امنح ذكاءك الاصطناعي سياقاً قابلاً للبحث: نظام RAG على Postgres مع pgvector، دورة مكثفة
15 مفهوماً · 80% من الاستخدام الحقيقي · يبنيه وكيلك لا يداك
تخيّل أنك تستطيع أن تقول لحاسوبك: "خذ هذا المجلد من المستندات، وأنشئ قاعدة بيانات تفهم معناها، وابنِ لي بحثاً يُعيد لي عند طلب «المدينة التي لا تنام» اقتباسات عن نيويورك، حتى تلك التي لا تذكر اسمها أبداً." وأنه ينفّذ ذلك فعلاً.
ثلاث كلمات، تحسّباً لكونها جديدة عليك. قاعدة البيانات مستودع للبيانات: المبنى الذي تخزّن فيه الشركة بضائعها، إلا أن البضائع هنا معلومات. وSQL هي اللغة التي تخاطب بها ذلك المستودع، فكل طلب لتخزين البيانات أو إيجادها أو تغييرها جملةٌ بها. أما Postgres (قاعدة البيانات في عنوان هذه الدورة) فهي من أكثرها استعمالاً في العالم. والمستودع العادي لا يجد صندوقاً إلا بملصقه الدقيق، أما الذي ستبنيه أنت فيجد الأشياء بحسب معناها.
نظام البحث بالمعنى هذا هو ما تعلّمه هذه الدورة، وهنا المفاجأة: لن تكتب SQL بيدك؛ Claude Code أو OpenCode هو من يبني ذلك كله. مهمتك أن تعرف ما يكفي عن Postgres وpgvector (الإضافة التي تمنحها تلك القدرة) لتعطي تعليمات واضحة، ولكي تحكم بنفسك إن كان الوكيل قد أصاب. هذا الجزء الثاني هو المهارة كلها، وفي النهاية ستعرف أيّ المقابض مهمّ وأيّها يُترك وشأنه.
فكرة واحدة تجعل هذه الدورة كلها تتّضح. نموذج الذكاء الاصطناعي لا ينتبه إلا لقدر محدود في وقت واحد: فكل ما يقرؤه ليجيبك لا بد أن يتّسع في نافذة السياق خاصته، وكلما زاد فيها من مواد غير ذات صلة ساءت الإجابة. لذا فالمهمة الجوهرية في أيّ نظام ذكاء اصطناعي هي وضع المعلومة الصحيحة أمام النموذج في اللحظة الصحيحة، وإبقاء كل ما عداها خارجاً. أنت تفعل هذا بالفعل لوكيل البرمجة لديك: ملف قواعد، وفقط الملفات التي تحتاجها المهمة. وقاعدة البيانات المتّجهة تؤدي المهمة نفسها لمستخدمي تطبيقك: فمن بين مليون صف مخزّن، تجد القليل الذي يطابق معنى السؤال وتسلّمه وحده للنموذج. لهذه الحركة اسم، هو RAG، أي التوليد المعزَّز بالاسترجاع، وهي إدارة السياق نفسها على طبقة أدنى: ما تفعله أنت لوكيل البرمجة يدوياً يفعله تطبيقك لمستخدميه آلياً. كل مفهوم هنا يعود إلى ذلك.

تفترض هذه الدورة أنك أنجزت الدورة المكثفة في البرمجة الوكيلة، فينبغي أن تكون مرتاحاً في قيادة Claude Code أو OpenCode، واستخدام نمط التخطيط، وإدارة السياق. وهي تبني أيضاً على صياغة تعليمات الذكاء الاصطناعي في 2026: حرفة أن تطلب من الذكاء الاصطناعي ما تريده بالضبط. وإن كان «التضمين» و«المتّجه» جديدين عليك تماماً فلا تقلق، إذ يشرحهما المفهوم 2 من الصفر.
📚 وسيلة تعليمية
شاهد العرض التقديمي الكامل: سياق قابل للبحث للذكاء الاصطناعي
أداتان، ومجموعة مهارات واحدة
الوكيل هو من يقود؛ وقاعدة بيانات Postgres لديك هي ما يقوده. تعيش قاعدة البيانات على Neon، وهي خدمة سحابية تشغّل Postgres نيابةً عنك، فلا شيء تثبّته ولا جهاز تديره (وهذا كل ما يعنيه بدون خادم: تستيقظ حين تستعملها، وتنام حين لا تستعملها). يشغّل الوكيل Neon عبر خادم Neon MCP: ينشئ المشروع، ويفتح فرعاً، ويشغّل SQL، ويعرض كل تغيير على ذلك الفرع قبل تثبيته. أنت لا تتنقّل في لوحة تحكّم Neon ولا تفتح psql بنفسك أبداً. والانضباط واحد في الأداتين: Claude Code وOpenCode متكافئتان هنا، وحين يختلف أمرٌ ما اختلافاً حقيقياً أنبّه إلى الفرق في موضعه.
ماذا تغطّي هذه الدورة
| الجزء | الموضوع | ماذا تتعلّم |
|---|---|---|
| 1 | الأساسيات | مهمتك بوصفك مهندس الذكاء الاصطناعي، والمتّجهات من الصفر، وما يحتاجه Postgres للبحث بالمعنى، ووكيلك متّصلاً بخدمة Neon |
| 2 | أول نظام RAG لك | حمّل بياناتك، وقسّمها إلى قطع، وحوّل كل قطعة إلى متّجه معنى، وابحث بالمعنى، ودع نموذجاً لغوياً يجيب منها |
| 3 | تسريع البحث | متى يحتاج البحث المتباطئ إلى فهرس، وكيف تختار واحداً، والمقبض الوحيد بين السرعة والدقة الذي يهمّ |
| 4 | تحسين البحث فعلاً | قِس إن كانت الإجابات صحيحة حقاً، وأضف مرشّحات، وامزج المعنى بالكلمات الدقيقة، واعزل بيانات كل عميل، واسأل قاعدة بياناتك بلغة بسيطة |
| 5 | مثال عملي كامل | مهمة كاملة واحدة، من قاعدة بيانات فارغة إلى نظام RAG يعمل، مع توجيهها في الأداتين |
| 6 | اشحنه أداةً | غلّف نظام RAG في خادم MCP ليتمكّن أيّ وكيل، سواء Claude Code أو OpenCode أو موظف رقمي تبنيه لاحقاً، من استدعائه |
| 7 | أين يعمل | اختبر التغييرات على نُسخ فورية من قاعدة بياناتك، وأبقِ المتّجهات حديثة مع تغيّر البيانات، وما الذي يختلف في بيئة الإنتاج |
| 8 | سلّمه إلى وكيل | اربط نظام RAG لديك بوكيل (OpenAI Agents SDK)، وهو الجسر إلى دورة بناء الوكلاء |
إليك النظام كله في صفحة واحدة، وهي الخريطة التي ستنمو إليها مع استيعاب كل مفهوم:
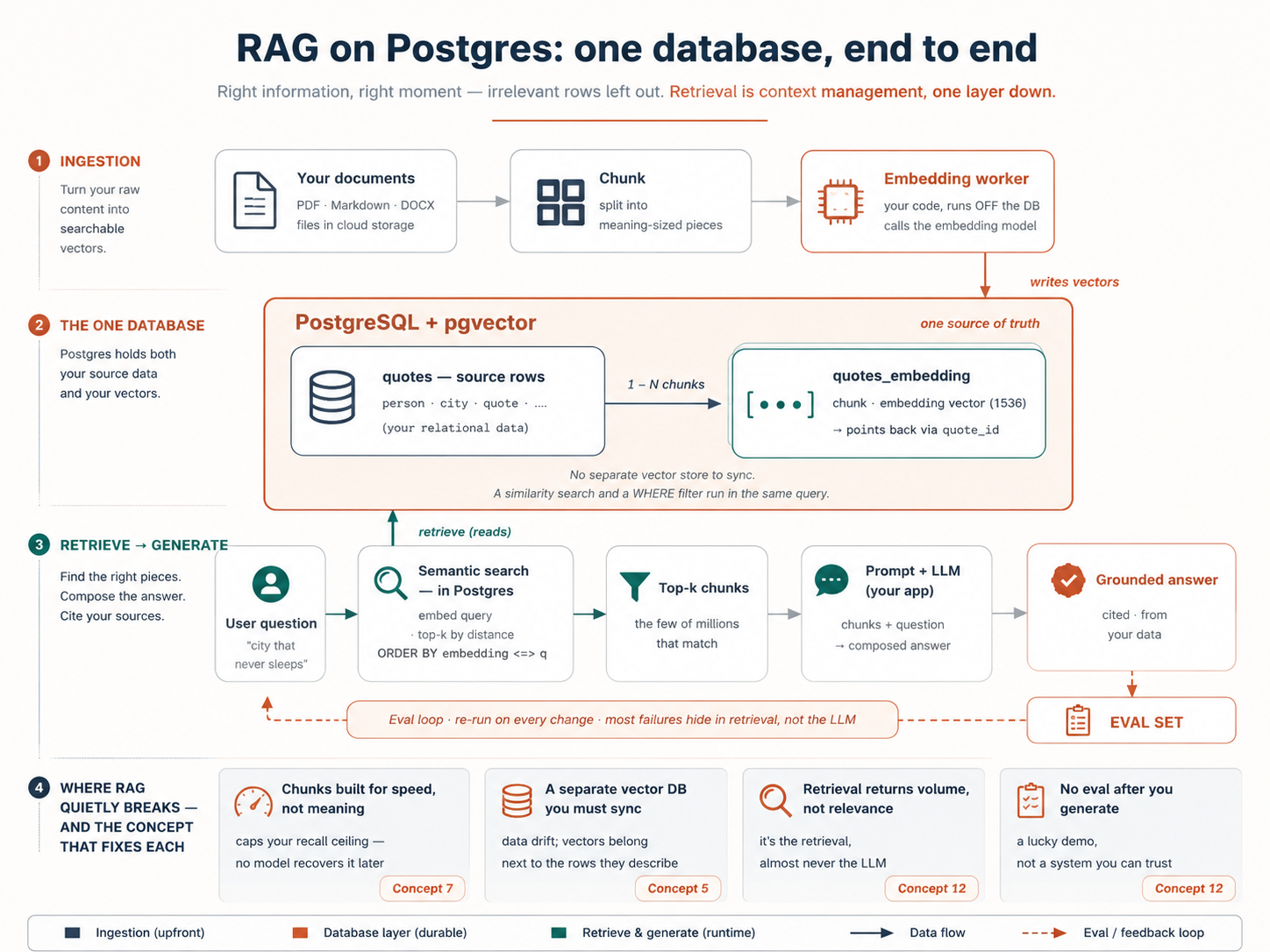 |
|
في النهاية سيكون لديك مشروع RAG يعمل: مجلد المستندات docs/ لديك محمّلاً في قاعدة بيانات Neon مع تفعيل pgvector، وعامل صغير يُبقي متّجهات المعنى محدّثة مع تغيّر المستندات، وبحث يجد بالمعنى، ودالة answer_question() تجيب من بياناتك أنت، وتقرير يبيّن إن كانت خمسة أسئلة اختبارية تعود بإجابات صحيحة. ولن تتوقّف عند نسبة 80% السهلة: ستكون قد قِست أداء فهرس HNSW من بطيء إلى فوري، وصفّيت البحث حسب الفئة، ودمجت الكلمات المفتاحية بالمعنى عبر البحث الهجين، وعزلت مستأجراً عن آخر بأمان مستوى الصف، وكل ذلك مُنفّذٌ فعلاً ومقيسٌ على مجموعة تقييمك. واختيارياً، يسلّم خادم MCP الأمر كله إلى أيّ وكيل.
كيف تقرأ هذا. الجزآن 1 و2 (المفاهيم 1 إلى 9) إضافةً إلى المثال العملي في الجزء 5 هما النظام الكامل من طرفه إلى طرفه، أي قراءة نحو ساعتين بفهم حقيقي (وأكثر إن كان «المتّجه» جديداً عليك)، مع بضع ساعات على لوحة المفاتيح للبناء. والجزآن 3 و4 (المفاهيم 10 إلى 15) هما طبقة الضبط: ما يجعل البحث سريعاً (الجزء 3) وجيّداً (الجزء 4). اقرأهما لفهم السبب، ثم شغّل كلاً منهما: الجزء 5 ينتهي بحلقة عملية (الخطوات 5 إلى 8) تبني فيها معيار قياس فهرس، ومرشّحاً، وبحثاً هجيناً، وعزل مستأجرين على نحو حقيقي، على البيانات التي حمّلتها لتوّك. فالعمق ليس قراءةً اختياريةً قد تعود إليها، بل هو النصف الثاني من البناء، والكل يفعله. أتفضّل أن تبني أولاً ثم تقرأ السبب لاحقاً؟ اقفز مباشرةً إلى الجزء 5.
جهّز بيئتك (مرة واحدة)
كل ما تبنيه في هذه الدورة يجري داخل مجلد صغير واحد: قاعدة الدورة. يأتي موصولاً مسبقاً، إذ يعرف وكيلك أصلاً كيف يصل إلى Neon (قاعدة البيانات السحابية التي تستعملها هذه الدورة) وإلى Context7 (بحث مباشر في التوثيق، فيراجع الوكيل التوثيق الحالي بدل أن يخمّن)، ويأتي معه ملف قواعد قصير، AGENTS.md، فيه التعليمات الثابتة للمشروع. يقرأ وكيلك ذلك الملف تلقائياً في كل مرة يبدأ فيها، ولهذا تستطيع تعليماتك في هذه الدورة أن تبقى قصيرة.
نزّله مرة واحدة؛ فالمجلد نفسه يخدم الدورة كلها، المثال العملي في الجزء 5 وخادم MCP في الجزء 6 على حدّ سواء. جهّزه الآن أو لاحقاً، فالقراءة نفسها لا تحتاج تثبيت أيّ شيء.
فُكّ ضغطه، ثم افتح وكيلك داخل المجلد:
cd postgres-ai
claude
cd postgres-ai
opencode
شرط واحد: نموذج قادر. إن بدت خطة الوكيل الأولى يوماً غامضةً بدل أن تكون محدّدة، فانتقل إلى نموذج أقوى (Claude Sonnet أو Opus، أو GPT-5، أو ما شابه) قبل المضيّ قدماً.
جهّز القاعدة (نحو 3 دقائق). الوكيل يتولّى إعداده بنفسه، فأنت تلصق تعليمة واحدة وتجيب عمّا يسأل عنه. الصق هذا:
جهّز هذه القاعدة: ثبّت المهارات التي تذكرها، وأعدّ ملف
.envالخاص بي، وأخبرني بالضبط بما تحتاجه مني لتشغيل خادمي Neon وContext7 على MCP.
راقِب: يثبّت الوكيل مهارتين (neon-postgres وmcp-builder)، وينشئ .env، ثم يطلب منك أمرين: مفتاح API واحداً (المفتاح نفسه يغطّي التضمينات والإجابات)، ونقرة واحدة في المتصفح لتفويض Neon. المفتاح مجاني. تعمل هذه الدورة على الطبقة المجانية من Google Gemini (بلا بطاقة ائتمان)، لذلك يوجّهك الوكيل إلى aistudio.google.com/apikey؛ سجّل الدخول بحساب Google، وأنشئ مفتاحاً في نحو دقيقة، والصقه، وسيثبت الوكيل أنه يعمل فوراً. (لديك مفتاح OpenAI أصلاً وتفضّله؟ قل ذلك فقط، وسيستعمله الوكيل؛ لا يتغيّر شيء آخر في الدورة.) وNeon مجاني أيضاً؛ ولا حساب لديك بعد؟ أنشئ واحداً عند شاشة التفويض مباشرةً. وإن لم تُفتح نافذة المتصفح من تلقائها، فاكتب /mcp في الوكيل، واختر Neon، وسيبدأ لك تسجيل الدخول.
تنتهي عندما: تكون المهارات مثبّتة، ويحمل .env مفتاحك وقد أكّده الوكيل باستدعاء اختبار سريع، وNeon مفوَّضاً، وتكون قد أعدت تشغيل الوكيل (اخرج ثم أعد التشغيل) لتُحمَّل المهارات الجديدة وخوادم MCP (فلا شيء منها يُحمَّل في منتصف الجلسة).
الجزء 1: الأساسيات
1. ما الذي تبنيه فعلاً (ومهمتك فيه)
أشيع سوء فهم: أن بناء تطبيقات الذكاء الاصطناعي يستلزم فريقاً لتعلّم الآلة. وهذا غير صحيح. فالنماذج جاهزة للاستعمال، والبنية التحتية قاعدة بيانات قد تشغّلها أصلاً. والباقي هو عمل مهندس الذكاء الاصطناعي: من يستعمل الذكاء الاصطناعي ليبني منتجات، لا الباحث الذي يدرّب النماذج. هذا هو الدور الذي يهيّئك له هذا الكتاب كله، وهو في متناولك تماماً.
أما سوء الفهم الثاني فهو ما وُجدت هذه الدورة لتصحّحه: أنه يجب عليك كتابة كل SQL يدوياً. وهذا غير صحيح. فأنت توجّه وكيلاً يعرف عن ظهر قلب عوامل pgvector وسير عمل التضمين. قيمتك تصعد في المكدّس: من كتابة CREATE INDEX إلى تقرير أيّ فهرس، ومن كتابة الاستعلام إلى الحكم على جودة النتائج.
وهذا يغيّر معنى «معرفة هذه المادة». فأنت لا تحفظ صيغاً نحوية، بل تبني من النموذج الذهني ما يكفي للآتي:
- إعطاء الوكيل تعليمةً دقيقة («خزّن التضمين في الجدول نفسه، واستعمل مسافة جيب التمام، وافهرسه عبر HNSW»)،
- وقراءة ما أنتجه واكتشاف موضع خطئه،
- وتقرير اختيارات البنية التي لا ينبغي للوكيل أن يقرّرها عنك.
هذه هي عادة التخطيط ثم التنفيذ نفسها من دورة البرمجة، وهي هنا أهمّ، لأن الوكيل على وشك اتخاذ قرارات (أيّ إضافة، وأيّ فهرس، وأيّ دالة مسافة) يصعب التراجع عنها بعد أن تصبح لديك بيانات.
نقلة العقلية: كفّ عن السؤال «ما هو SQL للبحث الدلالي؟» وابدأ بالقول «ابنِ لي بحثاً دلالياً على هذا الجدول؛ وهذه قيودي؛ وأرني الخطة أولاً.»
