هل هذه مهمة لوكيل؟ دورة مكثفة
3 بوابات · 3 منعطفات خاطئة · مسار واحد واضح
يدير شخصان متجراً صغيراً على الإنترنت. صباح الاثنين، يصل إليهما العمل نفسه: تراكمت كومة من 400 رسالة عميل، وعليهما تصنيف الرسائل إلى مجموعات (شكاوى، وأسئلة، وطلبات، وأخرى) وكتابة ملخص قصير قبل يوم الجمعة.
تتوقف Ana وتفكّر عشر دقائق قبل أن تفتح أي أداة. تسأل نفسها ثلاثة أسئلة بسيطة. أولاً: هل هذه مهمة للذكاء الاصطناعي أصلاً، أم يستطيع بحث تطبيق الرسائل وفلاتره إنجازها؟ تحتاج المجموعات إلى حُكم، فتحديد ما يُعدّ "شكوى" ليس شيئاً يقدر عليه فلتر بسيط، فنعم، هذه مهمة للذكاء الاصطناعي. ثانياً: هل ستفعل هذا مرة واحدة أم كل أسبوع؟ كل أسبوع. لذلك تدوّن ملاحظة لتبني لاحقاً شيئاً يفعل هذا من تلقاء نفسه، وتنجز الآن نسخة سريعة يدوياً لتلحق بالجمعة. ثالثاً: كيف ينبغي أن يبدو العمل المنتهي؟ جدول بيانات بصف واحد لكل رسالة، مع ملخص من صفحة واحدة. تفتح أداة الذكاء الاصطناعي وهي تعرف تماماً ما تريد.
يفتح Yusuf أداة الذكاء الاصطناعي فوراً ويكتب "ساعدني في رسائل العملاء هذه". تسأله الأداة عمّا يريد. وهو غير متأكد، فيرتجل وهو يمضي. بعد ساعتين لديه ملخص لا يثق تماماً بصحته، ولا طريقة لتكرار العمل الأسبوع القادم، والكومة نفسها تنتظره من جديد يوم الاثنين التالي، وسيصنّفها مرة أخرى يدوياً.
العمل نفسه. الأداة نفسها. مرّرت Ana العمل عبر ثلاث بوابات قبل أن تكتب أي شيء. أما Yusuf فدخل مباشرة إلى الأداة وتركها تطرح الأسئلة. تعلّمك هذه الدورة تلك البوابات الثلاث.
لمن هذه الدورة؟
كل من لديه إحدى أدوات الذكاء الاصطناعي هذه، أي Claude Code أو OpenCode أو Cowork أو OpenWork، وكومة من العمل الحقيقي، وليس متأكداً دائماً أن الأداة هي المكان الصحيح لوضعه فيه. تقع هذه الدورة في المنتصف: بعد أن تكون قد تعرّفت على هذه الأدوات ورأيت ما تستطيع فعله، لكن قبل أن تتعلم حلّ المشكلات الحقيقية بها. إنها عن تقرير ماذا تعطي الأداة، وأين ينبغي أن يذهب العمل.
يُقرأ هذا الكتاب في أنحاء العالم كله، من أناس يعملون ويدرسون بلغات كثيرة مختلفة. تستخدم الأمثلة في هذه الصفحة إنجليزية مبسطة ومواقف يومية، مثل متجر صغير، ومجلد ملفات، وكومة رسائل، تعني الشيء نفسه أينما عشت. لست بحاجة إلى معرفة أدوات بلد بعينه أو قوانينه أو عملته كي تتابع.
الوكيل العام أداة ذكاء اصطناعي لا تتكلم فحسب، بل تفعل أشياء. يستطيع أن يفتح ملفاتك، ويقرأها، ويكتب ملفات جديدة، ويشغّل برامج صغيرة، ويستخدم تطبيقات أخرى نيابة عنك. الوكلاء العامون الأربعة في هذا الكتاب هم Claude Code وOpenCode وCowork وOpenWork؛ ف Claude Code وOpenCode لمن يعملون بالكود، أما Cowork وOpenWork فلبقية الناس. والطريقة المختصرة لتذكّر الفرق: روبوت المحادثة يجيب عن سؤالك؛ أما الوكيل فيذهب وينجز المهمة. هذا الفرق الوحيد هو ما بُنيت عليه هذه الدورة كلها.
شيئان قبل هذه الصفحة. أولاً، أنهِ كيف تفكّر في عصر الذكاء الاصطناعي، فهو يعلّمك كيف تحافظ على حكمك الخاص وأنت تعمل مع الذكاء الاصطناعي. لا تكرّر هذه الدورة ذلك. ثانياً، أنهِ دورة أداة واحدة على الأقل، Claude Code وOpenCode أو Cowork وOpenWork، حتى تكون قد رأيت ما يستطيع الوكيل فعله. لا تستطيع أن تقرر "هل هذه مهمة لوكيل" قبل أن تعرف ما هو الوكيل.
📚 وسيلة تعليمية
شاهد العرض التقديمي الكامل: هل هذه مهمة لوكيل؟
القاعدة في سطر واحد
أرخص خطأ تصلحه هو الذي تكتشفه قبل أن تبدأ.
إليك ما يعنيه ذلك. خطأ في خطتك لا يكلّفك شيئاً لإصلاحه، فأنت تغيّر رأيك فحسب. أما خطأ لا تلاحظه إلا بعد أن يقضي الوكيل ساعة في فعل الشيء الخطأ فيكلّفك تلك الساعة كاملة. فأذكى مكان لإنفاق جهدك هو البداية تماماً، قبل أن تكتب أي شيء.
كل ما يسوء مع وكيل تقريباً ساء هنا، في البداية:
- استخدمت وكيلاً لشيء يفعله جدول بيانات في خطوة واحدة.
- أنجزت المهمة نفسها يدوياً كل أسبوع لشهرين، بينما كان بإمكانك بناء شيء يفعلها نيابة عنك.
- فتحت الوكيل بفكرة ملتبسة عمّا تريد، فأنجز عملاً أنيقاً، لكن على الشيء الخطأ.
