答案是不会,就删掉它。比如说,你不需要告诉 AI 你的项目用 Python,只要所有文件都以 .py 结尾 —— AI 看得见。但你 确实 需要告诉 AI「绝不要编辑 published/ 文件夹里的文件」,因为光看文件,AI 没法知道这一点。
出了问题再加规则,别提前加。 如果 AI 犯了一个本可以被你的规则文件挡住的错,那就把那条规则加上。别试图提前猜到每一种可能的错误。久而久之,你的规则文件会自然长成一个有用的东西。

第 4 部分:个性化你的工具
两款工具都让你添加几类自定义功能。每一类解决一个不同的问题:

| 类型 | 它做什么 | 何时用 |
|---|---|---|
| 命令 / 技能 | 一个存档的、可复用的提示词,放在一个文件里。你输入 /name 来调用它,或者当任务与它的描述匹配时由模型自动调用。 | 你发现自己一遍又一遍地敲同样的指令,或者你想让模型在你没记得开口时也用上对的指令。 |
| 钩子 / 插件 | 一条不管怎样每次都自动运行的规则 | 有件事必须总是发生(比如「绝不要删这个文件夹」) |
| 子智能体 | 一个自己干活、只把答案送回来的独立 AI 助手 | 你需要 AI 做一次大搜索或研究任务,又不想弄乱你的主对话 |
它们全都是让你对话保持干净、AI 保持专注的办法。接下来的几节逐一讲解。
9. 命令与技能
这两个名字说的是同一个想法:一个 存档的、可复用的指令,放在一个文件里,省得你重新敲。唯一变化的是它怎么被调用。
- 你来调用它。 输入
/review它就运行 —— 由你决定何时。 - 模型来调用它。 给文件一个
description,当你的任务匹配时模型会自己运行它,省得你还要记得它存在。
这样一个文件也可以携带配套材料 —— 一个装着模板、风格指南或参考文档的文件夹,它们 只在提示词真正运行时才加载 —— 再加上几行前置元数据(frontmatter),用来设定它的名字、何时激活、可以用哪些工具。
「如果模型本来就会做这件事,那为什么还要写技能?」 这个问题让大多数人懒得去写 —— 它有一个清楚的答案。模型从训练里带来了海量的通用知识,但通用知识有三个缺口,而技能正好补上:
- 它不了解 你的 具体情况。 模型大体知道提交信息(commit message)一般怎么写;它不知道你团队的格式、你项目的怪癖、你内部工具的确切参数,或者任何在它训练截止之后才出现的东西。技能补上的正是从来没进过它训练的那部分。
- 「会做」不等于「每次都用同样的方式做」。 让模型「清理一下这份转录稿」五次,你会得到五个略有不同的流程。技能把确切的步骤钉死,于是你每次得到的是同一套 流程,而不是一次次现场即兴。
- 它不会主动去够对的做法。 训练里的知识只在你的提示词碰巧触发它时才浮上来。技能的
description就是 那个触发器 —— 它在任务一匹配的当下就把对的流程摆到模型面前,省得你还要记着去开口。
而它做到这一切,不会让你的对话变臃肿:只有那段简短的描述在前期待在上下文里;完整的指令和任何参考文件只在技能真正触发时才加载 —— 还是第 2 部分里那套上下文纪律。一句话:模型带来通用知识;技能带来 你的 具体情况、一致的做法,以及 在对的时刻给出的对的指令。(把它想成一位聪明的新员工,他懂整个领域,但仍然需要你的手册、一份清单,以及在对的时刻把对的那一页递到他手上。)
大语言模型是概率性的:模型从一系列选项里采样下一个词,所以同一个提示词回来时措辞可能不同,同一个技能也是如此。技能并不会关掉这一点。它做的是 收窄 可能输出的范围 —— 它去掉的是「模型这一次又自己发明了一套不同的做法」那种变化,而不是字词层面的变化。你从 五个不同的流程 走到 同一套流程、每次措辞略有不同。这是 做法 上的一致,而不是输出完全相同。
当某一步必须有保证 —— 同样的结果、每一次、毫无例外 —— 别让模型凭记忆去做。把它推进代码里:让技能去跑一个脚本、格式化工具或测试,或者用一个 钩子/插件(下一节)去强制它,那是普通的代码,因而是确定的。经验法则:技能让 做法 可靠;脚本和钩子让 结果 有保证。
在 Claude Code 里,命令和技能是同一个东西。把你的提示词文件放进 .claude/skills/:一个文件夹,里面有一个 SKILL.md。文件夹名就成了命令名,所以 .claude/skills/review/SKILL.md 给你 /review。
最简单的情况 —— 一个你自己调用的提示词。没有 description 时,模型不会自动运行它;你用 /review 来触发它:
Review the current diff for:
1. Bugs and edge cases
2. Test coverage gaps
3. Naming and readability
4. Adherence to @docs/conventions.md
Be specific. Quote the lines you're commenting on.
加上一个 description,当任务匹配时模型也能自己去够它:
---
name: extract-transcript
description: Extract a clean transcript from a YouTube video URL. Use when the user provides a YouTube link and asks for the transcript, captions, or text of the video.
---
# Extract YouTube transcript
1. Take the URL from the user's message.
2. Run `yt-dlp --skip-download --write-auto-sub --sub-format vtt "$URL"`.
3. Convert the VTT to plain text: strip timestamps, deduplicate overlapping captions.
4. Save to `transcripts/{video-id}.txt`.
For formatting conventions (paragraph breaks, speaker labels), see `references/style.md`.
那个 references/style.md 就是「携带更多」的部分:模型只在这个技能运行时才读它,所以其余时间它一分钱都不花你的。注意那个 普通的相对路径 —— 在技能里你 不 用规则文件里的 @ 自动导入语法(第 3 部分)。@ 会在规则文件一加载的当下就把一个文件强行塞进上下文;而技能引用本就该保持不加载,直到模型真正需要、自己去读它。一个普通路径(或者一个相对的 markdown 链接如 [style](references/style.md))正是让那种惰性加载继续生效的写法。
OpenCode 把命令和技能保持为 两个分开的东西 —— 它没有像 Claude Code 那样把它们合并:
- 技能 是一个装着指令的
SKILL.md文件夹,当任务与它的描述匹配时智能体会自己加载它。格式与 Claude Code 完全相同,而且 OpenCode 会在.opencode/skills/、~/.config/opencode/skills/以及 Claude Code 的.claude/skills/里查找 —— 所以一个为任一工具写的技能,在两边都能原封不动地用。 - 命令 是一个你自己输入
/name来触发的存档提示词,作为一个 markdown 文件存放在.opencode/commands/(项目级)或~/.config/opencode/commands/(个人级)。
OpenCode 也会把每个技能都列进斜杠菜单,作为一个可调用的命令(带 :skill 后缀显示),所以你 可以 手动触发一个技能 —— 但两者在底层仍是分开的:命令是你发出的提示词,技能是智能体在相关时拉进来的知识。
一个你自己调用的提示词 —— .opencode/commands/review.md(前置元数据是可选的;它支持 description、agent、model 和 subtask):
---
description: Review the current diff
agent: plan
subtask: true
---
Review the current diff for:
1. Bugs and edge cases
2. Test coverage gaps
3. Naming and readability
4. Adherence to docs/conventions.md
Be specific. Quote the lines you're commenting on.
一个智能体可以自动调用的技能 —— .opencode/skills/extract-transcript/SKILL.md(与上面 Claude Code 的技能完全相同;它也会作为 /extract-transcript:skill 出现在斜杠菜单里):
---
name: extract-transcript
description: Extract a clean transcript from a YouTube video URL. Use when the user provides a YouTube link and asks for the transcript, captions, or text of the video.
---
# Extract YouTube transcript
1. Take the URL from the user's message.
2. Run `yt-dlp --skip-download --write-auto-sub --sub-format vtt "$URL"`.
3. Convert the VTT to plain text: strip timestamps, deduplicate overlapping captions.
4. Save to `transcripts/{video-id}.txt`.
For formatting conventions (paragraph breaks, speaker labels), see `references/style.md`.