لهذا اسم أكبر. بلغة الكتاب، قاعدة البيانات التي توشك أن تبنيها هي نظام سجلّات لعصر الوكلاء: الحقيقة المرجعية الموثوقة التي تقرأ منها وكلاؤك، وتكتب إليها، وتتحقّق في مقابلها. وحجّة جنسن هوانغ أن الوكلاء لا يلغون الحاجة إلى نظام سجلّات، بل يعتمدون عليه. فمن دون حقيقة مرجعية موثوقة يهلوس الوكيل؛ ومعها ينفّذ. ونظام RAG على Postgres هو كيف تسلّم الوكيل تلك الحقيقة المرجعية، وهذا بالضبط سبب معاملة بقية الدورة جودة الاسترجاع بوصفها ما يقرّر إن كان الوكيل جديراً بالثقة.
خذ هذا حرفياً لبقية الدورة: كل كتلة SQL أدناه معروضة لكي تقرأ وتحكم على ما أنتجه الوكيل، لا لتكتبها. ومعرفة قراءته هي ما يتيح لك التقاط دالة مسافة خاطئة أو مرشّح ناقص قبل أن يُشحَن.
2. المتّجهات والتضمينات، في دقيقة واحدة
إن كانت «المتّجه» و«التضمين» جديدتين عليك، فهذا كل ما تحتاجه للبدء.
المتّجه مجرد قائمة أرقام، مثل [0.021, -0.88, 0.14, …]. ونموذج التضمين يأخذ قطعة محتوى (جملة، أو فقرة، أو صورة) ويحوّلها إلى واحدة من هذه القوائم. والحيلة أن القائمة تلتقط معنى المحتوى: فقطعتا نص متقاربتان في المعنى تحصلان على قائمتَي أرقام تجلسان قريباً إحداهما من الأخرى. وعبارتان تعنيان الشيء نفسه، مثل «المدينة التي لا تنام» و«شوارع نيويورك التي لا تهدأ»، تقعان قرب بعضهما رغم أنهما لا تشتركان في أيّ كلمة.
وقاعدة البيانات المتّجهة مجرد نظام يخزّن هذه القوائم ويجد الأقرب منها إلى قائمة معطاة، بسرعة. هذا كل شيء. فحين يسأل المستخدم سؤالاً، يضمّن تطبيقك سؤاله في متّجه، ثم يسأل قاعدة البيانات: «أيّ المتّجهات المخزّنة أقرب إلى هذا؟» والأقرب هي الأوثق صلةً دلالياً، وهكذا يجلب تطبيقك السياق الصحيح ليسلّمه لنموذج لغوي. (انظر المخطّط الافتتاحي: هذه إدارة سياق لمستخدميك.)
لست بحاجة إلى فهم كيف يعمل نموذج التضمين داخلياً أكثر من حاجتك إلى فهم كيف يضغط JPEG صورة. تحتاج أن تعرف أنه موجود، وأنه يحوّل المحتوى إلى متّجهات معنى، وأن القرب يساوي التشابه.
افتح جلسة واسأل وكيلك: «اشرح لي بلغة بسيطة ما هو التضمين، ثم أرني جملتين قصيرتين يكون لهما متّجهان متقاربان واثنتين يكونان متباعدين، ولماذا. ثم الطريف: هل تقع أغنية شهيرة أو لقب لمدينتي قرب اسم المدينة، حتى لو لم تذكره الكلمات أبداً؟» قراءة إجابته فحصٌ حدسيّ لفهمك أسرع من إعادة قراءة هذا القسم.
3. الإضافات، وما تحصل عليه على Neon
يصبح Postgres قاعدة بيانات متّجهة عبر الإضافات: مكوّنات إضافية تمنحه قدرات جديدة دون أن تتخلّى عمّا يجيده Postgres أصلاً (المعاملات، والوصلات، والموثوقية، وSQL). ولهذه الدورة كلها هناك حقاً واحدة فقط لتتعلّمها: pgvector. تضيف ثلاثة أشياء: نوع vector لتخزين التضمينات، وعوامل مسافة لمقارنتها، وفهارس للبحث فيها بسرعة، وهي على Neon تأتي مثبّتة مسبقاً، فتعليمة واحدة تشغّلها. هذا هو محرّك RAG الكامل لديك. احتفظ بهذا فقط. (حاشيتان يمكن أن تتركهما جانباً: تُوجد إضافة ثانية، pgvectorscale، للنطاق الكبير جداً، وهي المستوى الذي تترقّى إليه لا حيث تبدأ. والتضمينات نفسها ليست إضافة أصلاً؛ فهي تأتي من عامل صغير يكتبه وكيلك، يُبنى في المفهوم 6.)
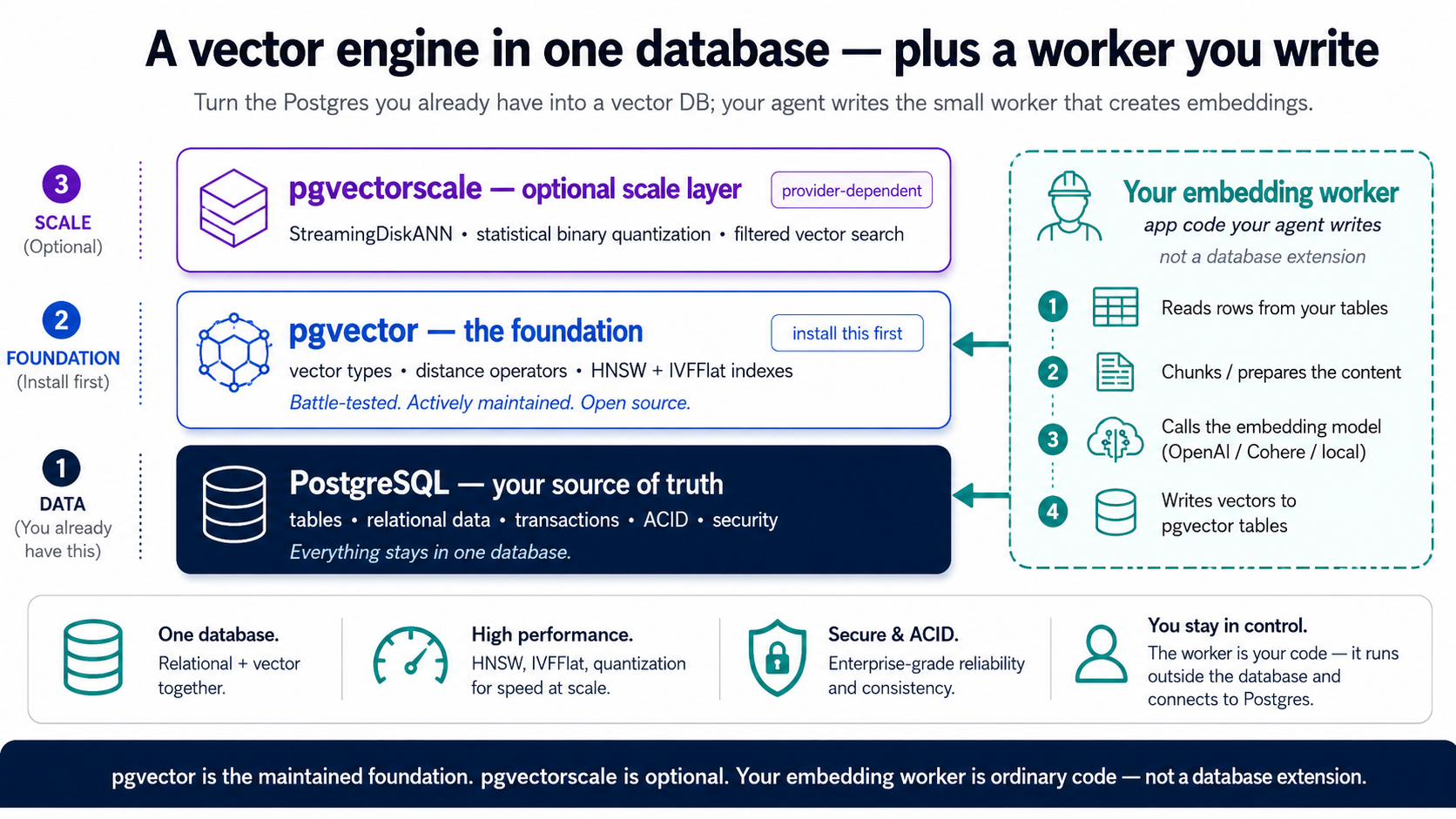
| الإضافة | ماذا تضيف | متى تحتاجها |
|---|---|---|
| pgvector | نوع البيانات vector، وعوامل المسافة، وفهرسا HNSW وIVFFlat | دائماً، وعلى Neon هي مثبّتة مسبقاً |
| pgvectorscale | فهرس StreamingDiskANN، وضغط المتّجهات، والبحث المرشَّح العالي الدقة على نطاق كبير | أصلي على TigerData؛ ليس على Neon، حيث هو المستوى الذي تترقّى إليه |
أسماء الفهارس في هذا الجدول، أي HNSW وIVFFlat وStreamingDiskANN، مجرد عناوين الآن؛ ويعلّمك الجزء 3 ماذا تفعل ومتى تستعمل كلاً منها.
على Neon، pgvector هو مكدّسك كله. تأتي مدمجة، وكل ما تفعله هذه الدورة بعد التضمين، أي البحث الدلالي، والفهرسة، والتقييمات، والمرشّحات، والبحث الهجين، وRLS، وخادم MCP في الجزء 6، هو pgvector خالص. والتضمينات تأتي من العامل (المفهوم 6)، لا من إضافة مُدارة. أما pgvectorscale: فهي ليست ضمن مجموعة Neon المعتمدة، فعاملها بوصفها المضيف الذي تترقّى إليه فقط إن تجاوزت قدرة HNSW، وpgvector مع عامل يحملك مسافة طويلة أولاً. أتريد مستوى النطاق أصلياً من اليوم الأول بدلاً من ذلك؟ ذاك هو TigerData Cloud، بسير العمل نفسه طوال الوقت، والملاحظة الوحيدة في نهاية المفهوم 4 تغطّيه، ويمكنك خلا ذلك أن تقرأ هذه الدورة كلها بوصفها مقتصرةً على Neon.
ويبقى عائد قاعدة البيانات الواحدة قائماً: فمتّجهاتك تعيش بجوار الصفوف التي تصفها، فيحدث بحث التشابه ومرشّح WHERE price < 2000 AND in_stock في الاستعلام نفسه، على مصدر الحقيقة نفسه. لا قاعدة بيانات ثانية، ولا خط مزامنة، ولا انحراف بيانات. (احتفظ بهذا، فهو السبب الكامل لكون البحث المرشَّح في المفهوم 13 بهذه السهولة.)
pgvector إضافة Postgres ناضجة وواسعة الاستعمال، الأساس المتين الذي تقوم عليه هذه الدورة كلها. وكل ما يأتي بعد التضمين (البحث الدلالي، والفهرسة، والتقييمات، والمرشّحات، والبحث الهجين، وRLS، وخادم MCP) هو pgvector خالص.
الشيء الوحيد الذي لا يفعله pgvector عنك هو إنشاء التضمينات: استدعاء نموذج تضمين وكتابة المتّجهات إلى الجدول. والطريقة النظيفة المحمولة لفعل ذلك هي عامل صغير يكتبه وكيلك: جدول المصدر ← قطّع ← ضمّن عبر استدعاء API ← اكتب المتّجهات إلى جدول تضمينات ← ابحث عبر pgvector. وإبقاء هذا العمل خارج قاعدة البيانات هو المقصد، لا حيلة التفافية، فنظام سجلّات ذو حالة لا ينبغي أن يعتمد على API خارجي متقلّب، فيعيش التضمين (واستدعاءات النموذج اللغوي في المفهوم 9) في طبقتَي العامل والتطبيق، حيث يمكنها أن تفشل وتعيد المحاولة وتتوسّع دون أن تمسّ بياناتك، وينتقل الأمر كله بنظافة إلى أيّ مضيف أو حاوية. (طبقة راحة مُدارة دمجت التضمين داخل قاعدة البيانات ذات مرة، أي Vectorizer من pgai، لكن ذلك الاقتران ثبت هشّاً، وأرشف القائم عليه مستودعه في فبراير 2026؛ وهذه الدورة لا تعتمد عليه.) والعامل بضعة أسطر يُنتجها وكيلك وتراجعها أنت. تعلّم النمط؛ فهو يعمّر أكثر من أيّ حزمة بعينها.
4. اربط وكيلك بخدمة Neon
نحن لا نثبّت قاعدة بياناتنا ولا نشغّلها. نستعمل Neon: Postgres بدون خادم مع pgvector مدمجاً أصلاً، وندع الوكيل يشغّله عبر خادم Neon MCP. وMCP هو آلية الموصّل نفسها من دورة البرمجة؛ وهي هنا تسلّم Claude Code وOpenCode مجموعة أدوات (create_project وcreate_branch وrun_sql وget_database_tables وprepare_database_migration وcomplete_database_migration) ليديرا Neon بالكامل بلغة طبيعية. أنت لا تفتح لوحة تحكّم Neon ولا صدفة psql بنفسك أبداً. (تستعمل هذه الدورة Neon مضيفاً افتراضياً؛ وكل شيء يعمل بالطريقة نفسها على TigerData Cloud، انظر «أتفضّل TigerData؟» في نهاية هذا المفهوم.)
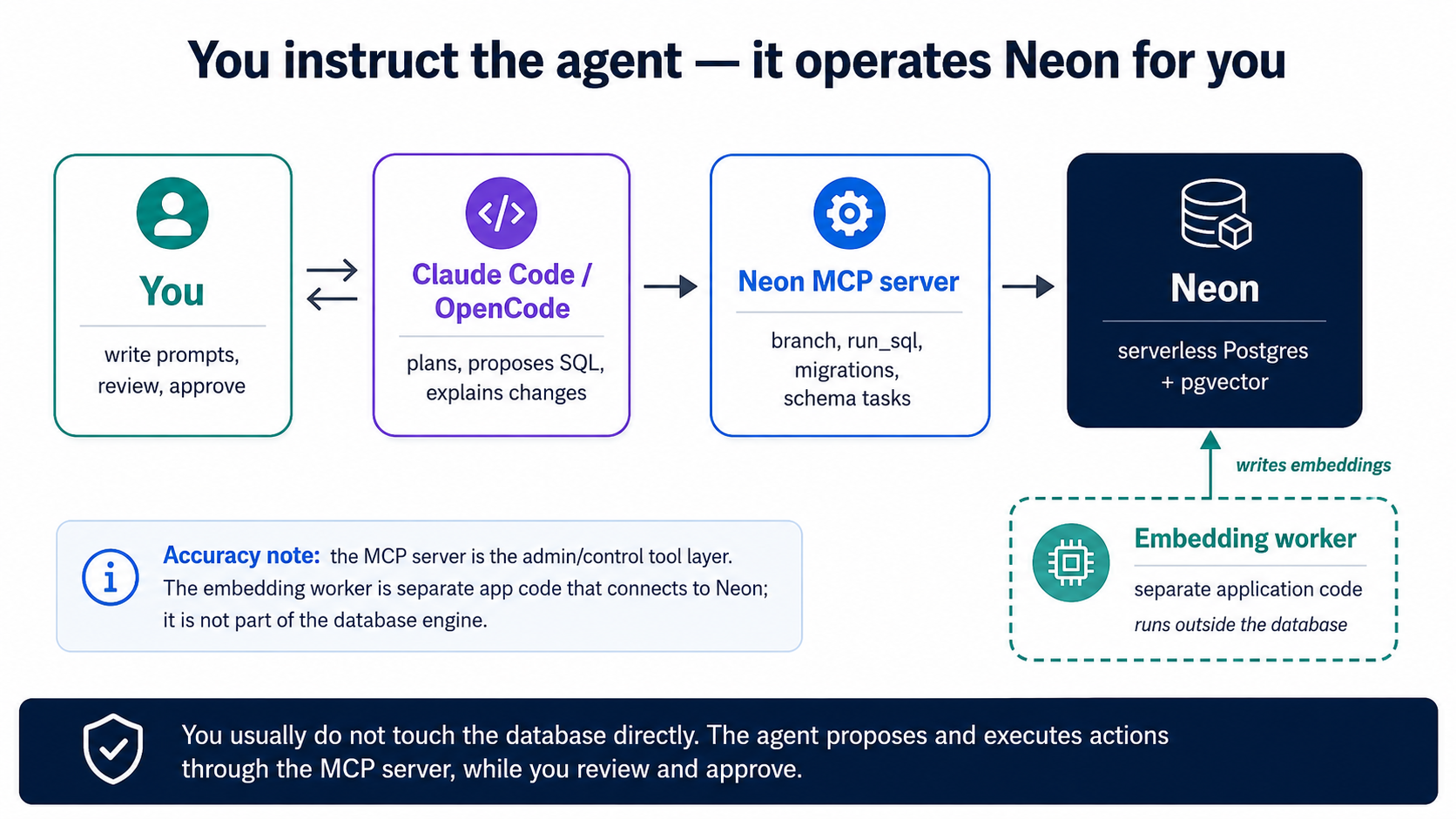
توصيل لمرة واحدة. إن بدأت من قاعدة الدورة، فخادم Neon MCP مُعلَن أصلاً في .mcp.json (Claude Code) وopencode.json (OpenCode)، تفوّضه مرة واحدة في المتصفح عبر OAuth، دون مفتاح API لتديره. (وتوصيله يدوياً بدل ذلك هو الخطوة المفردة نفسها: أضف خادم Neon MCP إلى أداتك وفوّضه.) هذا هو الإعداد اليدوي الوحيد؛ ومن هنا فصاعداً يحدث كل شيء بتوجيه الوكيل. شغّله في نمط التخطيط:
باستعمال خادم Neon MCP، أنشئ مشروعاً اسمه
agent-factory-ragوفعّل عليه إضافة pgvector. ثم أنشئ فرعاً اسمهdevلنبني عليه، واحفظ سلسلة اتصال ذلك الفرع في.envباسمDATABASE_URLليتمكّن العامل والتطبيق من قراءتها لاحقاً (لا تطبع مفتاح API الخاص بي أبداً). أرني الخطة قبل أن تشغّل أيّ شيء.