لا شيء من هذه سببه كتابة سيئة. بل سببها البدء في المكان الخطأ. ولا قدر من الصياغة الذكية يصلحها، لأن إجابة مثالية عن السؤال الخطأ تبقى خاطئة. تعطيك هذه الدورة ثلاثة فحوص، نسمّيها بوابات، تمرّر عملك عبرها قبل أن تبدأ. وكل بوابة تمنع خطأً شائعاً واحداً.
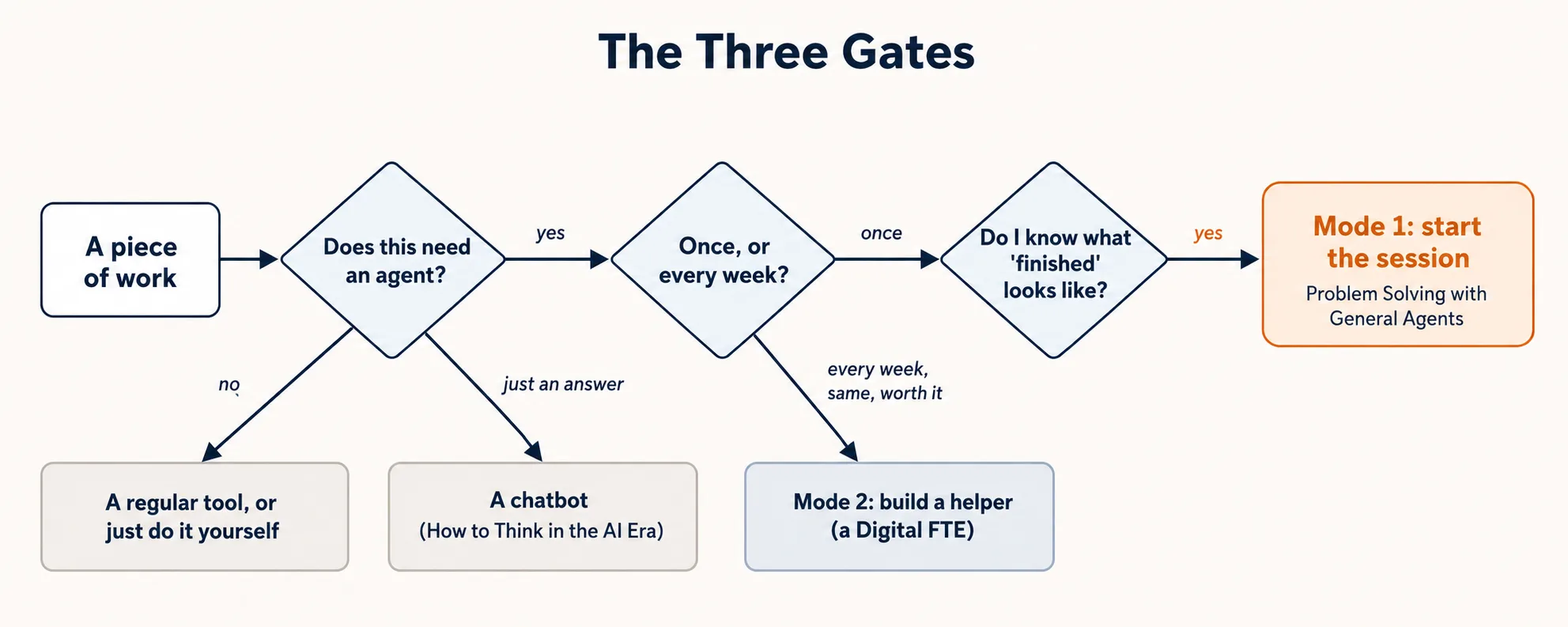 ثلاث بوابات، وإلى أين يرسلك كل جواب. معظم الوقت المهدور يأتي من القفز مباشرة إلى النهاية.
ثلاث بوابات، وإلى أين يرسلك كل جواب. معظم الوقت المهدور يأتي من القفز مباشرة إلى النهاية.
البوابات الثلاث، بالترتيب:
| البوابة | السؤال | الخطأ الذي تمنعه |
|---|---|---|
| 1 | هل يحتاج هذا إلى وكيل أصلاً؟ | استخدام أداة كبيرة لمهمة صغيرة، أو أداة صغيرة لمهمة كبيرة |
| 2 | مرة واحدة، أم كل أسبوع؟ | بناء مساعد لمهمة لمرة واحدة، أو إنجاز مهمة متكررة يدوياً إلى الأبد |
| 3 | كيف يبدو العمل المنتهي؟ | عمل أنيق موجَّه نحو هدف خاطئ |
خذها بالترتيب. البوابة 2 لا تهمّ إلا بعد أن تقول البوابة 1 "نعم، وكيل". والبوابة 3 لا تهمّ إلا بعد أن تقول البوابة 2 "افعلها الآن". تخطَّ بوابة فترتكب خطأها.
كيف تقرأ هذه الصفحة
| الوقت المتاح لك | ماذا تقرأ |
|---|---|
| 15 دقيقة | القاعدة، والصورة أعلاه، والملخص القصير تحت كل بوابة. يكفي لتصنيف مهمتك التالية. |
| 45 دقيقة | البوابات الثلاث كلها مع الأمثلة، قراءةً فقط. |
| يوم عمل كامل (الأفضل) | كل شيء، مع تجربة كل "دورك" على مهمة حقيقية من أسبوعك. |
تثبت هذه البوابات حين تجرّبها على عملك أنت. القراءة تريك الحركات. وإنجازها على ثلاث مهام حقيقية هو ما يجعلها عادة.
النسخة المختصرة (ثلاث نقاط)
إذا تذكّرت هذه الثلاث فقط، فقد امتلكت معظم ما يهم:
- ليست كل مهمة مهمةً للذكاء الاصطناعي، وليست كل مهمة للذكاء الاصطناعي تحتاج إلى وكيل. إذا أنجزها جدول بيانات، أو مربع بحث، أو ثلاثون ثانية من وقتك، فافعل ذلك. إذا كنت تحتاج إلى إجابة فقط، فذلك روبوت محادثة. أما الوكيل فهو للعمل الملتبس، المنتشر عبر أنواع مختلفة من الملفات، والذي يحتاج إلى أن تفعل الأداة شيئاً فعلياً بملفاتك أو بياناتك أو تطبيقاتك، لا أن تتحدث عنها فحسب.