你在一个 已存在 的文件夹(.claude/skills/、~/.claude/skills/,或 OpenCode 的对应目录)里添加或编辑一个命令或技能,改动会立刻生效 —— 无需重启。唯一仍需重启的情况,是创建一个会话启动时还不存在的全新顶层技能目录,因为工具只能监视它在启动时就已知道的文件夹。
为什么要存下来,而不是每次现敲。 一个软弱的审查提示词 —— 「审查一下我的成果」 —— 几乎总是换来一句欢快的「看起来很棒!」,因为模型倾向于附和你(谄媚,出自 AI 提示词课)。真正管用的是一份清单,逼它逐项去查具体的东西,这样它就没法躲在「看起来不错」后面。但一份清单重新敲起来很烦 —— 于是忙的那天你就不会敲,正好在你最需要严谨的时候退回到偷懒的版本。把它存成 /review 去掉了那道阻力:你只把那个苛刻的提示词写一次,从此一个按键就每次都跑完整份清单。这才是存下来的真正好处 —— 不是一个更好的提示词(那个你手敲也行),而是一个更好的提示词成了毫不费力的默认,而不是你会跳过的那件事。
这对非编程任务同样管用。 一个 /standup,从你的笔记里写一份每日小结 —— 把它存成一个技能(Claude Code)或一个命令(OpenCode),主体如下:
Read yesterday's note in `journal/`. Produce a 4-line standup:
1. What I shipped yesterday (1 line)
2. What I'm working on today (1 line)
3. Blockers (1 line, "none" if clear)
4. One thing I learned (1 line)
Tone: telegraphic. No filler.
跟 /review 是同样的形状,只是换了领域。同样的窍门也适用于 /digest(把一个装满邮件的文件夹变成待办事项)、/draft-reply(给这个路径下的邮件写一封礼貌的回复),或者任何你反复重敲的杂务。判断标准:如果你把同样的指令敲了超过两次,就存下来。想自己触发它?用 /name 调用。想让模型自己去够它?给它一个 description。
有几条规则能让这些更可靠:
- 描述是最要紧的一行。 模型读它来决定要不要触发这个技能。模糊(「帮忙处理视频」)会触发得太频繁;具体(「当用户提供一个 YouTube 链接并索要转录稿时使用」)只在该触发时才触发。
- 让
SKILL.md保持简短。 把主要指令放进SKILL.md,把额外细节(风格指南、模板、参考材料)挪进同一文件夹里的单独文件。它们只在需要时才加载。 - 做小技能,别做大的。 要研究、起草、格式化、审查,别造一个巨型技能 —— 造四个(
research、draft、format、review),每个只做一件事,通过文件来交接。每个只需要它自己那一步的上下文,这让对话保持干净。
你不必从零开始写它们。 Claude Code 自带一个技能生成器,能一步步搭出新技能;OpenCode 有一个类似的智能体创建流程。(具体命令请查你工具的当前文档 —— 这些名字常被改动。)那个深入版(文件夹布局、前置元数据、参数传递、构建一个多步骤技能)见 第 14 章 § 教 Claude 你的工作方式 和 第 14 章 § 构建你自己的技能。
10. 钩子(Claude Code)/ 插件(OpenCode)
命令和技能依赖于模型选择去用它们。但有时你需要一条 不管怎样、每一次都运行 的规则,不依赖模型记得它。这就是钩子(在 Claude Code 里)和插件(在 OpenCode 里)的用途。
举个例子:「绝不让 AI 运行一条删除所有文件的命令。」你不希望 AI 去 自行决定 要不要遵守那条规则。你希望它被自动强制执行,每一次,毫无例外。
两款工具都支持这个,但在每款里的设置方式不同。这是两款工具差别最大的一节。
Claude Code 用「hook(钩子)」这个词来指这些自动规则。OpenCode 用「plugin(插件)」这个词。它们做的是同一件事,只是名字不同。(Claude Code 另外还有一个叫「plugins」的功能,意思完全不一样。现在先别管那个。)
钩子 是你加进 .claude/settings.json 的自动规则。它们在特定时刻运行:会话开始时、你发消息时,或者 AI 即将运行一条命令之前 —— 这三个只是例子;Claude Code 可以在 大约 30 个生命周期事件 上触发钩子,从会话开始、提示词提交,到工具使用前后、压缩、会话结束。一个钩子有两部分:一个 matcher,挑出 要盯哪个工具(按名字,比如 "Bash" 或 "Edit|Write"),以及一个 command(一条 shell 命令或脚本),决定 要不要 放行这个操作。如果那条命令以退出码 2 退出,AI 就被挡住、做不了这个操作。
这里有一个例子,挡住 AI 永远不能运行 rm -rf(一条会删掉一切的危险命令):
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "jq -r '.tool_input.command' | grep -q 'rm -rf' && { echo 'Blocked dangerous command' >&2; exit 2; } || exit 0"
}
]
}
]
}
}
它是怎么运作的:matcher("Bash")意味着这个钩子只在 Bash 命令之前运行。当 AI 即将运行一条时,Claude Code 把命令的细节以 JSON 形式从标准输入交给你的脚本。脚本用 jq 取出实际的命令文本,用 grep 检查里面有没有 rm -rf —— 如果匹配,就往 stderr 打一条消息并以退出码 2 退出。退出码 2 是那个特定的信号,告诉 Claude Code「挡住这个操作」;任何别的退出码都放行,这就是为什么安全的那条分支以 exit 0 收尾。关键想法:matcher 挑工具,脚本决定要不要挡。现在你需要知道的就这些。下面第 6 部分里有一个更详细的例子。
有两个小东西能让钩子更好相处。第一,较新的 Claude Code 版本加了一个 if 字段,用与权限规则相同的语法按工具 和参数 预先过滤一个钩子 —— 所以 "if": "Bash(rm -rf *)" 让钩子只在匹配的命令上触发,你就可以省掉脚本里的 grep。(较旧的版本忽略 if、每次都运行钩子,这就是为什么上面那个 grep 版本到处都能用。)第二,钩子可以放在 ~/.claude/settings.json 里,对你所有项目生效,而不只是某一个项目的 .claude/settings.json;如果一个钩子没触发,输入 /hooks 确认它是否已注册。
插件 是一些小的 JavaScript(或 TypeScript)文件,你把它们放进你的 OpenCode 插件文件夹 —— 单个项目放 .opencode/plugins/,要处处生效就放 ~/.config/opencode/plugins/。它们做的和 Claude Code 钩子一样的事(自动挡住或修改操作),但你用代码而不是 JSON 来写。这里是同一个「挡住 rm -rf」的例子:
// .opencode/plugins/block-dangerous.js
export const BlockDangerousPlugin = async () => {
return {
"tool.execute.before": async (input, output) => {
if (input.tool === "bash" && output.args.command?.includes("rm -rf")) {
throw new Error("Blocked dangerous command");
}
},
};
};
OpenCode 插件能做的不只是挡操作。它们可以对许多不同事件作出反应:会话开始时、AI 干完活时、文件被编辑时,等等。它们还能给你发通知、添加自定义工具,以及在对话被压缩时重塑它怎么被总结。你不需要一上来就学这些全部。只要知道:如果你以后需要,插件是更强大的那个选项。
注意文件夹是复数 ——
plugins/,不是plugin/。 一个插件悄无声息地从不触发,最常见的原因是它放错了目录;加载器只监视.opencode/plugins/(项目级)和~/.config/opencode/plugins/(全局级)。OpenCode 演进得快,所以如果有什么行为异常,瞥一眼当前文档。
一个实用的例子: 假设你有时会在草稿里留下 [TODO] 标记,发布前忘了删掉。你可以设一个钩子(Claude Code)或插件(OpenCode),自动挡住 AI,只要某个文件还含有 [TODO] 标记,就不许它存进 published/ 文件夹。你永远不必记得去检查;工具替你做了。
你该用哪一个?