ثم اقرأ الخطة. وما تتحقّق منه:
- أنها تعمل على فرع، لا على الإنتاج مباشرةً. والتفريع هو قوة Neon الخارقة: فالفرع نسخة فورية من قاعدة بياناتك كلها (نسخ-عند-الكتابة: يخزّن فقط ما تغيّره، فالاستنساخ مجاني وفوري). يجري الوكيل تغييرات المخطّط على فرع، فتعاينها أنت، ثم تثبّتها على الفرع الافتراضي فقط بعد ذلك، وهو انضباط التخطيط ثم التنفيذ نفسه، تفرضه المنصّة. (وهو أيضاً كيف ستقيس أداء الفهارس وتشغّل التقييمات لاحقاً: فرّع، واختبر، ثم ارمِ الفرع.)
- أنها تفعّل pgvector، الإضافة الوحيدة التي تحتاجها هذه الدورة، بتعليمة واحدة:
CREATE EXTENSION IF NOT EXISTS vector; -- pgvector is pre-installed on Neon; this just switches it on
- وبالنسبة إلى التضمينات (المفهوم 6)، يبني الوكيل عاملاً صغيراً، أي سكربت Python قصير أو خدمة، يقرأ الصفوف الجديدة أو المتغيّرة، ويستدعي نموذج التضمين، ويكتب المتّجهات في جدول تضمينات. يعمل خارج Neon، ويصل إلى فرعك عبر سلسلة اتصاله. ومفتاح API لمزوّد التضمين يعيش في بيئة العامل، لا في قاعدة البيانات أبداً.
لست بحاجة إلى حفظ أسماء أدوات MCP أو واجهة Neon البرمجية. والمقصد من نمط التخطيط أن تقرأ الخطة، وتتأكّد أنها تعمل على فرع وتفعّل pgvector، وثم توافق. وإن فعلت الخطة شيئاً لا تعرفه، فاسأل الوكيل عن سببه قبل أن تقول نعم، فذلك السؤال هو مهمتك الحقيقية.
توجيه Neon نفسه هو أن خادم MCP مخصّص للتطوير المحلي وتكاملات بيئة التطوير، فهو يستطيع تشغيل عمليات قوية، لذا أبقِه ضمن سير عملك التطويري وراجع كل إجراء يقترحه الوكيل قبل الموافقة. وتغييرات الإنتاج تمرّ كالعادة عبر عملية الترحيل المراجَعة المعتادة لديك.
تتضمّن قاعدة الدورة أصلاً ملف AGENTS.md / CLAUDE.md قصيراً فيه القواعد التي تحتاجها هذه الدورة: أيّ فرع Neon أنت عليه، وأن المفاتيح تعيش في البيئة (لا تُودَع أبداً)، ودالة المسافة التي اخترتها، وقاعدتان صارمتان: «اجرِ دائماً تغييرات المخطّط على فرع Neon ودعني أعاين قبل التثبيت»، و*«لا تشغّل SQL مدمّراً (DROP أو TRUNCATE أو DELETE بلا WHERE) دون أن تريني أولاً.»* أتبني دون القاعدة؟ شغّل /init وشذّبه إلى ذلك بالضبط.
كل شيء في هذه الدورة يعمل دون تغيير على TigerData Cloud، الفريق وراء إضافات pgvector الرفيقة، الذي يصفها بأنها «Postgres وكيلي». والحلقة الموجَّهة بالوكيل متطابقة؛ ولا تتغيّر إلا الأسماء:
- Tiger MCP بدل خادم Neon MCP. وهو مدمج في Tiger CLI، ثبّته بالأمر
tiger mcp install، ثم شغّل Tiger Cloud بلغة طبيعية تماماً كما سبق («أنشئ خدمة، واشتقّها، وفعّل الإضافات، وأرني الخطة أولاً»). بل إنه يأتي معه Skills خاصة بنظام Postgres تعلّم الوكيل أفضل الممارسات. - الاشتقاقات بدل الفروع:
tiger service fork …يصنع نسخةً فوريةً بلا نسخ، أي انضباط اشتقّ ← اختبر ← ارمِ نفسه الذي ستستعمله للتقييمات ومعايير قياس الفهارس. - pgvectorscale أصلية (إلى جانب pgvector)، فمستوى التخرّج StreamingDiskANN (المفهوم 11) في الصندوق من اليوم الأول، وفهرسه يدعم متّجهات حتى 16000 بُعد (فالنماذج الكبيرة مثل
text-embedding-3-largeلا تحتاج عندئذٍ إلىhalfvec). ويعمل عامل التضمين لديك بالطريقة نفسها كما على Neon.
ويعيش عامل التضمين لديك وخطوة التوليد كلاهما في كود التطبيق، تماماً كما على Neon. وقاعدة عامة: Neon لأبسط بداية بدون خادم؛ وTigerData حين تريد نطاق pgvectorscale وأداء البحث المرشَّح دون ترحيل أبداً.
تستعمل هذه الدورة Neon لسببين: طبقة مجانية بلا بطاقة ائتمان، وتفريع فوري يشغّله الوكيل عبر خادم Neon MCP. تفضّل تشغيل Postgres محلياً (Homebrew أو Docker) أو على مضيف آخر؟ جانب البيانات مطابق: CREATE EXTENSION vector نفسه، والمخطّط نفسه، والعامل نفسه، والاستعلامات نفسها؛ وجّه DATABASE_URL فقط إلى نسختك. ما تتخلّى عنه هو التفريع الموجَّه عبر MCP (حركة «افرع، اختبر، ارمِ» التي ستستعملها للفهارس والتقييمات)، فتشغّل تلك الخطوات مباشرةً بدلاً من ذلك. كل ما تتعلّمه هنا ينتقل دون تغيير.
الجزء 2: أول نظام RAG لك، يبنيه وكيلك
سنبني مثالاً صغيراً كلاسيكياً: جدول اقتباسات لشخصيات تاريخية عن مدن أمريكية، ثم نبحث فيه بالمعنى، ثم ندع نموذجاً لغوياً يجيب عن أسئلة منه.
5. المخطّط: المتّجهات تعيش بجوار بياناتك
اطلب من الوكيل جدول المصدر أولاً. وشيء واحد لتحتفظ به: متّجهات المعنى لن تعيش في مخزن منفصل، بل تذهب إلى قاعدة البيانات نفسها، في الجدول الرفيق الذي ستبنيه في المفهوم التالي، بجوار البيانات التي تصفها مباشرةً.
أنشئ جدول
quotesبالأعمدة:personوcityوquote. سنضيف التضمينات في جدول رفيق تالياً، يملؤه عامل صغير، فلتكتفِ الآن ببيانات المصدر. ثم أدرج حفنة من اقتباسات حقيقية عن نيويورك وسان فرانسيسكو وشيكاغو ليكون لدينا ما نبحث فيه.
سيبدو الجدول الذي يكتبه الوكيل قريباً من هذا:
CREATE TABLE quotes (
id bigint GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
person text NOT NULL,
city text NOT NULL,
quote text NOT NULL
);
والنموذج الذهني لتحتفظ به: مصدر واحد للحقيقة. فالاقتباس، ومن قاله، والمدينة، و(قريباً) متّجه معناه، كلها تعيش في قاعدة البيانات نفسها. وهذا ما يجعل الترشيح في الجزء 4 بديهياً.
6. أنشئ التضمينات: العامل الذي يبنيه وكيلك
يحمل جدول quotes لديك نصاً. ولتبحث قاعدة البيانات في ذلك النص بالمعنى، تحتاج كل قطعة منه إلى متّجه، وصنع تلك المتّجهات هو العمل الوحيد الذي لا يفعله pgvector عنك. فيكتب الوكيل برنامجاً صغيراً: عامل التضمين. ومهمّته كلها حلقة واحدة: اعثر على الاقتباسات التي لا متّجهات لها بعد ← قسّم أيّ نص طويل إلى قطع (مقاطع) ← اطلب من نموذج التضمين متّجه كل قطعة ← احفظ المتّجهات. شغّله مرة فيغطّي كل اقتباس موجود؛ وأعد تشغيله على جدول زمني فتُغطّى الاقتباسات الجديدة أو المحرَّرة أيضاً. هذه هي الآلة كلها.
أين تُحفظ المتّجهات؟ في جدول ثانٍ، الجدول الرفيق، صفّ واحد لكل مقطع، يشير كل منها إلى الاقتباس الذي جاء منه. وهذا يجيب عن السؤال الذي يطرحه الجميع هنا (صف واحد، تضمين واحد؟): فالاقتباس القصير مقطع واحد، فصفّ متّجه واحد؛ والخطاب الطويل يصير عدة قطع، فعدة صفوف. (ولماذا التقسيم أصلاً؟ ذاك المفهوم 7، بُعيد هذا.) جدولان، ويبدوان هكذا:
quotes (your source table) quotes_embedding (companion table)
┌────┬─────────────────────┐ ┌─────┬──────────┬──────────────┬───────────┐
│ id │ quote │ │ id │ quote_id │ chunk │ embedding │
├────┼─────────────────────┤ ├─────┼──────────┼──────────────┼───────────┤
│ 7 │ a short quote │ ────→ │ 1 │ 7 │ whole quote │ [0.02, …] │
│ 8 │ a long speech… │ ──┬─→ │ 2 │ 8 │ first piece │ [0.11, …] │
└────┴─────────────────────┘ └─→ │ 3 │ 8 │ second piece │ [0.54, …] │
└─────┴──────────┴──────────────┴───────────┘
one row per quote one row per CHUNK (its own id),
pointing back via quote_id
قرار واحد قبل أن يبنيه الوكيل: أيّ نموذج تضمين يحوّل النص إلى متّجهات. وهو الاختيار الوحيد هنا المزعج التراجع عنه، لأن تبديل النماذج يعني إعادة تضمين كل شيء، لذلك يستحق الفهم حتى لو كانت القاعدة قد اختارت لك افتراضياً معقولاً. هذا الافتراضي هو المزوّد الذي أعددته: gemini-embedding-001 من Google في المسار المجاني على Gemini، أو text-embedding-3-small من OpenAI إن اخترت OpenAI. كلاهما يعمل هنا عند 1536 بُعداً، وكلاهما كافٍ لمعظم أنظمة RAG، وGemini مجاني، لذلك لا تختار اسم نموذج بنفسك؛ فقد ضبطته القاعدة ليلائم المفتاح الذي قدّمته. وسببان فقط قد يدفعانك إلى الحيود: ألا يكون محتواك بالإنجليزية (أو أن يكون متخصّصاً للغاية، قانونياً أو طبياً أو برمجياً)، حيث قد يفوز نموذج متعدّد اللغات أو مضبوط للمجال؛ أو أن تُظهر تقييماتك لاحقاً أن نموذجاً أكبر يسترجع فعلاً على نحو أفضل. والنموذج في العامل إعداد مفرد، فتختبر البدائل على مجموعة تقييمك (المفهوم 12) بدل التخمين: رشّح المرشّحين من لوحة صدارة MTEB (المعيار العام القياسي لنماذج التضمين) ودع بياناتك تنتقي الفائز.
التفاصيل الدقيقة للأبعاد (اقرأها حين تحيد عن الافتراضي)
أبعاد أكثر تعني تخزيناً وذاكرةً أكثر وبحثاً أبطأ قليلاً. ملاحظتان عمليتان: كثير من النماذج الحديثة يتيح لك طلب أبعاد أقل دون إعادة تدريب (وتستعمل هذه الدورة ذلك بالضبط لتثبيت المزوّدين كليهما عند 1536)، وهناك مطبّ حقيقي، إذ تحدّ فهارس HNSW/IVFFlat في pgvector نوع vector عند 2000 بُعد (ويمدّد نوع halfvec ذلك إلى 4000)، فنموذج كامل الحجم من 3072 بُعداً، مثل text-embedding-3-large من OpenAI أو Gemini بالحجم الكامل، يحتاج halfvec أو أبعاداً مخفَّضة ليصبح قابلاً للفهرسة. البقاء عند 1536 يجنبك هذا كله؛ وينبغي أن ينبّهك وكيلك إلى الحد إن رفعت الأبعاد يوماً، وينبغي أن تتعرّفه حين يفعل. (على TigerData، يدعم فهرس StreamingDiskANN في pgvectorscale متّجهات حتى 16000 بُعد، فنادراً ما يصبح الحدّ مزعجاً.)
أولاً، امنح الكود بيتاً، أي مشروع Python واحد، يديره uv (مدير مشاريع Python؛ يعرفه الوكيل، وتمرير كل اعتمادية عبره يُبقي المشروع قابلاً لإعادة الإنتاج):
أعدّ مشروع Python في هذا المجلد باستخدام uv. ومن هنا فصاعداً، أضف كل اعتمادية وشغّل كل سكربت عبر uv.
ثم اطلب من الوكيل أن يبني العامل وجدوله:
أنشئ جدولاً رفيقاً
quotes_embeddingبمفتاح أجنبي إلىquotes، ونص المقطع، وعمودembedding vector(1536). ثم اكتب عامل تضمين صغيراً يعثر على الاقتباسات التي لا تضمين حالياً لها، ويقطّع نصquote، ويضمّن كل مقطع بنموذج التضمين الخاص بالدورة، ويدرج المتّجهات فيquotes_embedding. شغّله مرة للملء بأثر رجعي، وأرني كيف أتأكّد أن الصفوف وصلت، واشرح كيف أجدوله. اقرأ مفتاح API من البيئة.
راقِب: ينشئ الوكيل الجدول الرفيق (الشكل نفسه في المخطّط أعلاه)، ويشغّل العامل مرة، ويريك صفوف المتّجهات التي وصلت. وإن مات العامل عند أول استدعاء تضمين برمز 401 أو 429، فلا شيء في كودك معطّل؛ المشكلة في المفتاح، وغالباً كنت قد التقطتها أصلاً في الإعداد حيث اختبره الوكيل باستدعاء. على Gemini، أعد نسخ المفتاح المجاني من aistudio.google.com/apikey؛ وعلى OpenAI، يحتاج الحساب الجديد غالباً إلى طريقة دفع قبل أن يضمّن. و429 حدّ معدّل، فانتظر قليلاً وأعد التشغيل. أصلح المفتاح، ثم أعد التشغيل. أما إن رأيت expected 1536 dimensions, got 3072، فاستدعاء التضمين لم يطلب 1536 بُعداً؛ فكلا المزوّدين يختار متّجهاً أكبر افتراضياً، لذلك يجب أن يطلب الاستدعاء 1536 ليطابق عمود vector(1536). عامل القاعدة يفعل ذلك أصلاً، فذلك الخطأ يعني أن استدعاءً عُدّل يدوياً أسقطه. تنتهي عندما: يكون لكل اقتباس صفّ واحد على الأقل في quotes_embedding، وتعرف الأمر الوحيد الذي يعيد تشغيل العامل.
أبسط نسخة تستطلع: يعيد العامل التشغيل على جدول زمني ويعيد تضمين الصفوف التي تغيّر نصّها. أتريد تحديثات مدفوعة بالتغيير بدلاً من ذلك؟ يستطيع مشغّل INSERT/UPDATE أن يعلّم الصف متّسخاً، أي يضع علامة «هذا يحتاج تضميناً جديداً»، فيلتقط العامل تلك الصفوف المعلّمة في مروره التالي. وإن شغّلت يوماً أكثر من نسخة واحدة من العامل لمواكبة الحمل، فيجب ألّا تمسك نسختان الصف نفسه مرتين؛ ويتولّى Postgres ذلك عنك، مسلّماً كل عامل دفعةً مختلفة من الصفوف غير المطالَب بها (حيلة SKIP LOCKED). فقائمة المهام للصفوف-المحتاجة-للتضمين مجرد جدول Postgres عادي، لا خدمة طابور منفصلة لتشغيلها، أي عائد قاعدة البيانات الواحدة نفسه كمتّجهاتك. وبأيّ الطريقتين، المشغّل يعلّم فقط؛ ويبقى استدعاء التضمين خارج النطاق في العامل، وقاعدة البيانات نفسها لا تستدعي API التضمين أبداً.
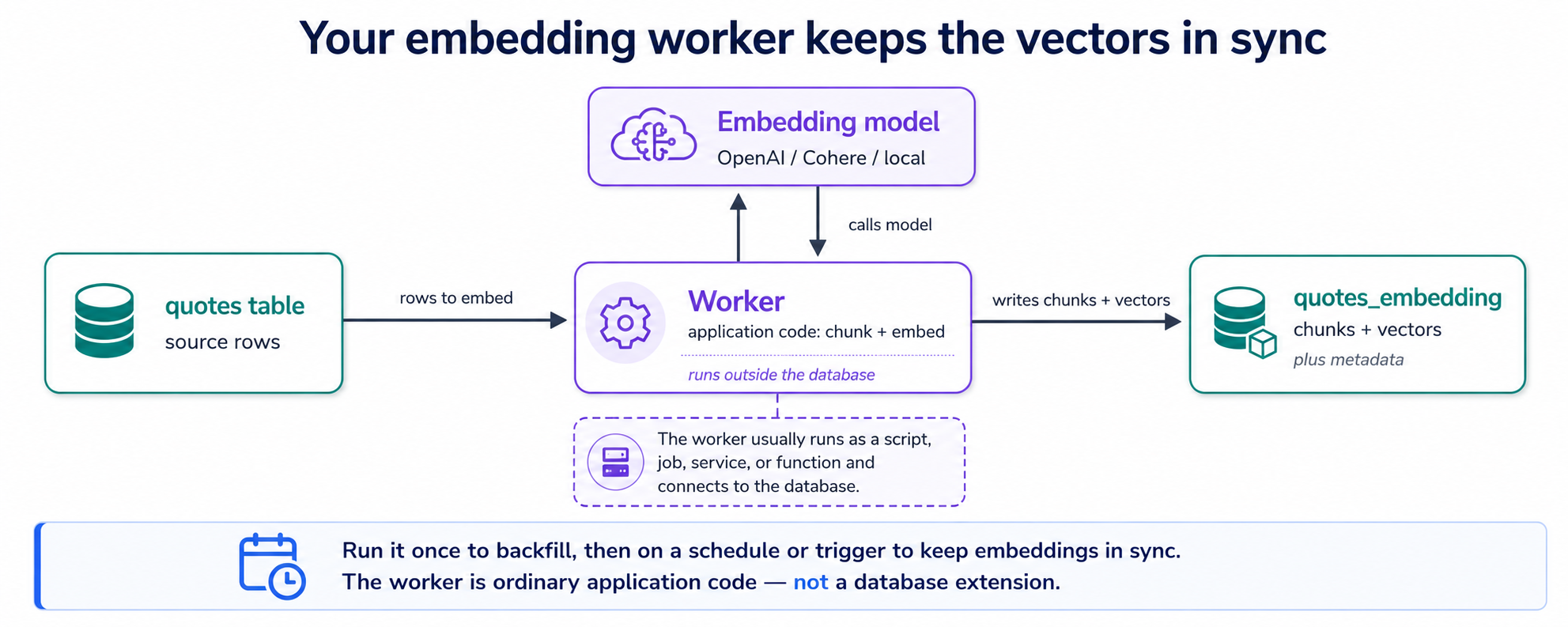
نمط العامل نفسه يضمّن المستندات، لا مجرد حقول قصيرة، وجّهه إلى ملفات PDF أو DOCX أو ملفات في تخزين سحابي (دلو Amazon S3 مثلاً) ودعه يحلّلها ويقطّعها ويضمّنها في الجدول الرفيق نفسه. ولأن النموذج إعداد مفرد في العامل، تستطيع تبديل المزوّدين (Gemini أو OpenAI أو Cohere أو Voyage أو نموذج محلي) لتختبر أيّها يسترجع أفضل على بياناتك، أي تجربة النموذج أعلاه.