- عدد مرات إنجازك له يقرر كل شيء. مهمة تنجزها مرة واحدة → افتح وكيلاً، وحُلّها، وانتهى الأمر. مهمة تنجزها كل أسبوع، بالطريقة نفسها → توقّف عن إنجازها يدوياً وابنِ مساعداً يفعلها نيابة عنك. أكثر أنواع الهدر شيوعاً في العالم هو إنجاز مهمة من نوع "ابنِ مساعداً" يدوياً، مراراً وتكراراً.
- قرّر كيف يبدو "المنتهي" قبل أن تفتح الوكيل. سمِّ ثلاثة أشياء: ما الذي ينطلق منه، وما تريده في النهاية، والفحص الواحد الذي يخبرك أنه صحيح. الوكيل ذو الهدف الواضح يصيبه. والوكيل ذو الهدف الملتبس يصنع شيئاً أنيقاً وخاطئاً.
تحوّل بقية الصفحة هذه الثلاث إلى بوابات يمكنك تشغيلها فعلاً.
البوابة 1 — هل يحتاج هذا إلى وكيل أصلاً؟
الخطأ الذي تمنعه: "قضيت عشرين دقيقة أجعل وكيلاً ينجز شيئاً يفعله جدول بيانات في خطوة واحدة، أو فتحت وكيلاً كاملاً لمجرد الإجابة عن سؤال يجيب عنه روبوت محادثة في خمس ثوانٍ."
لهذه البوابة فحصان صغيران، بالترتيب.
الفحص 1a — هل يحتاج إلى ذكاء اصطناعي، أم إلى أداة عادية تملكها بالفعل؟
الوكلاء جيدون في العمل الملتبس: العمل الذي يحتاج إلى حُكم، ويمزج أنواعاً مختلفة من الملفات، ولم يُبنَ أي تطبيق عادي لإنجازه. وهم ليسوا الخيار الأفضل لعمل تنجزه أداة عادية ببراعة بالفعل.
إليك الاختبار البسيط. إذا استطعت وصف المهمة كخطوة واحدة دقيقة هي نفسها في كل مرة، فالأرجح أن أداة عادية أسرع وأوثق:
- "اجمع هذا العمود من الأرقام." → ذلك جدول بيانات. ليس ذكاءً اصطناعياً.
- "جد كل من في جهات اتصالي اسمه Khan." → ذلك مربع البحث في تطبيق جهات اتصالك. ليس ذكاءً اصطناعياً.
- "غيّر كل '2024' إلى '2025' في هذا المستند." → ذلك البحث والاستبدال. ليس ذكاءً اصطناعياً.
في اللحظة التي تحتاج فيها المهمة إلى حُكم (مثل "صنّف هذه الرسائل بحسب الموضوع"، حيث عليك أن تقرر ماذا يعني كل موضوع)، أو تمزج أنواعاً مختلفة من الملفات لا يستطيع تطبيق واحد فتحها معاً (صور وملفات PDF ولقطات شاشة)، أو لا يوجد ببساطة أي تطبيق يفعلها، فقد تجاوزت الفحص 1a. إنها مهمة ذكاء اصطناعي.
الفحص 1b — هل يحتاج إلى وكيل، أم مجرد روبوت محادثة؟
هذا هو الفحص الذي يتخطّاه الناس أكثر من غيره. تذكّر القاعدة من صندوق التذكير: روبوت المحادثة يجيب، والوكيل يفعل.
فاسأل: هل تحتاج هذه المهمة إلى أن تلمس الأداة أشيائي الفعلية؟
- "اشرح الفرق بين المدين والدائن." → هذه تحتاج إلى إجابة. ولا تمسّ شيئاً من أشيائك. تلك مهمة روبوت محادثة. والمهارة للحصول على إجابات جيدة من روبوت المحادثة هي كيف تفكّر في عصر الذكاء الاصطناعي، لا هذه الدورة.
- "راجع رسائل عملائي ال 400 وضع كل واحدة في مجموعة." → هذه تحتاج إلى أن تفتح الأداة ملفاتك الحقيقية وتتصرف فيها. تلك مهمة وكيل.
الفرق كله هو الإجابة مقابل الفعل. إن كنت تحتاج فقط إلى معرفة شيء، أو تريد مسودة أو بعض الأفكار، فذلك عمل إجابة، أي روبوت محادثة. وإن كنت تحتاج إلى أن تفتح الأداة ملفاتك، أو تغيّرها، أو تشغّل شيئاً، أو تستخدم تطبيقاً آخر نيابة عنك، فذلك عمل فعل، أي وكيل.