| Claude Code 钩子 | OpenCode 插件 | |
|---|---|---|
| 怎么写 | 设置文件里几行 JSON,指向一条 shell 命令或脚本 | 一个小的 JavaScript 文件 |
| 更适合 | 像「挡住这条命令」这样的简单规则 | 需要检查多件事的复杂规则 |
| 你需要懂 | 基本的终端命令(外加一点 jq/grep 来做内容检查) | 基本的 JavaScript |
一个好习惯:在提交时检查,而不是每次编辑时。 让一个钩子在每次文件改动时触发很诱人,但在任务中途打断 AI 往往会把它搞糊涂 —— 它正想到一半被叫停。换个做法:让它把活儿干完,把你的检查放在 提交 那一刻(它试图用 git commit 保存一个检查点的时候)。那时再跑你的测试和格式化工具。如果通过,提交就放行。如果失败,你的钩子挡住这次提交、把错误交还给 AI —— AI 读完它,自己在再次尝试前修好问题。你什么都不用做;那个失败的检查 本身 就是指令。(第 6 部分第 6 步就展示了这一幕。)
对那些你需要 100% 都成立的事,用钩子/插件。对那些你希望模型大多数时候记得的事,用技能。
11. 子智能体
一个子智能体是一个有自己上下文窗口的、隔离的智能体实例。你把一个任务委派给它;它在私下里干活;它返回一份摘要。它的文件搜索、日志倾倒和探索性阅读,永远不会碰到你的主线程。
为什么这在上下文管理的意义上要紧:最能毒害上下文的一件事,就是「探索代码库、找出 X 发生在哪里」。这类任务会把几十个文件拽进上下文,其中大部分你都用不上。把它放进一个子智能体里做,意味着你的主会话只看到那个结论(「X 发生在 src/services/billing.ts:142」),而不是那一通搜索。
有两种,把它们分清楚有帮助:你工具 自带 的子智能体(这些你不用写 —— 它们就在那儿、会自动触发),以及你自己 自定义 编写的那些。
内置子智能体 —— 你已经有了这些。 无需设置;当一个任务合适时工具会去够它们。
- Claude Code 自带
Explore(只读的代码库搜索,跑在一个快而便宜的模型上)、Plan(计划模式期间用到的只读研究),以及一个用于「多步且也需要做改动」工作的通用智能体。 - OpenCode 自带
Explore(只读搜索)、General(更宽泛的委派工作),以及Scout(只读的外部文档和依赖研究)。
在 Claude Code 里,计划模式会自动把它的代码库研究交给一个只读子智能体,所以你大多会不假思索地用到这些 —— 被要求时模型甚至能自己进入计划模式。在 OpenCode 里,Plan 智能体(一个你用 Tab 切过去的 主 智能体)以同样的方式自动调用子智能体,或者你可以用 @explore 显式调用一个。
自定义子智能体 —— 你来写这些,当你不断生成同一种、带同样指令的工人时。一个自定义子智能体是一个 markdown 文件,带一点前置元数据(它的名字、何时使用、能碰哪些工具)外加一段系统提示词。(提醒:OpenCode 内置的 Scout 已经能做外部文档研究,所以下面这个 doc-fetcher 在那边更像一个教学例子,而不是你需要去造的东西。)
.claude/agents/doc-fetcher.md:
---
name: doc-fetcher
description: Fetches and summarizes external library documentation. Use when the user references a library and we need to understand its current API.
tools: WebFetch, Read, Write
---
You are a documentation researcher. Given a library name and a topic, fetch the official docs, extract only the API surface relevant to the topic, and write a focused summary to `tmp/docs-{library}.md`. Don't paste full pages: extract the patterns and signatures we need.
.opencode/agents/doc-fetcher.md:
---
description: Fetches and summarizes external library documentation. Use when the user references a library and we need to understand its current API.
mode: subagent
permission:
edit: ask
bash: deny
webfetch: allow
---
You are a documentation researcher. Given a library name and a topic, fetch the official docs, extract only the API surface relevant to the topic, and write a focused summary to `tmp/docs-{library}.md`. Don't paste full pages: extract the patterns and signatures we need.
把它们放哪,以及一个更省事的做法。 把文件存进你的 项目 文件夹,整个团队都能用上它;或者存进你的 个人 文件夹,跨每个项目使用:
- Claude Code:
.claude/agents/(项目级)或~/.claude/agents/(个人级)。与其手写这个文件,不如运行/agents,通过一段引导式提示来生成一个。有一个小坑:你在磁盘上添加或编辑的文件,只在下一次会话开始时才加载,而通过/agents做出来的智能体立即生效。 - OpenCode:
.opencode/agents/(项目级)或~/.config/opencode/agents/(个人级)—— 文件名就成了智能体的名字。或者运行opencode agent create来搭一个。(如果你更喜欢配置而非单独文件,也可以在opencode.json里内联定义智能体。)
两件值得知道的事。 你可以给一个子智能体配它自己更便宜、更快的模型 —— 跟概念 4 是同一个「模型匹配」的想法,也是为什么 Claude Code 的 Explore 默认跑在一个快速经济的模型上。而且在 Claude Code 里,一个子智能体不能再生成更多子智能体(不能无限嵌套);要做多阶段委派,就从你的主会话里把它们串起来,或者去够动态工作流(见下文)。
自定义子智能体对非编程任务也管用。 比如说,想象你有一份很长的 PDF(一章教科书、一篇研究论文,或一份合同),你想要一份摘要。与其把整份文档粘进你的对话(那会很快填满你的聊天),你可以派一个子智能体去读它,只带回那份摘要:
---
name: pdf-summarizer
description: Reads a long PDF and writes a focused summary. Use when the user references a PDF and wants the key points without dumping the whole document into the conversation.
tools: Read, Write
---
You are a research summarizer. Given a PDF path and a question, read the document, extract only the passages relevant to the question, and write a focused summary to `tmp/summary-{pdf-name}.md`. Do not paste full pages: pull out the patterns, claims, and quotes the user actually needs.