يستدعي العامل مزوّد تضمين خارجياً، فيحتاج مفتاح API لذلك المزوّد. والمفتاح ملكٌ لبيئة العامل (أو مخزن أسرار مزوّدك السحابي)، لا يُكتب مباشرةً في SQL ولا يُودَع في مستودعك أبداً. أخبر وكيلك صراحةً: «اقرأ مفتاح API من متغيّر بيئة، ولا تكتبه أبداً في ملف نودِعه.» ثم تحقّق من الفرق قبل أن توافق. وتبديل مزوّدي التضمين لاحقاً (بين Gemini وOpenAI، أو إلى Cohere أو Voyage أو نموذج محلي) تغييرٌ من سطر واحد في العامل، وبقية تطبيقك لا تتحرّك.
7. التقطيع: الرافعة التي تضبط سقفك
التقطيع خطوة واحدة داخل عاملك، وهو بهدوء أهمّها. فالمستند الطويل المضمَّن متّجهاً واحداً يتحوّل إلى عجينة، أي متوسّط ضبابي واحد لكل ما يقوله، فتقسّمه إلى مقاطع أصغر، ويحصل كل مقطع على متّجهه الخاص. وما يُعَدّ مقطعاً يقرّر ما يستطيع بحثك استرجاعه أصلاً.
مقبضان:
- الحجم. كبير أكثر من اللازم فيمتدّ المقطع عبر عدة مواضيع، فيكون متّجهه غير مركَّز وتسترجع نتائج قريبةً مخطئة. وصغير أكثر من اللازم فيفقد المقطع السياق الذي جعله ذا معنى. وبضع مئات من الرموز نقطة بداية شائعة؛ والجواب الصحيح يعتمد على محتواك.
- التداخل. ترك المقاطع تتداخل قليلاً (لنقل 10 إلى 20%) يمنع جملةً تقع على حدّ من أن تتيتّم. وبعض التداخل يساعد دائماً تقريباً؛ والكثير منه يهدر التخزين ويسترجع شبه مكرّرات.
وهناك أيضاً الاستراتيجية: التقسيم بعدّ الأحرف (الافتراضي البسيط)، أو بالبنية (عناوين markdown، الفقرات)، أو دلالياً (تجميع الجمل المتماسكة معاً). وللمستندات المهيكلة، التقسيم على العناوين يتفوّق عادةً على عدّ الأحرف الأعمى.
ولماذا يستحقّ هذا مفهومه الخاص: التقطيع يضبط سقف الاستدعاء لديك، والاستدعاء يعني ببساطة هل سحب بحثك المقاطع الصحيحة في الأصل. فإن لم تقع الإجابة الصحيحة بنظافة في مقطع واحد، فلا نموذج تضمين ولا تعليمة بارعة تستطيع استعادتها، ولهذا فالتقطيع السيّئ أحد أشيع أسباب ضعف أداء نظام RAG بهدوء. فلا تخمّن: ما إن تعمل بمستندات حقيقية وتوجد مجموعة تقييمك (المفهوم 12)، تجعل الوكيل يجرّب بضعة إعدادات تقطيع على فروع Neon، ويقيس كلاً منها على أسئلة تقييمك، ويبقي الفائز، أي حركة الاختبار والرمي نفسها التي ستستعملها للفهارس في الجزء 3. وستفعل تلك الحركة بالضبط في المثال العملي (الجزء 5).
8. البحث الدلالي: رتّب حسب المسافة
الآن السحر من المقدّمة. لتجد اقتباسات متشابهة في المعنى مع عبارة، يحوّل تطبيقك العبارة إلى متّجه خاص بها، أي متّجه الاستعلام، وترتّب قاعدة البيانات المقاطع المخزّنة حسب قرب متّجهاتها منه.
والقطعة الوحيدة الجديدة من SQL هي عامل المسافة، أي الرمز الذي يسأل «ما درجة القرب؟». والوحيد الذي تحتاجه هو <=>، مسافة جيب التمام: الافتراضي لتضمينات النص، وما تستعمله هذه الدورة كلها. (لدى pgvector عاملان آخران، <-> للمسافة المستقيمة، و<#> للجداء الداخلي، ولن تلتقي بهما إلا إن طلب توثيق نموذج أحدهما تحديداً؛ وسيعرف وكيلك ذلك.)
اكتب لي استعلاماً يُعيد أعلى 5 اقتباسات تشابهاً في المعنى مع عبارة بحث. وسيُمرَّر تضمين العبارة معاملاً من كود التطبيق، لا تضمّنه داخل SQL.
والاستعلام الذي يسلّمه لك (لك أن تقرأه، لا أن تكتبه):
SELECT q.person, q.city, q.quote
FROM quotes_embedding e -- the table your worker populates: chunks + vectors
JOIN quotes q ON q.id = e.quote_id -- each chunk points back to its source quote
ORDER BY e.embedding <=> $1 -- $1 = the query phrase, embedded in app code
LIMIT 5;
ابحث عن «المدينة التي لا تنام» فتكون أعلى النتائج اقتباسات عن نيويورك، بما فيها التي لا تحوي كلمتَي «نيويورك» أبداً، لأن المعاني متقاربة. هذا، وقد صار أخيراً ملموساً، هو البحث الدلالي.
$1تحويل عبارة المستخدم إلى متّجه يحدث في كود تطبيقك، أي بضعة أسطر يكتبها الوكيل، وتُمرَّر النتيجة إلى الاستعلام معاملاً $1. ويبقى استدعاء النموذج في تطبيقك، حيث تتحكّم بالنموذج وإعادات المحاولة والتخزين المؤقت؛ ويفعل Postgres ما يجيده: تخزين المتّجهات وإيجاد الأقرب.
9. RAG: استرجع، ثم ولّد
البحث الدلالي يجد النص ذا الصلة. وRAG (التوليد المعزَّز بالاسترجاع) يذهب خطوة أبعد: يأخذ تلك المقاطع المسترجَعة، ويحشوها في تعليمة بوصفها سياقاً، ويطلب من نموذج لغوي أن يؤلّف إجابةً متجذّرةً في بياناتك. هذا هو بوت دعم العملاء، ومساعد التوثيق، وميزة «حادث ملفّاتي»، كلها هذه الحلقة.
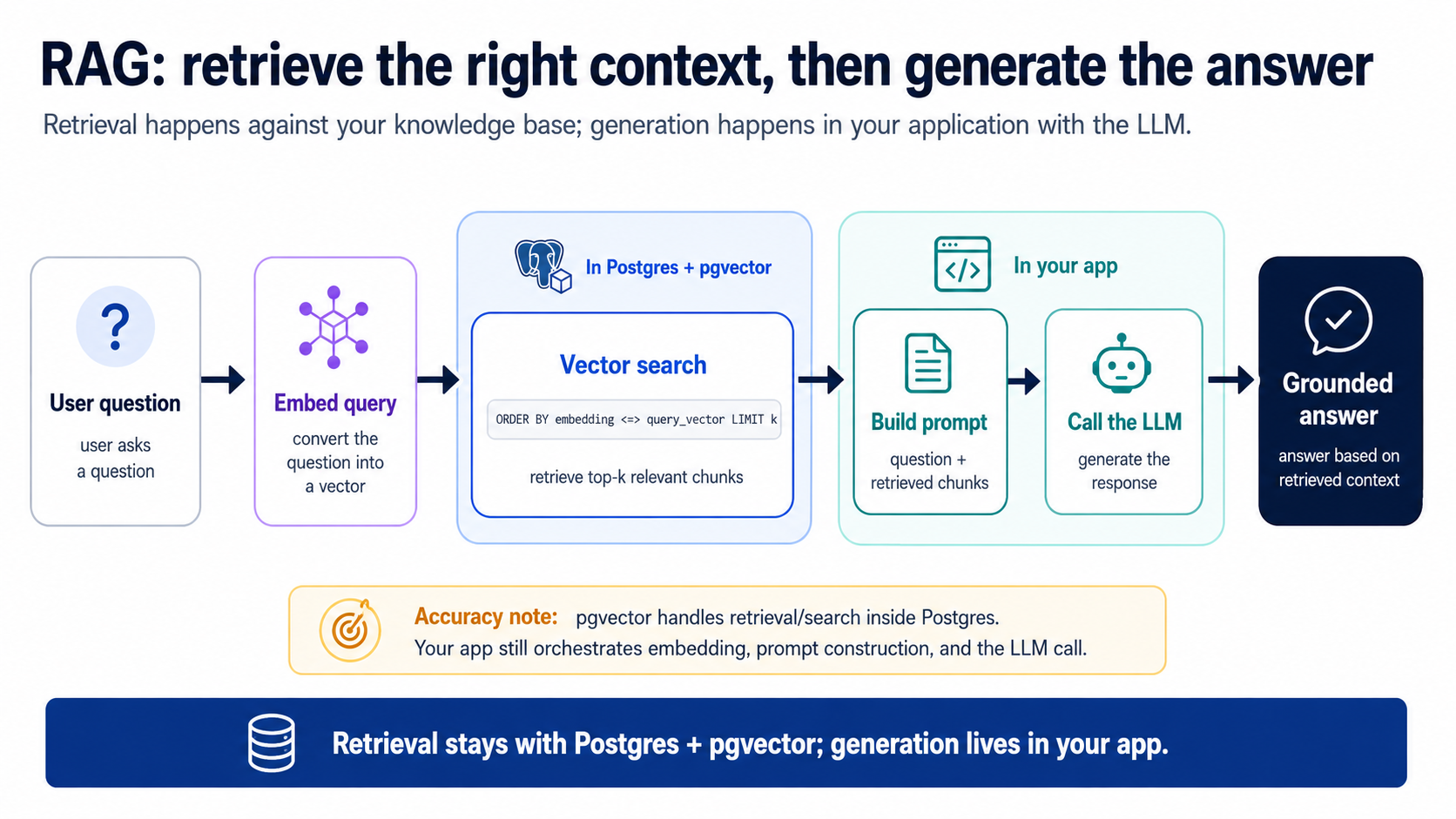
للحلقة مرحلتان، والفصل هو المقصد كله:
- استرجع (في Postgres): شغّل استعلام المفهوم 8 لسحب أعلى k مقاطع صلةً (k مجرد عدد ما تطلبه؛ 5 بداية جيدة). هذه خطوة إدارة السياق: اجلب الإشارة، واترك المليون صف غير ذي الصلة خارجاً.
- ولّد (في تطبيقك): ابنِ تعليمةً = تعليمات النظام + المقاطع المسترجَعة + سؤال المستخدم، أرسلها إلى نموذج لغوي، أعد الإجابة. يكتب الوكيل هذا الغراء الجانبي للتطبيق لك؛ وهو صغير.
ابنه على خطوتين، لترى الاسترجاع يعمل وحده قبل أن يلفّه التوليد. أولاً، تعليمة تدبير منزلي ليكون للكود بيت، وهذا صحيح أصلاً إن بنيت العامل في المفهوم 6، وفي تلك الحالة سيؤكّده الوكيل فقط:
تأكّد أن هذا المجلد مشروع Python يديره uv، أعدّه إن لم يكن كذلك، وأبقِ كل اعتمادية وسكربت يمرّ عبر uv.
والآن نصف البحث:
ابنِ دالة
search_quotes(question)في كود التطبيق: ضمّن السؤال، وشغّل بحثنا الدلالي لأعلى k علىquotes_embedding، وأعد المقاطع المطابقة مع اقتباساتها المصدر. ثم شغّلها على «المدينة التي لا تنام» وأرني ما يعود.
ما يعود هو المرحلة 1 وحدها، أي المقاطع الصحيحة، موجودةً بالمعنى، قبل كتابة أيّ إجابة. والآن لفّ المرحلة 2 حولها:
الآن ابنِ
answer_question(question)فوقها: استدعِsearch_quotes، ونسّق تلك المقاطع في تعليمة بوصفها سياقاً، واستدعِ النموذج اللغوي، وأعد الإجابة المتجذّرة، يبقى الاسترجاع في SQL، والتوليد في كود التطبيق. ثم اطرح سؤالاً وأرني المقاطع المسترجَعة بجوار الإجابة النهائية.
لاحظ ما تفعله المرحلة 1: تسلّم النموذج اللغوي بالضبط السياق الذي يحتاجه ولا شيء سواه، أي إدارة السياق، تماماً كما وعد المخطّط الافتتاحي. فإن كان الاسترجاع رديئاً، أي مقاطع خاطئة، أو كثيرة جداً، أو غير ذات صلة، يعطي النموذج اللغوي إجابةً سيّئة فيلوم الناس «الذكاء الاصطناعي». وهو الاسترجاع دائماً تقريباً. ولهذا وُجد الجزء 4.
ثم في الجملة التالية وصفوا نظاماً يفهرس الوثائق، ويضمّن الاستعلامات، ويسترجع المقاطع ذات الصلة قبل توليد إجابة. بكل احترام: هذا ما زال RAG.
لقد بنيت الآن كل خطوة فيه. ها هي الآلة كلها في بطاقة واحدة:
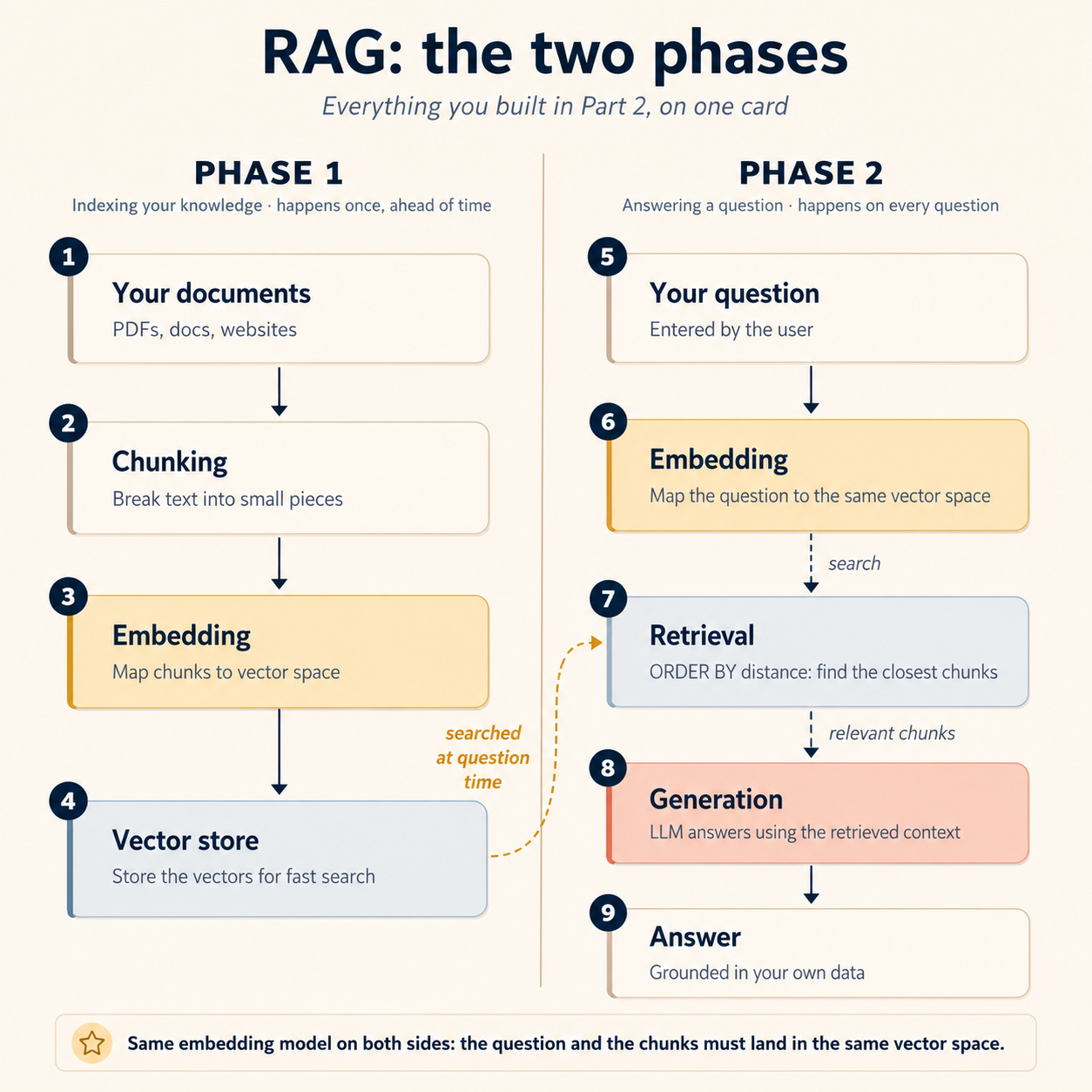
المرحلة 1: الفهرسة (تحدث مرة واحدة، مسبقاً):
- وثائقك تقسم إلى مقاطع (المفهوم 7)
- كل مقطع يضمّن في الفضاء المتجهي بواسطة العامل (المفهوم 6)
- المتجهات تهبط في Postgres، بجوار البيانات التي تصفها (المفهوم 5)
المرحلة 2: الإجابة (تحدث مع كل سؤال):
- سؤال المستخدم يضمّن في ذلك الفضاء المتجهي نفسه
- الاسترجاع يسحب المقاطع الأقرب إلى السؤال (المفهوم 8)
- تمرر تلك المقاطع إلى النموذج، فيولد إجابة متجذّرة فيها (هذا المفهوم)
الجزء الذي يوقع الناس في أول pipeline مخفي في كلمة واحدة أعلاه: نفسه. يجب أن يقع السؤال والوثائق في الفضاء المتجهي نفسه: نموذج embeddings نفسه، الأبعاد نفسها، الإعدادات نفسها، في الجانبين. ضمّن وثائقك بنموذج واستعلاماتك بنموذج آخر، وسينهار الاسترجاع بصمت، بلا أي خطأ في أي مكان: فضاءا المتجهات لنموذجين هما ببساطة نظاما إحداثيات مختلفان، فيتوقف "الأقرب" عن معنى "الأكثر شبهاً". لا ينقذك أي ترتيب leaderboard من هذا عدم التطابق. (إنه قريب الخطأ expected 1536 dimensions, got 3072 من المفهوم 6 على مستوى النموذج، إلا أن هذه النسخة لا تفشل بصوت عال أصلاً.)