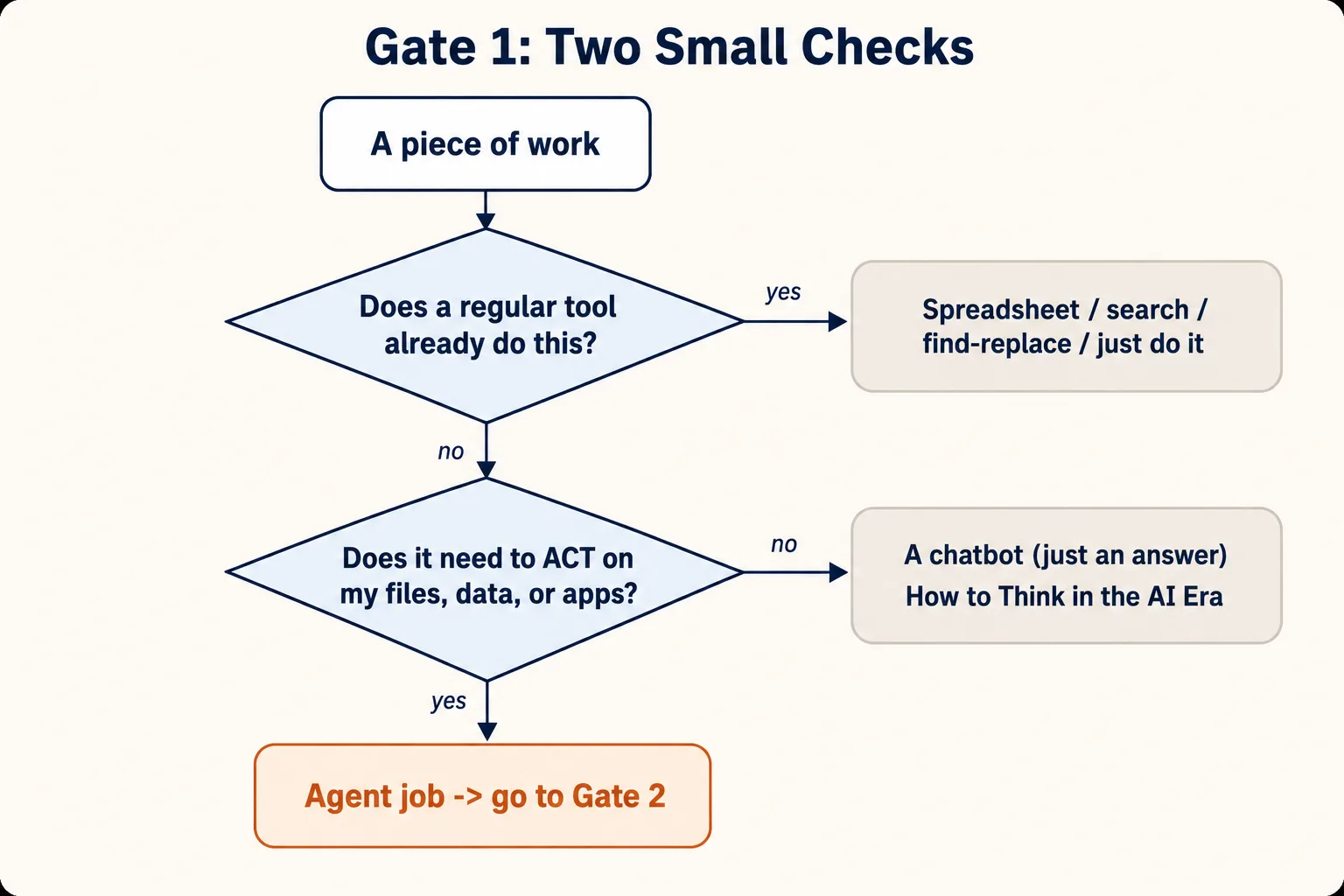 سؤالان صغيران، وثلاثة مخارج. المخرج الأسفل وحده وكيل.
سؤالان صغيران، وثلاثة مخارج. المخرج الأسفل وحده وكيل.
مثال يومي أولاً
فكّر في الطبخ. "كم أسلق البيضة؟" إجابة: تسأل، وتحصل على رقم، وانتهى. ذلك روبوت محادثة. أما "انظر في ثلاجتي، وانظر ماذا لديّ، وأعدّ لي قائمة تسوّق لثلاثة عشاءات هذا الأسبوع" فيحتاج إلى من يذهب فعلاً و_يفعل_ عدة أشياء. ذلك نوع المهمة التي وُجد الوكيل لها. أما "اجمع أسعار إيصال بقالتي" فلا هذا ولا ذاك، إنها مجرد آلة حاسبة.
مثال من العمل
تساعد Mei في إدارة مكتب شركة صغيرة. تصل أربع مهام في الصباح نفسه. تشغّل كل واحدة عبر البوابة 1:
- "ما مجموع قائمة المصروفات هذه؟" → جدول بيانات يجمعها. ليست ذكاءً اصطناعياً أصلاً. توقّف عند 1a.
- "اشرح ما هو أمر الشراء." → تحتاج إلى إجابة فقط؛ ولا يمسّ شيئاً من أشيائها. روبوت محادثة. توقّف عند 1b.
- "راجع هذا المجلد من الفواتير وجد ما ينقصه توقيع." → هذه تحتاج إلى حُكم (قراءة كل واحدة) وتتصرف في ملفاتها. وكيل. تجتاز البوابة 1.
- "قارن قائمة مدفوعات البنك بقائمتنا الخاصة وأخبرني بما لا يتطابق." → ملفان مختلفان، وتحتاج إلى حُكم، وتتصرف في بياناتها. وكيل. تجتاز البوابة 1.
اثنتان من "مهام الذكاء الاصطناعي" الأربع لديها لم تكونا مهمتي وكيل أصلاً. وهذا طبيعي وجيد. البوابة 1 ليست موجودة لدفع العمل نحو الوكيل. بل لإبقاء العمل الذي لا ينتمي إلى هناك بعيداً عنه.
دورك
خذ خمس مهام من أسبوعك أنت، أي شيء فكّرت في "طلبه من الذكاء الاصطناعي". لكل واحدة، اكتب أي مخرج تسلكه: أداة عادية، أو روبوت محادثة، أو وكيل. ثم اكتب جملة قصيرة واحدة تقول لماذا.
اسرد مهامك الخمس أدناه. يقيّم المصحّح تصنيفك ويضع علامة على المهمة الأرجح أنك أخطأت فيها، وخاصة أي مهمة أُرسلت إلى "وكيل" وهي تحتاج في الحقيقة إلى إجابة فقط.
Discuss with an AI. Question your scores.
Come back when you have your BEST evaluation.
إذا خرجت الخمس كلها "وكيل"، فالأرجح أنك تفرض ذلك فرضاً: انظر من جديد وجد الواحدة التي هي في الحقيقة جدول بيانات أو روبوت محادثة. وإذا لم تخرج أي واحدة "وكيل"، فتلك نتيجة حقيقية أيضاً. ربما لم يكن في هذا الأسبوع عمل بشكل الوكيل أصلاً. لا بأس بذلك.
لماذا ينجح هذا (البحث وراءه) — اختياري
للغريزة التي تدفعك إلى اللجوء إلى أداة مفضلة واحدة لكل مهمة اسمٌ. سمّاها Abraham Kaplan قانون الأداة سنة 1964، وأعطاها Abraham Maslow صورتها الشهيرة بعد عامين: إن كانت الأداة الوحيدة التي تملكها مطرقة، بدأت كل مشكلة تبدو كمسمار. الوكيل أداة قوية ومثيرة، فيصير المطرقة الجديدة، والبوابة 1 هي العادة التي تمنعك من ضربها على برغي.