子智能体自己读完整份 PDF。你的主对话从不看到那 200 页。它只在最后拿到那份简短摘要。这就是全部意义所在:把繁重的阅读隔开,好让你的主对话保持干净。
子智能体怎么被用上? 两种方式,内置和自定义一样,在两款工具里都一样:
- 自动地。 如果你给子智能体写了一个好的描述,AI 会在任务匹配时自己用它。这是你大多数时候用子智能体的方式。
- 手动地。 在你的消息里输入
@subagent-name,明确告诉 AI 用哪一个子智能体。当你想确保某个特定的跑起来时这么做。
简单规则:如果一个任务需要读大量你主对话并不需要的信息,就派一个子智能体去做。(第 14 章 § 子智能体与编排 有完整指南。)

技能还是子智能体?它们容易搞混。 两者都可复用,都能从一个 description 自动触发,而且都在第 4 部分露过面。区别归结于 活儿在哪里跑:
| 技能(概念 9) | 子智能体 | |
|---|---|---|
| 在哪运行 | 你当前的对话 —— 同一个窗口、同一个模型、同一套工具 | 它自己隔离的窗口 |
| 它是什么 | 一套你的智能体遵循的流程或专长 | 一个替你干一大块活儿的独立工人 |
| 回来的是什么 | 内联输出,作为正在进行的聊天的一部分 | 只有一份摘要;冗长的中间过程(搜索、文件倾倒、死胡同)永不进入你的上下文 |
| 模型与工具 | 会话当前用的那一套 | 可以跑一个更便宜/更快的模型,以及一套受限、沙盒化的工具 |
| 成本与延迟 | 便宜且即时 —— 它只是加载文本 | 有启动开销(它从一片空白开始、自己去搜集上下文),但让 你的 窗口保持干净 |
| 最适合 | 内联地施加一套一致的做法,并有来回切磋的余地 | 隔离高吞吐量的工作(探索、长文档、日志分诊),或沙盒化工具 |
一句话:技能改变你 当前 智能体的工作方式;子智能体把活儿交给一个 单独 的、会汇报回来的智能体。 技能是战术手册;子智能体是一个你委派任务的队友。
而且它们是相互组合而非彼此竞争的:一个子智能体可以使用技能。 在 Claude Code 里你要么预加载它们 —— 在子智能体的前置元数据里列出 skills: [api-conventions, error-handling],那些内容从第一轮起就在它的上下文里 —— 要么让它在运行时自己去够技能(只有当你想禁止这一点时,才从它的 tools 里去掉 Skill)。OpenCode 也一样:一个子智能体会使用技能,除非它的 skill 权限被拒。所以这个选择从来不是技能 或 子智能体;它常常是一个 持有 对的技能的子智能体。
做得更大(仅限 Claude Code): 对非常大的活儿,Claude Code 可以并行跑几十到几百个子智能体并检查它们的成果 —— 这叫 动态工作流。它仅限 Claude Code,而且消耗的 token 多得多,所以它落在成本可承受的默认栈之外。
第 5 部分:连接到外部世界
12. 诚实地使用 MCP
MCP 是 Model Context Protocol(模型上下文协议)的缩写。它是一种把 AI 连到你已经在用的其他应用和服务的方式:Slack、Google Docs、Notion、GitHub、数据库,等等。一旦连上,AI 就能直接从那些服务读取、向它们写入。
「这不就是个 API 吗?」 差不多 —— 在你接线之前,这值得说清楚。MCP 是一个 围绕 API 和其他工具的 标准封装,不是它们的替代品。一个裸 API 需要有人每次去写胶水代码(处理鉴权、组织请求,并告诉模型怎么调用它);一个 MCP 服务器已经把这些做好了,并把它的工具广而告之,于是智能体不用写集成代码就能发现并使用它们。所以真正的问题从来不是「MCP 还是 API」 —— 而是「这值不值得一个常驻连接,还是智能体直接调那个东西就行了?」下面的「用/跳过」规则正好回答这个。
Claude Code 和 OpenCode 都支持 MCP。因为 MCP 是一个开放标准,同一个 服务器 在两款工具里都能用 —— 但配置不通用,所以你要在每款里分别添加(它们把各自的连接存在不同的文件里)。
这里是在每款工具里添加一个 MCP 连接的方法:
用 CLI 添加服务器 —— claude mcp add --transport http <name> <url> —— 它默认写入 ~/.claude.json(个人级)。加上 --scope project 改为在你的项目根目录写一个可共享的 .mcp.json。然后在 Claude Code 里运行 /mcp 来查看状态,并登录任何需要 OAuth 的服务器。(注意:这 不是 .claude/settings.json,那个是管权限和钩子的。)
在 opencode.json 里声明。对一个托管服务器用 "type": "remote"(带一个 url),对一个作为本地进程运行的用 "type": "local"(带一个 command,比如 ["npx", "-y", "some-mcp"]):
{
"$schema": "https://opencode.ai/config.json",
"mcp": {
"sentry": {
"type": "remote",
"url": "https://mcp.sentry.dev/mcp",
"oauth": {}
},
"context7": {
"type": "remote",
"url": "https://mcp.context7.com/mcp"
}
}
}
对需要登录的服务器,运行 opencode mcp auth <name> 来走 OAuth 流程;opencode mcp list 显示每个服务器的状态。
为什么这有用: 没有 MCP 时,AI 只能处理你电脑上的文件。有了 MCP,AI 可以伸到你电脑之外,与在线服务交互。比如说:你可以让 AI「查一下我的 Slack,看今天团队有没有给我发消息」,或者「为这个 bug 在 GitHub 上建一个新 issue」,而 AI 会真的去做,而不只是告诉你该怎么自己做。
更正经的用途:连接你的记录系统。 一个 记录系统 是某一类数据的权威归处 —— 那个人人都当作真相的唯一副本:你的数据库、你的 CRM、你的工单系统、一个公司知识库。MCP 就是你把智能体指向其中之一的方式,好让它从鲜活、权威的数据作答,而不是从一份你粘进去的陈旧副本、或一个训练里半记得的事实。问「订单 4471 现在是什么状态?」,智能体就通过 MCP 去查真正的数据库,而不是瞎猜。这也是一团知识 —— 一本书、一套文档、一个内部维基 —— 变得 可查询 的方式:在它前面立一个 MCP 服务器,任何工具都能向它提问、得到扎根于源头的答案。每一个 AI 工人也都通过 MCP 跑在一个 记录系统 之上。
但要小心:别什么都连。 每一个 MCP 连接都可能占掉你对话里的空间,哪怕你没在用它。OpenCode 自己的文档警告说:「某些 MCP 服务器,比如 GitHub MCP 服务器,往往会加进大量 token,很容易超出上下文上限。」 有一个值得知道的差别:Claude Code 现在默认延迟加载 MCP 工具定义(只在即将用到时才加载一个工具的完整描述),所以在那边额外的服务器几乎不占上下文。OpenCode 是前期就加载它们,所以在那一侧要格外有选择。无论哪种,习惯都一样:只连你真正需要的。这也是「MCP 会让上下文臃肿」这个担忧的真正答案 —— 解法是 分层(惰性加载工具、简单活儿靠 CLI,把繁重的 MCP 工作推进概念 11 的一个子智能体里),而不是抛弃 MCP。
何时用 MCP、何时跳过:
- 用 MCP,当服务需要 AI 登录或保持连接时。比如:读你的 Google 日历、浏览一个网站,或查询一个需要密码的数据库。
- 跳过 MCP,当 AI 跑一条简单的终端命令就能拿到同样结果时。比如:与其通过 MCP 连到 GitHub,AI 不如直接在终端里跑
gh issue list来看你的 issue。无需登录、无需连接、无需额外设置。
从你真正需要的一两个连接开始。 别因为有十个就装十个。
第 6 部分:一个完整的实战示例,做两遍
这里是一切汇合的地方。你会用上面学到的概念,从头到尾做完一个完整任务。这个任务做两遍:一遍在 Claude Code 里,一遍在 OpenCode 里,好让你看到步骤几乎一模一样。
无需写代码。 这个例子用的是会议记录,但你不必是程序员也能跟着做。只要你在会议、课堂或小组项目里记过笔记,你就已经懂这个任务了。
你的任务
你有一个叫 notes/ 的文件夹,里面有五个会议记录文件。问题在于:它们很乱。每场会议写待办事项的方式都不一样。有些用标题「Action Items」。有些用「Todos」。有一个用小写的「todo」。有些待办事项埋在你想不到去翻的其他章节里。还有些事项标了 [private] 或 [HR],意味着它们绝不该被公开分享。
你的目标: 创建一个干净的文件,叫 weekly-actions.md,它要:
- 列出全部五场会议里的每一项待办事项
- 按谁负责来分组
- 标明每一项来自哪场会议
- 排除任何标了
[private]或[HR]的内容 - 一项都不漏
- 如果有任何截止日期落在公共假日上,就提醒你
📁 先拿到那五个起始文件(点击展开)
开始之前,把这些复制进一个 notes/ 文件夹。这个例子就是围绕它们设计的:每个文件都扮演一个特定角色,所以如果你漏掉一个,下面就有一步会失灵。(不想搭文件夹?把这五个文件直接粘进你工具的聊天里,让它把这些当作 notes/ 的内容。)
notes/2026-12-07-monday-team-meeting.md
# Monday Team Meeting - 2026-12-07
Attendees: @sara, @diego, @priya, @marcus
## Discussion
Reviewed last month's customer satisfaction scores. Renewals are down slightly in the small-business segment.
## Action Items
- @sara: draft a revised welcome email by Dec 18
- @diego: check spam-folder reports with our email vendor by Dec 16
- @marcus: pull renewal numbers for the last two quarters and share with the team
- @sara: finalize offer terms for the new account manager [HR]
notes/2026-12-08-customer-feedback.md
# Customer Feedback Review - 2026-12-08
Attendees: @sara, @amara, @marcus
## Summary
Read through the top twenty customer comments from last week. Three themes came up: pricing page is confusing, the call-back service is slow, and the FAQ on the website is out of date.