ما الذي تغيّر فعلاً منذ عناوين "RAG مات"؟ ليس الآلية، بل التغليف. صار agents وtool calls والتفكير متعدد الخطوات يجلسون فوق حلقة retrieve-then-generate نفسها. ستلفّ هذه الحلقة نفسها كأداة agent في الجزء 6 وتسلمها إلى agent في الجزء 8: الحلقة لا تموت، بل تترقى.
answer_question() ليست خلفيةً لبوت محادثة فقط، بل هي أداة يستدعيها وكيل. ففي فصول الوكلاء، يصير الاسترجاع إحدى الأدوات التي يمدّ إليها وكيل أكبر يده حين يحتاج حقائق متجذّرة، بالطريقة نفسها التي يمدّ بها يده إلى آلة حاسبة أو بحث ويب. وRAG هو السياق القابل للبحث الذي يستند إليه الوكيل.
الجزء 3: تسريع البحث، الفهارس
متوسّط من هنا. الجزآن 3 و4 هما طبقة الضبط: تستطيع الشحن بالجزأين 1 و2 وحدهما، لكنك لن تتوقّف عندهما، اقرأ هذين لفهم السبب، ثم شغّل كلاً منهما حقاً في الجزء 5، الخطوات 5 إلى 8. الأسرع (الجزء 3) والأحدّ (الجزء 4) مهارتان ستكون قد فعلتهما، لا قرأت عنهما فقط.
10. لماذا تحتاج فهرس متّجهات (ومتى لا تحتاجه)
دون فهرس، يقارن بحث التشابه متّجه الاستعلام بكل صف، أي مسح جار-أقرب دقيق. وهذا دقيق تماماً، وممتاز تماماً ما دمت صغيراً. ومع نموّ الجدول، يصير بطيئاً.
والإصلاح بحث تقريبي: تقايض شظيةً من الدقة بتسريع كبير بعدم فحص كل متّجه. وفهرس المتّجهات هو بنية البيانات التي تجعل ذلك التقريب جيداً.
العتبة التي تنقذك من الهندسة الزائدة: تحت نحو 100,000 متّجه تقريباً، يكون البحث الدقيق سريعاً بما يكفي غالباً، وصحيحاً دائماً. لكن العتبة الحقيقية تتغيّر مع الأبعاد، وحجم الحوسبة، وهدف السرعة، والمرشّحات، والتزامن، ومدى تكرار إعادة كتابة المتّجهات، فاجعل الوكيل يقيس الأداء قبل إضافة فهرس بدل المدّ إليه افتراضياً؛ أضفه حين تبطؤ عمليات البحث فعلاً، لا قبل ذلك. (وهذا يعكس قاعدة دورة البرمجة: «أضف قاعدة حين يقع خطأ، لا قبله.»)
11. الفهارس، وأيّها تستعمل، وكيف تضبطها

على Neon، الاختيار الحيّ هو البطاقة الوسطى: HNSW هو حصان عملك (مع IVFFlat خياراً قديماً). وبطاقة StreamingDiskANN أصلية على TigerData؛ ومن Neon، الوصول إليها يعني الانتقال إلى مضيف يأتي معه pgvectorscale.
يبني الوكيل الفهرس لك، ومهمتك أن تتعرّف ما بناه وتتأكّد أنه يناسب استعلاماتك. وقيد واحد لا تظهره البطاقات: العمود يستطيع حمل نوع فهرس متّجهات واحد فقط، فهذا إمّا/أو حقيقي. وإليك ما يبدو عليه كلٌّ منها:
-- HNSW — your default on Neon
CREATE INDEX ON quotes_embedding USING hnsw (embedding vector_cosine_ops);
-- IVFFlat — also on Neon; legacy, needs a lists parameter; recall drifts as data grows, so periodic rebuilds
CREATE INDEX ON quotes_embedding USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);
-- StreamingDiskANN — native on TigerData; on Neon only via a pgvectorscale host
CREATE INDEX ON quotes_embedding USING diskann (embedding vector_cosine_ops);
لاحظ vector_cosine_ops، فالفهرس يجب أن يطابق دالة المسافة التي تستعملها استعلاماتك (<=> ⇒ جيب التمام). إن لم تطابق هذا، فلن يساعد الفهرس بصمت.
كيف تقرّر فعلاً: قِس الأداء. لفهرس HNSW إعدادان لوقت البناء، m وef_construction، يشكّلان الرسم بينما يُبنى الفهرس. وهما بالضبط من النوع الذي لا تحفظه أبداً: صف حملك الحقيقي، ودع فرعاً مؤقّتاً يدفع ثمن التجربة. تعليمتان (أعداد الصفوف هنا بديل بمقياس حقيقي، ستشغّل هذا المعيار فعلاً في الجزء 5، الخطوة 5، على فرع مؤقّت مبذور بالمقياس، فيستقرّ مهارةً لا قصة):
لدينا نحو مليونَي متّجه اقتباس ونرشّح معظم عمليات البحث حسب المدينة. على فرع Neon جديد، ابنِ فهرس HNSW بإعداداته الافتراضية، وشغّل عشر عمليات بحث تمثيلية، وأبلغ عن زمن الاستجابة p95.
الآن اضبط
mوef_construction: جرّب بضعة إعدادات، وأعد تشغيل العشر عمليات نفسها على كلٍّ منها، وأوصِ بواحد، واشرح المقايضة في فقرة. ثم ارمِ الفرع.
تلك حركة مهندس الذكاء الاصطناعي: أنت لا تحفظ أيّ الإعدادات أسرع، بل تجعل الوكيل يقيس على فرع Neon ويأتيك بتوصية تستطيع التحقّق منها بحسّك في مقابل البطاقات أعلاه، ثم تتخلّص من الفرع بلا كلفة. وهذا المعيار يقيس السرعة، لا الاستدعاء: لا تحدّق هنا فيما إذا كانت النتائج «تبدو صحيحة»، بل تحكم على الاستدعاء بالطريقة الصادقة، على تضمينات حقيقية في مقابل مجموعة تقييمك (المفهوم 12)، لا بنظرة عابرة إلى تشغيل اصطناعي. (وزمن الاستجابة p95 يعني فقط السرعة التي تأتي تحتها 95% من الاستعلامات، أي أسوأ حالة معقولة تثبت عليها، لكن فقط على عدد كافٍ من الاستعلامات: فكّر بالمئات لا بالعشرة، وبعد بضع عمليات بحث تمهيدية تسخّن ذاكرة الفرع المؤقّتة فقط، إذ يخدم فرع Neon الجديد قراءاته الأولى باردةً من التخزين. وعلى عشر عيّنات باردة، يكون p95 عملياً أسوأ استعلام مفرد لديك.)
عدد الصفوف ليس المحور الوحيد، فمعدّل التبدّل هو الآخر. فمدى تكرار إعادة كتابة متّجهاتك (إعادة التقطيع، وتبديل نماذج التضمين، وإعادة الفهرسة بتلاشي الزمن) كلفة بذاتها. يأخذ HNSW الإدراجات والتحديثات التدريجية دون إعادة بناء كاملة، لكن حجم إعادة الكتابة الثقيل ينفخ الرسم مع الوقت، فينحرف الاستدعاء وتحتاج في النهاية إلى REINDEX، وإعادة التضمين نفسها حوسبة تدفع ثمنها. فالبيانات التي تُعاد كتابتها باستمرار قد تصير مكلفة قبل أن تصير كبيرة بكثير. أخبر الوكيل بنمط تحديثك الحقيقي، لا عدد صفوفك فقط، واجعله يقيس الأداء في مقابل ذلك.
المقبض الوحيد الجدير بالمعرفة يومياً: ef_search. فإعدادات وقت البناء أعلاه مخبوزة بمجرد وجود الفهرس؛ والقرص الذي ستمسّه فعلاً عند وقت الاستعلام هو ef_search، يتحكّم بمدى جدّ البحث في النظر: أعلى يعني استدعاءً أفضل واستعلامات أبطأ، وأدنى يعني أسرع وأقل دقة. يضبطه الوكيل لكل استعلام؛ وهذا السطر الذي ستراه يشغّله:
SET LOCAL hnsw.ef_search = 100; -- raise for more recall, lower for more speed
فالحركة هي: أخبر الوكيل بالاستدعاء الذي تحتاجه فعلاً واجعله يضبط ef_search ليبلغه، لا أن يرفعه أعمى إلى أقصاه. ثم اجعله يثبت أن الفهرس يؤدّي عمله: شغّل EXPLAIN ANALYZE، وتحقّق من وجود فحص فهرس بدل فحص تسلسلي، وأبلغ. وإليك الفرق، في الجزء من المخرَج الذي تقرؤه فعلاً (الجدول نفسه بمليونَي متّجه، مع فهرس قابل للاستعمال وبدونه):
✅ GOOD — the index is doing the work
-> Index Scan using quotes_embedding_hnsw_idx on quotes_embedding
Order By: (embedding <=> $1)
Execution Time: 0.8 ms
❌ BAD — no index used; every row got scanned and sorted
-> Seq Scan on quotes_embedding (rows=2000000)
Sort Key: (embedding <=> $1)
Execution Time: 52.4 ms
سطران يخبرانك أيّهما حصلت: سطر العامل (Index Scan using …hnsw… مقابل Seq Scan on …) وزمن التنفيذ (دون المللي ثانية مقابل عشرات الملّي ثانية على البيانات نفسها). وSeq Scan يعني أن الفهرس لا يُستعمل، عادةً لأن عامل مسافة الاستعلام لا يطابق الفهرس، أو لأنه لا فهرس بعد. وهذا الشيء الوحيد الذي تجعل الوكيل يؤكّده قبل أن تسمّي الفهرسة «منجَزة».
هذه طرق متكرّرة ينكسر بها بحث المتّجهات بهدوء، ولأن مهمتك الحكم على عمل الوكيل، فهي بالضبط ما تترقّبه:
- عدم تطابق الأبعاد، أبعاد العمود لا تطابق مخرَج نموذج التضمين.
- نوع المتّجه غير مسجّل في العميل، يجب على العامل (وكود البحث) تسجيل pgvector على كل اتصال قاعدة بيانات يمسّ عمود
embedding(register_vector)، وإلا تدور المتّجهات ذهاباً وإياباً بصمت بوصفها نصاً عادياً: فتسيء الإدراجات وعمليات البحث التصرّف بلا أيّ خطأ إطلاقاً. هذا هو نمط الفساد الصامت الوحيد غير المرئي في SQL، فاطلب من الوكيل أن يؤكّد أنه سجّل النوع. - لا فهرس بعد النقطة التي احتجته عندها، تباطؤ صامت، لا خطأ.
- عدم تطابق العامل / الفهرس، يستعمل الاستعلام
<->لكن الفهرس جيب تمام، فيُتجاهل الفهرس. - مستندات كاملة بدل مقاطع، خطأ المفهوم 7؛ فالاسترجاع لا يستطيع أن يجد شيئاً دقيقاً أبداً.
- تخطّي
EXPLAIN ANALYZE، فلا أحد يلتقط أيّاً مما سبق إلى أن يلتقطه المستخدمون.
للترشيح مطبّ يستحقّ المعرفة، وهو بالضبط حالة «نرشّح معظم عمليات البحث حسب المدينة» في المعيار أعلاه. يطبّق فهرس HNSW جملة WHERE لديك بعد مسح ميزانية مرشّحيه الثابتة (ef_search، 40 افتراضياً)، فمرشّح انتقائي قد يتركك بصفوف أقل من LIMIT ويُسقط بهدوء مطابقات حقيقية، فترقّب أعداد نتائج دون LIMIT حين تتحقّق من تلك العمليات. والروافع التي تبقي الاستدعاء عالياً هي عند وقت الاستعلام، لا رسم أكثف: ارفع ef_search، أو فعّل المسوح التكرارية (SET hnsw.iterative_scan = strict_order، معطّلة افتراضياً)، أو ابنِ فهرس HNSW جزئياً لكل قيمة مرشّح. ويساعد فهرس B-tree عادي على عمود الترشيح أيضاً، لكن ليس بتضييق مسح HNSW مسبقاً، إذ يستعمل Postgres فهرساً واحداً لكل مسح، فيمنح B-tree المخطّطَ بديلاً للمسافة الدقيقة يستطيع اختياره حين يكون المرشّح انتقائياً بما يكفي (استدعاء كامل، بلا فقد بعد الترشيح). (وStreamingDiskANN، البطاقة الثالثة أعلاه، مبنيّ للبحث المرشَّح الثقيل على نطاق كبير جداً.) على Neon، هذه الروافع مع فهارس ترشيح جيدة تحملك مسافة طويلة أولاً.
الجزء 4: تحسين البحث فعلاً، الطبقة المتقدّمة
نظام RAG العامل ليس نظام RAG جيّداً. هنا تتعثّر معظم المشاريع، وهنا تفصلك معرفة الحركات عمّن لا يستطيع إلا إنتاج عرض توضيحي.
12. التطوير المُوجَّه بالتقييم
العادة التي تفصل نظاماً قابلاً للشحن عن عرض محظوظ. يبدأ معظم الناس بالبناء، ثم يحدّقون فيما إذا كان المخرَج «يبدو صحيحاً». بدلاً من ذلك، ابدأ بالأسئلة. قبل كتابة أيّ شيء، اكتب دزّينة أسئلة سيسألها مستخدموك فعلاً وضعها في ملف. ذلك الملف هو مجموعة تقييمك، أي مسطرتك لقياس ما إذا كان تغيير قد حسّن الأمور أو أساءها.
ثم، كلما غيّرت النظام (نموذج تضمين جديد، أو استراتيجية تقطيع مختلفة، أو مرشّح مضاف)، تعيد تشغيل مجموعة التقييم وترى الأثر، بدل التخمين. ومع نموّ التطبيق، تنمو المجموعة معه (20، ثم 50 سؤالاً)، فتلتقط الانحدارات قبل مستخدميك.
والنصف الثاني هو فكّك المشكلة. حين تكون الإجابة سيّئة، لا تستنتج «الذكاء الاصطناعي غبي». تتبّع المراحل:
- الاسترجاع: هل أعاد البحث الدلالي المقاطع الصحيحة أصلاً؟ (المشكلة الحقيقية غالباً فجوة جرد: يسأل المستخدمون عن شيء لم تضعه في قاعدة البيانات أبداً.)
- السياق: هل مُرّرت المقاطع الصحيحة إلى النموذج اللغوي، أم كثيرة/قليلة جداً؟
- التوليد: بسياق جيد، هل ما زال النموذج يجيب رديئاً؟
تسعاً من كل عشر مرات يكون الفشل في الاسترجاع، لا في النموذج اللغوي. أصلح المرحلة المعطّلة فعلاً.
ابنِ مجموعتك الآن، في مقابل ما حمّلته، أي اقتباسات الجزء 2، أو بياناتك أنت. أولاً الأسئلة، الوكيل يصوغ وأنت تنسّق:
اقرأ جدول مصدرنا وصُغ 12 سؤال تقييم قد يسألها مستخدم واقعياً، بعضها بصفّ مصدر واحد بديهي، وبعضها تمتدّ إجابته عبر عدة صفوف، وزوج منها لا تستطيع بياناتنا الإجابة عنه أصلاً. دوّن الإجابة المتوقّعة لكلٍّ (أو «غير قابل للإجابة»)، واحفظها في
evals/questions.mdلأحرّرها.
حرّر ذلك الملف قبل أن تباركه، فأنت تعرف مستخدميك، والوكيل لا يعرفهم. ثم وصّل الإطار:
ابنِ إطاراً صغيراً يشغّل كل سؤال في
evals/questions.mdعبر خط الاسترجاع ثم التوليد لدينا، ولكلٍّ منها أظهر: المقاطع المسترجَعة، والإجابة النهائية، وما إذا كانت تطابق ما توقّعته. ولخّص أين يفشل، في الاسترجاع أم التوليد.
ومن الآن فصاعداً، يُقاس كل تغيير في مقابلها:
شغّل التقييمات واحفظ النتائج خطّ أساس اليوم. وبعد تغييرنا التالي، أعد التشغيل وأرني الفرق، أيّ الأسئلة تحسّن وأيّها ساء.
429 في منتصف الحلقة حدّ الطبقة المجانية، لا خطأ برمجيكل تشغيل للتقييمات يصنع استدعاء نموذج واحداً لكل سؤال، وستعيد تشغيل المجموعة مراراً. على طبقة مجانية ستصطدم في النهاية بحدّ الطلبات اليومي للمزوّد وترى 429 في منتصف التشغيل. هذا هو الحد، لا شيء كسرته: انتظر ثم أعد المحاولة، أو اجعل إطار الاختبار يتراجع ويعيد المحاولة آلياً، أو انتقل إلى نموذج مجاني أصغر للتشغيلات الروتينية، أو فعّل الفوترة. تتحرّك الحدود الدقيقة، لذلك راجع لوحة مزوّدك بدل الثقة برقم ثابت.
التطوير المُوجَّه بالتقييم هو العمود الفقري للوكلاء الموثوقين، لا لنظام RAG فقط. والمعالجة المخصّصة هي الدورة المكثفة في التطوير المُوجَّه بالتقييم، افعلها بعد هذه.