وهناك أيضاً نسخة مقيسة من الفكرة نفسها. سأل نموذج ملاءمة المهمة للتقنية (Task-Technology Fit) ل Goodhue وThompson (1995) لماذا تحسّن بعض البرمجيات عمل الناس فعلاً بينما لا يحسّنه بعضها الآخر، ووجد أن المكسب يعتمد على مدى ملاءمة الأداة للمهمة أكثر من اعتماده على جودة الأداة أو شعبيتها. أداة محبوبة تُستخدم في المهمة الخطأ تعطي قليلاً؛ وأداة أبسط تلائم المهمة تعطي كثيراً. البوابة 1 هي ملاءمة المهمة للتقنية مختزَلة في سؤالين تجيب عنهما في عشر ثوانٍ.
المصادر: Kaplan, A. (1964). The Conduct of Inquiry. Maslow, A. (1966). The Psychology of Science. Goodhue, D. L., & Thompson, R. L. (1995). "Task-Technology Fit and Individual Performance," MIS Quarterly, 19(2), 213–236.
البوابة 2 — مرة واحدة، أم كل أسبوع؟
الخطأ الذي تمنعه: "بنيت مساعداً دائماً كاملاً لشيء سأفعله مرة واحدة بالضبط، أو، وهذا أكثر شيوعاً بكثير، أنجزت المهمة نفسها يدوياً كل أسبوع لشهور، ولم ألحظ قط أنه كان بإمكاني بناء مساعد يفعلها نيابة عني."
حالما تقول البوابة 1 "نعم، وكيل"، يصبح السؤال التالي: أي نوع من عمل الوكيل هذا. هذه أهم فكرة في الكتاب كله، لذلك نعطي النوعين اسمين.
- Mode 1 — حُلّها مرة واحدة. تفتح وكيلاً، وتنجز المهمة، وتأخذ النتيجة، وتنصرف. لا يبقى شيء وراءك. هذا هو معظم العمل، في معظم الأوقات.
- Mode 2 — ابنِ مساعداً. تبني عاملاً دائماً بالذكاء الاصطناعي يفعل المهمة مراراً وتكراراً، من تلقاء نفسه، من دون أن تفعلها أنت في كل مرة. (يسمّي الكتاب هذا العامل Digital FTE، أي "موظفاً رقمياً بدوام كامل".) يتطلب هذا جهداً أكبر في الإعداد، ولا يستحق العناء إلا إذا كانت المهمة تتكرر كثيراً.
كيف تعرف أيهما أمامك؟ افحص ثلاثة أشياء. تخيّل كل واحد كمؤشر يمكنك رفعه أو خفضه. تكون المهمة Mode 2 فقط حين تكون المؤشرات الثلاثة كلها مرفوعة:
- كم مرة؟ هل تفعل هذا مرة واحدة أو نادراً (مؤشر منخفض → Mode 1)، أم مراراً وتكراراً، كل أسبوع أو كل يوم (مؤشر مرتفع → Mode 2)؟
- ما مدى التشابه؟ هل هي الشكل نفسه في كل مرة، أي المدخل نفسه، والخطوات نفسها، والنتيجة المنتهية نفسها (مؤشر مرتفع → Mode 2)؟ أم تبدو كل مرة مختلفة وتحتاج إلى تفكير جديد (مؤشر منخفض → Mode 1)؟
- هل يستحق؟ هل العمل كبير بما يكفي ليردّ جهد بناء مساعد (مؤشر مرتفع → Mode 2)؟ وازِن أكثر من مجرد عدد مرات حدوثه: كم من الوقت يكلّفك كل تشغيل، وكم عنصراً يعالج، وكم سيكون الخطأ مكلفاً، وكم يزعجك أن توقف عملاً آخر لتنجزه. مهمة تكررها كل أسبوع لكنها تستغرق أربع دقائق، وتعالج عنصرين، ولا تسبب ضرراً إن تأخّرت، قد لا تستحق البناء. (لهذا فإن الاسم الجذّاب للبوابة، "مرة واحدة أم كل أسبوع"، ليس إلا المُطلِق؛ أما هذا المؤشر فهو حيث يعيش القرار الحقيقي.)
إذا كان مؤشر واحد منخفضاً، أي أنك تفعلها نادراً، أو تتغير في كل مرة، أو أصغر من أن تستحق العناء، فابقَ في Mode 1. لا تبنِ مساعداً إلا حين تكون المهمة متكررة، والشكل نفسه في كل مرة، وتستحق العناء.
 يحتاج Mode 2 إلى رفع المؤشرات الثلاثة كلها. وأي واحد منها منخفض يبقيك في Mode 1.
يحتاج Mode 2 إلى رفع المؤشرات الثلاثة كلها. وأي واحد منها منخفض يبقيك في Mode 1.
الخطأ الأغلى ثمناً
هناك طريقتان للخطأ في البوابة 2. بناء مساعد دائم لمهمة لمرة واحدة هو الخطأ الأصغر: تهدر فترة بعد الظهر، وتلاحظ، وتمضي.
أما الخطأ المكلف فهادئ، ويقع فيه الجميع تقريباً: إنجاز مهمة Mode 2 يدوياً، مراراً وتكراراً، إلى الأبد.
إنه يختبئ لأن كل مرة تبدو صغيرة. في كل اثنين تقضي خمساً وعشرين دقيقة تجعل وكيلاً يجمع رسائل الأسبوع، ويصنّفها، ويكتب ملخصاً. يعمل جيداً في كل مرة. ولا تجمع المجموع أبداً. لكن على مدى سنة هذا أكثر من عشرين ساعة أُنفقت يدوياً على مهمة متكررة، والشكل نفسه في كل مرة، وتستحق البناء مرة واحدة بوضوح. لم تبنِ المساعد قط لأن أي اثنين بمفرده لم يبدُ كبيراً بما يكفي ليوقفك ويجعلك تقرر.