## Todos
- rewrite the pricing page in plain language
- @marcus: log a complaint with the call center vendor about response times
- look into why the FAQ has not been updated in six months
- @amara: draft a customer note explaining the upcoming changes
- review all printed brochures for outdated photos and pricing
notes/2026-12-08-q1-planning.md
# Q1 2027 Planning - 2026-12-08
Attendees: @sara, @diego, @amara, @lukas
## Initiatives
We walked through the four candidate initiatives for Q1.
### Year-end promotional campaign
Time-bound: wraps before the holiday break.
#### Action Items
- @amara: finalize the year-end promotional brochure by Dec 25
- @lukas: confirm placement with paid media partners by Dec 20
### Onboarding overhaul
Top priority next quarter.
## todo
- @diego: write the project brief by Jan 15
- @sara: own messaging and visual direction
notes/2026-12-09-all-hands-prep.md
# All-Hands Prep - 2026-12-09
Attendees: @sara, @marcus
## Agenda
Walked through the December all-hands agenda. Most slides are in good shape; a couple still need owners.
## Next Steps
- @marcus: set up the video call and record a practice run
- @sara: finalize the Q4 numbers slide
- @sara: prepare the bonus and compensation talking points [private]
- @marcus: book the venue for the team holiday dinner
notes/2026-12-11-vendor-review.md
# Vendor Review - 2026-12-11
Attendees: @sara, @amara, external partner
## Summary
Confidential contract negotiation with our printing and fulfillment vendor. Details under NDA.
## Action Items
- @sara: circulate the revised contract to the vendor [private]
- @amara: draft the internal announcement once terms are agreed [private]
- @sara: review the legal redlines on the new pricing schedule [private]
这次演练是怎么组织的
下面是八个步骤。每一步都遵循同样的模式:
- 在 Claude Code 里要做什么(确切的指令)
- 这一步为什么要紧(一段简短的解释)
- OpenCode 里有什么不同(如果有任何变化,会在这里注明。如果写着「相同」,那两款工具在这一步的做法就一样)
第 1 步:设好你的规则文件
在 Claude Code 里: 在你的项目文件夹里打开 Claude Code。运行 /init。AI 会扫描你的文件夹、创建一个叫 CLAUDE.md 的文件。它会太长。删掉大部分,只留下这些:
# weekly-rollup
## Layout
- `notes/`: meeting notes, one file per meeting
- `weekly-actions.md`: the rollup we are creating
- `plans/weekly-rollup-plan.md`: the plan we will save and reuse
## Critical rules
- Action items can appear under `## Action Items`, `## Todos`, `## Next Steps`, or `## todo` (one meeting uses lowercase). Look at all heading levels, not just the top.
- Owners are written as `@name`. Items with no owner go to an "Unassigned" section.
- Never include any bullet tagged `[private]` or `[HR]`.
为什么这要紧: AI 每发一条消息都读这个文件。一个长文件拖慢一切、浪费空间。所以你只留下 AI 没法靠看这文件夹本身就弄明白的东西。那条隐私规则尤其重要,因为 AI 没法知道 [private] 事项应当被隐藏。
在 OpenCode 里: 同样的事,只是文件叫 AGENTS.md 而不是 CLAUDE.md。如果你已经有一个 CLAUDE.md,OpenCode 也会读它。
后面有几步会用 git commit 保存你的成果(OpenCode 的撤销也依赖 git)。如果这个文件夹还不是一个仓库,现在运行一次 git init,好让那些步骤能用。顺便说一句,在 Claude Code 上,第 6 步的安全检查用到一个叫 jq 的小工具 —— 大多数系统都有,但如果第 6 步报错「jq: command not found」,就装一下(brew install jq,Linux 上是 apt install jq)。
第 2 步:动手之前先做计划
在 Claude Code 里: 按两次 Shift+Tab 打开计划模式(AI 能读但不能改任何东西)。然后输入:
Read every file in notes/. Produce weekly-actions.md grouped by
owner. For each item include the action, the source filename, and
the meeting date. Skip anything tagged [private] or [HR]. Do not
lose any action items.
AI 想一分钟,回来给你一份它将要做什么的书面计划。
为什么这要紧: 读一份计划要 30 秒。撤销一个错误要久得多。永远先计划。
在 OpenCode 里: 按 Tab 切到 Plan 模式。其余一切相同。
第 3 步:检查计划、纠正错误
在 Claude Code 里: 仔细读那份计划。它大概有两处会是错的。
第一处:它只会提到 顶层 标题(## Action Items、## Todos)。但你的某个会议文件(Q1 计划记录)把待办事项藏在 ### Year-end promotional campaign 里面,下面带一个 #### Action Items。这份计划会漏掉那些。
第二处:它不会说明,对那些没有负责人(旁边没有 @name,比如客户反馈文件里那条「rewrite the pricing page in plain language」)的待办事项该怎么办。那些会悄无声息地消失。
你提出异议:
Two changes. (1) Look at all heading levels, not just the top.
Some action items live under sub-headings. (2) Items without an
owner go to an "Unassigned" section at the bottom; never drop
them.
AI 更新了计划。让它把最终计划存到 plans/weekly-rollup-plan.md,这样你下周可以复用。
为什么这要紧: 改一份计划比改一份成稿容易得多。趁现在还不花成本,把问题逮住。
在 OpenCode 里: 同样的步骤,没有不同。
第 4 步:让 AI 干活
在 Claude Code 里: 按 Shift+Tab 离开计划模式。告诉 AI 动手。
AI 读完全部五个会议文件,创建 weekly-actions.md,按负责人分组,去掉 [private] 和 [HR] 事项,并把没有负责人的事项放进一个「Unassigned」小节。你看着它发生。
为什么这要紧: 因为你先做了计划,结果第一次就大体正确。
weekly-actions.md 应当在你的主项目文件夹里,挨着 notes/ 文件夹,而不是在它 里面。如果 AI 放错了地方,你第 1 步的规则文件可能少了 Layout 小节。
在 OpenCode 里: AI 在写每个文件之前会请求你批准。你可以说同意,或者在 opencode.json 里为以后的运行设好自动批准。
第 5 步:清理对话
在 Claude Code 里: 对话现在很长了。AI 读了每一份会议记录,所有那些文本仍占着空间,包括它跳过的那些隐私事项。你已经不再需要那些了。输入:
/compact keep the heading rules, the owner list, and the
private/HR exclusion rule
AI 总结这段对话、扔掉其余一切。只有你告诉它保留的部分留下来。
为什么这要紧: 一段又长又乱的对话让 AI 变差,而不是变好。它也更花钱。把你不再需要的清出去,尤其是那些不该留在记忆里的隐私内容。
在 OpenCode 里: 同样的命令,同样的结果。
第 6 步:加一道自动安全检查
在 Claude Code 里: 在保存你的成果之前,你想确保没有哪场会议被意外漏掉。你会加一个钩子:一道自动检查,每次 AI 试图保存(提交)你的成果时都运行。(这里的「保存」指的是 git commit 这个检查点 —— 你在 git 里记下一个快照的那一刻 —— 而不只是写 weekly-actions.md 文件。)
引言承诺过无需写代码,这一点仍然成立:你会在这里 粘贴 一个代码块,而不是写一个,而且你 不 需要看懂这段代码。紧随其后的大白话解释就是你需要的全部。(它也依赖于这个文件夹是一个 git 仓库 —— 见第 1 步的设置提示。)
这是本章里唯一一处你自己粘贴一个配置块、而不是让模型来写的地方。有两个理由,都是吃了亏才学到的。
(1)「Hook」有歧义。 如果你告诉模型「创建一个 hook」,Claude Code 可能会去够一个 git 钩子(.git/hooks/ 里的一个文件),而不是一个 Claude Code 钩子(.claude/settings.json 里的一项)。那是不同的东西;你要的是第二个。
(2) AI 会无意中破坏这道安全检查。 你的规则文件说要跳过 [private] 事项。如果你让 AI 来写这个钩子,它会读到那条规则,然后「热心地」把同样的跳过逻辑加进钩子里。这意味着那场供应商评审会议(其中每一项都是 [private])会被钩子悄无声息地忽略,永远不会有警告冒出来。但这个钩子的全部意义正是逮住恰好这种情况:一场看起来像被跳过了的会议。你没法让 AI 去造一道针对它自己规则的安全检查。它总会找到办法「热心」一把,然后把检查给打败。
稳妥的做法就是把配置粘进去。
打开 .claude/settings.json(如果文件不存在就创建它),把这个原样粘进去:
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "jq -r '.tool_input.command' | grep -q '^git commit' || exit 0; for f in notes/*.md; do grep -q \"$(basename $f)\" weekly-actions.md || { echo \"Missing: $f\" >&2; exit 2; }; done"
}
]
}
]
}
}
用大白话说它做什么: 每次 AI 试图保存(提交)你的成果时,这个钩子检查一件简单的事:notes/ 里的每一个会议文件,是不是都在 weekly-actions.md 的某处被提到了?如果有任何文件名缺失,它就挡住这次保存。它不检查内容、不看 [private] 标记、不做任何例外。它只检查文件名。这就是全部意义所在。
看会发生什么。 让 AI 提交。安全检查触发:Missing: notes/2026-12-11-vendor-review.md。为什么?因为那场会议里的每一项待办都被标了 [private],而你第 1 步的规则说要跳过隐私事项。所以当 AI 搭那份汇总时,从那个文件里它没有任何东西可写,于是那个文件名从未出现过。钩子不知道这些。它只看到一个缺失的文件名,就挡住了保存。
模型读了这个错误,给汇总打上一条占位条目,明确点出那个文件名,比如:
## From 2026-12-11-vendor-review.md
- All items confidential — see meeting owner.