13. البحث المرشَّح: جملة WHERE صديقتك
البحث الدلالي الخالص يُعيد الصفوف الأكثر تشابهاً عالمياً. وغالباً ما تريد الصفوف الأكثر تشابهاً التي تحقّق أيضاً شرطاً ما. ولأن متّجهاتك تعيش بجوار بياناتك (المفهوم 5)، فهذه مجرد جملة WHERE على الاستعلام نفسه، لا نظام ثانٍ، ولا مناورة. خمسة أنماط تغطّي كل شيء تقريباً:
| النمط | حالة استعمال مثال | الجملة المضافة (تخطيط) |
|---|---|---|
| مرشّح بيانات وصفية | بحث توثيق عبر منتجات متعدّدة | WHERE product = 'CRM' AND doc_type = 'api-reference' |
| مرشّح مركّب | توصيات تجارة إلكترونية | WHERE category = 'electronics' AND price BETWEEN 500 AND 2000 AND in_stock |
| مرشّح زمني | موصي أخبار، المقالات الحديثة فقط | WHERE published_at > now() - interval '7 days' |
| مرشّح أذونات | RAG داخلي يرى فيه المستخدمون ما صُرّح لهم به فقط | WHERE clearance_level <= $user_level |
| مرشّح جغرافي مكاني | «أوصِ بأشياء ضمن 5 كم» (أضف PostGIS) | WHERE ST_DWithin(location, $point, 5000) |
كلٌّ منها الشكل نفسه: ORDER BY embedding <=> $1 مع WHERE أمامه. ويستحقّ مرشّح الأذونات التأمّل، فهو كيف تمنع المستأجر A من استرجاع مستندات المستأجر B أبداً، مفروضاً في قاعدة البيانات بدل المأمول في كود التطبيق.
أضف مرشّح مدينة اختيارياً إلى بحثنا الدلالي. على فرع Neon، أضف فهرس B-tree على عمود
city، وتأكّد أن الاستعلامات المرشَّحة تبقى سريعة، وأرني زمن الاستجابة قبل وبعد على مجموعة تقييمنا.
14. البحث الهجين: المعنى والكلمات المفتاحية
بحلول 2026 صار البحث الهجين أقوى ترقية مرشَّحة للاسترجاع الجاد، مرشّحاً تؤكّده على مجموعة تقييمك، لا افتراضاً تشحنه أعمى. الفكرة: شغّل بحث الكلمات المفتاحية وبحث المتّجهات، ثم ادمج. ويغطّي كلٌّ منهما نقطة عمى الآخر، فبحث المتّجهات يفهم إعادة الصياغة لكنه يقلّل وزن المصطلحات النادرة الدقيقة (رمز منتج، اسم شخص)؛ وبحث الكلمات المفتاحية يصيب المصطلح الدقيق لكنه يفوته المعنى. وPostgres يفعل كليهما أصلاً، بحث الكلمات المفتاحية عبر البحث في النص الكامل (tsvector)، والمتّجهات عبر pgvector، فيبقى قاعدة بيانات واحدة، وغالباً استعلاماً واحداً.
(ملاحظة على جانب الكلمات المفتاحية: تستعمل هذه الدورة بحث الكلمات المفتاحية المدمج في Postgres (tsvector)، وهو موجود أصلاً وجيّد بما يكفي لمعظم البيانات. وإضافة أحدث، pg_textsearch، تؤدّي ترتيب BM25 أقوى، أي الطريقة نفسها التي يستعملها Elasticsearch، وتأتي مثبّتةً مسبقاً على TigerData. انتقل إليها فقط إن أظهرت تقييماتك أن البحث المدمج يفوته نتائج جيدة. وتبقى خطوة RRF أدناه كما هي بالضبط بأيّ الطريقتين.)
الشكل الذي صار قياسياً:
- استرجع من كليهما، مع جلب زائد، لنقل أعلى 20 من الكلمات المفتاحية وأعلى 20 من المتّجهات، ليكون للدمج إشارة يعمل بها.
- ادمج بدمج الرتب التبادلي (RRF). يدمج RRF القائمتين المرتّبتين حسب الموضع، لا الدرجة، فيتفادى الصداع الحقيقي وهو أن درجات الكلمات المفتاحية ومسافات جيب التمام تعيش على مقاييس مختلفة تماماً ولا يمكن متوسّطها بعقلانية. وهو بضعة أسطر من SQL ولا يحتاج نموذجاً.
- (اختياري) أعد ترتيب أعلى المرشّحين بمشفّر متقاطع (cross-encoder)، نموذج صغير يسجّل كل زوج استعلام-مقطع مباشرةً. هذه خطوة الدقة: يختار RRF حوضاً جيداً من نحو 100، ويرتّب المشفّر المتقاطع الحفنة النهائية التي تسلّمها للنموذج اللغوي. أضفه فقط إن قالت تقييماتك إن الرفع يستحقّ زمن الاستجابة الزائد.
الشكل الذي ينتجه الوكيل (لك أن تقرأه، لا أن تكتبه)، سيكون قد أضاف عمود نص كامل ts بجوار المتّجهات أولاً، قائمتان مرتّبتان مدموجتان عبر RRF، كلها في استعلام واحد:
WITH kw AS ( -- keyword side: full-text search, ranked
SELECT id, row_number() OVER (ORDER BY ts_rank_cd(ts, plainto_tsquery($1)) DESC) AS rank
FROM quotes_embedding WHERE ts @@ plainto_tsquery($1) LIMIT 20
),
vec AS ( -- vector side: semantic search, ranked
SELECT id, row_number() OVER (ORDER BY embedding <=> $2) AS rank
FROM quotes_embedding ORDER BY embedding <=> $2 LIMIT 20
)
SELECT id, SUM(1.0 / (60 + rank)) AS score -- RRF: k = 60, summed across both lists
FROM (SELECT * FROM kw UNION ALL SELECT * FROM vec) r
GROUP BY id ORDER BY score DESC LIMIT 10; -- $1 = query text, $2 = query vector
قراءته: يُعيد kw أعلى 20 بمطابقة الكلمات المفتاحية وvec أعلى 20 بالمعنى، كل صف موسوم برتبته في تلك القائمة (1 = الأفضل). ويجمع الاستعلام النهائي 1 / (60 + rank) لكل صف عبر القائمتين، فالصف القريب من قمة أيّ قائمة يسجّل جيداً، والصف الذي يقع في كلتيهما يفوز. والرقم 60 (ثابت RRF القياسي) يمنع أيّ رتبة عالية مفردة من الهيمنة، ولأنه يعمل على المواضع، لا تضطرّ أبداً إلى التوفيق بين درجات الكلمات المفتاحية ومسافات جيب التمام على مقاييس مختلفة.
أضف بحثاً في النص الكامل على عمود
quoteإلى جانب بحثنا المتّجه، وادمج الاثنين عبر RRF، وشغّل مجموعة تقييمنا متّجهاً فقط مقابل هجين. أخبرني أيّ الأسئلة تحسّن وبكم.
البحث الهجين يفوز أكثر ما يفوز على الاستعلامات التي تمزج مفهوماً بمصطلح محدّد، «ماذا قال ترومان كابوتي عن المدينة» يحتاج مطابقة الاسم بدقة وفهم المعنى. وهل يساعد فعلاً بياناتك، وبكم، سؤال لا تجيب عنه إلا مجموعة تقييمك، فقِس متّجهاً فقط مقابل هجين قبل أن تتحمّل الأجزاء المتحرّكة الزائدة.
15. تعدّد المستأجرين وتحويل النص إلى SQL
اثنان آخران ينبغي أن تتعرّفهما حتى لو لم تبنهما اليوم.
تعدّد المستأجرين. إن كنت تبني SaaS، فبيانات كل عميل يجب أن تبقى معزولةً عن كل عميل آخر. وهناك سلّم عزل، من الأرخى إلى الأصرم:
| المقاربة | العزل | الكلفة / التعقيد | الملاءمة النموذجية |
|---|---|---|---|
جدول مشترك + مرشّح tenant_id | الأضعف | الأرخص | أدوات داخلية، بيانات منخفضة الخطر |
| مخطّط لكل مستأجر | جيّد | متوسّط | النقطة المثلى لمعظم SaaS |
| قاعدة بيانات لكل مستأجر | الأصرم | الأعلى (نسخ احتياطية، عمليات) | عملاء عاليو الأمان / منظَّمون |
المخطّط-لكل-مستأجر هو التوازن المعتاد: عزل حقيقي، وقاعدة بيانات واحدة للتشغيل. وبأيّ الطريقتين، تبقى قاعدة المفهوم 13 قائمة: افرض الحدّ في قاعدة البيانات، لا في كود تطبيقك فقط. وأنظف آلية في Postgres هي أمان مستوى الصف (RLS): تجعل الوكيل يكتب سياسة مرة واحدة (تكون الصفوف مرئيةً فقط حيث، لنقل، tenant_id = current_setting('app.tenant')) فيطبّقها Postgres على كل استعلام تلقائياً، فلا تستطيع جملة WHERE منسيّة واحدة أن تسرّب متّجهات مستأجر إلى آخر. ومطبّ واحد يستحقّ المعرفة، لأنه يلدغ الجميع أول مرة: RLS يتجاوزه المستخدمون الخارقون ومالك الجدول، فيجب أن يتّصل تطبيقك بوصفه دوراً عادياً غير مالك (الدور القارئ فقط من الجزء 6 مناسب تماماً)، اختبر السياسة بذلك الدور، وإلا فلن ترى عزلاً وستستنتج خطأً أنه لا يعمل.
تحويل النص إلى SQL. يحمل Postgres بيانات مهيكلة أيضاً، أي أرقاماً وتواريخ وعلاقات. ويتيح تحويل النص إلى SQL للمستخدم أن يسأل بإنجليزية بسيطة («كم كانت مبيعات الربع الثالث حسب المنطقة؟») ويترجمه وكيل إلى استعلام SQL صحيح في مقابل جداولك الحقيقية. وما يجعله دقيقاً مخطّطٌ موصوف جيداً: أسماء جداول وأعمدة واضحة، وCOMMENTات تشرح ما يعنيه كلٌّ منها، وحفنة أزواج سؤال←استعلام مثالية يتعلّم منها الوكيل. امنح الوكيل ذلك السياق، وأبقِ إنساناً في الحلقة ليراجع SQL قبل تشغيله، وادمجه مع البحث الدلالي (لمستنداتك)، فالوكيل الذي ينتقي الأداة الصحيحة لكل سؤال هو أساس مساعد بيانات حقيقي.
اجعله حقيقياً على مخطّطنا بتعليمتين. أولاً، اجعل الوكيل يهيّئ الأرض:
وثّق جداولنا لتُترجم الأسئلة الإنجليزية جيداً: أضف تعليقات إلى الجداول والأعمدة تذكر ما يحمله كلٌّ منها، واحفظ بضعة أسئلة مثالية مع SQL الذي ينبغي أن تنتجه.
ثم اسأل فقط، بإنجليزية بسيطة:
أيّ شخص له أكثر اقتباسات، وكيف تتوزّع اقتباساته عبر المدن؟ أرني SQL الذي ستشغّله أولاً، نفّذ فقط بعد موافقتي.
تحويل النص إلى SQL هو نمط التخطيط باسم آخر: اجعل الوكيل يُظهر SQL أولاً، خصوصاً أيّ شيء يكتب. فاستعلام SELECT خاطئ يهدر ثانية؛ وUPDATE خاطئ يفسد ظهيرتك.
الجزء 5: مثال عملي كامل
مهمة واحدة، من البداية إلى النهاية: مشروع Neon فارغ إلى سؤال وجواب يعمل يجيب من مستنداتك. التعليمات أدناه هي العمل كله، اكتبها في أيّ من الأداتين. والطريقة هي حركة دورة البرمجة الواحدة بحجمها الكامل: خطّط بنموذج قوي، وراجع الخطة، ثم دع نموذجاً أرخص يقوم بالبناء الروتيني.
يعمل بأيّ الطريقتين وصلت. تبقى في مجلد postgres-ai/ نفسه، لكن البناء ينشئ مشروع Neon جديداً تماماً، فلا شيء من بناء الاقتباسات يُمَسّ، سواء عملت عبر المفاهيم 5 إلى 9 أو قفزت إلى هنا مباشرةً. وإن اقترحت الخطة إعادة استعمال دوال بنيتها أصلاً، فلا بأس؛ احكم عليها في المراجعة.
0. امنح البناء مستندات وبيتاً، القاعدة لا تأتي معها مستندات، فاصنع بعضها (وإن لم يكن هذا المجلد مشروع uv بعد، فهذا يصلح ذلك أيضاً). الصق:
أعدّ هذا المجلد مشروع Python يديره uv إن لم يكن كذلك أصلاً. ثم أنشئ مجلد
docs/بعشرة ملفات markdown قصيرة: دليل موظفين مصغّراً لشركة خيالية، الإجازات، والمصروفات، والأمن، والتأهيل، والمعدّات.
1. خطّط أولاً، ادخل نمط التخطيط (Shift+Tab في Claude Code، وTab في OpenCode) بنموذج قوي، ثم الصق:
لديّ مجلد
./docsمن ملفات markdown. ابنِ نظام RAG على Neon: باستعمال خادم Neon MCP، أنشئ مشروعاً وفرعdev، وفعّل pgvector، وحمّل المستندات إلى جدول، وابنِ عامل تضمين صغيراً يقطّعها ويضمّنها في جدول رفيقchunks، وامنحني دالةanswer_question()تسترجع ثم تولّد. أرني الخطة الكاملة والمخطّط قبل تشغيل أيّ شيء.
2. اقرأ الخطة قبل أن توافق. تحقّق: هل تعمل على فرع Neon؟ هل pgvector مفعّل؟ هل يقرأ عامل التضمين مفتاح API من البيئة (وهل يبقى المفتاح خارج المستودع)؟ هل التوليد في كود التطبيق؟ إن كان كل ذلك نعم، فوافق.
3. نفّذ، في ثلاث نقاط تفتيش، بدّل إلى نموذج أرخص (/model في أيّ من الأداتين) للبناء الروتيني، ولا تطلق الخطة كلها أعمى: شغّلها على مراحل، مع شيء تنظر إليه بعد كلٍّ. قاعدة البيانات أولاً:
يبدو صحيحاً. تابع مع قاعدة البيانات والعامل: أنشئ المشروع وفرع
dev، وفعّل pgvector، وحمّل المستندات، وشغّل العامل مرة. ثم أرني كم مقطعاً أنتج كل مستند، لأرى أن المستندات وصلت.
الاسترجاع تالياً، المقاطع قبل الإجابات، كما في المفهوم 9:
الآن نصف البحث. ابنِ دالة الاسترجاع وشغّلها على ثلاثة أسئلة قد يسألها موظف جديد، أرني فقط المقاطع التي تعود، لا إجابات بعد.
إن كانت المقاطع الصحيحة تعود، فالتوليد هو الجزء السهل:
لُفّ
answer_question()حولها. ثم اطرح خمسة أسئلة قد يسألها موظف جديد فعلاً وأرني المقاطع المسترجَعة بجوار كل إجابة.
4. قيّم، ثم كرّر، بعض الإجابات ستكون أضعف من غيرها؛ ذلك بدء الحلقة، لا فشل. الصق:
الإجابات الأضعف استعملت مقاطع غير ذات صلة. شخّص: أهو الاسترجاع أم التوليد؟ إن كان الاسترجاع، فجرّب استراتيجية تقطيع مختلفة على فرع جديد وأعد تشغيل الأسئلة الخمسة نفسها.
لديك الآن نظام RAG يعمل. والخطوات الأربع التالية هي طبقة الضبط (الجزآن 3 و4)، وسوف تشغّل كلاً منها، لا تقرأ عنها فقط. كل متعلّم يفعل هذه، على البيانات التي لديك أصلاً، ليستقرّ العمق مهارةً. وهي مستقلّة: افعلها بأيّ ترتيب، لا تتخطّ أيّاً منها.
5. اجعله سريعاً، وراقب الفهرس يكسب قوته (المفهوم 11). عشرة مستندات أصغر من أن تحتاج فهرساً، فستصنع المقياس بنفسك، على فرع ترميه، وتراقب البحث ينقلب من بطيء إلى فوري على البيانات نفسها. الصق:
على فرع Neon مؤقّت، أنشئ جدول معيار قياس واملأه بما يكفي من متّجهات عشوائية لتجاوز علامة 100 ألف حيث يبدأ الفهرس بالفوز، لا تضمينات ولا نصاً حقيقياً مطلوب، هذا لصنع المقياس بحتاً. تأكّد أن كل صف يحصل على متّجه عشوائي مميّز خاص به (خطأ شائع يملأ كل صف بالمتّجه نفسه، فاجعل الوكيل يتحقّق عبر
count(distinct embedding)). حجّمه ليبقى داخل تخزين Neon المجاني؛ استعمل بُعد متّجه أصغر لهذا الجدول الاصطناعي إن ساعد على الملاءمة. شغّل بحث جار-أقرب عبرEXPLAIN ANALYZEوأرني الخطة والوقت. ثم ابنِ فهرس HNSW، وارفعmaintenance_work_memللبناء حتى لا يزحف، وشغّل البحث المطابق نفسه مرة أخرى. ضع الاثنين جنباً إلى جنب: سطر العامل وزمن التنفيذ، قبل وبعد. ثم ارفعef_searchواخفضه وأرني كيف يتحرّك زمن الاستجابة. احذف الفرع حين ننتهي، ذلك يستعيد التخزين.
تنتهي عندما: تكون قد رأيت بعينيك Seq Scan يصير Index Scan using …hnsw… وزمن التنفيذ يهبط على بيانات متطابقة، وراقبت ef_search يحرّك زمن الاستجابة. هذا هو نصف السرعة من المفهوم 11، منجَزاً. (ثلاثة أشياء تبدو مشكلات وليست كذلك: بناء فهرس HNSW على أكثر من 100 ألف متّجه يأخذ بضع دقائق لا ثوانٍ، ذلك متوقّع لا تعليق، ورفع maintenance_work_mem للبناء يختصره بوضوح؛ واستعمال بُعد أصغر لهذا الجدول المؤقّت لا يغيّر شيئاً في الدرس، إذ يتصرّف فحص-الفهرس-مقابل-فحص-التسلسل وقرص ef_search بالطريقة نفسها عند أيّ بُعد؛ وهذه المتّجهات العشوائية تُظهر السرعة بصدق، لكنها لا تستطيع إظهار الاستدعاء الحقيقي، فالنقاط العشوائية لا تملك بنية جوار، لذلك لا يعني رقم استدعاء ضعيف هنا شيئاً. احكم على الاستدعاء على التضمينات الحقيقية في مقابل مجموعة تقييمك، لا على بيانات اصطناعية. أنت تقيس أداء الفهرس، لا استرجاعك.)
6. رشّح بالمعنى وبشرط (المفهوم 13). مستندات دليلك تقع في فئات طبيعية (الإجازات، المصروفات، الأمن، التأهيل، المعدّات)، فتستطيع الترشيح حقاً:
وسم كل مقطع بفئة المستند الذي جاء منه. أضف مرشّح
categoryاختيارياً إلى بحثنا. اسأل «كم يوم إجازة أحصل عليها؟» مرتين، مرة عبر كل شيء، ومرة مرشَّحةً إلى فئة الإجازات، وأرني كيف تتغيّر المقاطع المسترجَعة. أضف فهرس B-tree علىcategoryوأكّد عبرEXPLAIN ANALYZEأن المرشّح يستعمله.