الإصلاح هو أن تجعل القرار فحصاً متعمَّداً، لا شيئاً تنتظر أن تشعر به. هناك رسم كرتوني قديم وشهير ل Randall Munroe بعنوان "Is It Worth the Time?" (xkcd رقم 1205). يعرض جدولاً بسيطاً: إذا تكررت مهمة كثيراً، فيمكنك أن تنفق قدراً معقولاً من الوقت في بناء شيء يفعلها، وتوفّر وقتاً إجمالاً مع ذلك. لست بحاجة إلى الأرقام الدقيقة. تحتاج إلى العادة فقط. وإليك القاعدة البسيطة:
في المرة الثالثة التي تنجز فيها المهمة نفسها بالطريقة نفسها، توقّف وشغّل البوابة 2. إذا كانت المؤشرات الثلاثة مرفوعة، فأنت لم تعد تحل مشكلة حقاً؛ بل صرت أنت المساعد الذي لم تبنه بعد. تلك إشارتك إلى أن تعبر بها إلى عامل.
مثال من العمل
يدير David العمل اليومي في شركة من 12 شخصاً. مهمتان كلتاهما تبدوان متكررتين:
- إعداد الحسابات والصلاحيات لموظف جديد. يحدث هذا ربما مرة كل بضعة أشهر، وكل شخص جديد مختلف قليلاً: دور مختلف، وتطبيقات مختلفة، وحالات خاصة مختلفة. كم مرة؟ منخفض. ما مدى التشابه؟ منخفض. مؤشران منخفضان. تبقى هذه Mode 1: حُلّها من جديد في كل مرة بوكيل. مساعد جامد سينكسر أول مرة ينضم فيها شخص غير معتاد.
- ملخص رسائل الاثنين. كل أسبوع، المدخل نفسه نوعاً، والنتيجة المنتهية نفسها، ويستغرق 25 دقيقة في كل مرة. كم مرة؟ مرتفع. ما مدى التشابه؟ مرتفع. هل يستحق؟ نعم. المؤشرات الثلاثة مرفوعة. هذه Mode 2. وحركة David هي أن يعبر بها إلى عامل: يواصل حلّها يدوياً حتى تثبت الطريقة، ثم يرقّيها لتعمل من دونه. يبيّن لك من مهمة لمرة واحدة إلى عامل كيف.
الشخص نفسه، والأسبوع نفسه، وجوابان متعاكسان. مهمة الموظف الجديد تبدو متكررة، لكنها تفشل في مؤشر "ما مدى التشابه؟". وملخص الاثنين يجتاز الثلاثة كلها. البوابة 2 هي ما يميّز أحدهما عن الآخر، قبل أن تفرط في بناء الأولى أو تظل تنجز الثانية يدوياً سنة كاملة.
دورك
اسرد ثلاث مهام أنجزتها بوكيل أكثر من مرة. لكل واحدة، اضبط المؤشرات الثلاثة (كم مرة، وما مدى التشابه، وهل يستحق) واكتب الجواب: Mode 1 أو Mode 2.
اسرد مهامك الثلاث أدناه مع مؤشراتها وأحكامها. يفحص المصحّح هل تدعم إعدادات مؤشراتك فعلاً كل حكم Mode 1 أو Mode 2، ويضع علامة على أي مهمة "Mode 2" تتغير في الحقيقة كثيراً جداً في كل تشغيل بحيث لا تُسلَّم إلى عامل جامد.
Discuss with an AI. Question your scores.
Come back when you have your BEST evaluation.
المهمة التي تفاجئك، تلك التي كنت تنجزها يدوياً فتبيّن أنها Mode 2، هي أثمن شيء ستجده في هذه الصفحة كلها. تلك ساعات أنت على وشك استعادتها.
لماذا ينجح هذا (البحث وراءه) — اختياري
البوابة 2 قاعدة قديمة بثوب جديد. في البرمجيات، شاع كتاب Refactoring (1999) ل Martin Fowler قاعدة الثلاث، التي ينسبها إلى Don Roberts: في المرة الأولى تفعل الشيء فحسب؛ وفي الثانية تفعله من جديد وإن تكرر؛ وفي الثالثة تتوقف وتبني النسخة القابلة لإعادة الاستخدام. التكرار الثالث هو الإشارة، لا الأول، لأن البناء المبكر جداً يعني بناء الشيء الخطأ قبل أن تفهم النمط. وهذا بالضبط مُطلِق البوابة 2: في المرة الثالثة التي تنجز فيها المهمة نفسها بالطريقة نفسها، توقّف وقرّر هل تبني المساعد.
يردّد مؤشر "هل يستحق؟" تحذيراً ثانياً معروفاً. مقولة Donald Knuth إن التحسين المبكر أصل كل الشرور (1974) تتعلق في الحقيقة بالجهد: لا تصبّ العمل في جعل شيء آلياً قبل أن تعرف أنه يستحق الأتمتة. وبناء مساعد دائم لمهمة ستفعلها مرة واحدة هو الخطأ نفسه معكوساً. أما الحساب التقريبي لمتى تؤتي الأتمتة ثمارها فيلتقطه جدول Randall Munroe "Is It Worth the Time?" (xkcd 1205): كلما تكررت المهمة أكثر، أمكنك أن تنفق وقتاً أطول في بناء مساعد وتوفّر وقتاً إجمالاً مع ذلك.
المصادر: Fowler, M. (1999). Refactoring: Improving the Design of Existing Code (Rule of Three, attributed to Don Roberts). Knuth, D. E. (1974). "Structured Programming with go to Statements," ACM Computing Surveys, 6(4). Munroe, R. "Is It Worth the Time?", xkcd 1205.
البوابة 3 — كيف يبدو العمل المنتهي؟
الخطأ الذي تمنعه: "أنجز الوكيل عملاً رائعاً. لكنه لم يكن العمل الذي احتجته، ولم أكتشف ذلك إلا بعد أن انتهى فعلاً."
قررت أنها مهمة وكيل (البوابة 1) وأنك ستحلّها مرة واحدة (البوابة 2). البوابة الأخيرة قبل أن تفتح الوكيل: قرّر ماذا يعني المنتهي، كتابةً، في ثلاثة أسطر قصيرة.