现在文件名出现在 weekly-actions.md 里了,钩子的 grep 找得到它,提交就放行。没有任何隐私内容泄进汇总;审计线索完好无损。
这一整轮里你什么都没做。安全网逮住了错误,模型自己修好了。
为什么。 那些你想要 每一次 都成立的事,不该指望模型记得。它们应当被自动检查。而且这道检查应当住在一个模型没法悄悄改写来取悦自己的地方:这正是为什么这一个是粘贴、而不是提示词。
OpenCode 里有什么变化。 OpenCode 把这些叫 插件 而不是钩子,而且它们写成一个小的 JavaScript 文件。同样的想法、同样的结果、同样的「粘贴别提示」逻辑。创建 .opencode/plugins/check-rollup-complete.js(这个文件夹可能还不存在),把这个粘进去:
// .opencode/plugins/check-rollup-complete.js
import { readdirSync, readFileSync } from "fs";
export const CheckRollupCompletePlugin = async ({ $ }) => {
return {
"tool.execute.before": async (input, output) => {
if (
input.tool === "bash" &&
output.args.command?.startsWith("git commit")
) {
const rollup = readFileSync("weekly-actions.md", "utf8");
const missing = readdirSync("notes")
.filter((f) => f.endsWith(".md"))
.filter((f) => !rollup.includes(f));
if (missing.length) {
throw new Error(`Missing from rollup: ${missing.join(", ")}`);
}
}
},
};
};
同样的形状:列出 notes/ 里的每个文件、检查每个文件名是否在汇总里、若有缺失就抛出。里面没有 [private] 过滤。行为与 Claude Code 版本完全相同:文件缺失,提交被挡,模型自己修好。
钩子/插件更深入的材料(退出码、matcher 语法、完整事件列表)见 第 14 章 § 钩子与可扩展性(OpenCode 那一侧见 插件:把一切串起来)。
第 7 步:把一个旁支任务派给一个助手
在 Claude Code 里: 有些待办事项带着像「by Dec 25」或「before year-end」这样的截止日期。你想查一查那些日期里有没有落在公共假日上的。输入:
Use a research helper to look up the 2026 international public
holidays list and write the dates to tmp/holidays-2026.md.
一个助手(子智能体)跑到网上、找到假日日期、把它们存进一个小文件。你的主对话从不看到那整张网页。它只看到那个带着日期的小文件。
这跟概念 11 里的子智能体是同一个模式 —— 一个能联网、只返回摘要的助手。那边那个叫 doc-fetcher,描述得窄、专门用于 库文档,所以对这样一次通用查找,要么给那个助手一个更宽的描述(比如「获取并总结外部参考和查找」),要么造一个带 WebFetch 和 Write 工具的小 researcher 智能体。这一步的重点是委派,而不是具体哪个智能体。
然后 AI 把你那份摘要里的截止日期与假日日期作比对,在任何落到假日上的截止日期旁边加一条警告,像 ⚠ falls on Christmas Day。
为什么这要紧: 如果 AI 直接去取那张网页,它会把一大堆文本倾倒进你的对话。派一个助手让你的对话保持干净。
在 OpenCode 里: 直接按名字调用你的研究助手 —— 比如 @researcher。同样的结果。
第 8 步:把它存成一个技能,留着下次用
在 Claude Code 里: 你每周都要做这个任务。与其下周五再去记住所有这些步骤,不如让 AI 把这一切存成一个技能:
Create a skill at ~/.claude/skills/weekly-meeting-rollup/SKILL.md
based on what we just did. Include: the four heading variants,
the all-headings rule, the private/HR exclusion, the Unassigned
section, the missing-file check, and the holiday cross-reference.
下周五,只要输入「do the weekly rollup」,AI 就会自动用这个技能。你今天设好的所有规则(标题变体、隐私过滤、未分配小节、假日检查)每次都被应用,你什么都不用记。
为什么这要紧: 你今天做的活儿不只是为了今天。你教会了 AI 从今往后怎么做这个任务。
在 OpenCode 里: 技能存到一个略有不同的文件夹,但文件本身完全相同。你可以在两款工具之间复制它,它在两边都能用。
刚才发生了什么
回头看看这八个步骤。没有一步要求你写代码。没有一步要求你知道 API 是什么。你实际做的,是八个 管理模型注意力 的小动作:告诉它看什么、何时计划、何时遗忘、何时委派、何时别再信任自己、何时记住。
这就是整一章。
再看看两款工具之间差别有多小:
- 规则文件用了不同的文件名(
CLAUDE.md对AGENTS.md) - 进入计划模式用了不同的按键(
Shift+Tab对Tab) - 安全网文件用了不同的语言(JSON 对 JavaScript)
- 最后技能放在不同的文件夹(但 同一个文件)
就这些。

思考才是工具,配置只是装饰。学会这样思考,无论哪款工具最终胜出,你的技能都能存活。
13. 终端、IDE,还是桌面?