تنتهي عندما: يُعيد الاستعلام المرشَّح مقاطع أضيق في صلب الموضوع، وتكون قد رأيت فهرس B-tree في الخطة، أي عائد جملة-WHERE-على-الاستعلام-نفسه من المفهوم 5، مصنوعاً حقيقياً.
7. التقط المصطلح الدقيق الذي يفوته المعنى وحده (المفهوم 14). هنا تشعر لماذا صار البحث الهجين الافتراضي:
ضع رمزاً دقيقاً نادراً في مستند واحد، لنقل
EXP-2031في ملف المصروفات. اسأل «ما هو EXP-2031؟» ببحث متّجه فقط وأرني أين يحتلّ مرتبته. الآن أضف بحثاً في النص الكامل على نص المقطع، وادمج القائمتين عبر RRF، واسأل مجدّداً، أرني كيف تتغيّر رتبة المطابقة الدقيقة. ثم أعد تشغيل أسئلة تقييمنا الخمسة متّجهاً فقط مقابل هجين وأخبرني أيّها تحسّن.
تنتهي عندما: تكون قد قارنت موضع الرمز في بحث متّجه فقط وفي البحث الهجين، ودعوت مجموعة تقييمك تُظهر الأثر الصافي، فتكون قد قرّرت الهجين على دليل، لا لأن عنواناً أخبرك بذلك. (على متن بهذا الصغر، قد يرتّب البحث المتّجهي رمزاً نادراً قرب القمة أصلاً؛ تتّسع الفجوة التي يسدّها الهجين حين يكبر المتن ويتخفّف الرمز النادر بين مقاطع كثيرة. إن لم يحرّك الهجين الأشياء بوضوح هنا، فهذا أثر المقياس، لا فشل: أكّد أن استعلام RRF يعمل، ودع مقارنة التقييمات تكون الحكم.)
8. اعزل مستأجراً عن آخر (المفهوم 15). العزل الذي يحوّل هذا إلى شيء قد تبيعه لعميلين في آن:
وسم مقاطعنا بمستأجرين متظاهرَين، اقسم المستندات نصفين. اكتب سياسة أمان مستوى الصف بحيث لا تستطيع جلسة مضبوطة على المستأجر A أن تسترجع إلا مقاطع المستأجر A. ثم أثبت ذلك من دور قاعدة بيانات عادي غير مالك (RLS يتجاوزه المستخدمون الخارقون ومالك الجدول، فالاختبار بدور المسؤول الذي بنى الجدول لا يُظهر عزلاً، استعمل دوراً قارئاً فقط عادياً بدلاً منه): اجعل الوكيل ينشئ ذلك الدور لك (
CREATE ROLEمعGRANT SELECT، متصلاً عبرSET ROLEأو دور Neon وسلسلة اتصال منفصلين، لا شيئاً تضبطه بيدك)، واضبط الجلسة على المستأجر A وشغّل بحثاً كان سيطابق مقطع المستأجر B لولا ذلك، أظهر أنه لا يعود أبداً، ثم بدّل إلى المستأجر B وأظهر الصورة المرآة.
تنتهي عندما: يُعيد الاستعلام المتطابق صفوفاً مختلفة بناءً فقط على المستأجر الذي ضُبطت عليه الجلسة، وقد شغّلته بدور غير مالك (فالجدار حقيقي). ذاك «افرضه في قاعدة البيانات» من المفهوم 15 مصنوعاً حقيقياً، RLS، لا جملة WHERE قد تنساها.
لاحظ الإيقاع، ولاحظ أنه لم يتغيّر للأجزاء الصعبة: خطّط ← راجع ← نفّذ ← قيّم ← كرّر. فالفهارس والمرشّحات والهجين وعزل المستأجرين هي الحلقة نفسها كأول بناء RAG، والشيء الجديد الوحيد في كل مرة هو ما تراجعه (المخطّط، أو العامل، أو خطة الفهرس، أو سياسة RLS). أتقن تلك الحلقة فيتوقّف SQL المحدّد عن الأهمية، لأنك تستطيع دائماً أن تجعل الوكيل ينتجه وتستطيع دائماً أن تعرف إن كان صحيحاً، عند أيّ عمق، لا السهل وحده.
الجزء 6: اشحن نظام RAG لديك أداةً على MCP
بنيت search_quotes() وanswer_question() (المفهوم 9)، وفي الجزء 5 توأميهما من المستندات؛ ويلفّ هذا الجزء أيّهما تريد أن تخدمه. الآن لا يستطيع استدعاءهما إلا كودك أنت. لُفّهما في خادم بروتوكول سياق النموذج (MCP) فيصير الاسترجاع نفسه أداةً يستطيع أيّ وكيل اكتشافها واستدعاءها، Claude Code، أو OpenCode، أو Claude Desktop، أو Cursor، أو موظف رقمي تبنيه لاحقاً. وMCP هو المعيار المفتوح الذي يعود إليه هذا الكتاب مراراً: اكتب القدرة مرة، ويخاطبها كل وكيل بالطريقة نفسها.
هذا هو وعد المفهوم 9، أن الاسترجاع هو السياق القابل للبحث الذي يستند إليه الوكيل، مصنوعاً حقيقياً. فيتوقّف بحثك المتّجه عن كونه ميزةً مدفونةً في تطبيق واحد ويصير قدرةً قابلةً لإعادة الاستعمال: شيئاً يمدّ إليه الوكيل يده كما يمدّها إلى آلة حاسبة.
التقيت الآن بكليهما، وهما يؤدّيان عملين متعاكسين:
- خادم Neon MCP (المفهوم 4) أداة إدارة وقت التطوير. يتيح لوكيلك تشغيل قاعدة البيانات بينما تبني، أنشئ فروعاً، وشغّل SQL، وعاين الترحيلات. وهو ليس للإنتاج ولا للمستخدمين النهائيين.
- خادم RAG MCP (هذا الجزء) هو سطح منتجك عند وقت التشغيل. يعرض استرجاعاً قارئاً فقط، «ابحث في معرفتي»، «أجب من بياناتي»، لأيّ وكيل توجّهه إليه.
الأول يبني النظام. والثاني هو النظام، معروضاً على الوكلاء. لا تسلّم خادم Neon الإداري للمستخدمين النهائيين أبداً.
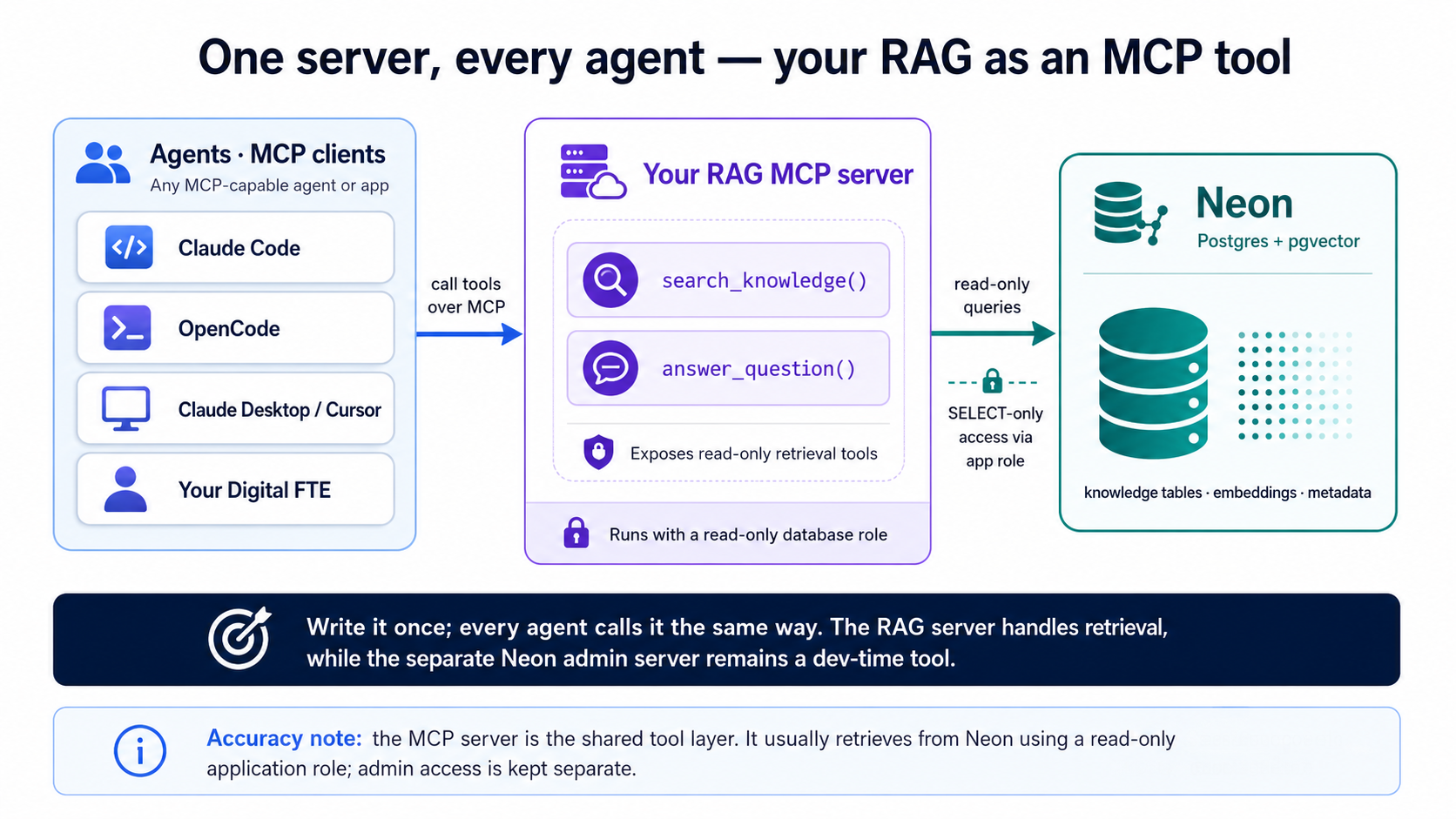
كيف يبدو الخادم
خادم MCP برنامج صغير يعلن قائمة أدوات يستطيع وكيل استدعاءها. ومع FastMCP، مكتبة Python القياسية، طبقة مزخرِفات رقيقة فوق SDK الرسمي لبروتوكول MCP، كل أداة مجرد دالة موسومة بأنواع ولها سلسلة توثيق؛ ولا تكتب أيّاً من سباكة JSON-RPC. وكالعادة، يكتب الوكيل هذا، معروضٌ لتحكم عليه:
# server.py — your RAG, exposed as MCP tools (review material, not to type)
import os
from fastmcp import FastMCP
from rag import search_quotes, answer_question as rag_answer # your Concept 9 functions —
# renamed on import so the MCP tool below can keep the public name "answer_question"
mcp = FastMCP("agent-factory-rag")
@mcp.tool()
def search_knowledge(query: str, limit: int = 5) -> list[dict]:
"""Search the knowledge base by meaning and return the closest chunks.
Use this when you need grounded facts from the user's own data."""
# embeds `query` in app code, runs the Concept 8 search on Neon,
# returns [{text, source, score}, ...] — retrieval only, read-only role
return search_quotes(query, limit)
@mcp.tool()
def answer_question(question: str) -> str:
"""Answer a question grounded in the knowledge base (retrieve, then generate)."""
return rag_answer(question) # the Concept 9 pipeline
if __name__ == "__main__":
# Streamable HTTP, stateless — the production shape. The same file runs on
# your laptop and in the cloud; stateless means no session is held between
# requests, so it scales behind a load balancer. (host="0.0.0.0" binds all
# interfaces so a container can route to it; locally you reach it on localhost.)
mcp.run(transport="http", host="0.0.0.0", port=8000, stateless_http=True)
شيئان يهمّان أكثر من البقية. سلسلة التوثيق هي الواجهة، فهي النص الذي يقرؤه الوكيل المستدعي ليقرّر متى يستعمل الأداة، فيجب أن تقول بوضوح ما تفعله الأداة ومتى يمدّ إليها يده. ويبقى الاسترجاع قارئاً فقط: تشغّل الأداة البحث المعامَل من المفهوم 8 تحت دور قاعدة بيانات قارئ فقط، فلا يستطيع وسيط أداة أن يطفر بياناتك أو يسرّبها أبداً. والسطر الثالث الجدير بالنظر هو الأخير، mcp.run(transport="http", …, stateless_http=True)، الذي يجعل هذا خدمةً تستطيع استضافتها بدل عملية فرعية محلية؛ ستشغّله تالياً، ثم تنشر الملف نفسه عينه.
ابنه بوكيلك
الانضباط نفسه كما في كل مكان آخر، خطّط، راجع، نفّذ. وهذه أيضاً اللحظة التي تكسب فيها مهارة mcp-builder من إعدادك قوتها، سمّها، فيبني الوكيل الخادم بالطريقة التي تعلّمها المهارة. في نمط التخطيط:
باستعمال مهارة mcp-builder، لُفّ استرجاعنا في خادم FastMCP اسمه
agent-factory-rag. اعرض أداتين:search_knowledge(query, limit)تُعيد أعلى المقاطع المطابقة مع مصدرها ودرجة تشابهها، وanswer_question(question)تُعيد إجابةً متجذّرة. أعد استعمال دالتَينا الموجودتينsearch_quotesوanswer_question. اقرأ سلسلة اتصال Neon المجمّعة ومفاتيح API للنموذج من البيئة، واتّصل بدور قاعدة بيانات قارئ فقط. اكتب سلاسل توثيق أدوات واضحة موجَّهة نحو الفعل، فذلك ما يقرؤه الوكيل المستدعي ليقرّر متى يستعمل كل أداة. أرني الخطة وقائمة الأدوات قبل كتابة أيّ كود.
اقرأ الخطة، وأكّد قائمة الأدوات والدور القارئ فقط، ثم وافق ودعه يبني.
شغّله، ثم اتّصل
هنا تكمن النقلة عن خادم Neon الإداري: ذاك يطلقه العميل نيابةً عنك؛ وهذا تبدؤه أنت، فيتّصل به الوكلاء عبر رابطه. تلك هي شكل الإنتاج، متطابقة سواء عمل على حاسوبك المحمول أو في السحابة. شغّله:
uv run server.py
يبقى يعمل ويطبع أين يخدم، فترى http://0.0.0.0:8000/mcp في الشعار (0.0.0.0 يعني فقط «يستمع على كل واجهة»؛ تتّصل به أنت على أنه localhost). اتركه قائماً في هذه الطرفية، وافتح أخرى لوكيلك، وسجّله على localhost:
claude mcp add --transport http rag http://localhost:8000/mcp
تحقّق منه بالأمر claude mcp list؛ وأعد الاتصال في منتصف الجلسة بالأمر /mcp.
أضف كتلة remote إلى opencode.json:
{
"$schema": "https://opencode.ai/config.json",
"mcp": {
"rag": {
"type": "remote",
"url": "http://localhost:8000/mcp",
"enabled": true
}
}
}
ثم قل فقط «استعمل أداة rag» في تعليمة، وهو تدفّق أضف ← تحقّق ← استعمل نفسه الذي تعرفه من خادم Neon في المفهوم 4، إلا أنك هنا تشير إلى رابط بدل أمر. جرّبه:
استعمل أداة rag للإجابة: ماذا قال الناس عن نيويورك؟ أرني أيّ مقاطع استرجعتها أولاً.
راقب الوكيل يستدعي search_knowledge، ويستعيد مقاطعك، ويجذّر إجابته فيها. تلك الرحلة ذهاباً وإياباً هي المقصد كله: بياناتك صارت الآن شيئاً يستطيع أيّ وكيل أن يفكّر فيه.
اشحنه إلى السحابة
خادم محلي لا يصل إليه إلا أنت ليس منتجاً بعد، وأداة MCP يُراد لها أن تعمل حيث يستطيع أيّ وكيل استدعاءها. وهنا يثمر بناؤه عديم الحالة من البداية: لا يتغيّر في الخادم شيء كي تنشره. تدفع server.py نفسه إلى أيّ مضيف يشغّل خدمة Python (حاوية على Cloud Run أو Render أو Railway أو Fly، أو جهازك الافتراضي الخاص)، وتضبط متغيّرات البيئة نفسها هناك، وتسجّل الرابط العام بدل localhost:
claude mcp add --transport http rag https://your-host/mcp
أودِع ذلك .mcp.json فيصل كل من يستنسخ المستودع إلى الخادم المستضاف الواحد نفسه (يطالبهم Claude Code مرة واحدة بالموافقة عليه)؛ وفي OpenCode، وجّه كتلة "type": "remote" نفسها إلى الرابط العام. أضف OAuth ما إن يتّصل أكثر من شخص واحد.
ولماذا انعدام الحالة هو ما يجعل ذلك آمناً: كل طلب يحمل سياقه الخاص، بلا جلسة محفوظة بين النداءات، فيتجاوز الخادم بدايات serverless الباردة ويعمل بوصفه عدة نسخ خلف موازِن حمل بلا جلسات لاصقة، وأداة الاسترجاع، التي لا تحفظ محادثة لكل مستخدم، لا تخسر بذلك شيئاً. والنقل الذي تبني عليه، Streamable HTTP، هو هدف الإنتاج المستقر؛ والتفصيلة الوحيدة السريعة التغيّر هي كلمة FastMCP المفتاحية بالضبط، فدع مهارة mcp-builder أو التوثيق الحيّ يؤكّد transport="http" وstateless_http حين يكتبه الوكيل. ويبقى خادم Neon الإداري أداة تطوير محلية بأيّ الحالين.
بضع قواعد تجعل الوكيل يتبعها، وتؤكّدها في المراجعة:
- دور قارئ فقط. أدوات الاسترجاع لا تفعل إلا
SELECT. اتّصل بدور قاعدة بيانات لا يستطيع الكتابة، فلا يستطيع وسيط أداة أن يحذف بيانات أو يغيّرها. - استعلامات معامَلة. يصل نص الاستعلام معاملاً مربوطاً، لا مسلسلاً نصياً داخل SQL، القاعدة نفسها كما في المفهوم 8.