- ما الذي ينطلق منه (المدخل). بالضبط ما ينبغي للوكيل أن ينظر إليه: أي مجلد، وأي ملفات، وأي رسائل. كن محدداً. "رسائلي" غامضة جداً. أما "ال 400 رسالة في مجلد الدعم خلال آخر 7 أيام" فواضحة.
- ما تريده في النهاية (المخرج). الشيء الذي تريده أن يوجد حين تنتهي: جدول بيانات، أو ملخص من صفحة واحدة، أو مجلد ملفات أُعيدت تسميتها. قل الشكل، لا الموضوع فحسب.
- الفحص الذي يعني أنها انتهت (فحص الإتمام). الشيء الواحد الذي يمكنك النظر إليه لتعرف أن المهمة منتهية وصحيحة. مثلاً: "كل رسالة في مجموعة واحدة بالضبط، ومجموع أعداد المجموعات 400." حين يصدق ذلك، تكون قد انتهيت. وحين لا يصدق، لم تنتهِ.
هذا كل شيء، ثلاثة أسطر. أنت لا تكتب التعليمات الكاملة بعد، ولا تخبر الوكيل كيف ينجز العمل. أنت تقرر الهدف فقط، حتى إذا أصابه الوكيل عرفتَ ذلك.
تقرر البوابة 3 كيف يبدو المنتهي، أي الهدف. أما التعليمات الفعلية التي تعطيها للوكيل وهو يعمل (كيف تصوغ الطلب، وطلب الجداول، وفحص النتيجة) فتُعلَّم في الدورة التالية، حل المشكلات مع الوكلاء العامين. فكّر في الأمر هكذا: البوابة 3 هي اختيار الهدف. والدورة التالية هي تعلّم إصابته. اختر الهدف هنا، ثم اذهب إلى تلك الدورة لتتعلم التصويب.
 ثلاثة أسطر قبل أن تبدأ. الوكيل يستطيع إصابة هدف يراه.
ثلاثة أسطر قبل أن تبدأ. الوكيل يستطيع إصابة هدف يراه.
مثال من العمل
عودة إلى Ana من المقدمة، مع رسائلها ال 400. (مهمتها لها مستقبل Mode 2، لكن إلى أن يوجد ذلك العامل فهي ما زالت تحلّها مرة كل أسبوع، فتنطبق البوابة 3 على كل تشغيل.) قبل أن تفتح الوكيل، تكتب الأسطر الثلاثة:
ينطلق من: ال 400 رسالة في مجلد الدعم خلال آخر 7 أيام.
أريد في النهاية: جدول بيانات بصف واحد لكل رسالة، بأعمدة لمن أرسلها، والتاريخ، والمجموعة (واحدة من: شكوى، أو سؤال، أو طلب، أو أخرى)، وملخص من سطر واحد. مع مذكرة من صفحة واحدة فيها عدد كل مجموعة، وأكثر ثلاث شكاوى تكراراً.
ينتهي عندما: كل رسالة في مجموعة واحدة بالضبط، ومجموع أعداد المجموعات 400، وأرقام المذكرة تطابق جدول البيانات.
الآن تفتح الوكيل. وحين يعود، لديها طريقة دقيقة لتفحص هل انتهى حقاً، وفحص الإتمام ("مجموع الأعداد 400") شيء يمكنها هي أو الوكيل تأكيده في ثوانٍ. أما Yusuf الذي فتح الوكيل بعبارة "ساعدني في هذه الرسائل" فلم يكن لديه أي من هذا. ولهذا بالضبط كانت نتيجته شيئاً لا يستطيع الوثوق به ولا فحصه.
دورك
خذ أحدث مهمة حقيقية أعطيتها لوكيل، أو التالية التي توشك أن تعطيها. اكتب الأسطر الثلاثة: ينطلق من، وأريد في النهاية، وينتهي عندما. ثم انظر مليّاً في فحص الإتمام: هل تستطيع فعلاً فحصه؟ هل يمكنك أنت، أو الوكيل، تأكيده في أقل من دقيقة؟ إذا كان فحص الإتمام شيئاً غامضاً مثل "الملخص جيد"، فهو ليس فحصاً حقيقياً بعد. اجعله أحدّ حتى يصير شيئاً يمكنك اختباره بوضوح.
اكتب أسطرك الثلاثة أدناه. أحدّ اختبارات المصحّح هو سطر "ينتهي عندما": هل هو شيء يمكنك فعلاً فحصه في أقل من دقيقة، أم رأي غامض متنكّر؟
Discuss with an AI. Question your scores.
Come back when you have your BEST evaluation.
لماذا ينجح هذا (البحث وراءه) — اختياري
عقود من البحث في الأهداف تشير إلى الاتجاه نفسه. وجدت نظرية تحديد الأهداف ل Edwin Locke وGary Latham (المُلخَّصة في ورقتهما سنة 2002 في American Psychologist)، عبر مئات الدراسات، أن الأهداف المحددة والقابلة للقياس تقود إلى أداء أفضل بكثير من الأهداف الغامضة من نوع "ابذل قصارى جهدك"، لأن الهدف المحدد يخبرك بالضبط ما تصوّب نحوه ومتى أصبته بالضبط. والتعليمة الملتبسة لوكيل ("اصنع ملخصاً جيداً") هي هدف "ابذل قصارى جهدك". أما الأسطر الثلاثة فتحوّلها إلى هدف محدد.
وصلت فرق البرمجيات إلى الاستنتاج نفسه عملياً وسمّته تعريف الإنجاز (Definition of Done). قبل أن يبدأ العمل، يتفق الفريق على قائمة التحقق الدقيقة التي تحدّد اكتمال المهمة، حتى يصير "المنتهي" حقيقة مشتركة قابلة للفحص لا رأياً يُتجادل فيه لاحقاً. البوابة 3 هي تعريف الإنجاز الخاص بك لمهمة واحدة، مكتوباً قبل أن يبدأ الوكيل، حتى يكون له هدف يراه.
المصادر: Locke, E. A., & Latham, G. P. (2002). "Building a Practically Useful Theory of Goal Setting and Task Motivation," American Psychologist, 57(9), 705–717. "Definition of Done"، ممارسة قياسية في تطوير البرمجيات بمنهجية Agile/Scrum.