两款工具都能在好几个地方运行。
Claude Code: 终端(CLI)、VS Code / JetBrains 插件、一个桌面应用(macOS 和 Windows 上的一个 Code 工作区 —— 不含 Linux —— 专为并行运行多个会话而造,每个会话在自己的 git worktree 里)、网页(claude.com)、一个手机应用,以及用于异步工作的云端托管会话,这些会话你从上述任何一处都能查看。
OpenCode: 终端(TUI 是旗舰)、一个桌面应用(测试版,在 macOS / Windows / Linux 上)、一个 VS Code 扩展外加其他编辑器(如 Zed,通过它的 ACP 服务器)、一个通过 SDK 提供的网页界面,以及诸如一个 GitHub 智能体和一个 Slack 机器人这样的集成。
挑一个适合你正在做的事的。如果你在写代码,VS Code 或 JetBrains 插件很棒,因为你能实时看着 AI 编辑你的文件。如果你在跑更长的任务、想在等待时做点别的,终端就很好用。对非编程工作,最省事的选择是网页应用,或者 —— 在 Claude 这一侧 —— 桌面应用的 Cowork 标签页,那是与同一个应用里的 Code 标签页(也就是 Claude Code)并列的知识工作模式。
强烈的建议,在任一工具里都一样:从终端或一个 IDE 插件开始。 一旦你弄懂了底下在发生什么(模型读哪些文件、跑哪些命令、做哪些决定),其他每一个界面都成了一层你能看穿的薄壳。如果你从一个高度抽象的 UI 起步,出岔子时你会很难调试,因为你不知道 有什么 会出岔子。
14. 慢慢建一个个人上下文库
一旦你用任一工具做了几个项目,你会注意到自己在往每个规则文件里写类似的东西:你的代码风格、你的提交约定、你的测试理念。别再复制粘贴了。
把共享的部分放进你的主目录配置,从每个项目的规则文件里引用它们:
~/.claude/CLAUDE.md(在每个项目里都会加载):
# CLAUDE.md
@~/.claude/style/typescript.md
@~/.claude/style/commits.md
然后让每个项目自己的 CLAUDE.md 只放那个项目独有的东西 —— 上面那个全局文件(以及它导入的那些风格文件)会自动在每处被拉进来。
~/.config/opencode/:
// ~/.config/opencode/opencode.json
{
"$schema": "https://opencode.ai/config.json",
"instructions": ["style/typescript.md", "style/commits.md"]
}
外加一个项目专属的 AGENTS.md,放那个项目独有的东西。
同样的想法也适用于技能。一个放在 ~/.claude/skills/(OpenCode 也会读它)或 ~/.config/opencode/skills/ 里的 commit-message 技能或 code-review 技能,会自动在每处可用。
别想一次把这些全建好。 花一个周末搭起完美的个人库很诱人。别这么做。换个做法:一次加一样,只在你真正需要时。AI 用错风格写了代码之后,再加一个风格指南。你第三次敲同样的提交指令之后,再加一个提交技能。一个从真实问题里长出来的库,会保持小而有用。一个提前设计的库,最后会又大又没人用。
15. 基础之外的记忆
对大多数人来说,恢复旧对话、加上保持一个好的规则文件,就够了。但如果你想让 AI 在你开一段全新对话之后也记住一些东西,这里是你的选项:
- 项目里的一个
notes/文件夹。 做完一个任务后,让 AI 写一份它做了什么、做了哪些决定的简短小结。把它存进一个notes/文件夹。下次,AI 可以读那些笔记来快速进入状态。简单、无需设置、两款工具都能用。 - 一个记忆 MCP 服务器。 这些给 AI 一种跨对话保存和回忆信息的方式。有好几个免费的,两款工具都能用。
- 跨旧对话搜索。 有些搭法让你搜索你过去的对话,找出「这个我以前解决过吗?」查你工具的文档,看看有什么可用的。
这些工具正开始替你做那个简单版本。 Claude Code 现在有一个内置的 自动记忆:你工作时,它会自己写一些关于你的纠正和偏好的简短笔记,并在每段会话开始时重新加载它们 —— 就是那个 notes/ 文件夹的想法,自动化了。(它跑在 Claude Pro 和 Max 套餐上、而且还在逐步铺开,所以别指望它处处都有;手动的 notes/ 文件夹才是那种在任何工具、任何模型上都管用的做法。)无论哪种,这都只是更印证了下面这条规则。
按你真正需要的来选。 如果你只想记住关于一个项目的决定,一个 notes/ 文件夹就够了。如果你想让 AI 跨你所有项目记住一切,你需要更进阶的东西。在你有一个真实问题要解决之前,别去搭复杂的工具。
第 8 部分:组合 Claude Code 和 OpenCode
到目前为止,这门课把 Claude Code 和 OpenCode 当作两个选项:挑一个、学会它。但一旦你对基础上手了,你其实可以在同一个项目上同时使用两款工具。这不只是一个备用方案。每款工具都有另一款缺的长处,把它们组合起来可以比单用任何一款更有效。
保持安全:git worktree
在我们看那些模式之前,有一个安全问题得先解决。
如果你在同一个项目上同时跑两个 AI 会话,而两个都试图编辑同一个文件,那么一个会覆盖另一个的改动。那就乱了。
解法叫做 git worktree。把它想成给你的项目文件夹做一份副本,但更聪明。每份副本(叫一个「worktree」)是它自己的工作空间,AI 可以在里面独立干活。一个 worktree 里的改动不影响另一个。两边都做完后,你用 git 把结果合并到一起。
这是设置方法:
它一步步是怎么运作的:
# Step 1: Go to your project folder
cd myproject
# Step 2: Create two worktrees (two separate copies, each on a NEW branch)
# The -b flag creates the branch; without it, git expects the branch to already exist.
git worktree add -b my-branch-1 ../myproject-copy1
git worktree add -b my-branch-2 ../myproject-copy2
现在你有了两个独立的文件夹(myproject-copy1 和 myproject-copy2),每个都在不同的分支上有自己那份项目副本。
# Step 3: Open Claude Code in one copy
cd ../myproject-copy1
claude
# Step 4: Open OpenCode in the other copy (in a separate terminal window)
cd ../myproject-copy2
opencode
两款 AI 工具现在同时在不同的副本上工作。它们没法覆盖彼此的文件。
# Step 5: When you're happy with the work, go back to the main folder and
# merge each branch into your main branch (it may be called main or master).
# Because the two sessions worked in different files (see the rule below),
# these merges should apply cleanly.
cd ../myproject
git merge my-branch-1
git merge my-branch-2
# Step 6: Clean up the copies (this removes the worktrees; your merged
# commits are safe in the main branch)
git worktree remove ../myproject-copy1
git worktree remove ../myproject-copy2
文件编辑规则,分三档:
| 模式 | 结论 |
|---|---|
| 两个会话同时编辑同一个文件 | 糟糕:后写的覆盖前者,另一个会话的编辑丢失 |
| 两个会话编辑不同的目录 | 好:没有争用,并行提速是真实的 |
| 一个会话编辑、提交,交接给另一个 | 可以接受:那次提交就是交接物 |
经验法则: 从「一个任务一个会话」开始。只在你能清楚指出每个会话各自拥有哪些文件时,才加上第二个。在两个智能体会话之间来回切换的认知成本是真实的;只有当工作真正切得开时,它才算划算。
让这一切得以运作的共享层,是项目的规则和技能。两款工具读同一个 CLAUDE.md 和同一个 .claude/skills/ 目录(概念 8 和 9 讲过这个)。一个项目约定的唯一真相来源;两款工具消费它。
模式 1:计划 / 执行分工
任何任务的难点是想清楚 做什么:读项目、定方案、考虑哪里可能出错。简单的部分是:一旦有了清晰的计划,实际去做。AI 模型也反映这一点:最强(也最贵)的模型最擅长思考和计划那部分。更便宜的模型可以把直白的「照这些指令做」那部分干得很好。
实际怎么做:
- 在 Claude Code 里打开计划模式。描述你想要什么。让它创建一份详细计划。
- 把计划存到一个文件(比如
docs/plans/my-feature.md)。 - 在一个单独的 worktree 里打开 OpenCode,用一个更便宜的 AI 模型。告诉它:
read docs/plans/my-feature.md and implement it。 - OpenCode 照着计划做:编辑文件、运行测试、修格式。