- تعدّد المستأجرين: لا تثق أبداً بقيمة
tenant_idمُمرَّراً وسيط أداة عادياً. اشتقّه من الجلسة المصادَق عليها وافرضه عبر RLS (المفهوم 15)، فلا يستطيع وكيل مستأجر أن يقرأ متّجهات آخر. ومطبّ واحد إن شغّلت تمرين RLS (الجزء 5، الخطوة 8) على الجدول الذي يقرأ منه هذا الخادم: يجب على الدور القارئ فقط ضبط المستأجر في كل طلب، وإلا تُعيد RLS، على نحو صحيح، صفر صفوف، وهذا يبدو كأنه نتائج فارغة بلا خطأ. اضبط المستأجر لكل طلب، أو وجّه هذا الخادم إلى جدول بلا RLS ما دمت تتعلّم. - ثق بالإعداد. خادم MCP المحلي هو أمر يشغّله جهاز آخر. لا تسجّل إلا الخوادم، ولا تفتح إلا ملفات
.mcp.json/opencode.json، التي تثق بها؛ فإعداد مشروع يستطيع إطلاق عملية على جهازك.
والاسترجاع لا يكون أبداً أفضل من البيانات وراءه، فتبقى مجموعة تقييمك سيّدة الموقف: وجّهها إلى أداة MCP فتكون تقيس الشيء نفسه الذي ستختبره وكلاؤك.
الجزء 7: أين يعمل
| أين | أفضل ملاءمة | ملاحظات |
|---|---|---|
| Neon (هذه الدورة) | من أول بناء إلى الإنتاج | Postgres بدون خادم، وpgvector مدمج، وتفريع فوري، وتوسّع تلقائي. أنت لا تشغّل شيئاً. |
| فروع Neon | التطوير، والمعاينة، والتقييمات، والمعايير | كل فرع نسخة فورية، ابنِ على dev، وعاين، وثبّت على الفرع الافتراضي. |
| TigerData Cloud | بديل متكامل عن Neon | «Postgres وكيلي»: pgvector + pgvectorscale أصلياً، وTiger MCP، واشتقاقات فورية بلا نسخ. اخترها لنطاق StreamingDiskANN والبحث المرشَّح دون ترحيل أبداً. |
أنت لست مقفلاً داخل أيٍّ من هذه. ما تعلّمته هو Postgres عادي مع pgvector، وعمل التضمين في عامل يعمل خارج قاعدة البيانات، لذلك فالمهارة ليست خاصة بNeon. المخطّط نفسه، والعامل نفسه، والاستعلامات نفسها تعمل على أي مضيف Postgres: Supabase أو Xata (Postgres أيضاً مع pgvector)، أو Amazon RDS، أو عنقود CloudNativePG خاص بك على عتاد تتحكّم فيه. نقل المضيفين هو pg_dump / pg_restore، لا إعادة كتابة. وقابلية النقل هذه هي السبب الكامل لإبقاء الدورة التضمين والتوليد في كود التطبيق، لا مخبوزين داخل إضافة مُدارة. Neon وTigerData هما فقط المكانان اللذان تعمل فيهما هذه الدورة حرفياً، مع حلقة MCP الموجَّهة بالوكيل من طرفها إلى طرفها.
كيف تختار مضيفاً فعلاً (حين تتجاوز الطبقة المجانية)
لا تختر بناءً على سعر الجيجابايت من درس تعليمي؛ اختر بناءً على شكل حمل العمل، ثم قارِن الفاتورة بحركتك أنت.
- متقطّع أو كثير الخمول (مشروع جانبي، مساعد منخفض الحركة، فروع تطوير وتقييم): مضيف بدون خادم مقاس بالاستهلاك يتوسّع إلى الصفر، مثل Neon، لا يفرض رسوماً إلا حين تعمل فعلاً. فترات الخمول الطويلة تكاد لا تكلّف شيئاً.
- حركة ثابتة تعمل دائماً (خدمة لا تنام): سعر مثيل ثابت يكون غالباً أبسط وأرخص من عدّاد لا يتوقف. يتوقّف التوسّع إلى الصفر عن المساعدة لحظة يُبقي شيءٌ ما قاعدة البيانات مستيقظة، بما في ذلك عامل تضمين يستطلع باستمرار (انظر ملاحظة العامل أعلاه).
- أسطول قواعد بيانات، أو احتياجات سيادة بيانات: الاستضافة الذاتية (CloudNativePG على عنقودك) تجعل الكلفة الهامشية لقاعدة البيانات التالية قريبة من الصفر، بثمن تشغيلها بنفسك.
أمران يحسمان أكثر من سعر الملصق: هل تحتاج الطبقة المجانية إلى بطاقة ائتمان (غالباً لا، وهذا مهم للطلاب)، وهل مسار الترقية منحدر سلس أم حافة (قفزة من بضعة دولارات إلى مئات عند الطبقة التالية كلفة حقيقية، لا تفصيلاً). تحقّق من الاثنين على صفحة أسعار المزوّد الحالية، فهذه الأرقام تتحرّك، ولذلك لا تذكر هذه الدورة أرقاماً عمداً.
بضع حقائق إنتاج تستحقّ التنبيه لوكيلك مقدّماً:
- عامل التضمين عملية حقيقية، يجب أن يكون قيد التشغيل لتبقى التضمينات متزامنة. وفي الإنتاج هو خدمة تنشرها وتراقبها، لا شيء تبدؤه يدوياً.
- الترحيلات: اجرِ تغييرات المخطّط والعامل على فرع Neon، وعاينها، ثم ثبّتها على الفرع الافتراضي، يشغّل الوكيل هذا عبر أدوات ترحيل Neon MCP. مُصدَّر، ومراجَع، وقابل للعكس، ولا تحرير ارتجالي في مقابل الإنتاج أبداً.
- الكلفة تعيش في استدعاءات التضمين واستدعاءات التوليد، وكلاهما يضرب APIات نماذج خارجية. ادمج دفعياً حيث تستطيع، وخزّن مؤقّتاً حيث تستطيع، واستعمل عادة مطابقة النموذج، نموذج رخيص للتوليد الروتيني، وقوي حيث تهمّ الجودة.
- التوسّع إلى الصفر مقابل العامل. يوسّع Neon قاعدة البيانات إلى الصفر عند الخمول لتوفير المال، لكن عامل تضمين يستطلع باستمرار يبقيها مستيقظة، فيهزم ذلك بهدوء. وللتطبيقات منخفضة الحركة، اجعل الوكيل يضبط العامل ليعمل على جدول زمني (أو يدمج التضمينات دفعياً) بدل الاستطلاع المحكم، فتحصل فعلاً على التوفير.
- استعمل سلسلة الاتصال المجمّعة لحركة التطبيق. نقطة نهاية Neon المجمّعة (مضيف
-pooler، أي PgBouncer في نمط المعاملة) مبنيّة للاتصالات القصيرة العمر الكثيرة التي تفتحها تطبيقات بدون خادم وعالية التزامن. اجعل الوكيل يوجّه تطبيقك الذي يخدم RAG إليها؛ ويستطيع الترحيل والعامل استعمال السلسلة المباشرة. - العامل يعمل خارج Neon. لا تستطيع تشغيل عمليات جانبية على حوسبة Neon المُدارة، فيعيش عامل التضمين على مضيف تطبيقك، أو جهاز افتراضي صغير، أو مهمة مجدوَلة، يصل إلى Neon عبر سلسلة اتصاله. أخبر وكيلك أين ينبغي أن يعمل.
هذا هو السؤال الحقيقي وراء الضجيج، والجواب الصادق غالباً لا. إن كنت تشغّل Postgres أصلاً، فإنّ pgvector يُبقي متّجهاتك بجوار البيانات التي تصفها، مصدر واحد للحقيقة، ومرشّحات ووصلات في الاستعلام نفسه، ولا نظام ثانٍ لتزامنه وتأمينه ودفع ثمنه. وHNSW يغطّي نطاق نحو 100 ألف إلى 10 ملايين بأريحية، وStreamingDiskANN من pgvectorscale يمتدّ إلى ما بعد مليار متّجه، فنادراً ما يكون النطاق الخام العامل الحاسم كما كان. ولمعظم التطبيقات، Postgres هو قاعدة البيانات المتّجهة.
ويكسب مخزن مخصّص (Pinecone، أو Weaviate، أو Qdrant، أو Milvus، وغيرها) مكانه حين تكون قد قِست حاجةً يلبّيها ولا يستطيع Postgres، لنقل إنتاجية استعلام عالية جداً على نطاق مليار فأكثر، أو هدف استدعاء/زمن استجابة محدّد تُظهر معاييرك أن pgvector يفوته، أو خدمة متّجهات مُدارة بالكامل تفضّل استئجارها على تشغيلها. تلك حالات حقيقية؛ لكنها الأقلية. والمطبّ هو المدّ إلى أحدها افتراضياً لأن درساً أو عنواناً فعل ذلك. قرّرها كما تقرّر الفهارس (المفهوم 11): دع مجموعة تقييمك ومعياراً على حملك الحقيقي، بما فيه معدّل تبدّله، يتّخذان القرار، وزِن الكلفة الدائمة لنظام ثانٍ في مقابل المكسب الذي يقدّمه فعلاً.
الجزء 8: سلّمه إلى وكيل
بنيت الاسترجاع ولففته أداةً (الجزء 6). والخطوة الطبيعية التالية وكيل يستعمل تلك الأداة لإنجاز عمل حقيقي، وهذا بالضبط حيث تلتقطه الدورة المكثفة بناء وكلاء الذكاء الاصطناعي. أنت لا تعيد بناء أيّ من هذا هناك؛ بل تسلّم الوكيل الأداة التي لديك أصلاً.
وإليك الجسر كله في فكرة واحدة. تلك الدورة تعلّم حلقة الوكيل عبر OpenAI Agents SDK: فإنّ Agent نموذجٌ مزوّدٌ بتعليمات وأدوات، وRunner يشغّل حلقة النموذج ← الأداة ← النموذج إلى أن يُنجَز العمل. ونظام RAG لديك إحدى تلك الأدوات. فحيث تنتهي هذه الدورة، search_knowledge / answer_question قابلتان للاستدعاء، تبدأ تلك.
طريقتان لوصل ما بنيته (دورة الوكلاء تغطّي الحلقة؛ وأنت فقط تورّد الأداة):
- بوصفه خادم MCP من الجزء 6. يستطيع Agents SDK استهلاك خوادم MCP مباشرةً، فتوجّه الوكيل إلى خادمك
agent-factory-ragوتظهر أدواته في صندوق أدوات الوكيل تلقائياً، الخادم نفسه الذي سجّلته أصلاً في Claude Code وOpenCode. - بوصفه أداة دالة. إن فضّلت إبقاءه ضمن العملية، فلُفّ الاستعلام القارئ فقط نفسه في
@function_toolمن SDK، أسلوب الأداة الأصلي لتلك الدورة. الاسترجاع نفسه، معبَّراً عنه دالة Python يستطيع الوكيل استدعاءها.
الجسر الأعمق: الذاكرة مقابل المعرفة. تؤطّر دورة الوكلاء كل وكيل حول سؤالين: ما يستطيع الاستناد إليه (الحالة) وما يُسمَح له بفعله (الثقة). ونوع من الحالة هو الذاكرة، ما يستحضره من المحادثة الجارية، وتتولّاه تلك الدورة عبر الجلسات. ونظام RAG لديك يوفّر النوع الآخر: المعرفة، سياق دائم قابل للبحث يستطيع البحث فيه، عبر بيانات أكثر بكثير مما يتّسع في أيّ نافذة. الجلسات تحمل المحادثة؛ وPostgres + pgvector لديك يحمل كل ما قد يحتاج الوكيل استرجاعه. والوكيل الموصول بكليهما يستطيع أن يتذكّر ما قيل للتوّ ويبحث عمّا لم يعرفه قطّ، وانضباط «اجلب المقاطع ذات الصلة فقط، واترك المليون صف غير ذي الصلة خارجاً» من هذه الدورة هو بالضبط ما يمنع ذلك السياق المسترجَع من إغراق النافذة. الخيط نفسه، يخدم الآن وكيلاً بدل تطبيق.
وبلغة الكتاب، نصف المعرفة ذاك هو نظام سجلّات الوكيل، الحقيقة المرجعية التي يقرأ منها (الاسترجاع)، ويكتب إليها (العامل يبقيها حديثة)، ويتحقّق في مقابلها (مجموعة تقييمك). وهو ما يحوّل مخمِّناً فصيحاً إلى وكيل ينفّذ.
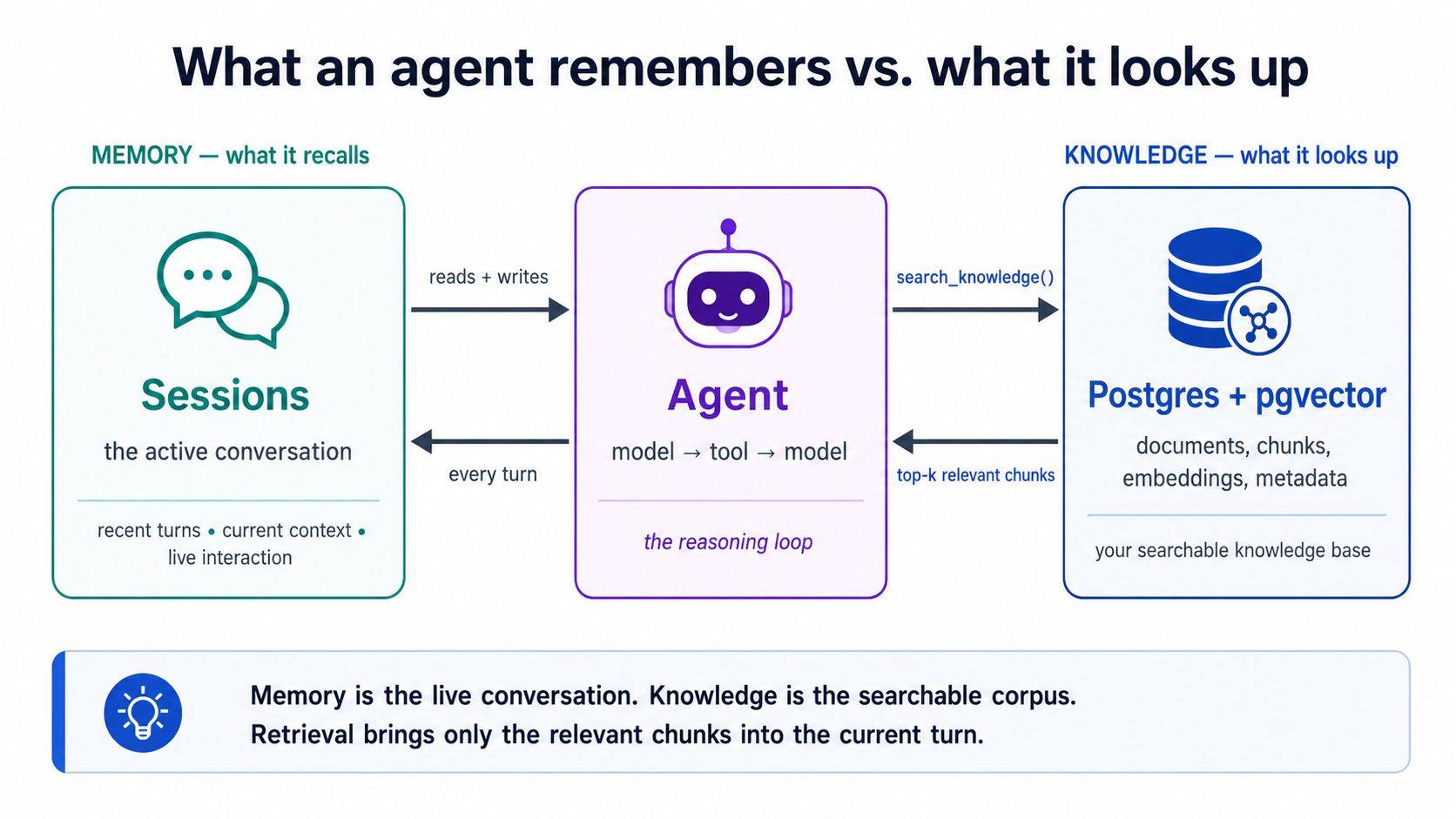
وصّله بالطريقة التي بنيت بها كل شيء آخر، عبر الوكيل. في نمط التخطيط:
ابنِ هيكل الوكيل الأدنى من الدورة المكثفة في بناء وكلاء الذكاء الاصطناعي (OpenAI Agents SDK،
Agentمع حلقةRunner). امنحه أداةً واحدة بالضبط: استرجاعنا. إمّا أن توصله بخادمagent-factory-ragعلى MCP من الجزء 6 ليظهرsearch_knowledgeوanswer_questionأداتين، أو لُفّ الاستعلام القارئ فقط نفسه@function_tool، أوصِ بأيّهما يناسب وقل لماذا. اترك آليات الوكيل نفسها (الجلسات، وحواجز الأمان، وتوجيه النموذج) لتلك الدورة؛ هنا، فقط أثبت أن الوكيل يستطيع استدعاء استرجاعنا وتجذير إجابة فيه. أرني الخطة أولاً.
وافق عليها، وشغّل سؤالاً يفرض استدعاء الأداة، وراقب الوكيل يسترجع من قاعدة بيانات Neon (أو TigerData) لديك ويجيب منها. ذاك هو التسليم: بناء وكلاء الذكاء الاصطناعي تعلّم الحلقة، وحواجز الأمان، والجلسات، والنشر؛ وهذه الدورة منحت الوكيل شيئاً صادقاً ليقوله. وتعبر مجموعة تقييمك سليمةً، فهي ما تزال تقيس الاسترجاع الذي يعتمد عليه الوكيل الآن.
أين تذهب بعد ذلك
لديك الآن نسبة 80%: تستطيع تحويل Neon إلى قاعدة بيانات متّجهة، وبناء نظام RAG متجذّر، واختيار فهرس على دليل، وتحسين الاسترجاع بالمرشّحات والبحث الهجين والتقييمات، كلها بتوجيه وكيل والحكم على عمله.
- اجعله موثوقاً: الدورة المكثفة في التطوير المُوجَّه بالتقييم
- اجعله وكيلاً: الجزء 8 يجسر أداة RAG لديك إلى وكيل؛ والحلقة الكاملة، وحواجز الأمان، والجلسات، والنشر في بناء وكلاء الذكاء الاصطناعي
- اجعله منتجاً: حوّل المساعد إلى موظف رقمي قابل للنشر
الخيط لا يتغيّر أبداً: المعلومة الصحيحة، في اللحظة الصحيحة، والمعلومة غير ذات الصلة خارجاً. تعلّمته لوكيلك. والآن تستطيع بناءه لوكلاء كل الآخرين.