والآن شغّل الثلاث على مهمة حقيقية واحدة
تبقى البوابات نظرية حتى تدفع مهمة حقيقية واحدة عبر البوابات الثلاث في جلسة واحدة.
اختر شيئاً تحتاج إلى إنجازه الآن. سِر به عبرها:
- البوابة 1. أداة عادية، أم روبوت محادثة، أم وكيل؟ إذا توقف قبل "الوكيل"، فقد وفّرت على نفسك جلسة كاملة للتو: استخدم الأداة الصحيحة وامضِ.
- البوابة 2. إن كانت مهمة وكيل: أتفعلها مرة واحدة (Mode 1)، أم تبني مساعداً (Mode 2)؟ إذا كانت المؤشرات الثلاثة مرفوعة، فهي مهمة Mode 2: واصل حلّها يدوياً حتى تتوقف الطريقة عن التغيّر، ثم اعبر بها إلى عامل. يبيّن لك من مهمة لمرة واحدة إلى عامل متى تثبت وكيف ترقّيها.
- البوابة 3. إن كانت مهمة وكيل تُحلّ مرة واحدة: اكتب الأسطر الثلاثة. ينطلق من، وأريد في النهاية، وينتهي عندما.
إذا خرجت المهمة من الطرف الآخر، أي وكيل، وMode 1، وثلاثة أسطر مكتوبة، فحينئذٍ تفتح الوكيل. والآن تدخل حل المشكلات مع الوكلاء العامين بمهمة مصنَّفة وواضحة، وتتعلم المبادئ السبعة لحلّها فعلاً.
لماذا يهم هذا. تستغرق البوابات نحو عشر دقائق. أما الأخطاء التي تمنعها فتستغرق فترات بعد الظهر، وأخطاء Mode 2 تستغرق شهوراً. تلك هي المقايضة كلها: قليل من التفكير قبل أن تبدأ، في مقابل الساعات التي كنت ستخسرها لولا ذلك بالبدء في المكان الخطأ.
لم يكن القرار الأول قط هو كيف تتحدث إلى الوكيل. بل كان هل تتحدث إليه أصلاً، وأي نوع من العمل هذا، ونحو ماذا. أصِب ذلك، فيصير جزء التحدث إلى الوكيل سهلاً.
إلى أين يقودك كل جواب (بطاقة مرجعية)
وجّهت البوابات الثلاث عملك من دون أن تسمّي أداة قط، عن قصد. البوابة التي تصل إليها هي الثابت؛ أما الأداة التي تستخدمها فهي المتغيّر، والأدوات تتغير كل بضعة أشهر. وإليك المتغيّر كما هو في 2026. اقرأه بدءاً من البوابة التي وصلت إليها، لا العكس.
| إلى أين أرسلتك البوابات | ماذا يعني ذلك | الأدوات التي تُستخدم (2026) |
|---|---|---|
| مجرد إجابة (البوابة 1 → روبوت محادثة) | احتجت إلى معرفة، أو مسودة، أو أفكار. لا يُلمَس أي شيء من أشيائك. | claude.ai أو ChatGPT أو Gemini. والمهارة لهذا هي كيف تفكّر في عصر الذكاء الاصطناعي. |
| حُلّها مرة واحدة (البوابة 1 → وكيل، ثم البوابة 2 → Mode 1) | وكيل تقوده داخل جلسة: يتصرف، وأنت تراقب، ثم تشحن، ثم تنصرف. | Claude Code أو OpenCode (الطرفية أو محرر الكود)؛ Cowork أو OpenWork (تطبيق سطح المكتب). هذا ما تعلّمه حل المشكلات مع الوكلاء العامين. |
| امتلك العامل (خيار ملكية، لا نمط) | تريد عاملاً متيناً تشغّله وتملكه بنفسك، عاملاً يتذكّر عبر الأسابيع ويستطيع أن يجيب وأنت نائم. | منظومة تشغيل شخصية (برمجية تُبقي العامل حياً ومتذكّراً نيابة عنك): OpenClaw التي تصلك عبر تطبيقات محادثة كثيرة، أو Hermes التي تتذكّر عملك بعمق. راجع منظومات تشغيل الوكلاء الشخصية. |
| صنّعه (البوابة 2 → Mode 2) | عامل مبنيّ لمؤسسة، أي Digital FTE (موظف رقمي بدوام كامل) منشور ليعمل بموثوقية وعلى نطاق واسع. | OpenAI Agents SDK، أو إعداد مُدار لوكيل Claude. هذا هو مسار Mode 2 — التصنيع كاملاً؛ واختيار البِنى الوكيلية يساعدك على الاختيار. |
الموضع الوحيد الذي يتداخلان فيه. الصفّان الثالث والرابع كلاهما "عامل متين يعمل من دونك". والشيء الذي يميّز أحدهما عن الآخر هو لمن العامل. إن كان لك أنت، أي صندوق بريدك، وكودك، ومهامك، فهو منظومة تشغيل شخصية، ولا تحتاج إلى مسار Mode 2 الكامل لبنائه. وإن كان لمؤسسة، أي منشوراً، ومحكوماً، ومقصوداً به التوسّع، فهو Mode 2. النشاط نفسه، ومالك مختلف.
وامتلاك منظومة تشغيل شخصية ليس نمطاً ثالثاً. إنه سؤال منفصل عن الملكية: يمكنك أن تشغّل إمّا Mode 1 (حلّ مهمة لمرة واحدة) أو Mode 2 (بناء ليدوم) فوق منظومة تملكها. سؤالان منفصلان، ولا يتصادمان أبداً: يسأل الملكية "هل أقودها، أم أملكها؟"؛ ويسأل النمط "هل أحلّها مرة واحدة، أم أبنيها لتدوم؟".
ما زلت غير متأكد أي أداة تناسبك؟ يحتفظ الكتاب بمقارنة محدَّثة في أي موظفي ذكاء اصطناعي في 2026.
وسيلة دراسة بالبطاقات التعليمية
اختبار المعرفة
اختبار ذاتي سريع ومُبوَّب للأفكار التي مررت بها للتو.