- (可选)回到 Claude Code 在合并之前审查改动。
那个计划文件就是契约。它在会话丢失后依然存活、把架构决策编码下来,并让那个便宜会话不必重做昂贵的思考就能干活。光这一个模式,常常就交付了团队从「换一个更便宜的模型」里希望得到的大部分成本节省,而不损失前沿模型做计划的质量。
模式 2:跨模型审查
在 AI 提示词课 里你学到,让第二个 AI 检查第一个 AI 的成果能逮住更多错误。这里,我们用编程工具做同样的事。
为什么这管用: 写了代码的那个 AI 是最不适合审查它的那个。它有跟当初造成错误一样的盲点。一个 不同的 AI 模型(来自不同公司、在不同数据上训练)会注意到第一个漏掉的东西。
怎么做:
- 工具 A(任意模型)在它自己的 worktree 里写代码。
- 工具 B(一个不同的 AI 模型)读那些改动、把一份审查写到
docs/reviews/my-feature.md。它不编辑任何代码;它只写反馈。 - 工具 A 读那份审查、决定采纳哪些建议。
这比听起来有用。哪怕一个便宜的 AI 模型用来当审查者,也能逮住真实问题:漏掉的边界情况、安全问题、令人困惑的命名、没用的代码。跑一次审查的成本很小;在你已经发布之后才发现一个 bug 的成本要大得多。
最佳结果来自混用不同的 AI 供应商。 Claude 审查 Claude 自己的代码会漏掉同样的东西。但 GPT 审查 Claude 的代码(反之亦然)会逮住不同类型的错误。用同一个 AI 既写又审,仍然好过不审;但用不同的 AI 要好得多。
什么仍然单工具
你并不总是需要两款工具。 把两款一起用要额外设置:两套配置、两份权限清单、两套通知设置。对小任务(修一个 bug、写一个函数、清理一个文件),一款工具、一个会话更快也更简单。
何时把两款工具一起用:
- 任务大到「计划」和「构建」明显是分开的步骤
- 你想用一个更便宜的模型做构建部分来省钱
- 你想在合并前让一个不同的 AI 做一次独立审查
其余一切,一款工具就够了。 你在第 1 到 7 部分学到的技能,才是你大多数时候要用的。
怎样真正把这件事练好
读这门速成课并不会让你擅长这些工具。真正用它们才会。学习过程是这个样子的:
你会从手动做每一件事开始。你会撞上问题。那些问题正是你学习的方式。每个问题都指回这门课里十五个概念中的某一个:
| 你撞上的问题 | 该修什么 |
|---|---|
| 「为什么 AI 老忘记我的项目规则?」 | 你的规则文件缺失或太长了(概念 8) |
| 「为什么 AI 刚刚删了一个重要文件夹?」 | 你的权限不够严(概念 3) |
| 「为什么聊了一个小时后 AI 越来越差?」 | 对话太长了;用 /compact(概念 6) |
| 「为什么我的账单(或用量上限)在简单工作上爆了?」 | 你对什么都在跑一个昂贵模型;让模型与任务匹配(概念 4) |
| 「为什么我每周都在敲同样的指令?」 | 把那些指令变成一个技能(概念 9) |
| 「为什么 AI 一试图保存就什么都崩了?」 | 你需要一个钩子或插件来逮住它(概念 10) |
| 「为什么翻文件会弄乱我的对话?」 | 用一个子智能体单独去做那个搜索(概念 11) |
撞上每个问题时再去修它,别提前修。 从一个小规则文件开始。出问题时加一行。当你注意到自己在重复时,创建你的第一个技能。当本该被自动逮住的东西崩了时,加一个钩子。让你的配置从真实经验里自然长大。
真正的本事不是背下十五个概念。 而是当一个问题冒出来时,认出该用哪个概念。那只来自练习。
你的技能在工具之间通用。 一旦你在一款工具里学会这样思考,切到另一款就很容易。按钮和设置不同,但思考是一样的。挑一款工具、从一个项目开始、用计划模式、让你的对话保持短小。其余一切都从这里建起。
速查
一句话说清的 15 个概念
- 这些工具会动手干活,而不只是回答问题。(它们是什么)下指令,别问问题。
- 计划模式。(功能)让 AI 在改动任何东西之前先给你看它的计划。(Claude Code 里是
Shift+Tab,OpenCode 里是Tab。) - 权限。(设置)AI 每次操作前都问。先手动批准。安全操作以后再自动批准。
- 让模型与任务匹配。(模型选择)强模型做计划和推理;便宜或免费模型做执行。用
/model(Claude Code)或/models(OpenCode)切换。 - 对话越长越糟。(上下文)AI 跟丢细节、也更花钱。让对话保持聚焦。
/clear= 从头开始。/compact= 同一任务、更少杂乱。(命令)别搞混了。- 恢复旧对话。(命令)明天回来、从停下的地方继续。把计划存到文件作为备份。
- 规则文件。(
CLAUDE.md/AGENTS.md)保持简短。只写 AI 没法靠看你的文件就弄明白的东西。 - 命令与技能。(
.claude/skills/)一套「存档提示词」系统:你用/name调用它,或者模型根据它的描述自动调用。 - 钩子 / 插件。(
settings.json/.opencode/plugins/)不管怎样每次都运行的规则。AI 没法跳过它们。 - 子智能体。(
.claude/agents/)派一个助手去做繁重的阅读,好让你的主对话保持干净。 - MCP。(外部连接)把 AI 连到在线服务(Slack、GitHub、数据库)。只加你真正需要的。
- 在哪运行。(终端 / IDE / 网页)从终端或一个 IDE 插件开始,好让你看到 AI 在做什么。
- 个人库。(
~/.claude//~/.config/opencode/)跨项目共享你的规则和技能。从真实问题里慢慢建。 - 记忆。(
notes/文件夹)对大多数人,恢复对话加一个好的规则文件就够了。需要更多就加一个notes/文件夹。
命令速查
| 想要… | Claude Code | OpenCode |
|---|---|---|
| 初始化项目规则文件 | /init | /init |
| 进入计划模式 | Shift+Tab(两次) | Tab(循环到 Plan 智能体) |
| 切换模型 | /model | /models |
| 清空对话、从头开始 | /clear | /new(或 /clear) |
| 总结并继续 | /compact | /compact(或 /summarize) |
| 恢复一个保存的会话 | claude --resume | /sessions(或 /resume) |
| 跳回上一条消息 | Esc Esc(或 /rewind) | /undo |
| 回退模型的文件编辑 | Esc Esc(检查点) | /undo(需要 git) |
| 回退 bash 命令造成的文件改动 | (未追踪) | /undo(全树差异) |
重做(撤销上一次 /undo) | (未捆绑) | /redo |
| 导出或分享对话 | /export(保存一份转录稿) | /share(公开链接)或 /export |
文件位置速查
| 是什么 | Claude Code | OpenCode |
|---|---|---|
| 项目规则 | CLAUDE.md | AGENTS.md(也会读 CLAUDE.md 作为兜底) |
| 项目权限 | .claude/settings.json | opencode.json |
| 项目命令 | .claude/commands/*.md | .opencode/commands/*.md |
| 项目技能 | .claude/skills/<name>/SKILL.md | .opencode/skills/<name>/SKILL.md(也会读 .claude/skills/) |
| 项目钩子/插件 | .claude/settings.json(hooks 块) | .opencode/plugins/*.{js,ts} |
| 项目子智能体 | .claude/agents/*.md | .opencode/agents/*.md |
| 个人/全局规则 | ~/.claude/CLAUDE.md | ~/.config/opencode/AGENTS.md |
| 个人命令/技能/智能体 | ~/.claude/{commands,skills,agents}/ | ~/.config/opencode/{commands,skills,agents}/ |
| MCP 服务器 | .mcp.json(项目)/ ~/.claude.json(个人) | opencode.json(mcp 块) |
扩展类型判断树
Need to do the same thing repeatedly, manually?
→ Slash command (CC) / Custom command (OC)
Want the model to apply expertise automatically when a task matches?
→ Skill
Need something to happen every single time, no model judgment?
→ Hook (CC) / Plugin (OC)
Need a chunk of work done in isolation so it doesn't pollute main context?
→ Subagent
当有什么感觉不对劲时
Model apologizing without progress, rewriting the same code,
hallucinating variables, contradicting earlier constraints?
→ Context is poisoned. Stop typing. Run /compact or /clear.
Don't try to fix it with another prompt.
闪卡学习辅助
小测验:关于 15 个概念的 52 道题
测一测你学到了什么。每次会话会出一组全新的 18 道题,所以你每次重做都会拿到新题。